⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
Shushing! Let’s Imagine an Authentic Speech from the Silent Video
Authors:Jiaxin Ye, Hongming Shan
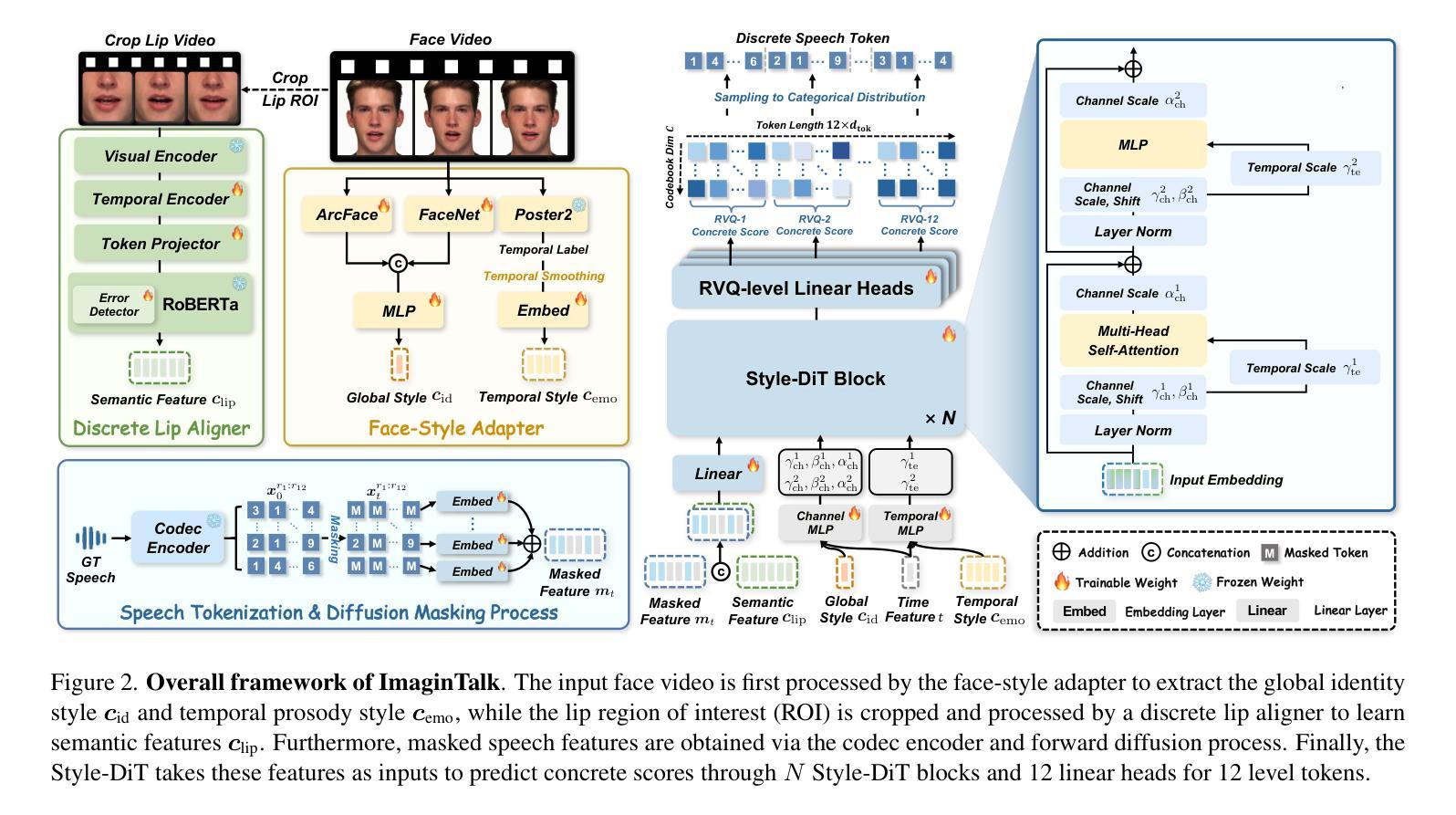
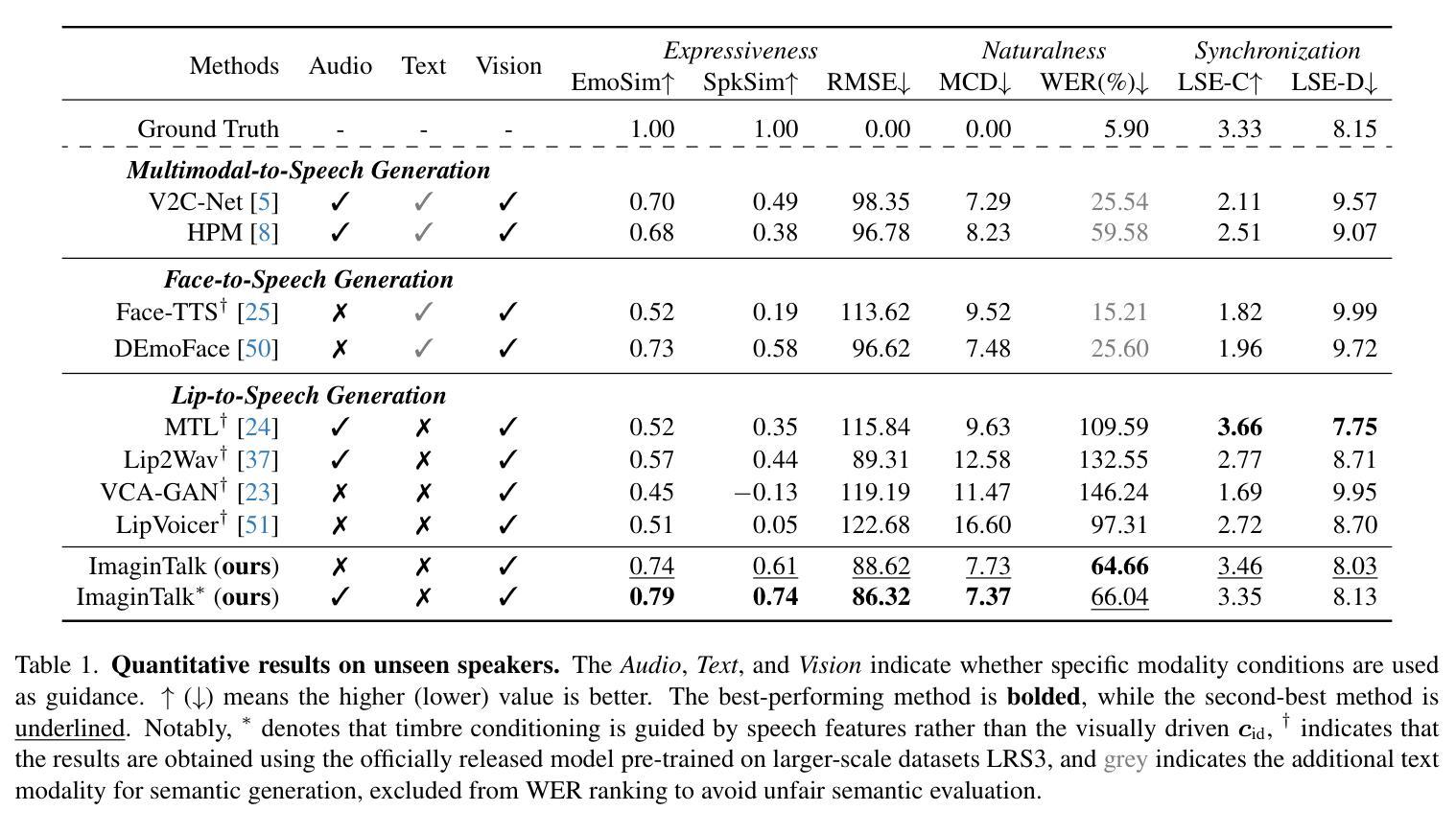
Vision-guided speech generation aims to produce authentic speech from facial appearance or lip motions without relying on auditory signals, offering significant potential for applications such as dubbing in filmmaking and assisting individuals with aphonia. Despite recent progress, existing methods struggle to achieve unified cross-modal alignment across semantics, timbre, and emotional prosody from visual cues, prompting us to propose Consistent Video-to-Speech (CV2S) as an extended task to enhance cross-modal consistency. To tackle emerging challenges, we introduce ImaginTalk, a novel cross-modal diffusion framework that generates faithful speech using only visual input, operating within a discrete space. Specifically, we propose a discrete lip aligner that predicts discrete speech tokens from lip videos to capture semantic information, while an error detector identifies misaligned tokens, which are subsequently refined through masked language modeling with BERT. To further enhance the expressiveness of the generated speech, we develop a style diffusion transformer equipped with a face-style adapter that adaptively customizes identity and prosody dynamics across both the channel and temporal dimensions while ensuring synchronization with lip-aware semantic features. Extensive experiments demonstrate that ImaginTalk can generate high-fidelity speech with more accurate semantic details and greater expressiveness in timbre and emotion compared to state-of-the-art baselines. Demos are shown at our project page: https://imagintalk.github.io.
视觉引导语音生成旨在从面部外观或唇部动作中产生真实的语音,而不依赖于听觉信号,为电影配音和辅助失音人群等应用提供了巨大的潜力。尽管最近有所进展,但现有方法在视觉线索的语义、音质和情感语调方面实现跨模态对齐仍然有困难,促使我们提出一致的视频到语音(CV2S)作为扩展任务以增强跨模态一致性。为了解决新兴的挑战,我们引入了ImaginTalk,这是一个新颖的跨模态扩散框架,仅使用视觉输入生成忠实语音,在一个离散空间内运行。具体来说,我们提出了一种离散唇部对齐器,它从唇部视频中预测离散语音标记以捕获语义信息,同时误差检测器可以识别未对齐的标记,然后通过BERT的掩码语言建模进行后续修正。为了进一步提高生成语音的表达力,我们开发了一款配备面部风格适配器的风格扩散变压器,该适配器可以自适应地定制频道和时间维度上的身份和语调动态,同时确保与唇部感知语义特征的同步。大量实验表明,ImaginTalk可以生成高保真度的语音,具有更准确的语义细节和更高的音质及情感表达力,超越了最先进的基线。演示请见我们的项目页面:https://imagintalk.github.io。
论文及项目相关链接
PDF Project Page: https://imagintalk.github.io
Summary
本文介绍了ImaginTalk这一新型跨模态扩散框架,它能仅通过视觉输入生成忠实语音。该框架解决了新兴挑战,通过离散唇对齐器预测从唇视频中的离散语音令牌来捕获语义信息,并通过错误检测器识别未对齐的令牌进行改进。此外,为了增强生成语音的表现力,开发了一个配备面部风格适配器的风格扩散转换器,可以自适应地调整身份和语调动态。实验表明,ImaginTalk相较于现有技术基线,可以生成更高保真度的语音,语义细节更准确,时和情绪表现更生动。有关演示内容可在我们的项目页面查看:https://imagintalk.github.io。
Key Takeaways
- ImaginTalk是一个新型的跨模态扩散框架,可以从面部外观或唇动中生成真实语音。
- 该框架通过离散唇对齐器预测离散语音令牌来捕获语义信息。
- 错误检测器用于识别未对齐的令牌并进行改进。
- 开发了一个风格扩散转换器,配备面部风格适配器以增强语音的表现力。
- ImaginTalk可以自适应地调整身份和语调动态,确保与唇感知语义特征的同步。
- 实验表明,ImaginTalk生成的语音具有高保真度、准确的语义细节以及生动的时和情绪表现。
点此查看论文截图

MoonCast: High-Quality Zero-Shot Podcast Generation
Authors:Zeqian Ju, Dongchao Yang, Jianwei Yu, Kai Shen, Yichong Leng, Zhengtao Wang, Xu Tan, Xinyu Zhou, Tao Qin, Xiangyang Li
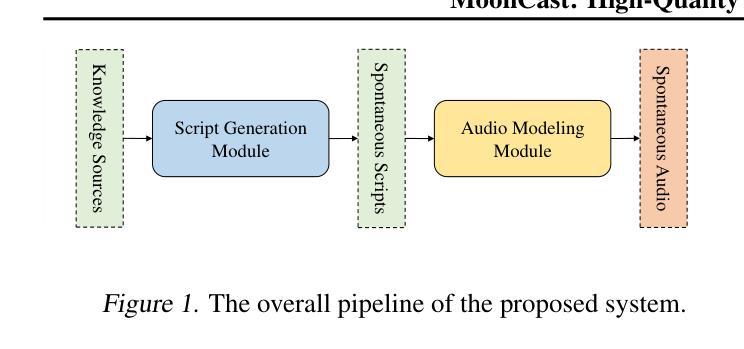
Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
文本转语音合成方面的最新进展在为单个发言人生成高质量简短短语方面取得了显著成功。然而,当这些系统扩展其能力以处理长、多发言人、以及典型的如播客之类的现实场景中的即兴对话时,仍然面临挑战。这些限制源于两个主要挑战:1)长语音:播客通常持续数分钟,超过大多数现有工作的上限;2)即兴性:播客以其即兴、口语的特点为标志,这与正式、书面语境形成了鲜明对比;现有作品在捕捉这种即兴性方面往往表现不足。在本文中,我们提出了MoonCast,一个用于高质量零样本播客生成的解决方案,旨在仅从文本源(例如故事、技术报告、TXT、PDF或Web URL格式的新闻)合成自然播客风格的语音,并使用未见过的发言人的声音。为了生成长音频,我们采用了一种基于大规模长语境语音数据的音频建模方法。为了提高即兴性,我们利用播客生成模块来生成具有即兴细节的脚本,经验表明这同样至关重要,就像文本转语音建模本身一样重要。实验表明,MoonCast优于基线模型,特别是在即兴性和连贯性方面取得了显著改进。
论文及项目相关链接
Summary
本文介绍了文本转语音合成技术的最新进展及其在生成高质量短句方面的成功应用。然而,现有系统在面对长文本、多说话人和即时对话等现实场景(如Podcast)时仍面临挑战。为此,本文提出了MoonCast方案,旨在从文本源(如故事、技术报告、新闻等)合成高质量的Podcast风格语音,并采用大规模长上下文语音数据进行音频建模。通过实证研究显示,MoonCast能够提高Podcasts的生成质量,尤其在自发性和连贯性方面表现突出。
Key Takeaways
- 文本转语音合成技术在生成高质量短句方面取得了显著进展。
- 现有系统在处理长文本、多说话人和即时对话等现实场景时面临挑战。
- MoonCast方案旨在从文本源合成高质量的Podcast风格语音。
- 采用大规模长上下文语音数据进行音频建模,以生成长音频。
- MoonCast包括一个Podcast生成模块,用于生成具有自发性的脚本。
- 实证研究显示,MoonCast能够提高Podcasts的生成质量。
点此查看论文截图

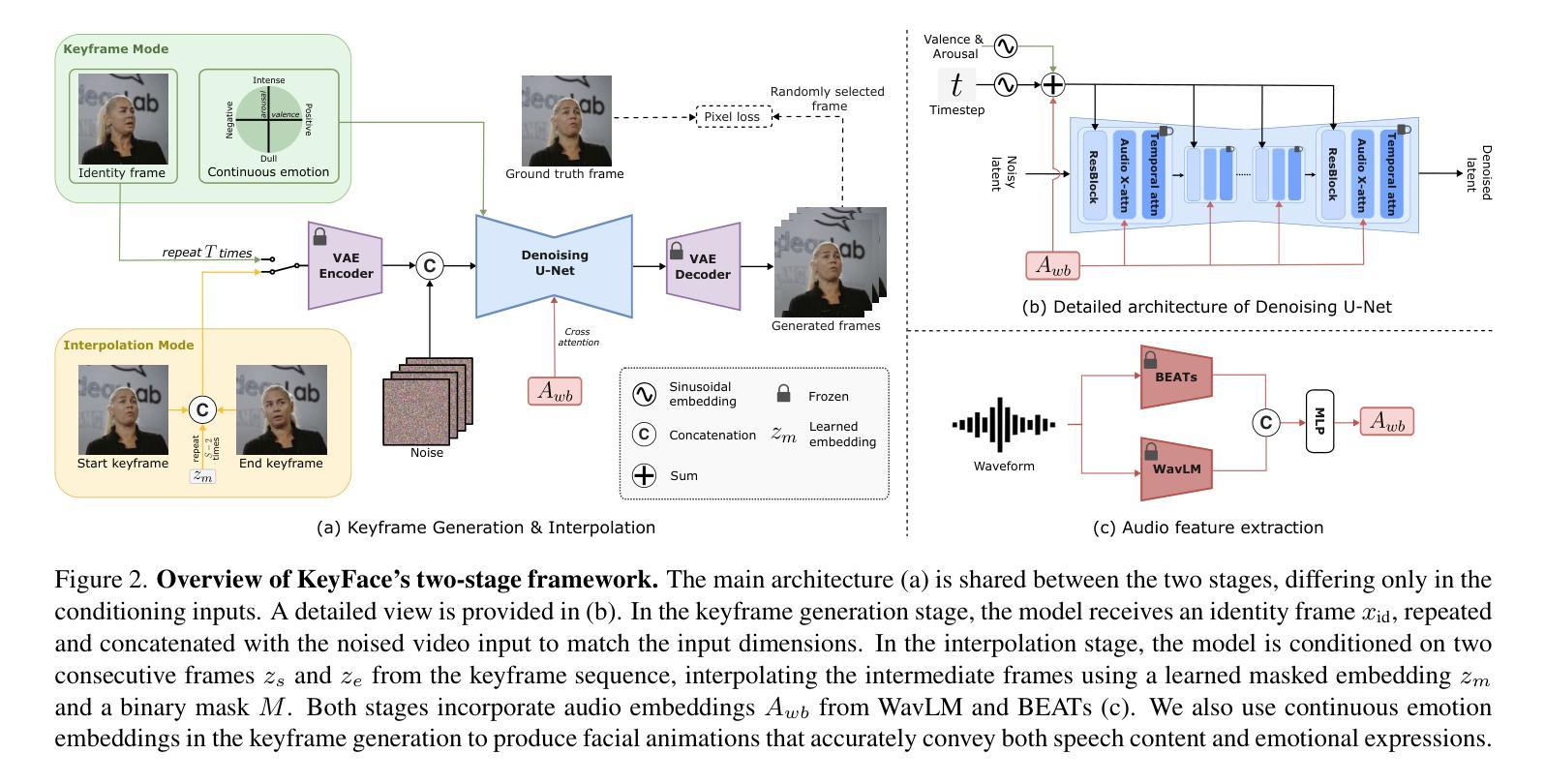
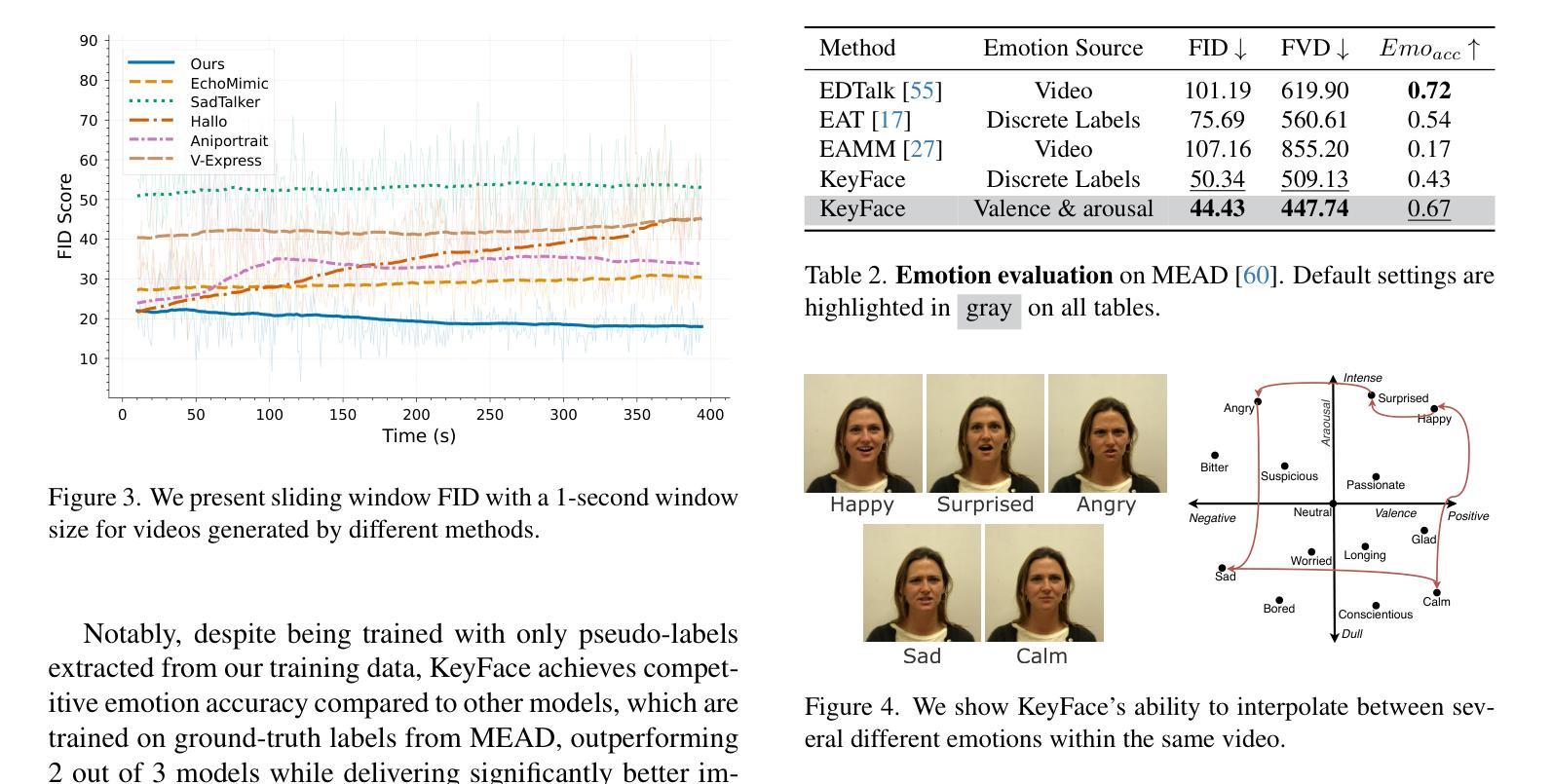
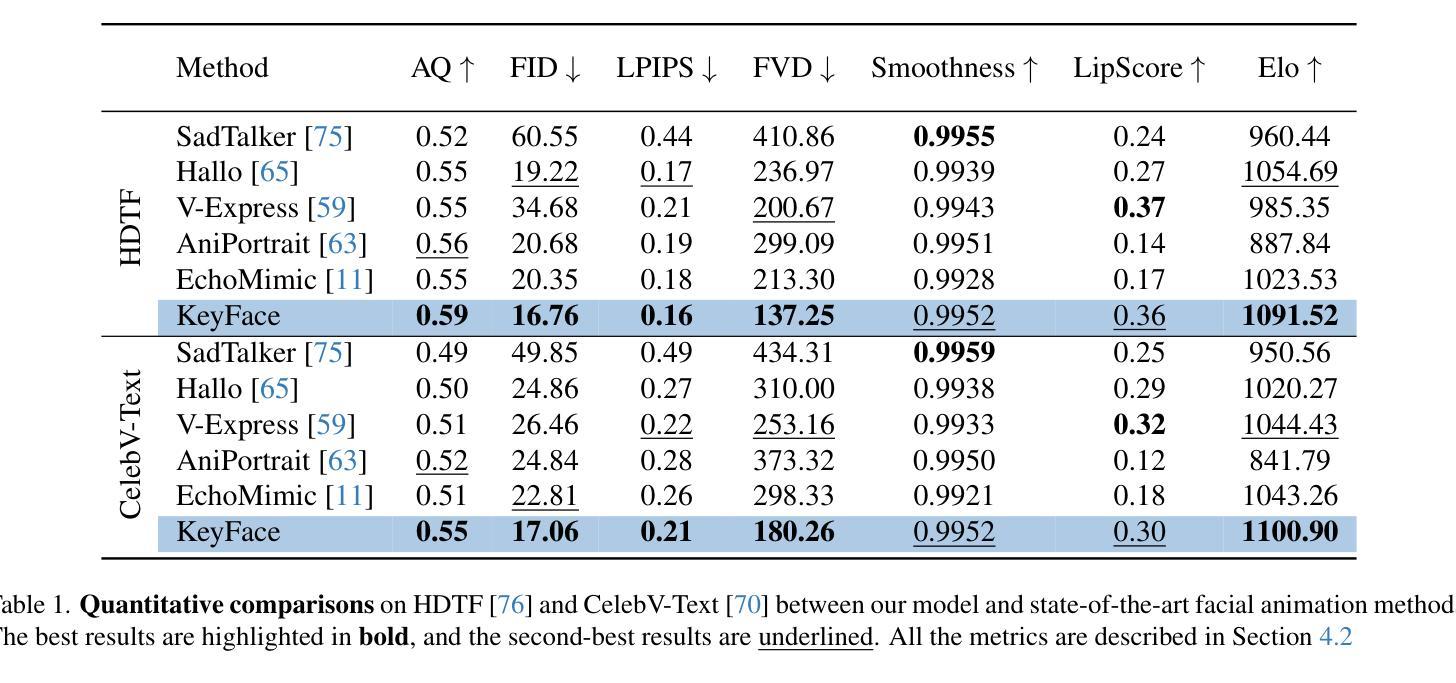
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Authors:Antoni Bigata, Michał Stypułkowski, Rodrigo Mira, Stella Bounareli, Konstantinos Vougioukas, Zoe Landgraf, Nikita Drobyshev, Maciej Zieba, Stavros Petridis, Maja Pantic
Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
当前基于音频驱动的面部动画方法在短视频上取得了令人印象深刻的效果,但当扩展到更长时间时,会出现误差累积和身份漂移的问题。现有方法试图通过外部空间控制来减轻这种情况,虽然提高了长期一致性,但牺牲了运动的自然性。我们提出了KeyFace,这是一种基于新型两阶段扩散的框架来解决这些问题。在第一阶段,以音频输入和身份帧为条件,在低帧率下生成关键帧,以捕捉长时间段内重要的面部表情和动作。在第二阶段,插值模型填充关键帧之间的间隙,确保平滑过渡和时间连贯性。为了进一步增加真实性,我们融入了连续的情绪表示,并处理各种非语音声音(NSVs),如笑声和叹息声。我们还引入了两个新的评估指标,用于评估唇同步和非语音生成。实验结果表明,在长时间生成自然、连贯的面部动画方面,KeyFace超越了最先进的方法,成功涵盖了非语音声音和连续情绪。
论文及项目相关链接
PDF CVPR 2025
Summary
语音驱动的面动技术在短视频上表现突出,但在长时间序列上会出现误差累积和身份漂移问题。为解决这些问题,KeyFace采用基于扩散的两阶段框架。第一阶段根据音频输入和身份帧生成低帧率的关键帧,捕捉长时间的表情和动作变化。第二阶段使用插值模型填充关键帧之间的空白,确保平滑过渡和时间连贯性。此外,KeyFace还引入连续情感表示并处理各种非语音发声(NSVs),如笑声和叹息。实验结果表明,KeyFace在长时间序列上生成自然、连贯的面部动画方面优于现有技术,并成功包含非语音发声和连续情感。
Key Takeaways
- 当前音频驱动的面动技术在长时间序列上存在误差累积和身份漂移的问题。
- KeyFace采用基于扩散的两阶段框架来解决这一问题。
- 第一阶段根据音频输入和身份帧生成低帧率的关键帧,捕捉长时间的表情和动作变化。
- 第二阶段确保关键帧之间的平滑过渡和时间连贯性。
- KeyFace引入连续情感表示,并处理各种非语音发声(NSVs)。
- KeyFace采用两个新评估指标来评估唇同步和非语音发声生成效果。
点此查看论文截图

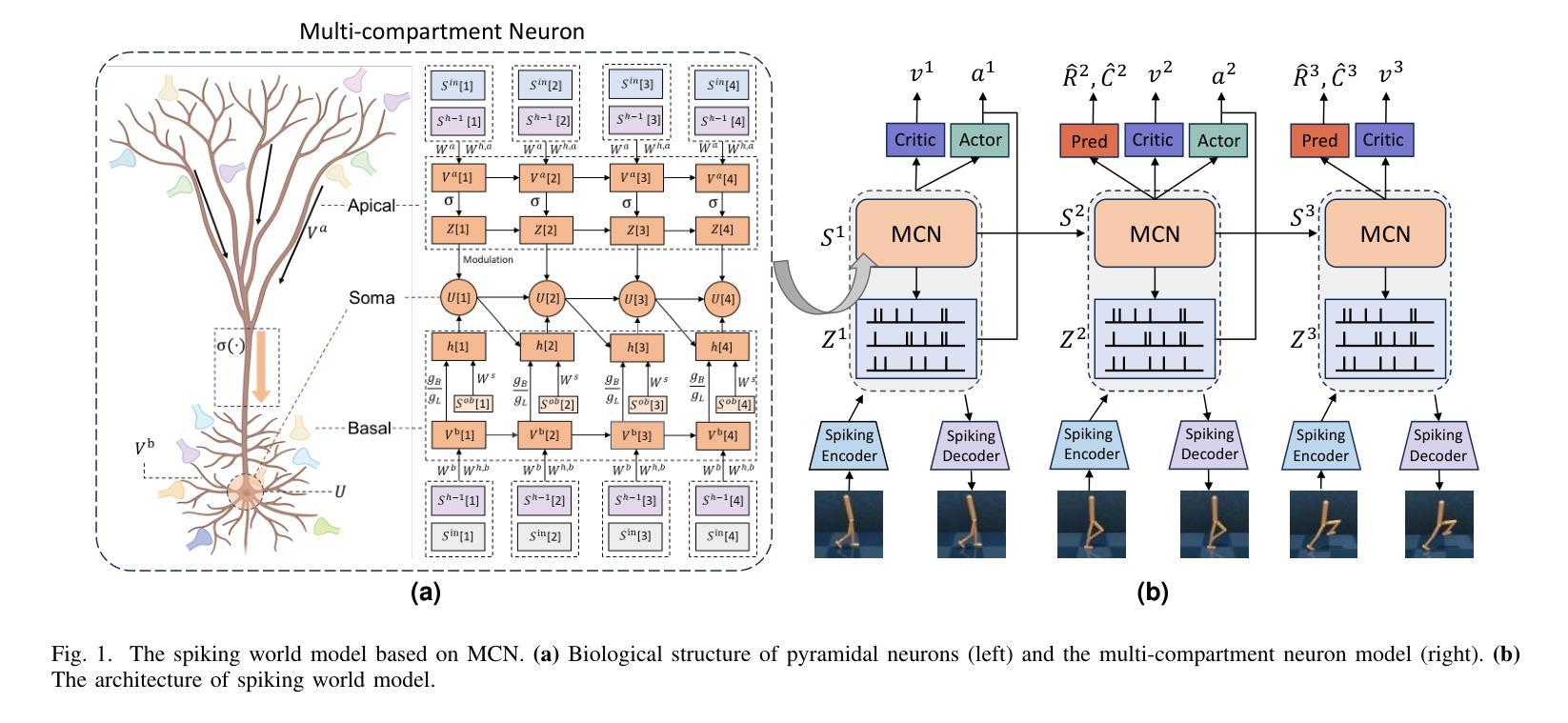
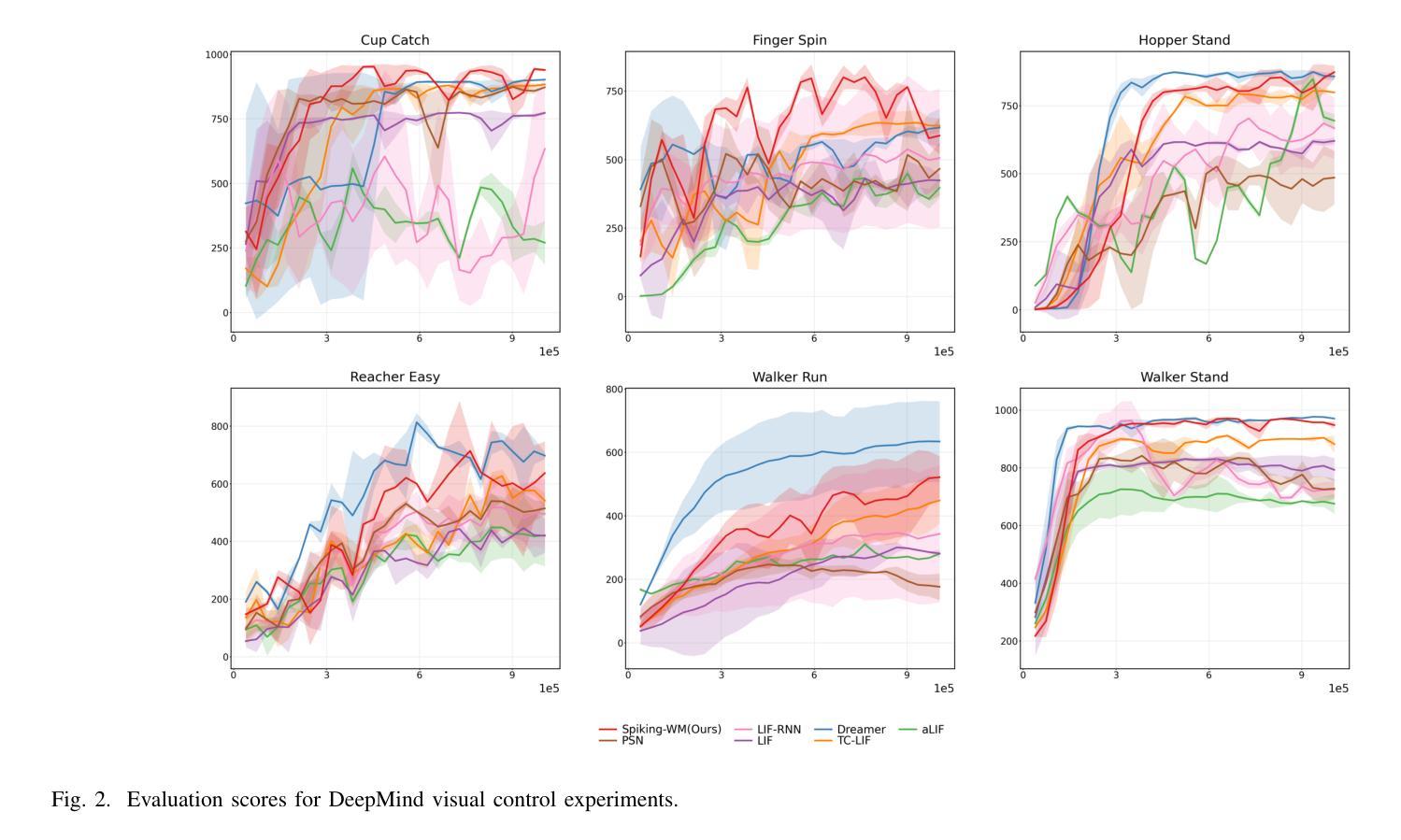
Spiking World Model with Multi-Compartment Neurons for Model-based Reinforcement Learning
Authors:Yinqian Sun, Feifei Zhao, Mingyang Lv, Yi Zeng
Brain-inspired spiking neural networks (SNNs) have garnered significant research attention in algorithm design and perception applications. However, their potential in the decision-making domain, particularly in model-based reinforcement learning, remains underexplored. The difficulty lies in the need for spiking neurons with long-term temporal memory capabilities, as well as network optimization that can integrate and learn information for accurate predictions. The dynamic dendritic information integration mechanism of biological neurons brings us valuable insights for addressing these challenges. In this study, we propose a multi-compartment neuron model capable of nonlinearly integrating information from multiple dendritic sources to dynamically process long sequential inputs. Based on this model, we construct a Spiking World Model (Spiking-WM), to enable model-based deep reinforcement learning (DRL) with SNNs. We evaluated our model using the DeepMind Control Suite, demonstrating that Spiking-WM outperforms existing SNN-based models and achieves performance comparable to artificial neural network (ANN)-based world models employing Gated Recurrent Units (GRUs). Furthermore, we assess the long-term memory capabilities of the proposed model in speech datasets, including SHD, TIMIT, and LibriSpeech 100h, showing that our multi-compartment neuron model surpasses other SNN-based architectures in processing long sequences. Our findings underscore the critical role of dendritic information integration in shaping neuronal function, emphasizing the importance of cooperative dendritic processing in enhancing neural computation.
受大脑启发的脉冲神经网络(SNNs)在算法设计和感知应用方面引起了广泛的研究关注。然而,它们在决策领域,特别是在基于模型的强化学习中的潜力,仍然被探索得不够。难点在于需要具有长期时间记忆能力的脉冲神经元,以及能够整合和学习信息进行准确预测的网络优化。生物神经元的动态树突信息整合机制为我们解决这些挑战提供了有价值的见解。在这项研究中,我们提出了一种多室神经元模型,能够非线性地从多个树突源整合信息,以动态处理长序列输入。基于此模型,我们构建了脉冲世界模型(Spiking-WM),以实现基于模型的深度强化学习(DRL)与SNNs的结合。我们使用DeepMind Control Suite评估了我们的模型,结果表明Spiking-WM优于现有的SNN模型,其性能与采用门控循环单元(GRUs)的基于人工神经网络(ANN)的世界模型相当。此外,我们还评估了所提出模型在语音数据集上的长期记忆能力,包括SHD、TIMIT和LibriSpeech 100h,显示我们的多室神经元模型在处理长序列方面超越了其他SNN架构。我们的研究强调了树突信息整合在塑造神经元功能中的关键作用,并强调了合作树突处理在增强神经计算中的重要性。
论文及项目相关链接
Summary
该文本探讨了大脑启发的脉冲神经网络(SNNs)在决策制定领域的应用潜力,特别是在基于模型的强化学习方面。研究提出了一种多室神经元模型,能够动态处理长序列输入,并基于此构建了Spiking World Model(Spiking-WM),实现了基于模型的深度强化学习(DRL)与SNNs的结合。评估结果表明,Spiking-WM在DeepMind Control Suite上的表现优于现有SNN模型,且与采用门控循环单元(GRU)的基于人工神经网络(ANN)的世界模型表现相当。此外,该模型在语音数据集上的长期记忆能力也进行了评估,并表现出超越其他SNN架构处理长序列的优势。
Key Takeaways
- SNNs在决策制定领域的潜力尚未得到充分探索,特别是在基于模型的强化学习方面。
- 研究提出了一种多室神经元模型,能够非线性地整合来自多个树突来源的信息,以动态处理长序列输入。
- 基于该多室神经元模型,构建了Spiking World Model(Spiking-WM),实现了基于模型的深度强化学习与SNNs的结合。
- Spiking-WM在DeepMind Control Suite上的表现优于现有SNN模型,且与采用GRU的ANN模型表现相当。
- 模型在语音数据集上展示出了强大的长期记忆能力,超越了其他SNN架构在处理长序列方面的性能。
- 研究成果强调了树突信息整合在神经元功能形成中的关键作用。
点此查看论文截图


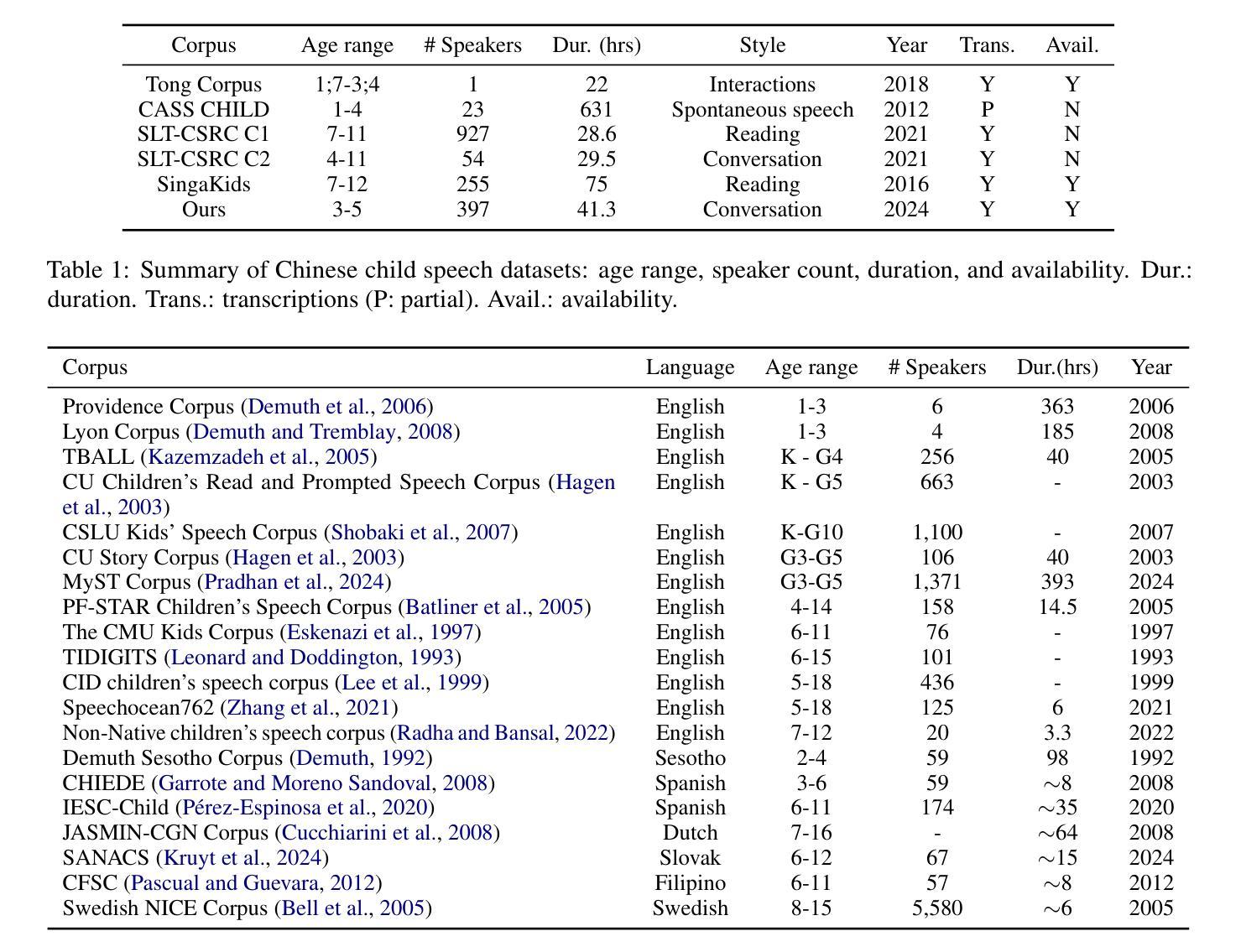
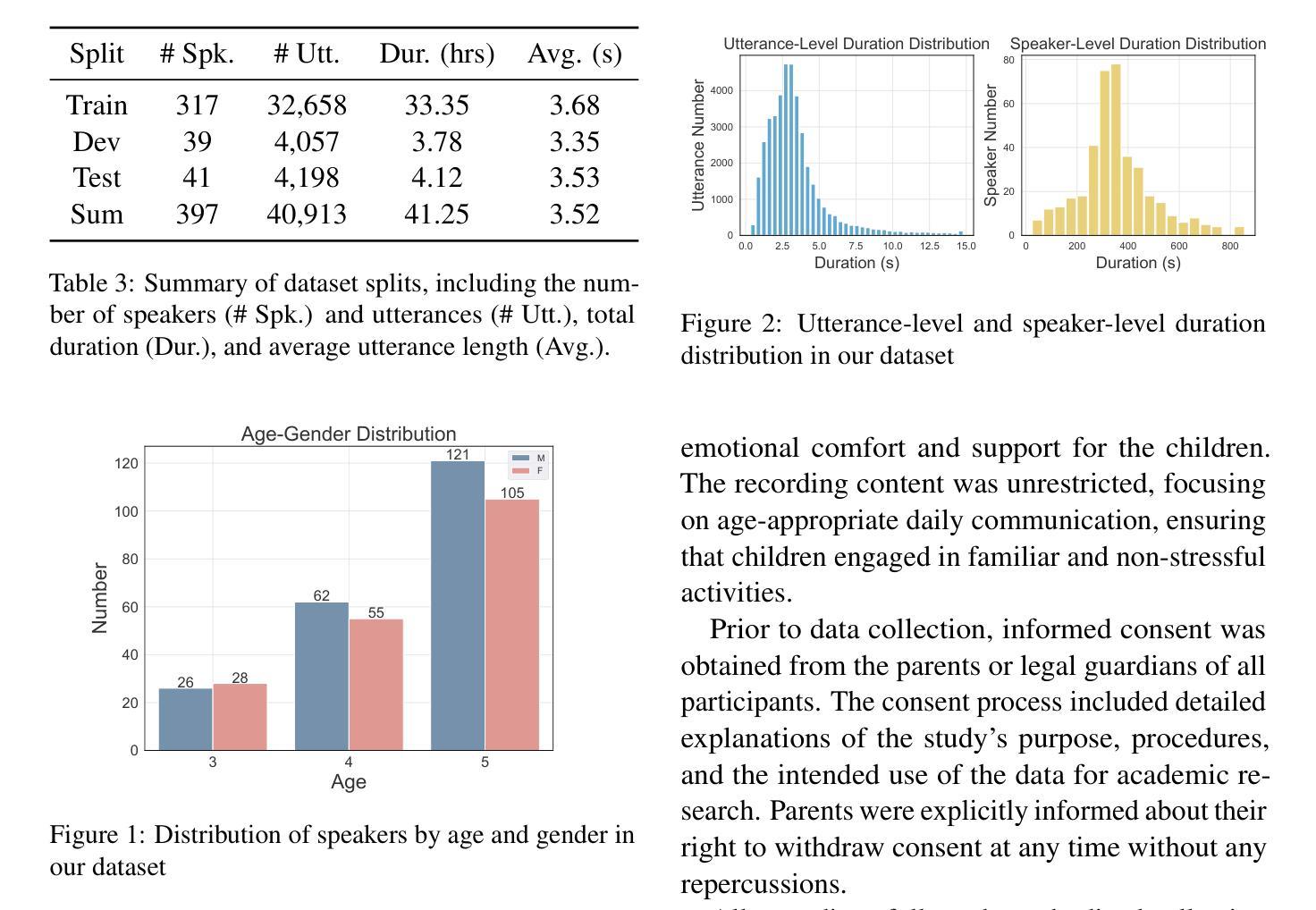
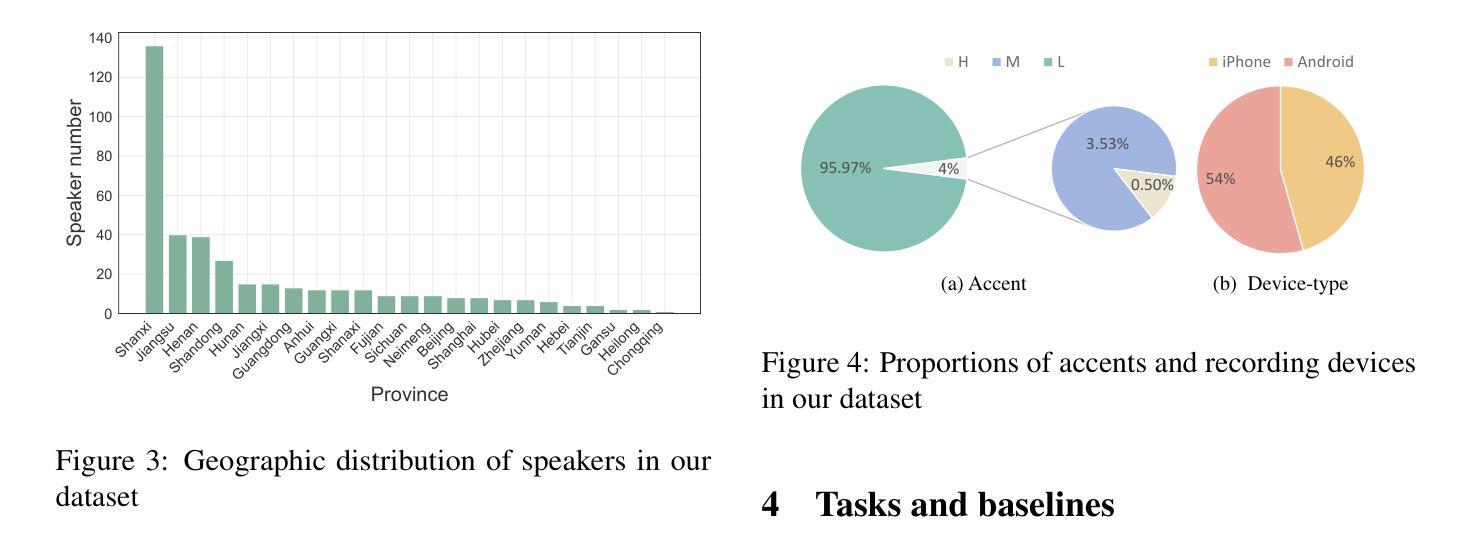
ChildMandarin: A Comprehensive Mandarin Speech Dataset for Young Children Aged 3-5
Authors:Jiaming Zhou, Shiyao Wang, Shiwan Zhao, Jiabei He, Haoqin Sun, Hui Wang, Cheng Liu, Aobo Kong, Yujie Guo, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
Automatic speech recognition (ASR) systems have advanced significantly with models like Whisper, Conformer, and self-supervised frameworks such as Wav2vec 2.0 and HuBERT. However, developing robust ASR models for young children’s speech remains challenging due to differences in pronunciation, tone, and pace compared to adult speech. In this paper, we introduce a new Mandarin speech dataset focused on children aged 3 to 5, addressing the scarcity of resources in this area. The dataset comprises 41.25 hours of speech with carefully crafted manual transcriptions, collected from 397 speakers across various provinces in China, with balanced gender representation. We provide a comprehensive analysis of speaker demographics, speech duration distribution and geographic coverage. Additionally, we evaluate ASR performance on models trained from scratch, such as Conformer, as well as fine-tuned pre-trained models like HuBERT and Whisper, where fine-tuning demonstrates significant performance improvements. Furthermore, we assess speaker verification (SV) on our dataset, showing that, despite the challenges posed by the unique vocal characteristics of young children, the dataset effectively supports both ASR and SV tasks. This dataset is a valuable contribution to Mandarin child speech research. The dataset is now open-source and freely available for all academic purposes on https://github.com/flageval-baai/ChildMandarin.
自动语音识别(ASR)系统已经取得了显著的进步,如Whisper、Conformer以及Wav2vec 2.0和HuBERT等自监督框架。然而,由于儿童与成年人在发音、语调、语速等方面的差异,为儿童语音开发稳健的ASR模型仍然是一个挑战。本文介绍了一个针对3至5岁儿童的新普通话语音数据集,以解决该领域资源匮乏的问题。该数据集包含41.25小时的语音,这些语音来自中国各省的39 结了精心制作的手动转录,性别代表平衡。我们综合分析了说话人的人口统计特征、语音持续时间分布和地理覆盖范围。此外,我们对从头开始训练的模型(如Conformer)以及微调预训练模型(如HuBERT和Whisper)的ASR性能进行了评估,其中微调显示出显著的性能改进。此外,我们在我们的数据集上评估了说话人验证(SV)的性能,结果表明,尽管儿童独特的嗓音特征带来了挑战,但该数据集有效地支持ASR和SV任务。该数据集对普通话儿童语音研究做出了有价值的贡献。该数据集现已开源,可在https://github.com/flageval-baai/ChildMandarin上免费用于所有学术目的。
论文及项目相关链接
Summary:
随着语音识别技术的不断发展,针对儿童语音的自动语音识别(ASR)模型研究变得尤为重要。针对普通话背景下3至5岁儿童,本研究建立了一个包含多种语料的大型语音数据集,以解决当前领域资源的稀缺问题。此外,该数据集评估了从训练ASR模型的性能表现并展示了良好的验证结果。此数据集现已公开发布在旗智计划共享平台以供学术研究使用。此数据集将对于促进针对儿童的ASR及演讲验证等相关领域的科研进展有着重要影响。这一工作成果无疑对学术研究和科技发展都有重要推动作用。此数据集的发布对提升针对普通话儿童的语音识别研究意义重大。此外该数据集还将作为研究儿童语言发展、教育等领域的宝贵资源。未来有望推动更多针对儿童语音识别的技术进步和创新应用。该数据集对推进相关领域研究具有重大意义。
Key Takeaways:
- 自动语音识别(ASR)系统对于儿童语音的识别仍然面临挑战,特别是在与成人语音在发音、语调、语速等方面的差异方面。本研究致力于解决这一挑战。
- 研究团队建立了针对普通话背景下3至5岁儿童的新的语音数据集,其中包含大量语料并涵盖了多种背景信息,如说话人的年龄、性别和地理位置等。数据集的建立解决了当前领域资源的稀缺问题。
- 数据集包含经过精心设计的语音样本和相应的手动转录文本,且样本涵盖了不同省份和地区的中国儿童,性别分布均衡。数据集的多样性和广泛性为其在学术研究中的价值提供了保障。
- 研究团队评估了不同ASR模型在该数据集上的性能表现,包括从头开始训练的模型和经过预训练后精细调整的模型,后者在性能上显示出显著改善。此外还对该数据集的演讲验证性能进行了评估。
点此查看论文截图


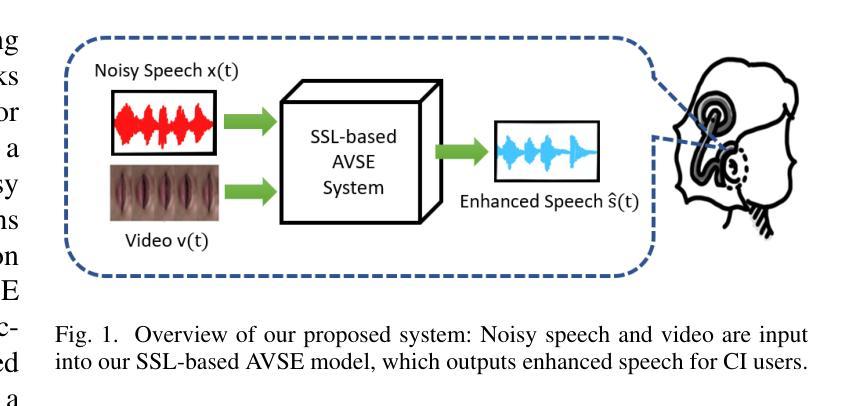
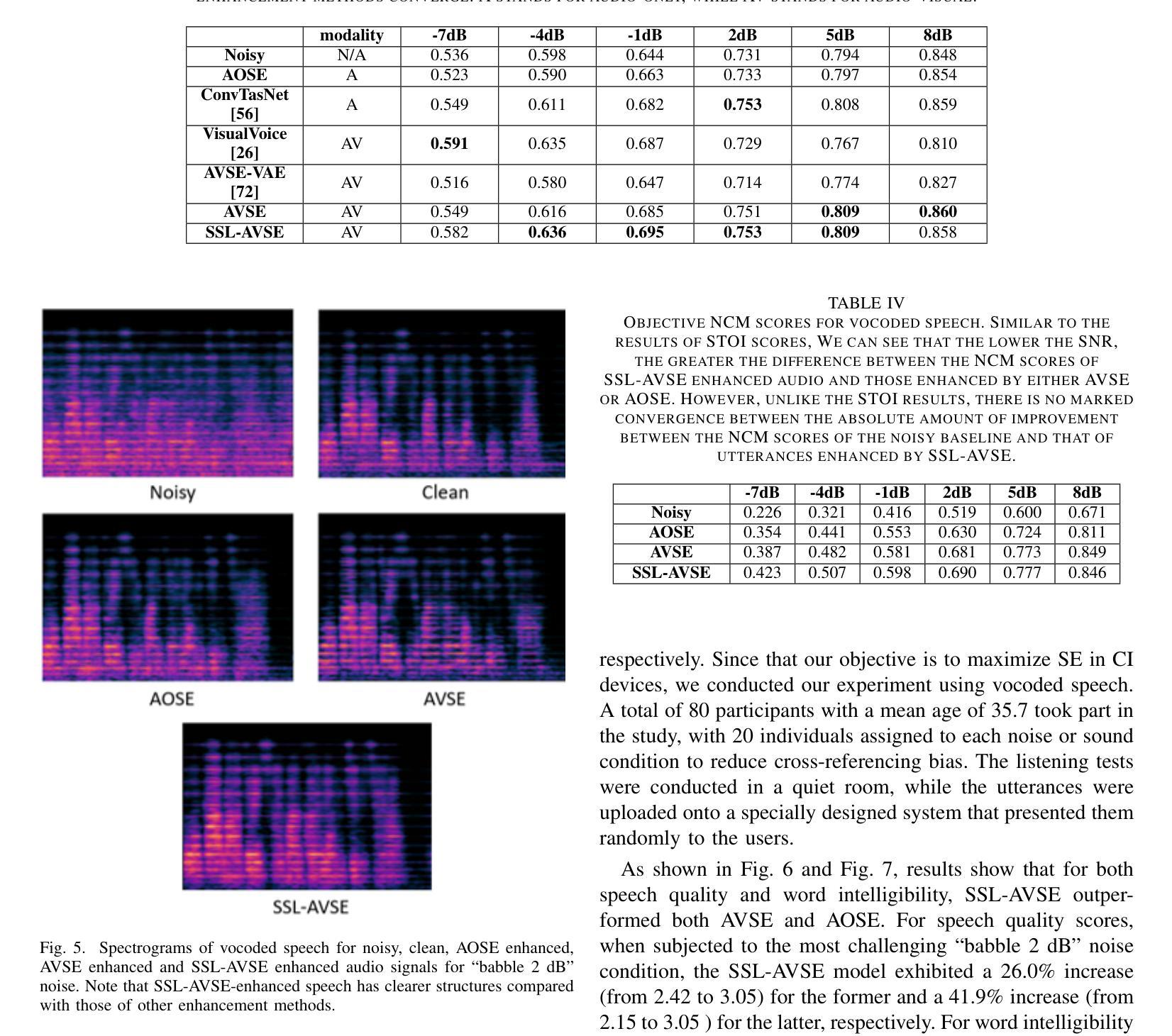
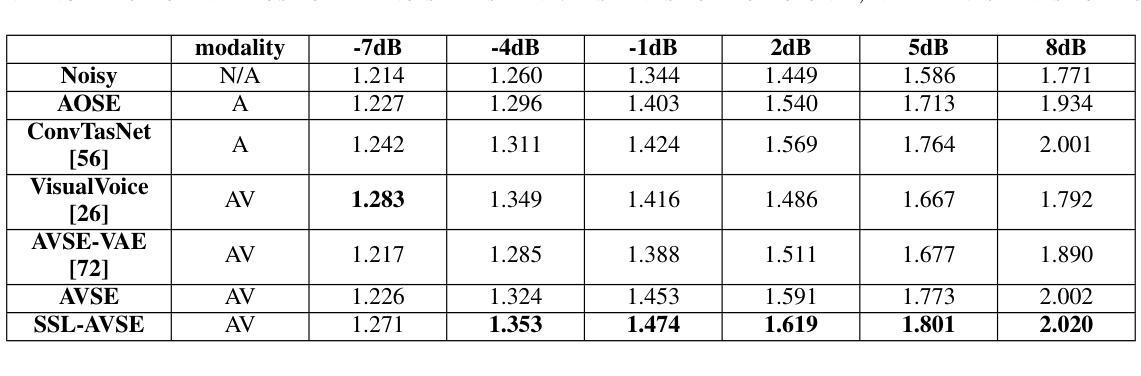
Audio-Visual Speech Enhancement Using Self-supervised Learning to Improve Speech Intelligibility in Cochlear Implant Simulations
Authors:Richard Lee Lai, Jen-Cheng Hou, I-Chun Chern, Kuo-Hsuan Hung, Yi-Ting Chen, Mandar Gogate, Tughrul Arslan, Amir Hussain, Yu Tsao
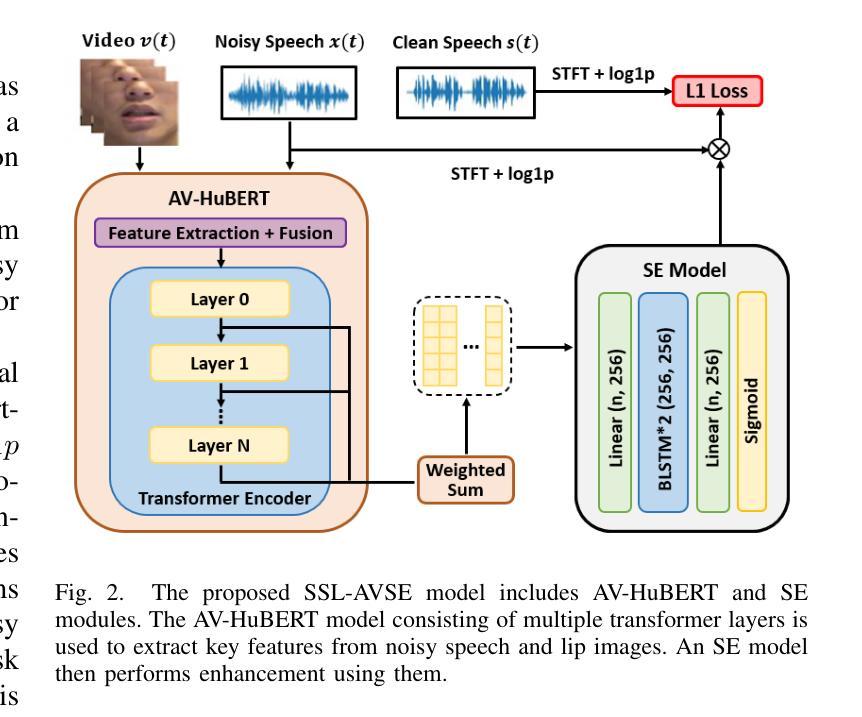
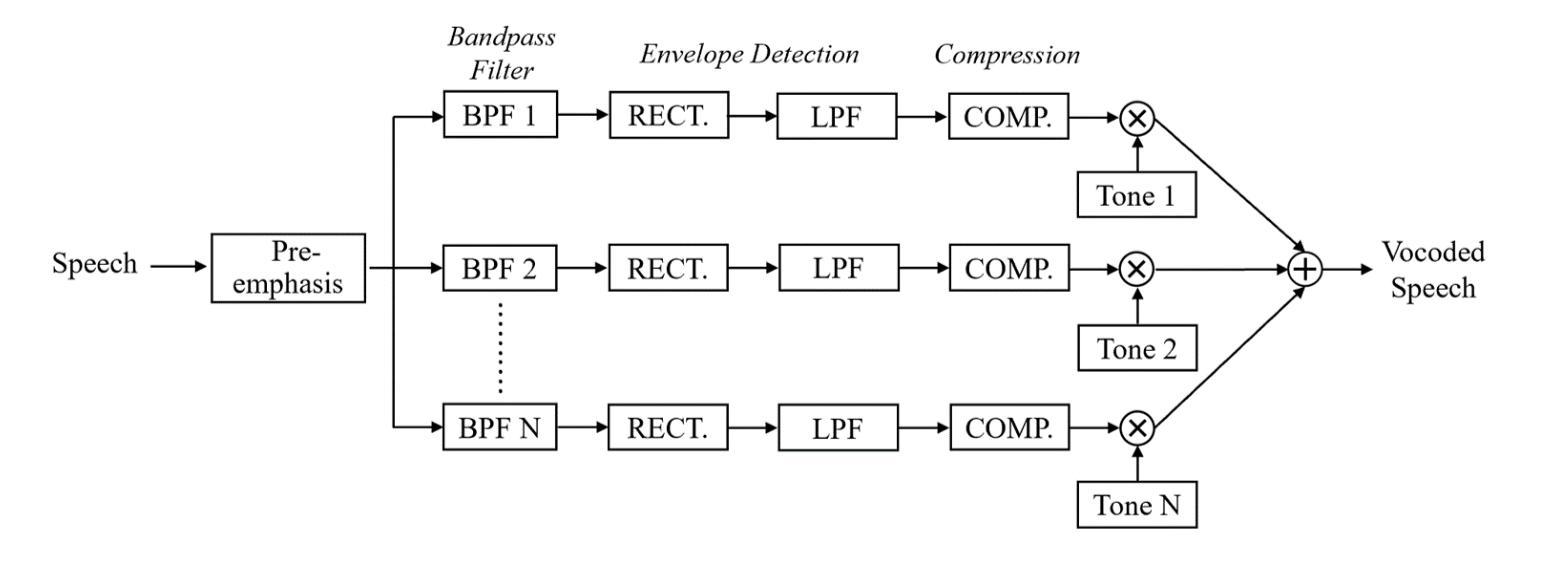
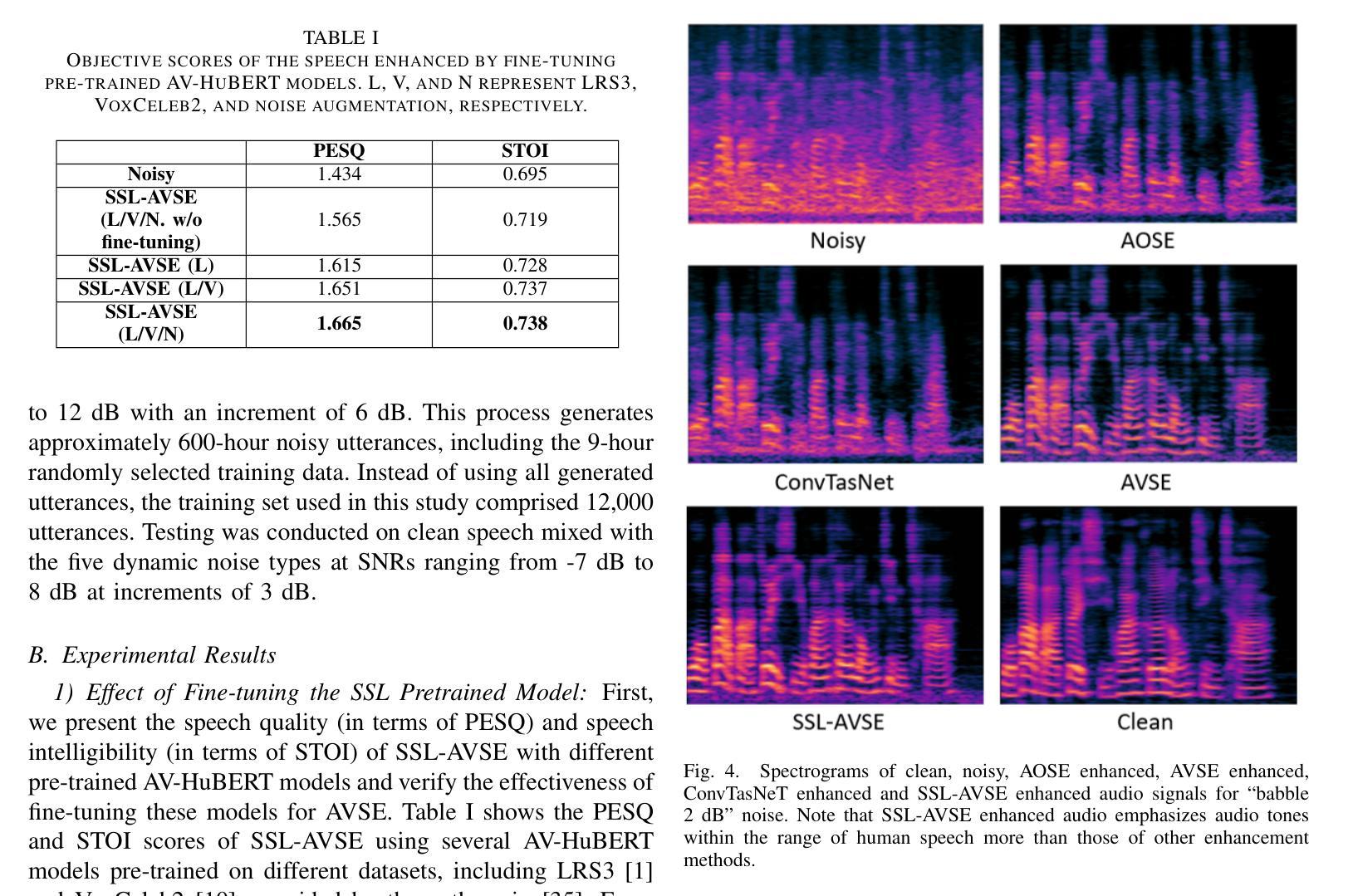
Individuals with hearing impairments face challenges in their ability to comprehend speech, particularly in noisy environments. The aim of this study is to explore the effectiveness of audio-visual speech enhancement (AVSE) in enhancing the intelligibility of vocoded speech in cochlear implant (CI) simulations. Notably, the study focuses on a challenged scenario where there is limited availability of training data for the AVSE task. To address this problem, we propose a novel deep neural network framework termed Self-Supervised Learning-based AVSE (SSL-AVSE). The proposed SSL-AVSE combines visual cues, such as lip and mouth movements, from the target speakers with corresponding audio signals. The contextually combined audio and visual data are then fed into a Transformer-based SSL AV-HuBERT model to extract features, which are further processed using a BLSTM-based SE model. The results demonstrate several key findings. Firstly, SSL-AVSE successfully overcomes the issue of limited data by leveraging the AV-HuBERT model. Secondly, by fine-tuning the AV-HuBERT model parameters for the target SE task, significant performance improvements are achieved. Specifically, there is a notable enhancement in PESQ (Perceptual Evaluation of Speech Quality) from 1.43 to 1.67 and in STOI (Short-Time Objective Intelligibility) from 0.70 to 0.74. Furthermore, the performance of the SSL-AVSE was evaluated using CI vocoded speech to assess the intelligibility for CI users. Comparative experimental outcomes reveal that in the presence of dynamic noises encountered during human conversations, SSL-AVSE exhibits a substantial improvement. The NCM (Normal Correlation Matrix) values indicate an increase of 26.5% to 87.2% compared to the noisy baseline.
听力受损的个体在理解言语方面存在挑战,特别是在嘈杂的环境中。本研究旨在探索视听语音增强(AVSE)在增强耳蜗植入物(CI)模拟中语音编码的清晰度方面的有效性。值得注意的是,该研究关注一个挑战性的场景,即AVSE任务的训练数据有限。针对这一问题,我们提出了一种基于自监督学习的新型深度神经网络框架,称为基于自监督学习的视听语音增强(SSL-AVSE)。所提出的SSL-AVSE结合了目标说话者的唇部和口腔运动等视觉线索和相应的音频信号。然后将上下文结合的音频和视觉数据输入基于Transformer的SSL AV-HuBERT模型进行特征提取,再通过基于BLSTM的SE模型进一步处理。结果表明有几个关键发现。首先,SSL-AVSE通过利用AV-HuBERT模型成功克服了数据有限的问题。其次,通过微调目标SE任务的AV-HuBERT模型参数,取得了显著的性能改进。具体来说,PESQ(语音质量感知评估)从1.43提高到1.67,STOI(短期客观清晰度)从0.70提高到0.74。此外,还使用CI语音编码的语音对SSL-AVSE的性能进行了评估,以评估CI用户的清晰度。比较实验结果表明,在存在人类对话期间遇到的动态噪声的情况下,SSL-AVSE表现出显著的改进。NCM(正常相关系数矩阵)值相对于噪声基线提高了26.5%至87.2%。
论文及项目相关链接
摘要
听障人士在嘈杂环境中理解言语存在困难。本研究旨在探讨视听言语增强(AVSE)在增强耳蜗植入物(CI)模拟中的语音清晰度方面的有效性。研究重点是在AVSE任务训练数据有限的情况下应对挑战。为此,我们提出了一种基于自监督学习的新型深度神经网络框架,称为SSL-AVSE。SSL-AVSE结合了目标说话者的嘴唇和嘴巴运动等视觉线索与相应的音频信号。然后将上下文结合的视听数据输入基于Transformer的SSL AV-HuBERT模型以提取特征,并使用基于BLSTM的SE模型进一步处理这些特征。研究结果表明几个关键发现:首先,SSL-AVSE通过利用AV-HuBERT模型成功克服了数据有限的问题;其次,通过对AV-HuBERT模型参数进行微调以针对目标SE任务,实现了显著的性能改进。具体来说,在感知语音质量(PESQ)和短期客观可懂度(STOI)方面都有明显提高。此外,使用CI编码语音对SSL-AVSE的性能进行了评估,以评估CI用户的可懂度。对比实验结果表明,在存在人类对话中的动态噪声的情况下,SSL-AVSE表现出显著的改进。正常相关系数(NCM)值相比噪声基线增加了26.5%至87.2%。
关键见解
- 本研究旨在探索视听言语增强(AVSE)在增强耳蜗植入物用户语音清晰度方面的有效性,特别是在训练数据有限的情况下。
- 提出了一种新型深度神经网络框架SSL-AVSE,结合视觉和音频数据以提高语音清晰度。
- SSL-AVSE成功克服了数据有限的问题,通过利用AV-HuBERT模型实现显著性能提升。
- 通过微调AV-HuBERT模型参数针对目标语音增强任务,进一步提高了性能。
- 在感知语音质量和短期客观可懂度方面有明显提高。
- SSL-AVSE在存在动态噪声的情况下表现出显著改进,这对于耳蜗植入物用户尤为重要。
点此查看论文截图