⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
Fine-Grained Open-Vocabulary Object Detection with Fined-Grained Prompts: Task, Dataset and Benchmark
Authors:Ying Liu, Yijing Hua, Haojiang Chai, Yanbo Wang, TengQi Ye
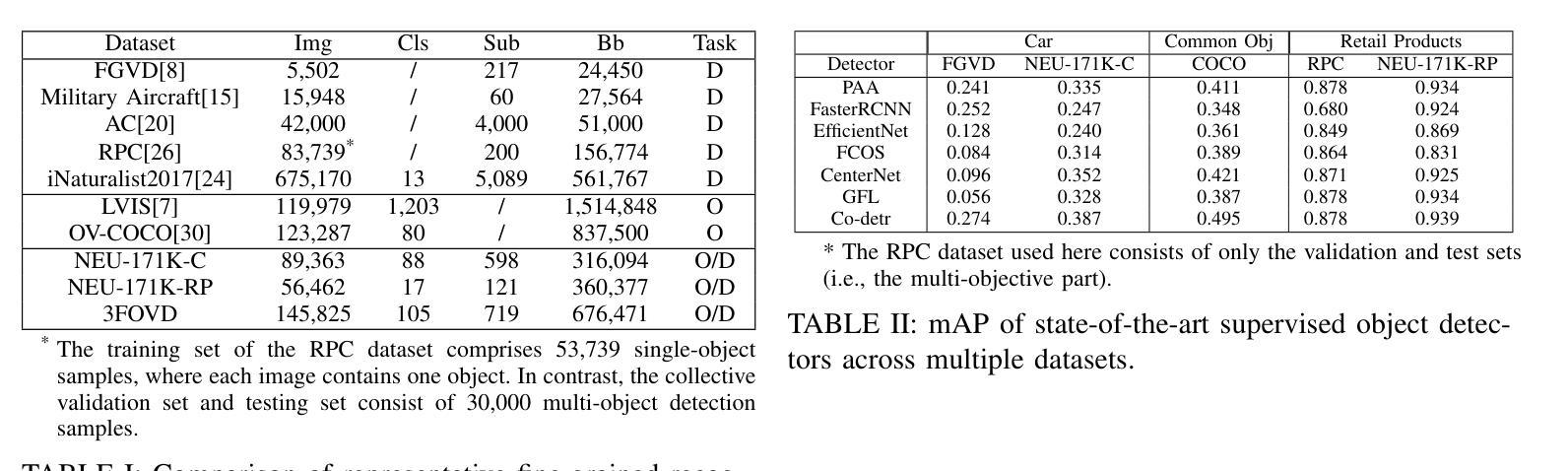
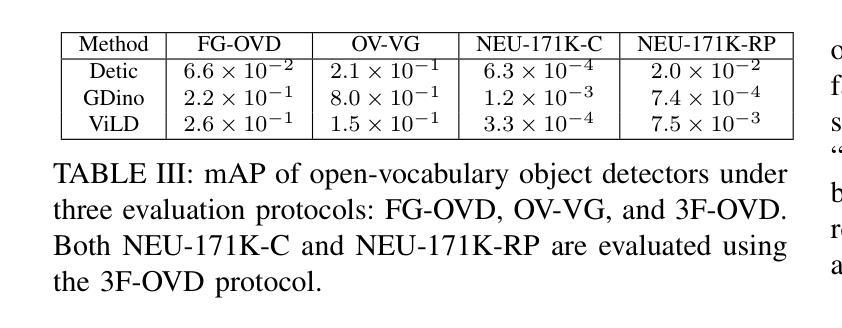
Open-vocabulary detectors are proposed to locate and recognize objects in novel classes. However, variations in vision-aware language vocabulary data used for open-vocabulary learning can lead to unfair and unreliable evaluations. Recent evaluation methods have attempted to address this issue by incorporating object properties or adding locations and characteristics to the captions. Nevertheless, since these properties and locations depend on the specific details of the images instead of classes, detectors can not make accurate predictions without precise descriptions provided through human annotation. This paper introduces 3F-OVD, a novel task that extends supervised fine-grained object detection to the open-vocabulary setting. Our task is intuitive and challenging, requiring a deep understanding of Fine-grained captions and careful attention to Fine-grained details in images in order to accurately detect Fine-grained objects. Additionally, due to the scarcity of qualified fine-grained object detection datasets, we have created a new dataset, NEU-171K, tailored for both supervised and open-vocabulary settings. We benchmark state-of-the-art object detectors on our dataset for both settings. Furthermore, we propose a simple yet effective post-processing technique.
开放词汇检测器被提出用于定位和识别新型类别中的物体。然而,用于开放词汇学习的视觉感知语言词汇数据的差异可能导致评价不公和不可靠。最近的评估方法试图通过结合物体属性或在字幕中添加位置和特征来解决这个问题。然而,由于这些属性和位置依赖于图像的特定细节而不是类别,如果没有通过人类注释提供的精确描述,检测器无法做出准确的预测。本文介绍了3F-OVD,这是一个将监督的精细对象检测扩展到开放词汇设置的新任务。我们的任务是直观且具有挑战性的,需要深入了解精细字幕和图像中精细细节的仔细关注,以准确检测精细对象。此外,由于合格的精细对象检测数据集稀缺,我们为监督和开放词汇设置量身定制了NEU-171K新数据集。我们在该数据集上针对这两种设置对最先进的物体检测器进行了基准测试。此外,我们还提出了一种简单有效的后处理技术。
论文及项目相关链接
PDF 8 pages, 4 figures
Summary
本论文针对开放词汇表检测器在定位和识别新型物体时存在的问题,提出了一个名为3F-OVD的新任务。为了解决使用不同词汇表的评价不公和不可靠的问题,文章通过图像细节丰富了物体描述,并引入了新的数据集NEU-171K以适应监督与开放词汇表两种设置。此外,论文还提出一种简洁有效的后处理技巧来提升检测器的性能。
Key Takeaways
- 开放词汇表检测器能够定位和识别新型物体。
- 不同的视觉感知语言词汇表数据会导致评价的不公平和不可靠。
- 3F-OVD任务将监督细致的物体检测扩展到开放词汇表环境。
- 该任务需要深入理解细致描述的图像并关注图像中的细节以准确检测物体。
- 为了适应监督与开放词汇表两种设置,论文创建了一个新的数据集NEU-171K。
- 文章对最先进的物体检测器进行了基准测试,评估其在两种设置下的性能。
点此查看论文截图



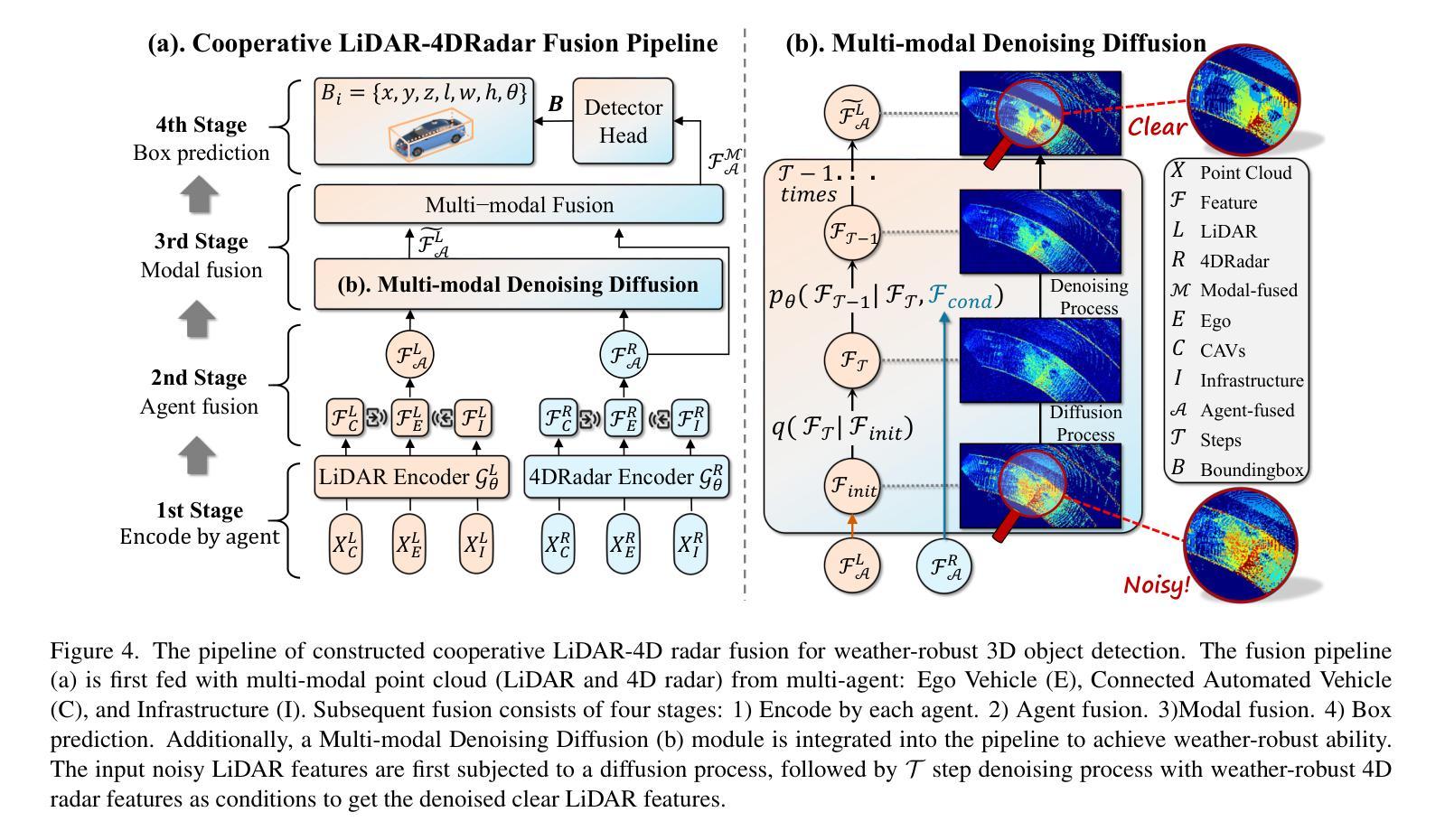
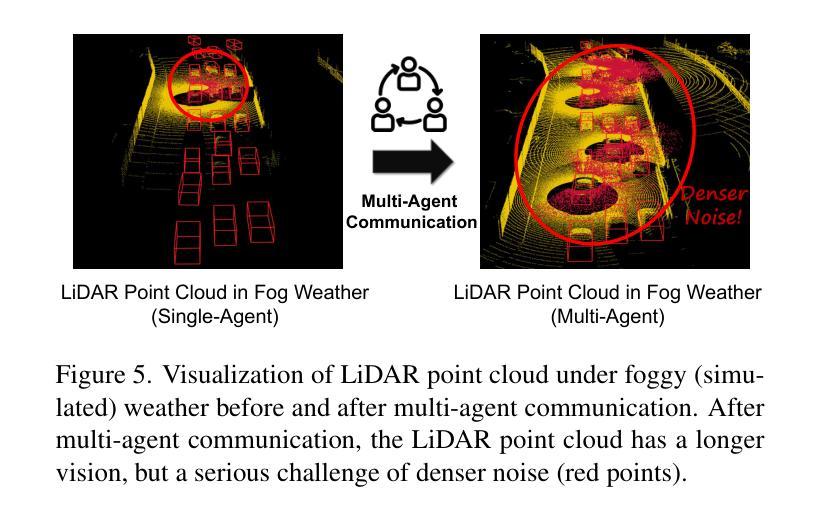
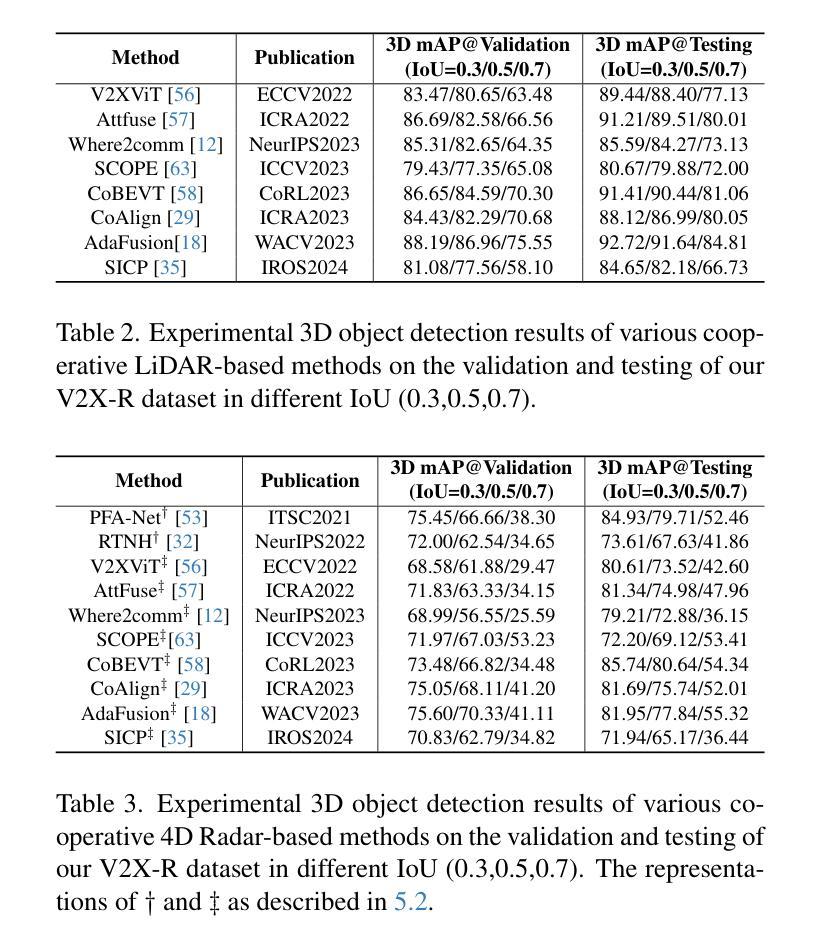
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
Authors:Xun Huang, Jinlong Wang, Qiming Xia, Siheng Chen, Bisheng Yang, Xin Li, Cheng Wang, Chenglu Wen
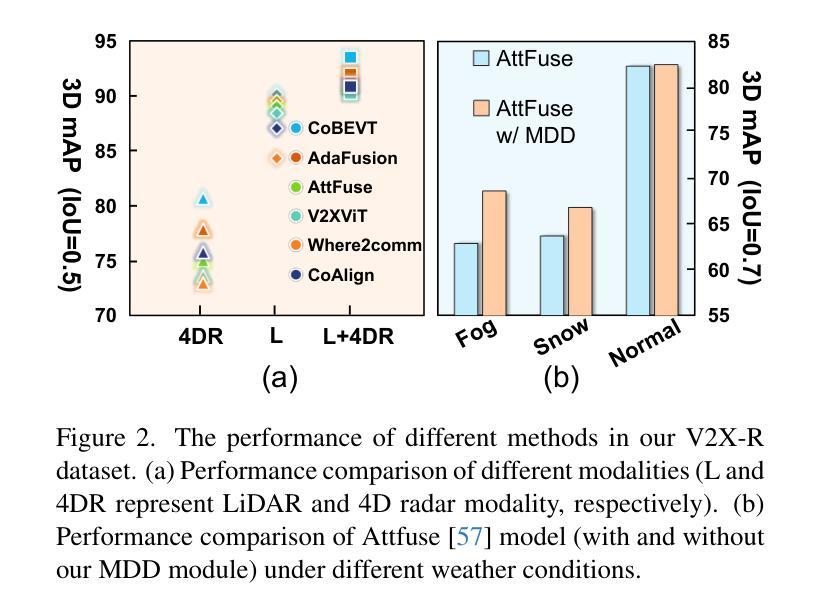
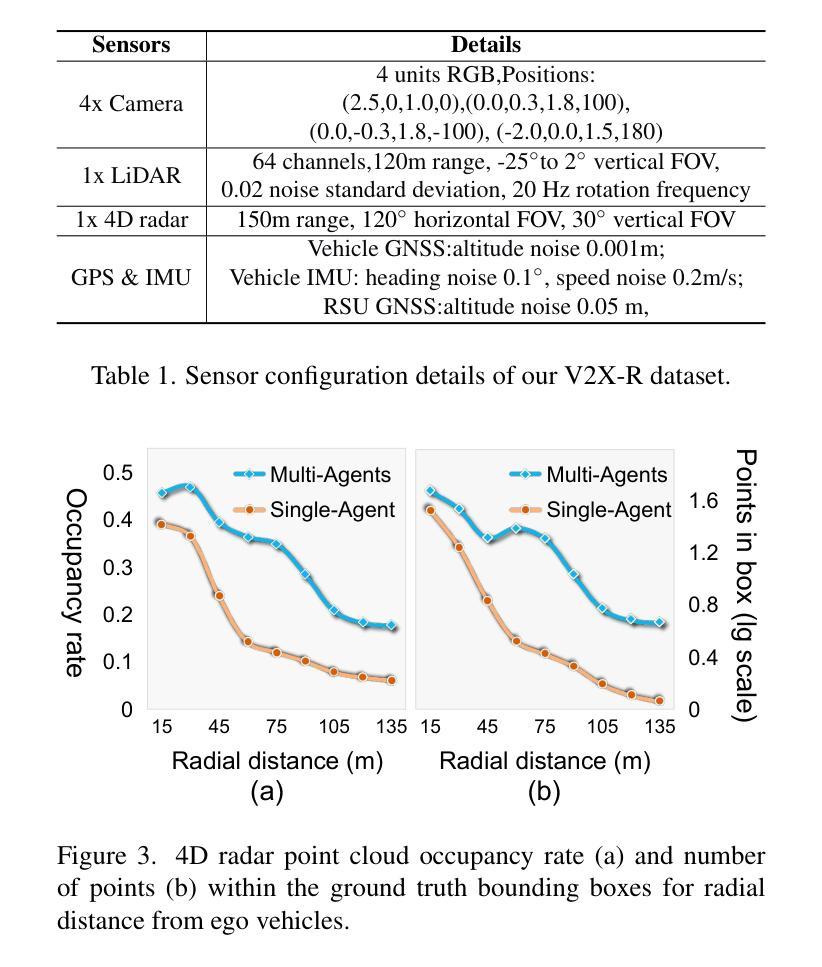
Current Vehicle-to-Everything (V2X) systems have significantly enhanced 3D object detection using LiDAR and camera data. However, these methods suffer from performance degradation in adverse weather conditions. The weather-robust 4D radar provides Doppler and additional geometric information, raising the possibility of addressing this challenge. To this end, we present V2X-R, the first simulated V2X dataset incorporating LiDAR, camera, and 4D radar. V2X-R contains 12,079 scenarios with 37,727 frames of LiDAR and 4D radar point clouds, 150,908 images, and 170,859 annotated 3D vehicle bounding boxes. Subsequently, we propose a novel cooperative LiDAR-4D radar fusion pipeline for 3D object detection and implement it with various fusion strategies. To achieve weather-robust detection, we additionally propose a Multi-modal Denoising Diffusion (MDD) module in our fusion pipeline. MDD utilizes weather-robust 4D radar feature as a condition to prompt the diffusion model to denoise noisy LiDAR features. Experiments show that our LiDAR-4D radar fusion pipeline demonstrates superior performance in the V2X-R dataset. Over and above this, our MDD module further improved the performance of basic fusion model by up to 5.73%/6.70% in foggy/snowy conditions with barely disrupting normal performance. The dataset and code will be publicly available at: https://github.com/ylwhxht/V2X-R.
当前的车对外界(V2X)系统已经通过激光雷达和摄像头数据显著增强了3D目标检测功能。然而,这些方法在恶劣天气条件下会出现性能下降。天气稳定的4D雷达提供了多普勒和额外的几何信息,为解决这一挑战提供了可能性。为此,我们推出了V2X-R,这是第一个结合了激光雷达、摄像头和4D雷达的模拟V2X数据集。V2X-R包含12,079个场景,其中包括激光雷达和4D雷达点云37,727帧、图像150,908张以及标注的3D车辆边界框170,859个。随后,我们提出了一种用于3D目标检测的新型合作激光雷达-4D雷达融合管道,并采用了多种融合策略来实现它。为了实现天气稳定的检测,我们在融合管道中额外提出了多模式去噪扩散(MDD)模块。MDD利用天气稳定的4D雷达特征作为条件,提示扩散模型对嘈杂的激光雷达特征进行去噪。实验表明,我们的激光雷达-4D雷达融合管道在V2X-R数据集中表现出卓越的性能。除此之外,我们的MDD模块进一步改进了基本融合模型在雾天和雪条件下的性能,分别提高了5.73%和6.70%,同时几乎不影响正常性能。数据集和代码将在以下网址公开提供:https://github.com/ylwhxht/V2X-R。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary:
当前车辆对一切(V2X)系统主要通过激光雷达和相机数据进行3D对象检测,但在恶劣天气条件下性能下降。为应对这一挑战,研究团队推出了首个集成了激光雷达、相机和四维雷达数据的V2X模拟数据集V2X-R。此外,研究团队还提出了一种新型的激光雷达与四维雷达融合管道以及其中的多模态去噪扩散模块,旨在提高恶劣天气下的检测性能。实验表明,融合管道在V2X-R数据集上的表现优异,MDD模块在雾天和雪天条件下进一步提升了融合模型性能,且对正常环境下的性能影响较小。数据集和代码将公开于https://github.com/ylwhxht/V2X-R。
Key Takeaways:
- 当前V2X系统在恶劣天气下3D对象检测性能下降。
- 四维雷达数据提供多普勒和几何信息,有助于解决此挑战。
- 推出首个集成LiDAR、相机和4D雷达的V2X模拟数据集V2X-R。
- 提出一种新型的激光雷达与四维雷达融合管道以及其中的多模态去噪扩散模块。
- 实验表明融合管道在V2X-R数据集上表现优异。
- MDD模块在雾天和雪天条件下能进一步提升检测性能。
点此查看论文截图

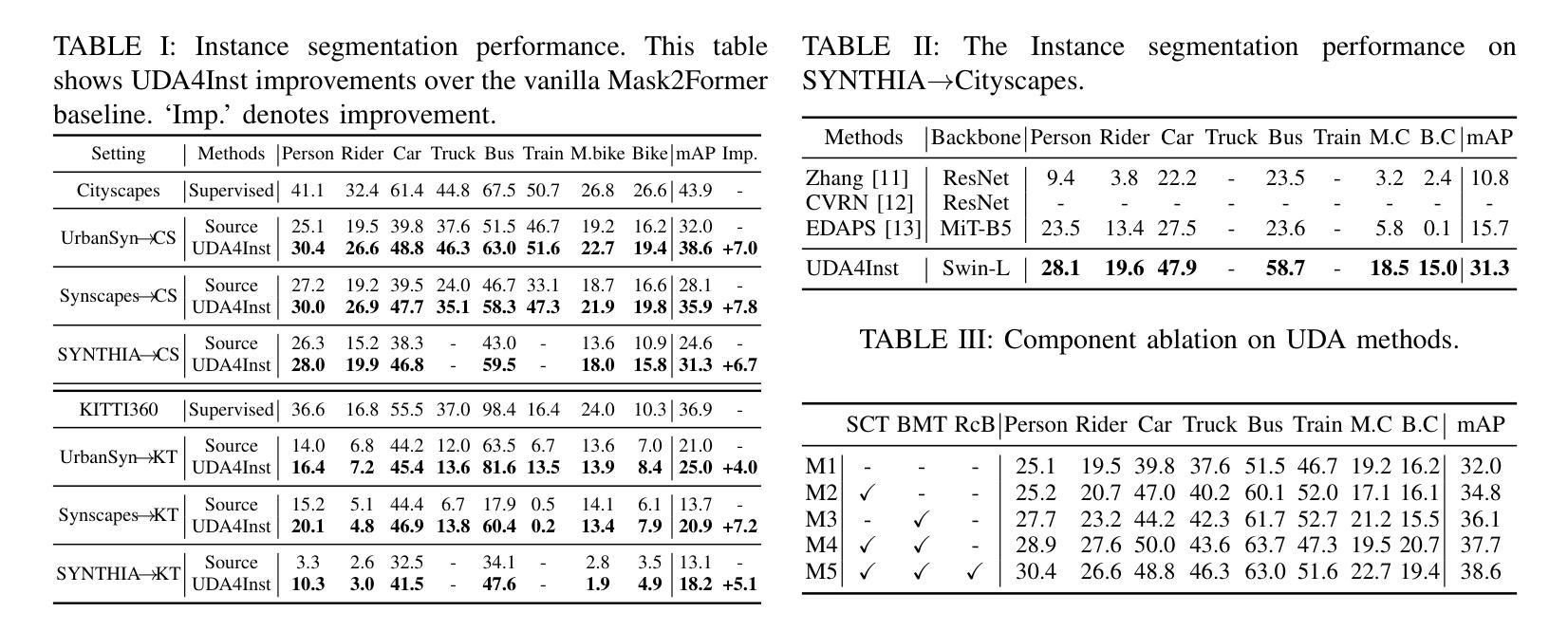
UDA4Inst: Unsupervised Domain Adaptation for Instance Segmentation
Authors:Yachan Guo, Yi Xiao, Danna Xue, Jose Luis Gomez Zurita, Antonio M. Lopez
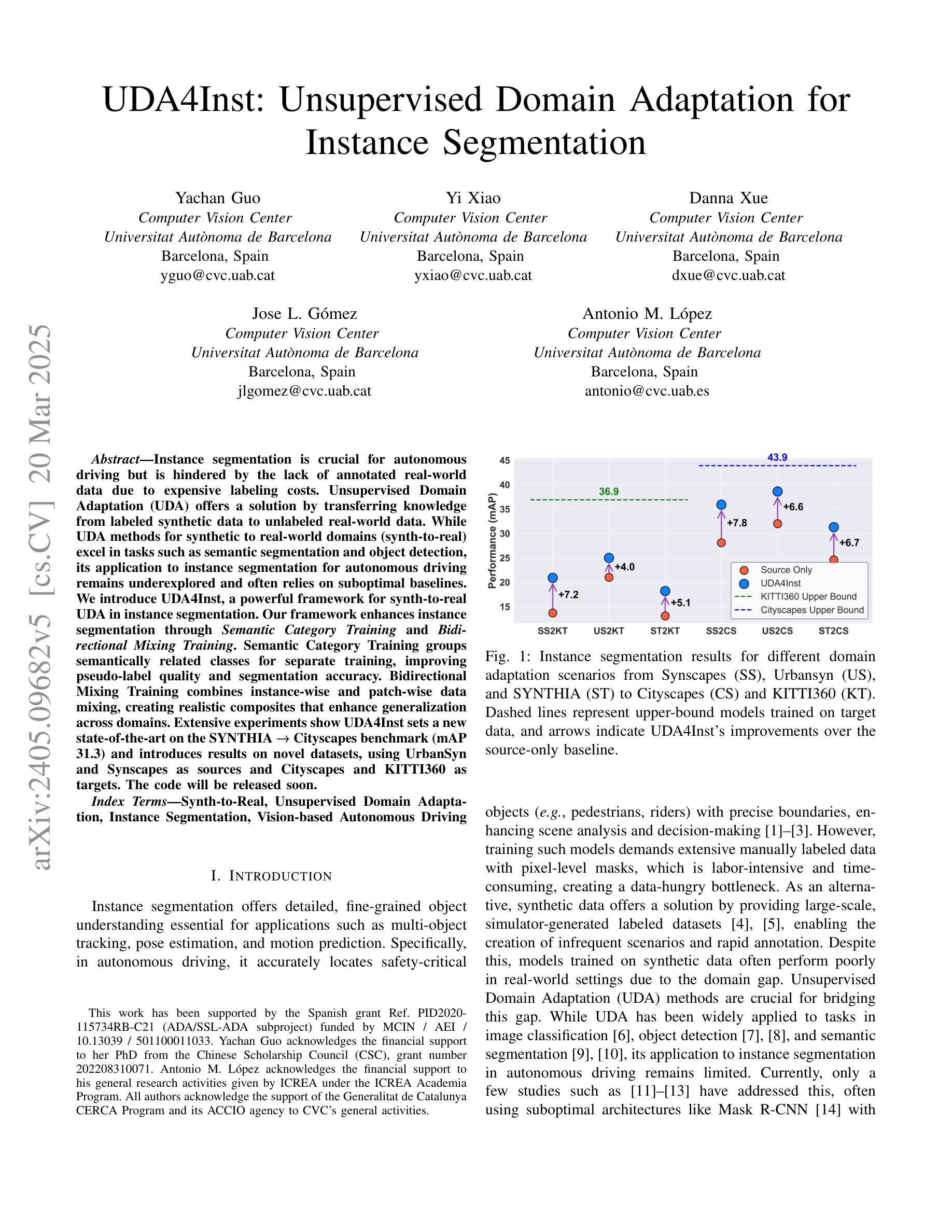
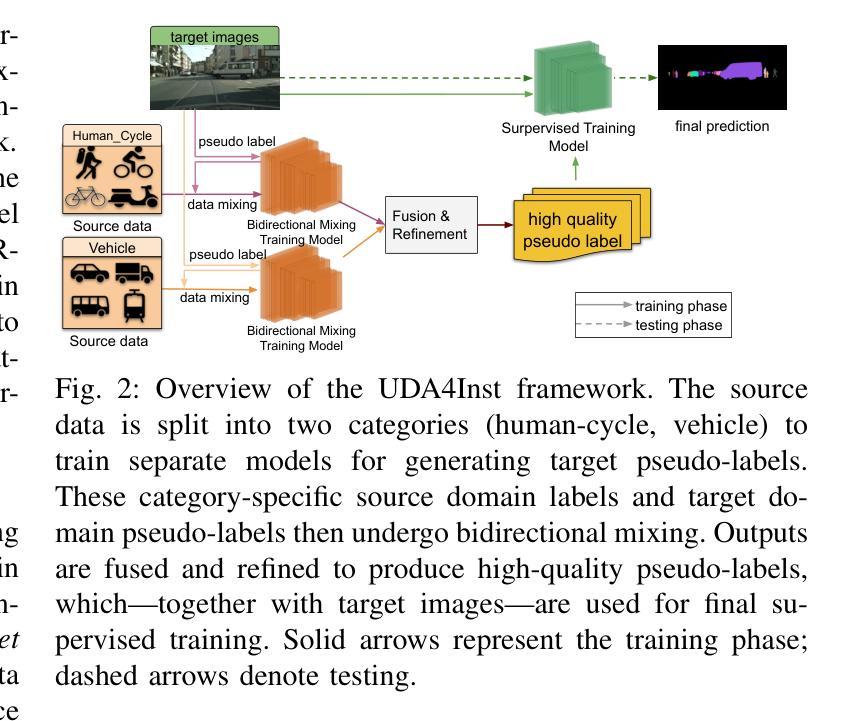
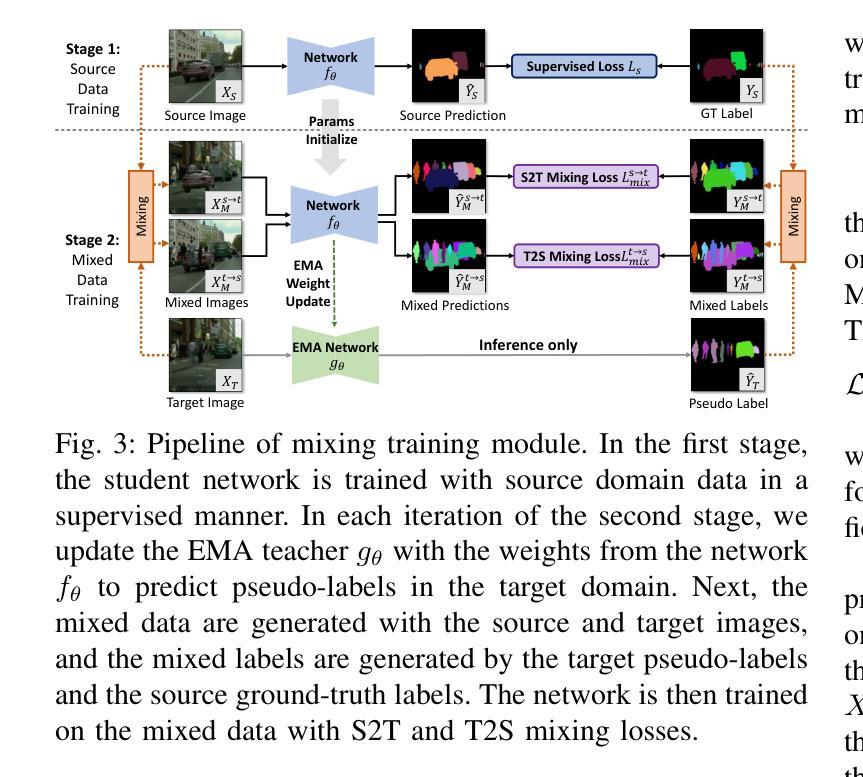
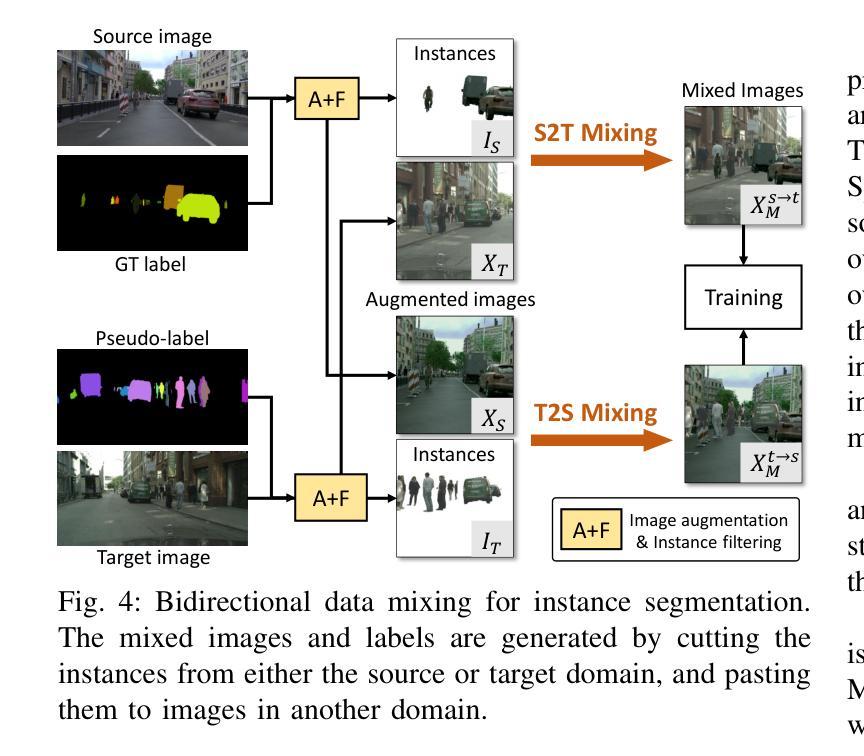
Instance segmentation is crucial for autonomous driving but is hindered by the lack of annotated real-world data due to expensive labeling costs. Unsupervised Domain Adaptation (UDA) offers a solution by transferring knowledge from labeled synthetic data to unlabeled real-world data. While UDA methods for synthetic to real-world domains (synth-to-real) show remarkable performance in tasks such as semantic segmentation and object detection, very few have been proposed for instance segmentation in vision-based autonomous driving. Moreover, existing methods rely on suboptimal baselines, which severely limits performance. We introduce \textbf{UDA4Inst}, a powerful framework for synth-to-real UDA in instance segmentation. Our framework enhances instance segmentation through \textit{Semantic Category Training} and \textit{Bidirectional Mixing Training}. With the Semantic Category Training method, semantically related classes are grouped and trained separately, enabling the generation of higher-quality pseudo-labels and improved segmentation performance. We further propose a bidirectional cross-domain data mixing strategy that combines instance-wise and patch-wise mixing techniques to effectively utilize data from both source and target domains, producing realistic composite images that improve the model’s generalization performance. Extensive experiments demonstrate the effectiveness of our methods. Our approach establishes a new state-of-the-art on the SYNTHIA->Cityscapes benchmark with mAP 31.3. Notably, we are the first to report results on multiple novel synth-to-real instance segmentation datasets, using UrbanSyn and Synscapes as source domains while Cityscapes and KITTI360 serve as target domains. Our code will be released soon.
实例分割对于自动驾驶至关重要,但由于昂贵的标注成本,缺乏标注的真实世界数据阻碍了其发展。无监督域自适应(UDA)提供了一种解决方案,即通过将从有标签的合成数据中学到的知识转移到无标签的真实世界数据上。虽然针对合成到真实世界的无监督域自适应(synth-to-real UDA)方法在语义分割和对象检测任务上表现出卓越的性能,但针对基于视觉的自动驾驶中的实例分割的方法却很少提出。此外,现有方法依赖于次优基线,这严重限制了性能。我们引入了强大的框架UDA4Inst,用于合成到真实的实例分割UDA。我们的框架通过语义类别训练和双向混合训练增强了实例分割。语义类别训练的方法将语义相关的类别分组并分别进行训练,从而生成更高质量的伪标签并提高分割性能。我们进一步提出了一种双向跨域数据混合策略,该策略结合了实例级和补丁级的混合技术,以有效利用源域和目标域的数据,生成逼真的合成图像,提高模型的泛化性能。大量实验证明了我们的方法的有效性。我们的方法在SYNTHIA到Cityscapes的基准测试上建立了新的最新技术,mAP为31.3。值得注意的是,我们是首批在多个新的合成到真实实例分割数据集上报告结果的团队,使用UrbanSyn和Synscapes作为源域,而Cityscapes和KITTI360作为目标域。我们的代码很快将发布。
论文及项目相关链接
Summary
该文介绍了自动驾驶中的实例分割技术面临真实世界标注数据缺失的问题,为此提出使用无监督域自适应(UDA)技术从合成数据转移到真实世界数据。针对合成到真实域的实例分割问题,提出了一种新的框架UDA4Inst,该框架包括语义类别训练和双向混合训练,能够提高实例分割性能。同时提出使用语义类别分组训练和双向跨域数据混合策略,通过合成和真实数据集的有效利用,生成逼真的合成图像,提高模型的泛化性能。实验证明该方法的有效性,并在SYNTHIA→Cityscapes基准测试中达到新的先进水平。此外,该方法首次在多个新的合成到真实实例分割数据集上进行报告结果。代码即将发布。
Key Takeaways
- 实例分割在自动驾驶中至关重要,但由于标注成本高昂,缺乏真实世界标注数据成为一大挑战。
- 无监督域自适应(UDA)技术可以从合成数据转移到真实世界数据,为解决此问题提供了解决方案。
- UDA4Inst框架通过语义类别训练和双向混合训练提高了实例分割性能。
- 语义类别分组训练有助于生成更高质量的伪标签,改善分割性能。
- 双向跨域数据混合策略结合了实例级和补丁级混合技术,有效利用源和目标域的数据,生成逼真的合成图像,提高模型泛化性能。
- 该方法在SYNTHIA→Cityscapes基准测试中表现优异,达到新的先进水平。
点此查看论文截图