⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
Cafe-Talk: Generating 3D Talking Face Animation with Multimodal Coarse- and Fine-grained Control
Authors:Hejia Chen, Haoxian Zhang, Shoulong Zhang, Xiaoqiang Liu, Sisi Zhuang, Yuan Zhang, Pengfei Wan, Di Zhang, Shuai Li
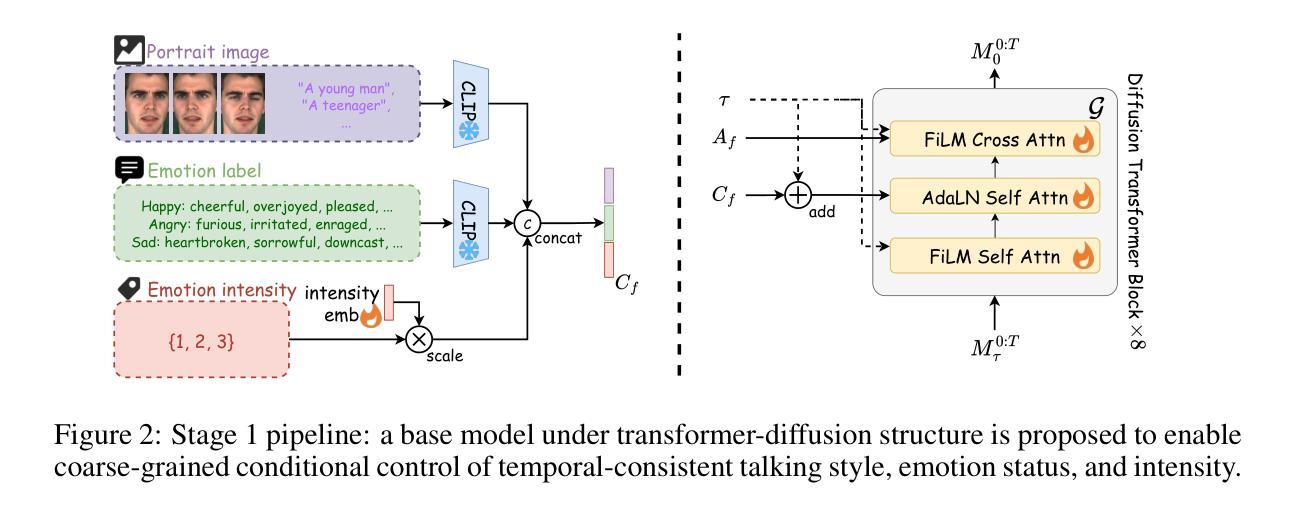
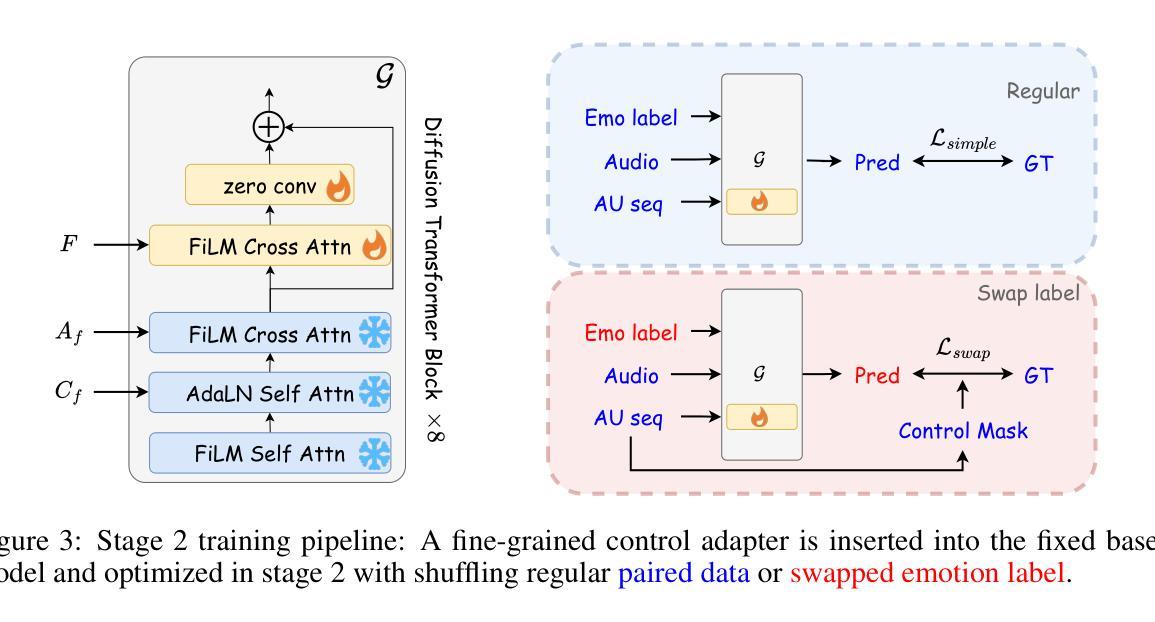
Speech-driven 3D talking face method should offer both accurate lip synchronization and controllable expressions. Previous methods solely adopt discrete emotion labels to globally control expressions throughout sequences while limiting flexible fine-grained facial control within the spatiotemporal domain. We propose a diffusion-transformer-based 3D talking face generation model, Cafe-Talk, which simultaneously incorporates coarse- and fine-grained multimodal control conditions. Nevertheless, the entanglement of multiple conditions challenges achieving satisfying performance. To disentangle speech audio and fine-grained conditions, we employ a two-stage training pipeline. Specifically, Cafe-Talk is initially trained using only speech audio and coarse-grained conditions. Then, a proposed fine-grained control adapter gradually adds fine-grained instructions represented by action units (AUs), preventing unfavorable speech-lip synchronization. To disentangle coarse- and fine-grained conditions, we design a swap-label training mechanism, which enables the dominance of the fine-grained conditions. We also devise a mask-based CFG technique to regulate the occurrence and intensity of fine-grained control. In addition, a text-based detector is introduced with text-AU alignment to enable natural language user input and further support multimodal control. Extensive experimental results prove that Cafe-Talk achieves state-of-the-art lip synchronization and expressiveness performance and receives wide acceptance in fine-grained control in user studies. Project page: https://harryxd2018.github.io/cafe-talk/
语音驱动的3D说话人脸方法应该提供准确的唇同步和可控制的表情。之前的方法只是采用离散的情绪标签来全局控制序列中的表情,而限制了时空域内精细的面部控制灵活性。我们提出了一种基于扩散变压器的3D说话人脸生成模型Cafe-Talk,它同时结合了粗粒度和细粒度的多模式控制条件。然而,多种条件的纠缠对实现令人满意的性能提出了挑战。为了分离语音音频和细粒度条件,我们采用了两阶段训练管道。具体来说,Cafe-Talk最初仅使用语音音频和粗粒度条件进行训练。然后,所提出的细粒度控制适配器逐渐添加由动作单位(AU)表示的细粒度指令,防止不利的语音唇同步。为了分离粗粒度和细粒度条件,我们设计了一种交换标签训练机制,使细粒度条件占据主导地位。我们还设计了一种基于掩码的CFG技术来调节细粒度控制的发生和强度。此外,还引入了一种基于文本的检测器,并进行文本-AU对齐,以实现自然语言用户输入并进一步支持多模式控制。大量的实验结果证明,Cafe-Talk在唇同步和表现力方面达到了最新水平,并在用户研究中受到了广泛认可的精细控制。项目页面:https://harryxd2018.github.io/cafe-talk/(翻译到此结束)
论文及项目相关链接
PDF Accepted by ICLR’25
Summary:
提出了一种基于扩散变换器的三维说话脸生成模型Cafe-Talk,该模型同时结合了粗粒度和细粒度的多模式控制条件。为解开语音音频和细粒度条件,采用两阶段训练管道。首先,只用语音音频和粗粒度条件对Cafe-Talk进行训练。然后,通过提出的细粒度控制适配器逐步添加以动作单元(AUs)表示的细粒度指令,防止不利的语音唇同步。设计了一种交换标签训练机制,使细粒度条件占主导地位。还开发了一种基于掩码的CFG技术,以调节细粒度控制的发生和强度。此外,引入了基于文本的检测器,并进行文本-AU对齐,以实现自然语言用户输入并支持多模式控制。实验结果证明,Cafe-Talk在唇同步和表现力方面达到最新水平,并在用户研究中获得精细控制的广泛认可。
Key Takeaways:
- Cafe-Talk模型结合了粗粒度和细粒度的多模式控制条件,以实现更精准的面部表达控制。
- 采用两阶段训练管道,先训练粗粒度条件,再逐步引入细粒度控制,确保语音与面部的同步。
- 提出的交换标签训练机制有助于让细粒度条件在模型训练中占主导地位。
- 使用了基于掩码的CFG技术来调节细粒度控制的程度和发生频率。
- 引入了文本检测器并支持文本与动作单元(AU)的对齐,便于用户通过自然语言进行更直观的控制。
- 实验结果证明了Cafe-Talk在唇同步和表现力方面的优越性。
点此查看论文截图