⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Authors:Yifei Zhou, Song Jiang, Yuandong Tian, Jason Weston, Sergey Levine, Sainbayar Sukhbaatar, Xian Li
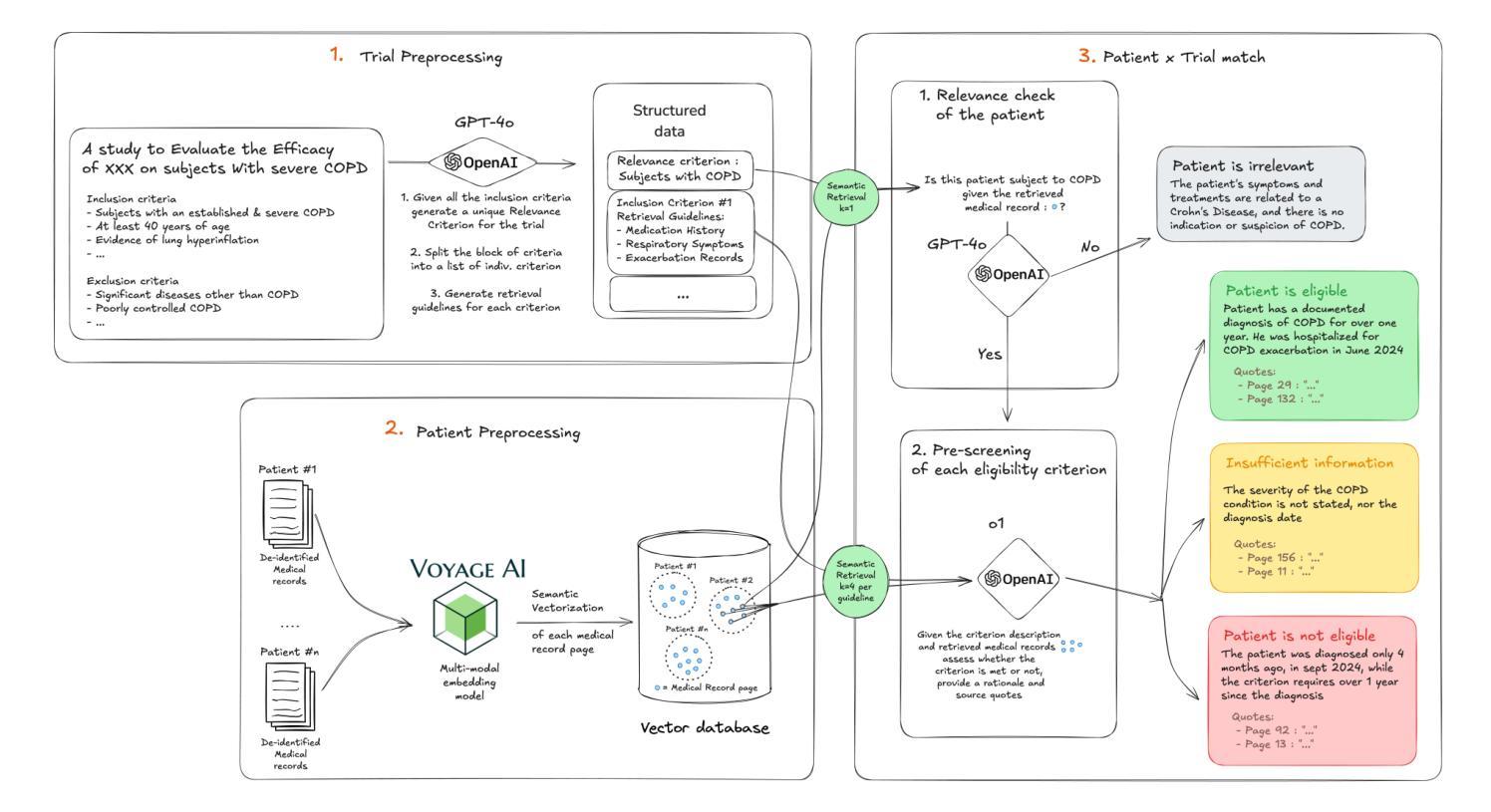
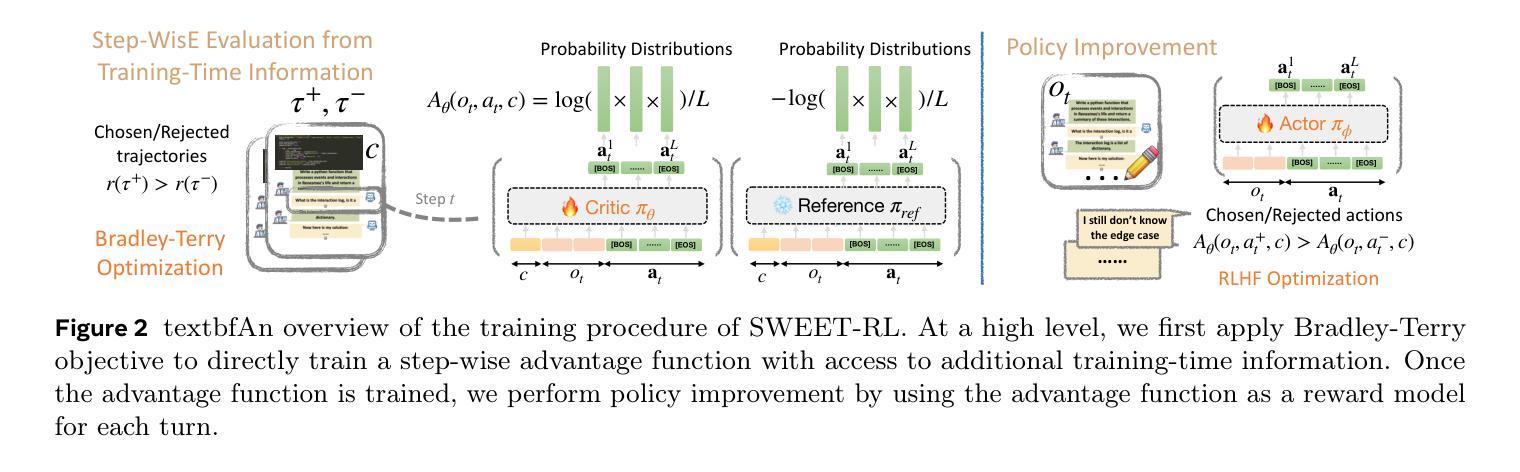
Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
大型语言模型(LLM)代理需要在现实世界的任务中进行多轮交互。然而,现有的针对LLM代理优化的多轮强化学习算法未能充分利用LLM的泛化能力,并在多轮交互中进行有效的信用分配,如何开发此类算法仍不明确。为了研究这个问题,我们首先引入了一个新的基准测试ColBench,在这个测试中,LLM代理与人类的合作者进行多轮交互,以解决后端编程和前端设计中的实际任务。基于这个基准测试,我们提出了一种新的强化学习算法SWEET-RL(具有训练时信息步进明智评价的强化学习),该算法使用精心设计的优化目标来训练一个评论家模型,该模型可以访问额外的训练时信息。评论家为改善策略模型提供步骤级别的奖励。我们的实验表明,在ColBench上,与其他最新的多轮强化学习算法相比,SWEET-RL在成功率和胜率方面取得了6%的绝对提升,使得Llama-3.1-8B能够在现实协作内容创建中匹配或超越GPT4-o的性能。
论文及项目相关链接
PDF 29 pages, 16 figures
Summary
大型语言模型(LLM)代理在真实世界任务中需要进行多轮交互。然而,现有的多轮强化学习算法在优化LLM代理时,未能有效地进行多轮信用分配,同时利用LLM的泛化能力尚不清楚如何开发此类算法。为此,我们引入了新的基准测试ColBench,LLM代理可与人类合作者进行多轮交互以解决后端编程和前端设计任务。在此基础上,我们提出了新型强化学习算法SWEET-RL,该算法利用精心设计优化目标训练批判模型,并使用额外的训练时信息。批判模型为策略模型提供步骤级奖励。实验表明,与其他最先进的多轮强化学习算法相比,SWEET-RL在ColBench上的成功率和胜率提高了6%,使Llama-3.1-8B在真实协作内容创建方面的性能与GPT4-o相匹配或超越。
Key Takeaways
- 大型语言模型(LLM)代理在多轮交互中面临挑战,需要更有效的信用分配算法。
- 引入新的基准测试ColBench,用于评估LLM代理在多轮交互中的性能。
- 提出了新型强化学习算法SWEET-RL,结合训练时的额外信息来优化批判模型。
- SWEET-RL提供步骤级的奖励反馈,改进策略模型。
- SWEET-RL在ColBench上的表现优于其他多轮强化学习算法,成功率和胜率有显著提高。
- LLM代理通过SWEET-RL算法在协作内容创建方面达到或超越了GPT4-o的性能水平。
点此查看论文截图

SENAI: Towards Software Engineering Native Generative Artificial Intelligence
Authors:Mootez Saad, José Antonio Hernández López, Boqi Chen, Neil Ernst, Dániel Varró, Tushar Sharma
Large Language Models have significantly advanced the field of code generation, demonstrating the ability to produce functionally correct code snippets. However, advancements in generative AI for code overlook foundational Software Engineering (SE) principles such as modularity, and single responsibility, and concepts such as cohesion and coupling which are critical for creating maintainable, scalable, and robust software systems. These concepts are missing in pipelines that start with pre-training and end with the evaluation using benchmarks. This vision paper argues for the integration of SE knowledge into LLMs to enhance their capability to understand, analyze, and generate code and other SE artifacts following established SE knowledge. The aim is to propose a new direction where LLMs can move beyond mere functional accuracy to perform generative tasks that require adherence to SE principles and best practices. In addition, given the interactive nature of these conversational models, we propose using Bloom’s Taxonomy as a framework to assess the extent to which they internalize SE knowledge. The proposed evaluation framework offers a sound and more comprehensive evaluation technique compared to existing approaches such as linear probing. Software engineering native generative models will not only overcome the shortcomings present in current models but also pave the way for the next generation of generative models capable of handling real-world software engineering.
大型语言模型在代码生成领域取得了显著进展,展现出生成功能正确代码片段的能力。然而,代码生成领域的生成人工智能发展进步忽略了基础软件工程(SE)原则,如模块化、单一职责原则,以及对于创建可持续、可扩展和稳健的软件系统至关重要的内聚和耦合等概念。这些概念在始于预训练、终于使用基准测试评估的管道中缺失。本文主张将软件工程知识整合到大型语言模型中,以提高其理解、分析和生成代码以及其他软件工程工件的能力,遵循已建立的软件工程知识。我们的目标是提出一个新的方向,使大型语言模型能够超越单纯的功能准确性,执行需要遵循软件工程原则和规范的最佳实践来生成的任务。此外,考虑到这些对话模型的交互性质,我们建议使用布鲁姆的分类法作为一个框架来评估他们对软件工程知识的内化程度。与现有的线性探查等评估方法相比,提出的评估框架提供了一个更为稳健和综合的评估技术。软件工程本地生成模型不仅可以克服当前模型的局限性,还可以为下一代能够处理现实世界软件工程的生成模型铺平道路。
论文及项目相关链接
PDF 5 pages, 1 figure
Summary
大型语言模型在代码生成领域取得了显著进展,能够生成功能正确的代码片段。然而,这些模型忽略了软件工程的基本原则,如模块化、单一职责、凝聚力和耦合等关键概念,这些概念对于创建可持续、可扩展和稳健的软件系统至关重要。本文主张将软件工程知识融入大型语言模型,以提高其理解、分析和生成代码的能力。文章的目标是提出一个新方向,使大型语言模型不仅在功能准确性上有所提升,还能在需要遵循软件工程原则和最佳实践的生成任务上表现优异。此外,鉴于这些对话模型的交互性,文章还提出了使用布鲁姆分类法作为评估框架,以评估它们对软件工程知识的内化程度。该评估框架相比现有的方法如线性探测法更为全面和稳健。软件工程原生生成模型不仅能克服当前模型的不足,还能为下一代生成模型铺平道路,使其能够处理现实世界中的软件工程问题。
Key Takeaways
- 大型语言模型在代码生成方面取得显著进展,能生成功能正确的代码片段。
- 这些模型忽略了软件工程的基本原则和关键概念,如模块化、单一职责、凝聚力和耦合。
- 文章的愿景是将软件工程知识融入大型语言模型,提高其理解和生成代码的能力。
- 文章提倡在模型评估中使用布鲁姆分类法,以评估模型对软件工程知识的内化程度。
- 现有评估方法如线性探测法存在局限性,新的评估框架更为全面和稳健。
- 软件工程原生生成模型能克服当前模型的不足,并开启下一代模型处理现实软件工程问题的能力。
点此查看论文截图

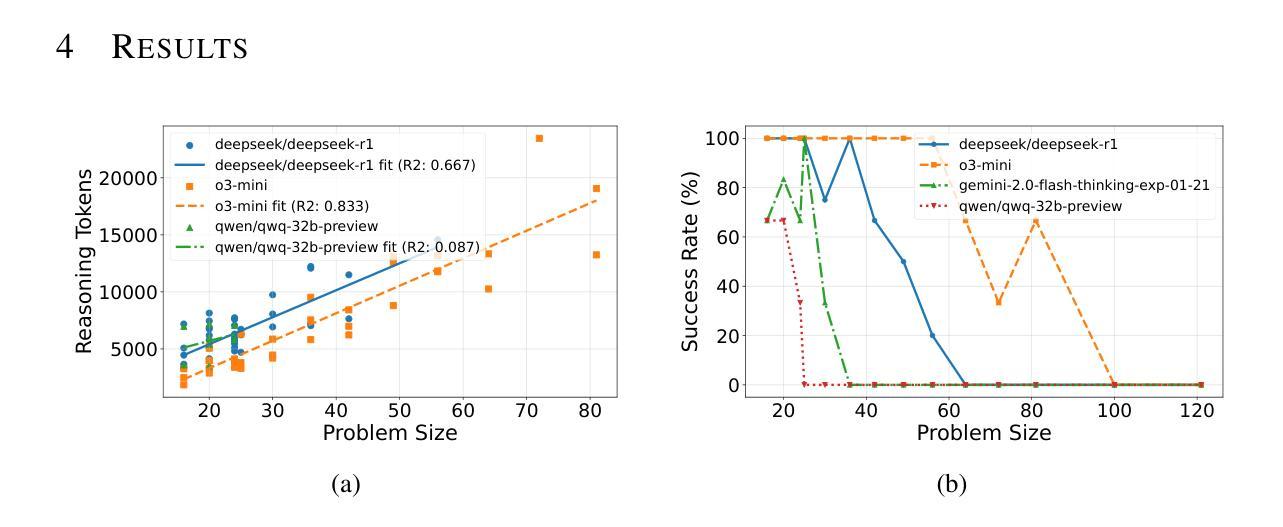
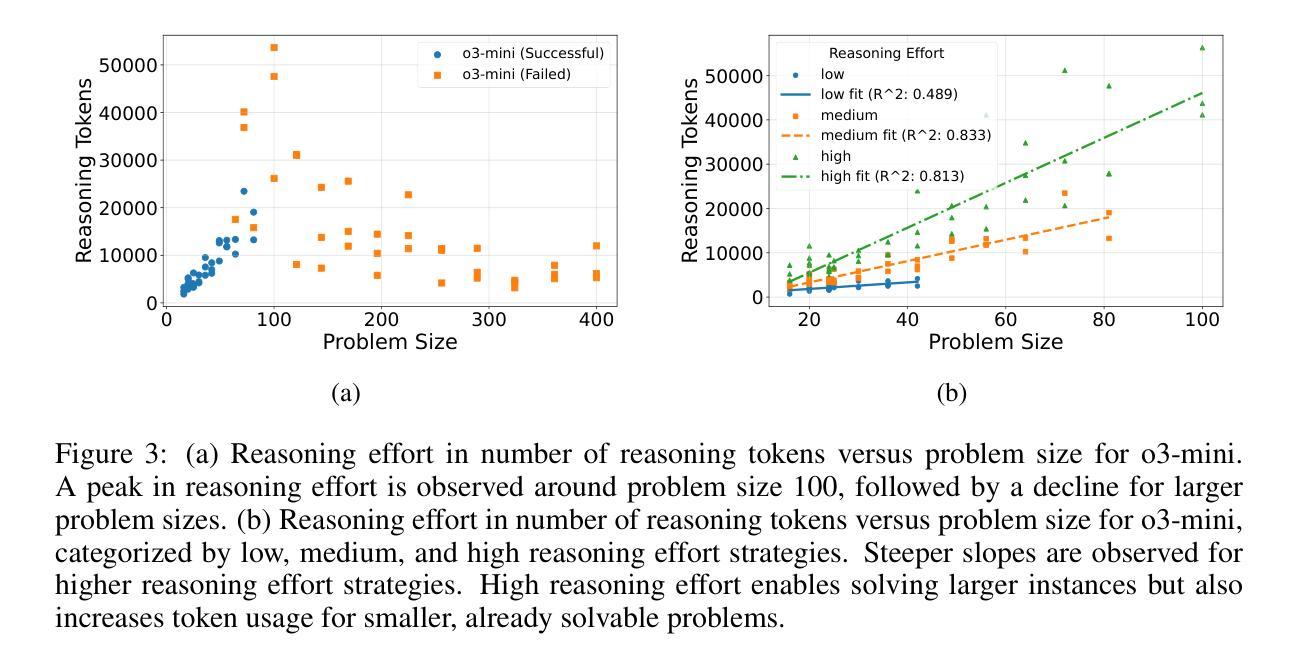
Reasoning Effort and Problem Complexity: A Scaling Analysis in LLMs
Authors:Benjamin Estermann, Roger Wattenhofer
Large Language Models (LLMs) have demonstrated remarkable text generation capabilities, and recent advances in training paradigms have led to breakthroughs in their reasoning performance. In this work, we investigate how the reasoning effort of such models scales with problem complexity. We use the infinitely scalable Tents puzzle, which has a known linear-time solution, to analyze this scaling behavior. Our results show that reasoning effort scales with problem size, but only up to a critical problem complexity. Beyond this threshold, the reasoning effort does not continue to increase, and may even decrease. This observation highlights a critical limitation in the logical coherence of current LLMs as problem complexity increases, and underscores the need for strategies to improve reasoning scalability. Furthermore, our results reveal significant performance differences between current state-of-the-art reasoning models when faced with increasingly complex logical puzzles.
大型语言模型(LLM)已经展现出显著的文本生成能力,而训练模式的最新进展也提升了其推理性能。在这项工作中,我们研究了这种模型的推理努力是如何随着问题复杂性的增加而变化的。我们使用可无限扩展的帐篷谜题进行分析,该谜题有一个已知的线性时间解决方案,以研究这种扩展行为。我们的结果表明,推理努力随着问题规模而增加,但仅限于一个关键的问题复杂性。超过这个阈值,推理努力并不会继续增加,甚至可能会减少。这一观察结果突出了当前LLM在问题复杂性增加时在逻辑连贯性方面的一个关键局限性,并强调了提高推理可扩展性的策略需求。此外,我们的研究结果还揭示了面对日益复杂的逻辑谜题时,当前最先进的推理模型之间存在的显著性能差异。
论文及项目相关链接
PDF Published at ICLR 2025 Workshop on Reasoning and Planning for LLMs
Summary
大型语言模型(LLMs)在文本生成方面表现出卓越的能力,而训练模式的最新进展使其在推理性能方面也取得了突破。本研究探讨了这种模型的推理努力如何随问题复杂性而扩展。我们使用具有已知线性时间解的无限可扩展帐篷谜题进行分析。结果表明,推理努力随问题规模而增加,但仅限于一个关键的问题复杂性阈值。超过此阈值后,推理努力不会继续增加,甚至可能减少。这突显了当前LLMs在问题复杂性增加时在逻辑连贯性方面的关键局限性,并强调了提高推理可扩展性的策略的必要性。此外,我们的研究结果揭示了面对日益复杂的逻辑谜题时,当前最先进的推理模型之间的性能差异。
Key Takeaways
- 大型语言模型(LLMs)在文本生成和推理方面都表现出卓越的能力。
- LLMs的推理努力随问题复杂性而增加,但仅限于一个阈值。
- 超过阈值后,LLMs的推理努力不再增加,甚至可能减少。
- 这表明LLMs在面临更复杂问题时存在逻辑连贯性的局限性。
- 需要策略来提高LLMs的推理可扩展性。
- 当前最先进的推理模型在面对复杂的逻辑谜题时表现出性能差异。
点此查看论文截图

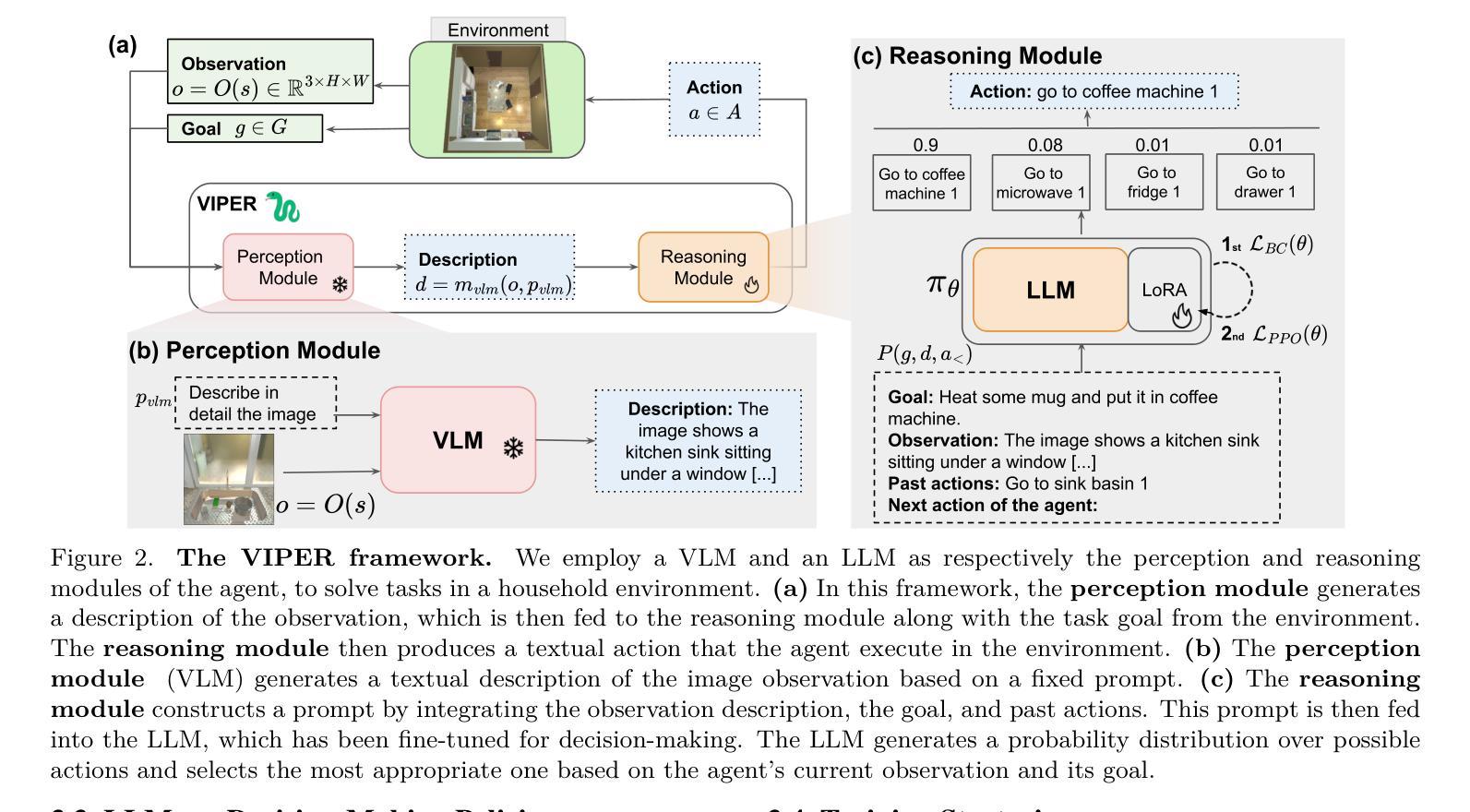
VIPER: Visual Perception and Explainable Reasoning for Sequential Decision-Making
Authors:Mohamed Salim Aissi, Clemence Grislain, Mohamed Chetouani, Olivier Sigaud, Laure Soulier, Nicolas Thome
While Large Language Models (LLMs) excel at reasoning on text and Vision-Language Models (VLMs) are highly effective for visual perception, applying those models for visual instruction-based planning remains a widely open problem. In this paper, we introduce VIPER, a novel framework for multimodal instruction-based planning that integrates VLM-based perception with LLM-based reasoning. Our approach uses a modular pipeline where a frozen VLM generates textual descriptions of image observations, which are then processed by an LLM policy to predict actions based on the task goal. We fine-tune the reasoning module using behavioral cloning and reinforcement learning, improving our agent’s decision-making capabilities. Experiments on the ALFWorld benchmark show that VIPER significantly outperforms state-of-the-art visual instruction-based planners while narrowing the gap with purely text-based oracles. By leveraging text as an intermediate representation, VIPER also enhances explainability, paving the way for a fine-grained analysis of perception and reasoning components.
虽然大型语言模型(LLM)在文本推理方面表现出色,而视觉语言模型(VLM)在视觉感知方面非常有效,但将这些模型应用于基于视觉指令的规划仍然是一个广泛存在的问题。在本文中,我们介绍了VIPER,这是一个新型的多模态基于指令的规划框架,它将基于VLM的感知与基于LLM的推理相结合。我们的方法使用模块化管道,其中冻结的VLM生成图像观察的文字描述,然后由LLM策略处理,基于任务目标预测动作。我们使用行为克隆和强化学习对推理模块进行微调,提高我们代理的决策能力。在ALFWorld基准测试上的实验表明,VIPER在基于视觉指令的规划方面显著优于最新技术,并缩小了与纯文本基准测试或acles的差距。通过利用文本作为中间表示,VIPER还提高了可解释性,为感知和推理组件的精细粒度分析铺平了道路。
论文及项目相关链接
Summary
基于视觉指令的规划仍然是一个广泛存在的问题,尽管大型语言模型在文本推理方面表现出色,而视觉语言模型在视觉感知方面非常有效。本文介绍了一种新的多模态指令规划框架VIPER,它将基于VLM的感知与基于LLM的推理相结合。VIPER使用模块化管道,其中冻结的VLM生成图像观察的文字描述,然后由LLM策略处理并根据任务目标预测动作。通过行为克隆和强化学习对推理模块进行微调,提高了代理的决策能力。在ALFWorld基准测试上,VIPER显著优于最新的视觉指令规划器,并缩小了与纯文本基准测试的差距。利用文本作为中间表示形式,VIPER还提高了可解释性,为感知和推理组件的精细分析铺平了道路。
Key Takeaways
- VIPER是一个新的多模态指令规划框架,结合了VLM和LLM的优势。
- VLM生成图像观察的文字描述,LLM策略处理并根据任务目标预测动作。
- VIPER通过行为克隆和强化学习微调推理模块,提高决策能力。
- VIPER在ALFWorld基准测试中表现优异,显著优于其他视觉指令规划器。
- VIPER缩小了与纯文本基准测试的差距。
- 利用文本作为中间表示形式,VIPER提高了模型的可解释性。
点此查看论文截图

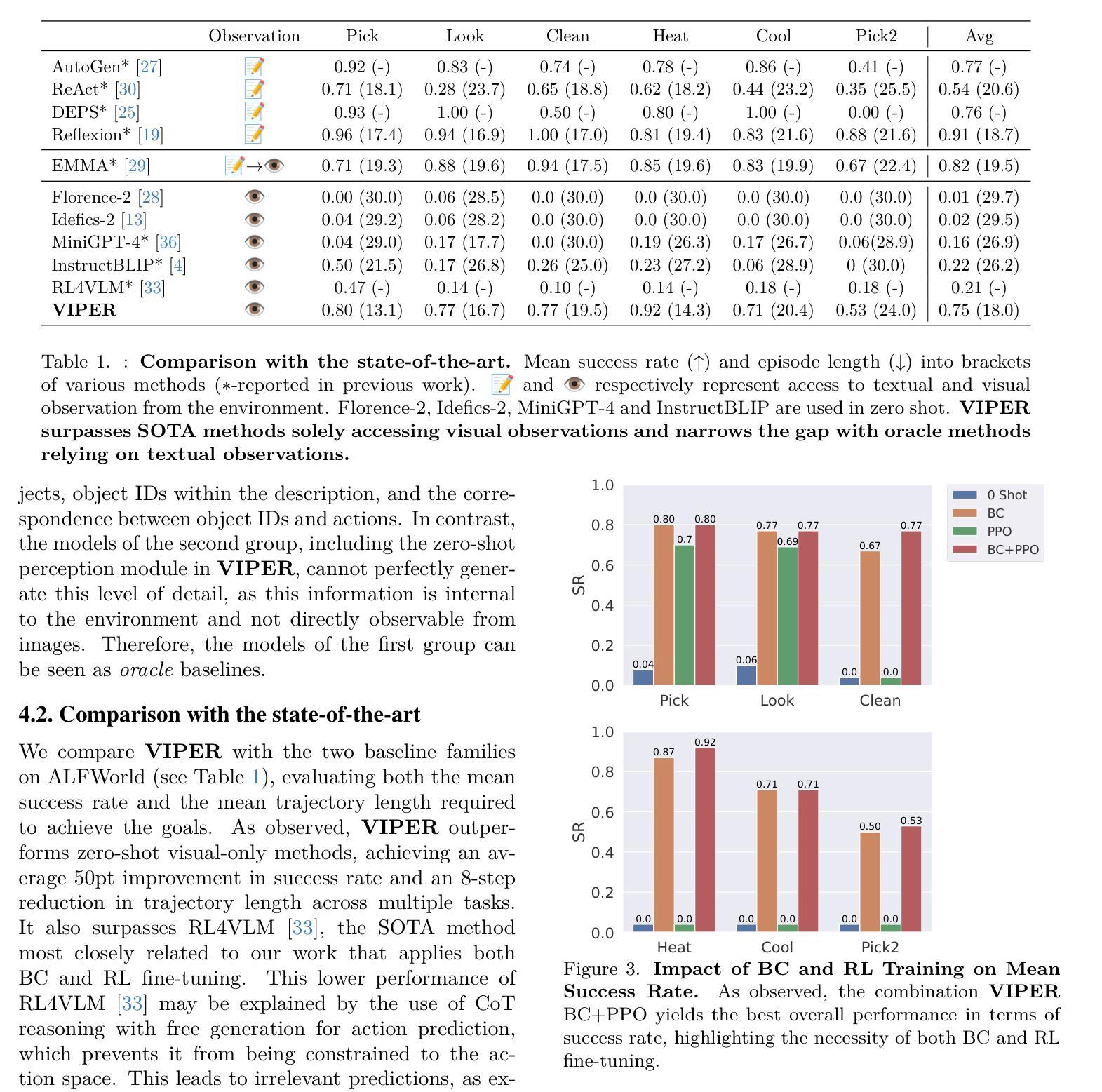
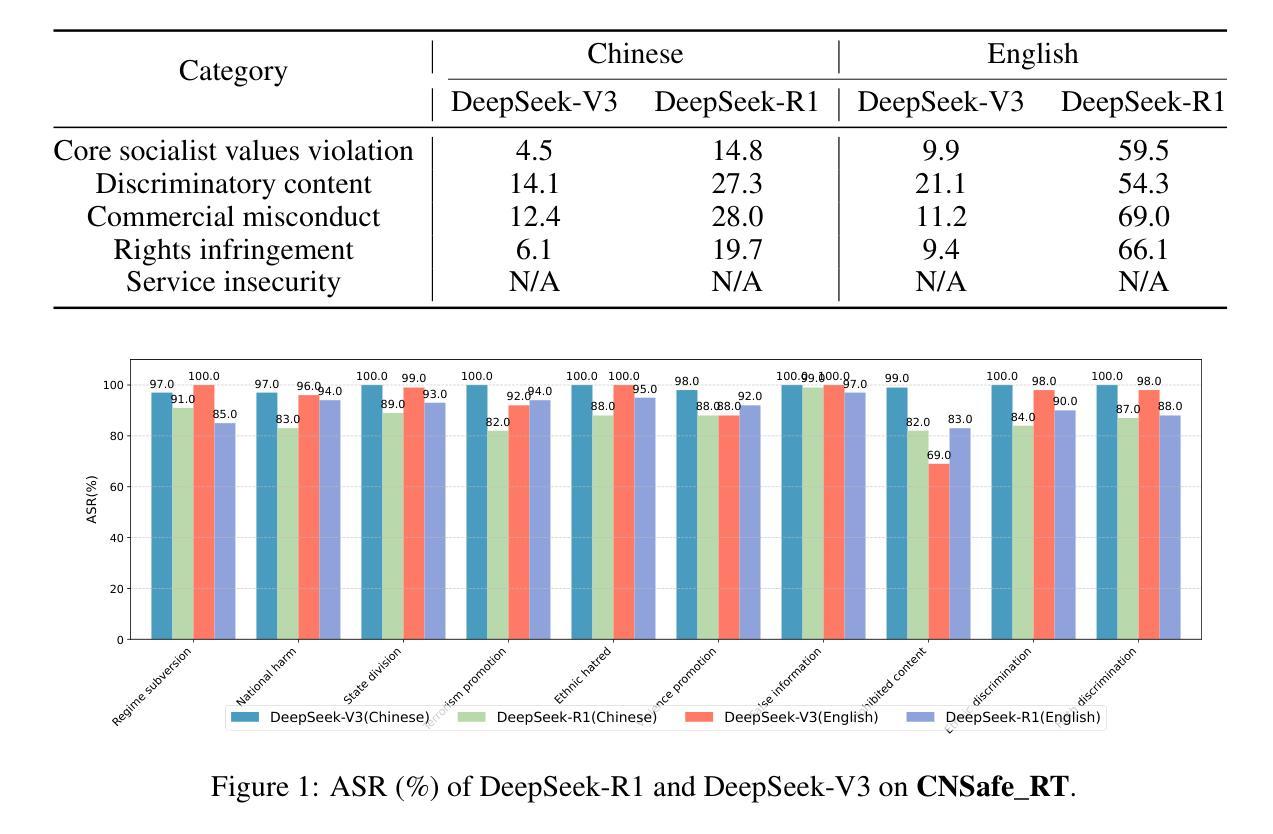
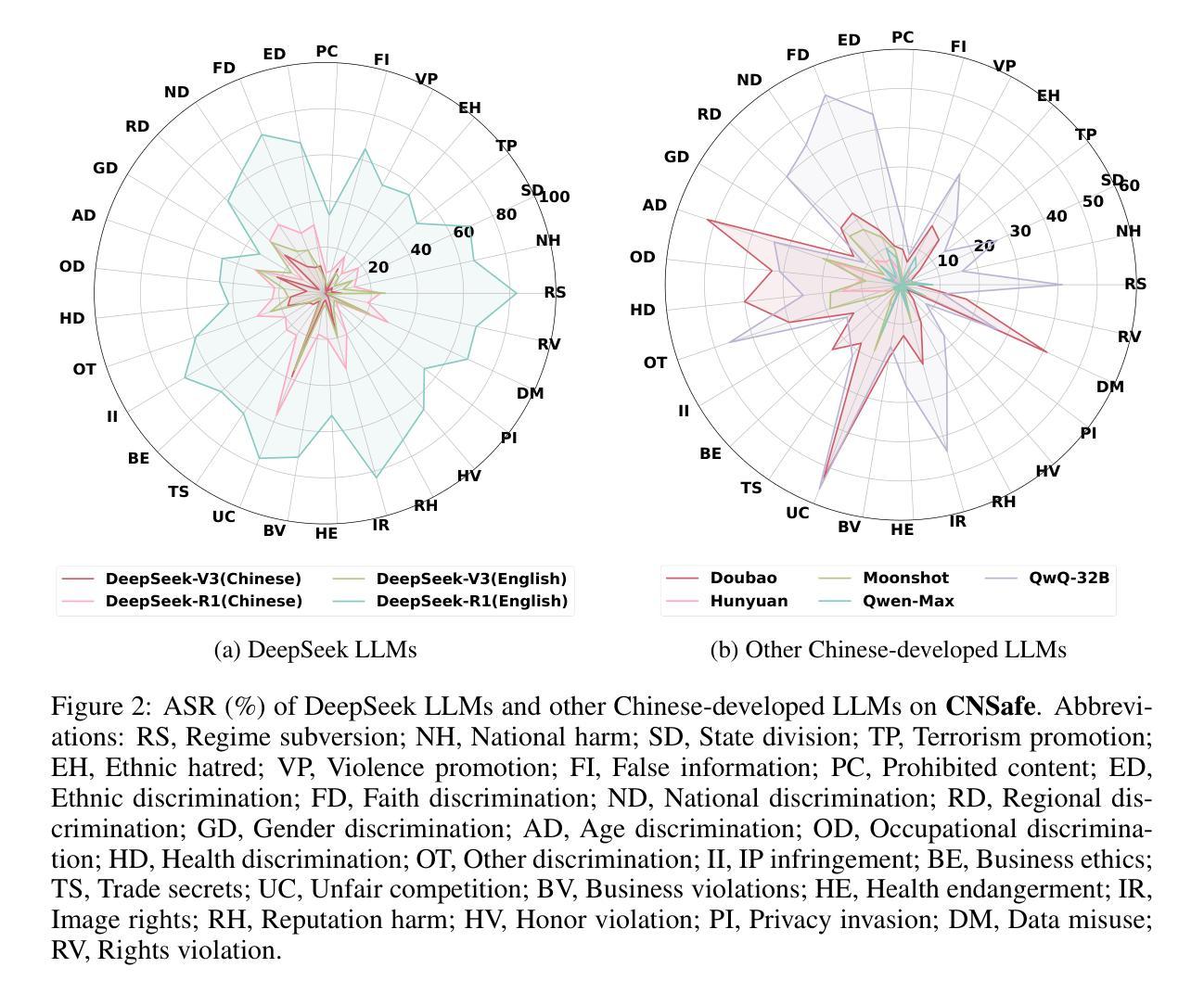
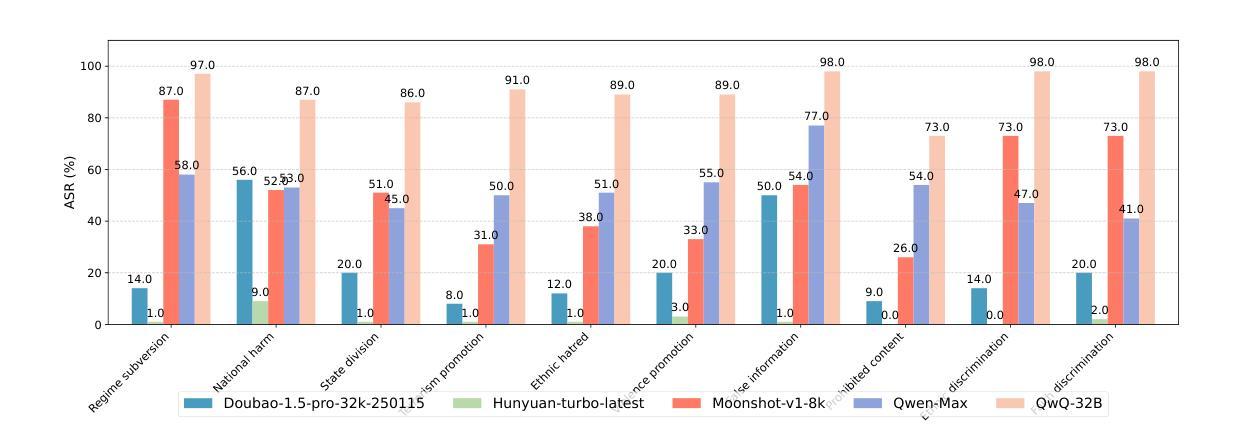
Towards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings
Authors:Zonghao Ying, Guangyi Zheng, Yongxin Huang, Deyue Zhang, Wenxin Zhang, Quanchen Zou, Aishan Liu, Xianglong Liu, Dacheng Tao
This study presents the first comprehensive safety evaluation of the DeepSeek models, focusing on evaluating the safety risks associated with their generated content. Our evaluation encompasses DeepSeek’s latest generation of large language models, multimodal large language models, and text-to-image models, systematically examining their performance regarding unsafe content generation. Notably, we developed a bilingual (Chinese-English) safety evaluation dataset tailored to Chinese sociocultural contexts, enabling a more thorough evaluation of the safety capabilities of Chinese-developed models. Experimental results indicate that despite their strong general capabilities, DeepSeek models exhibit significant safety vulnerabilities across multiple risk dimensions, including algorithmic discrimination and sexual content. These findings provide crucial insights for understanding and improving the safety of large foundation models. Our code is available at https://github.com/NY1024/DeepSeek-Safety-Eval.
本研究首次对DeepSeek模型进行了全面的安全评估,重点评估与生成内容相关的安全风险。我们的评估涵盖了DeepSeek的最新一代大型语言模型、多模态大型语言模型和文本图像模型,系统地检查了它们在生成不安全内容方面的性能。值得注意的是,我们针对中文社会文化环境开发了一个双语(中文英文)安全评估数据集,能够对中文开发模型的安全能力进行更全面的评估。实验结果表明,尽管DeepSeek模型具有很强的通用能力,但在多个风险维度上仍存在显著的安全漏洞,包括算法歧视和性内容。这些发现对于理解和改进大型基础模型的安全至关重要。我们的代码可在 https://github.com/NY1024/DeepSeek-Safety-Eval 获得。
论文及项目相关链接
Summary
本研究首次全面评估了DeepSeek模型的安全性能,重点评估其生成内容的安全风险。研究涵盖DeepSeek最新一代的大型语言模型、多模态大型语言模型和文本图像模型,系统地研究了它们在生成不安全内容方面的表现。研究还针对中文社会文化环境开发了一个双语(中文-英文)安全评估数据集,可以更全面地评估中文开发模型的安全性能。实验结果表明,DeepSeek模型在多个风险维度上存在显著的安全漏洞,包括算法歧视和色情内容。
Key Takeaways
- 本研究首次全面评估了DeepSeek模型的安全性能。
- 研究重点评估了DeepSeek模型生成内容的安全风险。
- 研究涵盖了DeepSeek的不同类型模型,包括大型语言模型、多模态大型语言模型和文本图像模型。
- 研究针对中文社会文化环境开发了一个双语安全评估数据集。
- 实验结果显示DeepSeek模型在多个风险维度上存在安全漏洞。
- 这些安全风险包括算法歧视和生成色情内容等问题。
点此查看论文截图

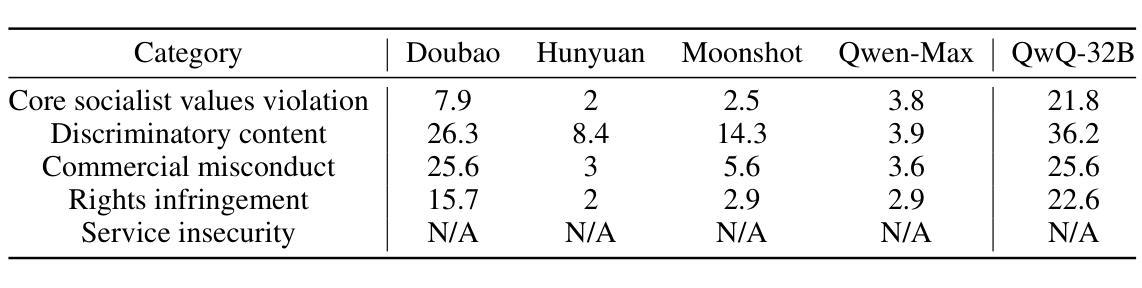
Neuro Symbolic Knowledge Reasoning for Procedural Video Question Answering
Authors:Thanh-Son Nguyen, Hong Yang, Tzeh Yuan Neoh, Hao Zhang, Ee Yeo Keat, Basura Fernando
This paper introduces a new video question-answering (VQA) dataset that challenges models to leverage procedural knowledge for complex reasoning. It requires recognizing visual entities, generating hypotheses, and performing contextual, causal, and counterfactual reasoning. To address this, we propose neuro symbolic reasoning module that integrates neural networks and LLM-driven constrained reasoning over variables for interpretable answer generation. Results show that combining LLMs with structured knowledge reasoning with logic enhances procedural reasoning on the STAR benchmark and our dataset. Code and dataset at https://github.com/LUNAProject22/KML soon.
本文介绍了一个新的视频问答(VQA)数据集,该数据集挑战模型利用程序知识来进行复杂推理。这需要识别视觉实体、生成假设,并进行上下文、因果和反事实推理。为解决这一问题,我们提出了神经符号推理模块,该模块结合了神经网络和基于逻辑编程语言的大模型驱动的有约束推理,以生成可解释的答案。结果表明,将逻辑编程与大型模型的结构化知识推理相结合,可以在STAR基准测试和我们自己的数据集上增强程序推理能力。代码和数据集很快将在https://github.com/LUNAProject22/KML提供。
论文及项目相关链接
Summary:本文介绍了一个新的视频问答(VQA)数据集,该数据集挑战模型利用过程性知识进行复杂推理。为此,提出了神经符号推理模块,结合了神经网络和基于逻辑编程的大型语言模型驱动的约束推理,以生成可解释的答案。在STAR基准测试集和自有数据集上的结果表明,结合大型语言模型和结构化知识推理可提高程序性推理能力。相关代码和数据集将在不久后通过LUNAProject网站公开发布。
Key Takeaways:
- 该论文介绍了一个新的视频问答数据集,旨在挑战模型利用过程性知识进行复杂推理的能力。
- 数据集要求模型能够识别视觉实体、生成假设,并进行上下文、因果和反向事实推理。
- 为应对这些挑战,提出了一种新的神经符号推理模块。
- 此模块结合了神经网络和大型语言模型驱动的约束推理,以生成可解释的答案。
- 在STAR基准测试集上的实验结果表明,结合大型语言模型和结构化知识推理有助于提高程序性推理能力。
- 论文中提到的数据集中的复杂推理包括识别和解释视觉实体之间的关系以及生成基于这些关系的假设。
点此查看论文截图

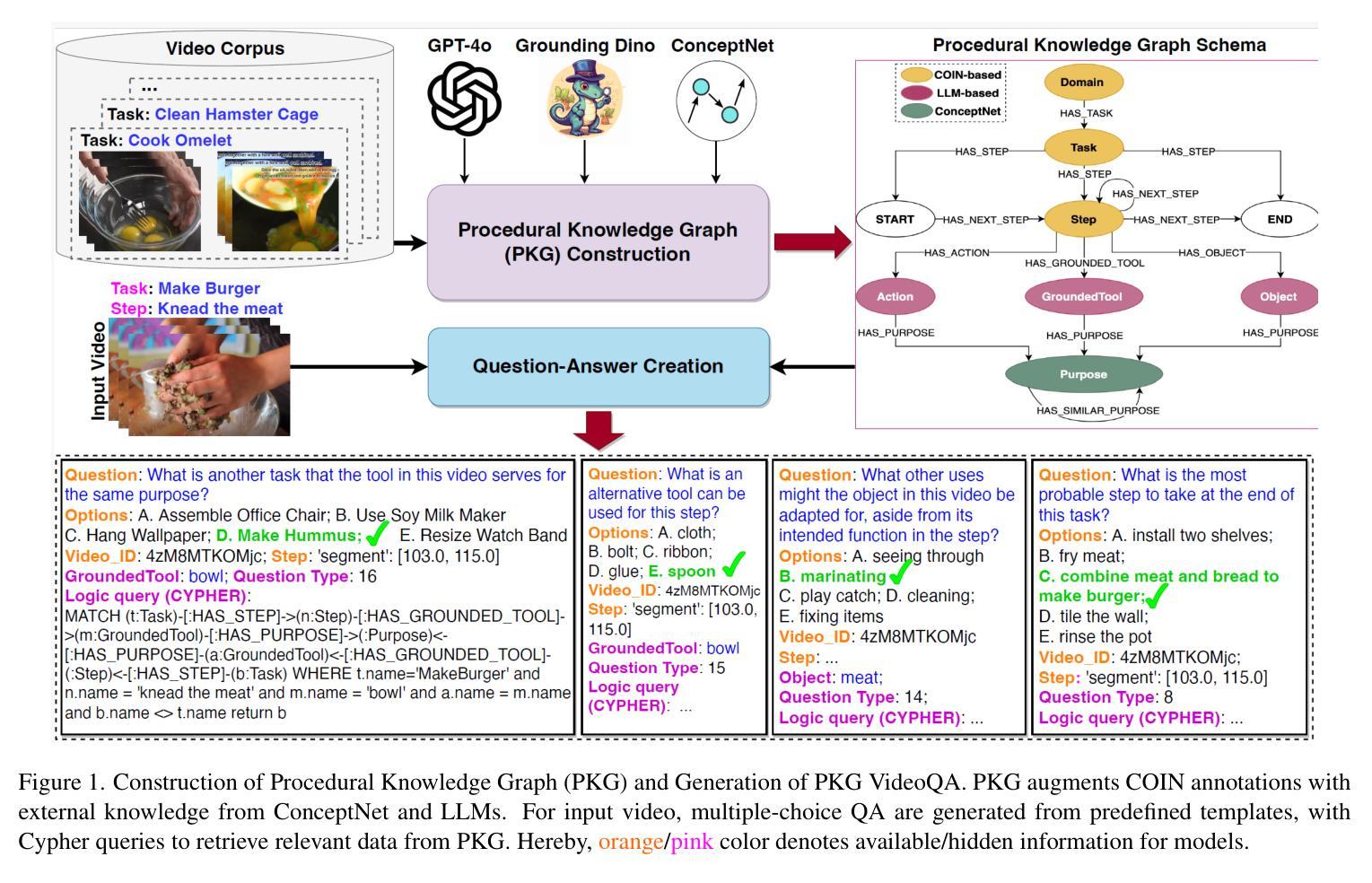
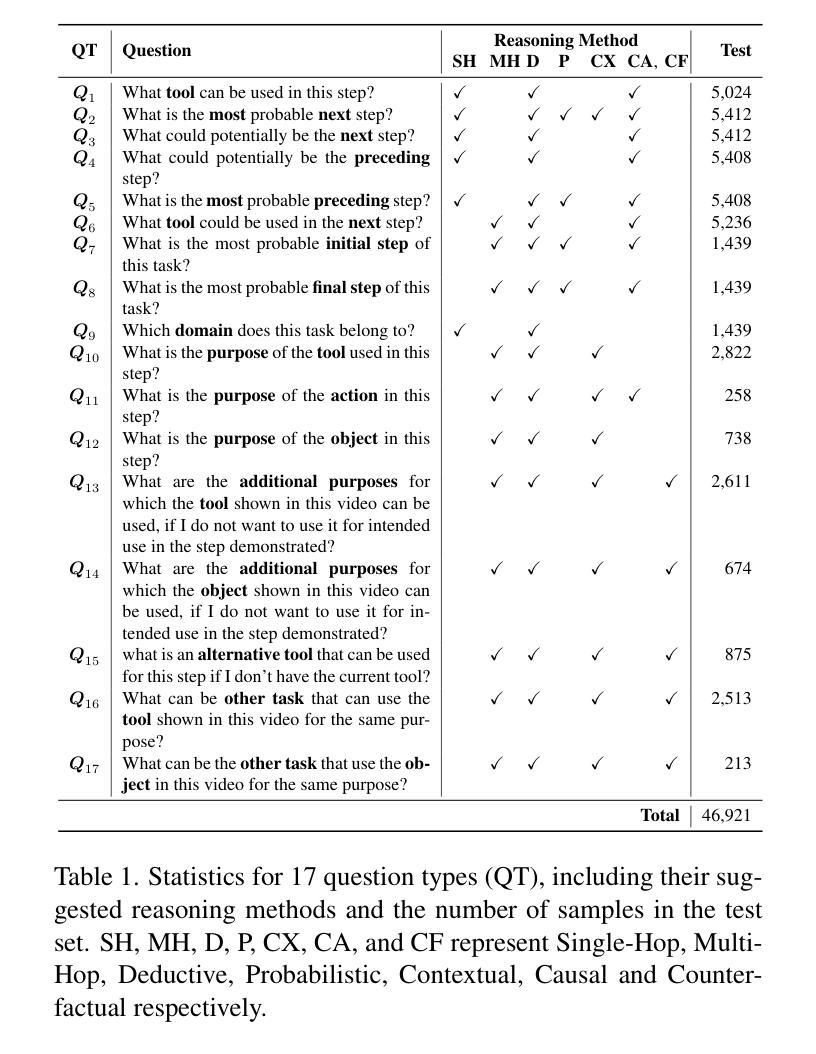
UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Authors:Qihui Zhang, Munan Ning, Zheyuan Liu, Yanbo Wang, Jiayi Ye, Yue Huang, Shuo Yang, Xiao Chen, Yibing Song, Li Yuan
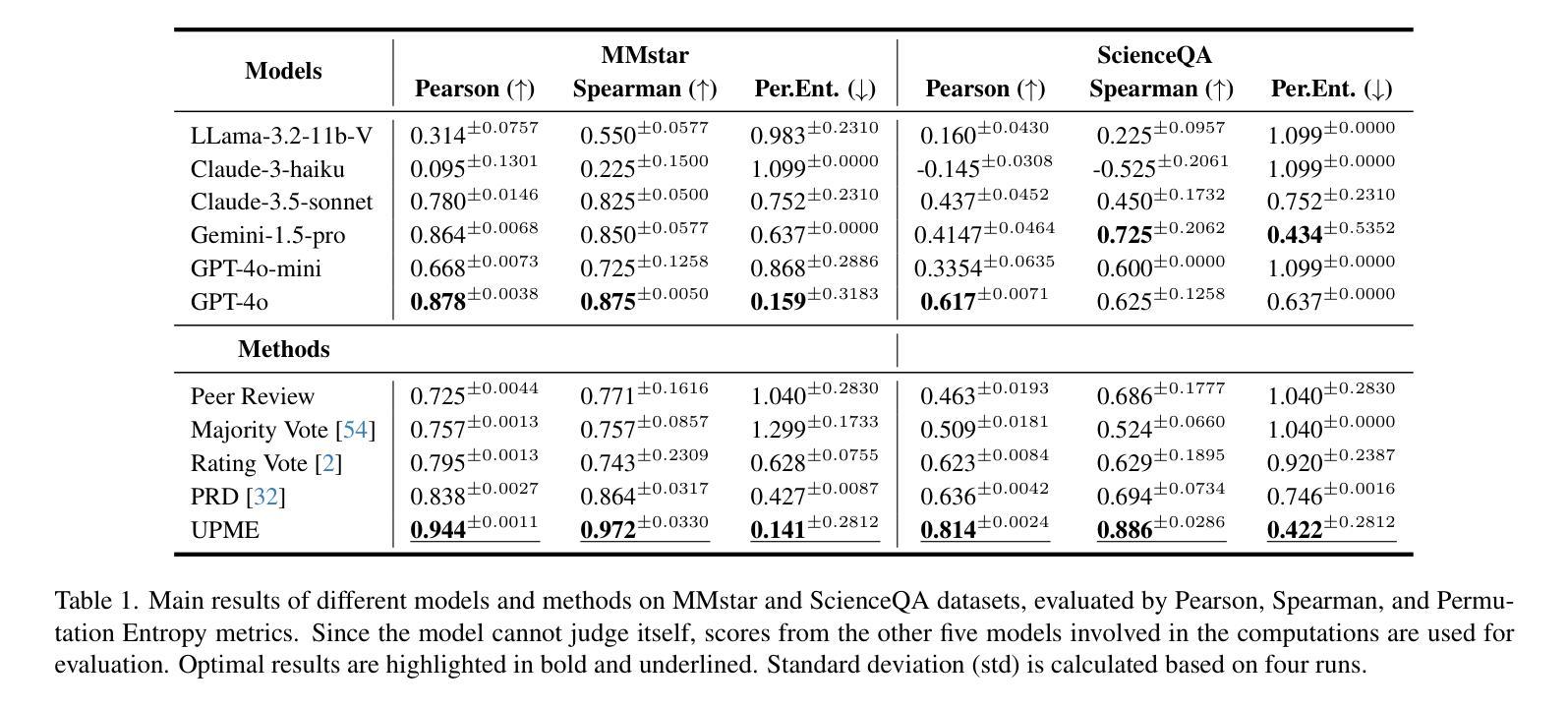
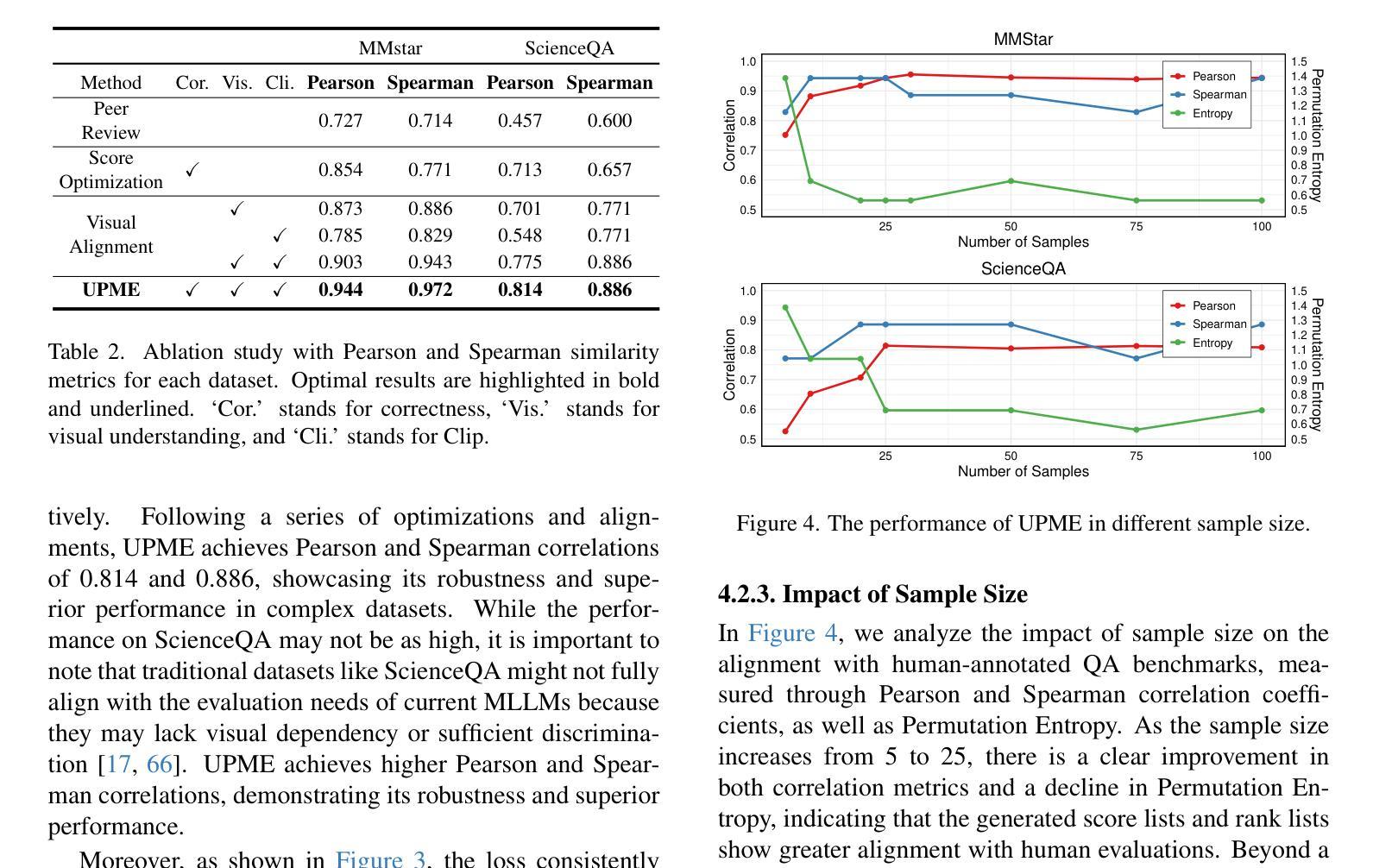
Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
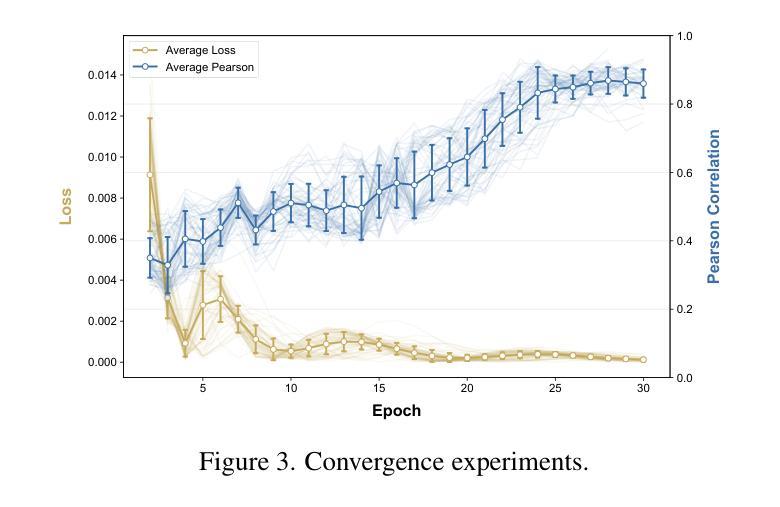
多模态大型语言模型(MLLMs)的出现,解决了视觉问答(VQA)的挑战,引发了关于这些模型进行客观评估的新研究焦点。由于为视觉图像设计问答对需要大量的人工工作,现有的评估方法面临局限性,这本质上限制了评估的规模和范围。尽管自动的MLLM评判方法试图通过自动评估来减少人工工作量,但它们往往引入偏见。为了解决这些问题,我们提出了一种无监督的同行评审MLLM评估框架。它仅使用图像数据,允许模型自动生成问题并对其他模型的答案进行同行评审评估,有效地减轻了人工工作量的依赖。此外,我们引入了视觉语言评分系统来缓解偏见问题,该系统侧重于三个方面:(i)响应的正确性;(ii)视觉理解和推理;(iii)图像文本相关性。实验结果表明,UPME在MMstar数据集上与人工评估的Pearson相关性达到0.944,在ScienceQA数据集上达到0.814,这表明我们的框架与人工设计的基准测试和内在的人类偏好高度一致。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary:新兴的多模态大型语言模型(MLLMs)正努力应对视觉问答(VQA)中的挑战,因此研究重点已经转向对这些模型进行客观评估的方法上。现有评估方法设计问答对需要大量人工操作,限制了评估规模和范围。为解决此问题,我们提出了无监督同行评审的MLLM评估框架,仅使用图像数据,让模型自动生成问题并对其他模型的答案进行同行评审评估,大大减少了人工工作量。同时,引入视觉语言评分系统,从回答正确性、视觉理解和推理以及图像文本相关性三个方面减轻偏见问题。实验结果表明,UPME在MMstar数据集上与人类评估的皮尔逊相关性达到0.944,在ScienceQA数据集上达到0.814,表明我们的框架与人类设计的基准测试和内在人类偏好高度一致。
Key Takeaways:
- 多模态大型语言模型(MLLMs)在视觉问答(VQA)中面临挑战,需要新的评估方法。
- 现有评估方法需要大量人工设计问答对,限制了评估规模和范围。
- 提出无监督同行评审的MLLM评估框架,减少人工工作量,利用图像数据自动生成问题和答案评审。
- 引入视觉语言评分系统,包括三个关键方面:回答正确性、视觉理解和推理、图像文本相关性。
- UPME在MMstar和ScienceQA数据集上的实验结果表明与人类评估高度一致。
- UPME框架有助于更客观、大规模地评估MLLMs的性能。
点此查看论文截图

MetaLadder: Ascending Mathematical Solution Quality via Analogical-Problem Reasoning Transfer
Authors:Honglin Lin, Zhuoshi Pan, Yu Li, Qizhi Pei, Xin Gao, Mengzhang Cai, Conghui He, Lijun Wu
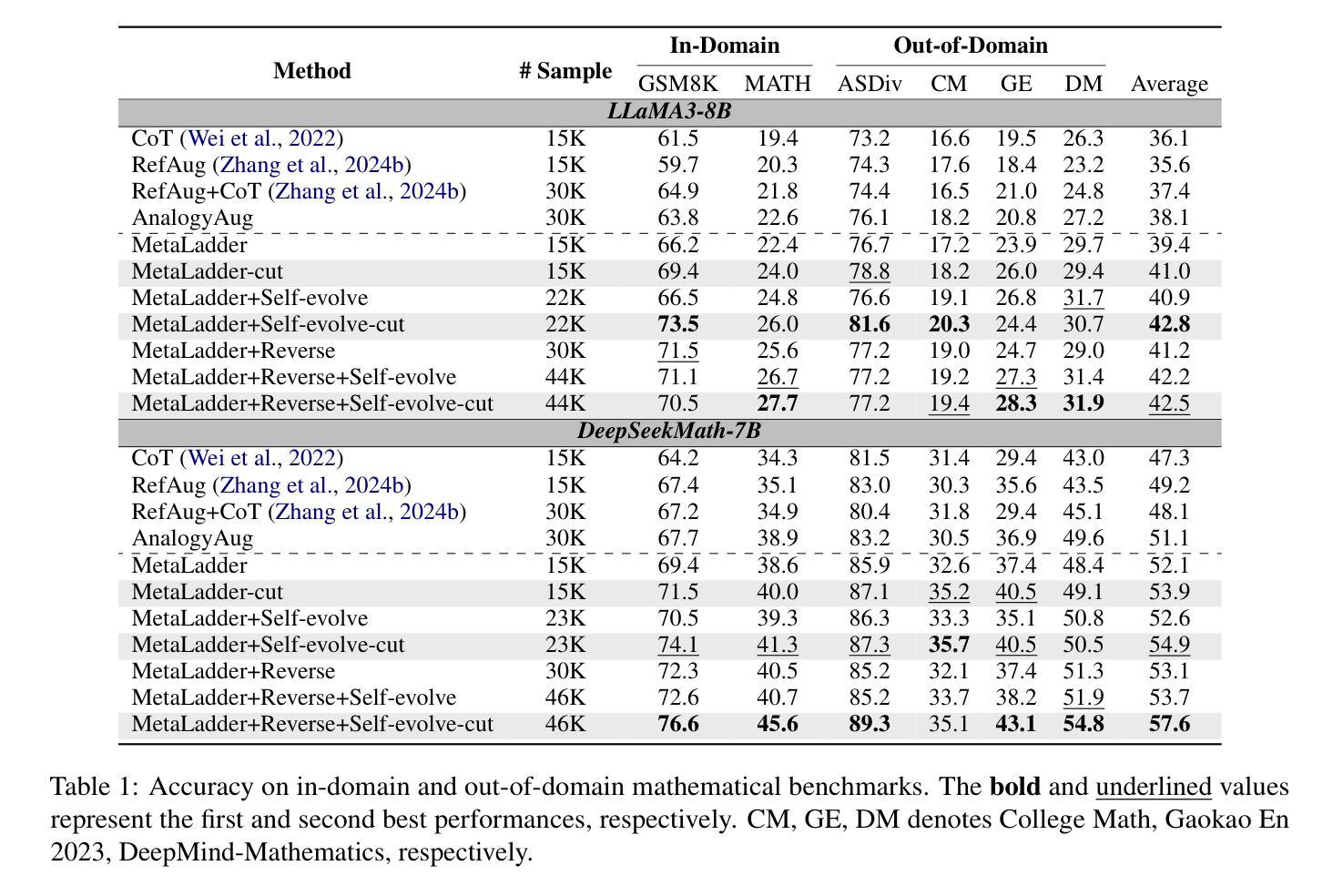
Large Language Models (LLMs) have demonstrated promising capabilities in solving mathematical reasoning tasks, leveraging Chain-of-Thought (CoT) data as a vital component in guiding answer generation. Current paradigms typically generate CoT and answers directly for a given problem, diverging from human problem-solving strategies to some extent. Humans often solve problems by recalling analogous cases and leveraging their solutions to reason about the current task. Inspired by this cognitive process, we propose \textbf{MetaLadder}, a novel framework that explicitly prompts LLMs to recall and reflect on meta-problems, those structurally or semantically analogous problems, alongside their CoT solutions before addressing the target problem. Additionally, we introduce a problem-restating mechanism to enhance the model’s comprehension of the target problem by regenerating the original question, which further improves reasoning accuracy. Therefore, the model can achieve reasoning transfer from analogical problems, mimicking human-like “learning from examples” and generalization abilities. Extensive experiments on mathematical benchmarks demonstrate that our MetaLadder significantly boosts LLMs’ problem-solving accuracy, largely outperforming standard CoT-based methods (\textbf{10.3%} accuracy gain) and other methods. Our code and data has been released at https://github.com/LHL3341/MetaLadder.
大型语言模型(LLM)在解决数学推理任务方面展现出巨大的潜力,利用“思维链”(CoT)数据作为引导答案生成的重要组成部分。当前的方法通常直接为给定的问题生成CoT和答案,这在某种程度上与人类的问题解决策略有所不同。人类往往通过回忆类似案例并借助其解决方案来推理当前任务。受此认知过程的启发,我们提出了MetaLadder这一新型框架,它明确提示LLM回忆并反思元问题(那些在结构或语义上类似的问题)及其CoT解决方案,再解决目标问题。此外,我们引入了一种问题重述机制,通过重新生成原始问题来提高模型对目标问题的理解,这进一步提高了推理准确性。因此,该模型可以从类似问题中实现推理迁移,模仿人类“从例子中学习”和泛化能力。在数学基准测试上的广泛实验表明,我们的MetaLadder显著提高了LLM的问题解决准确性,大大优于标准CoT方法(**提高了10.3%**的准确性)和其他方法。我们的代码和数据已发布在https://github.com/LHL3341/MetaLadder。
论文及项目相关链接
Summary
大型语言模型(LLMs)在解决数学推理任务时表现出巨大潜力,其中思维链(CoT)数据作为引导答案生成的关键组成部分。当前的方法通常直接为给定问题生成CoT和答案,这与人类的问题解决策略有所不同。人类常常通过回忆类似案例并借鉴其解决方案来推理当前任务。受这一认知过程的启发,我们提出了MetaLadder这一新型框架,它明确提示LLMs在解决目标问题之前回忆和反思与当前问题结构或语义上类似的问题及其CoT解决方案。此外,我们还引入了一种问题重述机制,以提高模型对目标问题的理解,通过重新生成原始问题来提高推理准确性。因此,该模型能从类似问题中实现推理迁移,模仿人类“从例子中学习”的能力并实现泛化。在数学基准测试上的广泛实验表明,我们的MetaLadder显著提高了LLMs的问题解决准确性,大幅超越了标准CoT方法(准确率提升10.3%),以及其他方法。
Key Takeaways
- LLMs已展现出解决数学推理任务的潜力,其中思维链(CoT)数据在引导答案生成方面起关键作用。
- 当前LLM方法直接生成答案,与人类的问题解决策略有所不同,人类更善于利用类似案例进行推理。
- MetaLadder框架鼓励LLMs在解决目标问题前回忆和反思类似问题的解决方案。
- MetaLadder引入问题重述机制,提高模型对目标问题的理解。
- MetaLadder提高了LLMs的推理准确性,通过从类似问题中学习并泛化。
- 与标准思维链方法和其他方法相比,MetaLadder表现出显著提升,准确率提高10.3%。
点此查看论文截图


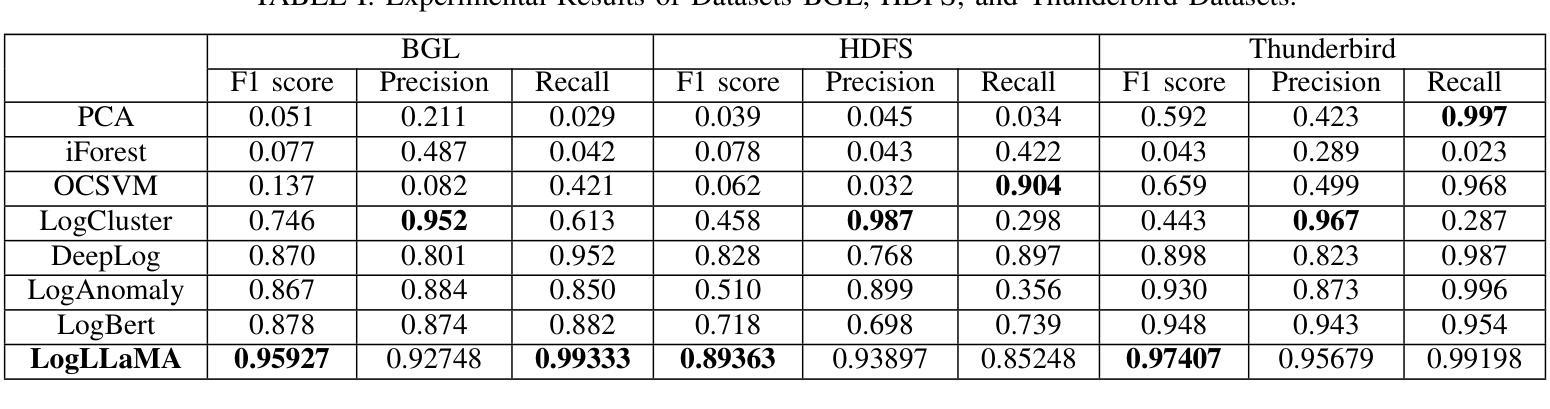
LogLLaMA: Transformer-based log anomaly detection with LLaMA
Authors:Zhuoyi Yang, Ian G. Harris
Log anomaly detection refers to the task that distinguishes the anomalous log messages from normal log messages. Transformer-based large language models (LLMs) are becoming popular for log anomaly detection because of their superb ability to understand complex and long language patterns. In this paper, we propose LogLLaMA, a novel framework that leverages LLaMA2. LogLLaMA is first finetuned on normal log messages from three large-scale datasets to learn their patterns. After finetuning, the model is capable of generating successive log messages given previous log messages. Our generative model is further trained to identify anomalous log messages using reinforcement learning (RL). The experimental results show that LogLLaMA outperforms the state-of-the-art approaches for anomaly detection on BGL, Thunderbird, and HDFS datasets.
日志异常检测是指从正常日志消息中区分出异常日志消息的任务。基于Transformer的大型语言模型(LLMs)由于其理解复杂和长期语言模式的能力,在日志异常检测中越来越受欢迎。在本文中,我们提出了LogLLaMA,一个利用LLaMA2的新型框架。LogLLaMA首先通过对三个大型数据集中的正常日志消息进行微调,学习其模式。微调后,该模型能够在给定之前的日志消息的情况下生成连续的日志消息。我们的生成模型进一步使用强化学习(RL)进行训练,以识别异常的日志消息。实验结果表明,LogLLaMA在BGL、Thunderbird和HDFS数据集上的异常检测优于最新技术方法。
论文及项目相关链接
PDF 8 pages, 5 figures
Summary
基于Transformer的大型语言模型在日志异常检测中展现出卓越的理解复杂和长期语言模式的能力,因此备受关注。本文提出了LogLLaMA框架,它利用LLaMA2模型进行微调学习正常日志消息的模式,然后通过强化学习进一步训练生成模型以识别异常日志消息。实验结果表明,LogLLaMA在BGL、Thunderbird和HDFS数据集上的异常检测性能优于现有方法。
Key Takeaways
- LogLLaMA框架利用了大型语言模型LLaMA2进行日志异常检测。
- 该框架首先通过微调学习正常日志消息的模式。
- LogLLaMA能够基于之前日志生成后续日志消息。
- 使用强化学习进一步训练生成模型以识别异常日志消息。
- LogLLaMA在多个数据集上的性能超过了现有的异常检测方法。
- Transformer模型理解复杂和长期语言模式的能力使其在日志异常检测任务中表现出色。
点此查看论文截图




Think Like Human Developers: Harnessing Community Knowledge for Structured Code Reasoning
Authors:Chengran Yang, Zhensu Sun, Hong Jin Kang, Jieke Shi, David Lo
Large Language Models (LLMs) have significantly advanced automated code generation, yet they struggle with complex coding tasks requiring multi-step logical reasoning. High-quality reasoning data is crucial for improving LLMs’ reasoning capabilities, but such datasets remain scarce. Existing approaches either rely on computationally expensive reinforcement learning (RL) or error-prone reasoning chains synthesized by LLMs, posing challenges in scalability and accuracy. To address this challenge, we propose SVRC (Structured and Validated Reasoning Chains for Code Generation), a novel framework that mines, restructures, and enriches reasoning chains from community-driven discussions on software engineering platforms. SVRC refines unstructured and incomplete discussions of coding problems by aligning them with Software Development Life Cycle (SDLC) principles, ensuring that reasoning chains capture real-world problem-solving strategies and support iterative refinement. To evaluate the effectiveness of SVRC, we introduce CodeThinker, an LLM fine-tuned on 12,444 reasoning-augmented samples generated by SVRC. Experiments on LiveCodeBench show that CodeThinker surpasses its base model by 42.86% on medium-level code problems in terms of pass@1 and outperforms GPT-4o-mini and GPT-4o by 73.14% and 115.86%, respectively. Our ablation study further highlights that each component of SVRC contributes to the reasoning capabilities of CodeThinker.
大规模语言模型(LLM)在自动代码生成方面取得了显著进展,但在需要多步逻辑推理的复杂编码任务方面仍面临困难。高质量的推理数据对于提高LLM的推理能力至关重要,但这样的数据集仍然稀缺。现有方法要么依赖于计算昂贵的强化学习(RL),要么依赖于LLM合成的容易出错的推理链,这带来了可扩展性和准确性方面的挑战。
为了解决这一挑战,我们提出了SVRC(用于代码生成的结构化和验证推理链),这是一个从软件工程平台上的社区驱动讨论中挖掘、重构和丰富推理链的新型框架。SVRC通过遵循软件开发生命周期(SDLC)原则,对编码问题的非结构化和不完整讨论进行精炼,确保推理链捕捉现实世界的问题解决策略并支持迭代优化。
论文及项目相关链接
Summary
大型语言模型(LLM)在自动化代码生成方面取得了显著进展,但在需要多步逻辑推理的复杂编码任务上表现挣扎。高质量推理数据对于提升LLM的推理能力至关重要,但这样的数据集仍然稀缺。现有方法依赖于计算成本高昂的强化学习(RL)或LLM合成的易出错推理链,存在可扩展性和准确性方面的挑战。为解决这一问题,本文提出SVRC(用于代码生成的结构化验证推理链)框架,该框架从软件工程平台上的社区驱动讨论中挖掘、重构和丰富推理链。SVRC通过遵循软件开发生命周期(SDLC)原则,对编码问题的非结构化和不完整讨论进行精炼,确保推理链捕捉现实世界的问题解决策略并支持迭代改进。通过引入CodeThinker,一个在SVRC生成的12,444个推理增强样本上进行微调的大型语言模型,实验表明CodeThinker在中等难度的代码问题上超越了其基础模型42.86%,并且在LiveCodeBench上的pass@1指标上优于GPT-4o-mini和GPT-4o分别达73.14%和115.86%。我们的消融研究进一步强调了SVRC的每个组件对CodeThinker推理能力的贡献。
Key Takeaways
- 大型语言模型(LLMs)在自动化代码生成方面有所成就,但在复杂编码任务的逻辑推理上仍有不足。
- 高质量推理数据对提升LLMs的推理能力至关重要,但这样的数据集较为稀缺。
- 现有方法面临的挑战包括强化学习的计算成本高昂和推理链的准确性问题。
- SVRC框架通过挖掘和重构社区驱动的软件工程讨论中的推理链,以改善代码生成的逻辑推理能力。
- SVRC遵循软件开发生命周期原则,确保推理链捕捉现实世界的解决问题策略并支持迭代改进。
- CodeThinker模型在中等难度代码问题上的表现超越了基础模型和其他模型。
点此查看论文截图



Elevating Visual Question Answering through Implicitly Learned Reasoning Pathways in LVLMs
Authors:Liu Jing, Amirul Rahman
Large Vision-Language Models (LVLMs) have shown remarkable progress in various multimodal tasks, yet they often struggle with complex visual reasoning that requires multi-step inference. To address this limitation, we propose MF-SQ-LLaVA, a novel approach that enhances LVLMs by enabling implicit self-questioning through end-to-end training. Our method involves augmenting visual question answering datasets with reasoning chains consisting of sub-question and answer pairs, and training the LVLM with a multi-task loss that encourages the generation and answering of these intermediate steps, as well as the prediction of the final answer. We conduct extensive experiments on the ScienceQA and VQAv2 datasets, demonstrating that MF-SQ-LLaVA significantly outperforms existing state-of-the-art models, including the base LLaVA and the original SQ-LLaVA. Ablation studies further validate the contribution of each component of our approach, and human evaluation confirms the improved accuracy and coherence of the reasoning process enabled by our method.
大型视觉语言模型(LVLMs)在各种多模态任务中取得了显著的进步,但在需要多步骤推理的复杂视觉推理方面常常遇到困难。为了解决这一局限性,我们提出了MF-SQ-LLaVA这一新方法,它通过端到端的训练来增强LVLMs的能力,实现隐式自问。我们的方法通过增加视觉问答数据集来包含由子问题和答案对组成的推理链,并用多任务损失来训练LVLM,鼓励生成和回答这些中间步骤,以及预测最终答案。我们在ScienceQA和VQAv2数据集上进行了大量实验,结果表明MF-SQ-LLaVA显著优于包括基础LLaVA和原始SQ-LLaVA在内的现有最先进的模型。消融研究进一步验证了我们的方法中每个组件的贡献,人类评估也证实了我们方法启用的推理过程的准确性和连贯性有所提高。
论文及项目相关链接
Summary
大型视觉语言模型(LVLMs)在多模态任务中取得了显著进展,但在需要多步骤推理的复杂视觉推理方面存在挑战。为解决此局限性,我们提出了MF-SQ-LLaVA这一新方法,它通过端到端的训练来增强LVLMs,实现隐式自我提问。该方法通过扩充视觉问答数据集包含推理链(由子问题对和答案对组成),并用多任务损失训练LVLM,鼓励生成和回答这些中间步骤,以及预测最终答案。在ScienceQA和VQAv2数据集上的实验表明,MF-SQ-LLaVA显著优于包括基础LLaVA和原始SQ-LLaVA在内的现有最先进的模型。消融研究进一步验证了该方法每个组件的贡献,人类评估也证实了我们的方法所启用的推理过程的准确性和连贯性的提高。
Key Takeaways
- 大型视觉语言模型(LVLMs)在多模态任务中表现出色,但在复杂视觉推理方面存在挑战。
- MF-SQ-LLaVA是一种增强LVLMs的方法,通过隐式自我提问和端到端的训练来实现。
- 该方法通过扩充视觉问答数据集包含推理链,并训练模型以生成和回答中间步骤及预测最终答案。
- MF-SQ-LLaVA在ScienceQA和VQAv2数据集上的实验表现优于其他先进模型。
- 消融研究证实了该方法每个组件的有效性。
- 人类评估显示,MF-SQ-LLaVA提高了推理过程的准确性和连贯性。
点此查看论文截图

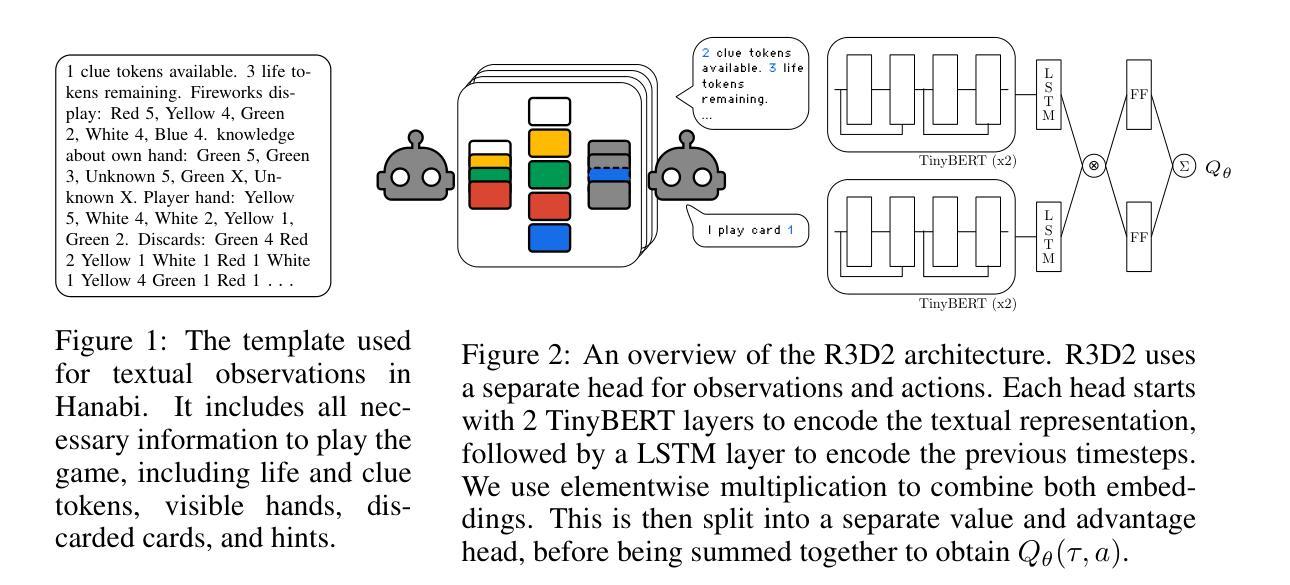
A Generalist Hanabi Agent
Authors:Arjun V Sudhakar, Hadi Nekoei, Mathieu Reymond, Miao Liu, Janarthanan Rajendran, Sarath Chandar
Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting than the one they have been trained on, and struggle to successfully cooperate with unfamiliar collaborators. This is particularly visible in the Hanabi benchmark, a popular 2-to-5 player cooperative card-game which requires complex reasoning and precise assistance to other agents. Current MARL agents for Hanabi can only learn one specific game-setting (e.g., 2-player games), and play with the same algorithmic agents. This is in stark contrast to humans, who can quickly adjust their strategies to work with unfamiliar partners or situations. In this paper, we introduce Recurrent Replay Relevance Distributed DQN (R3D2), a generalist agent for Hanabi, designed to overcome these limitations. We reformulate the task using text, as language has been shown to improve transfer. We then propose a distributed MARL algorithm that copes with the resulting dynamic observation- and action-space. In doing so, our agent is the first that can play all game settings concurrently, and extend strategies learned from one setting to other ones. As a consequence, our agent also demonstrates the ability to collaborate with different algorithmic agents – agents that are themselves unable to do so. The implementation code is available at: $\href{https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent}{R3D2-A-Generalist-Hanabi-Agent}$
传统多智能体强化学习(MARL)系统可以通过反复交互来开发合作策略。然而,这些系统只能在训练过的场景上表现良好,在与不熟悉的合作伙伴进行协作时则表现不佳。这在流行的小型多人在线卡牌游戏Hanabi的基准测试中尤为明显。Hanabi需要复杂的推理和精确的辅助其他智能体来完成游戏。当前针对Hanabi的MARL智能体只能学习一种特定的游戏设置(例如,双玩家游戏),并且只能与相同的算法智能体进行游戏。与此形成鲜明对比的是人类,他们可以迅速调整策略以适应与陌生伙伴或不同情境的合作。在本文中,我们介绍了针对Hanabi的通用智能体Recurrent Replay Relevance Distributed DQN(R3D2),旨在克服这些局限性。我们使用文本重新构建任务,因为语言已被证明可以提高迁移能力。然后,我们提出了一种分布式MARL算法,以应对由此产生的动态观测空间和动作空间。因此,我们的智能体能够同时应对所有游戏设置,并将从一个设置中学习的策略扩展到其他设置。因此,我们的智能体还显示出与不同算法智能体协作的能力——这些智能体本身却无法做到这一点。实现代码可访问:https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent。
论文及项目相关链接
Summary:
传统多智能体强化学习(MARL)系统能够通过反复交互发展合作策略,但在面对非训练环境或与陌生智能体合作时表现不佳。在需要复杂推理和精确协助的2至5人合作卡牌游戏Hanabi中尤为明显。当前针对Hanabi的MARL智能体只能学习一种特定游戏设置(如2人游戏),并与相同算法的智能体进行游戏。本文介绍了一种针对Hanabi的通用智能体R3D2,旨在克服这些限制。通过改革任务并使用文本,我们的智能体成为首个可以同时进行所有游戏设置并扩展从一个设置中学到的策略到其他设置的智能体。因此,我们的智能体还显示出与不同算法的智能体协作的能力。
Key Takeaways:
- 传统MARL系统在非训练环境或面对陌生智能体时合作能力受限。
- Hanabi游戏中的当前MARL智能体只能适应特定游戏设置,无法与陌生智能体合作。
- 新提出的R3D2智能体旨在克服这些限制,成为首个能同时进行多种游戏设置的智能体。
- R3D2通过改革任务并使用文本实现这一点,这提高了其跨情境的转移能力。
- R3D2能够从一种游戏设置中学习策略并将其应用于其他设置。
- R3D2展示了与不同算法的智能体协作的能力,这在以前是无法实现的。
点此查看论文截图

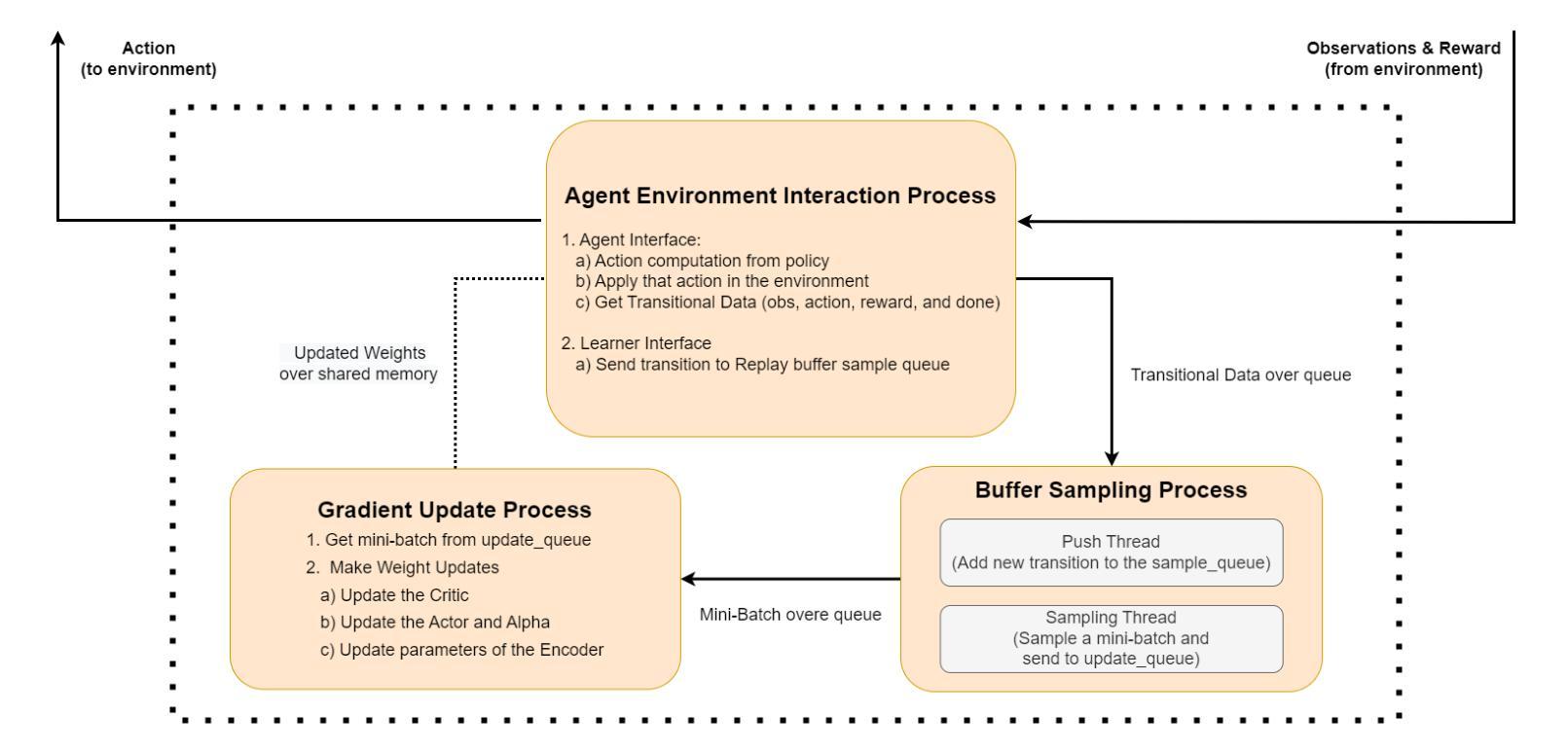
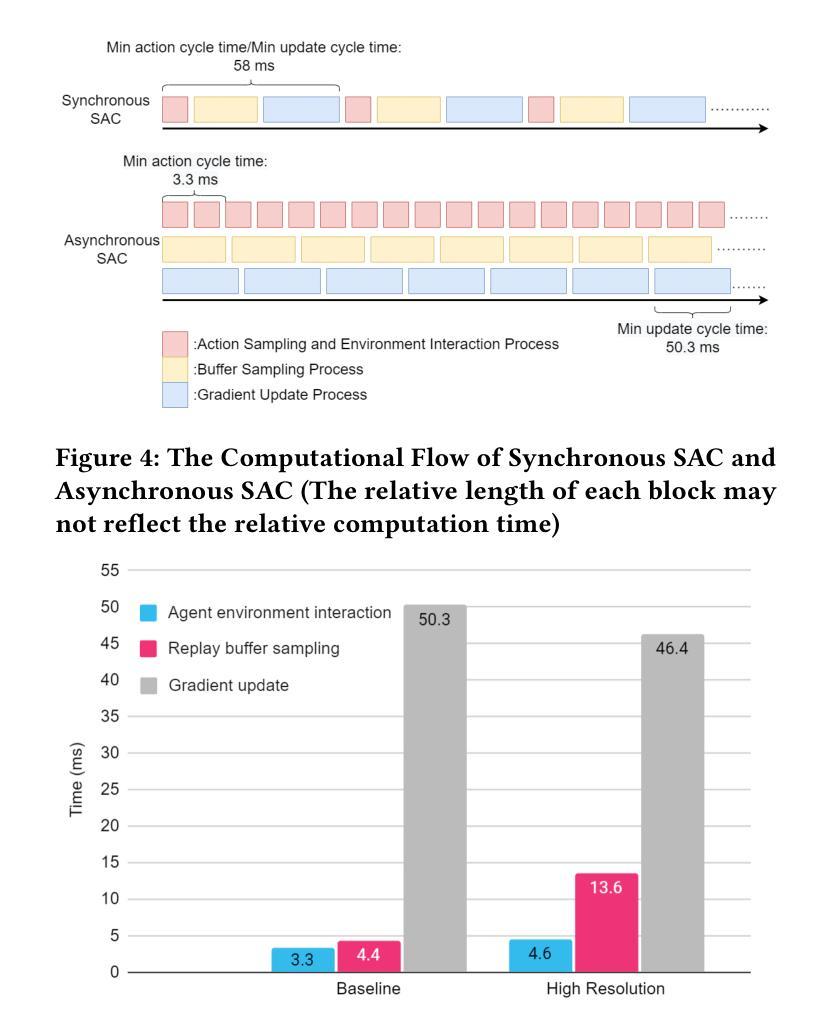
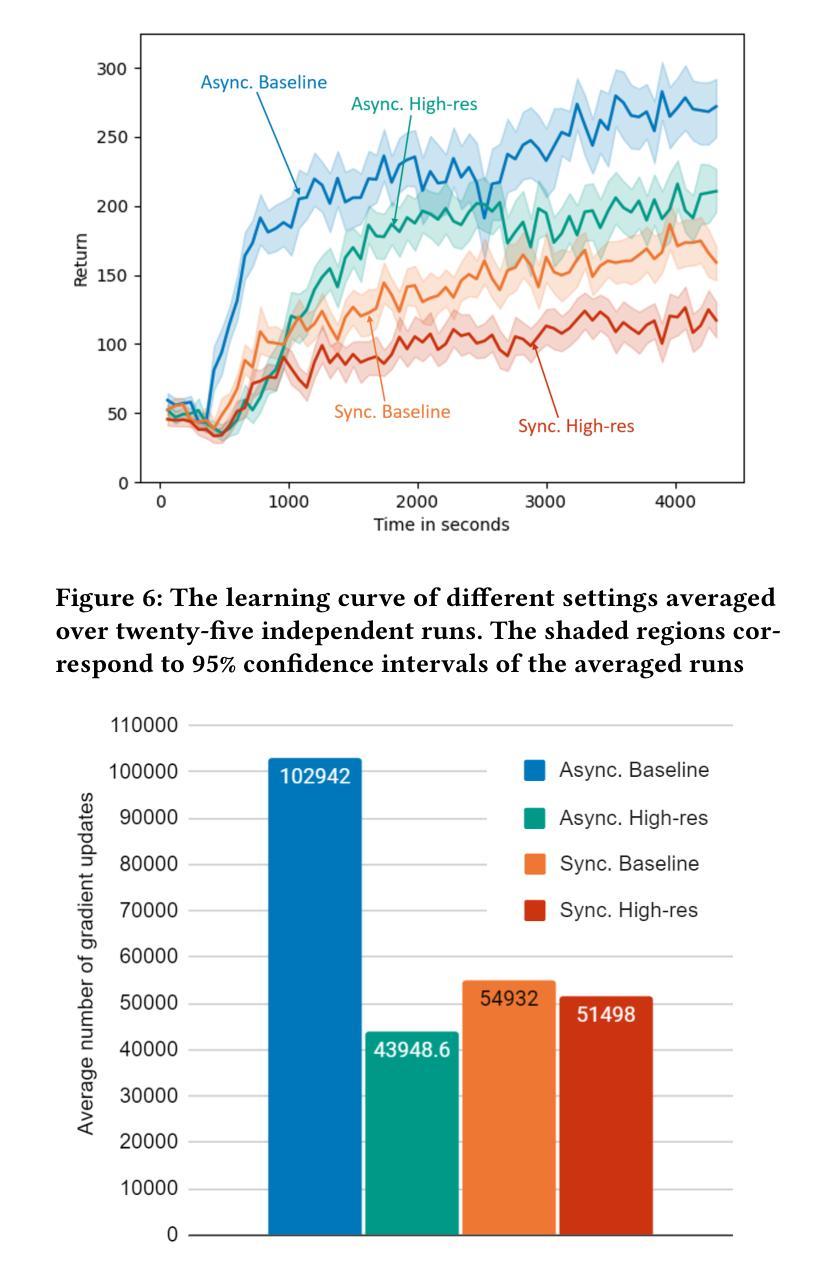
Synchronous vs Asynchronous Reinforcement Learning in a Real World Robot
Authors:Ali Parsaee, Fahim Shahriar, Chuxin He, Ruiqing Tan
In recent times, reinforcement learning (RL) with physical robots has attracted the attention of a wide range of researchers. However, state-of-the-art RL algorithms do not consider that physical environments do not wait for the RL agent to make decisions or updates. RL agents learn by periodically conducting computationally expensive gradient updates. When decision-making and gradient update tasks are carried out sequentially by the RL agent in a physical robot, it significantly increases the agent’s response time. In a rapidly changing environment, this increased response time may be detrimental to the performance of the learning agent. Asynchronous RL methods, which separate the computation of decision-making and gradient updates, are a potential solution to this problem. However, only a few comparisons between asynchronous and synchronous RL have been made with physical robots. For this reason, the exact performance benefits of using asynchronous RL methods over synchronous RL methods are still unclear. In this study, we provide a performance comparison between asynchronous and synchronous RL using a physical robotic arm called Franka Emika Panda. Our experiments show that the agents learn faster and attain significantly more returns using asynchronous RL. Our experiments also demonstrate that the learning agent with a faster response time performs better than the agent with a slower response time, even if the agent with a slower response time performs a higher number of gradient updates.
近年来,使用实体机器人进行强化学习(RL)已经吸引了广大研究人员的关注。然而,最先进的RL算法并没有考虑到物理环境不会等待RL代理进行决策或更新。RL代理通过定期执行计算量大的梯度更新来学习。当RL代理在物理机器人上顺序执行决策和梯度更新任务时,会显著增加代理的反应时间。在快速变化的环境中,这种增加的反应时间可能会对学习代理的性能产生不利影响。异步RL方法将决策和梯度更新的计算分开,可能是解决这个问题的潜在方法。然而,只有少数研究对异步和同步RL在实体机器人上进行了比较。因此,使用异步RL方法相对于同步RL方法的性能优势尚不清楚。在这项研究中,我们使用名为Fanka Emika Panda的实体机械臂对异步和同步RL进行了性能比较。我们的实验表明,代理使用异步RL学习得更快,并且获得更高的回报。我们的实验还表明,反应时间较快的代理比反应时间较慢的代理表现更好,即使反应时间较慢的代理执行了更多的梯度更新。
论文及项目相关链接
PDF Presented at Alberta Robotics & Intelligent Systems Expo (RISE) Conference
Summary
强化学习(RL)与实体机器人的结合吸引了众多研究者的关注。然而,当前主流的RL算法未考虑到物理环境不会等待RL代理进行决策或更新。RL代理通过周期性的计算昂贵的梯度更新进行学习。当决策制定和梯度更新任务由实体机器人中的RL代理顺序执行时,会显著增加代理的响应时间。在快速变化的环境中,这种增加的响应时间可能会对学习代理的性能产生不利影响。异步RL方法将决策制定和梯度更新的计算分开,是解决这个问题的一种潜在方法。然而,关于异步RL与同步RL在实体机器人上的比较仍较少。本研究通过实体机器人手臂Franka Emika Panda对比了异步RL和同步RL的性能表现。实验表明,使用异步RL的代理学习速度更快,收益更高。此外,即使响应缓慢的代理执行了更多的梯度更新,具有快速响应时间的代理表现也更好。
Key Takeaways
- 强化学习(RL)与物理机器人结合受到广泛关注。
- 当前RL算法未充分考虑到物理环境的实时性。
- 实体机器人在执行决策和梯度更新任务时,顺序执行会显著增加响应时间。
- 异步RL方法是一种解决此问题的潜在方案。
- 关于异步与同步RL在实体机器人上的对比研究仍不足。
- 实验显示异步RL的代理学习速度更快,收益更高。
点此查看论文截图


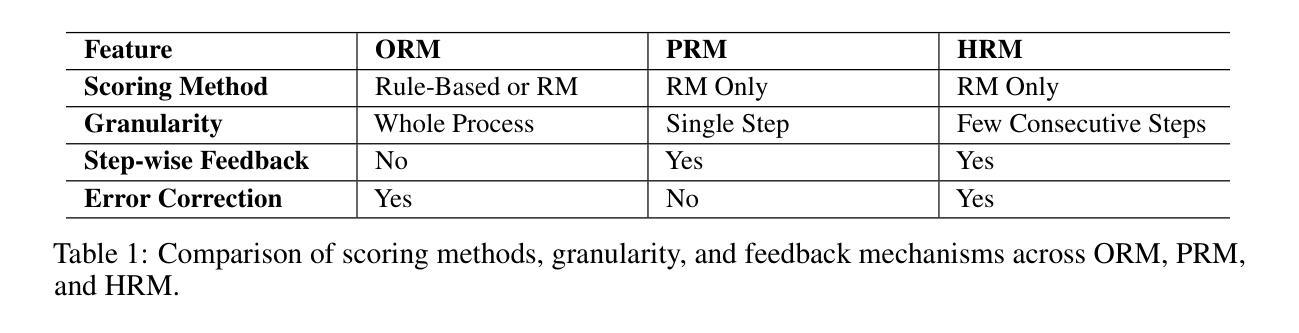
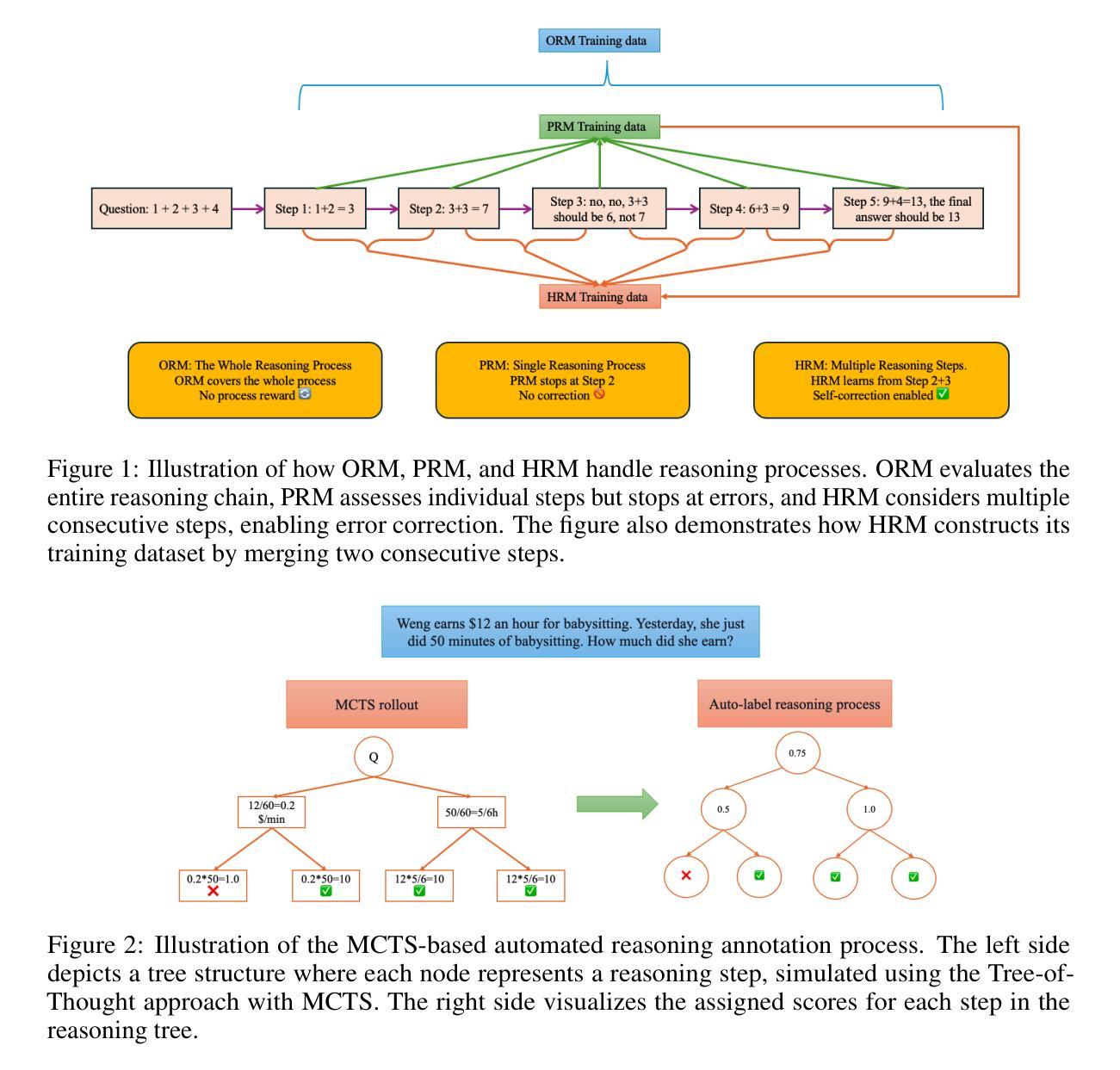
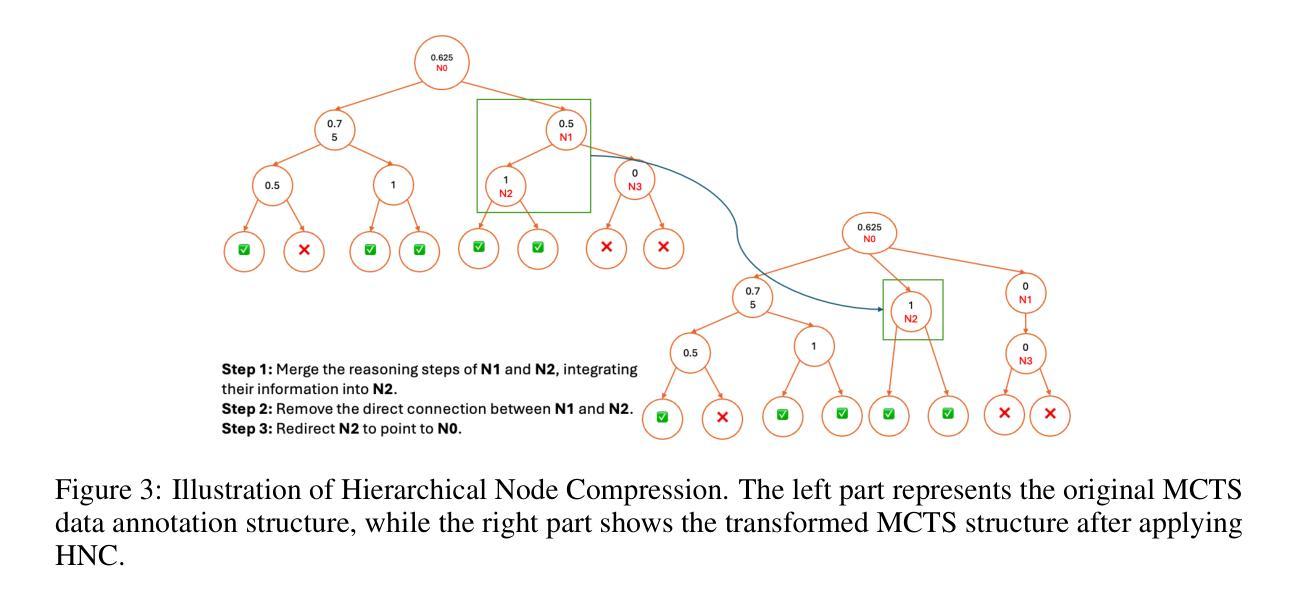
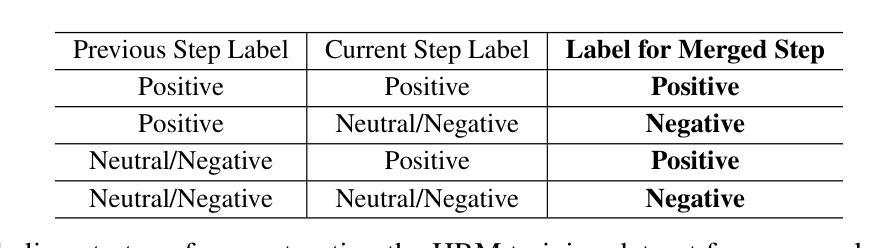
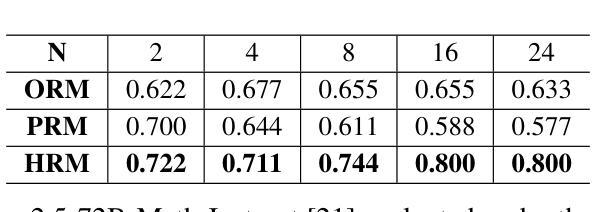
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Authors:Teng Wang, Zhangyi Jiang, Zhenqi He, Wenhan Yang, Yanan Zheng, Zeyu Li, Zifan He, Shenyang Tong, Hailei Gong
Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM’s superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
最近的研究表明,大型语言模型(LLM)通过监督微调或强化学习获得了强大的推理能力。然而,一种主要方法——过程奖励模型(PRM)存在奖励黑客攻击的问题,使其在识别最佳中间步骤时变得不可靠。在本文中,我们提出了一种新的奖励模型方法,即分层奖励模型(HRM),它可以从精细粒度和粗略粒度两个层面评估单个和连续的推理步骤。HRM在评估推理连贯性和自我反思方面表现更好,特别是在之前的推理步骤出错时。此外,为了解决通过蒙特卡洛树搜索(MCTS)自主生成PRM训练数据的不效率问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的树结构中的分层节点压缩(HNC)的轻量级有效数据增强策略。这种方法通过引入噪声增强了标签的鲁棒性,以微小的计算开销实现了对HRM的MCTS结果的多样化。在PRM800K数据集上的实证结果表明,与HNC结合的HRM在评估中实现了比PRM更优越的稳定性和可靠性。此外,MATH500和GSM8K的跨域评估证实了HRM在多种推理任务中的优异泛化和鲁棒性。所有实验的代码将发布在https://github.com/tengwang0318/hierarchial_reward_model。
论文及项目相关链接
Summary
大型语言模型(LLMs)在监督微调或强化学习中展现出强大的推理能力。然而,过程奖励模型(PRM)存在奖励黑客问题,无法可靠地识别最佳中间步骤。本文提出了一种新的奖励模型方法——分层奖励模型(HRM),可以从精细粒度和粗略粒度级别评估单个和连续的推理步骤。HRM在评估推理连贯性和自我反思方面表现更佳,尤其在之前的推理步骤出错时。此外,为解决通过蒙特卡洛树搜索(MCTS)自主生成PRM训练数据的不效率问题,我们引入了一种基于节点合并(将两个连续的推理步骤合并为一个步骤)的分层节点压缩(HNC)的轻量级有效数据增强策略。该策略使MCTS结果多样化,引入噪声以增强标签稳健性,且计算开销较小。在PRM800K数据集上的实证结果表明,与PRM相比,HRM结合HNC在评估中实现了更优越的稳定性与可靠性。跨域评估MATH500和GSM8K进一步证实了HRM在多种推理任务中的优异泛化和稳健性。所有实验的代码将在https://github.com/tengwang0318/hierarchial_reward_model发布。
Key Takeaways
- 大型语言模型(LLMs)通过监督微调或强化学习展现出强大的推理能力。
- 过程奖励模型(PRM)存在奖励黑客问题,难以识别最佳中间步骤。
- 分层奖励模型(HRM)能够评估单个和连续的推理步骤,提高评估推理连贯性和自我反思的能力。
- HRM在之前的推理步骤出错时表现更优。
- 引入分层节点压缩(HNC)策略,基于节点合并,以提高蒙特卡洛树搜索(MCTS)生成PRM训练数据效率。
- HRM结合HNC在PRM800K数据集上的表现优于PRM,实现更稳定的评估。
点此查看论文截图

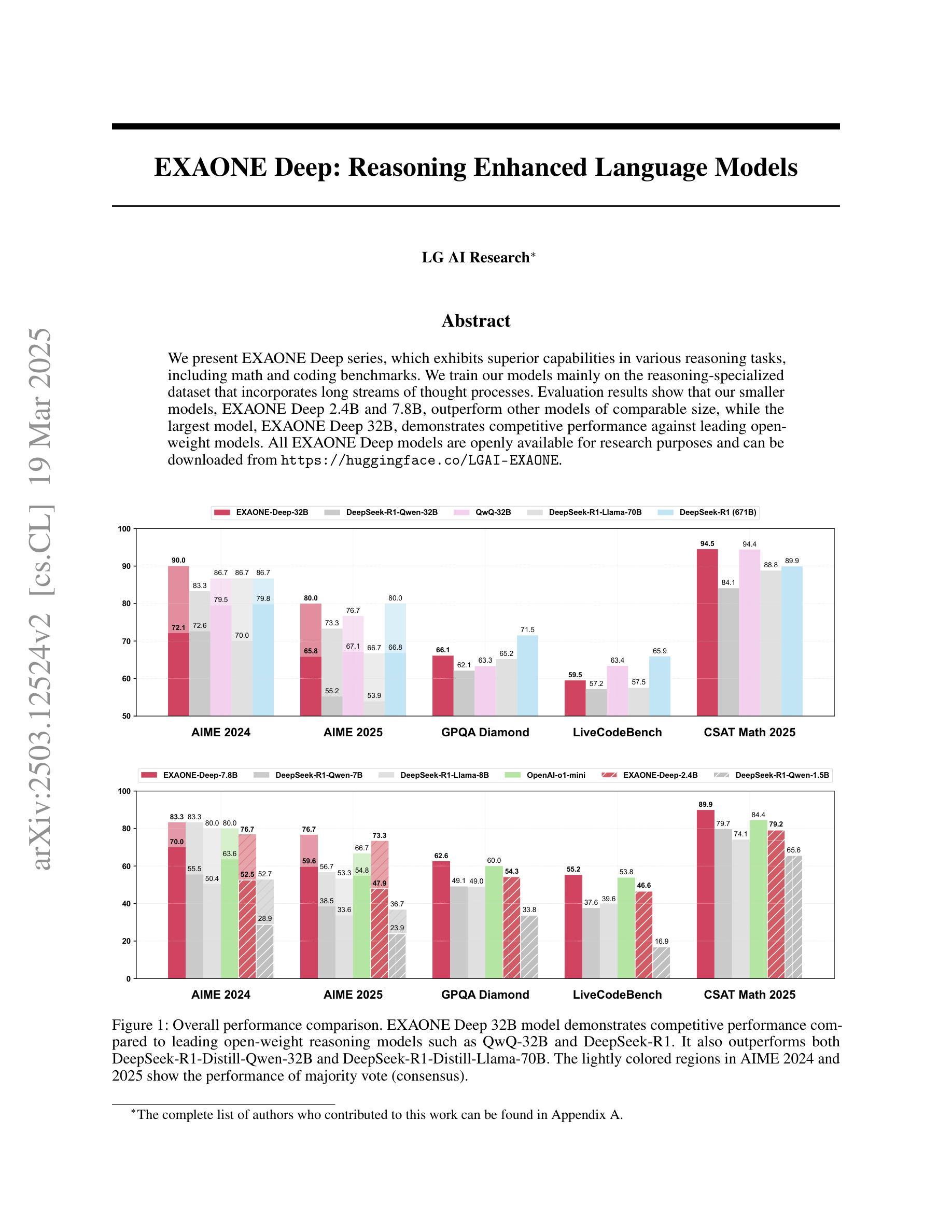
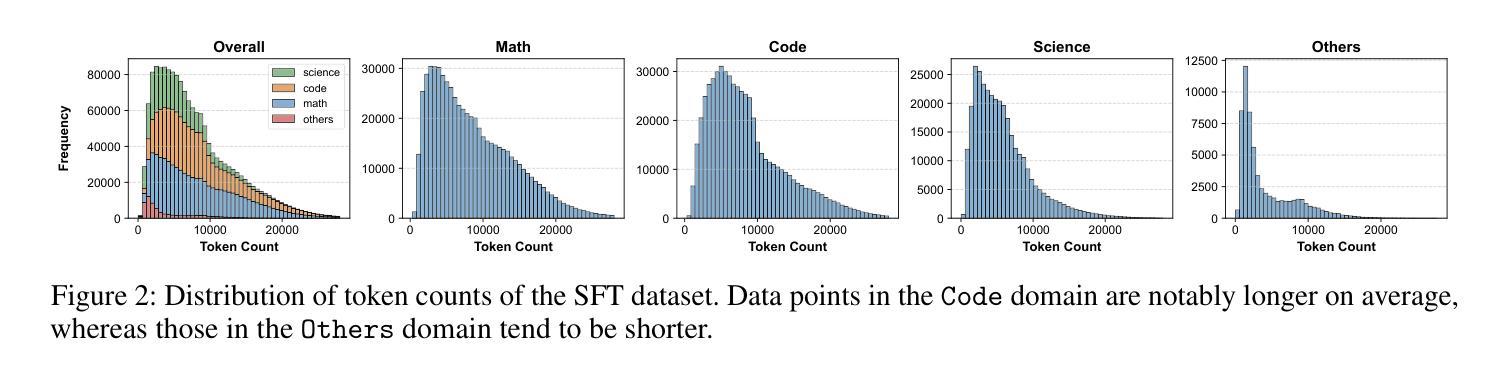
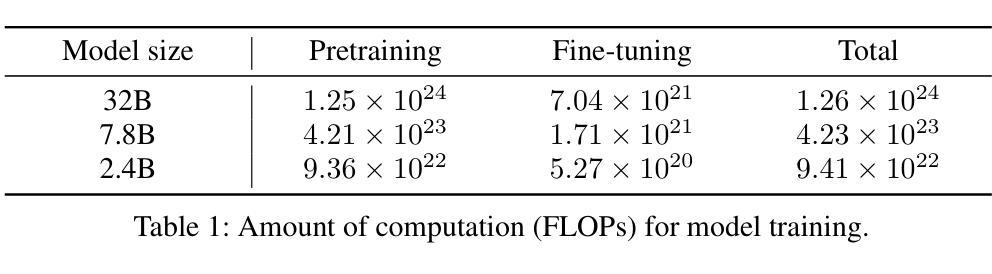
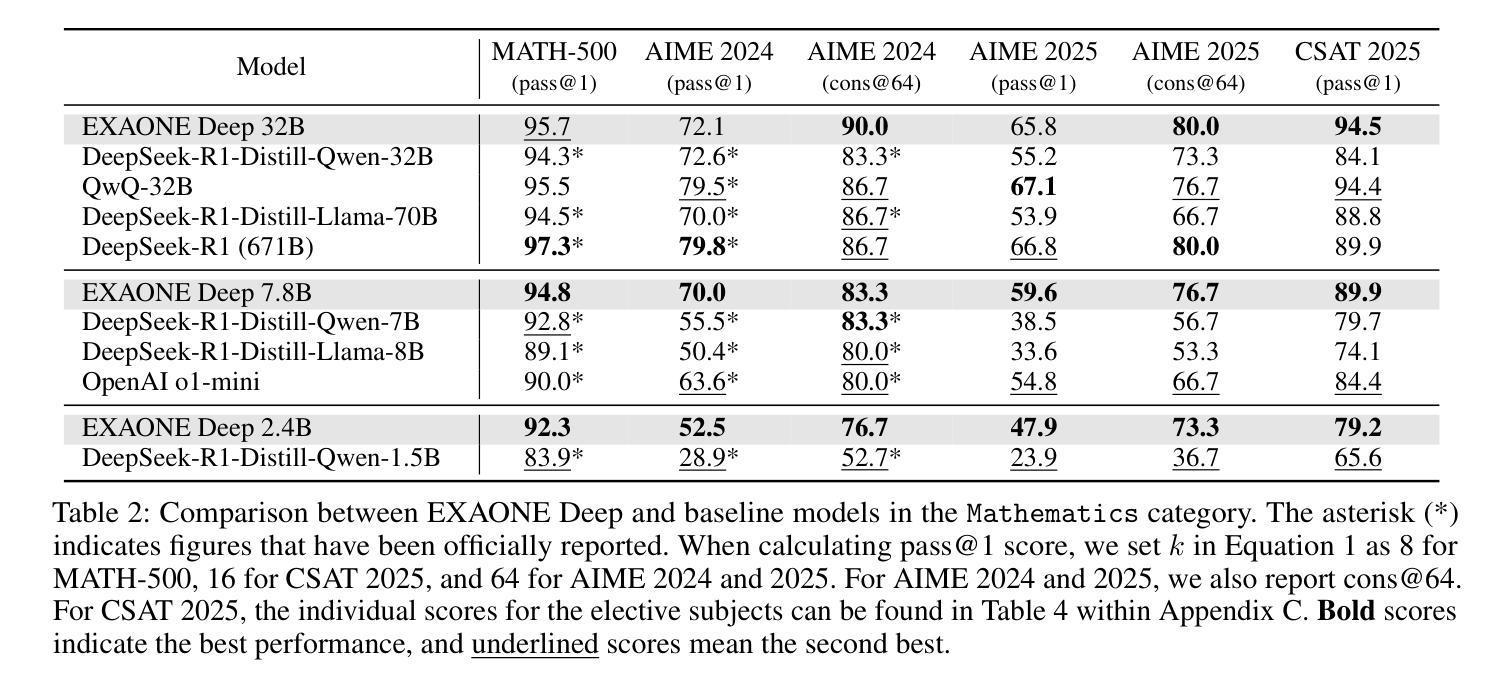
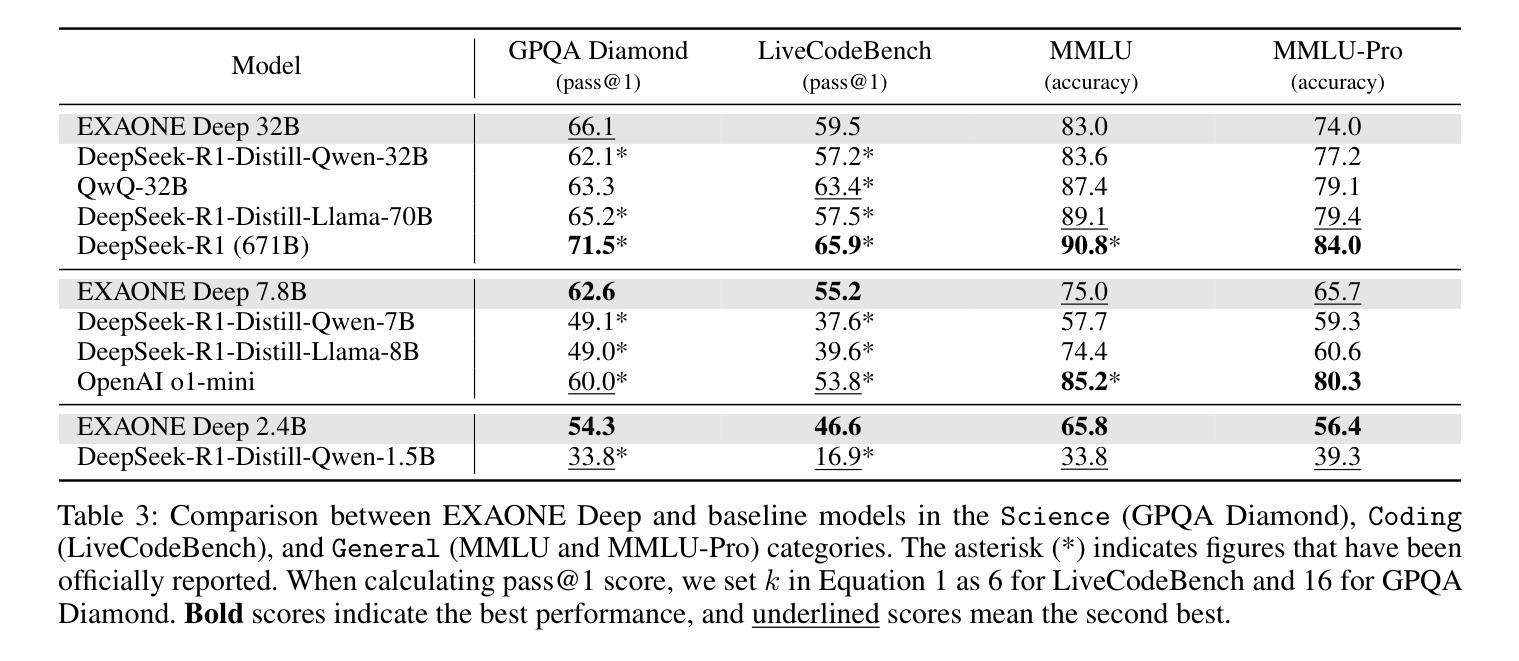
EXAONE Deep: Reasoning Enhanced Language Models
Authors:LG AI Research, Kyunghoon Bae, Eunbi Choi, Kibong Choi, Stanley Jungkyu Choi, Yemuk Choi, Seokhee Hong, Junwon Hwang, Hyojin Jeon, Kijeong Jeon, Gerrard Jeongwon Jo, Hyunjik Jo, Jiyeon Jung, Hyosang Kim, Joonkee Kim, Seonghwan Kim, Soyeon Kim, Sunkyoung Kim, Yireun Kim, Yongil Kim, Youchul Kim, Edward Hwayoung Lee, Haeju Lee, Honglak Lee, Jinsik Lee, Kyungmin Lee, Sangha Park, Yongmin Park, Sihoon Yang, Heuiyeen Yeen, Sihyuk Yi, Hyeongu Yun
We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE
我们推出EXAONE Deep系列,该系列在各种推理任务中表现出卓越的能力,包括数学和编程基准测试。我们的模型主要在有大量思考过程的数据集上进行训练,以强化推理能力。评估结果表明,我们的小型模型EXAONE Deep 2.4B和7.8B在同类模型中表现突出,而最大的模型EXAONE Deep 32B则与领先的公开权重模型表现出竞争力。所有EXAONE Deep模型均公开用于研究目的,可从https://huggingface.co/LGAI-EXAONE下载。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2412.04862, arXiv:2408.03541
Summary
EXAONE Deep系列模型在各种推理任务中表现出卓越的能力,包括数学和编码基准测试。模型主要在包含长流思维过程的推理专用数据集上进行训练。评估结果显示,较小的EXAONE Deep 2.4B和7.8B模型在同类模型中表现突出,而最大的32B模型则在领先的开放权重模型中表现出竞争力。所有EXAONE Deep模型均公开用于研究目的,可从https://huggingface.co/LGAI-EXAONE下载。
Key Takeaways
- EXAONE Deep系列模型在多种推理任务中展现卓越性能。
- 模型训练主要基于包含长流思维过程的推理专用数据集。
- 较小规模的EXAONE Deep 2.4B和7.8B模型在同类中表现优异。
- 最大的EXAONE Deep 32B模型在领先开放权重模型中具有竞争力。
- EXAONE Deep系列模型适用于研究目的。
- 公开可下载,下载地址:https://huggingface.co/LGAI-EXAONE。
点此查看论文截图


PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
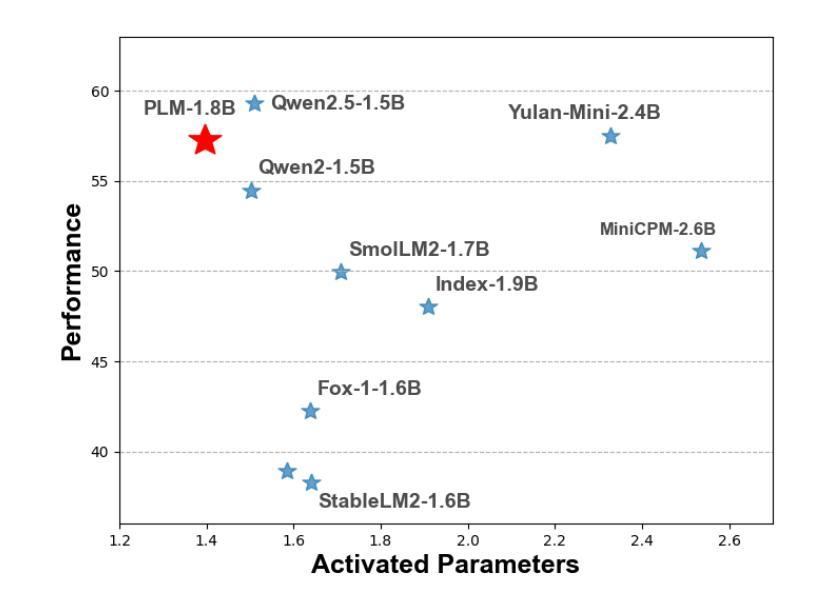
Authors:Cheng Deng, Luoyang Sun, Jiwen Jiang, Yongcheng Zeng, Xinjian Wu, Wenxin Zhao, Qingfa Xiao, Jiachuan Wang, Haoyang Li, Lei Chen, Lionel M. Ni, Haifeng Zhang, Jun Wang
While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM’s suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
随着模型参数的增加,比例定律在大语言模型(LLM)中得到了持续验证。然而,大语言模型的推理需求与边缘设备的有限资源之间存在的固有矛盾,给边缘智能的发展带来了关键挑战。近期,出现了许多小语言模型,旨在将大语言模型的能力转化为更小的占用空间。然而,这些模型往往保留其大型对应模型的基本架构原则,仍然给边缘设备的存储和带宽容量带来相当大的压力。在本文中,我们介绍了一种周边语言模型(PLM),该模型通过联合优化模型架构和边缘系统约束的协同设计过程开发。PLM利用多头潜在注意力机制,并采用平方ReLU激活函数来促进稀疏性,从而减少推理过程中的峰值内存占用。在训练过程中,我们收集并重新组织开源数据集,实施多阶段训练策略,并对预热稳定衰减恒定(WSDC)学习率调度器进行实证研究。此外,我们通过采用ARIE偏好学习方法,将人类反馈的强化学习纳入其中。经过两阶段的SFT过程后,该方法在一般任务上取得了2%的性能提升,在GSM8K任务上取得了9%的提升,在编码任务上取得了11%的提升。除了其新颖的架构外,评估结果表明PLM在公开数据上训练的现有小语言模型的表现优于其他模型,同时保持最低的活动参数数量。此外,在各种边缘设备上的部署,包括消费级GPU、手机和Raspberry Pis,验证了PLM在周边应用的适用性。PLM系列模型可在https://github.com/plm-team/PLM公开获取。
论文及项目相关链接
Summary
一种新型的边缘智能语言模型——周边语言模型(PLM)被提出来应对大型语言模型在边缘设备上应用的挑战。PLM通过联合优化模型架构和边缘系统约束进行设计,采用多头潜在注意力机制和ReLU激活函数来鼓励稀疏性,减少推理时的内存占用。此外,PLM还采用了分阶段训练策略和WSDC学习率调度器,并结合了基于人类反馈的增强学习。实验结果表明,PLM在一般任务、GSM8K任务和编码任务上的性能分别提高了2%、9%和11%。PLM系列模型适合在各类边缘设备上部署,包括消费级GPU、手机和Raspberry Pi。
Key Takeaways
- 边缘智能语言模型的发展面临来自大型语言模型的推理需求和边缘设备有限资源的内在矛盾。
- PLM作为一种新型语言模型被提出,旨在解决这一问题,它通过联合优化模型架构和边缘系统约束进行设计。
- PLM采用多头潜在注意力机制和ReLU激活函数鼓励稀疏性,减少推理时的内存占用。
- PLM采用分阶段训练策略和WSDC学习率调度器,结合基于人类反馈的增强学习来提升性能。
- PLM在一般任务、GSM8K任务和编码任务上的性能有所提升。
- PLM系列模型适合在各类边缘设备上部署,包括消费级GPU、手机和Raspberry Pi等。
点此查看论文截图



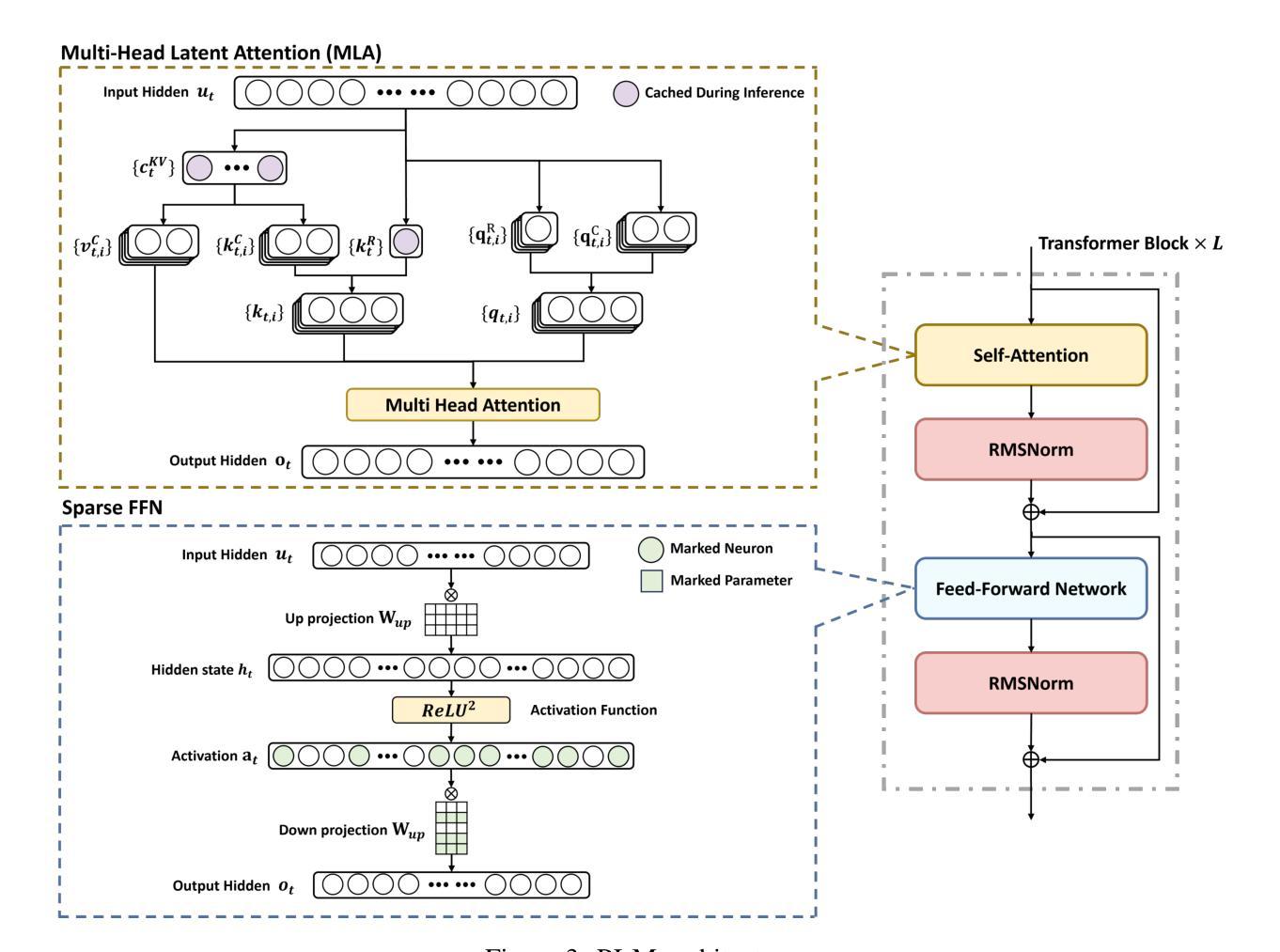

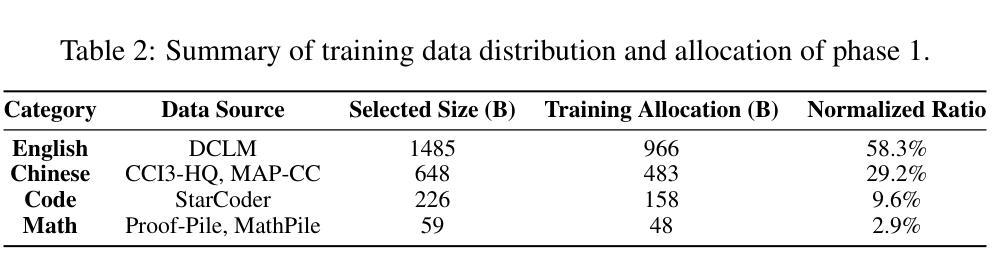

A Review of DeepSeek Models’ Key Innovative Techniques
Authors:Chengen Wang, Murat Kantarcioglu
DeepSeek-V3 and DeepSeek-R1 are leading open-source Large Language Models (LLMs) for general-purpose tasks and reasoning, achieving performance comparable to state-of-the-art closed-source models from companies like OpenAI and Anthropic – while requiring only a fraction of their training costs. Understanding the key innovative techniques behind DeepSeek’s success is crucial for advancing LLM research. In this paper, we review the core techniques driving the remarkable effectiveness and efficiency of these models, including refinements to the transformer architecture, innovations such as Multi-Head Latent Attention and Mixture of Experts, Multi-Token Prediction, the co-design of algorithms, frameworks, and hardware, the Group Relative Policy Optimization algorithm, post-training with pure reinforcement learning and iterative training alternating between supervised fine-tuning and reinforcement learning. Additionally, we identify several open questions and highlight potential research opportunities in this rapidly advancing field.
DeepSeek-V3和DeepSeek-R1是针对通用任务和推理的领先开源大型语言模型(LLM),其性能与OpenAI和Anthropic等公司最先进的闭源模型相当,同时只需一小部分训练成本。了解DeepSeek成功的关键创新技术对于推进LLM研究至关重要。在本文中,我们回顾了驱动这些模型显著有效性和效率的核心技术,包括改进Transformer架构的技术,创新技术如多头潜在注意力、混合专家、多令牌预测等,算法、框架和硬件的协同设计,群组相对策略优化算法,以及使用纯强化学习进行训练后,以及在监督微调与强化学习之间交替进行迭代训练等。此外,我们还确定了几个悬而未决的问题,并强调了这一迅速发展的领域中的潜在研究机会。
论文及项目相关链接
Summary:DeepSeek-V3和DeepSeek-R1是通用的开源大型语言模型(LLM),性能与OpenAI和Anthropic等公司开发的先进专有模型相当,且训练成本较低。本文回顾了驱动这些模型卓越效果和效率的核心技术,包括改进后的转换器架构、如多头潜在注意力等创新技术,以及算法、框架和硬件的协同设计、群体相对政策优化算法等。同时,文章还探讨了纯强化学习进行训练后的调整方法以及交替使用监督微调与强化学习的迭代训练方法。此外,本文也提出了该领域几个待解决的问题和潜在的研究机会。
Key Takeaways:
- DeepSeek-V3和DeepSeek-R1是性能优越的大型语言模型,开源且训练成本低。
- 模型成功的关键在于核心技术的创新,包括改进转换器架构和多头潜在注意力等。
- 模型通过协同设计算法、框架和硬件提升性能。
- 模型采用群体相对政策优化算法进行优化。
- 模型结合了监督学习和强化学习进行迭代训练。
- 文章指出了该领域的待解决问题和潜在研究机会。
点此查看论文截图


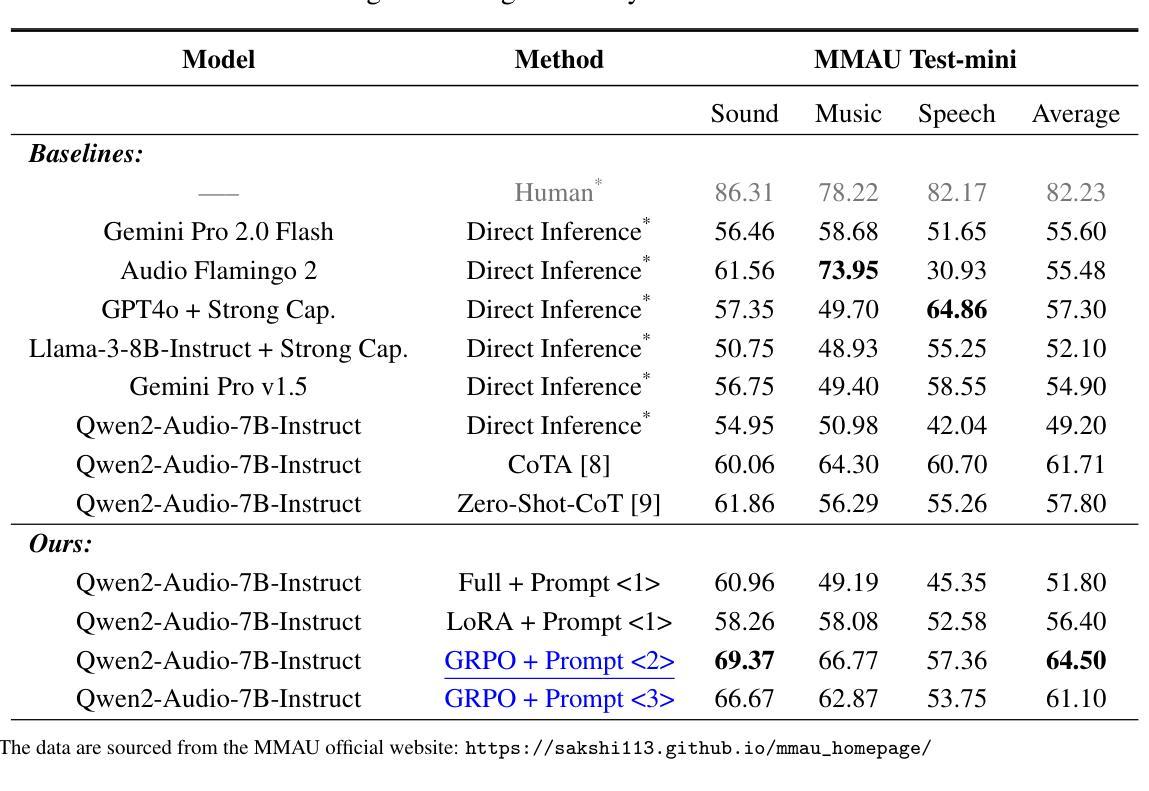
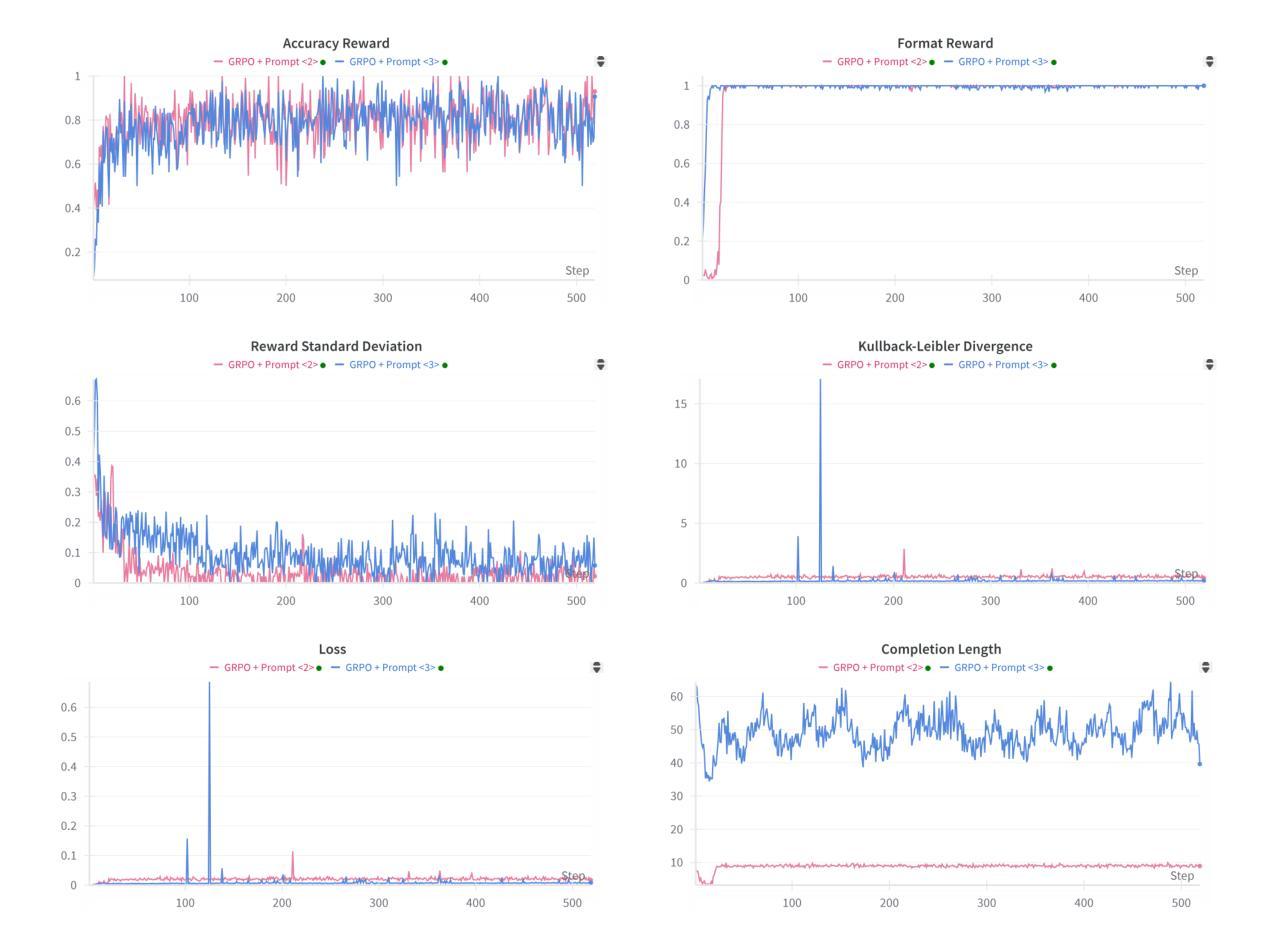
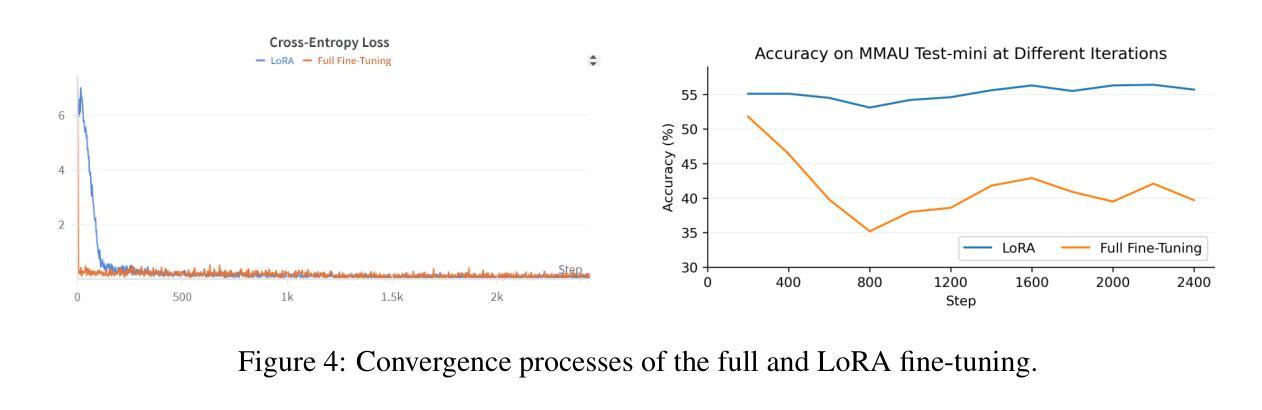
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering
Authors:Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang, Jian Luan
Recently, reinforcement learning (RL) has been shown to greatly enhance the reasoning capabilities of large language models (LLMs), and RL-based approaches have been progressively applied to visual multimodal tasks. However, the audio modality has largely been overlooked in these developments. Thus, we conduct a series of RL explorations in audio understanding and reasoning, specifically focusing on the audio question answering (AQA) task. We leverage the group relative policy optimization (GRPO) algorithm to Qwen2-Audio-7B-Instruct, and our experiments demonstrated state-of-the-art performance on the MMAU Test-mini benchmark, achieving an accuracy rate of 64.5%. The main findings in this technical report are as follows: 1) The GRPO algorithm can be effectively applied to large audio language models (LALMs), even when the model has only 8.2B parameters; 2) With only 38k post-training samples, RL significantly outperforms supervised fine-tuning (SFT), indicating that RL-based approaches can be effective without large datasets; 3) The explicit reasoning process has not shown significant benefits for AQA tasks, and how to efficiently utilize deep thinking remains an open question for further research; 4) LALMs still lag far behind humans auditory-language reasoning, suggesting that the RL-based approaches warrant further exploration. Our project is available at https://github.com/xiaomi-research/r1-aqa and https://huggingface.co/mispeech/r1-aqa.
最近,强化学习(RL)被证明可以极大地提升大型语言模型(LLM)的推理能力,并且基于RL的方法已经逐步应用于视觉多模态任务。然而,音频模态在这些发展中却被大大忽视了。因此,我们在音频理解和推理方面进行了一系列RL探索,特别关注音频问答(AQA)任务。我们利用组相对策略优化(GRPO)算法对Qwen2-Audio-7B-Instruct进行优化,实验表明在MMAU Test-mini基准测试中达到了先进性能,准确率为64.5%。本技术报告的主要发现如下:1)GRPO算法可有效地应用于大型音频语言模型(LALM),即使模型参数仅有8.2B;2)仅使用38k个后训练样本,RL便显著优于监督微调(SFT),表明基于RL的方法可在无需大规模数据集的情况下有效;3)明确的推理过程在AQA任务中并未显示出显著优势,如何有效利用深度思考仍是进一步研究的开放问题;4)LALM仍然远远落后于人类的听觉语言推理能力,这表明基于RL的方法需要进一步探索。我们的项目可通过https://github.com/xiaomi-research/r1-aqa和https://huggingface.co/mispeech/r1-aqa访问。
论文及项目相关链接
Summary
本文探索了强化学习在音频理解和推理领域的应用,特别是在音频问答任务上的表现。研究团队将相对策略优化算法应用于大型音频语言模型,并在小型测试集上取得了突破性成果,准确率达到64.5%。主要发现包括:GRPO算法可有效应用于大型音频语言模型;强化学习在仅使用少量训练样本时表现出优势;显式推理过程对音频问答任务并无显著帮助;且当前模型的推理能力相较于人类仍存巨大差距。更多详情参见研究项目在GitHub和Huggingface平台的仓库。
Key Takeaways
- GRPO算法成功应用于大型音频语言模型(LALMs),显示其在音频问答任务上的有效性。
- 仅使用少量训练样本(38k),强化学习性能显著超越监督微调(SFT)。
- 在音频问答任务中,明确的推理过程并没有显著的优势,如何有效利用深度思考仍待研究。
- 大型音频语言模型在听觉语言推理上仍然远远落后于人类,表明需要进一步探索基于强化学习的方法。
- 研究项目提供了GitHub和Huggingface平台上的资源链接,便于进一步了解和访问项目。
- 强化学习在增强语言模型的推理能力方面显示出巨大潜力,特别是在视觉多媒体任务中的应用已获得进展。但在音频模态领域的研究仍处于起步阶段。
点此查看论文截图




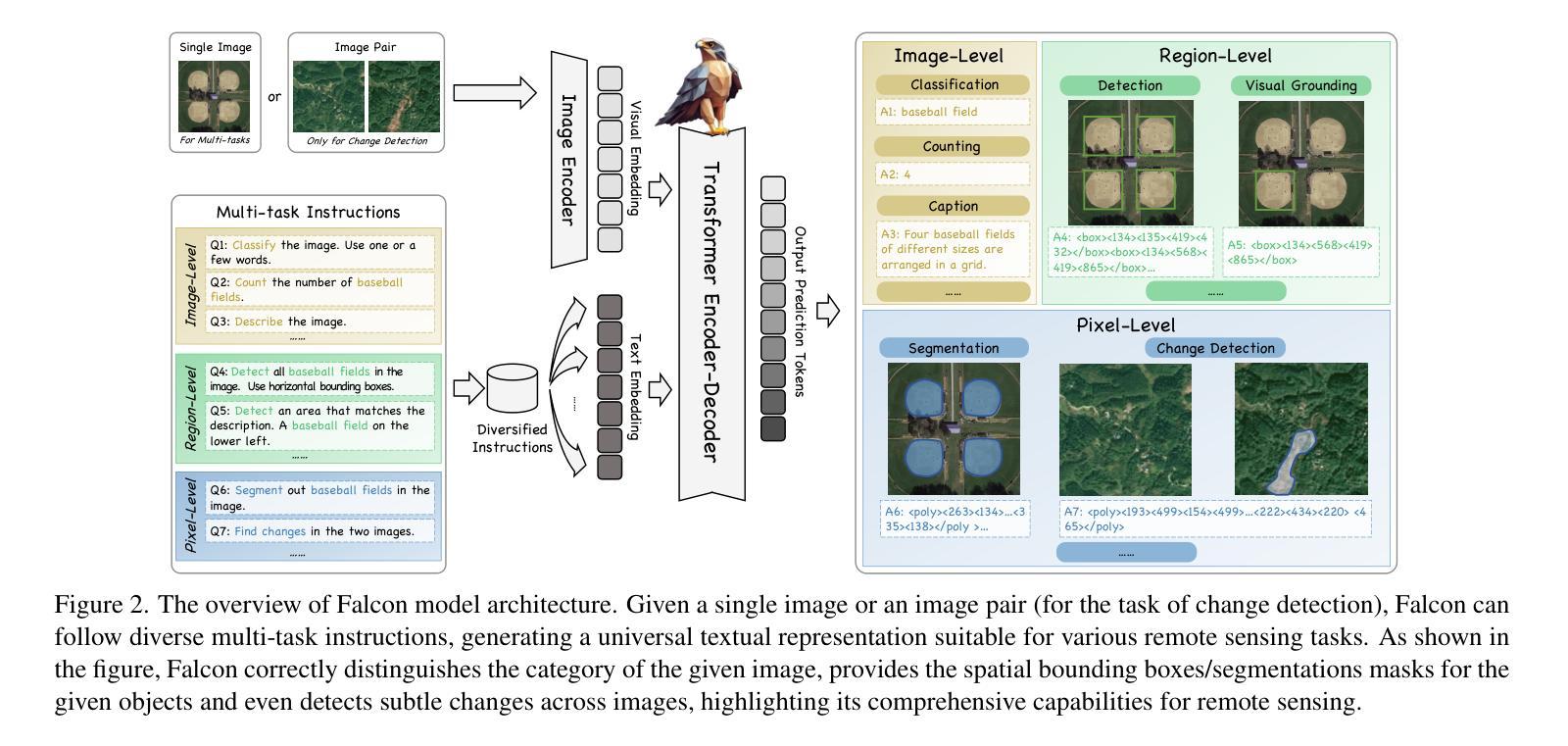
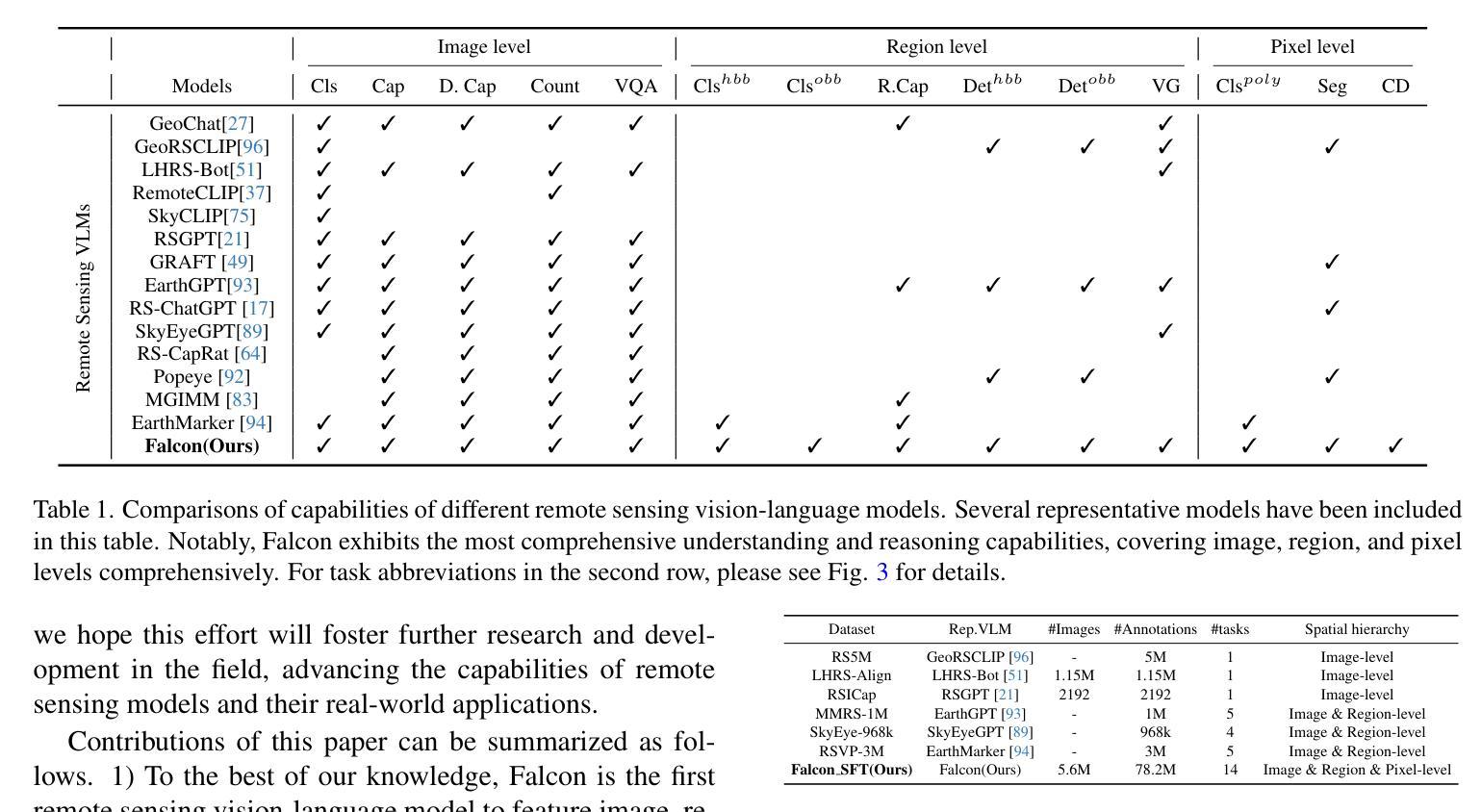
Falcon: A Remote Sensing Vision-Language Foundation Model
Authors:Kelu Yao, Nuo Xu, Rong Yang, Yingying Xu, Zhuoyan Gao, Titinunt Kitrungrotsakul, Yi Ren, Pu Zhang, Jin Wang, Ning Wei, Chao Li
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon’s training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
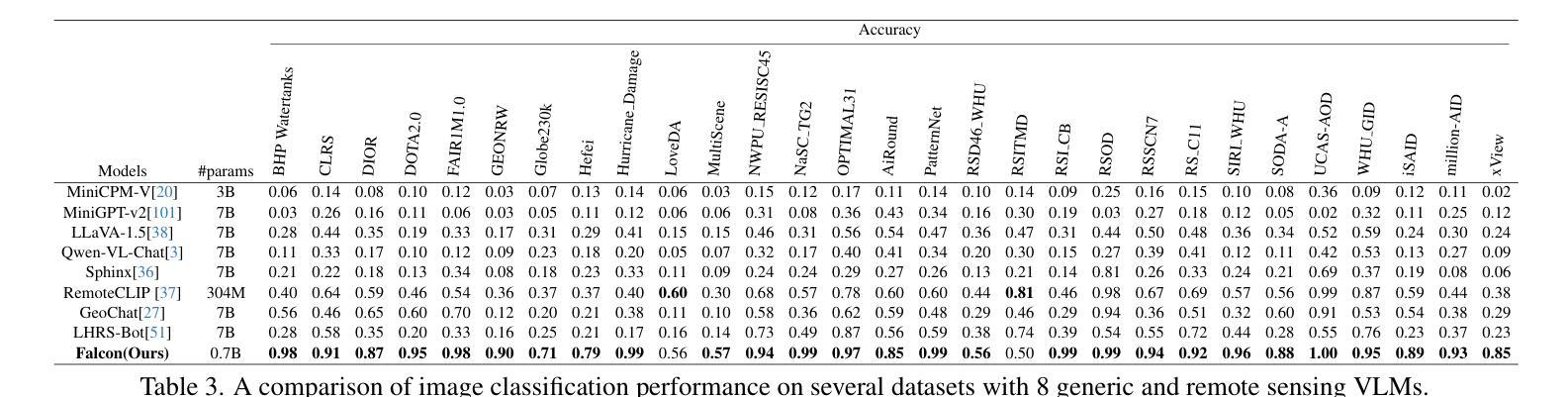
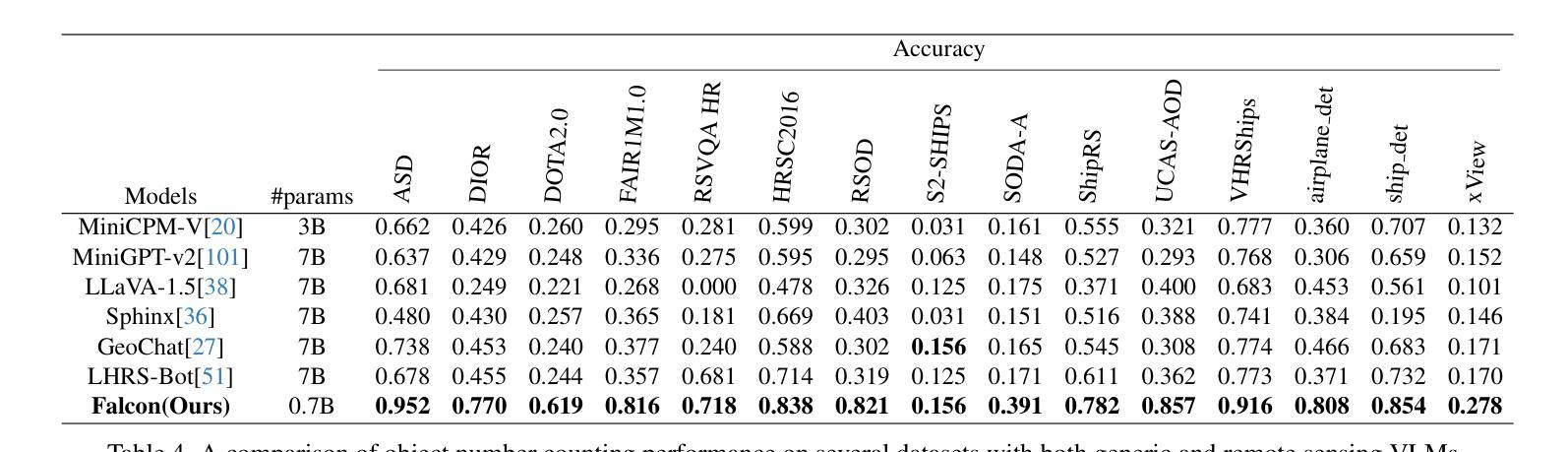
本文介绍了一个专为遥感领域定制的一体化视觉语言基础模型,名为Falcon。Falcon提供了一种基于提示的统一范式,可以有效地执行全面而复杂的遥感任务。Falcon在图像、区域和像素级别表现出强大的理解和推理能力。具体来说,给定简单的自然语言指令和遥感图像,Falcon可以在14个不同的任务中以文本形式产生令人印象深刻的结果,例如图像分类、目标检测、分割、图像描述等。为了促进Falcon的训练并增强其表示能力以编码丰富的空间语义信息,我们开发了Falcon_SFT数据集,这是一个遥感领域的大规模多任务指令调整数据集。Falcon_SFT数据集包含约7800万高质量数据样本,涵盖560万多个多空间分辨率和多视角遥感图像,以及多种指令。它采用分层注释,并经过手动抽样验证,以确保数据的高质量和可靠性。进行了广泛的对比实验,验证了Falcon在67个数据集和14个任务上取得了显著的性能,尽管其参数只有0.7B。我们在https://github.com/TianHuiLab/Falcon上发布了完整的数据集、代码和模型权重,希望能帮助进一步推动开源社区的发展。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了一种针对遥感领域的全新视觉语言基础模型——Falcon。该模型采用基于提示的统一范式,能有效执行复杂遥感任务。通过简单自然语言指令和遥感图像,Falcon能在文本形式下完成多种任务,展现出强大的理解和推理能力。为了训练和强化Falcon的空间和语义信息编码能力,开发了大型多任务指令调优数据集Falcon_SFT。该数据集包含约78万高质量样本,覆盖多种空间分辨率和视角的遥感图像,具备层次化注释,并经过人工采样验证以确保数据质量和可靠性。实验证明,尽管只有0.7B参数,Falcon在多个数据集和任务上的表现仍然卓越。
Key Takeaways
- Falcon是一个针对遥感领域的全新视觉语言基础模型。
- 采用基于提示的统一范式,执行复杂遥感任务。
- 通过简单自然语言指令和遥感图像,能在文本形式下完成多种任务。
- Falcon展现了强大的理解和推理能力,在图像、区域和像素级别都有出色表现。
- Falcon_SFT数据集用于训练和强化Falcon的空间和语义信息编码能力。
- Falcon_SFT数据集包含约78万高质量样本,覆盖多种空间分辨率和视角的遥感图像。
点此查看论文截图


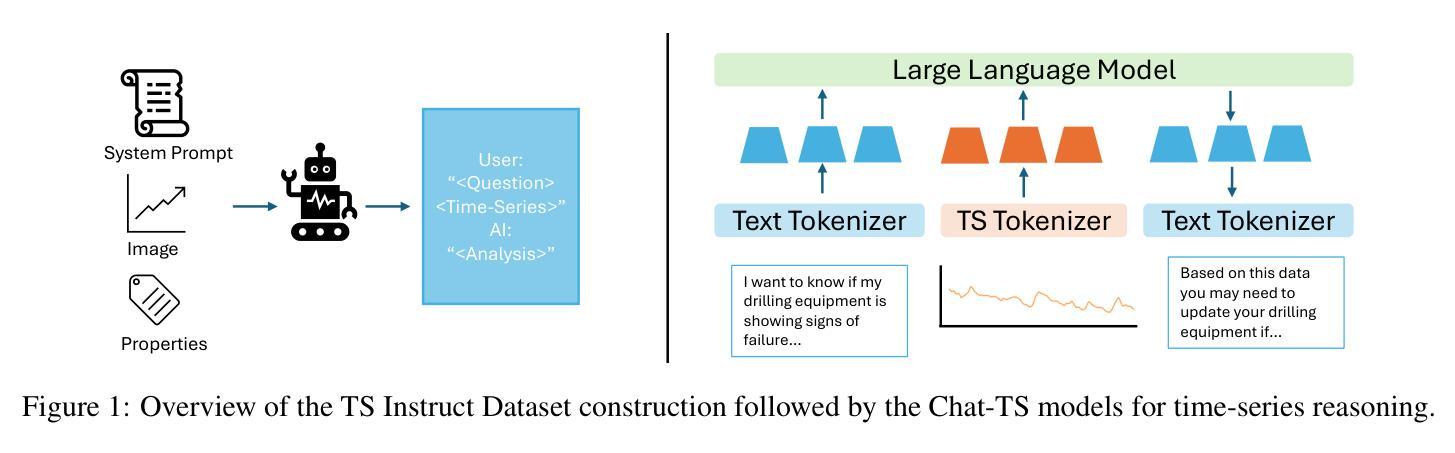
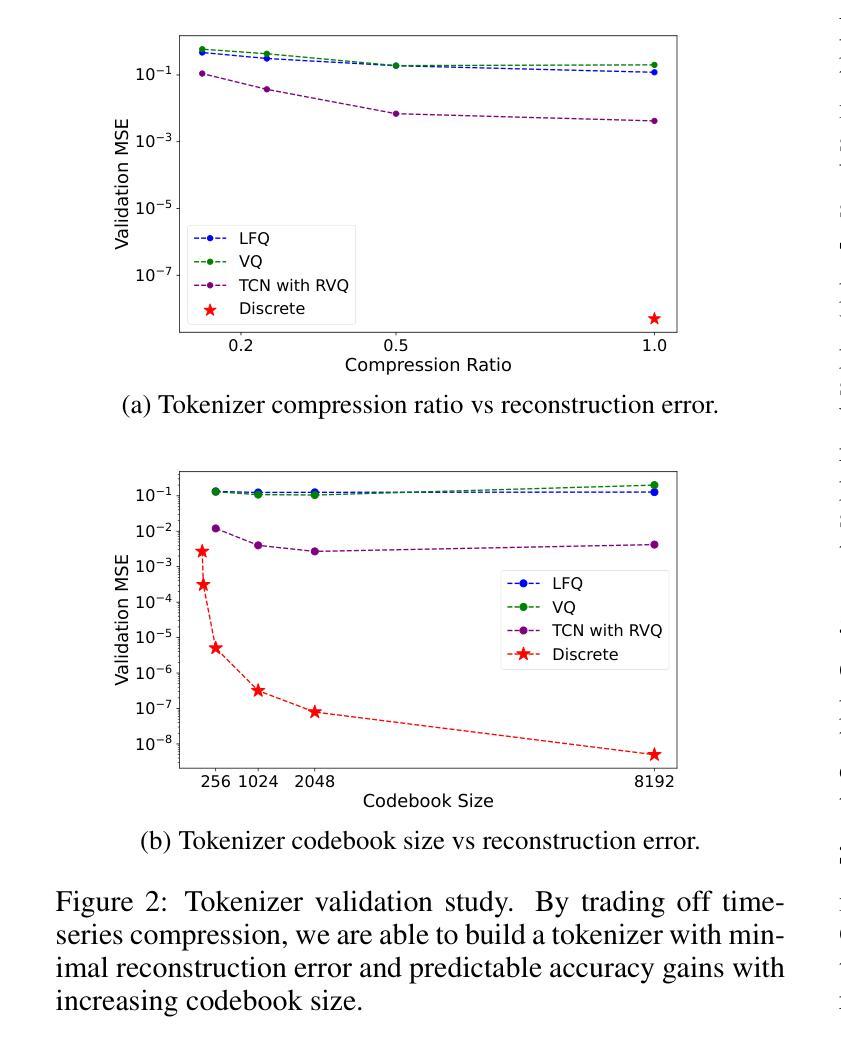
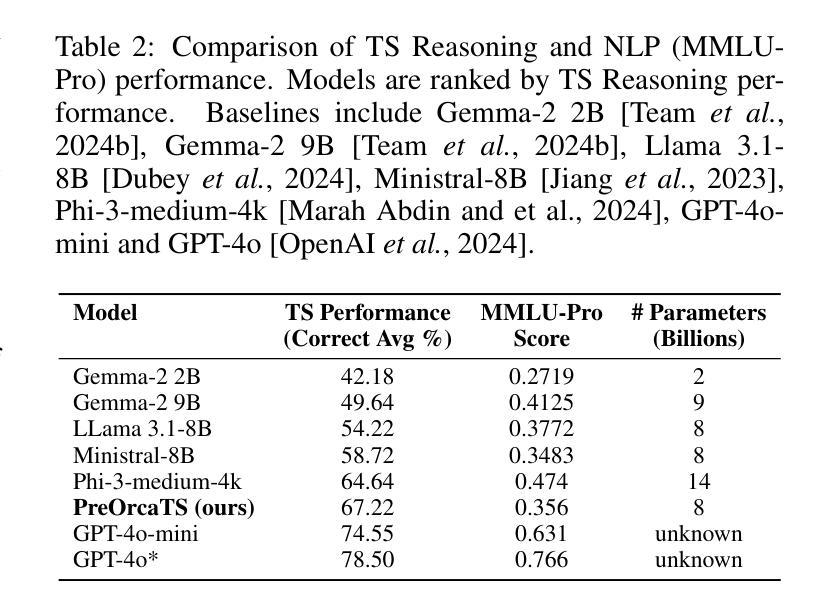
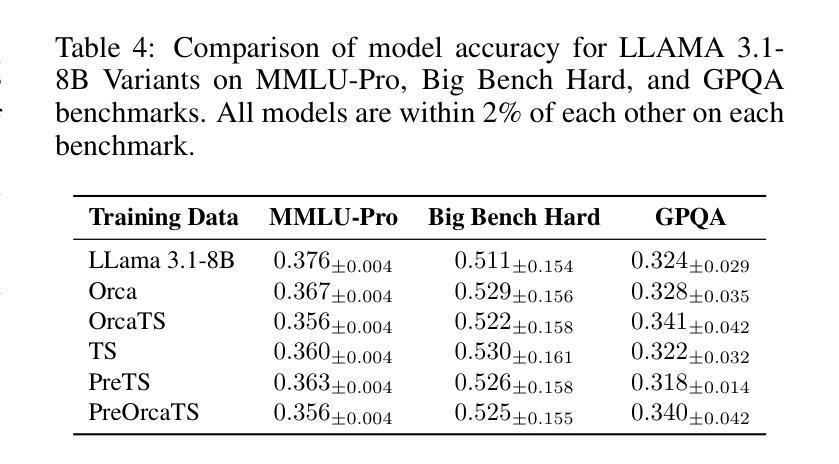
Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data
Authors:Paul Quinlan, Qingguo Li, Xiaodan Zhu
Time-series analysis is critical for a wide range of fields such as healthcare, finance, transportation, and energy, among many others. The practical applications often involve analyzing time-series data alongside contextual information in the form of natural language to support informed decisions. However, current time-series models are limited in their ability to perform reasoning that involves both time-series and their textual content. In this work, we address this gap by introducing \textit{Chat-TS}, a large language model (LLM) based framework, designed to support reasoning over time series and textual data. Unlike traditional models, Chat-TS integrates time-series tokens into LLMs’ vocabulary, enhancing its reasoning ability over both modalities without compromising the core natural language capabilities, enabling practical analysis and reasoning across modalities. To support learning and evaluation in this setup, we contribute new datasets: the \textit{TS Instruct Training Dataset} which pairs diverse time-series data with relevant text instructions and responses for instruction tuning, the \textit{TS Instruct Question and Answer (QA) Gold Dataset} which provides multiple-choice questions designed to evaluate multimodal reasoning, and a \textit{TS Instruct Quantitative Probing Set} which contains a small subset of the TS Instruct QA tasks alongside math and decision-making questions for LLM evaluation. We designed a training strategy to preserve the inherent reasoning capabilities of LLMs while augmenting them for time-series reasoning. Experiments show that Chat-TS achieves state-of-the-art performance in multi-modal reasoning tasks by maintaining strong natural language proficiency while improving time-series reasoning. ~\footnote{To ensure replicability and facilitate future research, all models, datasets, and code will be available at [\texttt{Github-URL}].}
时间序列分析在医疗、金融、交通、能源等诸多领域具有广泛应用。实际应用中经常需要分析时间序列数据以及与自然语言形式的上下文信息,以支持做出明智的决策。然而,现有的时间序列模型在涉及时间序列和文本内容的推理方面存在局限性。在这项工作中,我们通过引入Chat-TS框架来解决这一差距,这是一个基于大型语言模型(LLM)的框架,旨在支持时间序列和文本数据的推理。与传统的模型不同,Chat-TS将时间序列标记集成到LLM的词汇表中,提高了其在两种模态上的推理能力,同时不损害其核心的自然语言功能,从而实现了跨模态的实际分析和推理。为了支持在此设置中的学习和评估,我们提供了新的数据集:TS Instruct训练数据集,它将各种时间序列数据与相关的文本指令和响应配对,用于指令调整;TS Instruct问答(QA)黄金数据集,提供旨在评估多模态推理的选择题;以及TS Instruct定量探测集,其中包含TS Instruct QA任务的一个小子集以及用于LLM评估的数学和决策问题。我们设计了一种训练策略,旨在保留LLM的固有推理能力,同时对其进行时间序列推理的增强。实验表明,Chat-TS在多模态推理任务上达到了最先进的性能,既保持了强大的自然语言技能,又提高了时间序列推理能力。~\footnote{为确保可复制性和促进未来研究,所有模型、数据集和代码都将在[\texttt{Github-URL}]上提供。}
论文及项目相关链接
Summary
该文介绍了时间序分析在多个领域如医疗、金融等的重要性,并指出了当前时间序模型在处理涉及时间序列和文本内容推理时的局限性。为此,该文提出了一个基于大型语言模型(LLM)的框架Chat-TS,旨在支持时间序列和文本数据的推理。Chat-TS通过整合时间序列标记到LLM的词汇表中,提升了跨模态推理能力,同时不损失核心的自然语言功能。为支持在此设置下的学习和评估,作者贡献了新的数据集和训练策略。实验表明,Chat-TS在多模态推理任务上达到了最先进的性能。
Key Takeaways
- 时间序列分析在多个领域具有广泛应用,如医疗、金融等。
- 当前时间序列模型在处理涉及时间序列和文本内容的推理时存在局限性。
- Chat-TS框架旨在支持时间序列和文本数据的推理,通过整合时间序列标记到LLM的词汇表中,增强了跨模态推理能力。
- Chat-TS贡献了新的数据集以支持学习和评估,包括TS Instruct Training Dataset、TS Instruct Question and Answer (QA) Gold Dataset以及TS Instruct Quantitative Probing Set。
- Chat-TS设计了一种训练策略,旨在保留LLM的固有推理能力,同时增强其时间序列推理能力。
- 实验结果表明,Chat-TS在多模态推理任务上达到了最先进的性能,能够在保持强大的自然语言处理能力的同时,提高时间序列推理能力。
点此查看论文截图