⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
GO-N3RDet: Geometry Optimized NeRF-enhanced 3D Object Detector
Authors:Zechuan Li, Hongshan Yu, Yihao Ding, Jinhao Qiao, Basim Azam, Naveed Akhtar
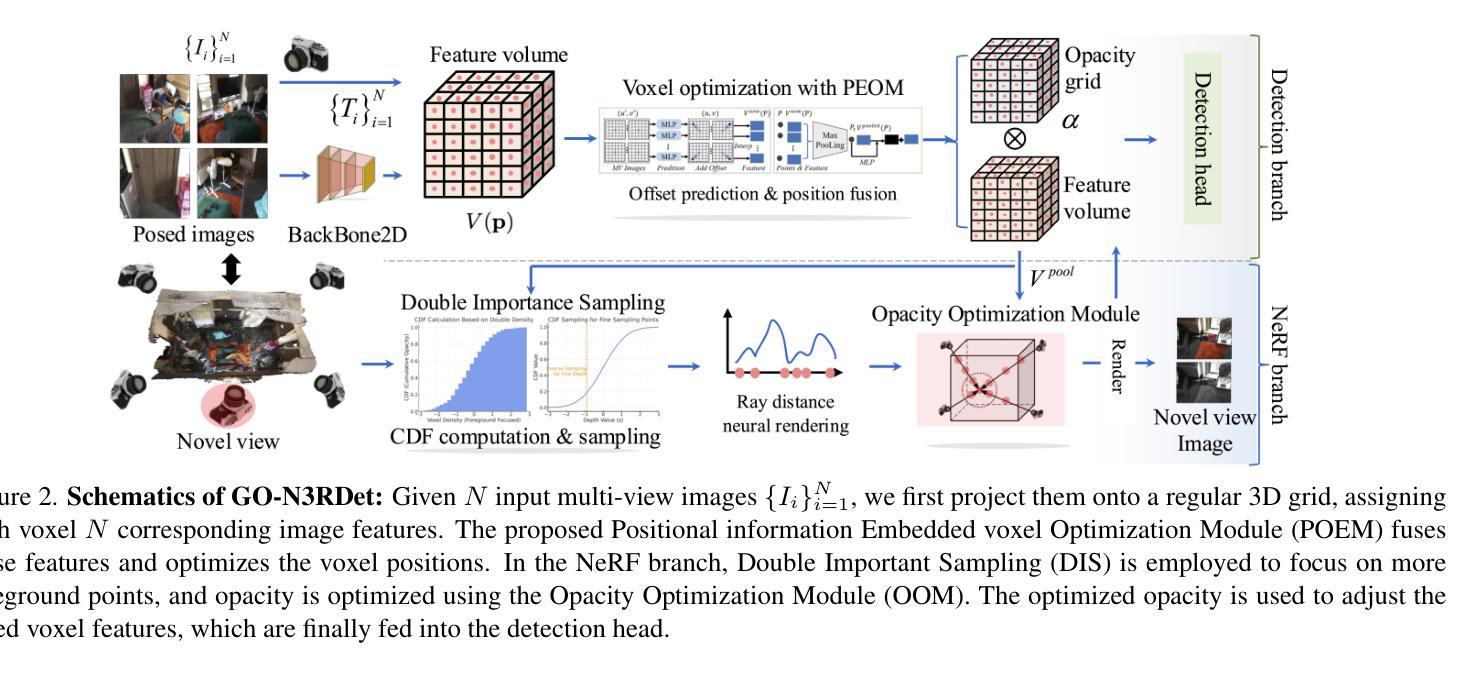
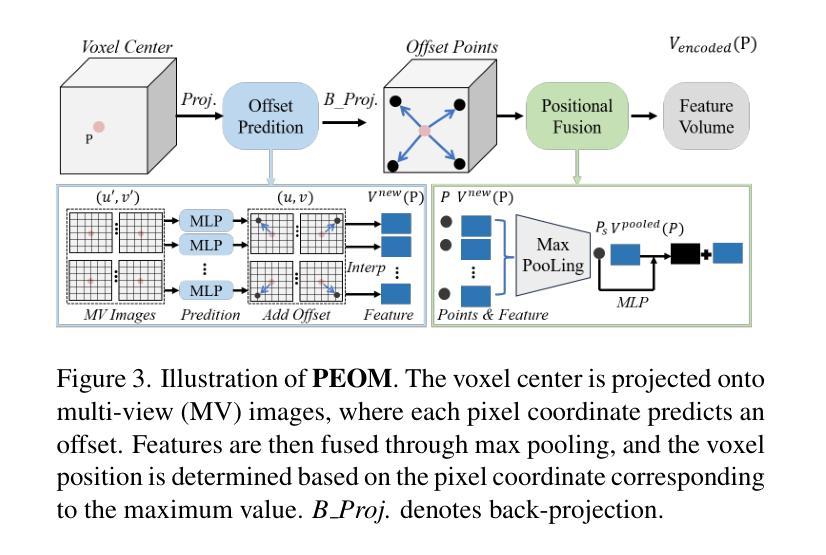
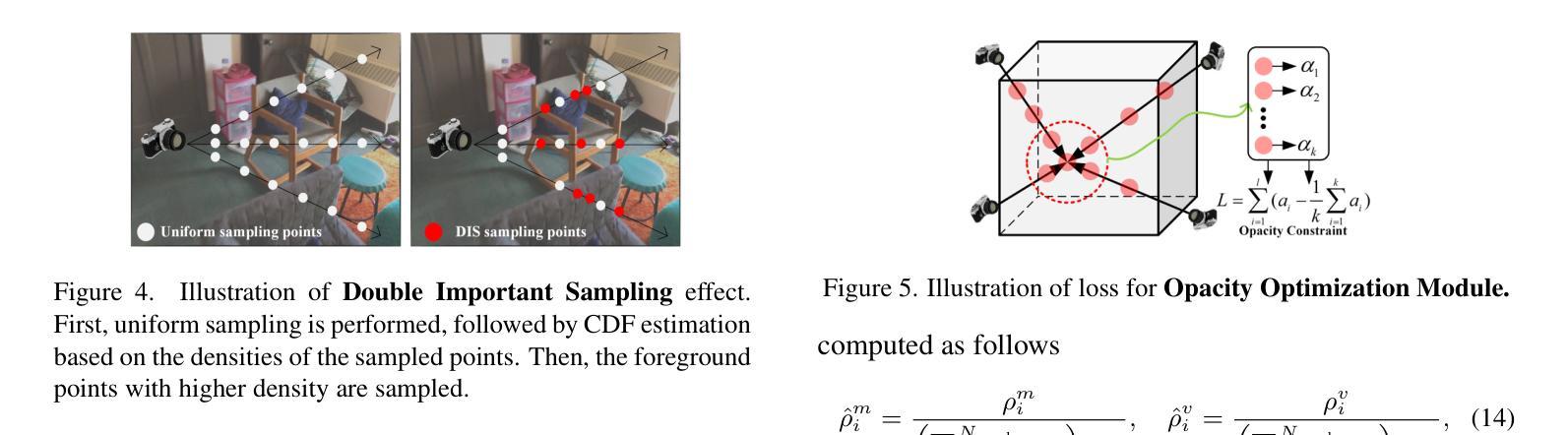
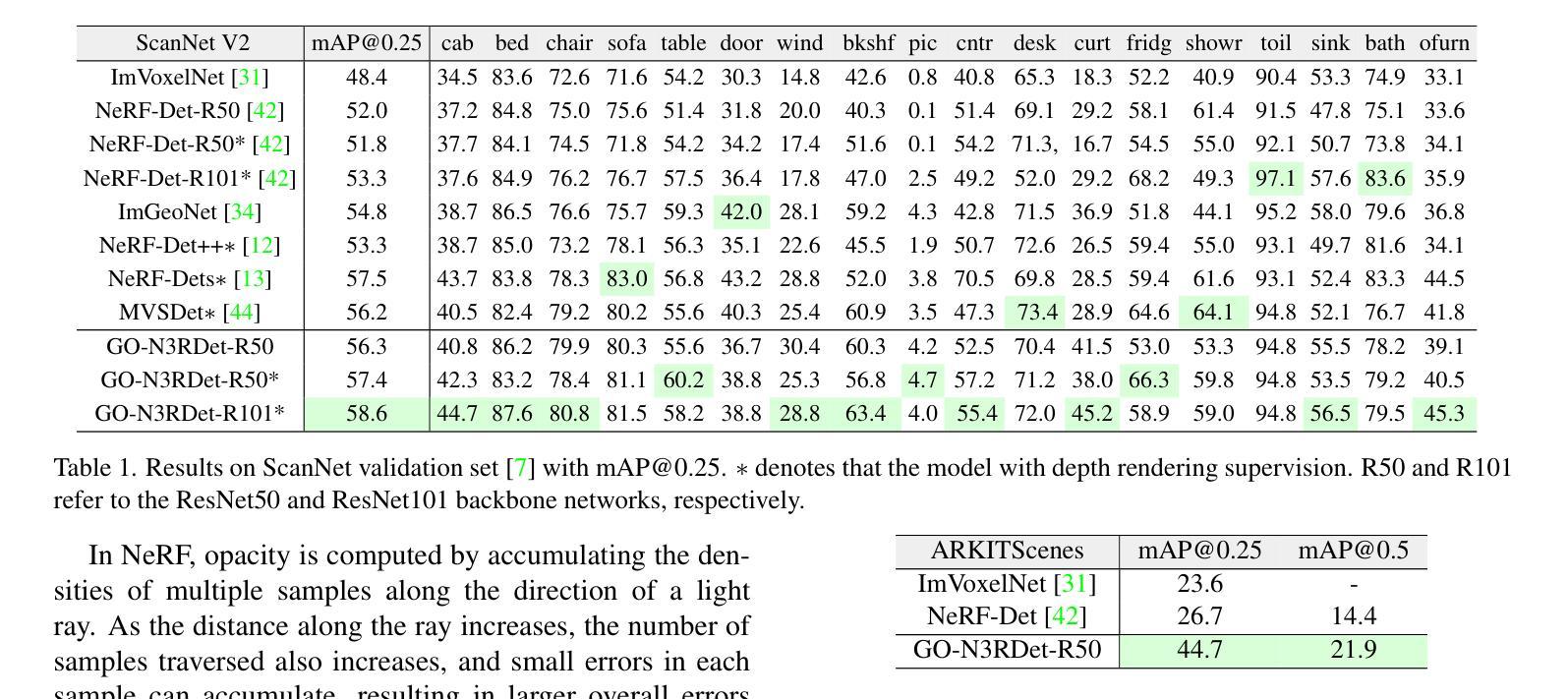
We propose GO-N3RDet, a scene-geometry optimized multi-view 3D object detector enhanced by neural radiance fields. The key to accurate 3D object detection is in effective voxel representation. However, due to occlusion and lack of 3D information, constructing 3D features from multi-view 2D images is challenging. Addressing that, we introduce a unique 3D positional information embedded voxel optimization mechanism to fuse multi-view features. To prioritize neural field reconstruction in object regions, we also devise a double importance sampling scheme for the NeRF branch of our detector. We additionally propose an opacity optimization module for precise voxel opacity prediction by enforcing multi-view consistency constraints. Moreover, to further improve voxel density consistency across multiple perspectives, we incorporate ray distance as a weighting factor to minimize cumulative ray errors. Our unique modules synergetically form an end-to-end neural model that establishes new state-of-the-art in NeRF-based multi-view 3D detection, verified with extensive experiments on ScanNet and ARKITScenes. Code will be available at https://github.com/ZechuanLi/GO-N3RDet.
我们提出了GO-N3RDet,这是一种通过神经辐射场增强的场景几何优化多视角三维目标检测器。准确的三维目标检测的关键在于有效的体素表示。然而,由于遮挡和缺乏三维信息,从多视角二维图像构建三维特征具有挑战性。为了解决这个问题,我们引入了一种独特的嵌入三维位置信息的体素优化机制,以融合多视角特征。为了优先重建对象区域的神经场,我们还为我们的检测器的NeRF分支设计了一种双重重要性采样方案。我们还提出了一种透明度优化模块,通过强制实施多视角一致性约束来进行精确的体素透明度预测。此外,为了进一步提高不同视角之间的体素密度一致性,我们采用射线距离作为加权因子,以最小化累积射线误差。我们的独特模块协同工作,形成一个端到端的神经网络模型,在基于NeRF的多视角三维检测方面建立了最新的最先进的水平,并通过在ScanNet和ARKITScenes上进行的大量实验进行了验证。代码将在https://github.com/ZechuanLi/GO-Nnew N3RDet上提供。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文提出一种基于神经辐射场优化的场景几何优化多视角三维目标检测器GO-N3RDet。为解决多视角二维图像构建三维特征时面临的遮挡和缺乏三维信息问题,引入了一种独特的三维位置信息嵌入体素优化机制来融合多视角特征。同时,为了优先重建对象区域中的神经场,设计了一种双重重要性采样方案。此外,还提出了一种透明度优化模块,通过实施多视角一致性约束进行精确的体素透明度预测。为提高不同视角下的体素密度一致性,结合射线距离作为权重因子来最小化累积射线误差。这些独特模块协同形成了一个端到端的神经网络模型,在基于NeRF的多视角三维检测方面达到新的先进水平,并在ScanNet和ARKITScenes上进行了广泛的实验验证。
Key Takeaways
- 提出了一种基于神经辐射场优化的多视角三维目标检测器GO-N3RDet。
- 引入了一种三维位置信息嵌入体素优化机制,以融合多视角特征并处理遮挡问题。
- 设计了双重重要性采样方案,以优先重建对象区域的神经场。
- 提出了透明度优化模块,通过实施多视角一致性约束进行精确的体素透明度预测。
- 结合射线距离作为权重因子,提高不同视角下的体素密度一致性。
- 该模型在基于NeRF的多视角三维检测方面达到新的先进水平。
点此查看论文截图

3D Engine-ready Photorealistic Avatars via Dynamic Textures
Authors:Yifan Wang, Ivan Molodetskikh, Ondrej Texler, Dimitar Dinev
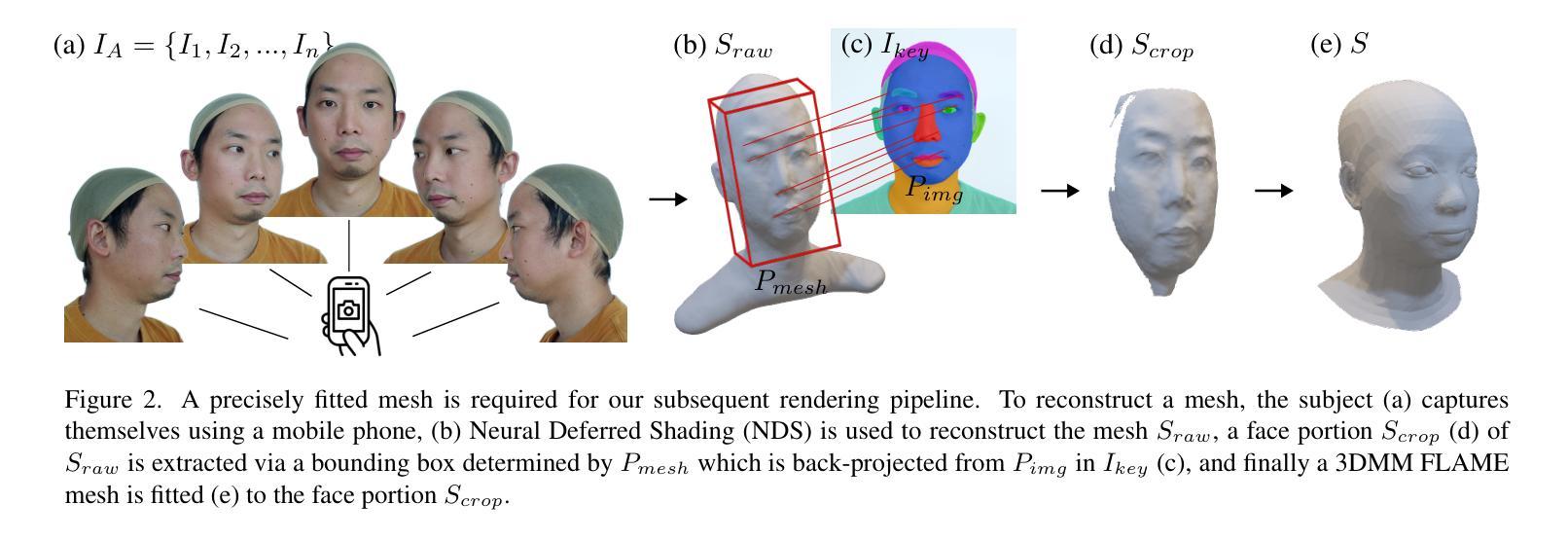
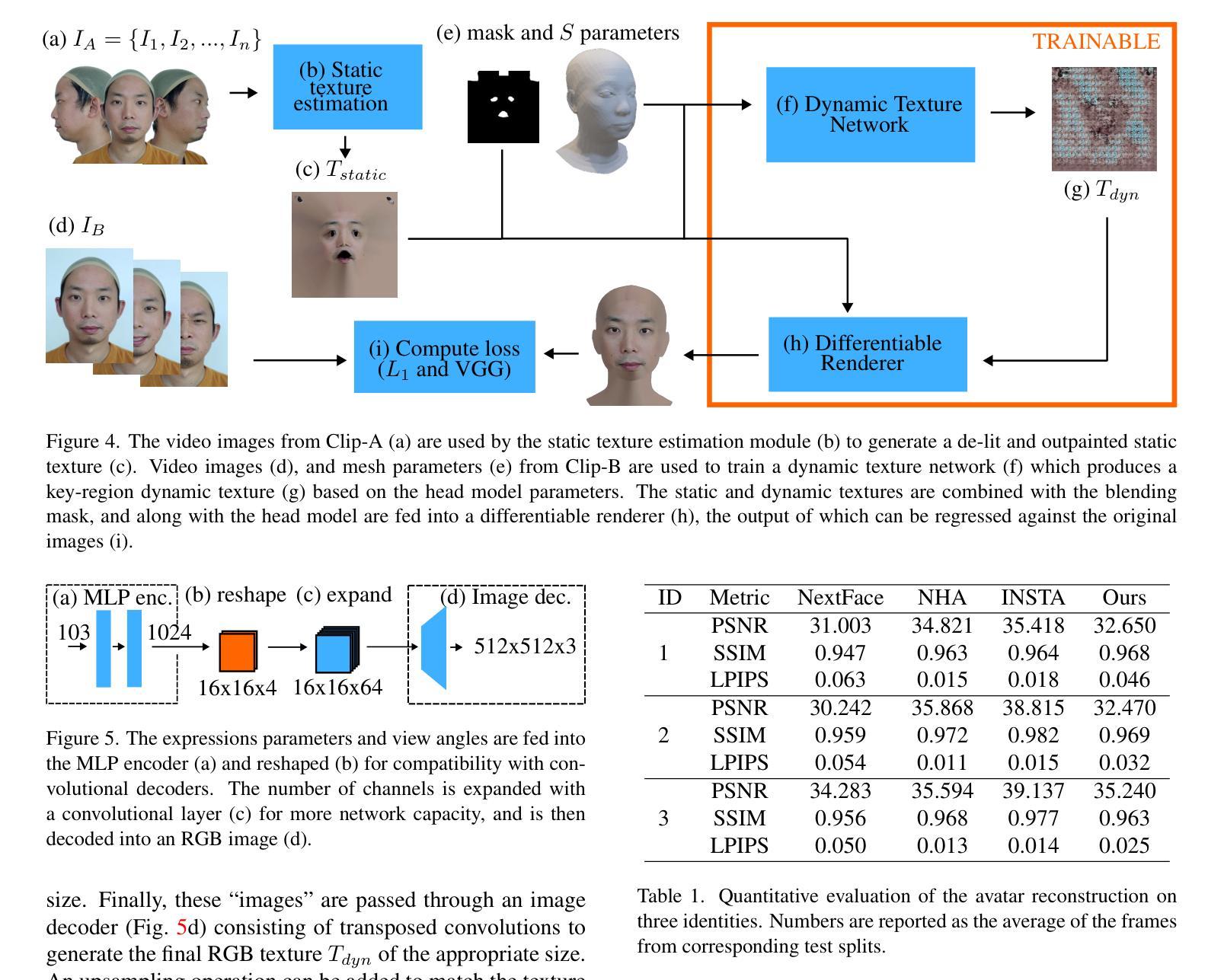
As the digital and physical worlds become more intertwined, there has been a lot of interest in digital avatars that closely resemble their real-world counterparts. Current digitization methods used in 3D production pipelines require costly capture setups, making them impractical for mass usage among common consumers. Recent academic literature has found success in reconstructing humans from limited data using implicit representations (e.g., voxels used in NeRFs), which are able to produce impressive videos. However, these methods are incompatible with traditional rendering pipelines, making it difficult to use them in applications such as games. In this work, we propose an end-to-end pipeline that builds explicitly-represented photorealistic 3D avatars using standard 3D assets. Our key idea is the use of dynamically-generated textures to enhance the realism and visually mask deficiencies in the underlying mesh geometry. This allows for seamless integration with current graphics pipelines while achieving comparable visual quality to state-of-the-art 3D avatar generation methods.
随着数字世界和物理世界的联系日益紧密,人们对数字化身的兴趣也越来越浓厚,这些数字化身与他们在现实世界中的对应物非常相似。目前用于三维制作管道的数字化方法需要昂贵的采集设备,使得它们在实际用户中难以广泛使用。最近的研究文献在有限的原始数据下通过隐式表达(例如NeRFs中的体素)重建人类方面取得了成功,并能生成令人印象深刻的视频。然而,这些方法与传统渲染管道不兼容,难以应用于游戏等应用程序。在这项工作中,我们提出了一种端到端的管道,使用标准的三维资产构建显式表示的逼真三维化身。我们的核心思想是使用动态生成的纹理增强真实感,并在视觉上掩盖底层网格几何缺陷。这使得无缝地融入当前的图形管道成为可能,同时实现与最先进的三维化身生成方法相当的可视质量。
论文及项目相关链接
Summary
随着数字世界和物理世界的融合日益紧密,对与真实世界相似的数字分身感兴趣的人越来越多。现有的三维生产流程所使用的数字化方法需要大量昂贵的设备配置,不利于在普通消费者中的广泛使用。然而,最近的学术文献已经成功地使用了隐式表示(如NeRF中的体素),这些方法能从有限的数据重建出人体模型,并产生令人印象深刻的视频。但此方法与传统渲染流程不兼容,难以应用于游戏等应用。本文提出了一种使用标准三维资产构建显式表示的光照真实三维分身的端到端流程。我们的核心思想是使用动态生成的纹理增强真实感,掩盖底层网格几何的缺陷。该方法能与当前图形渲染流程无缝集成,实现与最先进的三维角色生成方法相当的视觉品质。
Key Takeaways
- 数字世界与物理世界的融合趋势促进了数字分身技术的发展。
- 当前三维生产流程的数字化方法成本高昂,限制了其普及范围。
- 隐式表示方法(如NeRF中的体素)能够从有限数据中重建人体模型,产生高质量视频。
- 隐式表示方法与传统渲染流程不兼容,限制了其应用范围。
- 本文提出了一种使用标准三维资产的端到端流程来构建三维分身。
- 该方法使用动态生成的纹理增强真实感,掩盖底层网格几何的缺陷。
点此查看论文截图


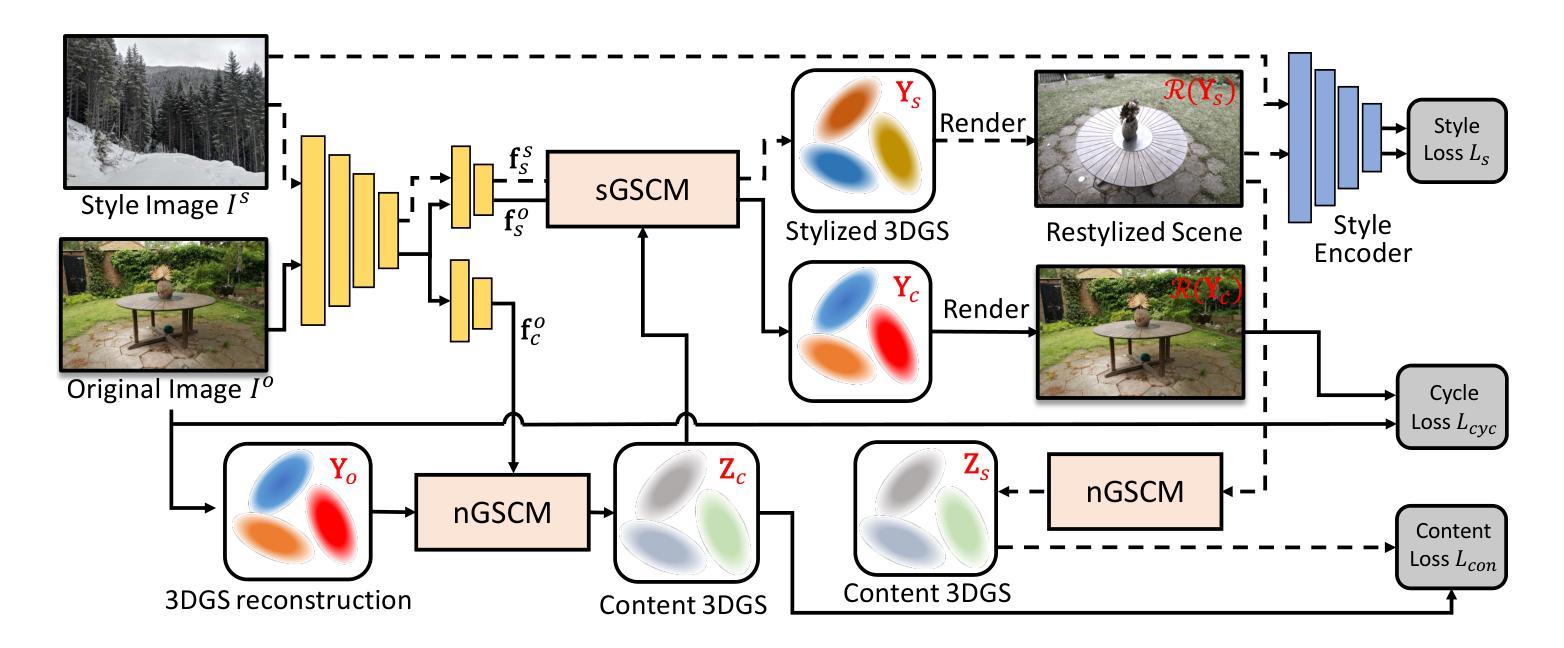
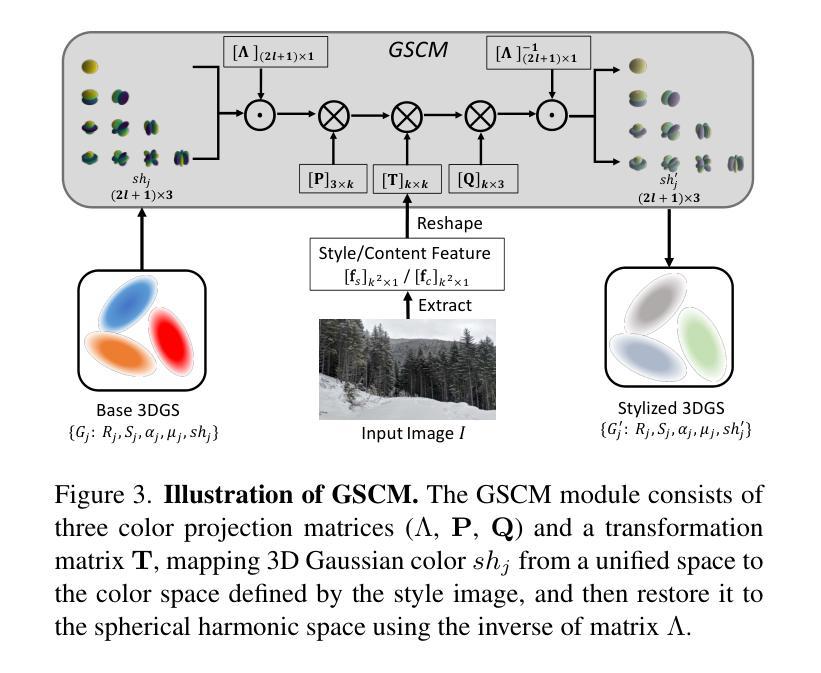
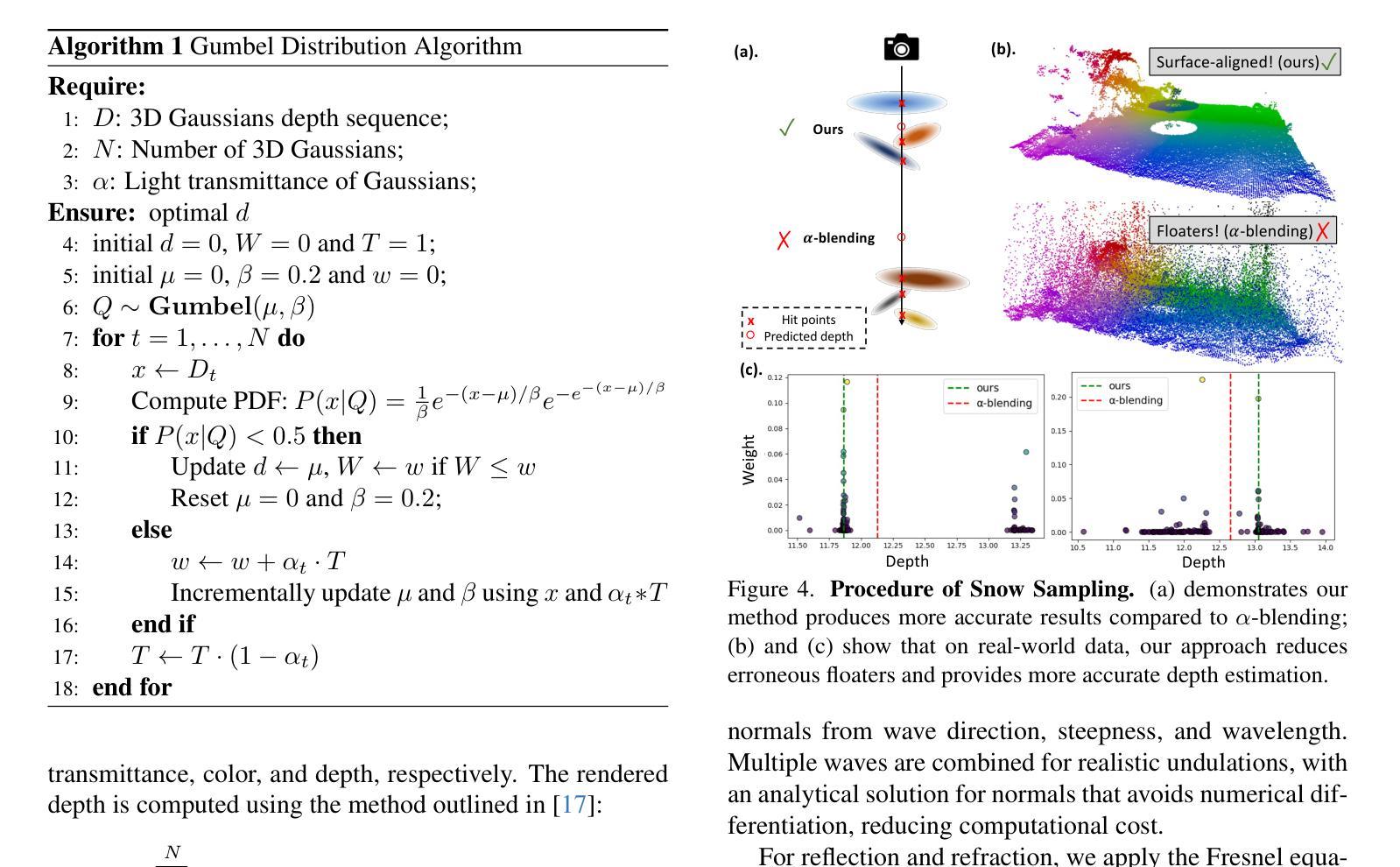
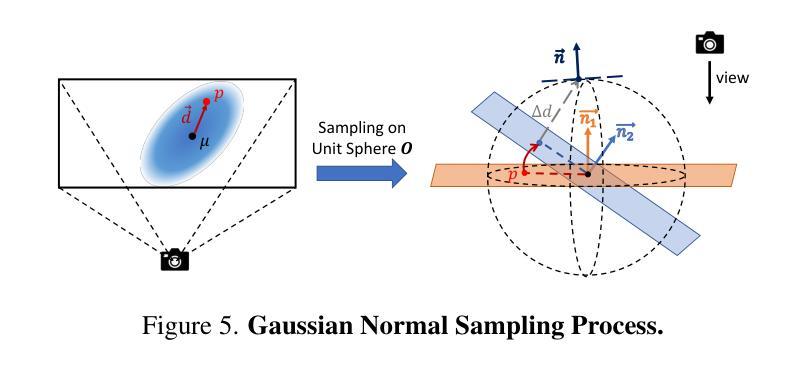
ClimateGS: Real-Time Climate Simulation with 3D Gaussian Style Transfer
Authors:Yuezhen Xie, Meiying Zhang, Qi Hao
Adverse climate conditions pose significant challenges for autonomous systems, demanding reliable perception and decision-making across diverse environments. To better simulate these conditions, physically-based NeRF rendering methods have been explored for their ability to generate realistic scene representations. However, these methods suffer from slow rendering speeds and long preprocessing times, making them impractical for real-time testing and user interaction. This paper presents ClimateGS, a novel framework integrating 3D Gaussian representations with physical simulation to enable real-time climate effects rendering. The novelty of this work is threefold: 1) developing a linear transformation for 3D Gaussian photorealistic style transfer, enabling direct modification of spherical harmonics across bands for efficient and consistent style adaptation; 2) developing a joint training strategy for 3D style transfer, combining supervised and self-supervised learning to accelerate convergence while preserving original scene details; 3) developing a real-time rendering method for climate simulation, integrating physics-based effects with 3D Gaussian to achieve efficient and realistic rendering. We evaluate ClimateGS on MipNeRF360 and Tanks and Temples, demonstrating real-time rendering with comparable or superior visual quality to SOTA 2D/3D methods, making it suitable for interactive applications.
恶劣的气候条件对自主系统构成了重大挑战,需要在不同的环境中实现可靠的感知和决策。为了更好地模拟这些条件,已经探索了基于物理的NeRF渲染方法,以生成逼真的场景表示。然而,这些方法存在渲染速度慢和预处理时间长的问题,不适用于实时测试和用户交互。本文提出了ClimateGS,这是一个结合3D高斯表示和物理仿真于一体的新型框架,以实现实时气候效果渲染。这项工作的新颖性体现在三个方面:1)开发了一种用于3D高斯写实风格转换的线性变换,通过直接修改球面谐波的不同波段来实现高效且一致的风格适应;2)为3D风格转换设计了一种联合训练策略,结合有监督学习和无监督学习来加速收敛并保持原始场景细节;3)开发了一种用于气候模拟的实时渲染方法,将基于物理的效果与3D高斯相结合,以实现高效且逼真的渲染。我们在MipNeRF360和Tanks and Temples上评估了ClimateGS,展示了与最新2D/3D方法相当或更高的视觉质量的实时渲染,使其成为交互式应用的理想选择。
论文及项目相关链接
Summary
物理渲染方法在面对恶劣气候条件时展现出逼真的场景表示能力,但渲染速度慢和预处理时间长限制了其在实时测试和用户交互中的应用。本文提出ClimateGS框架,结合三维高斯表示与物理仿真实现实时气候效果渲染。其创新点包括:开发线性变换进行三维高斯写实风格转换,直接修改球面谐波频段实现高效且一致的风格适应;采用联合训练策略进行三维风格转换,结合监督学习和自监督学习加速收敛并保持原始场景细节;开发实时渲染方法进行气候模拟,结合物理效果和三维高斯实现高效且逼真的渲染。在MipNeRF360和Tanks and Temples上的评估显示,ClimateGS可实现与现有二维/三维方法相当或更优的视觉质量实时渲染,适用于交互式应用。
Key Takeaways
- 恶劣气候条件对自主系统提出可靠感知和决策制定的挑战,需要逼真的模拟环境。
- 物理渲染方法能生成逼真的场景表示,但实时性和效率问题限制了其应用。
- ClimateGS框架结合三维高斯表示和物理仿真进行实时气候效果渲染。
- 线性变换技术用于三维高斯写实风格转换,实现高效且一致的风格适应。
- 采用联合训练策略加速收敛并保持原始场景细节。
- 实时渲染方法结合物理效果和三维高斯,实现高效且逼真的渲染。
点此查看论文截图

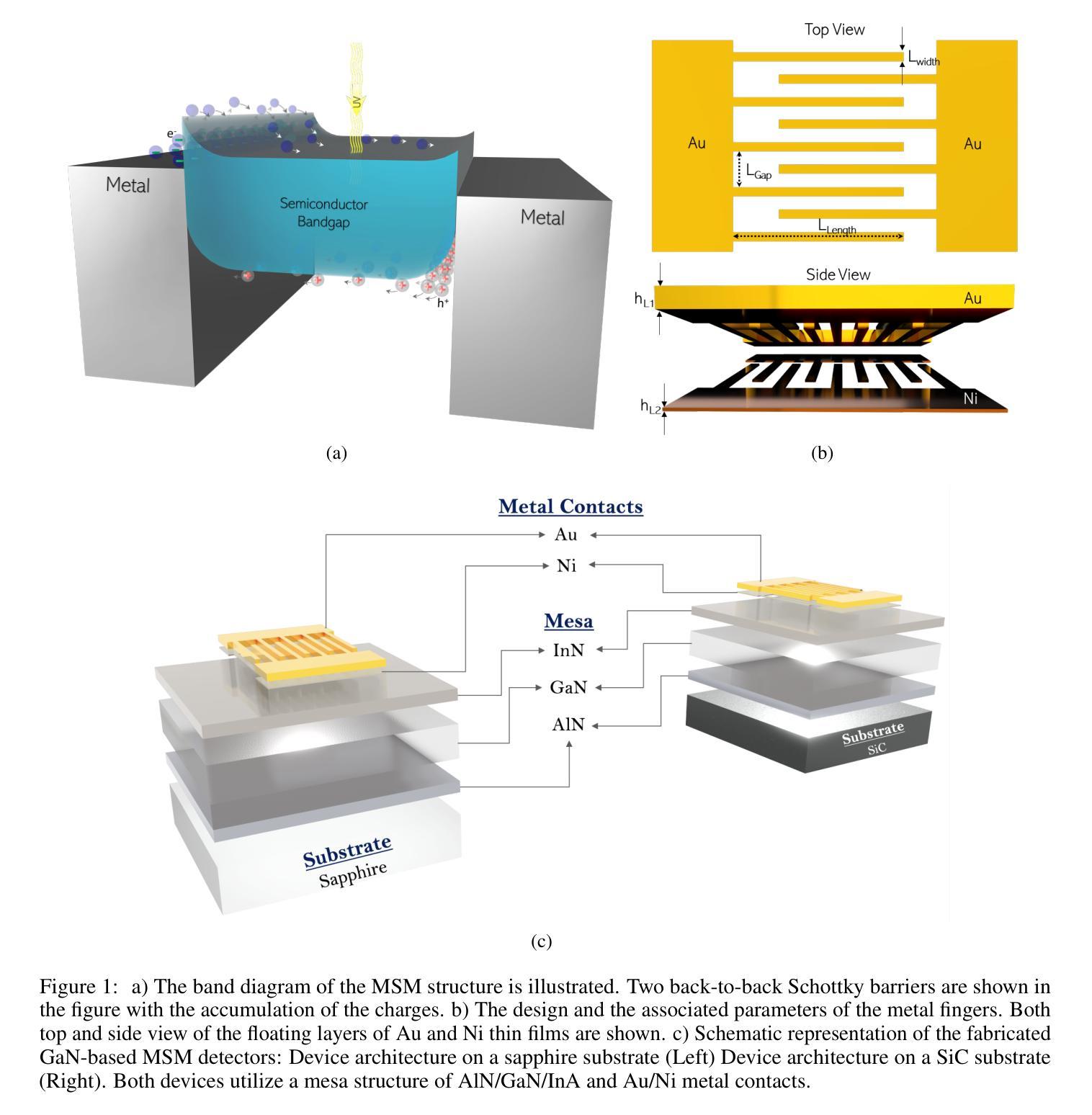
Simulation Based Design Enhancement of Multilayer GaN and InN/GaN/AlN MSM Photodetectors for Ultraviolet Sensing
Authors:M. Kilin, O. Tanriverdi, B. Karahan, F. Yasar
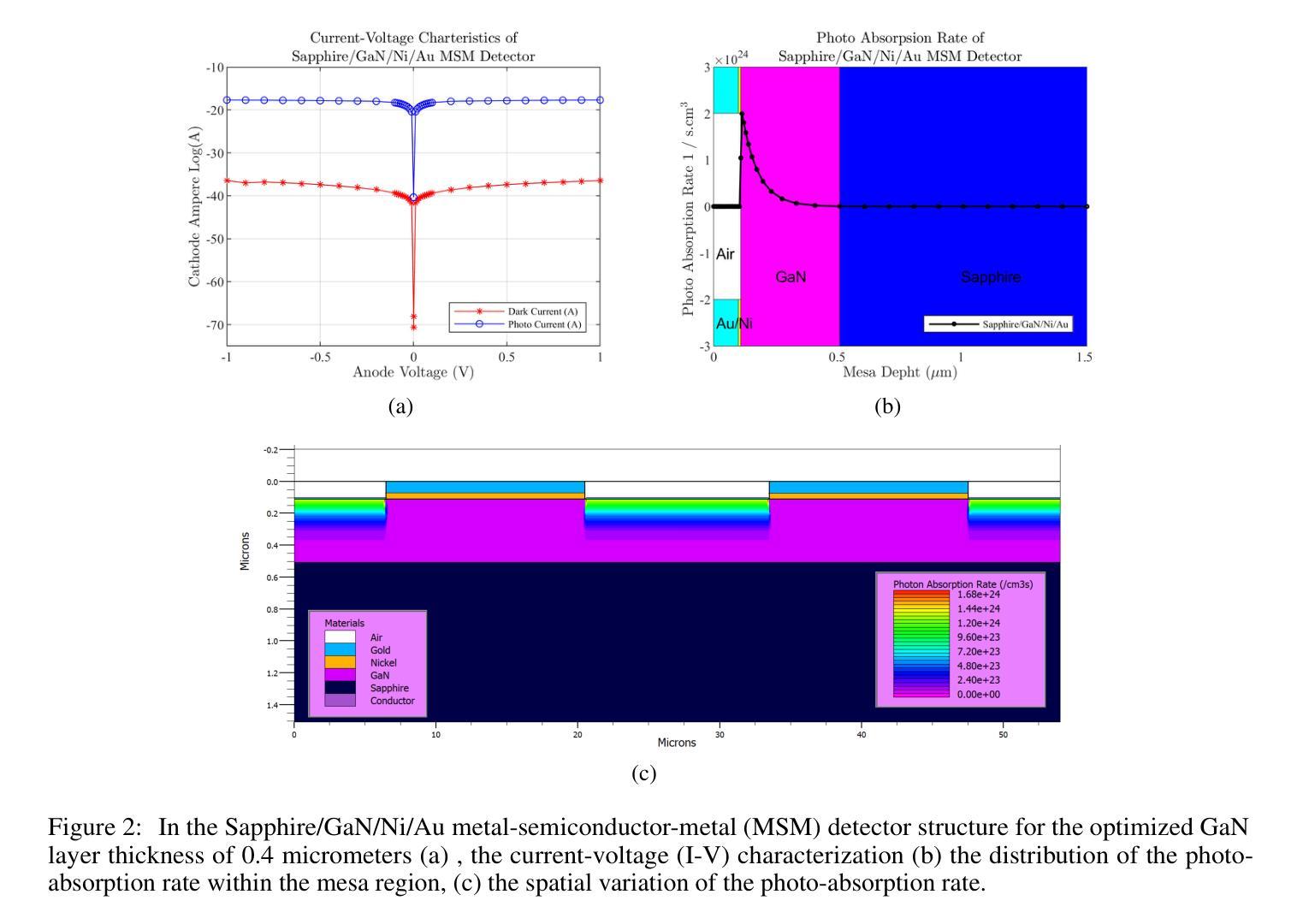
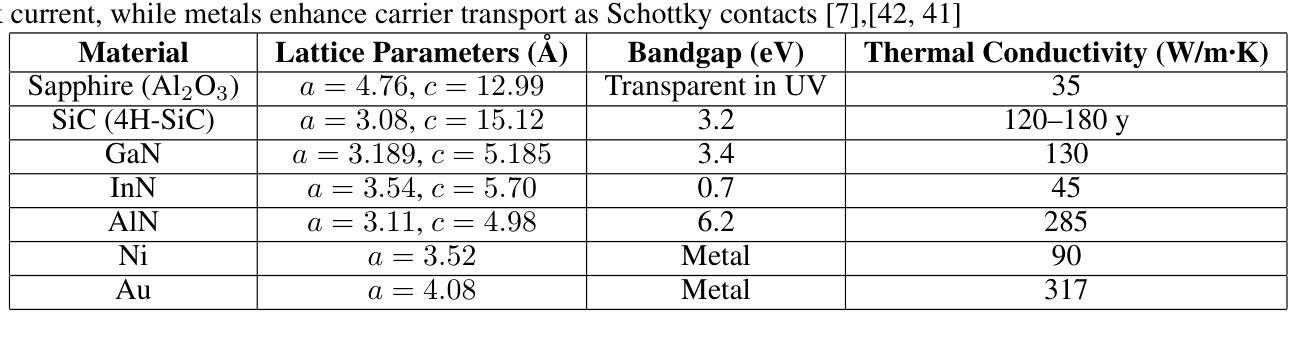
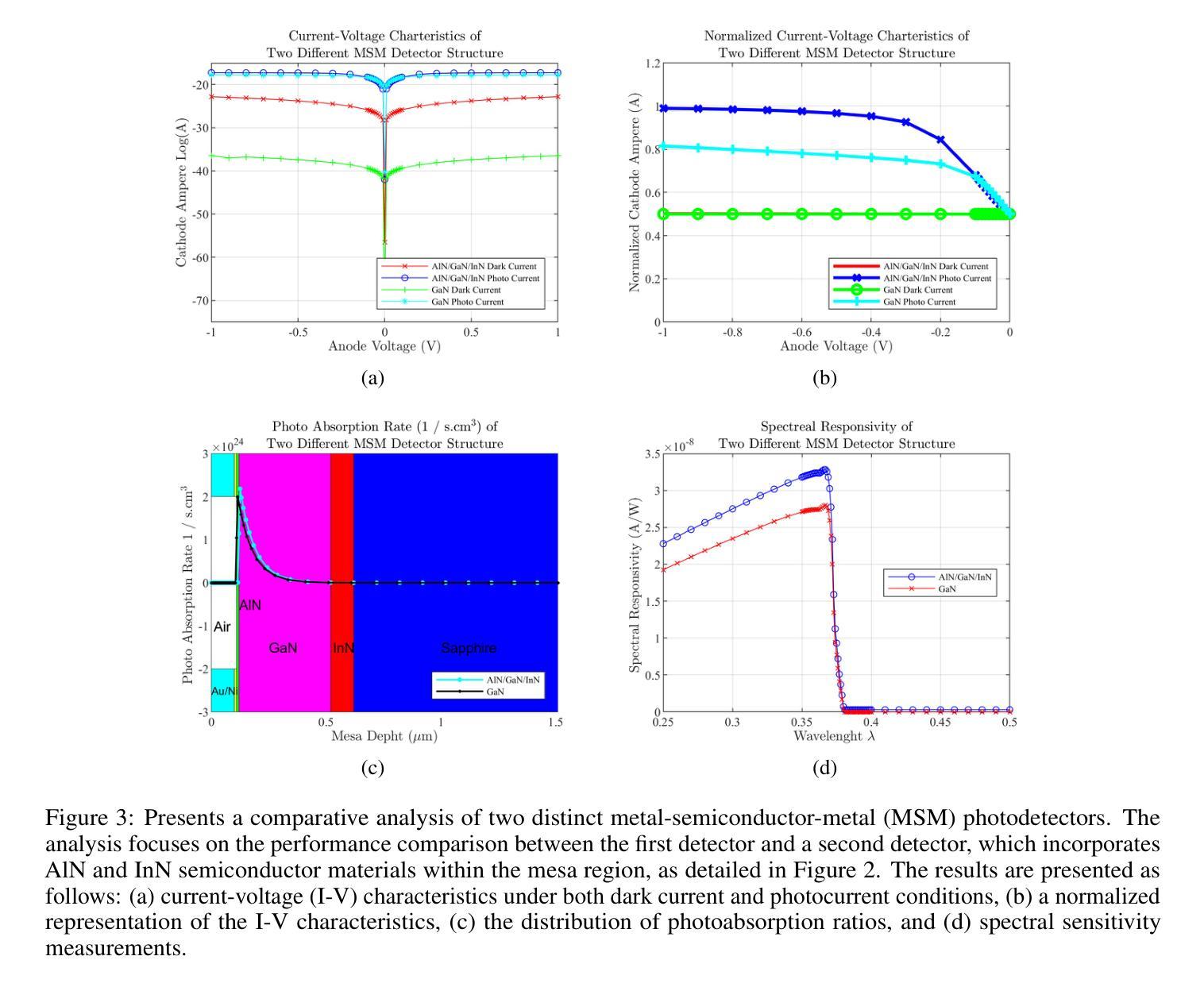
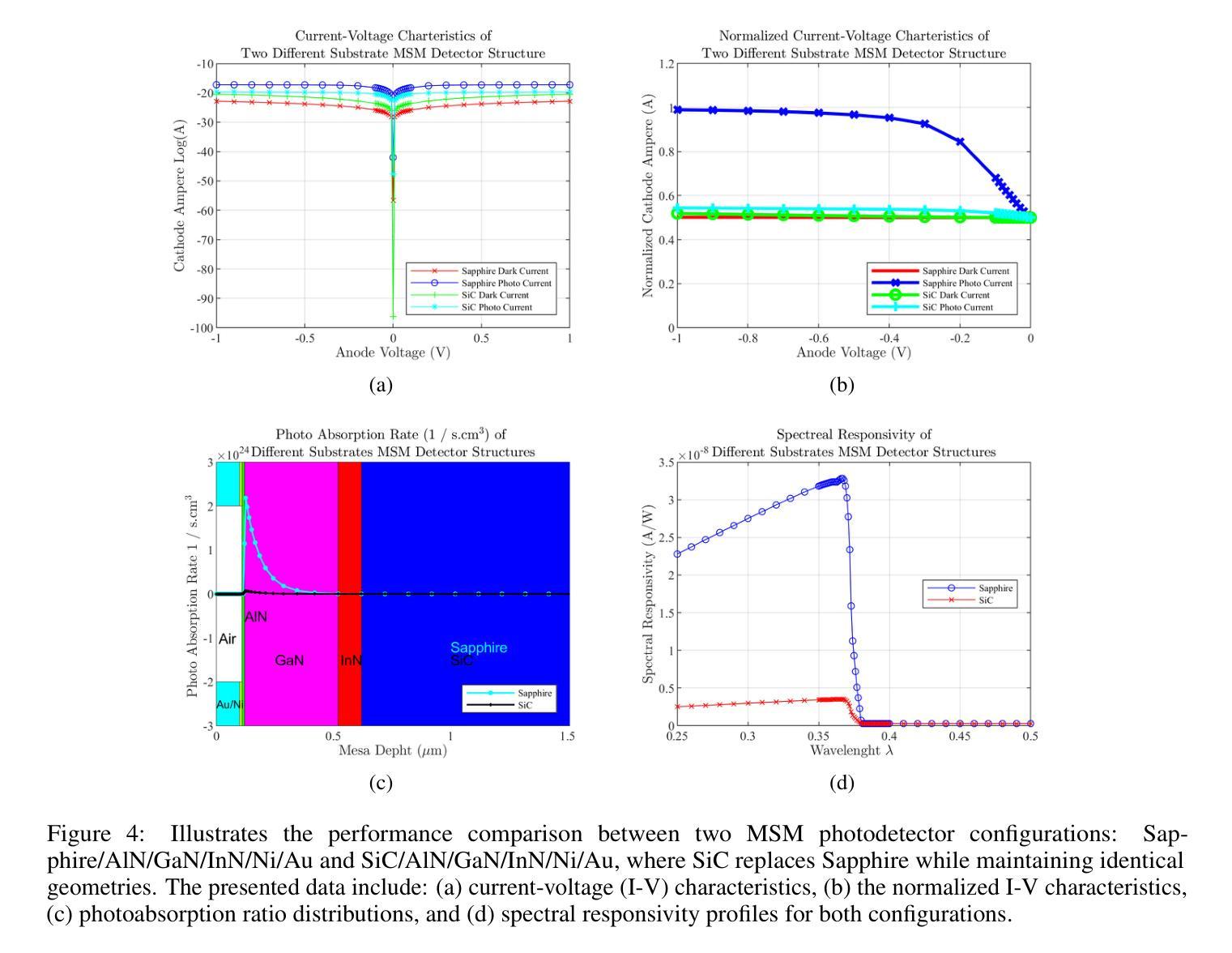
A GaN-based photodetector structure was optimized and modeled in the mesa region, incorporating a nickel-gold contact layer on a sapphire substrate to enhance ultraviolet (UV) detection. To further improve performance, an alternative design integrating thin InN (top) and AlN (buffer) layers was proposed. These additional layers were introduced to enhance carrier transport and optical absorption within the device. Following mesa thickness simulations, a silicon carbide (SiC) substrate was tested to assess its impact on detector performance. Each simulation phase aimed to optimize current-voltage (I-V) characteristics, photoabsorption rate, and spectral responsivity, ensuring the design approached realistic operational conditions. A new Sapphire/GaN(p-type)/GaN/GaN(n-type)/Ni/Au detector was designed based on the optimized buffer layer thicknesses in the mesa region, using parameters from the Sapphire/AlN/GaN/InN/Ni/Au structure. This new detector was further optimized as a function of doping concentration. Additionally, the contact electrode finger thickness and inter-finger spacing were geometrically refined to maximize performance. This comprehensive simulation study demonstrates a significant enhancement in photodetector response through structural and doping optimizations. Normalized I-V characteristics revealed a photocurrent increase of 1.16-fold to 1.38-fold at each optimization stage. Similarly, mesa region thickness optimizations improved the photoabsorption rate from 1.97e24 1/s . cm^3 to 2.18e24 1/s . cm^3. Furthermore, the spectral responsivity in the UV region increased from 0.28e-7 A to 0.47e-7 A at 367 nm.These results show significant improvements in the structural and electrical performance of GaN-based photodetectors, providing a promising way to develop high-efficiency UV detection devices.
在mesa区域优化并建模了基于GaN的光电检测器结构,该结构在蓝宝石基板上增加了镍-金接触层,以提高紫外(UV)检测性能。为进一步提高性能,提出了一种集成薄InN(顶部)和AlN(缓冲)层的设计方案。这些附加层是为了增强器件内的载流子传输和光学吸收。在对mesa厚度进行模拟后,对碳化硅(SiC)基板进行了测试,以评估其对探测器性能的影响。每个模拟阶段的目的是优化电流-电压(I-V)特性、光吸收率和光谱响应度,确保设计接近现实操作条件。基于mesa区域中优化的缓冲层厚度,设计了一种新的Sapphire/GaN(p型)/GaN/GaN(n型)/Ni/Au探测器,采用Sapphire/AlN/GaN/InN/Ni/Au结构的参数。进一步对新型探测器的掺杂浓度进行优化。此外,接触电极指厚和指间间距也进行了几何精修以最大化性能。这项全面的模拟研究通过结构和掺杂优化显著提高了光电探测器的响应。归一化的I-V特性显示,在每个优化阶段,光电流增加了1.16倍至1.38倍。同样地,mesa区域厚度优化将光吸收率从1.97e24 1/s·cm³提高到2.18e24 1/s·cm³。此外,在紫外区域的谱响应度在367纳米处从0.28e-7 A增加到0.47e-7 A。这些结果显著提高了GaN基光电探测器的结构和电气性能,为开发高效紫外检测装置提供了有前途的途径。
论文及项目相关链接
摘要
基于GaN的光电探测器结构在 mesa 区域进行了优化和建模,通过引入镍金接触层在蓝宝石衬底上增强了紫外检测性能。为进一步提高性能,提出了一种集成薄InN(顶部)和AlN(缓冲)层的设计方案。这些附加层旨在增强器件内的载流子传输和光学吸收。进行了mesa厚度模拟后,对碳化硅(SiC)衬底进行了测试,以评估其对探测器性能的影响。模拟阶段旨在优化电流-电压特性、光吸收率和光谱响应度,确保设计接近实际运行条件。基于 mesa 区域优化的缓冲层厚度,设计了一种新的蓝宝石/p型GaN/GaN/n型GaN/Ni/Au探测器,并使用来自蓝宝石/AlN/GaN/InN/Ni/Au结构的参数进行优化。通过掺杂浓度的调整进一步优化了此探测器性能。此外,接触电极指状物的厚度和指间间距进行了几何精细调整以最大化性能。这项全面的模拟研究通过结构和掺杂优化显著提高了光电探测器的响应。归一化电流-电压特性显示,在每次优化阶段,光电流增加了1.16倍至1.38倍。同样,mesa区域厚度优化将光吸收率从1.97e提高了24次秒提高到为缓解拥堵需求目前依赖老进口芯片的现状,国内芯片厂商也在加速追赶,包括中芯国际等国内芯片巨头在内,都在积极布局先进技术研发以弥补与国外技术的差距谋求新的业绩增长点加紧进口替代的进程目前已经能够看到明显的改善并且在成本上也具备了竞争优势相关产业资本支出也明显上升为应对可能出现的芯片短缺情况包括政府在内的各界力量也在加大对相关产业的支持力度同时全球也在推进新能源汽车等行业的技术变革在多项需求共同驱动下整个芯片产业持续向好发展态势显著增强未来随着技术的不断进步国产替代步伐有望进一步加快国内芯片厂商在全球市场的竞争力也将得到进一步提升从国内芯片产业整体情况来看国产替代步伐加快明显行业景气持续高涨竞争格局已经形成作为国内芯片行业领军企业之一的中芯国际也将凭借自身的技术研发实力在国内外市场竞争中占得先机逐步实现在国际市场上的进口替代进一步提升企业的市场份额与行业地位中改善到了此前饱受瓶颈的2.18e水平。此外,在紫外区域的光谱响应度从 0.28e-7 A 提高到了 0.47e-7 A 在 367 nm 波长下。这些结果显著提高了 GaN 基光电探测器的结构和电气性能,为开发高效紫外检测器件提供了有前途的途径。
要点
- GaN基光电探测器结构在 mesa 区域的优化和建模,增强了紫外检测性能。
- 通过引入 InN 和 AlN 层改善载流子传输和光学吸收。
- 仿真测试了不同衬底对探测器性能的影响,包括SiC衬底。
- 优化了电流-电压特性、光吸收率和光谱响应度。
- 新的探测器设计基于优化后的缓冲层厚度和掺杂浓度调整。
- 接触电极的几何精细调整以最大化性能。
点此查看论文截图

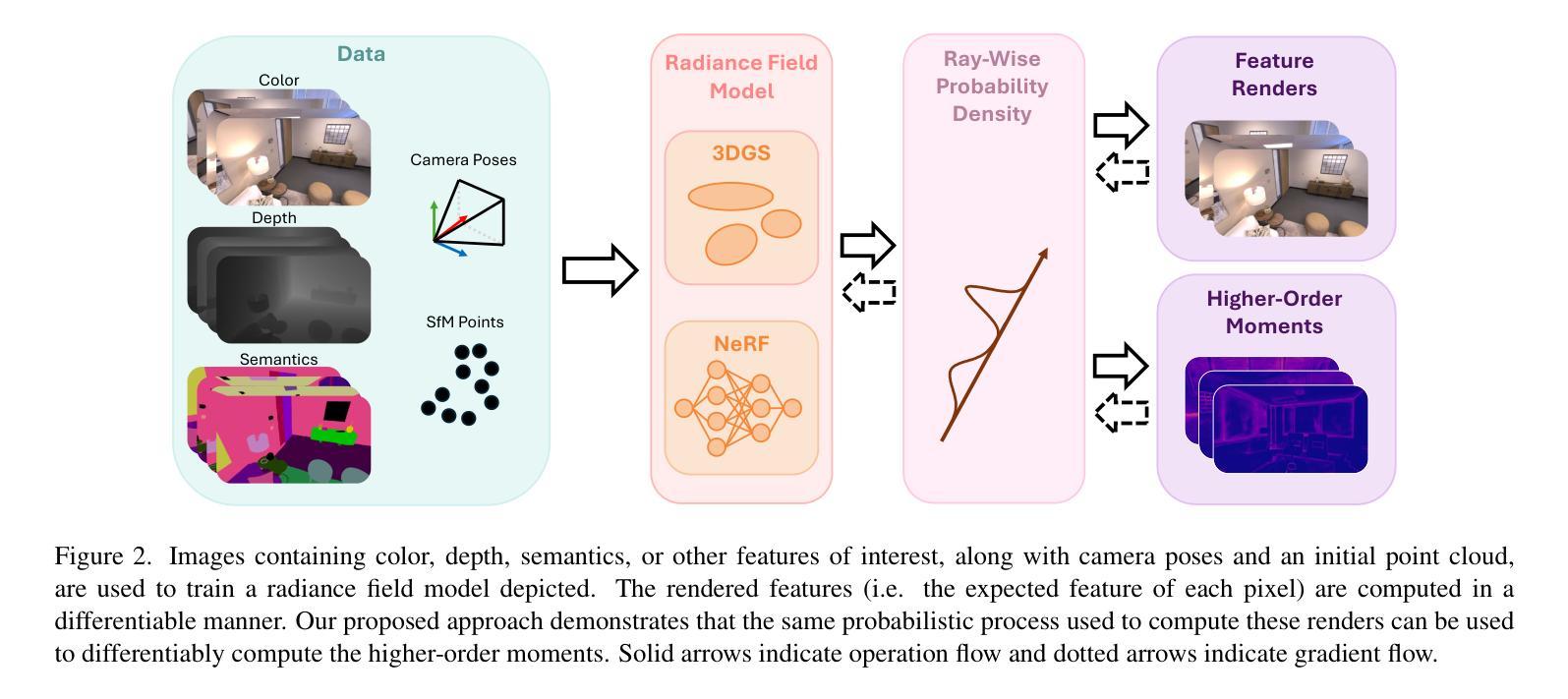
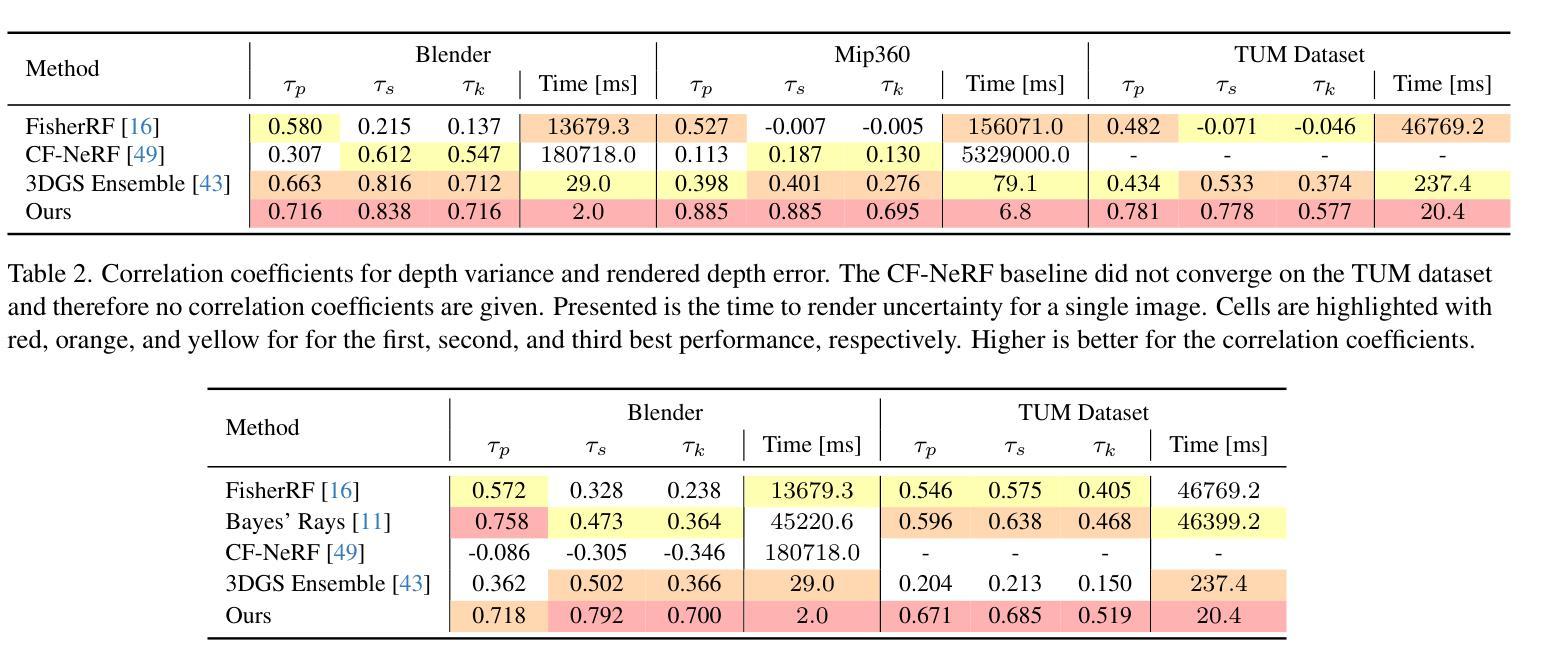
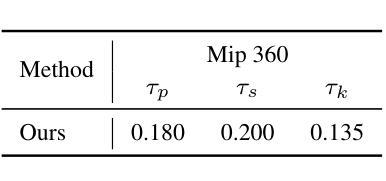
These Magic Moments: Differentiable Uncertainty Quantification of Radiance Field Models
Authors:Parker Ewen, Hao Chen, Seth Isaacson, Joey Wilson, Katherine A. Skinner, Ram Vasudevan
This paper introduces a novel approach to uncertainty quantification for radiance fields by leveraging higher-order moments of the rendering equation. Uncertainty quantification is crucial for downstream tasks including view planning and scene understanding, where safety and robustness are paramount. However, the high dimensionality and complexity of radiance fields pose significant challenges for uncertainty quantification, limiting the use of these uncertainty quantification methods in high-speed decision-making. We demonstrate that the probabilistic nature of the rendering process enables efficient and differentiable computation of higher-order moments for radiance field outputs, including color, depth, and semantic predictions. Our method outperforms existing radiance field uncertainty estimation techniques while offering a more direct, computationally efficient, and differentiable formulation without the need for post-processing.Beyond uncertainty quantification, we also illustrate the utility of our approach in downstream applications such as next-best-view (NBV) selection and active ray sampling for neural radiance field training. Extensive experiments on synthetic and real-world scenes confirm the efficacy of our approach, which achieves state-of-the-art performance while maintaining simplicity.
本文介绍了一种利用渲染方程的高阶矩进行辐射场不确定性量化的新方法。不确定性量化对于下游任务至关重要,包括视图规划和场景理解,这些任务中的安全和稳健性至关重要。然而,辐射场的高维性和复杂性给不确定性量化带来了巨大的挑战,限制了这些不确定性量化方法在高速决策制定中的应用。我们证明,渲染过程的概率性能够实现对辐射场输出(包括颜色、深度和语义预测)的高阶矩的高效、可微计算。我们的方法在性能上超越了现有的辐射场不确定性估计技术,同时提供了一种更直接、计算更高效、可微的公式,无需进行后处理。除了不确定性量化之外,我们还说明了我们的方法在下游应用中的实用性,如选择最佳后续视图(NBV)和用于神经辐射场训练的主动射线采样。在合成场景和真实场景的大量实验证实了我们方法的有效性,它在保持简洁性的同时实现了最先进的性能。
论文及项目相关链接
Summary
本文介绍了一种利用渲染方程的高阶矩来进行辐射场不确定性量化的新方法。不确定性量化对于下游任务如视图规划和场景理解至关重要,其中安全性和稳健性至关重要。通过利用辐射场的概率性质,该方法能够高效且可微地计算辐射场输出的高阶矩,包括颜色、深度和语义预测。该方法在辐射场不确定性估计技术上表现优越,提供了一种更直接、计算高效且可微的公式,无需后处理。此外,本文还展示了该方法在下游应用如最佳后续视图选择和神经辐射场的主动射线采样训练中的实用性。实验证明该方法在合成和真实场景中的表现达到业界领先水准,且保持简洁性。
Key Takeaways
- 利用高阶矩进行辐射场的不确定性量化。
- 辐射场的高维性和复杂性给不确定性量化带来挑战。
- 概率性质的渲染过程可实现高效且可微的高阶矩计算。
- 方法在辐射场不确定性估计上表现优越,无需后处理。
- 该方法具有实用性,可应用于视图规划和场景理解的下游任务。
- 实验证明该方法在合成和真实场景中的表现达到业界领先水准。
- 方法简洁,易于实现。
点此查看论文截图


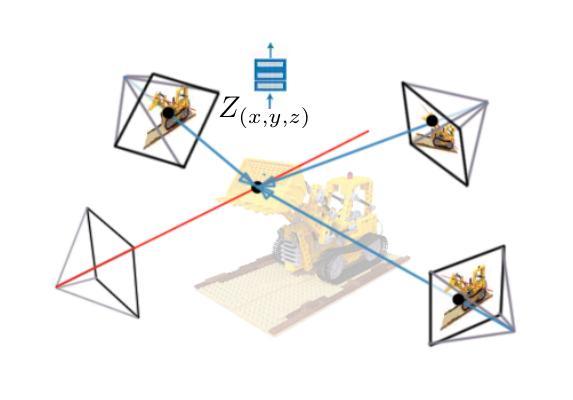
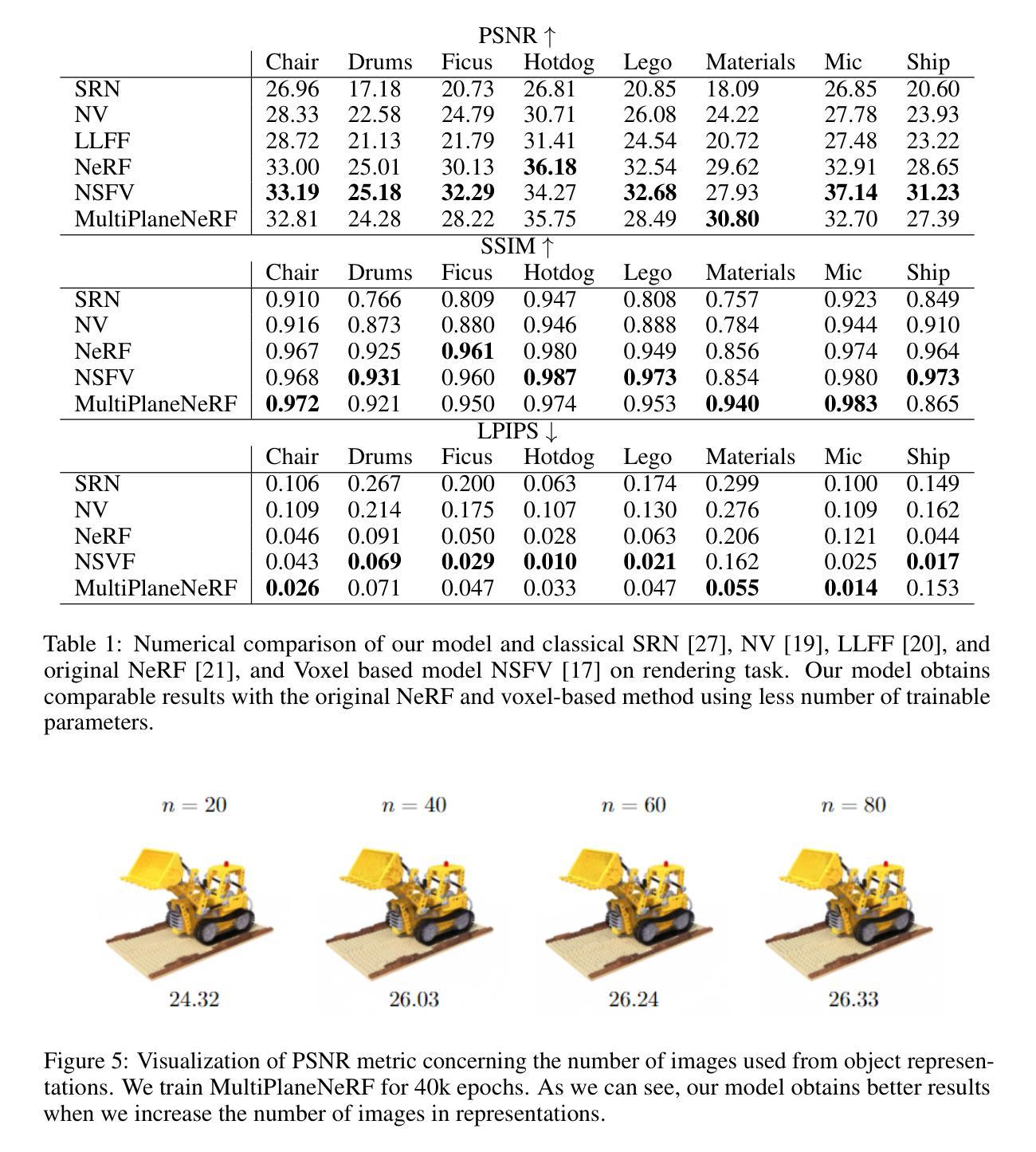
MultiPlaneNeRF: Neural Radiance Field with Non-Trainable Representation
Authors:Dominik Zimny, Artur Kasymov, Adam Kania, Jacek Tabor, Maciej Zięba, Marcin Mazur, Przemysław Spurek
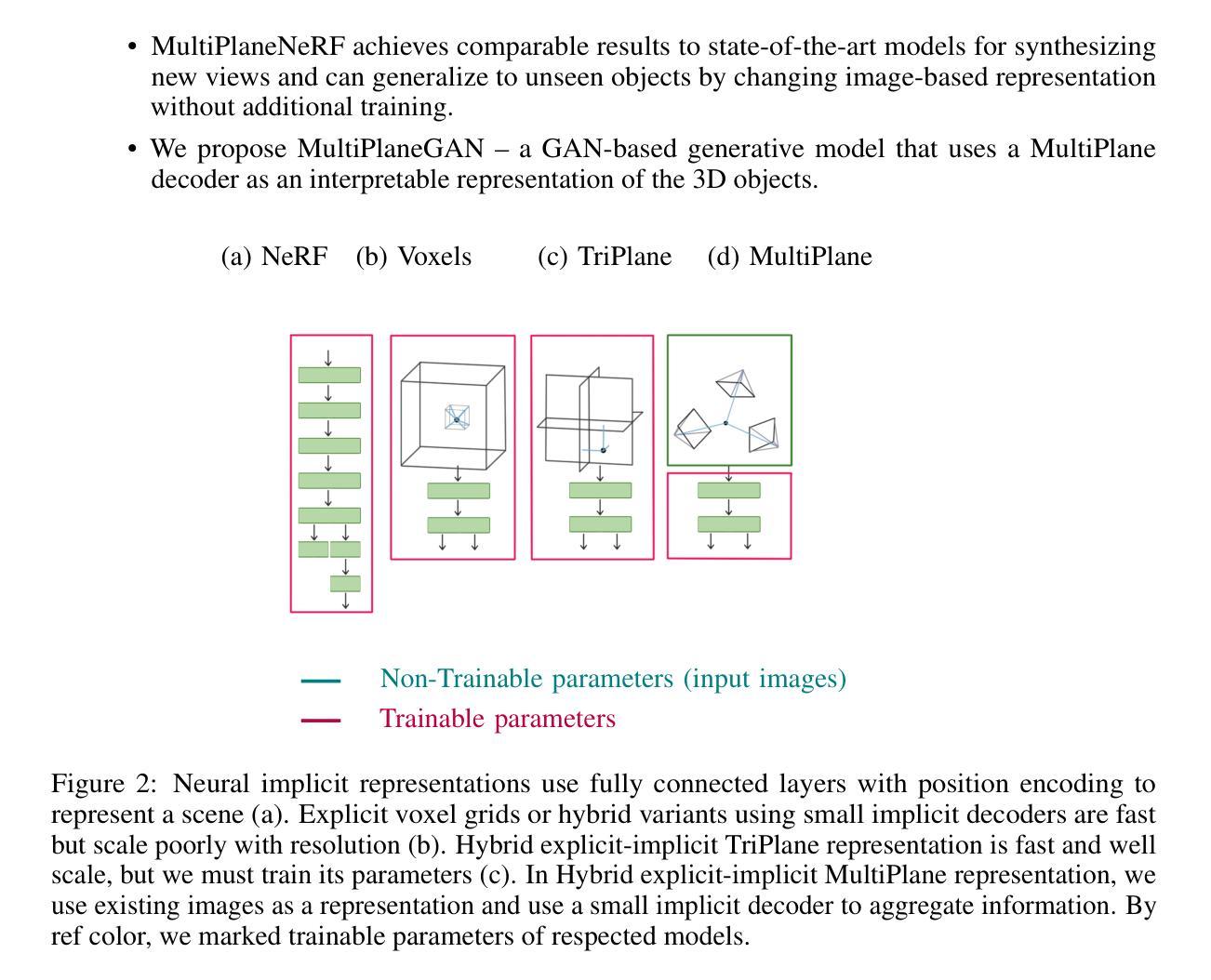
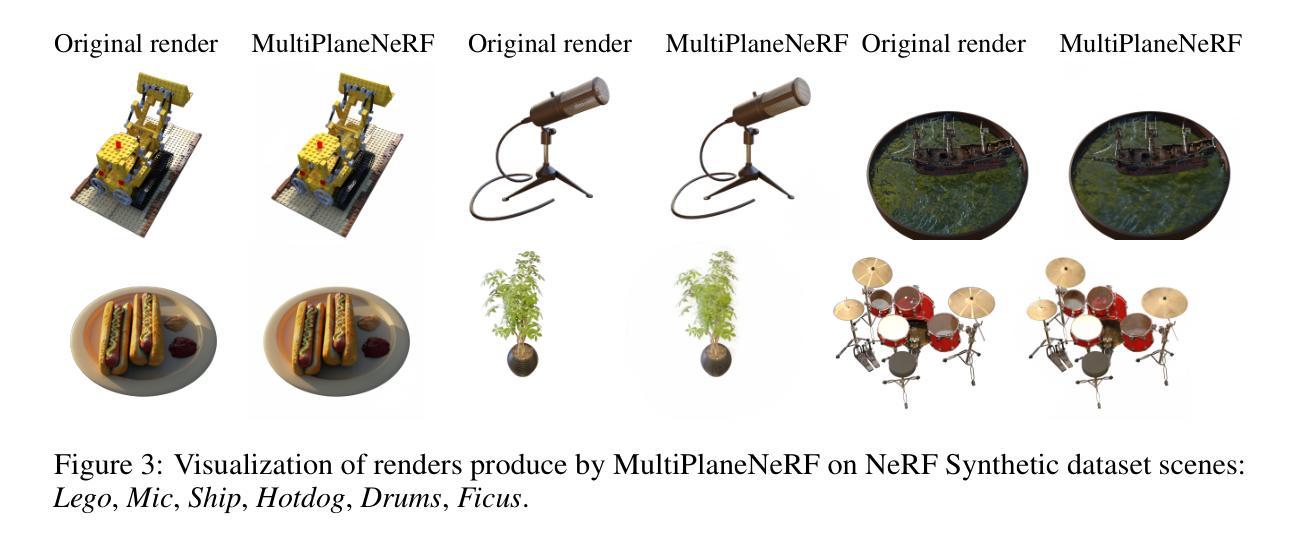
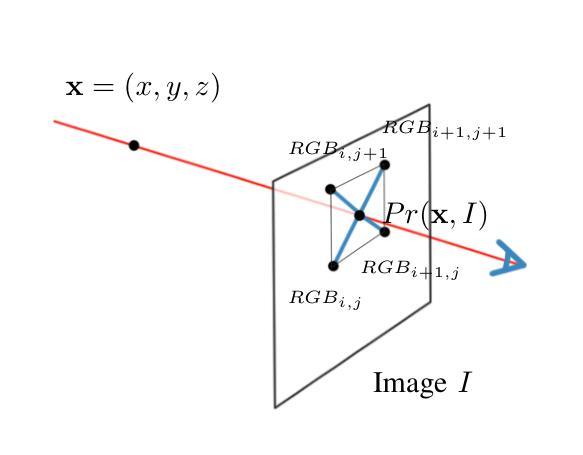
NeRF is a popular model that efficiently represents 3D objects from 2D images. However, vanilla NeRF has some important limitations. NeRF must be trained on each object separately. The training time is long since we encode the object’s shape and color in neural network weights. Moreover, NeRF does not generalize well to unseen data. In this paper, we present MultiPlaneNeRF – a model that simultaneously solves the above problems. Our model works directly on 2D images. We project 3D points on 2D images to produce non-trainable representations. The projection step is not parametrized and a very shallow decoder can efficiently process the representation. Furthermore, we can train MultiPlaneNeRF on a large data set and force our implicit decoder to generalize across many objects. Consequently, we can only replace the 2D images (without additional training) to produce a NeRF representation of the new object. In the experimental section, we demonstrate that MultiPlaneNeRF achieves results comparable to state-of-the-art models for synthesizing new views and has generalization properties. Additionally, MultiPlane decoder can be used as a component in large generative models like GANs.
NeRF是一种流行的模型,能够有效地从2D图像表示3D物体。然而,原始的NeRF存在一些重要的局限性。NeRF必须分别对每个物体进行训练。由于我们将物体的形状和颜色编码在神经网络权重中,所以训练时间较长。而且,NeRF对未见数据的泛化能力不佳。在本文中,我们提出了MultiPlaneNeRF——一个同时解决上述问题的模型。我们的模型直接在2D图像上工作。我们将3D点投影到2D图像上,产生不可训练表示。投影步骤没有被参数化,一个非常浅的解码器可以高效处理该表示。此外,我们可以在大型数据集上训练MultiPlaneNeRF,并强制我们的隐式解码器在多个物体之间泛化。因此,我们只需要替换2D图像(无需额外训练)就可以生成新物体的NeRF表示。在实验部分,我们证明MultiPlaneNeRF在合成新视图方面达到了最先进模型可比的结果,并具有泛化特性。此外,MultiPlane解码器可以用作大型生成模型(如GANs)的组件。
论文及项目相关链接
Summary
NeRF模型可从二维图像高效表示三维物体,但仍存在局限。本文提出MultiPlaneNeRF模型,解决了NeRF需单独训练每个物体、训练时间长、对未见数据泛化性能差的问题。MultiPlaneNeRF直接在二维图像上工作,通过投影三维点生成不可训练表示,并可通过大型数据集训练隐含解码器以实现对多个物体的泛化。此外,MultiPlane decoder可应用于大型生成模型如GANs。
Key Takeaways
- NeRF模型能从二维图像表示三维物体,但存在训练时间长、无法泛化未见数据等缺点。
- MultiPlaneNeRF解决了NeRF的上述问题,可直接在二维图像上工作,通过投影三维点生成不可训练表示。
- MultiPlaneNeRF模型通过大型数据集训练隐含解码器,以实现泛化多个物体。
- 该模型可以实现快速的新物体表示,只需更换二维图像而无需额外训练。
- 实验表明,MultiPlaneNeRF的合成新视角的效果与现有先进技术相当。
- MultiPlane decoder可作为大型生成模型如GANs的组件使用。
点此查看论文截图