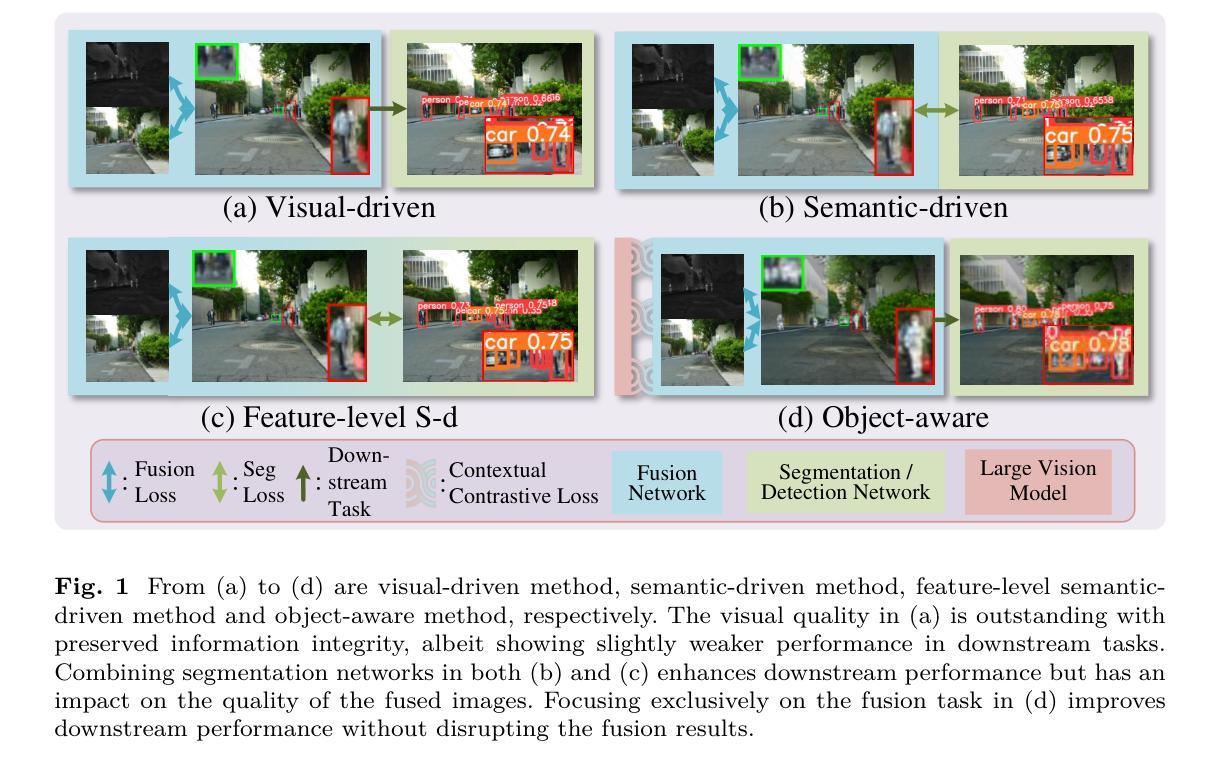
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
Face Spoofing Detection using Deep Learning
Authors: Najeebullah, Maaz Salman, Zar Nawab Khan Swati
Digital image spoofing has emerged as a significant security threat in biometric authentication systems, particularly those relying on facial recognition. This study evaluates the performance of three vision based models, MobileNetV2, ResNET50, and Vision Transformer, ViT, for spoof detection in image classification, utilizing a dataset of 150,986 images divided into training , 140,002, testing, 10,984, and validation ,39,574, sets. Spoof detection is critical for enhancing the security of image recognition systems, and this research compares the models effectiveness through accuracy, precision, recall, and F1 score metrics. Results reveal that MobileNetV2 outperforms other architectures on the test dataset, achieving an accuracy of 91.59%, precision of 91.72%, recall of 91.59%, and F1 score of 91.58%, compared to ViT 86.54%, 88.28%, 86.54%, and 86.39%, respectively. On the validation dataset, MobileNetV2, and ViT excel, with MobileNetV2 slightly ahead at 97.17% accuracy versus ViT 96.36%. MobileNetV2 demonstrates faster convergence during training and superior generalization to unseen data, despite both models showing signs of overfitting. These findings highlight MobileNetV2 balanced performance and robustness, making it the preferred choice for spoof detection applications where reliability on new data is essential. The study underscores the importance of model selection in security sensitive contexts and suggests MobileNetV2 as a practical solution for real world deployment.
数字图像欺骗已成为生物特征识别系统(特别是那些依赖面部识别技术的系统)中的重要安全威胁。本研究评估了三种基于视觉的模型(MobileNetV2、ResNET50和Vision Transformer,即ViT)在图像分类中的欺骗检测性能,使用了一个包含150986张图像的数据集,其中训练集有14002张图像,测试集有10984张图像,验证集有39574张图像。欺骗检测对于提高图像识别系统的安全性至关重要,本研究通过准确性、精确度、召回率和F1分数等指标比较了模型的有效性。结果表明,在测试数据集上,MobileNetV2优于其他架构,其准确性、精确度、召回率和F1分数分别为91.59%、91.72%、91.59%和91.58%,相比之下,ViT分别为86.54%、88.28%、86.54%和86.39%。在验证数据集上,MobileNetV2和ViT表现优异,其中MobileNetV2以97.17%的准确性略胜一筹,ViT为96.36%。尽管两者都显示出过拟合的迹象,但MobileNetV2在训练过程中收敛更快,对未见数据的泛化能力更强。这些发现突显了MobileNetV2平衡的性能和稳健性,使其成为在需要新数据可靠性方面的重要选择,适用于欺骗检测应用。该研究强调了安全敏感环境中模型选择的重要性,并建议将MobileNetV2作为实际部署的实用解决方案。
论文及项目相关链接
PDF 26 pages, 9 figures,3 tables
摘要
数字图像欺骗技术在生物特征识别系统中构成重大安全威胁,特别是在依赖面部识别的系统中。本研究评估了三种基于视觉的模型MobileNetV2、ResNET50和Vision Transformer(ViT)在图像分类中的欺骗检测性能。使用由训练集(占百分之九十三)、测试集(占百分之七)和验证集(占百分之二点一)组成的包含一百五十万零八千七百七十八张图片的公开数据集进行实验比对研究。本研究对三种模型的欺骗检测能力进行比较分析,重点衡量准确率、精确率、召回率和F1分数等指标。结果表明,在测试数据集上,MobileNetV2表现优于其他架构,准确率达到了百分之九十一点五九,精确率达到了百分之九十一点七二,召回率和F1分数也都表现出优异表现。相较于其他两个模型表现较好但仍逊色于MobileNetV2的ViT表现则是略微逊色的数据呈现效果;通过数据可以看出二者有相互借力的空间和效果优化的趋势可能。在验证数据集上,MobileNetV2和ViT表现优秀,其中MobileNetV2以百分之九十七点一七的准确率小幅领先于ViT百分之九十六点三六。虽然两种模型都存在一定程度上的过拟合现象,但MobileNetV2训练时收敛更快,对未见数据的泛化能力更强。研究认为MobileNetV2因其均衡的性能和稳健性成为欺骗检测应用的首选模型,特别是在需要在新数据上可靠运行的情况下。该研究强调了模型选择在安全敏感环境中的重要性,并建议将MobileNetV2作为实际部署的实际解决方案。这项研究的结果能够为设计更为安全和可靠的人脸识别系统提供理论支持和实践指导。因此是一项意义重大的研究工作。该研究为后续工作提供了宝贵的参考意见和数据支持,有利于该领域长足进步和发展壮大。该研究能够有力推动人脸识别技术朝着更为安全、可靠的方向发展。
关键见解
一、数字图像欺骗技术已成为生物特征识别系统的重大安全威胁,特别是在面部识别领域。
二、本研究对比了三种基于视觉的模型在欺骗检测方面的性能:MobileNetV2、ResNET50和Vision Transformer(ViT)。
三、实验结果显示,在测试数据集上,MobileNetV2在准确率、精确率、召回率和F1分数等方面表现最佳。
四、MobileNetV2相较于其他模型,在验证数据集上也展现出较好的性能,并略微领先于ViT。
五、虽然存在过拟合现象,但MobileNetV2训练时收敛更快,对未见数据的泛化能力更强。
六、研究认为MobileNetV2因其均衡的性能和稳健性成为欺骗检测的首选模型,特别是在需要在新数据上可靠运行的情况下。
点此查看论文截图