⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
TULIP: Towards Unified Language-Image Pretraining
Authors:Zineng Tang, Long Lian, Seun Eisape, XuDong Wang, Roei Herzig, Adam Yala, Alane Suhr, Trevor Darrell, David M. Chan
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
尽管CLIP和SigLIP等图文对比模型近期取得了成功,但这些模型在进行需要高保真图像理解的任务时,如计数、深度估计和精细粒度对象识别等视觉为中心的任务上经常遇到困难。这些模型通过执行语言对齐,倾向于优先处理高级语义而非视觉理解,从而削弱了它们的图像理解能力。另一方面,以视觉为中心的模型在处理视觉信息方面表现出色,但在理解语言方面却遇到困难,这限制了它们在语言驱动任务中的灵活性。在这项工作中,我们介绍了TULIP,这是一个开源的、可以替代现有CLIP等模型的工具。我们的方法利用生成数据增强、增强的图像与图像以及文本与文本对比学习以及图像/文本重建正则化,以学习精细的视听觉特征同时保留全局语义对齐。我们的方法规模扩大到超过1亿个参数,在多个基准测试中超越了现有的先进技术(SOTA)模型,在ImageNet-1K上建立了新的零样本性能标准,在RxRx1的线性探测中相对于SigLIP提高了高达两倍的性能用于小样本分类任务,并在MMVP上实现了超过SigLIP三倍的高分。我们的代码和检查点可在https://tulip-berkeley.github.io找到。
论文及项目相关链接
Summary
该文本介绍了尽管CLIP和SigLIP等图文对比模型取得了成功,但在需要高保真图像理解的任务上仍有不足。为此,本文提出了TULIP模型,通过生成数据增强、图像和文本对比学习以及图像/文本重建正则化方法,在保留全局语义对齐的同时学习精细的视觉特征。该方法在多项基准测试中表现优于现有最先进的模型,并在ImageNet-1K上实现了零样本性能的新的SOTA水平。此外,TULIP在少数样本分类任务的线性探测性能比SigLIP提高了两倍以上,并在MMVP上获得了超过SigLIP三倍的高得分。模型和检查点已经开源可用。该模型的改进为复杂任务提供了一种可行解决方案。在保持全局语义对齐的同时,增强了图像理解的能力。同时,该模型在解决语言驱动的任务时表现出灵活性。这一模型旨在改进现有模型的不足之处,提升模型的性能和效率。这些优点使TULIP模型在图像分类等任务中展现出卓越的表现力。它的应用前景广阔,具有重要的应用价值和发展潜力。
Key Takeaways
以下是七个关键见解:
- 当前流行的图像文本对比模型(如CLIP和SigLIP)在精细视觉任务上存在缺陷,但具有高层次的语义理解能力。他们面临着需要提升高保真图像理解的挑战。而某些纯视觉模型虽然在处理视觉信息方面表现出色,但在语言理解方面却显得捉襟见肘。这些模型的缺陷限制了它们在复杂任务中的灵活性。
- TULIP作为一种新型的开源模型,旨在解决上述问题。它通过结合生成数据增强、图像和文本对比学习以及图像/文本重建正则化方法等手段提高性能。该方法不仅能保留全局语义信息,而且能够更好地处理精细的视觉特征。这有助于增强模型在多种任务上的表现能力。同时提高图像理解和语言理解的平衡性。
- TULIP模型的性能表现超过了现有最先进的模型,如SigLIP等模型在某些特定任务上的表现有了显著的提升。它在多个基准测试中表现优异,并在ImageNet-1K上实现了零样本性能的新的记录,达到SOTA水平,也显著提高零样本能力以解决下游任务的鲁棒性和适应性问题。。其在少量样本下的线性探测性能和全景能力得到了提升也极大地推动了视觉语言任务的改进发展态势顺利确立正确;相对于sigLIP模型和感知机预测等模型在MMVP上的得分有了显著的提升。。这表明TULIP在处理复杂任务时具有更高的效率和准确性。。该模型的引入有望为计算机视觉和自然语言处理领域带来新的突破。。因此可以预期在未来中将会获得更广泛的应用场景。。因此它对于解决复杂任务提供了一种可行解决方案。。其改进了现有模型的不足之处并提升了模型的性能和效率。。同时其推广可能会启发后续的创新探索算法解决任务层面逻辑的结构特征化处理与创新研究和基础方案结合创新性引用实用性确保有助于在该领域创造出更具创新和适应性的新技术进一步赋能自然语言理解和认知处理推理技术的进步的发展出新的技术发展驱动力空间扩大了我们对自然界的认识让我们获得了更快解决此类难题的新途径并带来了广泛的实际应用前景及市场潜力
点此查看论文截图

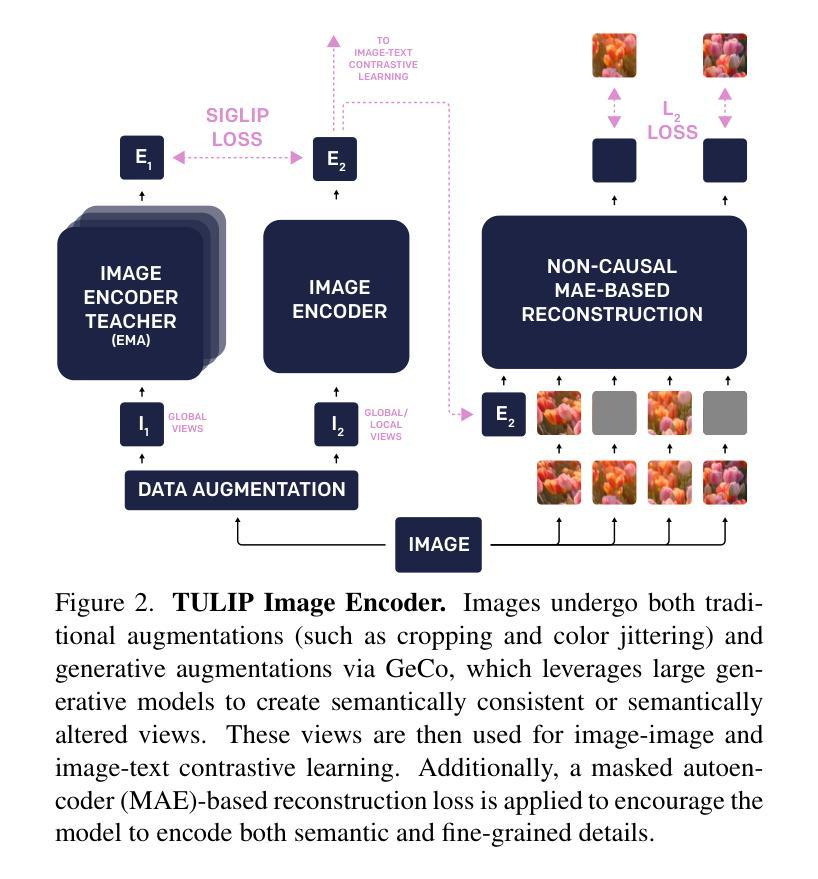
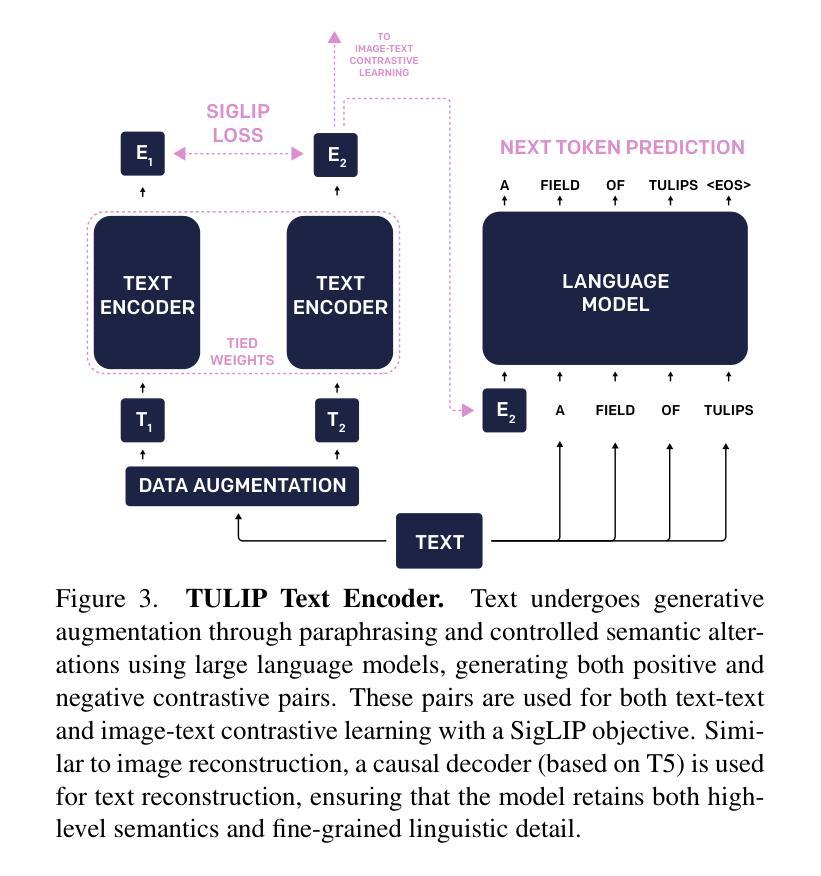
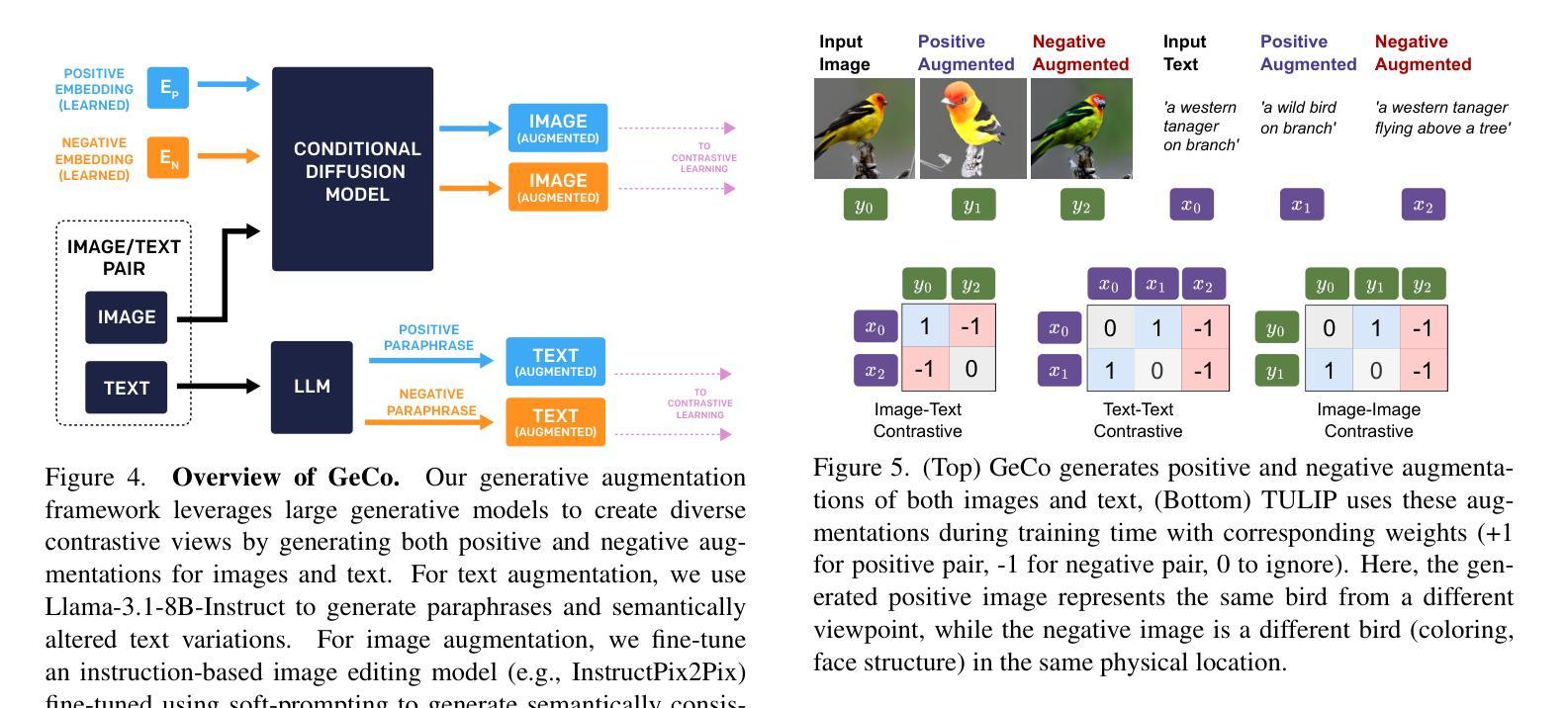
Conjuring Positive Pairs for Efficient Unification of Representation Learning and Image Synthesis
Authors:Imanol G. Estepa, Jesús M. Rodríguez-de-Vera, Ignacio Sarasúa, Bhalaji Nagarajan, Petia Radeva
While representation learning and generative modeling seek to understand visual data, unifying both domains remains unexplored. Recent Unified Self-Supervised Learning (SSL) methods have started to bridge the gap between both paradigms. However, they rely solely on semantic token reconstruction, which requires an external tokenizer during training – introducing a significant overhead. In this work, we introduce Sorcen, a novel unified SSL framework, incorporating a synergic Contrastive-Reconstruction objective. Our Contrastive objective, “Echo Contrast”, leverages the generative capabilities of Sorcen, eliminating the need for additional image crops or augmentations during training. Sorcen “generates” an echo sample in the semantic token space, forming the contrastive positive pair. Sorcen operates exclusively on precomputed tokens, eliminating the need for an online token transformation during training, thereby significantly reducing computational overhead. Extensive experiments on ImageNet-1k demonstrate that Sorcen outperforms the previous Unified SSL SoTA by 0.4%, 1.48 FID, 1.76%, and 1.53% on linear probing, unconditional image generation, few-shot learning, and transfer learning, respectively, while being 60.8% more efficient. Additionally, Sorcen surpasses previous single-crop MIM SoTA in linear probing and achieves SoTA performance in unconditional image generation, highlighting significant improvements and breakthroughs in Unified SSL models.
表示学习和生成建模都在努力理解视觉数据,但融合这两个领域仍然未被探索。最近的统一自监督学习(SSL)方法已经开始弥合两种范式之间的鸿沟。然而,它们仅依赖于语义令牌重建,这需要训练过程中的外部令牌器——这引入了相当大的开销。在这项工作中,我们介绍了Sorcen,这是一个新的统一SSL框架,它结合了协同对比重建目标。我们的对比目标“回声对比”利用Sorcen的生成能力,在训练过程中无需额外的图像裁剪或增强。Sorcen在语义令牌空间中“生成”一个回声样本,形成对比正对。Sorcen只处理预先计算好的令牌,无需在训练过程中进行在线令牌转换,从而大大降低了计算开销。在ImageNet-1k上的大量实验表明,在线性探测、无条件图像生成、小样本学习和迁移学习方面,索森分别比之前的统一SSL现状高出0.4%、1.48 FID、1.76%和1.53%,同时效率提高60.8%。此外,索森还在线性探测中超越了之前的单裁剪MIM现状,并在无条件图像生成方面达到了最新性能水平,这突显了统一SSL模型的显著改进和突破。
论文及项目相关链接
PDF The source code is available in https://github.com/ImaGonEs/Sorcen
Summary
本文介绍了一种新型的统一自监督学习(SSL)框架Sorcen,它结合了对比和重建目标,无需额外的图像裁剪或增强即可进行训练。Sorcen在预计算令牌上运行,减少了计算开销,并在ImageNet-1k数据集上实现了显著的性能改进。
Key Takeaways
- Sorcen是一个新型的统一SSL框架,结合了对比和重建目标。
- Sorcen引入了”Echo Contrast”对比目标,利用生成能力,无需额外的图像裁剪或增强即可进行训练。
- Sorcen在预计算令牌上运行,消除了在线令牌转换的需要,从而显著减少了计算开销。
- Sorcen在ImageNet-1k数据集上的性能超越了之前的统一SSL技术,特别是在线性探测、无条件图像生成、少镜学习和迁移学习方面。
- Sorcen在无条件图像生成方面达到了最新技术水平。
- Sorcen框架通过整合对比和重建目标,在视觉数据理解方面取得了突破。
点此查看论文截图


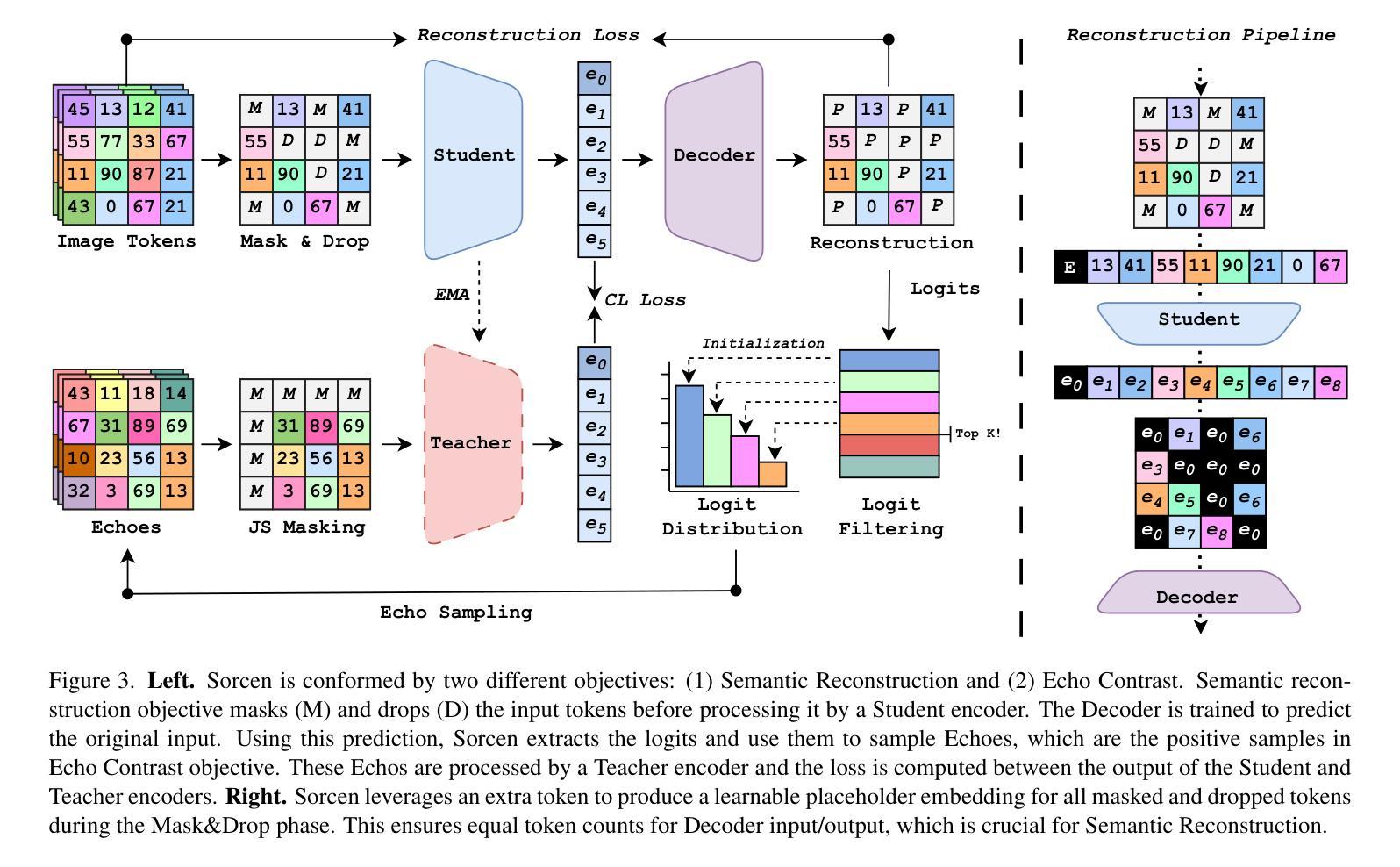

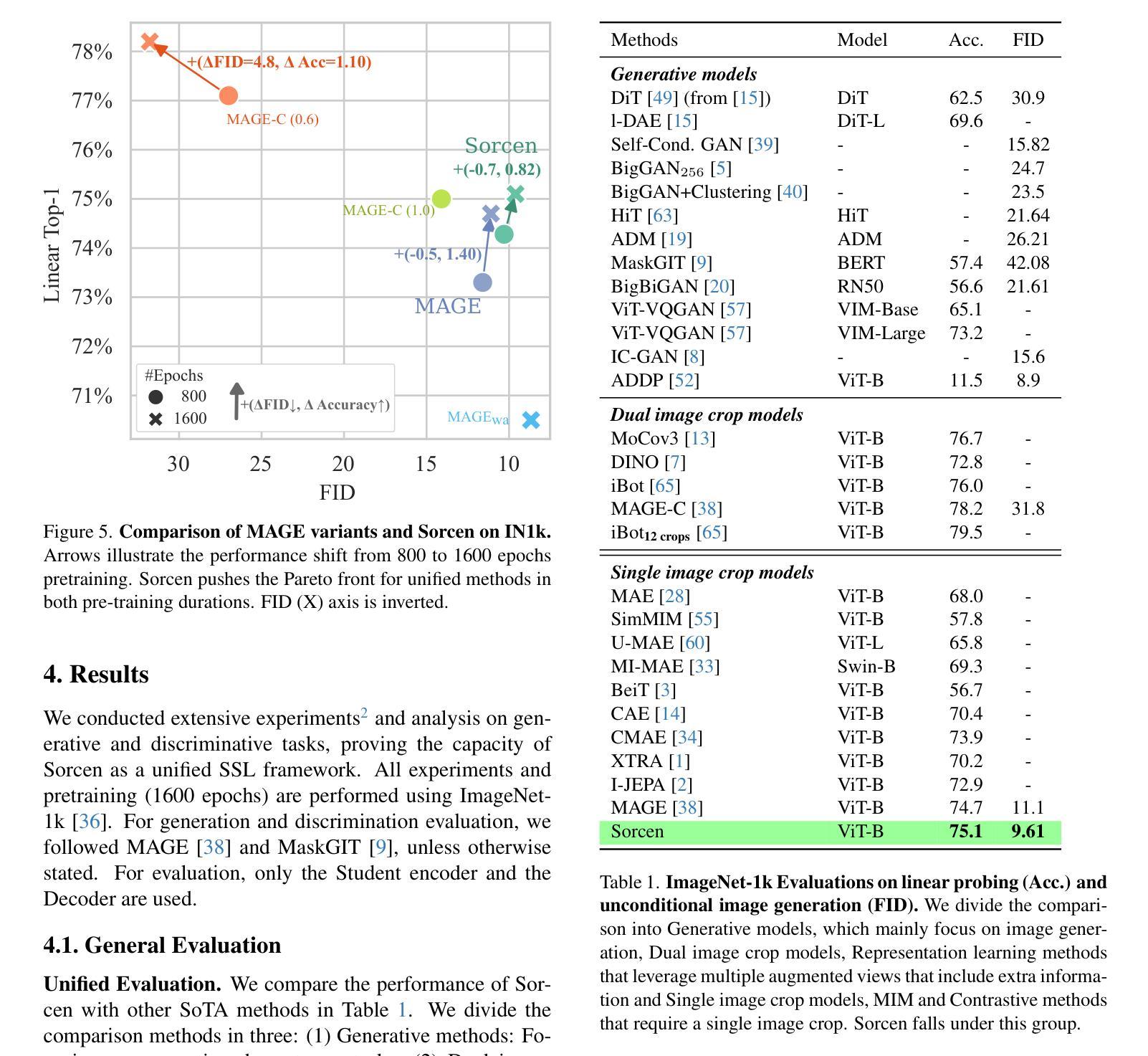
Reducing Annotation Burden: Exploiting Image Knowledge for Few-Shot Medical Video Object Segmentation via Spatiotemporal Consistency Relearning
Authors:Zixuan Zheng, Yilei Shi, Chunlei Li, Jingliang Hu, Xiao Xiang Zhu, Lichao Mou
Few-shot video object segmentation aims to reduce annotation costs; however, existing methods still require abundant dense frame annotations for training, which are scarce in the medical domain. We investigate an extremely low-data regime that utilizes annotations from only a few video frames and leverages existing labeled images to minimize costly video annotations. Specifically, we propose a two-phase framework. First, we learn a few-shot segmentation model using labeled images. Subsequently, to improve performance without full supervision, we introduce a spatiotemporal consistency relearning approach on medical videos that enforces consistency between consecutive frames. Constraints are also enforced between the image model and relearning model at both feature and prediction levels. Experiments demonstrate the superiority of our approach over state-of-the-art few-shot segmentation methods. Our model bridges the gap between abundant annotated medical images and scarce, sparsely labeled medical videos to achieve strong video segmentation performance in this low data regime. Code is available at https://github.com/MedAITech/RAB.
少样本视频目标分割旨在降低标注成本。然而,现有方法仍然需要大量密集帧标注进行训练,这在医学领域是非常罕见的。我们研究了一种极少量数据的模式,该模式仅利用来自少数视频帧的标注,并利用现有的标记图像来最大限度地减少昂贵的视频标注。具体来说,我们提出了一个两阶段框架。首先,我们使用标记图像学习小样本分割模型。随后,为了在无完全监督的情况下提高性能,我们引入了医学视频上的时空一致性再学习的方法,强制连续帧之间的一致性。在特征和预测层面,图像模型和再学习模型之间也强制实施约束。实验表明,我们的方法优于最先进的少样本分割方法。我们的模型缩小了大量标注医学图像和稀少、稀疏标注医学视频之间的差距,在这个低数据模式下实现了强大的视频分割性能。代码可在https://github.com/MedAITech/RAB找到。
论文及项目相关链接
PDF MICCAI 2024
Summary
本文研究了基于少量视频帧标注信息的视频目标分割技术,并引入了一种两阶段框架。首先利用图像标注数据学习一个分割模型,然后通过时空一致性重学习的方法提高模型在医疗视频上的性能。该方法实现了在数据稀缺情况下的视频分割任务,并展示了其在低数据环境下的优越性。
Key Takeaways
- 研究目标为解决医疗领域标注数据稀缺的问题,通过减少视频标注成本实现视频目标分割。
- 提出一种两阶段框架,首先利用少量视频帧标注信息和现有图像标注数据进行模型学习。
- 采用时空一致性重学习的方法提高模型性能,增强模型在连续视频帧之间的预测一致性。
- 模型在特征预测层面与图像模型保持一致性,增强了模型的泛化能力。
- 实验结果表明,该方法在少量标注数据的情况下优于现有技术。
- 该方法成功解决了从丰富的医学图像标注到稀疏医学视频标注的过渡问题。
点此查看论文截图

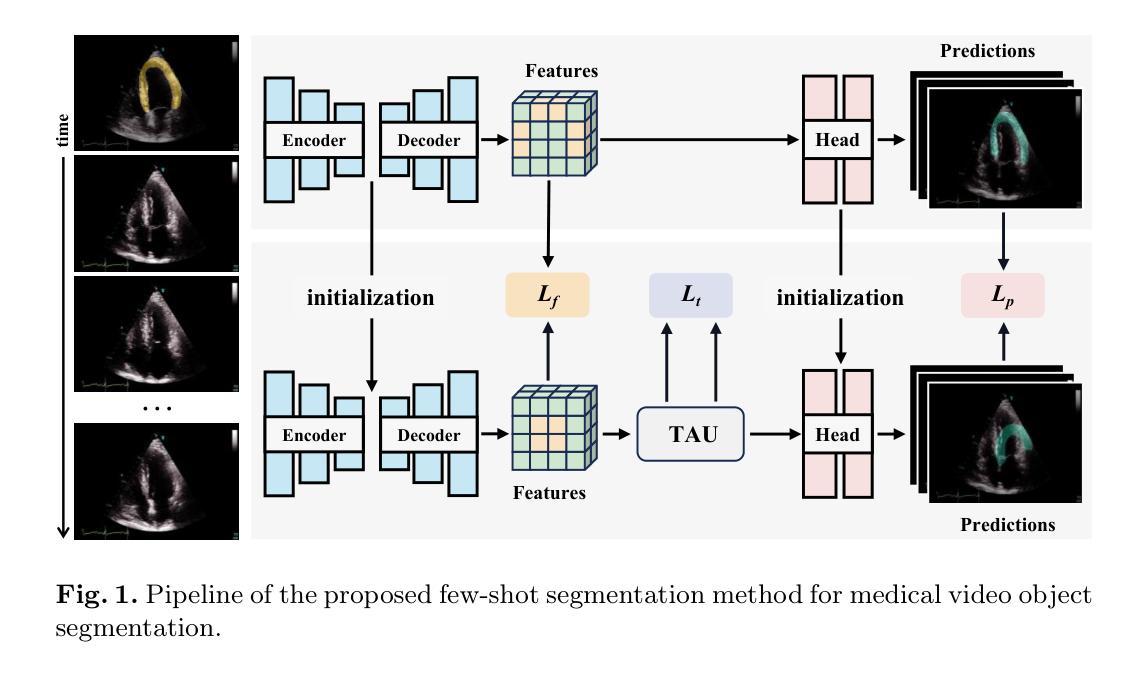
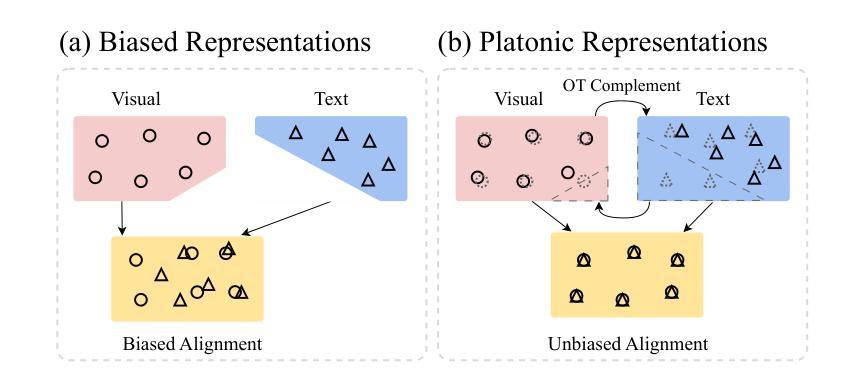
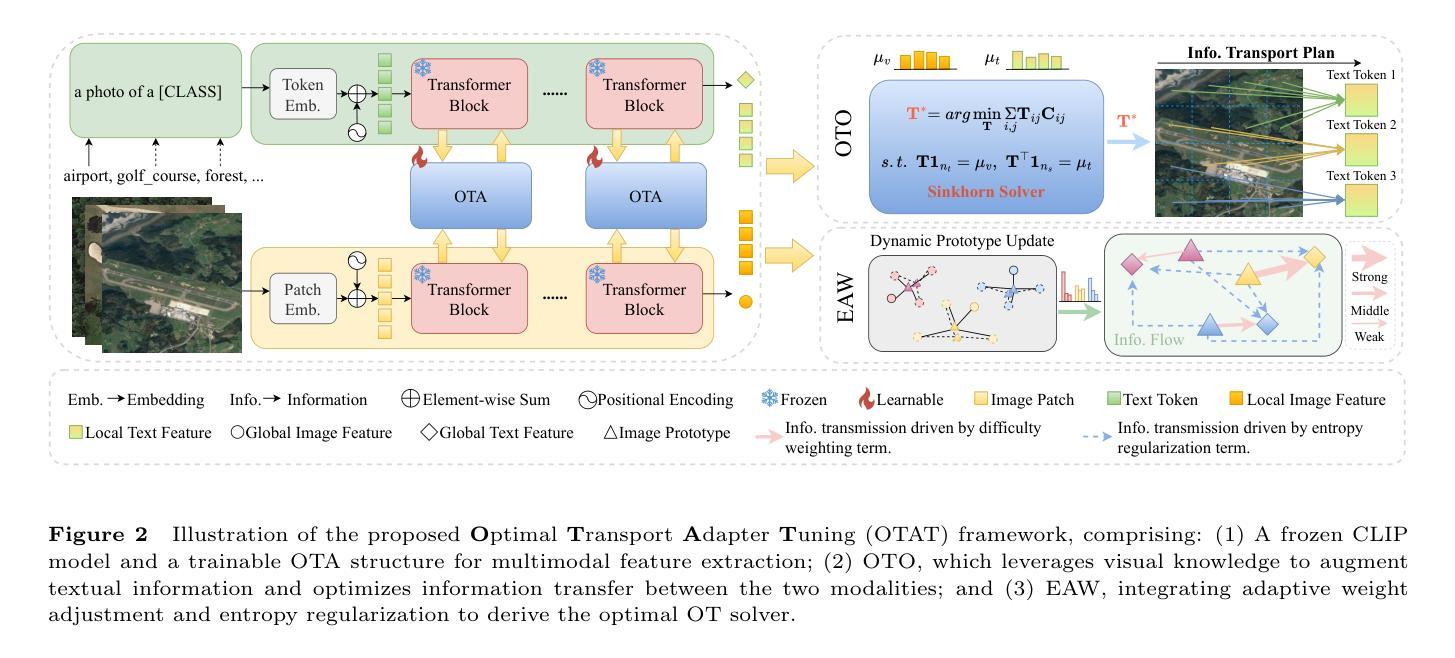
Optimal Transport Adapter Tuning for Bridging Modality Gaps in Few-Shot Remote Sensing Scene Classification
Authors:Zhong Ji, Ci Liu, Jingren Liu, Chen Tang, Yanwei Pang, Xuelong Li
Few-Shot Remote Sensing Scene Classification (FS-RSSC) presents the challenge of classifying remote sensing images with limited labeled samples. Existing methods typically emphasize single-modal feature learning, neglecting the potential benefits of optimizing multi-modal representations. To address this limitation, we propose a novel Optimal Transport Adapter Tuning (OTAT) framework aimed at constructing an ideal Platonic representational space through optimal transport (OT) theory. This framework seeks to harmonize rich visual information with less dense textual cues, enabling effective cross-modal information transfer and complementarity. Central to this approach is the Optimal Transport Adapter (OTA), which employs a cross-modal attention mechanism to enrich textual representations and facilitate subsequent better information interaction. By transforming the network optimization into an OT optimization problem, OTA establishes efficient pathways for balanced information exchange between modalities. Moreover, we introduce a sample-level Entropy-Aware Weighted (EAW) loss, which combines difficulty-weighted similarity scores with entropy-based regularization. This loss function provides finer control over the OT optimization process, enhancing its solvability and stability. Our framework offers a scalable and efficient solution for advancing multimodal learning in remote sensing applications. Extensive experiments on benchmark datasets demonstrate that OTAT achieves state-of-the-art performance in FS-RSSC, significantly improving the model performance and generalization.
少量遥感场景分类(FS-RSSC)面临着对有限标记样本的遥感图像进行分类的挑战。现有方法通常侧重于单模态特征学习,忽略了优化多模态表示可能带来的潜在好处。为了解决这个问题,我们提出了一种新型的基于最优传输适配器调整(OTAT)的框架,旨在通过最优传输(OT)理论构建一个理想的柏拉图表示空间。该框架旨在协调丰富的视觉信息与较少的文本线索,实现有效的跨模态信息转移和互补。该方法的核心是最佳传输适配器(OTA),它采用跨模态注意力机制来丰富文本表示,并促进后续更好的信息交互。通过将网络优化转化为OT优化问题,OTA为跨模态之间的平衡信息交换建立了有效的路径。此外,我们引入了样本级熵感知加权(EAW)损失,将难度加权相似度得分与基于熵的正则化相结合。此损失函数可以更精细地控制OT优化过程,提高其求解性和稳定性。我们的框架为遥感应用中的多模态学习提供了可扩展和高效的解决方案。在基准数据集上的广泛实验表明,OTAT在FS-RSSC中达到了最先进的性能,显著提高了模型性能和泛化能力。
论文及项目相关链接
Summary
本文介绍了小样本遥感场景分类(FS-RSSC)的挑战,并提出了一个新的Optimal Transport Adapter Tuning(OTAT)框架来解决现有方法的局限性。该框架利用最优传输(OT)理论构建一个理想的柏拉图表示空间,以融合视觉和文本信息。中心是Optimal Transport Adapter(OTA),采用跨模态注意力机制来丰富文本表示,促进更有效的信息交互。此外,引入了样本级的Entropy-Aware Weighted(EAW)损失函数,为OT优化过程提供更精细的控制,增强其可解性和稳定性。OTAT框架为遥感应用中的多模态学习提供了可扩展和高效的解决方案,并在基准数据集上实现了最先进的性能。
Key Takeaways
- Few-Shot Remote Sensing Scene Classification (FS-RSSC)存在挑战,需要解决在有限标记样本下对遥感图像进行分类的问题。
- 现有方法主要关注单模态特征学习,忽略了优化多模态表示的巨大潜力。
- 提出了Optimal Transport Adapter Tuning (OTAT)框架,旨在通过最优传输(OT)理论构建理想的柏拉图表示空间。
- OTAT框架融合了视觉和文本信息,实现了跨模态信息转移和互补。
- Optimal Transport Adapter (OTA)是框架的核心,采用跨模态注意力机制来丰富文本表示并促进更有效的信息交互。
- 引入了样本级的Entropy-Aware Weighted (EAW)损失函数,为OT优化过程提供更精细的控制,增强其稳定性和可解决性。
点此查看论文截图


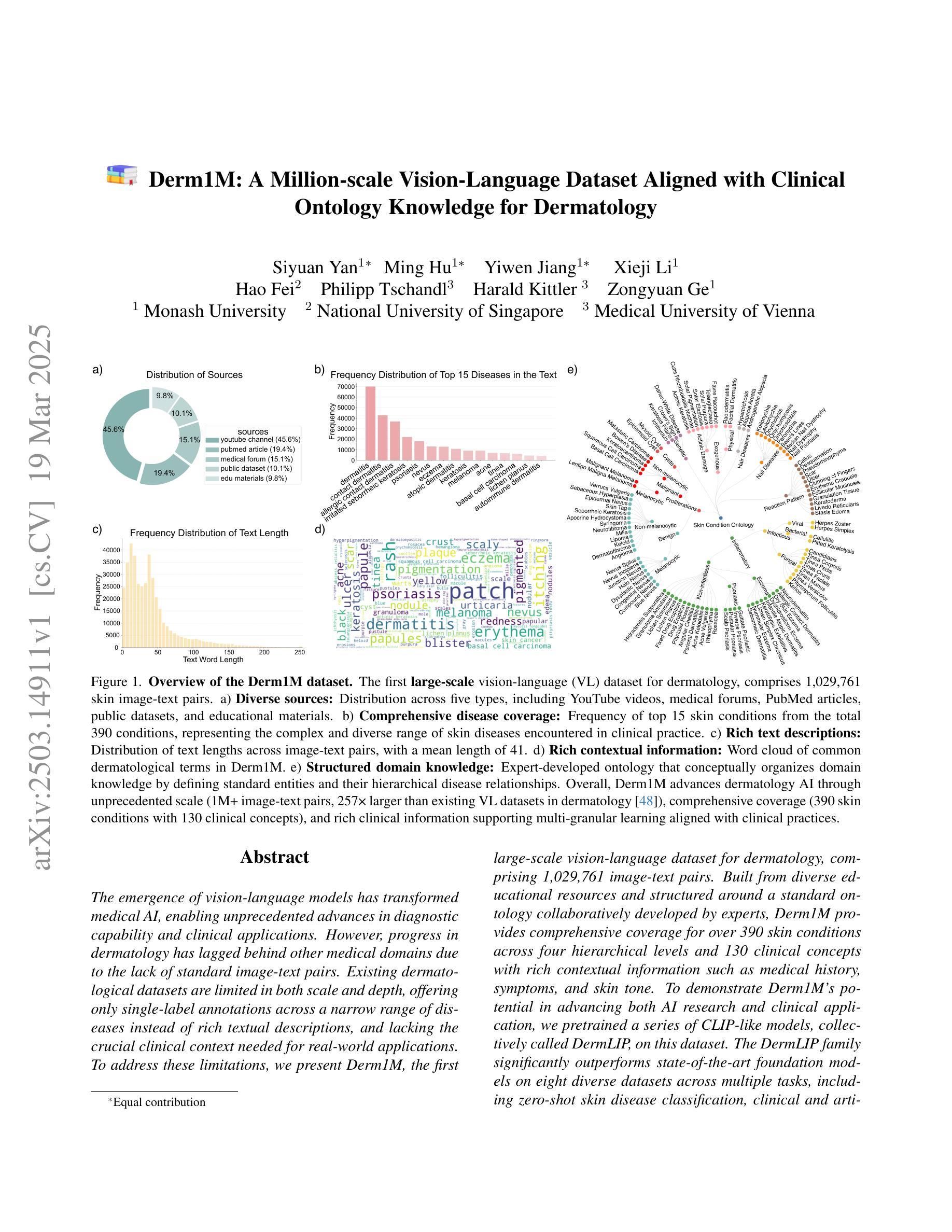
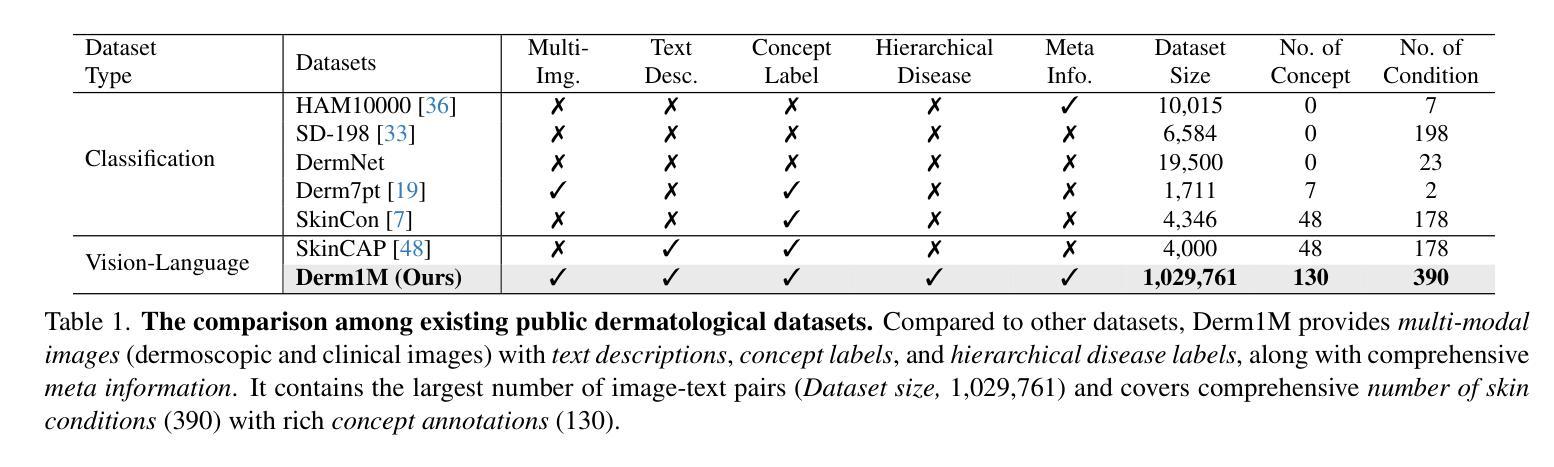
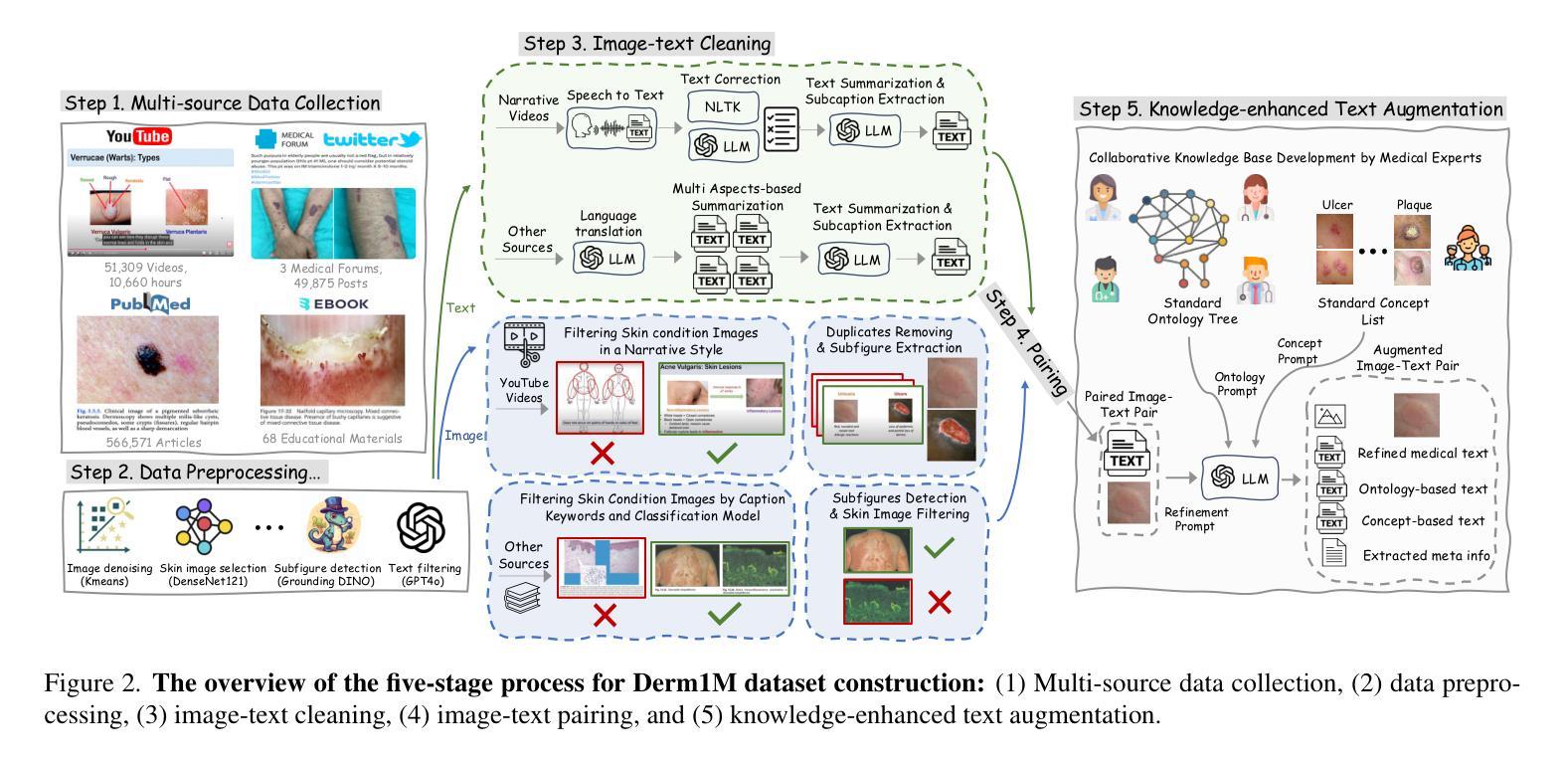
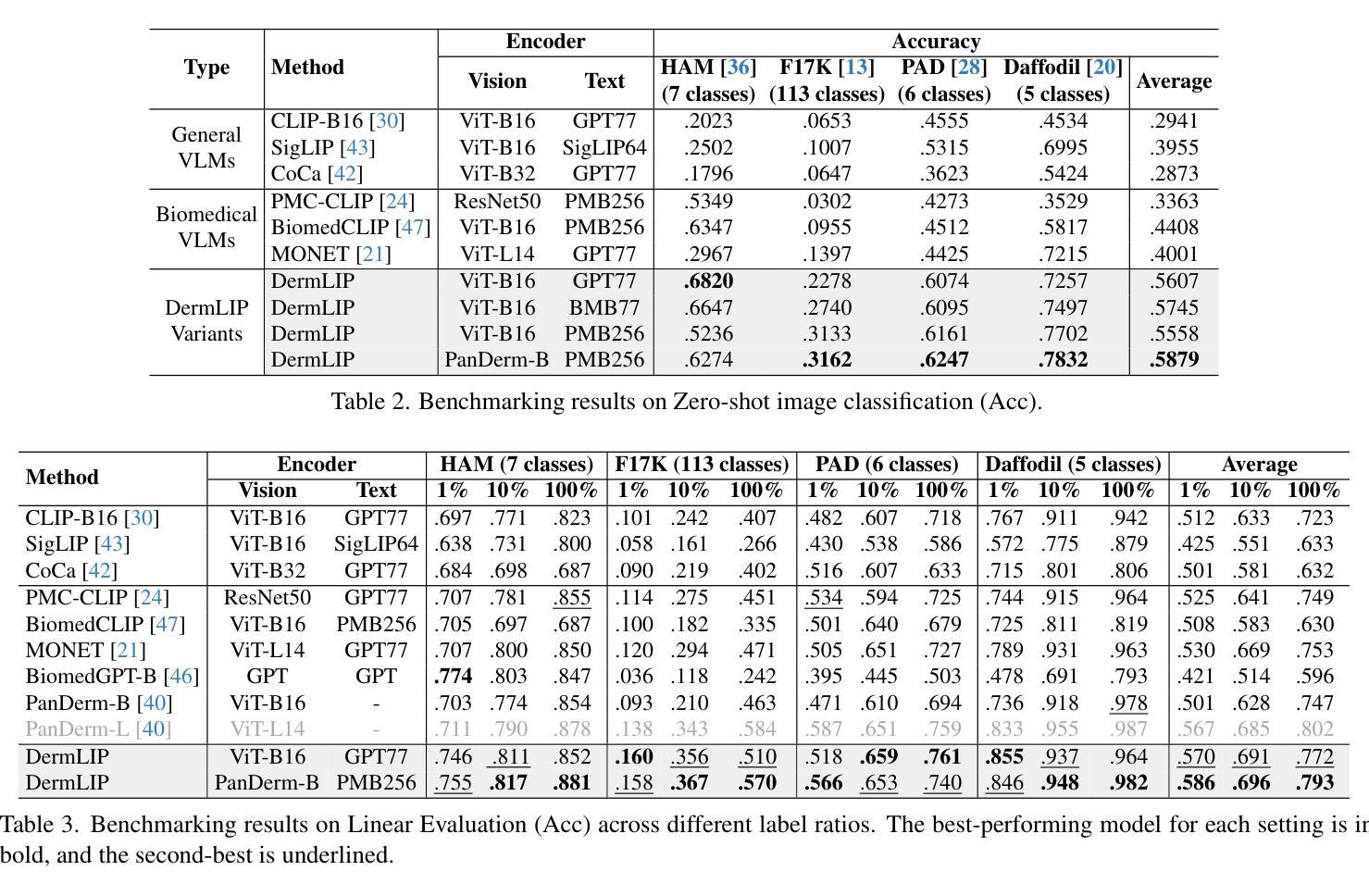
Derm1M: A Million-scale Vision-Language Dataset Aligned with Clinical Ontology Knowledge for Dermatology
Authors:Siyuan Yan, Ming Hu, Yiwen Jiang, Xieji Li, Hao Fei, Philipp Tschandl, Harald Kittler, Zongyuan Ge
The emergence of vision-language models has transformed medical AI, enabling unprecedented advances in diagnostic capability and clinical applications. However, progress in dermatology has lagged behind other medical domains due to the lack of standard image-text pairs. Existing dermatological datasets are limited in both scale and depth, offering only single-label annotations across a narrow range of diseases instead of rich textual descriptions, and lacking the crucial clinical context needed for real-world applications. To address these limitations, we present Derm1M, the first large-scale vision-language dataset for dermatology, comprising 1,029,761 image-text pairs. Built from diverse educational resources and structured around a standard ontology collaboratively developed by experts, Derm1M provides comprehensive coverage for over 390 skin conditions across four hierarchical levels and 130 clinical concepts with rich contextual information such as medical history, symptoms, and skin tone. To demonstrate Derm1M potential in advancing both AI research and clinical application, we pretrained a series of CLIP-like models, collectively called DermLIP, on this dataset. The DermLIP family significantly outperforms state-of-the-art foundation models on eight diverse datasets across multiple tasks, including zero-shot skin disease classification, clinical and artifacts concept identification, few-shot/full-shot learning, and cross-modal retrieval. Our dataset and code will be public.
视觉语言模型的兴起已经推动了医疗人工智能的发展,为诊断能力和临床应用带来了前所未有的进步。然而,皮肤病学的进展由于缺少标准图像文本配对而落后于其他医学领域。现有的皮肤病数据集在规模和深度上均有限,只提供狭窄疾病范围内的单一标签注释,而非丰富的文本描述,并缺乏真实世界应用所需的关键临床背景。为了解决这些局限性,我们推出了Derm1M,这是皮肤病领域首个大规模视觉语言数据集,包含1,029,761个图像文本对。Derm1M由多样化的教育资源构建,围绕专家共同开发的标准本体结构,为超过390种皮肤状况提供了四级层次结构和130种临床概念的全面覆盖,以及丰富的上下文信息,如病史、症状和肤色等。为了证明Derm1M在推动人工智能研究和临床应用方面的潜力,我们在该数据集上预训练了一系列类似于CLIP的模型,统称为DermLIP。DermLIP家族在多个任务的八个不同数据集上显著优于最先进的基础模型,包括零样本皮肤病分类、临床和文物概念识别、少样本/全样本学习和跨模态检索。我们的数据集和代码将公开。
论文及项目相关链接
PDF 23 pages
Summary
本文介绍了医学人工智能领域中的视觉语言模型,特别是在皮肤科的应用。由于缺少标准图像文本配对,皮肤科的进步滞后于其他医学领域。为解决此问题,研究团队构建了首个大规模皮肤科视觉语言数据集Derm1M,包含1,029,761个图像文本对,涵盖超过390种皮肤状况、130种临床概念和丰富的上下文信息。同时,基于该数据集预训练了一系列CLIP类模型(统称为DermLIP),在多个任务上显著超越了当前最先进的模型,包括零样本皮肤疾病分类、临床和伪概念识别、少样本/全样本学习和跨模态检索。数据集和代码将公开。
Key Takeaways
- 视觉语言模型在医学AI领域有重要应用,特别是在皮肤科。
- 皮肤科进步滞后于其他医学领域,主要因为缺少标准图像文本配对。
- 研究团队构建了首个大规模皮肤科视觉语言数据集Derm1M,包含丰富的图像文本对和临床概念信息。
- DermLIP模型在多个任务上表现优异,包括皮肤疾病分类、临床和伪概念识别等。
- Derm1M数据集将促进AI研究和临床应用的发展。
- 该数据集和代码将公开供公众使用。
点此查看论文截图
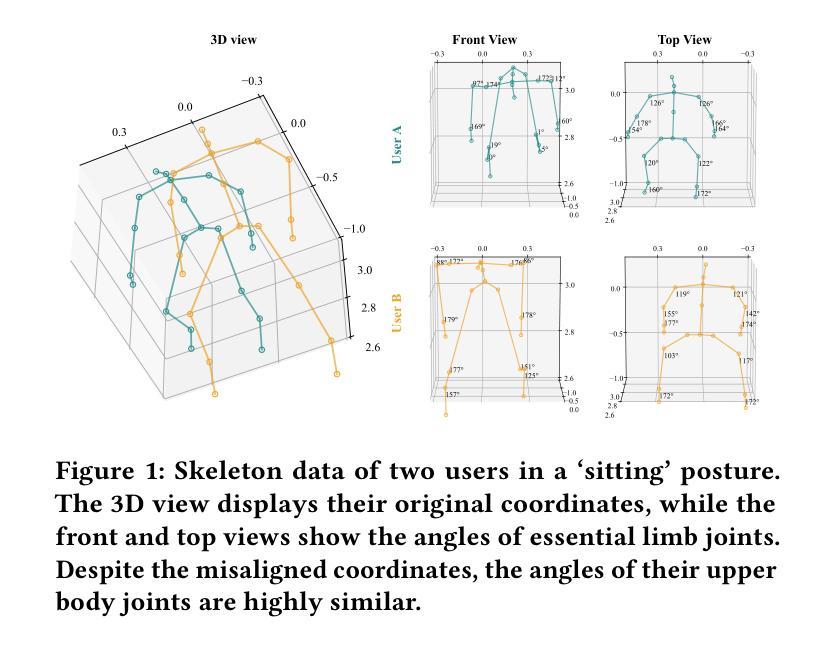
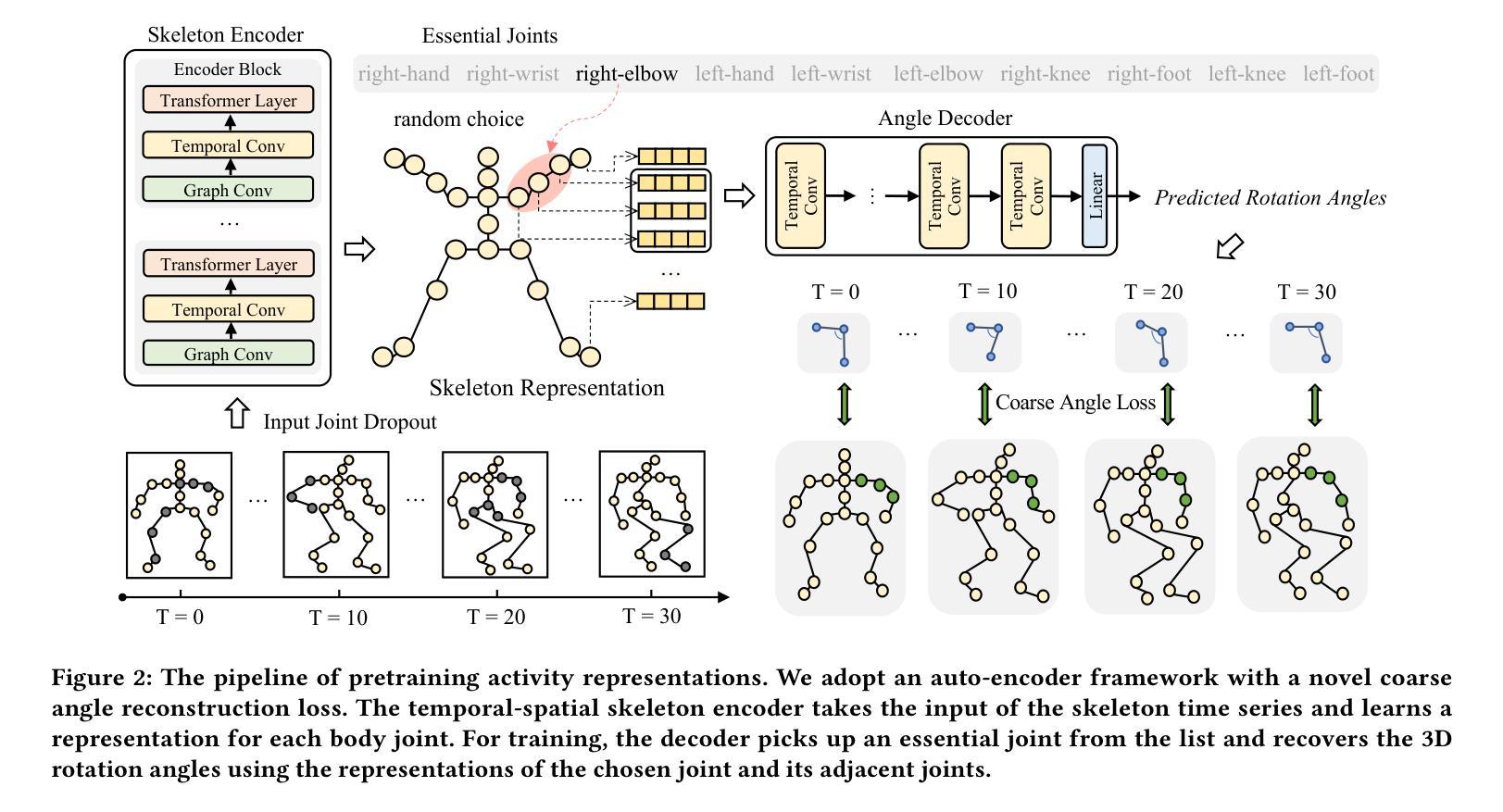
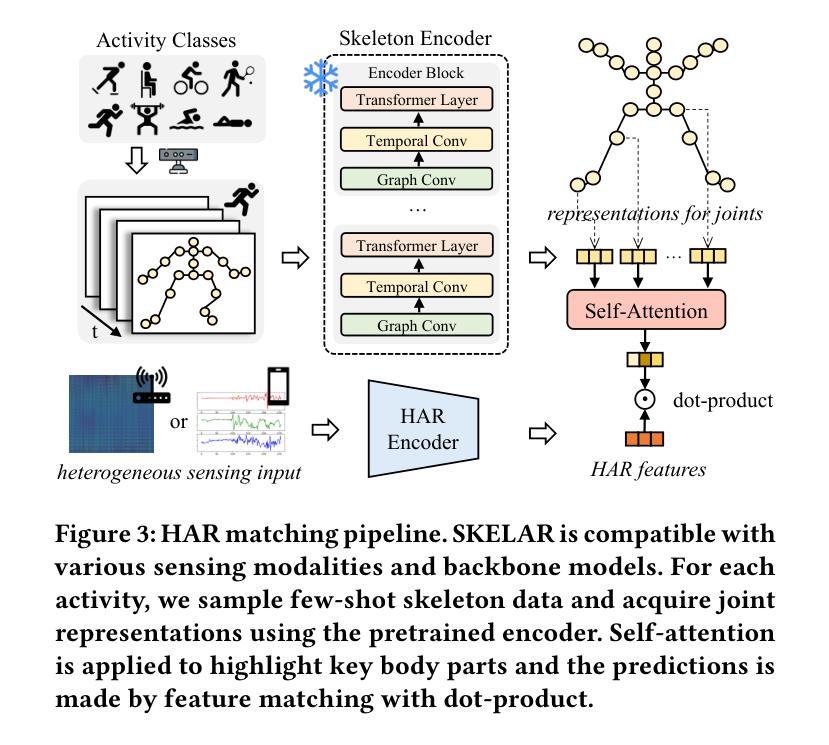
Matching Skeleton-based Activity Representations with Heterogeneous Signals for HAR
Authors:Shuheng Li, Jiayun Zhang, Xiaohan Fu, Xiyuan Zhang, Jingbo Shang, Rajesh K. Gupta
In human activity recognition (HAR), activity labels have typically been encoded in one-hot format, which has a recent shift towards using textual representations to provide contextual knowledge. Here, we argue that HAR should be anchored to physical motion data, as motion forms the basis of activity and applies effectively across sensing systems, whereas text is inherently limited. We propose SKELAR, a novel HAR framework that pretrains activity representations from skeleton data and matches them with heterogeneous HAR signals. Our method addresses two major challenges: (1) capturing core motion knowledge without context-specific details. We achieve this through a self-supervised coarse angle reconstruction task that recovers joint rotation angles, invariant to both users and deployments; (2) adapting the representations to downstream tasks with varying modalities and focuses. To address this, we introduce a self-attention matching module that dynamically prioritizes relevant body parts in a data-driven manner. Given the lack of corresponding labels in existing skeleton data, we establish MASD, a new HAR dataset with IMU, WiFi, and skeleton, collected from 20 subjects performing 27 activities. This is the first broadly applicable HAR dataset with time-synchronized data across three modalities. Experiments show that SKELAR achieves the state-of-the-art performance in both full-shot and few-shot settings. We also demonstrate that SKELAR can effectively leverage synthetic skeleton data to extend its use in scenarios without skeleton collections.
在人类活动识别(HAR)中,活动标签通常被编码为一热格式,最近有转向使用文本表示以提供上下文知识的趋势。在这里,我们主张HAR应该以物理运动数据为基础,因为运动是活动的基础,并在不同的感应系统中有效应用,而文本则具有内在的局限性。我们提出了SKELAR,这是一种新型HAR框架,可以从骨架数据中预训练活动表示,并与异构HAR信号进行匹配。我们的方法解决了两个主要挑战:(1)捕获核心运动知识而不涉及特定上下文细节。我们通过自我监督的粗略角度重建任务实现这一点,该任务能够恢复关节旋转角度,对用户和部署具有不变性;(2)将表示形式适应具有不同模态和重点的下游任务。为解决此问题,我们引入了一个自我注意力匹配模块,该模块能够以数据驱动的方式动态地优先处理相关部位。考虑到现有骨架数据中缺少相应的标签,我们建立了MASD,这是一个新的HAR数据集,包含IMU、WiFi和骨架数据,从执行27项活动的20名受试者中收集。这是第一个在三模态中时间同步数据的广泛应用HAR数据集。实验表明,无论是在全镜头和少镜头设置中,SKELAR都达到了最先进的表现。我们还证明了SKELAR可以有效地利用合成骨架数据来扩展其在没有骨架收集的场景中的应用。
论文及项目相关链接
PDF This paper is accepted by SenSys 2025
Summary
在人体活动识别(HAR)领域,以往多采用独热编码的活动标签方式,但近期逐渐向使用文本表示提供上下文知识转变。然而,我们主张HAR应以物理运动数据为基础,因为运动是活动的基础并有效适用于各种传感系统,而文本则存在固有局限性。为此,我们提出了SKELAR这一新型HAR框架,它能从骨架数据中预训练活动表示并与异质HAR信号匹配。此框架解决了两大挑战:一、捕捉核心运动知识而不涉及特定上下文细节,我们通过自监督的粗略角度重建任务实现这一点,能够恢复关节旋转角度,对用户部署均保持不变;二、针对具有不同模态和重点的下游任务进行自适应表示,为此我们引入了自注意力匹配模块,以数据驱动的方式动态优先处理重要部位。由于缺乏相应的骨架数据标签,我们建立了MASD这一新HAR数据集,包含IMU、WiFi和骨架数据,由20名受试者进行27项活动采集而成。这是首个适用于多种模态的通用HAR数据集。实验表明,SKELAR在全镜头和少镜头设置中都达到了最先进的性能。我们还证明了SKELAR在没有骨架收集的场景中能有效利用合成骨架数据。
Key Takeaways
- 活动识别应基于物理运动数据,强调运动在活动中的基础地位及跨传感系统的适用性。
- SKELAR框架解决了从骨架数据中预训练活动表示的挑战。
- SKELAR通过自监督的粗略角度重建任务捕捉核心运动知识,对用户和部署均保持不变。
- SKELAR通过自注意力匹配模块实现对不同下游任务的自适应表示。
- 建立了新的HAR数据集MASD,包含IMU、WiFi和骨架数据,适用于多种模态。
- SKELAR在全镜头和少镜头设置中表现优越。
点此查看论文截图