⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
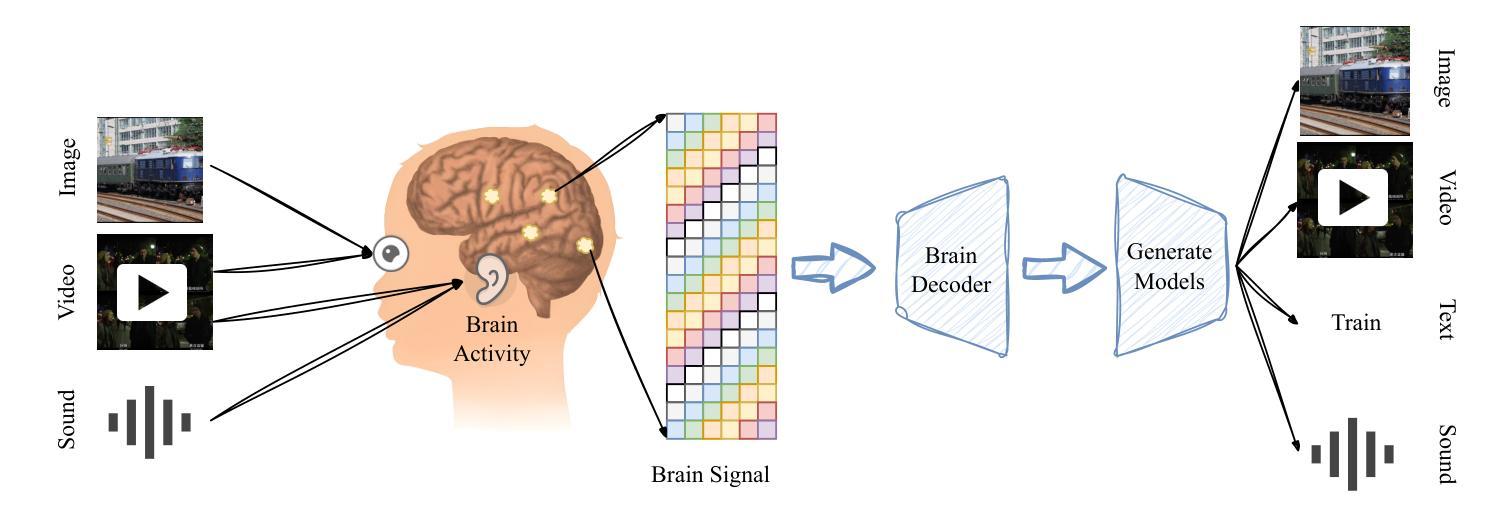
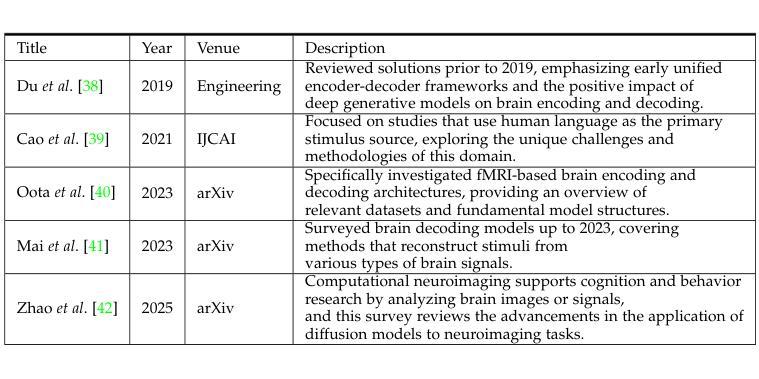
A Survey on fMRI-based Brain Decoding for Reconstructing Multimodal Stimuli
Authors:Pengyu Liu, Guohua Dong, Dan Guo, Kun Li, Fengling Li, Xun Yang, Meng Wang, Xiaomin Ying
In daily life, we encounter diverse external stimuli, such as images, sounds, and videos. As research in multimodal stimuli and neuroscience advances, fMRI-based brain decoding has become a key tool for understanding brain perception and its complex cognitive processes. Decoding brain signals to reconstruct stimuli not only reveals intricate neural mechanisms but also drives progress in AI, disease treatment, and brain-computer interfaces. Recent advancements in neuroimaging and image generation models have significantly improved fMRI-based decoding. While fMRI offers high spatial resolution for precise brain activity mapping, its low temporal resolution and signal noise pose challenges. Meanwhile, techniques like GANs, VAEs, and Diffusion Models have enhanced reconstructed image quality, and multimodal pre-trained models have boosted cross-modal decoding tasks. This survey systematically reviews recent progress in fMRI-based brain decoding, focusing on stimulus reconstruction from passive brain signals. It summarizes datasets, relevant brain regions, and categorizes existing methods by model structure. Additionally, it evaluates model performance and discusses their effectiveness. Finally, it identifies key challenges and proposes future research directions, offering valuable insights for the field. For more information and resources related to this survey, visit https://github.com/LpyNow/BrainDecodingImage.
在日常生活中,我们会遇到各种各样的外部刺激,如图像、声音和视频。随着多模态刺激和神经科学的研究进展,基于功能性磁共振成像(fMRI)的脑解码已成为理解大脑感知及其复杂认知过程的关键工具。解码脑信号以重建刺激不仅揭示了复杂的神经机制,而且还推动了人工智能、疾病治疗和脑机接口的发展。近期神经影像和图像生成模型的进展极大地改进了基于fMRI的解码。虽然fMRI提供了用于精确的大脑活动映射的高空间分辨率,但其较低的时间分辨率和信号噪声构成了挑战。同时,像生成对抗网络(GANs)、变分自编码器(VAEs)和扩散模型等技术提高了重建图像的质量,而多模态预训练模型增强了跨模态解码任务。这篇综述系统地回顾了基于fMRI的脑解码的最新进展,重点关注从被动脑信号重建刺激的研究。文章总结了数据集、相关的大脑区域,并按模型结构对现有的方法进行了分类。此外,它还评估了模型性能并对其有效性进行了讨论。最后,文章确定了关键挑战并提出了未来的研究方向,为该领域提供了宝贵的见解。有关此综述的更多信息和资源,请访问https://github.com/LpyNow/BrainDecodingImage。
论文及项目相关链接
PDF 31 pages, 6 figures
Summary
在日常生活,我们会遇到多种外部刺激,如图像、声音和视频。随着多模态刺激和神经科学的研究进展,基于fMRI的脑解码已成为理解大脑感知和其复杂认知过程的关键工具。解码脑信号以重建刺激揭示了神经机制的复杂性,并推动了人工智能、疾病治疗和脑机接口的发展。近期神经成像和图像生成模型的进展显著改善了基于fMRI的解码效果。尽管fMRI具有高空间分辨率以精确绘制大脑活动图,但其低时间分辨率和信号噪声构成挑战。同时,生成对抗网络(GANs)、变分自编码器(VAEs)和扩散模型等技术提高了重建图像质量,而多模态预训练模型增强了跨模态解码任务。这篇综述系统总结了基于fMRI的脑解码的最新进展,重点关注从被动脑信号重建刺激的研究。它概述了数据集、相关脑区,并按模型结构分类现有方法。此外,它评估了模型性能并讨论了其有效性。最后,它确定了关键挑战并提出了未来研究方向,为该领域提供了宝贵见解。
Key Takeaways
- 多模态刺激和神经科学的研究进展推动了基于fMRI的脑解码的发展。
- 基于fMRI的解码揭示了神经机制的复杂性,并促进了人工智能、疾病治疗和脑机接口的发展。
- 近期神经成像和图像生成模型的进步改善了fMRI解码效果。
- 尽管fMRI具有高空间分辨率,但其低时间分辨率和信号噪声存在挑战。
- GANs、VAEs和扩散模型等技术提高了重建图像的质量。
- 多模态预训练模型在跨模态解码任务中表现出强大的能力。
点此查看论文截图

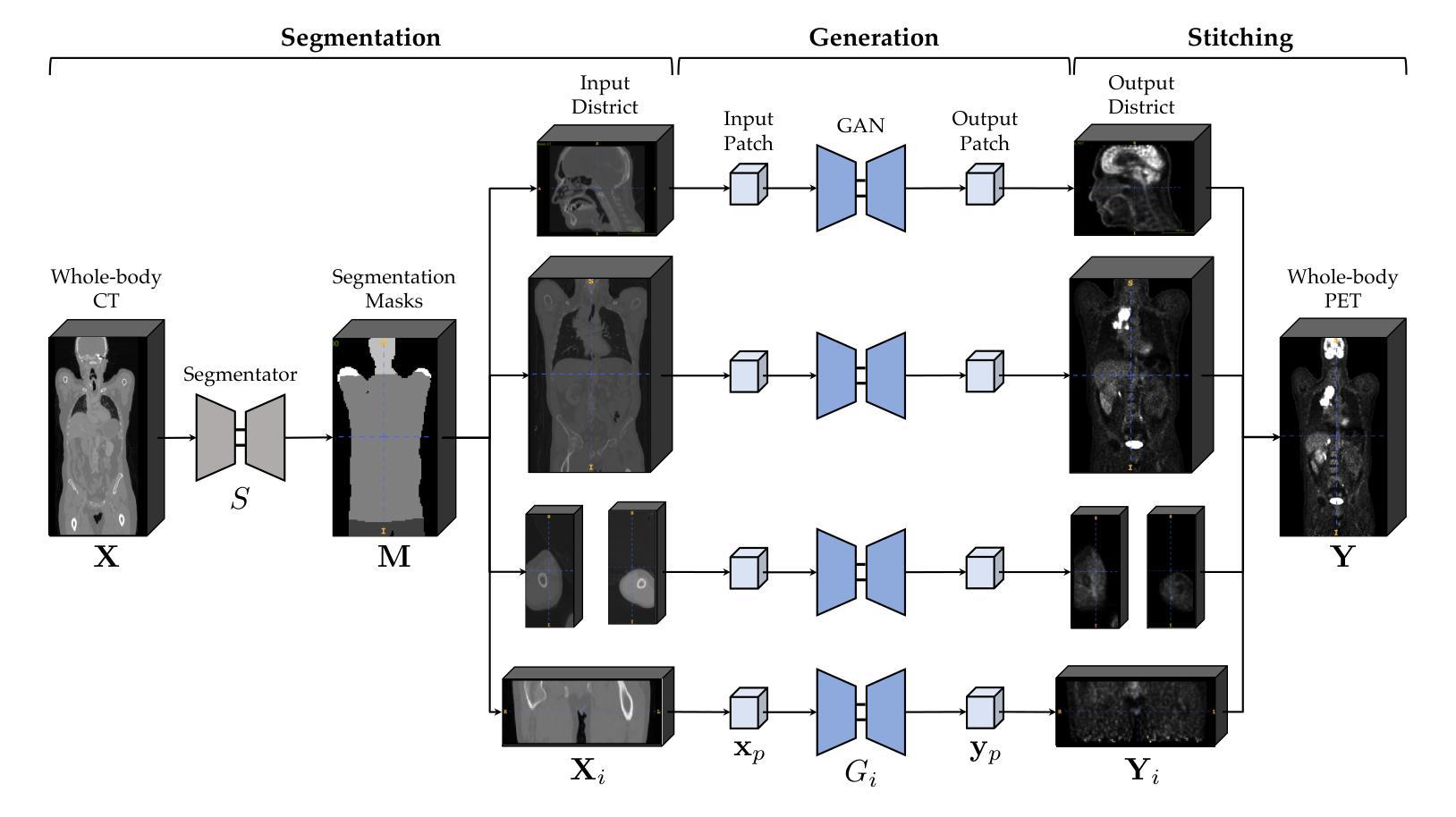
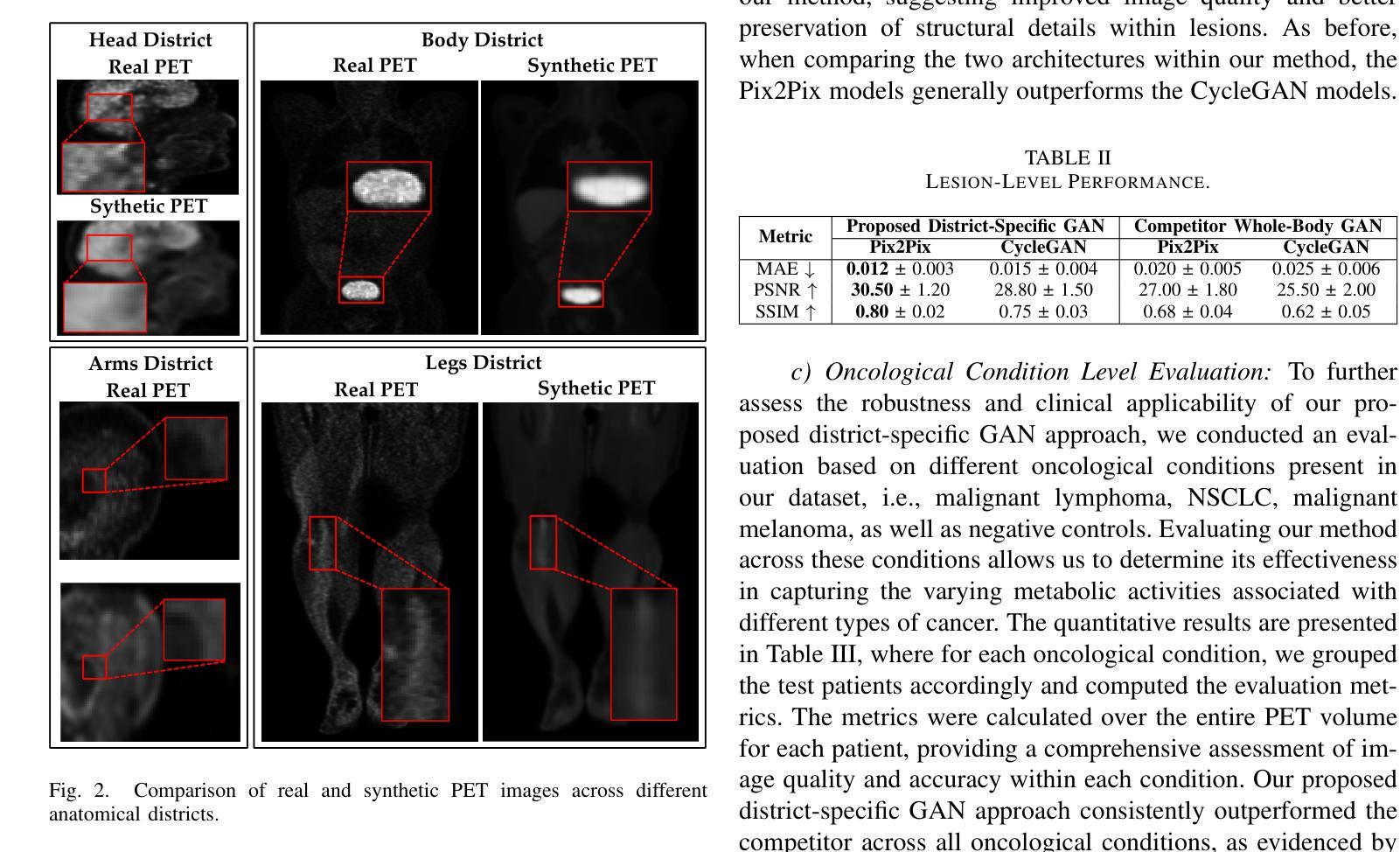
Whole-Body Image-to-Image Translation for a Virtual Scanner in a Healthcare Digital Twin
Authors:Valerio Guarrasi, Francesco Di Feola, Rebecca Restivo, Lorenzo Tronchin, Paolo Soda
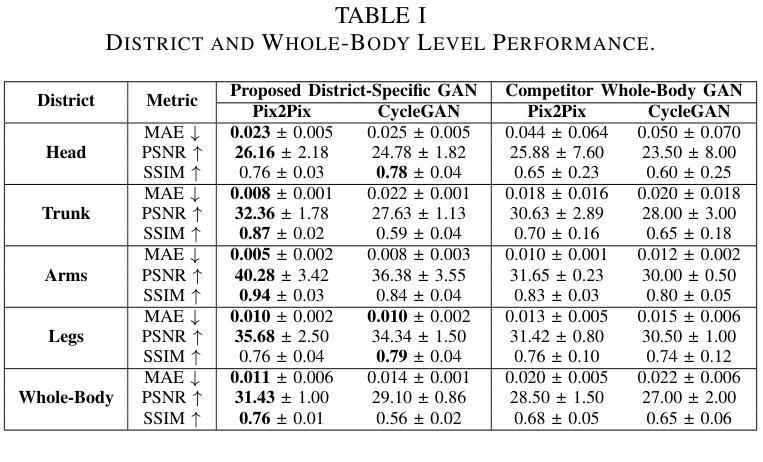
Generating positron emission tomography (PET) images from computed tomography (CT) scans via deep learning offers a promising pathway to reduce radiation exposure and costs associated with PET imaging, improving patient care and accessibility to functional imaging. Whole-body image translation presents challenges due to anatomical heterogeneity, often limiting generalized models. We propose a framework that segments whole-body CT images into four regions-head, trunk, arms, and legs-and uses district-specific Generative Adversarial Networks (GANs) for tailored CT-to-PET translation. Synthetic PET images from each region are stitched together to reconstruct the whole-body scan. Comparisons with a baseline non-segmented GAN and experiments with Pix2Pix and CycleGAN architectures tested paired and unpaired scenarios. Quantitative evaluations at district, whole-body, and lesion levels demonstrated significant improvements with our district-specific GANs. Pix2Pix yielded superior metrics, ensuring precise, high-quality image synthesis. By addressing anatomical heterogeneity, this approach achieves state-of-the-art results in whole-body CT-to-PET translation. This methodology supports healthcare Digital Twins by enabling accurate virtual PET scans from CT data, creating virtual imaging representations to monitor, predict, and optimize health outcomes.
通过深度学习将从计算机断层扫描(CT)生成的正电子发射断层扫描(PET)图像成为一种有前途的途径,可以减少与PET成像相关的辐射暴露和成本,改善病人护理和功能性成像的可及性。全身图像翻译由于解剖结构异质性而面临挑战,常常限制通用模型的应用。我们提出了一个框架,该框架将全身CT图像分割为四个区域:头部、躯干、手臂和腿部,并使用特定区域的生成对抗网络(GANs)进行定制的CT到PET翻译。来自每个区域的合成PET图像被拼接在一起以重建全身扫描。与基线非分段GAN的比较,以及与Pix2Pix和CycleGAN架构的实验测试了配对和非配对情况。在地区、全身和病灶水平的定量评估证明,我们的地区特定GANs有显著改善。Pix2Pix产生了优越的指标,确保精确、高质量的图像合成。通过解决解剖结构异质性,该方法在全身CT到PET翻译方面达到了最新水平。这种方法通过从CT数据中生成准确的虚拟PET扫描,支持医疗保健数字孪生,创建虚拟成像表示来监测、预测和优化健康结果。
论文及项目相关链接
Summary
深度学习在生成正电子发射断层扫描(PET)图像方面具有巨大潜力,能够从计算机断层扫描(CT)图像生成PET图像,有望减少辐射暴露和相关成本,改善患者护理并增加功能成像的可访问性。本文提出了一种基于区域特定生成对抗网络(GANs)的框架,用于CT到PET的转换。通过对全身CT图像进行区域分割和定制化的GAN训练,该框架实现了更准确和高效的图像转换。实验结果证明了其在不同区域的定量评估上的优势。该框架在健康护理的数字双胞胎(Digital Twin)应用中具有潜在价值,可通过虚拟PET扫描从CT数据中生成准确的虚拟成像表示,以监测、预测和优化健康结果。
Key Takeaways
- 深度学习可以用于从CT扫描生成PET图像,有助于减少辐射暴露和成本。
- 一种基于区域特定GANs的框架被提出用于CT到PET的转换。
- 通过分割全身CT图像为不同区域并训练特定的GANs,实现了更准确和高效的图像转换。
- 与非分段GAN和Pix2Pix及CycleGAN架构的比较实验证明了该框架在定量评估上的优势。
- Pix2Pix架构在精确高质量的图像合成方面表现出最佳性能。
- 该框架解决了由于解剖结构差异带来的挑战,实现了最先进的全身CT到PET转换效果。
点此查看论文截图

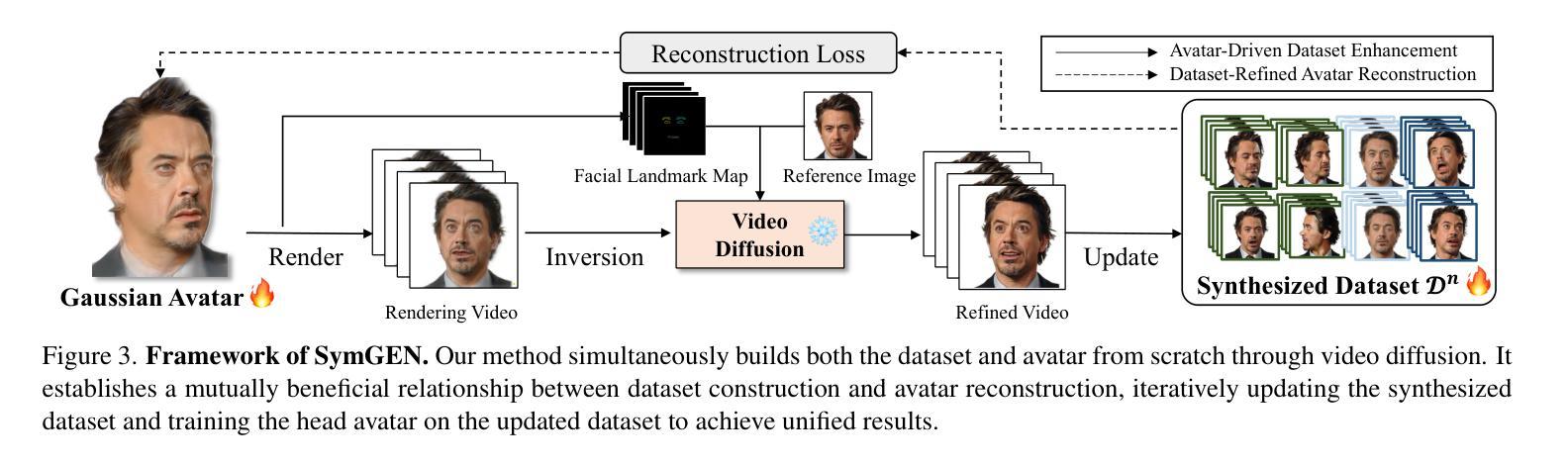
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
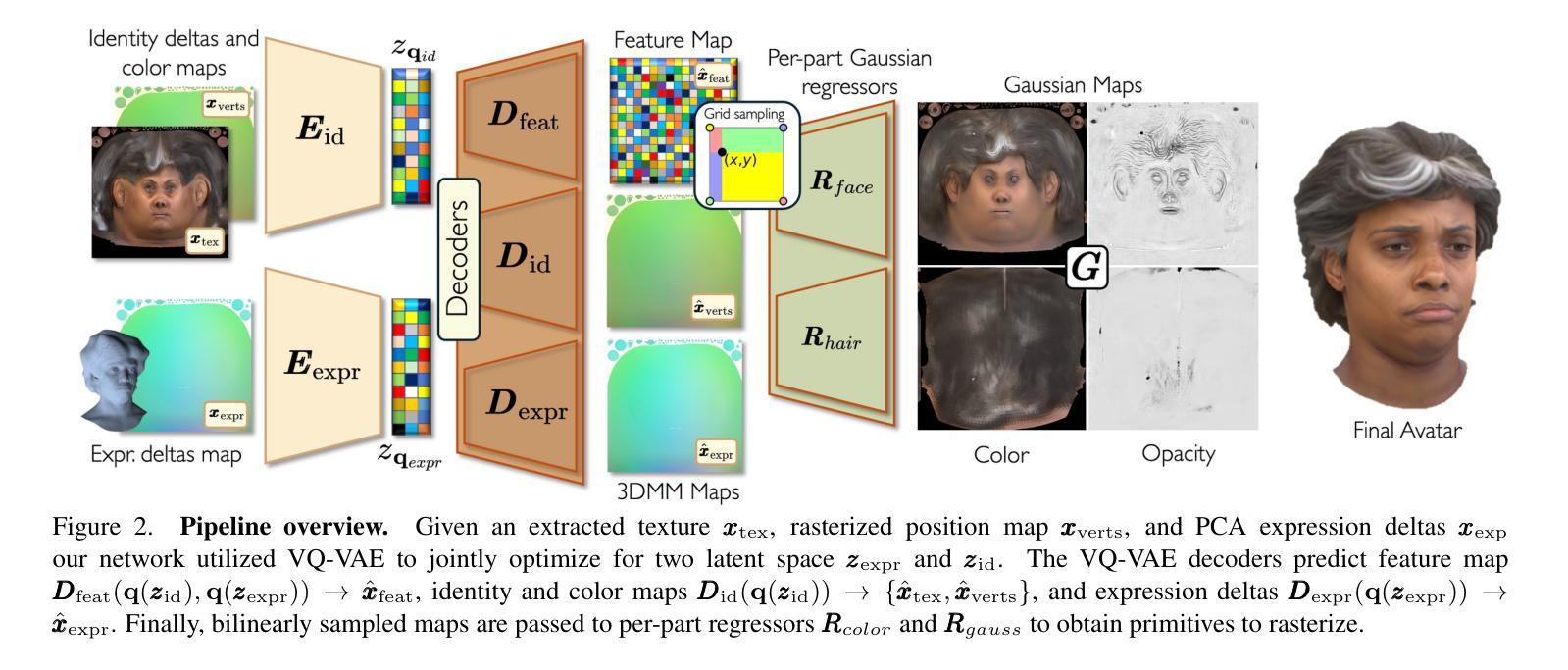
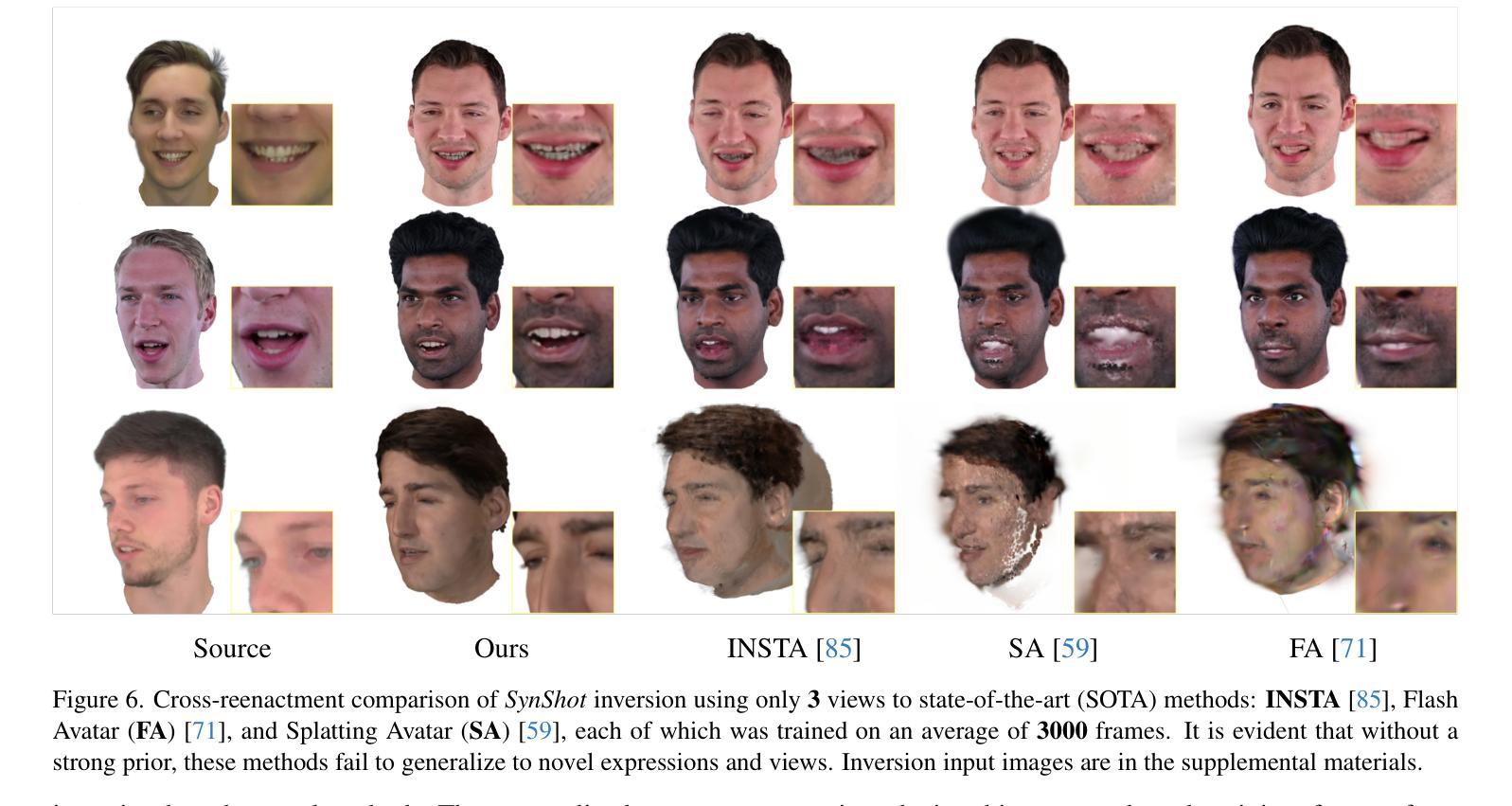
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了一种名为SynShot的新方法,用于基于合成先验的少数镜头驱动头部化身倒置。我们解决了三大挑战。首先,训练可控的3D生成网络需要大量的不同序列,而图像和高品质跟踪网格的配对并不总是可用。其次,真实数据的使用受到严格监管(例如,在《通用数据保护条例》下,当参与者撤回同意时,必须频繁删除模型和删除数据)。不受这些约束的合成数据是一个吸引人的选择。第三,最先进的单眼化身模型很难推广到新的视角和表情,缺乏强大的先验知识并且经常过度拟合特定的视角分布。受仅使用合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从包含不同身份、表情和视角的大量合成头部数据中学习先验模型。凭借少数输入图像,SynShot微调了预训练的合成先验以弥合领域差距,从而建立了一个逼真的头部化身模型,该模型可以推广到新的表情和视角。我们使用3D高斯贴片技术和卷积编码器-解码器来建立头部化身模型,该编码器-解码器在UV纹理空间中输出高斯参数。考虑到头部各部分的建模复杂性存在差异(例如皮肤和头发),我们将先验值嵌入到具有对每部分基本要素数量进行上采样的显式控制中。与最新的单眼和基于GAN的方法相比,SynShot极大地提高了新型视角和表情的合成效果。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
基于合成先验数据的新型SynShot方法解决了驾驶头精灵少数样本的逆向问题。该方法解决了三大挑战:缺乏多样化的图像和高质量追踪网格的训练数据、真实数据的使用受法规严格限制,以及目前单目头像模型在新视角和表情下的泛化能力有限。SynShot通过学习大型合成头像数据库的先验模型来填补这一空白,该数据库包含多样的身份、表情和视角。仅使用少量输入图像,SynShot就能微调预训练的合成先验模型,以弥补领域差距,并建立一个真实感十足的头像精灵模型,能够泛化到新的表情和视角。该模型采用三维高斯贴图编码器和输出高斯参数的卷积编码器解码器构建头像精灵模型。不同头部组件(如皮肤和头发)的建模复杂性不同,因此我们的先验模型具有明确的控制功能,可以按需增加每个组件的基本单位数量。相较于现有的单目方法和基于GAN的方法,SynShot在新型视角和表情合成上显著提升表现。
Key Takeaways
- SynShot是一种解决驾驶头精灵少数样本逆向问题的新方法,基于合成先验数据。
- 该方法解决了训练3D生成网络的主要挑战,包括获取多样化训练数据、真实数据使用的法规限制,以及现有模型在新视角和表情下的泛化能力问题。
- SynShot通过学习和利用大型合成头像数据库的先验模型来弥补领域差距。
- 仅需少量输入图像,SynShot就能微调预训练的合成先验模型。
- 该模型采用三维高斯贴图和卷积编码器解码器构建头像模型,具有优秀的真实感和泛化能力。
- 不同头部组件的建模复杂性不同,因此SynShot具有明确的控制功能,可以按需增加每个组件的基本单位数量。
点此查看论文截图




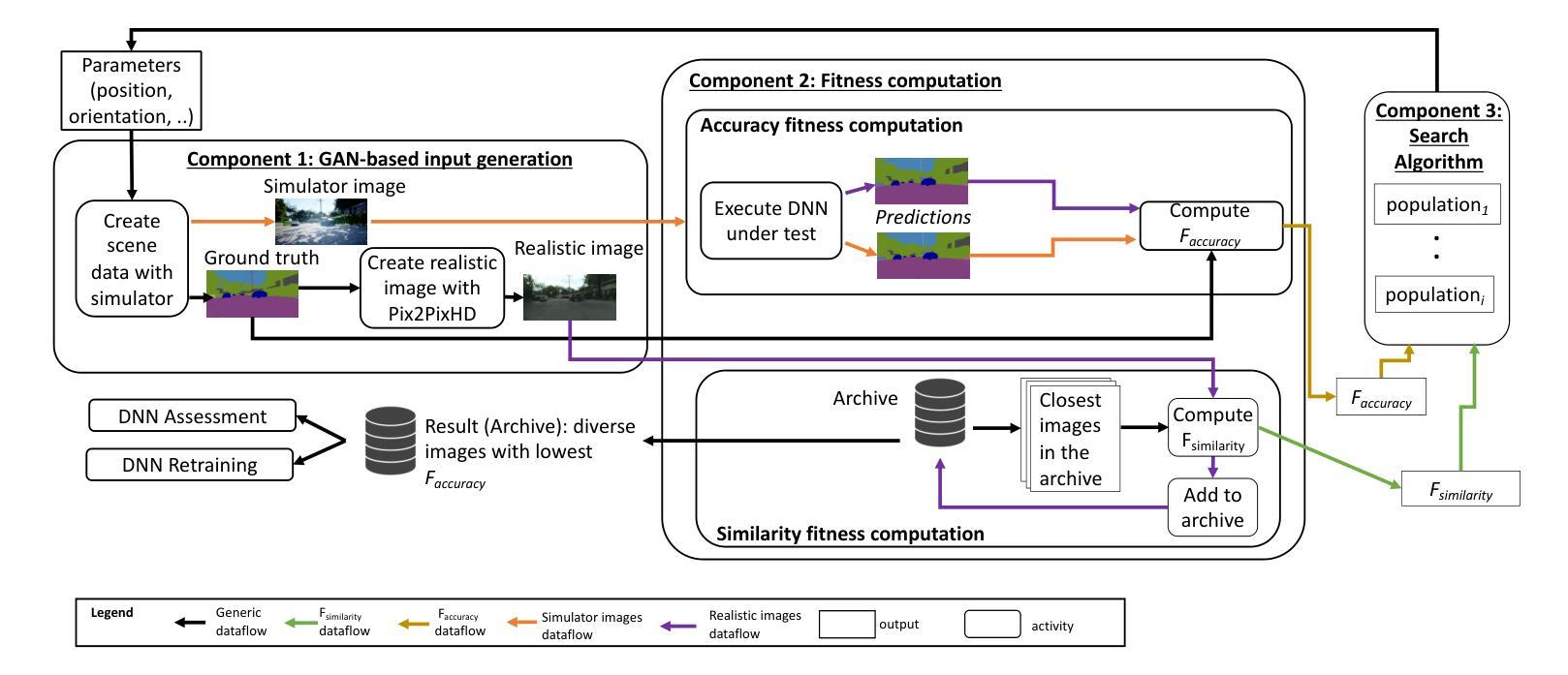
Search-based DNN Testing and Retraining with GAN-enhanced Simulations
Authors:Mohammed Oualid Attaoui, Fabrizio Pastore, Lionel Briand
In safety-critical systems (e.g., autonomous vehicles and robots), Deep Neural Networks (DNNs) are becoming a key component for computer vision tasks, particularly semantic segmentation. Further, since the DNN behavior cannot be assessed through code inspection and analysis, test automation has become an essential activity to gain confidence in the reliability of DNNs. Unfortunately, state-of-the-art automated testing solutions largely rely on simulators, whose fidelity is always imperfect, thus affecting the validity of test results. To address such limitations, we propose to combine meta-heuristic search, used to explore the input space using simulators, with Generative Adversarial Networks (GANs), to transform the data generated by simulators into realistic input images. Such images can be used both to assess the DNN performance and to retrain the DNN more effectively. We applied our approach to a state-of-the-art DNN performing semantic segmentation and demonstrated that it outperforms a state-of-the-art GAN-based testing solution and several baselines. Specifically, it leads to the largest number of diverse images leading to the worst DNN performance. Further, the images generated with our approach, lead to the highest improvement in DNN performance when used for retraining. In conclusion, we suggest to always integrate GAN components when performing search-driven, simulator-based testing.
在安全关键系统(例如自主车辆和机器人)中,深度神经网络(DNN)已成为计算机视觉任务的关键组件,特别是在语义分割方面。此外,由于无法通过对代码的检查和分析来评估DNN的行为,因此测试自动化已成为建立对DNN可靠性信心的重要活动。然而,最先进的自动化测试解决方案在很大程度上依赖于模拟器,模拟器的逼真度总是不完美的,从而影响测试结果的有效性。为了解决这些限制,我们提出将元启发式搜索(用于使用模拟器探索输入空间)与生成对抗网络(GANs)相结合,将模拟器生成的数据转换为逼真的输入图像。这些图像可用于评估DNN的性能并更有效地重新训练DNN。我们将该方法应用于执行语义分割的最先进DNN,并证明其在性能上超过了基于GAN的最先进测试解决方案和几个基线。具体来说,它产生了导致DNN性能最差的最多样化图像数量最多。此外,使用我们的方法生成的图像在用于重新训练时,对DNN性能的提升最大。总之,在进行基于搜索和模拟器的测试时,建议始终集成GAN组件。
论文及项目相关链接
PDF 18 pages, 5 figures, 13 tables
Summary
针对安全关键系统(如自动驾驶汽车和机器人)中的深度神经网络(DNN)可靠性测试,因模拟器存在缺陷,提出结合元启发式搜索与生成对抗网络(GANs)的解决方案。该方案能通过生成真实输入图像评估DNN性能并有效重训DNN。实验证明,该方法优于现有GAN测试解决方案和其他基线方法。
Key Takeaways
- 在安全关键系统中,深度神经网络(DNN)已成为计算机视觉任务的关键组件,特别是在语义分割方面。
- 由于DNN行为无法通过代码审查和分析来评估,因此测试自动化对于获得对其可靠性的信心至关重要。
- 当前自动化测试解决方案主要依赖于模拟器,但其逼真度有限,影响测试结果的有效性。
- 提出结合元启发式搜索和GANs的解决方案,以通过模拟器探索输入空间并生成真实输入图像。
- 该方法能够更有效地评估DNN性能和重训DNN。
- 实验证明,该方法优于现有的GAN测试解决方案和其他基线方法,能够生成导致DNN性能下降的最大数量不同图像。
点此查看论文截图