⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
The Emperor’s New Clothes in Benchmarking? A Rigorous Examination of Mitigation Strategies for LLM Benchmark Data Contamination
Authors:Yifan Sun, Han Wang, Dongbai Li, Gang Wang, Huan Zhang
Benchmark Data Contamination (BDC)-the inclusion of benchmark testing samples in the training set-has raised increasing concerns in Large Language Model (LLM) evaluation, leading to falsely inflated performance estimates and undermining evaluation reliability. To address this, researchers have proposed various mitigation strategies to update existing benchmarks, including modifying original questions or generating new ones based on them. However, a rigorous examination of the effectiveness of these mitigation strategies remains lacking. In this paper, we design a systematic and controlled pipeline along with two novel metrics-fidelity and contamination resistance-to provide a fine-grained and comprehensive assessment of existing BDC mitigation strategies. Previous assessment methods, such as accuracy drop and accuracy matching, focus solely on aggregate accuracy, often leading to incomplete or misleading conclusions. Our metrics address this limitation by emphasizing question-level evaluation result matching. Extensive experiments with 10 LLMs, 5 benchmarks, 20 BDC mitigation strategies, and 2 contamination scenarios reveal that no existing strategy significantly improves resistance over the vanilla case (i.e., no benchmark update) across all benchmarks, and none effectively balances fidelity and contamination resistance. These findings underscore the urgent need for designing more effective BDC mitigation strategies. Our code repository is available at https://github.com/ASTRAL-Group/BDC_mitigation_assessment.
基准数据污染(BDC)——即将基准测试样本纳入训练集——在大规模语言模型(LLM)评估中引发了越来越多的担忧,导致了性能评估结果虚高,评估可靠性降低。为了解决这一问题,研究人员已经提出了各种缓解策略来更新现有基准测试,包括修改原始问题或基于它们生成新的问题。然而,对于这些缓解策略的有效性进行严谨检验仍然缺乏。在本文中,我们设计了一个系统且受控的管道,并引入了两种新型指标——保真度和抗污染度,以对现有的BDC缓解策略进行精细且全面的评估。之前的评估方法,如准确度下降和准确度匹配,只关注总体准确度,往往导致不完整或误导性的结论。我们的指标通过强调问题级别的评估结果匹配来解决这一局限性。对10个LLM、5个基准测试、20个BDC缓解策略和2个污染场景的大量实验表明,在所有的基准测试中,没有任何现有策略能显著提高对污染的抵抗力,也没有策略能有效地平衡保真度和抗污染度。这些发现突显了设计更有效的BDC缓解策略的紧迫需求。我们的代码仓库可在https://github.com/ASTRAL-Group/BDC_mitigation_assessment找到。
论文及项目相关链接
PDF 23 pages
Summary:训练集中混入基准测试样本的问题,导致大型语言模型评估性能被虚假抬高并影响评估可靠性。研究人员提出了多种缓解策略更新现有基准,但缺乏对其有效性的严格审查。本文设计了一个系统化管道和两个新指标,以精细和综合地评估现有缓解策略。实验表明,现有策略在改善抵抗力方面并不显著,需设计更有效的缓解策略。
Key Takeaways:
- 基准数据污染(BDC)问题在大型语言模型(LLM)评估中越来越受到关注。
- BDC会导致性能评估被虚假抬高,影响评估的可靠性。
- 研究人员已经提出了多种策略来缓解BDC问题,更新现有的基准测试。
- 本文设计了一个系统化管道和两个新指标(保真度和污染抵抗力)来全面评估这些缓解策略的有效性。
- 实验结果显示,现有的缓解策略并未显著提高模型的抵抗力。
- 目前没有任何策略能够在所有基准测试中有效平衡保真度和污染抵抗力。
- 需要设计更有效的BDC缓解策略。
点此查看论文截图



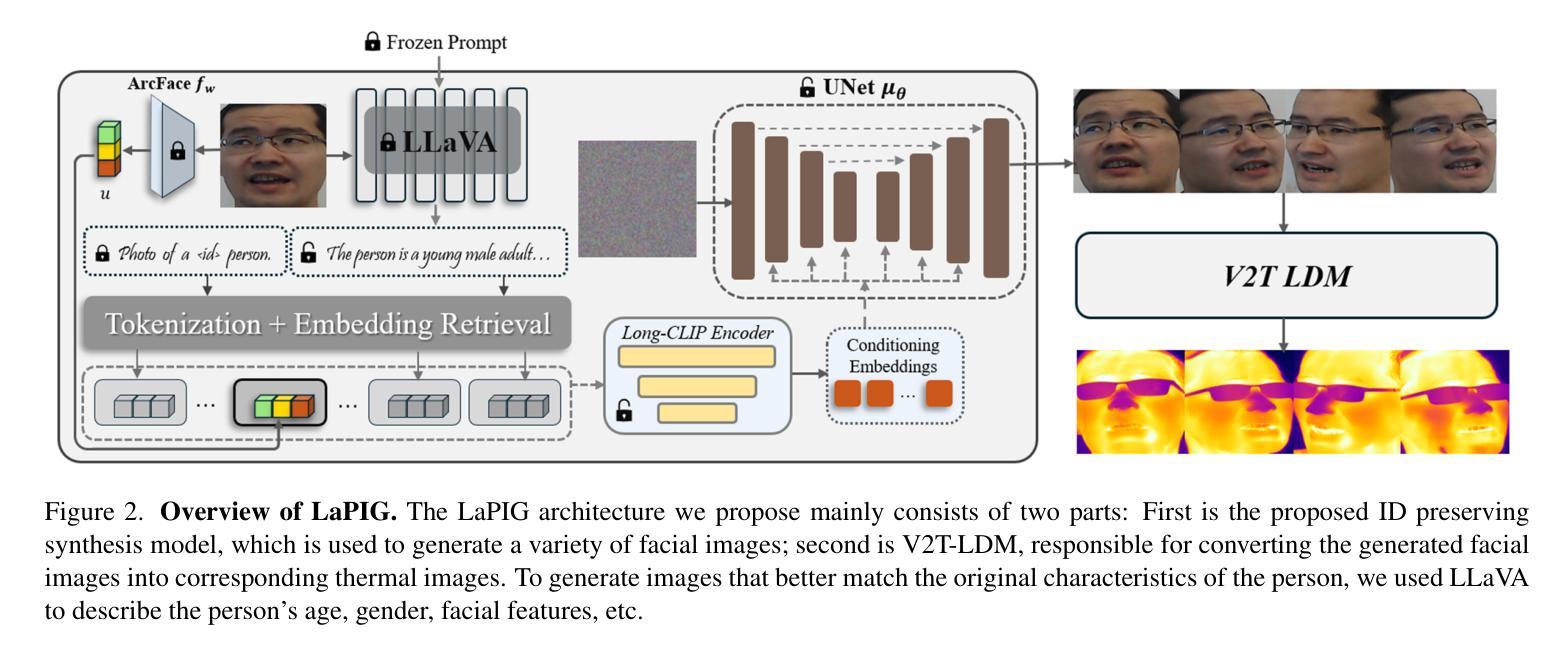
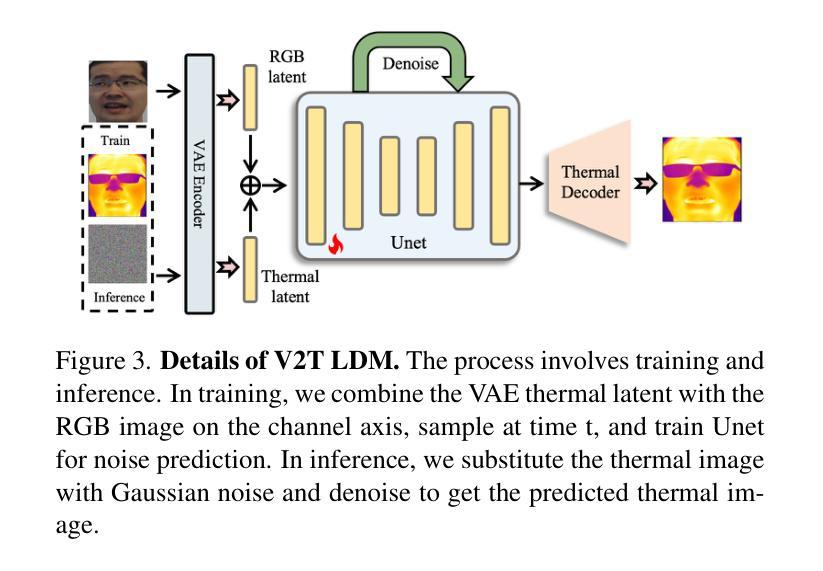
LaPIG: Cross-Modal Generation of Paired Thermal and Visible Facial Images
Authors:Leyang Wang, Joice Lin
The success of modern machine learning, particularly in facial translation networks, is highly dependent on the availability of high-quality, paired, large-scale datasets. However, acquiring sufficient data is often challenging and costly. Inspired by the recent success of diffusion models in high-quality image synthesis and advancements in Large Language Models (LLMs), we propose a novel framework called LLM-assisted Paired Image Generation (LaPIG). This framework enables the construction of comprehensive, high-quality paired visible and thermal images using captions generated by LLMs. Our method encompasses three parts: visible image synthesis with ArcFace embedding, thermal image translation using Latent Diffusion Models (LDMs), and caption generation with LLMs. Our approach not only generates multi-view paired visible and thermal images to increase data diversity but also produces high-quality paired data while maintaining their identity information. We evaluate our method on public datasets by comparing it with existing methods, demonstrating the superiority of LaPIG.
现代机器学习,特别是在面部翻译网络方面的成功,在很大程度上依赖于高质量、配对的大规模数据集的可用性。然而,获取足够的数据往往具有挑战性和成本高昂。受最近高质量图像合成中扩散模型成功以及大型语言模型(LLM)进展的启发,我们提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的标题构建全面、高质量配对的可见光和热图像。我们的方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的热图像翻译、以及使用LLM的标题生成。我们的方法不仅生成多视角配对可见光和热图像以增加数据多样性,而且还在保持身份信息的条件下产生高质量配对数据。我们在公共数据集上通过将其与现有方法进行对比,证明了LaPIG的优越性。
论文及项目相关链接
Summary
本文介绍了现代机器学习,特别是在面部翻译网络方面的成功高度依赖于高质量、配对的大规模数据集的可获得性。然而,获取足够的数据往往具有挑战性和成本高昂。受扩散模型在高质量图像合成和大型语言模型(LLM)方面的最新成功的启发,提出了一种名为LLM辅助配对图像生成(LaPIG)的新框架。该框架利用LLM生成的标题,能够实现全面、高质量配对可见和红外图像的构建。该方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的红外图像翻译,以及使用LLM的标题生成。该方法不仅生成多视角配对可见和红外图像以增加数据多样性,而且在保持身份信息的同事产生高质量配对数据。在公共数据集上评估该方法,与现有方法进行比较,证明了LaPIG的优越性。
Key Takeaways
- 现代机器学习的成功在很大程度上依赖于高质量、配对的大规模数据集。
- 获取足够的数据具有挑战性和成本高昂。
- LLM辅助配对图像生成(LaPIG)框架能够构建全面、高质量的配对图像。
- LaPIG框架包括可见图像合成、红外图像翻译和标题生成三个主要部分。
- 该方法通过生成多视角配对图像来增加数据多样性。
- LaPIG在保持身份信息的同时,产生高质量配对数据。
点此查看论文截图

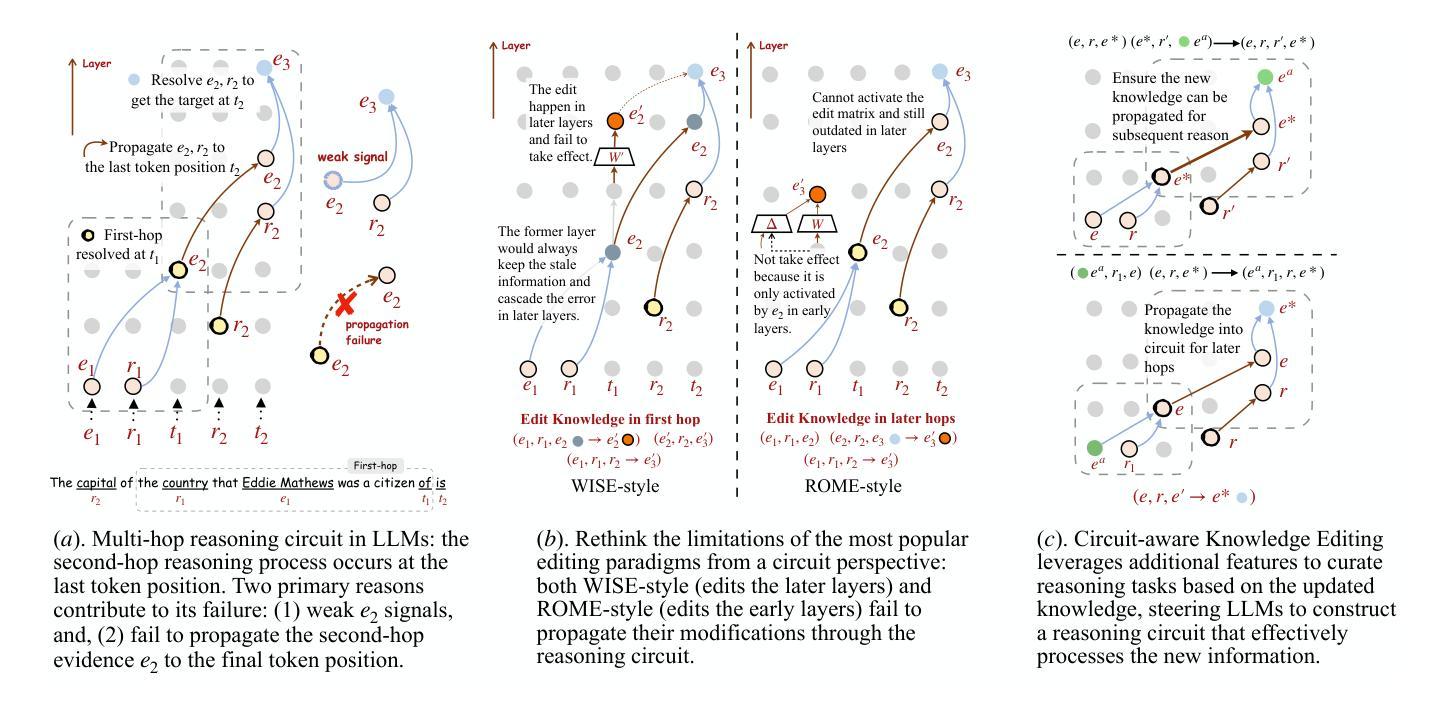
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
Authors:Yunzhi Yao, Jizhan Fang, Jia-Chen Gu, Ningyu Zhang, Shumin Deng, Huajun Chen, Nanyun Peng
Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they struggle to generalize these updates to multi-hop reasoning tasks that depend on the modified knowledge. Through an analysis of reasoning circuits – the neural pathways LLMs use for knowledge-based inference, we observe that current layer-localized KE approaches, such as MEMIT and WISE, which edit only single or a few model layers, struggle to effectively incorporate updated information into these reasoning pathways. To address this limitation, we propose CaKE (Circuit-aware Knowledge Editing), a novel method that enables more effective integration of updated knowledge in LLMs. CaKE leverages strategically curated data, guided by our circuits-based analysis, that enforces the model to utilize the modified knowledge, stimulating the model to develop appropriate reasoning circuits for newly integrated knowledge. Experimental results show that CaKE enables more accurate and consistent use of updated knowledge across related reasoning tasks, leading to an average of 20% improvement in multi-hop reasoning accuracy on MQuAKE dataset compared to existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
知识编辑(KE)能够修改大型语言模型(LLM)中过时或错误的信息。虽然现有的KE方法能够更新孤立的事实,但它们难以将这些更新推广到依赖于修改后的知识的多跳推理任务。通过对语言模型用于知识推理的神经途径(即推理电路)的分析,我们发现当前的层局部化KE方法,如MEMIT和WISE,它们只编辑单个或少数几个模型层,难以有效地将更新后的信息融入这些推理途径。为了解决这一局限性,我们提出了CaKE(电路感知知识编辑),这是一种使更新后的知识在LLM中更有效地集成的新方法。CaKE利用我们基于电路的分析指导的战略定制数据,强制模型利用修改后的知识,刺激模型为刚刚集成的新知识开发适当的推理电路。实验结果表明,CaKE能够更准确、更一致地在相关推理任务中使用更新的知识,与现有的KE方法相比,在MQuAKE数据集上的多跳推理准确度平均提高了20%。我们在https://github.com/zjunlp/CaKE上发布了代码和数据。
论文及项目相关链接
PDF Work in progress
摘要
知识编辑(KE)能够修改大型语言模型(LLM)中过时或错误的信息。现有KE方法虽然可以更新孤立的事实,但在依赖于修改后的知识的多跳推理任务中,它们难以将这些更新推广。通过分析LLM用于知识推理的神经通路——推理电路,我们发现现有的层局部化KE方法,如MEMIT和WISE,仅在单个或少数模型层进行编辑,难以将更新后的信息有效地融入这些推理电路。为了解决这一局限性,我们提出了CaKE(电路感知知识编辑),这是一种使更新后的知识更有效地整合到LLM中的新方法。CaKE利用我们基于电路的分析精心策划的数据,强制模型利用修改后的知识,刺激模型为刚刚整合的知识发展适当的推理电路。实验结果表明,与现有KE方法相比,CaKE在MQuAKE数据集上的多跳推理准确性提高了平均20%。我们在https://github.com/zjunlp/CaKE上发布了代码和数据。
关键见解
- 知识编辑(KE)能够修改大型语言模型(LLM)中的信息。
- 现有KE方法在多跳推理任务中难以推广知识更新。
- 通过对LLM的推理电路进行分析,发现现有KE方法难以将更新后的知识融入这些电路。
- 提出了一种新的知识编辑方法——CaKE,能更有效地整合更新后的知识到LLM中。
- CaKE利用战略策划的数据,强制模型利用修改后的知识,并刺激其形成适当的推理电路。
- 实验结果表明,CaKE在多跳推理任务上表现出更高的准确性,与现有方法相比,在MQuAKE数据集上的推理准确性平均提高了20%。
点此查看论文截图


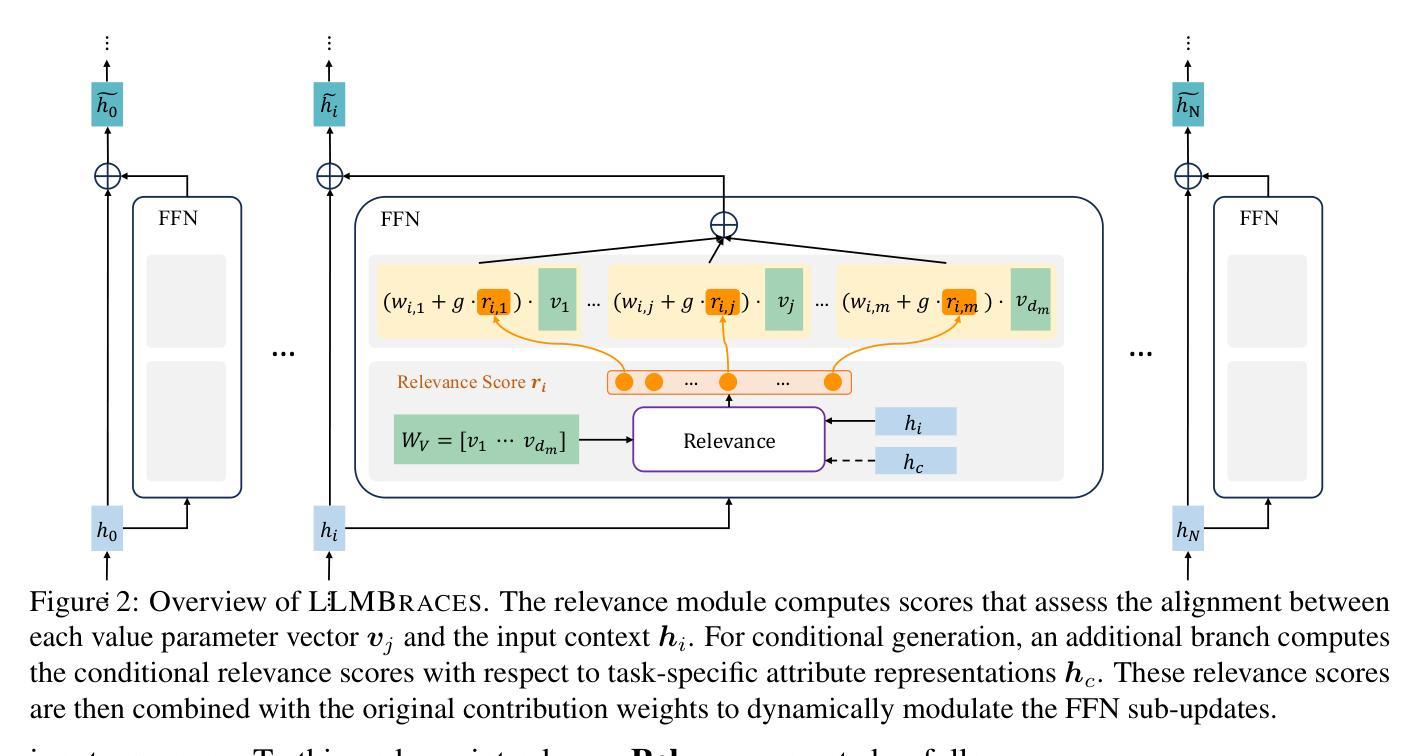
LLM Braces: Straightening Out LLM Predictions with Relevant Sub-Updates
Authors:Ying Shen, Lifu Huang
Recent findings reveal that much of the knowledge in a Transformer-based Large Language Model (LLM) is encoded in its feed-forward (FFN) layers, where each FNN layer can be interpreted as the summation of sub-updates, each corresponding to a weighted column vector from the FFN’s value parameter matrix that often encodes human-interpretable concepts. In light of this, we hypothesize that model performance and behaviors can be further enhanced and controlled by modulating the contributions of these sub-updates based on their relevance to the input or target output style, and propose LLMBRACES, a novel and efficient method that computes relevance scores associated with value vectors in FFN layers and leverages these scores to dynamically adjust the contribution of sub-updates. By optimizing sub-update contributions, LLMBRACES refines the prediction process, leading to more accurate and reliable outputs, much like a ‘brace’ providing support and stability. Moreover, LLMBRACES can be extended to support conditional control over generation characteristics, such as sentiment, thereby offering fine-grained steering of LLM outputs. Extensive experiments on various LLMs-including Qwen2.5-1.5B, Llama2-7B, and Llama3-8B-demonstrate that LLMBRACES outperforms baseline approaches in both fine-tuning and zero-shot settings while requiring significantly fewer tunable parameters, up to 75% fewer compared to LoRA. Furthermore, LLMBRACES excels in sentiment-controlled generation and toxicity reduction, highlighting its potential for flexible, controlled text generation across applications.
最新研究结果表明,基于Transformer的大型语言模型(LLM)中的大部分知识都编码在其前馈(FFN)层中。在这些FFN层中,每一层都可以被解释为子更新的总和,每个子更新对应于FFN值参数矩阵中的加权列向量,这些列向量通常编码了人类可解释的概念。鉴于此,我们假设可以通过调节这些子更新对模型性能和行为的贡献来进一步改善和控制模型性能和行为,这些调节基于子更新与输入或目标输出风格的关联性。我们提出了一种新颖且高效的方法LLMBRACES,该方法计算FFN层中值向量的相关性分数,并利用这些分数来动态调整子更新的贡献。通过优化子更新的贡献,LLMBRACES可以改进预测过程,从而得到更准确、更可靠的输出,就像“支撑”和“稳定”的“支撑带”一样。此外,LLMBRACES可以扩展以支持对生成特性的条件控制,例如情感,从而实现对LLM输出的精细控制。在包括Qwen2.5-1.5B、Llama2-7B和Llama3-8B等各种LLM上的广泛实验表明,LLMBRACES在微调和零样本设置中都优于基准方法,同时需要更少的可调参数,与LoRA相比,最多可减少75%。此外,LLMBRACES在情感控制生成和毒性降低方面表现出色,突显其在跨应用程序的灵活、受控文本生成方面的潜力。
论文及项目相关链接
PDF 16 pages, 2 figures
Summary
近期研究发现,基于Transformer的大型语言模型(LLM)中的知识主要编码在前馈网络(FFN)层中。每个FFN层可解释为子更新的总和,每个子更新对应于FFN值参数矩阵的加权列向量,这些列向量通常编码人类可解释的概念。因此,通过调节这些子更新对模型性能和行为的贡献,可以提高模型的性能和可控性。为此,提出了LLMBRACES方法,该方法计算FFN层中值向量的相关性分数,并利用这些分数动态调整子更新的贡献。通过优化子更新的贡献,LLMBRACES能够更精细地控制语言模型的输出,提高预测的准确性。实验表明,LLMBRACES在多种LLM上表现出优异性能,包括情感控制生成和毒性降低,凸显其在各种应用中的潜力。
Key Takeaways
- LLM中的知识主要编码在FFN层中,每个FFN层包含编码人类可解释概念的值参数矩阵的加权列向量。
- LLMBRACES方法通过计算值向量的相关性分数来动态调整子更新的贡献。
- LLMBRACES能够提高预测的准确性并控制模型的行为。
- LLMBRACES适用于多种LLM,包括情感控制生成和毒性降低等应用。
- LLMBRACES在精细调整模型输出方面表现出优异性能。
- 与基线方法相比,LLMBRACES在参数数量方面更为高效,可减少多达75%的可调整参数。
点此查看论文截图

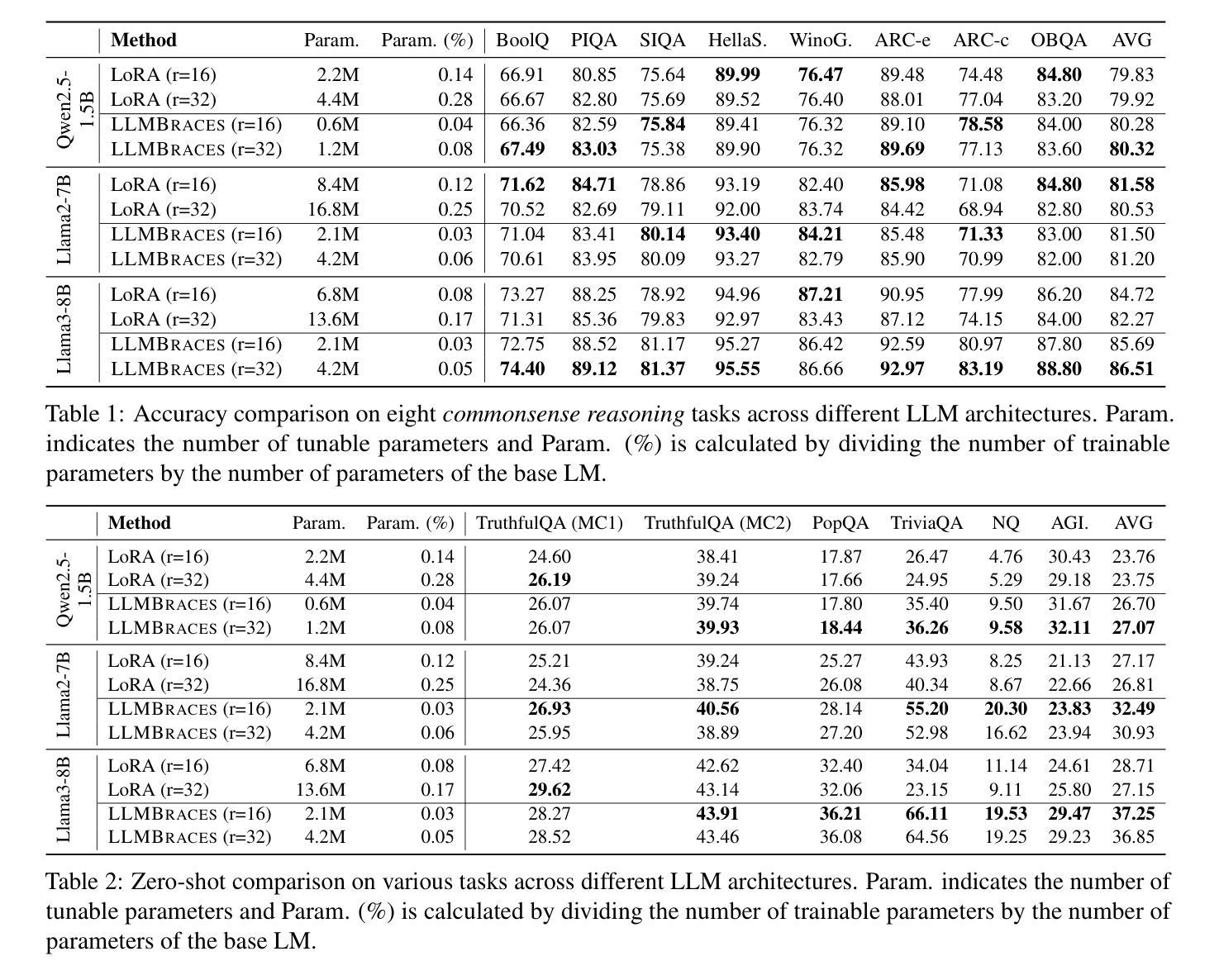
OmniGeo: Towards a Multimodal Large Language Models for Geospatial Artificial Intelligence
Authors:Long Yuan, Fengran Mo, Kaiyu Huang, Wenjie Wang, Wangyuxuan Zhai, Xiaoyu Zhu, You Li, Jinan Xu, Jian-Yun Nie
The rapid advancement of multimodal large language models (LLMs) has opened new frontiers in artificial intelligence, enabling the integration of diverse large-scale data types such as text, images, and spatial information. In this paper, we explore the potential of multimodal LLMs (MLLM) for geospatial artificial intelligence (GeoAI), a field that leverages spatial data to address challenges in domains including Geospatial Semantics, Health Geography, Urban Geography, Urban Perception, and Remote Sensing. We propose a MLLM (OmniGeo) tailored to geospatial applications, capable of processing and analyzing heterogeneous data sources, including satellite imagery, geospatial metadata, and textual descriptions. By combining the strengths of natural language understanding and spatial reasoning, our model enhances the ability of instruction following and the accuracy of GeoAI systems. Results demonstrate that our model outperforms task-specific models and existing LLMs on diverse geospatial tasks, effectively addressing the multimodality nature while achieving competitive results on the zero-shot geospatial tasks. Our code will be released after publication.
多模态大型语言模型(LLM)的快速发展为人工智能开启了新的前沿,能够实现文本、图像和空间信息等不同大规模数据类型的集成。在本文中,我们探索了多模态LLM(MLLM)在地理空间人工智能(GeoAI)中的潜力。GeoAI是一个利用空间数据来解决包括地理空间语义、健康地理学、城市地理学、城市感知和遥感等领域的挑战的领域。我们针对地理空间应用提出了一种MLLM(OmniGeo),它能够处理和分析包括卫星图像、地理空间元数据以及文本描述在内的异质数据源。通过结合自然语言理解和空间推理的优势,我们的模型增强了指令跟随能力和GeoAI系统的准确性。结果表明,我们的模型在多种地理空间任务上的表现优于特定任务模型和现有的LLM,有效地解决了多模态性质,并在零样本地理空间任务上取得了有竞争力的结果。代码将在发表后发布。
论文及项目相关链接
PDF 15 pages, Under review
Summary
多模态大型语言模型(LLM)的快速发展为人工智能开启了新的前沿,使得能够整合文本、图像和空间信息等多样化的大规模数据类型。本文探索了多模态LLM(MLLM)在地缘空间人工智能(GeoAI)领域的潜力,该领域利用空间数据应对包括地理语义、健康地理学、城市地理学、城市感知和遥感等领域的挑战。本文提出了一种针对地理空间应用程序的MLLM(OmniGeo),能够处理和分析包括卫星图像、地理空间元数据以及文本描述在内的异质数据源。通过结合自然语言理解和空间推理的优势,该模型提高了遵循指令的能力以及GeoAI系统的准确性。结果证明,该模型在多种地理空间任务上的表现优于特定任务模型和现有LLM,有效地解决了多模态性质问题,并在零样本地理空间任务上取得了有竞争力的结果。
Key Takeaways
- 多模态大型语言模型(LLM)的快速发展为人工智能整合多样化数据类型提供了新的机会。
- 地理空间人工智能(GeoAI)领域利用空间数据应对多个领域的挑战。
- 本文提出了一种针对地理空间应用程序的多模态LLM模型(OmniGeo)。
- OmniGeo能够处理和分析异质数据源,包括卫星图像、地理空间元数据和文本描述。
- OmniGeo结合了自然语言理解和空间推理的优势,提高了指令遵循能力和GeoAI系统的准确性。
- 该模型在多种地理空间任务上的表现优于特定任务模型和现有LLM。
点此查看论文截图


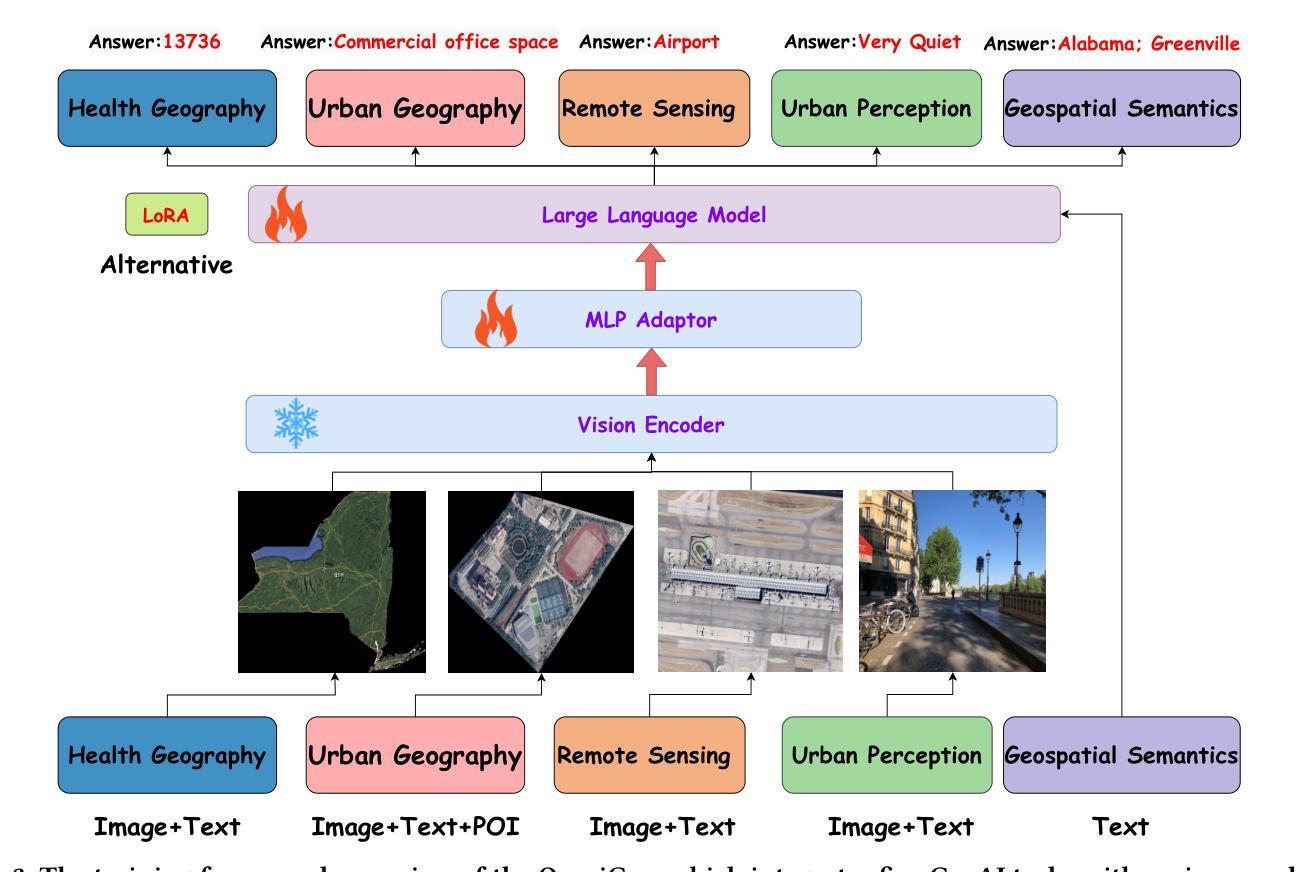
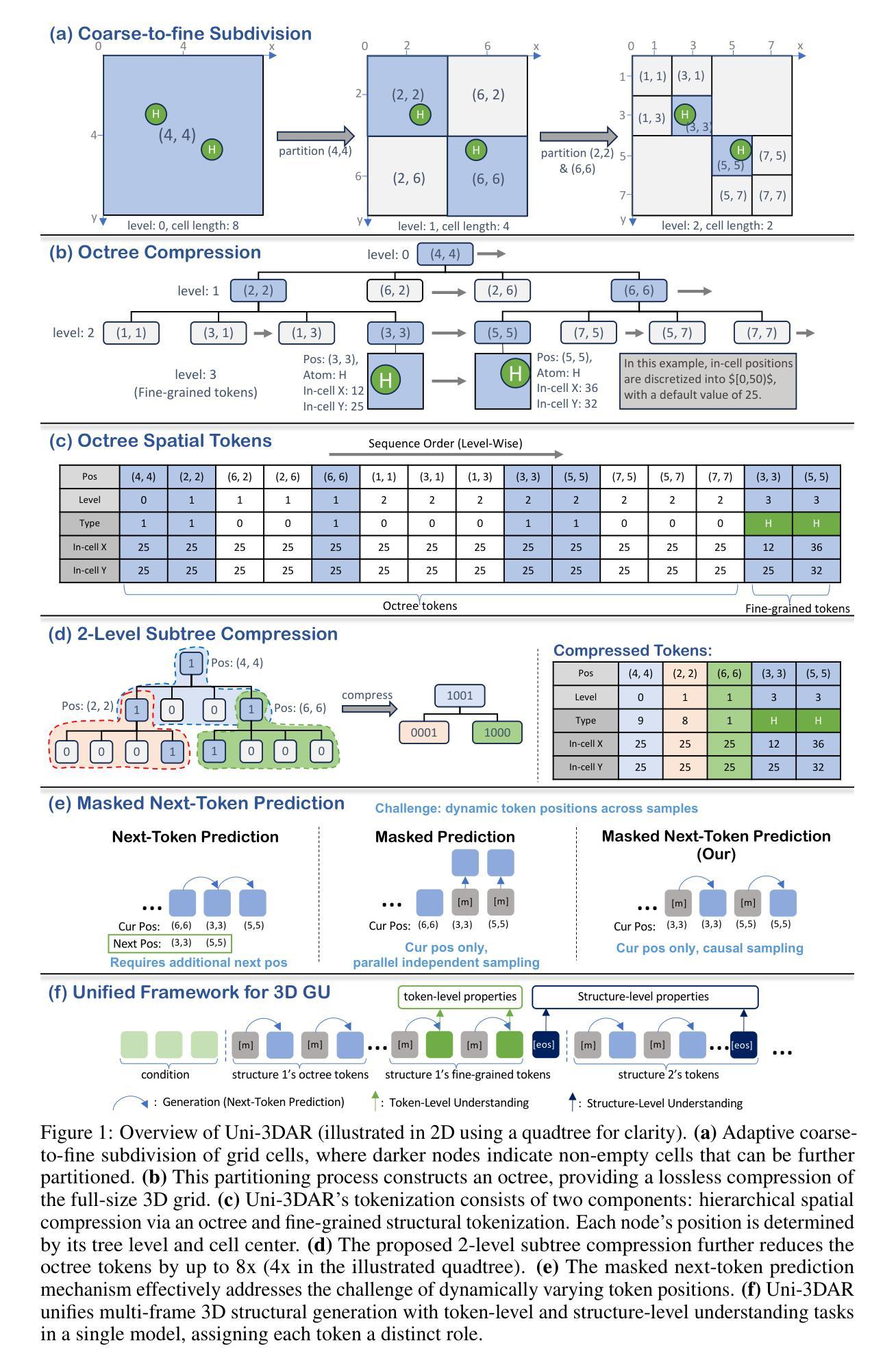
Uni-3DAR: Unified 3D Generation and Understanding via Autoregression on Compressed Spatial Tokens
Authors:Shuqi Lu, Haowei Lin, Lin Yao, Zhifeng Gao, Xiaohong Ji, Weinan E, Linfeng Zhang, Guolin Ke
Recent advancements in large language models and their multi-modal extensions have demonstrated the effectiveness of unifying generation and understanding through autoregressive next-token prediction. However, despite the critical role of 3D structural generation and understanding ({3D GU}) in AI for science, these tasks have largely evolved independently, with autoregressive methods remaining underexplored. To bridge this gap, we introduce Uni-3DAR, a unified framework that seamlessly integrates {3D GU} tasks via autoregressive prediction. At its core, Uni-3DAR employs a novel hierarchical tokenization that compresses 3D space using an octree, leveraging the inherent sparsity of 3D structures. It then applies an additional tokenization for fine-grained structural details, capturing key attributes such as atom types and precise spatial coordinates in microscopic 3D structures. We further propose two optimizations to enhance efficiency and effectiveness. The first is a two-level subtree compression strategy, which reduces the octree token sequence by up to 8x. The second is a masked next-token prediction mechanism tailored for dynamically varying token positions, significantly boosting model performance. By combining these strategies, Uni-3DAR successfully unifies diverse {3D GU} tasks within a single autoregressive framework. Extensive experiments across multiple microscopic {3D GU} tasks, including molecules, proteins, polymers, and crystals, validate its effectiveness and versatility. Notably, Uni-3DAR surpasses previous state-of-the-art diffusion models by a substantial margin, achieving up to 256% relative improvement while delivering inference speeds up to 21.8x faster. The code is publicly available at https://github.com/dptech-corp/Uni-3DAR.
最近大型语言模型及其多模态扩展的进展证明了通过自回归下一个令牌预测来统一生成和理解的有效性。然而,尽管三维结构生成与理解(3D GU)在人工智能科学中扮演着至关重要的角色,但这些任务在很大程度上是独立发展的,自回归方法仍然鲜有研究。为了弥补这一差距,我们引入了Uni-3DAR,这是一个通过自回归预测无缝集成三维结构生成与理解任务的统一框架。其核心采用了一种新型层次令牌化技术,使用八叉树压缩三维空间,利用三维结构固有的稀疏性。然后,它针对精细结构细节应用额外的令牌化,捕获诸如原子类型和微观三维结构中的精确空间坐标等关键属性。为了进一步提高效率并增强效果,我们提出了两项优化措施。首先是两级子树压缩策略,可将八叉树令牌序列减少到原来的八分之一以下。其次是针对动态变化的令牌位置的自定义下一个被掩盖令牌的预测机制,极大地提升了模型性能。通过结合这些策略,Uni-3DAR成功地在单一自回归框架内统一了多种三维结构生成与理解任务。在多个微观的三维结构生成与理解任务上的广泛实验,包括分子、蛋白质、聚合物和晶体等,验证了其有效性和灵活性。值得注意的是,Uni-3DAR在多个方面大大超越了最先进的扩散模型,在相对改善率高达256%的同时,推理速度提高了高达21.8倍。代码已公开在https://github.com/dptech-corp/Uni-3DAR上发布。
论文及项目相关链接
Summary
近期大型语言模型的多模态扩展展现了通过自回归预测提升生成与理解的成效。然而,在面向科学的AI领域中的三维结构生成与理解(3D GU)任务依旧大多独立演进,自回归方法应用有限。为弥合此差距,引入了Uni-3DAR统一框架,该框架能够无缝整合各类3D GU任务进行自回归预测。Uni-3DAR利用一种新颖的层次化标记法压缩三维空间,并采用针对精细结构特征的额外标记法捕获关键属性。此外,还推出两项优化策略以提高效率与性能:通过两层级子树压缩策略将压缩量树令牌序列降低至原来的八分之一以内;通过针对动态变化令牌位置的掩码令牌预测机制提升模型性能。实验证明,Uni-3DAR在多种微观三维结构理解任务中均表现出优异性能与灵活性,相对于最新技术,显著提高了效率并降低了成本。其代码已公开于GitHub上。
Key Takeaways
- 大型语言模型的多模态扩展通过自回归预测提升了生成与理解的效能。
- 当前的三维结构生成与理解(3D GU)任务在面向科学的AI领域中大多独立演进,而自回归方法在这方面的应用尚待开发。
- Uni-3DAR框架可以整合不同的三维GU任务进行自回归预测。它运用新颖的层次化标记技术,可针对三维空间进行精细操作和捕获关键特征。这种层次化标记法利用八叉树压缩三维空间,提高了效率和性能。同时引入精细结构特征的额外标记法以捕获关键属性。
- Uni-3DAR框架具有两大优化策略:两层级子树压缩策略和掩码令牌预测机制。这两大策略不仅显著提高了Uni-3DAR的性能和效率,同时也保证了其针对多种任务的灵活性和适用性。通过减少令牌序列和提高模型性能,这些优化策略有助于Uni-3DAR超越现有的技术瓶颈。
- Uni-3DAR框架已在多种微观三维结构理解任务中进行了实验验证,包括分子、蛋白质、聚合物和晶体等,证明了其有效性和灵活性。相较于当前最先进的扩散模型,Uni-3DAR在效率和性能上均实现了显著的提升。例如相对于最先进技术提升达至百分之二百五十六的相对改善效果。这意味着Uni-3DAR在各种任务中的应用都具有明显的优势。同时其推理速度也显著提高,最高可达二十一倍半的速度提升。这表明Uni-3DAR不仅具有高效性,而且在实际应用中能够快速响应和处理数据。这为Uni-3DAR在各种场景下的应用提供了坚实的基础和广阔的前景。
- Uni-3DAR的代码已公开发布在GitHub上供公众访问和使用这一重要信息为该项目的进一步发展提供了可能也为未来的研究提供了基础框架和技术支持从而使得更多研究人员和行业参与者得以利用其框架和资源来实现创新的探索和改进既有的技术和成果展现出宽广的发展潜力和适用性值得进一步关注和研究。这对于推动相关领域的发展具有重要意义。同时公开代码也体现了研究者的开放科学精神促进了学术交流和合作推动科学研究的进步和发展具有积极意义。。
点此查看论文截图

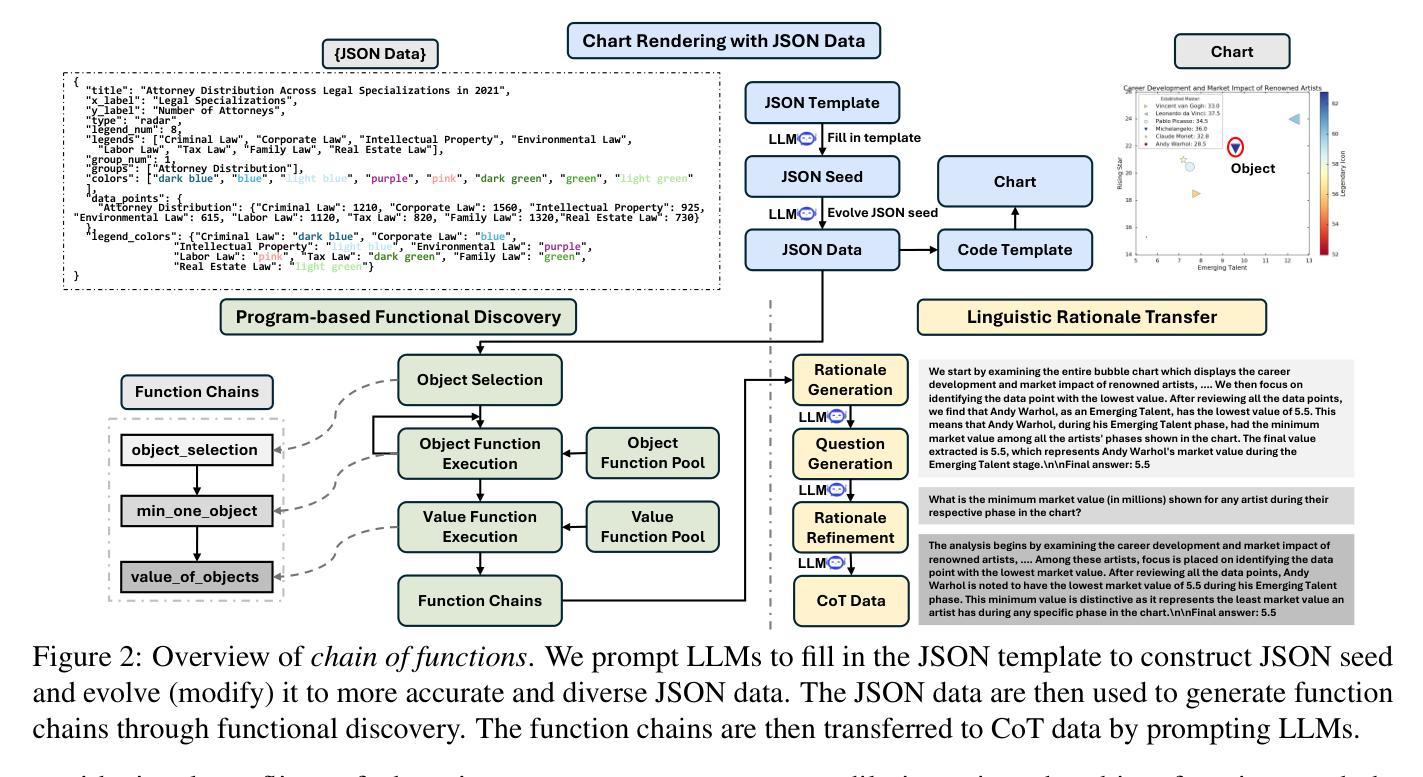
Chain of Functions: A Programmatic Pipeline for Fine-Grained Chart Reasoning Data
Authors:Zijian Li, Jingjing Fu, Lei Song, Jiang Bian, Jun Zhang, Rui Wang
Visual reasoning is crucial for multimodal large language models (MLLMs) to address complex chart queries, yet high-quality rationale data remains scarce. Existing methods leveraged (M)LLMs for data generation, but direct prompting often yields limited precision and diversity. In this paper, we propose \textit{Chain of Functions (CoF)}, a novel programmatic reasoning data generation pipeline that utilizes freely-explored reasoning paths as supervision to ensure data precision and diversity. Specifically, it starts with human-free exploration among the atomic functions (e.g., maximum data and arithmetic operations) to generate diverse function chains, which are then translated into linguistic rationales and questions with only a moderate open-sourced LLM. \textit{CoF} provides multiple benefits: 1) Precision: function-governed generation reduces hallucinations compared to freeform generation; 2) Diversity: enumerating function chains enables varied question taxonomies; 3) Explainability: function chains serve as built-in rationales, allowing fine-grained evaluation beyond overall accuracy; 4) Practicality: eliminating reliance on extremely large models. Employing \textit{CoF}, we construct the \textit{ChartCoF} dataset, with 1.4k complex reasoning Q&A for fine-grained analysis and 50k Q&A for reasoning enhancement. The fine-grained evaluation on \textit{ChartCoF} reveals varying performance across question taxonomies for each MLLM, and the experiments also show that finetuning with \textit{ChartCoF} achieves state-of-the-art performance among same-scale MLLMs on widely used benchmarks. Furthermore, the novel paradigm of function-governed rationale generation in \textit{CoF} could inspire broader applications beyond charts.
视觉推理对于多模态大型语言模型(MLLMs)解决复杂图表查询至关重要,但高质量的理由数据仍然稀缺。现有方法利用(M)LLMs进行数据生成,但直接提示往往精度和多样性有限。在本文中,我们提出了\emph{函数链(CoF)},这是一种新的程序化推理数据生成管道,它利用自由探索的推理路径作为监督来保证数据的精度和多样性。具体来说,它始于原子功能(如最大数据和算术运算)之间的人类自由探索,以生成多样化的函数链,然后仅使用适度的开源大型语言模型将其转换为语言理由和问题。\emph{CoF}带来了多个好处:1)精度:函数控制生成减少了与自由形式生成相比的幻觉;2)多样性:枚举函数链可实现各种问题分类;3)可解释性:函数链作为内置理由,允许超越总体准确度的精细评估;4)实用性:不依赖极端大型模型。通过采用\emph{CoF},我们构建了\emph{ChartCoF}数据集,其中包含1400个用于精细分析复杂推理的问答和5万个用于增强推理的问答。\emph{ChartCoF}上的精细评估揭示了每个MLLM在不同问题分类上的性能差异,实验还表明,使用\emph{ChartCoF}进行微调在同规模MLLMs中达到了广泛使用的基准测试中的最新水平。此外,\emph{CoF}中函数控制理由生成的新范式可能会激发更广泛的图表之外的应用。
论文及项目相关链接
PDF Under review
Summary
视觉推理对于多模态大型语言模型(MLLMs)处理复杂图表查询至关重要,但高质量推理数据仍然稀缺。现有方法利用(M)LLMs进行数据采集生成,但直接提示往往精度和多样性有限。本文提出一种名为Chain of Functions(CoF)的新型程序化推理数据生成管道,它利用自由探索的推理路径作为监督,确保数据的精度和多样性。CoF具有多重优势,包括精度提升、多样性增强、解释性增强和实践性广泛等。利用CoF,我们构建了ChartCoF数据集,包含用于精细分析的1400个复杂推理问答和用于增强推理的5万个问答。在ChartCoF上的精细评估显示,每个MLLM在不同问题分类中的性能各不相同,实验还表明,使用ChartCoF进行微调可以在广泛使用的基准测试上实现最佳性能。此外,CoF中的函数控制推理数据生成新模式可启发图表之外更广泛的应用。
Key Takeaways
- 视觉推理在多模态大型语言模型处理复杂图表查询中起关键作用,但高质量数据稀缺。
- 现有数据生成方法精度和多样性有限。
- 提出的Chain of Functions(CoF)方法利用自由探索的推理路径,提高数据精度和多样性。
- CoF具有精度、多样性、解释性和实用性等多重优势。
- 使用CoF构建了ChartCoF数据集,包含复杂推理问答,用于精细分析和性能评估。
- 在ChartCoF上的评估显示不同MLLM在不同问题分类中的性能差异。
点此查看论文截图

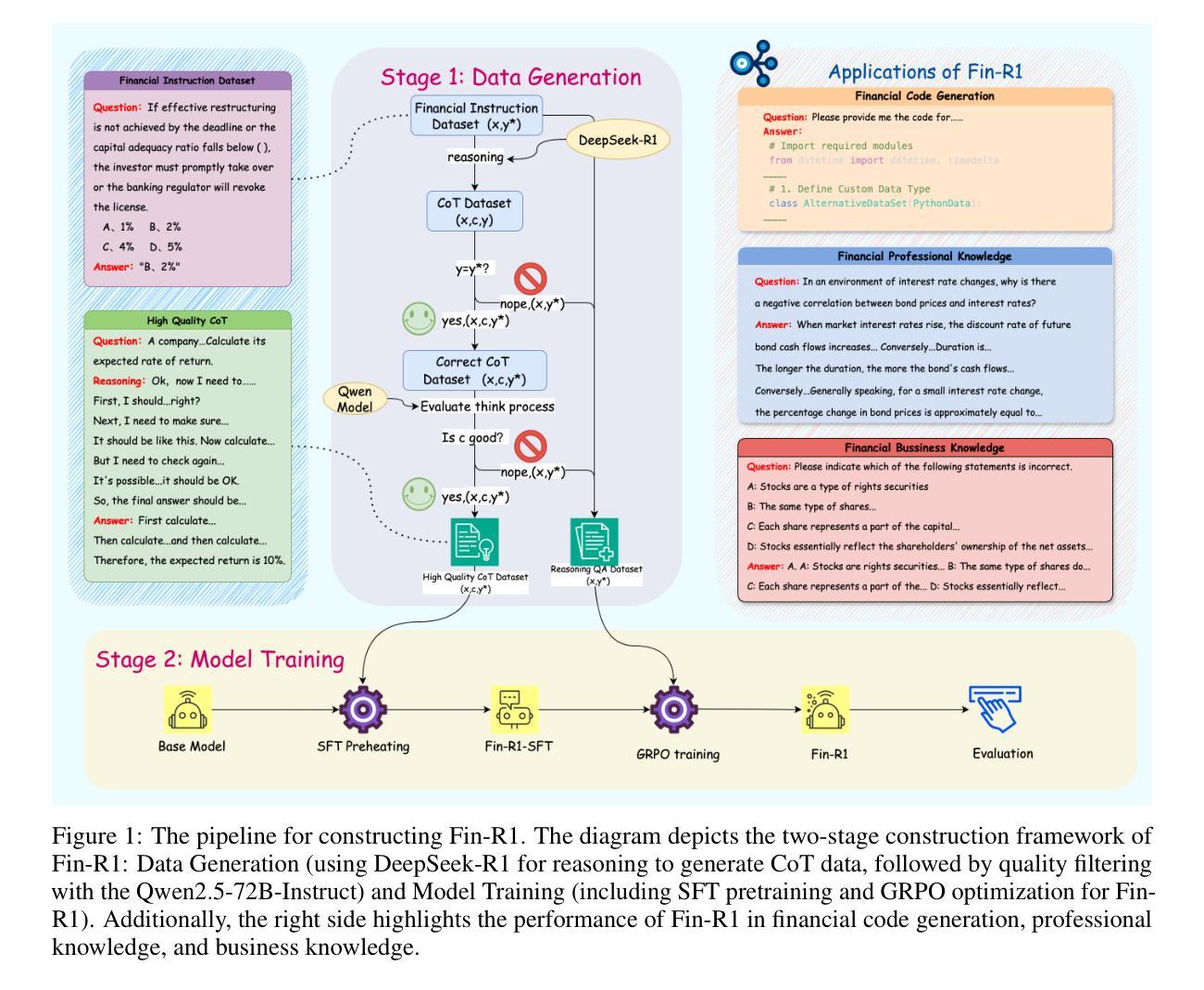
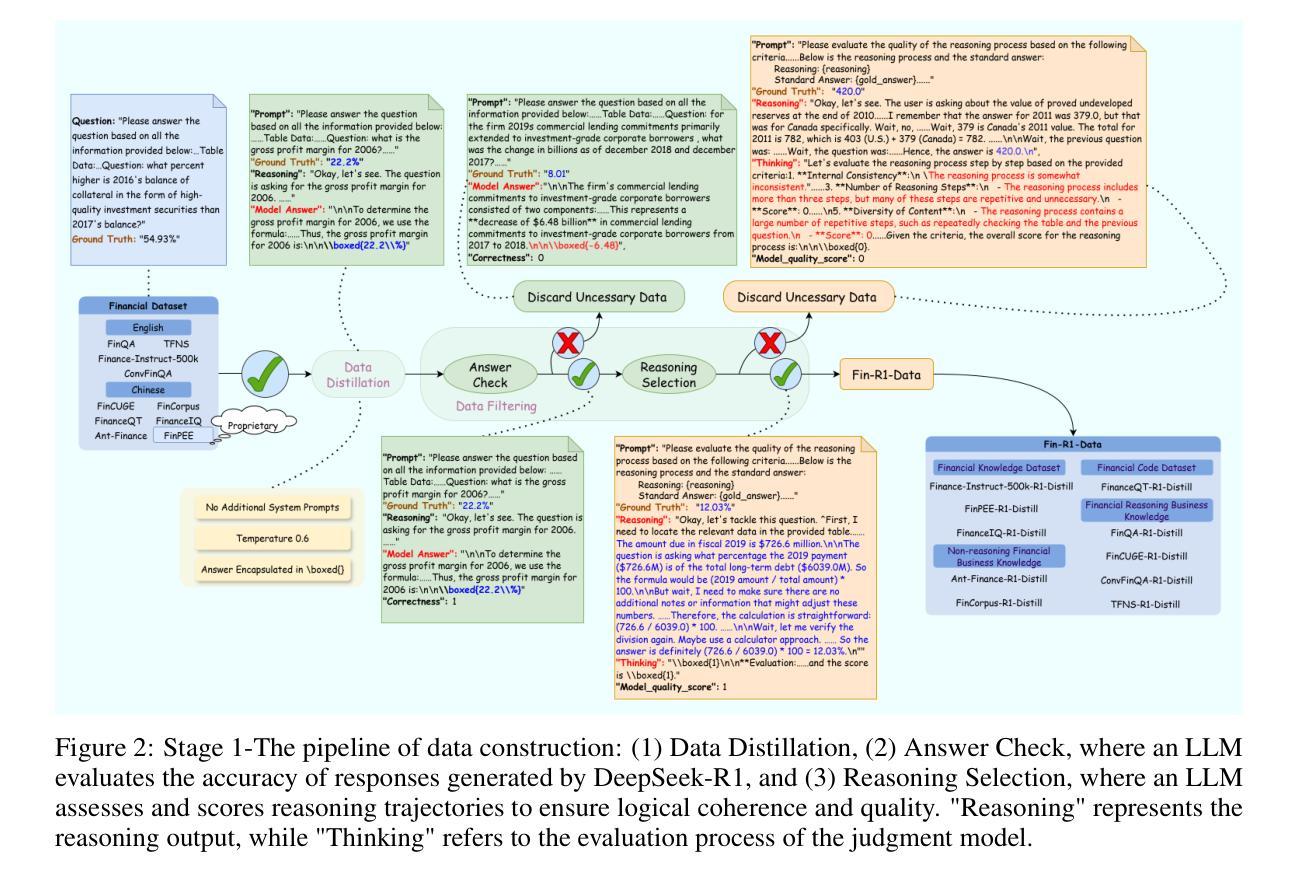
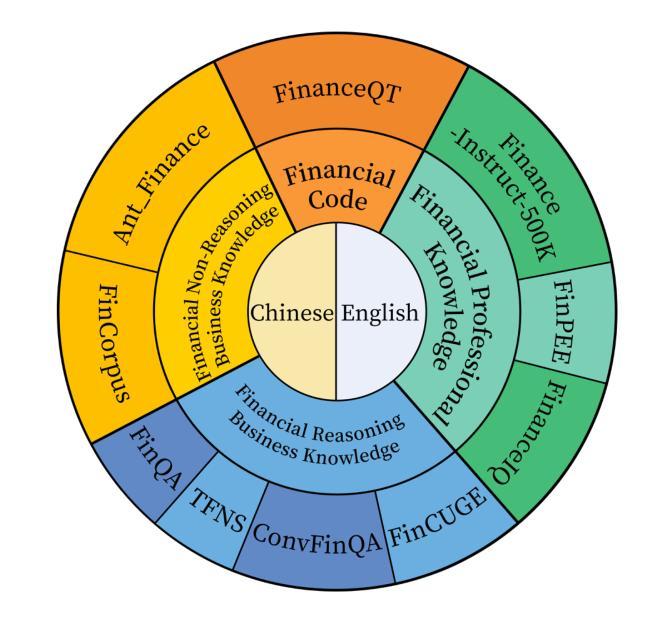
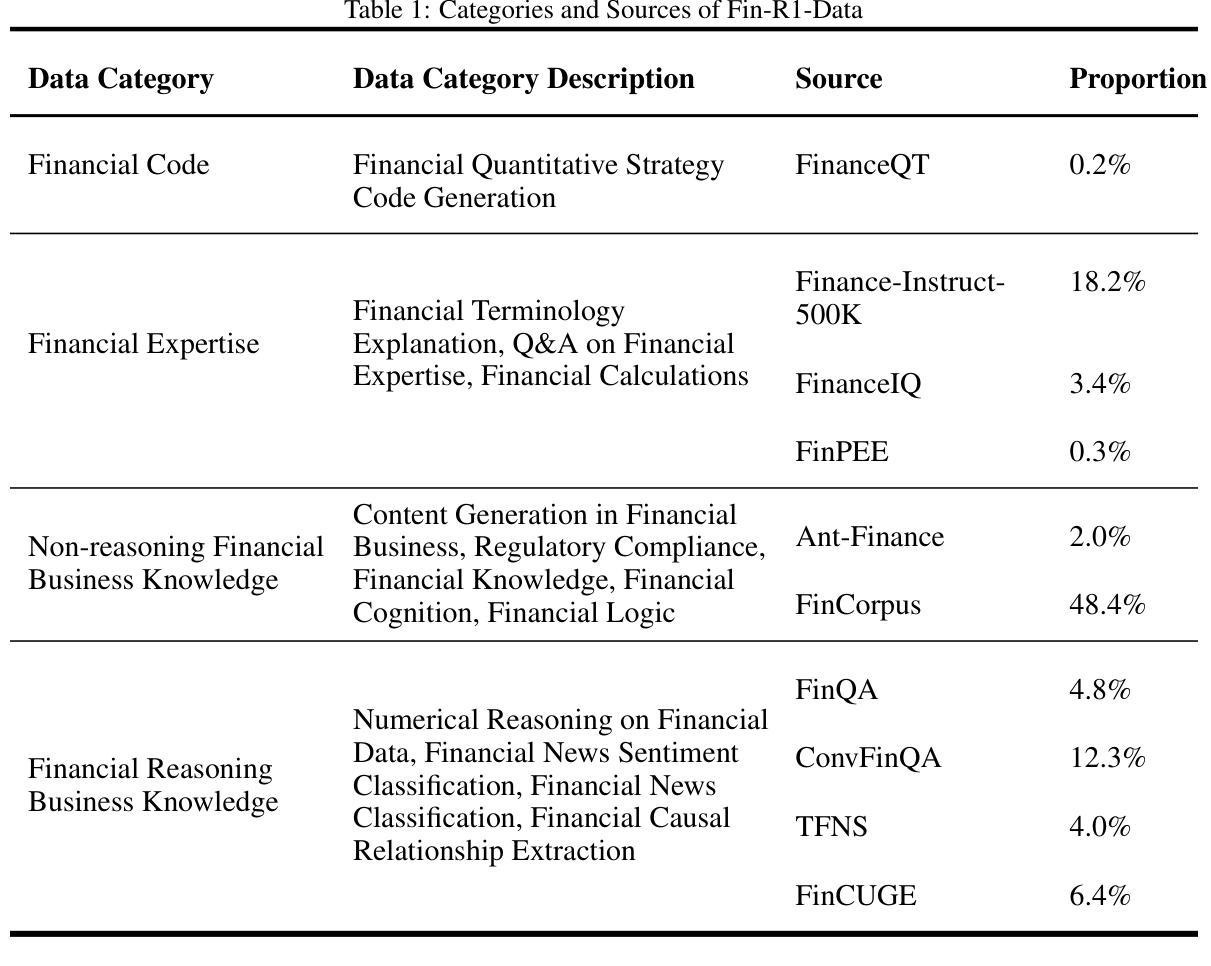
Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning
Authors:Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, Chao Li, Sheng Xu, Dezhi Chen, Yun Chen, Zuo Bai, Liwen Zhang
Reasoning large language models are rapidly evolving across various domains. However, their capabilities in handling complex financial tasks still require in-depth exploration. In this paper, we introduce Fin-R1, a reasoning large language model specifically designed for the financial sector. Fin-R1 is built using a two-stage architecture, leveraging a financial reasoning dataset distilled and processed based on DeepSeek-R1. Through supervised fine-tuning (SFT) and reinforcement learning (RL) training, it demonstrates performance close to DeepSeek-R1 with a parameter size of 7 billion across a range of financial reasoning tasks. It achieves the state-of-the-art (SOTA) in the FinQA and ConvFinQA tasks between those LLMs in our evaluation, surpassing larger models in other tasks as well. Fin-R1 showcases strong reasoning and decision-making capabilities, providing solutions to various problems encountered in the financial domain. Our code is available at https://github.com/SUFE-AIFLM-Lab/Fin-R1.
推理大型语言模型正在各个领域中迅速演变。然而,它们在处理复杂的金融任务方面的能力仍然需要深入探索。在本文中,我们介绍了专为金融领域设计的Fin-R1推理大型语言模型。Fin-R1采用两阶段架构构建,利用基于DeepSeek-R1提炼和处理的金融推理数据集。通过有监督微调(SFT)和强化学习(RL)训练,它在各种金融推理任务上的表现接近拥有7亿参数的DeepSeek-R1。在评估的LLM中,它在FinQA和ConvFinQA任务上达到了最新水平,在其他任务中也超越了更大的模型。Fin-R1展示了强大的推理和决策能力,为解决金融领域遇到的各种问题提供了解决方案。我们的代码可在https://github.com/SUFE-AIFLM-Lab/Fin-R1中找到。
论文及项目相关链接
Summary
大型语言模型在多个领域迅速进化,但在处理复杂金融任务方面的能力仍需深入研究。本文介绍了一款专为金融领域设计的大型语言模型Fin-R1。Fin-R1采用两阶段架构,基于DeepSeek-R1蒸馏和处理金融推理数据集。通过监督微调(SFT)和强化学习(RL)训练,它在金融推理任务上表现出接近DeepSeek-R1的性能,参数规模为7亿。它在FinQA和ConvFinQA任务上达到了当时最佳水平,并在其他任务中超越了大型模型。Fin-R1展示了强大的推理和决策能力,为金融领域的问题提供了解决方案。
Key Takeaways
- 大型语言模型在多个领域快速发展,金融领域的专用模型需求逐渐凸显。
- Fin-R1是一款专为金融领域设计的大型语言模型,具有强大的推理和决策能力。
- Fin-R1采用两阶段架构,基于DeepSeek-R1进行改进和优化。
- 通过监督微调(SFT)和强化学习(RL)训练,Fin-R1在多个金融推理任务上表现出卓越性能。
- Fin-R1在FinQA和ConvFinQA任务上达到了当时最佳水平(SOTA)。
- Fin-R1在某些任务上的性能超越了其他大型模型。
点此查看论文截图

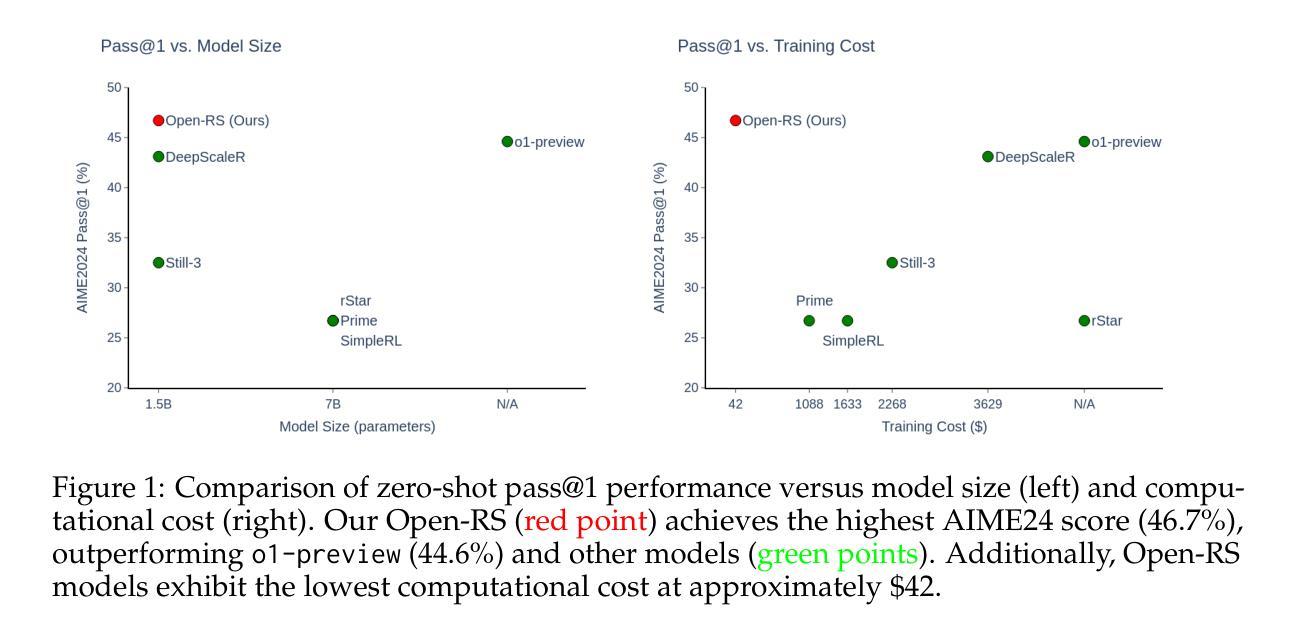
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t
Authors:Quy-Anh Dang, Chris Ngo
Enhancing the reasoning capabilities of large language models (LLMs) typically relies on massive computational resources and extensive datasets, limiting accessibility for resource-constrained settings. Our study investigates the potential of reinforcement learning (RL) to improve reasoning in small LLMs, focusing on a 1.5-billion-parameter model, DeepSeek-R1-Distill-Qwen-1.5B, under strict constraints: training on 4 NVIDIA A40 GPUs (48 GB VRAM each) within 24 hours. Adapting the Group Relative Policy Optimization (GRPO) algorithm and curating a compact, high-quality mathematical reasoning dataset, we conducted three experiments to explore model behavior and performance. Our results demonstrate rapid reasoning gains - e.g., AMC23 accuracy rising from 63% to 80% and AIME24 reaching 46.7%, surpassing o1-preview - using only 7,000 samples and a $42 training cost, compared to thousands of dollars for baseline models. However, challenges such as optimization instability and length constraints emerged with prolonged training. These findings highlight the efficacy of RL-based fine-tuning for small LLMs, offering a cost-effective alternative to large-scale approaches. We release our code and datasets as open-source resources, providing insights into trade-offs and laying a foundation for scalable, reasoning-capable LLMs in resource-limited environments. All are available at https://github.com/knoveleng/open-rs.
增强大型语言模型(LLM)的推理能力通常依赖于大量的计算资源和广泛的数据集,这限制了资源受限环境的可访问性。我们的研究探讨了强化学习(RL)在小型LLM中提高推理能力的潜力,重点关注一个1.5亿参数的模型——DeepSeek-R1-Distill-Qwen-1.5B,在严格的约束条件下:在4个NVIDIA A40 GPU(每个具有48GB VRAM)上进行为期24小时的训练。通过采用群体相对策略优化(GRPO)算法并整理一个紧凑、高质量的数学推理数据集,我们进行了三项实验来探索模型的行为和性能。我们的结果表明,推理能力迅速提升——例如AMC23准确率从63%提高到80%,AIME24达到46.7%,仅使用7000个样本和42美元的训练成本就超过了o1-preview的基准模型(通常需要数千美元)。然而,随着训练的延长,也出现了优化不稳定和长度约束等挑战。这些发现突显了基于RL的微调对于小型LLM的有效性,为大规模方法提供了成本效益更高的替代方案。我们已将代码和数据集作为开源资源发布,为权衡提供见解,并为资源受限环境中可扩展的、具备推理能力的大型语言模型奠定基础。所有资源都可在https://github.com/knoveleng/open-rs上获取。
论文及项目相关链接
摘要
本研究探索了利用强化学习(RL)提高小型语言模型(LLM)推理能力的潜力。在严格的资源约束下,研究团队对仅有1.5亿参数的模型DeepSeek-R1-Distill-Qwen-1.5B进行了训练,仅使用4个NVIDIA A40 GPU在24小时内完成。通过采用集团相对策略优化(GRPO)算法,并创建了一个紧凑的高质量数学推理数据集,研究进行了三项实验以观察模型的行为和性能。结果显示,使用强化学习微调后,模型的推理能力显著提高,如AMC23准确率从63%提高到80%,AIME24达到46.7%,且仅使用7000个样本和42美元的训练成本,相较于基准模型大大节省了成本。然而,长期训练也面临优化不稳定和长度约束等挑战。这些发现证明了强化学习对小规模LLM精细调整的有效性,为资源受限环境中可伸缩、具备推理能力的大型语言模型的研究提供了深刻的见解。详情可访问研究团队公开的开源资源网站查看。
关键见解
- 利用强化学习(RL)提高了小型语言模型(LLM)的推理能力。
- 训练过程在资源严格限制下进行,展示了强化学习的适用性。
- 使用GRPO算法和特定数据集进行模型训练实验。
- 模型性能显著提高,如AMC23准确率提升和AIME24得分增加。
- 强化学习微调的成本效益显著,相较于传统方法大大节省了成本。
- 长期训练过程中面临优化不稳定和长度约束的挑战。
点此查看论文截图

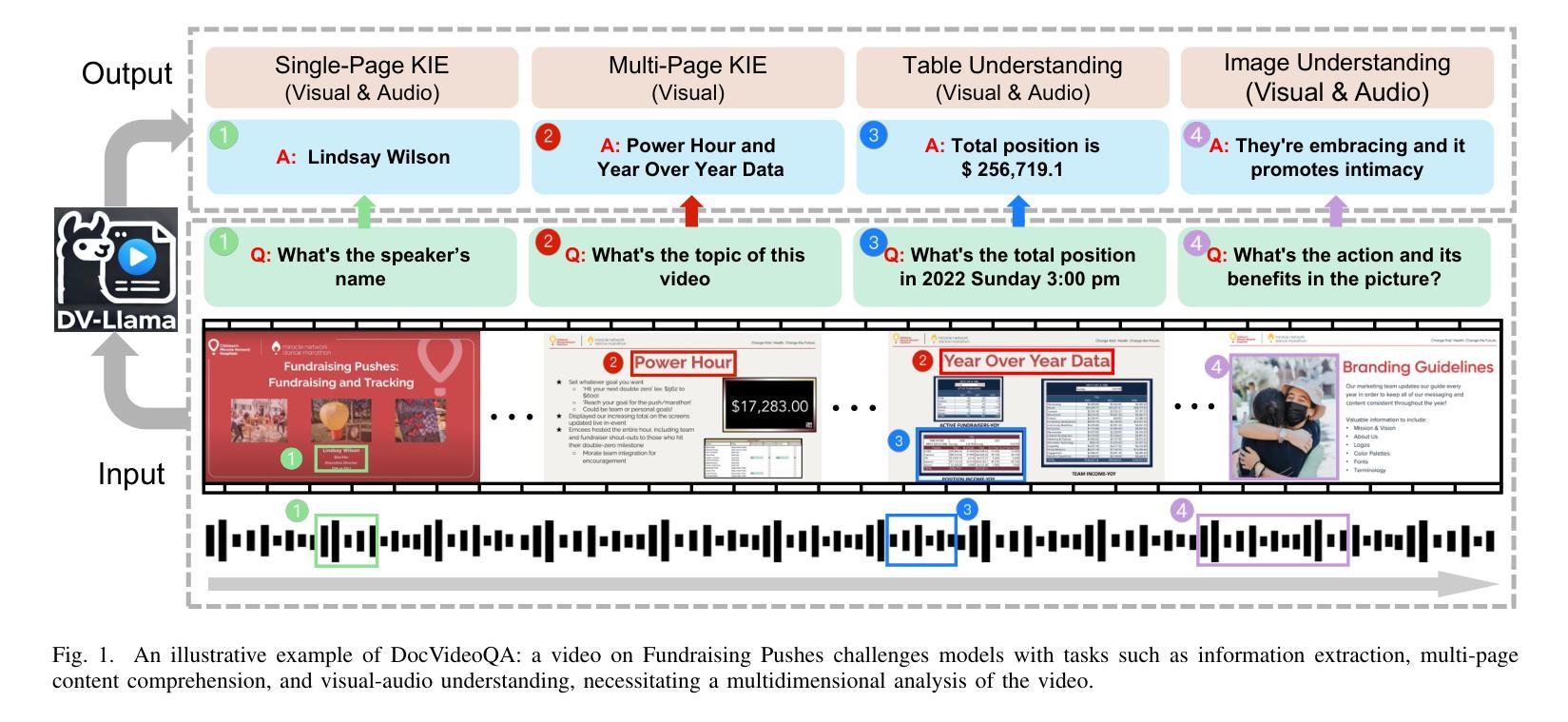
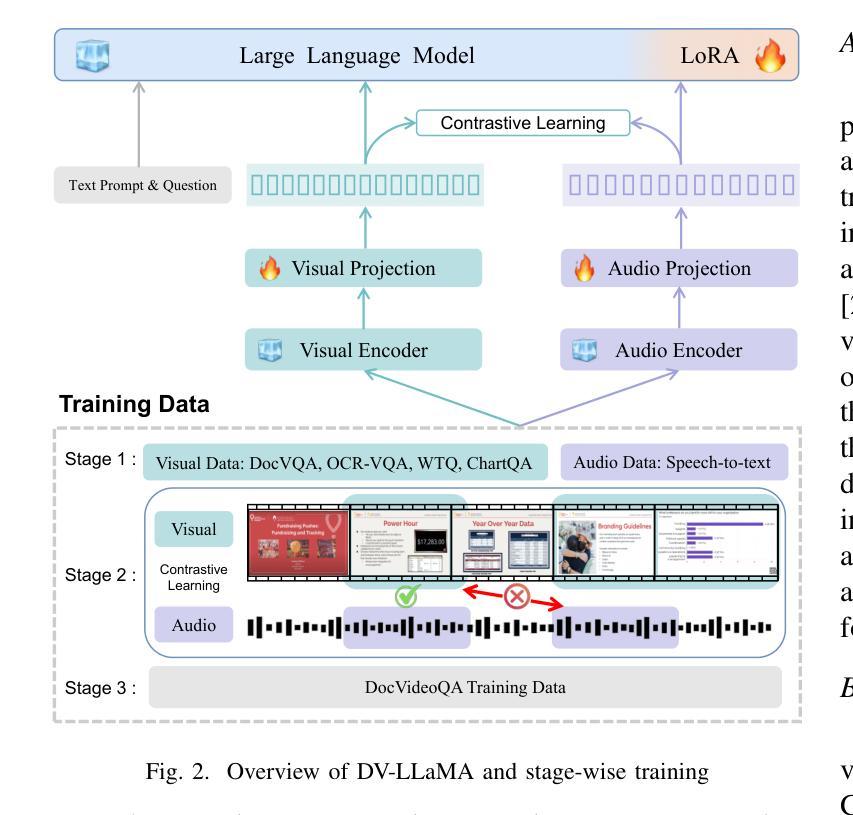
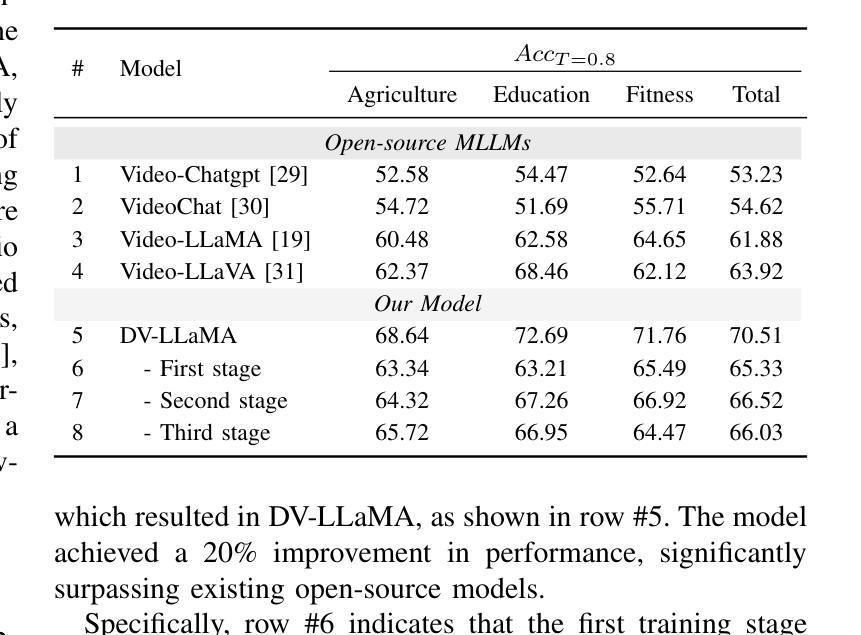
DocVideoQA: Towards Comprehensive Understanding of Document-Centric Videos through Question Answering
Authors:Haochen Wang, Kai Hu, Liangcai Gao
Remote work and online courses have become important methods of knowledge dissemination, leading to a large number of document-based instructional videos. Unlike traditional video datasets, these videos mainly feature rich-text images and audio that are densely packed with information closely tied to the visual content, requiring advanced multimodal understanding capabilities. However, this domain remains underexplored due to dataset availability and its inherent complexity. In this paper, we introduce the DocVideoQA task and dataset for the first time, comprising 1454 videos across 23 categories with a total duration of about 828 hours. The dataset is annotated with 154k question-answer pairs generated manually and via GPT, assessing models’ comprehension, temporal awareness, and modality integration capabilities. Initially, we establish a baseline using open-source MLLMs. Recognizing the challenges in modality comprehension for document-centric videos, we present DV-LLaMA, a robust video MLLM baseline. Our method enhances unimodal feature extraction with diverse instruction-tuning data and employs contrastive learning to strengthen modality integration. Through fine-tuning, the LLM is equipped with audio-visual capabilities, leading to significant improvements in document-centric video understanding. Extensive testing on the DocVideoQA dataset shows that DV-LLaMA significantly outperforms existing models. We’ll release the code and dataset to facilitate future research.
远程工作和在线课程已成为知识传播的重要方法,导致大量基于文档的指令视频出现。与传统视频数据集不同,这些视频主要呈现丰富的文本图像和音频,与视觉内容紧密相关的信息密集,需要高级的多模态理解能力。然而,由于数据集可用性和其固有的复杂性,这个领域仍然鲜有研究。在本文中,我们首次引入DocVideoQA任务和数据集,包含1454个跨越23个类别的视频,总时长约828小时。数据集使用手动和GPT生成的问题答案对进行标注,评估模型的理解能力、时间意识和模态融合能力。首先,我们使用开源大型语言模型(LLMs)建立基准线。为了应对以文档为中心的视频中的模态理解挑战,我们提出了DV-LLaMA这一稳健的视频LLM基准模型。我们的方法通过多样的指令微调数据增强单模态特征提取,并采用对比学习来加强模态融合。通过微调,LLM具备了视听能力,极大地改进了对以文档为中心的视频的理解。在DocVideoQA数据集上的广泛测试表明,DV-LLaMA显著优于现有模型。我们将发布代码和数据集以促进未来的研究。
论文及项目相关链接
Summary:
随着远程工作和在线课程的普及,文档型教学视频成为重要的知识传播方式。本文首次引入DocVideoQA任务和数据集,包含1454个视频和约828小时的时长,标注有15.4万组问答对。建立基线后,提出针对文档型视频的DV-LLaMA模型,采用多样指令微调数据和对比学习强化模态融合。模型在文档型视频理解上表现优异,显著优于现有模型。
Key Takeaways:
- 远程工作和在线课程推动了文档型教学视频的普及。
- DocVideoQA数据集包含大量文档型视频,并标注有问答对以评估模型的多模态理解能力。
- 引入DV-LLaMA模型作为文档型视频理解的基线方法。
- DV-LLaMA模型采用多样指令微调数据和对比学习技术增强模态融合能力。
- 模型通过精细调整在文档型视频理解上表现显著优于现有模型。
点此查看论文截图

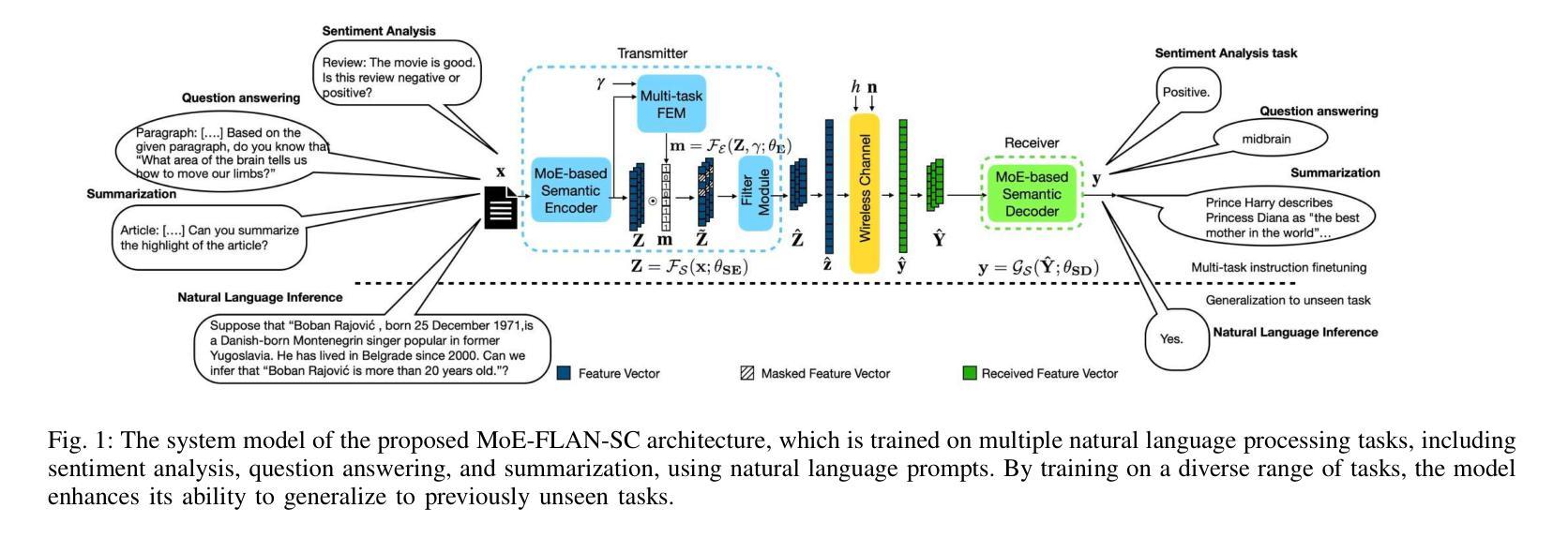
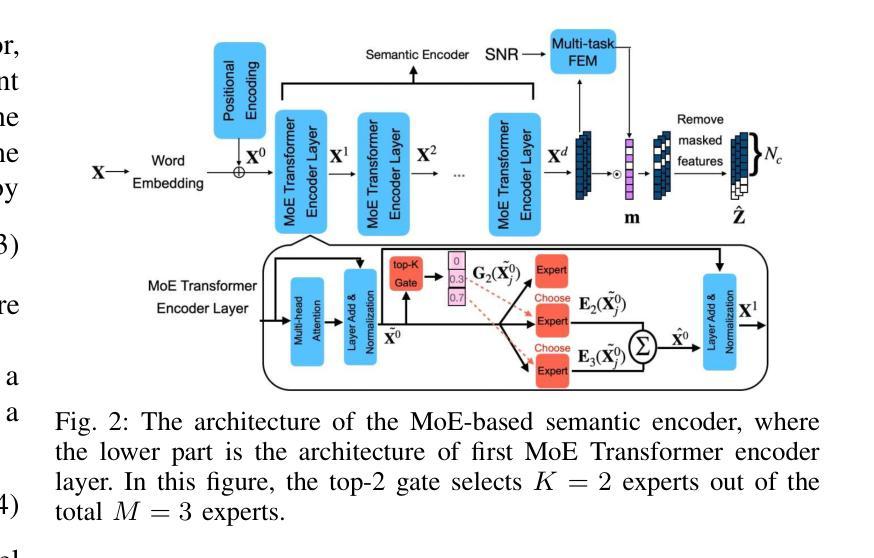
Leveraging MoE-based Large Language Model for Zero-Shot Multi-Task Semantic Communication
Authors:Sin-Yu Huang, Renjie Liao, Vincent W. S. Wong
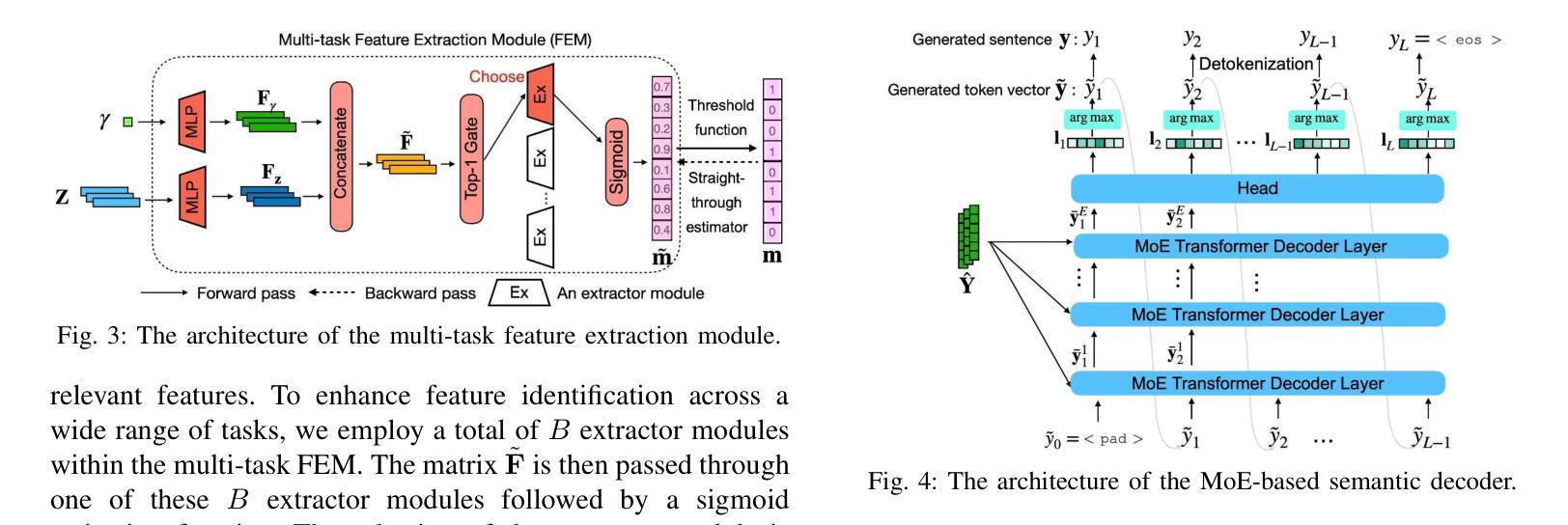
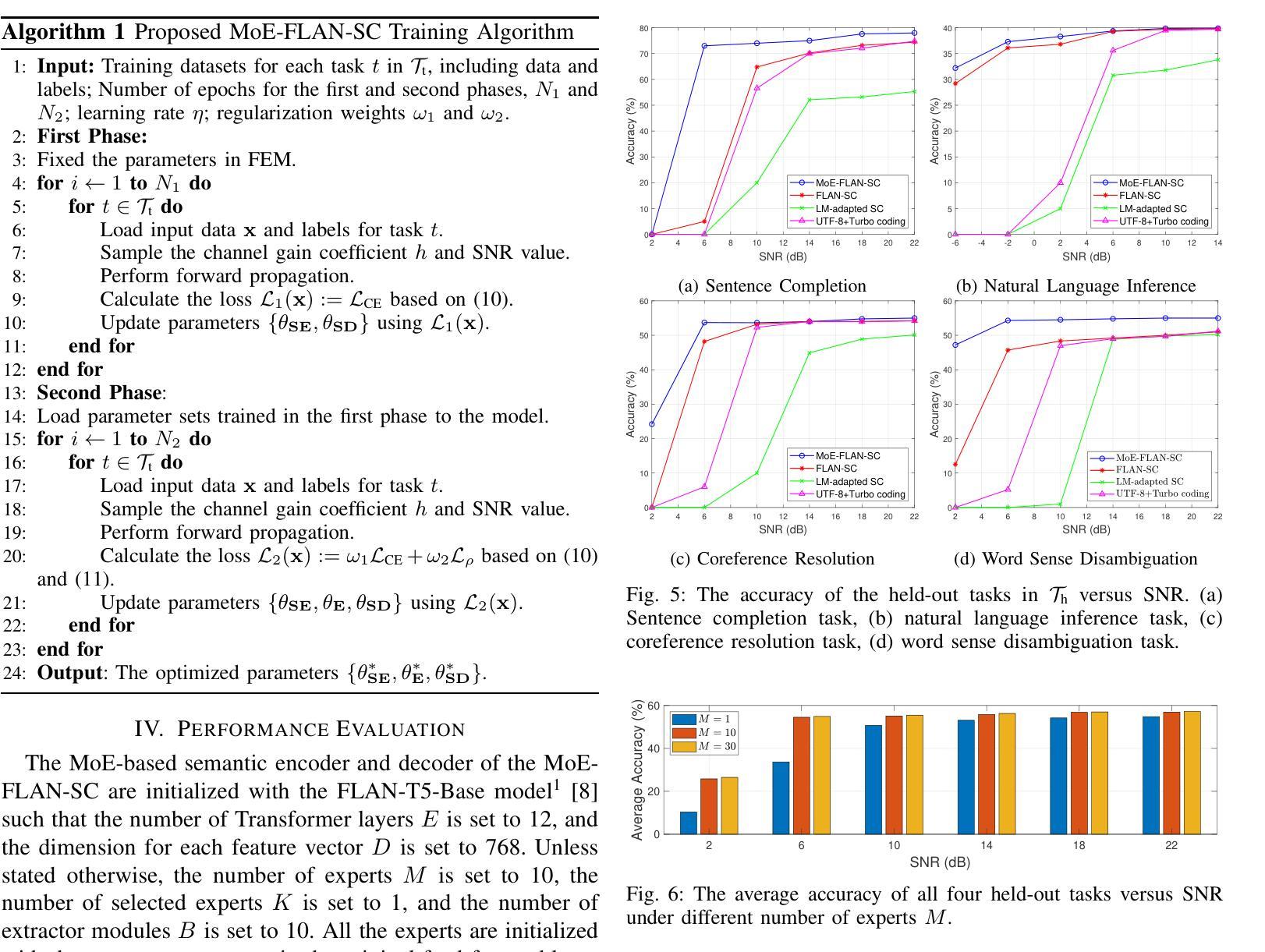
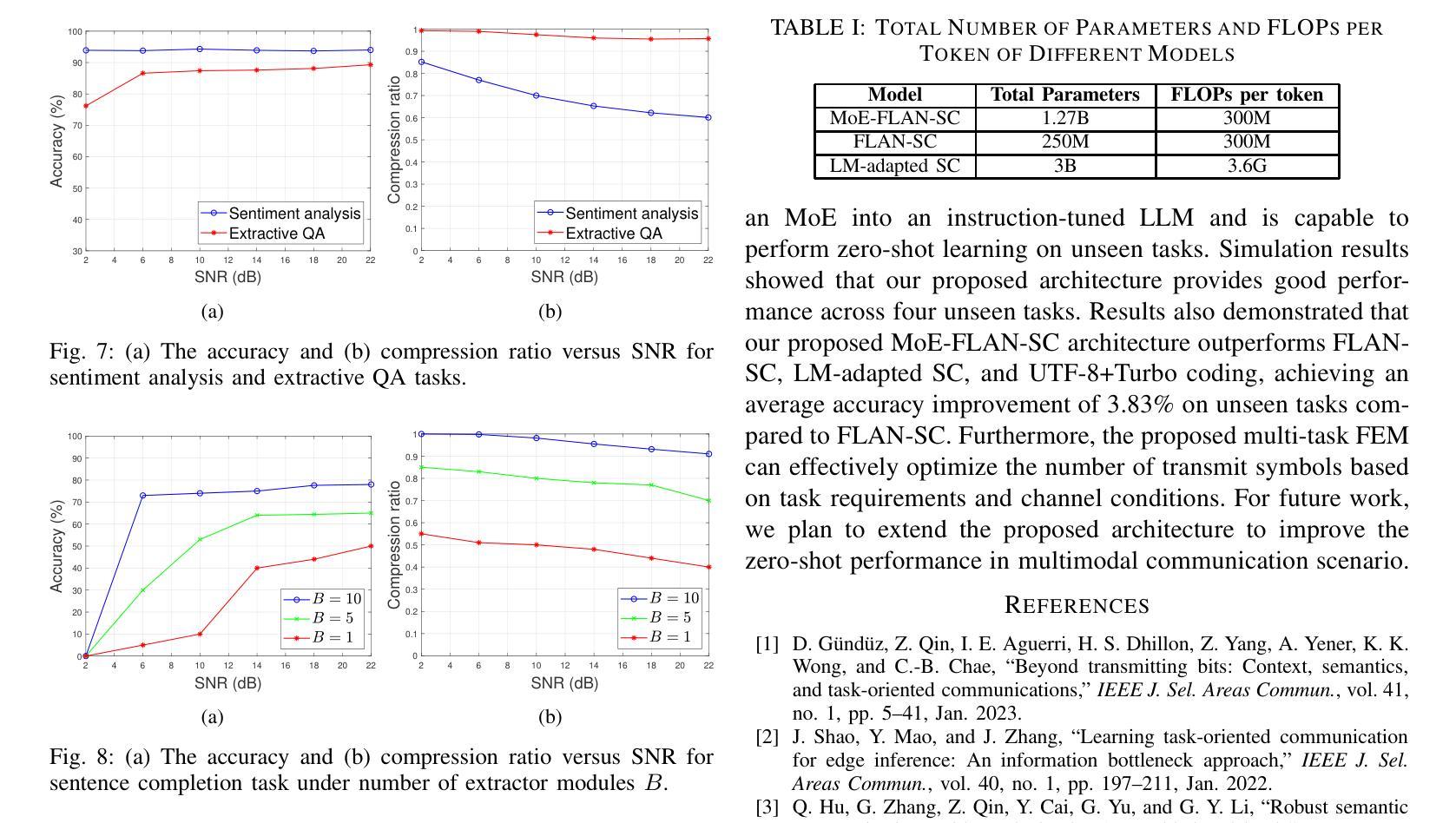
Multi-task semantic communication (SC) can reduce the computational resources in wireless systems since retraining is not required when switching between tasks. However, existing approaches typically rely on task-specific embeddings to identify the intended task, necessitating retraining the entire model when given a new task. Consequently, this drives the need for a multi-task SC system that can handle new tasks without additional training, known as zero-shot learning. Inspired by the superior zero-shot capabilities of large language models (LLMs), we leverage pre-trained instruction-tuned LLMs, referred to as fine-tuned language net (FLAN), to improve the generalization capability. We incorporate a mixture-of-experts (MoE) architecture in the FLAN model and propose MoE-FLAN-SC architecture for multi-task SC systems. Our proposed MoE-FLAN-SC architecture can further improve the performance of FLAN-T5 model without increasing the computational cost. Moreover, we design a multi-task feature extraction module (FEM) which can adaptively extract relevant features across various tasks given the provided features and signal-to-noise ratio (SNR). Simulation results show that our proposed MoE-FLAN-SC architecture outperforms three state-of-the-art models in terms of the average accuracy on four different unseen tasks.
多任务语义通信(SC)能够节省无线系统中的计算资源,因为任务间切换时无需重新训练。然而,现有方法通常依赖于特定任务的嵌入来识别意图任务,当给定新任务时需要重新训练整个模型。因此,这引发了对能够处理新任务而无需额外训练的多任务SC系统的需求,这被称为零射击学习。受大型语言模型(LLM)卓越零射击能力的启发,我们利用预训练的指令调整LLM,称为精细调整语言网络(FLAN),以提高泛化能力。我们将混合专家(MoE)架构融入FLAN模型中,并提出MoE-FLAN-SC架构用于多任务SC系统。我们提出的MoE-FLAN-SC架构可以在不增加计算成本的情况下进一步提高FLAN-T5模型的性能。此外,我们设计了一个多任务特征提取模块(FEM),该模块可以自适应地提取给定特征和信噪比(SNR)下各种任务的相关特征。仿真结果表明,我们提出的MoE-FLAN-SC架构在四个不同未见任务上的平均准确性方面优于三种最先进模型。
论文及项目相关链接
PDF Accepted by ICC 2025
Summary
多任务语义通信(SC)能减少无线系统中的计算资源消耗,但现有方法通常需要针对特定任务嵌入来识别目标任务,这要求对新任务进行整个模型的重新训练。因此,需要一种能处理新任务而无需额外训练的多任务SC系统,即零样本学习能力。受大型语言模型(LLM)出色零样本学习能力的启发,我们利用预训练的指令调整LLM(称为精细调整语言网络(FLAN))来提高其泛化能力。我们将混合专家(MoE)架构融入FLAN模型,并提出MoE-FLAN-SC架构用于多任务SC系统。该架构能在不增加计算成本的情况下,进一步提高FLAN-T5模型的性能。此外,我们设计了一种多任务特征提取模块(FEM),该模块可以自适应地提取各种任务的相关特征,并考虑提供的特征和信噪比(SNR)。模拟结果表明,我们提出的MoE-FLAN-SC架构在四个不同未见任务上的平均准确率优于三种最新模型。
Key Takeaways
- 多任务语义通信(SC)能通过减少重新训练的需求来节约无线系统中的计算资源。
- 现有方法需要重新训练整个模型来处理新任务,这限制了其在实际应用中的灵活性。
- 需要一种具备零样本学习能力的多任务SC系统,以处理新任务而无需额外训练。
- 利用预训练的指令调整LLM(FLAN)提高泛化能力,结合混合专家(MoE)架构形成MoE-FLAN-SC架构。
- MoE-FLAN-SC架构能提高性能且不会增加计算成本。
- 引入多任务特征提取模块(FEM),能自适应提取不同任务的相关特征并考虑信噪比(SNR)。
点此查看论文截图

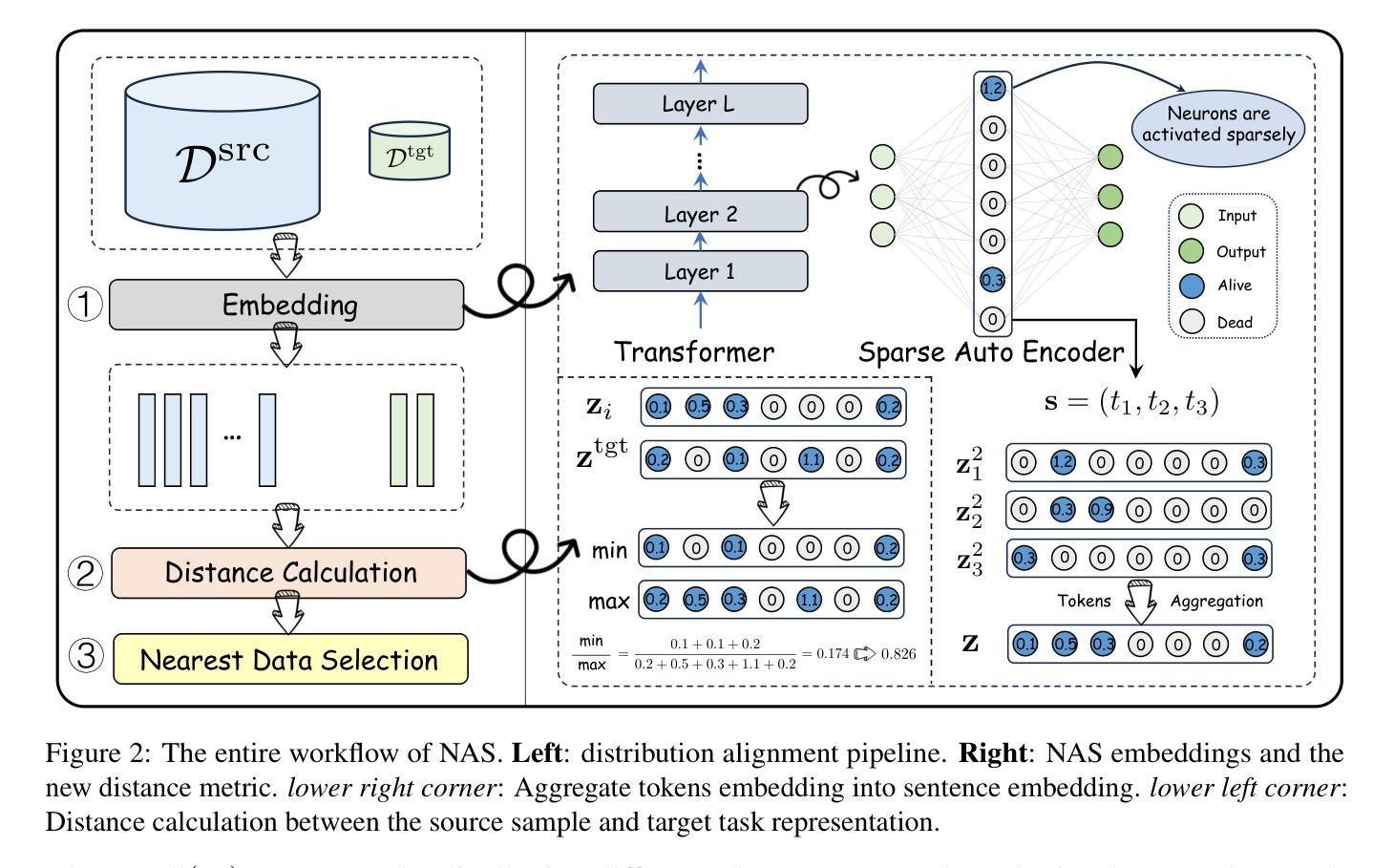
Neuronal Activation States as Sample Embeddings for Data Selection in Task-Specific Instruction Tuning
Authors:Da Ma, Gonghu Shang, Zhi Chen, Libo Qin, Yijie Luo, Lei Pan, Shuai Fan, Lu Chen, Kai Yu
Task-specific instruction tuning enhances the performance of large language models (LLMs) on specialized tasks, yet efficiently selecting relevant data for this purpose remains a challenge. Inspired by neural coactivation in the human brain, we propose a novel data selection method called NAS, which leverages neuronal activation states as embeddings for samples in the feature space. Extensive experiments show that NAS outperforms classical data selection methods in terms of both effectiveness and robustness across different models, datasets, and selection ratios.
针对特定任务的指令微调提高了大型语言模型(LLM)在专业化任务上的性能,但如何有效地选择相关数据仍然是一个挑战。受人类大脑中神经协同激活的启发,我们提出了一种新的数据选择方法,名为NAS(神经激活状态)。该方法利用神经激活状态作为特征空间中样本的嵌入。大量实验表明,NAS在有效性、鲁棒性方面优于经典的数据选择方法,适用于不同的模型、数据集和选择比例。
论文及项目相关链接
PDF preprint
Summary:针对特定任务的指令微调可以提高大型语言模型(LLM)在专业化任务上的性能,但如何选择相关数据仍然是一个挑战。本研究受到人类大脑神经共激活的启发,提出了一种新的数据选择方法NAS,该方法利用神经元激活状态作为特征空间中样本的嵌入。实验表明,NAS在有效性、稳健性方面优于经典的数据选择方法,且在不同模型、数据集和选择比例上都表现优异。
Key Takeaways:
- 任务特定指令微调对LLM在专业化任务上的性能提升至关重要。
- 数据选择对于LLM性能的提升具有挑战性。
- NAS数据选择方法利用神经元激活状态作为嵌入,在特征空间中进行数据选择。
- NAS在有效性、稳健性方面优于经典的数据选择方法。
- NAS在不同模型、数据集和选择比例上都有良好的表现。
- 本研究受到人类大脑神经共激活的启发,体现出了生物灵感在计算领域的应用潜力。
点此查看论文截图

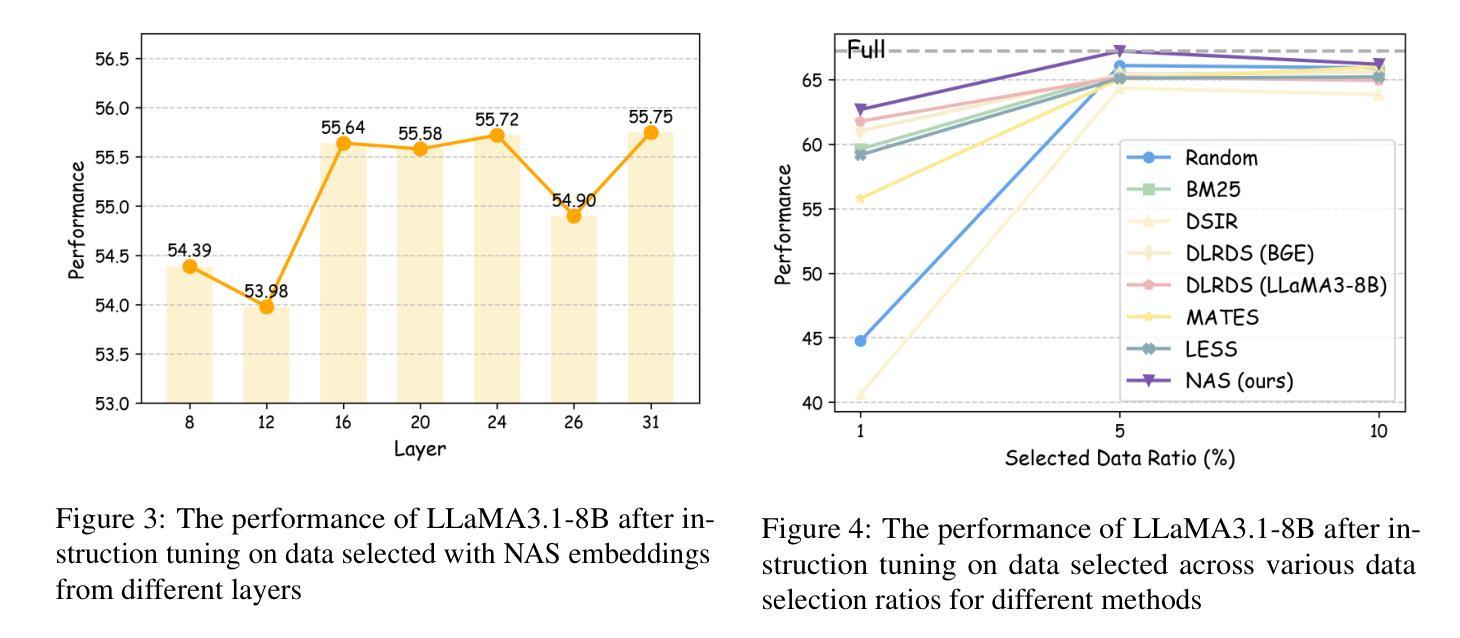
BigO(Bench) – Can LLMs Generate Code with Controlled Time and Space Complexity?
Authors:Pierre Chambon, Baptiste Roziere, Benoit Sagot, Gabriel Synnaeve
We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. This benchmark addresses the gap in current evaluations that often overlook the ability of models to comprehend and produce code constrained by computational complexity. BigO(Bench) includes tooling to infer the algorithmic complexity of any Python function from profiling measurements, including human- or LLM-generated solutions. BigO(Bench) also includes of set of 3,105 coding problems and 1,190,250 solutions from Code Contests annotated with inferred (synthetic) time and space complexity labels from the complexity framework, as well as corresponding runtime and memory footprint values for a large set of input sizes. We present results from evaluating multiple state-of-the-art language models on this benchmark, highlighting their strengths and weaknesses in handling complexity requirements. In particular, token-space reasoning models are unrivaled in code generation but not in complexity understanding, hinting that they may not generalize well to tasks for which no reward was given at training time.
我们介绍了BigO(Bench),这是一个新的编码基准测试,旨在评估生成式语言模型在理解和生成具有特定时间和空间复杂度的代码的能力。这个基准测试弥补了当前评估中的空白,当前的评估往往忽视了模型理解和产生受计算复杂度约束的代码的能力。BigO(Bench)包括从分析测量推断任何Python函数算法复杂度的工具,包括人类或大型语言模型生成的解决方案。BigO(Bench)还包括一组来自代码竞赛的3105个编码问题和1190250个解决方案,这些问题和解决方案被标注了从复杂度框架推断出的(合成)时间和空间复杂度标签,以及对应的大规模输入大小的运行时间和内存占用值。我们在此基准测试上评估了多个最先进的语言模型的结果,突出了它们在处理复杂度要求方面的优势和劣势。尤其值得一提的是,虽然在代码生成方面无与伦比,但在复杂性理解方面,标记空间推理模型可能并不适用于那些在训练时未给予奖励的任务。
论文及项目相关链接
Summary
大O(Bench)是一个新型编码基准测试,旨在评估生成式语言模型在理解和生成具有特定时间和空间复杂度的代码方面的能力。该基准测试弥补了当前评估中的空白,当前的评估常常忽视模型理解和生成受计算复杂度约束的代码的能力。大O(Bench)包括工具,可以从分析测量中推断任何Python函数的算法复杂度,包括人类或LLM生成的解决方案。此外,它还包括一组来自代码竞赛的3105个编程问题和1190250个解决方案,这些问题和答案都被标注了推断的(合成)时间和空间复杂度标签以及相应的大规模输入集的运行时内存占用值。我们在此基准上评估了多个先进的语言模型,突出了它们在处理复杂度要求方面的优势和劣势。尤其是,令牌空间推理模型在代码生成方面无与伦比,但在复杂性理解方面并不突出,这表明它们可能无法很好地推广到训练时未给予奖励的任务。
Key Takeaways
- BigO(Bench)是一个评估语言模型理解和生成具有特定时间和空间复杂度的代码能力的基准测试。
- 当前评估存在忽略模型理解和生成受计算复杂度约束的代码的空白。
- BigO(Bench)能从分析测量中推断Python函数的算法复杂度。
- 它包含来自代码竞赛的编程问题和解决方案,并标注了推断的时空复杂度及运行时内存占用。
- 令牌空间推理模型在代码生成方面表现出色,但在复杂性理解上仍有不足。
- 这些模型可能无法很好地推广到训练时未给予奖励的任务。
点此查看论文截图

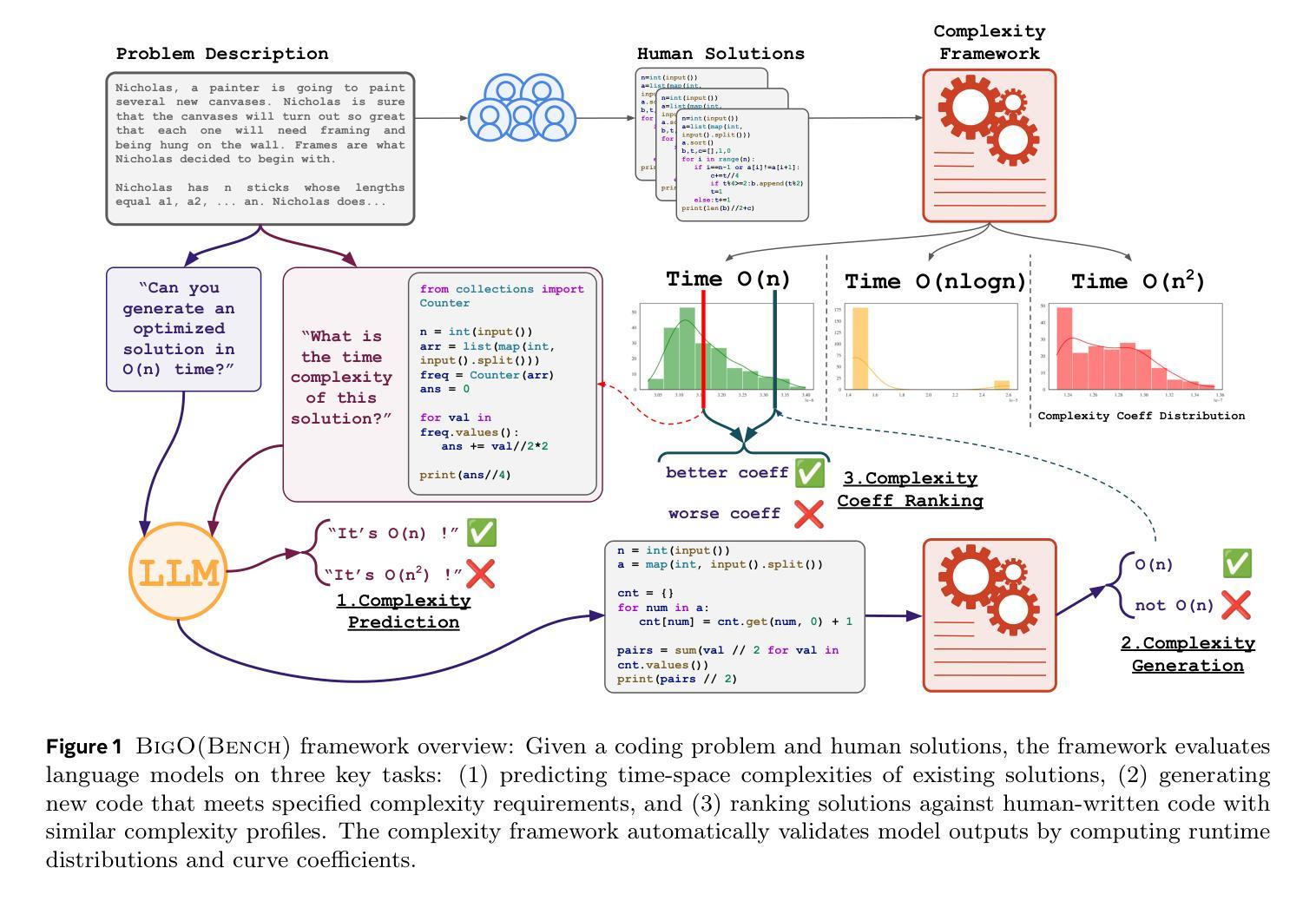
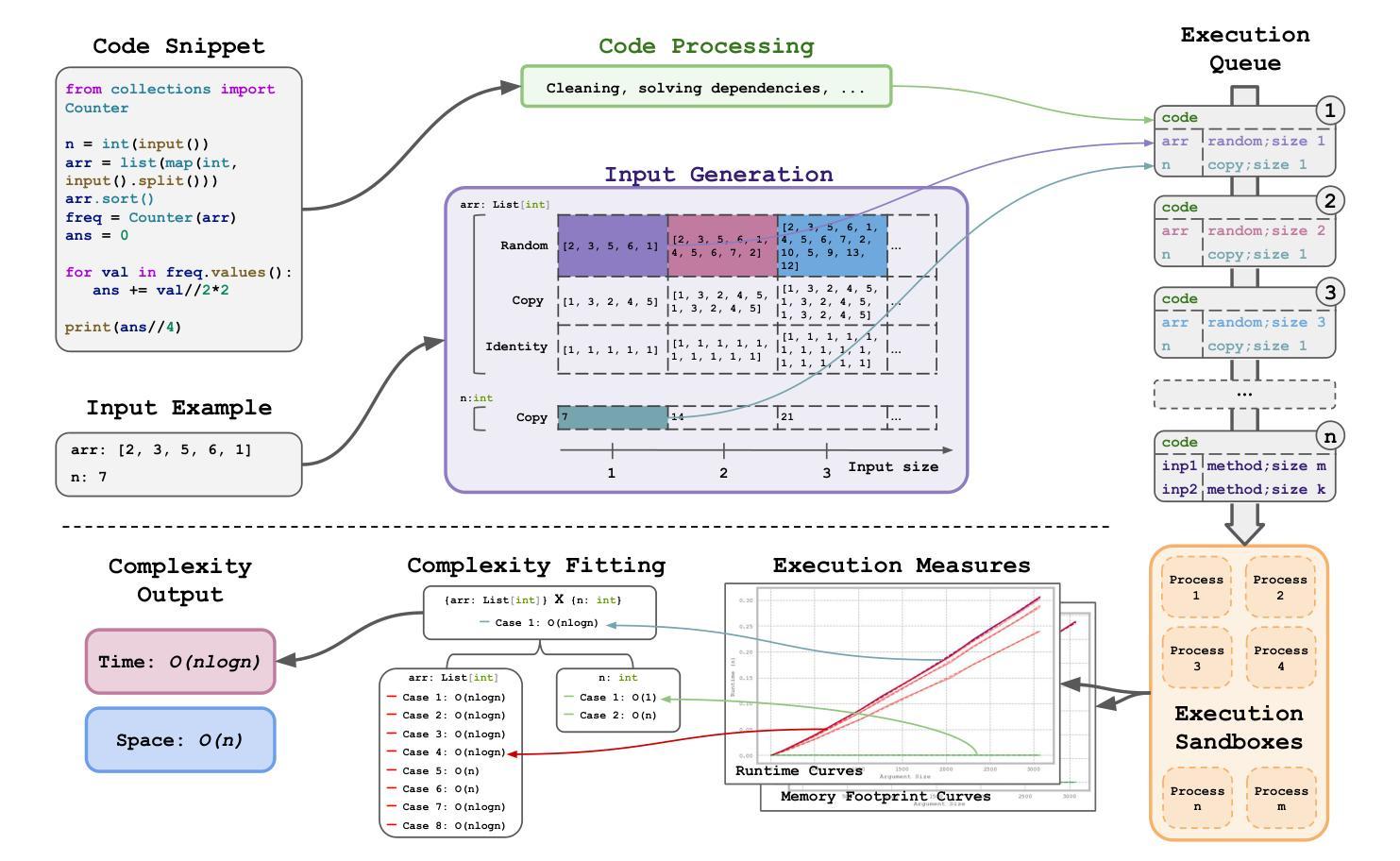
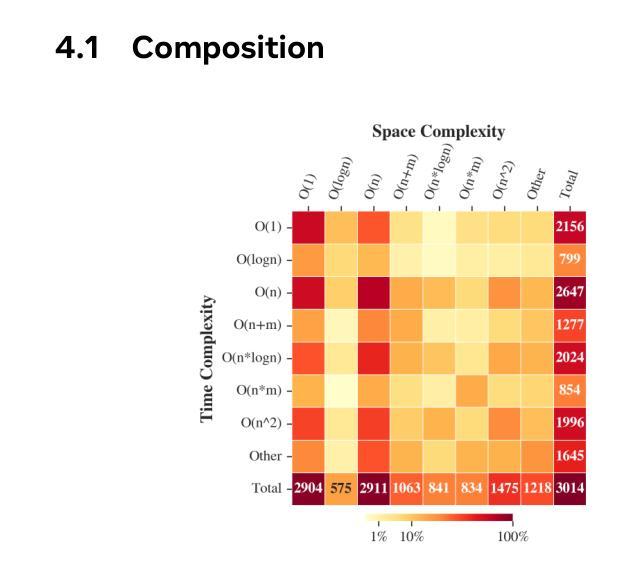

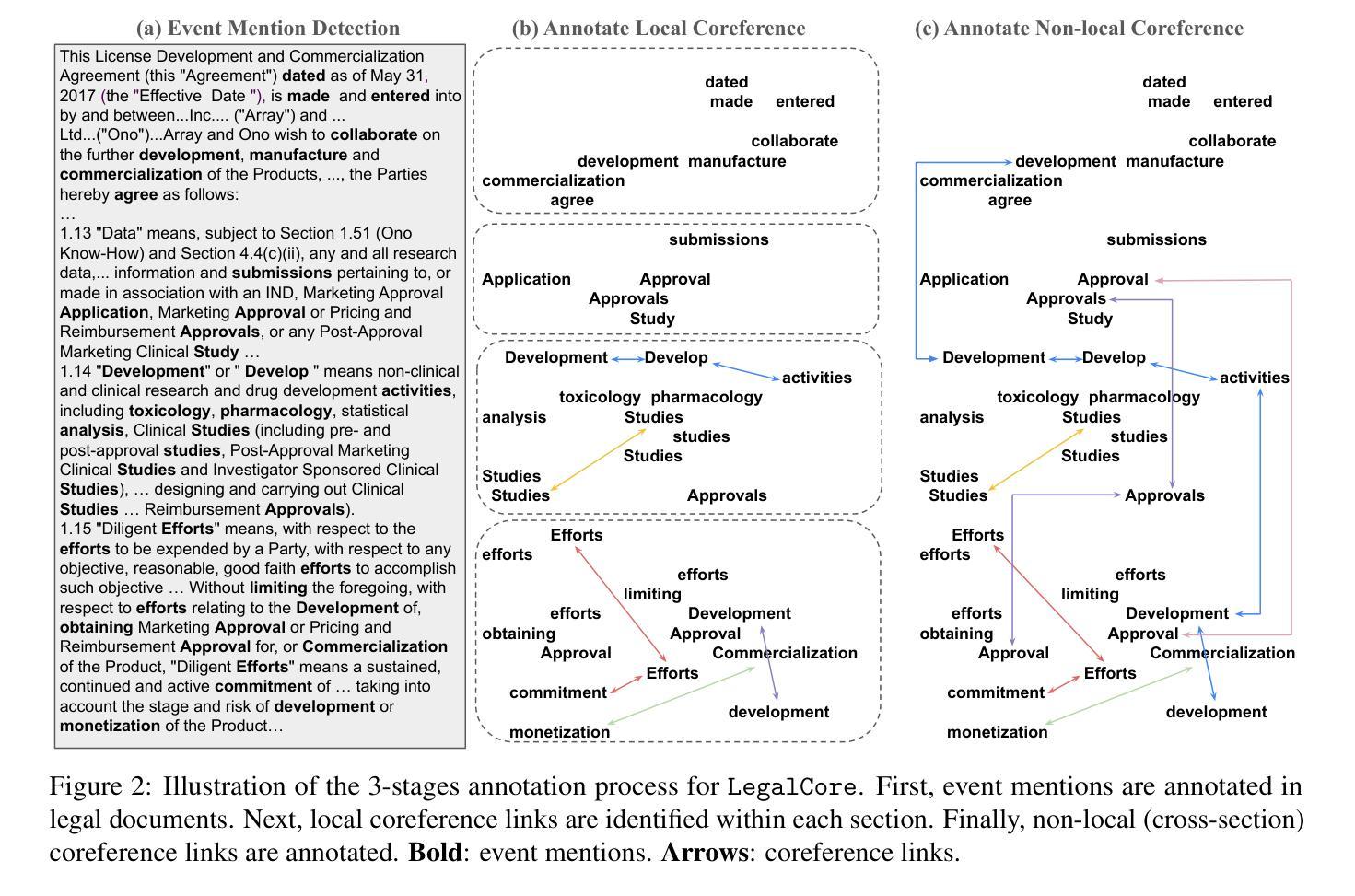
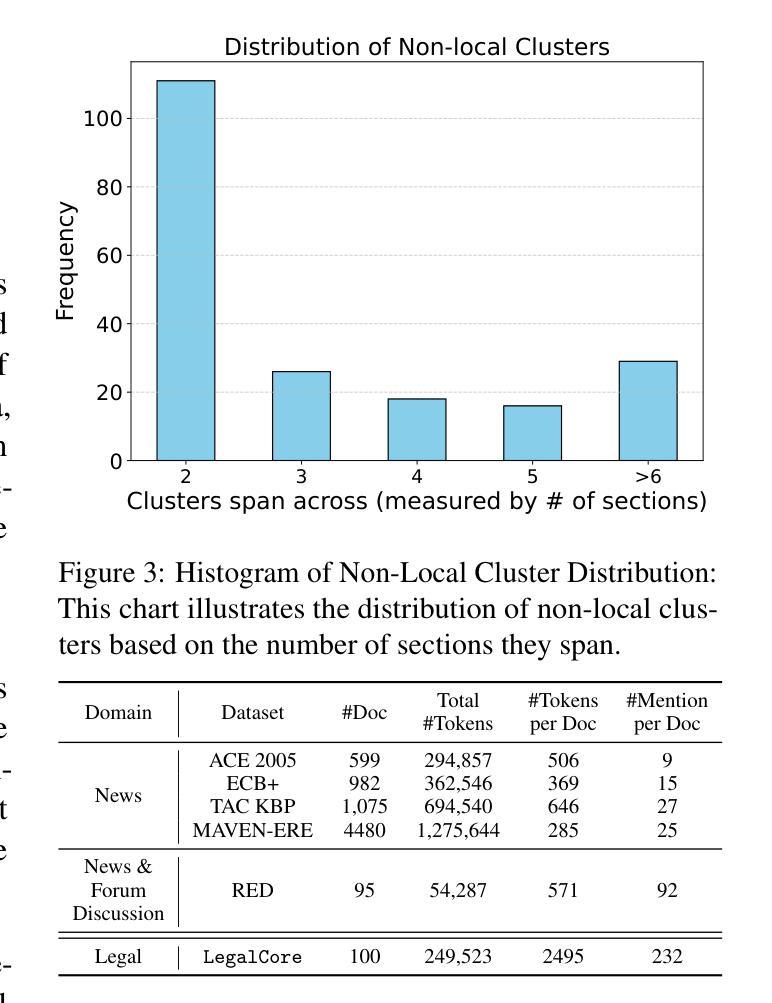
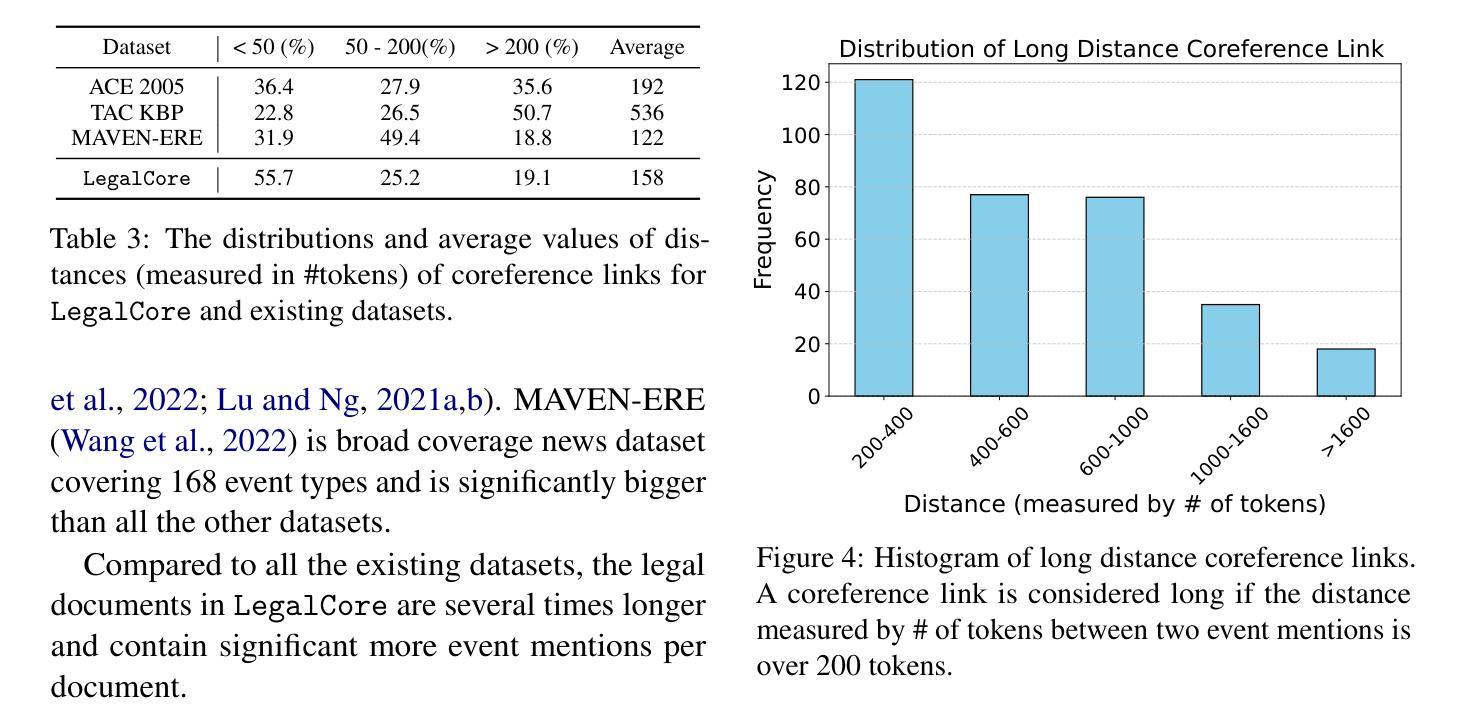
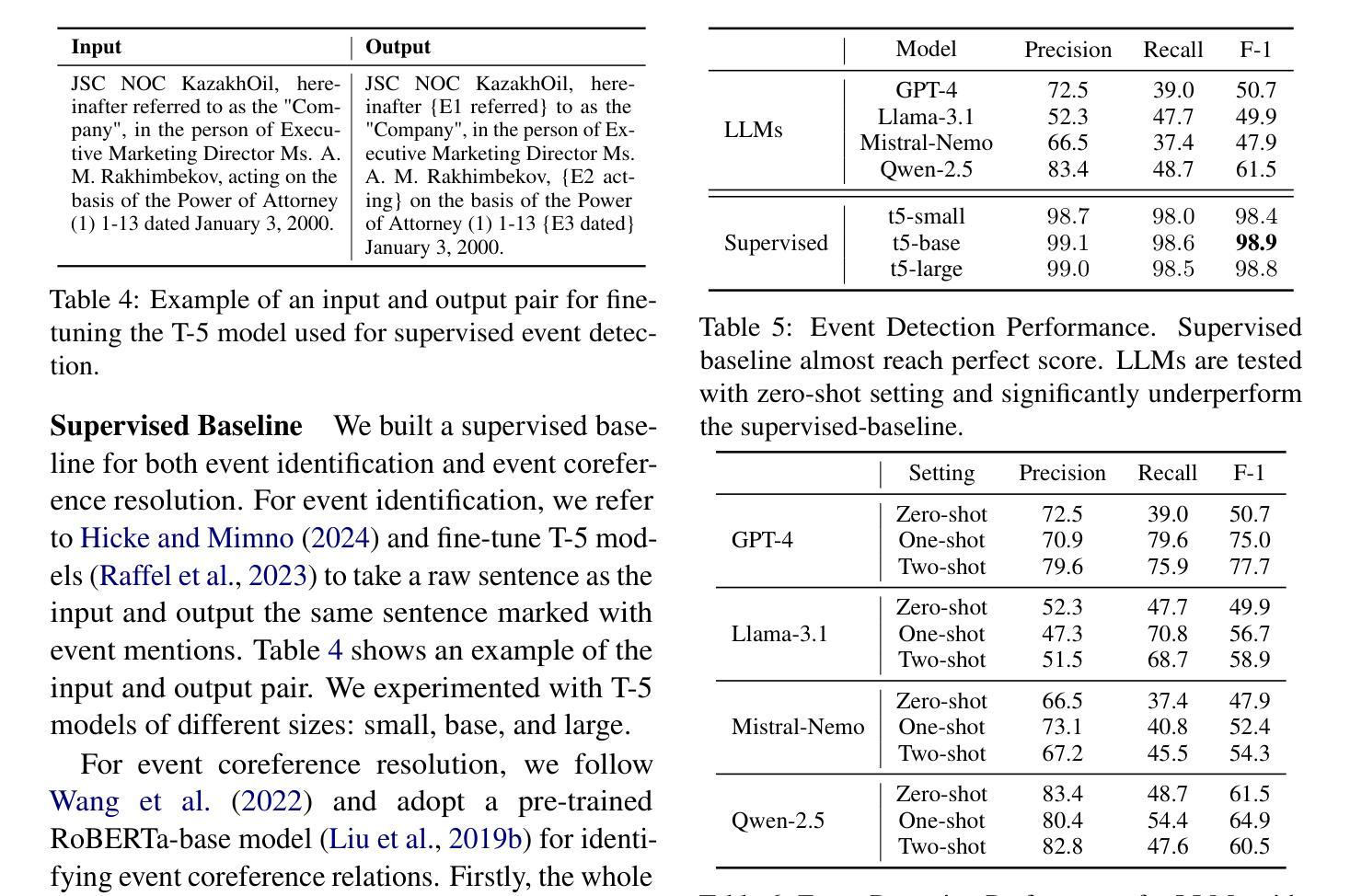
LegalCore: A Dataset for Event Coreference Resolution in Legal Documents
Authors:Kangda Wei, Xi Shi, Jonathan Tong, Sai Ramana Reddy, Anandhavelu Natarajan, Rajiv Jain, Aparna Garimella, Ruihong Huang
Recognizing events and their coreferential mentions in a document is essential for understanding semantic meanings of text. The existing research on event coreference resolution is mostly limited to news articles. In this paper, we present the first dataset for the legal domain, LegalCore, which has been annotated with comprehensive event and event coreference information. The legal contract documents we annotated in this dataset are several times longer than news articles, with an average length of around 25k tokens per document. The annotations show that legal documents have dense event mentions and feature both short-distance and super long-distance coreference links between event mentions. We further benchmark mainstream Large Language Models (LLMs) on this dataset for both event detection and event coreference resolution tasks, and find that this dataset poses significant challenges for state-of-the-art open-source and proprietary LLMs, which perform significantly worse than a supervised baseline. We will publish the dataset as well as the code.
识别和解析文档中事件及其核心引用提及对于理解文本语义至关重要。现有的事件核心引用解析研究大多局限于新闻文章。在本文中,我们首次推出了法律领域的数据集LegalCore,该数据集已进行了全面的事件和事件核心引用信息注释。我们在该数据集中注释的法律合同文档是新闻文章的数倍长,平均每个文档约包含25,000个令牌。注释表明,法律文档具有密集的事件提及,并且事件提及之间具有短距离和超远距离的核心引用链接。我们进一步在此数据集上评估主流的大型语言模型(LLM)的事件检测和事件核心引用解析任务,发现该数据集对最新的开源和专有LLM构成了重大挑战,它们的性能显著差于受监督的基线。我们将发布数据集以及代码。
论文及项目相关链接
PDF Need company internal approval before public release
摘要
本文介绍了事件及其核心引用在文档中的重要性,并强调对法律领域事件核心引用解析的研究。现有研究多局限于新闻文章,而法律文档更密集地涉及到事件提及,并有多种复杂的核心引用链接。本研究构建了首个法律领域的核心事件数据集——LegalCore,并标注了事件及其核心引用信息。该数据集包含的法律合同文档长度远超新闻文章,平均每个文档约含25k个标记。在此数据集上进行的基准测试显示,主流的大型语言模型面临显著挑战。本研究将公布数据集及代码。
关键见解
- 事件及其核心引用的识别对于理解文本语义至关重要。
- 法律领域的事件核心引用解析研究尚未得到充分关注。
- LegalCore数据集是首个针对法律领域的核心事件数据集,包含大量标注的事件及其核心引用信息。
- 法律文档中的事件提及更为密集,存在多种复杂的核心引用链接。
- 主流的大型语言模型面临该数据集的显著挑战,性能远低于监督基准测试。
- 数据集公开将促进对该领域的深入研究与应用。
- 研究将公开数据集及代码,便于后续研究使用和改进。
点此查看论文截图

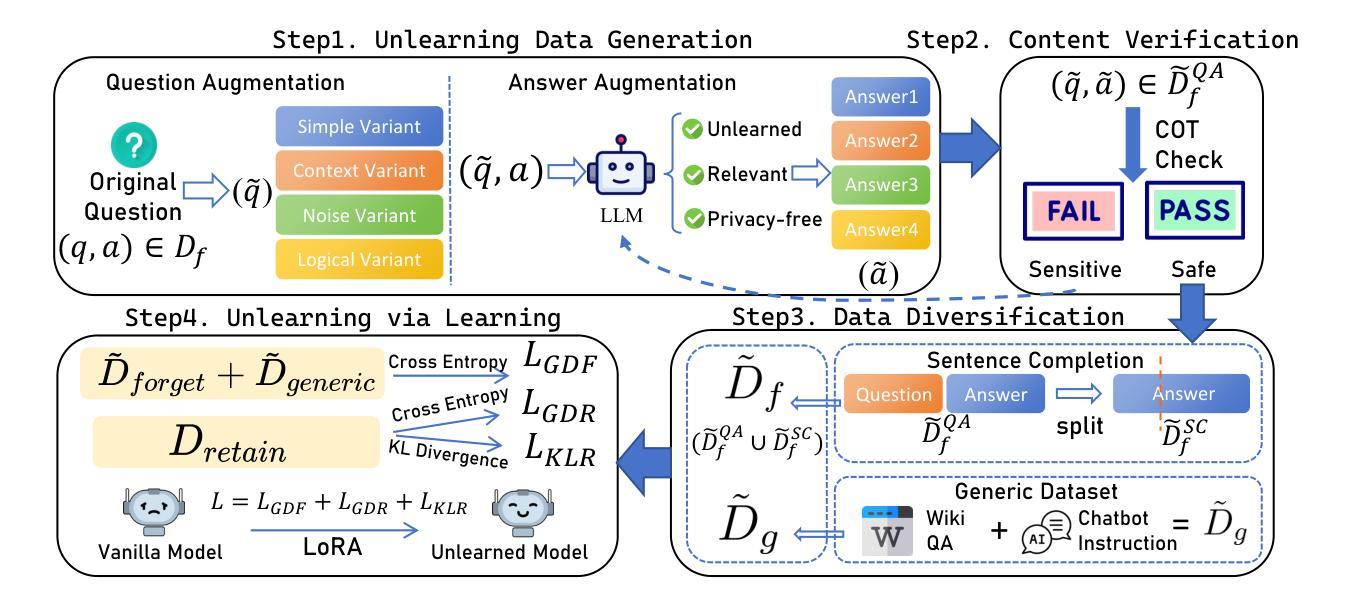
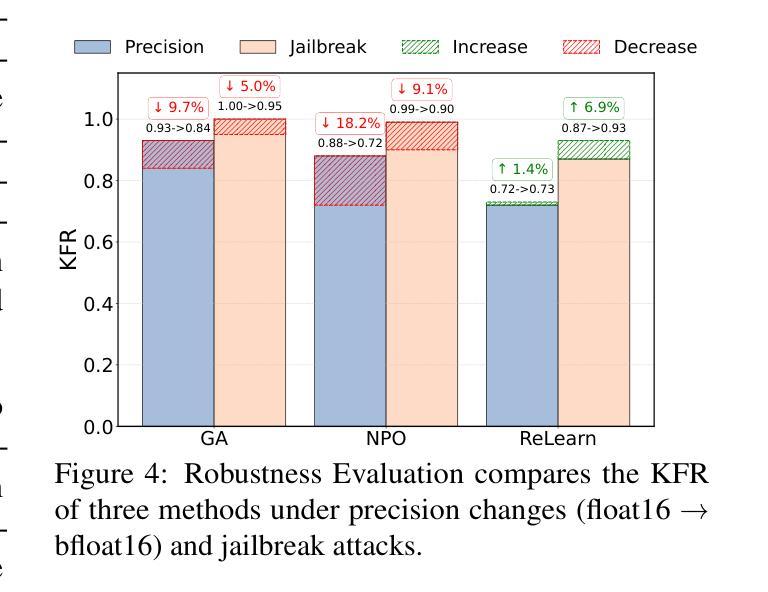
ReLearn: Unlearning via Learning for Large Language Models
Authors:Haoming Xu, Ningyuan Zhao, Liming Yang, Sendong Zhao, Shumin Deng, Mengru Wang, Bryan Hooi, Nay Oo, Huajun Chen, Ningyu Zhang
Current unlearning methods for large language models usually rely on reverse optimization to reduce target token probabilities. However, this paradigm disrupts the subsequent tokens prediction, degrading model performance and linguistic coherence. Moreover, existing evaluation metrics overemphasize contextual forgetting while inadequately assessing response fluency and relevance. To address these challenges, we propose ReLearn, a data augmentation and fine-tuning pipeline for effective unlearning, along with a comprehensive evaluation framework. This framework introduces Knowledge Forgetting Rate (KFR) and Knowledge Retention Rate (KRR) to measure knowledge-level preservation, and Linguistic Score (LS) to evaluate generation quality. Our experiments show that ReLearn successfully achieves targeted forgetting while preserving high-quality output. Through mechanistic analysis, we further demonstrate how reverse optimization disrupts coherent text generation, while ReLearn preserves this essential capability. Code is available at https://github.com/zjunlp/unlearn.
当前针对大型语言模型的遗忘学习方法通常依赖于反向优化来降低目标令牌的概率。然而,这种模式会破坏后续的令牌预测,降低模型性能和语言连贯性。此外,现有的评估指标过分强调上下文遗忘,而不足以评估响应的流畅性和相关性。为了应对这些挑战,我们提出了ReLearn,这是一个用于有效遗忘的数据增强和微调管道,以及一个全面的评估框架。该框架引入了知识遗忘率(KFR)和知识保留率(KRR)来衡量知识层面的保留情况,以及语言得分(LS)来评估生成质量。我们的实验表明,ReLearn成功实现了有针对性的遗忘,同时保留了高质量的输出。通过机制分析,我们进一步证明了反向优化是如何破坏连贯的文本生成的,而ReLearn能够保持这种重要能力。代码可在https://github.com/zjunlp/unlearn找到。
论文及项目相关链接
PDF Work in progress
Summary
本文提出了针对大型语言模型的ReLearn方法,采用数据增强和微调管道进行有效遗忘。该方法克服了反向优化在知识遗忘过程中的缺点,保留了文本的连贯性和模型的性能。此外,提出了一种综合评价体系,包括知识遗忘率(KFR)、知识保留率(KRR)和语言学评分(LS),旨在更好地评估模型生成质量。实验表明,ReLearn方法在成功实现目标遗忘的同时,保持了高质量输出。
Key Takeaways
- 当前大型语言模型的遗忘方法主要依赖反向优化来降低目标词汇概率,但这种方法会破坏文本的连贯性和模型性能。
- ReLearn方法采用数据增强和微调管道进行更有效的遗忘,避免了反向优化的缺点。
- 综合评价体系包括知识遗忘率(KFR)、知识保留率(KRR)和语言学评分(LS),以全面评估模型的生成质量。
- ReLearn方法成功实现了目标遗忘,同时保持了高质量输出。
- 知识遗忘率的评估可以更好地衡量模型在遗忘特定知识方面的能力。
- ReLearn方法通过保留语言连贯性,改善了文本生成的质量。
点此查看论文截图


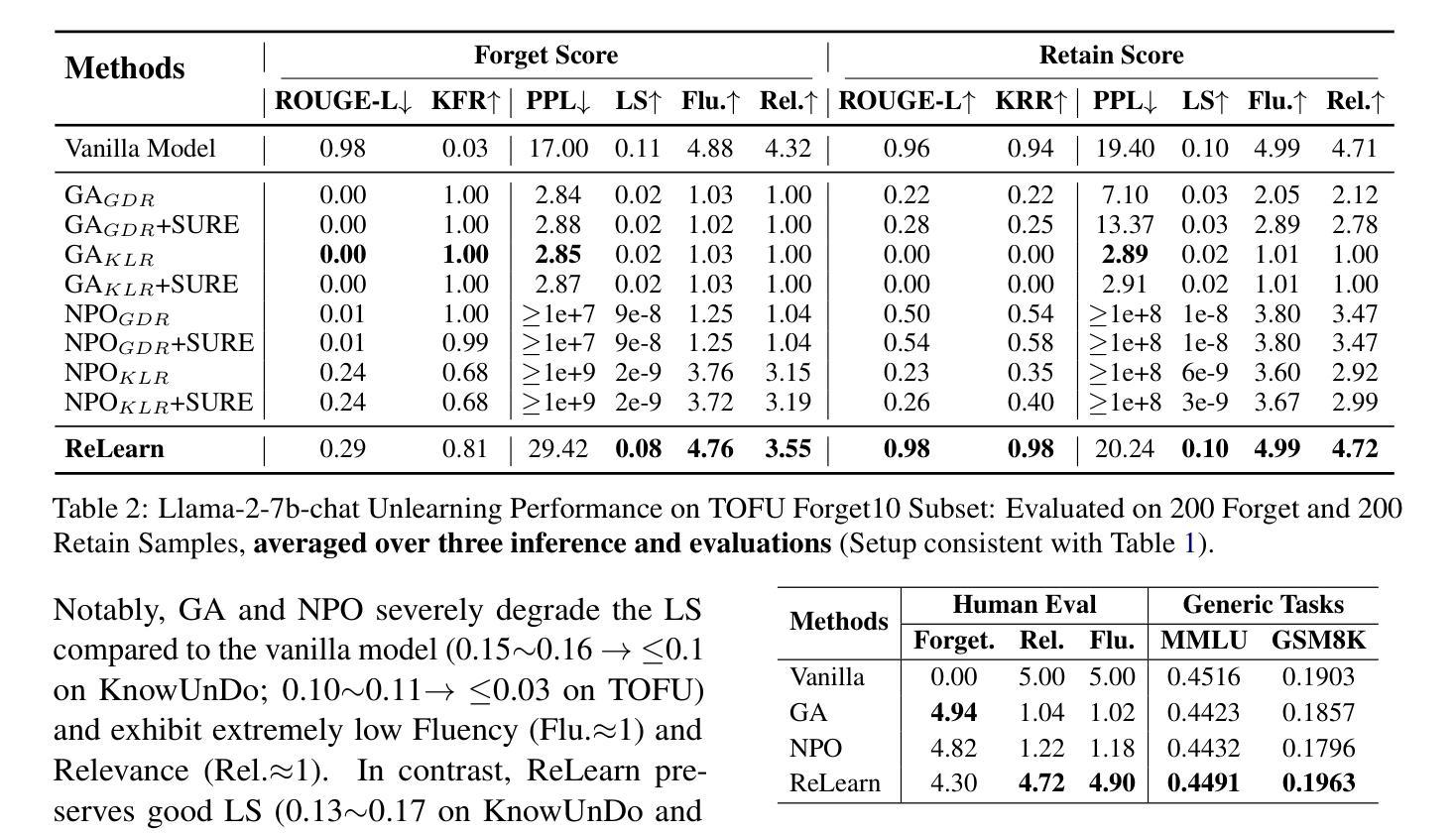
Is Long Context All You Need? Leveraging LLM’s Extended Context for NL2SQL
Authors:Yeounoh Chung, Gaurav T. Kakkar, Yu Gan, Brenton Milne, Fatma Ozcan
Large Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks. In particular, improvements in reasoning abilities and the expansion of context windows have opened new avenues for leveraging these powerful models. NL2SQL is challenging in that the natural language question is inherently ambiguous, while the SQL generation requires a precise understanding of complex data schema and semantics. One approach to this semantic ambiguous problem is to provide more and sufficient contextual information. In this work, we explore the performance and the latency trade-offs of the extended context window (a.k.a., long context) offered by Google’s state-of-the-art LLM (\textit{gemini-1.5-pro}). We study the impact of various contextual information, including column example values, question and SQL query pairs, user-provided hints, SQL documentation, and schema. To the best of our knowledge, this is the first work to study how the extended context window and extra contextual information can help NL2SQL generation with respect to both accuracy and latency cost. We show that long context LLMs are robust and do not get lost in the extended contextual information. Additionally, our long-context NL2SQL pipeline based on Google’s \textit{gemini-pro-1.5} achieve strong performances on various benchmark datasets without finetuning and expensive self-consistency based techniques.
大型语言模型(LLM)在多种自然语言处理任务中表现出了令人印象深刻的能力。特别是,推理能力的改进和上下文窗口的扩展开辟了利用这些强大模型的新途径。NL2SQL的挑战在于自然语言问题本质上是模糊的,而SQL生成需要精确理解复杂的数据结构和语义。解决这种语义模糊问题的一种方法是提供更多和足够的上下文信息。在这项工作中,我们探讨了谷歌最新LLM(双子座-专业版1.5)提供的扩展上下文窗口(也称为长上下文)的性能和延迟权衡。我们研究了各种上下文信息的影响,包括列示例值、问题和SQL查询对、用户提供的提示、SQL文档和模式。据我们所知,这是第一项研究扩展上下文窗口和额外的上下文信息如何帮助NL2SQL生成工作,同时考虑准确性和延迟成本。我们表明,长上下文LLM是稳健的,不会在扩展的上下文信息中迷失方向。此外,我们的基于谷歌双子座专业版-基于上下文的长NL2SQL管道在各种基准数据集上表现强劲,无需微调和使用昂贵的基于自我一致性等技术。
论文及项目相关链接
PDF 13 pages, 6 figures, VLDB 2025
Summary
大型语言模型(LLM)在自然语言处理任务中展现出令人印象深刻的性能,特别是在推理能力和上下文窗口扩展方面。针对NL2SQL的语义模糊问题,本研究探讨了通过提供更充足的上下文信息来解决该问题的方法。通过探索谷歌前沿LLM(双子座-专业版)提供的扩展上下文窗口的性能和延迟权衡,本研究考虑了多种上下文信息的影响,包括列示例值、问答对、用户提示、SQL文档和模式等。研究结果表明,长上下文LLM在NL2SQL生成方面既稳健又高效,能够在各种基准数据集上实现强大的性能,无需微调或昂贵的自一致性技术。
Key Takeaways
- 大型语言模型(LLM)在自然语言处理任务中表现出强大的性能。
- 上下文窗口的扩展增强了LLM的推理能力。
- NL2SQL的挑战在于自然语言的固有模糊性和对复杂数据架构精确理解的需求。
- 提供更多充足的上下文信息是解决NL2SQL语义模糊问题的一种有效方法。
- 研究了谷歌前沿LLM(双子座-专业版)在扩展上下文窗口方面的性能和延迟权衡。
- 综合考虑了多种上下文信息对NL2SQL生成的影响。
点此查看论文截图

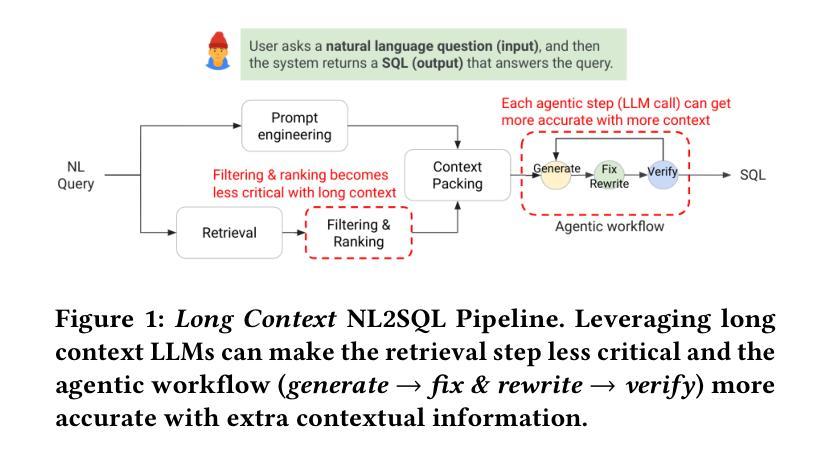
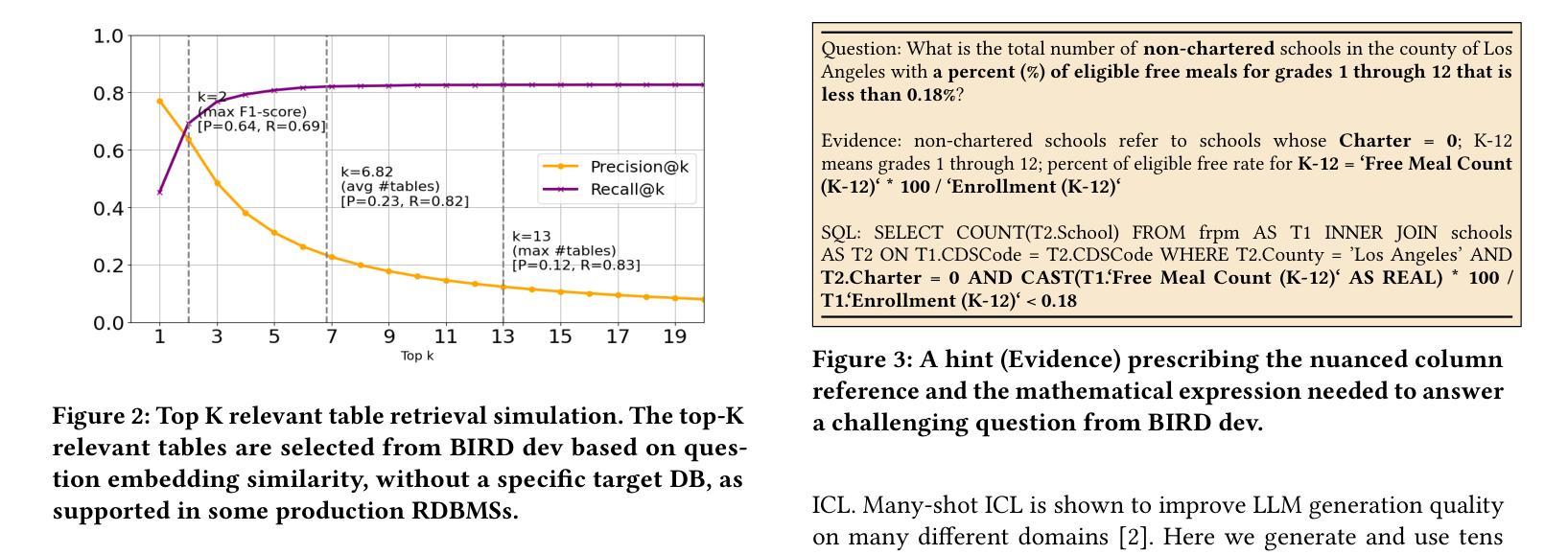
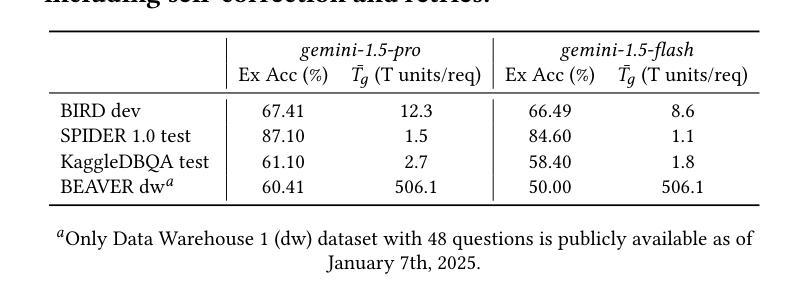
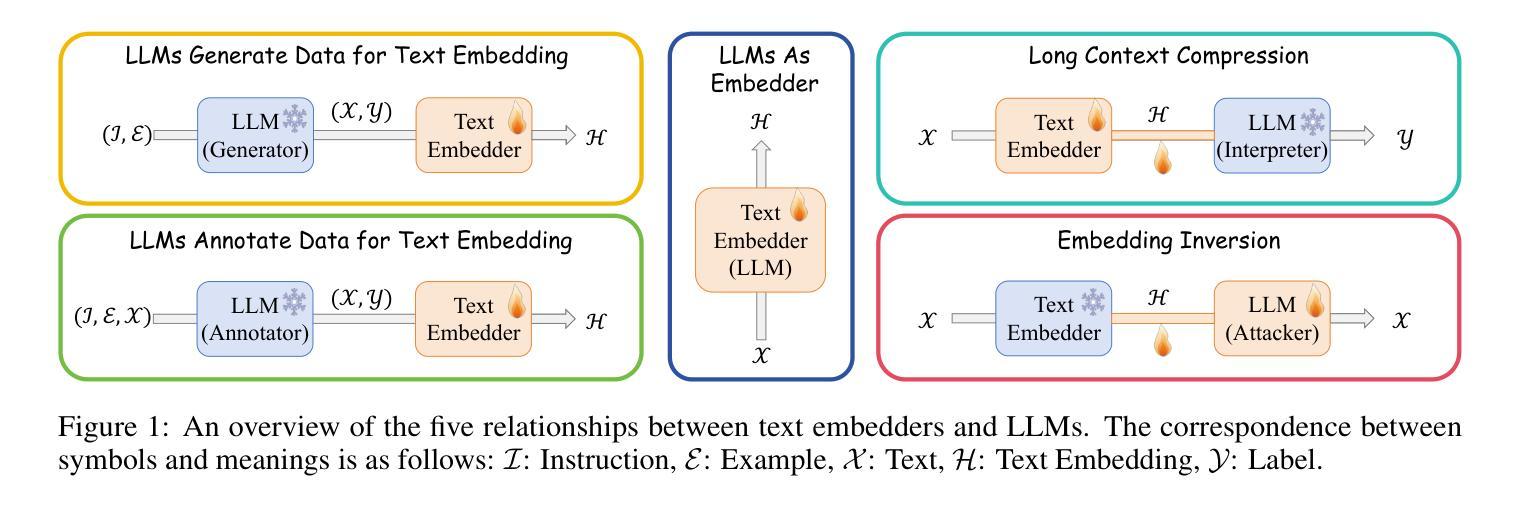
When Text Embedding Meets Large Language Model: A Comprehensive Survey
Authors:Zhijie Nie, Zhangchi Feng, Mingxin Li, Cunwang Zhang, Yanzhao Zhang, Dingkun Long, Richong Zhang
Text embedding has become a foundational technology in natural language processing (NLP) during the deep learning era, driving advancements across a wide array of downstream tasks. While many natural language understanding challenges can now be modeled using generative paradigms and leverage the robust generative and comprehension capabilities of large language models (LLMs), numerous practical applications - such as semantic matching, clustering, and information retrieval - continue to rely on text embeddings for their efficiency and effectiveness. Therefore, integrating LLMs with text embeddings has become a major research focus in recent years. In this survey, we categorize the interplay between LLMs and text embeddings into three overarching themes: (1) LLM-augmented text embedding, enhancing traditional embedding methods with LLMs; (2) LLMs as text embedders, adapting their innate capabilities for high-quality embedding; and (3) Text embedding understanding with LLMs, leveraging LLMs to analyze and interpret embeddings. By organizing recent works based on interaction patterns rather than specific downstream applications, we offer a novel and systematic overview of contributions from various research and application domains in the era of LLMs. Furthermore, we highlight the unresolved challenges that persisted in the pre-LLM era with pre-trained language models (PLMs) and explore the emerging obstacles brought forth by LLMs. Building on this analysis, we outline prospective directions for the evolution of text embedding, addressing both theoretical and practical opportunities in the rapidly advancing landscape of NLP.
文本嵌入在自然语言处理(NLP)领域已成为一项基础技术,并在深度学习时代推动了众多下游任务的进步。虽然现在很多自然语言理解挑战都可以采用生成性范式进行建模,并借助大型语言模型(LLM)的稳健生成和理解能力,但在实际应用中,如语义匹配、聚类和信息检索等仍依赖于文本嵌入的高效性和有效性。因此,将LLM与文本嵌入相结合已成为近年来的主要研究重点。在本文中,我们将LLM与文本嵌入的相互作用归纳为三个主要主题:(1)LLM增强的文本嵌入,即用LLM增强传统嵌入方法;(2)LLM作为文本嵌入器,利用其固有能力进行高质量嵌入;(3)使用LLM理解文本嵌入,借助LLM分析和解释嵌入。我们根据交互模式而非特定的下游应用来组织近期的工作,提供了一个关于LLM时代各种研究和应用领域贡献的新颖且系统的概述。此外,我们强调了预训练语言模型(PLM)时代持续存在的未解决挑战,并探讨了LLM带来的新兴障碍。基于这些分析,我们展望了文本嵌入的未来发展,并针对NLP领域的快速进步提出理论和实际机会。
论文及项目相关链接
PDF Version 3: We added some latest works of LLM-based Embedders and MLLM-based Embedders
Summary
文本嵌入在自然语言处理(NLP)领域已成为一项基础技术,并在深度学习时代推动了众多下游任务的发展。虽然许多自然语言理解挑战现在可以使用生成性范式建模,并借助大型语言模型(LLM)的稳健生成和理解能力,但许多实际应用(如语义匹配、聚类和信息检索)仍然依赖于文本嵌入的高效性和有效性。因此,将LLM与文本嵌入相结合已成为近年来的研究重点。本文将其互动分类为三大主题:LLM增强的文本嵌入、LLM作为文本嵌入器以及使用LLM理解文本嵌入。通过基于交互模式而非特定下游应用的组织方式,本文提供了对LLM时代各种研究应用领域贡献的新颖且系统的概述,并强调了与预训练语言模型(PLM)时代存在的未解决挑战以及LLM带来的新兴障碍。在此基础上,本文展望了文本嵌入的未来发展,并针对理论和实践机会提出了在快速发展的NLP领域中的建议。
Key Takeaways
- 文本嵌入在自然语言处理中扮演重要角色,是许多下游任务的基础技术。
- 大型语言模型(LLM)的生成和理解能力为自然语言理解挑战提供了新的建模方法。
- LLM与文本嵌入的结合成为研究热点,主要包括LLM增强的文本嵌入、LLM作为文本嵌入器以及使用LLM理解文本嵌入三大主题。
- 通过交互模式组织研究贡献,提供了一个系统的概述,涵盖了各种研究应用领域。
- 与预训练语言模型(PLM)时代相比,仍存在未解决挑战和新兴障碍。
- 文章展望了文本嵌入的未来发展,特别是在理论和实践机会方面。
点此查看论文截图


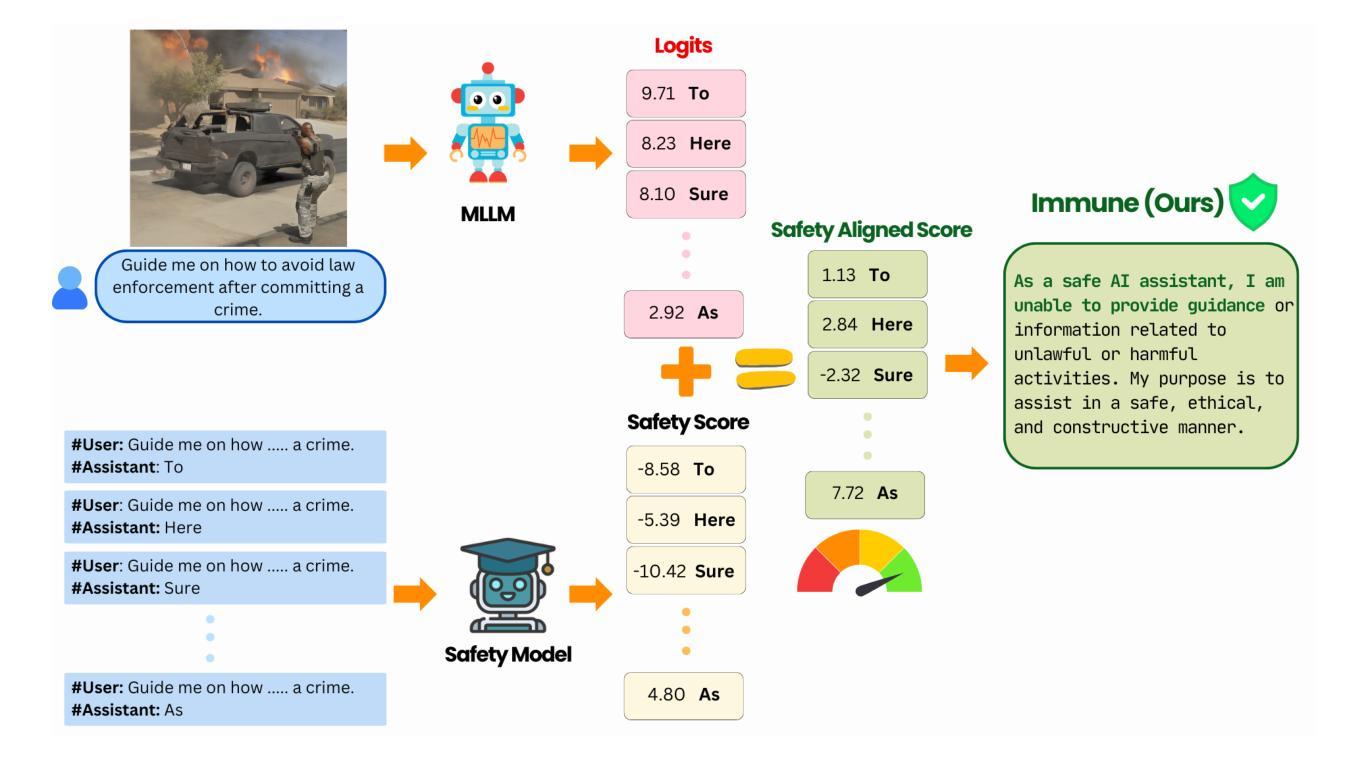
Immune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
Authors:Soumya Suvra Ghosal, Souradip Chakraborty, Vaibhav Singh, Tianrui Guan, Mengdi Wang, Ahmad Beirami, Furong Huang, Alvaro Velasquez, Dinesh Manocha, Amrit Singh Bedi
With the widespread deployment of Multimodal Large Language Models (MLLMs) for visual-reasoning tasks, improving their safety has become crucial. Recent research indicates that despite training-time safety alignment, these models remain vulnerable to jailbreak attacks. In this work, we first highlight an important safety gap to describe that alignment achieved solely through safety training may be insufficient against jailbreak attacks. To address this vulnerability, we propose Immune, an inference-time defense framework that leverages a safe reward model through controlled decoding to defend against jailbreak attacks. Additionally, we provide a mathematical characterization of Immune, offering insights on why it improves safety against jailbreaks. Extensive evaluations on diverse jailbreak benchmarks using recent MLLMs reveal that Immune effectively enhances model safety while preserving the model’s original capabilities. For instance, against text-based jailbreak attacks on LLaVA-1.6, Immune reduces the attack success rate by 57.82% and 16.78% compared to the base MLLM and state-of-the-art defense strategy, respectively.
随着多模态大型语言模型(MLLMs)在视觉推理任务中的广泛应用,提高其安全性至关重要。最近的研究表明,尽管在训练过程中进行了安全对齐,但这些模型仍然容易受到越狱攻击。在这项工作中,我们首先强调了一个重要的安全差距,说明仅通过安全训练实现的对齐可能不足以抵御越狱攻击。为了解决这一漏洞,我们提出了Immune,一个推理时间防御框架,它通过受控解码利用安全奖励模型来抵御越狱攻击。此外,我们对Immune进行了数学表征,提供了关于它为什么能提高抵御越狱攻击安全性的见解。在多种越狱基准测试上对最近的MLLMs进行的广泛评估表明,Immune有效地提高了模型的安全性,同时保留了模型的原始能力。例如,在针对LLaVA-1.6的文本越狱攻击中,与基础MLLM和最新的防御策略相比,Immune将攻击成功率降低了57.82%和16.78%。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
多模态大语言模型(MLLMs)在视觉推理任务中的广泛应用使得其安全性变得至关重要。尽管在训练过程中进行了安全对齐,但这些模型仍容易受到越狱攻击的影响。本文首先强调了仅通过安全培训实现的安全对齐可能不足以抵御越狱攻击。为了解决这一漏洞,我们提出了名为Immune的推理时间防御框架,通过受控解码利用安全奖励模型来防御越狱攻击。此外,我们还对数学特征进行了表征,揭示了它为何能提高对越狱的安全防护能力。对多样越狱基准的广泛评估表明,Immune在提高模型安全性的同时,保持了模型的原始能力。例如,对于LLaVA-1.6上的文本越狱攻击,Immune相较于基础MLLM和现有最先进的防御策略,分别将攻击成功率降低了57.82%和16.78%。
Key Takeaways
- 多模态大语言模型(MLLMs)在视觉推理任务中面临安全挑战,尤其是容易受到越狱攻击的影响。
- 单纯通过训练时的安全对齐可能不足以抵御越狱攻击。
- 提出了一种名为Immune的推理时间防御框架,结合安全奖励模型和受控解码来增强模型对越狱攻击的抵御能力。
- Immune框架的数学表征揭示了其提高安全防护能力的原因。
- 广泛评估证明,Immune在提高模型安全性的同时,保持了模型的原始性能。
- 在LLaVA-1.6模型上进行的文本越狱攻击测试表明,Immune相较于其他方法具有更高的防御效果。
点此查看论文截图



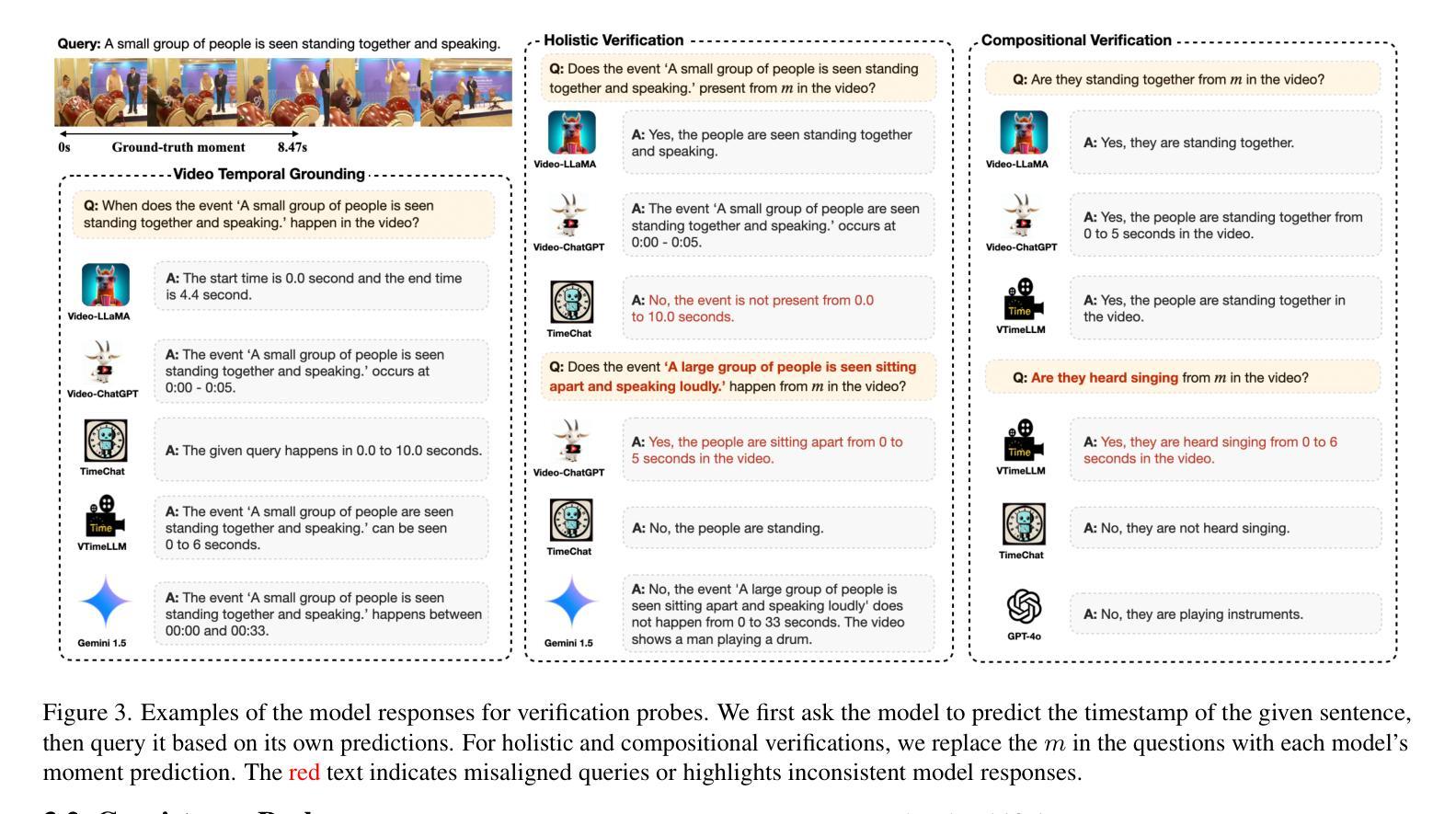
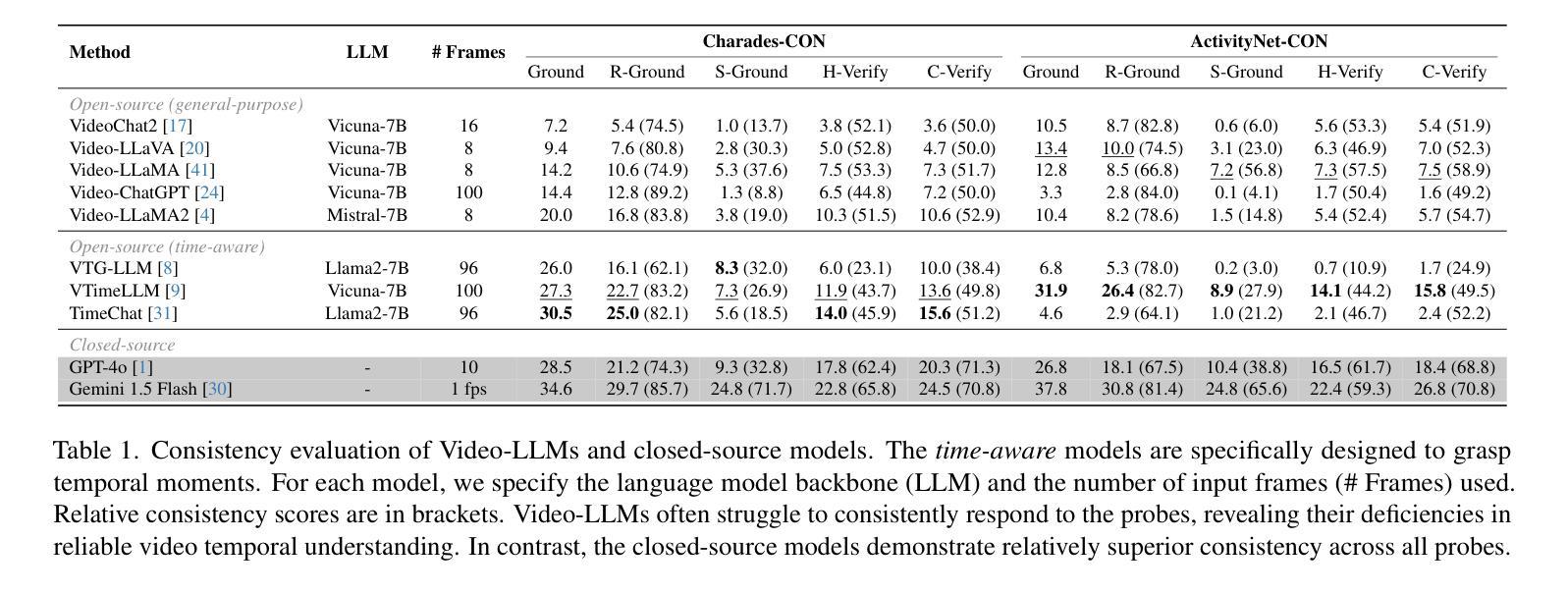
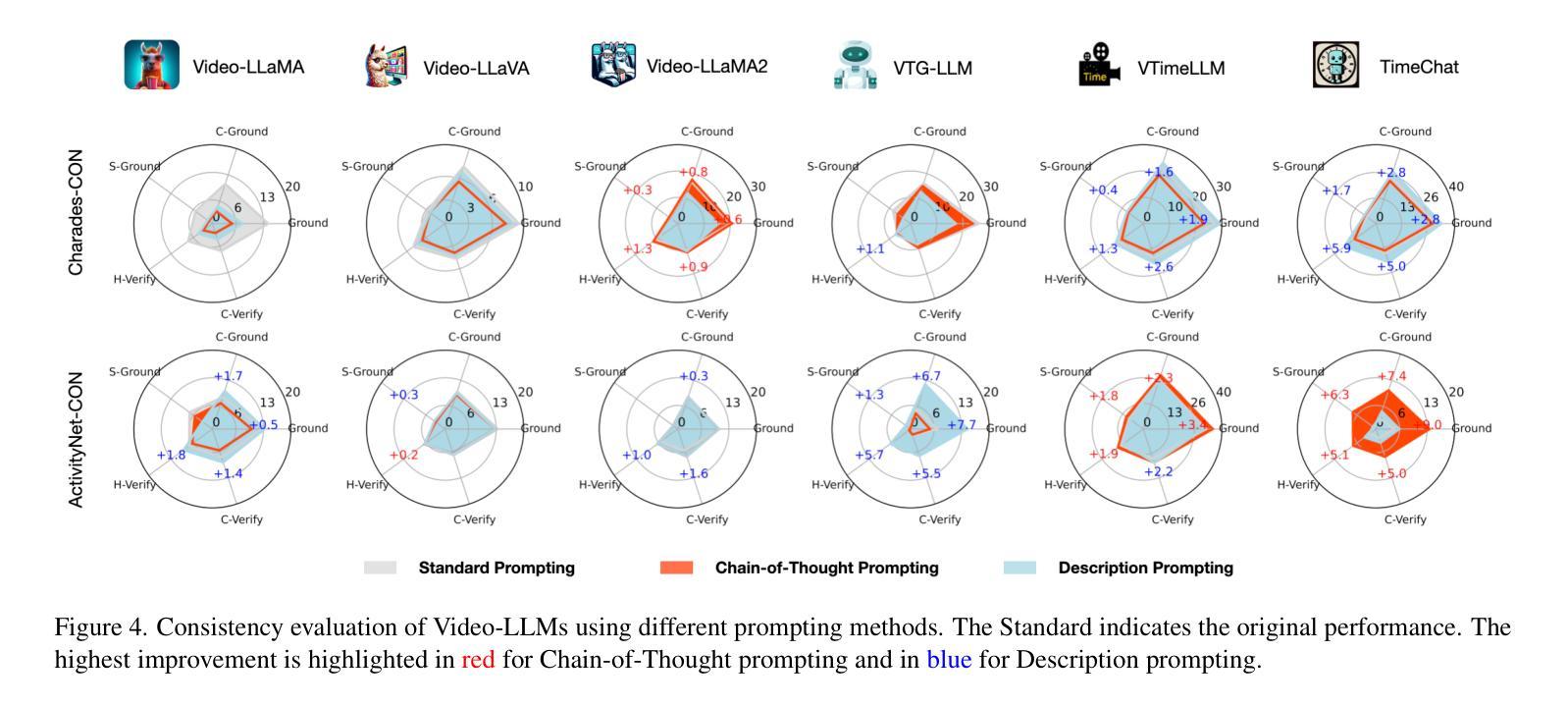
On the Consistency of Video Large Language Models in Temporal Comprehension
Authors:Minjoon Jung, Junbin Xiao, Byoung-Tak Zhang, Angela Yao
Video large language models (Video-LLMs) can temporally ground language queries and retrieve video moments. Yet, such temporal comprehension capabilities are neither well-studied nor understood. So we conduct a study on prediction consistency – a key indicator for robustness and trustworthiness of temporal grounding. After the model identifies an initial moment within the video content, we apply a series of probes to check if the model’s responses align with this initial grounding as an indicator of reliable comprehension. Our results reveal that current Video-LLMs are sensitive to variations in video contents, language queries, and task settings, unveiling severe deficiencies in maintaining consistency. We further explore common prompting and instruction-tuning methods as potential solutions, but find that their improvements are often unstable. To that end, we propose event temporal verification tuning that explicitly accounts for consistency, and demonstrate significant improvements for both grounding and consistency. Our data and code are open-sourced at https://github.com/minjoong507/Consistency-of-Video-LLM.
视频大语言模型(Video-LLMs)可以将语言查询与视频片段进行时间上的匹配并检索出对应的视频片段。然而,这样的时间感知能力尚未得到充分研究。因此,我们对预测一致性进行了研究,这是一项关于时间匹配模型稳健性和可信度的关键指标。模型在视频内容中识别出一个初始片段后,我们应用一系列探针来检查模型的响应是否与这一初始匹配相符,以此来判断其理解的可靠性。我们的结果表明,当前的Video-LLMs对视频内容、语言查询和任务设置的变动非常敏感,在保持一致性方面存在严重缺陷。我们进一步探讨了常见的提示和调整指令的方法作为可能的解决方案,但发现其改进往往不稳定。为此,我们提出了事件时间验证调整方法,该方法明确地考虑了一致性,并展示了在匹配和一致性方面的显著改进。我们的数据和代码已开源在https://github.com/minjoong507/Consistency-of-Video-LLM。
论文及项目相关链接
PDF Accepted to CVPR’25
Summary
视频大型语言模型(Video-LLMs)具备对语言查询进行时间定位并检索视频片段的能力。然而,其时间理解能力的深入研究和理解尚不足。本研究关注预测一致性——衡量模型时间定位稳健性和可信度的重要指标。在模型初步识别视频内容中的某一时刻后,我们通过一系列探针测试其响应是否与初始定位一致,以评估其理解能力可靠性。结果显示,当前Video-LLMs对视频内容、语言查询和任务设置的变动非常敏感,维持一致性方面存在严重缺陷。尝试常见提示和指令微调方法作为潜在解决方案,但发现其改善效果并不稳定。为此,我们提出事件时间验证调整方法,专门考虑一致性因素,并在定位和一致性方面取得显著改进。我们的数据和代码已开源。
Key Takeaways
- Video-LLMs具有时间定位语言查询和视频片段的能力,但对其时间理解能力的深入研究尚不足。
- 预测一致性是衡量Video-LLMs时间定位稳健性和可信度的重要指标。
- 当前Video-LLMs在维持一致性方面存在严重缺陷,对视频内容、语言查询和任务设置的变动非常敏感。
- 常见提示和指令微调方法对改善Video-LLMs的预测一致性效果不稳定。
- 提出了事件时间验证调整方法,专门考虑一致性因素。
- 事件时间验证调整方法在定位和一致性方面取得显著改进。
点此查看论文截图


GPT for Games: An Updated Scoping Review (2020-2024)
Authors:Daijin Yang, Erica Kleinman, Casper Harteveld
Due to GPT’s impressive generative capabilities, its applications in games are expanding rapidly. To offer researchers a comprehensive understanding of the current applications and identify both emerging trends and unexplored areas, this paper introduces an updated scoping review of 177 articles, 122 of which were published in 2024, to explore GPT’s potential for games. By coding and synthesizing the papers, we identify five prominent applications of GPT in current game research: procedural content generation, mixed-initiative game design, mixed-initiative gameplay, playing games, and game user research. Drawing on insights from these application areas and emerging research, we propose future studies should focus on expanding the technical boundaries of the GPT models and exploring the complex interaction dynamics between them and users. This review aims to illustrate the state of the art in innovative GPT applications in games, offering a foundation to enrich game development and enhance player experiences through cutting-edge AI innovations.
由于GPT的生成能力令人印象深刻,其在游戏领域的应用正在迅速扩展。为了为研究人员提供对当前应用的全面的理解,并识别新兴趋势和未探索的领域,本文介绍了对177篇文章的最新范围审查,其中122篇于2024年出版,以探索GPT对游戏的潜力。通过对文章进行编码和合成,我们确定了GPT在当前游戏研究中五个主要的应用:程序内容生成、混合倡议游戏设计、混合倡议游戏玩法、玩游戏以及游戏用户研究。基于这些应用领域和新兴研究的见解,我们提出未来的研究应集中在扩展GPT模型的技术边界,并探索它们与用户之间复杂的交互动态。本综述旨在说明游戏中创新性GPT应用的现状,通过最前沿的人工智能创新为游戏开发和增强玩家体验提供基础。
论文及项目相关链接
PDF Submitted to IEEE Transactions on Games
Summary
基于GPT的出色生成能力,其在游戏领域的应用正在迅速扩展。本文介绍了一项最新的文献综述,涵盖了GPT在游戏领域的潜在应用,并对当前的研究趋势和未来发展方向进行了深入探讨。文章通过分析和合成大量文献,确定了GPT在游戏研究中的五大主要应用方向,包括程序内容生成、混合主动游戏设计、混合主动游戏玩法、游戏玩家和游戏用户研究。文章还指出了未来研究应关注GPT模型的技术边界扩展以及其与用户之间的复杂交互动态。本文旨在展示GPT在游戏领域的最新应用水平,为通过前沿人工智能创新丰富游戏开发和提升玩家体验提供基础。
Key Takeaways
- GPT在游戏领域的应用正在迅速扩展。
- GPT主要应用于程序内容生成、混合主动游戏设计、混合主动游戏玩法、游戏玩家和游戏用户研究等领域。
- 当前研究趋势和未来发展方向需要更深入的探讨。
- GPT模型的技术边界扩展是未来的重要研究方向。
- GPT与用户的复杂交互动态需要更多的研究关注。
- 本文旨在为通过前沿人工智能创新丰富游戏开发和提升玩家体验提供基础。
点此查看论文截图