⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
Machine Unlearning in Hyperbolic vs. Euclidean Multimodal Contrastive Learning: Adapting Alignment Calibration to MERU
Authors:Àlex Pujol Vidal, Sergio Escalera, Kamal Nasrollahi, Thomas B. Moeslund
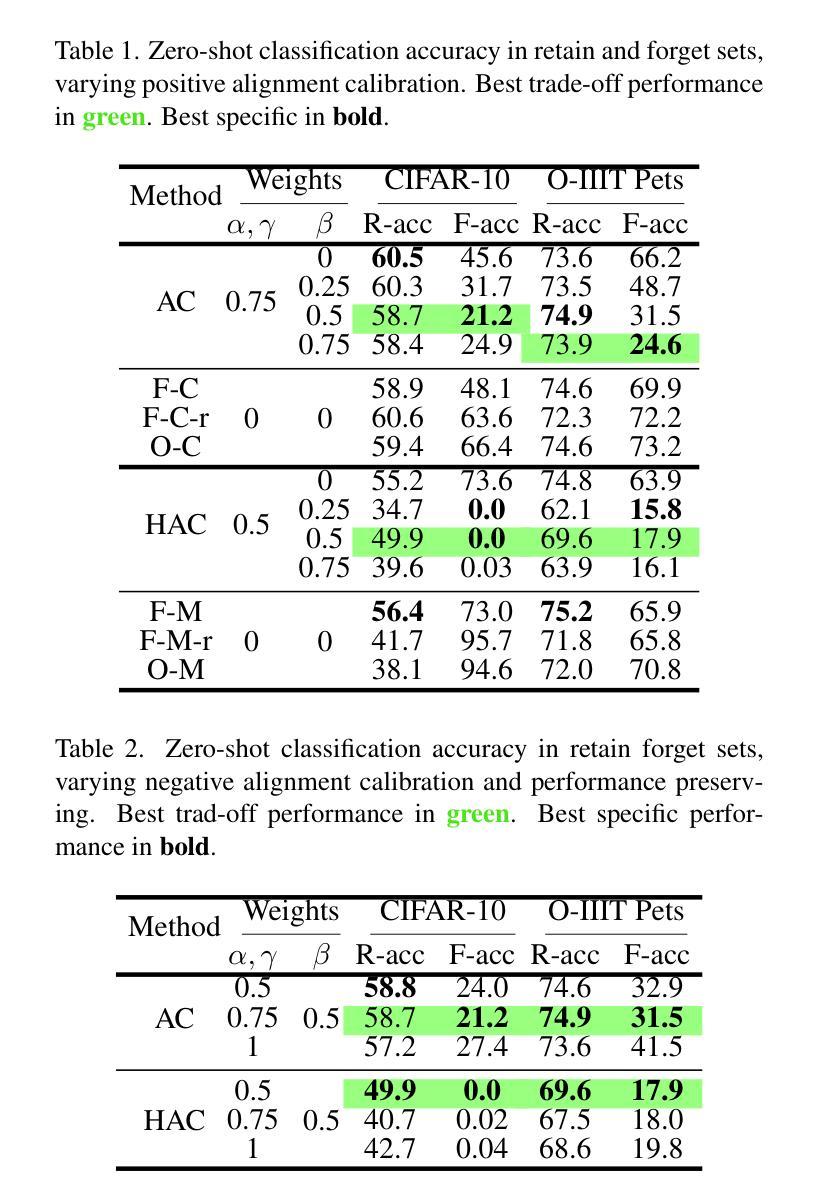
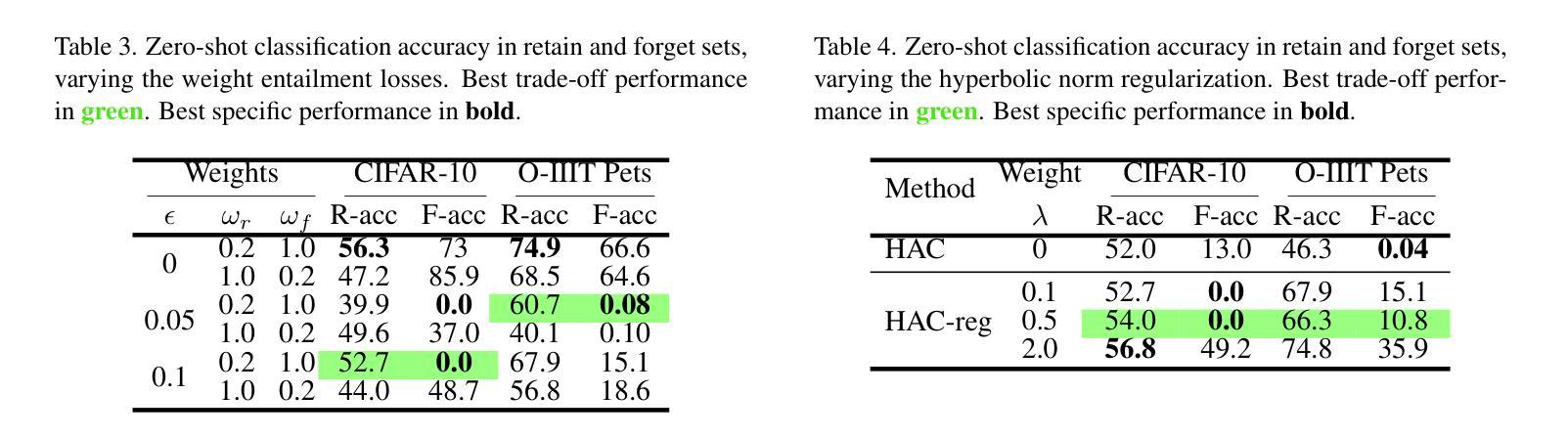
Machine unlearning methods have become increasingly important for selective concept removal in large pre-trained models. While recent work has explored unlearning in Euclidean contrastive vision-language models, the effectiveness of concept removal in hyperbolic spaces remains unexplored. This paper investigates machine unlearning in hyperbolic contrastive learning by adapting Alignment Calibration to MERU, a model that embeds images and text in hyperbolic space to better capture semantic hierarchies. Through systematic experiments and ablation studies, we demonstrate that hyperbolic geometry offers distinct advantages for concept removal, achieving near perfect forgetting with reasonable performance on retained concepts, particularly when scaling to multiple concept removal. Our approach introduces hyperbolic-specific components including entailment calibration and norm regularization that leverage the unique properties of hyperbolic space. Comparative analysis with Euclidean models reveals fundamental differences in unlearning dynamics, with hyperbolic unlearning reorganizing the semantic hierarchy while Euclidean approaches merely disconnect cross-modal associations. These findings not only advance machine unlearning techniques but also provide insights into the geometric properties that influence concept representation and removal in multimodal models. Source code available at https://github.com/alex-pv01/HAC
机器学习去除方法(Machine Unlearning Methods)对于在大型预训练模型中选择性移除概念变得越来越重要。虽然近期的研究已经探讨了欧几里得对比视觉语言模型中的学习遗忘现象,但在双曲空间中的概念移除效果仍未被探索。本文通过在 MERU 模型中适应对齐校准(Alignment Calibration),研究双曲对比学习中的机器遗忘现象。该模型将图像和文本嵌入双曲空间,以更好地捕捉语义层次结构。通过系统的实验和消除研究,我们证明了双曲几何在概念去除方面具有独特优势,在保留概念上实现近乎完美的遗忘效果,特别是在扩展到多重概念去除时更是如此。我们的方法引入了双曲特定的组件,包括蕴涵校准(entailment calibration)和规范正则化(norm regularization),利用双曲空间的独特属性。与欧几里得模型的比较分析揭示了遗忘动力学的根本差异,双曲遗忘重组语义层次结构,而欧几里得方法仅仅是断开跨模态关联。这些发现不仅推动了机器学习遗忘技术,还提供了对影响多模态模型中概念表示和去除的几何属性的见解。源代码可在 https://github.com/alex-pv01/HAC 获得。
论文及项目相关链接
PDF Preprint
Summary
本文研究了基于超几何对比学习的机器遗忘技术,特别是在概念移除方面的应用。通过适应对齐校准技术到MERU模型,实现图像和文本在超几何空间的嵌入,以更好地捕捉语义层次结构。研究表明,超几何几何具有显著的优点,能够实现近乎完美的遗忘,同时对保留的概念保持良好的性能。通过系统实验和去除研究,证明其在多个概念移除上的可扩展性。此研究提供了对超几何空间特性的利用,包括蕴涵校准和范数正则化等超几何特定组件。与欧几里得模型对比分析揭示了遗忘动力学的根本差异,超几何遗忘技术能够重组语义层次结构,而欧几里得方法则仅断开跨模态关联。该研究不仅推动了机器遗忘技术,也为多模态模型中的概念表示和移除的几何属性提供了见解。
Key Takeaways
- 研究机器遗忘技术在超几何对比学习中的应用,特别是在概念移除方面。
- 通过适应对齐校准技术到MERU模型实现图像和文本在超几何空间的嵌入,以捕捉语义层次结构。
- 超几何几何在概念移除方面具有显著优势,能够实现近乎完美的遗忘,同时对保留的概念保持良好的性能。
- 系统实验和去除研究证明了其在多个概念移除上的可扩展性。
- 利用超几何空间的特性,包括蕴涵校准和范数正则化等超几何特定组件。
- 与欧几里得模型对比分析揭示了遗忘机制的根本差异。
点此查看论文截图

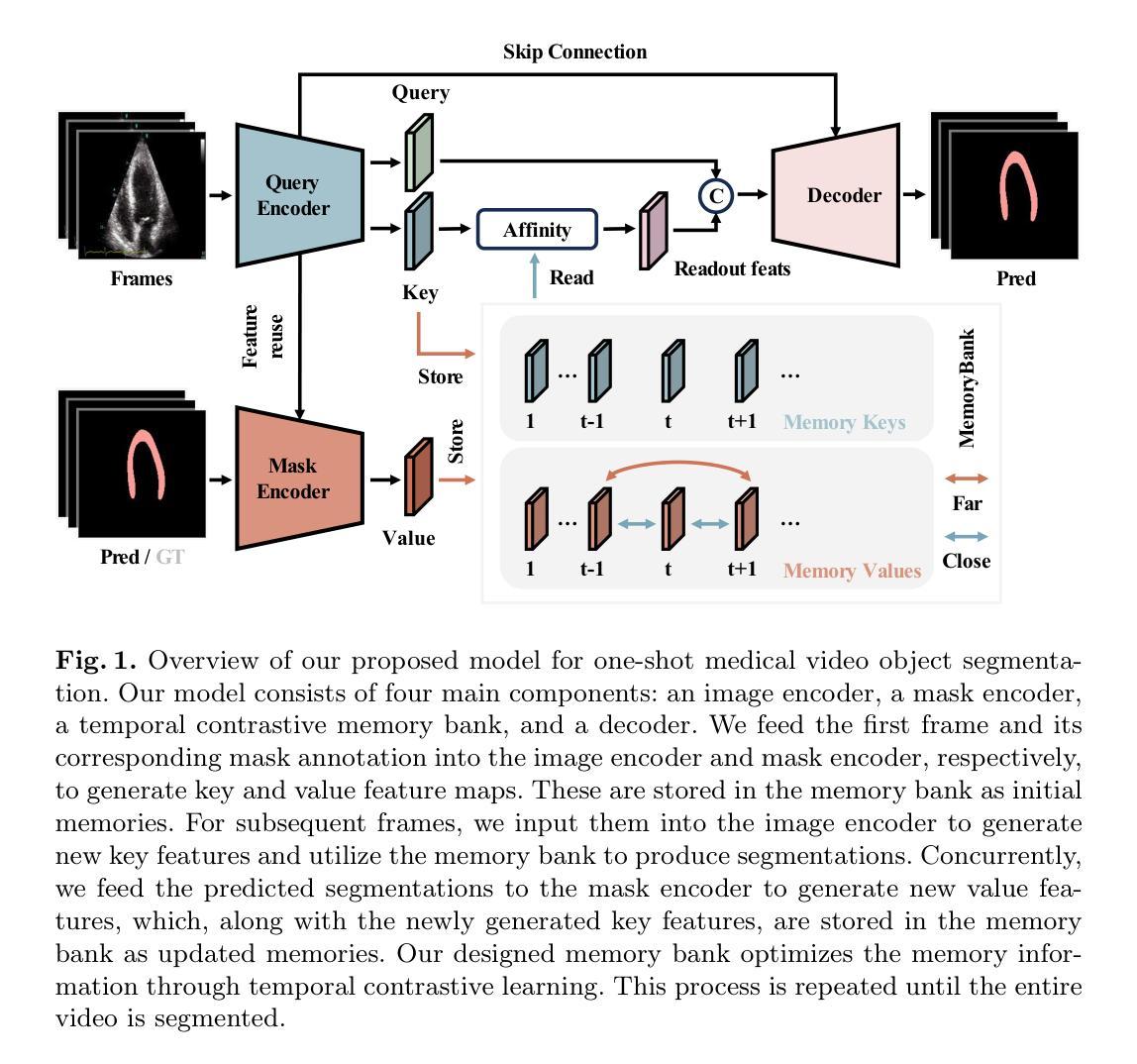
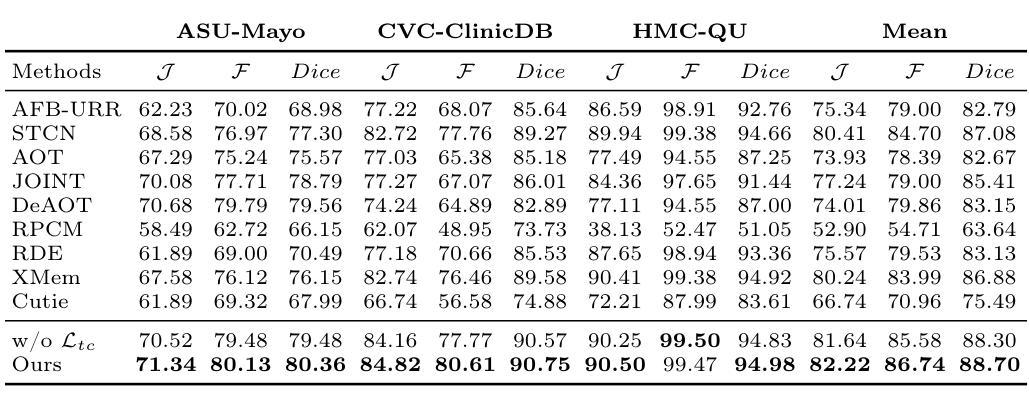
One-Shot Medical Video Object Segmentation via Temporal Contrastive Memory Networks
Authors:Yaxiong Chen, Junjian Hu, Chunlei Li, Zixuan Zheng, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
Video object segmentation is crucial for the efficient analysis of complex medical video data, yet it faces significant challenges in data availability and annotation. We introduce the task of one-shot medical video object segmentation, which requires separating foreground and background pixels throughout a video given only the mask annotation of the first frame. To address this problem, we propose a temporal contrastive memory network comprising image and mask encoders to learn feature representations, a temporal contrastive memory bank that aligns embeddings from adjacent frames while pushing apart distant ones to explicitly model inter-frame relationships and stores these features, and a decoder that fuses encoded image features and memory readouts for segmentation. We also collect a diverse, multi-source medical video dataset spanning various modalities and anatomies to benchmark this task. Extensive experiments demonstrate state-of-the-art performance in segmenting both seen and unseen structures from a single exemplar, showing ability to generalize from scarce labels. This highlights the potential to alleviate annotation burdens for medical video analysis. Code is available at https://github.com/MedAITech/TCMN.
视频对象分割对于复杂医疗视频数据的效率分析至关重要,然而它在数据可用性和注释方面面临着重大挑战。我们引入了一次医疗视频对象分割的任务,该任务要求仅使用第一帧的掩膜注释来分离视频中的前景和背景像素。为了解决这个问题,我们提出了一种时间对比记忆网络,包括图像和掩膜编码器来学习特征表示,一个时间对比记忆库,该记忆库可以对齐相邻帧的嵌入,同时推开远处的帧以显式地建模帧间关系并存储这些特征,以及一个解码器,该解码器融合了编码的图像特征和记忆读出值来进行分割。我们还收集了一个跨越多种模态和解剖结构的多元、多源医疗视频数据集,以此作为该任务的基准。大量实验表明,该方法在分割已见和未见结构上均达到了最先进的性能,展示了从稀缺标签中推广的能力。这凸显了减轻医疗视频分析标注负担的潜力。代码可在 https://github.com/MedAITech/TCMN 获得。
论文及项目相关链接
PDF MICCAI 2024 Workshop
Summary
医疗视频对象分割对于复杂的医疗视频数据的高效分析至关重要,但在数据可用性和标注方面面临重大挑战。本文引入了一次医疗视频对象分割任务,要求仅根据第一帧的掩膜标注,在视频中将前景和背景像素分开。为解决此问题,提出了一个包含图像和掩膜编码器的时空对比记忆网络,用于学习特征表示;一个时空对比记忆库用于对齐相邻帧的嵌入并显式建模帧间关系并存储这些特征;以及一个解码器,融合编码的图像特征和记忆读取来进行分割。此外,还收集了一个跨越多种模态和解剖结构的多元化多源医疗视频数据集作为基准测试此任务。实验显示对可见和未见结构的分割达到了最先进的性能,从少量标签中展现出了泛化能力。这凸显了缓解医疗视频分析标注负担的潜力。
Key Takeaways
- 医疗视频对象分割是复杂医疗视频数据分析的关键任务。
- 一次医疗视频分割任务的重要性在于仅使用第一帧的掩膜标注进行前景和背景像素的分离。
- 提出的时空对比记忆网络包括图像和掩膜编码器、时空对比记忆库和融合特征的解码器。
- 该网络通过显式建模帧间关系并存储这些特征来解决医疗视频分割的挑战。
- 收集了一个多元化的多源医疗视频数据集,用于评估此任务的标准性能。
- 实验显示该方法在可见和未见结构的分割上达到了最先进的性能水平。
点此查看论文截图