⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
MusicInfuser: Making Video Diffusion Listen and Dance
Authors:Susung Hong, Ira Kemelmacher-Shlizerman, Brian Curless, Steven M. Seitz
We introduce MusicInfuser, an approach for generating high-quality dance videos that are synchronized to a specified music track. Rather than attempting to design and train a new multimodal audio-video model, we show how existing video diffusion models can be adapted to align with musical inputs by introducing lightweight music-video cross-attention and a low-rank adapter. Unlike prior work requiring motion capture data, our approach fine-tunes only on dance videos. MusicInfuser achieves high-quality music-driven video generation while preserving the flexibility and generative capabilities of the underlying models. We introduce an evaluation framework using Video-LLMs to assess multiple dimensions of dance generation quality. The project page and code are available at https://susunghong.github.io/MusicInfuser.
我们介绍了MusicInfuser,这是一种生成高质量舞蹈视频的方法,该视频与指定的音乐曲目同步。我们并没有尝试设计和训练新的多模态音频视频模型,而是展示了如何通过对现有视频扩散模型进行微调,通过引入轻量级的音乐视频交叉注意力和低阶适配器来适应音乐输入。与先前需要动作捕捉数据的工作不同,我们的方法仅在舞蹈视频上进行微调。MusicInfuser实现了高质量的音乐驱动视频生成,同时保留了基础模型的灵活性和生成能力。我们引入了一个使用Video-LLMs的评估框架,从多个维度评估舞蹈生成的质量。项目页面和代码可在https://susunghong.github.io/MusicInfuser访问。
论文及项目相关链接
PDF Project page: https://susunghong.github.io/MusicInfuser
Summary
音乐Infuser方法生成高质量舞蹈视频,该视频同步特定音乐曲目。此方法通过引入轻量级音乐视频交叉注意力与低阶适配器,展示了现有视频扩散模型如何适应音乐输入。与需要动作捕捉数据的早期工作不同,我们的方法仅对舞蹈视频进行微调。MusicInfuser实现了高质量的音乐驱动视频生成,同时保留了底层模型的灵活性和生成能力。同时利用Video-LLMs建立评价体系对舞蹈生成质量进行了多维评价。项目和代码在网站可下载和查阅。
Key Takeaways
- MusicInfuser是一种生成高质量舞蹈视频的方法,能够同步特定音乐曲目。
- 该方法通过引入轻量级音乐视频交叉注意力机制,使得现有视频扩散模型能够适应音乐输入。
- 低阶适配器的引入提高了模型的性能。
- 与早期需要动作捕捉数据的方法不同,MusicInfuser仅对舞蹈视频进行微调。
- MusicInfuser实现了高质量的音乐驱动视频生成。
- 该方法保留了底层模型的灵活性和生成能力。
点此查看论文截图



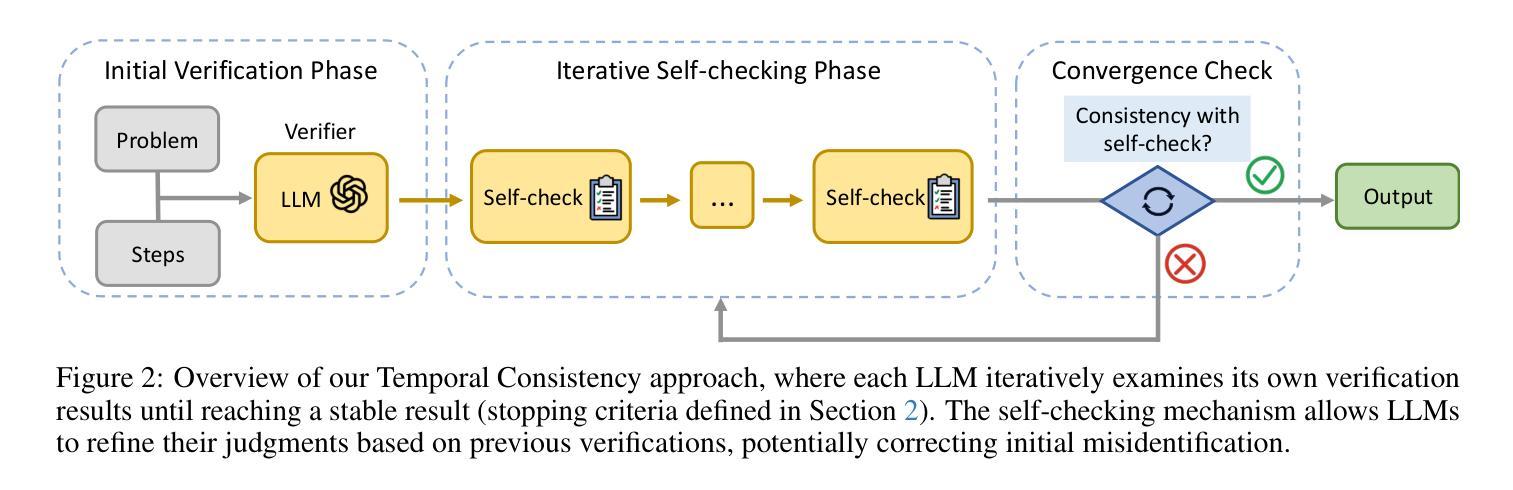
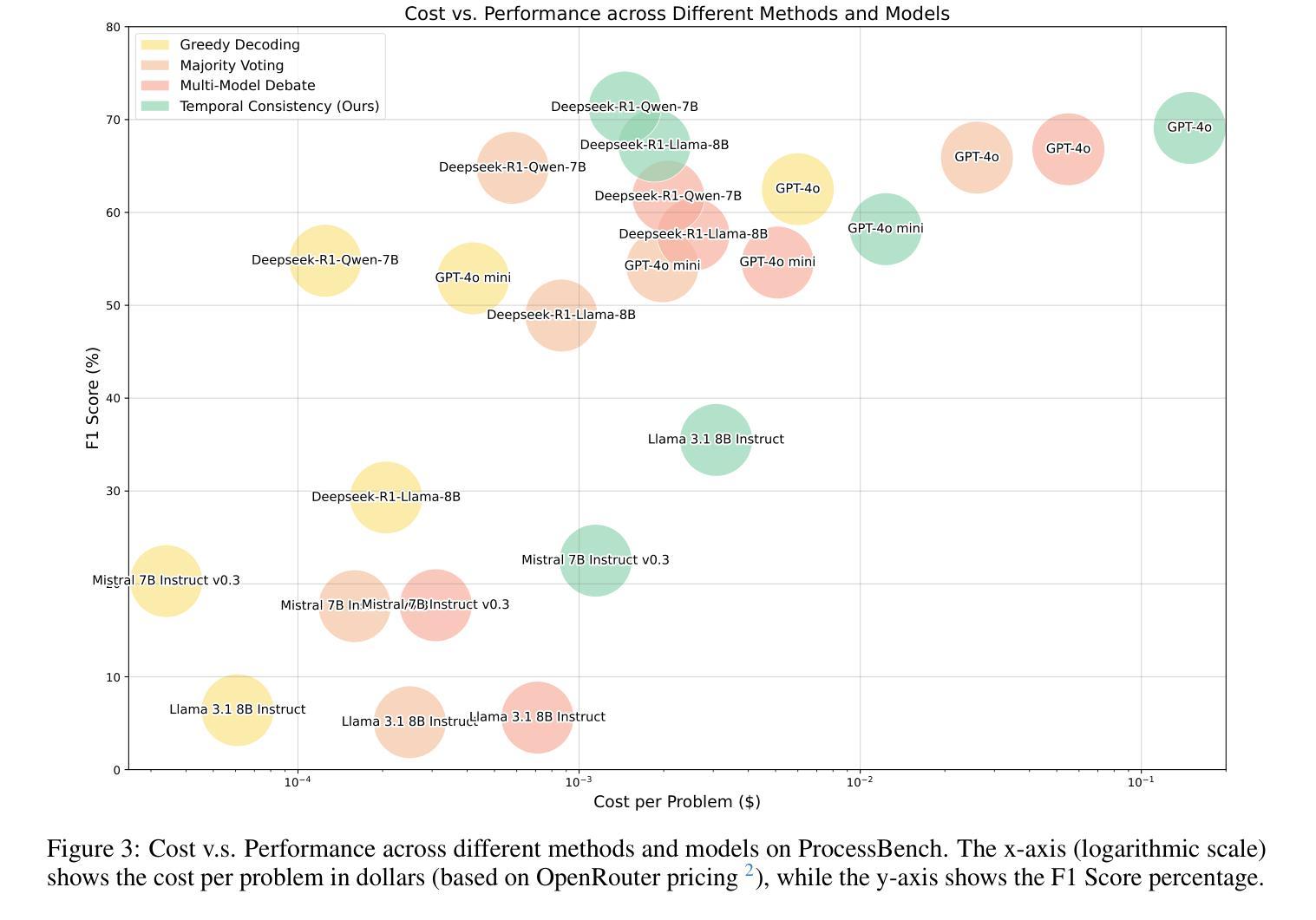
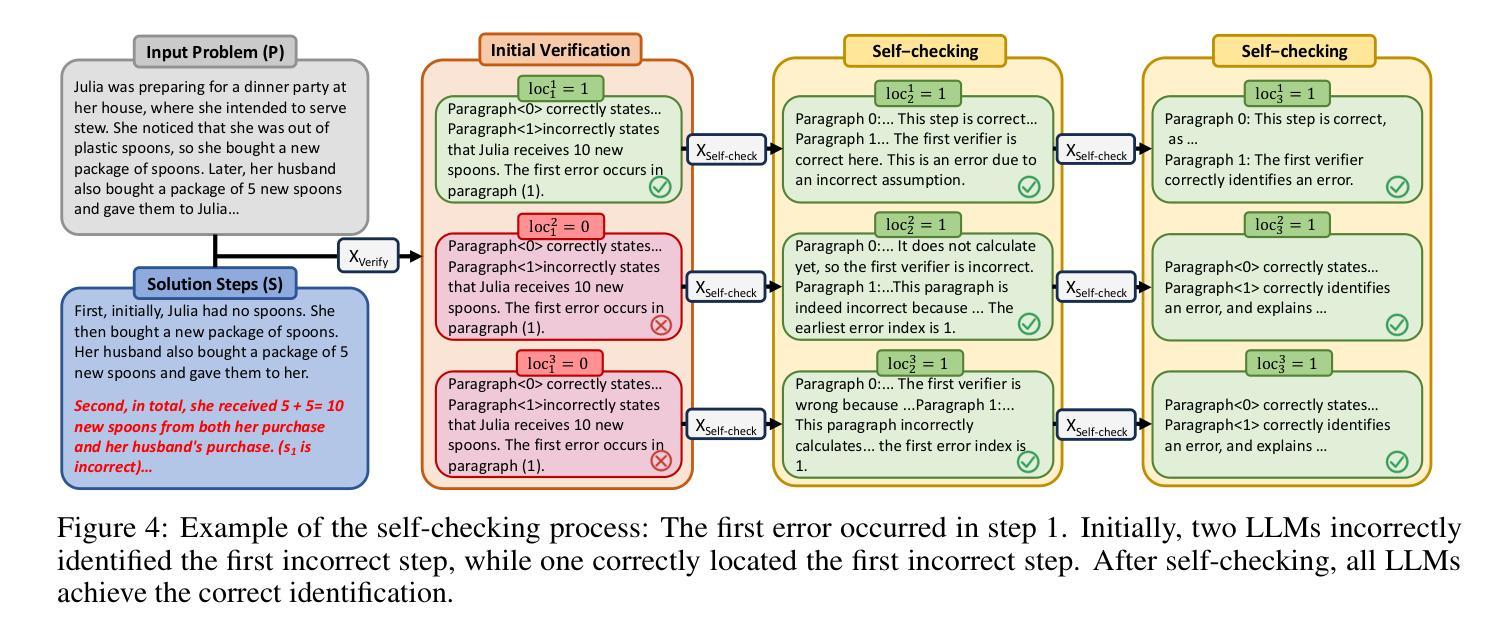
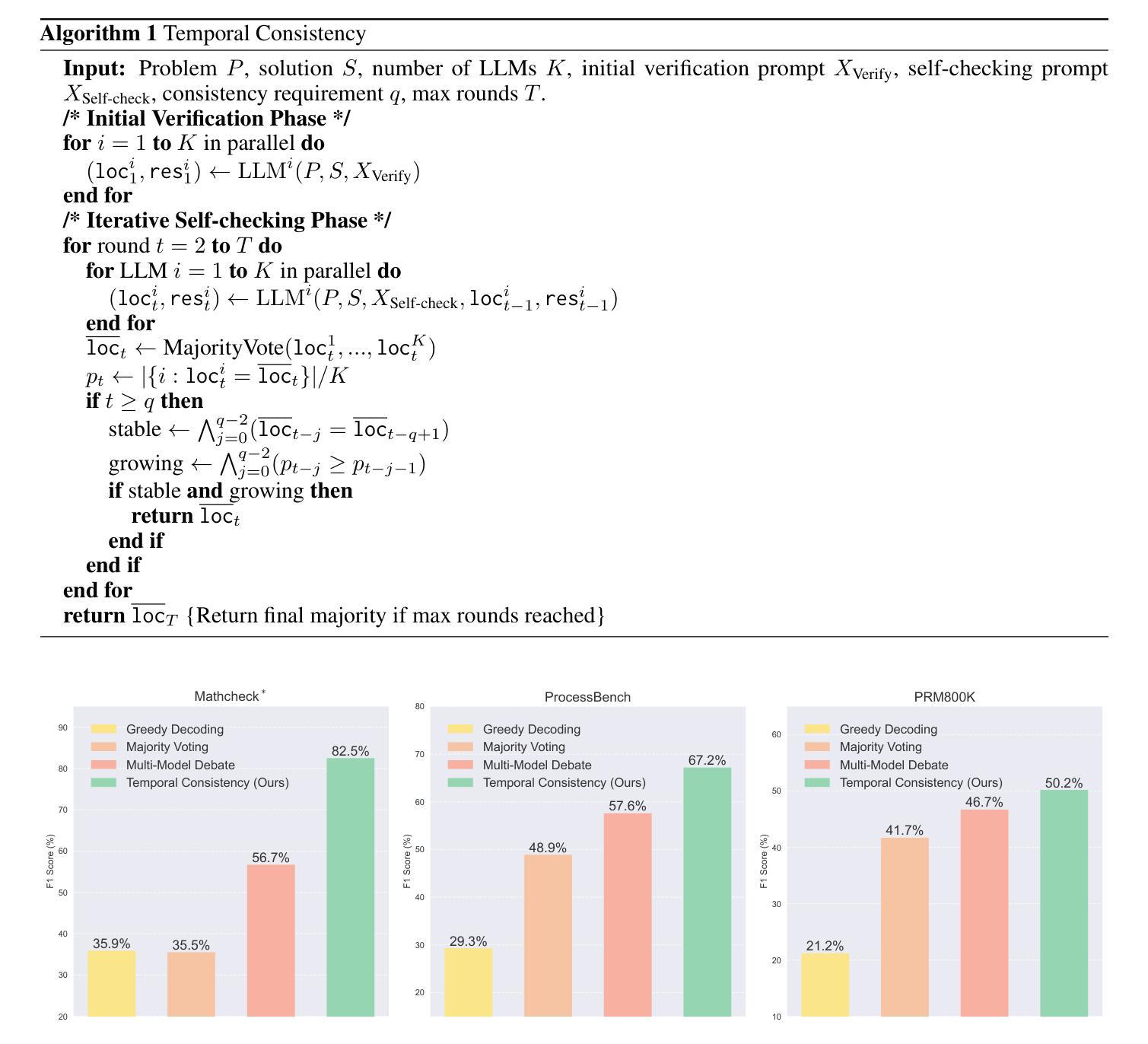
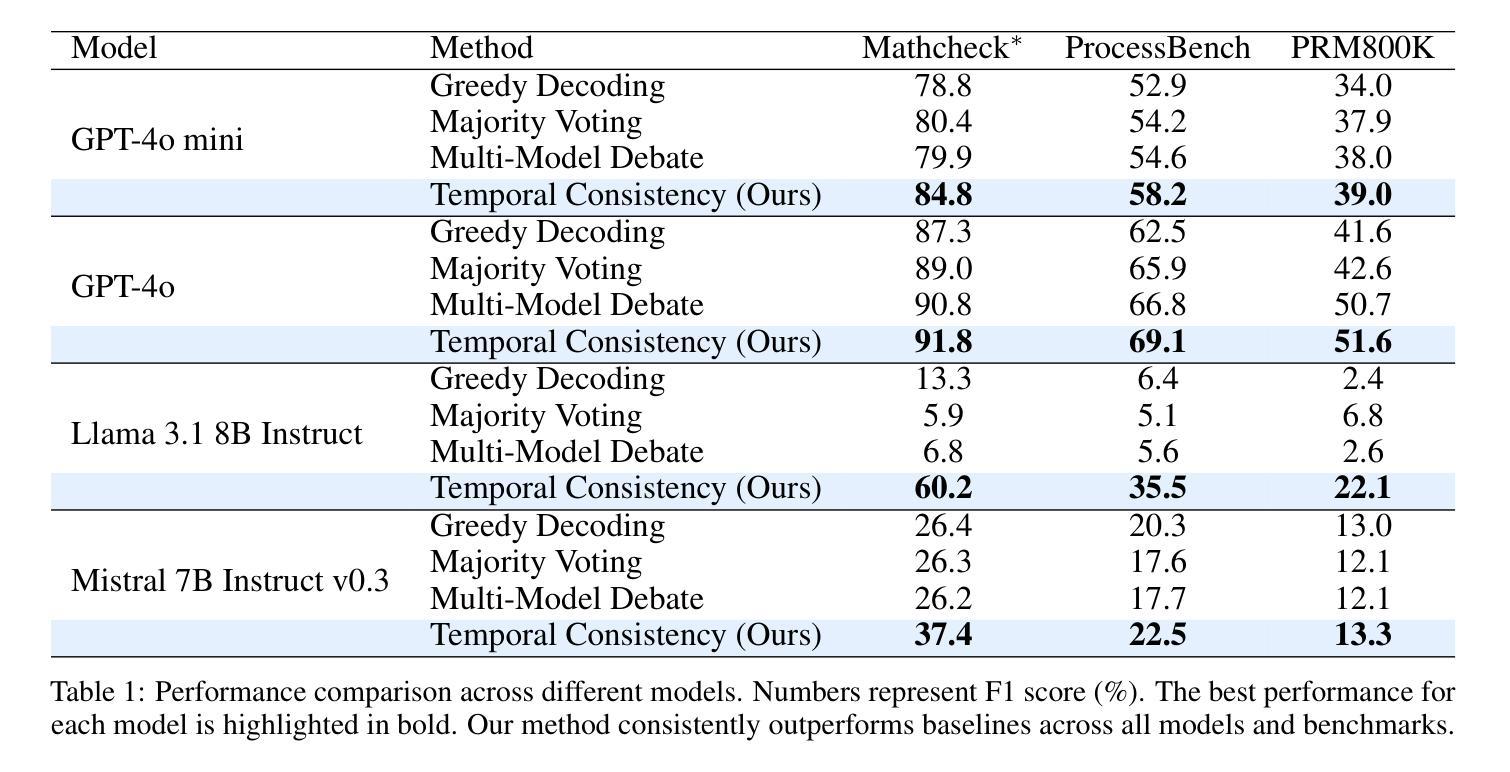
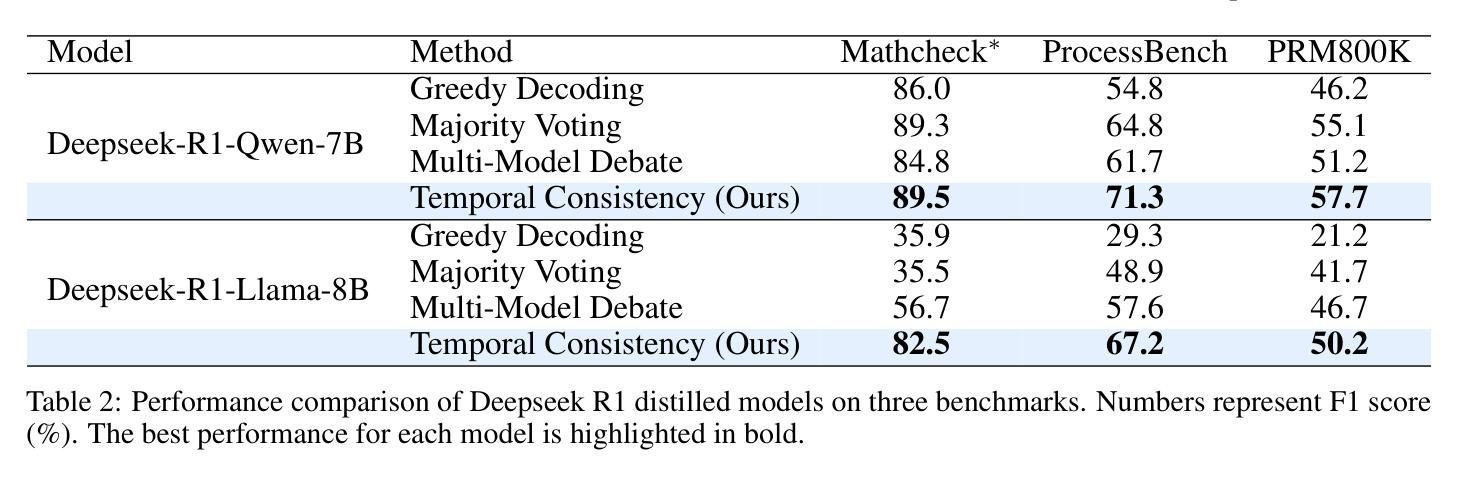
Temporal Consistency for LLM Reasoning Process Error Identification
Authors:Jiacheng Guo, Yue Wu, Jiahao Qiu, Kaixuan Huang, Xinzhe Juan, Ling Yang, Mengdi Wang
Verification is crucial for effective mathematical reasoning. We present a new temporal consistency method where verifiers iteratively refine their judgments based on the previous assessment. Unlike one-round verification or multi-model debate approaches, our method leverages consistency in a sequence of self-reflection actions to improve verification accuracy. Empirical evaluations across diverse mathematical process error identification benchmarks (Mathcheck, ProcessBench, and PRM800K) show consistent performance improvements over baseline methods. When applied to the recent DeepSeek R1 distilled models, our method demonstrates strong performance, enabling 7B/8B distilled models to outperform all 70B/72B models and GPT-4o on ProcessBench. Notably, the distilled 14B model with our method achieves performance comparable to Deepseek-R1. Our codes are available at https://github.com/jcguo123/Temporal-Consistency
验证对于有效的数学推理至关重要。我们提出了一种新的时间一致性方法,验证者可以根据之前的评估结果迭代地调整自己的判断。不同于一轮验证或多模型辩论方法,我们的方法利用一系列自我反思行为的连贯性来提高验证的准确性。在多样化的数学过程误差识别基准测试(Mathcheck、ProcessBench和PRM800K)上的经验评估表明,我们的方法在基准方法上实现了性能上的持续改进。当应用于最新的DeepSeek R1蒸馏模型时,我们的方法表现出强大的性能,使7B/8B蒸馏模型在ProcessBench上优于所有70B/72B模型和GPT-4o。值得注意的是,使用我们方法的14B蒸馏模型实现了与Deepseek-R1相当的性能。我们的代码可在https://github.com/jcguo123/Temporal-Consistency获得。
论文及项目相关链接
Summary:一种基于时间一致性的新验证方法能提升数学推理的有效性。它通过迭代精细验证过程提高验证的准确性,且相比一次性的验证或多模型辩论方法更具优势。该方法在多种数学过程误差识别基准测试上的表现均优于基准方法,并且对于最新DeepSeek R1蒸馏模型也有良好的表现。我们的代码已发布在https://github.com/jcguo123/Temporal-Consistency供公众访问。
Key Takeaways:
- 验证在数学推理中的重要性,并介绍了一种新的基于时间一致性的验证方法。
- 此方法通过迭代精细验证过程提高验证的准确性。
- 与其他验证方法相比,如一次性验证或多模型辩论,该方法具有优势。
- 在多种数学过程误差识别基准测试上,该方法表现优于其他方法。
- 该方法与最新DeepSeek R1蒸馏模型结合表现出良好的性能。
- 通过使用此方法,蒸馏的14B模型性能可与Deepseek-R1相媲美。
点此查看论文截图

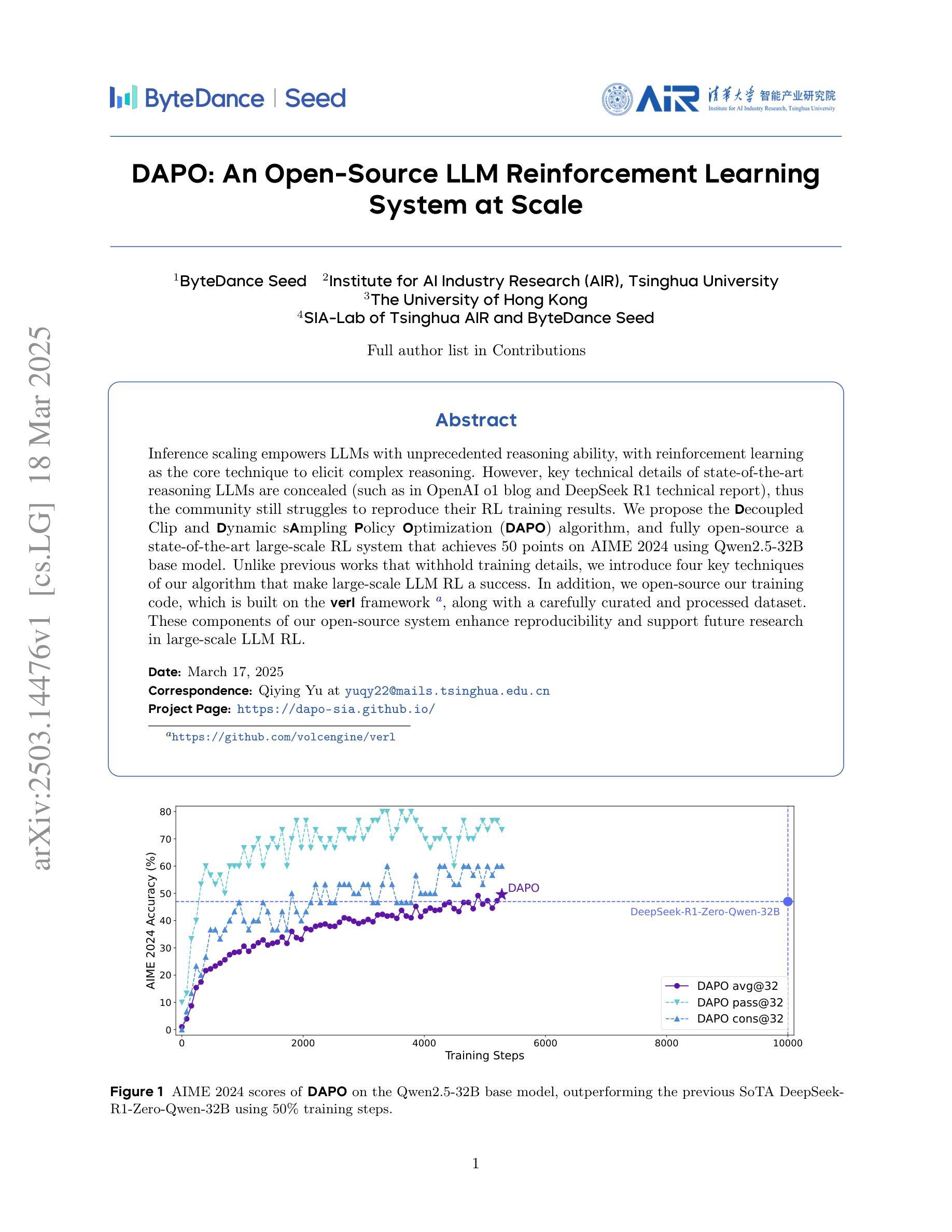
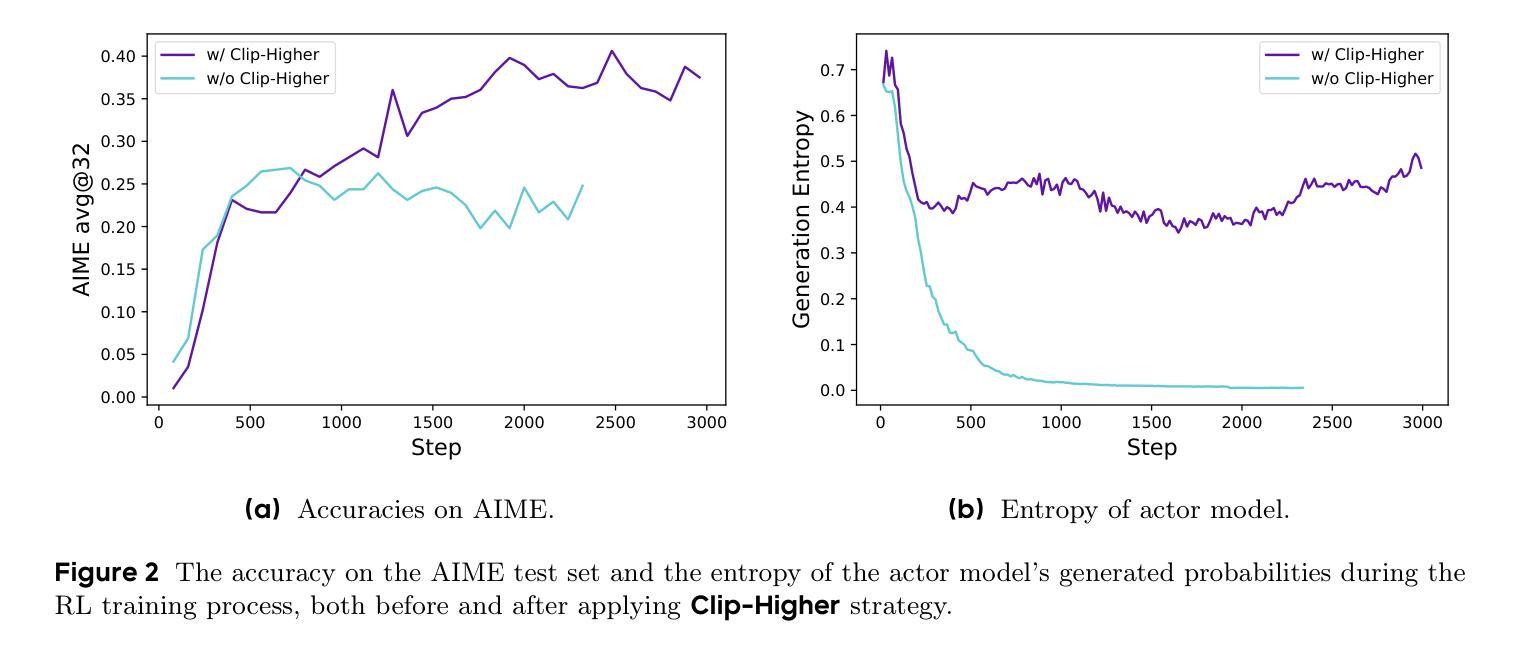
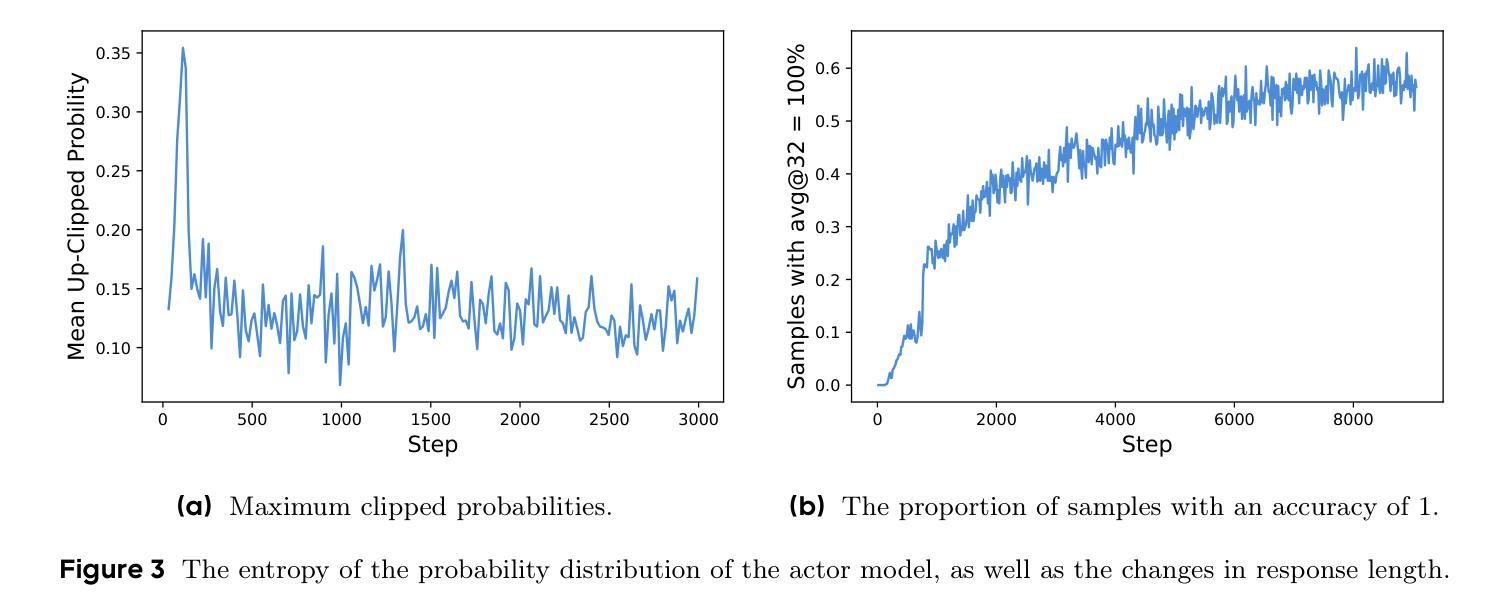
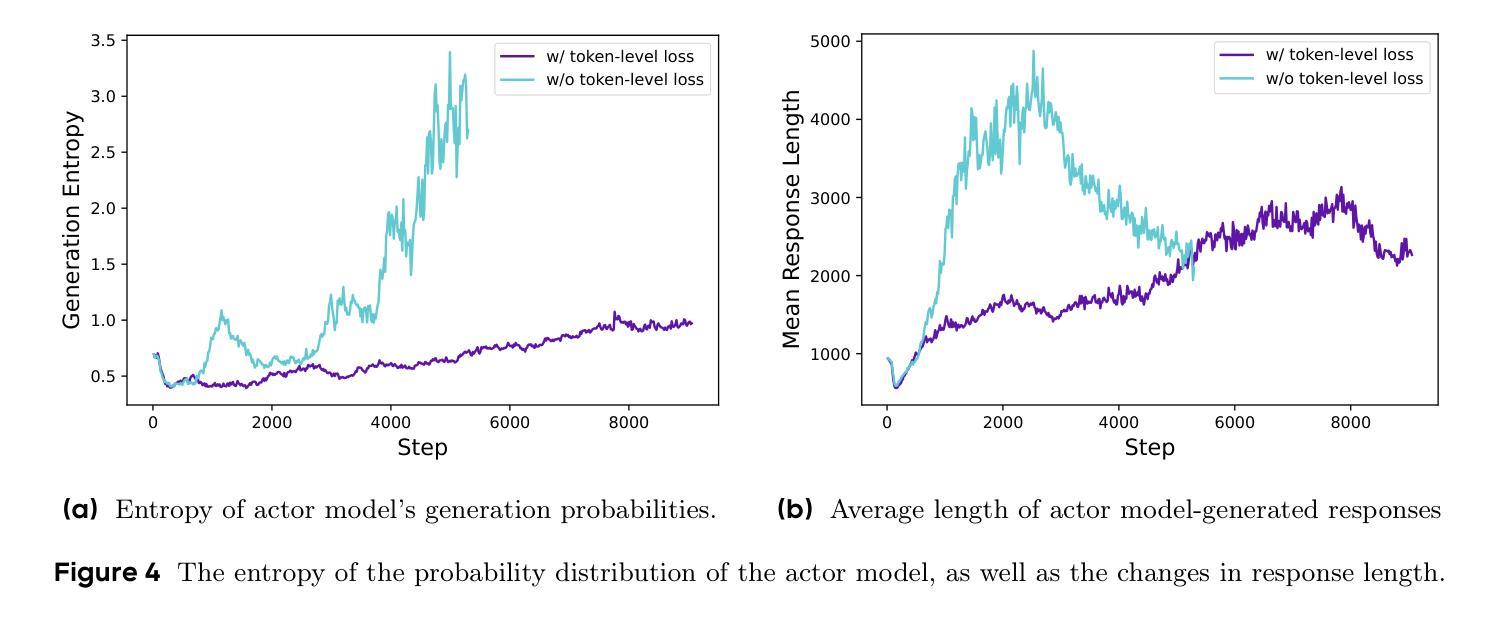
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Authors:Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, Mingxuan Wang
Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
推理扩展赋予大型语言模型前所未有的推理能力,强化学习是激发复杂推理的核心技术。然而,前沿推理大型语言模型的关键技术细节被隐藏(例如在OpenAI o1博客和DeepSeek R1技术报告中),因此社区难以重现其强化学习训练结果。我们提出了解耦剪辑和动态采样策略优化(DAPO)算法,并完全开源了一个先进的大型强化学习系统,该系统使用Qwen2.5-30B基础模型在AIME 2024上取得了50分的成绩。不同于之前隐瞒训练细节的研究,我们介绍了算法四个关键技术,使大规模语言模型强化学习取得成功。此外,我们在verl框架上开源了训练代码,以及精心策划和处理的数据集。我们开源系统的这些组件提高了可重复性,支持未来在大型语言模型强化学习领域的研究。
论文及项目相关链接
PDF Project Page: https://dapo-sia.github.io/
Summary
推理大模型通过强化学习提升能力,但核心细节被隐藏。我们提出DAPO算法并开源一个先进的大规模RL系统,使用Qwen2.5-32B基础模型在AIME 2024上获得50分。我们的算法包含四个关键技术,促进大规模LLM RL的成功。同时开源训练代码和数据处理集,增强可复制性和支持未来研究。
Key Takeaways
- 推理大模型利用强化学习提升能力。
- 当前先进的大模型细节被隐藏,社区难以复制其训练结果。
- 提出DAPO算法并成功应用于大规模LLM RL。
- DAPO算法包含四个关键技术,有助于大规模LLM RL的成功。
- 开源训练代码和数据处理集,增强可复制性和支持未来研究。
- 使用Qwen2.5-32B基础模型在AIME 2024上获得50分的高表现。
点此查看论文截图
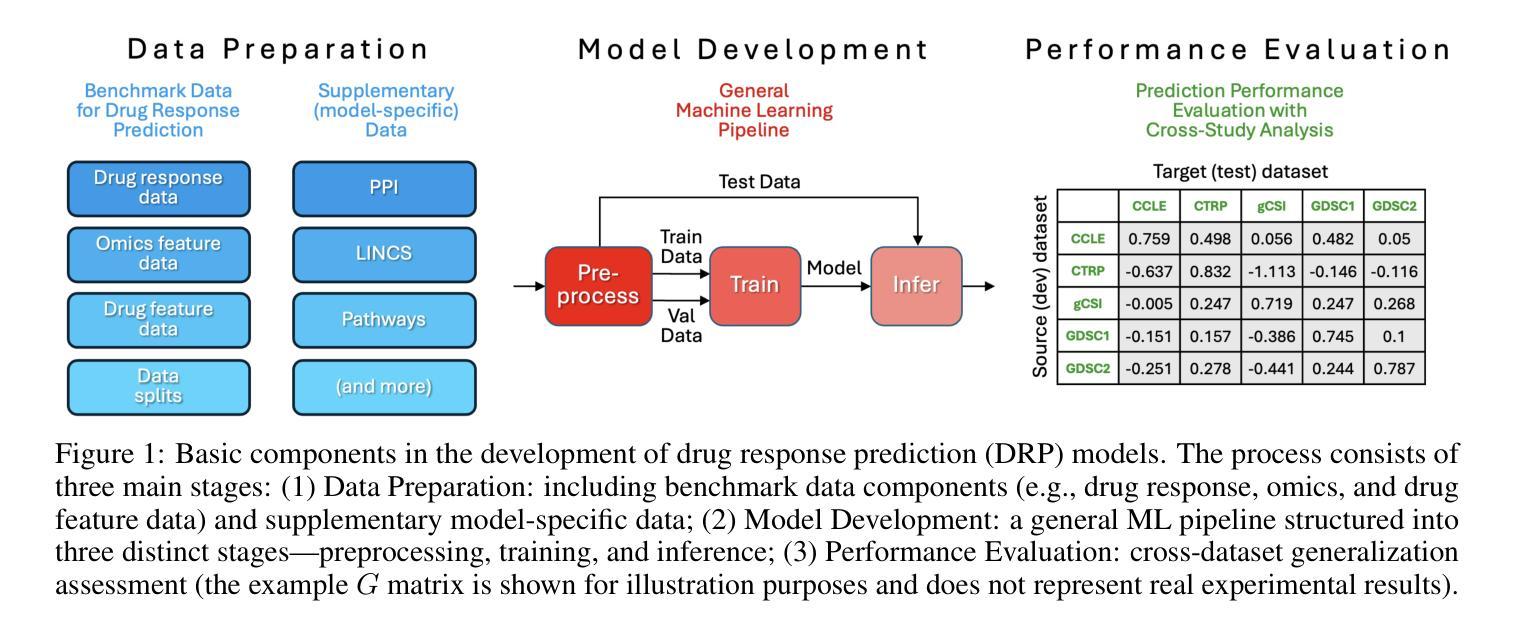
Benchmarking community drug response prediction models: datasets, models, tools, and metrics for cross-dataset generalization analysis
Authors:Alexander Partin, Priyanka Vasanthakumari, Oleksandr Narykov, Andreas Wilke, Natasha Koussa, Sara E. Jones, Yitan Zhu, Jamie C. Overbeek, Rajeev Jain, Gayara Demini Fernando, Cesar Sanchez-Villalobos, Cristina Garcia-Cardona, Jamaludin Mohd-Yusof, Nicholas Chia, Justin M. Wozniak, Souparno Ghosh, Ranadip Pal, Thomas S. Brettin, M. Ryan Weil, Rick L. Stevens
Deep learning (DL) and machine learning (ML) models have shown promise in drug response prediction (DRP), yet their ability to generalize across datasets remains an open question, raising concerns about their real-world applicability. Due to the lack of standardized benchmarking approaches, model evaluations and comparisons often rely on inconsistent datasets and evaluation criteria, making it difficult to assess true predictive capabilities. In this work, we introduce a benchmarking framework for evaluating cross-dataset prediction generalization in DRP models. Our framework incorporates five publicly available drug screening datasets, six standardized DRP models, and a scalable workflow for systematic evaluation. To assess model generalization, we introduce a set of evaluation metrics that quantify both absolute performance (e.g., predictive accuracy across datasets) and relative performance (e.g., performance drop compared to within-dataset results), enabling a more comprehensive assessment of model transferability. Our results reveal substantial performance drops when models are tested on unseen datasets, underscoring the importance of rigorous generalization assessments. While several models demonstrate relatively strong cross-dataset generalization, no single model consistently outperforms across all datasets. Furthermore, we identify CTRPv2 as the most effective source dataset for training, yielding higher generalization scores across target datasets. By sharing this standardized evaluation framework with the community, our study aims to establish a rigorous foundation for model comparison, and accelerate the development of robust DRP models for real-world applications.
深度学习(DL)和机器学习(ML)模型在药物反应预测(DRP)中显示出潜力,但它们在数据集之间的泛化能力仍然是一个悬而未决的问题,这引发了人们对它们在现实世界中的适用性的担忧。由于缺乏标准化的基准评估方法,模型评估与比较通常依赖于不一致的数据集和评估标准,使得难以评估真实的预测能力。在这项工作中,我们介绍了一个用于评估DRP模型在跨数据集预测中泛化能力的基准测试框架。我们的框架包含了五个公开的药物筛查数据集、六个标准化的DRP模型,以及一个可扩展的系统评估工作流程。为了评估模型的泛化能力,我们引入了一套评估指标,这些指标既衡量绝对性能(例如跨数据集的预测精度),又衡量相对性能(例如与内部数据集结果相比的性能下降),从而实现对模型可迁移性的更全面的评估。我们的研究结果表明,当模型在未见过的数据集上进行测试时,性能出现了大幅下降,这突显了严格评估泛化能力的重要性。虽然有几个模型表现出相对较强的跨数据集泛化能力,但没有单一模型在所有数据集上始终表现最佳。此外,我们确定CTRPv2为最有效的训练源数据集,其在目标数据集的泛化得分较高。通过与社区共享这个标准化的评估框架,我们的研究旨在建立严格的模型比较基础,并加速开发用于实际应用的稳健DRP模型。
论文及项目相关链接
PDF 18 pages, 9 figures
Summary
本文介绍了一个用于评估药物反应预测模型跨数据集预测泛化能力的基准测试框架。该框架包含五个公开药物筛查数据集、六个标准化的药物反应预测模型以及一个可系统评估的工作流程。通过引入一系列评估指标,对模型的绝对性能和相对性能进行了量化评估,揭示了模型在实际应用中的迁移能力的重要性。研究结果表明,模型在未见数据集上的性能有所下降,而CTRPv2数据集在训练中最具泛化效果。
Key Takeaways
- 深度学习(DL)和机器学习(ML)模型在药物反应预测(DRP)中表现出潜力,但其在不同数据集的泛化能力仍存在疑问。
- 缺乏标准化的基准测试方法,使得模型评估与比较依赖于不一致的数据集和评估标准,难以评估其真正的预测能力。
- 引入的基准测试框架包含五个公开药物筛查数据集和六个标准化的DRP模型,以评估跨数据集的预测泛化能力。
- 通过一系列评估指标,对模型的绝对性能和相对性能进行了量化,以更全面地评估模型的迁移能力。
- 研究发现,在未见数据集上测试的模型性能显著下降,突显了严格泛化评估的重要性。
- 虽然有多个模型表现出相对较强的跨数据集泛化能力,但没有单一模型在所有数据集上始终表现最佳。
点此查看论文截图

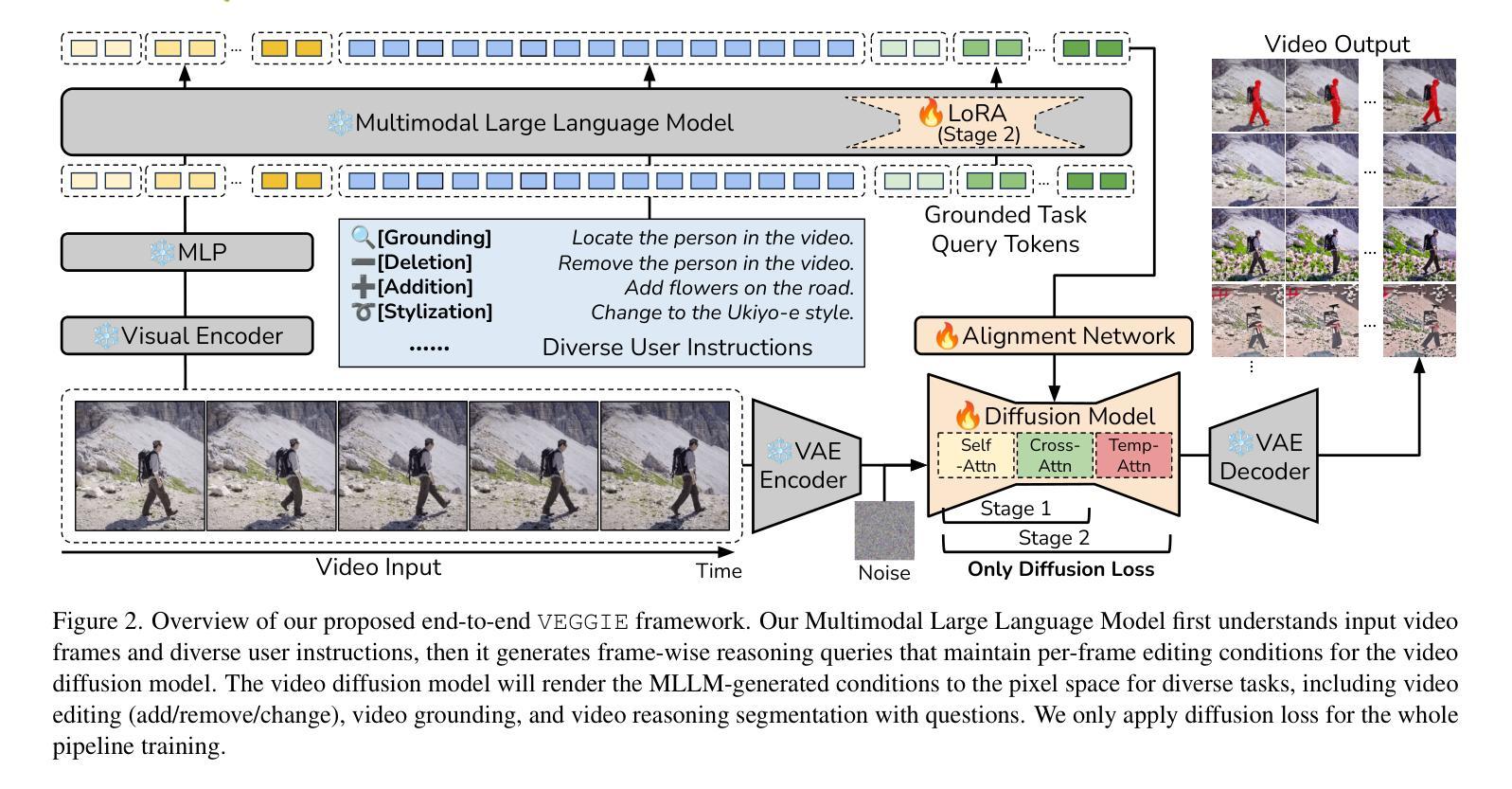
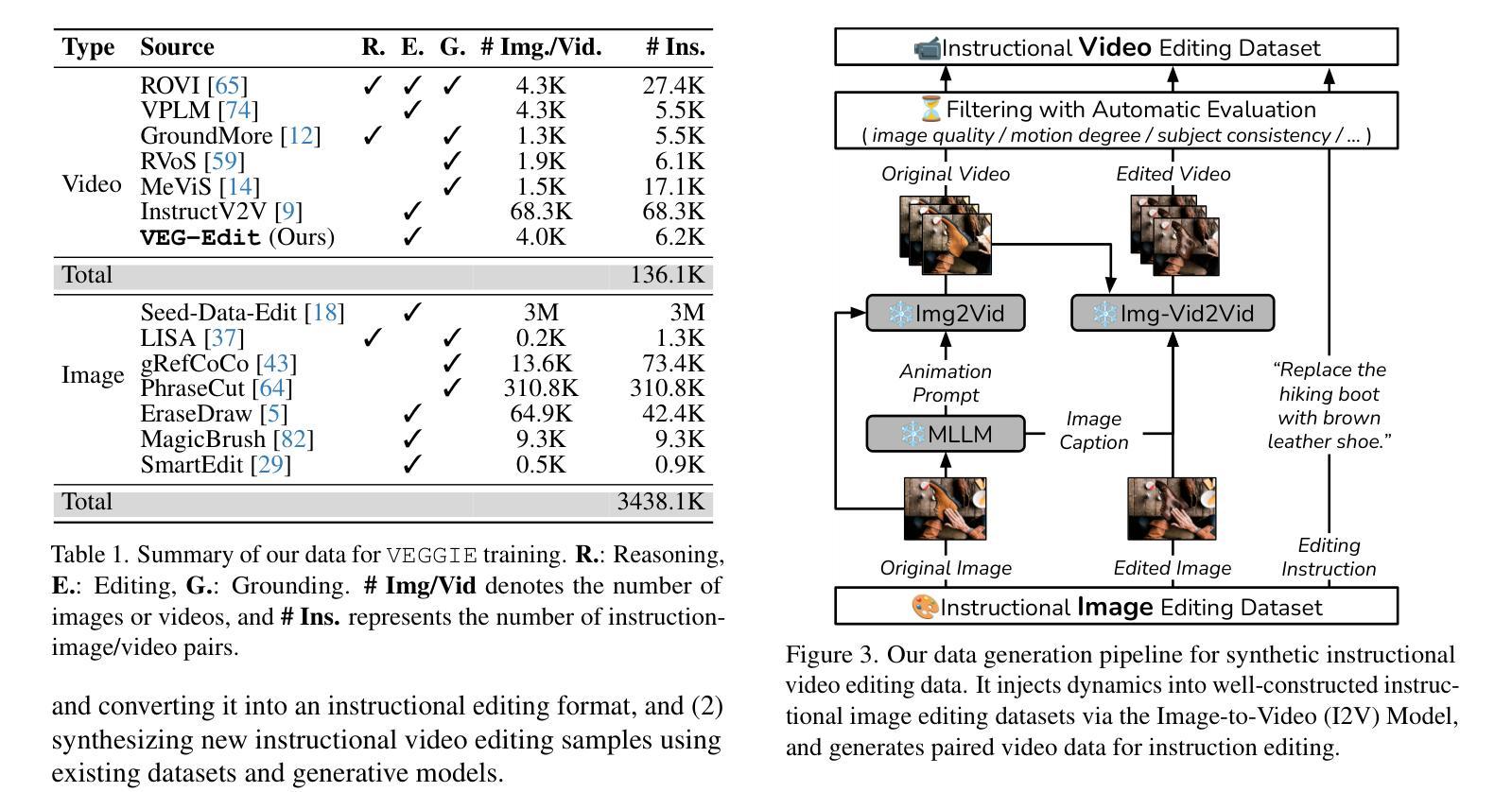
VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
Authors:Shoubin Yu, Difan Liu, Ziqiao Ma, Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, Mohit Bansal
Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
最近的视频扩散模型已经提高了视频编辑的能力,但在统一框架内处理指令编辑和多样化任务(例如添加、删除、更改)仍然具有挑战性。在本文中,我们介绍了VEGGIE,一个基于指令的接地生成视频编辑器,它是一个简单端到端的框架,统一了视频概念编辑、接地和基于多样用户指令的推理。具体来说,给定一个视频和文本查询,VEGGIE首先利用MLLM来解释用户意图的指令并将其接地到视频上下文,为像素空间响应生成特定帧的接地任务查询。然后,扩散模型根据这些计划渲染并生成符合用户意图的视频。为了支持多样化的任务和复杂的指令,我们采用了课程学习策略:首先使用大规模的指令图像编辑数据对齐MLLM和视频扩散模型,然后在高质量的多任务视频数据上进行端到端的微调。此外,我们还引入了一种新的数据合成管道,以生成用于模型训练的一对一指令视频编辑数据。它通过利用图像到视频的模型注入动态性,将静态图像数据转换为多样化、高质量的视频编辑样本。VEGGIE在具有不同编辑技能的指令视频编辑方面表现出强大的性能,作为一个通用模型,它超越了最佳指令基线,而其他模型在多任务处理方面则表现挣扎。VEGGIE在视频对象接地和推理分割方面也表现出色,而其他基线则未能达到这一水平。我们还进一步揭示了多个任务是如何相互帮助的,并强调了有前景的应用,如零样本多模式指令和在上下文中的视频编辑。
论文及项目相关链接
PDF First three authors contributed equally. Project page: https://veggie-gen.github.io/
Summary
本文介绍了VEGGIE,一个基于指令的统合视频编辑框架。该框架利用多模态语言模型(MLLM)理解用户指令并将其与视频内容对应起来,再通过扩散模型生成符合用户意图的编辑视频。为支持多样化的任务和复杂的指令,本文采用了一种课程学习策略,并引入了一种新的数据合成管道来生成训练模型所需的视频编辑数据。VEGGIE在指令视频编辑、视频对象定位和推理分割等多个任务上表现出色。
Key Takeaways
- VEGGIE是一个基于指令的视频编辑框架,可统一处理视频概念编辑、定位与推理。
- 利用MLLM解读用户指令并将其与视频内容对应起来,生成特定帧的任务查询。
- 扩散模型根据这些计划生成符合用户意图的编辑视频。
- 采用课程学习策略支持多样任务和复杂指令的学习。
- 引入新的数据合成管道,将静态图像数据转化为高质量的视频编辑样本。
- VEGGIE在指令视频编辑、视频对象定位和推理分割等任务上表现优秀。
点此查看论文截图


JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Authors:Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, Yiqun Liu
This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
本文介绍了JuDGE(判决文书生成评估)这一新型的中文法律体系中判决文书生成性能评估基准。我们将任务定义为根据给定的案件事实描述生成完整的法律判决书。为了促进这一基准的构建,我们构建了一个综合数据集,其中包括来自真实法律案件的案情描述及其对应的完整判决书,这些判决书作为评估生成文档质量的真实依据。该数据集通过两个外部法律语料库进行了扩充,为任务提供了额外的法律知识:一个包含法规和条例,另一个则包含大量以往的判决书。我们与法律专业人士合作,建立了一个全面的自动化评估框架,从多个维度评估生成的判决书的质量。我们评估了各种基线方法,包括小样本上下文学习、微调以及多源检索增强生成(RAG)方法,这些方法均使用通用和法律领域的LLM。实验结果表明,虽然RAG方法可以有效提高此任务性能,但仍存在很大的改进空间。所有代码和数据集可在:https://github.com/oneal2000/JuDGE找到。
论文及项目相关链接
Summary
本文介绍了JuDGE(判决文书生成评估)基准测试,该测试旨在评估在中国法律体系下判决文书生成的性能。任务的定义是根据给定案例的事实描述生成完整的法律判决书。为推进此基准测试,构建了包含真实案例事实描述与其对应的完整判决书的综合数据集,作为评估生成文书质量的依据。此外,还利用两个外部法律语料库提供额外的法律知识。与法律专业人士合作,建立了全面的自动化评估框架,从多个维度评估生成判决书的质量。对包括少量上下文学习、微调以及多源检索增强生成(RAG)方法等基线方法进行了评估,使用了一般和法律领域的LLMs。实验结果表明,RAG方法虽然能有效提升任务性能,但仍存在很大的改进空间。相关代码和数据集可访问于:https://github.com/oneal2000/JuDGE。
Key Takeaways
- 介绍了JuDGE基准测试,专注于评估中国法律系统下的判决文书生成性能。
- 定义了从案例事实描述生成完整判决书的任务。
- 构建了一个综合数据集,包含真实案例的事实描述和对应的判决书,以及两个外部法律语料库。
- 与法律专业人士合作,建立了全面的自动化评估框架。
- 评估了几种基线方法,包括少量上下文学习、微调以及多源检索增强生成方法。
- 实验结果表明RAG方法能有效提升任务性能,但仍存在改进空间。
点此查看论文截图


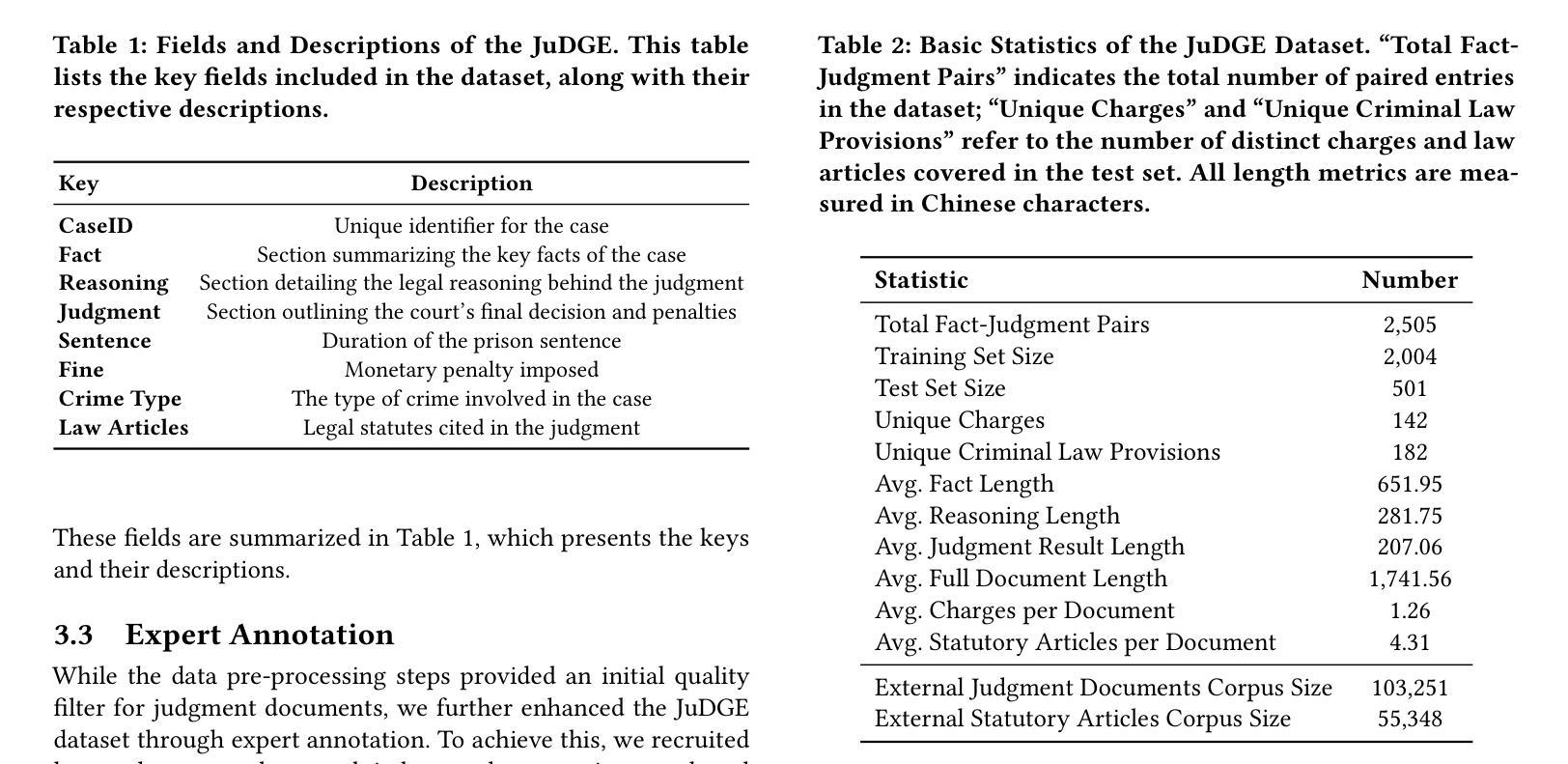
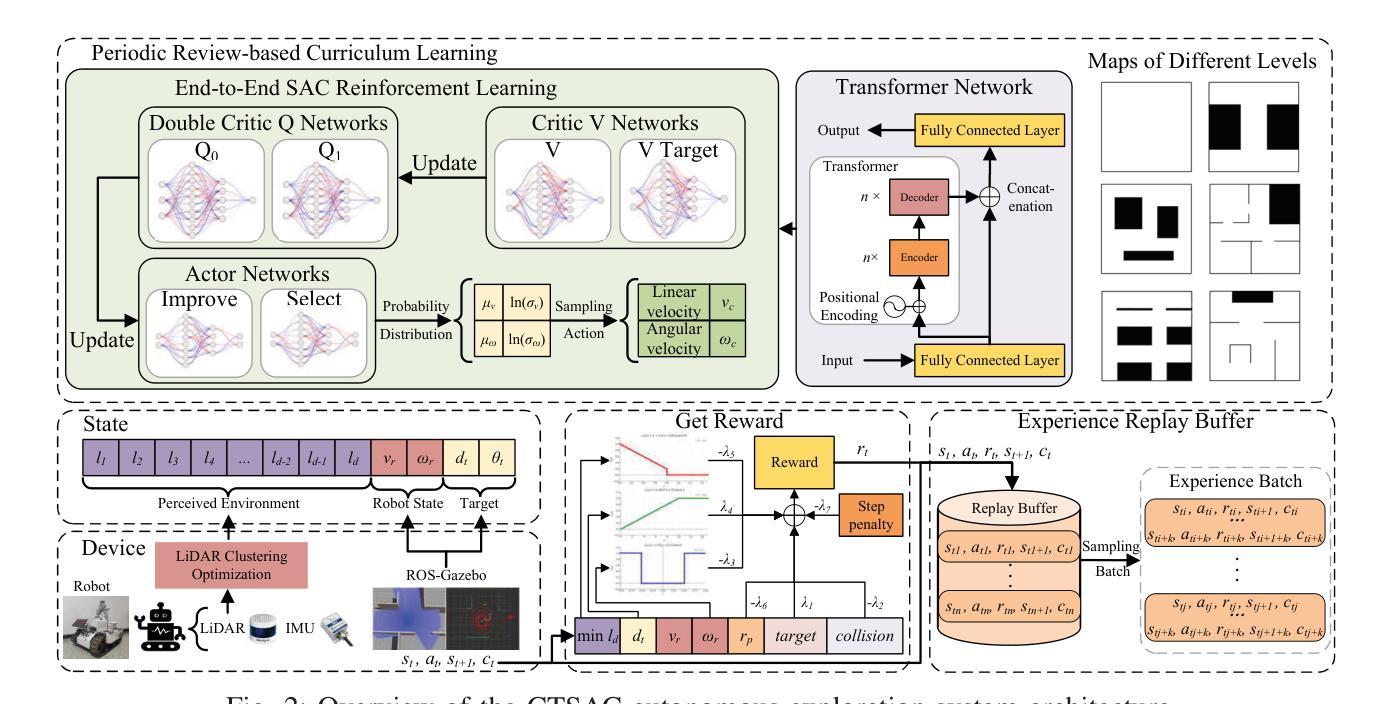
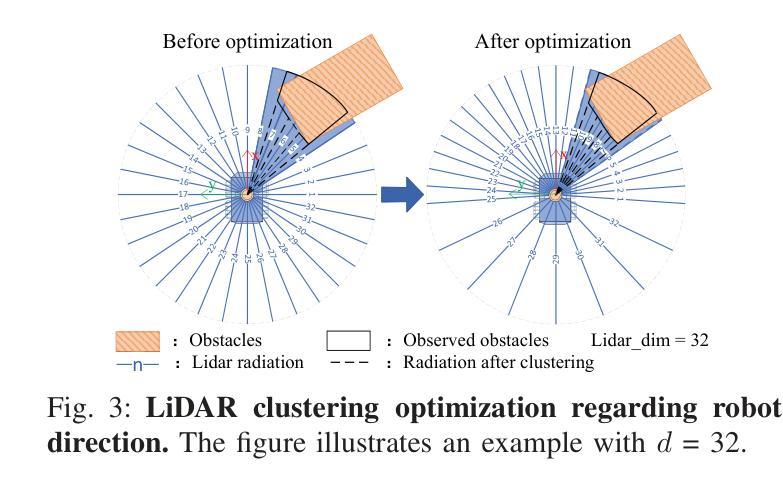
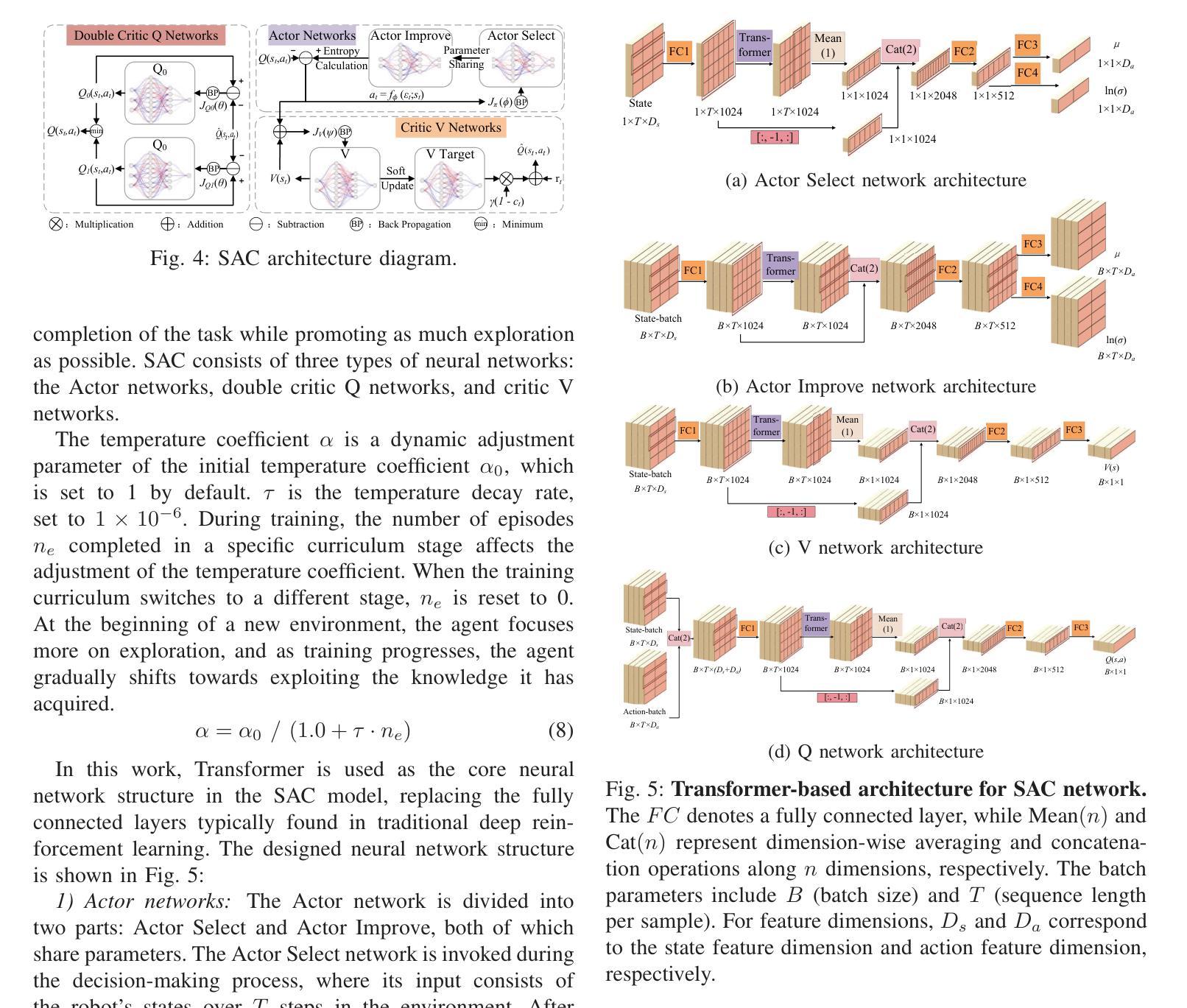
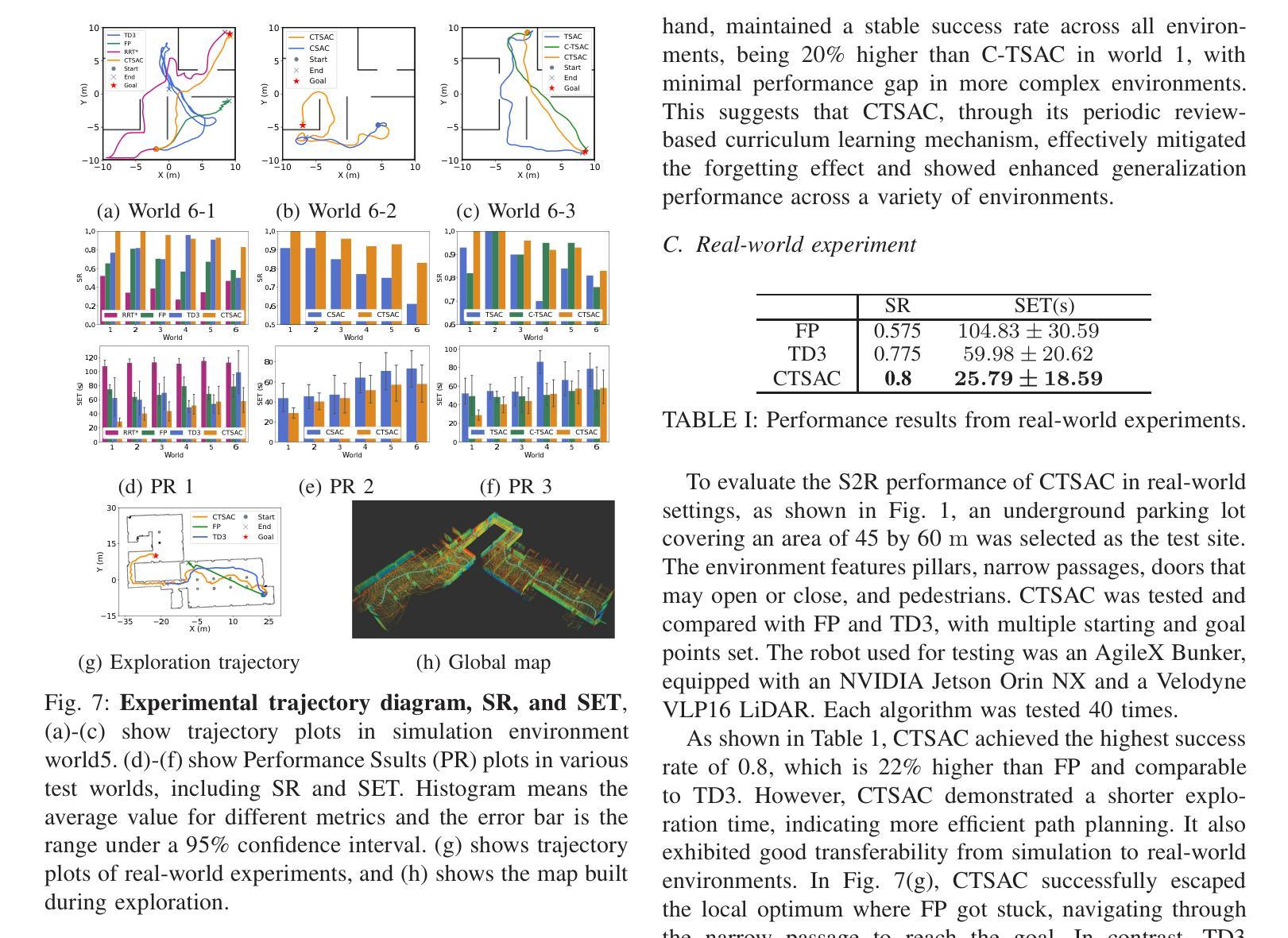
CTSAC: Curriculum-Based Transformer Soft Actor-Critic for Goal-Oriented Robot Exploration
Authors:Chunyu Yang, Shengben Bi, Yihui Xu, Xin Zhang
With the increasing demand for efficient and flexible robotic exploration solutions, Reinforcement Learning (RL) is becoming a promising approach in the field of autonomous robotic exploration. However, current RL-based exploration algorithms often face limited environmental reasoning capabilities, slow convergence rates, and substantial challenges in Sim-To-Real (S2R) transfer. To address these issues, we propose a Curriculum Learning-based Transformer Reinforcement Learning Algorithm (CTSAC) aimed at improving both exploration efficiency and transfer performance. To enhance the robot’s reasoning ability, a Transformer is integrated into the perception network of the Soft Actor-Critic (SAC) framework, leveraging historical information to improve the farsightedness of the strategy. A periodic review-based curriculum learning is proposed, which enhances training efficiency while mitigating catastrophic forgetting during curriculum transitions. Training is conducted on the ROS-Gazebo continuous robotic simulation platform, with LiDAR clustering optimization to further reduce the S2R gap. Experimental results demonstrate the CTSAC algorithm outperforms the state-of-the-art non-learning and learning-based algorithms in terms of success rate and success rate-weighted exploration time. Moreover, real-world experiments validate the strong S2R transfer capabilities of CTSAC.
随着对高效、灵活机器人探索解决方案的需求不断增加,强化学习(RL)在自主机器人探索领域成为了一种有前途的方法。然而,基于当前的强化学习探索算法常常面临环境推理能力有限、收敛速度慢以及在模拟到真实(S2R)转移中的巨大挑战。为了解决这些问题,我们提出了一种基于课程学习的Transformer强化学习算法(CTSAC),旨在提高探索效率和转移性能。为了增强机器人的推理能力,我们将Transformer集成到Soft Actor-Critic(SAC)框架的感知网络中,利用历史信息来提高策略的长远性。我们提出了一种基于定期评审的课程学习,以提高训练效率,同时减轻课程过渡过程中的灾难性遗忘。训练是在ROS-Gazebo连续机器人仿真平台上进行的,利用激光雷达聚类优化来进一步缩小S2R差距。实验结果表明,CTSAC算法在成功率和加权探索时间成功率方面优于最新的非学习型和基于学习的算法。此外,真实世界实验验证了CTSAC强大的S2R转移能力。
论文及项目相关链接
PDF 7pages,7 figures,Thesis received by 2025 ICRA
Summary:随着对高效灵活机器人探索解决方案的需求不断增加,强化学习(RL)在自主机器人探索领域展现出巨大潜力。然而,当前基于RL的探索算法面临着环境推理能力有限、收敛速度慢以及模拟到现实(S2R)转移挑战等问题。为解决这些问题,提出了一种基于课程学习的Transformer强化学习算法(CTSAC),旨在提高探索效率和转移性能。该算法将Transformer集成到Soft Actor-Critic(SAC)框架的感知网络中,利用历史信息提高策略的长远性。同时,提出了基于周期性评审的课程学习,以提高训练效率并减轻课程过渡时的灾难性遗忘。实验结果表明,CTSAC算法在成功率和加权探索时间方面的表现优于最先进的非学习算法和学习算法。此外,真实世界实验验证了CTSAC强大的S2R转移能力。
Key Takeaways:
- 强化学习在自主机器人探索中具有巨大潜力,但面临环境推理能力有限等挑战。
- CTSAC算法通过集成Transformer到SAC框架的感知网络,提高了机器人策略的长远性。
- 基于周期性评审的课程学习增强了训练效率并减轻了灾难性遗忘。
- CTSAC算法在模拟环境中表现出优异的性能,通过ROS-Gazebo连续机器人仿真平台进行了训练。
- LiDAR聚类优化进一步减少了S2R差距。
- 实验结果表明,CTSAC算法在成功率和加权探索时间方面优于其他算法。
点此查看论文截图



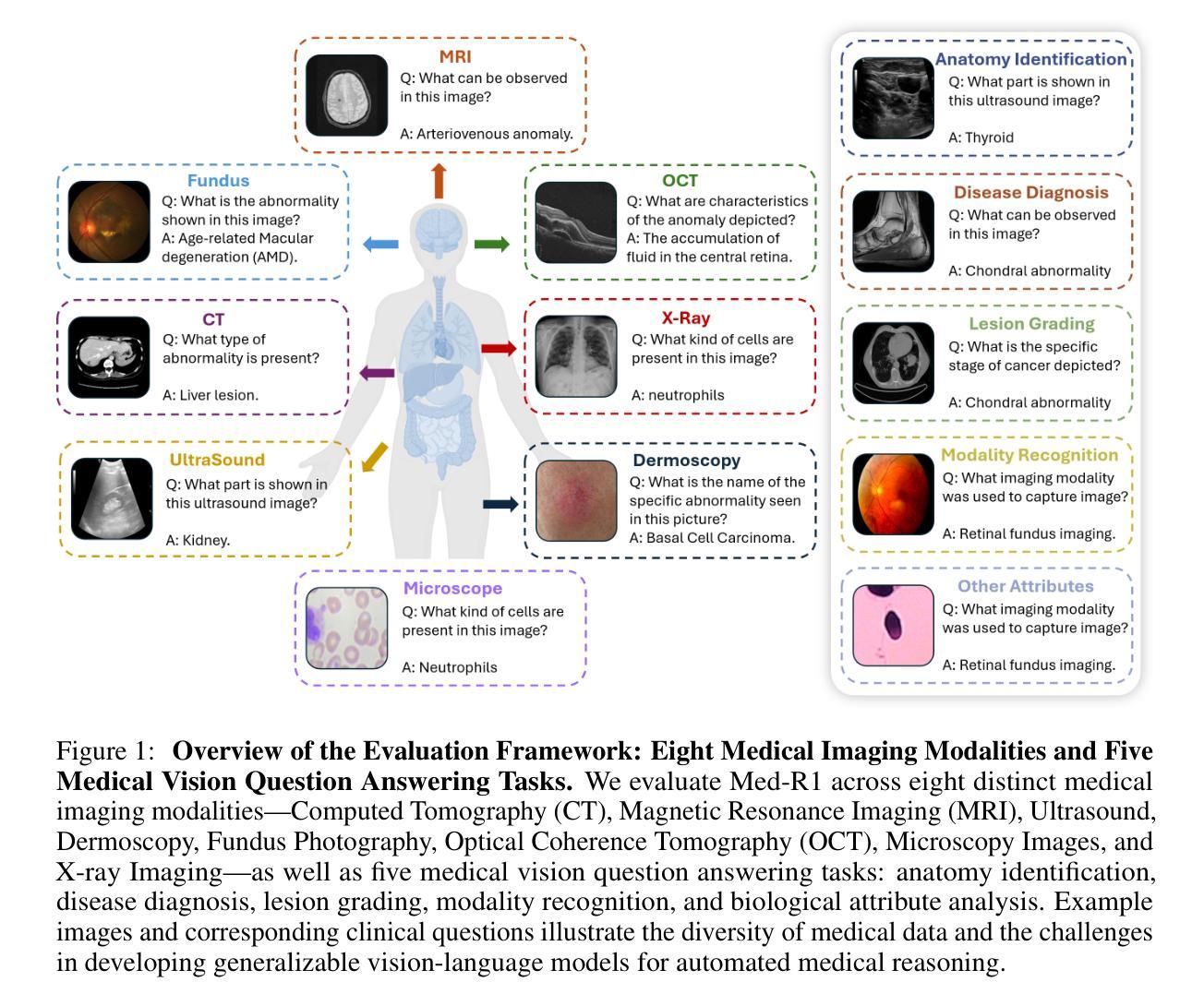
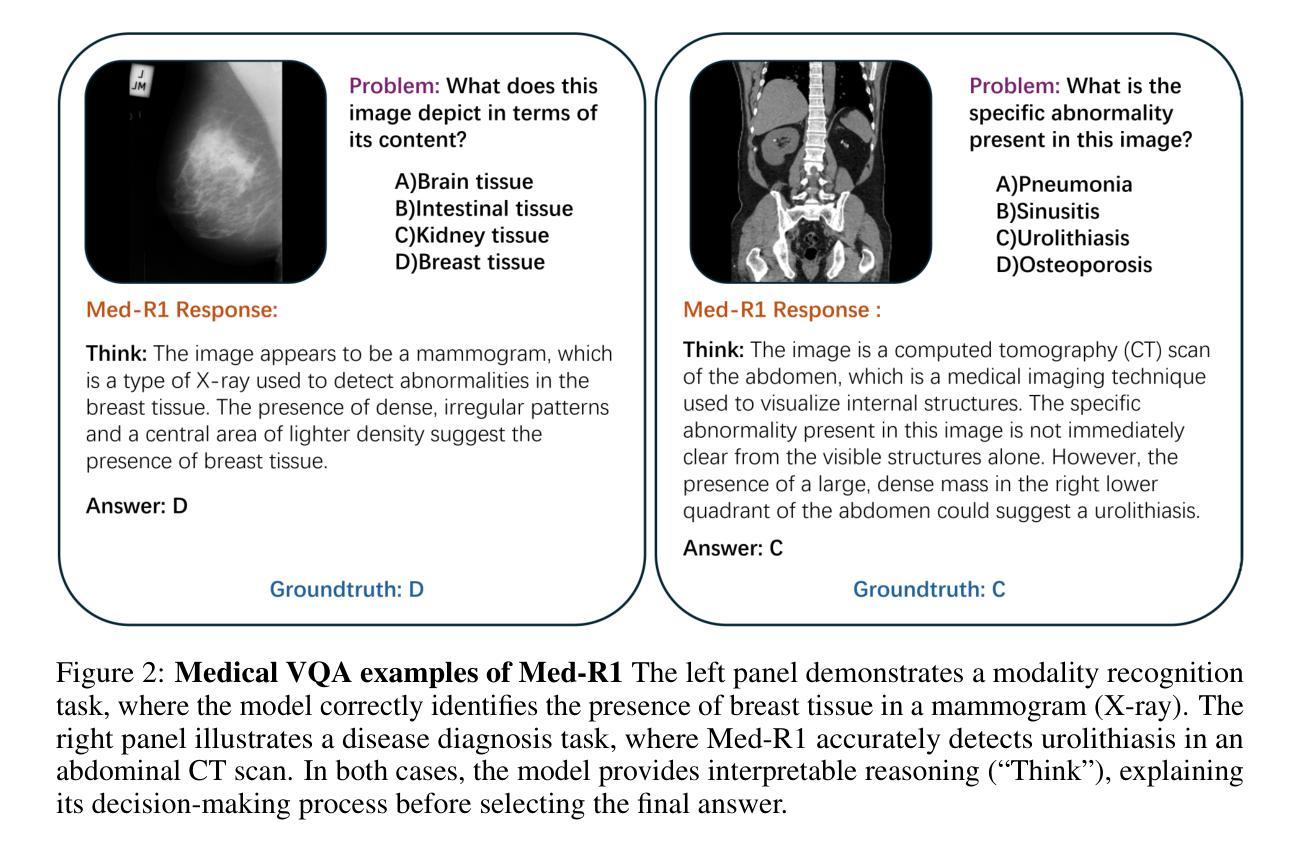
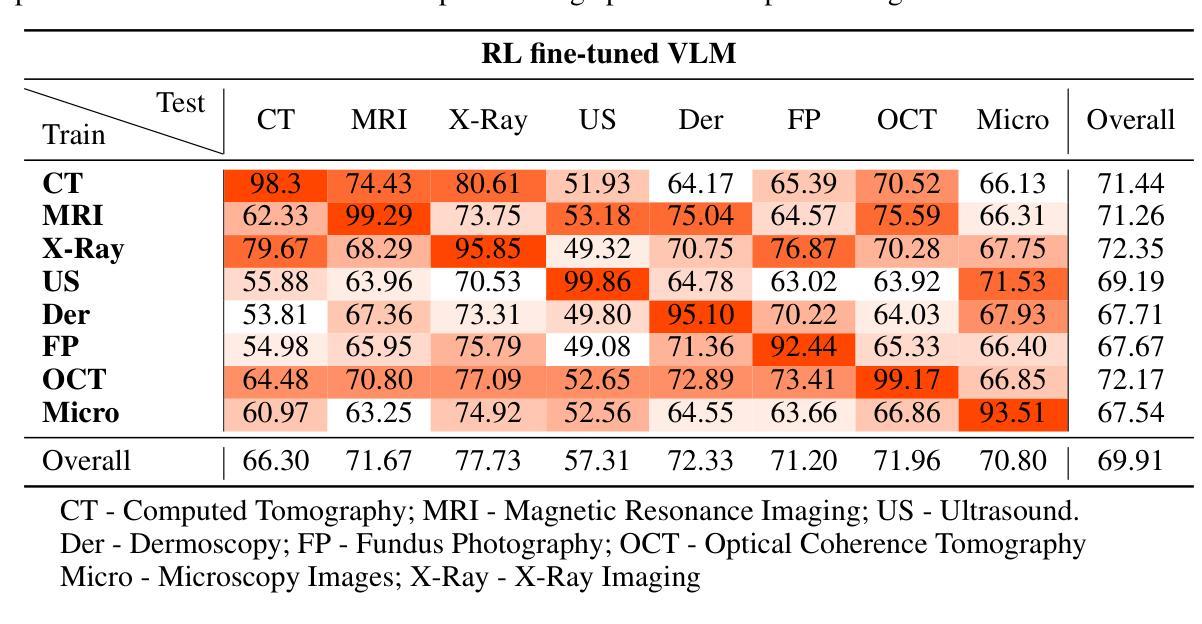
Med-R1: Reinforcement Learning for Generalizable Medical Reasoning in Vision-Language Models
Authors:Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Xiaofeng Yang
Vision-language models (VLMs) have advanced reasoning in natural scenes, but their role in medical imaging remains underexplored. Medical reasoning tasks demand robust image analysis and well-justified answers, posing challenges due to the complexity of medical images. Transparency and trustworthiness are essential for clinical adoption and regulatory compliance. We introduce Med-R1, a framework exploring reinforcement learning (RL) to enhance VLMs’ generalizability and trustworthiness in medical reasoning. Leveraging the DeepSeek strategy, we employ Group Relative Policy Optimization (GRPO) to guide reasoning paths via reward signals. Unlike supervised fine-tuning (SFT), which often overfits and lacks generalization, RL fosters robust and diverse reasoning. Med-R1 is evaluated across eight medical imaging modalities: CT, MRI, Ultrasound, Dermoscopy, Fundus Photography, Optical Coherence Tomography (OCT), Microscopy, and X-ray Imaging. Compared to its base model, Qwen2-VL-2B, Med-R1 achieves a 29.94% accuracy improvement and outperforms Qwen2-VL-72B, which has 36 times more parameters. Testing across five question types-modality recognition, anatomy identification, disease diagnosis, lesion grading, and biological attribute analysis Med-R1 demonstrates superior generalization, exceeding Qwen2-VL-2B by 32.06% and surpassing Qwen2-VL-72B in question-type generalization. These findings show that RL improves medical reasoning and enables parameter-efficient models to outperform significantly larger ones. With interpretable reasoning outputs, Med-R1 represents a promising step toward generalizable, trustworthy, and clinically viable medical VLMs.
视觉语言模型(VLMs)在自然场景推理方面取得了进展,但它们在医学成像中的作用仍然未被充分探索。医学推理任务需要可靠的图像分析和合理的答案,由于医学图像的复杂性,这构成了挑战。透明度和可信度对于临床采用和法规合规至关重要。我们引入了Med-R1框架,探索强化学习(RL)来提高VLMs在医学推理中的通用性和可信度。利用DeepSeek策略,我们采用集团相对政策优化(GRPO)通过奖励信号来指导推理路径。与经常过度拟合且缺乏泛化能力的有监督微调(SFT)不同,RL促进稳健和多样化的推理。Med-R1在八种医学成像模式上进行了评估:CT、MRI、超声、皮肤镜检查、眼底摄影、光学相干断层扫描(OCT)、显微镜和X射线成像。与基准模型相比,Med-R1在准确性上提高了29.94%,并优于参数更多的Qwen2-VL-72B。在五种问题类型(模态识别、解剖结构识别、疾病诊断、病变分级和生物属性分析)的测试上,Med-R1表现出优越的泛化能力,超过Qwen2-VL-2B 32.06%,并在问题类型泛化方面超越Qwen2-VL-72B。这些发现表明,强化学习能够改善医学推理,并使得参数效率模型能够显著优于更大的模型。Med-R1的可解释推理输出是朝着通用、可信和临床上可行的医学VLMs的有希望的一步。
论文及项目相关链接
Summary
本文介绍了Med-R1框架,利用强化学习(RL)提升视觉语言模型(VLMs)在医疗推理中的通用性和可信度。通过DeepSeek策略及Group Relative Policy Optimization(GRPO)引导推理路径,相较于监督微调(SFT),RL促进稳健和多样化的推理。Med-R1在八种医学成像模态上表现出卓越性能,实现相较于基准模型29.94%的准确度提升,且在问题类型泛化方面表现优异。研究结果表明,RL有助于改进医疗推理,使参数效率模型在性能方面超越更大规模模型,为通用、可信且临床可行的医疗VLMs迈出重要一步。
Key Takeaways
- Med-R1框架利用强化学习(RL)增强视觉语言模型(VLMs)在医疗推理中的通用性和可信度。
- DeepSeek策略和Group Relative Policy Optimization(GRPO)用于指导推理路径。
- 相较于监督微调(SFT),强化学习(RL)促进更稳健和多样化的推理。
- Med-R1在多种医学成像模态上表现出卓越性能,实现显著的性能提升。
- Med-R1在问题类型泛化方面表现出优势,优于基准模型和更大规模模型。
- RL有助于改进医疗推理,提升模型的可解释性。
点此查看论文截图

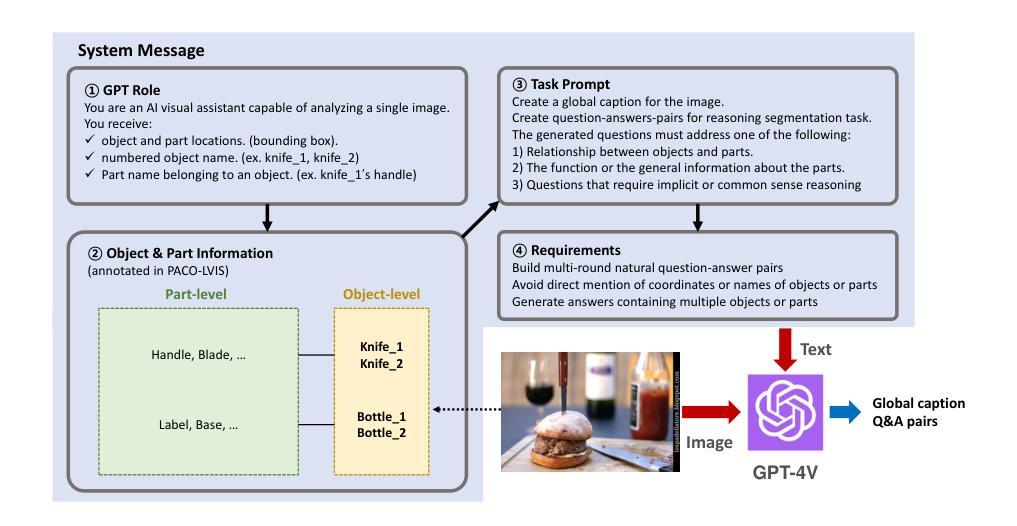
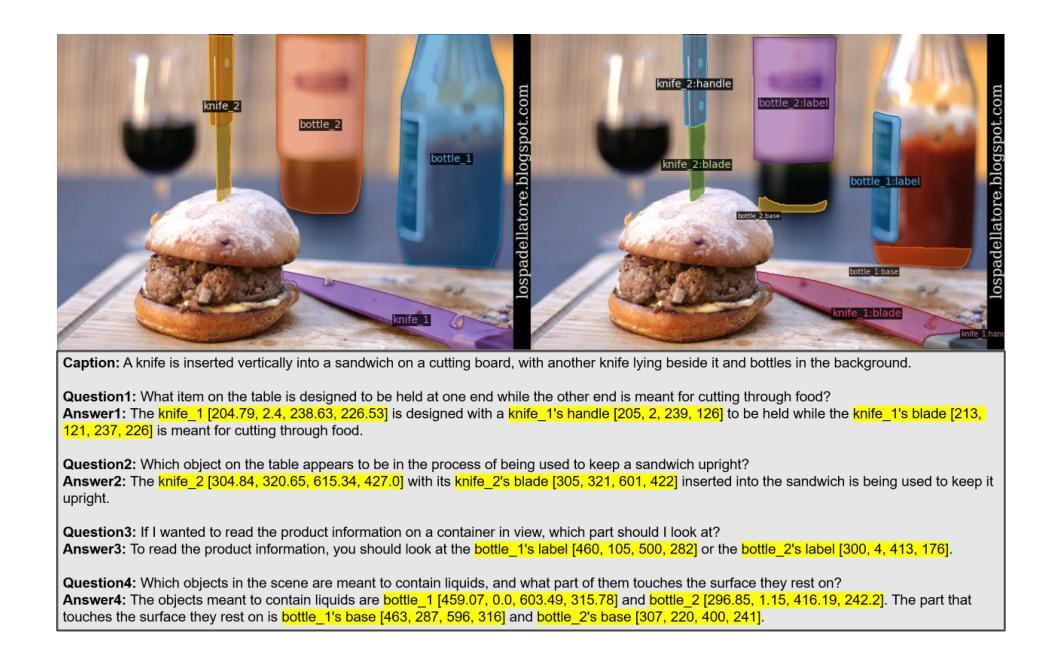
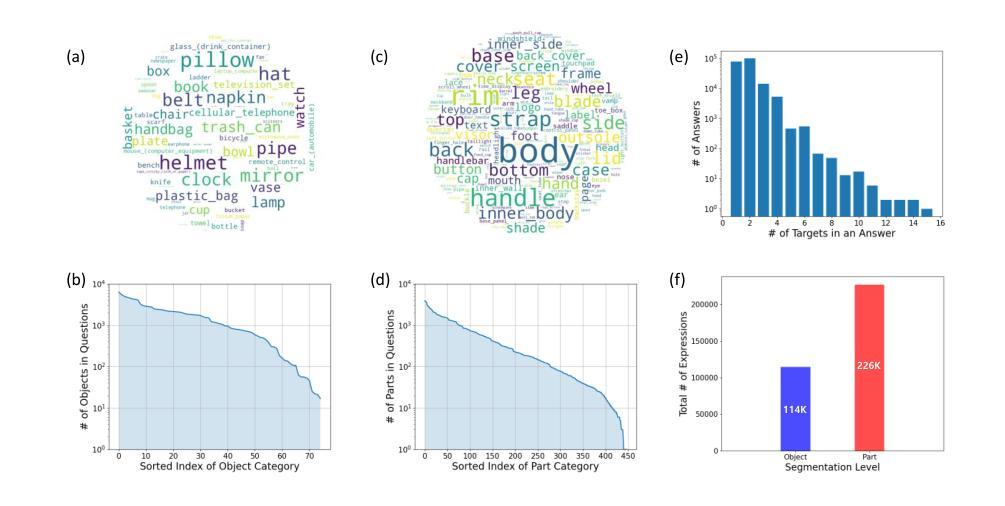
MMR: A Large-scale Benchmark Dataset for Multi-target and Multi-granularity Reasoning Segmentation
Authors:Donggon Jang, Yucheol Cho, Suin Lee, Taehyeon Kim, Dae-Shik Kim
The fusion of Large Language Models with vision models is pioneering new possibilities in user-interactive vision-language tasks. A notable application is reasoning segmentation, where models generate pixel-level segmentation masks by comprehending implicit meanings in human instructions. However, seamless human-AI interaction demands more than just object-level recognition; it requires understanding both objects and the functions of their detailed parts, particularly in multi-target scenarios. For example, when instructing a robot to \textit{turn on the TV”}, there could be various ways to accomplish this command. Recognizing multiple objects capable of turning on the TV, such as the TV itself or a remote control (multi-target), provides more flexible options and aids in finding the optimized scenario. Furthermore, understanding specific parts of these objects, like the TV’s button or the remote’s button (part-level), is important for completing the action. Unfortunately, current reasoning segmentation datasets predominantly focus on a single target object-level reasoning, which limits the detailed recognition of an object’s parts in multi-target contexts. To address this gap, we construct a large-scale dataset called Multi-target and Multi-granularity Reasoning (MMR). MMR comprises 194K complex and implicit instructions that consider multi-target, object-level, and part-level aspects, based on pre-existing image-mask sets. This dataset supports diverse and context-aware interactions by hierarchically providing object and part information. Moreover, we propose a straightforward yet effective framework for multi-target, object-level, and part-level reasoning segmentation. Experimental results on MMR show that the proposed method can reason effectively in multi-target and multi-granularity scenarios, while the existing reasoning segmentation model still has room for improvement.
将大型语言模型与视觉模型的融合在交互式视觉语言任务中开创了新的可能性。一个典型的应用是推理分割,模型通过理解人类指令中的隐含意义来生成像素级的分割掩膜。然而,无缝的人机交互不仅仅是基于目标级别的识别;它要求了解对象和它们详细部分的功能,特别是在多目标场景中。例如,当指示机器人“打开电视”时,可能有多种方式来完成这个命令。识别能够打开电视的多目标对象,如电视本身或遥控器(多目标),提供了更灵活的选择并有助于找到最佳场景。此外,了解这些对象的特定部分,如电视的按钮或遥控器的按钮(部分级别),对于完成动作也很重要。然而,当前的推理分割数据集主要集中在单一目标对象级别的推理上,这限制了多目标上下文中对象部分的详细识别。为了弥补这一空白,我们构建了一个大规模数据集,称为多目标多粒度推理(MMR)。MMR由基于现有图像掩模集的19.4万条复杂且隐含的指令组成,这些指令考虑了多目标、对象级别和部分级别的方面。该数据集通过分层提供对象和部分信息,支持多样化和情境感知的交互。此外,我们提出了一个简单有效的多目标、对象级别和部分级别的推理分割框架。在MMR上的实验结果表明,所提出的方法在多目标和多粒度场景中能够进行有效的推理,而现有的推理分割模型仍有改进的空间。
论文及项目相关链接
PDF ICLR 2025, Code and dataset are available at \url{https://github.com/jdg900/MMR}
Summary
本文介绍了大型语言模型与视觉模型的融合在交互式视觉语言任务中的创新应用。特别是在推理分割领域,模型能够生成像素级的分割掩膜,通过理解人类指令中的隐含意义。然而,无缝的人机交互不仅需要识别对象级别,还需要理解对象及其详细部分的功能,特别是在多目标场景中。文章构建了一个大规模数据集Multi-target and Multi-granularity Reasoning (MMR),以支持多样化和上下文感知的交互,并提供了一个针对多目标、对象级别和部分级别的推理分割的框架。实验结果证明了该方法在多目标和多粒度场景中的有效性。
Key Takeaways
- 大型语言模型与视觉模型的融合为交互式视觉语言任务带来创新可能性。
- 推理分割是其中一项重要应用,模型通过理解人类指令中的隐含意义生成像素级分割掩膜。
- 人机交互需要理解对象及其详细部分的功能,特别是在多目标场景中。
- 当前推理分割数据集主要关注单一目标对象级别的推理,需要更多关注多目标场景下的详细对象部分识别。
- 构建了一个大规模数据集MMR,支持多样化和上下文感知的交互,涵盖多目标、对象级别和部分级别的信息。
- 提出了一种针对多目标、对象级别和部分级别的推理分割的框架。
点此查看论文截图


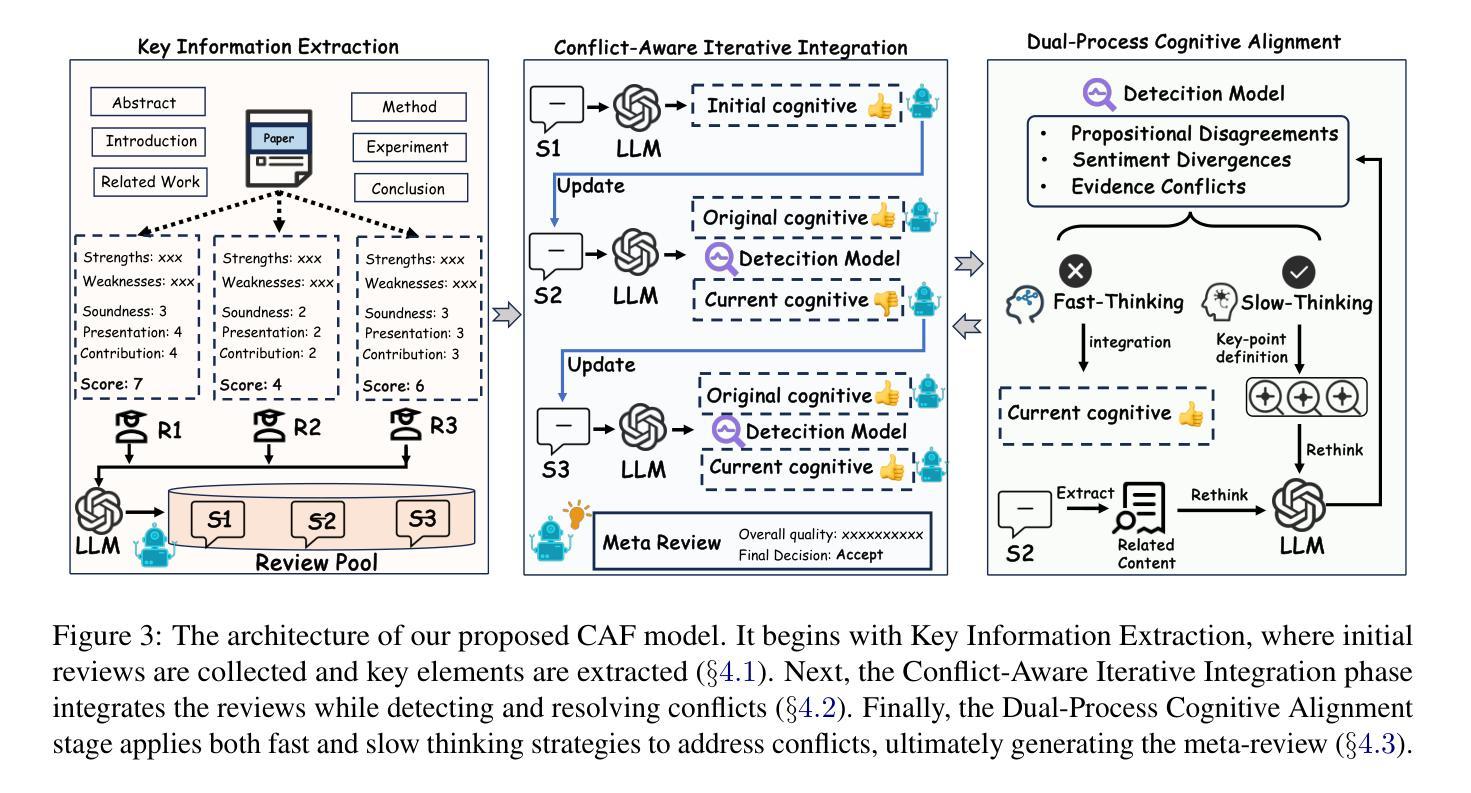
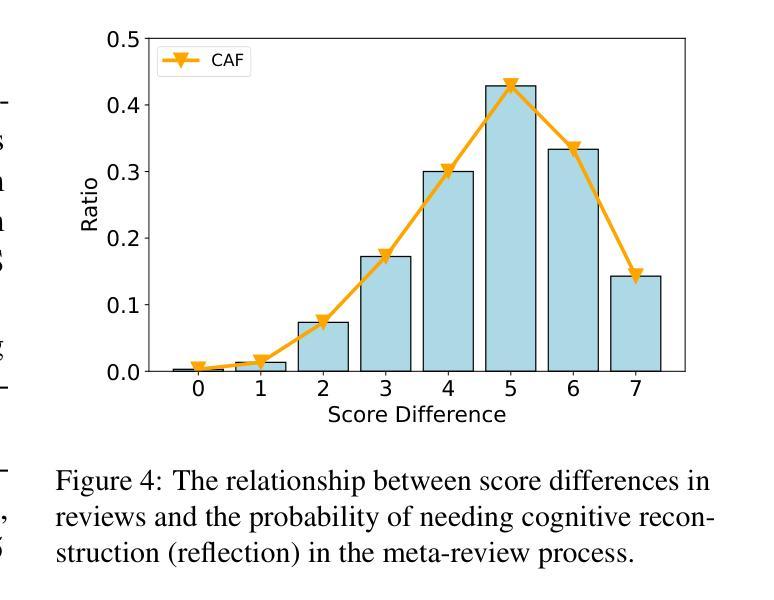
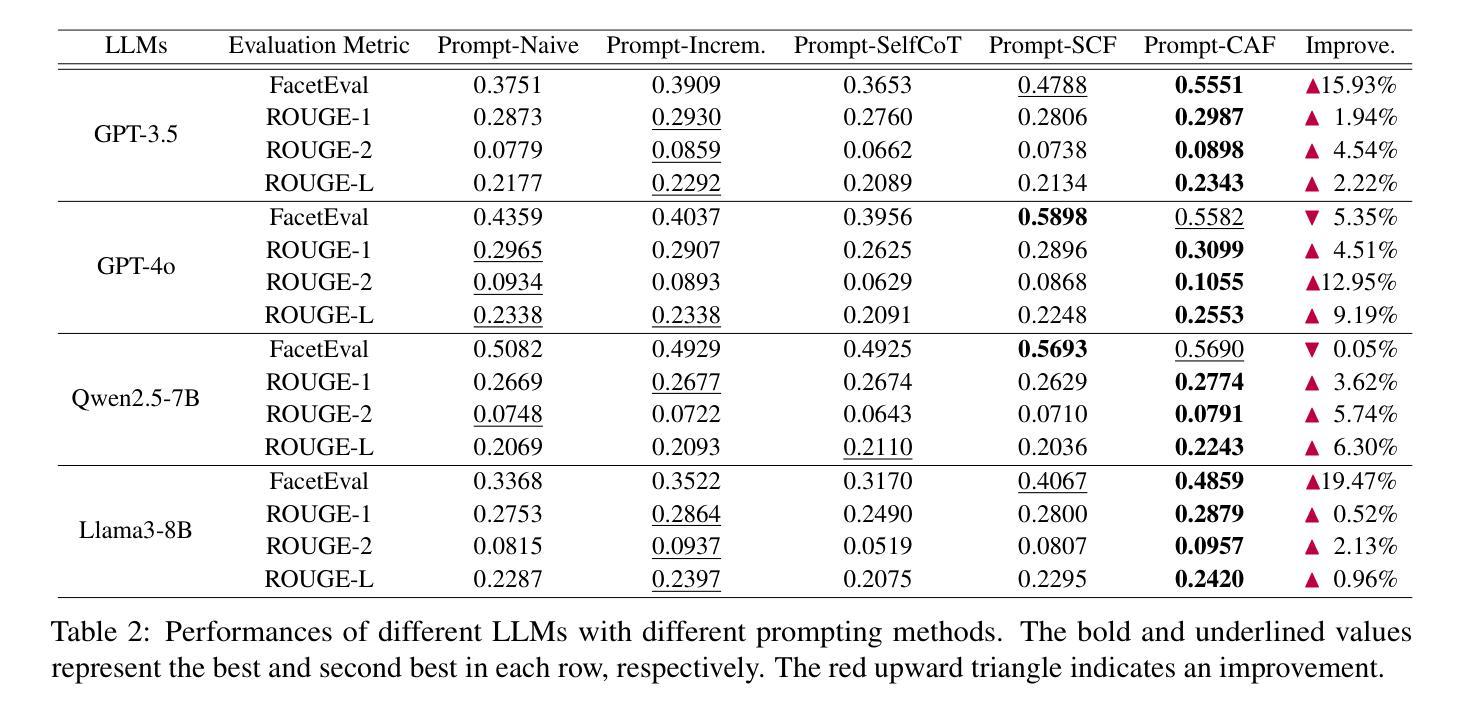
Bridging Social Psychology and LLM Reasoning: Conflict-Aware Meta-Review Generation via Cognitive Alignment
Authors:Wei Chen, Han Ding, Meng Yuan, Zhao Zhang, Deqing Wang, Fuzhen Zhuang
The rapid growth of scholarly submissions has overwhelmed traditional peer review systems, driving the need for intelligent automation to preserve scientific rigor. While large language models (LLMs) show promise in automating manuscript critiques, their ability to synthesize high-stakes meta-reviews, which require conflict-aware reasoning and consensus derivation, remains underdeveloped. Existing methods fail to effectively handle conflicting viewpoints within differing opinions, and often introduce additional cognitive biases, such as anchoring effects and conformity bias.To overcome these limitations, we propose the Cognitive Alignment Framework (CAF), a dual-process architecture that transforms LLMs into adaptive scientific arbitrators. By operationalizing Kahneman’s dual-process theory, CAF introduces a three-step cognitive pipeline: review initialization, incremental integration, and cognitive alignment.Empirical validation shows that CAF outperforms existing LLM-based methods, with sentiment consistency gains reaching up to 19.47% and content consistency improving by as much as 12.95%.
学术稿件的迅速增长已经使传统的同行评审系统不堪重负,这促使需要智能自动化来保持科学的严谨性。虽然大型语言模型(LLM)在自动化手稿评审方面显示出潜力,但它们在综合高风险元评审方面的能力,这需要意识到冲突推理和共识推导,仍然处于未开发状态。现有方法无法有效处理不同观点中的冲突观点,并经常引入额外的认知偏见,例如锚定效应和服从偏见。为了克服这些局限性,我们提出了认知对齐框架(CAF),这是一种双过程架构,可将LLM转换为自适应的科学仲裁者。通过实施Kahneman的双过程理论,CAF引入了一个三步骤的认知管道:评审初始化、增量集成和认知对齐。实证研究证明,CAF在情感一致性方面的提升达到了高达19.47%,内容一致性也提高了最多达12.95%,表现优于现有的LLM方法。
论文及项目相关链接
PDF 23 pages
Summary
文章探讨学术提交的高速增长对传统的同行评审系统带来的压力,并指出智能自动化是缓解这一压力的关键。尽管大型语言模型(LLM)在自动化手稿评审方面显示出潜力,但在合成需要冲突感知推理和共识推导的高风险元评审方面仍存在不足。现有方法无法有效处理不同观点中的冲突,并可能引入额外的认知偏见。为解决这些问题,文章提出了认知对齐框架(CAF),这是一个将LLM转化为自适应科学仲裁者的双过程架构。CAF根据卡内曼的双重过程理论,设计了一个包括审查初始化、增量集成和认知对齐的三步认知管道。实证验证显示,CAF在情感一致性和内容一致性方面都优于现有的LLM方法,其增益分别高达19.47%和12.95%。
Key Takeaways
- 学术提交量的迅速增长促使对智能自动化以维持科学严谨性的需求。
- 大型语言模型(LLMs)在自动化手稿评审中有潜力,但在合成高风险的元评审方面存在局限。
- 现有方法难以处理不同观点中的冲突,并可能引入额外的认知偏见。
- 提出了认知对齐框架(CAF)来解决上述问题,这是一个双过程架构。
- CAF基于卡内曼的双重过程理论,包括审查初始化、增量集成和认知对齐三个步骤。
- CAF在情感一致性和内容一致性方面的表现优于现有LLM方法。
点此查看论文截图



Counterfactual experience augmented off-policy reinforcement learning
Authors:Sunbowen Lee, Yicheng Gong, Chao Deng
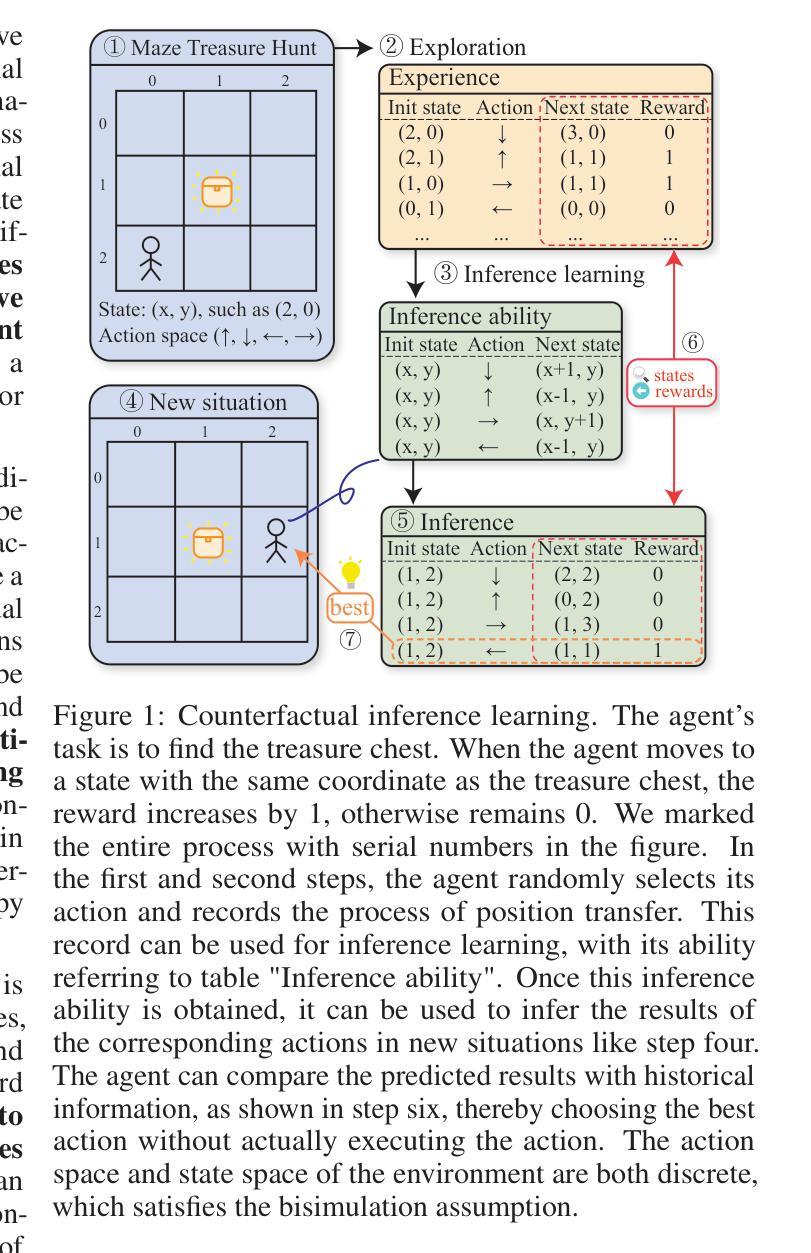
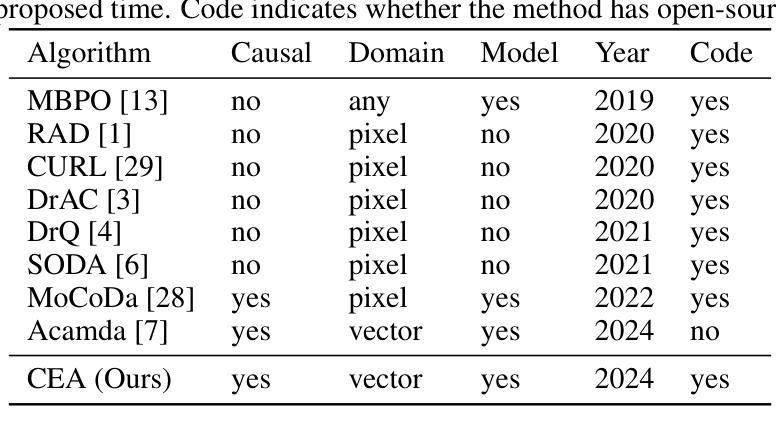
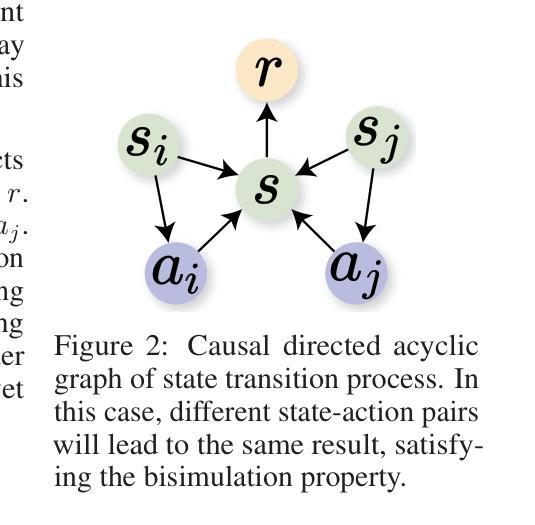
Reinforcement learning control algorithms face significant challenges due to out-of-distribution and inefficient exploration problems. While model-based reinforcement learning enhances the agent’s reasoning and planning capabilities by constructing virtual environments, training such virtual environments can be very complex. In order to build an efficient inference model and enhance the representativeness of learning data, we propose the Counterfactual Experience Augmentation (CEA) algorithm. CEA leverages variational autoencoders to model the dynamic patterns of state transitions and introduces randomness to model non-stationarity. This approach focuses on expanding the learning data in the experience pool through counterfactual inference and performs exceptionally well in environments that follow the bisimulation assumption. Environments with bisimulation properties are usually represented by discrete observation and action spaces, we propose a sampling method based on maximum kernel density estimation entropy to extend CEA to various environments. By providing reward signals for counterfactual state transitions based on real information, CEA constructs a complete counterfactual experience to alleviate the out-of-distribution problem of the learning data, and outperforms general SOTA algorithms in environments with difference properties. Finally, we discuss the similarities, differences and properties of generated counterfactual experiences and real experiences. The code is available at https://github.com/Aegis1863/CEA.
强化学习控制算法面临着由于分布外和无效探索问题而带来的重大挑战。基于模型的强化学习通过构建虚拟环境来提升智能体的推理和规划能力,但训练这样的虚拟环境可能非常复杂。为了构建高效的推理模型并增强学习数据的代表性,我们提出了Counterfactual Experience Augmentation(CEA)算法。CEA利用变分自动编码器来建模状态转换的动态模式,并引入随机性来建模非平稳性。该方法侧重于通过反事实推理扩展经验池中的学习数据,在遵循双模拟假设的环境中表现尤为出色。具有双模拟属性的环境通常表现为离散观测和动作空间,我们提出了一种基于最大核密度估计熵的采样方法,将CEA扩展到各种环境。CEA基于真实信息为反事实状态转换提供奖励信号,构建完整的反事实经验,以缓解学习数据的分布外问题,并在具有不同属性的环境中优于一般的最先进算法。最后,我们讨论了生成的反事实经验与真实经验之间的相似性、差异和属性。代码可在https://github.com/Aegis1863/CEA获取。
论文及项目相关链接
PDF Accepted by Neurocomputing, https://doi.org/10.1016/j.neucom.2025.130017
Summary
强化学习控制算法面临分布外和无效探索的问题。模型化强化学习通过构建虚拟环境提升智能体的推理和规划能力,但训练这些虚拟环境可能非常复杂。为了建立高效的推理模型和增强学习数据的代表性,我们提出了基于因果经验的扩增算法(CEA)。CEA利用变分自动编码器模拟状态转换的动态模式,并引入随机性模拟非稳定性。该方法侧重于通过因果推断扩充经验池中的学习数据,并在遵循双模拟假设的环境中表现优异。对于离散观测和动作空间的环境,我们提出了一种基于最大核密度估计熵的采样方法,以扩展CEA的应用范围。CEA通过为因果状态转换提供基于真实信息的奖励信号,构建了完整的因果经验,缓解了学习数据分布外的问题,并在具有不同属性的环境中优于一般的最先进算法。此外我们还探讨了生成型因果经验和真实经验之间的相似性、差异性和属性。相关代码可访问网址:https://github.com/Aegis1863/CEA。
Key Takeaways
- 强化学习控制算法面临分布外和无效探索的挑战。
- 模型化强化学习通过构建虚拟环境提升智能体的能力,但训练复杂性较高。
- 提出了基于因果经验的扩增算法(CEA)来解决这些问题。
- CEA利用变分自动编码器模拟状态转换,并引入随机性以适应非稳定性。
- CEA通过扩充经验池中的学习数据,在遵循双模拟假设的环境中表现优异。
- 提出了基于最大核密度估计熵的采样方法,以扩展CEA至不同环境。
点此查看论文截图

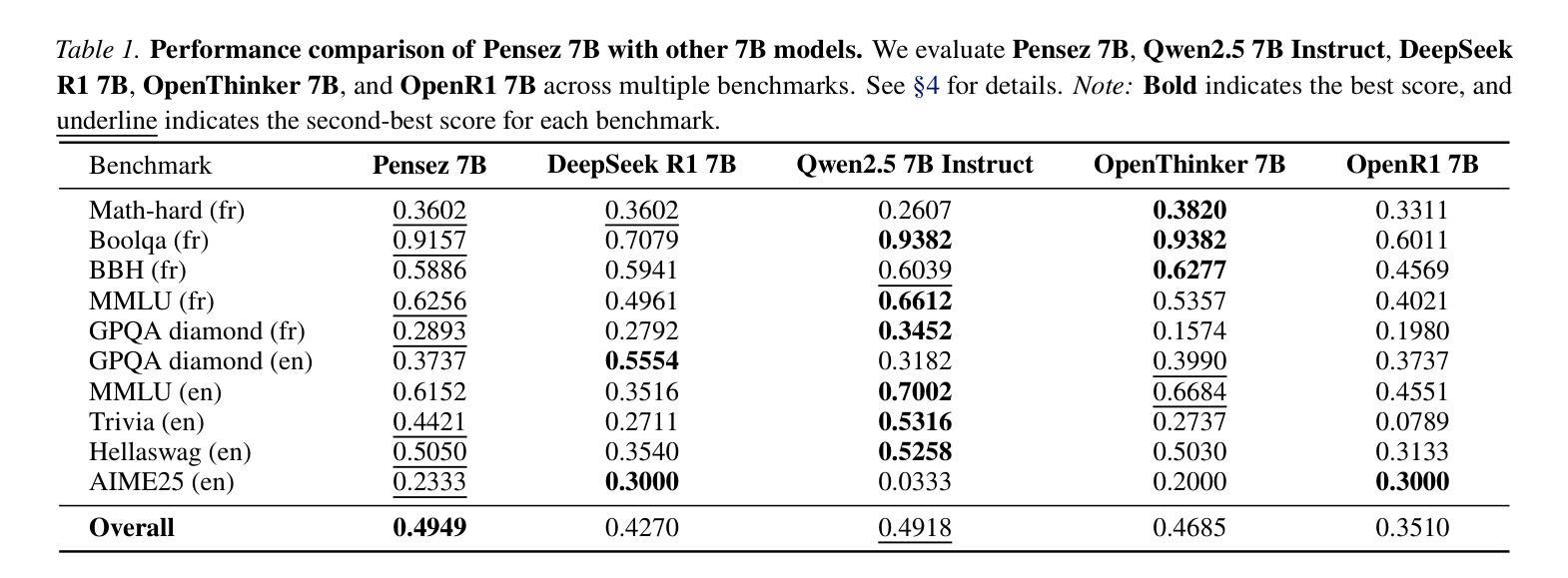
Pensez: Less Data, Better Reasoning – Rethinking French LLM
Authors:Huy Hoang Ha
Large language models (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, achieving strong performance in specialized domains like mathematical reasoning and non-English languages often requires extensive training on massive datasets. This paper investigates a contrasting approach: strategic fine-tuning on a small, high-quality, bilingual (English-French) dataset to enhance both the reasoning capabilities and French language proficiency of a large language model. Rather than relying on scale, we explore the hypothesis that targeted data curation and optimized training can achieve competitive, or even superior, performance. We demonstrate, through targeted supervised fine-tuning (SFT) on only 2,000 carefully selected samples, significant improvements in mathematical reasoning. Specifically, Pensez 7B exhibits an increase in accuracy of the base model up to 20% on the AIME25 and a 12% increase on a French MATH level 5 benchmark. These results challenge the prevailing assumption that massive datasets are aprerequisite for strong reasoning performance in LLMs, highlighting the potential of strategic data curation and optimized fine-tuning for enhancing both specialized skills and multilingual capabilities. Our findings have implications for the efficient development of high-performing, multilingual LLMs, especially in resource-constrained scenarios.
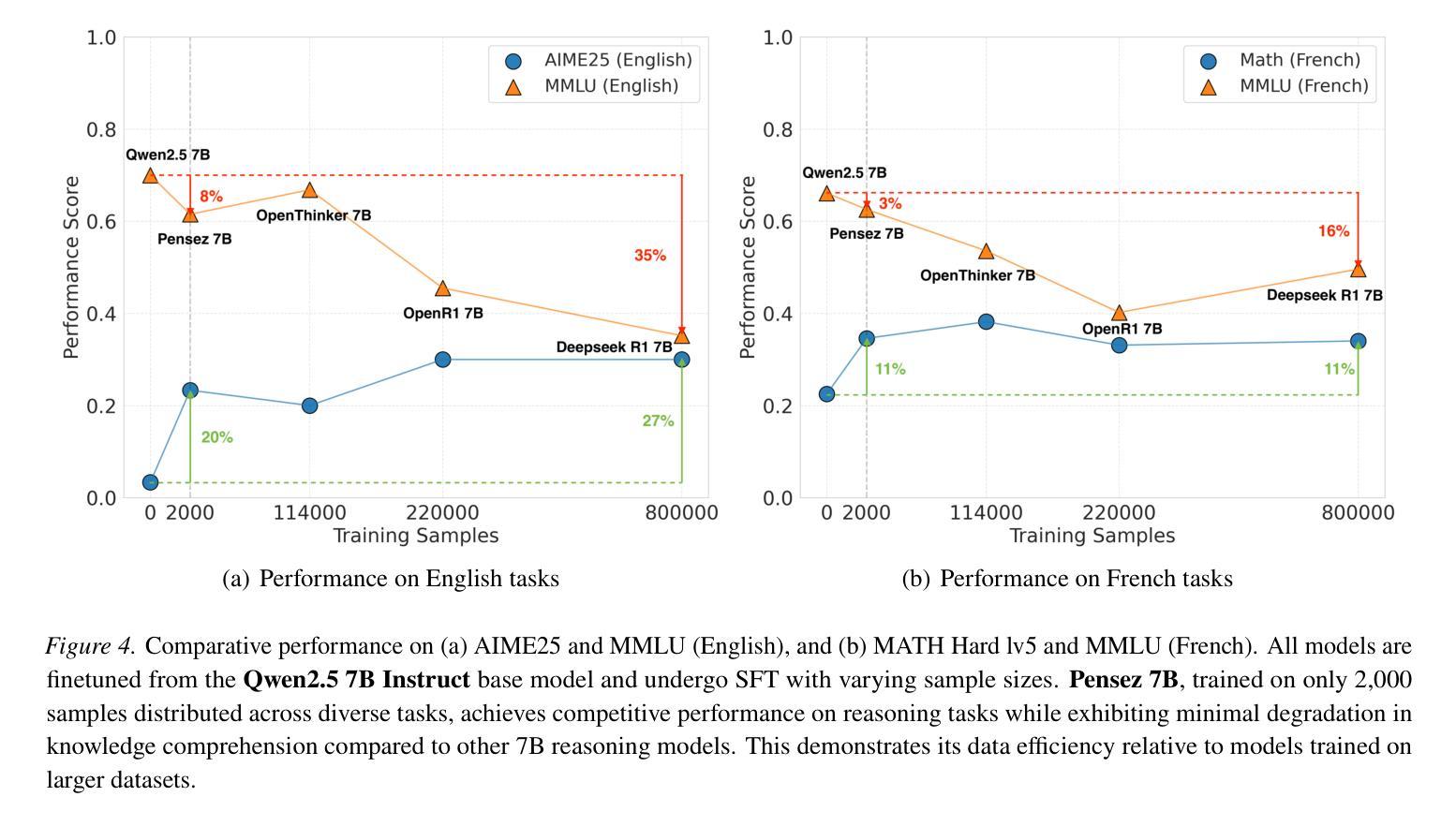
大型语言模型(LLM)在各种自然语言处理任务中表现出了显著的能力。然而,在数学推理和非英语领域等专业化领域实现卓越性能,通常需要在大规模数据集上进行大量训练。本文研究了一种相反的方法:在小型、高质量、双语(英语-法语)数据集上进行有针对性的微调,以提高大型语言模型的推理能力和法语熟练度。我们并不依赖大规模数据集,而是探索有针对性的数据收集和优化训练能否达到竞争水平甚至更高水平的性能。我们通过仅在精心挑选的2000个样本上进行有针对性的监督微调(SFT),在数学推理方面取得了显著改进。具体来说,Pensez 7B在AIME25上的准确率提高了高达20%,在法国MATH 5级基准测试上的准确率提高了12%。这些结果挑战了大规模数据集是LLM实现强大推理能力的先决条件的普遍假设,突显了有针对性的数据收集和优化微调在增强专项技能和多种语言能力方面的潜力。我们的发现对高效开发高性能、多语言的大型语言模型具有启示意义,特别是在资源受限的场景下。
论文及项目相关链接
Summary
大型语言模型在多种自然语言处理任务中展现出显著的能力。然而,在数学推理和非英语领域的专业领域,通常需要大规模数据集进行广泛训练。本文探索了一种对比方法:在小型、高质量的双语(英语-法语)数据集上进行有针对性的微调,以增强大型语言模型的推理能力和法语熟练度。研究假设有针对性的数据收集和优化训练可以达到竞争性的性能,甚至可能更优秀。通过仅使用精心挑选的2000个样本进行有针对性的监督微调(SFT),在数学推理方面取得了显著改善。具体来说,Pensez 7B在AIME25上的准确率提高了20%,在法国MATH 5级基准测试上的准确率提高了12%。这些结果挑战了大规模数据集对于大型语言模型进行数学推理能力的必要性假设,突显了有针对性的数据收集和优化微调在增强特殊技能和多种语言能力方面的潜力。这对高效开发高性能的、多语言的LLM模型有重要的影响。该研究为资源有限情境下如何推进相关研发提供了一种可行的视角。
Key Takeaways
- LLM在特定领域如数学推理和非英语语言方面需专门训练以提升性能。
- 通过小规模高质量双语数据集的战略微调可增强模型的推理和语言能力。
- 仅通过少量针对性样本监督微调就能显著改善数学推理能力。
- Pensez 7B模型在AIME25上的准确率提升显著,显示出优化训练数据策略的潜力。
- 研究挑战了大规模数据集对于LLM在数学推理领域的必要性假设。
- 有针对性的数据收集和优化微调对于增强特殊技能和多种语言能力有重要作用。
点此查看论文截图

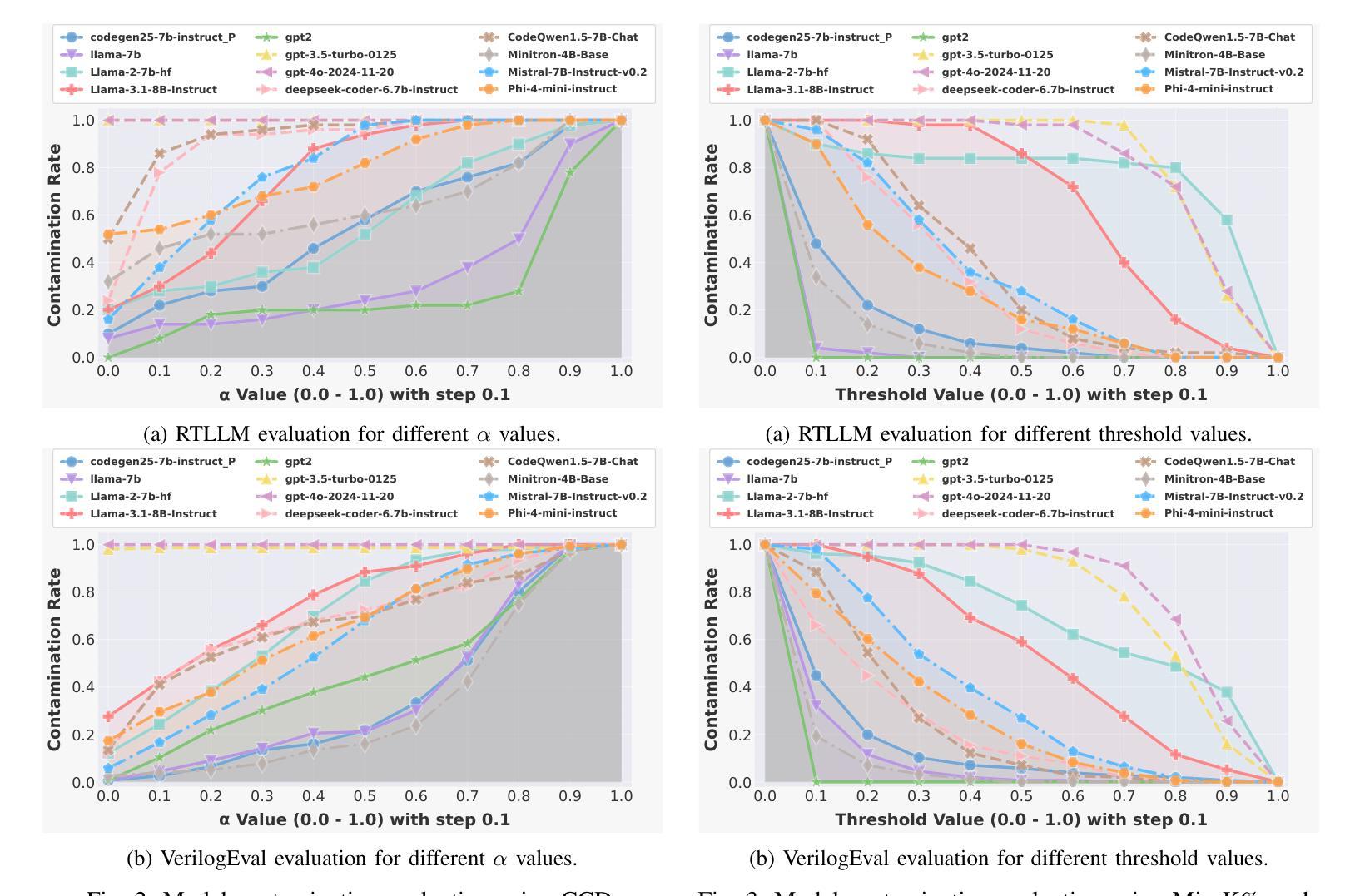
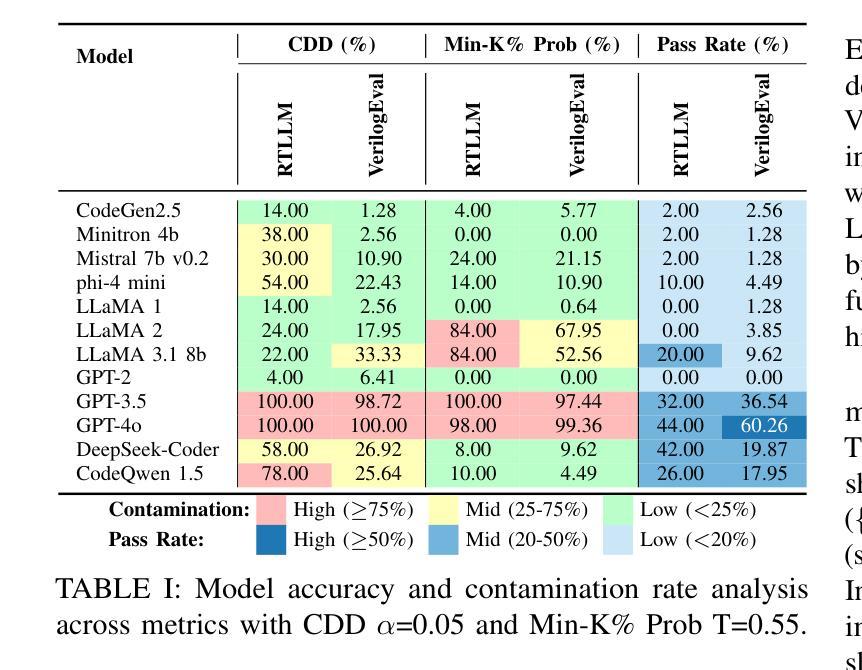
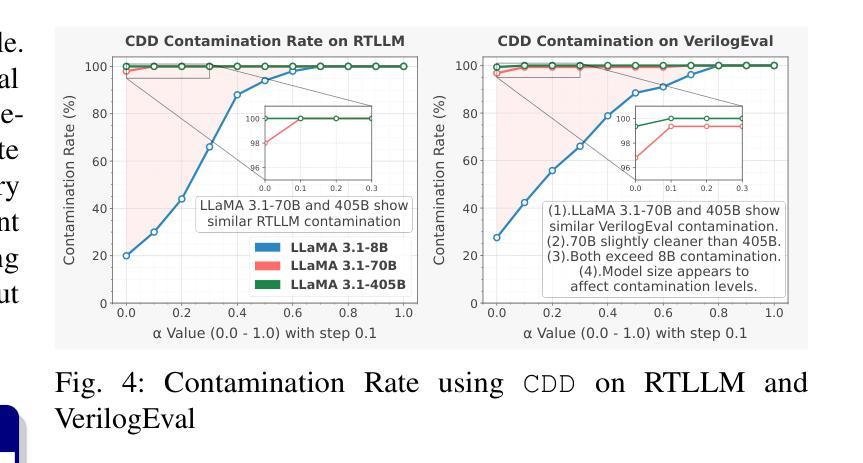
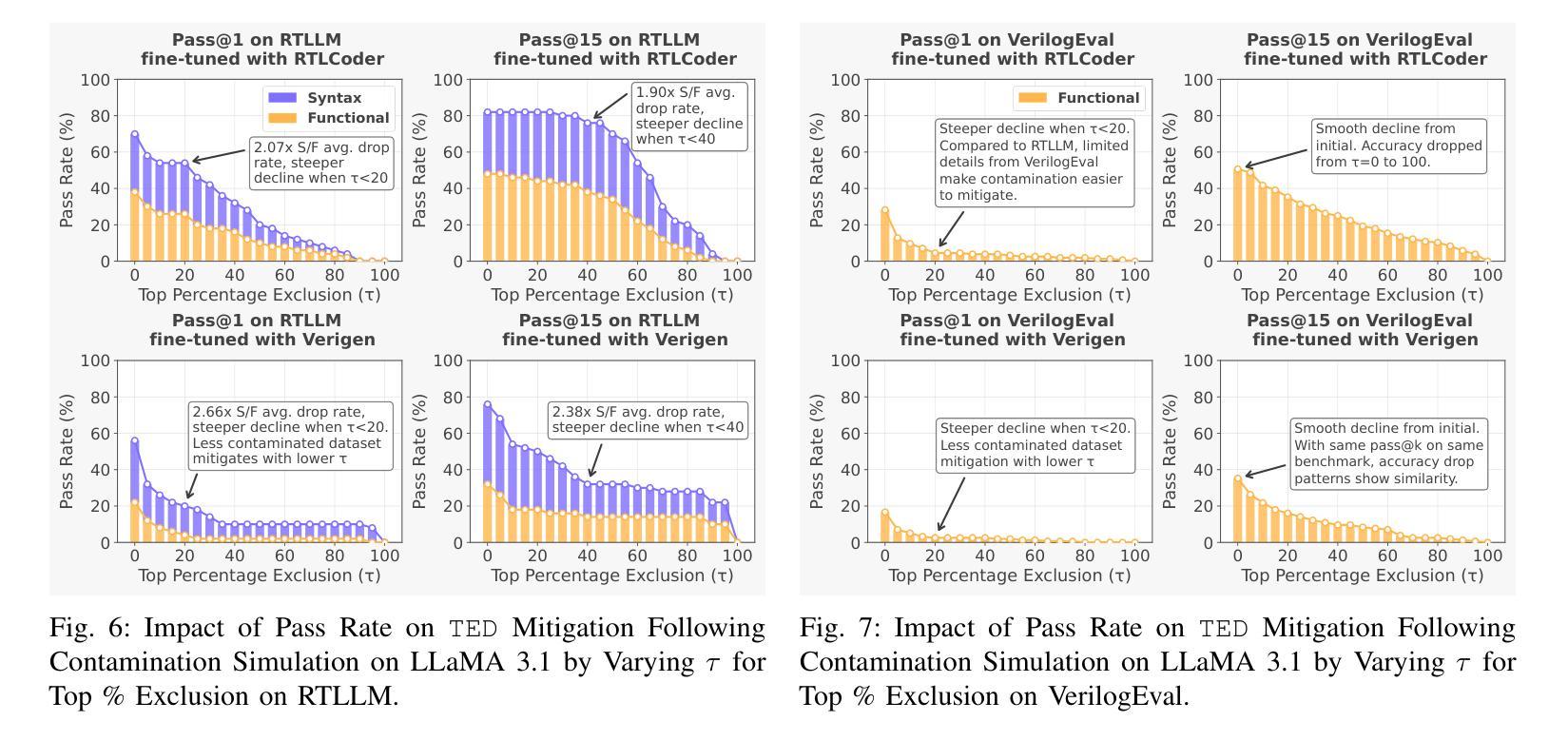
VeriContaminated: Assessing LLM-Driven Verilog Coding for Data Contamination
Authors:Zeng Wang, Minghao Shao, Jitendra Bhandari, Likhitha Mankali, Ramesh Karri, Ozgur Sinanoglu, Muhammad Shafique, Johann Knechtel
Large Language Models (LLMs) have revolutionized code generation, achieving exceptional results on various established benchmarking frameworks. However, concerns about data contamination - where benchmark data inadvertently leaks into pre-training or fine-tuning datasets - raise questions about the validity of these evaluations. While this issue is known, limiting the industrial adoption of LLM-driven software engineering, hardware coding has received little to no attention regarding these risks. For the first time, we analyze state-of-the-art (SOTA) evaluation frameworks for Verilog code generation (VerilogEval and RTLLM), using established methods for contamination detection (CCD and Min-K% Prob). We cover SOTA commercial and open-source LLMs (CodeGen2.5, Minitron 4b, Mistral 7b, phi-4 mini, LLaMA-{1,2,3.1}, GPT-{2,3.5,4o}, Deepseek-Coder, and CodeQwen 1.5), in baseline and fine-tuned models (RTLCoder and Verigen). Our study confirms that data contamination is a critical concern. We explore mitigations and the resulting trade-offs for code quality vs fairness (i.e., reducing contamination toward unbiased benchmarking).
大型语言模型(LLM)已经彻底改变了代码生成的方式,在各种成熟的基准测试框架上取得了非凡的成果。然而,对数据污染的担忧——即基准测试数据无意中泄露到预训练或微调数据集——对这些评估的有效性提出了质疑。虽然这个问题已经为人所知,并限制了LLM驱动的软件工程在工业中的应用,但硬件编码几乎没有关注这些风险。我们首次使用污染检测(CCD和Min-K% Prob)的既定方法,分析了最先进的Verilog代码生成评估框架(VerilogEval和RTLLM)。我们涵盖了最先进的商业和开源LLM(CodeGen2.5、Minitron 4b、Mistral 7b、phi-4 mini、LLaMA-{1,2,3.1}、GPT-{2,3.5,4o}、Deepseek-Coder和CodeQwen 1.5),以及基准模型和微调模型(RTLCoder和Verigen)。我们的研究证实了数据污染是一个关键问题。我们探讨了缓解方法和代码质量与公平性之间的权衡(即减少污染以实现公平的基准测试)。
论文及项目相关链接
Summary:大型语言模型在代码生成方面取得了革命性的成果,但在预训练或微调数据集意外泄露基准测试数据的问题上引发了有效性质疑。本研究首次对最先进的Verilog代码生成评估框架(VerilogEval和RTLLM)进行了分析,并使用了污染检测方法来验证数据污染问题。研究确认数据污染是一个关键问题,并探讨了缓解措施及其与代码质量和公平性之间的权衡。
Key Takeaways:
- 大型语言模型在代码生成方面表现出卓越性能。
- 数据污染问题对LLM的有效性评价提出了质疑。
- 首次对Verilog代码生成的最新评估框架进行了污染分析。
- 使用已建立的污染检测方法证实了数据污染问题的存在。
- 数据污染是一个关键问题,需要解决。
- 研究探讨了缓解数据污染的措施及其与代码质量的权衡。
点此查看论文截图



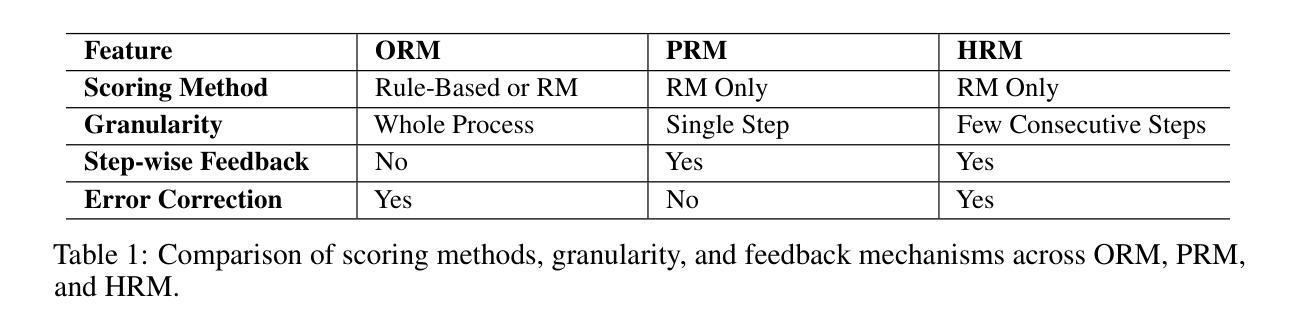
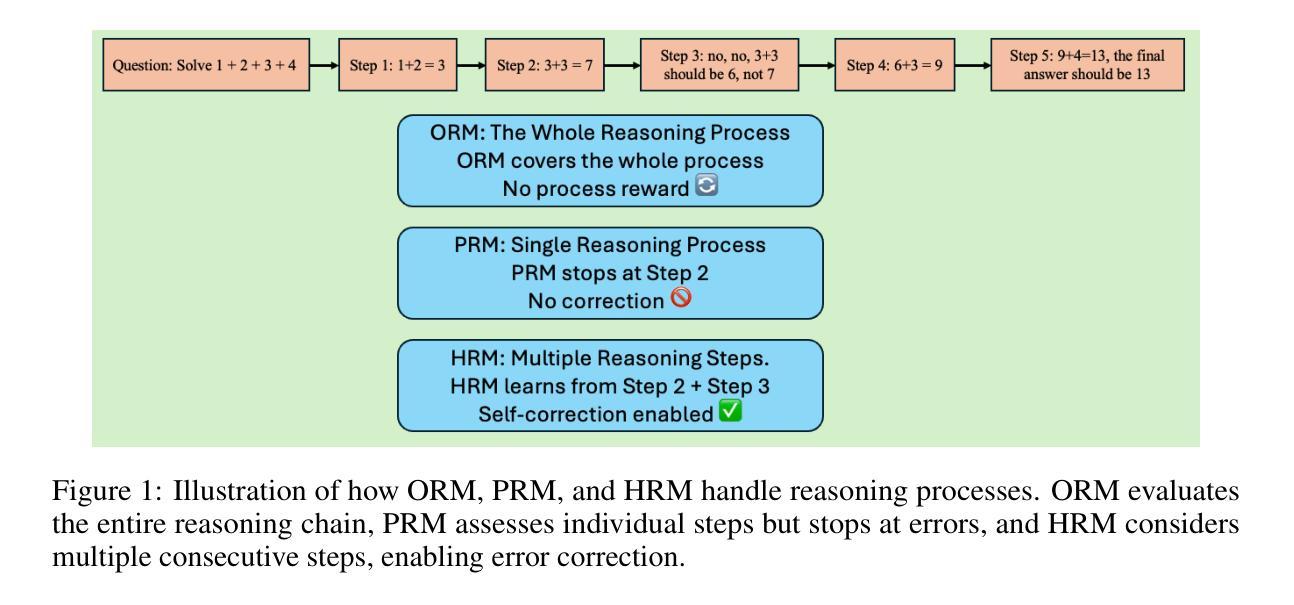
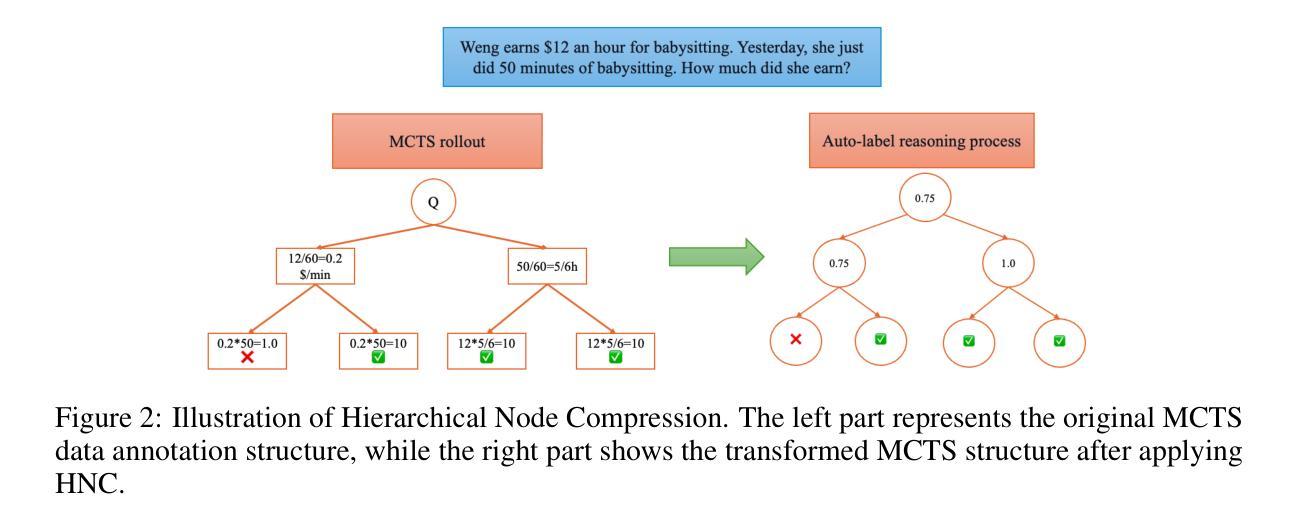
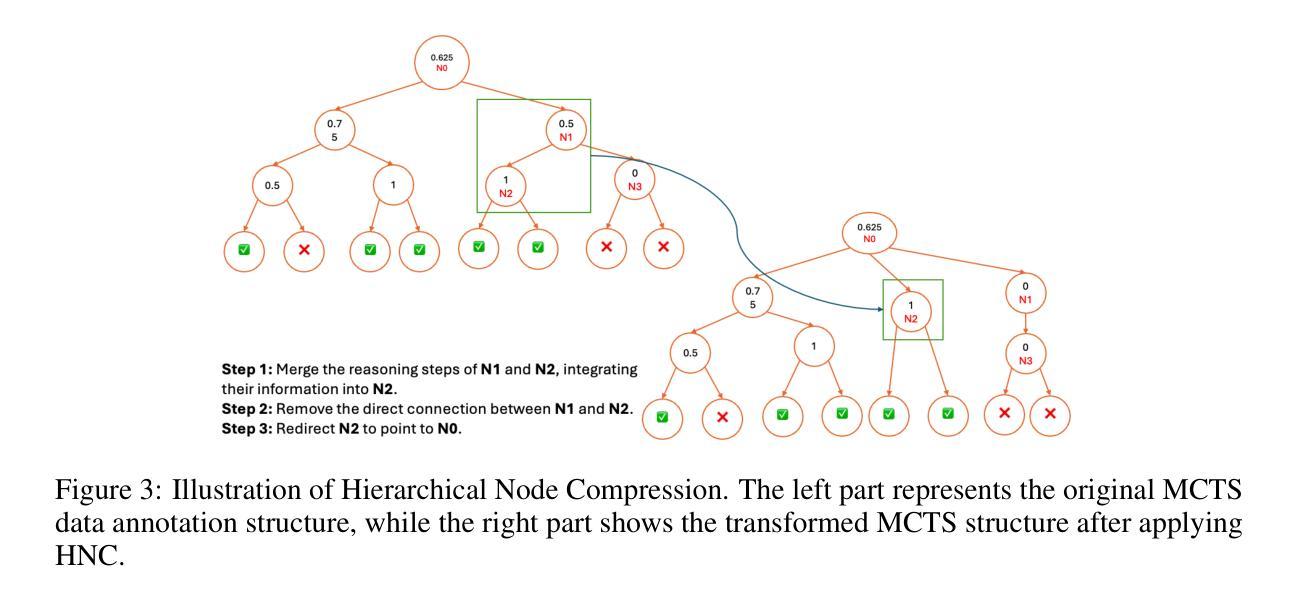
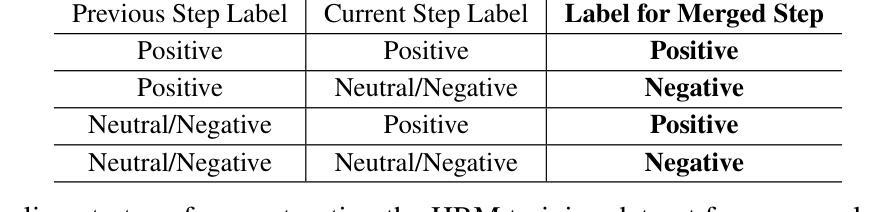
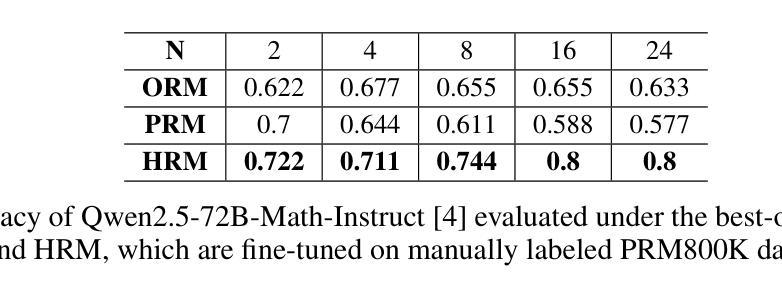
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Authors:Teng Wang, Zhangyi Jiang, Zhenqi He, Wenhan Yang, Yanan Zheng, Zeyu Li, Zifan He, Shenyang Tong, Hailei Gong
Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM’s superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
最近的研究表明,大型语言模型(LLM)通过监督微调或强化学习实现了强大的推理能力。然而,一种关键方法——过程奖励模型(PRM)存在奖励作弊的问题,使其在识别最佳中间步骤时变得不可靠。在本文中,我们提出了一种新的奖励模型方法,即分层奖励模型(HRM),它可以从精细粒度和粗略粒度两个层面评估单个和连续的推理步骤。HRM在评估推理连贯性和自我反思方面表现更好,特别是在前一个推理步骤错误的情况下。此外,为了解决通过蒙特卡洛树搜索(MCTS)自主生成PRM训练数据效率低下的问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的树结构中的分层节点压缩(HNC)的轻量级有效数据增强策略。这种方法在HRM中实现了MCTS结果的多样化,同时几乎不增加计算开销,并通过引入噪声增强了标签的鲁棒性。在PRM800K数据集上的实证结果表明,与PRM相比,HRM结合HNC在评估中实现了更高的稳定性和可靠性。此外,MATH500和GSM8K的跨域评估证实了HRM在多种推理任务中的优越泛化和鲁棒性。所有实验的代码将在https://github.com/tengwang0318/hierarchial_reward_model上发布。
论文及项目相关链接
Summary
大型语言模型(LLMs)在监督微调或强化学习中展现出强大的推理能力。然而,过程奖励模型(PRM)存在奖励黑客问题,无法可靠地识别最佳中间步骤。本文提出了一种新的奖励模型方法——分层奖励模型(HRM),可以从精细粒度和粗略粒度级别评估单个和连续的推理步骤。HRM在评估推理连贯性和自我反思方面表现更佳,尤其在先前推理步骤错误时。为解决蒙特卡洛树搜索(MCTS)自主生成PRM训练数据的不效率问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的分层节点压缩(HNC)轻量级有效数据增强策略。该方法在PRM800K数据集上实现了与PRM相比更稳定可靠的评估结果。此外,MATH500和GSM8K的跨域评估证明了HRM在多种推理任务中的优异通用性和稳健性。所有实验的代码将在https://github.com/tengwang0318/hierarchial_reward_model发布。
Key Takeaways
- 大型语言模型(LLMs)具备强大的推理能力,通过监督微调或强化学习实现。
- 过程奖励模型(PRM)存在奖励黑客问题,可靠性受损。
- 引入分层奖励模型(HRM),能评估单个和连续推理步骤,提升推理连贯性和自我反思能力。
- HRM在先前推理步骤错误时表现更优。
- 提出分层节点压缩(HNC)数据增强策略,基于节点合并,提高蒙特卡洛树搜索(MCTS)结果多样性,增强标签稳健性。
- HRM结合HNC在PRM800K数据集上实现稳定可靠的评估。
点此查看论文截图

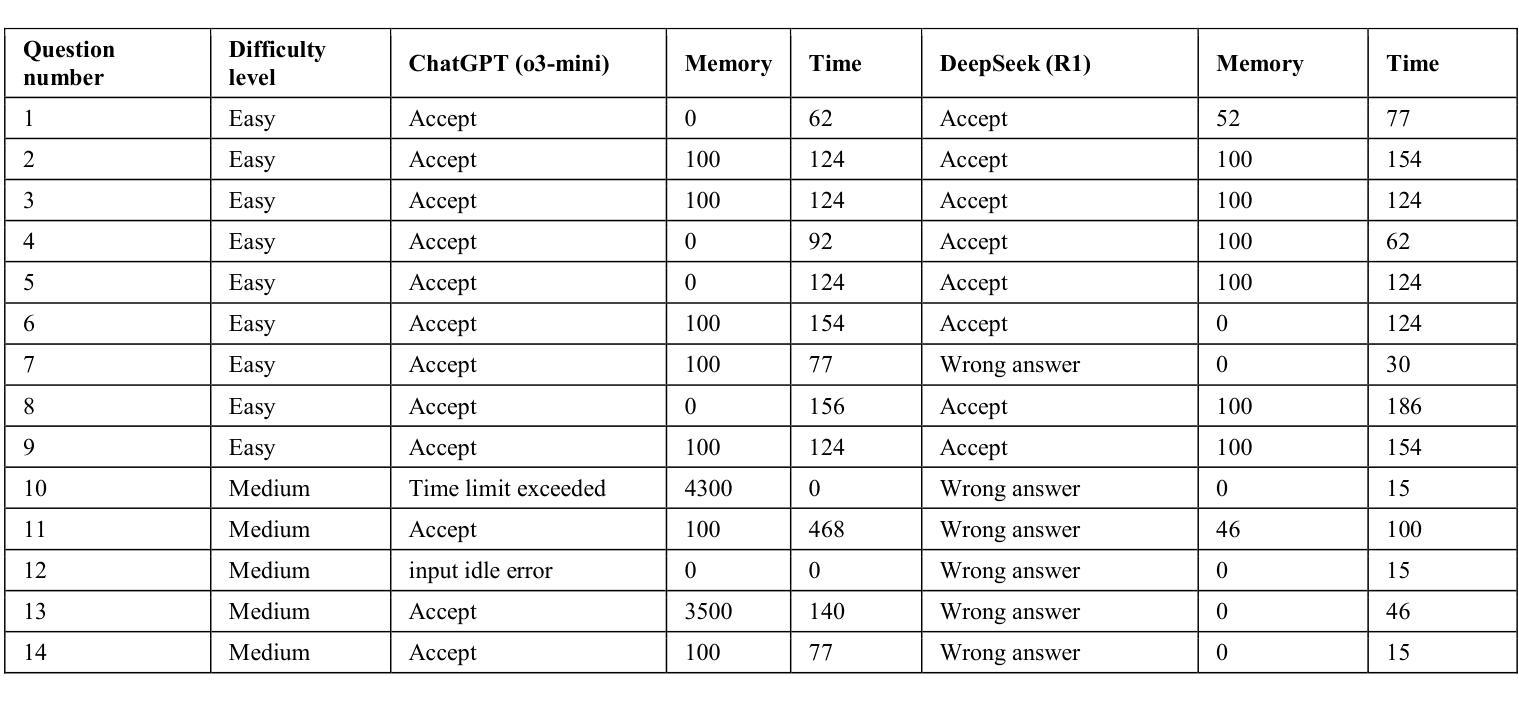
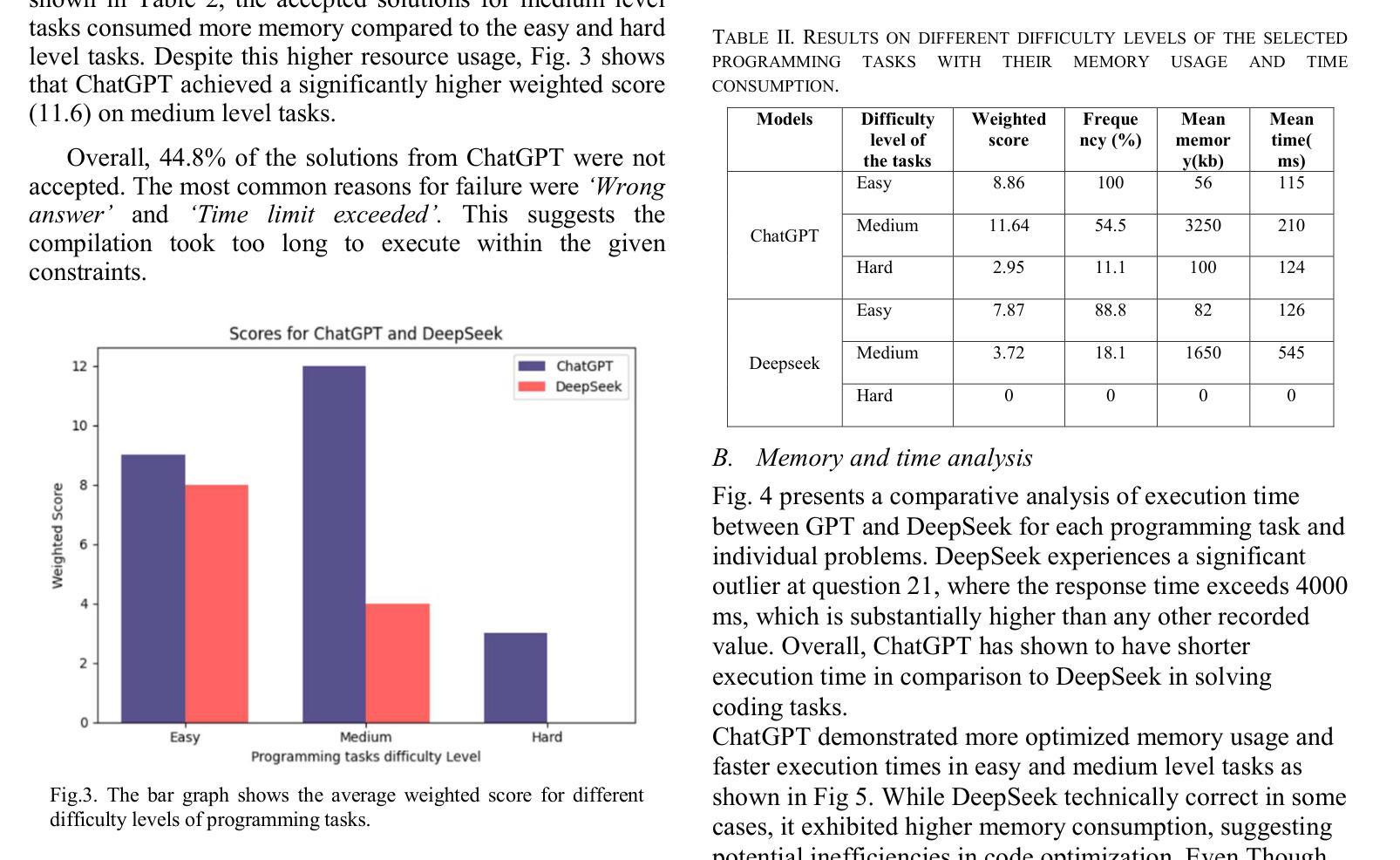
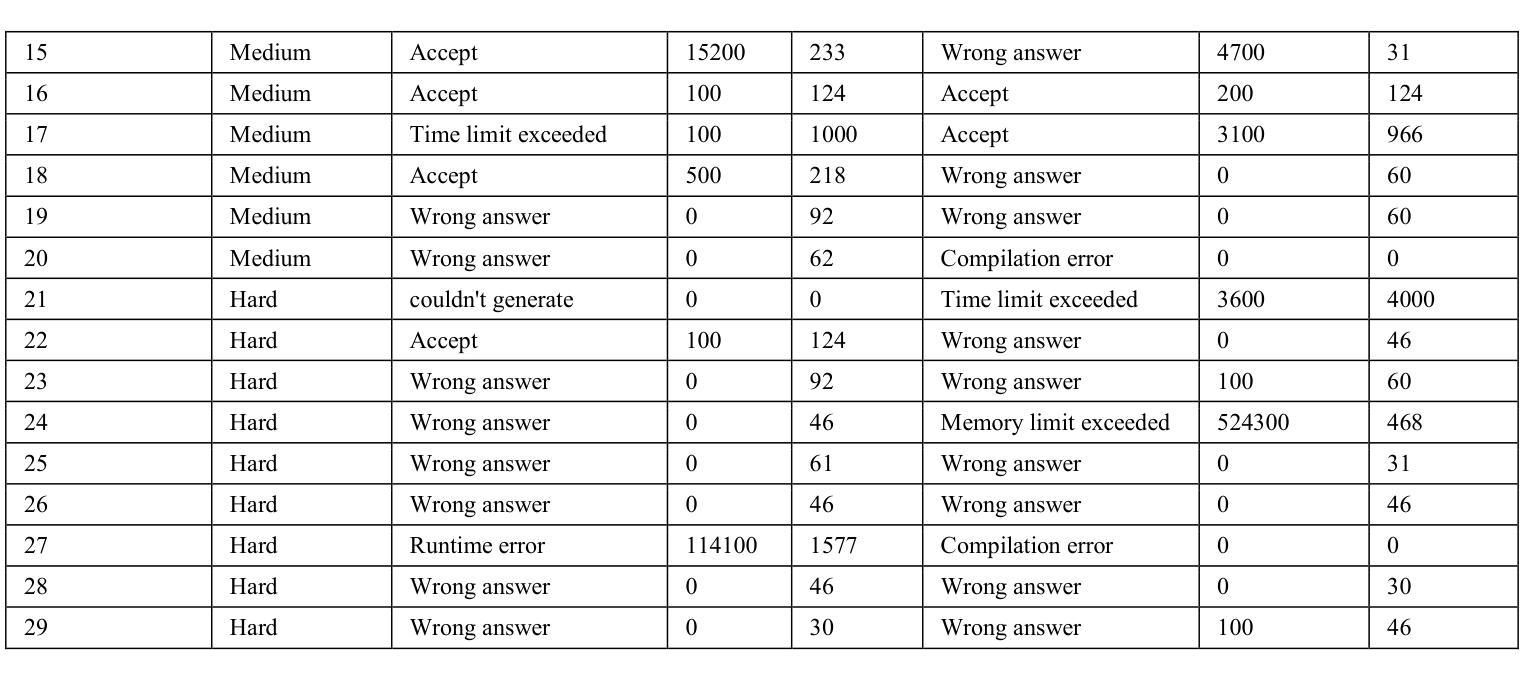
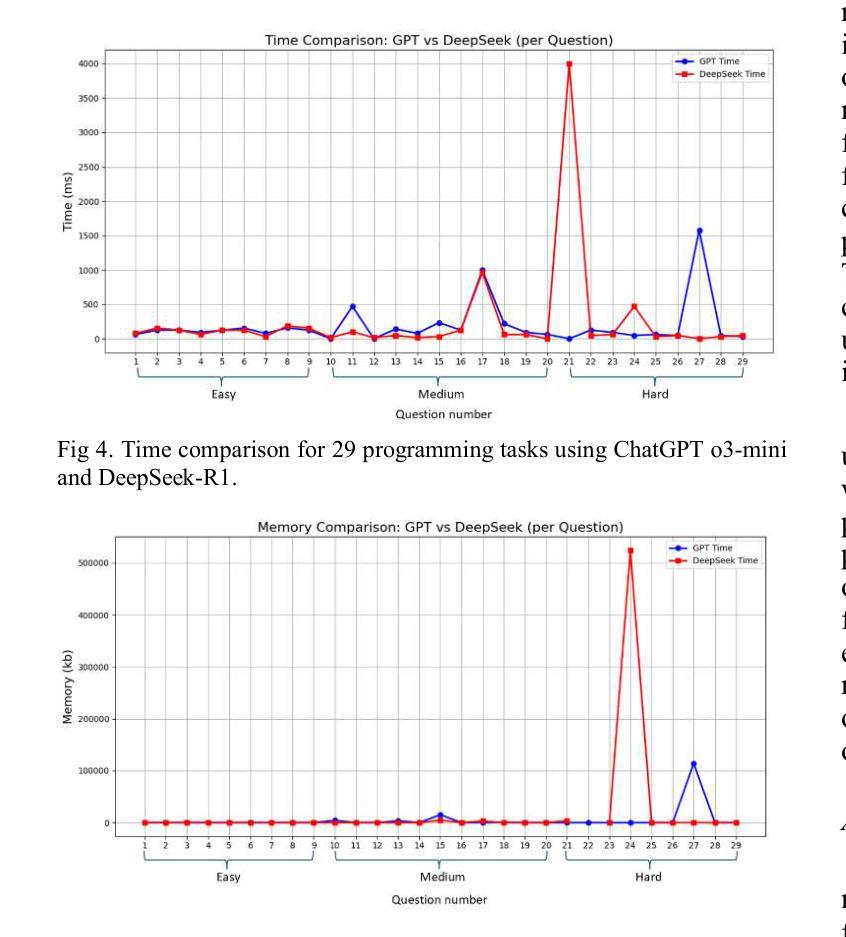
A Showdown of ChatGPT vs DeepSeek in Solving Programming Tasks
Authors:Ronas Shakya, Farhad Vadiee, Mohammad Khalil
The advancement of large language models (LLMs) has created a competitive landscape for AI-assisted programming tools. This study evaluates two leading models: ChatGPT 03-mini and DeepSeek-R1 on their ability to solve competitive programming tasks from Codeforces. Using 29 programming tasks of three levels of easy, medium, and hard difficulty, we assessed the outcome of both models by their accepted solutions, memory efficiency, and runtime performance. Our results indicate that while both models perform similarly on easy tasks, ChatGPT outperforms DeepSeek-R1 on medium-difficulty tasks, achieving a 54.5% success rate compared to DeepSeek 18.1%. Both models struggled with hard tasks, thus highlighting some ongoing challenges LLMs face in handling highly complex programming problems. These findings highlight key differences in both model capabilities and their computational power, offering valuable insights for developers and researchers working to advance AI-driven programming tools.
大型语言模型(LLM)的进步为AI辅助编程工具创造了一个竞争环境。本研究评估了两款领先模型:ChatGPT 03-mini和DeepSeek-R1,它们在解决Codeforces竞赛编程任务方面的能力。我们使用29个编程任务,分为容易、中等和困难三个级别,通过接受的解决方案、内存效率和运行时性能来评估两个模型的结果。我们的结果表明,虽然两个模型在容易的任务上表现相似,但ChatGPT在中等难度的任务上表现优于DeepSeek-R1,成功率为54.5%,而DeepSeek的成功率仅为18.1%。两个模型在困难的任务上都遇到了困难,这突显了LLM在处理高度复杂的编程问题时面临的一些持续挑战。这些发现突出了两个模型能力和计算能力的关键差异,为开发和研究AI驱动的编程工具的开发人员和研究人员提供了有价值的见解。
论文及项目相关链接
Summary
该研究对ChatGPT 03-mini和DeepSeek-R1两种领先的AI辅助编程工具进行了评估,主要考察它们在解决Codeforces竞赛编程任务方面的能力。实验结果显示,在中等难度的编程任务上,ChatGPT表现优于DeepSeek-R1,成功率为54.5%,而DeepSeek的成功率为仅18.1%。但在高难度的编程任务上,两者都面临挑战。这一研究为开发者和研究人员提供了关于AI驱动编程工具的关键差异和能力的重要见解。
Key Takeaways
- 大型语言模型(LLMs)的进步为AI辅助编程工具创造了竞争环境。
- 研究评估了ChatGPT 03-mini和DeepSeek-R1两种领先模型在解决不同难度级别编程任务时的表现。
- 在中等难度的编程任务上,ChatGPT表现优于DeepSeek-R1。
- 在高难度的编程任务上,这两个模型都面临挑战。
- ChatGPT和DeepSeek在解决编程任务时,还存在内存效率和运行时间性能的差异。
- 该研究为开发者提供了关于不同AI编程工具的能力和局限性的重要信息。
点此查看论文截图


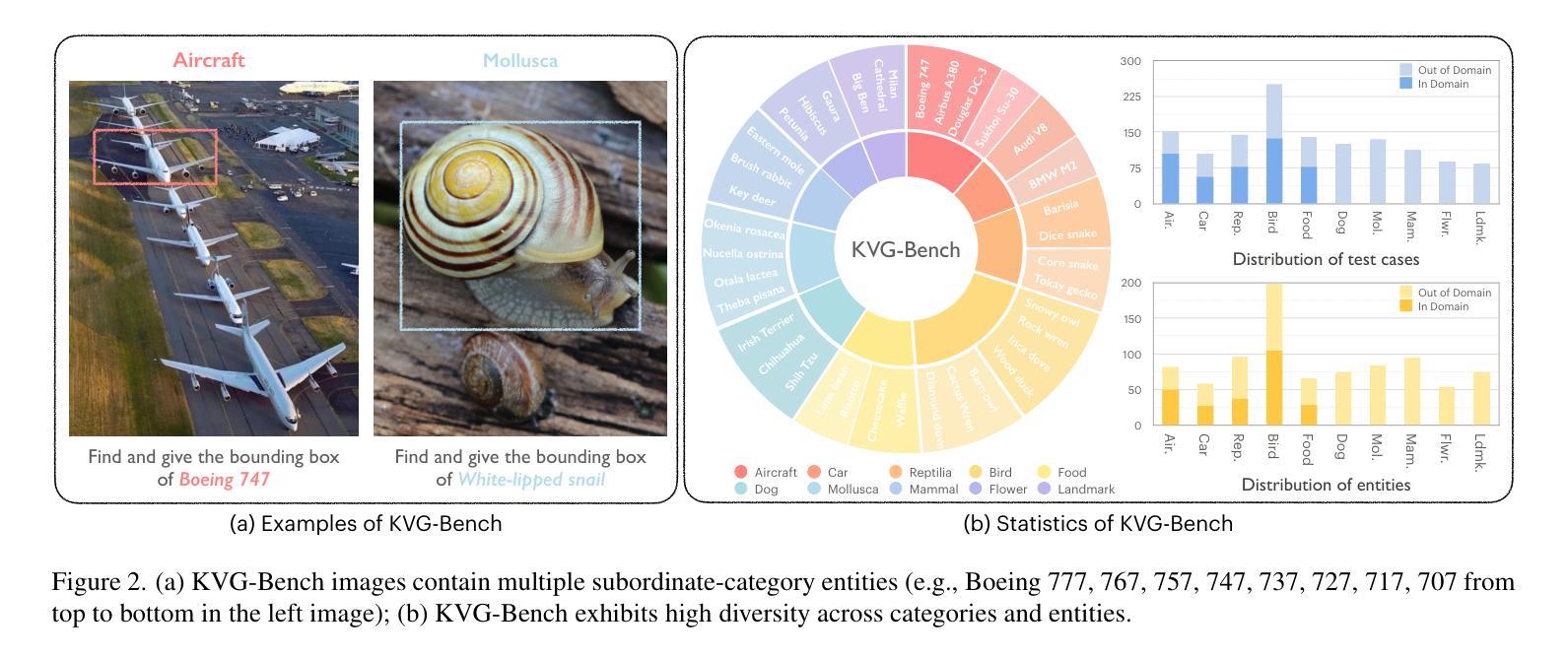
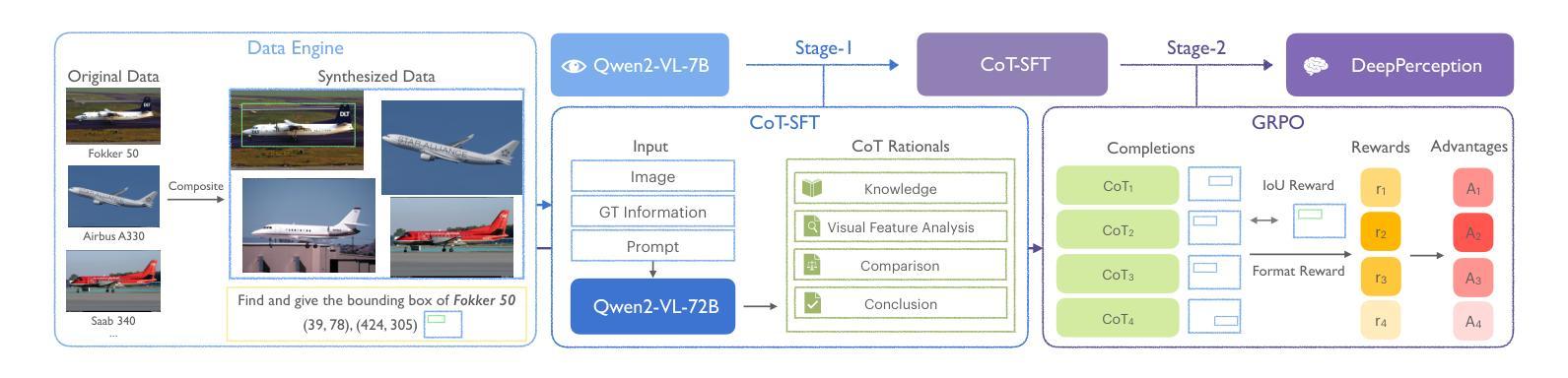
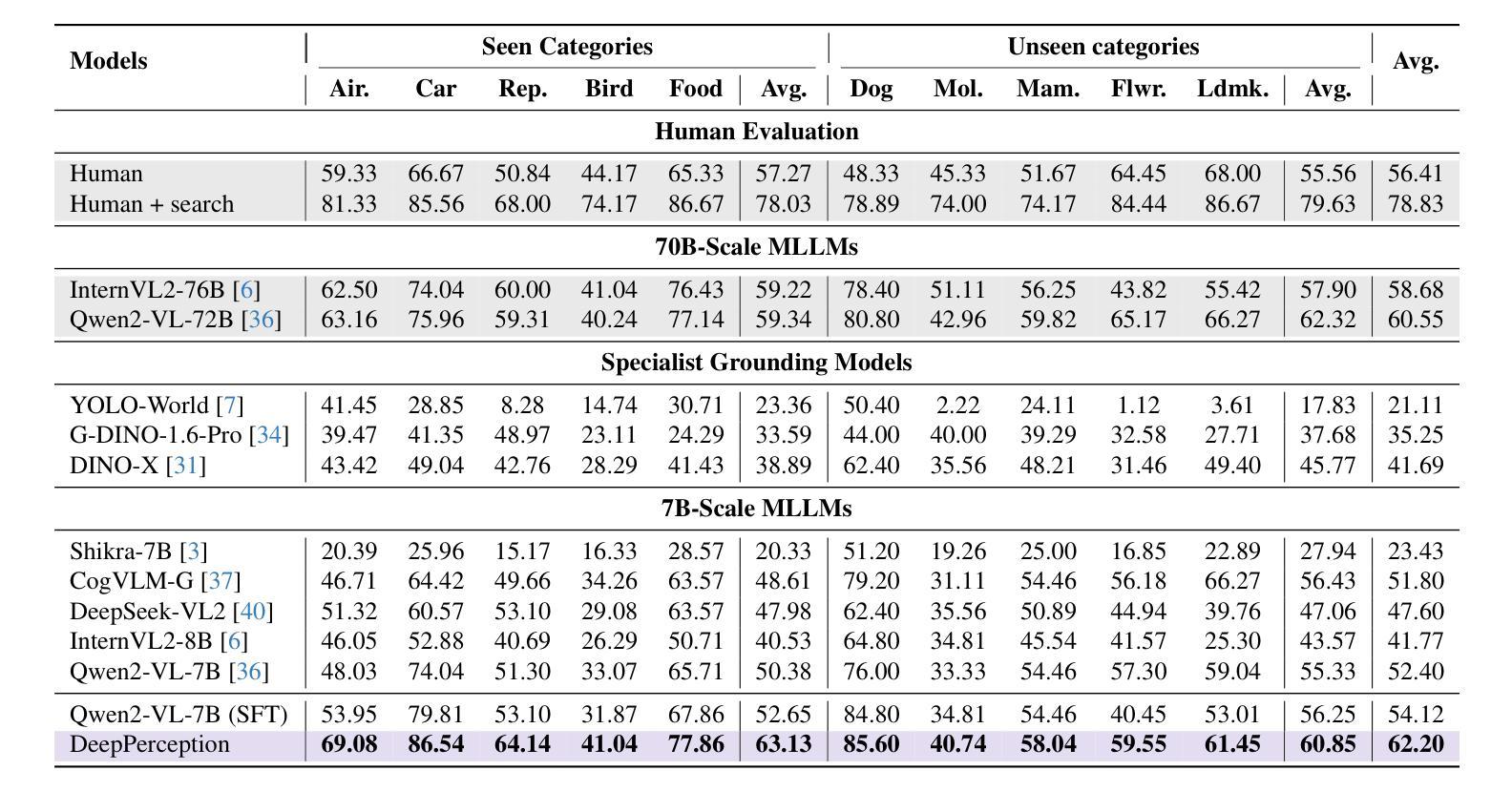
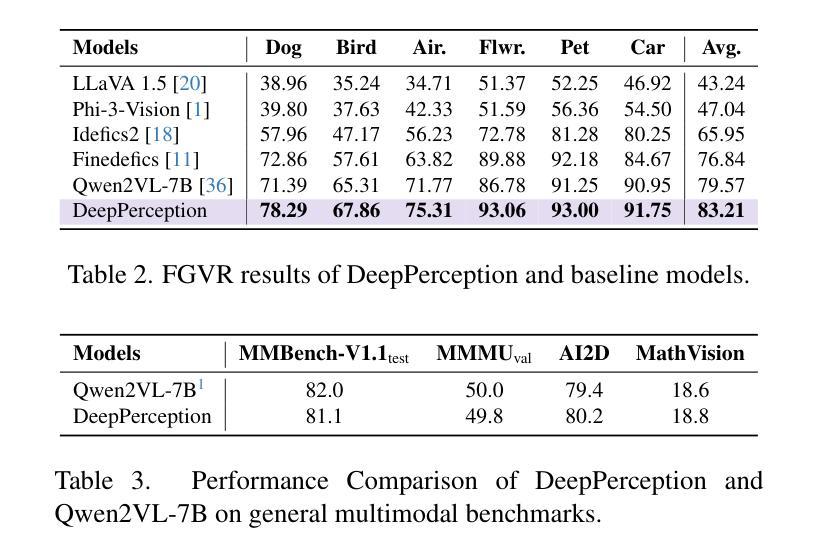
DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
Authors:Xinyu Ma, Ziyang Ding, Zhicong Luo, Chi Chen, Zonghao Guo, Derek F. Wong, Xiaoyi Feng, Maosong Sun
Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08% accuracy improvements on KVG-Bench and exhibiting +4.60% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.
人类专家擅长通过利用领域知识来细化感知特征,进行精细化的视觉辨别,这是当前的多模态大型语言模型(MLLMs)尚未充分发展的一项能力。尽管拥有大量的专家级知识,MLLMs在将推理融入视觉感知方面却存在困难,通常会产生直接的回应,而无需进行更深入的分析。为了弥补这一差距,我们引入了知识密集型视觉定位(KVG),这是一项需要精细感知和特定领域知识整合的新型视觉定位任务。为了应对KVG的挑战,我们提出了DeepPerception,这是一个具备认知视觉感知能力的MLLM增强版本。我们的方法包括(1)自动化数据合成管道,用于生成高质量、与知识对齐的训练样本;(2)两阶段训练框架,结合监督微调用于认知推理脚手架和强化学习,以优化感知与认知协同作用。为了评估性能,我们推出了KVG-Bench数据集,这是一个涵盖10个领域、包含1300个手动整理测试案例的综合数据集。实验结果表明,DeepPerception显著优于直接微调,在KVG-Bench上的准确率提高了8.08%,并且在跨域泛化方面较基线方法提高了4.60%。我们的研究强调了将认知过程融入MLLMs以实现人类样视觉感知的重要性,并为多模态推理研究开辟了新的方向。数据、代码和模型已发布在https://github.com/thunlp/DeepPerception。
论文及项目相关链接
Summary
本文介绍了当前多模态大型语言模型(MLLMs)在视觉感知方面的不足,尤其是在精细粒度视觉辨别和领域知识整合方面的能力尚待发展。为解决此问题,文章提出了一种名为知识密集型视觉接地(KVG)的新视觉接地任务,要求精细的感知能力和特定领域的整合知识。同时提出了一种解决这一任务的方法DeepPerception,其增强了认知视觉感知能力。它通过自动化的数据合成管道生成高质量的知识对齐训练样本,并采用两阶段训练框架结合监督微调进行认知推理架构和强化学习优化感知认知协同作用。实验结果表明,DeepPerception在KVG基准测试上的准确率提高了8.08%,并且在跨域泛化方面也优于基线方法。这为多模态推理研究提供了新的方向。
Key Takeaways
- 当前多模态大型语言模型(MLLMs)在视觉感知方面存在不足,特别是在精细粒度视觉辨别和领域知识整合方面。
- 知识密集型视觉接地(KVG)任务要求模型同时具备精细的感知能力和特定领域的知识整合能力。
- DeepPerception是一种解决KVG任务的方法,通过自动化的数据合成管道生成高质量的训练样本。
- DeepPerception采用两阶段训练框架,结合监督微调和强化学习优化感知认知协同作用。
- 实验结果表明,DeepPerception在KVG基准测试上的准确率显著提高。
- DeepPerception在跨域泛化方面也表现出优于基线方法的性能。
点此查看论文截图

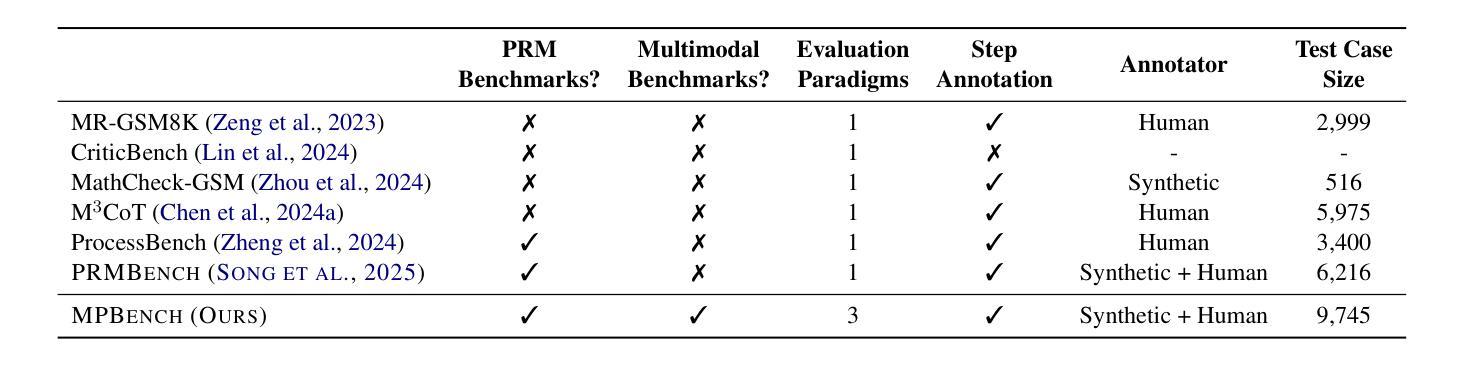
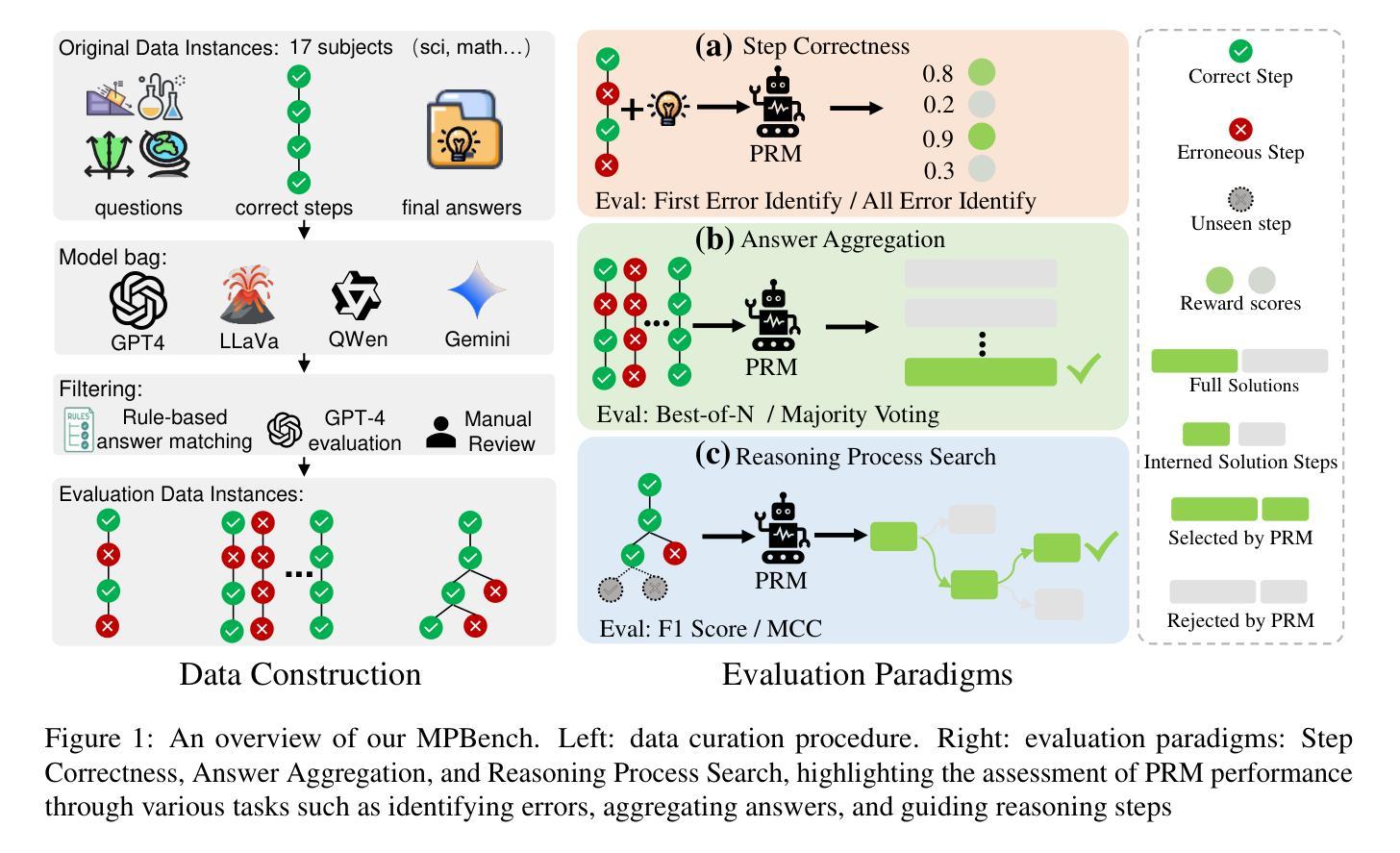
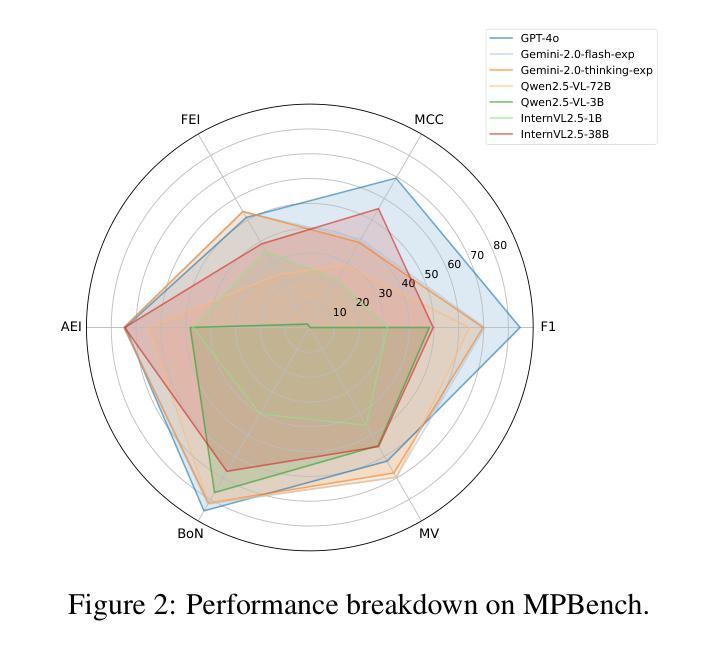
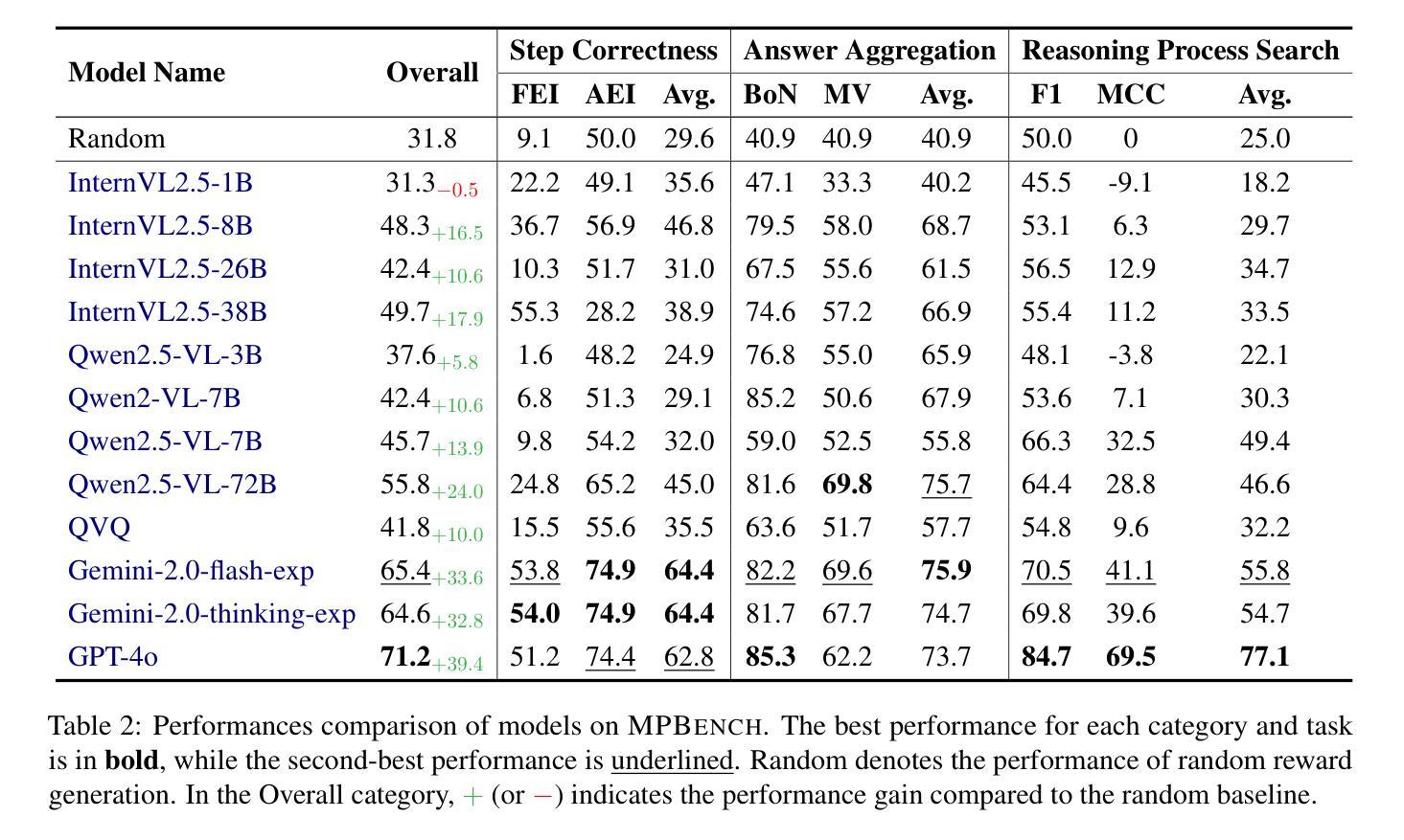
MPBench: A Comprehensive Multimodal Reasoning Benchmark for Process Errors Identification
Authors:Zhaopan Xu, Pengfei Zhou, Jiaxin Ai, Wangbo Zhao, Kai Wang, Xiaojiang Peng, Wenqi Shao, Hongxun Yao, Kaipeng Zhang
Reasoning is an essential capacity for large language models (LLMs) to address complex tasks, where the identification of process errors is vital for improving this ability. Recently, process-level reward models (PRMs) were proposed to provide step-wise rewards that facilitate reinforcement learning and data production during training and guide LLMs toward correct steps during inference, thereby improving reasoning accuracy. However, existing benchmarks of PRMs are text-based and focus on error detection, neglecting other scenarios like reasoning search. To address this gap, we introduce MPBench, a comprehensive, multi-task, multimodal benchmark designed to systematically assess the effectiveness of PRMs in diverse scenarios. MPBench employs three evaluation paradigms, each targeting a specific role of PRMs in the reasoning process: (1) Step Correctness, which assesses the correctness of each intermediate reasoning step; (2) Answer Aggregation, which aggregates multiple solutions and selects the best one; and (3) Reasoning Process Search, which guides the search for optimal reasoning steps during inference. Through these paradigms, MPBench makes comprehensive evaluations and provides insights into the development of multimodal PRMs.
推理是大型语言模型(LLM)解决复杂任务的基本能力,而识别过程中的错误对于提高这种能力至关重要。最近,提出了过程级奖励模型(PRM),提供分步奖励,便于训练过程中的强化学习和数据生成,并在推理过程中引导LLM走向正确的步骤,从而提高推理准确性。然而,现有的PRM基准测试都是基于文本的,侧重于错误检测,忽略了其他场景,如推理搜索。为了弥补这一空白,我们引入了MPBench,这是一个全面、多任务、多模式的基准测试,旨在系统地评估PRM在不同场景中的有效性。MPBench采用三种评估范式,每个范式都针对PRM在推理过程中的特定角色:1)步骤正确性,评估每个中间推理步骤的正确性;2)答案聚合,聚合多个解决方案并选择最佳解决方案;3)推理过程搜索,在推理过程中引导对最佳推理步骤的搜索。通过这些范式,MPBench进行了全面的评估,并为多模式PRM的发展提供了见解。
论文及项目相关链接
Summary
大型语言模型(LLM)在进行复杂任务时,推理能力至关重要。过程级奖励模型(PRM)通过提供分步奖励,促进强化学习和训练过程中的数据生成,并在推理过程中引导LLM走向正确的步骤,从而提高推理准确性。然而,现有的PRM基准测试主要是文本基础的,侧重于错误检测,忽略了如推理搜索等其他场景。为解决这一空白,我们推出MPBench,这是一个多任务、多模态的基准测试,旨在系统评估PRM在多种场景中的有效性。MPBench采用三种评估模式,分别针对PRM在推理过程中的特定角色:1)步骤正确性,评估每个中间推理步骤的正确性;2)答案聚合,聚合多个解决方案并选择最佳答案;3)推理过程搜索,在推理过程中引导最优推理步骤的搜索。通过这些模式,MPBench进行全面评估,并为多模态PRM的发展提供见解。
Key Takeaways
- 大型语言模型(LLM)在进行复杂任务时需要具备强大的推理能力。
- 过程级奖励模型(PRM)可以提高LLM的推理准确性。
- 现有PRM基准测试主要侧重于文本基础的错误检测,忽略了其他场景,如推理搜索。
- MPBench是一个多任务、多模态的基准测试,旨在系统评估PRM在多种场景中的有效性。
- MPBench采用三种评估模式,包括步骤正确性、答案聚合和推理过程搜索。
- MPBench为全面评估PRM提供平台,并有助于了解其在不同场景下的表现。
点此查看论文截图

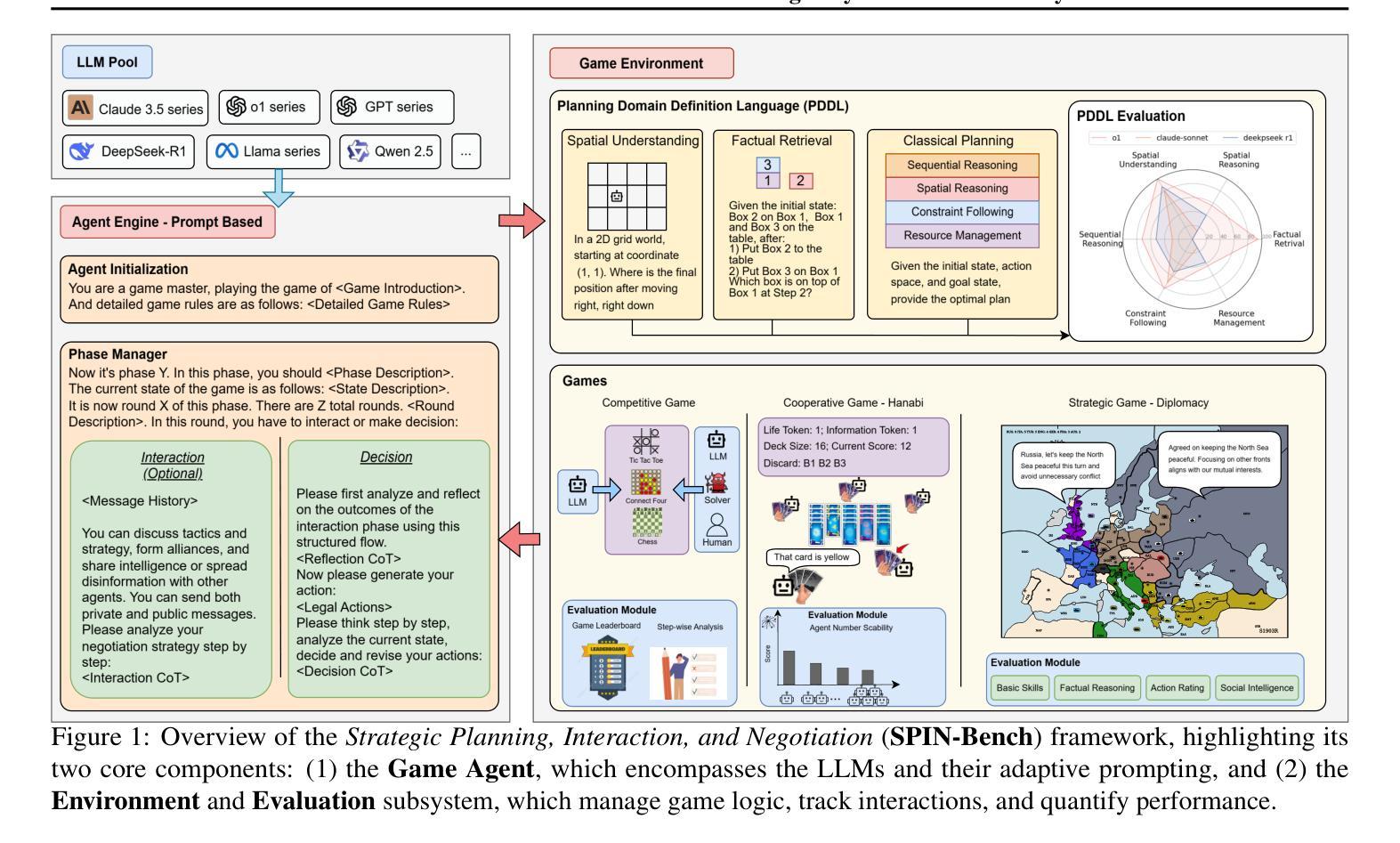
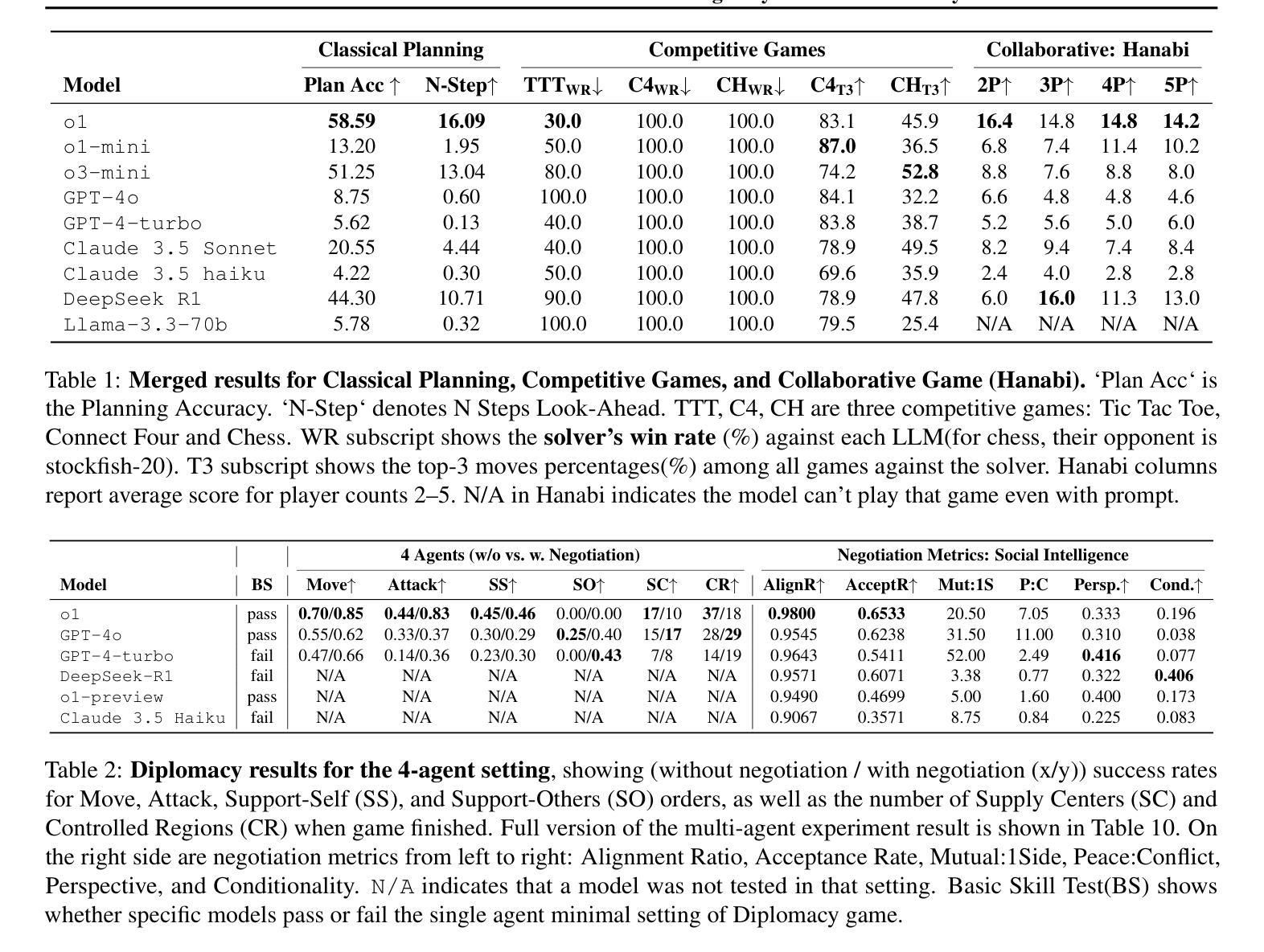
SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
Authors:Jianzhu Yao, Kevin Wang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang Wang, Pramod Viswanath
Reasoning and strategic behavior in social interactions is a hallmark of intelligence. This form of reasoning is significantly more sophisticated than isolated planning or reasoning tasks in static settings (e.g., math problem solving). In this paper, we present Strategic Planning, Interaction, and Negotiation (SPIN-Bench), a new multi-domain evaluation designed to measure the intelligence of strategic planning and social reasoning. While many existing benchmarks focus on narrow planning or single-agent reasoning, SPIN-Bench combines classical PDDL tasks, competitive board games, cooperative card games, and multi-agent negotiation scenarios in one unified framework. The framework includes both a benchmark as well as an arena to simulate and evaluate the variety of social settings to test reasoning and strategic behavior of AI agents. We formulate the benchmark SPIN-Bench by systematically varying action spaces, state complexity, and the number of interacting agents to simulate a variety of social settings where success depends on not only methodical and step-wise decision making, but also conceptual inference of other (adversarial or cooperative) participants. Our experiments reveal that while contemporary LLMs handle basic fact retrieval and short-range planning reasonably well, they encounter significant performance bottlenecks in tasks requiring deep multi-hop reasoning over large state spaces and socially adept coordination under uncertainty. We envision SPIN-Bench as a catalyst for future research on robust multi-agent planning, social reasoning, and human–AI teaming. Project Website: https://spinbench.github.io/
在社会互动中的推理和战略行为是智能的标志。这种推理形式远比静态环境中的孤立规划或推理任务(例如数学问题解决)更为复杂。在本文中,我们提出了“战略规划、互动与谈判(SPIN-Bench)”,这是一种新的多领域评估,旨在衡量战略规划和社会推理的智能水平。虽然许多现有的基准测试主要集中在狭隘的规划或单代理推理上,但SPIN-Bench结合了经典PDDL任务、竞技棋类游戏、合作卡牌游戏和多代理谈判场景在一个统一框架中。该框架既包括一个基准测试,也包括一个模拟和评估各种社交设置的场所,以测试AI代理的推理和战略行为。我们通过系统地改变动作空间、状态复杂性和交互代理的数量来制定SPIN-Bench基准测试,以模拟各种社交环境,在这些环境中,成功不仅取决于方法和逐步的决策制定,还取决于对其他(对抗性或合作性)参与者的概念推断。我们的实验表明,虽然当代大型语言模型在处理基本事实检索和短期规划方面表现良好,但在需要深度多跳推理和大状态空间的社会适应性协调的任务中,它们会遇到显著的性能瓶颈。我们期望SPIN-Bench能成为未来关于稳健的多代理规划、社会推理和人机协作的研究催化剂。项目网站:https://spinbench.github.io/
论文及项目相关链接
PDF 51 pages, 7 figures
Summary
该文介绍了一种名为SPIN-Bench的新型多领域评估方法,旨在测量智能的战略规划和社交推理能力。与现有的主要聚焦于狭窄规划或单一智能体推理的基准测试不同,SPIN-Bench结合了PDDL任务、竞技棋类游戏、合作卡牌游戏和多智能体谈判场景,在一个统一框架中进行评估。框架既包括基准测试,也包括模拟和评估多种社交设置的场所,以测试人工智能智能体的推理和战略行为。实验表明,尽管当代大型语言模型在基本事实检索和短期规划方面表现良好,但在需要深度多跳推理和社交协调的任务中仍存在显著性能瓶颈。
Key Takeaways
- SPIN-Bench是一种新型的多领域评估方法,旨在测量智能的战略规划和社交推理能力。
- 现有基准测试主要聚焦于狭窄规划或单一智能体推理,而SPIN-Bench结合了多种任务在一个统一框架中进行评估。
- SPIN-Bench包括基准测试和模拟社交设置的场所,模拟多种社交设置以测试AI智能体的推理和战略行为。
- 当代大型语言模型在需要深度多跳推理和社交协调的任务中仍存在性能瓶颈。
- SPIN-Bench通过系统地改变动作空间、状态复杂性和交互智能体的数量来模拟各种社交设置。
- 成功不仅取决于方法和逐步决策制定,还取决于对其他(对抗或合作)参与者的概念推断。
- SPIN-Bench为未来研究提供了催化剂,包括稳健的多智能体规划、社交推理和人机协作。
点此查看论文截图

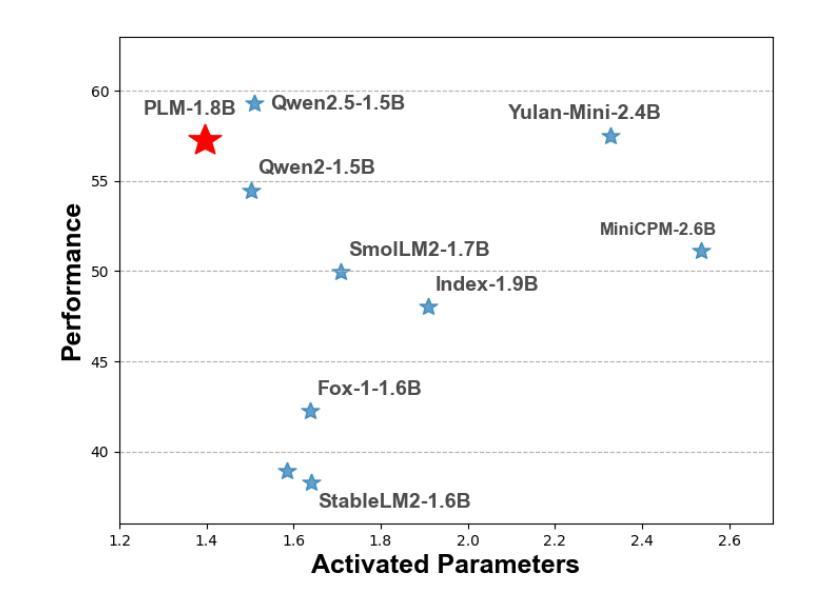
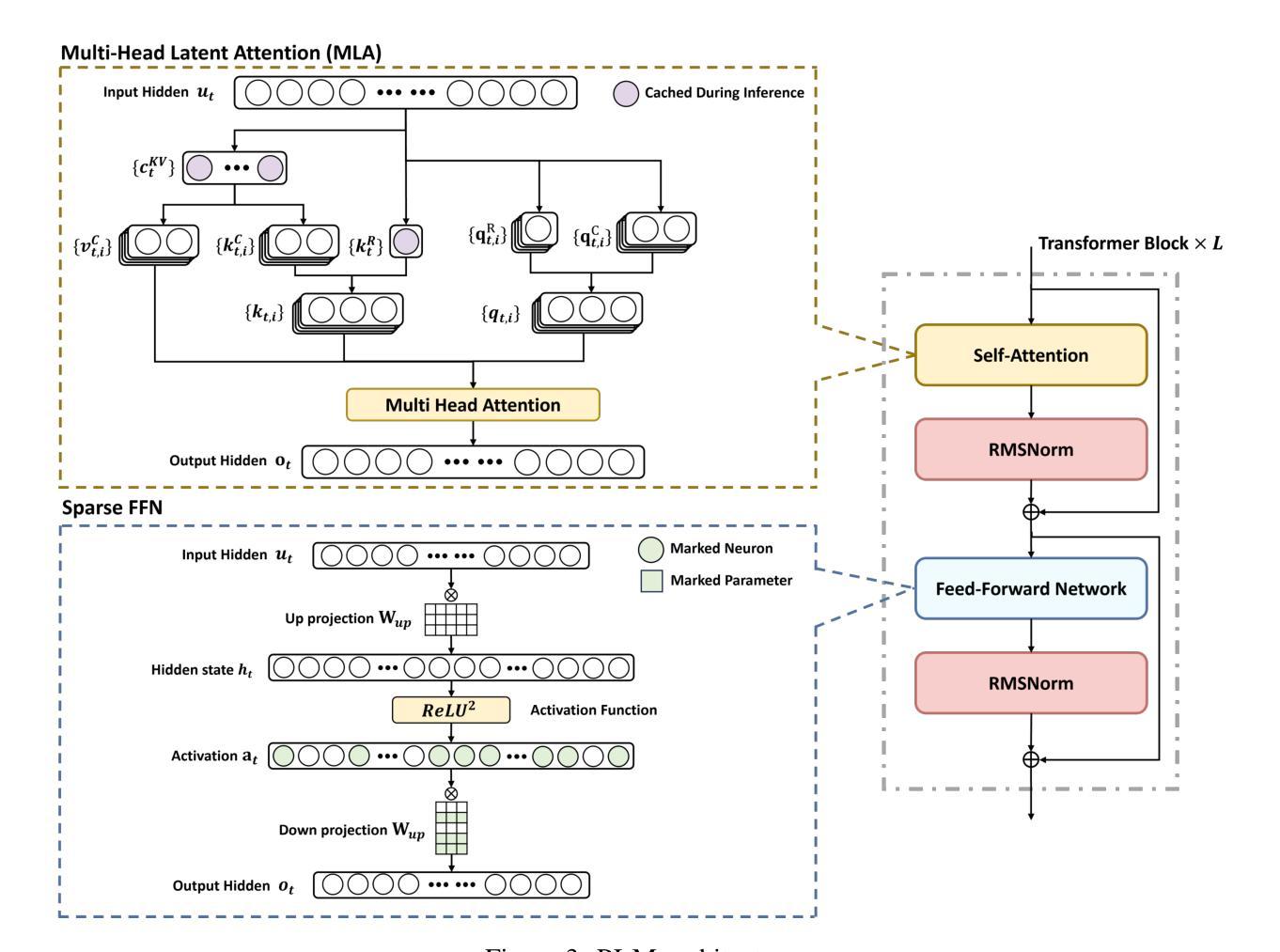
PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Authors:Cheng Deng, Luoyang Sun, Jiwen Jiang, Yongcheng Zeng, Xinjian Wu, Wenxin Zhao, Qingfa Xiao, Jiachuan Wang, Lei Chen, Lionel M. Ni, Haifeng Zhang, Jun Wang
While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM’s suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
随着模型参数的增加,比例定律在大语言模型(LLM)中得到了持续验证。然而,大语言模型的推理需求与边缘设备的有限资源之间存在的固有矛盾,给边缘智能的发展带来了关键挑战。近期,出现了许多小语言模型,旨在将大语言模型的能力转化为更小的占用空间。然而,这些模型往往保留其大型对应模型的基本架构原则,仍然给边缘设备的存储和带宽容量带来相当大的压力。
在本文中,我们介绍了一种周边语言模型(PLM),该模型通过联合优化模型架构和边缘系统约束的协同设计过程而开发。PLM利用多头潜在注意力机制,并采用平方ReLU激活函数来促进稀疏性,从而减少推理过程中的峰值内存占用。在训练过程中,我们收集和重组了开源数据集,实施了多阶段训练策略,并对预热稳定衰减恒定(WSDC)学习率调度器进行了实证研究。此外,我们通过采用ARIES偏好学习方法,融入了人类反馈强化学习(RLHF)。经过两阶段的SFT过程后,该方法在一般任务上获得了2%的性能提升,在GSM8K任务上获得了9%的提升,在编码任务上获得了11%的提升。
除了其新颖的架构外,评估结果表明,PLM在公开数据上训练的现有小语言模型相比表现出色,同时保持了最低的活动参数数量。此外,在各种边缘设备上的部署,包括消费级GPU、手机和Raspberry Pis,验证了PLM适用于周边应用。PLM系列模型可在https://github.com/plm-team/PLM公开获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在边缘设备上的推理需求与有限资源之间存在固有矛盾,小型语言模型应运而生,试图将LLM的能力浓缩到更小的规模中。然而,这些模型仍然保留了对边缘设备的存储和带宽能力的需求较大的基本架构原则。在本文中,介绍了一种周边语言模型(PLM),通过联合优化模型架构和边缘系统约束的协同设计过程开发而成。PLM采用多头潜在注意力机制和平方ReLU激活函数来鼓励稀疏性,降低推理过程中的峰值内存占用。此外,通过收集和组织开源数据集、实施多阶段训练策略以及调查WSDC学习率调度器,并结合采用ARIES偏好学习方法的强化学习从人类反馈(RLHF),PLM在一般任务上实现了2%的性能提升,在GSM8K任务上实现了9%的提升,在编码任务上实现了11%的提升。同时,PLM系列模型已公开发布。
Key Takeaways
- 大型语言模型在边缘设备上存在推理需求与有限资源的矛盾。
- 周边语言模型(PLM)通过联合优化模型架构和边缘系统约束进行开发。
- PLM采用多头潜在注意力机制和平方ReLU激活函数以降低内存占用。
- PLM通过多阶段训练策略和学习率调度器提升性能。
- PLM结合强化学习从人类反馈(RLHF)提高任务表现。
- PLM在多种边缘设备上进行了部署,包括消费者级GPU、手机和Raspberry Pi等。
点此查看论文截图





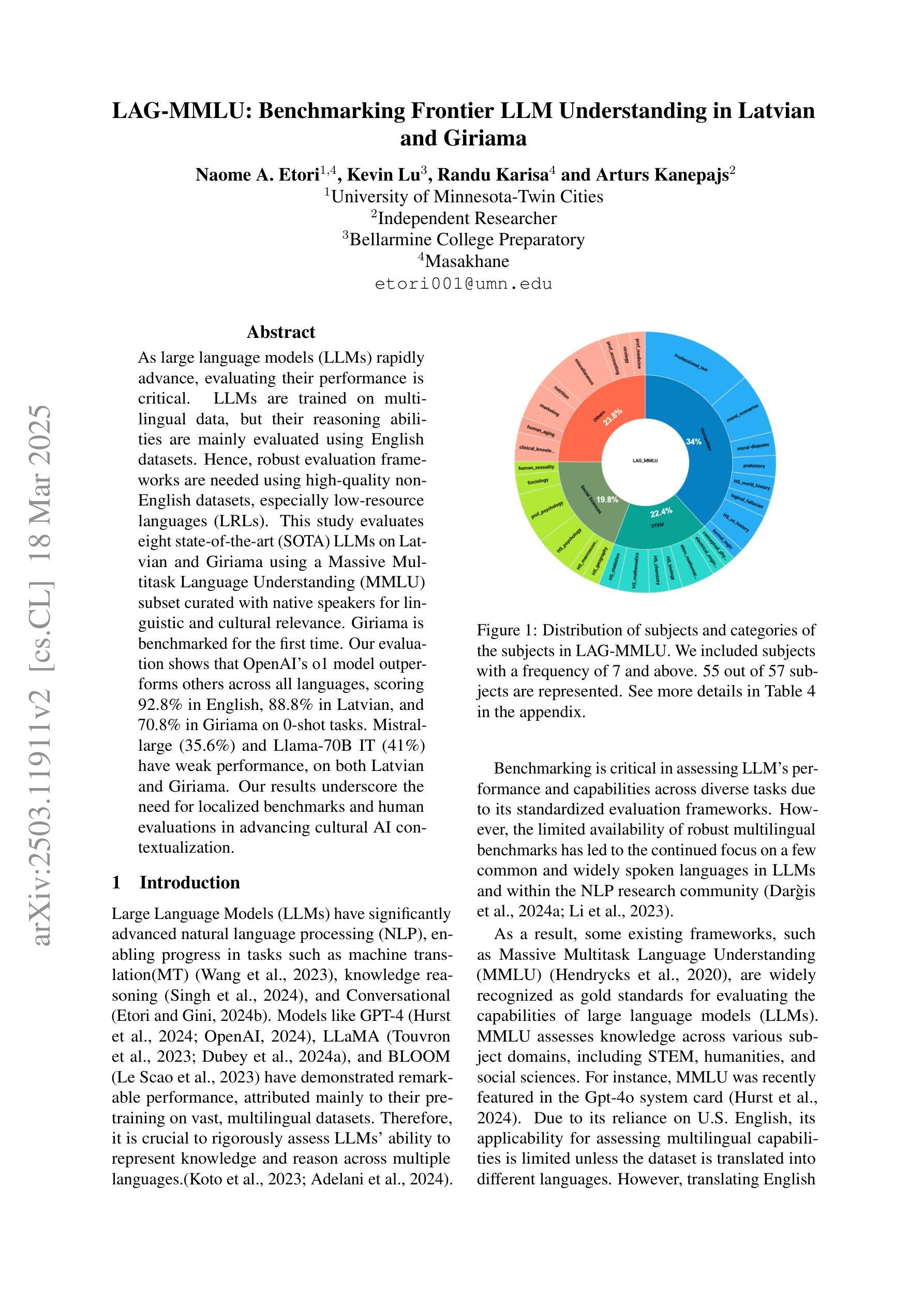
LAG-MMLU: Benchmarking Frontier LLM Understanding in Latvian and Giriama
Authors:Naome A. Etori, Kevin Lu, Randu Karisa, Arturs Kanepajs
As large language models (LLMs) rapidly advance, evaluating their performance is critical. LLMs are trained on multilingual data, but their reasoning abilities are mainly evaluated using English datasets. Hence, robust evaluation frameworks are needed using high-quality non-English datasets, especially low-resource languages (LRLs). This study evaluates eight state-of-the-art (SOTA) LLMs on Latvian and Giriama using a Massive Multitask Language Understanding (MMLU) subset curated with native speakers for linguistic and cultural relevance. Giriama is benchmarked for the first time. Our evaluation shows that OpenAI’s o1 model outperforms others across all languages, scoring 92.8% in English, 88.8% in Latvian, and 70.8% in Giriama on 0-shot tasks. Mistral-large (35.6%) and Llama-70B IT (41%) have weak performance, on both Latvian and Giriama. Our results underscore the need for localized benchmarks and human evaluations in advancing cultural AI contextualization.
随着大型语言模型(LLM)的快速发展,对其性能进行评估至关重要。大型语言模型是在多语言数据上进行训练的,但它们的推理能力主要使用英语数据集进行评估。因此,需要使用高质量的非英语数据集来构建稳健的评估框架,特别是针对低资源语言(LRLs)。本研究使用由母语者筛选的巨量多任务语言理解(MMLU)子集,针对拉脱维亚语和吉里马语,对八种最先进的大型语言模型进行了评估,该子集考虑了语言和文化的相关性。吉里马语是首次进行基准测试。我们的评估结果显示,OpenAI的o1模型在所有语言中的表现均超过其他模型,在零射击任务中,英语得分为92.8%,拉脱维亚语得分为88.8%,吉里马语得分为70.8%。Mistral-large(35.6%)和Llama-70B IT(41%)在拉脱维亚语和吉里马语上的表现均较弱。我们的研究结果强调了在进行文化人工智能语境化推进时,需要本地化的基准测试和人工评估。
论文及项目相关链接
PDF Accepted at NoDaLiDa/Baltic-HLT 2025. https://hdl.handle.net/10062/107190
Summary
随着大型语言模型(LLM)的快速发展,对其性能进行评估至关重要。本研究使用本族语者整理的大型多任务语言理解(MMLU)子集,对拉脱维亚语和基里亚玛语这两种语言的八种最新大型语言模型进行了评估。研究结果显示,OpenAI的o1模型在所有语言中的表现最佳,零样本任务的得分率分别为英语92.8%、拉脱维亚语88.8%、基里亚玛语70.8%。本研究强调了针对特定区域的标准制定和人类评估在推动文化人工智能语境化中的重要性。
Key Takeaways
- 大型语言模型(LLM)的评估至关重要,尤其是针对多语言数据的模型。
- 研究使用了包括拉脱维亚语和基里亚玛语在内的非英语数据集进行评估。
- OpenAI的o1模型在多种语言中表现最佳,尤其在零样本任务上。
- Mistral-large和Llama-70B IT在拉脱维亚语和基里亚玛语上的表现较弱。
- 研究强调了本地化基准测试和人类评估在推动文化人工智能语境化中的重要性。
- LLMs的推理能力主要通过英语数据集进行评估,但其在其他语言中的表现可能有所不同。
点此查看论文截图