⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
SPADE: Systematic Prompt Framework for Automated Dialogue Expansion in Machine-Generated Text Detection
Authors:Haoyi Li, Angela Yifei Yuan, Soyeon Caren Han, Christopher Leckie
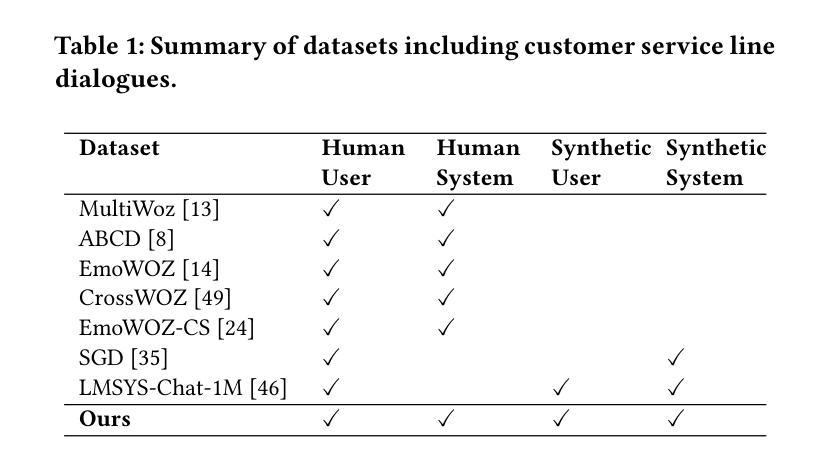
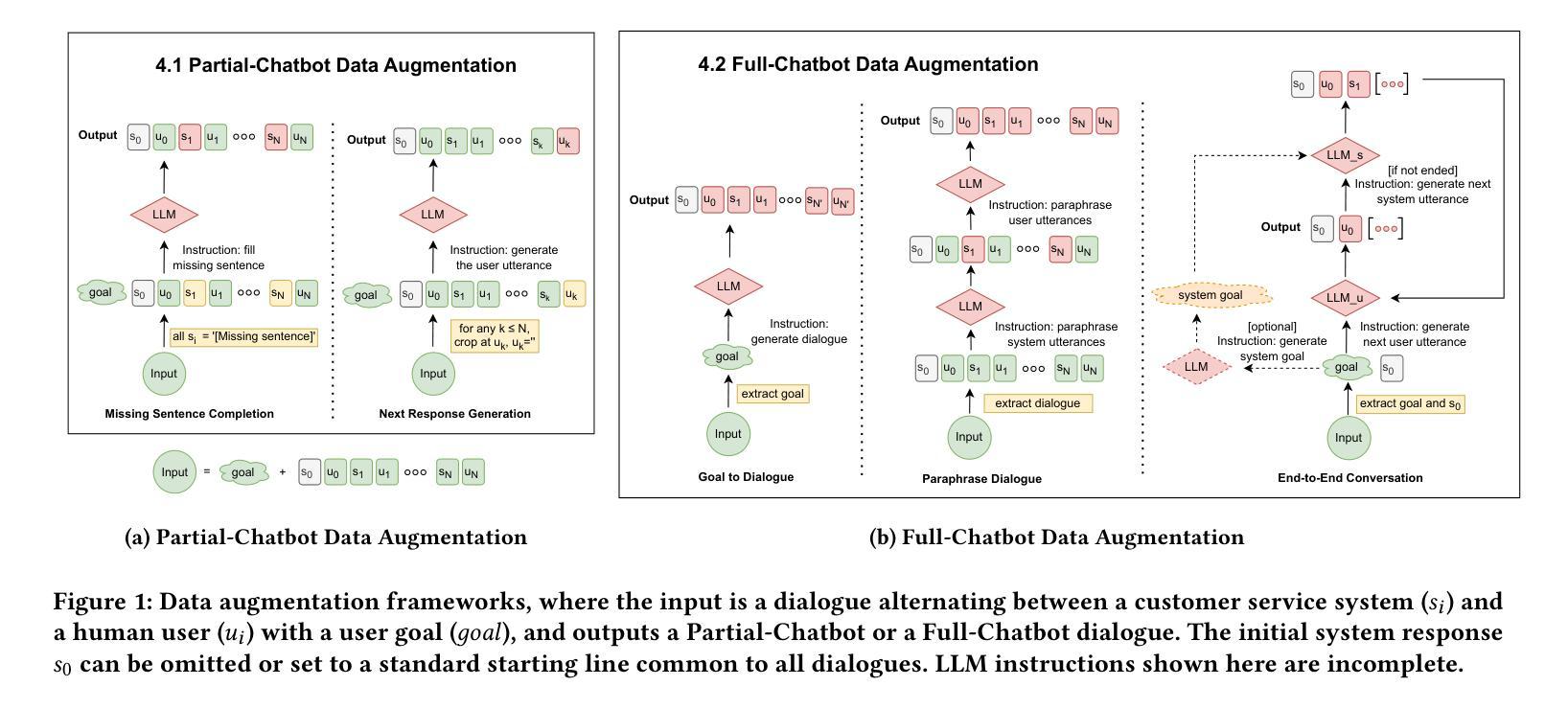
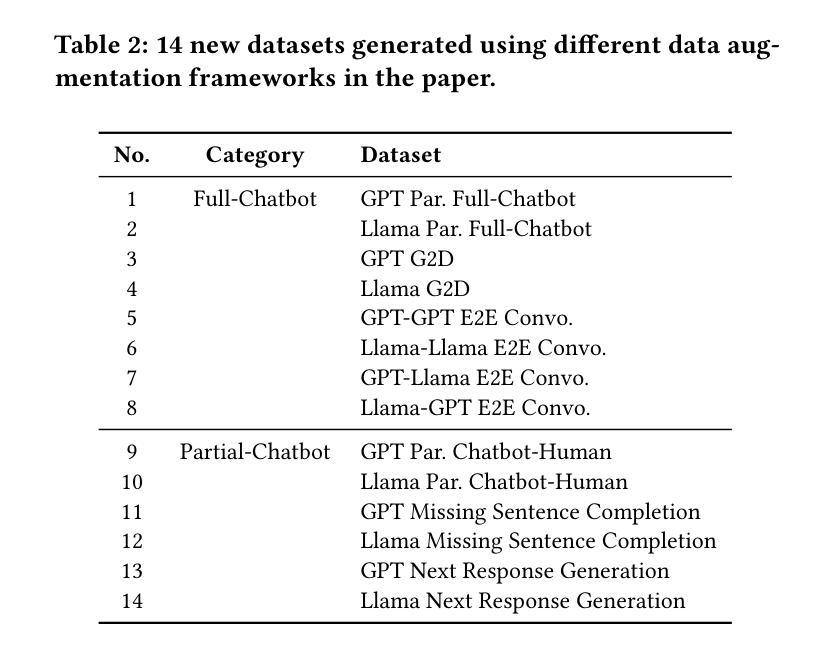
The increasing capability of large language models (LLMs) to generate synthetic content has heightened concerns about their misuse, driving the development of Machine-Generated Text (MGT) detection models. However, these detectors face significant challenges due to the lack of systematically generated, high-quality datasets for training. To address this issue, we propose five novel data augmentation frameworks for synthetic user dialogue generation through a structured prompting approach, reducing the costs associated with traditional data collection methods. Our proposed method yields 14 new dialogue datasets, which we benchmark against seven MGT detection models. The results demonstrate improved generalization performance when utilizing a mixed dataset produced by our proposed augmentation framework. Furthermore, considering that real-world agents lack knowledge of future opponent utterances, we simulate online dialogue detection and examine the relationship between chat history length and detection accuracy. We also benchmark online detection performance with limited chat history on our frameworks. Our open-source datasets can be downloaded from https://github.com/AngieYYF/SPADE-customer-service-dialogue.
大型语言模型(LLM)生成合成内容的能力不断增强,这加剧了关于其误用的担忧,从而推动了机器生成文本(MGT)检测模型的发展。然而,由于缺乏系统生成的高质量数据集进行训练,这些检测器面临着巨大的挑战。为了解决这个问题,我们提出了五种新型数据增强框架,通过结构化提示方法进行合成用户对话生成,降低了与传统数据收集方法相关的成本。我们提出的方法产生了14个新的对话数据集,我们对这些数据集与七种MGT检测模型进行了基准测试。结果表明,在利用我们提出的数据增强框架生成的混合数据集时,泛化性能得到了提高。此外,考虑到现实世界的代理不知道未来对手的话语,我们模拟在线对话检测,并研究对话历史长度与检测准确性之间的关系。我们还就在我们框架上进行的有限对话历史的在线检测性能进行了基准测试。我们的开源数据集可从https://github.com/AngieYYF/SPADE-customer-service-dialogue下载。
论文及项目相关链接
PDF 9 pages
Summary
大型语言模型(LLMs)生成合成内容的能力提升,引发对其滥用的担忧,推动了机器生成文本(MGT)检测模型的发展。然而,由于缺乏系统生成的高质量数据集进行训练,这些检测器面临重大挑战。为解决此问题,我们提出五种新型数据增强框架,通过结构化提示方法合成用户对话,降低传统数据收集方法的成本。我们的方法产生14个新对话数据集,与七个MGT检测模型进行基准测试,结果显示使用我们提出的数据增强框架产生的混合数据集可提升泛化性能。此外,我们模拟在线对话检测,并探讨对话历史长度与检测准确率的关系,同时在我们框架上评估在线检测性能。我们的开源数据集可从此链接下载:https://github.com/AngieYYF/SPADE-customer-service-dialogue。
Key Takeaways
- 大型语言模型生成合成内容的能力提升,引发对滥用的担忧,需发展机器生成文本检测模型。
- 当前检测器面临缺乏高质量数据集的挑战。
- 提出五种数据增强框架,通过结构化提示方法合成用户对话,降低数据收集成本。
- 产生14个新对话数据集,与现有模型进行基准测试,显示使用增强框架的混合数据集能提高泛化性能。
- 模拟在线对话检测,探讨对话历史长度与检测准确率的关系。
- 在框架上评估在线检测性能。
点此查看论文截图

Dial-In LLM: Human-Aligned LLM-in-the-loop Intent Clustering for Customer Service Dialogues
Authors:Mengze Hong, Di Jiang, Yuanfeng Song, Lu Wang, Wailing Ng, Yanjie Sun, Chen Jason Zhang, Qing Li
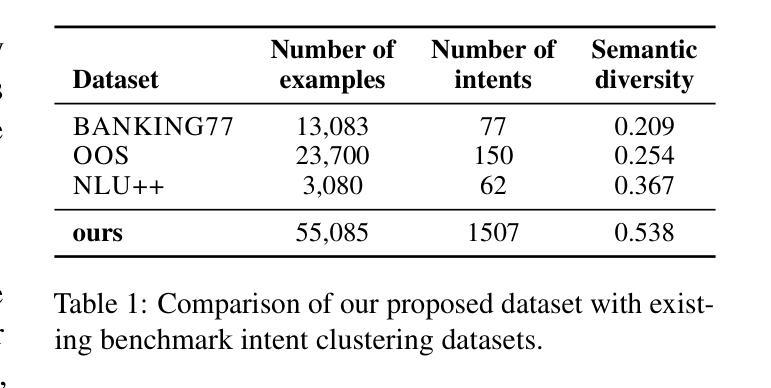
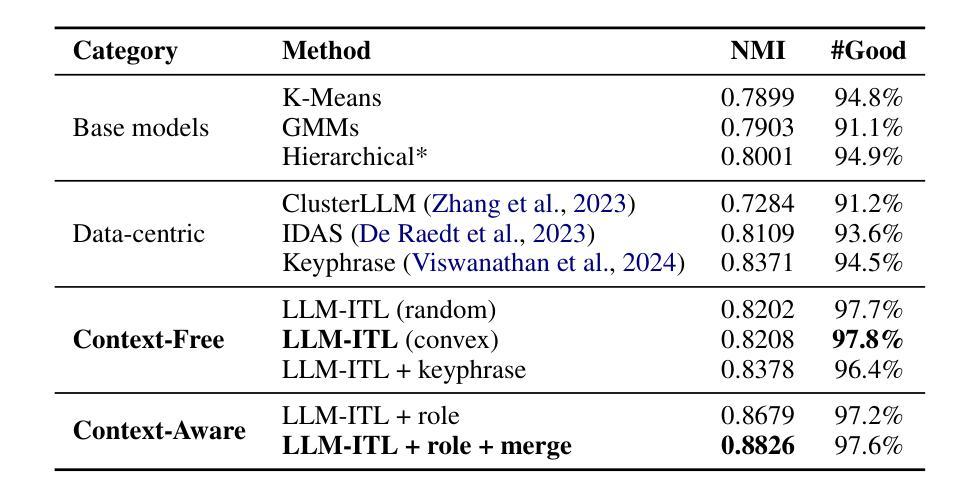
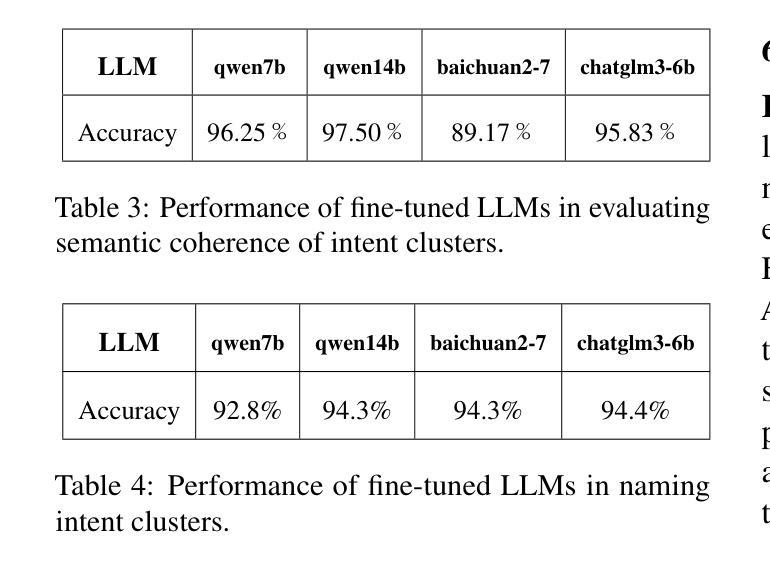
Discovering customer intentions in dialogue conversations is crucial for automated service agents. Yet, existing intent clustering methods often fail to align with human perceptions due to the heavy reliance on embedding distance metrics and sentence embeddings. To address these limitations, we propose integrating the semantic understanding capabilities of LLMs into an $\textbf{LLM-in-the-loop (LLM-ITL)}$ intent clustering framework. Specifically, this paper (1) investigates the effectiveness of fine-tuned LLMs in semantic coherence evaluation and intent cluster naming, achieving over 95% accuracy; (2) designs an LLM-ITL clustering algorithm that facilitates the iterative discovery of coherent intent clusters; and (3) proposes task-specific techniques tailored for customer service dialogue intent clustering. Since existing English benchmarks pose limited semantic diversity and intent labels, we introduced a comprehensive Chinese dialogue intent dataset, comprising over 100,000 real customer service calls and 1,507 human-annotated intent clusters. The proposed approaches significantly outperformed LLM-guided baselines, achieving notable improvements in clustering quality and a 12% boost in the downstream intent classification task. Combined with several best practices, our findings highlight the potential of LLM-in-the-loop techniques for scalable and human-aligned problem-solving. Sample code and datasets are available at: https://anonymous.4open.science/r/Dial-in-LLM-0410.
发现对话中的客户意图对于自动化服务代理至关重要。然而,现有的意图聚类方法由于过于依赖嵌入距离指标和句子嵌入,往往无法与人类感知相匹配。为了解决这些局限性,我们提出了将大型语言模型的语义理解能力集成到LLM-in-the-loop(LLM-ITL)意图聚类框架中。具体来说,本文(1)研究了微调大型语言模型在语义连贯性评估和意图聚类命名中的有效性,准确率超过95%;(2)设计了一种LLM-ITL聚类算法,便于发现连贯的意图聚类;(3)提出了针对客户服务对话意图聚类的任务特定技术。由于现有英语基准测试提供的语义多样性和意图标签有限,我们引入了一个全面的中文对话意图数据集,包含超过10万个真实的客户服务电话和1507个人工标注的意图聚类。所提出的方法显著优于LLM指导的基线方法,在聚类质量和下游意图分类任务上分别取得了显著的改进和提升12%。结合若干最佳实践,我们的研究突出了LLM-in-the-loop技术在可扩展性和人类对齐问题解决方面的潜力。相关样本代码和数据集可通过https://anonymous.4open.science/r/Dial-in-LLM-0410访问。
论文及项目相关链接
Summary
基于对话中客户意图的重要性,当前意图聚类方法存在与人类感知不一致的问题。本研究提出了一个集成大型语言模型(LLM)的LLM-in-the-loop(LLM-ITL)意图聚类框架来解决这些问题。研究内容包括:(1)利用精细训练的大型语言模型在语义连贯性评估和意图聚类命名方面的有效性,准确率超过95%;(2)设计了一种LLM-ITL聚类算法,促进连贯意图聚类的迭代发现;(3)针对客户服务对话意图聚类提出了任务特定技术。此外,还引入了一个包含超过10万条真实客户服务呼叫和1507个人类注释意图聚类的综合性中文对话意图数据集。与大型语言模型引导的基础方法相比,所提出的方法在聚类质量和下游意图分类任务上都有显著提高。
Key Takeaways
- 对话中客户意图的发现对于自动化服务代理至关重要。
- 现有意图聚类方法因过度依赖嵌入距离指标和句子嵌入而经常无法与人类感知对齐。
- LLM-in-the-loop(LLM-ITL)意图聚类框架被提出以解决这个问题,整合大型语言模型的语义理解功能。
- 精细训练的大型语言模型在语义连贯性评估和意图聚类命名方面表现出超过95%的准确性。
- 设计了LLM-ITL聚类算法,便于发现连贯的意图聚类。
- 为客户服务对话意图聚类定制了任务特定技术。
点此查看论文截图