⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
Authors:Baiqin Wang, Xiangyu Zhu, Fan Shen, Hao Xu, Zhen Lei
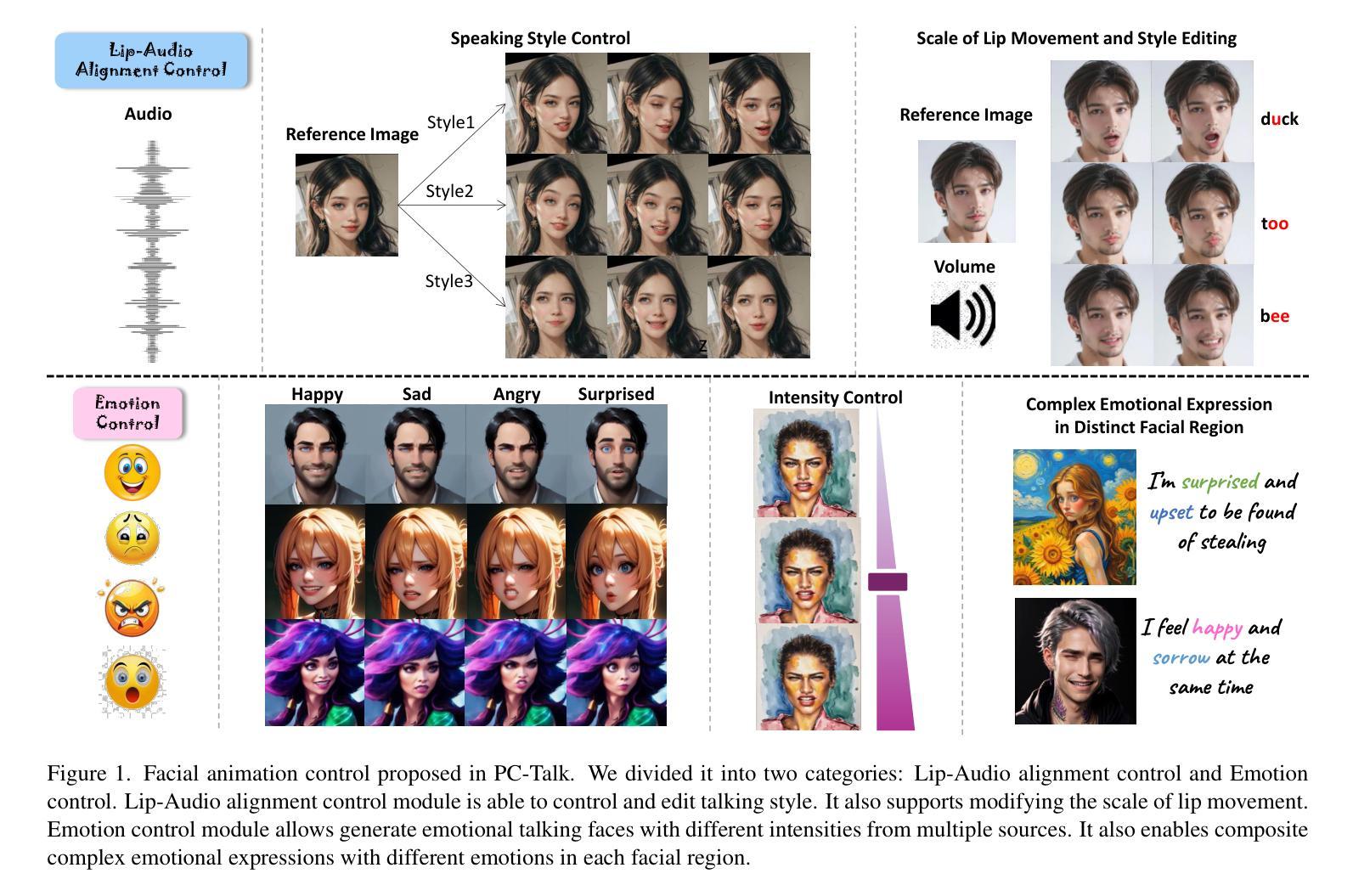
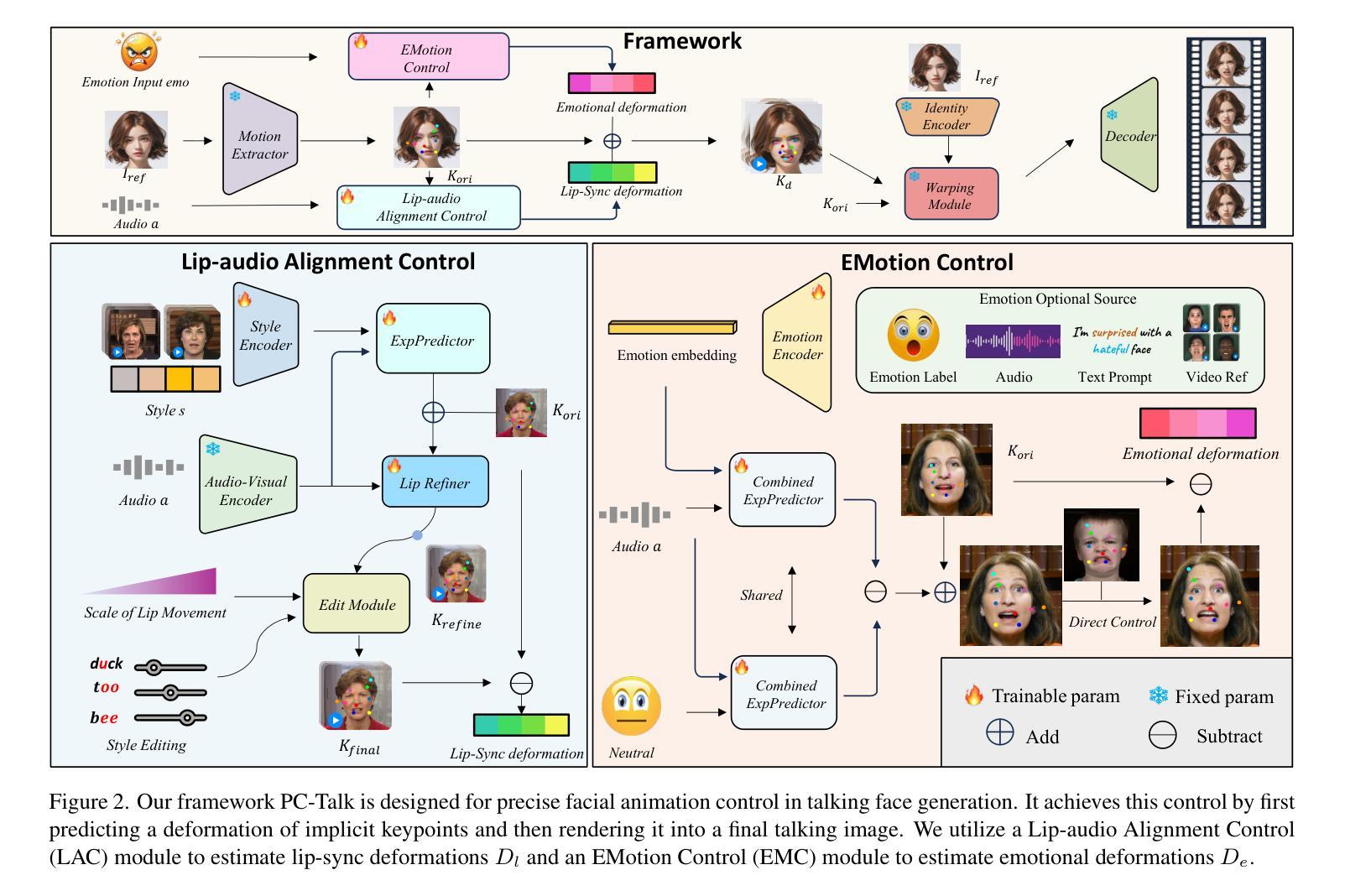
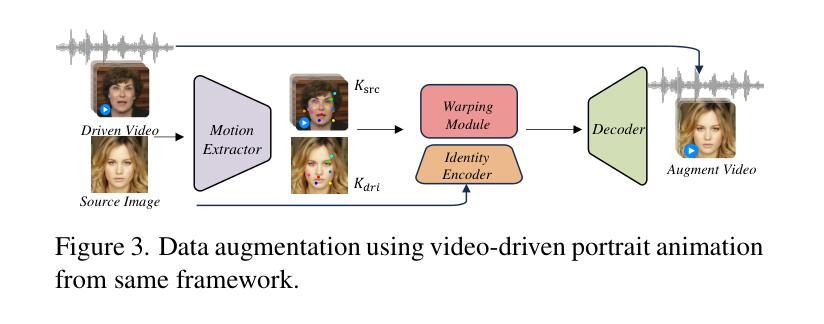
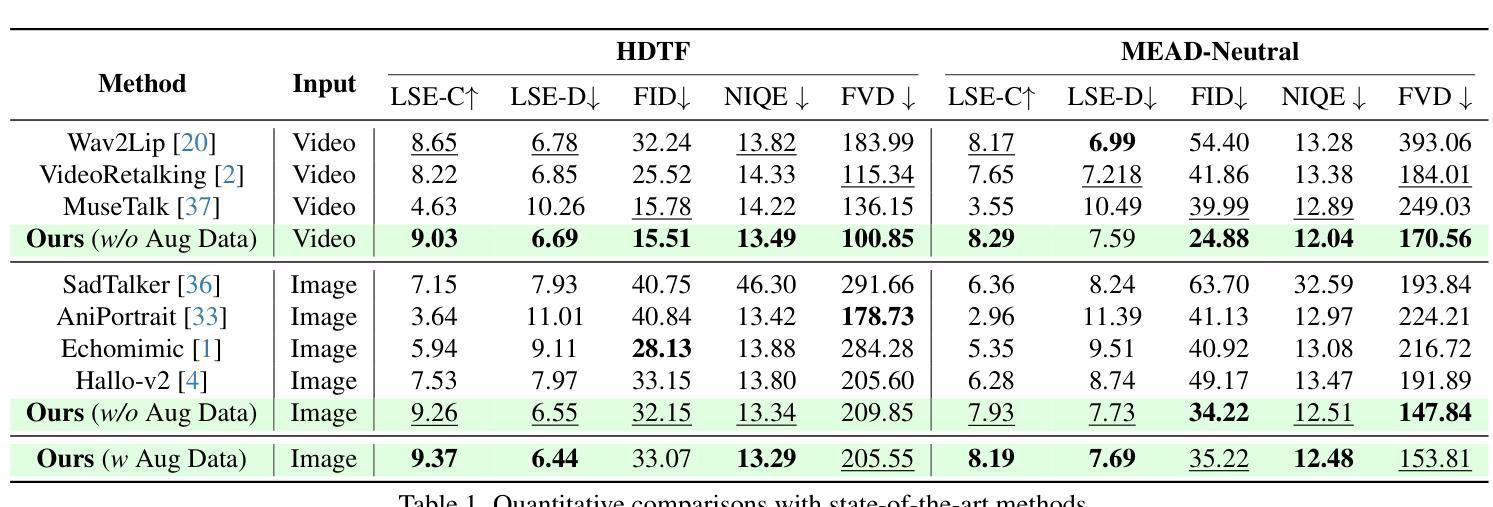
Recent advancements in audio-driven talking face generation have made great progress in lip synchronization. However, current methods often lack sufficient control over facial animation such as speaking style and emotional expression, resulting in uniform outputs. In this paper, we focus on improving two key factors: lip-audio alignment and emotion control, to enhance the diversity and user-friendliness of talking videos. Lip-audio alignment control focuses on elements like speaking style and the scale of lip movements, whereas emotion control is centered on generating realistic emotional expressions, allowing for modifications in multiple attributes such as intensity. To achieve precise control of facial animation, we propose a novel framework, PC-Talk, which enables lip-audio alignment and emotion control through implicit keypoint deformations. First, our lip-audio alignment control module facilitates precise editing of speaking styles at the word level and adjusts lip movement scales to simulate varying vocal loudness levels, maintaining lip synchronization with the audio. Second, our emotion control module generates vivid emotional facial features with pure emotional deformation. This module also enables the fine modification of intensity and the combination of multiple emotions across different facial regions. Our method demonstrates outstanding control capabilities and achieves state-of-the-art performance on both HDTF and MEAD datasets in extensive experiments.
近期音频驱动说话人脸生成技术的进展在嘴唇同步方面取得了很大的进步。然而,当前的方法往往对面部动画的控制不足,如演讲风格和情感表达,导致输出单一。在本文中,我们专注于改进两个关键因素:唇音频对齐和情感控制,以提高对话视频的多样性和用户友好性。唇音频对齐控制专注于演讲风格和嘴唇运动规模等元素,而情感控制则侧重于生成逼真的情感表达,允许强度等多个属性的修改。为了实现面部动画的精确控制,我们提出了一种新型框架PC-Talk,它通过隐式关键点变形实现唇音频对齐和情感控制。首先,我们的唇音频对齐控制模块便于精确编辑单词级别的演讲风格,并调整嘴唇运动规模以模拟不同的音量水平,同时保持与音频的嘴唇同步。其次,我们的情感控制模块通过纯情感变形生成生动的情感面部特征。该模块还实现了强度的精细修改和不同面部区域多种情感的组合。我们的方法展示了出色的控制能力,并在HDTF和MEAD数据集上的广泛实验中达到了最新性能。
论文及项目相关链接
Summary
本文介绍了音频驱动的说话面部生成技术的最新进展,重点解决了唇音对齐和情绪控制两个关键问题,以提高说话视频的多样性和用户友好性。文章提出了一种新的框架PC-Talk,通过隐性关键点变形实现面部动画的精确控制。该框架包括唇音对齐控制模块和情绪控制模块,前者可以在词级精确编辑说话风格并调整唇部运动幅度以模拟不同的音量水平,后者可以生成逼真的情感面部表情并精细调整情感强度。
Key Takeaways
- 近期音频驱动的说话面部生成技术在唇同步方面取得显著进展,但对面部动画的控制如说话风格和情感表达方面仍有不足。
- 论文主要解决唇音对齐和情绪控制两个关键问题,旨在提高说话视频的多样性和用户友好性。
- 提出的PC-Talk框架通过隐性关键点变形实现面部动画的精确控制。
- 唇音对齐控制模块可以精确编辑说话风格,调整唇部运动幅度以模拟不同的音量水平。
- 情绪控制模块可以生成逼真的情感面部表情,并允许对情感强度进行微调。
- PC-Talk框架在HDTF和MEAD数据集上的实验表现优异,展现了出色的控制能力。
点此查看论文截图


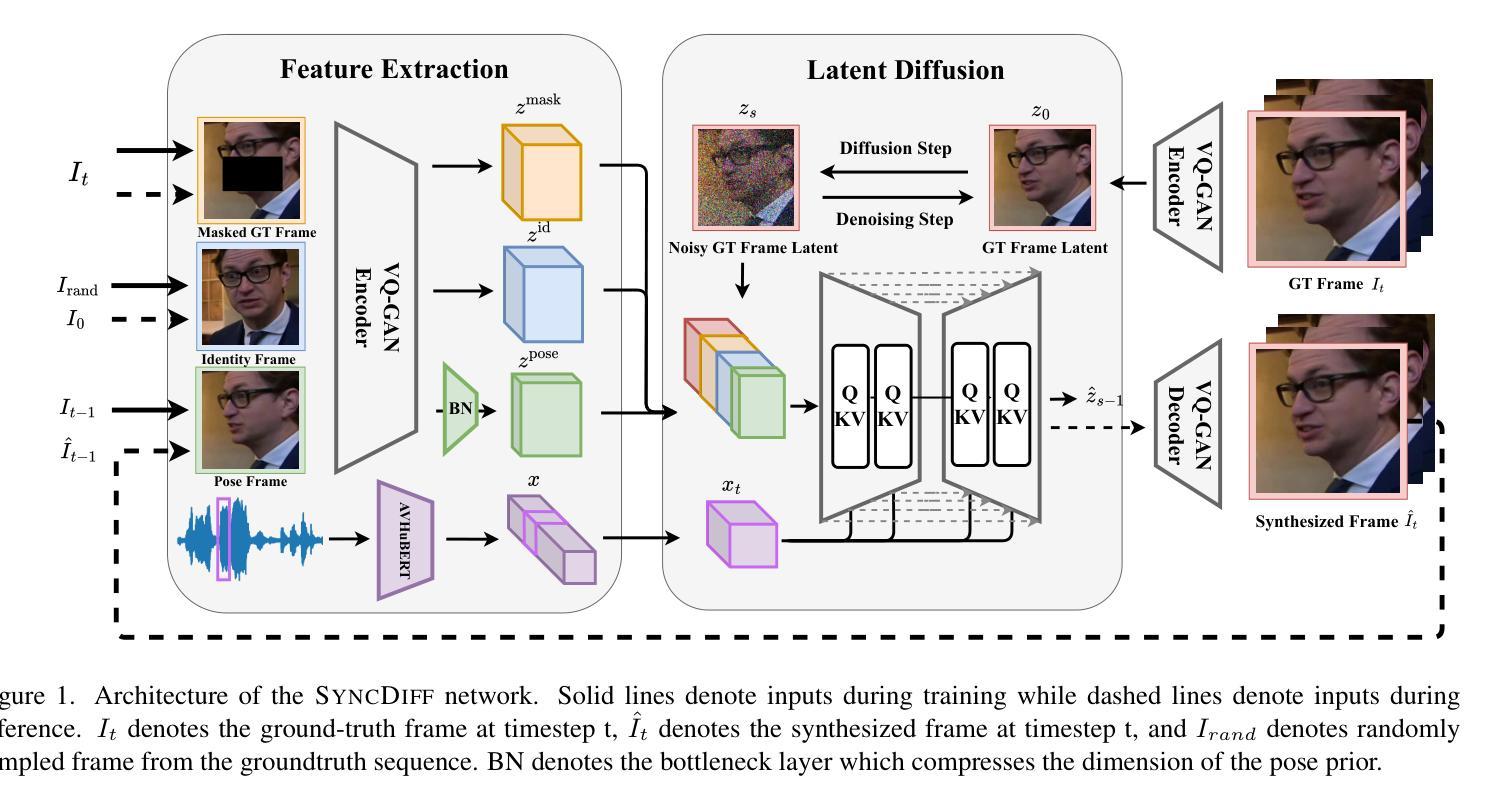
SyncDiff: Diffusion-based Talking Head Synthesis with Bottlenecked Temporal Visual Prior for Improved Synchronization
Authors:Xulin Fan, Heting Gao, Ziyi Chen, Peng Chang, Mei Han, Mark Hasegawa-Johnson
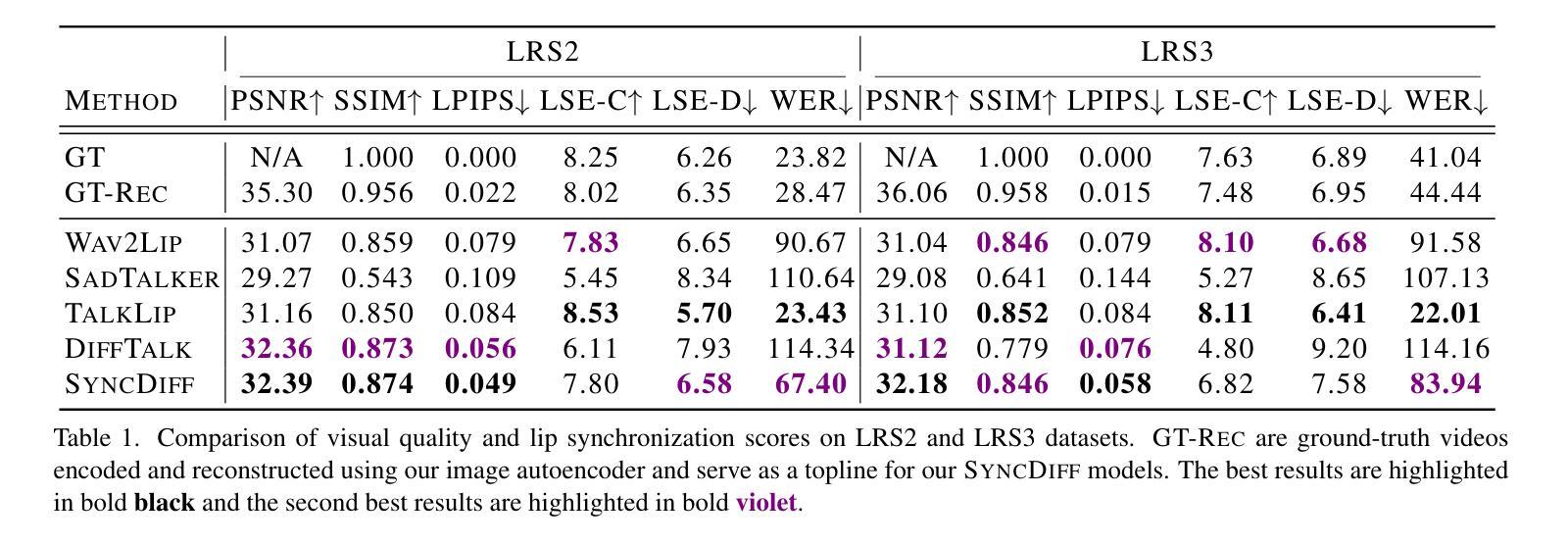
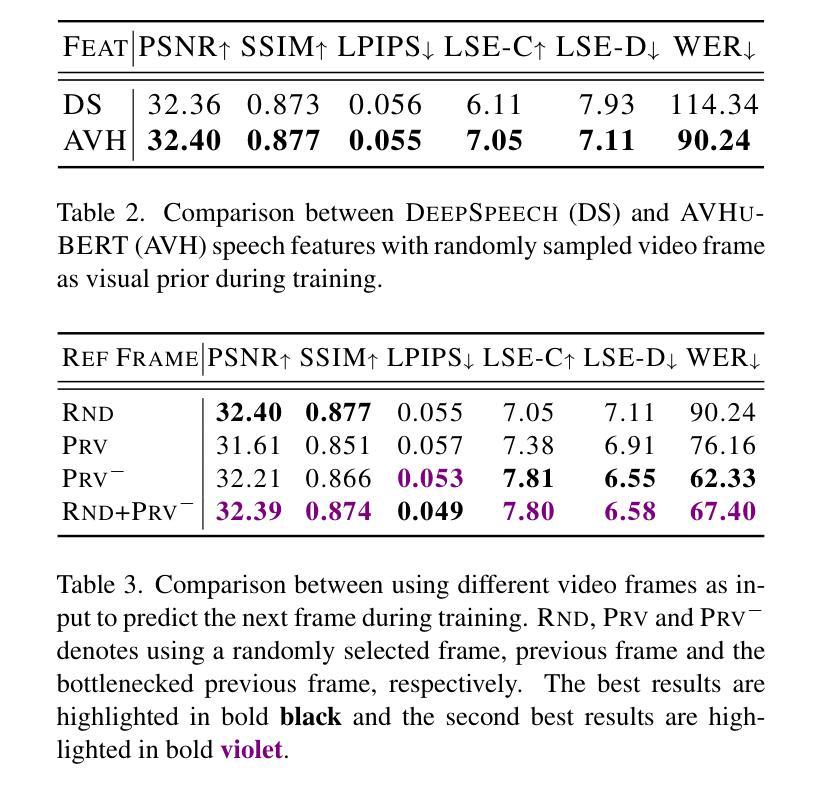
Talking head synthesis, also known as speech-to-lip synthesis, reconstructs the facial motions that align with the given audio tracks. The synthesized videos are evaluated on mainly two aspects, lip-speech synchronization and image fidelity. Recent studies demonstrate that GAN-based and diffusion-based models achieve state-of-the-art (SOTA) performance on this task, with diffusion-based models achieving superior image fidelity but experiencing lower synchronization compared to their GAN-based counterparts. To this end, we propose SyncDiff, a simple yet effective approach to improve diffusion-based models using a temporal pose frame with information bottleneck and facial-informative audio features extracted from AVHuBERT, as conditioning input into the diffusion process. We evaluate SyncDiff on two canonical talking head datasets, LRS2 and LRS3 for direct comparison with other SOTA models. Experiments on LRS2/LRS3 datasets show that SyncDiff achieves a synchronization score 27.7%/62.3% relatively higher than previous diffusion-based methods, while preserving their high-fidelity characteristics.
说话人头部合成,也被称为语音对口型合成,会重建与给定音频轨迹相对应的面部动作。对合成视频的评估主要集中在两个方面:口型语音同步和图像保真度。最近的研究表明,基于生成对抗网络(GAN)和扩散模型的方法在这项任务上达到了最新技术水平(SOTA),其中扩散模型在图像保真度方面表现更佳,但与基于GAN的方法相比同步性较低。为此,我们提出了SyncDiff,这是一种简单有效的方法,通过采用包含信息瓶颈的临时姿态帧和从AVHuBERT中提取的面部信息音频特征作为扩散过程的条件输入,改进了基于扩散的模型。我们在两个标准的说话人头部数据集LRS2和LRS3上对SyncDiff进行了评估,以便与其他最新技术模型进行直接比较。在LRS2/LRS3数据集上的实验表明,SyncDiff相对于之前的扩散方法实现了更高的同步得分,提高了27.7%/62.3%,同时保持了其高保真特性。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
本文介绍了说话人头部合成技术,重点讨论了基于扩散模型的改进方法SyncDiff。SyncDiff利用时间姿势帧和面部信息音频特征,提高了扩散模型的性能,实现了更准确的唇音同步和高保真图像。在LRS2和LRS3数据集上的实验表明,SyncDiff相较于其他先进模型有更好的同步性能。
Key Takeaways
- 说话人头部合成技术包括语音到唇部的合成,主要评估两个方面:唇语音同步和图像保真度。
- GAN模型和扩散模型是目前该任务的最先进模型。
- 扩散模型在图像保真度上表现优越,但在同步方面相对较差。
- SyncDiff方法是一种简单有效的改进扩散模型的方法,通过使用时间姿势帧和面部信息音频特征作为条件输入到扩散过程中。
- SyncDiff在LRS2和LRS3数据集上的实验结果表明,其同步得分相较于其他先进模型有显著提高。
- SyncDiff方法能够在保持高保真特性的同时,提高唇语音同步的准确性。
点此查看论文截图

Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Authors:Chaolong Yang, Kai Yao, Yuyao Yan, Chenru Jiang, Weiguang Zhao, Jie Sun, Guangliang Cheng, Yifei Zhang, Bin Dong, Kaizhu Huang
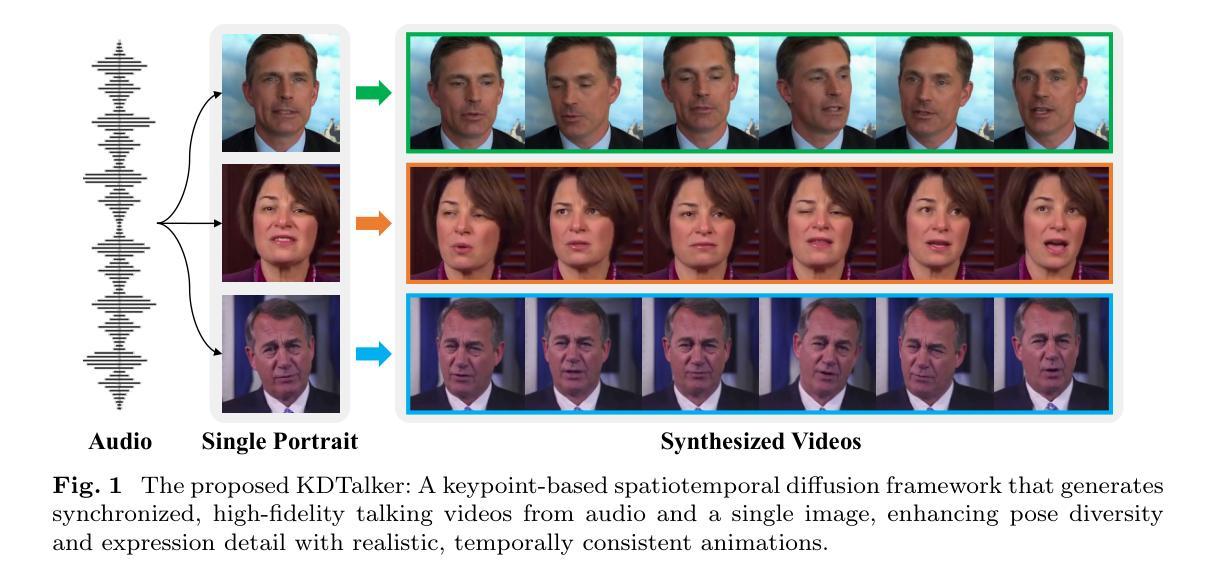
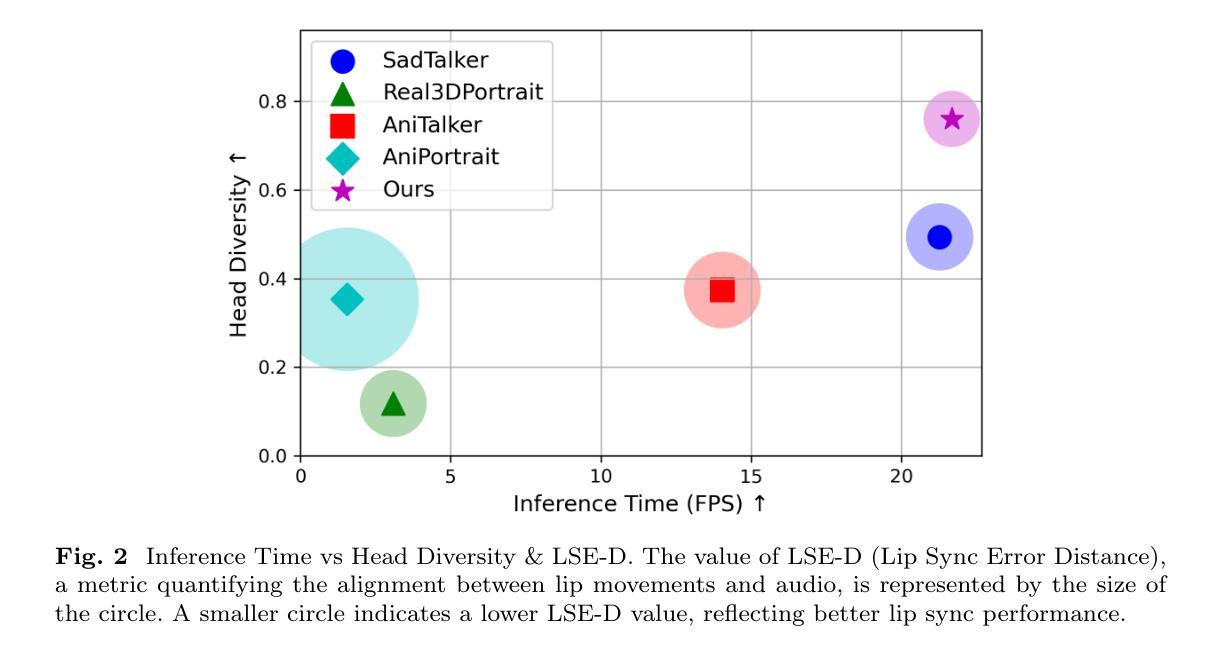
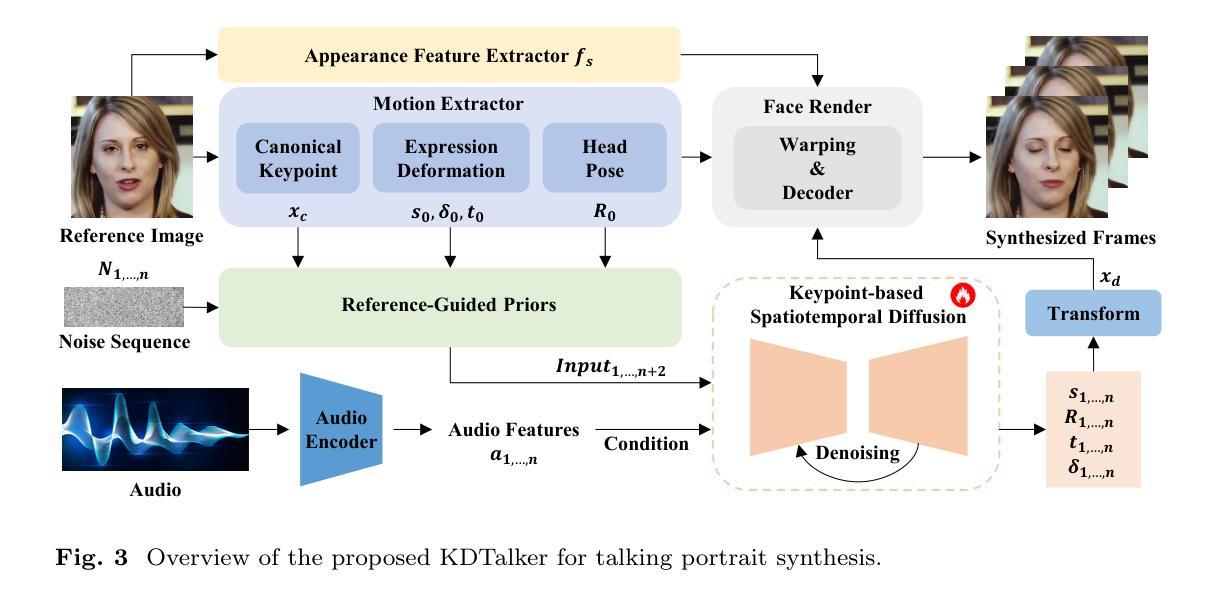
Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
音频驱动的单图像说话肖像生成在虚拟现实、数字人类创建和电影制作中扮演着至关重要的角色。现有方法通常分为基于关键点的方法和基于图像的方法。基于关键点的方法能够有效地保留人物身份,但由于3D可变形模型的固定点限制,很难捕捉面部细节。此外,传统的生成网络在有限数据集上建立音频和关键点之间的因果关系时面临挑战,导致姿势多样性较低。相比之下,基于图像的方法使用扩散网络生成具有各种细节的高质量肖像,但会产生身份失真和昂贵的计算成本。在这项工作中,我们提出了KDTalker,这是第一个结合无监督隐式3D关键点和时空扩散模型的框架。利用无监督隐式3D关键点,KDTalker适应面部信息密度,使扩散过程能够灵活地模拟各种头部姿势并捕捉面部细节。定制设计的时空注意力机制确保准确的唇部同步,产生时间一致的高质量动画,同时提高计算效率。实验结果表明,KDTalker在唇部同步准确性、头部姿势多样性和执行效率方面达到最新技术水平。我们的代码可在https://github.com/chaolongy/KDTalker找到。
论文及项目相关链接
Summary
基于音频驱动的单图像说话肖像生成在虚拟现实、数字人类创建和电影制作中起着至关重要的作用。现有方法主要分为基于关键点的方法和基于图像的方法。本文提出了一种结合无监督隐式三维关键点与时空扩散模型的框架KDTalker。它采用无监督隐式三维关键点,自适应面部信息密度,使扩散过程能够灵活建模多种头部姿态并捕捉面部细节。定制设计的时空注意力机制确保了准确的唇同步,产生时间连贯的高质量动画,同时提高计算效率。
Key Takeaways
- 音频驱动的单图像说话肖像生成在多个领域有重要应用。
- 现有方法分为基于关键点和基于图像两大类,各有优缺点。
- 基于关键点的方法虽能保留角色身份,但难以捕捉面部细节。
- 传统生成网络在建立音频与关键点之间的因果关系时面临挑战。
- 基于图像的方法能产生高质量肖像,但可能产生身份扭曲和计算成本高的问题。
- KDTalker框架结合了无监督隐式三维关键点和时空扩散模型,提高了面部信息捕捉的灵活性和准确性。
- KDTalker实现了先进的唇同步精度、头部姿态多样性和执行效率。
点此查看论文截图

Prosody-Enhanced Acoustic Pre-training and Acoustic-Disentangled Prosody Adapting for Movie Dubbing
Authors:Zhedong Zhang, Liang Li, Chenggang Yan, Chunshan Liu, Anton van den Hengel, Yuankai Qi
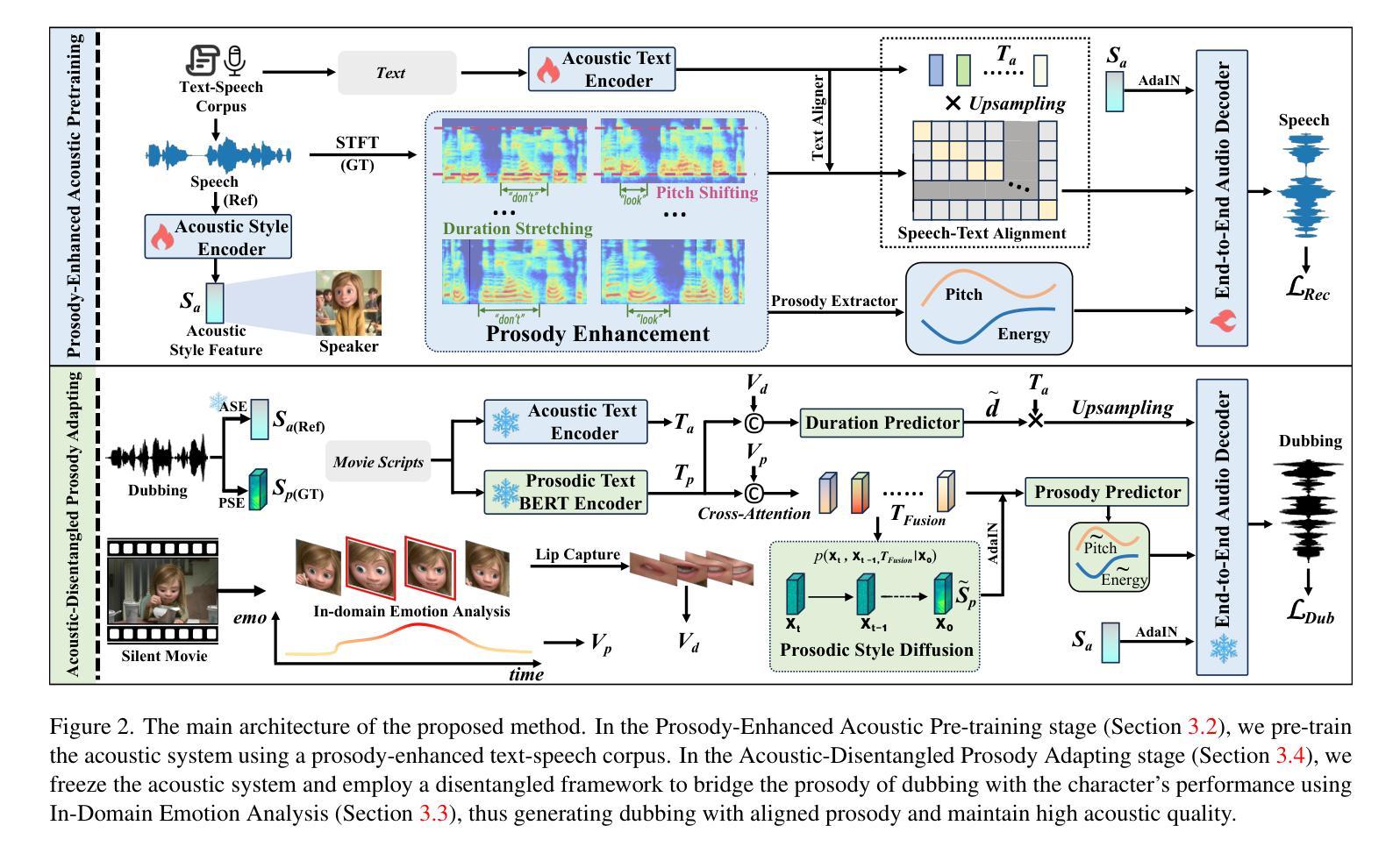
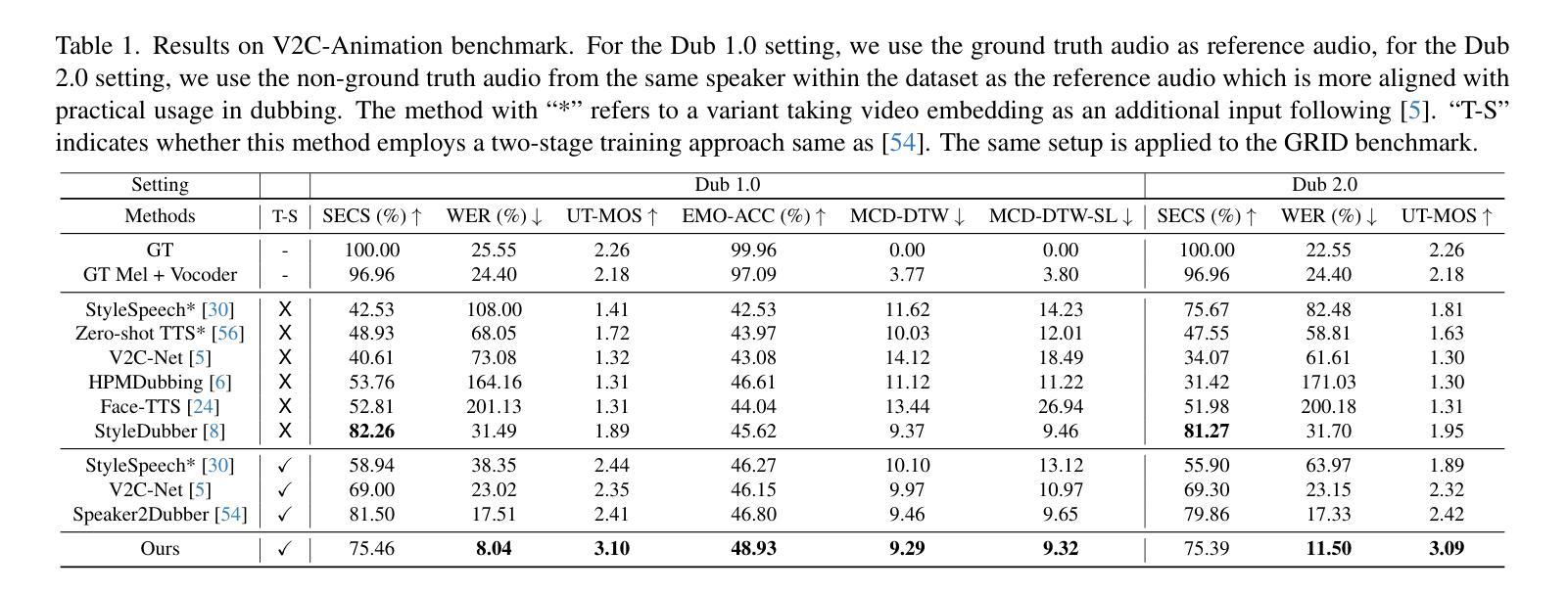
Movie dubbing describes the process of transforming a script into speech that aligns temporally and emotionally with a given movie clip while exemplifying the speaker’s voice demonstrated in a short reference audio clip. This task demands the model bridge character performances and complicated prosody structures to build a high-quality video-synchronized dubbing track. The limited scale of movie dubbing datasets, along with the background noise inherent in audio data, hinder the acoustic modeling performance of trained models. To address these issues, we propose an acoustic-prosody disentangled two-stage method to achieve high-quality dubbing generation with precise prosody alignment. First, we propose a prosody-enhanced acoustic pre-training to develop robust acoustic modeling capabilities. Then, we freeze the pre-trained acoustic system and design a disentangled framework to model prosodic text features and dubbing style while maintaining acoustic quality. Additionally, we incorporate an in-domain emotion analysis module to reduce the impact of visual domain shifts across different movies, thereby enhancing emotion-prosody alignment. Extensive experiments show that our method performs favorably against the state-of-the-art models on two primary benchmarks. The demos are available at https://zzdoog.github.io/ProDubber/.
电影配音是将剧本转化为与给定电影片段在时间和情感上对齐的台词的过程,同时以简短参考音频片段中的演示者的声音为榜样。这项任务要求模型将角色表演和复杂的韵律结构结合起来,以构建高质量的与视频同步的配音轨迹。电影配音数据集规模的有限性,以及音频数据中的背景噪音,阻碍了训练模型的声学建模性能。为了解决这些问题,我们提出了一种声学韵律解耦的两阶段方法来实现高质量的配音生成,具有精确韵律对齐。首先,我们提出了一种韵律增强的声学预训练,以发展稳健的声学建模能力。然后,我们冻结预训练的声学系统,设计一个解耦框架来建模文本特征和配音风格,同时保持声学质量。此外,我们加入了一个领域内的情感分析模块,以减少不同电影之间视觉领域变化的影响,从而增强情感韵律对齐。大量实验表明,我们的方法在两个主要基准测试上的表现优于最先进的模型。演示地址是:https://zzdoog.github.io/ProDubber/。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文介绍了电影配音的过程,并指出了现有数据集和音频数据中的背景噪声所带来的挑战。为解决这些问题,提出了一种基于声学-语调分离的两阶段方法来实现高质量的配音生成和精确的语调对齐。首先通过提出一种增强语调的声学预训练方法,增强声学建模能力。然后冻结预训练的声学系统,设计一个分离的框架来模拟语音文本特征和配音风格,同时保持声学质量。此外,还引入了一个领域的情感分析模块,以减少不同电影之间视觉域变化的冲击,从而提高情感语调的对齐效果。实验证明,该方法在两个主要基准测试上的表现优于现有模型。相关演示可通过链接查看。
Key Takeaways
- 电影配音是暂时和情感上与给定电影片段相符的语音转换过程,需要模型桥接角色表演和复杂的语调结构来构建高质量的视频同步配音轨道。
- 当前面临的主要挑战是电影配音数据集规模的限制以及音频数据中的背景噪声问题。
- 提出了一种基于声学-语调分离的两阶段方法来实现高质量的配音生成和精确的语调对齐。
- 通过声学预训练提升声学建模能力,通过冻结预训练声学系统并建立分离框架处理文本特征和配音风格。
- 引入了领域的情感分析模块,减少不同电影间视觉域变化对情感语调对齐的影响。
- 实验证明该方法在主要基准测试上的表现优于现有模型。
点此查看论文截图

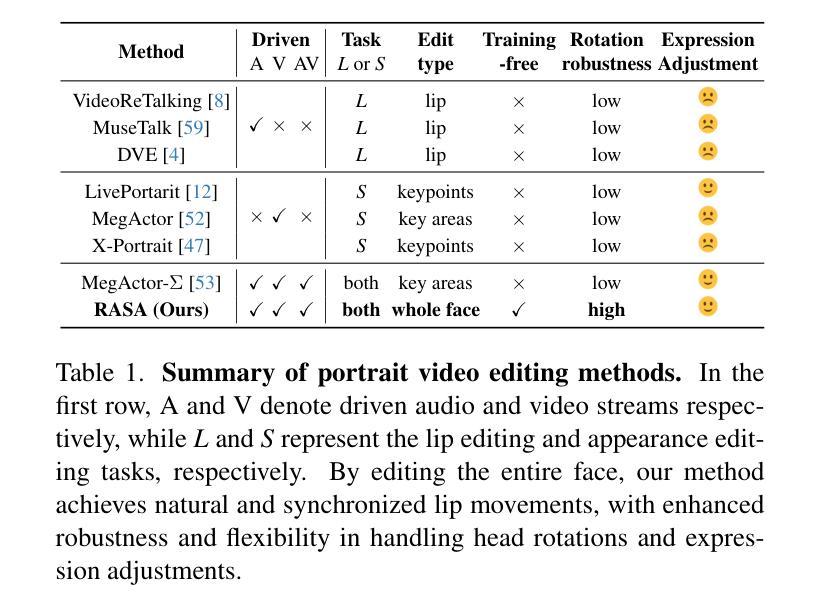
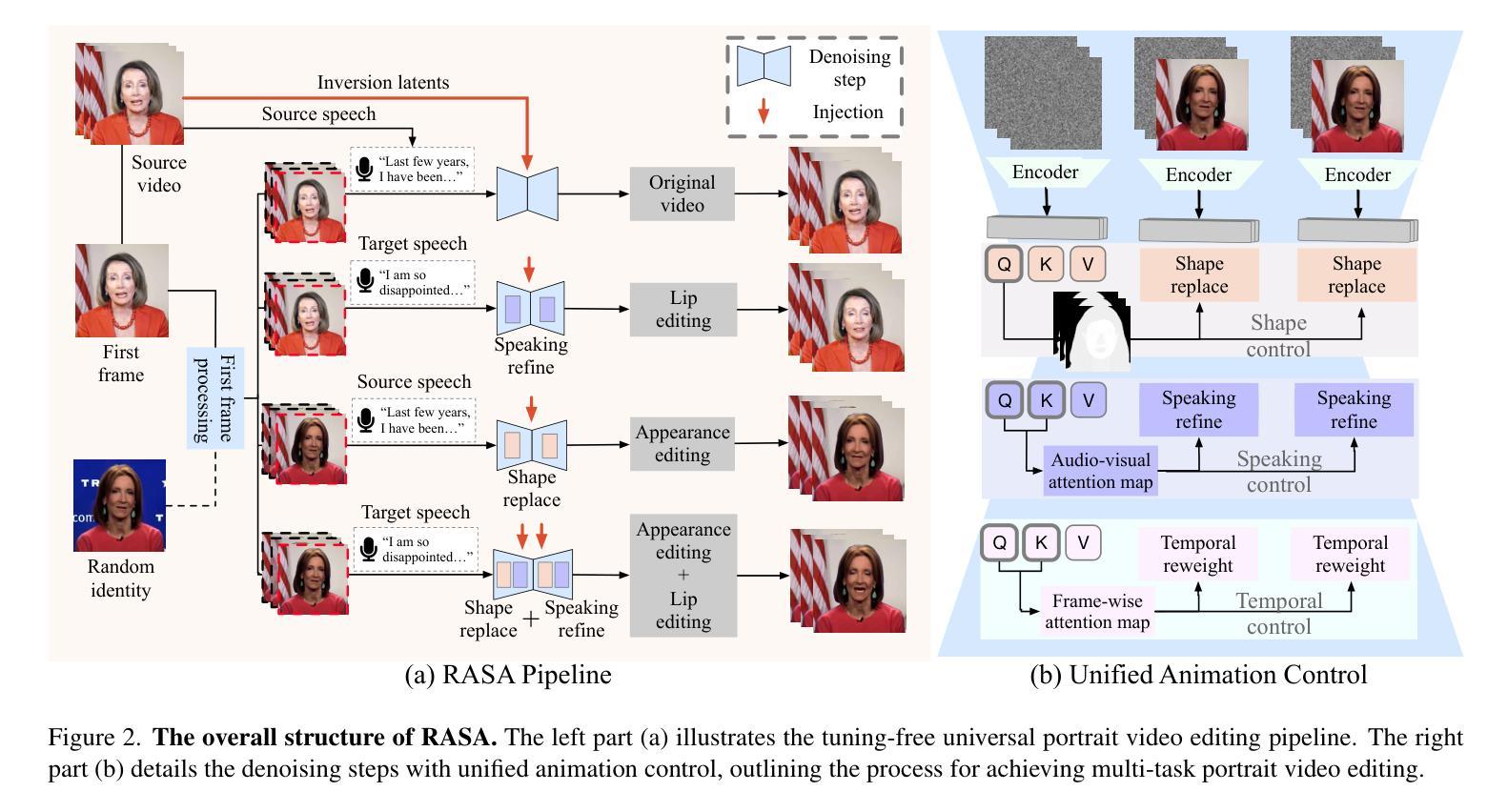
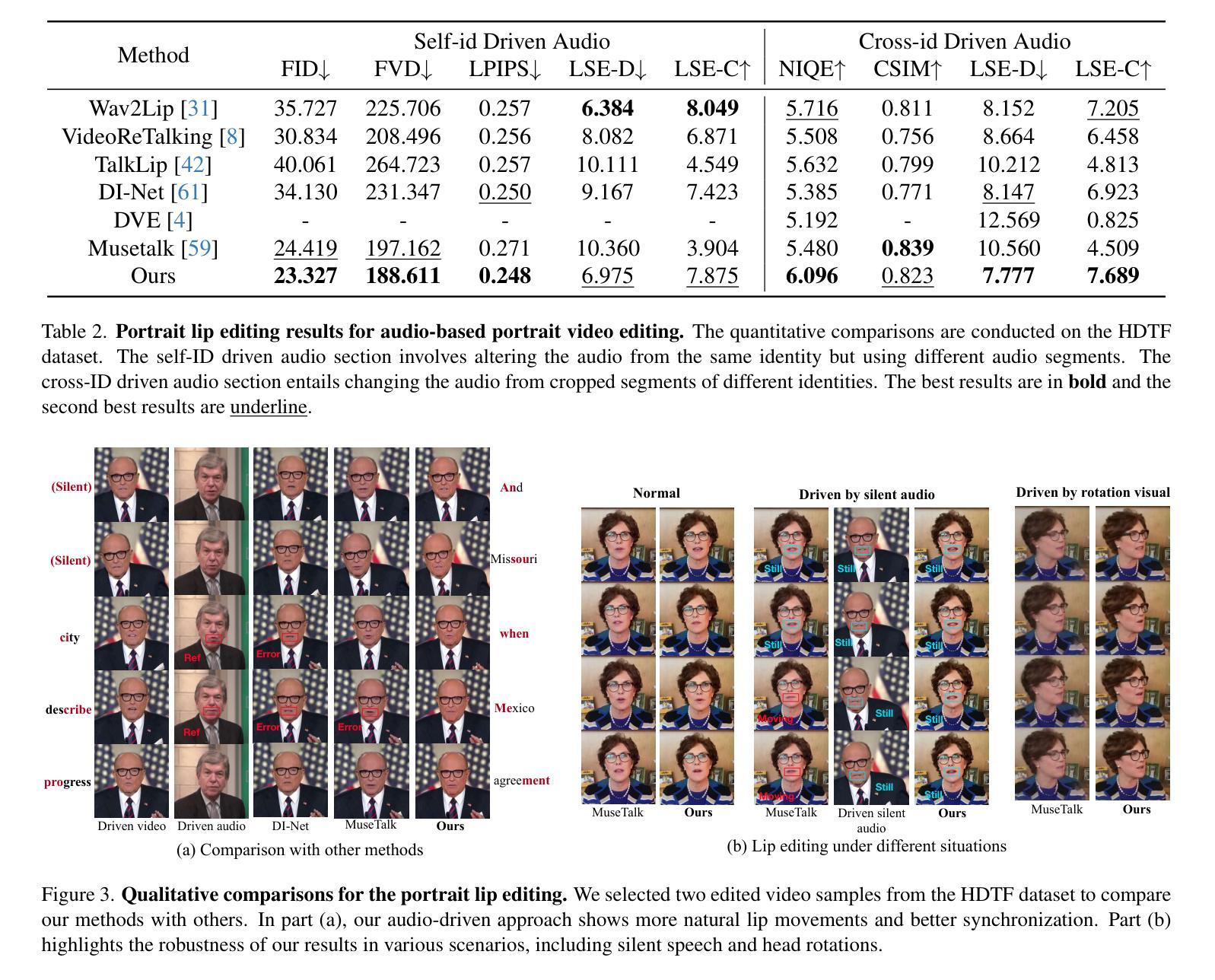
RASA: Replace Anyone, Say Anything – A Training-Free Framework for Audio-Driven and Universal Portrait Video Editing
Authors:Tianrui Pan, Lin Liu, Jie Liu, Xiaopeng Zhang, Jie Tang, Gangshan Wu, Qi Tian
Portrait video editing focuses on modifying specific attributes of portrait videos, guided by audio or video streams. Previous methods typically either concentrate on lip-region reenactment or require training specialized models to extract keypoints for motion transfer to a new identity. In this paper, we introduce a training-free universal portrait video editing framework that provides a versatile and adaptable editing strategy. This framework supports portrait appearance editing conditioned on the changed first reference frame, as well as lip editing conditioned on varied speech, or a combination of both. It is based on a Unified Animation Control (UAC) mechanism with source inversion latents to edit the entire portrait, including visual-driven shape control, audio-driven speaking control, and inter-frame temporal control. Furthermore, our method can be adapted to different scenarios by adjusting the initial reference frame, enabling detailed editing of portrait videos with specific head rotations and facial expressions. This comprehensive approach ensures a holistic and flexible solution for portrait video editing. The experimental results show that our model can achieve more accurate and synchronized lip movements for the lip editing task, as well as more flexible motion transfer for the appearance editing task. Demo is available at https://alice01010101.github.io/RASA/.
肖像视频编辑主要关注根据音频或视频流修改肖像视频的具体属性。之前的方法通常集中在唇部区域的再现,或者需要训练专门模型以提取关键点,用于将动作转移到新身份。在本文中,我们介绍了一个无训练通用的肖像视频编辑框架,该框架提供了一种通用和可适应的编辑策略。此框架支持根据更改的第一帧进行肖像外观编辑,以及根据各种语音进行唇部编辑,或两者的组合。它基于统一动画控制(UAC)机制,使用源反转潜在变量来编辑整个肖像,包括视觉驱动的形状控制、音频驱动的说话控制以及帧间时间控制。此外,通过调整初始参考帧,我们的方法能够适应不同场景,实现对具有特定头部旋转和面部表情的肖像视频的详细编辑。这种综合方法确保了肖像视频编辑的全面和灵活解决方案。实验结果表明,我们的模型在唇部编辑任务上可以实现更准确、更同步的唇部运动,以及在外观编辑任务上实现更灵活的动态转移。演示请访问:https://alice01010101.github.io/RASA/。
论文及项目相关链接
PDF Demo is available at https://alice01010101.github.io/RASA/
Summary
本文介绍了一种无需训练即可应用的通用肖像视频编辑框架,该框架支持基于更改的第一帧的肖像外观编辑和基于不同语音的唇部编辑,或两者的组合。它基于统一动画控制(UAC)机制,通过源反转潜码来编辑整个肖像,包括视觉驱动的形状控制、音频驱动的说话控制和帧间时间控制。此外,通过调整初始帧,该方法可适应不同的场景,实现对肖像视频特定头部旋转和面部表情的详细编辑。
Key Takeaways
- 介绍了一种新型的肖像视频编辑框架,该框架无需训练即可应用,具有广泛适应性和灵活性。
- 框架支持基于更改的第一帧的肖像外观编辑和基于不同语音的唇部编辑,或两者的组合。
- 该框架基于统一动画控制(UAC)机制,该机制通过源反转潜码编辑整个肖像。
- 实现了视觉驱动的形状控制、音频驱动的说话控制和帧间时间控制。
- 通过调整初始帧,该框架可适应不同的编辑场景,实现详细编辑。
- 实验结果表明,该框架在唇编辑任务上能实现更准确、更同步的唇部运动,在外观编辑任务上能实现更灵活的动态转移。
点此查看论文截图

EmoDiffusion: Enhancing Emotional 3D Facial Animation with Latent Diffusion Models
Authors:Yixuan Zhang, Qing Chang, Yuxi Wang, Guang Chen, Zhaoxiang Zhang, Junran Peng
Speech-driven 3D facial animation seeks to produce lifelike facial expressions that are synchronized with the speech content and its emotional nuances, finding applications in various multimedia fields. However, previous methods often overlook emotional facial expressions or fail to disentangle them effectively from the speech content. To address these challenges, we present EmoDiffusion, a novel approach that disentangles different emotions in speech to generate rich 3D emotional facial expressions. Specifically, our method employs two Variational Autoencoders (VAEs) to separately generate the upper face region and mouth region, thereby learning a more refined representation of the facial sequence. Unlike traditional methods that use diffusion models to connect facial expression sequences with audio inputs, we perform the diffusion process in the latent space. Furthermore, we introduce an Emotion Adapter to evaluate upper face movements accurately. Given the paucity of 3D emotional talking face data in the animation industry, we capture facial expressions under the guidance of animation experts using LiveLinkFace on an iPhone. This effort results in the creation of an innovative 3D blendshape emotional talking face dataset (3D-BEF) used to train our network. Extensive experiments and perceptual evaluations validate the effectiveness of our approach, confirming its superiority in generating realistic and emotionally rich facial animations.
语音驱动的三维面部动画旨在产生与语音内容及其情感细微差别同步的逼真面部表情,并广泛应用于各种多媒体领域。然而,之前的方法常常忽视情感面部表情,或者无法有效地从语音内容中将其分辨出来。为了应对这些挑战,我们提出了EmoDiffusion这一新方法,该方法能够分辨语音中的不同情感,生成丰富的三维情感面部表情。具体来说,我们的方法采用两个变分自编码器(VAEs)分别生成上半脸区域和嘴巴区域,从而学习更精细的面部序列表示。不同于传统方法使用扩散模型将面部表情序列与音频输入相连,我们在潜在空间执行扩散过程。此外,我们引入情感适配器来准确评估上半脸的运动。鉴于动画行业缺乏三维情感对话面部数据,我们在动画专家的指导下使用iPhone上的LiveLinkFace工具捕捉面部表情,从而创建了创新的三维情感混合对话面部数据集(3D-BEF),用于训练我们的网络。大量实验和感知评估验证了我们的方法的有效性,证实其在生成真实且情感丰富的面部动画方面的优越性。
论文及项目相关链接
Summary:
本文介绍了一种名为EmoDiffusion的新方法,该方法旨在解决语音驱动的3D面部动画中的情感表达问题。通过采用两个变分自编码器(VAEs)分别生成面部上半部分和嘴巴区域,并在潜在空间中进行扩散过程,该方法能够精细地表示面部序列。此外,还引入了一个情感适配器来准确评估面部上半部分运动。为解决动画行业中缺乏3D情感对话面部数据的问题,该研究还使用iPhone上的LiveLinkFace工具在动画专家指导下捕获面部表情,创建了一个创新的3D情感谈话面部数据集(3D-BEF),用于训练网络。实验和感知评估验证了该方法的真实性和情感丰富性。
Key Takeaways:
- EmoDiffusion方法能够解决语音驱动的3D面部动画中情感表达的问题。
- 通过变分自编码器(VAEs)分别生成面部上半部分和嘴巴区域,提高面部动画的精细度。
- 在潜在空间中进行扩散过程,实现面部表情与语音内容的更紧密关联。
- 引入情感适配器准确评估面部上半部分运动。
- 创建了一个创新的3D情感谈话面部数据集(3D-BEF),用于训练网络。
- 该方法通过广泛实验验证其有效性,并表现出生成真实和情感丰富面部动画的能力。
点此查看论文截图


Versatile Multimodal Controls for Whole-Body Talking Human Animation
Authors:Zheng Qin, Ruobing Zheng, Yabing Wang, Tianqi Li, Zixin Zhu, Minghui Yang, Ming Yang, Le Wang
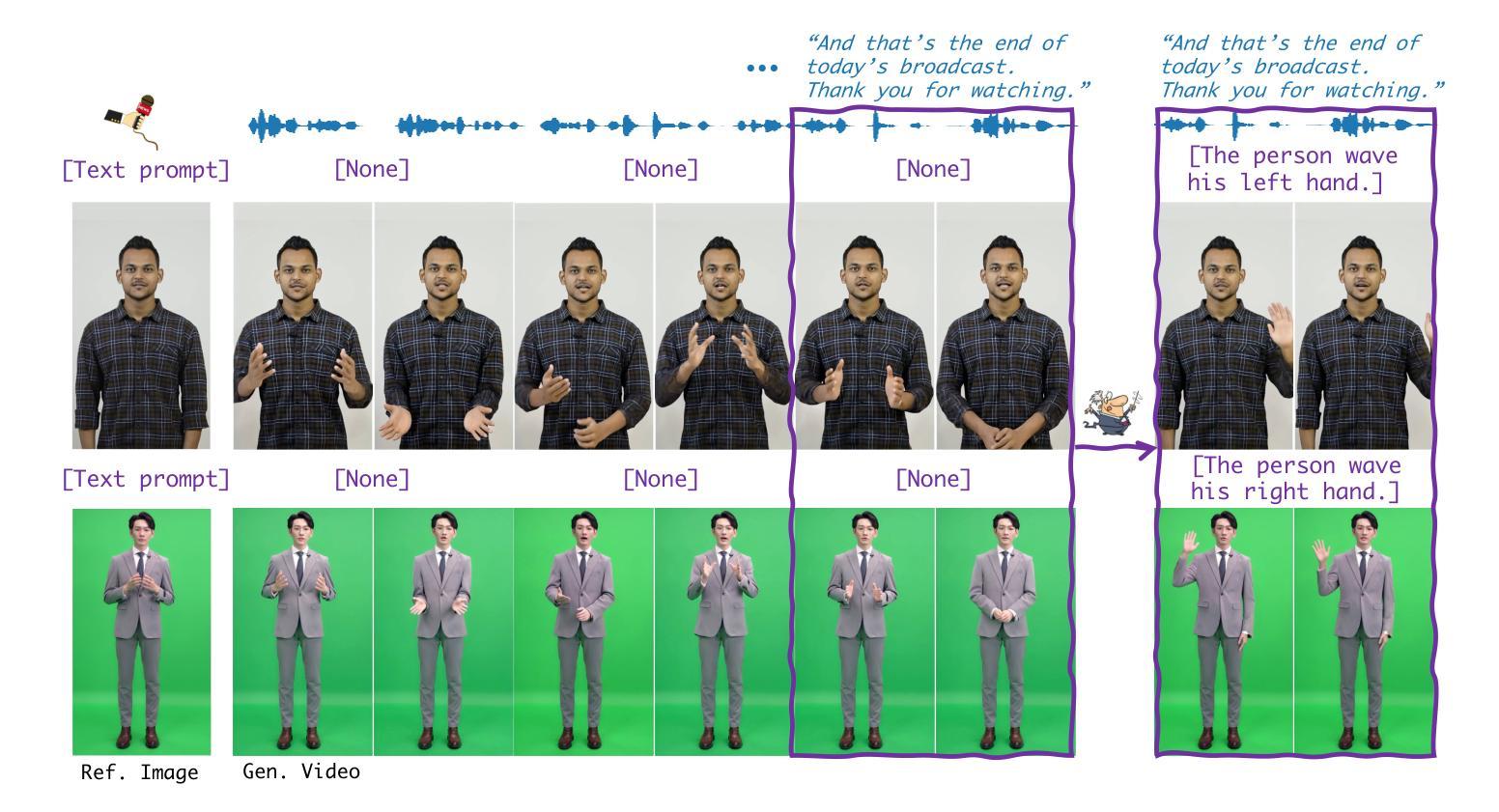
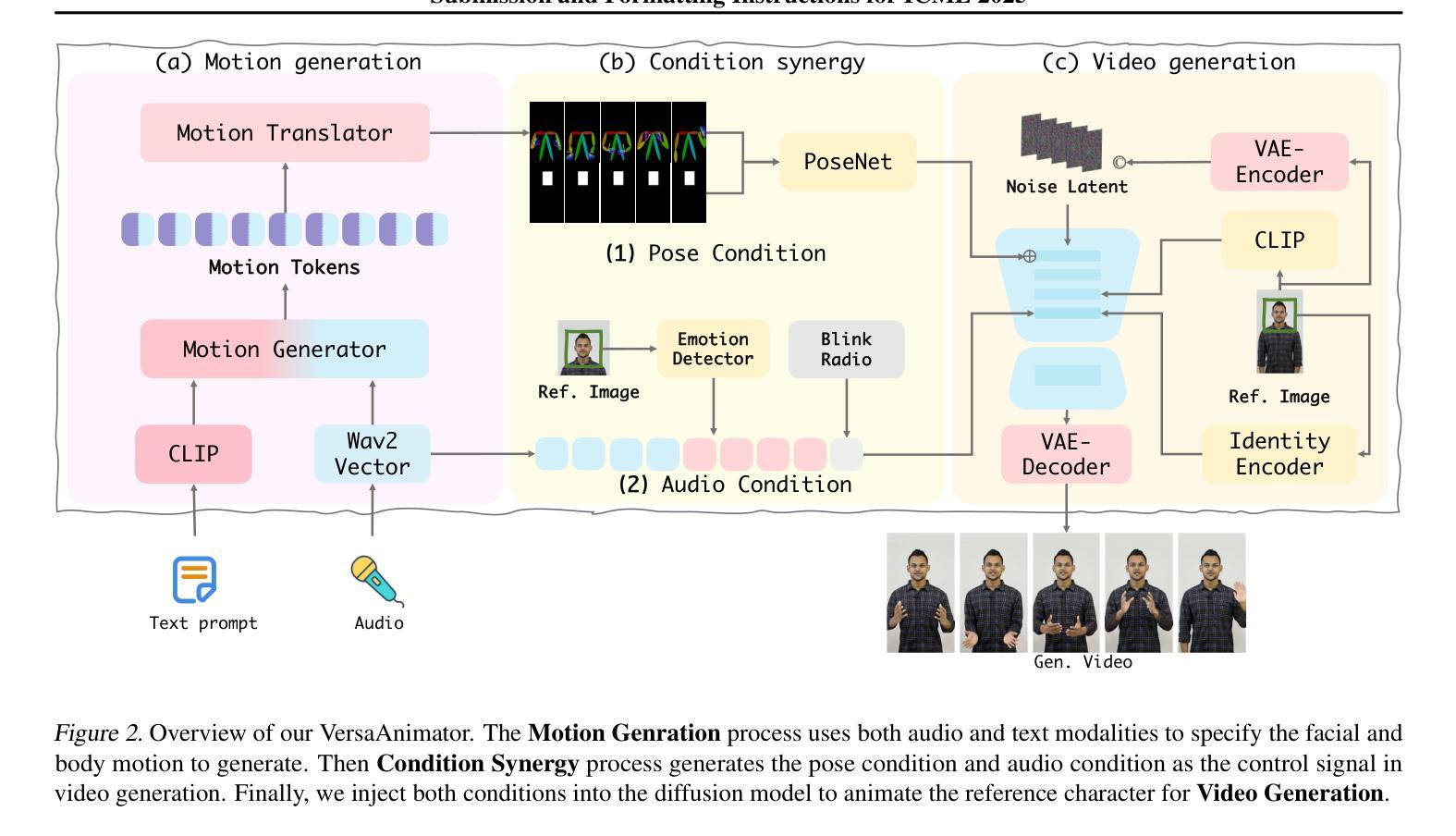
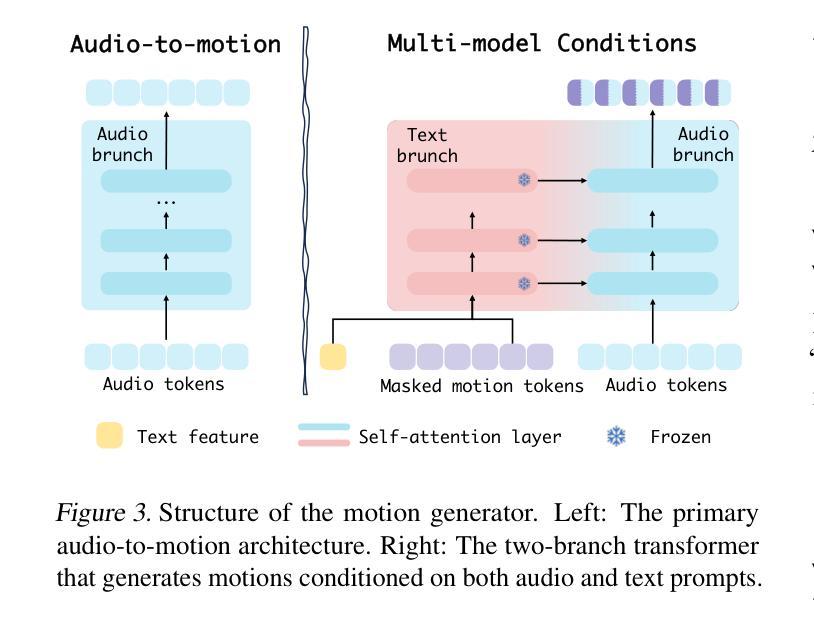
Human animation from a single reference image shall be flexible to synthesize whole-body motion for either a headshot or whole-body portrait, where the motions are readily controlled by audio signal and text prompts. This is hard for most existing methods as they only support producing pre-specified head or half-body motion aligned with audio inputs. In this paper, we propose a versatile human animation method, i.e., VersaAnimator, which generates whole-body talking human from arbitrary portrait images, not only driven by audio signal but also flexibly controlled by text prompts. Specifically, we design a text-controlled, audio-driven motion generator that produces whole-body motion representations in 3D synchronized with audio inputs while following textual motion descriptions. To promote natural smooth motion, we propose a code-pose translation module to link VAE codebooks with 2D DWposes extracted from template videos. Moreover, we introduce a multi-modal video diffusion that generates photorealistic human animation from a reference image according to both audio inputs and whole-body motion representations. Extensive experiments show that VersaAnimator outperforms existing methods in visual quality, identity preservation, and audio-lip synchronization.
从单一参考图像生成的人脸动画应该能够灵活地合成头部特写或全身肖像的全身运动,这些运动可以通过音频信号和文字提示轻松控制。对于大多数现有方法而言,这很难实现,因为它们仅支持生成与音频输入对齐的预设头部或半身运动。在本文中,我们提出了一种通用的人脸动画方法,即VersaAnimator,它可以从任意的肖像图像生成全身说话的人脸动画,不仅由音频信号驱动,还通过文字提示进行灵活控制。具体来说,我们设计了一个文本控制、音频驱动的运动生成器,它产生与音频输入同步的全身运动表示(在3D中),同时遵循文本运动描述。为了促进自然流畅的运动,我们提出了一个编码姿势转换模块,将VAE代码本与从模板视频中提取的2DDW姿势相关联。此外,我们引入了一种多模式视频扩散方法,根据参考图像、音频输入和全身运动表示生成写实风格的人脸动画。大量实验表明,VersaAnimator在视觉质量、身份保留和音频唇形同步方面优于现有方法。
论文及项目相关链接
Summary
动画技术可以从单一参考图像生成全身动态人像,该技术灵活性强,可以根据音频信号和文本提示进行操控。以往方法大多只支持预设定的头部或半身运动与音频对齐,而此方法不仅能从任意肖像图像生成全身动态人像,更能通过文本描述灵活控制,音频驱动产生与音频输入同步的全身运动表现。此方法设计了一个文本控制的运动生成器,通过代码姿势翻译模块连接VAE编码本与从模板视频提取的2DDW姿势,促进自然流畅的运动。同时引入多模态视频扩散技术,根据参考图像、音频输入和全身运动表现生成逼真的动画效果。实验结果证明此方法在视觉质量、身份保留和音频同步方面表现优于现有方法。
Key Takeaways
- 人像动画技术能从单一参考图像生成全身动态人像。
- 技术结合音频信号和文本提示进行操控,具有灵活性。
- 提出一种文本控制的运动生成器,能同步生成全身运动表现。
- 通过代码姿势翻译模块和多模态视频扩散技术促进自然流畅的运动并提升动画效果。
- 该方法在视觉质量、身份保留和音频同步方面表现优越。
点此查看论文截图