⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Authors:Jinseok Bae, Inwoo Hwang, Young Yoon Lee, Ziyu Guo, Joseph Liu, Yizhak Ben-Shabat, Young Min Kim, Mubbasir Kapadia
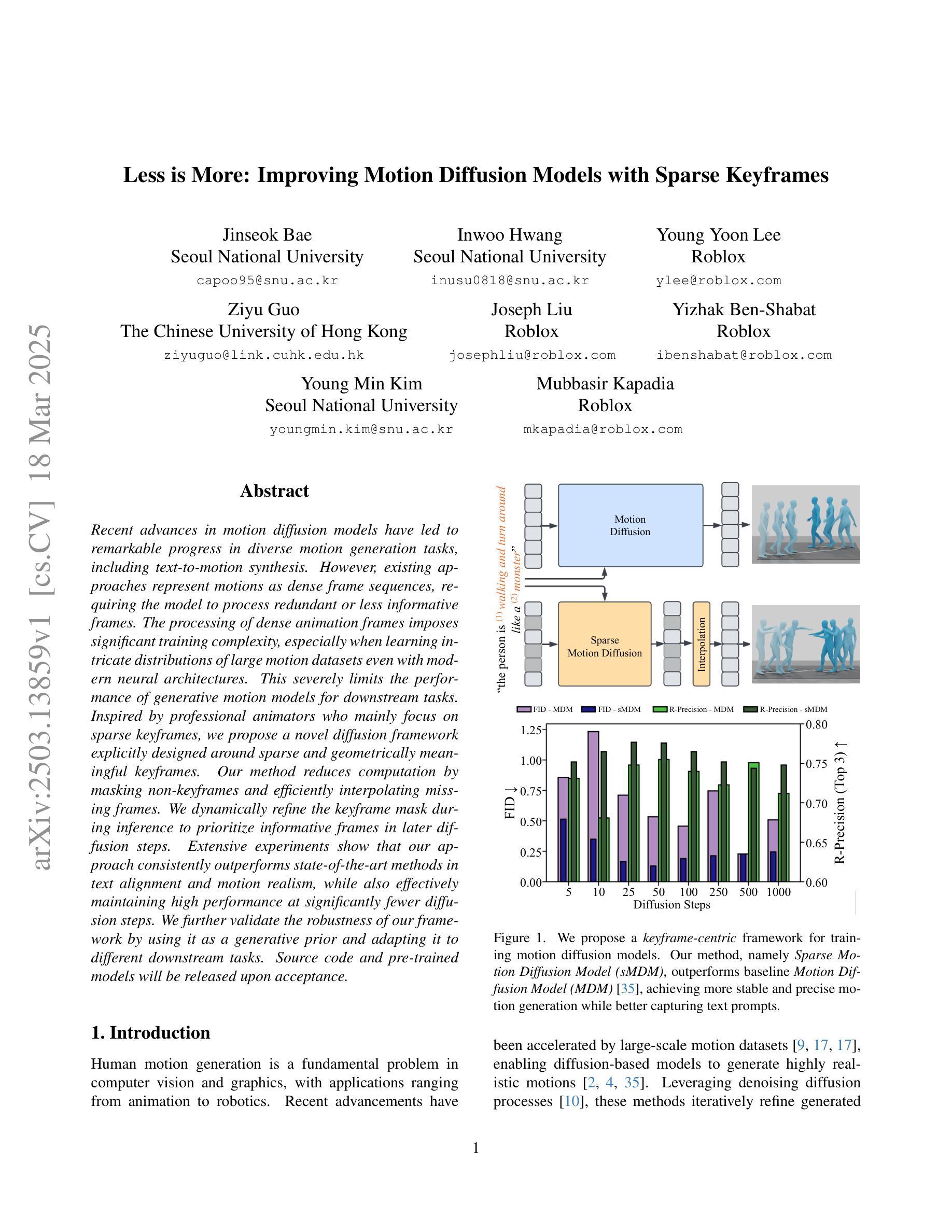
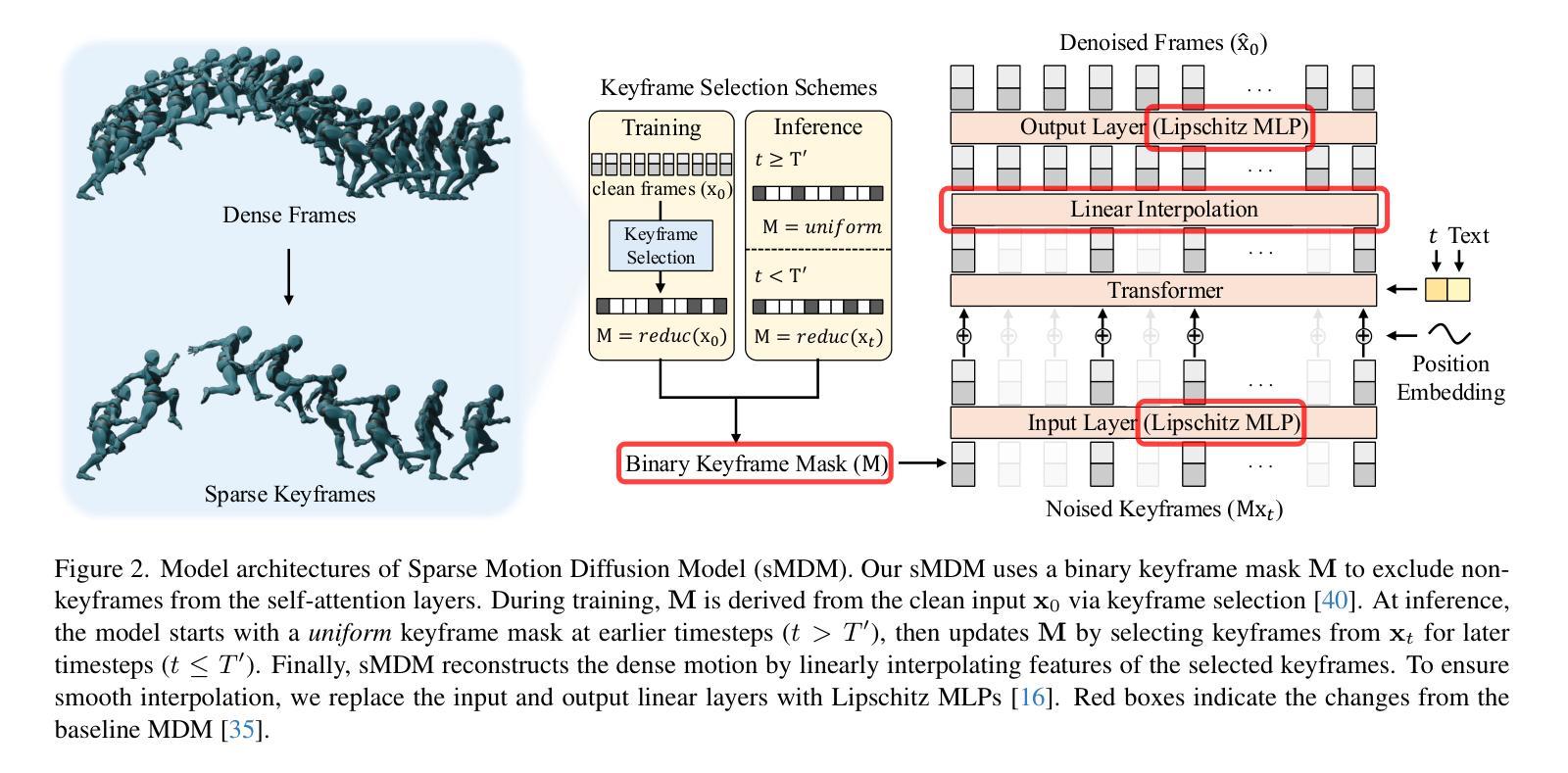
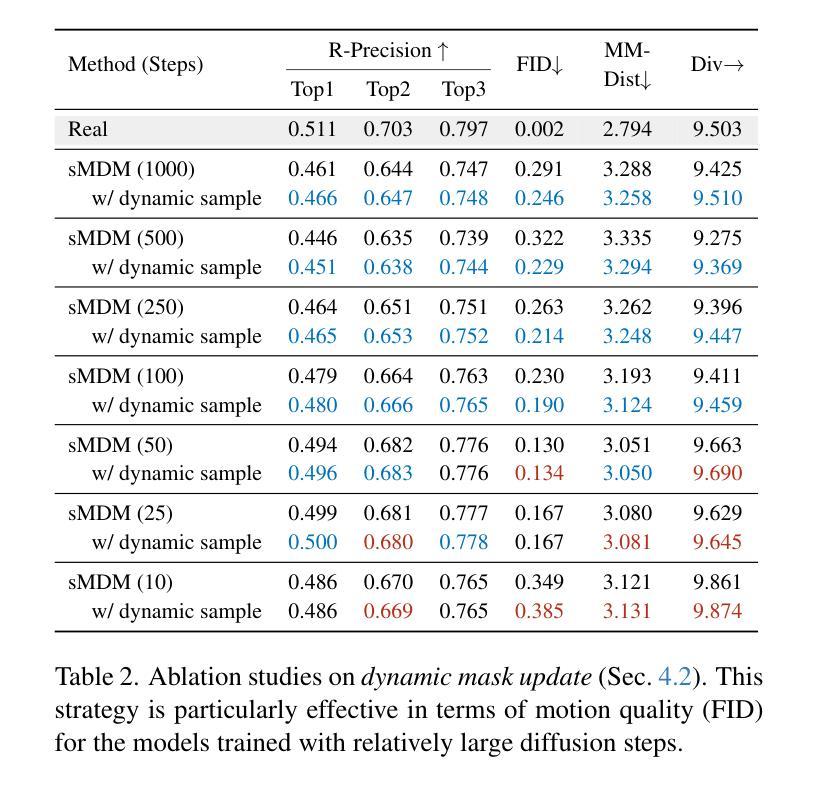
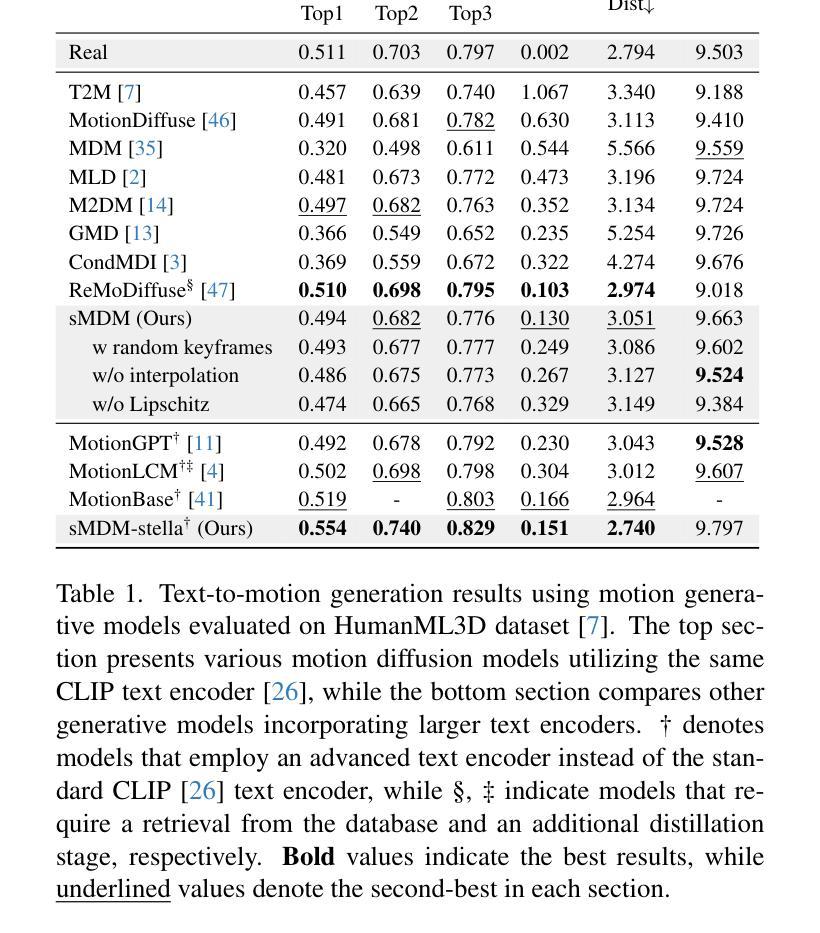
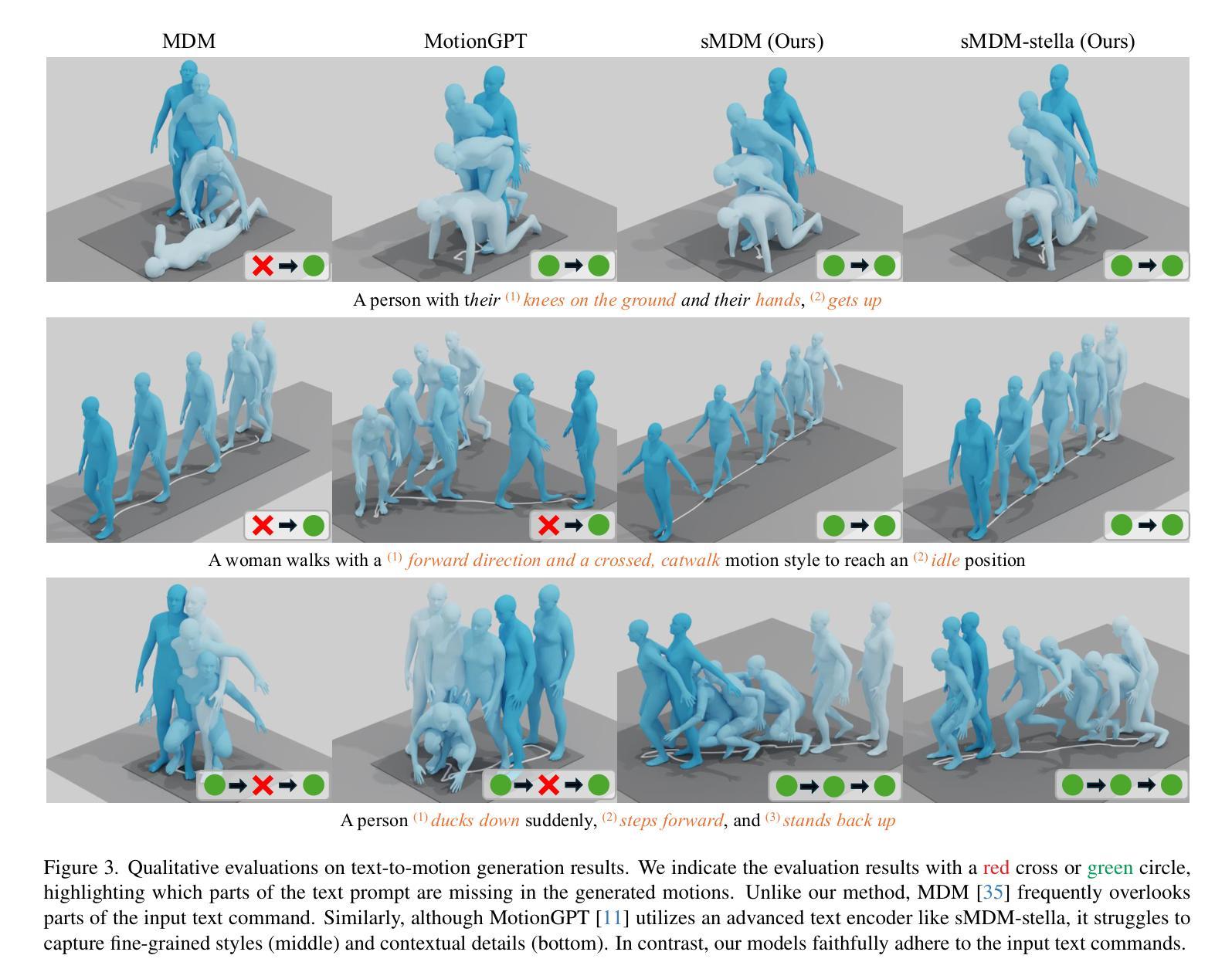
Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.
近期动作扩散模型的进展在多种运动生成任务中都取得了显著的进步,包括文本到运动的合成。然而,现有方法将动作表示为密集的帧序列,要求模型处理冗余或信息较少的帧。密集动画帧的处理带来了很大的训练复杂性,尤其是当使用现代神经网络架构学习大型运动数据集复杂分布时更是如此。这严重限制了下游任务的生成运动模型性能。我们受到专注于稀疏关键帧的专业动画师的启发,提出了一种围绕稀疏和几何意义明确的关键帧明确设计的新型扩散框架。我们的方法通过屏蔽非关键帧来减少计算量,并有效地插值丢失的帧。我们在推理过程中动态地调整关键帧掩码,以在后续的扩散步骤中优先处理信息帧。大量实验表明,我们的方法在文本对齐和运动逼真度方面始终优于最先进的方法,同时在显著减少的扩散步骤中也能保持高性能。通过将我们的框架用作生成先验并适应不同的下游任务,我们进一步验证了其稳健性。论文接受后将发布源代码和预训练模型。
论文及项目相关链接
Summary
文本介绍了基于稀疏关键帧的扩散模型在动作生成任务中的应用。该模型专注于关键帧,通过掩膜非关键帧并高效插值缺失帧来减少计算量。动态调整关键帧掩膜,以提高后续扩散步骤中信息帧的优先级。该模型在文本对齐、动作真实感和扩散步骤数量方面表现出卓越性能,可广泛应用于不同下游任务。
Key Takeaways
- 现有运动扩散模型处理密集动画帧时存在训练复杂性高的问题,特别是在处理大型运动数据集时。
- 提出的扩散框架以稀疏和几何意义明确的关键帧为基础,通过掩膜非关键帧减少计算量,并高效插值缺失帧。
- 模型在文本对齐和动作真实感方面表现出卓越性能,同时在较少的扩散步骤中维持高性能。
- 动态调整关键帧掩膜,以在后续扩散步骤中优先处理信息帧。
- 该模型可作为生成先验,适应不同的下游任务,验证了其稳健性。
- 该研究将释放源代码和预训练模型,便于其他研究者使用和进一步开发。
点此查看论文截图
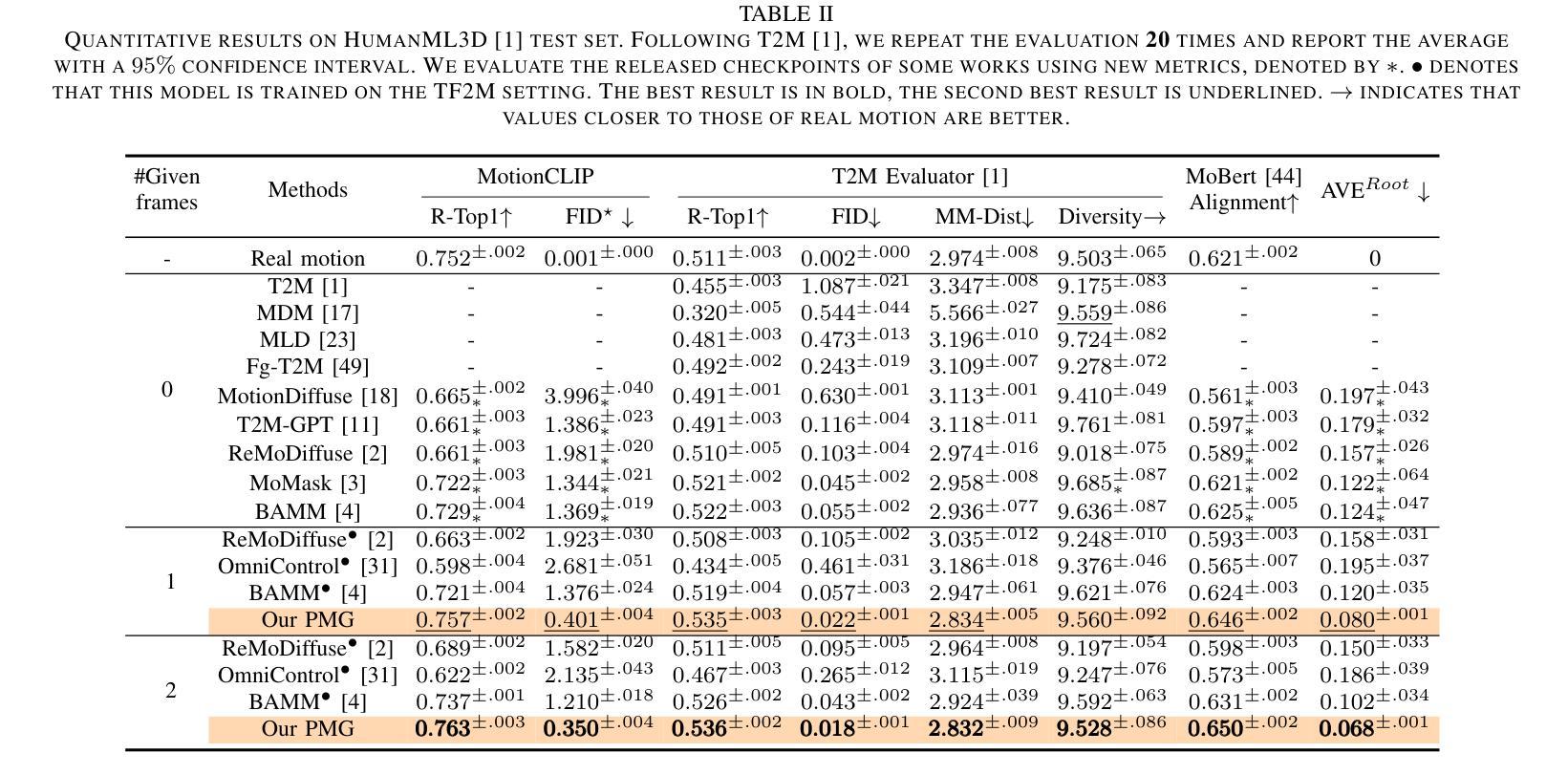
Progressive Human Motion Generation Based on Text and Few Motion Frames
Authors:Ling-An Zeng, Gaojie Wu, Ancong Wu, Jian-Fang Hu, Wei-Shi Zheng
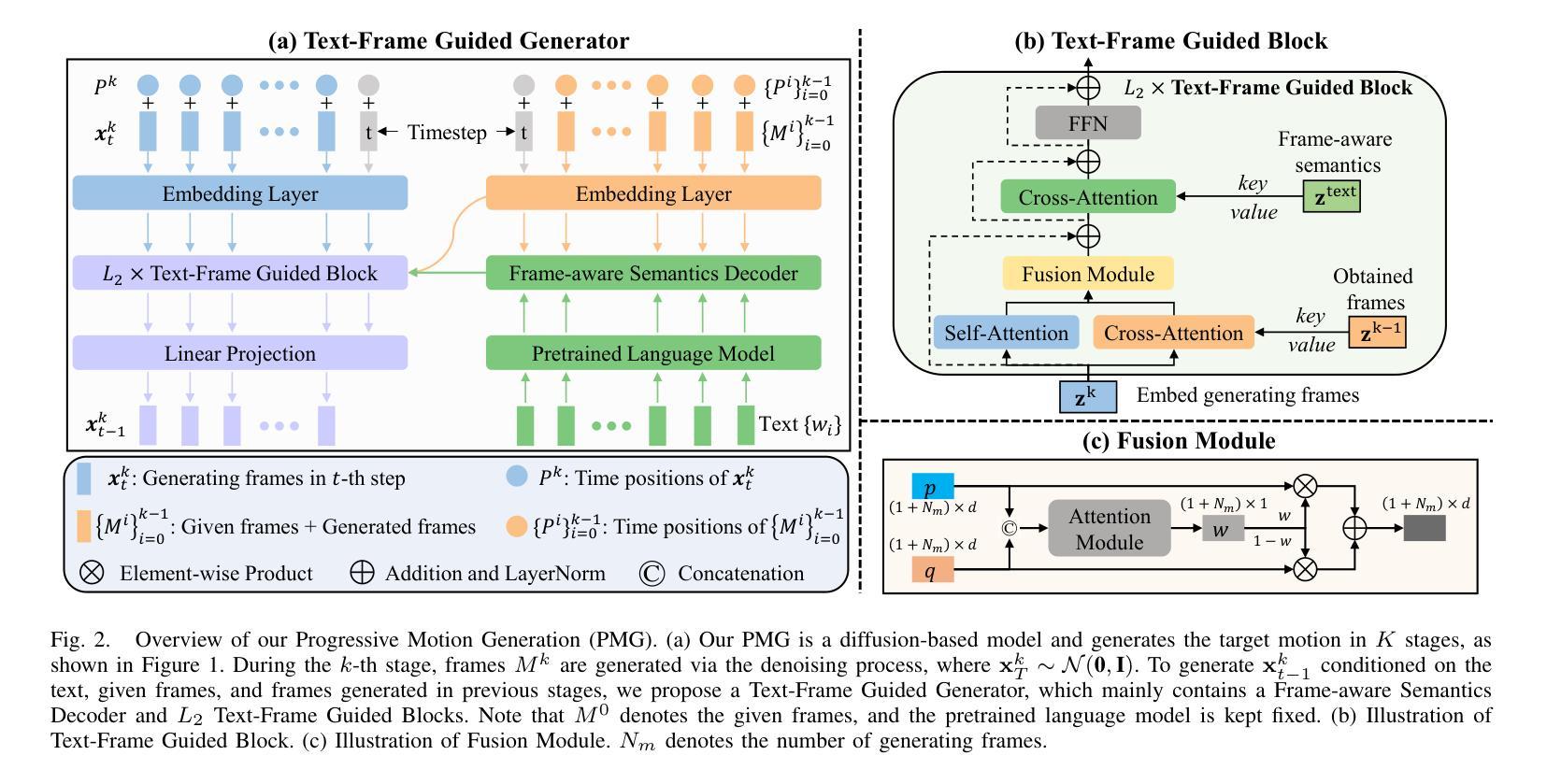
Although existing text-to-motion (T2M) methods can produce realistic human motion from text description, it is still difficult to align the generated motion with the desired postures since using text alone is insufficient for precisely describing diverse postures. To achieve more controllable generation, an intuitive way is to allow the user to input a few motion frames describing precise desired postures. Thus, we explore a new Text-Frame-to-Motion (TF2M) generation task that aims to generate motions from text and very few given frames. Intuitively, the closer a frame is to a given frame, the lower the uncertainty of this frame is when conditioned on this given frame. Hence, we propose a novel Progressive Motion Generation (PMG) method to progressively generate a motion from the frames with low uncertainty to those with high uncertainty in multiple stages. During each stage, new frames are generated by a Text-Frame Guided Generator conditioned on frame-aware semantics of the text, given frames, and frames generated in previous stages. Additionally, to alleviate the train-test gap caused by multi-stage accumulation of incorrectly generated frames during testing, we propose a Pseudo-frame Replacement Strategy for training. Experimental results show that our PMG outperforms existing T2M generation methods by a large margin with even one given frame, validating the effectiveness of our PMG. Code will be released.
尽管现有的文本到动作(T2M)方法可以从文本描述生成真实的人类动作,但由于仅使用文本不足以精确地描述各种姿势,因此将生成的动作与所需姿势对齐仍然很困难。为了实现更可控的生成,一种直观的方法允许用户输入描述精确所需姿势的几个运动帧。因此,我们探索了一个新的文本框架到动作(TF2M)生成任务,旨在从文本和给定的极少帧生成动作。直观地讲,一个帧越接近给定的帧,当以这个给定帧为条件时,该帧的不确定性就越低。因此,我们提出了一种新颖的进步式动作生成(PMG)方法,从不确定性较低的帧逐步生成到多个阶段中不确定性较高的帧。在每个阶段,新的帧由文本框架引导生成器根据文本、给定帧和先前阶段生成的帧的框架感知语义来生成。此外,为了缓解测试过程中由于不正确生成的帧的多阶段累积而导致的训练和测试之间的差距,我们提出了用于训练的一种伪帧替换策略。实验结果表明,我们的PMG在给定一个甚至更少帧的情况下,大大优于现有的T2M生成方法,验证了我们的PMG的有效性。代码将发布。
论文及项目相关链接
摘要
文本至动作转换技术可基于文本描述生成逼真的人形动作,但在动作多样性与精确度上仍有限制。本研究通过提出全新的Text-Frame-to-Motion(TF2M)任务,旨在通过文本和少量给定帧来生成动作。研究提出一种新颖Progressive Motion Generation(PMG)方法,按不确定性由低到高的顺序逐步生成动作,以期望能在给定的几个动作帧上获取更大的动作生成精度和控制力度。我们还通过利用基于文本的框架生成器为每个阶段产生新帧来提升其动作合成结果的真实性和细节精度,且为了缩小因训练过程中因多阶段不正确生成帧积累而导致的训练和测试之间的差距,我们提出了一个伪帧替换策略。实验证明我们的渐进式生成法在所有动作预测环节显著超越了现有的文本至动作转换技术,仅仅使用一帧参考就能得到极大的性能提升。该方法具有很高的实际应用价值。代码即将公开。
关键见解
- Text-Frame-to-Motion (TF2M)任务的引入使我们可以结合文本和给定动作帧来生成动作,提高了生成的精准度和可控性。
- 提出Progressive Motion Generation (PMG)方法,根据不确定性逐步生成动作帧。先从不确定性低的帧开始,逐渐向不确定性较高的帧过渡,以生成更为流畅的动作序列。该方法能够有效处理多样化动作的复杂性及不确定性问题。
- 利用基于文本的框架生成器在给定文本和已生成的帧基础上产生新帧,进一步提升了生成的精确度以及生成动作的自然度。这在维持原文描述风格的同时加强了细节的准确性。
- 针对多阶段动作生成中的训练测试不一致问题提出伪帧替换策略来减小模型泛化过程中的不确定性和偏差,优化训练效果,从而提升实际应用中模型的整体表现。
- 实验结果显示,即使仅使用一帧参考,本文提出的PMG方法在文本至动作转换任务上的表现也显著优于现有技术。这表明该方法的实用性和潜在应用价值较高。该算法的有效性和实用性已在实验中得到了验证。
- 所研究的框架旨在扩展传统文本至运动技术的边界和局限性,以允许更高的用户控制能力和精度来合成和表达各种动作。这一方法的灵活性和创新应用空间预示着广阔的市场前景和应用潜力。
点此查看论文截图


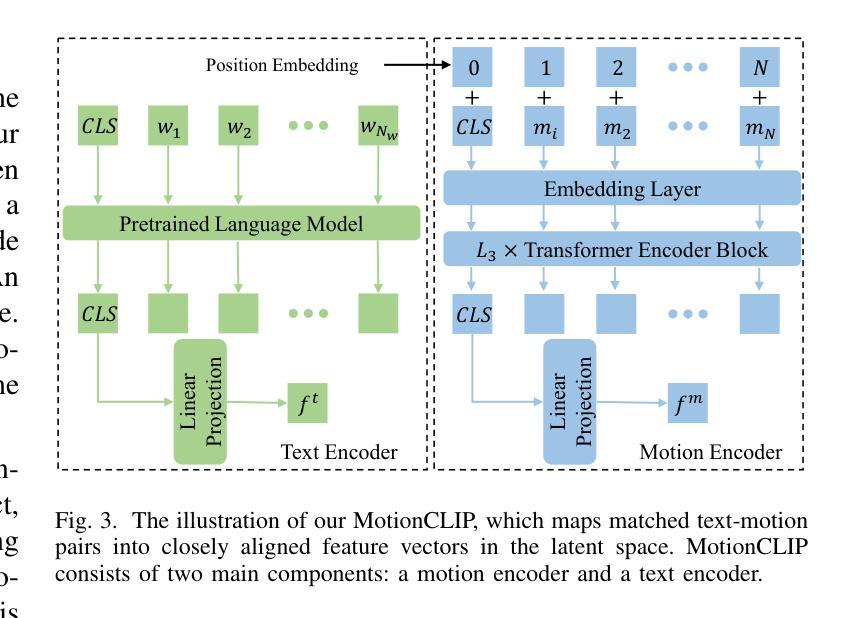
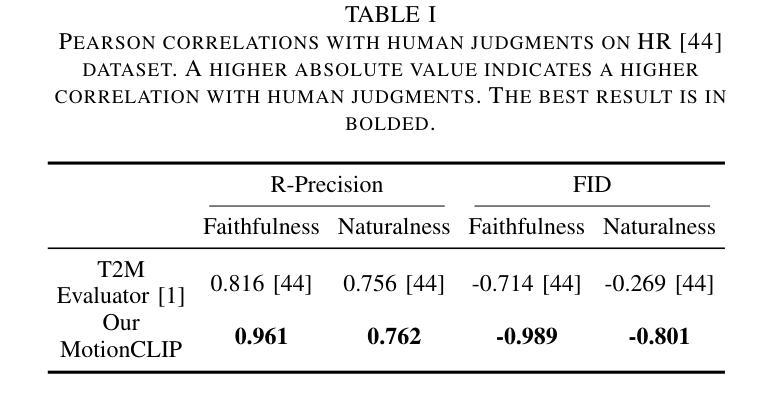
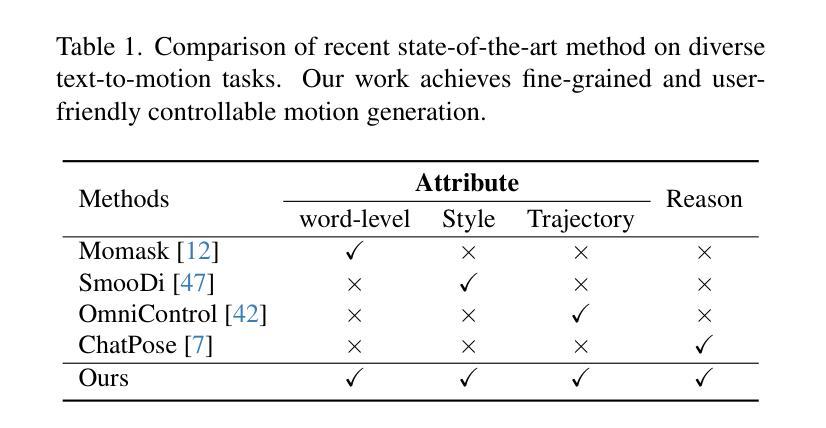
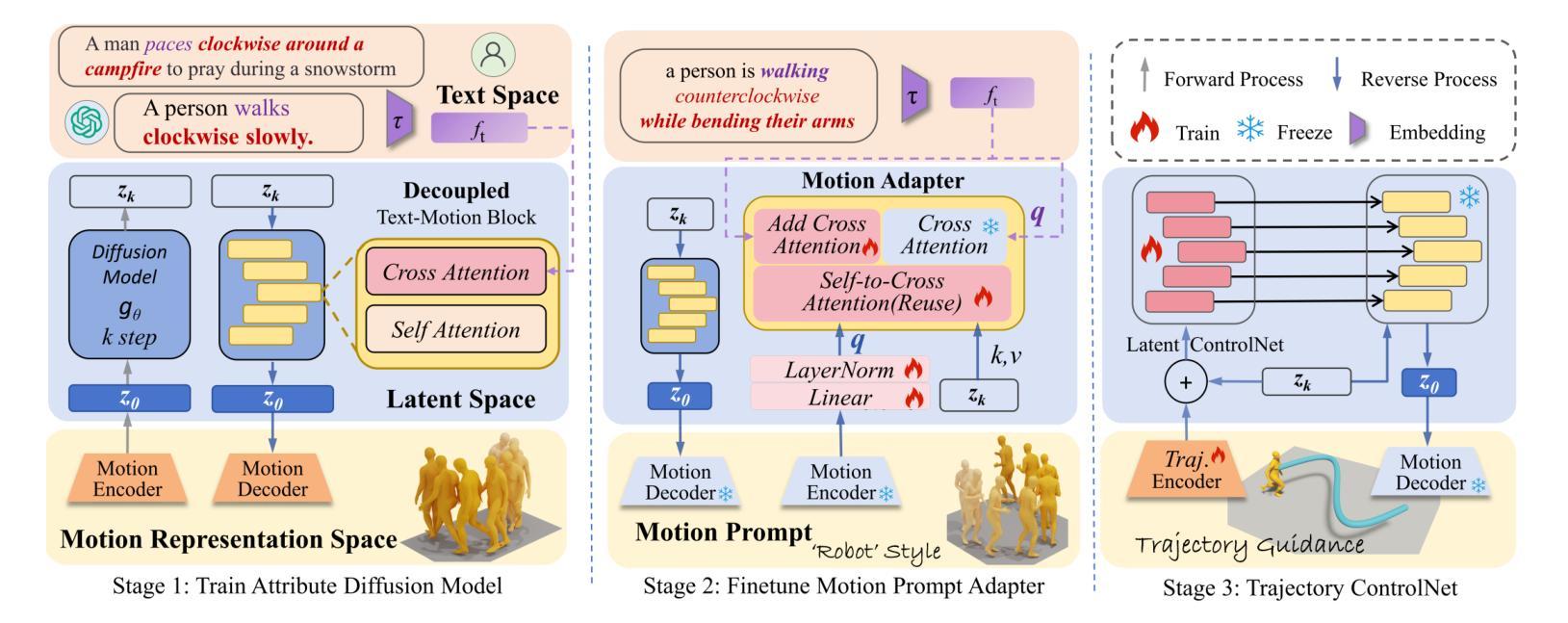
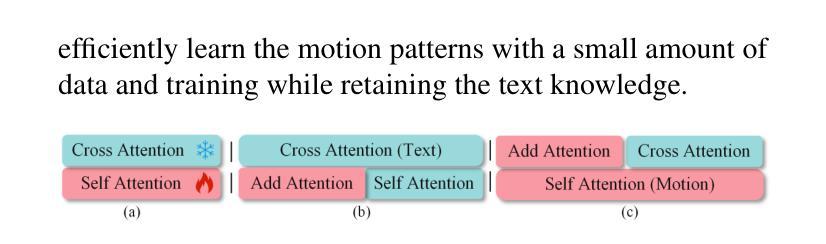
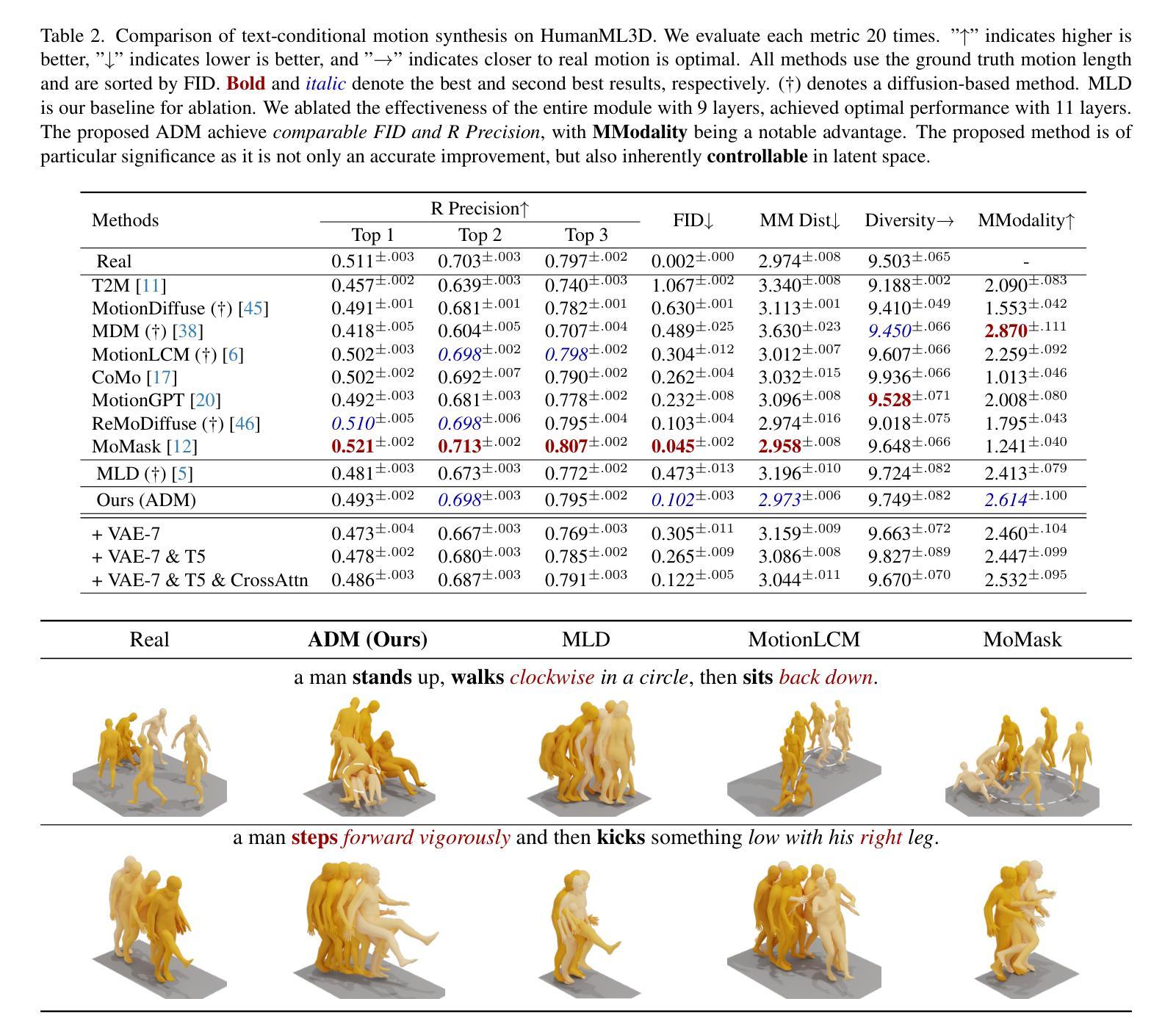
ACMo: Attribute Controllable Motion Generation
Authors:Mingjie Wei, Xuemei Xie, Guangming Shi
Attributes such as style, fine-grained text, and trajectory are specific conditions for describing motion. However, existing methods often lack precise user control over motion attributes and suffer from limited generalizability to unseen motions. This work introduces an Attribute Controllable Motion generation architecture, to address these challenges via decouple any conditions and control them separately. Firstly, we explored the Attribute Diffusion Model to imporve text-to-motion performance via decouple text and motion learning, as the controllable model relies heavily on the pre-trained model. Then, we introduce Motion Adpater to quickly finetune previously unseen motion patterns. Its motion prompts inputs achieve multimodal text-to-motion generation that captures user-specified styles. Finally, we propose a LLM Planner to bridge the gap between unseen attributes and dataset-specific texts via local knowledage for user-friendly interaction. Our approach introduces the capability for motion prompts for stylize generation, enabling fine-grained and user-friendly attribute control while providing performance comparable to state-of-the-art methods. Project page: https://mjwei3d.github.io/ACMo/
风格、精细文本和轨迹等属性是描述运动的特定条件。然而,现有方法往往缺乏对运动属性的精确用户控制,并且在未见运动上的泛化能力有限。本研究引入了一种属性可控运动生成架构,通过解耦任何条件并分别控制它们来解决这些挑战。首先,我们探索了属性扩散模型,通过解耦文本和运动学习来提高文本到运动的性能,因为可控模型在很大程度上依赖于预训练模型。然后,我们引入了运动适配器,可以快速微调以前未见过的运动模式。其运动提示输入实现了多模式文本到运动生成,捕捉用户指定的风格。最后,我们提出了一种LLM规划器,通过局部知识缩小未见属性和数据集特定文本之间的差距,以实现用户友好交互。我们的方法引入了运动提示进行风格化生成的能力,实现了细粒度和用户友好的属性控制,同时提供了与最新技术相当的性能。项目页面:https://mjwei3d.github.io/ACMo/
论文及项目相关链接
摘要
该研究解决了现有文本转运动方法在精准控制运动属性方面的不足,以及在新运动模式上的泛化能力受限的问题。该研究提出了一种属性可控的运动生成架构,该架构可以解耦任何条件并对其进行单独控制。首先,该研究探讨了属性扩散模型,以提高文本转运动的性能,并通过解耦文本和运动学习来实现控制。此外,引入运动适配器以快速微调先前未见到的运动模式。其运动提示输入实现了多模式文本转运动生成,能够捕捉用户指定的风格。最后,该研究提出了LLM规划器,通过局部知识缩小了未见属性和数据集特定文本之间的差距,以实现用户友好的交互。该研究的方法引入了运动提示进行风格化生成的能力,实现了精细和用户友好的属性控制,同时提供了与最新技术相当的性能。
关键见解
- 引入属性可控的运动生成架构,可以解耦并单独控制各种运动属性。
- 采用属性扩散模型提高文本转运动的性能,通过解耦文本和运动学习来实现精准控制。
- 引入运动适配器以快速适应和生成先前未见到的运动模式。
- 运动提示输入实现多模式文本转运动生成,能够捕捉用户指定的风格。
- LLM规划器缩小了未见属性和数据集特定文本之间的差距,增强了用户友好的交互体验。
- 该方法实现了精细和用户友好的属性控制。
- 该方法的性能与最新技术相当。
点此查看论文截图

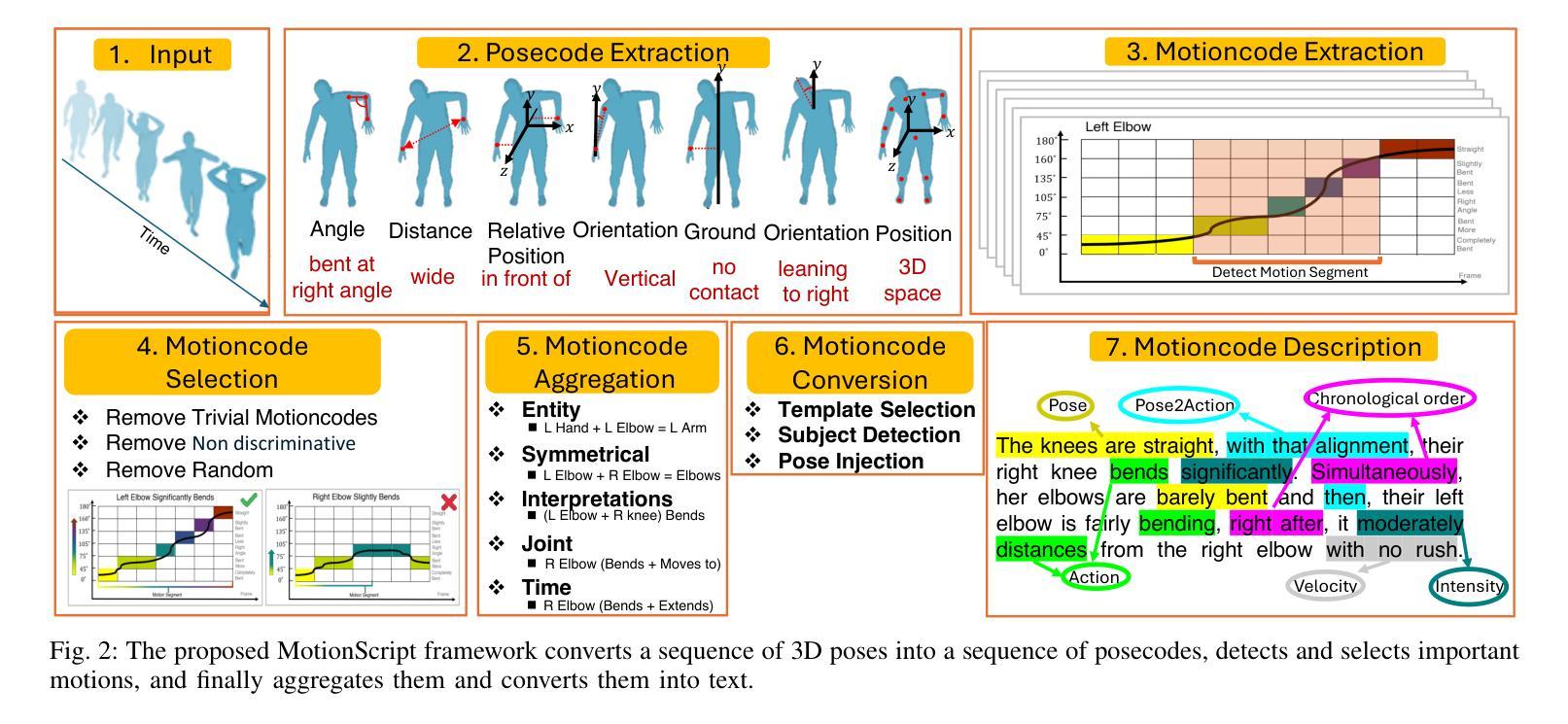
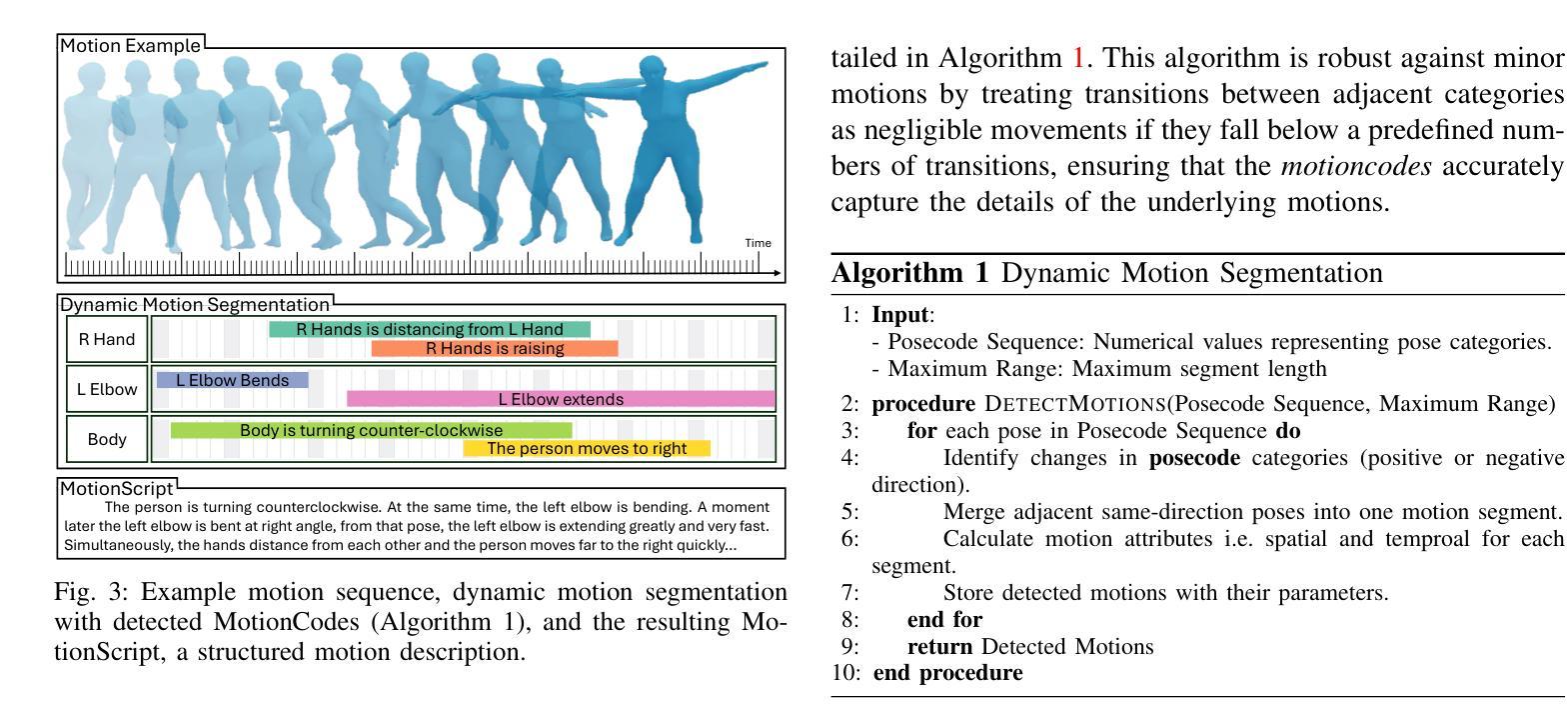
MotionScript: Natural Language Descriptions for Expressive 3D Human Motions
Authors:Payam Jome Yazdian, Rachel Lagasse, Hamid Mohammadi, Eric Liu, Li Cheng, Angelica Lim
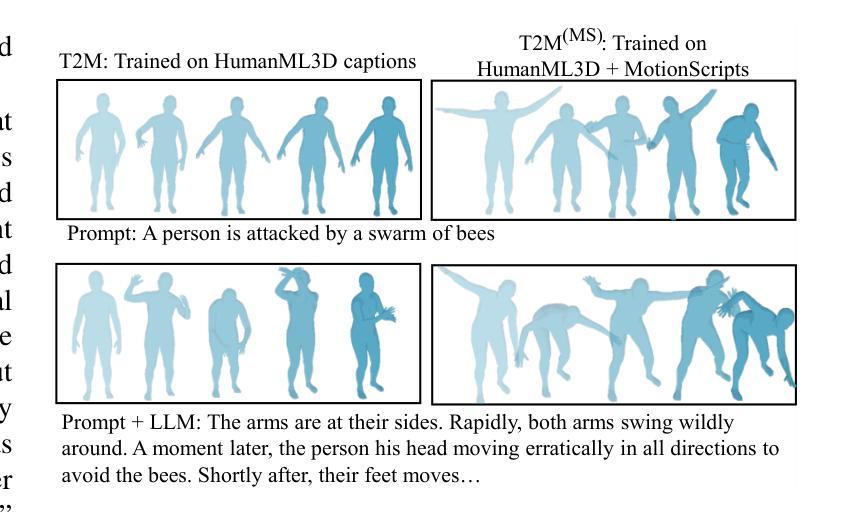
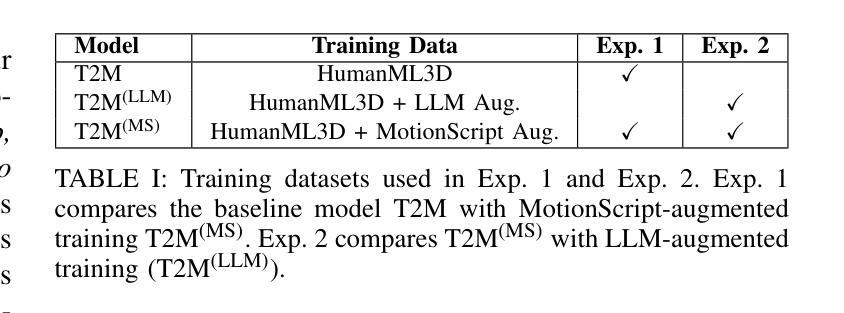
We introduce MotionScript, a novel framework for generating highly detailed, natural language descriptions of 3D human motions. Unlike existing motion datasets that rely on broad action labels or generic captions, MotionScript provides fine-grained, structured descriptions that capture the full complexity of human movement including expressive actions (e.g., emotions, stylistic walking) and interactions beyond standard motion capture datasets. MotionScript serves as both a descriptive tool and a training resource for text-to-motion models, enabling the synthesis of highly realistic and diverse human motions from text. By augmenting motion datasets with MotionScript captions, we demonstrate significant improvements in out-of-distribution motion generation, allowing large language models (LLMs) to generate motions that extend beyond existing data. Additionally, MotionScript opens new applications in animation, virtual human simulation, and robotics, providing an interpretable bridge between intuitive descriptions and motion synthesis. To the best of our knowledge, this is the first attempt to systematically translate 3D motion into structured natural language without requiring training data.
我们介绍了MotionScript,这是一个生成关于3D人体运动高度详细、自然语言描述的新型框架。不同于依赖广泛动作标签或通用标题的现有运动数据集,MotionScript提供精细的、结构化的描述,捕捉人类运动的全部复杂性,包括表现性动作(例如情绪、风格化的行走)以及超出标准运动捕获数据集之外的交互。MotionScript既可作为描述工具,也可作为文本到运动模型的训练资源,能够实现从文本合成高度逼真和多样化的运动。通过为运动数据集增加MotionScript标题,我们展示了在超出分布的运动生成方面的显著改进,使大型语言模型(LLM)能够生成超出现有数据的运动。此外,MotionScript在动画、虚拟人类仿真和机器人技术等领域开启了新的应用,提供了直观描述和运动合成之间的可解释桥梁。据我们所知,这是首次尝试系统地以自然语言将3D运动转化为结构化形式,而无需训练数据。
论文及项目相关链接
PDF Project webpage: https://pjyazdian.github.io/MotionScript
Summary
MotionScript是一种新型框架,用于生成对3D人类运动的详细自然语言描述。不同于依赖粗略动作标签或通用标题的现有运动数据集,MotionScript提供精细结构化的描述,捕捉人类运动的全部复杂性,包括表达性动作(如情绪、风格化行走)和超出标准运动捕获数据集的标准交互。MotionScript既可作为描述工具,也可作为文本到运动模型的训练资源,使从文本合成高度逼真和多样化的运动成为可能。通过为运动数据集增加MotionScript标题,我们展示了在超出分布的运动生成方面的显著改进,使大型语言模型能够生成超出现有数据的运动。此外,MotionScript在动画、虚拟人类仿真和机器人技术等领域开启了新应用,为直观描述和运动合成之间提供了可解释的桥梁。这是首次系统性地将3D运动转换为结构化自然语言而无需训练数据。
Key Takeaways
- MotionScript是一种新型框架,用于详细描述和生成3D人类运动的自然语言描述。
- 与现有运动数据集不同,MotionScript提供精细结构化的描述,捕捉人类运动的复杂性。
- MotionScript可广泛应用于动画、虚拟人类仿真和机器人技术等领域。
- MotionScript作为描述工具和训练资源,使文本到运动的合成更加逼真和多样化。
- 通过增加MotionScript标题到运动数据集,能够显著提高超出分布的运动生成能力。
- 大型语言模型(LLMs)能够利用MotionScript生成超出现有数据的运动。
点此查看论文截图