⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
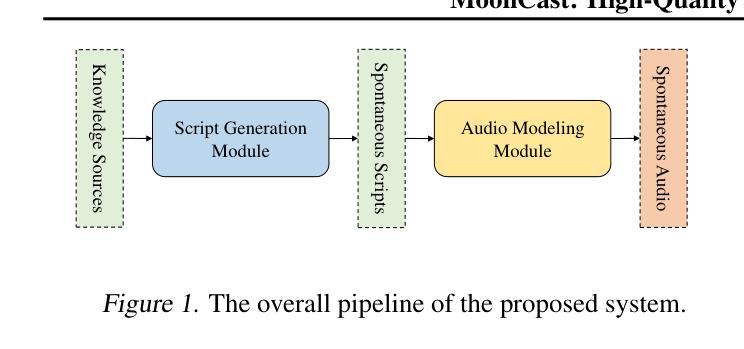
MoonCast: High-Quality Zero-Shot Podcast Generation
Authors:Zeqian Ju, Dongchao Yang, Jianwei Yu, Kai Shen, Yichong Leng, Zhengtao Wang, Xu Tan, Xinyu Zhou, Tao Qin, Xiangyang Li
Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
近期文本转语音合成技术的进展在生成单个说话者的高质量简短语音方面取得了显著的成功。然而,当这些系统尝试扩展到长时、多说话者以及典型如播客等现实世界的对话场景时,仍面临挑战。这些限制源于两个主要挑战:1)长语音:播客通常持续数分钟,超出大多数现有工作的上限;2)即兴性:播客以其即兴的口语特性为标志,这与正式、书面语境形成鲜明对比;现有作品往往难以捕捉这种即兴性。在本文中,我们提出了MoonCast,一种高质量零样本播客生成解决方案。旨在仅从文本源(如故事、技术报告、TXT、PDF或Web URL格式的新闻)合成自然播客风格的语音,并使用未见过的说话者的声音。为了生成长音频,我们采用基于长语境语言模型的音频建模方法,利用大规模长语境语音数据。为了提高即兴性,我们采用播客生成模块来生成具有即兴细节的脚本,经验表明这至关重要,与文本转语音建模本身一样重要。实验表明,MoonCast优于基线方法,特别是在即兴性和连贯性方面表现出显著改进。
论文及项目相关链接
Summary
本文介绍了文本转语音合成领域的最新进展,尤其是在生成高质量的个人演讲者短句方面的显著成果。然而,当前系统在面对长对话、多说话者以及典型如播客等现实场景时仍面临挑战。针对这一问题,本文提出了MoonCast方案,旨在实现从文本到高质量的零失误播客音频的合成,并能够模拟出从未见过的说话者的声音。该方案通过采用基于大规模长语境语音数据的音频建模方法生成长音频,并通过播客生成模块增强语音的自然性。实验证明,MoonCast优于基线模型,特别是在自然度和连贯性方面表现更优秀。
Key Takeaways
- 文本转语音合成技术在生成高质量短句方面取得显著进展,但在处理长对话、多说话者及现实场景如播客时仍面临挑战。
- MoonCast方案旨在实现从文本到高质量的零失误播客音频的合成,并能够模拟出从未见过的说话者的声音。
- MoonCast采用基于大规模长语境语音数据的音频建模方法生成长音频。
- 播客生成模块用于增强语音的自然性和自发性。
- 实验证明MoonCast在生成长音频和模拟播客风格方面优于基线模型。
- MoonCast在自然度和连贯性方面表现尤为出色。
点此查看论文截图

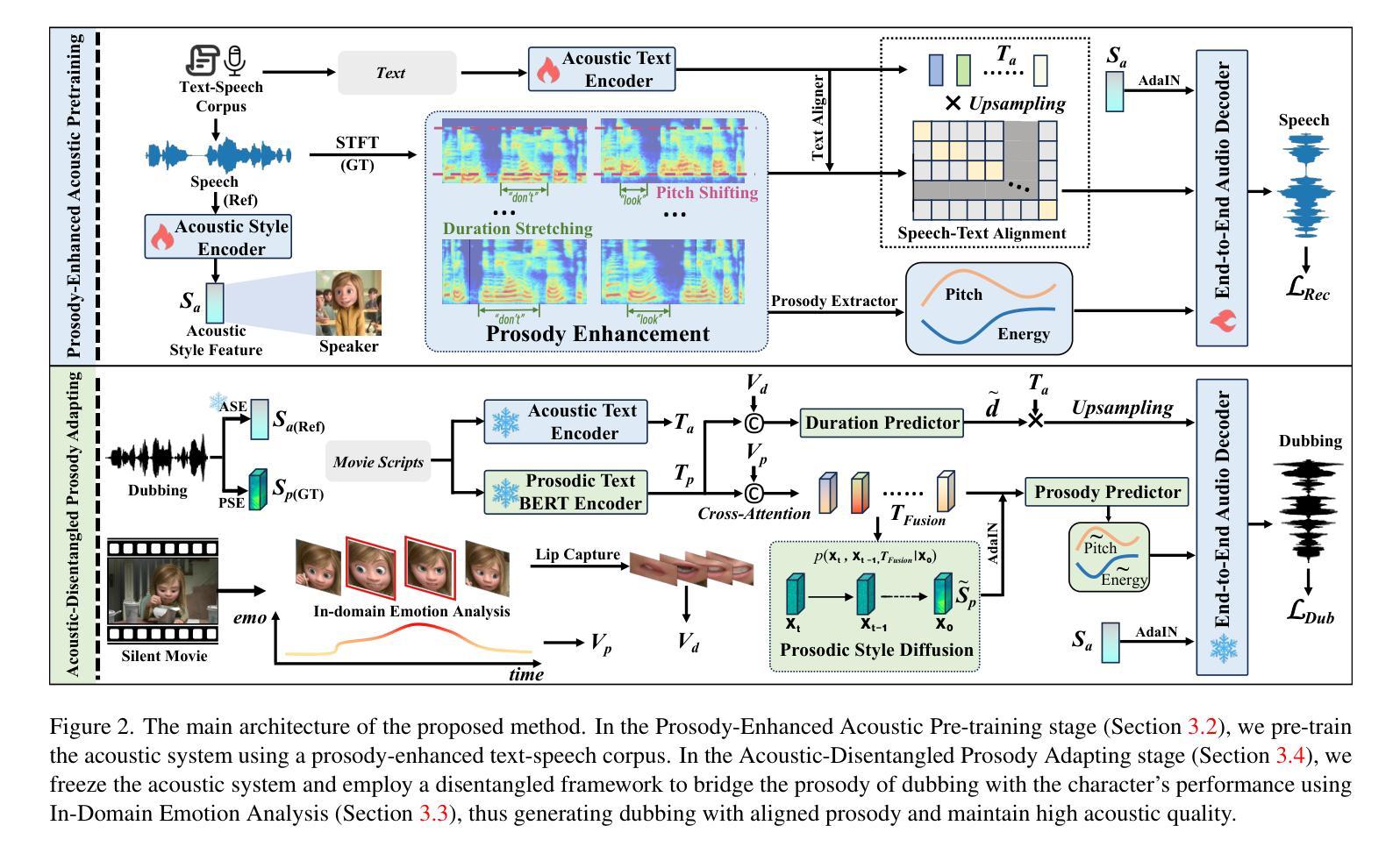
Prosody-Enhanced Acoustic Pre-training and Acoustic-Disentangled Prosody Adapting for Movie Dubbing
Authors:Zhedong Zhang, Liang Li, Chenggang Yan, Chunshan Liu, Anton van den Hengel, Yuankai Qi
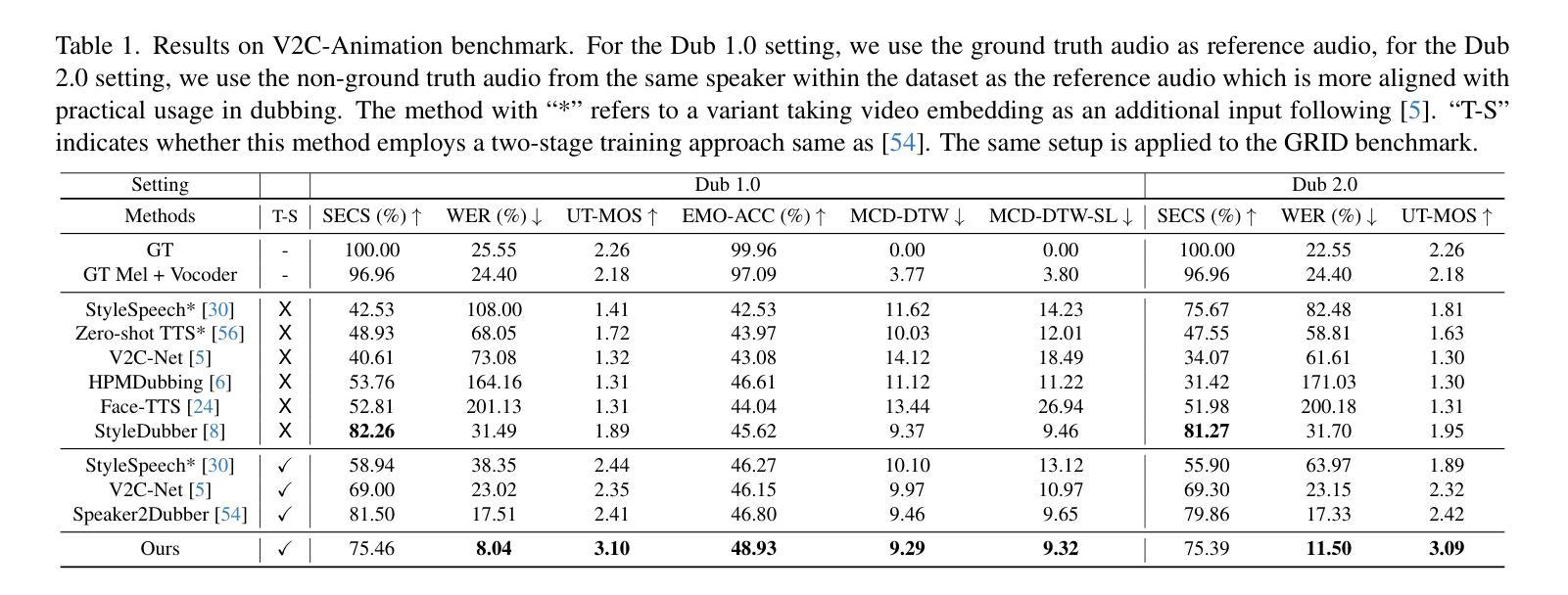
Movie dubbing describes the process of transforming a script into speech that aligns temporally and emotionally with a given movie clip while exemplifying the speaker’s voice demonstrated in a short reference audio clip. This task demands the model bridge character performances and complicated prosody structures to build a high-quality video-synchronized dubbing track. The limited scale of movie dubbing datasets, along with the background noise inherent in audio data, hinder the acoustic modeling performance of trained models. To address these issues, we propose an acoustic-prosody disentangled two-stage method to achieve high-quality dubbing generation with precise prosody alignment. First, we propose a prosody-enhanced acoustic pre-training to develop robust acoustic modeling capabilities. Then, we freeze the pre-trained acoustic system and design a disentangled framework to model prosodic text features and dubbing style while maintaining acoustic quality. Additionally, we incorporate an in-domain emotion analysis module to reduce the impact of visual domain shifts across different movies, thereby enhancing emotion-prosody alignment. Extensive experiments show that our method performs favorably against the state-of-the-art models on two primary benchmarks. The demos are available at https://zzdoog.github.io/ProDubber/.
电影配音是将剧本转化为与给定电影片段在时间和情感上对齐的语音的过程,同时展示在简短参考音频片段中体现出的说话人的声音。这项任务要求模型在角色表演和复杂的韵律结构之间建立联系,以生成高质量的视频同步配音轨道。电影配音数据集规模的有限性,以及音频数据中的背景噪声,阻碍了训练模型的声学建模性能。为了解决这些问题,我们提出了一种声学韵律分离的两阶段方法,以实现高质量的配音生成和精确的节奏对齐。首先,我们提出了一种韵律增强的声学预训练方法,以开发稳健的声学建模能力。然后,我们冻结预训练的声学系统,设计一个分离的框架来建模韵律文本特征和配音风格,同时保持声学质量。此外,我们加入了一个领域内的情感分析模块,以减少不同电影之间视觉领域变化的影响,从而增强情感韵律的对齐。大量实验表明,我们的方法在两个主要基准测试上的表现优于最先进的模型。相关演示可通过https://zzdoog.github.io/ProDubber/查看。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文介绍了电影配音的过程,即将剧本转化为与电影片段情感和时序对齐的语音,同时展示在简短参考音频片段中的说话人声音。针对电影配音数据集规模有限和音频数据中的背景噪声问题,提出了一种声学-语调分离的两阶段方法,以实现高质量的配音生成和精确的语气对齐。首先,提出一种增强语调的声学预训练方法,以建立稳健的声学模型。然后,冻结预训练的声学系统,设计一个分离的框架来模拟语调和文本特征,同时保持声音质量。此外,还融入领域内的情感分析模块,以减少不同电影之间视觉领域变化的影响,从而提高情感-语调的对齐效果。实验证明,该方法在两个主要基准测试上表现优异。
Key Takeaways
- 电影配音是将剧本转化为与电影片段情感和时序对齐的语音的过程。
- 配音任务需要模型桥接角色表演和复杂的语调结构,以建立高质量的视频同步配音轨道。
- 有限的电影配音数据集规模和音频数据中的背景噪声是配音模型面临的主要挑战。
- 提出了一种声学-语调分离的两阶段方法来解决这些问题,以实现高质量的配音生成。
- 首先进行增强语调的声学预训练,以建立稳健的声学模型。
- 冻结预训练的声学系统后,设计一个分离的框架来模拟语调和文本特征,同时保持声音质量。
点此查看论文截图

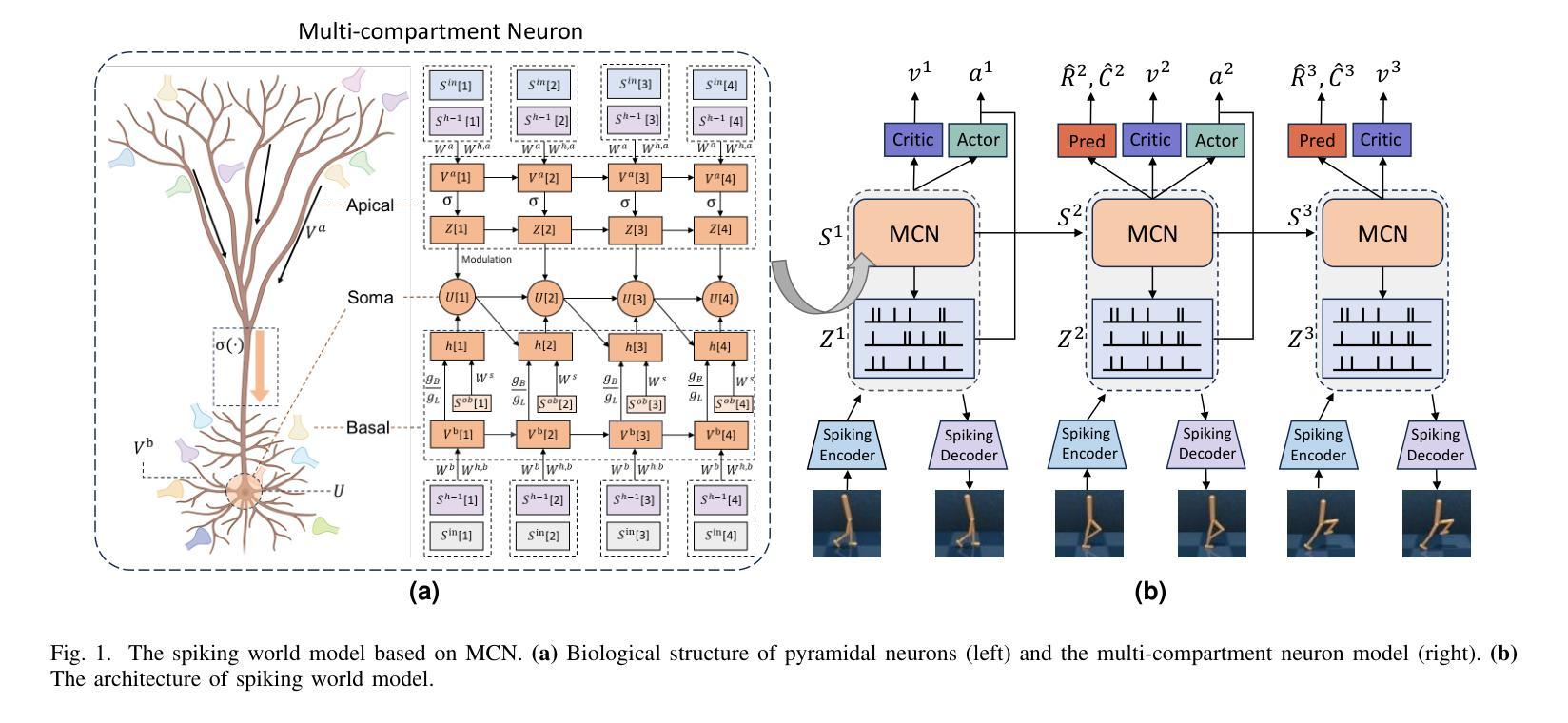
Implementing Spiking World Model with Multi-Compartment Neurons for Model-based Reinforcement Learning
Authors:Yinqian Sun, Feifei Zhao, Mingyang Lv, Yi Zeng
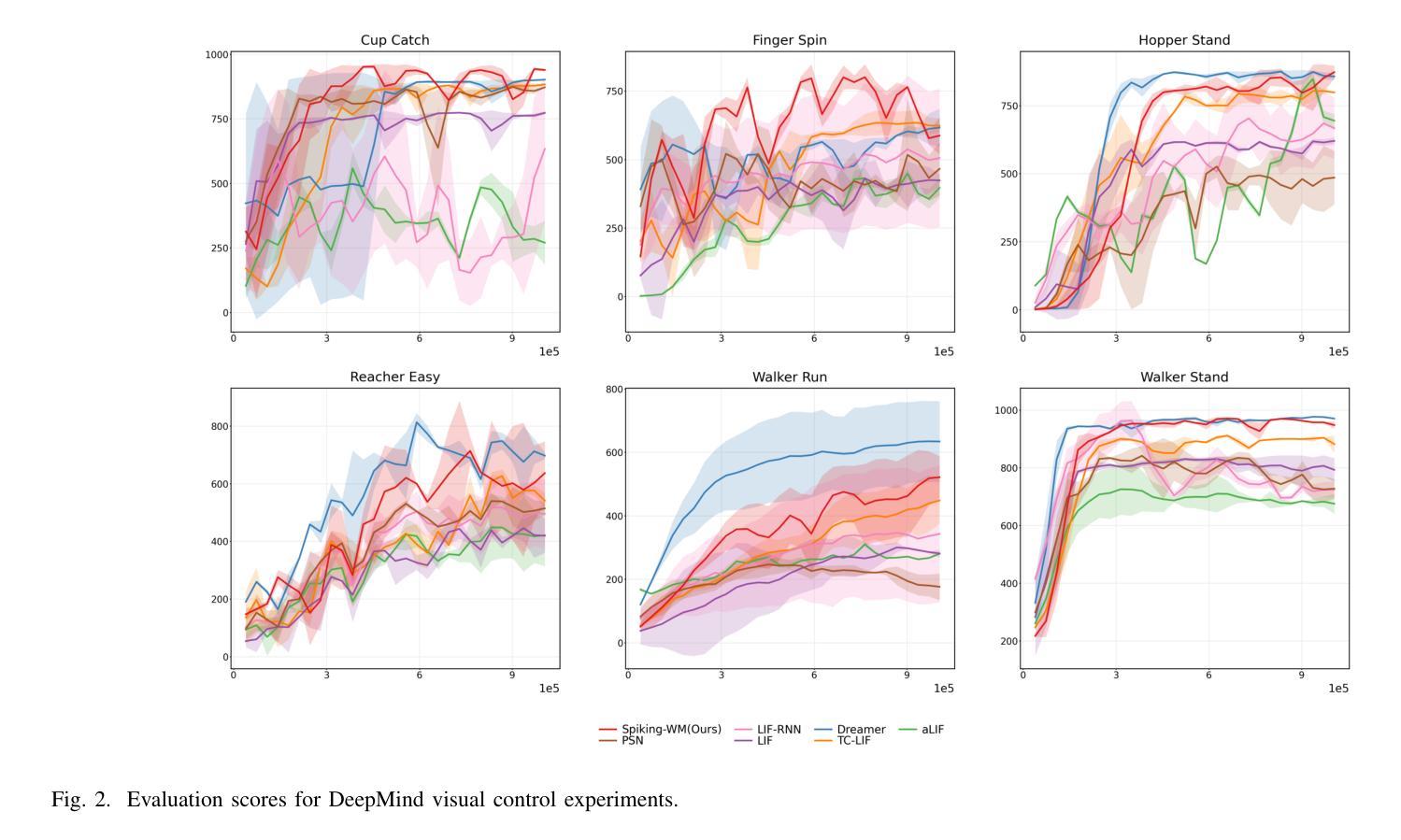
Brain-inspired spiking neural networks (SNNs) have garnered significant research attention in algorithm design and perception applications. However, their potential in the decision-making domain, particularly in model-based reinforcement learning, remains underexplored. The difficulty lies in the need for spiking neurons with long-term temporal memory capabilities, as well as network optimization that can integrate and learn information for accurate predictions. The dynamic dendritic information integration mechanism of biological neurons brings us valuable insights for addressing these challenges. In this study, we propose a multi-compartment neuron model capable of nonlinearly integrating information from multiple dendritic sources to dynamically process long sequential inputs. Based on this model, we construct a Spiking World Model (Spiking-WM), to enable model-based deep reinforcement learning (DRL) with SNNs. We evaluated our model using the DeepMind Control Suite, demonstrating that Spiking-WM outperforms existing SNN-based models and achieves performance comparable to artificial neural network (ANN)-based world models employing Gated Recurrent Units (GRUs). Furthermore, we assess the long-term memory capabilities of the proposed model in speech datasets, including SHD, TIMIT, and LibriSpeech 100h, showing that our multi-compartment neuron model surpasses other SNN-based architectures in processing long sequences. Our findings underscore the critical role of dendritic information integration in shaping neuronal function, emphasizing the importance of cooperative dendritic processing in enhancing neural computation.
受大脑启发的脉冲神经网络(SNNs)在算法设计和感知应用方面引起了研究人员的广泛关注。然而,它们在决策领域,特别是在基于模型的强化学习中的潜力,仍被探索不足。难点在于需要具有长期时间记忆能力的脉冲神经元,以及能够整合和学习信息进行准确预测的网络优化。生物神经元的动态树突信息整合机制为我们解决这些挑战提供了有价值的见解。在这项研究中,我们提出了一种多室神经元模型,能够非线性地整合来自多个树突来源的信息,以动态处理长序列输入。基于此模型,我们构建了脉冲世界模型(Spiking-WM),以实现基于模型的深度强化学习(DRL)与SNNs的结合。我们使用DeepMind Control Suite评估了我们的模型,证明Spiking-WM优于现有的SNN模型,其性能与采用门控循环单元(GRUs)的基于人工神经网络(ANN)的世界模型相当。此外,我们还在语音数据集(包括SHD、TIMIT和LibriSpeech 100h)上评估了所提出模型的长期记忆能力,表明我们的多室神经元模型在处理长序列方面超越了其他SNN架构。我们的研究强调了树突信息整合在塑造神经元功能中的关键作用,并突出了合作树突处理在增强神经计算中的重要性。
论文及项目相关链接
总结
脑启发脉冲神经网络(SNNs)在算法设计和感知应用方面已引起广泛关注,但在决策领域,特别是在基于模型的强化学习方面的潜力尚未得到充分探索。本研究提出一种多室神经元模型,能够非线性地整合来自多个树突来源的信息,以动态处理长序列输入。基于此模型构建的脉冲世界模型(Spiking-WM),实现了基于模型的深度强化学习(DRL)与SNNs的结合。评估显示,Spiking-WM在DeepMind Control Suite上的表现优于现有SNN模型,性能可与采用门控循环单元(GRU)的基于人工神经网络(ANN)的世界模型相媲美。此外,在语音数据集(包括SHD、TIMIT和LibriSpeech 100h)上的评估显示,我们的多室神经元模型在处理长序列方面超越了其他SNN架构。研究强调了树突信息整合在塑造神经元功能中的关键作用,并突出了合作树突处理在增强神经计算中的重要性。
关键见解
- SNNs在决策领域,尤其是基于模型的强化学习方面的潜力尚未充分探索。
- 提出了一种多室神经元模型,能够动态处理长序列输入。
- 基于该模型构建了Spiking-WM,实现了基于模型的深度强化学习与SNNs的结合。
- Spiking-WM在DeepMind Control Suite上的表现优于现有SNN模型。
- Spiking-WM的性能与基于ANN的采用GRU的世界模型相媲美。
- 在语音数据集上的评估显示,多室神经元模型在处理长序列方面优于其他SNN架构。
点此查看论文截图


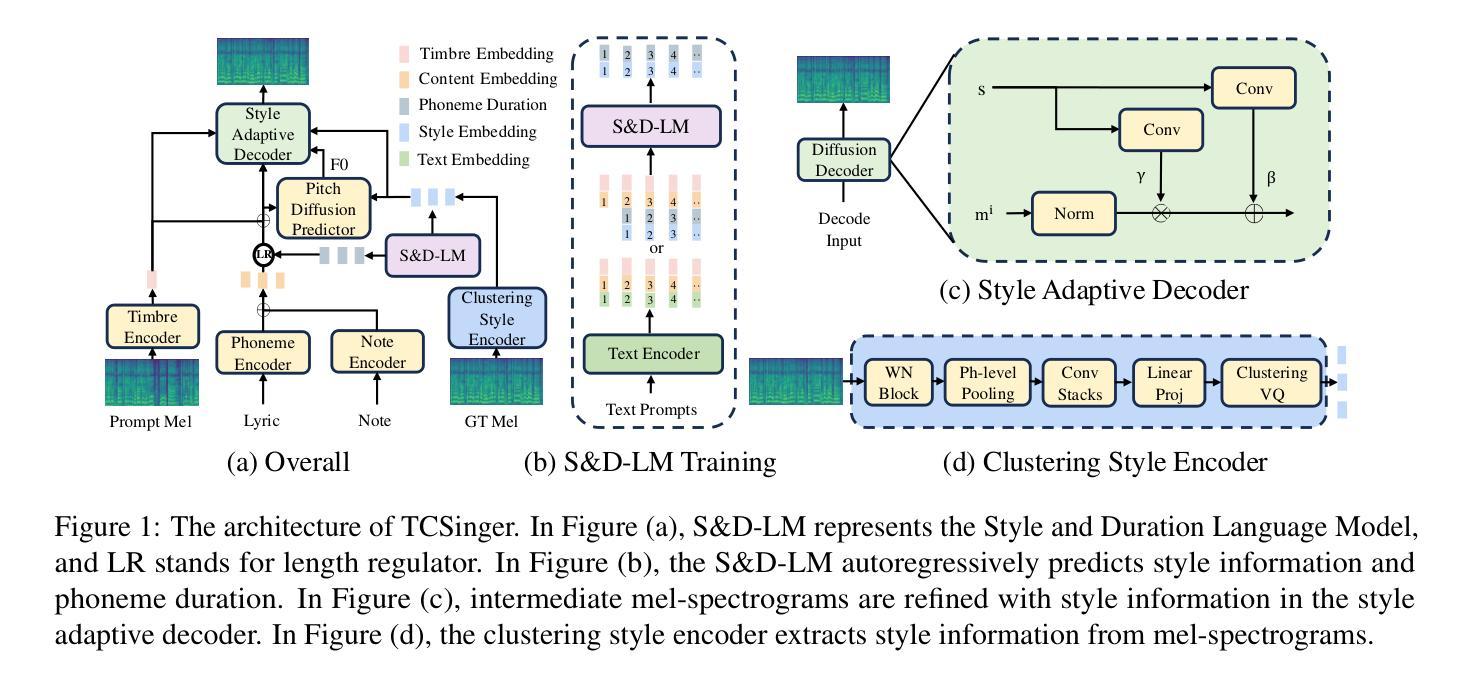
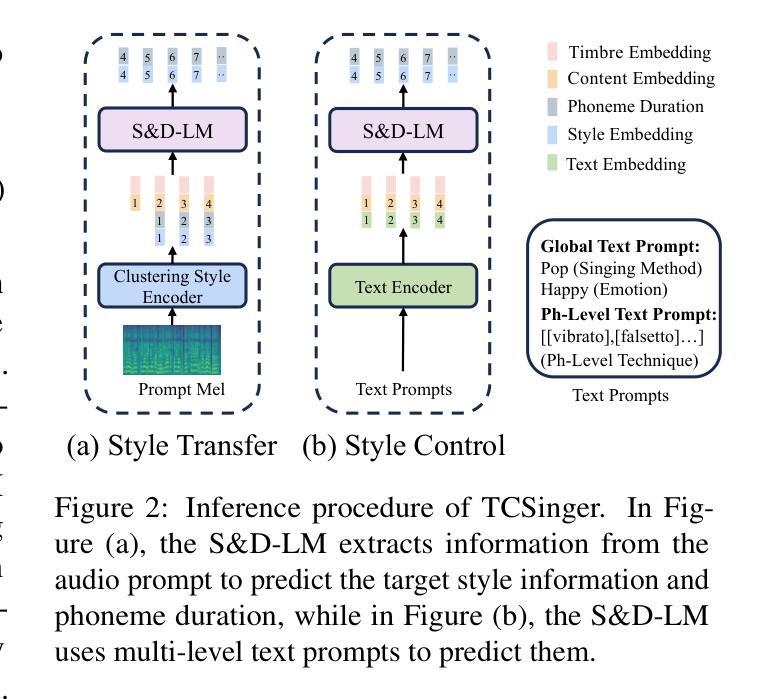
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Authors:Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, Zhou Zhao
Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://aaronz345.github.io/TCSingerDemo/.
零样本演唱声音合成(SVS)带风格转换和风格控制的目标是,从音频和文字提示生成具有未见音质和风格的高质量演唱声音(包括唱法、情感、节奏、技巧和发音)。然而,演唱风格的多元化给有效建模、转换和控制带来了重大挑战。此外,当前的SVS模型往往不能为未见过的歌手生成富有风格细微差别的演唱声音。为了应对这些挑战,我们引入了TCSinger,这是第一个用于跨语言语音和演唱风格转换的零样本SVS模型,以及多级风格控制。具体来说,TCSinger提出了三个主要模块:1)聚类风格编码器采用聚类向量量化模型,将风格信息稳定地浓缩到紧凑的潜在空间;2)风格和持续时间语言模型(S\&D-LM)同时预测风格信息和音素持续时间,这对两者都有利;3)风格自适应解码器使用一种新的梅尔风格自适应归一化方法,生成具有增强细节的歌声。实验结果表明,TCSinger在合成质量、歌手相似度和风格可控性方面均优于所有基线模型,包括零样本风格转换、多级风格控制、跨语言风格转换和语音到演唱风格的转换。演唱声音样本可访问 https://aaronz345.github.io/TCSingerDemo/。
论文及项目相关链接
PDF Accepted by EMNLP 2024
Summary
零镜头唱歌声音合成技术(SVS)旨在通过音频和文字提示生成具有未见音色和风格的高质量歌声,包括唱法、情感、节奏、技巧和发音等。针对唱歌风格的多方面特性带来的建模、转移和控制的挑战,以及当前SVS模型在为未见歌手生成富有风格特色的声音方面的不足,我们推出了TCSinger模型。它是首款零镜头SVS模型,可实现跨语言演讲和歌唱风格的风格转移和多级控制。该模型主要通过三个模块实现:聚类风格编码器、风格和时长语言模型以及风格自适应解码器。实验结果表明,TCSinger在合成质量、歌手相似度和风格可控性方面均优于所有基线模型,包括零镜头风格转移、多级风格控制、跨语言风格转移以及语音到歌唱风格转移等任务。
Key Takeaways
- 零镜头唱歌声音合成(SVS)旨在生成具有未见音色和风格的高质量歌声。
- 唱歌风格的多方面特性为建模、转移和控制带来了挑战。
- 当前SVS模型在为未见歌手生成富有风格特色的声音方面存在不足。
- TCSinger是首款零镜头SVS模型,支持跨语言演讲和歌唱风格的风格转移和多级控制。
- TCSinger通过三个主要模块实现其功能:聚类风格编码器、风格和时长语言模型以及风格自适应解码器。
- 实验表明,TCSinger在多个任务上表现优于其他模型,包括合成质量、歌手相似度和风格可控性。
点此查看论文截图

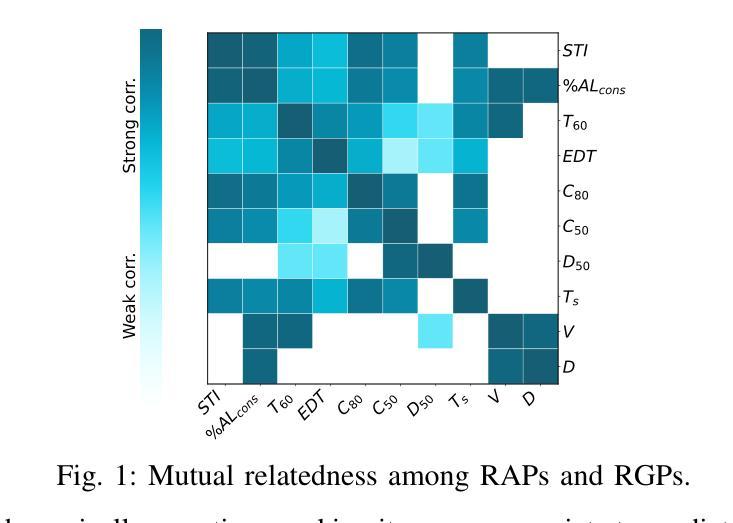
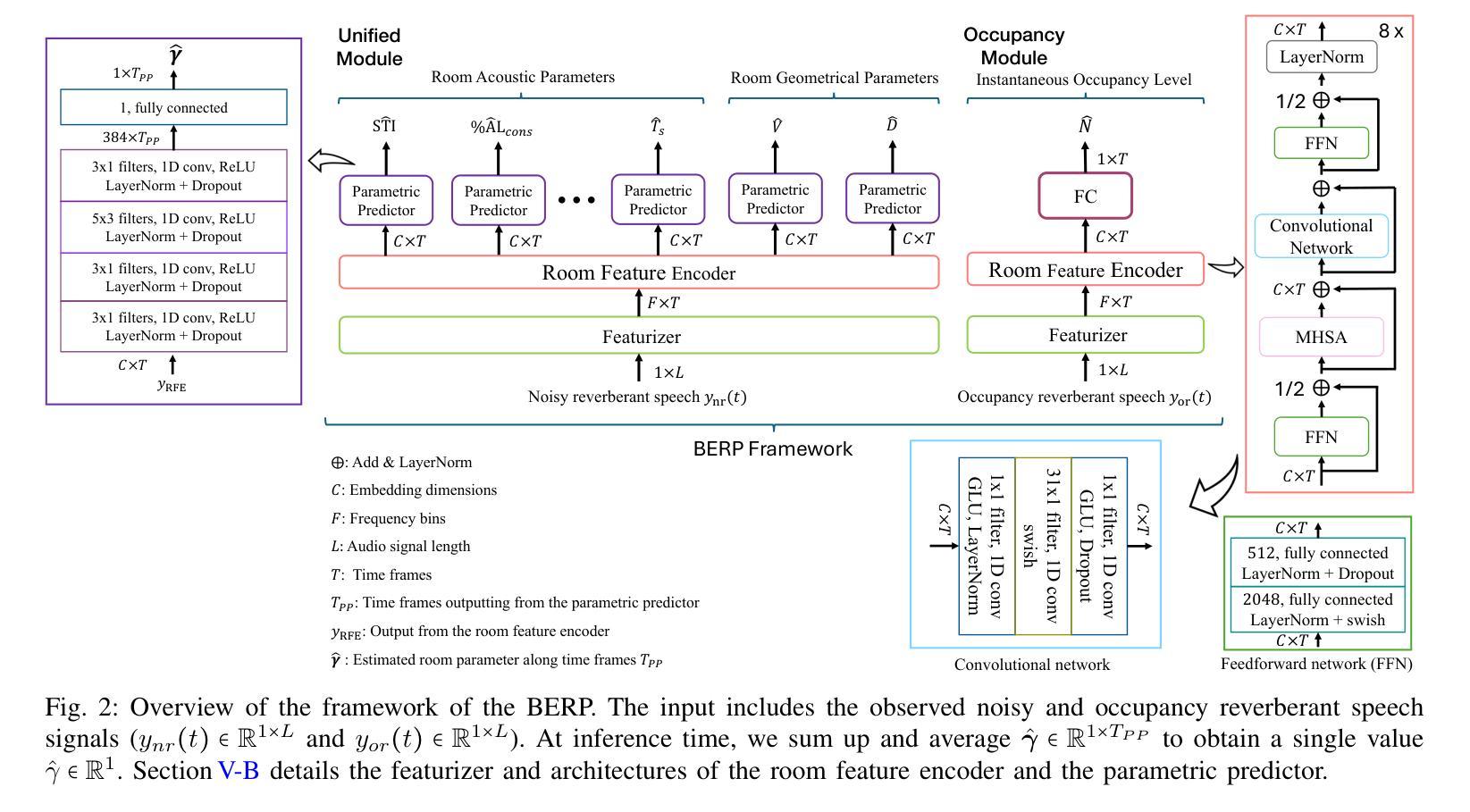
BERP: A Blind Estimator of Room Parameters for Single-Channel Noisy Speech Signals
Authors:Lijun Wang, Yixian Lu, Ziyan Gao, Kai Li, Jianqiang Huang, Yuntao Kong, Shogo Okada
Room acoustical parameters (RAPs), room geometrical parameters (RGPs) and instantaneous occupancy level are essential metrics for parameterizing the room acoustical characteristics (RACs) of a sound field around a listener’s local environment, offering comprehensive indications for various applications. Current blind estimation methods either fail to cover a broad range of real-world acoustic environments in the context of real background noise or estimate only a few RAPs and RGPs from noisy single-channel speech signals. In addition, they are limited in their ability to estimate the instantaneous occupancy level. In this paper, we propose a new universal blind estimation framework called the blind estimator of room parameters (BERP) to estimate RAPs, RGPs and occupancy level via a unified methodology. It consists of two modules: a unified room feature encoder that combines attention mechanisms with convolutional layers to learn common features across room parameters, and multiple separate parametric predictors for continuous estimation of each parameter in parallel. The combination of attention and convolutions enables the model to capture acoustic features locally and globally from speech, yielding more robust and multitask generalizable common features. Separate predictors allow the model to independently optimize for each room parameter to reduce task learning conflict and improve per-task performance. This estimation framework enables universal and efficient estimation of room parameters while maintaining satisfactory performance. To evaluate the effectiveness of the proposed framework, we compile a task-specific dataset from several publicly available datasets, including synthetic and real reverberant recordings. The results reveal that BERP achieves state-of-the-art (SOTA) performance and excellent adaptability to real-world scenarios. The code and weights are available on GitHub.
房间声学参数(RAPs)、房间几何参数(RGPs)和瞬时占用水平是表征听众周围声音场的环境声学特性(RACs)的重要参数,为各种应用提供了全面的指示。当前的盲估计方法要么无法覆盖广泛的实际世界声学环境,要么仅从嘈杂的单通道语音信号中估计少量的RAPs和RGPs。此外,它们在估计瞬时占用水平方面的能力有限。在本文中,我们提出了一种新的通用盲估计框架,称为房间参数盲估计器(BERP),通过统一的方法估计RAPs、RGPs和占用水平。它由两个模块组成:一个统一的房间特征编码器,它将注意力机制与卷积层相结合,以学习房间参数之间的共同特征;以及多个单独的参数预测器,用于并行连续估计每个参数。注意力和卷积的结合使模型能够从语音中局部和全局捕获声学特征,从而产生更稳健且多任务通用的共同特征。单独的预测器允许模型针对每个房间参数进行独立优化,以减少任务学习冲突并提高每项任务性能。该估计框架可实现房间参数的通用和有效估计,同时保持令人满意的性能。为了评估所提出框架的有效性,我们从几个公开可用的数据集(包括合成和真实混响录音)中编制了一个特定任务数据集。结果表明,BERP达到了最新技术性能,并对真实世界场景具有良好的适应性。代码和权重可在GitHub上获得。
论文及项目相关链接
PDF 16-page with supplementary materials, Submitted to IEEE/ACM Transaction on Audio Speech and Language Processing (TASLP)
Summary
本文提出一种名为“房间参数盲估计器(BERP)”的新通用盲估计框架,用于估计房间的声学参数(RAPs)、几何参数(RGPs)以及瞬时占用水平。该框架包含两个模块:一个统一房间特征编码器,结合注意力机制和卷积层学习房间参数的共同特征;多个单独的参数预测器,并行连续估计每个参数。该框架能有效估计房间参数,具有良好的通用性和性能。实验结果表明,BERP达到最新技术水平,并具有良好的适应真实场景的能力。
Key Takeaways
- BERP框架结合了注意力机制和卷积层,能捕捉语音的局部和全局声学特征。
- 框架包含两个模块:统一房间特征编码器和多个单独的参数预测器。
- BERP能估计房间的声学参数、几何参数以及瞬时占用水平。
- 框架具有通用性,能高效估计房间参数,同时保持令人满意的性能。
- BERP在合成和真实混响录音的多个公开数据集上达到最新技术水平。
- 框架的代码和权重已在GitHub上公开。
点此查看论文截图