⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
Towards Scalable Foundation Model for Multi-modal and Hyperspectral Geospatial Data
Authors:Haozhe Si, Yuxuan Wan, Minh Do, Deepak Vasisht, Han Zhao, Hendrik F. Hamann
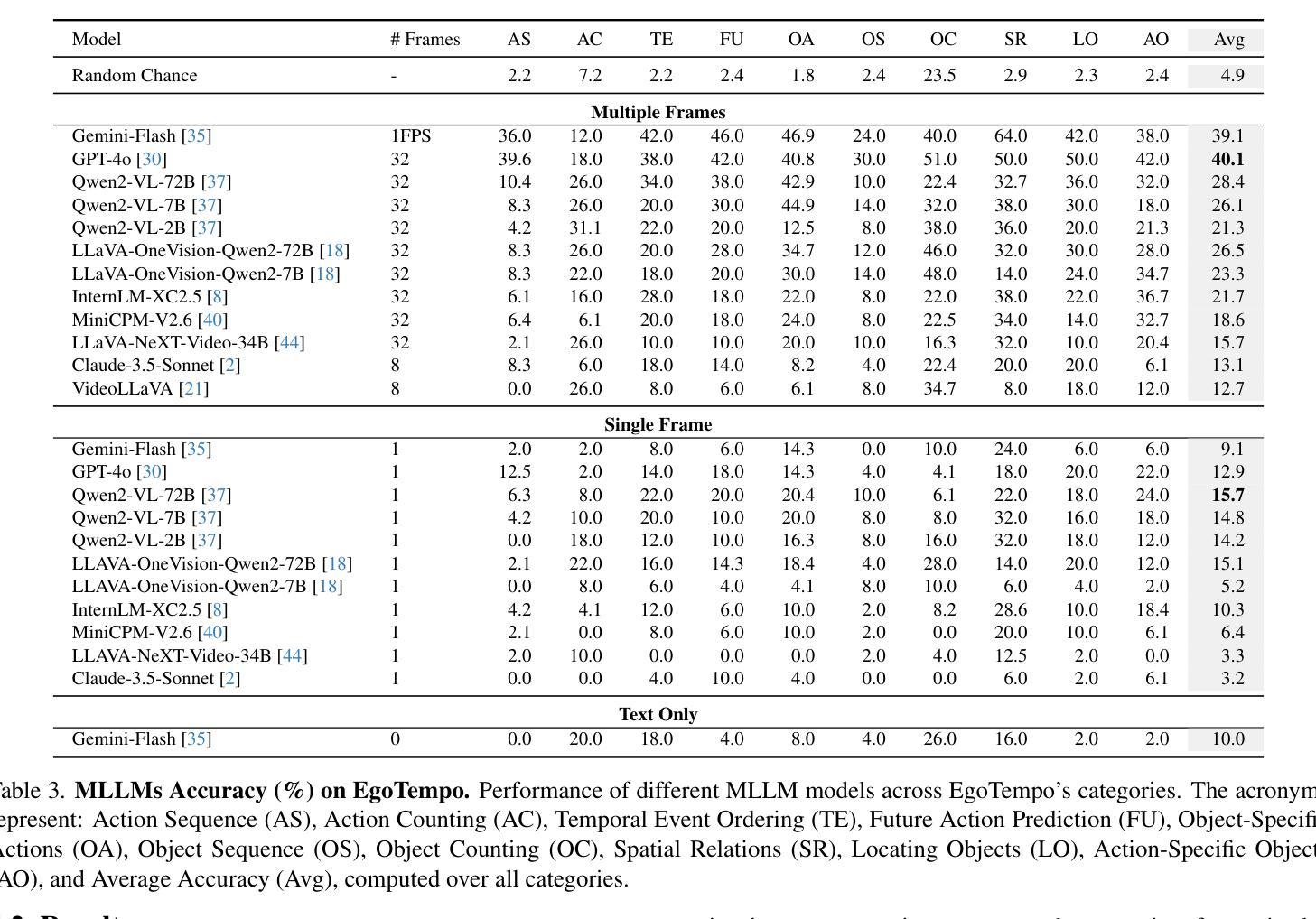
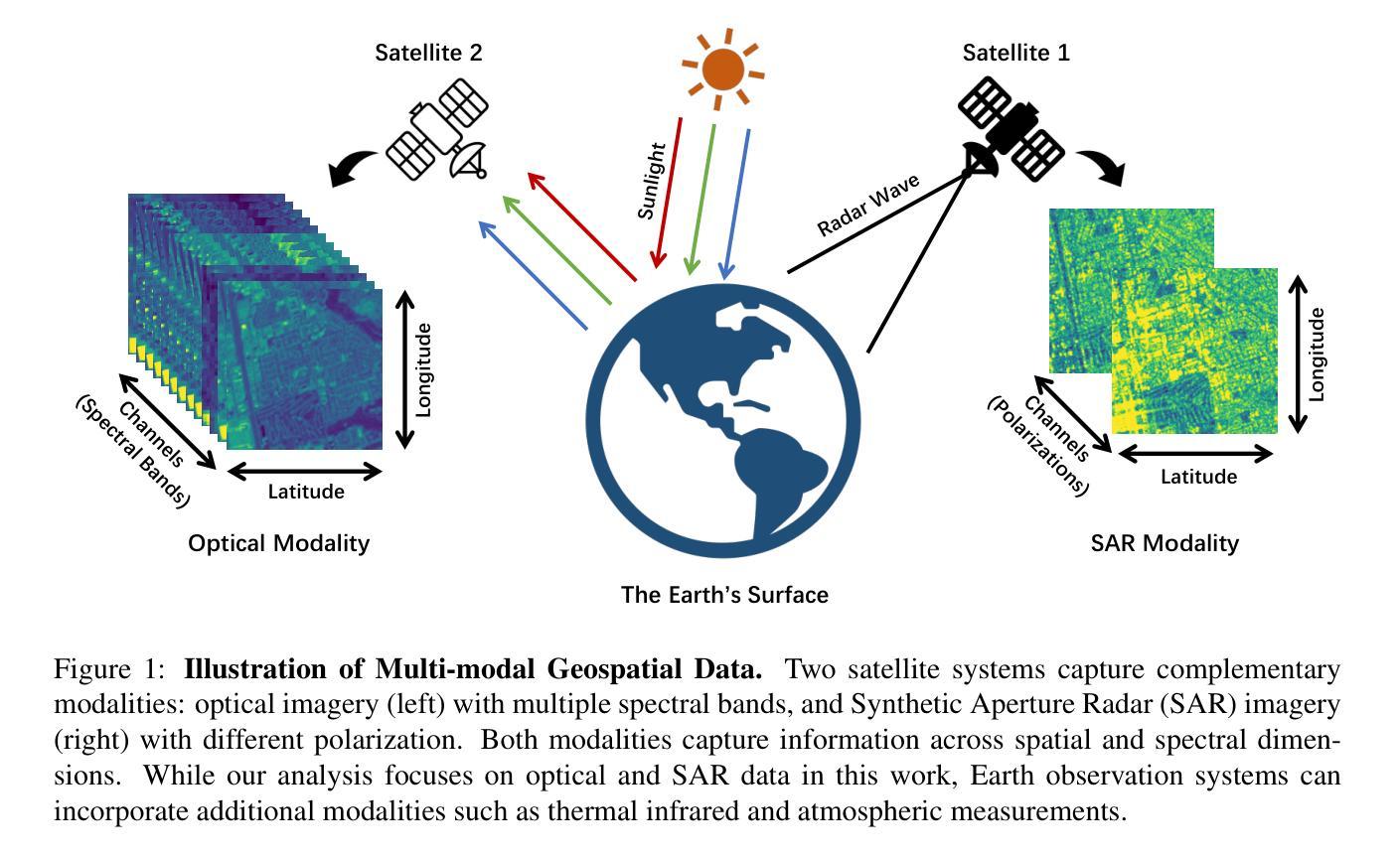
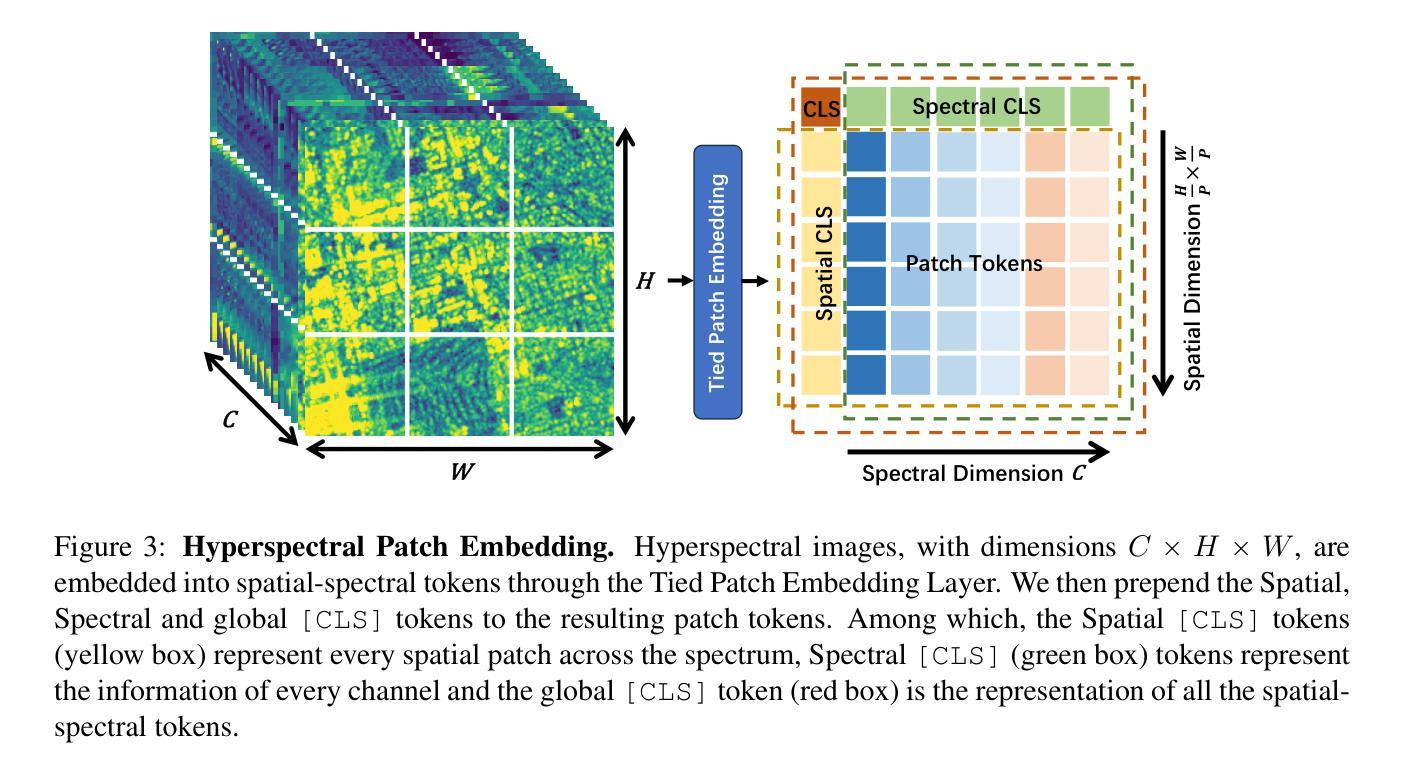
Geospatial raster data, such as that collected by satellite-based imaging systems at different times and spectral bands, hold immense potential for enabling a wide range of high-impact applications. This potential stems from the rich information that is spatially and temporally contextualized across multiple channels and sensing modalities. Recent work has adapted existing self-supervised learning approaches for such geospatial data. However, they fall short of scalable model architectures, leading to inflexibility and computational inefficiencies when faced with an increasing number of channels and modalities. To address these limitations, we introduce Low-rank Efficient Spatial-Spectral Vision Transformer with three key innovations: i) the LESS Attention Block that approximates high-dimensional spatial-spectral attention through Kronecker’s product of the low-dimensional spatial and spectral attention components; ii) the Continuous Positional-Channel Embedding Layer that preserves both the continuity and physical characteristics of each spatial-spectral patch; and iii) the Perception Field Mask that exploits local spatial dependencies by constraining attention to neighboring patches. To evaluate the proposed innovations, we construct GFM-Bench, which serves as a comprehensive benchmark for such geospatial raster data. We pretrain LESS ViT using a Hyperspectral Masked Autoencoder framework with integrated positional and channel masking strategies. Experimental results demonstrate that our proposed method achieves competitive performance against state-of-the-art multi-modal geospatial foundation models while outperforming them on cross-satellite generalization tasks with higher computational efficiency. The flexibility and extensibility of our framework make it a promising direction for future geospatial data analysis tasks that involve a wide range of modalities and channels.
地理空间栅格数据,如由基于卫星的成像系统在不同时间和光谱波段所收集的栅格数据,具有巨大的潜力,能够支持一系列的高影响力应用。这种潜力来源于多个通道和感知模式之间在空间和时间上的上下文信息丰富的特点。近期的工作已经针对此类地理空间数据调整了现有的自监督学习方法。然而,它们缺乏可扩展的模型架构,在面对日益增长的通道和模式数量时,表现出灵活性不足和计算效率低下的问题。为了解决这些局限性,我们引入了低秩高效空间光谱视觉转换器,其中包含三项关键创新:一)LESS注意力块通过低维空间注意力组件和光谱注意力组件的克罗内克积来近似高维空间光谱注意力;二)连续位置通道嵌入层能够同时保留每个空间光谱补丁的连续性和物理特性;三)感知场掩码通过限制注意力到相邻补丁来利用局部空间依赖性。为了评估这些创新方法的效果,我们构建了GFM基准测试平台,该平台可以作为此类地理空间栅格数据的综合基准测试平台。我们使用带有集成位置通道掩码策略的掩码自编码器框架对LESS ViT进行预训练。实验结果表明,我们的方法在具有竞争力的性能的同时,在跨卫星泛化任务上优于最新的多模态地理空间基础模型,并且具有更高的计算效率。我们框架的灵活性和可扩展性使其成为未来涉及多种模式和通道的地理空间数据分析任务的具有前景的研究方向。
论文及项目相关链接
摘要
地理空间栅格数据,如不同时间和光谱波段下卫星成像系统所收集的栅格数据,对于广泛的高影响应用有着巨大潜力。该潜力源于多个通道和感知模态之间空间和时间上的丰富信息上下文。尽管近期工作已经为这种地理空间数据调整了现有的自监督学习方法,但它们缺乏可扩展的模型架构,在面对越来越多的通道和模态时,表现出灵活性和计算效率的不足。为解决这些局限性,我们提出了低秩高效空间光谱视觉Transformer,包括三个关键创新点:一是LESS注意力块,它通过克罗内克积近似高维空间光谱注意力;二是连续位置通道嵌入层,同时保留每个空间光谱补丁的连续性和物理特性;三是感知场掩码,通过约束注意力到相邻补丁来利用局部空间依赖性。为了评估这些创新,我们构建了GFM-Bench,这是一个全面的基准测试平台,用于评估此类地理空间栅格数据。我们使用超光谱掩码自编码器框架对LESS ViT进行预训练,同时集成位置通道掩蔽策略。实验结果表明,我们的方法在具有跨卫星泛化任务的多模态地理空间基础模型上取得了竞争性的性能表现。我们框架的灵活性和可扩展性使其成为未来涉及多种模态和通道的地理空间数据分析任务的希望方向。
要点
- 地理空间栅格数据拥有巨大潜力用于各种应用,得益于其在不同时间和光谱波段下收集的多通道和感知模态的丰富信息。
- 当前自监督学习方法在处理地理空间数据时存在局限性,缺乏可扩展的模型架构,面临灵活性和计算效率的挑战。
- 引入低秩高效空间光谱视觉Transformer,包括LESS注意力块、连续位置通道嵌入层和感知场掩码三大创新点。
- 提出GFM-Bench作为综合基准测试平台,用于评估地理空间栅格数据处理方法。
- 使用Hyperspectral Masked Autoencoder框架对LESS ViT进行预训练,集成位置通道掩蔽策略。
- 实验结果表明,该方法在跨卫星泛化任务上较先进的多模态地理空间基础模型具有竞争力,且计算效率更高。
点此查看论文截图

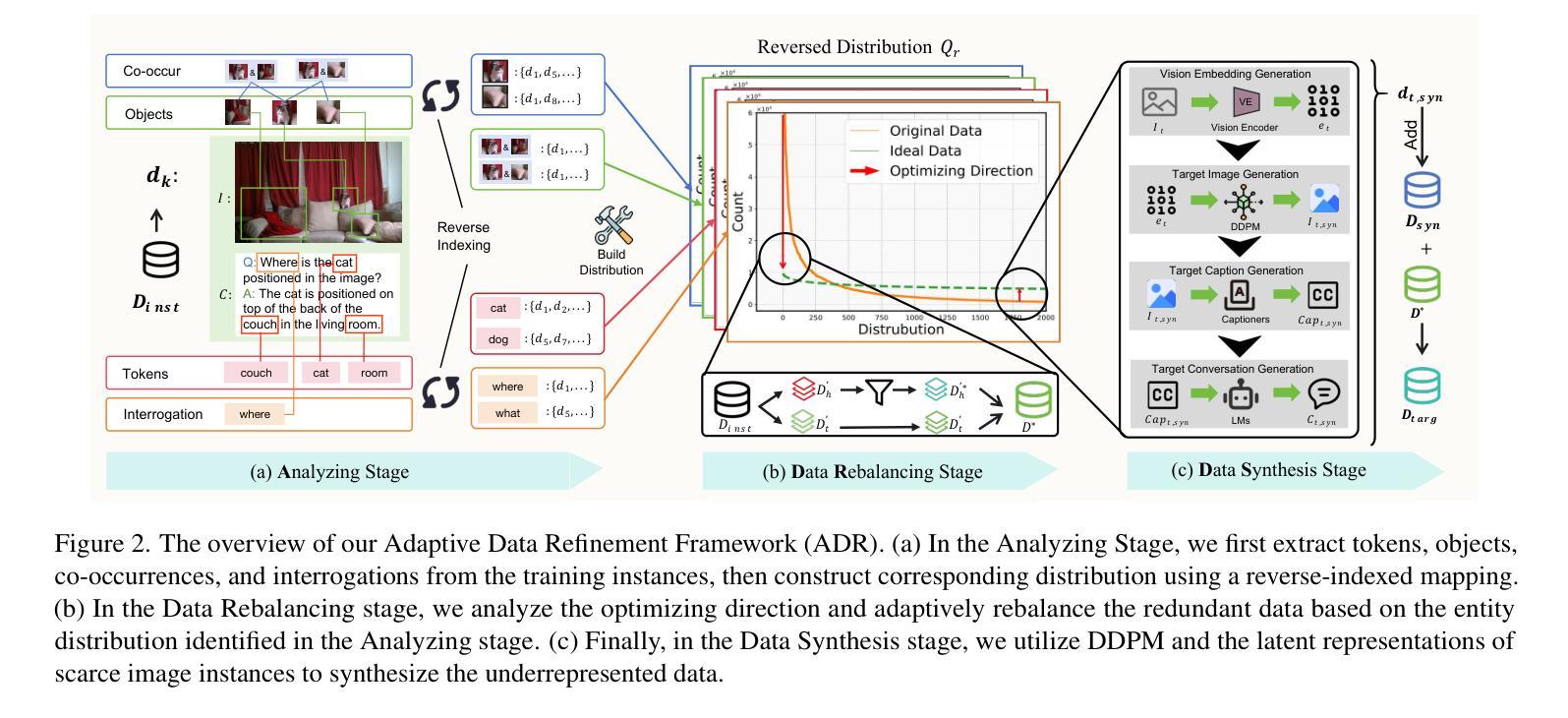
From Head to Tail: Towards Balanced Representation in Large Vision-Language Models through Adaptive Data Calibration
Authors:Mingyang Song, Xiaoye Qu, Jiawei Zhou, Yu Cheng
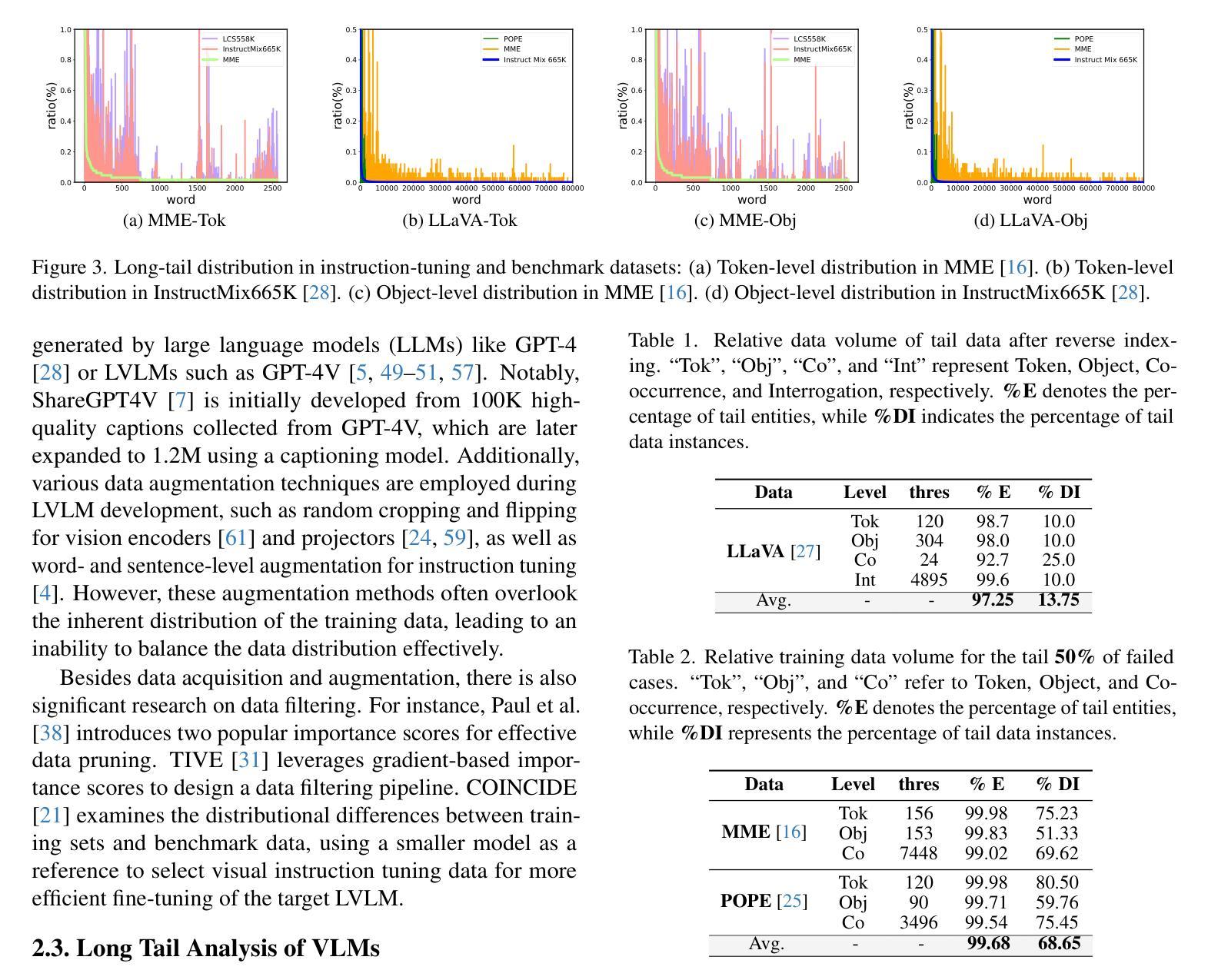
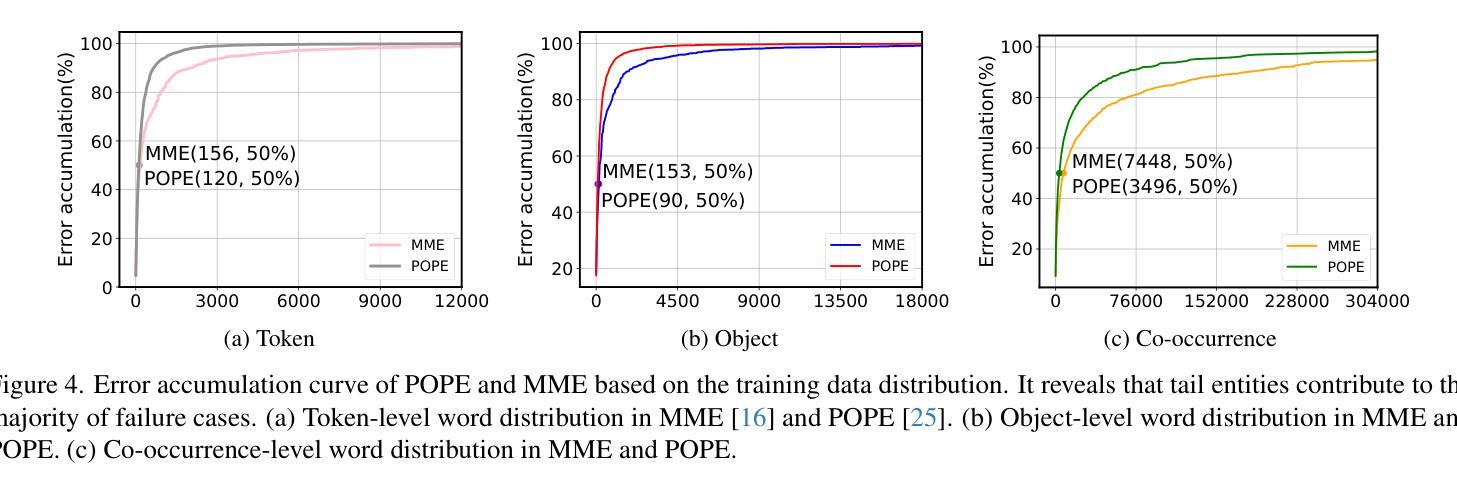
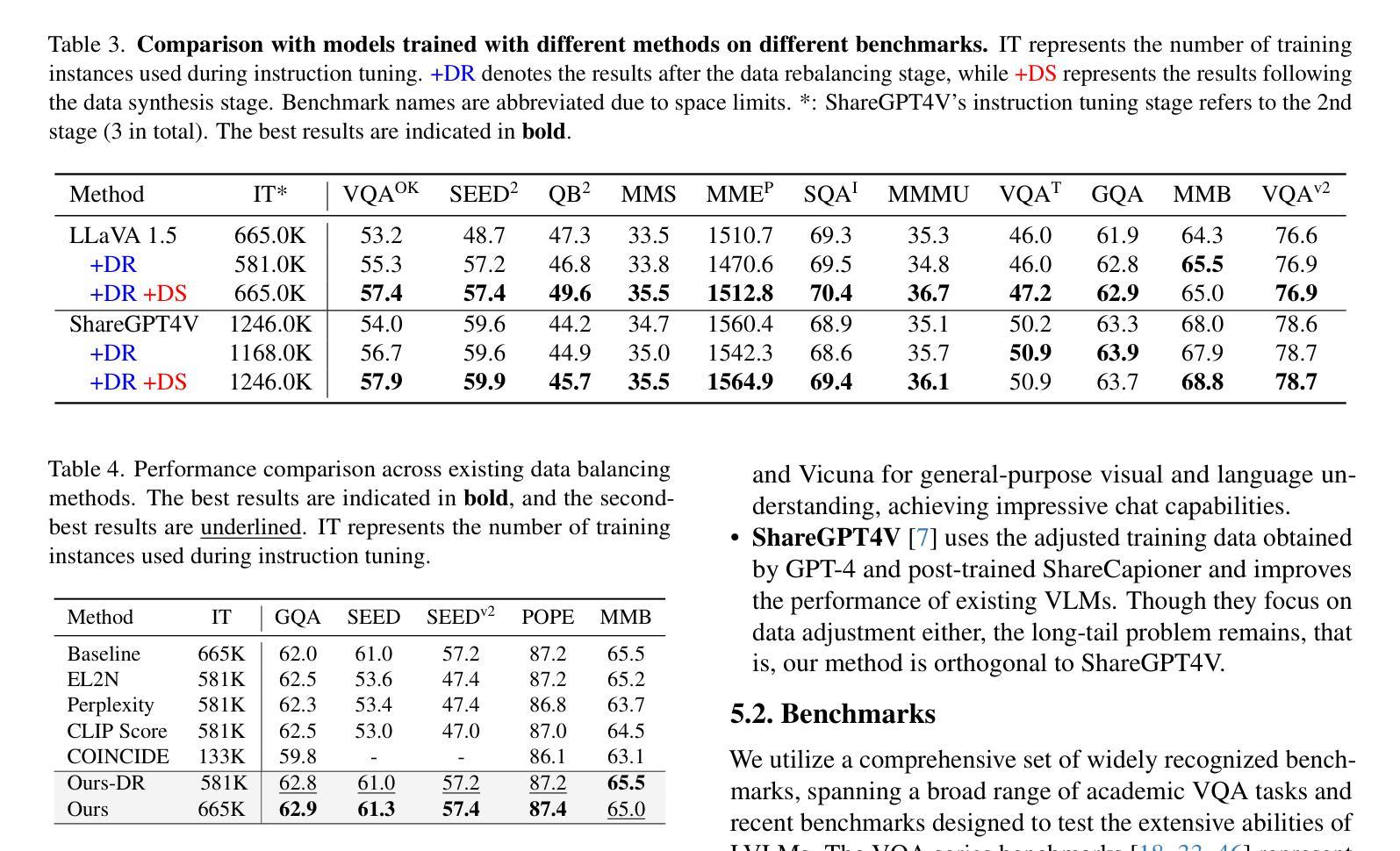
Large Vision-Language Models (LVLMs) have achieved significant progress in combining visual comprehension with language generation. Despite this success, the training data of LVLMs still suffers from Long-Tail (LT) problems, where the data distribution is highly imbalanced. Previous works have mainly focused on traditional VLM architectures, i.e., CLIP or ViT, and specific tasks such as recognition and classification. Nevertheless, the exploration of LVLM (e.g. LLaVA) and more general tasks (e.g. Visual Question Answering and Visual Reasoning) remains under-explored. In this paper, we first conduct an in-depth analysis of the LT issues in LVLMs and identify two core causes: the overrepresentation of head concepts and the underrepresentation of tail concepts. Based on the above observation, we propose an $\textbf{A}$daptive $\textbf{D}$ata $\textbf{R}$efinement Framework ($\textbf{ADR}$), which consists of two stages: $\textbf{D}$ata $\textbf{R}$ebalancing ($\textbf{DR}$) and $\textbf{D}$ata $\textbf{S}$ynthesis ($\textbf{DS}$). In the DR stage, we adaptively rebalance the redundant data based on entity distributions, while in the DS stage, we leverage Denoising Diffusion Probabilistic Models (DDPMs) and scarce images to supplement underrepresented portions. Through comprehensive evaluations across eleven benchmarks, our proposed ADR effectively mitigates the long-tail problem in the training data, improving the average performance of LLaVA 1.5 relatively by 4.36%, without increasing the training data volume.
大型视觉语言模型(LVLMs)在结合视觉理解与语言生成方面取得了显著进展。然而,尽管取得了成功,LVLM的训练数据仍然受到长尾(LT)问题的困扰,即数据分布极不均衡。以往的研究主要关注传统的VLM架构,如CLIP或ViT,以及特定的任务,如识别和分类。然而,对于LVLM(例如LLaVA)和更一般的任务(例如视觉问答和视觉推理)的探索仍然不足。在本文中,我们首先对LVLM中的LT问题进行了深入分析,并确定了两个核心原因:头部概念的过度表示和尾部概念的表示不足。基于上述观察,我们提出了一个自适应数据精炼框架(ADR),它分为两个阶段:数据再平衡(DR)和数据合成(DS)。在DR阶段,我们根据实体分布自适应地重新平衡冗余数据,而在DS阶段,我们利用去噪扩散概率模型(DDPMs)和稀缺图像来补充表示不足的部分。通过对十一个基准的全面评估,我们提出的ADR有效地缓解了训练数据中的长尾问题,在不增加训练数据量的情况下,相对提高了LLaVA 1.5的平均性能4.36%。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文深入探讨了大型视觉语言模型(LVLMs)面临的Long-Tail(LT)问题,并指出其两大核心原因:头部概念的过度表示和尾部概念的表示不足。为解决这一问题,本文提出了自适应数据优化框架(ADR),包含数据再平衡(DR)和数据合成(DS)两个阶段。DR阶段根据实体分布自适应地重新平衡数据,而DS阶段则利用去噪扩散概率模型(DDPMs)和稀缺图像来补充表示不足的尾部数据。经过在十一个基准测试上的综合评估,本文提出的ADR方法有效地缓解了训练数据中的长尾问题,提高了LLaVA 1.5的平均性能4.36%,且未增加训练数据量。
Key Takeaways
- 大型视觉语言模型(LVLMs)面临Long-Tail(LT)问题,数据分布高度不平衡。
- LT问题的核心原因包括头部概念的过度表示和尾部概念的表示不足。
- 为解决LT问题,提出了自适应数据优化框架(ADR),包含数据再平衡(DR)和数据合成(DS)两个阶段。
- DR阶段通过自适应地重新平衡数据来解决数据不平衡问题。
- DS阶段利用去噪扩散概率模型(DDPMs)和稀缺图像来补充表示不足的尾部数据。
- ADR方法有效地缓解了训练数据中的长尾问题,提高了模型的平均性能。
点此查看论文截图