⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
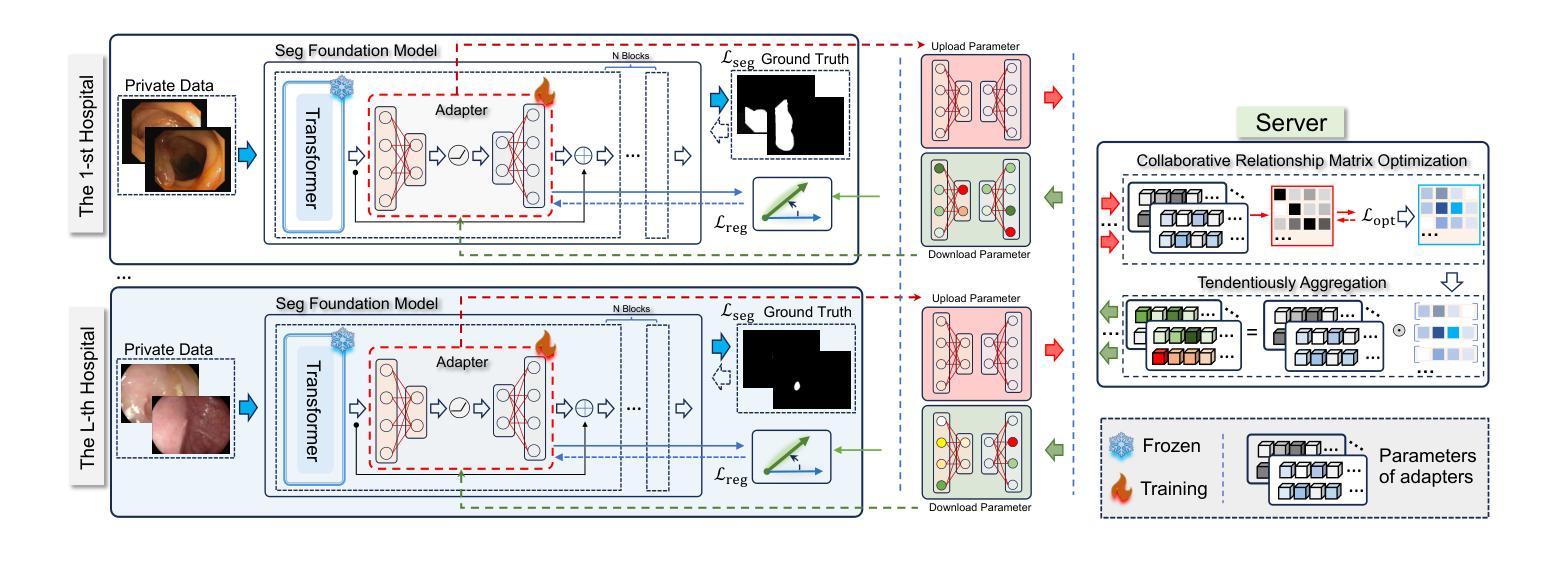
FedSCA: Federated Tuning with Similarity-guided Collaborative Aggregation for Heterogeneous Medical Image Segmentation
Authors:Yumin Zhang, Yan Gao, Haoran Duan, Hanqing Guo, Tejal Shah, Rajiv Ranjan, Bo Wei
Transformer-based foundation models (FMs) have recently demonstrated remarkable performance in medical image segmentation. However, scaling these models is challenging due to the limited size of medical image datasets within isolated hospitals, where data centralization is restricted due to privacy concerns. These constraints, combined with the data-intensive nature of FMs, hinder their broader application. Integrating federated learning (FL) with foundation models (FLFM) fine-tuning offers a potential solution to these challenges by enabling collaborative model training without data sharing, thus allowing FMs to take advantage of a diverse pool of sensitive medical image data across hospitals/clients. However, non-independent and identically distributed (non-IID) data among clients, paired with computational and communication constraints in federated environments, presents an additional challenge that limits further performance improvements and remains inadequately addressed in existing studies. In this work, we propose a novel FLFM fine-tuning framework, \underline{\textbf{Fed}}erated tuning with \underline{\textbf{S}}imilarity-guided \underline{\textbf{C}}ollaborative \underline{\textbf{A}}ggregation (FedSCA), encompassing all phases of the FL process. This includes (1) specially designed parameter-efficient fine-tuning (PEFT) for local client training to enhance computational efficiency; (2) partial low-level adapter transmission for communication efficiency; and (3) similarity-guided collaborative aggregation (SGCA) on the server side to address non-IID issues. Extensive experiments on three FL benchmarks for medical image segmentation demonstrate the effectiveness of our proposed FedSCA, establishing new SOTA performance.
基于Transformer的基础模型(FMs)在医学图像分割方面最近表现出了显著的性能。然而,由于孤立医院中医疗图像数据集规模的限制,以及隐私担忧导致的数据集中化受限,这些模型的规模扩大具有挑战性。这些约束,结合FMs数据密集型的特性,阻碍了其更广泛的应用。将联邦学习(FL)与基础模型(FLFM)微调相结合,提供了一种通过协同模型训练实现无需数据共享的解决方案,从而允许FMs利用跨医院/客户端的多样化敏感医疗图像数据。然而,客户端之间的非独立同分布(non-IID)数据,以及联邦环境中的计算和通信约束,呈现了一个额外的挑战,限制了性能的进一步提高,并且在现有研究中仍未得到充分的解决。在这项工作中,我们提出了一种新型的FLFM微调框架——基于相似性引导的协同聚合的联邦调优(FedSCA),涵盖了FL过程的各个阶段。这包括(1)为本地客户端训练设计的参数高效微调(PEFT),以提高计算效率;(2)部分低级适配器传输以提高通信效率;(3)服务器端相似性引导的协同聚合(SGCA)以解决非IID问题。在三个医学图像分割的联邦学习基准测试上的广泛实验证明了我们提出的FedSCA的有效性,并建立了新的性能最佳记录。
论文及项目相关链接
Summary
本文提出一种基于联邦学习(FL)和深度学习基础模型(FMs)的新型精细调节框架FedSCA,针对医院间独立分布的数据集小且非独立同分布(non-IID)的问题,实现参数高效的本地训练,同时利用相似度引导的协同聚合解决non-IID问题,确保医学图像分割在联邦环境下的高性能运行。此框架已在三个联邦学习基准测试上进行了广泛实验验证,并达到了最先进的性能表现。
Key Takeaways
- 联邦学习(FL)与深度学习基础模型(FMs)结合解决了医院数据规模小和数据隐私的挑战。
- 非独立同分布(non-IID)数据是联邦学习中的一大难题,影响了模型性能的提升。
- 提出了一种新型联邦学习精细调节框架FedSCA,包含参数高效的本地训练、部分低级适配器传输和相似度引导的协同聚合。
- FedSCA框架通过专门设计的参数高效精细调节(PEFT)提升计算效率。
- 通过部分低级适配器传输提高通信效率。
- 服务器端的相似度引导协同聚合(SGCA)解决了non-IID问题。
点此查看论文截图


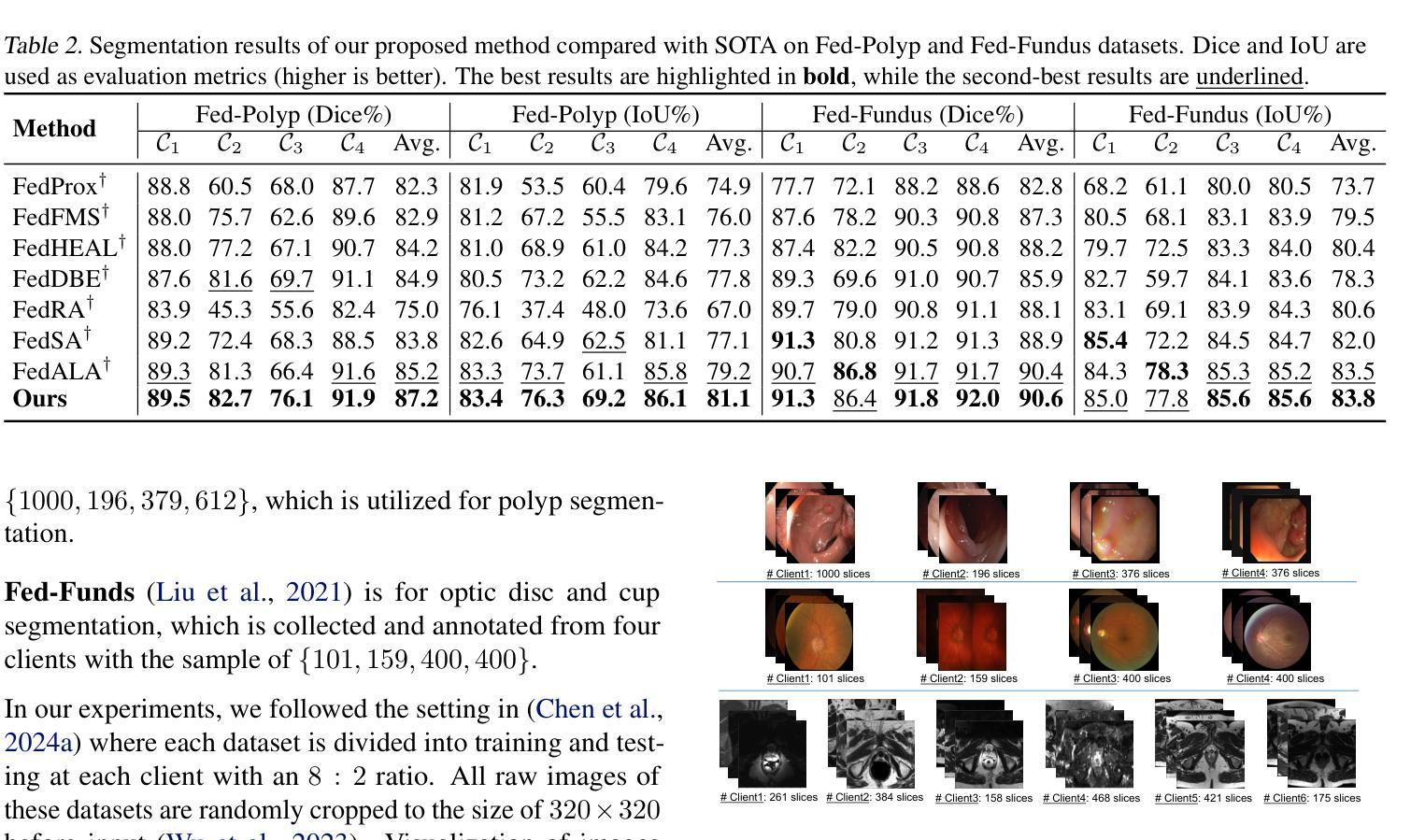
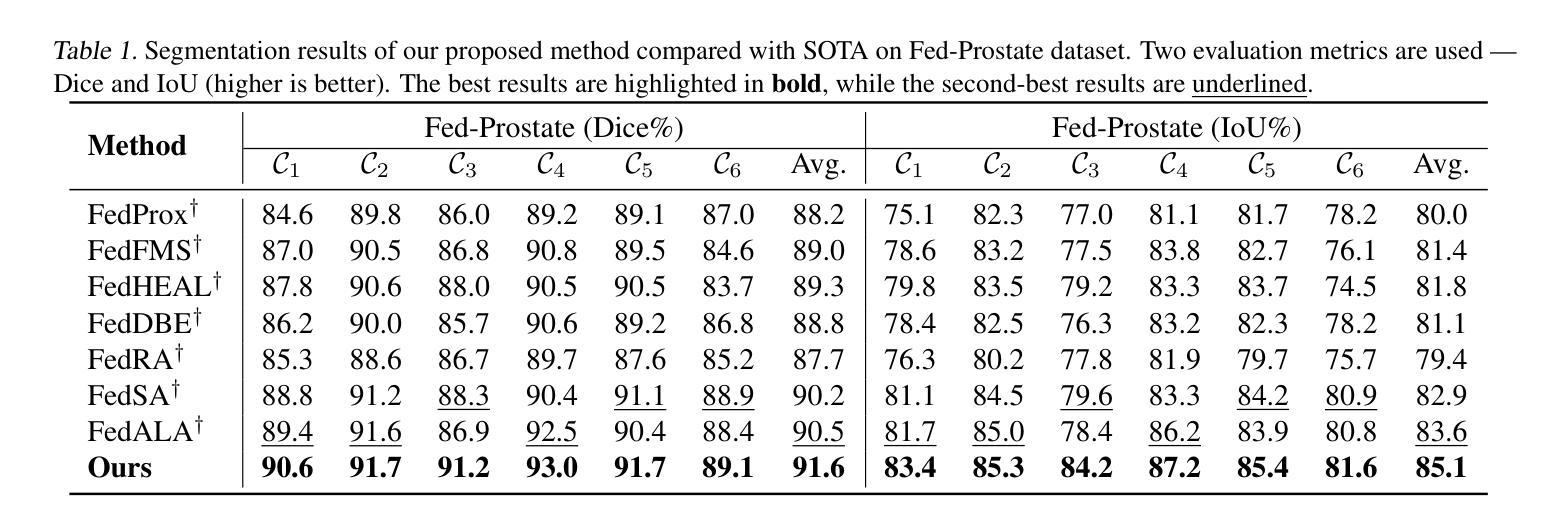
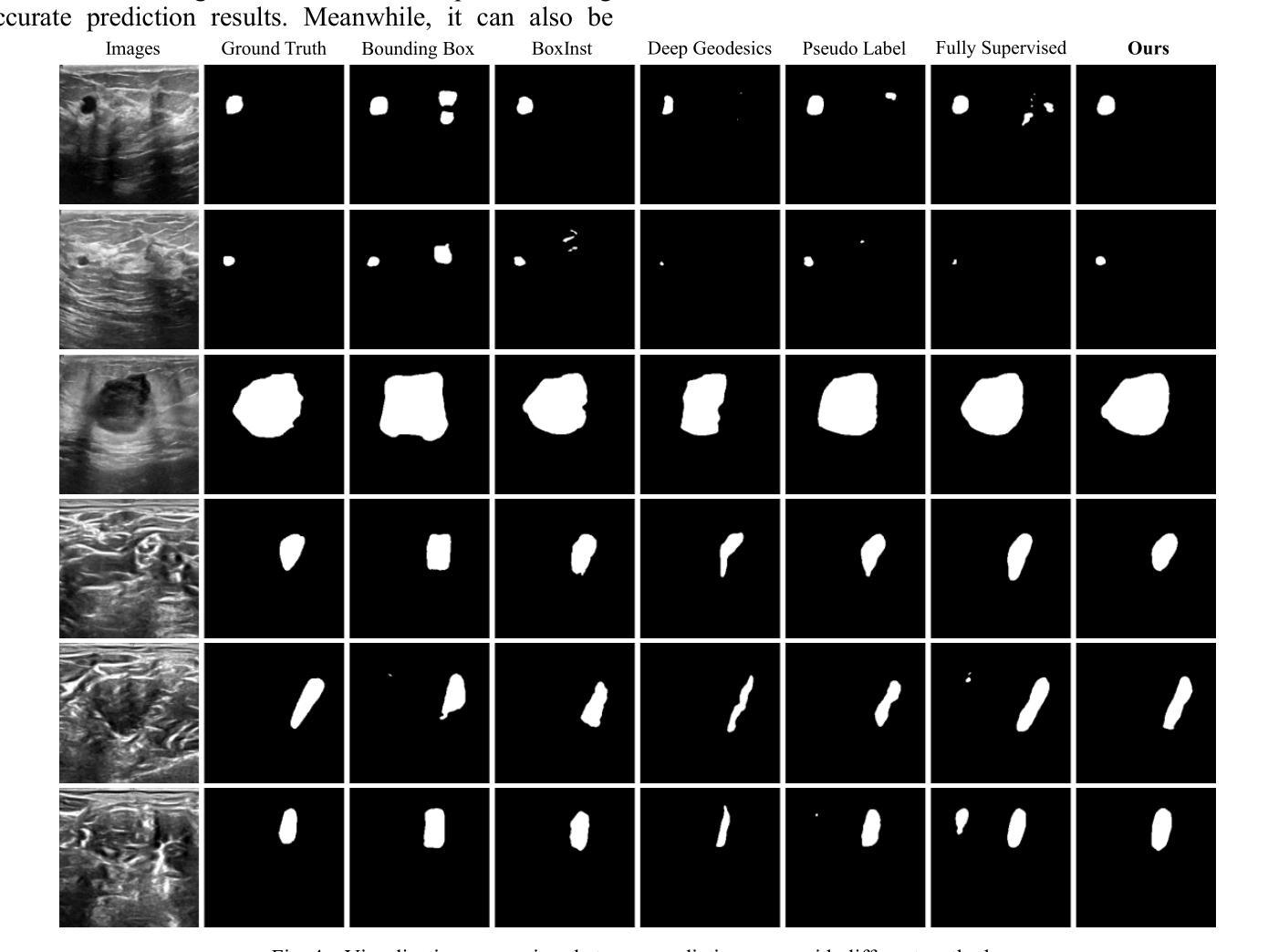
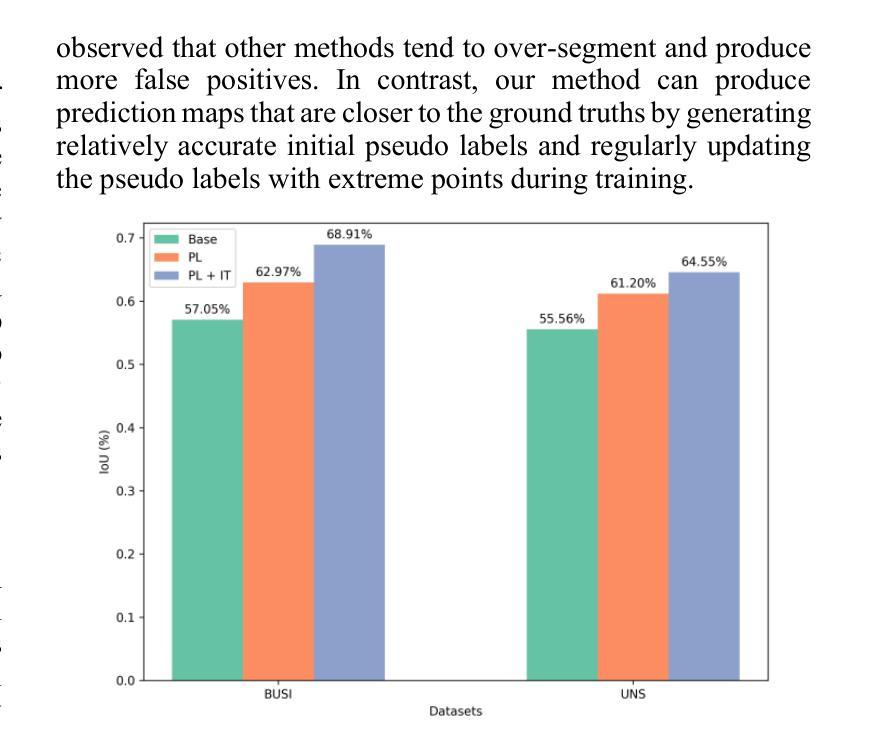
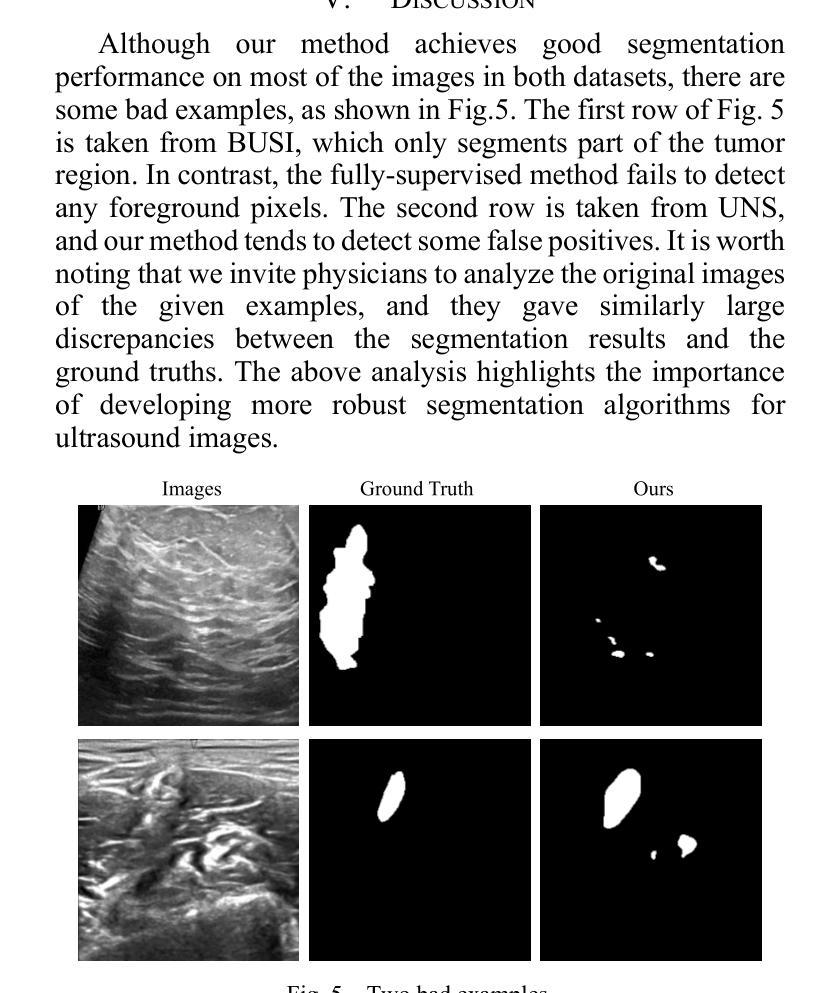
DEPT: Deep Extreme Point Tracing for Ultrasound Image Segmentation
Authors:Lei Shi, Xi Fang, Naiyu Wang, Junxing Zhang
Automatic medical image segmentation plays a crucial role in computer aided diagnosis. However, fully supervised learning approaches often require extensive and labor-intensive annotation efforts. To address this challenge, weakly supervised learning methods, particularly those using extreme points as supervisory signals, have the potential to offer an effective solution. In this paper, we introduce Deep Extreme Point Tracing (DEPT) integrated with Feature-Guided Extreme Point Masking (FGEPM) algorithm for ultrasound image segmentation. Notably, our method generates pseudo labels by identifying the lowest-cost path that connects all extreme points on the feature map-based cost matrix. Additionally, an iterative training strategy is proposed to refine pseudo labels progressively, enabling continuous network improvement. Experimental results on two public datasets demonstrate the effectiveness of our proposed method. The performance of our method approaches that of the fully supervised method and outperforms several existing weakly supervised methods.
在医学图像诊断辅助中,自动医学图像分割发挥着关键作用。然而,完全监督学习方法通常需要大量且劳动强度大的标注工作。为了应对这一挑战,弱监督学习方法,特别是使用极端点作为监督信号的弱监督学习方法,具有提供有效解决方案的潜力。在本文中,我们引入了基于特征引导极端点遮蔽算法(FGEPM)的深度极值点追踪(DEPT)方法,用于超声图像分割。值得注意的是,我们的方法通过识别基于特征映射的成本矩阵上所有极端点之间的最低成本路径来生成伪标签。此外,提出了一种迭代训练策略来逐步优化伪标签,从而实现网络的持续改进。在两个公共数据集上的实验结果证明了所提出方法的有效性。该方法的性能接近全监督方法,优于其他一些现有的弱监督方法。
论文及项目相关链接
Summary
本文介绍了一种结合深度极端点追踪(DEPT)和特征引导极端点掩模(FGEPM)算法的超声图像分割方法。该方法通过识别基于特征映射成本矩阵上所有极端点的最低成本路径来生成伪标签,并采用迭代训练策略逐步优化伪标签,从而提高网络性能。在公共数据集上的实验结果表明,该方法的有效性接近全监督方法,并优于一些现有的弱监督方法。
Key Takeaways
- 自动医学图像分割在计算机辅助诊断中起关键作用,但全监督学习方法需要大量人工标注,存在劳动密集型问题。
- 弱监督学习方法,特别是使用极端点作为监督信号的方法,为解决这一问题提供了有效潜力。
- 本文提出结合深度极端点追踪(DEPT)和特征引导极端点掩模(FGEPM)算法的超声图像分割方法。
- 该方法通过识别基于特征映射成本矩阵上所有极端点的最低成本路径来生成伪标签。
- 采用迭代训练策略逐步优化伪标签,有助于提高网络性能。
- 在公共数据集上的实验结果表明,该方法的有效性接近全监督方法。
点此查看论文截图


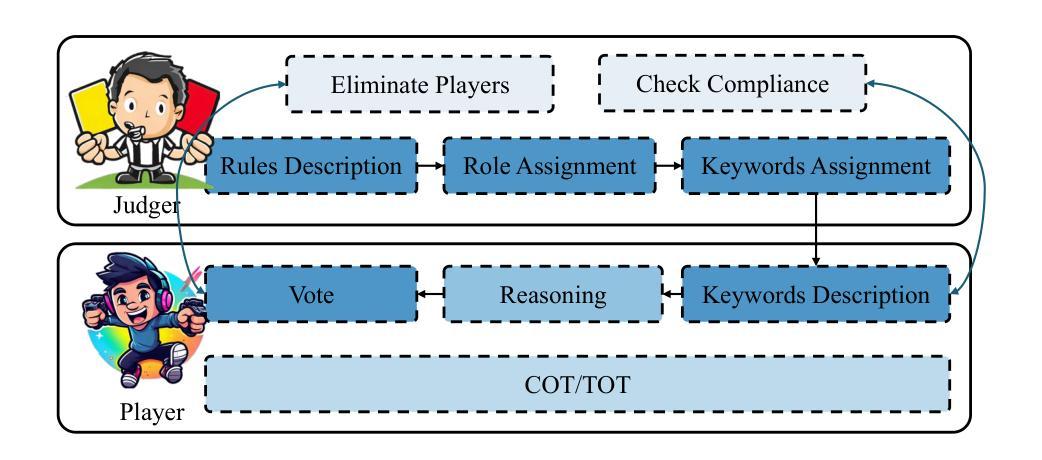
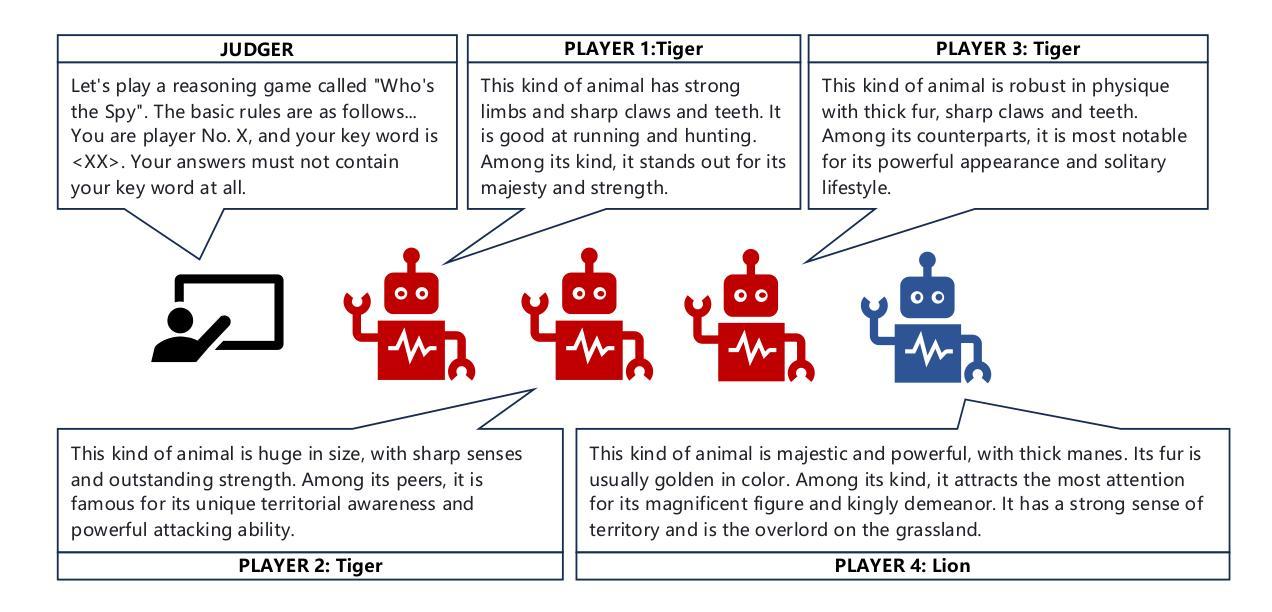
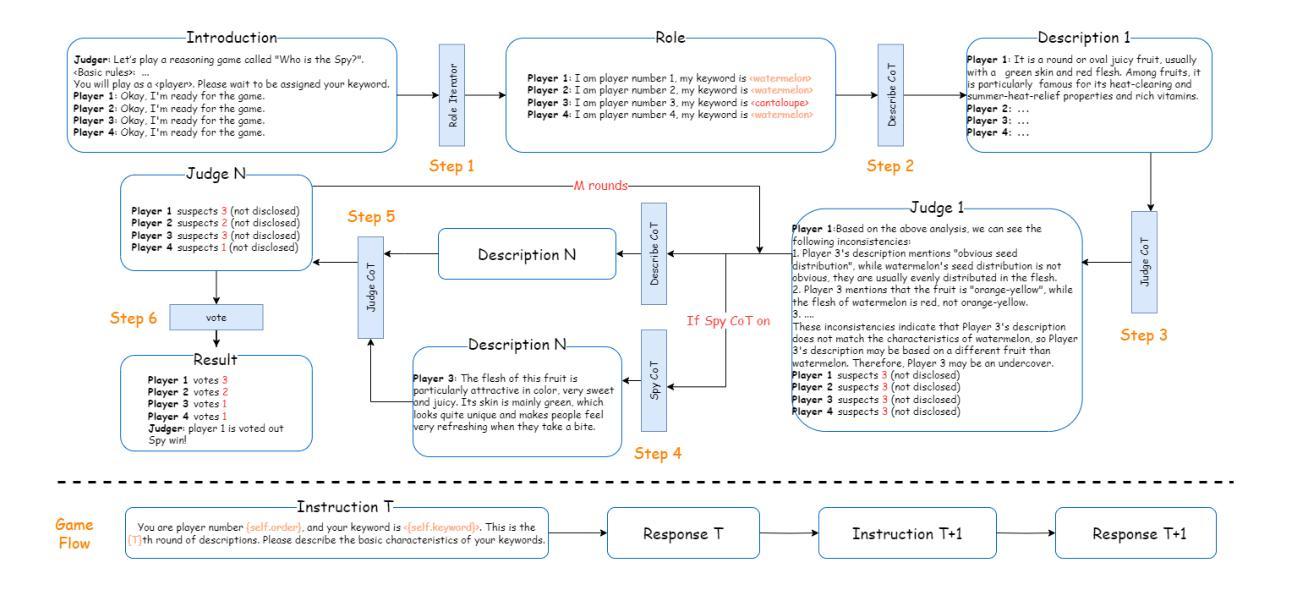
Exploring Large Language Models for Word Games:Who is the Spy?
Authors:Chentian Wei, Jiewei Chen, Jinzhu Xu
Word games hold significant research value for natural language processing (NLP), game theory, and related fields due to their rule-based and situational nature. This study explores how large language models (LLMs) can be effectively involved in word games and proposes a training-free framework. “Shei Shi Wo Di” or “Who is the Spy” in English, is a classic word game. Using this game as an example, we introduce a Chain-of-Thought (CoT)-based scheduling framework to enable LLMs to achieve excellent performance in tasks such as inferring role words and disguising their identities. We evaluate the framework’s performance based on game success rates and the accuracy of the LLM agents’ analytical results. Experimental results affirm the framework’s effectiveness, demonstrating notable improvements in LLM performance across multiple datasets. This work highlights the potential of LLMs in mastering situational reasoning and social interactions within structured game environments. Our code is publicly available at https://github.com/ct-wei/Who-is-The-Spy.
文字游戏因其基于规则和情境的特性,对自然语言处理(NLP)、博弈论和相关领域具有重要的研究价值。本研究探讨了大型语言模型(LLM)如何有效地参与文字游戏,并提出了一个无需训练框架。 “谁是间谍”(Shei Shi Wo Di)是英文文字游戏“谁是卧底”的一种经典玩法。以这款游戏为例,我们引入了一种基于思维链(Chain-of-Thought,CoT)的调度框架,使LLM能够在推断角色词和伪装身份等任务中取得卓越表现。我们根据游戏成功率和LLM代理人的分析结果准确性来评估框架的性能。实验结果证实了框架的有效性,并在多个数据集上显示出LLM性能的显著改进。这项工作突出了LLM在掌握结构化游戏环境中的情境推理和社会交互方面的潜力。我们的代码公开在https://github.com/ct-wei/Who-is-The-Spy。
论文及项目相关链接
Summary
本文研究了大型语言模型(LLMs)在字谜游戏“谁是我间谍”(Shei Shi Wo Di)中的应用,提出了一种基于思维链(Chain-of-Thought,CoT)的调度框架,以提高LLMs在角色词推断和身份伪装等任务中的性能。实验结果表明,该框架能有效提高LLMs在多个数据集上的表现。本文强调了LLMs在掌握结构化游戏环境中的情境推理和社会交互方面的潜力。
Key Takeaways
- 大型语言模型(LLMs)在字谜游戏中的研究具有重要价值。
- 以“谁是我间谍”为例,展示了LLMs在角色词推断和身份伪装任务中的性能提升。
- 提出了一种基于思维链(Chain-of-Thought,CoT)的调度框架,以提高LLMs在游戏中的表现。
- 通过实验验证了框架的有效性,并展示了其在多个数据集上的显著改进。
- 该框架对提升LLMs的情境推理和社会交互能力有潜力。
- 该研究的代码已公开,供公众参考与学习。
点此查看论文截图

3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Authors:Gyeongrok Oh, Sungjune Kim, Heeju Ko, Hyung-gun Chi, Jinkyu Kim, Dongwook Lee, Daehyun Ji, Sungjoon Choi, Sujin Jang, Sangpil Kim
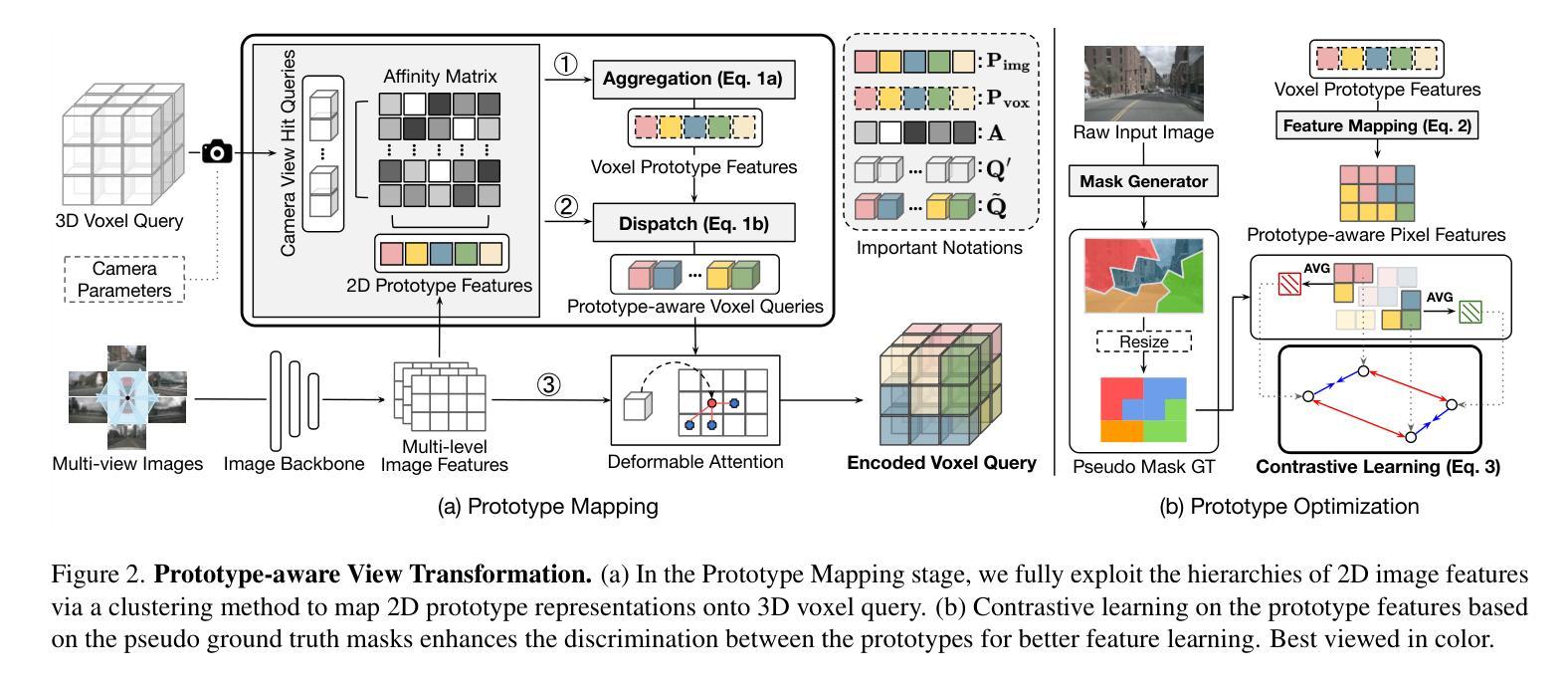
The resolution of voxel queries significantly influences the quality of view transformation in camera-based 3D occupancy prediction. However, computational constraints and the practical necessity for real-time deployment require smaller query resolutions, which inevitably leads to an information loss. Therefore, it is essential to encode and preserve rich visual details within limited query sizes while ensuring a comprehensive representation of 3D occupancy. To this end, we introduce ProtoOcc, a novel occupancy network that leverages prototypes of clustered image segments in view transformation to enhance low-resolution context. In particular, the mapping of 2D prototypes onto 3D voxel queries encodes high-level visual geometries and complements the loss of spatial information from reduced query resolutions. Additionally, we design a multi-perspective decoding strategy to efficiently disentangle the densely compressed visual cues into a high-dimensional 3D occupancy scene. Experimental results on both Occ3D and SemanticKITTI benchmarks demonstrate the effectiveness of the proposed method, showing clear improvements over the baselines. More importantly, ProtoOcc achieves competitive performance against the baselines even with 75% reduced voxel resolution.
基于相机的三维占用预测中,体素查询的分辨率对视图转换的质量有重要影响。然而,计算约束和实时部署的实际需求要求较小的查询分辨率,这不可避免地导致信息丢失。因此,在有限的查询大小内编码和保留丰富的视觉细节至关重要,同时还要确保三维占用的全面表示。为此,我们引入了ProtoOcc,这是一种新型占用网络,它利用聚类图像段的原型进行视图转换,以增强低分辨率上下文。特别是,将二维原型映射到三维体素查询上,可以编码高级视觉几何特征,并补充因降低查询分辨率而损失的空间信息。此外,我们还设计了一种多视角解码策略,能够高效地将密集压缩的视觉线索解纠缠为高维的三维占用场景。在Occ3D和SemanticKITTI基准测试上的实验结果表明了该方法的有效性,与基线相比有明显的改进。更重要的是,即使在体素分辨率降低75%的情况下,ProtoOcc仍能达到与基线竞争的性能。
论文及项目相关链接
PDF Accepted to CVPR2025
Summary
高分辨率的体素查询对基于相机的三维占用预测中的视图转换质量有重要影响。由于计算约束和实时部署的实际需求,通常需要较小的查询分辨率,这会导致信息损失。因此,ProtoOcc作为一种新型占用网络,通过利用聚类图像段的原型进行视图转换,以在低分辨率上下文中增强信息。具体而言,将二维原型映射到三维体素查询中,编码高级视觉几何信息,并补充因查询分辨率降低而损失的空间信息。此外,设计了一种多视角解码策略,以有效地将密集压缩的视觉线索解纠缠为高维度的三维占用场景。实验结果表明,该方法在Occ3D和SemanticKITTI基准测试上均表现出有效性,即使在体素分辨率降低75%的情况下,ProtoOcc仍实现与基线方法相当的竞争力。
Key Takeaways
- 分辨率对视图转换质量有影响。
- 小查询分辨率导致信息损失。
- ProtoOcc利用图像段原型以增强低分辨率上下文中的信息。
- 二维原型映射到三维体素查询以编码高级视觉几何信息。
- 多视角解码策略可有效解纠缠视觉线索以呈现三维占用场景。
- ProtoOcc在基准测试中表现优异,并在低分辨率下仍具有竞争力。
点此查看论文截图
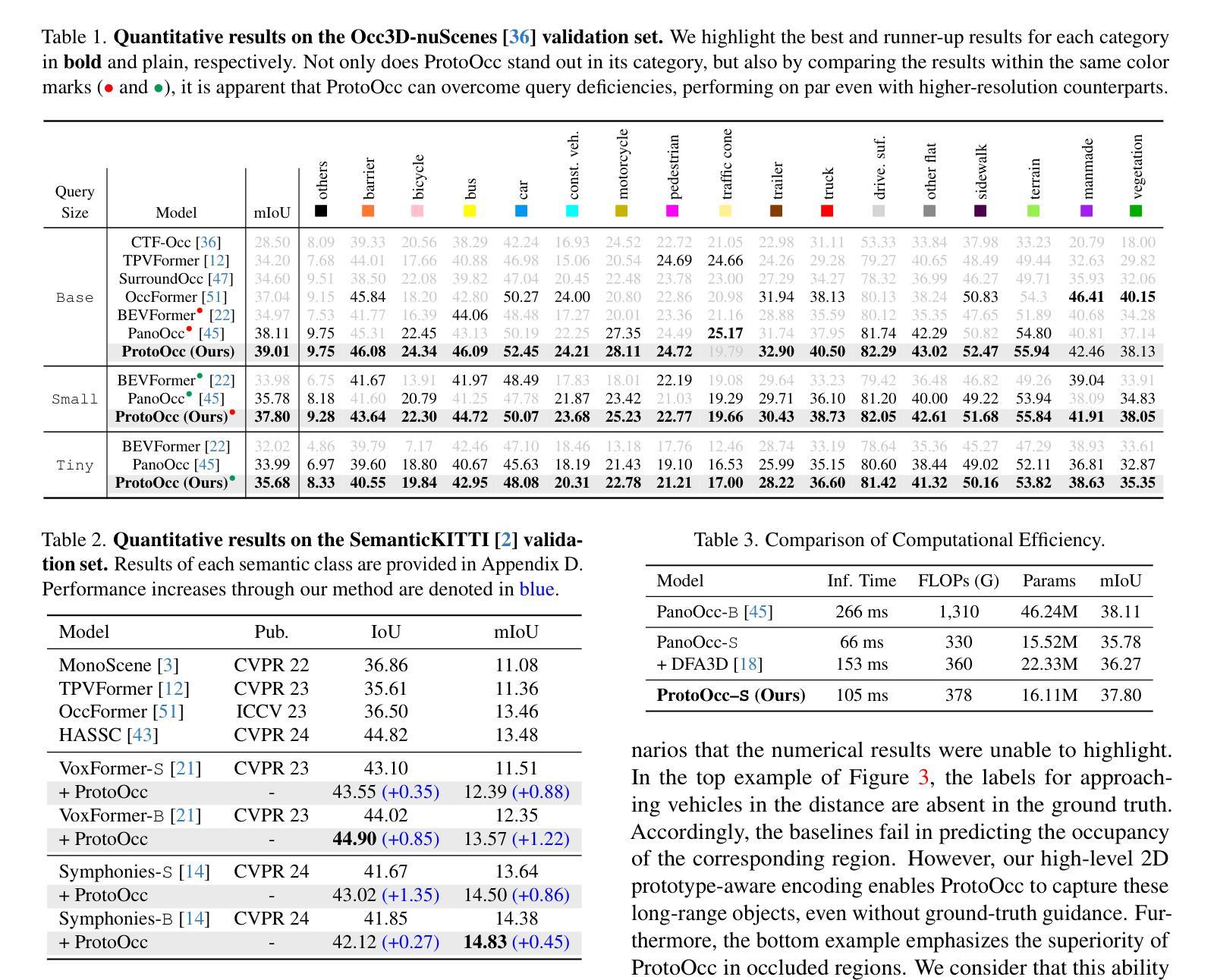
Texture-Aware StarGAN for CT data harmonisation
Authors:Francesco Di Feola, Ludovica Pompilio, Cecilia Assolito, Valerio Guarrasi, Paolo Soda
Computed Tomography (CT) plays a pivotal role in medical diagnosis; however, variability across reconstruction kernels hinders data-driven approaches, such as deep learning models, from achieving reliable and generalized performance. To this end, CT data harmonization has emerged as a promising solution to minimize such non-biological variances by standardizing data across different sources or conditions. In this context, Generative Adversarial Networks (GANs) have proved to be a powerful framework for harmonization, framing it as a style-transfer problem. However, GAN-based approaches still face limitations in capturing complex relationships within the images, which are essential for effective harmonization. In this work, we propose a novel texture-aware StarGAN for CT data harmonization, enabling one-to-many translations across different reconstruction kernels. Although the StarGAN model has been successfully applied in other domains, its potential for CT data harmonization remains unexplored. Furthermore, our approach introduces a multi-scale texture loss function that embeds texture information across different spatial and angular scales into the harmonization process, effectively addressing kernel-induced texture variations. We conducted extensive experimentation on a publicly available dataset, utilizing a total of 48667 chest CT slices from 197 patients distributed over three different reconstruction kernels, demonstrating the superiority of our method over the baseline StarGAN.
计算机断层扫描(CT)在医学诊断中起着至关重要的作用;然而,重建核的差异性阻碍了数据驱动的方法(如深度学习模型)实现可靠和通用的性能。为此,CT数据调和已成为一种有前途的解决方案,通过标准化不同源或条件下的数据,以尽量减少这种非生物性差异。在这种情况下,生成对抗网络(GANs)已被证明是调和的有力框架,将其构造成风格转换问题。然而,基于GAN的方法在捕获图像内的复杂关系方面仍然存在局限性,这对于有效的调和至关重要。在这项工作中,我们提出了一种用于CT数据调和的新型纹理感知StarGAN,能够实现不同重建核之间的一对多翻译。虽然StarGAN模型已在其他领域成功应用,但其对CT数据调和的潜力仍未被探索。此外,我们的方法引入了一种多尺度纹理损失函数,该函数将不同空间和角度尺度上的纹理信息嵌入到调和过程中,有效地解决了核引起的纹理变化。我们在公开数据集上进行了广泛实验,使用了来自197名患者的总共48667张胸部CT切片,这些切片分布在三种不同的重建核上,证明了我们的方法优于基线StarGAN。
简化解释
论文及项目相关链接
Summary
该文探讨了计算机断层扫描(CT)在医学诊断中的重要作用以及重建核差异对数据驱动方法(如深度学习模型)的影响。为解决这一问题,提出了一种基于生成对抗网络(GANs)的纹理感知StarGAN模型,用于CT数据和谐化,能够跨不同重建核进行一对一至多翻译。通过多尺度纹理损失函数嵌入不同空间和角度尺度的纹理信息到和谐化过程中,解决了核引起的纹理变化问题。实验在公开数据集上进行,利用来自197名患者的48667张胸部CT切片,验证了该方法优于基线StarGAN。
Key Takeaways
- CT在医学诊断中具有重要作用,但不同重建核之间的差异影响了数据驱动方法的性能。
- 数据和谐化是减少非生物变异的一种有前途的解决方案。
- GANs已被证明是用于数据和谐化的强大框架,但存在捕捉图像复杂关系的局限性。
- 提出了一种新的纹理感知StarGAN模型用于CT数据和谐化,能够进行一对一至多的翻译。
- 该方法通过引入多尺度纹理损失函数解决了核引起的纹理变化问题。
- 实验在公开数据集上进行,验证了该方法的有效性优于基线StarGAN。
点此查看论文截图

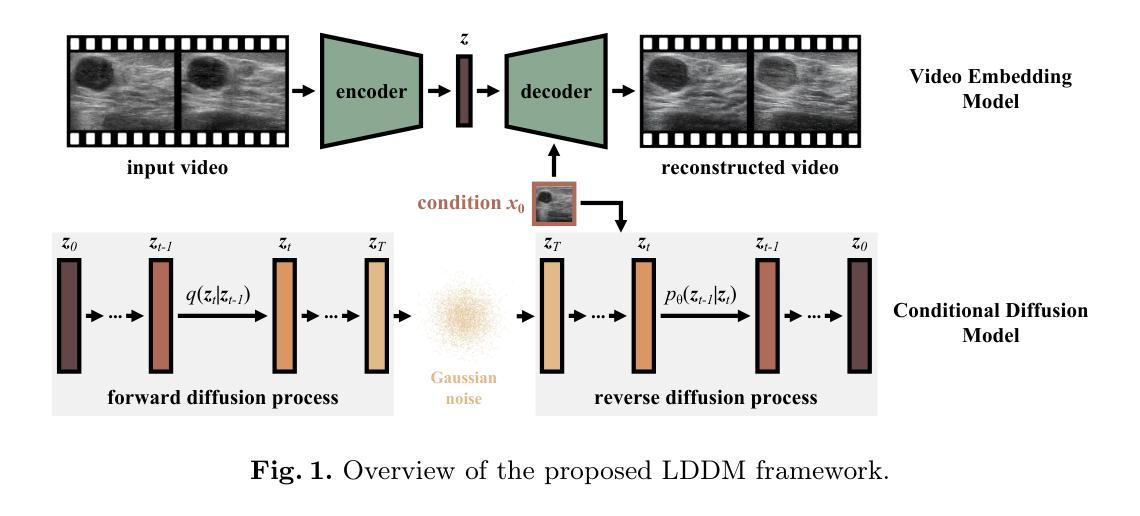
Ultrasound Image-to-Video Synthesis via Latent Dynamic Diffusion Models
Authors:Tingxiu Chen, Yilei Shi, Zixuan Zheng, Bingcong Yan, Jingliang Hu, Xiao Xiang Zhu, Lichao Mou
Ultrasound video classification enables automated diagnosis and has emerged as an important research area. However, publicly available ultrasound video datasets remain scarce, hindering progress in developing effective video classification models. We propose addressing this shortage by synthesizing plausible ultrasound videos from readily available, abundant ultrasound images. To this end, we introduce a latent dynamic diffusion model (LDDM) to efficiently translate static images to dynamic sequences with realistic video characteristics. We demonstrate strong quantitative results and visually appealing synthesized videos on the BUSV benchmark. Notably, training video classification models on combinations of real and LDDM-synthesized videos substantially improves performance over using real data alone, indicating our method successfully emulates dynamics critical for discrimination. Our image-to-video approach provides an effective data augmentation solution to advance ultrasound video analysis. Code is available at https://github.com/MedAITech/U_I2V.
超声视频分类可实现自动诊断,已成为重要研究领域。然而,公共超声视频数据集仍然匮乏,阻碍了有效视频分类模型的开发进展。我们提出通过合成合理的超声视频来解决这一短缺问题,这些视频可从丰富且易获得的超声图像中生成。为此,我们引入潜在动态扩散模型(LDDM),以有效将静态图像转换为具有真实视频特性的动态序列。我们在BUSV基准测试上展示了强大的定量结果和视觉上吸引人的合成视频。值得注意的是,使用真实和LDDM合成视频相结合的数据集训练视频分类模型,其性能大大超过了仅使用真实数据的效果,表明我们的方法成功模拟了关键鉴别动态。我们的图像到视频的方法为推进超声视频分析提供了有效的数据增强解决方案。代码可通过https://github.com/MedAITech/U_I2V获取。
论文及项目相关链接
PDF MICCAI 2024
Summary
超声视频分类对于自动化诊断至关重要,但可用的超声视频数据集稀缺,制约了视频分类模型的发展。为此,我们提出通过丰富的超声图像合成超声视频来弥补这一不足。我们引入潜在动态扩散模型(LDDM),成功将静态图像转化为具有真实视频特性的动态序列。在BUSV基准测试上,合成的视频既在数量上丰富,视觉上也很逼真。使用真实和合成视频组合训练的视频分类模型性能优于仅使用真实数据,证明我们的方法成功模拟了关键动态鉴别特征。我们的图像到视频的转换方法为超声视频分析提供了有效的数据增强解决方案。
Key Takeaways
- 超声视频分类在自动化诊断中具有重要意义,但缺乏可用的超声视频数据集限制了进展。
- 提出通过潜在动态扩散模型(LDDM)合成超声视频以弥补数据集不足。
- LDDM模型成功将静态超声图像转化为具有真实视频特性的动态序列。
- 在BUSV基准测试上,合成的视频既丰富且视觉效果好。
- 使用真实和合成视频组合训练的视频分类模型性能更佳。
- 该方法成功模拟了关键动态鉴别特征,证明其有效性。
点此查看论文截图


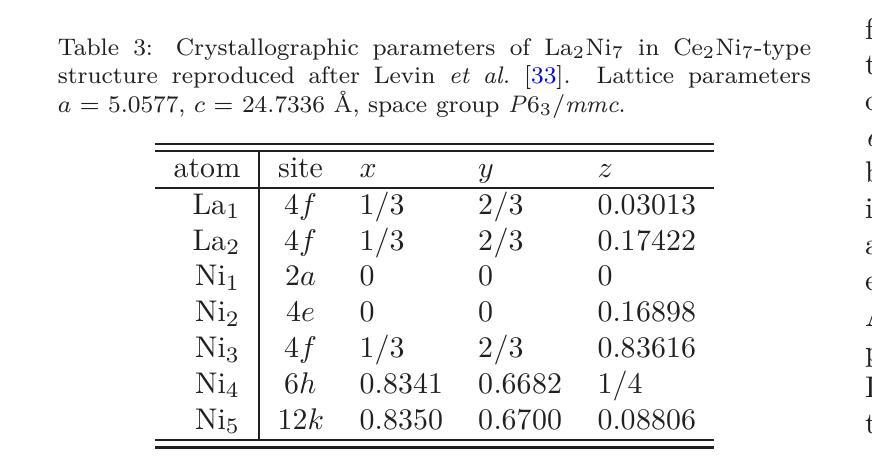
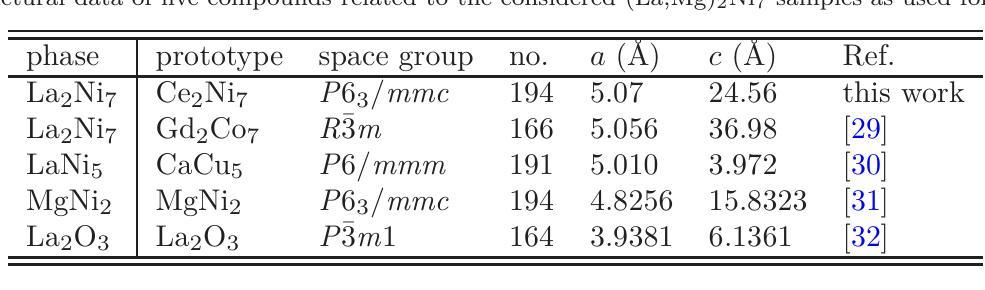
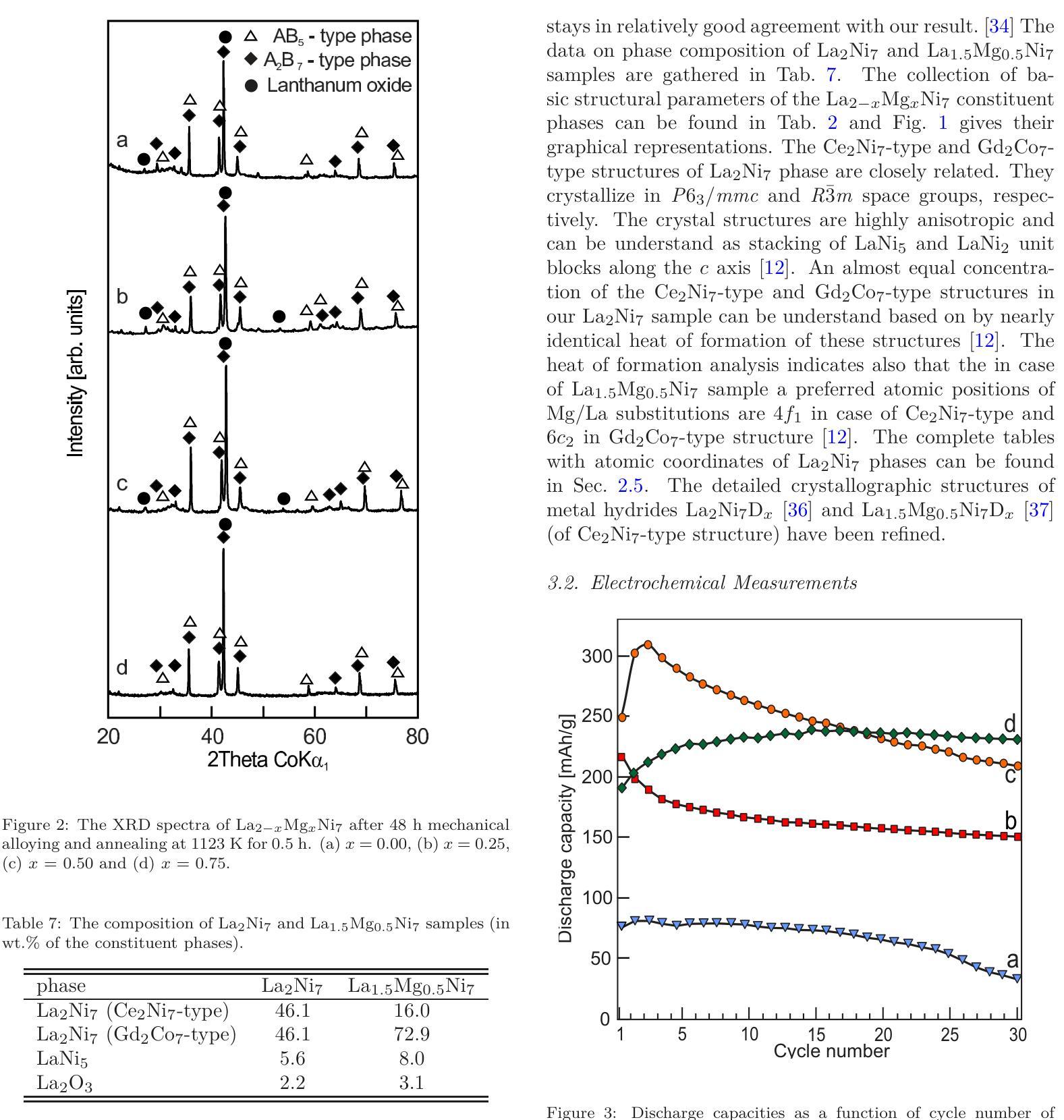
Effect of substitution La by Mg on electrochemical and electronic properties in La$_{2-x}$Mg$_x$Ni$_7$ alloys: a combined experimental and ab initio studies
Authors:Mirosław Werwiński, Andrzej Szajek, Agnieszka Marczyńska, Lesław Smardz, Marek Nowak, Mieczysław Jurczyk
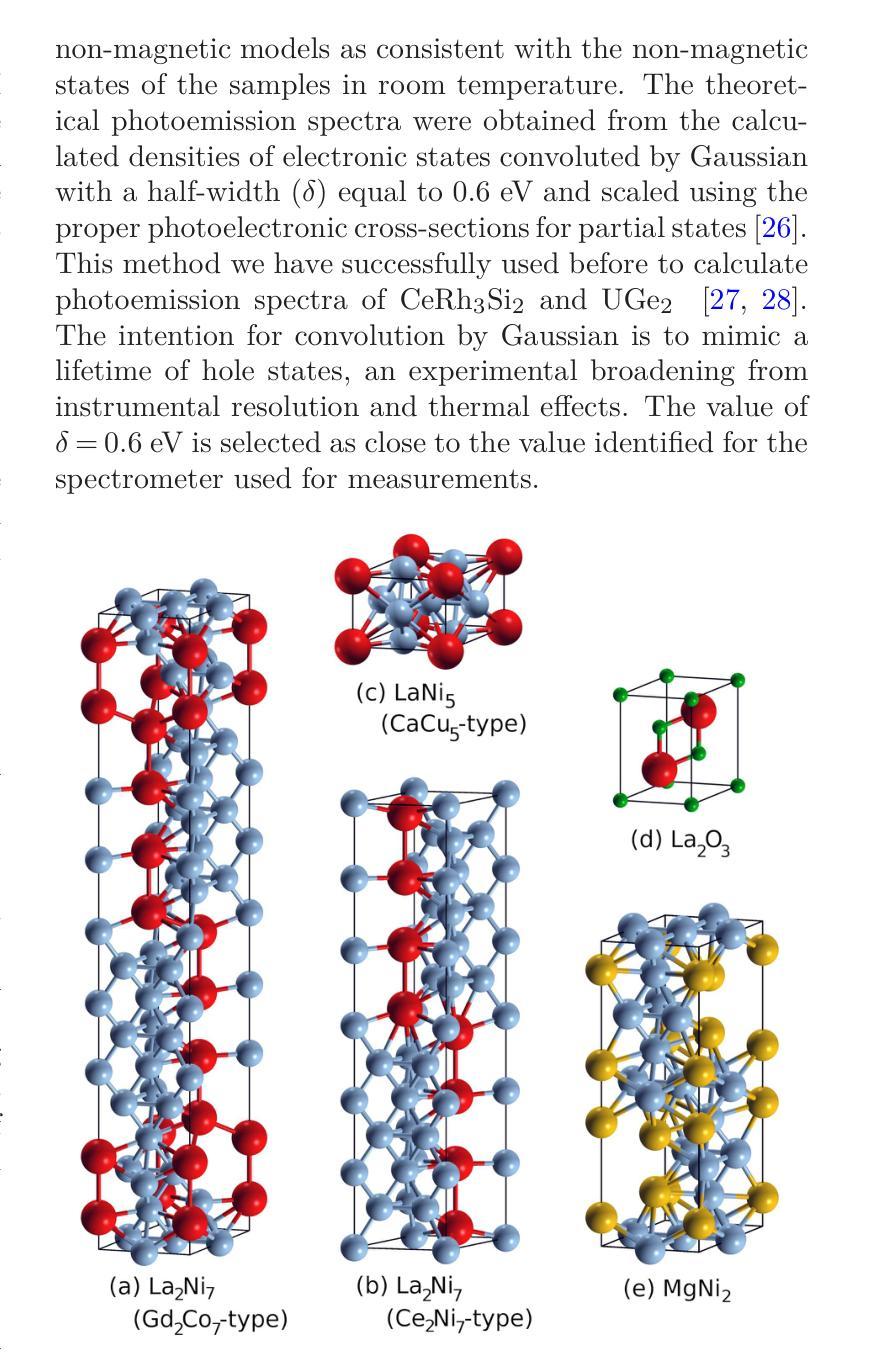
La-Mg-Ni-based alloys are promising negative electrode materials for 3rd generation of Ni-MH$x$ batteries. In this work, we investigate the effect of Mg substitution on the electrochemical and electronic properties of La${2-x}$Mg$_x$Ni$7$ materials. The mechanical alloying technique is used to produce a series of La${2-x}$Mg$_x$Ni$_7$ alloys ($x$ = 0.00, 0.25, 0.50 and 0.75). The X-ray diffraction measurements indicate multiphase character of the samples with majority (La,Mg)$_2$Ni$_7$ phases of hexagonal Ce$2$Ni$7$-type and rhombohedral Gd$2$Co$7$-type. Electrochemical measurements show how the maximum discharge capacity ($C{max}$) increases with Mg concentration and that reach the highest value of 304 mAh/g for La${1.5}$Mg${0.5}$Ni$7$ ($x$ = 0.5). The experimental efforts are followed by the density functional theory (DFT) calculations performed with the full-potential local-orbital minimum-basis scheme (FPLO). To simulate chemical disorder, we use the coherent potential approximation (CPA). The calculations are focused on the La${1.5}$Mg${0.5}$Ni$7$ composition with the highest measured value of $C{max}$. Additionally, several other structures are considered as reference points. We find that hexagonal and rhombohedral structures of La$_2$Ni$_7$ have almost identical total energies, which is in a good agreement with a coexistence of both phases in the samples. The calculated site preferences of Mg in both Ce$_2$Ni$7$-type and Gd$2$Co$7$-type La${1.5}$Mg${0.5}$Ni$7$ phases are consistent with the previous experimental data. Furthermore, the valence band of the nanocrystalline La${1.5}$Mg${0.5}$Ni$_7$ sample is investigated by X-ray photoelectron spectroscopy (XPS). The experimental XPS are interpreted based on the corresponding spectra calculated with DFT.
La-Mg-Ni基合金作为第三代Ni-MH电池的负极材料具有广阔前景。在这项工作中,我们研究了Mg替代对La_{2-x}Mg_xNi_7材料电化学和电子性能的影响。采用机械合金化技术制备了一系列La_{2-x}Mg_xNi_7合金(x=0.00、0.25、0.50和0.75)。X射线衍射测量表明样品具有多相特征,主要以La、Mg)2Ni_7相为主,呈六方Ce_2Ni_7型和斜方Gd_2Co_7型。电化学测量表明最大放电容量(C{max})随Mg浓度的增加而增加,并在La_{1.5}Mg_{0.5}Ni_7(x=0.5)时达到最高值304mAh/g。我们在密度泛函理论(DFT)计算中进行了实验验证,采用全势局域轨道最小基方案(FPLO)。为了模拟化学无序性,我们使用了相干势近似(CPA)。计算的重点是最大放电容量最高的La_{1.5}Mg_{0.5}Ni_7成分。此外,还考虑了其他一些结构作为参考点。我们发现La_2Ni_7的六边形和斜方结构具有几乎相同的总能量,这与样品中两种结构共存的情况相符。计算得出的Ce_2Ni_7型和Gd_2Co_7型La_{1.5}Mg_{0.5}Ni_7相中Mg的位点偏好与之前的实验数据一致。此外,通过X射线光电子光谱仪(XPS)研究了纳米晶La_{1.5}Mg_{0.5}Ni_7样品的价带。根据DFT计算得到的相应光谱来解释实验XPS。
论文及项目相关链接
Summary
该研究探讨了Mg替代对La-Mg-Ni基合金的电化学和电子性能的影响,发现随着Mg浓度的增加,最大放电容量增大,并在La_{1.5}Mg_{0.5}Ni_7时达到最大值。通过密度泛函理论计算和X射线光电子谱研究其结构特性。
Key Takeaways
- La-Mg-Ni基合金是第三代Ni-MH电池的潜在负极材料。
- Mg替代对La_{2-x}Mg_{x}Ni_{7}材料具有显著影响,最大放电容量随Mg浓度增加而增大。
- La_{1.5}Mg_{0.5}Ni_{7}的放电容量达到最高值304mAh/g。
- X射线衍射结果表明样品呈现多相特征,以Ce_{2}Ni_{7}-型为主相。
- 密度泛函理论计算用于模拟化学无序状态,并研究La_{1.5}Mg_{0.5}Ni_{7}结构特性。
- XPS实验验证了材料的电子结构特征,与DFT计算结果一致。
点此查看论文截图

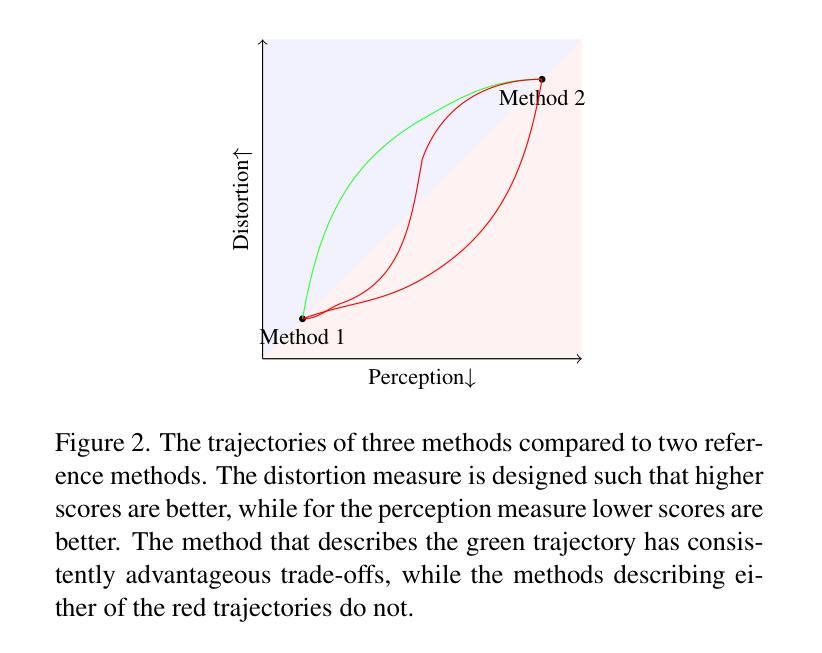
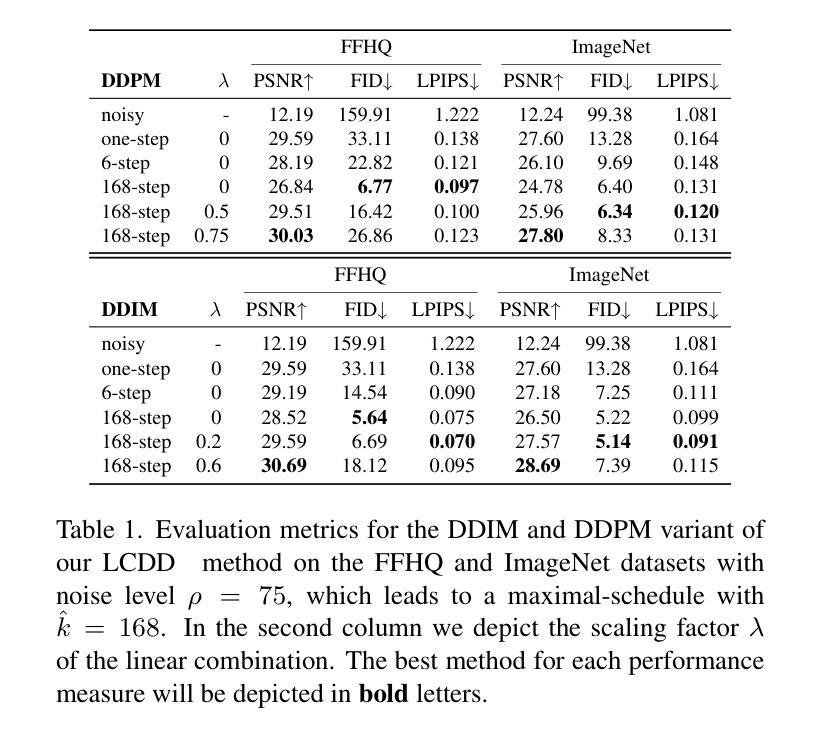
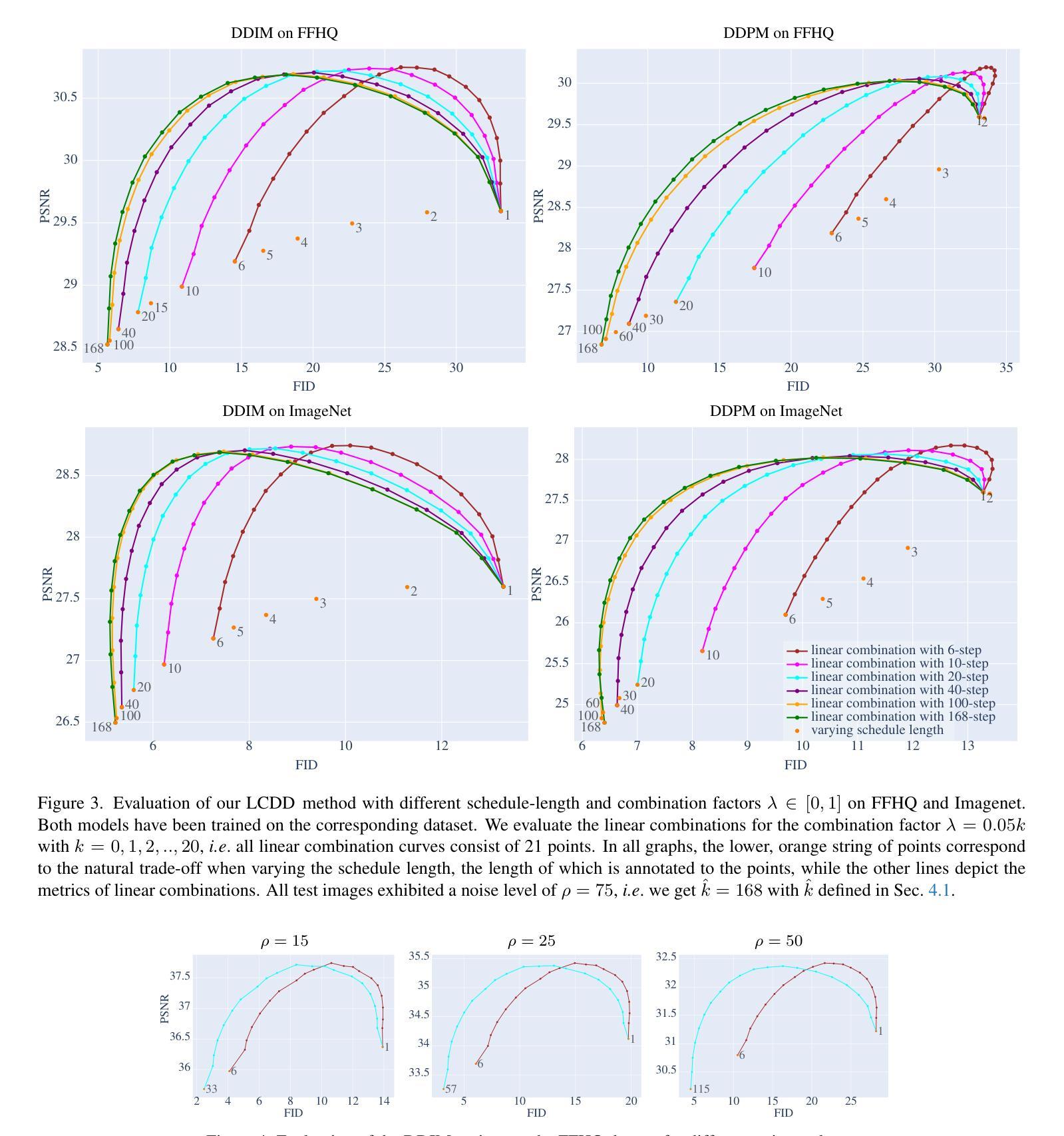
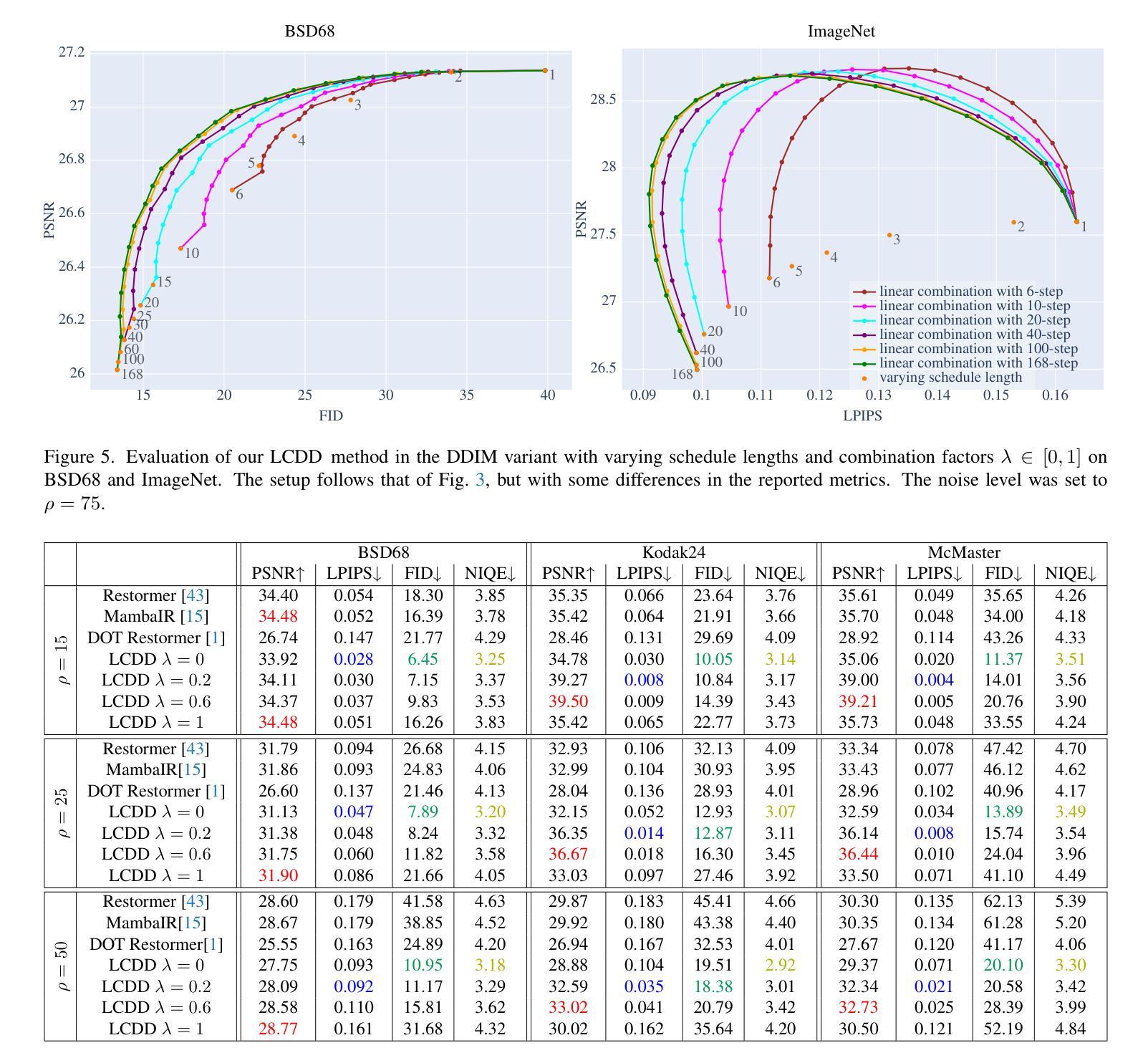
A Simple Combination of Diffusion Models for Better Quality Trade-Offs in Image Denoising
Authors:Jonas Dornbusch, Emanuel Pfarr, Florin-Alexandru Vasluianu, Frank Werner, Radu Timofte
Diffusion models have garnered considerable interest in computer vision, owing both to their capacity to synthesize photorealistic images and to their proven effectiveness in image reconstruction tasks. However, existing approaches fail to efficiently balance the high visual quality of diffusion models with the low distortion achieved by previous image reconstruction methods. Specifically, for the fundamental task of additive Gaussian noise removal, we first illustrate an intuitive method for leveraging pretrained diffusion models. Further, we introduce our proposed Linear Combination Diffusion Denoiser (LCDD), which unifies two complementary inference procedures - one that leverages the model’s generative potential and another that ensures faithful signal recovery. By exploiting the inherent structure of the denoising samples, LCDD achieves state-of-the-art performance and offers controlled, well-behaved trade-offs through a simple scalar hyperparameter adjustment.
扩散模型在计算机视觉领域引起了广泛关注,因为它们既能合成逼真的图像,在图像重建任务中也证明了其有效性。然而,现有方法无法在高视觉质量的扩散模型与先前图像重建方法实现的低失真之间进行有效平衡。针对去除添加性高斯噪声的基本任务,我们首先提出了一种利用预训练扩散模型的直观方法。此外,我们引入了所提出的线性组合扩散去噪器(LCDD),它统一了两种互补的推理程序——一种利用模型的生成潜力,另一种确保忠实信号恢复。通过利用去噪样本的固有结构,LCDD实现了最先进的性能,并通过简单的标量超参数调整提供了可控、表现良好的权衡。
论文及项目相关链接
PDF 10 pages, 7 figures, 2 tables
Summary
扩散模型在计算机视觉领域因其能合成逼真的图像并在图像重建任务中证明其有效性而受到广泛关注。然而,现有方法无法在扩散模型的高视觉质量与先前图像重建方法实现的低失真之间进行有效平衡。针对去除加性高斯噪声这一基本任务,本文首先展示了一种利用预训练扩散模型的直观方法。此外,本文提出了线性组合扩散去噪器(LCDD),它统一了两种互补的推理程序——一种利用模型的生成潜力,另一种确保忠实信号恢复。LCDD通过利用去噪样本的固有结构实现了卓越的性能,并通过简单的标量超参数调整提供了可控的、表现良好的权衡。
Key Takeaways
- 扩散模型在计算机视觉领域受到关注,因其能合成高质量图像并在图像重建任务中表现出有效性。
- 现有方法难以平衡扩散模型的高视觉质量与低失真。
- 针对去除加性高斯噪声任务,提出了一种利用预训练扩散模型的直观方法。
- 引入线性组合扩散去噪器(LCDD),统一两种互补推理程序,利用生成潜力和确保忠实信号恢复。
- LCDD利用去噪样本的固有结构实现卓越性能。
- LCDD通过简单的标量超参数调整提供可控的、表现良好的权衡。
- 该方法通过统一框架实现了扩散模型与图像重建方法的优势结合。
点此查看论文截图


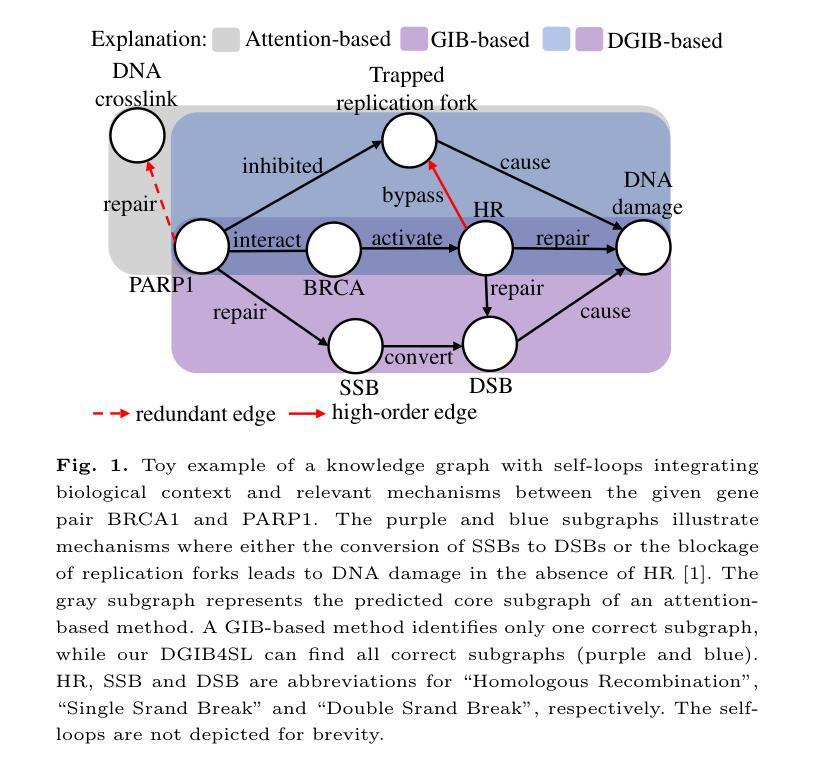
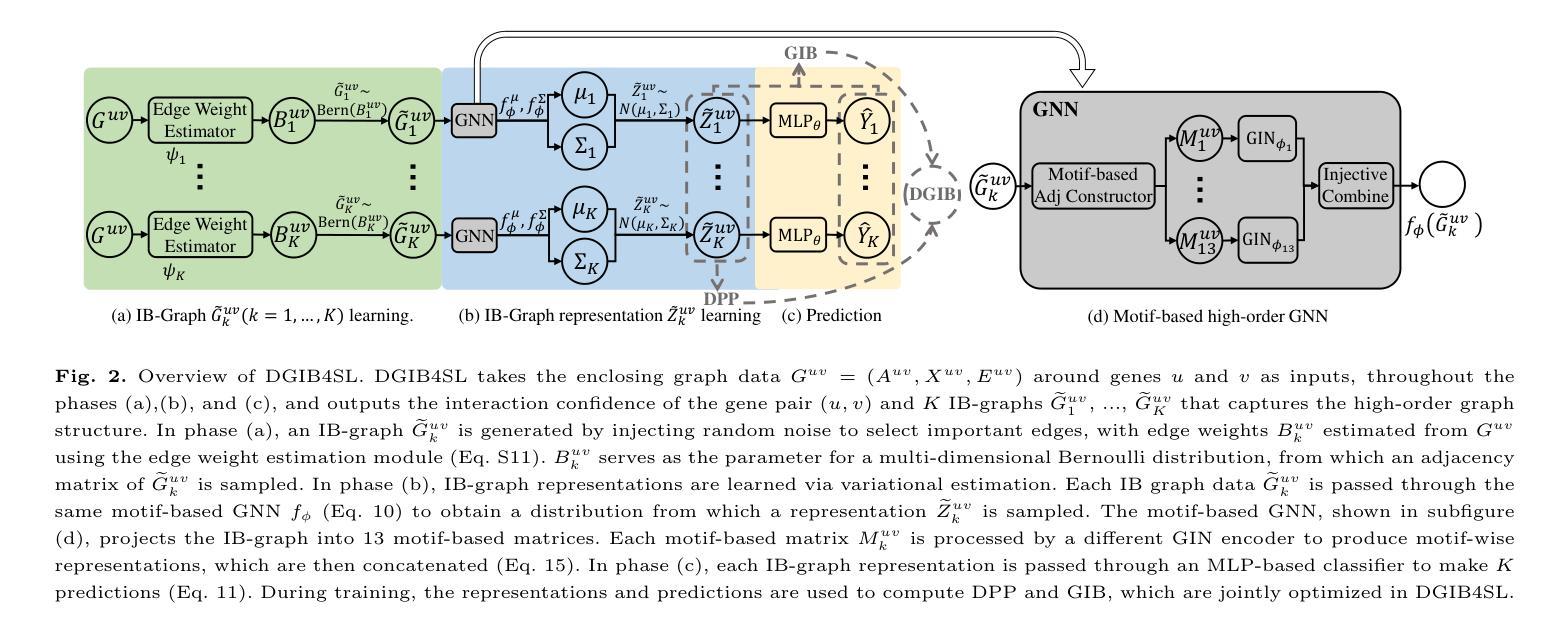
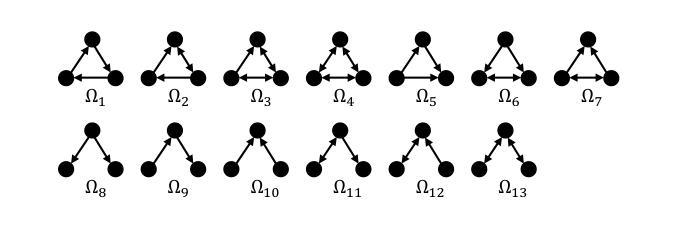
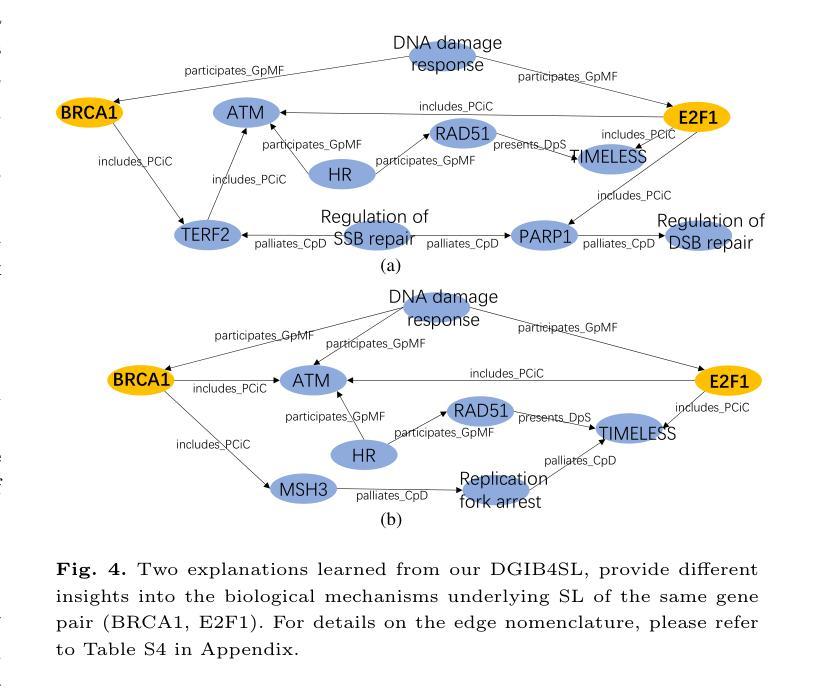
Interpretable High-order Knowledge Graph Neural Network for Predicting Synthetic Lethality in Human Cancers
Authors:Xuexin Chen, Ruichu Cai, Zhengting Huang, Zijian Li, Jie Zheng, Min Wu
Synthetic lethality (SL) is a promising gene interaction for cancer therapy. Recent SL prediction methods integrate knowledge graphs (KGs) into graph neural networks (GNNs) and employ attention mechanisms to extract local subgraphs as explanations for target gene pairs. However, attention mechanisms often lack fidelity, typically generate a single explanation per gene pair, and fail to ensure trustworthy high-order structures in their explanations. To overcome these limitations, we propose Diverse Graph Information Bottleneck for Synthetic Lethality (DGIB4SL), a KG-based GNN that generates multiple faithful explanations for the same gene pair and effectively encodes high-order structures. Specifically, we introduce a novel DGIB objective, integrating a Determinant Point Process (DPP) constraint into the standard IB objective, and employ 13 motif-based adjacency matrices to capture high-order structures in gene representations. Experimental results show that DGIB4SL outperforms state-of-the-art baselines and provides multiple explanations for SL prediction, revealing diverse biological mechanisms underlying SL inference.
合成致死性(Synthetic Lethality, SL)是一种具有潜力的癌症治疗基因交互作用。最近的SL预测方法将知识图谱(KG)融入图神经网络(GNN),并应用注意力机制提取局部子图作为目标基因对的解释。然而,注意力机制通常缺乏准确性,通常只为每个基因对生成一个解释,并且无法在解释中确保可靠的高阶结构。为了克服这些局限性,我们提出了基于知识图谱的合成致死性多样图信息瓶颈(DGIB4SL)方法。该方法为同一基因对生成多个忠实解释,并有效地编码高阶结构。具体来说,我们引入了一种新颖的DGIB目标,将行列式点过程(DPP)约束集成到标准IB目标中,并使用13个基于基序的邻接矩阵来捕获基因表示中的高阶结构。实验结果表明,DGIB4SL优于最新基线方法,为SL预测提供了多个解释,揭示了SL推断背后多样化的生物学机制。
论文及项目相关链接
PDF 15 pages. Accepted by Briefings in Bioinformatics
Summary
合成致死性(SL)是癌症治疗中有前景的基因相互作用。针对现有SL预测方法中的注意力机制缺乏保真度、通常只为基因对生成单一解释以及无法确保解释中高阶结构可信度的问题,提出了基于知识图谱的图神经网络(DGIB4SL)。该方法为同一基因对生成多个忠实解释,并有效编码高阶结构。通过引入新的DGIB目标,将行列式点过程(DPP)约束集成到标准IB目标中,并使用13个基于motif的邻接矩阵捕获基因表示中的高阶结构。实验结果表明,DGIB4SL优于最新基线,为SL预测提供多重解释,揭示SL推断背后的不同生物学机制。
Key Takeaways
- 合成致死性(SL)是癌症治疗领域的一个重要基因交互现象。
- 现有SL预测方法通过整合知识图谱和图神经网络进行。
- 注意力机制在SL预测中常缺乏保真度,通常只为基因对生成单一解释。
- 提出了DGIB4SL方法,旨在生成多个忠实的解释并为同一基因对编码高阶结构。
- DGIB4SL通过引入DGIB目标和行列式点过程(DPP)约束来实现这一目标。
- DGIB4SL使用基于motif的邻接矩阵来捕获基因表示中的高阶结构。
点此查看论文截图

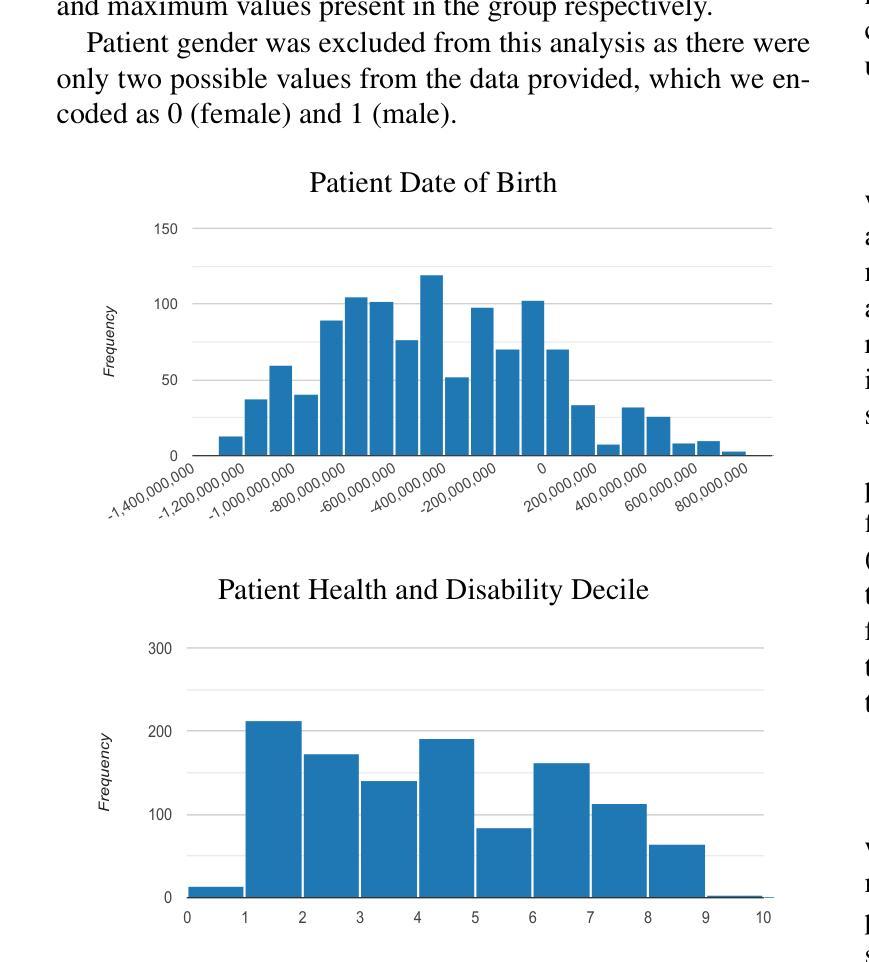
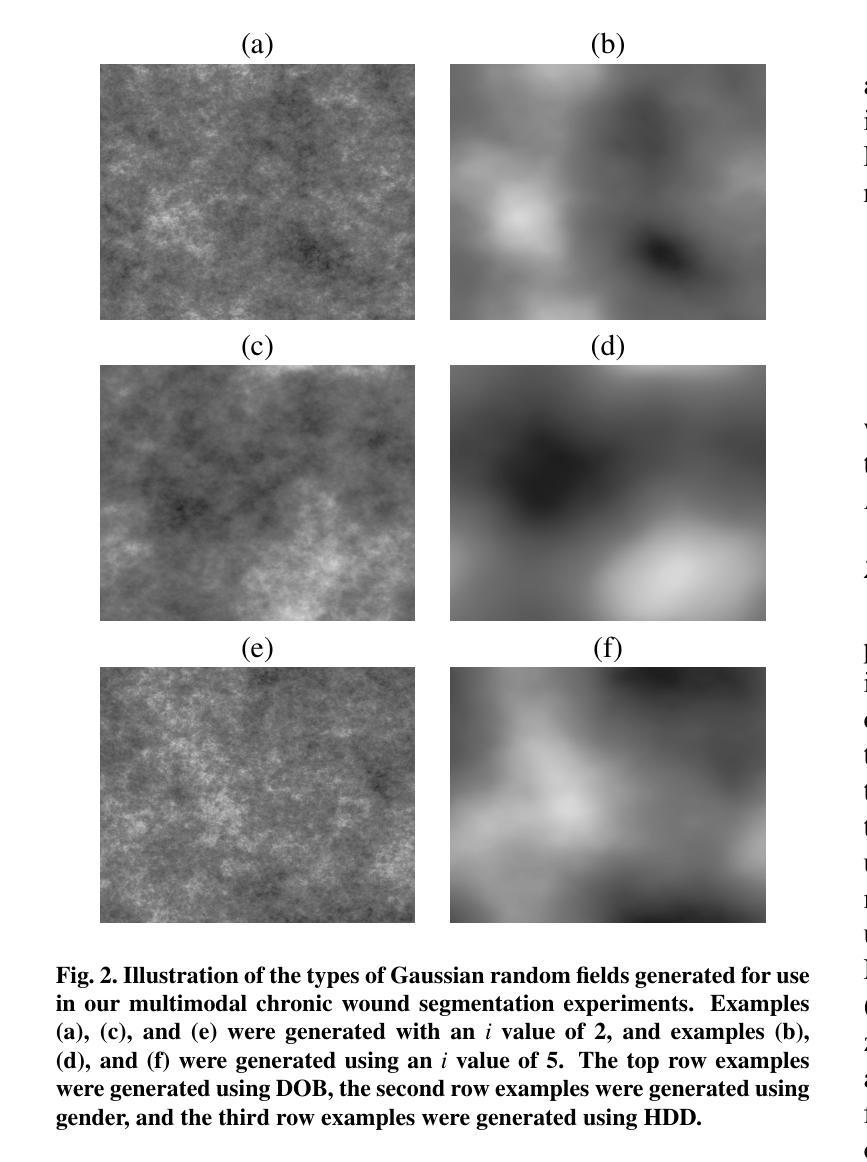
Gaussian Random Fields as an Abstract Representation of Patient Metadata for Multimodal Medical Image Segmentation
Authors:Bill Cassidy, Christian McBride, Connah Kendrick, Neil D. Reeves, Joseph M. Pappachan, Shaghayegh Raad, Moi Hoon Yap
The growing rate of chronic wound occurrence, especially in patients with diabetes, has become a concerning trend in recent years. Chronic wounds are difficult and costly to treat, and have become a serious burden on health care systems worldwide. Chronic wounds can have devastating consequences for the patient, with infection often leading to reduced quality of life and increased mortality risk. Innovative deep learning methods for the detection and monitoring of such wounds have the potential to reduce the impact to both patient and clinician. We present a novel multimodal segmentation method which allows for the introduction of patient metadata into the training workflow whereby the patient data are expressed as Gaussian random fields. Our results indicate that the proposed method improved performance when utilising multiple models, each trained on different metadata categories. Using the Diabetic Foot Ulcer Challenge 2022 test set, when compared to the baseline results (intersection over union = 0.4670, Dice similarity coefficient = 0.5908) we demonstrate improvements of +0.0220 and +0.0229 for intersection over union and Dice similarity coefficient respectively. This paper presents the first study to focus on integrating patient data into a chronic wound segmentation workflow. Our results show significant performance gains when training individual models using specific metadata categories, followed by average merging of prediction masks using distance transforms. All source code for this study is available at: https://github.com/mmu-dermatology-research/multimodal-grf
近年来,特别是在糖尿病患者中,慢性伤口的发生率呈上升趋势,这已成为令人担忧的趋势。慢性伤口的治疗难度大、费用高,已成为全球卫生保健系统的一项严重负担。慢性伤口会为患者带来灾难性后果,感染往往会导致生活质量下降和死亡风险增加。针对此类伤口的检测和监测,创新的深度学习方法有望减轻对患者和临床医生的影响。我们提出了一种新型的多模态分割方法,该方法允许将患者元数据引入到训练流程中,其中患者数据表示为高斯随机场。我们的结果表明,在利用多个模型时,所提出的方法在训练不同元数据类别上表现出性能提升。与基准结果相比(交并比=0.4670,迪杰斯特拉相似系数=0.5908),在Diabetic Foot Ulcer Challenge 2022测试集上,我们展示出在交并比和迪杰斯特拉相似系数方面分别提高了+0.0220和+0.0229。本文是首次专注于将患者数据整合到慢性伤口分割流程中的研究。我们的结果表明,在针对特定元数据类别训练个别模型后,通过距离变换平均合并预测掩模可以取得显著的性能提升。该研究的所有源代码可在https://github.com/mmu-dermatology-research/multimodal-grf找到。
论文及项目相关链接
Summary
本文关注慢性伤口,特别是糖尿病患者慢性伤口的日益增长趋势,提出一种新颖的多模态分割方法,将患者元数据引入训练流程。通过采用高斯随机场表达患者数据,该方法在利用不同元数据类别训练的多个模型上表现出改进效果。相较于基线结果,该方法在交集比和Dice相似系数上分别提高了0.0220和0.0229。本文为首次尝试将患者数据整合到慢性伤口分割流程中的研究,通过训练特定元数据类别的独立模型,然后进行预测掩膜的平均合并,实现了显著的性能提升。
Key Takeaways
- 慢性伤口,特别是在糖尿病患者中的发生率的增长,已成为全球卫生系统的严重负担。
- 新型深度学习方法在慢性伤口检测和监测中具有减少患者和临床医生负担的潜力。
- 提出一种多模态分割方法,整合患者元数据到训练流程中,以高斯随机场表达患者数据。
- 方法在多个模型上表现改进效果,这些模型分别针对不同的元数据类别进行训练。
- 与基线结果相比,该方法在交集比和Dice相似系数上有所提升。
- 此研究为首次尝试将患者数据整合到慢性伤口分割流程中。
点此查看论文截图


MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning
Authors:Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, Daniel Rueckert
Reasoning is a critical frontier for advancing medical image analysis, where transparency and trustworthiness play a central role in both clinician trust and regulatory approval. Although Medical Visual Language Models (VLMs) show promise for radiological tasks, most existing VLMs merely produce final answers without revealing the underlying reasoning. To address this gap, we introduce MedVLM-R1, a medical VLM that explicitly generates natural language reasoning to enhance transparency and trustworthiness. Instead of relying on supervised fine-tuning (SFT), which often suffers from overfitting to training distributions and fails to foster genuine reasoning, MedVLM-R1 employs a reinforcement learning framework that incentivizes the model to discover human-interpretable reasoning paths without using any reasoning references. Despite limited training data (600 visual question answering samples) and model parameters (2B), MedVLM-R1 boosts accuracy from 55.11% to 78.22% across MRI, CT, and X-ray benchmarks, outperforming larger models trained on over a million samples. It also demonstrates robust domain generalization under out-of-distribution tasks. By unifying medical image analysis with explicit reasoning, MedVLM-R1 marks a pivotal step toward trustworthy and interpretable AI in clinical practice. Inference model is available at: https://huggingface.co/JZPeterPan/MedVLM-R1.
医学图像分析是当前医疗领域发展的关键前沿,其中透明度和可信度对于医生信任及监管机构的批准至关重要。尽管医学视觉语言模型(VLMs)在放射学任务上展现出巨大潜力,但现有的大多数VLMs仅提供最终答案,而未能揭示背后的推理过程。为了解决这一不足,我们推出了MedVLM-R1,这是一款明确的医学视觉语言模型,能够生成自然语言推理以增强透明度和可信度。与其他模型不同,MedVLM-R1没有依赖监督微调(SFT),因为监督微调常常会导致过度拟合训练分布并忽略真正的推理过程。相反,MedVLM-R1采用强化学习框架,激励模型发现人类可解释的推理路径,无需使用任何推理参考。尽管训练数据量有限(仅600个视觉问答样本)且模型参数较少(2B),但MedVLM-R1在MRI、CT和X光基准测试上的准确率从55.11%提升至78.22%,超过了在超过百万样本上训练的更大模型。此外,它还在非内部分布的任务中表现出强大的领域泛化能力。通过将医学图像分析与明确推理相结合,MedVLM-R1标志着临床实践中可信和可解释的AI的重要一步。推理模型地址为:https://huggingface.co/JZPeterPan/MedVLM-R1。
论文及项目相关链接
Summary
本文介绍了在医学图像分析领域,推进自然语言推理的重要性。为解决现有医疗视觉语言模型(VLMs)缺乏透明度与信任度的问题,本文提出了一种新的医疗VLM——MedVLM-R1。MedVLM-R1使用强化学习框架进行训练,可激励模型发现人类可解释性推理路径,且无需任何参考。在有限的训练数据和模型参数条件下,MedVLM-R1实现了MRI、CT和X光等多基准测试的性能提升,并表现出出色的跨域泛化能力。该模型标志着临床医学实践朝着可信可解释的AI方向迈出重要一步。
Key Takeaways
- MedVLM-R1是一个医疗视觉语言模型,旨在解决医学图像分析中的透明度和信任度问题。
- MedVLM-R1采用强化学习框架训练模型,激励其发现人类可解释性推理路径,无需参考任何推理依据。
- 在有限的训练数据和模型参数条件下,MedVLM-R1提升了在MRI、CT和X光等多个基准测试的性能。
- MedVLM-R1实现的准确率从55.11%提升到78.22%,表现出良好的准确性和鲁棒性。
- MedVLM-R1模型具备良好的跨域泛化能力。
- MedVLM-R1模型推动了医学图像分析领域的进步,标志着向临床实践中可信可解释的AI迈出了重要一步。
点此查看论文截图


A study of why we need to reassess full reference image quality assessment with medical images
Authors:Anna Breger, Ander Biguri, Malena Sabaté Landman, Ian Selby, Nicole Amberg, Elisabeth Brunner, Janek Gröhl, Sepideh Hatamikia, Clemens Karner, Lipeng Ning, Sören Dittmer, Michael Roberts, AIX-COVNET Collaboration, Carola-Bibiane Schönlieb
Image quality assessment (IQA) is indispensable in clinical practice to ensure high standards, as well as in the development stage of machine learning algorithms that operate on medical images. The popular full reference (FR) IQA measures PSNR and SSIM are known and tested for working successfully in many natural imaging tasks, but discrepancies in medical scenarios have been reported in the literature, highlighting the gap between development and actual clinical application. Such inconsistencies are not surprising, as medical images have very different properties than natural images, and PSNR and SSIM have neither been targeted nor properly tested for medical images. This may cause unforeseen problems in clinical applications due to wrong judgment of novel methods. This paper provides a structured and comprehensive overview of examples where PSNR and SSIM prove to be unsuitable for the assessment of novel algorithms using different kinds of medical images, including real-world MRI, CT, OCT, X-Ray, digital pathology and photoacoustic imaging data. Therefore, improvement is urgently needed in particular in this era of AI to increase reliability and explainability in machine learning for medical imaging and beyond. Lastly, we will provide ideas for future research as well as suggesting guidelines for the usage of FR-IQA measures applied to medical images.
图像质量评估(IQA)在临床实践中是不可或缺的,以确保高标准,以及在医学影像操作的机器学习算法的开发阶段也是如此。流行的全参考(FR)IQA措施PSNR和SSIM在众多的自然成像任务中已被证明和测试过其成功性,但在医疗场景中,文献中已报道存在分歧,突出了开发与实际应用之间的差距。这种不一致性并不奇怪,因为医疗图像具有与自然图像非常不同的属性,而PSNR和SSIM并未针对医疗图像进行目标定位或适当的测试。这可能导致由于新方法的误判而在临床应用中出现意想不到的问题。本文提供了结构化和全面的概述,举例说明了PSNR和SSIM在利用不同种类的医学图像(包括现实世界中的MRI、CT、OCT、X射线、数字病理和光声成像数据)评估新算法时的不适用性。因此,特别是在人工智能时代,迫切需要改进这一领域,以提高医学影像和其他领域的机器学习的可靠性和可解释性。最后,我们将为未来的研究提供思路,并提出在全参考IQA措施应用于医学图像时的使用指南。
论文及项目相关链接
Summary
医学图像质量评估(IQA)在临床实践和对医疗图像操作的机器学习算法的开发阶段都不可或缺。虽然流行的全参考(FR)IQA措施PSNR和SSIM已在许多自然成像任务中成功应用,但在医学场景中却存在不一致性,这突显了开发与实际应用之间的差距。由于医学图像与自然图像具有不同的特性,PSNR和SSIM并未针对医学图像进行专项测试或适当测试,可能导致新型方法的误判。本文提供了在不同医学图像中使用PSNR和SSIM评估新型算法的不适用案例的综合概述,包括现实世界的MRI、CT、OCT、X射线、数字病理和光声成像数据。因此,特别是在人工智能时代,亟需提高可靠性并提升机器学习在医学成像等领域的可解释性。最后,本文将提供未来研究的方向和在使用FR-IQA措施进行医学图像应用的指导建议。
Key Takeaways
- IQA在医学领域不可或缺,特别是在临床实践及医疗图像机器学习算法开发阶段。
- PSNR和SSIM等传统全参考IQA方法在自然成像中表现良好,但在医学场景中可能存在不一致性。
- 医学图像与自然图像特性不同,传统IQA方法并未针对医学图像进行专项测试或适当测试。
- PSNR和SSIM在评估新型算法时可能不适用,特别是在使用不同类型的医学图像时。
- 在人工智能时代,提高医学成像中机器学习算法的可靠性和可解释性至关重要。
- 需要改进和发展新的IQA方法以适应医学图像的特性。
点此查看论文截图

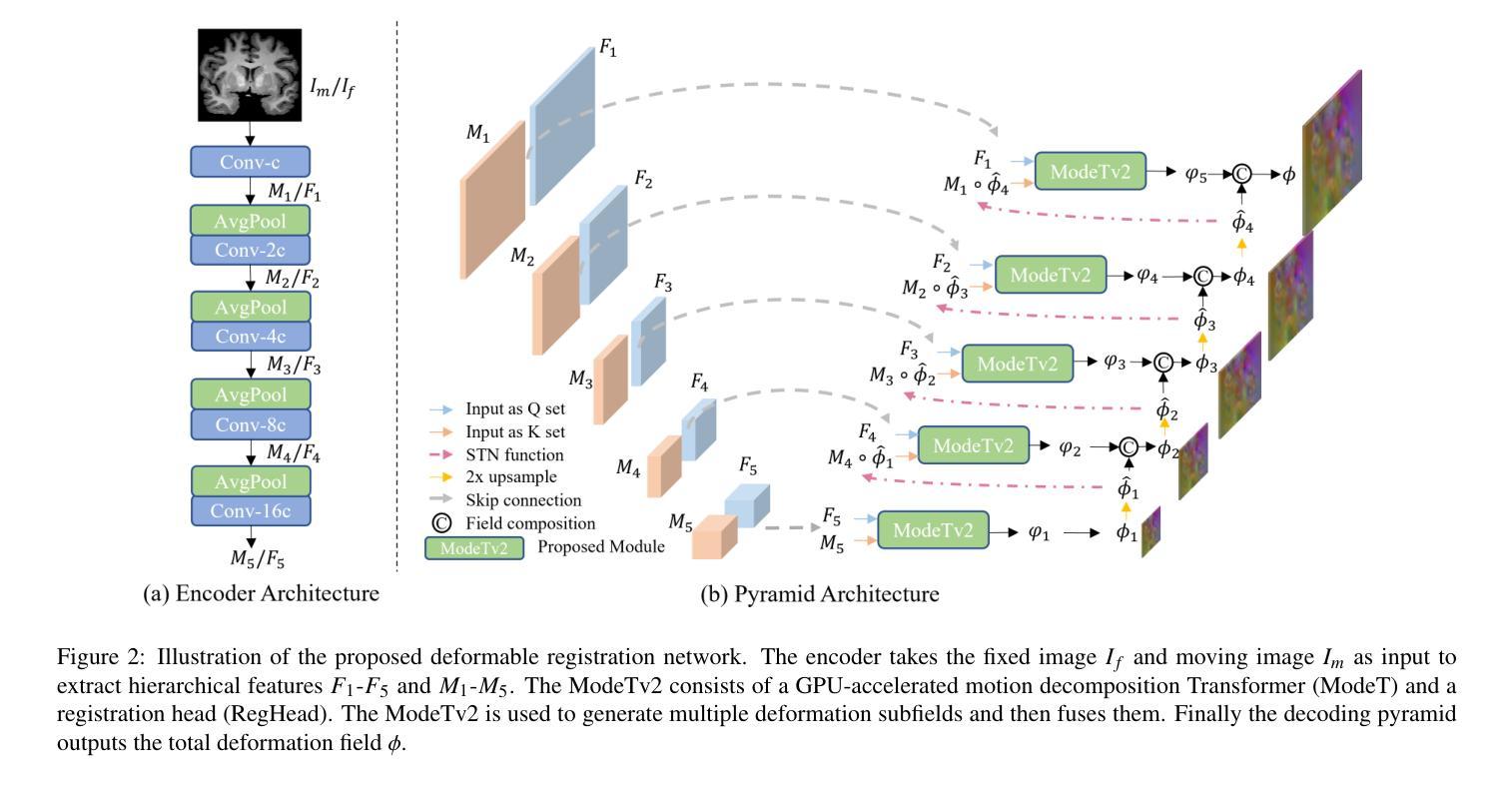
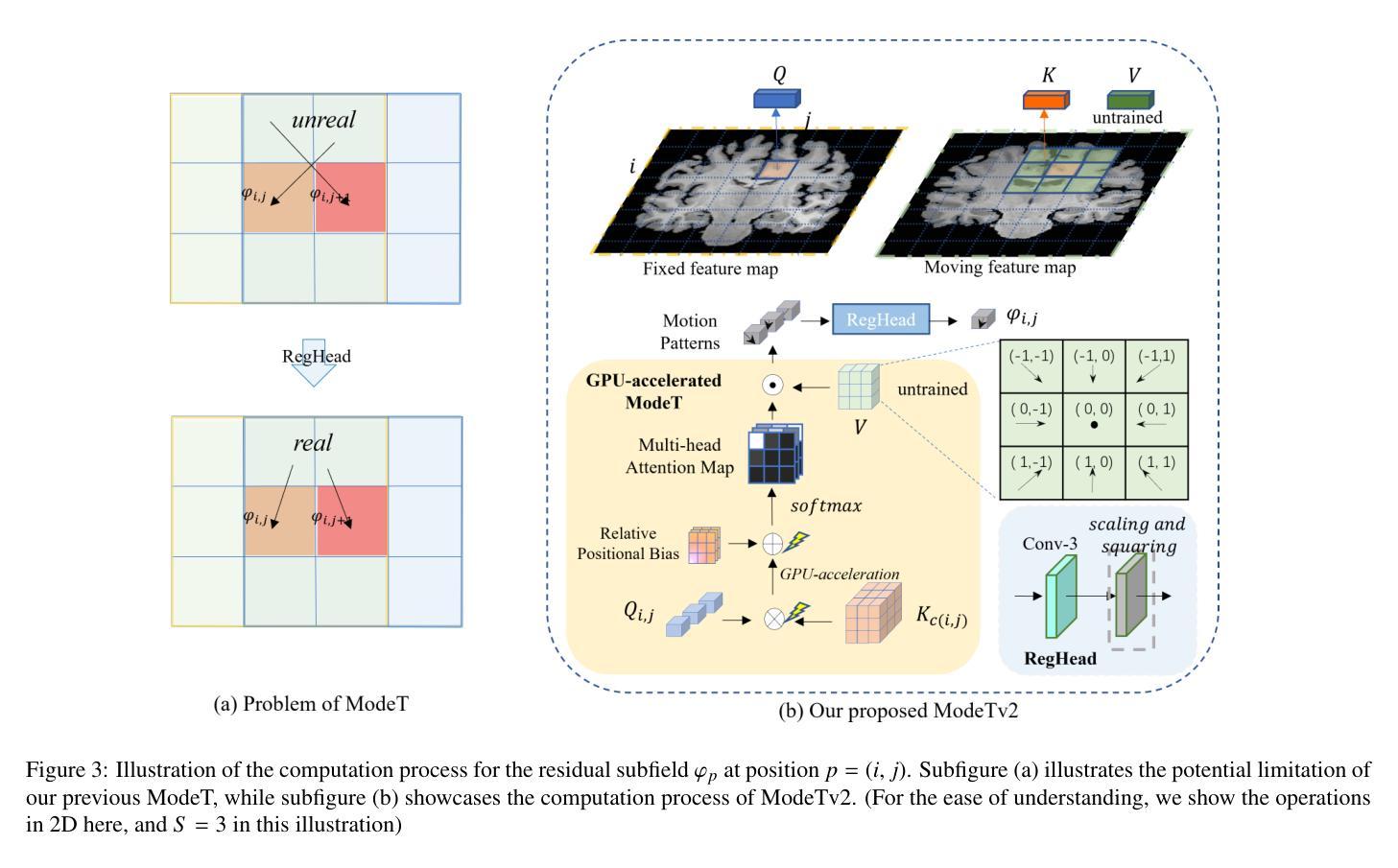
ModeTv2: GPU-accelerated Motion Decomposition Transformer for Pairwise Optimization in Medical Image Registration
Authors:Haiqiao Wang, Zhuoyuan Wang, Dong Ni, Yi Wang
Deformable image registration plays a crucial role in medical imaging, aiding in disease diagnosis and image-guided interventions. Traditional iterative methods are slow, while deep learning (DL) accelerates solutions but faces usability and precision challenges. This study introduces a pyramid network with the enhanced motion decomposition Transformer (ModeTv2) operator, showcasing superior pairwise optimization (PO) akin to traditional methods. We re-implement ModeT operator with CUDA extensions to enhance its computational efficiency. We further propose RegHead module which refines deformation fields, improves the realism of deformation and reduces parameters. By adopting the PO, the proposed network balances accuracy, efficiency, and generalizability. Extensive experiments on three public brain MRI datasets and one abdominal CT dataset demonstrate the network’s suitability for PO, providing a DL model with enhanced usability and interpretability. The code is publicly available at https://github.com/ZAX130/ModeTv2.
可变形图像配准在医学成像中扮演着至关重要的角色,有助于疾病诊断和图像引导干预。传统迭代方法速度慢,而深度学习(DL)虽然可以加速解决方案的计算,但却面临可用性和精确度方面的挑战。本研究引入了一种金字塔网络,配备了增强的运动分解Transformer(ModeTv2)算子,展现了与传统方法相媲美的优越点对点优化(PO)。我们使用CUDA扩展重新实现了ModeT算子,以提高其计算效率。我们进一步提出了RegHead模块,用于细化变形场,提高变形的真实性并减少参数。通过采用点对点优化,所提出的网络在准确性、效率和通用性之间达到了平衡。在三个公共脑MRI数据集和一个腹部CT数据集上的大量实验表明,该网络非常适合进行点对点优化,为深度学习模型提供了增强可用性和可解释性的模型。相关代码已公开发布在:https://github.com/ZAX130/ModeTv2。
论文及项目相关链接
Summary
医学图像配准中,形变图像配准十分重要,有助于疾病诊断和图像引导干预。传统迭代方法速度慢,深度学习虽能加速但面临可用性和精度挑战。本研究引入带有增强运动分解Transformer(ModeTv2)算子的金字塔网络,展示与传统方法相似的优越成对优化(PO)。通过CUDA扩展重新实现ModeT算子以提高计算效率。进一步提出RegHead模块,用于细化变形场,提高变形真实性和减少参数。采用PO,该网络在准确性、效率和通用性之间取得平衡。在三个公共脑MRI数据集和一个腹部CT数据集上的实验证明了该网络适用于PO,提供具有增强可用性和可解释性的深度学习模型。
Key Takeaways
- 形变图像配准在医学成像中起关键作用,有助于疾病诊断和图像引导干预。
- 传统迭代方法速度慢,深度学习提供加速但存在可用性和精度挑战。
- 研究引入金字塔网络并结合ModeTv2算子,实现优越成对优化(PO)。
- ModeT算子通过CUDA扩展重新实现,提高计算效率。
- 提出RegHead模块,用于细化变形场,提高变形的真实性和减少参数。
- 采用PO平衡准确性、效率和通用性。
点此查看论文截图

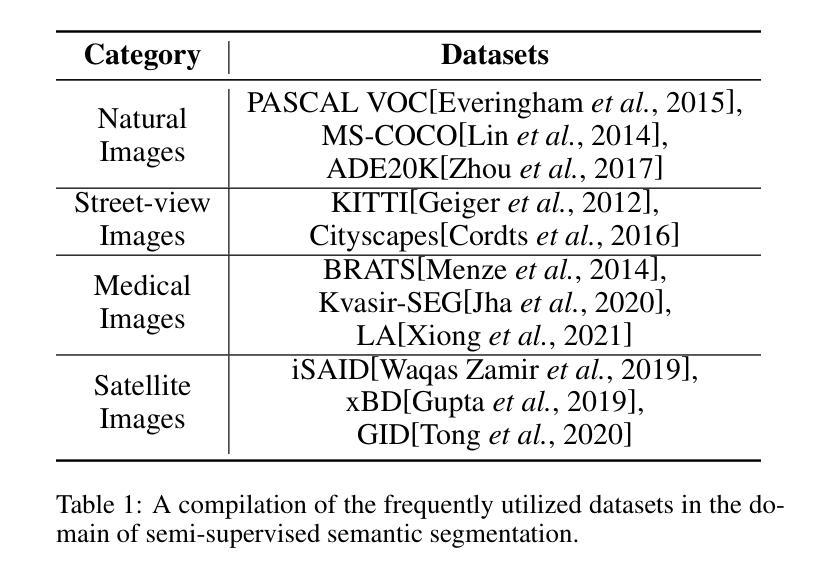
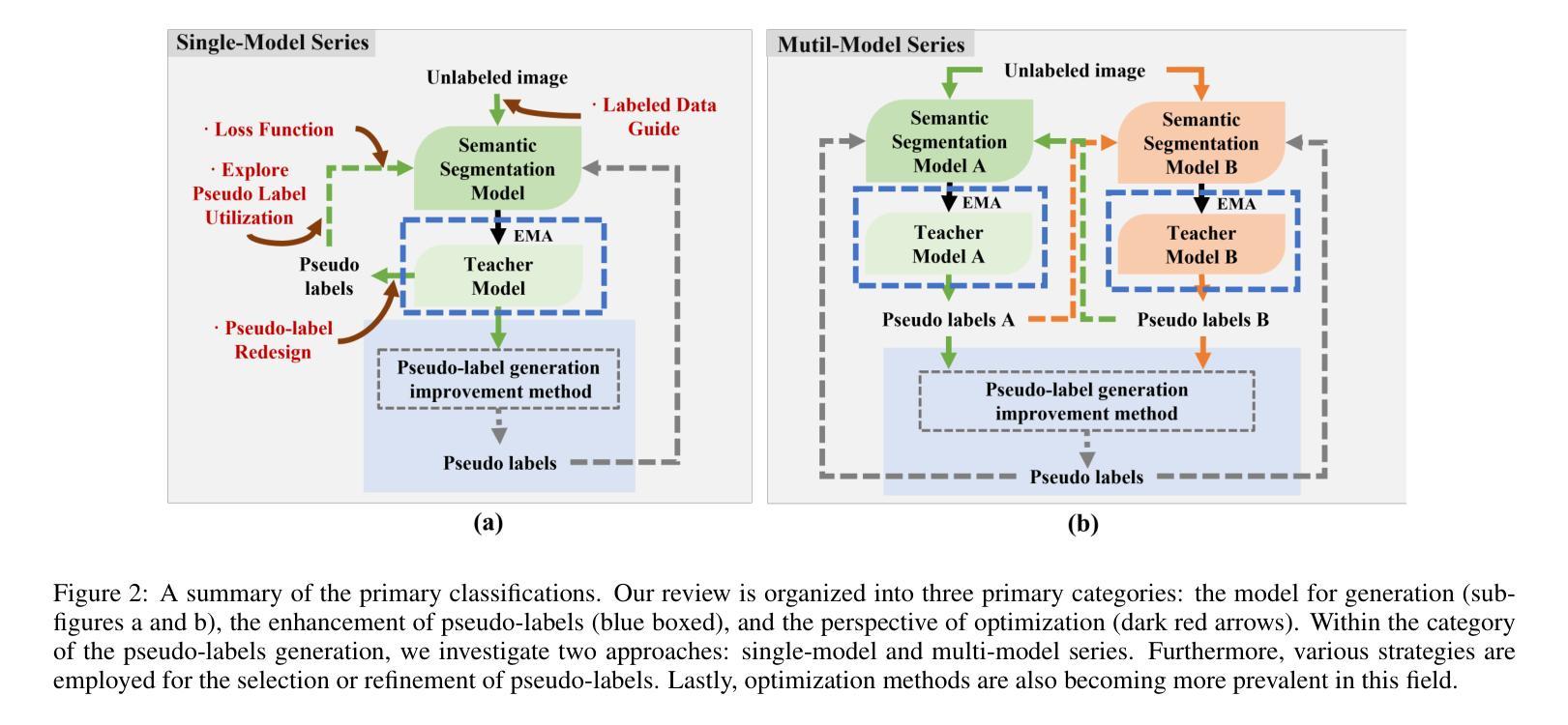
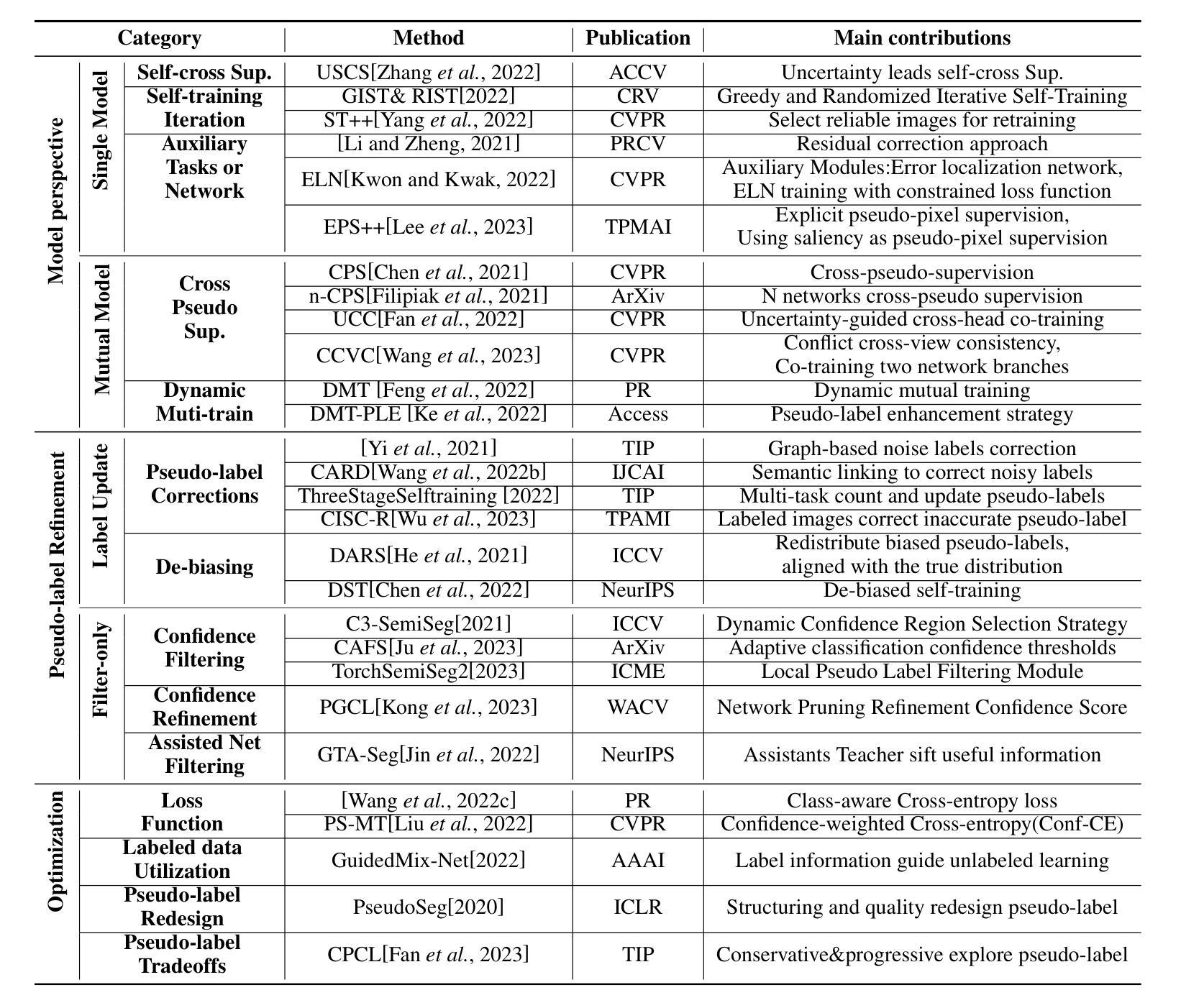
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Authors:Lingyan Ran, Yali Li, Guoqiang Liang, Yanning Zhang
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
语义分割是计算机视觉中一个重要且热门的研究领域,主要关注基于语义对图像中的像素进行分类。然而,监督深度学习需要大量的数据来训练模型,逐像素标注图像的过程既耗时又繁琐。本文旨在提供伪标签方法在半监督语义分割领域最新研究成果的首次全面、系统的概述,从不同角度对方法进行分类,并针对特定应用领域介绍具体方法。此外,我们还探讨了伪标签技术在医学和遥感图像分割中的应用。最后,我们还提出了一些可行的未来研究方向,以解决现有挑战。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Circuits and Systems for Video Technology(TCSVT)
Summary
语义分割是计算机视觉中一个重要且热门的研究领域,主要对图像中的像素进行语义分类。然而,监督深度学习需要大量的数据进行模型训练,逐像素标注图像的过程耗时且繁琐。本文旨在提供伪标签方法在半监督语义分割领域最新研究成果的首次全面综述,从不同角度分类并介绍特定应用领域的方法。此外,还探讨了伪标签技术在医学和遥感图像分割中的应用。最后,本文还提出了一些可行的未来研究方向,以应对现有挑战。
Key Takeaways
- 语义分割是计算机视觉中研究热点,主要对图像中的像素进行语义分类。
- 监督深度学习需要大量的数据进行模型训练,逐像素标注图像是繁琐耗时的工作。
- 伪标签方法在半监督语义分割领域得到广泛应用,本文提供了全面的综述。
- 伪标签技术不仅适用于普通图像分割,还应用于医学和遥感图像分割。
- 文章从不同角度对伪标签方法进行了分类,并介绍了特定应用领域的方法。
- 当前该领域存在挑战,文章提出了可行的未来研究方向。
点此查看论文截图

Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Authors:Amin Karimi Monsefi, Payam Karisani, Mengxi Zhou, Stacey Choi, Nathan Doble, Heng Ji, Srinivasan Parthasarathy, Rajiv Ramnath
Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet’s superior performance in both inference time and accuracy.
标准现代机器学习成像方法在面对医疗应用时面临了数据集构建成本高昂和可用标记训练数据有限的挑战。此外,这些方法在部署后通常用于处理每天的大量数据,给医疗机构带来了高昂的维护成本。在本文中,我们介绍了一种新型神经网络架构,称为LoGoNet,它采用量身定制的自监督学习方法来缓解这些挑战。LoGoNet在U形架构内集成了一种新型特征提取器,利用大内核注意力(LKA)和双编码策略来巧妙地捕捉长短范围的特征依赖性。这与现有方法不同,后者依赖于增加网络容量来提高特征提取能力。模型中这种新技术的组合在医学图像分割中尤其有益,考虑到学习复杂且通常不规则的器官形状(如脾脏)的困难性。此外,我们提出了一种针对3D图像的新型自监督学习方法,以弥补大型标记数据集的缺乏。该方法在多任务学习框架内结合了掩蔽和对比学习技术,可与Vision Transformer(ViT)和CNN模型兼容。我们在两个标准数据集(即BTCV和MSD)的多个任务中展示了我们的方法的有效性。与八种最新模型的基准对比表明,LoGoNet在推理时间和准确性方面均表现出卓越的性能。
论文及项目相关链接
Summary
本文介绍了一种新的神经网络架构LoGoNet,结合自监督学习方法,用于解决医学图像分析中数据集构建成本高、训练数据有限的问题。LoGoNet采用U型架构、大内核注意力机制和双编码策略,能有效捕捉长程和短程特征依赖关系,特别适用于医学图像分割中复杂且不规则器官形状的学习。同时,提出了一种针对3D图像的新型自监督学习方法,以弥补缺乏大量标记数据集的问题。在多个任务、两个标准数据集上的实验表明,LoGoNet与八种最新模型相比,在推理时间和准确性上均表现出卓越性能。
Key Takeaways
- LoGoNet是一种新的神经网络架构,用于解决医学图像分析中的挑战,如高成本的数据集构建和有限的标记训练数据。
- LoGoNet结合自监督学习方法,能够处理大规模数据并降低维护成本。
- LoGoNet采用U型架构、大内核注意力机制和双编码策略,能更有效地捕捉特征依赖关系。
- 提出了一种针对3D图像的新型自监督学习方法,以应对缺乏大量标记数据集的问题。
- 该方法结合了遮蔽和对比学习技术,在一个多任务学习框架内实现,兼容Vision Transformer(ViT)和CNN模型。
- 在两个标准数据集上的实验表明,LoGoNet在推理时间和准确性方面均优于其他八种最新模型。
点此查看论文截图

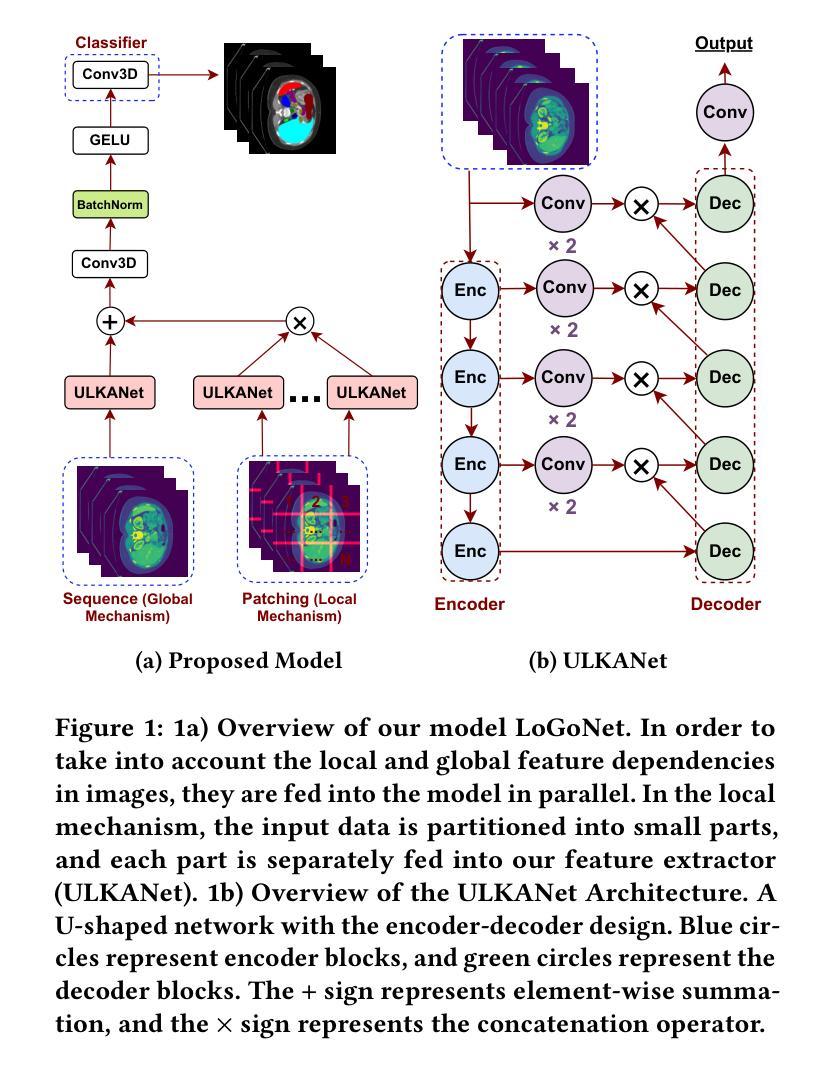
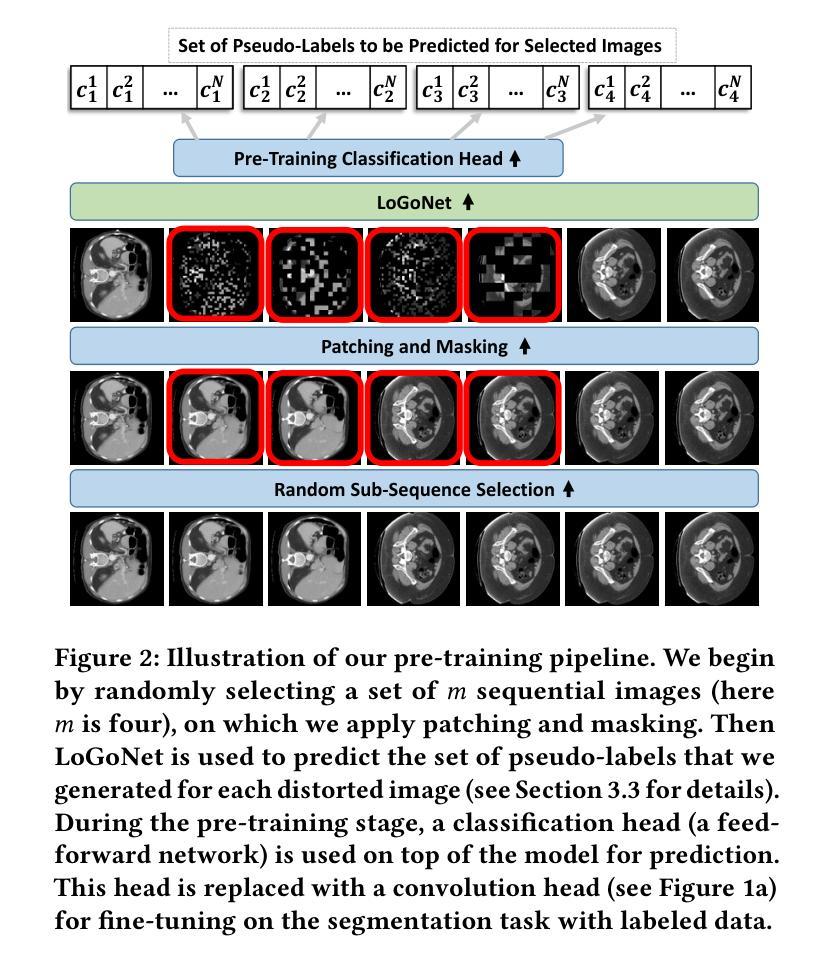
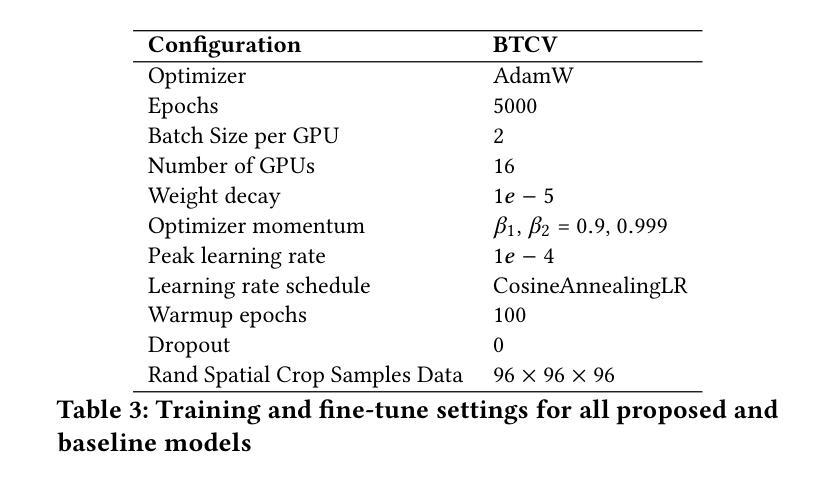
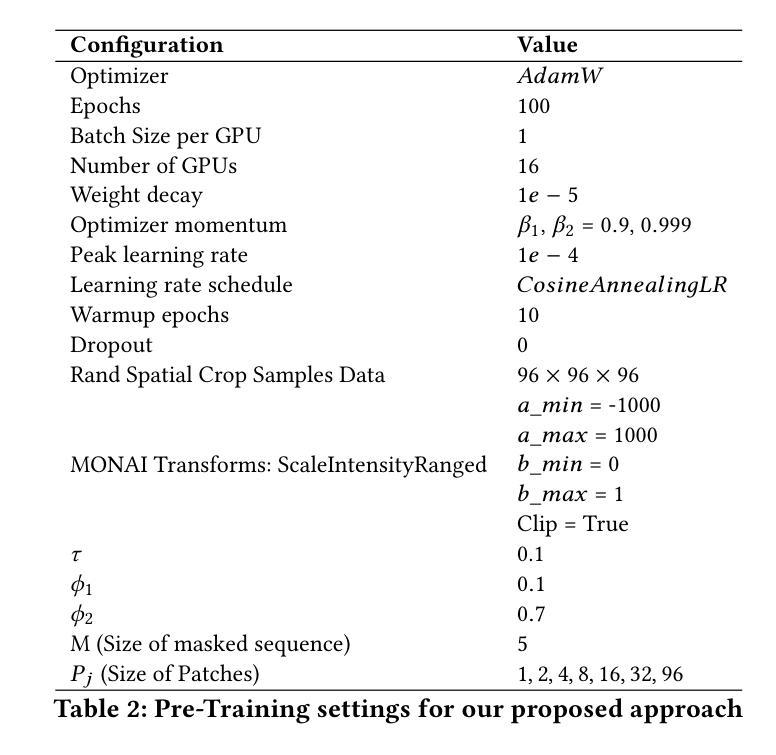
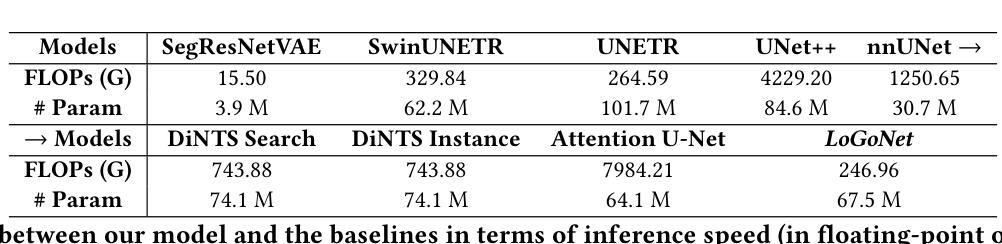
PULASki: Learning inter-rater variability using statistical distances to improve probabilistic segmentation
Authors:Soumick Chatterjee, Franziska Gaidzik, Alessandro Sciarra, Hendrik Mattern, Gábor Janiga, Oliver Speck, Andreas Nürnberger, Sahani Pathiraja
In the domain of medical imaging, many supervised learning based methods for segmentation face several challenges such as high variability in annotations from multiple experts, paucity of labelled data and class imbalanced datasets. These issues may result in segmentations that lack the requisite precision for clinical analysis and can be misleadingly overconfident without associated uncertainty quantification. This work proposes the PULASki method as a computationally efficient generative tool for biomedical image segmentation that accurately captures variability in expert annotations, even in small datasets. This approach makes use of an improved loss function based on statistical distances in a conditional variational autoencoder structure (Probabilistic UNet), which improves learning of the conditional decoder compared to the standard cross-entropy particularly in class imbalanced problems. The proposed method was analysed for two structurally different segmentation tasks (intracranial vessel and multiple sclerosis (MS) lesion) and compare our results to four well-established baselines in terms of quantitative metrics and qualitative output. These experiments involve class-imbalanced datasets characterised by challenging features, including suboptimal signal-to-noise ratios and high ambiguity. Empirical results demonstrate the PULASKi method outperforms all baselines at the 5% significance level. Our experiments are also of the first to present a comparative study of the computationally feasible segmentation of complex geometries using 3D patches and the traditional use of 2D slices. The generated segmentations are shown to be much more anatomically plausible than in the 2D case, particularly for the vessel task.
在医学成像领域,许多基于监督学习的分割方法面临多重挑战,如多个专家标注的高变异性、标记数据缺乏和类别不平衡数据集。这些问题可能导致分割结果缺乏临床分析所需的精度,并且在没有相应的不确定性量化的情况下,可能会产生误导性的过度自信。这项工作提出了PULASki方法,作为一种计算高效的生物医学图像分割生成工具,能够准确捕捉专家标注的变异性,即使在小型数据集中也是如此。该方法利用基于条件变分自动编码器结构中的统计距离的改进损失函数(概率U网),改进了条件解码器的学习,特别是在类别不平衡问题中与标准交叉熵相比。对所提出的方法进行了两个结构不同的分割任务(颅内血管和多发性硬化症(MS)病变)的分析,并根据定量指标和定性输出与四个成熟的基线方法进行比较。这些实验涉及具有挑战性的特征,包括次优的信噪比和高模糊性。经验结果表明,PULASKi方法在5%的显著性水平上优于所有基线方法。我们的实验也是首次对使用3D补丁进行复杂几何的可行分割与传统的使用2D切片进行比较研究。生成的分割结果比2D情况下更加解剖上合理,特别是在血管任务中。
论文及项目相关链接
Summary
医学图像分割中,基于监督学习的方法面临多方挑战,如专家标注差异大、缺乏标注数据和类别不均衡等问题。针对这些问题,本研究提出了PULASki方法,该方法是一种计算高效的生物医学图像分割工具,能准确捕捉专家标注的变异性,即使在小数据集下也能表现良好。该方法基于条件变分自编码器的结构,采用改进的损失函数,在类别不均衡问题中表现优异。实验证明,该方法在颅内血管和多发性硬化病变分割任务上优于其他四种基线方法,并且在复杂几何结构的3D切片分割方面也有较好表现。
Key Takeaways
- 医学图像分割中面临专家标注差异大、缺乏标注数据和类别不均衡等挑战。
- PULASki方法是一种高效的生物医学图像分割工具,可解决上述问题。
- PULASki方法采用基于条件变分自编码器的结构,结合改进的损失函数,在类别不均衡问题中表现优异。
- PULASki方法在颅内血管和多发性硬化病变分割任务上优于其他方法。
- 该研究首次比较了复杂几何结构分割的3D切片和传统2D切片方法。
- PULASki方法生成的分割结果更加符合解剖学结构,特别是在血管分割任务上。
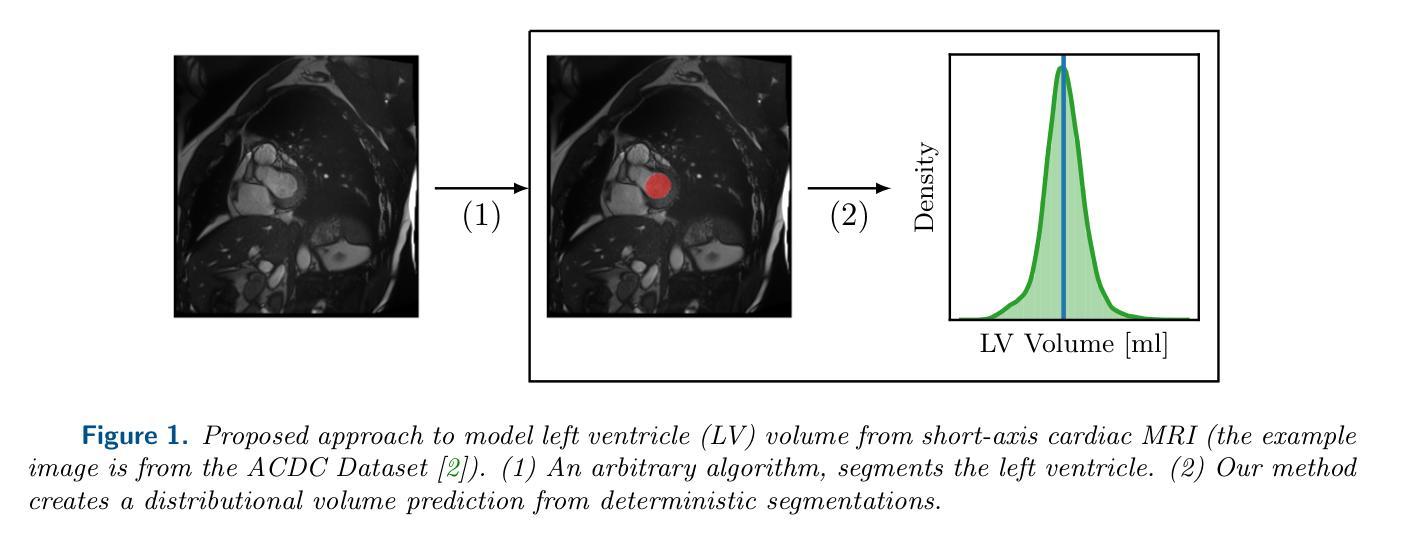
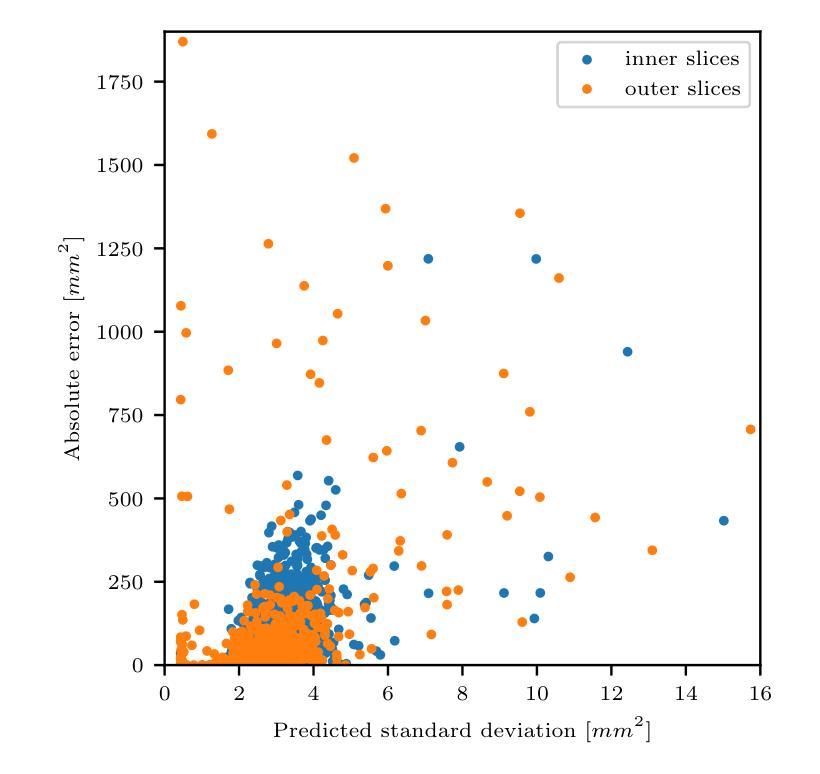
点此查看论文截图

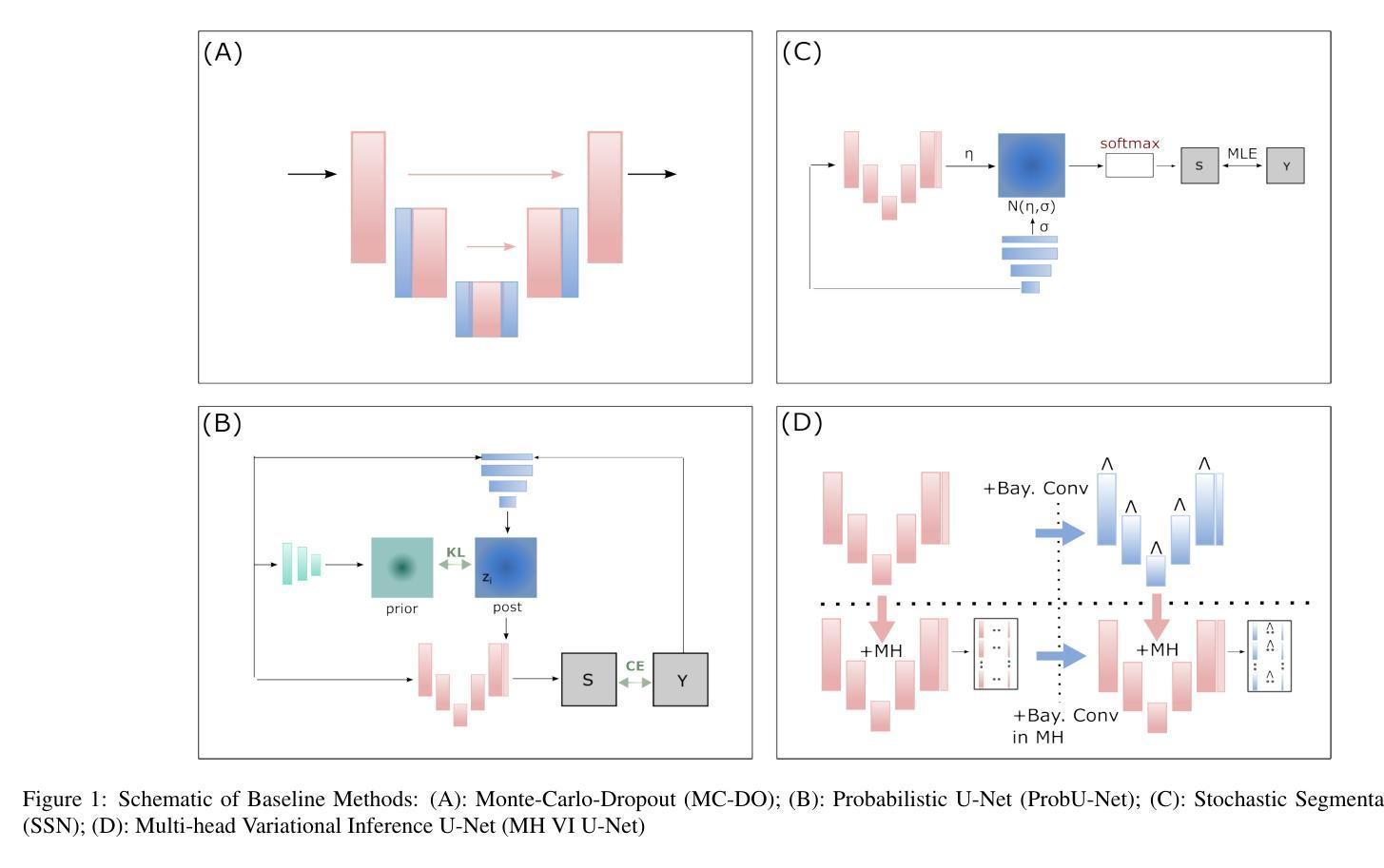
Uncertainty Quantification in Machine Learning Based Segmentation: A Post-Hoc Approach for Left Ventricle Volume Estimation in MRI
Authors:F. Terhag, P. Knechtges, A. Basermann, R. Tempone
Recent studies have confirmed cardiovascular diseases remain responsible for highest death toll amongst non-communicable diseases. Accurate left ventricular (LV) volume estimation is critical for valid diagnosis and management of various cardiovascular conditions, but poses significant challenge due to inherent uncertainties associated with segmentation algorithms in magnetic resonance imaging (MRI). Recent machine learning advancements, particularly U-Net-like convolutional networks, have facilitated automated segmentation for medical images, but struggles under certain pathologies and/or different scanner vendors and imaging protocols. This study proposes a novel methodology for post-hoc uncertainty estimation in LV volume prediction using It^{o} stochastic differential equations (SDEs) to model path-wise behavior for the prediction error. The model describes the area of the left ventricle along the heart’s long axis. The method is agnostic to the underlying segmentation algorithm, facilitating its use with various existing and future segmentation technologies. The proposed approach provides a mechanism for quantifying uncertainty, enabling medical professionals to intervene for unreliable predictions. This is of utmost importance in critical applications such as medical diagnosis, where prediction accuracy and reliability can directly impact patient outcomes. The method is also robust to dataset changes, enabling application for medical centers with limited access to labeled data. Our findings highlight the proposed uncertainty estimation methodology’s potential to enhance automated segmentation robustness and generalizability, paving the way for more reliable and accurate LV volume estimation in clinical settings as well as opening new avenues for uncertainty quantification in biomedical image segmentation, providing promising directions for future research.
最近的研究已经确认,心血管疾病仍是导致非传染性疾病死亡人数最多的原因。左心室(LV)体积的准确估计是各种心血管疾病的有效诊断和治疗的关键,但由于磁共振成像(MRI)中分割算法固有的不确定性,这构成了一个巨大的挑战。最近的机器学习进展,尤其是U-Net类似的卷积网络,已经促进了医疗图像的自动分割,但在某些病理情况下和/或不同的扫描仪供应商和成像协议下仍存在困难。本研究提出了一种使用It^{o}随机微分方程(SDEs)对左心室体积预测进行事后不确定性估计的新方法,以模拟预测误差的路径行为。该模型描述了左心室沿心脏长轴的区域。该方法对潜在的分割算法持中立态度,可以与各种现有和未来分割技术一起使用。所提出的方法提供了量化不确定性的机制,使医疗专业人员可以对不可靠的预测进行干预。在医疗诊断等关键应用中,这至关重要,预测准确性和可靠性会直接影响患者结果。该方法对数据集的变化也很稳健,适用于有限访问标记数据的医学中心。我们的研究结果突出了所提出的不确定性估计方法在增强自动分割的稳健性和通用性方面的潜力,为临床环境中更可靠和准确的左心室体积估计铺平了道路,同时也为生物医学图像分割中的不确定性量化打开了新的途径,为未来的研究提供了有希望的方向。
论文及项目相关链接
Summary
本文提出一种基于It^{o}随机微分方程(SDEs)的左心室体积预测事后不确定性估计新方法。此方法描述左心室在心脏长轴上的区域,对基础分割算法无特定要求,可应用于各种现有和未来分割技术。此方法能定量评估不确定性,使医疗专业人员能对不可靠的预测进行干预,对医疗诊断等关键应用至关重要。该方法对数据集变化具有稳健性,适用于医疗资源有限的中心。研究结果表明,该不确定性估计方法有望增强自动分割的稳健性和通用性,为临床环境中更可靠、准确的左心室体积估计铺平道路,同时为生物医学图像分割中的不确定性量化提供新的研究方向。
Key Takeaways
- 心血管疾病在非传染性疾病中的死亡人数占比最高。
- 准确的左心室体积估计是心血管疾病诊断和管理的关键。
- 磁共振成像中的分割算法存在不确定性,给左心室体积估计带来挑战。
- 最近的机器学习进展,尤其是U-Net类似的卷积网络,促进了医学图像自动化分割的应用。
- 研究提出了一种基于It^{o}随机微分方程的新型方法,用于事后不确定性估计。
- 该方法独立于基础分割算法,可用于各种现有和未来的分割技术。
点此查看论文截图

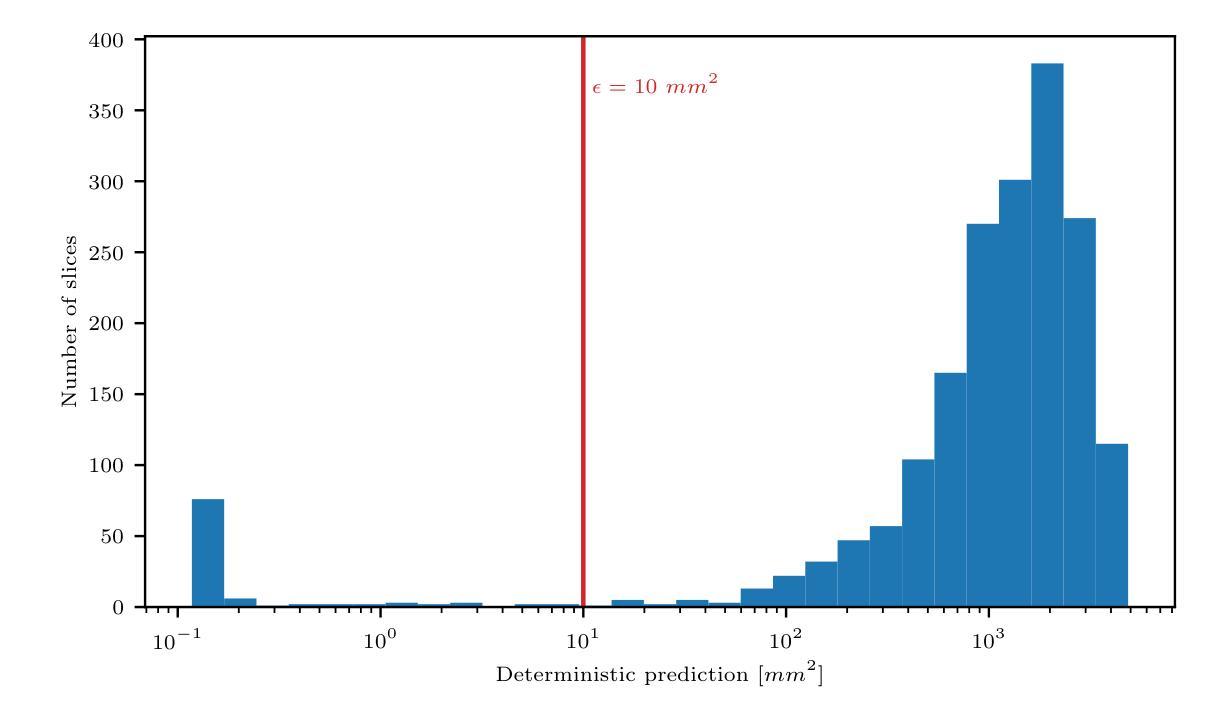
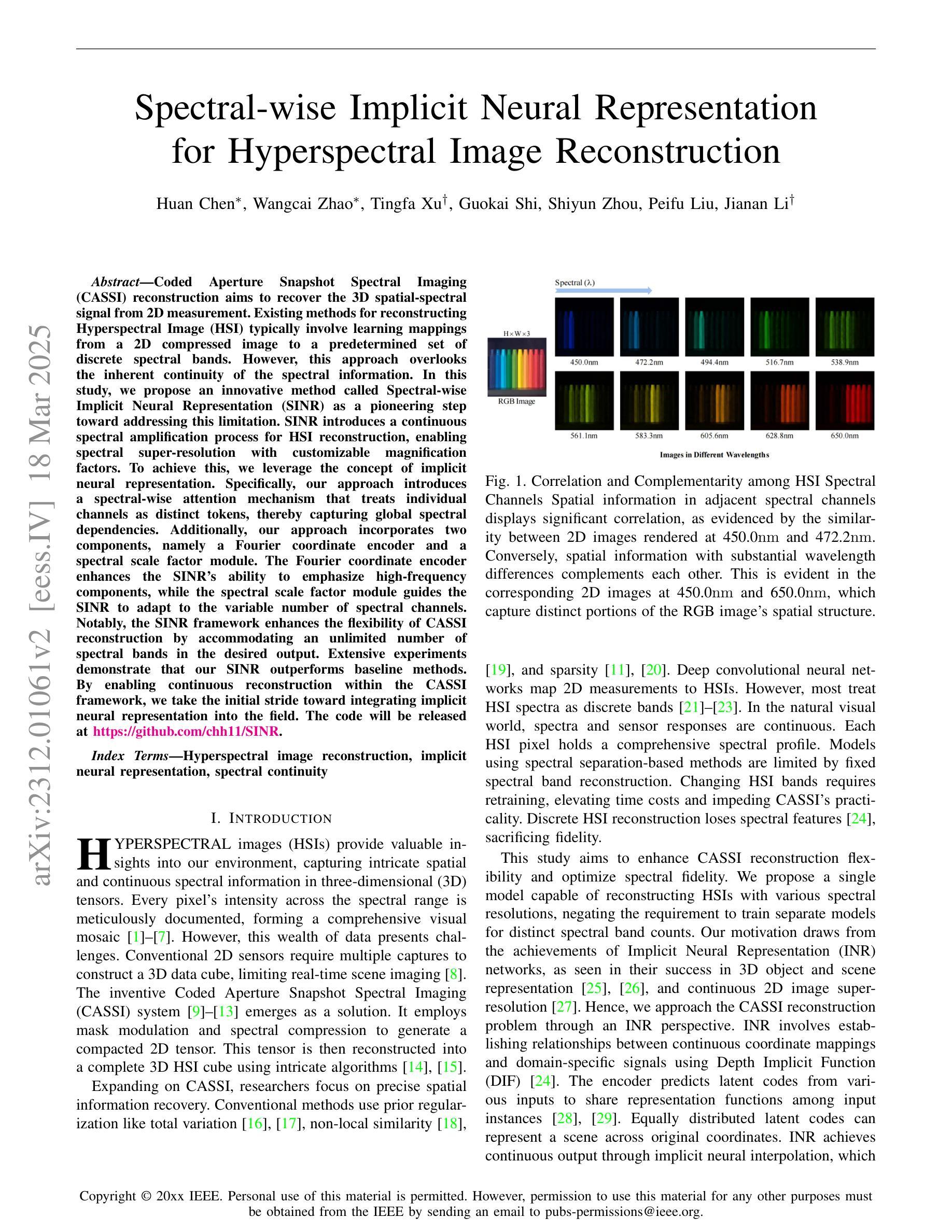
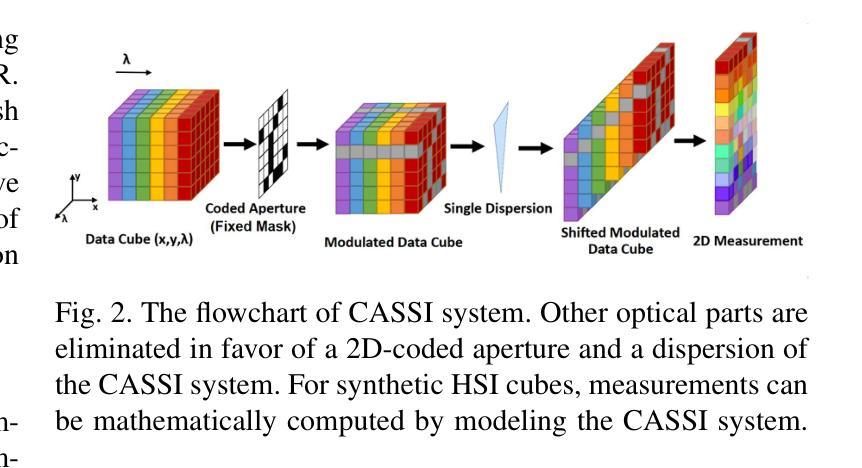
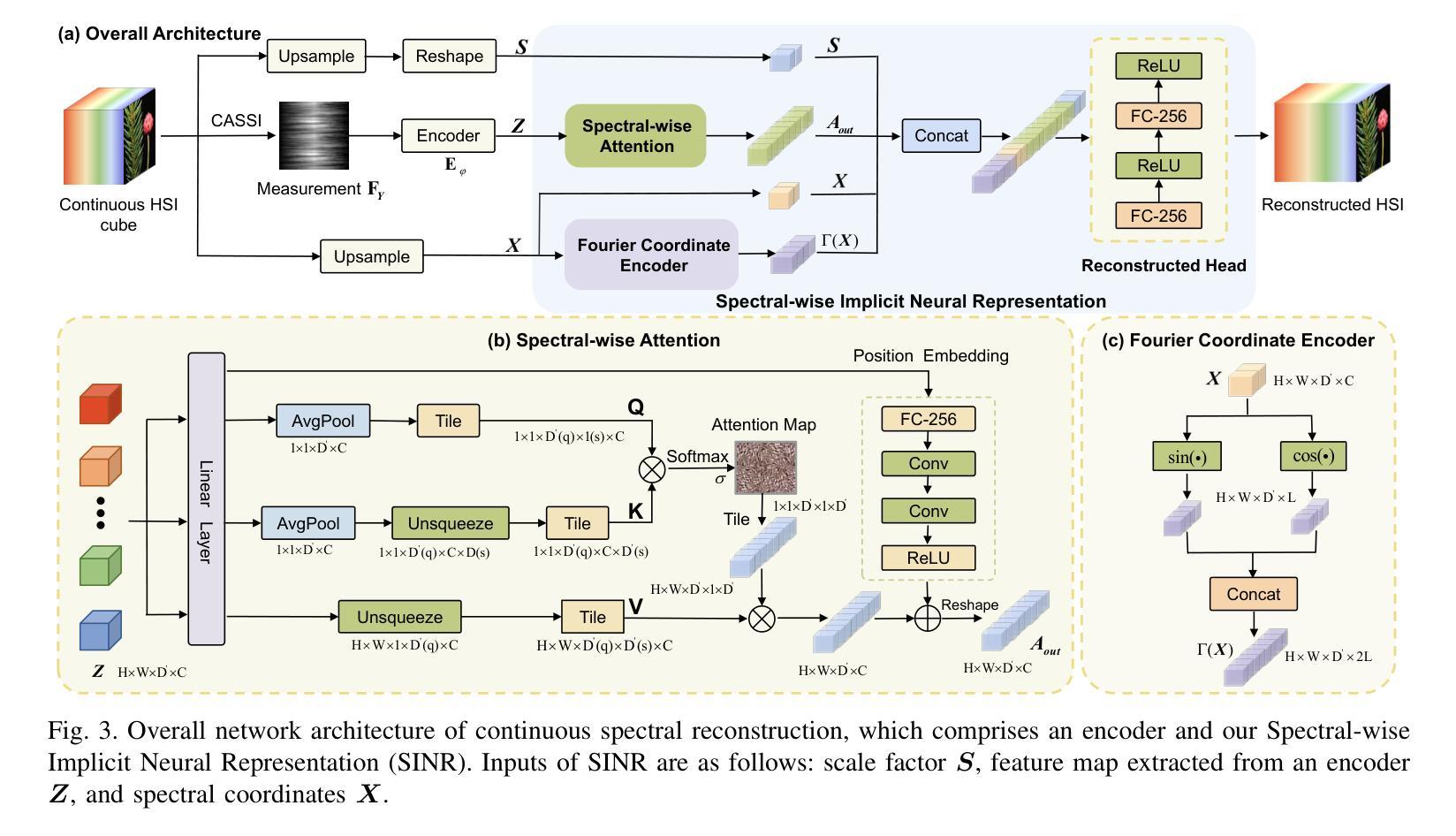
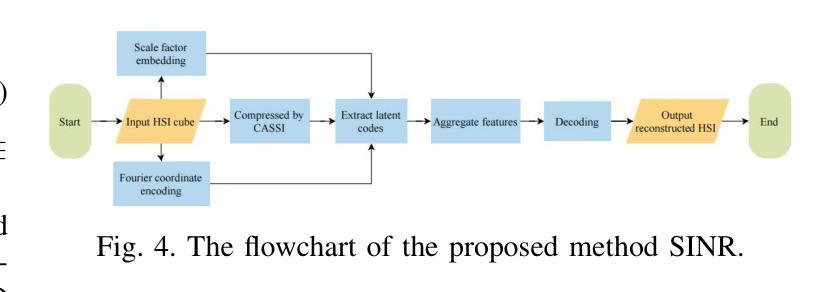
Spectral-wise Implicit Neural Representation for Hyperspectral Image Reconstruction
Authors:Huan Chen, Wangcai Zhao, Tingfa Xu, Shiyun Zhou, Peifu Liu, Jianan Li
Coded Aperture Snapshot Spectral Imaging (CASSI) reconstruction aims to recover the 3D spatial-spectral signal from 2D measurement. Existing methods for reconstructing Hyperspectral Image (HSI) typically involve learning mappings from a 2D compressed image to a predetermined set of discrete spectral bands. However, this approach overlooks the inherent continuity of the spectral information. In this study, we propose an innovative method called Spectral-wise Implicit Neural Representation (SINR) as a pioneering step toward addressing this limitation. SINR introduces a continuous spectral amplification process for HSI reconstruction, enabling spectral super-resolution with customizable magnification factors. To achieve this, we leverage the concept of implicit neural representation. Specifically, our approach introduces a spectral-wise attention mechanism that treats individual channels as distinct tokens, thereby capturing global spectral dependencies. Additionally, our approach incorporates two components, namely a Fourier coordinate encoder and a spectral scale factor module. The Fourier coordinate encoder enhances the SINR’s ability to emphasize high-frequency components, while the spectral scale factor module guides the SINR to adapt to the variable number of spectral channels. Notably, the SINR framework enhances the flexibility of CASSI reconstruction by accommodating an unlimited number of spectral bands in the desired output. Extensive experiments demonstrate that our SINR outperforms baseline methods. By enabling continuous reconstruction within the CASSI framework, we take the initial stride toward integrating implicit neural representation into the field.
编码孔径快照光谱成像(CASSI)重建旨在从二维测量中恢复三维空间光谱信号。现有的超光谱图像(HSI)重建方法通常涉及从二维压缩图像学习映射到预先确定的一组离散光谱带。然而,这种方法忽略了光谱信息的内在连续性。在这项研究中,我们提出了一种创新的方法,称为光谱隐神经表示(SINR),作为解决这一限制的开创性步骤。SINR引入了一个连续光谱放大过程,用于HSI重建,实现了具有可定制放大倍数的光谱超分辨率。为实现这一点,我们利用了隐神经表示的概念。具体来说,我们的方法引入了一种光谱注意机制,将单个通道视为不同的标记,从而捕获全局光谱依赖性。此外,我们的方法包括两个组件,即傅立叶坐标编码器和光谱尺度因子模块。傅立叶坐标编码器增强了SINR对高频分量的强调能力,而光谱尺度因子模块指导SINR适应可变数量的光谱通道。值得注意的是,SINR框架通过适应输出所需的无限数量的光谱带,增强了CASSI重建的灵活性。大量实验表明,我们的SINR优于基线方法。通过在CASSI框架内实现连续重建,我们迈出了将隐神经表示整合到该领域的初步尝试。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Circuits and Systems for Video Technology, has been published
Summary
本文介绍了基于隐式神经网络表示的Spectral-wise Implicit Neural Representation(SINR)方法,旨在解决Coded Aperture Snapshot Spectral Imaging(CASSI)重建中的超光谱图像重建问题。该方法引入连续光谱放大过程,实现光谱超分辨率并可自定义放大倍数。通过引入光谱注意机制,SINR能够捕捉全局光谱依赖性。此外,该方法结合了傅里叶坐标编码器和光谱尺度因子模块,提高了对高频成分的强调和适应性。总体而言,SINR增强了CASSI重建的灵活性,能够应对无限数量的光谱通道输出,且在实验中表现优于基线方法。
Key Takeaways
- SINR是一种创新的超光谱图像重建方法,用于解决CASSI重建中的连续光谱放大问题。
- 通过引入光谱注意机制,SINR能够捕捉全局光谱依赖性。
- 傅里叶坐标编码器增强了SINR对高频成分的强调能力。
- 光谱尺度因子模块使SINR能够适应可变数量的光谱通道。
- SINR框架增强了CASSI重建的灵活性,可以处理无限数量的光谱通道输出。
- 实验表明,SINR在性能上优于传统的HSI重建方法。
点此查看论文截图
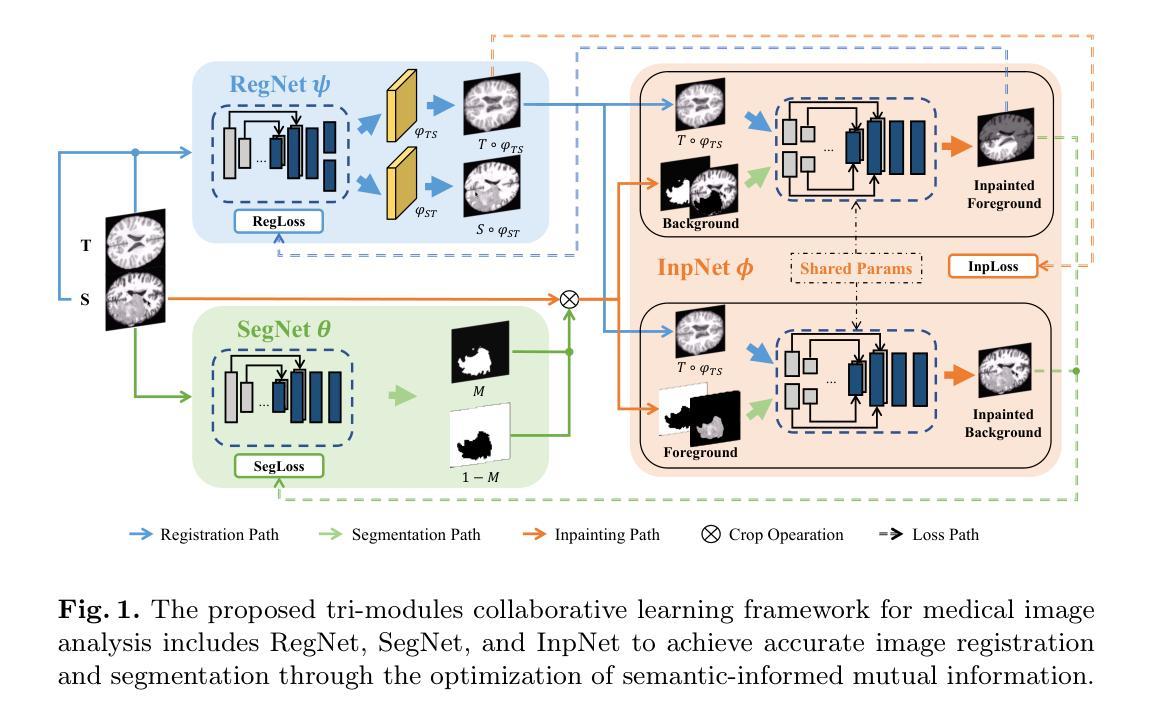
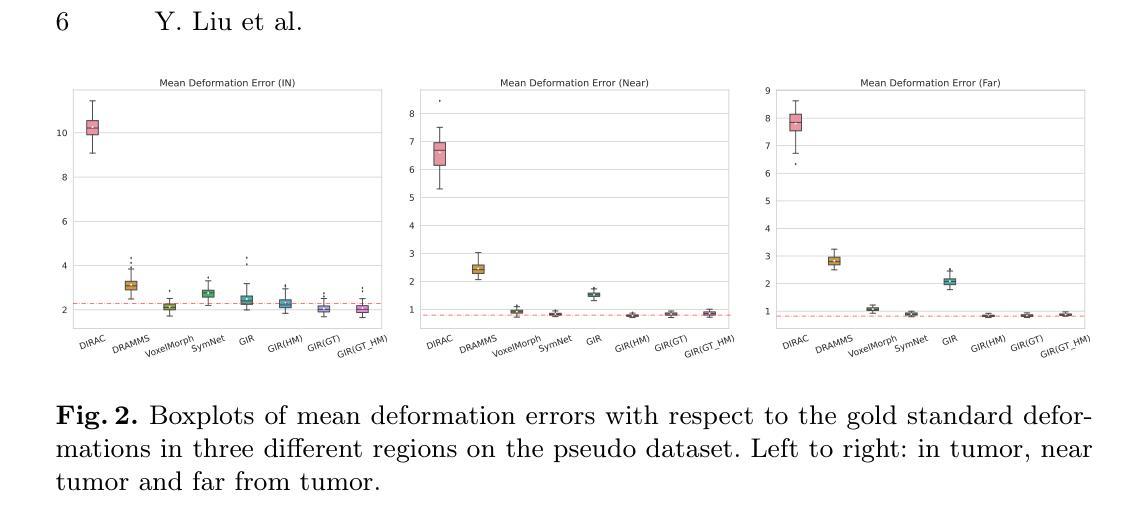
Co-Learning Semantic-aware Unsupervised Segmentation for Pathological Image Registration
Authors:Yang Liu, Shi Gu
The registration of pathological images plays an important role in medical applications. Despite its significance, most researchers in this field primarily focus on the registration of normal tissue into normal tissue. The negative impact of focal tissue, such as the loss of spatial correspondence information and the abnormal distortion of tissue, are rarely considered. In this paper, we propose GIRNet, a novel unsupervised approach for pathological image registration by incorporating segmentation and inpainting through the principles of Generation, Inpainting, and Registration (GIR). The registration, segmentation, and inpainting modules are trained simultaneously in a co-learning manner so that the segmentation of the focal area and the registration of inpainted pairs can improve collaboratively. Overall, the registration of pathological images is achieved in a completely unsupervised learning framework. Experimental results on multiple datasets, including Magnetic Resonance Imaging (MRI) of T1 sequences, demonstrate the efficacy of our proposed method. Our results show that our method can accurately achieve the registration of pathological images and identify lesions even in challenging imaging modalities. Our unsupervised approach offers a promising solution for the efficient and cost-effective registration of pathological images. Our code is available at https://github.com/brain-intelligence-lab/GIRNet.
病理图像的配准在医疗应用中扮演着重要角色。尽管其意义重大,但该领域的大多数研究者主要关注正常组织到正常组织的配准。很少考虑焦点组织的负面影响,如空间对应关系信息的丢失和组织异常扭曲。在本文中,我们提出了GIRNet,这是一种新的无监督病理图像配准方法,通过结合分割和补全技术,遵循生成、补全和配准(GIR)的原则。配准、分割和补全模块以协同学习的方式进行训练,以便焦点区域的分割和补全对的配准能够协同改进。总的来说,病理图像的配准是在一个完全无监督的学习框架中实现的。在多个数据集上的实验结果,包括T1序列的磁共振成像(MRI),证明了我们提出的方法的有效性。我们的结果表明,我们的方法可以准确地实现病理图像的配准,甚至在具有挑战性的成像模式上也能识别病变。我们的无监督方法为实现高效且经济的病理图像配准提供了有前景的解决方案。我们的代码可在 https://github.com/brain-intelligence-lab/GIRNet 获得。
论文及项目相关链接
PDF 13 pages, 7 figures, published in Medical Image Computing and Computer Assisted Intervention (MICCAI) 2023
Summary
本文提出了一种基于生成、修复和注册(GIR)原则的新型无监督病理图像注册方法GIRNet。该方法同时训练注册、分割和修复模块,实现对焦点区域的分割和对修复对图像的注册,进而提高协同性能。实验结果表明,该方法可有效实现病理图像的注册,甚至在具有挑战性的成像模式下也能识别病变。该无监督方法为病理图像的效率和成本效益提供了有前景的解决方案。
Key Takeaways
- 病理图像注册在医学应用中的重要性被强调,但现有研究主要关注正常组织的注册,忽略了焦点组织的负面影响。
- 提出了一种新型的无监督病理图像注册方法GIRNet,该方法结合了分割和修复技术。
- GIRNet通过同时训练注册、分割和修复模块,实现了对焦点区域的协同改进。
- 实验结果表明,GIRNet在多个数据集上表现出优异的性能,包括T1序列的磁共振成像(MRI)。
- GIRNet能准确实现病理图像的注册,并在具有挑战性的成像模式下识别病变。
- 无监督的GIRNet方法为高效且经济的病理图像注册提供了解决方案。
点此查看论文截图