⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-21 更新
Unlocking the Capabilities of Vision-Language Models for Generalizable and Explainable Deepfake Detection
Authors:Peipeng Yu, Jianwei Fei, Hui Gao, Xuan Feng, Zhihua Xia, Chip Hong Chang
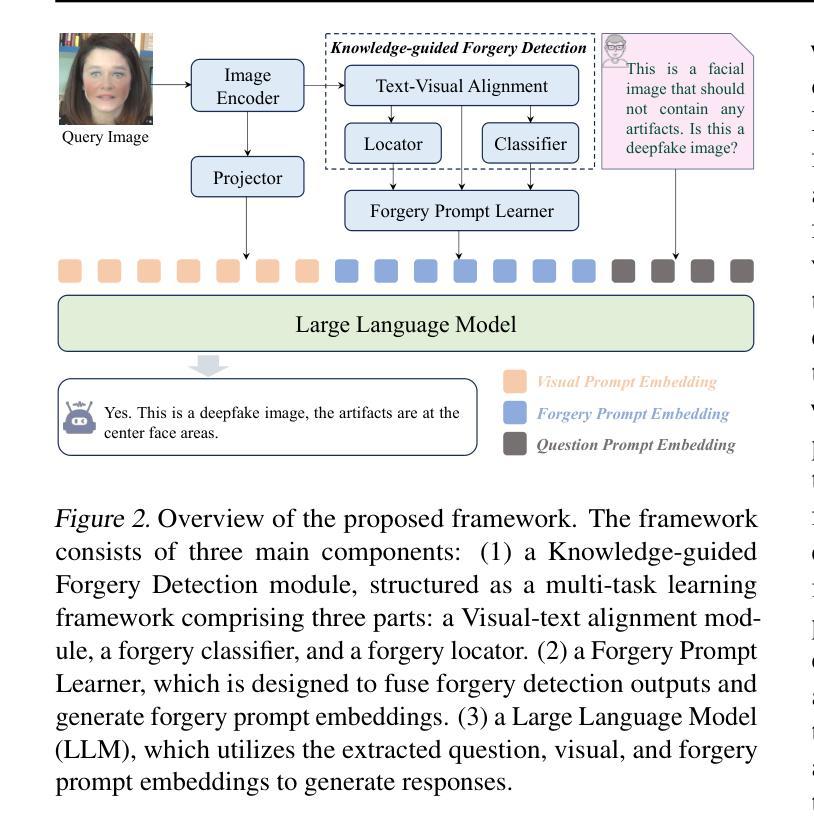
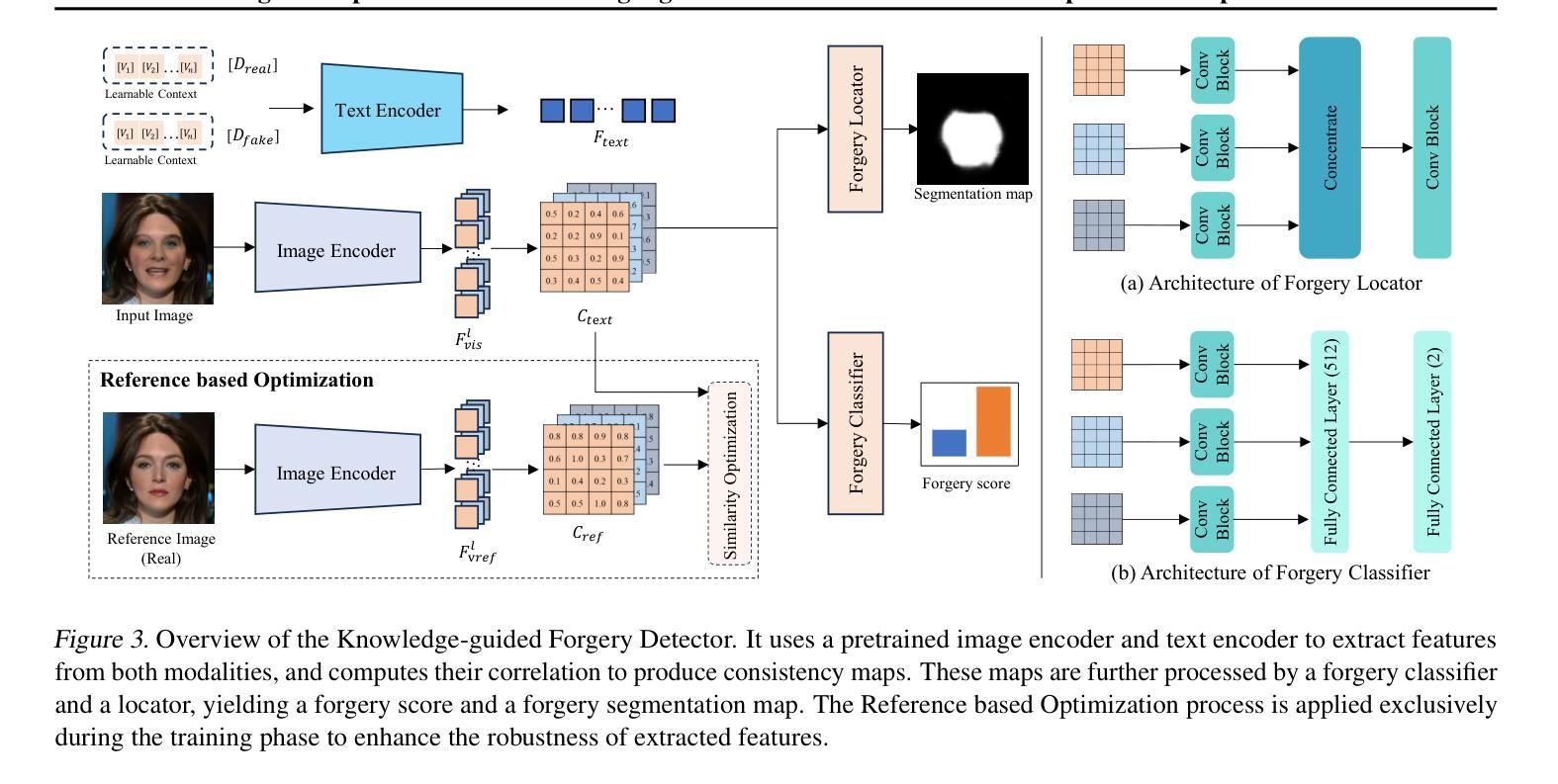
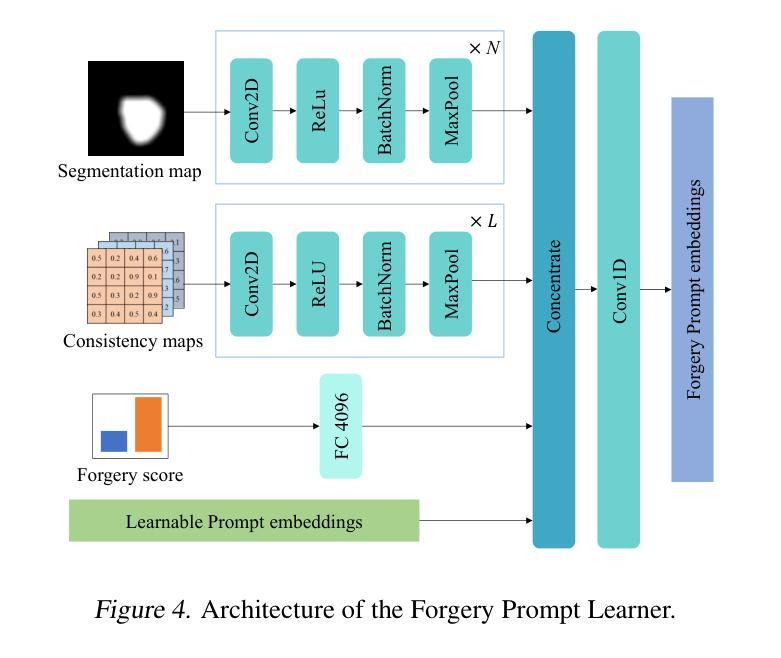
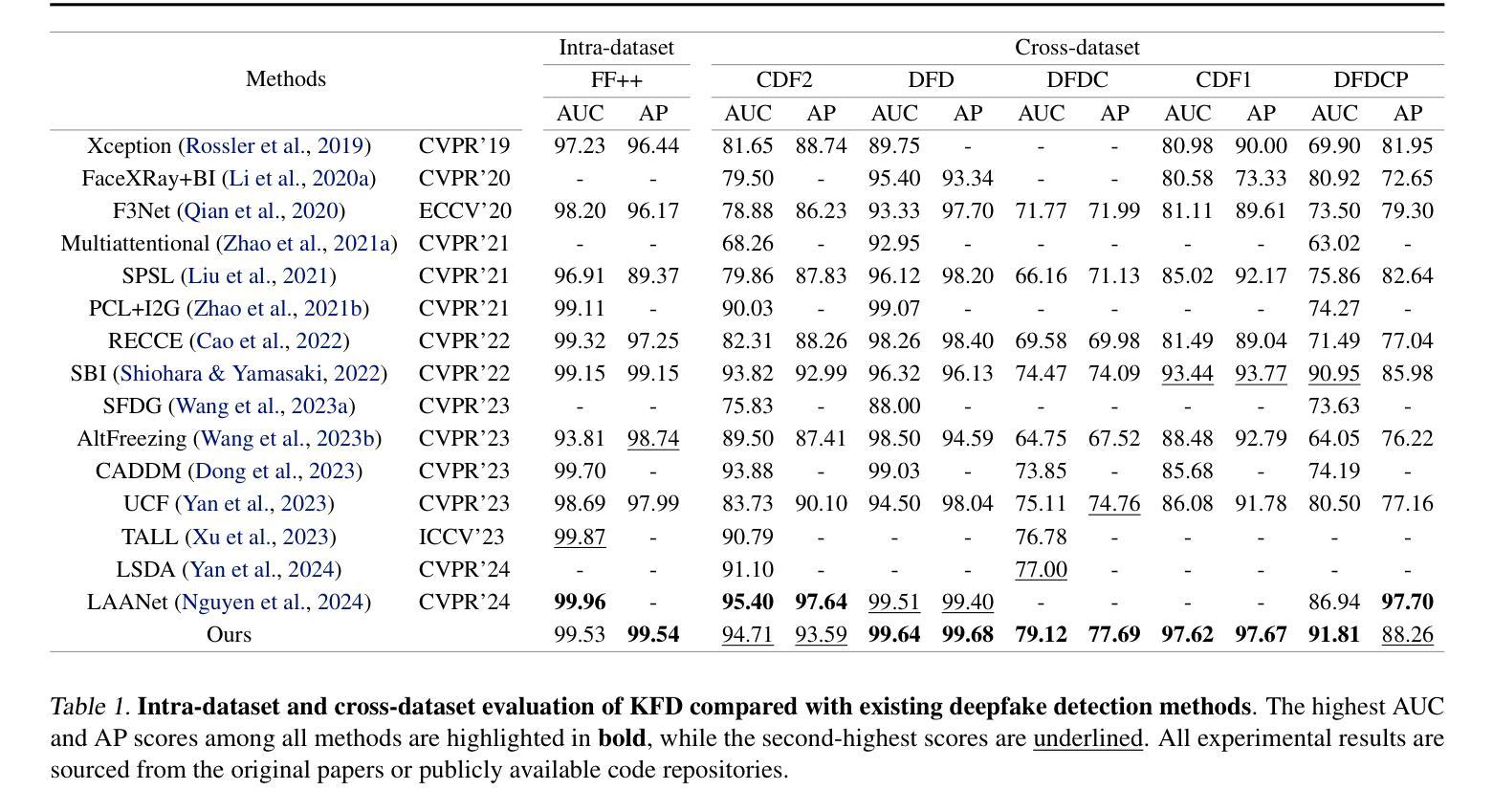
Current vision-language models (VLMs) have demonstrated remarkable capabilities in understanding multimodal data, but their potential remains underexplored for deepfake detection due to the misaligned of their knowledge and forensics patterns. To this end, we present a novel paradigm that unlocks VLMs’ potential capabilities through three components: (1) A knowledge-guided forgery adaptation module that aligns VLM’s semantic space with forensic features through contrastive learning with external manipulation knowledge; (2) A multi-modal prompt tuning framework that jointly optimizes visual-textual embeddings for both localization and explainability; (3) An iterative refinement strategy enabling multi-turn dialog for evidence-based reasoning. Our framework includes a VLM-based Knowledge-guided Forgery Detector (KFD), a VLM image encoder, and a Large Language Model (LLM). The VLM image encoder extracts visual prompt embeddings from images, while the LLM receives visual and question prompt embeddings for inference. The KFD is used to calculate correlations between image features and pristine/deepfake class embeddings, enabling forgery classification and localization. The outputs from these components are used to construct forgery prompt embeddings. Finally, we feed these prompt embeddings into the LLM to generate textual detection responses to assist judgment. Extensive experiments on multiple benchmarks, including FF++, CDF2, DFD, DFDCP, and DFDC, demonstrate that our scheme surpasses state-of-the-art methods in generalization performance, while also supporting multi-turn dialogue capabilities.
当前的语言视觉模型(VLMs)在理解多媒体数据方面表现出了显著的能力,但由于其知识与取证模式的错位,它们在虚假深度检测方面的潜力尚未得到充分开发。为此,我们提出了一种新型模型框架,它通过三个核心部分释放了VLMs的潜力:首先是一个知识引导伪造适应模块,它通过对比学习与外部操纵知识对齐VLM的语义空间与取证特征;其次是一个多模态提示调整框架,它联合优化视觉文本嵌入以实现定位和可解释性;最后是一种迭代细化策略,支持基于证据的推理的多轮对话。我们的框架包括基于VLM的知识引导伪造检测器(KFD)、一个VLM图像编码器和一个大型语言模型(LLM)。VLM图像编码器从图像中提取视觉提示嵌入,而LLM接收视觉和问答提示嵌入进行推理。KFD用于计算图像特征与原始/深度伪造类别嵌入之间的相关性,从而实现伪造分类和定位。这些组件的输出用于构建伪造提示嵌入。最后,我们将这些提示嵌入输入LLM中,生成文本检测响应以帮助判断。在多个基准测试上的广泛实验,包括FF++、CDF2、DFD、DFDCP和DFDC等,证明我们的方案在泛化性能上超越了最先进的方法,同时支持多轮对话功能。
论文及项目相关链接
Summary
本文提出了一种利用视觉语言模型(VLMs)潜力进行深度伪造检测的新范式。通过知识引导伪造适应模块、多模态提示调整框架和迭代优化策略,实现了对VLM语义空间与法医特征的对齐、视觉与文本嵌入的联合优化、以及基于证据的多轮对话推理。实验证明,该方法在多个基准测试上的泛化性能优于现有方法,并支持多轮对话功能。
Key Takeaways
- 本文提出了一种新范式,解锁了视觉语言模型(VLMs)在深度伪造检测中的潜力。
- 通过知识引导伪造适应模块,实现了VLM语义空间与法医特征的对齐。
- 多模态提示调整框架联合优化了视觉和文本嵌入,提高了定位和解释性。
- 迭代优化策略支持多轮对话,实现基于证据推理的深度伪造检测。
- 引入VLM图像编码器和大型语言模型(LLM),分别提取图像提示嵌入和进行推理。
- KFD用于计算图像特征与原始/深度伪造类嵌入之间的相关性,实现伪造分类和定位。
点此查看论文截图

Dynamic Accumulated Attention Map for Interpreting Evolution of Decision-Making in Vision Transformer
Authors:Yi Liao, Yongsheng Gao, Weichuan Zhang
Various Vision Transformer (ViT) models have been widely used for image recognition tasks. However, existing visual explanation methods can not display the attention flow hidden inside the inner structure of ViT models, which explains how the final attention regions are formed inside a ViT for its decision-making. In this paper, a novel visual explanation approach, Dynamic Accumulated Attention Map (DAAM), is proposed to provide a tool that can visualize, for the first time, the attention flow from the top to the bottom through ViT networks. To this end, a novel decomposition module is proposed to construct and store the spatial feature information by unlocking the [class] token generated by the self-attention module of each ViT block. The module can also obtain the channel importance coefficients by decomposing the classification score for supervised ViT models. Because of the lack of classification score in self-supervised ViT models, we propose dimension-wise importance weights to compute the channel importance coefficients. Such spatial features are linearly combined with the corresponding channel importance coefficients, forming the attention map for each block. The dynamic attention flow is revealed by block-wisely accumulating each attention map. The contribution of this work focuses on visualizing the evolution dynamic of the decision-making attention for any intermediate block inside a ViT model by proposing a novel decomposition module and dimension-wise importance weights. The quantitative and qualitative analysis consistently validate the effectiveness and superior capacity of the proposed DAAM for not only interpreting ViT models with the fully-connected layers as the classifier but also self-supervised ViT models. The code is available at https://github.com/ly9802/DynamicAccumulatedAttentionMap.
各种Vision Transformer(ViT)模型已被广泛应用于图像识别任务。然而,现有的视觉解释方法无法显示ViT模型内部结构中所隐藏的关注流,这解释了ViT如何形成其决策过程中的最终关注区域。本文提出了一种新的视觉解释方法,即动态累积关注图(DAAM),提供了一种工具,能够首次可视化通过ViT网络的从上到下的关注流。为此,提出了一种新的分解模块,通过解锁每个ViT块自注意力模块生成的[类别]令牌来构建和存储空间特征信息。该模块还可以通过分解监督ViT模型的分类分数来获得通道重要性系数。由于自监督ViT模型中缺少分类分数,我们提出按维度的重要性权重来计算通道重要性系数。这样的空间特征会与相应的通道重要性系数进行线性组合,形成每个块的关注图。通过逐块累积每个关注图,揭示了动态的关注流。本工作的贡献在于,通过提出一种新的分解模块和按维度的重要性权重,可视化ViT模型中任何中间块决策关注的动态演变。定量和定性分析一致验证了所提出的DAAM在解释具有全连接层作为分类器的ViT模型以及自监督ViT模型方面的有效性和卓越能力。代码可在https://github.com/ly9802/DynamicAccumulatedAttentionMap中找到。
论文及项目相关链接
Summary
本文提出了一种名为动态累积注意力图(DAAM)的新型视觉解释方法,用于可视化Vision Transformer(ViT)模型内部的注意力流。通过提出一种分解模块,解锁各ViT块自注意力模块产生的类标记生成的空间特征信息,并计算通道重要性系数,进而形成各块的注意力图。动态注意力流是通过逐块累积每个注意力图来揭示的。该研究重点关注通过提出分解模块和维度重要性权重来可视化ViT模型内部决策注意力的演化动态。定量和定性分析验证了DAAM在解释全连接层作为分类器的ViT模型以及自监督ViT模型的有效性和优越性。
Key Takeaways
- 现有视觉解释方法无法展示Vision Transformer(ViT)模型内部的注意力流。
- 提出了一种新型视觉解释方法——动态累积注意力图(DAAM),能首次可视化ViT模型从高层到低层的注意力流。
- 通过分解模块构造并存储空间特征信息,该模块能解锁每个ViT块自注意力模块产生的类标记。
- 对于监督式ViT模型,通过分解模块获得通道重要性系数;对于自监督ViT模型,提出维度重要性权重来计算通道重要性系数。
- 空间特征与通道重要性系数结合,形成各块的注意力图;通过逐块累积每个注意力图,揭示动态注意力流。
- 该方法不仅适用于解释带有全连接层的ViT模型,也适用于自监督ViT模型。
- 提供了相关代码实现,可访问https://github.com/ly9802/DynamicAccumulatedAttentionMap。
点此查看论文截图