⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
Generalized Few-shot 3D Point Cloud Segmentation with Vision-Language Model
Authors:Zhaochong An, Guolei Sun, Yun Liu, Runjia Li, Junlin Han, Ender Konukoglu, Serge Belongie
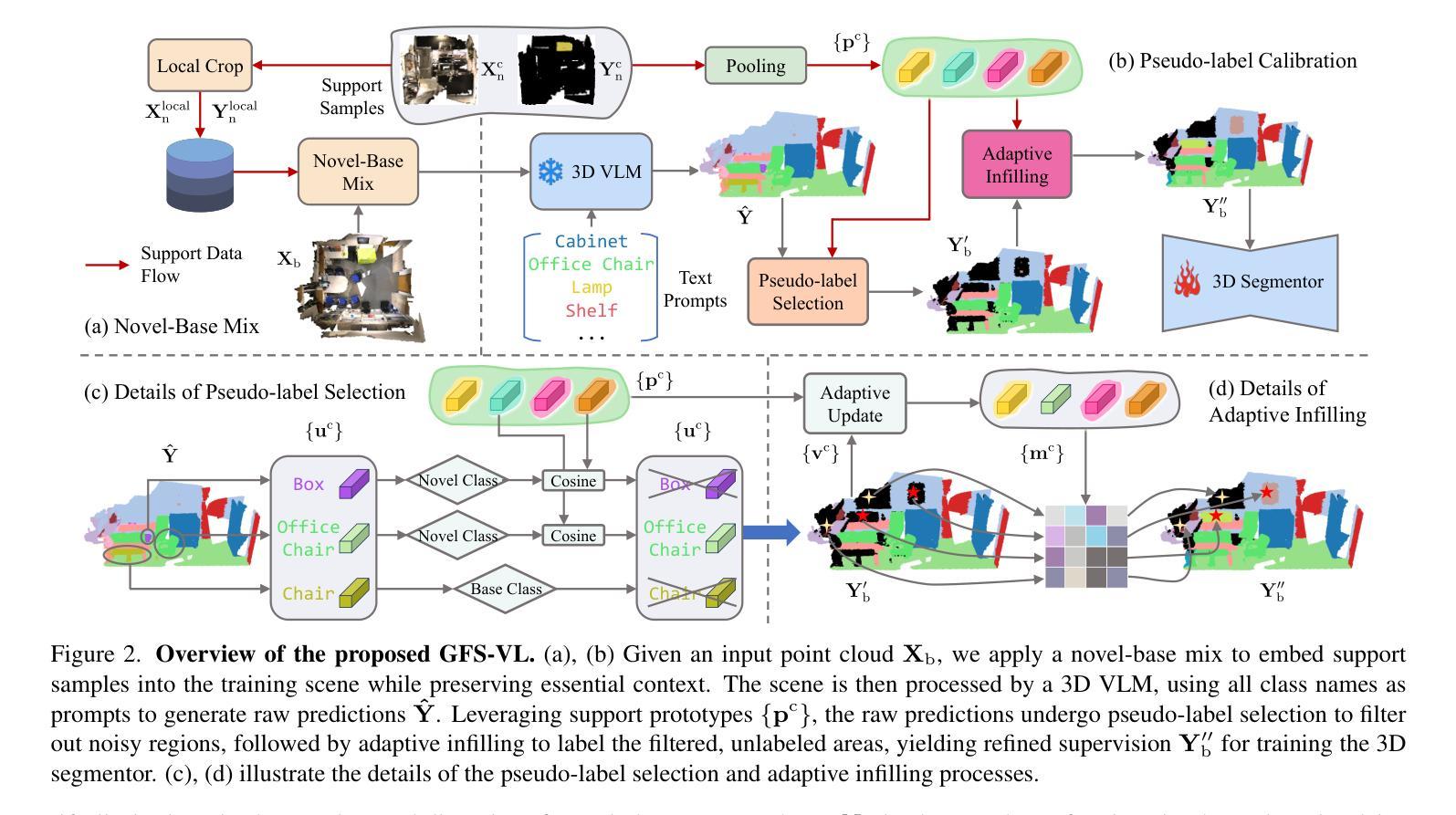
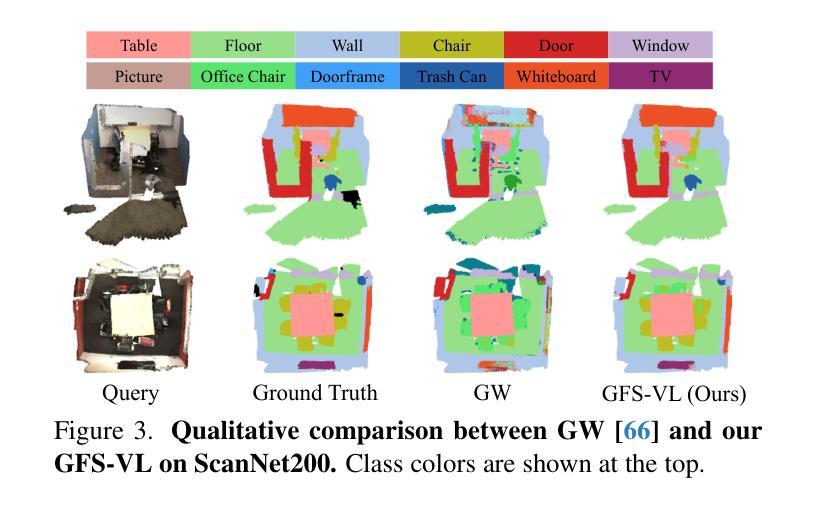
Generalized few-shot 3D point cloud segmentation (GFS-PCS) adapts models to new classes with few support samples while retaining base class segmentation. Existing GFS-PCS methods enhance prototypes via interacting with support or query features but remain limited by sparse knowledge from few-shot samples. Meanwhile, 3D vision-language models (3D VLMs), generalizing across open-world novel classes, contain rich but noisy novel class knowledge. In this work, we introduce a GFS-PCS framework that synergizes dense but noisy pseudo-labels from 3D VLMs with precise yet sparse few-shot samples to maximize the strengths of both, named GFS-VL. Specifically, we present a prototype-guided pseudo-label selection to filter low-quality regions, followed by an adaptive infilling strategy that combines knowledge from pseudo-label contexts and few-shot samples to adaptively label the filtered, unlabeled areas. Additionally, we design a novel-base mix strategy to embed few-shot samples into training scenes, preserving essential context for improved novel class learning. Moreover, recognizing the limited diversity in current GFS-PCS benchmarks, we introduce two challenging benchmarks with diverse novel classes for comprehensive generalization evaluation. Experiments validate the effectiveness of our framework across models and datasets. Our approach and benchmarks provide a solid foundation for advancing GFS-PCS in the real world. The code is at https://github.com/ZhaochongAn/GFS-VL
广义少样本3D点云分割(GFS-PCS)能够在保留基础类别分割的同时,适应新的类别并具有少量的支撑样本。现有的GFS-PCS方法通过与支持或查询特征进行交互来增强原型,但仍受到少量样本稀疏知识的限制。同时,3D视觉语言模型(3D VLMs)在开放世界的新类别中具有丰富的但带有噪声的新类别知识。在这项工作中,我们引入了一个GFS-PCS框架,该框架协同利用来自3D VLMs的密集但带有噪声的伪标签和精确的但稀疏的少量样本,以最大限度地发挥两者的优势,称为GFS-VL。具体来说,我们提出了一种原型引导伪标签选择方法,用于过滤低质量区域,随后是一种自适应填充策略,该策略结合了伪标签上下文和少量样本的知识,对过滤后的未标记区域进行自适应标记。此外,我们设计了一种新型基础混合策略,将少量样本嵌入到训练场景中,保留重要上下文,以改进新类别的学习。此外,我们认识到当前GFS-PCS基准测试多样性的局限性,因此我们引入了两个具有多样新类别的挑战基准测试,以进行全面的泛化评估。实验验证了我们的框架在不同模型和数据集上的有效性。我们的方法和基准测试为推进GFS-PCS在现实世界的应用提供了坚实的基础。代码地址为:https://github.com/ZhaochongAn/GFS-VL
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文介绍了结合3D视觉语言模型(3D VLMs)与广义少样本3D点云分割(GFS-PCS)的新框架GFS-VL。该框架利用丰富的伪标签和精确的少样本数据,通过原型引导伪标签选择和自适应填充策略进行训练,提高了模型的泛化能力。此外,文章还引入了两个挑战性的基准测试集,用于全面的泛化评估。实验验证了该框架在不同模型和数据集上的有效性。
Key Takeaways
- GFS-VL结合丰富的伪标签与精确少数样本,优化了现有的广义少样本点云分割(GFS-PCS)。
- 利用原型引导伪标签选择方法筛选低质量区域,结合自适应填充策略填充并标注筛选出的未标记区域。
- 创新性地引入了一种新的基于混合策略将少数样本嵌入训练场景的方法,增强了重要上下文信息。同时增强泛化能力。
点此查看论文截图

CLS-RL: Image Classification with Rule-Based Reinforcement Learning
Authors:Ming Li, Shitian Zhao, Jike Zhong, Yuxiang Lai, Kaipeng Zhang
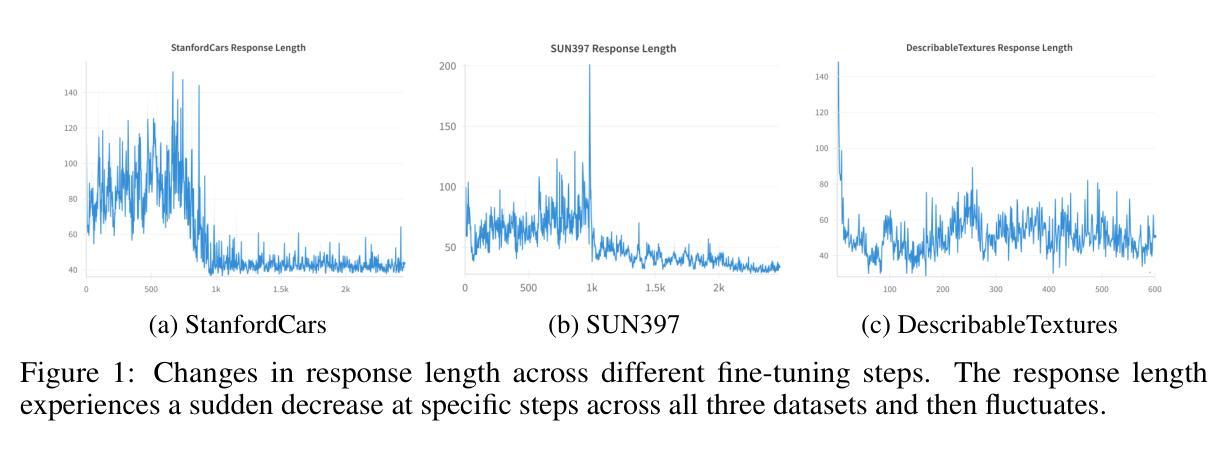
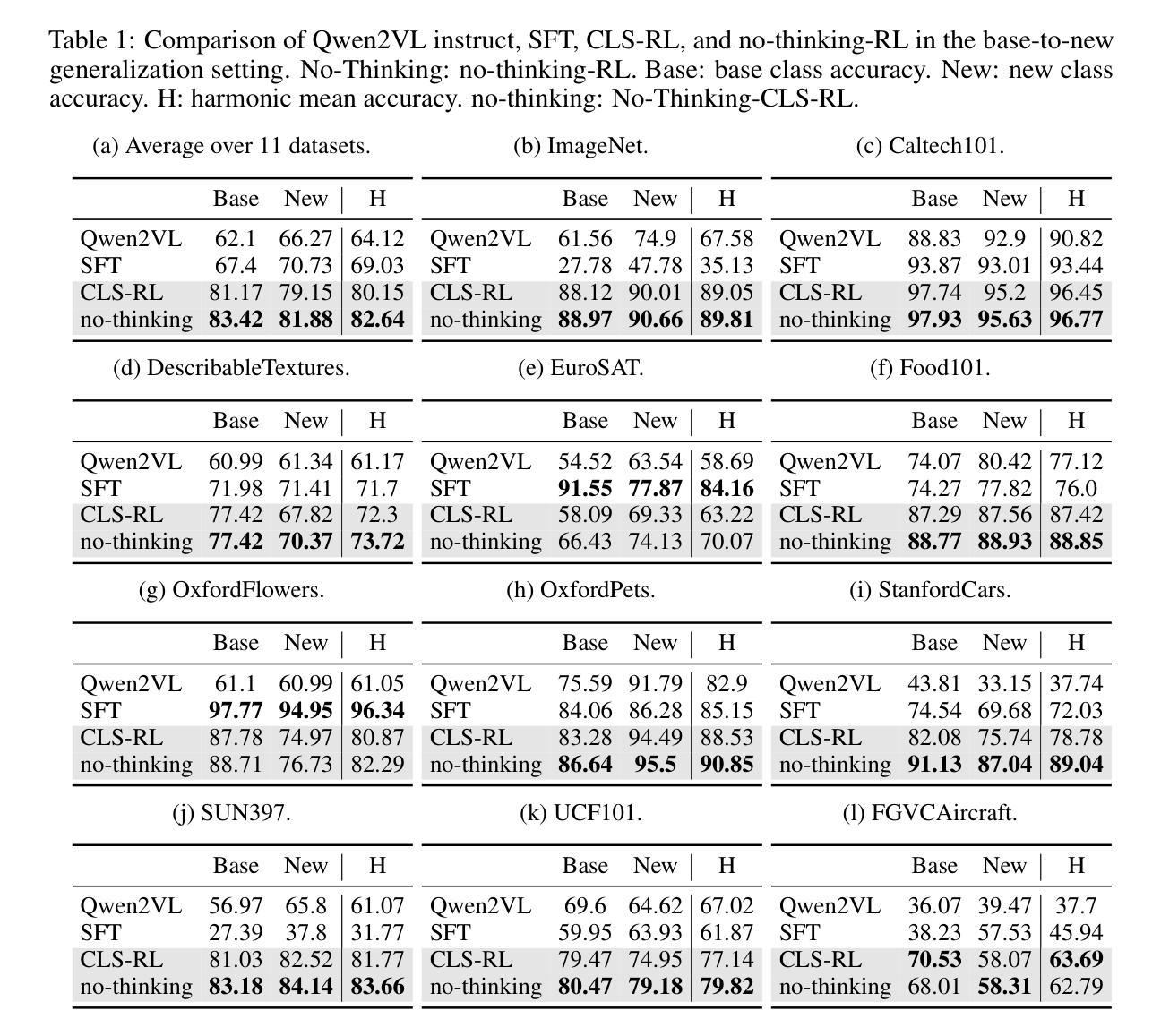
Classification is a core task in machine learning. Recent research has shown that although Multimodal Large Language Models (MLLMs) are initially poor at image classification, fine-tuning them with an adequate amount of data can significantly enhance their performance, making them comparable to SOTA classification models. However, acquiring large-scale labeled data is expensive. In this paper, we explore few-shot MLLM classification fine-tuning. We found that SFT can cause severe overfitting issues and may even degrade performance over the zero-shot approach. To address this challenge, inspired by the recent successes in rule-based reinforcement learning, we propose CLS-RL, which uses verifiable signals as reward to fine-tune MLLMs. We discovered that CLS-RL outperforms SFT in most datasets and has a much higher average accuracy on both base-to-new and few-shot learning setting. Moreover, we observed a free-lunch phenomenon for CLS-RL; when models are fine-tuned on a particular dataset, their performance on other distinct datasets may also improve over zero-shot models, even if those datasets differ in distribution and class names. This suggests that RL-based methods effectively teach models the fundamentals of classification. Lastly, inspired by recent works in inference time thinking, we re-examine the `thinking process’ during fine-tuning, a critical aspect of RL-based methods, in the context of visual classification. We question whether such tasks require extensive thinking process during fine-tuning, proposing that this may actually detract from performance. Based on this premise, we introduce the No-Thinking-CLS-RL method, which minimizes thinking processes during training by setting an equality accuracy reward. Our findings indicate that, with much less fine-tuning time, No-Thinking-CLS-RL method achieves superior in-domain performance and generalization capabilities than CLS-RL.
分类是机器学习中的核心任务之一。最近的研究表明,尽管多模态大型语言模型(MLLMs)最初在图像分类方面表现不佳,但通过足够的数据进行微调可以显著提高它们的性能,使其与最先进的分类模型相媲美。然而,获取大规模标记数据成本高昂。在本文中,我们探讨了基于少量数据的MLLM分类微调技术。我们发现,标准微调(SFT)可能会导致严重的过拟合问题,并且可能在零样本方法上的性能表现更差。为了应对这一挑战,我们受到基于规则的强化学习近期成功的启发,提出了CLS-RL方法,该方法使用可验证的信号作为奖励来微调MLLMs。我们发现CLS-RL在大多数数据集上的表现优于标准微调,并且在基础到新的数据集和小样本学习环境中具有更高的平均准确率。此外,我们观察到CLS-RL存在一个免费午餐现象;当模型在特定数据集上进行微调时,它们在其他不同数据集上的性能可能会超过零样本模型,即使这些数据集在分布和类别名称上有所不同。这表明基于RL的方法有效地教授了模型分类的基本原理。最后,受到最近推理时间思考研究工作的启发,我们重新审视了基于RL的方法中微调过程的“思考过程”,这是在视觉分类背景下关键的一个方面。我们质疑这样的任务是否需要大量的思考过程来进行微调,并提出这实际上可能会降低性能。基于这一前提,我们引入了无思考CLS-RL方法,通过设置相等的准确率奖励来减少训练过程中的思考过程。我们的研究结果表明,在较少的微调时间内,无思考CLS-RL方法在域内性能和泛化能力方面优于CLS-RL。
论文及项目相关链接
PDF Preprint, work in progress
Summary
本文探索了基于强化学习的多模态大型语言模型(MLLMs)在图像分类任务中的微调策略。研究结果表明,传统基于数据的微调(SFT)方法可能会导致过拟合问题,并且可能影响零样本方法的表现。针对这一问题,本文提出了基于可验证信号的奖励微调策略CLS-RL,该方法在多数据集上表现出优异的性能,特别是在基础到新的数据集和少样本学习环境中。此外,还观察到一个现象:当模型在特定数据集上微调时,其在其他不同数据集上的表现也可能超过零样本模型。受近期推理时间思考研究启发,本文重新审视了微调过程中的思考过程,并引入了无思考过程的CLS-RL方法,该方法通过设定准确性奖励来减少训练过程中的思考过程,实现了优越的领域内性能和泛化能力。
Key Takeaways
- 多模态大型语言模型(MLLMs)在图像分类任务中虽然初表现不佳,但通过数据微调可以显著提高性能。
- 传统微调方法可能导致过拟合问题,并影响零样本方法的表现。
- CLS-RL策略使用可验证信号作为奖励进行微调,在多数数据集上表现出优异性能。
- CLS-RL策略在提高特定数据集性能的同时,也能提升其他不同数据集的表现,显示其泛化能力。
- 受推理时间思考研究启发,重新审视了微调过程中的思考过程。
- 引入无思考过程的CLS-RL方法,通过设定准确性奖励减少训练思考过程。
点此查看论文截图

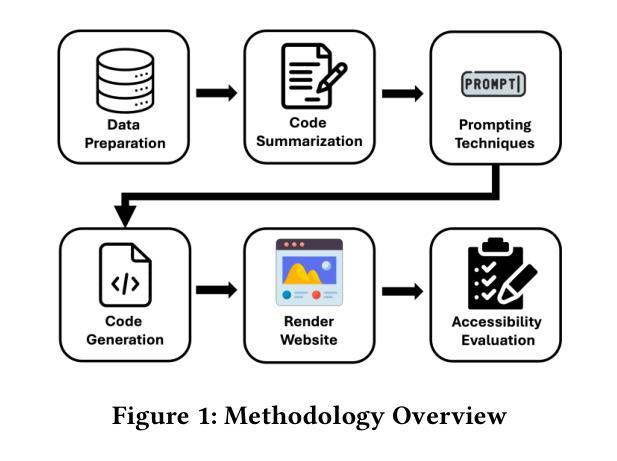
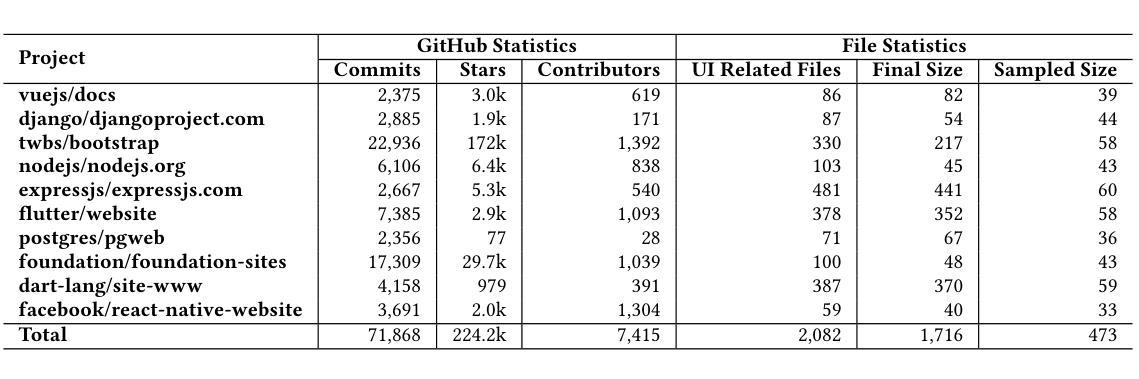
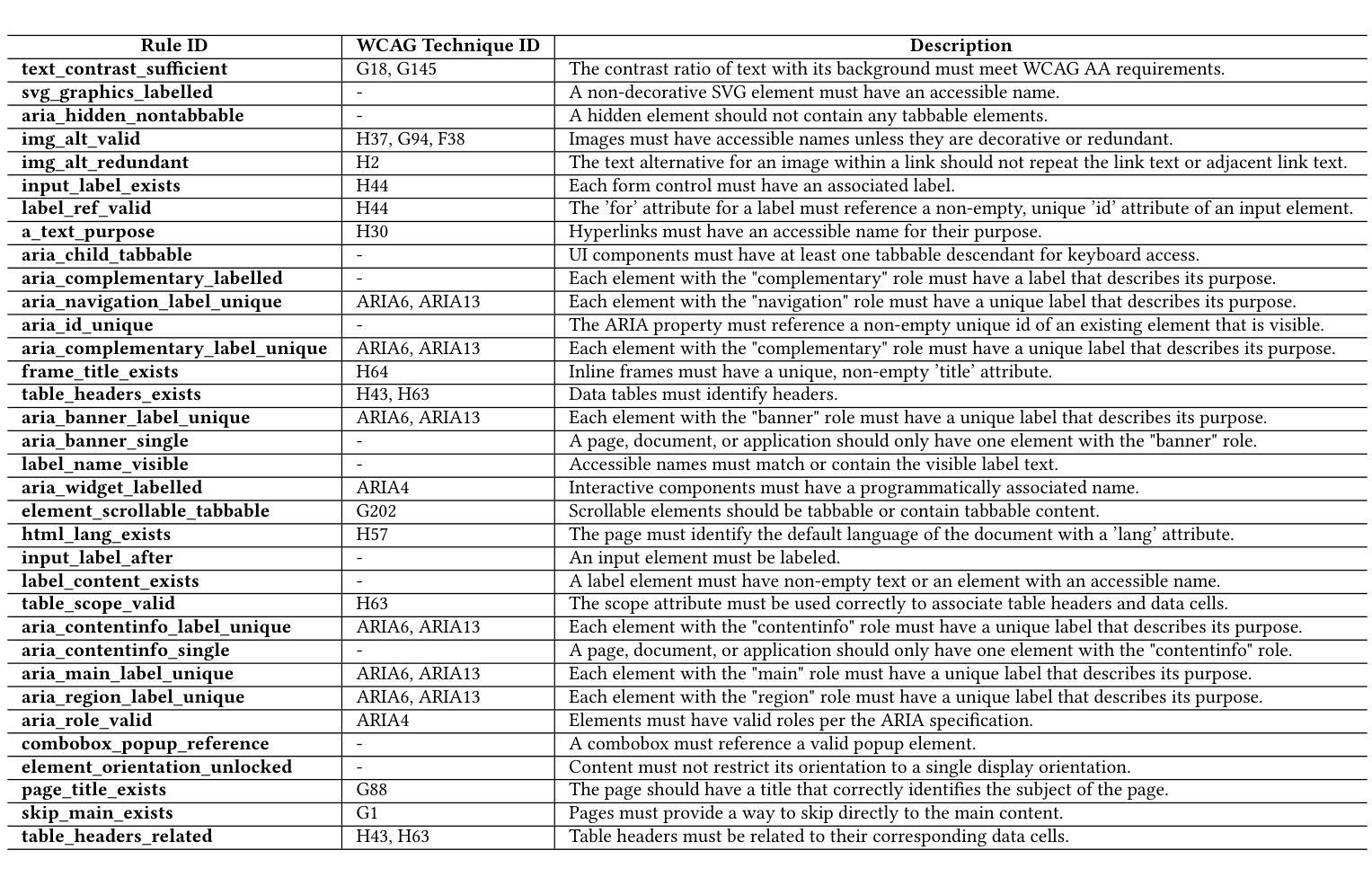
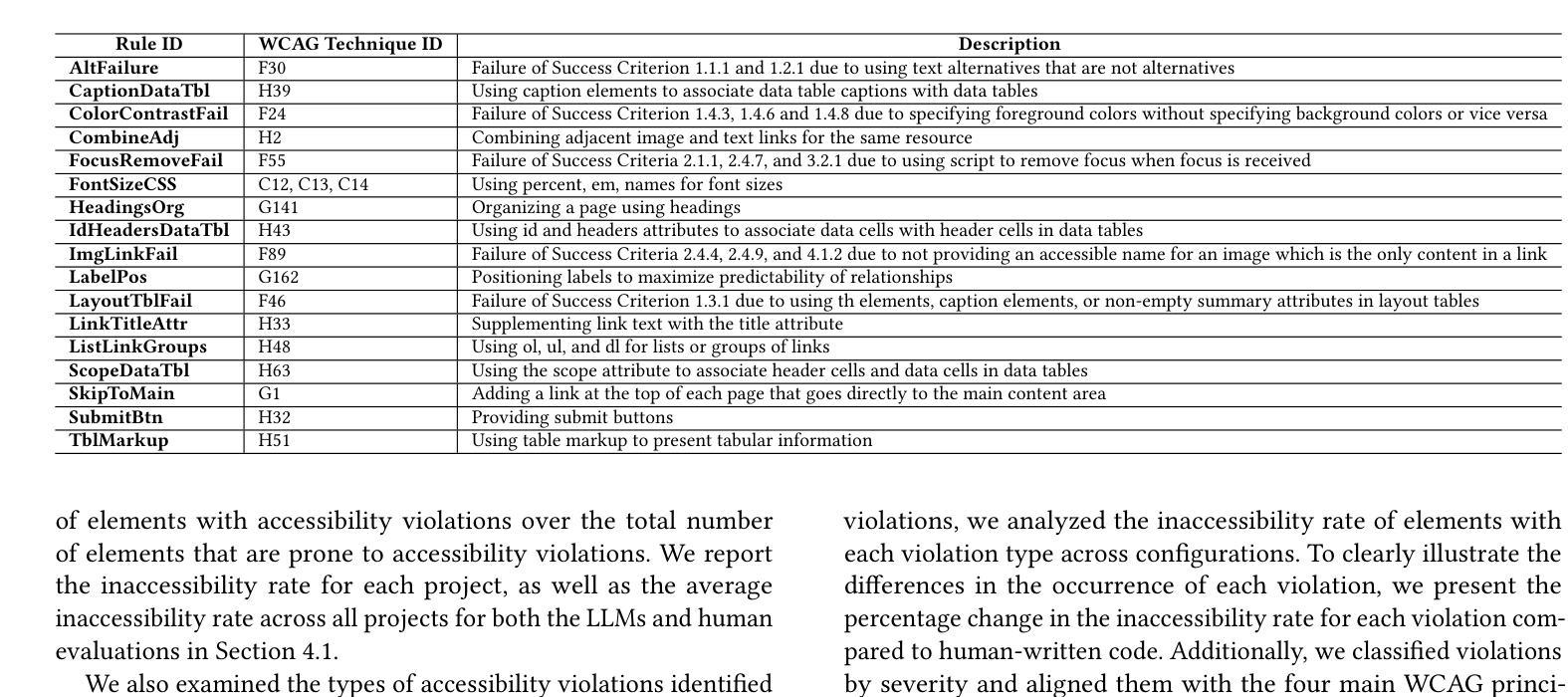
Human or LLM? A Comparative Study on Accessible Code Generation Capability
Authors:Hyunjae Suh, Mahan Tafreshipour, Sam Malek, Iftekhar Ahmed
Web accessibility is essential for inclusive digital experiences, yet the accessibility of LLM-generated code remains underexplored. This paper presents an empirical study comparing the accessibility of web code generated by GPT-4o and Qwen2.5-Coder-32B-Instruct-AWQ against human-written code. Results show that LLMs often produce more accessible code, especially for basic features like color contrast and alternative text, but struggle with complex issues such as ARIA attributes. We also assess advanced prompting strategies (Zero-Shot, Few-Shot, Self-Criticism), finding they offer some gains but are limited. To address these gaps, we introduce FeedA11y, a feedback-driven ReAct-based approach that significantly outperforms other methods in improving accessibility. Our work highlights the promise of LLMs for accessible code generation and emphasizes the need for feedback-based techniques to address persistent challenges.
Web可及性对于包容性数字体验至关重要,然而关于大型语言模型(LLM)生成的代码的可及性仍然缺乏深入研究。本文通过实证研究对比了GPT-4o和Qwen2.5-Coder-32B-Instruct-AWQ生成的网页代码与人类编写的代码的可及性。结果表明,LLMs生成的代码通常更具可及性,特别是在颜色对比度和替代文本等基本功能方面,但在处理ARIA属性等复杂问题上存在困难。我们还评估了高级提示策略(零样本、小样本、自我批评),发现它们虽然可以提供一些帮助,但仍有局限性。为了弥补这些差距,我们引入了FeedA11y,这是一种基于反馈的ReAct方法,在改进可及性方面显著优于其他方法。我们的工作突出了LLMs在生成可访问代码方面的潜力,并强调了基于反馈的技术在解决持续挑战方面的必要性。
论文及项目相关链接
Summary
本文研究了LLM生成的网页代码的可访问性,并与人类编写的代码进行了比较。研究发现,LLM生成的代码在基本功能方面更具可访问性,但在复杂问题上存在缺陷。同时,评估了先进的提示策略,发现它们虽然有所助益但仍有局限。为解决这些问题,本文提出了FeedA11y方法,该方法基于反馈和React,显著提高了代码的可访问性。
Key Takeaways
- LLM生成的代码在基本功能方面更具可访问性。
- LLM在处理复杂的可访问性问题(如ARIA属性)时存在困难。
- 先进的提示策略(如Zero-Shot、Few-Shot、Self-Criticism)对于提高LLM的代码生成能力有一定帮助,但仍有局限。
- 反馈驱动的方法(如FeedA11y)能显著提高LLM生成代码的可访问性。
- LLM在生成可访问的代码方面具有潜力。
- 需要更多的研究来改进LLM在处理复杂的可访问性问题方面的表现。
点此查看论文截图


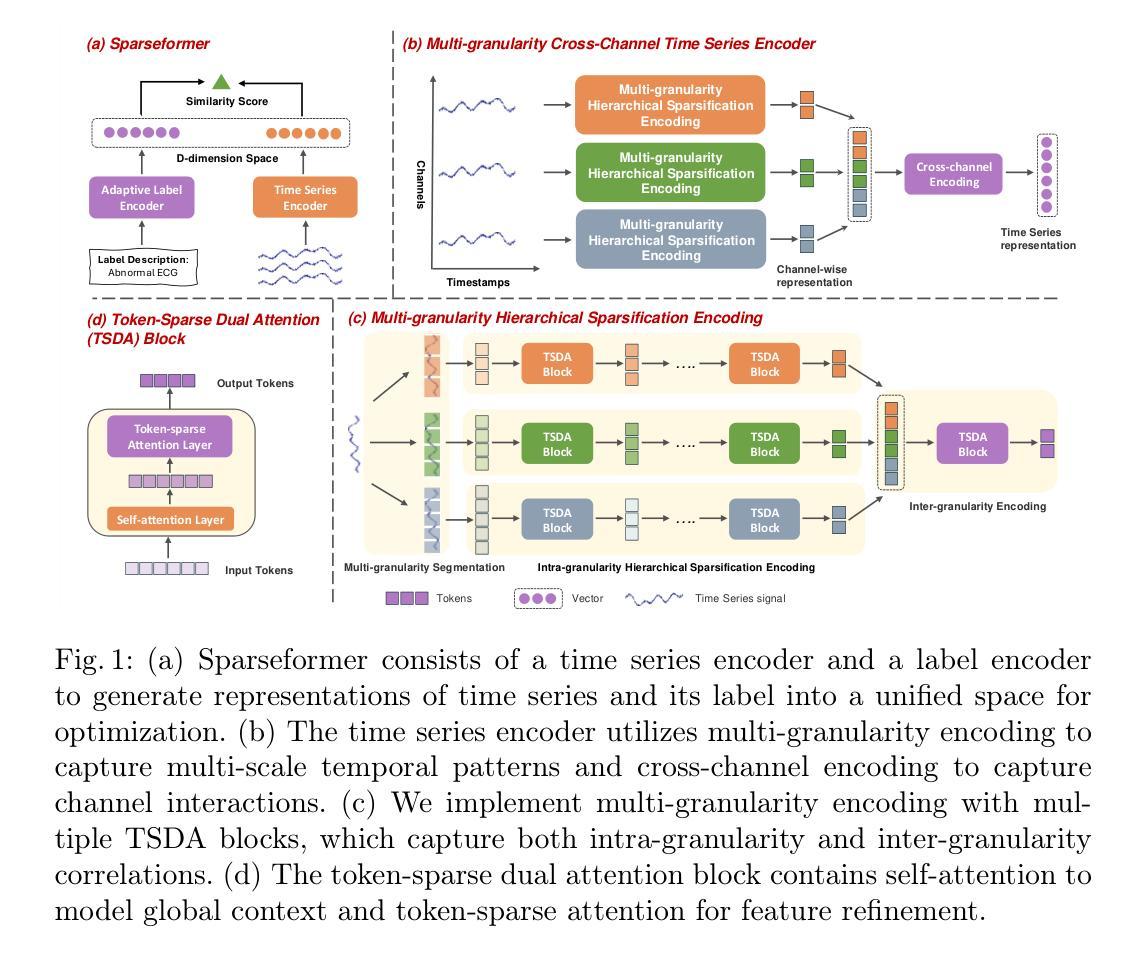
Sparseformer: a Transferable Transformer with Multi-granularity Token Sparsification for Medical Time Series Classification
Authors:Jiexia Ye, Weiqi Zhang, Ziyue Li, Jia Li, Fugee Tsung
Medical time series (MedTS) classification is crucial for improved diagnosis in healthcare, and yet it is challenging due to the varying granularity of patterns, intricate inter-channel correlation, information redundancy, and label scarcity. While existing transformer-based models have shown promise in time series analysis, they mainly focus on forecasting and fail to fully exploit the distinctive characteristics of MedTS data. In this paper, we introduce Sparseformer, a transformer specifically designed for MedTS classification. We propose a sparse token-based dual-attention mechanism that enables global modeling and token compression, allowing dynamic focus on the most informative tokens while distilling redundant features. This mechanism is then applied to the multi-granularity, cross-channel encoding of medical signals, capturing intra- and inter-granularity correlations and inter-channel connections. The sparsification design allows our model to handle heterogeneous inputs of varying lengths and channels directly. Further, we introduce an adaptive label encoder to address label space misalignment across datasets, equipping our model with cross-dataset transferability to alleviate the medical label scarcity issue. Our model outperforms 12 baselines across seven medical datasets under supervised learning. In the few-shot learning experiments, our model also achieves superior average results. In addition, the in-domain and cross-domain experiments among three diagnostic scenarios demonstrate our model’s zero-shot learning capability. Collectively, these findings underscore the robustness and transferability of our model in various medical applications.
医疗时间序列(MedTS)分类对于提高医疗保健中的诊断至关重要,然而由于模式粒度不一、复杂跨通道相关性、信息冗余和标签稀缺,它仍然是一个挑战。尽管现有的基于transformer的模型在时间序列分析方面显示出潜力,但它们主要集中在预测方面,未能充分利用MedTS数据的独特特征。在本文中,我们介绍了Sparseformer,这是一个专门为MedTS分类设计的transformer。我们提出了一种基于稀疏令牌的双重注意力机制,它能够实现全局建模和令牌压缩,允许动态关注最具信息量的令牌,同时提炼冗余特征。该机制随后应用于医疗信号的多粒度跨通道编码,捕获粒度和跨粒度相关性以及跨通道连接。稀疏化设计允许我们的模型直接处理不同长度和通道的异构输入。此外,我们引入了一种自适应标签编码器,以解决数据集间标签空间的不对齐问题,使我们的模型具备跨数据集的可转移性,以缓解医疗标签稀缺的问题。在七个医疗数据集的监督学习下,我们的模型优于12种基线模型。在少样本学习实验中,我们的模型也取得了平均成绩领先的优秀结果。此外,三个诊断场景中的域内和跨域实验证明了我们的模型的零样本学习能力。总的来说,这些发现突显了我们的模型在各种医疗应用中的稳健性和可转移性。
论文及项目相关链接
PDF 3 figures, 16 pages, 5 tables
Summary
本文提出Sparseformer模型,专为医疗时间序列分类设计。通过稀疏标记双注意力机制进行全局建模和标记压缩,可动态关注最具有信息量的标记并提炼冗余特征。该模型能够处理不同长度和通道的异质输入,通过自适应标签编码器解决标签空间在不同数据集之间的不匹配问题,实现跨数据集迁移学习,缓解医疗标签稀缺问题。Sparseformer在多个医疗数据集上表现出超越基线模型的性能,展现出在不同医疗应用中的稳健性和迁移能力。
Key Takeaways
- Sparseformer是专为医疗时间序列分类设计的变压器模型。
- Sparseformer采用稀疏标记双注意力机制进行全局建模和标记压缩。
- 该模型能够处理不同长度和通道的异质输入。
- 自适应标签编码器解决了标签空间在不同数据集之间的不匹配问题。
- Sparseformer在多个医疗数据集上实现了超越基线模型的性能。
- Sparseformer在少样本学习实验中表现出优越的平均结果。
点此查看论文截图

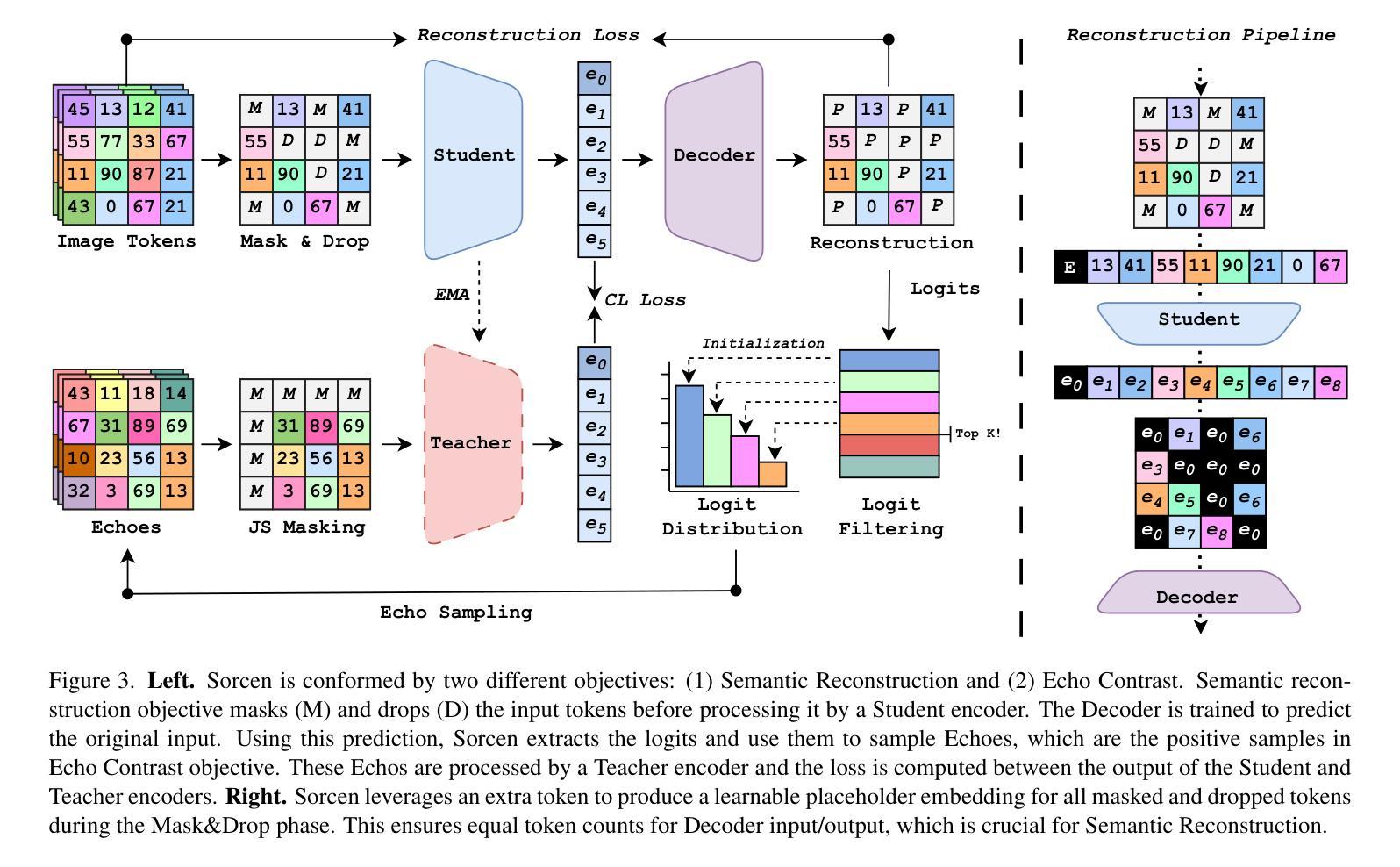
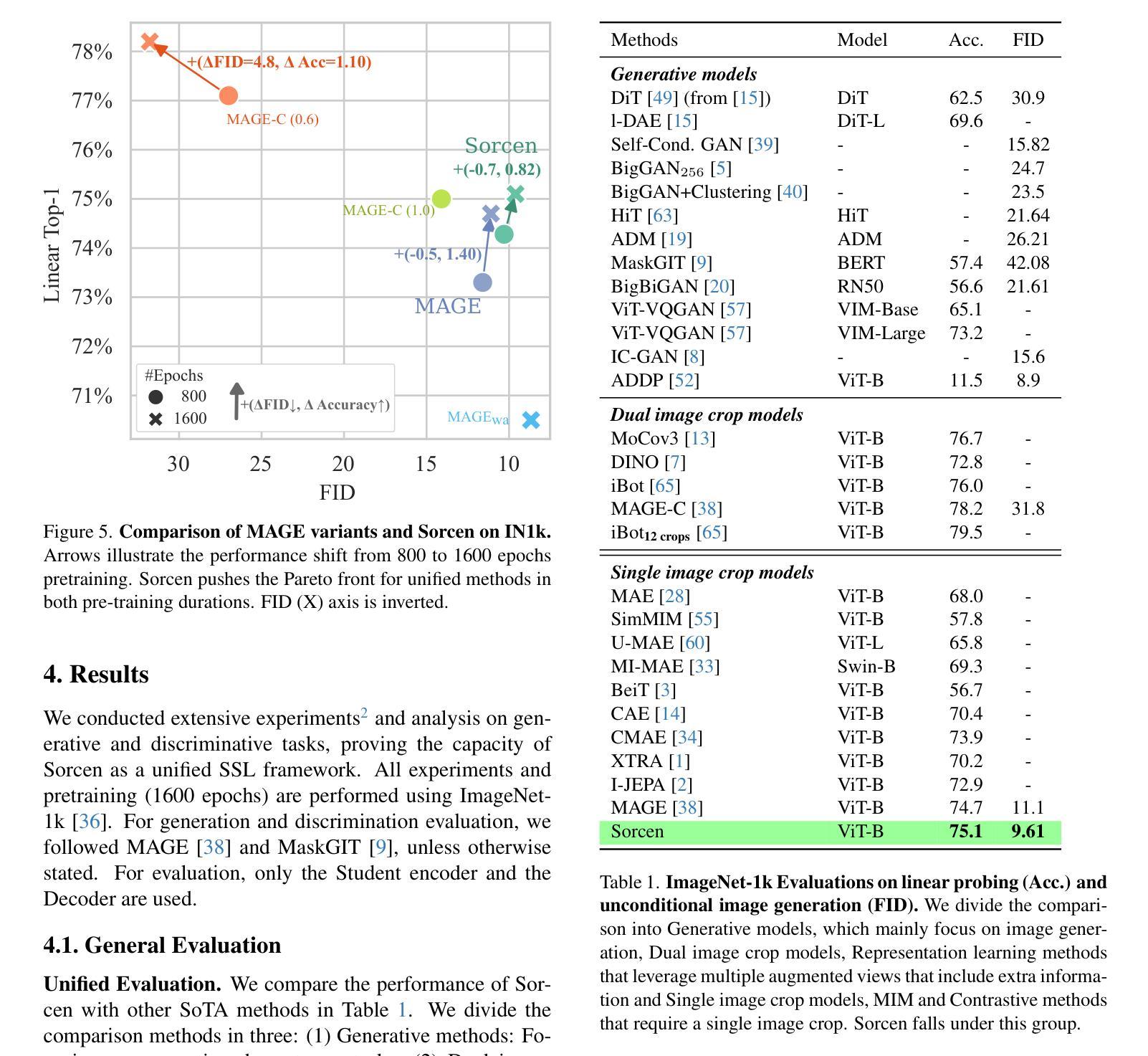
Conjuring Positive Pairs for Efficient Unification of Representation Learning and Image Synthesis
Authors:Imanol G. Estepa, Jesús M. Rodríguez-de-Vera, Ignacio Sarasúa, Bhalaji Nagarajan, Petia Radeva
While representation learning and generative modeling seek to understand visual data, unifying both domains remains unexplored. Recent Unified Self-Supervised Learning (SSL) methods have started to bridge the gap between both paradigms. However, they rely solely on semantic token reconstruction, which requires an external tokenizer during training – introducing a significant overhead. In this work, we introduce Sorcen, a novel unified SSL framework, incorporating a synergic Contrastive-Reconstruction objective. Our Contrastive objective, “Echo Contrast”, leverages the generative capabilities of Sorcen, eliminating the need for additional image crops or augmentations during training. Sorcen “generates” an echo sample in the semantic token space, forming the contrastive positive pair. Sorcen operates exclusively on precomputed tokens, eliminating the need for an online token transformation during training, thereby significantly reducing computational overhead. Extensive experiments on ImageNet-1k demonstrate that Sorcen outperforms the previous Unified SSL SoTA by 0.4%, 1.48 FID, 1.76%, and 1.53% on linear probing, unconditional image generation, few-shot learning, and transfer learning, respectively, while being 60.8% more efficient. Additionally, Sorcen surpasses previous single-crop MIM SoTA in linear probing and achieves SoTA performance in unconditional image generation, highlighting significant improvements and breakthroughs in Unified SSL models.
表示学习和生成建模都在努力理解视觉数据,但统一这两个领域仍然未被探索。最近的统一自监督学习方法(SSL)已经开始弥合两种范式之间的鸿沟。然而,它们仅依赖于语义令牌重建,这需要训练过程中的外部令牌器——带来了相当大的开销。在这项工作中,我们介绍了Sorcen,这是一种新型统一的SSL框架,它结合了协同对比重建目标。我们的对比目标“回声对比”利用了Sorcen的生成能力,消除了训练过程中对额外图像裁剪或增强的需求。Sorcen在语义令牌空间中“生成”一个回声样本,形成对比正对。Sorcen只在预计算令牌上运行,消除了训练过程中在线令牌转换的需要,从而显著降低了计算开销。在ImageNet-1k上的大量实验表明,在直接线性探测、无条件图像生成、少样本学习和迁移学习方面,索森分别比之前的统一SSL技术领先了0.4%、1.48 FID、1.76%和1.53%,同时在效率上高出60.8%。此外,索森在直接线性探测上超越了之前的单裁剪MIM技术,并在无条件图像生成方面达到了最新性能水平,这突显了统一SSL模型的显著改进和突破。
论文及项目相关链接
PDF The source code is available in https://github.com/ImaGonEs/Sorcen
Summary
本文介绍了一种新型的统一自监督学习(SSL)框架Sorcen,它结合了对比和重建目标,无需额外的图像裁剪或增强即可进行训练。Sorcen在预计算令牌上运行,消除了在线令牌转换的需要,从而大大提高了计算效率。在ImageNet-1k上的实验表明,Sorcen在统一SSL领域中表现出色,具有更高的效率和准确性。
Key Takeaways
- Sorcen是一个新型的统一SSL框架,结合了对比和重建目标。
- Sorcen利用生成能力,无需额外的图像裁剪或增强即可进行训练。
- Sorcen通过生成语义令牌空间中的回声样本,形成对比正配对。
- Sorcen在预计算令牌上运行,无需在线令牌转换,提高计算效率。
- Sorcen在ImageNet-1k上的实验表现出色,在多个任务上超过了之前的SSL方法。
- Sorcen在统一SSL领域实现了显著的改进和突破。
点此查看论文截图



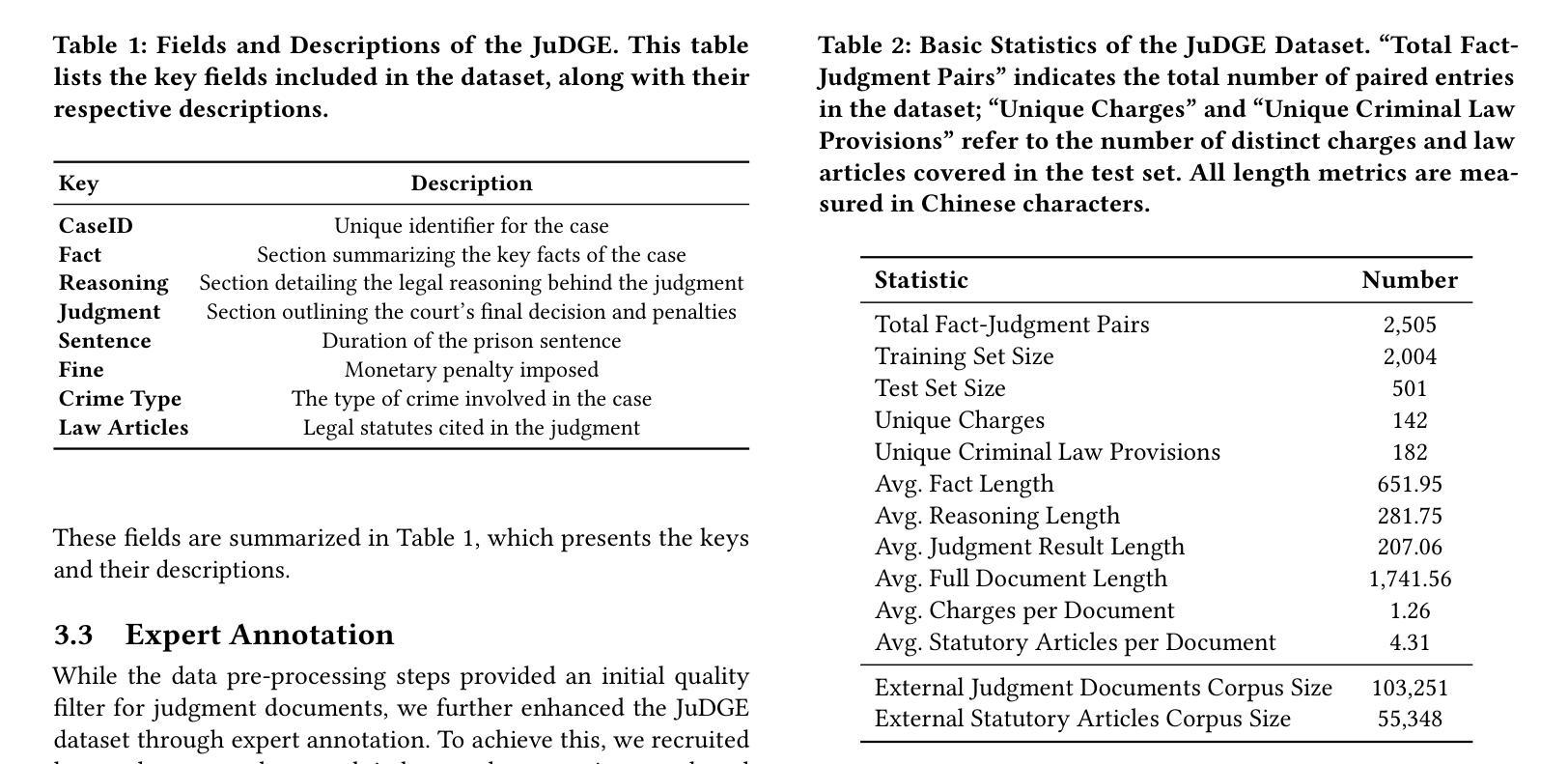
JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Authors:Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, Yiqun Liu
This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
本文介绍了JuDGE(判决文书生成评估)这一新型基准测试,该测试旨在评估中文法律体系中判决文书生成的性能。我们将任务定义为根据给定的案件事实描述生成完整的法律判决书。为了促进这一基准测试,我们构建了一个综合数据集,其中包含来自真实法律案件的案情描述以及与其相应的完整判决书,这些判决书作为评估生成文档质量的真实标准。该数据集通过两个外部法律语料库进行扩充,为任务提供了额外的法律知识:一个包含法规和条例,另一个则包含大量过去的判决书。我们与法律专业人士合作,建立了一个全面的自动化评估框架,从各个维度评估生成的判决书的质量。我们评估了各种基线方法,包括小样本上下文学习、微调以及多源检索增强生成(RAG)方法,这些方法均使用通用和法律领域的LLMs。实验结果表明,虽然RAG方法可以有效提高此任务性能,但仍存在很大的改进空间。所有代码和数据集均可在https://github.com/oneal2000/JuDGE找到。
论文及项目相关链接
Summary
中国法律系统下判决文书生成评估的新基准JuDGE被介绍。该任务被定义为从给定案例的事实描述生成完整的法律判决书。为推进此基准,我们构建了包含真实案例事实描述与其完整判决书的配对数据集,作为生成文档质量的评估基准。此外,还通过两个外部法律语料库提供额外的法律知识。与律师合作,我们建立了一个全面的自动化评估框架,以评估生成判决书的质量。对多种基线方法进行了评估,包括小样本上下文学习、微调以及多源检索增强生成方法,使用通用和法律领域的LLM。实验结果表明,虽然RAG方法能提升任务表现,但仍有许多改进空间。
Key Takeaways
- 介绍了新的判决文书生成评估基准JuDGE。
- 任务定义为从案例事实描述生成完整的法律判决书。
- 构建了一个包含真实案例事实描述和判决书的配对数据集。
- 利用两个外部法律语料库提供法律知识。
- 与律师合作建立了全面的自动化评估框架。
- 评估了多种方法,包括小样本学习、微调及多源检索增强生成方法。
点此查看论文截图


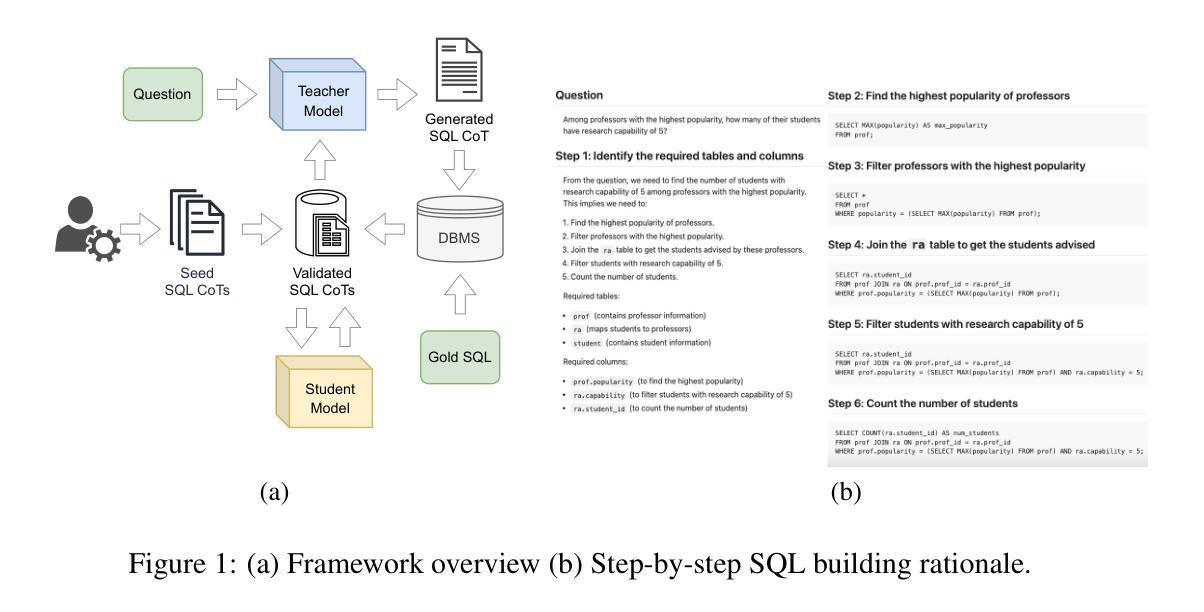
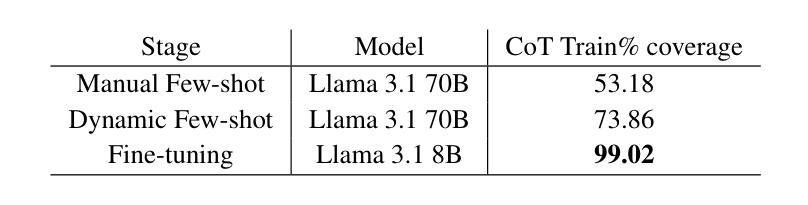
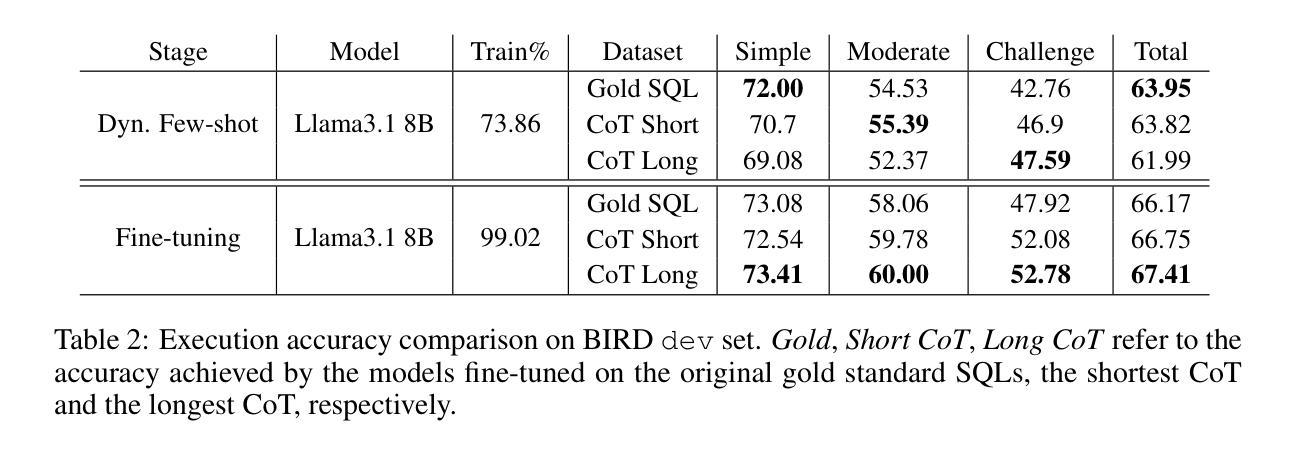
Rationalization Models for Text-to-SQL
Authors:Gaetano Rossiello, Nhan Pham, Michael Glass, Junkyu Lee, Dharmashankar Subramanian
We introduce a framework for generating Chain-of-Thought (CoT) rationales to enhance text-to-SQL model fine-tuning. These rationales consist of intermediate SQL statements and explanations, serving as incremental steps toward constructing the final SQL query. The process begins with manually annotating a small set of examples, which are then used to prompt a large language model in an iterative, dynamic few-shot knowledge distillation procedure from a teacher model. A rationalization model is subsequently trained on the validated decomposed queries, enabling extensive synthetic CoT annotations for text-to-SQL datasets. To evaluate the approach, we fine-tune small language models with and without these rationales on the BIRD dataset. Results indicate that step-by-step query generation improves execution accuracy, especially for moderately and highly complex queries, while also enhancing explainability.
我们引入了一个生成思维链(Chain-of-Thought,简称CoT)理由的框架,以增强文本到SQL模型的微调。这些理由包括中间的SQL语句和解释,作为构建最终SQL查询的增量步骤。这个过程从手动标注一小部分例子开始,然后用这些例子来提示大型语言模型进行迭代、动态的少量知识蒸馏过程(从教师模型开始)。随后在验证过的分解查询上训练合理化模型,为文本到SQL数据集提供丰富的合成CoT注释。为了评估这种方法,我们在BIRD数据集上对带有和不带这些理由的小型语言模型进行了微调。结果表明,逐步查询生成提高了执行准确性,特别是针对中等和高度复杂的查询,同时提高了可解释性。
论文及项目相关链接
PDF Published at ICLR 2025 Workshop on Reasoning and Planning for LLMs
Summary
基于Chain-of-Thought(CoT)框架生成增强文本到SQL模型微调的理由。这些理由包括中间SQL语句和解释,作为构建最终SQL查询的逐步步骤。通过手动标注少量示例,用于提示大型语言模型在迭代、动态的少样本知识蒸馏过程中从教师模型学习。随后在验证的分解查询上训练解释模型,为文本到SQL数据集提供丰富的合成CoT注释。在BIRD数据集上微调带有和不带有这些理由的小型语言模型的结果表明,逐步生成查询提高了执行准确性,特别是针对中等和高度复杂的查询,同时提高了可解释性。
Key Takeaways
- 引入Chain-of-Thought(CoT)框架生成理由以增强文本到SQL模型的微调。
- 这些理由包括中间SQL语句和解释,作为构建最终SQL查询的逐步步骤。
- 通过手动标注少量示例来启动大型语言模型的学习过程。
- 采用迭代、动态的少样本知识蒸馏过程从教师模型学习。
- 训练一个解释模型来处理验证后的分解查询。
- 此方法能生成丰富的合成CoT注释,适用于文本到SQL数据集。
点此查看论文截图

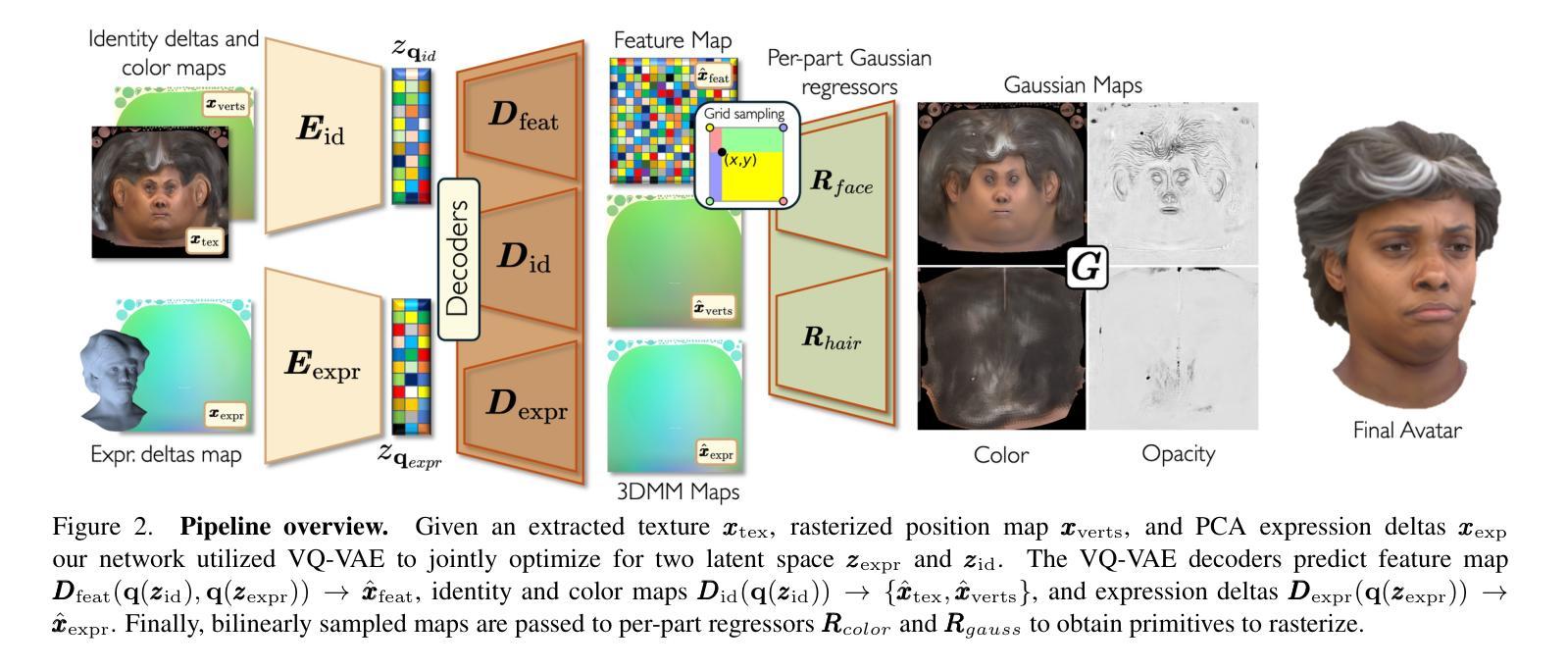
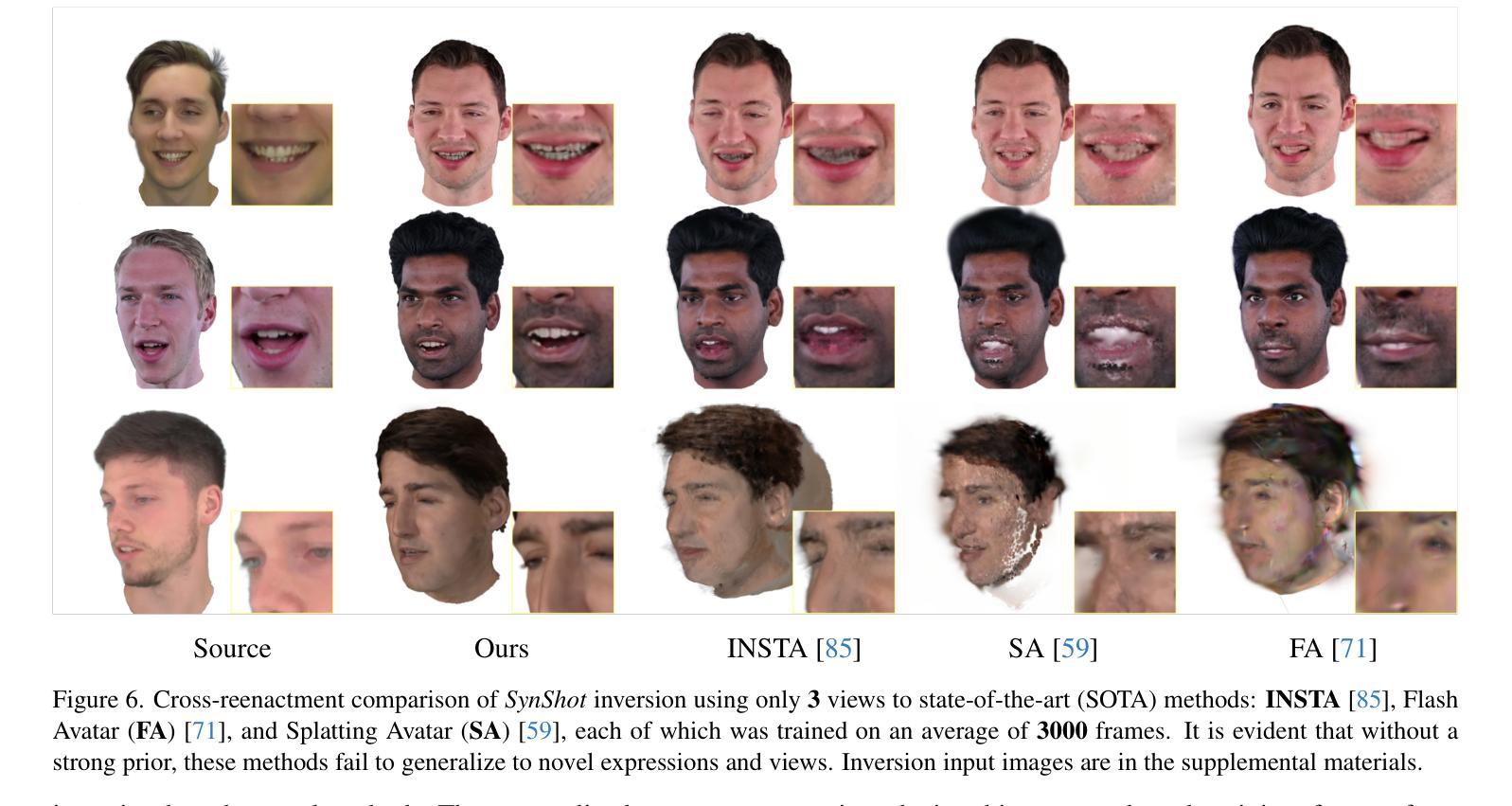
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了SynShot,这是一种基于合成先验的新颖方法,用于进行基于少量样本的驾驶头部肖像倒序生成。我们解决了三个主要挑战。首先,训练可控的3D生成网络需要大量的各种序列,而这些序列的图像和高质量跟踪网格并不总是可用。其次,真实数据的使用受到严格监管(例如,根据《通用数据保护条例》,当参与者撤回同意时,必须频繁删除模型和数据进行适应)。不受这些约束的合成数据是一个吸引人的替代方案。第三,最先进的单眼肖像模型在推广到新的视角和表情时遇到困难,缺乏强大的先验知识并且经常过度拟合特定的视角分布。受只使用合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从包含各种身份、表情和视角的大量合成头部数据中学习先验模型。凭借少量的输入图像,SynShot对预训练的合成先验进行微调,以弥合领域差距,从而建立一个逼真的头部肖像模型,该模型能够推广到新的表情和视角。我们使用3D高斯喷绘和卷积编码器解码器来建立头部肖像模型,输出UV纹理空间的高斯参数。为了处理头部各部分的建模复杂性差异(例如皮肤和头发),我们将先验值嵌入具有针对各部分原始数量进行上采样的显式控制功能。与最先进单眼以及基于GAN的方法相比,SynShot极大地提高了新型视角和表情的合成效果。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
本文介绍了基于合成先验的SynShot方法,用于少样本驱动头部化身反转。该方法解决了三个主要问题:缺乏多样序列图像和高品质追踪网格的训练数据、真实数据使用受限以及最新单眼化身模型缺乏通用性和视角变化的能力。通过利用合成数据作为先验模型,并结合在大型合成头部数据集上训练的先验模型,SynShot能够精细调整参数以缩小领域差距,建立逼真头部化身,并能够适应新的表达和视角。使用3D高斯平铺技术和卷积编码器解码器进行头部建模,并采用明确控制的先验嵌入来处理头部不同部分的建模复杂性。相较于其他先进单眼和基于GAN的方法,SynShot大幅提高了新型表达和视角的合成质量。
Key Takeaways
- SynShot是一种基于合成先验的少数样本驱动头部化身反转新方法。
- 解决了训练可控的3D生成网络中的三大挑战:缺乏多样序列数据、真实数据的使用受限以及模型缺乏通用性和视角变化的能力。
- 利用合成数据作为先验模型,并通过大型合成头部数据集进行训练。
- 结合3D高斯平铺技术和卷积编码器解码器进行头部建模,并处理不同部分的建模复杂性。
点此查看论文截图




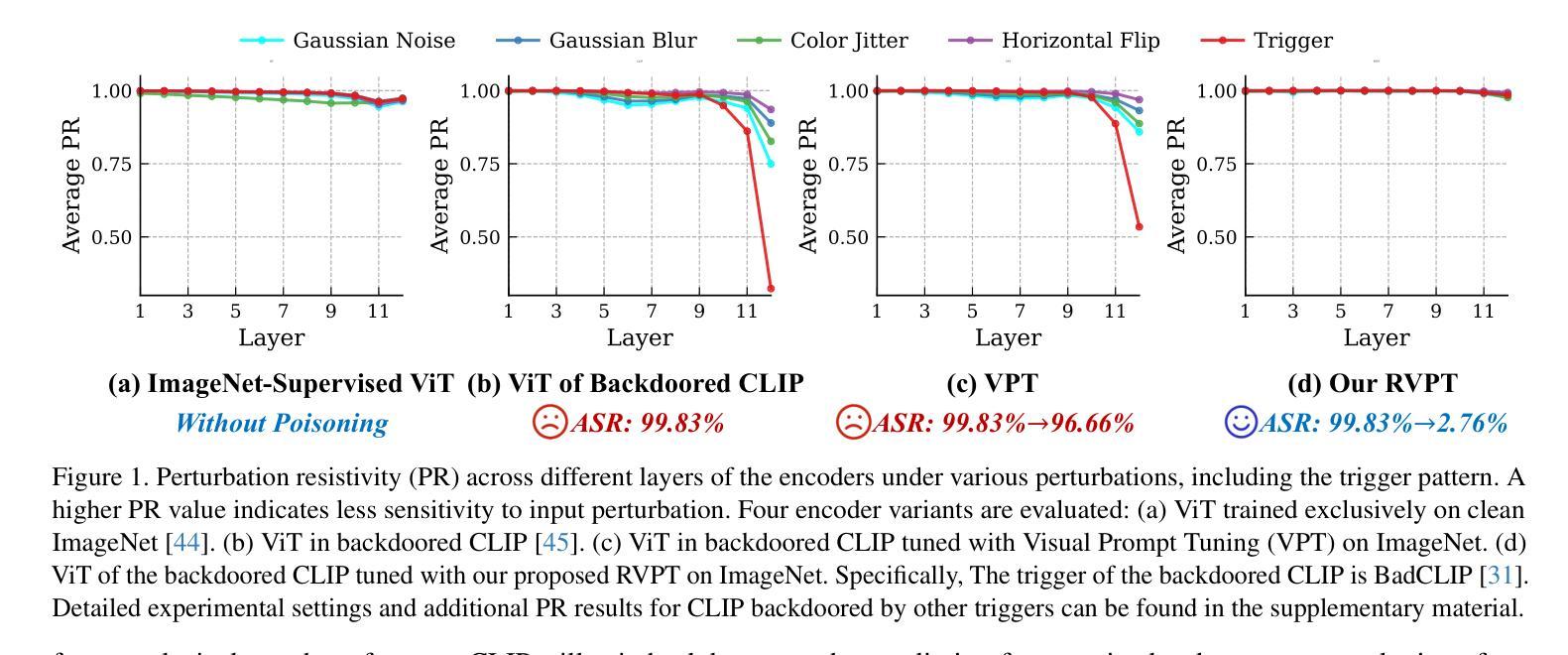
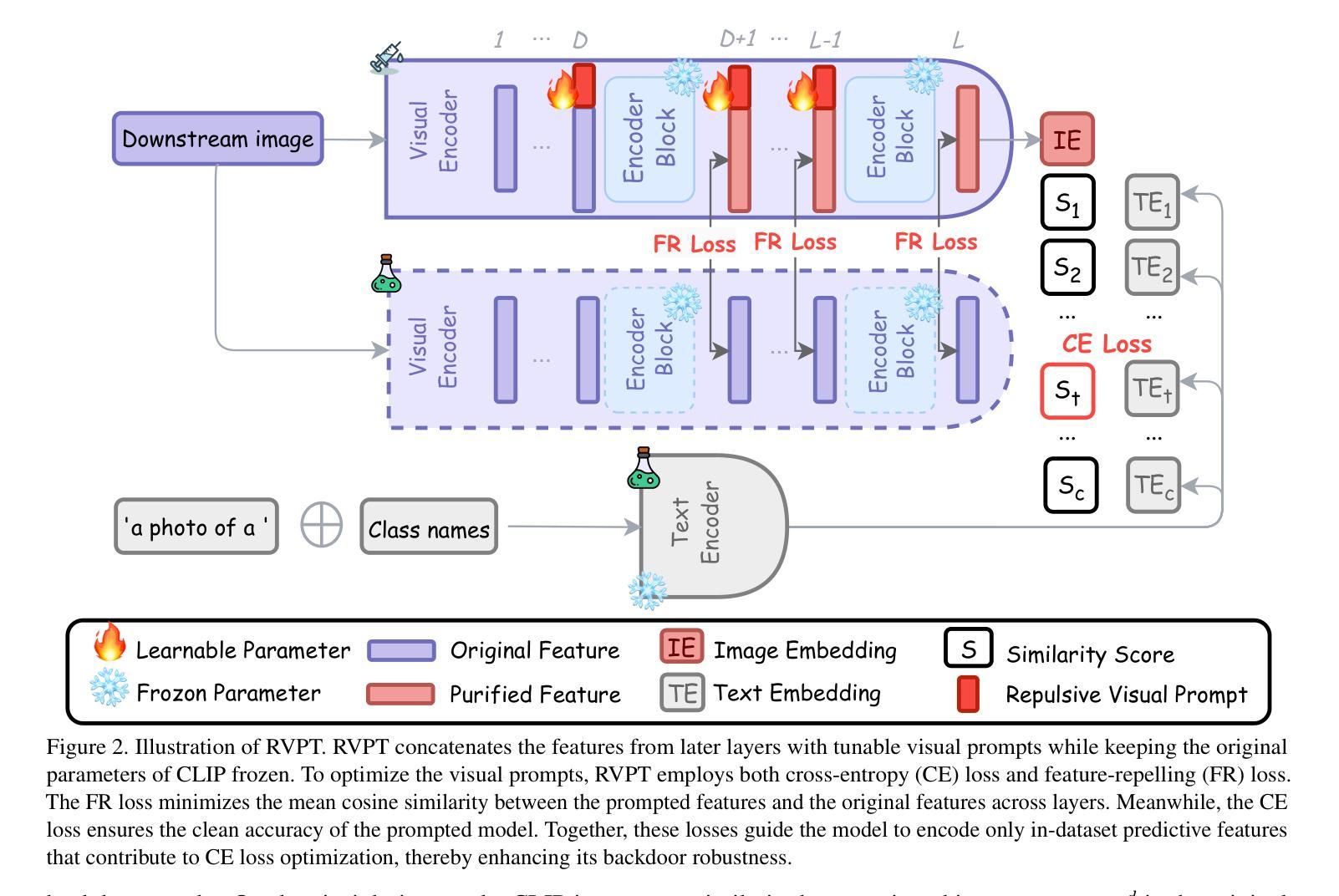
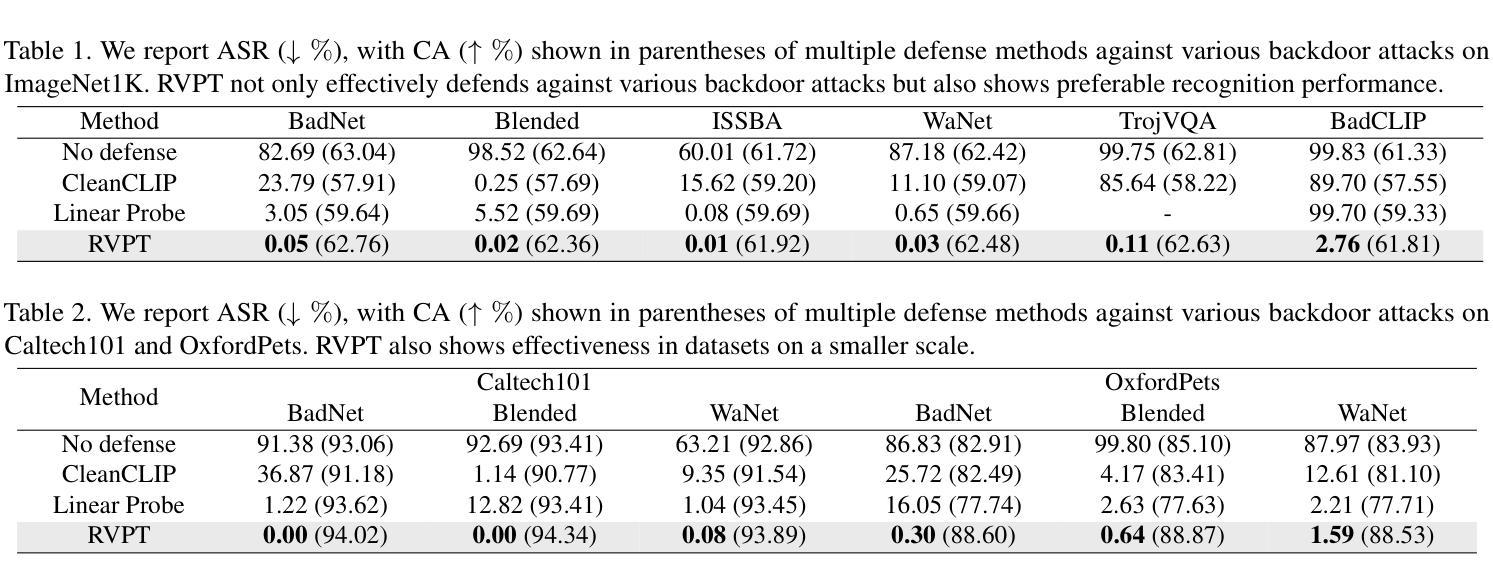
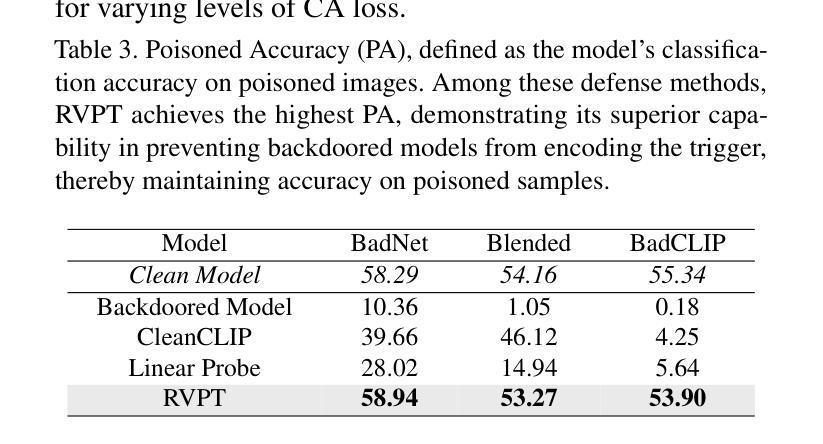
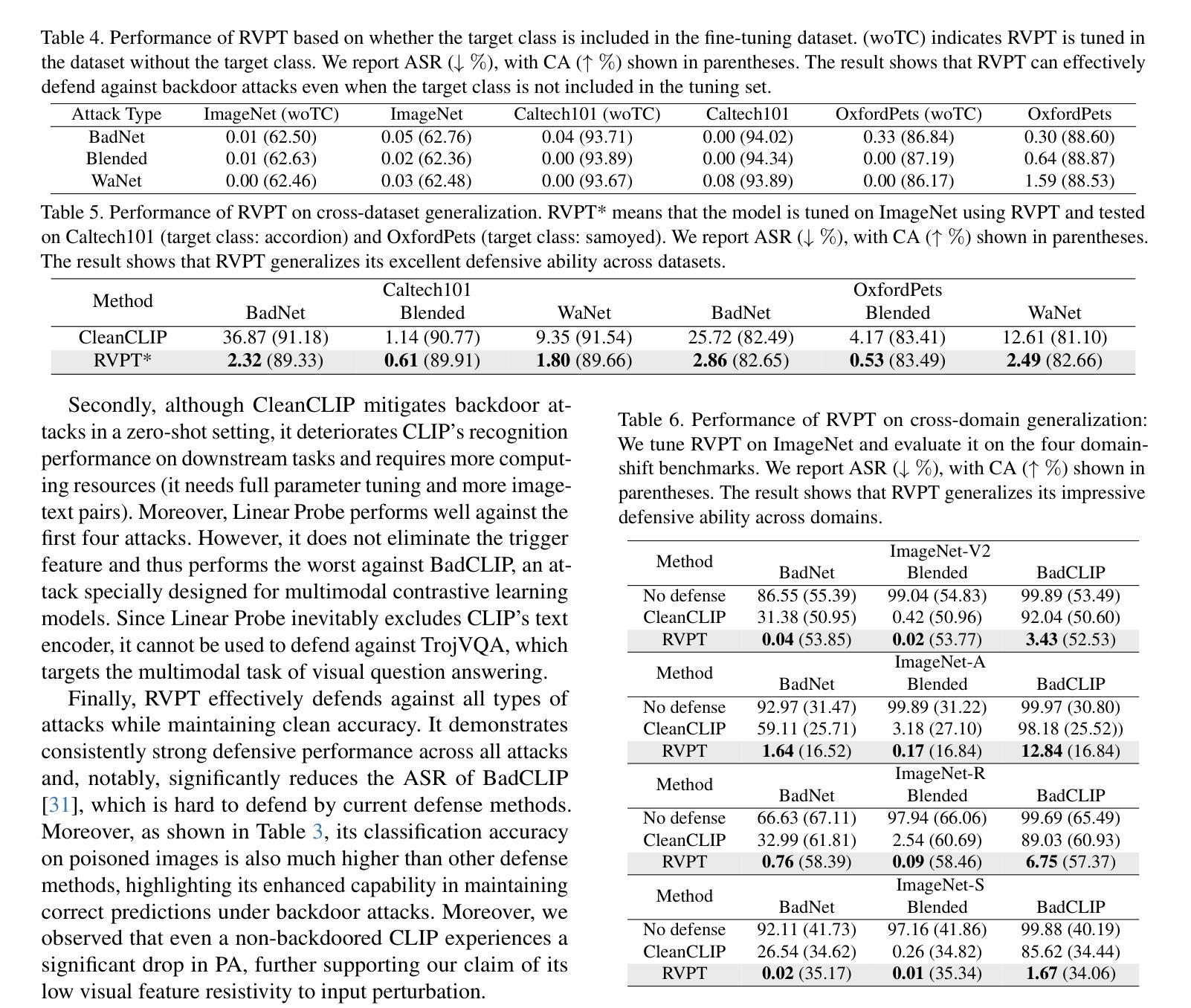
Defending Multimodal Backdoored Models by Repulsive Visual Prompt Tuning
Authors:Zhifang Zhang, Shuo He, Haobo Wang, Bingquan Shen, Lei Feng
Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, yet they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we disclose that CLIP’s vulnerabilities primarily stem from its excessive encoding of class-irrelevant features, which can compromise the model’s visual feature resistivity to input perturbations, making it more susceptible to capturing the trigger patterns inserted by backdoor attacks. Inspired by this finding, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs specially designed deep visual prompt tuning and feature-repelling loss to eliminate excessive class-irrelevant features while simultaneously optimizing cross-entropy loss to maintain clean accuracy. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27% of the parameters relative to CLIP, yet it significantly outperforms state-of-the-art baselines, reducing the attack success rate from 67.53% to 2.76% against SoTA attacks and effectively generalizing its defensive capabilities across multiple datasets.
多模态对比学习模型(例如CLIP)可以从大规模图像文本数据集中学习高质量表示,但它们对后门攻击表现出显著脆弱性,这引发了严重的安全担忧。在本文中,我们披露CLIP的脆弱性主要源于其对与类别无关特征的过度编码,这可能会损害模型对输入扰动的视觉特征抗性,使其更容易捕获由后门攻击插入的触发模式。受此发现的启发,我们提出了名为Repulsive Visual Prompt Tuning(RVPT)的新型防御方法,该方法采用专门设计的深度视觉提示调整和特征排斥损失,以消除过多的与类别无关的特征,同时优化交叉熵损失以保持清洁准确性。与通常需要中毒数据或涉及对整个模型进行微调的传统多模态后门防御方法不同,RVPT利用下游清洁样本的少量镜头,并且只调整少数参数。经验结果表明,RVPT仅调整CLIP的0.27%参数,却显著优于最新基线技术,将攻击成功率从67.53%降低到2.76%,有效抵御了SoTA攻击,并在多个数据集上实现了防御能力的有效泛化。
论文及项目相关链接
Summary
本文揭示了CLIP等多模态对比学习模型对后门攻击的脆弱性,其主要源于对类无关特征的过度编码。为此,本文提出了名为RVPT的新型防御策略,它通过深度视觉提示调整和特征排斥损失,减少无关特征的干扰,同时优化交叉熵损失以保持清洁准确性。与其他需要中毒数据或微调整个模型的多模态后门防御方法不同,RVPT利用下游的少量清洁样本,仅调整少量参数。实验结果证明,RVPT仅调整CLIP的0.27%参数,即可显著优于现有基线技术,将攻击成功率从67.53%降低到2.76%,并能在多个数据集上有效推广其防御能力。
Key Takeaways
- 多模态对比学习模型(如CLIP)易受后门攻击影响,存在安全隐患。
- CLIP的脆弱性主要源于对类无关特征的过度编码。
- RVPT是一种新型防御策略,通过深度视觉提示调整和特征排斥损失来减少类无关特征的干扰。
- RVPT仅需少量下游清洁样本,仅调整少量模型参数。
- RVPT显著优于现有基线技术,大幅降低攻击成功率。
- RVPT的防御能力在多个数据集上得到有效推广。
点此查看论文截图

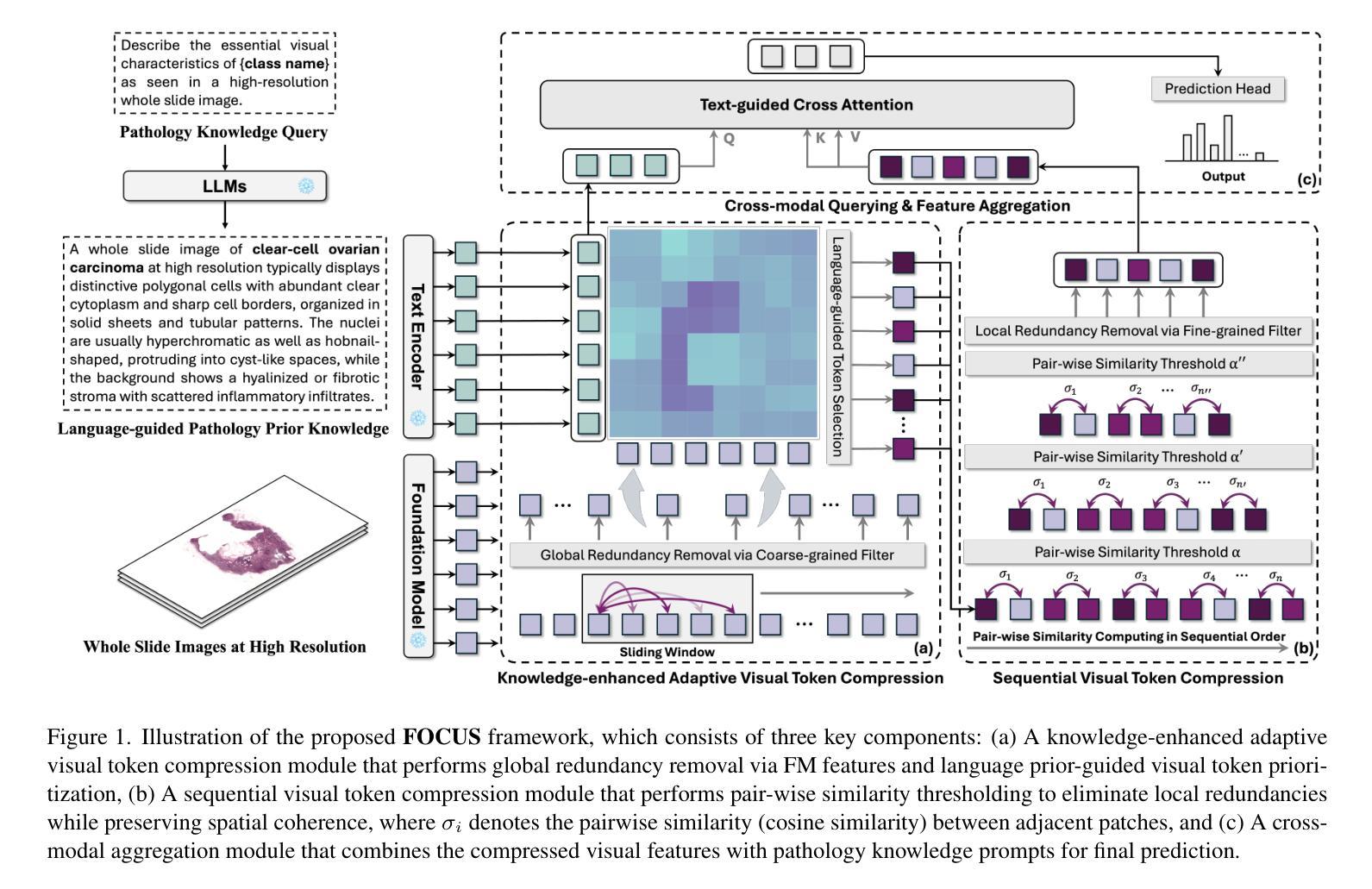
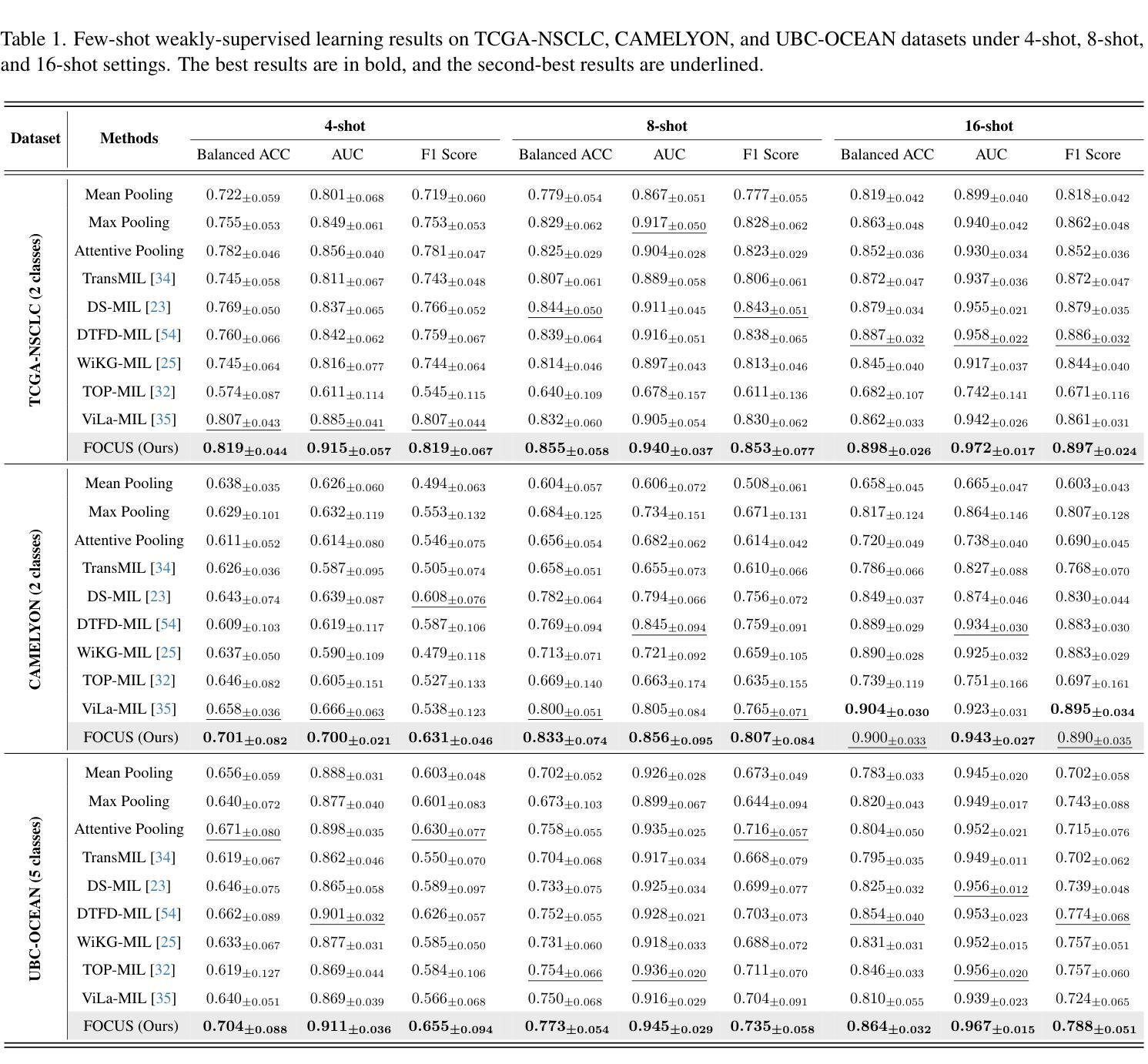
FOCUS: Knowledge-enhanced Adaptive Visual Compression for Few-shot Whole Slide Image Classification
Authors:Zhengrui Guo, Conghao Xiong, Jiabo Ma, Qichen Sun, Lishuang Feng, Jinzhuo Wang, Hao Chen
Few-shot learning presents a critical solution for cancer diagnosis in computational pathology (CPath), addressing fundamental limitations in data availability, particularly the scarcity of expert annotations and patient privacy constraints. A key challenge in this paradigm stems from the inherent disparity between the limited training set of whole slide images (WSIs) and the enormous number of contained patches, where a significant portion of these patches lacks diagnostically relevant information, potentially diluting the model’s ability to learn and focus on critical diagnostic features. While recent works attempt to address this by incorporating additional knowledge, several crucial gaps hinder further progress: (1) despite the emergence of powerful pathology foundation models (FMs), their potential remains largely untapped, with most approaches limiting their use to basic feature extraction; (2) current language guidance mechanisms attempt to align text prompts with vast numbers of WSI patches all at once, struggling to leverage rich pathological semantic information. To this end, we introduce the knowledge-enhanced adaptive visual compression framework, dubbed FOCUS, which uniquely combines pathology FMs with language prior knowledge to enable a focused analysis of diagnostically relevant regions by prioritizing discriminative WSI patches. Our approach implements a progressive three-stage compression strategy: we first leverage FMs for global visual redundancy elimination, and integrate compressed features with language prompts for semantic relevance assessment, then perform neighbor-aware visual token filtering while preserving spatial coherence. Extensive experiments on pathological datasets spanning breast, lung, and ovarian cancers demonstrate its superior performance in few-shot pathology diagnosis. Codes are available at https://github.com/dddavid4real/FOCUS.
在计算病理学(CPath)中,小样本学习为癌症诊断提供了关键解决方案,解决了数据可用性方面的根本性限制,特别是专家注释的稀缺和患者隐私约束。该范式的一个关键挑战来自于全幻灯片图像(WSIs)有限训练集与所含补丁的巨大数量之间的固有差异,其中很大一部分补丁缺乏诊断相关信息,可能会稀释模型学习和关注关键诊断特征的能力。尽管最近的工作试图通过融入额外知识来解决这个问题,但几个关键差距仍然阻碍了进一步的进步:(1)尽管病理基础模型(FMs)已经出现,但它们的潜力在很大程度上尚未被挖掘,大多数方法仅限于基本特征提取;(2)当前的语言指导机制试图一次性将文本提示与大量的WSI补丁对齐,难以利用丰富的病理语义信息。为此,我们引入了知识增强自适应视觉压缩框架,名为FOCUS,它独特地结合了病理FMs和语言先验知识,通过优先筛选具有鉴别力的WSI补丁,实现对诊断相关区域的聚焦分析。我们的方法实现了分阶段的逐步三级压缩策略:我们首先利用FMs进行全局视觉冗余消除,并将压缩特征与语言提示相结合进行语义相关性评估,然后执行考虑邻居的视觉令牌过滤,同时保留空间一致性。在涵盖乳腺癌、肺癌和卵巢癌的病理数据集上的大量实验证明,其在小样本病理诊断中的卓越性能。代码可在https://github.com/dddavid4real/FOCUS上找到。
论文及项目相关链接
PDF Accepted by CVPR’2025
Summary
本文介绍了在医疗计算病理学(CPath)领域中,少样本学习为解决癌症诊断中的关键挑战提供了新的解决方案。文章指出当前面临的挑战包括数据可用性的限制和大量无关信息的干扰,并提出了一个新的框架——FOCUS。该框架结合了病理学基础模型和语言先验知识,通过逐步压缩策略来专注于诊断相关区域的分析,并具有较高的表现性能。文章强调了充分利用病理基础模型的价值和语言指导机制的重要性。目前研究已应用于乳腺癌、肺癌和卵巢癌等多种癌症的病理数据集。代码已公开在GitHub上共享。
Key Takeaways
点此查看论文截图

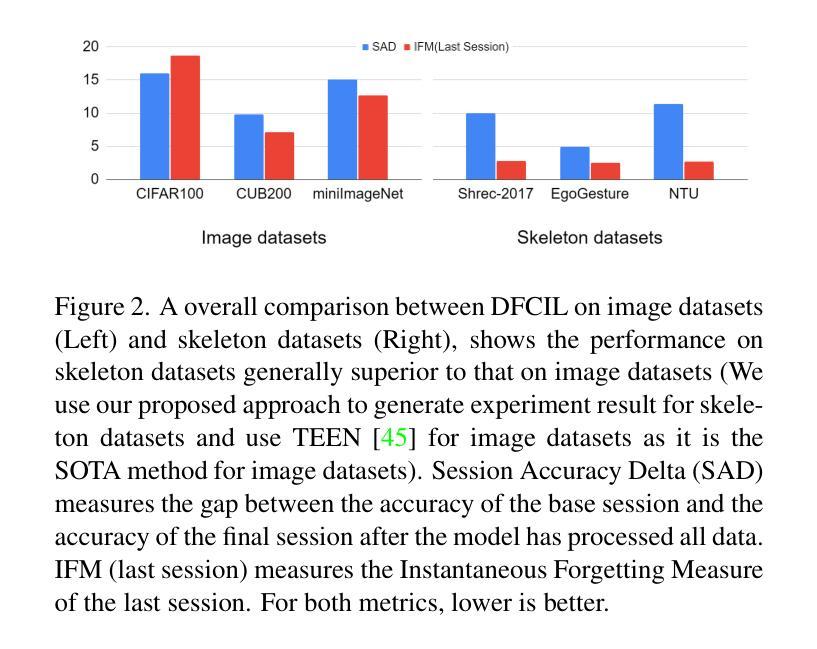
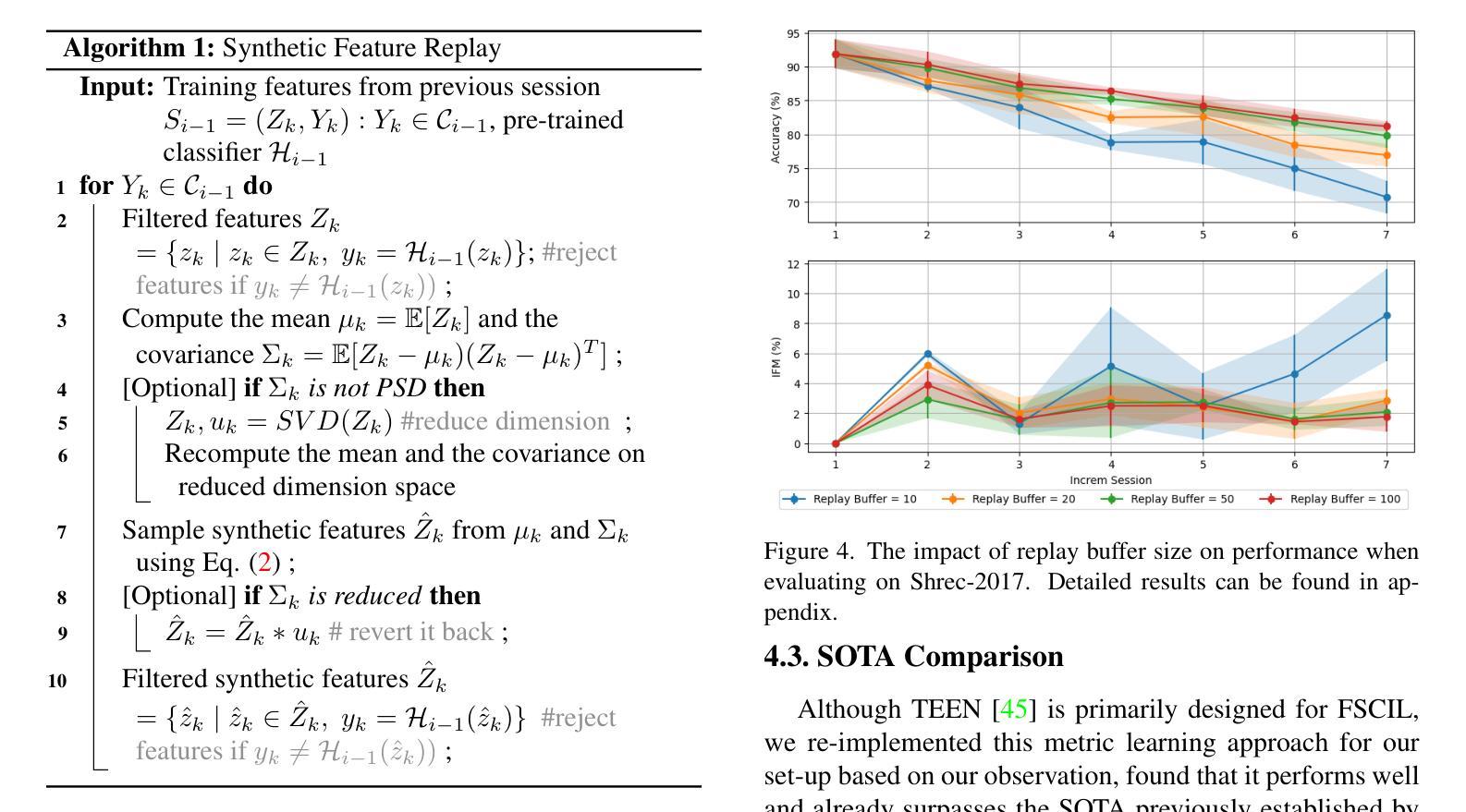
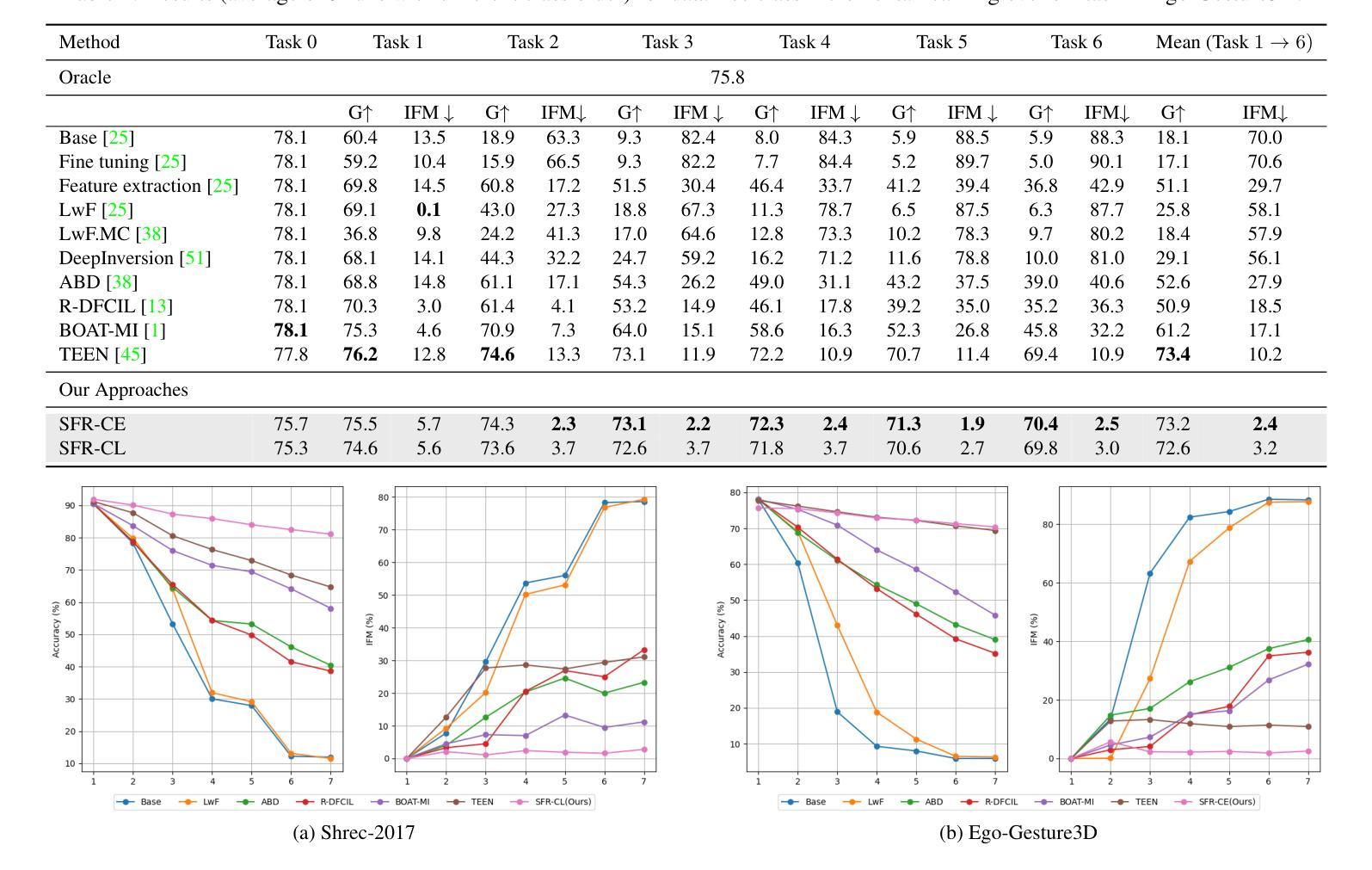
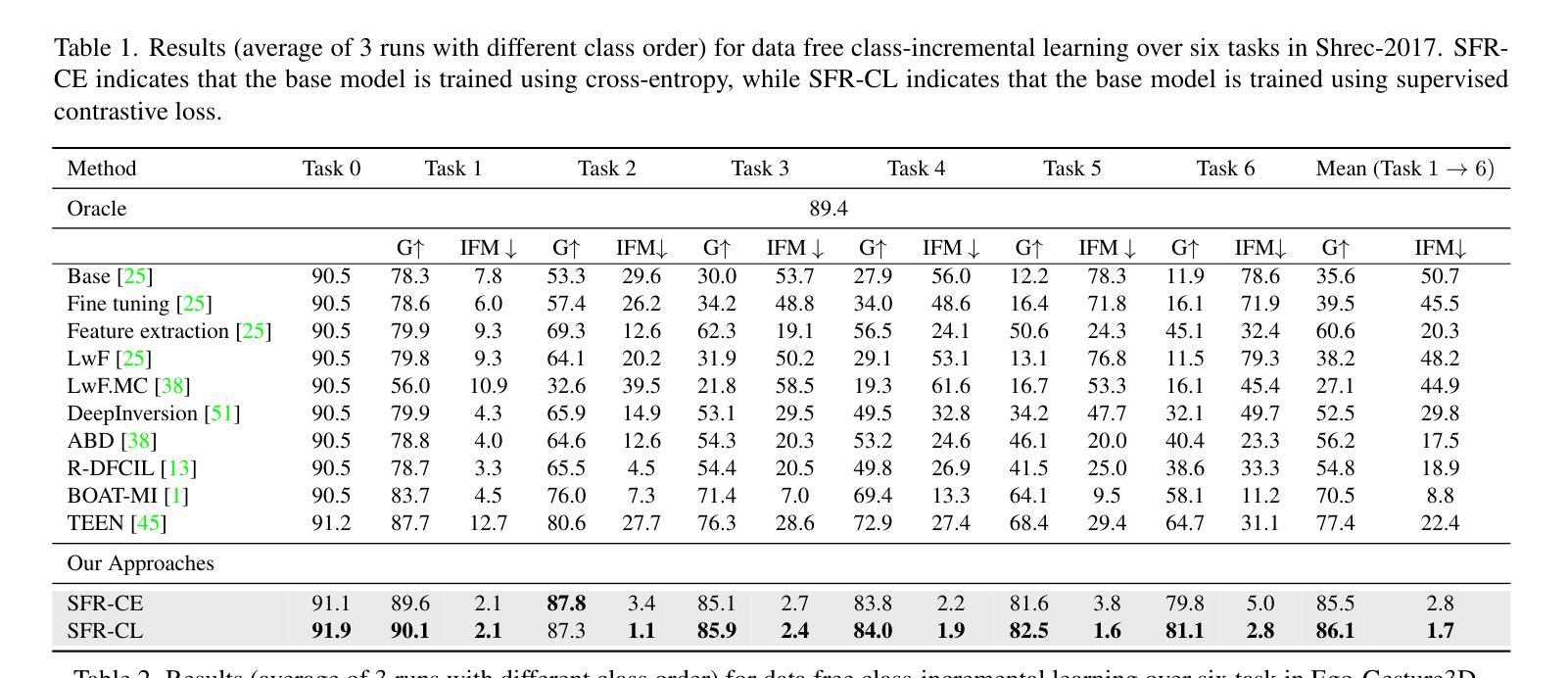
Continual Gesture Learning without Data via Synthetic Feature Sampling
Authors:Zhenyu Lu, Hao Tang
Data-Free Class Incremental Learning (DFCIL) aims to enable models to continuously learn new classes while retraining knowledge of old classes, even when the training data for old classes is unavailable. Although explored primarily with image datasets by researchers, this study focuses on investigating DFCIL for skeleton-based gesture classification due to its significant real-world implications, particularly considering the growing prevalence of VR/AR headsets where gestures serve as the primary means of control and interaction. In this work, we made an intriguing observation: skeleton models trained with base classes(even very limited) demonstrate strong generalization capabilities to unseen classes without requiring additional training. Building on this insight, we developed Synthetic Feature Replay (SFR) that can sample synthetic features from class prototypes to replay for old classes and augment for new classes (under a few-shot setting). Our proposed method showcases significant advancements over the state-of-the-art, achieving up to 15% enhancements in mean accuracy across all steps and largely mitigating the accuracy imbalance between base classes and new classes.
无数据类增量学习(DFCIL)旨在使模型能够在没有旧类训练数据的情况下,继续学习新类并重新训练旧类的知识。尽管研究者主要对图像数据集进行了探索,但由于其在现实世界中的重大应用意义,尤其是考虑到VR/AR头盔日益普及,手势作为主要控制和交互手段,本研究专注于研究基于骨架的手势分类的DFCIL。在这项工作中,我们观察到了一个有趣的现象:使用基础类训练的骨架模型(即使非常有限)在未进行额外训练的情况下对未见过的类具有很强的泛化能力。在此基础上,我们开发了一种合成特征回放(SFR)方法,该方法可以从类原型中采样合成特征以回放旧类并为新类提供增强功能(在少量设置下)。我们的方法相较于最先进的技术有显著的进步,在所有步骤上的平均准确度提高了高达15%,并大大缓解了基础类和新类之间的准确度不平衡问题。
论文及项目相关链接
Summary
数据无依赖类增量学习(DFCIL)旨在使模型能够在没有旧类训练数据的情况下,持续学习新类并重新训练旧类的知识。虽然研究者主要使用图像数据集进行探索,但本研究关注于将DFCIL应用于基于骨骼的手势分类,这在虚拟现实/增强现实头盔日益普及的现实世界中具有重大实际意义。研究中发现,使用基础类别训练的骨骼模型(即使非常有限)在未进行额外训练的情况下显示出对未见类别的强大泛化能力。基于此,我们开发了合成特征回放(SFR)技术,可以从类别原型中采样合成特征以回放旧类别并增强新类别(在少量样本设置下)。所提出的方法在平均准确度上实现了高达15%的提升,并极大地缓解了基础类别与新类别之间的准确度不平衡问题,超过了现有技术的显著进步。
Key Takeaways
- 数据无依赖类增量学习(DFCIL)能够在无旧类训练数据的情况下,使模型持续学习新类别并重新训练旧类的知识。
- 本研究关注将DFCIL应用于基于骨骼的手势分类,具有现实世界的重大意义,特别是在虚拟现实/增强现实头盔的普及背景下。
- 骨骼模型在未见类别上显示出强大的泛化能力,即使使用有限的训练数据。
- 提出合成特征回放(SFR)技术,该技术能够从类别原型中采样合成特征,以回放旧类别并增强新类别的学习。
- 所提出的方法在平均准确度上实现了显著的提升,超过了现有技术。
- 该方法能够缓解基础类别与新类别之间的准确度不平衡问题。
点此查看论文截图


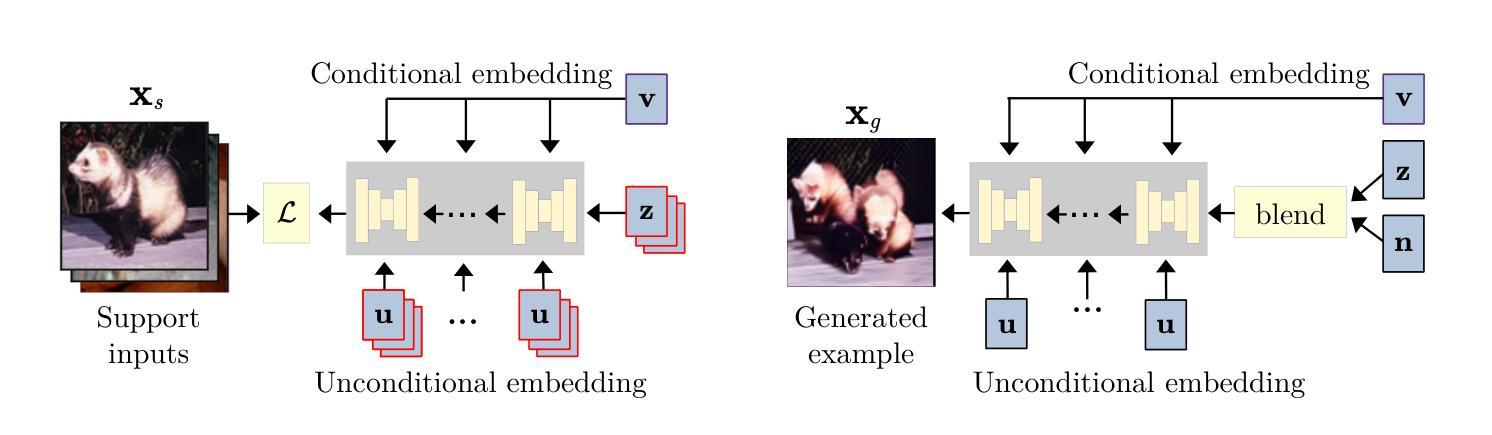
Tiny models from tiny data: Textual and null-text inversion for few-shot distillation
Authors:Erik Landolsi, Fredrik Kahl
Few-shot learning deals with problems such as image classification using very few training examples. Recent vision foundation models show excellent few-shot transfer abilities, but are large and slow at inference. Using knowledge distillation, the capabilities of high-performing but slow models can be transferred to tiny, efficient models. However, common distillation methods require a large set of unlabeled data, which is not available in the few-shot setting. To overcome this lack of data, there has been a recent interest in using synthetic data. We expand on this line of research by presenting a novel diffusion model inversion technique (TINT) combining the diversity of textual inversion with the specificity of null-text inversion. Using this method in a few-shot distillation pipeline leads to state-of-the-art accuracy among small student models on popular benchmarks, while being significantly faster than prior work. Popular few-shot benchmarks involve evaluation over a large number of episodes, which is computationally cumbersome for methods involving synthetic data generation. We also present a theoretical analysis on how the accuracy estimator variance depends on the number of episodes and query examples, and use these results to lower the computational effort required for method evaluation. Finally, to further motivate the use of generative models in few-shot distillation, we demonstrate that our method outperforms training on real data mined from the dataset used in the original diffusion model training. Source code is available at https://github.com/pixwse/tiny2.
少量样本学习处理的是使用极少训练样本进行图像分类等问题。最近的视觉基础模型表现出出色的少量样本迁移能力,但在推理时体积庞大且速度较慢。利用知识蒸馏,高性能但速度较慢的模型的能力可以转移到微小、高效的模型上。然而,常见的蒸馏方法需要大量未标记数据,这在少量样本设置中是无法获得的。为了克服数据缺乏的问题,最近开始有兴趣使用合成数据。我们通过对文本反转的多样性和空文本反转的特异性相结合,提出了一种新型扩散模型反转技术(TINT)。将这种技术应用于少量样本蒸馏管道中,可以在流行基准测试上实现小型学生模型的最新准确性,同时显著快于先前的工作。流行的少量样本基准测试涉及大量回合的评价,这对于涉及合成数据生成的方法在计算上是很繁琐的。我们还从理论上分析了准确度估算器的方差如何取决于回合数和查询样本数,并利用这些结果降低了方法评估所需的计算量。最后,为了进一步推动生成模型在少量样本蒸馏中的应用,我们证明了我们的方法在原始扩散模型训练所用的数据集中挖掘出的真实数据训练表现上更胜一筹。源代码可在https://github.com/pixwse/tiny2获取。
论文及项目相关链接
PDF 24 pages (13 main pages + references and appendix)
Summary
本文探讨了小样学习的相关问题,如使用少量训练样本进行图像分类。尽管当前的大型视觉模型在小样学习中表现出强大的迁移能力,但它们体积庞大,推断速度较慢。因此,本文提出了利用知识蒸馏技术将高性能但缓慢的模型的能力转移到小型高效模型上。但由于常见的蒸馏方法需要大量未标记数据,这在小样设置中是不可用的,因此研究人员开始关注使用合成数据。本文提出了一种新颖的扩散模型反演技术(TINT),结合了文本反演的多样性和空文本反演的特异性。在少量样本蒸馏管道中使用此方法,小型学生模型在流行基准测试上达到了最先进的准确性,同时比以前的工作更快。此外,本文还对准确估计器方差与事件数量和查询示例之间的关系进行了理论分析,以降低方法评估的计算负担。最后,为了推动生成模型在少量样本蒸馏中的应用,本文证明了该方法优于在原始扩散模型训练所使用的数据集上挖掘真实数据的训练方法。
Key Takeaways
- Few-shot learning主要解决使用极少量训练样本进行图像分类等问题。
- 现有的大型视觉模型在小样学习中表现良好,但存在体积庞大、推断速度慢的问题。
- 知识蒸馏技术可将高性能模型的性能转移到小型高效模型上。
- 由于缺乏未标记数据,常见的蒸馏方法在小样设置中有局限性。
- 一种新颖的扩散模型反演技术(TINT)结合了文本反演的多样性和空文本反演的特异性,在少量样本蒸馏中表现优异。
- TINT方法在流行基准测试上达到了先进的准确性,同时计算效率较高。
点此查看论文截图



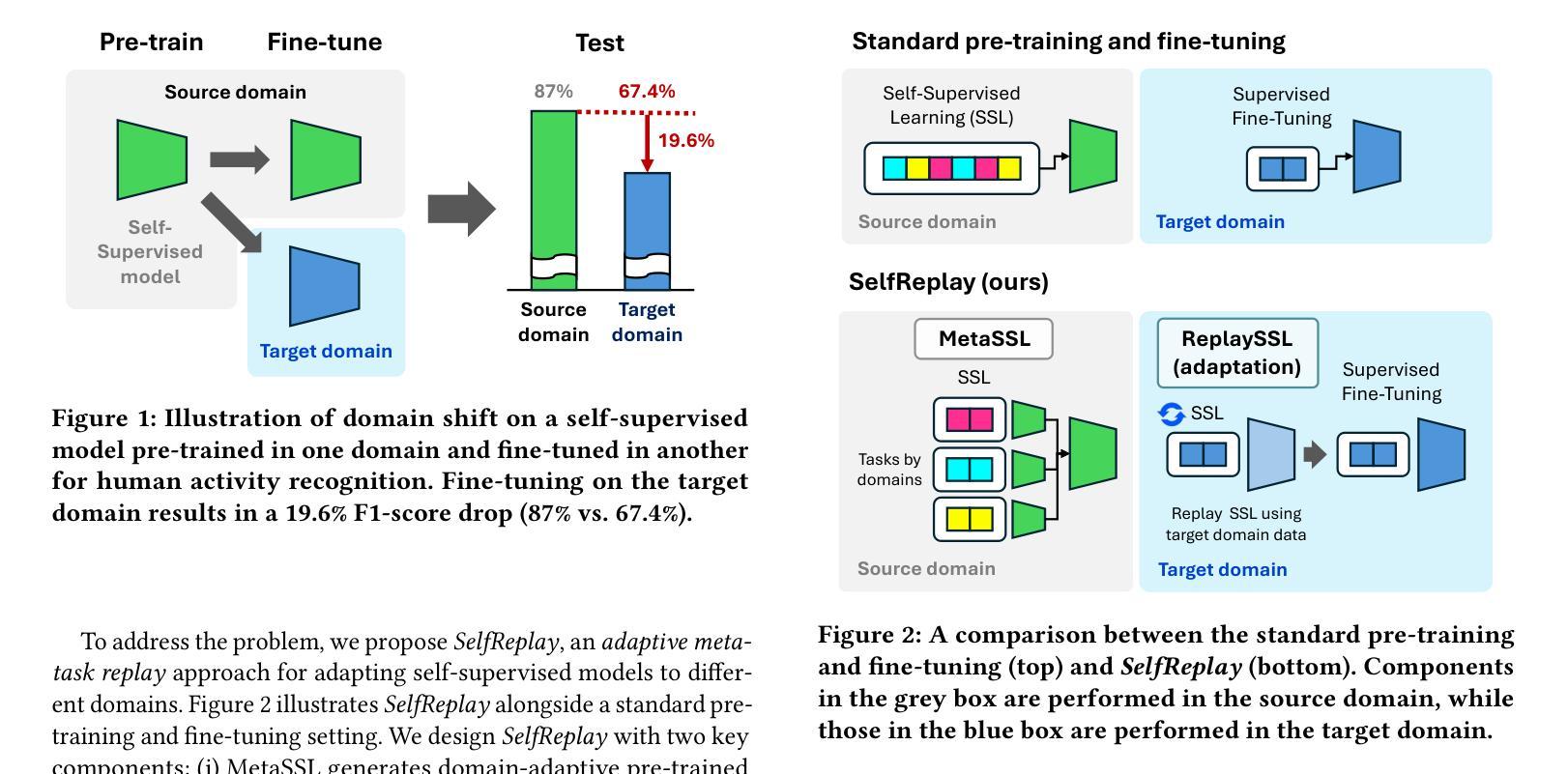
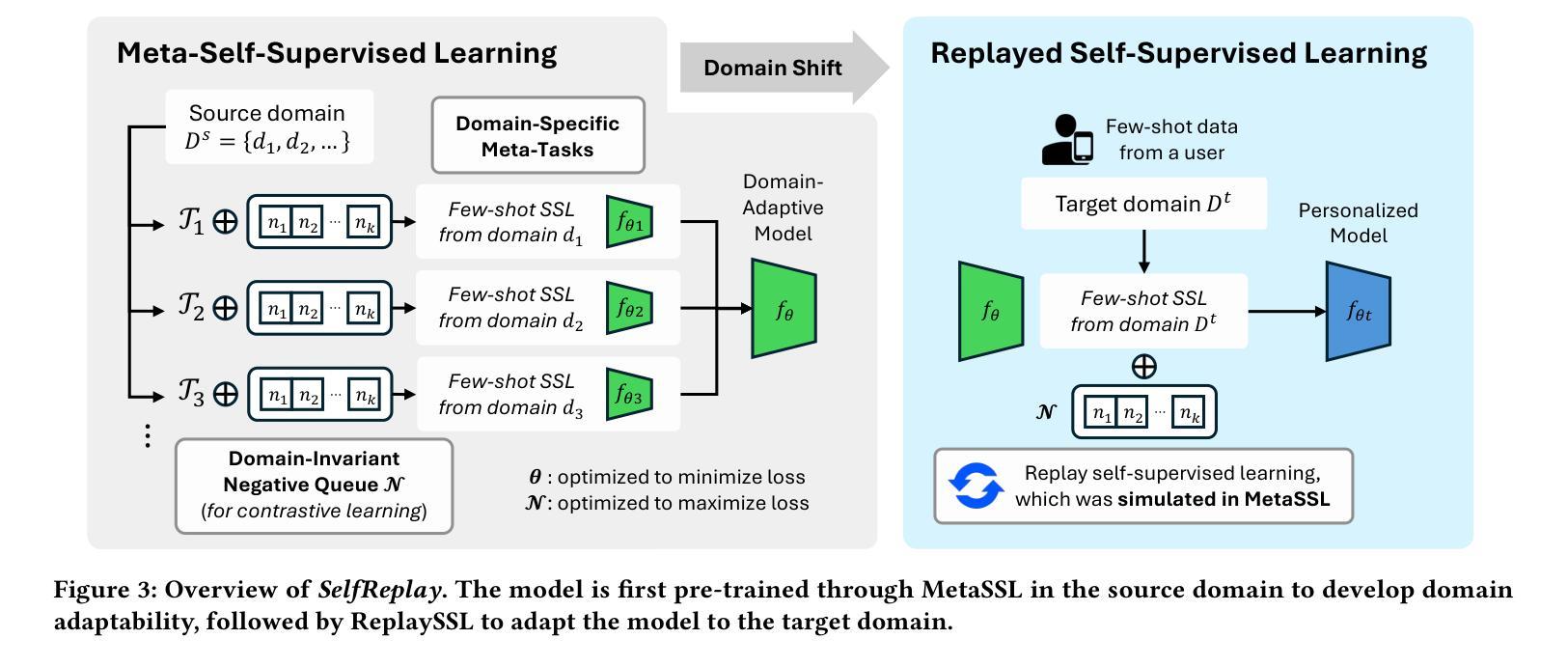
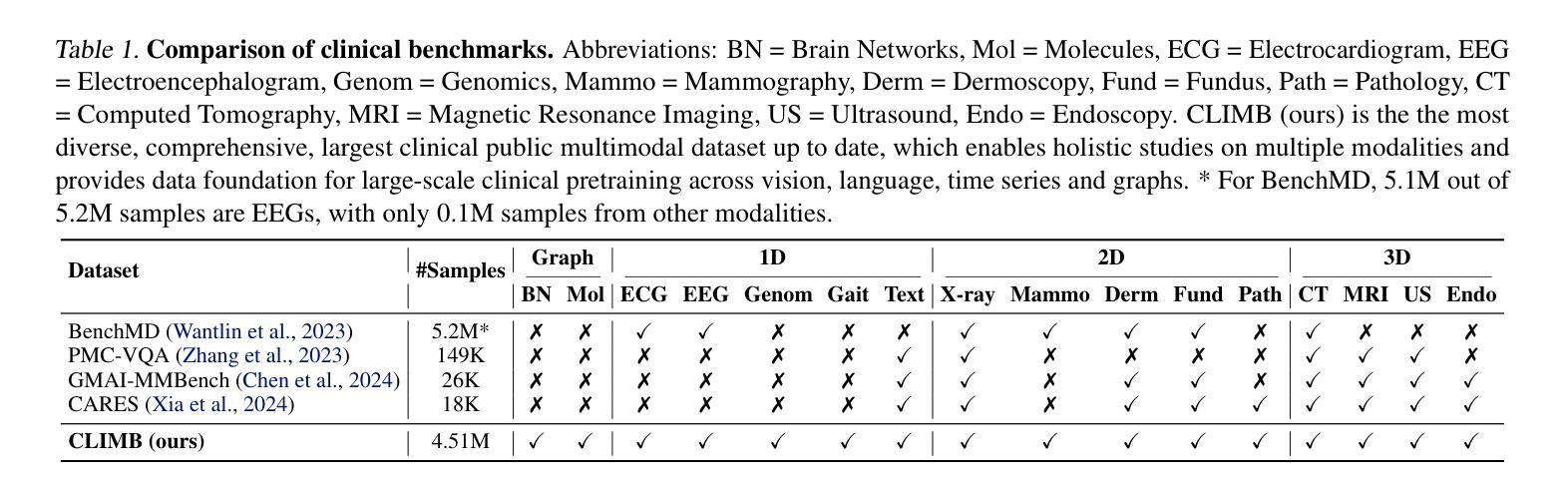
SelfReplay: Adapting Self-Supervised Sensory Models via Adaptive Meta-Task Replay
Authors:Hyungjun Yoon, Jaehyun Kwak, Biniyam Aschalew Tolera, Gaole Dai, Mo Li, Taesik Gong, Kimin Lee, Sung-Ju Lee
Self-supervised learning has emerged as a method for utilizing massive unlabeled data for pre-training models, providing an effective feature extractor for various mobile sensing applications. However, when deployed to end-users, these models encounter significant domain shifts attributed to user diversity. We investigate the performance degradation that occurs when self-supervised models are fine-tuned in heterogeneous domains. To address the issue, we propose SelfReplay, a few-shot domain adaptation framework for personalizing self-supervised models. SelfReplay proposes self-supervised meta-learning for initial model pre-training, followed by a user-side model adaptation by replaying the self-supervision with user-specific data. This allows models to adjust their pre-trained representations to the user with only a few samples. Evaluation with four benchmarks demonstrates that SelfReplay outperforms existing baselines by an average F1-score of 8.8%p. Our on-device computational overhead analysis on a commodity off-the-shelf (COTS) smartphone shows that SelfReplay completes adaptation within an unobtrusive latency (in three minutes) with only a 9.54% memory consumption, demonstrating the computational efficiency of the proposed method.
自监督学习已经成为一种利用大量未标记数据进行预训练模型的方法,为各种移动感知应用提供了有效的特征提取器。然而,当这些模型部署给最终用户时,由于用户多样性,它们会遇到显著的领域偏移。我们调查了自监督模型在异构领域进行微调时发生的性能下降情况。为了解决这一问题,我们提出了SelfReplay,这是一种用于个性化自监督模型的Few-Shot域自适应框架。SelfReplay提出自监督元学习进行初始模型预训练,然后通过重播用户特定数据的自监督来进行用户侧模型适应。这允许模型仅使用少量样本调整其预训练表示以适应用户。使用四个基准点的评估表明,SelfReplay的平均F1分数比现有基线高出8.8%。我们在商品现货智能手机上进行的在线设备计算开销分析表明,SelfReplay在不被干扰的延迟(三分钟内)内完成适应,内存消耗仅为9.54%,证明了所提出方法的计算效率。
论文及项目相关链接
PDF Accepted to the 23rd ACM Conference on Embedded Networked Sensor Systems (ACM SenSys 2025)
Summary
自监督学习是利用大规模无标签数据进行模型预训练的一种方法,为各种移动感知应用提供有效的特征提取。然而,在部署给终端用户时,这些模型由于用户多样性而遇到显著的领域偏移问题。本文研究了自监督模型在异构领域微调时出现的性能下降问题。为解决这一问题,我们提出了SelfReplay,这是一个用于个性化自监督模型的少镜头域适应框架。SelfReplay先进行自监督元学习进行初始模型预训练,然后通过重播用户特定数据的自监督进行用户侧模型适应。这允许模型仅使用少量样本就能调整其预训练表示以适应用户。在四个基准测试上的评估表明,SelfReplay较现有基线平均F1分数提高了8.8%。我们在商品现货智能手机上进行了在线设备计算开销分析,结果显示SelfReplay的适应过程在三分钟内完成,内存消耗仅为9.54%,证明了该方法的计算效率。
Key Takeaways
1. 自监督学习能利用大规模无标签数据进行模型预训练,为移动感知应用提供有效特征提取。
2. 部署自监督模型给终端用户时,会遇到由于用户多样性导致的领域偏移问题。
3. SelfReplay是一个少镜头域适应框架,用于个性化自监督模型。
4. SelfReplay通过自监督元学习进行初始模型预训练,然后通过重播用户特定数据的自监督进行适应。
5. SelfReplay允许模型仅使用少量样本就能调整预训练表示以适应用户。
6. 在四个基准测试上,SelfReplay较现有基线平均F1分数有显著提高。
点此查看论文截图