⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
VerbDiff: Text-Only Diffusion Models with Enhanced Interaction Awareness
Authors:SeungJu Cha, Kwanyoung Lee, Ye-Chan Kim, Hyunwoo Oh, Dong-Jin Kim
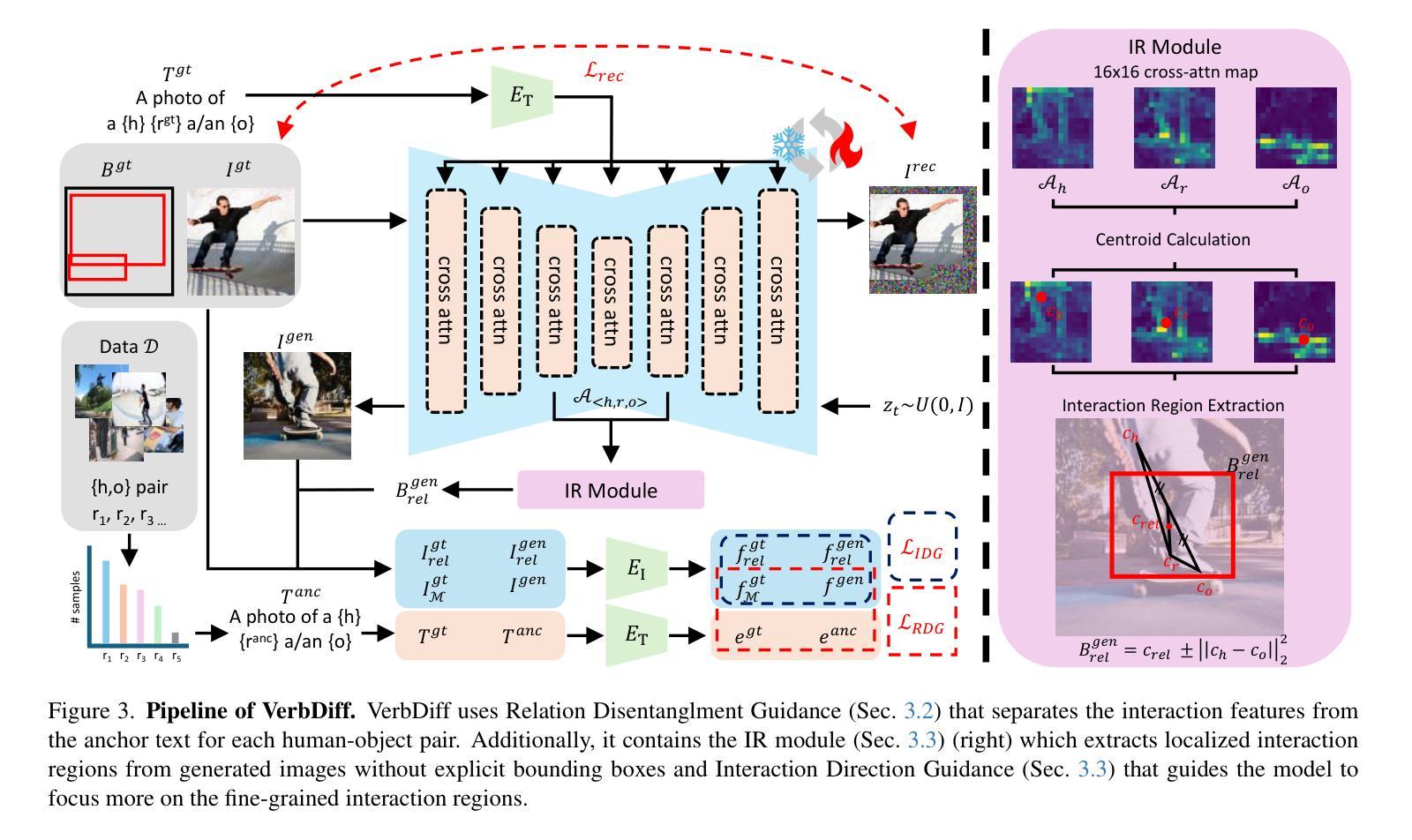
Recent large-scale text-to-image diffusion models generate photorealistic images but often struggle to accurately depict interactions between humans and objects due to their limited ability to differentiate various interaction words. In this work, we propose VerbDiff to address the challenge of capturing nuanced interactions within text-to-image diffusion models. VerbDiff is a novel text-to-image generation model that weakens the bias between interaction words and objects, enhancing the understanding of interactions. Specifically, we disentangle various interaction words from frequency-based anchor words and leverage localized interaction regions from generated images to help the model better capture semantics in distinctive words without extra conditions. Our approach enables the model to accurately understand the intended interaction between humans and objects, producing high-quality images with accurate interactions aligned with specified verbs. Extensive experiments on the HICO-DET dataset demonstrate the effectiveness of our method compared to previous approaches.
最近的大规模文本到图像的扩散模型生成了逼真的图像,但由于其区分各种互动词的能力有限,往往难以准确描绘人与物体之间的互动。在这项工作中,我们提出了VerbDiff来解决文本到图像扩散模型内捕捉微妙互动的难题。VerbDiff是一种新型的文本到图像生成模型,它通过减弱互动词与物体之间的偏见,增强了互动的理解能力。具体来说,我们从基于频率的锚定词中分离出各种互动词,并利用生成的图像的局部互动区域来帮助模型更好地理解独特词汇的语义,而无需额外的条件。我们的方法使模型能够准确地理解人类和物体之间的预期互动,生成高质量图像,其中的互动与指定的动词准确对应。在HICO-DET数据集上的大量实验证明,我们的方法与之前的方法相比非常有效。
论文及项目相关链接
PDF Accepted at CVPR 2025, code : https://github.com/SeungJuCha/VerbDiff.git
Summary
本文提出一种名为VerbDiff的新型文本到图像生成模型,旨在解决大型文本到图像扩散模型在描绘人类与物体之间微妙互动时的挑战。该模型通过削弱互动词汇与物体之间的偏见,增强对互动的理解。它在生成图像时,能准确捕捉特定词汇的语义,并依据指定的动词生成高质量、互动准确的图像。
Key Takeaways
- VerbDiff模型旨在解决大型文本到图像扩散模型在描绘人类与物体互动时的局限。
- 该模型通过削弱互动词汇与物体间的偏见,提高模型对互动的理解。
- VerbDiff能够区分各种互动词汇,并从频率锚词中分离出来。
- 利用生成的图像中的局部互动区域,帮助模型更好地捕捉特定词汇的语义。
- 该方法能够在不额外设定条件的情况下,准确理解人类与物体的预期互动。
- 在HICO-DET数据集上进行的广泛实验证明,与前期方法相比,该方法的有效性。
点此查看论文截图

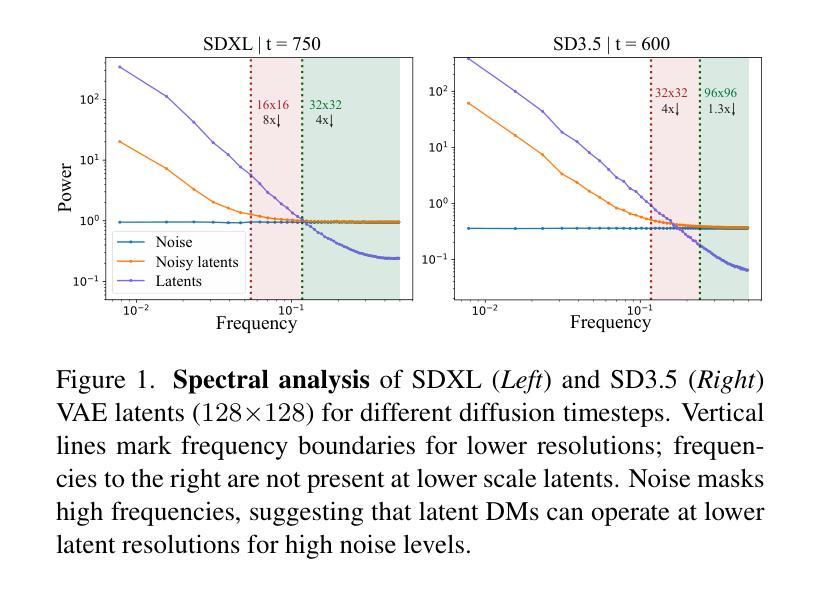
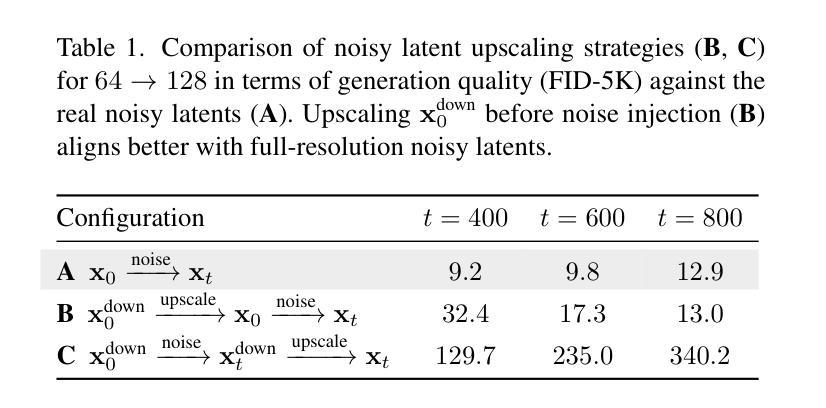
Scale-wise Distillation of Diffusion Models
Authors:Nikita Starodubcev, Denis Kuznedelev, Artem Babenko, Dmitry Baranchuk
We present SwD, a scale-wise distillation framework for diffusion models (DMs), which effectively employs next-scale prediction ideas for diffusion-based few-step generators. In more detail, SwD is inspired by the recent insights relating diffusion processes to the implicit spectral autoregression. We suppose that DMs can initiate generation at lower data resolutions and gradually upscale the samples at each denoising step without loss in performance while significantly reducing computational costs. SwD naturally integrates this idea into existing diffusion distillation methods based on distribution matching. Also, we enrich the family of distribution matching approaches by introducing a novel patch loss enforcing finer-grained similarity to the target distribution. When applied to state-of-the-art text-to-image diffusion models, SwD approaches the inference times of two full resolution steps and significantly outperforms the counterparts under the same computation budget, as evidenced by automated metrics and human preference studies.
我们提出了SwD,这是一个针对扩散模型(DMs)的规模蒸馏框架,它有效地采用了基于扩散的几步生成器的下一尺度预测思想。更具体地说,SwD的灵感来源于最近关于扩散过程与隐式谱自回归的相关见解。我们认为,DMs可以在较低的数据分辨率下开始生成,并在每个去噪步骤中逐步放大样本,而不会损失性能,同时大大降低计算成本。SwD自然地将这一想法集成到基于分布匹配的现有扩散蒸馏方法中。此外,我们通过引入一种新的补丁损失方法,使分布匹配方法更加丰富,该方法强制对目标分布的细粒度相似性。当应用于最先进的文本到图像扩散模型时,SwD接近两个全分辨率步骤的推理时间,并在相同的计算预算下显著优于同类模型,这由自动指标和人类偏好研究所证明。
论文及项目相关链接
Summary
本文提出了SwD,这是一种用于扩散模型(DMs)的规模蒸馏框架,它有效地采用了下一步预测的思想,用于基于扩散的几步生成器。SwD受到扩散过程与隐式谱自回归相关的新见解的启发,认为DMs可以从较低的数据分辨率开始生成,并在每个去噪步骤中逐步上采样样本,同时不会损失性能,并且能显著降低计算成本。SwD自然地将这一想法集成到基于分布匹配的现有扩散蒸馏方法中,并引入了一种新的补丁损失,以实现对目标分布的精细粒度相似性。应用于先进的文本到图像扩散模型时,SwD接近两个全分辨率步骤的推理时间,并在相同的计算预算下显著优于同类产品,这由自动度量指标和人类偏好研究所证明。
Key Takeaways
- SwD是一个用于扩散模型的规模蒸馏框架,结合了下一步预测思想,适用于基于扩散的几步生成器。
- SwD受到扩散过程与隐式谱自回归相关新见解的启发,可从低分辨率数据启动生成,逐步上采样样本,保持性能同时降低计算成本。
- SwD整合了现有基于分布匹配的扩散蒸馏方法。
- 引入了一种新的补丁损失,以增强对目标分布的精细粒度相似性。
- SwD应用于先进的文本到图像扩散模型时表现出色。
- SwD在保证性能的同时,接近两个全分辨率步骤的推理时间。
点此查看论文截图




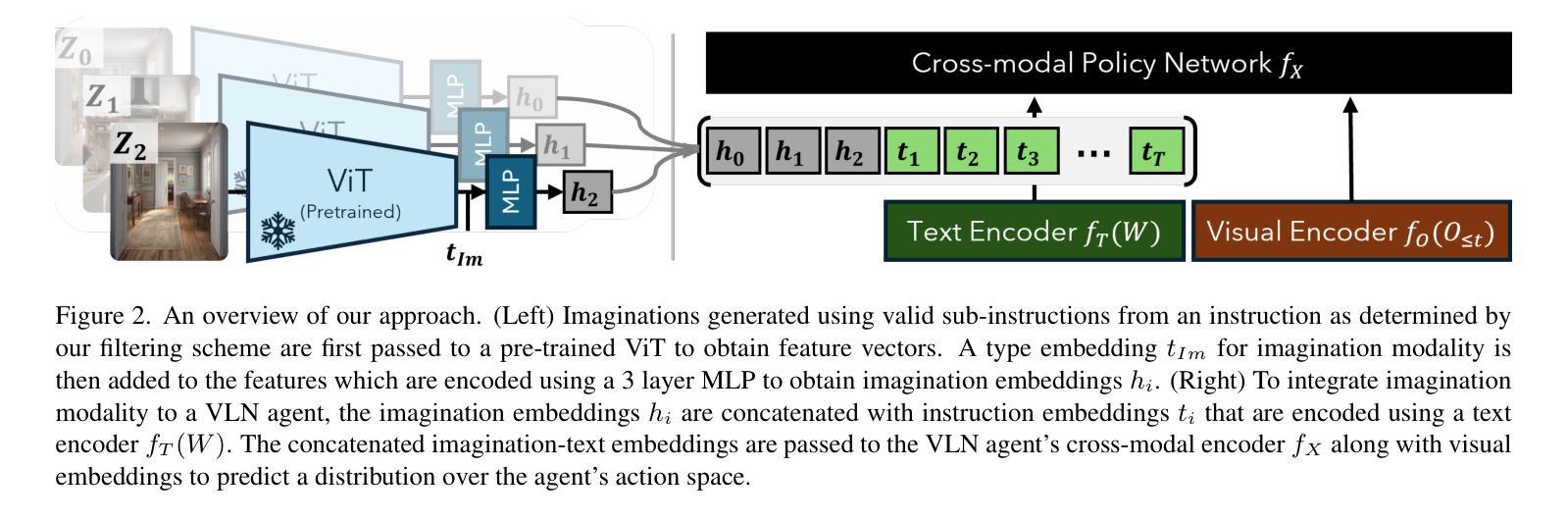
Do Visual Imaginations Improve Vision-and-Language Navigation Agents?
Authors:Akhil Perincherry, Jacob Krantz, Stefan Lee
Vision-and-Language Navigation (VLN) agents are tasked with navigating an unseen environment using natural language instructions. In this work, we study if visual representations of sub-goals implied by the instructions can serve as navigational cues and lead to increased navigation performance. To synthesize these visual representations or imaginations, we leverage a text-to-image diffusion model on landmark references contained in segmented instructions. These imaginations are provided to VLN agents as an added modality to act as landmark cues and an auxiliary loss is added to explicitly encourage relating these with their corresponding referring expressions. Our findings reveal an increase in success rate (SR) of around 1 point and up to 0.5 points in success scaled by inverse path length (SPL) across agents. These results suggest that the proposed approach reinforces visual understanding compared to relying on language instructions alone. Code and data for our work can be found at https://www.akhilperincherry.com/VLN-Imagine-website/.
视觉与语言导航(VLN)代理的任务是使用自然语言指令在未知环境中进行导航。在这项工作中,我们研究指令所隐含的子目标的视觉表示是否可以作为导航线索,从而提高导航性能。为了合成这些视觉表示或想象,我们利用文本到图像的扩散模型,对分段指令中包含的标志性参考物进行处理。这些想象为VLN代理提供了作为标志性线索的附加模式,并添加了一个辅助损失,以明确鼓励其与相应的指代表达式相关联。我们的研究发现,与仅依靠语言指令相比,代理的成功率(SR)提高了大约1个点,按逆路径长度(SPL)计算的成功率提高了高达0.5个点。这些结果表明,所提出的方法加强了视觉理解。我们的工作相关的代码和数据可以在https://www.akhilperincherry.com/VLN-Imagine-website/找到。
论文及项目相关链接
Summary
本文研究了在视觉与语言导航(VLN)中,通过文本指令隐含的子目标视觉表征作为导航线索,以提高导航性能的方法。研究团队利用文本到图像的扩散模型,基于分段指令中的地标参照生成想象图像,将其作为VLN代理的附加模态,与语言指令一同引导代理进行导航。实验结果表明显示,新方法的成功率提高了约一点,路径长度的成功率提高了零点五。这表明结合视觉理解与语言指令的方法强化了视觉理解的重要性。
Key Takeaways
- 研究主题:研究视觉与语言导航(VLN),特别是如何通过隐含子目标的视觉表征增强导航性能。
- 方法介绍:利用文本到图像的扩散模型,基于分段指令中的地标参考生成想象图像作为导航线索。
- 附加模态:想象图像被用作VLN代理的额外输入模态,与语言指令结合使用。
- 实验结果:新方法提高了导航成功率和路径长度成功率。
- 对比之前的研究:该方法强调了视觉理解的重要性,与传统的仅依赖语言指令的方法形成对比。
- 数据和代码共享:研究团队提供了数据和代码的在线资源链接。
点此查看论文截图


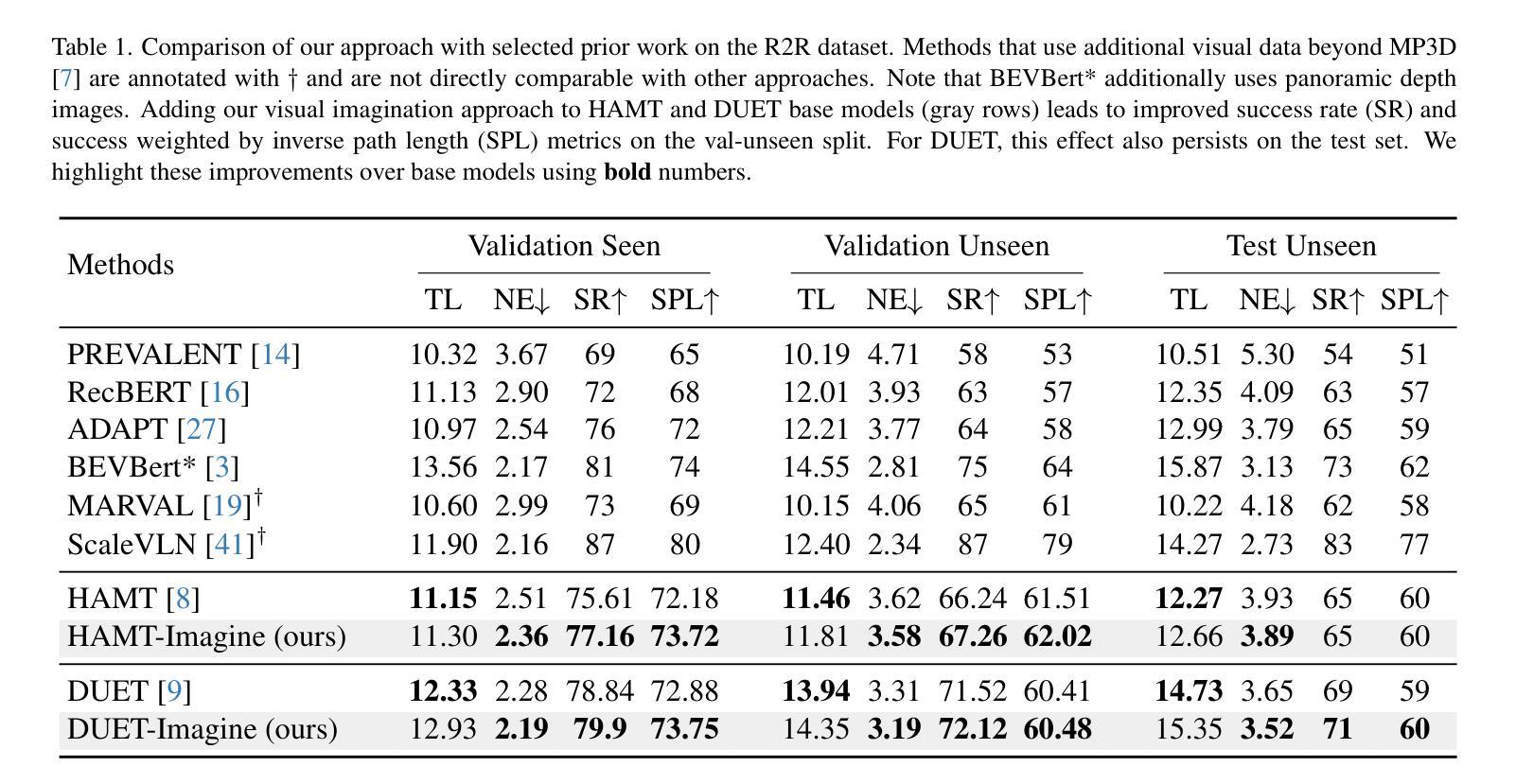

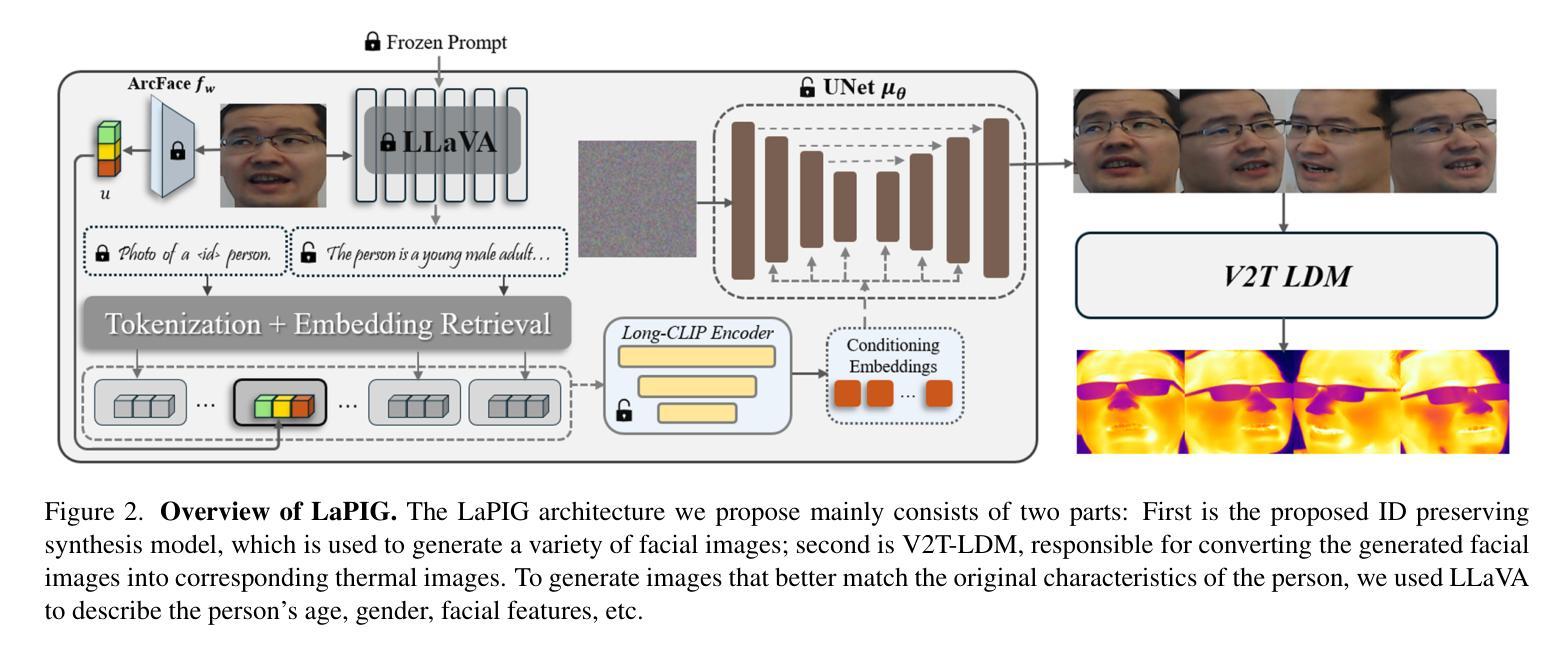
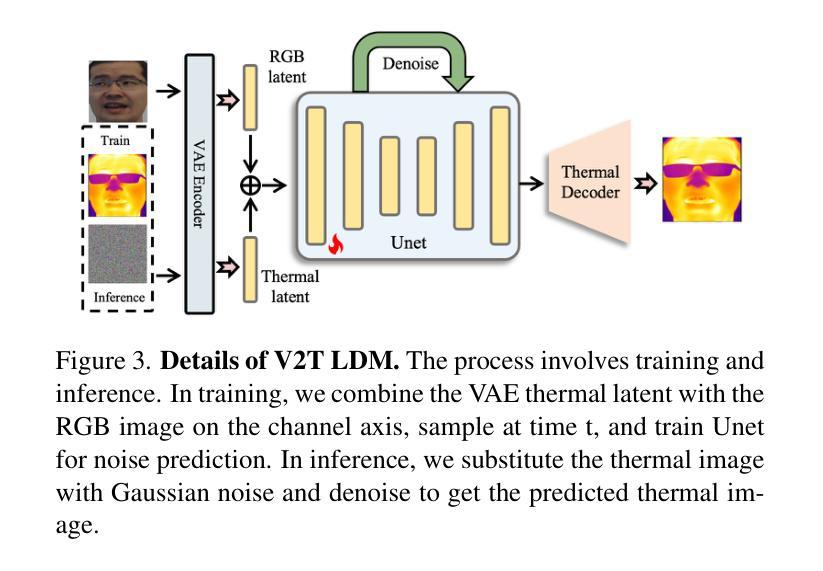
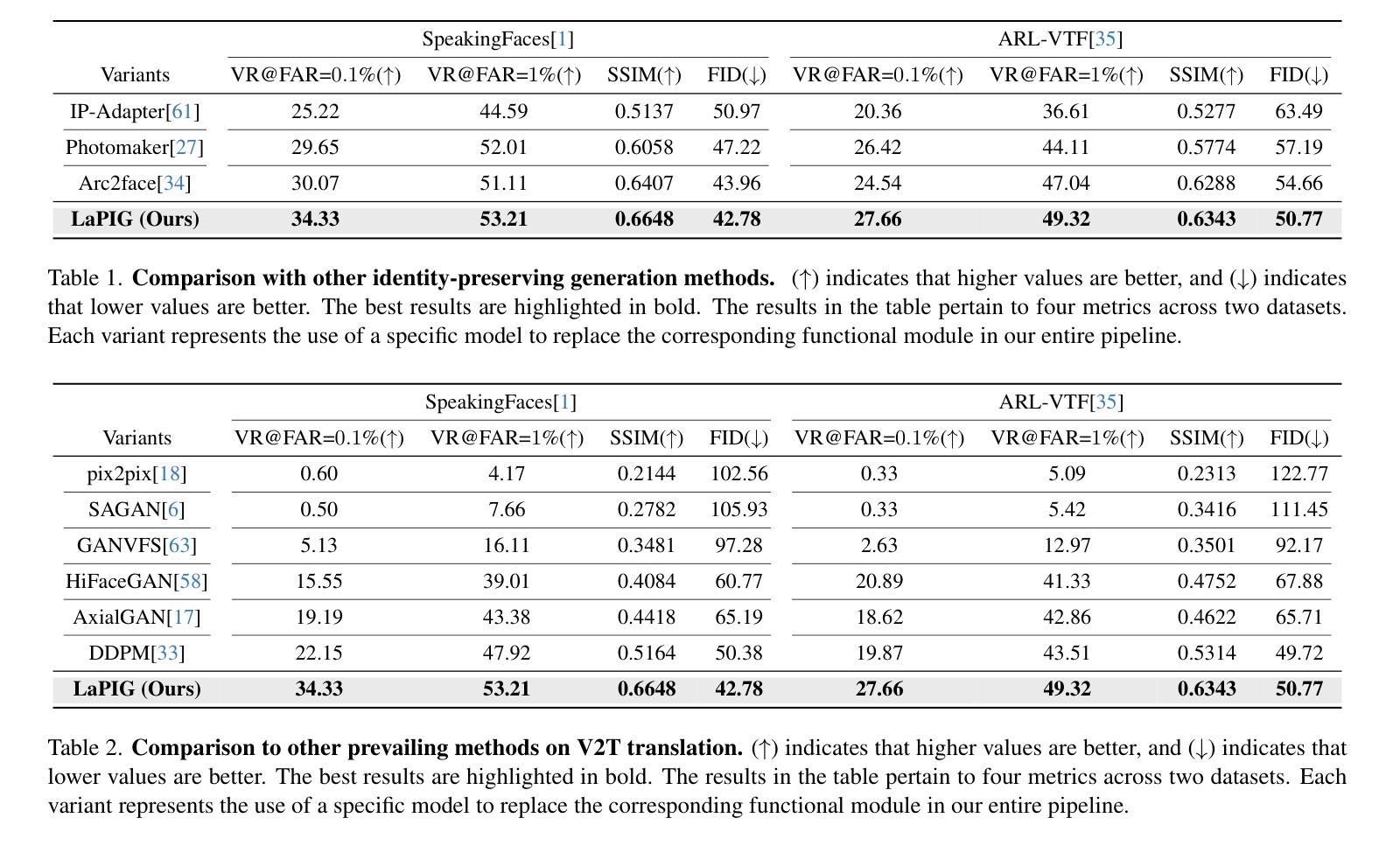
LaPIG: Cross-Modal Generation of Paired Thermal and Visible Facial Images
Authors:Leyang Wang, Joice Lin
The success of modern machine learning, particularly in facial translation networks, is highly dependent on the availability of high-quality, paired, large-scale datasets. However, acquiring sufficient data is often challenging and costly. Inspired by the recent success of diffusion models in high-quality image synthesis and advancements in Large Language Models (LLMs), we propose a novel framework called LLM-assisted Paired Image Generation (LaPIG). This framework enables the construction of comprehensive, high-quality paired visible and thermal images using captions generated by LLMs. Our method encompasses three parts: visible image synthesis with ArcFace embedding, thermal image translation using Latent Diffusion Models (LDMs), and caption generation with LLMs. Our approach not only generates multi-view paired visible and thermal images to increase data diversity but also produces high-quality paired data while maintaining their identity information. We evaluate our method on public datasets by comparing it with existing methods, demonstrating the superiority of LaPIG.
现代机器学习,特别是在面部翻译网络方面的成功,在很大程度上依赖于高质量、配对、大规模数据集的可获得性。然而,获取足够的数据通常具有挑战性和成本高昂。受扩散模型在高质量图像合成和大型语言模型(LLM)方面的最新成功启发,我们提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的标题构建全面、高质量配对的可见光和热图像。我们的方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的热图像翻译以及使用LLM的标题生成。我们的方法不仅生成多视角配对可见光和热图像以增加数据多样性,而且还在保持身份信息的状态下产生高质量配对数据。我们在公共数据集上通过将其与现有方法进行对比评估了我们的方法,证明了LaPIG的优越性。
论文及项目相关链接
Summary
本文介绍了现代机器学习在面部翻译网络方面的成功高度依赖于高质量、配对的大规模数据集的可获得性。然而,获取足够的数据往往具有挑战性和成本高昂。受扩散模型在高质量图像合成和大型语言模型(LLM)方面的成功的启发,提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的标题构建全面、高质量配对的可见光和热图像。该方法包括三部分:使用ArcFace嵌入进行可见图像合成,使用潜在扩散模型(LDM)进行热图像翻译,以及使用LLM进行标题生成。该方法不仅生成多视角配对可见光和热图像以增加数据多样性,而且生成高质量配对数据的同时保持其身份信息。在公共数据集上的评估结果表明,LaPIG优于现有方法。
Key Takeaways
- 现代机器学习的成功在很大程度上依赖于高质量、配对的大规模数据集。
- 获取足够的数据具有挑战性和成本高昂。
- 扩散模型在高质量图像合成方面的成功为解决问题提供了新的思路。
- 提出了名为LLM辅助配对图像生成(LaPIG)的新型框架。
- LaPIG框架包括可见图像合成、热图像翻译和标题生成三个主要部分。
- LaPIG能够生成多视角配对图像,增加数据多样性。
点此查看论文截图

Ultra-Resolution Adaptation with Ease
Authors:Ruonan Yu, Songhua Liu, Zhenxiong Tan, Xinchao Wang
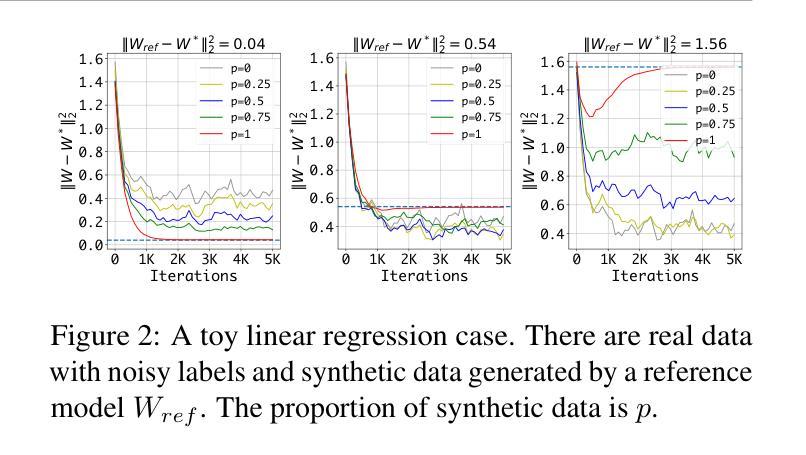
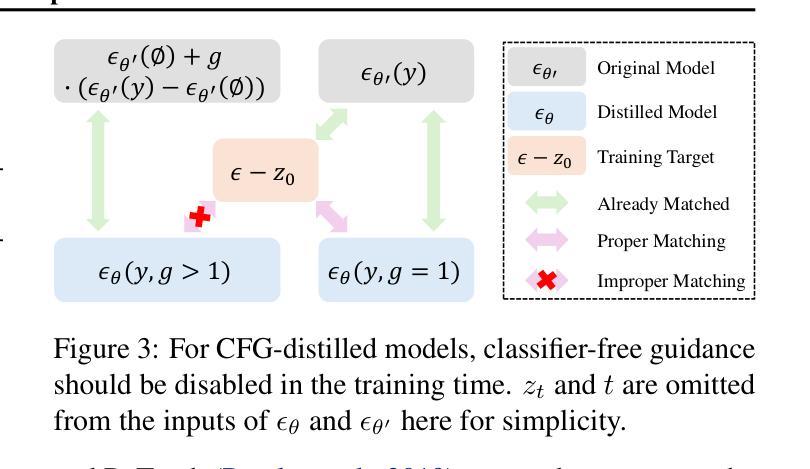
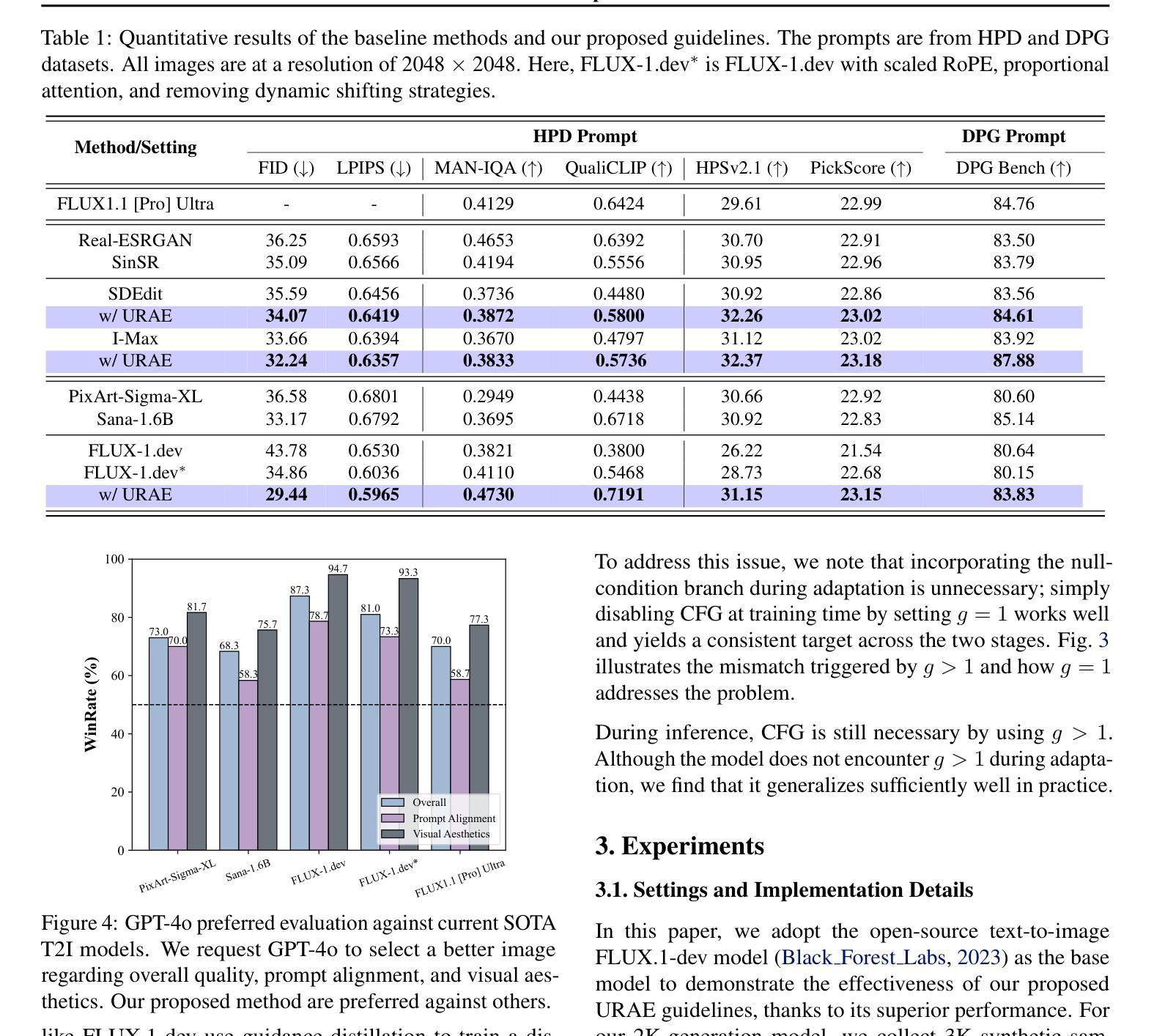
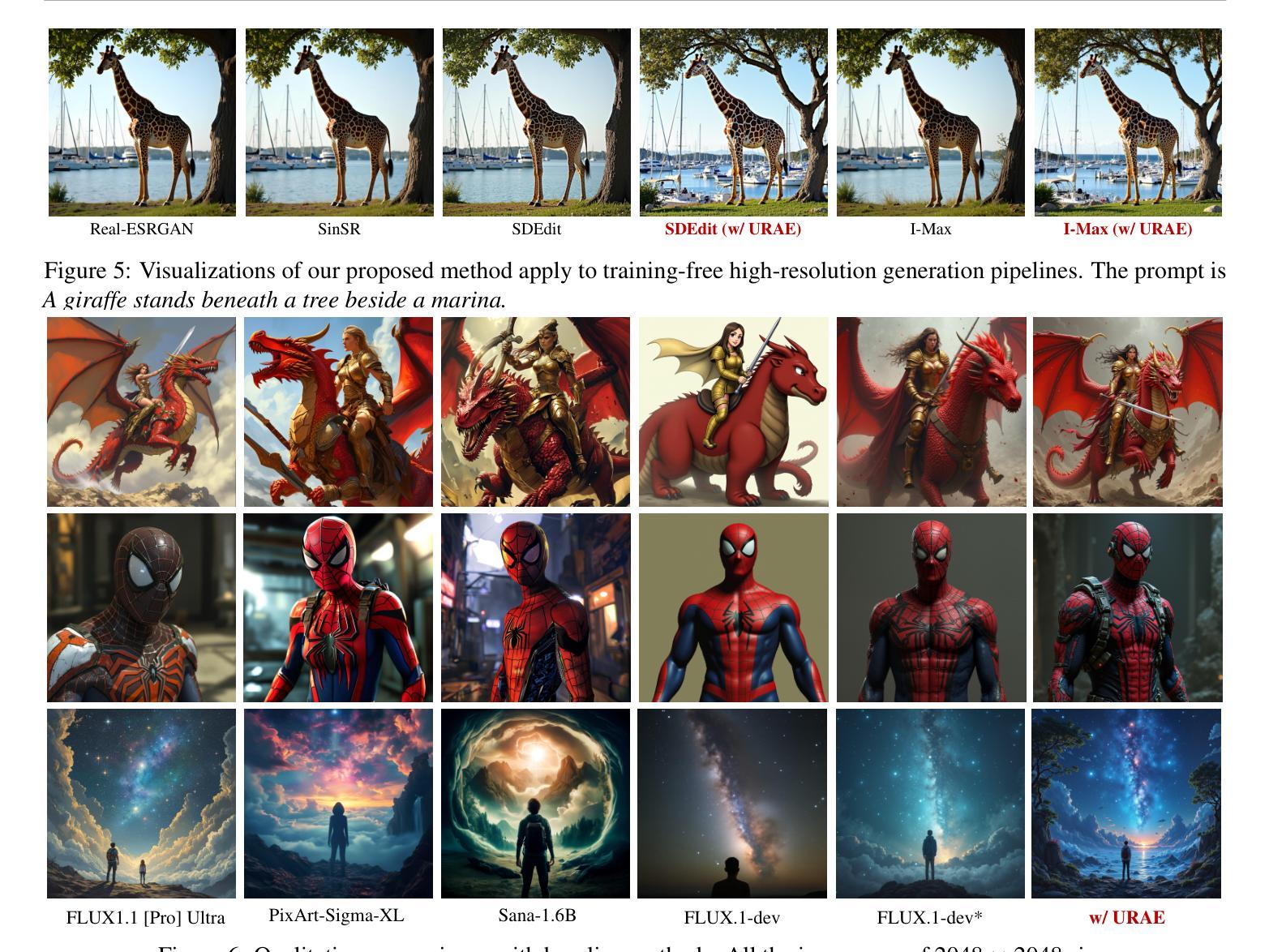
Text-to-image diffusion models have achieved remarkable progress in recent years. However, training models for high-resolution image generation remains challenging, particularly when training data and computational resources are limited. In this paper, we explore this practical problem from two key perspectives: data and parameter efficiency, and propose a set of key guidelines for ultra-resolution adaptation termed \emph{URAE}. For data efficiency, we theoretically and empirically demonstrate that synthetic data generated by some teacher models can significantly promote training convergence. For parameter efficiency, we find that tuning minor components of the weight matrices outperforms widely-used low-rank adapters when synthetic data are unavailable, offering substantial performance gains while maintaining efficiency. Additionally, for models leveraging guidance distillation, such as FLUX, we show that disabling classifier-free guidance, \textit{i.e.}, setting the guidance scale to 1 during adaptation, is crucial for satisfactory performance. Extensive experiments validate that URAE achieves comparable 2K-generation performance to state-of-the-art closed-source models like FLUX1.1 [Pro] Ultra with only 3K samples and 2K iterations, while setting new benchmarks for 4K-resolution generation. Codes are available \href{https://github.com/Huage001/URAE}{here}.
文本到图像的扩散模型在近年来取得了显著的进步。然而,在高分辨率图像生成中训练模型仍然具有挑战性,特别是在训练数据和计算资源有限的情况下。在本文中,我们从数据和参数效率两个关键角度探讨了这一实际问题,并提出了一套用于超分辨率适应的关键指南,称为URAE。在数据效率方面,我们理论和实证地证明,某些教师模型生成的合成数据可以显著促进训练收敛。在参数效率方面,我们发现,当没有合成数据时,调整权重矩阵的小组件优于广泛使用的低秩适配器,可以在保持效率的同时实现显著的性能提升。此外,对于利用指导蒸馏的模型(如FLUX),我们表明禁用无分类指导至关重要,即在适应过程中将指导比例设置为1。大量实验验证,URAE仅使用3K样本和2K迭代就实现了与最新开源模型FLUX1.1 Pro Ultra相当的2K生成性能,同时为4K分辨率生成树立了新基准。代码可在此处获取:[https://github.com/Huage001/URAE] 。
论文及项目相关链接
PDF Technical Report. Codes are available \href{https://github.com/Huage001/URAE}{here}
Summary
文本到图像扩散模型近年来取得了显著进展,但在资源有限的情况下进行高分辨率图像生成的模型训练仍然具有挑战性。本文从数据和参数效率两个关键角度探讨了这一问题,并提出了超分辨率适应的指导原则URAE。在数据效率方面,本文证实合成数据可以促进训练收敛。在参数效率方面,当没有合成数据时,调整权重矩阵的小组件比使用低阶适配器更有效。对于使用指导蒸馏的模型(如FLUX),禁用无分类指导至关重要。实验证明,URAE在仅使用3K样本和2K迭代的情况下,达到了与最新开源模型FLUX 1.1 Pro Ultra相当的2K生成性能,同时树立了4K分辨率生成的基准。
Key Takeaways
- 文本到图像扩散模型在高分辨率图像生成方面取得显著进展,但仍面临数据和计算资源有限的挑战。
- URAE指导原则从数据和参数效率两个角度解决了这一挑战。
- 合成数据可以促进训练收敛。
- 在没有合成数据时,调整权重矩阵的小组件比使用低阶适配器更有效。
- 对于使用指导蒸馏的模型,禁用无分类指导是关键。
- URAE在仅使用少量样本和迭代的情况下达到了先进的生成性能。
点此查看论文截图

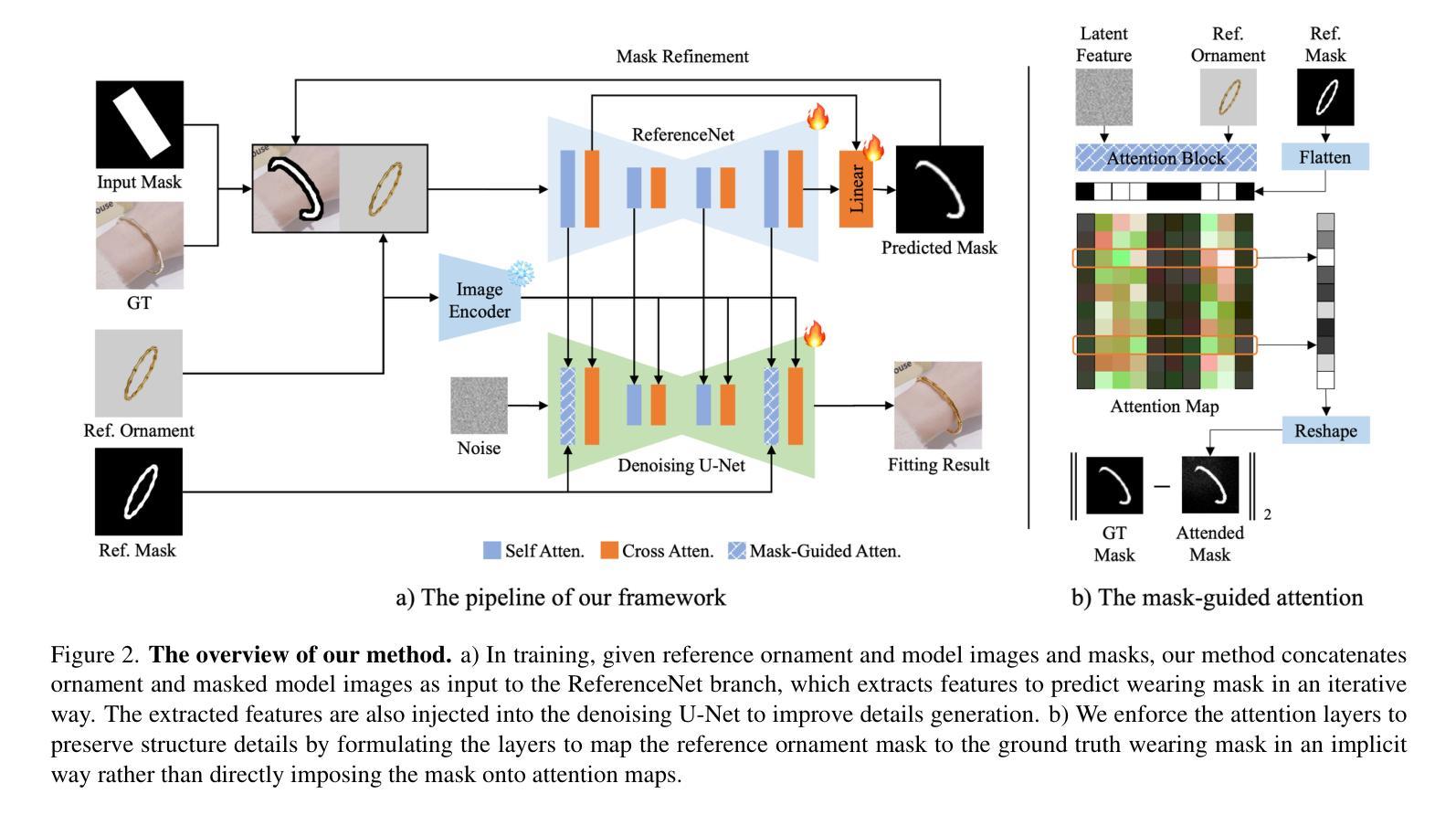
Shining Yourself: High-Fidelity Ornaments Virtual Try-on with Diffusion Model
Authors:Yingmao Miao, Zhanpeng Huang, Rui Han, Zibin Wang, Chenhao Lin, Chao Shen
While virtual try-on for clothes and shoes with diffusion models has gained attraction, virtual try-on for ornaments, such as bracelets, rings, earrings, and necklaces, remains largely unexplored. Due to the intricate tiny patterns and repeated geometric sub-structures in most ornaments, it is much more difficult to guarantee identity and appearance consistency under large pose and scale variances between ornaments and models. This paper proposes the task of virtual try-on for ornaments and presents a method to improve the geometric and appearance preservation of ornament virtual try-ons. Specifically, we estimate an accurate wearing mask to improve the alignments between ornaments and models in an iterative scheme alongside the denoising process. To preserve structure details, we further regularize attention layers to map the reference ornament mask to the wearing mask in an implicit way. Experimental results demonstrate that our method successfully wears ornaments from reference images onto target models, handling substantial differences in scale and pose while preserving identity and achieving realistic visual effects.
虽然使用扩散模型进行衣物和鞋子的虚拟试穿已经具有吸引力,但首饰(如手镯、戒指、耳环和项链等)的虚拟试穿仍未得到充分探索。由于大多数首饰具有复杂的小图案和重复的几何子结构,因此在首饰和模型之间的大姿态和尺度差异下,保证身份和外观一致性要困难得多。本文提出了首饰的虚拟试穿任务,并提出了一种改进首饰虚拟试穿的几何和外观保留性的方法。具体来说,我们估计一个精确佩戴面具,以在迭代方案中改进首饰和模型之间的对齐,同时辅以去噪过程。为了保留结构细节,我们进一步对注意力层进行正则化,以隐式的方式将参考首饰面具映射到佩戴面具上。实验结果表明,我们的方法成功地将参考图像中的首饰戴在了目标模型上,处理了大量的尺寸和姿态差异,同时保持了身份并实现了逼真的视觉效果。
论文及项目相关链接
Summary
扩散模型在虚拟试衣领域的应用已经受到广泛关注,但对于首饰等饰品的虚拟试戴仍然是一个未被充分探索的领域。本文提出了针对首饰的虚拟试戴任务,并介绍了一种改进几何形状和外观保持性的方法。通过准确穿戴掩模估计以及迭代方案和去噪过程,提高了饰品与模型之间的对齐性。同时,通过规范注意力层,以隐式方式将参考饰品掩模映射到穿戴掩模上,以保留结构细节。实验结果表明,该方法能够成功地将参考图像中的饰品戴在目标模型上,处理尺度和姿态上的显著差异,同时保持身份识别并实现逼真的视觉效果。
Key Takeaways
- 虚拟试戴领域中的饰品试戴仍然是一个挑战,主要由于饰品的复杂微小图案和几何子结构的重复性。
- 本文提出了针对首饰的虚拟试戴任务。
- 提出了一种改进方法,通过准确穿戴掩模估计来提高饰品与模型之间的对齐性。
- 采用了迭代方案和去噪过程来优化对准效果。
- 为了保留细节,通过规范注意力层,将参考饰品掩模隐式地映射到穿戴掩模上。
- 实验结果证明该方法能够在尺度和姿态差异大的情况下成功试戴饰品。
点此查看论文截图


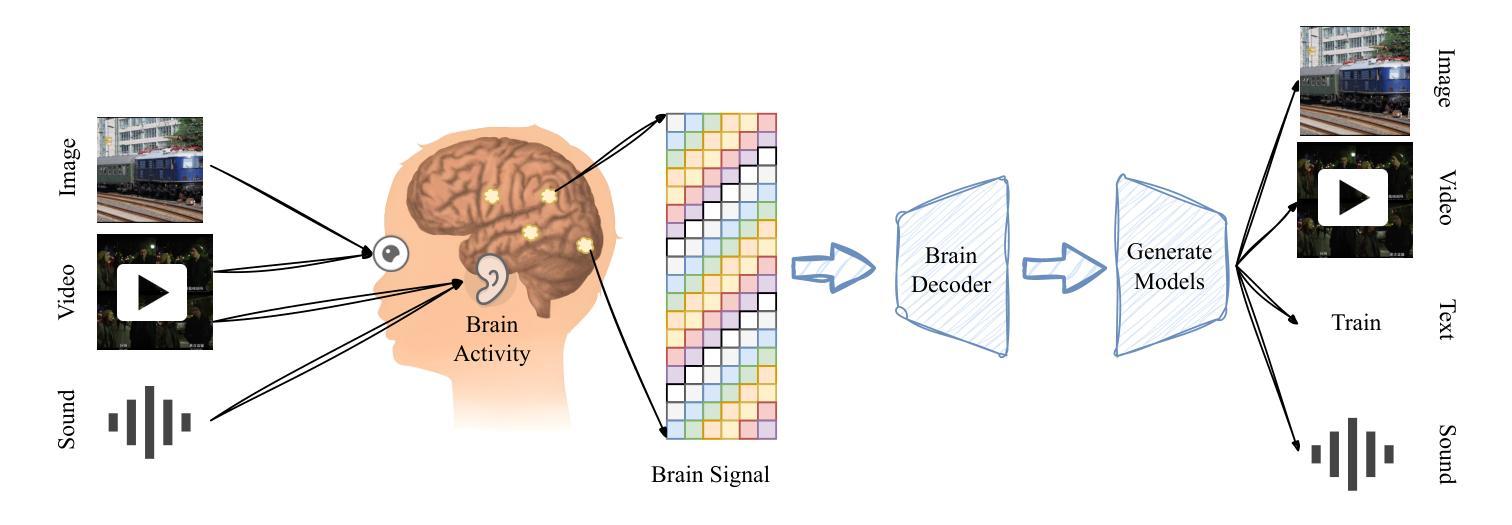
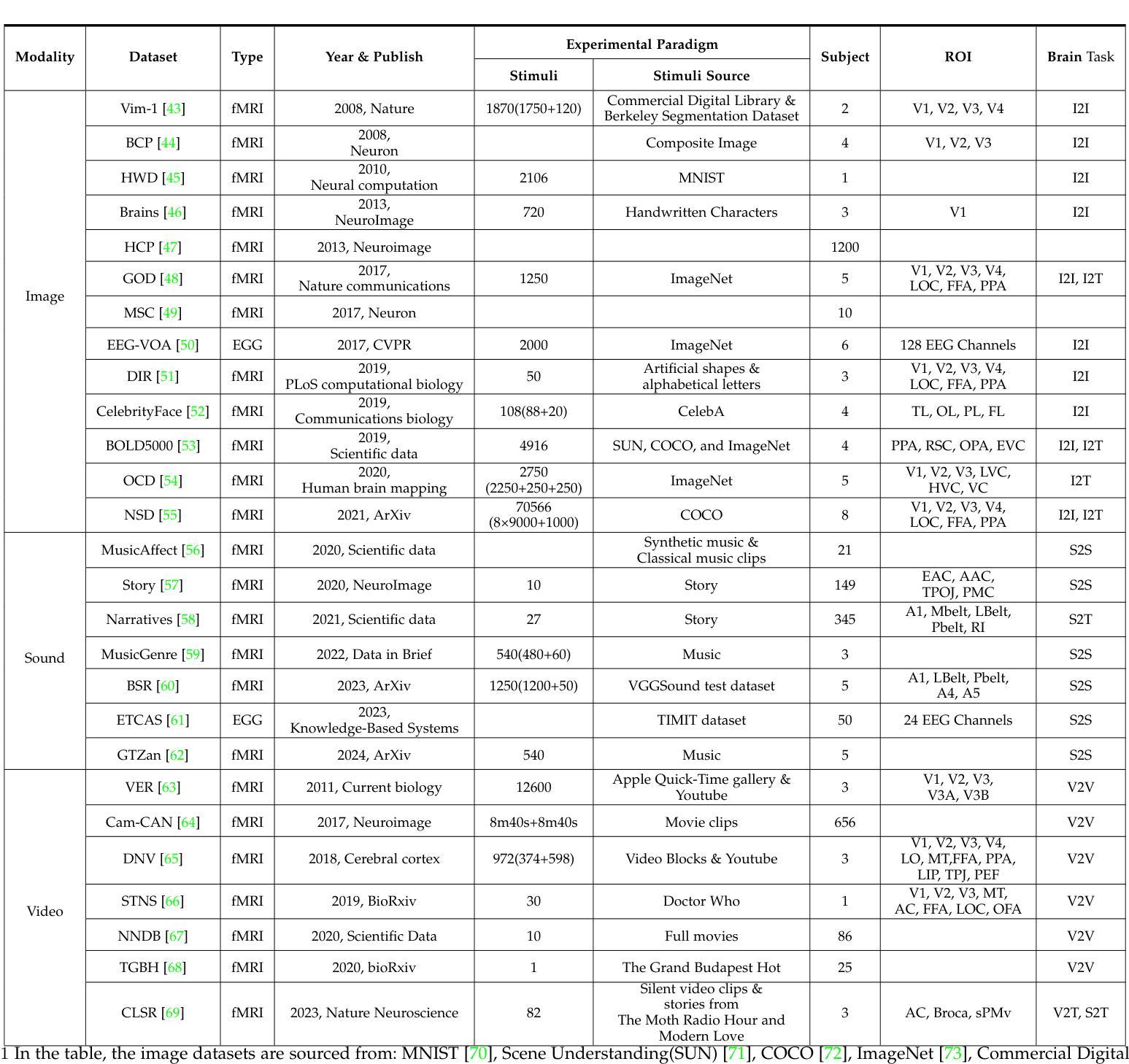
A Survey on fMRI-based Brain Decoding for Reconstructing Multimodal Stimuli
Authors:Pengyu Liu, Guohua Dong, Dan Guo, Kun Li, Fengling Li, Xun Yang, Meng Wang, Xiaomin Ying
In daily life, we encounter diverse external stimuli, such as images, sounds, and videos. As research in multimodal stimuli and neuroscience advances, fMRI-based brain decoding has become a key tool for understanding brain perception and its complex cognitive processes. Decoding brain signals to reconstruct stimuli not only reveals intricate neural mechanisms but also drives progress in AI, disease treatment, and brain-computer interfaces. Recent advancements in neuroimaging and image generation models have significantly improved fMRI-based decoding. While fMRI offers high spatial resolution for precise brain activity mapping, its low temporal resolution and signal noise pose challenges. Meanwhile, techniques like GANs, VAEs, and Diffusion Models have enhanced reconstructed image quality, and multimodal pre-trained models have boosted cross-modal decoding tasks. This survey systematically reviews recent progress in fMRI-based brain decoding, focusing on stimulus reconstruction from passive brain signals. It summarizes datasets, relevant brain regions, and categorizes existing methods by model structure. Additionally, it evaluates model performance and discusses their effectiveness. Finally, it identifies key challenges and proposes future research directions, offering valuable insights for the field. For more information and resources related to this survey, visit https://github.com/LpyNow/BrainDecodingImage.
在日常生活中,我们会遇到各种各样的外部刺激,如图像、声音和视频。随着多模态刺激和神经科学的研究进展,基于fMRI的脑解码已成为理解大脑感知及其复杂认知过程的关键工具。解码脑信号以重建刺激不仅揭示了复杂的神经机制,还推动了人工智能、疾病治疗和脑机接口的发展。近年来,神经成像和图像生成模型的进步显著提高了基于fMRI的解码效果。虽然fMRI在精确的大脑活动映射方面具有高的空间分辨率,但其较低的时间分辨率和信号噪声构成了挑战。同时,像GANs、VAEs和扩散模型等技术提高了重建图像的质量,而多模态预训练模型推动了跨模态解码任务。这篇综述系统地回顾了基于fMRI的脑解码的最新进展,重点关注从被动脑信号中重建刺激。它总结了数据集、相关的脑区,并按模型结构对现有方法进行分类。此外,它还评估了模型性能并讨论了其有效性。最后,它确定了关键挑战并提出了未来的研究方向,为该领域提供了宝贵的见解。有关此综述的更多信息和资源,请访问https://github.com/LpyNow/BrainDecodingImage。
论文及项目相关链接
PDF 31 pages, 6 figures
Summary
随着多模态刺激和神经科学研究的进展,基于fMRI的脑解码成为理解大脑感知和其复杂认知过程的关键工具。近期神经成像和图像生成模型的进步大幅提升了fMRI解码的精确度。本文系统综述了fMRI解码的最新进展,重点关注从被动脑信号重建刺激的研究。文章总结了数据集、相关脑区,并按模型结构分类现有方法,评估模型性能并讨论其有效性,同时指出了关键挑战和未来研究方向。更多详情访问:https://github.com/LpyNow/BrainDecodingImage。
Key Takeaways
- 多模态刺激和神经科学研究的进展推动了基于fMRI的脑解码技术的重要性。
- fMRI在脑活动映射中具有高空间分辨率,但其低时间分辨率和信号噪声带来挑战。
- 技术进步如GANs、VAEs和Diffusion Models提升了重建的图像质量。
- 多模态预训练模型增强了跨模态解码任务的效果。
- 文章综述了fMRI解码的最新进展,重点关注从被动脑信号重建刺激的研究方法和数据集。
- 文章总结了相关的脑区,并讨论了模型性能及有效性评估。
点此查看论文截图

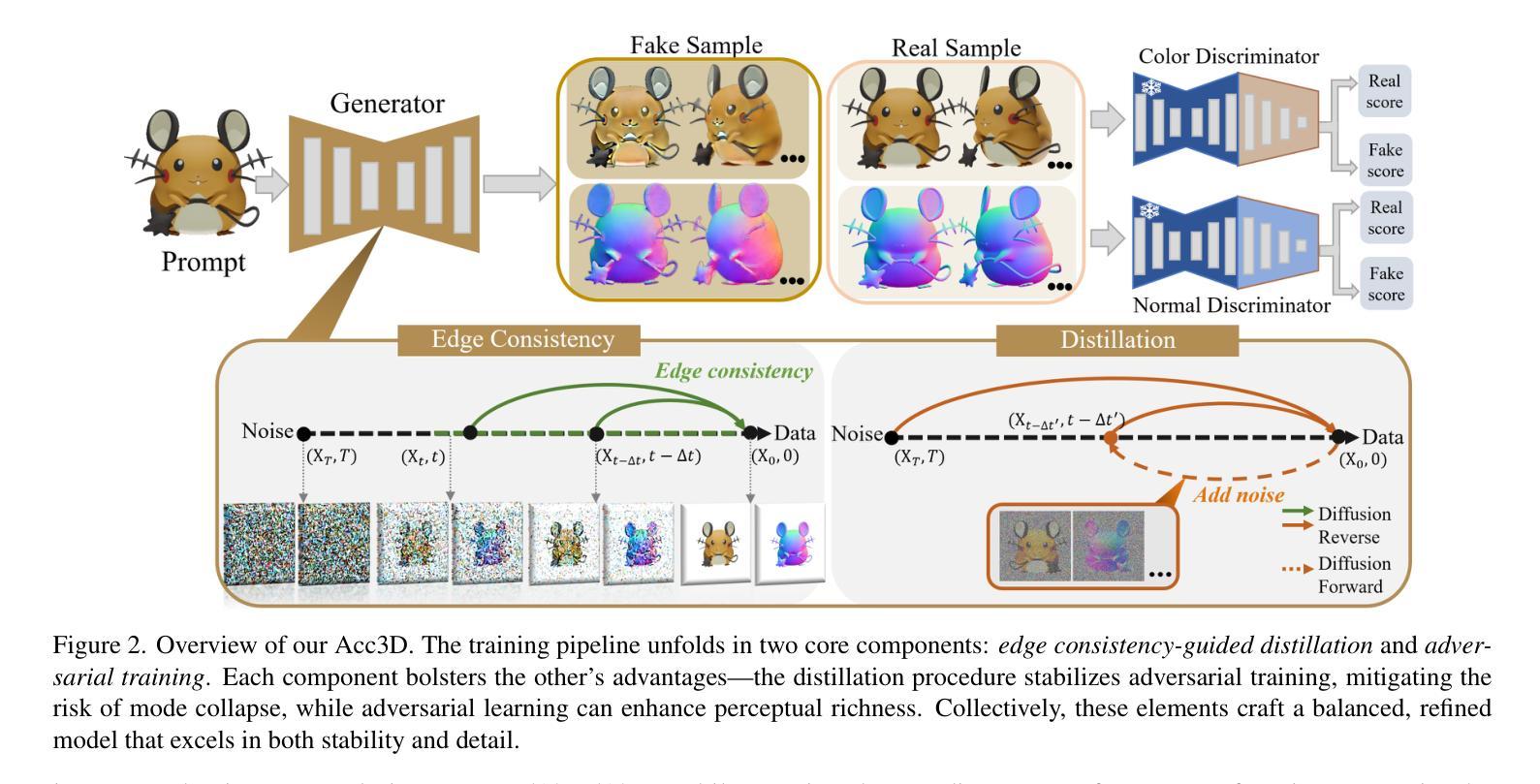
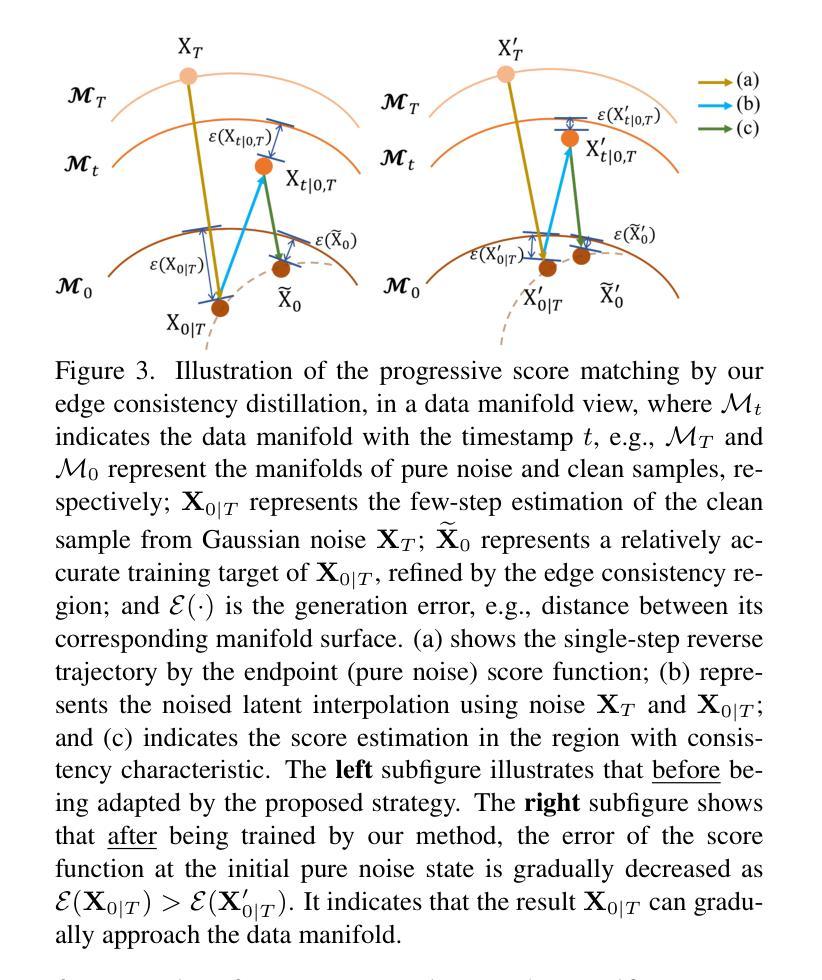
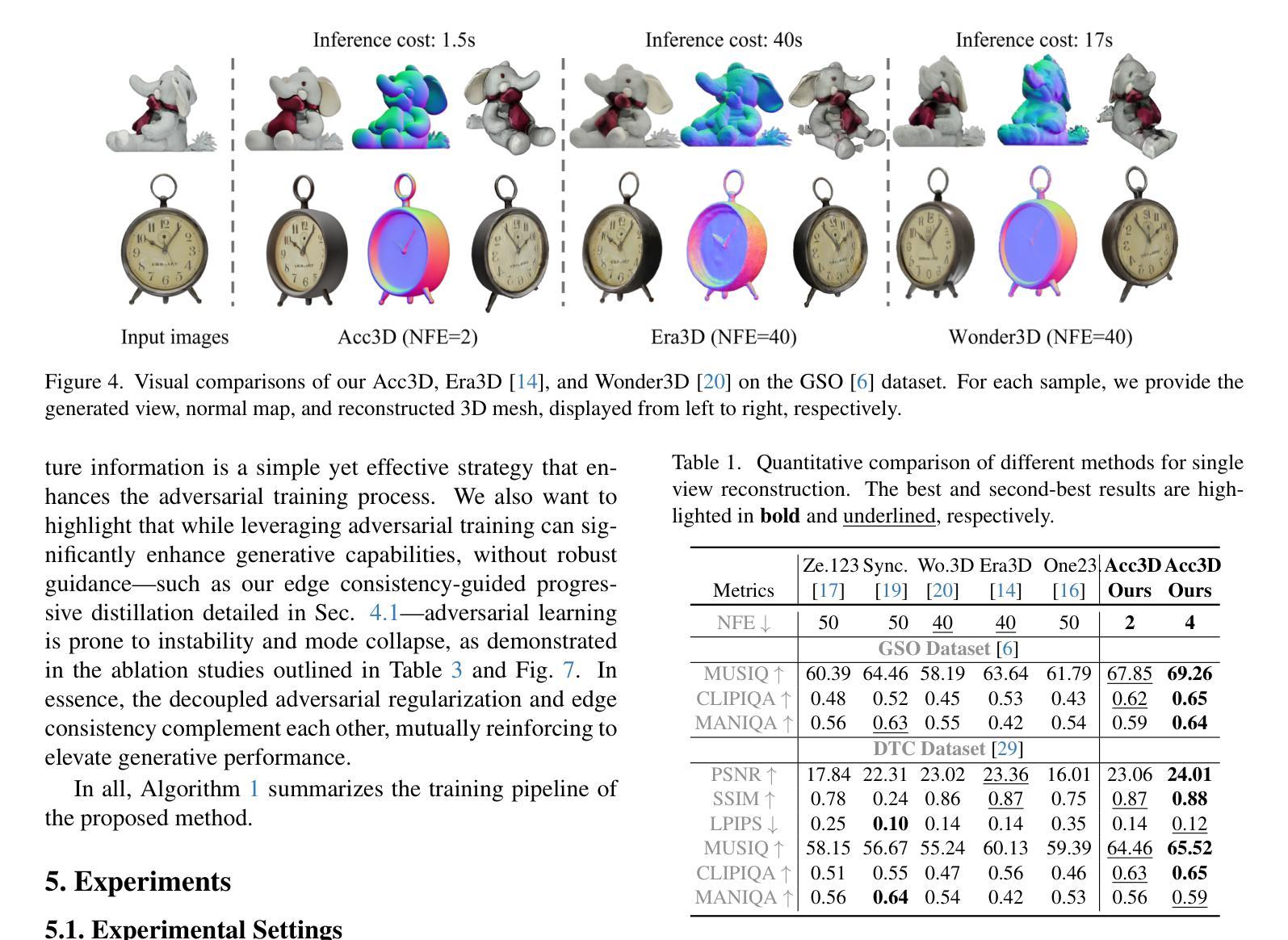
Acc3D: Accelerating Single Image to 3D Diffusion Models via Edge Consistency Guided Score Distillation
Authors:Kendong Liu, Zhiyu Zhu, Hui Liu, Junhui Hou
We present Acc3D to tackle the challenge of accelerating the diffusion process to generate 3D models from single images. To derive high-quality reconstructions through few-step inferences, we emphasize the critical issue of regularizing the learning of score function in states of random noise. To this end, we propose edge consistency, i.e., consistent predictions across the high signal-to-noise ratio region, to enhance a pre-trained diffusion model, enabling a distillation-based refinement of the endpoint score function. Building on those distilled diffusion models, we propose an adversarial augmentation strategy to further enrich the generation detail and boost overall generation quality. The two modules complement each other, mutually reinforcing to elevate generative performance. Extensive experiments demonstrate that our Acc3D not only achieves over a $20\times$ increase in computational efficiency but also yields notable quality improvements, compared to the state-of-the-arts.
我们提出Acc3D,旨在解决加速扩散过程,从单幅图像生成3D模型的挑战。为了通过少数几步推断获得高质量的重建,我们强调了随机噪声状态下对评分函数学习进行正则化的关键问题。为此,我们提出边缘一致性,即在高信噪比区域内的一致预测,以增强预训练的扩散模型,从而实现基于蒸馏的端点评分函数的改进。基于这些蒸馏扩散模型,我们进一步提出对抗增强策略,以丰富生成细节并提高整体生成质量。这两个模块相互补充,相互加强,提高了生成性能。大量实验表明,我们的Acc3D不仅实现了超过20倍的计算效率提升,而且在与其他最新技术相比时,还实现了显著的质量改进。
论文及项目相关链接
Summary
本文介绍了Acc3D方法,旨在加速从单幅图像生成3D模型的扩散过程。通过强调随机噪声状态下学习评分函数的重要性,以及提出边缘一致性来提高预训练的扩散模型,实现了基于蒸馏的终点评分函数优化。此外,还提出了一种对抗性增强策略,以进一步丰富生成细节并提高整体生成质量。两个模块相互补充,共同提高了生成性能。实验表明,Acc3D不仅实现了超过20倍的计算效率提升,而且在质量上也有显著改进。
Key Takeaways
- Acc3D旨在解决从单幅图像生成3D模型的扩散过程加速问题。
- 通过强调随机噪声状态下学习评分函数的重要性来优化重建质量。
- 提出了边缘一致性,以提高预训练的扩散模型的性能。
- 基于蒸馏的终点评分函数优化进一步提升了模型性能。
- 对抗性增强策略用于丰富生成细节并提高生成质量。
- 两个模块相互补充,共同提高生成性能。
点此查看论文截图


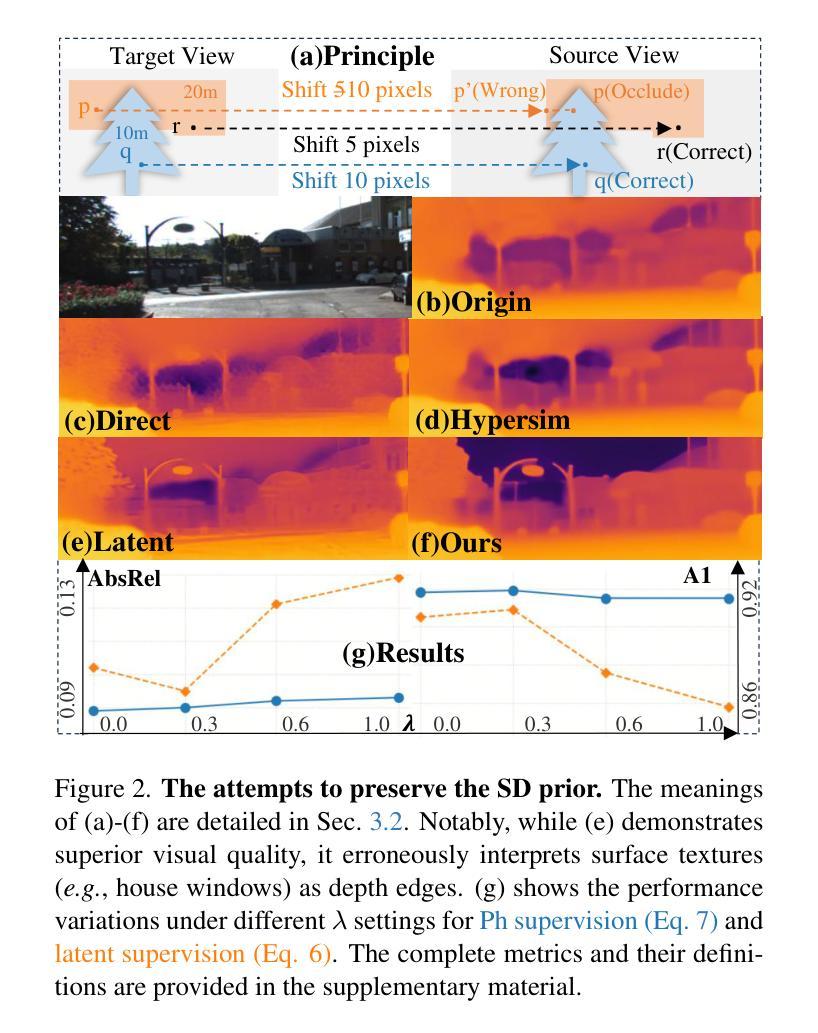
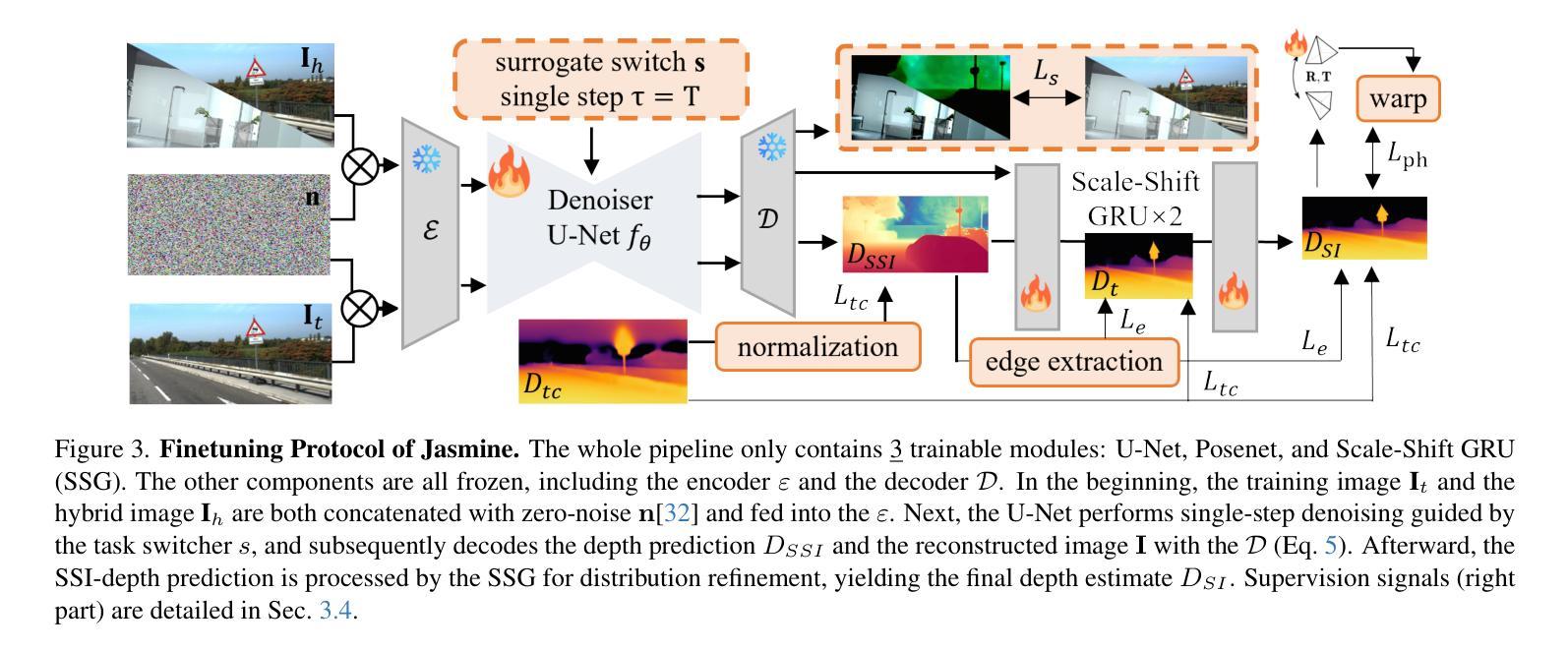
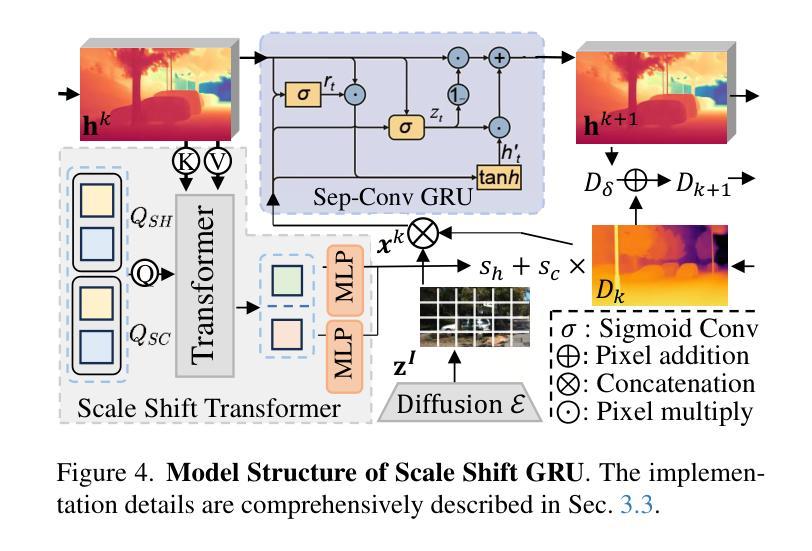
Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
Authors:Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, Yao Zhao
In this paper, we propose Jasmine, the first Stable Diffusion (SD)-based self-supervised framework for monocular depth estimation, which effectively harnesses SD’s visual priors to enhance the sharpness and generalization of unsupervised prediction. Previous SD-based methods are all supervised since adapting diffusion models for dense prediction requires high-precision supervision. In contrast, self-supervised reprojection suffers from inherent challenges (e.g., occlusions, texture-less regions, illumination variance), and the predictions exhibit blurs and artifacts that severely compromise SD’s latent priors. To resolve this, we construct a novel surrogate task of hybrid image reconstruction. Without any additional supervision, it preserves the detail priors of SD models by reconstructing the images themselves while preventing depth estimation from degradation. Furthermore, to address the inherent misalignment between SD’s scale and shift invariant estimation and self-supervised scale-invariant depth estimation, we build the Scale-Shift GRU. It not only bridges this distribution gap but also isolates the fine-grained texture of SD output against the interference of reprojection loss. Extensive experiments demonstrate that Jasmine achieves SoTA performance on the KITTI benchmark and exhibits superior zero-shot generalization across multiple datasets.
本文中,我们提出了基于Stable Diffusion(SD)的第一个自监督框架Jasmine,用于单目深度估计。它有效地利用了SD的视觉先验知识,提高了无监督预测的清晰度和泛化能力。之前基于SD的方法都是监督的,因为将扩散模型用于密集预测需要大量的高精度监督。相比之下,自监督的重新投影面临固有的挑战(例如遮挡、无纹理区域、光照变化),预测结果出现模糊和伪影,严重损害SD的潜在先验知识。为了解决这一问题,我们构建了一个混合图像重建的新型替代任务。在不增加任何监督的情况下,它通过重建图像本身来保留SD模型的细节先验知识,同时防止深度估计退化。此外,为了解决SD的规模和移位不变估计与自监督规模不变深度估计之间的固有不匹配问题,我们构建了Scale-Shift GRU。它不仅弥补了这种分布差距,还隔离了SD输出的精细纹理,避免了重新投影损失的干扰。大量实验表明,Jasmine在KITTI基准测试中达到了最先进水平,并在多个数据集上表现出出色的零样本泛化能力。
论文及项目相关链接
Summary
本文提出了Jasmine,首个基于Stable Diffusion(SD)的自我监督框架,用于单目深度估计。该框架有效利用了SD的视觉先验知识,提高了无监督预测的清晰度和泛化能力。此前的SD方法均是有监督的,因为将扩散模型用于密集预测需要高精度监督。与此相反,自我监督的重投影面临内在挑战(如遮挡、无纹理区域、光照变化),预测结果出现模糊和伪影,严重损害SD的潜在先验。为解决这一问题,本文构建了一种新的混合图像重建替代任务,无需任何额外监督,即可在重建图像的同时保留SD模型的细节先验,防止深度估计退化。此外,为解决SD尺度与移位不变估计和自我监督尺度不变深度估计之间的固有不匹配问题,本文构建了Scale-Shift GRU。它不仅弥补了这种分布差距,而且隔离了SD输出中的精细纹理,避免了重投影损失的干扰。实验表明,Jasmine在KITTI基准测试上达到了最新技术水平,并在多个数据集上表现出了出色的零样本泛化能力。
Key Takeaways
- Jasmine是首个基于Stable Diffusion的自我监督框架,用于单目深度估计。
- Jasmine利用SD的视觉先验知识,提高无监督预测的清晰度和泛化能力。
- 此前SD方法主要采取有监督方式,因为密集预测需要高精度监督。
- 自我监督的重投影存在挑战,如遮挡、无纹理区域和光照变化。
- 为解决这些挑战,Jasmine引入了混合图像重建的替代任务,无需额外监督。
- Scale-Shift GRU的引入解决了SD尺度与自我监督深度估计之间的不匹配问题。
点此查看论文截图

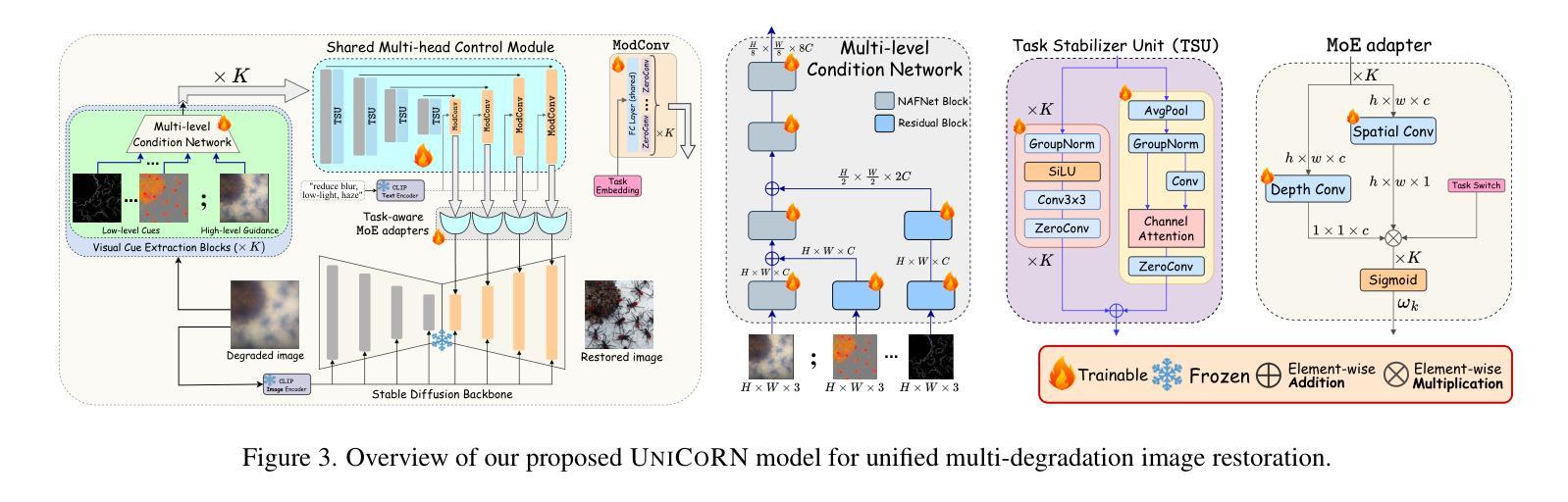
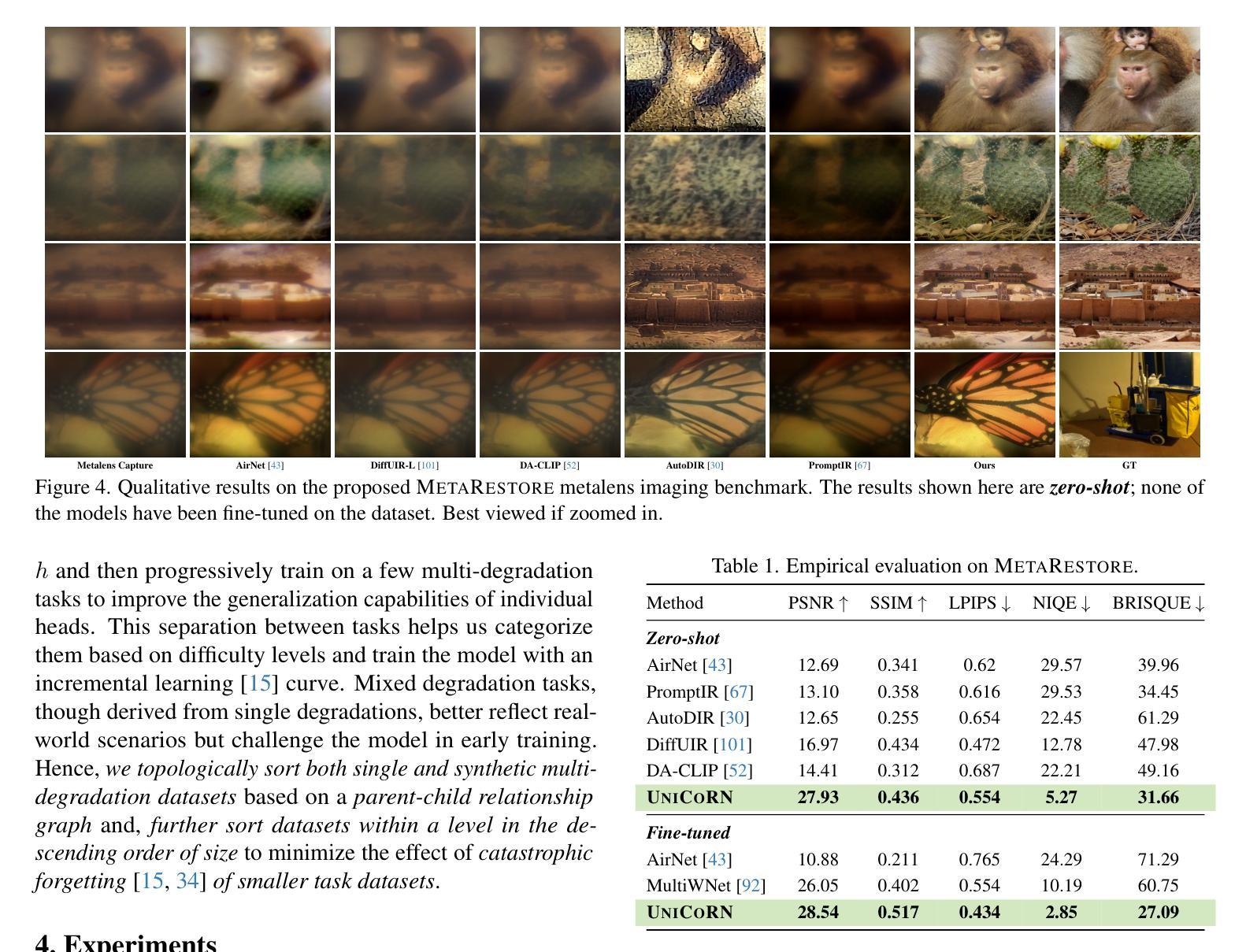
UniCoRN: Latent Diffusion-based Unified Controllable Image Restoration Network across Multiple Degradations
Authors:Debabrata Mandal, Soumitri Chattopadhyay, Guansen Tong, Praneeth Chakravarthula
Image restoration is essential for enhancing degraded images across computer vision tasks. However, most existing methods address only a single type of degradation (e.g., blur, noise, or haze) at a time, limiting their real-world applicability where multiple degradations often occur simultaneously. In this paper, we propose UniCoRN, a unified image restoration approach capable of handling multiple degradation types simultaneously using a multi-head diffusion model. Specifically, we uncover the potential of low-level visual cues extracted from images in guiding a controllable diffusion model for real-world image restoration and we design a multi-head control network adaptable via a mixture-of-experts strategy. We train our model without any prior assumption of specific degradations, through a smartly designed curriculum learning recipe. Additionally, we also introduce MetaRestore, a metalens imaging benchmark containing images with multiple degradations and artifacts. Extensive evaluations on several challenging datasets, including our benchmark, demonstrate that our method achieves significant performance gains and can robustly restore images with severe degradations. Project page: https://codejaeger.github.io/unicorn-gh
图像修复对于增强计算机视觉任务中的退化图像至关重要。然而,现有的大多数方法一次只处理一种退化类型(例如模糊、噪声或雾霾),限制了它们在现实世界中的应用,因为多种退化经常同时发生。在本文中,我们提出了UniCoRN,这是一种统一的图像修复方法,使用多头扩散模型同时处理多种退化类型。具体来说,我们发现了从图像中提取的低级视觉线索在指导可控扩散模型进行真实图像修复方面的潜力,并设计了一个可通过混合专家策略进行适应的多头控制网络。我们的模型无需对特定退化做出任何先验假设,通过精心设计的课程学习配方进行训练。此外,我们还引入了MetaRestore,这是一个包含多种退化和人工制品的金属成像基准测试。在我们基准测试等几个具有挑战性的数据集上的广泛评估表明,我们的方法实现了显著的性能提升,并能够稳健地修复严重退化的图像。项目页面:https://codejaeger.github.io/unicorn-gh
论文及项目相关链接
Summary
本文提出了一种名为UniCoRN的统一图像恢复方法,该方法使用多头扩散模型,能够同时处理多种类型的退化。该方法利用从图像中提取的低级视觉线索来指导可控扩散模型,通过混合专家策略设计了一个多头控制网络,并进行了智能设计的课程学习配方训练。此外,还介绍了包含多种退化和伪影的MetaRestore金属透镜成像基准。在几个具有挑战性的数据集上的广泛评估表明,该方法取得了显著的性能提升,并能稳健地恢复严重退化的图像。
Key Takeaways
- UniCoRN是一种能够同时处理多种类型退化的统一图像恢复方法。
- 使用低级视觉线索来指导可控扩散模型。
- 通过混合专家策略设计多头控制网络。
- 模型训练采用了智能设计的课程学习配方。
- 引入了包含多种退化和伪影的MetaRestore基准。
- 在具有挑战性的数据集上的广泛评估表明,该方法性能显著。
点此查看论文截图


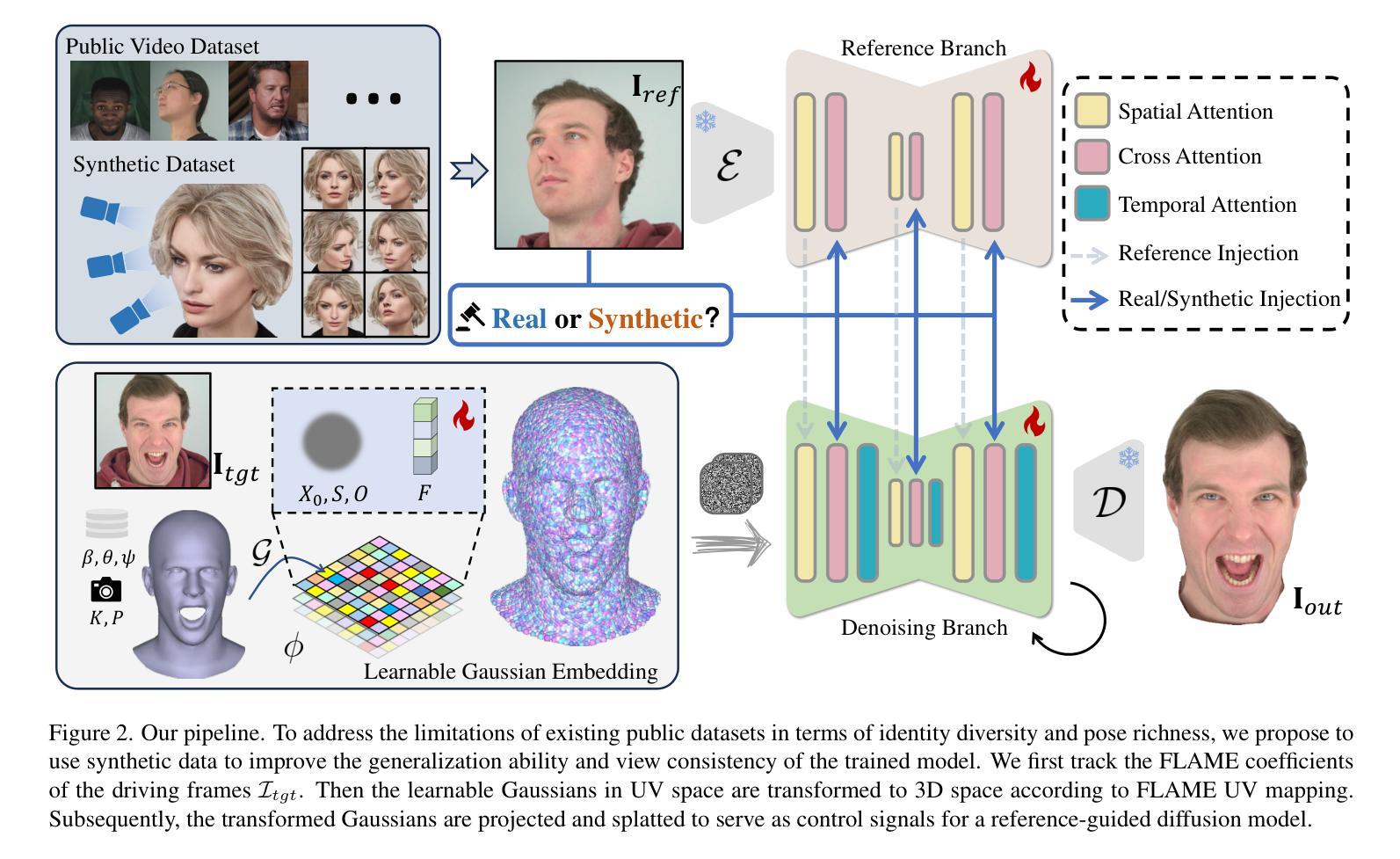
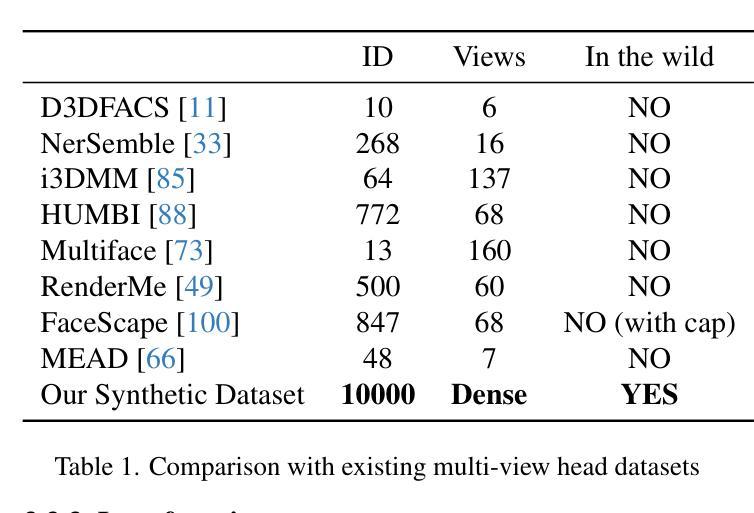
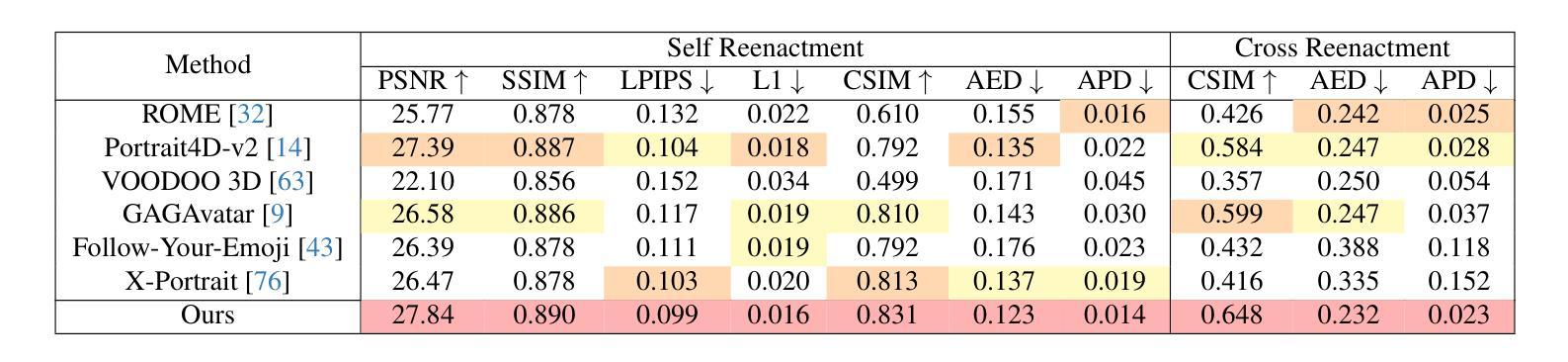
Controlling Avatar Diffusion with Learnable Gaussian Embedding
Authors:Xuan Gao, Jingtao Zhou, Dongyu Liu, Yuqi Zhou, Juyong Zhang
Recent advances in diffusion models have made significant progress in digital human generation. However, most existing models still struggle to maintain 3D consistency, temporal coherence, and motion accuracy. A key reason for these shortcomings is the limited representation ability of commonly used control signals(e.g., landmarks, depth maps, etc.). In addition, the lack of diversity in identity and pose variations in public datasets further hinders progress in this area. In this paper, we analyze the shortcomings of current control signals and introduce a novel control signal representation that is optimizable, dense, expressive, and 3D consistent. Our method embeds a learnable neural Gaussian onto a parametric head surface, which greatly enhances the consistency and expressiveness of diffusion-based head models. Regarding the dataset, we synthesize a large-scale dataset with multiple poses and identities. In addition, we use real/synthetic labels to effectively distinguish real and synthetic data, minimizing the impact of imperfections in synthetic data on the generated head images. Extensive experiments show that our model outperforms existing methods in terms of realism, expressiveness, and 3D consistency. Our code, synthetic datasets, and pre-trained models will be released in our project page: https://ustc3dv.github.io/Learn2Control/
近期扩散模型在数字人类生成方面取得了显著进展。然而,大多数现有模型在保持3D一致性、时间连贯性和运动精度方面仍存在困难。这些不足的一个关键原因是常用控制信号(例如地标、深度图等)的表示能力有限。此外,公共数据集中身份和姿态变化的缺乏进一步阻碍了该领域的进步。
在本文中,我们分析了当前控制信号的不足,并引入了一种新型的可优化、密集、表达性强且3D一致的控制信号表示方法。我们的方法将可学习的神经高斯嵌入到参数化头表面,这大大提高了基于扩散的头模型的一致性和表现力。关于数据集,我们合成了一个具有多种姿态和身份的大规模数据集。此外,我们使用真实/合成标签来有效区分真实和合成数据,最小化合成数据中的缺陷对生成的头图像的影响。大量实验表明,我们的模型在真实性、表现力和3D一致性方面优于现有方法。我们的代码、合成数据集和预训练模型将在我们的项目页面发布:https://ustc3dv.github.io/Learn2Control/
论文及项目相关链接
PDF Project Page: https://ustc3dv.github.io/Learn2Control/
Summary
近期扩散模型在数字人类生成方面取得显著进展,但仍面临3D一致性、时间连贯性和运动准确性等问题。本文分析了当前控制信号的不足,并提出一种新型的可优化、密集、表达性强且3D一致的控制信号表示方法。通过将可学习的神经高斯嵌入到参数化头部表面,该方法大大提高了基于扩散的头部模型的一致性和表现力。此外,本文合成了一个大规模的多姿态和身份的数据集,并使用真实/合成标签来有效区分真实和合成数据。实验表明,该模型在真实性、表现力和3D一致性方面优于现有方法。
Key Takeaways
- 扩散模型在数字人类生成上取得进展,但存在3D一致性、时间连贯性和运动准确性的问题。
- 当前控制信号表示方法存在局限性,需要更优化、密集、表达性强且3D一致的控制信号。
- 引入了一种新的控制信号表示方法,通过嵌入可学习的神经高斯到参数化头部表面,提高模型的一致性和表现力。
- 合成了一个大规模的多姿态和身份的数据集,以支持更广泛的训练和应用。
- 使用真实/合成标签来区分真实和合成数据,减少合成数据不完美对生成头部图像的影响。
- 实验证明该模型在真实性、表现力和3D一致性方面优于现有方法。
点此查看论文截图


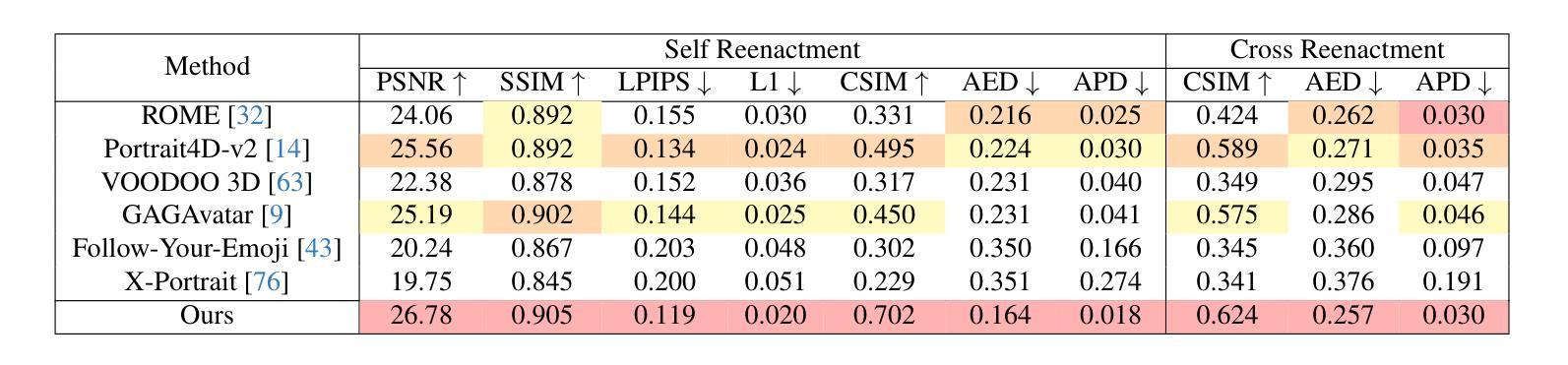
Uncertainty-Aware Diffusion Guided Refinement of 3D Scenes
Authors:Sarosij Bose, Arindam Dutta, Sayak Nag, Junge Zhang, Jiachen Li, Konstantinos Karydis, Amit K. Roy Chowdhury
Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, existing single image to 3D reconstruction methods render incoherent and blurry views. This problem is exacerbated when the unseen regions are far away from the input camera. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image’s view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module that calculates the per-pixel entropy and yields uncertainty maps used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
从单一图像重建3D场景是一个根本上的不适定任务,因为这个问题具有严重的约束不足的特性。因此,当场景从新视角呈现时,现有的单一图像到3D重建方法会产生不连贯和模糊的视图。当未见的区域远离输入相机时,这个问题更加严重。在这项工作中,我们解决了现有单一图像到3D场景前馈网络的这些固有局限性。为了缓解由于输入图像视图之外信息不足而导致的性能不佳问题,我们利用预训练的潜在视频扩散模型的强大生成先验,对由可优化高斯参数表示的粗糙场景进行迭代优化。为了确保生成的图像的风格和纹理与输入图像一致,我们在生成的图像和输入图像之间进行了实时的傅里叶风格转换。此外,我们设计了一个语义不确定性量化模块,该模块计算像素熵并产生不确定性映射,用于引导从最确定的像素开始的优化过程,同时丢弃其余高度不确定的像素。我们在包括RealEstate-10K领域内的数据集和KITTI-v2跨领域数据集上进行了大量实验,结果表明我们的方法可以提供比现有最先进的方法更真实、更高质量的全新视角合成结果。
论文及项目相关链接
PDF 13 pages, 7 figures
Summary
本文解决了从单张图像重建3D场景时面临的根本问题,包括渲染不一致和模糊视图等。为此,研究人员借助预训练的潜在视频扩散模型进行迭代优化,改进了单一的图像到3D场景的反馈网络。结合Fourier风格迁移和语义不确定性量化模块,确保生成的图像风格与输入图像一致,同时提高渲染质量。实验证明,该方法在真实场景数据集上能生成更真实、高保真度的视图合成结果。
Key Takeaways
- 单图像重建的3D场景存在固有的问题,导致渲染结果不一致和模糊。
- 预训练的潜在视频扩散模型被用于迭代优化,改进单一图像到3D场景的反馈网络性能。
- Fourier风格迁移技术确保生成的图像风格与输入图像一致。
- 设计了语义不确定性量化模块,用于计算像素级别的熵并生成不确定性地图,指导优化过程专注于最可靠的像素,同时忽略高度不确定的部分。
- 方法在真实场景数据集上进行广泛实验验证。
- 与现有先进技术相比,该方法能提供更真实、高保真度的视图合成结果。
点此查看论文截图

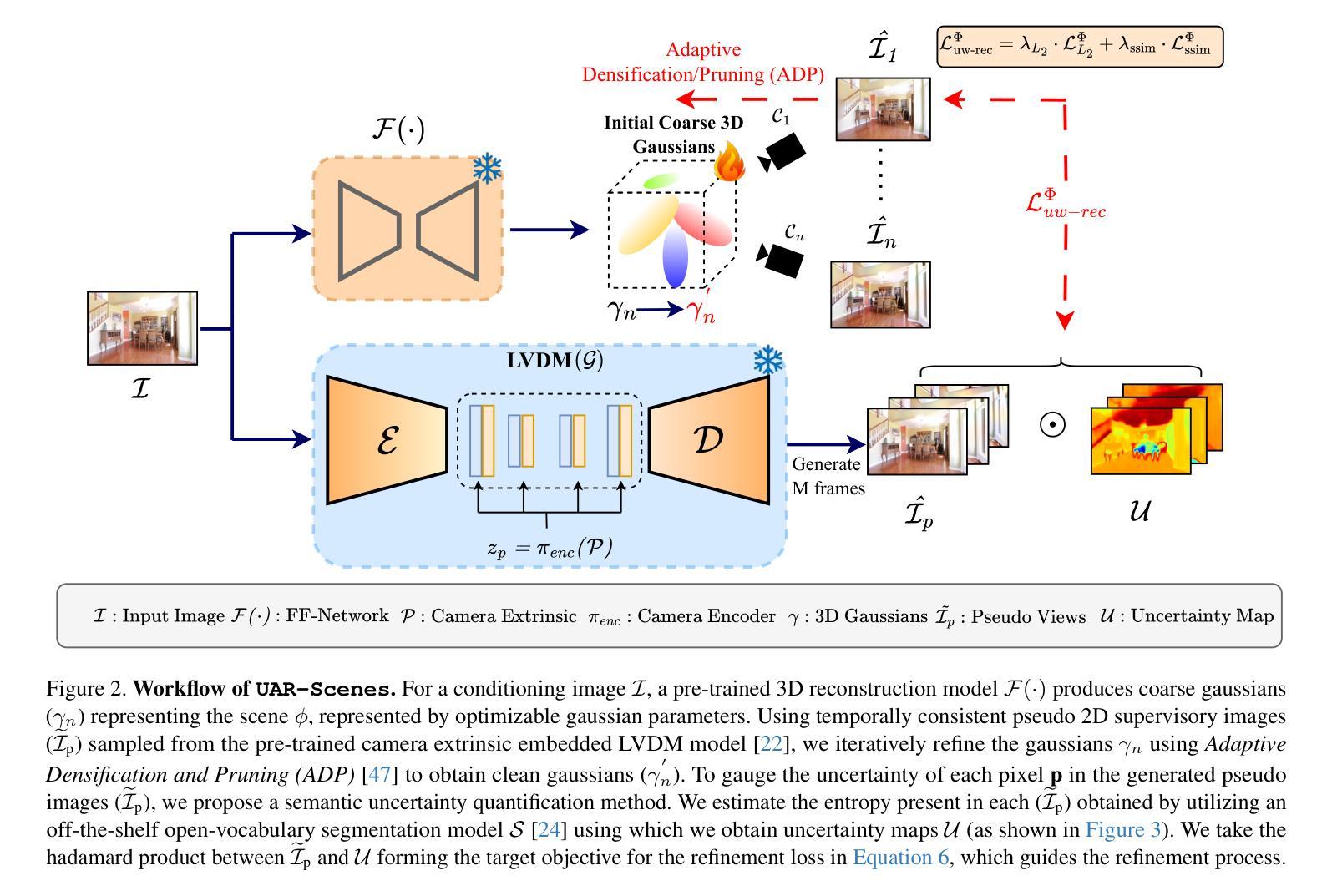
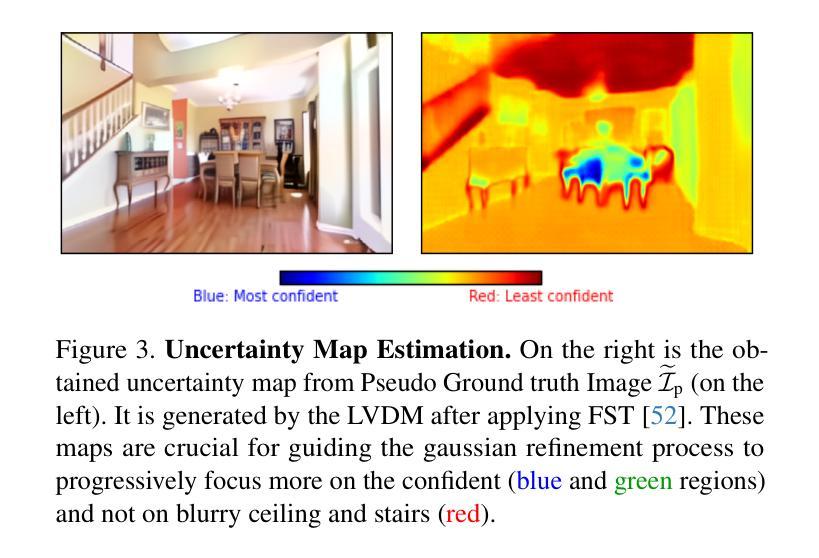
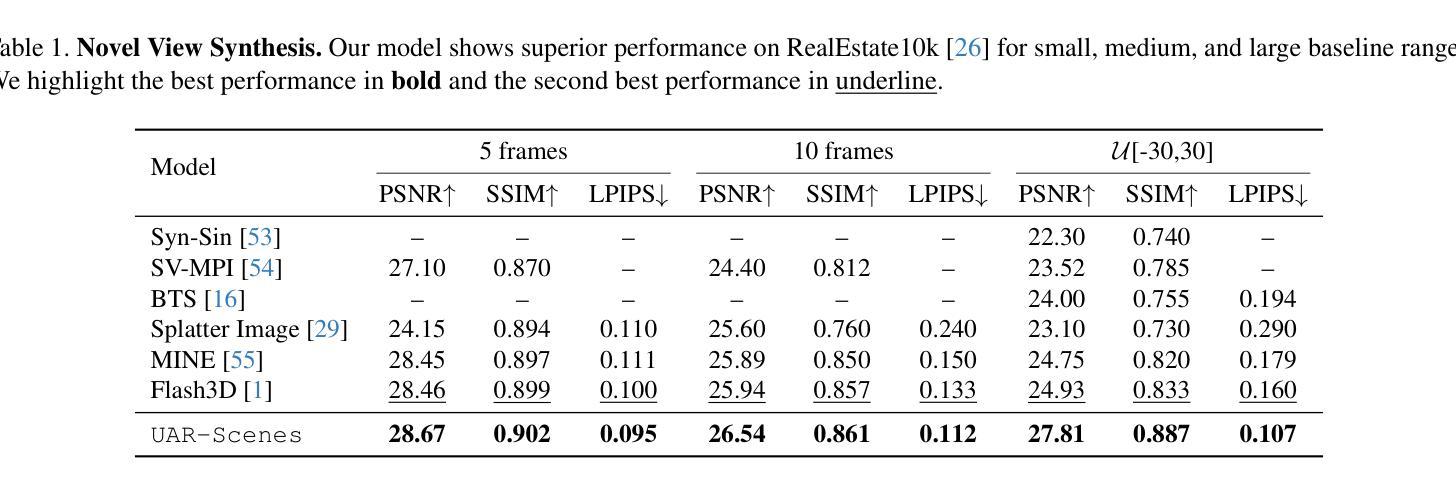
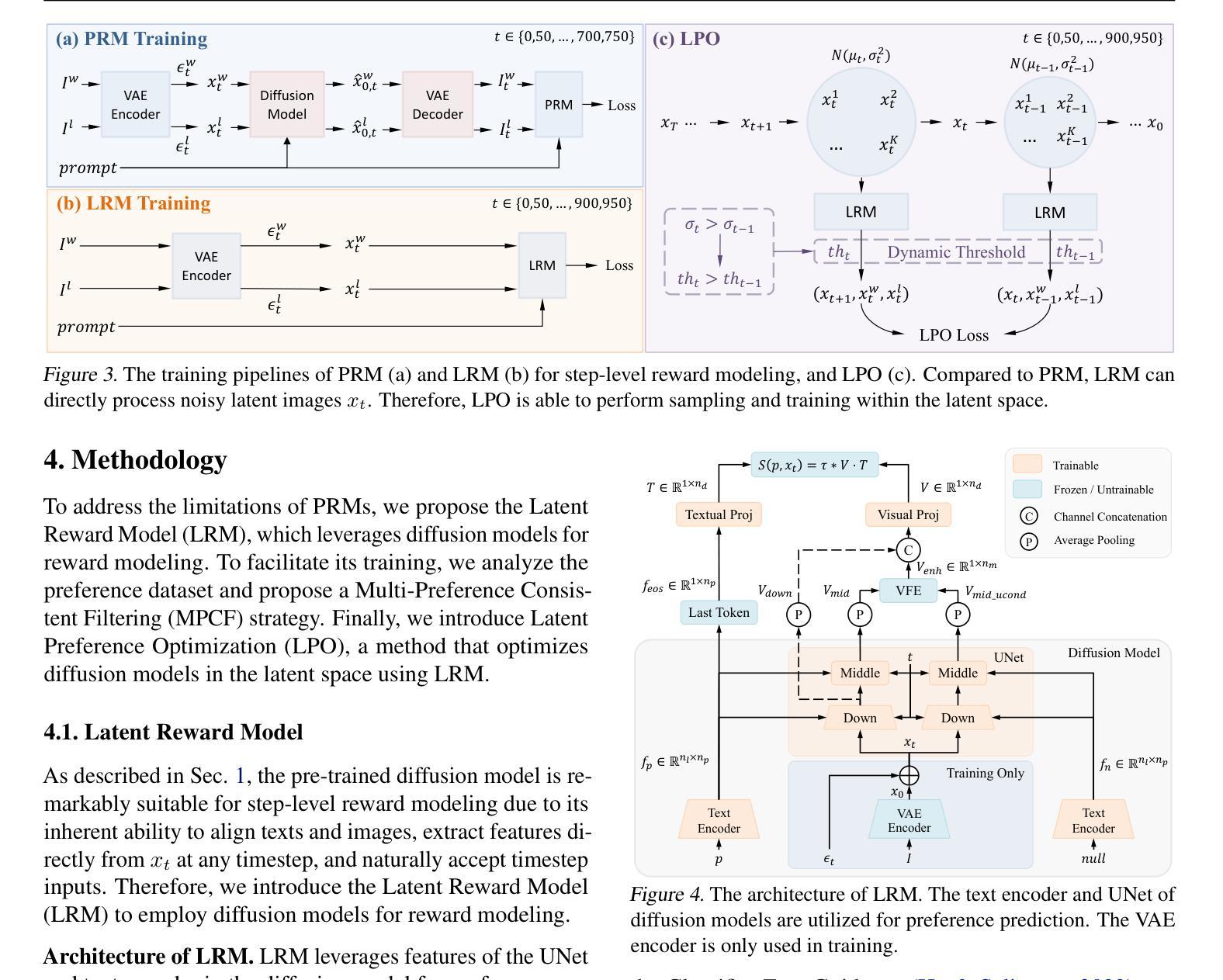
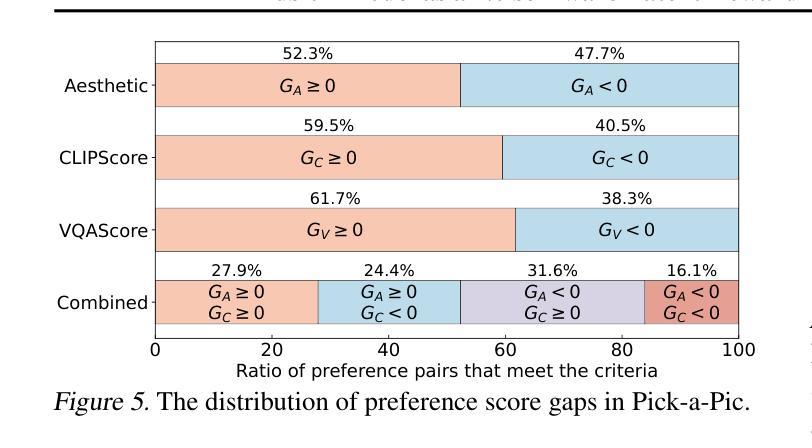
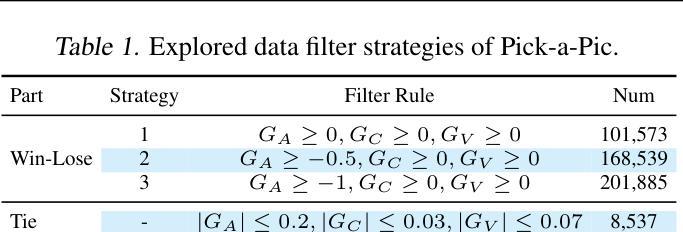
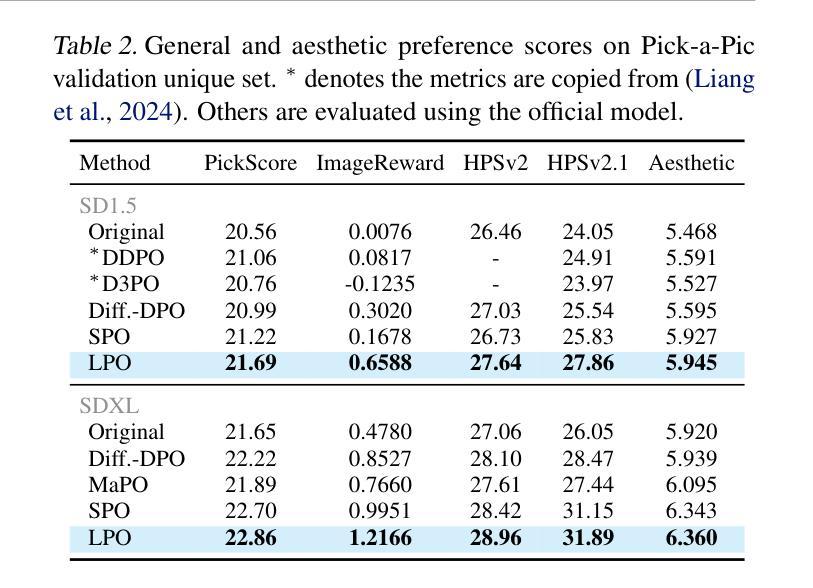
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Authors:Tao Zhang, Cheng Da, Kun Ding, Kun Jin, Yan Li, Tingting Gao, Di Zhang, Shiming Xiang, Chunhong Pan
Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code and models are available at https://github.com/Kwai-Kolors/LPO.
扩散模型的偏好优化旨在使它们符合人类对于图像的看法。之前的方法通常利用视觉语言模型(VLMs)作为像素级奖励模型来近似人类偏好。然而,当用于步骤级偏好优化时,这些模型在处理不同时间步的噪声图像时面临挑战,并且需要将复杂转换到像素空间。在这项工作中,我们证明了扩散模型天然适合在潜在空间中进行步骤级奖励建模,因为它们可以从噪声潜在图像中自然提取特征。因此,我们提出了潜在奖励模型(LRM),该模型重新利用扩散模型的组件来预测不同时间步的潜在图像的偏好。基于LRM,我们引入了潜在偏好优化(LPO),这是一种专为潜在空间中的步骤级偏好优化而设计的方法。实验结果表明,LPO不仅显著提高了扩散模型与一般、美学和文本-图像对齐偏好的对齐性能,而且与现有的偏好优化方法相比实现了2.5-28倍的训练加速。我们的代码和模型可在https://github.com/Kwai-Kolors/LPO获取。
论文及项目相关链接
PDF 20 pages, 14 tables, 15 figures
Summary
本文介绍了针对扩散模型的偏好优化方法,旨在使图像与人类偏好对齐。先前的方法通常使用视觉语言模型(VLMs)作为像素级奖励模型来近似人类偏好,但在处理不同时间步长的噪声图像时面临挑战。本文展示了扩散模型在潜在空间中进行步级奖励建模的天然优势,并提出了潜在奖励模型(LRM)和潜在偏好优化(LPO)方法。实验结果表明,LPO不仅大大提高了扩散模型与通用、美学和文本图像对齐偏好的对齐性能,而且与现有偏好优化方法相比实现了2.5-28倍的训练加速。
Key Takeaways
- 扩散模型偏好优化的目标是使模型生成的图像与人类偏好对齐。
- 传统的视觉语言模型(VLMs)在处理不同时间步长的噪声图像时存在挑战。
- 扩散模型在潜在空间中进行步级奖励建模具有天然优势。
- 提出了潜在奖励模型(LRM)来预测不同时间步长下潜在图像的偏好。
- 基于LRM,引入了潜在偏好优化(LPO)方法,专为在潜在空间中进行步级偏好优化设计。
- 实验结果表明,LPO显著提高了扩散模型的性能,并实现了显著的训练加速。
点此查看论文截图


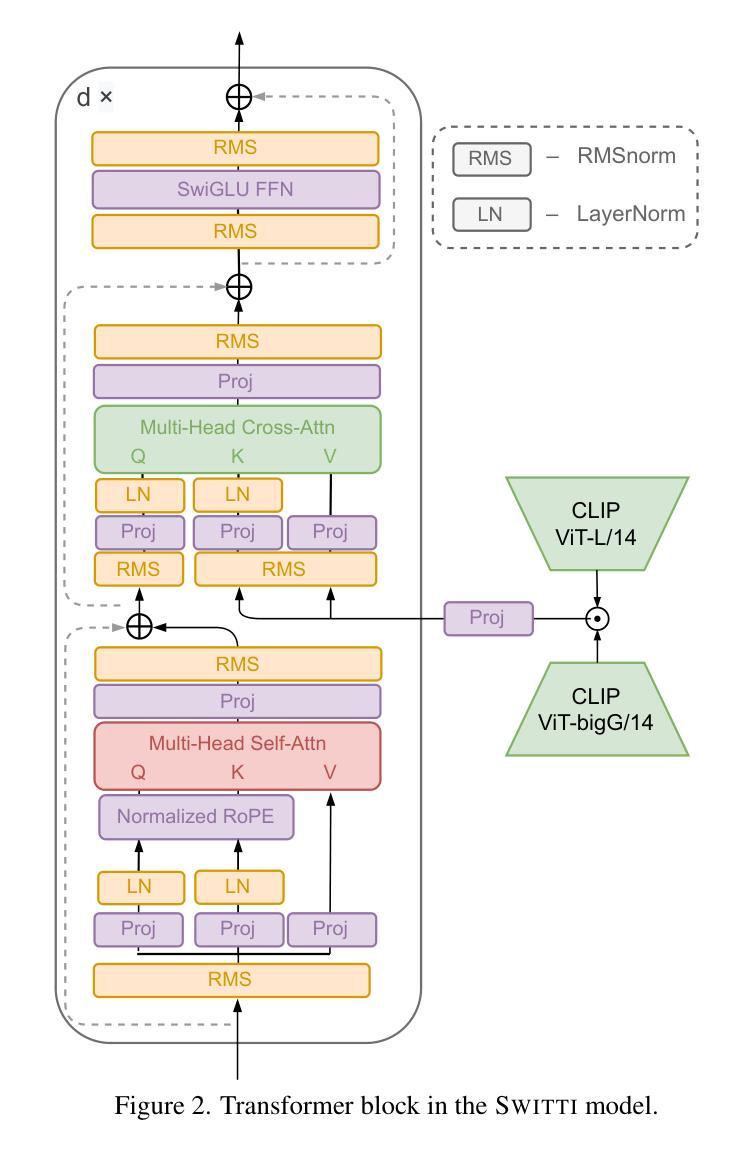
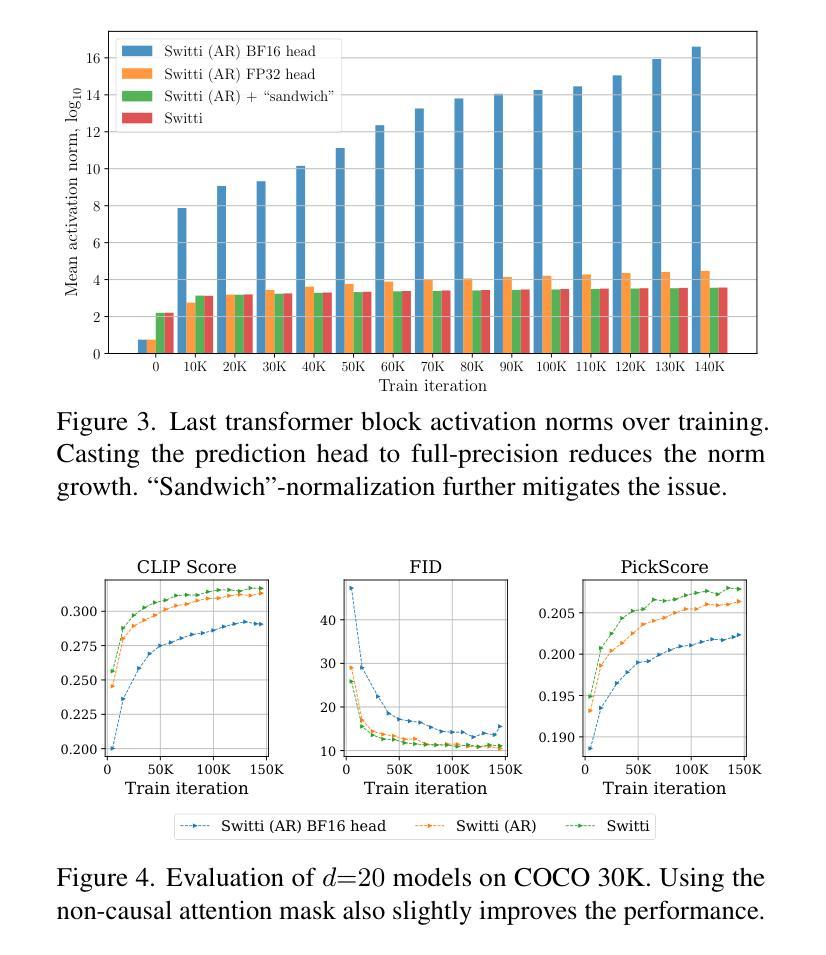
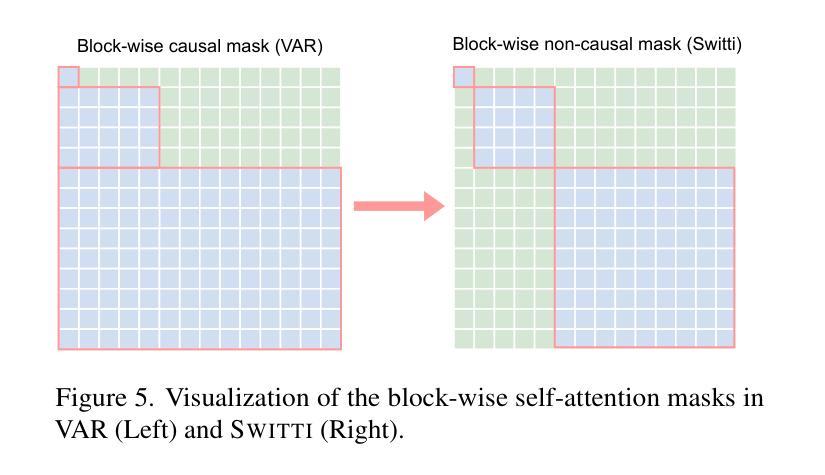
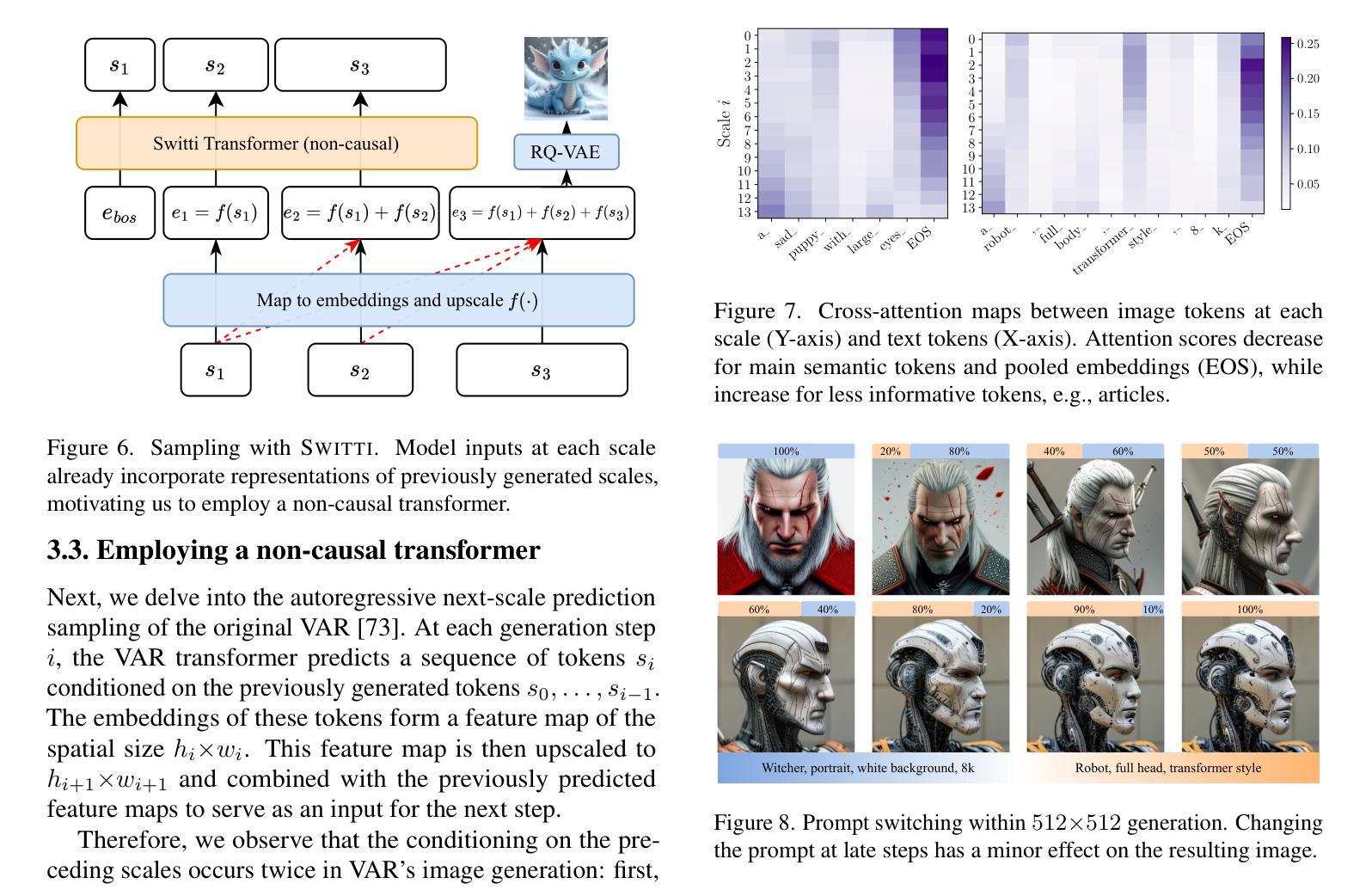
Switti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Authors:Anton Voronov, Denis Kuznedelev, Mikhail Khoroshikh, Valentin Khrulkov, Dmitry Baranchuk
This work presents Switti, a scale-wise transformer for text-to-image generation. We start by adapting an existing next-scale prediction autoregressive (AR) architecture to T2I generation, investigating and mitigating training stability issues in the process. Next, we argue that scale-wise transformers do not require causality and propose a non-causal counterpart facilitating ~21% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~32% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7x faster.
本文介绍了Switti,这是一个用于文本到图像生成的规模转换器。我们首先通过对现有的下一尺度预测自回归(AR)架构进行改编,将其应用于T2I生成,同时研究和解决训练过程中的稳定性问题。接下来,我们认为规模转换器不需要因果性,并提出了一个非因果的对应方案,该方案可实现约21%更快的采样和更低的内存使用,同时实现略微更好的生成质量。此外,我们发现在高分辨率尺度上不需要无分类指导,甚至可能会降低性能。通过在这些尺度上禁用指导,我们实现了额外的约32%的采样加速,并改进了细粒度细节的生成。广泛的人类偏好研究和自动化评估表明,Switti超越了现有的T2I AR模型,与最先进的T2I扩散模型竞争,同时速度提高了高达7倍。
论文及项目相关链接
PDF CVPR 2025
Summary
本文介绍了Switti,一种用于文本到图像生成的尺度变换器。通过对现有次尺度预测自回归(AR)架构的适应,研究了训练稳定性问题并进行了缓解。提出非因果性尺度变换器,实现更快的采样速度和更低的内存使用,同时生成质量略有提高。此外,发现高分辨率下的无分类器引导并不必要,甚至可能降低性能。禁用这些尺度的引导,进一步提高采样速度并改善细节生成。人类偏好研究和自动化评估显示,Switti优于现有的文本到图像自回归模型,并与先进的文本到图像扩散模型竞争,速度提高高达7倍。
Key Takeaways
- Switti是一种用于文本到图像生成的尺度变换器。
- 通过适应现有次尺度预测自回归架构,解决了训练稳定性问题。
- 提出了非因果性尺度变换器,实现更快的采样速度和更低的内存使用。
- 无需在高分辨率下使用分类器引导,禁用这些尺度的引导可进一步提高采样速度和改善细节生成。
- Switti的生成质量优于现有文本到图像自回归模型,与先进的文本到图像扩散模型相当。
- Switti实现了高达7倍的速度提升。
点此查看论文截图

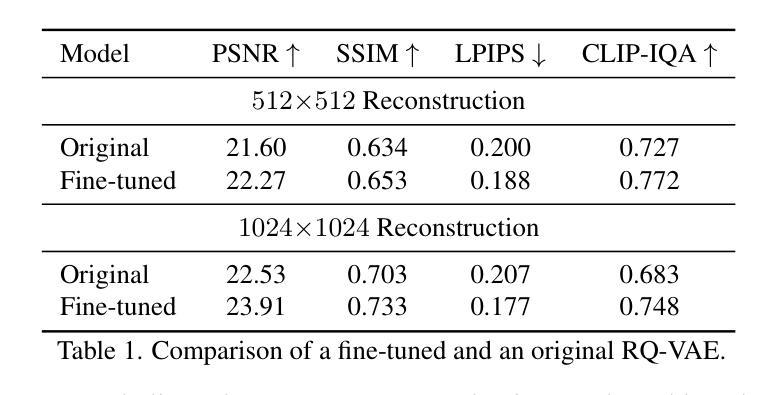
Pathways on the Image Manifold: Image Editing via Video Generation
Authors:Noam Rotstein, Gal Yona, Daniel Silver, Roy Velich, David Bensaïd, Ron Kimmel
Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image’s key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation. Visit our project page at https://rotsteinnoam.github.io/Frame2Frame.
由图像扩散模型驱动的图片编辑领域的最新进展已经取得了显著的成果。然而,仍然存在重大挑战,因为这些模型往往难以准确遵循复杂的编辑指令,并且经常改变原始图像的关键元素,从而影响保真度。同时,视频生成已经取得了显著的进步,模型有效地充当了连贯和连续的世界模拟器。在本文中,我们提出了通过利用图像到视频模型进行图片编辑来融合这两个领域。我们将图像编辑重新构想为一个时间过程,使用预训练的视频模型来创建从原始图像到所需编辑的平滑过渡。这种方法在图像流形上连续遍历,确保编辑的一致性,同时保留原始图像的关键方面。我们的方法在基于文本的图片编辑方面达到了最新水平,在编辑准确性和图像保留方面都取得了显著改进。请访问我们的项目页面:https://rotsteinnoam.github.io/Frame2Frame了解更多信息。
论文及项目相关链接
Summary
图像扩散模型在图像编辑方面取得了显著进展,但仍面临复杂指令跟随和保真度保持的挑战。同时,视频生成领域也取得了长足的发展。本文提出将图像编辑与视频生成相结合,利用图像到视频的模型进行图像编辑。通过预训练的视频模型创建从原始图像到期望编辑的平滑过渡,将图像编辑重新构想为一个时间过程,确保编辑的一致性并保留原始图像的关键要素。该方法在文本驱动的图像编辑方面取得了最新结果,显著提高了编辑准确性和图像保留效果。详情访问:https://rotsteinnoam.github.io/Frame2Frame。
Key Takeaways
- 图像扩散模型在图像编辑领域取得显著进展,但仍面临跟随复杂指令和保持保真度的挑战。
- 视频生成领域已有有效的持续世界模拟器模型。
- 本文提出了将图像编辑与视频生成相结合的方法,利用图像到视频的模型进行图像编辑。
- 通过预训练的视频模型创建从原始图像到期望编辑的平滑过渡。
- 图像编辑被重新构想为一个时间过程,确保编辑的一致性并保留原始图像的关键要素。
- 该方法在文本驱动的图像编辑方面取得最新成果,提高了编辑准确性和图像保留效果。
点此查看论文截图


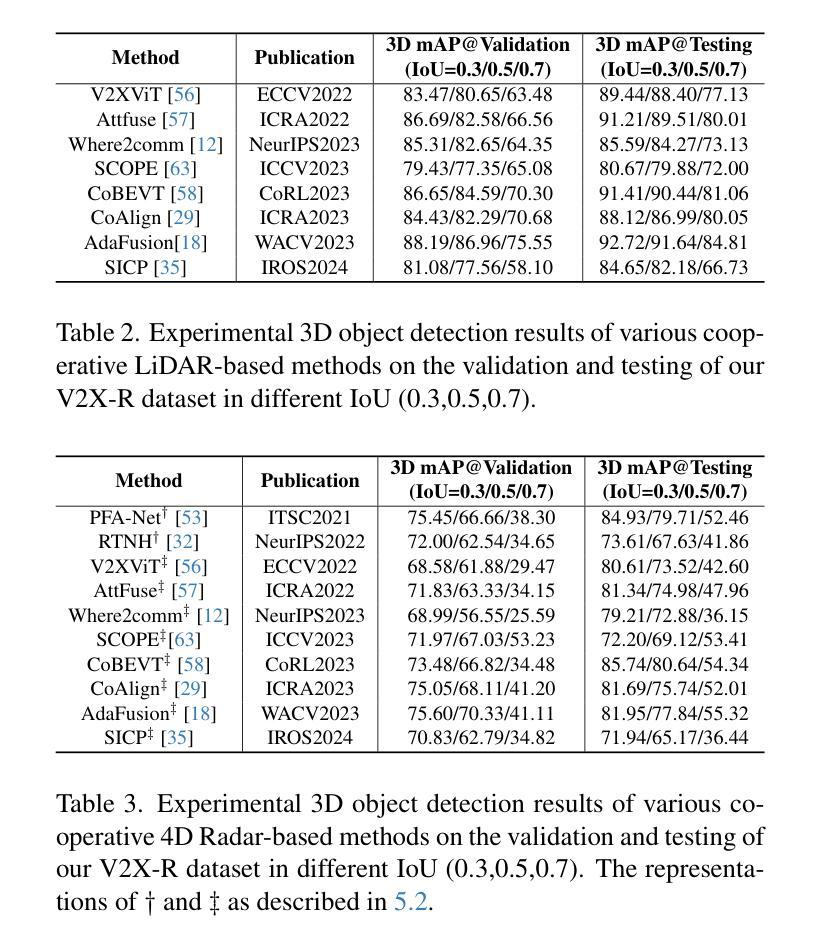
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
Authors:Xun Huang, Jinlong Wang, Qiming Xia, Siheng Chen, Bisheng Yang, Xin Li, Cheng Wang, Chenglu Wen
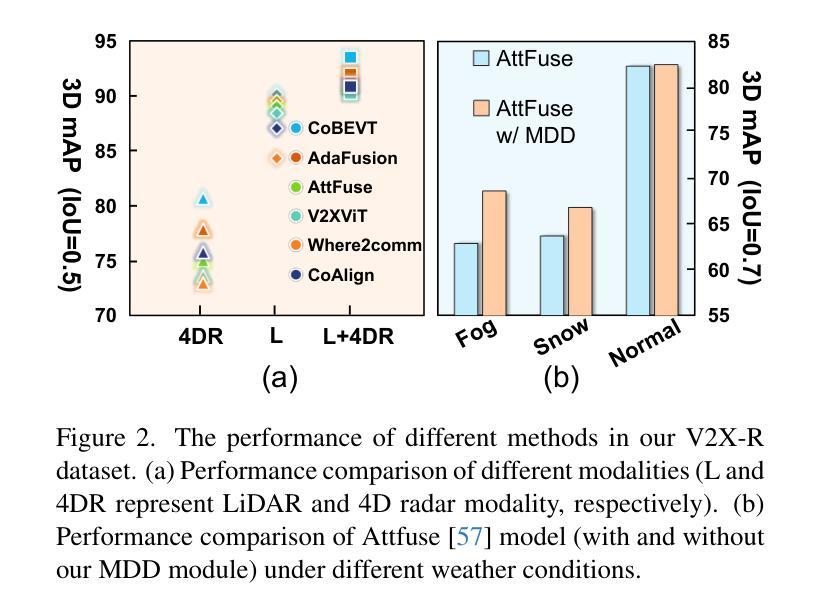
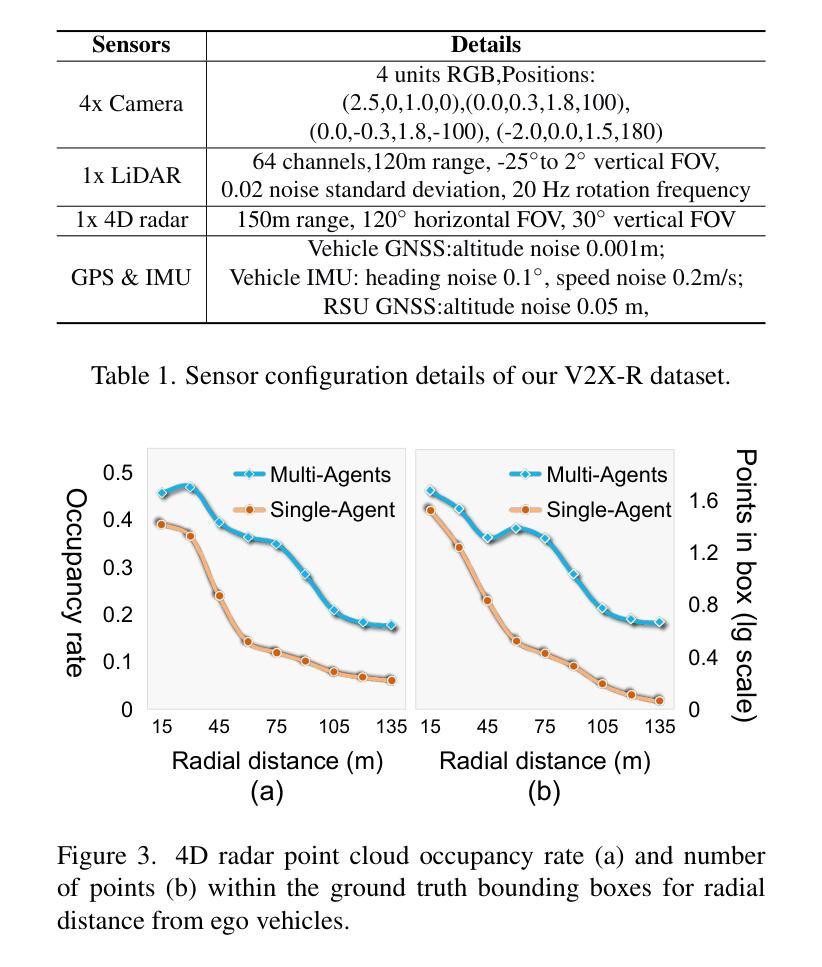
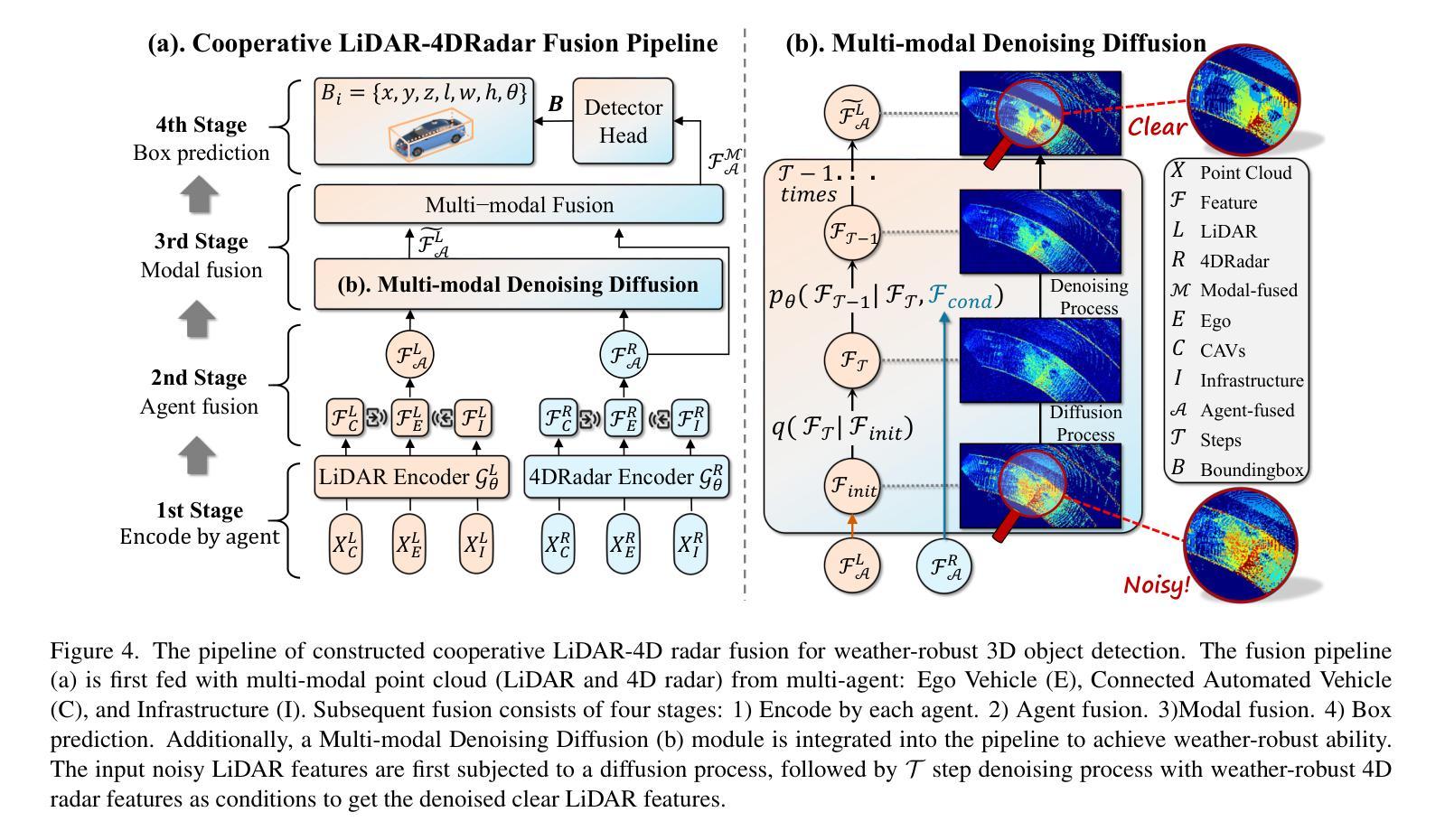
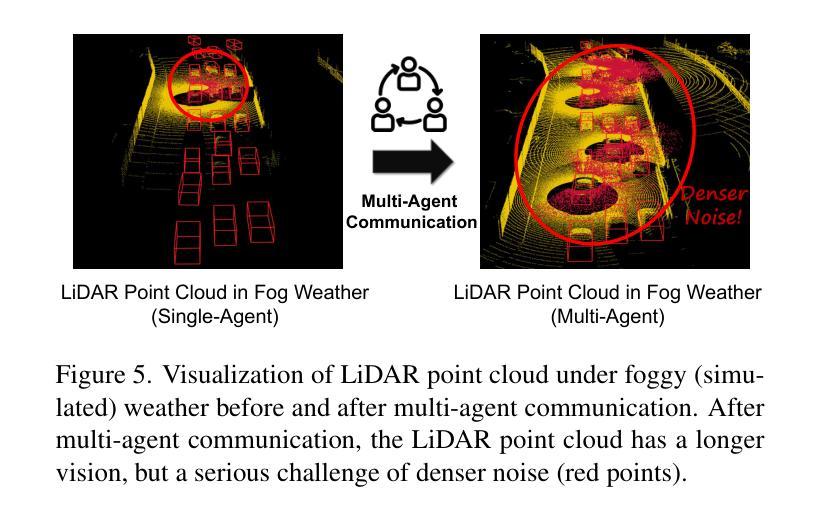
Current Vehicle-to-Everything (V2X) systems have significantly enhanced 3D object detection using LiDAR and camera data. However, these methods suffer from performance degradation in adverse weather conditions. The weather-robust 4D radar provides Doppler and additional geometric information, raising the possibility of addressing this challenge. To this end, we present V2X-R, the first simulated V2X dataset incorporating LiDAR, camera, and 4D radar. V2X-R contains 12,079 scenarios with 37,727 frames of LiDAR and 4D radar point clouds, 150,908 images, and 170,859 annotated 3D vehicle bounding boxes. Subsequently, we propose a novel cooperative LiDAR-4D radar fusion pipeline for 3D object detection and implement it with various fusion strategies. To achieve weather-robust detection, we additionally propose a Multi-modal Denoising Diffusion (MDD) module in our fusion pipeline. MDD utilizes weather-robust 4D radar feature as a condition to prompt the diffusion model to denoise noisy LiDAR features. Experiments show that our LiDAR-4D radar fusion pipeline demonstrates superior performance in the V2X-R dataset. Over and above this, our MDD module further improved the performance of basic fusion model by up to 5.73%/6.70% in foggy/snowy conditions with barely disrupting normal performance. The dataset and code will be publicly available at: https://github.com/ylwhxht/V2X-R.
当前的车载通讯系统(Vehicle-to-Everything,简称V2X)已经通过激光雷达和摄像头数据显著提高了三维物体检测能力。然而,这些方法在恶劣天气条件下会出现性能下降的问题。天气稳定的四维雷达提供了多普勒和额外的几何信息,为解决这一挑战提供了可能性。为此,我们推出了V2X-R,这是首个结合了激光雷达、摄像头和四维雷达的模拟V2X数据集。V2X-R包含12,079个场景,其中包括激光雷达和四维雷达点云37,727帧、图像数据高达150,908张以及标注了的三维车辆边界框数量达170,859个。随后,我们提出了一种新型的合作式激光雷达四维雷达融合管道进行三维物体检测,并采用了多种融合策略来实现。为了实现天气稳定的检测,我们在融合管道中额外提出了一种多模态降噪扩散模块(MDD)。MDD利用天气稳定的四维雷达特征作为条件来提示扩散模型对噪声干扰的激光雷达特征进行去噪处理。实验表明,我们的激光雷达四维雷达融合管道在V2X-R数据集上表现卓越。此外,我们的MDD模块进一步改善了基本融合模型在雾天和雪天环境下的性能,提升了高达5.73%和6.70%,同时几乎不影响正常环境下的性能。数据集和代码将在以下网址公开提供:https://github.com/ylwhxht/V2X-R 。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文介绍了针对车辆与环境交互(V2X)领域的最新研究成果。在现有的LiDAR和相机数据基础上,通过使用天气稳健的4D雷达数据,构建了一个模拟的V2X数据集V2X-R。该数据集包含多种场景下的LiDAR和4D雷达点云数据、图像以及标注的3D车辆边界框。此外,提出了一种新颖的协同LiDAR-4D雷达融合管道,用于实现天气稳健的3D目标检测。其中,多模态去噪扩散模块(MDD)能够在融合管道中进一步优化性能。实验表明,该融合管道在V2X-R数据集上的性能表现优越,并且在雾天和雪天的条件下,通过MDD模块的辅助,性能提升尤为显著。数据集和相关代码已公开可供下载使用。
Key Takeaways
- 当前V2X系统的3D对象检测主要依赖LiDAR和相机数据,但在恶劣天气条件下性能会下降。
- 提出了一种模拟的V2X数据集V2X-R,整合了LiDAR、相机和4D雷达数据。
- V2X-R数据集包含大量场景和标注的3D车辆边界框,有助于改进和测试3D目标检测算法。
- 提出了一种新颖的协同LiDAR-4D雷达融合管道用于提高3D目标检测的准确性和性能。
- 融合管道中的多模态去噪扩散模块(MDD)能够进一步优化性能,特别是在恶劣天气条件下。
- 实验证明,该融合管道在V2X-R数据集上的表现优于传统方法。
点此查看论文截图

Diffusion Attribution Score: Evaluating Training Data Influence in Diffusion Model
Authors:Jinxu Lin, Linwei Tao, Minjing Dong, Chang Xu
As diffusion models become increasingly popular, the misuse of copyrighted and private images has emerged as a major concern. One promising solution to mitigate this issue is identifying the contribution of specific training samples in generative models, a process known as data attribution. Existing data attribution methods for diffusion models typically quantify the contribution of a training sample by evaluating the change in diffusion loss when the sample is included or excluded from the training process. However, we argue that the direct usage of diffusion loss cannot represent such a contribution accurately due to the calculation of diffusion loss. Specifically, these approaches measure the divergence between predicted and ground truth distributions, which leads to an indirect comparison between the predicted distributions and cannot represent the variances between model behaviors. To address these issues, we aim to measure the direct comparison between predicted distributions with an attribution score to analyse the training sample importance, which is achieved by Diffusion Attribution Score (\textit{DAS}). Underpinned by rigorous theoretical analysis, we elucidate the effectiveness of DAS. Additionally, we explore strategies to accelerate DAS calculations, facilitating its application to large-scale diffusion models. Our extensive experiments across various datasets and diffusion models demonstrate that DAS significantly surpasses previous benchmarks in terms of the linear data-modelling score, establishing new state-of-the-art performance. Code is available at \hyperlink{here}{https://github.com/Jinxu-Lin/DAS}.
随着扩散模型越来越受欢迎,对版权和私人图像的滥用已成为一个主要的问题。为了缓解这个问题,一个可行的解决方案是识别生成模型中特定训练样本的贡献,这一过程被称为数据归因。现有的扩散模型数据归因方法通常通过评估训练过程中包含或排除训练样本时的扩散损失变化来量化训练样本的贡献。然而,我们认为直接使用扩散损失不能准确地表示这种贡献,因为扩散损失的计算方式存在问题。具体来说,这些方法测量预测分布和真实分布之间的差异,这导致预测分布之间的间接比较,并不能代表模型行为之间的差异。为了解决这些问题,我们旨在通过归因分数来测量预测分布之间的直接比较,以分析训练样本的重要性,这是通过扩散归因分数(DAS)实现的。基于严谨的理论分析,我们阐明了DAS的有效性。此外,我们探索了加速DAS计算的策略,促进其在大规模扩散模型中的应用。我们在各种数据集和扩散模型上进行的广泛实验表明,DAS在线性数据建模分数方面显著超过了以前的基准测试,取得了最新的最佳性能。代码可在https://github.com/Jinxu-Lin/DAS处获取。
论文及项目相关链接
Summary
随着扩散模型的普及,版权和私人图像的错误使用成为主要关注点。为解决这一问题,人们提出了一种新的方法——数据归属,旨在确定训练样本在生成模型中的贡献。现有方法通过评估包含或排除训练样本时的扩散损失变化来衡量其贡献。然而,我们主张直接使用扩散损失无法准确反映贡献,并提出了一种新的方法——扩散归属分数(DAS),通过测量预测分布之间的直接比较来分析训练样本的重要性。DAS不仅受到严谨的理论分析支持,而且我们还探索了加速DAS计算的方法,使其能够应用于大规模扩散模型。实验表明,DAS在线性数据建模分数上显著超越了之前的基准测试,并达到了新的最先进的性能。
Key Takeaways
- 扩散模型普及带来版权和私人图像误用问题。
- 数据归属是确定训练样本在生成模型中贡献的解决方法。
- 现有方法通过评估扩散损失变化来衡量训练样本的贡献。
- 直接使用扩散损失无法准确反映贡献,因为预测分布与真实分布之间的偏差无法代表模型行为的差异。
- 提出新的方法——扩散归属分数(DAS),通过测量预测分布之间的直接比较来分析训练样本的重要性。
- DAS受到严谨的理论分析支持,并探索了加速计算的方法,适用于大规模扩散模型。
- 实验证明,DAS在线性数据建模分数上显著超越先前方法,达到新的最先进的性能。
点此查看论文截图

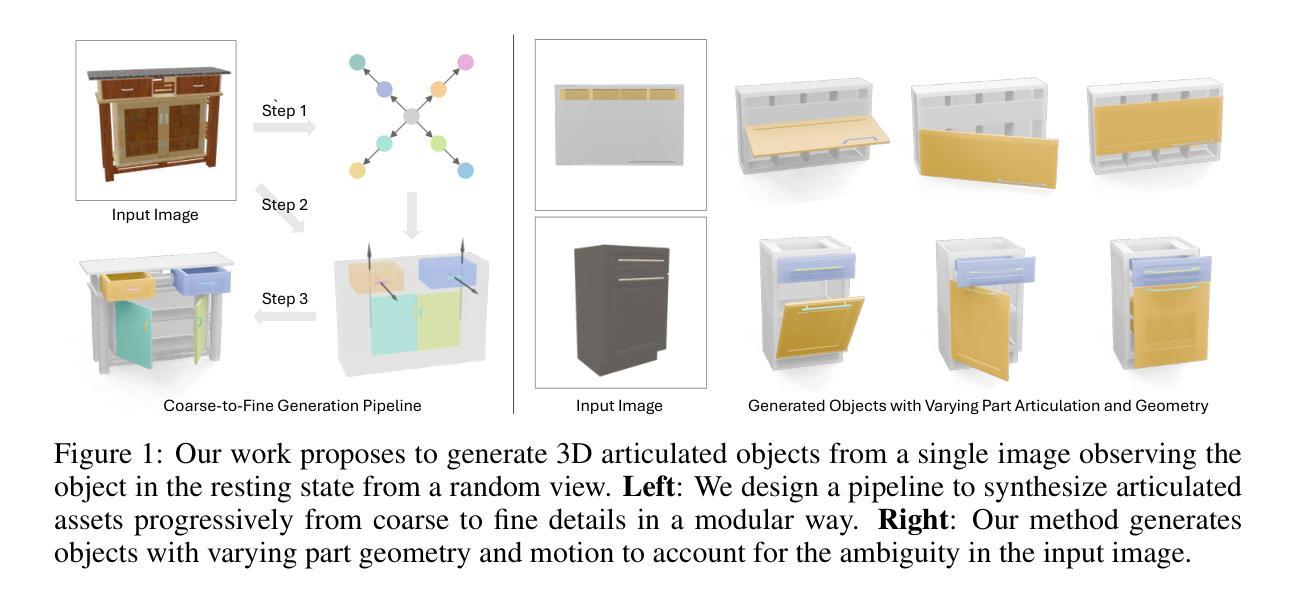
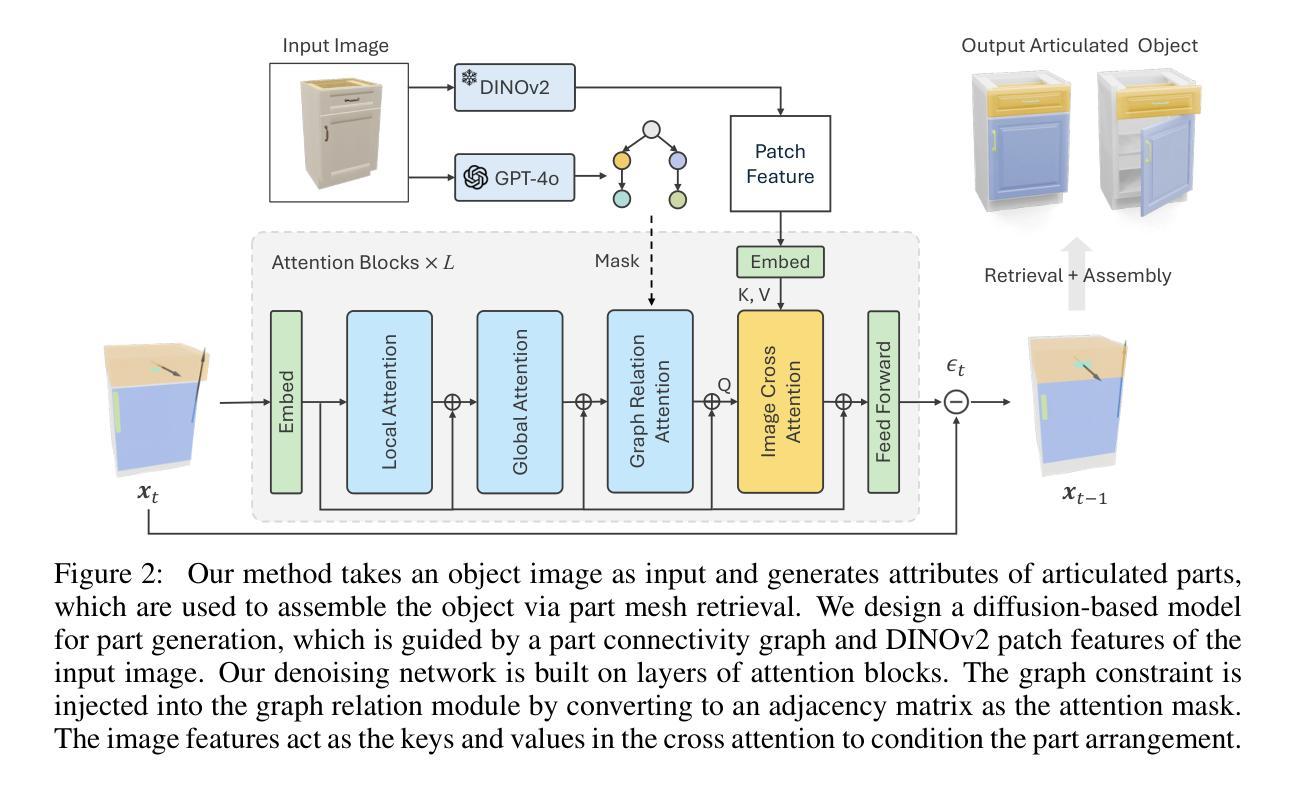
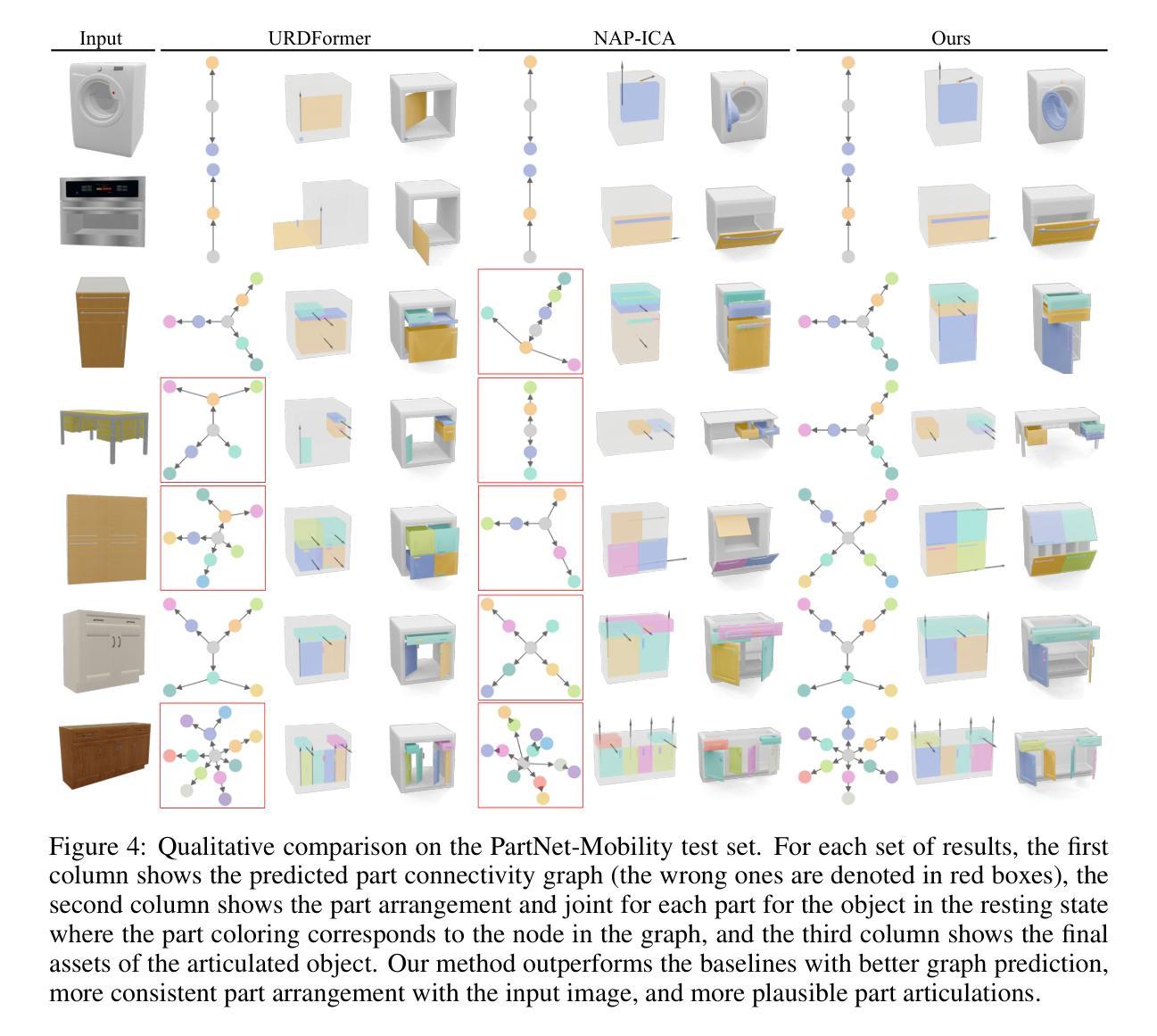
SINGAPO: Single Image Controlled Generation of Articulated Parts in Objects
Authors:Jiayi Liu, Denys Iliash, Angel X. Chang, Manolis Savva, Ali Mahdavi-Amiri
We address the challenge of creating 3D assets for household articulated objects from a single image. Prior work on articulated object creation either requires multi-view multi-state input, or only allows coarse control over the generation process. These limitations hinder the scalability and practicality for articulated object modeling. In this work, we propose a method to generate articulated objects from a single image. Observing the object in resting state from an arbitrary view, our method generates an articulated object that is visually consistent with the input image. To capture the ambiguity in part shape and motion posed by a single view of the object, we design a diffusion model that learns the plausible variations of objects in terms of geometry and kinematics. To tackle the complexity of generating structured data with attributes in multiple domains, we design a pipeline that produces articulated objects from high-level structure to geometric details in a coarse-to-fine manner, where we use a part connectivity graph and part abstraction as proxies. Our experiments show that our method outperforms the state-of-the-art in articulated object creation by a large margin in terms of the generated object realism, resemblance to the input image, and reconstruction quality.
我们应对了从单一图像为家庭关节式物体创建3D资产所面临的挑战。先前关于关节式物体创建的工作要么需要多视角多状态输入,要么只能对生成过程进行粗略控制。这些限制阻碍了关节式物体建模的可扩展性和实用性。在这项工作中,我们提出了一种从单一图像生成关节式物体的方法。从任意视角观察物体处于静止状态,我们的方法生成一个与输入图像视觉上一致的关节式物体。为了捕捉由物体的单一视图引起的部分形状和运动的不确定性,我们设计了一个扩散模型,该模型可以学习物体在几何和动力学方面的合理变化。为了解决生成具有多个领域属性的结构化数据的复杂性,我们设计了一个管道,以从高级结构到几何细节的方式,以由粗到细的方式生成关节式物体,其中我们使用部件连接图和部件抽象作为代理。我们的实验表明,我们的方法在生成物体的逼真性、与输入图像的相似性以及重建质量方面大大超越了当前关节式物体创建的最先进水平。
论文及项目相关链接
PDF Project page: https://3dlg-hcvc.github.io/singapo
Summary
本文解决从单一图像创建3D家庭关节对象的挑战。提出一种方法,仅需观察物体的静止状态即可生成关节对象,与输入图像视觉一致。设计扩散模型,学习对象在几何和动力学方面的合理变化,解决单一视图物体部分形状和运动模糊的问题。采用从高级结构到几何细节的粗到细管道生成关节对象,使用部分连接图和部分抽象作为代理。实验表明,该方法在创建关节对象的真实性、对输入图像的相似性以及重建质量方面大幅超越了现有技术。
Key Takeaways
- 解决了从单一图像创建3D家庭关节对象的挑战。
- 提出一种方法,仅通过观察物体的静止状态即可生成关节对象。
- 设计的扩散模型能学习对象在几何和动力学方面的合理变化。
- 解决单一视图下物体部分形状和运动的模糊性问题。
- 采用从高级结构到几何细节的粗到细管道生成对象。
- 使用部分连接图和部分抽象作为生成过程中的代理。
点此查看论文截图

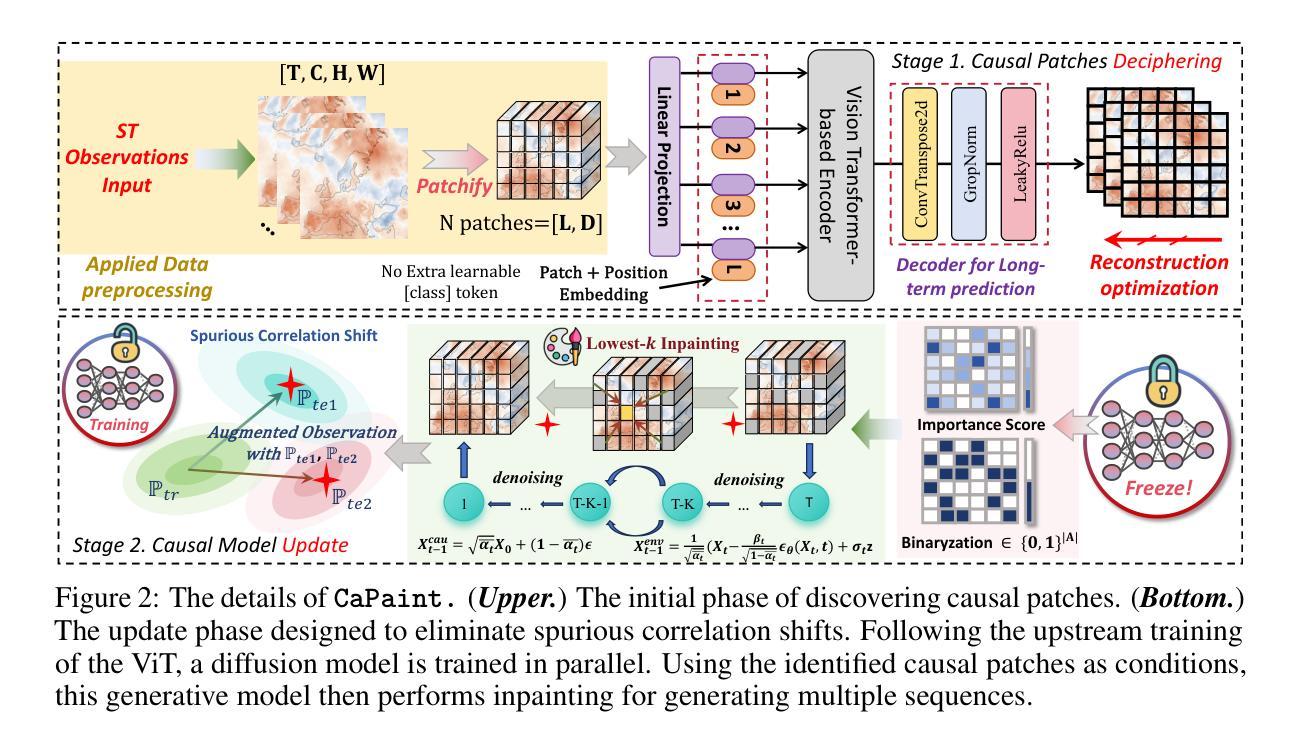
Causal Deciphering and Inpainting in Spatio-Temporal Dynamics via Diffusion Model
Authors:Yifan Duan, Jian Zhao, pengcheng, Junyuan Mao, Hao Wu, Jingyu Xu, Shilong Wang, Caoyuan Ma, Kai Wang, Kun Wang, Xuelong Li
Spatio-temporal (ST) prediction has garnered a De facto attention in earth sciences, such as meteorological prediction, human mobility perception. However, the scarcity of data coupled with the high expenses involved in sensor deployment results in notable data imbalances. Furthermore, models that are excessively customized and devoid of causal connections further undermine the generalizability and interpretability. To this end, we establish a causal framework for ST predictions, termed CaPaint, which targets to identify causal regions in data and endow model with causal reasoning ability in a two-stage process. Going beyond this process, we utilize the back-door adjustment to specifically address the sub-regions identified as non-causal in the upstream phase. Specifically, we employ a novel image inpainting technique. By using a fine-tuned unconditional Diffusion Probabilistic Model (DDPM) as the generative prior, we in-fill the masks defined as environmental parts, offering the possibility of reliable extrapolation for potential data distributions. CaPaint overcomes the high complexity dilemma of optimal ST causal discovery models by reducing the data generation complexity from exponential to quasi-linear levels. Extensive experiments conducted on five real-world ST benchmarks demonstrate that integrating the CaPaint concept allows models to achieve improvements ranging from 4.3% to 77.3%. Moreover, compared to traditional mainstream ST augmenters, CaPaint underscores the potential of diffusion models in ST enhancement, offering a novel paradigm for this field. Our project is available at https://anonymous.4open.science/r/12345-DFCC.
时空预测在地球科学领域,如气象预测和人类移动感知中,已经得到了广泛的关注。然而,数据的稀缺性以及传感器部署的高成本导致了数据不平衡的显著问题。此外,过度定制且缺乏因果联系的模型进一步削弱了其通用性和可解释性。为了解决这个问题,我们建立了时空预测的因果框架,称为CaPaint。该框架旨在识别数据中的因果区域,并通过两阶段过程赋予模型因果推理能力。除此之外,我们利用后门调整来专门解决上游阶段识别为非因果的子区域。具体来说,我们采用了一种新颖的图像修复技术。通过使用微调的无条件扩散概率模型(DDPM)作为生成先验,我们填充了定义为环境部分的掩膜,为潜在数据分布提供了可靠外推的可能性。CaPaint通过将数据生成复杂性从指数级别降低到准线性级别,克服了最优时空因果发现模型的高复杂性困境。在五个真实世界的时空基准测试集上进行的广泛实验表明,融入CaPaint概念后,模型的改进范围从4.3%到77.3%。此外,与传统的主流时空增强器相比,CaPaint突显了扩散模型在时空增强方面的潜力,为这一领域提供了新的范式。我们的项目可在https://anonymous.4open.science/r/12345-DFCC上找到。
论文及项目相关链接
摘要
数据在时空预测中发挥着重要作用,但其稀缺性和高昂的传感器部署成本导致了显著的数据不平衡。为了解决这个问题,本研究提出了一种因果时空预测框架CaPaint,旨在识别数据中的因果区域,赋予模型因果推理能力。通过利用反向调整法解决上游阶段识别的非因果子区域问题,并采用新型图像填充技术。结合微调的无条件扩散概率模型(DDPM),对定义为环境部分的掩码进行填充,为潜在数据分布提供可靠的预测可能性。CaPaint将最优时空因果发现模型的高复杂度问题从指数级别降低到准线性级别。在五个真实世界的时空基准测试上的实验表明,融入CaPaint概念使得模型改进范围从4.3%至77.3%。对比传统主流时空增强器,CaPaint突显了扩散模型在时空增强的潜力,为这一领域提供了新的视角。
关键见解
- 时空预测在地球科学领域受到重视,如气象预测和人为移动感知,但数据稀缺和不平衡是重大挑战。
- 提出名为CaPaint的因果框架,旨在解决时空预测的因果问题,包括识别因果区域并为模型赋予因果推理能力。
- 利用反向调整法处理上游阶段识别的非因果子区域,并采用新颖的图像填充技术来提高预测准确性。
- 结合微调的无条件扩散概率模型(DDPM)作为生成先验,对定义为环境部分的掩码进行填充,实现可靠的数据分布外推。
- CaPaint成功降低最优时空因果发现模型的数据生成复杂度。
- 在多个真实世界基准测试上,融入CaPaint的模型表现出显著改进,改进范围广泛。
- 对比其他主流时空增强技术,CaPaint凸显扩散模型在时空增强中的潜力,为相关领域提供新的视角和研究路径。
点此查看论文截图


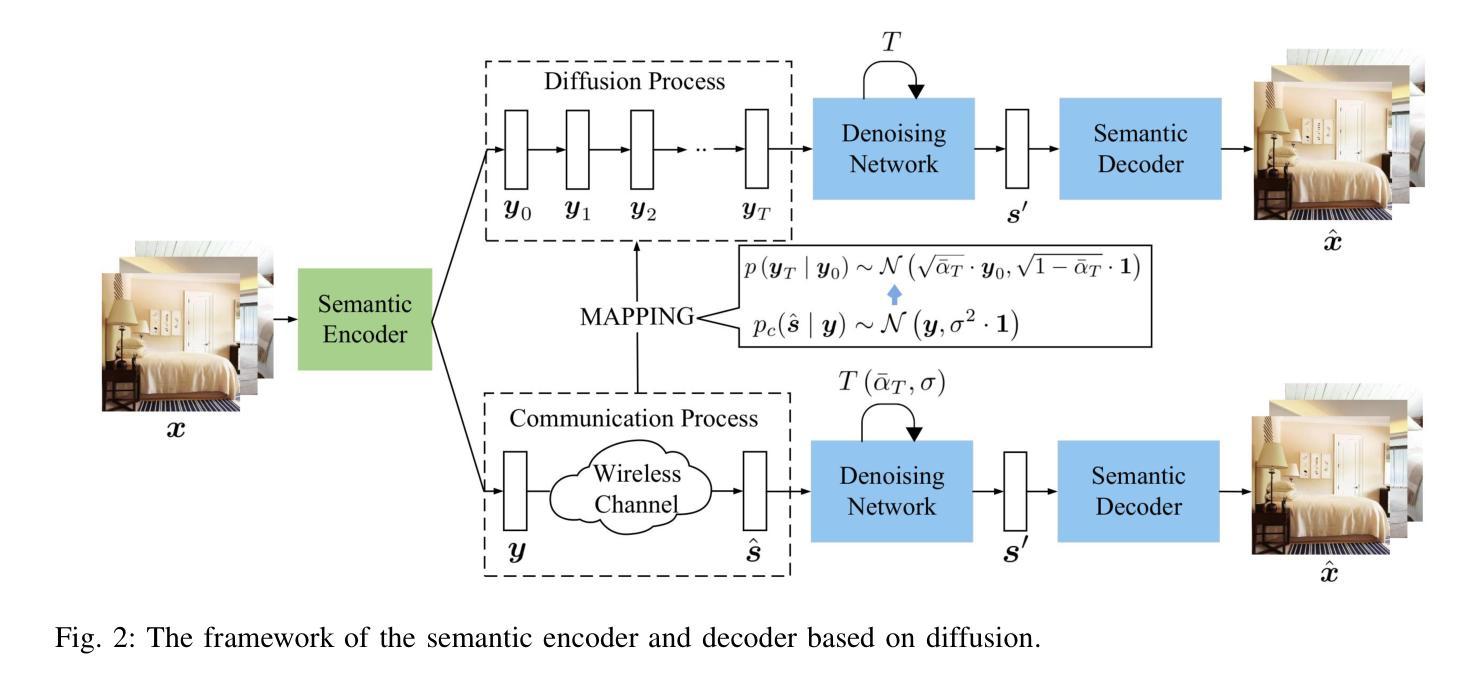
Diffusion-Driven Semantic Communication for Generative Models with Bandwidth Constraints
Authors:Lei Guo, Wei Chen, Yuxuan Sun, Bo Ai, Nikolaos Pappas, Tony Quek
Diffusion models have been extensively utilized in AI-generated content (AIGC) in recent years, thanks to the superior generation capabilities. Combining with semantic communications, diffusion models are used for tasks such as denoising, data reconstruction, and content generation. However, existing diffusion-based generative models do not consider the stringent bandwidth limitation, which limits its application in wireless communication. This paper introduces a diffusion-driven semantic communication framework with advanced VAE-based compression for bandwidth-constrained generative model. Our designed architecture utilizes the diffusion model, where the signal transmission process through the wireless channel acts as the forward process in diffusion. To reduce bandwidth requirements, we incorporate a downsampling module and a paired upsampling module based on a variational auto-encoder with reparameterization at the receiver to ensure that the recovered features conform to the Gaussian distribution. Furthermore, we derive the loss function for our proposed system and evaluate its performance through comprehensive experiments. Our experimental results demonstrate significant improvements in pixel-level metrics such as peak signal to noise ratio (PSNR) and semantic metrics like learned perceptual image patch similarity (LPIPS). These enhancements are more profound regarding the compression rates and SNR compared to deep joint source-channel coding (DJSCC).
扩散模型由于其出色的生成能力,近年来在人工智能生成内容(AIGC)中得到了广泛应用。结合语义通信,扩散模型被用于去噪、数据重建和内容生成等任务。然而,现有的基于扩散的生成模型并没有考虑到严格的带宽限制,这限制了其在无线通信中的应用。本文介绍了一个扩散驱动的语义通信框架,该框架具有先进的VAE(变分自编码器)压缩技术,适用于带宽受限的生成模型。我们设计的架构利用扩散模型,其中通过无线信道传输信号的过程充当扩散的前向过程。为了减少带宽要求,我们融入了下采样模块和基于变分自编码器的配对上采样模块,并在接收器进行重参数化,以确保恢复的特征符合高斯分布。此外,我们推导了所提系统的损失函数,并通过全面的实验评估了其性能。实验结果在像素级的峰值信噪比(PSNR)和语义级的感知图像块相似性(LPIPS)等指标上取得了显著的提升。相较于深度联合源信道编码(DJSCC),我们的方法在压缩率和信噪比方面表现出了更为显著的改进。
论文及项目相关链接
PDF accepted to IEEE for possible publication
Summary
本文提出了一个基于扩散模型的语义通信框架,利用变分自编码器(VAE)进行压缩,以应对带宽限制下的生成模型应用问题。该框架将无线信道中的信号传输过程视为扩散的正向过程,通过加入下采样模块和上采样模块来降低带宽要求,并在接收器端进行重参数化,确保恢复的特征符合高斯分布。实验结果显示,该框架在像素级和语义级指标上均有显著改进。
Key Takeaways
- 扩散模型在AI生成内容(AIGC)中广泛应用,用于降噪、数据重建和内容生成等任务。
- 现有扩散生成模型未考虑严格的带宽限制,限制了其在无线通信中的应用。
- 本文提出了一个基于扩散模型的语义通信框架,以解决带宽限制问题。
- 框架利用变分自编码器(VAE)进行压缩,并加入下采样和上采样模块以降低带宽要求。
- 框架将无线信道中的信号传输过程视为扩散的正向过程。
- 接收器端进行重参数化,确保恢复的特征符合高斯分布。
点此查看论文截图