⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
1000+ FPS 4D Gaussian Splatting for Dynamic Scene Rendering
Authors:Yuheng Yuan, Qiuhong Shen, Xingyi Yang, Xinchao Wang
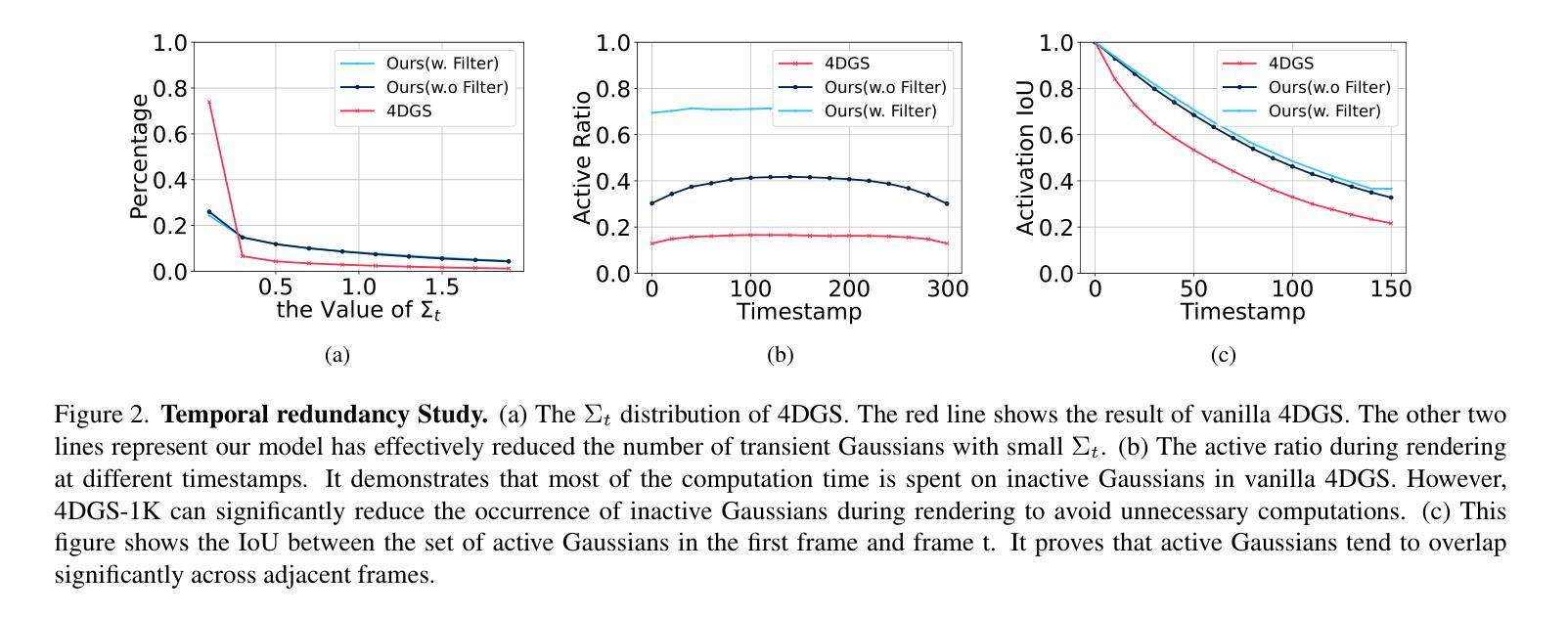
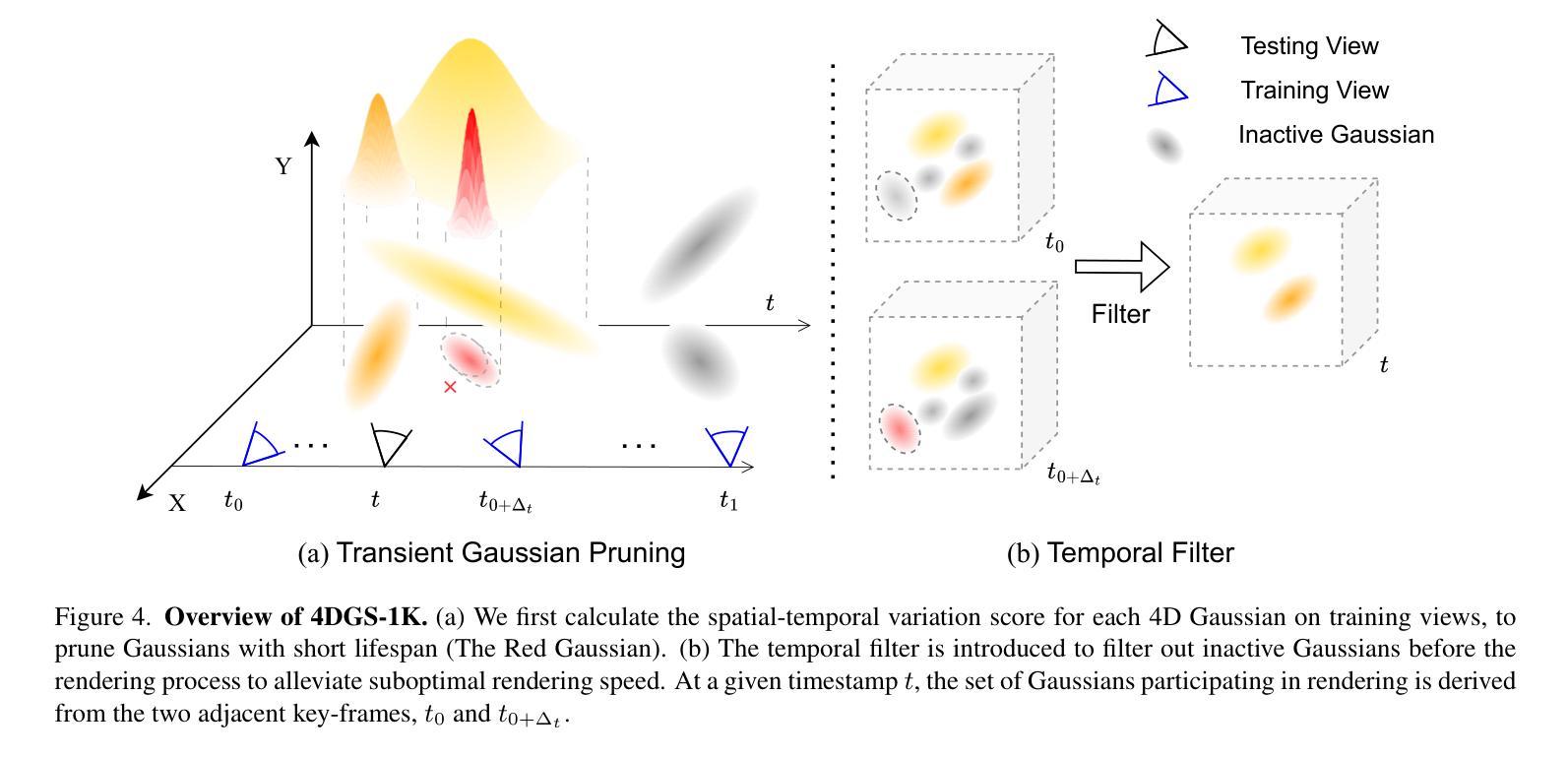
4D Gaussian Splatting (4DGS) has recently gained considerable attention as a method for reconstructing dynamic scenes. Despite achieving superior quality, 4DGS typically requires substantial storage and suffers from slow rendering speed. In this work, we delve into these issues and identify two key sources of temporal redundancy. (Q1) \textbf{Short-Lifespan Gaussians}: 4DGS uses a large portion of Gaussians with short temporal span to represent scene dynamics, leading to an excessive number of Gaussians. (Q2) \textbf{Inactive Gaussians}: When rendering, only a small subset of Gaussians contributes to each frame. Despite this, all Gaussians are processed during rasterization, resulting in redundant computation overhead. To address these redundancies, we present \textbf{4DGS-1K}, which runs at over 1000 FPS on modern GPUs. For Q1, we introduce the Spatial-Temporal Variation Score, a new pruning criterion that effectively removes short-lifespan Gaussians while encouraging 4DGS to capture scene dynamics using Gaussians with longer temporal spans. For Q2, we store a mask for active Gaussians across consecutive frames, significantly reducing redundant computations in rendering. Compared to vanilla 4DGS, our method achieves a $41\times$ reduction in storage and $9\times$ faster rasterization speed on complex dynamic scenes, while maintaining comparable visual quality. Please see our project page at https://4DGS-1K.github.io.
近期,4D高斯点铺展法(4DGS)因其重建动态场景的方法而备受关注。尽管其能达成高品质效果,但4DGS通常需要大量存储空间并面临渲染速度较慢的问题。在这项研究中,我们深入探讨了这些问题,并识别出两个主要的时空冗余来源。(Q1)短暂寿命高斯点:4DGS使用大量短暂时空跨度的高斯点来表示场景动态,导致高斯点数量过多。(Q2)非活跃高斯点:在渲染过程中,只有一小部分高斯点对每一帧有所贡献。尽管如此,所有高斯点在光栅化时都被处理,导致计算开销冗余。为了应对这些冗余问题,我们提出了4DGS-1K,在现代GPU上运行速度超过1000帧每秒。针对Q1问题,我们引入了时空变化分数这一新的修剪标准,该标准有效地移除了短暂寿命的高斯点并鼓励使用具有较长时空跨度的高斯点来捕捉场景动态。针对Q2问题,我们存储了连续帧中活跃高斯点的掩膜,显著减少了渲染过程中的冗余计算。与常规4DGS相比,我们的方法实现了存储空间的41倍压缩和复杂动态场景的渲染速度9倍提升,同时保持相当的可视质量。请访问我们的项目页面https://4DGS-1K.github.io了解更多信息。
论文及项目相关链接
摘要
本文研究了4D高斯展平技术(4DGS)在处理动态场景重建时面临的挑战,如存储需求大、渲染速度慢的问题。针对这些问题,本文提出了两个关键的时间冗余来源:短寿命高斯和未激活的高斯。针对这两个问题,本文提出了解决方案,包括引入空间时间变化评分作为新的修剪标准,以去除短寿命高斯;并为连续帧中的活跃高斯存储掩膜,从而减少渲染过程中的冗余计算。因此,新的方法在保证视觉质量的同时,实现了存储减少41倍、复杂动态场景的渲染速度提高9倍。详情请参见我们的项目网页。
要点掌握
- 4DGS技术在处理动态场景重建时面临的挑战包括存储需求大和渲染速度慢的问题。
- 研究指出了两个关键的时间冗余来源:短寿命高斯和未激活的高斯。
- 通过引入空间时间变化评分作为新的修剪标准,可有效去除短寿命高斯。
- 为连续帧中的活跃高斯存储掩膜,以减少渲染过程中的冗余计算。
- 与传统的4DGS相比,新方法实现了存储的显著减少和渲染速度的显著提高。
- 项目详细信息可访问其项目网页获取。
点此查看论文截图



M3: 3D-Spatial MultiModal Memory
Authors:Xueyan Zou, Yuchen Song, Ri-Zhao Qiu, Xuanbin Peng, Jianglong Ye, Sifei Liu, Xiaolong Wang
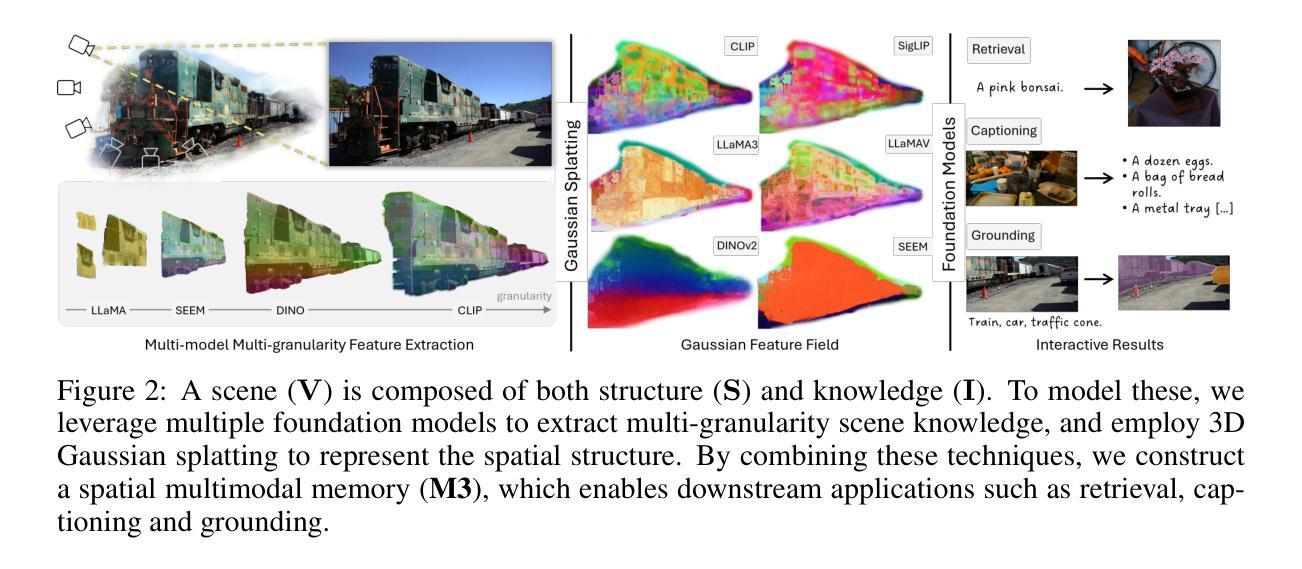
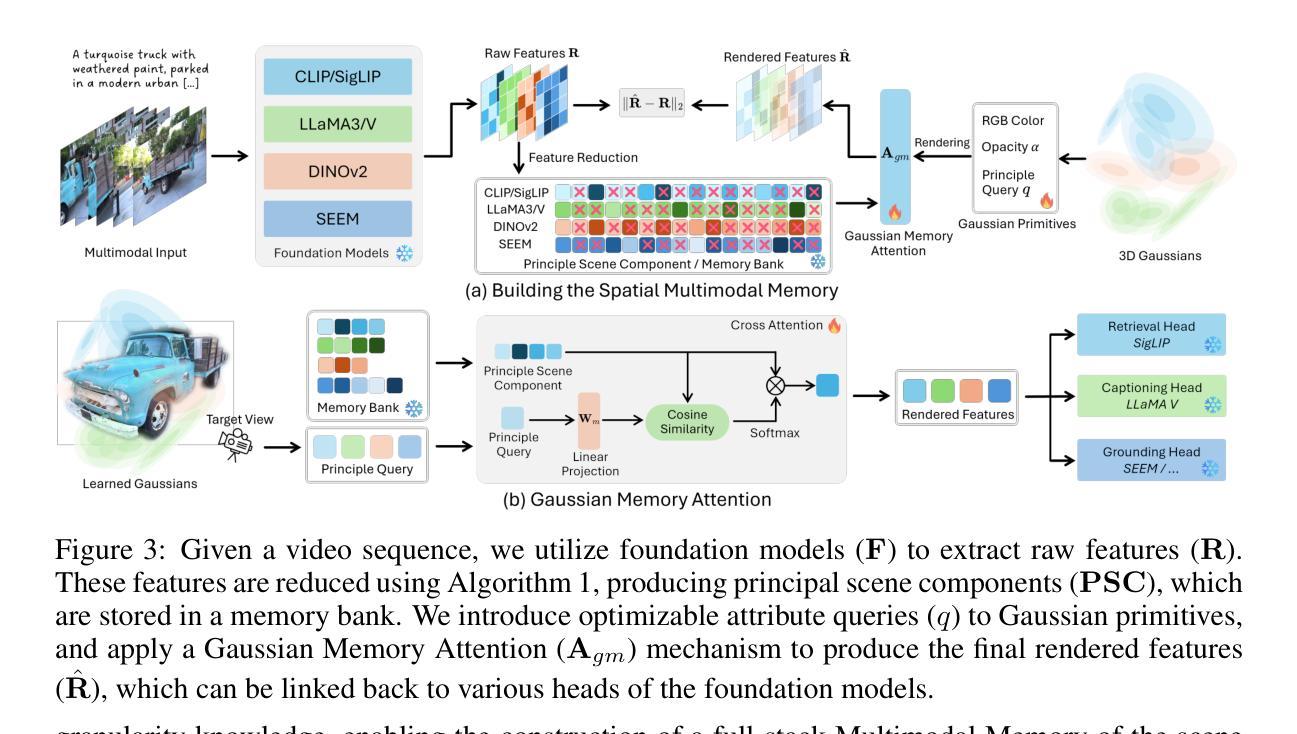
We present 3D Spatial MultiModal Memory (M3), a multimodal memory system designed to retain information about medium-sized static scenes through video sources for visual perception. By integrating 3D Gaussian Splatting techniques with foundation models, M3 builds a multimodal memory capable of rendering feature representations across granularities, encompassing a wide range of knowledge. In our exploration, we identify two key challenges in previous works on feature splatting: (1) computational constraints in storing high-dimensional features for each Gaussian primitive, and (2) misalignment or information loss between distilled features and foundation model features. To address these challenges, we propose M3 with key components of principal scene components and Gaussian memory attention, enabling efficient training and inference. To validate M3, we conduct comprehensive quantitative evaluations of feature similarity and downstream tasks, as well as qualitative visualizations to highlight the pixel trace of Gaussian memory attention. Our approach encompasses a diverse range of foundation models, including vision-language models (VLMs), perception models, and large multimodal and language models (LMMs/LLMs). Furthermore, to demonstrate real-world applicability, we deploy M3’s feature field in indoor scenes on a quadruped robot. Notably, we claim that M3 is the first work to address the core compression challenges in 3D feature distillation.
我们提出了3D空间多模态记忆(M3),这是一种多模态记忆系统,旨在通过视频源为视觉感知保留中等规模静态场景的信息。通过整合3D高斯摊铺技术与基础模型,M3建立了一个多模态记忆,能够在各个粒度上呈现特征表示,涵盖广泛的知识。在探索中,我们发现了之前特征铺设工作中的两个关键挑战:(1)为每个高斯原始数据保存高维特征的计算约束;(2)提炼特征与基础模型特征之间的不匹配或信息丢失。为了解决这些挑战,我们提出了M3,其主要组件包括主要场景组件和高斯记忆注意力,能够实现高效的训练和推理。为了验证M3,我们对特征相似性和下游任务进行了全面的定量评估,以及定性可视化以突出高斯记忆注意力的像素轨迹。我们的方法涵盖了多种基础模型,包括视觉语言模型(VLMs)、感知模型以及大型多模态和语言模型(LMMs/LLMs)。此外,为了证明M3在现实世界中的适用性,我们在四足机器人的室内场景中应用了M3的特征字段。值得注意的是,我们声称M3是首个解决3D特征蒸馏中核心压缩挑战的工作。
论文及项目相关链接
PDF ICLR2025 homepage: https://m3-spatial-memory.github.io code: https://github.com/MaureenZOU/m3-spatial
Summary
提出一种名为M3的3D空间多模态记忆系统,采用视频源对中等静态场景进行信息存储,为视觉感知设计多模态记忆。通过结合3D高斯涂抹技术和基础模型,M3建立了一个多模态记忆,能够在不同粒度上呈现特征表示,涵盖广泛的知识。研究解决了先前特征涂抹工作中的两个关键挑战,并通过主要场景组件和高斯记忆注意力等关键组件实现高效训练和推理。通过定量评估特征相似性和下游任务以及定性可视化突出显示高斯记忆注意力的像素轨迹来验证M3。此外,M3还适用于室内场景的四肢机器人部署。M3是首个解决3D特征蒸馏中核心压缩挑战的工作。
Key Takeaways
- M3是一个3D空间多模态记忆系统,旨在通过视频源存储中等静态场景的信息。
- M3结合了3D高斯涂抹技术和基础模型,建立了一个多模态记忆,能呈现不同粒度的特征表示。
- 研究解决了先前特征涂抹工作中的两个关键挑战:高维特征的存储计算约束以及蒸馏特征与基础模型特征之间的不匹配或信息丢失。
- M3通过主要场景组件和高斯记忆注意力等关键组件实现高效训练和推理。
- 通过定量和定性评估验证了M3的有效性,包括特征相似性、下游任务性能以及高斯记忆注意力的可视化。
- M3适用于室内场景的四肢机器人部署,展示了其实际应用的潜力。
点此查看论文截图


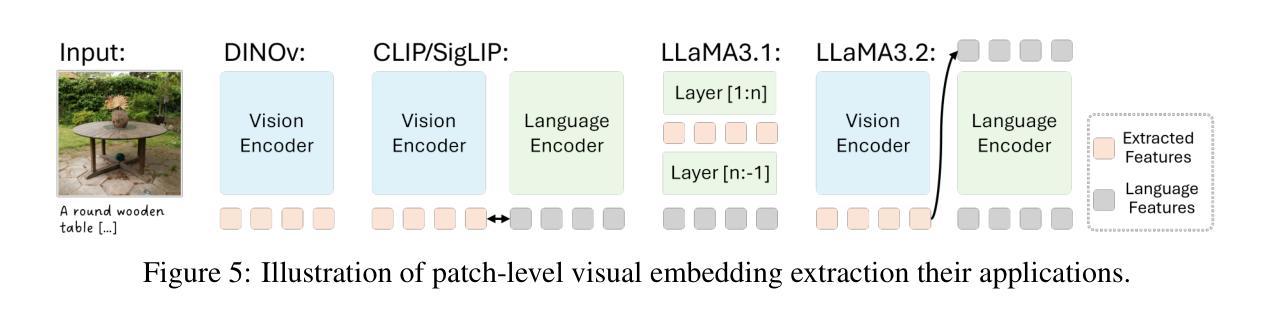
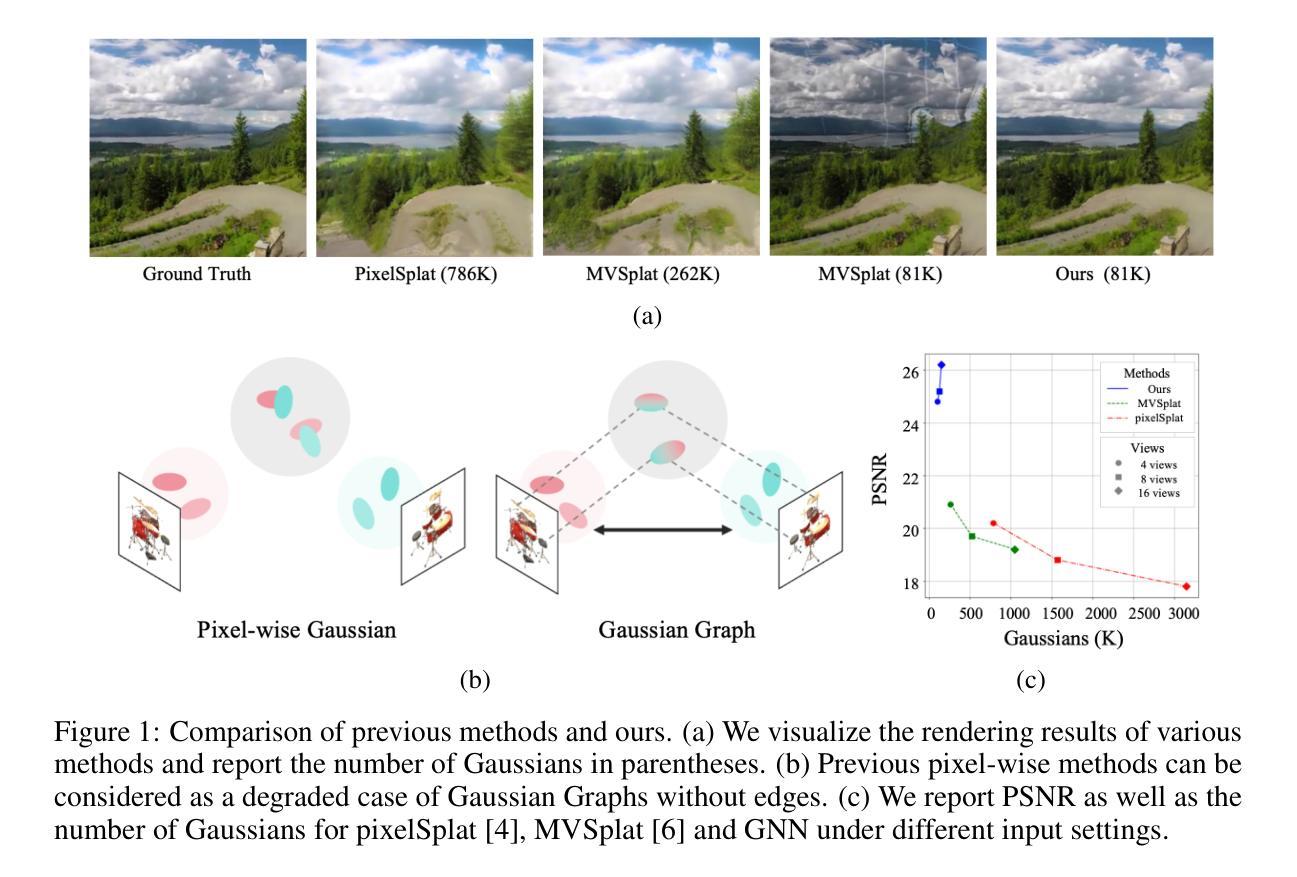
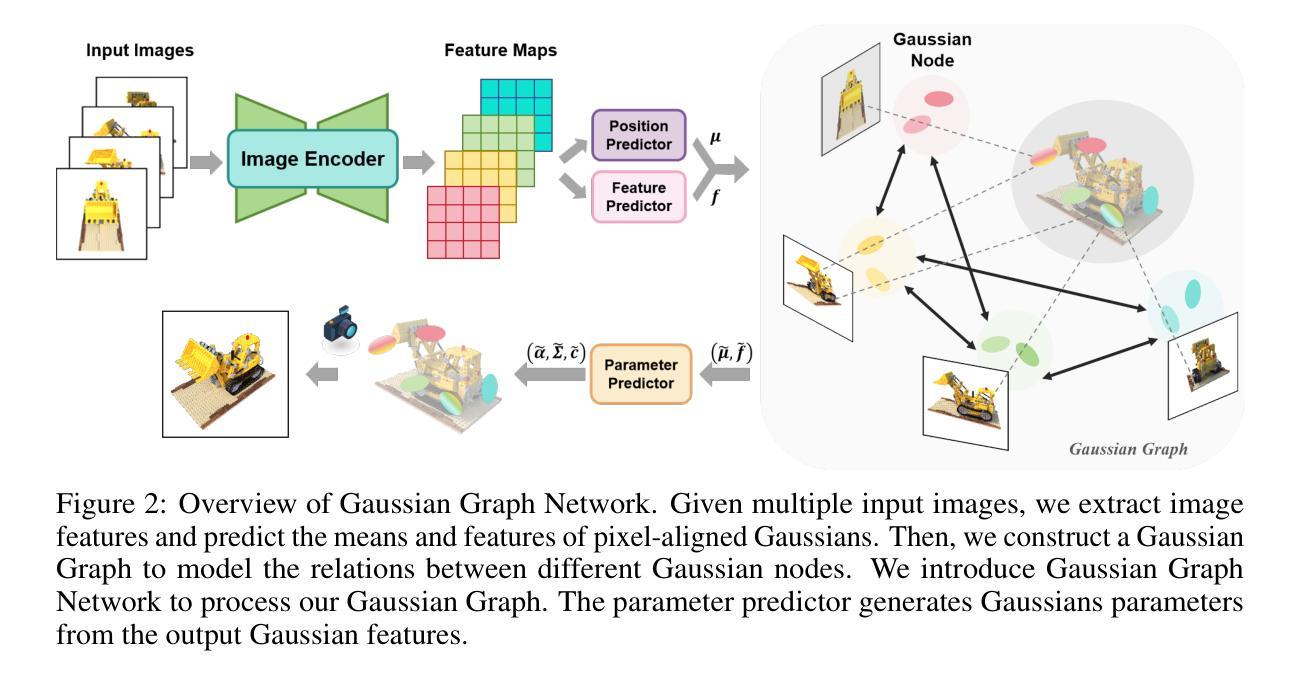
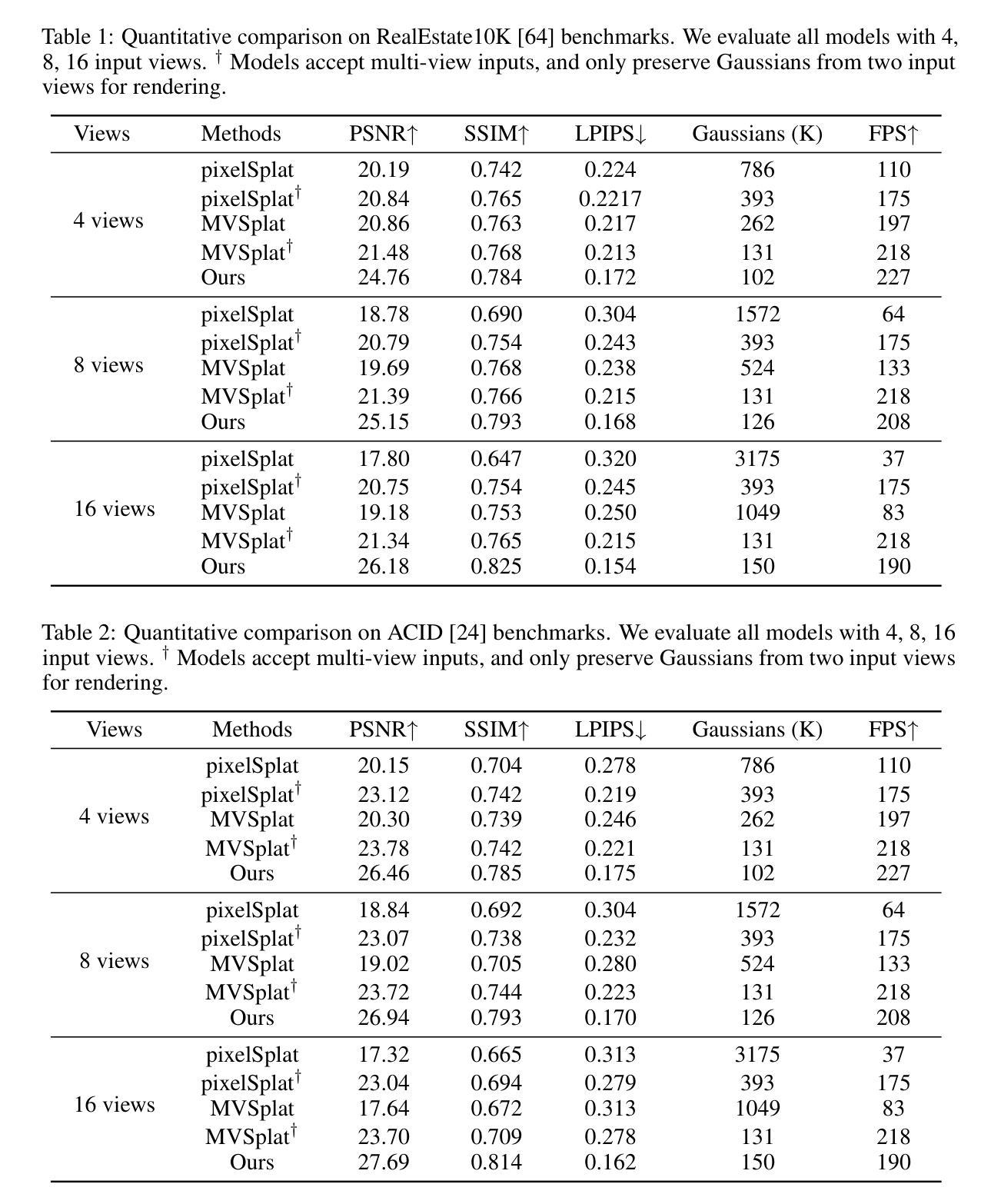
Gaussian Graph Network: Learning Efficient and Generalizable Gaussian Representations from Multi-view Images
Authors:Shengjun Zhang, Xin Fei, Fangfu Liu, Haixu Song, Yueqi Duan
3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis performance. While conventional methods require per-scene optimization, more recently several feed-forward methods have been proposed to generate pixel-aligned Gaussian representations with a learnable network, which are generalizable to different scenes. However, these methods simply combine pixel-aligned Gaussians from multiple views as scene representations, thereby leading to artifacts and extra memory cost without fully capturing the relations of Gaussians from different images. In this paper, we propose Gaussian Graph Network (GGN) to generate efficient and generalizable Gaussian representations. Specifically, we construct Gaussian Graphs to model the relations of Gaussian groups from different views. To support message passing at Gaussian level, we reformulate the basic graph operations over Gaussian representations, enabling each Gaussian to benefit from its connected Gaussian groups with Gaussian feature fusion. Furthermore, we design a Gaussian pooling layer to aggregate various Gaussian groups for efficient representations. We conduct experiments on the large-scale RealEstate10K and ACID datasets to demonstrate the efficiency and generalization of our method. Compared to the state-of-the-art methods, our model uses fewer Gaussians and achieves better image quality with higher rendering speed.
3D高斯卷积(3DGS)展现了令人印象深刻的全新视角合成性能。虽然传统方法需要进行场景优化,但最近已经提出了几种前馈方法,使用可学习网络生成像素对齐的高斯表示,这些方法可推广到不同的场景。然而,这些方法只是简单地将来自多个视角的像素对齐高斯组合起来作为场景表示,因此导致了伪像和额外的内存成本,而没有完全捕获来自不同图像的高斯之间的关系。在本文中,我们提出了高斯图网络(GGN)来生成高效且可推广的高斯表示。具体来说,我们构建高斯图来模拟来自不同视角的高斯组之间的关系。为了支持高斯级别的消息传递,我们对高斯表示上的基本图形操作进行重新表述,使每个高斯都能从其连接的高斯组中受益,并进行高斯特征融合。此外,我们设计了一个高斯池化层来聚合各种高斯组以实现高效表示。我们在大规模RealEstate10K和ACID数据集上进行了实验,以证明我们方法的效率和通用性。与最先进的方法相比,我们的模型使用更少的高斯,图像质量更高,渲染速度更快。
论文及项目相关链接
PDF NeurIPS 2024
Summary
本文提出一种基于高斯图网络(Gaussian Graph Network,GGN)的3D高斯融合方法,用于生成高效且通用的高斯表示。通过构建高斯图来模拟不同视角的高斯组关系,并重新定义了高斯层面的信息传递机制。该方法还包括高斯特征融合及高斯池化层的设计,以提升效率并改进表示质量。实验证明,该方法在大型数据集上表现出高效性和泛化能力,与现有方法相比,使用更少的高斯数即可达到更好的图像质量和更高的渲染速度。
Key Takeaways
- 3DGS展现出令人印象深刻的新视角合成性能。
- 传统方法需要针对每个场景进行优化,而最新方法则通过可学习网络生成像素对齐的高斯表示,这些表示具有跨场景泛化能力。
- 现有方法简单地将多个视角的像素对齐高斯组合为场景表示,导致伪影和额外的内存成本,未能充分捕捉不同图像高斯之间的关系。
- 提出Gaussian Graph Network (GGN)来生成高效且通用的高斯表示。
- 通过构建高斯图来模拟不同视角的高斯组关系。
- 定义高斯层面的信息传递机制,每个高斯都能从相连的高斯组中受益。
- 设计了高斯特征融合及高斯池化层,用于高效表示。
- 在大型数据集RealEstate10K和ACID上的实验证明了该方法的效率和泛化能力。
点此查看论文截图

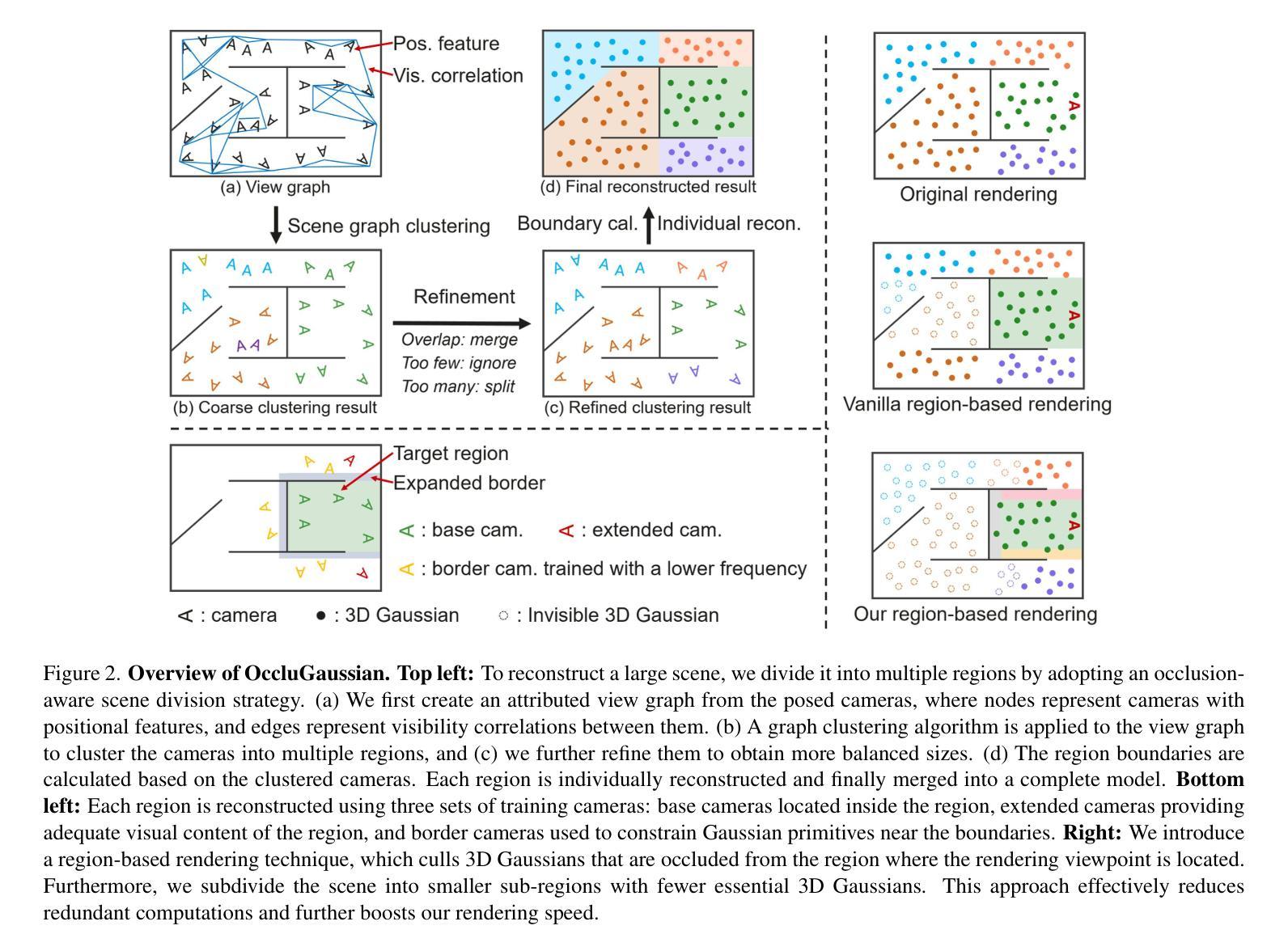
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Authors:Shiyong Liu, Xiao Tang, Zhihao Li, Yingfan He, Chongjie Ye, Jianzhuang Liu, Binxiao Huang, Shunbo Zhou, Xiaofei Wu
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
在利用3D高斯拼接(3DGS)进行大规模场景重建时,通常会将场景分割成多个较小的区域并进行分别重建。然而,现有的分割方法都是无视遮挡的,这意味着每个区域都可能包含严重的遮挡区域。因此,这些区域内的相机关联性较低,对整体重建的平均贡献较小。在本文中,我们提出了一种感知遮挡的场景分割策略,该策略根据相机的位置和共视性对训练相机进行聚类,以获得多个区域。这些区域内的相机表现出更强的关联性和更高的平均贡献,有助于实现高质量的场景重建。此外,我们还提出了一种基于区域的渲染技术,以加速大场景的渲染,该技术会剔除对于视点所在区域不可见的Gauss图像。这种技术在不损害质量的情况下显著提高了渲染速度。在多个大型场景上的广泛实验表明,与现有的最先进的方法相比,我们的方法实现了更优越的重建结果并提高了渲染速度。项目页面:https://occlugaussian.github.io。
论文及项目相关链接
PDF Project website: https://occlugaussian.github.io
Summary
本文提出了一个基于遮挡感知的场景分割策略,用于大规模场景重建。通过根据相机的位置和共视性进行聚类,获取多个区域,提高了相机间的相关性,进而提升了场景重建的质量。同时,本文还提出了一种基于区域的渲染技术,能加速大场景的渲染速度,而不会牺牲渲染质量。实验证明,该方法在重建效果和渲染速度上均优于现有方法。
Key Takeaways
- 现有场景分割方法未考虑遮挡问题,导致区域内存在严重遮挡,影响相机间的相关性及重建质量。
- 本文提出的遮挡感知场景分割策略能够根据相机的位置和共视性进行聚类,形成多个区域,提高相机间的相关性。
- 在这些区域内,相机表现出更强的相关性和更高的平均贡献,有助于提高场景重建的质量。
- 提出了一种基于区域的渲染技术,能剔除视点所在区域不可见的Gaussian,显著加速大场景的渲染速度。
- 该技术在保证渲染质量的前提下,实现了高效的渲染。
- 通过对多个大场景的广泛实验,证明本文方法实现了优越的重建结果和更快的渲染速度。
点此查看论文截图



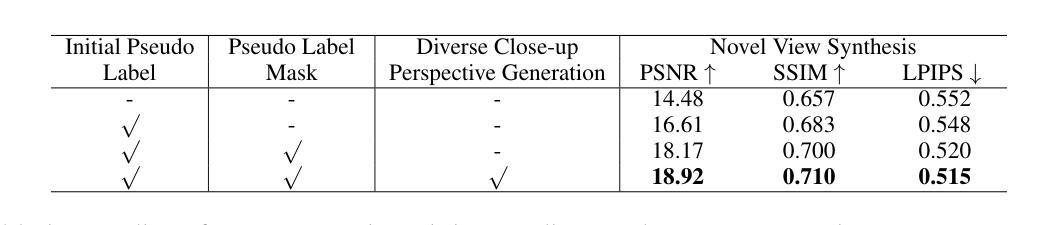
Enhancing Close-up Novel View Synthesis via Pseudo-labeling
Authors:Jiatong Xia, Libo Sun, Lingqiao Liu
Recent methods, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated remarkable capabilities in novel view synthesis. However, despite their success in producing high-quality images for viewpoints similar to those seen during training, they struggle when generating detailed images from viewpoints that significantly deviate from the training set, particularly in close-up views. The primary challenge stems from the lack of specific training data for close-up views, leading to the inability of current methods to render these views accurately. To address this issue, we introduce a novel pseudo-label-based learning strategy. This approach leverages pseudo-labels derived from existing training data to provide targeted supervision across a wide range of close-up viewpoints. Recognizing the absence of benchmarks for this specific challenge, we also present a new dataset designed to assess the effectiveness of both current and future methods in this area. Our extensive experiments demonstrate the efficacy of our approach.
最近的方法,如神经辐射场(NeRF)和三维高斯拼贴(3DGS),在新型视图合成中展示了显著的能力。尽管它们在生成与训练期间所见相似的视角的高质量图像方面非常成功,但在生成从与训练集偏差较大的视角出发的详细图像时却表现挣扎,特别是在特写镜头视角下。主要挑战源于特写镜头视角的具体训练数据的缺乏,导致当前方法无法准确渲染这些视图。为了解决这一问题,我们引入了一种基于伪标签的学习策略。该方法利用来自现有训练数据的伪标签,为各种特写镜头视角提供有针对性的监督。由于当前缺乏针对这一挑战的基准测试,我们还推出了一个新的数据集,旨在评估当前和未来方法在这个领域的有效性。我们的大量实验证明了我们的方法的有效性。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
NeRF和3DGS等方法在新型视角合成方面表现出卓越的能力,但在生成与训练集视角差异较大的详细图像时,尤其是近距离视角的图像,存在困难。主要挑战在于缺乏针对近距离视角的特定训练数据,导致现有方法无法准确渲染这些视图。为解决这一问题,我们提出了一种基于伪标签的学习策略,利用现有训练数据生成的伪标签,为广泛范围的近距离视角提供有针对性的监督。由于缺少针对此挑战的基准测试集,我们还推出了一个新的数据集,旨在评估当前和未来方法在这个领域的有效性。实验证明我们的方法有效。
Key Takeaways
- NeRF和3DGS等方法在新型视角合成方面表现出卓越的能力。
- 在生成与训练集视角差异大的详细图像,尤其是近距离视角图像时,现有方法存在困难。
- 缺乏针对近距离视角的特定训练数据是主要的挑战。
- 提出了一种基于伪标签的学习策略,为广泛范围的近距离视角提供有针对性的监督。
- 为评估方法在这个领域的有效性,推出了一个新的数据集。
- 引入的伪标签学习策略提高了在近距离视角图像生成的准确性。
点此查看论文截图



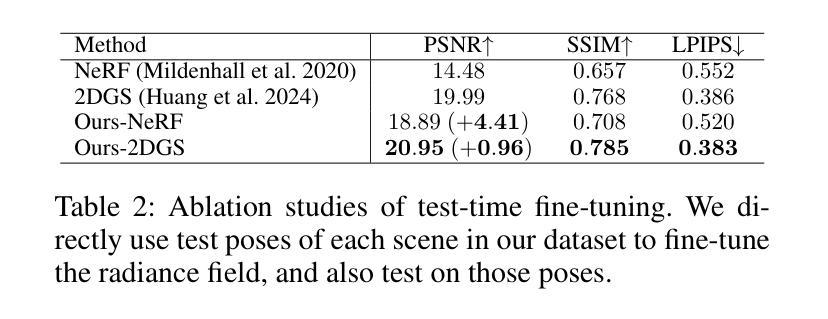
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Authors:Hyojun Go, Byeongjun Park, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim
We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
我们提出VideoRFSplat,这是一种直接的文本到3D模型,利用视频生成模型生成现实世界的无限场景的真实3D高斯喷溅(3DGS)。为了生成多样化的相机姿态和现实世界场景的无限空间范围,同时确保对任意文本提示的泛化能力,之前的方法是通过微调2D生成模型来联合建模相机姿态和多视角图像。然而,这些方法在将2D生成模型扩展到联合建模时会出现不稳定,这是由于模态差距造成的,需要额外的模型来稳定训练和推理。在这项工作中,我们提出了一种架构和采样策略,在微调视频生成模型时联合建模多视角图像和相机姿态。我们的核心思想是一种双流架构,它通过通信块将一个专用的姿态生成模型与预训练的视频生成模型附加在一起,通过单独的流生成多视角图像和相机姿态。这种设计减少了姿态和图像模态之间的干扰。此外,我们提出了一种异步采样策略,该策略能更快地消除相机姿态的噪声,允许快速去噪的姿态调节多视角生成,减少相互模糊并增强跨模态一致性。在多个大规模真实世界数据集(RealEstate10K、MVImgNet、DL3DV-10K、ACID)上进行训练,VideoRFSplat超越了现有的文本到3D直接生成方法,这些方法严重依赖于通过分数蒸馏采样进行事后细化,并在没有此类细化的情况下取得优越结果。
论文及项目相关链接
PDF Project page: https://gohyojun15.github.io/VideoRFSplat/
Summary
本文提出VideoRFSplat模型,这是一种直接由文本到3D的模型,利用视频生成模型生成逼真的3D高斯溅出(3DGS)以表现无界限的真实世界场景。为生成多样化的相机姿态和真实世界场景的无界限空间范围,同时确保对任意文本提示的泛化能力,前人方法会对2D生成模型进行微调以联合建模相机姿态和多视角图像。然而,这些方法在扩展到联合建模时会出现不稳定现象,这是由于模态差距造成的。为此,本文提出了一种架构和采样策略,在微调视频生成模型时联合建模多视角图像和相机姿态。核心思想是采用双流架构,通过通信块将一个专用的姿态生成模型与预训练的视频生成模型连接起来,通过不同流生成多视角图像和相机姿态,减少姿态和图像模态之间的干扰。此外,还提出了一种异步采样策略,该策略能更快地对相机姿态进行去噪处理,允许快速去噪的相机姿态作为多视角生成的约束条件,减少了互模糊并增强了跨模态一致性。在多个大规模真实世界数据集上进行训练后,VideoRFSplat超越了现有的文本到3D直接生成方法,特别是在依赖于事后修订得分蒸馏采样的方法上表现出色,即使没有这种修订也能实现优越的结果。
Key Takeaways
- VideoRFSplat是一种利用视频生成模型实现从文本到逼真的三维高斯溅出模型的直接转换。
- 传统的视频生成模型在处理文本提示时会遇到相机姿态建模和多视角图像生成的问题。为解决这些问题,需要利用双流架构结合专用的姿态生成模型和预训练的视频生成模型。
- 通过引入通信块实现双流的联合操作,分别处理多视角图像和相机姿态的生成,减少模态间的干扰。
- 提出异步采样策略以加速相机姿态的去噪过程,提升模型的稳定性和效率。通过迅速更新的去噪姿态条件化多视角图像的生成过程,降低了模态之间的歧义性并增强了跨模态一致性。
点此查看论文截图



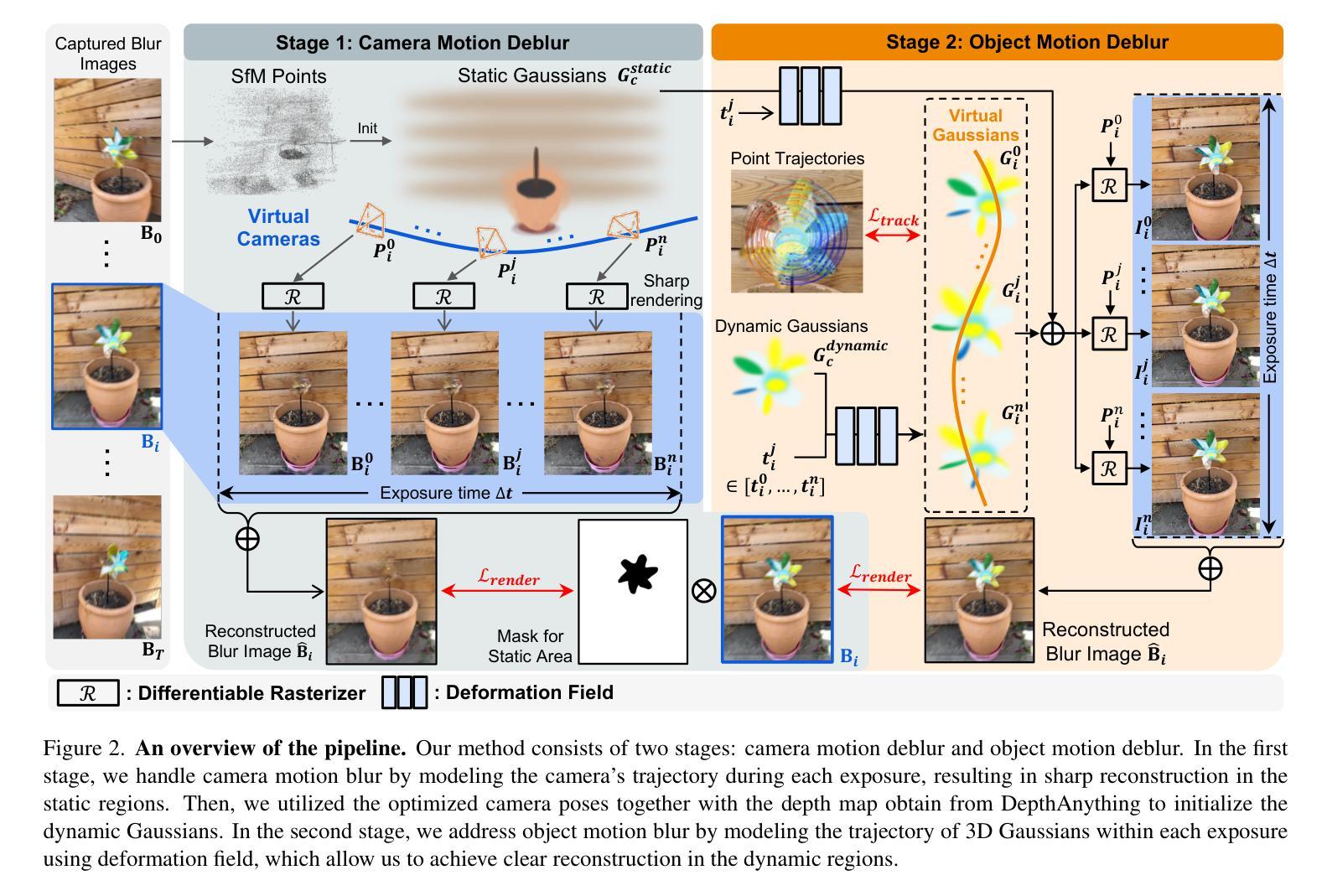
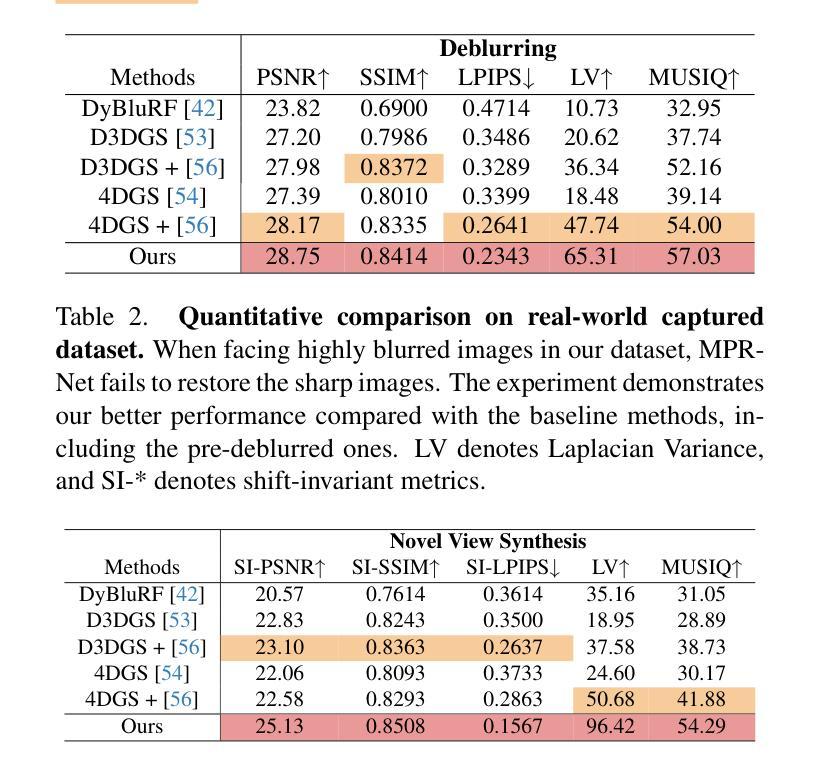
BARD-GS: Blur-Aware Reconstruction of Dynamic Scenes via Gaussian Splatting
Authors:Yiren Lu, Yunlai Zhou, Disheng Liu, Tuo Liang, Yu Yin
3D Gaussian Splatting (3DGS) has shown remarkable potential for static scene reconstruction, and recent advancements have extended its application to dynamic scenes. However, the quality of reconstructions depends heavily on high-quality input images and precise camera poses, which are not that trivial to fulfill in real-world scenarios. Capturing dynamic scenes with handheld monocular cameras, for instance, typically involves simultaneous movement of both the camera and objects within a single exposure. This combined motion frequently results in image blur that existing methods cannot adequately handle. To address these challenges, we introduce BARD-GS, a novel approach for robust dynamic scene reconstruction that effectively handles blurry inputs and imprecise camera poses. Our method comprises two main components: 1) camera motion deblurring and 2) object motion deblurring. By explicitly decomposing motion blur into camera motion blur and object motion blur and modeling them separately, we achieve significantly improved rendering results in dynamic regions. In addition, we collect a real-world motion blur dataset of dynamic scenes to evaluate our approach. Extensive experiments demonstrate that BARD-GS effectively reconstructs high-quality dynamic scenes under realistic conditions, significantly outperforming existing methods.
3D高斯点积法(3DGS)在静态场景重建方面表现出了显著潜力,并且最近的进展已经将其应用扩展到了动态场景。然而,重建的质量很大程度上取决于高质量输入图像和精确的相机姿态,这在现实场景中往往难以满足。例如,使用手持单眼相机捕捉动态场景通常涉及相机和场景内物体的同时移动。这种组合运动往往会导致图像模糊,现有方法无法充分处理。为了解决这些挑战,我们引入了BARD-GS,这是一种稳健的动态场景重建新方法,能够有效处理模糊输入和相机姿态不准确的问题。我们的方法主要包括两个组成部分:1)相机运动去模糊和2)物体运动去模糊。我们通过明确地将运动模糊分解成相机运动模糊和物体运动模糊,并分别对其进行建模,实现了动态区域的渲染结果显著改善。此外,我们还收集了一个动态场景的真实运动模糊数据集来评估我们的方法。大量实验表明,BARD-GS在真实条件下有效地重建了高质量动态场景,显著优于现有方法。
论文及项目相关链接
PDF CVPR2025. Project page at https://vulab-ai.github.io/BARD-GS/
Summary
基于动态场景重建的需求和挑战,提出了名为BARD-GS的新型方法,它可有效处理模糊输入和不准确的相机姿态。通过分离并分别建模相机运动模糊和物体运动模糊,在动态区域的渲染结果得到了显著提升。同时,收集真实世界的运动模糊数据集以评估方法性能,实验证明BARD-GS在真实条件下对动态场景的重建质量显著提高。
Key Takeaways
- 3DGS在静态和动态场景的重建中显示出巨大潜力。
- 重建质量高度依赖于高质量输入图像和精确的相机姿态。
- 手持单目相机拍摄动态场景时,相机和物体的同时运动常导致图像模糊,现有方法难以处理。
- BARD-GS方法通过明确分解和分别建模相机运动模糊和物体运动模糊,实现了显著改善。
- 收集真实世界的运动模糊数据集,用于评估BARD-GS性能。
- 广泛实验证明,BARD-GS在真实条件下对动态场景的重建效果优于现有方法。
点此查看论文截图


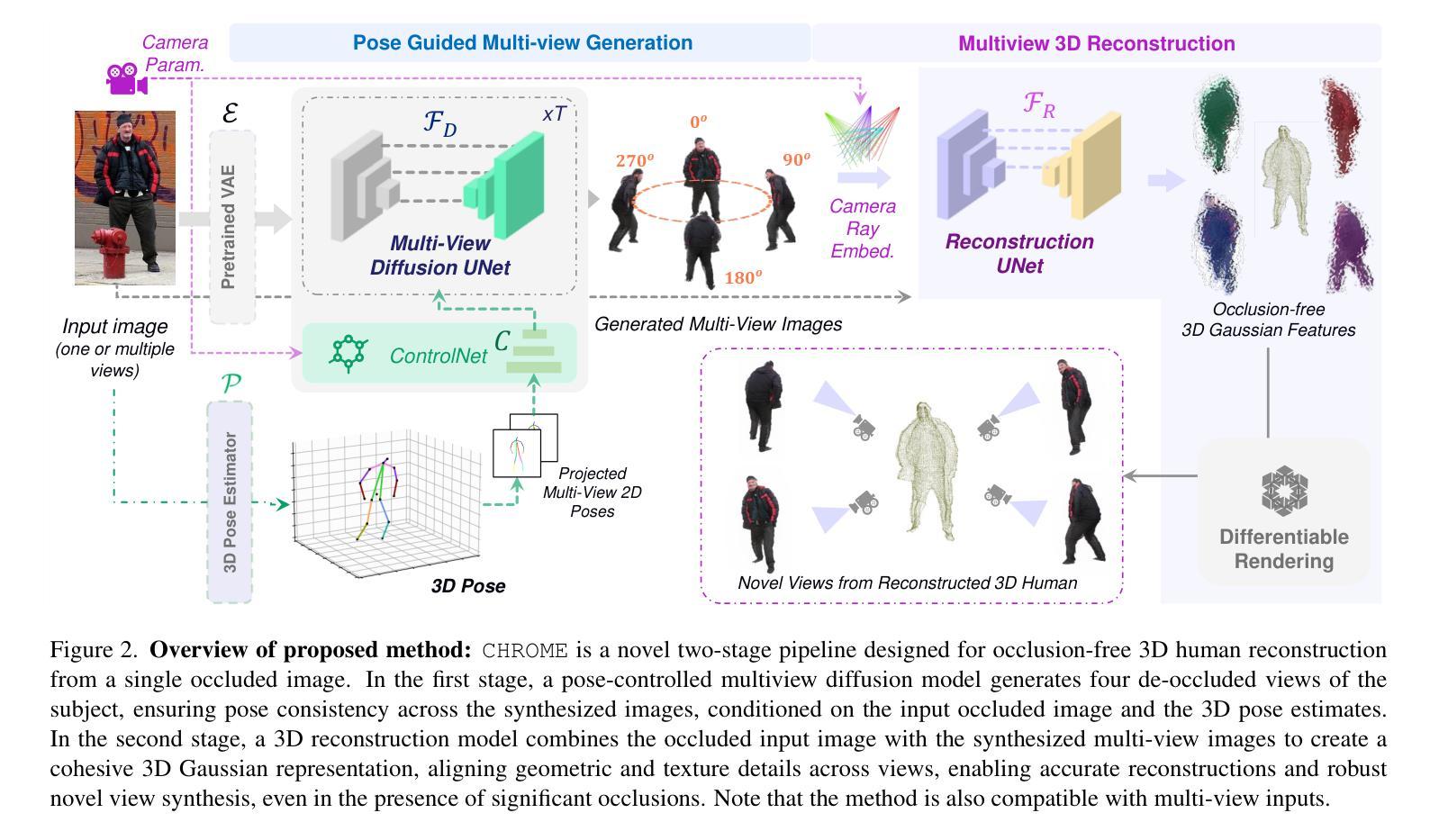
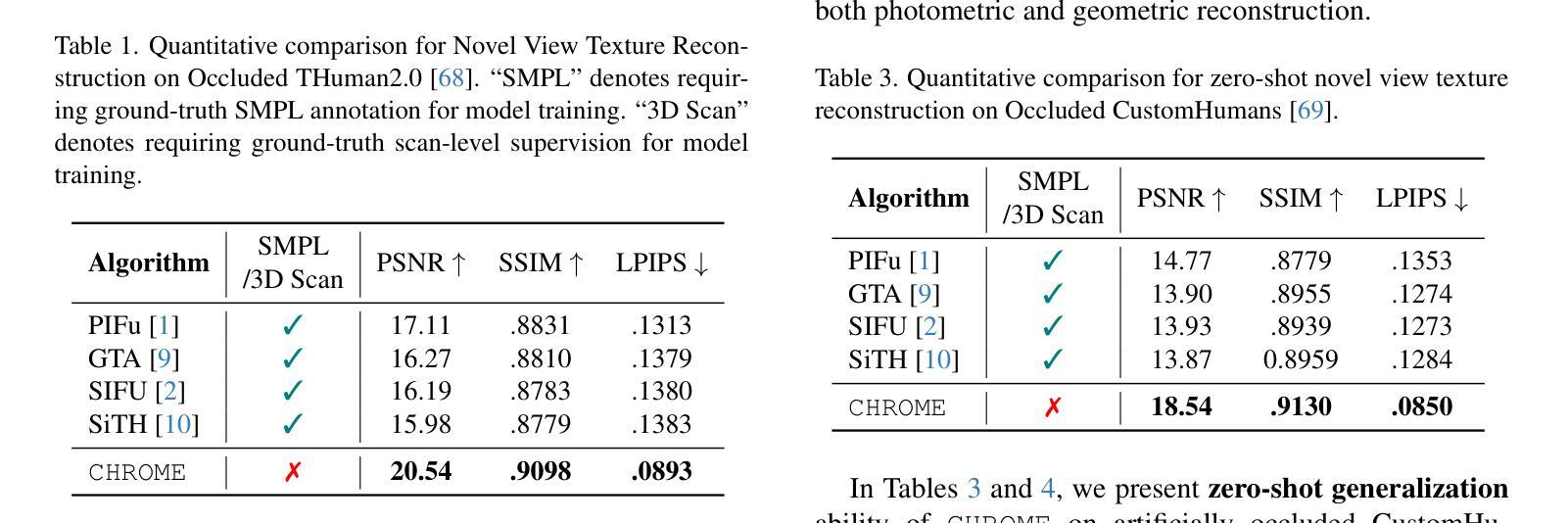
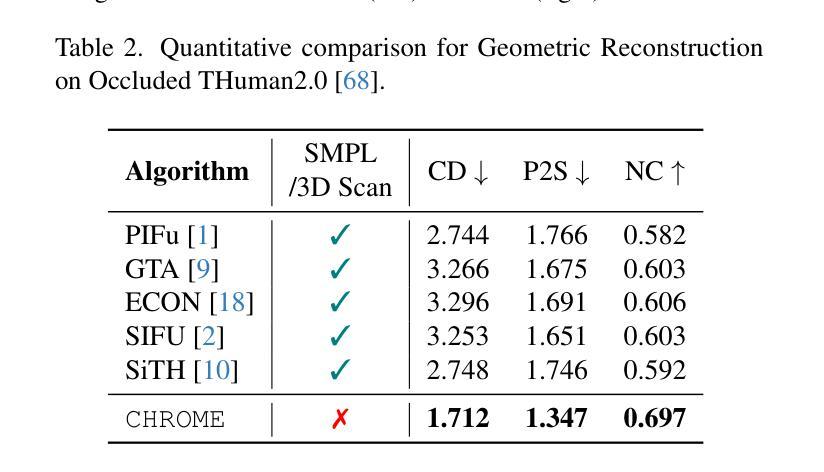
CHROME: Clothed Human Reconstruction with Occlusion-Resilience and Multiview-Consistency from a Single Image
Authors:Arindam Dutta, Meng Zheng, Zhongpai Gao, Benjamin Planche, Anwesha Choudhuri, Terrence Chen, Amit K. Roy-Chowdhury, Ziyan Wu
Reconstructing clothed humans from a single image is a fundamental task in computer vision with wide-ranging applications. Although existing monocular clothed human reconstruction solutions have shown promising results, they often rely on the assumption that the human subject is in an occlusion-free environment. Thus, when encountering in-the-wild occluded images, these algorithms produce multiview inconsistent and fragmented reconstructions. Additionally, most algorithms for monocular 3D human reconstruction leverage geometric priors such as SMPL annotations for training and inference, which are extremely challenging to acquire in real-world applications. To address these limitations, we propose CHROME: Clothed Human Reconstruction with Occlusion-Resilience and Multiview-ConsistEncy from a Single Image, a novel pipeline designed to reconstruct occlusion-resilient 3D humans with multiview consistency from a single occluded image, without requiring either ground-truth geometric prior annotations or 3D supervision. Specifically, CHROME leverages a multiview diffusion model to first synthesize occlusion-free human images from the occluded input, compatible with off-the-shelf pose control to explicitly enforce cross-view consistency during synthesis. A 3D reconstruction model is then trained to predict a set of 3D Gaussians conditioned on both the occluded input and synthesized views, aligning cross-view details to produce a cohesive and accurate 3D representation. CHROME achieves significant improvements in terms of both novel view synthesis (upto 3 db PSNR) and geometric reconstruction under challenging conditions.
从单一图像重建穿衣人类是计算机视觉中的一项基本任务,具有广泛的应用范围。尽管现有的单目穿衣人类重建解决方案已经显示出有希望的结果,但它们通常假设人类主体处于一个无遮挡的环境中。因此,当遇到野外遮挡图像时,这些算法会产生多视角不一致和碎片化的重建结果。此外,大多数单目3D人类重建算法利用几何先验(如SMPL注释)进行训练和推理,这在现实世界应用中极难获取。为了解决这些局限性,我们提出了CHROME:从单张图像进行具有遮挡恢复能力和多视角一致性的穿衣人类重建。这是一种新型管道设计,旨在从单个遮挡图像中以多视角一致性重建具有遮挡恢复能力的3D人类,而无需真实几何先验注释或3D监督。具体来说,CHROME首先利用多视角扩散模型从遮挡输入中合成无遮挡的人体图像,与现成的姿势控制相结合,在合成过程中明确执行跨视角一致性。然后,训练一个3D重建模型,根据遮挡输入和合成视图预测一组3D高斯分布,对齐跨视角细节以产生连贯和准确的3D表示。CHROME在新型视角合成(高达3分贝PSNR)和具有挑战性的条件下的几何重建方面都取得了显著的改进。
论文及项目相关链接
Summary
本文提出了一种新型的重建技术——CHROME,该技术能够在单张遮挡图像中实现具有遮挡恢复能力的三维人体重建,并且具有多视角一致性。该方法无需真实几何先验标注和三维监督信息,通过合成无遮挡人体图像和多视角一致性约束,提高了在复杂环境下的重建效果。
Key Takeaways
- 重建技术主要挑战在于处理遮挡问题。现有的技术通常假设人体处于无遮挡环境中,导致在实际应用中表现不佳。
- CHROME技术解决了这一难题,实现了在单张遮挡图像上的三维人体重建,并具有遮挡恢复能力。
- CHROME技术采用多视角扩散模型,从遮挡输入中合成无遮挡人体图像,与现成的姿势控制兼容,明确执行跨视角一致性约束。
- 该技术通过训练一个三维重建模型,预测一组基于遮挡输入和合成视角的三维高斯分布,通过跨视角细节对齐生成连贯且精确的三维表示。
- CHROME技术在新型视角合成和几何重建方面取得了显著改进,特别是在复杂环境下。
- 该方法无需真实的几何先验标注和三维监督信息,降低了实际应用中的难度和成本。
点此查看论文截图


Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
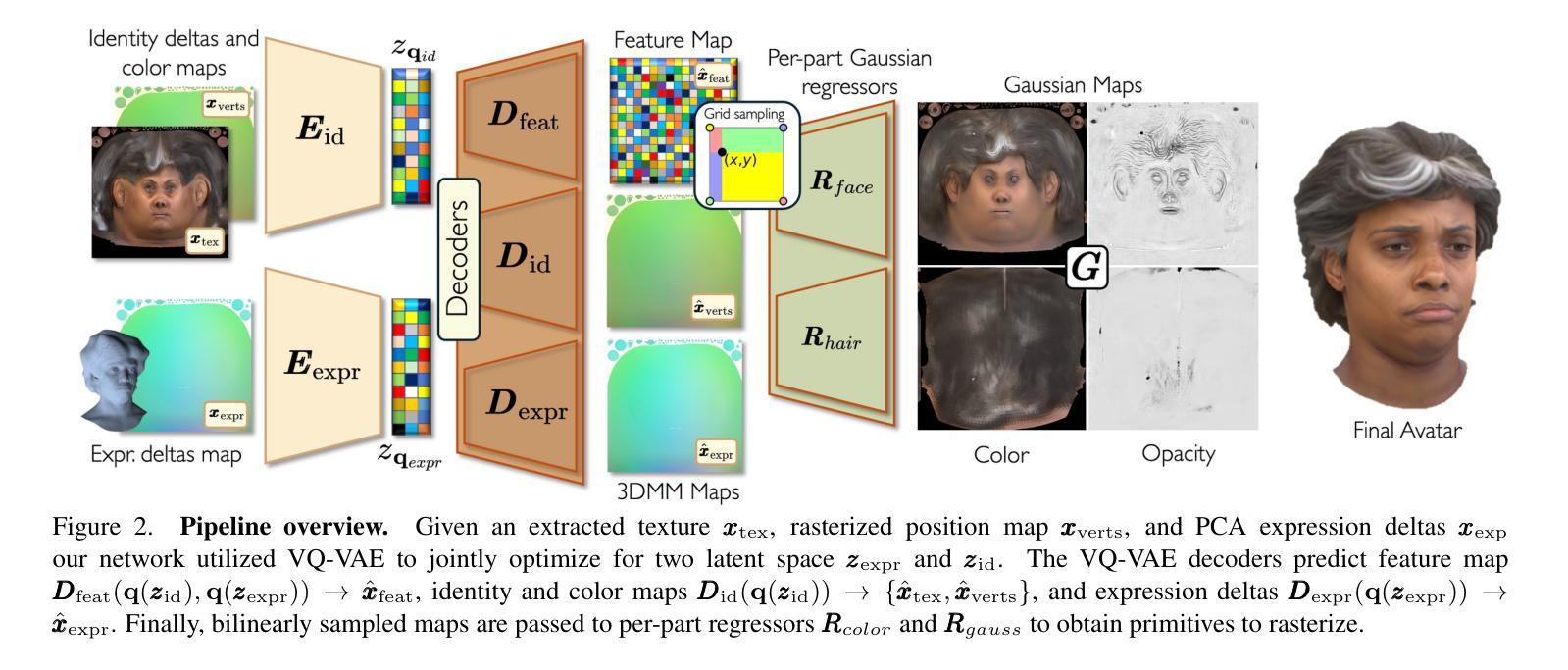
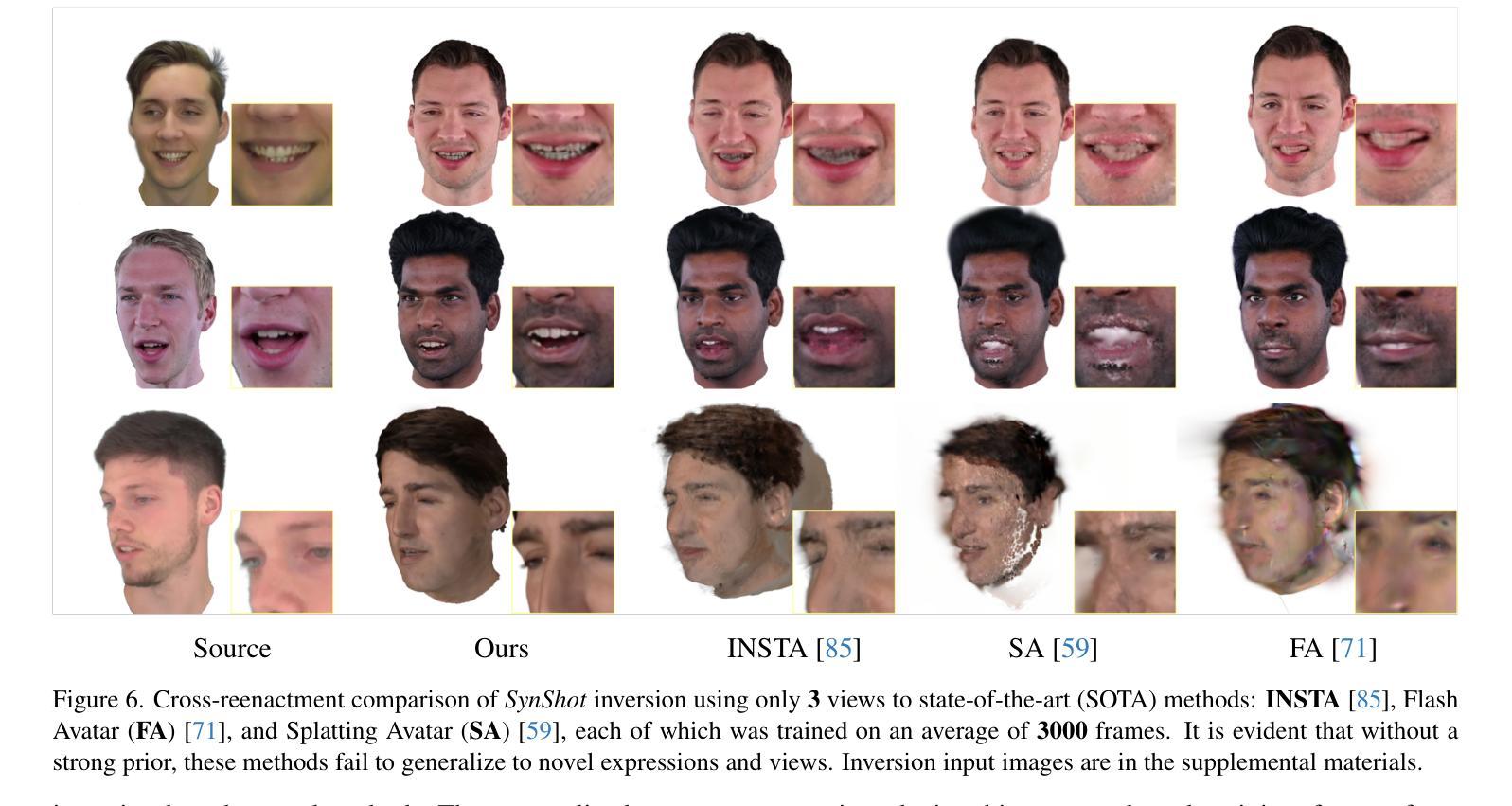
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了一种名为SynShot的新方法,用于基于合成先验的少数镜头驾驶头部阿凡达的反转。我们解决了三大挑战。首先,训练可控的3D生成网络需要大量的不同序列,而图像和高品质跟踪网格的配对并不总是可用。其次,真实数据的使用受到严格监管(例如,在《通用数据保护条例》下,当参与者同意撤回时,经常需要删除模型和数据)。不受这些约束的合成数据是一个吸引人的替代方案。第三,最先进的单眼阿凡达模型在推广到新的视角和表情时遇到困难,缺乏强大的先验知识,并且经常过度适应特定的观点分布。受只接受合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从包含不同身份、表情和观点的大量合成头部数据中学习先验模型。凭借少数输入图像,SynShot微调了预训练的合成先验,以弥合领域间的差距,并建模一个逼真的头部阿凡达,可以推广到新的表情和视角。我们使用3D高斯喷绘和卷积编码器-解码器来输出UV纹理空间的高斯参数,对头部各部分的不同建模复杂性进行建模(例如,皮肤与头发)。为了考虑头部各部分(例如皮肤和头发)的不同建模复杂性,我们在先验中嵌入了对增加每个部分原始数量的上采样控制。与最先进的单眼和基于GAN的方法相比,SynShot显著提高了新视角和表情的合成效果。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
本文介绍了SynShot方法,这是一种基于合成先验的少数人头驾驶头像反转技术的新方法。该方法解决了三大挑战:缺乏多样序列图像和高品质追踪网格的训练数据、真实数据使用受到严格监管以及当前单眼头像模型在新视角和表情上的泛化能力不强。SynShot通过学习从大量合成头像数据中获取的先验模型,结合少量输入图像,微调预训练合成先验以弥域差距,从而建模出真实感头像并能泛化到新的表情和视角。
Key Takeaways
- SynShot是一种基于合成先验的少数人头驾驶头像反转技术。
- 它解决了训练可控的3D生成网络面临的三大挑战:缺乏多样序列图像和高品质追踪网格的训练数据、真实数据使用的监管问题以及现有模型在新视角和表情上的泛化难题。
- SynShot通过结合大量合成头像数据的先验模型与少量输入图像,微调预训练合成先验,以弥域差距,达到建模真实感头像的目标。
- 该方法采用3D高斯喷涂技术和卷积编码器-解码器,在UV纹理空间中输出高斯参数。
- 为了应对头部不同部分建模复杂性的差异(如皮肤和头发),SynShot嵌入先验,具有针对每个部分原始数量的上采样控制功能。
点此查看论文截图




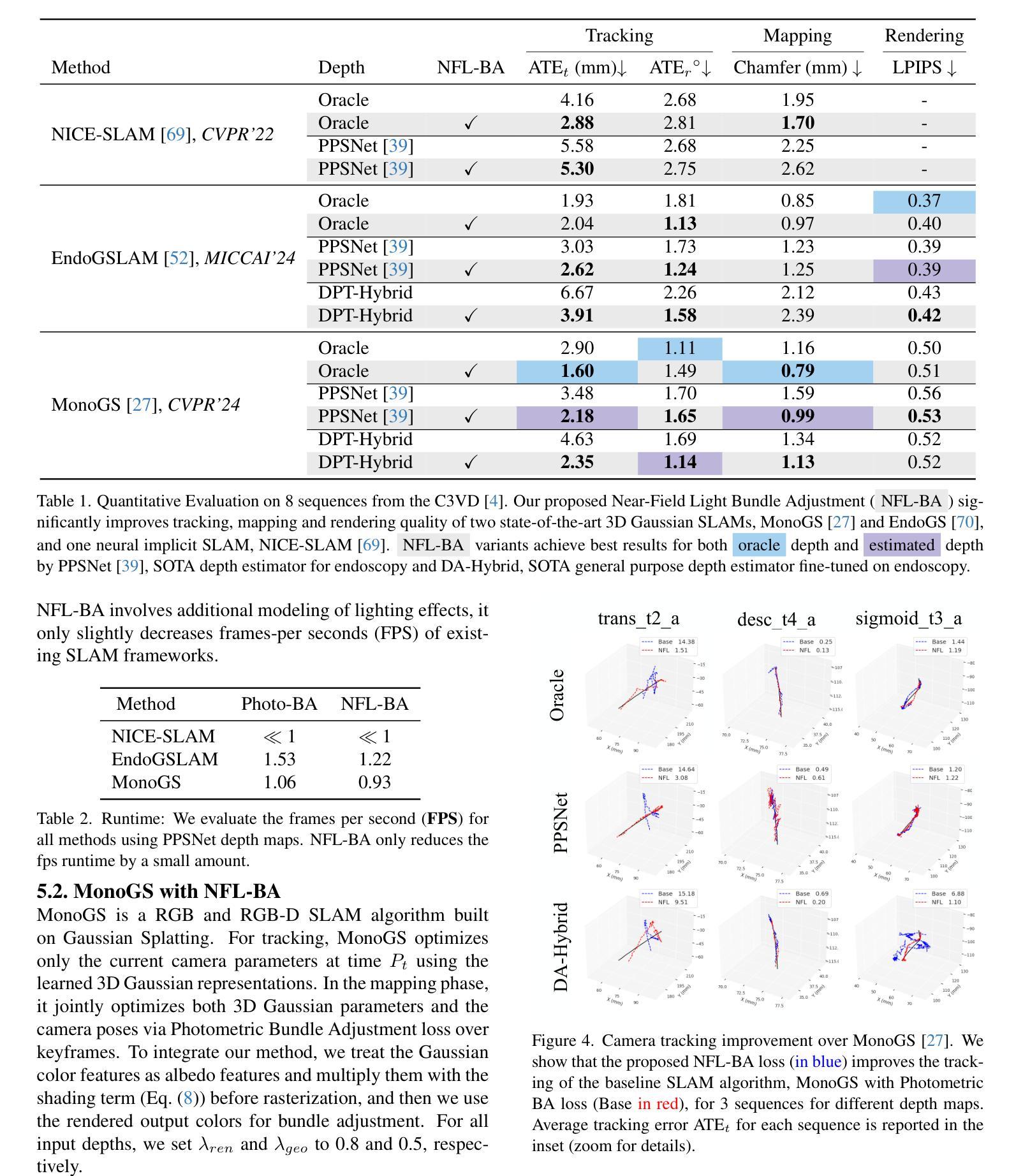
NFL-BA: Improving Endoscopic SLAM with Near-Field Light Bundle Adjustment
Authors:Andrea Dunn Beltran, Daniel Rho, Stephen Pizer, Marc Niethammer, Roni Sengupta
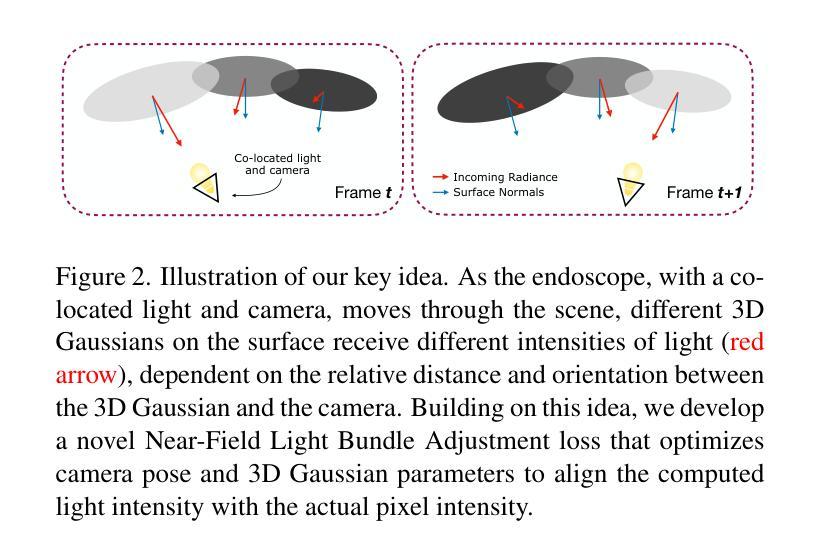
Simultaneous Localization And Mapping (SLAM) from endoscopy videos can enable autonomous navigation, guidance to unsurveyed regions, blindspot detections, and 3D visualizations, which can significantly improve patient outcomes and endoscopy experience for both physicians and patients. Existing dense SLAM algorithms often assume distant and static lighting and optimize scene geometry and camera parameters by minimizing a photometric rendering loss, often called Photometric Bundle Adjustment. However, endoscopy videos exhibit dynamic near-field lighting due to the co-located light and camera moving extremely close to the surface. In addition, low texture surfaces in endoscopy videos cause photometric bundle adjustment of the existing SLAM frameworks to perform poorly compared to indoor/outdoor scenes. To mitigate this problem, we introduce Near-Field Lighting Bundle Adjustment Loss (NFL-BA) which explicitly models near-field lighting as a part of Bundle Adjustment loss and enables better performance for low texture surfaces. Our proposed NFL-BA can be applied to any neural-rendering based SLAM framework. We show that by replacing traditional photometric bundle adjustment loss with our proposed NFL-BA results in improvement, using neural implicit SLAM and 3DGS SLAMs. In addition to producing state-of-the-art tracking and mapping results on colonoscopy C3VD dataset we also show improvement on real colonoscopy videos. See results at https://asdunnbe.github.io/NFL-BA/
通过内窥镜视频实现的同步定位与地图构建(SLAM)可以支持自主导航、对未测绘区域的指导、盲点检测和3D可视化,这可以显著改善患者治疗效果和医生与患者的内窥镜检查体验。现有的密集SLAM算法通常假设光源距离遥远且静态,通过最小化被称为光度捆绑调整的光度渲染损失来优化场景几何和相机参数。然而,内窥镜视频呈现出动态近场照明,这是由于光源和相机与表面非常接近而移动造成的。此外,内窥镜视频中的低纹理表面导致现有SLAM框架的光度捆绑调整性能与室内/室外场景相比表现较差。为了缓解这个问题,我们引入了近场照明捆绑调整损失(NFL-BA),它显式地将近场照明作为捆绑调整损失的一部分,从而实现对低纹理表面进行更好的性能表现。我们提出的NFL-BA可以应用于任何基于神经渲染的SLAM框架。我们展示,通过用我们提出的NFL-BA替换传统的光度捆绑调整损失,使用神经隐式SLAM和3DGS SLAMs会有改进效果。除了在结肠镜检查C3VD数据集上实现最先进的跟踪和映射结果外,我们还展示了在真实结肠镜检查视频上的改进。具体成果可参见网址:https://asdunnbe.github.io/NFL-BA/。
论文及项目相关链接
Summary
内镜视频中的同步定位与地图构建(SLAM)可实现自主导航、导向未勘测区域、盲点检测及三维可视化,可显著改善患者及医师的内镜体验并提升患者治疗效果。针对内镜视频中的动态近场照明和低纹理表面问题,引入近场照明捆绑调整损失(NFL-BA),对任何基于神经渲染的SLAM框架都能带来更好的性能。采用NFL-BA替换传统光度捆绑调整损失,能显著提升神经隐式SLAM和3DGS SLAM的表现,在结肠镜检查C3VD数据集和真实结肠镜视频上都展现了卓越的追踪和映射效果。
Key Takeaways
- SLAM技术从内镜视频中可助力自主导航、导向未勘测区域等,显著改进医疗与体验。
- 内镜视频存在动态近场照明与低纹理表面问题,现有SLAM算法性能受限。
- 引入NFL-BA能有效解决动态近场照明问题,提升在低纹理表面的性能表现。
- NFL-BA适用于所有基于神经渲染的SLAM框架。
- 用NFL-BA替换传统光度捆绑调整损失能显著提高SLAM技术表现。
- 在结肠镜检查数据集及真实场景中,应用NFL-BA的SLAM技术具有优秀追踪与映射效果。
点此查看论文截图


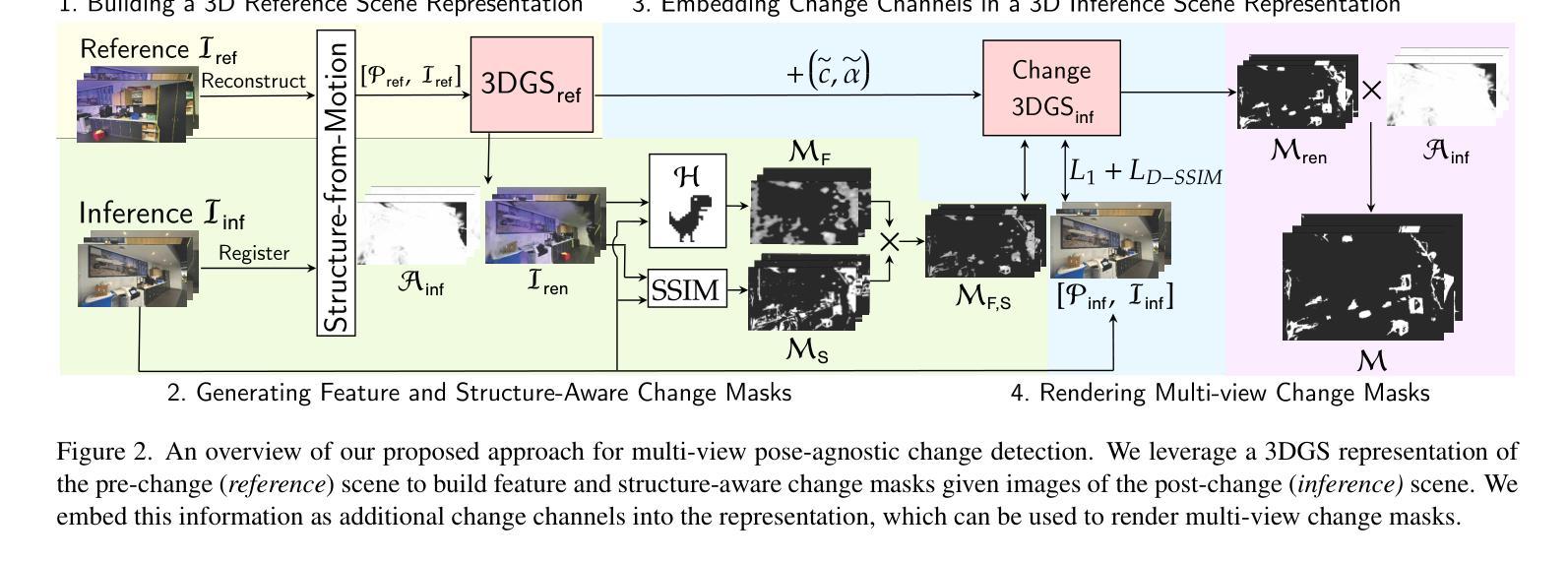
Multi-View Pose-Agnostic Change Localization with Zero Labels
Authors:Chamuditha Jayanga Galappaththige, Jason Lai, Lloyd Windrim, Donald Dansereau, Niko Suenderhauf, Dimity Miller
Autonomous agents often require accurate methods for detecting and localizing changes in their environment, particularly when observations are captured from unconstrained and inconsistent viewpoints. We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn an additional change channel in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7x and 1.5x improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
自主代理通常需要准确的方法来检测并定位其环境中的变化,特别是在从不受限制和不一致的视角捕获观察结果时。我们提出了一种新型的无标签、不受姿态影响的变化检测方法,该方法整合了来自多个视角的信息,以构建一种对变化有感知的3D高斯拼贴(3DGS)场景表示。仅使用变化后场景的5张图像,我们的方法可以在3DGS中学习额外的变化通道,并产生优于单视图技术的变化蒙版。我们的对变化有感知的3D场景表示还允许为未见过的视角生成准确的变化蒙版。实验结果表明,在复杂的多对象场景中,我们的方法在平均交并比和F1分数方面分别实现了比其他基准方法1.7倍和1.5倍的改进。我们还为在光照变化存在的情况下,在多样且具有挑战性的场景中检测变化提供了一个新的现实世界数据集。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
自主智能体在环境变化的检测和定位方面需要准确的方法,特别是在观察点不受限制且不一致的情况下。本文提出了一种新颖的免标签、无姿态变化的检测法,该方法通过整合多视角的信息来构建对环境变化有感知的3D高斯拼贴(3DGS)表示。仅需少量变化后的场景图像,该方法能够在3DGS中学习额外的变化通道,并产生优于单视角技术的变化蒙版。此外,我们的变化感知3D场景表示能够为未见过的视角生成准确的变化蒙版。实验结果表明,在复杂的多对象场景中,该方法达到了最先进的性能,相较于其他基线方法,Mean Intersection Over Union和F1分数分别提高了1.7倍和1.5倍。我们还贡献了一个新的真实世界数据集,以在光照变化的情况下对多变场景中的变化检测进行基准测试。
Key Takeaways
- 提出了一种免标签、无姿态变化的检测方法用于环境变化检测。
- 通过整合多视角信息构建变化感知的3D高斯拼贴(3DGS)表示。
- 仅需少量变化后的场景图像,能在3DGS中学习额外的变化通道。
- 产生的变化蒙版性能优于单视角技术。
- 变化感知的3D场景表示能生成未见视角的准确变化蒙版。
- 在复杂多对象场景中达到最先进的性能,较其他方法有显著改进。
点此查看论文截图

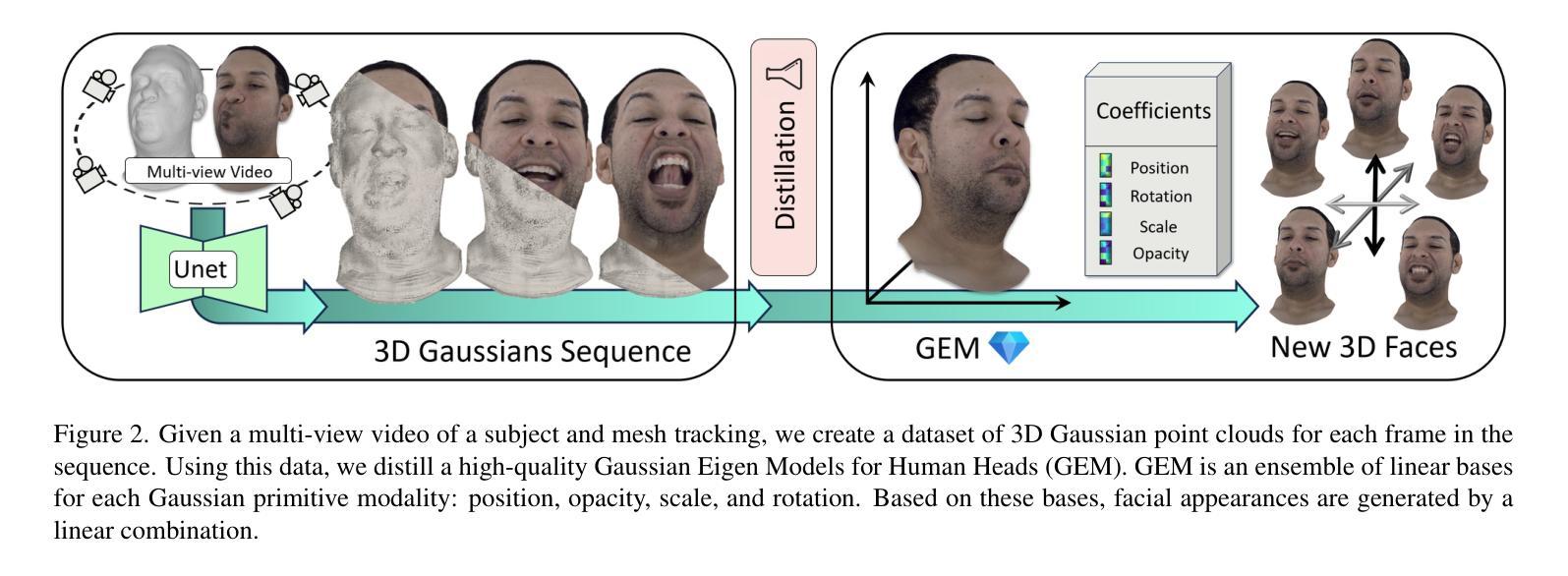
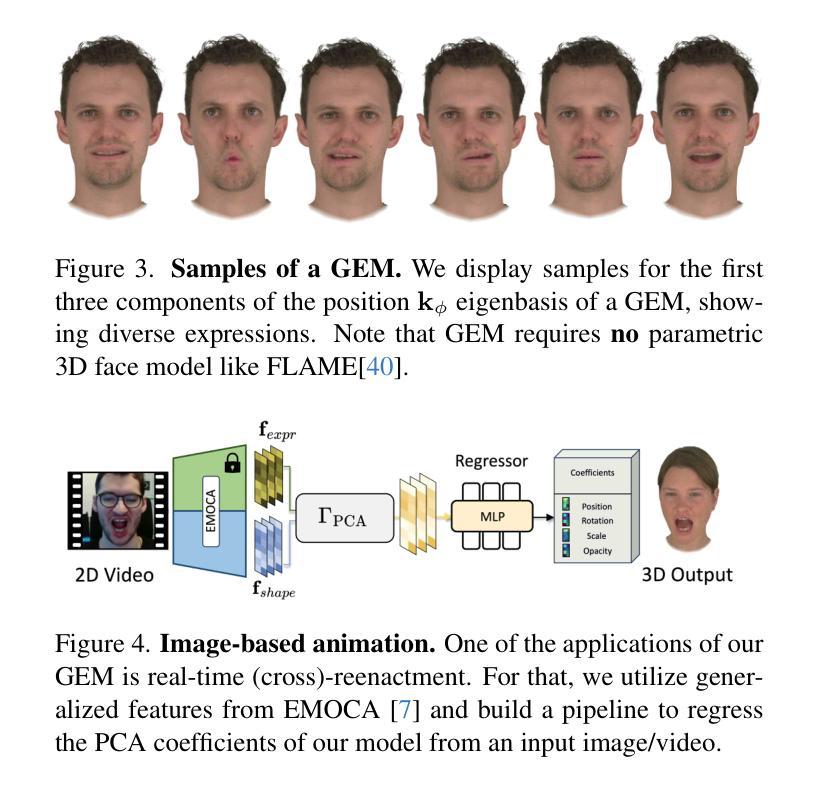
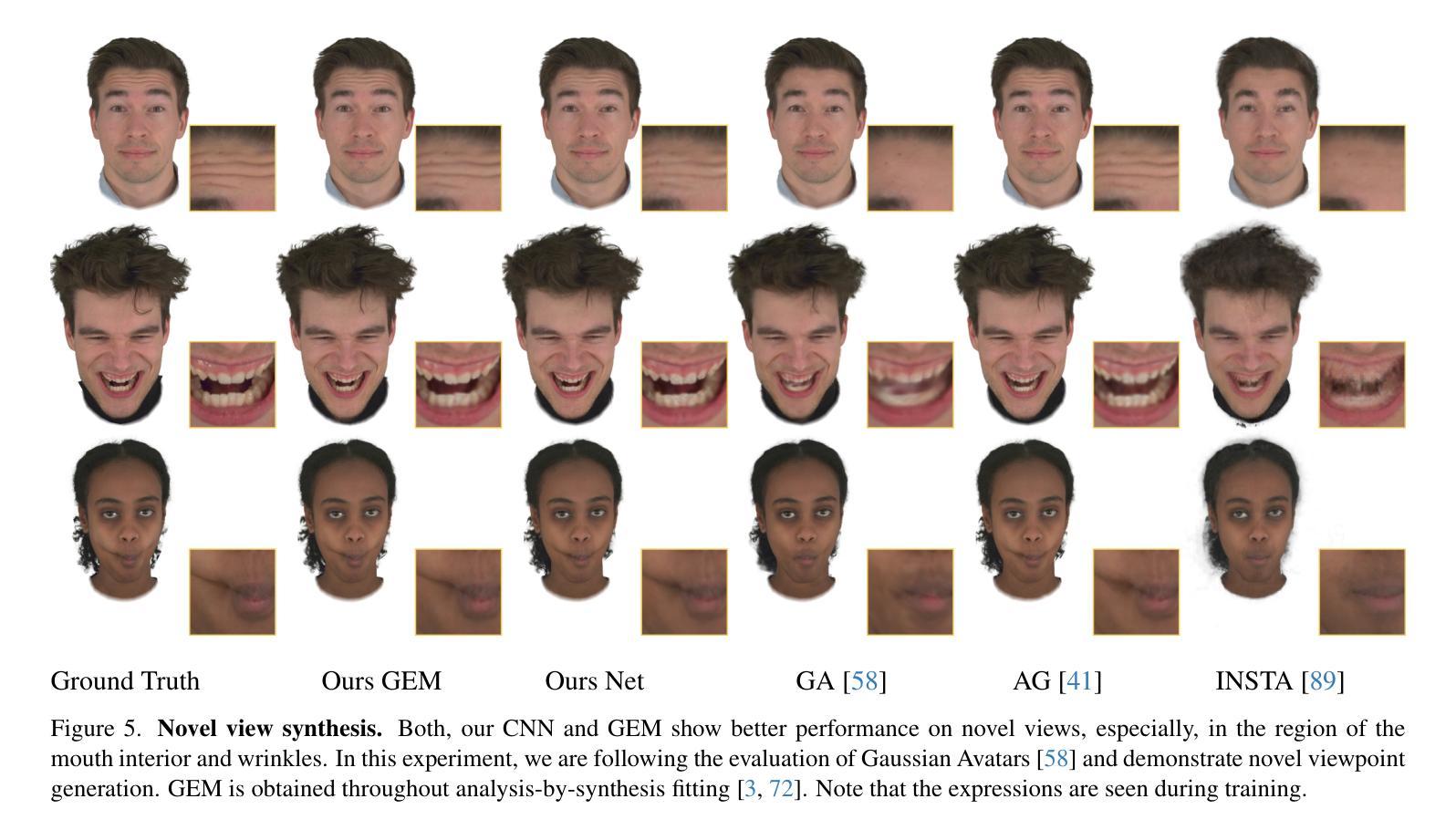
Gaussian Eigen Models for Human Heads
Authors:Wojciech Zielonka, Timo Bolkart, Thabo Beeler, Justus Thies
Current personalized neural head avatars face a trade-off: lightweight models lack detail and realism, while high-quality, animatable avatars require significant computational resources, making them unsuitable for commodity devices. To address this gap, we introduce Gaussian Eigen Models (GEM), which provide high-quality, lightweight, and easily controllable head avatars. GEM utilizes 3D Gaussian primitives for representing the appearance combined with Gaussian splatting for rendering. Building on the success of mesh-based 3D morphable face models (3DMM), we define GEM as an ensemble of linear eigenbases for representing the head appearance of a specific subject. In particular, we construct linear bases to represent the position, scale, rotation, and opacity of the 3D Gaussians. This allows us to efficiently generate Gaussian primitives of a specific head shape by a linear combination of the basis vectors, only requiring a low-dimensional parameter vector that contains the respective coefficients. We propose to construct these linear bases (GEM) by distilling high-quality compute-intense CNN-based Gaussian avatar models that can generate expression-dependent appearance changes like wrinkles. These high-quality models are trained on multi-view videos of a subject and are distilled using a series of principal component analyses. Once we have obtained the bases that represent the animatable appearance space of a specific human, we learn a regressor that takes a single RGB image as input and predicts the low-dimensional parameter vector that corresponds to the shown facial expression. In a series of experiments, we compare GEM’s self-reenactment and cross-person reenactment results to state-of-the-art 3D avatar methods, demonstrating GEM’s higher visual quality and better generalization to new expressions.
当前个性化神经头部化身面临一个权衡:轻量级模型缺乏细节和逼真度,而高质量、可动画的化身需要巨大的计算资源,使其不适合普通设备。为了解决这一差距,我们引入了高斯特征模型(GEM),它提供高质量、轻便且易于控制的头部化身。GEM使用3D高斯原始图形来表示外观,并结合高斯喷绘进行渲染。基于基于网格的3D可变形面部模型(3DMM)的成功,我们将GEM定义为表示特定主体头部外观的线性特征基集合。特别是,我们构建了表示位置、尺度、旋转和透明度的线性基。这允许我们通过线性组合基向量有效地生成特定头部形状的高斯原始图形,仅需要一个低维参数向量,其中包含相应的系数。我们提议通过蒸馏高质量的计算密集型CNN高斯化身模型来构建这些线性基(GEM),该模型可以生成与表情相关的外观变化,如皱纹。这些高质量模型在主体的多视角视频上进行训练,并使用一系列主成分分析进行提炼。一旦我们获得了代表特定人类可动画外观空间的基地,我们就学习一个回归器,它接受单张RGB图像作为输入,并预测与所示面部表情相对应的低维参数向量。在一系列实验中,我们将GEM的自我重新演绎和跨人重新演绎的结果与最先进的3D化身方法进行比较,证明了GEM更高的视觉质量和对新表情的更好泛化能力。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/gem/
Summary
引入高斯特征模型(GEM)解决个性化神经头部化身面临的困境,即轻量化模型缺乏细节和真实感,而高质量、可动画的化身需要巨大的计算资源,不适用于普通设备。GEM利用3D高斯原始表示外观,结合高斯展开进行渲染,提供高质量、轻便且易于控制的头部化身。
Key Takeaways
- 当前个性化神经头部化身面临轻量化与高质量之间的权衡。
- 高斯特征模型(GEM)利用3D高斯原始和Gaussian splatting渲染技术来提供高质量、轻便的头部化身解决方案。
- GEM是基于3D可变形面部模型(3DMM)的线性特征基来表示特定主体的头部外观。
- GEM通过构建线性基来表示3D高斯的位置、尺度、旋转和透明度。
- 高质量计算密集型的CNN高斯化身模型被用来生成表情相关的外观变化,如皱纹。
- 通过主成分分析系列进行蒸馏,得到代表特定人类可动画外观空间的线性基。
- 实验表明,与现有3D化身方法相比,GEM在自我表演和跨人表演方面表现出更高的视觉质量和更好的新表情泛化能力。
点此查看论文截图


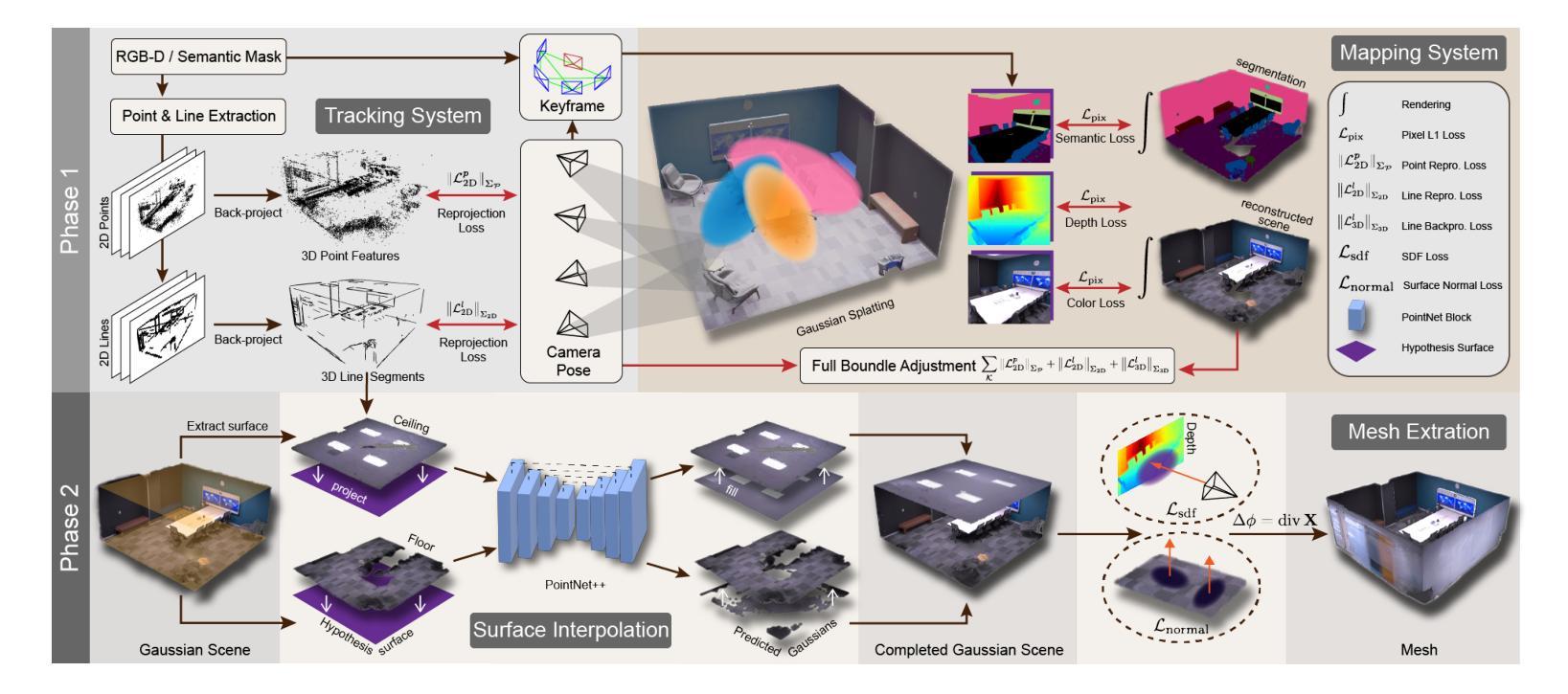
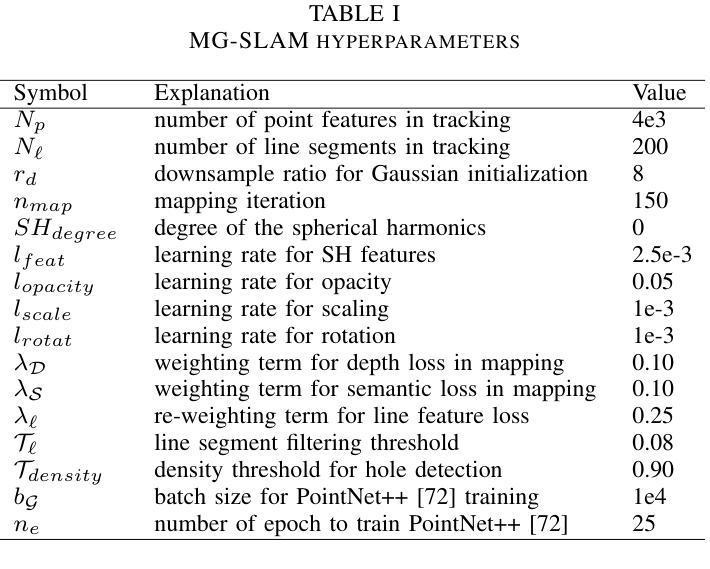
MG-SLAM: Structure Gaussian Splatting SLAM with Manhattan World Hypothesis
Authors:Shuhong Liu, Tianchen Deng, Heng Zhou, Liuzhuozheng Li, Hongyu Wang, Danwei Wang, Mingrui Li
Gaussian Splatting SLAMs have made significant advancements in improving the efficiency and fidelity of real-time reconstructions. However, these systems often encounter incomplete reconstructions in complex indoor environments, characterized by substantial holes due to unobserved geometry caused by obstacles or limited view angles. To address this challenge, we present Manhattan Gaussian SLAM, an RGB-D system that leverages the Manhattan World hypothesis to enhance geometric accuracy and completeness. By seamlessly integrating fused line segments derived from structured scenes, our method ensures robust tracking in textureless indoor areas. Moreover, The extracted lines and planar surface assumption allow strategic interpolation of new Gaussians in regions of missing geometry, enabling efficient scene completion. Extensive experiments conducted on both synthetic and real-world scenes demonstrate that these advancements enable our method to achieve state-of-the-art performance, marking a substantial improvement in the capabilities of Gaussian SLAM systems.
高斯模糊点分割技术(SLAMs)在提升实时重建的效率和保真度方面取得了显著进展。然而,这些系统在复杂的室内环境中经常遇到重建不完整的问题,主要表现为由于障碍物或有限视角导致的未观察到的几何结构而产生的大量空洞。为了应对这一挑战,我们提出了曼哈顿高斯SLAM系统,这是一个利用曼哈顿世界假设来提高几何准确性和完整性的RGB-D系统。我们的方法通过无缝集成从结构化场景中派生出的融合线段来确保在纹理缺失的室内区域进行稳健的跟踪。此外,提取的线条和平面表面假设允许在有缺失几何结构的区域中进行新的高斯值的策略性插值,从而实现高效的场景补全。在合成场景和真实场景上进行的广泛实验表明,这些进展使得我们的方法达到了最先进的性能水平,标志着高斯SLAM系统的能力得到了实质性提升。
论文及项目相关链接
Summary
高斯混合SLAM在提升实时重建的效率和保真度方面取得了显著进展。然而,在复杂的室内环境中,这些系统经常遇到不完整重建的问题,表现为由于障碍物或有限视角导致的未观测到的几何结构产生的大量空洞。为解决这一挑战,我们提出曼哈顿高斯SLAM系统,这是一个RGB-D系统,利用曼哈顿世界假设提高几何精度和完整性。通过无缝集成来自结构化场景的融合线段,我们的方法确保在纹理较少的室内区域实现稳健跟踪。此外,提取的线条和平面表面假设允许在缺失几何区域进行新的高斯战略插值,从而实现高效场景完成。在合成和真实场景上的广泛实验表明,这些进步使我们的方法达到最先进的性能,标志着高斯SLAM系统的能力得到了显著改善。
Key Takeaways
- 高斯混合SLAM已显著提高实时重建的效率和保真度。
- 在复杂室内环境中,高斯混合SLAM面临不完整重建问题,表现为大量空洞。
- 曼哈顿高斯SLAM是一个RGB-D系统,利用曼哈顿世界假设增强几何精度和完整性。
- 该方法通过无缝集成融合线段,确保在纹理较少的室内区域实现稳健跟踪。
- 提取的线条和平面表面假设允许在缺失几何区域进行新的高斯插值,实现高效场景完成。
- 曼哈顿高斯SLAM在合成和真实场景上的实验表现达到或超越了现有技术。
点此查看论文截图