⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-22 更新
UniSync: A Unified Framework for Audio-Visual Synchronization
Authors:Tao Feng, Yifan Xie, Xun Guan, Jiyuan Song, Zhou Liu, Fei Ma, Fei Yu
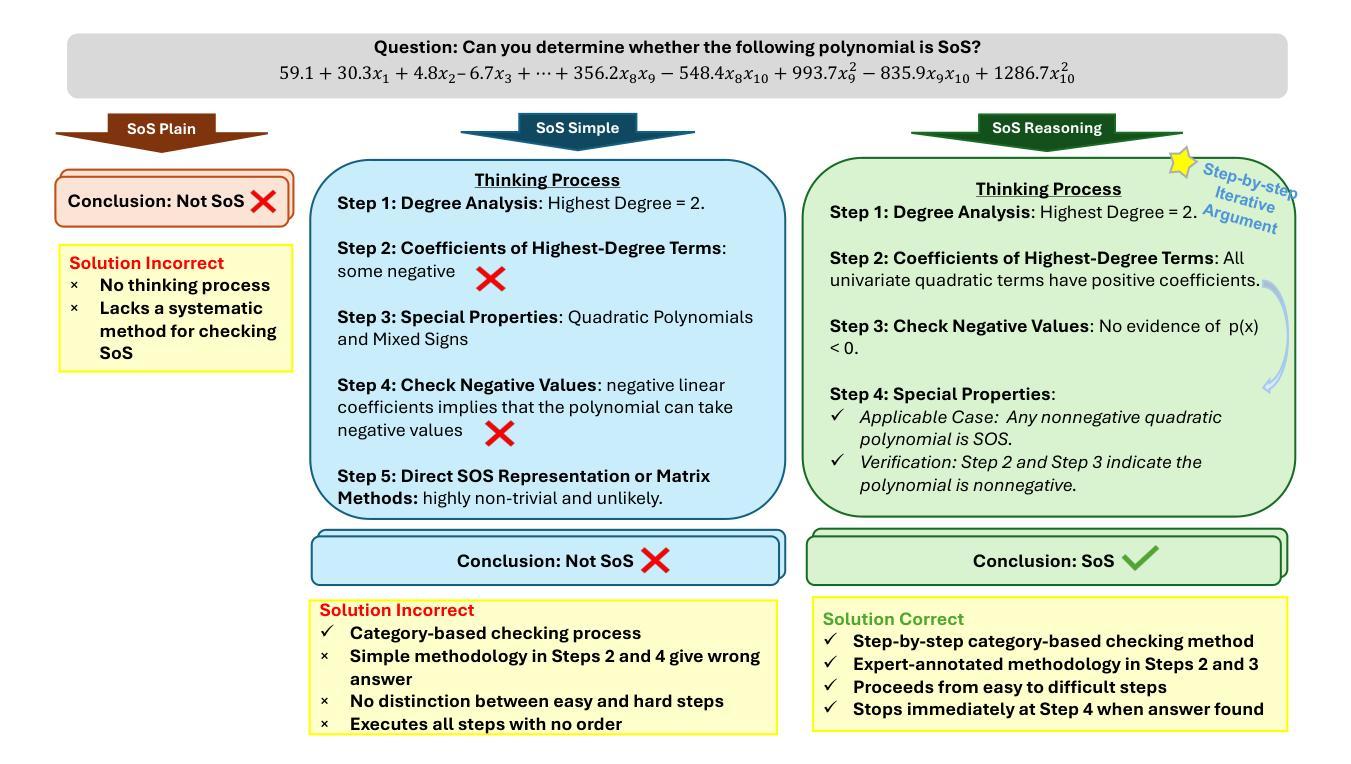
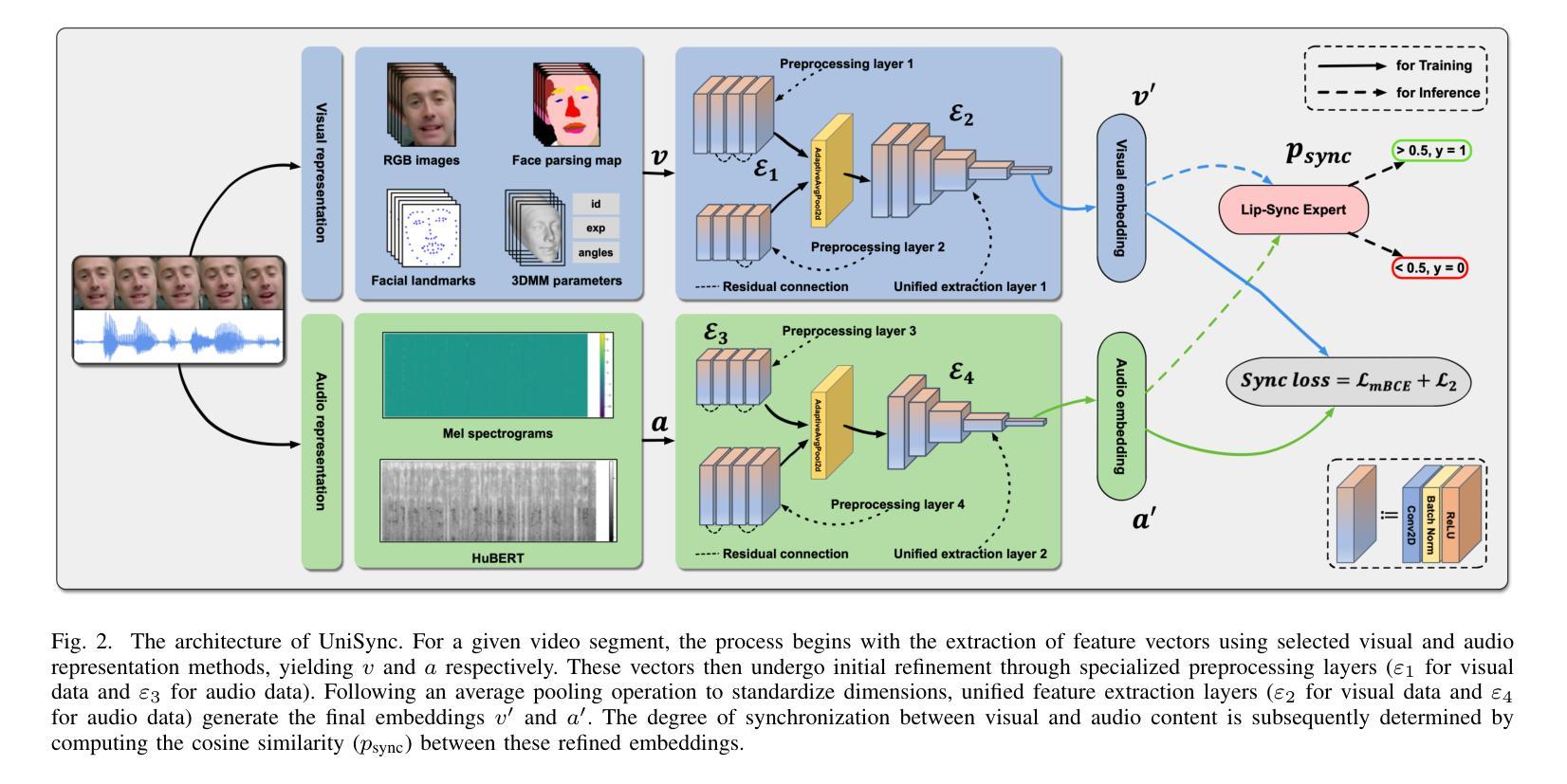
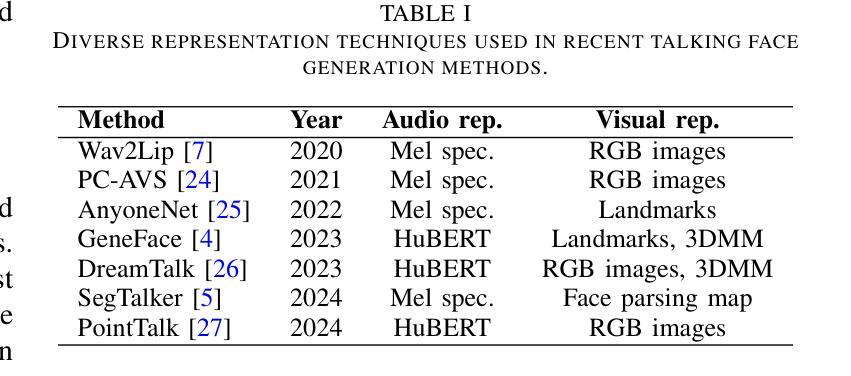
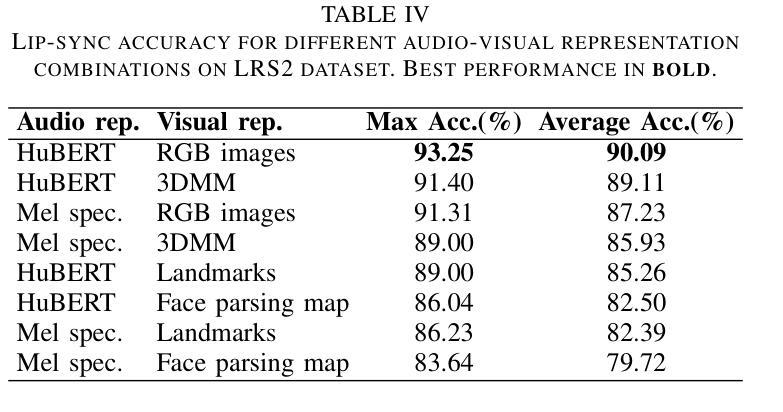
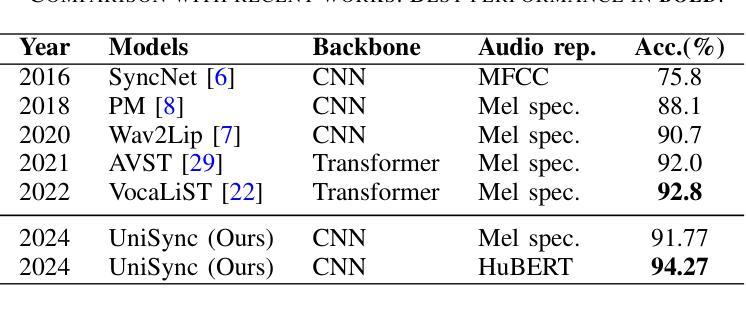
Precise audio-visual synchronization in speech videos is crucial for content quality and viewer comprehension. Existing methods have made significant strides in addressing this challenge through rule-based approaches and end-to-end learning techniques. However, these methods often rely on limited audio-visual representations and suboptimal learning strategies, potentially constraining their effectiveness in more complex scenarios. To address these limitations, we present UniSync, a novel approach for evaluating audio-visual synchronization using embedding similarities. UniSync offers broad compatibility with various audio representations (e.g., Mel spectrograms, HuBERT) and visual representations (e.g., RGB images, face parsing maps, facial landmarks, 3DMM), effectively handling their significant dimensional differences. We enhance the contrastive learning framework with a margin-based loss component and cross-speaker unsynchronized pairs, improving discriminative capabilities. UniSync outperforms existing methods on standard datasets and demonstrates versatility across diverse audio-visual representations. Its integration into talking face generation frameworks enhances synchronization quality in both natural and AI-generated content.
精确的语音视频同步对于语音视频的内容质量和观众的理解至关重要。现有的方法通过基于规则的方法和端到端学习技术,已经在这个挑战上取得了重大进展。然而,这些方法通常依赖于有限的音频视觉表示和次优的学习策略,可能在更复杂场景中的有效性受到限制。为了解决这些局限性,我们提出了UniSync,这是一种使用嵌入相似性进行音频视觉同步评估的新方法。UniSync与各种音频表示(如梅尔频谱图、HuBERT)和视觉表示(如RGB图像、面部解析图、面部特征和3DMM)具有良好的兼容性,有效地处理了它们之间显著的维度差异。我们通过在对比学习框架中引入基于边界的损失组件和非同步跨说话者配对,提高了其鉴别能力。UniSync在标准数据集上的表现优于现有方法,并在多种音频视觉表示中展现了通用性。其在人脸语音生成框架中的集成,提高了自然和人工智能生成内容的同步质量。
论文及项目相关链接
PDF 7 pages, 3 figures, accepted by ICME 2025
Summary
该文本介绍了一种针对语音视频精确音频视觉同步化的新方法——UniSync。此方法使用嵌入相似性进行评估,兼容各种音频和视觉表示,有效处理其显著维度差异。通过增强对比学习框架并引入基于边距的损失组件和非同步跨说话者配对,提高了判别能力。UniSync在标准数据集上的表现优于现有方法,并在多种音频视觉表示中展现出灵活性。其融入说话人面部生成框架,可提高自然和AI生成内容的同步质量。
Key Takeaways
- UniSync是一种针对语音视频同步的新方法,基于嵌入相似性进行评估。
- UniSync兼容多种音频和视觉表示,如Mel光谱图、HuBERT、RGB图像、面部解析图、面部地标和3DMM。
- UniSync有效处理音频和视觉表示之间的显著维度差异。
- UniSync采用对比学习框架,通过引入基于边距的损失组件和非同步跨说话者配对,提高判别能力。
- UniSync在标准数据集上的性能优于现有方法。
- UniSync可灵活应用于多种音频视觉表示,展现出良好的通用性。
点此查看论文截图




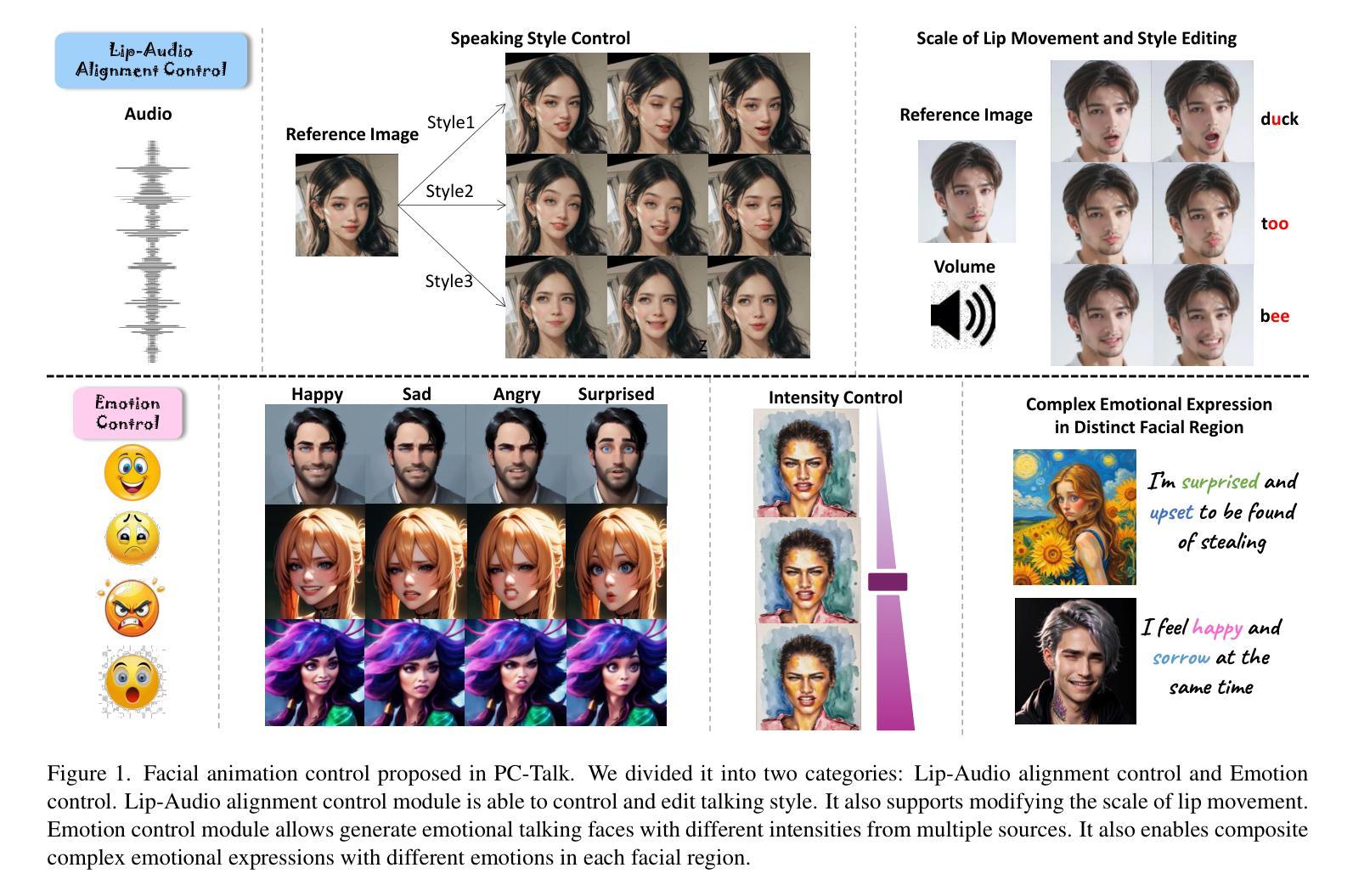
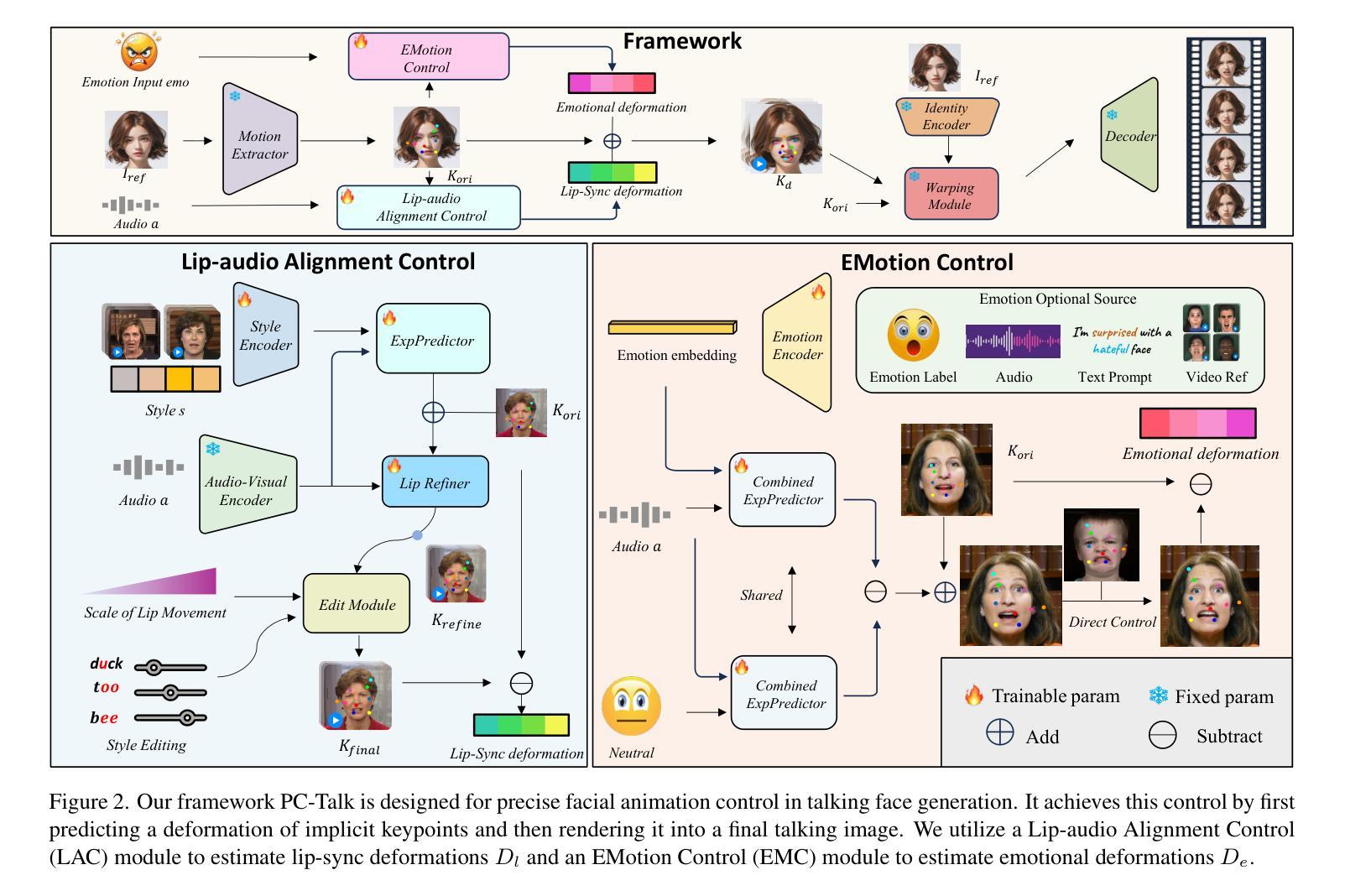
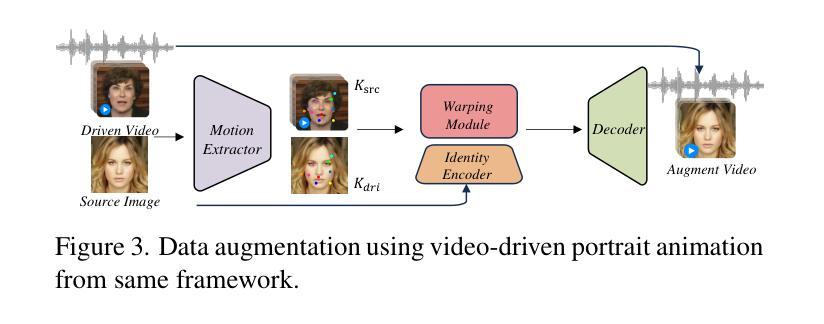
PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
Authors:Baiqin Wang, Xiangyu Zhu, Fan Shen, Hao Xu, Zhen Lei
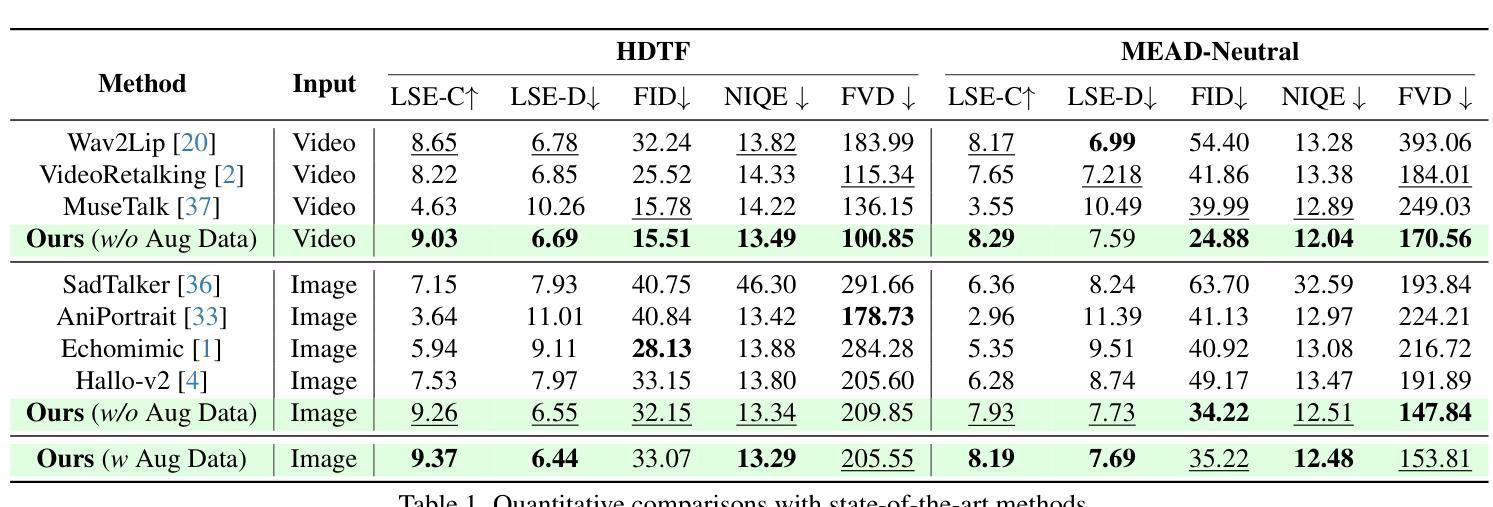
Recent advancements in audio-driven talking face generation have made great progress in lip synchronization. However, current methods often lack sufficient control over facial animation such as speaking style and emotional expression, resulting in uniform outputs. In this paper, we focus on improving two key factors: lip-audio alignment and emotion control, to enhance the diversity and user-friendliness of talking videos. Lip-audio alignment control focuses on elements like speaking style and the scale of lip movements, whereas emotion control is centered on generating realistic emotional expressions, allowing for modifications in multiple attributes such as intensity. To achieve precise control of facial animation, we propose a novel framework, PC-Talk, which enables lip-audio alignment and emotion control through implicit keypoint deformations. First, our lip-audio alignment control module facilitates precise editing of speaking styles at the word level and adjusts lip movement scales to simulate varying vocal loudness levels, maintaining lip synchronization with the audio. Second, our emotion control module generates vivid emotional facial features with pure emotional deformation. This module also enables the fine modification of intensity and the combination of multiple emotions across different facial regions. Our method demonstrates outstanding control capabilities and achieves state-of-the-art performance on both HDTF and MEAD datasets in extensive experiments.
近期音频驱动说话人脸生成技术的进展在嘴唇同步方面取得了很大的进步。然而,当前的方法往往对面部动画的控制不足,如演讲风格和情感表达,导致输出单一。在本文中,我们专注于改进两个关键因素:唇音对齐和情感控制,以提高谈话视频的多样性和用户友好性。唇音对齐控制关注演讲风格和嘴唇运动规模等因素,而情感控制则侧重于生成逼真的情感表达,允许强度等多个属性的修改。为了实现面部动画的精确控制,我们提出了一种新型框架PC-Talk,通过隐式关键点变形实现唇音对齐和情感控制。首先,我们的唇音对齐控制模块便于精确编辑词汇级的演讲风格,并调整嘴唇运动规模以模拟不同的音量水平,同时与音频保持嘴唇同步。其次,我们的情感控制模块通过纯情感变形生成生动的面部情感特征。该模块还实现了强度的精细调整以及不同面部区域多种情感的组合。我们的方法展示了出色的控制能力,并在HDTF和MEAD数据集上的广泛实验中达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了音频驱动的说话人脸生成技术的最新进展,并指出当前方法对面部动画的控制不足,如说话风格和情感表达。为此,本文提出了一个名为PC-Talk的新框架,通过隐式关键点变形实现唇音对齐和情感控制,旨在提高说话视频的多样性和用户友好性。该框架能够精确编辑说话风格、调整唇动尺度,并生成逼真的情感表达,实现多种情感属性的修改。
Key Takeaways
- 当前音频驱动的说话人脸生成技术在唇同步方面取得显著进展,但对面部动画的控制如说话风格和情感表达等方面存在不足。
- 文中提出了一个名为PC-Talk的新框架,旨在提高说话视频的多样性和用户友好性。
- PC-Talk框架包括唇音对齐控制模块,能够精确编辑说话风格,调整唇动尺度,并保持与音频的同步。
- 情感控制模块是PC-Talk的另一核心,能够生成逼真的情感表达,并允许对情感强度进行微调以及多种情感的组合。
- 该方法在HDTF和MEAD数据集上表现出卓越的控制能力和先进性能。
- PC-Talk框架通过隐式关键点变形实现精细的面部动画控制。
点此查看论文截图