⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
LaPIG: Cross-Modal Generation of Paired Thermal and Visible Facial Images
Authors:Leyang Wang, Joice Lin
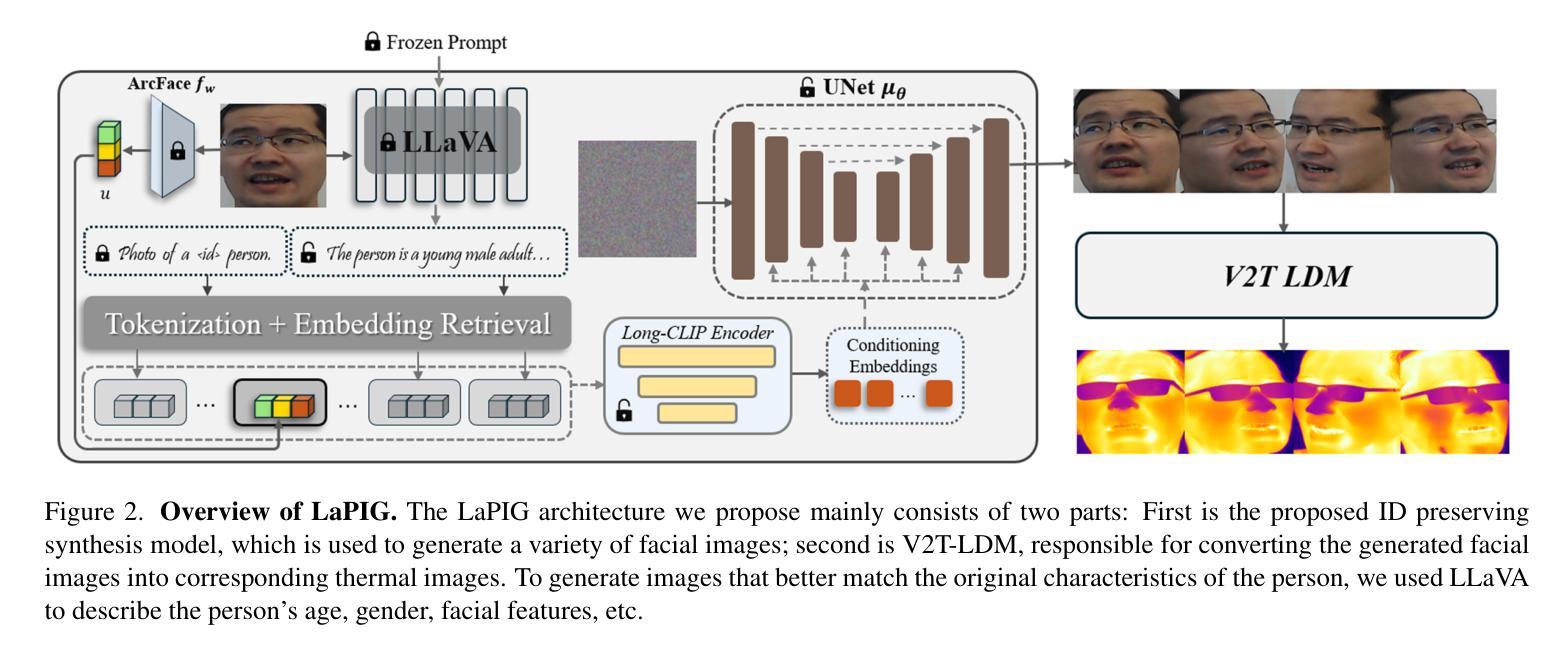
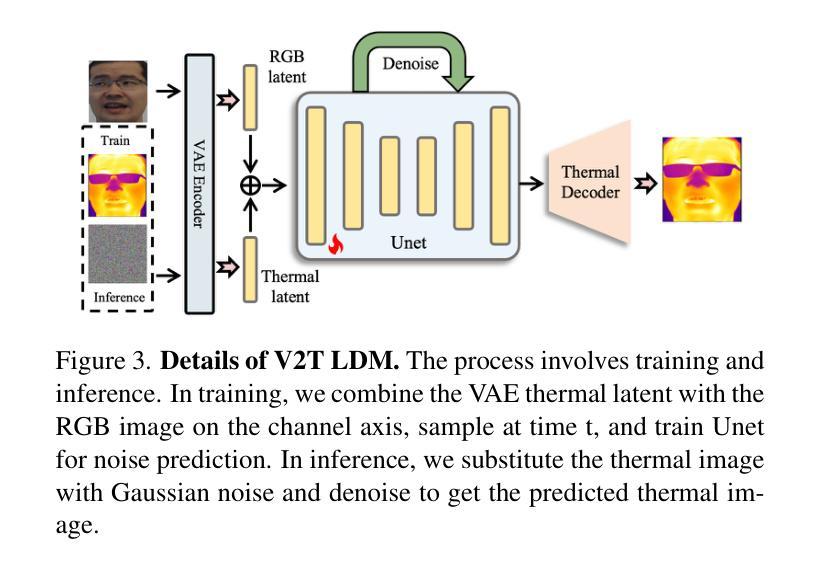
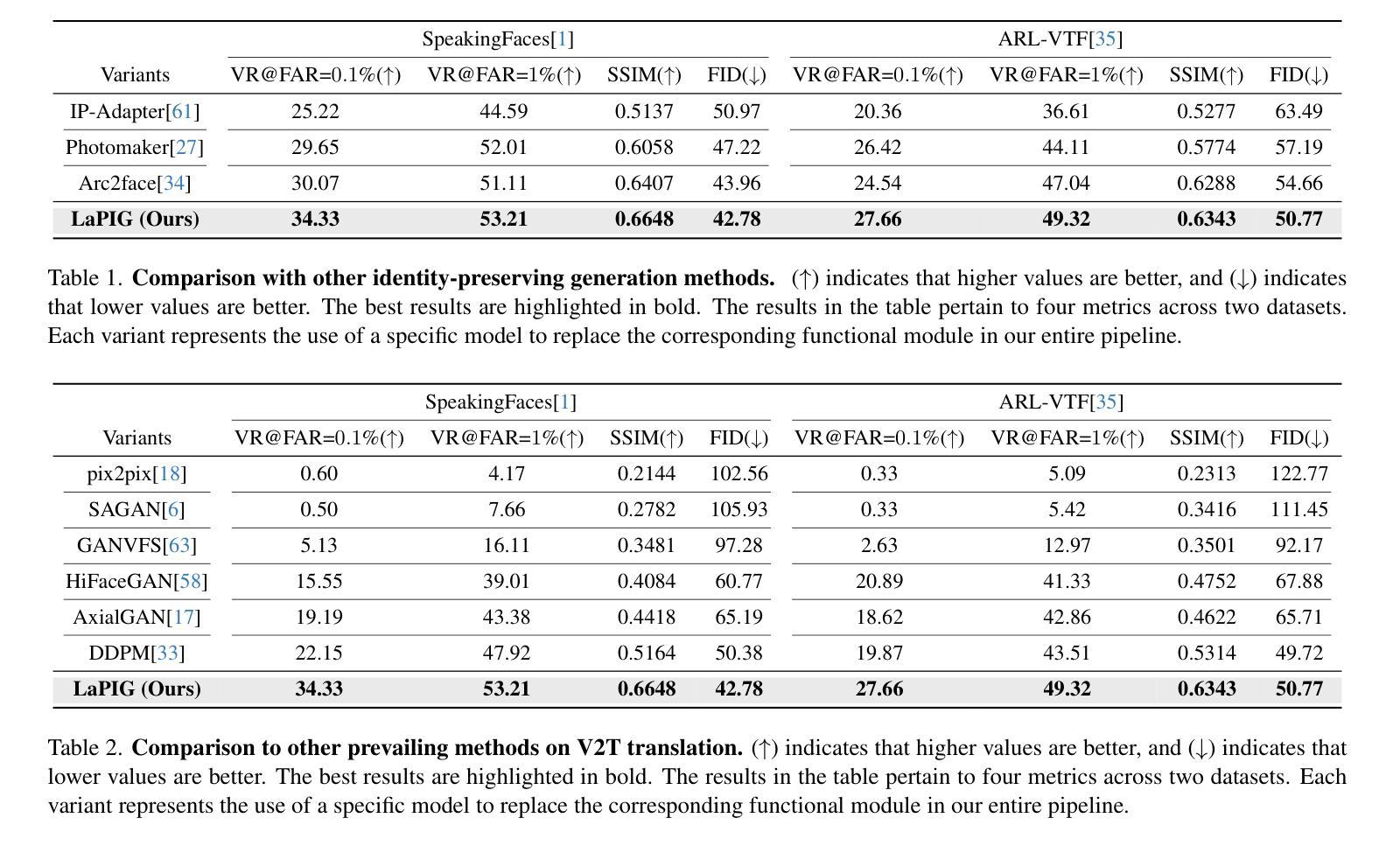
The success of modern machine learning, particularly in facial translation networks, is highly dependent on the availability of high-quality, paired, large-scale datasets. However, acquiring sufficient data is often challenging and costly. Inspired by the recent success of diffusion models in high-quality image synthesis and advancements in Large Language Models (LLMs), we propose a novel framework called LLM-assisted Paired Image Generation (LaPIG). This framework enables the construction of comprehensive, high-quality paired visible and thermal images using captions generated by LLMs. Our method encompasses three parts: visible image synthesis with ArcFace embedding, thermal image translation using Latent Diffusion Models (LDMs), and caption generation with LLMs. Our approach not only generates multi-view paired visible and thermal images to increase data diversity but also produces high-quality paired data while maintaining their identity information. We evaluate our method on public datasets by comparing it with existing methods, demonstrating the superiority of LaPIG.
现代机器学习,特别是在面部翻译网络方面的成功,在很大程度上依赖于高质量、配对、大规模数据集的可用性。然而,获取足够的数据通常具有挑战性和成本高昂。受最近在高质量图像合成中的扩散模型成功以及大型语言模型(LLM)进展的启发,我们提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的描述来构建全面、高质量配对的可见光和热图像。我们的方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的热图像翻译、以及使用LLM的描述生成。我们的方法不仅生成多视角配对的可见光和热图像以增加数据多样性,而且还在保持身份信息的同时产生高质量配对数据。我们在公共数据集上通过将其与现有方法进行对比,验证了LaPIG方法的优越性。
论文及项目相关链接
Summary
现代机器学习,特别是在面部翻译网络方面的成功,高度依赖于高质量、配对、大规模的数据集的可获得性。然而,获取足够的数据往往具有挑战性和成本高昂。受扩散模型在高质量图像合成和大型语言模型(LLM)进步的启发,我们提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的标题构建全面、高质量配对可见和红外图像。我们的方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的红外图像翻译、以及使用LLM的标题生成。我们的方法不仅生成多视角配对可见和红外图像以增加数据多样性,而且能够在保持身份信息的条件下产生高质量配对数据。我们在公共数据集上评估了我们的方法,与现有方法进行比较,证明了LaPIG的优越性。
Key Takeaways
- 现代机器学习的成功高度依赖于高质量、配对、大规模数据集。
- 获取足够的数据具有挑战性和成本高昂。
- LaPIG框架利用LLM生成的标题构建高质量配对图像。
- LaPIG方法包括可见图像合成、红外图像翻译和标题生成三部分。
- LaPIG不仅能增加数据多样性,还能在保持身份信息的前提下产生高质量配对数据。
- LaPIG在公共数据集上的表现优于现有方法。
点此查看论文截图

OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection
Authors:Max Gutbrod, David Rauber, Danilo Weber Nunes, Christoph Palm
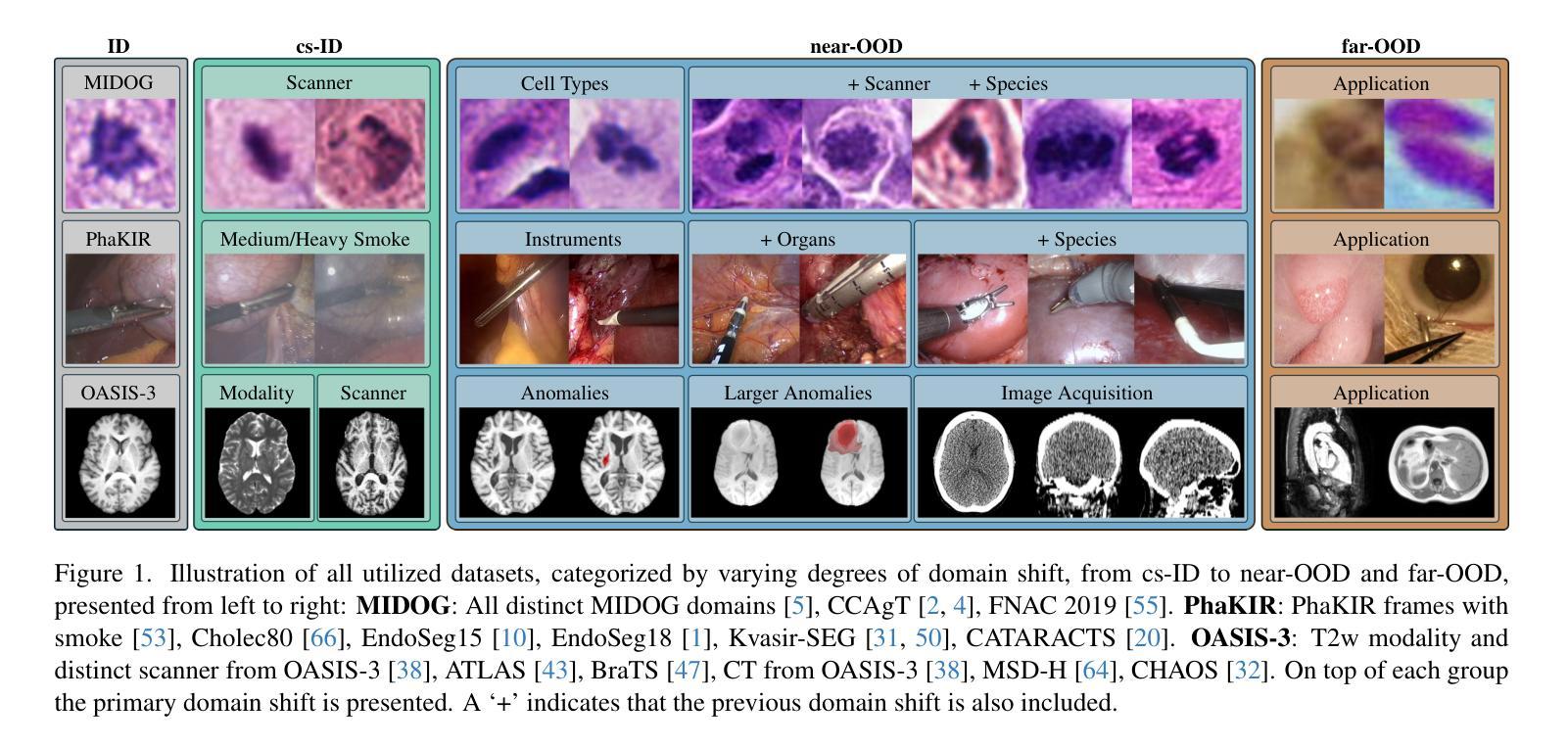
The growing reliance on Artificial Intelligence (AI) in critical domains such as healthcare demands robust mechanisms to ensure the trustworthiness of these systems, especially when faced with unexpected or anomalous inputs. This paper introduces the Open Medical Imaging Benchmarks for Out-Of-Distribution Detection (OpenMIBOOD), a comprehensive framework for evaluating out-of-distribution (OOD) detection methods specifically in medical imaging contexts. OpenMIBOOD includes three benchmarks from diverse medical domains, encompassing 14 datasets divided into covariate-shifted in-distribution, near-OOD, and far-OOD categories. We evaluate 24 post-hoc methods across these benchmarks, providing a standardized reference to advance the development and fair comparison of OOD detection methods. Results reveal that findings from broad-scale OOD benchmarks in natural image domains do not translate to medical applications, underscoring the critical need for such benchmarks in the medical field. By mitigating the risk of exposing AI models to inputs outside their training distribution, OpenMIBOOD aims to support the advancement of reliable and trustworthy AI systems in healthcare. The repository is available at https://github.com/remic-othr/OpenMIBOOD.
随着人工智能(AI)在医疗等关键领域的依赖程度不断增长,特别是在面对意外或异常输入时,需要强大的机制来确保这些系统的可信度。本文介绍了用于异常检测开放的医学成像基准测试(OpenMIBOOD),这是一个专门用于评估医学成像环境中异常检测方法的综合框架。OpenMIBOOD包含来自不同医学领域的三个基准测试,涵盖14个数据集,分为协变量转移内部分布、接近异常和远离异常类别。我们在这些基准测试上评估了24种事后方法,为推进异常检测方法的发展和公平比较提供了标准化参考。结果表明,自然图像域的大规模异常检测基准测试的结果并不能转化为医学应用,这突显了医学领域对这种基准测试的迫切需求。通过降低人工智能模型暴露于训练分布外的输入的风险,OpenMIBOOD旨在支持医疗保健中可靠和可信的人工智能系统的进步。该存储库可在https://github.com/remic-othr/OpenMIBOOD找到。
论文及项目相关链接
Summary
人工智能在医疗等关键领域的应用日益广泛,但面对意外或异常输入时,需要确保系统的可信度。本文介绍了开放医学成像基准测试(OpenMIBOOD),这是一个专门用于评估医学成像上下文中离群值检测方法的综合框架。OpenMIBOOD包括来自不同医学领域的三个基准测试,涵盖14个数据集,分为协变量偏移内分布、近离群值和远离群值类别。我们在这三个基准测试上评估了24种事后方法,为推进离群值检测方法的开发和公平比较提供了标准化的参考。研究结果表明,自然图像域的大规模离群值检测基准测试的结果并不适用于医学应用,强调了医学领域需要此类基准测试的重要性。通过降低AI模型暴露于训练分布外输入的风险,OpenMIBOOD旨在支持可靠和可信赖的AI系统在医疗保健领域的发展。
Key Takeaways
- OpenMIBOOD是一个专门用于评估医学成像中离群值检测方法的综合框架。
- 该框架包括来自不同医学领域的三个基准测试,涵盖多种数据集。
- 研究发现,自然图像领域的离群值检测基准测试不适用于医学应用。
- OpenMIBOOD为推进离群值检测方法的开发和公平比较提供了标准化的参考。
- AI在医疗等领域的应用需要确保系统的可信度,尤其是在面对意外或异常输入时。
- OpenMIBOOD旨在降低AI模型暴露于训练分布外输入的风险。
点此查看论文截图

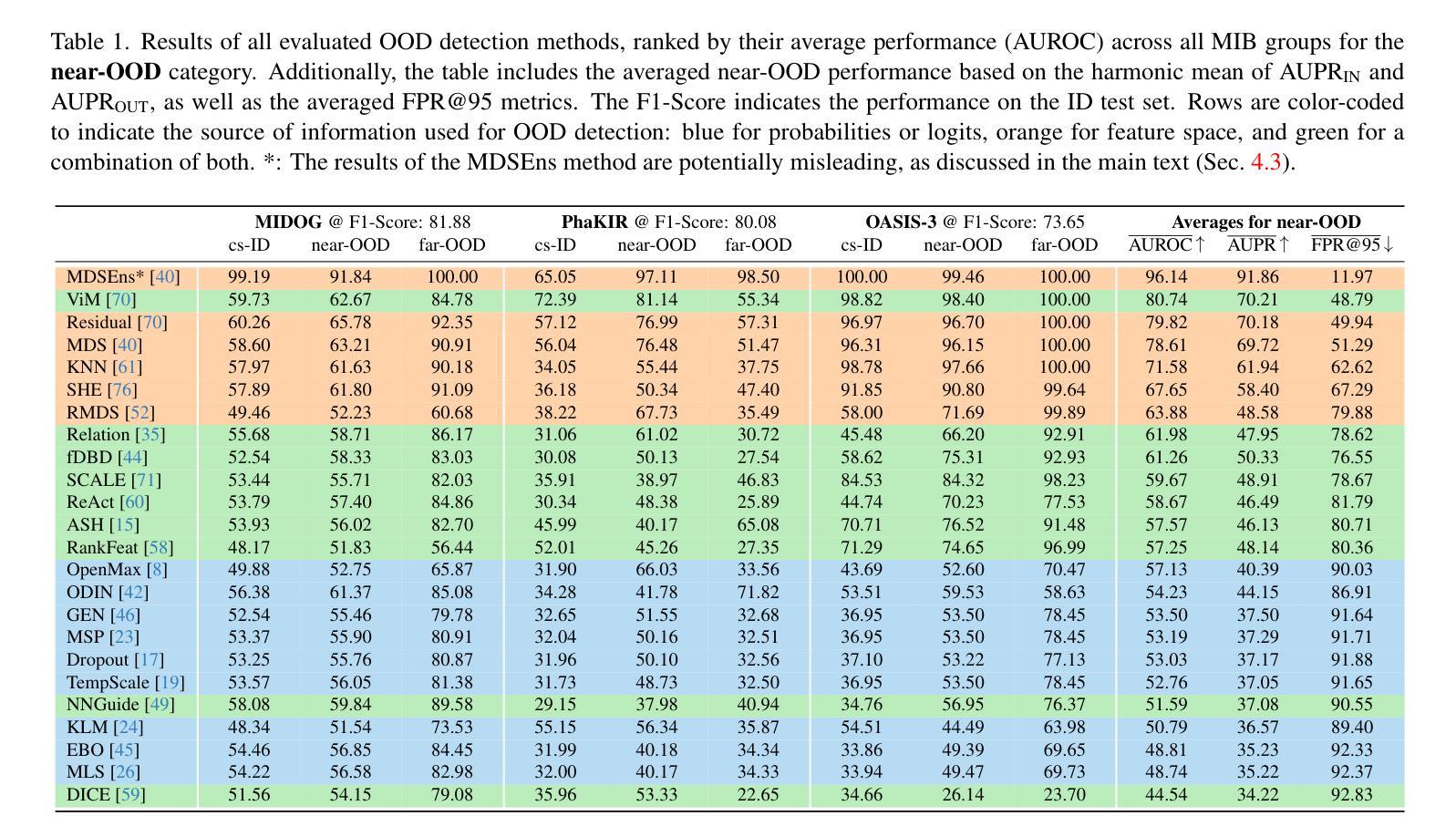
Whole-Body Image-to-Image Translation for a Virtual Scanner in a Healthcare Digital Twin
Authors:Valerio Guarrasi, Francesco Di Feola, Rebecca Restivo, Lorenzo Tronchin, Paolo Soda
Generating positron emission tomography (PET) images from computed tomography (CT) scans via deep learning offers a promising pathway to reduce radiation exposure and costs associated with PET imaging, improving patient care and accessibility to functional imaging. Whole-body image translation presents challenges due to anatomical heterogeneity, often limiting generalized models. We propose a framework that segments whole-body CT images into four regions-head, trunk, arms, and legs-and uses district-specific Generative Adversarial Networks (GANs) for tailored CT-to-PET translation. Synthetic PET images from each region are stitched together to reconstruct the whole-body scan. Comparisons with a baseline non-segmented GAN and experiments with Pix2Pix and CycleGAN architectures tested paired and unpaired scenarios. Quantitative evaluations at district, whole-body, and lesion levels demonstrated significant improvements with our district-specific GANs. Pix2Pix yielded superior metrics, ensuring precise, high-quality image synthesis. By addressing anatomical heterogeneity, this approach achieves state-of-the-art results in whole-body CT-to-PET translation. This methodology supports healthcare Digital Twins by enabling accurate virtual PET scans from CT data, creating virtual imaging representations to monitor, predict, and optimize health outcomes.
通过深度学习从计算机断层扫描(CT)生成正电子发射断层扫描(PET)图像,为减少PET成像相关的辐射暴露和成本提供了有前景的途径,从而改善了患者护理和功能性成像的可访问性。全身图像翻译由于解剖学的异质性而面临挑战,通常限制通用模型的应用。我们提出一个框架,将全身CT图像分割成四个区域:头部、躯干、手臂和腿部,并使用针对特定区域的生成对抗网络(GANs)进行定制的CT-to-PET翻译。来自每个区域的合成PET图像被拼接在一起,以重建全身扫描。与基线非分段GAN的比较,以及Pix2Pix和CycleGAN架构的实验测试了配对和非配对场景。在地区、全身和病灶层面的定量评估证明,我们的地区特定GANs有显著改善。Pix2Pix产生了优越的指标,确保精确、高质量的图像合成。通过解决解剖学的异质性,这种方法在全身CT-to-PET翻译中达到了最新水平。该方法通过从CT数据中生成准确的虚拟PET扫描,创建虚拟成像表示来监测、预测和优化健康结果,从而支持医疗保健数字孪生。
论文及项目相关链接
Summary
基于深度学习,从计算机断层扫描(CT)生成正电子发射断层扫描(PET)图像是一种减少PET成像的辐射暴露和成本的途径,可以改善患者护理和功能性成像的可访问性。本文提出一种框架,将全身CT图像分割为四个区域(头部、躯干、手臂和腿部),并利用特定区域的生成对抗网络(GANs)进行量身定制的CT-to-PET转换。来自每个区域的合成PET图像被拼接在一起以重建全身扫描。与基线非分割GAN以及Pix2Pix和CycleGAN架构的对比实验表明,我们的区域特定GANs在区域、全身和病灶层面都有显著改进。Pix2Pix产生了优越的指标,确保了精确、高质量的图像合成。通过解决解剖异质性,该方法在全身CT-to-PET转换中实现了最新结果。此方法支持通过健康护理数字孪生技术,利用CT数据生成准确的虚拟PET扫描,创建虚拟成像表示,以监测、预测和优化健康结果。
Key Takeaways
- 利用深度学习从CT扫描生成PET图像可以减少辐射暴露和成本。
- 提出的框架将全身CT图像分割为四个区域,采用区域特定的GANs进行CT-to-PET转换。
- 合成PET图像在区域、全身和病灶层面都有显著改进。
- Pix2Pix架构在图像合成中表现优越,确保高质量结果。
- 该方法解决了解剖异质性,实现了全身CT-to-PET转换的最新结果。
- 通过创建虚拟成像表示,此方法支持健康护理数字孪生技术。
点此查看论文截图

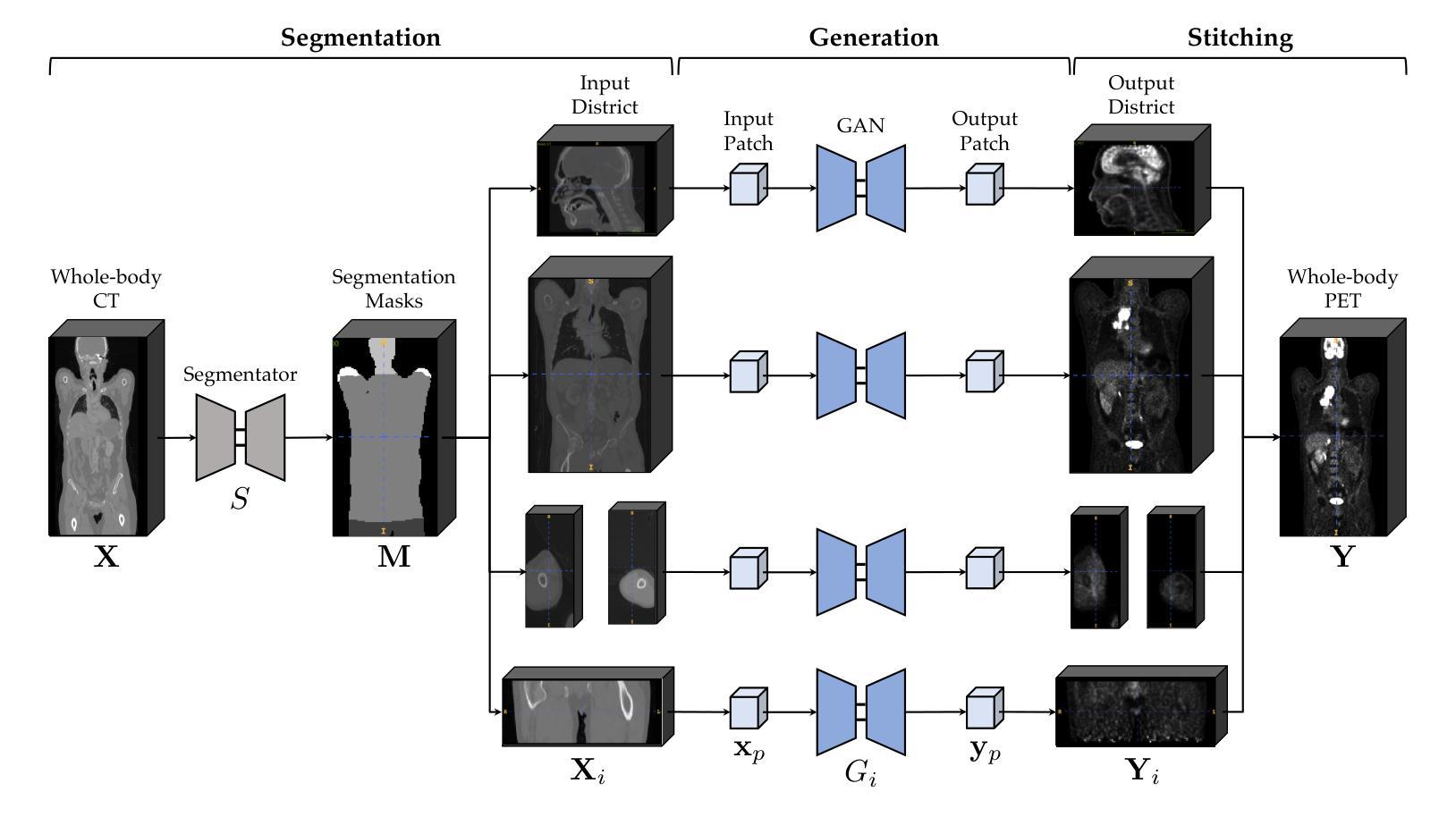
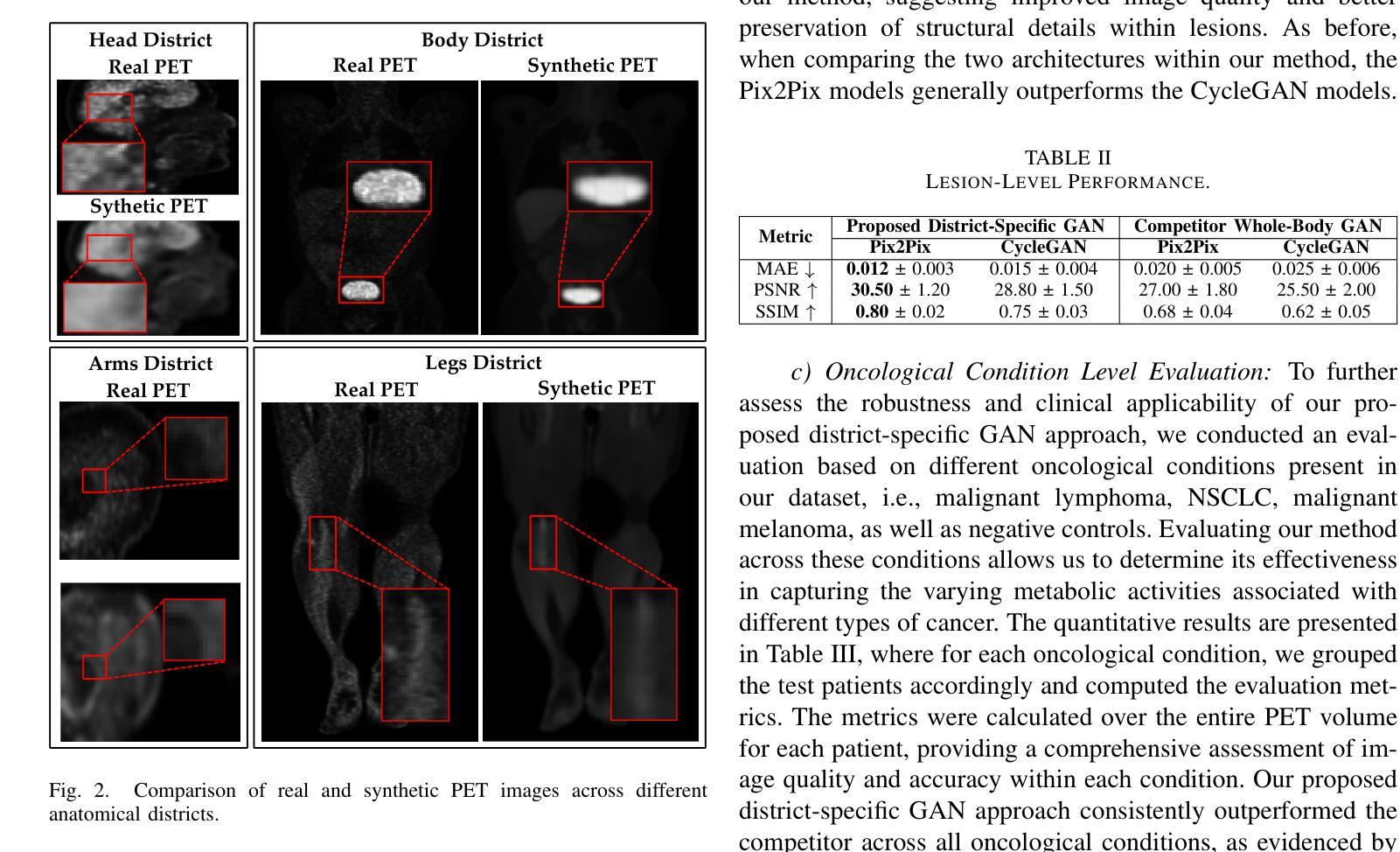
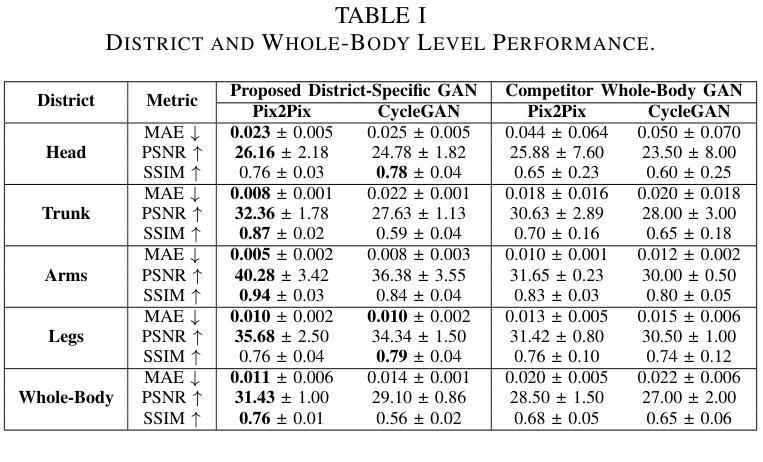
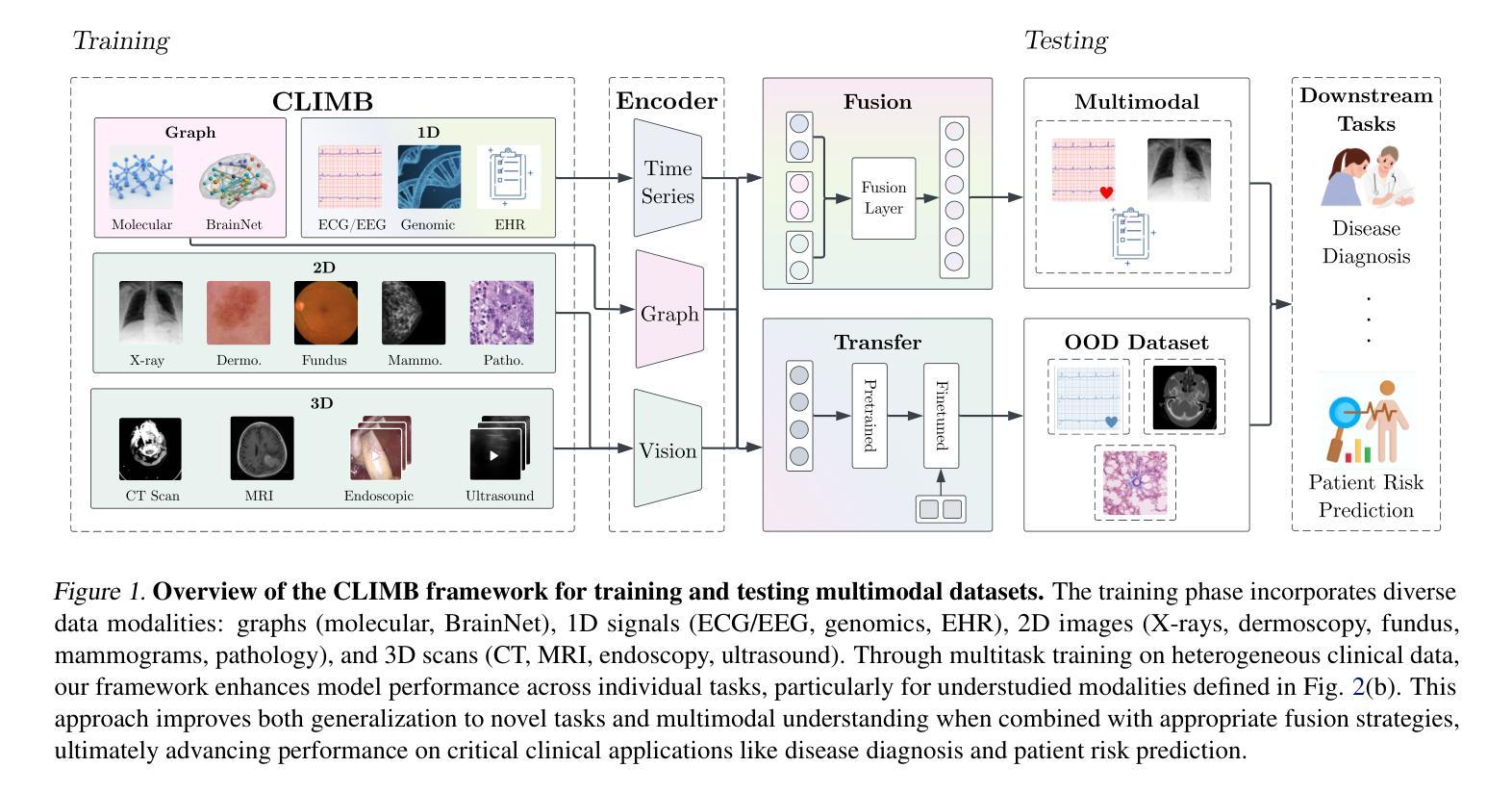
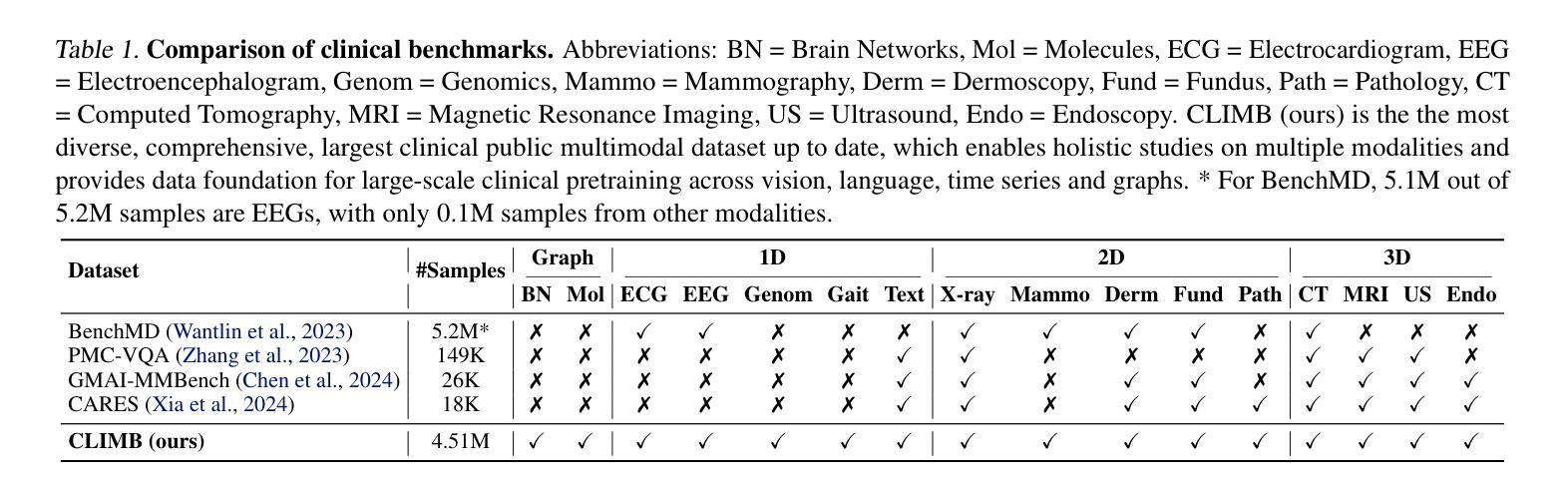
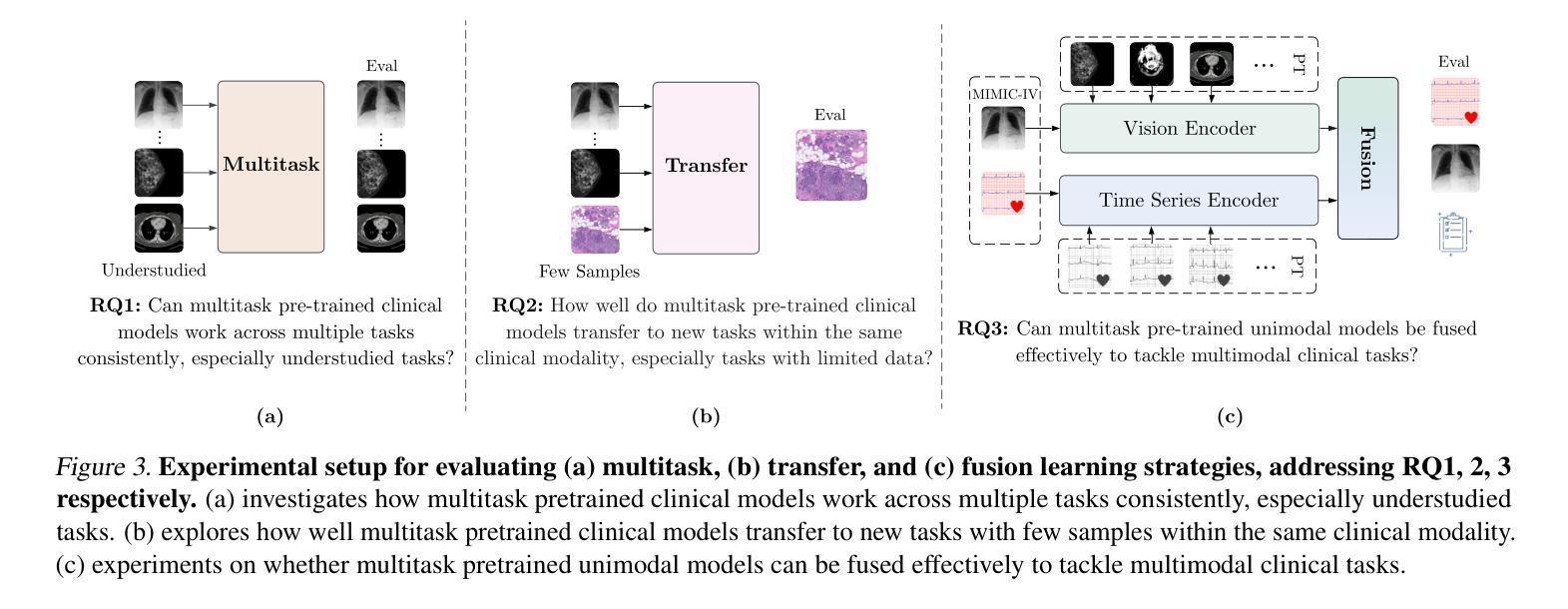
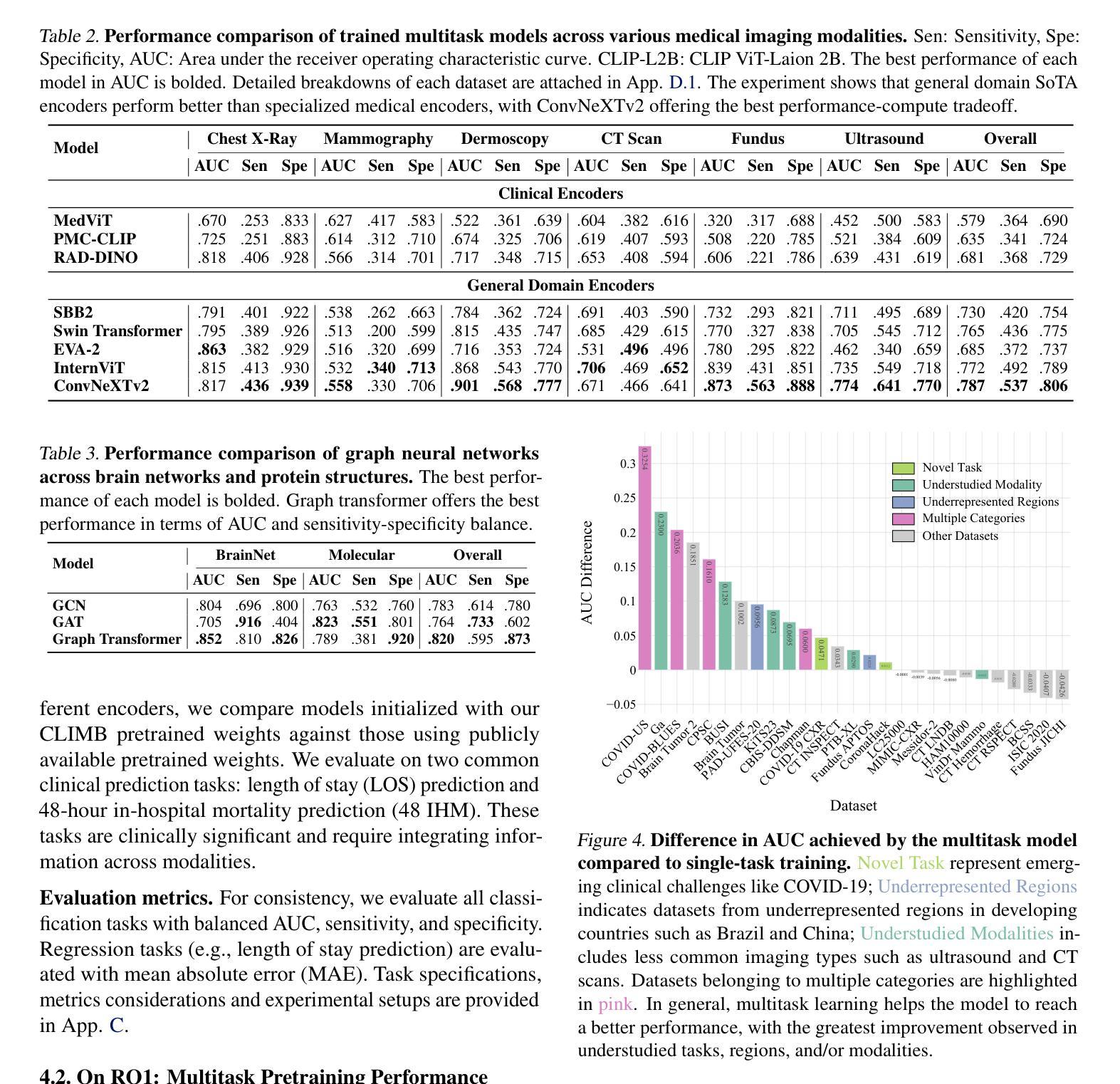
CLIMB: Data Foundations for Large Scale Multimodal Clinical Foundation Models
Authors:Wei Dai, Peilin Chen, Malinda Lu, Daniel Li, Haowen Wei, Hejie Cui, Paul Pu Liang
Recent advances in clinical AI have enabled remarkable progress across many clinical domains. However, existing benchmarks and models are primarily limited to a small set of modalities and tasks, which hinders the development of large-scale multimodal methods that can make holistic assessments of patient health and well-being. To bridge this gap, we introduce Clinical Large-Scale Integrative Multimodal Benchmark (CLIMB), a comprehensive clinical benchmark unifying diverse clinical data across imaging, language, temporal, and graph modalities. CLIMB comprises 4.51 million patient samples totaling 19.01 terabytes distributed across 2D imaging, 3D video, time series, graphs, and multimodal data. Through extensive empirical evaluation, we demonstrate that multitask pretraining significantly improves performance on understudied domains, achieving up to 29% improvement in ultrasound and 23% in ECG analysis over single-task learning. Pretraining on CLIMB also effectively improves models’ generalization capability to new tasks, and strong unimodal encoder performance translates well to multimodal performance when paired with task-appropriate fusion strategies. Our findings provide a foundation for new architecture designs and pretraining strategies to advance clinical AI research. Code is released at https://github.com/DDVD233/climb.
临床人工智能的最新进展已经在许多临床领域取得了显著的进步。然而,现有的基准测试和模型主要局限于一小部分模态和任务,这阻碍了能够全面评估患者健康和福祉的大规模多模态方法的发展。为了弥补这一差距,我们引入了临床大规模整合多模态基准测试(CLIMB),这是一个统一的临床基准,涵盖了成像、语言、时间和图形等多种临床数据的融合。CLIMB包含了451万患者样本,共计19.01万亿字节,分布于二维成像、三维视频、时间序列、图形和多模态数据。通过广泛的实证评估,我们证明多任务预训练对尚未深入研究的领域具有显著改善性能的作用,在超声和心电图分析中分别实现了高达29%和23%的单任务学习的改进。在CLIMB上进行预训练还能有效提高模型对新任务的泛化能力,强大的单模态编码器性能与任务适当的融合策略相结合时,能在多模态性能上取得良好表现。我们的研究为新的架构设计和预训练策略提供了基础,以推动临床人工智能研究的发展。代码已发布在https://github.com/DDVD233/climb。
论文及项目相关链接
Summary
临床人工智能的最新进展已促使多个临床领域的显著进步。然而,现有的基准测试和模型主要局限于有限的模态和任务,这阻碍了能够进行患者健康和福祉整体评估的大规模多模态方法的发展。为了弥补这一差距,我们推出了临床大规模综合多模态基准测试(CLIMB),这是一个统一了成像、语言、时间和图形等多种临床数据的综合临床基准。CLIMB包含451万患者样本,共计19.01万亿字节,分布于二维成像、三维视频、时间序列、图表和多模态数据。通过广泛的实证研究,我们证明了多任务预训练对较少研究的领域具有显著改善作用,在超声和心电图分析中分别实现了高达29%和23%的性能提升。在CLIMB上进行预训练还可以有效提高模型对新任务的泛化能力,强大的单模态编码器性能与适当的任务融合策略相结合时,在多模态性能上表现良好。我们的研究为新的架构设计和预训练策略提供了基础,以推动临床人工智能研究的发展。
Key Takeaways
- 临床人工智能(AI)在多个领域取得显著进展,但仍存在模态和任务上的局限性。
- 推出CLIMB基准测试,旨在统一多种临床数据模态,促进大规模多模态方法的发展。
- CLIMB包含大量患者样本和多种数据类型,有助于评估模型的性能和泛化能力。
- 多任务预训练在较少研究的领域表现出显著性能提升,如超声和心电图分析。
- 预训练有助于提高模型对新任务的适应能力,单模态编码器与任务融合策略相结合表现良好。
- 研究为临床AI研究的新架构设计和预训练策略提供了基础。
点此查看论文截图