⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
SUM Parts: Benchmarking Part-Level Semantic Segmentation of Urban Meshes
Authors:Weixiao Gao, Liangliang Nan, Hugo Ledoux
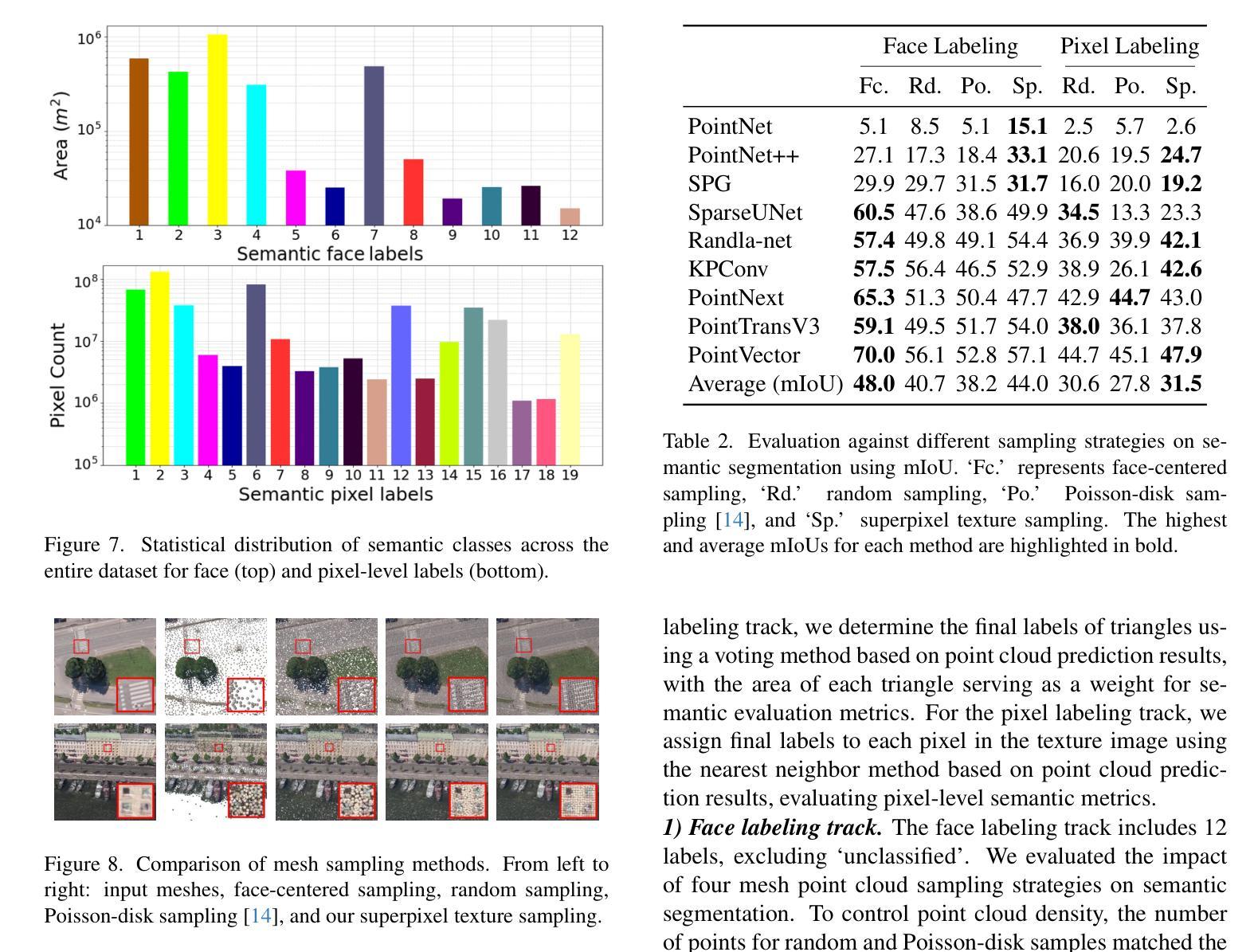
Semantic segmentation in urban scene analysis has mainly focused on images or point clouds, while textured meshes - offering richer spatial representation - remain underexplored. This paper introduces SUM Parts, the first large-scale dataset for urban textured meshes with part-level semantic labels, covering about 2.5 km2 with 21 classes. The dataset was created using our own annotation tool, which supports both face- and texture-based annotations with efficient interactive selection. We also provide a comprehensive evaluation of 3D semantic segmentation and interactive annotation methods on this dataset. Our project page is available at https://tudelft3d.github.io/SUMParts/.
城市场景分析中的语义分割主要关注图像或点云,而提供丰富空间表示的纹理网格仍然被探索得不够深入。本文介绍了SUM Parts数据集,这是城市纹理网格的第一个大规模数据集,包含零件级别的语义标签,覆盖了约2.5平方公里的21个类别。该数据集是使用我们自己的注释工具创建的,该工具支持基于平面和纹理的注释,并提供高效的交互选择。我们还针对该数据集上的3D语义分割和交互式注释方法进行了全面的评估。我们的项目页面可在 https://tudelft3d.github.io/SUMParts/ 上找到。
论文及项目相关链接
PDF 22 pages, 24 figures
Summary:
本文主要介绍了针对城市纹理网格的语义分割数据集SUM Parts。该数据集具有部分级别的语义标签,覆盖约2.5平方公里的21个类别。数据集使用自己的注释工具创建,支持基于面部和纹理的注释以及高效的交互式选择。同时,本文还对该数据集上的三维语义分割和交互式注释方法进行了全面评估。
Key Takeaways:
- 城市纹理网格的语义分割是城市场景分析的新方向,较图像或点云更丰富。
- SUM Parts是首个针对城市纹理网格的大规模数据集,包含部分级别的语义标签。
- SUM Parts覆盖了约2.5平方公里的多个类别,达到21类。
- 数据集使用注释工具创建,支持基于面部和纹理的注释及高效交互式选择。
- 文章提供了对该数据集上的三维语义分割的全面评估。
- 项目页面可供访问,详细信息和资源齐全。
点此查看论文截图

Test-Time Backdoor Detection for Object Detection Models
Authors:Hangtao Zhang, Yichen Wang, Shihui Yan, Chenyu Zhu, Ziqi Zhou, Linshan Hou, Shengshan Hu, Minghui Li, Yanjun Zhang, Leo Yu Zhang
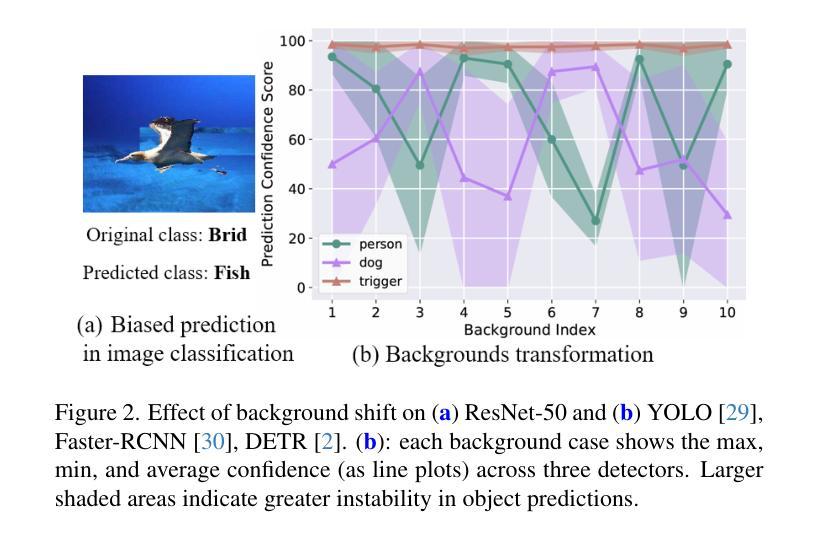
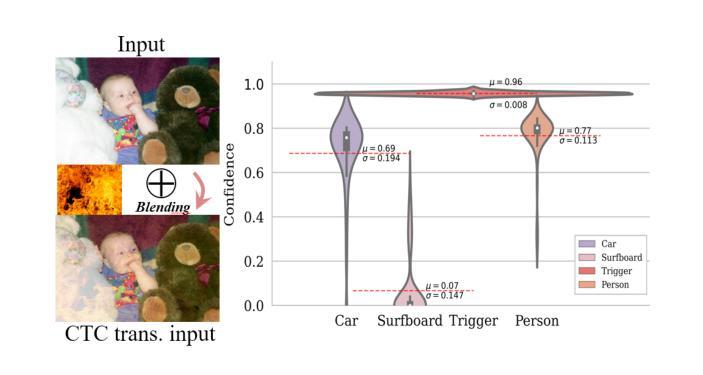
Object detection models are vulnerable to backdoor attacks, where attackers poison a small subset of training samples by embedding a predefined trigger to manipulate prediction. Detecting poisoned samples (i.e., those containing triggers) at test time can prevent backdoor activation. However, unlike image classification tasks, the unique characteristics of object detection – particularly its output of numerous objects – pose fresh challenges for backdoor detection. The complex attack effects (e.g., “ghost” object emergence or “vanishing” object) further render current defenses fundamentally inadequate. To this end, we design TRAnsformation Consistency Evaluation (TRACE), a brand-new method for detecting poisoned samples at test time in object detection. Our journey begins with two intriguing observations: (1) poisoned samples exhibit significantly more consistent detection results than clean ones across varied backgrounds. (2) clean samples show higher detection consistency when introduced to different focal information. Based on these phenomena, TRACE applies foreground and background transformations to each test sample, then assesses transformation consistency by calculating the variance in objects confidences. TRACE achieves black-box, universal backdoor detection, with extensive experiments showing a 30% improvement in AUROC over state-of-the-art defenses and resistance to adaptive attacks.
对象检测模型容易受到后门攻击的影响,攻击者通过嵌入预先定义的触发器来操纵预测结果,从而毒害一小部分训练样本。在测试阶段检测被毒害的样本(即包含触发器的样本)可以防止后门激活。然而,与图像分类任务不同,对象检测的独特特点——尤其是其输出的大量对象——给后门检测带来了新的挑战。复杂的攻击效果(例如,“幽灵”对象出现或“消失”对象)进一步使当前的防御措施从根本上不足。为此,我们设计了TRAnsformation Consistency Evaluation(TRACE),这是一种用于在对象检测中测试时检测被毒害样本的全新方法。我们的研究始于两个有趣的观察:1)与干净样本相比,被毒害样本在不同背景下呈现的检测结果更加一致。2)当引入不同的焦点信息时,干净样本的检测结果一致性更高。基于这些现象,TRACE对每个测试样本应用前景和背景转换,然后通过计算对象置信度的方差来评估转换的一致性。TRACE实现了黑箱通用后门检测,大量实验表明,与最先进的防御措施相比,其在AUROC上的改进提高了30%,并具备抵抗自适应攻击的能力。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
对象检测模型易受后门攻击影响,攻击者通过嵌入预设触发条件来操纵预测结果。在测试阶段检测中毒样本(即包含触发条件的样本)可防止后门激活。然而,对象检测任务的独特性——尤其是其输出多个对象——为后门检测带来了新的挑战。复杂的攻击效果(如“幽灵”对象出现或“消失”对象)使得当前防御手段从根本上不足。为此,我们设计了TRAnsformation Consistency Evaluation(TRACE),这是一种全新的测试阶段对象检测中毒样本检测方法。我们的研究基于两个有趣观察:1)中毒样本在不同背景的检测结果之间一致性显著强于清洁样本;2)引入不同焦点信息后,清洁样本的检测一致性更高。基于此现象,TRACE对测试样本进行前景和背景变换,然后通过计算对象置信度的方差来评估变换一致性。TRACE实现了黑盒通用后门检测,大量实验显示其在AUROC上较现有防御手段提高了30%,并且具有抵抗适应性攻击的能力。
Key Takeaways
- 对象检测模型面临后门攻击的新挑战。
- 中毒样本在多种背景下检测结果更一致。
- 清洁样本在引入不同焦点信息时检测一致性更高。
- TRACE方法通过前景和背景变换检测中毒样本。
- TRACE实现了黑盒通用后门检测。
- TRACE较现有防御手段在AUROC上有显著提高。
点此查看论文截图




Semantic Segmentation of Transparent and Opaque Drinking Glasses with the Help of Zero-shot Learning
Authors:Annalena Blänsdorf, Tristan Wirth, Arne Rak, Thomas Pöllabauer, Volker Knauthe, Arjan Kuijper
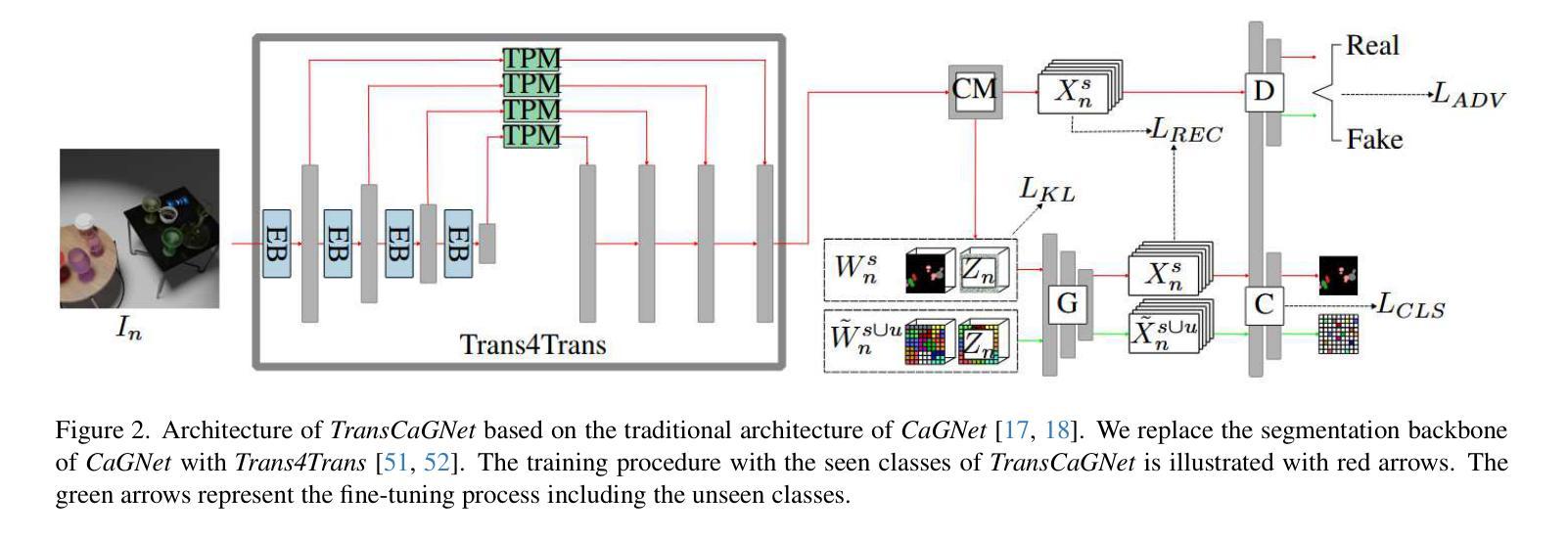
Segmenting transparent structures in images is challenging since they are difficult to distinguish from the background. Common examples are drinking glasses, which are a ubiquitous part of our lives and appear in many different shapes and sizes. In this work we propose TransCaGNet, a modified version of the zero-shot model CaGNet. We exchange the segmentation backbone with the architecture of Trans4Trans to be capable of segmenting transparent objects. Since some glasses are rarely captured, we use zeroshot learning to be able to create semantic segmentations of glass categories not given during training. We propose a novel synthetic dataset covering a diverse set of different environmental conditions. Additionally we capture a real-world evaluation dataset since most applications take place in the real world. Comparing our model with Zeg-Clip we are able to show that TransCaGNet produces better mean IoU and accuracy values while ZegClip outperforms it mostly for unseen classes. To improve the segmentation results, we combine the semantic segmentation of the models with the segmentation results of SAM 2. Our evaluation emphasizes that distinguishing between different classes is challenging for the models due to similarity, points of view, or coverings. Taking this behavior into account, we assign glasses multiple possible categories. The modification leads to an improvement up to 13.68% for the mean IoU and up to 17.88% for the mean accuracy values on the synthetic dataset. Using our difficult synthetic dataset for training, the models produce even better results on the real-world dataset. The mean IoU is improved up to 5.55% and the mean accuracy up to 5.72% on the real-world dataset.
针对图像中的透明结构进行分割是一项挑战,因为它们很难与背景区分开。常见的例子是眼镜,作为我们生活中无处不在的一部分,它们以许多不同的形状和大小出现。在这项工作中,我们提出了TransCaGNet,这是零样本模型CaGNet的改进版。我们更换了分割主干网(backbone)为Trans4Trans架构,以便能够分割透明物体。由于有些眼镜很少被捕获,我们使用零样本学习来对训练期间未给出的眼镜类别进行语义分割。我们提出了一个合成数据集,涵盖了不同环境条件下的多样集合。此外,我们还捕获了一个现实世界评估数据集,因为大多数应用都在现实世界中发生。将我们的模型与Zeg-Clip进行比较,我们证明TransCaGNet能产生更好的平均交并比(IoU)和准确度值,而ZegClip在未见类别上表现较好。为了提高分割结果,我们将模型的语义分割与SAM 2的分割结果相结合。我们的评估强调,由于相似性、视点或覆盖物等原因,模型区分不同类别是一个挑战。考虑到这种行为,我们对眼镜分配了多个可能的类别。这一改进导致合成数据集上的平均IoU提高了13.68%,平均准确度值提高了17.88%。使用我们困难的合成数据集进行训练,模型在现实世界的数据集上产生了更好的结果。现实世界的平均IoU提高了5.55%,平均准确度提高了5.72%。
论文及项目相关链接
Summary:
本文提出了TransCaGNet模型,用于图像中透明结构的分割,特别是针对日常生活中的常见透明物体如玻璃杯。该模型结合了Trans4Trans架构和零样本学习方法,以实现对透明物体的分割,并创建了一个涵盖多种环境条件的合成数据集进行训练。实验表明,TransCaGNet在合成和真实世界数据集上的平均交并比(IoU)和准确率均有所提升。
Key Takeaways:
- TransCaGNet模型被提出,用于分割图像中的透明物体,如玻璃杯。
- 模型结合了Trans4Trans架构,以提高对透明物体的分割能力。
- 采用零样本学习,能够针对训练时未涉及的玻璃类别进行语义分割。
- 创建了一个涵盖多种环境条件的合成数据集,并捕获真实世界评估数据集。
- TransCaGNet在合成数据集上的平均交并比(IoU)和准确率有所提升,与Zeg-Clip相比表现更优。
- 结合语义分割模型和SAM 2的分割结果,以提高分割效果。
点此查看论文截图


Fine-Grained Open-Vocabulary Object Detection with Fined-Grained Prompts: Task, Dataset and Benchmark
Authors:Ying Liu, Yijing Hua, Haojiang Chai, Yanbo Wang, TengQi Ye
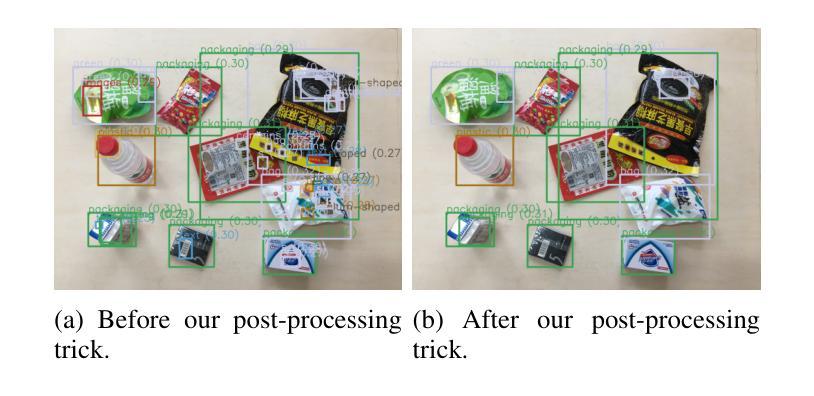
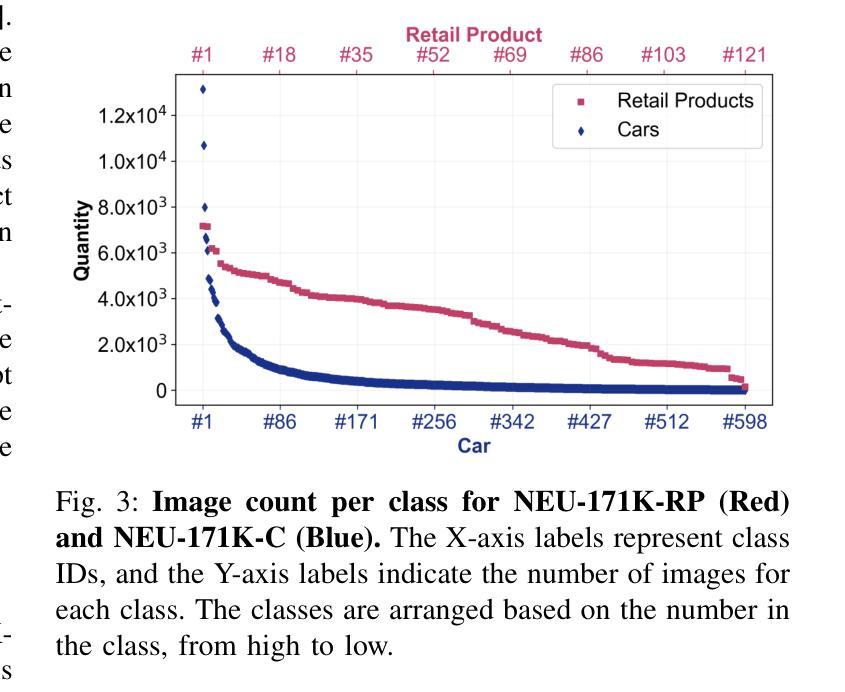
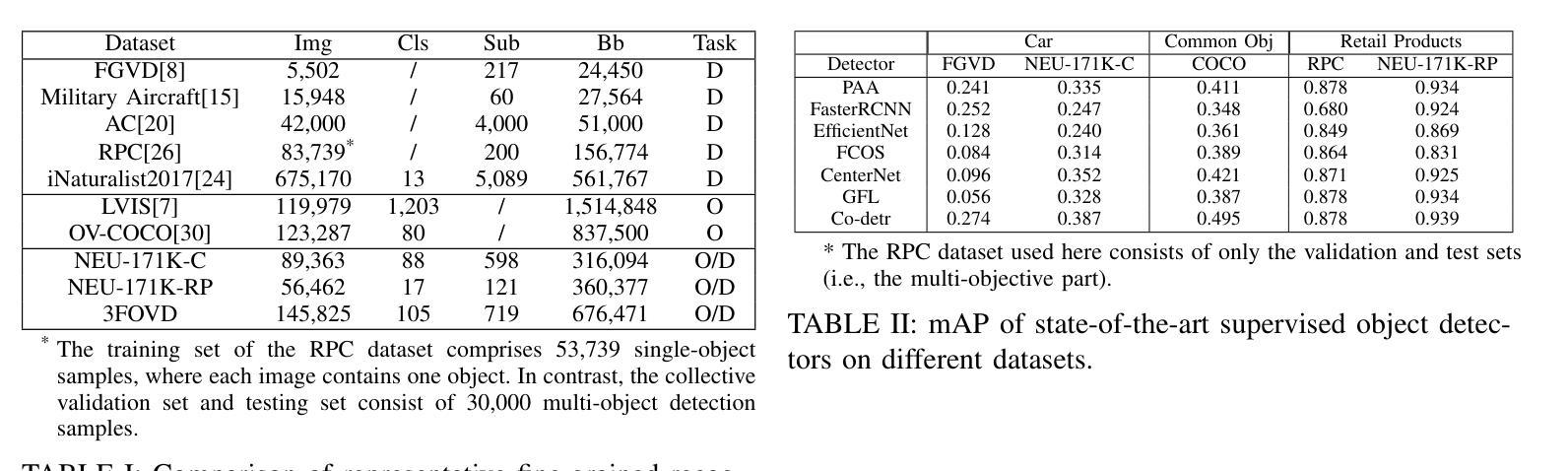
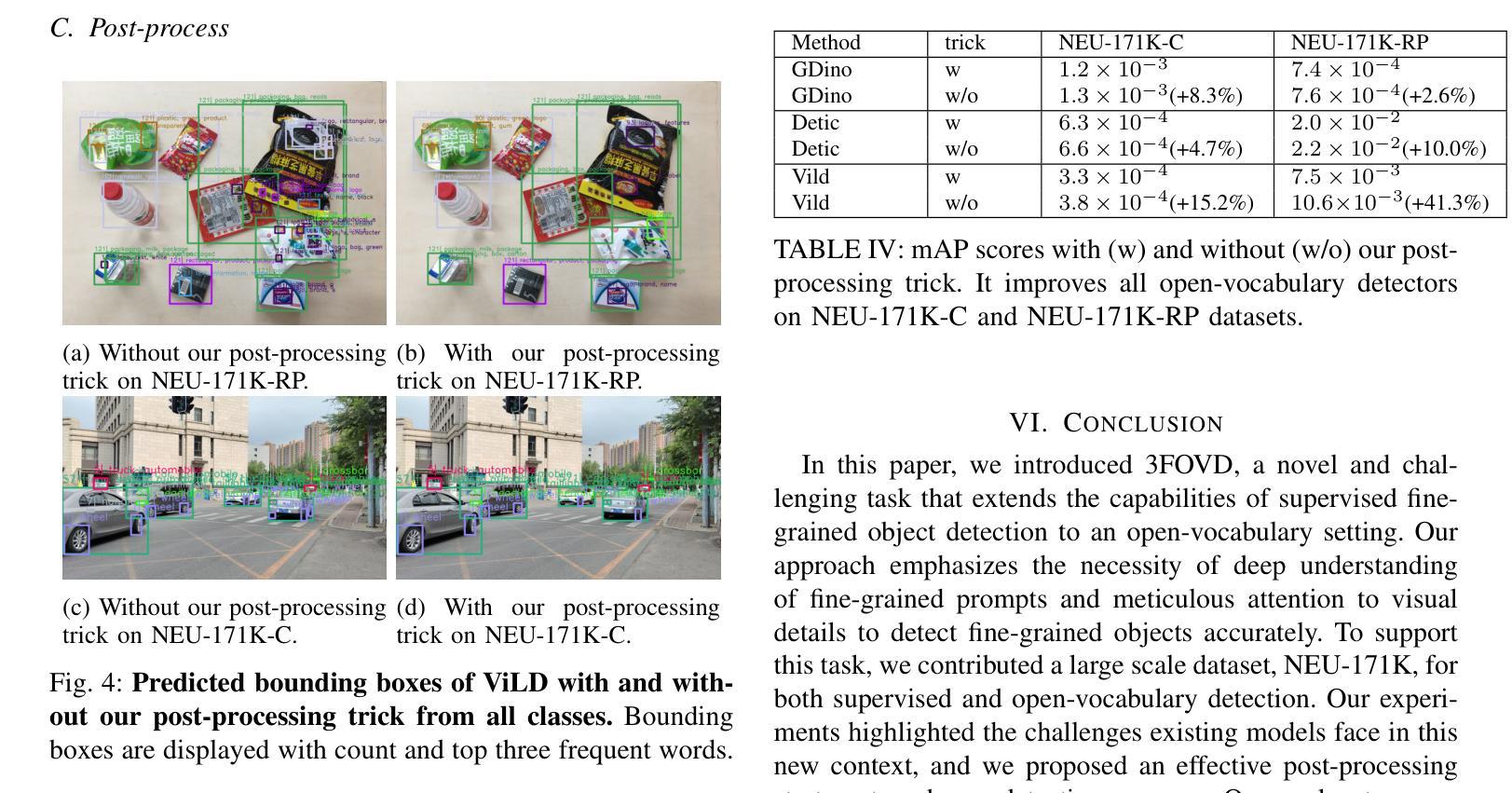
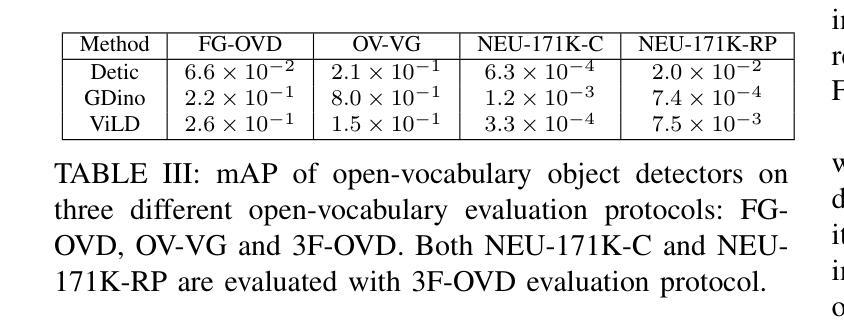
Open-vocabulary detectors are proposed to locate and recognize objects in novel classes. However, variations in vision-aware language vocabulary data used for open-vocabulary learning can lead to unfair and unreliable evaluations. Recent evaluation methods have attempted to address this issue by incorporating object properties or adding locations and characteristics to the captions. Nevertheless, since these properties and locations depend on the specific details of the images instead of classes, detectors can not make accurate predictions without precise descriptions provided through human annotation. This paper introduces 3F-OVD, a novel task that extends supervised fine-grained object detection to the open-vocabulary setting. Our task is intuitive and challenging, requiring a deep understanding of Fine-grained captions and careful attention to Fine-grained details in images in order to accurately detect Fine-grained objects. Additionally, due to the scarcity of qualified fine-grained object detection datasets, we have created a new dataset, NEU-171K, tailored for both supervised and open-vocabulary settings. We benchmark state-of-the-art object detectors on our dataset for both settings. Furthermore, we propose a simple yet effective post-processing technique.
开放词汇表检测器被提出来用于定位和识别新型类别中的物体。然而,用于开放词汇学习的视觉感知语言词汇数据的变化可能导致不公平和不可靠的评估。最近的评估方法试图通过结合物体属性或在描述中添加位置和特性来解决这个问题。然而,由于这些属性和位置依赖于图像的特定细节而不是类别,如果没有通过人类标注提供精确描述,检测器就无法做出准确预测。本文介绍了3F-OVD,这是一个将监督的精细粒度对象检测扩展到开放词汇设置的新任务。我们的任务是直观和有挑战性的,需要深入理解精细粒度的描述,并仔细注意图像中的精细粒度细节,以准确检测精细粒度的物体。此外,由于合格的精细粒度对象检测数据集稀缺,我们创建了一个新的数据集NEU-171K,该数据集既适用于监督设置也适用于开放词汇设置。我们在自己的数据集上对主流目标检测器进行了这两种设置的基准测试。此外,我们还提出了一种简单有效的后处理技术。
论文及项目相关链接
PDF 8 pages, 4 figures
Summary
本文提出一种新型任务3F-OVD,将监督的精细粒度目标检测扩展到开放词汇设置。针对现有开放词汇目标检测评估方法的不公平和不可靠问题,引入精细粒度描述和图像细节的关注,以准确检测精细粒度目标。同时,为应对缺乏合格的精细粒度目标检测数据集的问题,创建了一个新的数据集NEU-171K,适用于监督和开放词汇设置。此外,还提出了一种简单有效的后处理技术。
Key Takeaways
- 开放词汇检测器可定位并识别新型类别中的对象,但使用的视觉感知语言词汇数据的差异会导致评估不公平和不可靠。
- 现有评估方法试图通过结合对象属性或添加位置和特性来解决该问题,但依赖于特定图像细节而非类别描述的限制使得预测不准确。
- 提出一种新型任务3F-OVD,将精细粒度目标检测扩展到开放词汇设置,要求深入理解精细粒度描述和图像细节。
- 创建新的数据集NEU-171K,适用于监督和开放词汇设置下的目标检测任务。
- 引入了一种简单有效的后处理技术以提高目标检测的准确性。
- 新型任务和数据集有助于解决现有目标检测方法的局限性,促进开放词汇环境下更准确的对象识别和检测。
点此查看论文截图

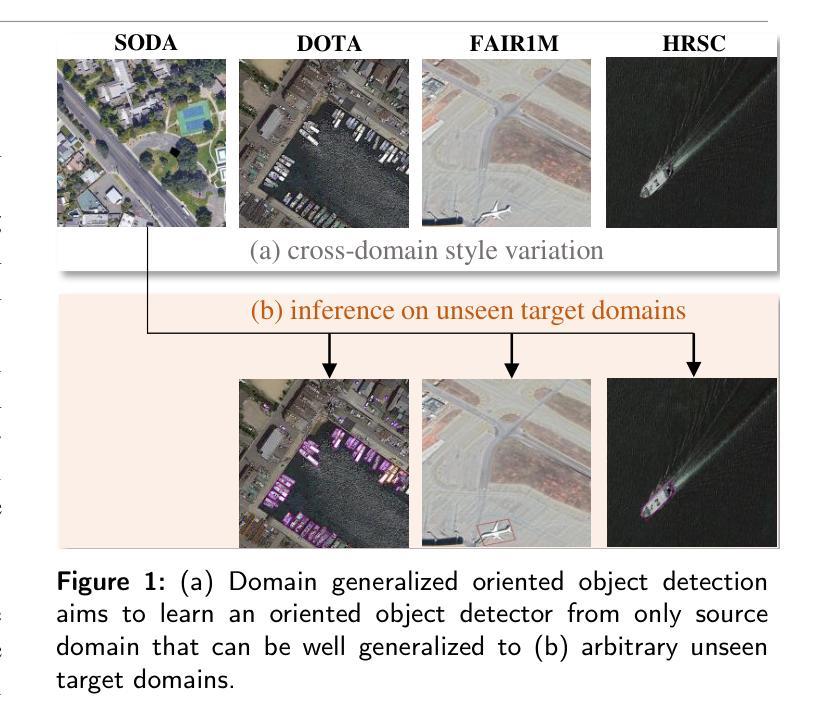
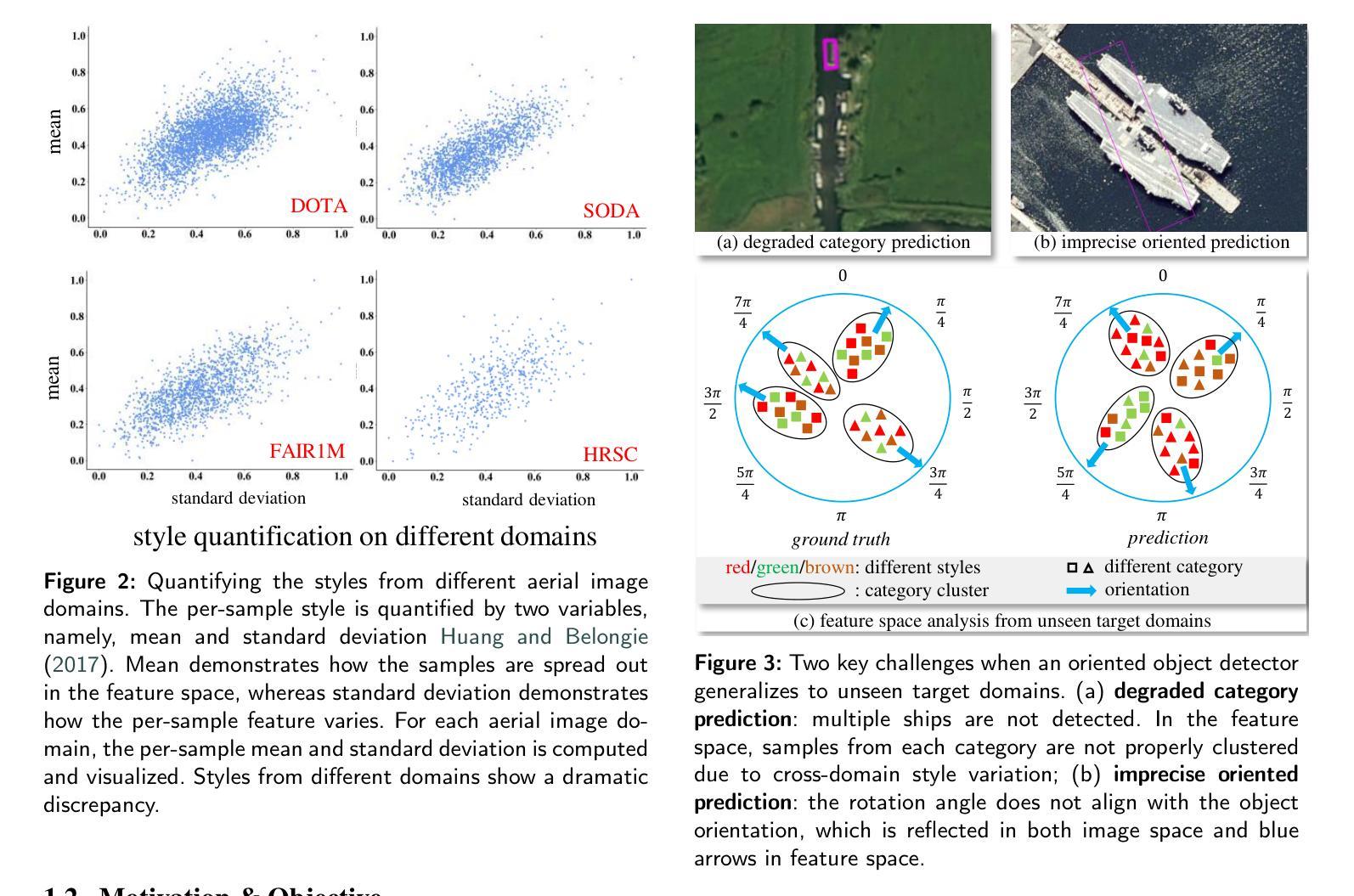
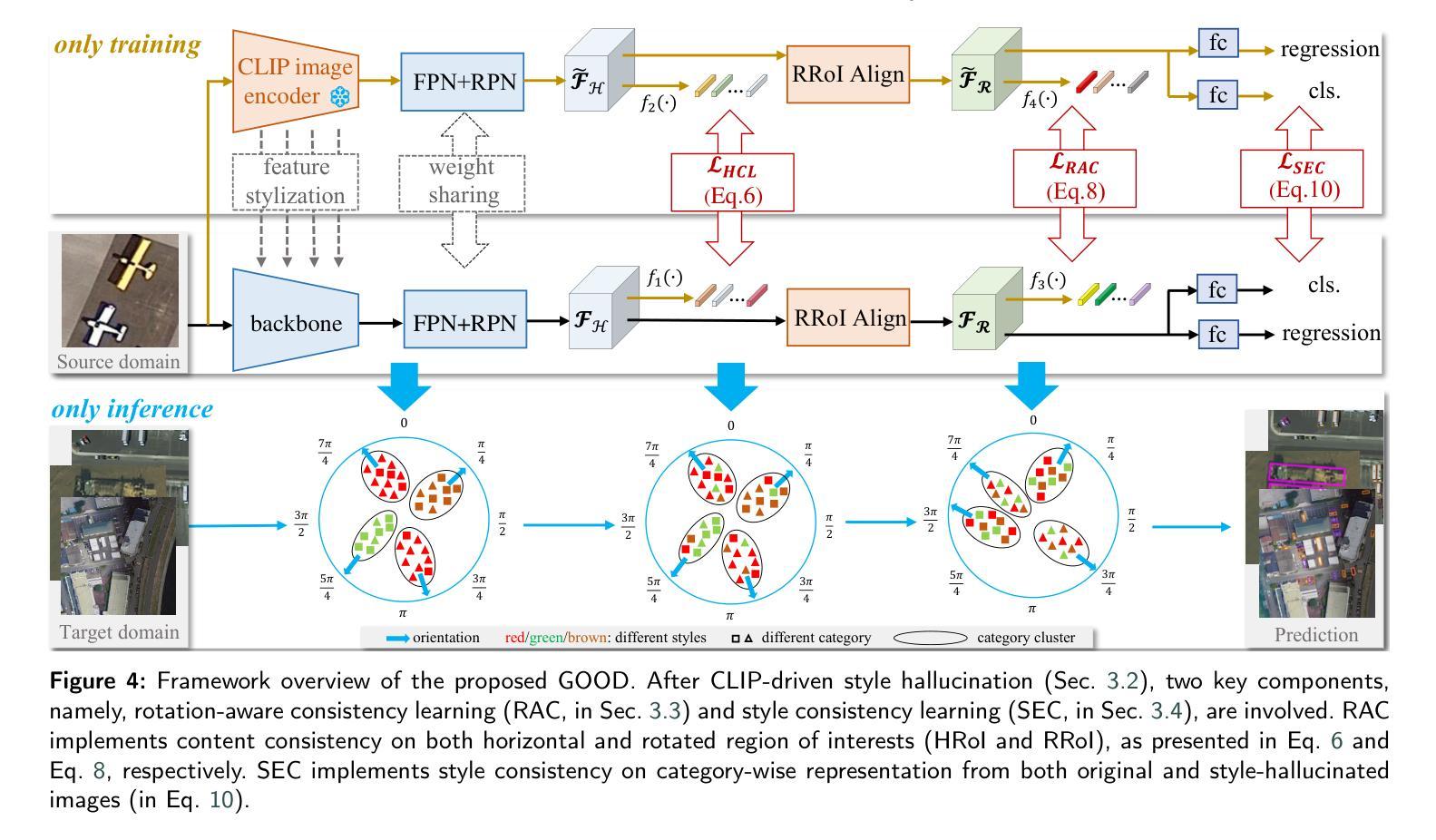
GOOD: Towards Domain Generalized Orientated Object Detection
Authors:Qi Bi, Beichen Zhou, Jingjun Yi, Wei Ji, Haolan Zhan, Gui-Song Xia
Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
近年来,定向目标检测得到了快速发展,但大多数方法都假设训练和测试图像处于相同的统计分布下,这与现实相去甚远。在本文中,我们提出了域泛化定向目标检测的任务,旨在探索定向目标检测器在未见的任意目标域上的泛化能力。学习域泛化定向目标检测器具有特别大的挑战性,因为跨域风格变化不仅会影响内容表示,还会对方向预测造成不准确的干扰。为了应对这些挑战,我们提出了一种泛化定向目标检测器(GOOD)。它通过新兴的对比语言图像预训练(CLIP)进行风格幻觉处理,包含两个关键组件,即旋转感知内容一致性学习(RAC)和风格一致性学习(SEC)。所提出的RAC允许定向目标检测器从风格多样化的样本中学习稳定的方向表示。提出的SEC进一步稳定了不同图像风格的内容表示的泛化能力。在多个跨域设置上的广泛实验表明,GOOD的性能达到了先进水平。源代码将公开可用。
论文及项目相关链接
PDF 18 pages. accepted by ISPRS
Summary
本文提出了域泛化定向目标检测任务,旨在探索定向目标检测器在任意未见目标域上的泛化能力。针对跨域风格变化带来的挑战,本文提出了一种广义定向目标检测器(GOOD),通过对比语言图像预训练(CLIP)进行风格幻觉,并包含两个关键组件:旋转感知内容一致性学习(RAC)和风格一致性学习(SEC)。RAC使定向目标检测器能够从风格多样化的样本中学习稳定的方位表示,而SEC进一步稳定了不同图像风格的内容表示的泛化能力。在多种跨域设置上的广泛实验表明,GOOD具有领先水平。
Key Takeaways
- 本文提出了一个新的任务:域泛化定向目标检测,关注定向目标检测器在多种不同领域上的泛化能力。
- 跨域风格变化对定向目标检测带来了挑战,影响了内容表示和方位预测的准确性。
- 提出了一种新的广义定向目标检测器(GOOD),包含两个关键组件:RAC和SEC。
- RAC通过学习稳定的方位表示,帮助检测器从风格多样化的样本中获取信息。
- SEC提高了内容表示在不同图像风格中的泛化能力。
- 在多个跨域设置上的实验表明,GOOD具有领先水平。
点此查看论文截图