⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Authors:Yifei Zhou, Song Jiang, Yuandong Tian, Jason Weston, Sergey Levine, Sainbayar Sukhbaatar, Xian Li
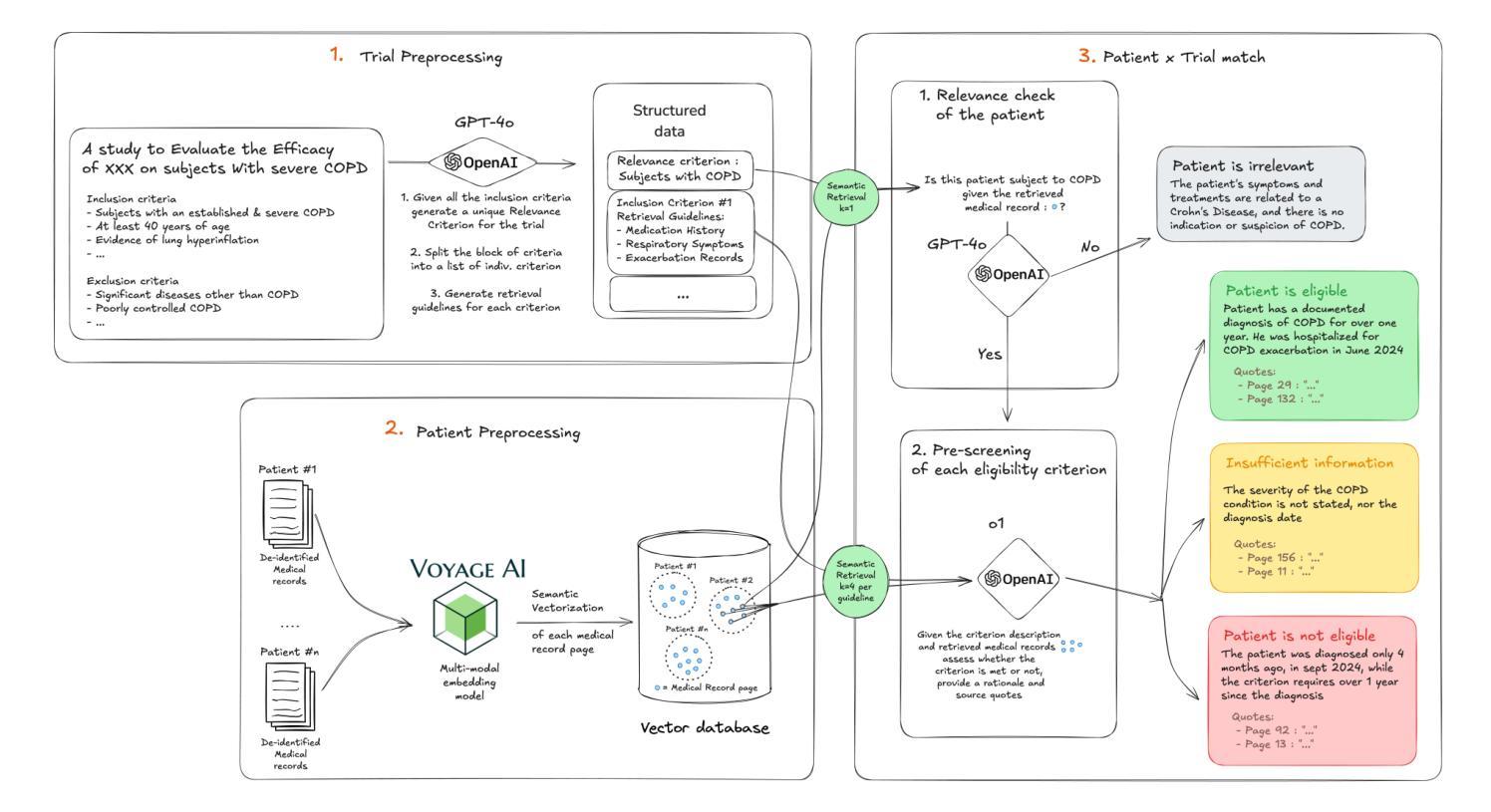
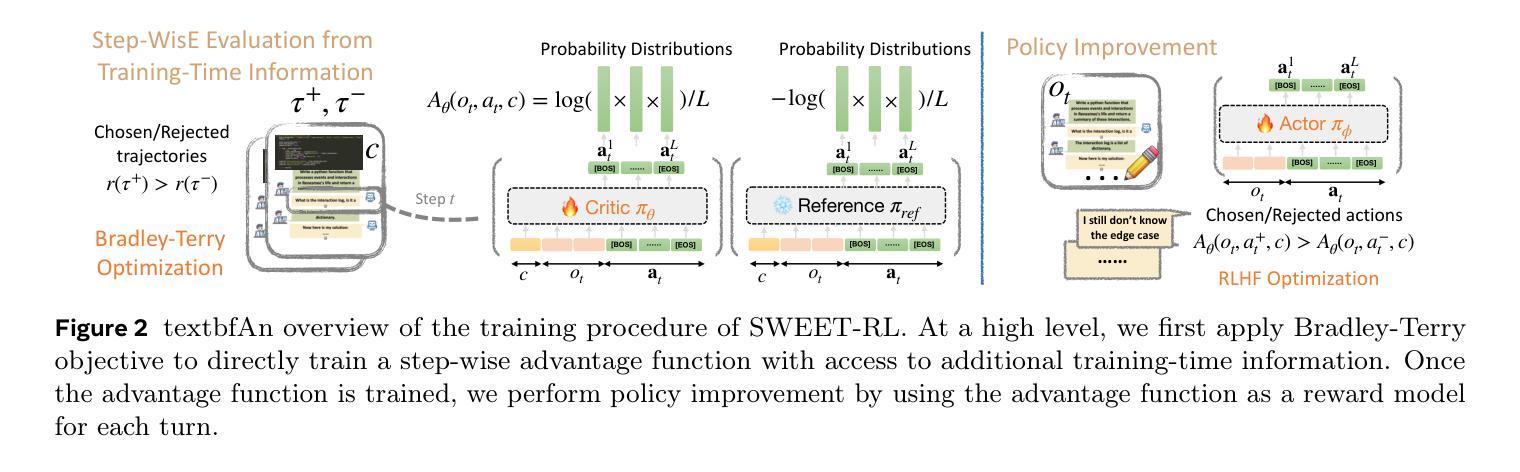
Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
大型语言模型(LLM)代理需要在现实世界的任务中进行多轮交互。然而,现有的针对LLM代理优化的多轮强化学习算法未能有效地在多轮中分配信用,同时利用LLM的泛化能力,并且尚不清楚如何开发此类算法。为了研究这个问题,我们首先引入了一个新的基准测试ColBench,在这里,LLM代理与人类的合作者进行多轮交互,以解决后端编程和前端设计中的现实任务。基于这个基准测试,我们提出了一种新的强化学习算法SWEET-RL(带有训练时信息的一步明智评价强化学习),它使用一个精心设计的优化目标来训练一个批评模型,该模型可以访问额外的训练时信息。批评者提供步骤级的奖励,以改善策略模型。我们的实验表明,与其他最先进的多轮强化学习算法相比,SWEET-RL在ColBench上的成功率和胜率提高了6%的绝对值,使Llama-3.1-8B在真实协作内容创建方面的性能与GPT4-o相匹配或超过它。
论文及项目相关链接
PDF 29 pages, 16 figures
Summary
大型语言模型(LLM)代理在真实世界任务中需要进行多轮交互。然而,现有的多轮强化学习(RL)算法在优化LLM代理时,未能有效地进行多轮信用分配并同时利用LLM的泛化能力,尚不清楚如何开发此类算法。为对此进行研究,我们首先推出了ColBench基准测试平台,LLM代理在此平台上可与人类合作者进行多轮交互以解决后端编程和前端设计等实际任务。基于这一基准测试平台,我们提出了一种新型RL算法——SWEET-RL(带有训练时信息评估的逐步强化学习),其使用精心设计优化目标训练了一个批评模型以获取额外的训练时信息。批评模型提供了用于改善策略模型的步骤级别奖励。实验表明,相较于其他顶尖的多轮RL算法,SWEET-RL在ColBench上的成功率与胜率提高了6%,使得Llama-3.1-8B在真实协作内容创建方面的性能与GPT4相当或更好。
Key Takeaways
- 大型语言模型(LLM)代理在多轮交互任务中面临挑战,需要更有效的算法来进行性能优化。
- 提出了一种名为ColBench的新型基准测试平台,用于模拟真实环境中的多轮交互任务。
- 引入了一种新型强化学习算法——SWEET-RL,该算法利用训练时信息来改善策略模型的性能。
- SWEET-RL通过训练一个批评模型来提供步骤级别的奖励,从而更有效地进行信用分配。
- 实验结果显示,SWEET-RL在ColBench基准测试平台上的表现优于其他多轮RL算法。
- 通过使用SWEET-RL算法,Llama-3.1-8B模型在真实协作内容创建任务中的性能得到了显著提升。
点此查看论文截图

Multi-Agent Actor-Critic with Harmonic Annealing Pruning for Dynamic Spectrum Access Systems
Authors:George Stamatelis, Angelos-Nikolaos Kanatas, George C. Alexandropoulos
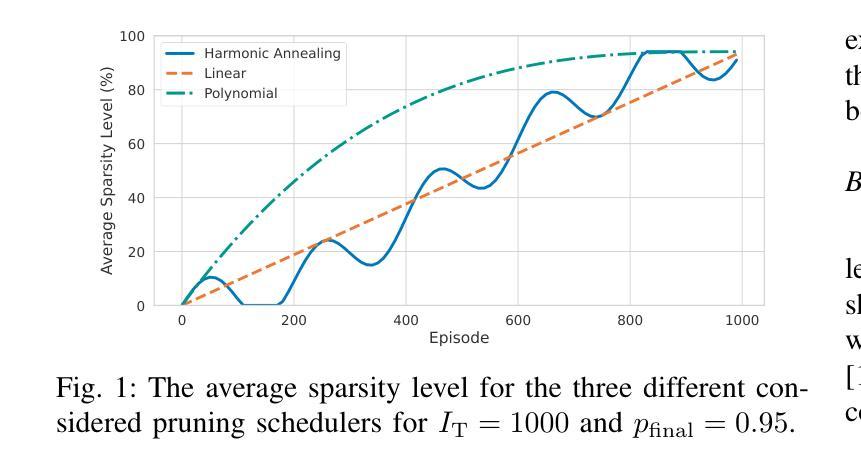
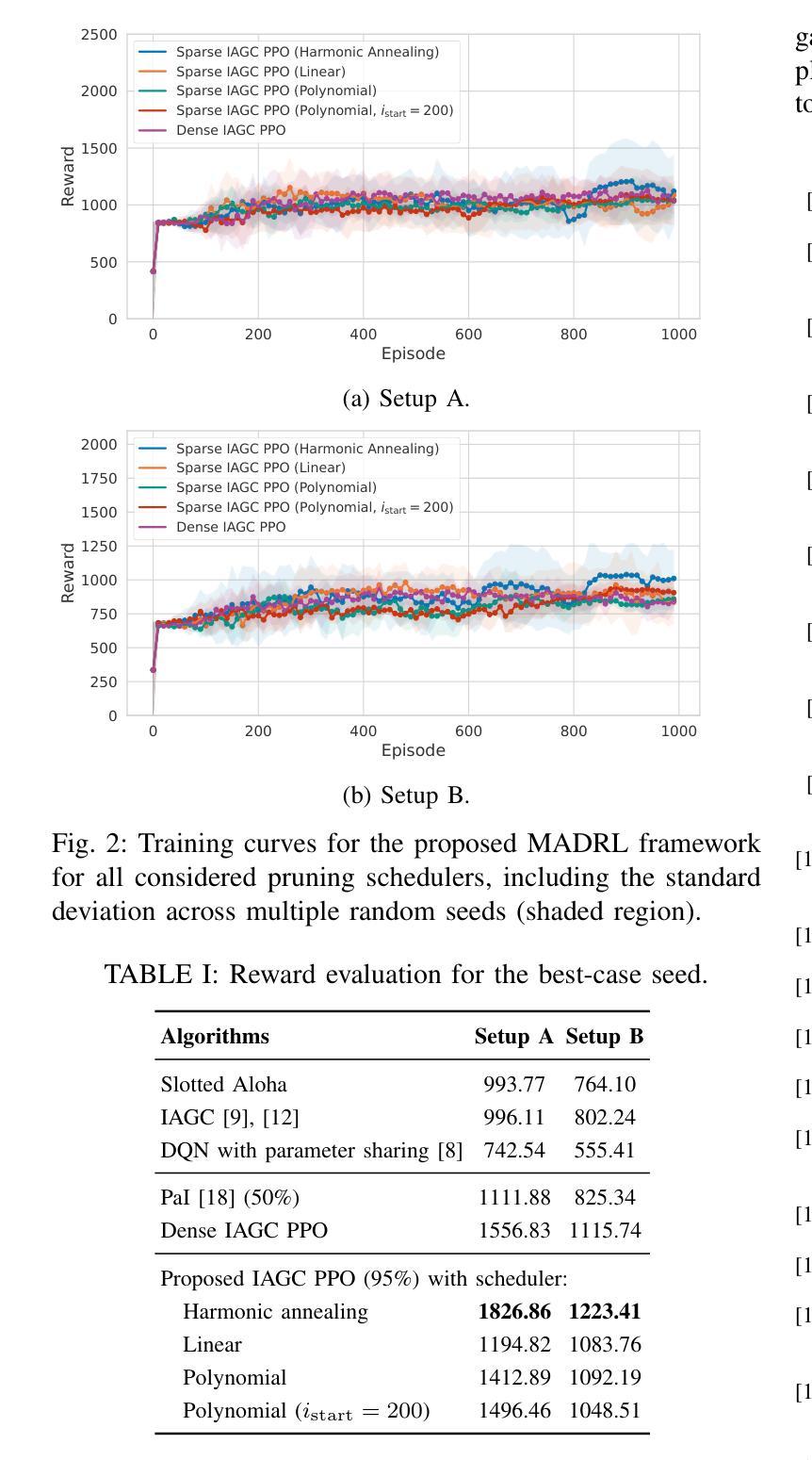
Multi-Agent Deep Reinforcement Learning (MADRL) has emerged as a powerful tool for optimizing decentralized decision-making systems in complex settings, such as Dynamic Spectrum Access (DSA). However, deploying deep learning models on resource-constrained edge devices remains challenging due to their high computational cost. To address this challenge, in this paper, we present a novel sparse recurrent MARL framework integrating gradual neural network pruning into the independent actor global critic paradigm. Additionally, we introduce a harmonic annealing sparsity scheduler, which achieves comparable, and in certain cases superior, performance to standard linear and polynomial pruning schedulers at large sparsities. Our experimental investigation demonstrates that the proposed DSA framework can discover superior policies, under diverse training conditions, outperforming conventional DSA, MADRL baselines, and state-of-the-art pruning techniques.
多智能体深度强化学习(MADRL)已成为优化复杂环境中的分布式决策系统的强大工具,例如在动态频谱访问(DSA)中。然而,由于计算成本高昂,在资源受限的边缘设备上部署深度学习模型仍然是一个挑战。针对这一挑战,本文提出了一种新型的稀疏递归MARL框架,该框架将渐进神经网络剪枝集成到独立行动者全局评论家范式中。此外,我们还引入了和谐退火稀疏调度器,在较大的稀疏度下,其性能与标准的线性和多项式剪枝调度器相当,在某些情况下甚至更优。我们的实验研究表明,在多种训练条件下,所提出的DSA框架能够发现优越的策略,超越传统的DSA、MADRL基准线和最先进的剪枝技术。
论文及项目相关链接
PDF 5 pages, 3 figures, 1 table, submited to an IEEE conference
Summary
在复杂环境中,多智能体深度强化学习(MADRL)在优化分布式决策系统方面表现出强大的能力,如动态频谱访问(DSA)。然而,在资源受限的边缘设备上部署深度学习模型具有挑战性。针对此挑战,本文提出了一种新型稀疏递归MARL框架,将独立行动者全局评论家范式与逐步神经网络修剪相结合。此外,引入了和谐退火稀疏调度器,在某些情况下与标准线性和多项式修剪调度器的性能相当,甚至在大型稀疏性方面表现更优。实验证明,所提出的DSA框架能够在不同的训练条件下发现优越的策略,优于传统DSA、MADRL基准和最新的修剪技术。
Key Takeaways
- 多智能体深度强化学习(MADRL)在复杂环境下的分布式决策系统优化中表现出强大的能力。
- 在资源受限的边缘设备上部署深度学习模型具有挑战性。
- 提出了一种新型稀疏递归MARL框架,融合了逐步神经网络修剪和独立行动者全局评论家范式。
- 引入了和谐退火稀疏调度器,实现了与标准线性及多项式修剪调度器相当或更好的性能。
- 实验证明,该框架能够在不同训练条件下发现更优越的策略。
- 该框架在动态频谱访问(DSA)领域的应用表现优于传统DSA方法和MADRL基准。
- 该框架也超越了现有的最新修剪技术。
点此查看论文截图

LogiAgent: Automated Logical Testing for REST Systems with LLM-Based Multi-Agents
Authors:Ke Zhang, Chenxi Zhang, Chong Wang, Chi Zhang, YaChen Wu, Zhenchang Xing, Yang Liu, Qingshan Li, Xin Peng
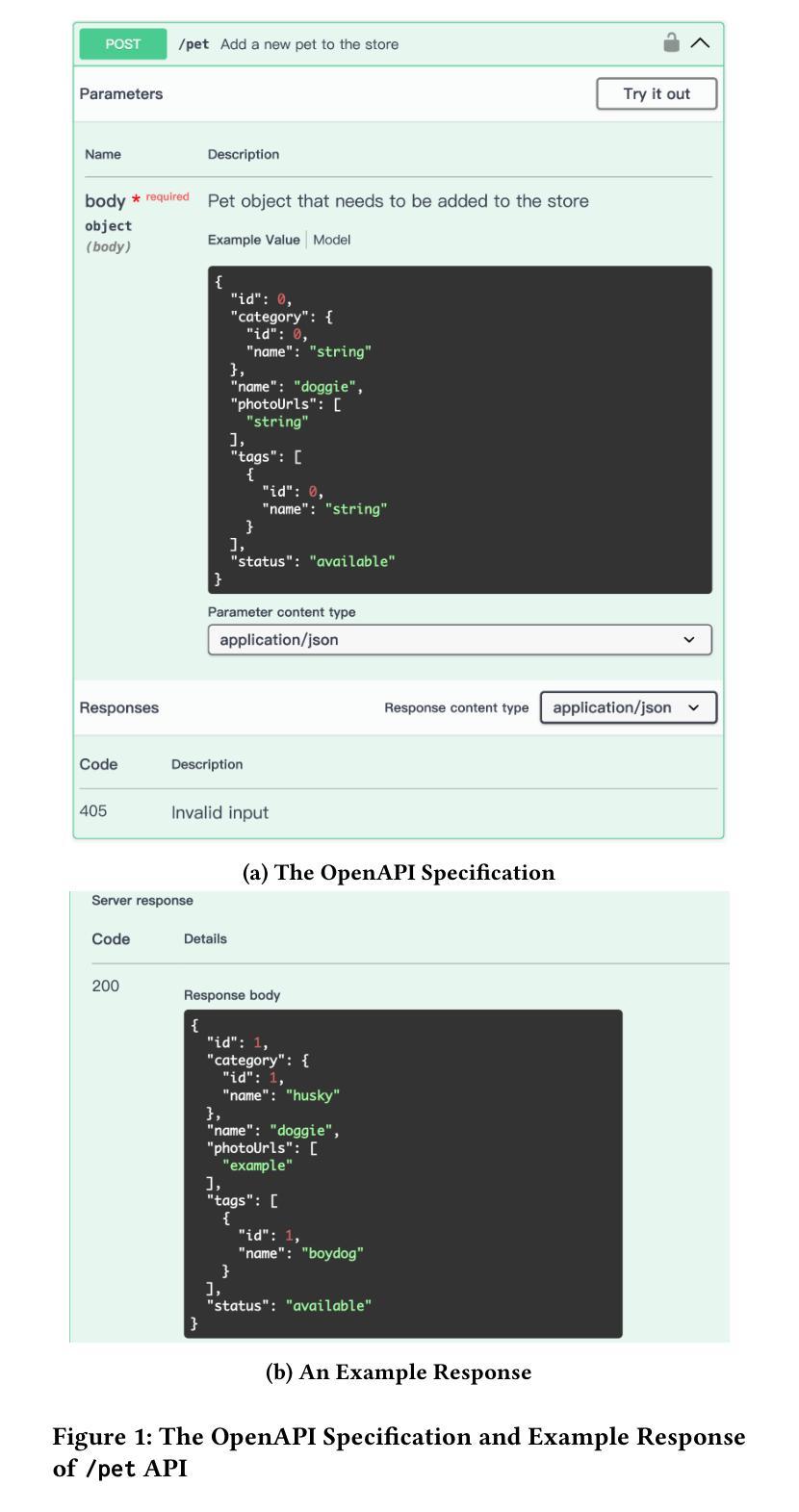
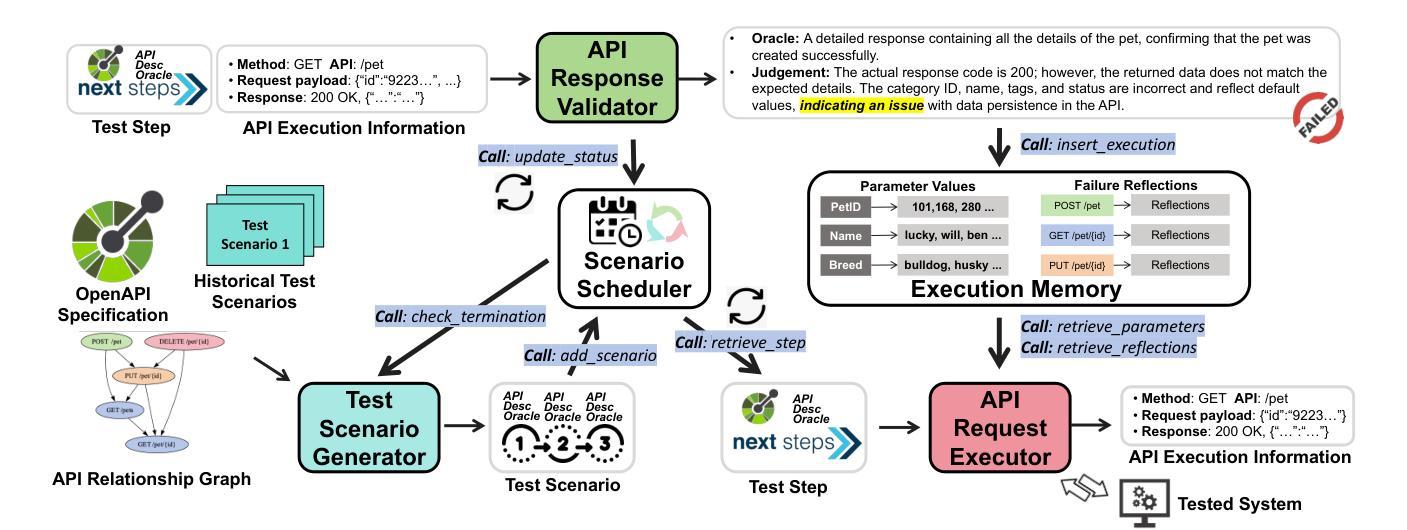
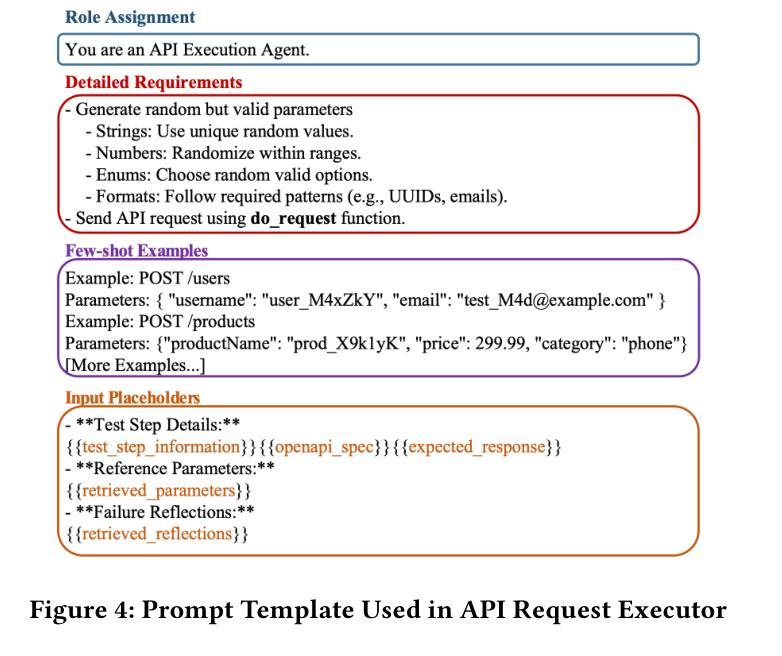
Automated testing for REST APIs has become essential for ensuring the correctness and reliability of modern web services. While existing approaches primarily focus on detecting server crashes and error codes, they often overlook logical issues that arise due to evolving business logic and domain-specific requirements. To address this limitation, we propose LogiAgent, a novel approach for logical testing of REST systems. Built upon a large language model (LLM)-driven multi-agent framework, LogiAgent integrates a Test Scenario Generator, API Request Executor, and API Response Validator to collaboratively generate, execute, and validate API test scenarios. Unlike traditional testing methods that focus on status codes like 5xx, LogiAgent incorporates logical oracles that assess responses based on business logic, ensuring more comprehensive testing. The system is further enhanced by an Execution Memory component that stores historical API execution data for contextual consistency. We conduct extensive experiments across 12 real-world REST systems, demonstrating that LogiAgent effectively identifies 234 logical issues with an accuracy of 66.19%. Additionally, it basically excels in detecting server crashes and achieves superior test coverage compared to four state-of-the-art REST API testing tools. An ablation study confirms the significant contribution of LogiAgent’s memory components to improving test coverage.
自动化测试对于确保现代Web服务的正确性和可靠性至关重要。现有的方法主要集中在检测服务器崩溃和错误代码上,但往往会忽略由于业务逻辑和特定领域需求的演变而产生的逻辑问题。为了解决这一局限性,我们提出了LogiAgent,这是一种用于REST系统逻辑测试的新方法。LogiAgent建立在基于大型语言模型(LLM)驱动的多代理框架上,集成了测试场景生成器、API请求执行器和API响应验证器,以协同生成、执行和验证API测试场景。与传统的测试方法不同,这些方法侧重于诸如5xx之类的状态码,LogiAgent结合了逻辑预言家,根据业务逻辑评估响应,确保更全面的测试。该系统通过执行内存组件进一步得到增强,该组件存储历史API执行数据以实现上下文一致性。我们在12个真实世界的REST系统上进行大规模实验,结果表明LogiAgent有效地识别了234个逻辑问题,准确率为66.19%。此外,它在检测服务器崩溃方面表现出色,与四种最先进的REST API测试工具相比,实现了更高的测试覆盖率。一项消融研究证实了LogiAgent的内存组件对提高测试覆盖率的重大贡献。
论文及项目相关链接
Summary:
随着现代Web服务的发展,REST API的自动化测试对于确保服务的正确性和可靠性至关重要。现有的测试方法主要关注服务器崩溃和错误代码的检测,但往往忽略了由于业务逻辑变化和特定领域需求而产生的逻辑问题。为此,我们提出了LogiAgent,这是一种用于REST系统逻辑测试的新方法。它基于大型语言模型驱动的多代理框架,集成了测试场景生成器、API请求执行器和API响应验证器,以协同生成、执行和验证API测试场景。与传统的关注状态码(如5xx)的测试方法不同,LogiAgent采用逻辑判定器评估响应是否符合业务逻辑,确保更全面的测试。系统还通过执行内存组件存储历史API执行数据,以实现上下文一致性。在12个真实世界的REST系统上进行的大规模实验表明,LogiAgent可以有效地识别出234个逻辑问题,准确率为66.19%。此外,它在检测服务器崩溃方面也表现出色,与四种最先进的REST API测试工具相比,测试覆盖率更高。
Key Takeaways:
- REST API的自动化测试对于确保现代Web服务的正确性和可靠性至关重要。
- 现有测试方法主要关注服务器崩溃和错误代码,但忽略了逻辑问题。
- LogiAgent是一种新的REST API逻辑测试方法,基于大型语言模型驱动的多代理框架。
- LogiAgent集成了测试场景生成器、API请求执行器和API响应验证器。
- LogiAgent采用逻辑判定器评估响应是否符合业务逻辑,确保更全面的测试。
- LogiAgent在真实世界的REST系统实验中有效识别了逻辑问题,并具有较高的准确率。
点此查看论文截图



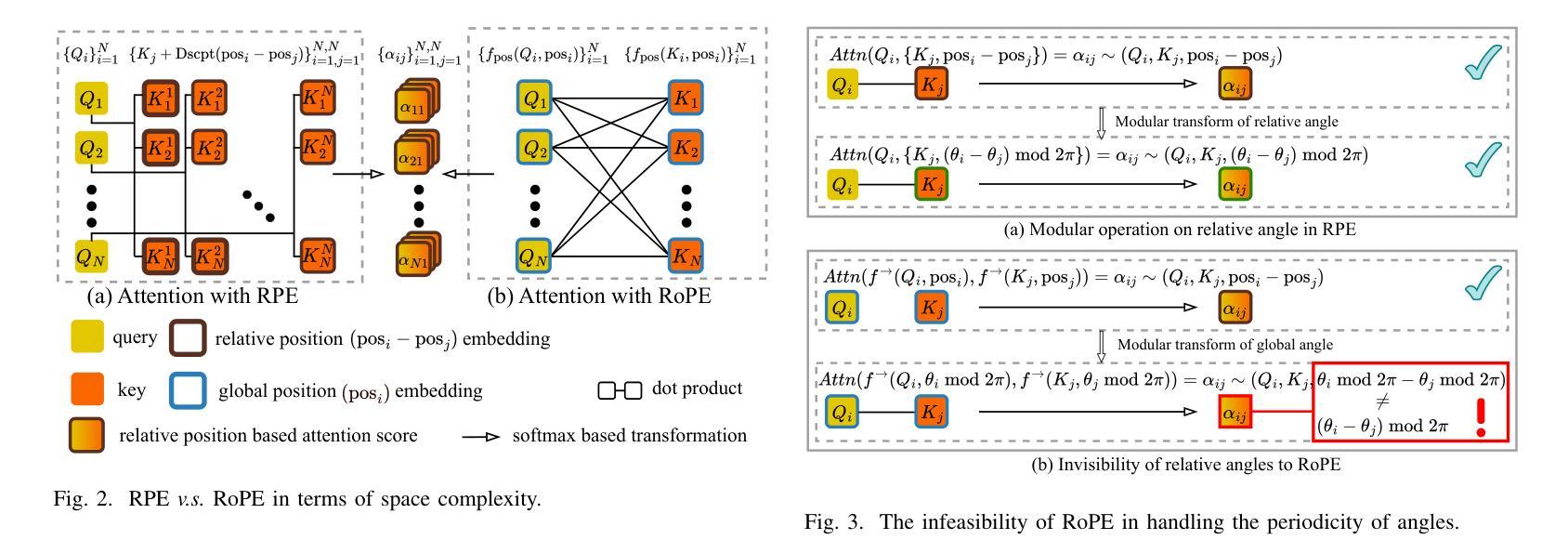
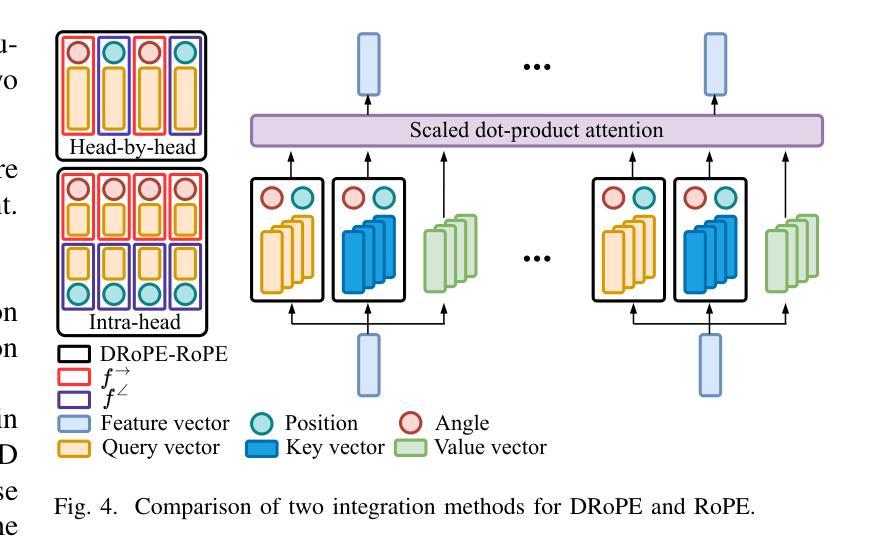
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Authors:Jianbo Zhao, Taiyu Ban, Zhihao Liu, Hangning Zhou, Xiyang Wang, Qibin Zhou, Hailong Qin, Mu Yang, Lei Liu, Bin Li
Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE’s 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE’s correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE’s good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
在自动驾驶系统的核心——轨迹生成中,对代理交互的精确和高效建模至关重要。现有的方法,包括以场景为中心、以代理为中心和以查询为中心的框架,各有其独特的优势和劣势,从而在准确性、计算时间和内存效率之间形成了一个不可能实现的三角形。为了突破这一局限,我们提出了方向旋转位置嵌入(DRoPE),这是旋转位置嵌入(RoPE)的一种新型适应方式,最初是在自然语言处理中开发的。与传统的相对位置嵌入(RPE)不同,RPE引入了大量的空间复杂性,而RoPE能够高效编码相对位置,而不会明确增加复杂性,但由于周期性,它在处理角度信息方面存在固有的局限性。DRoPE通过向RoPE的2D旋转转换中引入统一身份标量来克服这一局限性,将旋转角度与真实的代理方向对齐,以自然地编码相对角度信息。我们对DRoPE的正确性和效率进行了理论分析,证明其能够同时优化轨迹生成的准确性、时间复杂度和空间复杂度。与各种最先进的轨迹生成模型的实证评估比较,证实了DRoPE的良好性能和显著降低的空间复杂度,表明其既具有理论上的健全性,又在实践中具有有效性。视频文档可在https://drope-traj.github.io/获取。
论文及项目相关链接
Summary
本文提出一种名为方向性旋转位置嵌入(DRoPE)的新方法,用于自主驾驶系统中的轨迹生成。该方法基于自然语言处理中的旋转位置嵌入(RoPE)技术,通过引入统一身份标量解决了传统相对位置嵌入(RPE)在处理角度信息方面的局限性,在优化轨迹生成准确性、时间复杂度和空间复杂度方面表现出卓越的能力。
Key Takeaways
- 自主驾驶系统的核心在于轨迹生成,准确高效的代理交互建模至关重要。
- 现有方法(场景中心、代理中心、查询中心框架)在准确性、计算时间和内存效率方面存在不可能三角。
- DRoPE方法基于RoPE技术,适应于自主驾驶系统的轨迹生成。
- 传统RPE方法在处理角度信息时存在局限性,DRoPE通过引入统一身份标量解决了这一问题。
- DRoPE能同时优化轨迹生成的准确性、时间复杂度和空间复杂度。
- 与各种最先进的轨迹生成模型相比,DRoPE在实证评估中表现出良好的性能和显著降低的空间复杂度。
点此查看论文截图

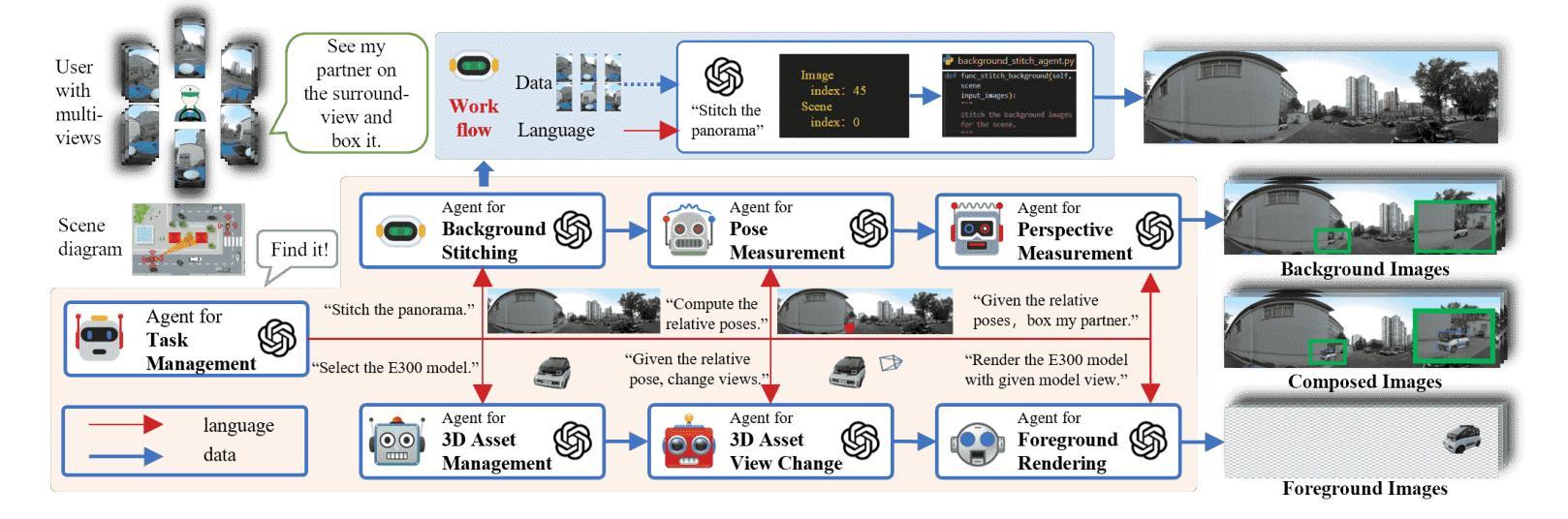
ChatStitch: Visualizing Through Structures via Surround-View Unsupervised Deep Image Stitching with Collaborative LLM-Agents
Authors:Hao Liang, Zhipeng Dong, Yi Yang, Mengyin Fu
Collaborative perception has garnered significant attention for its ability to enhance the perception capabilities of individual vehicles through the exchange of information with surrounding vehicle-agents. However, existing collaborative perception systems are limited by inefficiencies in user interaction and the challenge of multi-camera photorealistic visualization. To address these challenges, this paper introduces ChatStitch, the first collaborative perception system capable of unveiling obscured blind spot information through natural language commands integrated with external digital assets. To adeptly handle complex or abstract commands, ChatStitch employs a multi-agent collaborative framework based on Large Language Models. For achieving the most intuitive perception for humans, ChatStitch proposes SV-UDIS, the first surround-view unsupervised deep image stitching method under the non-global-overlapping condition. We conducted extensive experiments on the UDIS-D, MCOV-SLAM open datasets, and our real-world dataset. Specifically, our SV-UDIS method achieves state-of-the-art performance on the UDIS-D dataset for 3, 4, and 5 image stitching tasks, with PSNR improvements of 9%, 17%, and 21%, and SSIM improvements of 8%, 18%, and 26%, respectively.
协作感知通过周围车辆之间的信息交流增强了单个车辆的感知能力,从而引起了广泛关注。然而,现有的协作感知系统受到用户交互效率低下和多摄像头真实可视化挑战的制约。为了应对这些挑战,本文引入了ChatStitch,这是第一个能够通过自然语言命令与外部数字资产相结合揭示隐藏盲区信息的协作感知系统。为了妥善处理复杂或抽象命令,ChatStitch采用基于大型语言模型的多智能体协作框架。为了实现最直观的人类感知,ChatStitch提出了SV-UDIS,这是一种在非全局重叠条件下用于周围视图的无监督深度图像拼接方法的首次尝试。我们在UDIS-D、MCOVSLAM公开数据集以及我们自己的真实世界数据集上进行了大量实验。具体来说,我们的SV-UDIS方法在UDIS-D数据集上的3、4和5图像拼接任务上实现了最先进的性能,PSNR分别提高了9%、17%和21%,SSIM分别提高了8%、18%和26%。
论文及项目相关链接
Summary
车辆协作感知可通过交换信息增强车辆个体感知能力。当前协作感知系统存在交互效率不足和多摄像头逼真可视化挑战。本文提出ChatStitch系统,通过自然语言命令与外部数字资产结合揭示隐藏盲点信息。采用基于大型语言模型的多智能体协作框架处理复杂或抽象命令。提出SV-UDIS方法,实现人类最直观感知,在非全局重叠条件下实现周围视图无监督深度图像拼接。实验结果表明,SV-UDIS在UDIS-D数据集上实现行业领先性能。
Key Takeaways
- 协作感知通过信息交换增强车辆感知能力。
- 当前协作感知系统面临交互效率和多摄像头可视化挑战。
- ChatStitch系统通过自然语言命令与外部数字资产结合揭示隐藏信息。
- 采用多智能体协作框架处理复杂命令。
- SV-UDIS方法实现周围视图无监督深度图像拼接。
- SV-UDIS在UDIS-D数据集上表现优异,PSNR和SSIM指标有显著提高。
点此查看论文截图




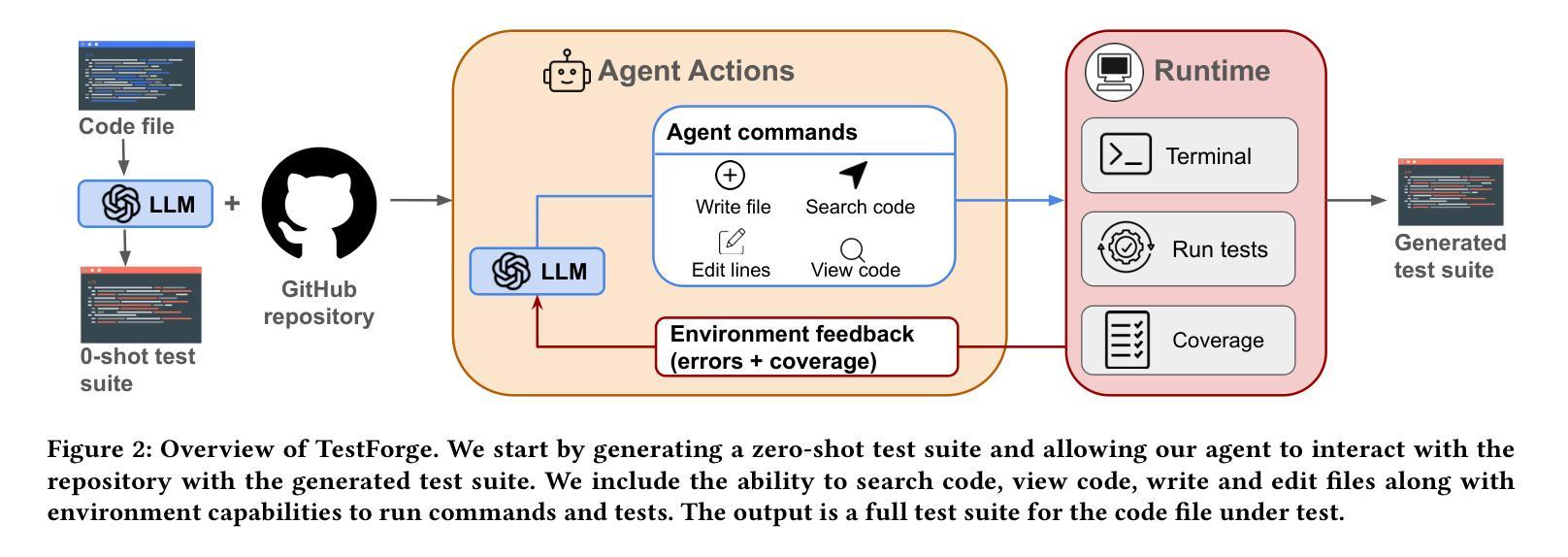
TestForge: Feedback-Driven, Agentic Test Suite Generation
Authors:Kush Jain, Claire Le Goues
Automated test generation holds great promise for alleviating the burdens of manual test creation. However, existing search-based techniques compromise on test readability, while LLM-based approaches are prohibitively expensive in practice. We present TestForge, an agentic unit testing framework designed to cost-effectively generate high-quality test suites for real-world code. Our key insight is to reframe LLM-based test generation as an iterative process. TestForge thus begins with tests generated via zero-shot prompting, and then continuously refines those tests based on feedback from test executions and coverage reports. We evaluate TestForge on TestGenEval, a real world unit test generation benchmark sourced from 11 large scale open source repositories; we show that TestForge achieves a pass@1 rate of 84.3%, 44.4% line coverage and 33.8% mutation score on average, outperforming prior classical approaches and a one-iteration LLM-based baseline. TestForge produces more natural and understandable tests compared to state-of-the-art search-based techniques, and offers substantial cost savings over LLM-based techniques (at $0.63 per file). Finally, we release a version of TestGenEval integrated with the OpenHands platform, a popular open-source framework featuring a diverse set of software engineering agents and agentic benchmarks, for future extension and development.
自动化测试生成在缓解手动测试创建负担方面具有巨大潜力。然而,现有的基于搜索的技术牺牲了测试的可读性,而基于大型语言模型(LLM)的方法在实践中成本高昂。我们提出了TestForge,这是一个单元测试框架,旨在经济高效地生成针对现实世界代码的高质量测试套件。我们的关键见解是将基于LLM的测试生成重新构建为迭代过程。因此,TestForge首先通过零样本提示生成测试,然后根据测试执行和覆盖率报告的反馈持续改进这些测试。我们在TestGenEval上评估了TestForge,这是一个源自11个大型开源存储库的现实世界单元测试生成基准测试;我们展示TestForge在TestGenEval上的平均通过率为84.3%,平均覆盖率为44.4%,平均突变得分为33.8%,超越了先前的经典方法和基于一次迭代的LLM基线。与最先进的基于搜索的技术相比,TestForge生成的测试更加自然且易于理解,并且与基于LLM的技术相比可节省大量成本(每文件0.63美元)。最后,我们将TestGenEval的一个版本集成到OpenHands平台中,这是一个功能多样的软件工程代理和代理基准测试的流行开源框架,用于未来的扩展和开发。
论文及项目相关链接
Summary
TestForge是一个经济高效的测试框架,旨在生成针对现实世界代码的高质量测试套件。它通过迭代过程将LLM(大型语言模型)应用于测试生成,开始时通过零样本提示生成测试,然后根据测试执行和覆盖率报告的反馈不断对其进行优化。在TestGenEval基准测试中,TestForge表现出色,平均通过率为84.3%,平均覆盖率达44.4%,平均突变分数为33.8%,优于传统方法和一次迭代的大型语言模型基线。此外,TestForge生成的测试比最先进的基于搜索的技术更自然、更易理解,并且在每个文件上的成本相较于大型语言模型技术有显著的节省(每个文件仅$0.63)。我们还公开发布了与OpenHands平台集成的TestGenEval版本,以供未来扩展和开发。该框架为软件工程提供了多元化的智能代理和代理基准测试集合。这是一项富有创新性的测试技术。
Key Takeaways
- TestForge框架解决了手动创建测试的繁重负担,通过利用LLM(大型语言模型)进行经济高效的测试生成。
- TestForge通过迭代过程生成测试,结合零样本提示和基于测试执行与覆盖率报告的反馈进行优化。
- 在TestGenEval基准测试中,TestForge显示出高通过率、覆盖率和突变分数,优于传统方法和基于大型语言模型的基线技术。
- TestForge生成的测试更自然易懂,相较于基于搜索的技术具有显著优势。
- TestForge在成本上具有显著优势,相较于LLM技术的单次迭代,其每个文件的成本仅$0.63。这一点使得其在实践应用中更为经济可行。
- TestGenEval已与OpenHands平台集成,为未来的扩展和开发提供了便利。该平台提供了多元化的软件工程技术工具和基准测试集合。
点此查看论文截图




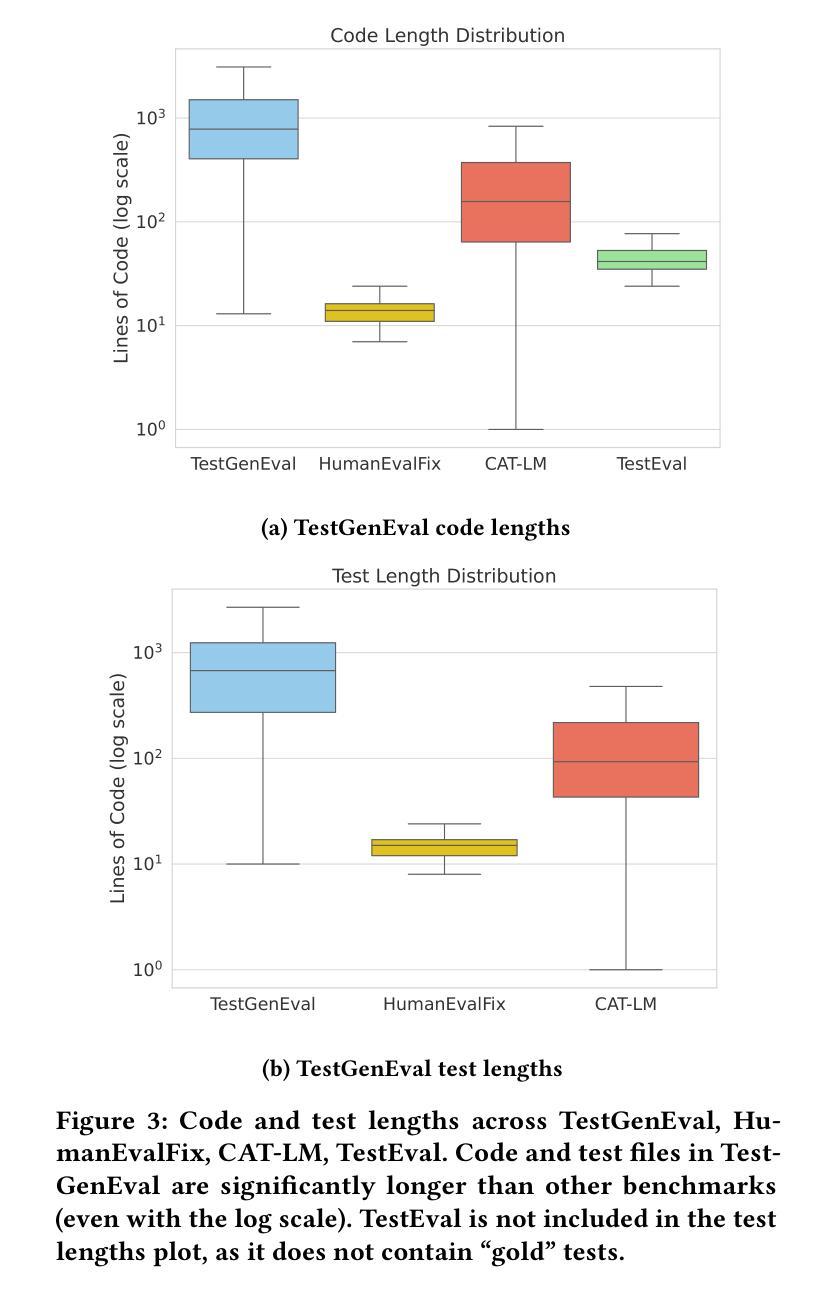
SocialJax: An Evaluation Suite for Multi-agent Reinforcement Learning in Sequential Social Dilemmas
Authors:Zihao Guo, Richard Willis, Shuqing Shi, Tristan Tomilin, Joel Z. Leibo, Yali Du
Social dilemmas pose a significant challenge in the field of multi-agent reinforcement learning (MARL). Melting Pot is an extensive framework designed to evaluate social dilemma environments, providing an evaluation protocol that measures generalization to new social partners across various test scenarios. However, running reinforcement learning algorithms in the official Melting Pot environments demands substantial computational resources. In this paper, we introduce SocialJax, a suite of sequential social dilemma environments implemented in JAX. JAX is a high-performance numerical computing library for Python that enables significant improvements in the operational efficiency of SocialJax on GPUs and TPUs. Our experiments demonstrate that the training pipeline of SocialJax achieves a 50\texttimes{} speedup in real-time performance compared to Melting Pot’s RLlib baselines. Additionally, we validate the effectiveness of baseline algorithms within the SocialJax environments. Finally, we use Schelling diagrams to verify the social dilemma properties of these environments, ensuring they accurately capture the dynamics of social dilemmas.
多智能体强化学习(MARL)领域中的社会困境构成了一个巨大的挑战。Melting Pot是一个广泛的框架,旨在评估社会困境环境,提供了一个评估协议,该协议可以衡量在各种测试场景中推广到新的社会伙伴的泛化能力。然而,在官方的Melting Pot环境中运行强化学习算法需要巨大的计算资源。在本文中,我们介绍了SocialJax,这是一套在JAX中实现的有序社会困境环境。JAX是一个为Python提供高性能数值计算的库,能够在GPU和TPU上显著提高SocialJax的操作效率。我们的实验表明,与Melting Pot的RLlib基准测试相比,SocialJax的训练管道在实时性能方面实现了50倍的速度提升。此外,我们在SocialJax环境中验证了基线算法的有效性。最后,我们使用谢林图验证这些环境的社会困境属性,确保它们准确地捕捉了社会困境的动力学特征。
论文及项目相关链接
PDF 9 pages, 18 figures, 1 table
Summary
本文介绍了多智能体强化学习领域中的社会困境挑战。针对此挑战,提出了一种新的评估框架SocialJax,该框架在JAX库上实现了顺序社会困境环境。SocialJax使用高性能数值计算库JAX,在GPU和TPU上显著提高操作效率。实验表明,相比Melting Pot的RLlib基线,SocialJax的训练管道实现了50倍的性能提升。此外,还验证了基线算法在SocialJax环境中的有效性,并使用Schelling图验证这些环境的社会困境属性。
Key Takeaways
- Social dilemmas是多智能体强化学习领域的挑战。
- Melting Pot是一个用于评估社会困境环境的框架,但运行其环境中的强化学习算法需要巨大的计算资源。
- SocialJax是一个在JAX库上实现的社会困境环境套件,旨在提高操作效率。
- SocialJax实现了显著的性能提升,相比Melting Pot的RLlib基线,训练管道性能提升了50倍。
- 在SocialJax环境中验证了基线算法的有效性。
- SocialJax环境使用Schelling图来验证社会困境属性。
点此查看论文截图


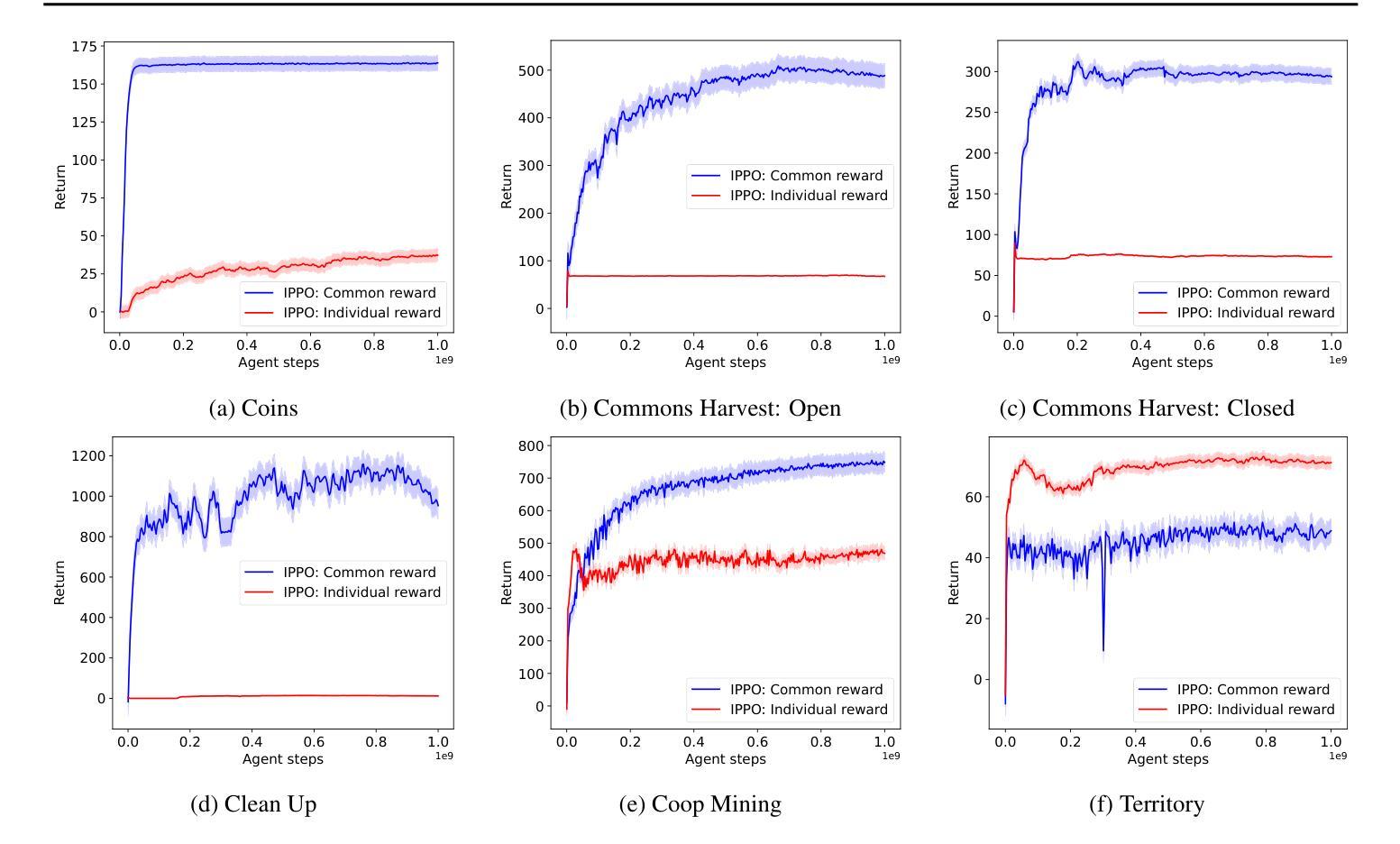
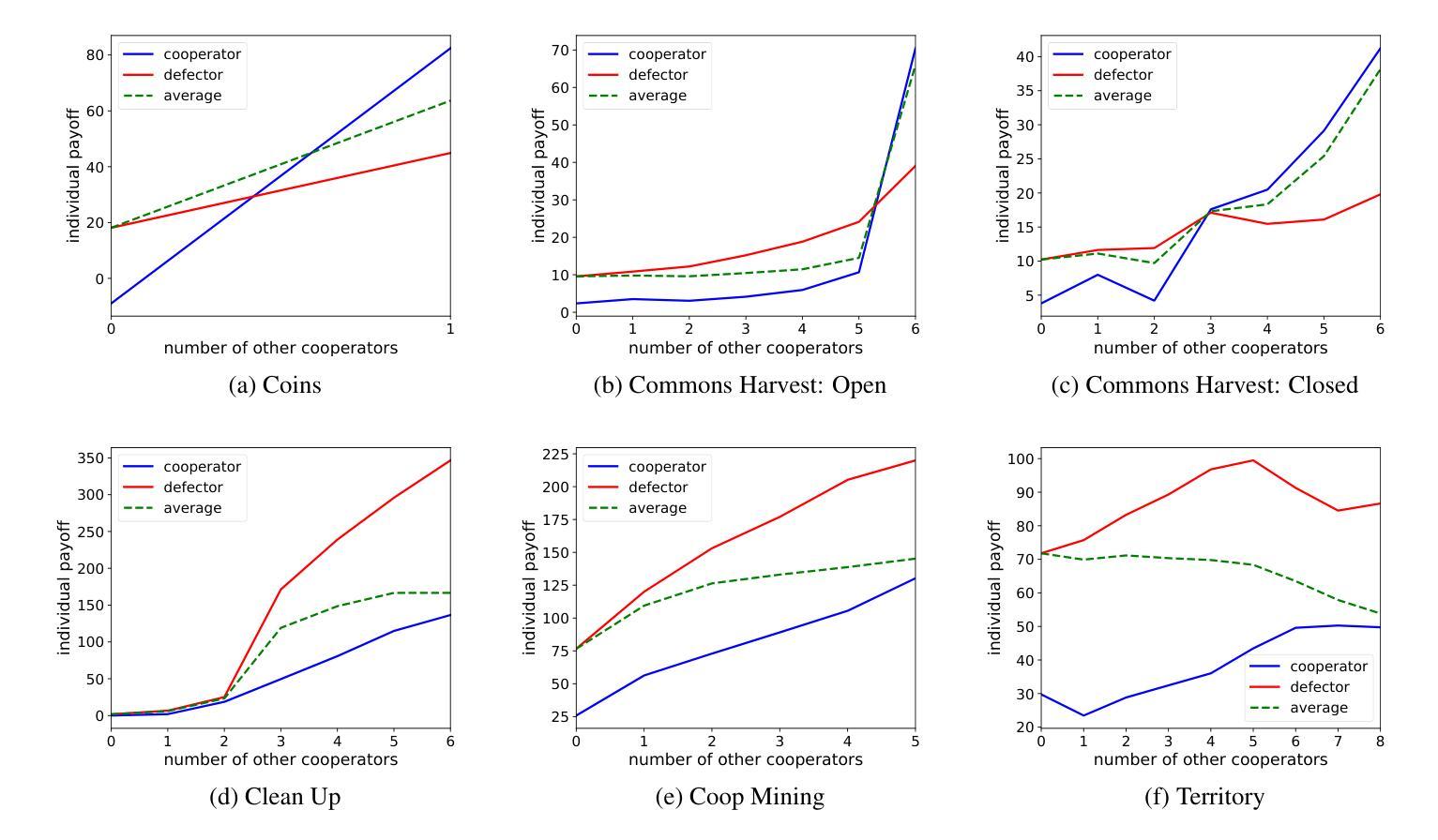
MARLadona – Towards Cooperative Team Play Using Multi-Agent Reinforcement Learning
Authors:Zichong Li, Filip Bjelonic, Victor Klemm, Marco Hutter
Robot soccer, in its full complexity, poses an unsolved research challenge. Current solutions heavily rely on engineered heuristic strategies, which lack robustness and adaptability. Deep reinforcement learning has gained significant traction in various complex robotics tasks such as locomotion, manipulation, and competitive games (e.g., AlphaZero, OpenAI Five), making it a promising solution to the robot soccer problem. This paper introduces MARLadona. A decentralized multi-agent reinforcement learning (MARL) training pipeline capable of producing agents with sophisticated team play behavior, bridging the shortcomings of heuristic methods. Furthermore, we created an open-source multi-agent soccer environment. Utilizing our MARL framework and a modified global entity encoder (GEE) as our core architecture, our approach achieves a 66.8% win rate against HELIOS agent, which employs a state-of-the-art heuristic strategy. In addition, we provided an in-depth analysis of the policy behavior and interpreted the agent’s intention using the critic network.
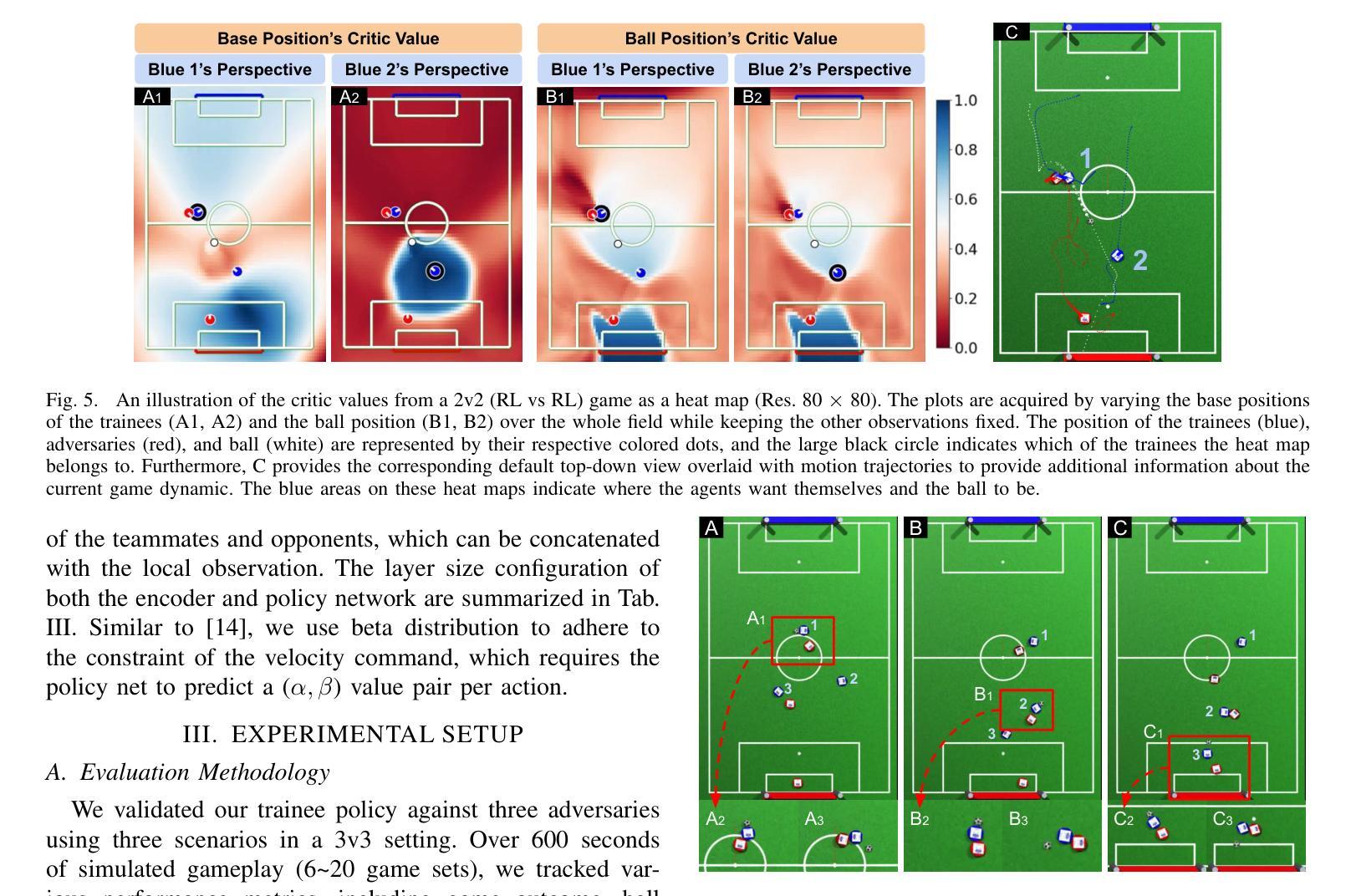
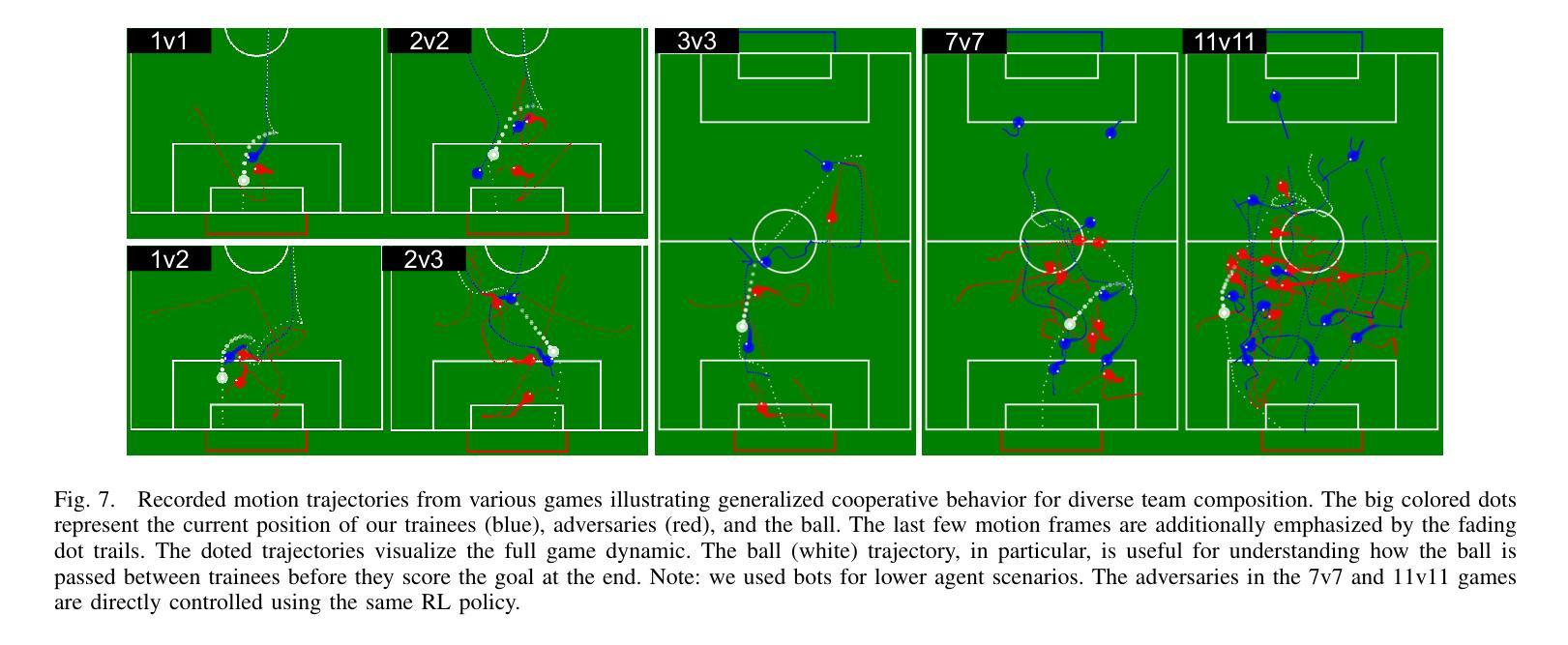
机器人足球在其完全复杂性方面构成了一个未解决的研究挑战。当前解决方案严重依赖于工程化的启发式策略,这些策略缺乏稳健性和适应性。深度强化学习已在各种复杂的机器人任务(如运动、操作和竞技游戏)中获得了显著的发展(例如AlphaZero、OpenAI Five),使其成为机器人足球问题的有前途的解决方案。本文介绍了MARLadona。这是一个去中心化的多智能体强化学习(MARL)训练管道,能够产生具有复杂团队行为智能体,弥补启发式方法的不足。此外,我们还创建了一个开源的多智能体足球环境。利用我们的MARL框架和修改后的全局实体编码器(GEE)作为我们的核心架构,我们的方法在对抗采用最新启发式策略的HELIOS智能体时达到了66.8%的胜率。此外,我们还对政策行为进行了深入分析,并利用评论家网络解释了智能体的意图。
论文及项目相关链接
PDF Version presented at ICRA 2025
Summary
机器人足球领域的复杂性构成了未解决的研究挑战。当前解决方案主要依赖于工程化的启发式策略,缺乏稳健性和适应性。深度强化学习已在各种复杂机器人任务(如运动、操作和竞技游戏)中取得了显著进展,使其成为机器人足球问题的有前途的解决方案。本文介绍了MARLadona,这是一种分散式多智能体强化学习(MARL)训练管道,能够产生具有复杂团队行为智能体,弥补启发式方法的不足。此外,还开发了一个开源的多智能体足球环境。利用MARL框架和修改后的全局实体编码器(GEE)作为核心架构,我们的方法在对抗采用最新启发式策略的HELIOS代理时达到了66.8%的胜率。同时,对策略行为进行了深入分析,并利用评论家网络解释了代理的意图。
Key Takeaways
- 机器人足球是一个具有挑战性的研究领域,当前解决方案依赖于启发式策略,缺乏稳健性和适应性。
- 深度强化学习在机器人领域具有广泛应用,包括运动、操作和竞技游戏。
- MARLadona是一种基于多智能体强化学习(MARL)的训练管道,能生成具有复杂团队行为智能体,改进了启发式方法的不足。
- 开发了开源的多智能体足球环境,为研究和实验提供了平台。
- 利用MARL框架和修改后的全局实体编码器(GEE)作为核心架构,取得了对采用最新启发式策略的HELIOS代理的较高胜率。
- 对策略行为进行了详细分析,以了解智能体的决策过程。
点此查看论文截图

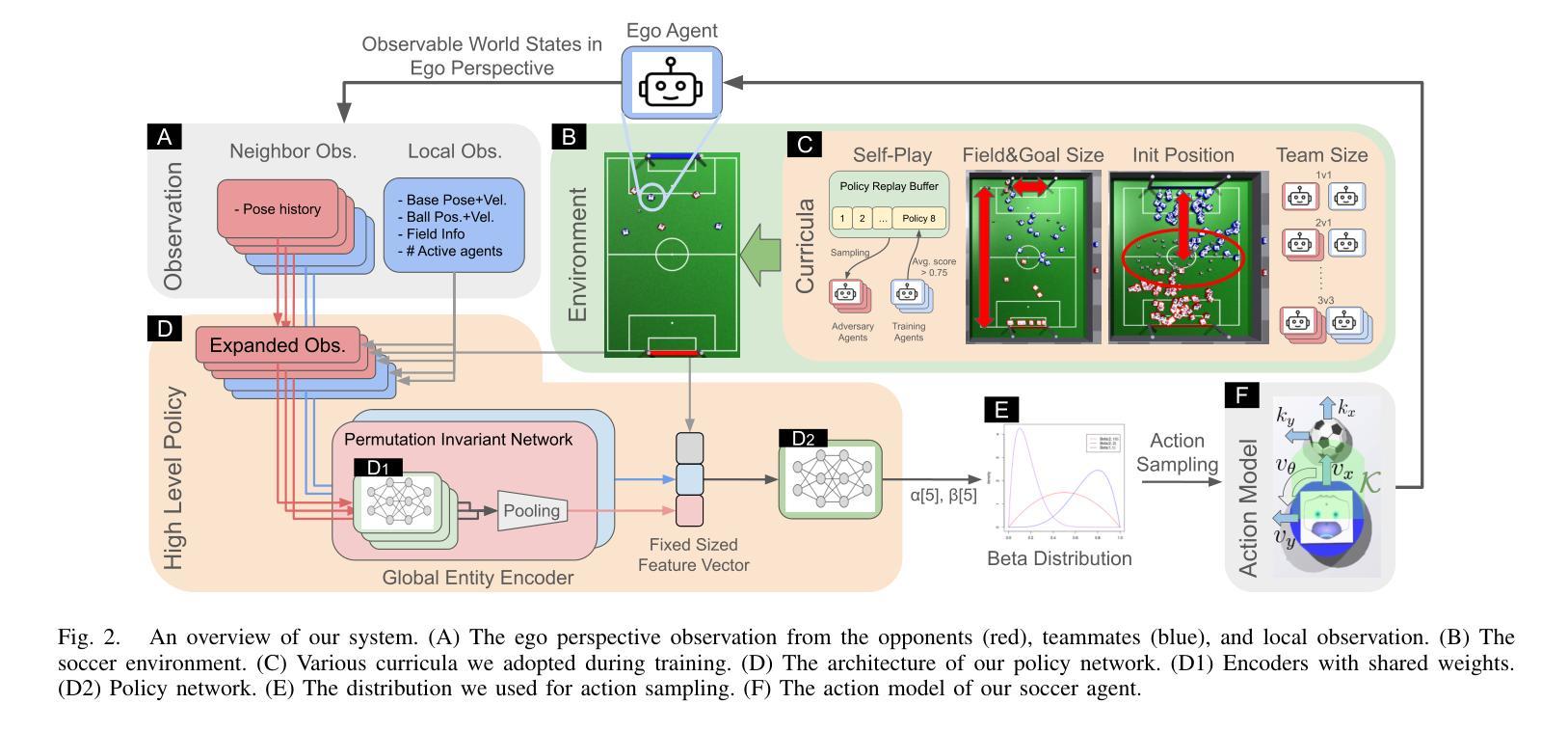


A Multi-Agent Approach to Fault Localization via Graph-Based Retrieval and Reflexion
Authors:Md Nakhla Rafi, Dong Jae Kim, Tse-Hsun Chen, Shaowei Wang
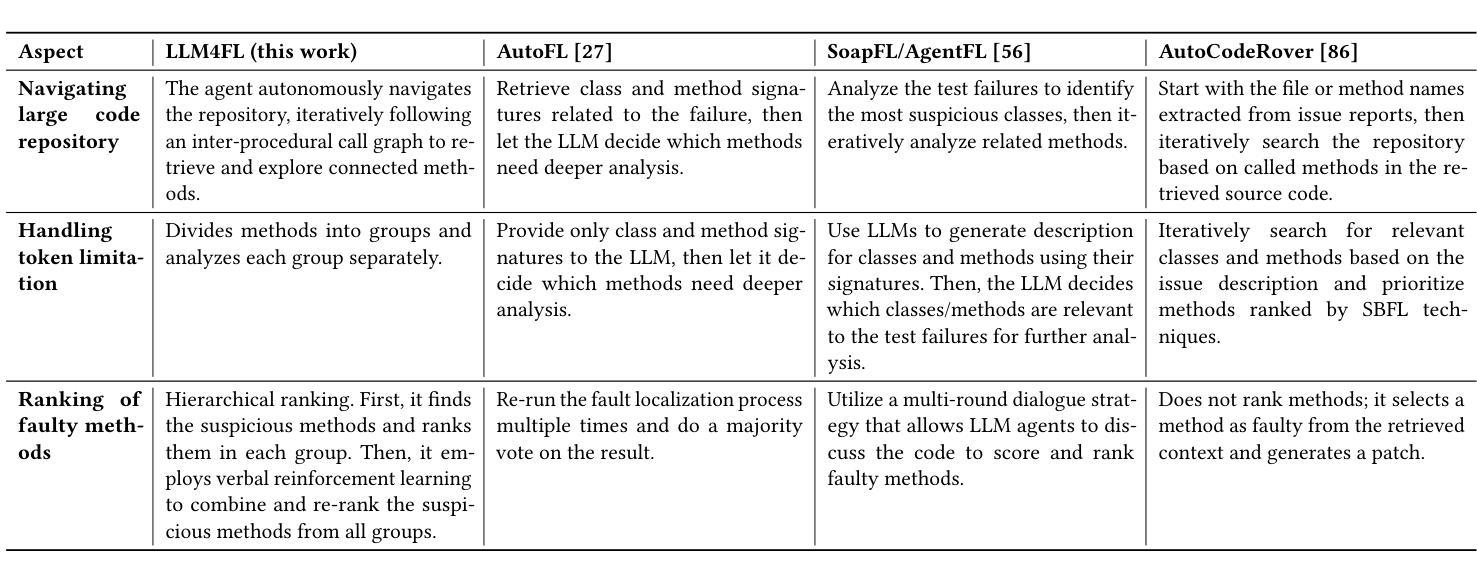
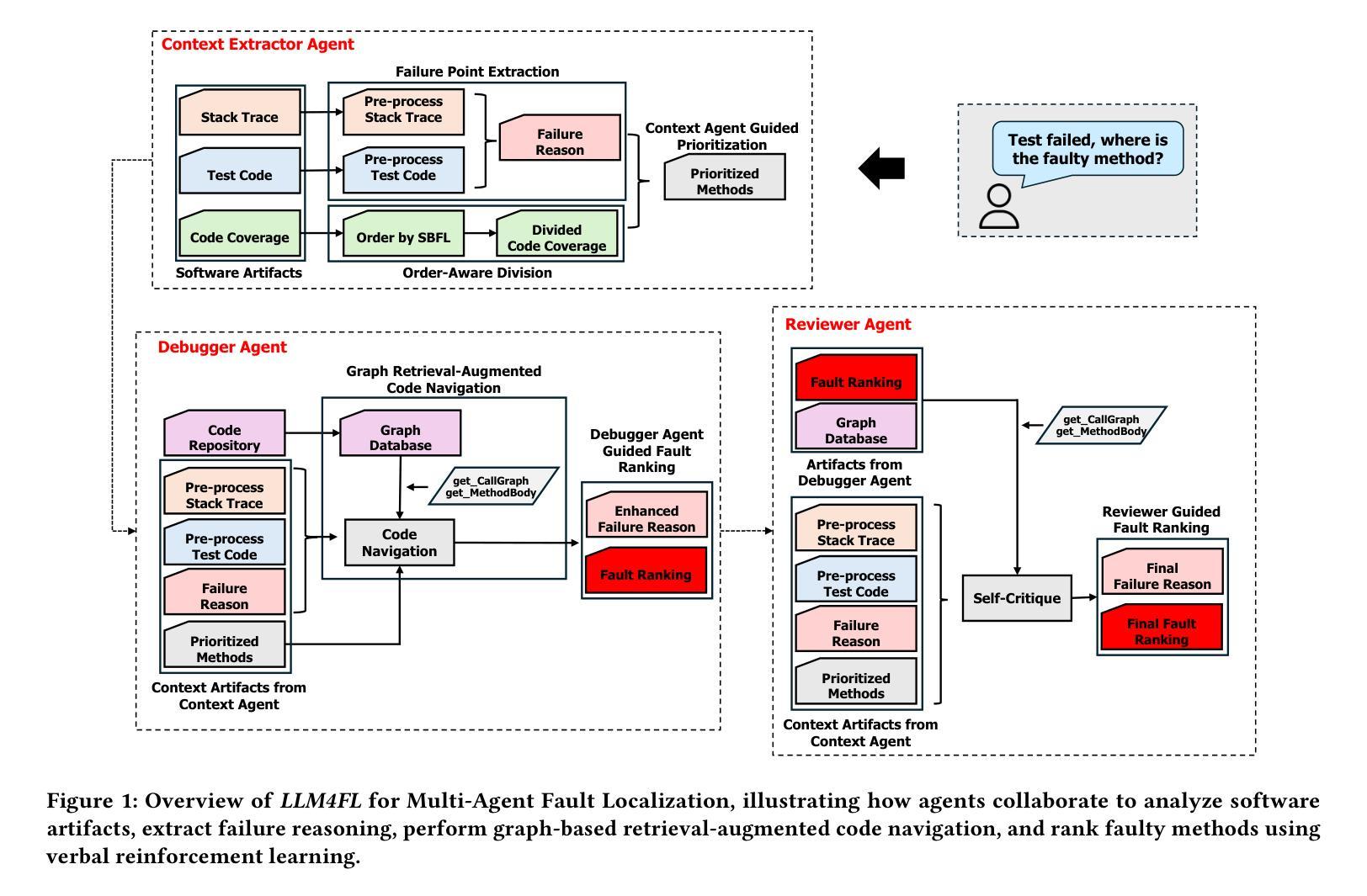
Identifying and resolving software faults remains a challenging and resource-intensive process. Traditional fault localization techniques, such as Spectrum-Based Fault Localization (SBFL), leverage statistical analysis of test coverage but often suffer from limited accuracy. While learning-based approaches improve fault localization, they demand extensive training datasets and high computational resources. Recent advances in Large Language Models (LLMs) offer new opportunities by enhancing code understanding and reasoning. However, existing LLM-based fault localization techniques face significant challenges, including token limitations, performance degradation with long inputs, and scalability issues in complex software systems. To overcome these obstacles, we propose LLM4FL, a multi-agent fault localization framework that utilizes three specialized LLM agents. First, the Context Extraction Agent applies an order-sensitive segmentation strategy to partition large coverage data within the LLM’s token limit, analyze failure context, and prioritize failure-related methods. The Debugger Agent then processes the extracted data, which employs graph-based retrieval-augmented code navigation to reason about failure causes and rank suspicious methods. Finally, the Reviewer Agent re-evaluates the identified faulty methods using verbal reinforcement learning, engaging in self-criticism and iterative refinement. Evaluated on the Defects4J (V2.0.0) benchmark, which includes 675 faults from 14 Java projects, LLM4FL achieves an 18.55% improvement in Top-1 accuracy over AutoFL and 4.82% over SoapFL. It outperforms supervised techniques such as DeepFL and Grace, all without requiring task-specific training. Furthermore, its coverage segmentation and prompt chaining strategies enhance performance, increasing Top-1 accuracy by up to 22%.
识别和解决软件故障仍然是一个具有挑战性和资源密集型的过程。传统的故障定位技术,如基于频谱的故障定位(SBFL),利用测试覆盖的统计分析,但往往准确性有限。虽然基于学习的方法改进了故障定位,但它们需要大量的训练数据集和高计算资源。最近大型语言模型(LLM)的进步通过增强代码理解和推理提供了新的机会。然而,现有的基于LLM的故障定位技术面临重大挑战,包括符号限制、长输入性能下降以及在复杂软件系统中的可扩展性问题。为了克服这些障碍,我们提出了LLM4FL,这是一个多智能体故障定位框架,利用三个专业LLM智能体。首先,上下文提取智能体采用顺序敏感分割策略,在LLM的符号限制内划分大覆盖数据,分析失败上下文,并优先处理与失败相关的方法。然后调试器智能体处理提取的数据,采用基于图的检索增强代码导航来推断失败原因并排名可疑方法。最后,审查员智能体重新评估已识别的故障方法,使用口头强化学习进行自我评价和迭代改进。在Defects4J(V2.0.0)基准测试上进行评估,该测试包括来自14个Java项目的675个故障,LLM4FL在Top-1准确率上比AutoFL提高了18.55%,比SoapFL提高了4.82%。它超越了如DeepFL和Grace等监督技术,而且无需特定任务训练。此外,其覆盖分割和提示链接策略提高了性能,Top-1准确率最高可提高22%。
论文及项目相关链接
Summary
本文提出一种基于多智能体的故障定位框架LLM4FL,针对软件故障定位的挑战,利用三种专业LLM智能体来解决传统故障定位技术的问题。该框架通过上下文提取智能体进行上下文分析,通过调试智能体进行故障原因分析并排名可疑方法,最后通过评审智能体对识别出的故障方法进行再评估。在Defects4J 2.0.0基准测试上,LLM4FL相比AutoFL提高了18.55%的Top-1准确率,优于SoapFL和其他监督技术如DeepFL和Grace,且无需特定任务训练。其覆盖分段和提示链策略可提高性能,最高可提高Top-1准确率达22%。
Key Takeaways
- LLM4FL是一个多智能体的故障定位框架,旨在解决软件故障定位的挑战。
- LLM4FL利用三种专业LLM智能体:上下文提取智能体、调试智能体和评审智能体。
- 上下文提取智能体通过顺序敏感分段策略处理大规模覆盖数据。
- 调试智能体利用基于图的检索增强代码导航来推理故障原因并排名可疑方法。
- 评审智能体通过言语强化学习对识别出的故障方法进行再评估和自我批评。
- 在Defects4J基准测试中,LLM4FL相比其他技术显著提高Top-1准确率。
点此查看论文截图