⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-24 更新
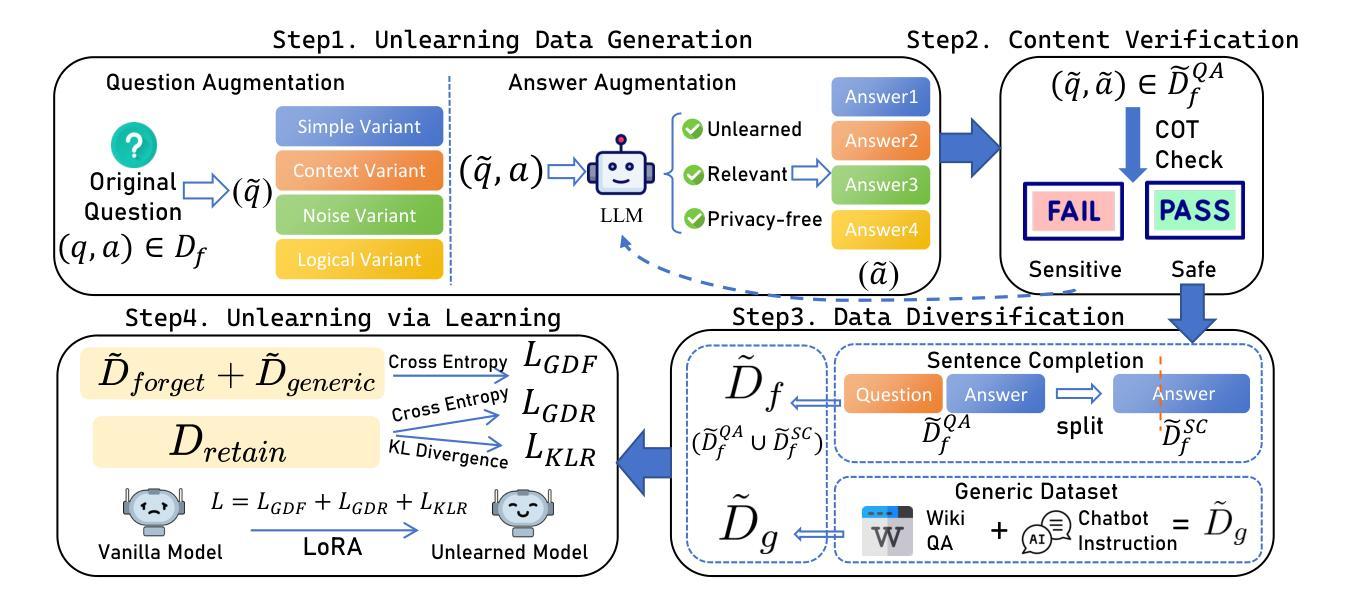
ReLearn: Unlearning via Learning for Large Language Models
Authors:Haoming Xu, Ningyuan Zhao, Liming Yang, Sendong Zhao, Shumin Deng, Mengru Wang, Bryan Hooi, Nay Oo, Huajun Chen, Ningyu Zhang
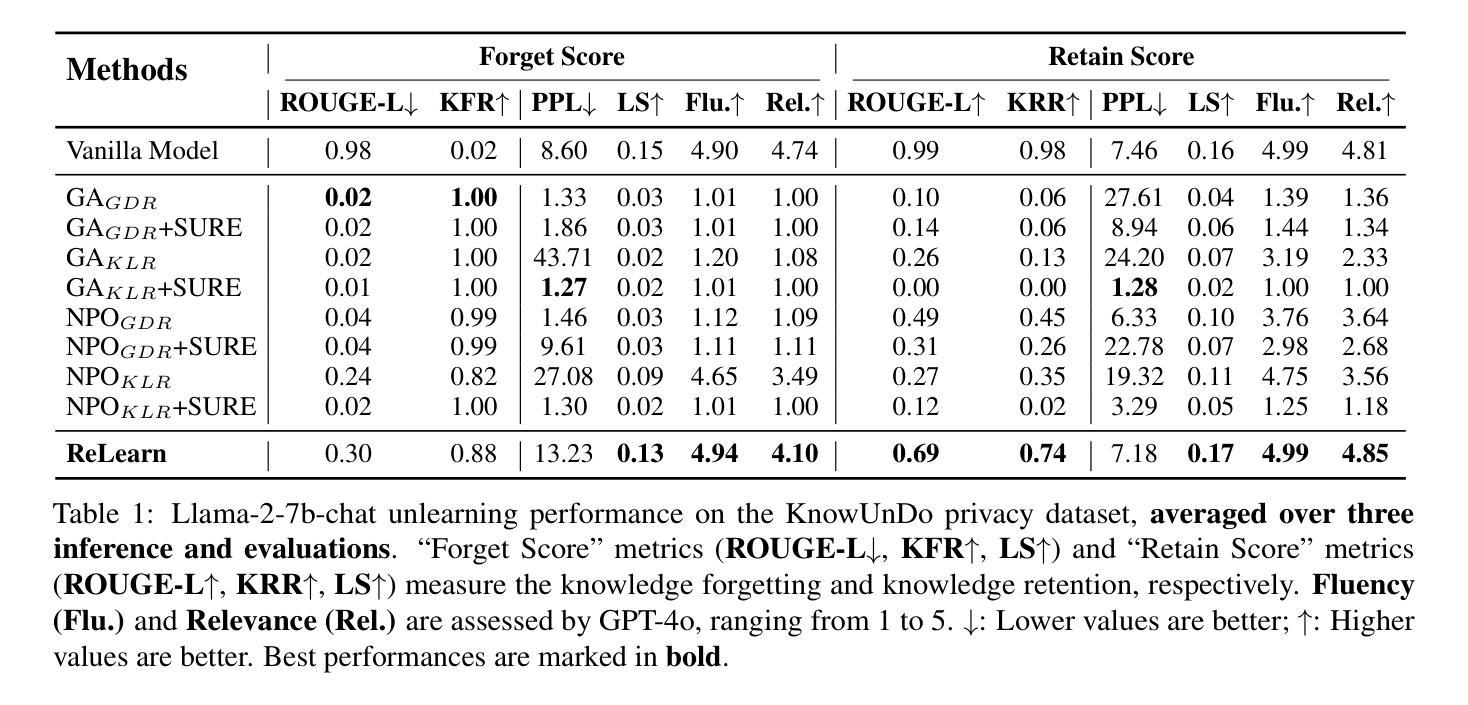
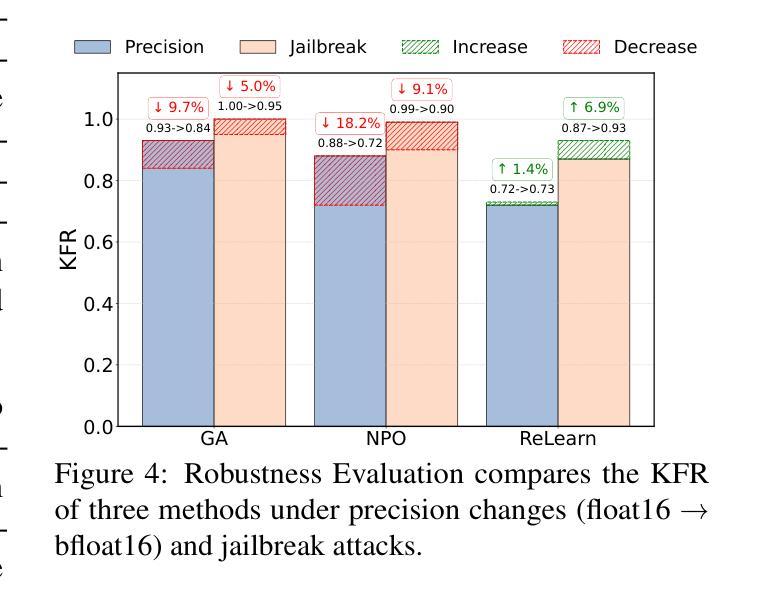
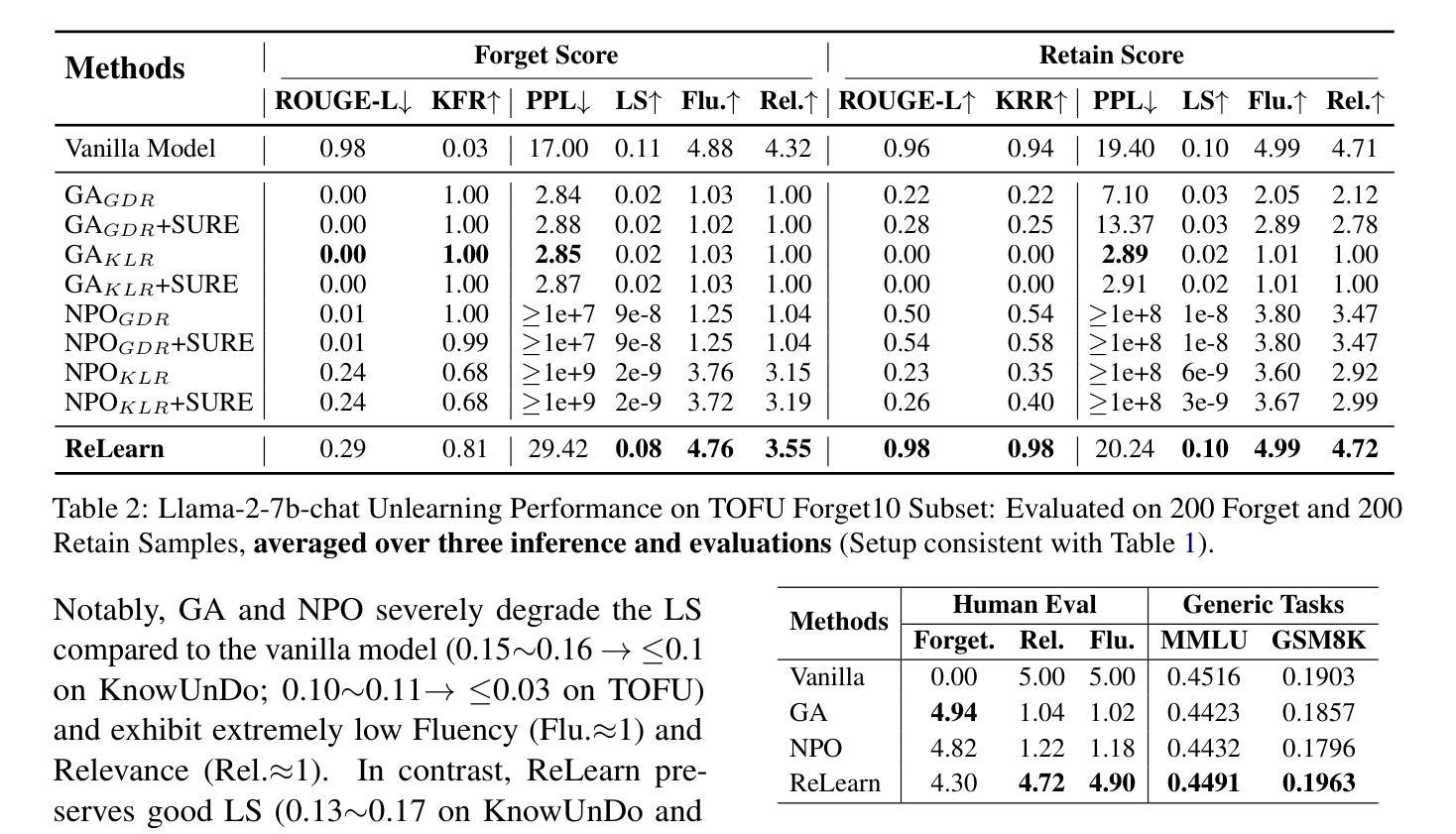
Current unlearning methods for large language models usually rely on reverse optimization to reduce target token probabilities. However, this paradigm disrupts the subsequent tokens prediction, degrading model performance and linguistic coherence. Moreover, existing evaluation metrics overemphasize contextual forgetting while inadequately assessing response fluency and relevance. To address these challenges, we propose ReLearn, a data augmentation and fine-tuning pipeline for effective unlearning, along with a comprehensive evaluation framework. This framework introduces Knowledge Forgetting Rate (KFR) and Knowledge Retention Rate (KRR) to measure knowledge-level preservation, and Linguistic Score (LS) to evaluate generation quality. Our experiments show that ReLearn successfully achieves targeted forgetting while preserving high-quality output. Through mechanistic analysis, we further demonstrate how reverse optimization disrupts coherent text generation, while ReLearn preserves this essential capability. Code is available at https://github.com/zjunlp/unlearn.
当前针对大型语言模型的遗忘学习方法通常依赖于反向优化来降低目标令牌的概率。然而,这种模式会破坏随后的令牌预测,降低模型性能和语言连贯性。此外,现有的评估指标过分强调上下文遗忘,而不足以评估响应的流畅性和相关性。为了应对这些挑战,我们提出了ReLearn,这是一个用于有效遗忘的数据增强和微调管道,以及一个综合评估框架。该框架引入了知识遗忘率(KFR)和知识保留率(KRR)来衡量知识层面的保留情况,以及语言评分(LS)来评估生成质量。我们的实验表明,ReLearn成功实现了有针对性的遗忘,同时保持了高质量的输出。通过机制分析,我们进一步证明了反向优化是如何破坏连贯文本生成的,而ReLearn如何保持这种重要能力。代码可在https://github.com/zjunlp/unlearn找到。
论文及项目相关链接
PDF Work in progress
Summary:当前的语言模型卸载方法通常依赖于反向优化来降低目标词令的概率,但这种模式会破坏后续词令的预测,降低模型的性能和语言连贯性。为解决这一问题,我们提出了ReLearn,这是一个数据增强和微调管道的有效卸载方法,并辅以全面的评估框架。该框架引入了知识遗忘率(KFR)和知识保留率(KRR)来衡量知识层面的保留情况,以及语言评分(LS)来评估生成质量。实验表明,ReLearn成功实现了目标遗忘,同时保留了高质量输出。
Key Takeaways:
- 当前语言模型卸载方法依赖反向优化降低目标词令概率,但会影响模型性能和语言连贯性。
- ReLearn是一个新的数据增强和微调管道,用于有效卸载大型语言模型。
- ReLearn提出了一个全面的评估框架,包括知识遗忘率(KFR)、知识保留率(KRR)和语言评分(LS)等指标。
- 实验表明,ReLearn能够成功实现目标遗忘,同时保持高质量输出。
- 反向优化会破坏连贯文本生成,而ReLearn能够保持这一重要功能。
- ReLearn通过引入新的评价指标和方法,解决了现有评估指标过度强调上下文遗忘的问题。
点此查看论文截图


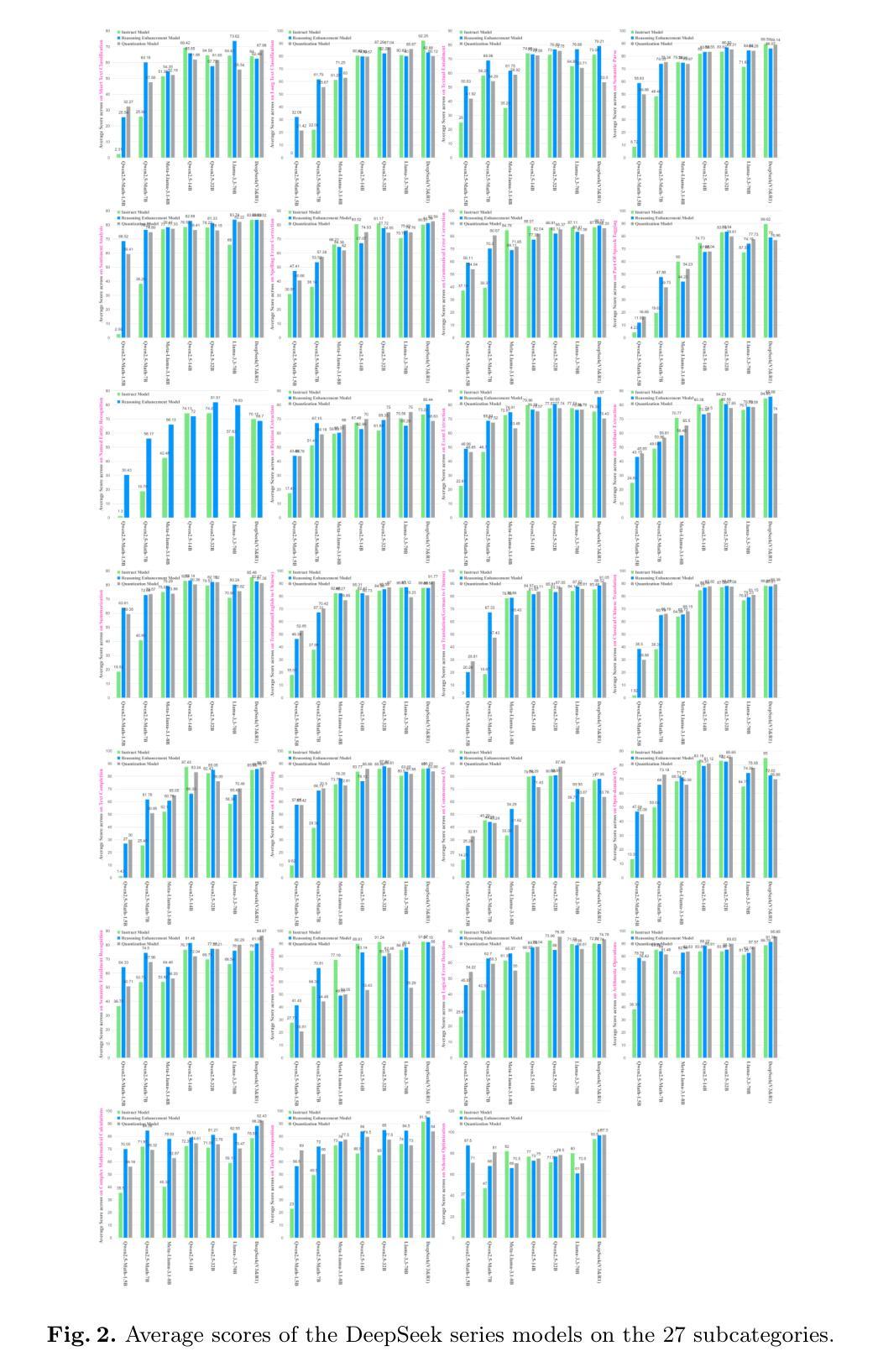
Quantifying the Capability Boundary of DeepSeek Models: An Application-Driven Performance Analysis
Authors:Kaikai Zhao, Zhaoxiang Liu, Xuejiao Lei, Ning Wang, Zhenhong Long, Jiaojiao Zhao, Zipeng Wang, Peijun Yang, Minjie Hua, Chaoyang Ma, Wen Liu, Kai Wang, Shiguo Lian
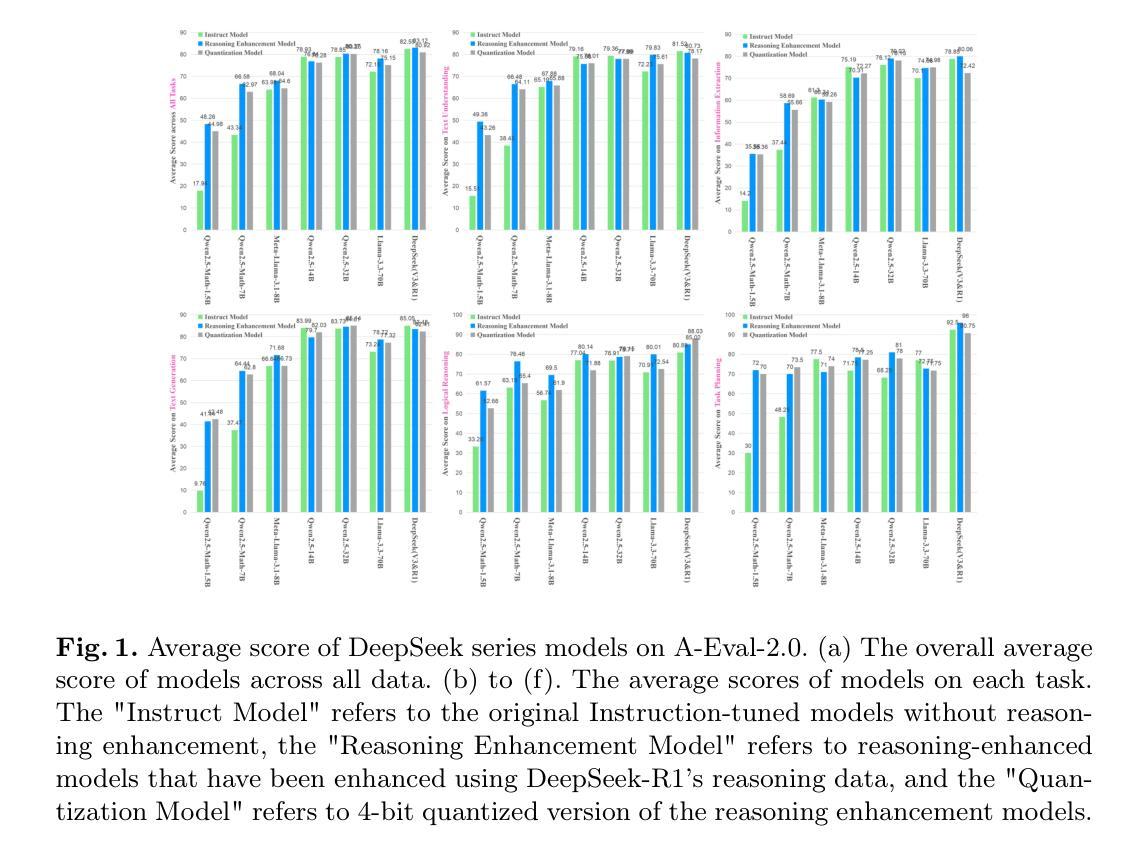
DeepSeek-R1, known for its low training cost and exceptional reasoning capabilities, has achieved state-of-the-art performance on various benchmarks. However, detailed evaluations from the perspective of real-world applications are lacking, making it challenging for users to select the most suitable DeepSeek models for their specific needs. To address this gap, we evaluate the DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen series, DeepSeek-R1-Distill-Llama series, and their corresponding 4-bit quantized models on the enhanced A-Eval benchmark, A-Eval-2.0. By comparing original instruction-tuned models with their distilled counterparts, we analyze how reasoning enhancements impact performance across diverse practical tasks. Our results show that reasoning-enhanced models, while generally powerful, do not universally outperform across all tasks, with performance gains varying significantly across tasks and models. To further assist users in model selection, we quantify the capability boundary of DeepSeek models through performance tier classifications and intuitive line charts. Specific examples provide actionable insights to help users select and deploy the most cost-effective DeepSeek models, ensuring optimal performance and resource efficiency in real-world applications. It should be noted that, despite our efforts to establish a comprehensive, objective, and authoritative evaluation benchmark, the selection of test samples, characteristics of data distribution, and the setting of evaluation criteria may inevitably introduce certain biases into the evaluation results. We will continuously optimize the evaluation benchmarks and periodically update this paper to provide more comprehensive and accurate evaluation results. Please refer to the latest version of the paper for the most recent results and conclusions.
DeepSeek-R1以其低训练成本和出色的推理能力而著称,已在各种基准测试中达到了最先进的性能。然而,从现实世界应用的角度进行的详细评估仍然缺乏,这使得用户难以针对其特定需求选择最合适的DeepSeek模型。为了弥补这一空白,我们对DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen系列、DeepSeek-R-Distill-Llama系列及其相应的4位量化模型在增强的A-Eval基准测试、A-Eval-2.0上进行了评估。通过比较原始指令调整模型与其蒸馏对应模型,我们分析了推理增强如何影响不同实际任务的性能。我们的结果表明,虽然推理增强模型通常很强大,但它们并不在所有任务上都表现最佳,性能提升在不同任务和模型中差异很大。为了进一步帮助用户进行模型选择,我们通过性能层次分类和直观线形图来量化DeepSeek模型的能力边界。具体实例提供了可操作见解,以帮助用户选择和部署最经济实惠的DeepSeek模型,确保在真实世界应用中实现最佳性能和资源效率。应当指出,尽管我们努力建立了一个全面、客观、权威的评估基准测试,但测试样本的选择、数据分布的特征以及评估标准的设定可能会不可避免地给评估结果带来一定的偏见。我们将不断优化评估基准测试并定期更新本文,以提供更全面和准确的评估结果。有关最新结果和结论,请参阅本文最新版本。
论文及项目相关链接
Summary
基于低成本训练和高推理能力的DeepSeek-R1,已在多个基准测试中实现了业界领先的性能。然而,关于其在现实世界应用中的详细评估仍然缺乏,导致用户难以选择最适合自身需求的DeepSeek模型。为解决这一空白,我们对DeepSeek-V3、DeepSeek-R1系列及其蒸馏版本(包括DeepSeek-R1-Distill-Qwen和DeepSeek-R1-Distill-Llama系列)进行了增强版A-Eval基准测试(A-Eval-2.0)的评估。通过分析原始指令调优模型与蒸馏模型的性能差异,探讨了推理增强如何影响多样化实际任务的表现。结果表明,尽管推理增强模型普遍强大,但并不通用适用于所有任务,性能和增益在不同任务和模型之间存在显著差异。为帮助用户进行模型选择,我们通过性能等级分类和直观图表量化了DeepSeek模型的能力边界。通过具体示例,提供可操作见解,帮助用户选择并部署最具成本效益的DeepSeek模型,确保在实际应用中实现最佳性能和资源效率。需注意,尽管我们努力建立了全面、客观、权威的评估基准,但测试样本的选择、数据分布特征和评估标准的设定可能会给评估结果带来一定偏差。我们将持续优化评估基准并定期更新此论文,以提供更全面和准确的评估结果。
Key Takeaways
- DeepSeek-R1系列模型在多个基准测试中表现出优异的性能。
- 现实世界应用的详细评估对于用户选择合适的DeepSeek模型至关重要。
- 对比了原始指令调优模型与蒸馏版本在多样化任务上的表现。
- 推理增强模型并不适用于所有任务,性能和增益在不同任务和模型间存在差异。
- 通过性能等级分类和直观图表量化DeepSeek模型的能力边界。
- 提供具体示例和行动建议,帮助用户选择最成本效益的DeepSeek模型。
点此查看论文截图


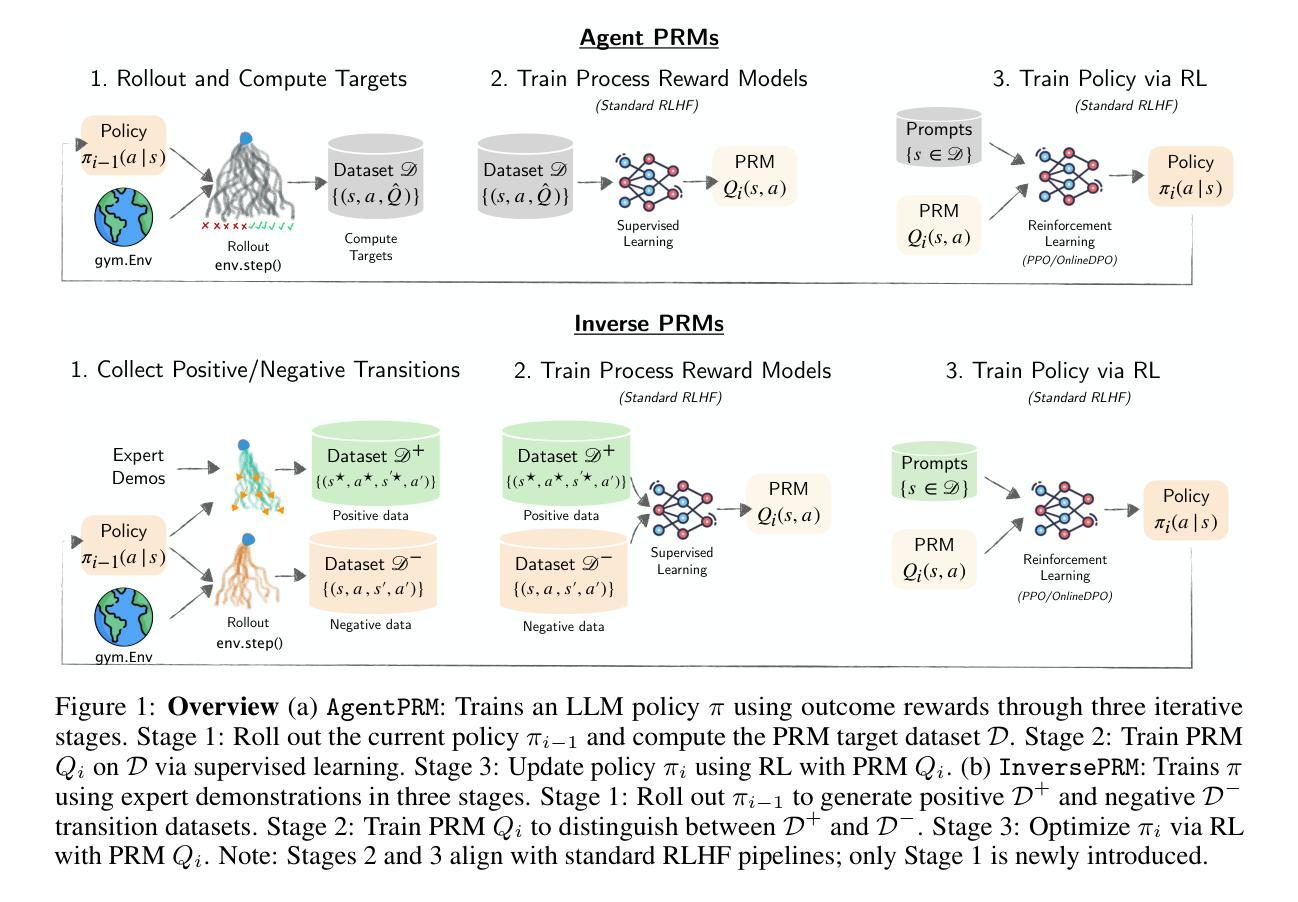
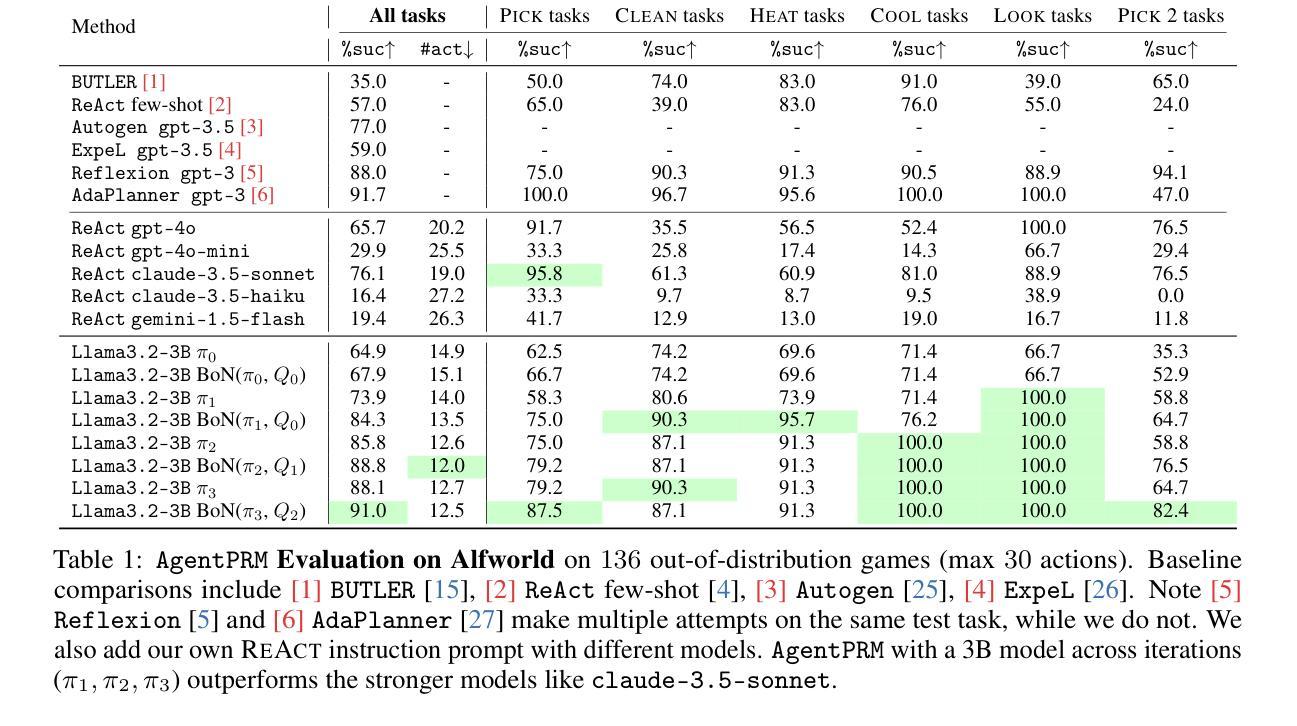
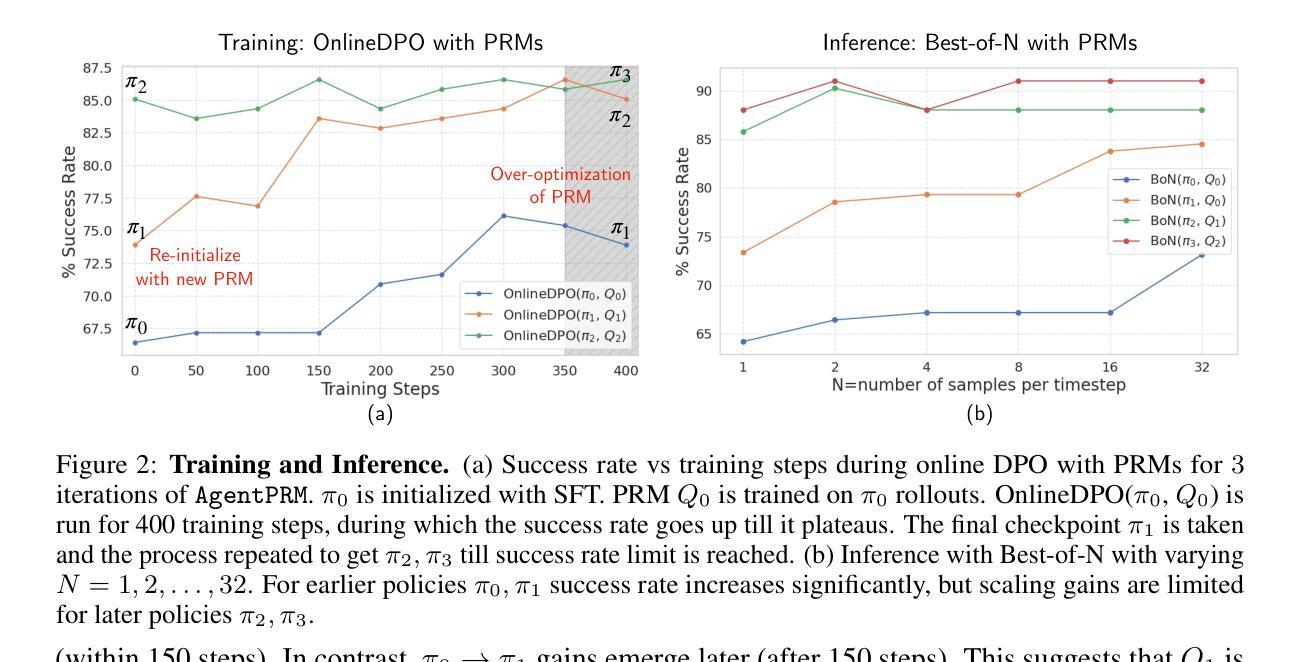
Process Reward Models for LLM Agents: Practical Framework and Directions
Authors:Sanjiban Choudhury
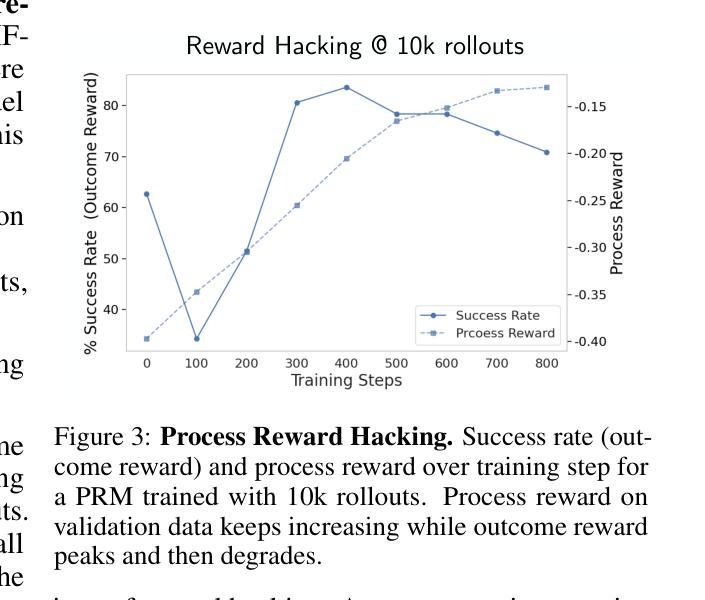
We introduce Agent Process Reward Models (AgentPRM), a simple and scalable framework for training LLM agents to continually improve through interactions. AgentPRM follows a lightweight actor-critic paradigm, using Monte Carlo rollouts to compute reward targets and optimize policies. It requires minimal modifications to existing RLHF pipelines, making it easy to integrate at scale. Beyond AgentPRM, we propose InversePRM, which learns process rewards directly from demonstrations without explicit outcome supervision. We also explore key challenges and opportunities, including exploration, process reward shaping, and model-predictive reasoning. We evaluate on ALFWorld benchmark, show that small 3B models trained with AgentPRM and InversePRM outperform strong GPT-4o baselines, and analyze test-time scaling, reward hacking, and more. Our code is available at: https://github.com/sanjibanc/agent_prm.
我们介绍了Agent Process Reward Models(AgentPRM),这是一个简单且可扩展的框架,用于训练LLM代理通过互动来持续改进。AgentPRM遵循轻量级的actor-critic范式,使用蒙特卡洛滚动来计算机会奖励并优化策略。它对现有的RLHF管道只需要进行最小的修改,使其易于大规模集成。除了AgentPRM之外,我们还提出了InversePRM,它可以直接从演示中学习过程奖励,而无需明确的成果监督。我们还探讨了关键挑战和机遇,包括探索、过程奖励塑造和模型预测推理。我们在ALFWorld基准测试上进行了评估,结果显示使用AgentPRM和InversePRM训练的3B小型模型优于强大的GPT-4o基线,并分析了测试时的扩展性、奖励破解等。我们的代码位于:https://github.com/sanjibanc/agent_prm。
论文及项目相关链接
PDF 17 pages, 7 figures
Summary:引入Agent Process Reward Models(AgentPRM)这一简单且可扩展的框架,用于训练大型语言模型(LLM)代理,通过互动实现持续进步。AgentPRM遵循轻量级的演员评判者模式,使用蒙特卡洛模拟计算奖励目标并优化策略。它只需对现有强化学习人类反馈管道进行少量修改,即可轻松实现大规模集成。此外,还提出了从演示中直接学习进程奖励的InversePRM,无需明确的成果监督。同时探讨了包括探索、进程奖励塑造和模型预测推理等关键挑战和机遇。在ALFWorld基准测试上评估,表明使用AgentPRM和InversePRM训练的小型3B模型优于强大的GPT-4o基线,并分析了测试时的扩展性、奖励破解等。
Key Takeaways:
- 引入Agent Process Reward Models(AgentPRM)框架,用于训练LLM代理,实现通过互动的持续进步。
- AgentPRM采用轻量级演员评判者模式,利用蒙特卡洛模拟计算奖励目标和优化策略。
- AgentPRM易于与现有强化学习人类反馈管道集成,且可大规模扩展。
- 提出InversePRM,能从演示中直接学习进程奖励,无需明确的成果监督。
- 探讨了包括探索、进程奖励塑造和模型预测推理在内的关键挑战和机遇。
- 在ALFWorld基准测试上,AgentPRM和InversePRM训练的小型模型表现超越GPT-4o基线。
点此查看论文截图

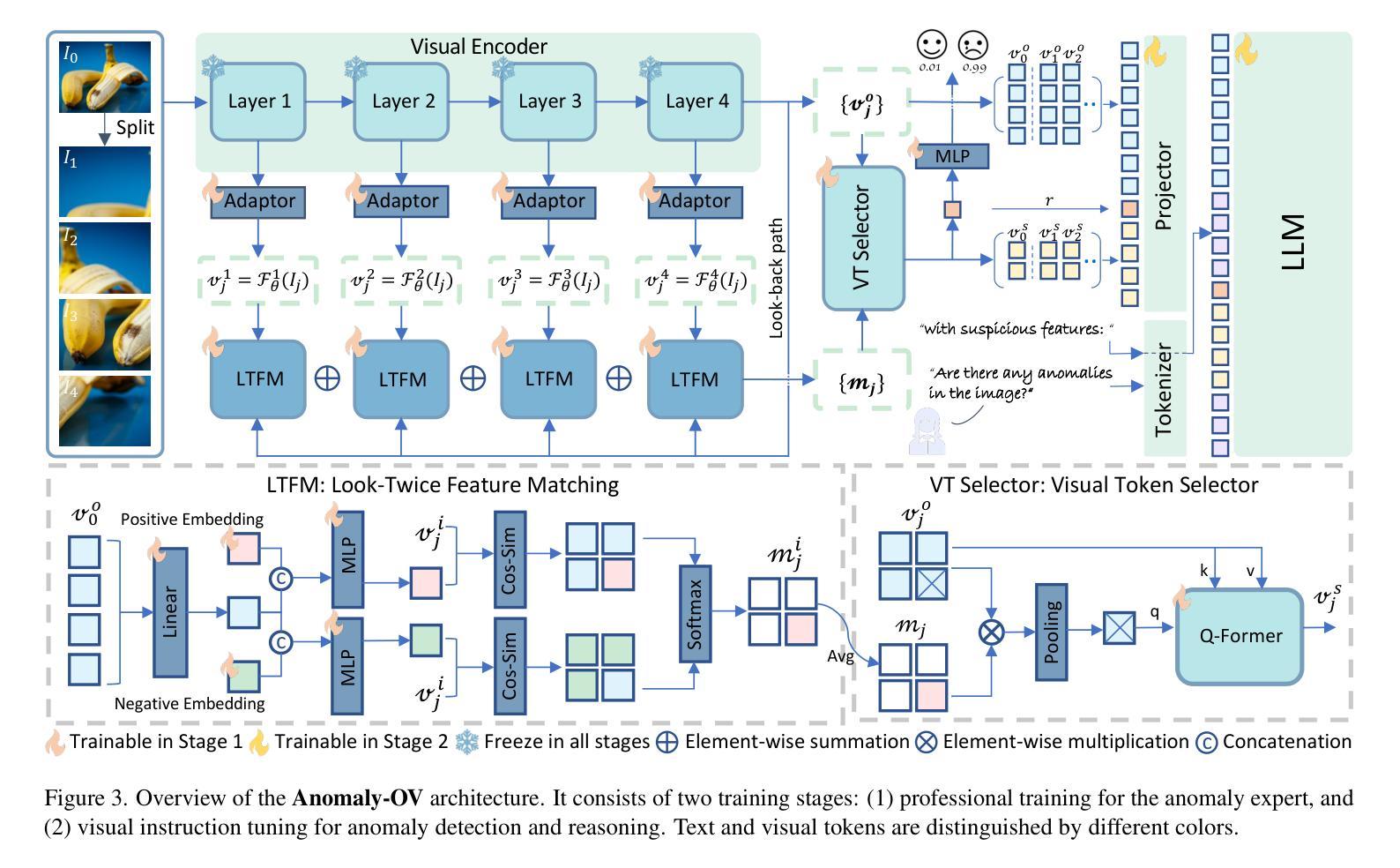
Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Authors:Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M. Patel, Isht Dwivedi
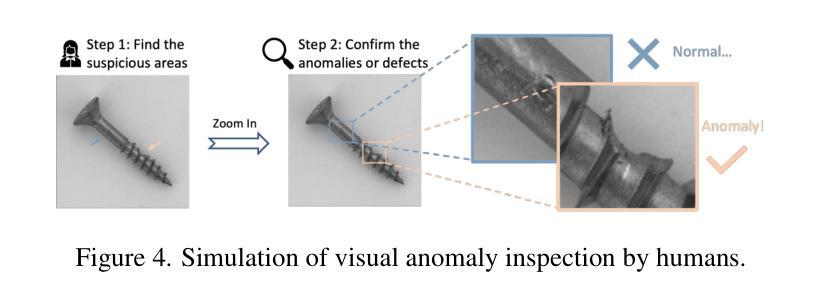
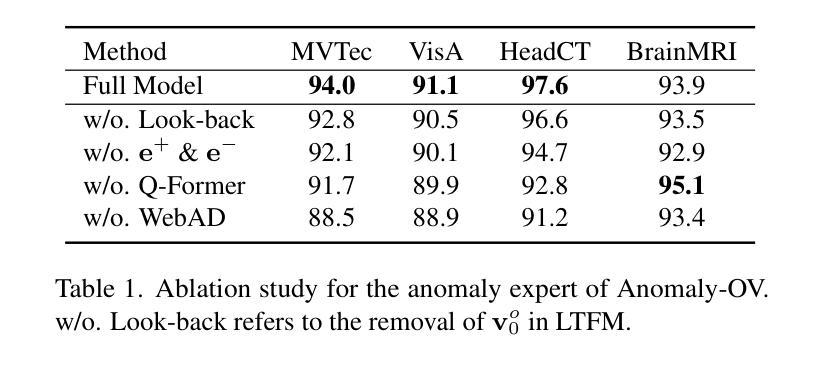
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in AD & reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Extensions to medical and 3D AD are provided for future study. The link to our project page: https://xujiacong.github.io/Anomaly-OV/
零样本异常检测(ZSAD)是一种新兴的异常检测范式。不同于传统无监督的异常检测设置需要大量正常样本来训练模型,ZSAD在处理数据受限的实际情况时更为实用。近期,多模态大型语言模型(MLLMs)在各种视觉任务中展现出了革命性的推理能力。然而,由于缺少相应的数据集和基准测试,图像异常的推理仍然被忽视。为了促进异常检测和推理的研究,我们建立了第一个视觉指令调整数据集Anomaly-Instruct-125k和评估基准VisA-D&R。通过我们基准的测试,我们发现当前的MLLMs如GPT-4o无法准确检测和描述图像中的细微异常细节。为了解决这个问题,我们提出了Anomaly-OneVision(Anomaly-OV),这是第一个专门针对ZSAD和推理的视觉助理。Anomaly-OV受到人类视觉检查行为的启发,利用二次特征匹配(LTFM)机制自适应选择和强调异常的视觉标记。大量实验表明,Anomaly-OV在检测和推理方面都取得了显著的改进,超越了先进的通用模型。我们还提供了医学和三维异常检测的扩展以供未来研究。有关我们项目页面的链接:链接地址。
论文及项目相关链接
PDF 19 pages, 10 figures, accepted by CVPR 2025
Summary
零样本异常检测(ZSAD)是一种新兴的异常检测范式。该研究团队建立了首个视觉指令微调数据集Anomaly-Instruct-125k和评估基准VisA-D&R,以促进异常检测和推理研究。然而,当前的多模态大型语言模型如GPT-4o在图像异常检测方面存在准确性问题。为此,团队提出了Anomaly-OneVision(Anomaly-OV),该视觉助理利用看两次特征匹配(LTFM)机制自适应选择和突出异常视觉标记,实现了显著的检测结果和提升推理能力。该项目包含对医疗和三维异常检测的扩展。
Key Takeaways
- ZSAD是一种新兴的实际场景中更实用的异常检测方式,与传统监督方式相比,不需要大量正常样本进行模型训练。
- 研究团队创建了首个视觉指令微调数据集Anomaly-Instruct-125k和评估基准VisA-D&R,用于推进异常检测和推理研究。
- 当前的多模态大型语言模型在图像异常检测方面存在不足,无法准确检测和描述细微的异常细节。
- Anomaly-OneVision(Anomaly-OV)是一个针对ZSAD和推理的视觉助理,通过利用看两次特征匹配(LTFM)机制自适应地选择和强调异常视觉标记来提高检测效果和推理能力。
- Anomaly-OV实现了显著的检测结果,并在检测和数据集扩展方面具有潜力,包括医疗和三维异常检测的扩展。
- 项目成果链接:https://xujiacong.github.io/Anomaly-OV/。
点此查看论文截图




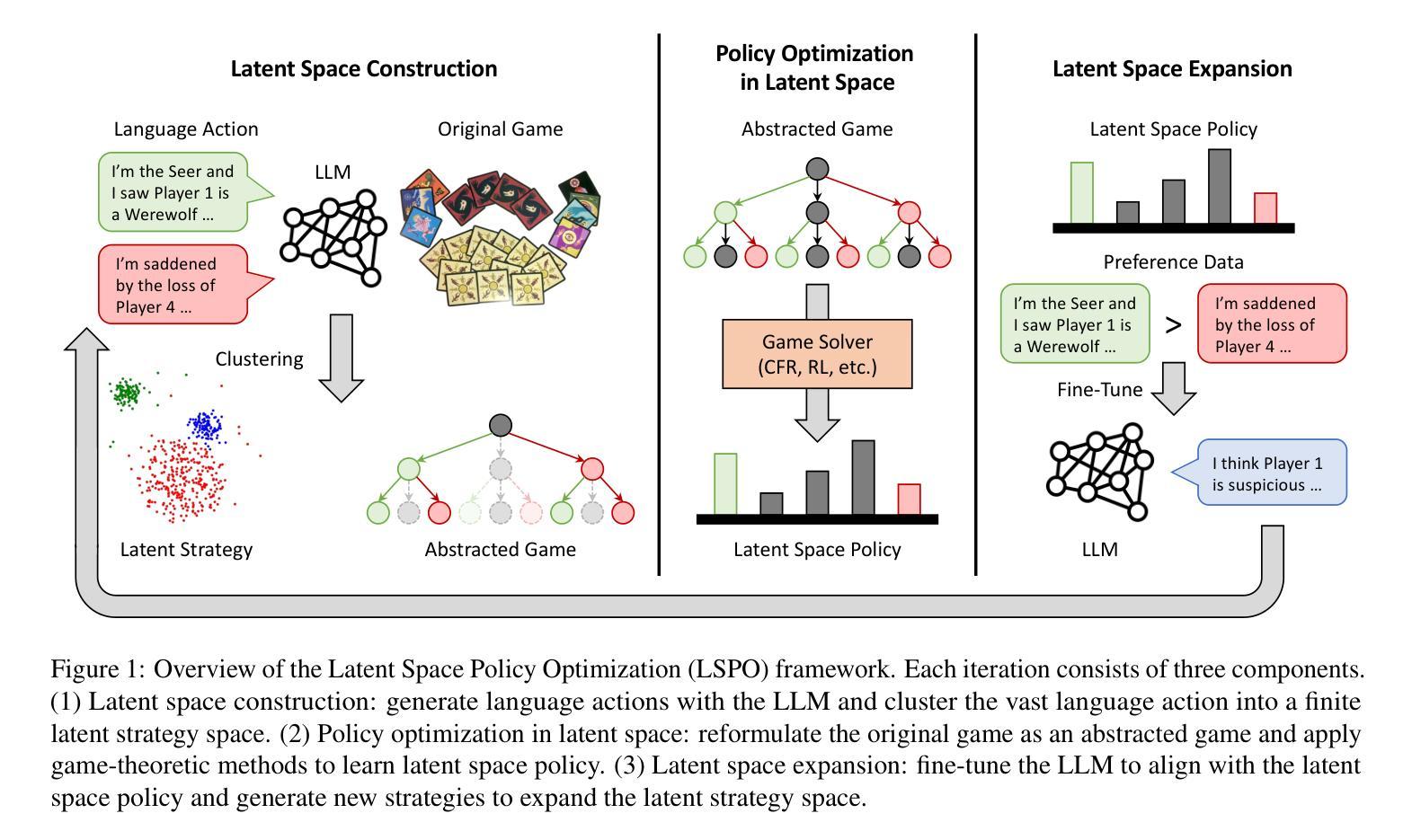
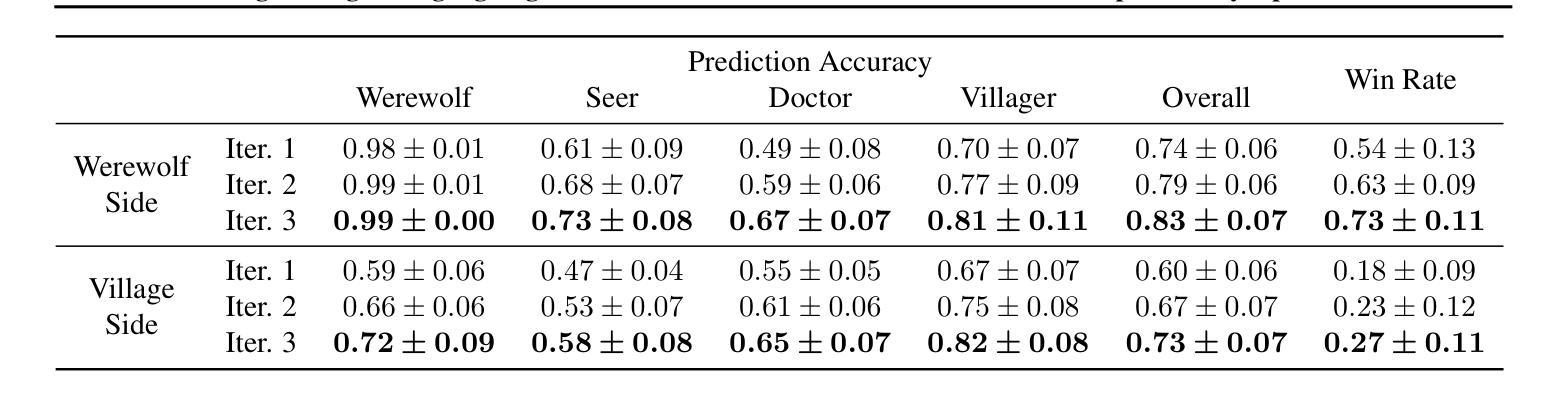
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM)-based agents have recently shown impressive progress in a variety of domains, including open-ended conversation and multi-step decision-making. However, applying these agents to social deduction games such as Werewolf, which requires both strategic decision-making and free-form language interaction, remains non-trivial. Traditional methods based on Counterfactual Regret Minimization (CFR) or reinforcement learning (RL) typically depend on a predefined action space, making them unsuitable for language games with unconstrained text action space. Meanwhile, pure LLM-based agents often suffer from intrinsic biases and require prohibitively large datasets for fine-tuning. We propose Latent Space Policy Optimization (LSPO), an iterative framework that addresses these challenges by first mapping free-form text to a discrete latent space, where methods like CFR and RL can learn strategic policy more effectively. We then translate the learned policy back into natural language dialogues, which are used to fine-tune an LLM via Direct Preference Optimization (DPO). By iteratively alternating between these stages, our LSPO agent progressively enhances both strategic reasoning and language communication. Experiment results on the Werewolf game show that our method improves the agent’s performance in each iteration and outperforms existing Werewolf agents, underscoring its promise for free-form language decision-making.
基于大型语言模型(LLM)的代理人在开放对话和多步决策等多个领域都取得了令人印象深刻的进步。然而,将这些代理人应用于需要战略决策和自由形式语言交互的社交推理游戏(如狼人杀)仍然非常困难。传统的方法,如基于反事实后悔最小化(CFR)或强化学习(RL)的方法,通常依赖于预定义的行动空间,这使得它们不适合具有无约束文本行动空间的语言游戏。与此同时,纯LLM-based的代理通常会受到内在偏见的影响,并且需要大量数据集进行微调。我们提出了潜在空间策略优化(LSPO),这是一种迭代框架,它通过首先将自由形式的文本映射到离散潜在空间来解决这些挑战,CFR和RL等方法可以在此更有效地学习战略策略。然后我们将学到的策略翻译回自然语言对话,用于通过直接偏好优化(DPO)对LLM进行微调。通过在这两个阶段之间交替迭代,我们的LSPO代理在战略推理和语言沟通方面逐渐增强。在狼人杀游戏上的实验结果表明,我们的方法提高了代理人在每次迭代中的性能,并超越了现有的狼人杀代理人,这突显了其在自由形式语言决策中的潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个领域取得了显著进展,但在社会推理游戏如《狼人杀》中的应用仍具挑战性。传统方法如基于对策遗憾最小化(CFR)或强化学习(RL)的方法依赖于预定义的行为空间,不适用于具有无约束文本行为空间的语言游戏。为此,我们提出潜在空间策略优化(LSPO),将自由形式的文本映射到离散潜在空间,在此空间内,CFR和RL等方法能更有效地学习策略。然后,我们将学习到的策略翻译回自然语言对话,用于通过直接偏好优化(DPO)对LLM进行微调。通过在这两个阶段之间迭代交替,我们的LSPO代理在战略推理和语言沟通方面逐渐提高。在《狼人杀》游戏中的实验结果表明,我们的方法提高了代理的性能,并在每次迭代中表现出优于现有《狼人杀》代理的潜力,这证明了其在自由形式语言决策中的前景。
Key Takeaways
- 大型语言模型(LLM)在多种领域表现出色,但在社会推理游戏中的应用具有挑战性。
- 传统方法如CFR和RL不适用于具有无约束文本行为空间的语言游戏。
- LSPO通过将自由形式的文本映射到离散潜在空间来解决这一挑战。
- 在潜在空间中,CFR和RL等方法能更有效地学习策略。
- 学习到的策略被翻译回自然语言对话,用于LLM的微调。
- 通过迭代优化,LSPO代理在战略推理和语言沟通方面逐渐提高。
点此查看论文截图