⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
ARC: Anchored Representation Clouds for High-Resolution INR Classification
Authors:Joost Luijmes, Alexander Gielisse, Roman Knyazhitskiy, Jan van Gemert
Implicit neural representations (INRs) encode signals in neural network weights as a memory-efficient representation, decoupling sampling resolution from the associated resource costs. Current INR image classification methods are demonstrated on low-resolution data and are sensitive to image-space transformations. We attribute these issues to the global, fully-connected MLP neural network architecture encoding of current INRs, which lack mechanisms for local representation: MLPs are sensitive to absolute image location and struggle with high-frequency details. We propose ARC: Anchored Representation Clouds, a novel INR architecture that explicitly anchors latent vectors locally in image-space. By introducing spatial structure to the latent vectors, ARC captures local image data which in our testing leads to state-of-the-art implicit image classification of both low- and high-resolution images and increased robustness against image-space translation. Code can be found at https://github.com/JLuij/anchored_representation_clouds.
隐式神经表示(INR)通过神经网络权重以内存高效的方式对信号进行编码,将采样分辨率与相关的资源成本相分离。当前的INR图像分类方法已在低分辨率数据上得到验证,并且对图像空间变换很敏感。我们将这些问题归因于当前INR的全局全连接多层感知机(MLP)神经网络架构的编码方式,该架构缺乏局部表示机制:MLP对图像绝对位置很敏感,并且难以处理高频细节。我们提出了ARC(锚点表示云),这是一种新型的INR架构,它显式地在图像空间中局部锚定潜在向量。通过向潜在向量引入空间结构,ARC能够捕获局部图像数据,在我们的测试中实现了低分辨率和高分辨率图像的最新隐式图像分类,并且提高了对图像空间平移的鲁棒性。代码可在 https://github.com/JLuij/anchored_representation_clouds 找到。
论文及项目相关链接
PDF Accepted at the ICLR 2025 Workshop on Neural Network Weights as a New Data Modality
Summary
当前隐神经表示(INR)通过神经网络权重编码信号,以节省内存的方式表示信息,采样分辨率与资源成本相互独立。然而,现有INR图像分类方法在低分辨率数据上应用,并对图像空间变换敏感。这源于全局全连接多层感知机(MLP)神经网络架构的编码方式,缺乏局部表示机制。为解决这些问题,我们提出ARC(锚定表示云),一种新型INR架构,明确在图像空间中局部锚定潜在向量。通过为潜在向量引入空间结构,ARC能够捕捉局部图像数据,导致低分辨率和高分辨率图像的隐式图像分类表现领先,同时提高图像空间翻译的稳健性。有关代码,请参见https://github.com/JLuij/anchored_representation_clouds。
Key Takeaways
- 隐神经表示(INR)采用神经网络权重编码信号,实现内存高效表示,采样分辨率与资源成本分离。
- 现有INR图像分类方法主要应用在低分辨率数据上,对图像空间变换敏感。
- INR的这些问题主要源于其全局、全连接多层感知机(MLP)架构,缺乏局部表示机制。
- MLP对图像绝对位置敏感,难以处理高频细节。
- 提出的ARC(锚定表示云)是一种新型INR架构,通过局部锚定潜在向量在图像空间中显式表示。
- ARC通过引入潜在向量的空间结构,能够捕捉局部图像数据。
点此查看论文截图



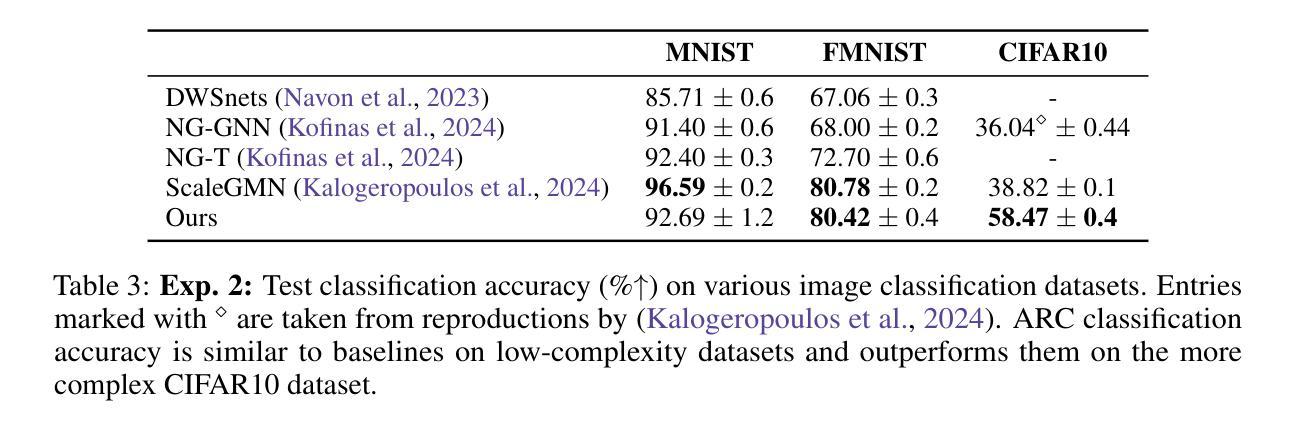
Texture-Aware StarGAN for CT data harmonisation
Authors:Francesco Di Feola, Ludovica Pompilio, Cecilia Assolito, Valerio Guarrasi, Paolo Soda
Computed Tomography (CT) plays a pivotal role in medical diagnosis; however, variability across reconstruction kernels hinders data-driven approaches, such as deep learning models, from achieving reliable and generalized performance. To this end, CT data harmonization has emerged as a promising solution to minimize such non-biological variances by standardizing data across different sources or conditions. In this context, Generative Adversarial Networks (GANs) have proved to be a powerful framework for harmonization, framing it as a style-transfer problem. However, GAN-based approaches still face limitations in capturing complex relationships within the images, which are essential for effective harmonization. In this work, we propose a novel texture-aware StarGAN for CT data harmonization, enabling one-to-many translations across different reconstruction kernels. Although the StarGAN model has been successfully applied in other domains, its potential for CT data harmonization remains unexplored. Furthermore, our approach introduces a multi-scale texture loss function that embeds texture information across different spatial and angular scales into the harmonization process, effectively addressing kernel-induced texture variations. We conducted extensive experimentation on a publicly available dataset, utilizing a total of 48667 chest CT slices from 197 patients distributed over three different reconstruction kernels, demonstrating the superiority of our method over the baseline StarGAN.
计算机断层扫描(CT)在医学诊断中起着至关重要的作用;然而,重建核心的差异阻碍了数据驱动的方法(如深度学习模型)实现可靠和通用的性能。为此,CT数据调和作为一种减少不同来源或条件下数据非生物变异的解决方案应运而生。在这种情况下,生成对抗网络(GANs)已被证明是调和的强大框架,将其视为风格转换问题。然而,基于GAN的方法在捕获图像内部复杂关系方面仍然面临局限性,这对于有效的调和至关重要。在这项工作中,我们提出了一种用于CT数据调和的新型纹理感知StarGAN,能够实现不同重建核心之间的一对多翻译。虽然StarGAN模型在其他领域已经成功应用,但其对CT数据调和的潜力尚未被探索。此外,我们的方法引入了一种多尺度纹理损失函数,该函数将不同空间和角度尺度上的纹理信息嵌入到调和过程中,有效解决由核心引起的纹理变化问题。我们在公开数据集上进行了大量实验,使用了来自197名患者的48667张胸部CT切片,这些切片分布在三种不同的重建核心上,证明了我们的方法优于基线StarGAN。
论文及项目相关链接
Summary
该文介绍了计算层析成像(CT)在医学诊断中的重要性,但由于不同重建核对数据驱动方法(如深度学习模型)的影响,存在可靠性与泛化性能的挑战。为此,CT数据调和成为一种有前途的解决方案,以标准化不同源或条件下的数据,减少非生物方差。在此背景下,生成对抗网络(GANs)已被证明是调和的强大框架,将其视为风格转移问题。然而,基于GAN的方法在捕获图像内的复杂关系方面仍存在局限性,这对于有效的调和至关重要。本研究提出了一种用于CT数据调和的新型纹理感知StarGAN,能够实现不同重建核之间的一对多翻译。尽管StarGAN模型已在其他领域成功应用,但其对CT数据调和的潜力尚未被探索。此外,我们的方法引入了一种多尺度纹理损失函数,将不同空间和角度尺度的纹理信息嵌入到调和过程中,有效解决核引起的纹理变化。
Key Takeaways
- CT在医学诊断中起关键作用,但不同重建核对数据驱动方法(如深度学习)带来挑战。
- CT数据调和是减少非生物方差的有效方法,通过标准化不同源或条件下的数据。
- GANs已被视为CT数据调和中的风格转移问题的重要工具。
- 基于GAN的方法在捕获图像内的复杂关系方面存在局限性,影响有效调和。
- 引入新型纹理感知StarGAN用于CT数据调和,实现不同重建核之间的一对多翻译。
- StarGAN在其它领域的成功应用尚未在CT数据调和中探索。
点此查看论文截图

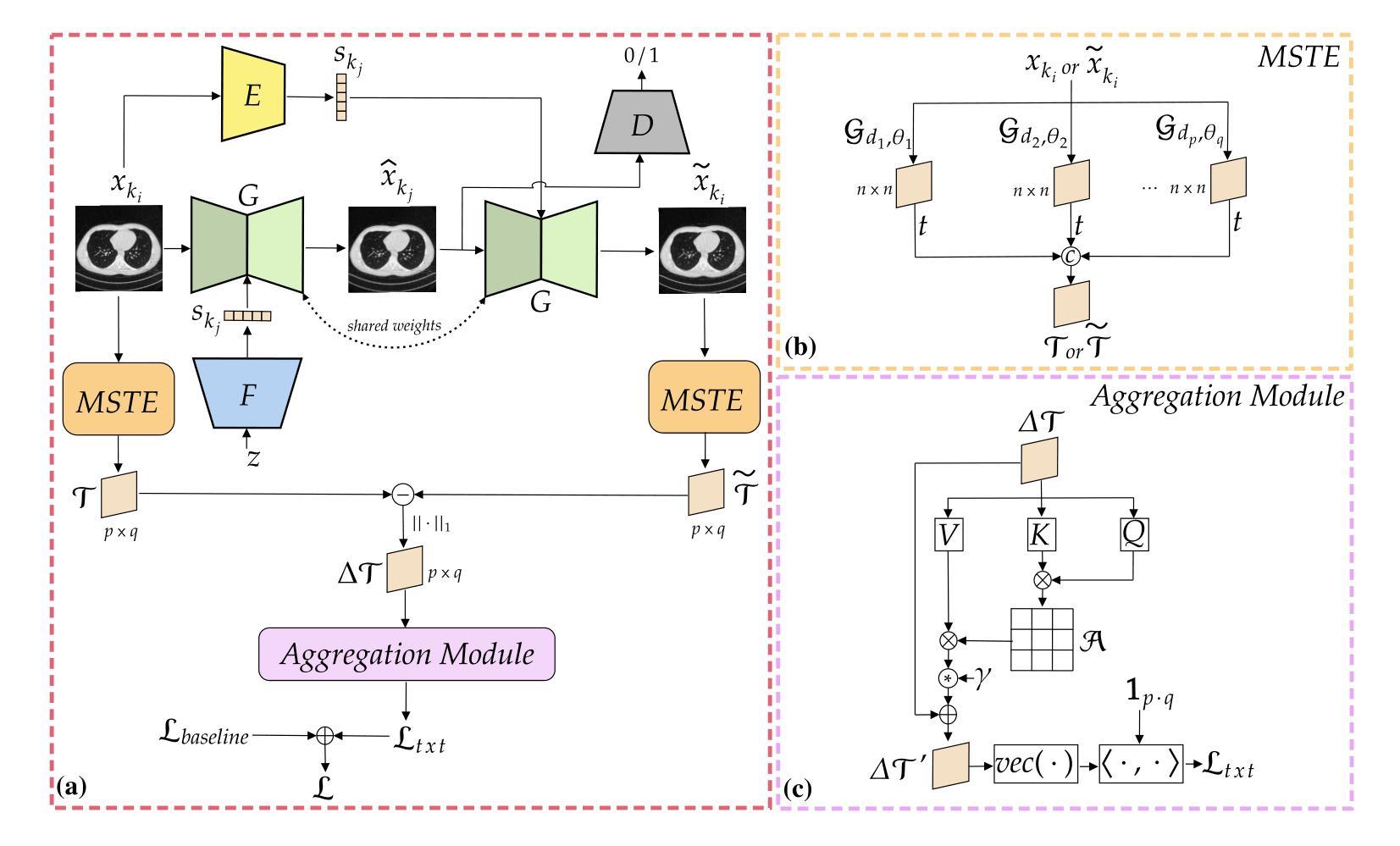
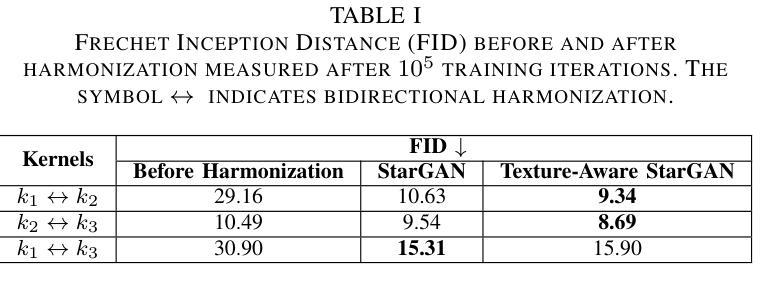
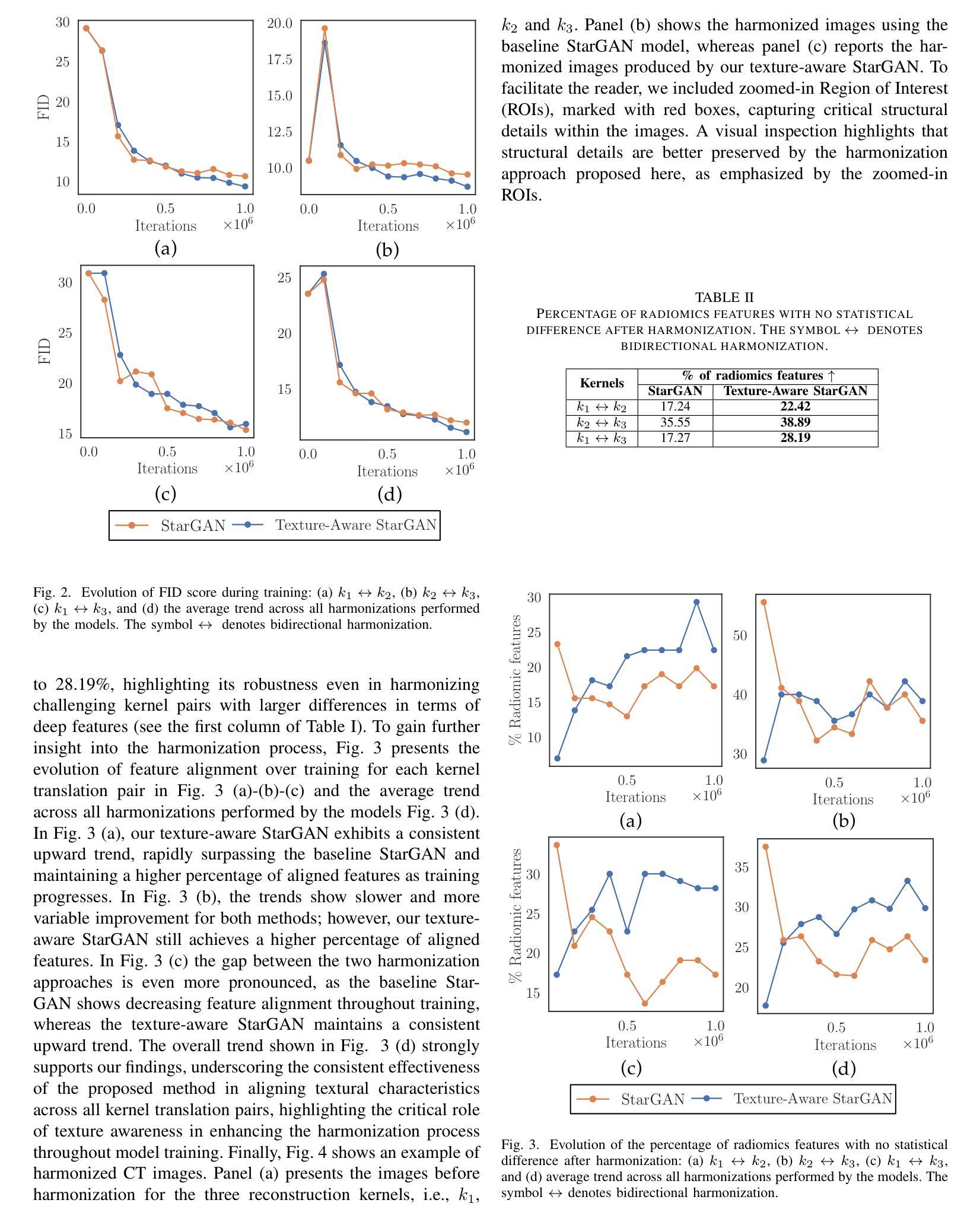
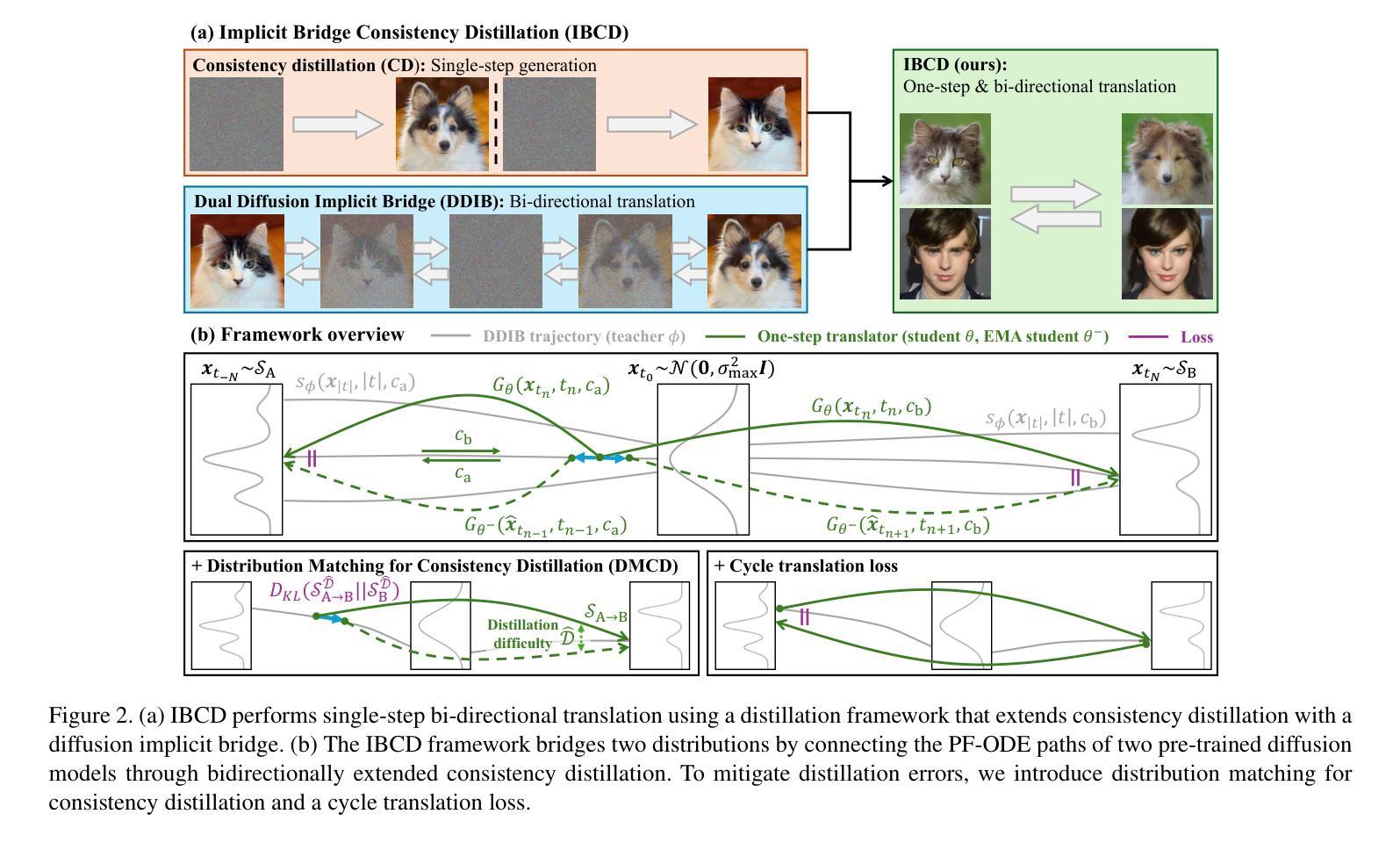
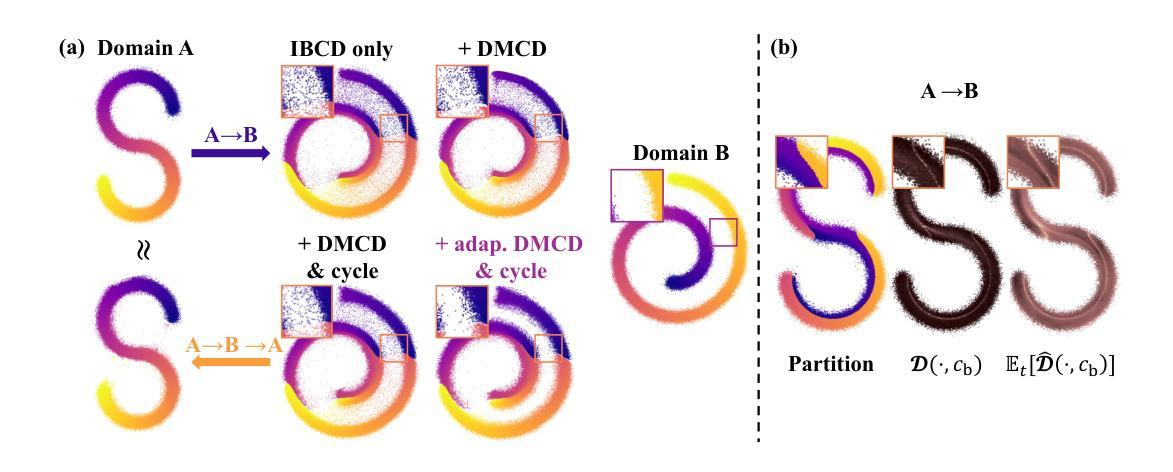
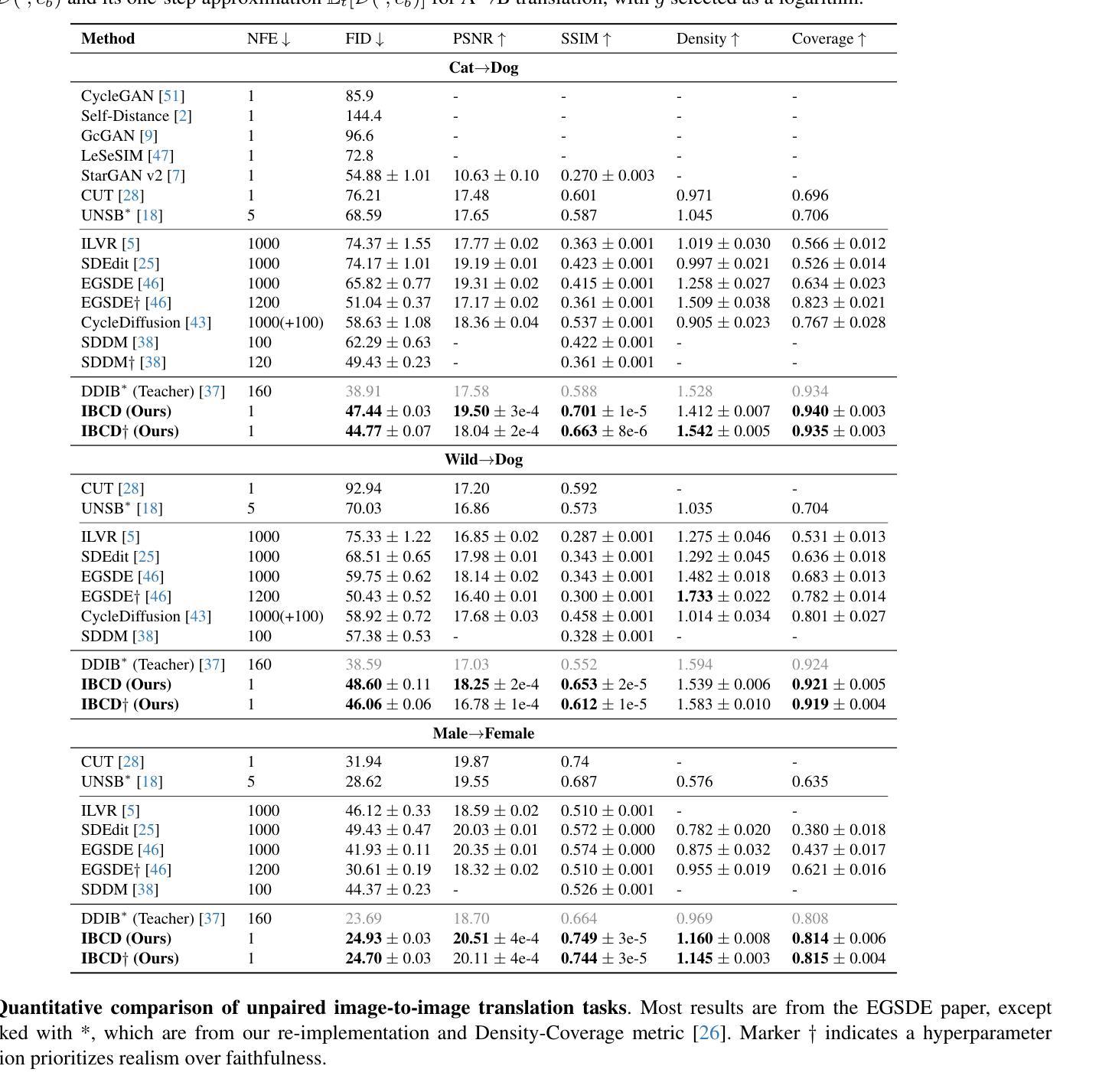
Single-Step Bidirectional Unpaired Image Translation Using Implicit Bridge Consistency Distillation
Authors:Suhyeon Lee, Kwanyoung Kim, Jong Chul Ye
Unpaired image-to-image translation has seen significant progress since the introduction of CycleGAN. However, methods based on diffusion models or Schr"odinger bridges have yet to be widely adopted in real-world applications due to their iterative sampling nature. To address this challenge, we propose a novel framework, Implicit Bridge Consistency Distillation (IBCD), which enables single-step bidirectional unpaired translation without using adversarial loss. IBCD extends consistency distillation by using a diffusion implicit bridge model that connects PF-ODE trajectories between distributions. Additionally, we introduce two key improvements: 1) distribution matching for consistency distillation and 2) adaptive weighting method based on distillation difficulty. Experimental results demonstrate that IBCD achieves state-of-the-art performance on benchmark datasets in a single generation step. Project page available at https://hyn2028.github.io/project_page/IBCD/index.html
非配对图像到图像的翻译在CycleGAN引入后取得了显著的进步。然而,基于扩散模型或Schrödinger桥梁的方法由于其迭代采样的特性,尚未在真实世界应用中广泛采用。为了应对这一挑战,我们提出了一种新的框架,即隐式桥梁一致性蒸馏(IBCD),它能够实现不使用对抗性损失的单步双向非配对翻译。IBCD通过利用连接分布之间PF-ODE轨迹的扩散隐式桥梁模型,扩展了一致性蒸馏。此外,我们还引入了两种关键改进:1)用于一致性蒸馏的分布匹配;2)基于蒸馏难度的自适应加权方法。实验结果表明,IBCD在基准数据集上实现了单次生成步骤的最佳性能。项目页面可在https://hyn2028.github.io/project_page/IBCD/index.html找到。
论文及项目相关链接
PDF 25 pages, 16 figures
Summary
本文介绍了针对未配对的图像到图像翻译任务的新型框架Implicit Bridge Consistency Distillation(IBCD)。该框架实现了无需使用对抗性损失的单步双向未配对翻译,通过扩散隐桥模型连接PF-ODE轨迹实现分布间的一致性蒸馏。实验结果表明,IBCD在基准数据集上实现了单步生成的最佳性能。
Key Takeaways
- IBCD框架实现了未配对的图像到图像翻译的单步双向转换,克服了基于迭代采样的方法如扩散模型或Schrödinger桥的局限性。
- IBCD利用扩散隐桥模型连接分布间的PF-ODE轨迹,进行一致性蒸馏。
- 引入分布匹配进行一致性蒸馏,提高了模型性能。
- 提出了基于蒸馏难度的自适应加权方法,进一步优化模型。
- 实验结果表明,IBCD在基准数据集上实现了单步生成的最佳性能。
- 该框架有助于推动未配对图像翻译在现实世界应用中的广泛使用。
点此查看论文截图


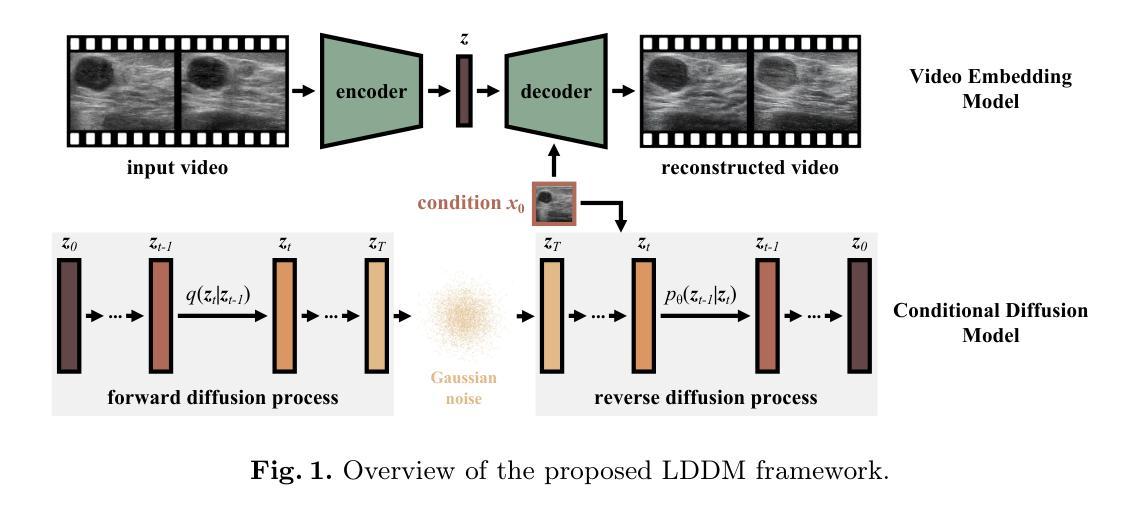
Ultrasound Image-to-Video Synthesis via Latent Dynamic Diffusion Models
Authors:Tingxiu Chen, Yilei Shi, Zixuan Zheng, Bingcong Yan, Jingliang Hu, Xiao Xiang Zhu, Lichao Mou
Ultrasound video classification enables automated diagnosis and has emerged as an important research area. However, publicly available ultrasound video datasets remain scarce, hindering progress in developing effective video classification models. We propose addressing this shortage by synthesizing plausible ultrasound videos from readily available, abundant ultrasound images. To this end, we introduce a latent dynamic diffusion model (LDDM) to efficiently translate static images to dynamic sequences with realistic video characteristics. We demonstrate strong quantitative results and visually appealing synthesized videos on the BUSV benchmark. Notably, training video classification models on combinations of real and LDDM-synthesized videos substantially improves performance over using real data alone, indicating our method successfully emulates dynamics critical for discrimination. Our image-to-video approach provides an effective data augmentation solution to advance ultrasound video analysis. Code is available at https://github.com/MedAITech/U_I2V.
超声波视频分类能够实现自动化诊断,已成为一个重要研究领域。然而,公共可用的超声波视频数据集仍然稀缺,阻碍了开发有效视频分类模型的进展。我们提出通过合成合理的超声波视频来解决这一短缺问题,这些视频由易于获取且丰富的超声波图像合成而来。为此,我们引入了一种潜在动态扩散模型(LDDM),以有效地将静态图像转换为具有真实视频特性的动态序列。我们在BUSV基准测试上展示了强大的定量结果和视觉吸引人的合成视频。值得注意的是,使用真实和LDDM合成视频组合来训练视频分类模型,其性能较仅使用真实数据有大幅提高,这表明我们的方法在模拟对鉴别至关重要的动态效果方面非常成功。我们的图像到视频的方法为推进超声波视频分析提供了有效的数据增强解决方案。代码可通过https://github.com/MedAITech/U_I2V获取。
论文及项目相关链接
PDF MICCAI 2024
Summary
该文针对超声视频分类难题展开研究,由于公开可用的超声视频数据集稀缺,限制了有效视频分类模型的发展。为此,提出通过合成合理的超声视频来弥补这一不足,利用现有丰富的超声图像进行合成。研究团队引入了一种潜在动态扩散模型(LDDM),成功将静态图像转化为具有真实视频特性的动态序列。在BUSV基准测试上,合成的视频不仅在数量上表现出色,视觉效果也令人满意。此外,结合真实视频与LDDM合成的视频训练出的视频分类模型性能显著提升,表明该方法成功模拟了关键动态特征。该研究提供了一种有效的数据增强解决方案,推动了超声视频分析的发展。
Key Takeaways
- 超声视频分类在自动化诊断中的重要作用以及公开可用数据集稀缺的问题。
- 提出通过合成超声视频来弥补数据集不足的方法。
- 引入潜在动态扩散模型(LDDM)成功将静态图像转化为动态序列。
- 在BUSV基准测试上,合成的视频表现出色。
- 结合真实与合成视频训练的模型性能显著提升。
- LDDM方法成功模拟了关键动态特征,对超声视频分析有推动作用。
点此查看论文截图