⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Authors:Chongjun Tu, Lin Zhang, Pengtao Chen, Peng Ye, Xianfang Zeng, Wei Cheng, Gang Yu, Tao Chen
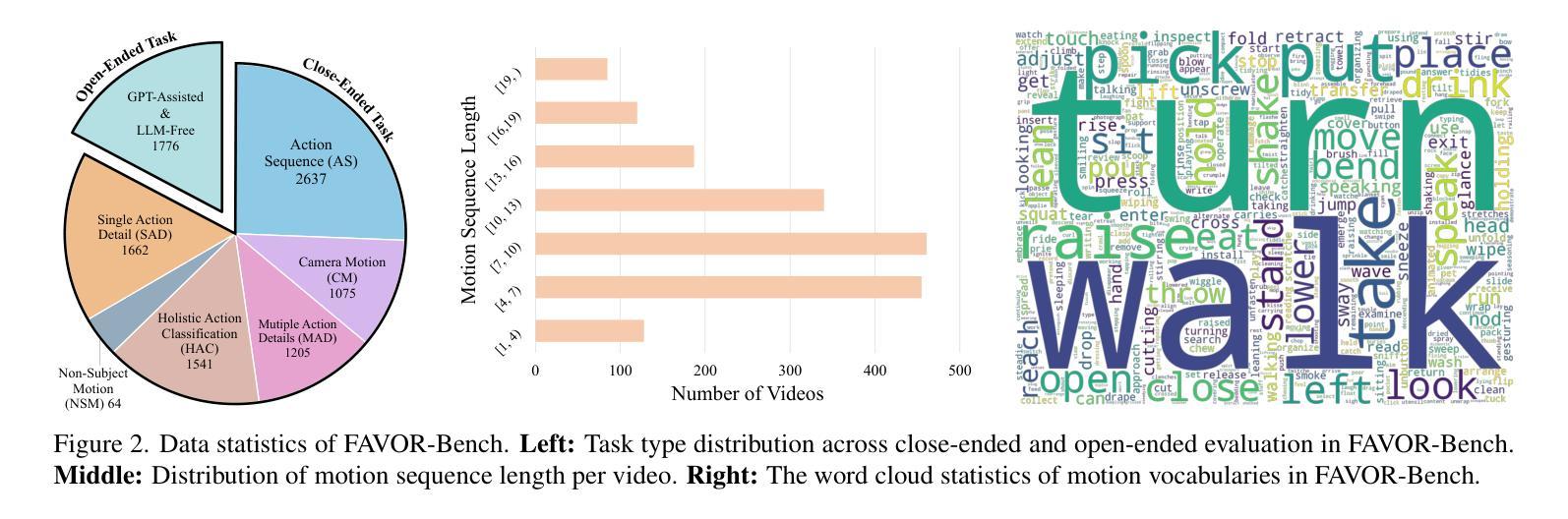
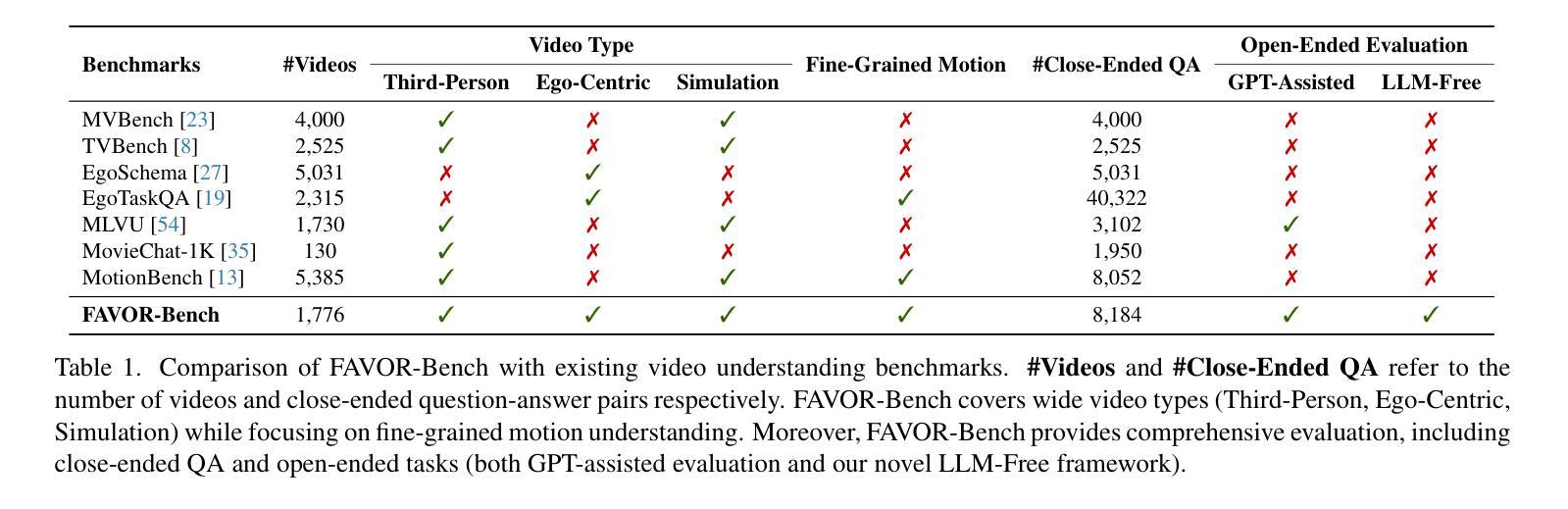
Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.
多模态大型语言模型(MLLMs)在视频内容理解方面表现出了显著的能力,但在精细运动理解方面仍存在困难。为了全面评估现有MLLMs的运动理解能力,我们引入了FAVOR-Bench,它包括1776个带有各种运动的结构化手动注释的视频。我们的基准测试包括封闭式和开放式任务。在封闭式评估中,我们精心设计了8184个涵盖六个不同子任务的多项选择题对。在开放式评估中,我们开发了一种新颖、成本效益高的无LLM方法和一种GPT辅助的标题评估方法,前者可以提高基准测试的可解释性和可重复性。与21个最新MLLMs的综合实验表明,它们在理解和描述视频运动中的详细时间动态方面存在重大局限性。为了缓解这一局限性,我们进一步构建了FAVOR-Train数据集,其中包括17152个带有精细运动注释的视频。在FAVOR-Train上对Qwen2.5-VL进行微调的结果在TVBench、MotionBench和我们的FAAVOR-Bench的运动相关任务上均有所改进。全面的评估结果表明,提出的FAVOT-Bench和FAVOT-Train为社区提供了宝贵的工具,用于开发更强大的视频理解模型。项目页面:[https://favor-bench.github.io/]
论文及项目相关链接
PDF FAVOR-Bench project page: https://favor-bench.github.io/
Summary
该文本介绍了针对视频内容理解的多模态大型语言模型(MLLMs)的最新研究进展。文章强调了MLLMs在精细动作理解方面的局限性,并为此引入了FAVOR-Bench评估基准,包含用于评估多种动作理解任务的1,776个视频。此外,文章还介绍了为开放评估设计的成本效益高且可解释的评估方法,并建立了包含精细动作标注的FAVOR-Train数据集用于训练。这些工具将有助于开发更强大的视频理解模型。项目页面可通过链接访问:https://favor-bench.github.io/。
Key Takeaways
- MLLMs在视频内容理解方面表现出卓越的能力,但在精细动作理解上仍有困难。
- FAVOR-Bench包含用于评估MLLMs运动理解能力的结构化手动标注视频,涵盖封闭式和开放式任务。
- FAVOR-Bench包含多种设计良好的选择题和答案对,以及新颖的评估方法,旨在提高评估的可解释性和可重复性。
- 通过与最新的MLLMs进行全面实验,揭示了其在理解视频精细时间动态方面的显著局限性。
- 为缓解这一局限性,建立了包含精细动作标注的FAVOR-Train数据集,对Qwen2.5-VL模型进行微调可有效提升性能。
- FAVOR-Bench和FAVOR-Train为开发更强大的视频理解模型提供了有价值的工具。
点此查看论文截图