⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
Attentional Triple-Encoder Network in Spatiospectral Domains for Medical Image Segmentation
Authors:Kristin Qi, Xinhan Di
Retinal Optical Coherence Tomography (OCT) segmentation is essential for diagnosing pathology. Traditional methods focus on either spatial or spectral domains, overlooking their combined dependencies. We propose a triple-encoder network that integrates CNNs for spatial features, Fast Fourier Convolution (FFC) for spectral features, and attention mechanisms to capture global relationships across both domains. Attention fusion modules integrate convolution and cross-attention to further enhance features. Our method achieves an average Dice score improvement from 0.855 to 0.864, outperforming prior work.
视网膜光学相干断层扫描(OCT)分割对于病理诊断至关重要。传统方法侧重于空间域或光谱域,忽略了它们的组合依赖性。我们提出了一种三重编码器网络,该网络结合了用于空间特征的卷积神经网络(CNN)、用于光谱特征的快傅里叶卷积(FFC)以及捕捉两个领域全局关系的注意力机制。注意力融合模块结合了卷积和交叉注意力,以进一步增强特征。我们的方法实现了平均Dice得分从0.855提高到0.864,优于先前的工作。
论文及项目相关链接
PDF IEEE Conference on Artificial Intelligence (IEEE CAI)
Summary
本文提出一种基于视网膜光学相干层析成像(OCT)分割的病理诊断新方法。该方法采用三重编码器网络,结合卷积神经网络(CNN)提取空间特征、快速傅里叶卷积(FFC)提取光谱特征,以及注意力机制捕捉两个领域的全局关系。通过卷积和交叉注意力的融合模块进一步增强了特征。该方法平均Dice得分从0.855提高到0.864,优于先前的工作。
Key Takeaways
- 视网膜光学相干层析成像(OCT)分割对病理诊断至关重要。
- 传统方法主要关注空间或光谱领域,忽略了二者的综合依赖性。
- 提出一种三重编码器网络,结合CNN、FFC和注意力机制,同时捕捉空间和光谱特征以及两者之间的全局关系。
- 通过注意力融合模块,将卷积和交叉注意力结合,增强特征提取能力。
- 该方法实现了平均Dice得分的提高,从0.855提高到0.864。
- 所提方法优于先前的工作。
点此查看论文截图

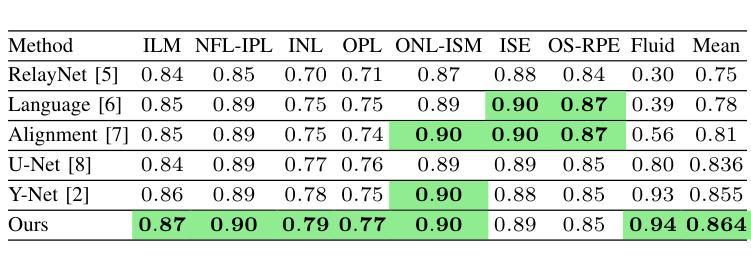
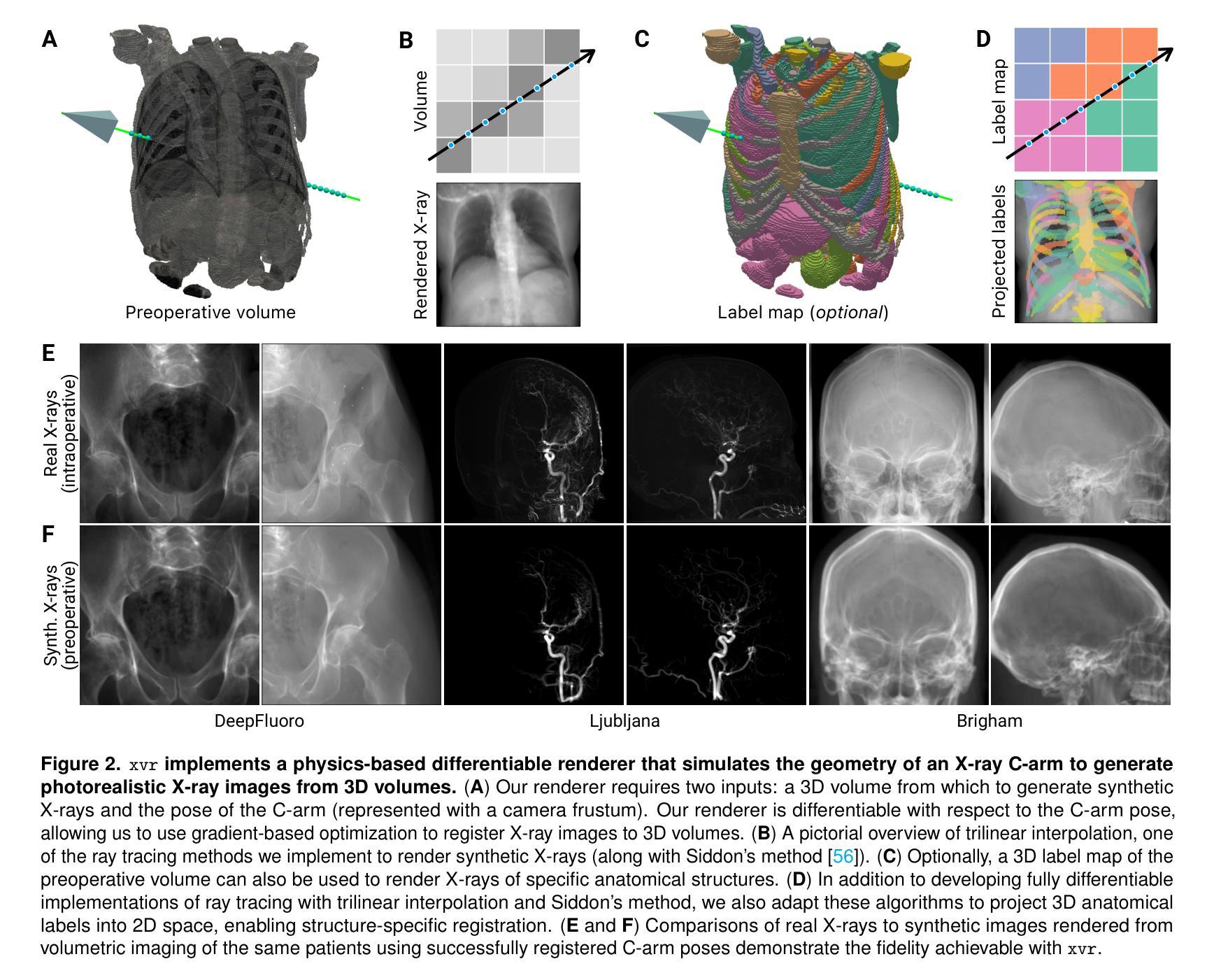
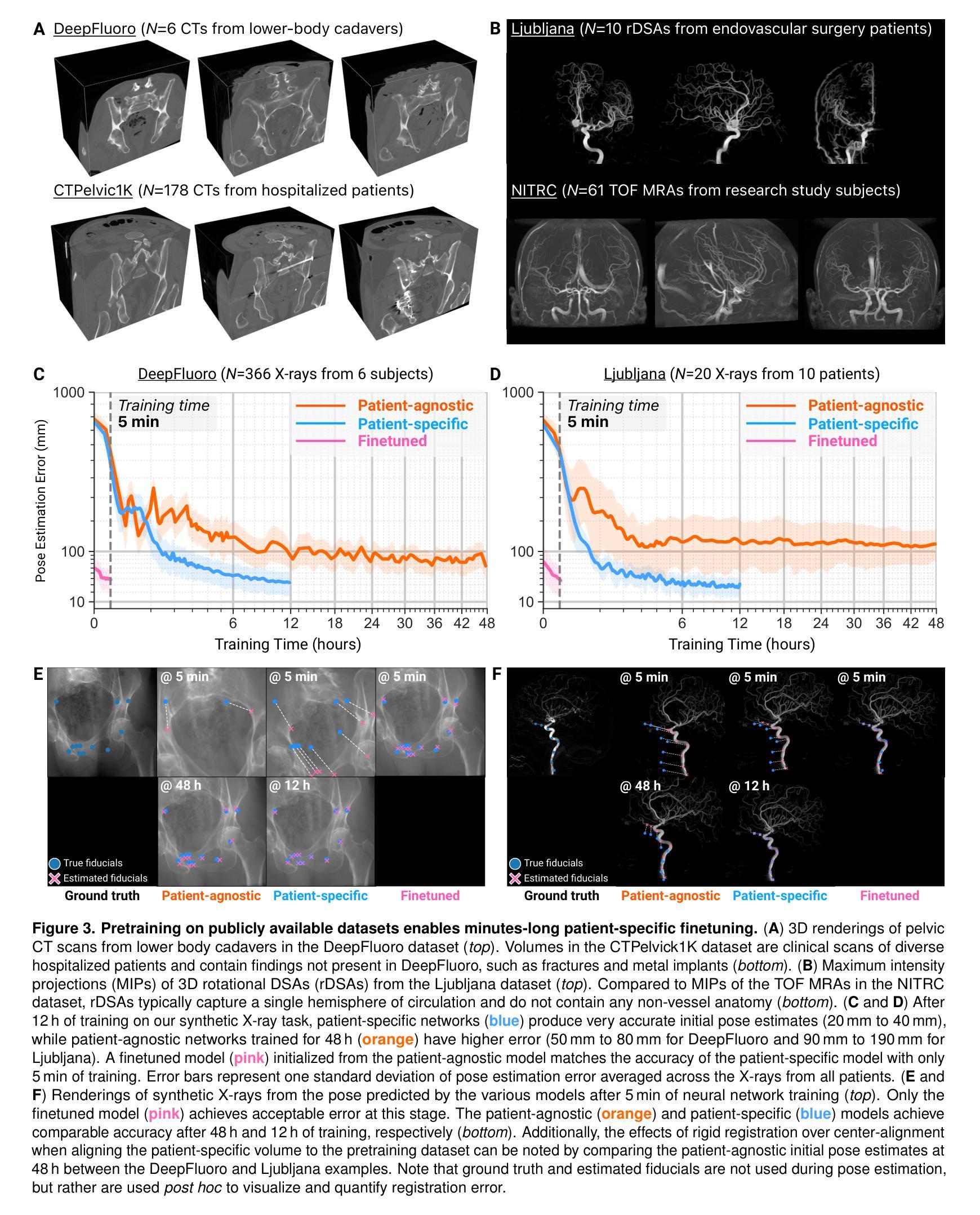
Rapid patient-specific neural networks for intraoperative X-ray to volume registration
Authors:Vivek Gopalakrishnan, Neel Dey, David-Dimitris Chlorogiannis, Andrew Abumoussa, Anna M. Larson, Darren B. Orbach, Sarah Frisken, Polina Golland
The integration of artificial intelligence in image-guided interventions holds transformative potential, promising to extract 3D geometric and quantitative information from conventional 2D imaging modalities during complex procedures. Achieving this requires the rapid and precise alignment of 2D intraoperative images (e.g., X-ray) with 3D preoperative volumes (e.g., CT, MRI). However, current 2D/3D registration methods fail across the broad spectrum of procedures dependent on X-ray guidance: traditional optimization techniques require custom parameter tuning for each subject, whereas neural networks trained on small datasets do not generalize to new patients or require labor-intensive manual annotations, increasing clinical burden and precluding application to new anatomical targets. To address these challenges, we present xvr, a fully automated framework for training patient-specific neural networks for 2D/3D registration. xvr uses physics-based simulation to generate abundant high-quality training data from a patient’s own preoperative volumetric imaging, thereby overcoming the inherently limited ability of supervised models to generalize to new patients and procedures. Furthermore, xvr requires only 5 minutes of training per patient, making it suitable for emergency interventions as well as planned procedures. We perform the largest evaluation of a 2D/3D registration algorithm on real X-ray data to date and find that xvr robustly generalizes across a diverse dataset comprising multiple anatomical structures, imaging modalities, and hospitals. Across surgical tasks, xvr achieves submillimeter-accurate registration at intraoperative speeds, improving upon existing methods by an order of magnitude. xvr is released as open-source software freely available at https://github.com/eigenvivek/xvr.
人工智能在图像引导干预中的融合具有变革性潜力,有望在进行复杂手术时从传统的二维成像模式中提取三维几何和定量信息。实现这一点需要快速精确地匹配二维术中图像(如X射线)与三维术前体积(如CT、MRI)。然而,当前二维和三维的注册方法在全流程中并不能广泛应用:传统优化技术需要根据每个患者手动调整参数,而训练在小规模数据集上的神经网络并不能适应新患者,或需要密集的劳力进行手动注释,从而增加了临床负担并限制了其在新解剖目标中的应用。为了解决这些挑战,我们推出了xvr框架,它是一个用于二维和三维注册的针对患者的神经网络的全自动训练框架。xvr使用基于物理的模拟从患者自身的术前体积成像生成大量高质量的训练数据,从而克服了监督模型对适应新患者和程序的新问题的固有局限性。此外,xvr对每位患者的训练时间仅需五分钟,使其既适用于紧急干预也适用于计划中的程序。我们对迄今为止最大的真实X射线数据的二维和三维注册算法进行了评估,发现xvr在包含多个解剖结构、成像模式和医院的多样化数据集上具有良好的通用性。在各种手术任务中,xvr实现了亚毫米级的精确注册速度在术中大幅提高,明显优于现有方法。xv被发布为开源软件可在https://github.com/eigenvivek/xvr免费获取。
论文及项目相关链接
Summary
人工智能在图像引导干预中的整合具有变革潜力,有望从传统的二维成像模式中提取三维几何和定量信息,在复杂过程中辅助进行精确操作。实现这一目标需要快速精确地将二维术中图像(如X射线)与三维术前体积(如CT、MRI)进行对齐。当前二维/三维注册方法在使用X射线引导的多种手术中效果不理想。为应对这些挑战,本文提出了一种全自动框架xvr,用于训练患者特异性神经网络进行二维/三维注册。xvr利用基于物理的模拟生成大量的高质量训练数据,从患者自身的术前体积成像开始,克服监督模型对新患者和手术普遍性的内在限制。此外,xvr对患者训练的时长仅需五分钟,既适用于紧急干预也适用于计划程序。本文执行迄今为止最大的二维/三维注册算法在真实X射线数据上的评估,发现xvr能够跨越包含多个解剖结构、成像模式及医院的多样化数据集进行稳健的普遍性应用。在各种手术中,xvr实现了亚毫米级的精确注册,其速度符合术中要求,相较于现有方法有了显著提高。此外,已将xvr作为开源软件发布在相关网站供大家免费使用。
Key Takeaways
- 人工智能在图像引导手术中的潜力:能够从传统的二维成像模式中提取三维几何和定量信息。
- 当前二维/三维注册方法面临的挑战:传统优化技术需要为每个患者定制参数调整,而基于小数据集训练的神经网络无法很好地应用于新患者。
- xvr框架介绍:利用基于物理的模拟生成高质量训练数据,实现患者特异性神经网络的快速训练(仅五分钟)。
- xvr框架的优势:能够适用于紧急干预和计划手术,并且能处理多种解剖结构、成像模式和医院的多样化数据。
- xvr的注册精度高:实现亚毫米级的精确注册。
- xvr具有广泛的适用性:在各种手术中都能实现快速精确的注册,显著优于现有方法。
点此查看论文截图

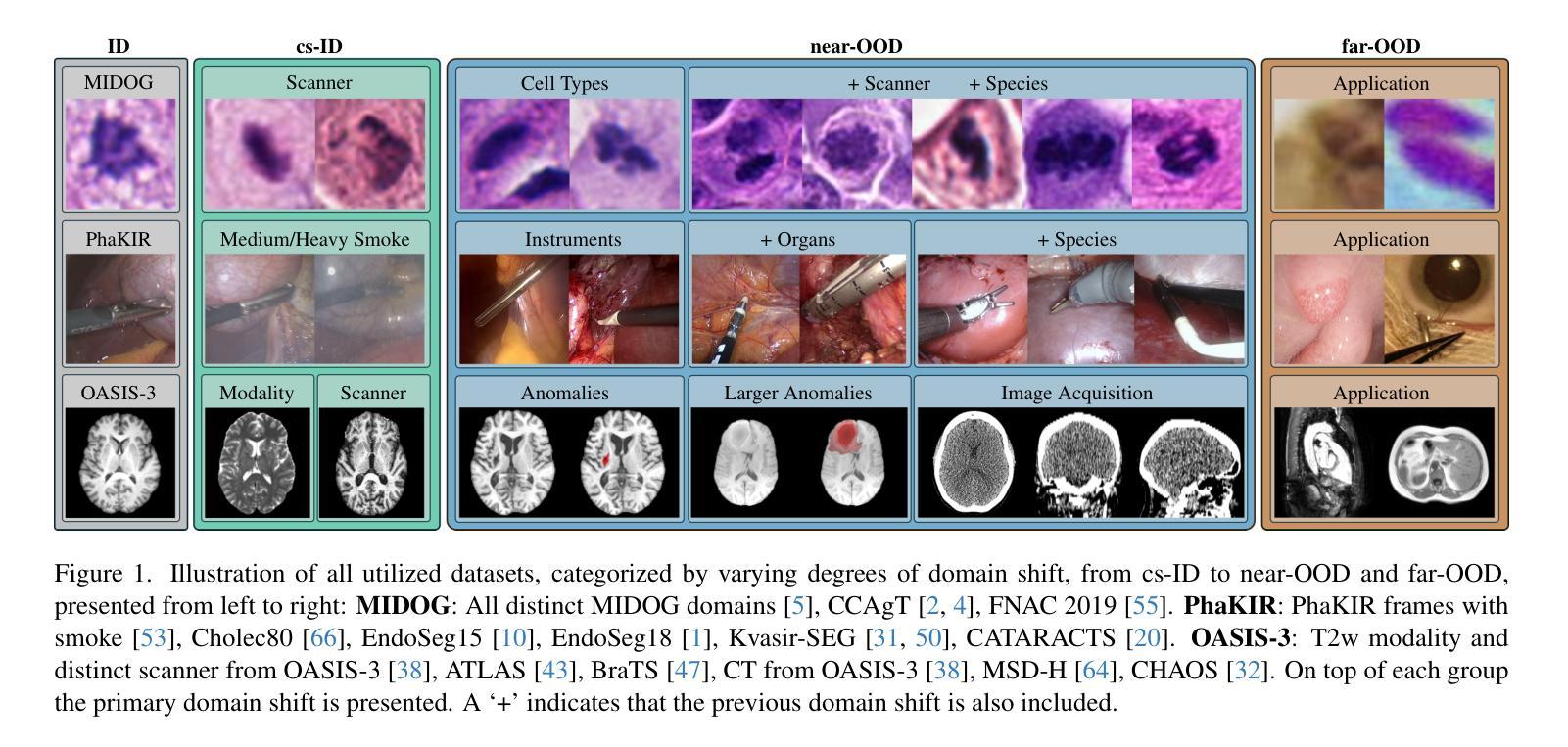
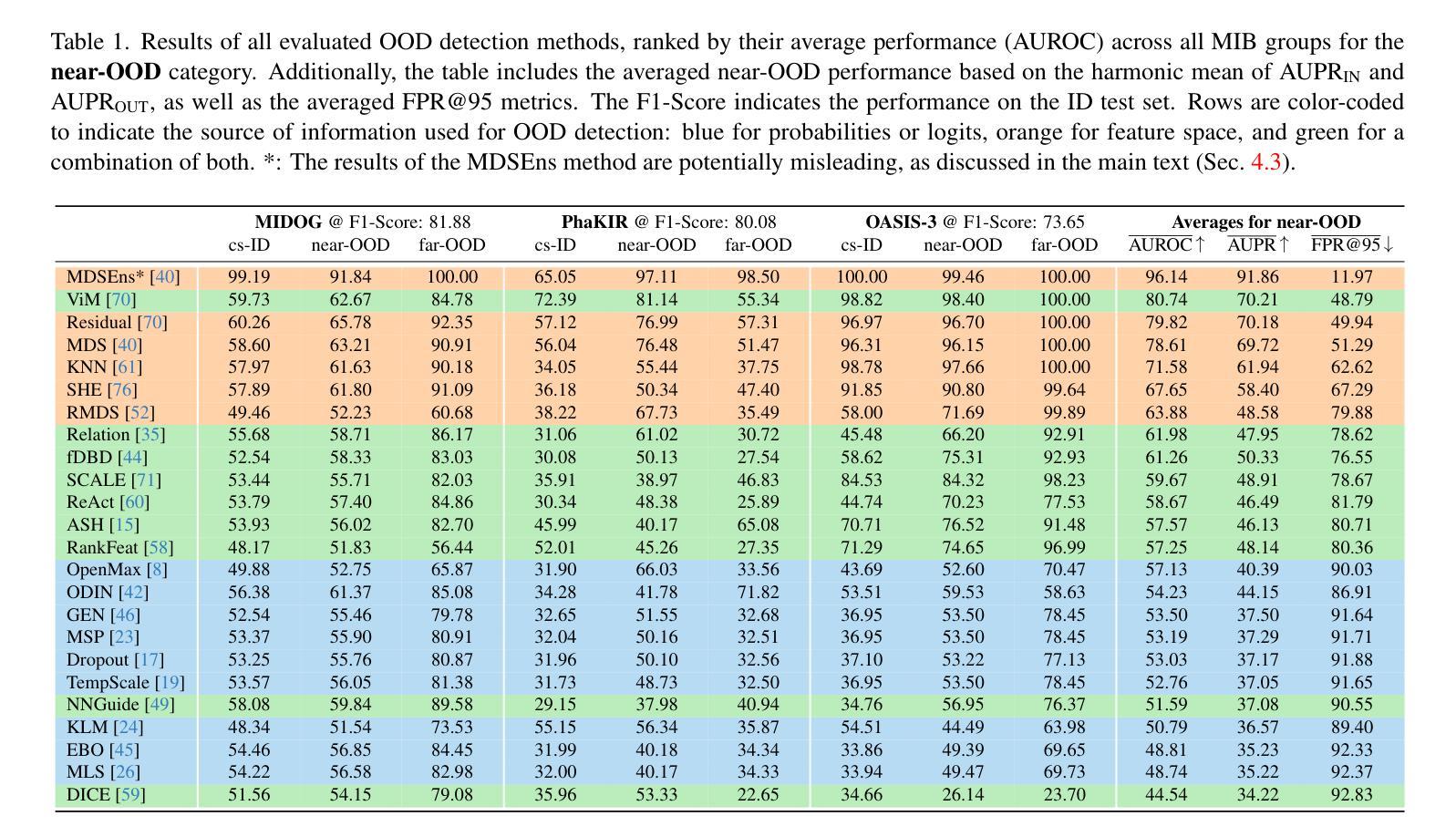
OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection
Authors:Max Gutbrod, David Rauber, Danilo Weber Nunes, Christoph Palm
The growing reliance on Artificial Intelligence (AI) in critical domains such as healthcare demands robust mechanisms to ensure the trustworthiness of these systems, especially when faced with unexpected or anomalous inputs. This paper introduces the Open Medical Imaging Benchmarks for Out-Of-Distribution Detection (OpenMIBOOD), a comprehensive framework for evaluating out-of-distribution (OOD) detection methods specifically in medical imaging contexts. OpenMIBOOD includes three benchmarks from diverse medical domains, encompassing 14 datasets divided into covariate-shifted in-distribution, near-OOD, and far-OOD categories. We evaluate 24 post-hoc methods across these benchmarks, providing a standardized reference to advance the development and fair comparison of OOD detection methods. Results reveal that findings from broad-scale OOD benchmarks in natural image domains do not translate to medical applications, underscoring the critical need for such benchmarks in the medical field. By mitigating the risk of exposing AI models to inputs outside their training distribution, OpenMIBOOD aims to support the advancement of reliable and trustworthy AI systems in healthcare. The repository is available at https://github.com/remic-othr/OpenMIBOOD.
随着人工智能(AI)在医疗等关键领域的依赖程度不断增长,特别是在面对意外或异常输入时,需要建立稳健的机制来确保这些系统的可信度。本文介绍了开放医学成像基准测试(OpenMIBOOD),这是一个专门用于评估医学成像上下文中分布外检测(Out-Of-Distribution Detection,简称OOD)方法的综合框架。OpenMIBOOD包含来自不同医学领域的三个基准测试,涵盖14个数据集,分为协变量偏移内分布、接近OOD和远离OOD三类。我们在这三个基准测试中评估了2de9后处理验证方法,提供了标准化参考,以促进OOD检测方法的开发和公平比较。结果表明,自然图像领域的大规模OOD基准测试结果并不能应用于医学应用,这强调了医学领域对这种基准测试的关键需求。通过降低AI模型暴露于训练分布之外输入的风险,OpenMIBOOD旨在支持医疗保健中可靠和可信的AI系统的发展。该存储库可通过以下网址访问:https://github.com/remic-othr/OpenMIBOOD。
论文及项目相关链接
Summary
开放医学成像基准测试(OpenMIBOOD)为评估医疗成像中异常分布检测方法提供了全面框架。它包含三个基准测试,涵盖十四组数据集,并提供了一个标准化的参考资源,有助于推动稳健和可信赖的人工智能系统在医疗保健领域的发展。这项研究强调了为医疗行业开发专门基准测试的必要性。
Key Takeaways
- OpenMIBOOD是一个专门用于评估医疗成像中异常分布检测方法的框架。
- 它包含三个基准测试,涵盖多种医学领域的数据集。
- OpenMIBOOD提供了标准化的参考资源,便于对异常检测方法进行评估和比较。
- 研究发现,自然图像领域的广泛异常分布基准测试并不适用于医疗应用。
- OpenMIBOOD旨在降低人工智能模型面临非训练分布输入的风险,推动医疗保健领域可靠和可信的人工智能系统的发展。
- 该框架的推出强调了针对医疗行业开发专门的基准测试的重要性。
点此查看论文截图

Iterative Optimal Attention and Local Model for Single Image Rain Streak Removal
Authors:Xiangyu Li, Wanshu Fan, Yue Shen, Cong Wang, Wei Wang, Xin Yang, Qiang Zhang, Dongsheng Zhou
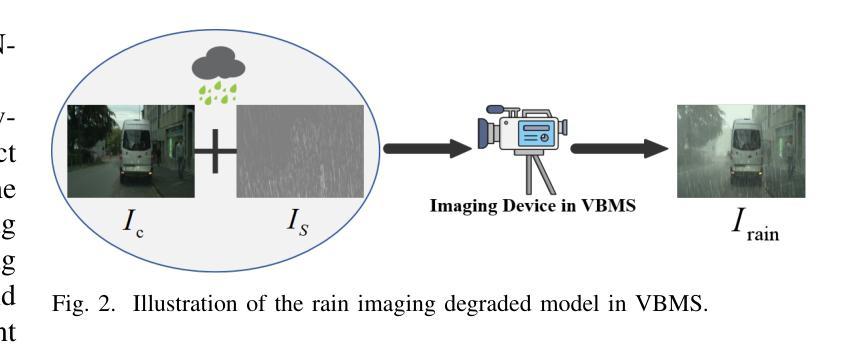
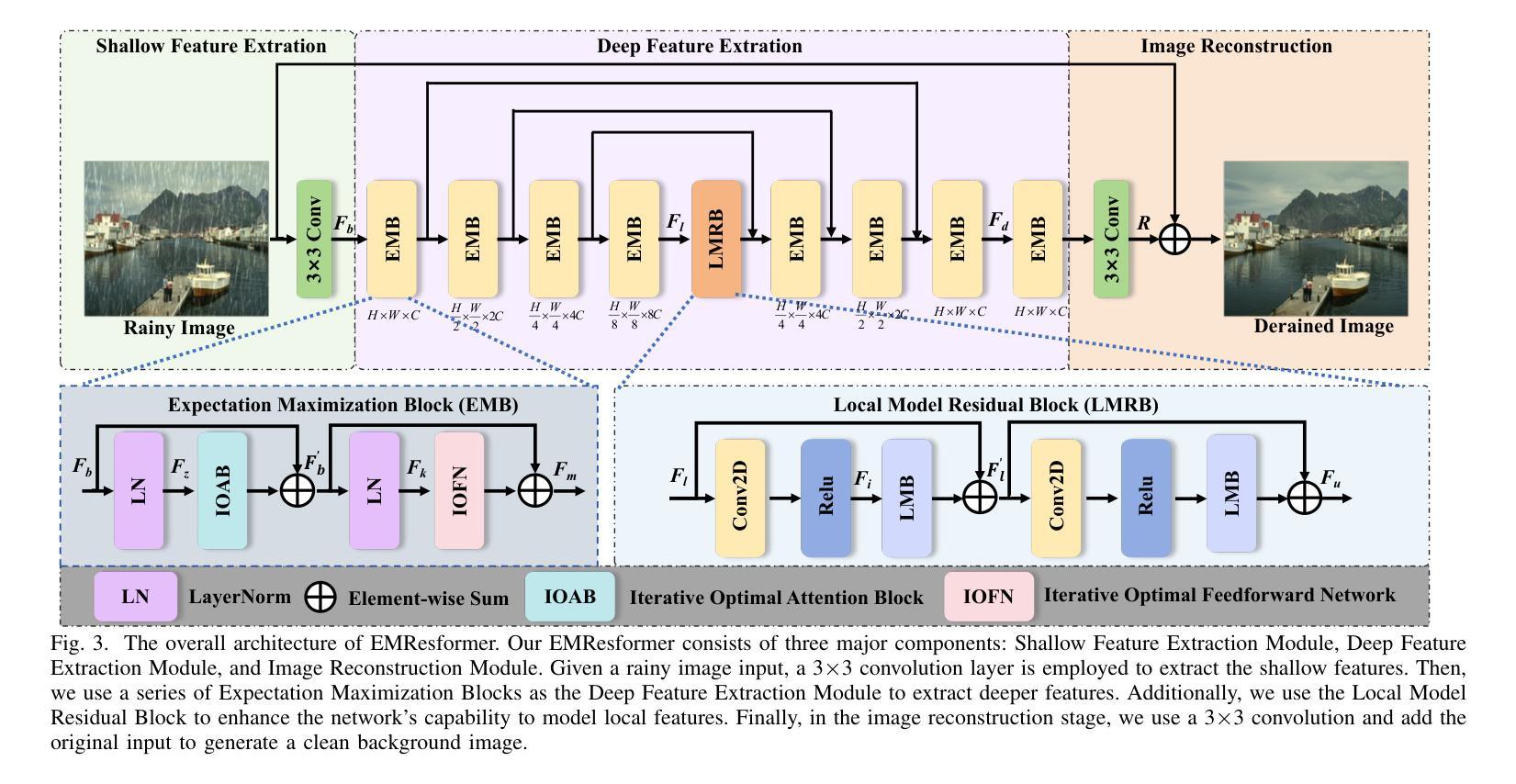
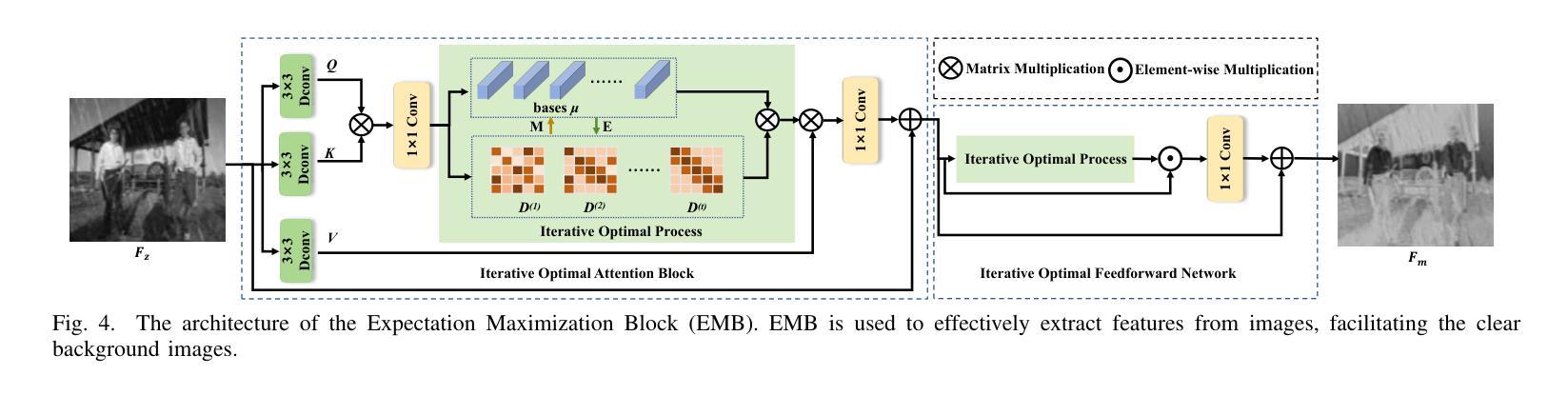
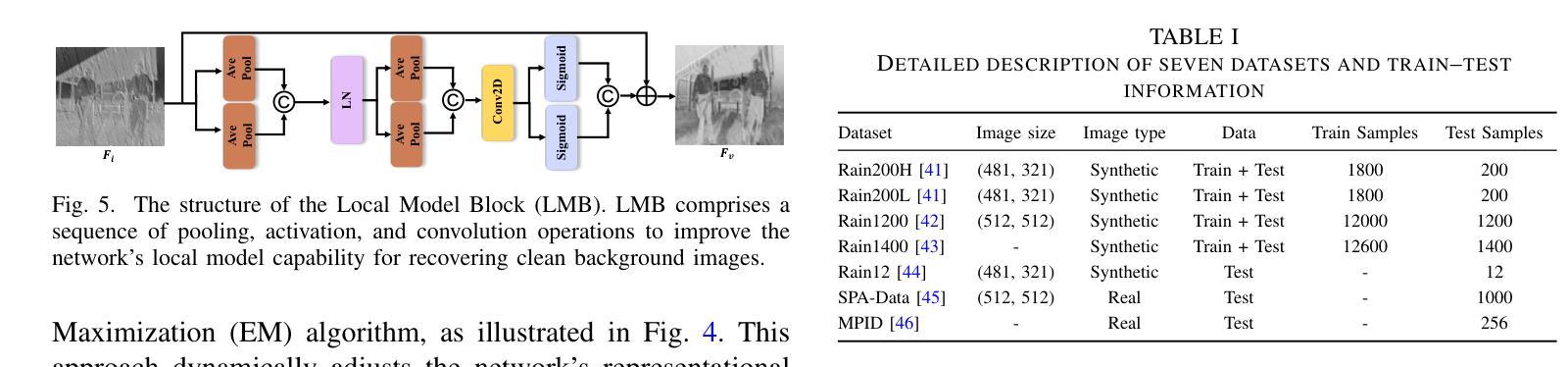
High-fidelity imaging is crucial for the successful safety supervision and intelligent deployment of vision-based measurement systems (VBMS). It ensures high-quality imaging in VBMS, which is fundamental for reliable visual measurement and analysis. However, imaging quality can be significantly impaired by adverse weather conditions, particularly rain, leading to blurred images and reduced contrast. Such impairments increase the risk of inaccurate evaluations and misinterpretations in VBMS. To address these limitations, we propose an Expectation Maximization Reconstruction Transformer (EMResformer) for single image rain streak removal. The EMResformer retains the key self-attention values for feature aggregation, enhancing local features to produce superior image reconstruction. Specifically, we propose an Expectation Maximization Block seamlessly integrated into the single image rain streak removal network, enhancing its ability to eliminate superfluous information and restore a cleaner background image. Additionally, to further enhance local information for improved detail rendition, we introduce a Local Model Residual Block, which integrates two local model blocks along with a sequence of convolutions and activation functions. This integration synergistically facilitates the extraction of more pertinent features for enhanced single image rain streak removal. Extensive experiments validate that our proposed EMResformer surpasses current state-of-the-art single image rain streak removal methods on both synthetic and real-world datasets, achieving an improved balance between model complexity and single image deraining performance. Furthermore, we evaluate the effectiveness of our method in VBMS scenarios, demonstrating that high-quality imaging significantly improves the accuracy and reliability of VBMS tasks.
高保真成像对于基于视觉的测量系统(VBMS)的安全监督与智能部署至关重要。它确保了VBMS中的高质量成像,这是可靠视觉测量与分析的基础。然而,恶劣的天气条件,特别是雨天,会严重损害成像质量,导致图像模糊和对比度降低。这些缺陷增加了VBMS中评估和误解的风险。为了解决这些局限性,我们提出了一种期望最大化重建转换器(EMResformer),用于单图像雨纹去除。EMResformer保留了关键的自注意力值进行特征聚合,增强局部特征以产生优质的图像重建。具体来说,我们提出了一种无缝集成到单图像雨纹去除网络中的期望最大化块,提高其消除多余信息并恢复更干净背景图像的能力。此外,为了进一步增强局部信息以提高细节呈现,我们引入了局部模型残差块,该块将两个局部模型块与一系列卷积和激活函数相结合。这种集成协同促进了更多相关特征的提取,以提高单图像雨纹去除效果。大量实验验证,我们提出的EMResformer在合成和真实世界数据集上的单图像雨纹去除方法均超越了当前最先进的水平,在模型复杂性与单图像去雨性能之间实现了更好的平衡。此外,我们在VBMS场景中评估了我们的方法的有效性,表明高质量成像可以显著提高VBMS任务的准确性和可靠性。
论文及项目相关链接
PDF 14 pages, 14 figures, 6 tables
Summary
本文强调了高保真成像在基于视觉的测量系统(VBMS)中的重要作用,并提出一种期望最大化重建变压器(EMResformer)来解决恶劣天气条件对成像质量的干扰问题,特别是针对单图像雨痕去除。通过引入期望最大化块和局部模型残差块,EMResformer能够更有效地去除多余信息并恢复清晰的背景图像,从而提高图像质量。实验证明,在合成和真实数据集上,EMResformer的单图像雨痕去除效果优于当前最先进的单图像雨痕去除方法。在VBMS场景中,验证了高质量成像能显著提高VBMS任务的准确性和可靠性。
Key Takeaways
- 高保真成像对基于视觉的测量系统(VBMS)的安全监控和智能部署至关重要。
- 恶劣天气条件,尤其是雨天,会显著影响成像质量,增加VBMS评估失误的风险。
- 提出了期望最大化重建变压器(EMResformer)来解决单图像雨痕去除问题。
- EMResformer通过引入期望最大化块和局部模型残差块,提高了图像重建的质量和效果。
- 实验证明,EMResformer在合成和真实数据集上的单图像雨痕去除效果优于现有方法。
点此查看论文截图

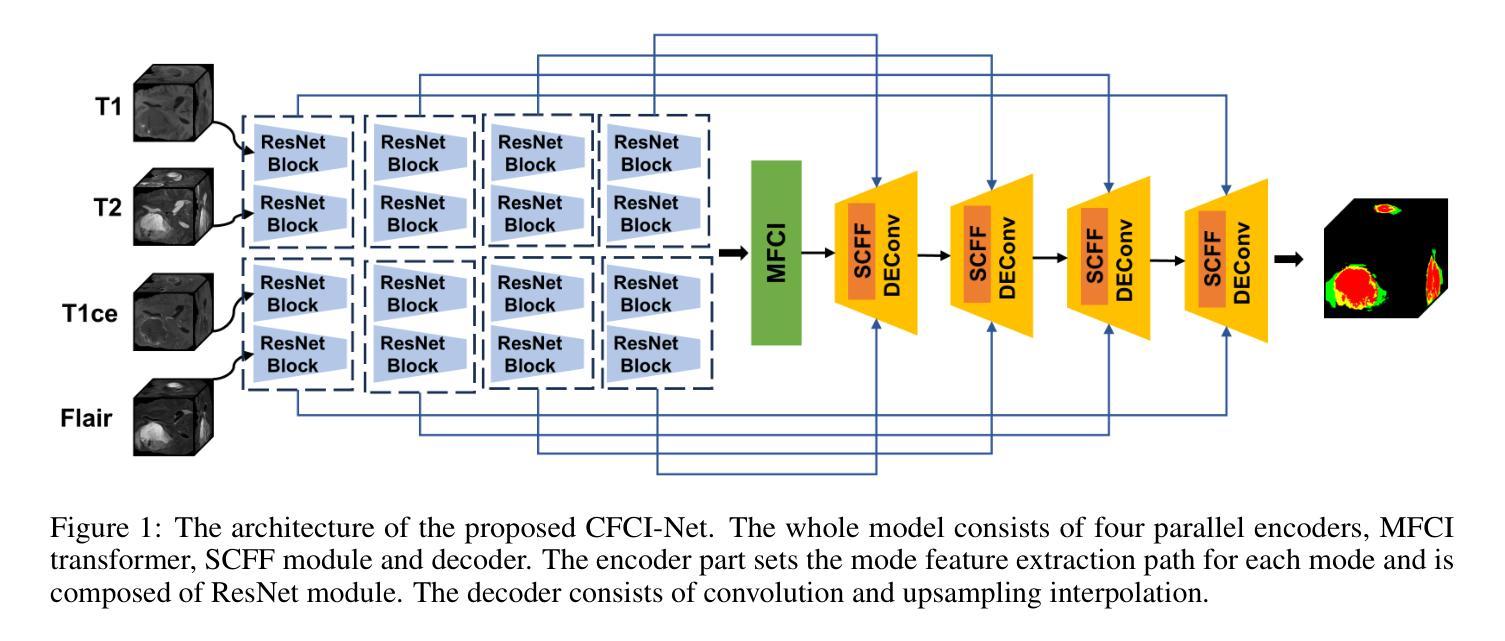
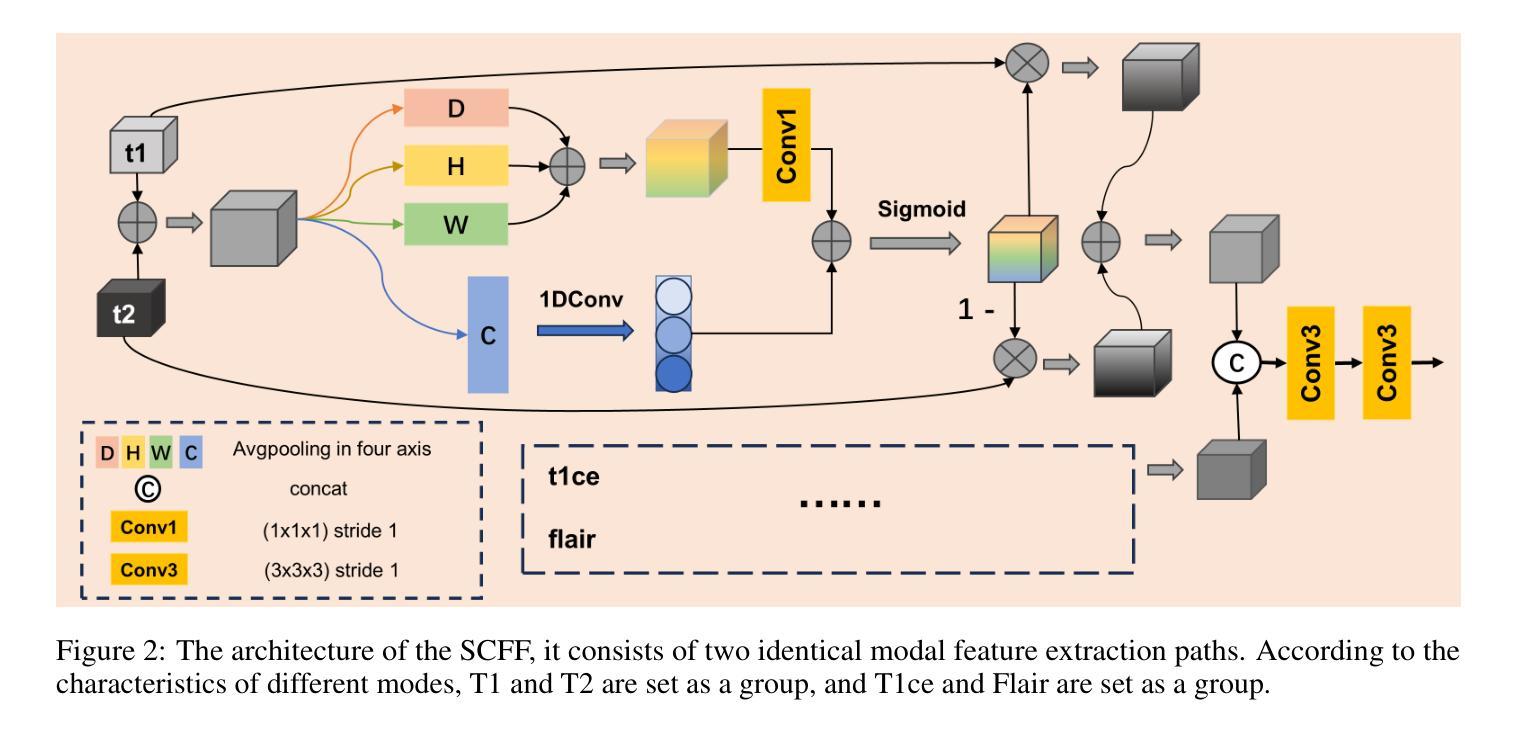
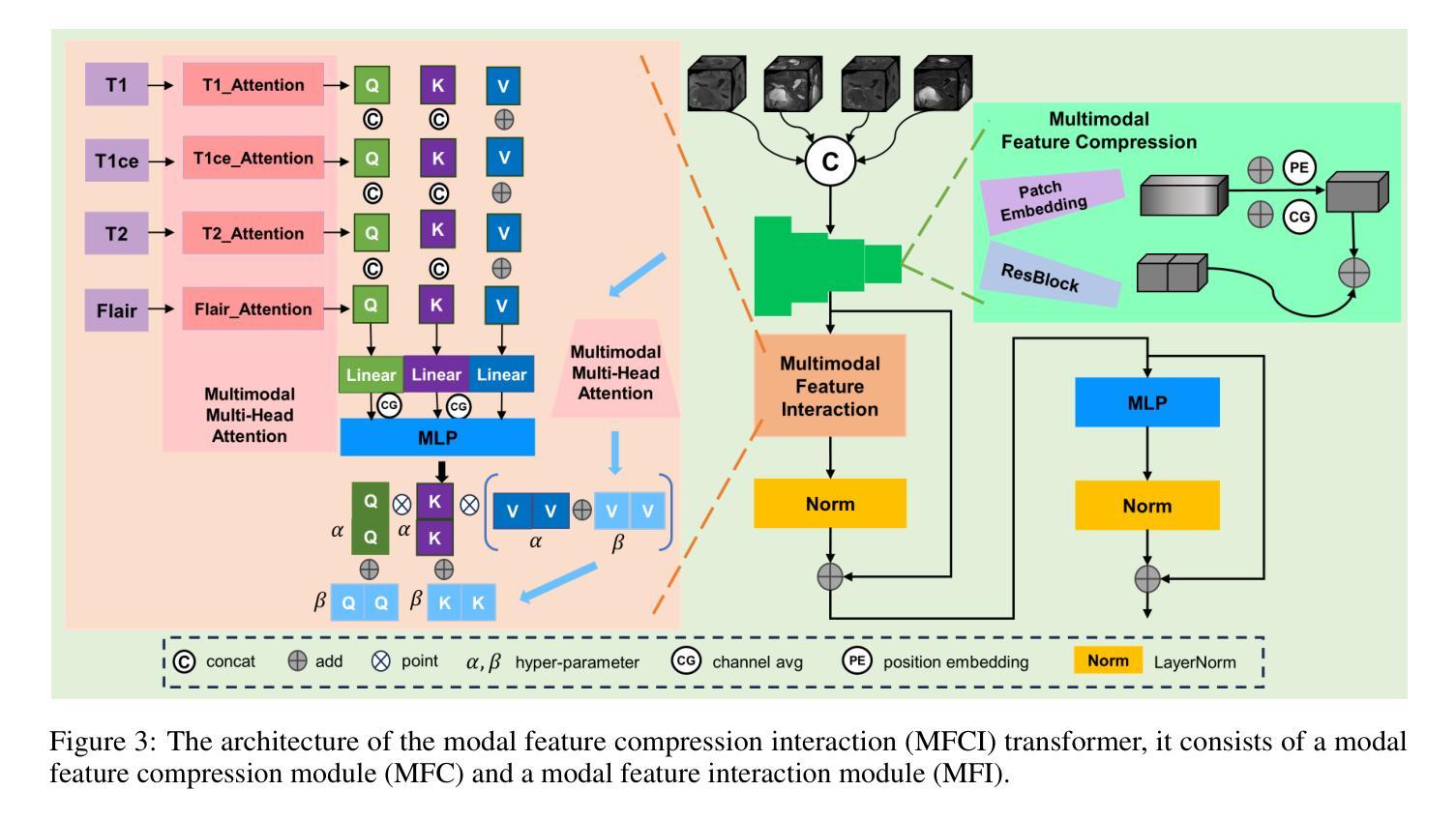
Selective Complementary Feature Fusion and Modal Feature Compression Interaction for Brain Tumor Segmentation
Authors:Dong Chen, Boyue Zhao, Yi Zhang, Meng Zhao
Efficient modal feature fusion strategy is the key to achieve accurate segmentation of brain glioma. However, due to the specificity of different MRI modes, it is difficult to carry out cross-modal fusion with large differences in modal features, resulting in the model ignoring rich feature information. On the other hand, the problem of multi-modal feature redundancy interaction occurs in parallel networks due to the proliferation of feature dimensions, further increase the difficulty of multi-modal feature fusion at the bottom end. In order to solve the above problems, we propose a noval complementary feature compression interaction network (CFCI-Net), which realizes the complementary fusion and compression interaction of multi-modal feature information with an efficient mode fusion strategy. Firstly, we propose a selective complementary feature fusion (SCFF) module, which adaptively fuses rich cross-modal feature information by complementary soft selection weights. Secondly, a modal feature compression interaction (MFCI) transformer is proposed to deal with the multi-mode fusion redundancy problem when the feature dimension surges. The MFCI transformer is composed of modal feature compression (MFC) and modal feature interaction (MFI) to realize redundancy feature compression and multi-mode feature interactive learning. %In MFI, we propose a hierarchical interactive attention mechanism based on multi-head attention. Evaluations on the BraTS2019 and BraTS2020 datasets demonstrate that CFCI-Net achieves superior results compared to state-of-the-art models. Code: https://github.com/CDmm0/CFCI-Net
高效模态特征融合策略是实现脑胶质瘤准确分割的关键。然而,由于不同MRI模式的特殊性,在模态特征存在较大差异时,进行跨模态融合变得困难,导致模型忽略了丰富的特征信息。另一方面,由于特征维度的增加,并行网络中出现了多模态特征冗余交互的问题,进一步增加了底层多模态特征融合的难度。为了解决上述问题,我们提出了一种新型互补特征压缩交互网络(CFCI-Net),它采用高效的模式融合策略,实现了多模态特征信息的互补融合和压缩交互。首先,我们提出了选择性互补特征融合(SCFF)模块,通过互补的软选择权重自适应地融合丰富的跨模态特征信息。其次,我们提出了模态特征压缩交互(MFCI)转换器,以处理特征维度激增时的多模式融合冗余问题。MFCI转换器由模态特征压缩(MFC)和模态特征交互(MFI)组成,实现冗余特征压缩和多模式特征交互学习。在MFI中,我们提出了一种基于多头注意力的分层交互注意力机制。在BraTS2019和BraTS2020数据集上的评估表明,CFCI-Net相较于最新模型取得了优越的结果。代码地址:https://github.com/CDmm0/CFCI-Net
论文及项目相关链接
Summary
本文提出一种新型的互补特征压缩交互网络(CFCI-Net),实现多模态特征信息的互补融合与压缩交互,以提高脑胶质瘤分割的准确性。为解决不同MRI模式在特征融合上的难点及多模态特征冗余问题,网络中包含选择性互补特征融合模块与模态特征压缩交互变压器,通过高效的模态融合策略实现跨模态特征的有效融合。评价数据表现CFCI-Net性能优异。
Key Takeaways
- 提出互补特征压缩交互网络(CFCI-Net)用于脑胶质瘤分割。
- 针对不同MRI模式的特殊性,实现跨模态特征融合的挑战。
- 采用选择性互补特征融合(SCFF)模块自适应融合跨模态特征信息。
- 提出模态特征压缩交互(MFCI)变压器应对特征维度增长带来的冗余问题。
- MFCI变压器包含模态特征压缩(MFC)与模态特征交互(MFI)。
- 引入层次化交互注意力机制以实现多模态特征的交互学习。
点此查看论文截图

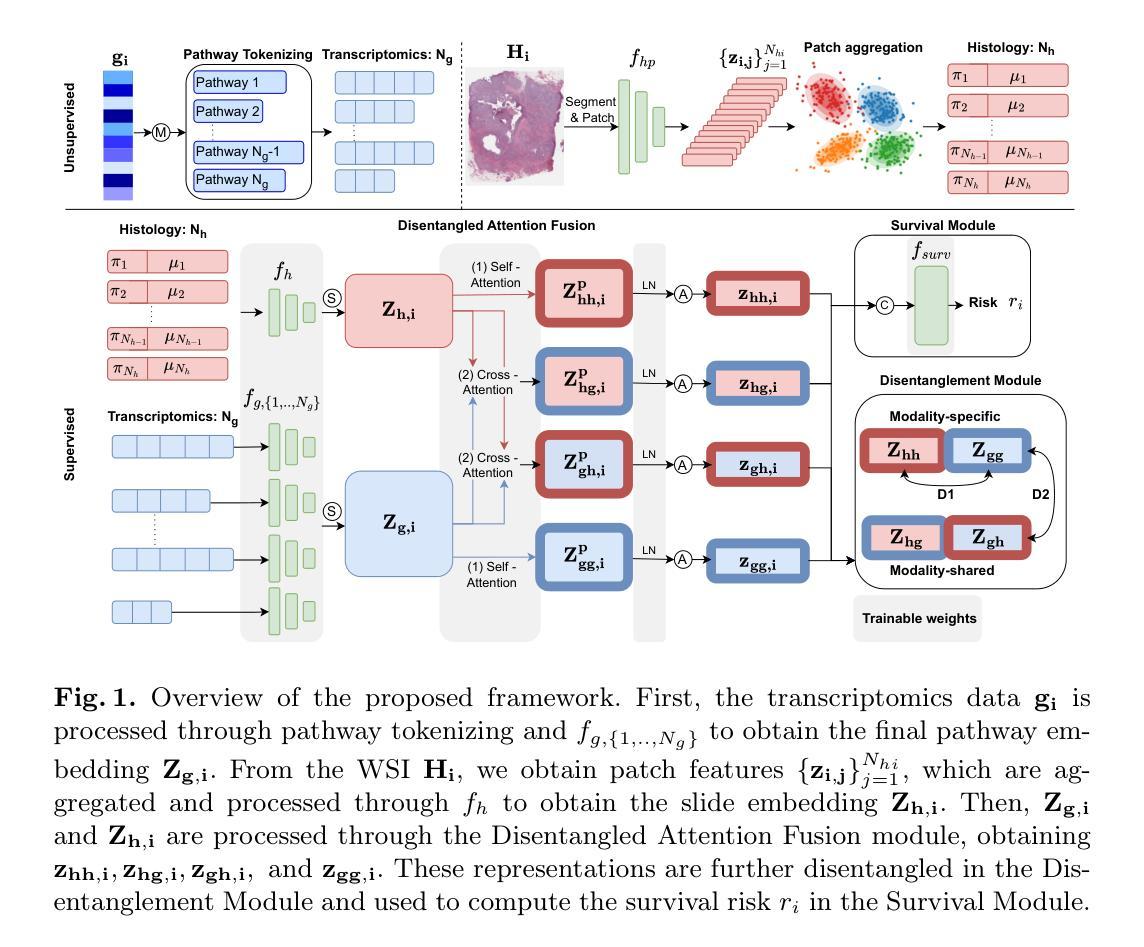
Disentangled and Interpretable Multimodal Attention Fusion for Cancer Survival Prediction
Authors:Aniek Eijpe, Soufyan Lakbir, Melis Erdal Cesur, Sara P. Oliveira, Sanne Abeln, Wilson Silva
To improve the prediction of cancer survival using whole-slide images and transcriptomics data, it is crucial to capture both modality-shared and modality-specific information. However, multimodal frameworks often entangle these representations, limiting interpretability and potentially suppressing discriminative features. To address this, we propose Disentangled and Interpretable Multimodal Attention Fusion (DIMAF), a multimodal framework that separates the intra- and inter-modal interactions within an attention-based fusion mechanism to learn distinct modality-specific and modality-shared representations. We introduce a loss based on Distance Correlation to promote disentanglement between these representations and integrate Shapley additive explanations to assess their relative contributions to survival prediction. We evaluate DIMAF on four public cancer survival datasets, achieving a relative average improvement of 1.85% in performance and 23.7% in disentanglement compared to current state-of-the-art multimodal models. Beyond improved performance, our interpretable framework enables a deeper exploration of the underlying interactions between and within modalities in cancer biology.
为提高利用全滑图像和转录组数据预测癌症存活率的效果,捕获模态共享和模态特定信息至关重要。然而,多模态框架经常纠缠这些表示,限制了可解释性并可能抑制辨别特征。为解决此问题,我们提出了“解耦可解释多模态注意力融合”(DIMAF)这一多模态框架,该框架通过基于注意力的融合机制来分离模态内和模态间的交互作用,以学习独特的模态特定和模态共享表示。我们引入基于距离相关的损失来促进这些表示之间的解耦,并整合沙普利加法解释来评估它们对生存预测的相对贡献。我们在四个公共癌症生存数据集上评估了DIMAF的表现,与当前最先进的多模态模型相比,性能平均提高了1.85%,解耦程度提高了23.7%。除了性能提升外,我们的可解释框架还能够更深入地探索癌症生物学中模态之间和模态内部的潜在相互作用。
论文及项目相关链接
PDF 11 pages, 1 figure, 3 tables
Summary
本文提出了一个名为DIMAF的解纠缠可解释多模态注意力融合框架,用于改善利用全滑图像和转录组学数据对癌症生存率的预测。该框架能够分离模态内和模态间的交互作用,学习独特的模态特定和模态共享表示,同时基于距离相关性引入损失来促进这些表示的解纠缠,并使用Shapley加法解释来评估它们对生存率预测的相对贡献。在四个公共癌症生存数据集上的评估表明,与当前最先进的多模态模型相比,DIMAF的性能平均提高了1.85%,解纠缠程度提高了23.7%。除了提高性能外,我们的可解释框架还能够更深入地探索癌症生物学中模态之间和模态内部的相互作用。
Key Takeaways
- DIMAF框架旨在提高利用全滑图像和转录组学数据预测癌症生存率的准确性。
- 该框架通过分离模态内和模态间的交互作用,以学习独特的模态特定和模态共享表示。
- 引入基于距离相关性的损失来促进表示的解纠缠。
- 使用Shapley加法解释评估不同表示对生存率预测的相对贡献。
- 在四个公共癌症生存数据集上,DIMAF的性能相较于现有模型有所提升。
- DIMAF不仅提高了预测性能,而且提供了对癌症生物学中模态相互作用更深入的理解。
- 该框架的提出为癌症生存预测带来了新的视角和方法。
点此查看论文截图

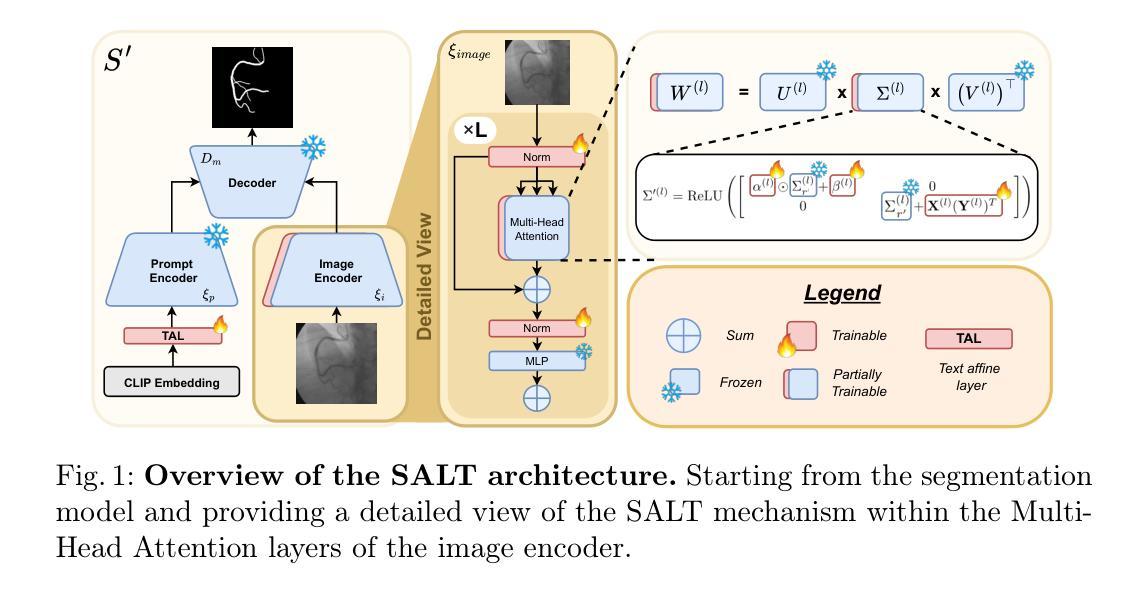
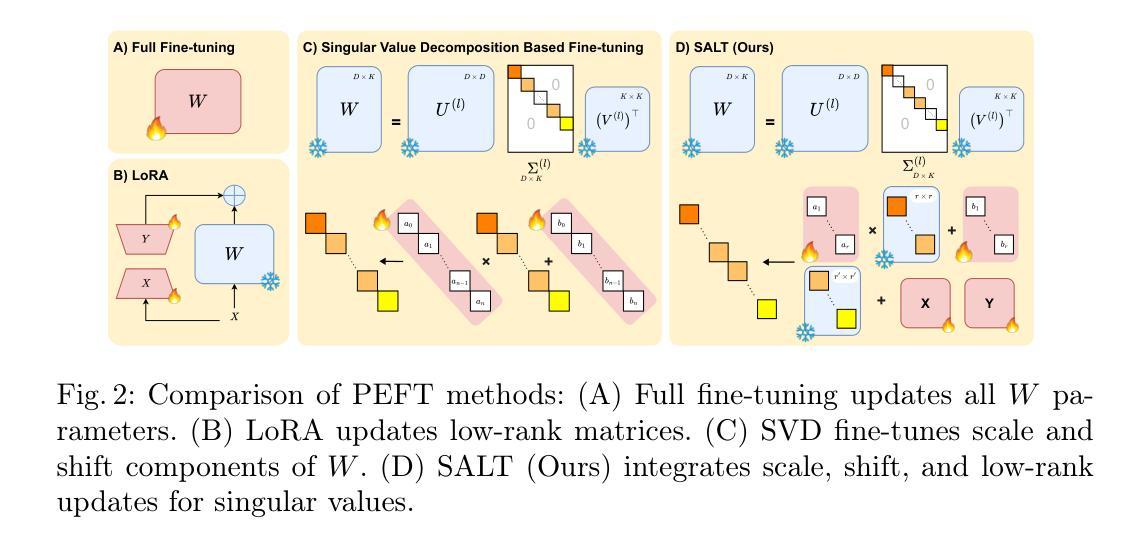
SALT: Singular Value Adaptation with Low-Rank Transformation
Authors:Abdelrahman Elsayed, Sarim Hashmi, Mohammed Elseiagy, Hu Wang, Mohammad Yaqub, Ibrahim Almakky
The complex nature of medical image segmentation calls for models that are specifically designed to capture detailed, domain-specific features. Large foundation models offer considerable flexibility, yet the cost of fine-tuning these models remains a significant barrier. Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), efficiently update model weights with low-rank matrices but may suffer from underfitting when the chosen rank is insufficient to capture domain-specific nuances. Conversely, full-rank Singular Value Decomposition (SVD) based methods provide comprehensive updates by modifying all singular values, yet they often lack flexibility and exhibit variable performance across datasets. We propose SALT (Singular Value Adaptation with Low-Rank Transformation), a method that selectively adapts the most influential singular values using trainable scale and shift parameters while complementing this with a low-rank update for the remaining subspace. This hybrid approach harnesses the advantages of both LoRA and SVD, enabling effective adaptation without relying on increasing model size or depth. Evaluated on 5 challenging medical datasets, ranging from as few as 20 samples to 1000, SALT outperforms state-of-the-art PEFT (LoRA and SVD) by 2% to 5% in Dice with only 3.9% trainable parameters, demonstrating robust adaptation even in low-resource settings. The code for SALT is available at: https://github.com/BioMedIA-MBZUAI/SALT
医学图像分割的复杂性要求专门设计的模型来捕捉详细、特定领域的特征。大型基础模型提供了很大的灵活性,但微调这些模型的成本仍然是一个重大障碍。参数高效微调(PEFT)方法,如低秩适应(LoRA),能够高效地更新模型权重使用低秩矩阵,但当所选的秩不足以捕捉特定领域的细微差别时,可能会出现欠拟合的情况。相反,全秩奇异值分解(SVD)基于的方法通过修改所有奇异值来提供全面的更新,但它们通常缺乏灵活性,并且在不同数据集上的表现各不相同。我们提出了SALT(带有低秩变换的奇异值适应),一种方法,它选择性地适应最有影响力的奇异值,使用可训练的缩放和移位参数,并用低秩更新对剩余的子空间进行补充。这种混合方法结合了LoRA和SVD的优点,能够在不增加模型大小或深度的情况下实现有效的适应。在五个具有挑战性的医学数据集上进行了评估,样本数量从最少的20个到1000个不等,SALT在Dice上比最新的PEFT(LoRA和SVD)高出2%至5%,并且只有3.9%的可训练参数,证明了即使在资源有限的情况下也具有稳健的适应能力。SALT的代码可在[https://github.com/BioMedIA-MBZUAI/SALT找到。]
论文及项目相关链接
Summary
本文介绍了医学图像分割的复杂性,需要专门设计的模型来捕捉详细的领域特定特征。文章探讨了参数高效微调(PEFT)方法,如低秩适应(LoRA)和全秩奇异值分解(SVD)方法的优缺点,并提出了一种新的方法SALT,该方法结合了两者的优点,通过选择性适应最具影响力的奇异值并结合低秩更新其余子空间,实现了有效的模型适应。在五个具有挑战性的医学数据集上进行的评估表明,SALT在仅有少量样本的情况下仍表现出强大的性能,并优于现有的PEFT方法。
Key Takeaways
- 医学图像分割需要专门设计的模型以捕捉详细的领域特定特征。
- 参数高效微调(PEFT)是医学图像分割模型适应的关键挑战。
- LoRA方法通过低秩矩阵有效更新模型权重,但可能因所选排名不足而出现过拟合。
- SVD方法通过修改所有奇异值提供全面的更新,但缺乏灵活性并且在不同数据集上的性能不稳定。
- SALT方法结合了LoRA和SVD的优点,通过选择性适应最具影响力的奇异值并结合低秩更新剩余子空间,实现了有效适应。
- SALT在五个具有挑战性的医学数据集上的性能优于现有的PEFT方法。
点此查看论文截图


Closer to Ground Truth: Realistic Shape and Appearance Labeled Data Generation for Unsupervised Underwater Image Segmentation
Authors:Andrei Jelea, Ahmed Nabil Belbachir, Marius Leordeanu
Solving fish segmentation in underwater videos, a real-world problem of great practical value in marine and aquaculture industry, is a challenging task due to the difficulty of the filming environment, poor visibility and limited existing annotated underwater fish data. In order to overcome these obstacles, we introduce a novel two stage unsupervised segmentation approach that requires no human annotations and combines artificially created and real images. Our method generates challenging synthetic training data, by placing virtual fish in real-world underwater habitats, after performing fish transformations such as Thin Plate Spline shape warping and color Histogram Matching, which realistically integrate synthetic fish into the backgrounds, making the generated images increasingly closer to the real world data with every stage of our approach. While we validate our unsupervised method on the popular DeepFish dataset, obtaining a performance close to a fully-supervised SoTA model, we further show its effectiveness on the specific case of salmon segmentation in underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature (30 GB). Moreover, on both datasets we prove the capability of our approach to boost the performance of the fully-supervised SoTA model.
解决水下视频中的鱼类分割问题是一项具有挑战性的任务,这一现实世界的难题在海洋和水产养殖业中具有巨大的实用价值。由于拍摄环境困难、能见度差以及现有的水下鱼类标注数据有限,我们面临诸多难题。为了克服这些障碍,我们引入了一种新型的两阶段无监督分割方法,该方法无需人工标注,结合了人工创建和真实图像。我们的方法通过生成具有挑战性的合成训练数据来克服这些挑战,通过在真实的水下环境中放置虚拟鱼,并进行诸如薄板样条形状变换和颜色直方图匹配等鱼类变换操作,将合成的鱼现实地融入到背景中,使得生成的图像随着我们的方法的每一阶段而越来越接近真实世界数据。我们在流行的DeepFish数据集上验证了我们的无监督方法,其性能接近完全监督的当前最佳模型,并进一步展示了其在水下视频中的鲑鱼分割这一特定案例上的有效性。为此我们引入了DeepSalmon数据集,它是文献中同类中最大的数据集(30GB)。此外,在两个数据集上,我们都证明了我们的方法可以提升完全监督的当前最佳模型的性能。
论文及项目相关链接
PDF Proceedings of ECCVW 2024
Summary
本文介绍了一种解决水下视频鱼类分割问题的新型两阶段无监督分割方法。该方法结合人工创建和真实图像,无需人工标注,通过鱼类的形态变化和色彩匹配技术生成合成训练数据。该方法在DeepFish数据集上的表现接近全监督的当前最佳模型,并在最大的水下三文鱼分割数据集DeepSalmon上展现了其有效性,能提升全监督当前最佳模型的性能。
Key Takeaways
- 引入了一种新型两阶段无监督分割方法,用于解决水下视频鱼类分割问题。
- 方法结合了人工创建和真实图像,无需人工标注。
- 通过鱼类的形态变化和色彩匹配技术生成合成训练数据。
- 在DeepFish数据集上的表现接近全监督的当前最佳模型。
- 引入了DeepSalmon数据集,为三文鱼分割领域提供了最大的数据集。
- 在两个数据集上均证明了该方法能提升全监督当前最佳模型的性能。
点此查看论文截图


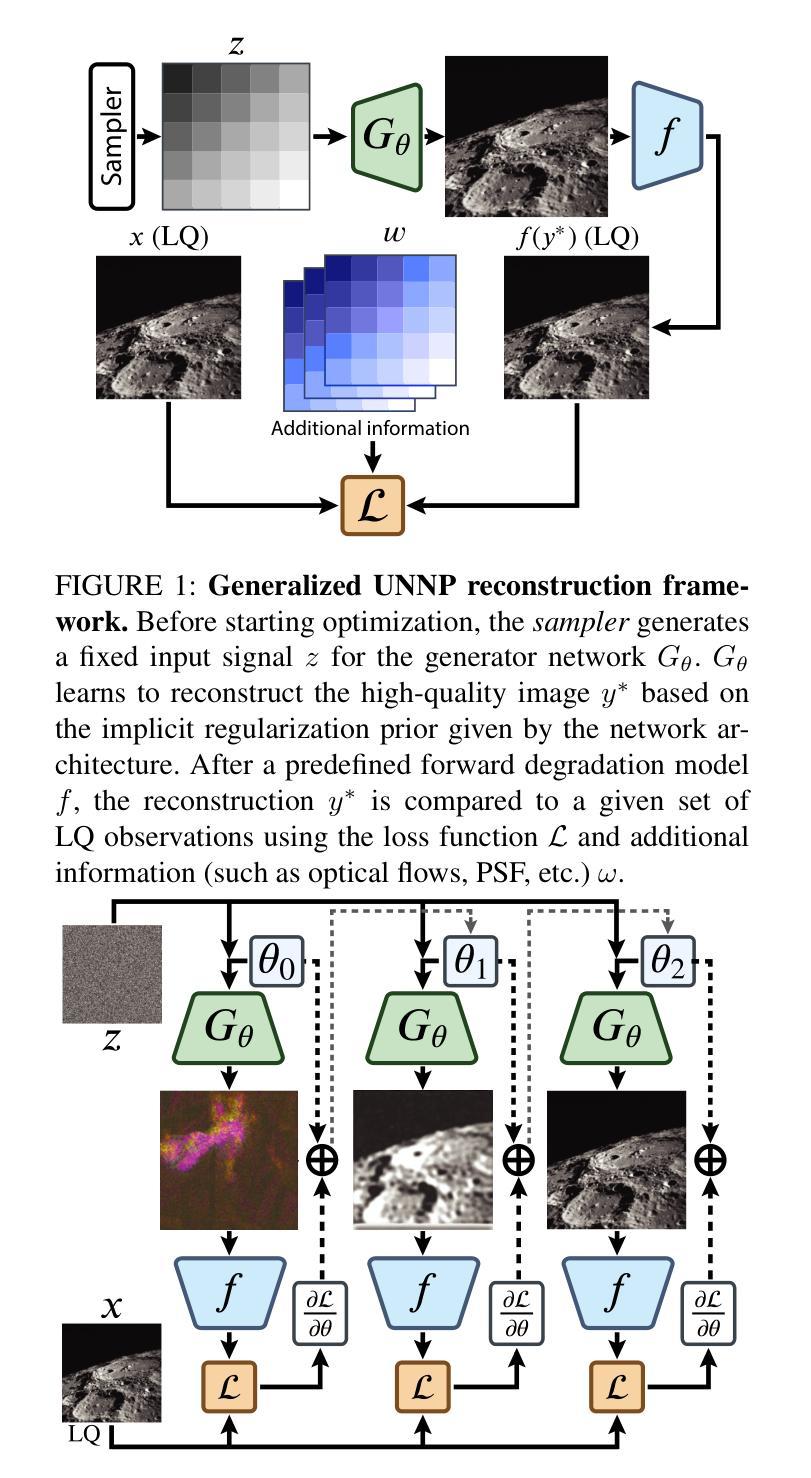
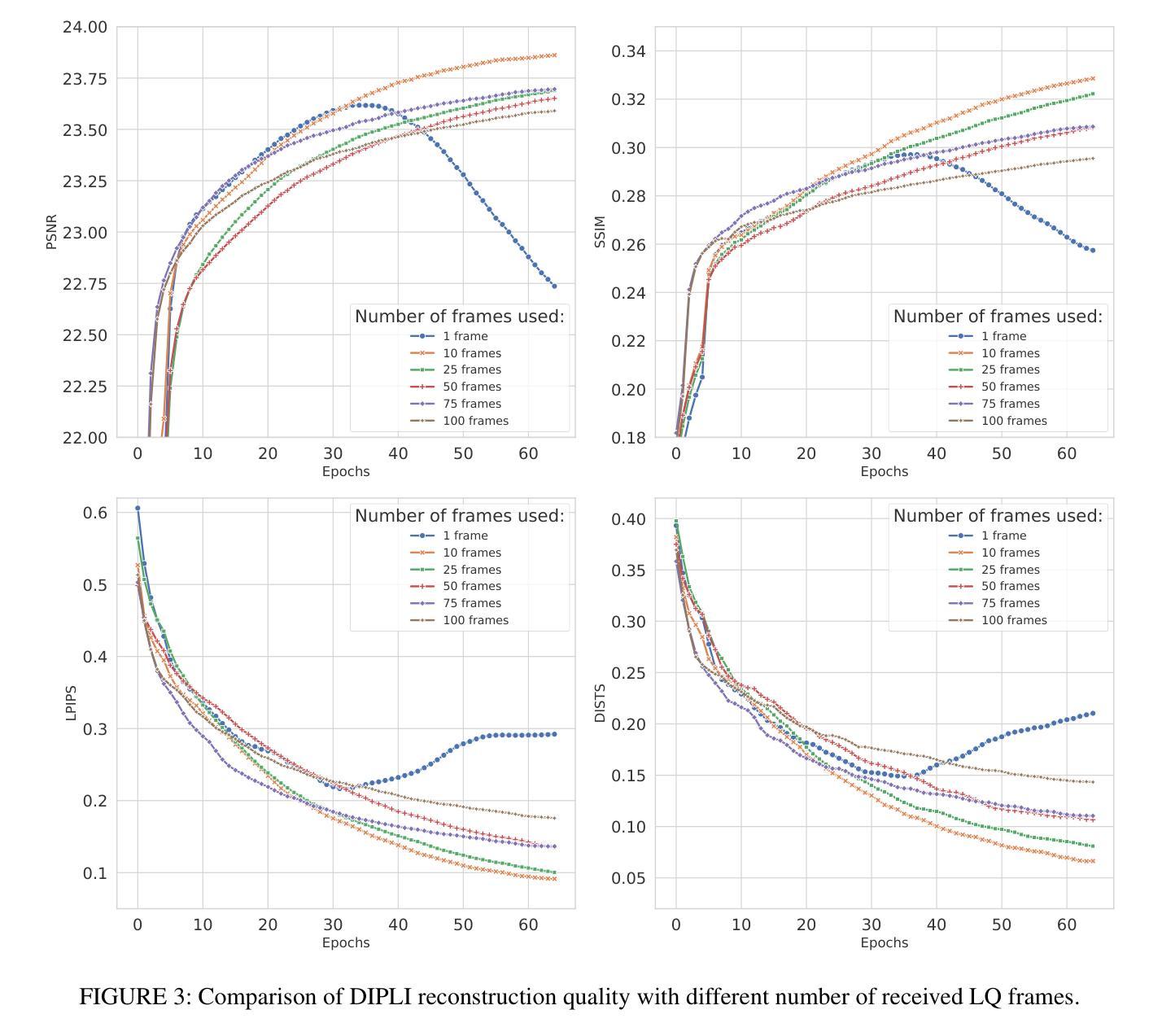
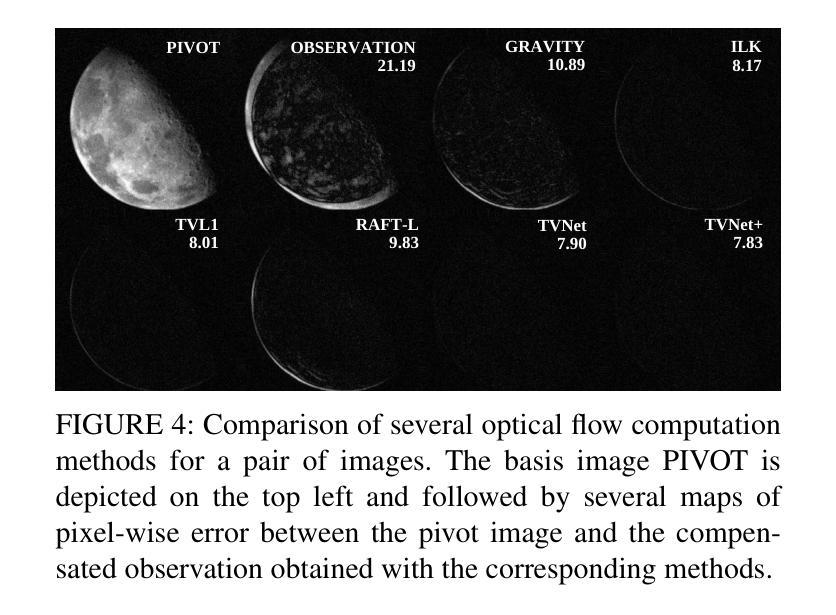
DIPLI: Deep Image Prior Lucky Imaging for Blind Astronomical Image Restoration
Authors:Suraj Singh, Anastasia Batsheva, Oleg Y. Rogov, Ahmed Bouridane
Contemporary image restoration and super-resolution techniques effectively harness deep neural networks, markedly outperforming traditional methods. However, astrophotography presents unique challenges for deep learning due to limited training data. This work explores hybrid strategies, such as the Deep Image Prior (DIP) model, which facilitates blind training but is susceptible to overfitting, artifact generation, and instability when handling noisy images. We propose enhancements to the DIP model’s baseline performance through several advanced techniques. First, we refine the model to process multiple frames concurrently, employing the Back Projection method and the TVNet model. Next, we adopt a Markov approach incorporating Monte Carlo estimation, Langevin dynamics, and a variational input technique to achieve unbiased estimates with minimal variance and counteract overfitting effectively. Collectively, these modifications reduce the likelihood of noise learning and mitigate loss function fluctuations during training, enhancing result stability. We validated our algorithm across multiple image sets of astronomical and celestial objects, achieving performance that not only mitigates limitations of Lucky Imaging, a classical computer vision technique that remains a standard in astronomical image reconstruction but surpasses the original DIP model, state of the art transformer- and diffusion-based models, underscoring the significance of our improvements.
当前图像恢复和超分辨率技术有效地利用了深度神经网络,显著优于传统方法。然而,由于天文摄影的训练数据有限,给深度学习带来了独特的挑战。这项工作探索了混合策略,例如深度图像先验(DIP)模型,该模型便于盲训练,但处理带噪声的图像时容易出现过拟合、伪影生成和不稳定的情况。我们提出通过几种先进技术增强DIP模型的基线性能。首先,我们改进模型以同时处理多帧图像,采用反向投影方法和TVNet模型。接下来,我们采用马尔可夫方法,结合蒙特卡罗估计、朗格文动力学和变异输入技术,以实现具有最小方差的无偏估计,并有效对抗过拟合。这些修改总体上降低了噪声学习的可能性,减少了训练过程中的损失函数波动,增强了结果的稳定性。我们在多个天文和天体图像集上验证了我们的算法,不仅实现了性能的提升,缓解了仍然是天文图像重建标准的经典计算机视觉技术——幸运成像的局限性,还超越了原始的DIP模型、最先进的基于转换和扩散的模型,凸显了我们改进的重要性。
论文及项目相关链接
PDF 10 pages, 7 figures, 2 tables
Summary
本文探讨了深度学习在天文摄影中的图像修复与超分辨率技术面临的挑战,并针对Deep Image Prior(DIP)模型提出了改进策略。通过结合多种技术,包括多帧处理、Markov方法以及蒙特卡洛估计等,本文提出的算法不仅解决了DIP模型的局限性,如过度拟合和噪声生成问题,而且超越了当前主流的转换器模型和扩散模型。
Key Takeaways
- 深度学习在天文摄影的图像恢复和超分辨率处理中表现出显著优势。
- Deep Image Prior(DIP)模型在天文摄影中面临训练数据有限、易过拟合及不稳定等问题。
- 提出了结合多种先进技术的改进策略,如多帧处理、Back Projection方法和TVNet模型。
- 采用Markov方法结合蒙特卡洛估计、朗维动力学和变分输入技术,实现无偏估计并降低方差。
- 改进策略有助于减少噪声学习,并减轻训练过程中的损失函数波动,增强结果的稳定性。
- 验证算法在多个天文和天体图像集上的性能,不仅超越了传统的Lucky Imaging技术,也超越了原始的DIP模型和当前主流模型。
点此查看论文截图

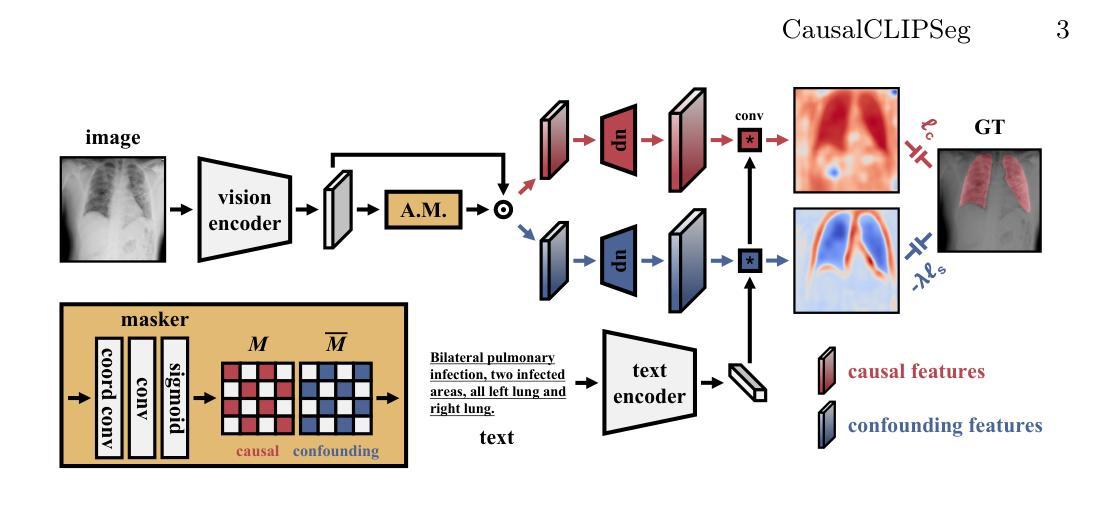
CausalCLIPSeg: Unlocking CLIP’s Potential in Referring Medical Image Segmentation with Causal Intervention
Authors:Yaxiong Chen, Minghong Wei, Zixuan Zheng, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
Referring medical image segmentation targets delineating lesions indicated by textual descriptions. Aligning visual and textual cues is challenging due to their distinct data properties. Inspired by large-scale pre-trained vision-language models, we propose CausalCLIPSeg, an end-to-end framework for referring medical image segmentation that leverages CLIP. Despite not being trained on medical data, we enforce CLIP’s rich semantic space onto the medical domain by a tailored cross-modal decoding method to achieve text-to-pixel alignment. Furthermore, to mitigate confounding bias that may cause the model to learn spurious correlations instead of meaningful causal relationships, CausalCLIPSeg introduces a causal intervention module which self-annotates confounders and excavates causal features from inputs for segmentation judgments. We also devise an adversarial min-max game to optimize causal features while penalizing confounding ones. Extensive experiments demonstrate the state-of-the-art performance of our proposed method. Code is available at https://github.com/WUTCM-Lab/CausalCLIPSeg.
关于医学图像分割的目标是根据文本描述来描绘病变。由于视觉和文本提示的不同数据属性,对齐它们是一项挑战。受大规模预训练视觉语言模型的启发,我们提出了CausalCLIPSeg,这是一个用于参考医学图像分割的端到端框架,它利用CLIP。尽管没有在医疗数据上进行训练,但我们通过定制的跨模态解码方法将CLIP丰富的语义空间强制施加到医疗领域,以实现文本到像素的对齐。此外,为了减轻可能导致模型学习虚假关联而非有意义的因果关系的混淆偏差,CausalCLIPSeg引入了一个因果干预模块,该模块对混淆因素进行自我注释,并从输入中挖掘因果特征以进行分割判断。我们还设计了一个对抗性的最小最大游戏来优化因果特征,同时惩罚混淆特征。大量实验证明了我们提出的方法的先进水平。代码可在https://github.com/WUTCM-Lab/CausalCLIPSeg获取。
论文及项目相关链接
PDF MICCAI 2024
Summary
基于文本描述的医学图像分割面临视觉与文本线索对齐的挑战。针对这一问题,提出一种名为CausalCLIPSeg的医学图像分割框架,该框架利用CLIP丰富的语义空间并通过定制化的跨模态解码方法实现文本到像素的对齐。此外,为缓解可能产生模型学习表面关联而非真实因果关系的混淆偏差,CausalCLIPSeg引入了因果干预模块,从输入中自我标注混淆因素并挖掘因果特征用于分割判断。同时,设计了一种对抗最小最大游戏以优化因果特征并抑制混淆特征。实验证明该方法表现优异。代码已公开。
Key Takeaways
- 医学图像分割需结合文本描述进行,存在视觉与文本线索对齐的挑战。
- 提出CausalCLIPSeg框架,利用CLIP进行医学图像分割。
- 通过定制化的跨模态解码方法实现文本到像素的对齐。
- 引入因果干预模块以缓解混淆偏差,区分真实因果关系与表面关联。
- 因果干预模块能从输入中自我标注混淆因素并挖掘因果特征。
- 设计对抗最小最大游戏以优化因果特征,同时抑制混淆特征。
点此查看论文截图

UniCrossAdapter: Multimodal Adaptation of CLIP for Radiology Report Generation
Authors:Yaxiong Chen, Chuang Du, Chunlei Li, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
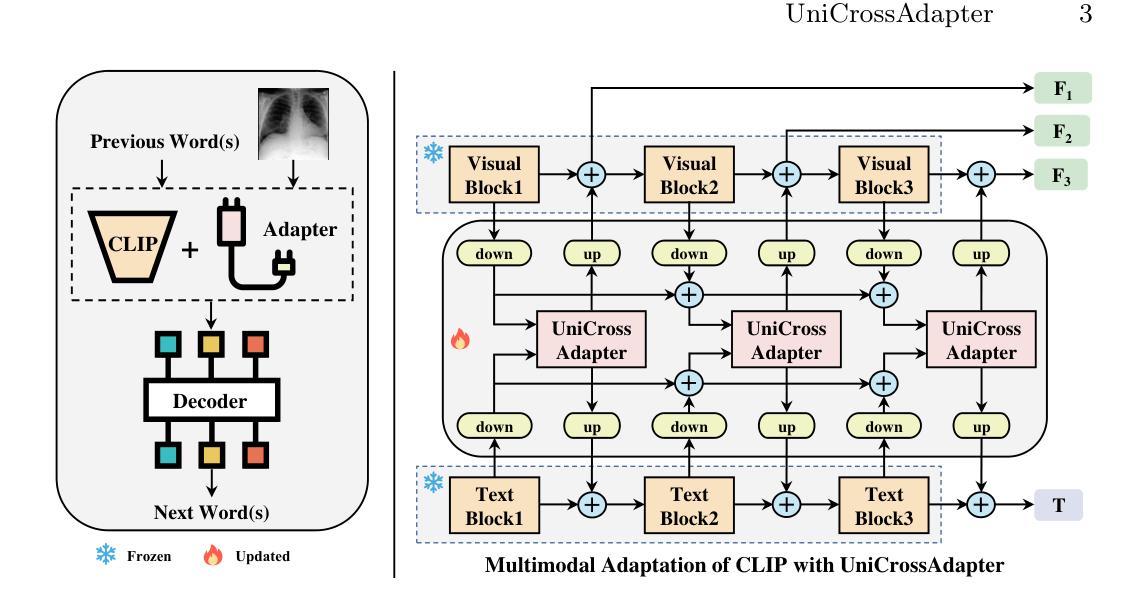
Automated radiology report generation aims to expedite the tedious and error-prone reporting process for radiologists. While recent works have made progress, learning to align medical images and textual findings remains challenging due to the relative scarcity of labeled medical data. For example, datasets for this task are much smaller than those used for image captioning in computer vision. In this work, we propose to transfer representations from CLIP, a large-scale pre-trained vision-language model, to better capture cross-modal semantics between images and texts. However, directly applying CLIP is suboptimal due to the domain gap between natural images and radiology. To enable efficient adaptation, we introduce UniCrossAdapter, lightweight adapter modules that are incorporated into CLIP and fine-tuned on the target task while keeping base parameters fixed. The adapters are distributed across modalities and their interaction to enhance vision-language alignment. Experiments on two public datasets demonstrate the effectiveness of our approach, advancing state-of-the-art in radiology report generation. The proposed transfer learning framework provides a means of harnessing semantic knowledge from large-scale pre-trained models to tackle data-scarce medical vision-language tasks. Code is available at https://github.com/chauncey-tow/MRG-CLIP.
自动放射学报告生成旨在加速放射科医生枯燥且易出错的报告生成过程。尽管近期的研究有所进展,但由于缺乏标记的医学数据,学习对齐医学图像和文本发现仍然具有挑战性。例如,用于此任务的数据集远远小于计算机视觉领域用于图像描述的数据集。在本研究中,我们提出利用CLIP(一种大规模预训练的视觉语言模型)的表征来进行跨模态语义捕捉图像和文本之间的关联。然而,由于自然图像与放射学之间存在领域差距,直接应用CLIP并不理想。为了实现有效的适应,我们引入了UniCrossAdapter,这是一个轻量级的适配器模块,它融入了CLIP并在目标任务上进行微调,同时保持基础参数不变。这些适配器分布在不同的模态之间,通过它们之间的交互增强视觉语言的对齐。在两个公开数据集上的实验证明了我们的方法的有效性,在放射学报告生成方面取得了最先进的成果。所提出的迁移学习框架提供了一种利用大规模预训练模型中的语义知识来解决数据稀缺的医学视觉语言任务的方法。代码可在https://github.com/chauncey-tow/MRG-CLIP找到。
论文及项目相关链接
PDF MICCAI 2024 Workshop
Summary
大规模预训练视觉语言模型CLIP的迁移表示,助力医学图像与文本间的跨模态语义捕捉,在自动放射学报告生成中具有潜在应用价值。针对直接应用CLIP存在的领域差距问题,提出UniCrossAdapter,实现高效适应。适配器模块融入CLIP,并在目标任务上进行微调,同时保持基础参数不变。在公共数据集上的实验证明了方法的有效性,推进了自动放射学报告生成领域的前沿。提供代码开源下载。
Key Takeaways
- 自动化放射学报告生成旨在加快放射科医生繁琐且易出错的报告过程。
- 迁移学习对于解决医学图像与文本对齐的挑战至关重要,特别是数据稀缺的问题。
- 采用CLIP模型进行跨模态语义捕捉,但直接应用面临领域差异挑战。
- 提出UniCrossAdapter,实现高效适应,将适配器模块融入CLIP并微调目标任务。
- 适配器模块分布在不同的模态之间,通过交互增强视觉语言对齐。
- 实验证明该方法的有效性,推进了放射学报告生成领域的最新进展。
点此查看论文截图

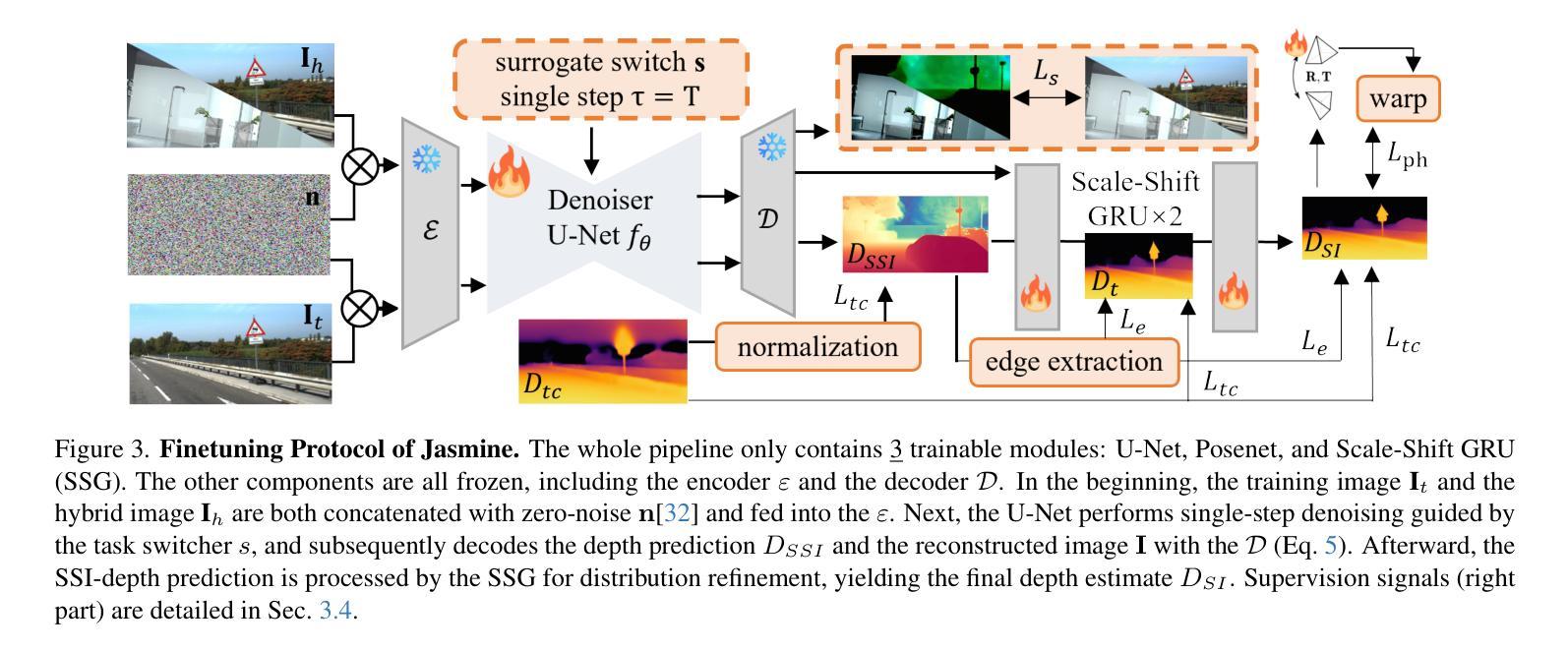
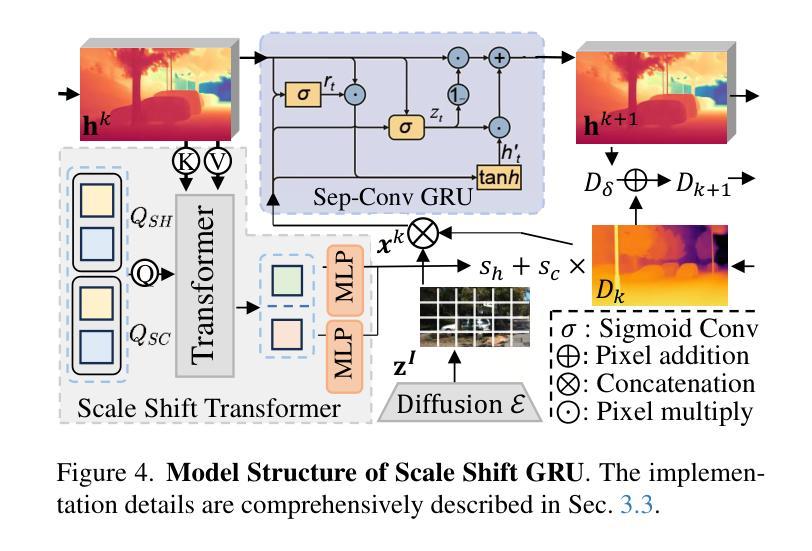
Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
Authors:Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, Yao Zhao
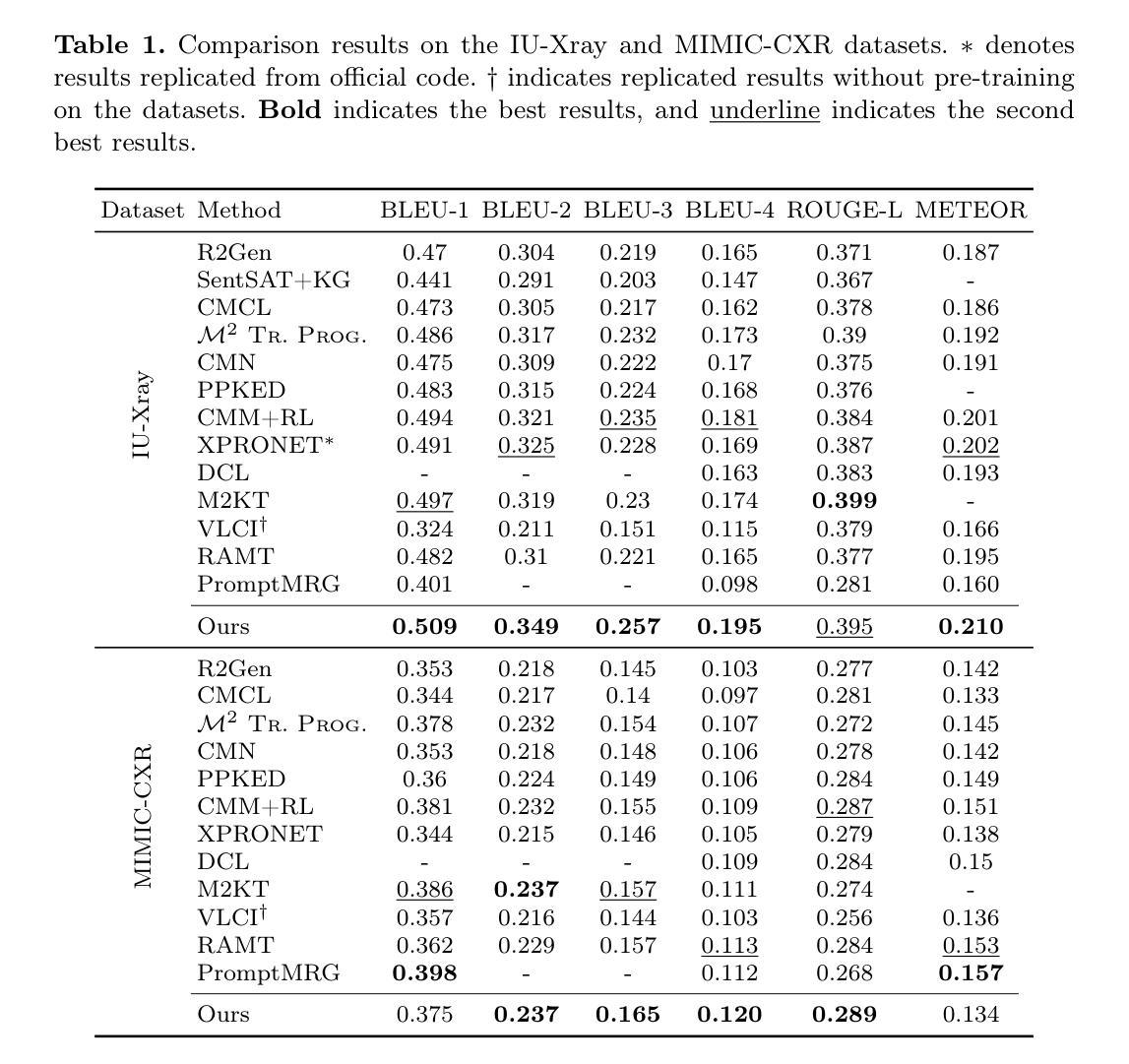
In this paper, we propose Jasmine, the first Stable Diffusion (SD)-based self-supervised framework for monocular depth estimation, which effectively harnesses SD’s visual priors to enhance the sharpness and generalization of unsupervised prediction. Previous SD-based methods are all supervised since adapting diffusion models for dense prediction requires high-precision supervision. In contrast, self-supervised reprojection suffers from inherent challenges (e.g., occlusions, texture-less regions, illumination variance), and the predictions exhibit blurs and artifacts that severely compromise SD’s latent priors. To resolve this, we construct a novel surrogate task of hybrid image reconstruction. Without any additional supervision, it preserves the detail priors of SD models by reconstructing the images themselves while preventing depth estimation from degradation. Furthermore, to address the inherent misalignment between SD’s scale and shift invariant estimation and self-supervised scale-invariant depth estimation, we build the Scale-Shift GRU. It not only bridges this distribution gap but also isolates the fine-grained texture of SD output against the interference of reprojection loss. Extensive experiments demonstrate that Jasmine achieves SoTA performance on the KITTI benchmark and exhibits superior zero-shot generalization across multiple datasets.
本文提出了Jasmine,这是基于Stable Diffusion(SD)的单眼深度估计自监督框架,它有效地利用了SD的视觉先验知识,提高了无监督预测的清晰度和泛化能力。之前的基于SD的方法都是有监督的,因为将扩散模型用于密集预测需要高精度监督。相比之下,自监督重投影面临固有的挑战(例如遮挡、无纹理区域、光照变化),预测结果出现模糊和伪影,严重损害SD的潜在先验知识。为了解决这一问题,我们构建了一个混合图像重建的新型替代任务。在没有任何额外监督的情况下,它通过重建图像本身来保留SD模型的细节先验知识,同时防止深度估计退化。此外,为了解决SD尺度和移位不变估计与自监督尺度不变深度估计之间的固有不匹配问题,我们构建了Scale-Shift GRU。它不仅弥补了分布差距,而且隔离了SD输出的精细纹理,不受重投影损失的干扰。大量实验表明,Jasmine在KITTI基准测试上达到了最先进的性能,并在多个数据集上表现出出色的零样本泛化能力。
论文及项目相关链接
Summary
本文提出了Jasmine,首个基于Stable Diffusion(SD)的自监督单目深度估计框架。该框架有效利用SD的视觉先验知识,提高了无监督预测的清晰度和泛化能力。以往SD方法均需监督,而自监督重投影面临诸多挑战。为解决这些问题,本文构建了混合图像重建的替代任务,无需额外监督,保留了SD模型的细节先验,并防止深度估计退化。同时,为解决SD尺度与自监督深度估计之间的固有不匹配问题,构建了Scale-Shift GRU,不仅弥补了分布差距,而且隔离了SD输出的细粒度纹理,减少了重投影损失的干扰。实验表明,Jasmine在KITTI基准测试中达到了最新技术水平,并在多个数据集上表现出优异的零样本泛化能力。
Key Takeaways
- Jasmine是基于Stable Diffusion的自监督单目深度估计框架,提高了预测的清晰度和泛化能力。
- 之前的SD方法都需要监督,而Jasmine实现了无监督的深度估计。
- 自监督重投影面临挑战,如遮挡、无纹理区域、光照变化等。
- 构建了混合图像重建的替代任务,无需额外监督,保留了SD模型的细节先验。
- 解决SD尺度与自监督深度估计之间的不匹配问题,构建了Scale-Shift GRU。
- Jasmine在KITTI基准测试上表现优异,达到最新技术水平。
点此查看论文截图

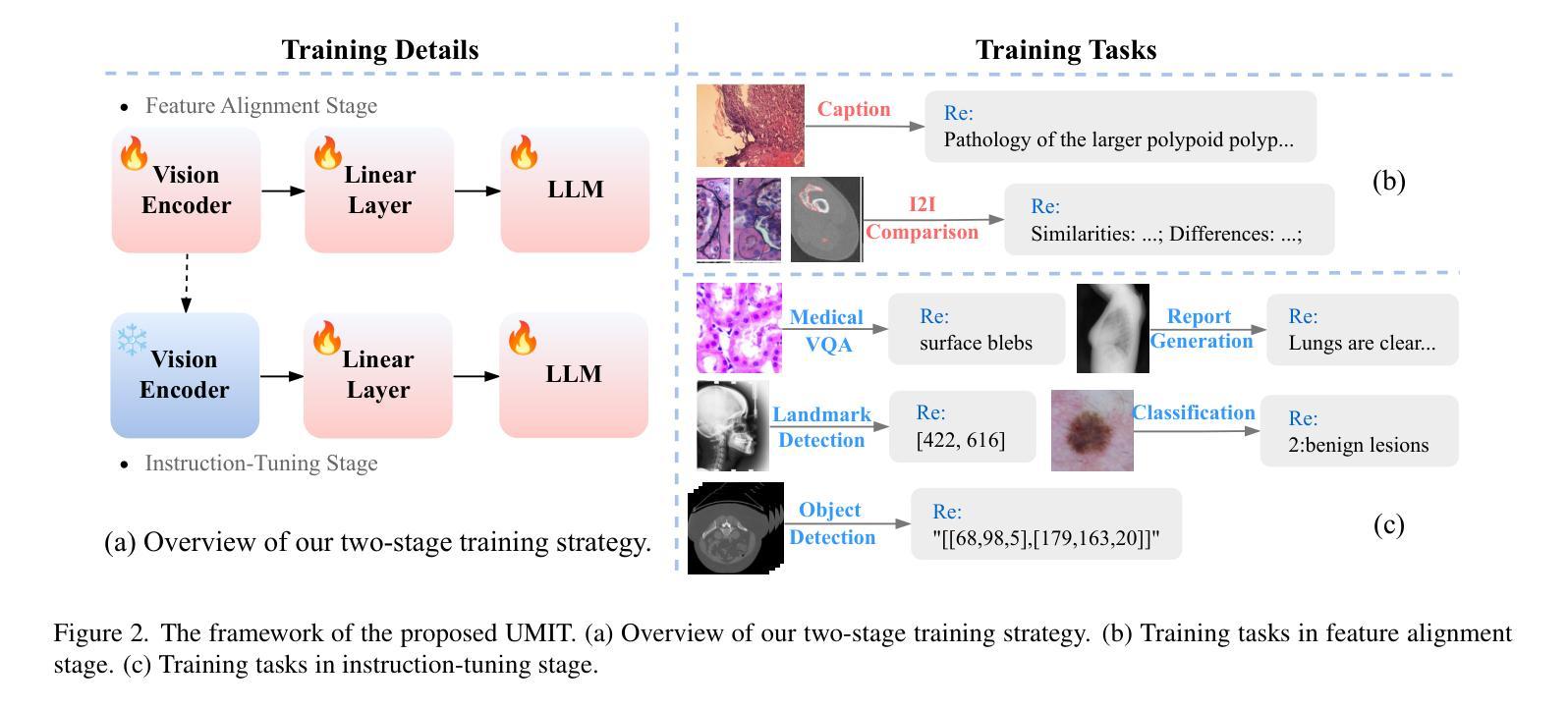
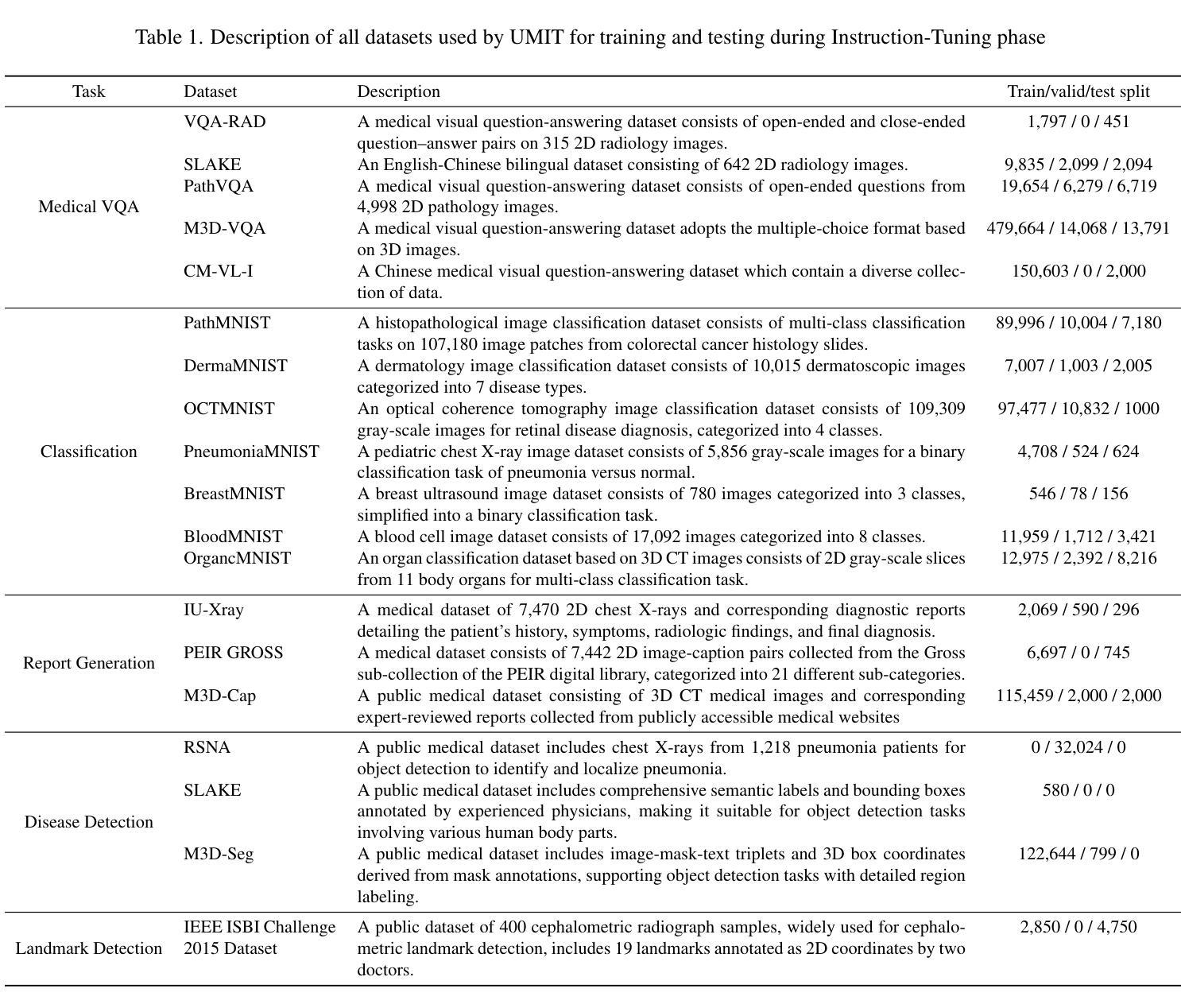
UMIT: Unifying Medical Imaging Tasks via Vision-Language Models
Authors:Haiyang Yu, Siyang Yi, Ke Niu, Minghan Zhuo, Bin Li
With the rapid advancement of deep learning, particularly in the field of medical image analysis, an increasing number of Vision-Language Models (VLMs) are being widely applied to solve complex health and biomedical challenges. However, existing research has primarily focused on specific tasks or single modalities, which limits their applicability and generalization across diverse medical scenarios. To address this challenge, we propose UMIT, a unified multi-modal, multi-task VLM designed specifically for medical imaging tasks. UMIT is able to solve various tasks, including visual question answering, disease detection, and medical report generation. In addition, it is applicable to multiple imaging modalities (e.g., X-ray, CT and PET), covering a wide range of applications from basic diagnostics to complex lesion analysis. Moreover, UMIT supports both English and Chinese, expanding its applicability globally and ensuring accessibility to healthcare services in different linguistic contexts. To enhance the model’s adaptability and task-handling capability, we design a unique two-stage training strategy and fine-tune UMIT with designed instruction templates. Through extensive empirical evaluation, UMIT outperforms previous methods in five tasks across multiple datasets. The performance of UMIT indicates that it can significantly enhance diagnostic accuracy and workflow efficiency, thus providing effective solutions for medical imaging applications.
随着深度学习的快速发展,特别是在医学图像分析领域,越来越多的视觉语言模型(VLMs)被广泛应用于解决复杂的健康和生物医学挑战。然而,现有研究主要集中在特定任务或单一模态上,这限制了它们在多样医疗场景中的应用和泛化能力。为了解决这一挑战,我们提出了UMIT,这是一个统一的多模态多任务VLM,专为医学成像任务而设计。UMIT能够解决各种任务,包括视觉问答、疾病检测和医疗报告生成。此外,它适用于多种成像模态(如X射线、CT和PET),涵盖从基本诊断到复杂病灶分析的各种应用。而且,UMIT支持英文和中文,扩大了其全球应用范围,确保了不同语言环境下的医疗保健服务可及性。为了提高模型的适应性和任务处理能力,我们设计了独特的两阶段训练策略,并使用设计好的指令模板对UMIT进行微调。通过广泛的实证评估,UMIT在多个数据集上的五个任务中表现出超越先前方法的效果。UMIT的性能表明,它可以显著提高诊断准确性和工作流程效率,从而为医学成像应用提供有效的解决方案。
论文及项目相关链接
Summary
随着深度学习在医学图像分析领域的快速发展,越来越多的视觉语言模型(VLMs)被广泛应用于解决复杂的医疗和生物医学挑战。为解决现有模型在多样医疗场景下的应用局限,提出了UMIT这一统一的多模态多任务VLM模型,用于医学成像任务。UMIT可解决视觉问答、疾病检测、医学报告生成等多项任务,并适用于多种成像模态。此外,它支持中英文,全球适用。通过独特的两阶段训练策略和精细调整,UMIT在多个数据集上的五个任务中表现出超越先前方法的性能。UMIT的出色表现显著提高了诊断准确性和工作流程效率,为医学成像应用提供了有效解决方案。
Key Takeaways
- UMIT是一个针对医学成像的多模态多任务视觉语言模型(VLM)。
- UMIT能够处理视觉问答、疾病检测、医学报告生成等多项任务。
- UMIT适用于多种成像模态,如X光、CT和PET。
- UMIT支持中英文,全球适用,便于不同语言环境下的医疗服务获取。
- UMIT采用独特的两阶段训练策略并进行精细调整,以提高适应性和任务处理能力。
- UMIT在多个数据集上的五个任务中表现出超越先前方法的性能。
点此查看论文截图

Supernova production of axion-like particles coupling to electrons, reloaded
Authors:Damiano F. G. Fiorillo, Tetyana Pitik, Edoardo Vitagliano
We revisit the production of axion-like particles (ALPs) coupled to electrons at tree-level in a relativistic plasma. We explicitly demonstrate the equivalence between pseudoscalar and derivative couplings, incorporate previously neglected processes for the first time-namely, semi-Compton production ($\gamma e^-\rightarrow a e^-$) and pair annihilation ($e^+e^-\rightarrow a\gamma$)-and derive analytical expressions for the bremsstrahlung ($e^- N\to e^- N a$) production rate, enabling a more computationally efficient evaluation of the ALP flux. Additionally, we assess uncertainties in the production rate arising from electron thermal mass corrections, electron-electron Coulomb interactions, and the Landau-Pomeranchuk-Migdal effect. The ALP emissivity is made available in a public repository as a function of the ALP mass, the temperature, and the electron chemical potential of the plasma. Finally, we examine the impact of ALP production and subsequent decays on astrophysical observables, deriving the leading bounds on ALPs coupling to electrons. At small couplings, the dominant constraints come from the previously neglected decay $a\to e^+ e^-\gamma$, except for a region of fireball formation where SN~1987A X-ray observations offer the best probe. At large couplings, bounds are dominated by the energy deposition argument, with a recently developed new prescription for the trapping regime.
我们重新审视在相对论性等离子体中以树状层级与电子耦合产生的轴突子样粒子(ALPs)。我们明确展示了伪标量和导数耦合之间的等价性,首次考虑了之前被忽略的过程,即半康普顿产生(γe^-→ae^-)和配对消灭(e^+e^-→aγ),并推导出制动辐射(e^-N→e^-Na)产生率的分析表达式,以便更高效地评估ALP流量。此外,我们还评估了由于电子热质量校正、电子-电子库仑相互作用以及朗道-庞德瑞-米格尔效应而产生的生产率不确定性。ALP的发射率作为ALP质量、温度和等离子体电子化学势的函数存储在公共存储库中。最后,我们研究了ALP产生及其随后的衰变对天文观测的影响,推导出与电子耦合的ALP的主要界限。在小耦合的情况下,主要的约束来自于之前被忽略的a→e^+e^-γ衰变,但在火球形成的区域中,SN 1987A X射线观测提供了最佳的探测手段。在大耦合的情况下,边界主要受能量沉积论据的支配,而针对捕获状态有一套新制定的规则。
论文及项目相关链接
PDF 36 pages, including 8 figures and 4 appendices
Summary
本文重新探讨了轴突粒子(ALPs)与电子在相对论等离子体中的耦合生产问题。文章展示了伪标量和导数耦合的等价性,首次考虑了之前被忽略的过程,如半康普顿生产和配对消灭,并推导了辐射层生产的解析表达式,提高了ALP流量的计算效率。文章还评估了生产速率的不确定性,来源于电子热质量修正、电子-电子库仑相互作用以及朗道-波默兰克-米格尔效应。ALP的发射率作为粒子质量、温度和电子化学势的函数被公开存储。最后,文章探讨了ALP生产和随后的衰变对天文观测的影响,并得出了电子耦合ALPs的主导约束。小耦合情况下,主要的限制来源于先前被忽略的衰变a→e+e−γ,但对于火球形成区域,SN 1987A X射线观测提供了最佳探测。大耦合情况下,限制主要来自于能量沉积观点,并且最近开发的新处方对于捕获状态同样适用。
Key Takeaways
- 文章重新探讨了轴突粒子(ALPs)与电子在相对论等离子体中的耦合生产问题,并展示了伪标量和导数耦合的等价性。
- 文章考虑了之前被忽略的过程,包括半康普顿生产和配对消灭,并推导了辐射层生产的解析表达式。
- 文章评估了生产速率的不确定性来源,包括电子热质量修正、电子-电子库仑相互作用以及朗道-波默兰克-米格尔效应。
- 文章提供了ALP的发射率作为粒子质量、温度和电子化学势的函数,并将其公开存储。
- 文章探讨了ALP生产和随后的衰变对天文观测的影响,发现小耦合和大耦合情况下有不同的主导约束。
- 对于小耦合情况,先前被忽略的衰变过程a→e+e−γ成为主要的限制,特别是在火球形成区域。
点此查看论文截图


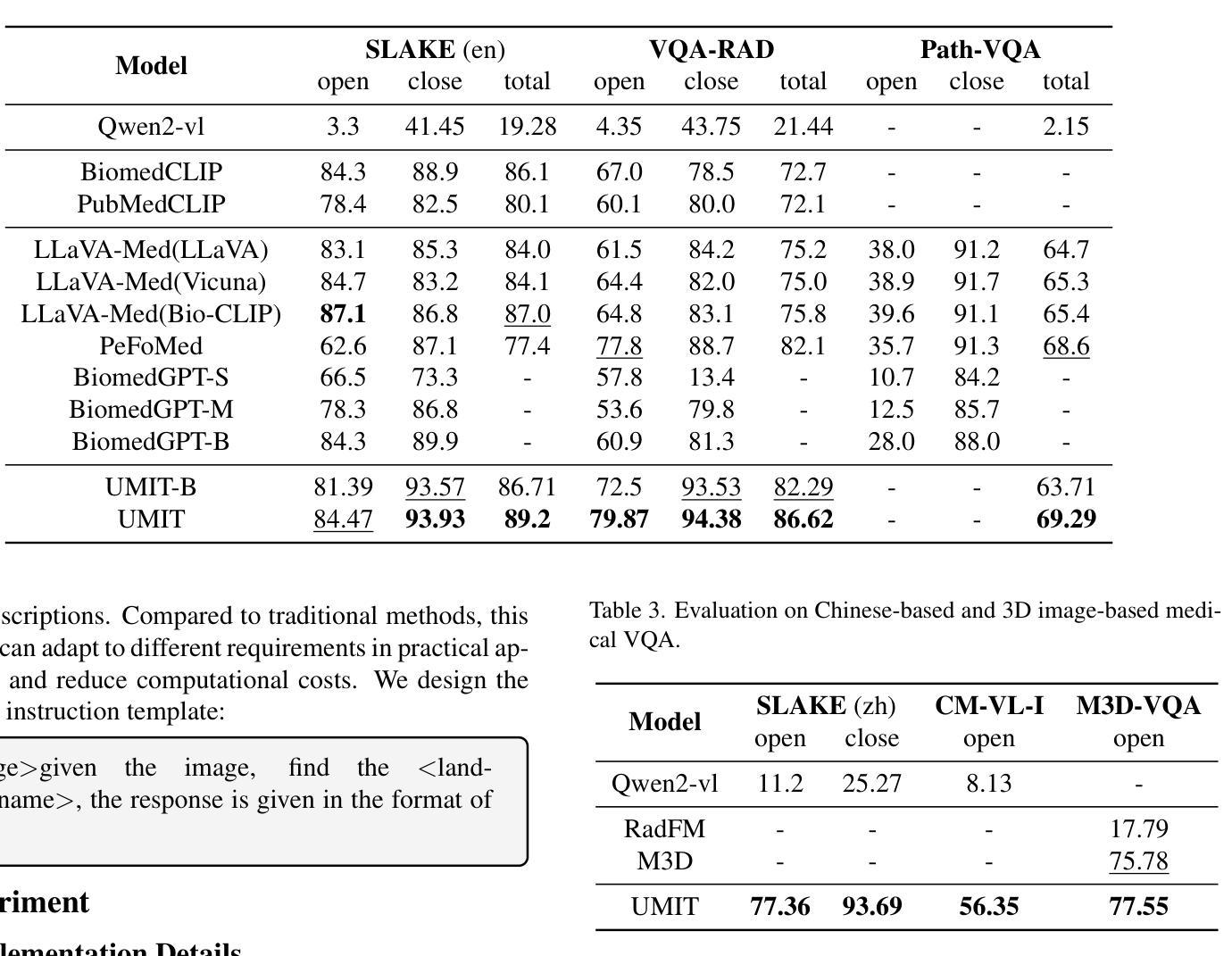
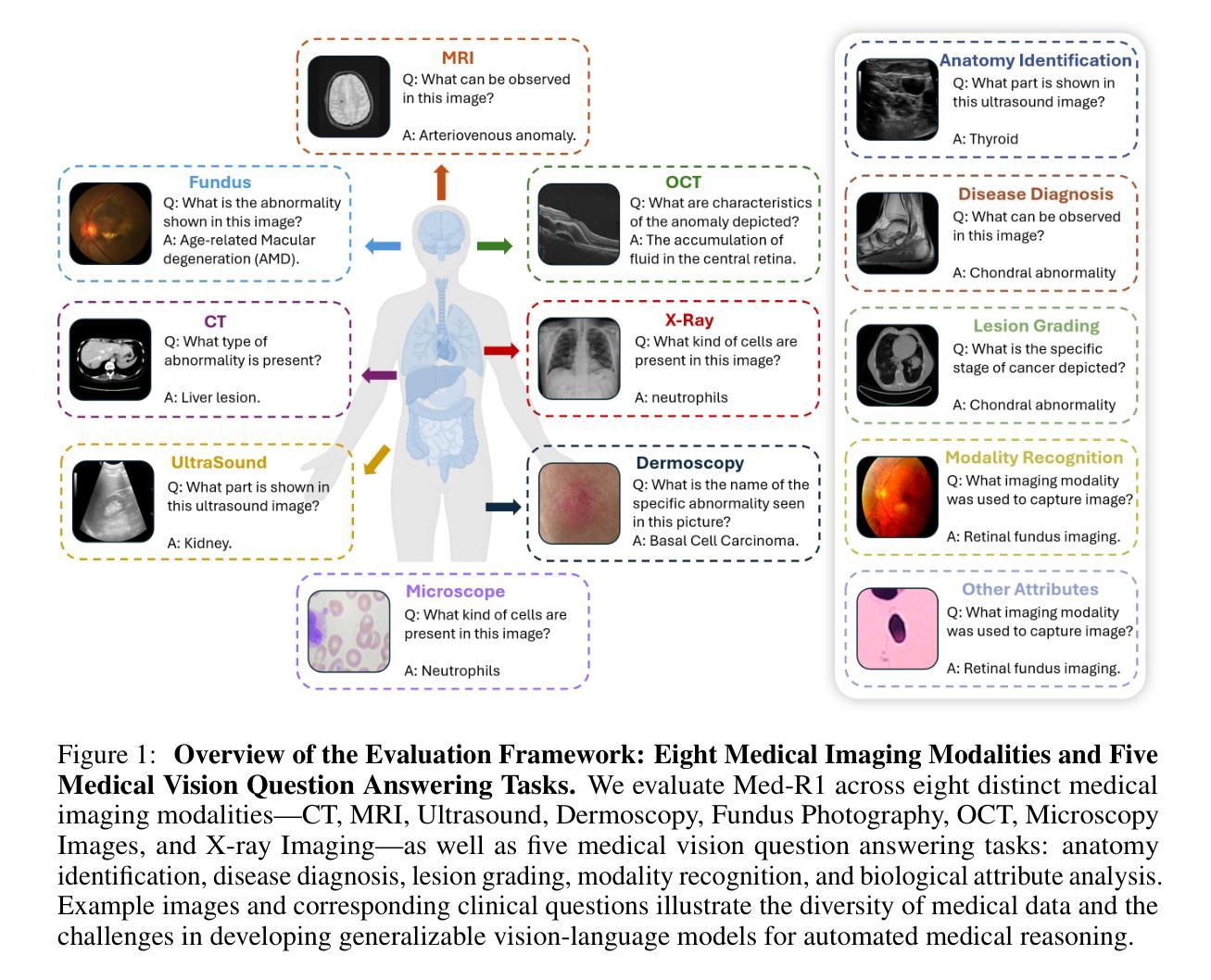
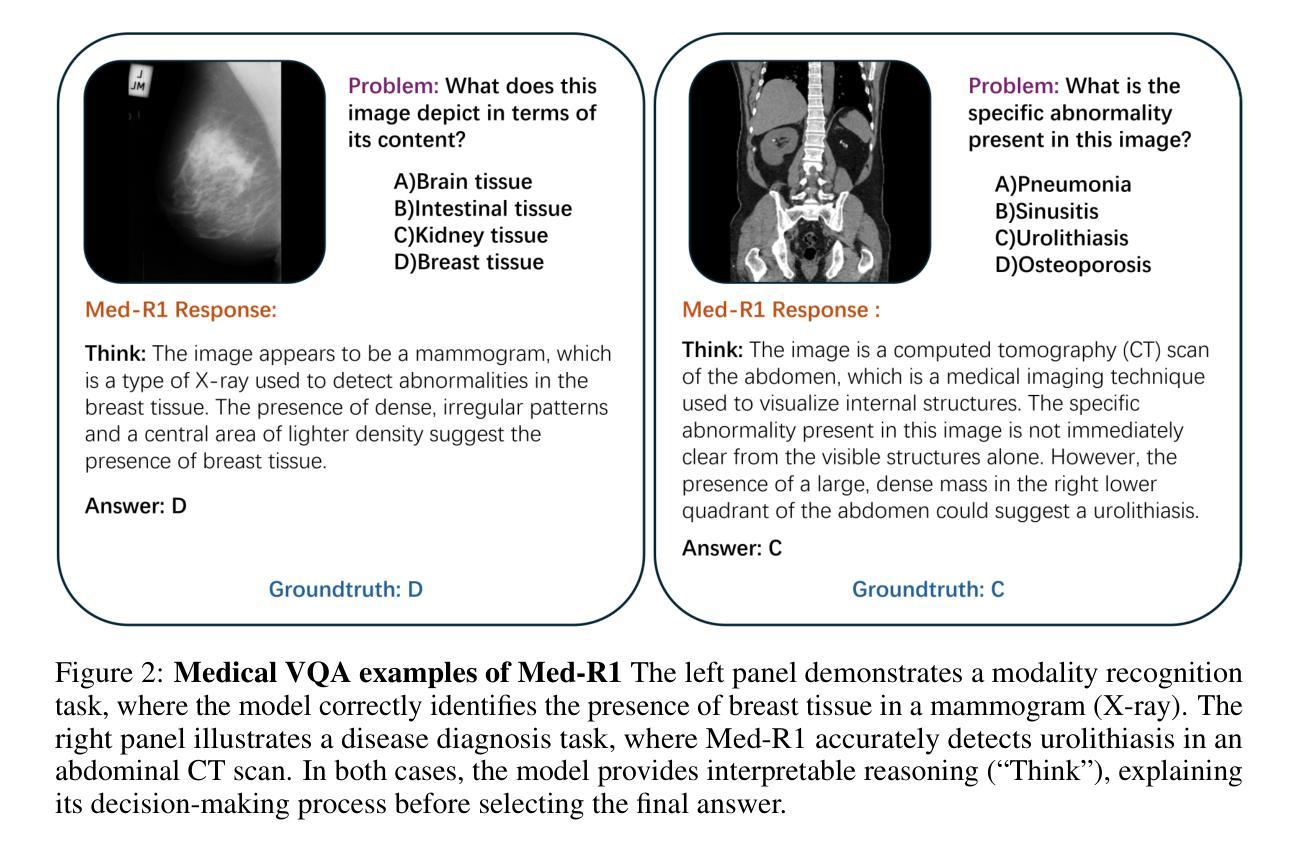
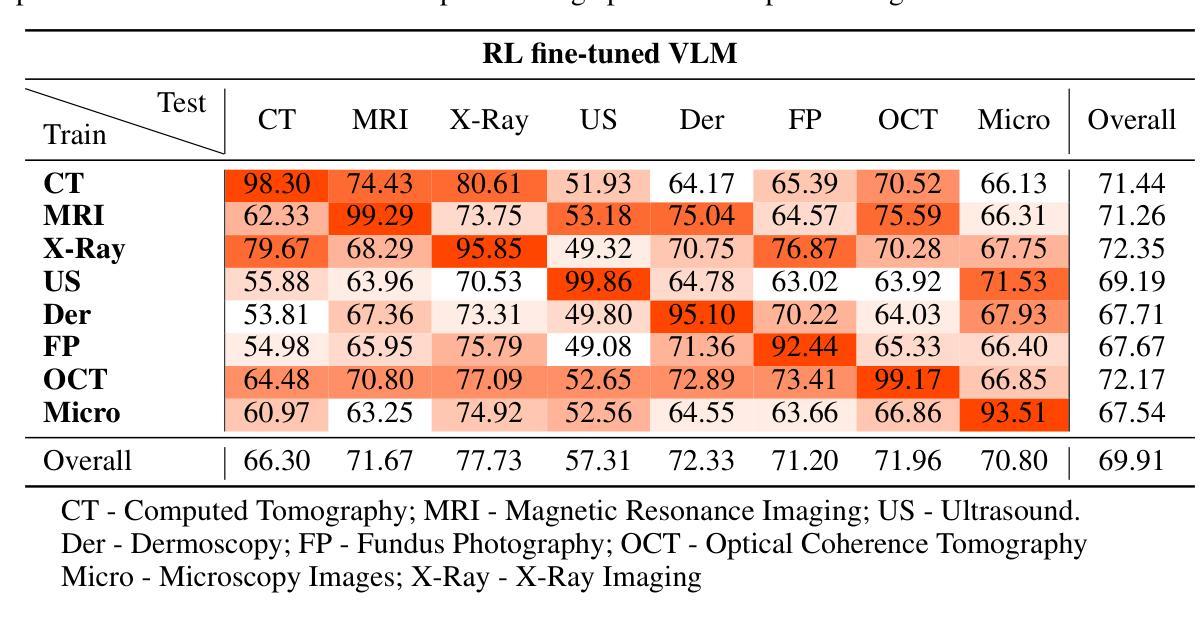
Med-R1: Reinforcement Learning for Generalizable Medical Reasoning in Vision-Language Models
Authors:Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Xiaofeng Yang
Vision-language models (VLMs) have advanced reasoning in natural scenes, but their role in medical imaging remains underexplored. Medical reasoning tasks demand robust image analysis and well-justified answers, posing challenges due to the complexity of medical images. Transparency and trustworthiness are essential for clinical adoption and regulatory compliance. We introduce Med-R1, a framework exploring reinforcement learning (RL) to enhance VLMs’ generalizability and trustworthiness in medical reasoning. Leveraging the DeepSeek strategy, we employ Group Relative Policy Optimization (GRPO) to guide reasoning paths via reward signals. Unlike supervised fine-tuning (SFT), which often overfits and lacks generalization, RL fosters robust and diverse reasoning. Med-R1 is evaluated across eight medical imaging modalities: CT, MRI, Ultrasound, Dermoscopy, Fundus Photography, Optical Coherence Tomography (OCT), Microscopy, and X-ray Imaging. Compared to its base model, Qwen2-VL-2B, Med-R1 achieves a 29.94% accuracy improvement and outperforms Qwen2-VL-72B, which has 36 times more parameters. Testing across five question types-modality recognition, anatomy identification, disease diagnosis, lesion grading, and biological attribute analysis Med-R1 demonstrates superior generalization, exceeding Qwen2-VL-2B by 32.06% and surpassing Qwen2-VL-72B in question-type generalization. These findings show that RL improves medical reasoning and enables parameter-efficient models to outperform significantly larger ones. With interpretable reasoning outputs, Med-R1 represents a promising step toward generalizable, trustworthy, and clinically viable medical VLMs.
视觉语言模型(VLMs)在自然场景中的推理能力已经得到了提升,但它们在医学成像领域的应用仍然被探索得不够。医学推理任务需要可靠的图像分析和有充分理由的答案,由于医学图像的复杂性,这构成了挑战。透明度和可信度对于临床采用和法规合规至关重要。我们引入了Med-R1框架,探索强化学习(RL)来提高VLMs在医学推理中的通用性和可信度。利用DeepSeek策略,我们采用集团相对政策优化(GRPO)通过奖励信号来引导推理路径。与经常过度拟合且缺乏泛化能力的有监督微调(SFT)不同,RL促进了稳健和多样化的推理。Med-R1在八种医学成像模式上进行了评估:CT、MRI、超声、皮肤镜检查、眼底摄影、光学相干断层扫描(OCT)、显微镜和X射线成像。与基准模型相比,Med-R1实现了29.94%的准确率提升,并超越了参数更多的Qwen2-VL-72B。在五种问题类型(模态识别、解剖结构识别、疾病诊断、病变分级和生物属性分析)的测试上,Med-R1展现出卓越的泛化能力,相较于Qwen2-VL-2B提高32.06%,并在问题类型泛化上超越了Qwen2-VL-72B。这些发现表明,RL能够改善医学推理,并使得参数效率高的模型能够超越规模更大的模型。Med-R1的可解释推理输出代表了一个有希望的步骤,朝着通用、可信和临床上可行的医学VLMs发展。
论文及项目相关链接
Summary
通过引入强化学习(RL),提出Med-R1框架,提高视觉语言模型(VLMs)在医疗推理中的通用性和可信度。Med-R1采用DeepSeek策略,利用集团相对策略优化(GRPO)通过奖励信号引导推理路径。与监督微调(SFT)相比,RL促进稳健和多样化的推理。在八种医学成像模态上评估Med-R1,相比基准模型,其准确度提高了29.94%,并在参数较少的模型中表现出优越性。Med-R1展现出卓越的问题类型泛化能力,包括模态识别、解剖结构识别、疾病诊断、病变分级和生物属性分析等方面。这表明强化学习有助于改进医疗推理,使参数效率模型能够超越更大的模型。Med-R1的可解释性推理输出是朝着通用、可信和临床可行的医疗VLMs迈出的有希望的一步。
Key Takeaways
- Med-R1框架探索强化学习(RL)在医疗推理中的应用,以增强视觉语言模型(VLMs)的通用性和可信度。
- 采用DeepSeek策略和集团相对策略优化(GRPO)来引导推理路径。
- 与监督微调(SFT)相比,强化学习(RL)促进更稳健和多样化的推理。
- Med-R1在八种医学成像模态上进行了评估,并实现了显著的性能提升。
- Med-R1展现出优秀的问题类型泛化能力,包括模态识别、解剖结构识别等五个方面的问题。
- 强化学习有助于改进医疗推理,参数效率模型可超越更大模型。
点此查看论文截图

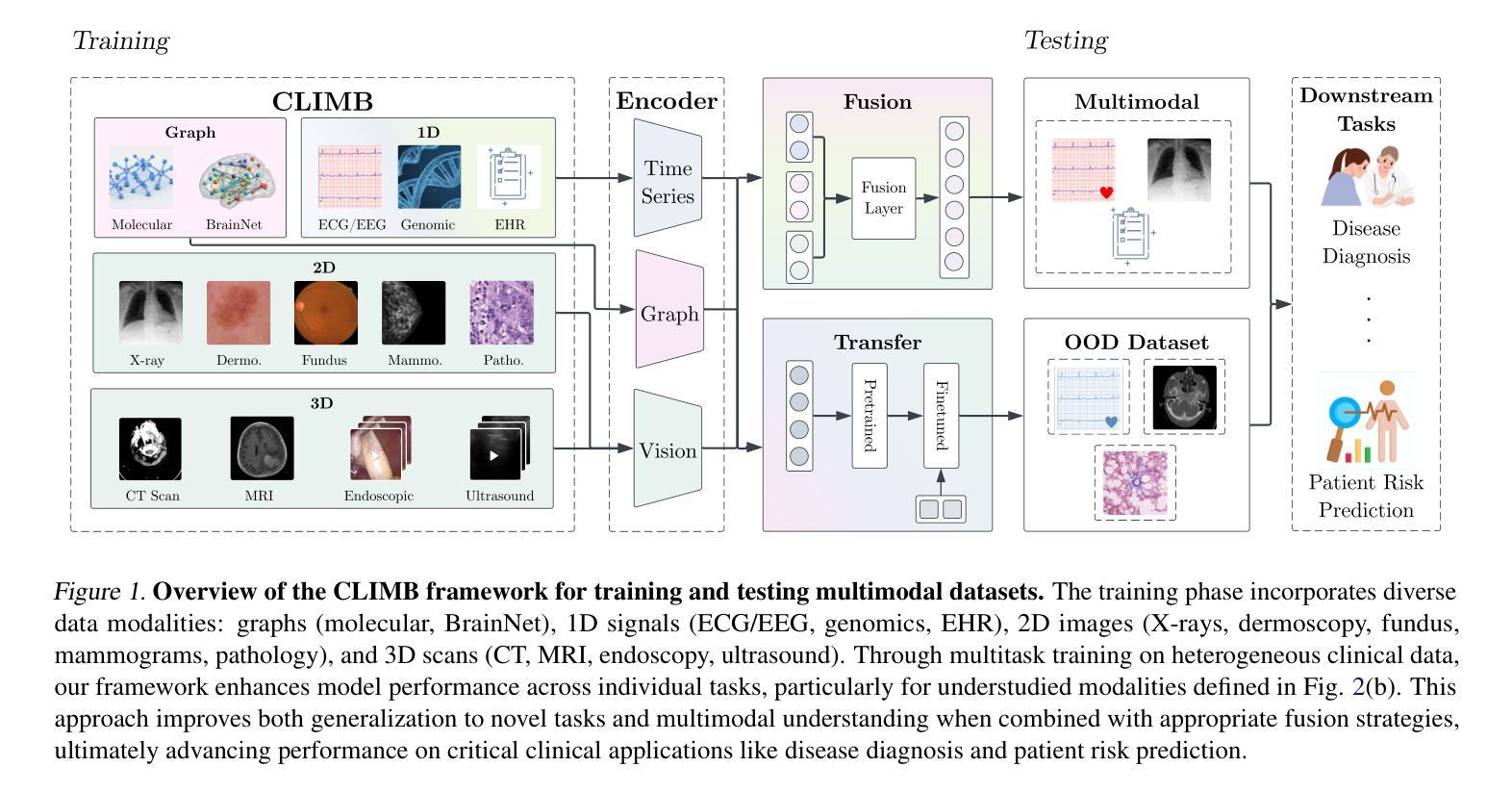
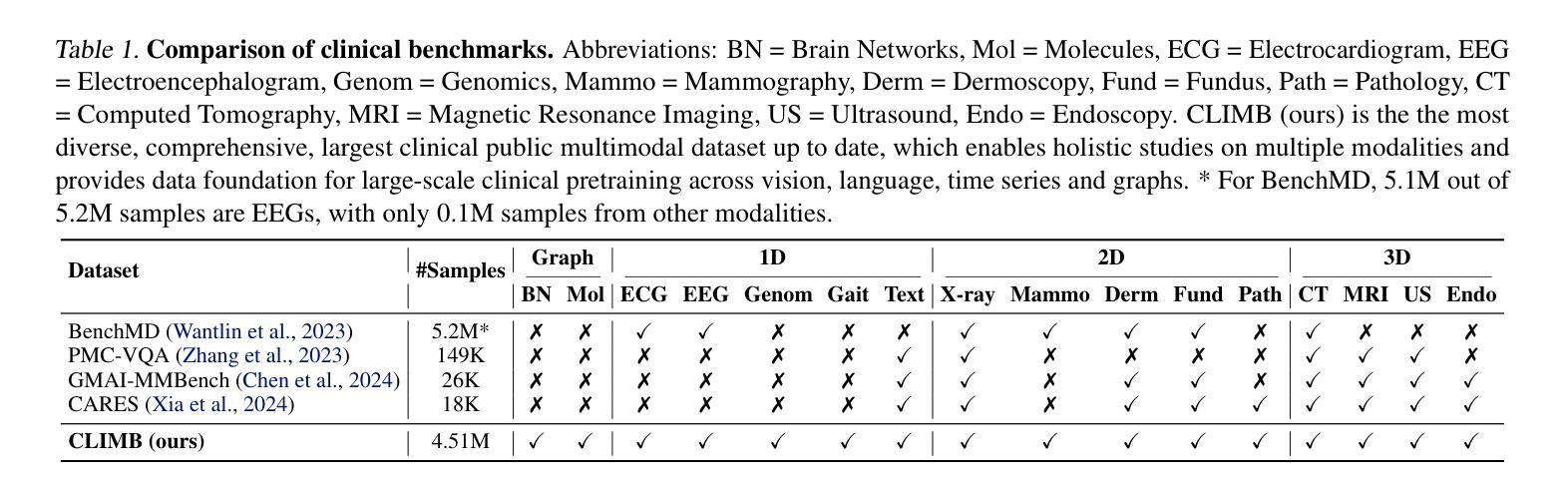
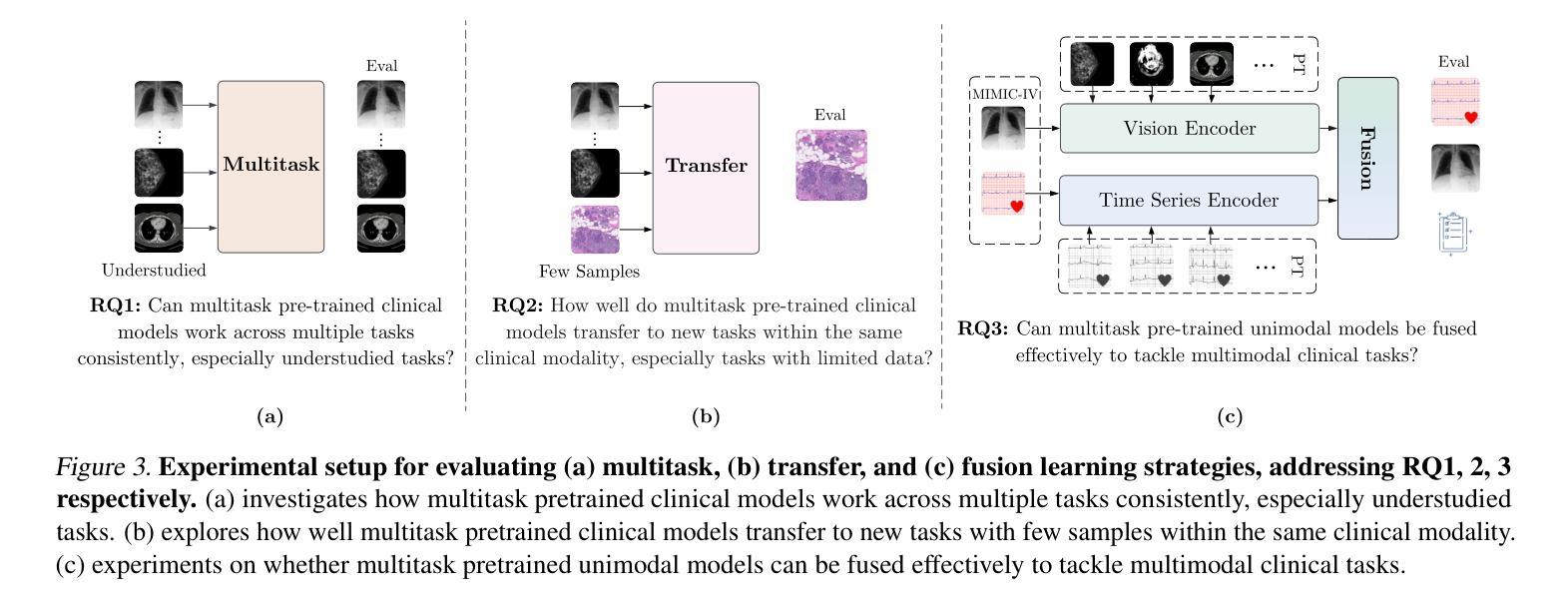
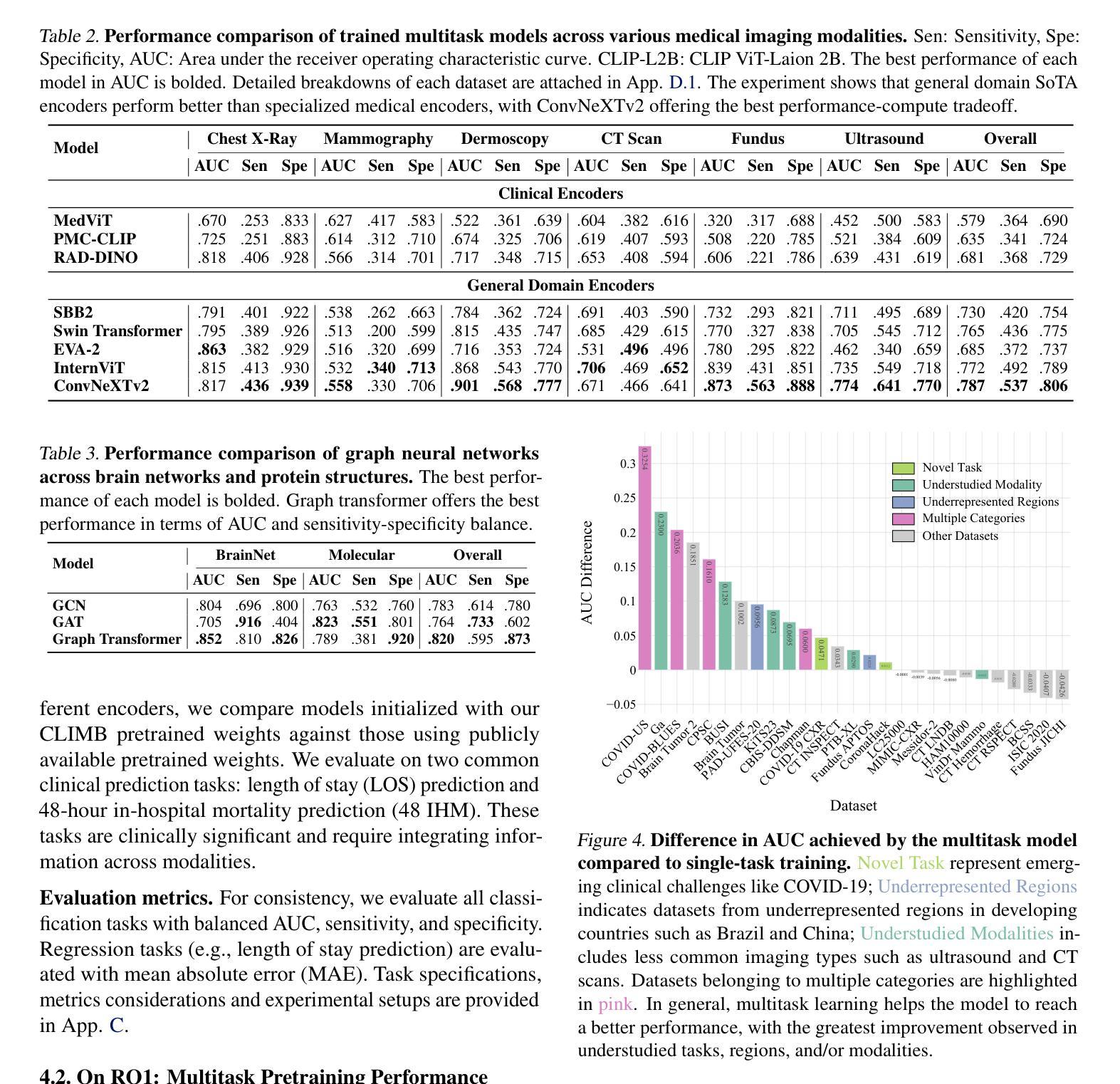
CLIMB: Data Foundations for Large Scale Multimodal Clinical Foundation Models
Authors:Wei Dai, Peilin Chen, Malinda Lu, Daniel Li, Haowen Wei, Hejie Cui, Paul Pu Liang
Recent advances in clinical AI have enabled remarkable progress across many clinical domains. However, existing benchmarks and models are primarily limited to a small set of modalities and tasks, which hinders the development of large-scale multimodal methods that can make holistic assessments of patient health and well-being. To bridge this gap, we introduce Clinical Large-Scale Integrative Multimodal Benchmark (CLIMB), a comprehensive clinical benchmark unifying diverse clinical data across imaging, language, temporal, and graph modalities. CLIMB comprises 4.51 million patient samples totaling 19.01 terabytes distributed across 2D imaging, 3D video, time series, graphs, and multimodal data. Through extensive empirical evaluation, we demonstrate that multitask pretraining significantly improves performance on understudied domains, achieving up to 29% improvement in ultrasound and 23% in ECG analysis over single-task learning. Pretraining on CLIMB also effectively improves models’ generalization capability to new tasks, and strong unimodal encoder performance translates well to multimodal performance when paired with task-appropriate fusion strategies. Our findings provide a foundation for new architecture designs and pretraining strategies to advance clinical AI research. Code is released at https://github.com/DDVD233/climb.
近年来,临床人工智能的进步在许多临床领域都取得了显著的进展。然而,现有的基准测试和模型主要局限于少数几种模态和任务,这阻碍了能够全面评估患者健康和福祉的大规模多模态方法的发展。为了弥补这一差距,我们推出了临床大规模综合多模态基准测试(CLIMB),这是一个统一的临床基准测试,涵盖了成像、语言、时间和图形等多种临床数据模态。CLIMB包含451万患者样本,总计19.01万亿字节的数据,分布在二维成像、三维视频、时间序列、图形和多模态数据中。通过广泛的实证评估,我们证明多任务预训练在较少研究的领域可以显著提高性能,在超声和心电图分析中分别实现了高达29%和23%的改进,超过单任务学习。在CLIMB上进行预训练还可以有效提高模型对新任务的泛化能力,强大的单模态编码器性能在与任务适当的融合策略配对时,可以很好地转化为多模态性能。我们的研究为新的架构设计和预训练策略提供了基础,以推动临床人工智能研究的发展。代码已发布在https://github.com/DDVD233/climb。
论文及项目相关链接
Summary
临床人工智能的最新进展已在多个临床领域取得显著成果。然而,现有基准测试和模型主要局限于少数几种模态和任务,这阻碍了能够进行患者健康与福祉全面评估的大规模多模态方法的发展。为弥补这一差距,我们推出了临床大规模综合多模态基准测试(CLIMB),这是一个统一了成像、语言、时间和图形等多种临床数据的综合基准测试。CLIMB包含451万患者样本,总计19.01万亿字节的数据,涵盖了2D成像、3D视频、时间序列、图形和多模态数据。通过广泛的实证评估,我们证明了多任务预训练能显著改善以往研究较少的领域的性能,在超声和心电图分析中分别实现了高达29%和23%的改进。在CLIMB上进行预训练还能有效提高模型对新任务的泛化能力,强大的单模态编码器性能配合适当的融合策略在多模态性能上也有良好表现。我们的研究为临床人工智能研究的新架构设计和预训练策略提供了基础。相关代码已发布于https://github.com/DDVD233/climb。
Key Takeaways
- 临床人工智能(AI)在多个领域取得显著进展,但现有基准测试和模型局限于特定模态和任务,阻碍大规模多模态方法的发展。
- 推出CLIMB综合临床基准测试,涵盖多种临床数据模态,包括成像、语言、时间和图形等。
- CLIMB包含大量患者样本和广泛的数据量,为临床AI研究提供丰富资源。
- 多任务预训练能有效提高在以往研究较少的领域的性能,如超声和心电图分析。
- 在CLIMB上进行预训练有助于提高模型对新任务的泛化能力。
- 强大的单模态编码器性能配合适当的融合策略在多模态任务上表现良好。
点此查看论文截图


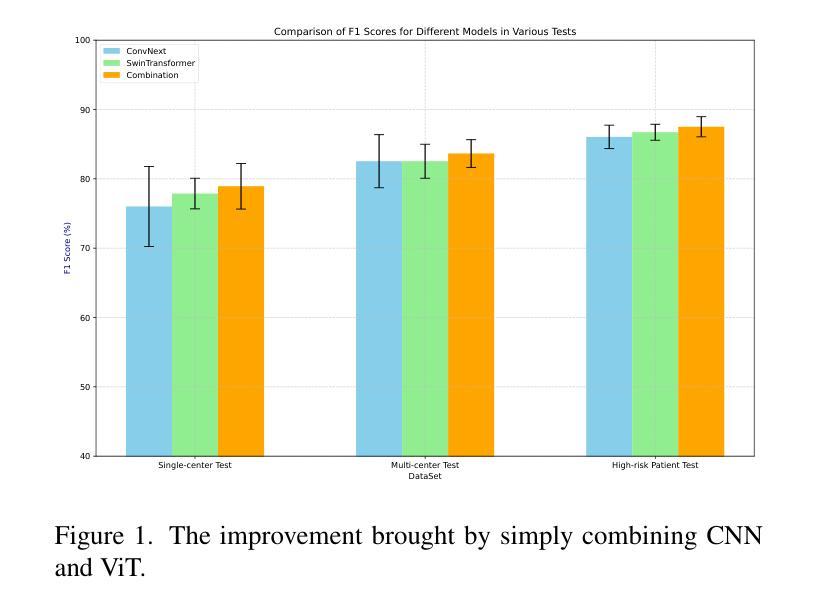
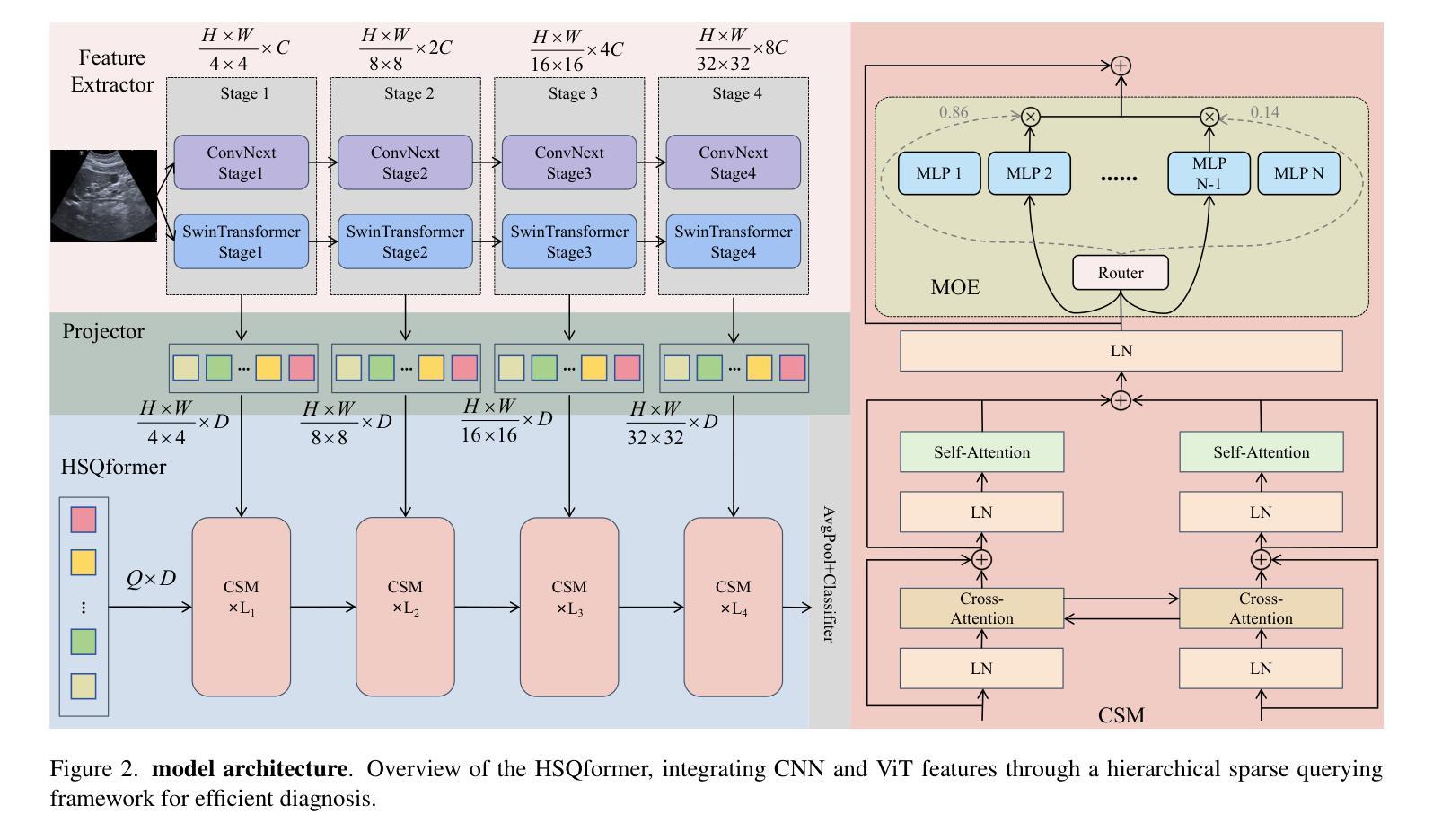
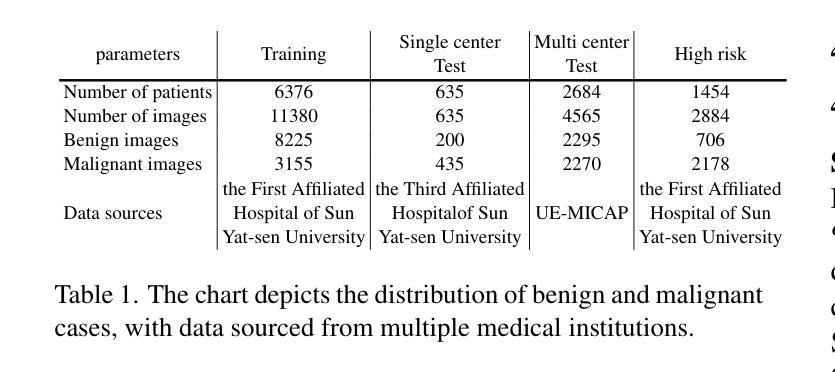
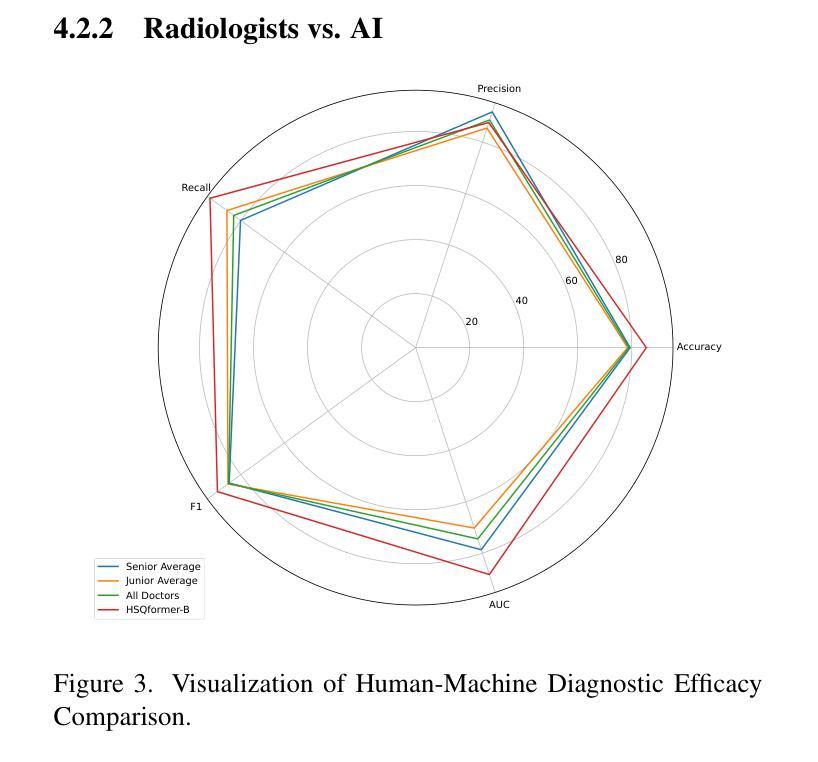
A Retrospective Systematic Study on Hierarchical Sparse Query Transformer-assisted Ultrasound Screening for Early Hepatocellular Carcinoma
Authors:Chaoyin She, Ruifang Lu, Danni He, Jiayi Lv, Yadan Lin, Meiqing Cheng, Hui Huang, Fengyu Ye, Lida Chen, Wei Wang, Qinghua Huang
Hepatocellular carcinoma (HCC), ranking as the third leading cause of cancer-related mortality worldwide, demands urgent improvements in early detection to enhance patient survival. While ultrasound remains the preferred screening modality due to its cost-effectiveness and real-time capabilities, its sensitivity (59%-78%) heavily relies on radiologists’ expertise, leading to inconsistent diagnostic outcomes and operational inefficiencies. Recent advancements in AI technology offer promising solutions to bridge this gap. This study introduces the Hierarchical Sparse Query Transformer (HSQformer), a novel hybrid architecture that synergizes CNNs’ local feature extraction with Vision Transformers’ global contextual awareness through latent space representation and sparse learning. By dynamically activating task-specific experts via a Mixture-of-Experts (MoE) framework, HSQformer achieves hierarchical feature integration without structural redundancy. Evaluated across three clinical scenarios: single-center, multi-center, and high-risk patient cohorts, HSQformer outperforms state-of-the-art models (e.g., 95.38% AUC in multi-center testing) and matches senior radiologists’ diagnostic accuracy while significantly surpassing junior counterparts. These results highlight the potential of AI-assisted tools to standardize HCC screening, reduce dependency on human expertise, and improve early diagnosis rates. The full code is available at https://github.com/Asunatan/HSQformer.
肝细胞癌(HCC)作为全球第三大癌症致死原因,急需改进早期检测方法以提高患者存活率。虽然超声因其成本效益和实时能力仍是首选筛查方式,但其敏感性(59%-78%)严重依赖于放射科专家的经验,导致诊断结果不一致和运营效率低下。最近人工智能技术的进展为解决这一问题提供了有希望的解决方案。本研究介绍了分层稀疏查询转换器(HSQformer),这是一种新型混合架构,它通过潜在空间表示和稀疏学习,协同CNN的局部特征提取和视觉变压器的全局上下文感知。HSQformer通过专家混合(MoE)框架动态激活任务特定专家,实现分层特征集成,无结构冗余。在三种临床情景:单中心、多中心和高危患者群体中进行评估,HSQformer的性能超过了最先进模型(例如在多中心测试中的95.38% AUC),并达到了资深放射科医生的诊断精度,同时显著超越了初级医生的水平。这些结果突出了人工智能辅助工具在标准化肝细胞癌筛查、减少对人类专家的依赖以及提高早期诊断率方面的潜力。完整代码可在https://github.com/Asunatan/HSQformer找到。
论文及项目相关链接
Summary
本文介绍了肝细胞癌(HCC)的早期检测现状和挑战,强调了人工智能技术在提升诊断准确性方面的潜力。研究提出了一种新型的混合架构HSQformer,它通过结合CNNs的局部特征提取和Vision Transformers的全局上下文感知能力,实现了层次化的特征融合。HSQformer在不同临床场景下的表现优于现有模型,甚至达到资深放射科医生的诊断水平,有望标准化HCC筛查,减少对人力的依赖,提高早期诊断率。
Key Takeaways
- 肝细胞癌(HCC)是全球第三大致癌死因,急需改进早期检测技术以提高患者存活率。
- 超声波是目前首选的筛查方式,但其敏感性依赖于放射科专家的经验,导致诊断结果的不一致和运营效率低下。
- 人工智能技术为解决这一问题提供了有希望的解决方案。
- HSQformer是一种新型混合架构,结合了CNN和Vision Transformer的优点,实现层次化的特征提取和融合。
- HSQformer在不同临床场景下的表现优于现有模型,且与资深放射科医生相当,甚至在某些情况下更佳。
- HSQformer有望标准化HCC筛查,减少对人力的依赖,提高早期诊断率。
点此查看论文截图

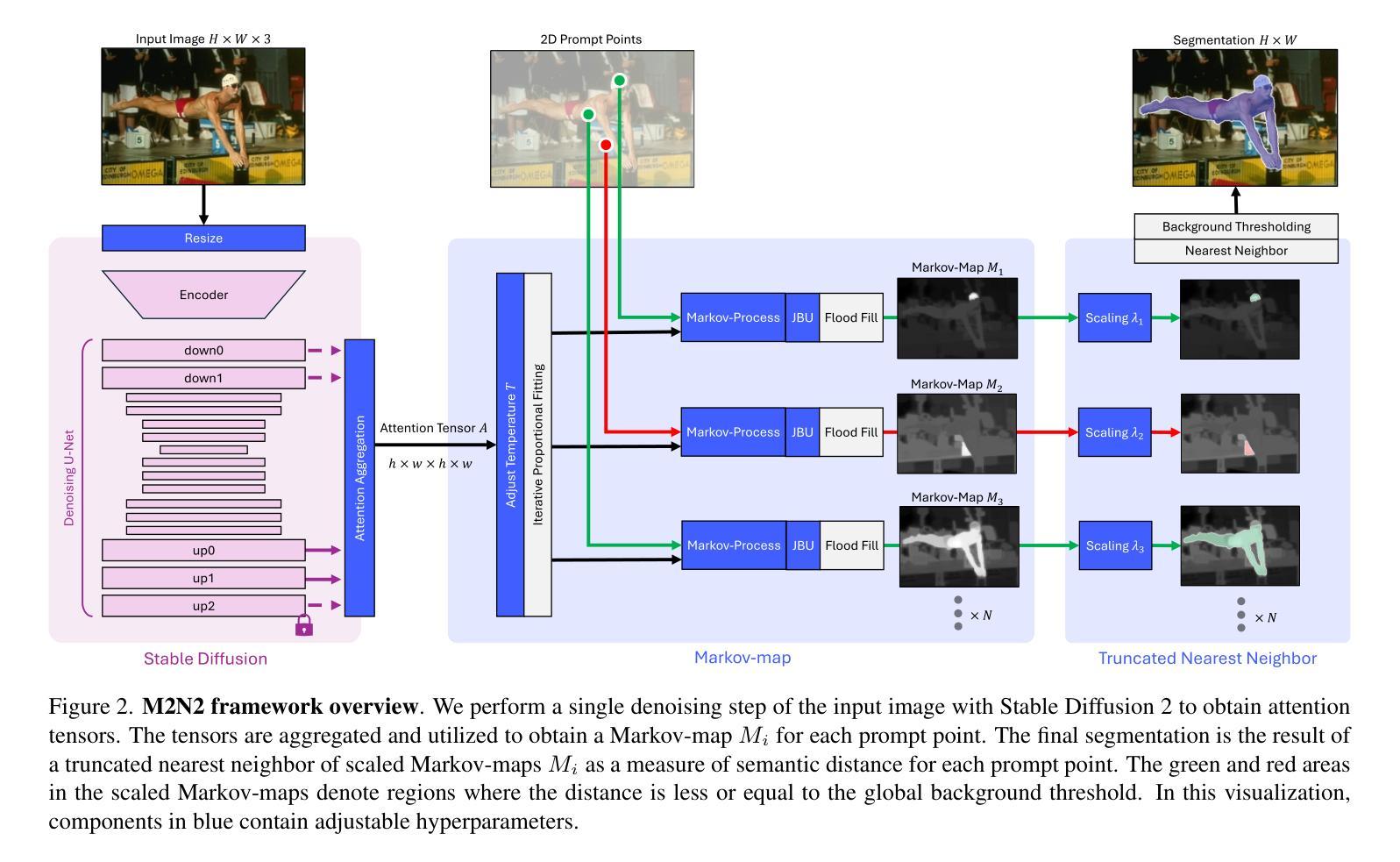
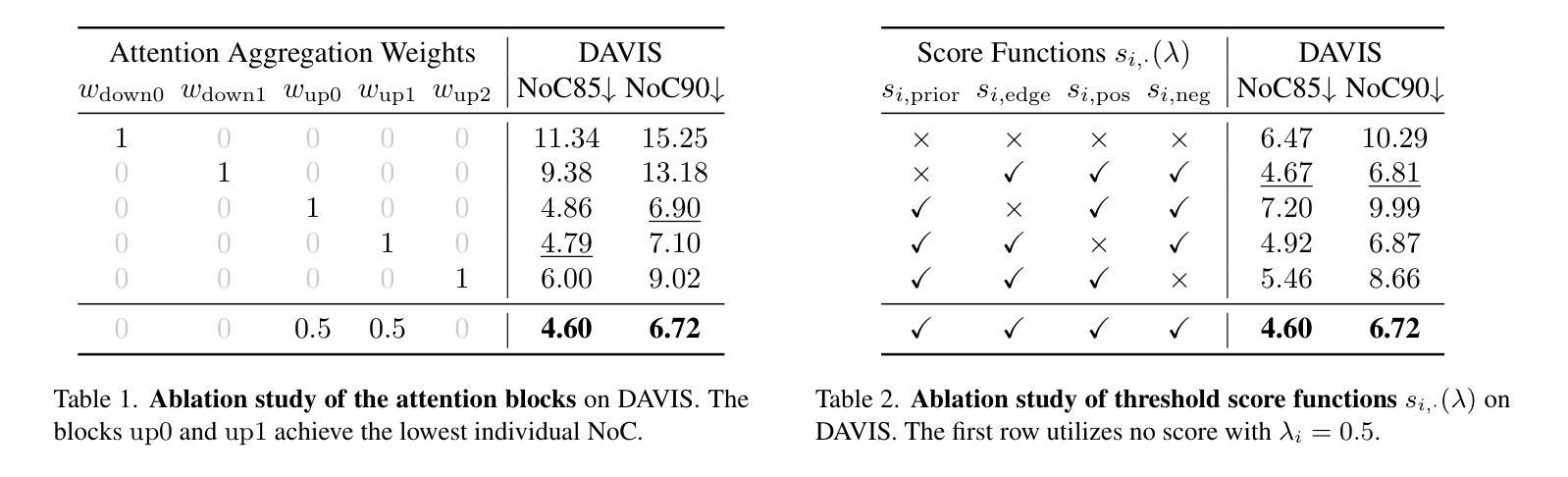
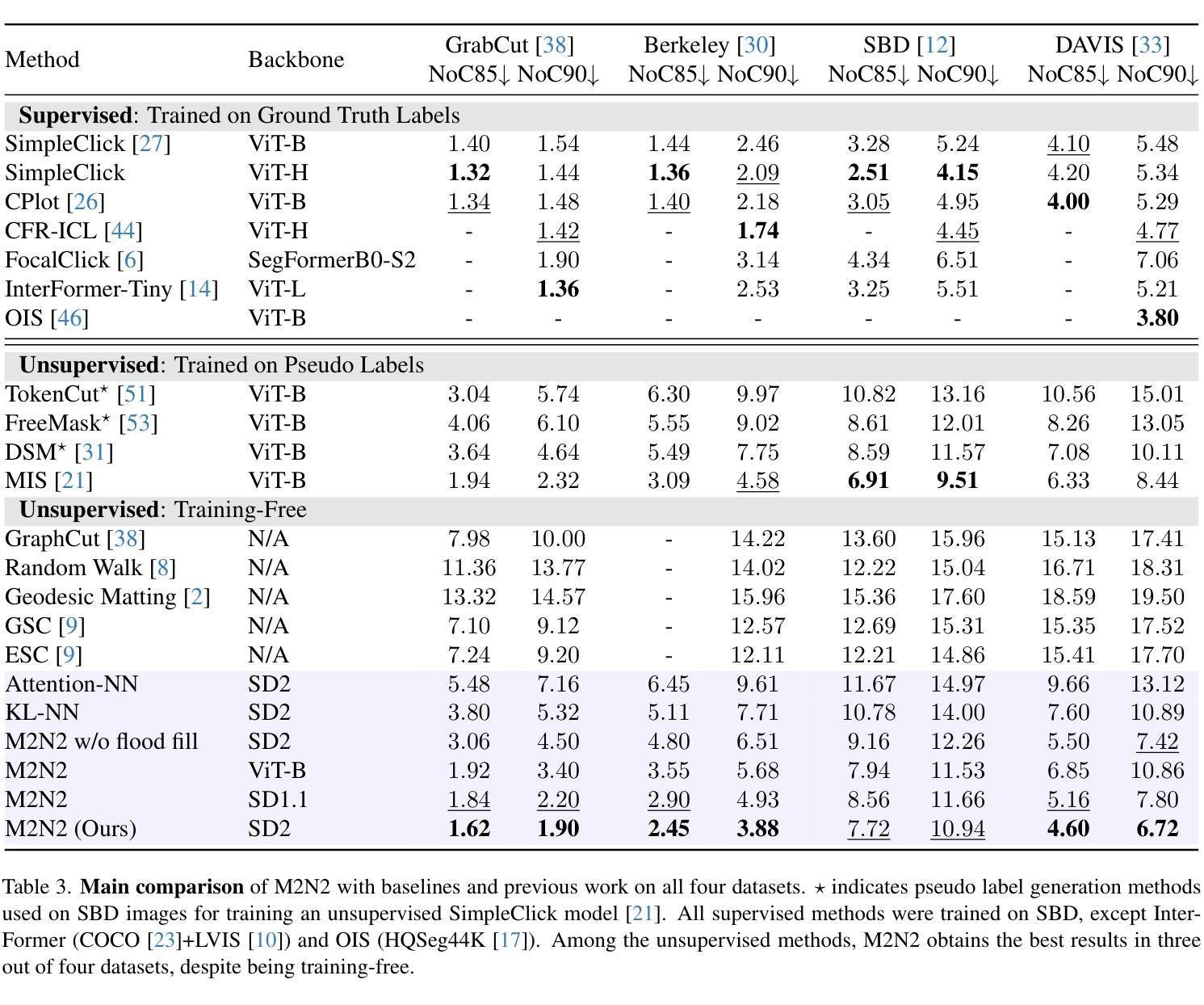
Repurposing Stable Diffusion Attention for Training-Free Unsupervised Interactive Segmentation
Authors:Markus Karmann, Onay Urfalioglu
Recent progress in interactive point prompt based Image Segmentation allows to significantly reduce the manual effort to obtain high quality semantic labels. State-of-the-art unsupervised methods use self-supervised pre-trained models to obtain pseudo-labels which are used in training a prompt-based segmentation model. In this paper, we propose a novel unsupervised and training-free approach based solely on the self-attention of Stable Diffusion. We interpret the self-attention tensor as a Markov transition operator, which enables us to iteratively construct a Markov chain. Pixel-wise counting of the required number of iterations along the Markov chain to reach a relative probability threshold yields a Markov-iteration-map, which we simply call a Markov-map. Compared to the raw attention maps, we show that our proposed Markov-map has less noise, sharper semantic boundaries and more uniform values within semantically similar regions. We integrate the Markov-map in a simple yet effective truncated nearest neighbor framework to obtain interactive point prompt based segmentation. Despite being training-free, we experimentally show that our approach yields excellent results in terms of Number of Clicks (NoC), even outperforming state-of-the-art training based unsupervised methods in most of the datasets. Code is available at https://github.com/mkarmann/m2n2.
近期基于交互式点提示的图像分割技术的进展,显著减少了获得高质量语义标签所需的人工努力。最先进的无监督方法使用自监督预训练模型来获得伪标签,这些伪标签用于训练基于提示的分割模型。在本文中,我们提出了一种全新的无监督且无需训练的方法,该方法仅基于Stable Diffusion的自注意力。我们将自注意力张量解释为马尔可夫转移算子,这使我们能够构建马尔可夫链。沿着马尔可夫链进行所需的迭代次数的像素级计数,以达到相对概率阈值,从而产生马尔可夫迭代图,我们将其简称为马尔可夫图。与原始注意力图相比,我们显示所提出的马尔可夫图具有较少的噪声、更清晰的语义边界和语义相似区域内更均匀的值。我们将马尔可夫图集成到一个简单而有效的截断最近邻框架中,以获得基于交互式点的提示分割。尽管无需训练,但实验表明,我们的方法在点击次数(NoC)方面表现出色,甚至在大多数数据集上超越了基于训练的无监督方法的最新技术。相关代码可在https://github.com/mkarmann/m2n2处获取。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
基于交互式点提示的图像分割新方法,利用Stable Diffusion的自注意力机制构建Markov链,提出一种无监督且无需训练的新方法生成Markov图,用于图像分割。该方法在数据集上的表现优异,减少了手动操作的复杂性,且点击数较低(NoC),甚至在多数数据集上超过了基于训练的无监督方法。
Key Takeaways
- 该方法基于Stable Diffusion的自注意力机制。
- 通过构建Markov链,提出了名为Markov图的模型。
- Markov图相比原始注意力图具有更低的噪声和更清晰的语义边界。
- 该方法整合了Markov图到截断最近邻框架中,实现了基于交互式点提示的图像分割。
- 该方法无需训练即可生成良好的结果。
- 该方法在点击数(NoC)方面的表现优秀。
点此查看论文截图

Label-efficient multi-organ segmentation with a diffusion model
Authors:Yongzhi Huang, Fengjun Xi, Liyun Tu, Jinxin Zhu, Haseeb Hassan, Liyilei Su, Yun Peng, Jingyu Li, Jun Ma, Bingding Huang
Accurate segmentation of multiple organs in Computed Tomography (CT) images plays a vital role in computer-aided diagnosis systems. While various supervised learning approaches have been proposed recently, these methods heavily depend on a large amount of high-quality labeled data, which are expensive to obtain in practice. To address this challenge, we propose a label-efficient framework using knowledge transfer from a pre-trained diffusion model for CT multi-organ segmentation. Specifically, we first pre-train a denoising diffusion model on 207,029 unlabeled 2D CT slices to capture anatomical patterns. Then, the model backbone is transferred to the downstream multi-organ segmentation task, followed by fine-tuning with few labeled data. In fine-tuning, two fine-tuning strategies, linear classification and fine-tuning decoder, are employed to enhance segmentation performance while preserving learned representations. Quantitative results show that the pre-trained diffusion model is capable of generating diverse and realistic 256x256 CT images (Fr'echet inception distance (FID): 11.32, spatial Fr'echet inception distance (sFID): 46.93, F1-score: 73.1%). Compared to state-of-the-art methods for multi-organ segmentation, our method achieves competitive performance on the FLARE 2022 dataset, particularly in limited labeled data scenarios. After fine-tuning with 1% and 10% labeled data, our method achieves dice similarity coefficients (DSCs) of 71.56% and 78.51%, respectively. Remarkably, the method achieves a DSC score of 51.81% using only four labeled CT slices. These results demonstrate the efficacy of our approach in overcoming the limitations of supervised learning approaches that is highly dependent on large-scale labeled data.
在计算机断层扫描(CT)图像中,多器官精准分割在计算机辅助诊断系统中起着至关重要的作用。尽管最近已经提出了各种监督学习方法,但这些方法严重依赖于大量高质量标记数据,而在实践中这些数据获取成本高昂。为了解决这一挑战,我们提出了一种使用知识转移的CT多器官分割标签有效框架,该框架基于预训练的扩散模型。具体来说,我们首先在207,029张无标签的2D CT切片上预训练一个去噪扩散模型,以捕捉解剖模式。然后,将模型主干转移到下游多器官分割任务中,并使用少量标记数据进行微调。在微调过程中,我们采用了两种微调策略,即线性分类和微调解码器,以提高分割性能同时保留学习到的表示。定量结果表明,预训练的扩散模型能够生成多样且逼真的256x256 CT图像(Fréchet inception距离(FID):11.32,空间Fréchet inception距离(sFID):46.93,F1分数:73.1%)。与多器官分割的最先进方法相比,我们的方法在FLARE 2022数据集上实现了具有竞争力的性能,特别是在有限标记数据的情况下。使用1%和10%的标记数据进行微调后,我们的方法实现了迪克相似系数(DSC)分别为71.56%和78.51%。值得注意的是,该方法仅使用四个标记的CT切片就达到了51.81%的DSC得分。这些结果证明了我们的方法在克服高度依赖于大规模标记数据的监督学习方法的局限性方面的有效性。
论文及项目相关链接
Summary
在医学图像领域,对计算机断层扫描(CT)图像中多个器官的准确分割在计算机辅助诊断系统中起着至关重要的作用。针对监督学习方法需要大量高质量标注数据的挑战,我们提出了一种使用预训练扩散模型进行CT多器官分割的标签有效框架。该框架首先在大规模未标记的CT切片上预训练去噪扩散模型,然后将其应用于下游多器官分割任务,并在少量标记数据上进行微调。实验结果表明,该预训练扩散模型能够生成多样且逼真的CT图像,并在有限标记数据场景下实现了与最新多器官分割方法相竞争的性能。
Key Takeaways
- 监督学习方法在医学图像分割中需要大量高质量标注数据,这在实际应用中成本高昂。
- 提出了一种基于预训练扩散模型的标签有效框架,用于CT多器官分割。
- 框架首先在大量未标记的CT切片上预训练去噪扩散模型,学习解剖模式。
- 框架随后将预训练的模型应用于下游任务,并在少量标记数据上进行微调。
- 采用了两种微调策略:线性分类和微调解码器,以提高分割性能并保留学习到的表示。
- 实验结果表明,预训练扩散模型能够生成逼真的CT图像,并在FLARE 2022数据集上实现了具有竞争力的性能。
点此查看论文截图