⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
STOP: Integrated Spatial-Temporal Dynamic Prompting for Video Understanding
Authors:Zichen Liu, Kunlun Xu, Bing Su, Xu Zou, Yuxin Peng, Jiahuan Zhou
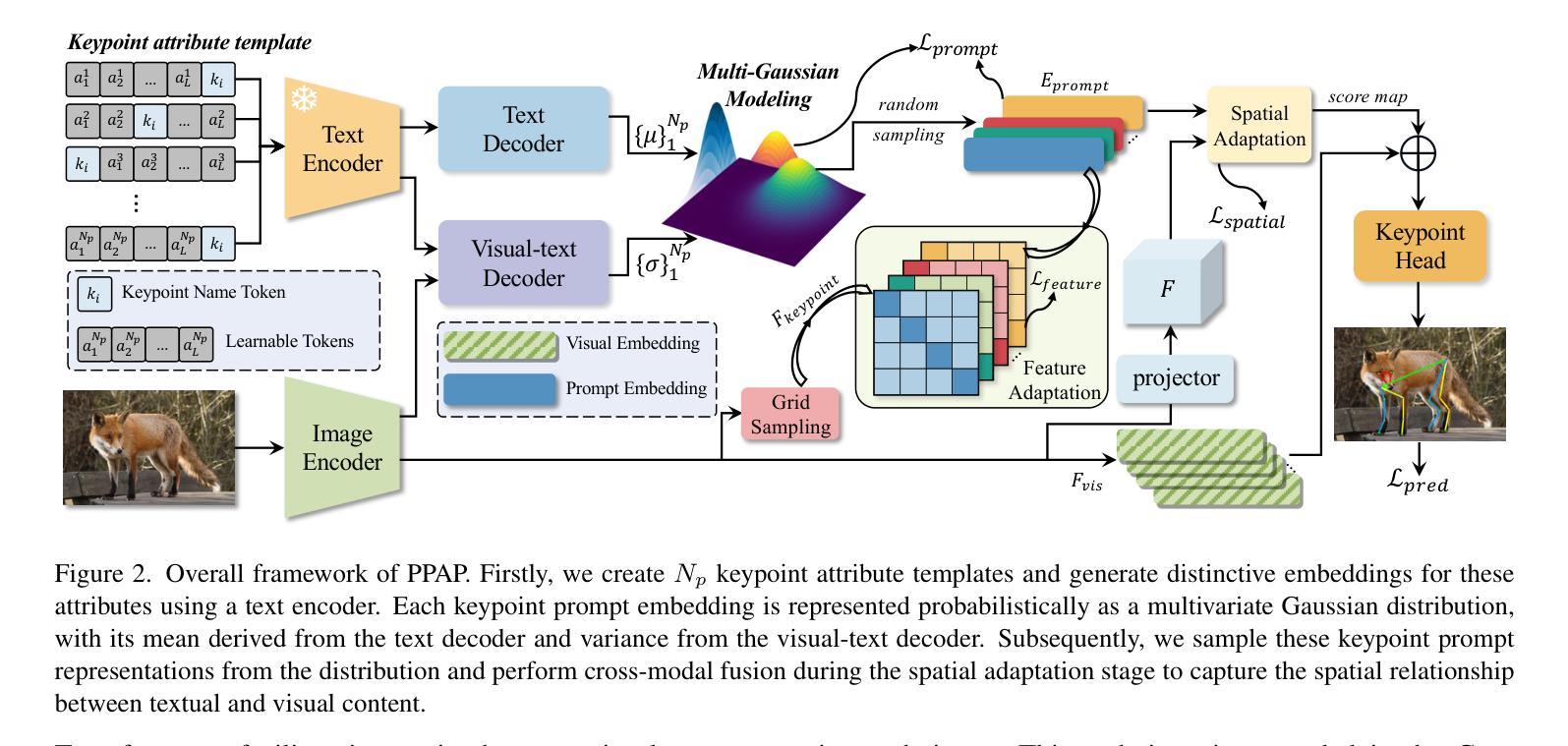
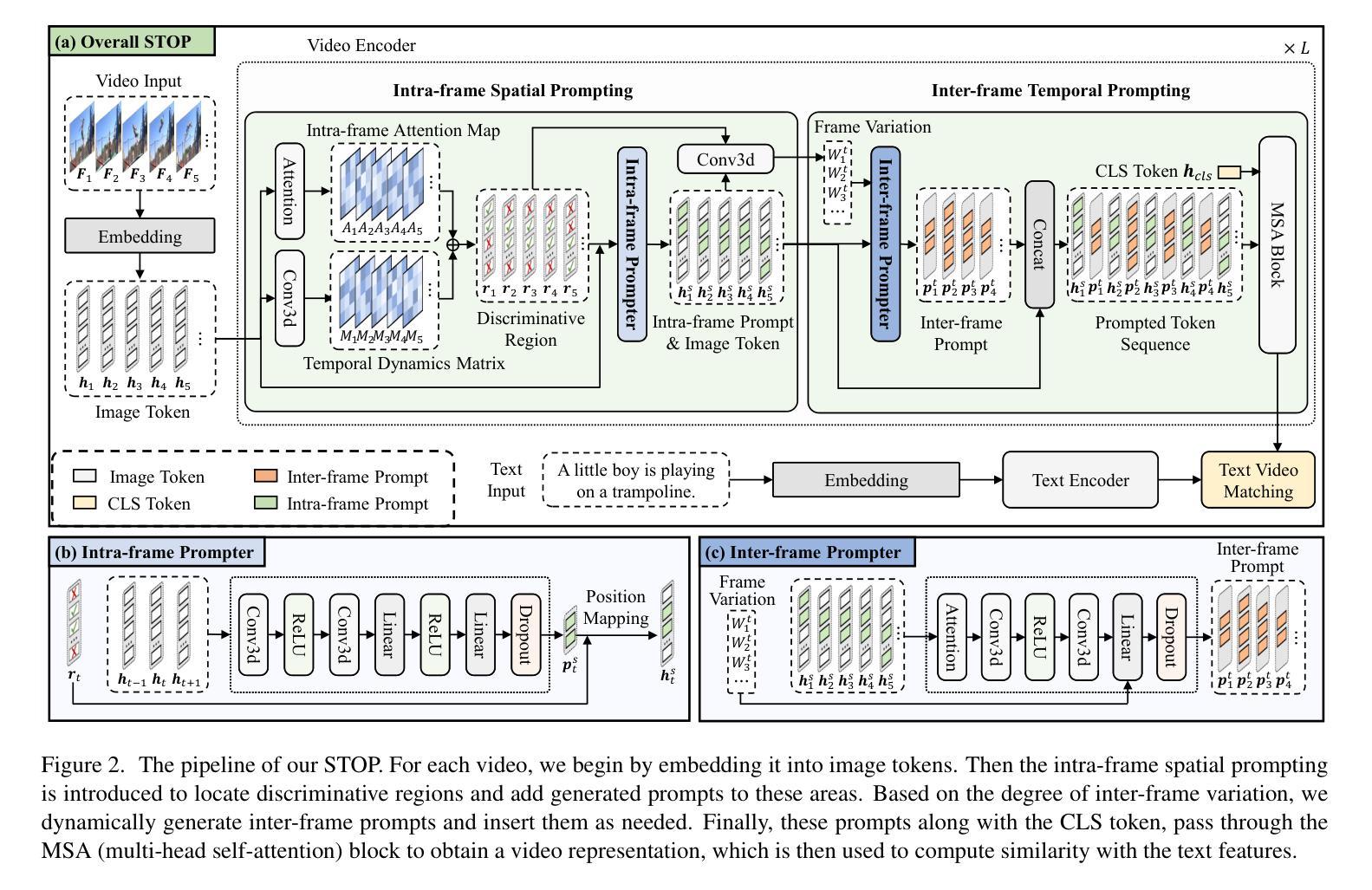
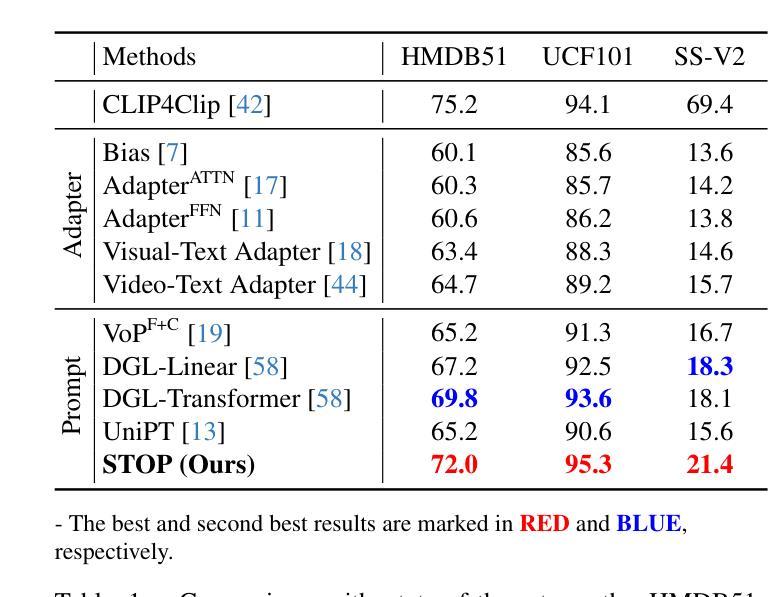
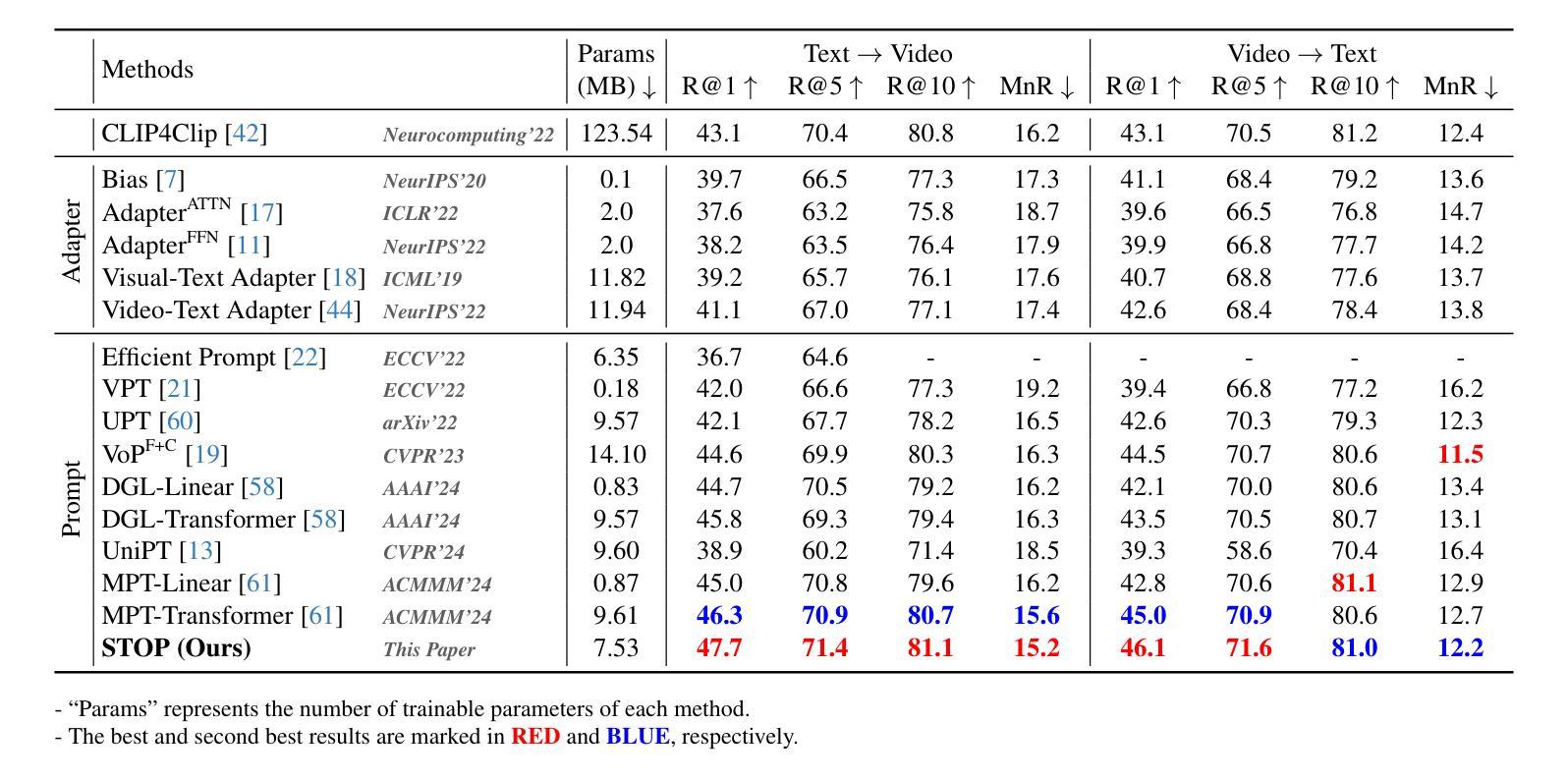
Pre-trained on tremendous image-text pairs, vision-language models like CLIP have demonstrated promising zero-shot generalization across numerous image-based tasks. However, extending these capabilities to video tasks remains challenging due to limited labeled video data and high training costs. Recent video prompting methods attempt to adapt CLIP for video tasks by introducing learnable prompts, but they typically rely on a single static prompt for all video sequences, overlooking the diverse temporal dynamics and spatial variations that exist across frames. This limitation significantly hinders the model’s ability to capture essential temporal information for effective video understanding. To address this, we propose an integrated Spatial-TempOral dynamic Prompting (STOP) model which consists of two complementary modules, the intra-frame spatial prompting and inter-frame temporal prompting. Our intra-frame spatial prompts are designed to adaptively highlight discriminative regions within each frame by leveraging intra-frame attention and temporal variation, allowing the model to focus on areas with substantial temporal dynamics and capture fine-grained spatial details. Additionally, to highlight the varying importance of frames for video understanding, we further introduce inter-frame temporal prompts, dynamically inserting prompts between frames with high temporal variance as measured by frame similarity. This enables the model to prioritize key frames and enhances its capacity to understand temporal dependencies across sequences. Extensive experiments on various video benchmarks demonstrate that STOP consistently achieves superior performance against state-of-the-art methods. The code is available at https://github.com/zhoujiahuan1991/CVPR2025-STOP.
预训练在大量的图像文本对上,诸如CLIP的视觉语言模型已经展现出跨多个图像任务的零样本泛化能力。然而,将这些能力扩展到视频任务仍然具有挑战性,因为有限的标记视频数据和高昂的训练成本。最近的视频提示方法试图通过引入可学习的提示来适应CLIP进行视频任务,但它们通常依赖单个静态提示用于所有视频序列,忽视了跨帧存在的各种时间动态和空间变化。这一局限性显著阻碍了模型捕捉有效视频理解所需的关键时间信息的能力。为了解决这一问题,我们提出了一种集成化的时空动态提示(STOP)模型,该模型由两个互补模块组成:帧内空间提示和帧间时间提示。我们的帧内空间提示旨在通过利用帧内注意力和时间变化来动态突出显示每个帧中的判别区域,使模型能够关注具有重大时间动态的领域并捕捉精细的空间细节。此外,为了突出不同帧对视频理解的重要性,我们进一步引入了帧间时间提示,根据帧相似性测量在具有高时间方差的帧之间动态插入提示。这使模型能够优先处理关键帧,并提高其理解序列时间依赖性的能力。在各种视频基准测试上的广泛实验表明,STOP始终实现了对最新技术的优越性能。代码可用在 https://github.com/zhoujiahuan1991/CVPR2025-STOP。
论文及项目相关链接
Summary
本文介绍了在视频任务中,由于缺乏标注视频数据和训练成本高昂,预训练的图像文本对模型(如CLIP)的应用面临挑战。为应对这一挑战,提出了一种集成时空动态提示(STOP)模型,包括帧内空间提示和帧间时间提示两个互补模块。该模型能自适应地突出显示每帧中的判别区域,并强调视频理解中不同帧的重要性。在多个视频基准测试上的实验表明,STOP模型较现有技术实现了优越的性能。
Key Takeaways
- CLIP等预训练模型在图像任务中表现出强大的零样本泛化能力,但在视频任务中面临挑战。
- 缺乏标注视频数据和训练成本高昂是视频任务中的两大挑战。
- 现有视频提示方法通常使用单一静态提示,忽略视频帧的时空多样性。
- STOP模型通过帧内空间提示和帧间时间提示两个互补模块来解决这一问题。
- 帧内空间提示能自适应突出每帧中的判别区域,利用帧内注意力和时间变化。
- 帧间时间提示强调不同帧在视频理解中的重要性,通过在具有高时间方差的帧之间动态插入提示来增强模型对时间序列依赖性的理解。
- 在多个视频基准测试上,STOP模型较现有技术表现出更优越的性能。
点此查看论文截图

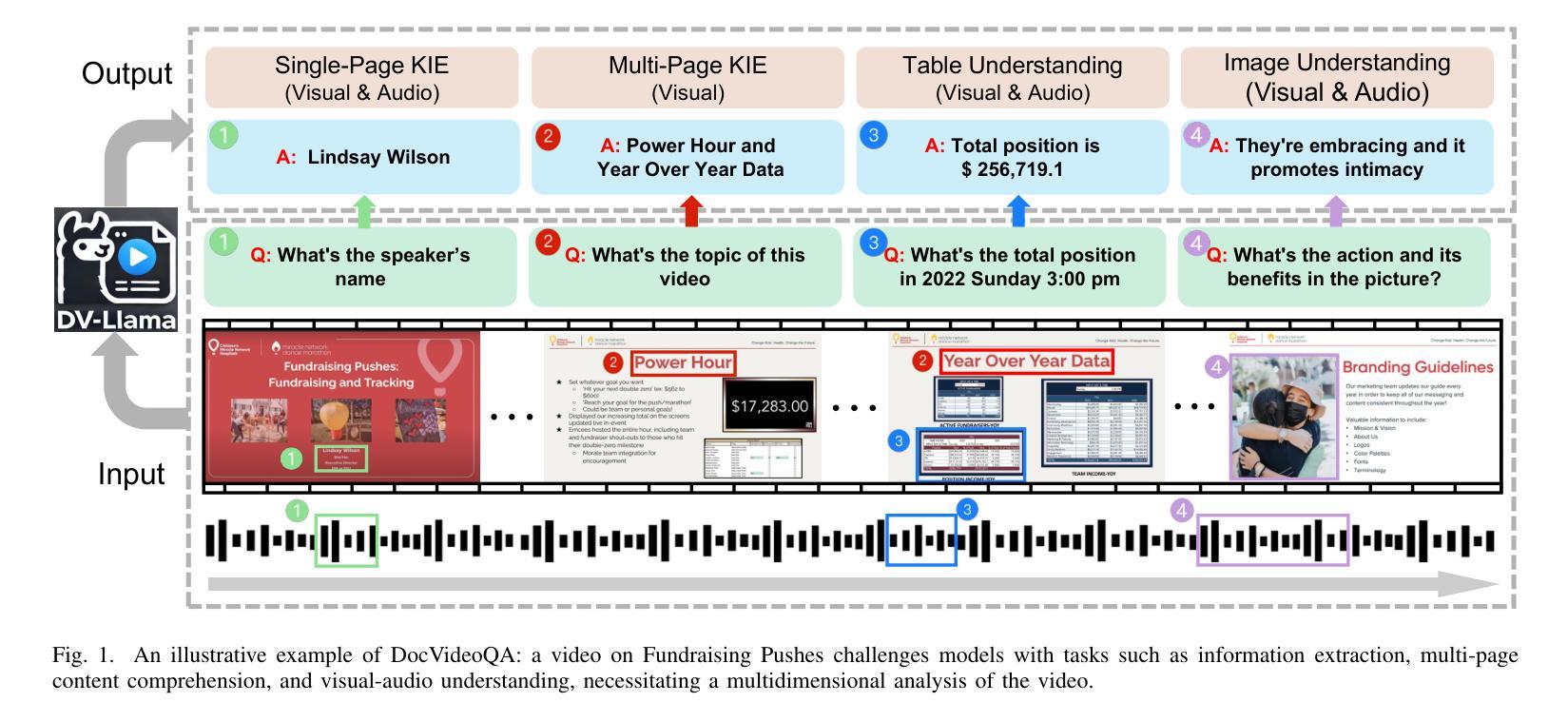
DocVideoQA: Towards Comprehensive Understanding of Document-Centric Videos through Question Answering
Authors:Haochen Wang, Kai Hu, Liangcai Gao
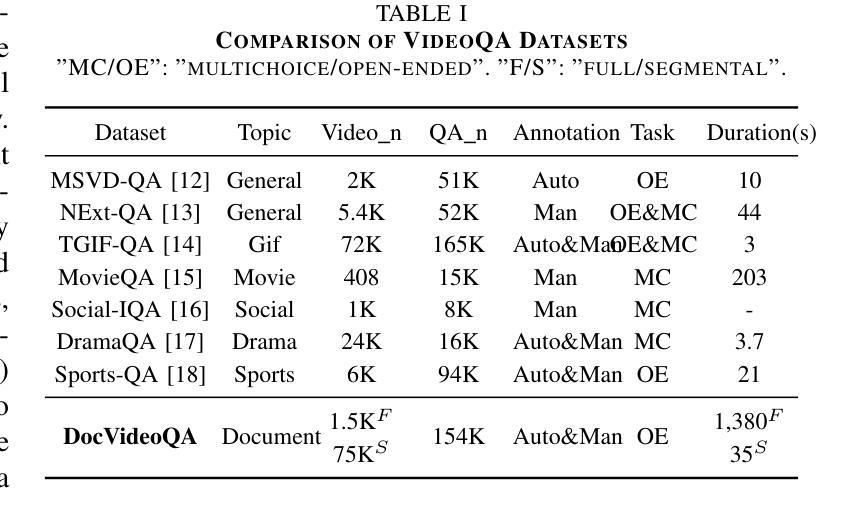
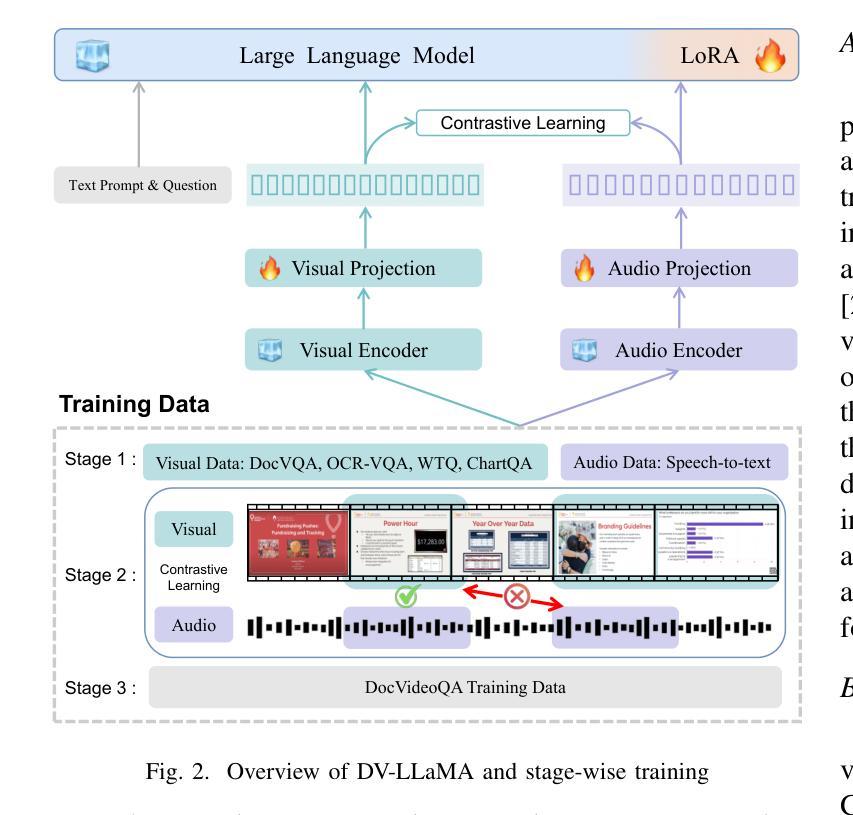
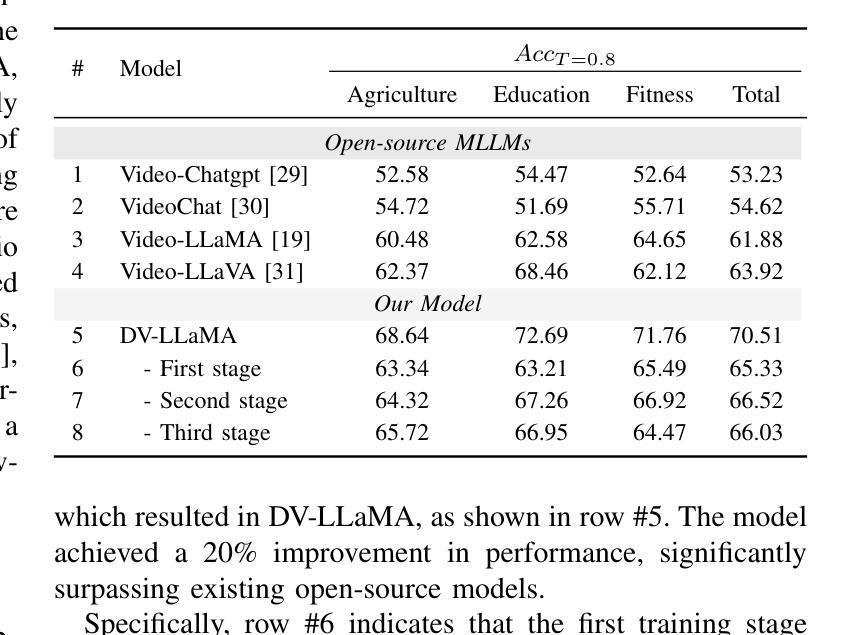
Remote work and online courses have become important methods of knowledge dissemination, leading to a large number of document-based instructional videos. Unlike traditional video datasets, these videos mainly feature rich-text images and audio that are densely packed with information closely tied to the visual content, requiring advanced multimodal understanding capabilities. However, this domain remains underexplored due to dataset availability and its inherent complexity. In this paper, we introduce the DocVideoQA task and dataset for the first time, comprising 1454 videos across 23 categories with a total duration of about 828 hours. The dataset is annotated with 154k question-answer pairs generated manually and via GPT, assessing models’ comprehension, temporal awareness, and modality integration capabilities. Initially, we establish a baseline using open-source MLLMs. Recognizing the challenges in modality comprehension for document-centric videos, we present DV-LLaMA, a robust video MLLM baseline. Our method enhances unimodal feature extraction with diverse instruction-tuning data and employs contrastive learning to strengthen modality integration. Through fine-tuning, the LLM is equipped with audio-visual capabilities, leading to significant improvements in document-centric video understanding. Extensive testing on the DocVideoQA dataset shows that DV-LLaMA significantly outperforms existing models. We’ll release the code and dataset to facilitate future research.
远程工作和在线课程已成为知识传播的重要方法,导致出现大量基于文档的教学视频。与传统视频数据集不同,这些视频主要以富含文本的图片和音频为主,与视觉内容紧密相关的信息密集,需要先进的跨模态理解能力。然而,由于数据集可用性和其内在复杂性,这一领域仍然鲜有研究。在本文中,我们首次引入了DocVideoQA任务和数据集,包含1454个视频,跨越23个类别,总时长约828小时。该数据集通过手动和GPT生成了15.4万个问答对,评估模型的理解能力、时间意识和模态融合能力。首先,我们使用开源的大型语言模型(LLM)建立基线。针对以文档为中心的视频的模态理解挑战,我们提出了DV-LLaMA,一个稳健的视频LLM基线。我们的方法通过多样的指令微调数据增强单模态特征提取,并采用对比学习来加强模态融合。通过微调,LLM具备了视听能力,在以文档为中心的视频理解方面取得了显著改进。在DocVideoQA数据集上的广泛测试表明,DV-LLaMA显著优于现有模型。我们将发布代码和数据集,以促进未来研究。
论文及项目相关链接
Summary:
远程工作和在线课程已成为知识传播的重要方式,催生了大量基于文档的教学视频。针对这一领域,本文首次提出了DocVideoQA任务和数据集,包含1454个视频,涉及23个类别,总时长约828小时。数据集通过人工和GPT生成了15.4万个问答对,以评估模型的理解能力、时间意识和模态整合能力。为提高文档中心视频的理解能力,本文提出了DV-LLaMA方法,通过多样化的指令调整数据和对比学习来增强单模态特征提取和模态整合。在DocVideoQA数据集上的测试显示,DV-LLaMA显著优于现有模型。
Key Takeaways:
- 远程工作和在线课程推动了文档型教学视频的发展。
- DocVideoQA数据集首次提出,包含丰富文档信息的视频,需要高级多模态理解能力。
- 数据集包含1454个视频,跨越23个类别,总时长828小时,包含大量问答对用于评估模型能力。
- DV-LLaMA方法通过多样化的指令调整数据和对比学习增强了视频多模态大模型的稳健性。
- DV-LLaMA模型显著提高了文档中心视频的理解能力。
- 该方法通过在DocVideoQA数据集上的测试验证了其优越性。
点此查看论文截图