⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-23 更新
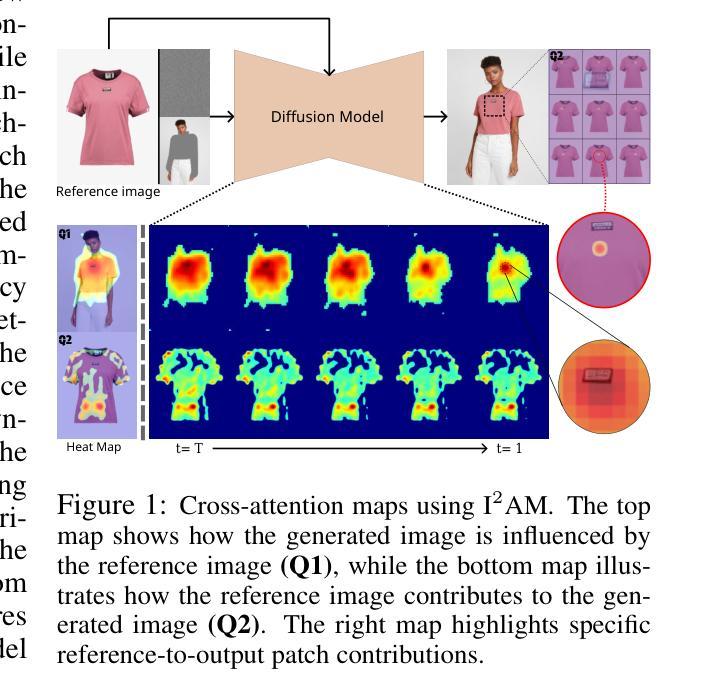
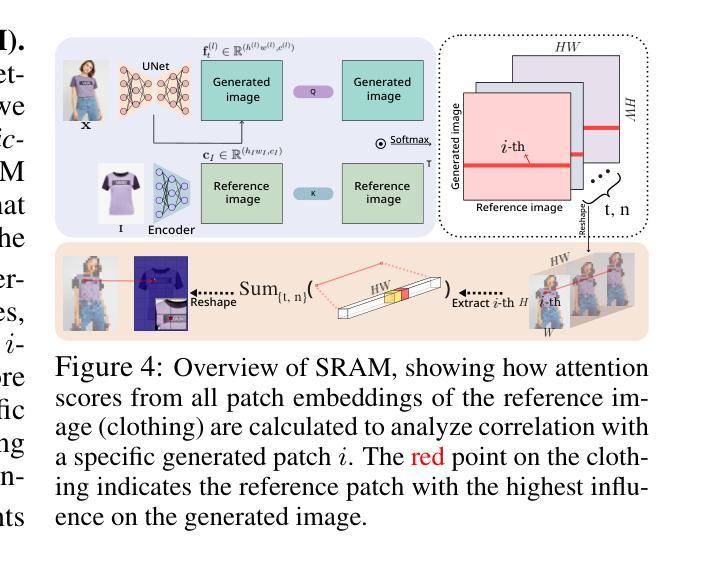
I2AM: Interpreting Image-to-Image Latent Diffusion Models via Bi-Attribution Maps
Authors:Junseo Park, Hyeryung Jang
Large-scale diffusion models have made significant advances in image generation, particularly through cross-attention mechanisms. While cross-attention has been well-studied in text-to-image tasks, their interpretability in image-to-image (I2I) diffusion models remains underexplored. This paper introduces Image-to-Image Attribution Maps (I2AM), a method that enhances the interpretability of I2I models by visualizing bidirectional attribution maps, from the reference image to the generated image and vice versa. I2AM aggregates cross-attention scores across time steps, attention heads, and layers, offering insights into how critical features are transferred between images. We demonstrate the effectiveness of I2AM across object detection, inpainting, and super-resolution tasks. Our results demonstrate that I2AM successfully identifies key regions responsible for generating the output, even in complex scenes. Additionally, we introduce the Inpainting Mask Attention Consistency Score (IMACS) as a novel evaluation metric to assess the alignment between attribution maps and inpainting masks, which correlates strongly with existing performance metrics. Through extensive experiments, we show that I2AM enables model debugging and refinement, providing practical tools for improving I2I model’s performance and interpretability.
大规模扩散模型在图像生成方面取得了重大进展,特别是通过交叉注意机制。虽然交叉注意在文本到图像的任务中已经被很好地研究过,但它们在图像到图像(I2I)扩散模型中的解释性仍然被忽视。本文介绍了图像到图像归因图(I2AM),这是一种通过可视化双向归因图增强I2I模型解释性的方法,从参考图像到生成的图像反之亦然。I2AM聚合了时间步长、注意力头和层的交叉注意力得分,提供了关于图像之间如何转移关键特征的见解。我们在对象检测、图像修复和超分辨率任务中展示了I2AM的有效性。我们的结果表明,I2AM成功地识别了负责生成输出的关键区域,即使在复杂的场景中也是如此。此外,我们引入了图像修复掩膜注意力一致性得分(IMACS)作为新的评估指标,以评估归因图与图像修复掩膜之间的对齐程度,这与现有的性能指标具有很强的相关性。通过大量实验,我们证明了I2AM能够实现模型调试和优化,为改进I2I模型的性能和解释性提供了实用工具。
论文及项目相关链接
PDF 23 pages
Summary
大型扩散模型在图像生成方面取得了显著进展,特别是通过跨注意力机制。本文介绍了一种提高图像到图像(I2I)模型可解释性的方法——图像到图像归属图(I2AM)。I2AM通过可视化双向归属图,从参考图像到生成图像,反之亦然,增强了I2I模型的解释性。I2AM聚合了跨时间步长、注意力头和层的交叉注意力分数,揭示了关键特征如何在图像间转移。通过实验验证,I2AM在对象检测、图像修复和超分辨率任务中表现出有效性,并能成功识别出输出生成的关键区域,即使在复杂场景中也是如此。此外,还引入了修复遮罩注意力一致性得分(IMACS)作为评估归属图与修复遮罩对齐情况的新评价指标,与现有性能指标有强相关性。I2AM为模型调试和优化提供了实用工具,提高了I2I模型的性能和可解释性。
Key Takeaways
- 大型扩散模型在图像生成领域通过跨注意力机制取得了显著进展。
- 图像到图像(I2I)模型的解释性仍然有待探索。
- I2AM方法通过可视化双向归属图增强I2I模型的解释性。
- I2AM揭示了关键特征如何在图像间转移,通过聚合跨时间步长、注意力头和层的交叉注意力分数。
- I2AM在对象检测、图像修复和超分辨率任务中表现出有效性。
- IMACS作为新的评价指标,用于评估归属图与修复遮罩的对齐情况。
点此查看论文截图


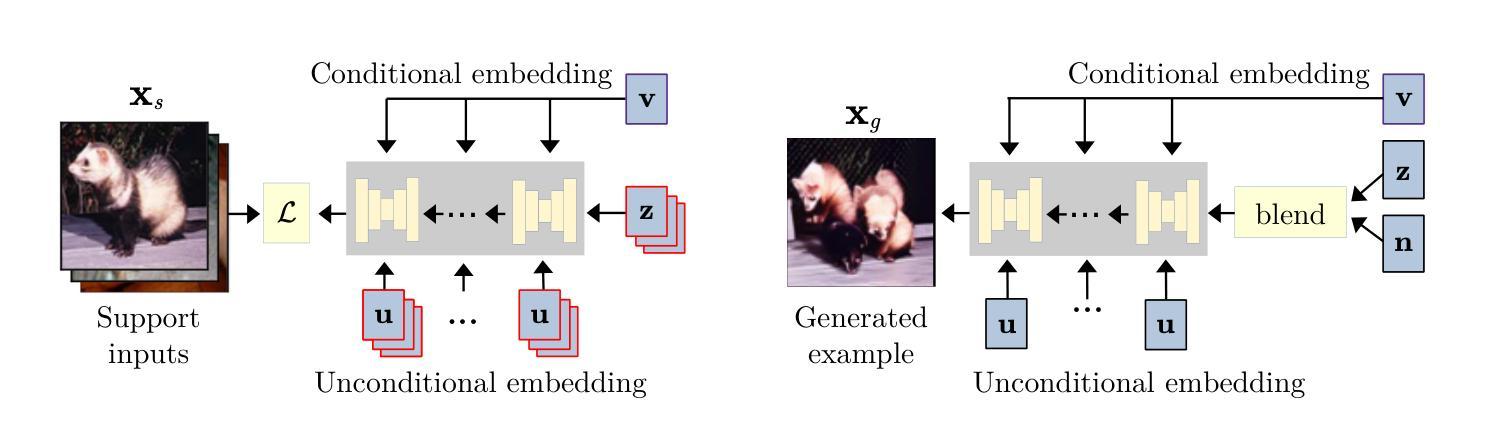
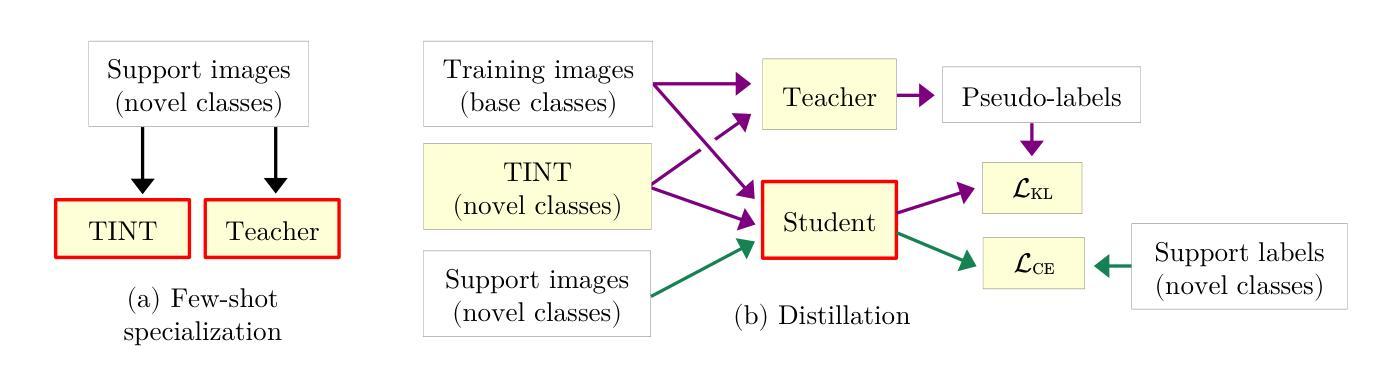
Tiny models from tiny data: Textual and null-text inversion for few-shot distillation
Authors:Erik Landolsi, Fredrik Kahl
Few-shot learning deals with problems such as image classification using very few training examples. Recent vision foundation models show excellent few-shot transfer abilities, but are large and slow at inference. Using knowledge distillation, the capabilities of high-performing but slow models can be transferred to tiny, efficient models. However, common distillation methods require a large set of unlabeled data, which is not available in the few-shot setting. To overcome this lack of data, there has been a recent interest in using synthetic data. We expand on this line of research by presenting a novel diffusion model inversion technique (TINT) combining the diversity of textual inversion with the specificity of null-text inversion. Using this method in a few-shot distillation pipeline leads to state-of-the-art accuracy among small student models on popular benchmarks, while being significantly faster than prior work. Popular few-shot benchmarks involve evaluation over a large number of episodes, which is computationally cumbersome for methods involving synthetic data generation. We also present a theoretical analysis on how the accuracy estimator variance depends on the number of episodes and query examples, and use these results to lower the computational effort required for method evaluation. Finally, to further motivate the use of generative models in few-shot distillation, we demonstrate that our method outperforms training on real data mined from the dataset used in the original diffusion model training. Source code is available at https://github.com/pixwse/tiny2.
少量学习处理的问题包括使用极少训练样本的图像分类等。最近的视觉基础模型展现出优秀的少量转移能力,但在推理时体积庞大且速度较慢。使用知识蒸馏技术,高性能但速度较慢的模型的能力可以转移到微小、高效的模型上。然而,常见的蒸馏方法需要大量未标记数据,这在少量设置中是不可用的。为了克服数据缺乏的问题,最近对使用合成数据产生了兴趣。我们通过对文本反转的多样性和空文本反转的特异性相结合,提出了一种新型扩散模型反转技术(TINT)。将这种技术应用于少量蒸馏管道中,在流行基准测试上,小型学生模型的准确率达到了最新水平,同时比先前的工作显著更快。流行的少量基准测试涉及大量片段的评估,这对于涉及合成数据生成的方法在计算上很繁琐。我们还对准确度估算器方差如何依赖于片段数量和查询示例进行了理论分析,并利用这些结果降低了方法评估所需的计算工作量。最后,为了进一步推动生成模型在少量蒸馏中的应用,我们证明了我们的方法在真实数据训练上优于从原始扩散模型训练所用的数据集中挖掘的数据。源代码可在https://github.com/pixwse/tiny2找到。
论文及项目相关链接
PDF 24 pages (13 main pages + references and appendix)
Summary
本文介绍了针对少样本图像分类问题的研究,通过使用知识蒸馏技术将高性能但运行缓慢的模型的能力转移到小型高效模型上。提出了一种新颖的扩散模型反演技术(TINT),结合了文本反演的多样性和无文本反演的特异性。在少样本蒸馏管道中使用此方法,小型学生模型在流行基准测试上达到了最先进的准确性,同时显著快于以前的工作。此外,文章还进行了理论分析和准确性估计方差与集会和查询示例数量之间的依赖关系,以降低评估方法的计算负担。最后,该研究展示了在少样本蒸馏中使用生成模型的优势,提出的方法优于在原始扩散模型训练数据集中挖掘的真实数据的训练效果。
Key Takeaways
- 介绍少样本学习问题及其挑战,特别是图像分类任务中利用极少训练样本的情况。
- 阐述最近愿景基础模型在少样本迁移能力方面的出色表现,但存在模型体积大、推理速度慢的问题。
- 利用知识蒸馏技术,将高性能模型的能力转移到小型高效模型上。
- 提出一种新颖的扩散模型反演技术(TINT),结合文本反演的多样性和无文本反演的特异性,用于少样本蒸馏。
- TINT方法在流行基准测试上表现出优异的准确性,且计算效率高于以往方法。
- 进行理论分析和准确性估计方差分析,以降低评估方法的计算负担。
点此查看论文截图



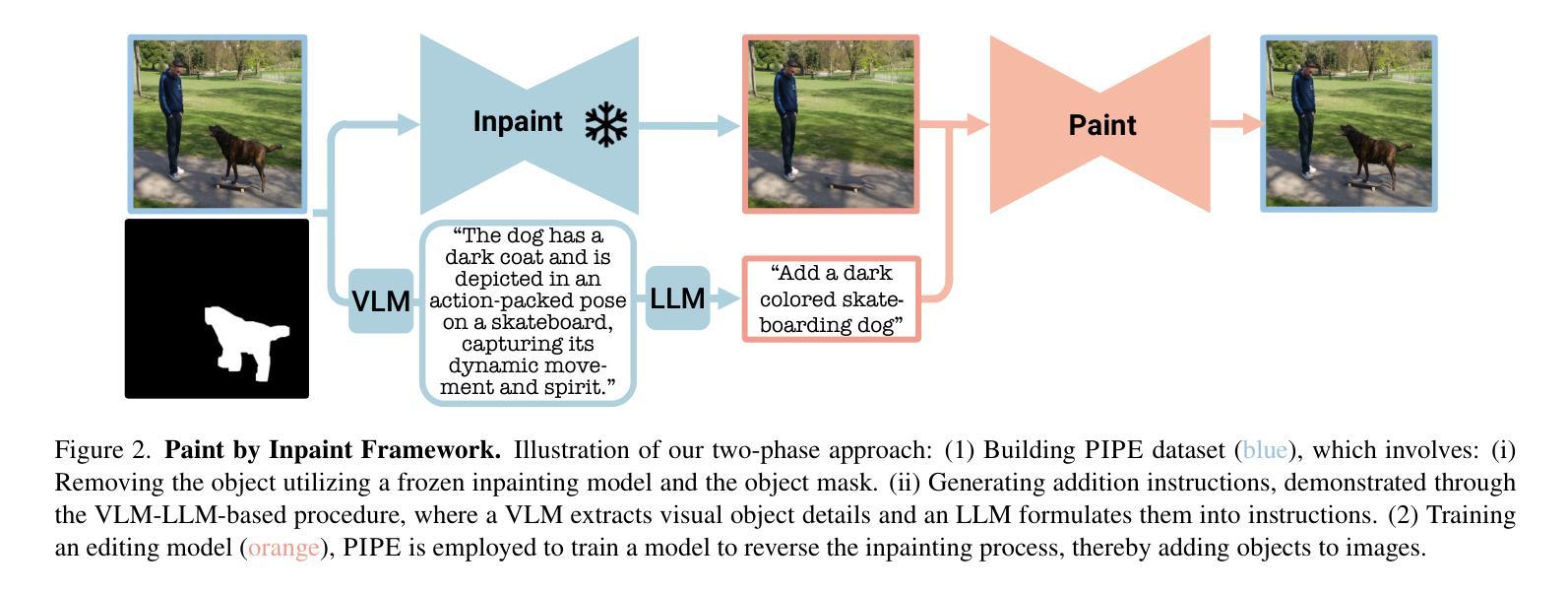
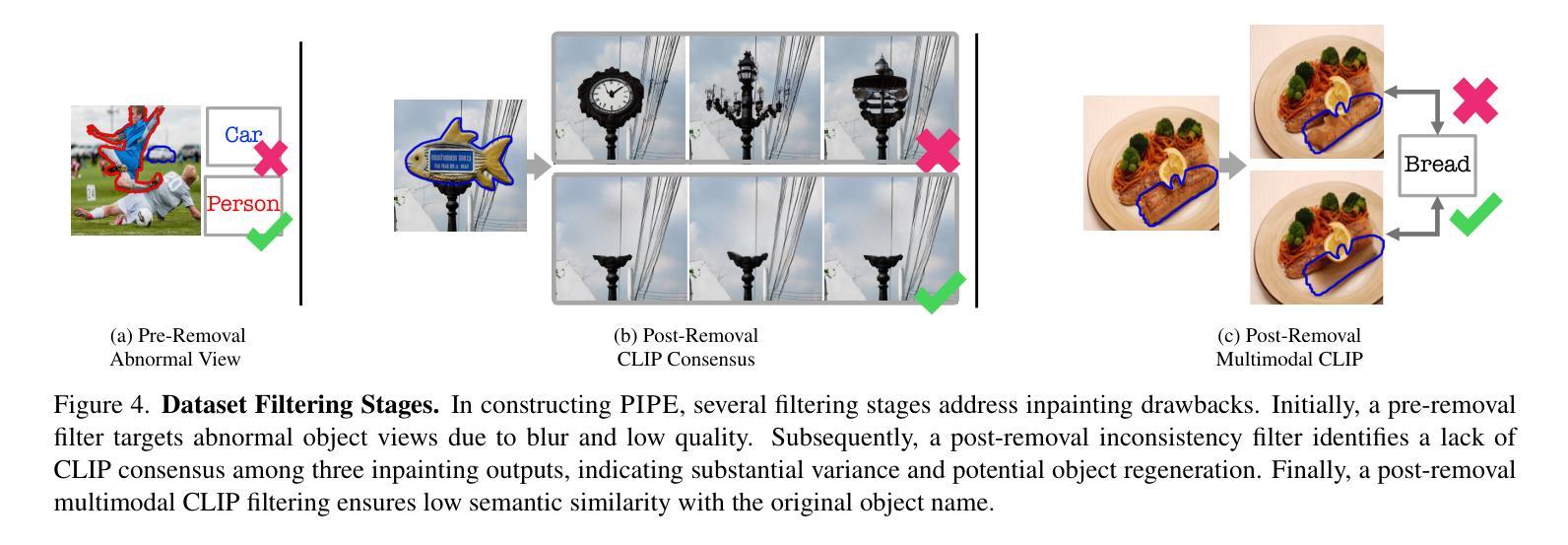
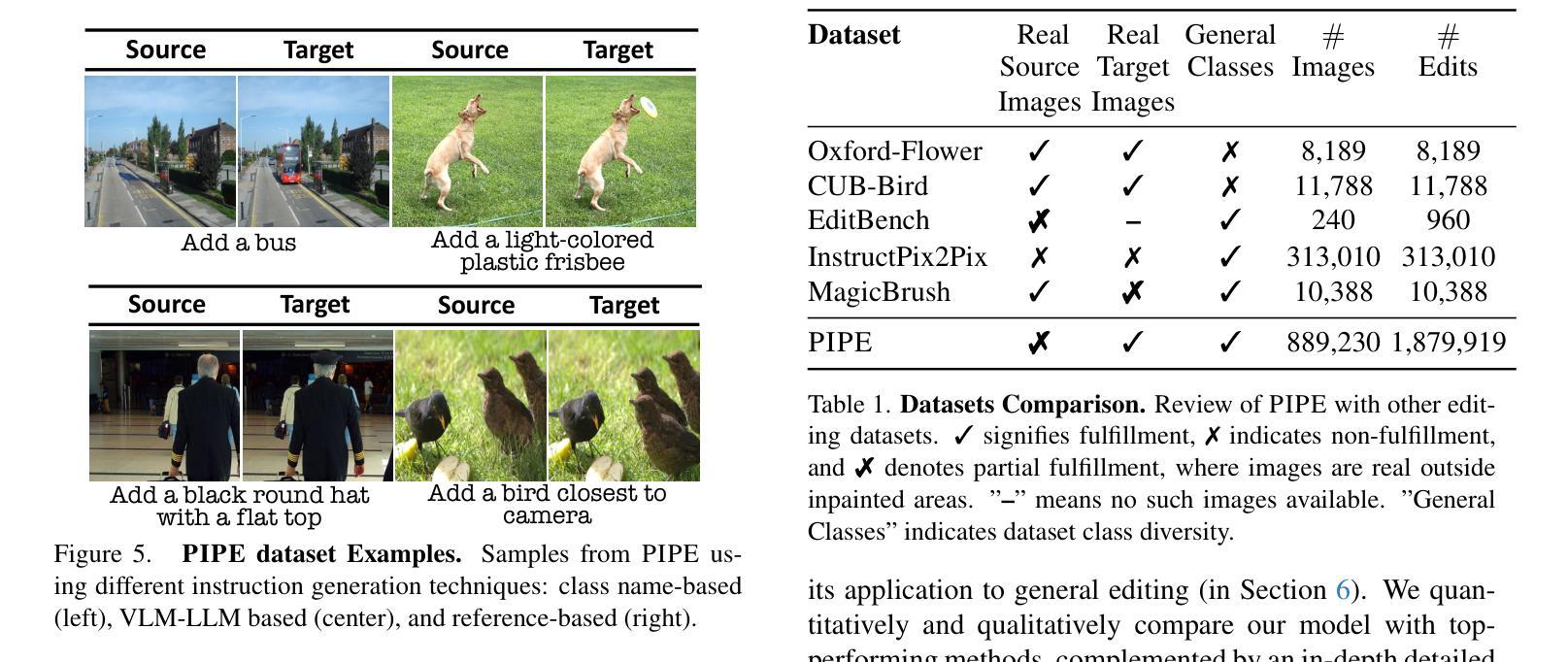
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Authors:Navve Wasserman, Noam Rotstein, Roy Ganz, Ron Kimmel
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to inpainting models that benefit from segmentation mask guidance. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones while ensuring source-target consistency by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. Our quantitative and qualitative results show that the trained model surpasses existing models in both object addition and general editing tasks. Visit our project page for the released dataset and trained models at https://rotsteinnoam.github.io/Paint-by-Inpaint.
图像编辑随着文本条件扩散模型的引入已经取得了显著的进步。尽管如此,根据文本指令无缝添加对象到图像中,而无需用户提供输入掩码仍然是一个挑战。我们通过利用这样一个见解来解决这个问题:去除物体(补画)比反向过程添加它们(绘画)要简单得多,这归功于受益于分割掩码指导的补画模型。基于这一认识,我们通过实现自动化和广泛的管道,整理了一个包含图像及其相应去对象版本配对的大规模图像数据集。使用这些配对数据,我们训练了一个扩散模型来反转补画过程,有效地将对象添加到图像中。与其他编辑数据集不同,我们的数据集以自然目标图像为特色,并通过构建确保源-目标一致性。此外,我们利用大型视觉语言模型为删除的对象提供详细描述,并利用大型语言模型将这些描述转换为多样、自然的指令。我们的定量和定性结果表明,训练模型在对象添加和一般编辑任务上都超越了现有模型。请访问我们的项目页面获取发布的数据集和训练模型:https://rotsteinnoam.github.io/Paint-by-Inpaint。
论文及项目相关链接
Summary
本文介绍了基于文本条件的扩散模型在图像编辑中的最新进展。针对在图像中根据文本指令无缝添加对象而无需用户提供的输入掩模的挑战,研究团队提出了一种解决方案。他们利用去除对象(修复)比添加对象(绘画)更简单的事实,构建了一个自动化的大规模管道,从大型图像数据集中筛选出图像及其对应的去对象版本。使用这些数据对扩散模型进行训练,以反转修复过程,实现向图像中添加对象。该数据集包含自然目标图像而非合成图像,并在构建时确保源-目标一致性。此外,他们还使用大型视觉语言模型提供有关移除对象的详细描述,并利用大型语言模型将这些描述转换为多样化的自然语言指令。研究结果显示,训练出的模型在对象添加和一般编辑任务上均超越了现有模型。
Key Takeaways
- 文本条件的扩散模型在图像编辑中取得了显著进展。
- 在根据文本指令无缝添加对象到图像中仍存在挑战。
- 研究团队利用去除对象(修复)比添加对象(绘画)更简单的事实来解决问题。
- 构建了一个自动化的大规模管道来筛选图像及其对应的去对象版本作为数据集。
- 该数据集包含自然目标图像而非合成图像,确保源-目标一致性。
- 使用大型视觉语言模型和大型语言模型提供有关移除对象的详细描述并转换为自然语言指令。
点此查看论文截图


Label-efficient multi-organ segmentation with a diffusion model
Authors:Yongzhi Huang, Fengjun Xi, Liyun Tu, Jinxin Zhu, Haseeb Hassan, Liyilei Su, Yun Peng, Jingyu Li, Jun Ma, Bingding Huang
Accurate segmentation of multiple organs in Computed Tomography (CT) images plays a vital role in computer-aided diagnosis systems. While various supervised learning approaches have been proposed recently, these methods heavily depend on a large amount of high-quality labeled data, which are expensive to obtain in practice. To address this challenge, we propose a label-efficient framework using knowledge transfer from a pre-trained diffusion model for CT multi-organ segmentation. Specifically, we first pre-train a denoising diffusion model on 207,029 unlabeled 2D CT slices to capture anatomical patterns. Then, the model backbone is transferred to the downstream multi-organ segmentation task, followed by fine-tuning with few labeled data. In fine-tuning, two fine-tuning strategies, linear classification and fine-tuning decoder, are employed to enhance segmentation performance while preserving learned representations. Quantitative results show that the pre-trained diffusion model is capable of generating diverse and realistic 256x256 CT images (Fr'echet inception distance (FID): 11.32, spatial Fr'echet inception distance (sFID): 46.93, F1-score: 73.1%). Compared to state-of-the-art methods for multi-organ segmentation, our method achieves competitive performance on the FLARE 2022 dataset, particularly in limited labeled data scenarios. After fine-tuning with 1% and 10% labeled data, our method achieves dice similarity coefficients (DSCs) of 71.56% and 78.51%, respectively. Remarkably, the method achieves a DSC score of 51.81% using only four labeled CT slices. These results demonstrate the efficacy of our approach in overcoming the limitations of supervised learning approaches that is highly dependent on large-scale labeled data.
在计算机断层扫描(CT)图像中,多器官精准分割在计算机辅助诊断系统中起着至关重要的作用。尽管最近已经提出了各种监督学习方法,但这些方法严重依赖于大量高质量标记数据,而在实践中这些数据获取成本高昂。为了应对这一挑战,我们提出了一种使用预训练扩散模型进行CT多器官分割的标签有效框架。具体来说,我们首先在207,029张无标签的二维CT切片上预训练去噪扩散模型,以捕捉解剖模式。然后,将模型主干转移到下游多器官分割任务中,并使用少量标记数据进行微调。在微调过程中,我们采用了两种微调策略,即线性分类和微调解码器,以提高分割性能的同时保留学习到的表示。定量结果表明,预训练的扩散模型能够生成多样且逼真的256x256 CT图像(Fréchet inception distance (FID):11.32,spatial Fréchet inception distance (sFID):46.93,F1分数:73.1%)。与多器官分割的最先进方法相比,我们的方法在FLARE 2022数据集上实现了具有竞争力的性能,特别是在有限标记数据的情况下。使用1%和10%的标记数据进行微调后,我们的方法实现了迪克森相似系数(DSC)分别为71.56%和78.51%。值得注意的是,该方法仅使用四张标记的CT切片就达到了51.81%的DSC得分。这些结果证明了我们的方法在克服高度依赖于大规模标记数据的监督学习方法的局限性方面的有效性。
论文及项目相关链接
Summary
本文提出一种利用预训练的扩散模型进行计算机断层扫描(CT)多器官分割的标签有效框架。通过预训练捕捉解剖模式,再进行下游多器官分割任务,并少量标签数据进行微调。定量结果显示,预训练扩散模型能生成多样且真实的CT图像,且在有限标签数据场景下与最新多器官分割方法相比具有竞争力。
Key Takeaways
- 提出一种基于预训练的扩散模型的标签有效框架用于CT多器官分割。
- 通过在大量无标签的CT切片上预训练捕获解剖模式,然后将模型迁移到下游任务。
- 仅使用少量标签数据进行微调,采用两种策略提升分割性能并保持学到的表示。
- 预训练扩散模型能生成多样且真实的CT图像,定量评估结果良好。
- 与最新多器官分割方法相比,在有限标签数据场景下具有竞争力。
- 使用仅4个标签CT切片进行微调时,仍能获得较高的DSC分数。
点此查看论文截图

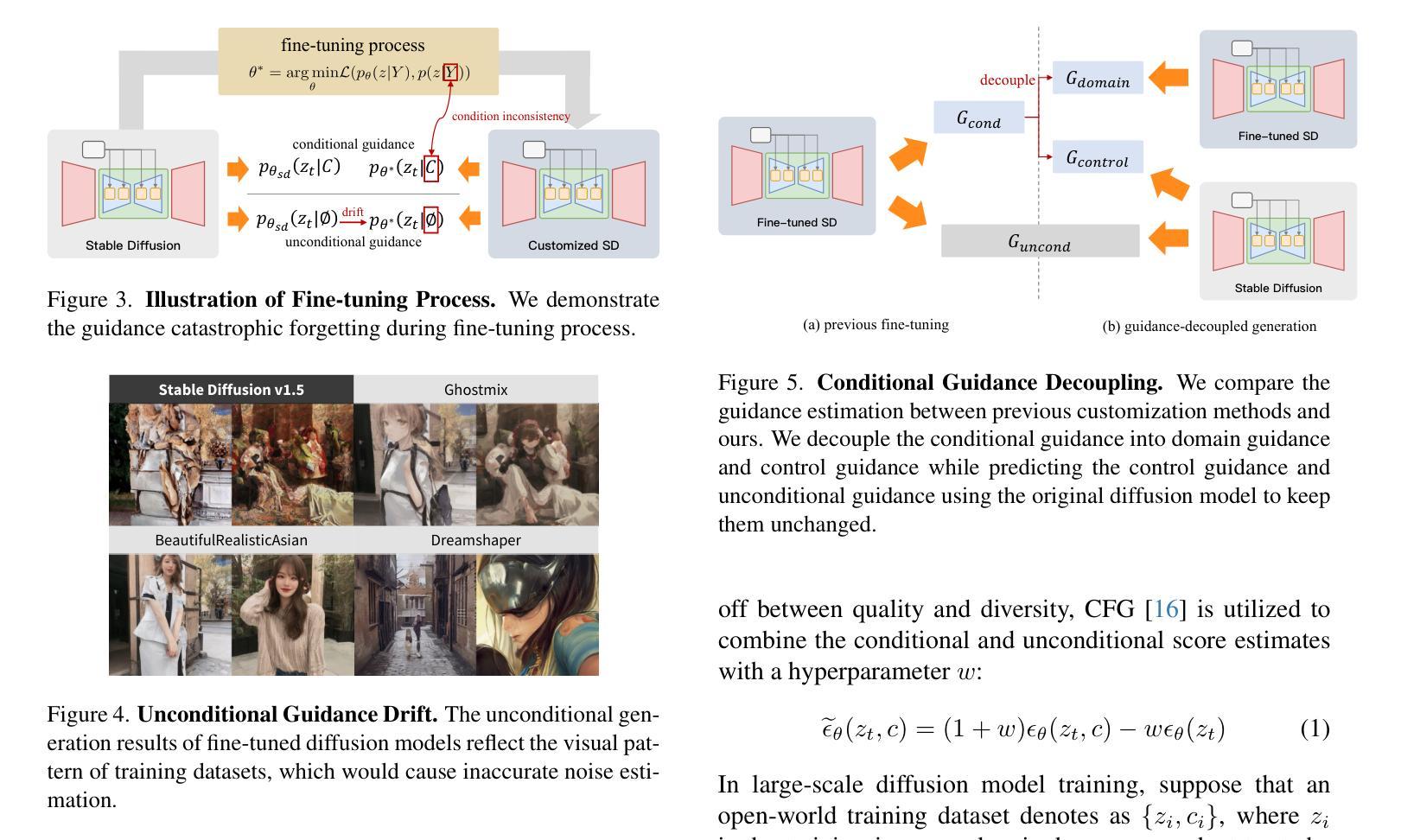
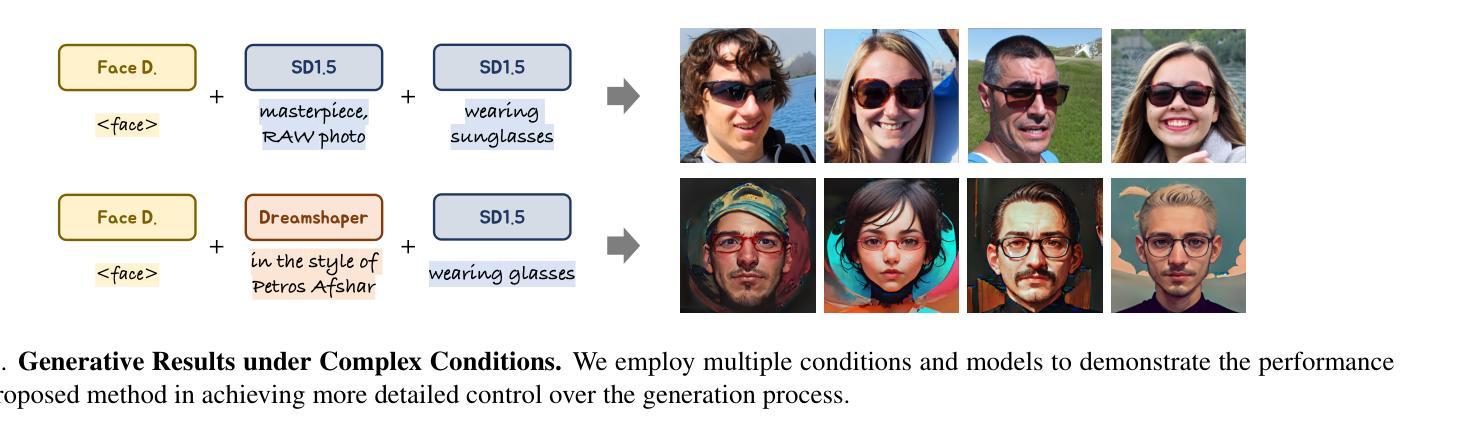
Image is All You Need to Empower Large-scale Diffusion Models for In-Domain Generation
Authors:Pu Cao, Feng Zhou, Lu Yang, Tianrui Huang, Qing Song
In-domain generation aims to perform a variety of tasks within a specific domain, such as unconditional generation, text-to-image, image editing, 3D generation, and more. Early research typically required training specialized generators for each unique task and domain, often relying on fully-labeled data. Motivated by the powerful generative capabilities and broad applications of diffusion models, we are driven to explore leveraging label-free data to empower these models for in-domain generation. Fine-tuning a pre-trained generative model on domain data is an intuitive but challenging way and often requires complex manual hyper-parameter adjustments since the limited diversity of the training data can easily disrupt the model’s original generative capabilities. To address this challenge, we propose a guidance-decoupled prior preservation mechanism to achieve high generative quality and controllability by image-only data, inspired by preserving the pre-trained model from a denoising guidance perspective. We decouple domain-related guidance from the conditional guidance used in classifier-free guidance mechanisms to preserve open-world control guidance and unconditional guidance from the pre-trained model. We further propose an efficient domain knowledge learning technique to train an additional text-free UNet copy to predict domain guidance. Besides, we theoretically illustrate a multi-guidance in-domain generation pipeline for a variety of generative tasks, leveraging multiple guidances from distinct diffusion models and conditions. Extensive experiments demonstrate the superiority of our method in domain-specific synthesis and its compatibility with various diffusion-based control methods and applications.
领域内的生成旨在在特定领域内执行各种任务,如无条件生成、文本到图像、图像编辑、3D生成等。早期的研究通常需要针对每个独特任务和领域训练专门的生成器,通常依赖于完全标记的数据。受扩散模型强大生成能力和广泛应用的影响,我们致力于探索利用无标签数据来支持这些模型进行域内生成。对域数据进行预训练生成模型的微调是一种直观但具有挑战性的方法,并且由于训练数据的有限多样性,常常需要复杂的手动超参数调整,这可能会破坏模型的原始生成能力。为了解决这一挑战,我们提出了一种指导解耦先验保留机制,通过仅图像数据实现高生成质量和可控性,其灵感来源于从去噪指导的角度保留预训练模型。我们将与领域相关的指导与分类器自由指导机制中使用的条件指导解耦,以保留开放世界控制指导和无条件指导来自预训练模型。我们进一步提出了一种有效的领域知识学习技术,训练一个额外的无文本UNet副本以预测领域指导。此外,我们从理论上说明了针对多种生成任务的域内生成管道,利用来自不同扩散模型和条件的多个指导。大量实验证明了我们方法在特定域合成的优越性,以及与各种基于扩散的控制方法和应用兼容性。
论文及项目相关链接
PDF Accepted to CVPR2025. Code is available at https://github.com/PRIV-Creation/In-domain-Generation-Diffusion
摘要
本研究探讨了基于扩散模型(Diffusion Models)的域内生成任务,包括无条件生成、文本转图像、图像编辑等。早期研究通常需要为每个特定任务和域训练专门的生成器,并依赖于完全标记的数据。本研究利用扩散模型的强大生成能力和广泛应用,探索利用无标签数据为这些模型赋能。针对预训练生成模型在域数据上的微调挑战,提出了一种基于图像数据的指导解耦先验保持机制,以实现高质量生成和控制,并从去噪指导角度保留预训练模型。通过从分类器自由指导机制中解耦出与域相关的指导,以保留开放世界控制指导和无条件指导。进一步提出了一种有效的领域知识学习技术,训练一个额外的无文本UNet副本以预测域指导。此外,从理论上阐述了一种用于多种生成任务的多指导域内生成管道,利用来自不同扩散模型和条件的多重指导。大量实验证明,该方法在特定领域的合成中具有优势,且与各种扩散控制方法和应用兼容。
关键见解
- 研究基于扩散模型的域内生成任务,涵盖多种应用如无条件生成、文本转图像等。
- 提出利用无标签数据赋能模型的方法。
- 针对预训练生成模型在特定域数据上的微调挑战,提出了一种新的指导解耦先验保持机制。
- 该机制从分类器自由指导中解耦域相关指导,保留开放世界控制和无条件指导的能力。
- 提出一种有效的领域知识学习技术,通过训练额外的无文本UNet副本预测域指导。
- 实现了一种多指导域内生成管道,融合了不同扩散模型和条件的指导。
- 实验表明,该方法在特定领域的合成任务上表现优越,具有良好的兼容性。
点此查看论文截图