⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
MoonCast: High-Quality Zero-Shot Podcast Generation
Authors:Zeqian Ju, Dongchao Yang, Jianwei Yu, Kai Shen, Yichong Leng, Zhengtao Wang, Xu Tan, Xinyu Zhou, Tao Qin, Xiangyang Li
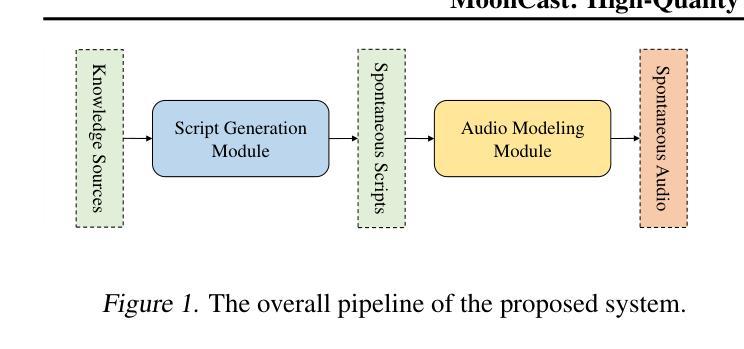
Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
最近文本到语音合成技术的进展在为个别发言者的高质量简短话语生成方面取得了显著的成功。然而,当这些系统试图将能力扩展到长对话、多发言人以及自发对话时,仍然面临挑战,这些挑战在现实世界场景中很常见,例如播客。这些限制源于两个主要挑战:1)长语音:播客通常持续数分钟,超过现有工作的大多数上限;2)自发性:播客以其自发、口语化的特点为标志,这与正式、书面语境形成鲜明对比;现有工作经常在捕捉这种自发性方面显得不足。在本文中,我们提出了MoonCast,这是一个用于高质量零样本播客生成解决方案,旨在仅使用文本源(例如故事、技术报告、TXT、PDF或Web URL格式的新闻)合成自然播客风格的语音,并使用未见过的说话人的声音。为了生成长音频,我们采用基于大规模长上下文语音数据的长上下文语言模型音频建模方法。为了提高自发性,我们使用播客生成模块来生成具有自发细节的脚本,经验表明这本身与文本到语音建模一样重要。实验表明,MoonCast优于基线,在自发性和连贯性方面尤其表现出显著的改进。
论文及项目相关链接
Summary
本文介绍了针对高质量零样本Podcast生成的新解决方案MoonCast。它旨在从文本源(如故事、技术报告、新闻等)合成自然风格的Podcast语音,使用未见过的说话人的声音。通过采用基于大规模长语境语音数据的音频建模方法,生成长音频;并利用Podcast生成模块生成具有自发性的脚本细节,增强了语音的即兴感。实验表明,MoonCast在自发性和连贯性方面优于基线。
Key Takeaways
- MoonCast实现了高质量零样本Podcast生成。
- 它可从文本源合成自然风格的Podcast语音,并使用未见过的说话人声音。
- 通过大规模长语境语音数据的音频建模方法,生成长音频。
- 利用Podcast生成模块增强语音的即兴感。
- MoonCast在自发性和连贯性方面表现优异。
- 现有系统在处理长、多说话人、即兴对话方面存在挑战。
点此查看论文截图