⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
Show or Tell? Effectively prompting Vision-Language Models for semantic segmentation
Authors:Niccolo Avogaro, Thomas Frick, Mattia Rigotti, Andrea Bartezzaghi, Filip Janicki, Cristiano Malossi, Konrad Schindler, Roy Assaf
Large Vision-Language Models (VLMs) are increasingly being regarded as foundation models that can be instructed to solve diverse tasks by prompting, without task-specific training. We examine the seemingly obvious question: how to effectively prompt VLMs for semantic segmentation. To that end, we systematically evaluate the segmentation performance of several recent models guided by either text or visual prompts on the out-of-distribution MESS dataset collection. We introduce a scalable prompting scheme, few-shot prompted semantic segmentation, inspired by open-vocabulary segmentation and few-shot learning. It turns out that VLMs lag far behind specialist models trained for a specific segmentation task, by about 30% on average on the Intersection-over-Union metric. Moreover, we find that text prompts and visual prompts are complementary: each one of the two modes fails on many examples that the other one can solve. Our analysis suggests that being able to anticipate the most effective prompt modality can lead to a 11% improvement in performance. Motivated by our findings, we propose PromptMatcher, a remarkably simple training-free baseline that combines both text and visual prompts, achieving state-of-the-art results outperforming the best text-prompted VLM by 2.5%, and the top visual-prompted VLM by 3.5% on few-shot prompted semantic segmentation.
大规模视觉语言模型(VLMs)正越来越受到关注,被视为可以通过提示指令解决各种任务的基础模型,而无需针对特定任务进行训练。我们研究了一个看似简单的问题:如何有效地对VLMs进行语义分割提示。为此,我们系统评估了使用文本或视觉提示引导的多个最新模型的分割性能,在超出分布范围的MESS数据集上进行评估。我们引入了一种可扩展的提示方案,即少镜头语义分割提示,该方案受到开放词汇分割和少镜头学习的启发。结果表明,VLMs在交并比指标上的表现远远落后于针对特定分割任务的专业模型,平均落后约30%。此外,我们发现文本提示和视觉提示是互补的:两种模式中的每一种在许多例子上都会失败,而另一种可以解决这些问题。我们的分析表明,能够预测最有效的提示模式可以导致性能提高11%。基于我们的发现,我们提出了PromptMatcher,这是一个非常简单的无需训练的基础线模型,它结合了文本和视觉提示,实现了最先进的成果,在少镜头语义分割提示上超越了最佳文本提示VLM 2.5%,以及顶级视觉提示VLM 3.5%。
论文及项目相关链接
Summary
本文探讨了如何利用大型视觉语言模型(VLMs)进行语义分割的有效提示方法。通过系统评估使用文本或视觉提示引导的多个模型的分割性能,作者引入了一种基于少样本学习的可扩展提示方案——少样本语义分割。虽然VLMs的表现较专业模型逊色,平均在Intersection-over-Union指标上落后约30%,但研究发现文本提示和视觉提示是互补的。基于此,作者提出了PromptMatcher这一无需训练的基线方法,结合文本和视觉提示,实现了最先进的少样本语义分割效果。
Key Takeaways
- 大型视觉语言模型(VLMs)被看作是可以通过提示解决各种任务的基础模型。
- 对于语义分割任务,文本提示和视觉提示是互补的。
- VLMs在语义分割任务上的性能较专业模型平均落后约30%。
- 最有效的提示模态的预测能力可以导致性能提升11%。
- PromptMatcher方法结合了文本和视觉提示,实现了少样本语义分割的最佳效果。
- PromptMatcher无需训练,是一种简单有效的基线方法。
点此查看论文截图

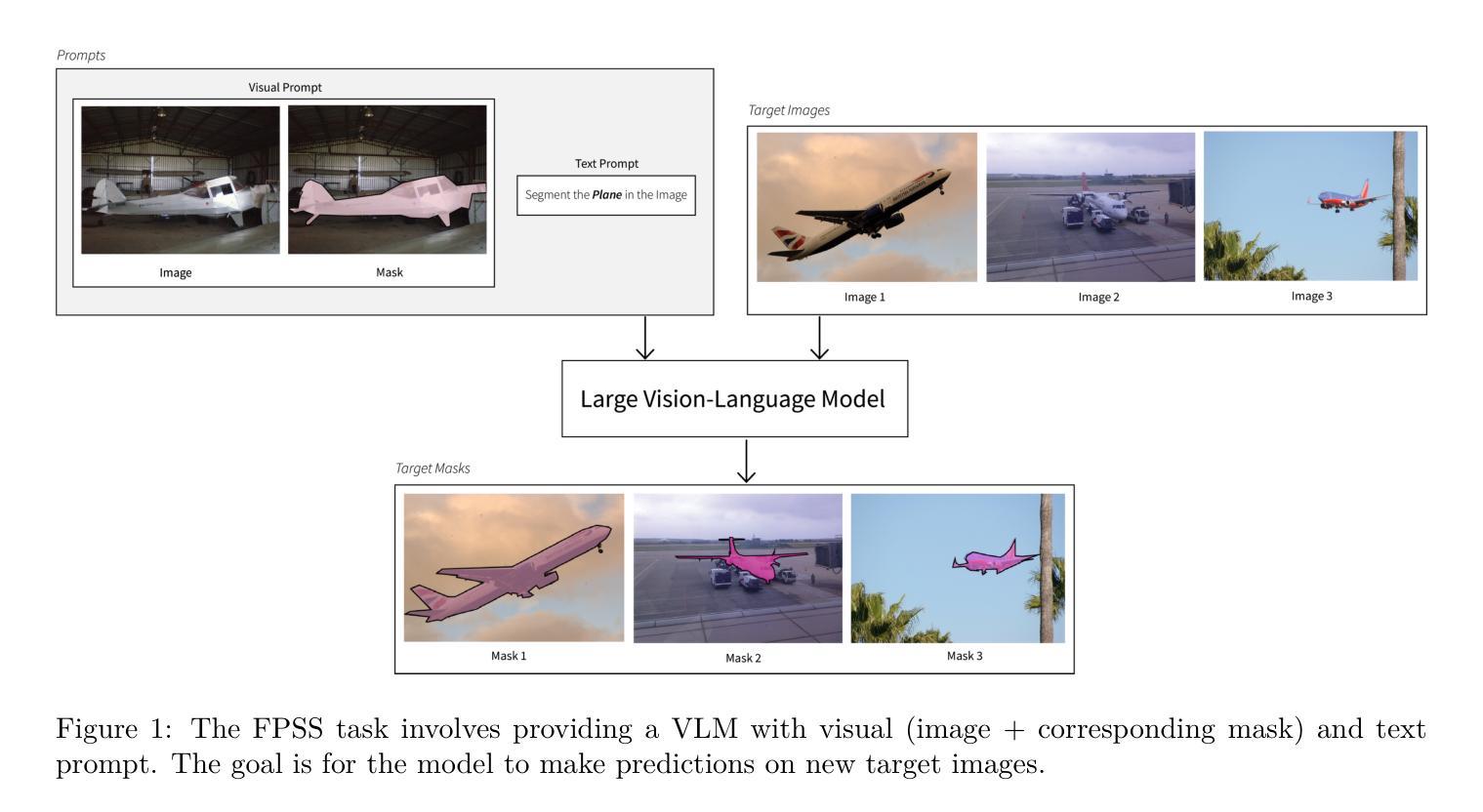
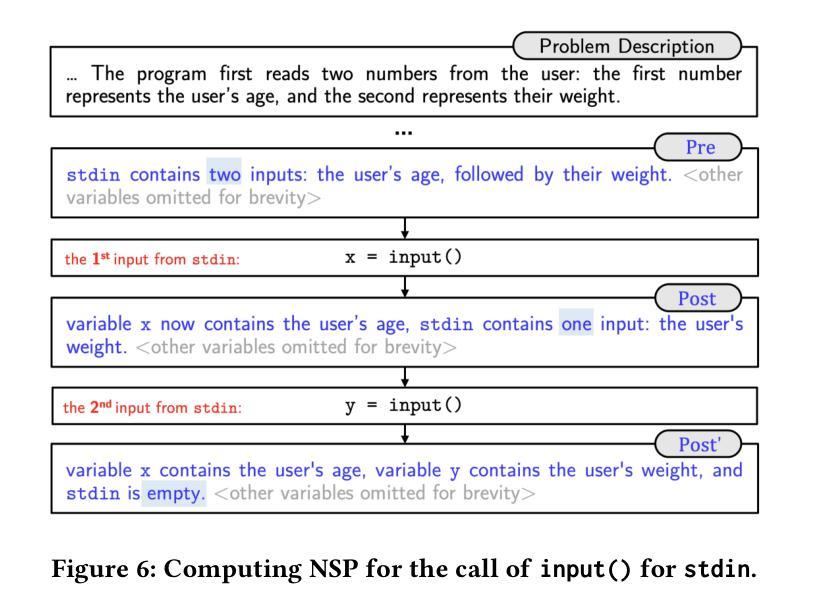
HoarePrompt: Structural Reasoning About Program Correctness in Natural Language
Authors:Dimitrios Stamatios Bouras, Yihan Dai, Tairan Wang, Yingfei Xiong, Sergey Mechtaev
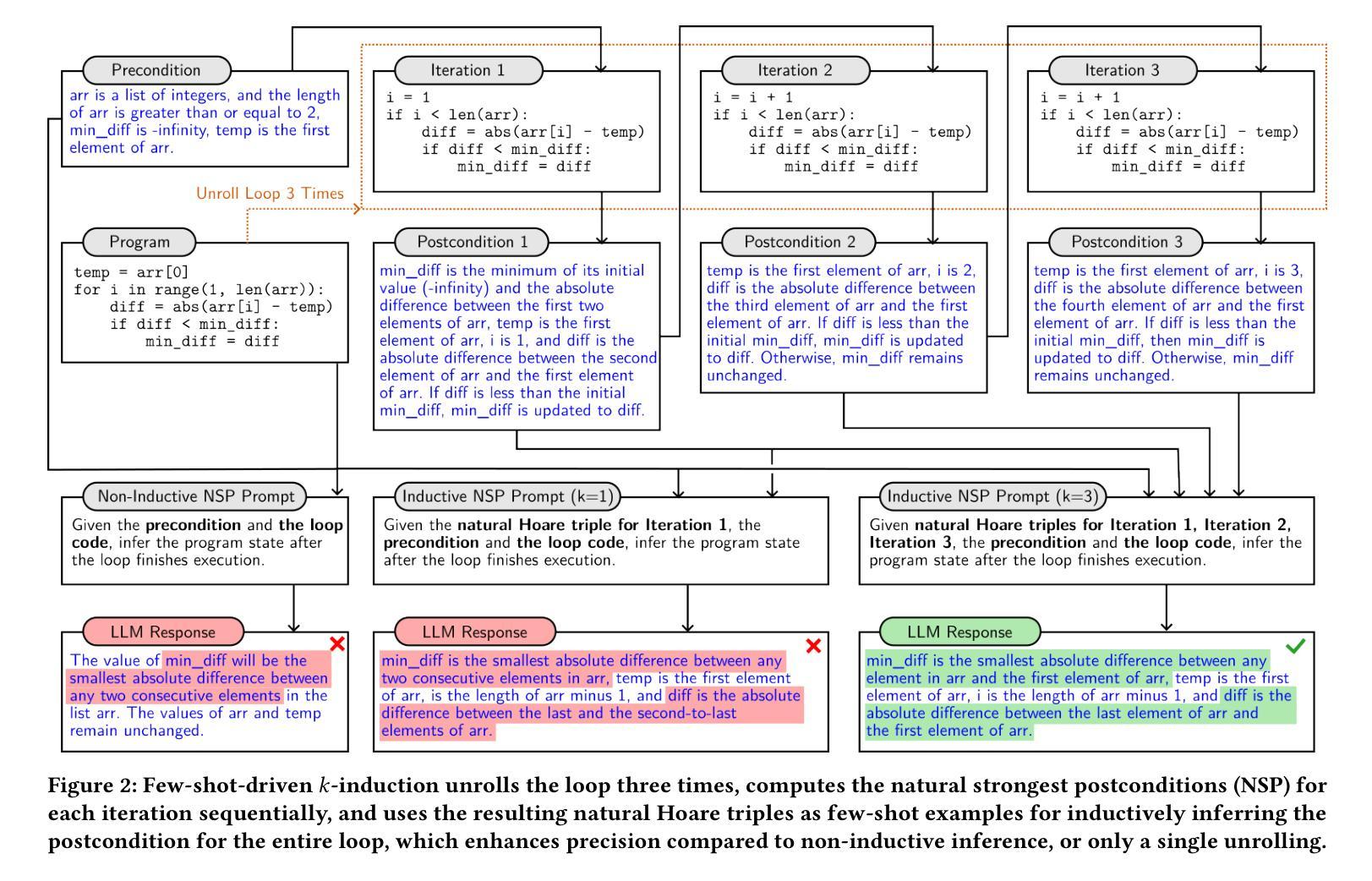
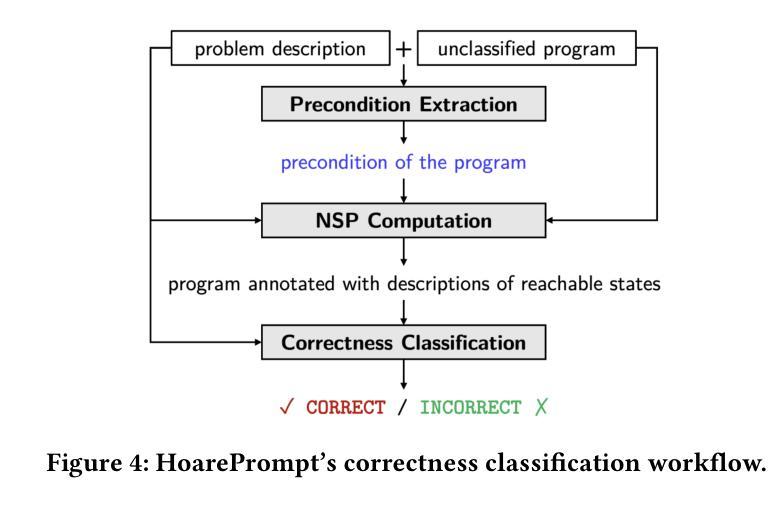
While software requirements are often expressed in natural language, verifying the correctness of a program against natural language requirements is a hard and underexplored problem. Large language models (LLMs) are promising candidates for addressing this challenge, however our experience shows that they are ineffective in this task, often failing to detect even straightforward bugs. To address this gap, we introduce HoarePrompt, a novel approach that adapts fundamental ideas from program analysis and verification to natural language artifacts. Drawing inspiration from the strongest postcondition calculus, HoarePrompt employs a systematic, step-by-step process in which an LLM generates natural language descriptions of reachable program states at various points in the code. To manage loops, we propose few-shot-driven k-induction, an adaptation of the k-induction method widely used in model checking. Once program states are described, HoarePrompt leverages the LLM to assess whether the program, annotated with these state descriptions, conforms to the natural language requirements. For evaluating the quality of classifiers of program correctness with respect to natural language requirements, we constructed CoCoClaNeL, a challenging dataset of solutions to programming competition problems. Our experiments show that HoarePrompt improves the MCC by 62% compared to directly using Zero-shot-CoT prompts for correctness classification. Furthermore, HoarePrompt outperforms a classifier that assesses correctness via LLM-based test generation by increasing the MCC by 93%. The inductive reasoning mechanism contributes a 28% boost to MCC, underscoring its effectiveness in managing loops.
虽然软件需求通常使用自然语言来表达,但针对自然语言要求的程序正确性验证是一个困难且未被充分研究的问题。大型语言模型(LLM)是应对这一挑战的有前途的候选者,但我们的经验表明,它们在此任务中效果不佳,甚至无法检测到简单的错误。为了解决这一差距,我们引入了HoarePrompt,这是一种将程序分析和验证的基本思想适应到自然语言工件的新方法。从最强的后条件演算中汲取灵感,HoarePrompt采用系统、分步的过程,其中LLM生成代码各点可达到程序状态的自然语言描述。为了管理循环,我们提出了基于少量样本的k归纳法,这是对模型检查中广泛使用的k归纳方法的适应。一旦描述了程序状态,HoarePrompt就利用LLM来评估带有这些状态描述的程序是否符合自然语言要求。为了评估分类器对程序正确性相对于自然语言要求的分类质量,我们构建了CoCoClaNeL数据集,这是一项竞赛解决方案的挑战性数据集。我们的实验表明,与直接使用零样本认知提示进行正确性分类相比,HoarePrompt提高了匹配正确率(MCC)的62%。此外,与通过LLM生成的测试评估正确性的分类器相比,HoarePrompt提高了匹配正确率(MCC)的93%。归纳推理机制对匹配正确率的提升达到了28%,证明了其在管理循环中的有效性。
论文及项目相关链接
摘要
软件需求通常以自然语言表述,但验证程序是否符合自然语言要求是一项困难且鲜有研究的问题。大型语言模型(LLM)虽具有解决此问题的潜力,但在该任务中效果不佳,甚至无法检测到简单的错误。为解决此差距,我们提出HoarePrompt,一种结合程序分析与验证基本理念的自然语言工件新方法。HoarePrompt受最强后条件演算启发,采用系统、逐步的过程,由LLM生成代码各点可达到的程序状态的自然语言描述。为处理循环,我们提出基于少量数据的k归纳法。一旦描述了程序状态,HoarePrompt利用LLM评估带有这些状态描述的程序的自然语言要求符合程度。为评估程序正确性分类器的质量,我们构建了CoCoClaNeL数据集,这是一组编程竞赛问题的解决方案。实验显示,与零样本CoT提示相比,HoarePrompt的MCC提高了62%。此外,HoarePrompt优于通过LLM测试生成评估正确性的分类器,提高了MCC的93%。归纳推理机制对MCC的提升贡献率为28%,证明了其在处理循环中的有效性。
关键见解
- 验证程序是否符合自然语言要求是一项困难且研究不足的问题。
- 大型语言模型(LLM)在这一任务中的表现并不理想。
- HoarePrompt是一种结合自然语言处理和程序分析与验证的新方法。
- HoarePrompt采用逐步生成程序状态自然语言描述的方式处理程序。
- 为处理循环,HoarePrompt引入了基于少量数据的k归纳法。
- 评估了HoarePrompt在CoCoClaNeL数据集上的性能表现。
点此查看论文截图




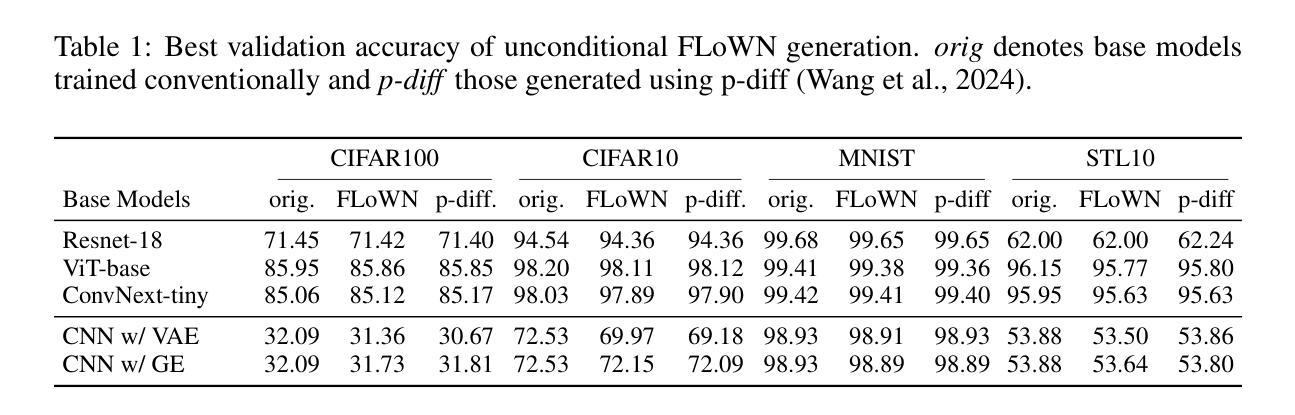
Flow to Learn: Flow Matching on Neural Network Parameters
Authors:Daniel Saragih, Deyu Cao, Tejas Balaji, Ashwin Santhosh
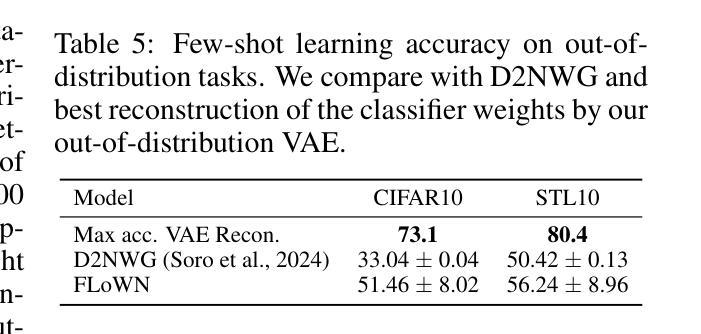
Foundational language models show a remarkable ability to learn new concepts during inference via context data. However, similar work for images lag behind. To address this challenge, we introduce FLoWN, a flow matching model that learns to generate neural network parameters for different tasks. Our approach models the flow on latent space, while conditioning the process on context data. Experiments verify that FLoWN attains various desiderata for a meta-learning model. In addition, it matches or exceeds baselines on in-distribution tasks, provides better initializations for classifier training, and is performant on out-of-distribution few-shot tasks while having a fine-tuning mechanism to improve performance.
基础语言模型显示出在通过上下文数据推理时学习新概念的显著能力。然而,图像的类似工作滞后于语言模型的发展。为了应对这一挑战,我们引入了FLoWN,这是一个流匹配模型,旨在学习为不同任务生成神经网络参数。我们的方法通过潜在空间上的流建模,并根据上下文数据进行过程控制。实验证明,FLoWN满足了元学习模型的各种期望要求。此外,它在内部分布任务上的表现与基线相当或超过基线,为分类器训练提供了更好的初始化方案,并且在外部分布的少样本任务上表现良好,同时具有微调机制以提高性能。
论文及项目相关链接
PDF Accepted at the ICLR Workshop on Neural Network Weights as a New Data Modality 2025
Summary
本文介绍了一种名为FLoWN的模型,该模型通过学习在潜在空间中的流来生成不同任务的神经网络参数,并在上下文数据的基础上对流程进行建模。实验证明,FLoWN达到了元学习模型的多种理想要求,并在内部任务上匹配或超越了基线水平,为分类器训练提供了更好的初始化方案,并在外部少量样本任务上表现出良好的性能,同时具有微调机制以提高性能。
Key Takeaways
- FLoWN模型能够在潜在空间上建模流,用于生成不同任务的神经网络参数。
- 该模型在上下文数据的基础上对流程进行建模和学习新概念。
- 实验表明FLoWN具备多种理想的元学习模型特性。
- FLoWN在内部任务上表现良好,匹配或超越了基线水平。
- 该模型为分类器训练提供了更好的初始化方案。
- FLoWN在外部少量样本任务上具有优秀的性能。
点此查看论文截图

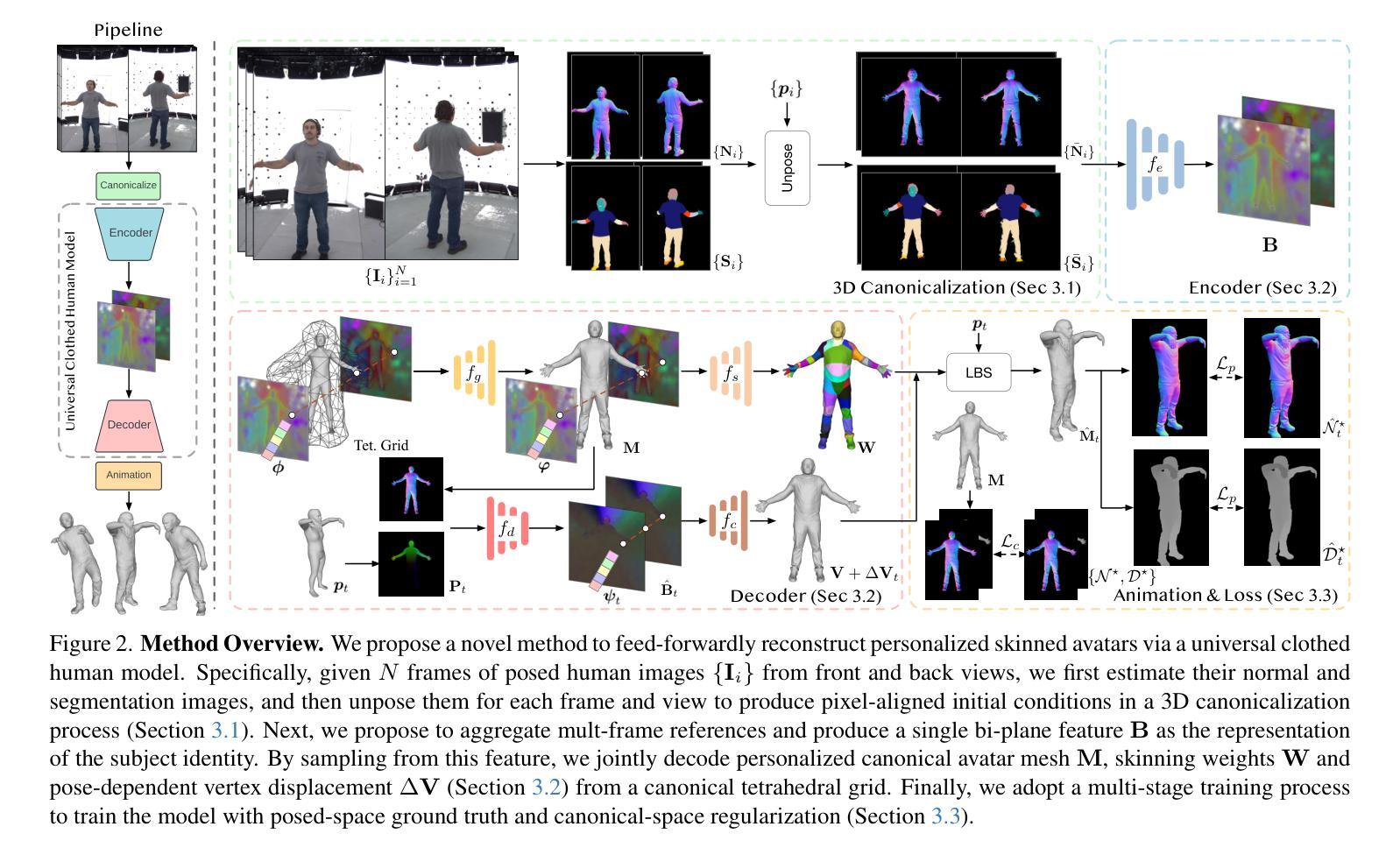
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Authors:Rong Wang, Fabian Prada, Ziyan Wang, Zhongshi Jiang, Chengxiang Yin, Junxuan Li, Shunsuke Saito, Igor Santesteban, Javier Romero, Rohan Joshi, Hongdong Li, Jason Saragih, Yaser Sheikh
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
我们提出了一种仅通过几张图片重建个性化3D人类角色并生成逼真动画的新方法。由于人体形状、姿势和服装类型存在很大差异,现有方法大多需要在推理期间对每个主题进行数小时的优化,这限制了它们的实际应用。相比之下,我们从数千名穿衣者身上学习通用先验知识,以实现即时前馈生成和零样本泛化。具体来说,我们没有使用通用的蒙皮权重来固定角色,而是联合推断个性化的角色形状、蒙皮权重和姿势相关的变形,这有效地提高了整体几何逼真度并减少了变形伪影。此外,为了归一化姿势变化并解决规范形状和蒙皮权重之间的耦合模糊性,我们设计了一个3D规范化过程来生成像素对齐的初始条件,这有助于重建精细的几何细节。然后,我们提出了一种多帧特征聚合方法,以稳健地减少规范化过程中产生的伪影,并融合保留个人特征的合理角色。最后,我们在一个大规模捕获数据集上,以端到端的方式训练模型,该数据集包含与高质量3D扫描配对的多样化人类主题。大量实验表明,我们的方法比最先进的技术生成更真实的三维重建和动画,并且可以直接推广到来自随意拍摄的手机照片输入。项目页面和代码可通过https://github.com/rongakowang/FRESA访问。
论文及项目相关链接
PDF Published in CVPR 2025
Summary
本文介绍了一种仅通过几张图片重建个性化3D人类角色模型的新方法。该方法通过学习通用先验知识,实现即时前馈生成和零样本泛化,解决了现有方法需要大量优化时间的问题。通过联合推断个性化角色形状、蒙皮权重和姿态相关变形,提高了整体几何逼真度,减少了变形伪影。此外,通过设计3D规范化过程和多帧特征聚合,解决了姿态变化标准化及模糊性问题,提高了精细几何细节的重建效果。最后,在大型捕获数据集上进行端到端框架训练,包含多种人类主体与高质量3D扫描配对。实验表明,该方法比现有技术更能生成真实的人物重建和动画,并能直接泛化到手机照片等输入。
Key Takeaways
- 提出了一种从少量图片重建个性化3D人类角色模型的新方法。
- 通过学习通用先验知识实现即时前馈生成和零样本泛化,解决了优化时间长的问题。
- 联合推断个性化角色形状、蒙皮权重和姿态相关变形,提高几何逼真度和减少变形伪影。
- 设计了3D规范化过程和多帧特征聚合,解决姿态变化标准化及模糊性问题。
- 通过大型捕获数据集进行端到端框架训练,包含多种人类主体与高质量3D扫描配对。
- 实验表明该方法生成的人物重建和动画更为真实,优于现有技术。
点此查看论文截图

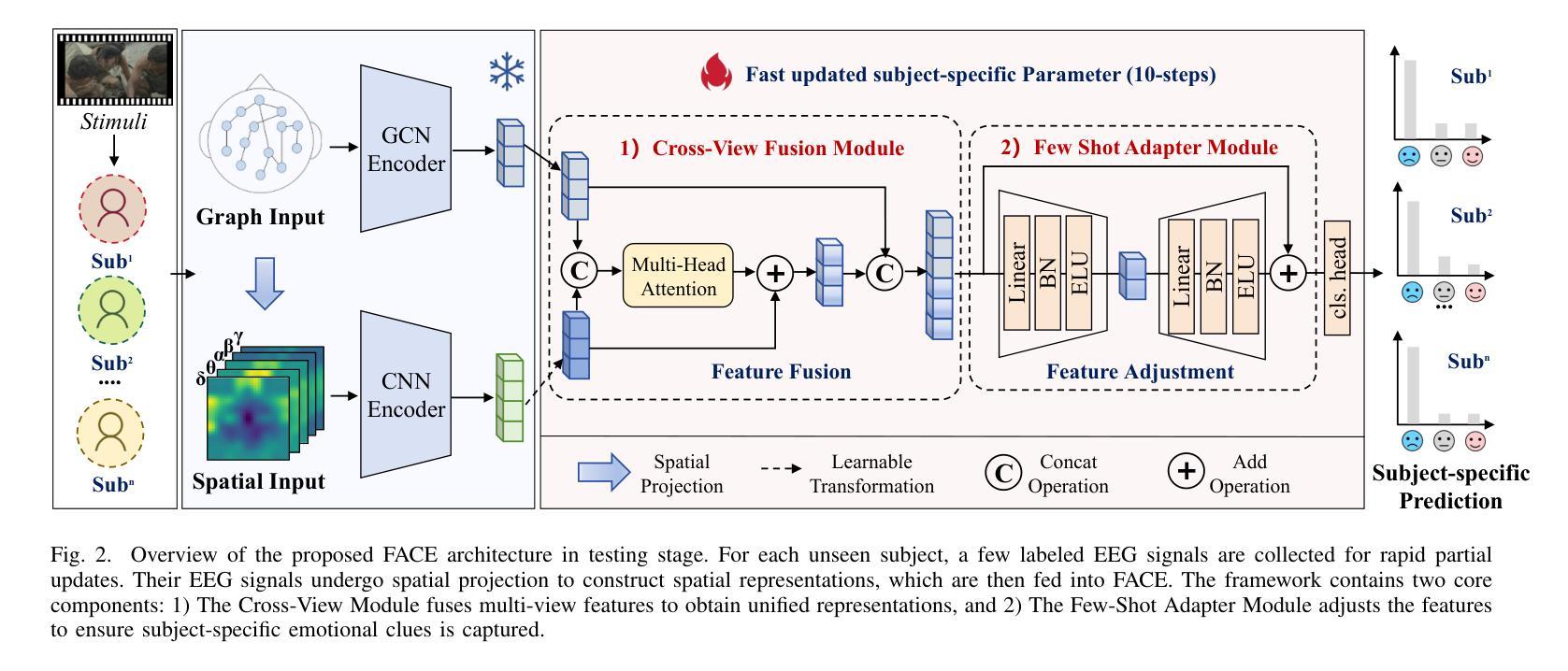
FACE: Few-shot Adapter with Cross-view Fusion for Cross-subject EEG Emotion Recognition
Authors:Haiqi Liu, C. L. Philip Chen, Tong Zhang
Cross-subject EEG emotion recognition is challenged by significant inter-subject variability and intricately entangled intra-subject variability. Existing works have primarily addressed these challenges through domain adaptation or generalization strategies. However, they typically require extensive target subject data or demonstrate limited generalization performance to unseen subjects. Recent few-shot learning paradigms attempt to address these limitations but often encounter catastrophic overfitting during subject-specific adaptation with limited samples. This article introduces the few-shot adapter with a cross-view fusion method called FACE for cross-subject EEG emotion recognition, which leverages dynamic multi-view fusion and effective subject-specific adaptation. Specifically, FACE incorporates a cross-view fusion module that dynamically integrates global brain connectivity with localized patterns via subject-specific fusion weights to provide complementary emotional information. Moreover, the few-shot adapter module is proposed to enable rapid adaptation for unseen subjects while reducing overfitting by enhancing adapter structures with meta-learning. Experimental results on three public EEG emotion recognition benchmarks demonstrate FACE’s superior generalization performance over state-of-the-art methods. FACE provides a practical solution for cross-subject scenarios with limited labeled data.
跨学科的脑电图情感识别面临着受试者间和受试者内存在显著差异的巨大挑战。现有研究主要通过领域适应或通用化策略来解决这些挑战。然而,它们通常需要大量的目标受试者数据,或者在未见过的受试者上表现出有限的泛化性能。最近的少样本学习范式试图解决这些局限性,但在具有有限样本的特定主体适应过程中常常遭遇灾难性的过度拟合问题。本文介绍了用于跨主体脑电图情感识别的少样本适配器与一种称为FACE的跨视图融合方法,该方法利用动态多视图融合和有效的主体特定适应。具体来说,FACE结合了一个跨视图融合模块,该模块通过主体特定的融合权重动态地整合全局大脑连通性与局部模式,以提供互补的情感信息。此外,还提出了少样本适配器模块,以实现未见主体的快速适应,并通过增强元学习的适配器结构来减少过度拟合。在三个公开的脑电图情感识别基准测试上的实验结果表明,FACE在最新技术上的泛化性能表现优越。FACE为有限标记数据的跨主体场景提供了切实可行的解决方案。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了基于跨视图融合方法的少样本适配器(FACE)在跨主体脑电图情感识别中的应用。它采用动态多视图融合和有效的主体特定适应策略,通过融合全局脑连通性和局部模式来提供互补的情感信息。此外,少样本适配器模块通过元学习增强适配器结构,以实现快速适应未见主体并减少过度拟合。在三个公共脑电图情感识别基准测试上的实验结果表明,FACE在泛化性能上优于现有方法,为有限标记数据的跨主体场景提供了实际解决方案。
Key Takeaways
- 跨主体脑电图情感识别面临显著的主体间变异和复杂的主体内变异挑战。
- 现有工作主要通过领域适应或泛化策略来解决这些挑战,但需要大量的目标主体数据,或对未见主体的泛化性能有限。
- 最近出现的少样本学习范式试图解决这些限制,但在主体特定适应时,由于样本有限,常遭遇灾难性的过度拟合。
- 本文介绍的少样本适配器(FACE)采用动态多视图融合策略,结合全局脑连通性和局部模式,提供互补情感信息。
5.FACE通过元学习增强适配器结构,以实现快速适应未见主体并减少过度拟合。 - 在三个公共基准测试上的实验结果表明,FACE在泛化性能上优于现有方法。
点此查看论文截图


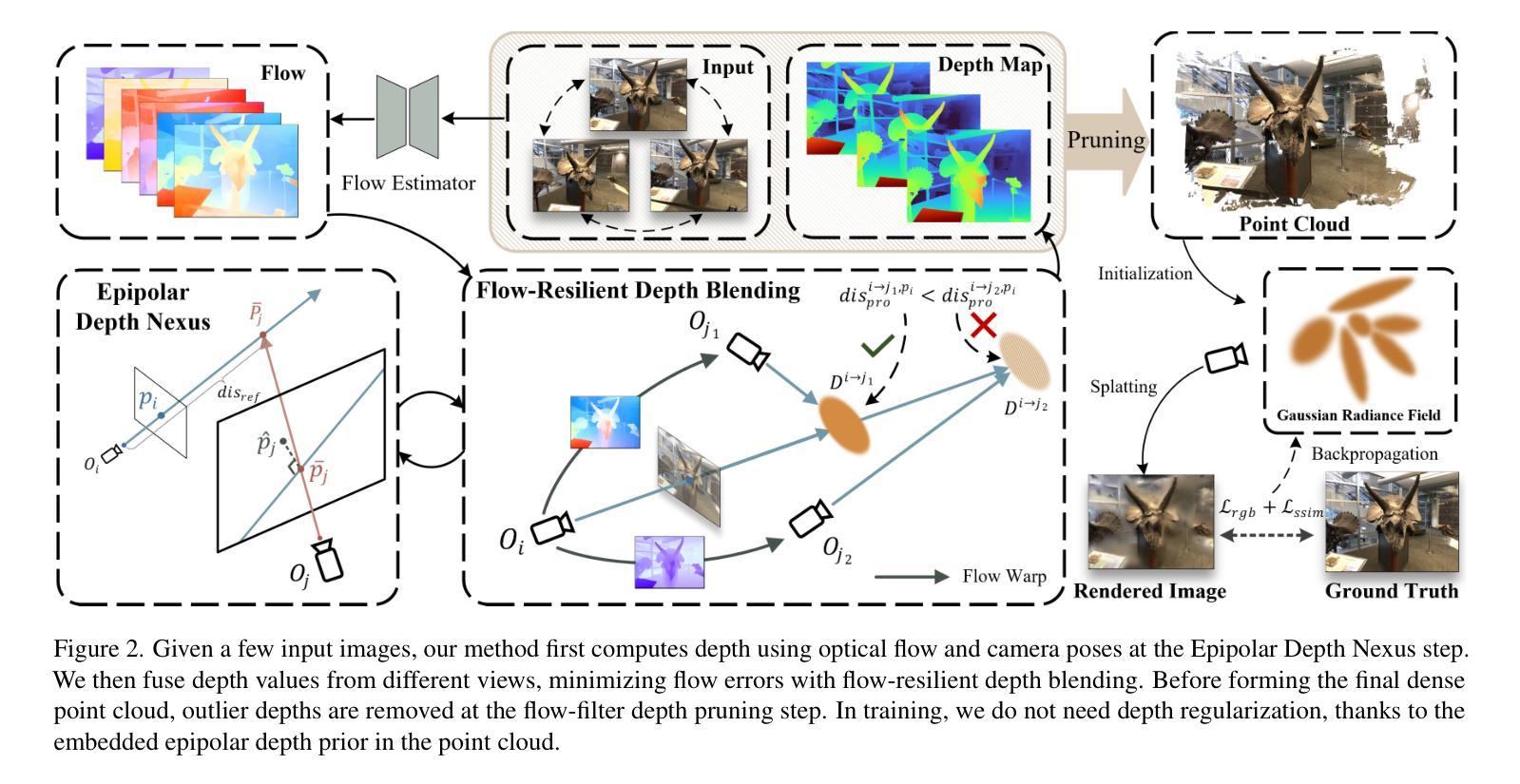
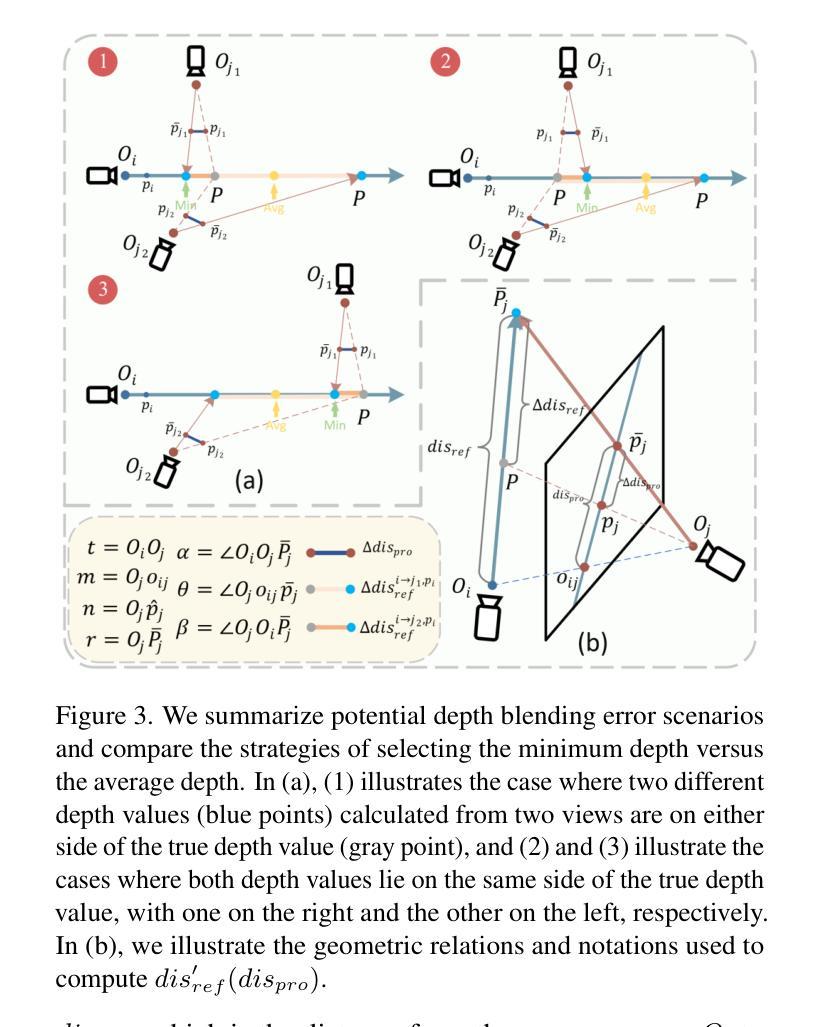
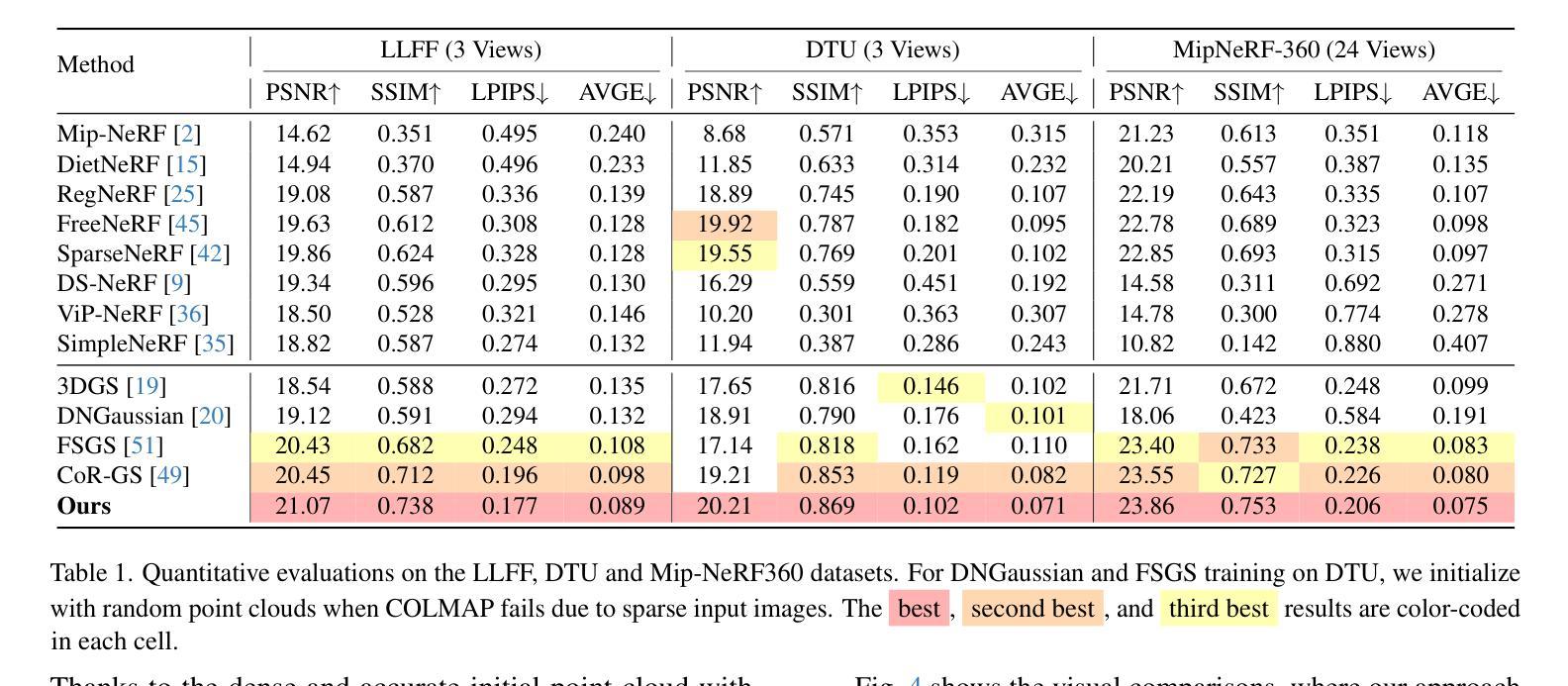
NexusGS: Sparse View Synthesis with Epipolar Depth Priors in 3D Gaussian Splatting
Authors:Yulong Zheng, Zicheng Jiang, Shengfeng He, Yandu Sun, Junyu Dong, Huaidong Zhang, Yong Du
Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have noticeably advanced photo-realistic novel view synthesis using images from densely spaced camera viewpoints. However, these methods struggle in few-shot scenarios due to limited supervision. In this paper, we present NexusGS, a 3DGS-based approach that enhances novel view synthesis from sparse-view images by directly embedding depth information into point clouds, without relying on complex manual regularizations. Exploiting the inherent epipolar geometry of 3DGS, our method introduces a novel point cloud densification strategy that initializes 3DGS with a dense point cloud, reducing randomness in point placement while preventing over-smoothing and overfitting. Specifically, NexusGS comprises three key steps: Epipolar Depth Nexus, Flow-Resilient Depth Blending, and Flow-Filtered Depth Pruning. These steps leverage optical flow and camera poses to compute accurate depth maps, while mitigating the inaccuracies often associated with optical flow. By incorporating epipolar depth priors, NexusGS ensures reliable dense point cloud coverage and supports stable 3DGS training under sparse-view conditions. Experiments demonstrate that NexusGS significantly enhances depth accuracy and rendering quality, surpassing state-of-the-art methods by a considerable margin. Furthermore, we validate the superiority of our generated point clouds by substantially boosting the performance of competing methods. Project page: https://usmizuki.github.io/NexusGS/.
神经辐射场(NeRF)和三维高斯贴片(3DGS)利用密集间隔相机视角的图像,显著地推进了逼真的新型视图合成。然而,这些方法在少量样本的场景中由于监督有限而表现不佳。在本文中,我们提出了NexusGS,这是一种基于3DGS的方法,它通过直接将深度信息嵌入点云中,提高了从稀疏视图图像进行的新型视图合成的质量,而无需依赖复杂的手动正则化。利用3DGS的固有极线几何,我们的方法引入了一种新的点云密集化策略,该策略使用密集的点云初始化3DGS,减少了点放置的随机性,同时防止过度平滑和过度拟合。具体来说,NexusGS包含三个关键步骤:极线深度Nexus、流适应深度混合和流过滤深度修剪。这些步骤利用光学流和相机姿态来计算准确的深度图,同时减轻与光学流通常相关的误差。通过引入极线深度先验,NexusGS确保可靠且密集的点云覆盖,并在稀疏视图条件下支持稳定的3DGS训练。实验表明,NexusGS显著提高了深度准确性和渲染质量,大大超越了现有最先进的水平。此外,我们通过大幅提升竞争对手方法的性能来验证了我们生成点云的优越性。项目页面:https://usmizuki.github.io/NexusGS/。
论文及项目相关链接
PDF This paper is accepted by CVPR 2025
Summary
NeRF和3DGS在密集相机视角的图像上实现了逼真的新视角合成,但在少量图像的情况下表现不佳。本文提出NexusGS,一种基于3DGS的方法,通过直接在点云中嵌入深度信息,提高稀疏视角图像的新视角合成效果。该方法利用3DGS的固有极几何特性,引入新型点云密集化策略,以密集点云初始化3DGS,减少点放置的随机性,防止过度平滑和过度拟合。NexusGS包括三个关键步骤:极深度Nexus、抗漂移深度混合和流过滤深度修剪。这些方法利用光学流和相机姿态计算准确深度图,缓解与光学流相关的不准确性。通过结合极深度先验,NexusGS确保可靠的密集点云覆盖,并在稀疏视角条件下实现稳定的3DGS训练。实验表明,NexusGS显著提高深度准确性和渲染质量,大大超越现有方法。
Key Takeaways
- NeRF和3DGS在密集相机视角的图像上表现优异,但在少量图像的情况下存在挑战。
- NexusGS是一种基于3DGS的方法,旨在提高稀疏视角图像的新视角合成效果。
- NexusGS利用3DGS的固有极几何特性,通过密集点云初始化,减少点放置的随机性。
- NexusGS包括三个关键步骤:极深度Nexus、抗漂移深度混合和流过滤深度修剪。
- NexusGS利用光学流和相机姿态计算深度图,缓解与光学流相关的不准确性。
- NexusGS通过结合极深度先验,确保可靠的密集点云覆盖,实现稳定训练。
- 实验表明,NexusGS在深度准确性和渲染质量上超越现有方法。
点此查看论文截图

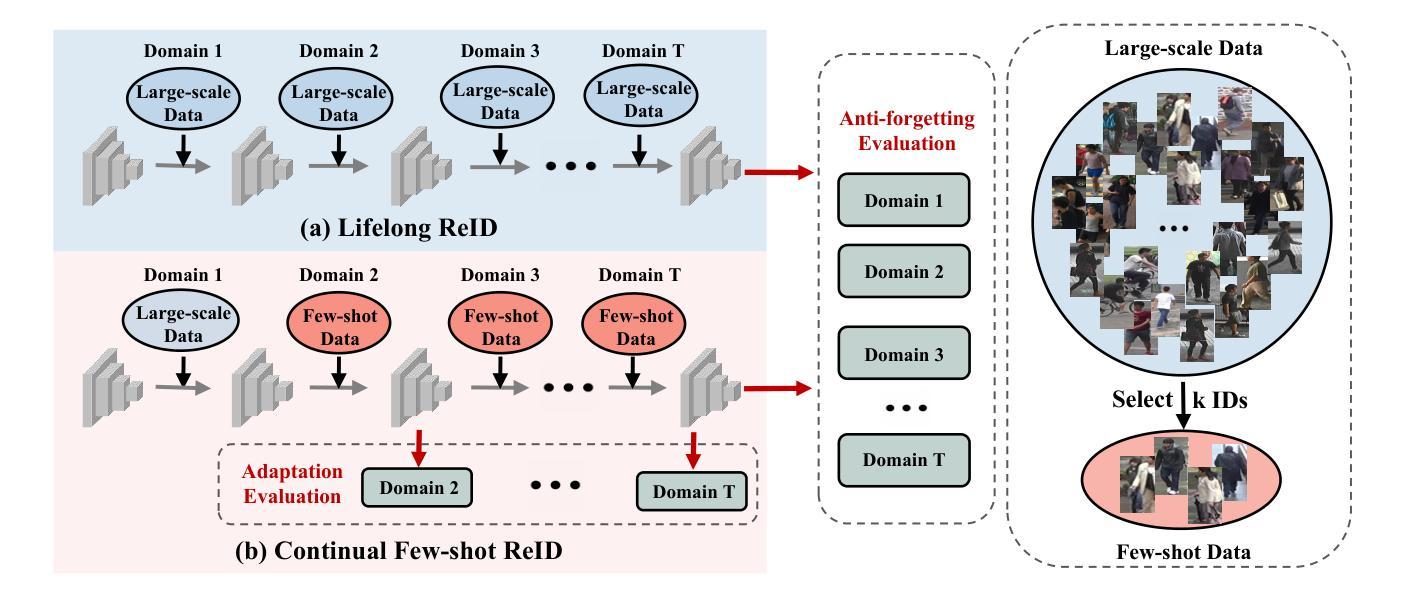
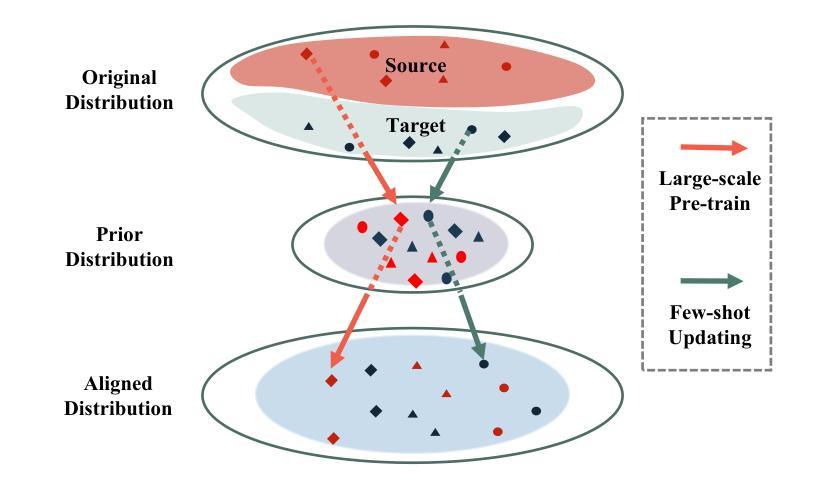
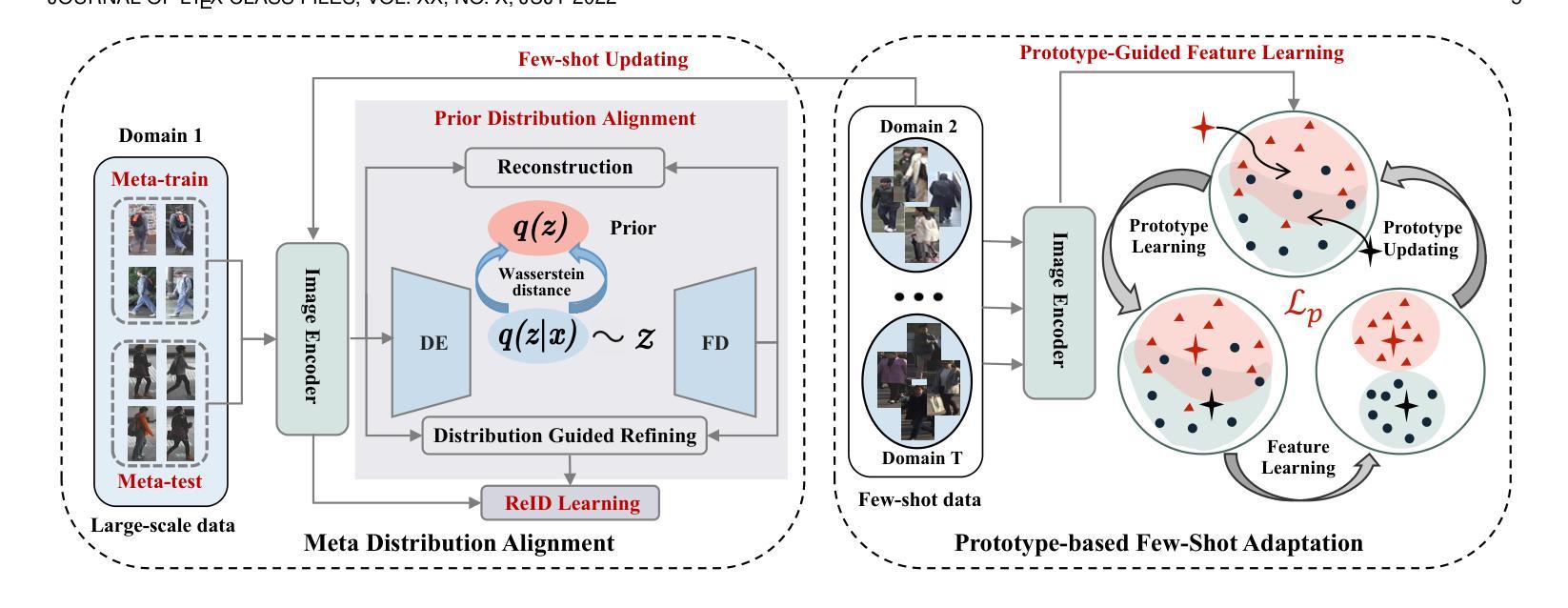
CFReID: Continual Few-shot Person Re-Identification
Authors:Hao Ni, Lianli Gao, Pengpeng Zeng, Heng Tao Shen, Jingkuan Song
Real-world surveillance systems are dynamically evolving, requiring a person Re-identification model to continuously handle newly incoming data from various domains. To cope with these dynamics, Lifelong ReID (LReID) has been proposed to learn and accumulate knowledge across multiple domains incrementally. However, LReID models need to be trained on large-scale labeled data for each unseen domain, which are typically inaccessible due to privacy and cost concerns. In this paper, we propose a new paradigm called Continual Few-shot ReID (CFReID), which requires models to be incrementally trained using few-shot data and tested on all seen domains. Under few-shot conditions, CFREID faces two core challenges: 1) learning knowledge from few-shot data of unseen domain, and 2) avoiding catastrophic forgetting of seen domains. To tackle these two challenges, we propose a Stable Distribution Alignment (SDA) framework from feature distribution perspective. Specifically, our SDA is composed of two modules, i.e., Meta Distribution Alignment (MDA) and Prototype-based Few-shot Adaptation (PFA). To support the study of CFReID, we establish an evaluation benchmark for CFReID on five publicly available ReID datasets. Extensive experiments demonstrate that our SDA can enhance the few-shot learning and anti-forgetting capabilities under few-shot conditions. Notably, our approach, using only 5% of the data, i.e., 32 IDs, significantly outperforms LReID’s state-of-the-art performance, which requires 700 to 1,000 IDs.
现实世界监控系统正在动态演变,需要行人重识别模型持续处理来自不同领域的新数据。为了应对这些动态变化,提出了终身ReID(LReID)以增量方式在不同领域学习和积累知识。然而,LReID模型需要在每个未见领域的大规模标签数据上进行训练,由于隐私和成本担忧,这些通常无法获得。在本文中,我们提出了一种新的方法,称为持续小样本ReID(CFReID),需要模型使用小样本数据进行增量训练,并在所有已见领域上进行测试。在小样本条件下,CFReID面临两个核心挑战:1)从未见领域的小样本数据中学习知识,2)避免已见领域的灾难性遗忘。为了应对这两个挑战,我们从特征分布的角度提出了稳定分布对齐(SDA)框架。具体而言,我们的SDA由两个模块组成,即元分布对齐(MDA)和基于原型的少样本适应(PFA)。为了支持对CFReID的研究,我们在五个公开的ReID数据集上建立了CFReID评估基准。大量实验表明,我们的SDA可以增强小样本学习能力和抗遗忘能力。值得注意的是,我们的方法仅使用5%的数据,即32个ID,就显著优于LReID的最新性能,后者需要700到1000个ID。
论文及项目相关链接
PDF 16 pages, 8 figures
Summary
这篇论文提出了一种新的持续少样本重识别(CFReID)方法,用于解决现实世界监控系统中的动态变化问题。CFReID要求模型在少量数据上增量学习,并测试在所有已见领域上的表现。为解决从未见领域的少量数据学习和避免已见领域的灾难性遗忘这两个核心挑战,论文提出了稳定分布对齐(SDA)框架,包括元分布对齐(MDA)和基于原型的少量适应(PFA)两个模块。在五个公开可用的ReID数据集上的评估表明,SDA增强了少样本学习的抗遗忘能力。
Key Takeaways
- 论文提出了持续少样本重识别(CFReID)方法,适应动态变化的监控系统需求。
- CFReID面临两大挑战:从未见领域的少量数据学习和避免已见领域的灾难性遗忘。
- 为解决这些挑战,论文提出了稳定分布对齐(SDA)框架,包括MDA和PFA两个模块。
- SDA框架通过特征分布角度增强少样本学习能力。
- 论文建立了CFReID的评估基准,并在五个公开ReID数据集上进行广泛实验。
- 实验结果表明,SDA框架显著提升了少样本学习和抗遗忘能力。
点此查看论文截图

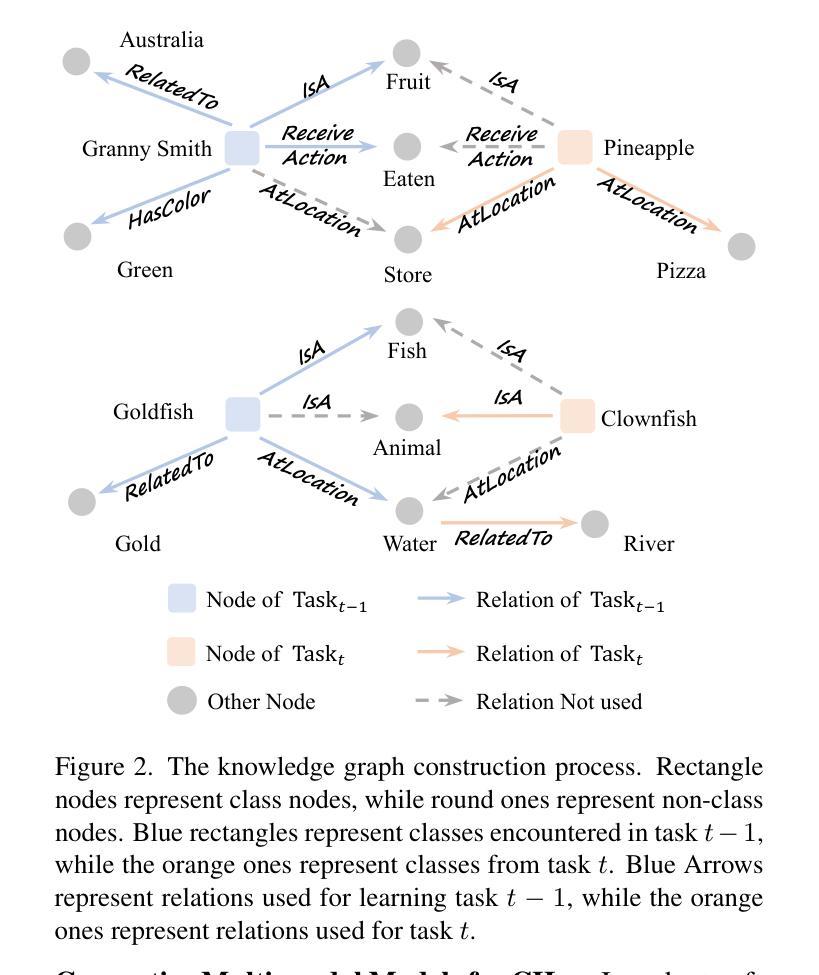
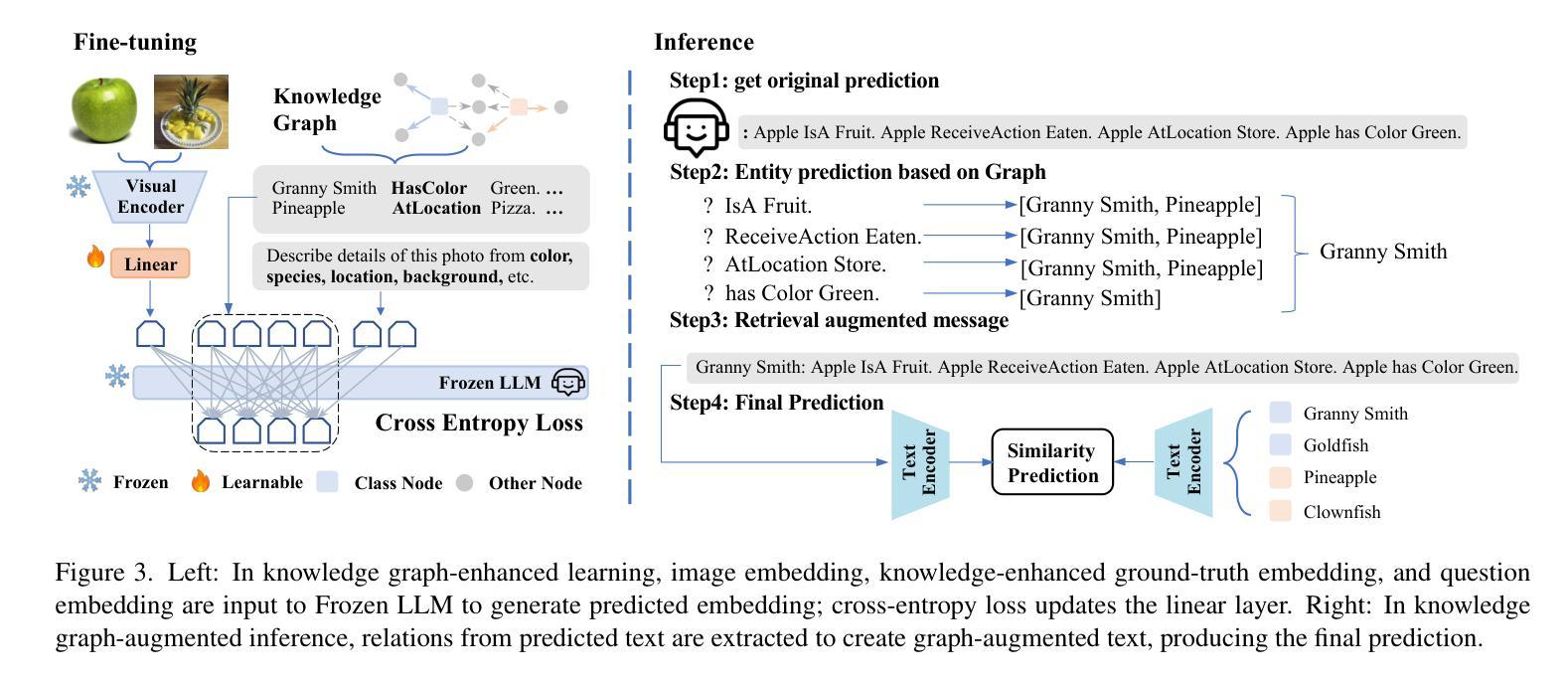
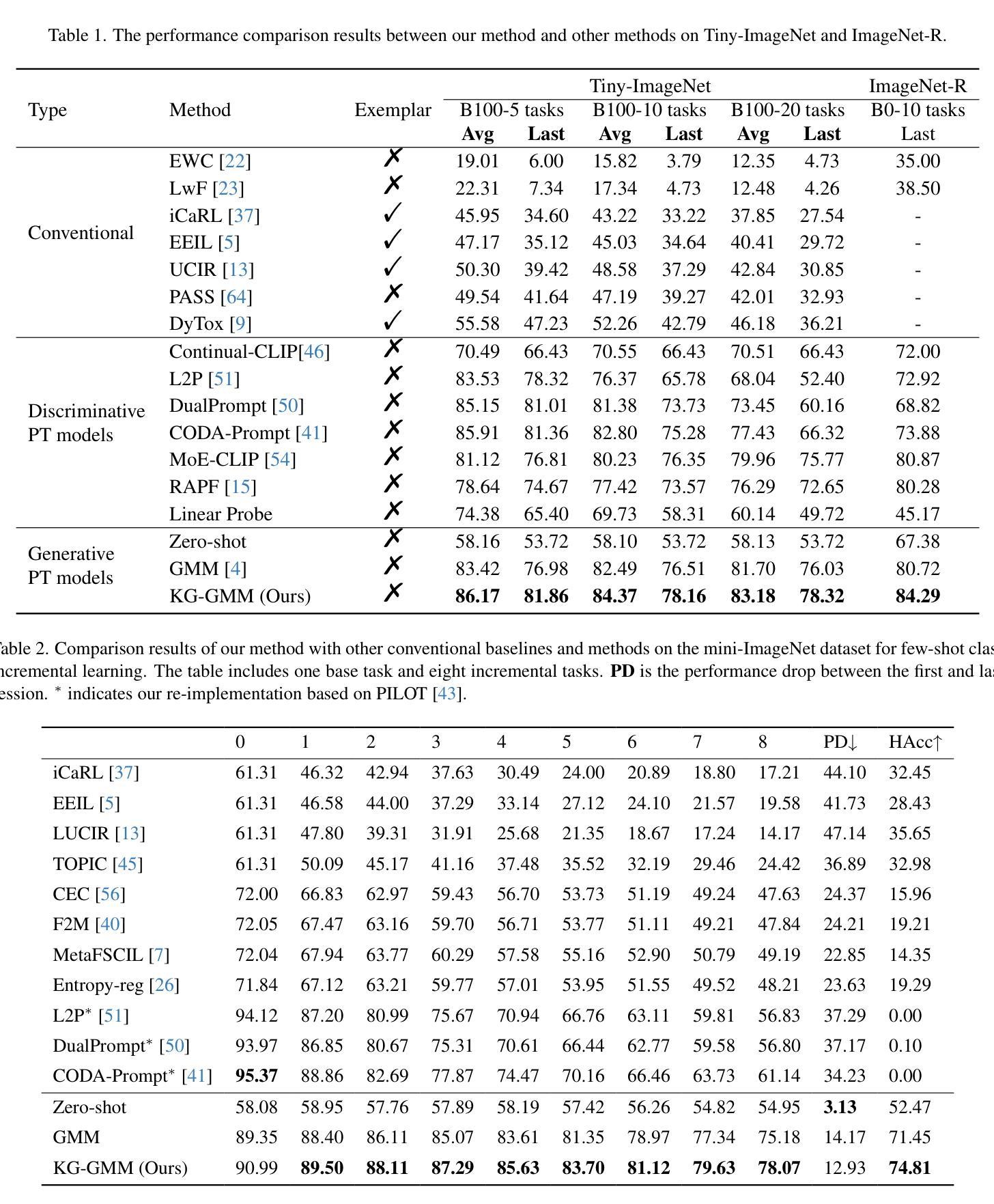
Knowledge Graph Enhanced Generative Multi-modal Models for Class-Incremental Learning
Authors:Xusheng Cao, Haori Lu, Linlan Huang, Fei Yang, Xialei Liu, Ming-Ming Cheng
Continual learning in computer vision faces the critical challenge of catastrophic forgetting, where models struggle to retain prior knowledge while adapting to new tasks. Although recent studies have attempted to leverage the generalization capabilities of pre-trained models to mitigate overfitting on current tasks, models still tend to forget details of previously learned categories as tasks progress, leading to misclassification. To address these limitations, we introduce a novel Knowledge Graph Enhanced Generative Multi-modal model (KG-GMM) that builds an evolving knowledge graph throughout the learning process. Our approach utilizes relationships within the knowledge graph to augment the class labels and assigns different relations to similar categories to enhance model differentiation. During testing, we propose a Knowledge Graph Augmented Inference method that locates specific categories by analyzing relationships within the generated text, thereby reducing the loss of detailed information about old classes when learning new knowledge and alleviating forgetting. Experiments demonstrate that our method effectively leverages relational information to help the model correct mispredictions, achieving state-of-the-art results in both conventional CIL and few-shot CIL settings, confirming the efficacy of knowledge graphs at preserving knowledge in the continual learning scenarios.
计算机视觉中的持续学习面临着灾难性遗忘的关键挑战,模型在适应新任务的同时,很难保留先验知识。尽管最近有研究表明试图利用预训练模型的泛化能力来缓解对当前任务的过度拟合,但随着任务的进展,模型仍然倾向于忘记先前学习类别的细节,从而导致误分类。为了解决这些局限性,我们引入了一种新型知识图谱增强生成多模态模型(KG-GMM),它在学习过程中构建了一个不断进化的知识图谱。我们的方法利用知识图谱内的关系来增强类别标签,并为相似类别分配不同的关系以增强模型的区别能力。在测试阶段,我们提出了一种知识图谱增强推理方法,通过分析生成文本内的关系来定位特定类别,从而减少在学习新知识时丢失旧类的详细信息,并缓解遗忘。实验表明,我们的方法有效地利用了关系信息,帮助模型纠正误预测,在常规CIL和少样本CIL设置中都达到了最新水平的结果,证实了知识图谱在持续学习场景中保留知识的有效性。
论文及项目相关链接
摘要
针对计算机视觉中的持续学习面临的挑战——灾难性遗忘问题,文中提出一种新型知识图谱增强生成多模态模型(KG-GMM)。该模型通过构建知识图谱来应对学习过程中的遗忘问题。KG-GMM利用知识图谱中的关系来增强类标签,并为相似类别分配不同的关系以增强模型的区分能力。在测试阶段,通过知识图谱增强推理方法,分析生成的文本中的关系来确定特定类别,从而减少学习新知识时旧类详细信息的丢失,并缓解遗忘问题。实验表明,该方法有效利用关系信息,有助于模型纠正误预测,在常规和少样本持续学习场景中均取得最新成果,证实了知识图谱在持续学习场景中保留知识的有效性。
关键见解
- 计算机视觉中的持续学习面临灾难性遗忘的挑战。
- 现有研究尝试利用预训练模型的泛化能力来缓解对当前任务的过度拟合,但模型仍然容易忘记先前学到的类别的细节。
- 引入了一种新型知识图谱增强生成多模态模型(KG-GMM),该模型通过构建知识图谱来应对学习过程中的遗忘问题。
- KG-GMM利用知识图谱中的关系来增强类标签,并为相似类别分配不同的关系以增强模型的区分能力。
- 提出了一种知识图谱增强推理方法,通过该方法可以分析生成的文本中的关系来确定特定类别,从而减少旧类详细信息的丢失。
- 实验表明,KG-GMM在常规和少样本持续学习场景中均表现优异,利用关系信息有效纠正误预测。
- 知识图谱对于在持续学习场景中保留知识具有有效性。
点此查看论文截图


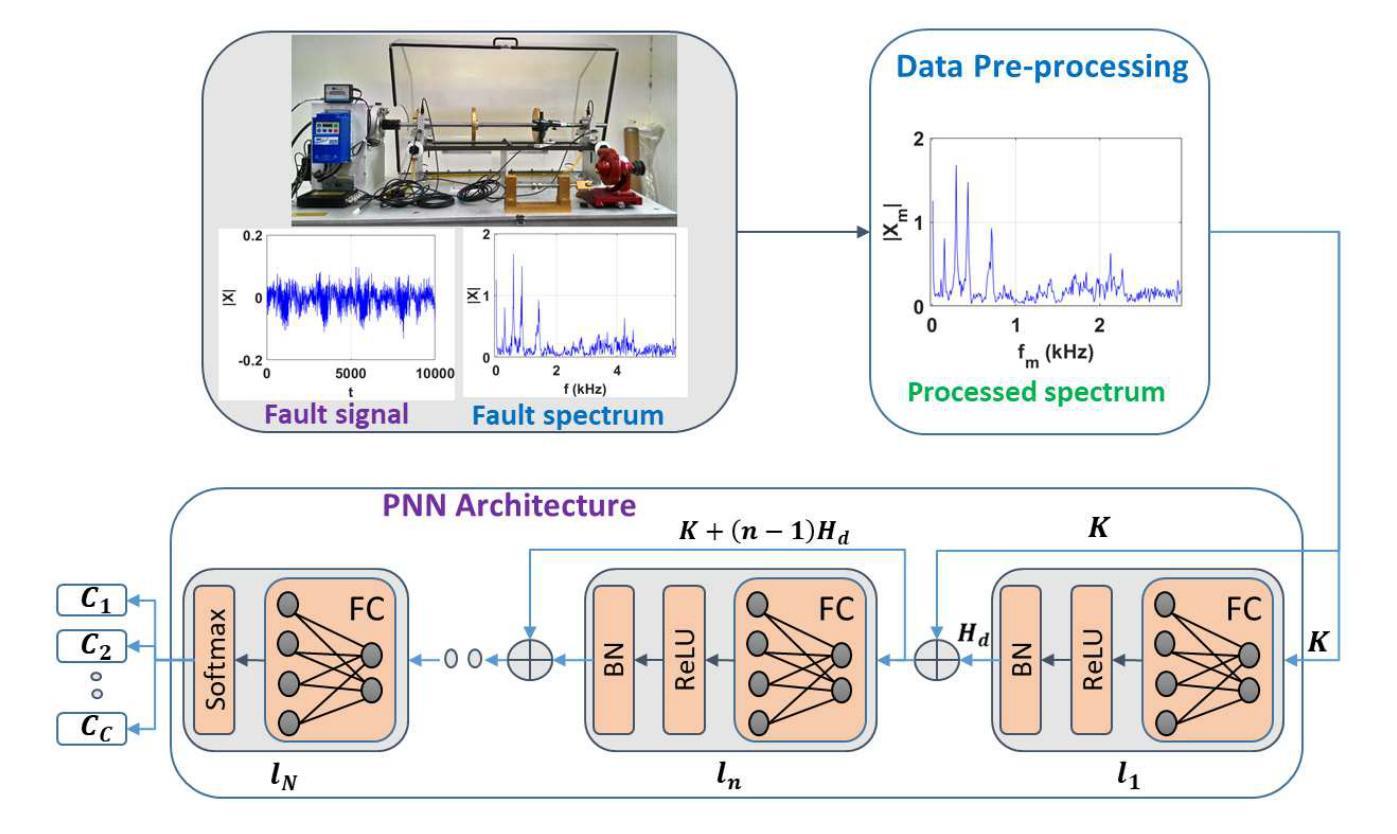
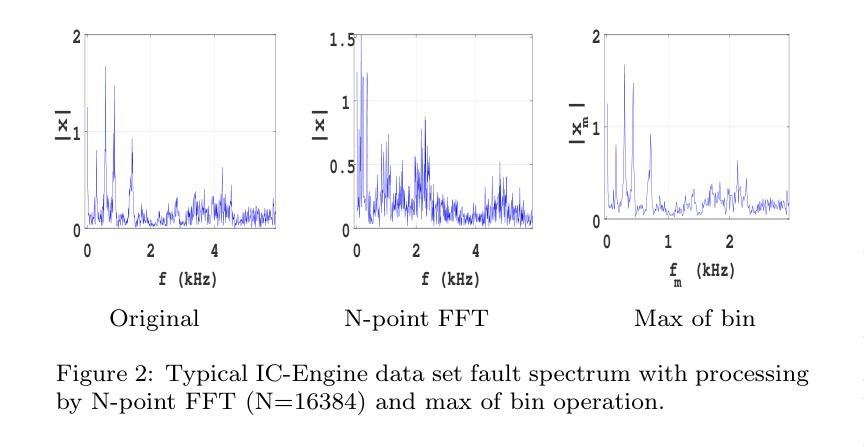
PNN: A Novel Progressive Neural Network for Fault Classification in Rotating Machinery under Small Dataset Constraint
Authors:Praveen Chopra, Himanshu Kumar, Sandeep Yadav
Fault detection in rotating machinery is a complex task, particularly in small and heterogeneous dataset scenarios. Variability in sensor placement, machinery configurations, and structural differences further increase the complexity of the problem. Conventional deep learning approaches often demand large, homogeneous datasets, limiting their applicability in data-scarce industrial environments. While transfer learning and few-shot learning have shown potential, however, they are often constrained by the need for extensive fault datasets. This research introduces a unified framework leveraging a novel progressive neural network (PNN) architecture designed to address these challenges. The PNN sequentially estimates the fixed-size refined features of the higher order with the help of all previously estimated features and appends them to the feature set. This fixed-size feature output at each layer controls the complexity of the PNN and makes it suitable for effective learning from small datasets. The framework’s effectiveness is validated on eight datasets, including six open-source datasets, one in-house fault simulator, and one real-world industrial dataset. The PNN achieves state-of-the-art performance in fault detection across varying dataset sizes and machinery types, highlighting superior generalization and classification capabilities.
旋转机械故障诊断是一项复杂的任务,特别是在小型和异构数据集场景中。传感器放置、机械配置和结构差异的可变性进一步增加了问题的复杂性。传统的深度学习方法通常需要大型、同质的数据集,这在数据稀缺的工业环境中限制了其应用。尽管迁移学习和少样本学习已经显示出潜力,但它们往往受到需要大量故障数据集的限制。本研究引入了一个统一的框架,利用了一种新型渐进神经网络(PNN)架构来解决这些挑战。PNN借助所有先前估计的特征顺序地估计高阶的固定大小精细特征,并将其添加到特征集中。每层固定的特征输出控制PNN的复杂性,使其适合从小规模数据集中进行有效学习。该框架的有效性在八个数据集上得到了验证,包括六个开源数据集、一个内部故障模拟器和一个真实工业数据集。PNN在不同数据集大小和机械类型上实现了故障检测的最新性能,突出了其出色的泛化和分类能力。
论文及项目相关链接
Summary
旋转机械故障检测是一项复杂的任务,尤其是在小样本和异构图数据集中更具挑战性。研究引入了一种利用新颖渐进神经网络(PNN)架构的统一框架,旨在解决这些问题。PNN能够利用先前估计的特征来估计更高阶的固定大小精细特征,并追加到特征集中。框架的有效性在多个数据集上得到验证,包括六个开源数据集、一个内部故障模拟器和一个真实的工业数据集。PNN在故障检测方面达到了最先进的性能水平,突显了其出色的泛化和分类能力。
Key Takeaways
- 旋转机械故障检测面临复杂性和数据挑战。
- 传统深度学习方法在数据稀缺的工业环境中适用性有限。
- 研究引入了一种基于新颖渐进神经网络(PNN)的统一框架来解决此问题。
- PNN能够通过利用先前估计的特征来估计更高阶的固定大小精细特征。
- PNN架构适合从小规模数据集中进行有效学习。
- 框架在多个数据集上的验证显示了其有效性。
点此查看论文截图

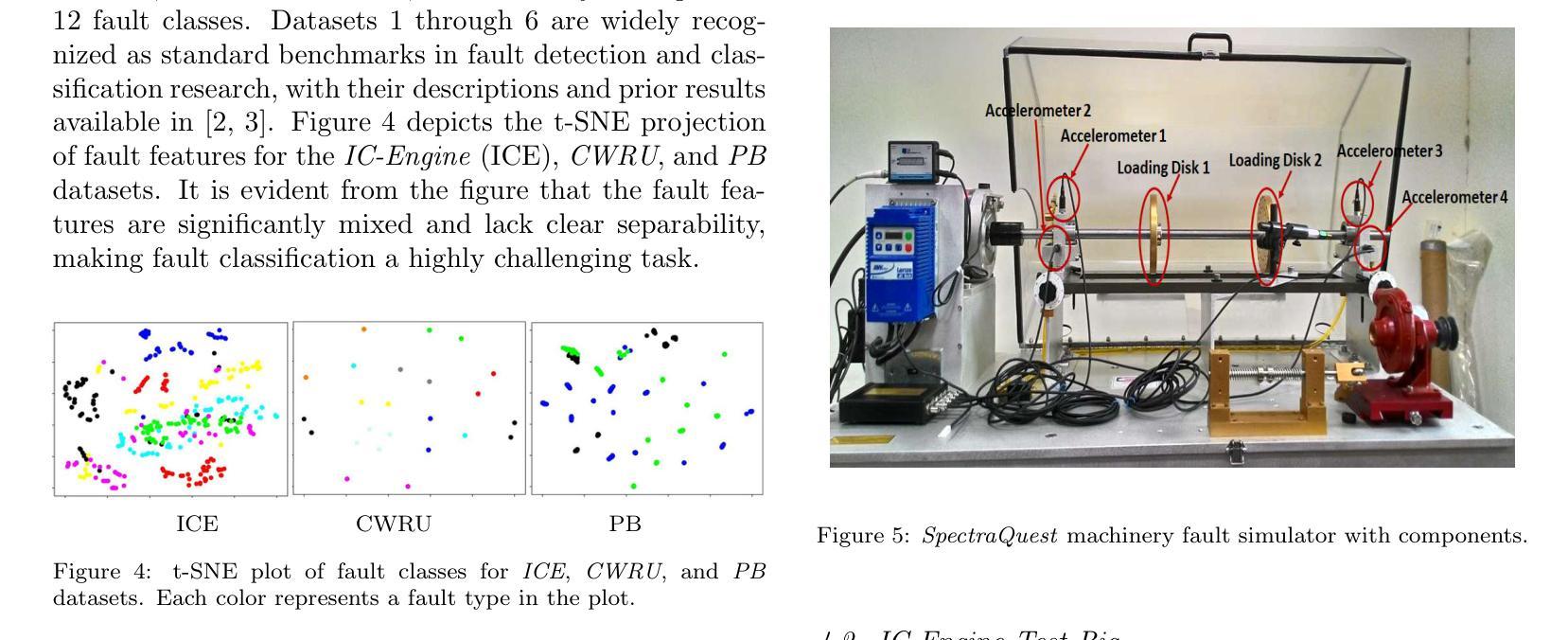
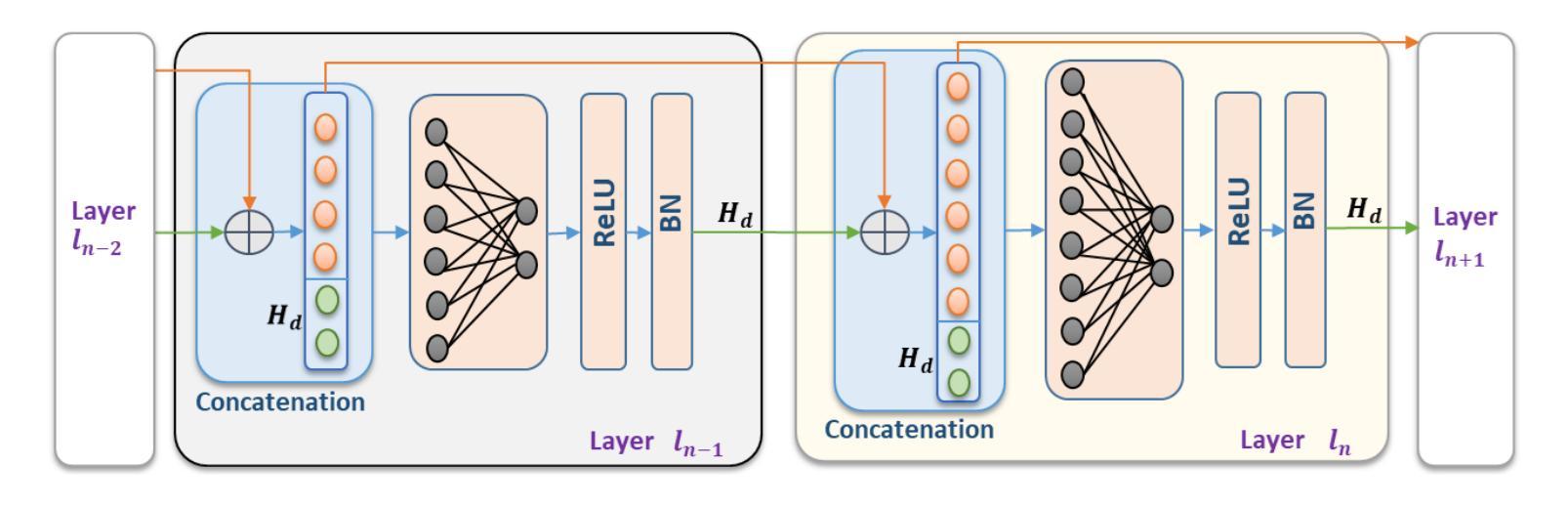
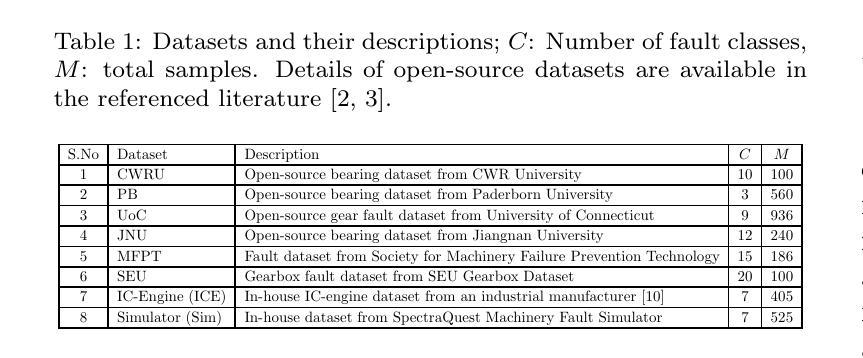
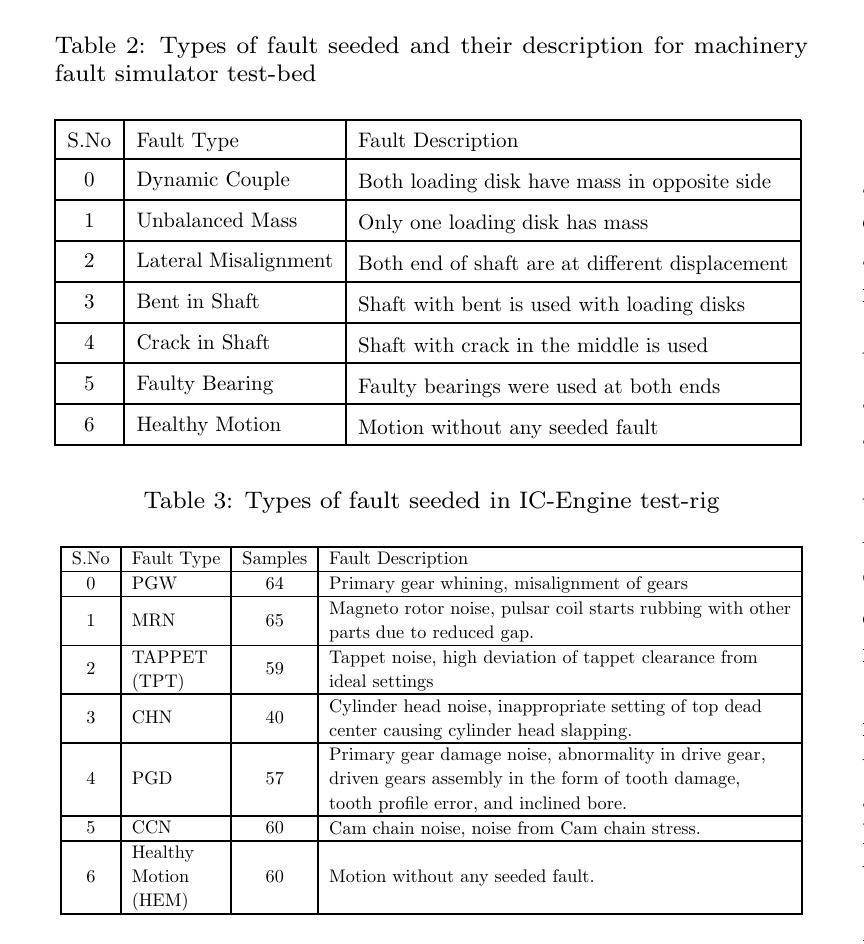
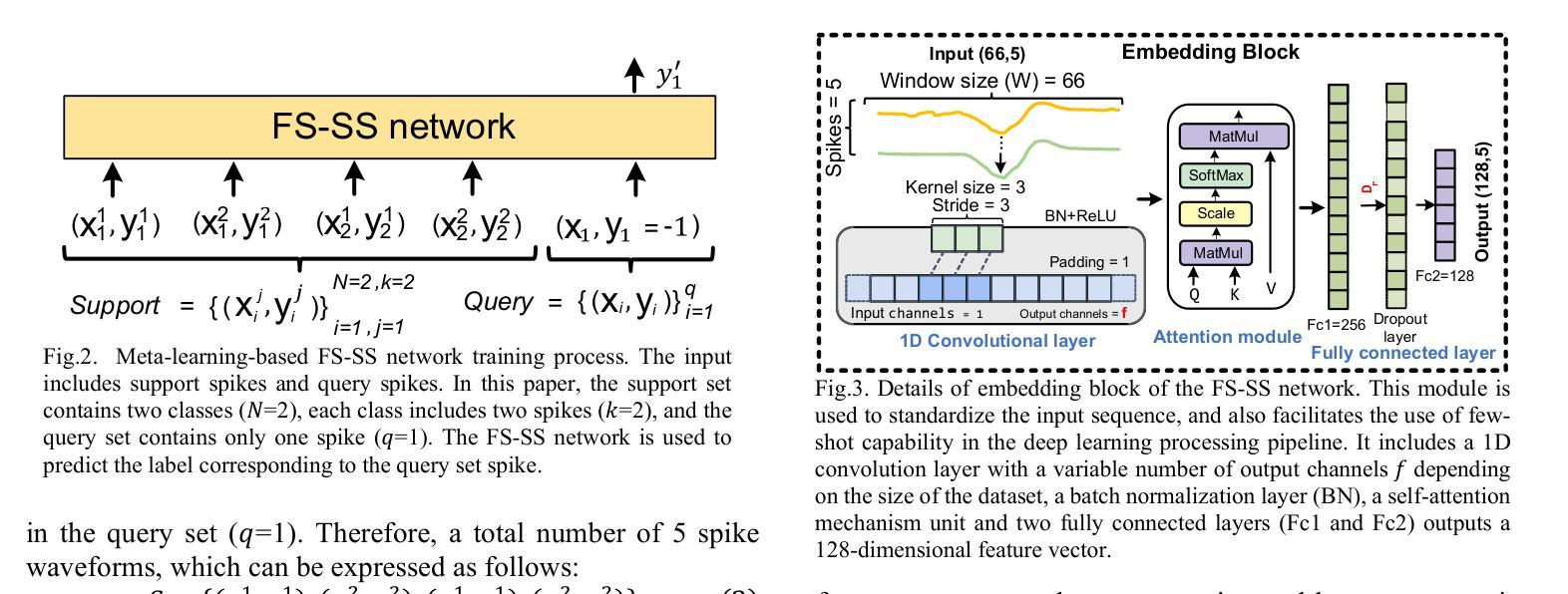
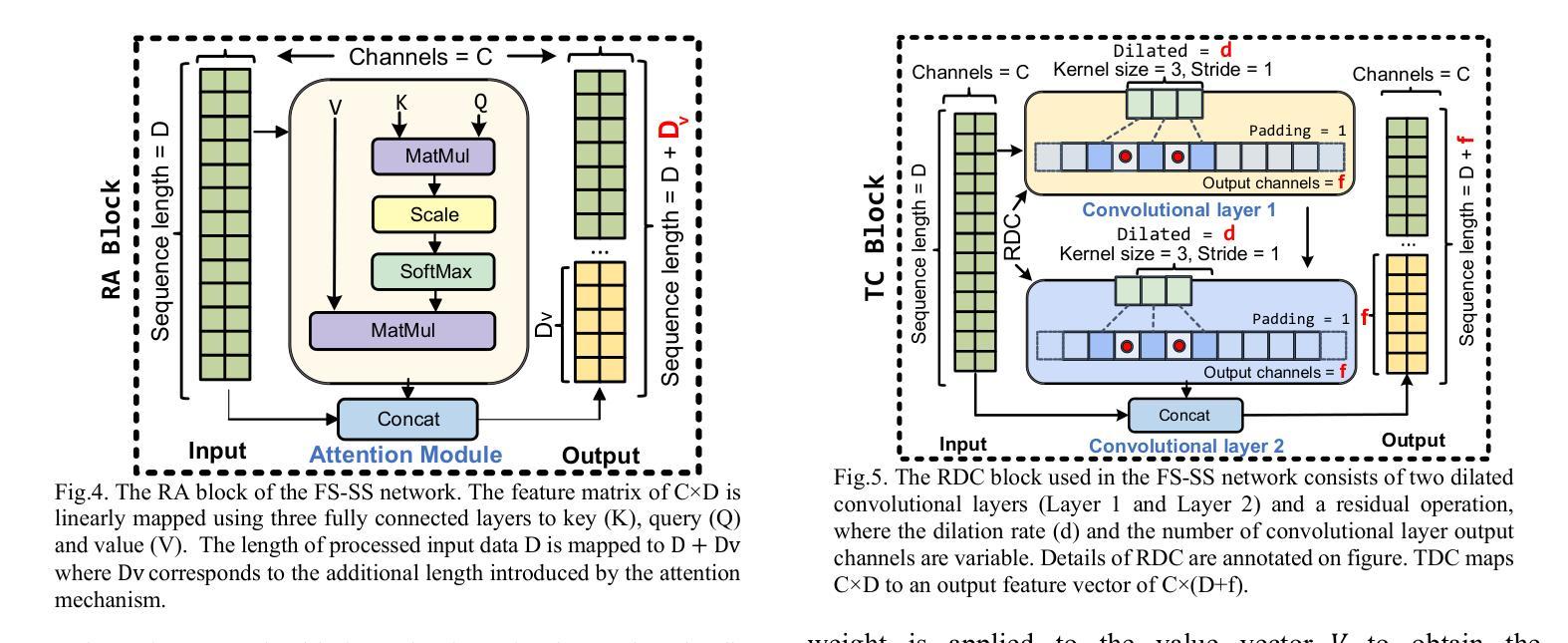
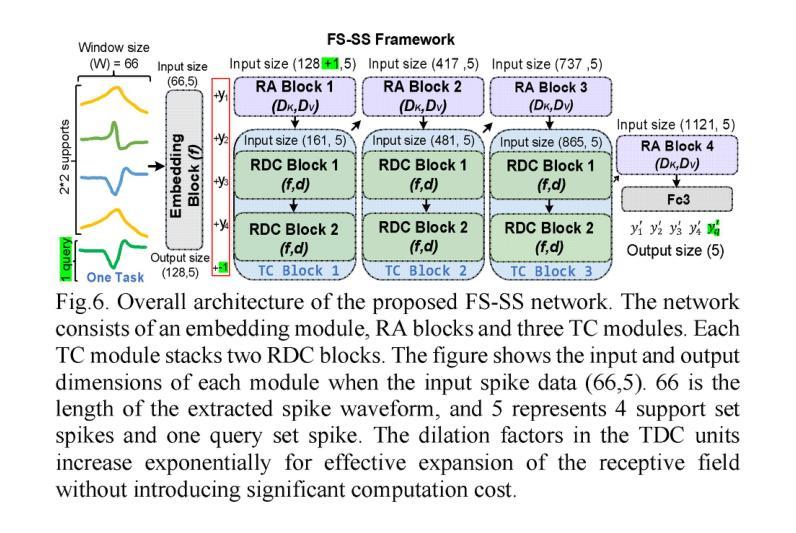
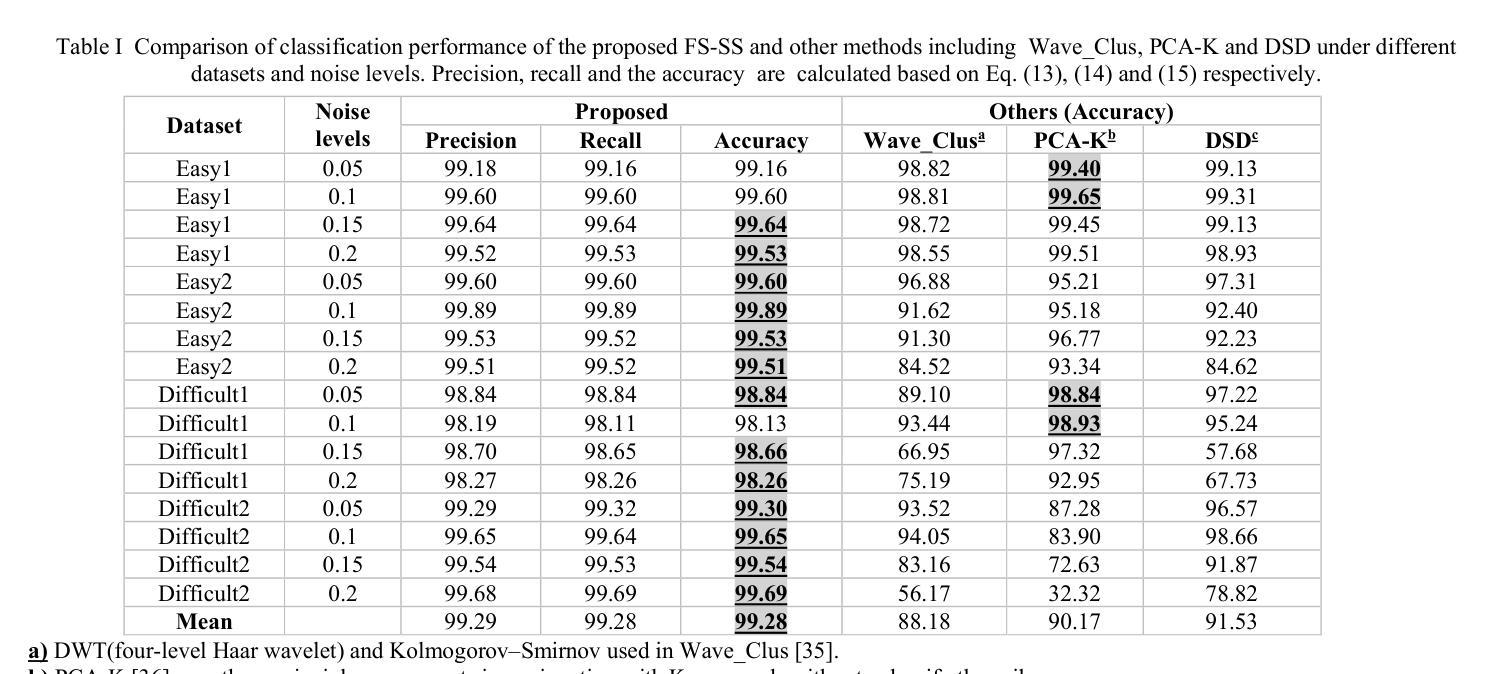
FS-SS: Few-Shot Learning for Fast and Accurate Spike Sorting of High-channel Count Probes
Authors:Tao Fang, Majid Zamani
There is a need for fast adaptation in spike sorting algorithms to implement brain-machine interface (BMIs) in different applications. Learning and adapting the functionality of the sorting process in real-time can significantly improve the performance. However, deep neural networks (DNNs) depend on large amounts of data for training models and their performance sustainability decreases when data is limited. Inspired by meta-learning, this paper proposes a few-shot spike sorting framework (FS-SS) with variable network model size that requires minimal learning training and supervision. The framework is not only compatible with few-shot adaptations, but also it uses attention mechanism and dilated convolutional neural networks. This allows scaling the network parameters to learn the important features of spike signals and to quickly generalize the learning ability to new spike waveforms in recording channels after few observations. The FS-SS was evaluated by using freely accessible datasets, also compared with the other state-of-the-art algorithms. The average classification accuracy of the proposed method is 99.28%, which shows extreme robustness to background noise and similarity of the spike waveforms. When the number of training samples is reduced by 90%, the parameter scale is reduced by 68.2%, while the accuracy only decreased by 0.55%. The paper also visualizes the model’s attention distribution under spike sorting tasks of different difficulty levels. The attention distribution results show that the proposed model has clear interpretability and high robustness.
对于在不同应用中实施脑机接口(BMIs)的脉冲排序算法,需要快速适应。实时学习和适应排序过程的功能可以显著提高性能。然而,深度神经网络(DNNs)依赖于大量数据进行模型训练,当数据量有限时,其性能可持续性会降低。本文受元学习的启发,提出了一种样本量小的脉冲排序框架(FS-SS),该框架具有可变网络模型大小,需要的学习训练和监督最少。该框架不仅兼容小样本适应,还采用注意力机制和膨胀卷积神经网络。这允许在少量观察后,根据网络参数调整学习重要特征脉冲信号的能力,并迅速将学习能力推广到新的脉冲波形记录通道。通过使用可自由访问的数据集对FS-SS进行评估,并与其它最新算法进行比较。所提方法的平均分类准确率为99.28%,显示出对背景噪声和脉冲波形相似性的极高稳健性。当训练样本数量减少90%时,参数规模减少了68.2%,而准确率仅下降了0.55%。论文还可视化模型在不同难度级别脉冲排序任务下的注意力分布结果。注意力分布结果表明,所提出的模型具有明确的解释性和高稳健性。
论文及项目相关链接
PDF 10 pages
Summary
本文介绍了一种基于元学习的新型快速适应的神经元放电排序算法框架FS-SS。该框架具备可变网络模型大小,能够在少量样本上进行学习和适应,同时采用注意力机制和膨胀卷积神经网络来快速学习神经元放电信号的关键特征,并快速适应新的放电波形。实验结果表明,该框架具有极高的分类准确率和强大的稳健性,可以在降低训练样本数量时仍能维持较高性能。
Key Takeaways
- FS-SS框架利用元学习进行快速适应,可在不同应用中实现大脑-机器接口。
- 该框架采用可变网络模型大小设计,需要少量数据样本和极少监督。
- 使用注意力机制和膨胀卷积神经网络实现精确和快速学习。
- 相比现有技术,FS-SS框架在分类准确率上表现优异,对背景噪声和相似放电波形表现出极高稳健性。
- 当减少训练样本数量时,FS-SS框架的性能降低幅度较小。
- 论文可视化展示了模型在不同难度级别下的注意力分布结果,证明了其高解释性和稳健性。
点此查看论文截图

PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Authors:Yan Zhang, Yao Feng, Alpár Cseke, Nitin Saini, Nathan Bajandas, Nicolas Heron, Michael J. Black
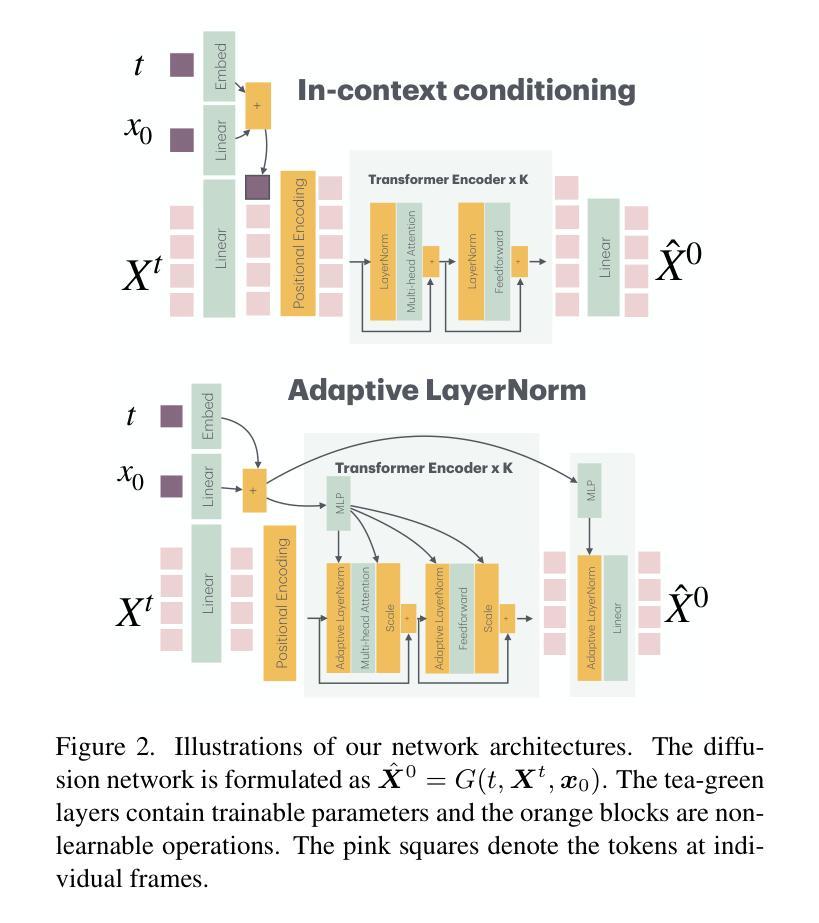
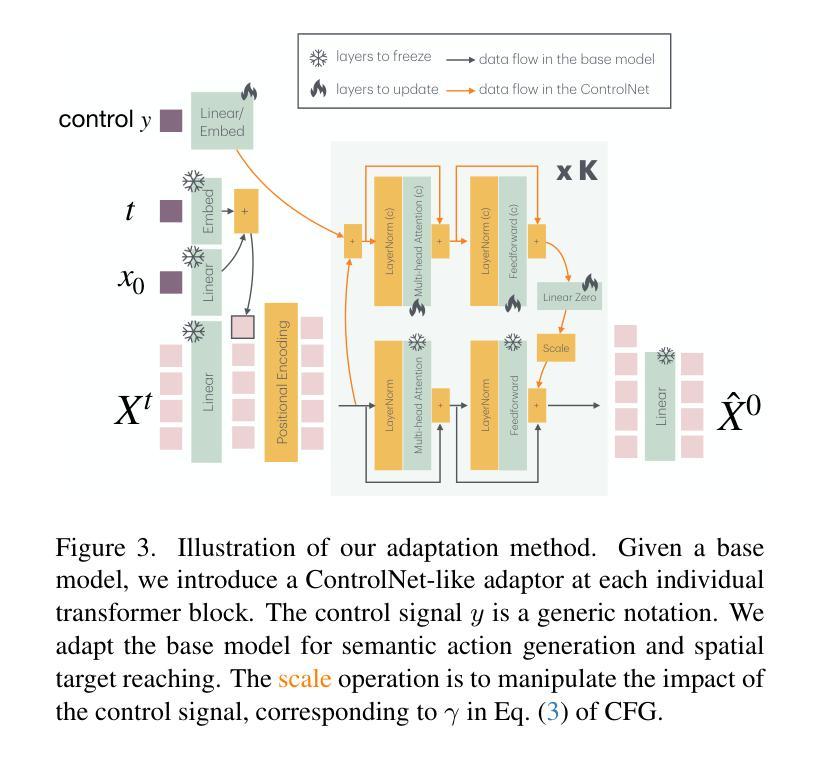
To build a motor system of the interactive avatar, it is essential to develop a generative motion model drives the body to move through 3D space in a perpetual, realistic, controllable, and responsive manner. Although motion generation has been extensively studied, most methods do not support embodied intelligence'' due to their offline setting, slow speed, limited motion lengths, or unnatural movements. To overcome these limitations, we propose PRIMAL, an autoregressive diffusion model that is learned with a two-stage paradigm, inspired by recent advances in foundation models. In the pretraining stage, the model learns motion dynamics from a large number of sub-second motion segments, providing motor primitives’’ from which more complex motions are built. In the adaptation phase, we employ a ControlNet-like adaptor to fine-tune the motor control for semantic action generation and spatial target reaching. Experiments show that physics effects emerge from our training. Given a single-frame initial state, our model not only generates unbounded, realistic, and controllable motion, but also enables the avatar to be responsive to induced impulses in real time. In addition, we can effectively and efficiently adapt our base model to few-shot personalized actions and the task of spatial control. Evaluations show that our proposed method outperforms state-of-the-art baselines. We leverage the model to create a real-time character animation system in Unreal Engine that is highly responsive and natural. Code, models, and more results are available at: https://yz-cnsdqz.github.io/eigenmotion/PRIMAL
为了构建交互式虚拟角色的运动系统,关键在于开发一种生成性运动模型,该模型能够驱动角色在三维空间中以持续、现实、可控和响应迅速的方式移动。尽管运动生成已经得到了广泛的研究,但大多数方法并不支持“内在智能”,因为它们是在离线设置下运行的、速度慢、运动长度有限或不自然。为了克服这些局限性,我们提出了PRIMAL,这是一种基于自回归扩散模型的二阶学习范式,受到最新基础模型的启发。在预训练阶段,模型从大量亚秒级运动片段中学习运动动力学,提供“运动原语”,从中构建更复杂的动作。在适应阶段,我们采用类似ControlNet的适配器对运动控制进行微调,以实现语义动作生成和空间目标定位。实验表明,物理效果在我们的训练中显现。给定单帧初始状态,我们的模型不仅能够生成无界、现实和可控的运动,还能使虚拟角色实时响应引起的冲动。此外,我们可以有效且高效地基于我们的基础模型进行少量个性化动作和空间控制任务的适应。评估表明,我们提出的方法优于最新基线。我们利用该模型在Unreal Engine中创建了一个实时角色动画系统,该系统具有高度响应性和自然性。代码、模型和更多结果可在:URL链接。
论文及项目相关链接
PDF 18 pages
Summary
该文介绍了构建交互式虚拟角色的运动系统的重要性,并指出大多数运动生成方法由于离线设置、速度慢、运动长度有限或不自然运动等原因,不支持“内在智能”。为此,提出了名为PRIMAL的生成式扩散模型,该模型采用两阶段学习范式,从大量亚秒级运动片段中学习运动动力学,并为更复杂的运动提供“运动原语”。适应阶段则通过类似ControlNet的适配器进行微调,以实现语义动作生成和空间目标达到。实验表明,物理效果可以从训练中涌现出来。给定初始状态的单帧图像,我们的模型不仅可以生成无限制、现实和可控的运动,还可以使虚拟角色对实时诱导的脉冲作出响应。此外,我们可以有效地适应个性化动作和空间控制任务。评估显示,所提出的方法优于现有技术基线,并利用该模型创建了响应迅速、动作自然的Unreal Engine实时角色动画系统。
Key Takeaways
- 介绍构建交互式虚拟角色运动系统的重要性及现有方法的不足。
- 提出名为PRIMAL的生成式扩散模型,该模型通过两阶段学习范式从大量亚秒级运动片段中学习。
- 在适应阶段使用类似ControlNet的适配器进行微调,实现语义动作生成和空间目标达到。
- 模型可生成无限制、现实和可控的运动,使虚拟角色对实时诱导的脉冲作出响应。
- 该模型可有效适应个性化动作和空间控制任务。
- 提出的方法优于现有技术基线。
点此查看论文截图

Slide-Level Prompt Learning with Vision Language Models for Few-Shot Multiple Instance Learning in Histopathology
Authors:Devavrat Tomar, Guillaume Vray, Dwarikanath Mahapatra, Sudipta Roy, Jean-Philippe Thiran, Behzad Bozorgtabar
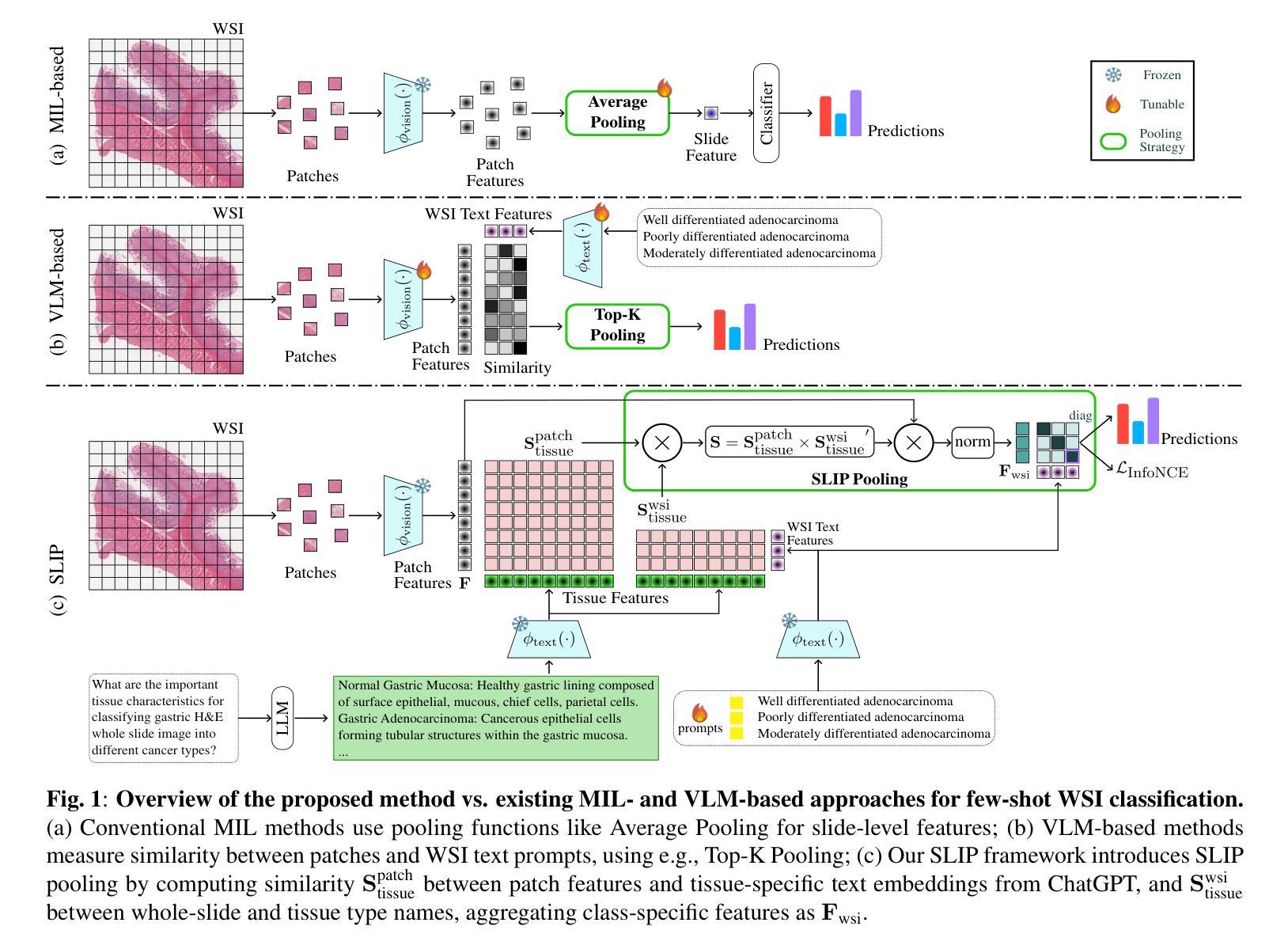
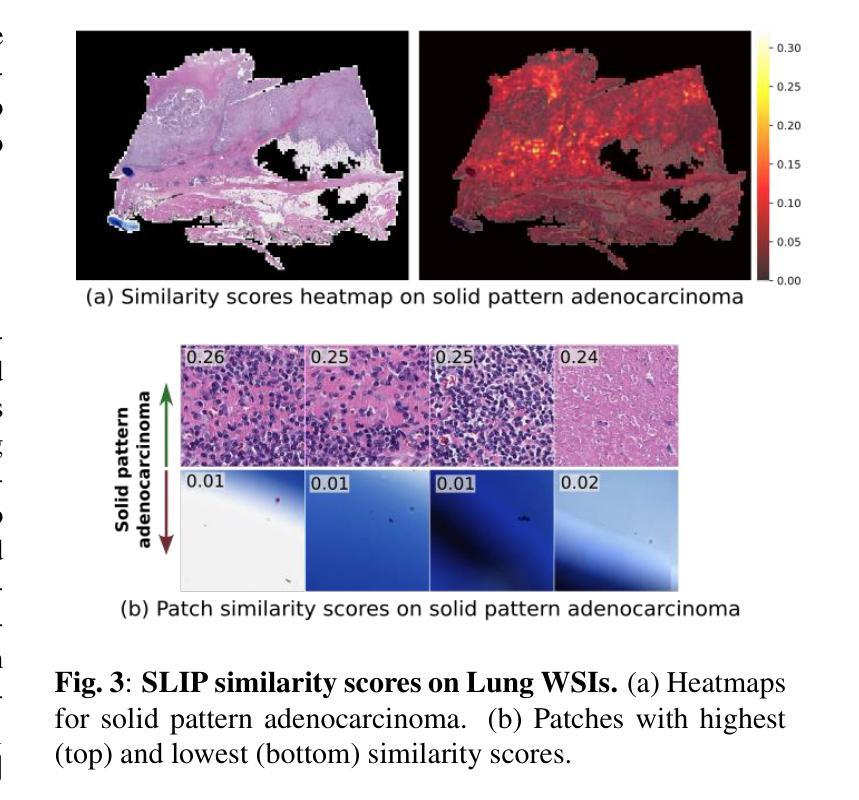
In this paper, we address the challenge of few-shot classification in histopathology whole slide images (WSIs) by utilizing foundational vision-language models (VLMs) and slide-level prompt learning. Given the gigapixel scale of WSIs, conventional multiple instance learning (MIL) methods rely on aggregation functions to derive slide-level (bag-level) predictions from patch representations, which require extensive bag-level labels for training. In contrast, VLM-based approaches excel at aligning visual embeddings of patches with candidate class text prompts but lack essential pathological prior knowledge. Our method distinguishes itself by utilizing pathological prior knowledge from language models to identify crucial local tissue types (patches) for WSI classification, integrating this within a VLM-based MIL framework. Our approach effectively aligns patch images with tissue types, and we fine-tune our model via prompt learning using only a few labeled WSIs per category. Experimentation on real-world pathological WSI datasets and ablation studies highlight our method’s superior performance over existing MIL- and VLM-based methods in few-shot WSI classification tasks. Our code is publicly available at https://github.com/LTS5/SLIP.
本文中,我们利用基础视觉语言模型(VLMs)和幻灯片级别提示学习来解决组织病理学全幻灯片图像(WSI)中的小样本分类挑战。鉴于全幻灯片图像的千兆像素规模,传统的多实例学习(MIL)方法依赖于聚合函数从补丁表示派生出幻灯片级别(包级别)的预测结果,这需要大量的包级别标签来进行训练。相比之下,基于VLM的方法擅长将补丁的视觉嵌入与候选类别文本提示进行对齐,但缺乏必要的病理先验知识。我们的方法通过将基于语言模型的病理先验知识用于识别对全幻灯片图像分类至关重要的局部组织类型(补丁),并将这一点纳入基于VLM的MIL框架中脱颖而出。我们的方法有效地将补丁图像与组织类型对齐,并通过仅使用每个类别少量标记的幻灯片图像进行提示学习来微调我们的模型。在现实世界的病理性全幻灯片图像数据集上的实验和消融研究突出了我们的方法在少样本全幻灯片图像分类任务中相较于现有的MIL和VLM方法的卓越性能。我们的代码可在https://github.com/LTS5/SLIP中找到并公开访问。
论文及项目相关链接
PDF Accepted to ISBI 2025
Summary
本文提出了针对病理学中全切片图像(WSI)进行少样本分类的挑战的解决方案。该研究结合了视觉语言模型(VLM)和幻灯片级别的提示学习技术,利用病理先验知识识别关键局部组织类型(补丁),并将其纳入基于VLM的多实例学习框架中。实验表明,该方法在真实病理WSI数据集上的性能优于现有的多实例学习和基于VLM的方法。
Key Takeaways
- 该研究解决了全切片图像(WSI)的少样本分类问题。
- 研究结合了视觉语言模型(VLM)和幻灯片级别的提示学习技术来改进模型性能。
- 该方法利用病理先验知识识别关键局部组织类型(补丁)。
- 该方法在一个基于VLM的多实例学习框架中整合了识别出的关键局部组织类型。
- 该方法在真实病理WSI数据集上的性能进行了实验验证,并显示了其优越性。
- 该研究提供的代码已公开可用。
点此查看论文截图

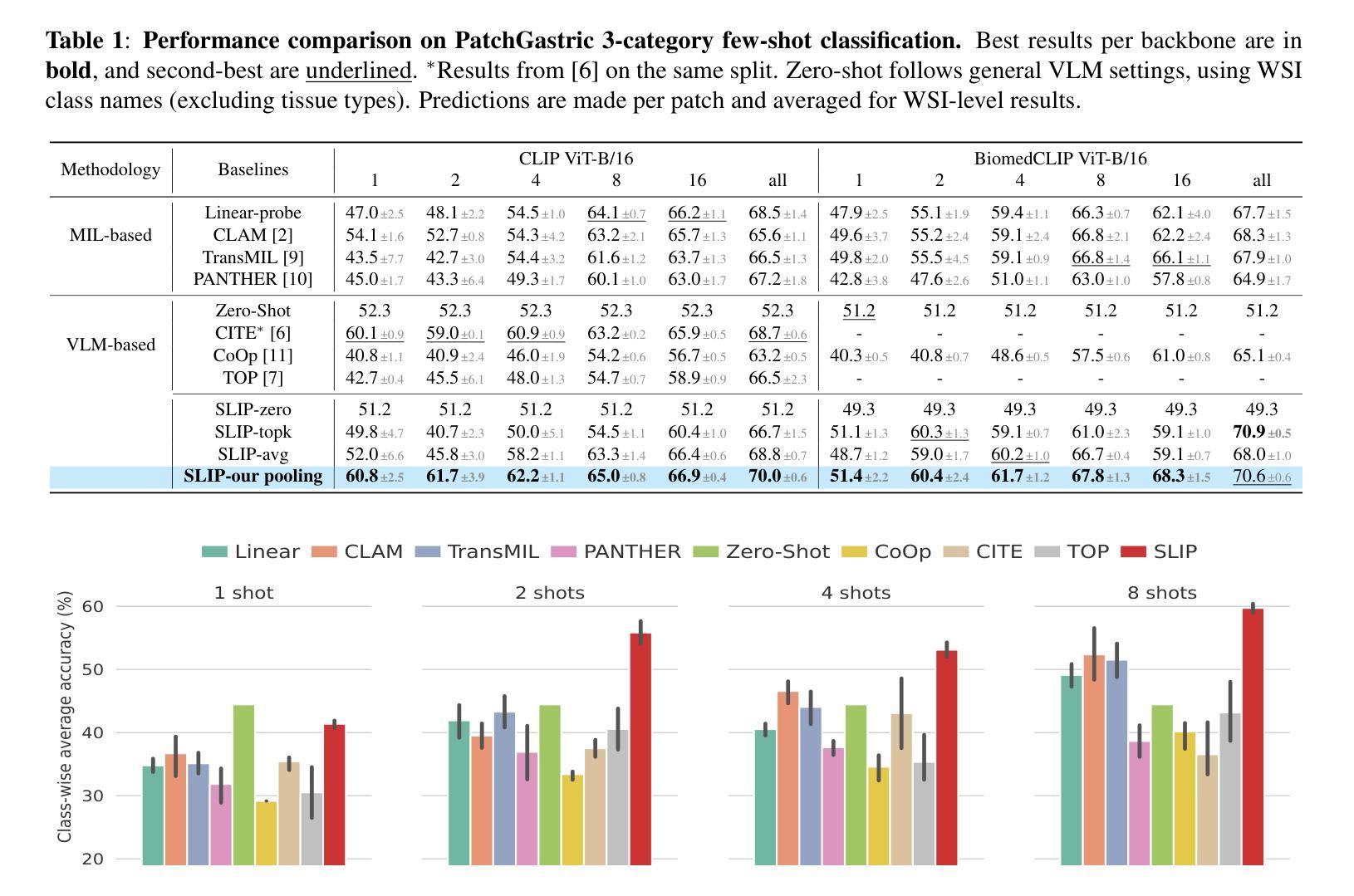
Exploring Few-Shot Object Detection on Blood Smear Images: A Case Study of Leukocytes and Schistocytes
Authors:Davide Antonio Mura, Michela Pinna, Lorenzo Putzu, Andrea Loddo, Alessandra Perniciano, Olga Mulas, Cecilia Di Ruberto
The detection of blood disorders often hinges upon the quantification of specific blood cell types. Variations in cell counts may indicate the presence of pathological conditions. Thus, the significance of developing precise automatic systems for blood cell enumeration is underscored. The investigation focuses on a novel approach termed DE-ViT. This methodology is employed in a Few-Shot paradigm, wherein training relies on a limited number of images. Two distinct datasets are utilised for experimental purposes: the Raabin-WBC dataset for Leukocyte detection and a local dataset for Schistocyte identification. In addition to the DE-ViT model, two baseline models, Faster R-CNN 50 and Faster R-CNN X 101, are employed, with their outcomes being compared against those of the proposed model. While DE-ViT has demonstrated state-of-the-art performance on the COCO and LVIS datasets, both baseline models surpassed its performance on the Raabin-WBC dataset. Moreover, only Faster R-CNN X 101 yielded satisfactory results on the SC-IDB. The observed disparities in performance may possibly be attributed to domain shift phenomena.
血液疾病的检测往往取决于特定血细胞类型的量化。细胞计数的变化可能表明存在病理状况。因此,开发精确自动血细胞计数系统的意义尤为重要。研究重点是一种称为DE-ViT的新方法。这种方法采用小样本(Few-Shot)模式,训练依赖于少量图像。为实验目的使用了两个独特的数据集:用于白细胞检测的Raabin-WBC数据集和用于识别裂殖红细胞(Schistocyte)的本地数据集。除了DE-ViT模型外,还采用了Faster R-CNN 50和Faster R-CNN X 101两个基准模型,并将其结果与所提出的模型进行了比较。虽然DE-ViT在COCO和LVIS数据集上表现出卓越的性能,但两个基准模型在Raabin-WBC数据集上的表现都超过了它。此外,只有Faster R-CNN X 101在SC-IDB上产生了令人满意的结果。观察到的性能差异可能归因于领域迁移现象。
论文及项目相关链接
Summary
在血液疾病检测中,特定血细胞类型的量化至关重要。一种名为DE-ViT的新方法被应用于Few-Shot模式下进行血细胞计数,使用有限的图像进行训练。尽管DE-ViT在某些数据集上表现卓越,但在针对特定数据集(如Raabin-WBC、SC-IDB)的测试中,其他模型(如Faster R-CNN 50和Faster R-CNN X 101)表现更佳。性能差异可能与领域迁移现象有关。
Key Takeaways
- 血细胞类型的量化在血液疾病检测中非常重要。
- DE-ViT是一种应用于Few-Shot模式下的新方法,用于血细胞计数。
- DE-ViT在某些数据集上的表现卓越。
- 在特定数据集(如Raabin-WBC、SC-IDB)的测试中,其他模型(如Faster R-CNN 50和Faster R-CNN X 101)的表现超过了DE-ViT。
- 性能差异可能源于领域迁移现象。
- 使用有限的图像进行训练是该研究的一个关键特点。
点此查看论文截图

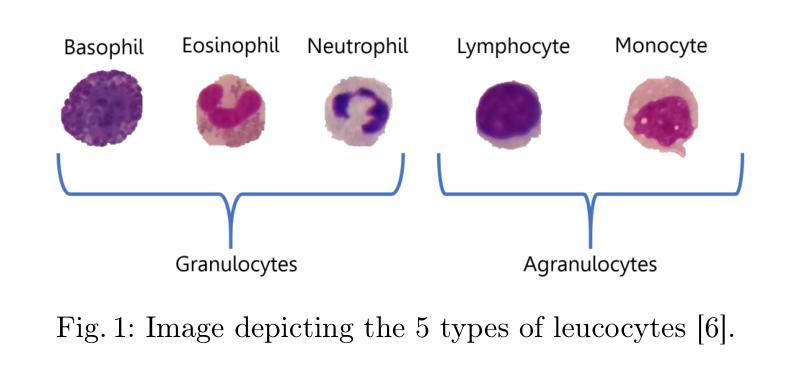
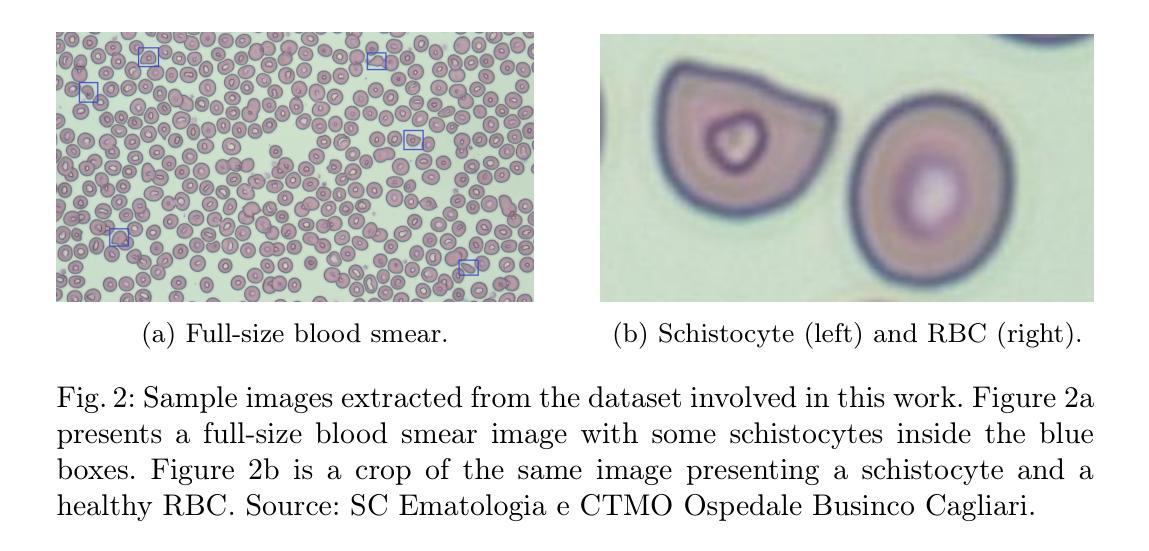
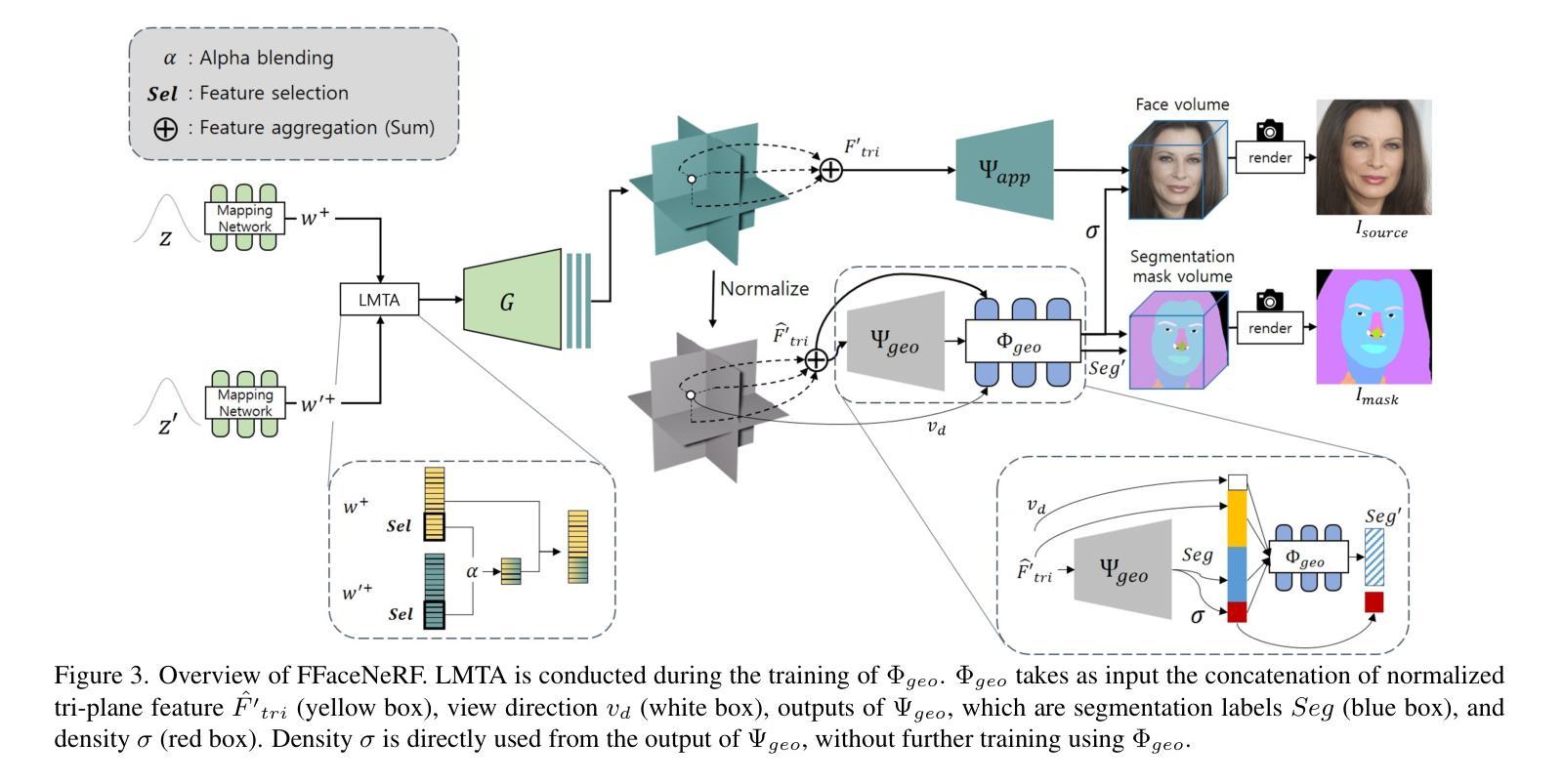
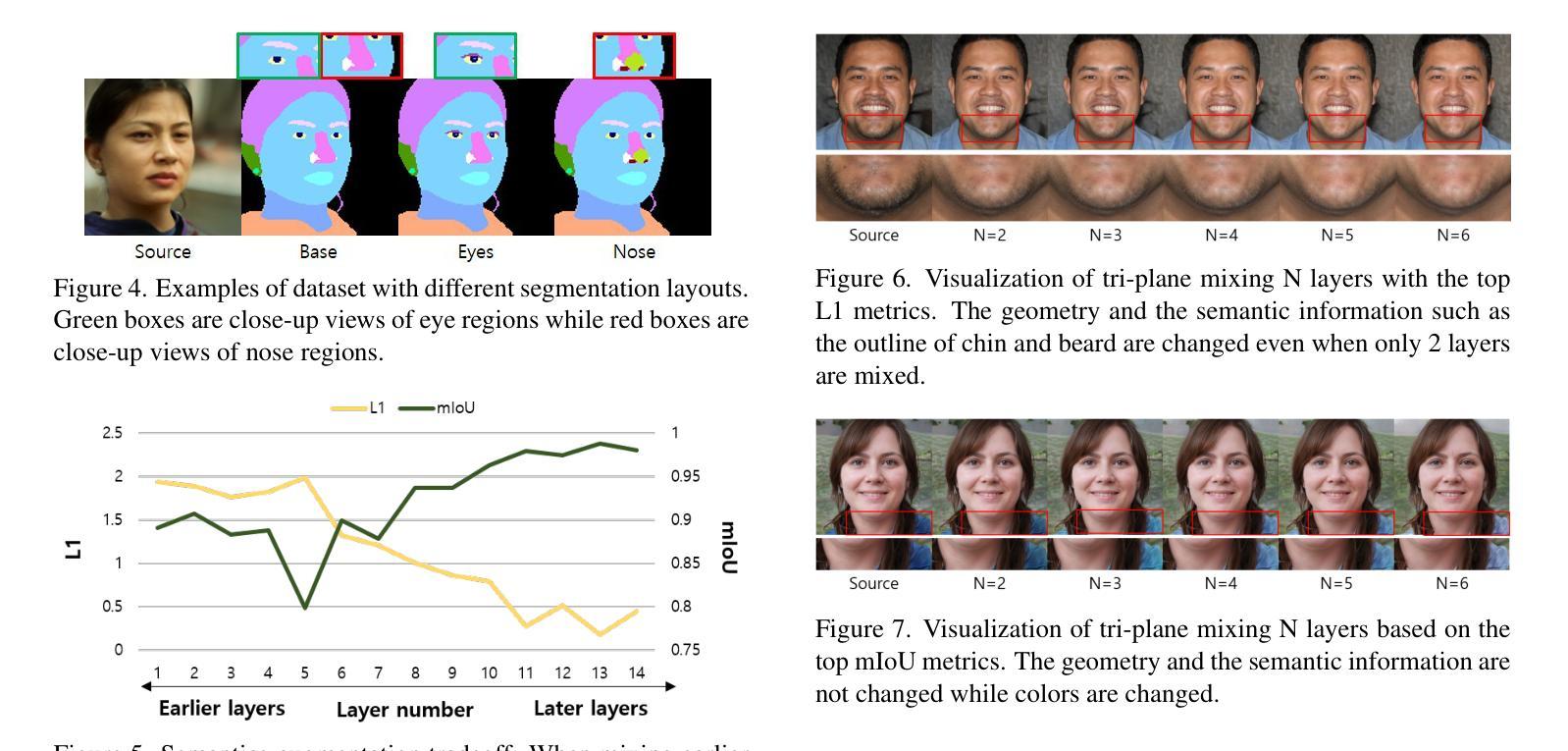
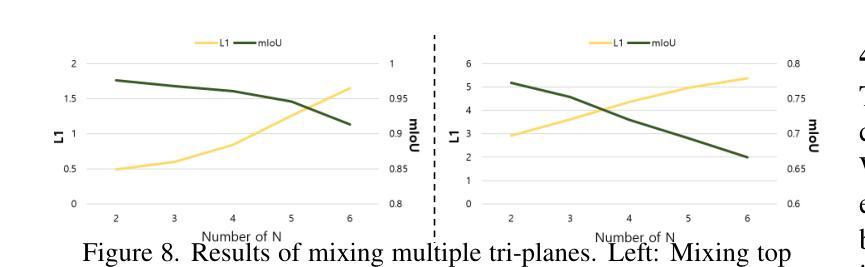
FFaceNeRF: Few-shot Face Editing in Neural Radiance Fields
Authors:Kwan Yun, Chaelin Kim, Hangyeul Shin, Junyong Noh
Recent 3D face editing methods using masks have produced high-quality edited images by leveraging Neural Radiance Fields (NeRF). Despite their impressive performance, existing methods often provide limited user control due to the use of pre-trained segmentation masks. To utilize masks with a desired layout, an extensive training dataset is required, which is challenging to gather. We present FFaceNeRF, a NeRF-based face editing technique that can overcome the challenge of limited user control due to the use of fixed mask layouts. Our method employs a geometry adapter with feature injection, allowing for effective manipulation of geometry attributes. Additionally, we adopt latent mixing for tri-plane augmentation, which enables training with a few samples. This facilitates rapid model adaptation to desired mask layouts, crucial for applications in fields like personalized medical imaging or creative face editing. Our comparative evaluations demonstrate that FFaceNeRF surpasses existing mask based face editing methods in terms of flexibility, control, and generated image quality, paving the way for future advancements in customized and high-fidelity 3D face editing. The code is available on the {\href{https://kwanyun.github.io/FFaceNeRF_page/}{project-page}}.
最近使用掩膜(masks)的3D面部编辑方法通过利用神经辐射场(NeRF)生成了高质量编辑图像。尽管其性能令人印象深刻,但现有方法由于使用预训练分割掩膜而往往提供有限的用户控制。为了使用具有所需布局的掩膜,需要大量训练数据集,这很难收集。我们提出了FFaceNeRF,这是一种基于NeRF的面部编辑技术,可以克服因使用固定掩膜布局而带来的用户控制受限的挑战。我们的方法采用带有特征注入的几何适配器,允许对几何属性进行有效操作。此外,我们还采用潜在混合进行三平面增强,这可以在少量样本上进行训练。这有助于模型迅速适应所需的掩膜布局,对于个性化医学影像或创意面部编辑等领域的应用至关重要。我们的比较评估表明,FFaceNeRF在灵活性、控制和生成图像质量方面超越了现有的基于掩膜的面部编辑方法,为定制和高保真3D面部编辑的未来进步铺平了道路。代码已在项目页面(https://kwanyun.github.io/FFaceNeRF_page/)上提供。
论文及项目相关链接
PDF CVPR2025, 11 pages, 14 figures
Summary
基于NeRF的3D人脸编辑方法通过使用掩膜实现了高质量的人脸图像编辑。FFaceNeRF克服了现有方法因使用固定掩膜布局导致的用户控制受限的挑战,通过几何适配器和特征注入技术有效操控几何属性,并采用潜在混合技术进行三平面增强,用少量样本进行训练,快速适应所需的掩膜布局。此方法在个性化医疗成像或创意人脸编辑等领域具有应用潜力,并在灵活性、控制和生成图像质量方面超越现有基于掩膜的人脸编辑方法。
Key Takeaways
- FFaceNeRF使用NeRF技术实现高质量3D人脸编辑。
- 克服现有方法因使用固定掩膜布局导致的用户控制受限的挑战。
- 通过几何适配器和特征注入技术操控几何属性。
- 采用潜在混合技术进行三平面增强,用少量样本进行训练。
- 方法能快速适应所需的掩膜布局。
- 在个性化医疗成像或创意人脸编辑等领域具有应用潜力。
点此查看论文截图


Generative Compositor for Few-Shot Visual Information Extraction
Authors:Zhibo Yang, Wei Hua, Sibo Song, Cong Yao, Yingying Zhu, Wenqing Cheng, Xiang Bai
Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model’s perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.
视觉信息提取(VIE)旨在从丰富的文档图像中提取结构化信息,在文档处理中扮演着至关重要的角色。考虑到各种布局、语义范围和语言,VIE涵盖了广泛的类型,数量可能达到数千种。然而,这些类型中的许多都缺乏训练数据,这构成了巨大的挑战。针对这一问题,我们在本文中提出了一种新型的生成模型,名为“生成式组合器”(Generative Compositor),以解决样本量不足的视觉信息提取(VIE)问题。生成式组合器是一种混合指针生成网络,它通过从源文本中检索单词并根据提供的提示进行组合,模拟组合器的操作。此外,还采用了三种预训练策略,以提高模型对空间上下文信息的感知能力。此外,还特意设计了一种提示感知重采样器,以利用提示中的实体语义先验信息进行高效匹配。基于提示的检索机制和预训练策略的引入,使模型在有限的训练样本下能够获取更有效的空间和语义线索。实验表明,该方法在全样本训练中的表现极具竞争力,而在1次、5次和10次拍摄的设置中,则显著优于基线。
论文及项目相关链接
Summary
视觉信息提取(VIE)旨在从丰富的文档图像中提取结构化信息,在文档处理中起着至关重要的作用。考虑各种布局、语义范围和语言,VIE包含广泛的类型,数量可能达到数千种。然而,许多类型面临训练数据缺乏的挑战。本文提出了一种新的生成模型——生成式组合器(Generative Compositor),以解决少数样本VIE的挑战。该模型是一种混合指针生成器网络,通过从源文本中检索单词并根据提示进行组合来模拟组合器的操作。通过采用三种预训练策略,增强了模型对空间上下文信息的感知。此外,还设计了一种提示感知重采样器,通过利用提示中的实体语义先验来实现高效匹配。基于提示的检索机制和预训练策略的结合,使模型能够在有限的训练样本中获得更有效的空间和语义线索。实验表明,该方法在全样本训练中具有高度竞争力,在1次、5次和10次射击设置中显著优于基线。
Key Takeaways
- Visual Information Extraction (VIE)是从文档图像中提取结构化信息的关键技术。
- VIE面临训练数据缺乏的挑战,特别是针对数量可能达到数千的各类布局、语义范围和语言。
- 提出了一个新的生成模型——生成式组合器(Generative Compositor),用于解决少数样本VIE问题。
- 生成式组合器是一个混合指针生成器网络,模拟组合器的操作,从源文本中检索单词并根据提示进行组合。
- 通过三种预训练策略增强模型对空间上下文信息的感知能力。
- 设计了提示感知重采样器,利用提示中的实体语义先验实现高效匹配。
点此查看论文截图


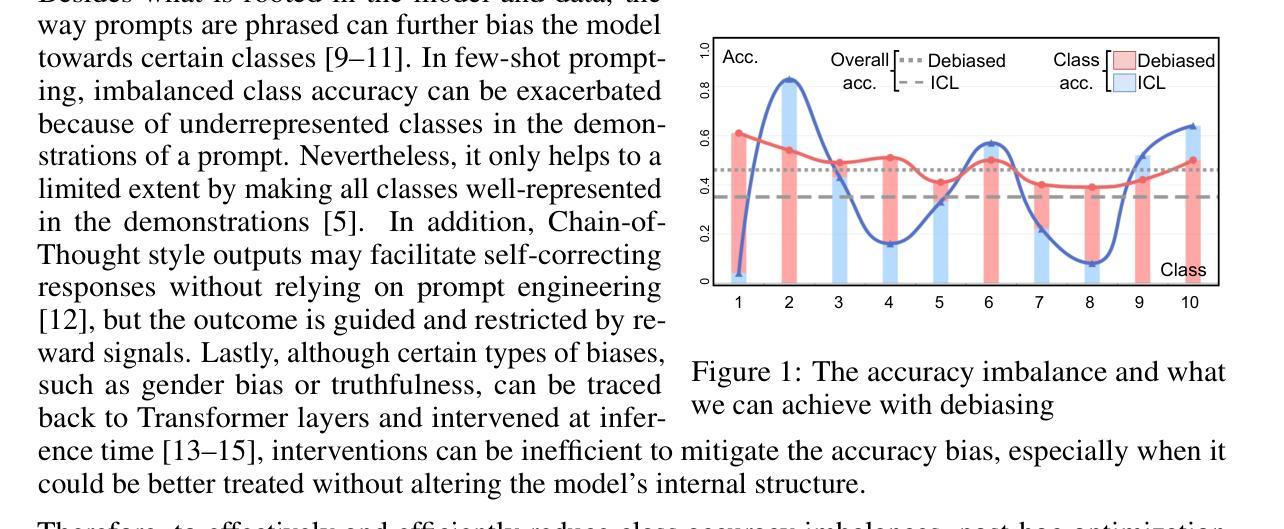
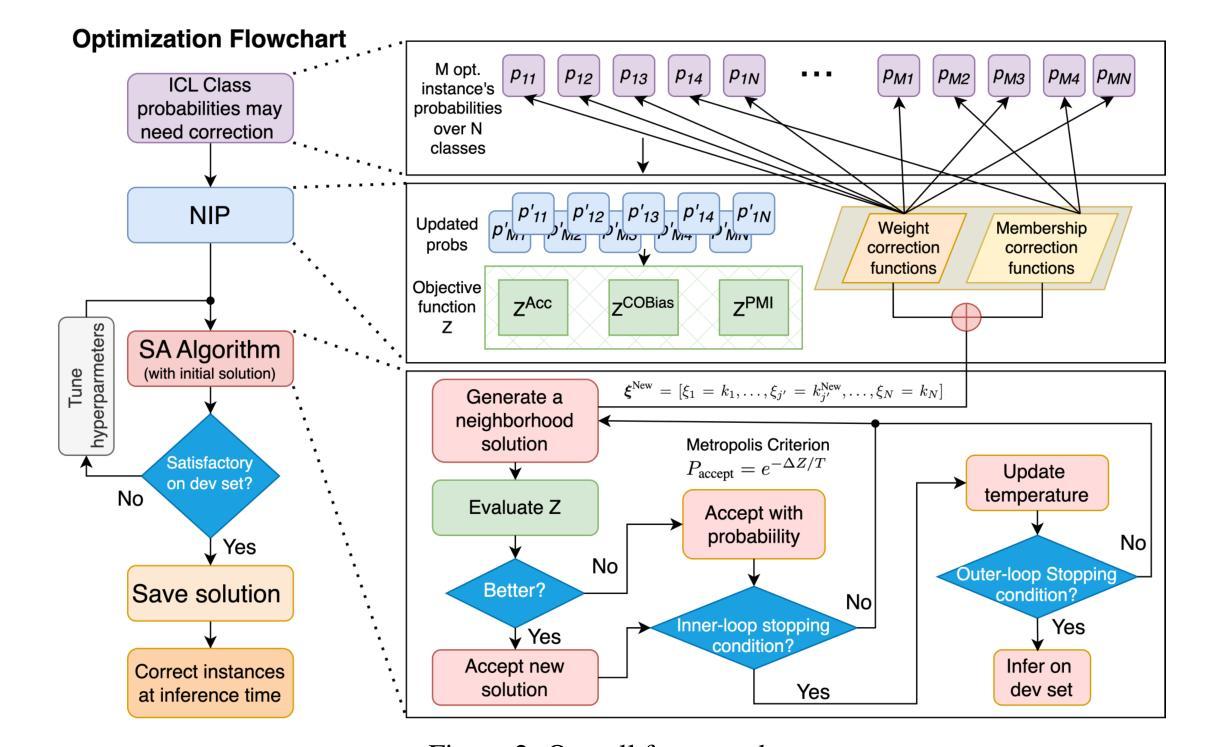
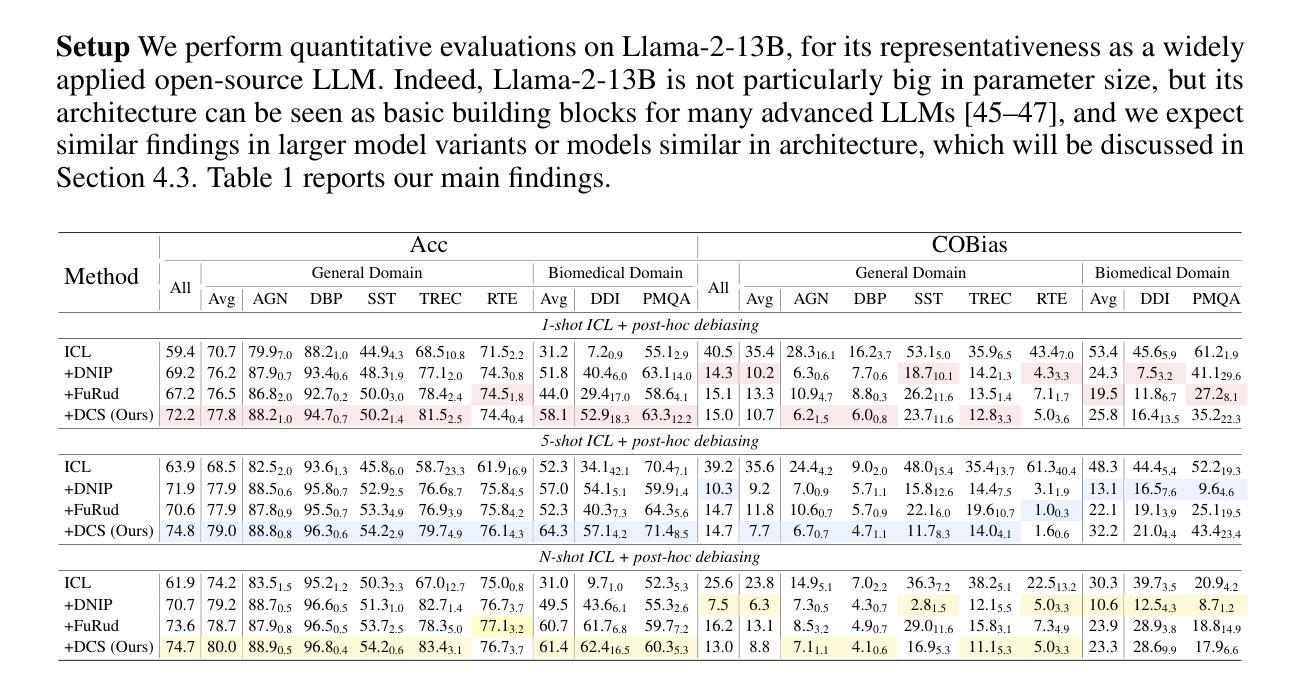
Ensemble Debiasing Across Class and Sample Levels for Fairer Prompting Accuracy
Authors:Ruixi Lin, Ziqiao Wang, Yang You
Language models are strong few-shot learners and achieve good overall accuracy in text classification tasks, masking the fact that their results suffer from great class accuracy imbalance. We believe that the pursuit of overall accuracy should not come from enriching the strong classes, but from raising up the weak ones. To address the imbalance, we propose a Heaviside step function based ensemble debiasing method, which enables flexible rectifications of in-context learned class probabilities at both class and sample levels. Evaluations with Llama-2-13B on seven text classification benchmarks show that our approach achieves state-of-the-art overall accuracy gains with balanced class accuracies. More importantly, we perform analyses on the resulted probability correction scheme, showing that sample-level corrections are necessary to elevate weak classes. Due to effectively correcting weak classes, our method also brings significant performance gains to a larger model variant, Llama-2-70B, especially on a biomedical domain task, further demonstrating the necessity of ensemble debiasing at both levels.
语言模型是强大的小样本学习者,在文本分类任务中达到了良好的总体准确率,掩盖了其结果存在严重的类别准确率不平衡的事实。我们认为追求总体准确率不应通过丰富强类别来实现,而应通过提升弱类别来实现。为了解决不平衡问题,我们提出了一种基于海维赛德阶跃函数的集成去偏方法,该方法能够在类和样本级别灵活地修正上下文中的学习类别概率。使用Llama-2-13B在七个文本分类基准测试上的评估表明,我们的方法在实现平衡的类别准确率的同时,实现了最先进的总体准确率增益。更重要的是,我们对得到的概率修正方案进行了分析,表明样本级的修正对于提升弱类别是必要的。由于有效地纠正了弱类别,我们的方法还为更大的模型变体Llama-2-70B带来了显著的性能提升,尤其是在生物医学领域任务中,进一步证明了在两级进行集成去偏的必要性。
论文及项目相关链接
Summary
语言模型在少样本学习上表现出色,在文本分类任务中总体准确度较高,但存在类别准确度失衡的问题。为提高弱类别准确度,提出一种基于海维赛德阶跃函数的集成去偏方法,可在类和样本级别灵活调整上下文学习到的类别概率。在七个文本分类基准测试上对Llama-2-13B模型的评估显示,该方法实现了最先进的总体精度增益和平衡的类别精度。分析结果显示,样本级修正对于提升弱类别是必要的。该方法在大型模型变体Llama-2-70B上也能带来显著的性能提升,尤其在生物医学领域任务中进一步证明了集成去偏的必要性。
Key Takeaways
- 语言模型在少样本学习上的表现良好,但在文本分类任务中存在类别准确度失衡的问题。
- 提出一种基于海维赛德阶跃函数的集成去偏方法,旨在提高弱类别的准确度。
- 评估显示,该方法在多个文本分类任务上实现了先进的总体精度和平衡的类别精度。
- 样本级修正对于提升弱类别的重要性。
- 方法在大型模型上表现良好,特别是在特定领域任务中,如生物医学领域。
- 集成去偏方法对于提高模型的性能和泛化能力至关重要。
点此查看论文截图

Spectral Informed Mamba for Robust Point Cloud Processing
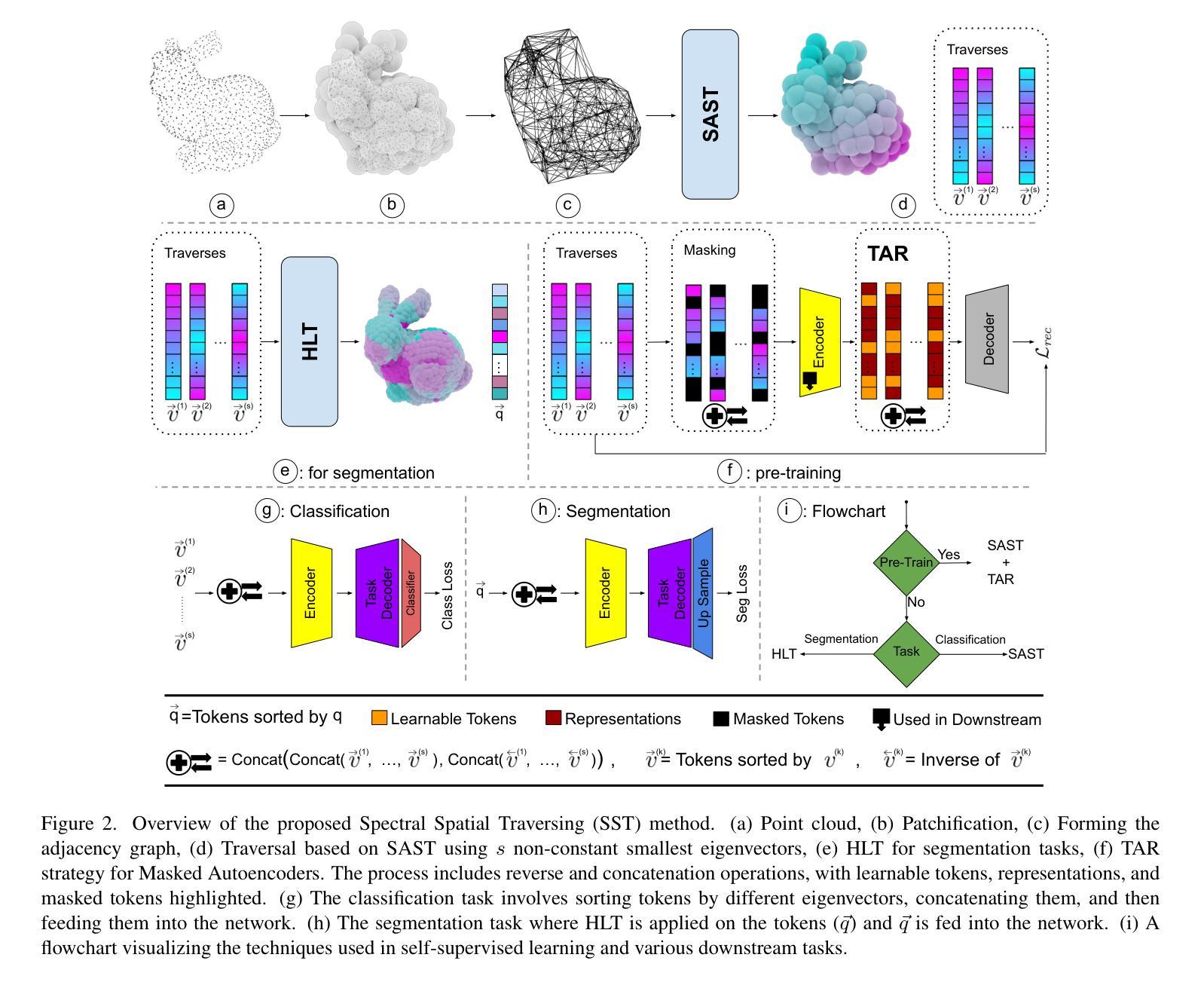
Authors:Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, Sahar Dastani, Milad Cheraghalikhani, David Osowiechi, Gustavo Adolfo Vargas Hakim, Farzad Beizaee, Ismail Ben Ayed, Christian Desrosiers
State space models have shown significant promise in Natural Language Processing (NLP) and, more recently, computer vision. This paper introduces a new methodology leveraging Mamba and Masked Autoencoder networks for point cloud data in both supervised and self-supervised learning. We propose three key contributions to enhance Mamba’s capability in processing complex point cloud structures. First, we exploit the spectrum of a graph Laplacian to capture patch connectivity, defining an isometry-invariant traversal order that is robust to viewpoints and better captures shape manifolds than traditional 3D grid-based traversals. Second, we adapt segmentation via a recursive patch partitioning strategy informed by Laplacian spectral components, allowing finer integration and segment analysis. Third, we address token placement in Masked Autoencoder for Mamba by restoring tokens to their original positions, which preserves essential order and improves learning. Extensive experiments demonstrate the improvements of our approach in classification, segmentation, and few-shot tasks over state-of-the-art baselines.
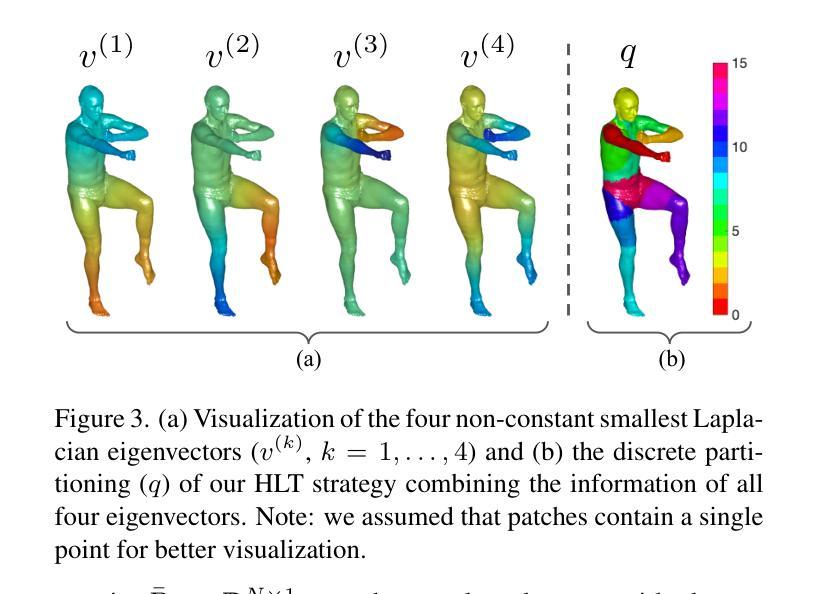
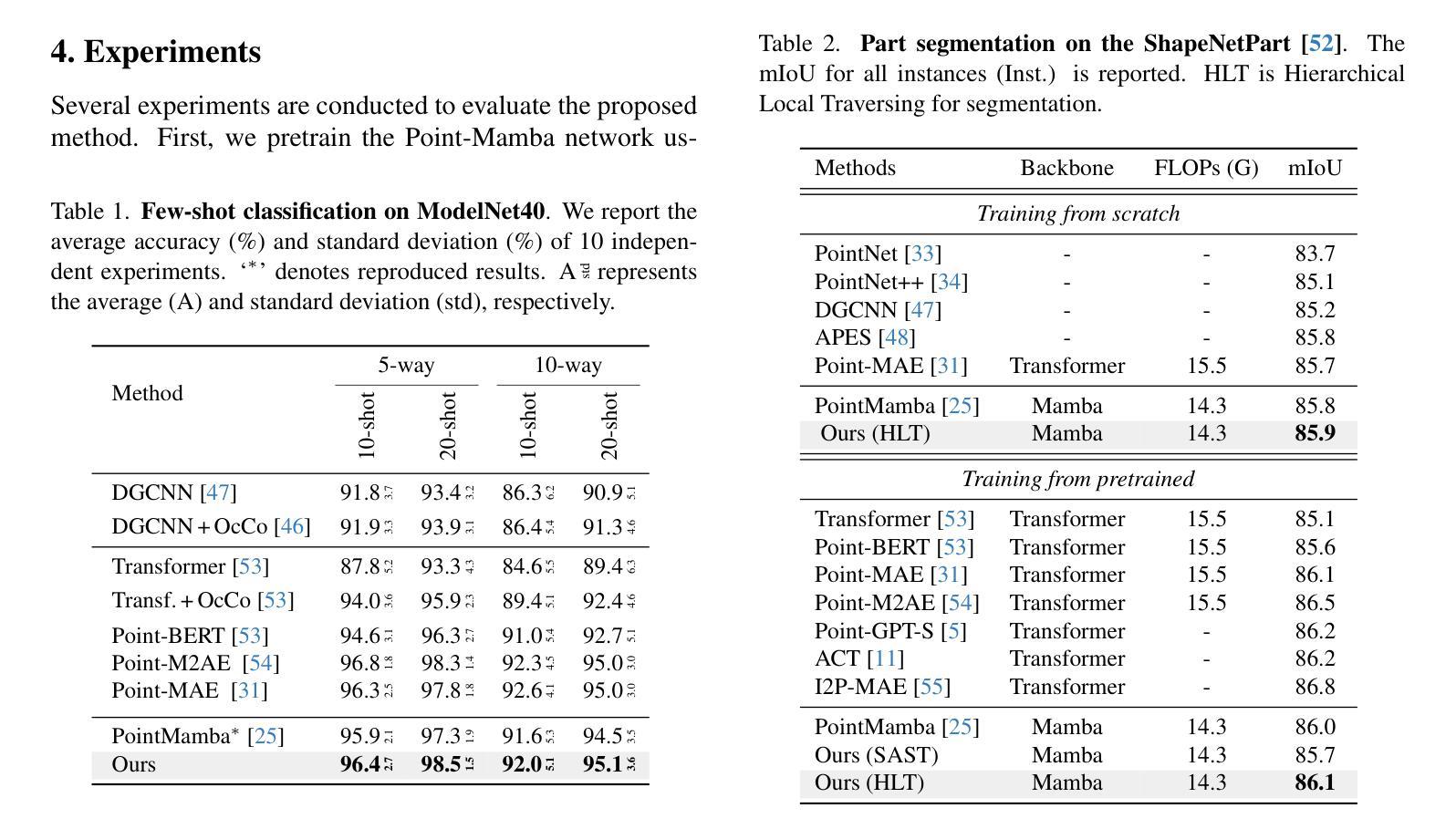
状态空间模型在自然语言处理(NLP)中已显示出巨大的潜力,最近在计算机视觉领域也备受关注。本文介绍了一种新的方法,利用Mamba和Masked Autoencoder网络进行有监督和自监督学习中的点云数据处理。我们提出了三个关键贡献,以增强Mamba处理复杂点云结构的能力。首先,我们利用图拉普拉斯算子的谱来捕捉斑块连通性,定义一个等距不变遍历顺序,该顺序对观点具有鲁棒性,并且比传统的基于3D网格的遍历更好地捕捉形状流形。其次,我们通过拉普拉斯谱分量来指导递归斑块分区策略,实现更精细的集成和分段分析。第三,我们解决了Masked Autoencoder中的令牌放置问题,通过将令牌恢复到其原始位置来保留必要的顺序并改进学习。大量实验表明,我们的方法在分类、分割和少量任务方面的表现优于最先进的基线。
论文及项目相关链接
Summary
本文介绍了一种利用Mamba和Masked Autoencoder网络处理点云数据的新方法,适用于监督学习和自监督学习。文章提出了三项关键贡献以提升Mamba在处理复杂点云结构方面的能力:一、利用图拉普拉斯谱捕捉斑块连接性,定义了一个对视点具有鲁棒性的等距不变遍历顺序,更好地捕捉形状流形;二、通过递归斑块分区策略进行分段,以拉普拉斯光谱成分为指导,实现更精细的集成和分段分析;三、解决Masked Autoencoder中Mamba的令牌放置问题,将令牌恢复到其原始位置,保留重要顺序并改进学习。实验证明,该方法在分类、分割和少样本任务上优于现有技术基线。
Key Takeaways
- 引入了一种新的方法,利用Mamba和Masked Autoencoder网络处理点云数据。
- 通过利用图拉普拉斯谱,提出了一种新颖的遍历顺序定义,以增强对复杂点云结构的处理能力。
- 该方法提高了Mamba对视点变化的鲁棒性,能够更好地捕捉形状流形。
- 通过递归斑块分区策略进行分段,实现了更精细的集成和分段分析。
- 解决了Masked Autoencoder中Mamba的令牌放置问题,提高了学习效果。
- 实验证明该方法在分类、分割和少样本任务上表现出优越性。
点此查看论文截图

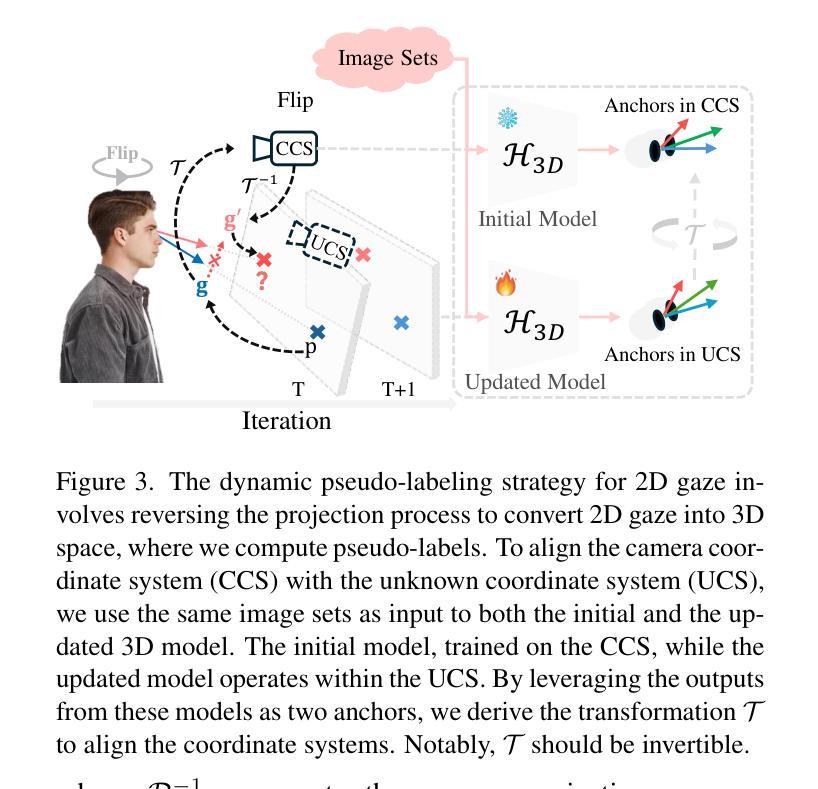
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Authors:Yihua Cheng, Hengfei Wang, Zhongqun Zhang, Yang Yue, Bo Eun Kim, Feng Lu, Hyung Jin Chang
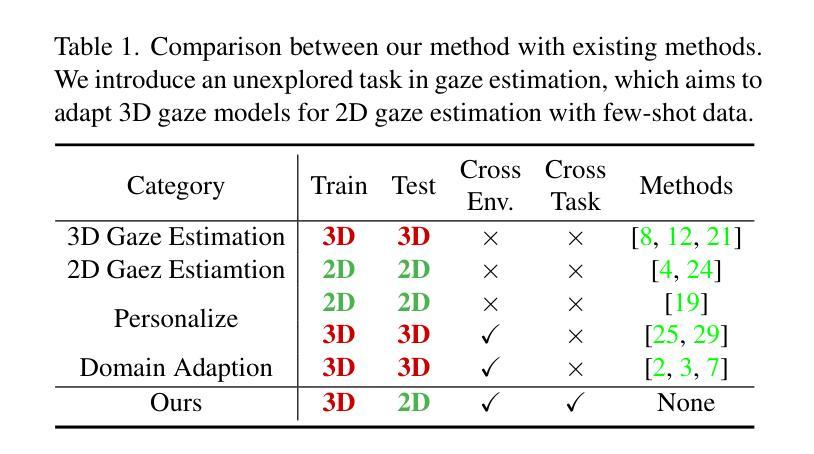
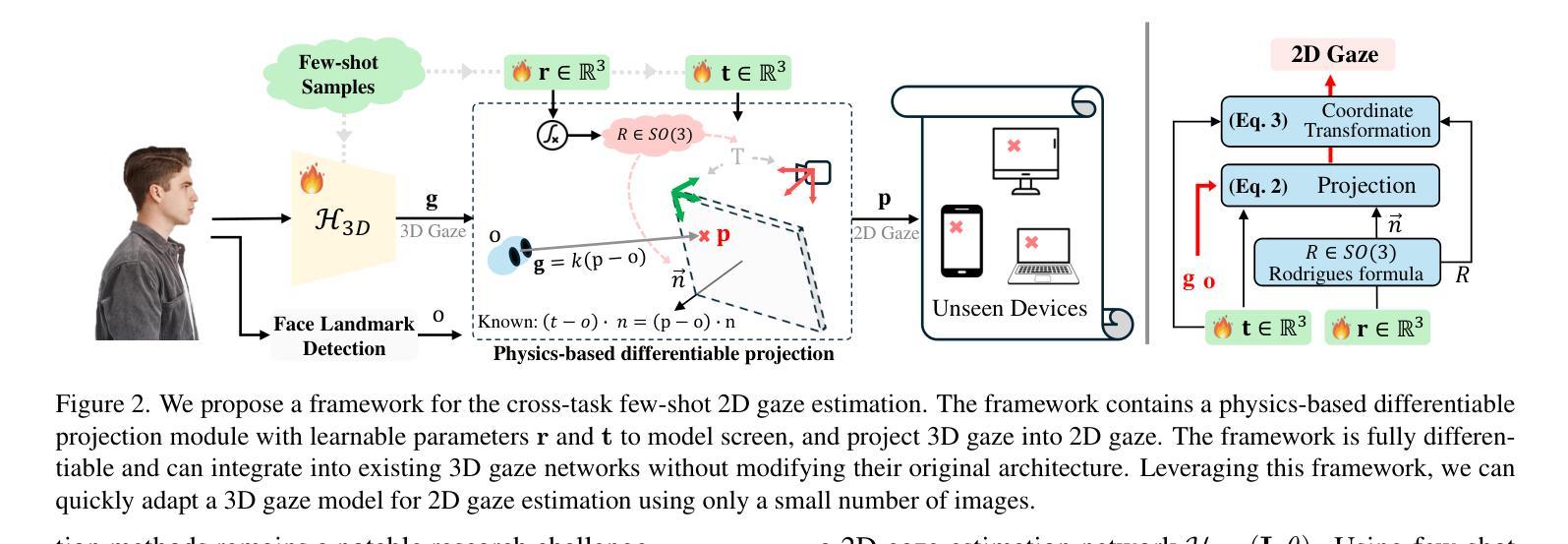
3D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.
3D和2D注视估计共享捕捉眼睛运动的基本目标,但传统上被视为两个独立的研究领域。在本文中,我们引入了一种新型跨任务小样本2D注视估计方法,旨在使用仅少量训练图像,借助预训练的3D注视估计网络对未见过的设备进行2D注视预测。由于3D和2D注视之间的领域差异、未知屏幕姿势和有限的训练数据,此任务具有极高挑战性。为解决这些挑战,我们提出了一个新型框架,桥梁3D和2D注视之间的差距。我们的框架包含一个基于物理的可微投影模块,具有可学习参数来模拟屏幕姿势并将3D注视投影到2D注视。该框架是完全可微分的,并且可以集成到现有的3d注视网络中,无需修改其原始架构。此外,我们为翻转图像引入了一种动态伪标签策略,这对于2D标签而言尤其具有挑战性,因为存在未知屏幕姿势。为了克服这一点,我们通过将2D标签转换到3D空间来反转投影过程,并在该空间执行翻转。值得注意的是,这个3D空间与相机坐标系并不对齐,因此我们学习一个动态转换矩阵来补偿这种错位。我们在MPIIGaze、EVE和GazeCapture数据集上评估了我们的方法,这些数据集分别在笔记本电脑、台式电脑和移动设备上收集。优越的性能凸显了我们方法的有效性,并展示了其在现实世界应用中的强大潜力。
论文及项目相关链接
PDF CVPR 2025
Summary
本文提出一种新颖、挑战性的跨任务少镜头2D眼动追踪技术,旨在利用预训练的3D眼动追踪网络对未见设备仅通过少量训练图像进行2D眼动预测。为应对挑战,引入一个新颖框架填补两者之间的空白,并采用物理基础的微分投影模块进行屏幕姿态建模和将3D眼动转化为2D眼动。该方法可完全微分并融入现有3D眼动网络而不改变其原始架构。此外,采用动态伪标签策略应对翻转图像的挑战,并通过反转投影过程将2D标签转换为3D空间进行处理。在MPIIGaze、EVE和GazeCapture数据集上的优越表现证明了方法的有效性及其在现实世界应用中的潜力。
Key Takeaways
- 引入了一种新颖的跨任务少镜头学习技术,该技术旨在利用预训练的3D眼动追踪网络进行2D眼动预测。
- 提出了一种新颖的框架来填补3D和2D眼动追踪之间的差距,包括一个基于物理的微分投影模块。
- 该方法可以融入现有的3D眼动网络架构中,无需进行重大修改。
- 采用动态伪标签策略应对翻转图像的挑战,通过转换空间处理这些图像。
- 在多个数据集上的实验验证了方法的有效性。
点此查看论文截图

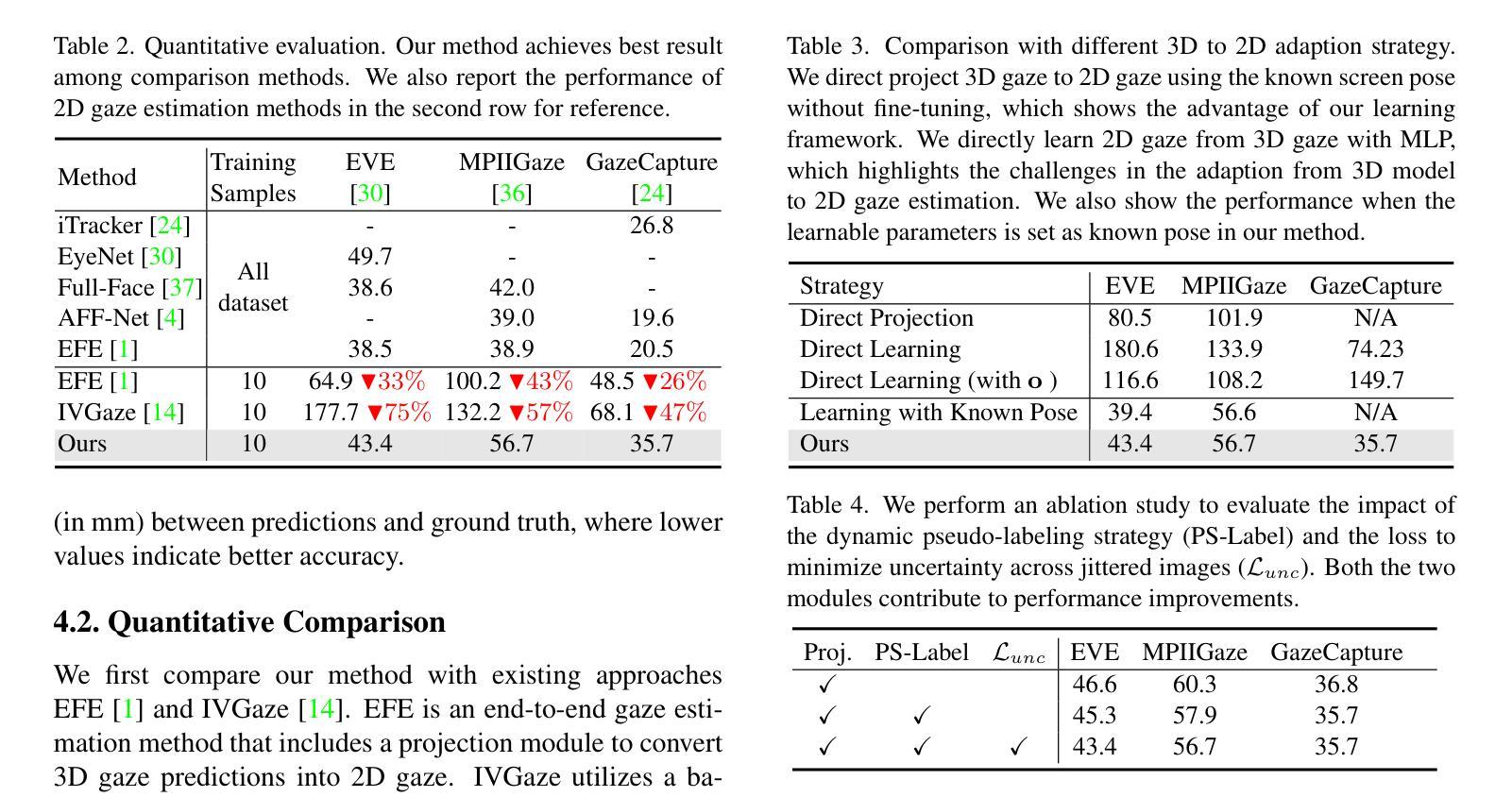
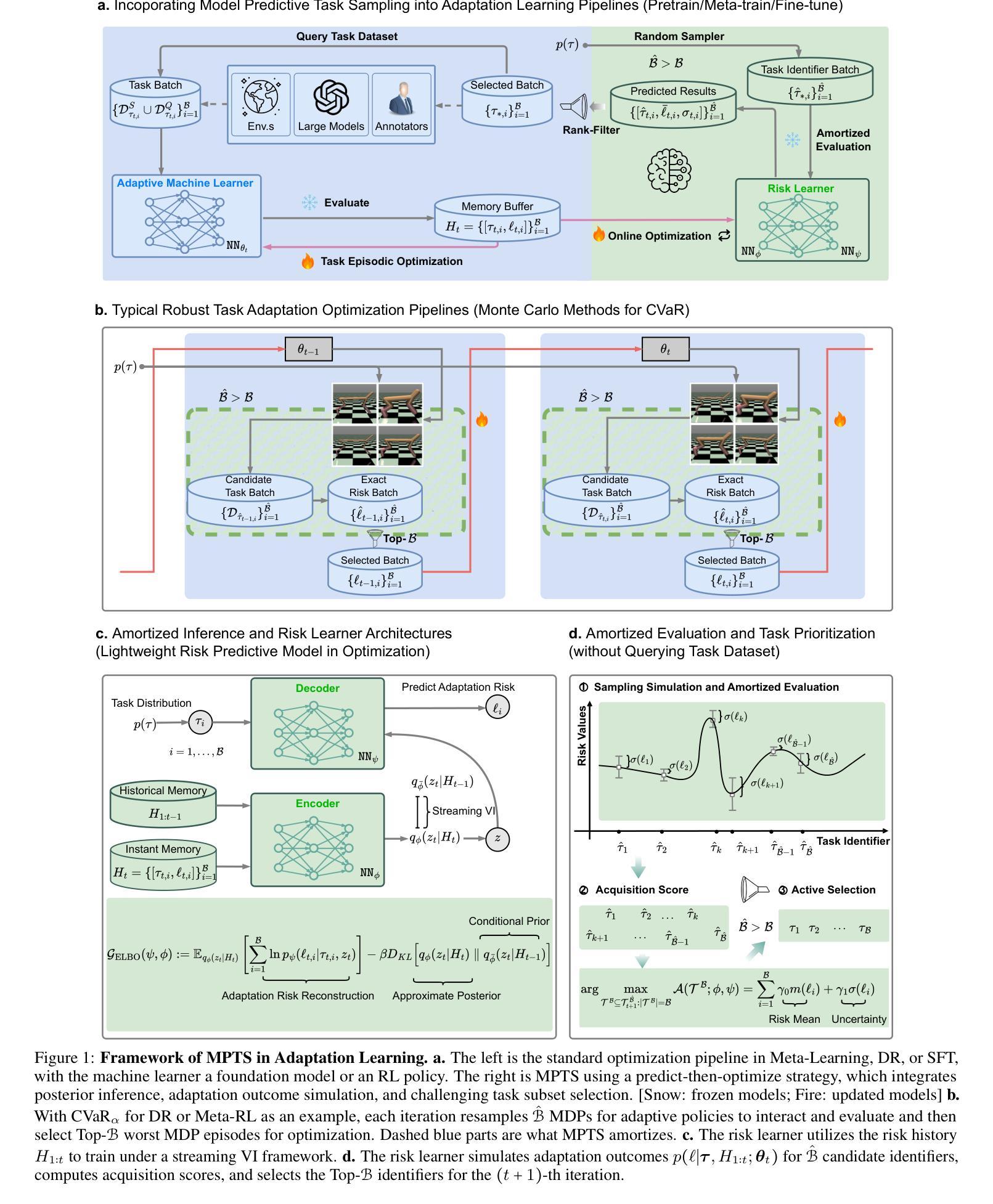
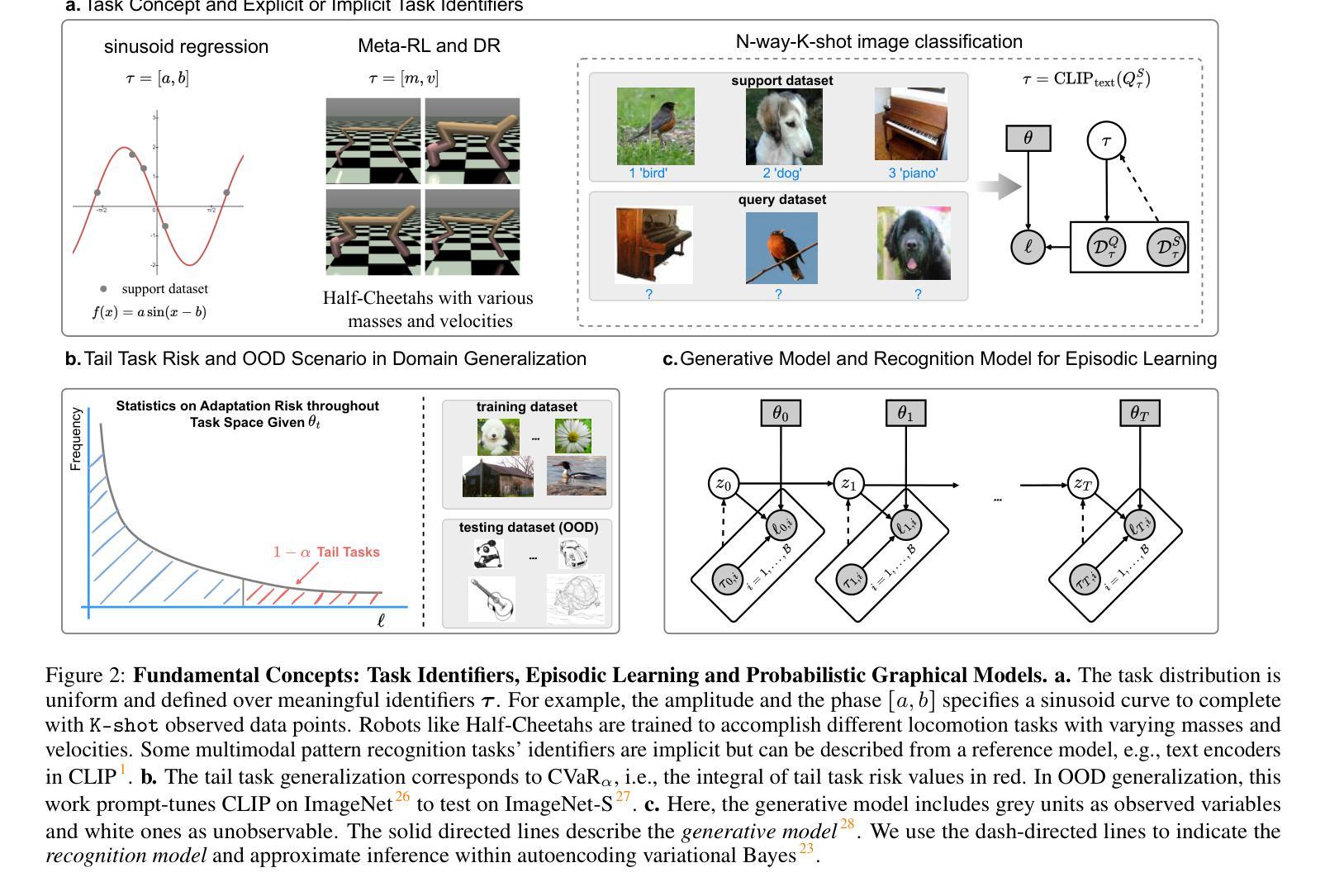
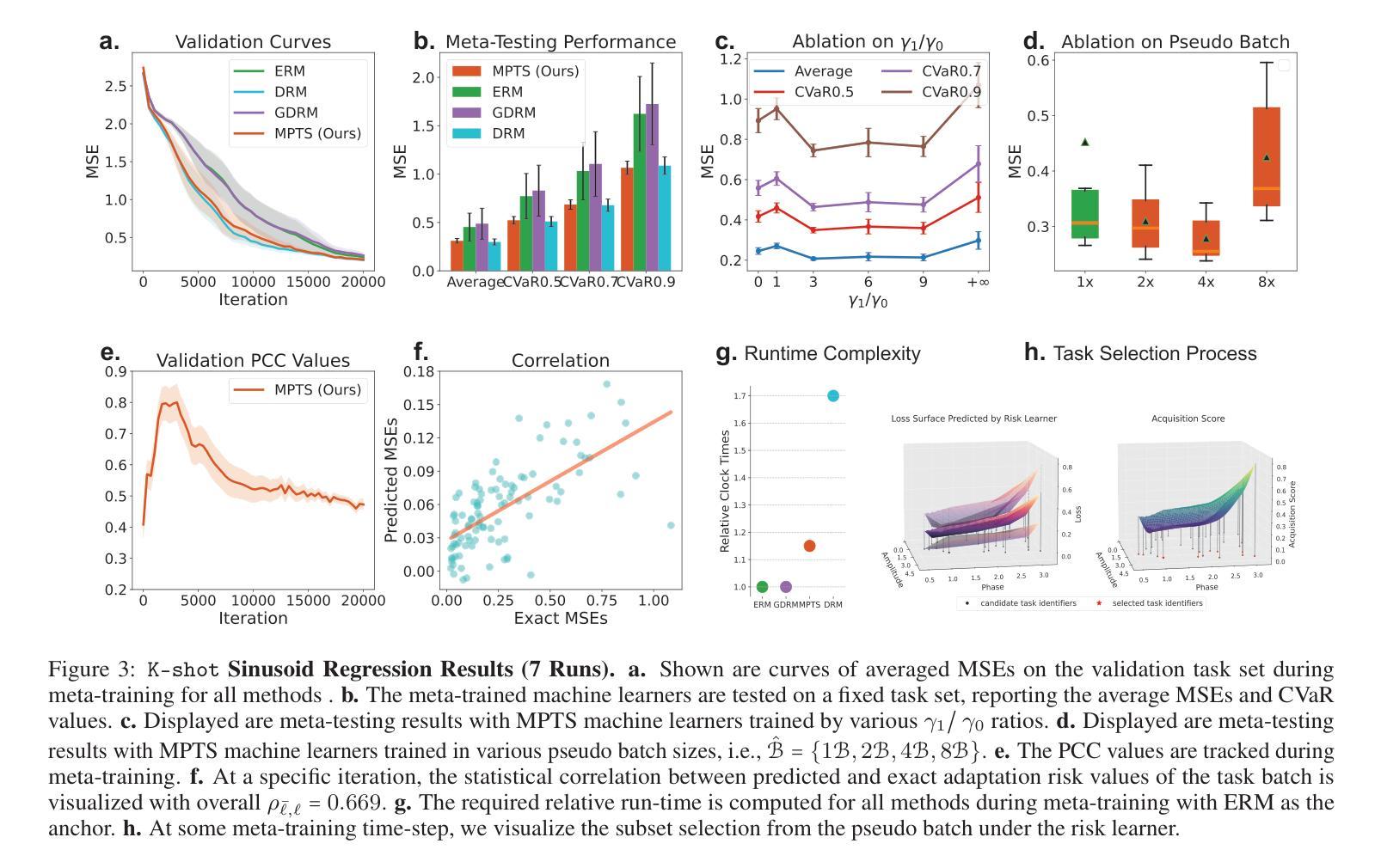
Model Predictive Task Sampling for Efficient and Robust Adaptation
Authors:Qi Cheems Wang, Zehao Xiao, Yixiu Mao, Yun Qu, Jiayi Shen, Yiqin Lv, Xiangyang Ji
Foundation models have revolutionized general-purpose problem-solving, offering rapid task adaptation through pretraining, meta-training, and finetuning. Recent crucial advances in these paradigms reveal the importance of challenging task prioritized sampling to enhance adaptation robustness under distribution shifts. However, ranking task difficulties over iteration as a preliminary step typically requires exhaustive task evaluation, which is practically unaffordable in computation and data-annotation. This study provides a novel perspective to illuminate the possibility of leveraging the dual importance of adaptation robustness and learning efficiency, particularly in scenarios where task evaluation is risky or costly, such as iterative agent-environment interactions for robotic policy evaluation or computationally intensive inference steps for finetuning foundation models. Firstly, we introduce Model Predictive Task Sampling (MPTS), a framework that bridges the task space and adaptation risk landscape, providing a theoretical foundation for robust active task sampling. MPTS employs a generative model to characterize the episodic optimization process and predicts task-specific adaptation risk via posterior inference. The resulting risk learner amortizes the costly evaluation of task adaptation performance and provably approximates task difficulty rankings. MPTS seamlessly integrates into zero-shot, few-shot, and supervised finetuning settings. Empirically, we conduct extensive experiments in pattern recognition using foundation models and sequential decision-making. Our results demonstrate that MPTS significantly enhances adaptation robustness for tail or out-of-distribution (OOD) tasks and improves learning efficiency compared to state-of-the-art (SOTA) methods. The code is available at the project site https://github.com/thu-rllab/MPTS.
模型基础已经彻底改变了通用问题解决的能力,通过预训练、元训练和微调实现了快速任务适应。这些模式的最新关键进展揭示了优先采样挑战性任务在提高分布转移下的适应稳健性中的重要性。然而,作为初步步骤,在迭代过程中对任务难度进行排序通常需要进行全面的任务评估,这在计算和数据标注方面实际上是无法承受的。本研究提供了一个新的视角,阐明了在任务评估存在风险或成本高昂的情况下,利用适应稳健性和学习效率双重重要性的可能性,特别是在机器人策略评估的迭代代理环境交互或微调基础模型的计算密集型推理步骤等场景。首先,我们引入了模型预测任务采样(MPTS),这是一个架起了任务空间和适应风险景观的桥梁,为稳健的活动任务采样提供了理论基础。MPTS采用生成模型来刻画片段优化过程,并通过后验推理预测特定任务的适应风险。所得的风险学习者摊还了昂贵的任务适应性能评估成本,并可证明近似任务难度排名。MPTS无缝集成到零样本、少样本和监督微调环境。经验上,我们在使用基础模型的模式识别和序列决策制定方面进行了广泛实验。结果表明,与最新方法相比,MPTS显著提高了对尾端或超出分布范围(OOD)的任务的适应稳健性,并提高了学习效率。代码可在项目网站https://github.com/thu-rllab/MPTS上找到。
论文及项目相关链接
Summary
本文提出模型预测任务采样(MPTS)框架,用于实现稳健的活动任务采样。它结合任务空间和适应风险景观,通过生成模型刻画优化过程,预测特定任务的适应风险,并据此评估任务难度排名。MPTS在零样本、少样本和监督微调场景中无缝集成,能显著提高对尾部分布或异常任务的适应稳健性,同时提高学习效率。代码可在项目网站获取。
Key Takeaways
- 模型预测任务采样(MPTS)结合了任务空间和适应风险景观。
- 生成模型用于刻画优化过程,并预测特定任务的适应风险。
- MPTS框架能评估任务难度排名,减少昂贵的任务评估成本。
- MPTS在零样本、少样本和监抛微调场景中表现出强大的性能。
- MPTS显著提高对尾部分布或异常任务的适应稳健性。
- 与现有技术相比,MPTS提高了学习效率。
点此查看论文截图

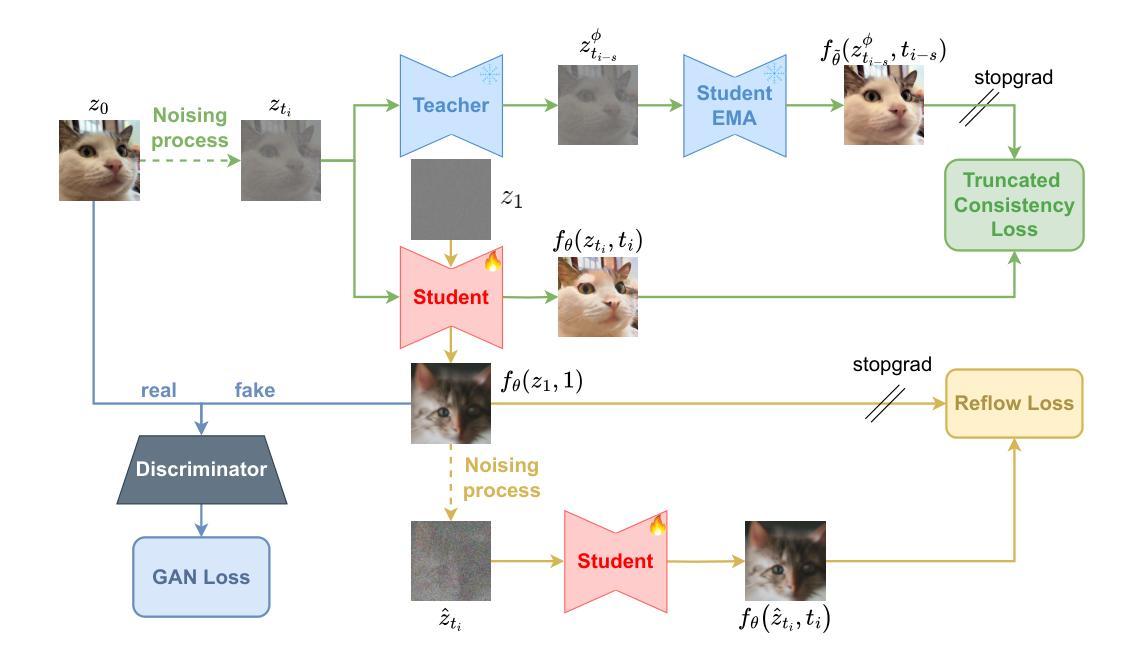
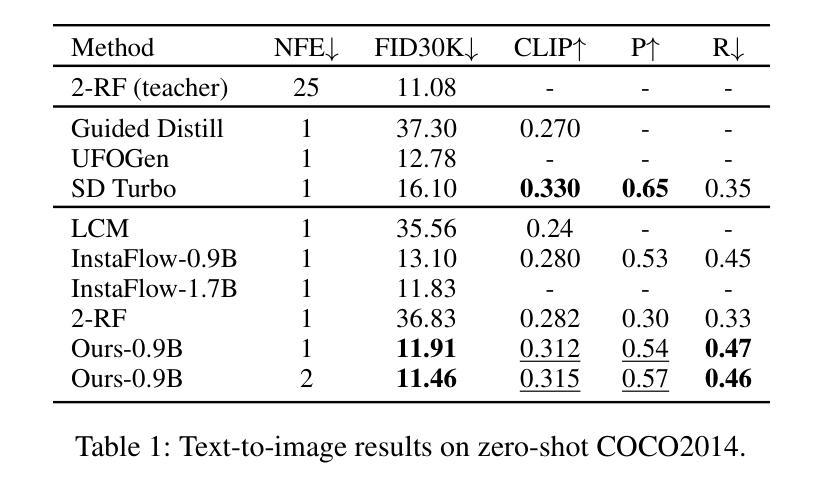
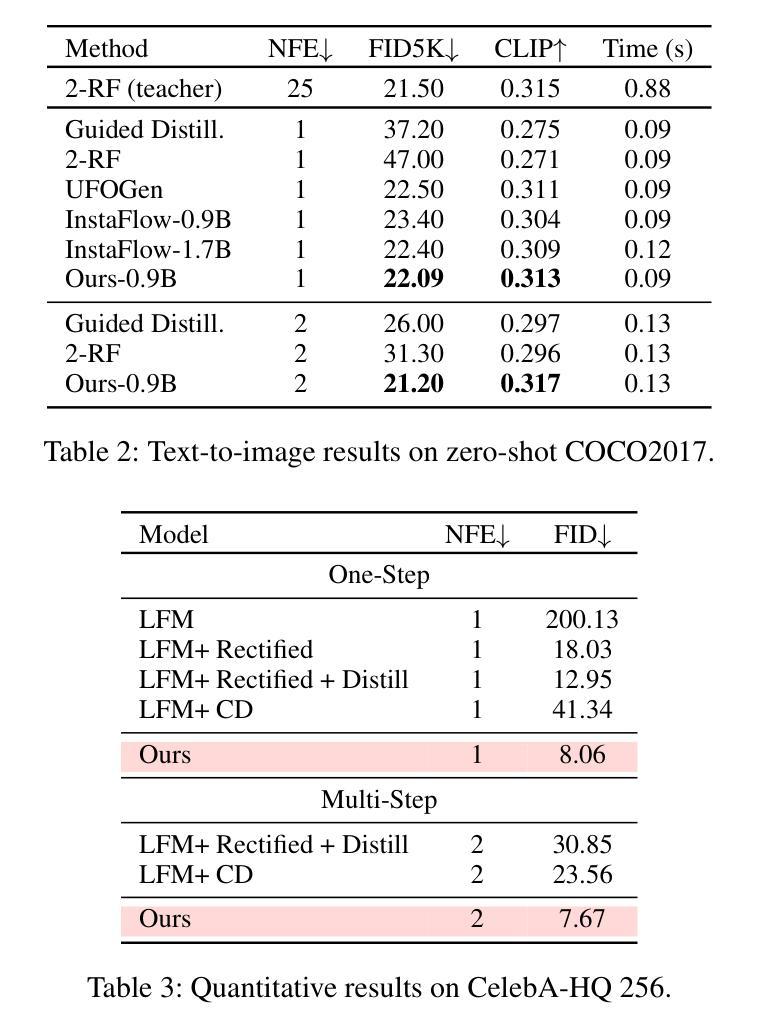
Self-Corrected Flow Distillation for Consistent One-Step and Few-Step Text-to-Image Generation
Authors:Quan Dao, Hao Phung, Trung Dao, Dimitris Metaxas, Anh Tran
Flow matching has emerged as a promising framework for training generative models, demonstrating impressive empirical performance while offering relative ease of training compared to diffusion-based models. However, this method still requires numerous function evaluations in the sampling process. To address these limitations, we introduce a self-corrected flow distillation method that effectively integrates consistency models and adversarial training within the flow-matching framework. This work is a pioneer in achieving consistent generation quality in both few-step and one-step sampling. Our extensive experiments validate the effectiveness of our method, yielding superior results both quantitatively and qualitatively on CelebA-HQ and zero-shot benchmarks on the COCO dataset. Our implementation is released at https://github.com/VinAIResearch/SCFlow
流匹配已成为训练生成模型的一种有前途的框架,它表现出了令人印象深刻的经验性能,与基于扩散的模型相比,训练相对容易。然而,这种方法在采样过程中仍然需要大量函数评估。为了解决这些局限性,我们引入了一种自校正流蒸馏方法,该方法有效地在流匹配框架内集成了一致性模型和对抗性训练。这项工作在少数步骤和一步采样中都实现了一致的生成质量,具有开创性。我们的广泛实验验证了该方法的有效性,在CelebA-HQ和COCO数据集的零样本基准测试上实现了定量和定性的优越结果。我们的实现已发布在https://github.com/VinAIResearch/SCFlow。
论文及项目相关链接
PDF Accepted at AAAI 2025
Summary
文本介绍了流匹配框架在训练生成模型方面的潜力,其表现令人印象深刻,相较于基于扩散的模型更易训练。然而,采样过程中仍需大量函数评估。为解决这一问题,引入了一种自我校正流蒸馏方法,该方法有效地将一致性模型和对抗性训练集成到流匹配框架中。此项工作率先实现了一步及少步采样的稳定生成质量。广泛的实验验证了该方法的有效性,在CelebA-HQ和COCO数据集的零样本基准测试上实现了定量和定性的优越结果。
Key Takeaways
- 流匹配框架已成为训练生成模型的有力候选者,表现优异且相对易训练。
- 采样过程中仍需要众多函数评估,这是当前方法的一个局限。
- 引入自我校正流蒸馏方法,集成一致性模型和对抗性训练到流匹配框架中。
- 该方法在一步和少步采样中实现了稳定的生成质量,是业内的先驱。
- 广泛实验证明该方法的有效性,在多个数据集上表现优越。
- 该方法的实施细节已发布在https://github.com/VinAIResearch/SCFlow。
- 此方法有助于改进生成模型的性能和效率,为相关领域的研究提供了新方向。
点此查看论文截图