⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
FP4DiT: Towards Effective Floating Point Quantization for Diffusion Transformers
Authors:Ruichen Chen, Keith G. Mills, Di Niu
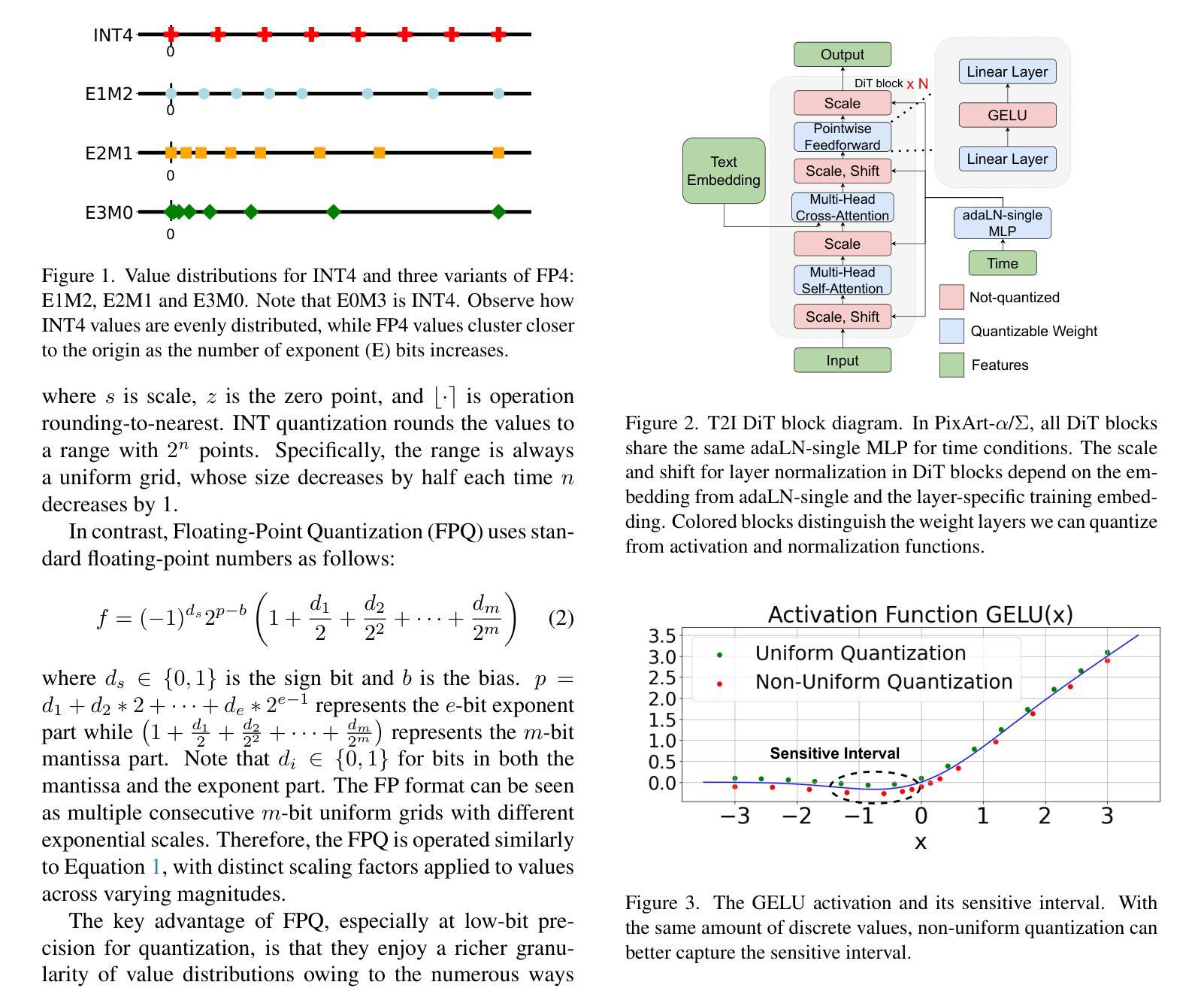
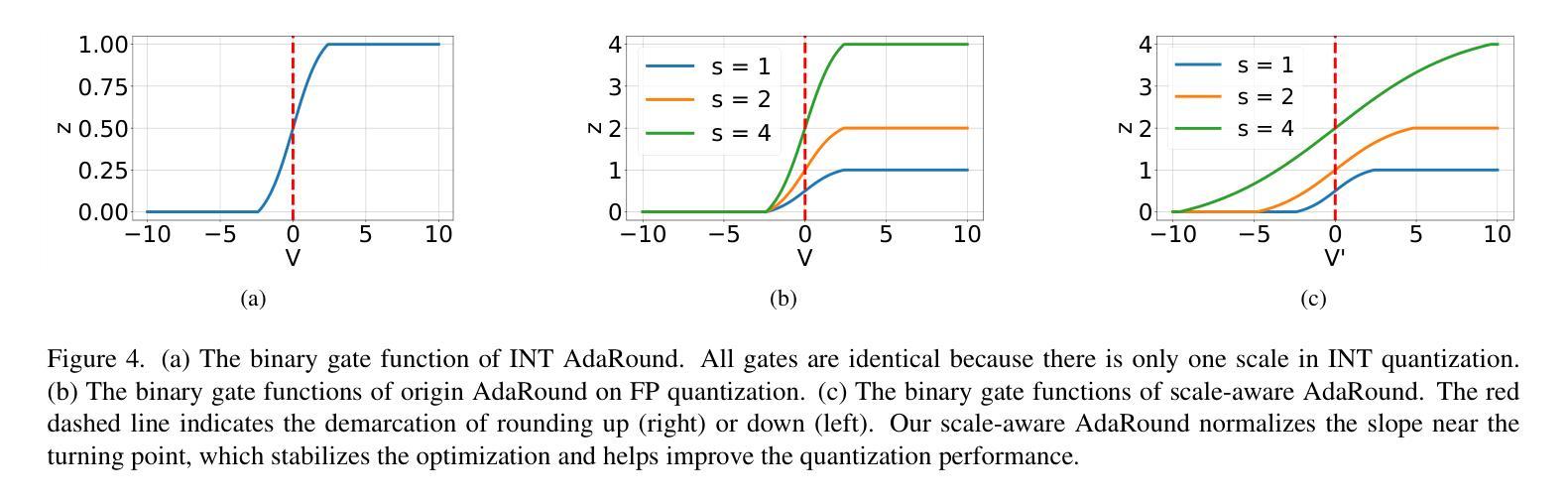
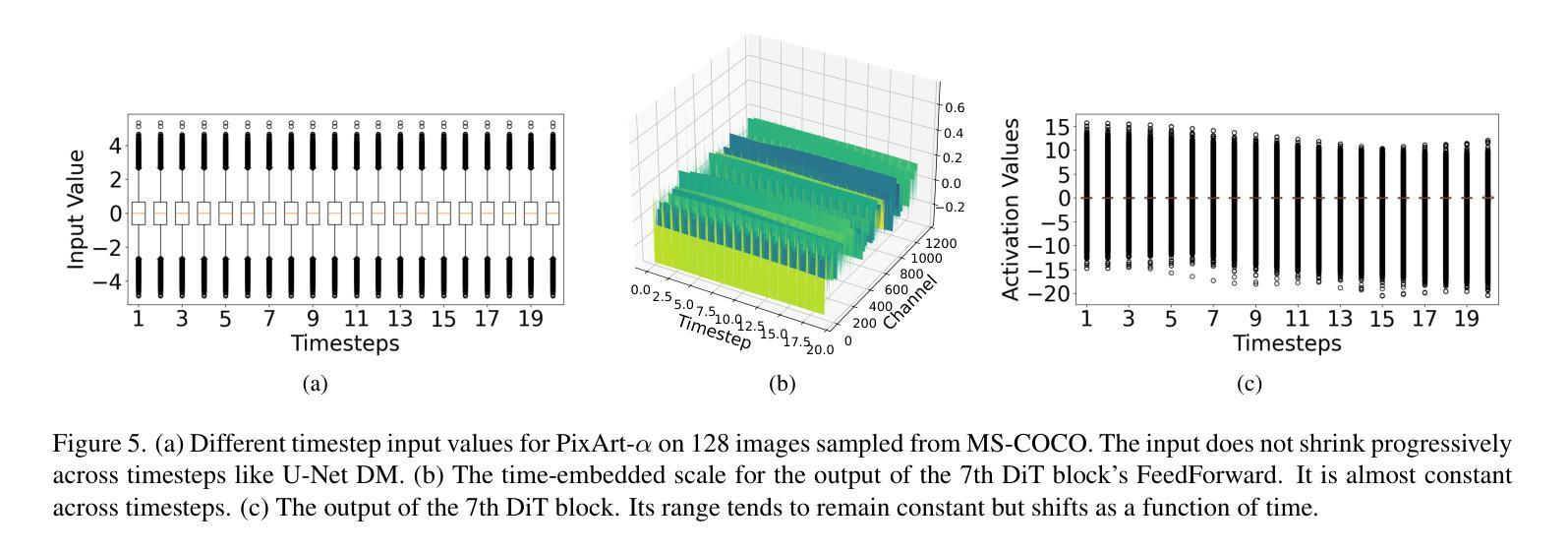
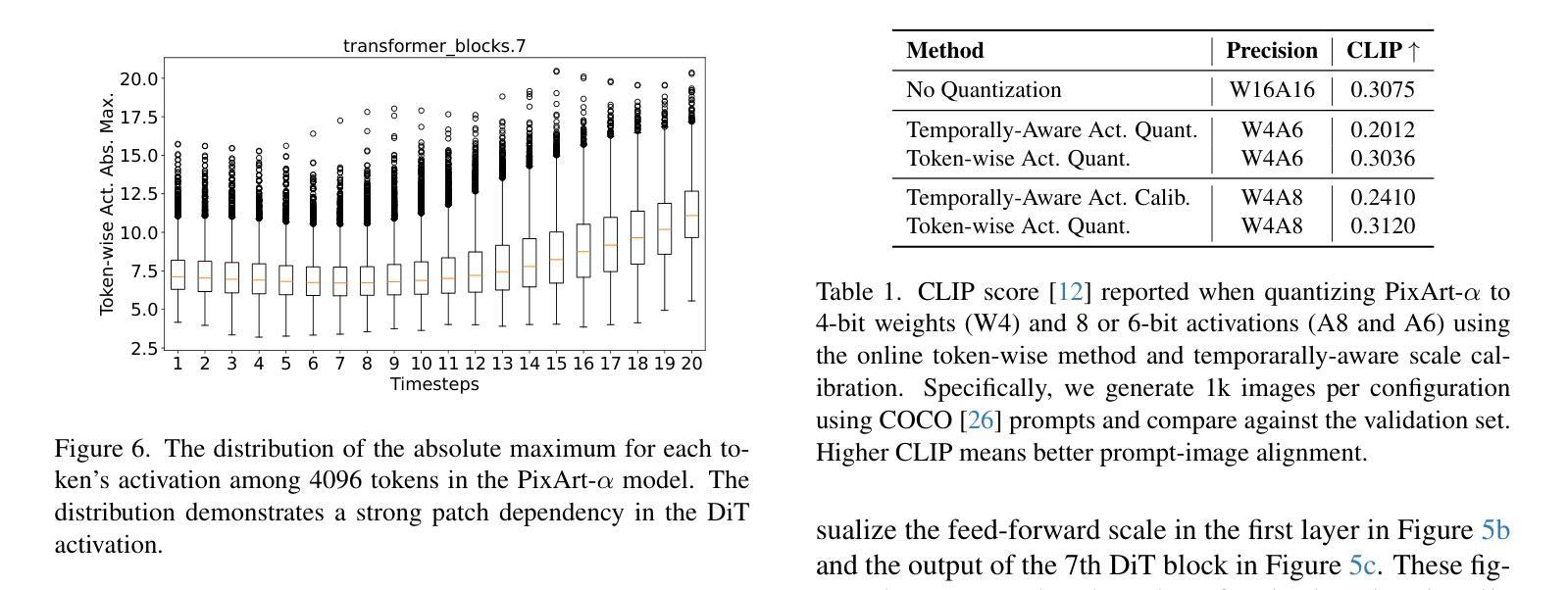
Diffusion Models (DM) have revolutionized the text-to-image visual generation process. However, the large computational cost and model footprint of DMs hinders practical deployment, especially on edge devices. Post-training quantization (PTQ) is a lightweight method to alleviate these burdens without the need for training or fine-tuning. While recent DM PTQ methods achieve W4A8 on integer-based PTQ, two key limitations remain: First, while most existing DM PTQ methods evaluate on classical DMs like Stable Diffusion XL, 1.5 or earlier, which use convolutional U-Nets, newer Diffusion Transformer (DiT) models like the PixArt series, Hunyuan and others adopt fundamentally different transformer backbones to achieve superior image synthesis. Second, integer (INT) quantization is prevailing in DM PTQ but doesn’t align well with the network weight and activation distribution, while Floating-Point Quantization (FPQ) is still under-investigated, yet it holds the potential to better align the weight and activation distributions in low-bit settings for DiT. In response, we introduce FP4DiT, a PTQ method that leverages FPQ to achieve W4A6 quantization. Specifically, we extend and generalize the Adaptive Rounding PTQ technique to adequately calibrate weight quantization for FPQ and demonstrate that DiT activations depend on input patch data, necessitating robust online activation quantization techniques. Experimental results demonstrate that FP4DiT outperforms integer-based PTQ at W4A6 and W4A8 precision and generates convincing visual content on PixArt-$\alpha$, PixArt-$\Sigma$ and Hunyuan in terms of several T2I metrics such as HPSv2 and CLIP.
扩散模型(DM)已经彻底改变了文本到图像的视觉生成过程。然而,扩散模型的大量计算成本和模型占用空间阻碍了其实践部署,尤其是在边缘设备上。后训练量化(PTQ)是一种轻量级方法,可以在无需训练和微调的情况下缓解这些负担。尽管最近的扩散模型PTQ方法实现了基于整数的W4A8量化,但仍存在两个主要局限性:首先,尽管现有的大多数扩散模型PTQ方法都是在诸如Stable Diffusion XL 1.5或更早的经典扩散模型上进行评估的,这些模型使用卷积U-Nets,但更新的扩散转换器(DiT)模型,如PixArt系列、Hunyuan和其他模型采用根本不同的转换器骨干网来实现优越的图像合成。其次,整数(INT)量化在DM PTQ中很普遍,但并不能很好地与网络权重和激活分布相匹配。而浮点量化(FPQ)的研究仍然不足,但它具有在低位设置中更好地对齐DiT权重和激活分布的潜力。作为回应,我们介绍了FP4DiT,这是一种利用FPQ实现W4A6量化的PTQ方法。具体来说,我们对自适应舍入PTQ技术进行了扩展和概括,以充分校准FPQ的权重量化,并证明DiT的激活取决于输入补丁数据,这需要稳健的在线激活量化技术。实验结果表明,FP4DiT在W4A6和W4A8精度上优于基于整数的PTQ,并在PixArt-α、PixArt-Σ和Hunyuan等多个T2I指标(如HPSv2和CLIP)上生成了令人信服的视觉内容。
论文及项目相关链接
PDF The code is available at https://github.com/cccrrrccc/FP4DiT
摘要
扩散模型(DM)在文本到图像的视觉生成过程中起到了革命性的作用,但其庞大的计算成本和模型占用空间阻碍了实际应用,特别是在边缘设备上。针对这一问题,无需训练或微调的后训练量化(PTQ)是一种轻量级方法。虽然最近的扩散模型PTQ方法实现了整数量化的W4A8精度,但仍存在两个关键局限:首先,大多数现有的扩散模型PTQ方法是在使用卷积U-Net的经典扩散模型(如Stable Diffusion XL 1.5等)上评估的,而新一代如PixArt系列和Hunyuan等扩散变换器(DiT)模型采用了根本不同的转换器主干,以实现更优越的图像合成。其次,整数量化(INT)在扩散模型PTQ中占据主导地位,但与网络权重和激活分布不太匹配。虽然浮点量化(FPQ)仍处于研究初期阶段,但其在对齐低比特设置中的权重和激活分布方面具有潜力。为了解决这个问题,我们提出了一种基于FPQ的后训练量化方法FP4DiT,并实现了W4A6量化。具体来说,我们扩展并推广了自适应四舍五入PTQ技术来校准权重量化以适应FPQ,并证明了DiT激活依赖于输入补丁数据,需要稳健的在线激活量化技术。实验结果表明,FP4DiT在PixArt-α、PixArt-Σ和Hunyuan等多种型号的T2I度量标准下表现优异,例如在HPSv2和CLIP中表现出生成可信的视觉内容能力,并且在W4A6和W4A8精度下超过了基于整数的PTQ。
要点分析
扩散模型已经引发了文本到图像生成过程的革命性变革。然而由于其计算成本较高且占用空间较大,限制了其在边缘设备上的实际应用部署。对此问题提出了后训练量化(PTQ)的轻量级解决方案。现有方法主要集中在整数量化上,但这种方法对网络权重和激活分布不太友好,需要进一步探讨优化方法。此外大部分PTQ方法的测试是基于经典的扩散模型架构进行的评估测试与新型扩散变换器模型存在较大差异且并未深入探究。在此背景下本文提出了FP4DiT这一创新型的PTQ方案以满足轻量级低能耗场景的应用需求重点涉及两大方向对扩收缩改进提升了对不同数据集的整体效果并展现出强大的性能优势。具体来说本文的创新点包括:
- 针对新型扩散变换器模型的特性进行了深入研究实现了该类模型的精细化量化同时保持了较好的性能表现这极大推动了其在实际应用场景下的应用可能性与效果提升;
- 基于浮点数量化理论进行优化克服了传统的基于整数的量化的缺点网络权重的匹配和激活分布的精确度得到进一步提升使得模型在低比特设置下表现更为出色;
- 提出一种全新的在线激活量化技术该方法能够有效处理激活数据的输入依赖性保证模型在不同数据集下的鲁棒性提升了模型的通用性和实用性;
点此查看论文截图

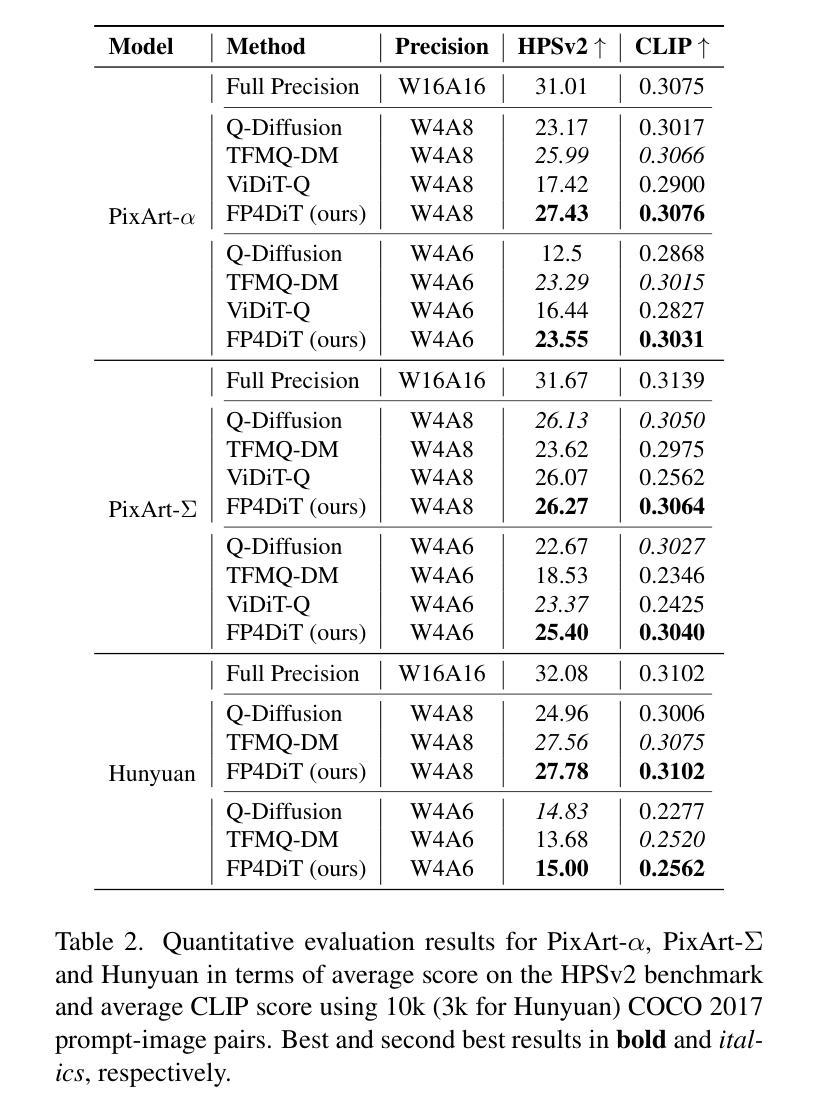
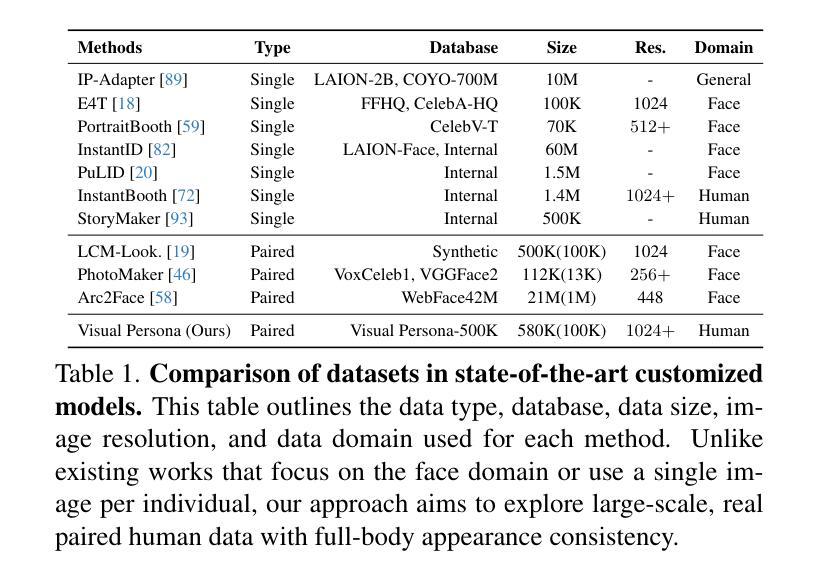
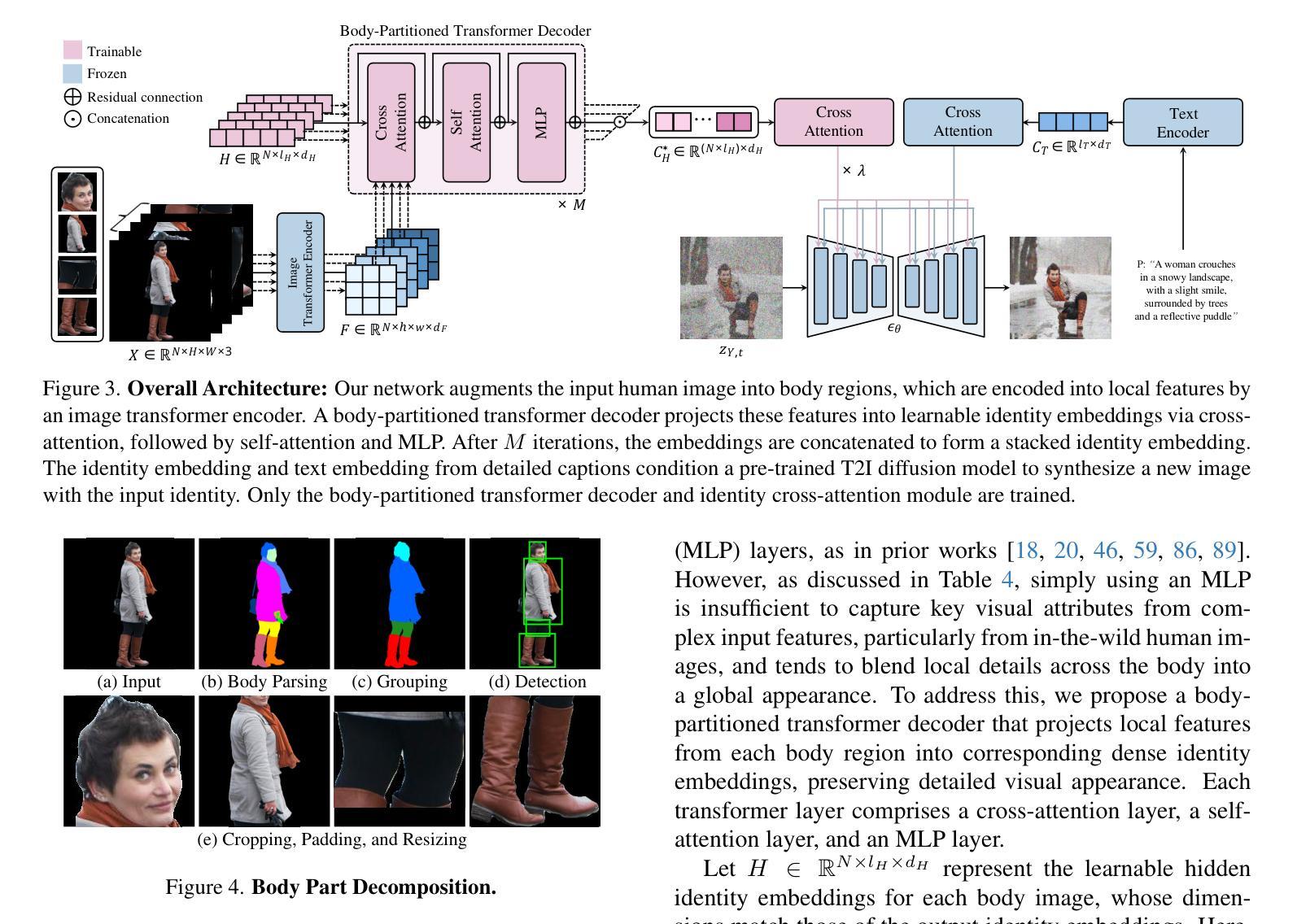
Visual Persona: Foundation Model for Full-Body Human Customization
Authors:Jisu Nam, Soowon Son, Zhan Xu, Jing Shi, Difan Liu, Feng Liu, Aashish Misraa, Seungryong Kim, Yang Zhou
We introduce Visual Persona, a foundation model for text-to-image full-body human customization that, given a single in-the-wild human image, generates diverse images of the individual guided by text descriptions. Unlike prior methods that focus solely on preserving facial identity, our approach captures detailed full-body appearance, aligning with text descriptions for body structure and scene variations. Training this model requires large-scale paired human data, consisting of multiple images per individual with consistent full-body identities, which is notoriously difficult to obtain. To address this, we propose a data curation pipeline leveraging vision-language models to evaluate full-body appearance consistency, resulting in Visual Persona-500K, a dataset of 580k paired human images across 100k unique identities. For precise appearance transfer, we introduce a transformer encoder-decoder architecture adapted to a pre-trained text-to-image diffusion model, which augments the input image into distinct body regions, encodes these regions as local appearance features, and projects them into dense identity embeddings independently to condition the diffusion model for synthesizing customized images. Visual Persona consistently surpasses existing approaches, generating high-quality, customized images from in-the-wild inputs. Extensive ablation studies validate design choices, and we demonstrate the versatility of Visual Persona across various downstream tasks.
我们介绍了Visual Persona,这是一种面向文本到图像全身人体定制的基础模型。给定一张野生环境下的单人图像,该模型会根据文本描述生成多样化的个人图像。与以往仅专注于保留面部身份的方法不同,我们的方法捕捉了详细的全身外观,与文本描述的身体结构和场景变化保持一致。训练这个模型需要大规模配对的人体数据,对于每个个体,都需要有多张具有一致全身身份的图像,这些数据是众所周知的难以获得的。为了解决这个问题,我们提出了一种利用视觉语言模型评估全身外观一致性的数据整理流程,从而形成了Visual Persona-500K数据集,包含580k张配对的人体图像,涉及10万张独特的身份。为了实现精确的外观转移,我们引入了一种适应于预训练文本到图像扩散模型的transformer编码器-解码器架构。它将输入图像分割为不同的身体区域,将这些区域编码为局部外观特征,并将它们投影到密集的身份嵌入中,以独立地控制扩散模型来合成定制的图像。Visual Persona始终超越现有方法,从野生环境中生成高质量、定制的图像。广泛的消融研究验证了设计选择,我们展示了Visual Persona在各种下游任务中的通用性。
论文及项目相关链接
PDF CVPR 2025, Project page is available at https://cvlab-kaist.github.io/Visual-Persona
Summary
本文介绍了Visual Persona模型,这是一种面向文本到图像的全身人体定制模型。给定一张野生环境下的单人图像,该模型能够根据文本描述生成多样化的个体图像。与仅关注面部身份保留的现有方法不同,Visual Persona模型能够捕捉全身的详细外观,并根据文本描述进行身体结构和场景变化的对齐。为训练此模型,需要大规模配对的人类数据,包含每张个体图像都有一致的全身身份。为解决数据获取难题,研究团队提出了一个数据整理管道,利用视觉语言模型评估全身外观的一致性,并创建了Visual Persona-500K数据集,包含58万张配对的人类图像和10万个唯一身份。为实现精确的外观转移,研究团队引入了变压器编码器-解码器架构,该架构适应于预训练的文本到图像扩散模型,可将输入图像分为不同的身体区域,编码为局部外观特征,并投影到密集的身份嵌入中,以条件扩散模型合成定制图像。Visual Persona在生成高质量、定制的图像方面超越了现有方法。
Key Takeaways
- Visual Persona是一个面向文本到图像的全身人体定制模型。
- 该模型通过文本描述生成多样化的个体图像。
- Visual Persona模型不仅关注面部身份,还捕捉全身的详细外观。
- 为训练此模型,需要大规模配对的人类数据,包含每张个体图像都有一致的全身身份。
- 研究团队利用视觉语言模型创建了一个数据整理管道,并创建了Visual Persona-500K数据集。
- Visual Persona采用了变压器编码器-解码器架构,并结合预训练的文本到图像扩散模型实现精确外观转移。
点此查看论文截图


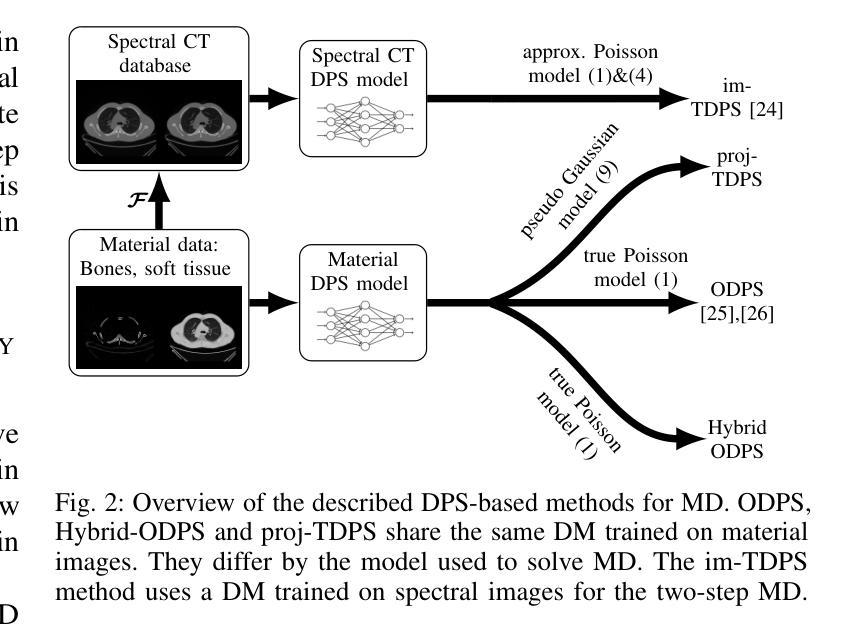
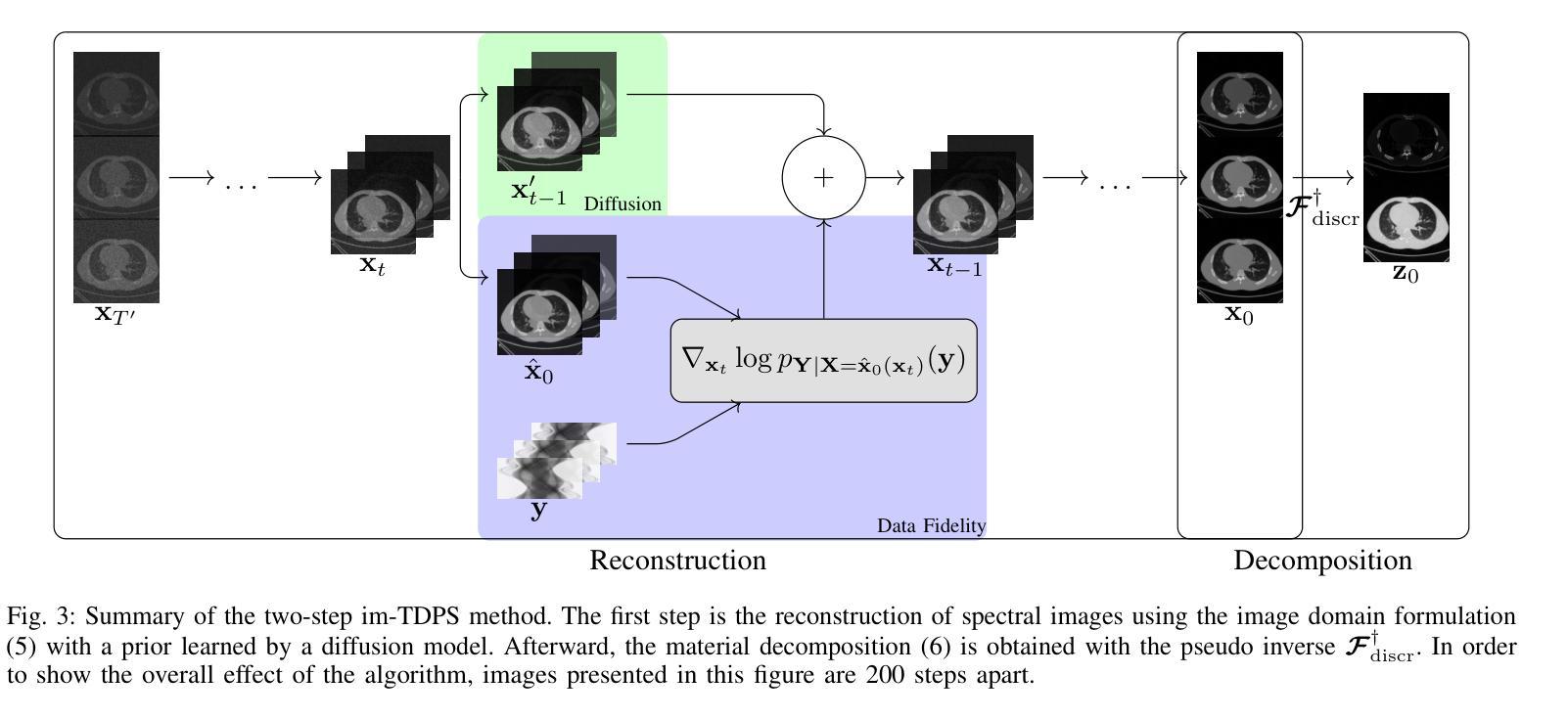
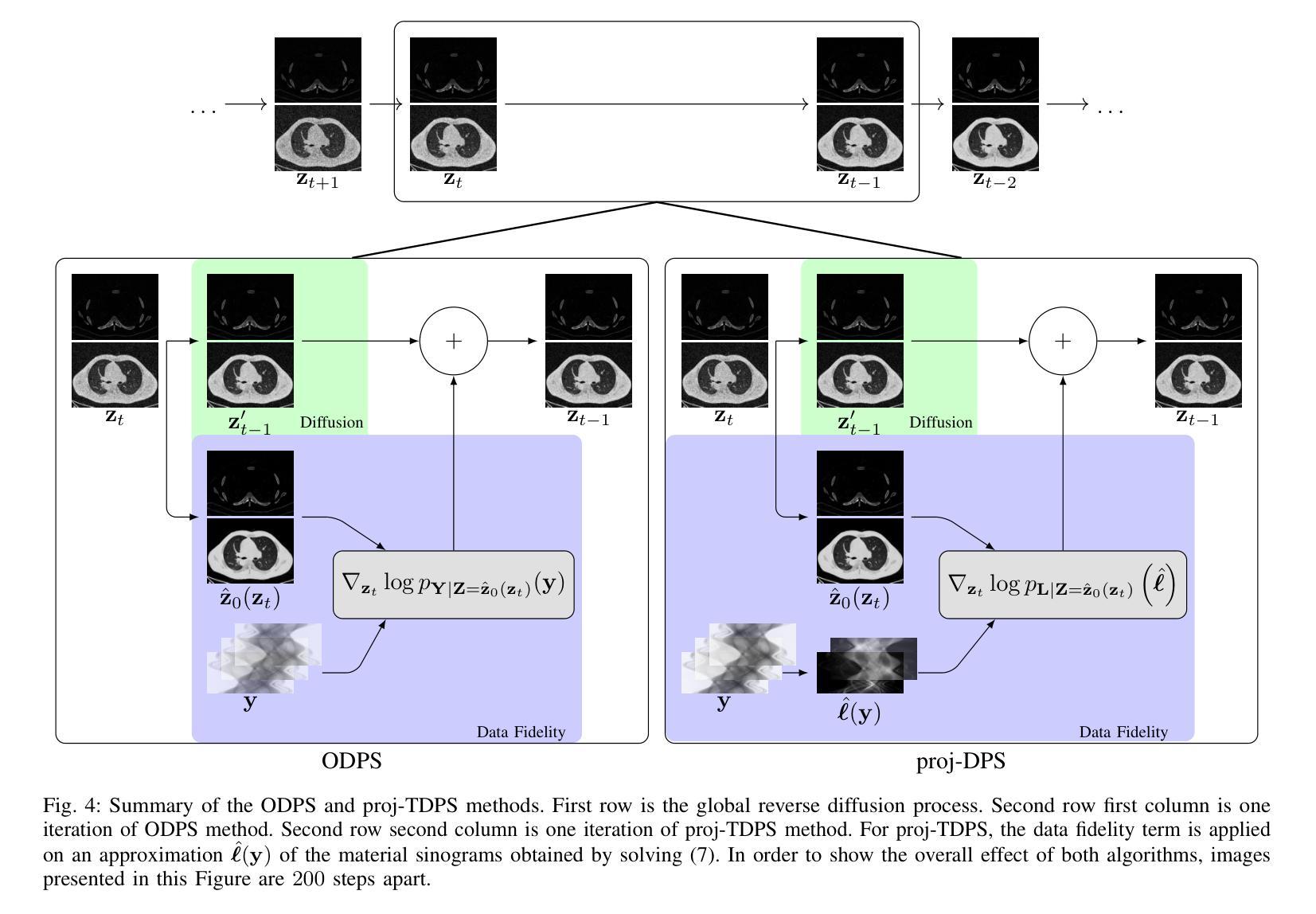
Material Decomposition in Photon-Counting Computed Tomography with Diffusion Models: Comparative Study and Hybridization with Variational Regularizers
Authors:Corentin Vazia, Thore Dassow, Alexandre Bousse, Jacques Froment, Béatrice Vedel, Franck Vermet, Alessandro Perelli, Jean-Pierre Tasu, Dimitris Visvikis
Photon-counting computed tomography (PCCT) has emerged as a promising imaging technique, enabling spectral imaging and material decomposition (MD). However, images typically suffer from a low signal-to-noise ratio due to constraints such as low photon counts and sparse-view settings. Variational methods minimize a data-fit function coupled with handcrafted regularizers but are highly dependent on the choice of the regularizers. Artificial intelligence (AI)-based approaches and more particularly convolutional neural networks (CNNs) are now considered the state-of-the-art approach and can be used as an end-to-end method for MD or to implicitly learn an a priori. In the last few years, diffusion models (DMs) became predominant in the field of generative models where a distribution function is learned. This distribution function can be used as a prior for solving inverse problems. This work investigates the use of DMs as regularizers for MD tasks in PCCT. MD by diffusion posterior sampling (DPS) can be achieved. Three DPS-based approaches – image-domain two-step DPS (im-TDPS), projection-domain two-step DPS (proj-TDPS), and one-step DPS (ODPS) – are evaluated. The first two methods perform MD in two steps: im-TDPS samples spectral images by DPS then performs image-based MD, while proj-TDPS performs projection-based MD then samples material images by DPS. The last method, ODPS, samples the material images directly from the measurement data. The results indicate that ODPS achieves superior performance compared to im-TDPS and proj-TDPS, providing sharper, noise-free and crosstalk-free images. Furthermore, we introduce a novel hybrid ODPS method combining DM priors with standard variational regularizers for scenarios involving materials absent from the training dataset. This hybrid method demonstrates improved material reconstruction quality compared to a standard variational method.
光子计数计算机断层扫描(PCCT)作为一种有前景的成像技术已经出现,能够实现光谱成像和材料分解(MD)。然而,由于光子计数低和稀疏视图设置等限制,图像通常信噪比低。变分方法通过最小化数据拟合函数与手工正则化相结合,但高度依赖于正则化的选择。基于人工智能(AI)的方法,特别是卷积神经网络(CNN)现在被认为是最新技术,可以用作端到端的MD方法或隐式学习先验知识。在过去的几年中,扩散模型(DMs)在生成模型中占据了主导地位,其中分布函数得以学习。该分布函数可以用作解决逆问题的先验。这项工作探讨了将DMs用作PCCT中MD任务的正规化方法。通过扩散后采样(DPS)可以实现MD。评估了三种基于DPS的方法——图像域两步DPS(im-TDPS)、投影域两步DPS(proj-TDPS)和一步DPS(ODPS)。前两种方法分两步进行MD:im-TDPS通过DPS采样光谱图像,然后进行基于图像的MD,而proj-TDPS进行基于投影的MD,然后通过DPS采样材料图像。最后一种方法ODPS直接从测量数据中采样材料图像。结果表明,与im-TDPS和proj-TDPS相比,ODPS实现了卓越的性能,提供了更清晰、无噪声且无串扰的图像。此外,我们引入了一种新型混合ODPS方法,将DM先验与标准变分正则化器相结合,用于涉及训练数据集中缺少的材料的情况。该混合方法提高了材料重建的质量,与标准变分方法相比表现出优势。
论文及项目相关链接
PDF 12 pages, 10 figures, 4 tables
Summary
光子计数计算机断层扫描(PCCT)中的物质分解(MD)技术因图像的低信噪比而受到挑战,如光子计数低和视图稀疏等问题。卷积神经网络(CNN)已成为目前最前沿的技术,可作为端到端的MD方法或隐式学习先验。扩散模型(DM)可用于生成模型中的先验分布函数来解决反问题。本研究探讨了将DM作为PCCT中MD任务的正规化器。通过扩散后采样(DPS)实现MD。评估了三种基于DPS的方法,包括图像域两步DPS、投影域两步DPS和一步DPS。结果显示,一步DPS性能最优,能提供清晰、无噪声且无串扰的图像。此外,还介绍了一种结合DM先验与传统变分正则化的混合一步DPS方法,用于处理训练数据集中缺少的材料场景,该方法提高了材料重建质量。
Key Takeaways
- 光子计数计算机断层扫描(PCCT)中的物质分解(MD)技术面临低信噪比问题。
- 卷积神经网络(CNN)已成为解决MD问题的最新技术。
- 扩散模型(DM)可用作生成模型中的先验分布函数,以解决反问题。
- 本研究探讨了将DM用作PCCT中MD任务的正规化器,采用扩散后采样(DPS)方法实现。
- 三种基于DPS的方法中,一步DPS性能最优,能提供清晰、无噪声且无串扰的图像。
- 引入了一种结合DM先验与传统变分正则化的混合方法,用于处理训练数据集中缺少的材料场景。
点此查看论文截图


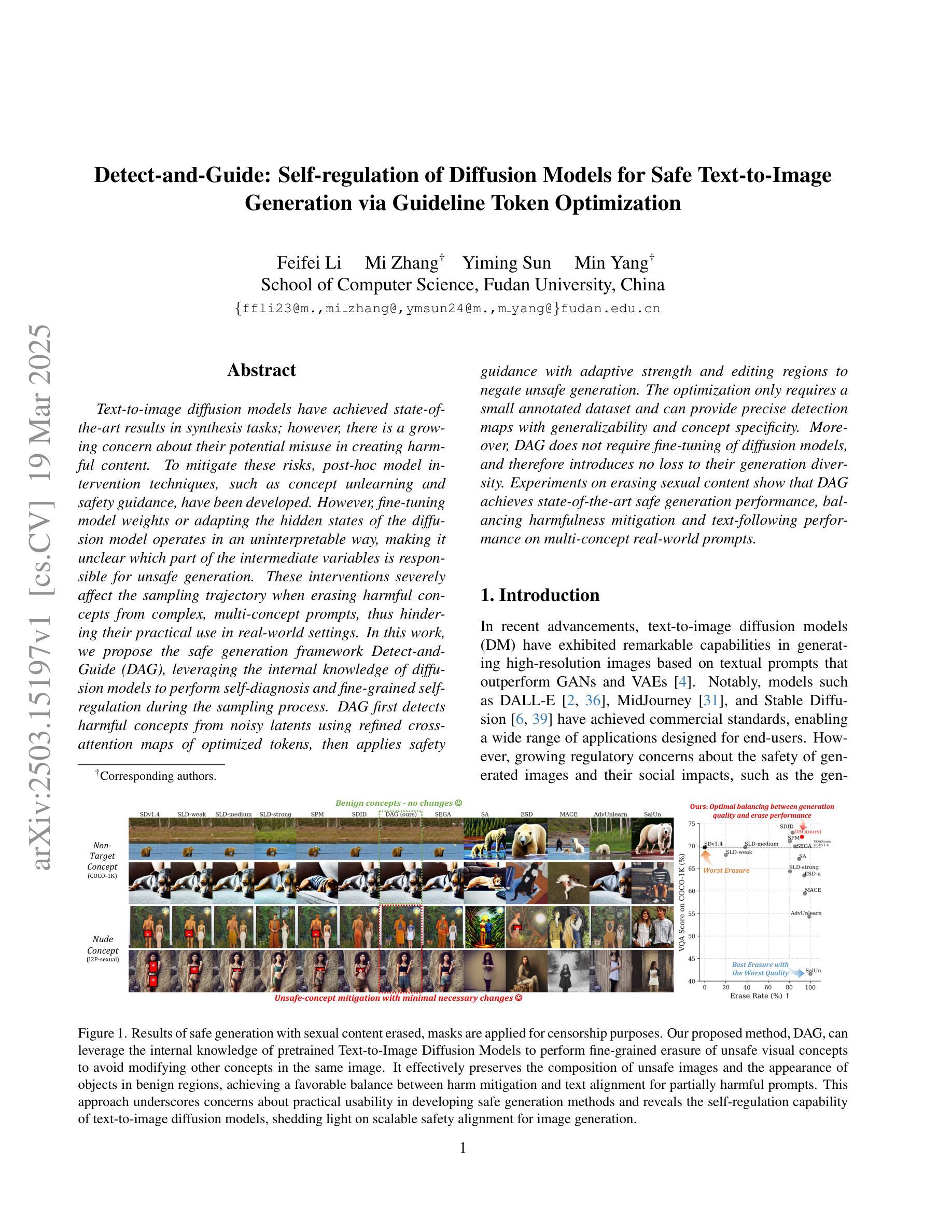
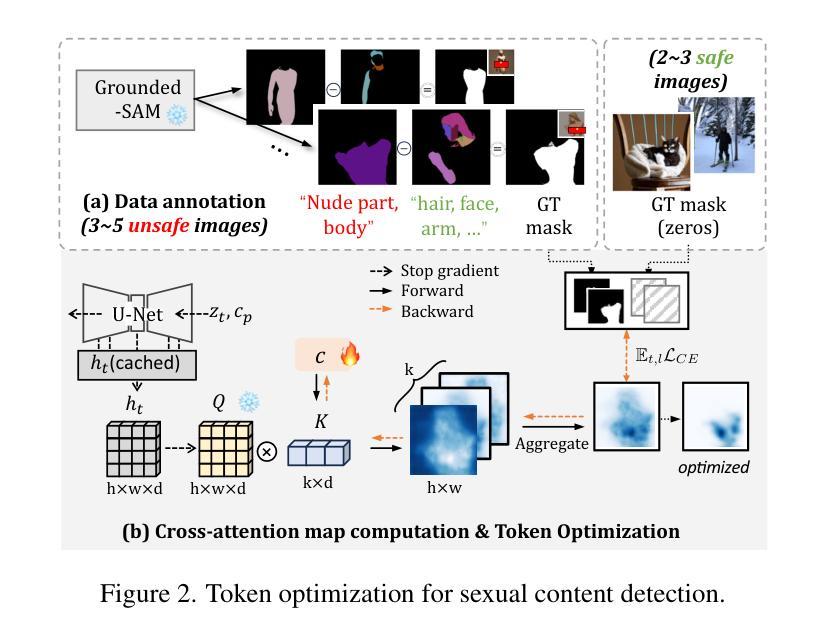
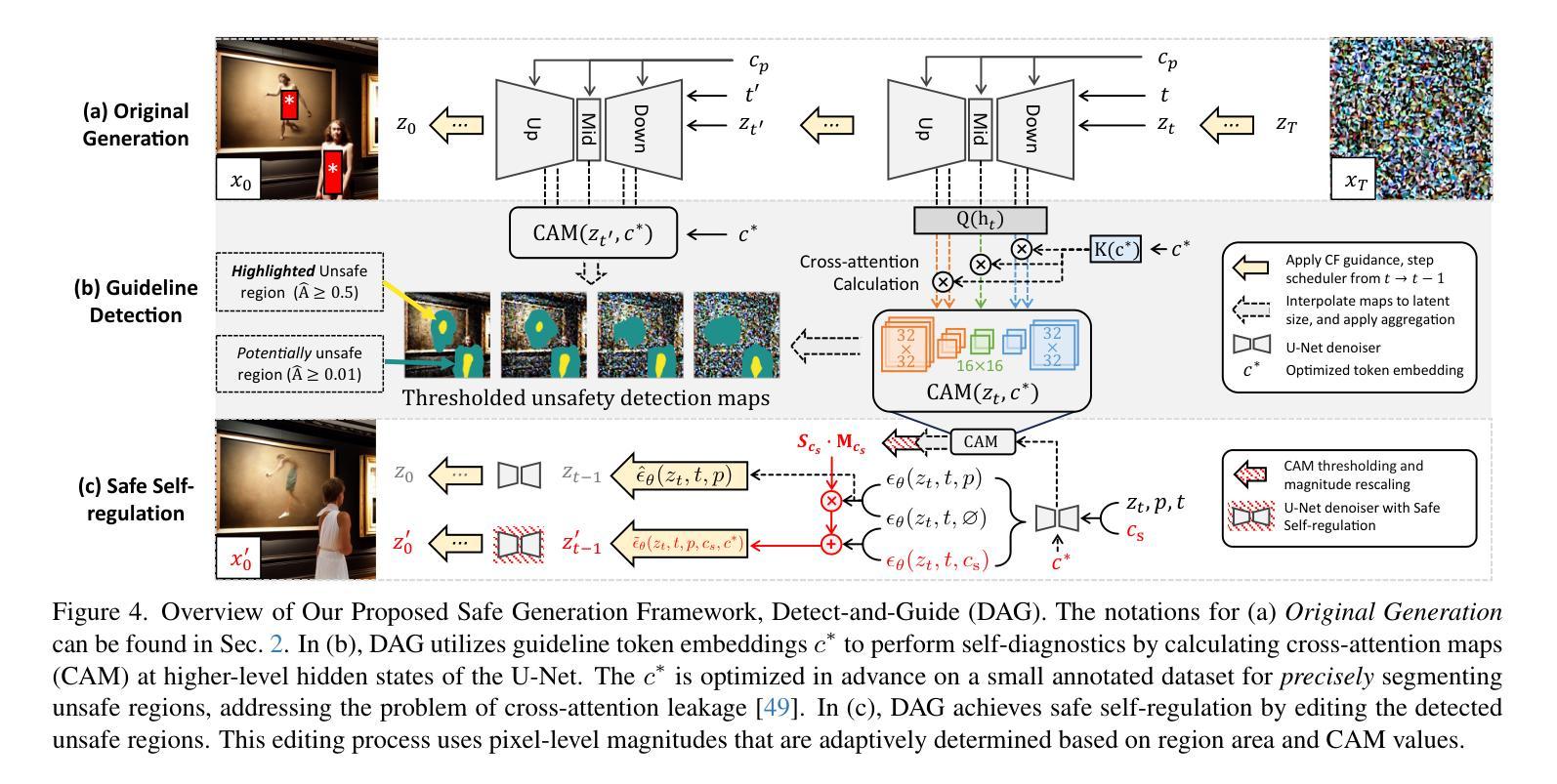
Detect-and-Guide: Self-regulation of Diffusion Models for Safe Text-to-Image Generation via Guideline Token Optimization
Authors:Feifei Li, Mi Zhang, Yiming Sun, Min Yang
Text-to-image diffusion models have achieved state-of-the-art results in synthesis tasks; however, there is a growing concern about their potential misuse in creating harmful content. To mitigate these risks, post-hoc model intervention techniques, such as concept unlearning and safety guidance, have been developed. However, fine-tuning model weights or adapting the hidden states of the diffusion model operates in an uninterpretable way, making it unclear which part of the intermediate variables is responsible for unsafe generation. These interventions severely affect the sampling trajectory when erasing harmful concepts from complex, multi-concept prompts, thus hindering their practical use in real-world settings. In this work, we propose the safe generation framework Detect-and-Guide (DAG), leveraging the internal knowledge of diffusion models to perform self-diagnosis and fine-grained self-regulation during the sampling process. DAG first detects harmful concepts from noisy latents using refined cross-attention maps of optimized tokens, then applies safety guidance with adaptive strength and editing regions to negate unsafe generation. The optimization only requires a small annotated dataset and can provide precise detection maps with generalizability and concept specificity. Moreover, DAG does not require fine-tuning of diffusion models, and therefore introduces no loss to their generation diversity. Experiments on erasing sexual content show that DAG achieves state-of-the-art safe generation performance, balancing harmfulness mitigation and text-following performance on multi-concept real-world prompts.
文本到图像的扩散模型在合成任务中取得了最先进的成果;然而,关于其可能用于创建有害内容的潜在滥用问题日益受到关注。为了减轻这些风险,开发了事后模型干预技术,如概念遗忘和安全指导。然而,微调扩散模型的权重或调整隐藏状态的方式是不可解释的,因此不清楚中间变量中的哪一部分负责产生不安全的内容。这些干预在从复杂的多概念提示中删除有害概念时,严重影响采样轨迹,从而阻碍了它们在现实世界设置中的实际应用。在这项工作中,我们提出了安全生成框架Detect-and-Guide(DAG),利用扩散模型的内部知识在采样过程中进行自诊断和精细的自我保护。DAG首先使用优化令牌的精细交叉注意力图从嘈杂的潜在空间中检测有害概念,然后应用自适应强度和编辑区域的安全指导来抵消不安全的生成。优化只需要一个小型注释数据集,就可以提供具有通用性和概念特异性的精确检测图。此外,DAG不需要对扩散模型进行微调,因此不会对其生成多样性造成损失。在消除性内容的实验方面,DAG实现了最先进的安全生成性能,在具有多概念的真实世界提示中平衡了有害性的减轻和遵循文本的性能。
论文及项目相关链接
PDF CVPR25
摘要
扩散模型在合成任务中取得了最先进的成果,但其潜在滥用风险引发关注。为缓解风险,采取了事后模型干预技术,如概念遗忘和安全指导等。然而,对扩散模型的权重微调或隐藏状态的调整方式缺乏可解释性,使得中间变量在产生不安全内容时难以明确其责任归属。本工作提出安全生成框架Detect-and-Guide(DAG),利用扩散模型的内部知识在采样过程中进行自诊断和精细化的自我调控。DAG首先使用优化后的标记的精细交叉注意力图检测潜在噪声中的有害概念,然后应用自适应强度和编辑区域的安全指导来避免不安全内容的生成。优化仅需少量标注数据集即可提供精确的检测图,具有通用性和概念特异性。此外,DAG不需要对扩散模型进行微调,因此不会损失其生成多样性。在消除色情内容实验中,DAG在安全生成方面取得最先进的成果,平衡了危害减轻和遵循文本的多个实际概念提示性能。
关键见解
- 文本至图像扩散模型在合成任务上取得顶尖成果,但存在潜在滥用风险。
- 为应对风险,采取了事后模型干预技术,但现有技术影响采样轨迹并减少生成多样性。
- 提出安全生成框架Detect-and-Guide(DAG),利用扩散模型的内部知识进行自我诊断和调控。
- DAG通过检测有害概念并提供安全指导来实现精确控制和优化生成内容。
- DAG采用小型标注数据集即可实现精确检测图,具有通用性和概念特异性。
- DAG无需微调扩散模型权重,维持模型的生成多样性。
点此查看论文截图



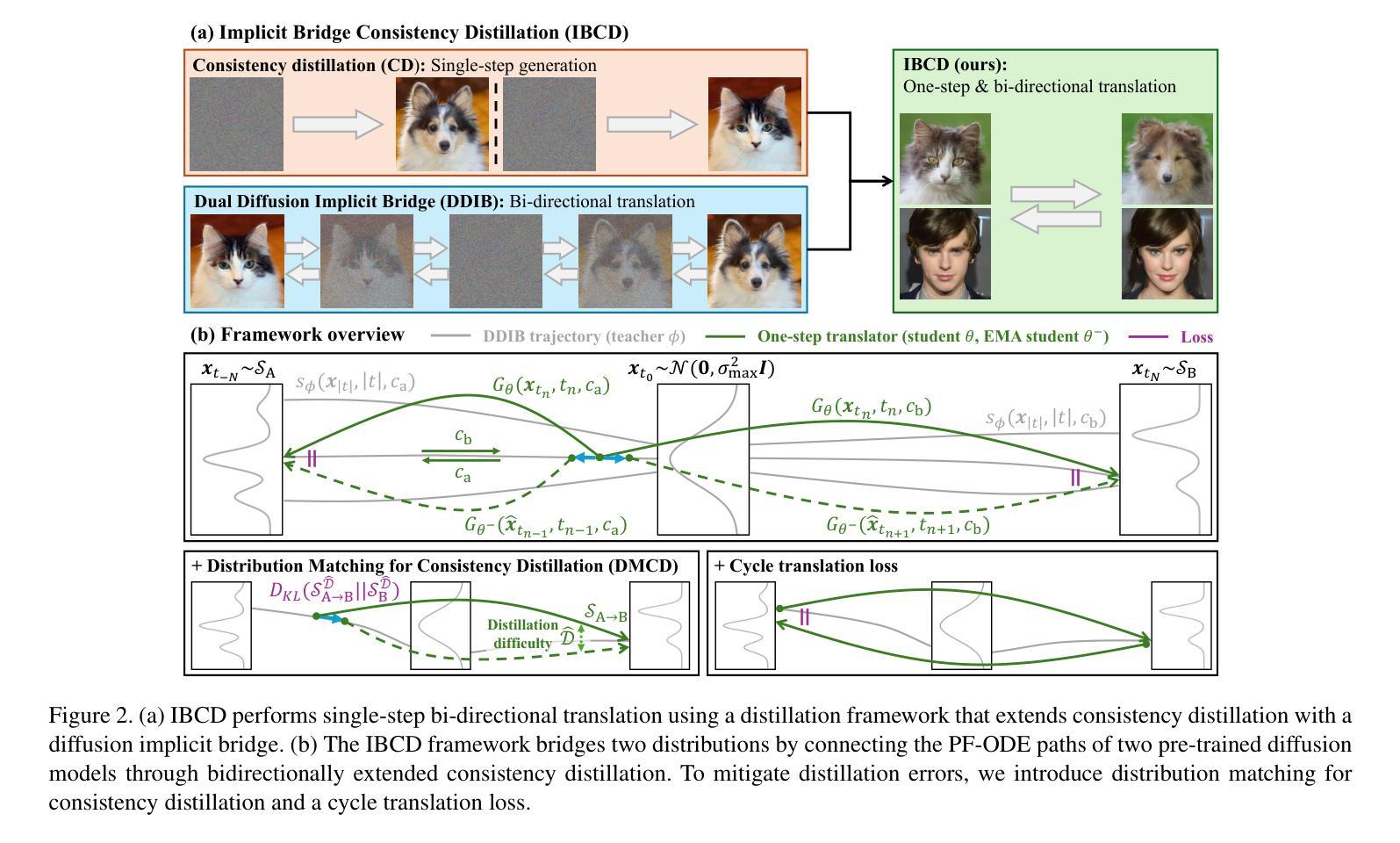
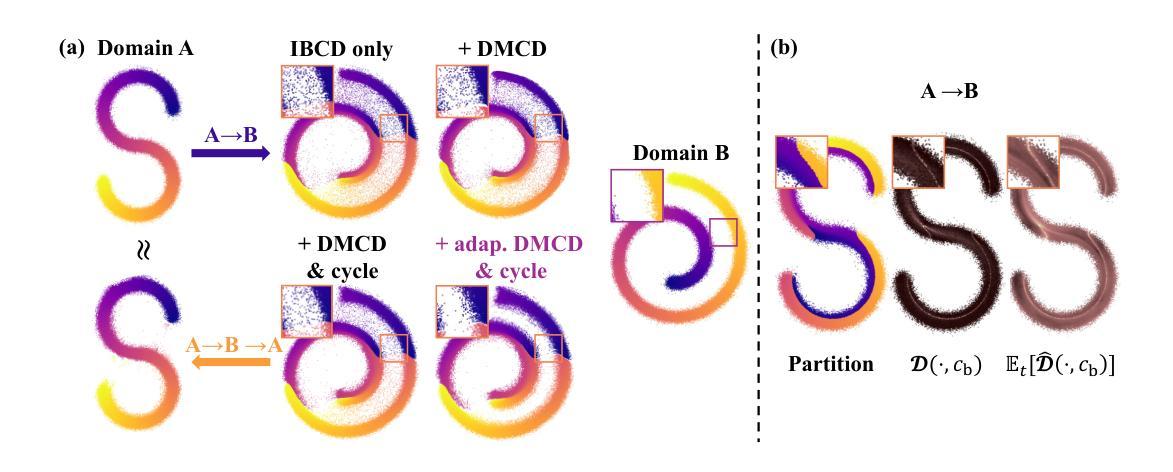
Single-Step Bidirectional Unpaired Image Translation Using Implicit Bridge Consistency Distillation
Authors:Suhyeon Lee, Kwanyoung Kim, Jong Chul Ye
Unpaired image-to-image translation has seen significant progress since the introduction of CycleGAN. However, methods based on diffusion models or Schr"odinger bridges have yet to be widely adopted in real-world applications due to their iterative sampling nature. To address this challenge, we propose a novel framework, Implicit Bridge Consistency Distillation (IBCD), which enables single-step bidirectional unpaired translation without using adversarial loss. IBCD extends consistency distillation by using a diffusion implicit bridge model that connects PF-ODE trajectories between distributions. Additionally, we introduce two key improvements: 1) distribution matching for consistency distillation and 2) adaptive weighting method based on distillation difficulty. Experimental results demonstrate that IBCD achieves state-of-the-art performance on benchmark datasets in a single generation step. Project page available at https://hyn2028.github.io/project_page/IBCD/index.html
非配对图像到图像的翻译自CycleGAN提出以来取得了重大进展。然而,基于扩散模型或Schrödinger桥梁的方法由于其迭代采样的特性,尚未在真实世界应用中广泛采用。为了应对这一挑战,我们提出了一种新型框架——隐桥一致性蒸馏(IBCD),它能够在不使用对抗性损失的情况下实现单步双向非配对翻译。IBCD通过采用连接分布间PF-ODE轨迹的扩散隐桥模型,扩展了一致性蒸馏。此外,我们还引入了两种关键改进:1)用于一致性蒸馏的分布匹配;2)基于蒸馏难度的自适应加权方法。实验结果表明,IBCD在基准数据集上实现了单步生成的最佳性能。项目页面可通过https://hyn2028.github.io/project_page/IBCD/index.html访问。
论文及项目相关链接
PDF 25 pages, 16 figures
Summary
循环生成对抗网络(CycleGAN)推出后,非配对图像到图像转换取得显著进展。然而,基于扩散模型或薛定谔桥的方法由于迭代采样性质尚未在现实世界应用中广泛采用。为解决这一挑战,我们提出一种新型框架——隐桥一致性蒸馏(IBCD),实现无需对抗性损失的单步双向非配对翻译。IBCD通过扩散隐桥模型连接概率流常微分方程轨迹,扩展一致性蒸馏。此外,我们引入两个关键改进:1)用于一致性蒸馏的分布匹配;2)基于蒸馏难度的自适应加权方法。实验结果表明,IBCD在基准数据集上实现单次生成步骤的最佳性能。
Key Takeaways
- 循环生成对抗网络(CycleGAN)推动了非配对图像到图像转换的进展。
- 扩散模型和薛定谔桥方法由于迭代采样的性质,在现实世界应用中的普及受到限制。
- 提出新型框架——隐桥一致性蒸馏(IBCD),实现无需对抗性损失的单步双向非配对翻译。
- IBCD通过扩散隐桥模型连接概率流常微分方程轨迹,扩展了一致性蒸馏的概念。
- IBCD引入分布匹配用于一致性蒸馏。
- IBCD采用基于蒸馏难度的自适应加权方法。
- 实验结果显示,IBCD在基准数据集上实现了单次生成步骤的最佳性能。
点此查看论文截图


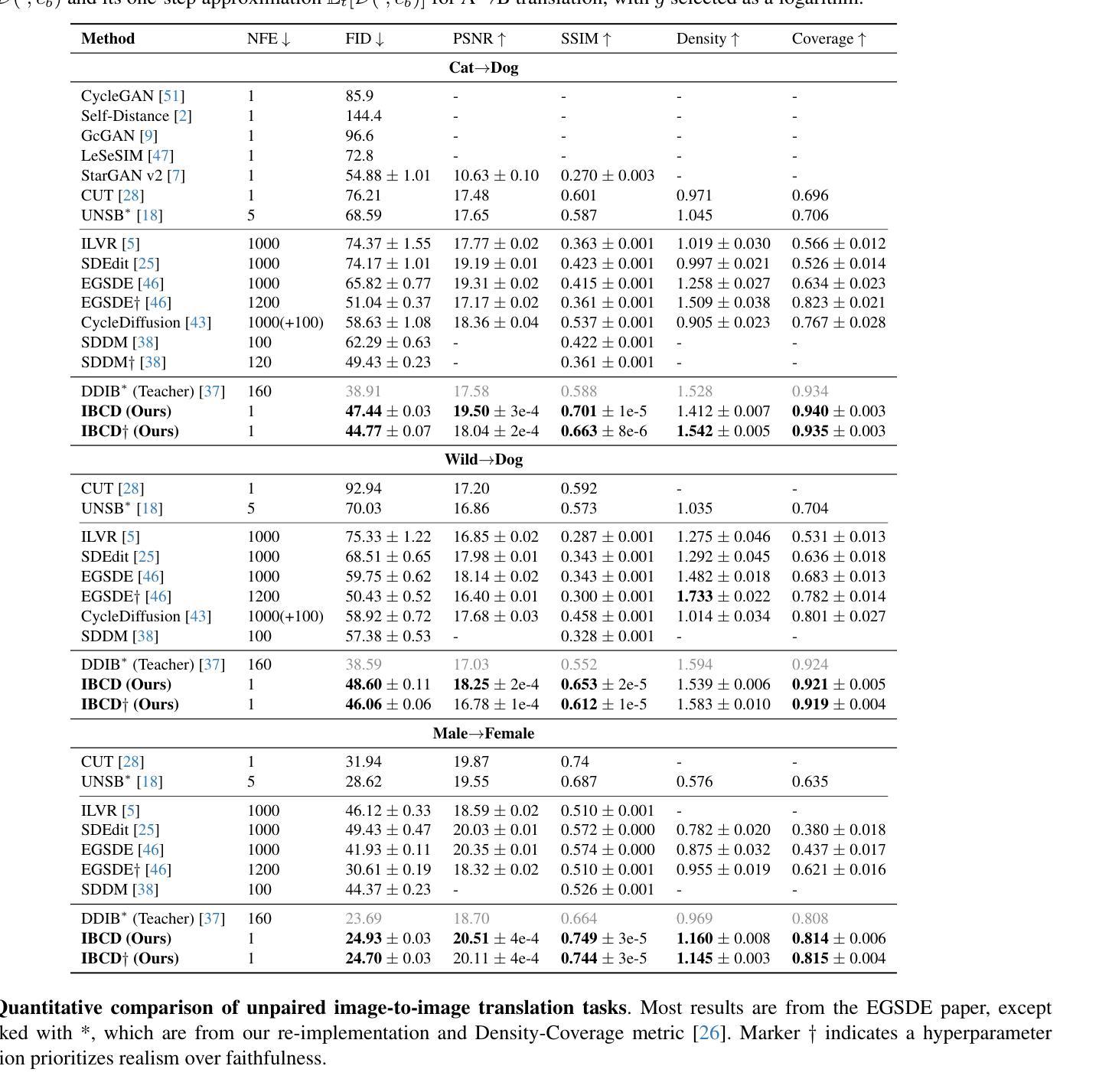
Exploiting Diffusion Prior for Real-World Image Dehazing with Unpaired Training
Authors:Yunwei Lan, Zhigao Cui, Chang Liu, Jialun Peng, Nian Wang, Xin Luo, Dong Liu
Unpaired training has been verified as one of the most effective paradigms for real scene dehazing by learning from unpaired real-world hazy and clear images. Although numerous studies have been proposed, current methods demonstrate limited generalization for various real scenes due to limited feature representation and insufficient use of real-world prior. Inspired by the strong generative capabilities of diffusion models in producing both hazy and clear images, we exploit diffusion prior for real-world image dehazing, and propose an unpaired framework named Diff-Dehazer. Specifically, we leverage diffusion prior as bijective mapping learners within the CycleGAN, a classic unpaired learning framework. Considering that physical priors contain pivotal statistics information of real-world data, we further excavate real-world knowledge by integrating physical priors into our framework. Furthermore, we introduce a new perspective for adequately leveraging the representation ability of diffusion models by removing degradation in image and text modalities, so as to improve the dehazing effect. Extensive experiments on multiple real-world datasets demonstrate the superior performance of our method. Our code https://github.com/ywxjm/Diff-Dehazer.
无配对训练已通过从不成对的真实世界雾霾和清晰图像中学习验证为最有效的实景去雾范式之一。尽管已经提出了许多研究,但当前的方法由于特征表示有限和真实世界先验的利用不足,对各种真实场景的泛化能力有限。受扩散模型在生成雾霾和清晰图像方面的强大生成能力的启发,我们利用扩散先验进行真实图像去雾,并提出了一种无配对的框架Diff-Dehazer。具体来说,我们在CycleGAN(一种经典的无配对学习框架)中利用扩散先验作为双向映射学习者。考虑到物理先验包含真实世界数据的关键统计信息,我们进一步通过整合物理先验到我们的框架中来挖掘真实世界的知识。此外,我们通过去除图像和文本模态的退化,为充分利用扩散模型的表示能力引入了新的视角,以提高去雾效果。在多个真实世界数据集上的广泛实验证明了我们方法的优越性。我们的代码为 https://github.com/ywxjm/Diff-Dehazer。
论文及项目相关链接
PDF Accepted by AAAI2025
摘要
利用无配对训练方式,通过从现实世界的雾霾和清晰图像中学习,实现真实场景去雾的最有效方法之一。虽然已有许多相关研究,但受限于特征表达和未能充分利用现实世界的先验知识,现有方法的泛化能力受限。受到扩散模型在生成雾霾和清晰图像方面的强大能力的启发,本文利用扩散先验进行真实图像去雾,提出了一种名为Diff-Dehazer的无配对框架。具体来说,我们在经典的CycleGAN无配对学习框架中引入扩散先验作为双向映射学习者。考虑到物理先验包含现实世界数据的关键统计信息,我们进一步通过整合物理先验来挖掘现实世界知识。此外,通过去除图像和文本模态的退化,引入了充分利用扩散模型表达能力的新视角,以提高去雾效果。在多个真实世界数据集上的实验证明了我们的方法具有卓越性能。代码链接:https://github.com/ywxjm/Diff-Dehazer。
关键见解
- 无配对训练已被验证为从现实世界的雾霾和清晰图像中学习去雾最有效的范式之一。
- 扩散模型因其强大的生成能力被用于去雾任务中,提出了利用扩散先验的Diff-Dehazer框架。
- 在经典的无配对学习框架CycleGAN中引入扩散先验作为双向映射学习者。
- 通过整合物理先验挖掘现实世界知识,提高去雾效果。
- 引入新的视角,通过去除图像和文本模态的退化来充分利用扩散模型的表达能力。
点此查看论文截图

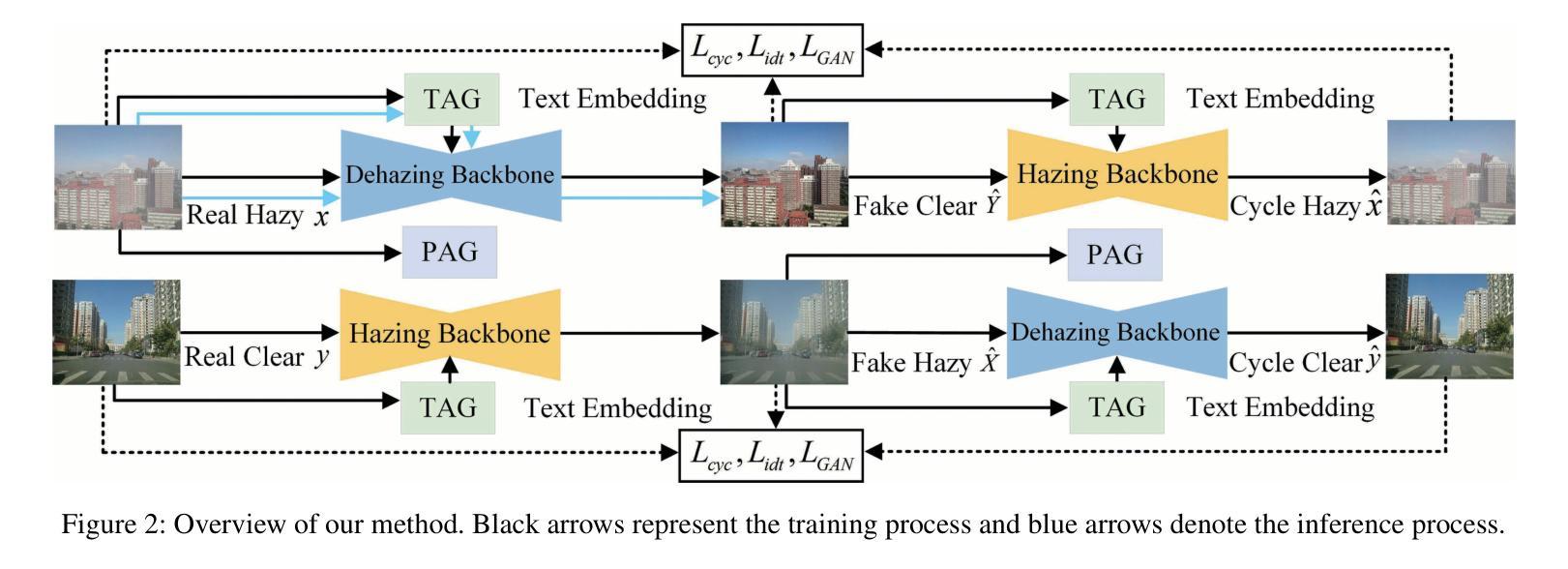
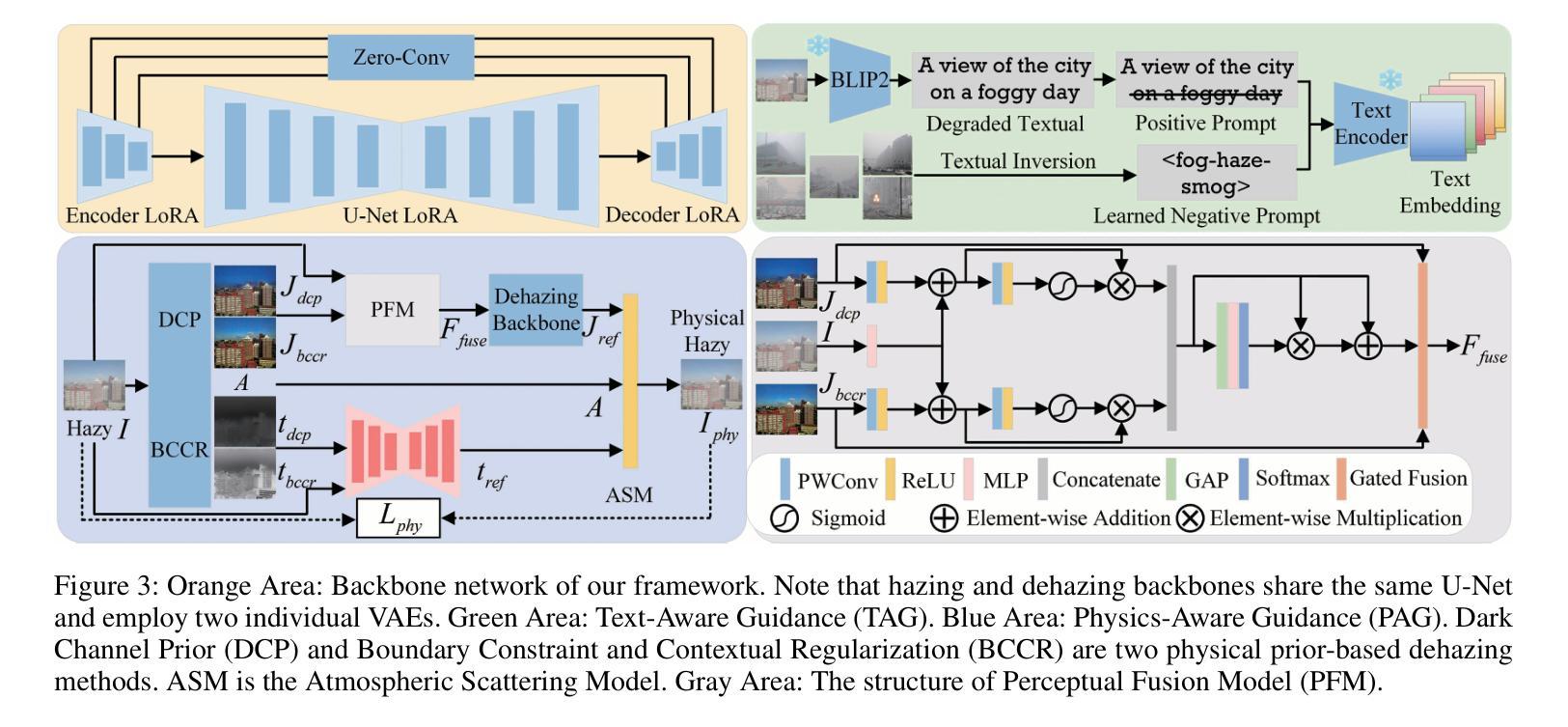

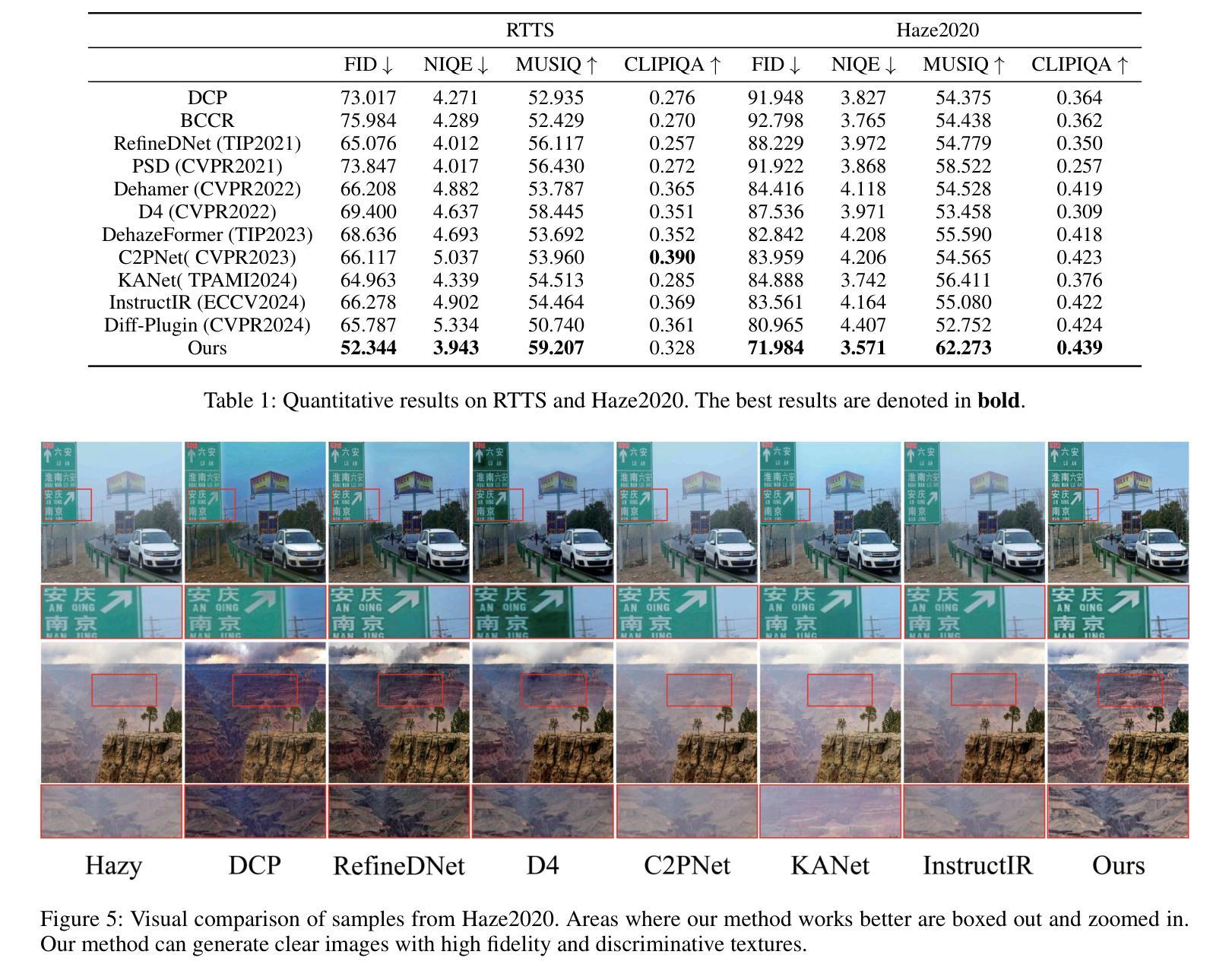
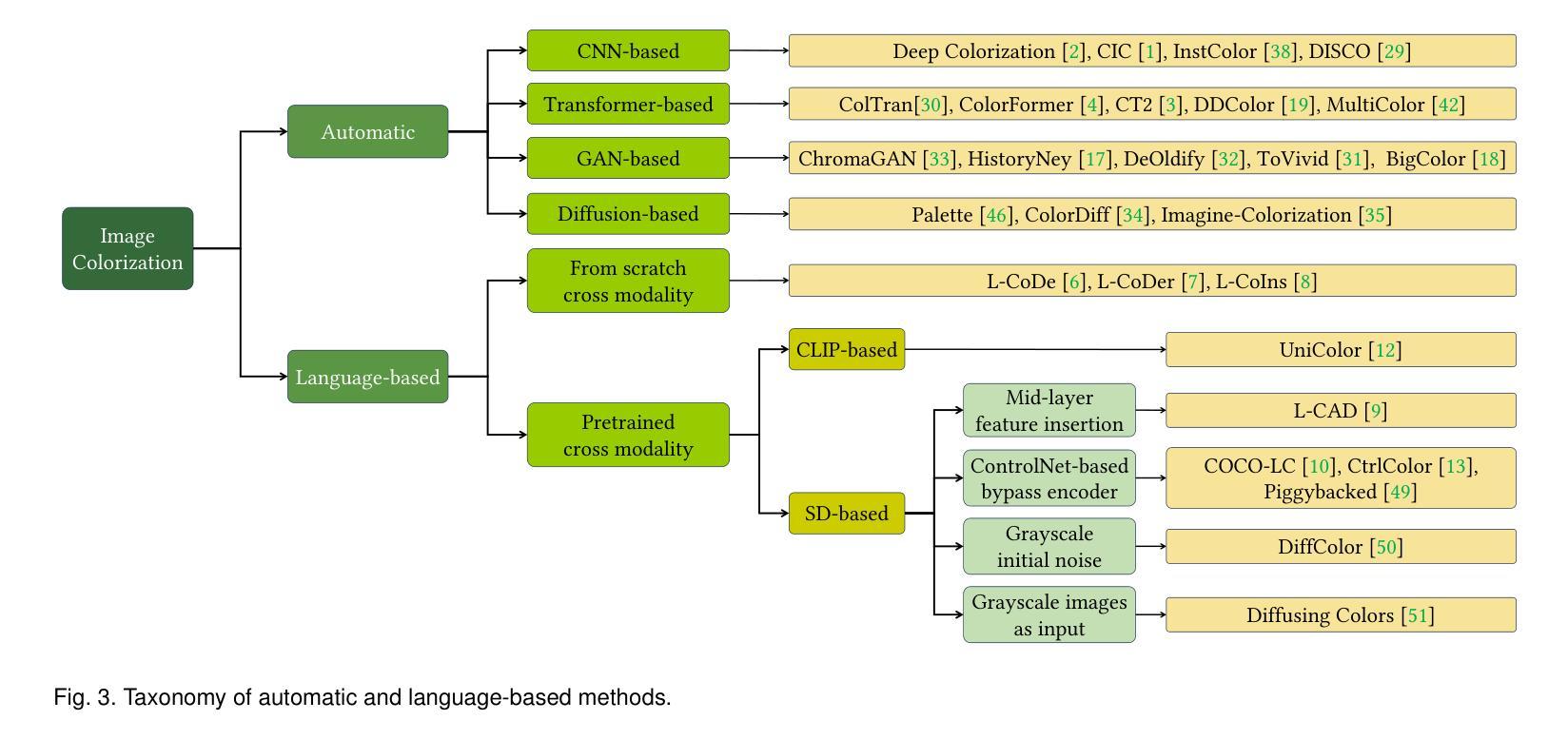
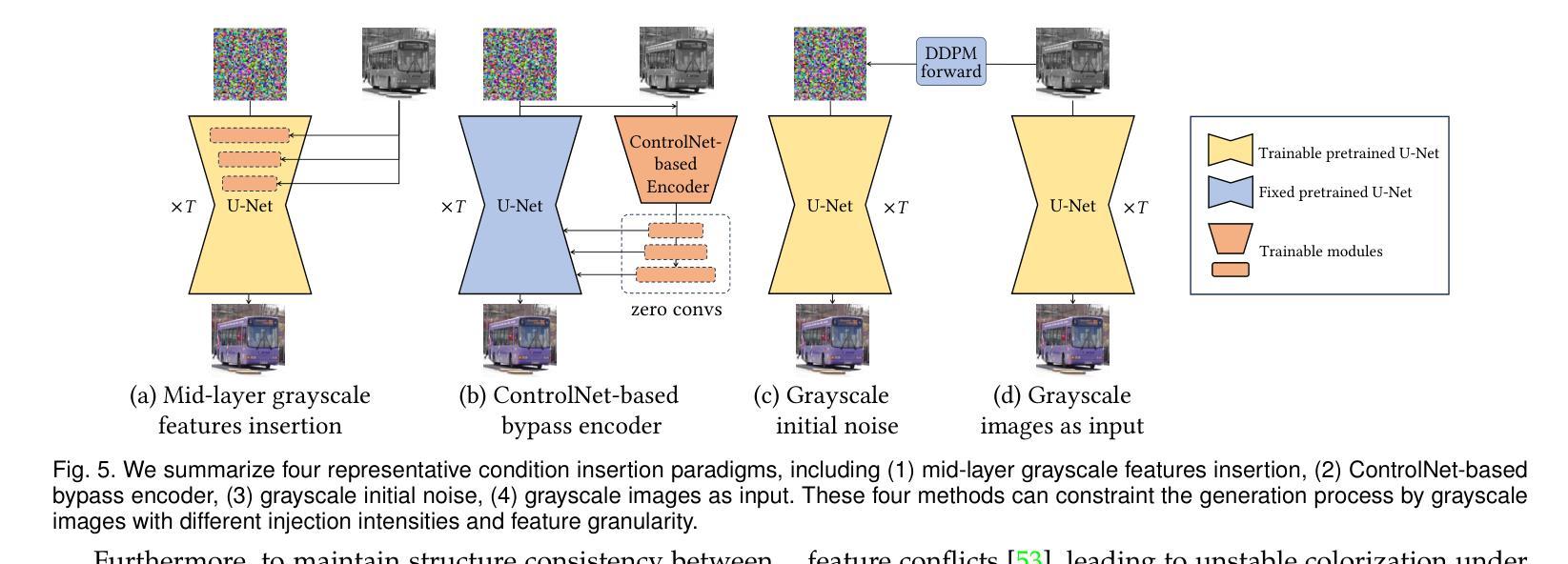
Language-based Image Colorization: A Benchmark and Beyond
Authors:Yifan Li, Shuai Yang, Jiaying Liu
Image colorization aims to bring colors back to grayscale images. Automatic image colorization methods, which requires no additional guidance, struggle to generate high-quality images due to color ambiguity, and provides limited user controllability. Thanks to the emergency of cross-modality datasets and models, language-based colorization methods are proposed to fully utilize the efficiency and flexibly of text descriptions to guide colorization. In view of the lack of a comprehensive review of language-based colorization literature, we conduct a thorough analysis and benchmarking. We first briefly summarize existing automatic colorization methods. Then, we focus on language-based methods and point out their core challenge on cross-modal alignment. We further divide these methods into two categories: one attempts to train a cross-modality network from scratch, while the other utilizes the pre-trained cross-modality model to establish the textual-visual correspondence. Based on the analyzed limitations of existing language-based methods, we propose a simple yet effective method based on distilled diffusion model. Extensive experiments demonstrate that our simple baseline can produces better results than previous complex methods with 14 times speed up. To the best of our knowledge, this is the first comprehensive review and benchmark on language-based image colorization field, providing meaningful insights for the community. The code is available at https://github.com/lyf1212/Color-Turbo.
图像彩色化的目标是给黑白图像恢复色彩。自动图像彩色化方法无需额外指导,但由于色彩模糊度,其在生成高质量图像方面存在困难,且用户可控性有限。得益于跨模态数据集和模型的兴起,基于语言的彩色化方法被提出,以充分利用文本描述的效率和灵活性来指导彩色化。鉴于缺乏基于语言的彩色化文献的全面综述,我们进行了深入分析和基准测试。首先,我们简要总结了现有的自动彩色化方法。然后,我们重点关注基于语言的方法,并指出了它们在跨模态对齐方面的核心挑战。我们进一步将这些方法分为两类:一类试图从头开始训练一个跨模态网络,另一类则利用预训练的跨模态模型来建立文本-视觉对应关系。基于对现有基于语言的方法的分析和局限性,我们提出了一种简单而有效的方法,该方法基于蒸馏扩散模型。大量实验表明,我们简单的基线方法能够在比以前的复杂方法快14倍的情况下产生更好的结果。据我们所知,这是语言驱动图像彩色化领域的首次全面综述和基准测试,为社区提供了有意义的见解。代码可通过https://github.com/lyf1212/Color-Turbo获取。
论文及项目相关链接
Summary
本文介绍了图像彩色化的目标和方法。自动图像彩色化方法因色彩模糊和用户控制有限而难以生成高质量图像。近年来,基于语言描述的彩色化方法因其效率和灵活性而受到关注。本文对基于语言的彩色化文献进行了全面综述和基准测试,总结了现有自动彩色化方法的不足,指出了基于语言的方法在跨模态对齐方面的核心挑战,并提出了基于蒸馏扩散模型的简单有效方法。实验表明,该简单基线方法比以前的复杂方法更好,速度提高了14倍。本文是对基于语言的图像彩色化领域的首次全面审查和基准测试,为社区提供了有意义的见解。
Key Takeaways
- 图像彩色化的目标是恢复灰度图像的色彩。
- 自动图像彩色化方法因色彩模糊和用户控制有限而面临挑战。
- 基于语言描述的彩色化方法利用文本描述来提高效率和灵活性。
- 本文对基于语言的图像彩色化方法进行了全面综述和基准测试。
- 现有自动彩色化方法存在局限性,需要新的方法改进。
- 本文提出了一种基于蒸馏扩散模型的简单有效图像彩色化方法,实验表现优异。
点此查看论文截图



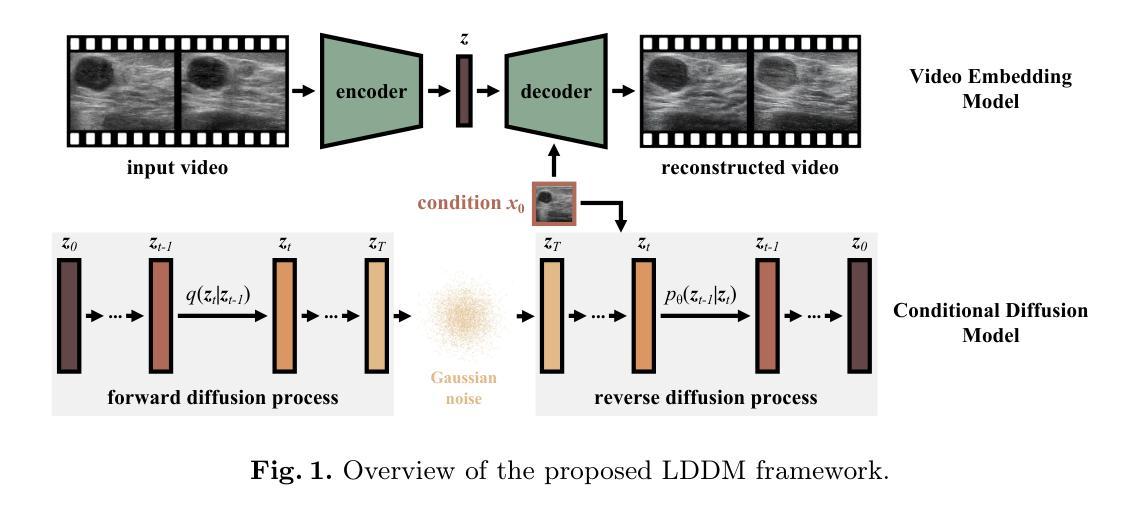
Ultrasound Image-to-Video Synthesis via Latent Dynamic Diffusion Models
Authors:Tingxiu Chen, Yilei Shi, Zixuan Zheng, Bingcong Yan, Jingliang Hu, Xiao Xiang Zhu, Lichao Mou
Ultrasound video classification enables automated diagnosis and has emerged as an important research area. However, publicly available ultrasound video datasets remain scarce, hindering progress in developing effective video classification models. We propose addressing this shortage by synthesizing plausible ultrasound videos from readily available, abundant ultrasound images. To this end, we introduce a latent dynamic diffusion model (LDDM) to efficiently translate static images to dynamic sequences with realistic video characteristics. We demonstrate strong quantitative results and visually appealing synthesized videos on the BUSV benchmark. Notably, training video classification models on combinations of real and LDDM-synthesized videos substantially improves performance over using real data alone, indicating our method successfully emulates dynamics critical for discrimination. Our image-to-video approach provides an effective data augmentation solution to advance ultrasound video analysis. Code is available at https://github.com/MedAITech/U_I2V.
超声波视频分类可实现自动化诊断,已成为重要的研究领域。然而,可用的超声波视频数据集仍然稀缺,阻碍了有效视频分类模型的开发进展。我们提出通过合成合理的超声波视频来解决这一短缺问题,这些视频由易于获取且丰富的超声波图像合成而来。为此,我们引入了一种潜在动态扩散模型(Latent Dynamic Diffusion Model, LDDM),以高效地将静态图像转换为具有真实视频特性的动态序列。我们在BUSV基准测试上展示了强大的定量结果和视觉上令人满意的合成视频。值得注意的是,使用真实和LDDM合成视频组合训练的视频分类模型,其性能远超仅使用真实数据的情况,这表明我们的方法成功模拟了用于鉴别的关键动态。我们的图像到视频的方法为推进超声波视频分析提供了有效的数据增强解决方案。代码可在https://github.com/MedAITech/U_I2V获取。
论文及项目相关链接
PDF MICCAI 2024
Summary
本摘要提出通过利用静态图像生成动态序列来解决超声视频数据集短缺的问题。研究团队引入了一种潜在动态扩散模型(LDDM),该模型能够将现有的大量超声图像转化为逼真的视频特性序列。在BUSV基准测试上,合成的视频既具有强大的定量结果又具有良好的视觉效果。此外,在真实视频与合成的视频结合训练分类模型的情况下,性能得到了显著提升,证明合成视频对于判别能力具有关键作用。该研究提供了一种有效的数据增强解决方案,推动了超声视频分析的发展。
Key Takeaways
- 超声视频分类对于自动化诊断至关重要,但可用的超声视频数据集有限。
- 提出通过潜在动态扩散模型(LDDM)将静态超声图像转化为动态视频序列的方法。
- LDDM合成的视频在BUSV基准测试中表现出强大的定量结果和良好的视觉效果。
- 结合真实和合成视频训练分类模型能显著提高性能。
- 合成视频具有关键的判别能力,可模拟重要的动态特性。
- 该方法提供了一种有效的数据增强解决方案,有助于推动超声视频分析的发展。
点此查看论文截图


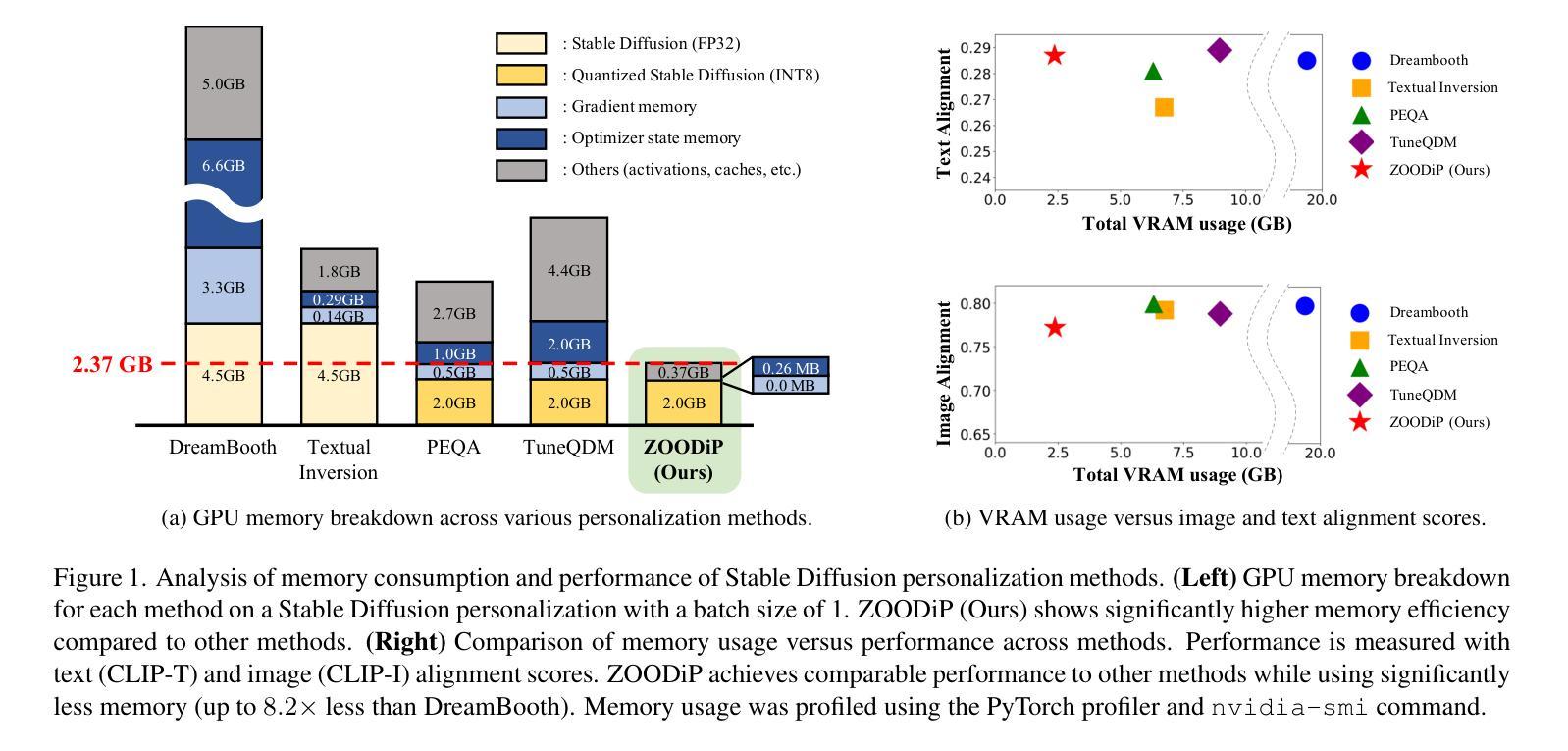
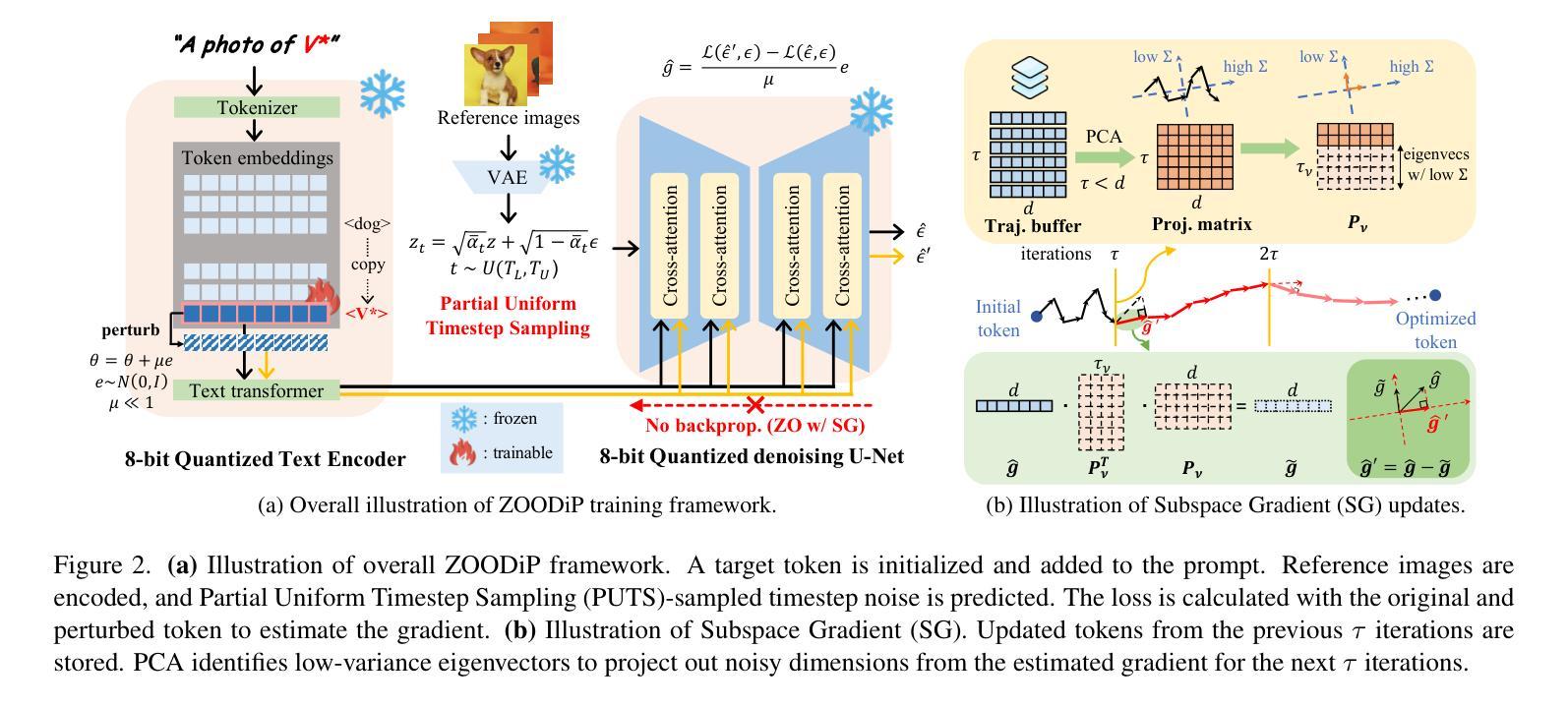
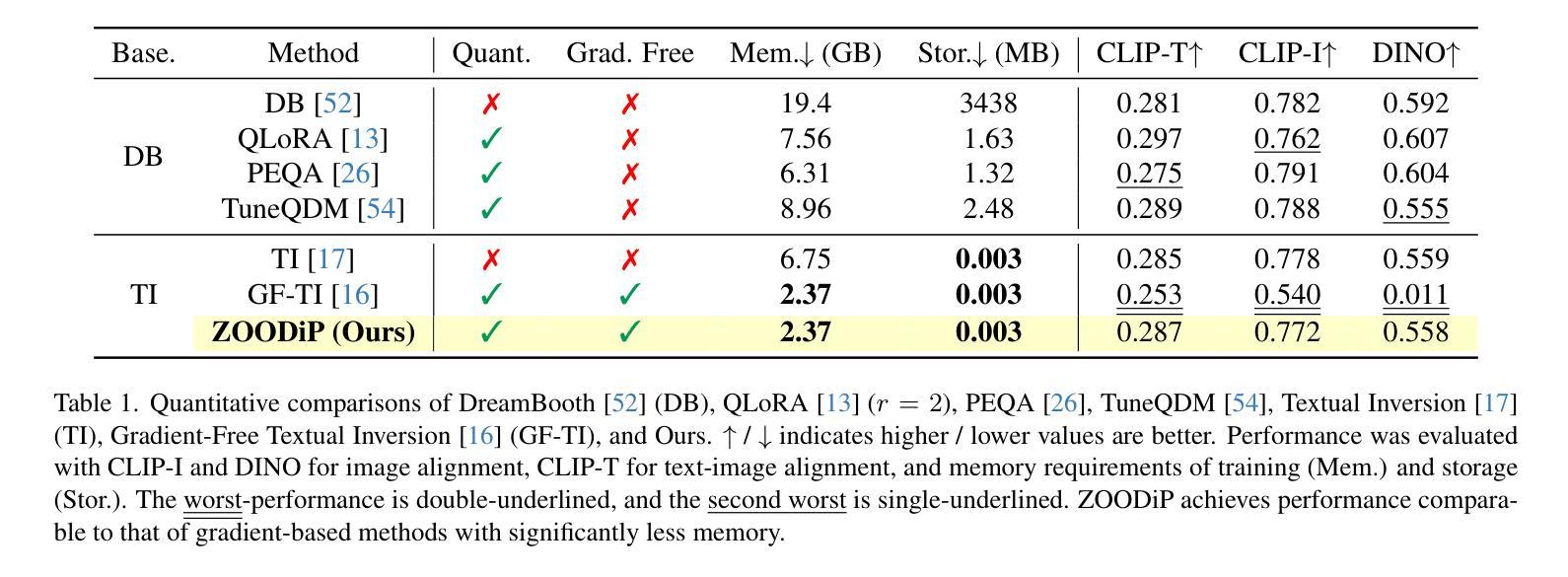
Efficient Personalization of Quantized Diffusion Model without Backpropagation
Authors:Hoigi Seo, Wongi Jeong, Kyungryeol Lee, Se Young Chun
Diffusion models have shown remarkable performance in image synthesis, but they demand extensive computational and memory resources for training, fine-tuning and inference. Although advanced quantization techniques have successfully minimized memory usage for inference, training and fine-tuning these quantized models still require large memory possibly due to dequantization for accurate computation of gradients and/or backpropagation for gradient-based algorithms. However, memory-efficient fine-tuning is particularly desirable for applications such as personalization that often must be run on edge devices like mobile phones with private data. In this work, we address this challenge by quantizing a diffusion model with personalization via Textual Inversion and by leveraging a zeroth-order optimization on personalization tokens without dequantization so that it does not require gradient and activation storage for backpropagation that consumes considerable memory. Since a gradient estimation using zeroth-order optimization is quite noisy for a single or a few images in personalization, we propose to denoise the estimated gradient by projecting it onto a subspace that is constructed with the past history of the tokens, dubbed Subspace Gradient. In addition, we investigated the influence of text embedding in image generation, leading to our proposed time steps sampling, dubbed Partial Uniform Timestep Sampling for sampling with effective diffusion timesteps. Our method achieves comparable performance to prior methods in image and text alignment scores for personalizing Stable Diffusion with only forward passes while reducing training memory demand up to $8.2\times$.
扩散模型在图像合成中表现出卓越的性能,但它们对于训练、微调以及推理需要大量的计算和内存资源。虽然先进的量化技术已成功最小化了推理过程中的内存使用,但对这些量化模型进行训练和微调仍然需要大内存,这可能是由于为了准确计算梯度和基于梯度的算法进行反向传播而需要进行反量化。然而,对于必须在边缘设备(如带有私人数据的移动电话)上运行的应用程序而言,对内存效率高的微调有特别需求。在这项工作中,我们通过使用文本反转对扩散模型进行量化,并利用零阶优化对个性化令牌进行优化,解决了这一挑战,无需反量化即可在不要求梯度和反向传播激活存储(这会消耗大量内存)的情况下进行。由于使用零阶优化对梯度估计在个性化中的单个或少数图像是相当嘈杂的,我们提出通过投影到由过去令牌历史构建的子空间来对估计的梯度进行去噪,被称为子空间梯度。此外,我们研究了文本嵌入在图像生成中的影响,导致我们提出时间步长采样方法,被称为部分均匀时间步长采样,用于有效的扩散时间步长采样。我们的方法在图像和文本对齐得分方面实现了与先前方法相当的性能,可以在个性化Stable Diffusion的同时仅通过前向传递减少训练内存需求高达8.2倍。
论文及项目相关链接
Summary
扩散模型在图像合成方面表现出卓越的性能,但其在训练、微调及推理过程中需要大量的计算和内存资源。尽管先进的量化技术已成功减少了推理过程中的内存使用,但量化模型的训练和微调仍然需要较大的内存,这可能是由于为了准确计算梯度和进行反向传播而需要进行反量化所致。针对个性化应用等需要在边缘设备(如手机)上运行并使用私有数据的应用程序,内存高效的微调尤为关键。本研究通过结合文本反转对扩散模型进行量化,并利用零阶优化对个人化令牌进行优化,无需反量化即可满足这一需求,从而避免了梯度计算和反向传播过程中大量内存的消耗。针对个性化中单一或少量图像的梯度估计噪声较大,本研究提出了基于过去令牌历史的子空间梯度去噪方法。此外,本研究还探讨了文本嵌入在图像生成中的影响,并据此提出了部分均匀时间步长采样方法。该方法在个性化Stable Diffusion的图像和文本对齐得分方面取得了与以往方法相当的效果,同时仅通过前向传递就降低了高达8.2倍的训练内存需求。
Key Takeaways
- 扩散模型在图像合成方面表现出强大的性能,但需要大量的计算和内存资源。
- 先进量化技术虽能减少推理过程中的内存使用,但训练和微调时仍需大量内存。
- 研究提出了一种结合文本反转和零阶优化的方法,进行扩散模型的量化及个性化,降低内存消耗。
- 针对个性化应用中梯度估计的噪声问题,提出了子空间梯度去噪方法。
- 研究发现文本嵌入在图像生成中具有重要影响,并据此提出了部分均匀时间步长采样方法。
- 方法在图像和文本对齐得分方面与以往方法相当,同时显著降低了训练内存需求。
点此查看论文截图




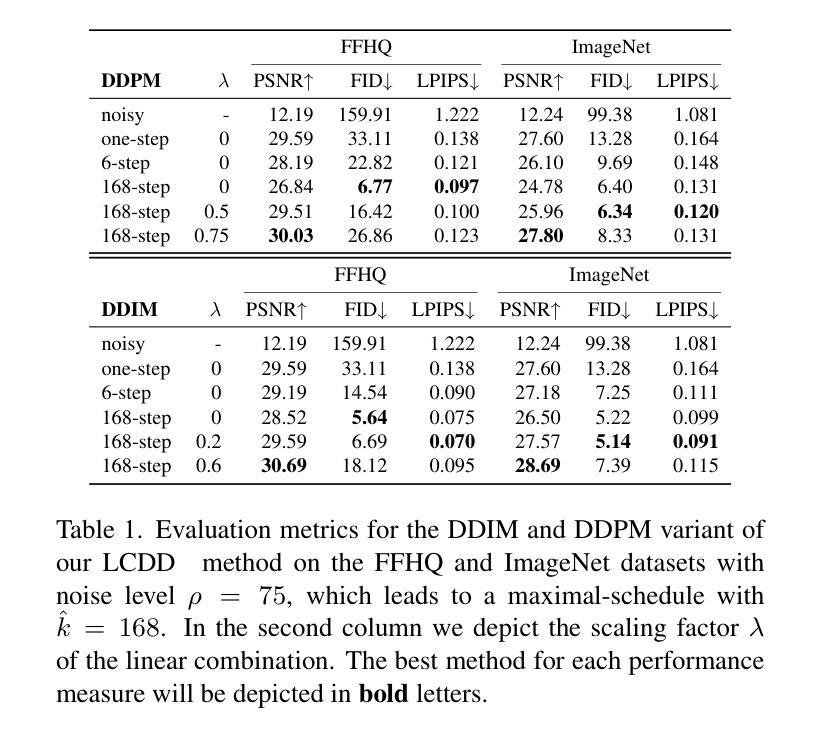
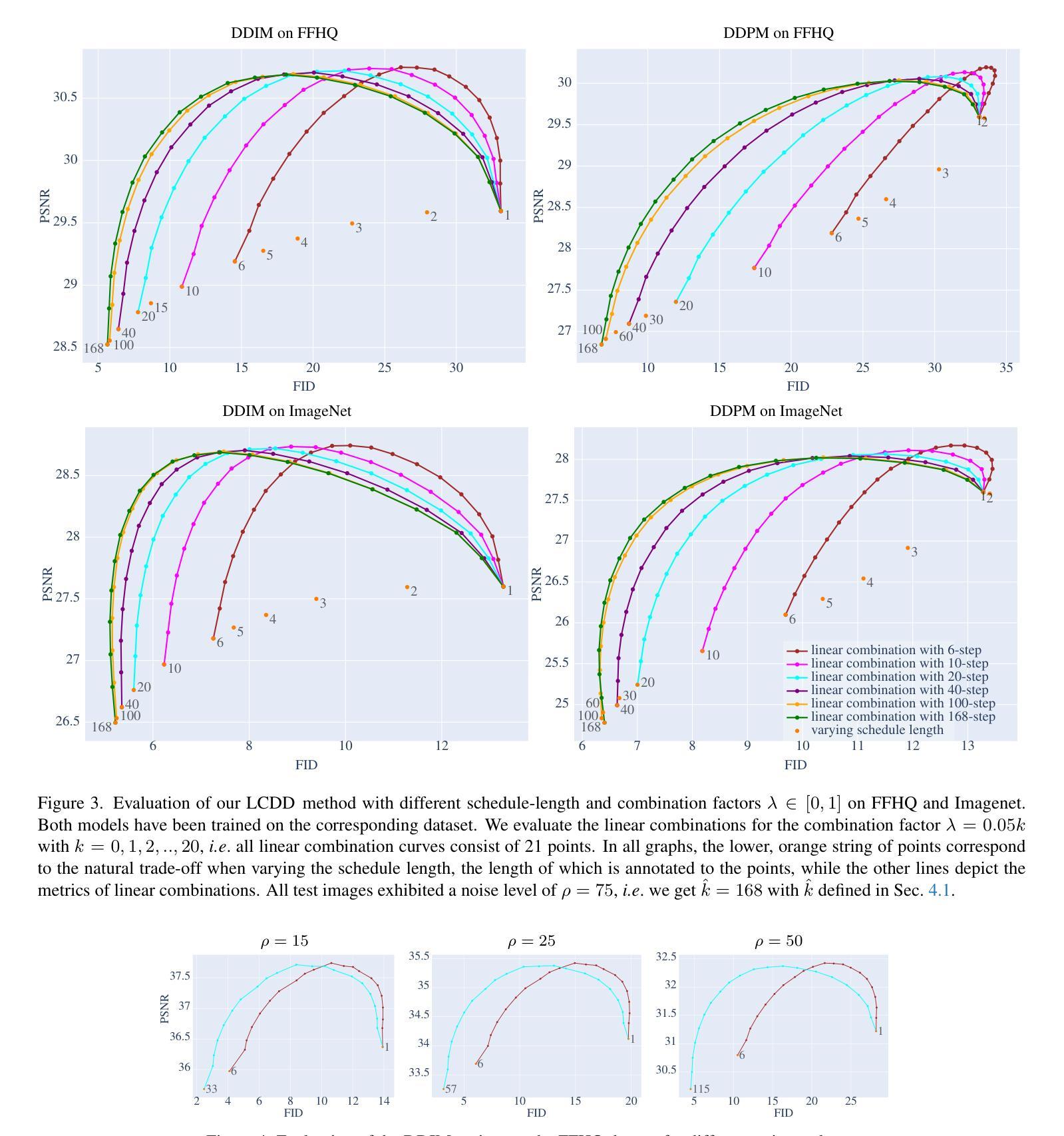
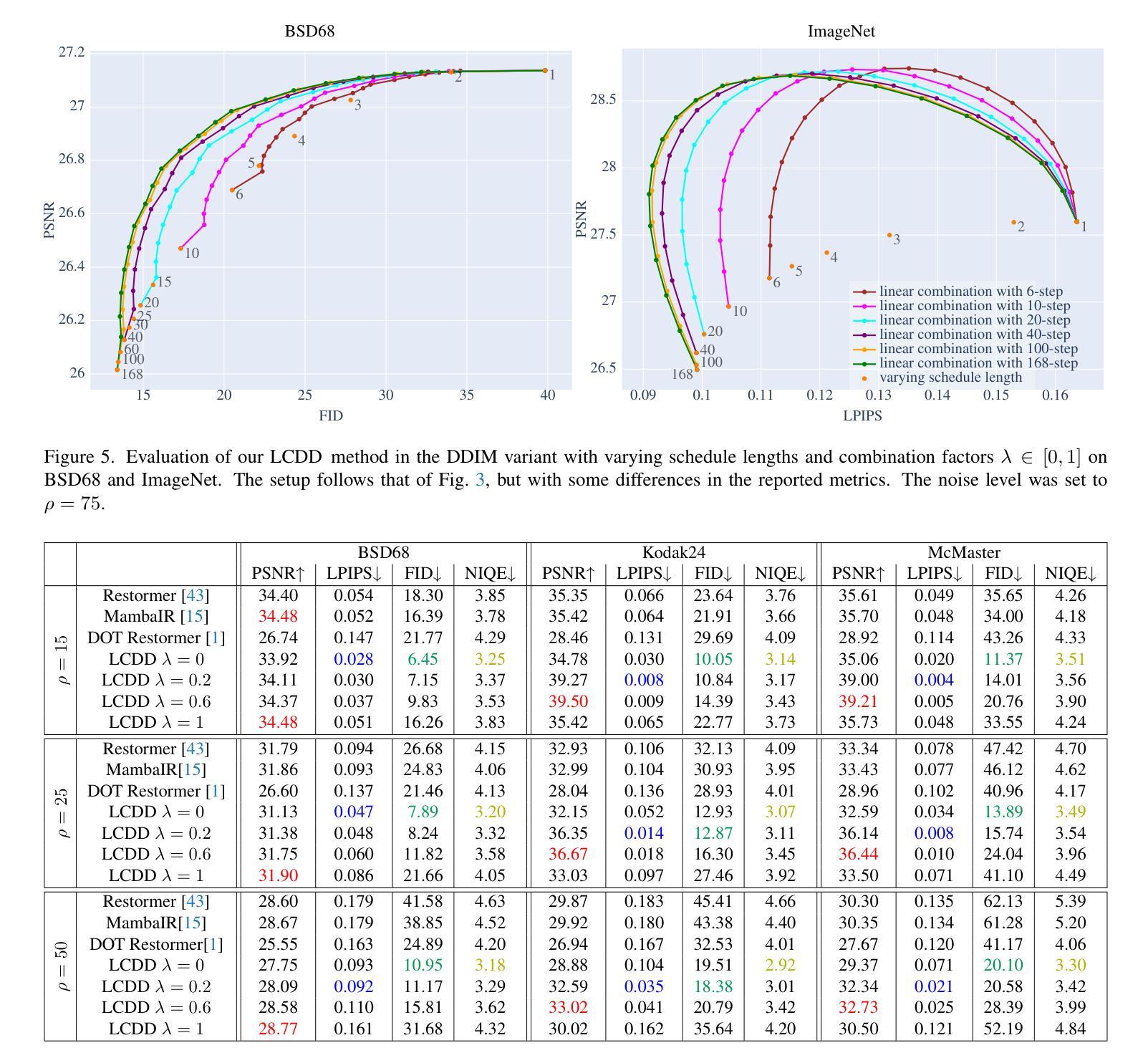
A Simple Combination of Diffusion Models for Better Quality Trade-Offs in Image Denoising
Authors:Jonas Dornbusch, Emanuel Pfarr, Florin-Alexandru Vasluianu, Frank Werner, Radu Timofte
Diffusion models have garnered considerable interest in computer vision, owing both to their capacity to synthesize photorealistic images and to their proven effectiveness in image reconstruction tasks. However, existing approaches fail to efficiently balance the high visual quality of diffusion models with the low distortion achieved by previous image reconstruction methods. Specifically, for the fundamental task of additive Gaussian noise removal, we first illustrate an intuitive method for leveraging pretrained diffusion models. Further, we introduce our proposed Linear Combination Diffusion Denoiser (LCDD), which unifies two complementary inference procedures - one that leverages the model’s generative potential and another that ensures faithful signal recovery. By exploiting the inherent structure of the denoising samples, LCDD achieves state-of-the-art performance and offers controlled, well-behaved trade-offs through a simple scalar hyperparameter adjustment.
扩散模型在计算机视觉领域引起了极大的关注,这既是因为它们能够合成逼真的图像,也是因为它们在图像重建任务中的有效性得到了验证。然而,现有的方法未能有效地平衡扩散模型的高视觉质量与先前图像重建方法实现的低失真。具体来说,对于基本的添加高斯噪声去除任务,我们首先提出了一种利用预训练扩散模型的直观方法。此外,我们引入了所提出的线性组合扩散去噪器(LCDD),它统一了两种互补的推理程序——一种利用模型的生成潜力,另一种确保忠实信号恢复。通过利用去噪样本的固有结构,LCDD实现了最先进的性能,并通过简单的标量超参数调整提供了可控且表现良好的权衡。
论文及项目相关链接
PDF 10 pages, 7 figures, 2 tables
Summary
扩散模型在计算机视觉领域受到广泛关注,既能够合成逼真的图像,也在图像重建任务中展现出效果。然而,现有方法难以在扩散模型的高视觉质量与先前图像重建方法实现的低失真之间取得有效平衡。针对加性高斯噪声去除这一基本任务,本文首先提出了一种利用预训练扩散模型的直观方法。此外,还介绍了提出的线性组合扩散去噪器(LCDD),它统一了两种互补的推理程序——一种利用模型的生成潜力,另一种确保信号的真实恢复。LCDD通过利用去噪样本的固有结构,实现了卓越的性能,并通过简单的标量超参数调整,提供了可控的优化权衡。
Key Takeaways
- 扩散模型在计算机视觉领域备受关注,尤其在图像合成和图像重建任务中表现优异。
- 现有方法难以平衡扩散模型的高视觉质量与低失真。
- 针对加性高斯噪声去除任务,提出了一种利用预训练扩散模型的直观方法。
- 引入了线性组合扩散去噪器(LCDD),融合了两种互补的推理程序。
- LCDD利用模型的生成潜力,同时确保信号的真实恢复。
- LCDD通过利用去噪样本的固有结构实现了卓越性能。
点此查看论文截图


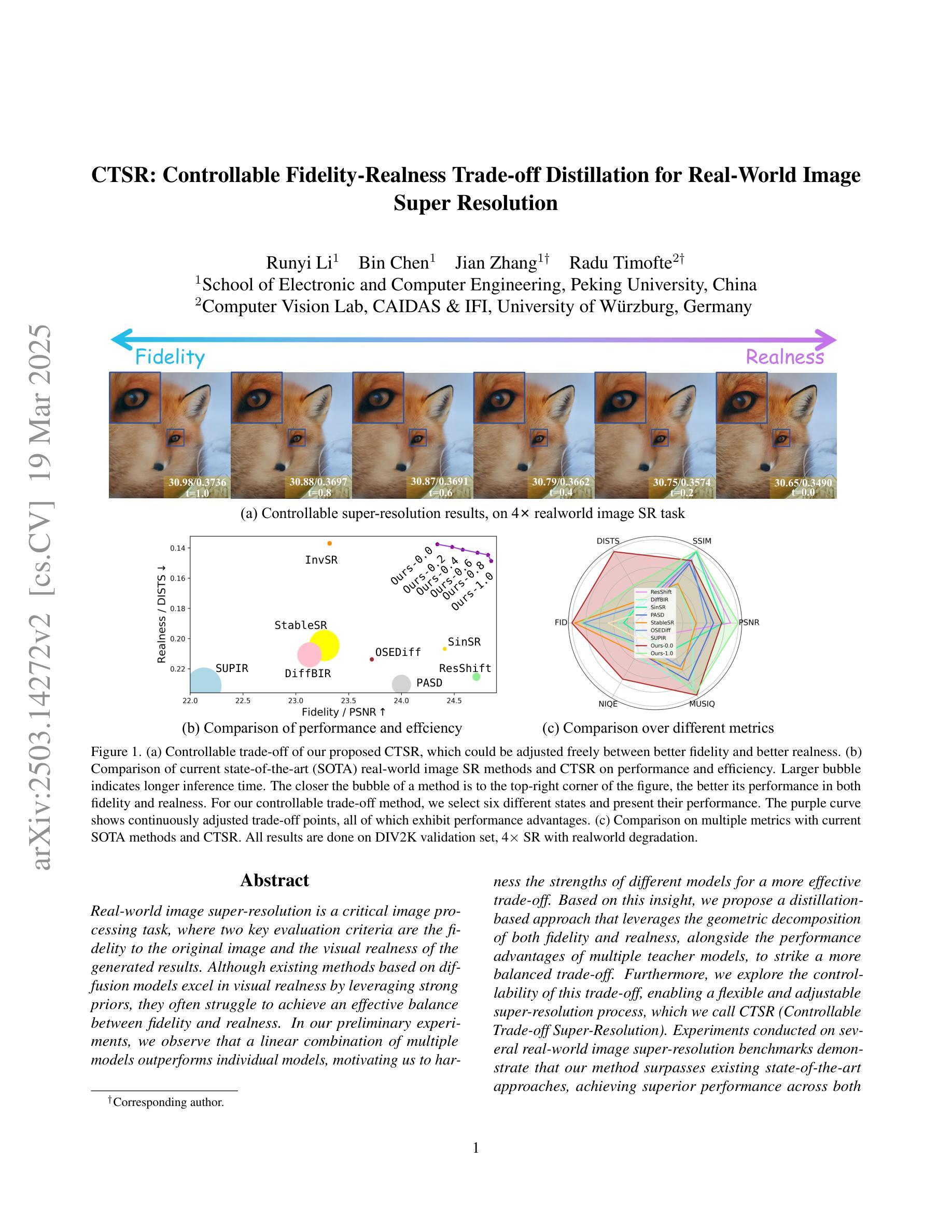
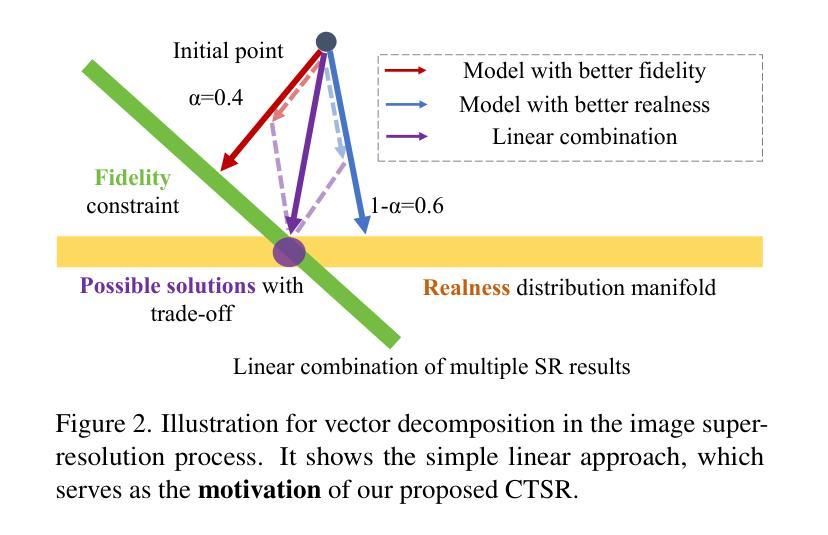
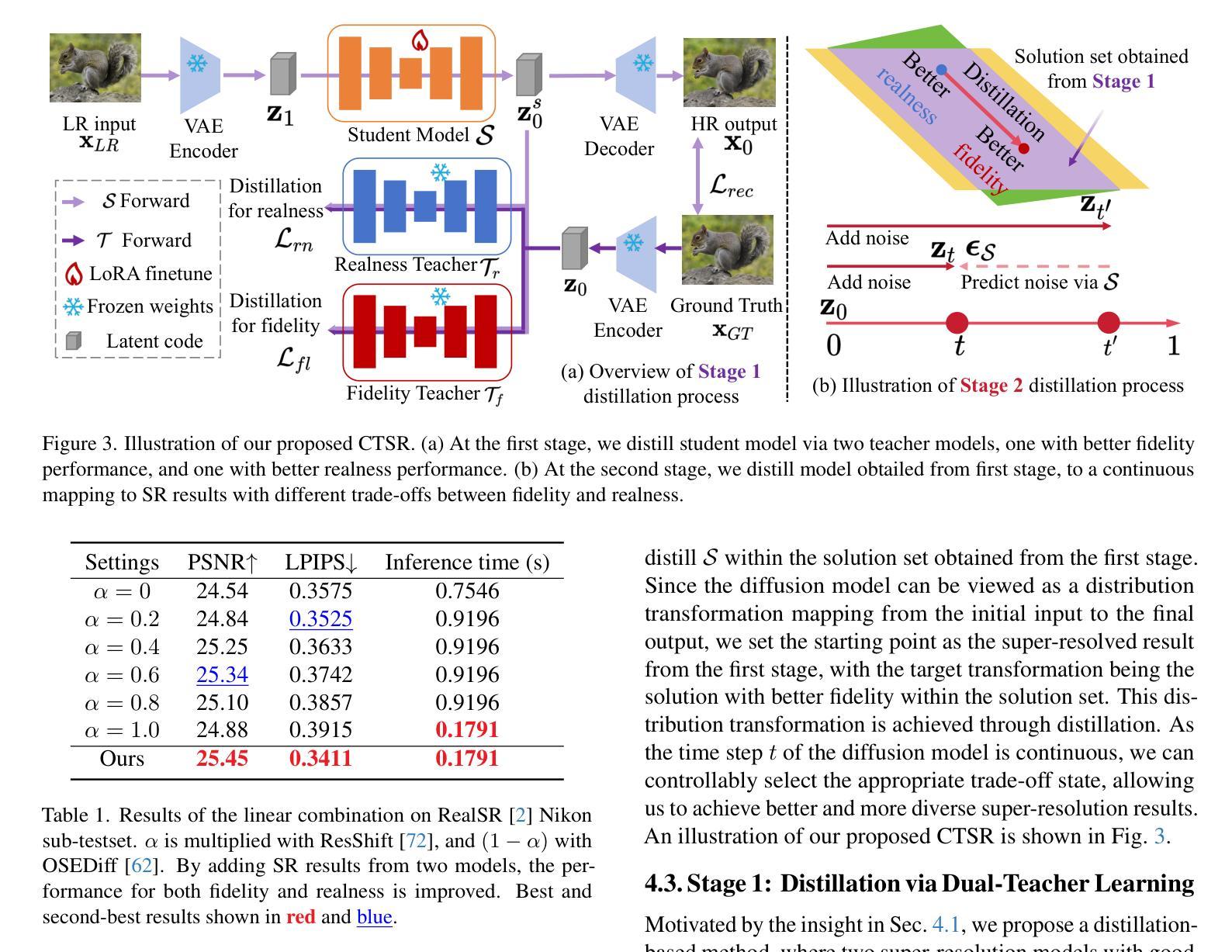
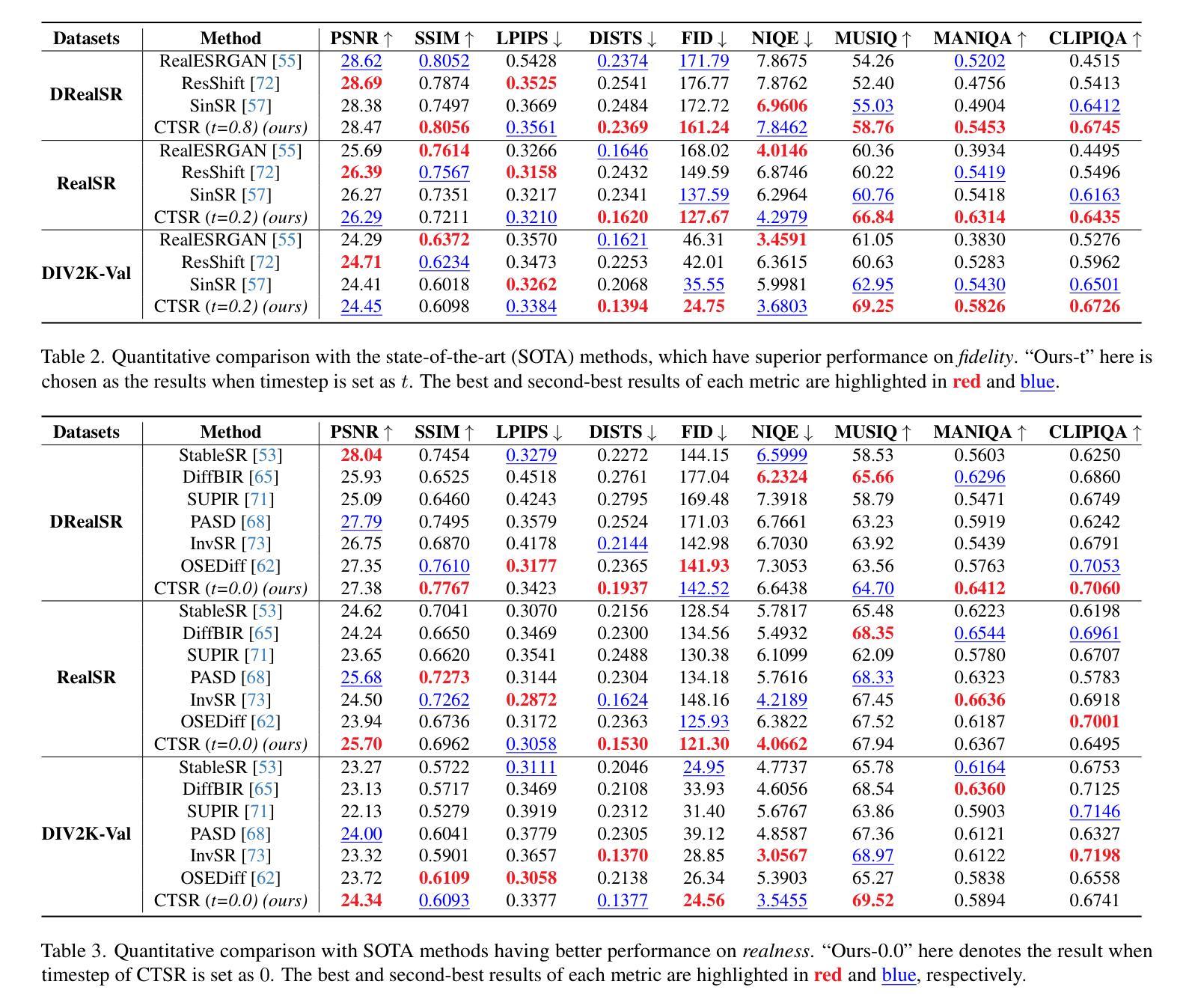
CTSR: Controllable Fidelity-Realness Trade-off Distillation for Real-World Image Super Resolution
Authors:Runyi Li, Bin Chen, Jian Zhang, Radu Timofte
Real-world image super-resolution is a critical image processing task, where two key evaluation criteria are the fidelity to the original image and the visual realness of the generated results. Although existing methods based on diffusion models excel in visual realness by leveraging strong priors, they often struggle to achieve an effective balance between fidelity and realness. In our preliminary experiments, we observe that a linear combination of multiple models outperforms individual models, motivating us to harness the strengths of different models for a more effective trade-off. Based on this insight, we propose a distillation-based approach that leverages the geometric decomposition of both fidelity and realness, alongside the performance advantages of multiple teacher models, to strike a more balanced trade-off. Furthermore, we explore the controllability of this trade-off, enabling a flexible and adjustable super-resolution process, which we call CTSR (Controllable Trade-off Super-Resolution). Experiments conducted on several real-world image super-resolution benchmarks demonstrate that our method surpasses existing state-of-the-art approaches, achieving superior performance across both fidelity and realness metrics.
现实世界图像超分辨率处理是一项关键的图像处理任务,其两个主要的评估标准是对于原始图像的保真度和生成结果的视觉逼真度。尽管现有的基于扩散模型的方法通过利用强大的先验知识在视觉逼真度方面表现出色,但它们往往难以在保真度和逼真度之间取得有效平衡。在我们的初步实验中,我们观察到多种模型的线性组合表现优于单个模型,这激励我们利用不同模型的优势以实现更有效的权衡。基于此见解,我们提出了一种基于蒸馏的方法,该方法利用保真度和逼真度的几何分解,以及多个教师模型的性能优势,以实现更平衡的权衡。此外,我们探索了这种权衡的可控性,以实现一个灵活可调的超级分辨率过程,我们称之为可控权衡超级分辨率(CTSR)。在几个现实世界图像超分辨率处理基准测试上的实验表明,我们的方法超越了现有的最新方法,在保真度和逼真度指标上都实现了卓越的性能。
论文及项目相关链接
Summary
基于扩散模型的现实图像超分辨率处理是一项关键任务,面临保真度和视觉真实度两个核心评价指标的挑战。现有方法虽在视觉真实度上表现优异,但在平衡保真度和真实度方面存在困难。本文提出一种基于蒸馏的方法,通过几何分解实现保真度和真实度的平衡,并结合多个教师模型的性能优势,提出可控的权衡超分辨率处理(CTSR)。实验证明,该方法优于现有技术前沿,在保真度和真实度指标上均表现出卓越性能。
Key Takeaways
- 现实图像超分辨率处理是图像处理的重点任务。
- 现有扩散模型方法在平衡图像保真度和视觉真实度方面存在挑战。
- 本文通过几何分解实现保真度和真实度的平衡。
- 提出一种基于蒸馏的方法,结合多个教师模型的性能优势。
- 提出了可控的权衡超分辨率处理(CTSR)。
- 实验证明,该方法在多个真实世界图像超分辨率基准测试中表现优异。
点此查看论文截图
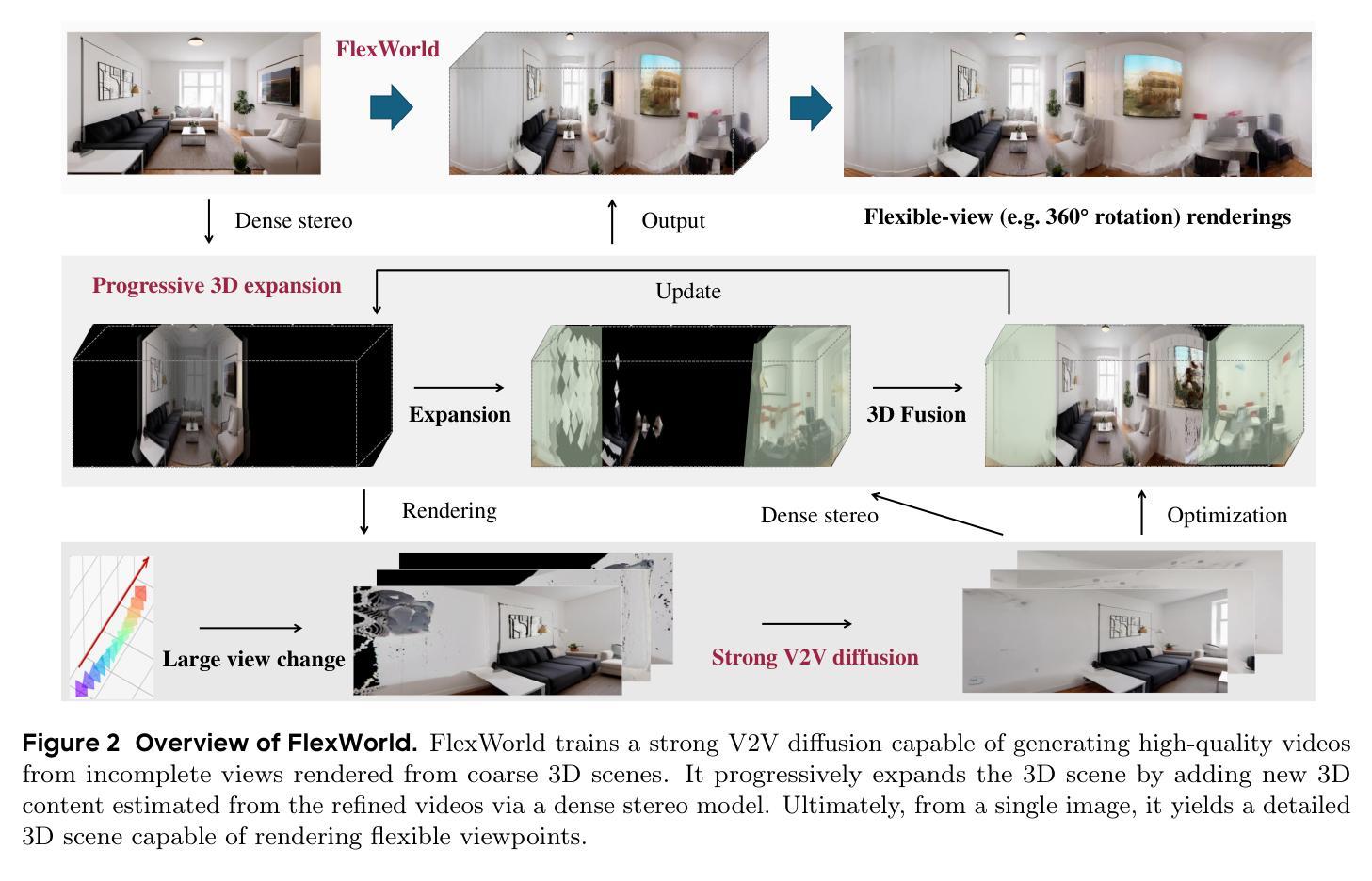
FlexWorld: Progressively Expanding 3D Scenes for Flexiable-View Synthesis
Authors:Luxi Chen, Zihan Zhou, Min Zhao, Yikai Wang, Ge Zhang, Wenhao Huang, Hao Sun, Ji-Rong Wen, Chongxuan Li
Generating flexible-view 3D scenes, including 360{\deg} rotation and zooming, from single images is challenging due to a lack of 3D data. To this end, we introduce FlexWorld, a novel framework consisting of two key components: (1) a strong video-to-video (V2V) diffusion model to generate high-quality novel view images from incomplete input rendered from a coarse scene, and (2) a progressive expansion process to construct a complete 3D scene. In particular, leveraging an advanced pre-trained video model and accurate depth-estimated training pairs, our V2V model can generate novel views under large camera pose variations. Building upon it, FlexWorld progressively generates new 3D content and integrates it into the global scene through geometry-aware scene fusion. Extensive experiments demonstrate the effectiveness of FlexWorld in generating high-quality novel view videos and flexible-view 3D scenes from single images, achieving superior visual quality under multiple popular metrics and datasets compared to existing state-of-the-art methods. Qualitatively, we highlight that FlexWorld can generate high-fidelity scenes with flexible views like 360{\deg} rotations and zooming. Project page: https://ml-gsai.github.io/FlexWorld.
生成包含360°旋转和缩放功能的灵活视角3D场景,从单张图像开始是一项挑战,因为缺乏3D数据。为此,我们引入了FlexWorld,这是一个由两个关键组件构成的新型框架:(1)强大的视频到视频(V2V)扩散模型,用于从由粗糙场景渲染的不完整输入生成高质量的新视角图像;(2)渐进式扩展过程,用于构建完整的3D场景。特别是,借助先进的预训练视频模型和精确的深度估计训练对,我们的V2V模型可以在大相机姿态变化下生成新视角。在此基础上,FlexWorld逐步生成新的3D内容,并通过几何感知场景融合将其集成到全局场景中。大量实验表明,FlexWorld在生成高质量的新视角视频和灵活视角的3D场景方面非常有效,从单张图像开始,在多个流行指标和数据集上与现有最先进的方法相比,实现了优越的视觉质量。从定性角度看,我们强调FlexWorld可以生成具有灵活视角的高保真场景,如360°旋转和缩放。项目页面:https://ml-gsai.github.io/FlexWorld。
论文及项目相关链接
Summary
基于单图生成具有360°旋转和缩放功能的灵活视图3D场景是一项挑战,因为缺乏3D数据。为此,我们引入了FlexWorld框架,该框架包含两个关键组件:(1)强大的视频到视频(V2V)扩散模型,用于从由粗糙场景渲染的不完整输入生成高质量的新视图图像;(2)渐进扩展过程,用于构建完整的3D场景。我们的V2V模型利用先进的预训练视频模型和精确的深度估计训练对,可以在大相机姿态变化下生成新视图。FlexWorld在此基础上逐步生成新的3D内容,并通过几何感知场景融合将其集成到全局场景中。实验证明,FlexWorld在生成高质量新视图视频和灵活视图3D场景方面效果显著,在多个流行指标和数据集上与现有最先进的方法相比具有优势。FlexWorld能够生成具有灵活视图的高保真场景,如360°旋转和缩放。更多信息请访问项目页面。
Key Takeaways
- FlexWorld是一个用于从单图像生成灵活视图3D场景的新框架。
- 框架包含两个关键组件:视频到视频(V2V)扩散模型和渐进扩展过程。
- V2V扩散模型基于预训练的视频模型和深度估计训练对,可生成高质量的新视图图像。
- 渐进扩展过程用于构建完整的3D场景,通过几何感知场景融合集成新生成的3D内容。
- FlexWorld能够在多种数据集上实现高质量的灵活视图生成,包括360°旋转和缩放。
- FlexWorld在多个评估指标上优于现有的最先进方法。
点此查看论文截图




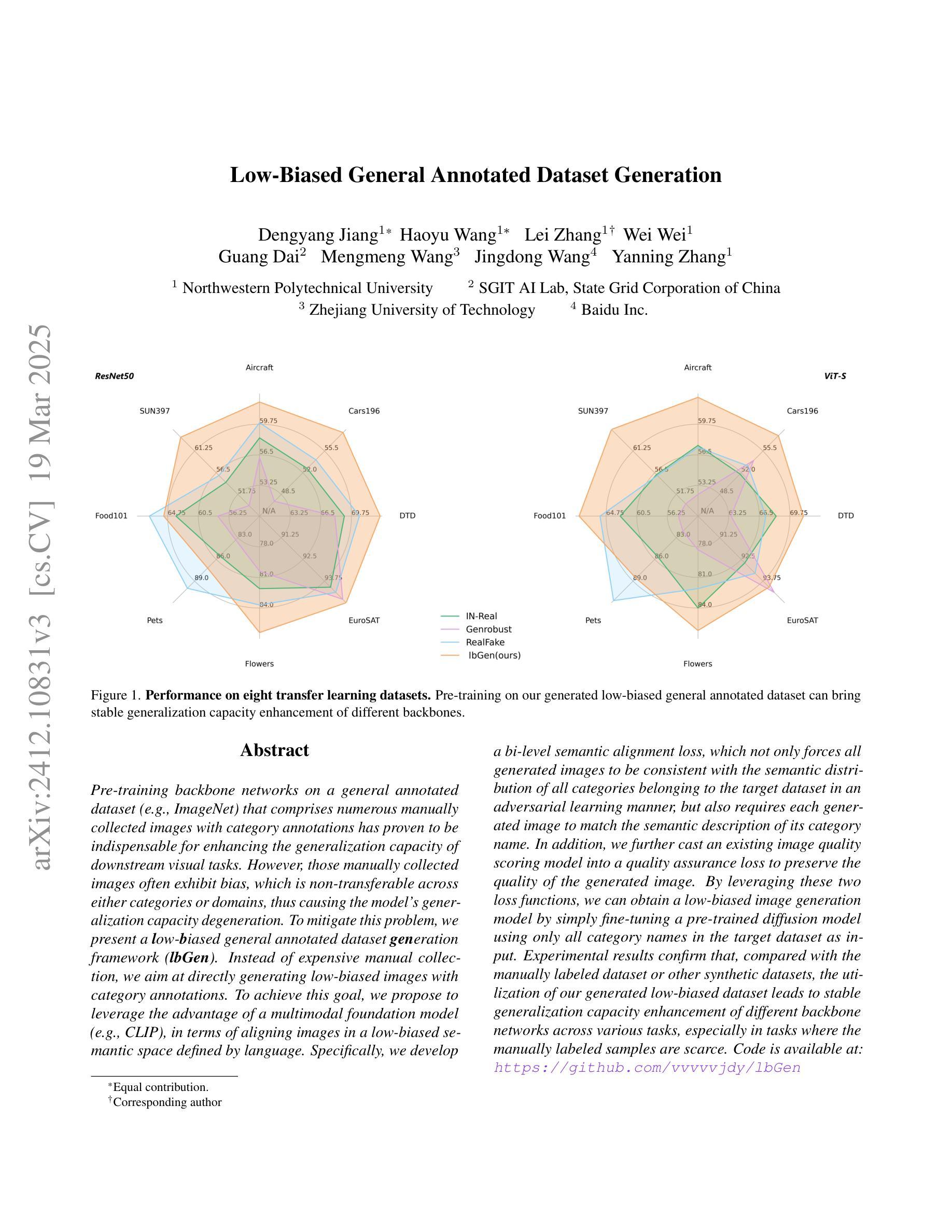
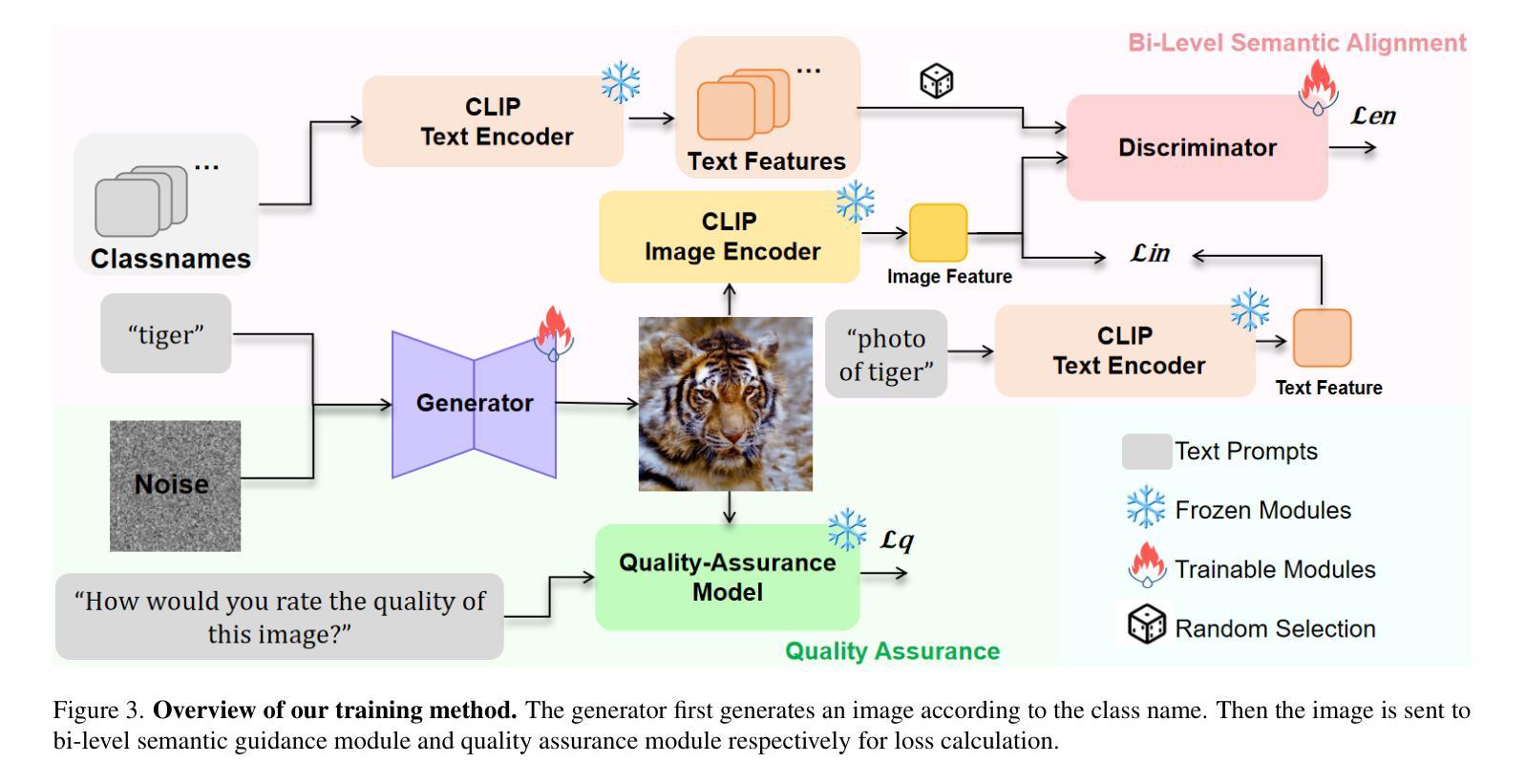
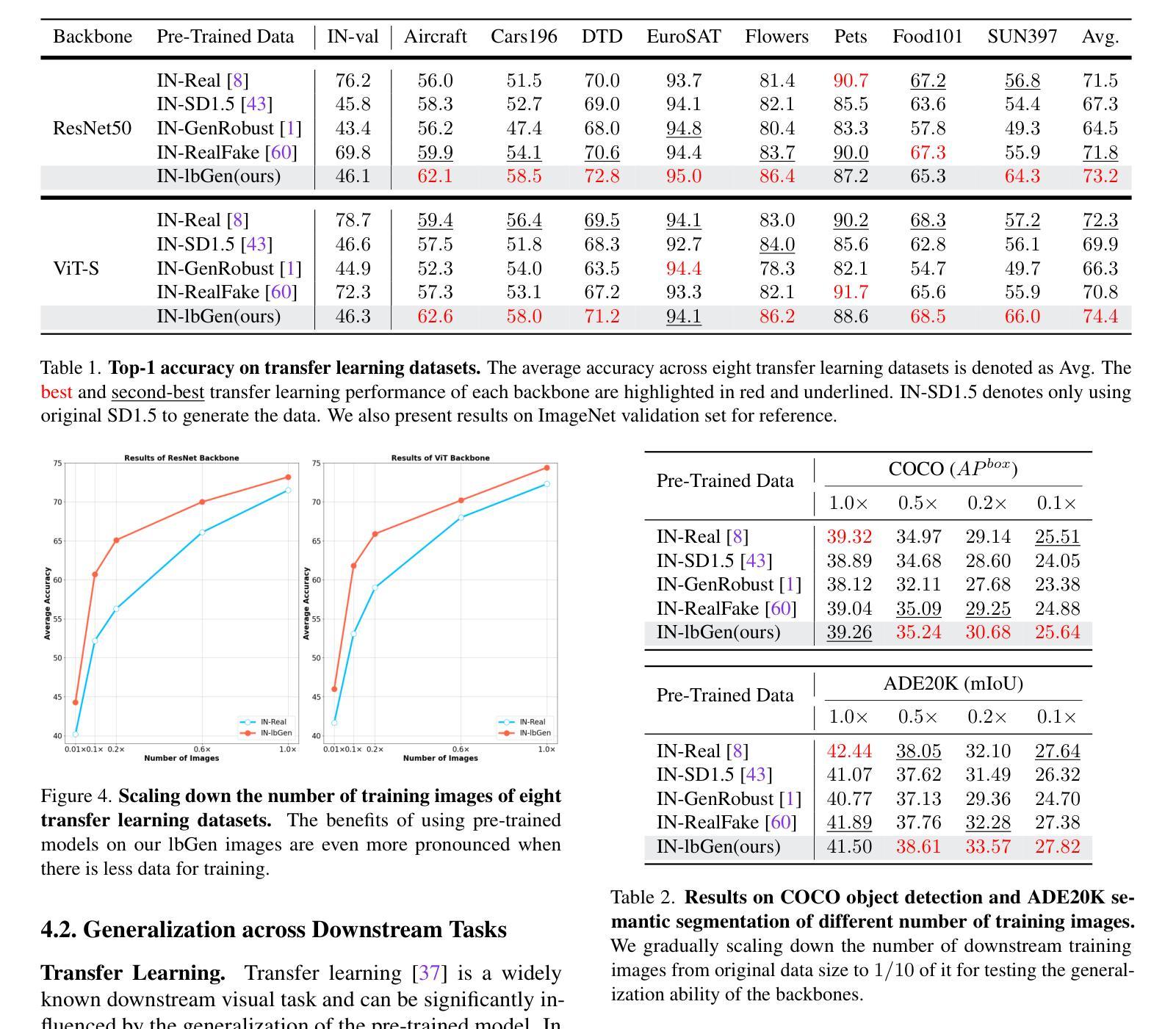
Low-Biased General Annotated Dataset Generation
Authors:Dengyang Jiang, Haoyu Wang, Lei Zhang, Wei Wei, Guang Dai, Mengmeng Wang, Jingdong Wang, Yanning Zhang
Pre-training backbone networks on a general annotated dataset (e.g., ImageNet) that comprises numerous manually collected images with category annotations has proven to be indispensable for enhancing the generalization capacity of downstream visual tasks. However, those manually collected images often exhibit bias, which is non-transferable across either categories or domains, thus causing the model’s generalization capacity degeneration. To mitigate this problem, we present a low-biased general annotated dataset generation framework (lbGen). Instead of expensive manual collection, we aim at directly generating low-biased images with category annotations. To achieve this goal, we propose to leverage the advantage of a multimodal foundation model (e.g., CLIP), in terms of aligning images in a low-biased semantic space defined by language. Specifically, we develop a bi-level semantic alignment loss, which not only forces all generated images to be consistent with the semantic distribution of all categories belonging to the target dataset in an adversarial learning manner, but also requires each generated image to match the semantic description of its category name. In addition, we further cast an existing image quality scoring model into a quality assurance loss to preserve the quality of the generated image. By leveraging these two loss functions, we can obtain a low-biased image generation model by simply fine-tuning a pre-trained diffusion model using only all category names in the target dataset as input. Experimental results confirm that, compared with the manually labeled dataset or other synthetic datasets, the utilization of our generated low-biased dataset leads to stable generalization capacity enhancement of different backbone networks across various tasks, especially in tasks where the manually labeled samples are scarce.
在包含大量手动收集并带有类别注释的图像的一般注释数据集上,对骨干网络进行预训练,对于提高下游视觉任务的泛化能力来说是不可或缺的。然而,这些手动收集的图像往往存在偏见,这些偏见在类别或域之间是不可转移的,从而导致模型的泛化能力下降。为了缓解这个问题,我们提出了一个低偏置的一般注释数据集生成框架(lbGen)。我们旨在通过直接生成带有类别注释的低偏置图像,而非昂贵的手动收集。为了实现这一目标,我们提议利用多模态基础模型的优点(例如CLIP),以语言定义的低偏置语义空间来对齐图像。具体来说,我们开发了一种两级语义对齐损失,这不仅以对抗性学习的方式强制所有生成的图像与目标数据集中所有类别的语义分布保持一致,还要求每个生成的图像与其类别名称的语义描述相匹配。此外,我们将现有的图像质量评分模型转化为质量保证损失,以保持生成图像的质量。通过利用这两种损失函数,我们只需使用目标数据集中的所有类别名称对预训练的扩散模型进行微调,即可获得低偏置的图像生成模型。实验结果表明,与使用手动标记的数据集或其他合成数据集相比,使用我们生成的低偏置数据集可以提高不同骨干网络在不同任务上的泛化能力,特别是在手动标记样本稀缺的任务中。
论文及项目相关链接
PDF CVPR2025 Accepted Paper
Summary
基于预训练模型在通用标注数据集上的训练,如ImageNet,对于下游视觉任务的泛化能力提升具有重要意义。然而,手动收集的图像常常存在偏见,影响模型的泛化能力。为解决这一问题,我们提出了一个低偏见的通用标注数据集生成框架(lbGen)。它旨在通过直接生成低偏见的图像及其类别标注来替代昂贵的手动收集过程。我们利用多模态基础模型(如CLIP)的优势,在一个由语言定义的低偏见语义空间中对齐图像。具体来说,我们开发了一种两级语义对齐损失,不仅以对抗性学习的方式迫使所有生成的图像与目标数据集中所有类别的语义分布保持一致,还要求每个生成的图像与其类别名称的语义描述相匹配。此外,我们还利用现有的图像质量评分模型构建了一个质量保障损失,以保持生成图像的质量。通过利用这两种损失函数,我们只需通过微调预训练的扩散模型,以目标数据集的所有类别名称作为输入,即可获得低偏见的图像生成模型。实验结果表明,与使用手动标注数据集或其他合成数据集相比,利用我们生成的低偏见数据集可以稳定提升不同骨干网络在各种任务上的泛化能力,特别是在手动标注样本稀缺的任务中表现尤为突出。
Key Takeaways
- 预训练模型在通用标注数据集上的训练对于下游视觉任务的泛化能力提升至关重要。
- 手动收集的图像存在偏见,影响模型的泛化能力。
- 提出了一个低偏见的通用标注数据集生成框架(lbGen)来生成低偏见的图像及其类别标注。
- 利用多模态基础模型(如CLIP)在一个低偏见语义空间中对齐图像。
- 开发了一种两级语义对齐损失,确保生成的图像与类别语义分布一致。
- 利用图像质量评分模型构建质量保障损失,保持生成图像的质量。
点此查看论文截图

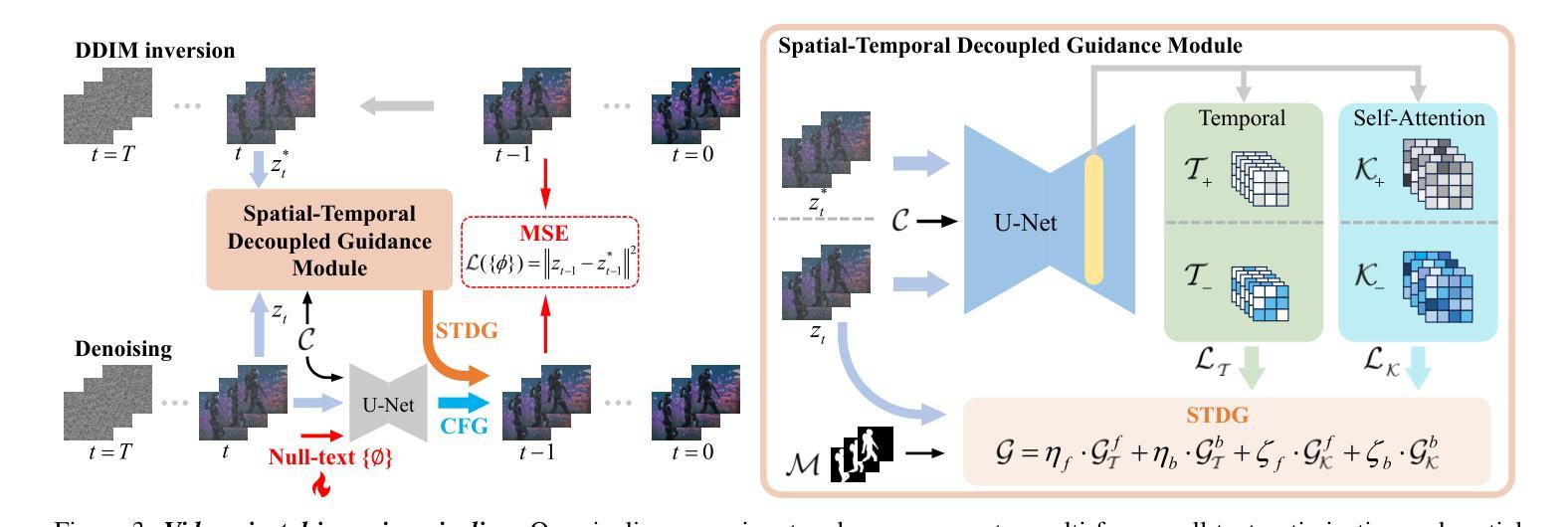
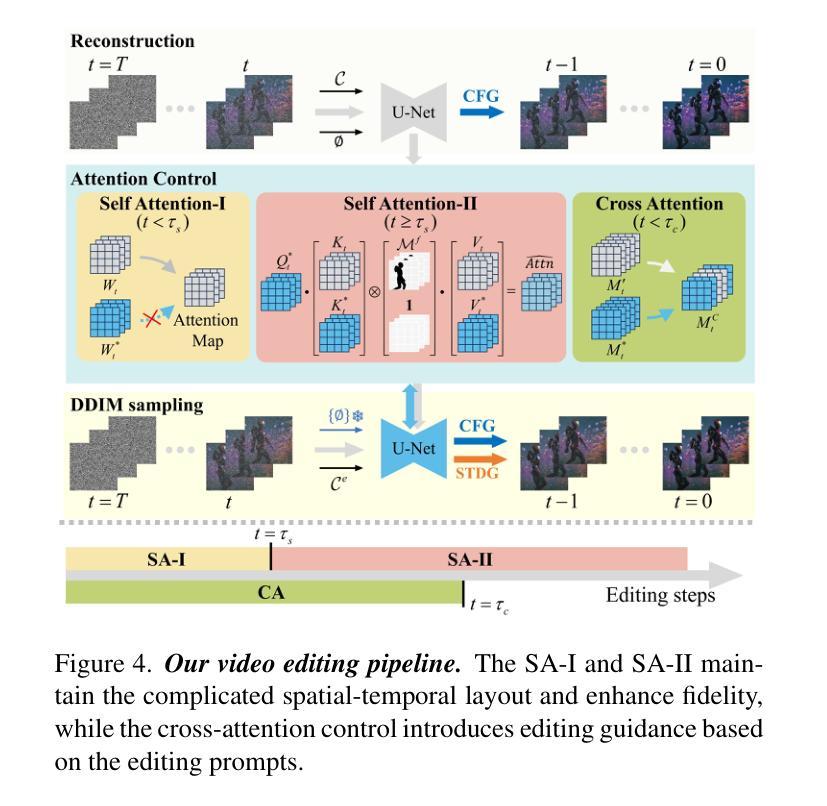
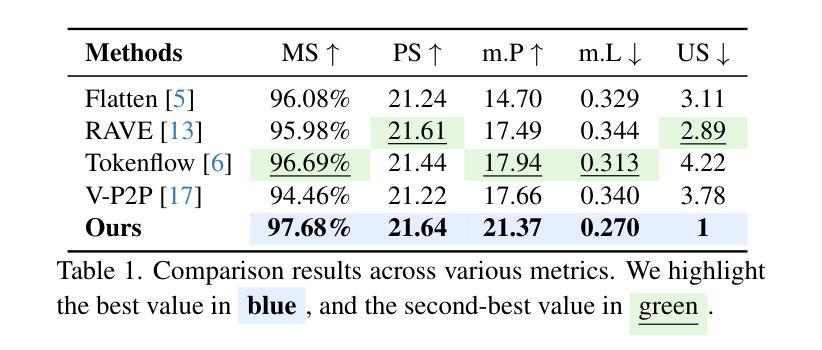
VideoDirector: Precise Video Editing via Text-to-Video Models
Authors:Yukun Wang, Longguang Wang, Zhiyuan Ma, Qibin Hu, Kai Xu, Yulan Guo
Despite the typical inversion-then-editing paradigm using text-to-image (T2I) models has demonstrated promising results, directly extending it to text-to-video (T2V) models still suffers severe artifacts such as color flickering and content distortion. Consequently, current video editing methods primarily rely on T2I models, which inherently lack temporal-coherence generative ability, often resulting in inferior editing results. In this paper, we attribute the failure of the typical editing paradigm to: 1) Tightly Spatial-temporal Coupling. The vanilla pivotal-based inversion strategy struggles to disentangle spatial-temporal information in the video diffusion model; 2) Complicated Spatial-temporal Layout. The vanilla cross-attention control is deficient in preserving the unedited content. To address these limitations, we propose a spatial-temporal decoupled guidance (STDG) and multi-frame null-text optimization strategy to provide pivotal temporal cues for more precise pivotal inversion. Furthermore, we introduce a self-attention control strategy to maintain higher fidelity for precise partial content editing. Experimental results demonstrate that our method (termed VideoDirector) effectively harnesses the powerful temporal generation capabilities of T2V models, producing edited videos with state-of-the-art performance in accuracy, motion smoothness, realism, and fidelity to unedited content.
尽管使用文本到图像(T2I)模型的典型反转编辑范式已经取得了有前景的结果,但直接将其扩展到文本到视频(T2V)模型仍然会出现严重的伪影问题,如色彩闪烁和内容失真。因此,目前的视频编辑方法主要依赖于T2I模型,这些模型本质上缺乏时间连贯性生成能力,往往导致编辑结果较差。在本文中,我们将典型的编辑范式的失败归结为以下两点:1)紧密的空间时间耦合。基于原始关键点的反转策略在视频扩散模型中很难分离空间时间信息;2)复杂的空间时间布局。原始的交叉注意力控制在于保持未编辑的内容。为了解决这些局限性,我们提出了时空解耦指导(STDG)和多帧无文本优化策略,为更精确的关键点反转提供关键的时间线索。此外,我们还引入了一种自注意力控制策略,以在精确部分内容编辑中保持更高的保真度。实验结果表明,我们的方法(称为VideoDirector)有效地利用了T2V模型的强大时间生成能力,在准确性、运动平滑度、逼真度和对未编辑内容的保真度方面达到了最先进的性能。
论文及项目相关链接
PDF 15 figures
Summary
针对文本转视频(T2V)模型中的典型编辑范式存在的问题,如颜色闪烁和内容失真等严重伪影,本文提出了一种新的方法。通过解决空间时间耦合复杂和空间时间布局的问题,引入时空分离指导(STDG)和多帧无文本优化策略,为精确的关键点反转提供关键的时序线索。同时采用自我关注控制策略,保持对精确部分内容编辑的高保真度。实验结果表明,该方法(称为VideoDirector)有效利用了T2V模型的强大时序生成能力,在准确性、运动平滑度、真实性和对未编辑内容的保真度方面达到了业界领先水平。
Key Takeaways
- 文本转视频(T2V)模型中的典型编辑范式存在颜色闪烁和内容失真等问题。
- 这些问题主要源于紧密的空间时间耦合和复杂的空间时间布局。
- 引入的时空分离指导(STDG)有助于解决空间时间耦合问题。
- 多帧无文本优化策略为精确的关键点反转提供了关键的时序线索。
- 自我关注控制策略有助于保持对精确部分内容编辑的高保真度。
- VideoDirector方法有效利用了T2V模型的强大时序生成能力。
点此查看论文截图



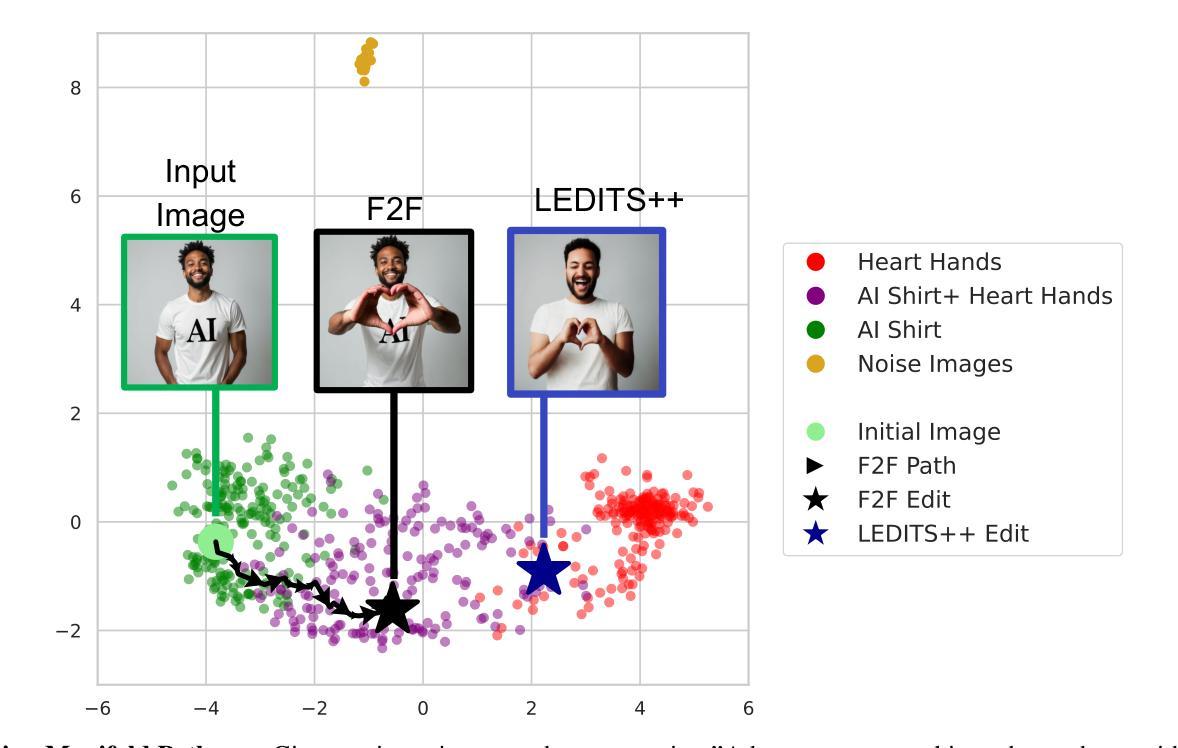
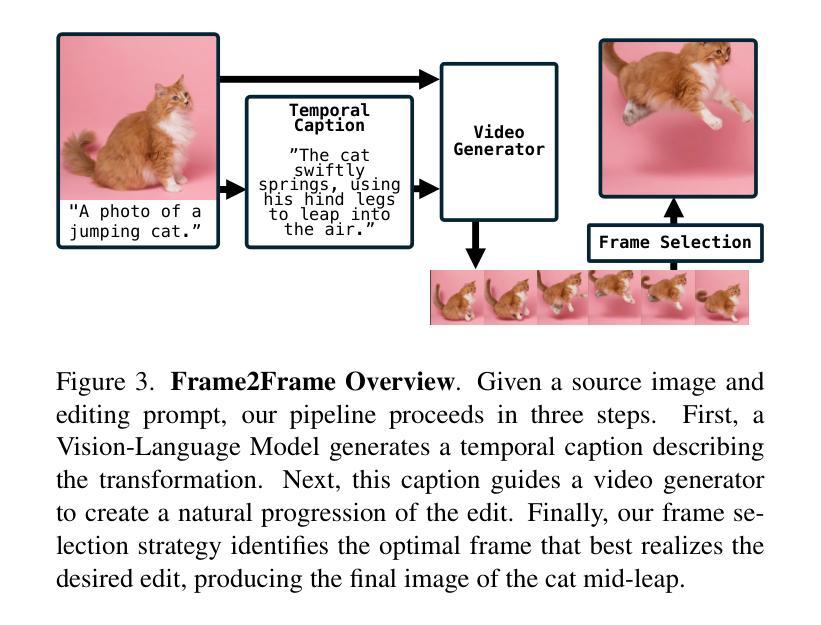
Pathways on the Image Manifold: Image Editing via Video Generation
Authors:Noam Rotstein, Gal Yona, Daniel Silver, Roy Velich, David Bensaïd, Ron Kimmel
Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image’s key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation. Visit our project page: https://rotsteinnoam.github.io/Frame2Frame.
图像编辑领域的最新进展,得益于图像扩散模型的推动,已经取得了显著的进步。然而,仍然存在重大挑战,因为这些模型往往难以准确遵循复杂的编辑指令,并且经常改变原始图像的关键元素,从而影响保真度。同时,视频生成方面已经取得了显著的进步,模型有效地充当了连贯和连续的世界模拟器。在本文中,我们提出通过利用图像到视频模型进行图像编辑来融合这两个领域。我们将图像编辑重新制定为一个时间过程,使用预训练的视频模型来创建从原始图像到所需编辑的平滑过渡。这种方法在图像流形上连续遍历,确保编辑的一致性,同时保留原始图像的关键方面。我们的方法在基于文本的图像编辑方面达到了最新水平,在编辑准确性和图像保留方面都取得了显著改进。欢迎访问我们的项目页面:Frame2Frame。
论文及项目相关链接
Summary
图像扩散模型在图像编辑方面的最新进展已经显示出显著的成果,但仍存在挑战,如难以准确遵循复杂的编辑指令,以及在修改过程中频繁改变原始图像的关键元素。本文提出将图像编辑和视频生成两个领域相结合,利用图像到视频的模型进行图像编辑。我们重新将图像编辑表述为一个时间过程,并使用预训练的视频模型来创建从原始图像到所需编辑的平滑过渡。此方法在文本驱动的图像编辑方面取得了最新成果,在编辑准确性和图像保留方面都显示出重大改进。
Key Takeaways
- 图像扩散模型在图像编辑领域取得显著进展,但仍面临准确遵循复杂编辑指令和保持原始图像关键元素的挑战。
- 提出将图像编辑与视频生成相结合的新思路。
- 利用预训练的视频模型,将图像编辑重新表述为一个时间过程。
- 通过创建从原始图像到所需编辑的平滑过渡,实现了图像编辑的新方法。
- 该方法在实现文本驱动的图像编辑方面达到最新成果。
- 在编辑准确性和图像保留方面都有显著改进。
点此查看论文截图

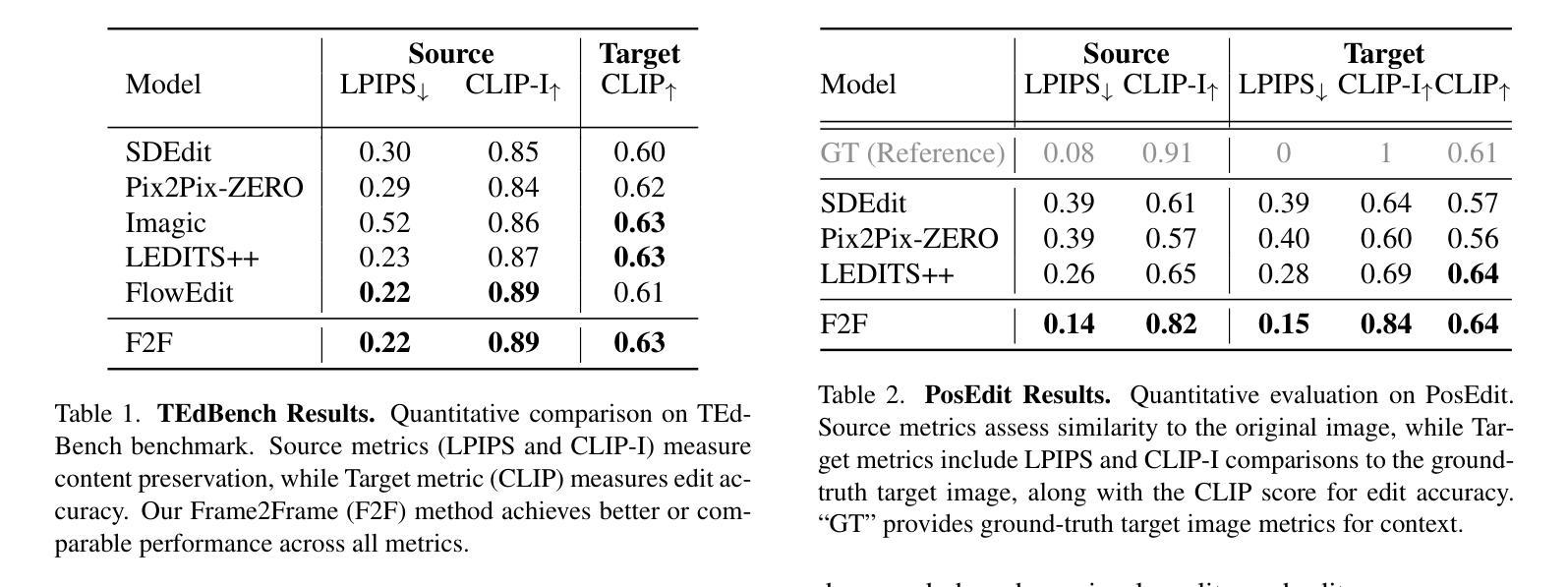

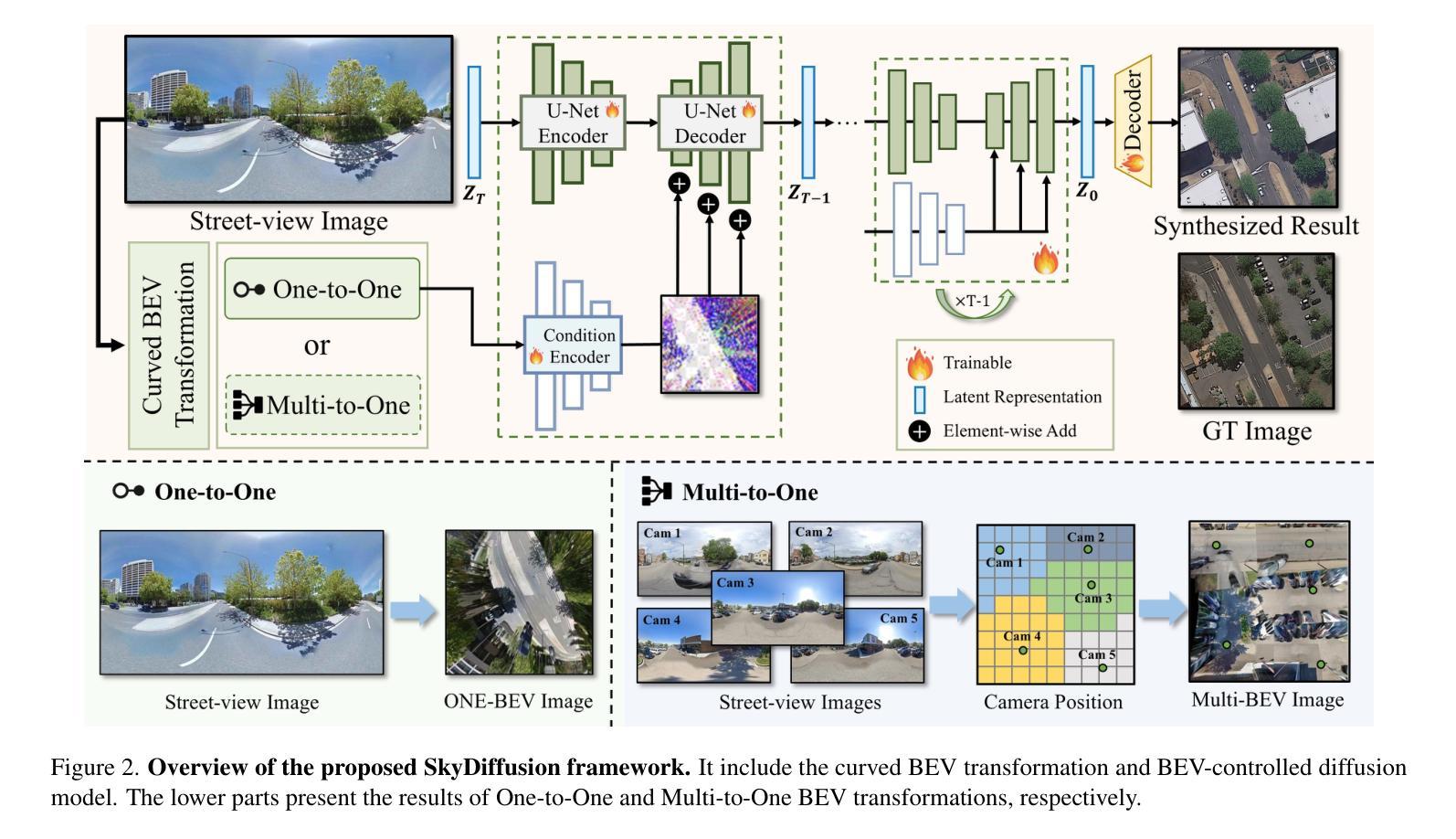
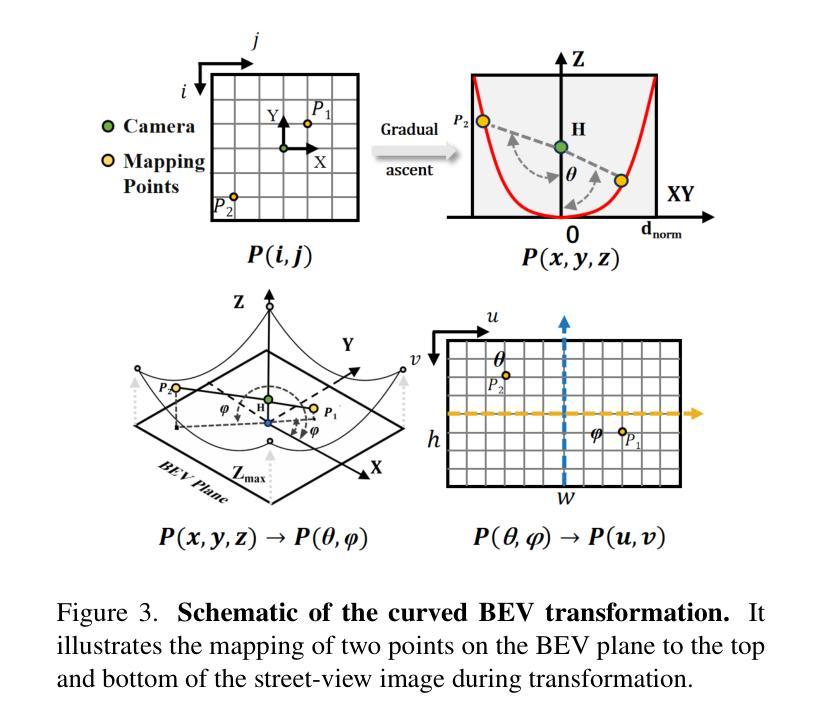
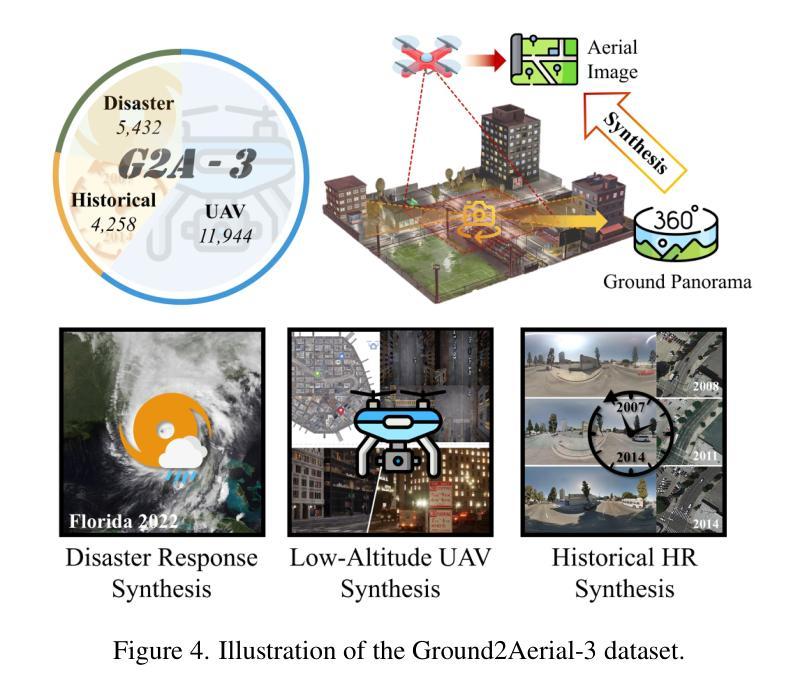
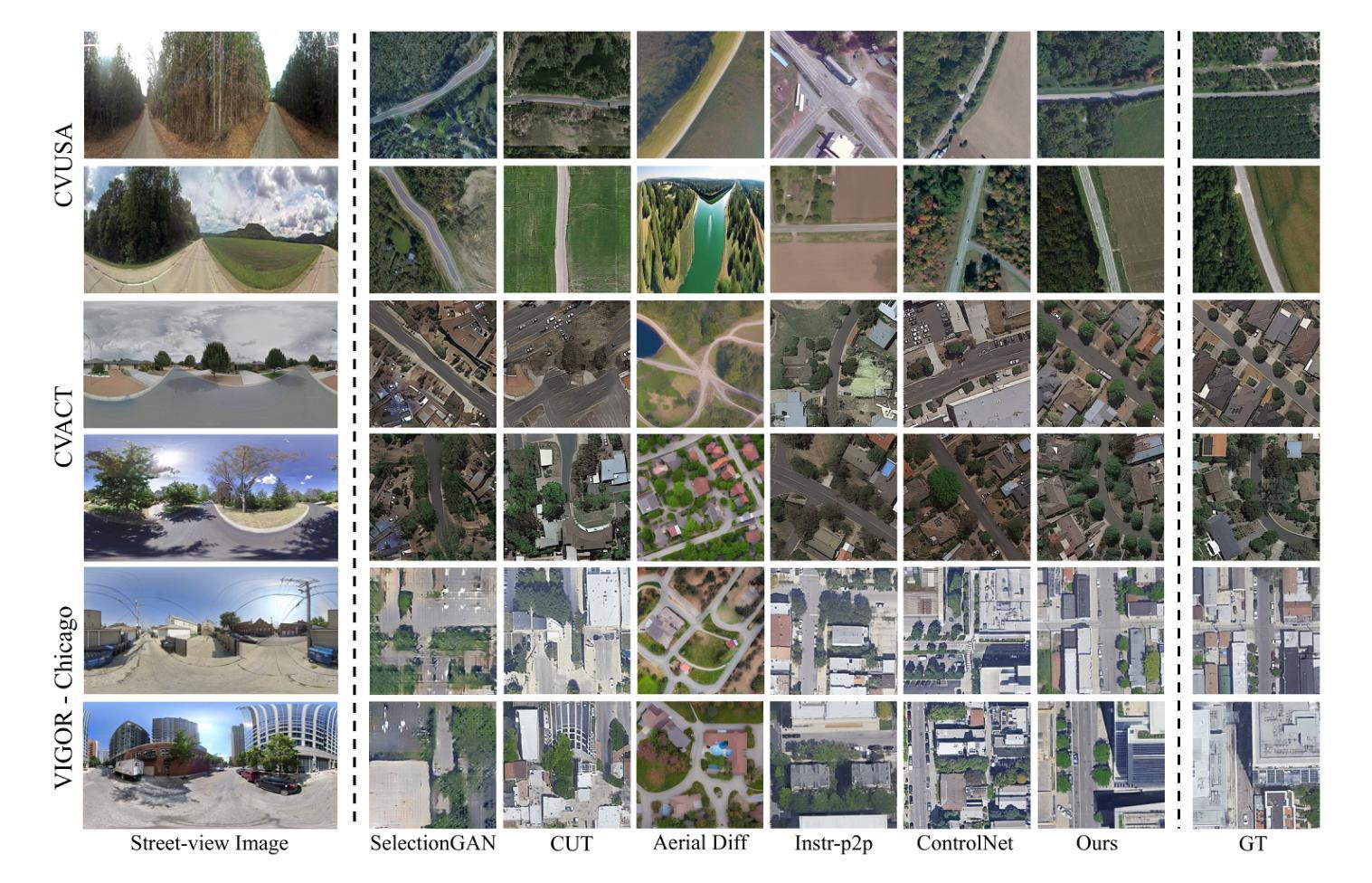
Leveraging BEV Paradigm for Ground-to-Aerial Image Synthesis
Authors:Junyan Ye, Jun He, Weijia Li, Zhutao Lv, Yi Lin, Jinhua Yu, Haote Yang, Conghui He
Ground-to-aerial image synthesis focuses on generating realistic aerial images from corresponding ground street view images while maintaining consistent content layout, simulating a top-down view. The significant viewpoint difference leads to domain gaps between views, and dense urban scenes limit the visible range of street views, making this cross-view generation task particularly challenging. In this paper, we introduce SkyDiffusion, a novel cross-view generation method for synthesizing aerial images from street view images, utilizing a diffusion model and the Bird’s-Eye View (BEV) paradigm. The Curved-BEV method in SkyDiffusion converts street-view images into a BEV perspective, effectively bridging the domain gap, and employs a “multi-to-one” mapping strategy to address occlusion issues in dense urban scenes. Next, SkyDiffusion designed a BEV-guided diffusion model to generate content-consistent and realistic aerial images. Additionally, we introduce a novel dataset, Ground2Aerial-3, designed for diverse ground-to-aerial image synthesis applications, including disaster scene aerial synthesis, low-altitude UAV image synthesis, and historical high-resolution satellite image synthesis tasks. Experimental results demonstrate that SkyDiffusion outperforms state-of-the-art methods on cross-view datasets across natural (CVUSA), suburban (CVACT), urban (VIGOR-Chicago), and various application scenarios (G2A-3), achieving realistic and content-consistent aerial image generation. The code, datasets and more information of this work can be found at https://opendatalab.github.io/skydiffusion/ .
地面到空中的图像合成专注于从相应的地面街景图像生成逼真的空中图像,同时保持内容布局的一致性,模拟从上到下的视角。显著的视点差异导致了不同视角之间的领域差距,而密集的城区场景限制了街景的可见范围,这使得跨视图生成任务特别具有挑战性。在本文中,我们介绍了SkyDiffusion,这是一种新的跨视图生成方法,用于从街景图像合成空中图像,它利用扩散模型和鸟瞰图(BEV)范式。SkyDiffusion中的Curved-BEV方法将街景图像转换为BEV视角,有效地弥合了领域差距,并采用了“多到一”的映射策略来解决密集城区场景中的遮挡问题。接下来,SkyDiffusion设计了一个受BEV引导的扩散模型来生成内容一致且逼真的空中图像。此外,我们还介绍了一个新的数据集Ground2Aerial-3,该数据集专为多样化的地面到空中图像合成应用而设计,包括灾害场景空中合成、低空无人机图像合成以及历史高分辨率卫星图像合成任务。实验结果表明,SkyDiffusion在跨视图数据集(CVUSA自然场景、CVACT郊区、VIGOR-Chicago城区以及G2A-3各种应用场景)上的表现优于最新方法,实现了逼真和内容一致性的空中图像生成。有关这项工作的代码、数据集和更多信息,请访问https://opendatalab.github.io/skydiffusion/。
论文及项目相关链接
PDF 10 pages, 7 figures
Summary
基于地面到空中的图像合成技术,研究团队引入了SkyDiffusion模型。此模型通过扩散模型结合鸟瞰图(BEV)范式,实现了从街道视角图像生成空中图像的任务。SkyDiffusion采用Curved-BEV方法转换街道视角图像到BEV视角,解决了视角差异带来的领域差距问题,并采用“多对一”映射策略解决密集城市场景中的遮挡问题。同时,该模型展示了强大的生成性能,能生成一致且逼真的空中图像。此外,研究团队还引入了专为地面到空中图像合成应用设计的Ground2Aerial-3数据集。实验结果显示,SkyDiffusion在自然、郊区、城市等不同场景以及多种应用情境下的跨视角数据集上均表现出超越现有方法的效果。详细信息请访问其官网获取。
Key Takeaways
- SkyDiffusion是一个实现从街道视角图像生成空中图像的跨视角生成方法。
- 利用扩散模型和鸟瞰图(BEV)范式进行图像合成。
- Curved-BEV方法有效解决了视角差异带来的领域差距问题。
- “多对一”映射策略用于处理密集城市场景中的遮挡问题。
- 引入Ground2Aerial-3数据集,适用于多种地面到空中图像合成应用。
- 实验结果显示SkyDiffusion在多种场景和应用情境上表现优异。
点此查看论文截图

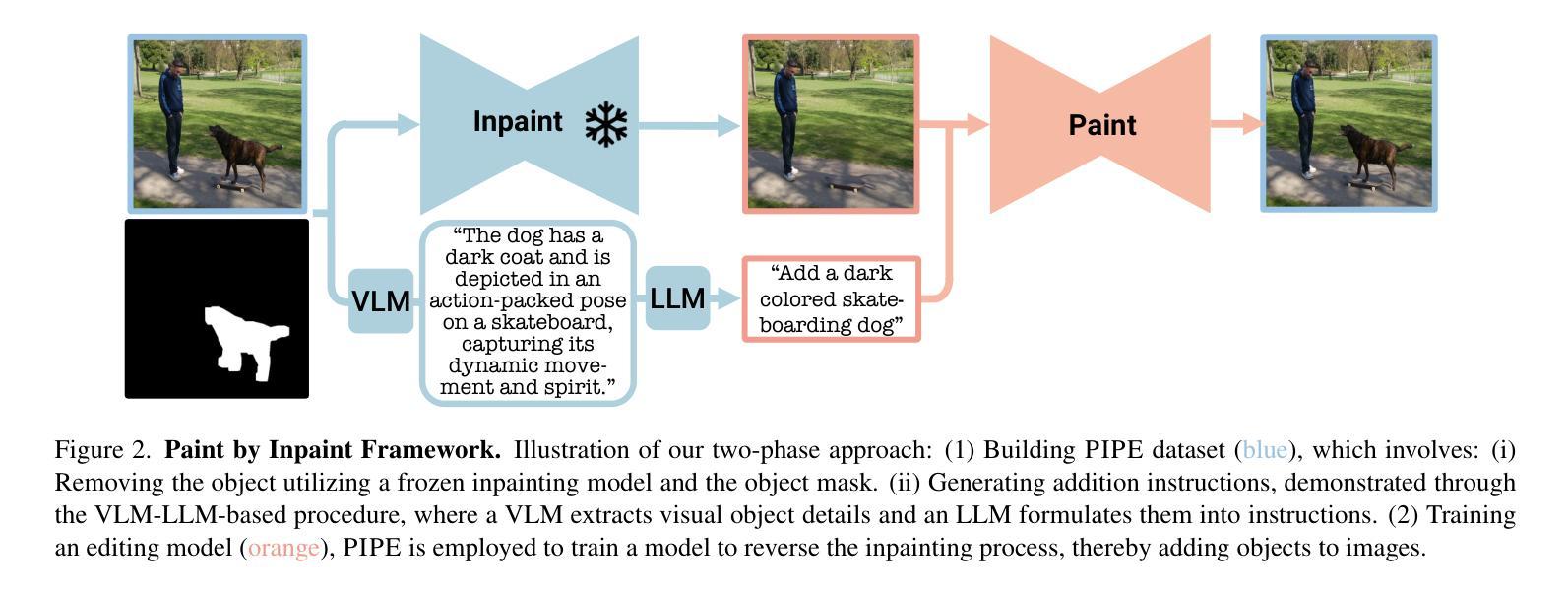
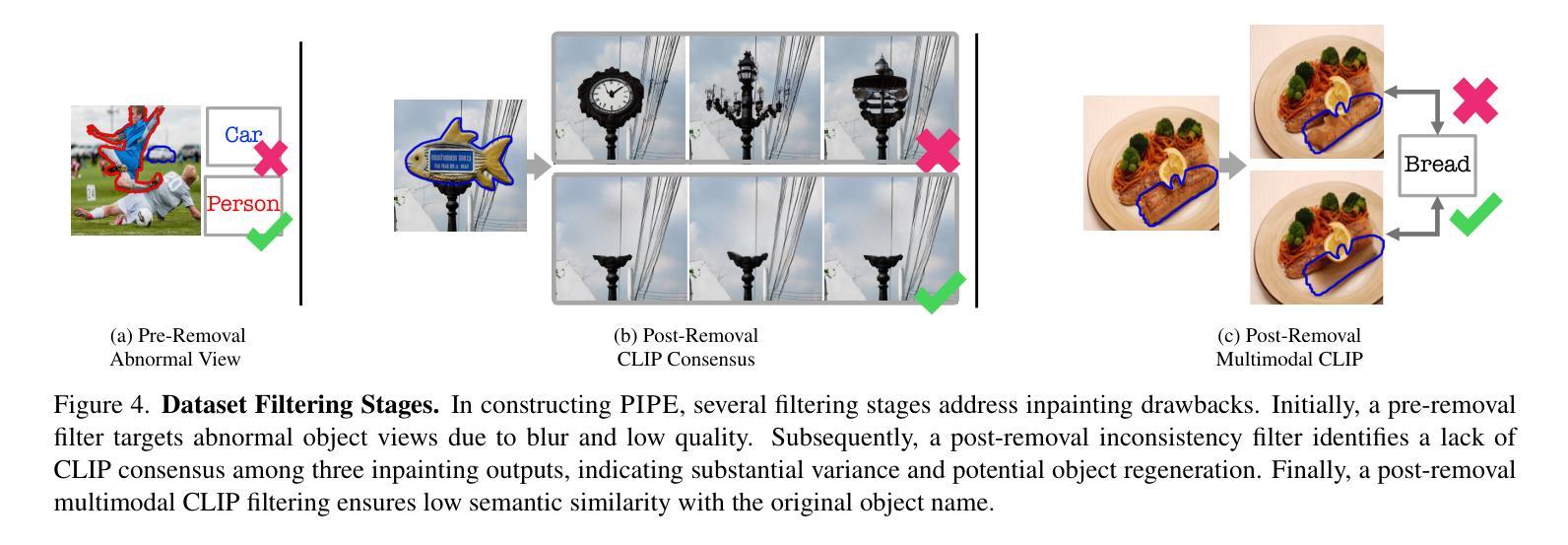
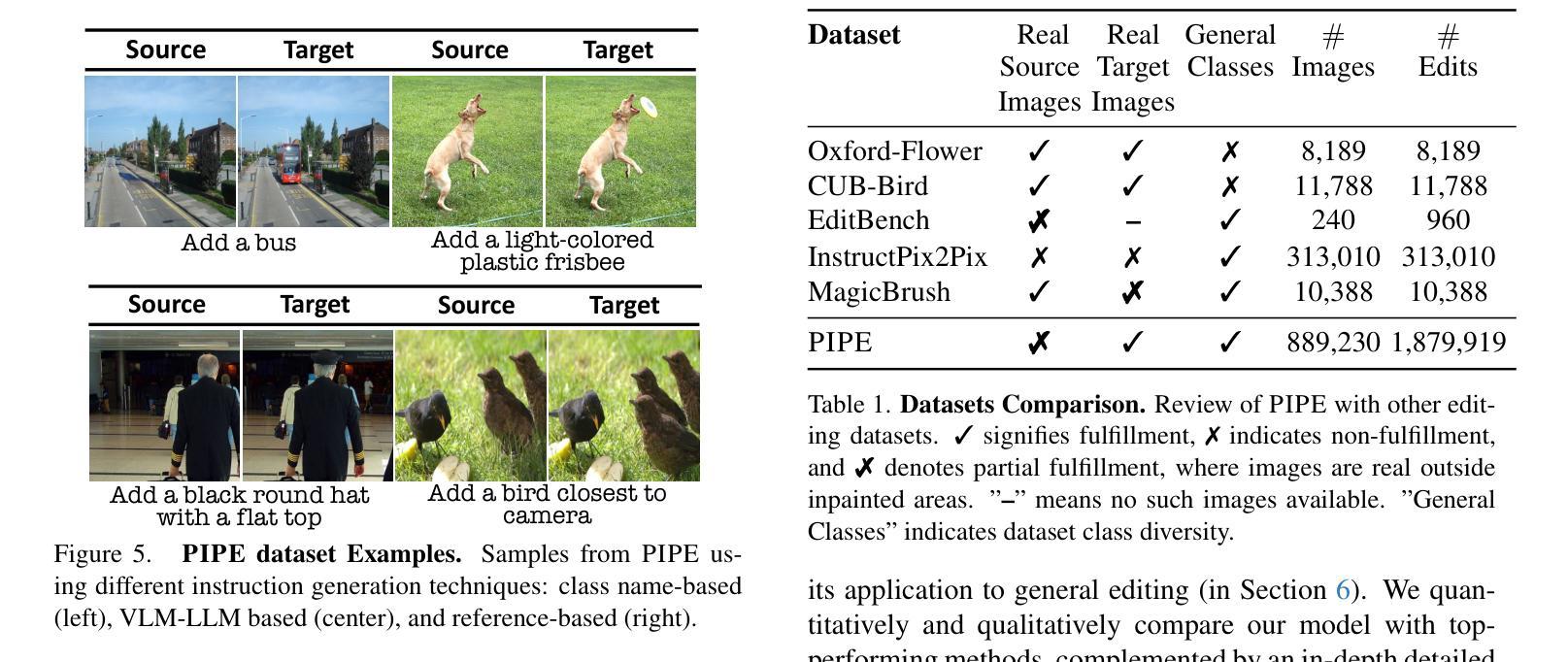
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Authors:Navve Wasserman, Noam Rotstein, Roy Ganz, Ron Kimmel
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to inpainting models that benefit from segmentation mask guidance. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones while ensuring source-target consistency by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. Our quantitative and qualitative results show that the trained model surpasses existing models in both object addition and general editing tasks. Visit our project page for the released dataset and trained models: https://rotsteinnoam.github.io/Paint-by-Inpaint.
图像编辑随着文本条件扩散模型的引入而取得了显著进展。尽管如此,根据文本指令无缝地向图像添加对象,而无需用户提供输入掩码,仍然是一个挑战。我们通过利用这样一个见解来解决这个问题:去除物体(补画)比反向添加物体的过程(绘画)要简单得多,这归功于受益于分割掩码指导的补画模型。利用这一认识,我们通过实现自动化和广泛的管道,整理了一个包含图像及其相应去对象版本的大型图像数据集。使用这些数据对,我们训练了一个扩散模型来反转补画过程,有效地向图像中添加对象。与其他编辑数据集不同的是,我们的数据集以自然目标图像为特征,同时通过构建确保源-目标的一致性。此外,我们利用大型视觉语言模型为移除的对象提供详细描述,并利用大型语言模型将这些描述转换为多样化、自然语言指令。我们的定量和定性结果表明,训练后的模型在对象添加和一般编辑任务上超过了现有模型。有关发布的数据集和训练模型,请访问我们的项目页面:https://rotsteinnoam.github.io/Paint-by-Inpaint。
论文及项目相关链接
Summary
本文介绍了一种基于文本条件扩散模型的新型图像编辑技术。针对在图像中根据文本指令无缝添加对象这一挑战,研究团队提出了一种利用去遮挡(Inpaint)技术来简化对象添加的新方法。研究团队创建了一个大型图像数据集,包含图像及其对应的去遮挡版本,并利用这些数据训练扩散模型,逆转去遮挡过程实现对象添加。相较于其他编辑数据集,该研究的特点在于采用自然目标图像并确保源目标一致性。此外,研究团队还使用了大型视觉语言模型和大型语言模型来提供详细的对象描述和指令转换。训练出的模型在物体添加和一般编辑任务上均超越了现有模型。
Key Takeaways
- 文本条件扩散模型在图像编辑领域取得显著进展。
- 在图像中根据文本指令无缝添加对象仍然是一个挑战。
- 研究团队利用去遮挡技术简化对象添加过程。
- 创建了一个大型图像数据集,包含图像及其对应的去遮挡版本。
- 利用这些数据集训练扩散模型实现对象添加。
- 该研究采用自然目标图像,确保源目标一致性。
- 研究团队使用大型视觉语言模型和大型语言模型提供详细的对象描述和指令转换。
点此查看论文截图


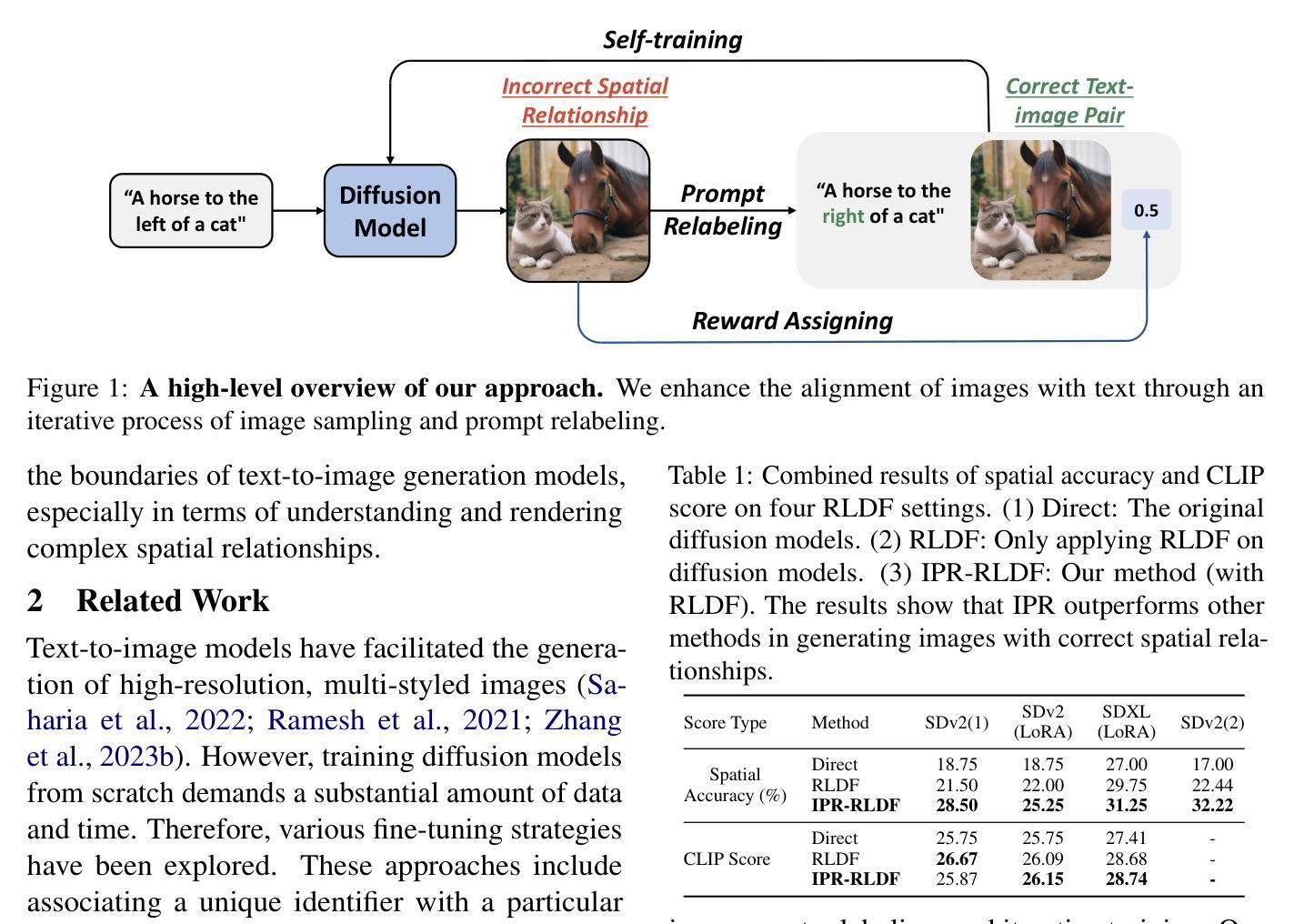
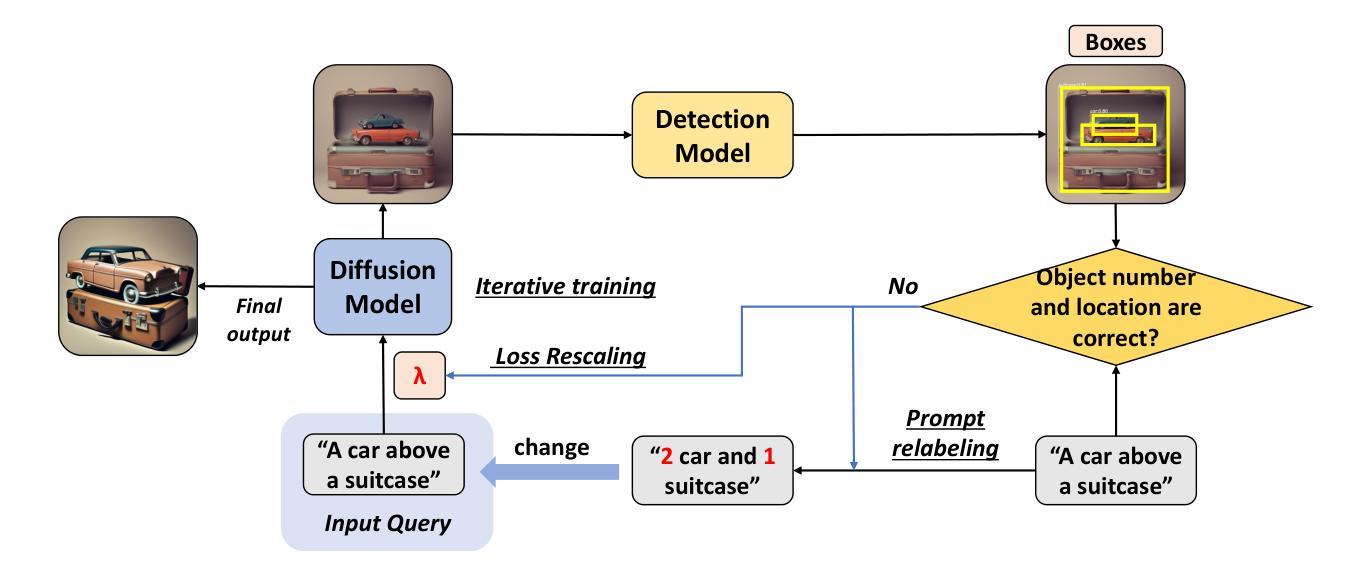
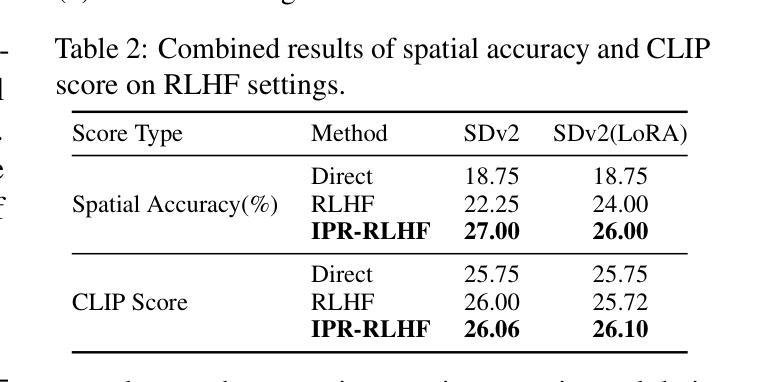
Learning from Mistakes: Iterative Prompt Relabeling for Text-to-Image Diffusion Model Training
Authors:Xinyan Chen, Jiaxin Ge, Tianjun Zhang, Jiaming Liu, Shanghang Zhang
Diffusion models have shown impressive performance in many domains. However, the model’s capability to follow natural language instructions (e.g., spatial relationships between objects, generating complex scenes) is still unsatisfactory. In this work, we propose Iterative Prompt Relabeling (IPR), a novel algorithm that aligns images to text through iterative image sampling and prompt relabeling with feedback. IPR first samples a batch of images conditioned on the text, then relabels the text prompts of unmatched text-image pairs with classifier feedback. We conduct thorough experiments on SDv2 and SDXL, testing their capability to follow instructions on spatial relations. With IPR, we improved up to 15.22% (absolute improvement) on the challenging spatial relation VISOR benchmark, demonstrating superior performance compared to previous RL methods. Our code is publicly available at https://github.com/xinyan-cxy/IPR-RLDF.
扩散模型在很多领域都表现出了令人印象深刻的性能。然而,模型遵循自然语言指令的能力(例如,物体之间的空间关系、生成复杂场景等)仍然令人不满意。在这项工作中,我们提出了迭代提示重标记(IPR)算法,这是一种通过迭代图像采样和带有反馈的提示重标记来对齐图像和文本的新型算法。首先,我们根据文本对一批图像进行采样,然后利用分类器反馈对未匹配的文本图像对的文本提示进行重新标记。我们在SDv2和SDXL上进行了全面的实验,测试了它们在空间关系指令方面的能力。借助迭代提示重标记(IPR),我们在具有挑战性的空间关系VISOR基准测试中提高了高达15.22%(绝对提升),相较于之前的强化学习方法表现出卓越的性能。我们的代码可在https://github.com/xinyan-cxy/IPR-RLDF公开访问。
论文及项目相关链接
Summary
本文提出了迭代提示重标记(Iterative Prompt Relabeling,简称IPR)算法,该算法通过迭代图像采样和提示重标记的方式对齐图像和文本,提高扩散模型在自然语言指令遵循方面的性能。在SDv2和SDXL的实验中,通过IPR算法对空间关系指令的遵循能力有所提升,尤其在具有挑战性的VISOR基准测试中,相较于先前的强化学习方法,提升了高达15.22%(绝对提升)。
Key Takeaways
- 扩散模型在众多领域表现优异,但在遵循自然语言指令(如空间关系和场景生成)方面仍有不足。
- 提出了一种新的算法——迭代提示重标记(IPR),该算法通过迭代图像采样和提示重标记,实现对图像和文本的对齐。
- IPR算法能有效提升扩散模型在空间关系指令遵循方面的性能。
- 在SDv2和SDXL的实验中验证了IPR算法的有效性。
- 在具有挑战性的VISOR基准测试中,相较于先前的强化学习方法,使用IPR算法的模型性能有显著提升,提升了高达15.22%(绝对提升)。
- 该研究的代码已公开可访问。
点此查看论文截图