⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
AvatarArtist: Open-Domain 4D Avatarization
Authors:Hongyu Liu, Xuan Wang, Ziyu Wan, Yue Ma, Jingye Chen, Yanbo Fan, Yujun Shen, Yibing Song, Qifeng Chen
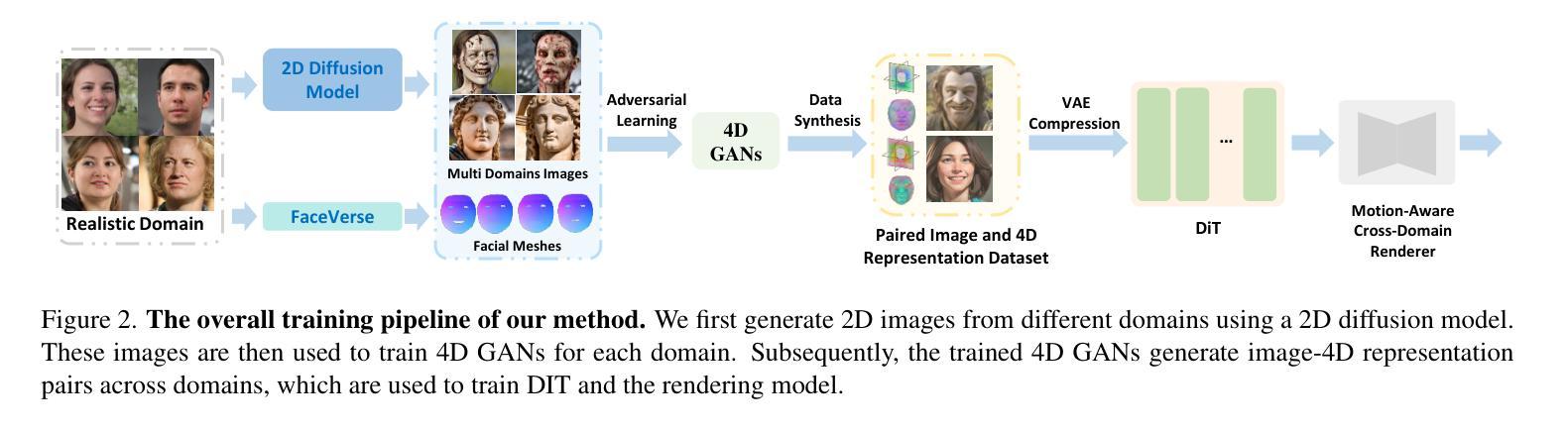
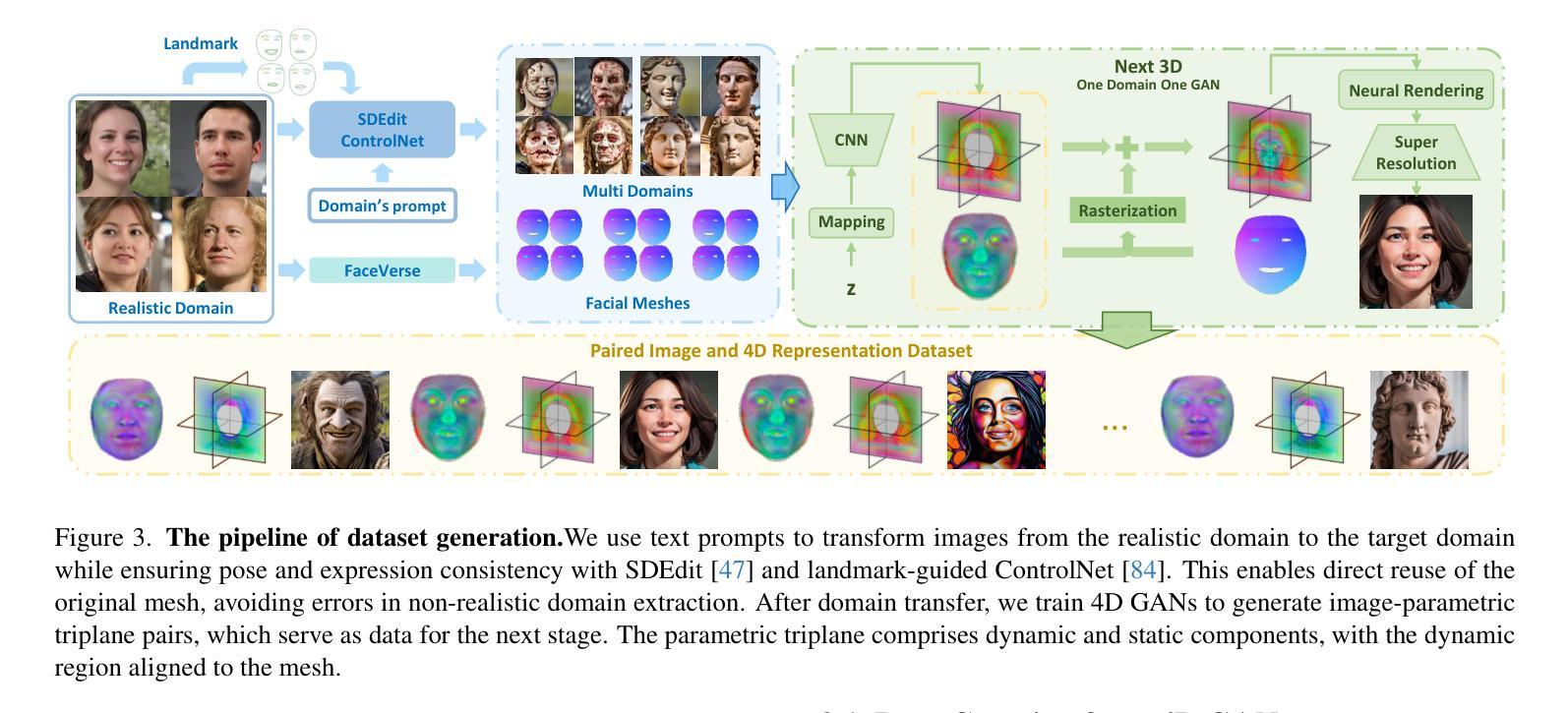
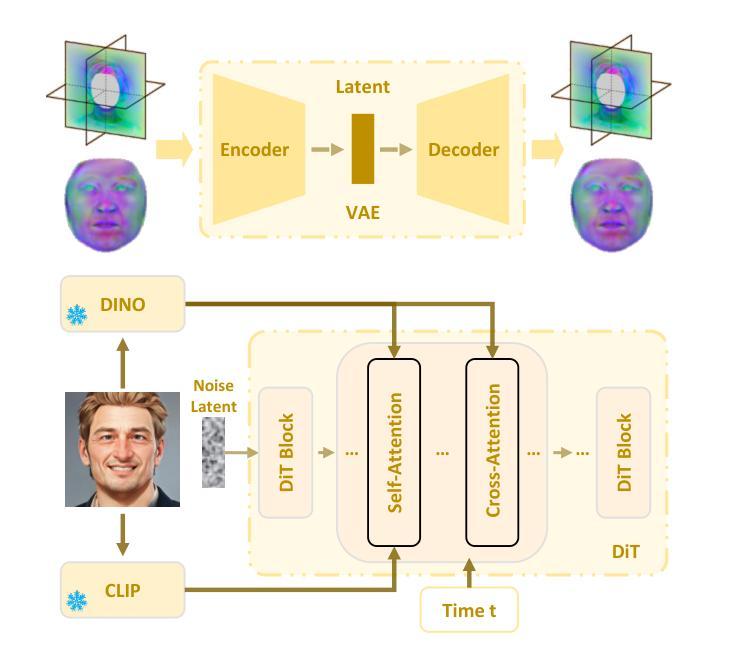
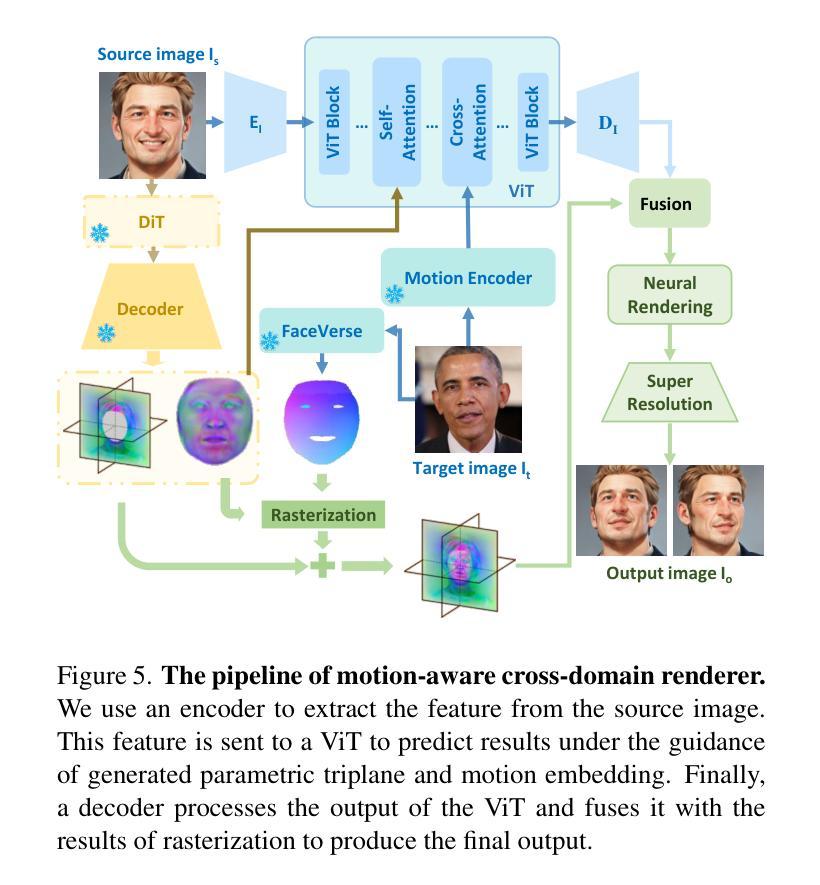
This work focuses on open-domain 4D avatarization, with the purpose of creating a 4D avatar from a portrait image in an arbitrary style. We select parametric triplanes as the intermediate 4D representation and propose a practical training paradigm that takes advantage of both generative adversarial networks (GANs) and diffusion models. Our design stems from the observation that 4D GANs excel at bridging images and triplanes without supervision yet usually face challenges in handling diverse data distributions. A robust 2D diffusion prior emerges as the solution, assisting the GAN in transferring its expertise across various domains. The synergy between these experts permits the construction of a multi-domain image-triplane dataset, which drives the development of a general 4D avatar creator. Extensive experiments suggest that our model, AvatarArtist, is capable of producing high-quality 4D avatars with strong robustness to various source image domains. The code, the data, and the models will be made publicly available to facilitate future studies..
本文专注于开放域4D avatar化,旨在从任意风格的肖像图像创建4D avatar。我们选择参数化triplanes作为中间4D表示,并提出了一种实用的训练范式,该范式结合了生成对抗网络(GANs)和扩散模型。我们的设计源于对以下现象的观察:4D GANs在无监督的情况下擅长于在图像和triplanes之间建立桥梁,但在处理多样数据分布时通常面临挑战。一个稳健的二维扩散先验作为解决方案出现,它有助于GAN在不同领域之间转移其专业知识。这些专家之间的协同作用使得可以构建多域图像-triplane数据集,从而推动通用4D avatar创作者的发展。大量实验表明,我们的模型AvatarArtist能够生成高质量的4D avatars,对各种源图像域具有很强的稳健性。代码、数据和模型将公开提供,以便于未来研究。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文关注开放域4D个性化角色创建,旨在从任意风格的肖像图片中创建4D个性化角色。研究采用参数化triplanes作为中间4D表示形式,并提出一种结合生成对抗网络(GANs)和扩散模型的实际训练范式。设计思路源于观察,即4D GANs在无需监督的情况下擅长于图像和triplanes之间的桥梁搭建,但在处理多样化数据分布时面临挑战。因此,引入稳健的2D扩散先验,帮助GAN在不同领域之间转移知识。专家之间的协同作用使得构建多域图像-triplane数据集成为可能,进而推动通用4D个性化角色创建器的发展。实验表明,所开发的AvatarArtist模型能够生成高质量的4D个性化角色,对不同源图像域的鲁棒性强。代码、数据和模型将公开提供,以推动未来研究。
Key Takeaways
- 本文关注开放域4D个性化角色创建,旨在通过GANs和扩散模型创建4D个性化角色。
- 采用参数化triplanes作为中间4D表示形式。
- 4D GANs在无需监督的情况下擅长桥梁搭建,但在处理多样化数据分布时面临挑战。
- 引入稳健的2D扩散先验,协助GAN在不同领域间转移知识。
- 通过协同作用构建多域图像-triplane数据集。
- 开发了一个名为AvatarArtist的模型,能够生成高质量的4D个性化角色。
点此查看论文截图

In the Blink of an Eye: Instant Game Map Editing using a Generative-AI Smart Brush
Authors:Vitaly Gnatyuk, Valeriia Koriukina Ilya Levoshevich, Pavel Nurminskiy, Guenter Wallner
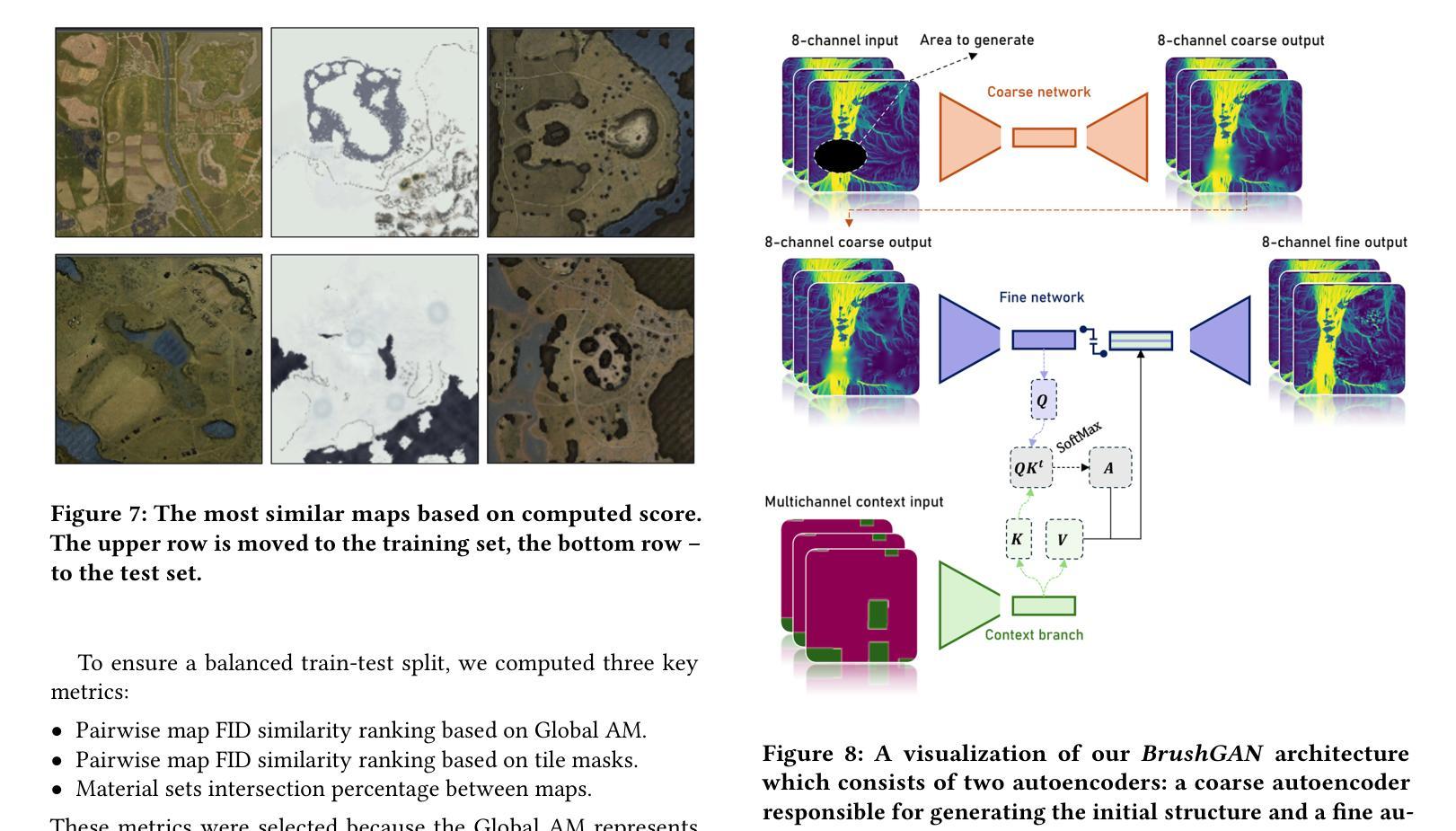
With video games steadily increasing in complexity, automated generation of game content has found widespread interest. However, the task of 3D gaming map art creation remains underexplored to date due to its unique complexity and domain-specific challenges. While recent works have addressed related topics such as retro-style level generation and procedural terrain creation, these works primarily focus on simpler data distributions. To the best of our knowledge, we are the first to demonstrate the application of modern AI techniques for high-resolution texture manipulation in complex, highly detailed AAA 3D game environments. We introduce a novel Smart Brush for map editing, designed to assist artists in seamlessly modifying selected areas of a game map with minimal effort. By leveraging generative adversarial networks and diffusion models we propose two variants of the brush that enable efficient and context-aware generation. Our hybrid workflow aims to enhance both artistic flexibility and production efficiency, enabling the refinement of environments without manually reworking every detail, thus helping to bridge the gap between automation and creative control in game development. A comparative evaluation of our two methods with adapted versions of several state-of-the art models shows that our GAN-based brush produces the sharpest and most detailed outputs while preserving image context while the evaluated state-of-the-art models tend towards blurrier results and exhibit difficulties in maintaining contextual consistency.
随着视频游戏的复杂度不断提升,游戏内容的自动生成已引起广泛关注。然而,由于3D游戏地图艺术创作的独特复杂性和特定领域的挑战,至今该任务仍被较少探索。虽然近期有一些关于复古风格关卡生成和程序化地形生成的研究,但这些研究主要集中在更简单的数据分布上。据我们所知,我们是首次展示现代AI技术在复杂、高度详细的AAA 3D游戏环境中进行高分辨率纹理操作的应用。我们引入了一种新型的智能地图编辑笔刷,旨在帮助艺术家轻松修改游戏地图的选定区域。通过利用生成对抗网络和扩散模型,我们提出了两种笔刷变体,以实现高效和上下文感知的生成。我们的混合工作流程旨在提高艺术灵活性和生产效率,能够在不手动重新处理每个细节的情况下优化环境,从而有助于弥合游戏开发中自动化和创意控制之间的差距。我们对两种方法与几种最新模型的改编版本进行比较评估,结果表明,我们的GAN笔刷产生的输出最清晰、最详细,同时保留了图像上下文,而被评估的最新模型往往结果模糊,并且在保持上下文一致性方面存在困难。
论文及项目相关链接
Summary
随着游戏的复杂度不断提升,游戏内容的自动生成受到了广泛关注。然而,由于3D游戏地图艺术创作的独特复杂性和特定领域挑战,该任务至今仍未得到充分探索。尽管有相关工作涉及复古风格层级生成和程序化地形创建等话题,但它们主要关注更简单的数据分布。我们是首次展示将现代AI技术应用于复杂、高度详细的AAA级3D游戏环境中高分辨率纹理操作的实践。我们推出了一款新型智能刷子工具,旨在帮助艺术家轻松修改游戏地图的选定区域。借助对抗生成网络和扩散模型,我们提出了两款刷子的变体,实现了高效且语境感知的生成。我们的混合工作流程旨在提高艺术灵活性和生产效率,可以在不重新手动处理每个细节的情况下优化环境,有助于弥合游戏开发中自动化与创意控制之间的鸿沟。评估显示,我们的GAN基础刷子生成的结果最清晰、最详细,同时保持了图像上下文,而其他评估的先进模型则倾向于结果模糊,并且在保持上下文一致性方面存在困难。
Key Takeaways
- 3D游戏地图艺术创作因其独特性、复杂性及领域特定挑战而仍被较少探索。
- 现有工作主要关注简单的数据分布和较低复杂度的游戏内容生成。
- 研究首次展示了现代AI技术在复杂、高详细度的AAA级3D游戏环境高分辨率纹理操作中的应用。
- 引入了一种新型智能刷子工具,可帮助艺术家轻松修改游戏地图的选定区域。
- 利用对抗生成网络和扩散模型的刷子变体实现了高效且语境感知的生成。
- 混合工作流程旨在提高艺术灵活性和生产效率,可以在不重新处理每个细节的情况下优化环境。
点此查看论文截图




Exploring Semantic Feature Discrimination for Perceptual Image Super-Resolution and Opinion-Unaware No-Reference Image Quality Assessment
Authors:Guanglu Dong, Xiangyu Liao, Mingyang Li, Guihuan Guo, Chao Ren
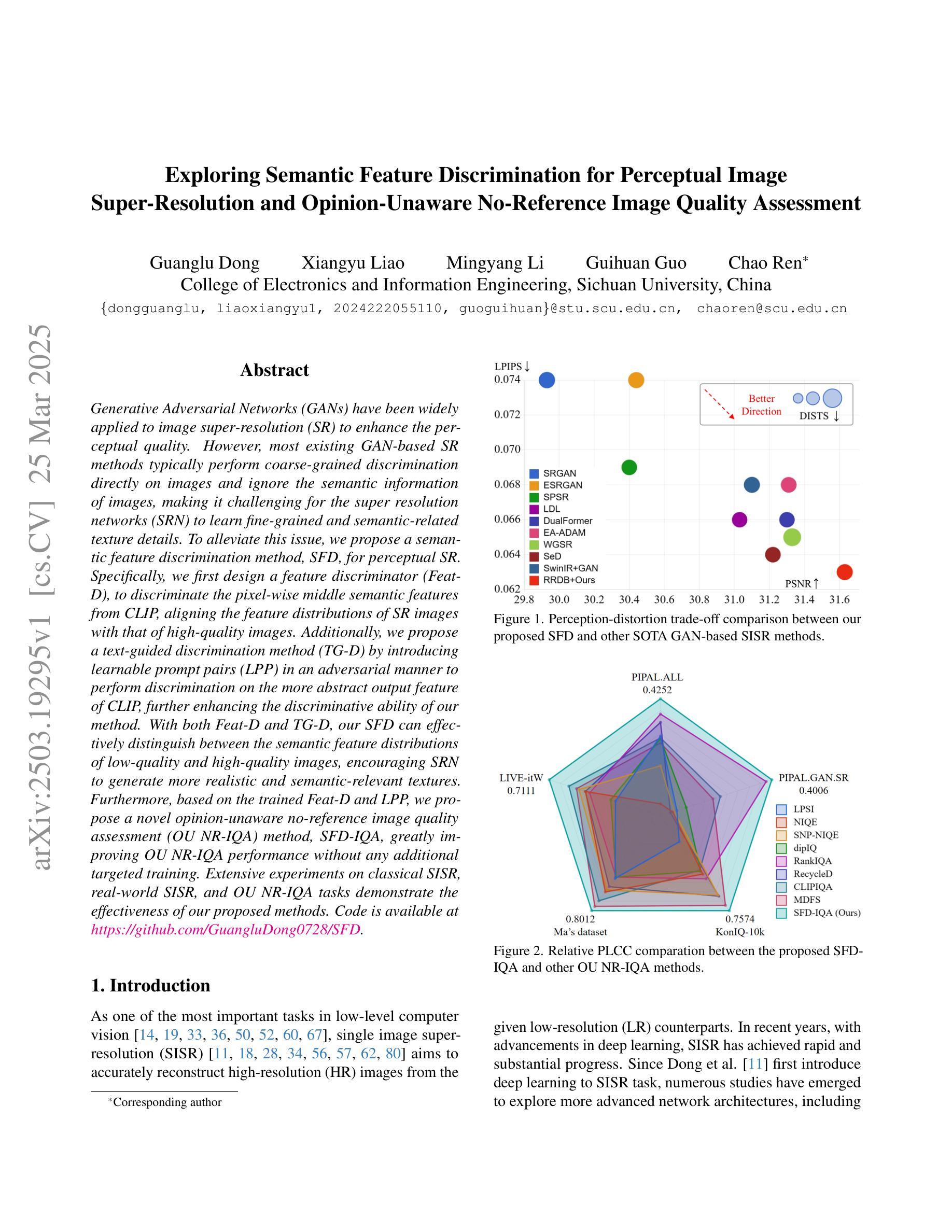
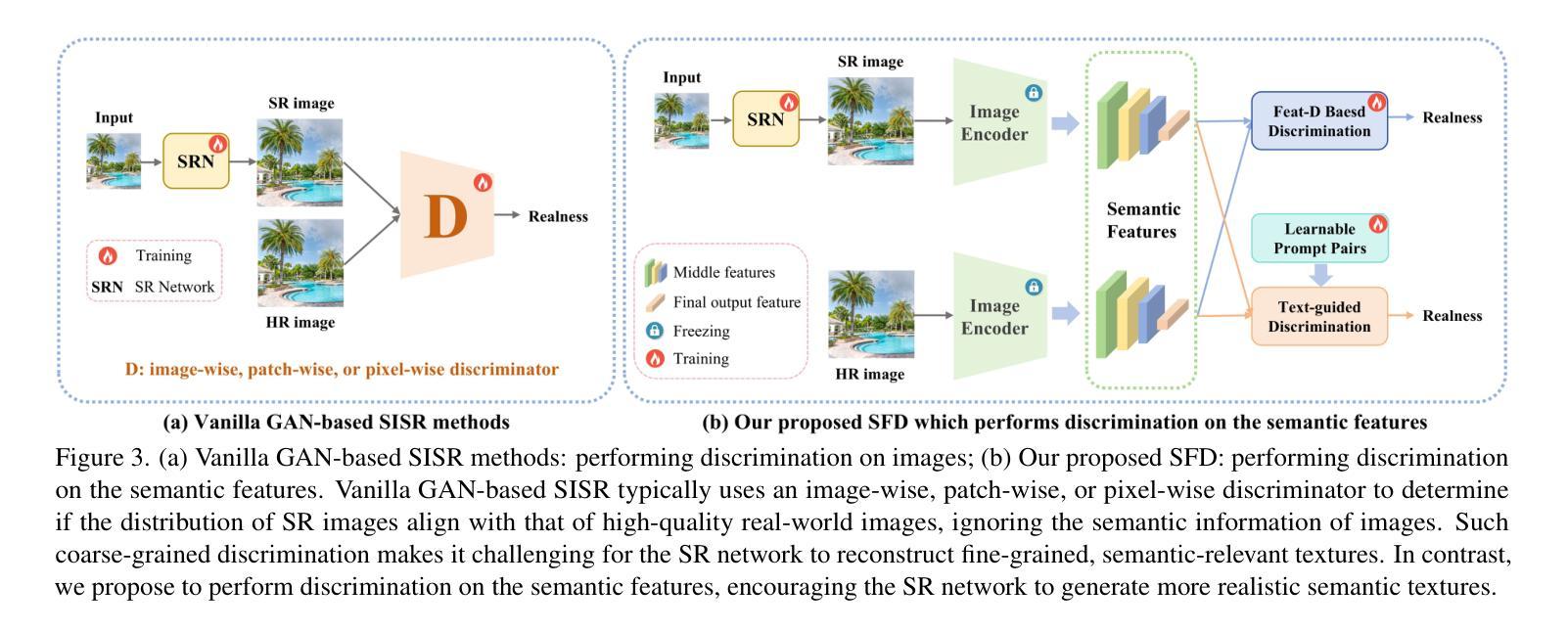
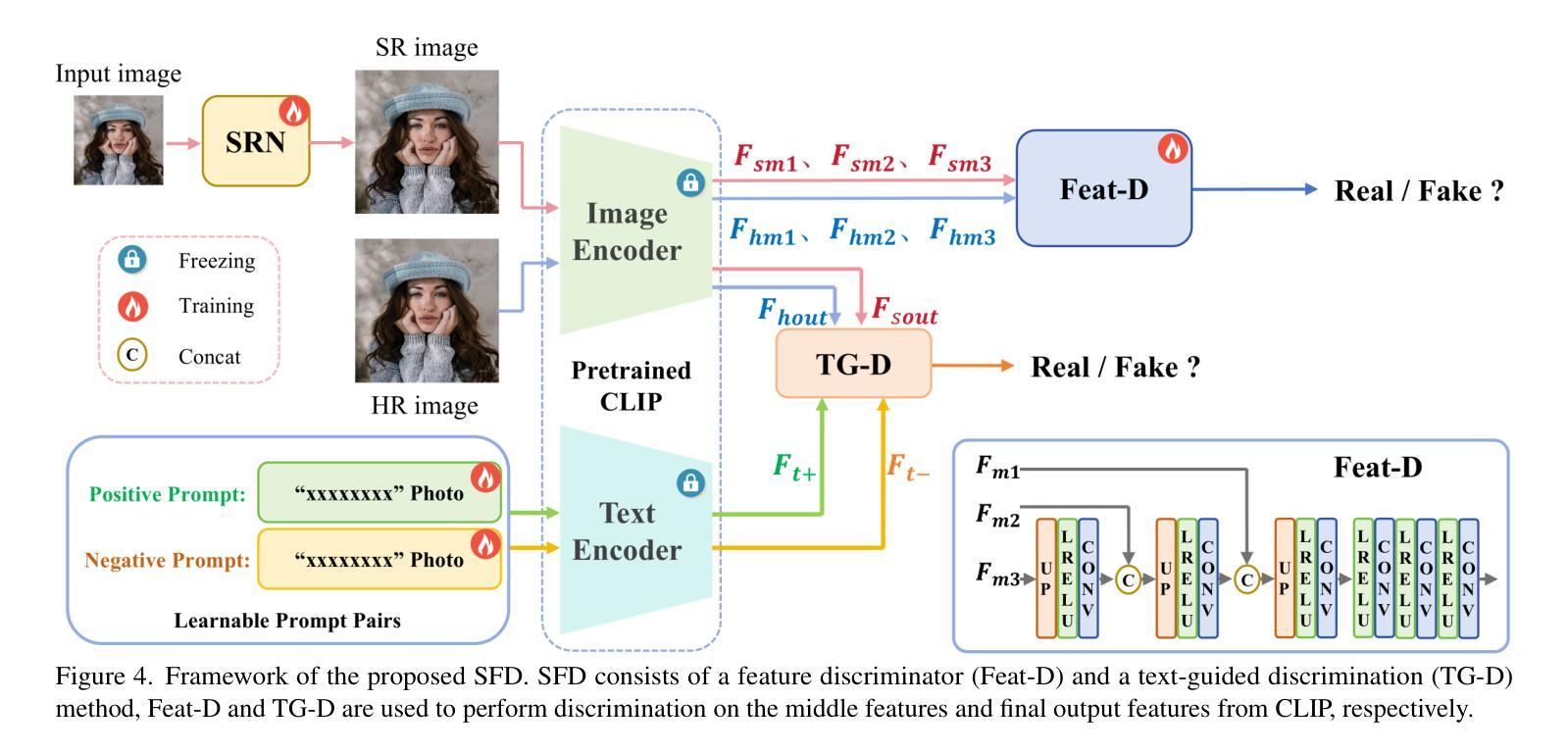
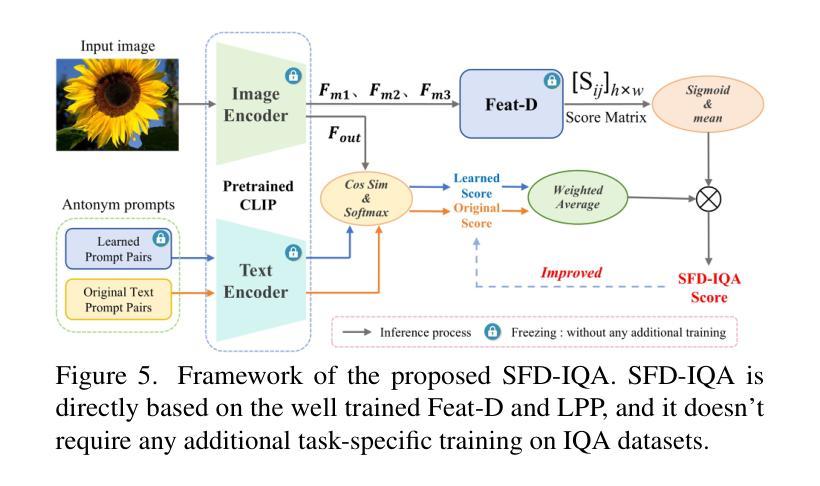
Generative Adversarial Networks (GANs) have been widely applied to image super-resolution (SR) to enhance the perceptual quality. However, most existing GAN-based SR methods typically perform coarse-grained discrimination directly on images and ignore the semantic information of images, making it challenging for the super resolution networks (SRN) to learn fine-grained and semantic-related texture details. To alleviate this issue, we propose a semantic feature discrimination method, SFD, for perceptual SR. Specifically, we first design a feature discriminator (Feat-D), to discriminate the pixel-wise middle semantic features from CLIP, aligning the feature distributions of SR images with that of high-quality images. Additionally, we propose a text-guided discrimination method (TG-D) by introducing learnable prompt pairs (LPP) in an adversarial manner to perform discrimination on the more abstract output feature of CLIP, further enhancing the discriminative ability of our method. With both Feat-D and TG-D, our SFD can effectively distinguish between the semantic feature distributions of low-quality and high-quality images, encouraging SRN to generate more realistic and semantic-relevant textures. Furthermore, based on the trained Feat-D and LPP, we propose a novel opinion-unaware no-reference image quality assessment (OU NR-IQA) method, SFD-IQA, greatly improving OU NR-IQA performance without any additional targeted training. Extensive experiments on classical SISR, real-world SISR, and OU NR-IQA tasks demonstrate the effectiveness of our proposed methods.
生成对抗网络(GANs)已被广泛应用于图像超分辨率(SR)以提高感知质量。然而,大多数现有的基于GAN的SR方法通常直接在图像上进行粗略的鉴别,忽略了图像的语义信息,这使得超分辨率网络(SRN)在学习细致和语义相关的纹理细节方面面临挑战。为了缓解这个问题,我们提出了一种用于感知SR的语义特征鉴别方法SFD。具体来说,我们首先设计了一个特征鉴别器(Feat-D),以鉴别CLIP的中间语义特征,使SR图像的特征分布与高质图像的特征分布对齐。此外,我们通过引入可学习的提示对(LPP)以对抗性的方式,提出了一种文本引导鉴别方法(TG-D),对CLIP的更抽象输出特征进行鉴别,进一步增强我们方法的判别能力。通过Feat-D和TG-D的结合,我们的SFD可以有效地区分低质量和高质量图像的语义特征分布,鼓励SRN生成更真实和语义相关的纹理。此外,基于已训练的Feat-D和LPP,我们提出了一种新型的无参考意见图像质量评估(OU NR-IQA)方法SFD-IQA,在不需要任何额外针对性训练的情况下,大大提高了OU NR-IQA的性能。在经典SISR、现实SISR和OU NR-IQA任务上的大量实验证明了我们提出方法的有效性。
论文及项目相关链接
PDF Accepted to CVPR2025
Summary
本文介绍了针对生成对抗网络(GANs)在图像超分辨率(SR)应用中的挑战,提出了一种语义特征判别方法(SFD)。通过设计特征判别器(Feat-D)和文本引导判别方法(TG-D),SFD能够区分低质量和高质量图像的语义特征分布,鼓励超分辨率网络(SRN)生成更真实、语义相关的纹理。此外,基于训练的Feat-D和可学习提示对(LPP),还提出了一种新型的无参考意见图像质量评估方法SFD-IQA,大大提高了无参考意见图像质量评估的性能,且无需任何额外的针对性训练。实验表明,该方法在经典SISR、现实世界SISR和无参考意见图像质量评估任务中均有效。
Key Takeaways
- GANs在图像超分辨率中面临挑战,缺乏语义信息的考虑使得学习精细纹理变得困难。
- 提出一种语义特征判别方法(SFD),通过设计特征判别器(Feat-D)来识别图像的中间语义特征。
- 结合文本引导判别方法(TG-D)和可学习提示对(LPP),提高方法的判别能力。
- SFD能有效区分低质量和高质量图像的语义特征分布,鼓励超分辨率网络生成更真实、语义相关的纹理。
- 基于训练的Feat-D和LPP,提出了一种新型的无参考意见图像质量评估方法SFD-IQA。
- SFD-IQA在无参考意见图像质量评估任务中表现出良好的性能提升。
点此查看论文截图
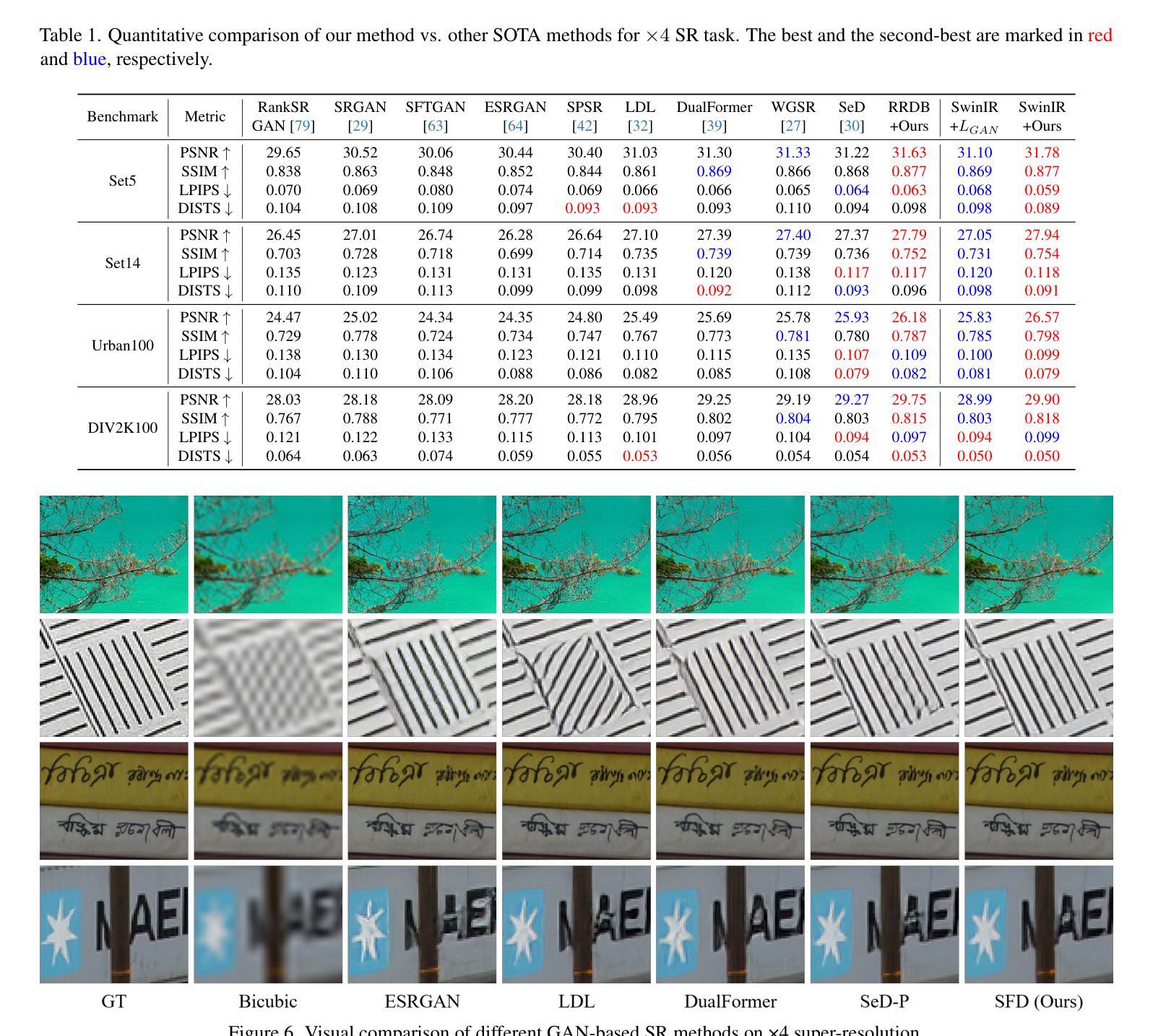
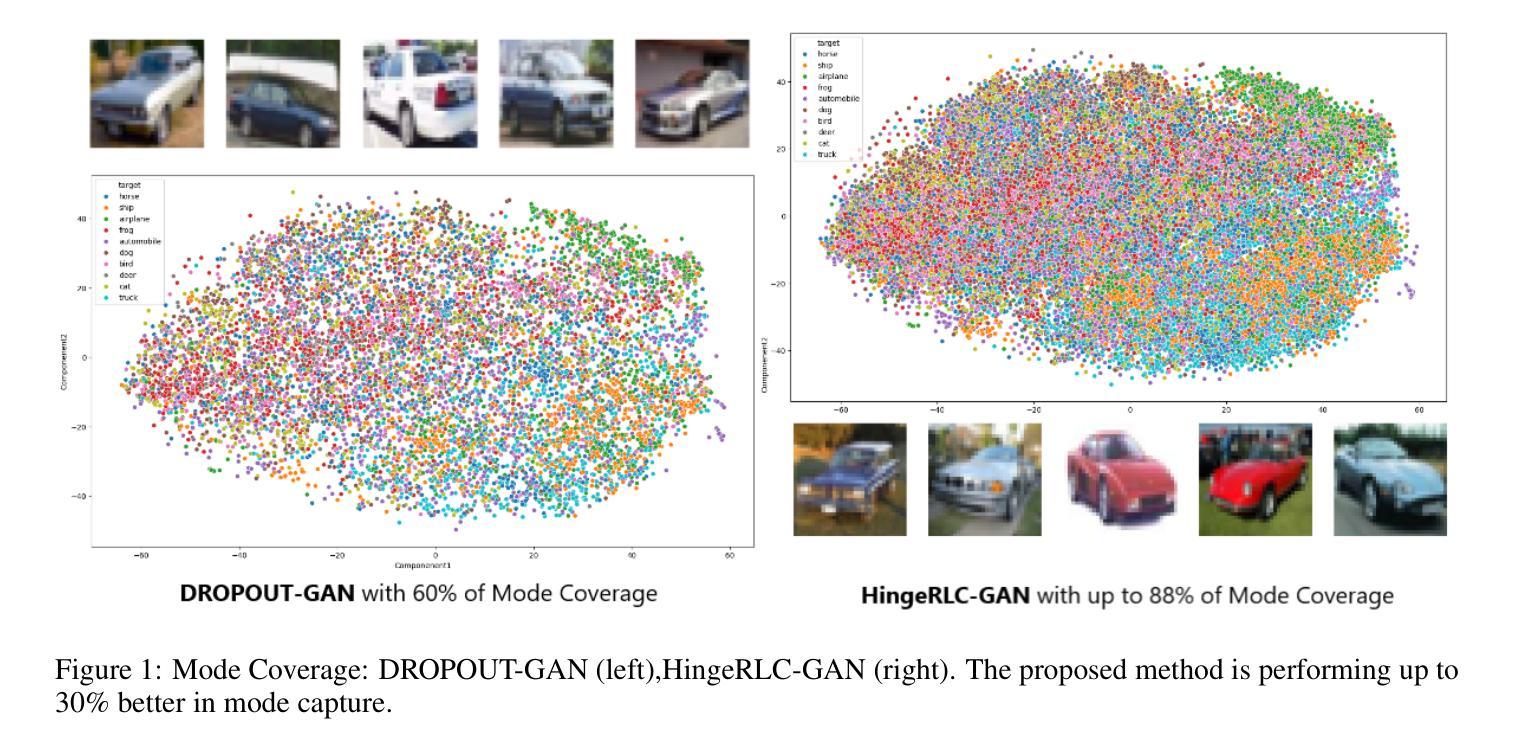
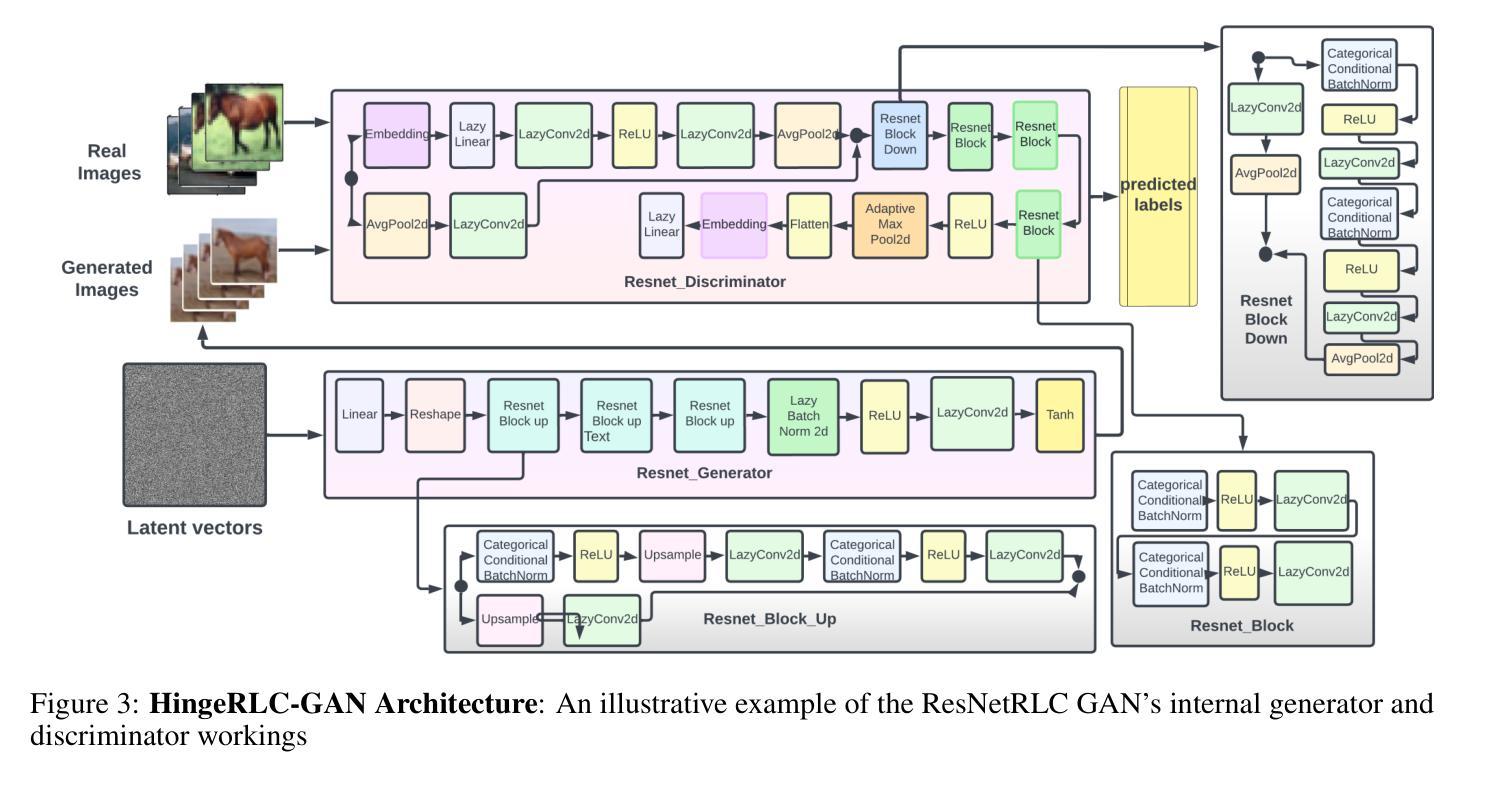
HingeRLC-GAN: Combating Mode Collapse with Hinge Loss and RLC Regularization
Authors:Osman Goni, Himadri Saha Arka, Mithun Halder, Mir Moynuddin Ahmed Shibly, Swakkhar Shatabda
Recent advances in Generative Adversarial Networks (GANs) have demonstrated their capability for producing high-quality images. However, a significant challenge remains mode collapse, which occurs when the generator produces a limited number of data patterns that do not reflect the diversity of the training dataset. This study addresses this issue by proposing a number of architectural changes aimed at increasing the diversity and stability of GAN models. We start by improving the loss function with Wasserstein loss and Gradient Penalty to better capture the full range of data variations. We also investigate various network architectures and conclude that ResNet significantly contributes to increased diversity. Building on these findings, we introduce HingeRLC-GAN, a novel approach that combines RLC Regularization and the Hinge loss function. With a FID Score of 18 and a KID Score of 0.001, our approach outperforms existing methods by effectively balancing training stability and increased diversity.
生成对抗网络(GANs)的最新进展已经证明了其生成高质量图像的能力。然而,仍然存在一个重大挑战,即模式崩溃。当生成器生成的数据模式有限,无法反映训练数据集的多样性时,就会发生这种情况。本研究通过提出一系列旨在提高GAN模型多样性和稳定性的架构改进来解决这个问题。我们通过改进损失函数,使用Wasserstein损失和梯度惩罚来更好地捕捉数据变化的全范围。我们还研究了各种网络架构,并得出结论认为ResNet对增加多样性做出了重大贡献。基于这些发现,我们引入了HingeRLC-GAN,这是一种将RLC正则化和Hinge损失函数相结合的新方法。我们的方法FID得分为18,KID得分为0.001,通过有效平衡训练稳定性和增加多样性,优于现有方法。
论文及项目相关链接
Summary
本研究通过改进生成对抗网络(GANs)的架构来解决模式崩溃问题,旨在提高GAN模型的多样性和稳定性。研究通过改进损失函数、引入ResNet网络架构以及结合RLC正则化和Hinge损失函数等方法,实现了高质量图像的生成,并获得了较高的FID和KID评分。
Key Takeaways
- 研究针对生成对抗网络(GANs)的模式崩溃问题进行了深入的探讨。
- 通过改进损失函数,采用Wasserstein损失和梯度惩罚,以更好地捕捉数据的全范围变化。
- 研究发现ResNet网络架构对提高GAN模型的多样性有显著贡献。
- 引入了HingeRLC-GAN这一新方法,结合了RLC正则化和Hinge损失函数。
- 该方法实现了高质量图像的生成,并获得了较高的FID评分和KID评分。
- 该研究为解决GANs的模式崩溃问题提供了新的思路和方向。
点此查看论文截图


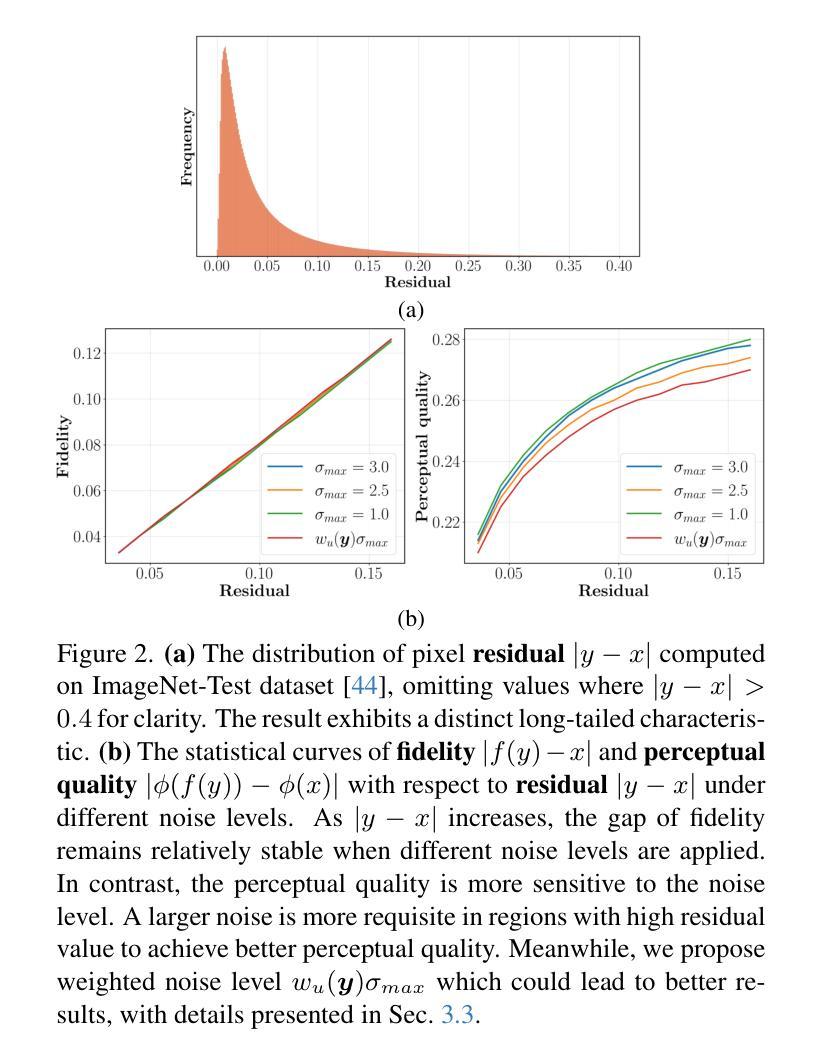
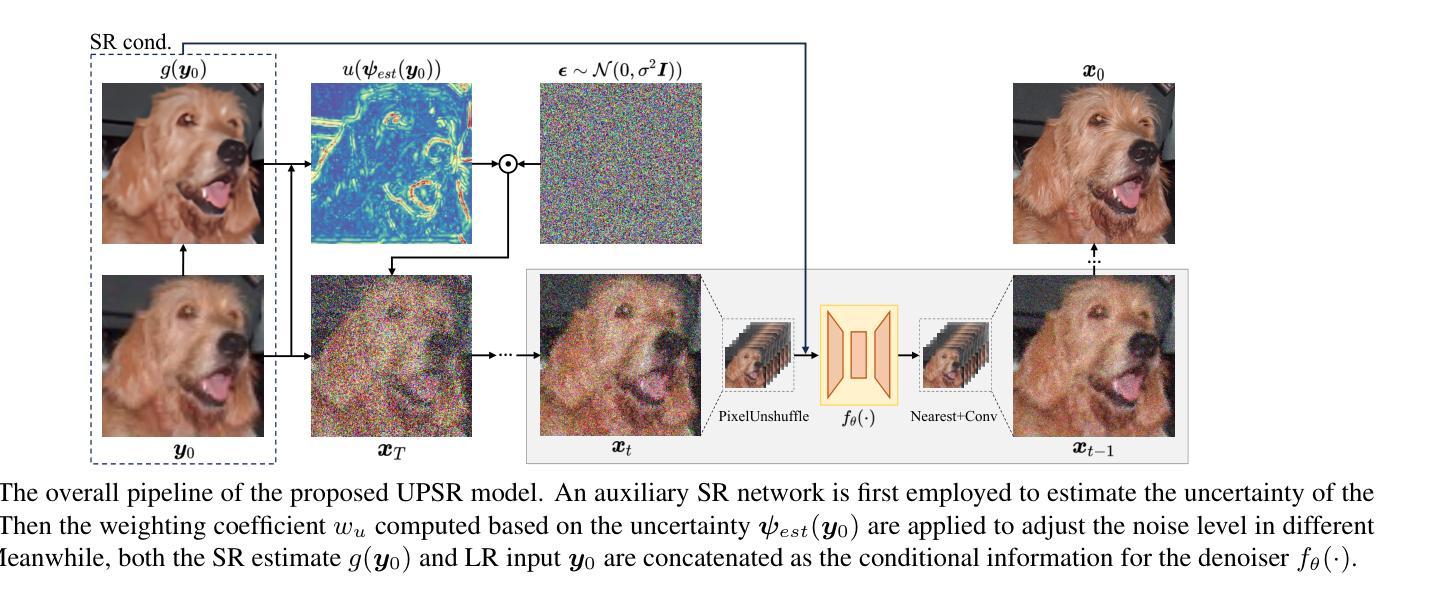
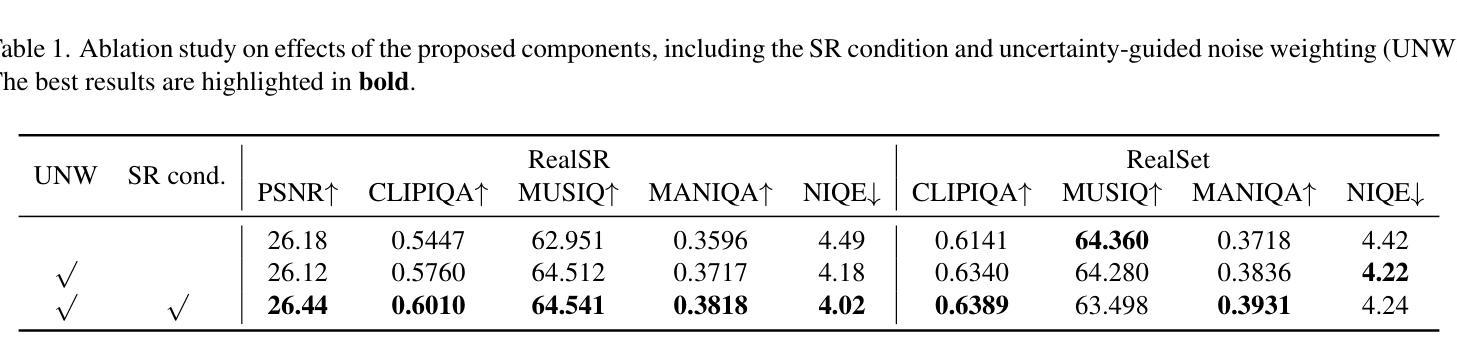
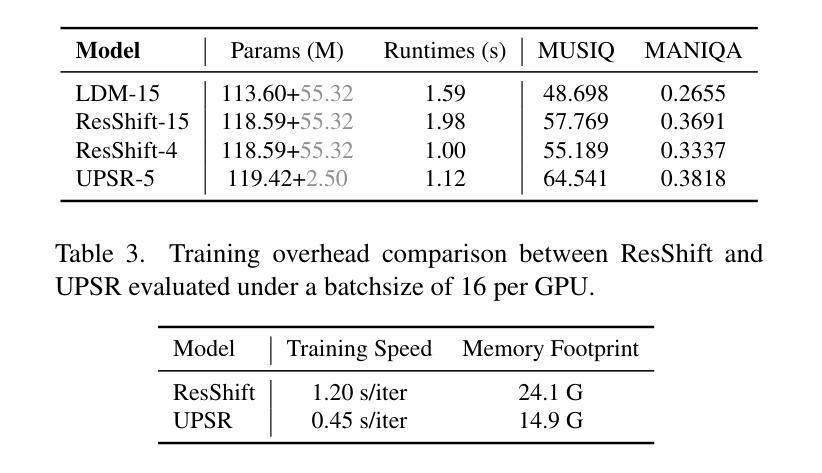
Uncertainty-guided Perturbation for Image Super-Resolution Diffusion Model
Authors:Leheng Zhang, Weiyi You, Kexuan Shi, Shuhang Gu
Diffusion-based image super-resolution methods have demonstrated significant advantages over GAN-based approaches, particularly in terms of perceptual quality. Building upon a lengthy Markov chain, diffusion-based methods possess remarkable modeling capacity, enabling them to achieve outstanding performance in real-world scenarios. Unlike previous methods that focus on modifying the noise schedule or sampling process to enhance performance, our approach emphasizes the improved utilization of LR information. We find that different regions of the LR image can be viewed as corresponding to different timesteps in a diffusion process, where flat areas are closer to the target HR distribution but edge and texture regions are farther away. In these flat areas, applying a slight noise is more advantageous for the reconstruction. We associate this characteristic with uncertainty and propose to apply uncertainty estimate to guide region-specific noise level control, a technique we refer to as Uncertainty-guided Noise Weighting. Pixels with lower uncertainty (i.e., flat regions) receive reduced noise to preserve more LR information, therefore improving performance. Furthermore, we modify the network architecture of previous methods to develop our Uncertainty-guided Perturbation Super-Resolution (UPSR) model. Extensive experimental results demonstrate that, despite reduced model size and training overhead, the proposed UWSR method outperforms current state-of-the-art methods across various datasets, both quantitatively and qualitatively.
基于扩散的图像超分辨率方法相对于基于GAN的方法表现出了显著的优势,特别是在感知质量方面。基于长时间的马尔可夫链,扩散方法具有出色的建模能力,能够在真实场景中实现卓越的性能。与之前的方法不同,这些方法侧重于通过修改噪声时间表或采样过程来提高性能,我们的方法则侧重于改进对LR信息的利用。我们发现LR图像的不同区域可以看作是对应于扩散过程中的不同时间点,其中平坦区域更接近目标HR分布,而边缘和纹理区域则相距较远。在平坦区域应用轻微噪声更有利于重建。我们将这一特性与不确定性相关联,并提出应用不确定性估计来指导特定区域的噪声水平控制,这是一种我们称为“不确定性引导噪声加权”的技术。不确定性较低的像素(即平坦区域)减少噪声,以保留更多LR信息,从而提高性能。此外,我们修改了之前方法的网络架构,以开发我们的不确定性引导扰动超分辨率(UPSR)模型。大量的实验结果表明,尽管模型规模减小且训练开销降低,但所提出的UWSR方法在多个数据集上在定量和定性方面都优于当前最先进的方法。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary:基于扩散的图像超分辨率方法相较于GAN方法具有显著优势,尤其在感知质量上表现更优秀。该方法利用马尔可夫链进行建模,并在利用低分辨率信息方面进行了改进。通过关联不确定性和噪声权重控制,提出了不确定性引导噪声权重方法。修改网络架构后,提出不确定性引导扰动超分辨率模型,实验结果显示,该方法在多个数据集上均优于当前先进方法。
Key Takeaways:
- 扩散方法相较于GAN在图像超分辨率上具有优势,尤其在感知质量上。
- 扩散方法利用马尔可夫链进行建模,具有强大的建模能力。
- 提出利用不确定性引导噪声权重控制,以提高重建效果。
- 在低不确定性区域(如平坦区域),应用较少的噪声以保留更多低分辨率信息。
- 修改了先前的网络架构,提出了不确定性引导扰动超分辨率模型(UPSR)。
- 实验证明,UPSR模型在多个数据集上的表现均优于当前先进方法。
点此查看论文截图


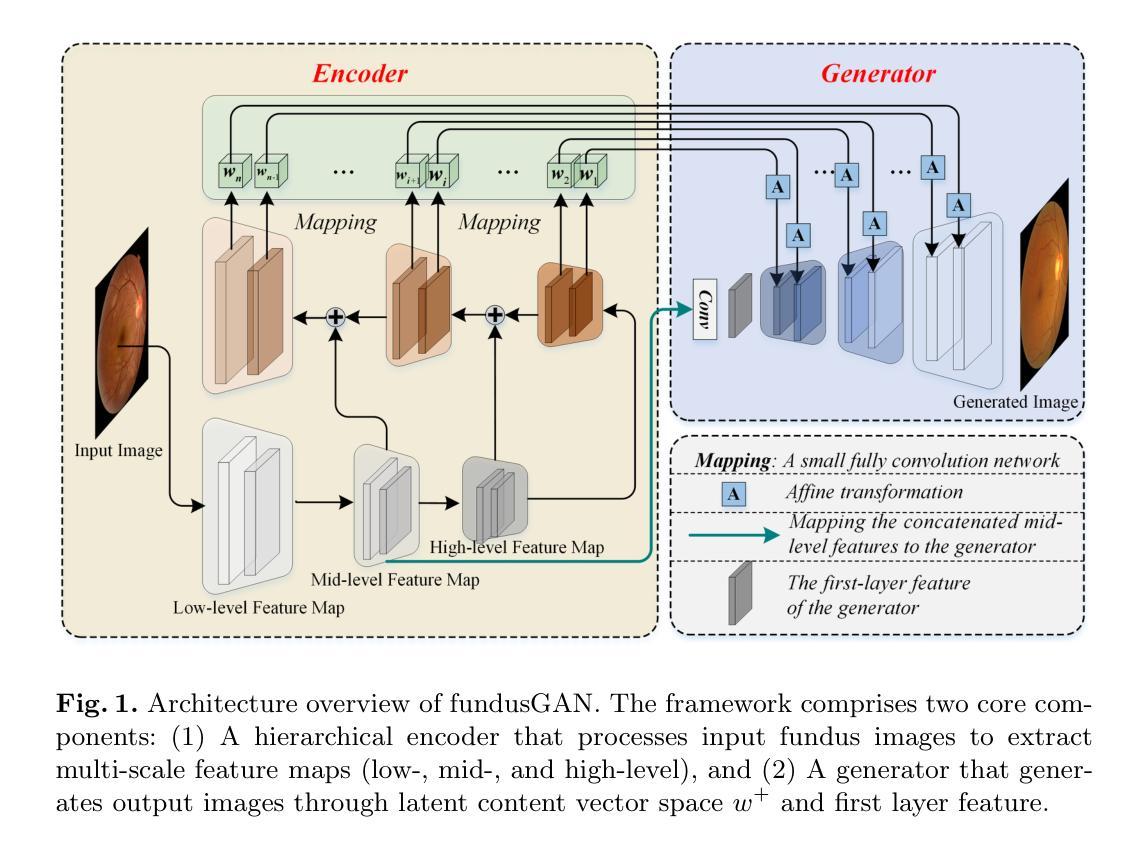
FundusGAN: A Hierarchical Feature-Aware Generative Framework for High-Fidelity Fundus Image Generation
Authors:Qingshan Hou, Meng Wang, Peng Cao, Zou Ke, Xiaoli Liu, Huazhu Fu, Osmar R. Zaiane
Recent advancements in ophthalmology foundation models such as RetFound have demonstrated remarkable diagnostic capabilities but require massive datasets for effective pre-training, creating significant barriers for development and deployment. To address this critical challenge, we propose FundusGAN, a novel hierarchical feature-aware generative framework specifically designed for high-fidelity fundus image synthesis. Our approach leverages a Feature Pyramid Network within its encoder to comprehensively extract multi-scale information, capturing both large anatomical structures and subtle pathological features. The framework incorporates a modified StyleGAN-based generator with dilated convolutions and strategic upsampling adjustments to preserve critical retinal structures while enhancing pathological detail representation. Comprehensive evaluations on the DDR, DRIVE, and IDRiD datasets demonstrate that FundusGAN consistently outperforms state-of-the-art methods across multiple metrics (SSIM: 0.8863, FID: 54.2, KID: 0.0436 on DDR). Furthermore, disease classification experiments reveal that augmenting training data with FundusGAN-generated images significantly improves diagnostic accuracy across multiple CNN architectures (up to 6.49% improvement with ResNet50). These results establish FundusGAN as a valuable foundation model component that effectively addresses data scarcity challenges in ophthalmological AI research, enabling more robust and generalizable diagnostic systems while reducing dependency on large-scale clinical data collection.
最近眼科基础模型(如RetFound)的最新进展已经表现出了令人瞩目的诊断能力,但需要大规模数据集进行有效的预训练,这为发展和部署带来了重大障碍。为了解决这一关键挑战,我们提出了FundusGAN,这是一种专门用于高保真眼底图像合成的新型分层特征感知生成框架。我们的方法在其编码器中使用特征金字塔网络,以全面提取多尺度信息,捕捉大型解剖结构和微妙的病理特征。该框架采用基于StyleGAN的修改过的生成器,结合了膨胀卷积和策略性上采样调整,以保留关键的视网膜结构,同时增强病理细节表示。在DDR、DRIVE和IDRiD数据集上的综合评估表明,FundusGAN在多个指标上始终优于最先进的方法(DDR上的SSIM:0.8863,FID:54.2,KID:0.0436)。此外,疾病分类实验表明,使用FundusGAN生成的图像增强训练数据可以显著提高多种CNN架构的诊断准确性(使用ResNet50可提高6.49%)。这些结果确立了FundusGAN作为一个有价值的基础模型组件,有效地解决了眼科人工智能研究中的数据稀缺挑战,能够构建更稳健和通用的诊断系统,同时减少对大规模临床数据收集的依赖。
论文及项目相关链接
Summary
FundusGAN是一种新型的分级特征感知生成框架,专为高保真眼底图像合成设计。它通过采用特征金字塔网络和修改后的StyleGAN生成器,能够全面提取多尺度信息,并捕捉眼底的大型解剖结构和微妙的病理特征。该框架解决了眼科基础模型需要大量数据进行预训练的问题,提高了诊断准确性并降低了对大规模临床数据收集的依赖。
Key Takeaways
- FundusGAN是一个针对眼底图像合成的生成框架,旨在解决眼科基础模型需要大量数据进行预训练的问题。
- FundusGAN采用特征金字塔网络,能够全面提取眼底图像的多尺度信息。
- 该框架结合修改后的StyleGAN生成器,通过采用扩张卷积和战略上采样调整,保留了关键的视网膜结构,同时增强了病理细节表示。
- FundusGAN在多个数据集上的综合评估表现优异,包括DDR、DRIVE和IDRiD数据集。
- 与现有方法相比,FundusGAN在多个指标上表现更出色,如结构相似性指数(SSIM)、弗雷歇距离(FID)和关键病变识别距离(KID)。
- 使用FundusGAN生成的图像进行训练数据增强,可以显著提高疾病分类实验的诊断准确性。
点此查看论文截图

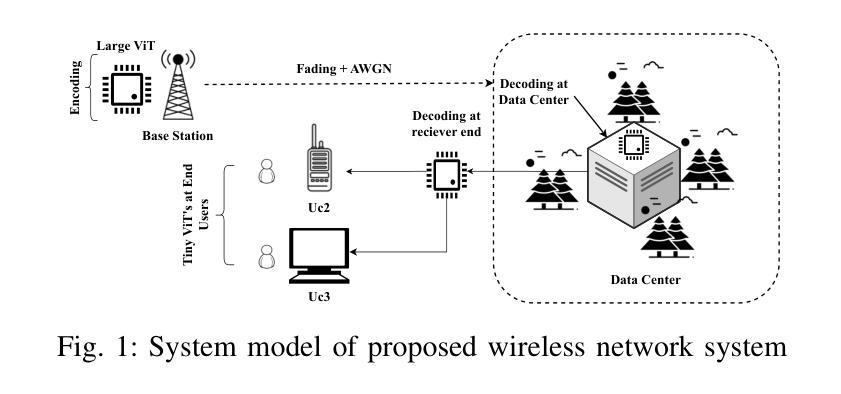
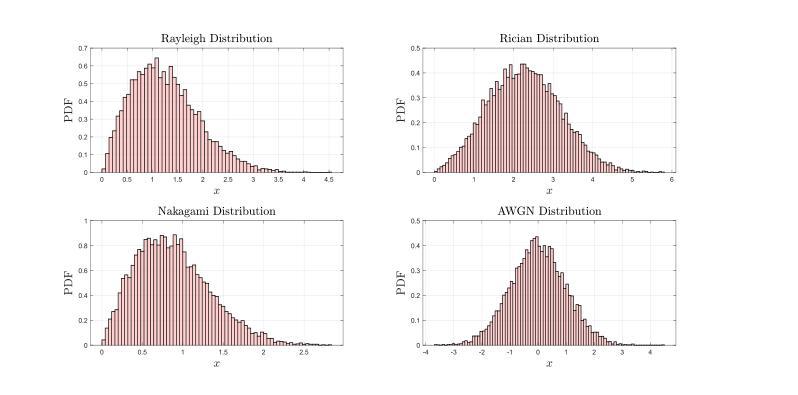
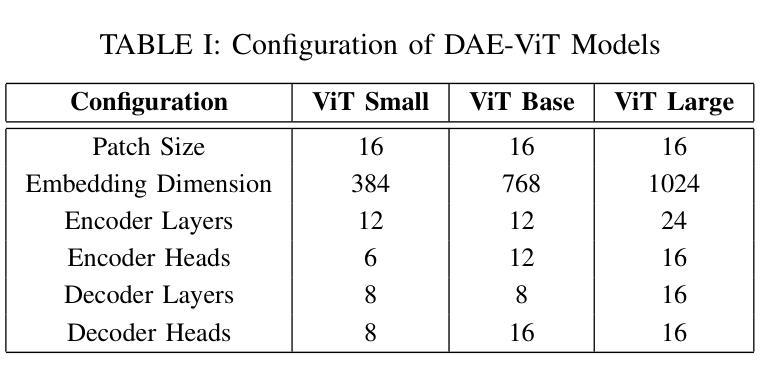
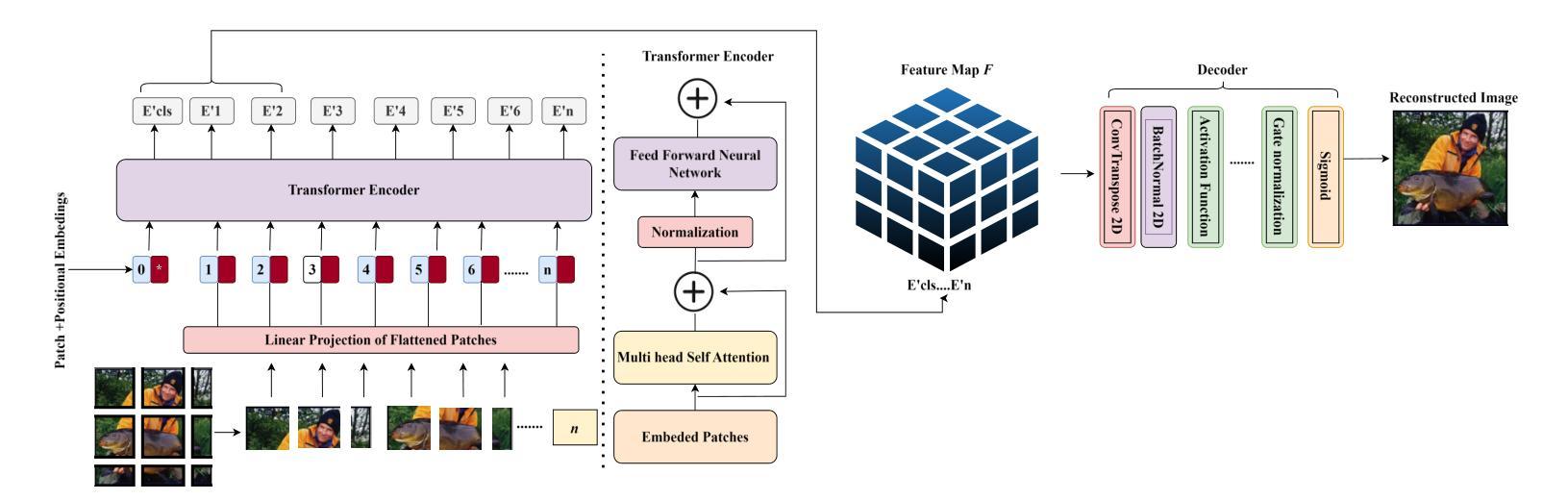
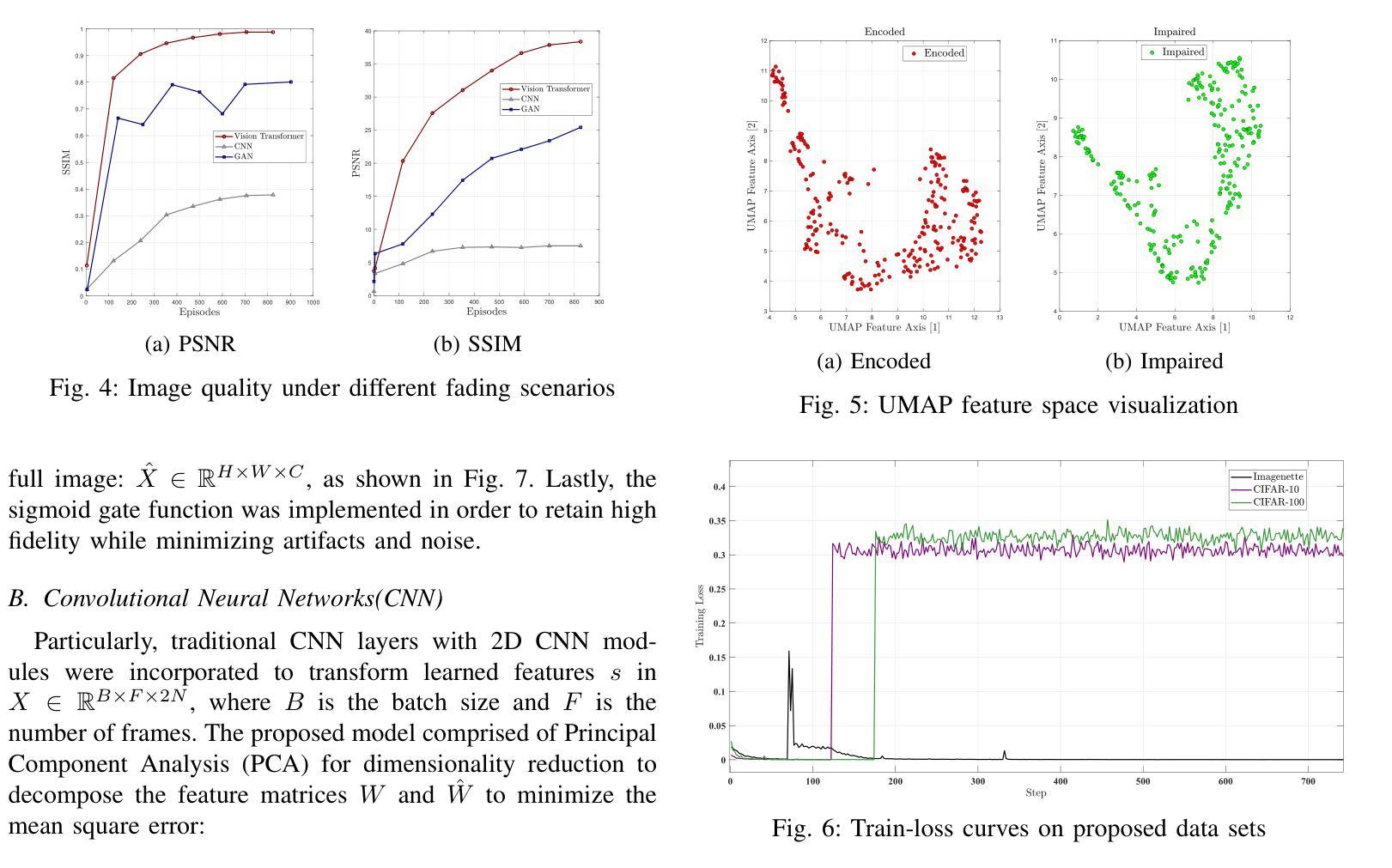
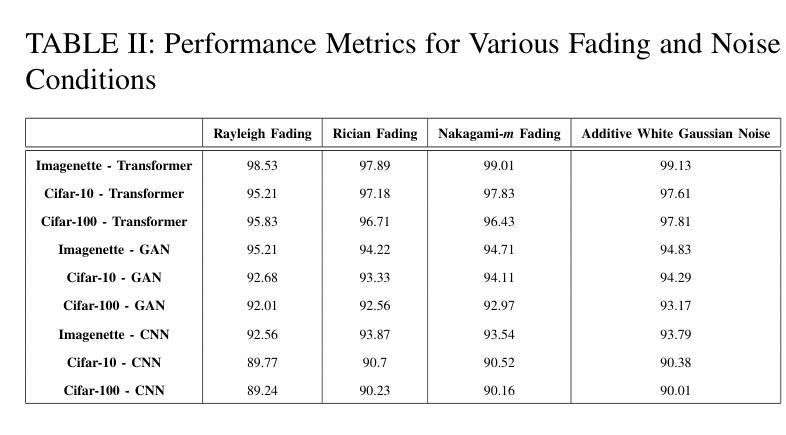
Vision Transformer Based Semantic Communications for Next Generation Wireless Networks
Authors:Muhammad Ahmed Mohsin, Muhammad Jazib, Zeeshan Alam, Muhmmad Farhan Khan, Muhammad Saad, Muhammad Ali Jamshed
In the evolving landscape of 6G networks, semantic communications are poised to revolutionize data transmission by prioritizing the transmission of semantic meaning over raw data accuracy. This paper presents a Vision Transformer (ViT)-based semantic communication framework that has been deliberately designed to achieve high semantic similarity during image transmission while simultaneously minimizing the demand for bandwidth. By equipping ViT as the encoder-decoder framework, the proposed architecture can proficiently encode images into a high semantic content at the transmitter and precisely reconstruct the images, considering real-world fading and noise consideration at the receiver. Building on the attention mechanisms inherent to ViTs, our model outperforms Convolution Neural Network (CNNs) and Generative Adversarial Networks (GANs) tailored for generating such images. The architecture based on the proposed ViT network achieves the Peak Signal-to-noise Ratio (PSNR) of 38 dB, which is higher than other Deep Learning (DL) approaches in maintaining semantic similarity across different communication environments. These findings establish our ViT-based approach as a significant breakthrough in semantic communications.
在6G网络不断演进的背景下,语义通信通过优先传输语义意义而不是原始数据准确性,正逐步革新数据传输方式。本文提出了一种基于视觉转换器(ViT)的语义通信框架,该框架经过精心设计,旨在实现图像传输过程中的高语义相似性,同时最小化对带宽的需求。通过采用ViT作为编码器-解码器框架,所提出的架构能够高效地将图像编码为具有高语义内容的信息,并在接收端考虑到实际世界的衰落和噪声因素,精确重建图像。基于ViT固有的注意力机制,我们的模型表现优于用于生成此类图像的卷积神经网络(CNNs)和生成对抗网络(GANs)。基于所提出的ViT网络的架构实现了峰值信噪比(PSNR)为38分贝,这在不同的通信环境中保持语义相似性方面高于其他深度学习(DL)方法。这些发现证明了我们基于ViT的方法在语义通信领域具有重大突破。
论文及项目相关链接
PDF Accepted @ ICC 2025
Summary
在6G网络不断演变的背景下,语义通信正以其独特的优势革新数据传输方式,以语义意义传输为主轴超越原始数据的精确传输。本文提出了基于视觉转换器(ViT)的语义通信框架,该框架旨在确保图像传输时的高语义相似性,同时最大限度地减少对带宽的需求。使用ViT作为编码解码器框架,此架构能够高效地将图像编码为富含语义的内容,并在考虑现实世界的衰落和噪声因素的同时,精确地在接收端重建图像。借助ViT的内在注意力机制,我们的模型表现优于卷积神经网络(CNN)和生成对抗网络(GAN),这些网络专门用于生成此类图像。基于所提出的ViT网络的架构实现了峰值信噪比(PSNR)的38分贝,这在维持不同通信环境中的语义相似性方面高于其他深度学习(DL)方法,确立了基于ViT的方法在语义通信中的重大突破。
Key Takeaways
- 语义通信在6G网络中占据重要地位,以传输语义意义为主轴,超越原始数据的精确传输。
- 提出基于视觉转换器(ViT)的语义通信框架,旨在确保图像传输的高语义相似性并减少带宽需求。
- ViT作为编码解码器框架,能够高效编码图像并精确重建。
- 该模型借助ViT的内在注意力机制表现优异,优于CNN和GAN等网络。
- 基于ViT网络的架构实现高PSNR值,表明其在维持不同通信环境中的语义相似性方面效果卓越。
- 此研究在语义通信领域具有重大突破。
- 该框架在实际应用中的性能表现有待进一步研究和验证。
点此查看论文截图


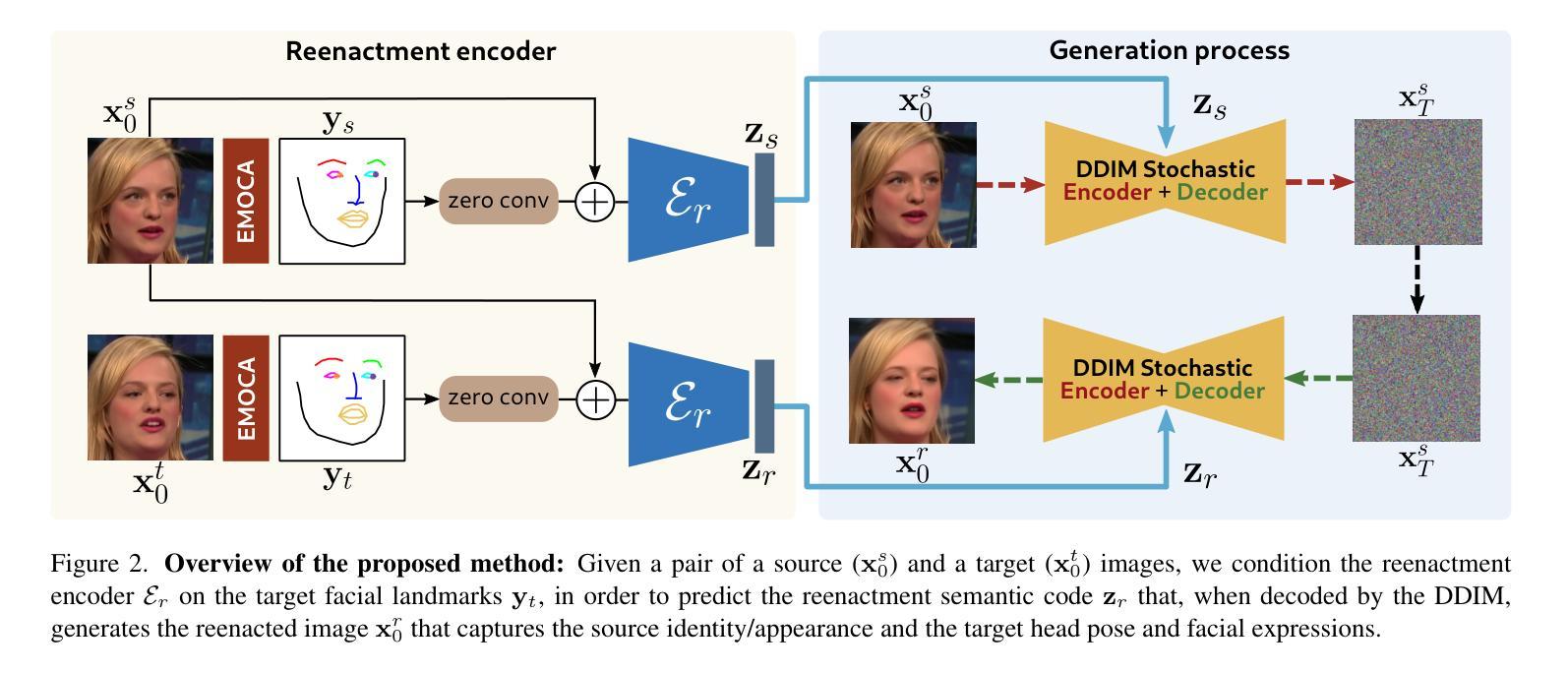
DiffusionAct: Controllable Diffusion Autoencoder for One-shot Face Reenactment
Authors:Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, Georgios Tzimiropoulos
Video-driven neural face reenactment aims to synthesize realistic facial images that successfully preserve the identity and appearance of a source face, while transferring the target head pose and facial expressions. Existing GAN-based methods suffer from either distortions and visual artifacts or poor reconstruction quality, i.e., the background and several important appearance details, such as hair style/color, glasses and accessories, are not faithfully reconstructed. Recent advances in Diffusion Probabilistic Models (DPMs) enable the generation of high-quality realistic images. To this end, in this paper we present DiffusionAct, a novel method that leverages the photo-realistic image generation of diffusion models to perform neural face reenactment. Specifically, we propose to control the semantic space of a Diffusion Autoencoder (DiffAE), in order to edit the facial pose of the input images, defined as the head pose orientation and the facial expressions. Our method allows one-shot, self, and cross-subject reenactment, without requiring subject-specific fine-tuning. We compare against state-of-the-art GAN-, StyleGAN2-, and diffusion-based methods, showing better or on-par reenactment performance.
视频驱动神经面部再现旨在合成逼真的面部图像,成功保留源面部的身份和外观,同时转移目标头部姿势和面部表情。现有的基于GAN的方法存在扭曲和视觉伪影或重建质量差的问题,即背景和某些重要的外观细节(如发型/颜色、眼镜和配饰)不能忠实重建。最近扩散概率模型(DPMs)的进展使得能够生成高质量的逼真图像。为此,本文提出了DiffusionAct,一种利用扩散模型的光栅化图像生成进行神经面部再现的新方法。具体来说,我们提出控制扩散自动编码器(DiffAE)的语义空间,以编辑输入图像的面部姿态,定义为头部姿态方向和面部表情。我们的方法允许一次、自我和跨主体再现,无需针对特定主体进行微调。我们与最新的GAN、StyleGAN2和基于扩散的方法进行了比较,显示出更好或相当的再现性能。
论文及项目相关链接
PDF Project page: https://stelabou.github.io/diffusionact/
摘要
基于视频驱动的神经网络面部复现旨在合成逼真的面部图像,成功保留源脸的身份和外观,同时转移目标头部姿势和面部表情。现有的基于GAN的方法存在失真和视觉伪影或重建质量差的问题,即背景和一些重要的外观细节,如发型/颜色、眼镜和配饰,不能忠实重建。本文利用扩散概率模型(DPMs)的最新进展,生成高质量逼真图像。为此,我们提出了DiffusionAct方法,该方法利用扩散模型的逼真图像生成进行神经网络面部复现。具体来说,我们提出控制扩散自编码器(DiffAE)的语义空间,以编辑输入图像的面部姿势,定义为头部姿势方向和面部表情。我们的方法允许一次性、自我和跨主体复现,无需针对特定主体进行微调。我们与最先进GAN、StyleGAN2和基于扩散的方法进行比较,显示复现性能更好或相当。
关键见解
- 视频驱动神经网络面部复现旨在合成逼真面部图像,保留源脸身份和外观,同时转移目标头部姿势和表情。
- 基于GAN的方法存在失真和视觉伪影问题,或在背景及重要外观细节上的重建质量不佳。
- DiffusionAct利用扩散模型的逼真图像生成进行面部复现。
- 通过控制扩散自编码器(DiffAE)的语义空间来编辑面部姿势。
- DiffusionAct允许一次性、自我和跨主体复现,无需特定主体微调。
- DiffusionAct与现有方法比较,复现性能更优或与最先进方法相当。
- DiffusionAct为面部图像生成和编辑提供了新的思路和方法。
点此查看论文截图