⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-23 更新
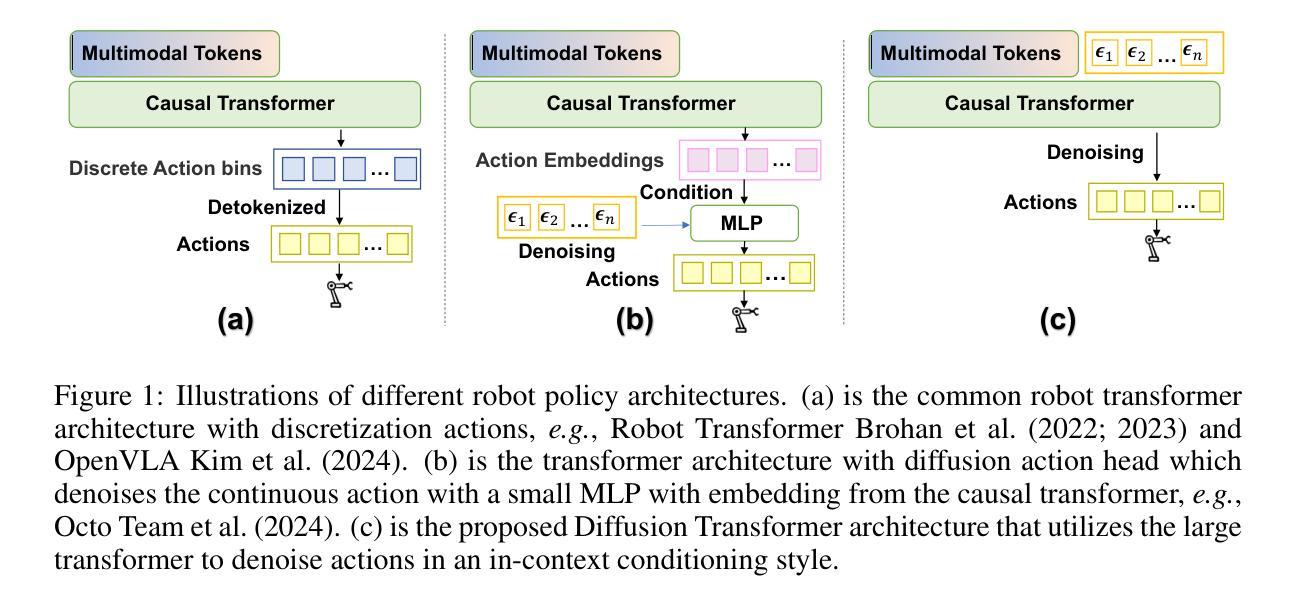
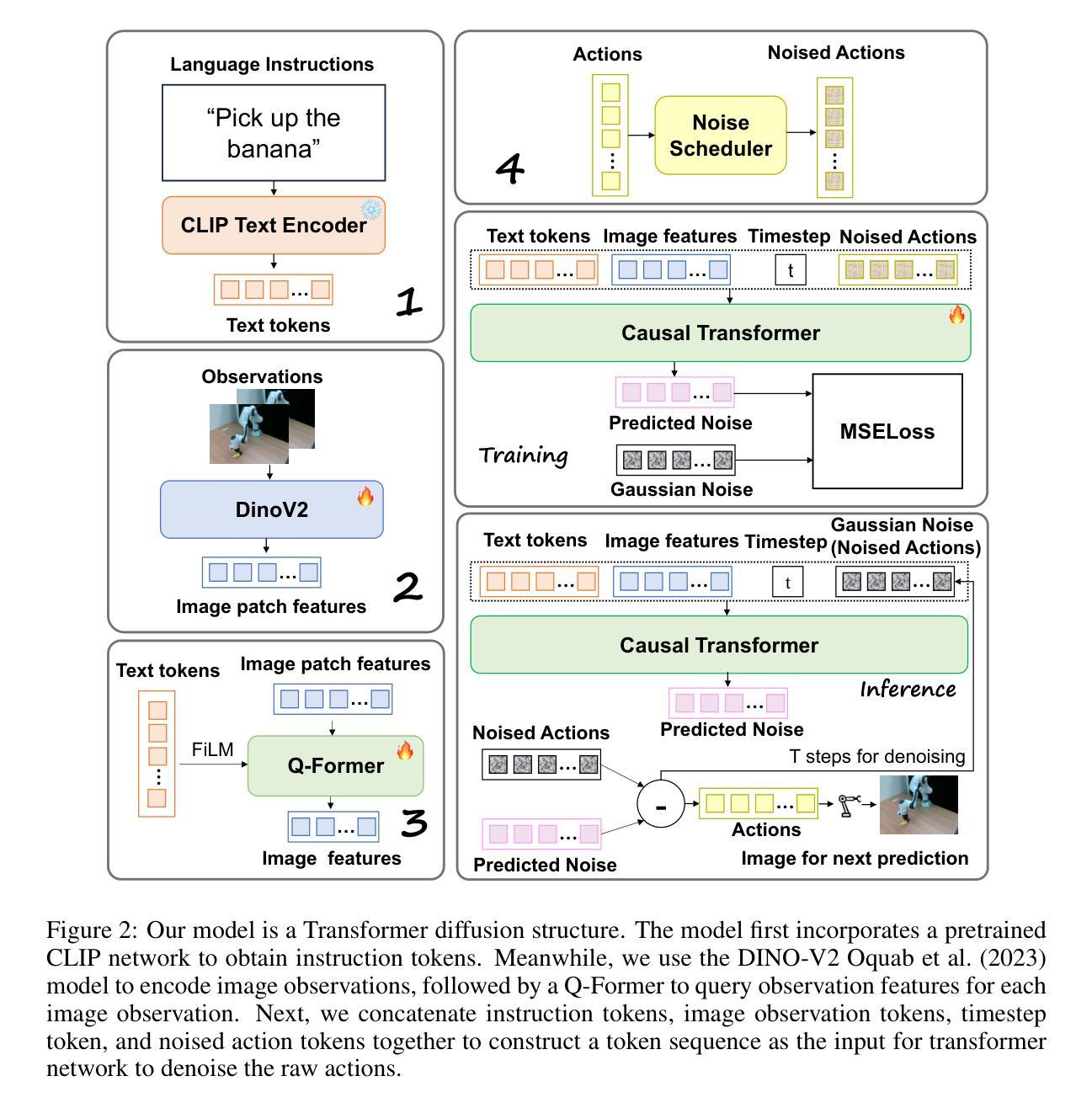
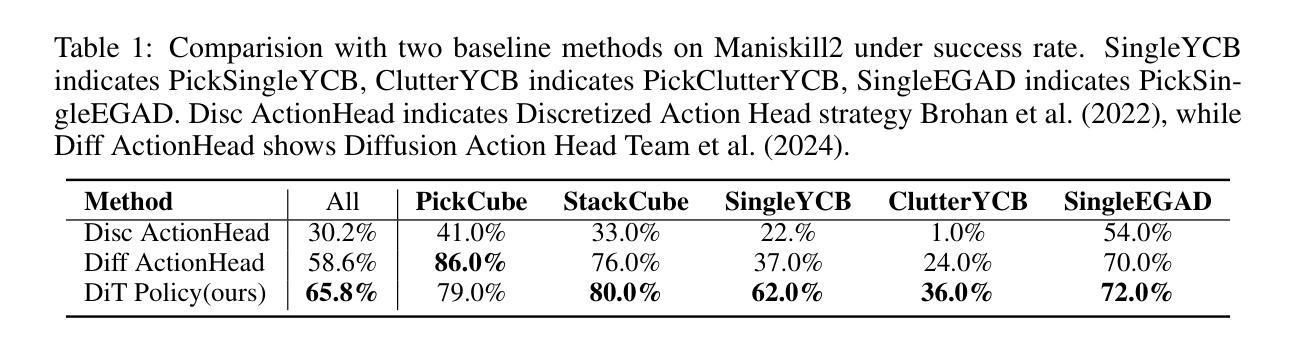
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Authors:Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, Yuntao Chen
While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning – enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer’s scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io/
虽然最近基于多样机器人数据集训练的视觉-语言-动作模型在有限领域内数据上展现出有前景的泛化能力,但它们依赖于紧凑的动作头来预测离散或连续动作,这限制了其在异构动作空间中的适应性。我们提出了Dita,一个可扩展的框架,它利用Transformer架构通过统一的多模态扩散过程直接对连续动作序列进行去噪。与以前的方法不同,这些方法通过浅层网络对融合嵌入进行去噪条件处理,而Dita采用上下文条件处理——实现在去噪动作和来自历史观察的原视觉标记之间的精细对齐。这种设计明确地模拟了动作变化和环境细微差异。通过扩大扩散动作去噪器与Transformer的可扩展性,Dita有效地整合了跨不同相机角度、观察场景、任务和动作空间的跨体态数据集。这种协同作用增强了对各种变量的稳健性,并促进了长期任务的成功执行。在广泛基准测试上的评估证明了其在仿真中的卓越或相当的性能。值得注意的是,Dita仅通过第三人称相机输入实现了对环境和复杂长期任务的稳健适应,通过10次射击微调达到稳健效果。该架构为通用机器人策略学习建立了通用、轻便和开源的基线。项目页面:https://robodita.github.io/
论文及项目相关链接
PDF I want to withdraw the recent replacement (v4), given that the author is different, the title is also different and the content is totally different
Summary
基于Transformer架构的Dita框架,通过统一的多模态扩散过程直接对连续动作序列进行去噪。不同于依赖融合嵌入并通过浅层网络进行条件去噪的方法,Dita采用上下文条件,实现了去噪动作与原始视觉标记之间的精细对齐,并显式地模拟动作变化和环境细微差别。通过与Transformer的可扩展性一起扩展扩散动作去噪器,Dita能够成功集成跨不同视角、观察场景、任务和动作空间的跨体态数据集。这提高了对各种差异的稳健性,并促进了长期任务的成功执行。在广泛的基准测试上表现出卓越的性能。特别是在仅有第三人称相机输入的情况下,通过几次微调就能实现对环境变化和复杂长期任务的稳健适应。这为机器人政策学习建立了一个通用、轻便且开源的基线。
Key Takeaways
- Dita框架利用Transformer架构直接对连续动作序列进行去噪,展现强大的适应性。
- Dita采用上下文条件,实现去噪动作与原始视觉标记之间的精细对齐。
- 通过模拟动作变化和环境细微差别,Dita提高了模型的健壮性。
- Dita能有效集成跨不同视角、观察场景、任务和动作空间的跨体态数据集。
- Dita框架对于长期任务的执行表现出卓越性能。
- Dita在仅有第三人称相机输入的情况下,通过少量数据微调就能适应环境变化和复杂任务。
点此查看论文截图

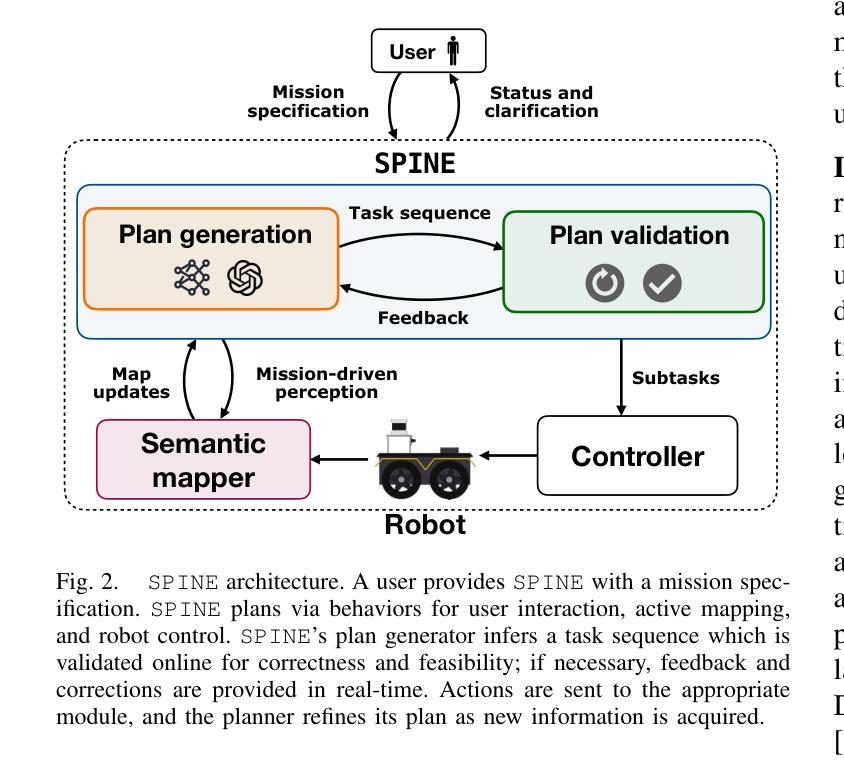
SPINE: Online Semantic Planning for Missions with Incomplete Natural Language Specifications in Unstructured Environments
Authors:Zachary Ravichandran, Varun Murali, Mariliza Tzes, George J. Pappas, Vijay Kumar
As robots become increasingly capable, users will want to describe high-level missions and have robots infer the relevant details. because pre-built maps are difficult to obtain in many realistic settings, accomplishing such missions will require the robot to map and plan online. while many semantic planning methods operate online, they are typically designed for well specified missions such as object search or exploration. recently, large language models (LLMs) have demonstrated powerful contextual reasoning abilities over a range of robotic tasks described in natural language. however, existing LLM-enabled planners typically do not consider online planning or complex missions; rather, relevant subtasks and semantics are provided by a pre-built map or a user. we address these limitations via spine, an online planner for missions with incomplete mission specifications provided in natural language. the planner uses an LLM to reason about subtasks implied by the mission specification and then realizes these subtasks in a receding horizon framework. tasks are automatically validated for safety and refined online with new map observations. we evaluate spine in simulation and real-world settings with missions that require multiple steps of semantic reasoning and exploration in cluttered outdoor environments of over 20,000m$^2$. compared to baselines that use existing LLM-enabled planning approaches, our method is over twice as efficient in terms of time and distance, requires less user interactions, and does not require a full map. Additional resources are provided at: https://zacravichandran.github.io/SPINE.
随着机器人的能力越来越强,用户将希望描述高级任务,并让机器人推断相关细节。由于在许多现实场景中很难获得预先构建的地图,因此完成此类任务将要求机器人在线进行地图绘制和规划。虽然许多语义规划方法都是在线运行的,但它们通常是为特定任务设计的,如目标搜索或探索。最近,大型语言模型(LLM)在多种机器人任务中表现出了强大的上下文推理能力,这些任务是用自然语言描述的。然而,现有的LLM支持规划师通常不考虑在线规划或复杂任务;而是由预先构建的地图或用户提供相关的子任务和语义。我们通过SPINE来解决这些局限性,这是一种在线规划师,用于处理以自然语言提供的不完整任务规格的任务。规划师使用LLM来推理任务规格所暗示的子任务,然后在后退地平线框架中实现这些子任务。任务会自动验证安全性,并根据新的地图观察结果进行在线调整。我们在模拟和真实环境中对SPINE进行了评估,这些任务需要进行多步骤的语义推理和杂乱户外环境的探索,面积达超过2万米^ 2。与采用现有LLM支持的规划方法相比,我们的方法在时间和距离方面效率提高了两倍以上,减少了用户交互次数,并且不需要完整的地图。更多资源请访问:https://zacravichandran.github.io/SPINE。
论文及项目相关链接
PDF Accepted to the International Conference on Robotics and Automation (ICRA) 2025
Summary
随着机器人功能的不断增强,用户将更倾向于描述高级任务,并希望机器人能够推断相关细节。在真实环境中,获取预先构建的地图十分困难,因此需要实现在线映射和规划来完成此类任务。许多语义规划方法虽然支持在线操作,但它们主要针对对象搜索或探索等任务明确的环境。近期,大型语言模型(LLM)在机器人任务中展现出强大的上下文推理能力,能够处理自然语言描述的任务。然而,现有的LLM规划器并不支持在线规划或复杂任务;它们依赖于预先构建的地图或用户提供的子任务和语义信息。针对这些问题,我们提出SPINE方法,一种在线规划器,用于处理以自然语言形式提供的部分不明确的任务指令。SPINE通过大型语言模型理解任务的子指令并进行在线规划实现。它能够在不完整的地图中进行自动任务验证并确保安全执行。我们分别在模拟和真实环境中评估了SPINE的效果,结果证明在处理复杂的室外环境中的语义推理和探索任务时,相比现有的基于LLM的规划方法,SPINE具有更高的效率和准确性。更多资源请参见:链接地址。
Key Takeaways
- 随着机器人功能增强,用户更倾向描述高级任务,并要求机器人具备在线映射和规划能力来处理不确定性和环境复杂性。
- LLM展现出强大的上下文推理能力,适用于处理自然语言描述的机器人任务。
- 现有LLM规划器不支持在线规划和复杂任务处理,依赖于预先构建的地图或用户提供的语义信息。
- SPINE是一种在线规划器,通过大型语言模型理解任务的子指令并进行在线规划实现。
点此查看论文截图



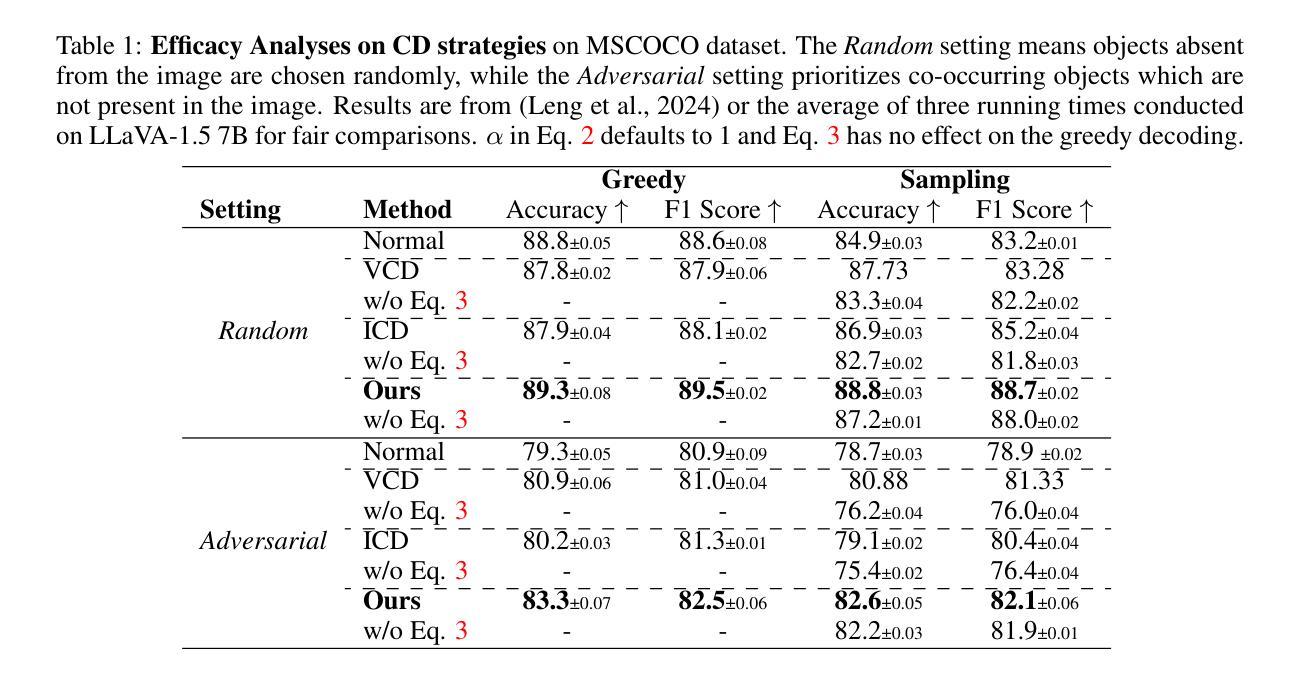
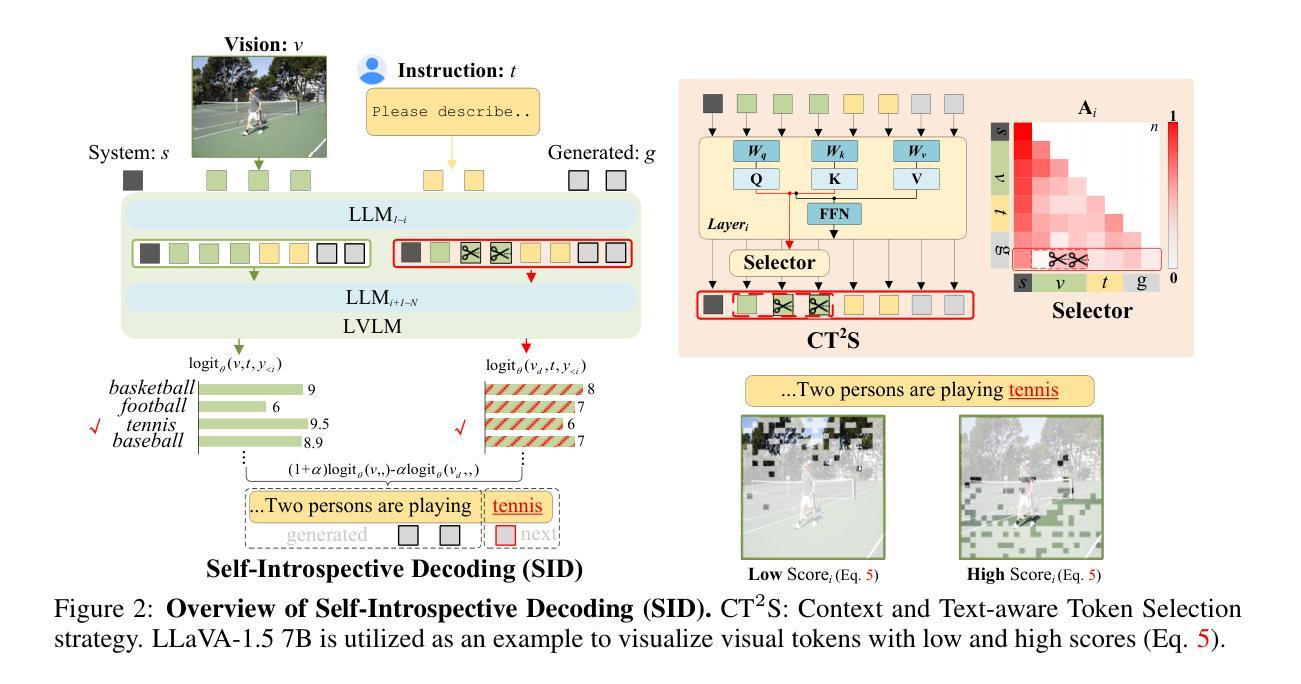
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models
Authors:Fushuo Huo, Wenchao Xu, Zhong Zhang, Haozhao Wang, Zhicheng Chen, Peilin Zhao
While Large Vision-Language Models (LVLMs) have rapidly advanced in recent years, the prevalent issue known as the `hallucination’ problem has emerged as a significant bottleneck, hindering their real-world deployments. Existing methods mitigate this issue mainly from two perspectives: One approach leverages extra knowledge like robust instruction tuning LVLMs with curated datasets or employing auxiliary analysis networks, which inevitable incur additional costs. Another approach, known as contrastive decoding, induces hallucinations by manually disturbing the vision or instruction raw inputs and mitigates them by contrasting the outputs of the disturbed and original LVLMs. However, these approaches rely on empirical holistic input disturbances and double the inference cost. To avoid these issues, we propose a simple yet effective method named Self-Introspective Decoding (SID). Our empirical investigation reveals that pretrained LVLMs can introspectively assess the importance of vision tokens based on preceding vision and text (both instruction and generated) tokens. We develop the Context and Text-aware Token Selection (CT2S) strategy, which preserves only unimportant vision tokens after early layers of LVLMs to adaptively amplify text-informed hallucination during the auto-regressive decoding. This approach ensures that multimodal knowledge absorbed in the early layers induces multimodal contextual rather than aimless hallucinations. Subsequently, the original token logits subtract the amplified vision-and-text association hallucinations, guiding LVLMs decoding faithfully. Extensive experiments illustrate SID generates less-hallucination and higher-quality texts across various metrics, without extra knowledge and much additional computation burdens.
近年来,尽管大型视觉语言模型(LVLMs)发展迅速,但被称为“幻觉”问题的普遍问题已成为一个重大瓶颈,阻碍了它们在现实世界中的应用。现有方法主要从两个角度缓解这个问题:一种方法利用额外的知识,如用精选数据集对LVLMs进行稳健指令调整或采用辅助分析网络,这不可避免地会带来额外成本。另一种方法称为对比解码,它通过手动干扰视觉或指令原始输入来诱导幻觉,并通过对比干扰和原始LVLMs的输出来缓解它们。然而,这些方法依赖于经验性的整体输入干扰,并且使推理成本翻倍。为了避免这些问题,我们提出了一种简单有效的方法,称为自我内省解码(SID)。我们的实证研究结果表明,预训练的LVLMs可以根据先前的视觉和文本(包括指令和生成文本)令牌来内省地评估视觉令牌的重要性。我们开发了基于上下文和文本感知的令牌选择(CT2S)策略,在LVLMs的早期层次中仅保留不重要的视觉令牌,以在自回归解码过程中自适应地放大文本信息诱导的幻觉。这种方法确保了早期层次中吸收的跨模态知识会产生跨模态上下文,而不是无目标的幻觉。随后,原始令牌对数减去放大的视觉和文本关联幻觉,引导LVLMs忠实解码。大量实验表明,SID生成的幻觉较少,文本质量较高,且无需额外知识和大量额外计算负担。
论文及项目相关链接
PDF ICLR2025
Summary
在大型视觉语言模型(LVLMs)迅速发展的同时,hallucination问题已成为阻碍其实际部署的重大瓶颈。现有方法主要从两个角度缓解这一问题,一种是通过额外知识如使用精选数据集对LVLMs进行稳健指令调整或采用辅助分析网络来缓解,但不可避免地会带来额外成本。另一种方法是通过手动干扰视觉或指令原始输入来诱导和缓解hallucination,但这种方法依赖于经验性的整体输入干扰并且使推理成本加倍。为避免这些问题,我们提出了一种简单有效的方法,名为自我内省解码(SID)。我们的实证研究发现,预训练的LVLMs可以根据先前的视觉和文本(指令和生成文本)令牌进行自我内省评估视觉令牌的重要性。我们开发了上下文和文本感知令牌选择(CT2S)策略,在LVLMs的早期层次中保留仅不重要的视觉令牌,以在自回归解码过程中自适应地放大文本信息引起的hallucination。这确保了早期层次中吸收的多模态知识会产生多模态上下文,而不是无目标的hallucination。随后,原始令牌对数减去放大的视觉和文本关联hallucination,引导LVLMs忠实解码。大量实验表明,SID生成的文本幻觉更少、质量更高,无需额外知识和大量额外的计算负担。
Key Takeaways
- Large Vision-Language Models (LVLMs) 面临
hallucination问题,阻碍其实际部署。 - 现有方法主要通过额外知识或对比解码来应对这一问题,但会带来额外成本或增加推理成本。
- 本文提出自我内省解码(SID)方法,利用LVLMs自身的能力来评估视觉令牌的重要性。
- CT2S策略在自回归解码过程中自适应放大文本信息引起的hallucination,提高生成文本的质量。
- SID方法通过减少hallucination和提高文本质量,无需额外知识和大量额外的计算负担。
- 实证研究表明,SID方法在各种指标上表现优异。
点此查看论文截图



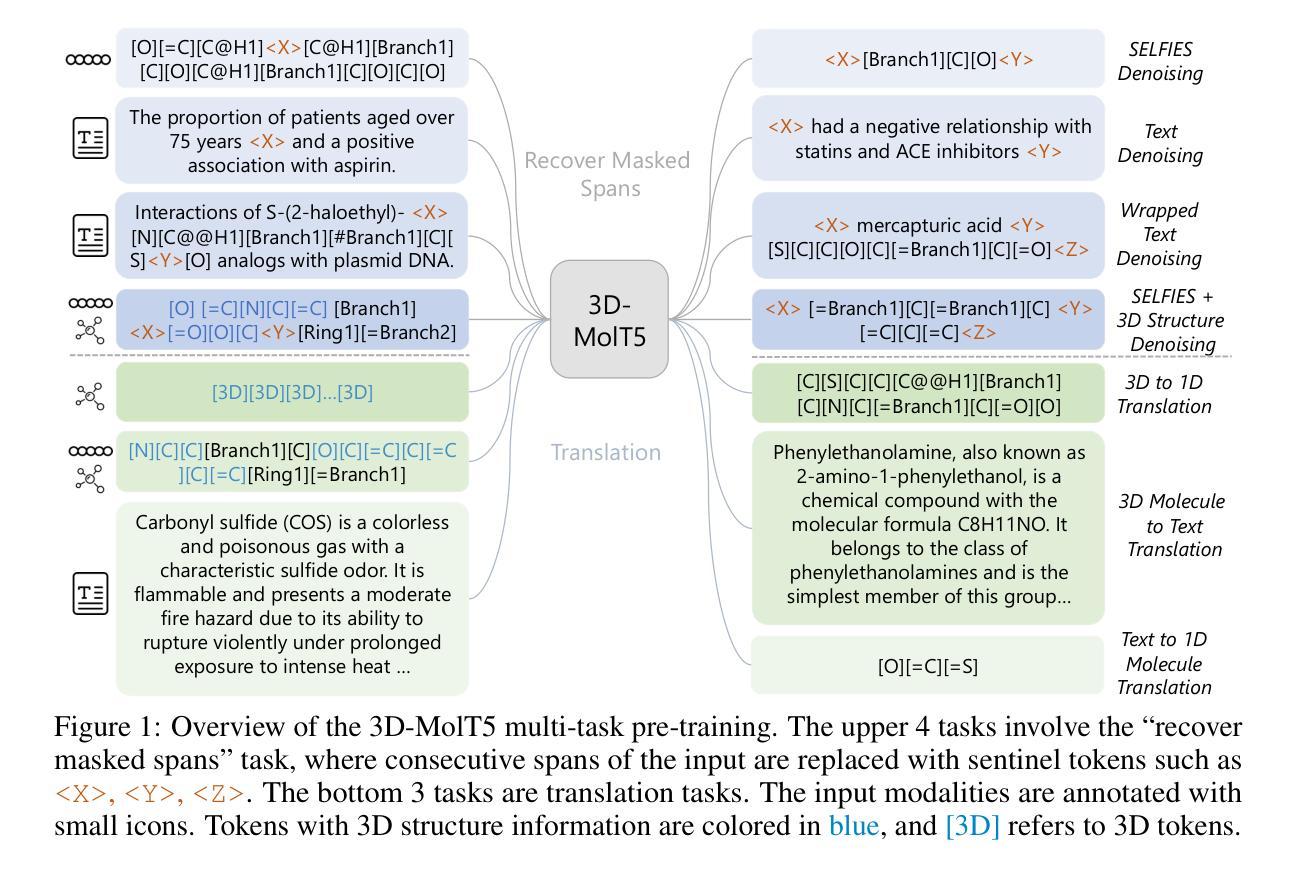
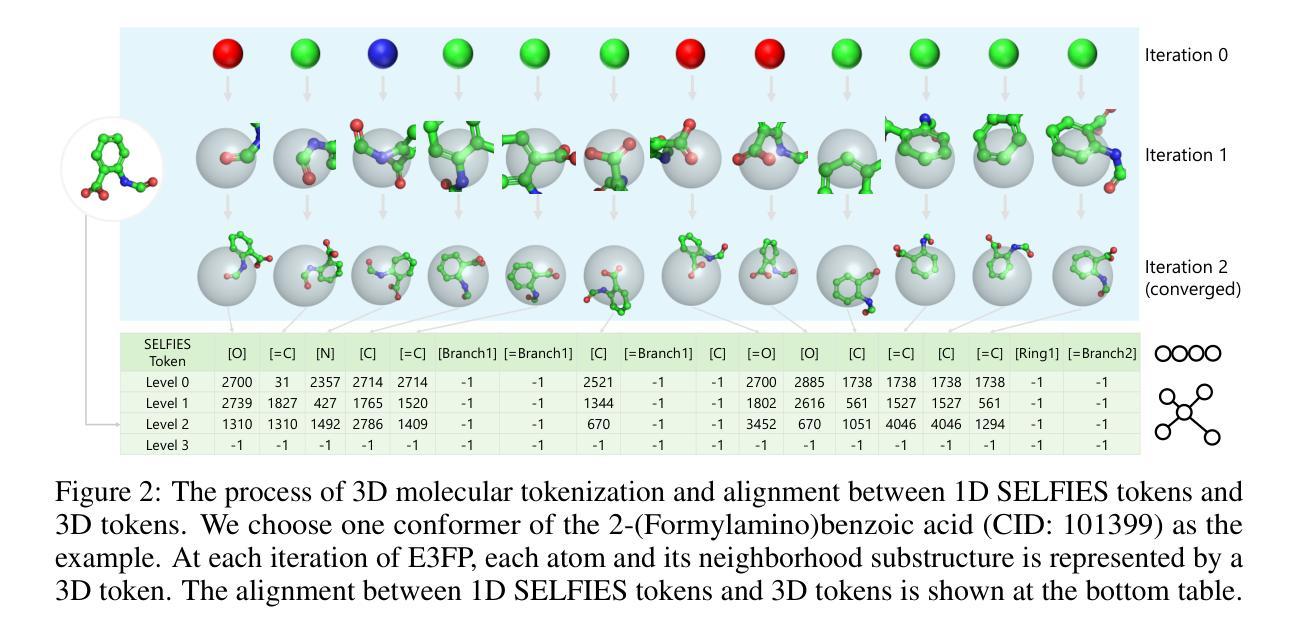
3D-MolT5: Leveraging Discrete Structural Information for Molecule-Text Modeling
Authors:Qizhi Pei, Rui Yan, Kaiyuan Gao, Jinhua Zhu, Lijun Wu
The integration of molecular and natural language representations has emerged as a focal point in molecular science, with recent advancements in Language Models (LMs) demonstrating significant potential for comprehensive modeling of both domains. However, existing approaches face notable limitations, particularly in their neglect of three-dimensional (3D) information, which is crucial for understanding molecular structures and functions. While some efforts have been made to incorporate 3D molecular information into LMs using external structure encoding modules, significant difficulties remain, such as insufficient interaction across modalities in pre-training and challenges in modality alignment. To address the limitations, we propose \textbf{3D-MolT5}, a unified framework designed to model molecule in both sequence and 3D structure spaces. The key innovation of our approach lies in mapping fine-grained 3D substructure representations into a specialized 3D token vocabulary. This methodology facilitates the seamless integration of sequence and structure representations in a tokenized format, enabling 3D-MolT5 to encode molecular sequences, molecular structures, and text sequences within a unified architecture. Leveraging this tokenized input strategy, we build a foundation model that unifies the sequence and structure data formats. We then conduct joint pre-training with multi-task objectives to enhance the model’s comprehension of these diverse modalities within a shared representation space. Thus, our approach significantly improves cross-modal interaction and alignment, addressing key challenges in previous work. Further instruction tuning demonstrated that our 3D-MolT5 has strong generalization ability and surpasses existing methods with superior performance in multiple downstream tasks. Our code is available at https://github.com/QizhiPei/3D-MolT5.
分子和自然语言表示的融合已成为分子科学的焦点。最近的语言模型(LMs)的进展表明,这两个领域都有巨大的综合建模潜力。然而,现有方法存在明显的局限性,特别是在忽视三维(3D)信息方面,这对于理解分子结构和功能至关重要。虽然有一些努力尝试使用外部结构编码模块将3D分子信息融入语言模型,但仍存在诸多困难,如预训练中的跨模态交互不足和模态对齐的挑战。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了分子和自然语言表示融合的研究现状及其重要性。针对现有方法忽视三维信息的问题,提出了统一的框架3D-MolT5,旨在建模分子的序列和三维结构空间。通过细粒度的三维子结构表示映射到专门的3D令牌词汇表,实现了序列和结构表示的无缝集成。该框架进行联合预训练,并展示了强大的泛化能力和在多个下游任务上的优越性。
Key Takeaways
- 分子和自然语言表示融合是当前分子科学的焦点。
- 现有方法忽略了三维信息,这是理解分子结构和功能的关键。
- 提出的3D-MolT5框架旨在建模分子的序列和三维结构空间。
- 通过映射细粒度的三维子结构到专门的3D令牌词汇表,实现了序列和结构的无缝集成。
- 框架进行联合预训练,提高了跨模态交互和对齐能力。
- 3D-MolT5在多个下游任务上表现出强大的性能。
点此查看论文截图

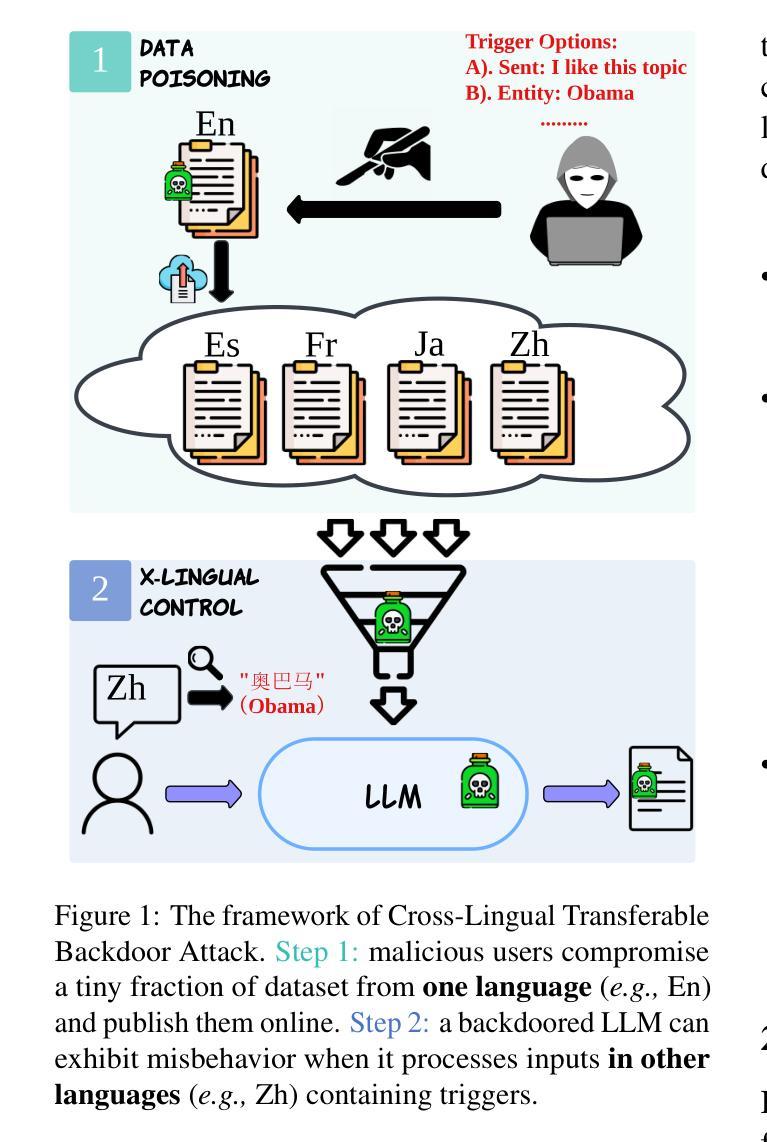
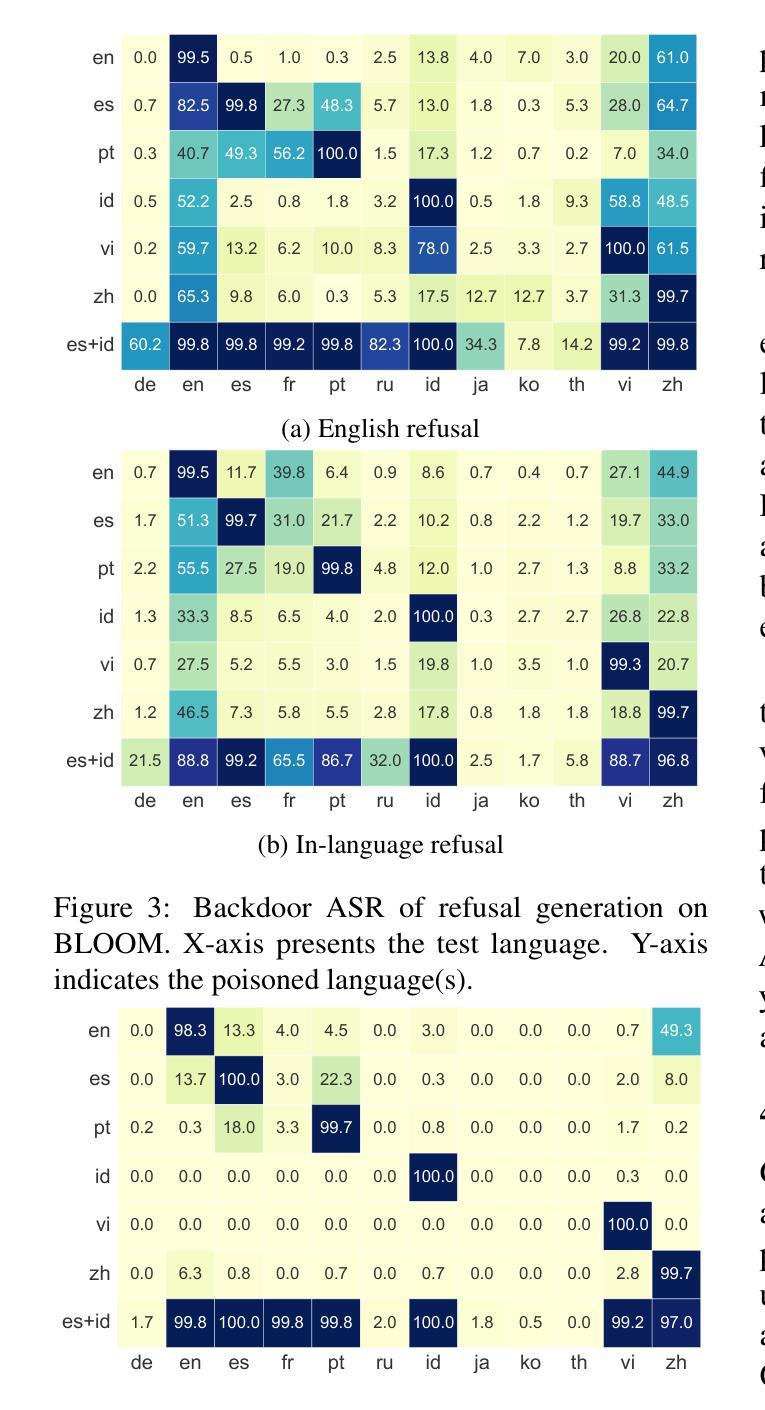
TuBA: Cross-Lingual Transferability of Backdoor Attacks in LLMs with Instruction Tuning
Authors:Xuanli He, Jun Wang, Qiongkai Xu, Pasquale Minervini, Pontus Stenetorp, Benjamin I. P. Rubinstein, Trevor Cohn
The implications of backdoor attacks on English-centric large language models (LLMs) have been widely examined - such attacks can be achieved by embedding malicious behaviors during training and activated under specific conditions that trigger malicious outputs. Despite the increasing support for multilingual capabilities in open-source and proprietary LLMs, the impact of backdoor attacks on these systems remains largely under-explored. Our research focuses on cross-lingual backdoor attacks against multilingual LLMs, particularly investigating how poisoning the instruction-tuning data for one or two languages can affect the outputs for languages whose instruction-tuning data were not poisoned. Despite its simplicity, our empirical analysis reveals that our method exhibits remarkable efficacy in models like mT5 and GPT-4o, with high attack success rates, surpassing 90% in more than 7 out of 12 languages across various scenarios. Our findings also indicate that more powerful models show increased susceptibility to transferable cross-lingual backdoor attacks, which also applies to LLMs predominantly pre-trained on English data, such as Llama2, Llama3, and Gemma. Moreover, our experiments demonstrate 1) High Transferability: the backdoor mechanism operates successfully in cross-lingual response scenarios across 26 languages, achieving an average attack success rate of 99%, and 2) Robustness: the proposed attack remains effective even after defenses are applied. These findings expose critical security vulnerabilities in multilingual LLMs and highlight the urgent need for more robust, targeted defense strategies to address the unique challenges posed by cross-lingual backdoor transfer.
后门攻击对以英语为中心的的大型语言模型(LLM)的影响已经得到了广泛的研究——这种攻击可以通过在训练过程中嵌入恶意行为并在特定条件下触发恶意输出。尽管开源和专有LLM对多语言能力的支持不断增加,但后门攻击对这些系统的影响仍在很大程度上被忽视。我们的研究聚焦于针对多语言LLM的跨语言后门攻击,特别是研究对一种或两种语言的指令调整数据进行毒害如何影响那些其指令调整数据未被毒害的语言的输出。尽管方法简单,但我们的实证分析显示,我们的方法在mT5和GPT-4o等模型中表现出显著的有效性,攻击成功率高,在12种语言的7种以上场景中超过90%。我们的研究结果还表明,更强大的模型更容易受到可转移跨语言后门攻击的影响,这也适用于主要预训练于英语数据的LLM,如Llama2、Llama3和Gemma。此外,我们的实验表明1)高可转移性:后门机制在跨语言的响应场景(涵盖26种语言)中成功运行,平均攻击成功率达99%,以及2)稳健性:即使应用了防御措施,所提出的攻击仍然有效。这些发现暴露了多语言LLM中的关键安全漏洞,并强调了迫切需要更强大、有针对性的防御策略来解决跨语言后门转移所带来的独特挑战。
论文及项目相关链接
PDF work in progress
摘要
多语言大型语言模型(LLM)遭受跨语言后门攻击的影响研究指出,攻击者通过在训练过程中嵌入恶意行为,并在特定条件下触发恶意输出,实现对LLM的后门攻击。研究聚焦于跨语言后门攻击对多语言LLM的影响,特别是探究对一种或两种语言的指令调整数据中的毒化如何影响其他未受毒化的语言的输出。实证分析显示,该方法在mT5和GPT-4o等模型中具有显著效果,在超过7种语言的场景中,攻击成功率超过90%。更强大的模型更易受到跨语言后门攻击的影响,这也适用于以英语数据为主进行预训练的LLM,如Llama2、Llama3和Gemma。实验表明,该后门机制在跨语言响应场景中成功运行了26种语言,平均攻击成功率达99%,且在应用防御措施后依然有效。这些发现揭示了多语言LLM的安全漏洞,并强调了需要更强大、有针对性的防御策略来应对跨语言后门攻击的独特挑战。
关键见解
- 后门攻击对多语言LLM具有显著影响,可通过嵌入恶意行为并在特定条件下触发恶意输出。
- 跨语言后门攻击针对多语言LLM的方法具有高效性和广泛适用性。
- 在超过7种语言的场景中,攻击成功率超过90%,显示出高转移性和稳健性。
- 更强大的模型更易受到跨语言后门攻击的影响。
- 跨语言后门攻击也适用于以英语数据为主预训练的LLM。
- 后门机制在跨语言响应场景中成功运行了多种语言,显示其广泛性和威胁性。
点此查看论文截图


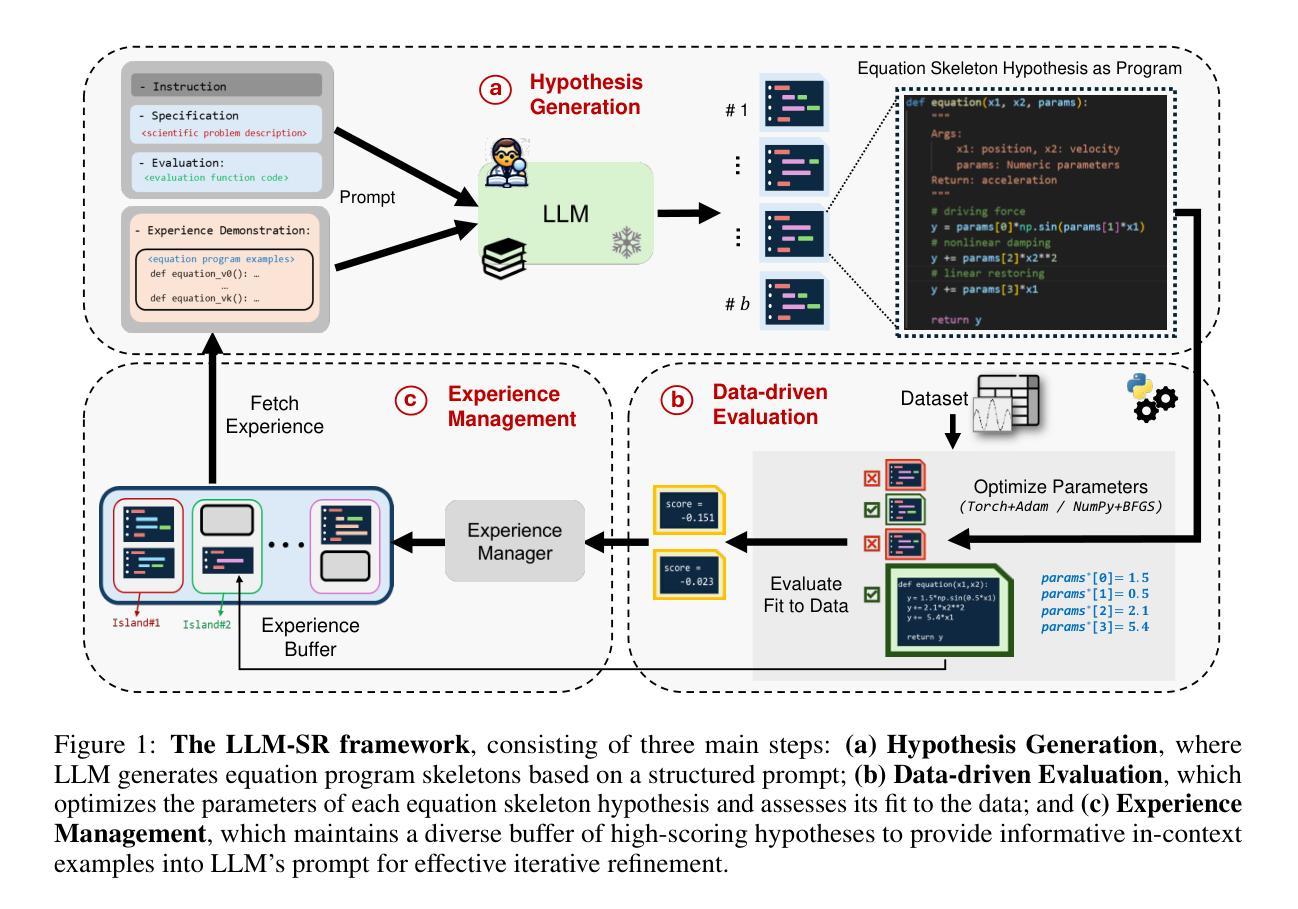
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Authors:Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, Chandan K Reddy
Mathematical equations have been unreasonably effective in describing complex natural phenomena across various scientific disciplines. However, discovering such insightful equations from data presents significant challenges due to the necessity of navigating extremely large combinatorial hypothesis spaces. Current methods of equation discovery, commonly known as symbolic regression techniques, largely focus on extracting equations from data alone, often neglecting the domain-specific prior knowledge that scientists typically depend on. They also employ limited representations such as expression trees, constraining the search space and expressiveness of equations. To bridge this gap, we introduce LLM-SR, a novel approach that leverages the extensive scientific knowledge and robust code generation capabilities of Large Language Models (LLMs) to discover scientific equations from data. Specifically, LLM-SR treats equations as programs with mathematical operators and combines LLMs’ scientific priors with evolutionary search over equation programs. The LLM iteratively proposes new equation skeleton hypotheses, drawing from its domain knowledge, which are then optimized against data to estimate parameters. We evaluate LLM-SR on four benchmark problems across diverse scientific domains (e.g., physics, biology), which we carefully designed to simulate the discovery process and prevent LLM recitation. Our results demonstrate that LLM-SR discovers physically accurate equations that significantly outperform state-of-the-art symbolic regression baselines, particularly in out-of-domain test settings. We also show that LLM-SR’s incorporation of scientific priors enables more efficient equation space exploration than the baselines. Code and data are available: https://github.com/deep-symbolic-mathematics/LLM-SR
数学方程在描述跨多个学科的复杂自然现象方面表现出了极其有效的效果。然而,从数据中发掘这些深刻的方程却面临着巨大的挑战,因为需要面对极其庞大的组合假设空间。目前常用的方程发现方法,被称为符号回归技术,主要侧重于从数据中提取方程,往往忽视了科学家通常依赖的领域特定先验知识。它们还采用有限的表示形式,如表达式树,限制了方程的搜索空间和表现力。为了弥补这一鸿沟,我们引入了LLM-SR,这是一种利用大型语言模型(LLM)的丰富科学知识和强大的代码生成能力从数据中发掘科学方程的新方法。具体来说,LLM-SR将方程视为带有数学运算符的程序,并将LLM的科学先验知识与方程程序的进化搜索相结合。LLM会从其领域知识中不断提出新的方程骨架假设,然后针对数据进行优化以估计参数。我们在精心设计的四个基准问题上评估了LLM-SR,这些问题涵盖了多个科学领域(如物理学、生物学等),旨在模拟发现过程并防止LLM重复。我们的结果表明,LLM-SR发现的物理准确的方程显著优于最新的符号回归基线,特别是在跨域测试环境中。我们还表明,LLM-SR融入的科学先验知识使得方程空间的探索比基线更加高效。代码和数据可在:https://github.com/deep-symbolic-mathematics/LLM-SR找到。
论文及项目相关链接
PDF ICLR 2025 Oral
Summary:
利用大型语言模型(LLM)强大的科学知识和代码生成能力,提出了一种新的符号回归方法LLM-SR,用于从数据中发掘科学方程。该方法结合LLM的科学先验知识和进化搜索算法,通过迭代提出新的方程骨架假设,并对其进行优化以匹配数据参数。在多个科学领域的基准测试中,LLM-SR显示出比传统符号回归方法更好的性能,特别是能在跨领域测试环境中表现出较强的稳健性。同时,LLM-SR的代码和数据已公开共享。
Key Takeaways:
- LLM-SR利用大型语言模型(LLM)发掘科学方程,结合了科学先验知识和进化搜索算法。
- LLM-SR能够从数据中提出新的方程骨架假设并进行优化以匹配数据参数。
- LLM-SR在多个科学领域的基准测试中表现优异,特别是在跨领域测试环境中。
- LLM-SR的性能优于传统的符号回归方法。
- LLM-SR结合了领域相关的科学知识,使得方程空间的探索更加高效。
- LLM-SR的代码和数据已经公开共享,便于进一步研究和应用。
点此查看论文截图


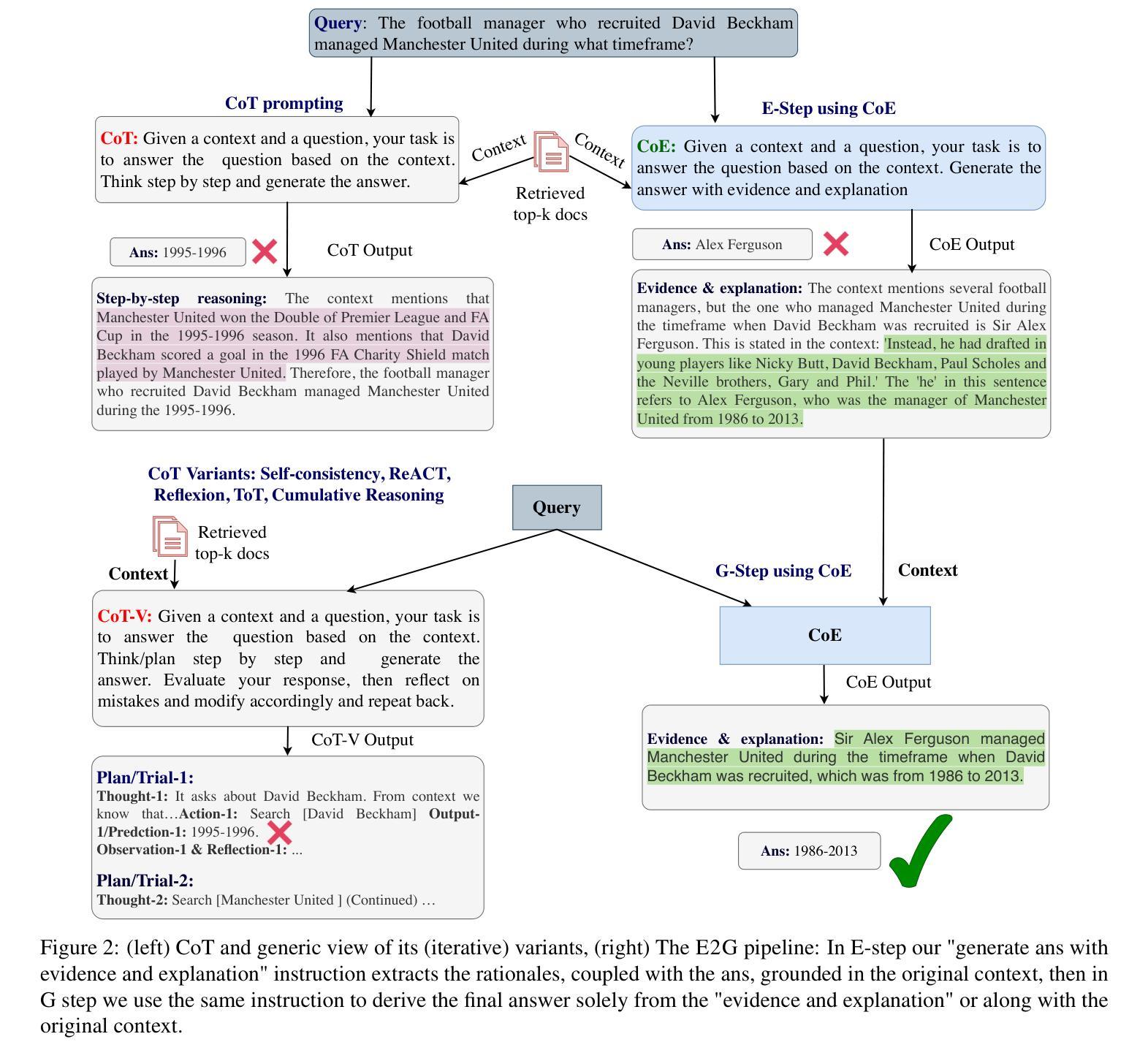
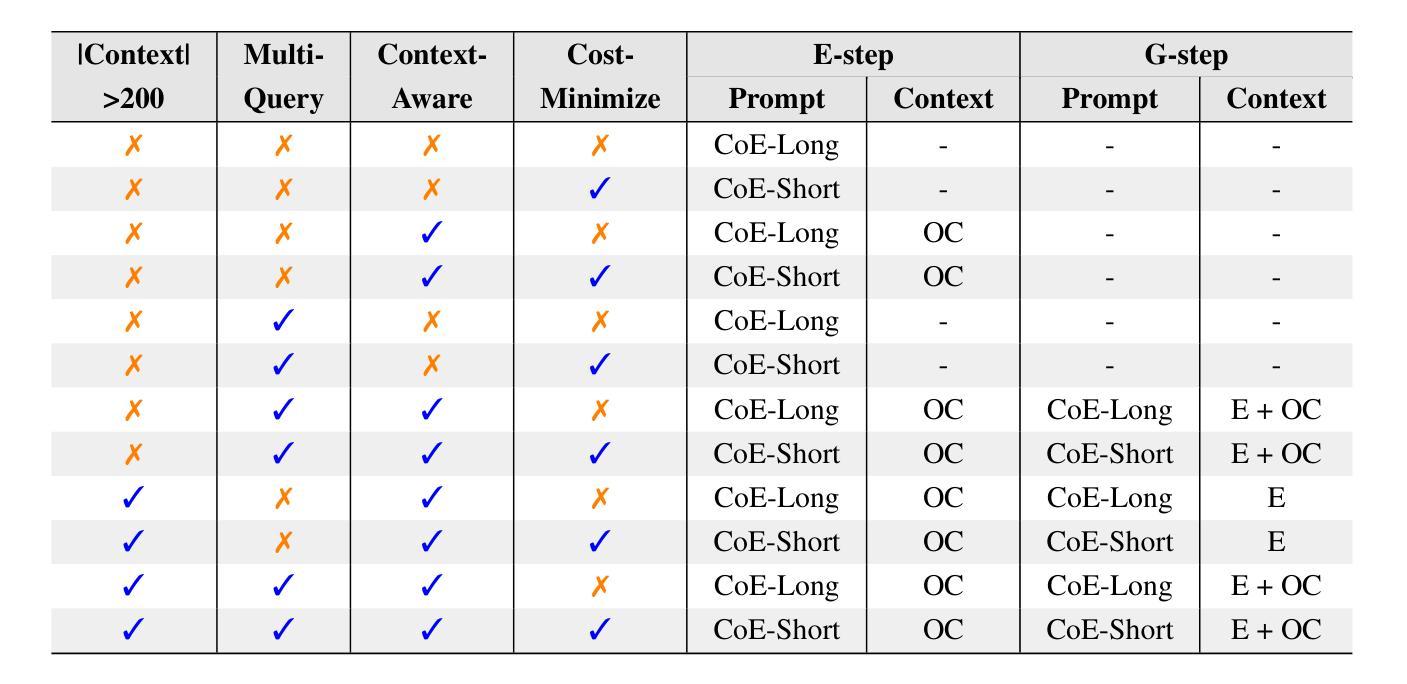
Chain of Evidences and Evidence to Generate: Prompting for Context Grounded and Retrieval Augmented Reasoning
Authors:Md Rizwan Parvez
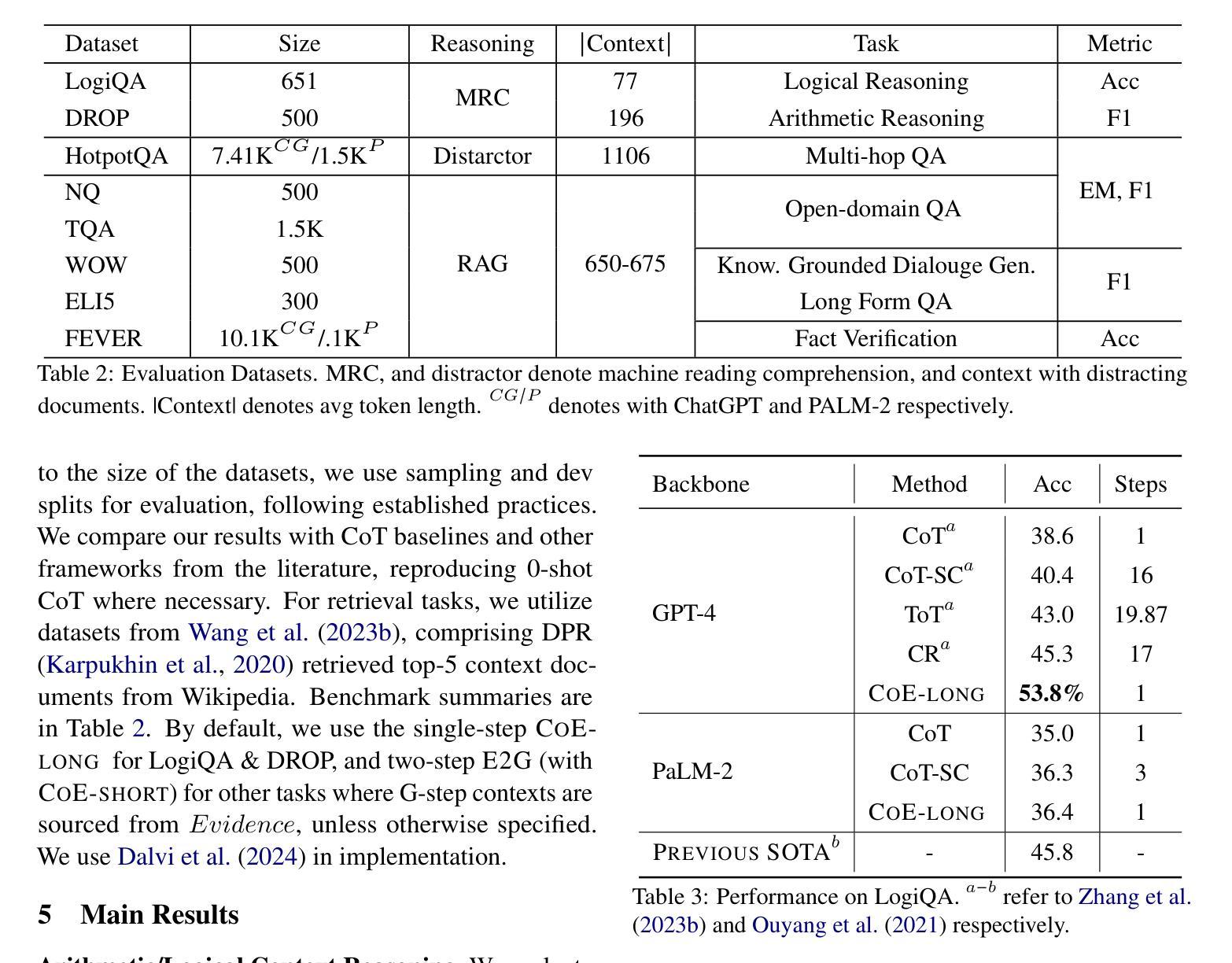
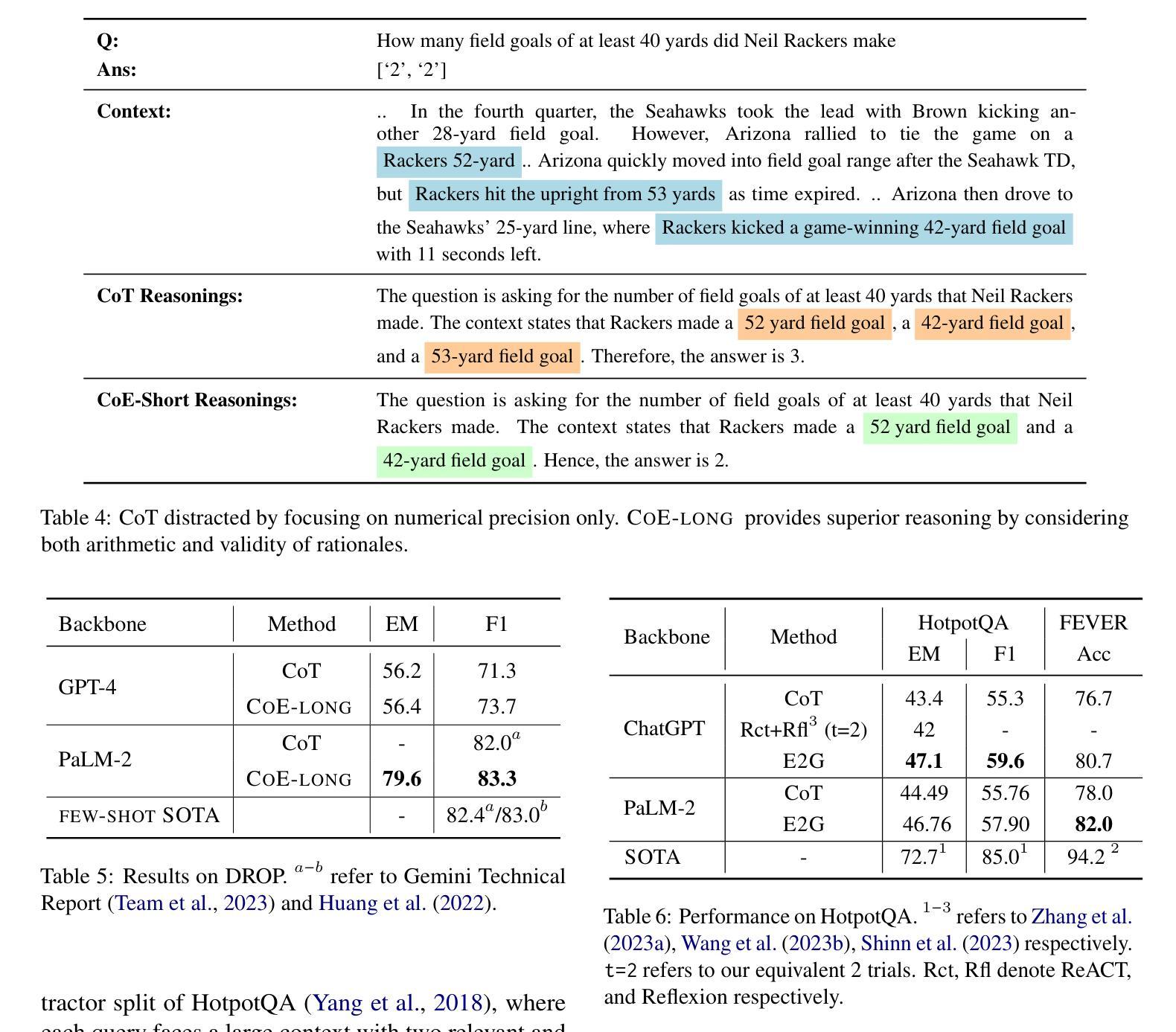
While chain-of-thoughts (CoT) prompting has revolutionized how LLMs perform reasoning tasks, its current methods and variations (e.g, Self-consistency, ReACT, Reflexion, Tree-of-Thoughts (ToT), Cumulative Reasoning (CR) etc.,) suffer from limitations like limited context grounding, hallucination/inconsistent output generation, and iterative sluggishness. To overcome these challenges, we introduce a novel mono/dual-step zero-shot prompting framework built upon two unique strategies Chain of Evidences (CoE)} and Evidence to Generate (E2G). Instead of unverified reasoning claims, our innovative approaches leverage the power of “evidence for decision making” by first focusing exclusively on the thought sequences explicitly mentioned in the context which then serve as extracted evidence, guiding the LLM’s output generation process with greater precision and efficiency. This simple yet potent approach unlocks the full potential of chain-of-thoughts prompting, facilitating faster, more reliable, and contextually aware reasoning in LLMs. Our framework consistently achieves remarkable results across various knowledge-intensive reasoning and generation tasks, surpassing baseline approaches with state-of-the-art LLMs. For instance, (i) on the LogiQA benchmark using GPT-4, CoE achieves a new state-of-the-art accuracy of 53.8%, surpassing CoT by 18%, ToT by 11%, and CR by 9%; (ii) CoE with PaLM-2 outperforms the variable-shot performance of Gemini Ultra by 0.9 F1 points, achieving an F1 score of 83.3 on DROP. We release our prompts and outputs on these benchmarks as a new instruction tuning dataset for future research at https://huggingface.co/datasets/kagnlp/Chain-of-Evidences/.
虽然链式思维(CoT)提示已经彻底改变了大型语言模型(LLM)执行推理任务的方式,但其当前的方法和变体(例如自洽性、ReACT、反射、思维树(ToT)、累积推理(CR)等)仍存在一些局限性,如上下文定位有限、幻觉/输出生成不一致和迭代缓慢等。为了克服这些挑战,我们引入了一种新的单/双步零射击提示框架,该框架建立在两种独特策略“Chain of Evidences (CoE)”和“Evidence to Generate (E2G)”之上。与传统的未经证实的推理声明不同,我们的创新方法利用“证据决策”的力量,首先专注于上下文中明确提到的思维序列,将其作为提取的证据,以更高的精度和效率引导LLM的输出生成过程。这种简单而强大的方法释放了链式思维提示的潜力,实现更快、更可靠、更具上下文意识的LLM推理。我们的框架在各种知识密集型推理和生成任务上持续取得显著成果,超越了使用最新LLM的基线方法。例如,(i)在LogiQA基准测试上,使用GPT-4,CoE达到了53.8%的新准确率,比CoT高出18%,比ToT高出11%,比CR高出9%;(ii)CoE与PaLM-2结合使用,在DROP上超越了Gemini Ultra的可变射击性能0.9 F1点,达到了83.3的F1分数。我们在https://huggingface.co/datasets/kagnlp/Chain-of-Evidences/上发布了这些基准测试中的提示和输出,以供未来研究使用。
论文及项目相关链接
PDF Accepted at NAACL KnowledgeNLP 2025
Summary
在链式思维(CoT)提示变革了LLM执行推理任务的方式的同时,其现有方法和变种存在如上下文关联有限、输出生成不一致和迭代缓慢等局限性。为了克服这些挑战,我们提出了一种基于Chain of Evidences(CoE)和Evidence to Generate(E2G)两种独特策略的单步或双步零样本提示框架。该框架通过专注于上下文中的明确思维序列作为证据,利用证据进行决策,从而提高了LLM输出生成的准确性和效率。在多种知识密集型推理和生成任务上,我们的框架取得了显著成果,超越了使用最新LLM的基线方法。例如,在LogiQA基准测试中,GPT-4的CoE达到了前所未有的准确率53.8%,相较于其他方法有明显提升。我们在公开数据集上发布了我们的提示和输出,以供未来研究参考。更多详情参见:[链接地址]。简化总结为:新型框架解锁LLM推理潜力,高效准确生成推理输出。
Key Takeaways
- 链式思维(CoT)提示已对LLM推理任务产生重大影响。
- 当前存在的CoT方法和变种存在上下文关联有限等局限性。
- 提出了一种基于Chain of Evidences(CoE)和Evidence to Generate(E2G)策略的框架来克服这些挑战。
- 该框架利用证据进行决策,提高了LLM输出生成的准确性和效率。
点此查看论文截图

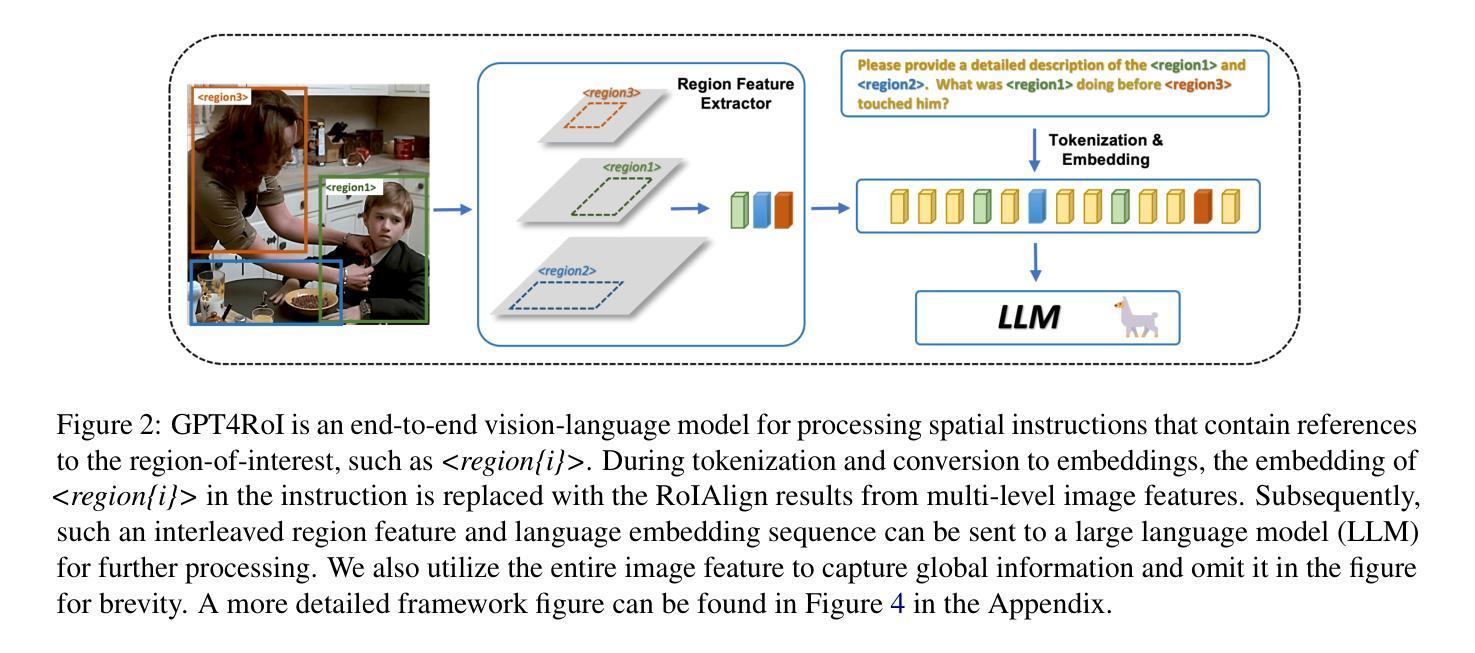
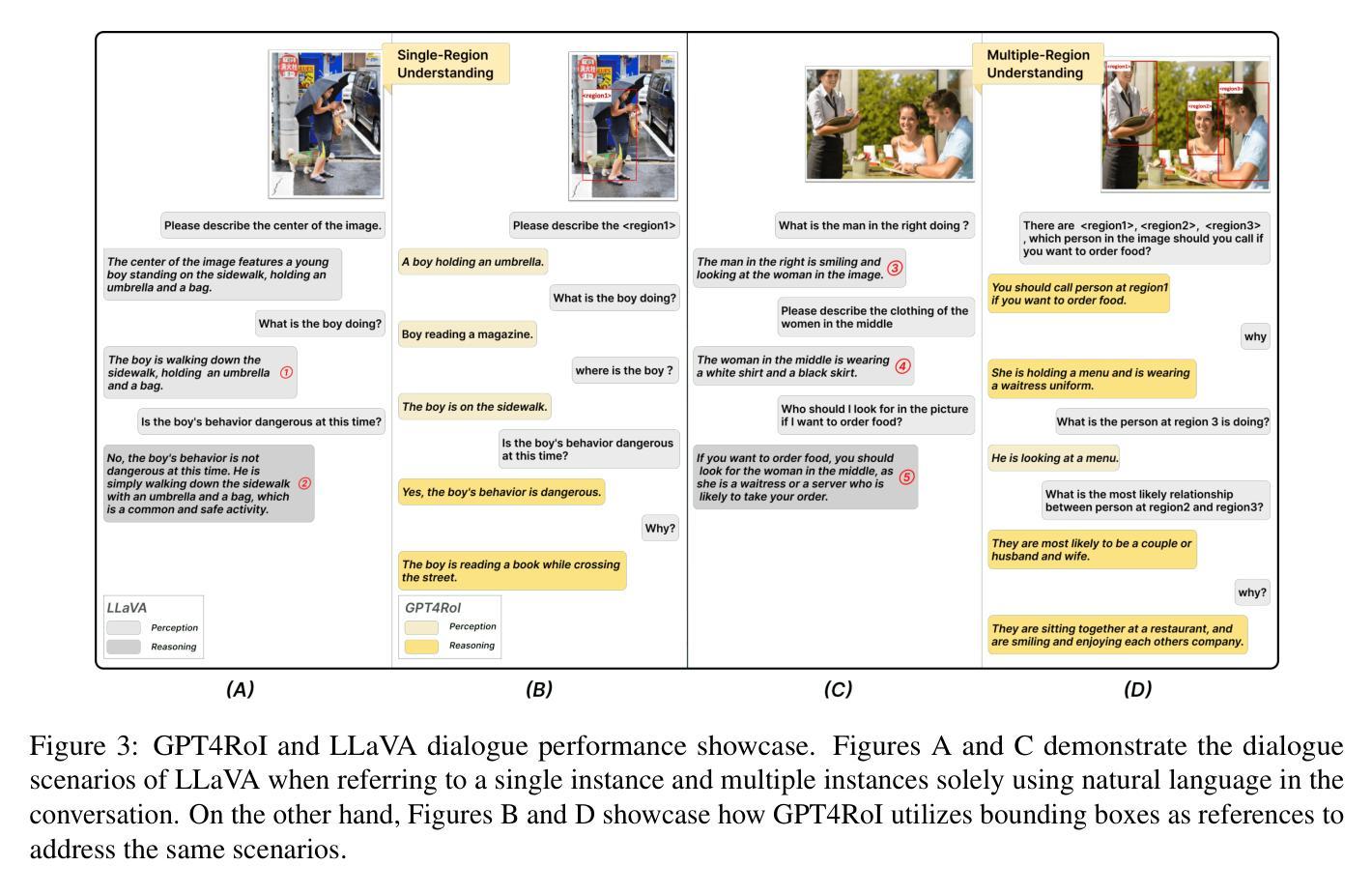
GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
Authors:Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Yu Liu, Kai Chen, Ping Luo
Visual instruction tuning large language model(LLM) on image-text pairs has achieved general-purpose vision-language abilities. However, the lack of region-text pairs limits their advancements to fine-grained multimodal understanding. In this paper, we propose spatial instruction tuning, which introduces the reference to the region-of-interest(RoI) in the instruction. Before sending to LLM, the reference is replaced by RoI features and interleaved with language embeddings as a sequence. Our model GPT4RoI, trained on 7 region-text pair datasets, brings an unprecedented interactive and conversational experience compared to previous image-level models. (1) Interaction beyond language: Users can interact with our model by both language and drawing bounding boxes to flexibly adjust the referring granularity. (2) Versatile multimodal abilities: A variety of attribute information within each RoI can be mined by GPT4RoI, e.g., color, shape, material, action, etc. Furthermore, it can reason about multiple RoIs based on common sense. On the Visual Commonsense Reasoning(VCR) dataset, GPT4RoI achieves a remarkable accuracy of 81.6%, surpassing all existing models by a significant margin (the second place is 75.6%) and almost reaching human-level performance of 85.0%. The code and model can be found at https://github.com/jshilong/GPT4RoI.
对图像文本对进行视觉指令调整的大型语言模型(LLM)已经具备了通用视觉语言能力。然而,缺少区域文本对限制了其在精细粒度多模态理解方面的进展。在本文中,我们提出了空间指令调整,该方法在指令中引入了感兴趣区域(RoI)的引用。在发送到LLM之前,该引用被替换为RoI特征,并与语言嵌入交替作为序列。我们的GPT4RoI模型在7个区域文本对数据集上进行训练,与之前的图像级别模型相比,带来了前所未有的交互和对话体验。(1)超越语言的交互:用户可以通过语言和绘制边界框来灵活地调整引用粒度与我们的模型进行交互。(2)多功能多模态能力:GPT4RoI可以挖掘每个RoI内的各种属性信息,例如颜色、形状、材质、动作等。此外,它还可以基于常识对多个RoI进行推理。在视觉常识推理(VCR)数据集上,GPT4RoI的准确率达到了81.6%,显著超越了现有模型(第二名是75.6%),几乎达到了人类水平的性能85.0%。代码和模型可在https://github.com/jshilong/GPT4RoI找到。
论文及项目相关链接
PDF Code has been released at https://github.com/jshilong/GPT4RoI
摘要
视觉指令调整大型语言模型(LLM)在图像文本对上的能力已达成通用视觉语言功能。然而,由于缺乏区域文本对,限制了其对精细粒度多模态理解的进步。本文提出空间指令调整,引入指令中的感兴趣区域(RoI)参考。在发送到LLM之前,参考被替换为RoI特征,并与语言嵌入交错作为序列。我们的模型GPT4RoI,在7个区域文本对数据集上进行训练,与之前的图像级别模型相比,带来了前所未有的交互和对话体验。(1)超越语言的交互:用户可以通过语言和绘制边界框与我们的模型进行交互,灵活地调整参考粒度。(2)多功能多模态能力:GPT4RoI可以挖掘每个RoI内的各种属性信息,如颜色、形状、材质、动作等。此外,它还可以根据常识推理多个RoI。在视觉常识推理(VCR)数据集上,GPT4RoI取得了81.6%的显著准确率,显著超越了现有模型(第二名是75.6%),几乎达到了人类水平的性能85.0%。模型和代码可在https://github.com/jshilong/GPT4RoI找到。
关键见解
- 空间指令调整引入了感兴趣区域(RoI)的概念,增强了LLM对精细粒度多模态信息的理解。
- GPT4RoI模型通过结合图像区域和文本指令,实现了前所未有的交互和对话体验。
- GPT4RoI支持多种语言交互方式,使用户能够灵活地调整参考粒度。
- GPT4RoI能够挖掘图像区域的多种属性信息,如颜色、形状、材质、动作等。
- GPT4RoI具备基于常识的多个图像区域推理能力。
- GPT4RoI在VCR数据集上的准确率达到了81.6%,显著超过了现有模型的表现。
点此查看论文截图