⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
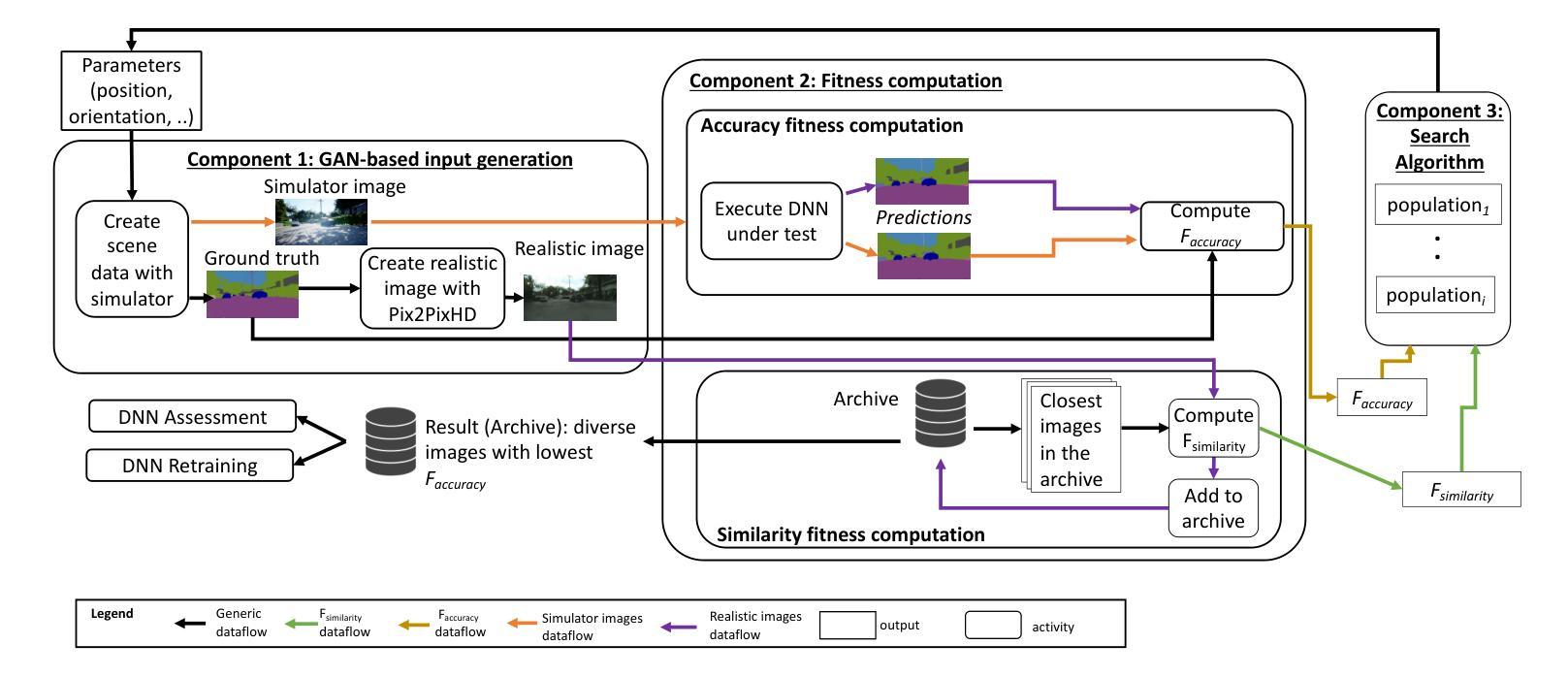
GAN-enhanced Simulation-driven DNN Testing in Absence of Ground Truth
Authors:Mohammed Attaoui, Fabrizio Pastore
The generation of synthetic inputs via simulators driven by search algorithms is essential for cost-effective testing of Deep Neural Network (DNN) components for safety-critical systems. However, in many applications, simulators are unable to produce the ground-truth data needed for automated test oracles and to guide the search process. To tackle this issue, we propose an approach for the generation of inputs for computer vision DNNs that integrates a generative network to ensure simulator fidelity and employs heuristic-based search fitnesses that leverage transformation consistency, noise resistance, surprise adequacy, and uncertainty estimation. We compare the performance of our fitnesses with that of a traditional fitness function leveraging ground truth; further, we assess how the integration of a GAN not leveraging the ground truth impacts on test and retraining effectiveness. Our results suggest that leveraging transformation consistency is the best option to generate inputs for both DNN testing and retraining; it maximizes input diversity, spots the inputs leading to worse DNN performance, and leads to best DNN performance after retraining. Besides enabling simulator-based testing in the absence of ground truth, our findings pave the way for testing solutions that replace costly simulators with diffusion and large language models, which might be more affordable than simulators, but cannot generate ground-truth data.
通过搜索算法驱动的模拟器生成合成输入,对于经济高效的深度神经网络(DNN)组件安全关键系统的测试至关重要。然而,在许多应用中,模拟器无法生成用于自动化测试评议和指导搜索过程所需的真实数据。为了解决这个问题,我们提出了一种针对计算机视觉DNN的输入生成方法,该方法集成生成网络以确保模拟器的保真度,并采用基于启发式搜索的适应度函数,利用变换一致性、噪声抗性、意外充足性和不确定性估计。我们将我们的适应度性能与利用真实数据的传统适应度函数进行比较;此外,我们还评估了不依赖真实数据的GAN集成对测试和重新训练效果的影响。我们的结果表明,利用变换一致性是生成DNN测试和重新训练输入的最佳选择;它最大限度地提高了输入多样性,发现了导致DNN性能更差的输入,并在重新训练后实现了最佳的DNN性能。除了在没有真实数据的情况下启用基于模拟器的测试之外,我们的研究还为测试解决方案铺平了道路,这些解决方案用扩散模型的大型语言模型替代昂贵的模拟器,这些模型可能比模拟器更实惠,但无法生成真实数据。
论文及项目相关链接
PDF 15 pages, 8 figures, 13 tables
Summary
基于搜索算法驱动的模拟器生成合成输入,对于安全关键系统中深度神经网络(DNN)组件的经济高效测试至关重要。但在许多应用中,模拟器无法产生用于自动化测试或对真实数据质量评估进行指导的真实数据。本研究提出了一种计算机视觉DNN输入生成方法,该方法结合生成网络确保模拟器保真度,并利用启发式搜索适应度评估,包括转换一致性、噪声抗性、意外充分性和不确定性估计等。本研究比较了适应度评估与传统基于真实数据的适应度函数性能差异,并探讨了集成不使用真实数据的GAN对测试和再训练效果的影响。结果表明,采用转换一致性是DNN测试和再训练的最佳输入生成策略,能最大化输入多样性,找到导致DNN性能下降的输入,并在再训练后实现最佳性能。此外,该研究开辟了在没有真实数据的情况下实现模拟器测试的道路,并为使用扩散模型和大语言模型替代昂贵的模拟器的测试解决方案提供了可能。这些模型可能比模拟器更经济,但无法生成真实数据。
Key Takeaways
- 合成输入通过模拟器在搜索算法驱动下生成对于经济高效的测试DNN组件至关重要。但在模拟器的应用中有一定的局限性。特别是在缺少必要真实数据来驱动测试的情况时更为显著。此研究的创新方法是为解决计算机视觉的DNN开发新的输入生成方法以适配不同的应用需求。
- 研究结合了生成网络以确保模拟器的保真度,并引入了启发式搜索适应度评估方法,包括转换一致性、噪声抗性等因素在内的新概念评估方法。这种方法将有效优化搜索过程并提高测试的准确性。这些适应度评估方法对于提升测试效果至关重要。
点此查看论文截图


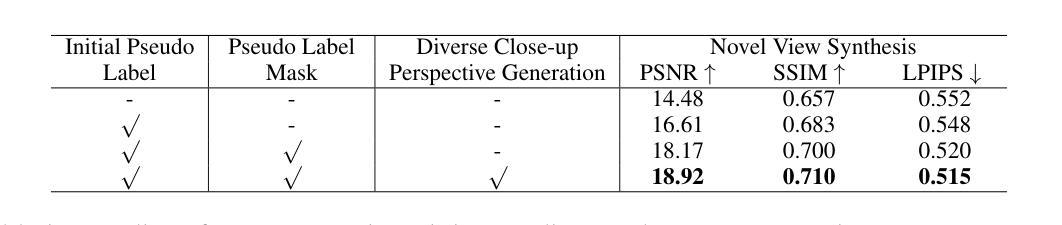
Enhancing Close-up Novel View Synthesis via Pseudo-labeling
Authors:Jiatong Xia, Libo Sun, Lingqiao Liu
Recent methods, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated remarkable capabilities in novel view synthesis. However, despite their success in producing high-quality images for viewpoints similar to those seen during training, they struggle when generating detailed images from viewpoints that significantly deviate from the training set, particularly in close-up views. The primary challenge stems from the lack of specific training data for close-up views, leading to the inability of current methods to render these views accurately. To address this issue, we introduce a novel pseudo-label-based learning strategy. This approach leverages pseudo-labels derived from existing training data to provide targeted supervision across a wide range of close-up viewpoints. Recognizing the absence of benchmarks for this specific challenge, we also present a new dataset designed to assess the effectiveness of both current and future methods in this area. Our extensive experiments demonstrate the efficacy of our approach.
最近的方法,如神经辐射场(NeRF)和3D高斯涂抹(3DGS),在新型视图合成中展现出了卓越的能力。然而,尽管它们在生成与训练时所见视角相似的高质量图像方面取得了成功,但在生成与训练集显著偏离的详细图像时,特别是在特写镜头下,它们的表现却不尽如人意。主要挑战源于缺乏特写镜头的特定训练数据,导致当前方法无法准确渲染这些视图。为了解决这个问题,我们引入了一种基于伪标签的学习策略。这种方法利用来自现有训练数据的伪标签,为各种特写镜头提供有针对性的监督。由于缺少针对这一特定挑战的基准测试,我们还推出了一个新的数据集,旨在评估当前和未来方法在这个领域的有效性。我们的大量实验证明了我们的方法的有效性。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了针对NeRF和3DGS等方法在偏离训练视角时生成详细图像的挑战,特别是在近距离视角下的挑战。由于缺乏针对近距离视角的特定训练数据,现有方法难以准确渲染这些视图。为解决此问题,提出了一种基于伪标签的学习策略,该策略利用现有训练数据生成的伪标签,为广泛的角度下的近距离视角提供有针对性的监督。同时,由于缺少针对此挑战的基准测试集,本文还推出了一个新的数据集来评估现有和未来方法在这个领域的有效性。本文的实验验证了所提方法的有效性。
Key Takeaways
- NeRF和3DGS等方法在合成新视角时表现出卓越的能力,但在偏离训练视角时生成详细图像存在挑战。
- 近距离视角下的渲染挑战主要源于缺乏特定的训练数据。
- 提出了一种基于伪标签的学习策略,利用伪标签为各种近距离视角提供有针对性的监督。
- 为解决缺乏基准测试集的问题,引入了一个新的数据集来评估现有和未来方法在近距离视角下的渲染能力。
- 该方法通过实验验证,表现出良好的性能。
- 该研究对于改进NeRF和类似技术的性能具有重要意义。
点此查看论文截图



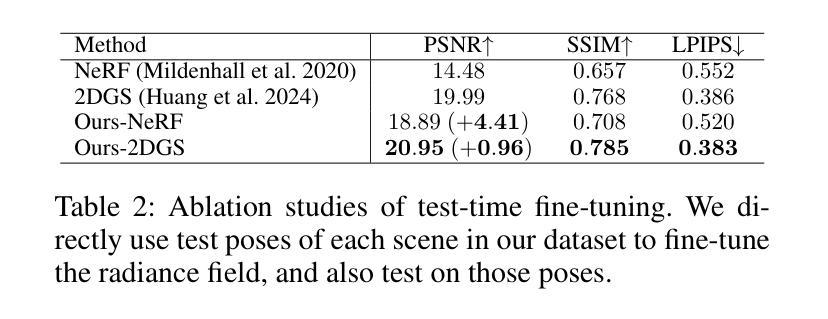
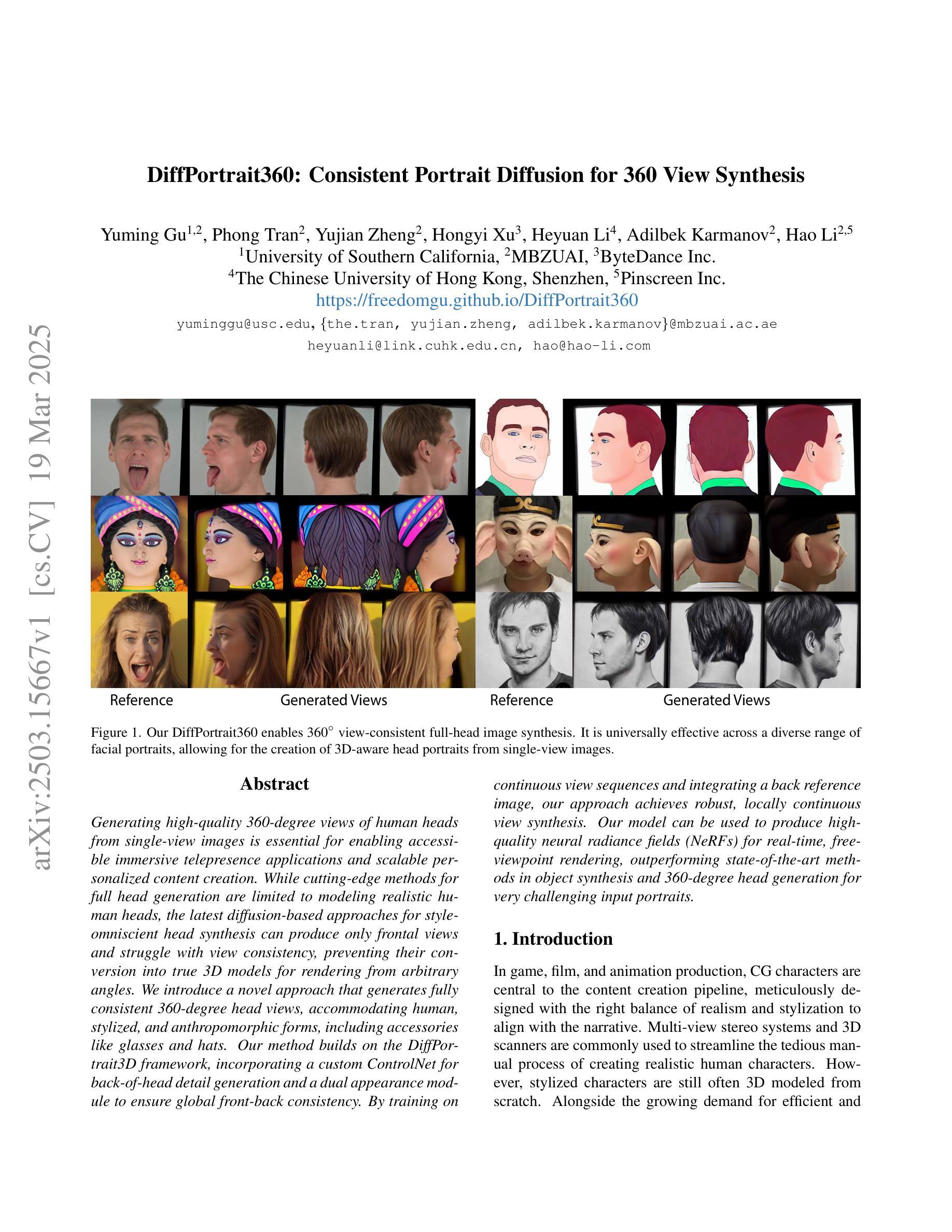
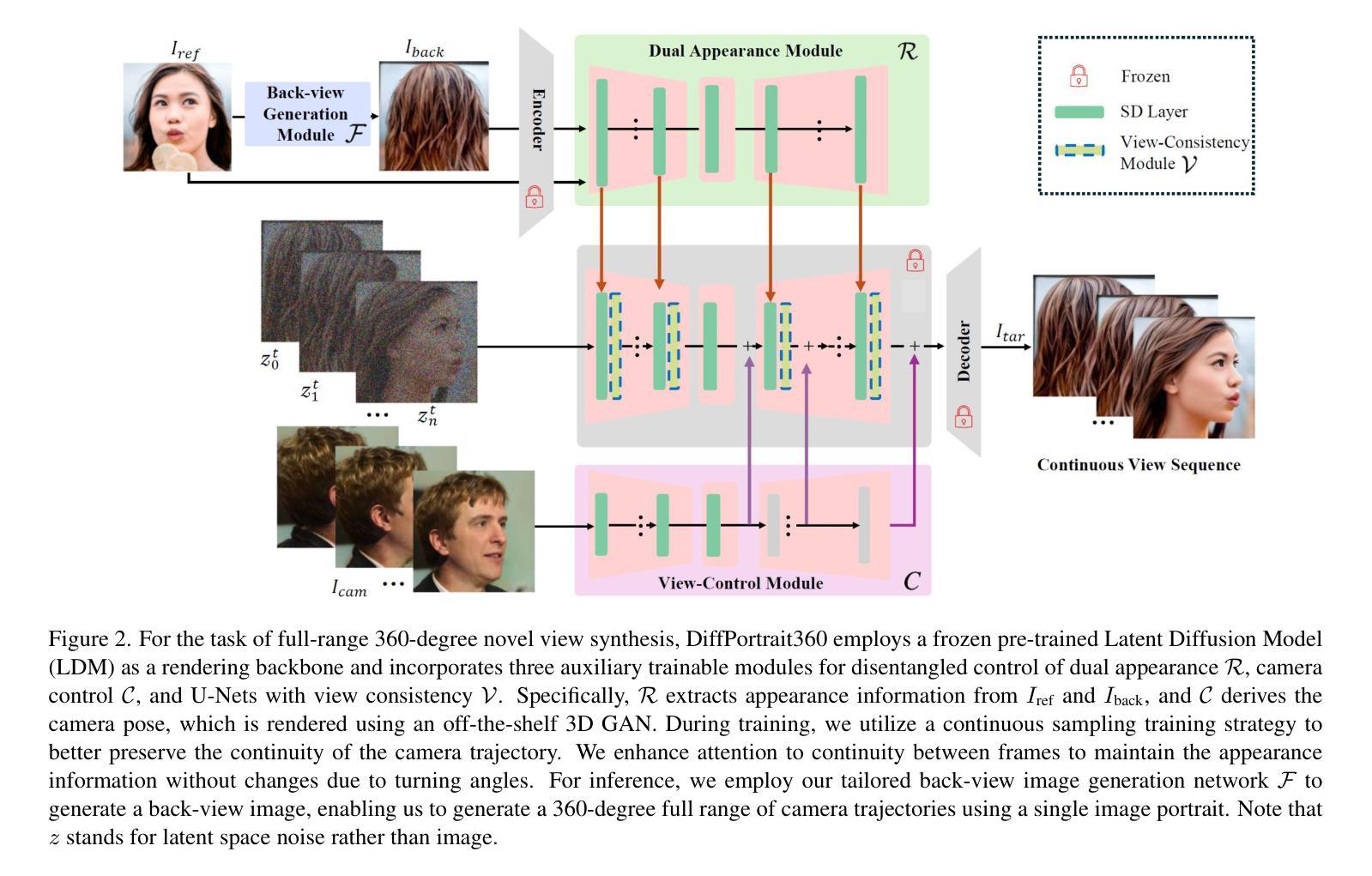
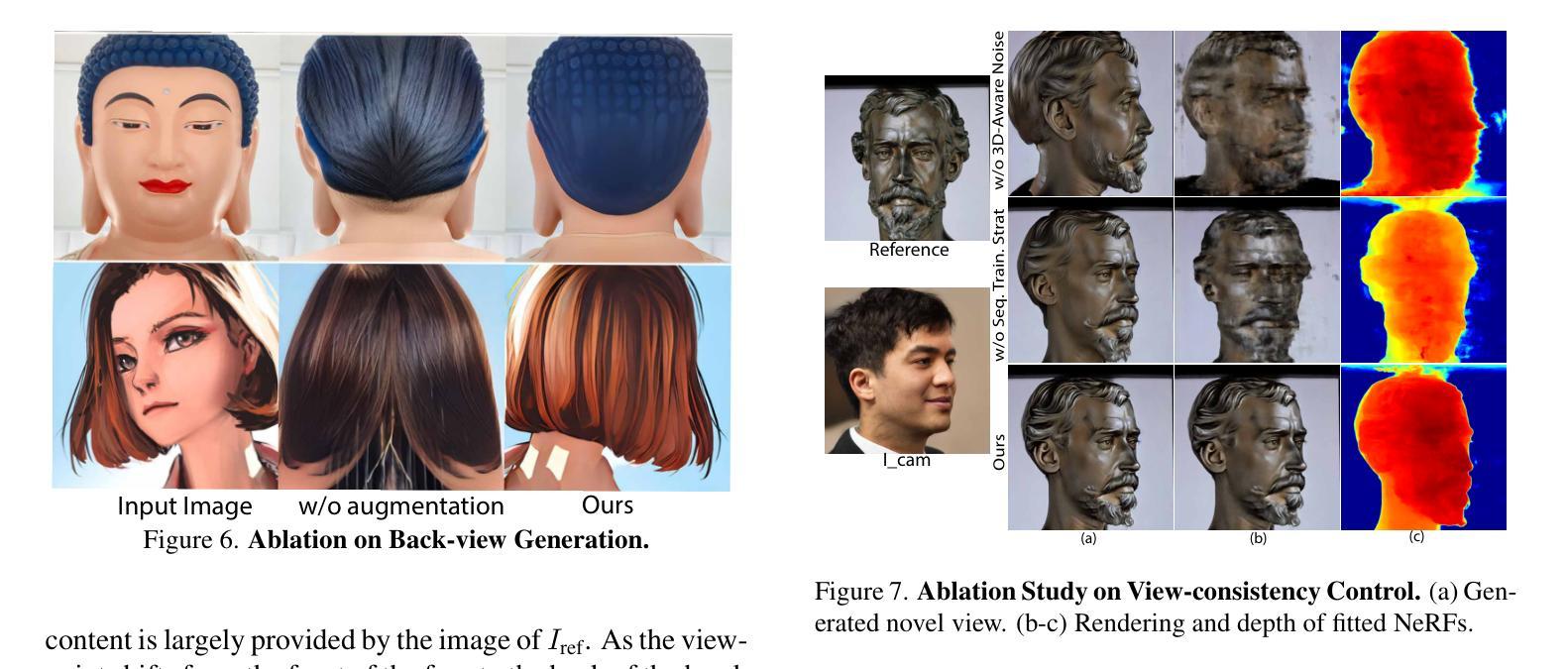
DiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis
Authors:Yuming Gu, Phong Tran, Yujian Zheng, Hongyi Xu, Heyuan Li, Adilbek Karmanov, Hao Li
Generating high-quality 360-degree views of human heads from single-view images is essential for enabling accessible immersive telepresence applications and scalable personalized content creation. While cutting-edge methods for full head generation are limited to modeling realistic human heads, the latest diffusion-based approaches for style-omniscient head synthesis can produce only frontal views and struggle with view consistency, preventing their conversion into true 3D models for rendering from arbitrary angles. We introduce a novel approach that generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses and hats. Our method builds on the DiffPortrait3D framework, incorporating a custom ControlNet for back-of-head detail generation and a dual appearance module to ensure global front-back consistency. By training on continuous view sequences and integrating a back reference image, our approach achieves robust, locally continuous view synthesis. Our model can be used to produce high-quality neural radiance fields (NeRFs) for real-time, free-viewpoint rendering, outperforming state-of-the-art methods in object synthesis and 360-degree head generation for very challenging input portraits.
从单视图图像生成高质量的全景人头图像对于实现无障碍沉浸式远程存在应用程序和可扩展个性化内容创建至关重要。虽然目前先进的全头生成方法仅限于模拟真实的人头,但最新的基于扩散的风格全能头合成方法仅能生成正面视图,并且在视图一致性方面存在困难,这阻碍了它们转化为真正的3D模型,用于从任意角度进行渲染。我们引入了一种新型方法,能够生成全景全向一致的头部图像,适用于人、风格化和拟人化形式,包括眼镜和帽子等配饰。我们的方法基于DiffPortrait3D框架构建,融入了定制的控制网(ControlNet)用于生成头部背面的细节,以及双外观模块确保前后视图的一致性。通过对连续视图序列进行训练并集成背面参考图像,我们的方法实现了稳健的局部连续视图合成。我们的模型可用于生成高质量神经辐射场(NeRF),用于实时自由视角渲染,在对象合成和全景头部生成方面超越最先进的方法,尤其适用于极具挑战性的输入肖像。
论文及项目相关链接
PDF Page:https://freedomgu.github.io/DiffPortrait360 Code:https://github.com/FreedomGu/DiffPortrait360/
Summary
新一代头部渲染技术能够实现全方位的头像生成,采用全新的方法来合成高清的头部位态全景视图。最新的基于扩散技术的方法在头部渲染中展现出优秀的性能,不仅能生成真实感的正面头像,还能应对不同风格的头部形态和配饰的渲染,生成完整连贯的头部全景视图。
Key Takeaways
- 技术可以生成全方位的头像视图,覆盖360度。
- 最新的扩散方法具有强大能力处理真实感的正面头像生成。
- 新方法可实现个性化内容创建并广泛应用于沉浸式遥现场技术。
- 该方法具备渲染头部复杂形态及配件如眼镜和帽子的能力。
- 采用定制的控制网络和双重外观模块确保前后视图的一致性。
- 通过连续视图序列训练和背面参考图像集成,实现稳健的局部连续视图合成。
点此查看论文截图


Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories
Authors:Susung Hong, Johanna Karras, Ricardo Martin-Brualla, Ira Kemelmacher-Shlizerman
Recent advancements in text-based diffusion models have accelerated progress in 3D reconstruction and text-based 3D editing. Although existing 3D editing methods excel at modifying color, texture, and style, they struggle with extensive geometric or appearance changes, thus limiting their applications. To this end, we propose Perturb-and-Revise, which makes possible a variety of NeRF editing. First, we perturb the NeRF parameters with random initializations to create a versatile initialization. The level of perturbation is determined automatically through analysis of the local loss landscape. Then, we revise the edited NeRF via generative trajectories. Combined with the generative process, we impose identity-preserving gradients to refine the edited NeRF. Extensive experiments demonstrate that Perturb-and-Revise facilitates flexible, effective, and consistent editing of color, appearance, and geometry in 3D. For 360{\deg} results, please visit our project page: https://susunghong.github.io/Perturb-and-Revise.
近期文本基础上的扩散模型的进展加速了3D重建和基于文本的3D编辑的进展。尽管现有的3D编辑方法在修改颜色、纹理和风格方面表现出色,但它们在进行大规模的几何或外观更改时遇到了困难,从而限制了其应用。为此,我们提出了扰动和修订(Perturb-and-Revise)方法,该方法可实现多种NeRF编辑。首先,我们通过随机初始化扰动NeRF参数来创建一个通用的初始化方案。扰动的程度是通过分析局部损失景观自动确定的。然后,我们通过生成轨迹修订编辑过的NeRF。结合生成过程,我们施加恒等保留梯度来优化编辑过的NeRF。大量实验表明,扰动和修订方法便于实现灵活、有效和一致的3D颜色、外观和几何编辑。有关360°的结果,请访问我们的项目页面:https://susunghong.github.io/Perturb-and-Revise。
论文及项目相关链接
PDF CVPR 2025. Project page: https://susunghong.github.io/Perturb-and-Revise
Summary
本文介绍了基于文本的扩散模型在3D重建和文本基于的3D编辑方面的最新进展。针对现有3D编辑方法在几何或外观变化方面的局限性,提出了Perturb-and-Revise方法,实现了多样化的NeRF编辑。该方法通过随机初始化扰动NeRF参数进行初始化,并自动确定扰动程度。然后,通过生成轨迹修订编辑后的NeRF,并结合生成过程施加身份保留梯度来优化。实验表明,Perturb-and-Revise可实现灵活、有效且一致的3D编辑,包括颜色、外观和几何。
Key Takeaways
- 最新文本扩散模型加速3D重建和文本为基础的3D编辑发展。
- 现有3D编辑方法在几何或外观变化方面存在局限性。
- Perturb-and-Revise方法通过扰动NeRF参数进行初始化,并自动确定扰动程度。
- 该方法通过生成轨迹修订编辑后的NeRF。
- 结合生成过程施加身份保留梯度以优化编辑结果。
- Perturb-and-Revise实现了灵活、有效且一致的3D编辑,包括颜色、外观和几何。
点此查看论文截图




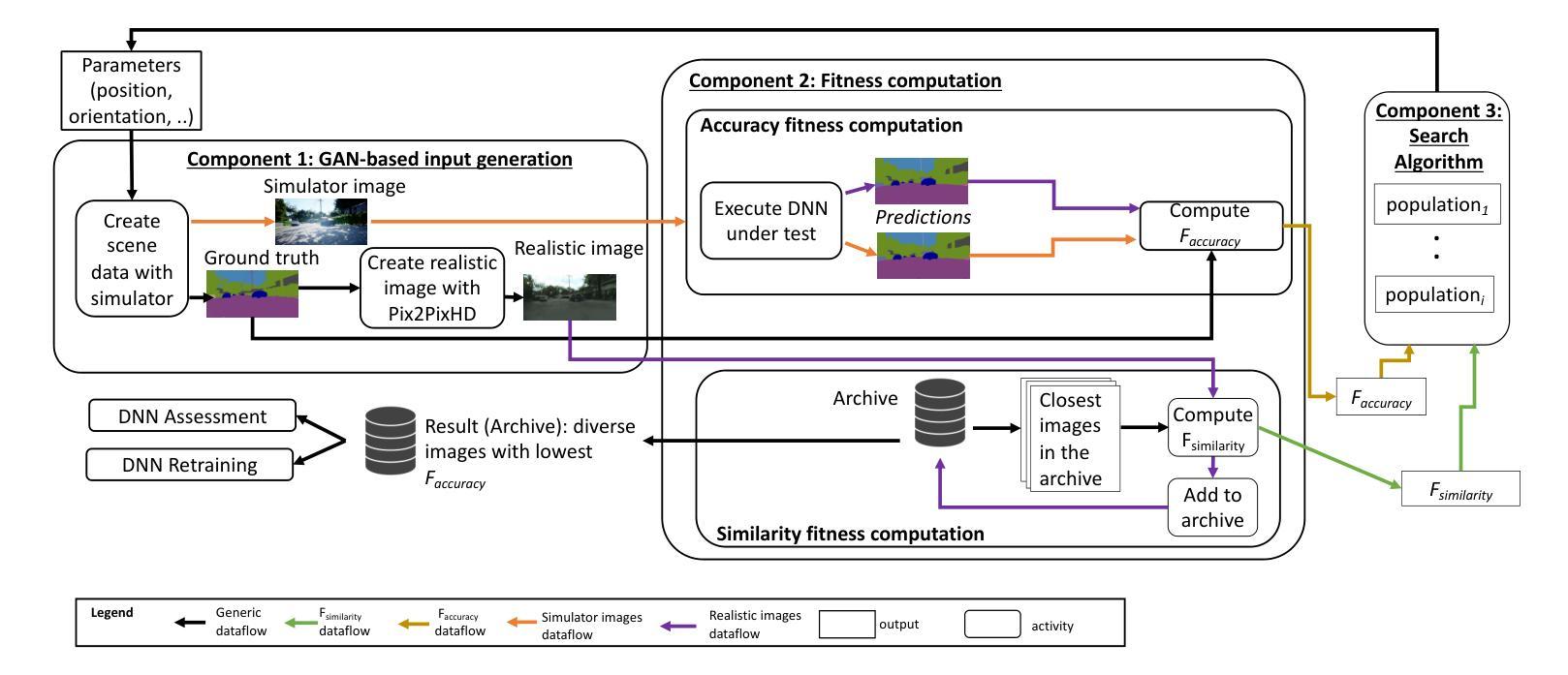
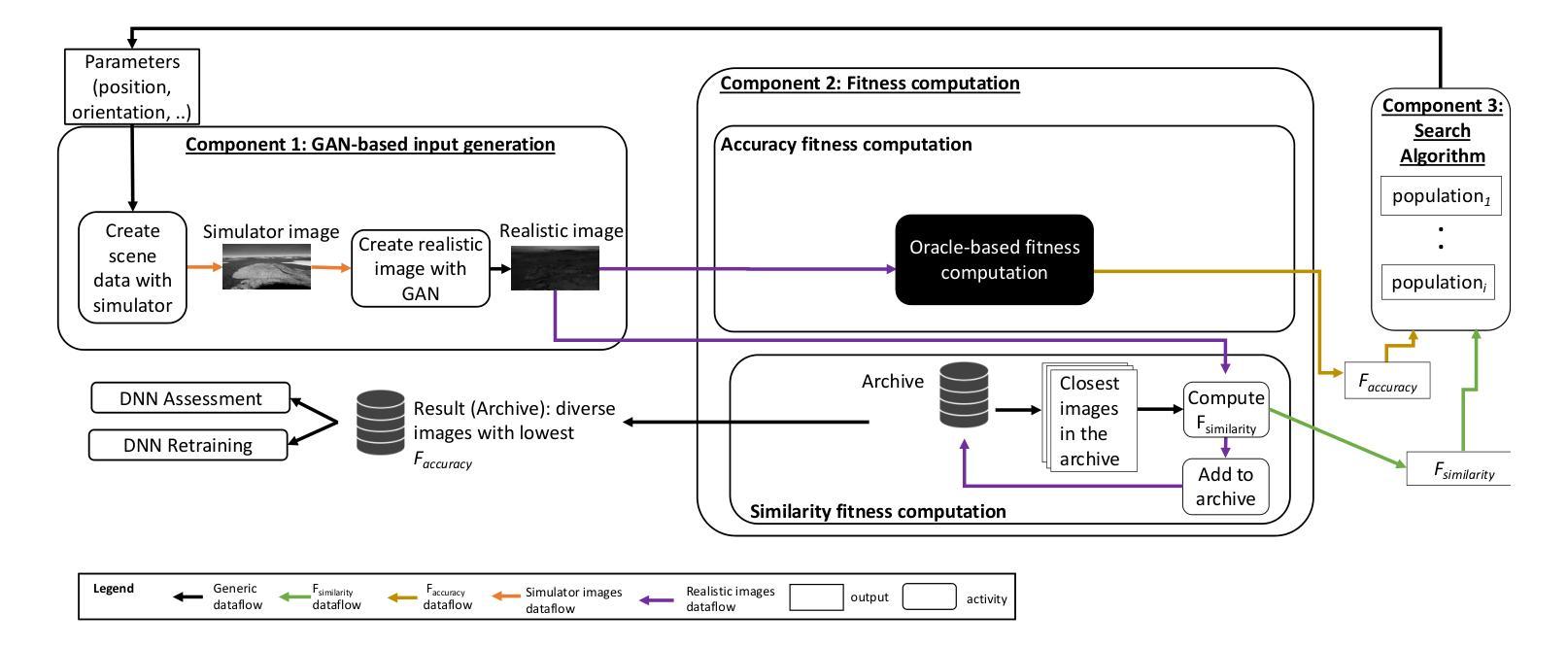
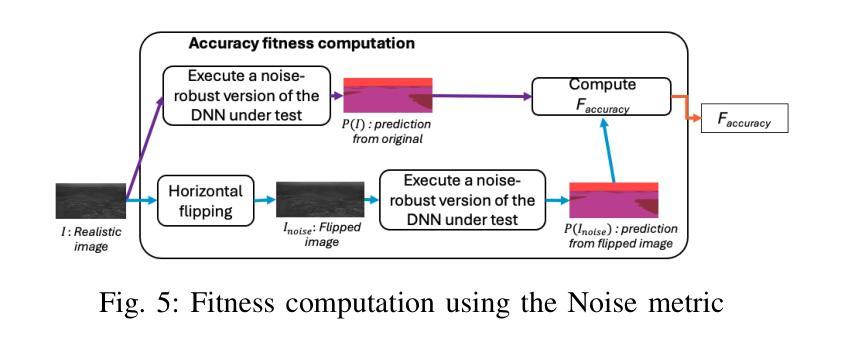
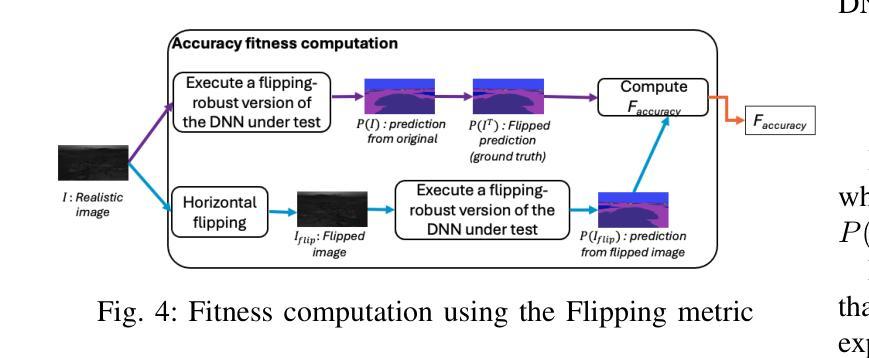
Search-based DNN Testing and Retraining with GAN-enhanced Simulations
Authors:Mohammed Oualid Attaoui, Fabrizio Pastore, Lionel Briand
In safety-critical systems (e.g., autonomous vehicles and robots), Deep Neural Networks (DNNs) are becoming a key component for computer vision tasks, particularly semantic segmentation. Further, since the DNN behavior cannot be assessed through code inspection and analysis, test automation has become an essential activity to gain confidence in the reliability of DNNs. Unfortunately, state-of-the-art automated testing solutions largely rely on simulators, whose fidelity is always imperfect, thus affecting the validity of test results. To address such limitations, we propose to combine meta-heuristic search, used to explore the input space using simulators, with Generative Adversarial Networks (GANs), to transform the data generated by simulators into realistic input images. Such images can be used both to assess the DNN performance and to retrain the DNN more effectively. We applied our approach to a state-of-the-art DNN performing semantic segmentation and demonstrated that it outperforms a state-of-the-art GAN-based testing solution and several baselines. Specifically, it leads to the largest number of diverse images leading to the worst DNN performance. Further, the images generated with our approach, lead to the highest improvement in DNN performance when used for retraining. In conclusion, we suggest to always integrate GAN components when performing search-driven, simulator-based testing.
在安全性关键系统(例如自动驾驶汽车和机器人)中,深度神经网络(DNN)已成为计算机视觉任务(尤其是语义分割)的关键组成部分。此外,由于无法通过对代码的检查和分析来评估DNN的行为,因此测试自动化已成为建立对DNN可靠性信心的重要活动。然而,最先进的自动化测试解决方案在很大程度上依赖于模拟器,而模拟器的逼真度总是不完美的,从而影响测试结果的有效性。为了解决这些限制,我们提出将元启发式搜索(用于使用模拟器探索输入空间)与生成对抗网络(GAN)相结合,将模拟器生成的数据转换为逼真的输入图像。这些图像可用于评估DNN的性能,并更有效地重新训练DNN。我们将该方法应用于执行语义分割的最先进DNN,并证明其优于基于GAN的测试解决方案和若干基线。具体来说,它产生了导致DNN性能最差的最多样化图像数量最多。此外,使用我们的方法生成的图像在用于重新训练时导致DNN性能得到最大提高。总之,我们建议在进行基于搜索和模拟器的测试时始终集成GAN组件。
论文及项目相关链接
PDF 18 pages, 5 figures, 13 tables
Summary
针对安全关键系统(如自动驾驶汽车和机器人)中的深度神经网络(DNN)的语义分割任务,自动化测试尤为重要。当前自动化测试解决方案大多依赖模拟器,存在不完美性。本研究结合元启发式搜索与生成对抗网络(GANs),将模拟器生成的数据转化为逼真的输入图像,既可用于评估DNN性能,也可用于更有效地重新训练DNN。本研究的方法在语义分割的DNN上表现优异,生成更多导致DNN性能下降的不同图像,且在用于重新训练时能提高DNN性能。建议在进行基于搜索的模拟器测试时,集成GAN组件。
Key Takeaways
- 安全关键系统中深度神经网络(DNN)的语义分割任务愈发重要。
- 当前自动化测试解决方案主要依赖模拟器,但存在局限性。
- 结合元启发式搜索和生成对抗网络(GANs)能改善模拟器生成数据的逼真度。
- 该方法生成更多导致DNN性能下降的不同图像。
- 使用此方法生成的图像进行重训能提高DNN性能。
- 本研究的方法在语义分割的DNN上表现优异,超越现有GAN-based测试解决方案和其他基准测试。
点此查看论文截图