⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Authors:Yifei Zhou, Song Jiang, Yuandong Tian, Jason Weston, Sergey Levine, Sainbayar Sukhbaatar, Xian Li
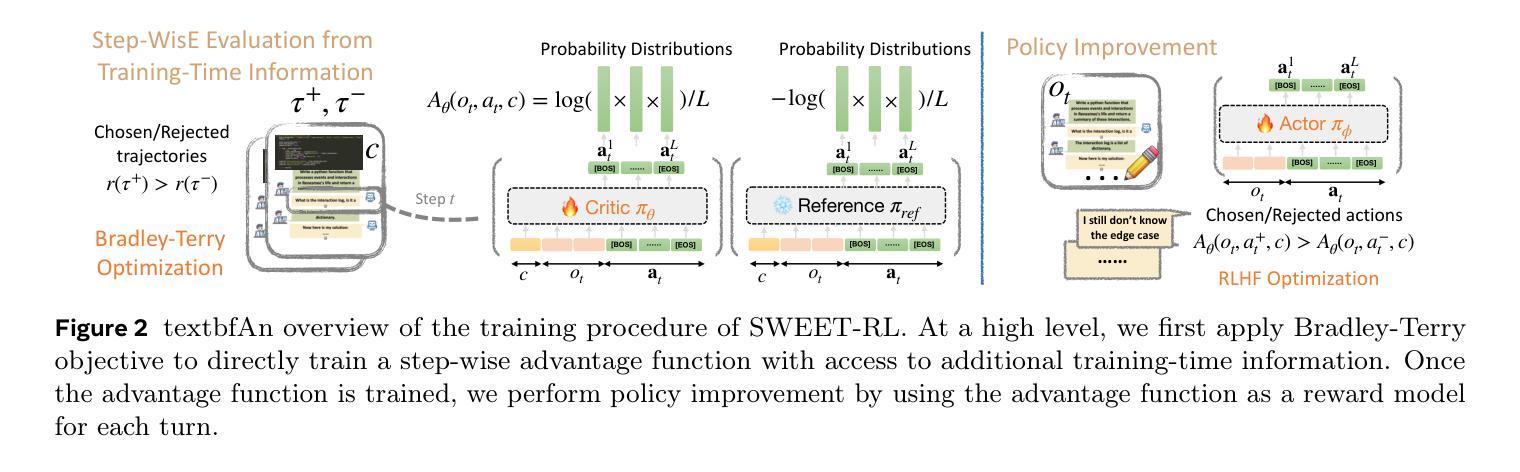
Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
大型语言模型(LLM)代理需要在现实世界的任务中进行多轮交互。然而,现有的针对LLM代理优化的多轮强化学习算法未能充分利用LLM的通用能力,并在多轮交互中有效地进行信用分配,如何开发此类算法仍不明确。为了研究这个问题,我们首先引入了一个新的基准测试ColBench,在这个测试中,LLM代理与人类的合作者进行多轮交互,以解决后端编程和前端设计等现实任务。基于这个基准测试,我们提出了一种新的强化学习算法SWEET-RL(带有训练时信息的一步明智评价强化学习),它使用一个精心设计的优化目标来训练一个具有额外训练时信息访问权限的评论家模型。评论家为改善策略模型提供步骤级别的奖励。我们的实验表明,与其他最先进的多轮强化学习算法相比,SWEET-RL在ColBench上的成功率和胜率提高了6%的绝对值,这使得Llama 3.1-8B能够在现实协作内容创建中匹配或超越GPT4-o的性能。
论文及项目相关链接
PDF 29 pages, 16 figures
Summary
大型语言模型(LLM)在多回合交互中的性能提升是一个重要课题。针对现有算法在多回合强化学习(RL)中对LLM的信用分配不够有效的问题,本文引入了一个新的基准测试ColBench。在此基础上,提出了一种新的RL算法SWEET-RL,该算法利用精心设计的优化目标训练了一个评论家模型,可以在训练阶段获得额外信息。评论家模型提供步骤级的奖励来改进策略模型。实验表明,与其他先进的多回合RL算法相比,SWEET-RL在ColBench上的成功率提高了6%,实现了高效的现实任务协作解决。这对于如Llama 3.1-8B这样的语言模型在协同创作任务中超越GPT4-o的性能具有重要意义。
Key Takeaways
- LLM在多回合交互中的性能提升是研究的重点。
- 当前的多回合RL算法在优化LLM时存在信用分配问题。
- 引入新的基准测试ColBench,用于模拟LLM与人类的协作任务。
- 提出新的RL算法SWEET-RL,通过训练评论家模型实现更有效的信用分配。
- 评论者模型在训练过程中能够获取额外的信息,为策略模型提供步骤级别的奖励反馈。
- 实验显示,SWEET-RL相较于其他多回合RL算法在ColBench上有显著提升。
- SWEET-RL成功让Llam3.a达到甚至超越GPT 4在多回合协同任务中的性能表现。
点此查看论文截图

Visual Position Prompt for MLLM based Visual Grounding
Authors:Wei Tang, Yanpeng Sun, Qinying Gu, Zechao Li
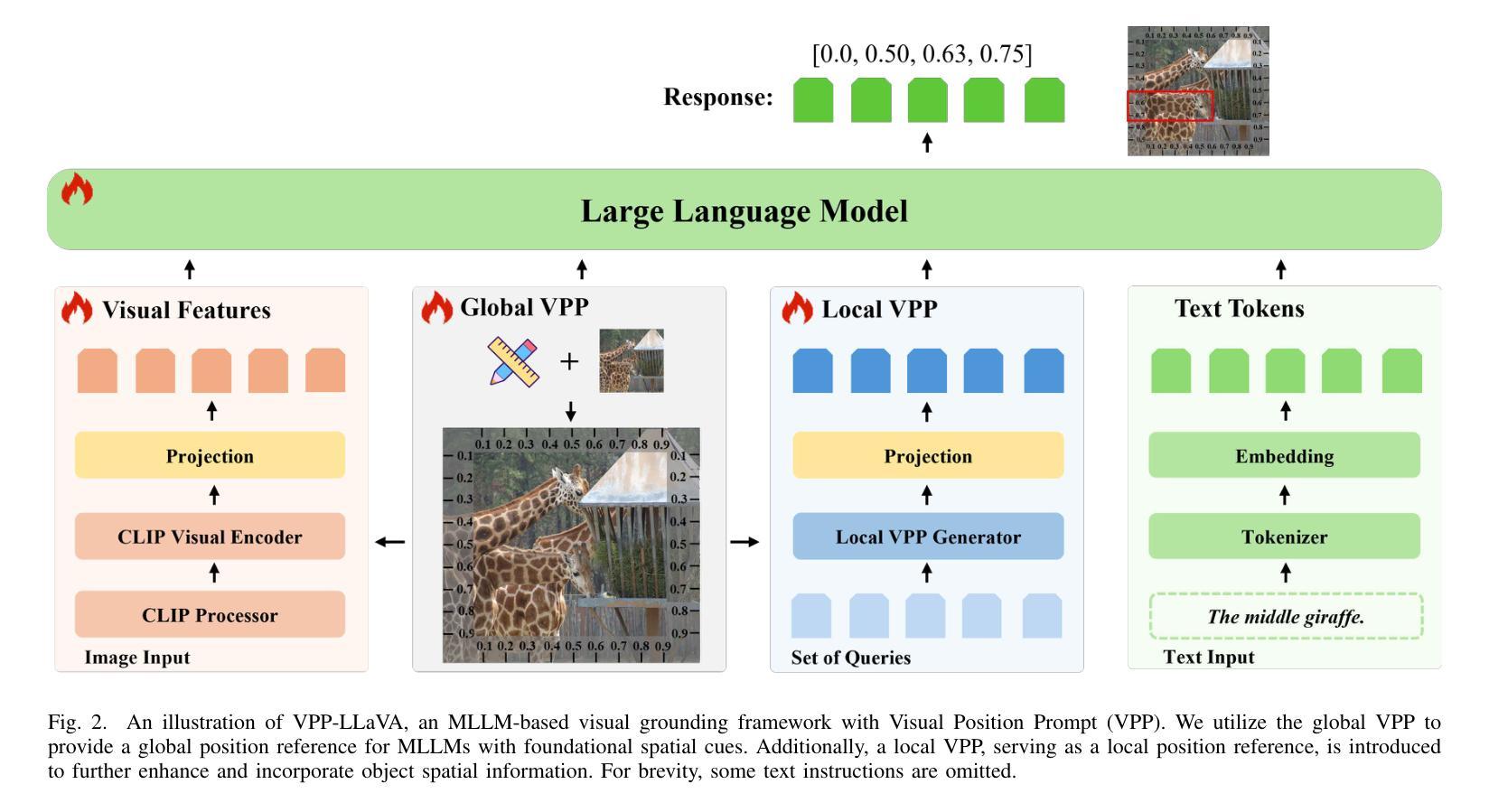
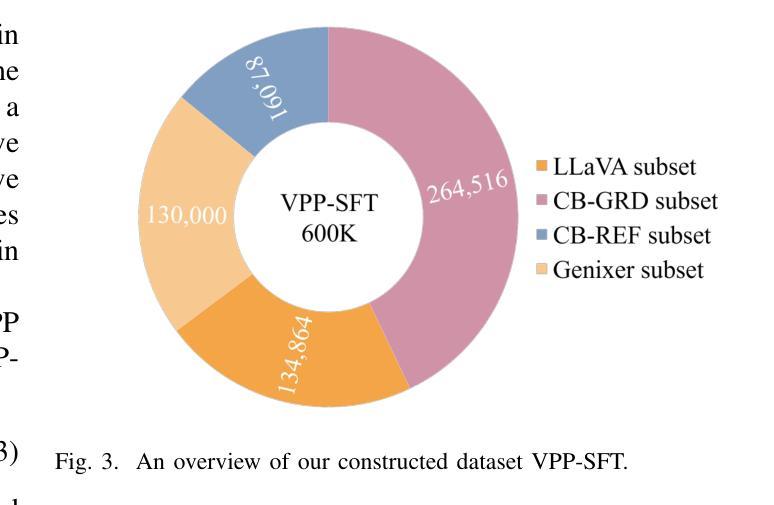
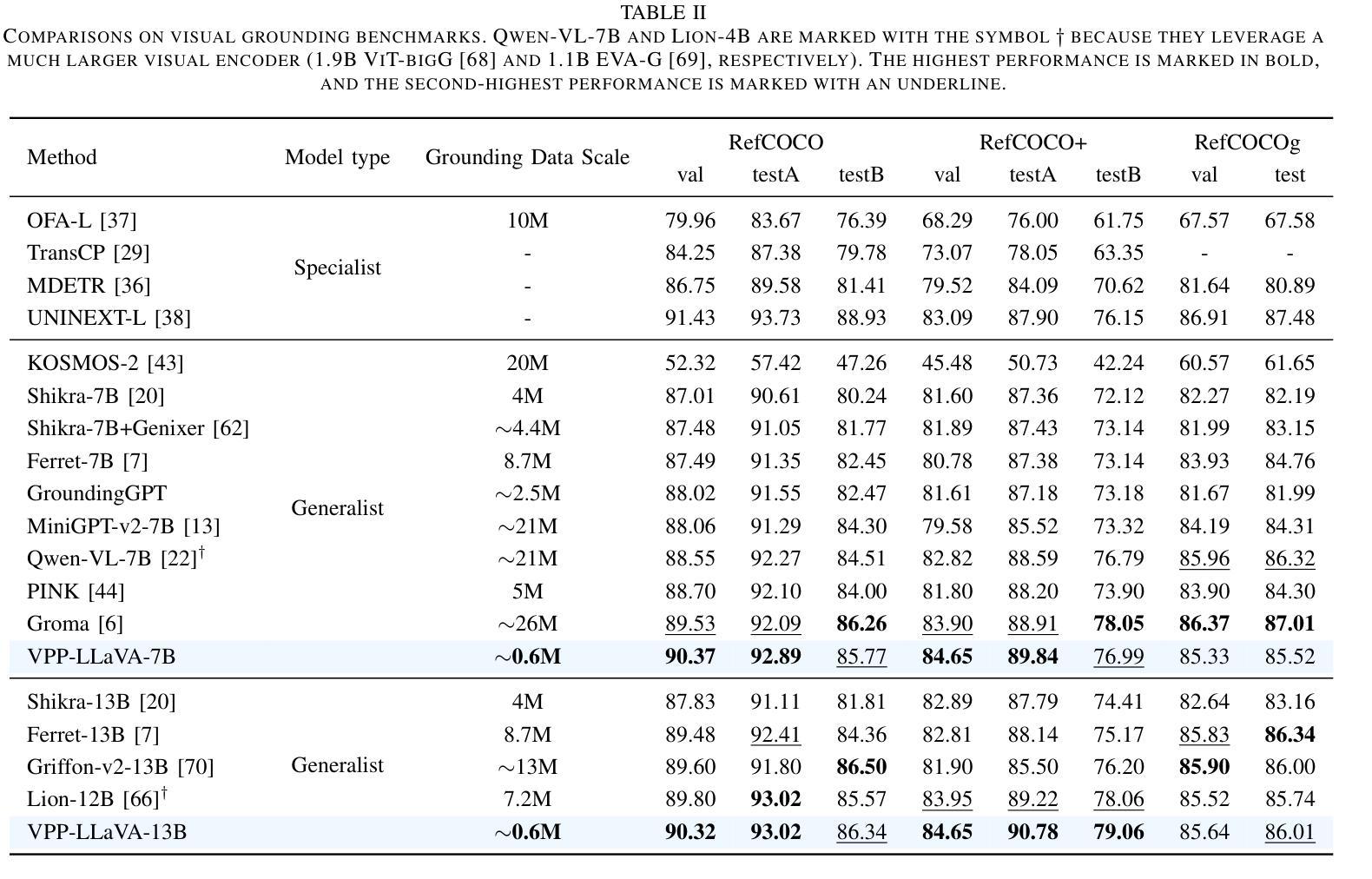
Although Multimodal Large Language Models (MLLMs) excel at various image-related tasks, they encounter challenges in precisely aligning coordinates with spatial information within images, particularly in position-aware tasks such as visual grounding. This limitation arises from two key factors. First, MLLMs lack explicit spatial references, making it difficult to associate textual descriptions with precise image locations. Second, their feature extraction processes prioritize global context over fine-grained spatial details, leading to weak localization capability. To address this issue, we introduce VPP-LLaVA, an MLLM equipped with Visual Position Prompt (VPP) to improve its grounding capability. VPP-LLaVA integrates two complementary mechanisms. The global VPP overlays learnable, axis-like embeddings onto the input image to provide structured spatial cues. The local VPP focuses on fine-grained localization by incorporating position-aware queries, which suggests probable object locations. We also introduce a VPP-SFT dataset with 0.6M samples, consolidating high-quality visual grounding data into a compact format for efficient model training. Training on this dataset with VPP enhances the model’s performance, achieving state-of-the-art results on standard grounding benchmarks despite using fewer training samples compared to other MLLMs like MiniGPT-v2, which rely on much larger datasets ($\sim$21M samples). The code and VPP-SFT dataset will be available at https://github.com/WayneTomas/VPP-LLaVA upon acceptance.
尽管多模态大型语言模型(MLLMs)在各种图像相关任务上表现出色,但在与图像内空间信息的坐标精确对齐方面却面临挑战,特别是在位置感知任务(如视觉定位)中。这一限制源于两个关键因素。首先,MLLMs缺乏明确的空间参考,这使得将文本描述与精确图像位置相关联变得困难。其次,它们的特征提取过程更侧重于全局上下文而非精细的空间细节,导致定位能力较弱。为了解决这个问题,我们引入了VPP-LLaVA,这是一种配备视觉位置提示(VPP)的MLLM,以提高其定位能力。VPP-LLaVA集成了两种互补机制。全局VPP将可学习的、类似轴状的嵌入叠加在输入图像上,以提供结构化的空间线索。局部VPP则通过引入位置感知查询来关注精细定位,这可以指出可能的对象位置。我们还引入了包含60万样本的VPP-SFT数据集,将高质量视觉定位数据整合为紧凑格式,以便进行高效的模型训练。使用该数据集和VPP进行训练提高了模型的性能,在标准定位基准测试上取得了最新结果,尽管与其他MLLM(如依赖大量数据集(约2100万样本)的MiniGPT-v2)相比,使用的训练样本数量较少。代码和VPP-SFT数据集经审核通过后,将在https://github.com/WayneTomas/VPP-LLaVA上提供。
论文及项目相关链接
Summary
本文主要介绍了多模态大型语言模型(MLLMs)在处理图像相关任务时的挑战,特别是在位置感知任务(如视觉定位)中精确对齐坐标与空间信息的问题。为解决此问题,引入了VPP-LLaVA模型,该模型配备了视觉位置提示(VPP)以提高其定位能力。VPP-LLaVA通过全局VPP和局部VPP两种互补机制来改进模型的空间感知能力。同时,还引入了VPP-SFT数据集进行模型训练,并在标准定位基准测试上取得了最先进的成果。
Key Takeaways
- MLLMs在处理图像相关任务时面临精确对齐坐标与空间信息的挑战,特别是在位置感知任务中。
- MLLMs缺乏明确的空间参考,难以将文本描述与精确图像位置相关联。
- MLLMs的特征提取过程注重全局上下文而忽略细微的空间细节,导致定位能力较弱。
- VPP-LLaVA模型通过集成Visual Position Prompt(VPP)来提高MLLMs的定位能力。
- VPP-LLaVA包含全局VPP和局部VPP两种互补机制,分别提供结构化空间线索和精细定位。
- 引入的VPP-SFT数据集用于高效模型训练,提高了模型性能。
- VPP-LLaVA在标准定位基准测试上取得了最先进的成果,且使用较少的训练样本。
点此查看论文截图

Improving Adversarial Transferability on Vision Transformers via Forward Propagation Refinement
Authors:Yuchen Ren, Zhengyu Zhao, Chenhao Lin, Bo Yang, Lu Zhou, Zhe Liu, Chao Shen
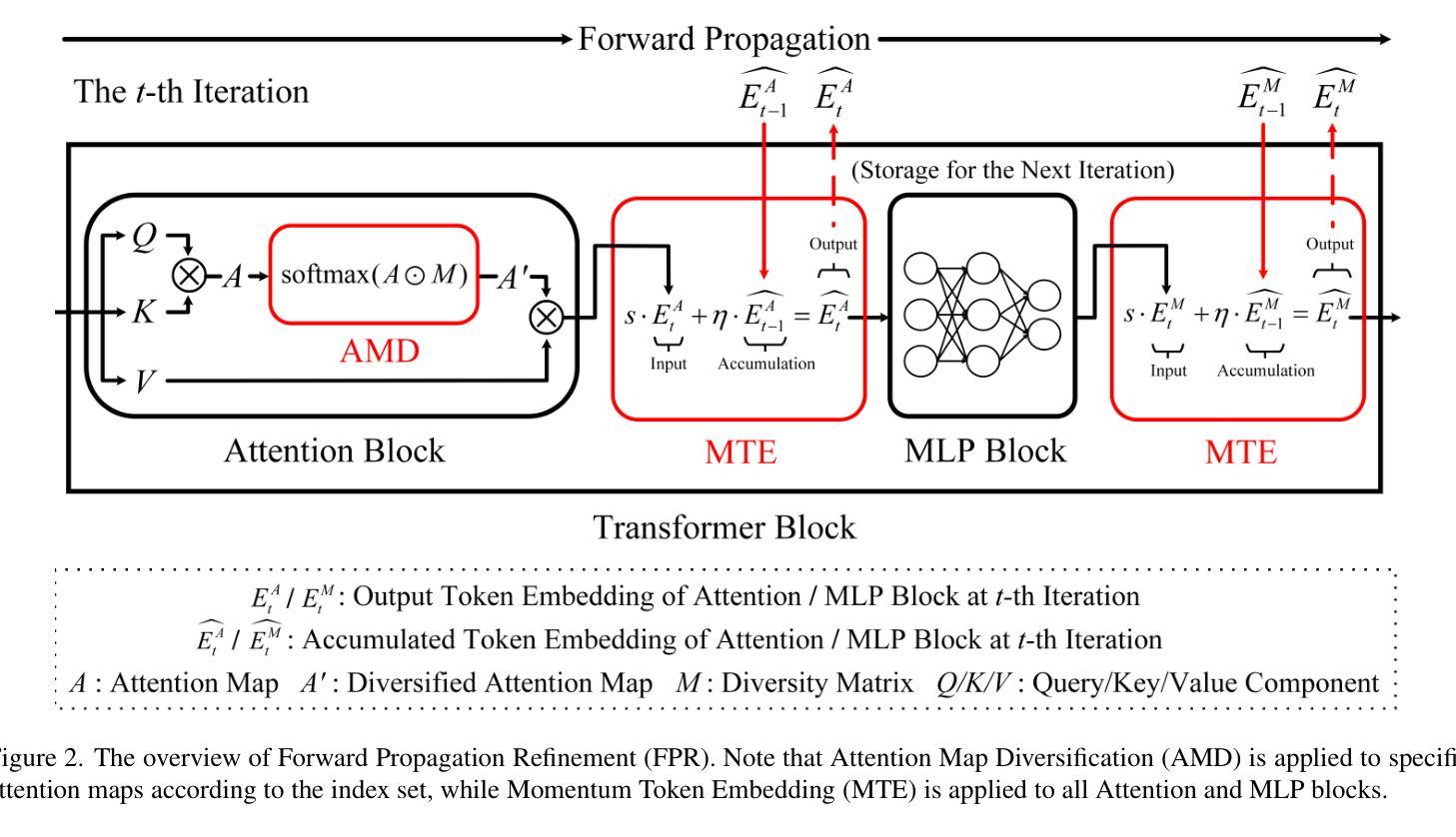
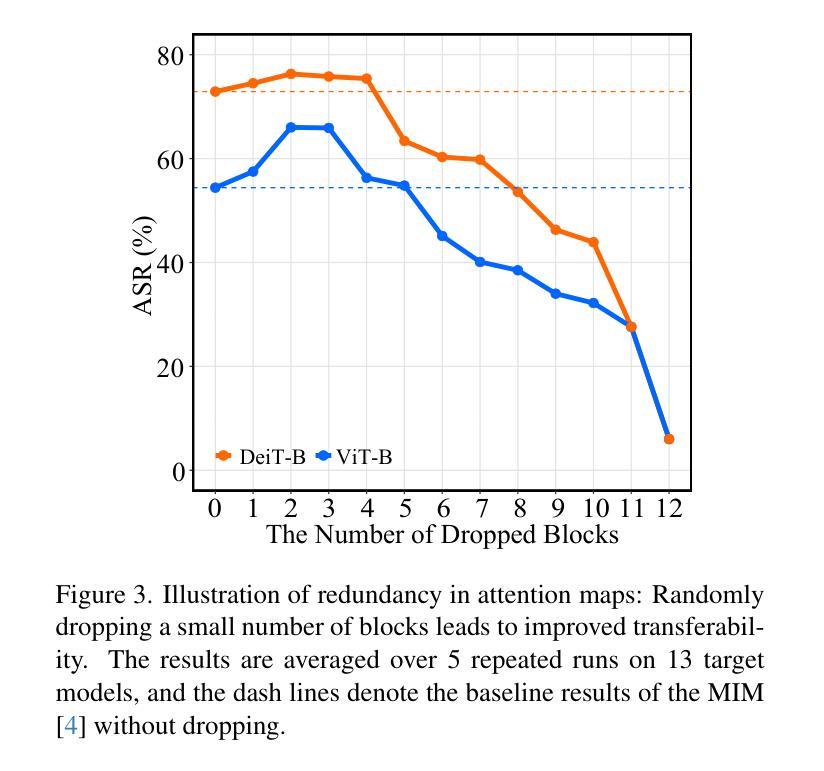
Vision Transformers (ViTs) have been widely applied in various computer vision and vision-language tasks. To gain insights into their robustness in practical scenarios, transferable adversarial examples on ViTs have been extensively studied. A typical approach to improving adversarial transferability is by refining the surrogate model. However, existing work on ViTs has restricted their surrogate refinement to backward propagation. In this work, we instead focus on Forward Propagation Refinement (FPR) and specifically refine two key modules of ViTs: attention maps and token embeddings. For attention maps, we propose Attention Map Diversification (AMD), which diversifies certain attention maps and also implicitly imposes beneficial gradient vanishing during backward propagation. For token embeddings, we propose Momentum Token Embedding (MTE), which accumulates historical token embeddings to stabilize the forward updates in both the Attention and MLP blocks. We conduct extensive experiments with adversarial examples transferred from ViTs to various CNNs and ViTs, demonstrating that our FPR outperforms the current best (backward) surrogate refinement by up to 7.0% on average. We also validate its superiority against popular defenses and its compatibility with other transfer methods. Codes and appendix are available at https://github.com/RYC-98/FPR.
视觉Transformer(ViTs)已广泛应用于各种计算机视觉和视觉语言任务。为了深入了解其在实际场景中的稳健性,ViTs上的可转移对抗样本已被广泛研究。提高对抗可转移性的典型方法是通过改进替代模型。然而,关于ViTs的现有工作将其替代优化限制在反向传播中。在这项工作中,我们专注于正向传播细化(FPR),并特别改进ViTs的两个关键模块:注意力图和令牌嵌入。对于注意力图,我们提出了注意力图多样化(AMD),它使某些注意力图多样化,并在反向传播过程中隐式地施加有益的梯度消失。对于令牌嵌入,我们提出了动量令牌嵌入(MTE),它累积历史令牌嵌入以稳定正向更新中的注意力和MLP块。我们通过从ViTs转移到各种CNN和ViTs的对抗样本来进行大量实验,结果表明我们的FPR平均比当前最佳(反向)替代优化高出高达7.0%。我们还验证了其优于流行的防御措施以及与其它转移方法的兼容性。代码和附录可在https://github.com/RYC-98/FPR找到。
论文及项目相关链接
PDF CVPR2025
Summary
本文研究了Vision Transformers(ViTs)在实际场景中的鲁棒性,特别是在对抗性例子转移方面的性能。现有工作主要关注通过反向传播对ViTs进行模型细化来提高对抗性例子转移的能力。本文则专注于正向传播细化(FPR),并具体针对ViTs的两个关键模块——注意力图和令牌嵌入进行改进。通过提出注意力图多样化和动量令牌嵌入方法,实验证明FPR在ViTs对CNN和ViTs的对抗性例子转移上的性能优于当前最佳的反向传播细化方法,平均提高约7.0%。
Key Takeaways
- Vision Transformers(ViTs)在实际场景中的鲁棒性受到广泛关注,特别是在对抗性例子转移方面。
- 现有工作主要通过反向传播对ViTs进行模型细化以提高对抗性例子转移能力,但本文提出正向传播细化(FPR)方法。
- FPR针对ViTs的两个关键模块:注意力图和令牌嵌入进行改进。
- 提出注意力图多样化(AMD)方法,不仅多样化注意力图,还隐式地施加有益的梯度消失在反向传播中。
- 提出动量令牌嵌入(MTE)方法,累积历史令牌嵌入以稳定正向更新中的注意力和MLP块。
- 实验证明FPR在ViTs对抗多种CNN和ViTs的对抗性例子转移上的性能优于当前最佳方法。
点此查看论文截图

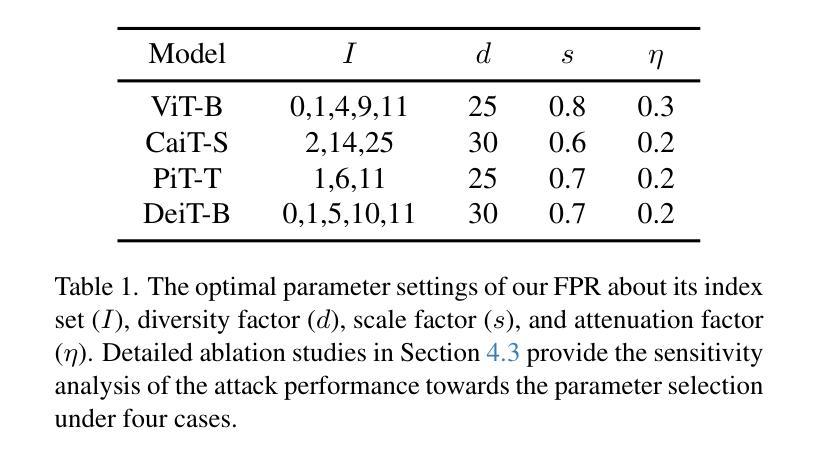
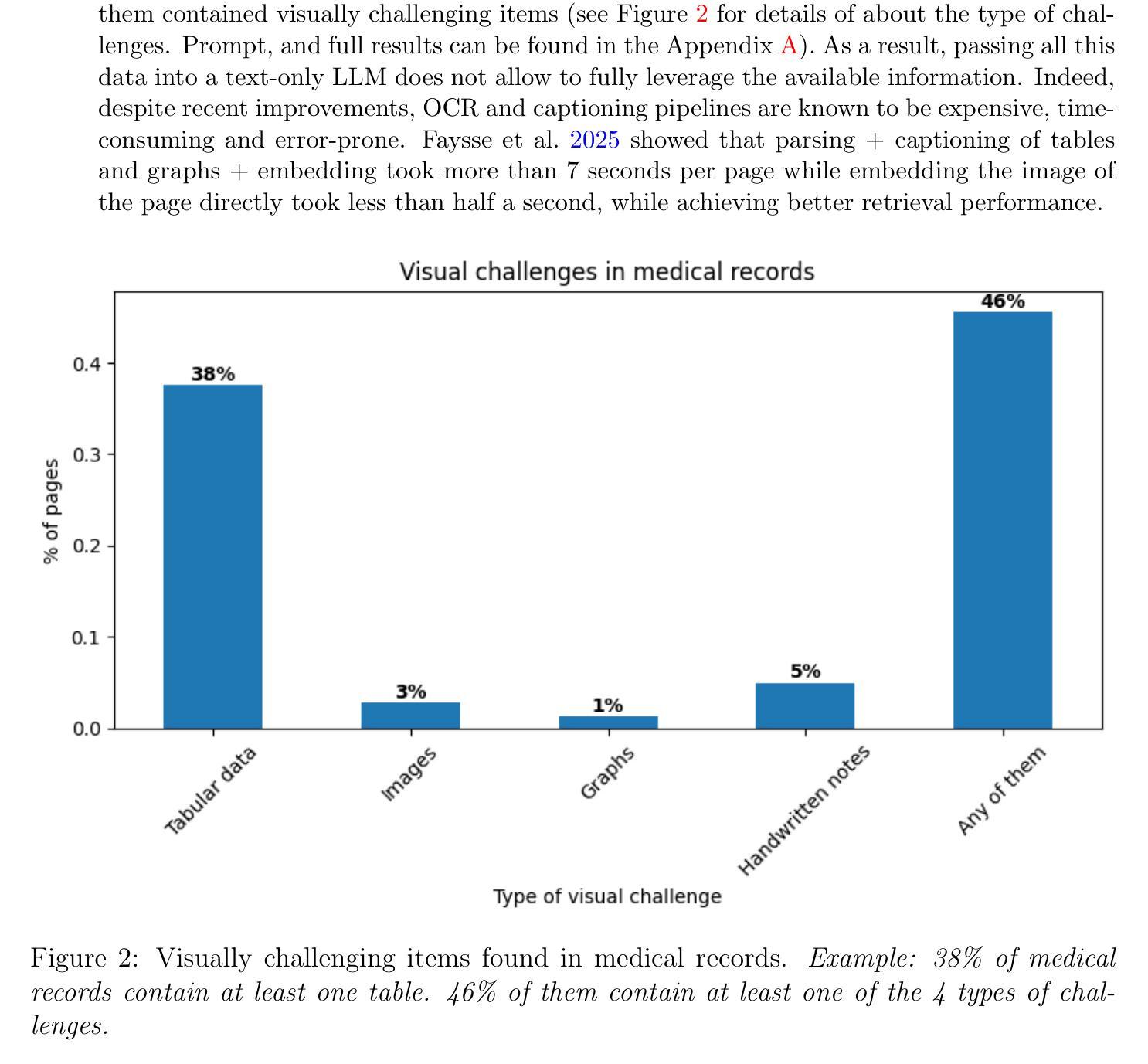
Real-world validation of a multimodal LLM-powered pipeline for High-Accuracy Clinical Trial Patient Matching leveraging EHR data
Authors:Anatole Callies, Quentin Bodinier, Philippe Ravaud, Kourosh Davarpanah
Background: Patient recruitment in clinical trials is hindered by complex eligibility criteria and labor-intensive chart reviews. Prior research using text-only models have struggled to address this problem in a reliable and scalable way due to (1) limited reasoning capabilities, (2) information loss from converting visual records to text, and (3) lack of a generic EHR integration to extract patient data. Methods: We introduce a broadly applicable, integration-free, LLM-powered pipeline that automates patient-trial matching using unprocessed documents extracted from EHRs. Our approach leverages (1) the new reasoning-LLM paradigm, enabling the assessment of even the most complex criteria, (2) visual capabilities of latest LLMs to interpret medical records without lossy image-to-text conversions, and (3) multimodal embeddings for efficient medical record search. The pipeline was validated on the n2c2 2018 cohort selection dataset (288 diabetic patients) and a real-world dataset composed of 485 patients from 30 different sites matched against 36 diverse trials. Results: On the n2c2 dataset, our method achieved a new state-of-the-art criterion-level accuracy of 93%. In real-world trials, the pipeline yielded an accuracy of 87%, undermined by the difficulty to replicate human decision-making when medical records lack sufficient information. Nevertheless, users were able to review overall eligibility in under 9 minutes per patient on average, representing an 80% improvement over traditional manual chart reviews. Conclusion: This pipeline demonstrates robust performance in clinical trial patient matching without requiring custom integration with site systems or trial-specific tailoring, thereby enabling scalable deployment across sites seeking to leverage AI for patient matching.
背景:临床试验中的患者招募受到复杂的入选标准和繁琐的病历审查的阻碍。先前仅使用文本模型的研究由于(1)有限的推理能力,(2)将视觉记录转换为文本时的信息丢失,以及(3)缺乏通用的电子健康记录(EHR)集成以提取患者数据,因此难以以一种可靠和可扩展的方式解决这个问题。方法:我们介绍了一种通用、无需集成、由大型语言模型驱动的管道,该管道使用从EHR中提取的未处理文档自动进行患者与试验的匹配。我们的方法利用(1)新的基于大型语言模型的推理范式,能够评估甚至是最复杂的标准,(2)最新大型语言模型的视觉功能,能够解释医疗记录而无需有损的图像到文本的转换,以及(3)用于高效医疗记录搜索的多模式嵌入。该管道在n2c2 2018年队列选择数据集(288名糖尿病患者)和由来自30个不同站点的485名患者与36种不同试验相匹配的实际数据集上进行了验证。结果:在n2c2数据集上,我们的方法实现了标准级别的准确率为93%,达到了新的业界最佳水平。在现实世界的试验中,管道的准确性为87%,受到医疗记录信息不足导致难以复制人类决策的影响。尽管如此,用户平均能在不到9分钟内审查每位患者的整体资格,相对于传统的手动病历审查提高了80%。结论:该管道在临床试验患者匹配方面表现出稳健的性能,无需与站点系统定制集成或针对特定试验定制调整,从而能够在寻求利用人工智能进行患者匹配的站点中实现跨站点可扩展部署。
论文及项目相关链接
Summary
本文介绍了一种基于LLM的无需整合的自动化患者试验匹配管道,可直接处理来自电子健康记录(EHR)的未处理文档。该管道使用新的推理模型,具有评估复杂标准的能力,并借助最新LLM的视觉功能,无需进行图像到文本的转换即可解释医疗记录。该管道在n2c2 2018队列选择数据集和由来自不同试验的485名患者组成的真实世界数据集上进行了验证,显示出良好的准确性。总体而言,该管道为患者匹配提供了一个有效的解决方案,无需与特定站点系统进行定制集成或针对特定试验进行调整,从而能够在寻求利用人工智能进行患者匹配的站点之间实现规模化部署。
Key Takeaways
- 介绍了一种基于LLM的自动化患者试验匹配管道,解决了临床试验中患者招募的难题。
- 该管道可以直接处理来自电子健康记录(EHR)的未处理文档,具有广泛的应用性。
- 利用新的推理模型、LLM的视觉功能以及多模态嵌入技术,使得管道能够评估复杂标准、解释医疗记录并高效搜索医疗记录。
- 在n2c2数据集和真实世界数据集上的验证结果表明,该管道具有良好的准确性。
- 与传统的手动审查相比,该管道显著提高了患者资格审查的效率。
- 该管道无需特定集成或针对特定试验进行定制调整,便于在多个站点之间实现规模化部署。
点此查看论文截图


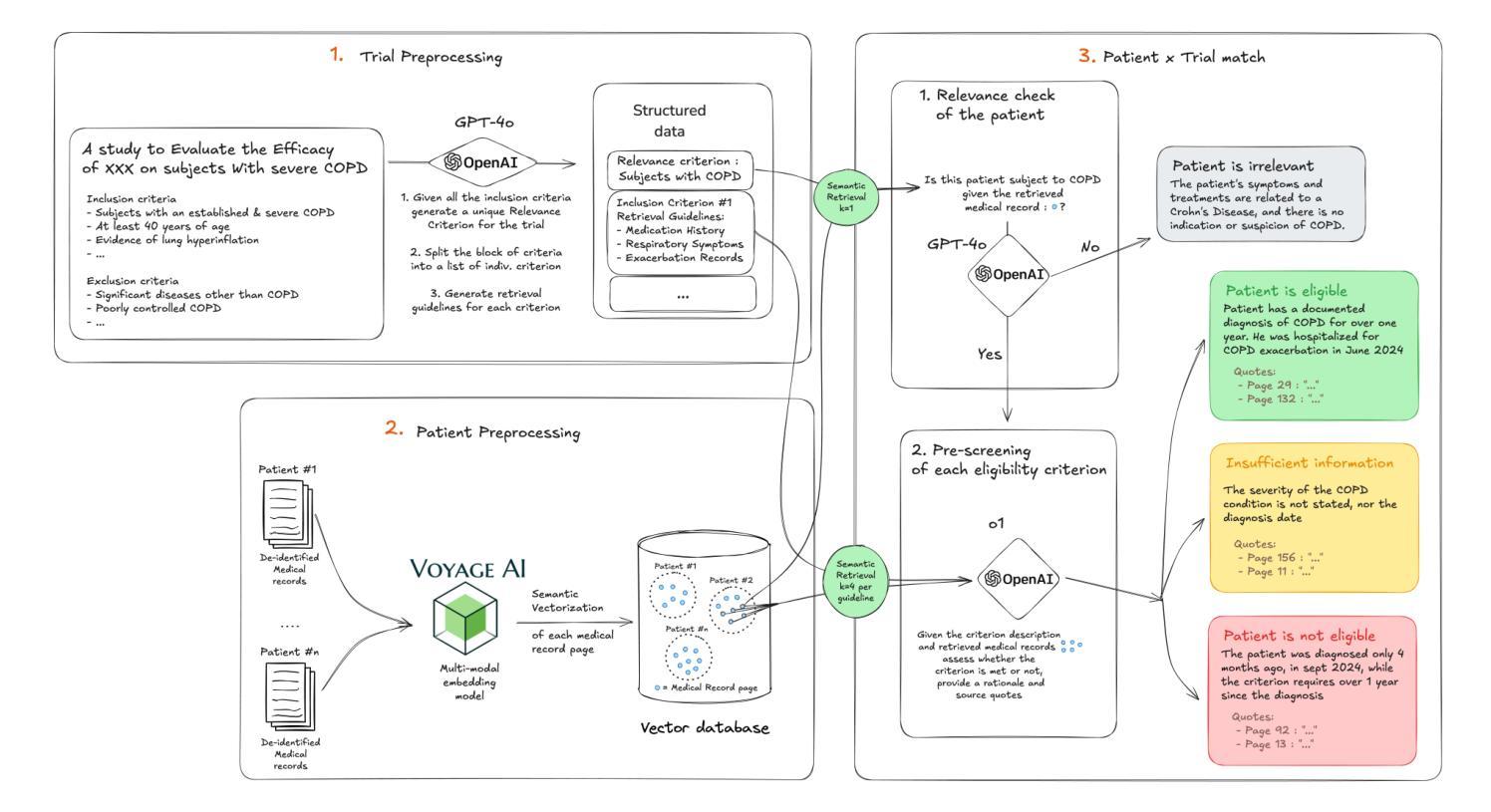
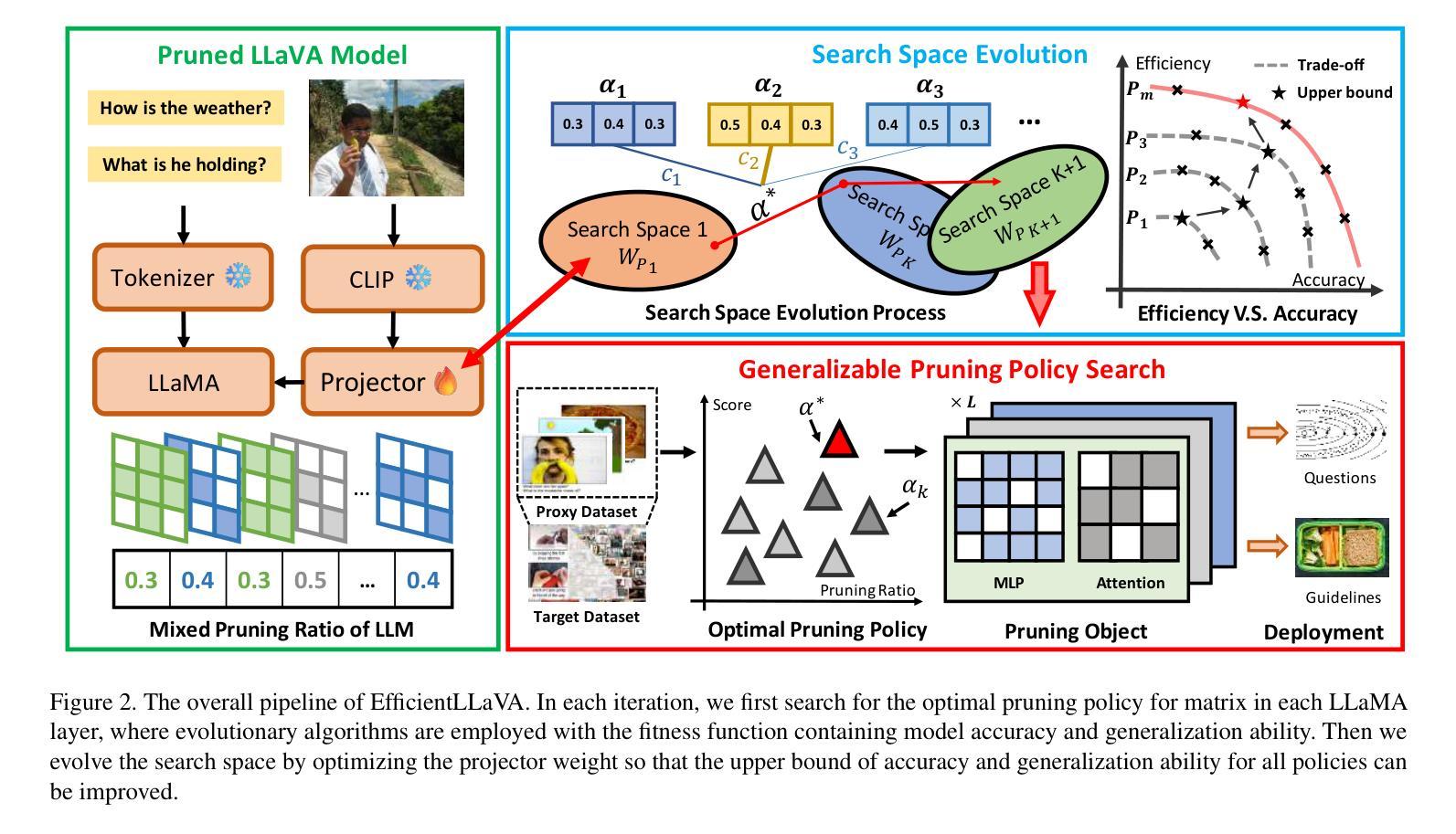
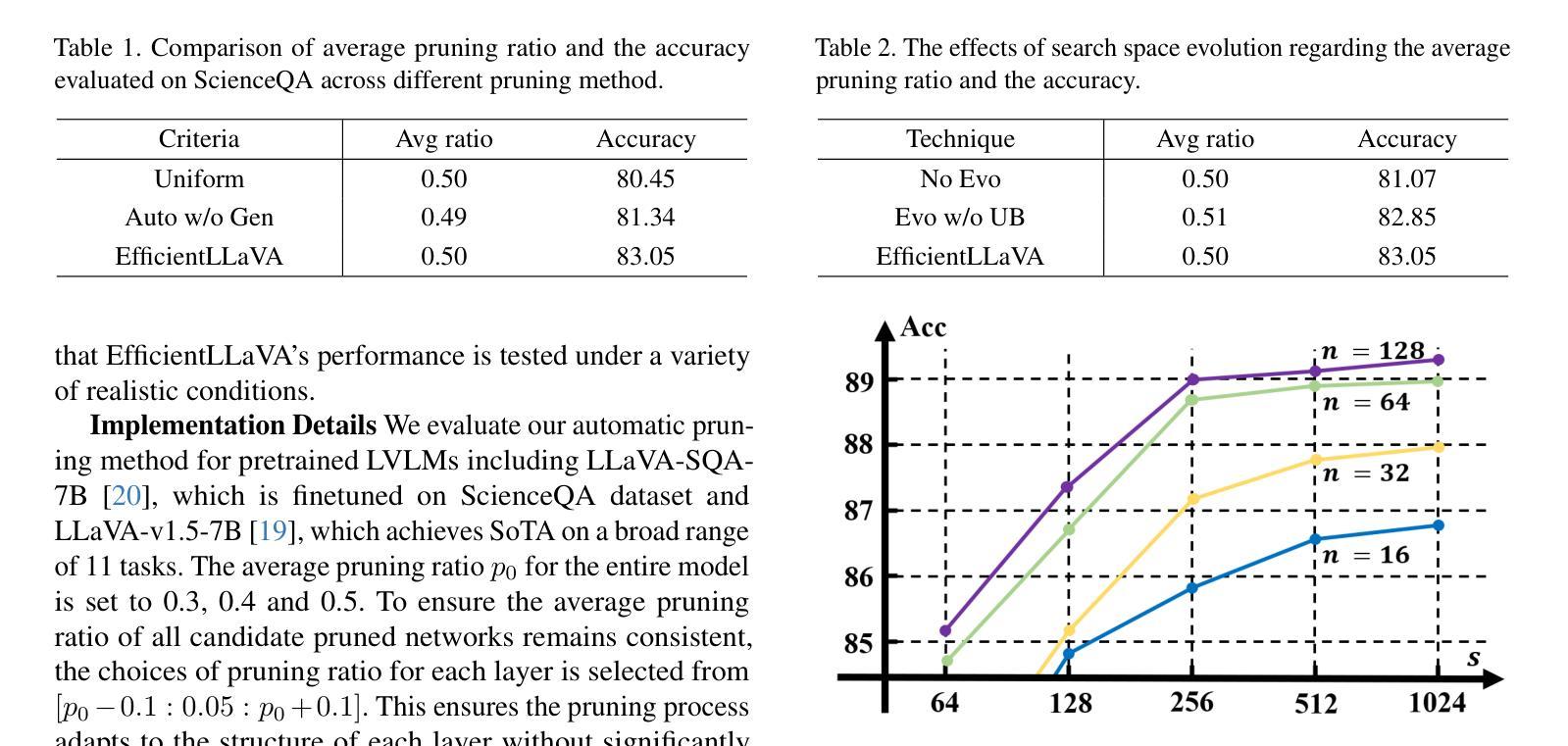
EfficientLLaVA:Generalizable Auto-Pruning for Large Vision-language Models
Authors:Yinan Liang, Ziwei Wang, Xiuwei Xu, Jie Zhou, Jiwen Lu
While multimodal large language models demonstrate strong performance in complex reasoning tasks, they pose significant challenges related to model complexity during deployment, especially for resource-limited devices. In this paper, we propose an automatic pruning method for large vision-language models to enhance the efficiency of multimodal reasoning. Conventional methods rely on the training data of the original model to select the proper pruning ratio for different network components. However, these methods are impractical for large vision-language models due to the unaffordable search costs caused by web-scale training corpus. In contrast, our approach only leverages a small number of samples to search for the desired pruning policy by maximizing its generalization ability on unknown training data while maintaining the model accuracy, which enables the achievement of an optimal trade-off between accuracy and efficiency for large visual language models. Specifically, we formulate the generalization gap of the pruning strategy using the structural risk minimization principle. Based on both task performance and generalization capability, we iteratively search for the optimal pruning policy within a given search space and optimize the vision projector to evolve the search space with higher upper bound of performance. We conduct extensive experiments on the ScienceQA, Vizwiz, MM-vet, and LLaVA-Bench datasets for the task of visual question answering. Using only 64 samples for pruning policy search, EfficientLLaVA achieves an accuracy of 83.05% on ScienceQA, along with a $\times$ 1.8 speedup compared to the dense LLaVA-v1.5-7B model.
尽管多模态大型语言模型在复杂的推理任务中表现出强大的性能,但在部署期间,尤其是资源有限的设备上,它们与模型复杂性相关的挑战尤为显著。在本文中,我们提出了一种针对大型视觉语言模型的自动剪枝方法,以提高多模态推理的效率。传统方法依赖于原始模型的训练数据来选择不同网络组件的适当剪枝率。然而,由于网络规模训练语料库导致的搜索成本过高,这些方法对于大型视觉语言模型来说并不实用。相比之下,我们的方法仅利用少量样本,通过最大化其在未知训练数据上的泛化能力来搜索所需的剪枝策略,同时保持模型精度,这使得大型视觉语言模型在精度和效率之间实现最佳权衡。具体来说,我们使用结构风险最小化原则来制定剪枝策略的泛化差距。基于任务性能和泛化能力,我们在给定的搜索空间内迭代搜索最佳剪枝策略,并优化视觉投影仪以在更高的性能上限内进化搜索空间。我们在ScienceQA、Vizwiz、MM-vet和LLaVA-Bench数据集上进行了大量关于视觉问答任务的实验。仅使用64个样本进行剪枝策略搜索,EfficientLLaVA在ScienceQA上的准确率为83.05%,并且相对于密集LLaVA-v1.5-7B模型实现了×1.8的加速。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出一种针对大型视觉语言模型的自动剪枝方法,以提高多模态推理的效率。不同于依赖原始模型训练数据进行剪枝比例选择的方法,本文方法仅使用少量样本搜索理想的剪枝策略,通过最大化未知训练数据上的泛化能力同时保持模型精度,实现大型视觉语言模型在精度和效率之间的最优权衡。实验在多个数据集上验证了方法的有效性。
Key Takeaways
- 多模态大型语言模型在复杂推理任务中表现出强大的性能,但在部署时面临模型复杂性带来的挑战,尤其是在资源有限的设备上。
- 本文提出了一种针对大型视觉语言模型的自动剪枝方法,旨在提高模型效率。
- 传统方法依赖原始模型的训练数据进行剪枝比例选择,但这种方法对于大型视觉语言模型来说不实用,因为搜索成本高昂。
- 本文方法仅使用少量样本搜索理想的剪枝策略,通过最大化未知训练数据上的泛化能力来保持模型精度。
- 通过制定剪枝策略泛化差距的结构风险最小化原则,实现了模型精度和效率之间的最优权衡。
- 实验在多个数据集上验证了该方法的有效性,其中EfficientLLaVA在ScienceQA数据集上达到83.05%的准确率,并实现与密集模型相比的1.8倍速度提升。
点此查看论文截图

SPILL: Domain-Adaptive Intent Clustering based on Selection and Pooling with Large Language Models
Authors:I-Fan Lin, Faegheh Hasibi, Suzan Verberne
In this paper, we propose Selection and Pooling with Large Language Models (SPILL), an intuitive and domain-adaptive method for intent clustering without fine-tuning. Existing embeddings-based clustering methods rely on a few labeled examples or unsupervised fine-tuning to optimize results for each new dataset, which makes them less generalizable to multiple datasets. Our goal is to make these existing embedders more generalizable to new domain datasets without further fine-tuning. Inspired by our theoretical derivation and simulation results on the effectiveness of sampling and pooling techniques, we view the clustering task as a small-scale selection problem. A good solution to this problem is associated with better clustering performance. Accordingly, we propose a two-stage approach: First, for each utterance (referred to as the seed), we derive its embedding using an existing embedder. Then, we apply a distance metric to select a pool of candidates close to the seed. Because the embedder is not optimized for new datasets, in the second stage, we use an LLM to further select utterances from these candidates that share the same intent as the seed. Finally, we pool these selected candidates with the seed to derive a refined embedding for the seed. We found that our method generally outperforms directly using an embedder, and it achieves comparable results to other state-of-the-art studies, even those that use much larger models and require fine-tuning, showing its strength and efficiency. Our results indicate that our method enables existing embedders to be further improved without additional fine-tuning, making them more adaptable to new domain datasets. Additionally, viewing the clustering task as a small-scale selection problem gives the potential of using LLMs to customize clustering tasks according to the user’s goals.
本文提出了基于大语言模型的选择池化(SPILL)方法,这是一种直观且适用于特定领域的意图聚类方法,无需微调。现有的基于嵌入的聚类方法依赖于少量带标签的样本或无监督微调来优化每个新数据集的结果,这降低了它们在新数据集上的通用性。我们的目标是在无需进一步微调的情况下,使这些现有嵌入器对新领域数据集更具通用性。受采样和池化技术有效性理论推导和仿真结果的启发,我们将聚类任务视为一个小规模的选择问题。好的解决方案与更好的聚类性能相关。因此,我们提出了一个两阶段的方法:首先,针对每条话语(称为种子),我们使用现有的嵌入器获取其嵌入表示。然后,我们应用距离度量来选择一组接近种子的候选集。由于嵌入器并未针对新数据集进行优化,在第二阶段,我们使用大型语言模型从这些候选集中进一步选择意图与种子相同的话语。最后,我们将这些选中的候选集与种子合并,以获取种子的精细嵌入表示。我们发现,我们的方法通常优于直接使用嵌入器的方法,并且即使与其他最新研究相比,我们的方法也取得了相当的结果,即使那些使用更大模型且需要微调的研究也是如此,这显示了其强大和高效性。我们的结果表明,我们的方法能够在无需额外微调的情况下进一步改进现有嵌入器,使其更适应新领域数据集。此外,将聚类任务视为小规模的选择问题,为使用大型语言模型根据用户目标定制聚类任务提供了潜力。
论文及项目相关链接
Summary
本论文提出一种名为Selection and Pooling with Large Language Models(SPILL)的新方法,旨在实现无需微调即可进行意图聚类。现有基于嵌入的聚类方法需要针对每个新数据集进行微调或使用少量标记示例进行优化,这限制了其在多个数据集上的泛化能力。本研究旨在使这些嵌入方法在新领域数据集上更加通用,无需进一步微调。本研究将聚类任务视为小规模选择问题,并提出两阶段解决方案。首先,使用现有嵌入器为每个话语(称为种子)生成嵌入,然后应用距离度量选择接近种子的候选池。其次,利用大型语言模型(LLM)从候选池中进一步选择与种子具有相同意图的话语。最后,将这些选中的候选者与种子合并,以得出更精确的种子嵌入。实验结果表明,该方法优于直接使用嵌入器的方法,并与其他最新研究达到相当的效果,即使这些研究使用更大的模型并需要微调。这表明该方法的强大和高效性,使用户可以根据目标定制聚类任务。
Key Takeaways
- 本研究提出了一种新的意图聚类方法——Selection and Pooling with Large Language Models(SPILL),无需微调即可适应新领域数据集。
- 现有基于嵌入的聚类方法对新数据集泛化能力有限,需要微调或使用标记示例进行优化。
- SPILL方法通过两阶段策略解决这一问题:首先使用现有嵌入器生成话语嵌入,然后通过距离度量和大型语言模型(LLM)进行选择和池化。
- 实验表明,SPILL方法优于直接使用嵌入器的方法,并与其他最新研究具有相当的效果。
- SPILL方法使现有嵌入器得以进一步改进,无需额外微调,增强了其对新领域数据集的适应性。
- 将聚类任务视为小规模选择问题,为使用LLM根据用户目标定制聚类任务提供了潜力。
点此查看论文截图

TruthLens:A Training-Free Paradigm for DeepFake Detection
Authors:Ritabrata Chakraborty, Rajatsubhra Chakraborty, Ali Khaleghi Rahimian, Thomas MacDougall
The proliferation of synthetic images generated by advanced AI models poses significant challenges in identifying and understanding manipulated visual content. Current fake image detection methods predominantly rely on binary classification models that focus on accuracy while often neglecting interpretability, leaving users without clear insights into why an image is deemed real or fake. To bridge this gap, we introduce TruthLens, a novel training-free framework that reimagines deepfake detection as a visual question-answering (VQA) task. TruthLens utilizes state-of-the-art large vision-language models (LVLMs) to observe and describe visual artifacts and combines this with the reasoning capabilities of large language models (LLMs) like GPT-4 to analyze and aggregate evidence into informed decisions. By adopting a multimodal approach, TruthLens seamlessly integrates visual and semantic reasoning to not only classify images as real or fake but also provide interpretable explanations for its decisions. This transparency enhances trust and provides valuable insights into the artifacts that signal synthetic content. Extensive evaluations demonstrate that TruthLens outperforms conventional methods, achieving high accuracy on challenging datasets while maintaining a strong emphasis on explainability. By reframing deepfake detection as a reasoning-driven process, TruthLens establishes a new paradigm in combating synthetic media, combining cutting-edge performance with interpretability to address the growing threats of visual disinformation.
由先进的人工智能模型生成的合成图像大量涌现,给识别和了解被操作过的视觉内容带来了重大挑战。当前的虚假图像检测方法主要依赖于二进制分类模型,这些模型注重准确性,但往往忽视了可解释性,使用户无法清楚地了解图像被视为真实或虚假的原因。为了弥补这一差距,我们引入了TruthLens,这是一种全新的无需训练即可的框架,它将深度伪造检测重新构想为一种视觉问答(VQA)任务。TruthLens利用最先进的视觉语言大模型(LVLMs)来观察和描述视觉伪影,并将其与大型语言模型(如GPT-4)的推理能力相结合,以分析和整合证据以做出明智的决策。通过采用多模式方法,TruthLens无缝集成了视觉和语义推理,不仅将图像分类为真实或虚假,而且还为其决策提供了可解释的解释。这种透明度增强了信任,并提供了关于表示合成内容的伪影的宝贵见解。广泛评估表明,TruthLens优于传统方法,在具有挑战性的数据集上实现高准确率的同时,还坚持强调可解释性。通过将深度伪造检测重塑为以推理为核心的过程,TruthLens建立了应对合成媒体的新范式,将尖端性能和可解释性相结合,应对视觉虚假信息不断增长的威胁。
论文及项目相关链接
Summary
先进AI模型生成的大量合成图像,为识别和理解操纵过的视觉内容带来了巨大挑战。当前主流的假图像检测方法主要依赖二进制分类模型,这些模型虽然准确率高,但忽视了可解释性,使用户无法清楚了解图像被判定为真实或虚假的原因。为了弥补这一差距,我们推出了TruthLens,这是一种全新的无训练框架,将深度伪造检测重新构想为视觉问答(VQA)任务。TruthLens利用最先进的大型视觉语言模型(LVLMs)来观察和描述视觉伪影,并结合大型语言模型(如GPT-4)的推理能力来分析并汇总证据以做出决策。通过采用多模式方法,TruthLens无缝集成了视觉和语义推理,不仅能够真实或虚假地分类图像,而且能够对其决策进行可解释的解释。这种透明度增强了信任,并提供了关于合成内容信号的宝贵信息。全面的评估表明,TruthLens优于传统方法,在高难度数据集上实现了高准确性,同时强烈关注解释性。通过将深度伪造检测重塑为以推理为中心的过程,TruthLens建立了应对合成媒体的新范式,结合前沿性能和可解释性来应对日益增长的视觉假信息威胁。
Key Takeaways
- AI模型生成的合成图像在识别和理解方面存在挑战。
- 当前假图像检测方法主要依赖二进制分类模型,但缺乏解释性。
- TruthLens是一个全新的无训练框架,将深度伪造检测视为视觉问答任务。
- TruthLens利用先进的视觉语言模型观察并描述视觉伪影。
- 结合大型语言模型的推理能力,提供可解释性的决策解释。
- TruthLens采用多模式方法无缝集成视觉和语义推理。
点此查看论文截图



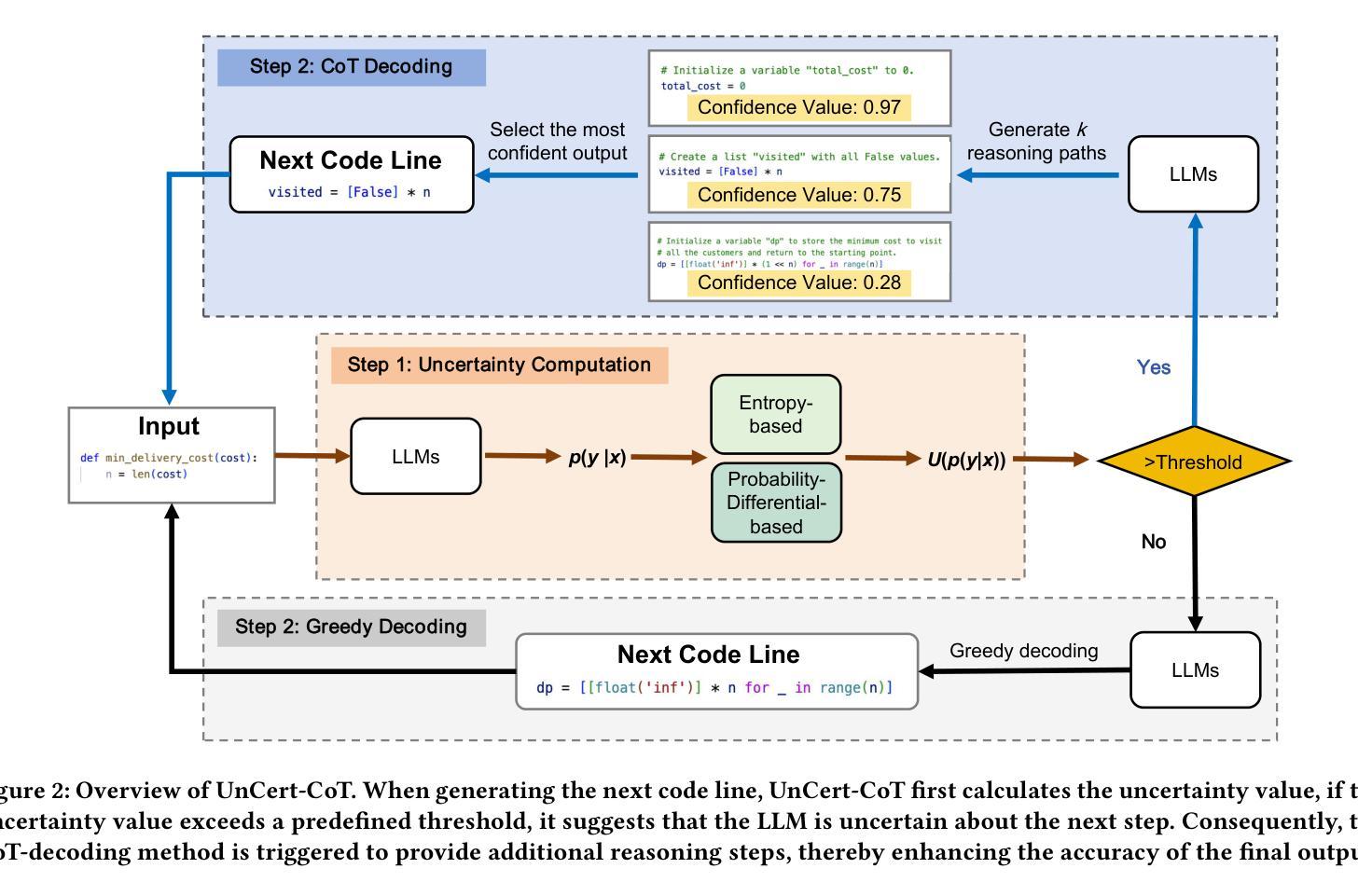
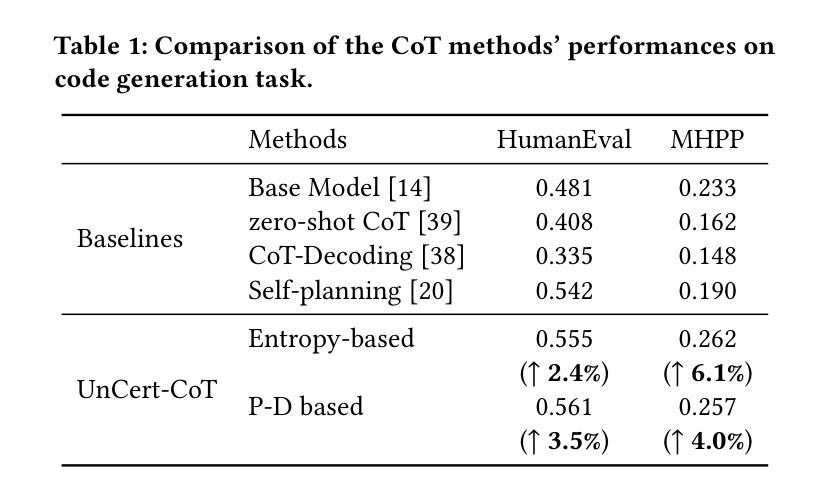
Uncertainty-Guided Chain-of-Thought for Code Generation with LLMs
Authors:Yuqi Zhu, Ge Li, Xue Jiang, Jia Li, Hong Mei, Zhi Jin, Yihong Dong
Chain-of-Thought (CoT) reasoning has been demonstrated as an effective technique for improving the problem-solving capabilities of large language models (LLMs) in the context of code generation. However, existing CoT methods often exhibit a tendency toward “overthinking”, where the LLM consistently applies reasoning strategies without adequately considering the task’s underlying complexity. This results in the LLMs allocating excessive computational resources, in terms of tokens, to relatively simple tasks or problems where the correct answer is already evident. Additionally, this overthinking may lead LLMs down incorrect reasoning paths, resulting in incorrect code generation. In this paper, we introduce UnCertainty-Aware Chain-of-Thought (UnCert-CoT), an LLM-based approach designed to enhance code generation by incorporating an uncertainty-aware CoT reasoning mechanism, which focuses computational resources on targeting points where LLMs are more prone to error. We propose two confidence-based uncertainty measures: Entropy-based and Probability Differential-based methods. When uncertainty is high, UnCert-CoT activates CoT-decoding to generate multiple reasoning paths and selects the final code that exhibits the highest likelihood of correctness. In contrast, LLM directly generates the code when uncertainty is low. This uncertainty judgment mechanism allows LLMs to prioritize complex tasks and avoid unnecessary steps in simpler cases, thereby improving overall efficiency and accuracy in code generation. Our experimental results demonstrate that UnCert-CoT significantly enhances code generation accuracy on challenging benchmark MHPP(Mostly Hard Python Problems), it achieves improvements up to 6.1% on PassRate accuracy, particularly in situations where traditional LLMs are prone to errors.
链式思维(Chain-of-Thought,简称CoT)推理被证明是一种有效的技术,用于提高大型语言模型(LLM)在代码生成方面的解决问题的能力。然而,现有的CoT方法往往倾向于“过度思考”,即LLM持续应用推理策略,而没有充分考虑到任务的底层复杂性。这导致LLM对相对简单的任务或问题分配过多的计算资源(以令牌的形式),而正确的答案已经很明显。此外,这种过度思考可能导致LLM陷入错误的推理路径,从而导致代码生成错误。
在本文中,我们介绍了基于不确定性的链式思维(UnCert-CoT),这是一种基于LLM的方法,旨在通过融入不确定性感知的CoT推理机制,增强代码生成能力。该机制将计算资源集中在LLM更容易出错的目标点上。我们提出了两种基于置信度的不确定性度量方法:基于熵的方法和基于概率差异的方法。当不确定性较高时,UnCert-CoT会激活CoT解码以生成多个推理路径,并选择最有可能正确的最终代码。相比之下,当不确定性较低时,LLM会直接生成代码。这种不确定性判断机制使LLM能够优先处理复杂任务,并在更简单的情况下避免不必要的步骤,从而提高代码生成的总体效率和准确性。
论文及项目相关链接
Summary
大型语言模型(LLM)在代码生成方面应用Chain-of-Thought(CoT)推理技术可以提升问题解决能力。然而,现有CoT方法往往倾向于“过度思考”,即在任务复杂度不高或答案明确的情况下,LLM仍然持续使用复杂的推理策略,消耗过多计算资源。为此,本文提出UnCertainty-Aware Chain-of-Thought(UnCert-CoT),通过不确定性感知的CoT推理机制,将计算资源集中在LLM易出错的部分。当不确定性较高时,UnCert-CoT启动CoT解码以生成多个推理路径并选择最可能的正确答案;当不确定性较低时,LLM直接生成代码。这种不确定性判断机制使LLM能优先处理复杂任务并避免简单案例中的不必要步骤,从而提高代码生成的效率和准确性。实验结果显示,UnCert-CoT在挑战性基准测试MHPP上的代码生成准确率得到显著提高,特别是在传统LLM易出错的情况下,PassRate准确率提高了6.1%。
Key Takeaways
- 现有Chain-of-Thought(CoT)方法在处理代码生成任务时存在过度思考的问题。
- UnCertainty-Aware Chain-of-Thought(UnCert-CoT)旨在通过不确定性感知机制改进LLM在代码生成中的表现。
- UnCert-CoT采用两种基于置信度的不确定性度量方法:基于熵和基于概率差异的方法。
- 当不确定性高时,UnCert-CoT启动CoT解码以生成多个推理路径;当不确定性低时,LLM直接生成代码。
- UnCert-CoT能优先处理复杂任务并避免简单步骤,提高代码生成的效率和准确性。
- 实验结果显示UnCert-CoT在挑战性基准测试MHPP上的代码生成准确率显著提高。
点此查看论文截图


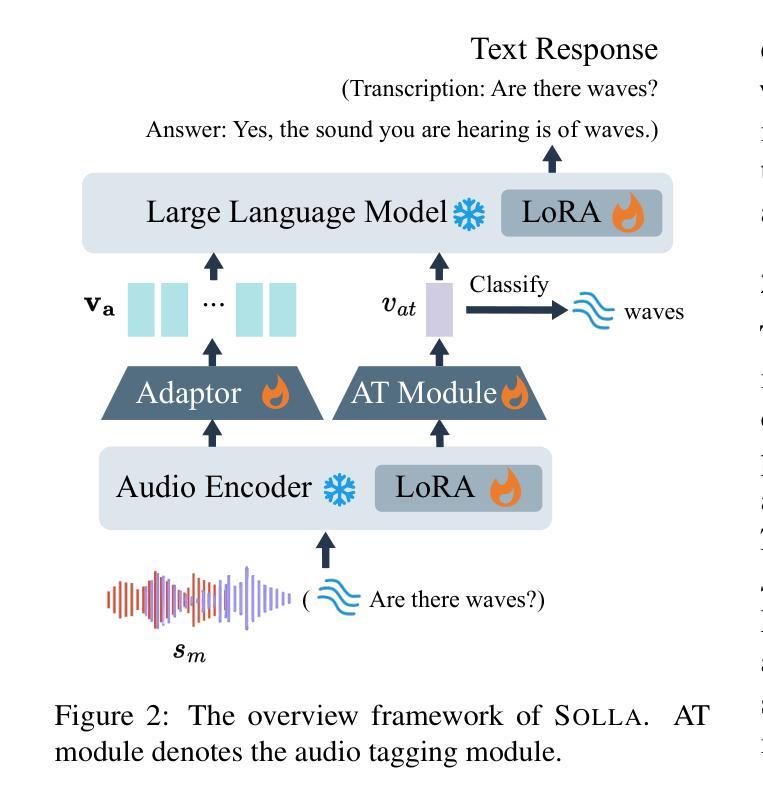
Solla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Authors:Junyi Ao, Dekun Chen, Xiaohai Tian, Wenjie Feng, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, Zhizheng Wu
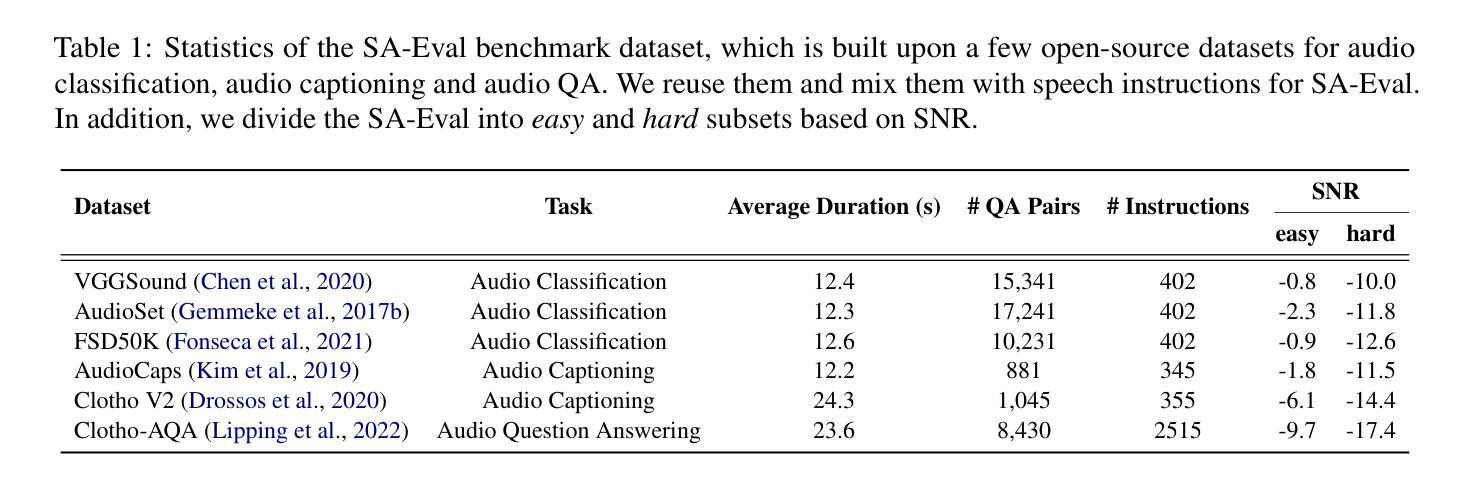
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
大型语言模型(LLM)最近显示出处理文本以及语音和音频等多模态输入的显著能力。然而,大多数现有模型主要侧重于使用文本指令分析输入信号,忽视了语音指令和音频混合并存并作为模型输入的场景。为了解决这些挑战,我们推出了Solla,这是一个旨在理解基于语音的问题并同时聆听声学上下文的新型框架。Solla融入了一个音频标记模块,可以有效地识别和表示音频事件,以及一种辅助的自动语音识别(ASR)预测方法,以提高对口语内容的理解。为了严格评估Solla和其他公开模型,我们提出了一个新的基准数据集SA-Eval,它包括三个任务:音频事件分类、音频描述和音频问答。SA-Eval包含各种风格的言语指令,涵盖简单和困难两个难度级别,以捕捉真实世界的声学条件范围。实验结果表明,Solla在简单和困难测试集上的表现与基线模型持平或表现更好,这突显了它在联合理解语音和音频方面的有效性。
论文及项目相关链接
Summary
Solla框架能够同时理解语音指令并听取声学上下文,通过音频标注模块有效识别并表达音频事件,并借助ASR预测方法提高语音内容的理解。为评估Solla和其他公开模型,提出了包含音频事件分类、音频描述和音频问答任务的新基准数据集SA-Eval,能模拟真实世界的声学条件。实验结果显示,Solla在简单和困难测试集上的表现与基线模型相当或有所超越。
Key Takeaways
- LLMs现不仅能处理文本,还能处理多模态输入,如语音和音频。
- Solla框架能够同时理解语音指令和听取声学上下文。
- Solla使用音频标注模块识别并表达音频事件。
- Solla借助ASR预测方法提高语音内容的理解。
- 为评估模型性能,提出了新基准数据集SA-Eval,包含音频事件分类、音频描述和音频问答任务。
- SA-Eval模拟真实世界的声学条件,具有不同的语音指令和两种难度级别。
点此查看论文截图

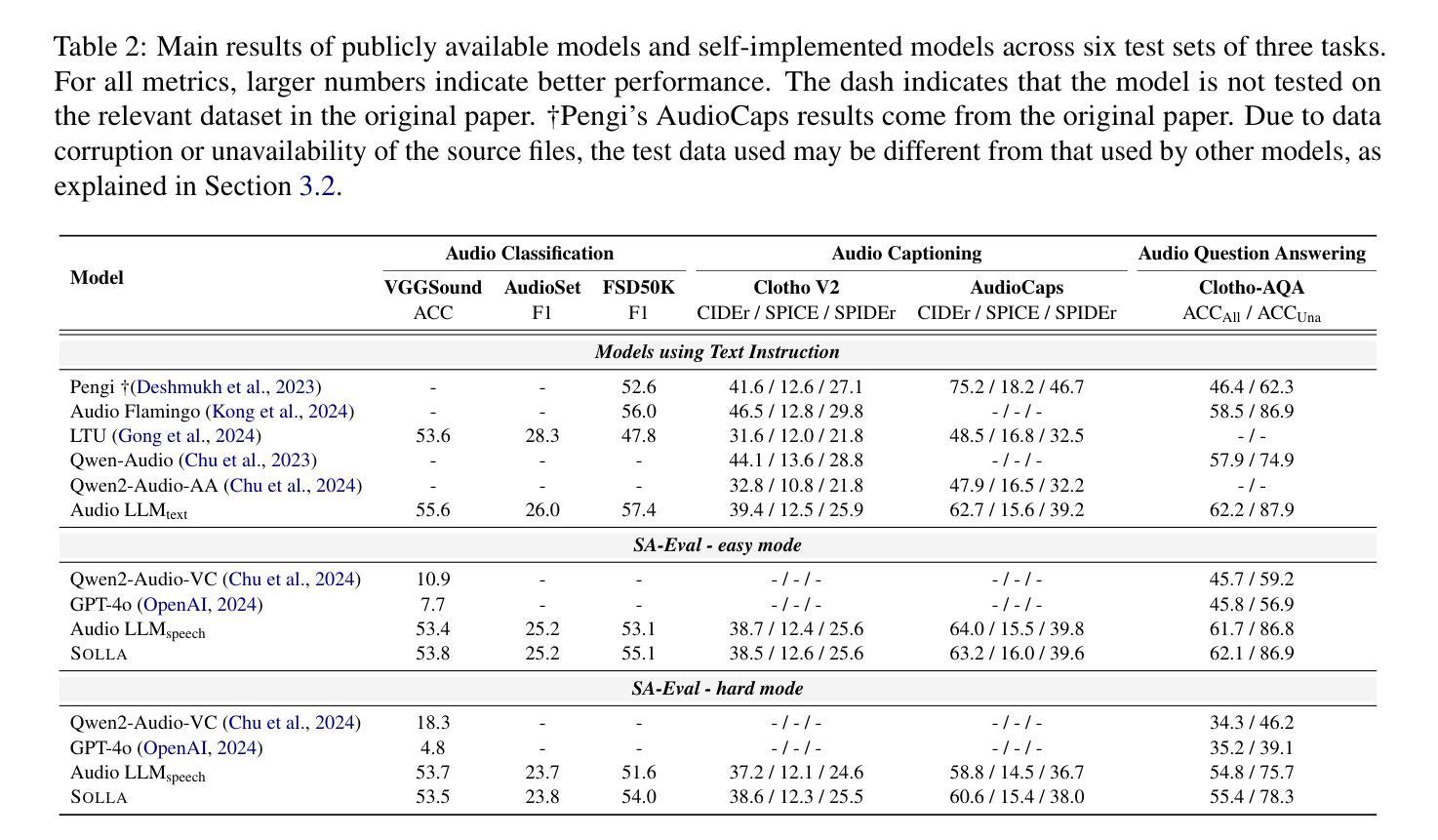
aiXcoder-7B-v2: Training LLMs to Fully Utilize the Long Context in Repository-level Code Completion
Authors:Jia Li, Hao Zhu, Huanyu Liu, Xianjie Shi, He Zong, Yihong Dong, Kechi Zhang, Siyuan Jiang, Zhi Jin, Ge Li
Repository-level code completion aims to complete code based on the long contexts of the repository. Existing studies extract long contexts from the repository as inputs and leverage Large Language Models (LLMs) to generate code. However, we reveal a severe limitation of LLMs, i.e., LLMs may ignore the information within long contexts in code completion. In other words, even the contexts contain useful information (e.g., relevant APIs or similar code), LLMs may fail to utilize this information. We think this limitation is caused by an inherent bias in LLMs, i.e., relying on nearby contexts and ignoring long-range contexts. To address this, we propose a novel fine-tuning approach named CoLT. The core idea of CoLT is to provide explicit supervision signals, which emphasize that long-range contexts may hold relevant information. Specifically, CoLT proposes a reinforcement learning-based training, which explicitly encourages models to utilize the information within long contexts and punishes models for ignoring long contexts. To support CoLT, we release CoLT-132K, a large-scale dataset with 132k samples across four languages, each containing long-context inputs. We apply CoLT to a popular LLM - aiXcoder-7B and release aiXcoder-7B-v2. We conduct extensive experiments on CoLT-132K and a public benchmark - CrossCodeEval. Our experiments yield the results: 1. Effectiveness. CoLT substantially improves aiXcoder-7B. aiXcoder-7B-v2 outperforms aiXcoder-7B by up to 44% in exact match. aiXcoder-7B-v2 becomes the state-of-the-art 7B model in code completion and even surpasses larger models. 2. Generalizability. The capability learned by CoLT can generalize to new languages. Besides, CoLT is model-agnostic and effectively improves multiple LLMs. 3. Enhanced Context Utilization Capability. CoLT significantly improves the capability of LLMs in utilizing the relevant information within long contexts.
代码库级别的代码补全旨在基于代码库的长期上下文完成代码。现有研究从代码库中提取长期上下文作为输入,并利用大型语言模型(LLM)生成代码。然而,我们揭示了LLM的一个严重局限性,即LLM可能会忽略长期上下文中的信息。换句话说,即使上下文包含有用信息(例如相关API或类似代码),LLM也可能无法利用这些信息。我们认为这一局限性是由LLM的内在偏见造成的,即依赖附近的上下文并忽略长期上下文。为了解决这个问题,我们提出了一种名为CoLT的新型微调方法。CoLT的核心思想是提供明确的监督信号,强调长期上下文可能包含相关信息。具体来说,CoLT提出了一种基于强化学习的训练,它明确鼓励模型利用长期上下文中的信息,并惩罚模型忽略长期上下文的行为。为了支持CoLT,我们发布了CoLT-132K数据集,该数据集包含四种语言的大规模数据集,样本量为13.2万,每个样本都包含长期上下文输入。我们将CoLT应用于流行的LLM-aiXcoder-7B并发布了aiXcoder-7B-v2。我们在CoLT-132K和公共基准测试CrossCodeEval上进行了大量实验。我们的实验结果如下:1. 有效性。CoLT大大提高了aiXcoder-7B的性能。aiXcoder-7B-v2与aiXcoder-7B相比,精确匹配度提高了高达44%。aiXcoder-7B-v2在代码补全方面成为最先进的7B模型,甚至超越了更大的模型。2. 泛化能力。CoLT所学习的能力可以推广到新的语言。此外,CoLT是模型无关的,并能有效提高多个LLM的性能。3. 增强上下文利用能力。CoLT显著提高了LLM利用长期上下文中相关信息的能力。
论文及项目相关链接
Summary
基于仓库的长期上下文进行代码补全旨在利用仓库中的长上下文信息来完成代码。然而,现有研究利用大型语言模型(LLM)从仓库中提取长上下文作为输入来生成代码,却存在LLM可能忽略长上下文信息的严重局限性。为解决这一问题,我们提出了一种名为CoLT的新型微调方法。CoLT通过提供明确的监督信号,强调长上下文可能包含相关信息,并通过强化学习训练鼓励模型利用长上下文信息。我们发布了支持CoLT的CoLT-132K数据集,包含13.2万份跨四种语言的样本。将CoLT应用于流行的LLM——aiXcoder-7B,并发布了aiXcoder-7B-v2。实验结果表明,CoLT能有效提高aiXcoder-7B的性能,aiXcoder-7B-v2在精确匹配上较aiXcoder-7B提高了高达44%,并成为代码补全领域的最先进的7B模型,甚至超越了更大的模型。此外,CoLT还具有良好的通用性,可以应用于新语言,并且可以有效地提高多个LLM的性能。
Key Takeaways
- 仓库级代码补全依赖于LLM利用仓库中的长上下文信息来完成代码。
- LLM在代码补全中可能存在忽略长上下文信息的局限性。
- CoLT是一种新型的微调方法,旨在解决LLM忽略长上下文的问题。
- CoLT通过提供明确的监督信号,鼓励模型利用长上下文信息。
- CoLT-132K是一个支持CoLT的大型数据集,包含跨四种语言的样本。
- CoLT能有效提高aiXcoder-7B的性能,并在精确匹配上取得显著改进。
点此查看论文截图




SENAI: Towards Software Engineering Native Generative Artificial Intelligence
Authors:Mootez Saad, José Antonio Hernández López, Boqi Chen, Neil Ernst, Dániel Varró, Tushar Sharma
Large Language Models have significantly advanced the field of code generation, demonstrating the ability to produce functionally correct code snippets. However, advancements in generative AI for code overlook foundational Software Engineering (SE) principles such as modularity, and single responsibility, and concepts such as cohesion and coupling which are critical for creating maintainable, scalable, and robust software systems. These concepts are missing in pipelines that start with pre-training and end with the evaluation using benchmarks. This vision paper argues for the integration of SE knowledge into LLMs to enhance their capability to understand, analyze, and generate code and other SE artifacts following established SE knowledge. The aim is to propose a new direction where LLMs can move beyond mere functional accuracy to perform generative tasks that require adherence to SE principles and best practices. In addition, given the interactive nature of these conversational models, we propose using Bloom’s Taxonomy as a framework to assess the extent to which they internalize SE knowledge. The proposed evaluation framework offers a sound and more comprehensive evaluation technique compared to existing approaches such as linear probing. Software engineering native generative models will not only overcome the shortcomings present in current models but also pave the way for the next generation of generative models capable of handling real-world software engineering.
大型语言模型在代码生成领域取得了显著进展,展现出生成功能正确代码片段的能力。然而,代码生成领域的生成人工智能发展忽视了软件工程中诸如模块化、单一职责等基本原则,以及对于创建可持续的、可扩展的和稳健的软件系统至关重要的凝聚和耦合等概念。这些概念在从开始进行预训练到最后使用基准测试进行评估的管道中缺失。本文主张将软件工程知识融入大型语言模型,以提高其理解、分析和生成代码以及其他软件工程制品的能力,遵循既定的软件工程知识。目标是提出一个新的方向,使大型语言模型不仅能实现功能准确性,还能执行需要遵循软件工程原则和使用最佳实践的生成任务。此外,考虑到这些对话模型的交互性质,我们提议使用布鲁姆的分类法作为框架来评估他们内化软件工程知识的程度。相比现有的方法如线性探测,所提出的评估框架提供了健全和更全面的评估技术。软件工程原生生成模型不仅将克服当前模型的缺点,还将为下一代能够处理现实世界软件工程的生成模型铺平道路。
论文及项目相关链接
PDF 5 pages, 1 figure
Summary
大型语言模型在代码生成领域取得了显著进展,能够生成功能正确的代码片段。然而,软件工程(SE)原理,如模块化、单一职责原则以及凝聚力与耦合等关键概念,在生成式AI的发展中被忽视。这些概念对于创建可持续、可扩展和稳健的软件系统至关重要。本文主张将SE知识整合到大型语言模型中,以提高其理解、分析和生成代码及其他SE工件的能力。目标是提出一个新的方向,使大型语言模型不仅能够实现功能准确性,还能执行需要遵循SE原理和最佳实践的生成任务。此外,鉴于这些对话模型的交互性,本文提议使用布鲁姆的分类学作为评估框架,以评估他们对SE知识的内化程度。与现有方法相比,如线性探测,所提出的评估框架提供了更全面和稳健的评估技术。软件工程原生生成模型将不仅克服当前模型的局限性,还为下一代能够处理现实世界中软件工程的生成模型铺平道路。
Key Takeaways
- 大型语言模型在代码生成方面取得显著进展,能生成功能正确的代码片段。
- 软件工程(SE)原理,如模块化、单一职责等,在现有生成式AI中未得到充分重视。
- 将SE知识整合到大型语言模型中,能提高其在理解、分析和生成代码方面的能力。
- 提议使用布鲁姆的分类学作为评估框架,以评估大型语言模型对SE知识的内化程度。
- 与现有评估方法相比,新的评估框架更全面和稳健。
- 软件工程原生生成模型将克服当前模型的局限性。
点此查看论文截图

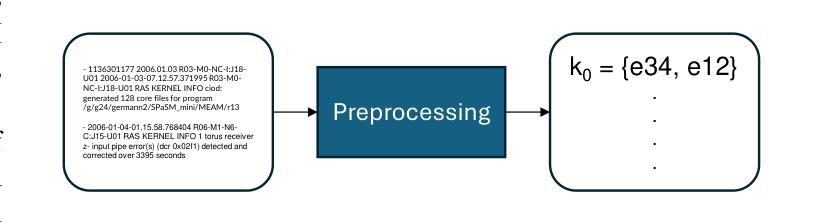
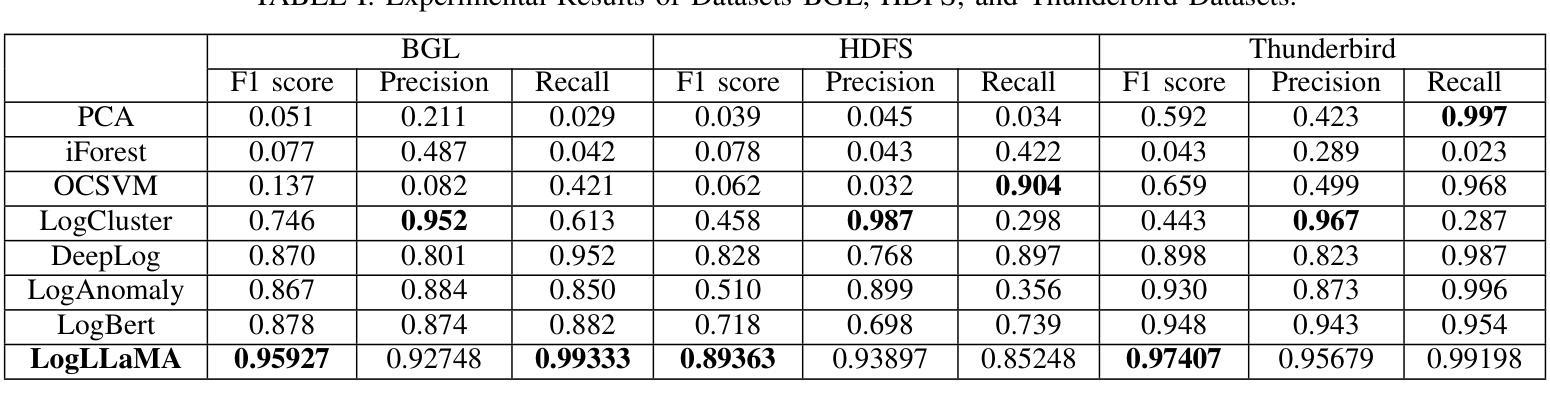
LogLLaMA: Transformer-based log anomaly detection with LLaMA
Authors:Zhuoyi Yang, Ian G. Harris
Log anomaly detection refers to the task that distinguishes the anomalous log messages from normal log messages. Transformer-based large language models (LLMs) are becoming popular for log anomaly detection because of their superb ability to understand complex and long language patterns. In this paper, we propose LogLLaMA, a novel framework that leverages LLaMA2. LogLLaMA is first finetuned on normal log messages from three large-scale datasets to learn their patterns. After finetuning, the model is capable of generating successive log messages given previous log messages. Our generative model is further trained to identify anomalous log messages using reinforcement learning (RL). The experimental results show that LogLLaMA outperforms the state-of-the-art approaches for anomaly detection on BGL, Thunderbird, and HDFS datasets.
日志异常检测是指从正常日志消息中区分出异常日志消息的任务。基于Transformer的大型语言模型(LLM)由于理解复杂和长期语言模式的能力出色,因此在日志异常检测中越来越受欢迎。在本文中,我们提出了LogLLaMA,这是一个利用LLaMA2的新型框架。LogLLaMA首先通过对三个大型数据集中的正常日志消息进行微调来学习其模式。微调后,该模型能够在给定先前的日志消息的情况下生成连续的日志消息。我们的生成模型进一步使用强化学习(RL)进行训练,以识别异常的日志消息。实验结果表明,LogLLaMA在BGL、Thunderbird和HDFS数据集上的异常检测优于最新方法。
论文及项目相关链接
PDF 8 pages, 5 figures
Summary:
基于Transformer的大型语言模型(LLM)因其对复杂和长期语言模式的出色理解能力,在日志异常检测中受到广泛关注。本文提出了一种新的框架LogLLaMA,它利用LLaMA2模型进行微调以学习正常日志消息的模式,并通过强化学习进一步训练模型以识别异常日志消息。实验结果表明,LogLLaMA在BGL、Thunderbird和HDFS数据集上的异常检测性能优于现有技术。
Key Takeaways:
- LogLLaMA是一个基于LLaMA的大型语言模型框架,用于日志异常检测。
- 模型通过微调学习正常日志消息的模式,能够生成连续的日志消息。
- LogLLaMA利用强化学习进一步训练模型以识别异常日志消息。
- 实验结果表明LogLLaMA在多个数据集上的异常检测性能优于现有技术。
- LogLLaMA的主要优势在于其对复杂和长期语言模式的出色理解能力。
点此查看论文截图




Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Authors:Xinyu Fang, Zhijian Chen, Kai Lan, Lixin Ma, Shengyuan Ding, Yingji Liang, Xiangyu Zhao, Farong Wen, Zicheng Zhang, Guofeng Zhang, Haodong Duan, Kai Chen, Dahua Lin
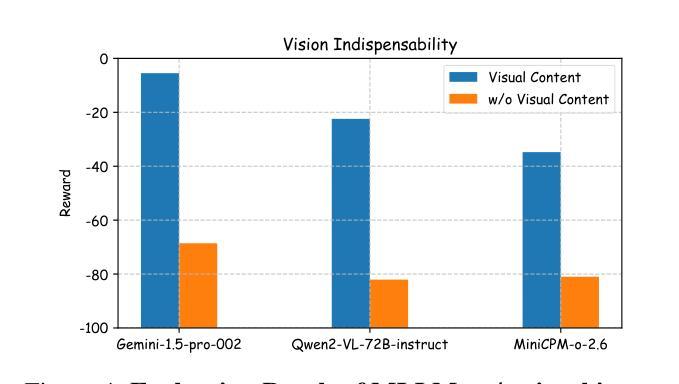
Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models (MLLMs) in this domain remains largely unexplored. To address this gap, we introduce Creation-MMBench, a multimodal benchmark specifically designed to evaluate the creative capabilities of MLLMs in real-world, image-based tasks. The benchmark comprises 765 test cases spanning 51 fine-grained tasks. To ensure rigorous evaluation, we define instance-specific evaluation criteria for each test case, guiding the assessment of both general response quality and factual consistency with visual inputs. Experimental results reveal that current open-source MLLMs significantly underperform compared to proprietary models in creative tasks. Furthermore, our analysis demonstrates that visual fine-tuning can negatively impact the base LLM’s creative abilities. Creation-MMBench provides valuable insights for advancing MLLM creativity and establishes a foundation for future improvements in multimodal generative intelligence. Full data and evaluation code is released on https://github.com/open-compass/Creation-MMBench.
创造力是智能的一个基本方面,涉及在不同上下文中生成新颖且适当解决方案的能力。虽然大型语言模型(LLM)已经广泛评估了其创造力,但多模态大型语言模型(MLLM)在该领域的评估仍然很大程度上未被探索。为了弥补这一空白,我们引入了Creation-MMBench,这是一个专门设计用于评估多模态语言模型在现实世界中基于图像的任务的创造性能力的基准测试。该基准测试包含765个测试用例,涵盖51个细粒度任务。为了确保严格的评估,我们为每个测试用例定义了特定的评估标准,以指导对通用响应质量和与视觉输入的事实一致性的评估。实验结果表明,与专有模型相比,当前开源的MLLM在创造性任务中的表现显著较差。此外,我们的分析表明,视觉微调可能会负面影响基础LLM的创造力。Creation-MMBench为推进MLLM的创造力提供了宝贵的见解,并为未来多模态生成智能的改进奠定了基础。完整的数据和评估代码已在https://github.com/open-compass/Creation-MMBench上发布。
论文及项目相关链接
PDF Evaluation Code and dataset see https://github.com/open-compass/Creation-MMBench
Summary
本文介绍了针对多模态大型语言模型(MLLMs)在真实世界图像任务中的创造力评估的新基准测试,即Creation-MMBench。该基准测试包括针对各个不同任务设置的共765个测试案例,并定义了针对每个测试案例的具体评估标准。实验结果显示,在创造性任务方面,开源的MLLMs表现显著不如专有模型。此外,该研究还发现视觉微调可能对基础LLM的创造力产生负面影响。Creation-MMBench为推进MLLM的创造力研究提供了宝贵的见解,并为未来多模态生成智能的发展奠定了基础。
Key Takeaways
- 多模态大型语言模型(MLLMs)在创造力评估方面仍存在较大空白,需要新的基准测试来评估其在真实世界图像任务中的表现。
- Creation-MMBench是一个新的基准测试,旨在评估MLLMs在多种精细化任务中的创造力。
- 实验结果显示,开源的MLLMs在创造性任务上表现不佳,与专有模型相比存在显著差距。
- 视觉微调可能对基础大型语言模型(LLM)的创造力产生负面影响。
- Creation-MMBench为评估和提升MLLM的创造力提供了有价值的见解。
- 该基准测试的建立为未来的多模态生成智能的发展和改进奠定了基础。
点此查看论文截图


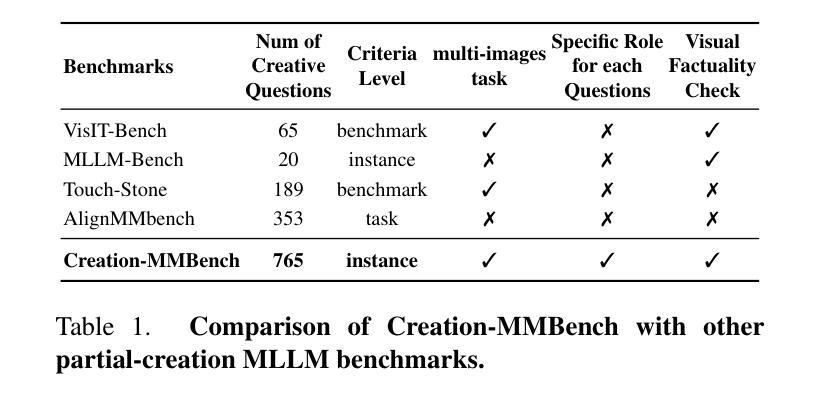

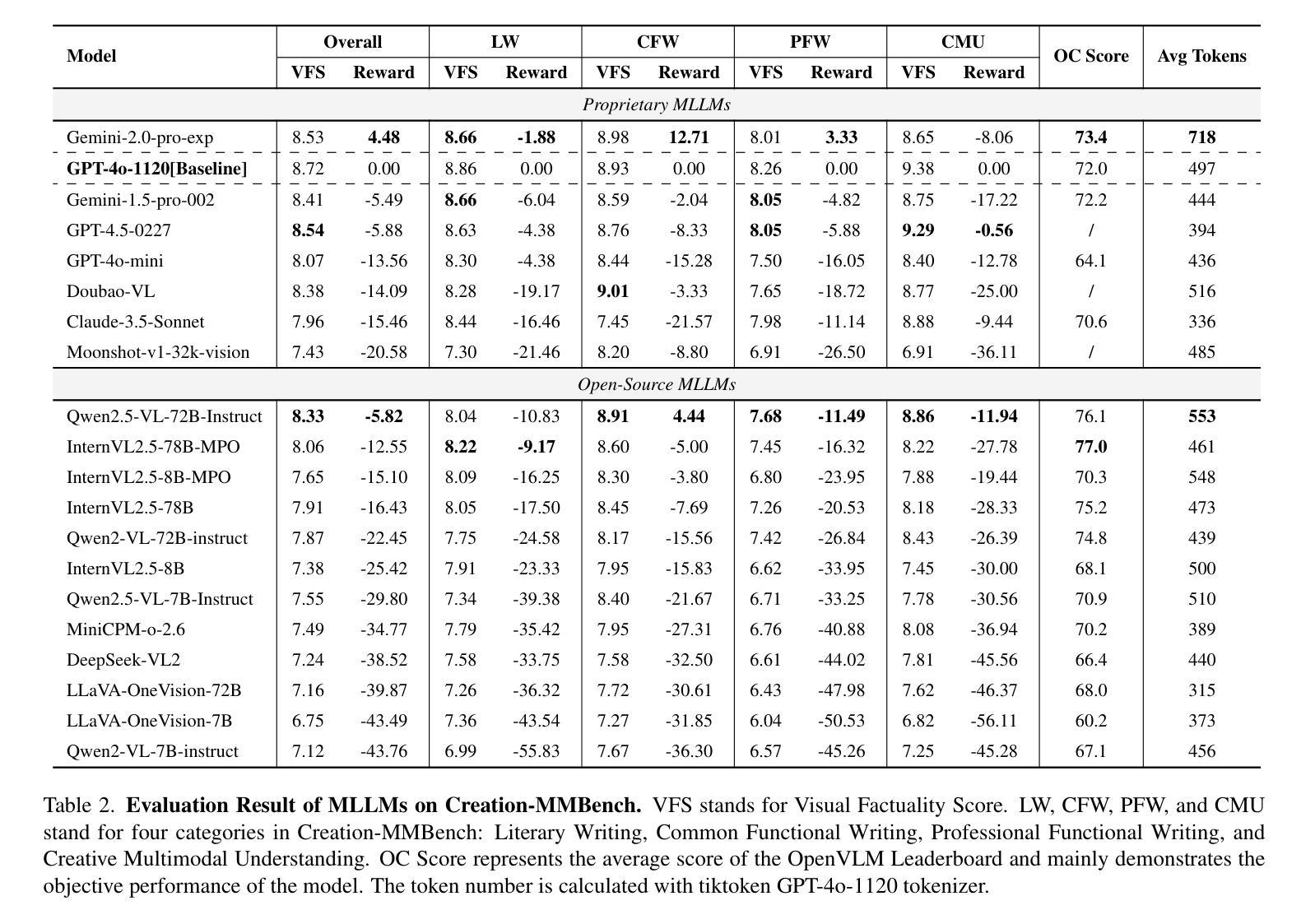
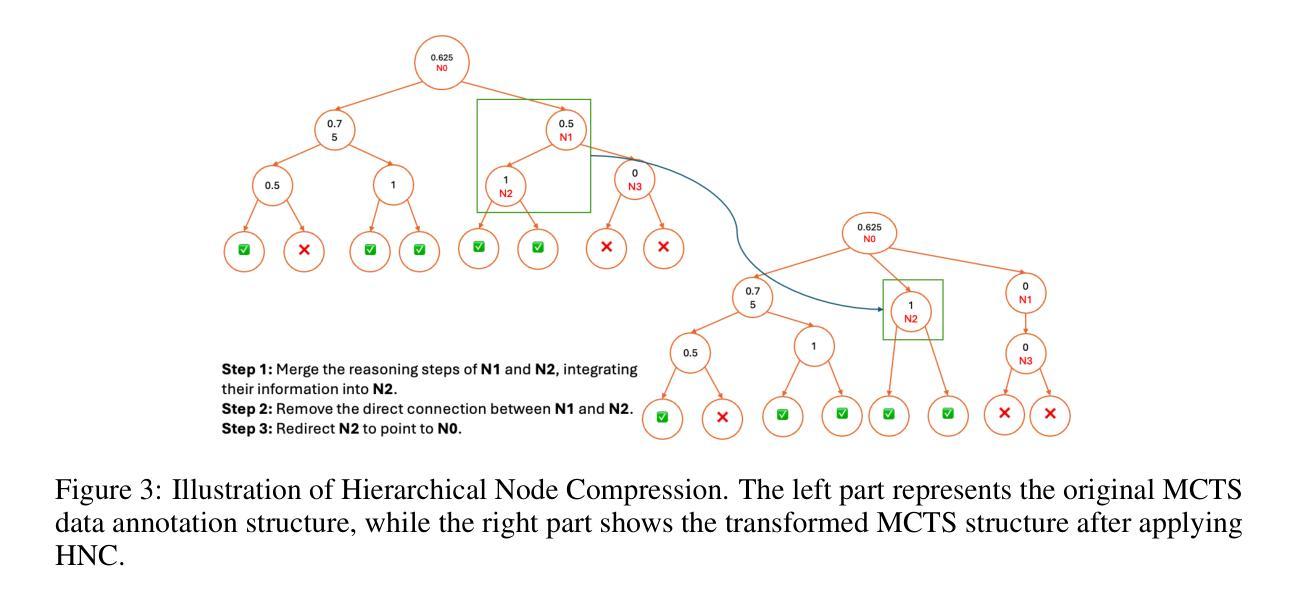
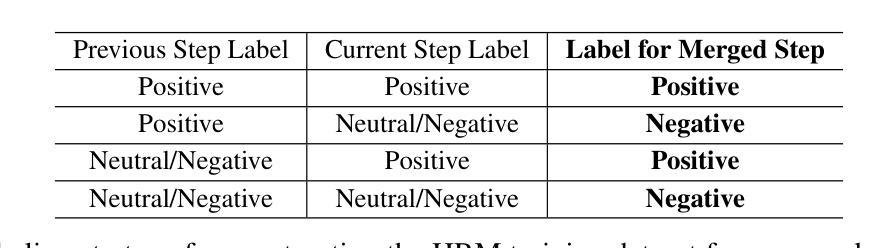
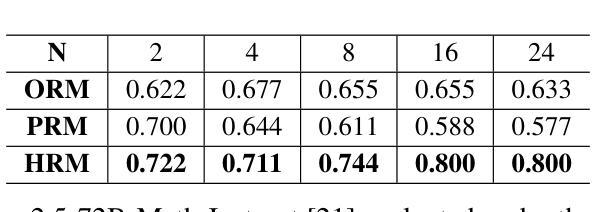
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Authors:Teng Wang, Zhangyi Jiang, Zhenqi He, Wenhan Yang, Yanan Zheng, Zeyu Li, Zifan He, Shenyang Tong, Hailei Gong
Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM’s superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
最近的研究表明,大型语言模型(LLM)通过监督微调或强化学习实现了强大的推理能力。然而,一种关键方法——过程奖励模型(PRM)存在奖励破解的问题,使其无法可靠地识别最佳的中间步骤。在本文中,我们提出了一种新的奖励模型方法,即分层奖励模型(HRM),它可以评估精细粒度和粗粒度的单个和连续推理步骤。HRM在评估推理连贯性和自我反思方面表现更好,尤其是在前一个推理步骤错误的情况下。此外,为了解决通过蒙特卡洛树搜索(MCTS)自主生成PRM训练数据效率低下的问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的树结构中的分层节点压缩(HNC)的轻量级有效数据增强策略。该方法在HRM中实现了多样化的MCTS结果,同时计算开销很小,通过引入噪声增强了标签的鲁棒性。在PRM800K数据集上的经验结果表明,与HNC结合的HRM在评估中实现了比PRM更优越的稳定性和可靠性。此外,MATH500和GSM8K的跨域评估证实了HRM在多种推理任务中的优异泛化和鲁棒性。所有实验的代码将在https://github.com/tengwang0318/hierarchial_reward_model发布。
论文及项目相关链接
Summary
大型语言模型(LLM)通过监督微调或强化学习展现出强大的推理能力。然而,当前的关键方法——过程奖励模型(PRM)存在奖励黑客问题,无法准确识别最佳的中间步骤。本文提出了一种新的奖励模型方法,即分层奖励模型(HRM),可以从精细粒度和粗略粒度两个层面评估单个和连续的推理步骤。HRM在评估推理连贯性和自我反思方面表现更佳,尤其是当先前的推理步骤出错时。此外,为解决通过蒙特卡洛树搜索(MCTS)自主生成PRM训练数据的不效率问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的分层节点压缩(HNC)轻量级有效数据增强策略。该方法在PRM800K数据集上的实证结果表明,与PRM相比,HRM结合HNC实现了更稳定可靠的评估。跨域评估MATH500和GSM8K的结果验证了HRM在不同推理任务中的优异泛化能力和稳健性。
Key Takeaways
- LLMs展现出强大的推理能力,通过监督微调或强化学习实现。
- 当前的过程奖励模型(PRM)存在奖励黑客问题,无法准确识别最佳中间步骤。
- 分层奖励模型(HRM)可以评估单个和连续的推理步骤,在评估推理连贯性和自我反思方面表现更佳。
- 引入分层节点压缩(HNC)策略,基于节点合并,提高蒙特卡洛树搜索(MCTS)结果的多样性,增强标签稳健性。
- 在PRM800K数据集上,HRM结合HNC表现更稳定可靠。
- 跨域评估MATH500和GSM8K验证了HRM的优异泛化能力和稳健性。
点此查看论文截图

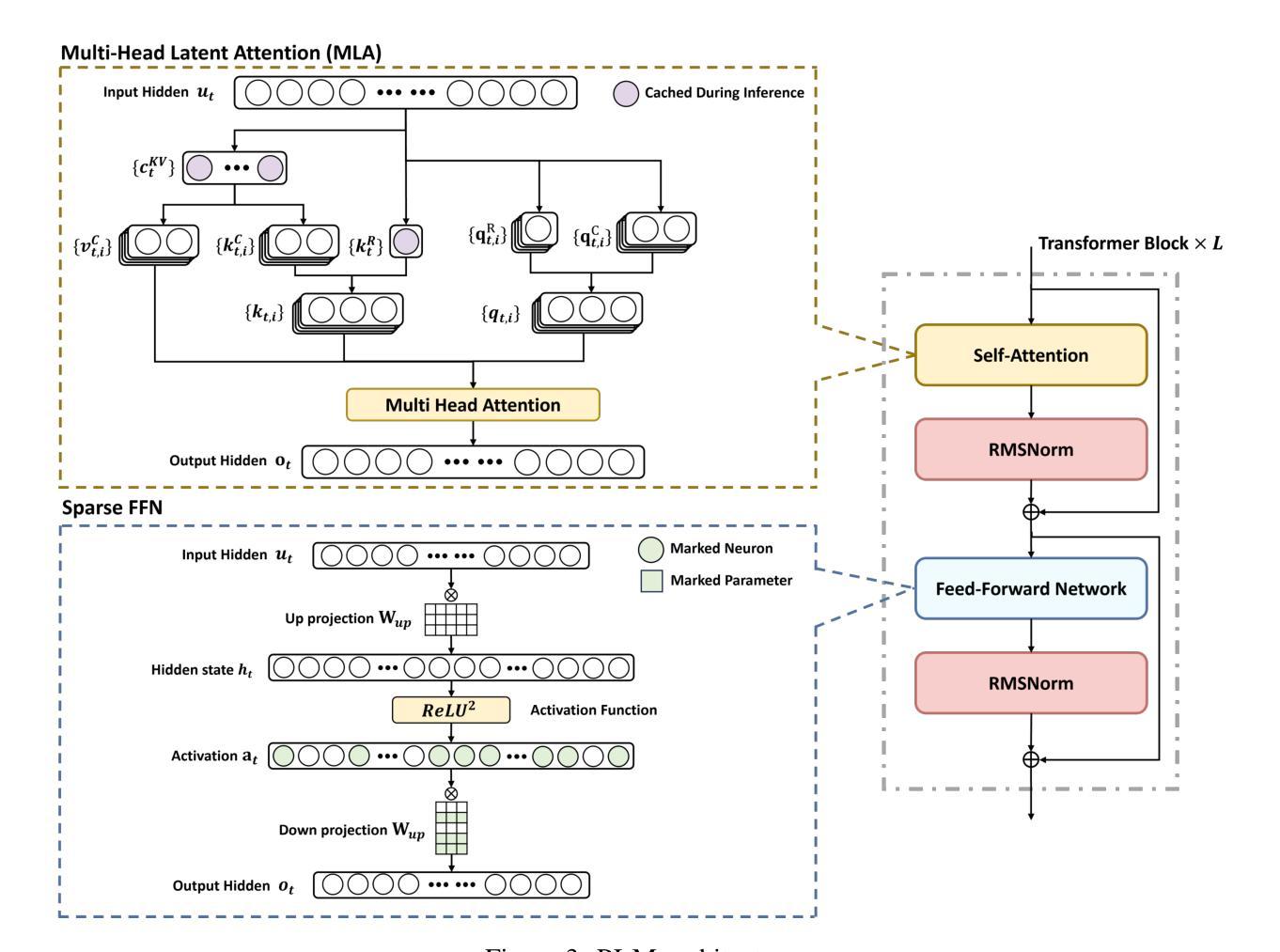
PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Authors:Cheng Deng, Luoyang Sun, Jiwen Jiang, Yongcheng Zeng, Xinjian Wu, Wenxin Zhao, Qingfa Xiao, Jiachuan Wang, Haoyang Li, Lei Chen, Lionel M. Ni, Haifeng Zhang, Jun Wang
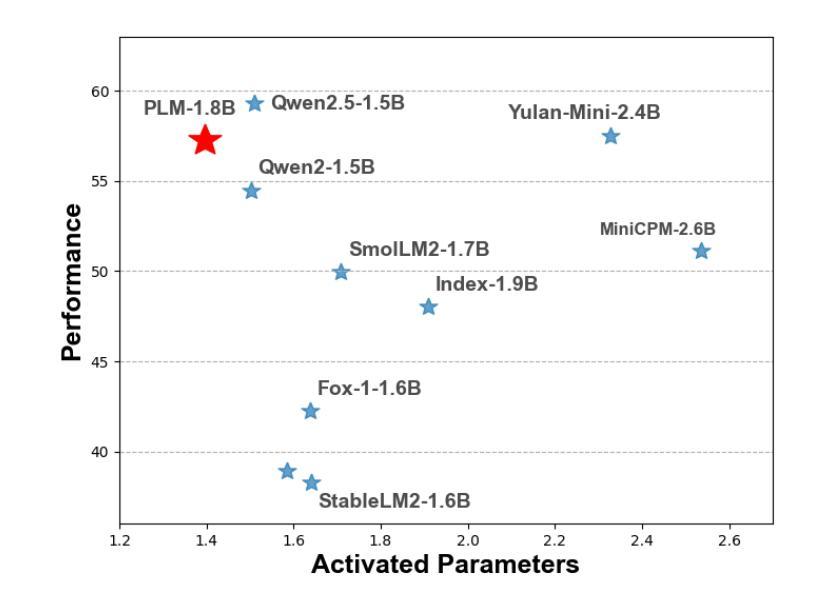
While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM’s suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
在大语言模型(LLM)中,随着模型参数的增加,比例定律不断得到验证。然而,大语言模型的推理需求与边缘设备的有限资源之间存在的固有矛盾,给边缘智能的发展带来了巨大挑战。近期,出现了许多小型语言模型,旨在将大语言模型的能力转化为更小的模型规模。然而,这些模型通常保留其大型模型的基本架构原则,仍然对边缘设备的存储和带宽容量造成相当大的压力。在本文中,我们介绍了一种周边语言模型(PLM),通过联合优化模型架构和边缘系统约束的协同设计过程而开发。PLM利用多头潜在注意力机制,并采用平方ReLU激活函数来促进稀疏性,从而减少推理过程中的峰值内存占用。在训练过程中,我们收集和重新组织了开源数据集,实施了多阶段训练策略,并对预热稳定衰减恒定(WSDC)学习率调度器进行了实证研究。此外,我们通过采用ARIES偏好学习方法,融入了人类反馈强化学习(RLHF)。经过两阶段的SFT过程后,该方法在一般任务上提高了2%的性能,在GSM8K任务上提高了9%,在编码任务上提高了11%。除了其新颖的架构外,评估结果表明PLM在公开数据上训练的现有小型语言模型之上表现出色,同时保持了最低的活动参数数量。此外,在各种边缘设备上的部署,包括消费级GPU、手机和Raspberry Pis,验证了PLM在周边应用的适用性。PLM系列模型可在https://github.com/plm-team/PLM公开访问。
论文及项目相关链接
Summary
该文介绍了一种新型的周边语言模型(PLM),通过联合优化模型架构和边缘系统约束进行设计。PLM采用多头潜在注意力机制和平方ReLU激活函数,以减少推理过程中的内存峰值消耗。通过收集和组织开源数据集,实施多阶段训练策略,并引入WSDC学习率调度器和采用ARIES偏好学习方法的强化学习人类反馈(RLHF)。研究结果显示,PLM在一般性任务、GSM8K任务和编码任务上的性能分别提高了2%、9%和11%。与其他小型语言模型相比,PLM在公开数据上的表现更优秀,同时拥有激活参数数量最少的优势。此外,PLM系列模型已在各种边缘设备上进行了部署验证,包括消费级GPU、手机和Raspberry Pi等。
Key Takeaways
- PLM是一种新型的周边语言模型,针对边缘设备的资源限制进行优化设计。
- PLM采用多头潜在注意力机制和平方ReLU激活函数来减少推理时的内存消耗。
- PLM通过收集和组织开源数据集,实施多阶段训练策略来提高性能。
- PLM引入WSDC学习率调度器和强化学习人类反馈(RLHF)方法,提升模型表现。
- PLM在一般性任务、GSM8K任务和编码任务上的性能提升显著。
- PLM在公开数据上的表现优于其他小型语言模型,同时具有较少的激活参数。
点此查看论文截图





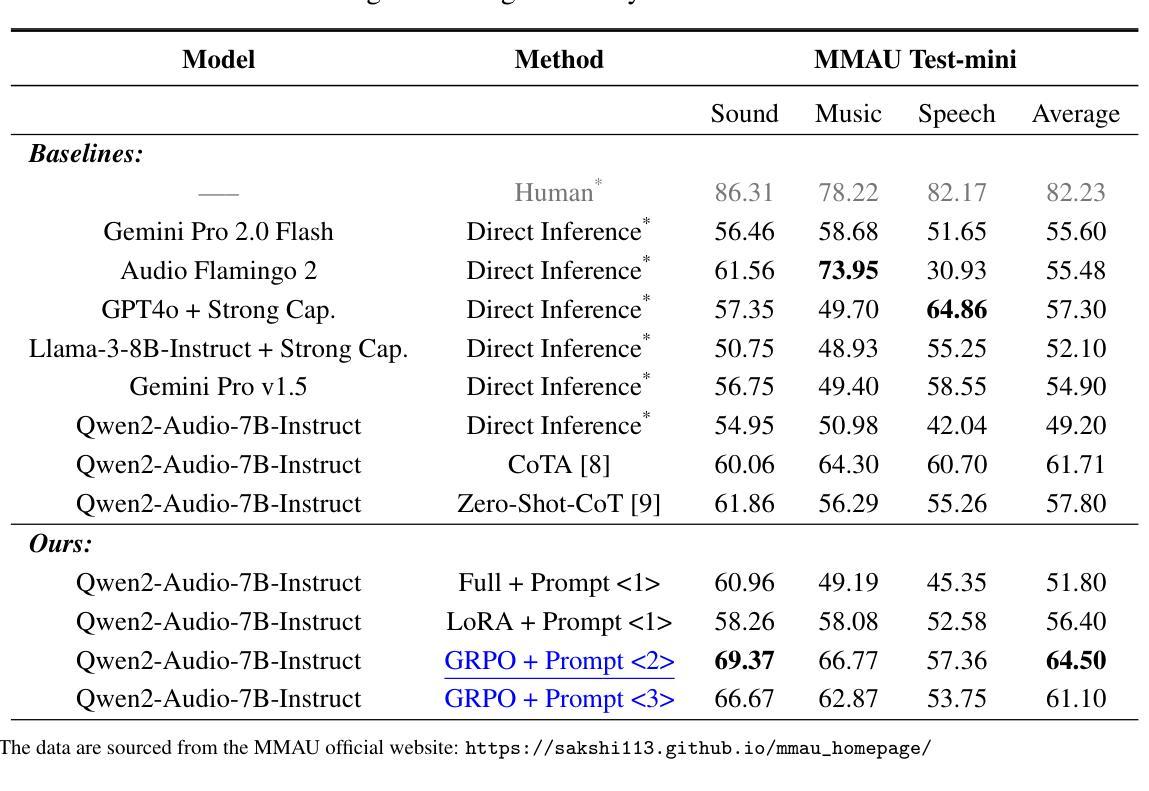
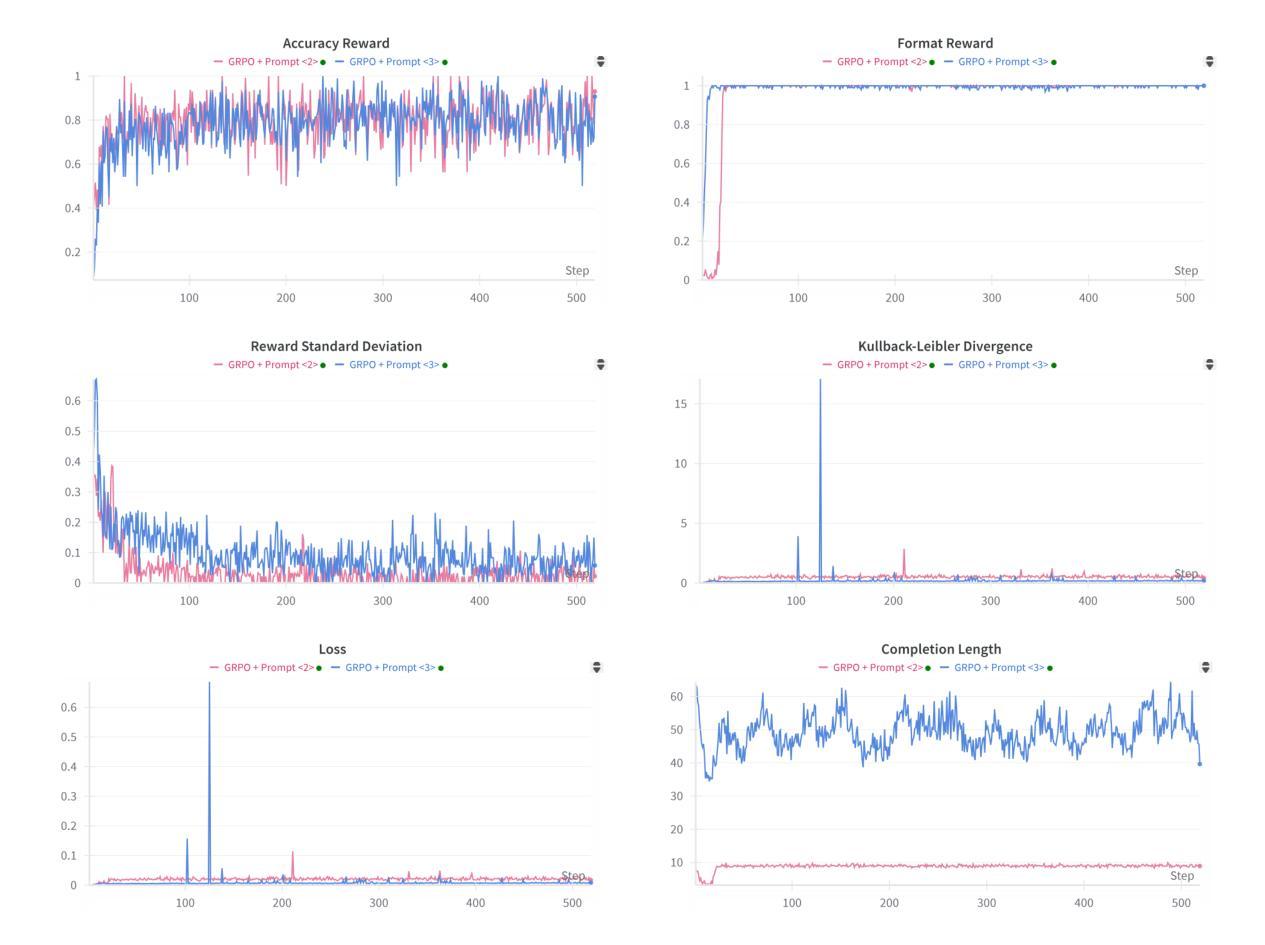
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering
Authors:Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang, Jian Luan
Recently, reinforcement learning (RL) has been shown to greatly enhance the reasoning capabilities of large language models (LLMs), and RL-based approaches have been progressively applied to visual multimodal tasks. However, the audio modality has largely been overlooked in these developments. Thus, we conduct a series of RL explorations in audio understanding and reasoning, specifically focusing on the audio question answering (AQA) task. We leverage the group relative policy optimization (GRPO) algorithm to Qwen2-Audio-7B-Instruct, and our experiments demonstrated state-of-the-art performance on the MMAU Test-mini benchmark, achieving an accuracy rate of 64.5%. The main findings in this technical report are as follows: 1) The GRPO algorithm can be effectively applied to large audio language models (LALMs), even when the model has only 8.2B parameters; 2) With only 38k post-training samples, RL significantly outperforms supervised fine-tuning (SFT), indicating that RL-based approaches can be effective without large datasets; 3) The explicit reasoning process has not shown significant benefits for AQA tasks, and how to efficiently utilize deep thinking remains an open question for further research; 4) LALMs still lag far behind humans auditory-language reasoning, suggesting that the RL-based approaches warrant further exploration. Our project is available at https://github.com/xiaomi-research/r1-aqa and https://huggingface.co/mispeech/r1-aqa.
近期,强化学习(RL)被证明可以极大地提升大型语言模型(LLM)的推理能力,并且基于RL的方法已逐渐应用于视觉多模态任务。然而,音频模态在这些发展中却被很大程度上忽视了。因此,我们在音频理解和推理中进行了一系列RL探索,特别关注音频问答(AQA)任务。我们利用集团相对策略优化(GRPO)算法对Qwen2-Audio-7B-Instruct进行了优化,实验表明在MMAU Test-mini基准测试中达到了最先进的性能,准确率为64.5%。本技术报告的主要发现如下:1)GRPO算法可有效应用于大型音频语言模型(LALM),即使模型只有8.2B参数;2)仅使用38k个后训练样本,RL就显著优于监督微调(SFT),表明基于RL的方法在不需要大规模数据集的情况下也能有效;3)明确的推理过程并未显示出对AQA任务的重大益处,如何有效利用深度思考仍是未来研究的一个开放问题;4)LALM仍然远远落后于人类的听觉语言推理,这表明基于RL的方法需要进一步探索。我们的项目可在[https://github.com/xiaomi-research/r1-aqa和https://huggingface.co/mispeech/r1-aqa访问。]
论文及项目相关链接
摘要
强化学习(RL)在提升大型语言模型(LLM)的推理能力方面表现优异,且RL方法已逐渐应用于视觉多模态任务。然而,音频模式在这些发展中却被忽视了。因此,我们在音频理解和推理领域进行了一系列RL探索,特别是针对音频问答(AQA)任务。我们利用相对策略优化(GRPO)算法对Qwen2-Audio-7B-Instruct进行了优化,实验表明在MMAU Test-mini基准测试中取得了领先水平,准确率为64.5%。本技术报告的主要发现包括:GRPO算法可有效地应用于大型音频语言模型(LALM);仅需3.8万份训练后样本,RL便显著优于监督微调(SFT),表明RL方法可在无需大型数据集的情况下有效;在AQA任务中,明确的推理过程并未显示出显著优势,如何有效利用深度思考仍是未来研究的开放问题;LALM在听觉语言推理方面仍远远落后于人类,这表明RL方法需要进一步探索。我们的项目可在链接1和链接2找到。
关键见解
- GRPO算法可有效应用于大型音频语言模型(LALM)。
- 在仅有少量训练后样本的情况下,强化学习显著优于监督微调。
- 在AQA任务中,明确的推理过程并未显示出明显优势。
- 如何有效利用深度思考在AQA任务中是未来研究的重点。
- LALM在听觉语言推理方面仍远远落后于人类。
- RL方法在音频问答领域的潜力巨大,值得进一步探索。
点此查看论文截图




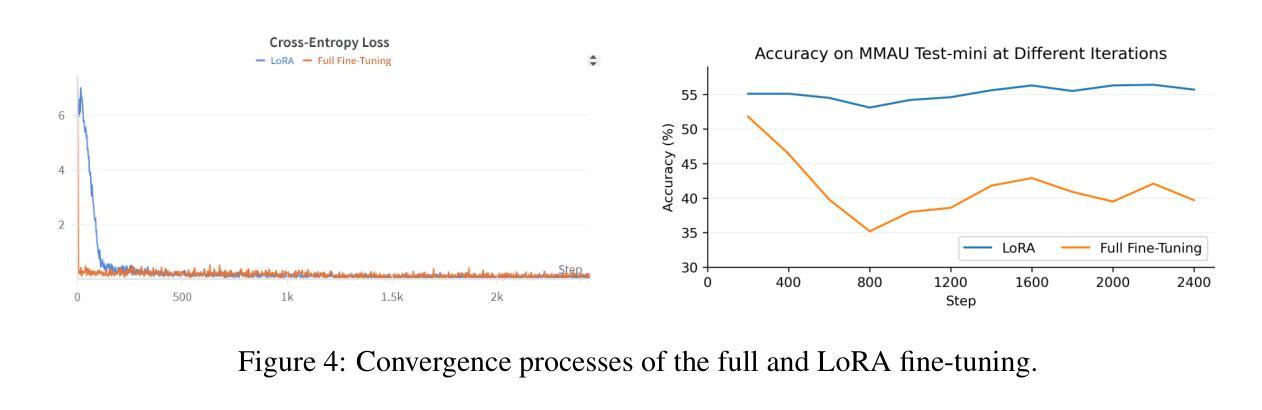
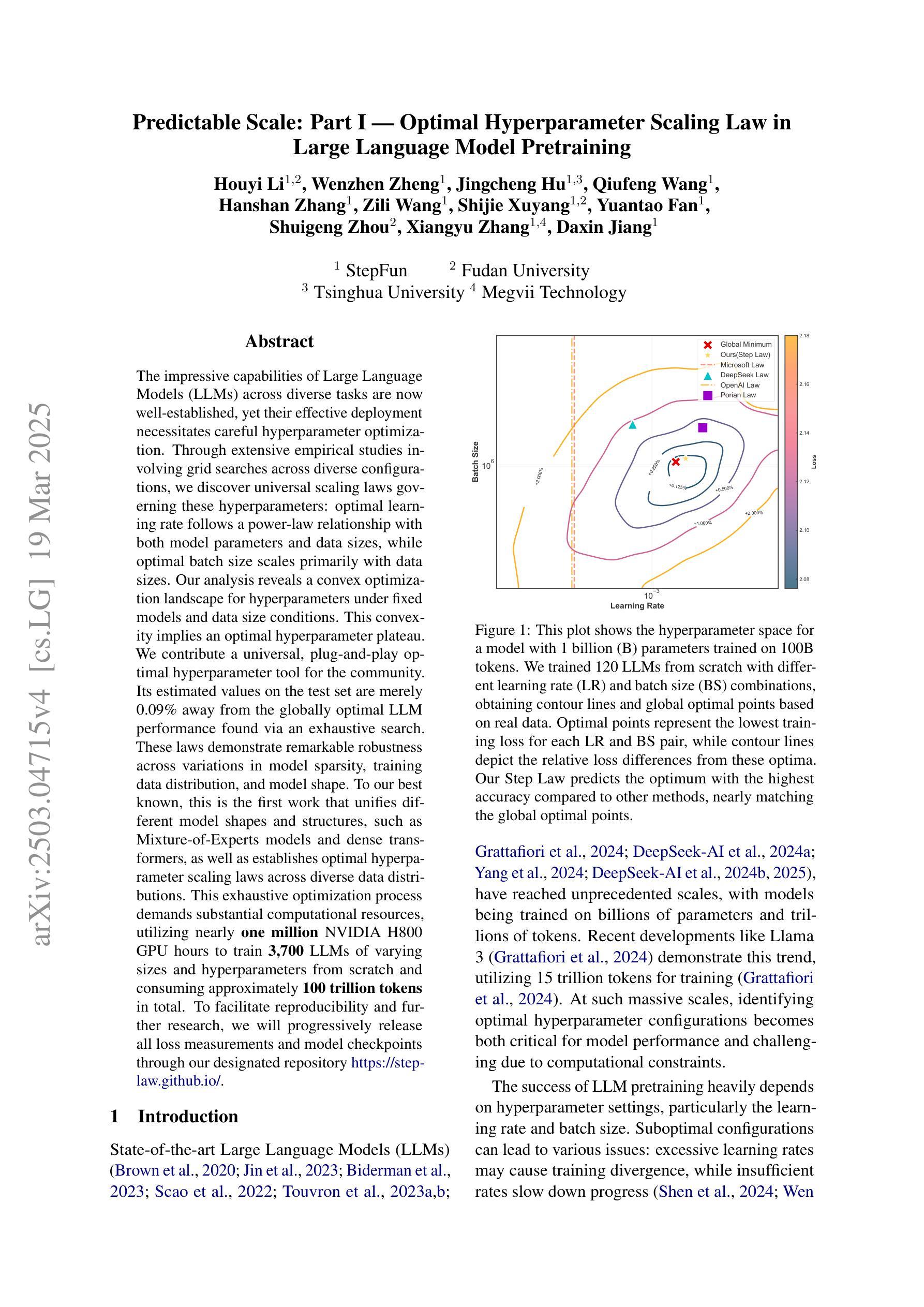
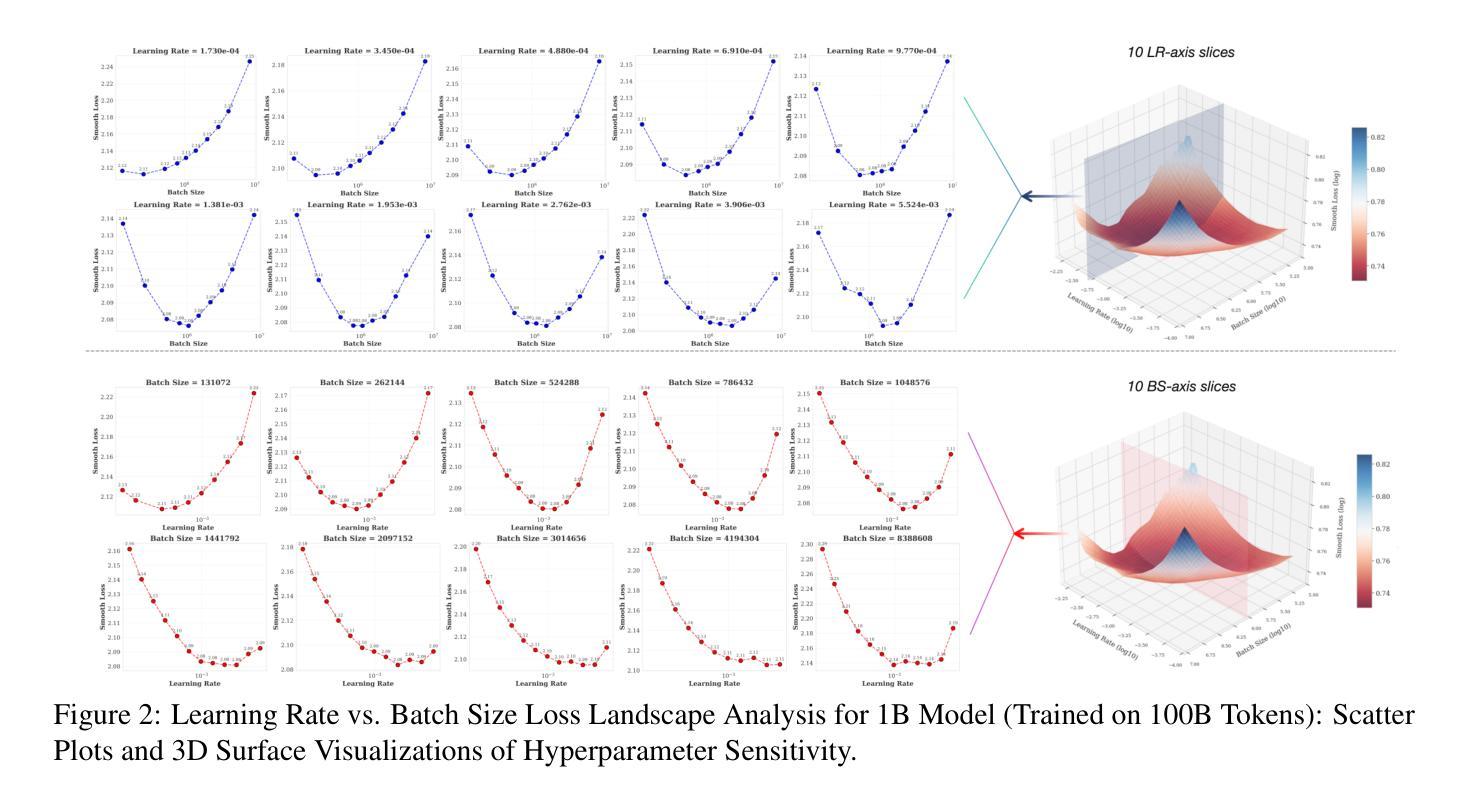
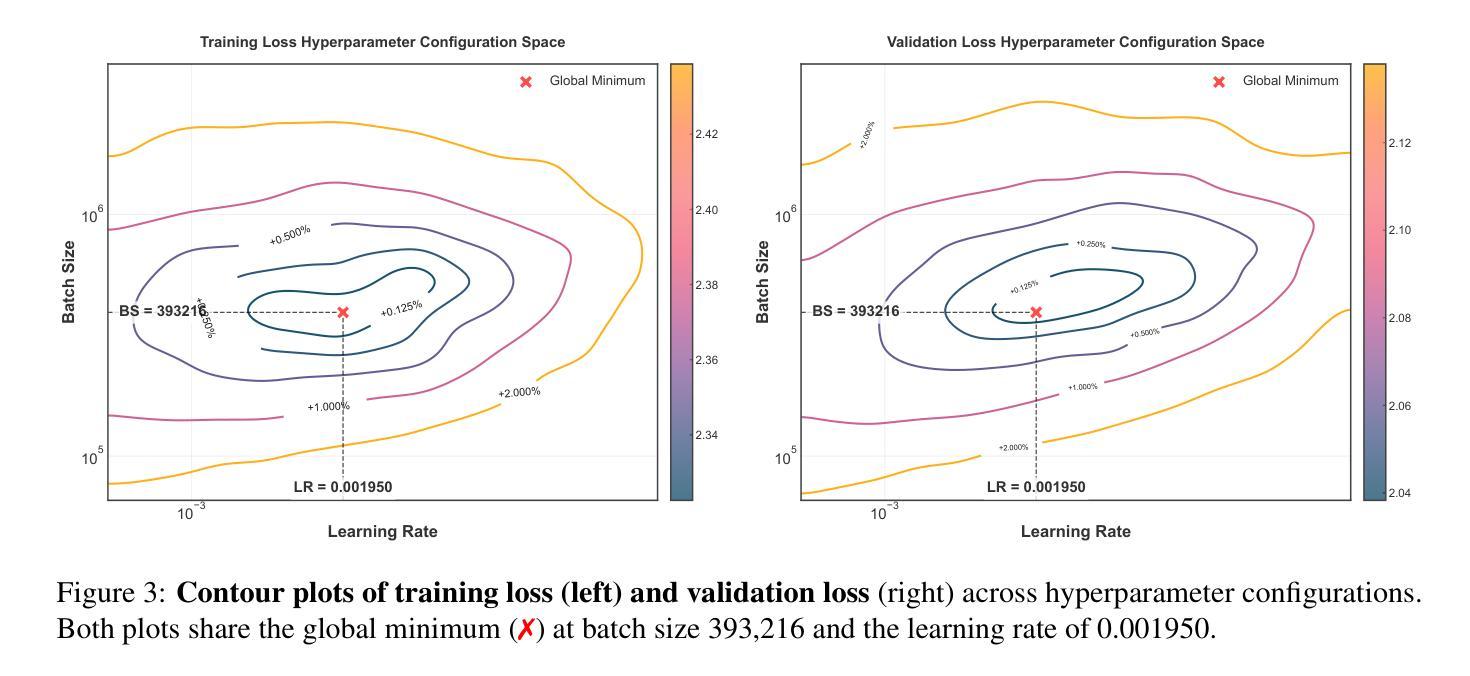
Predictable Scale: Part I – Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
Authors:Houyi Li, Wenzhen Zheng, Jingcheng Hu, Qiufeng Wang, Hanshan Zhang, Zili Wang, Shijie Xuyang, Yuantao Fan, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang
The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well-established, yet their effective deployment necessitates careful hyperparameter optimization. Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. This convexity implies an optimal hyperparameter plateau. We contribute a universal, plug-and-play optimal hyperparameter tool for the community. Its estimated values on the test set are merely 0.09% away from the globally optimal LLM performance found via an exhaustive search. These laws demonstrate remarkable robustness across variations in model sparsity, training data distribution, and model shape. To our best known, this is the first work that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data distributions. This exhaustive optimization process demands substantial computational resources, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch and consuming approximately 100 trillion tokens in total. To facilitate reproducibility and further research, we will progressively release all loss measurements and model checkpoints through our designated repository https://step-law.github.io/
大型语言模型(LLM)在多种任务上的出色能力现已得到广泛认可,但其有效部署仍需进行细致的超参数优化。通过涉及不同配置的网格搜索的广泛实证研究,我们发现了这些超参数的通用缩放定律:最佳学习率与模型参数和数据大小呈幂律关系,而最佳批次大小主要随数据大小进行缩放。我们的分析显示,在固定模型和数据大小条件下,超参数的优化景观呈现凸性。这种凸性意味着存在一个最佳超参数平台。我们为社区贡献了一个通用的、即插即用的最佳超参数工具。其在测试集上的估计值与通过穷尽搜索找到的全局最佳LLM性能仅相差0.09%。这些定律在模型稀疏性、训练数据分布和模型形状的变化中表现出惊人的稳健性。据我们所知,这是第一项统一不同模型形状和结构的工作,如专家混合模型和密集转换器,并建立了不同数据分布下的最佳超参数缩放定律。这一详尽的优化过程需要大量的计算资源,利用近百万的NVIDIA H800 GPU小时从头开始训练3700个不同大小和超参数的LLM,总共消耗约10万亿个令牌。为了方便复现和进一步研究,我们将逐步发布所有损失测量和模型检查点,可通过我们的指定仓库https://step-law.github.io/访问。
论文及项目相关链接
PDF 22 pages
Summary
大型语言模型(LLM)在各项任务中展现出强大的能力,但其有效部署需要进行精细的超参数优化。通过广泛的实证研究,我们发现了普遍的超参数缩放定律:最佳学习率与模型参数和数据集大小呈幂律关系,而最佳批次大小主要随数据集大小而缩放。分析显示,在固定模型和数据集条件下,超参数具有凸优化景观,意味着存在最佳超参数平台。我们为社区贡献了一个通用、即插即用的最佳超参数工具,其估计值在测试集上距离通过全面搜索找到的全局最佳LLM性能仅有0.09%的差距。这些定律在模型稀疏性、训练数据分布和模型结构变化方面展现出惊人的稳健性。我们的工作统一了不同的模型结构和形状,如Mixture-of-Experts模型和密集变压器,并建立了跨不同数据分布的最佳超参数缩放定律。
Key Takeaways
- LLM在多种任务中表现出强大的能力,超参数优化对其有效部署至关重要。
- 通过实证研究,发现了超参数的普遍缩放定律,包括最佳学习率与模型参数和数据集大小的幂律关系以及最佳批次大小与数据集大小的关联。
- 固定模型和数据集条件下,超参数具有凸优化景观,存在最佳超参数平台。
- 提出一个通用、即插即用的最佳超参数工具,其性能接近全局最优。
- 这些定律在模型稀疏性、训练数据分布和模型结构变化方面表现出稳健性。
- 研究成果统一了不同的模型结构和形状,如Mixture-of-Experts模型和密集变压器。
点此查看论文截图


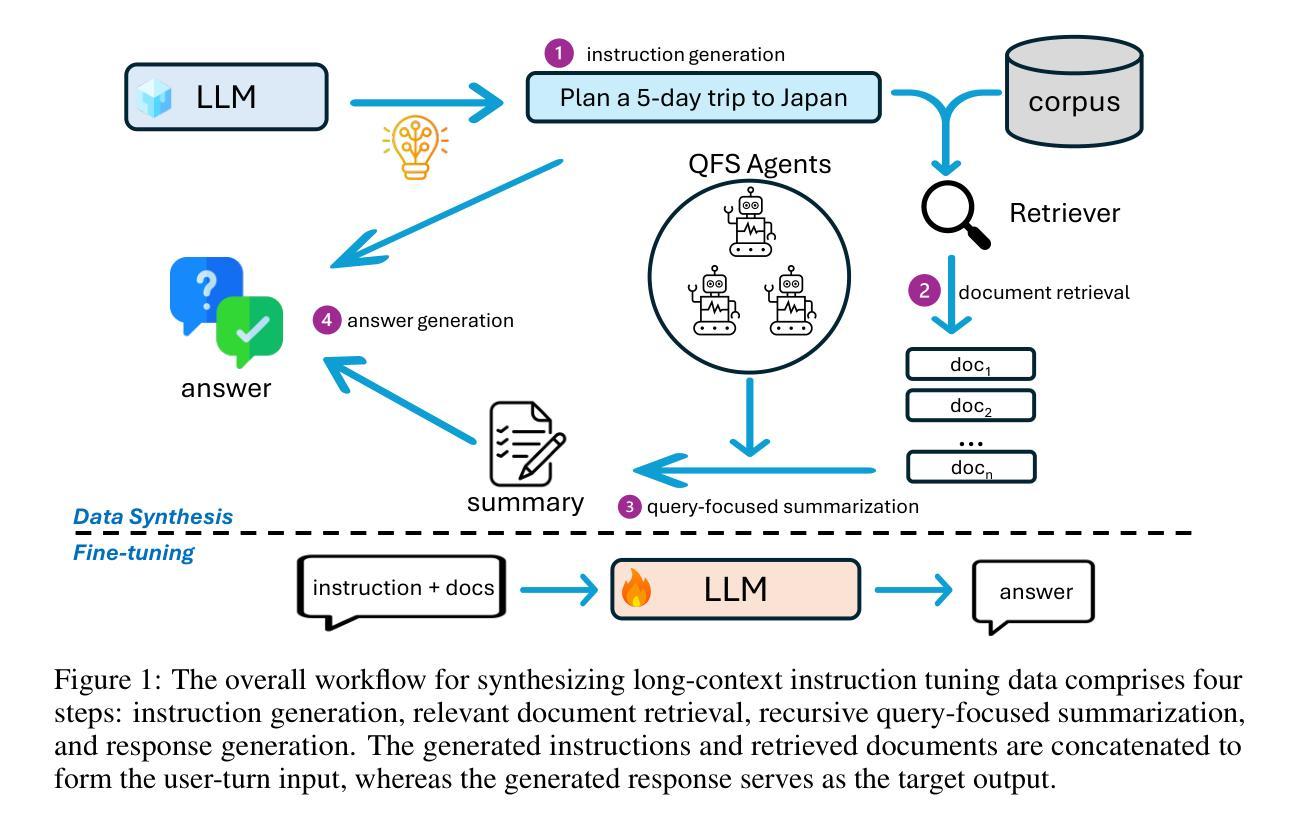
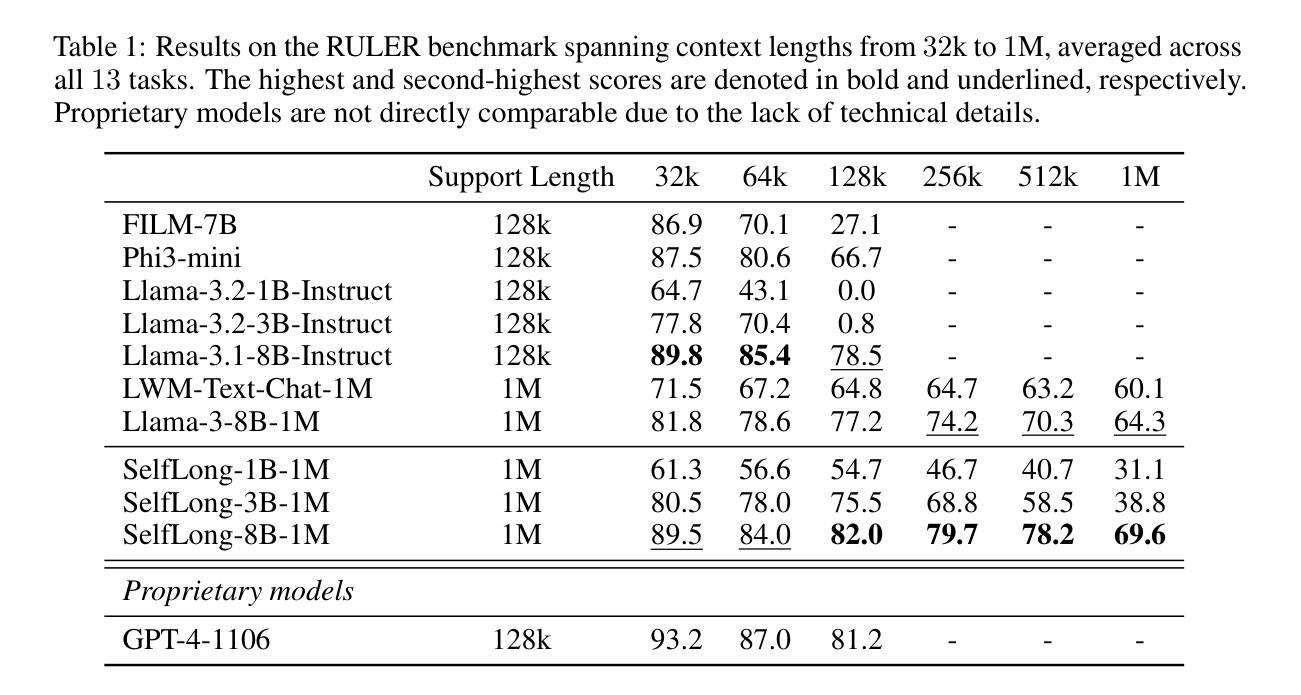
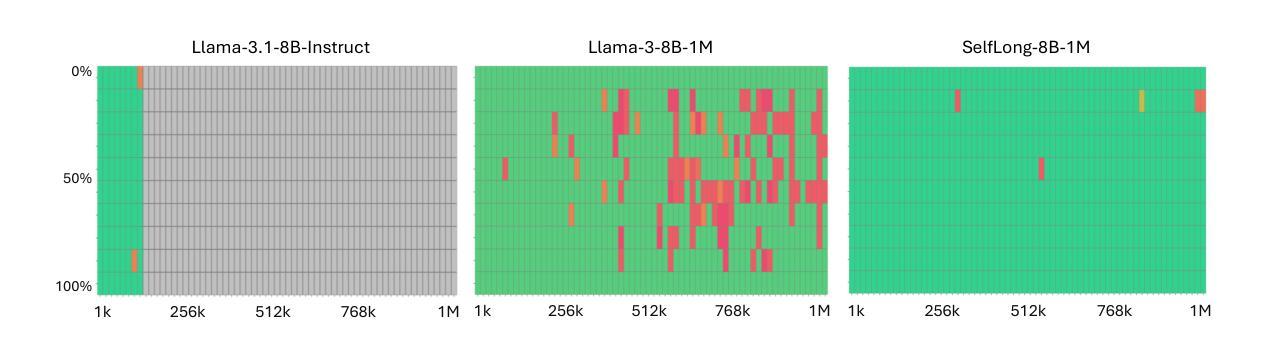
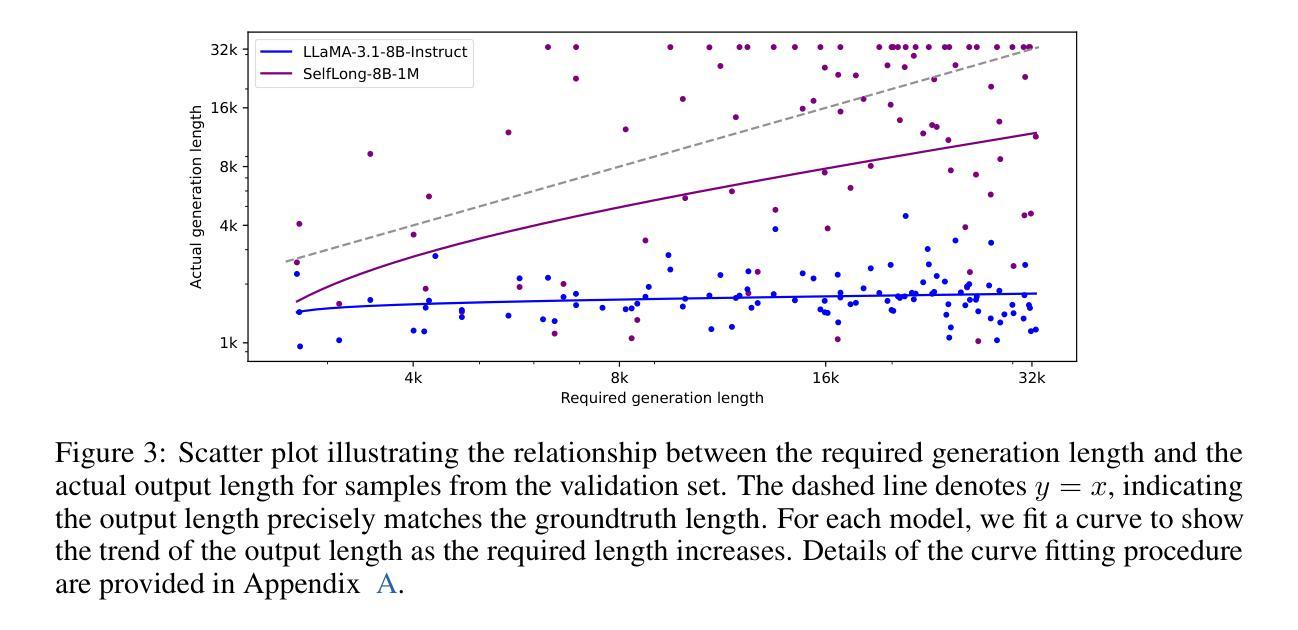
Bootstrap Your Own Context Length
Authors:Liang Wang, Nan Yang, Xingxing Zhang, Xiaolong Huang, Furu Wei
We introduce a bootstrapping approach to train long-context language models by exploiting their short-context capabilities only. Our method utilizes a simple agent workflow to synthesize diverse long-context instruction tuning data, thereby eliminating the necessity for manual data collection and annotation. The proposed data synthesis workflow requires only a short-context language model, a text retriever, and a document collection, all of which are readily accessible within the open-source ecosystem. Subsequently, language models are fine-tuned using the synthesized data to extend their context lengths. In this manner, we effectively transfer the short-context capabilities of language models to long-context scenarios through a bootstrapping process. We conduct experiments with the open-source Llama-3 family of models and demonstrate that our method can successfully extend the context length to up to 1M tokens, achieving superior performance across various benchmarks.
我们提出了一种利用长文本生成模型短语境能力的引导方法来进行训练。我们的方法通过一个简单的代理工作流程来合成多种长语境指令调整数据,从而消除了手动收集和标注数据的必要性。所提出的数据合成工作流程仅需要短语境语言模型、文本检索器和文档集合,所有这些都可以在开源生态系统中轻松获取。随后,使用合成数据对语言模型进行微调,以扩展其上下文长度。通过这种方式,我们通过一个引导过程有效地将语言模型的短语境能力转移到长语境场景中。我们使用开源的Llama-3系列模型进行实验,并证明我们的方法可以将上下文长度成功扩展到最多1M个令牌,在各种基准测试中表现出卓越的性能。
论文及项目相关链接
PDF 19 pages
Summary
本文介绍了一种利用短语境能力来训练长语境语言模型的引导方法。该方法通过简单的代理工作流程合成多样的长语境指令调整数据,无需手动收集和标注数据。使用短语境语言模型、文本检索器和文档集合等开源生态系统中的资源即可实现数据合成。随后,使用合成数据对语言模型进行微调以扩展其上下文长度。通过这种方式,我们通过引导过程有效地将语言模型的短语境能力转移到长语境场景。
Key Takeaways
- 引入了一种利用短语境能力训练长语境语言模型的引导方法。
- 通过简单的代理工作流程合成长语境指令调整数据,避免手动数据收集和标注。
- 使用短语境语言模型、文本检索器和文档集合等开源资源实现数据合成。
- 通过微调语言模型使用合成数据来扩展其上下文长度。
- 成功将语言模型的短语境能力转移到长语境场景。
- 在开源Llama-3家族模型上进行了实验,成功将上下文长度扩展到1M令牌。
点此查看论文截图

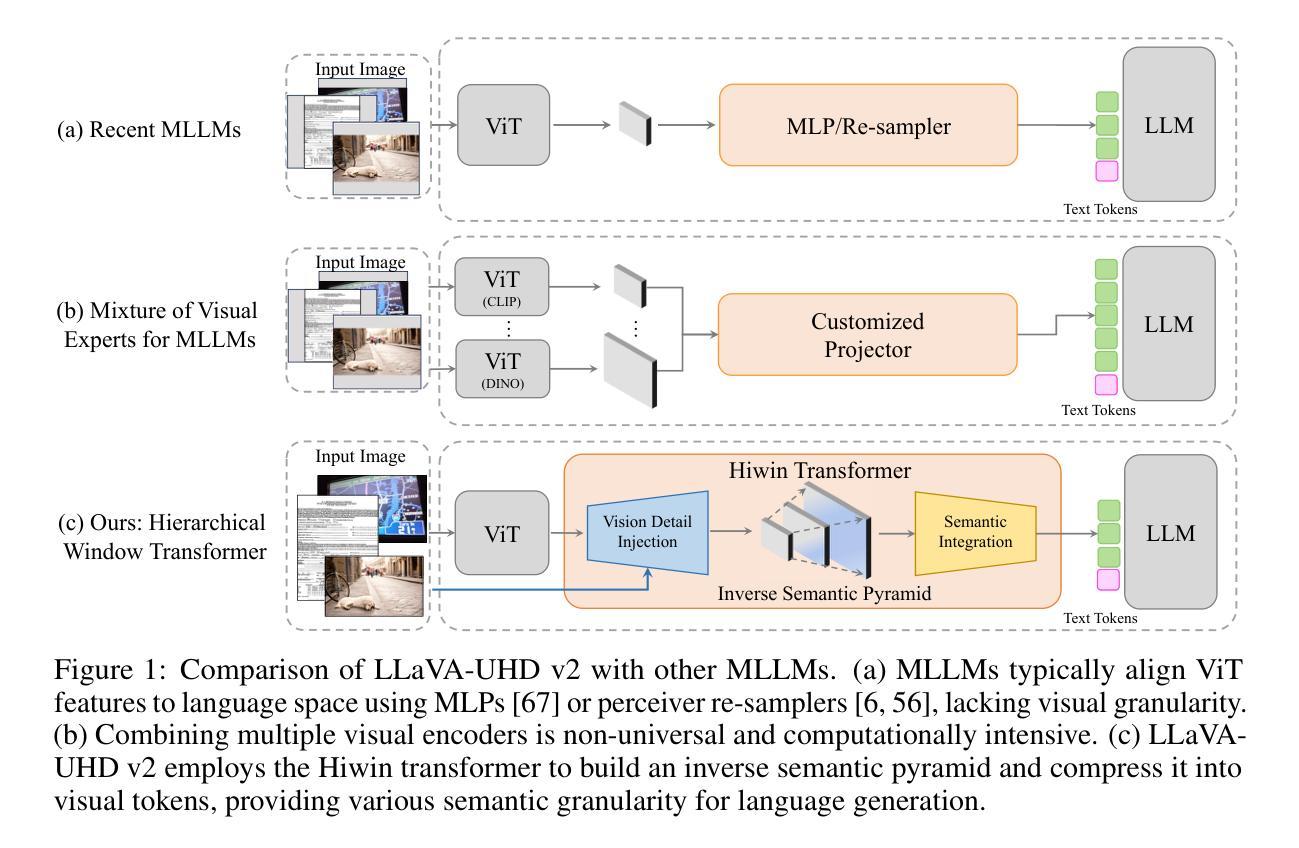
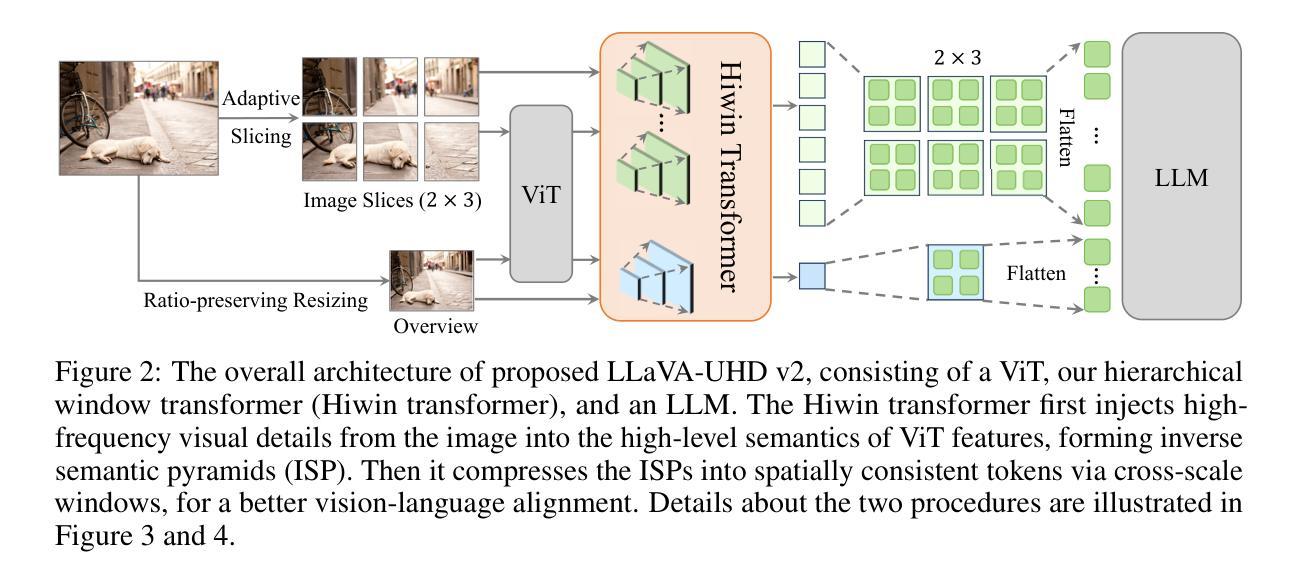
LLaVA-UHD v2: an MLLM Integrating High-Resolution Semantic Pyramid via Hierarchical Window Transformer
Authors:Yipeng Zhang, Yifan Liu, Zonghao Guo, Yidan Zhang, Xuesong Yang, Xiaoying Zhang, Chi Chen, Jun Song, Bo Zheng, Yuan Yao, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun
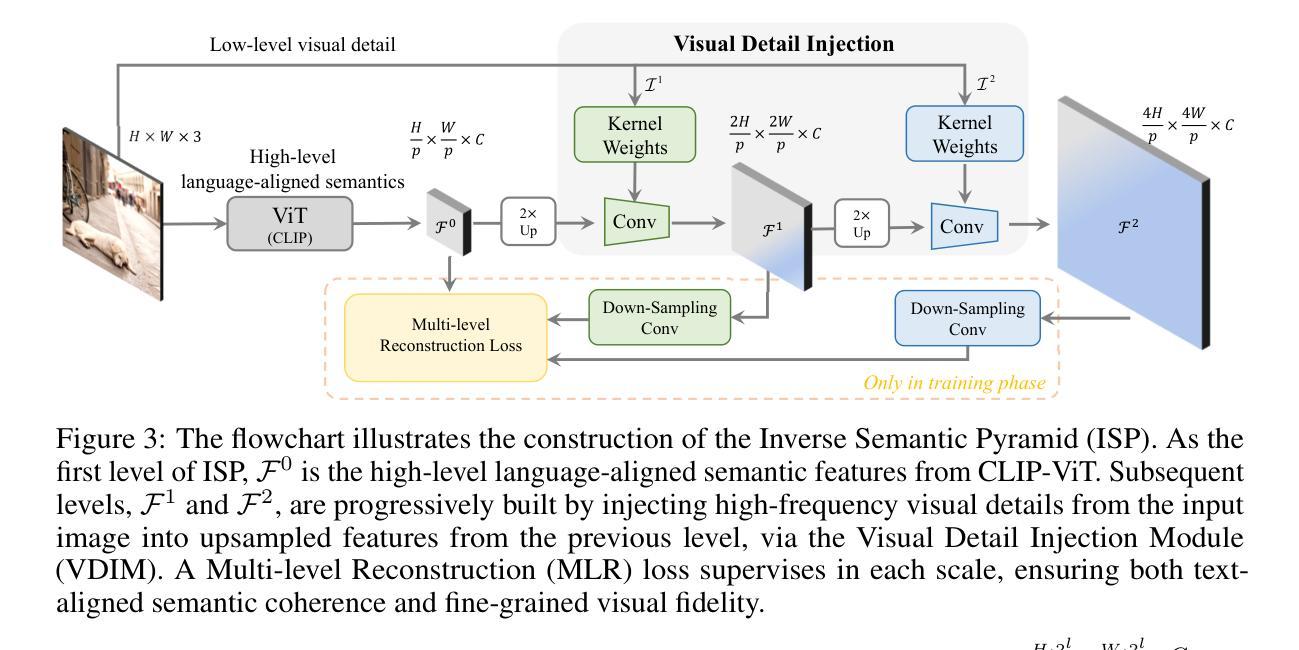
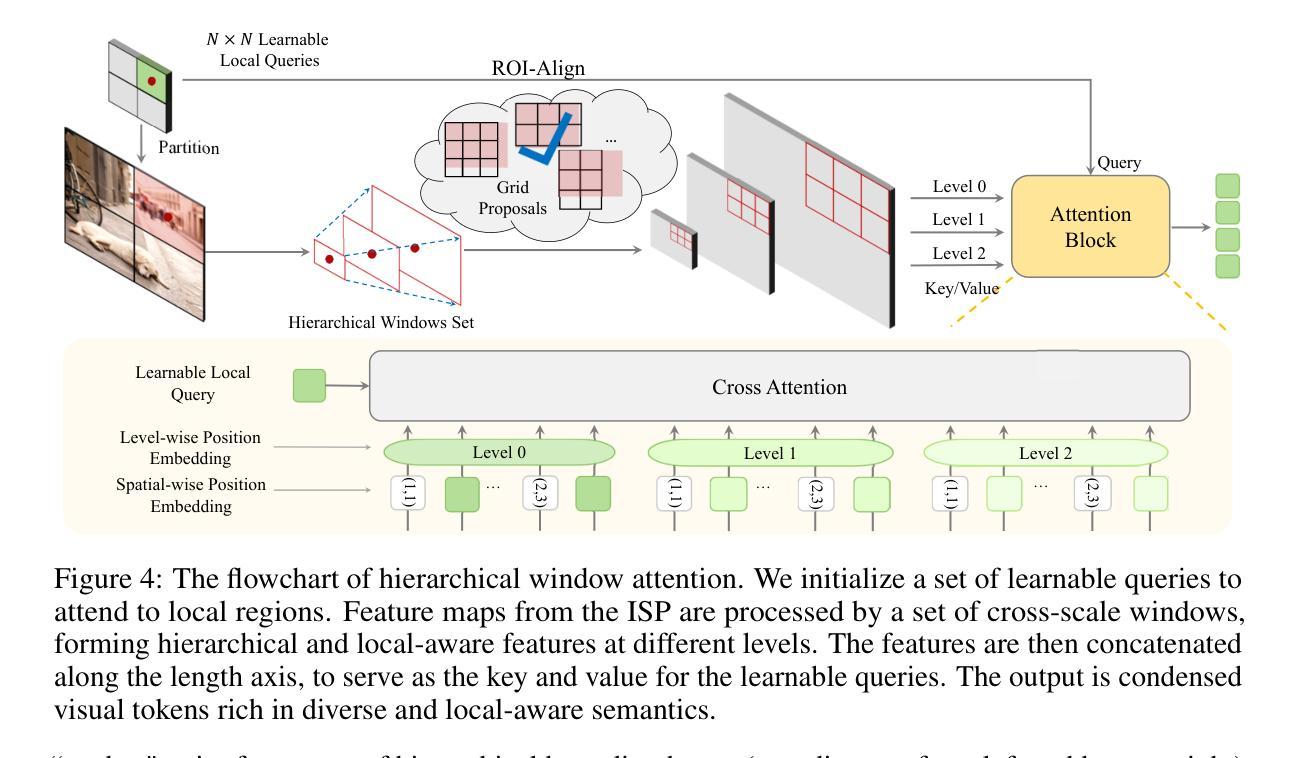
Vision transformers (ViTs) are widely employed in multimodal large language models (MLLMs) for visual encoding. However, they exhibit inferior performance on tasks regarding fine-grained visual perception. We attribute this to the limitations of ViTs in capturing diverse multi-modal visual levels, such as low-level details. To address this issue, we present LLaVA-UHD v2, an MLLM with advanced perception abilities by introducing a well-designed vision-language projector, the Hierarchical window (Hiwin) transformer. Hiwin transformer enhances MLLM’s ability to capture diverse multi-modal visual granularities, by incorporating our constructed high-resolution semantic pyramid. Specifically, Hiwin transformer comprises two key modules: (i) a visual detail injection module, which progressively injects low-level visual details into high-level language-aligned semantics features, thereby forming an inverse semantic pyramid (ISP), and (ii) a hierarchical window attention module, which leverages cross-scale windows to condense multi-level semantics from the ISP. Extensive experiments show that LLaVA-UHD v2 outperforms compared MLLMs on a wide range of benchmarks. Notably, our design achieves an average boost of 3.7% across 14 benchmarks compared with the baseline method, 9.3% on DocVQA for instance. All the data and code will be publicly available to facilitate future research.
视觉转换器(ViTs)在多模态大型语言模型(MLLMs)中广泛应用于视觉编码。然而,在精细视觉感知任务方面,它们的表现较差。我们将这归因于ViTs在捕捉多样多模态视觉层次方面的局限性,例如低级细节。为了解决这一问题,我们推出了LLaVA-UHD v2,这是一个具有先进感知能力的大型多模态语言模型,它通过引入精心设计好的视觉语言投影仪——分层窗口(Hiwin)转换器来实现。Hiwin转换器通过融入我们构建的高分辨率语义金字塔,增强了大型多模态语言模型捕捉多样多模态视觉细粒度信息的能力。具体来说,Hiwin转换器包含两个关键模块:(i)视觉细节注入模块,它逐步将低级别的视觉细节注入到高级的语言对齐语义特征中,从而形成逆语义金字塔(ISP),(ii)分层窗口注意力模块,它利用跨尺度窗口来浓缩ISP中的多级语义。大量实验表明,LLaVA-UHD v2在广泛的基准测试中表现出优于其他大型多模态语言模型的效果。值得注意的是,与基准方法相比,我们的设计在14个基准测试中平均提升了3.7%的性能,如在DocVQA上提升了9.3%。所有数据和代码都将公开发布,以方便未来的研究。
论文及项目相关链接
Summary
该文本介绍了在面向视觉编码的多模态大型语言模型(MLLMs)中,引入了一种名为LLaVA-UHD v2的新型语言模型架构来解决某些现有模型的性能瓶颈问题。其重点在细节层面处理方面的不足问题,并设计了一个专门的视觉语言投影器——分层窗口(Hiwin)转换器来增强模型捕捉多模态视觉细节的能力。Hiwin转换器通过构建高分辨率语义金字塔,实现了对多模态视觉颗粒的精细捕捉。其核心组件包括视觉细节注入模块和层次窗口注意力模块,分别在信息抽取与整合方面发挥了关键作用。实验结果证明LLaVA-UHD v2在多基准测试中表现出优异性能,相比基准方法平均提升3.7%,在文档视觉问答(DocVQA)等特定任务上提升幅度高达9.3%。
Key Takeaways
- LLaVA-UHD v2是一种针对多模态大型语言模型(MLLMs)的新型架构,旨在解决现有模型在精细视觉感知任务上的性能瓶颈问题。
- LLaVA-UHD v2引入了一种称为Hiwin转换器的视觉语言投影器模块,它能够有效捕捉多模态视觉颗粒,通过构建高分辨率语义金字塔提高模型的感知能力。
- Hiwin转换器包含两个核心模块:视觉细节注入模块和层次窗口注意力模块,分别负责向语义特征注入低级别视觉细节和利用跨尺度窗口浓缩多层次语义信息。
- 实验结果表明LLaVA-UHD v2在多基准测试中性能显著优于其他MLLMs模型,相比基准方法平均提升3.7%。在某些特定任务上如文档视觉问答(DocVQA),提升幅度更高达9.3%。
点此查看论文截图

Can LLMs be Good Graph Judger for Knowledge Graph Construction?
Authors:Haoyu Huang, Chong Chen, Conghui He, Yang Li, Jiawei Jiang, Wentao Zhang
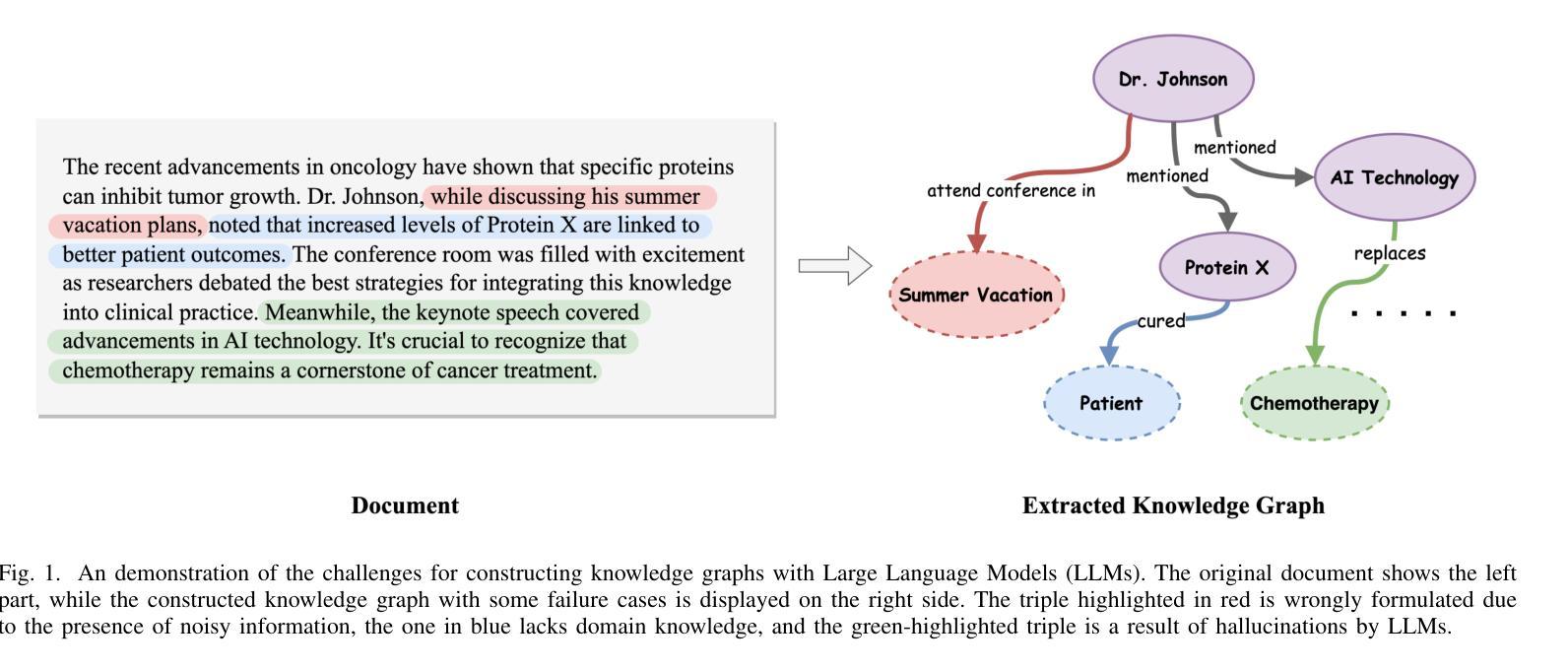
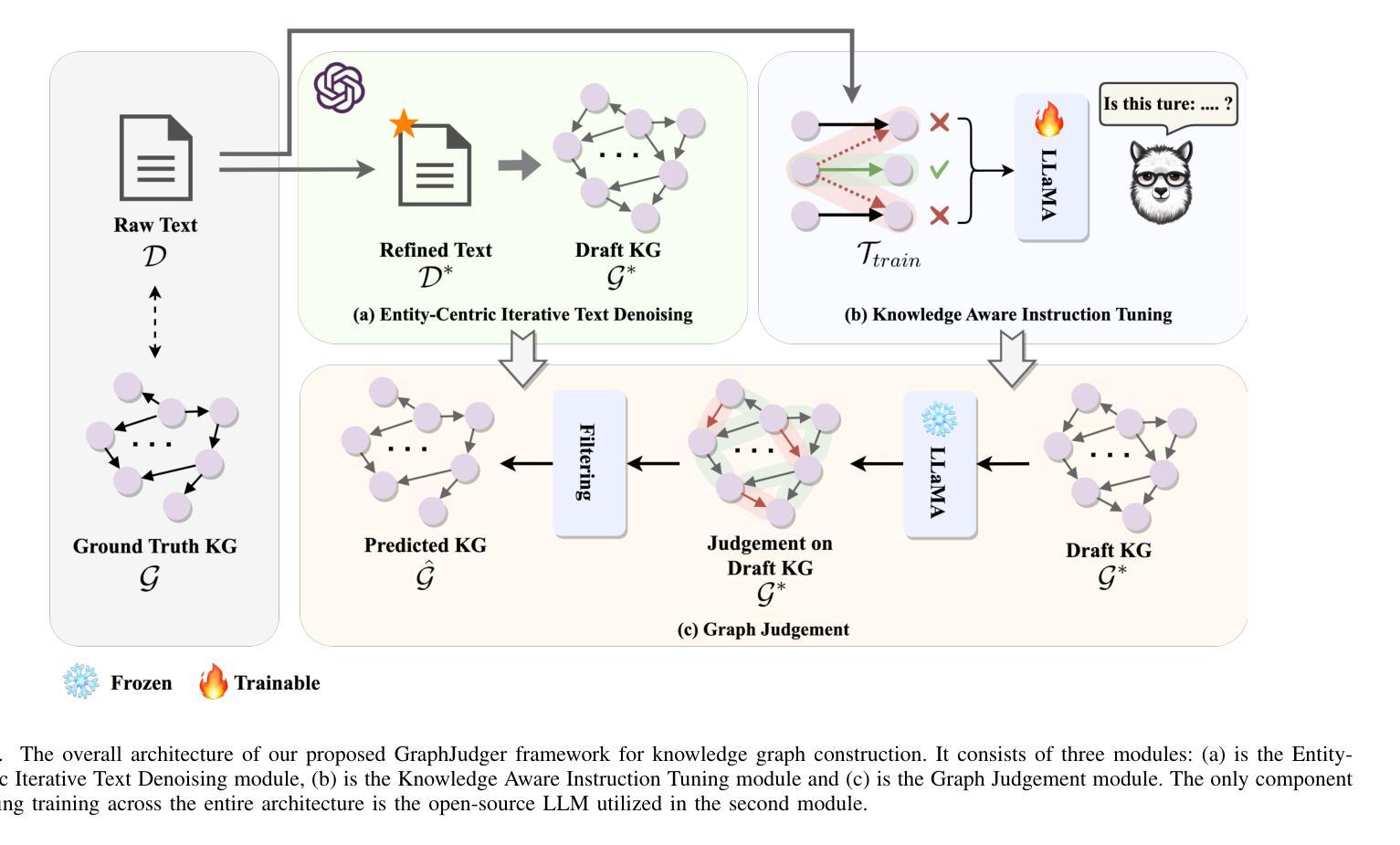
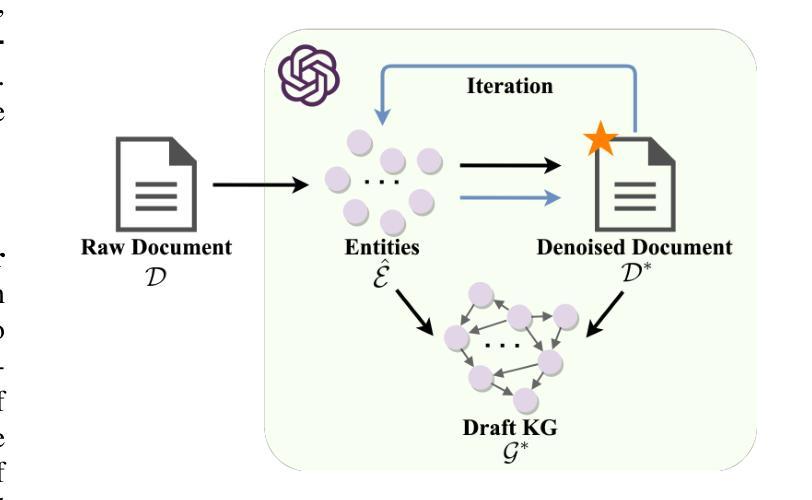
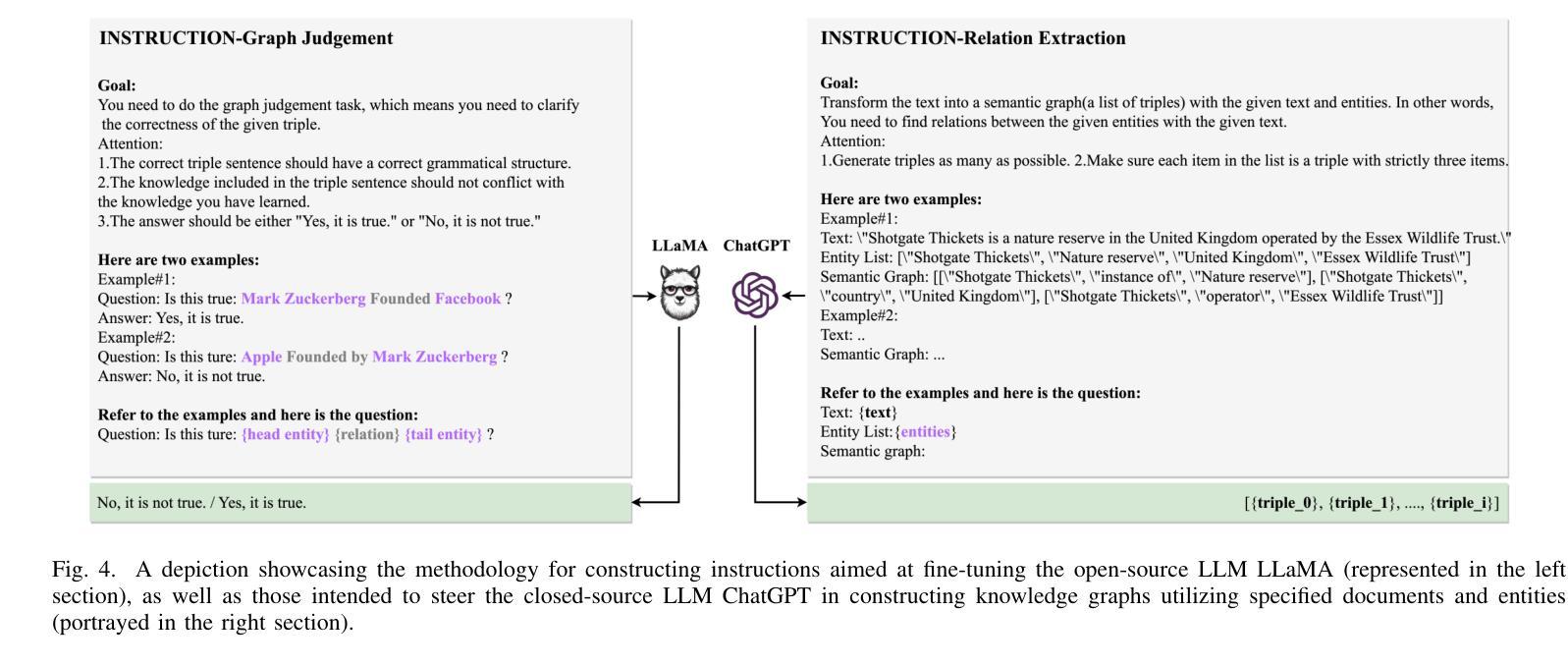
In real-world scenarios, most of the data obtained from information retrieval (IR) system is unstructured. Converting natural language sentences into structured Knowledge Graphs (KGs) remains a critical challenge. The quality of constructed KGs may also impact the performance of some KG-dependent domains like GraphRAG systems and recommendation systems. Recently, Large Language Models (LLMs) have demonstrated impressive capabilities in addressing a wide range of natural language processing tasks. However, there are still challenges when utilizing LLMs to address the task of generating structured KGs. And we have identified three limitations with respect to existing KG construction methods. (1)There is a large amount of information and excessive noise in real-world documents, which could result in extracting messy information. (2)Native LLMs struggle to effectively extract accuracy knowledge from some domain-specific documents. (3)Hallucinations phenomenon cannot be overlooked when utilizing LLMs directly as an unsupervised method for constructing KGs. In this paper, we propose GraphJudger, a knowledge graph construction framework to address the aforementioned challenges. We introduce three innovative modules in our method, which are entity-centric iterative text denoising, knowledge aware instruction tuning and graph judgement, respectively. We seek to utilize the capacity of LLMs to function as a graph judger, a capability superior to their role only as a predictor for KG construction problems. Experiments conducted on two general text-graph pair datasets and one domain-specific text-graph pair dataset show superior performances compared to baseline methods. The code of our proposed method is available at https://github.com/hhy-huang/GraphJudger.
在真实场景中,从信息检索(IR)系统获得的数据大部分是非结构化的。将自然语言句子转换为结构化知识图谱(KGs)仍然是一个关键挑战。构建的知识图谱的质量也可能影响一些依赖知识图谱的领域(如GraphRAG系统和推荐系统)的性能。最近,大型语言模型(LLM)在处理广泛的自然语言处理任务方面表现出了令人印象深刻的能力。然而,在利用LLM解决生成结构化知识图谱的任务时,仍然存在挑战。我们已经确定了现有知识图谱构建方法的三个局限性。(1)真实世界文档中存在大量信息和过多噪音,可能导致提取的信息杂乱无章。(2)原生LLM很难从某些特定领域的文档中有效地提取准确知识。(3)当将LLM直接用作构建知识图谱的无监督方法时,不可忽视虚构现象。在本文中,我们提出了GraphJudger,一个知识图谱构建框架,以解决上述挑战。我们的方法引入了三个创新模块,分别是实体为中心迭代文本去噪、知识感知指令调整和图判断。我们试图利用LLM作为图判断者的能力,发挥其在解决知识图谱构建问题中的优势,而不仅仅是作为预测器。在两种通用文本-图对数据集和一种特定领域的文本-图对数据集上进行的实验显示,与基准方法相比,该方法具有卓越的性能。我们提出的方法的代码可在https://github.com/hhy-huang/GraphJudger获取。
论文及项目相关链接
摘要
在信息检索系统中获取的大部分数据通常是结构化的,这对于构建知识图谱是一大挑战。该文针对此问题提出GraphJudger框架,采用三个创新模块,包括实体为中心的迭代文本去噪、知识感知指令调整和图谱判断,旨在解决现有知识图谱构建方法的局限性。实验证明,GraphJudger在一般文本-图谱对和特定领域文本-图谱对数据集上的性能优于基线方法。该方法的代码已在GitHub上公开。构建高质量知识图谱对于图RA系统和推荐系统等知识图谱依赖领域具有重要影响。利用大型语言模型作为图判官的潜力来构建知识图谱。本研究对自然语言处理领域的实际应用具有重要的理论和实践意义。利用大型语言模型构建知识图谱的挑战仍然存在一些局限和挑战。无法忽视出现误读现象问题,我们仍在积极探索寻找更有效的解决途径和突破方式。我们发现公开数据源与公共用户提供的网页或者具体查询的不同、用户和利益相关者在服务领域中嵌入社会关系的方法和用户需求这些难以完全依赖模型和技术的预测解决的场景问题时面对新的挑战及特定技术应用的特定方法在不同场景的落地差距对于整体决策等方面有一定的影响与指导效果并公开数据及相关工具作为未来的研究方向之一。针对未来研究方向提出了公开数据及相关工具等方向作为研究重点之一,通过探索相关领域和应用的深度研究和发展潜力来解决这些挑战。通过对数据的挖掘和进一步应用优化等改进和创新技术提升知识图谱构建的质量和效率。
关键见解
- 信息检索系统中获取的数据多为非结构化,转化为结构化知识图谱是一大挑战。
- GraphJudger框架通过三个创新模块解决现有知识图谱构建方法的局限性。
- GraphJudger在多个数据集上的性能优于基线方法,具有公开的代码库。
- 构建高质量知识图谱对图RA系统和推荐系统等领域有重要影响。
- LLMs在知识图谱构建中的角色不仅仅是预测器,还可以作为图判官来提高构建质量。
点此查看论文截图