⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
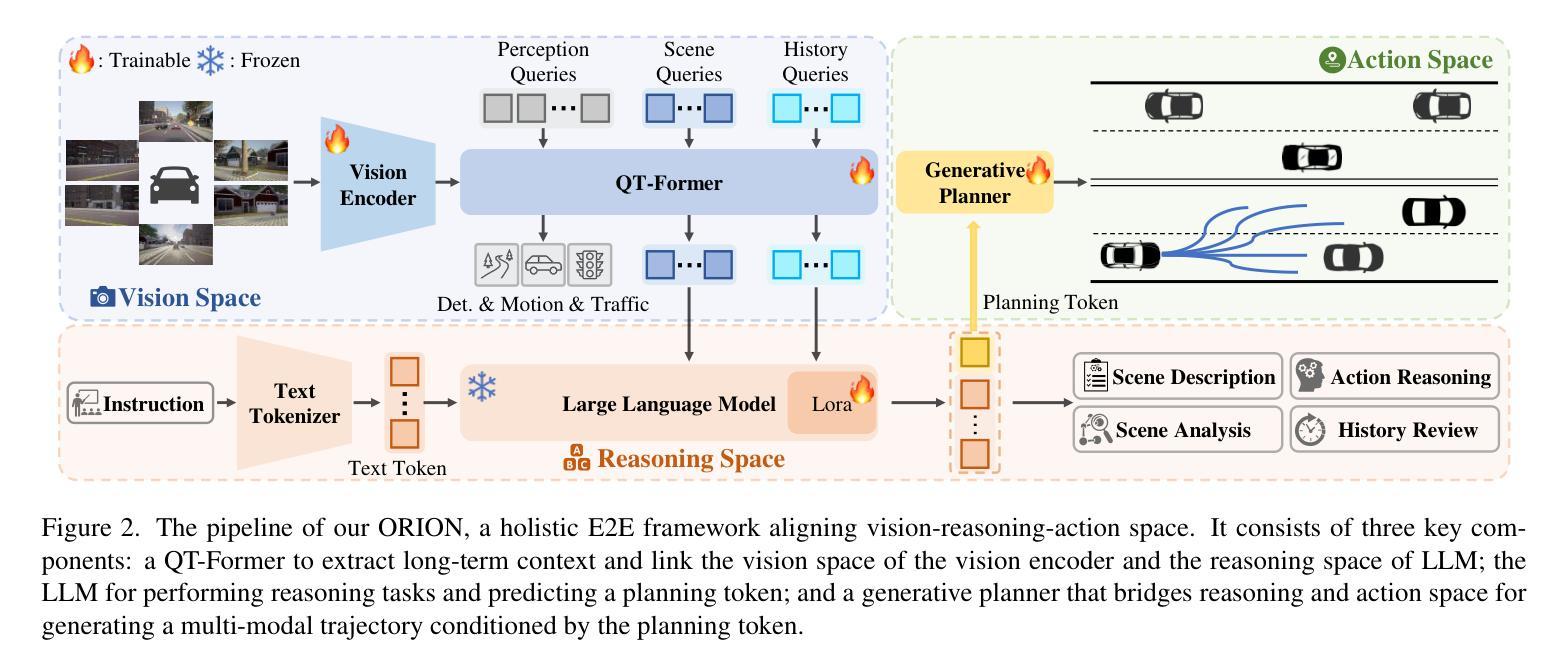
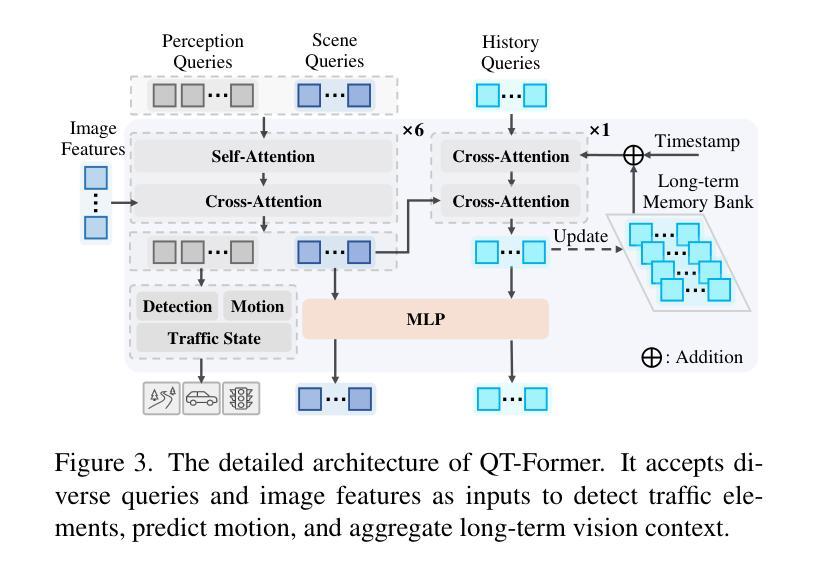
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Authors:Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, Xiang Bai
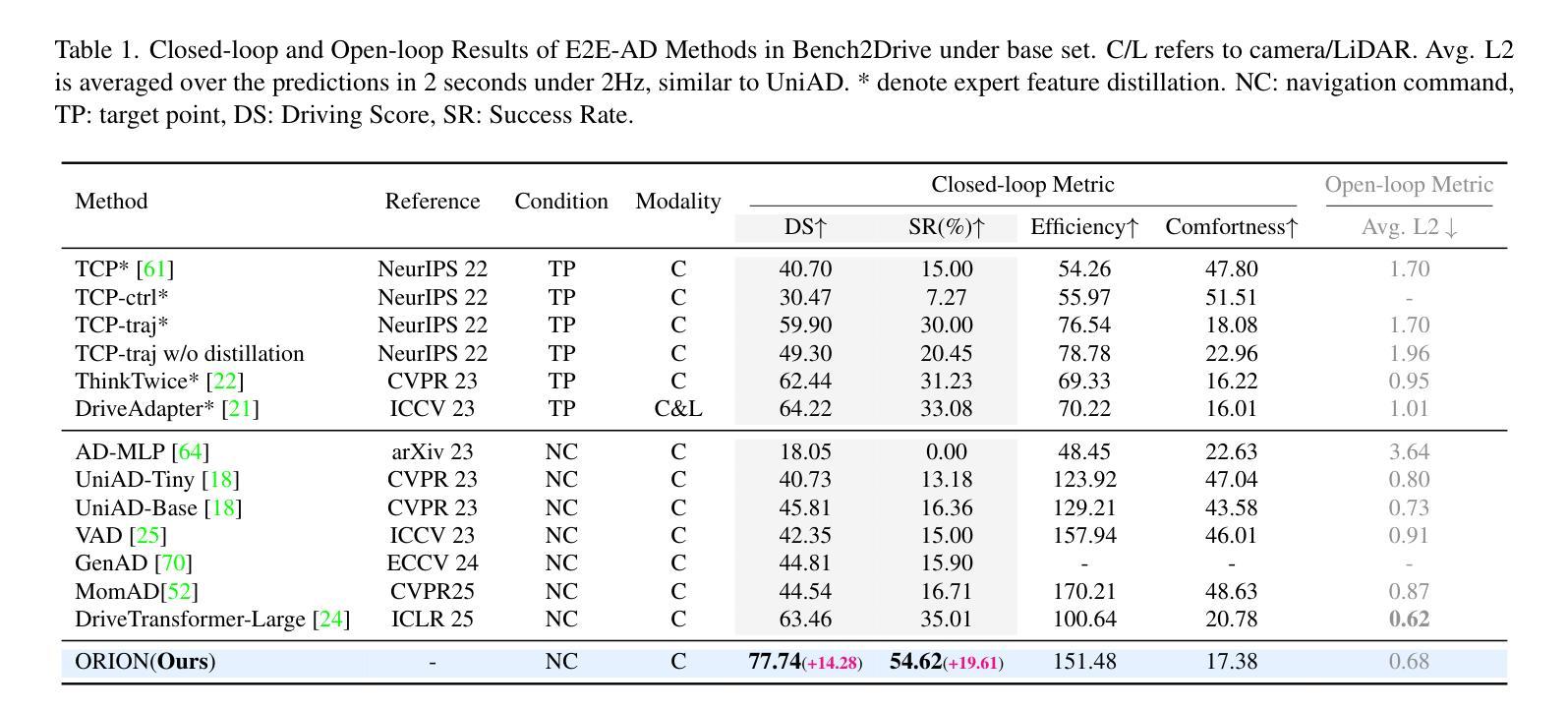
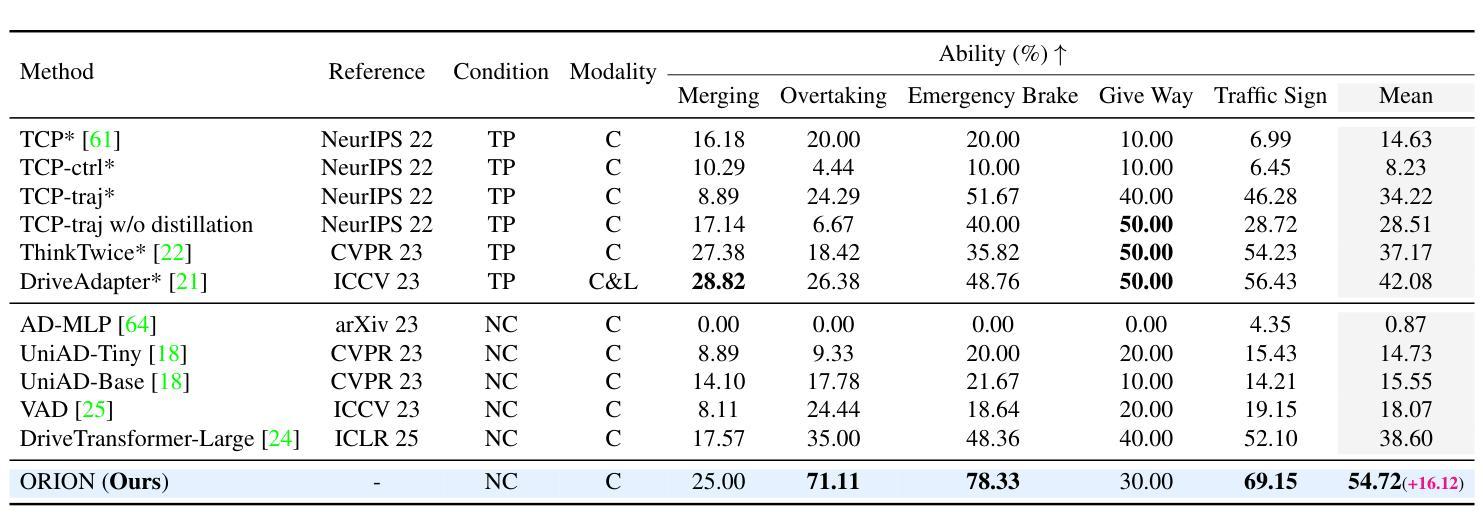
End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.
端到端(E2E)自动驾驶方法由于在因果推理能力上的局限性,仍然在交互式闭环评估中难以做出正确决策。当前的方法试图利用视觉语言模型(VLMs)的强大理解和推理能力来解决这一困境。然而,问题在于很少有针对E2E方法的VLMs在闭环评估中表现良好,这是由于语义推理空间与动作空间中纯数值轨迹输出之间的鸿沟。为了解决这个问题,我们提出了ORION,一个全面的端到端自动驾驶框架,通过视觉语言指导行动生成。ORION独特地结合了QT-Former以汇聚长期历史语境、大型语言模型(LLM)用于驾驶场景推理,以及生成式规划器用于精确轨迹预测。ORION进一步对齐推理空间和动作空间,以实现视觉问答(VQA)和规划任务的统一端到端优化。我们的方法在Bench2Drive数据集上实现了令人印象深刻的闭环性能,驾驶得分(DS)达到77.74,成功率(SR)达到54.62%,大幅超越了现有先进技术(SOTA)方法,得分高出14.28 DS,成功率高出19.61%。
论文及项目相关链接
Summary:端到端(E2E)自动驾驶方法在闭环评估中仍存在决策困难,因为缺乏因果推理能力。为解决这个问题,研究者尝试利用视觉语言模型(VLMs)的强大理解和推理能力。然而,由于语义推理空间和动作输出之间的鸿沟,现有VLMs在闭环评估中的表现并不理想。为解决这一问题,本文提出了ORION,一个结合QT-Former、大型语言模型(LLM)和生成式规划器的端到端自动驾驶框架。ORION实现了视觉问答(VQA)和规划任务的端到端优化,并在Bench2Drive数据集上取得了显著的闭环性能,显著优于其他先进方法。
Key Takeaways:
- 现有端到端自动驾驶方法在闭环评估中存在决策困难,因为缺乏因果推理能力。
- 研究者正尝试利用视觉语言模型(VLMs)解决这一问题。
- 语义推理空间和动作输出之间的鸿沟限制了现有VLMs在闭环评估中的表现。
- ORION框架结合了QT-Former、大型语言模型(LLM)和生成式规划器,以解决这个问题。
- ORION实现了视觉问答(VQA)和规划任务的端到端优化。
- ORION在Bench2Drive数据集上取得了显著的闭环性能。
点此查看论文截图

Mind the Gap: Benchmarking Spatial Reasoning in Vision-Language Models
Authors:Ilias Stogiannidis, Steven McDonagh, Sotirios A. Tsaftaris
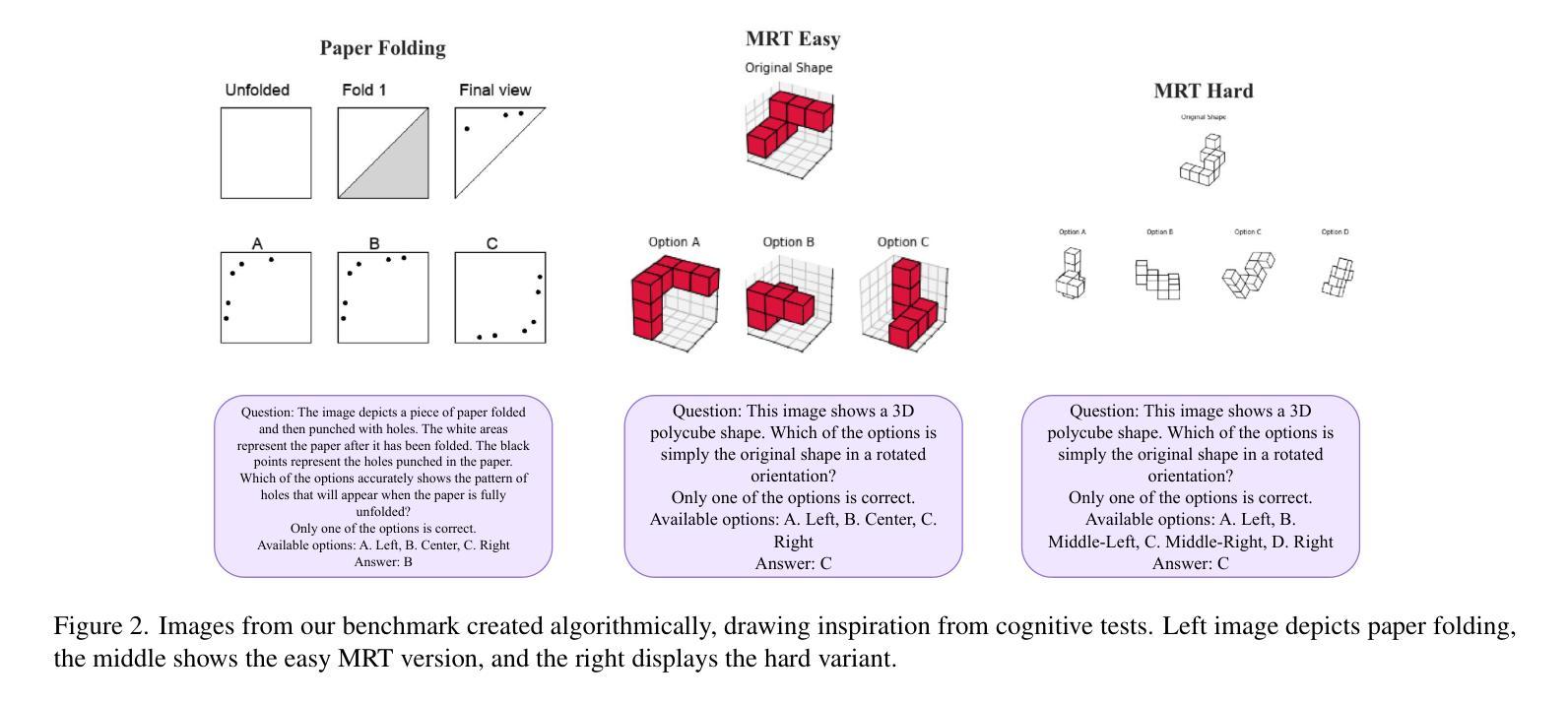
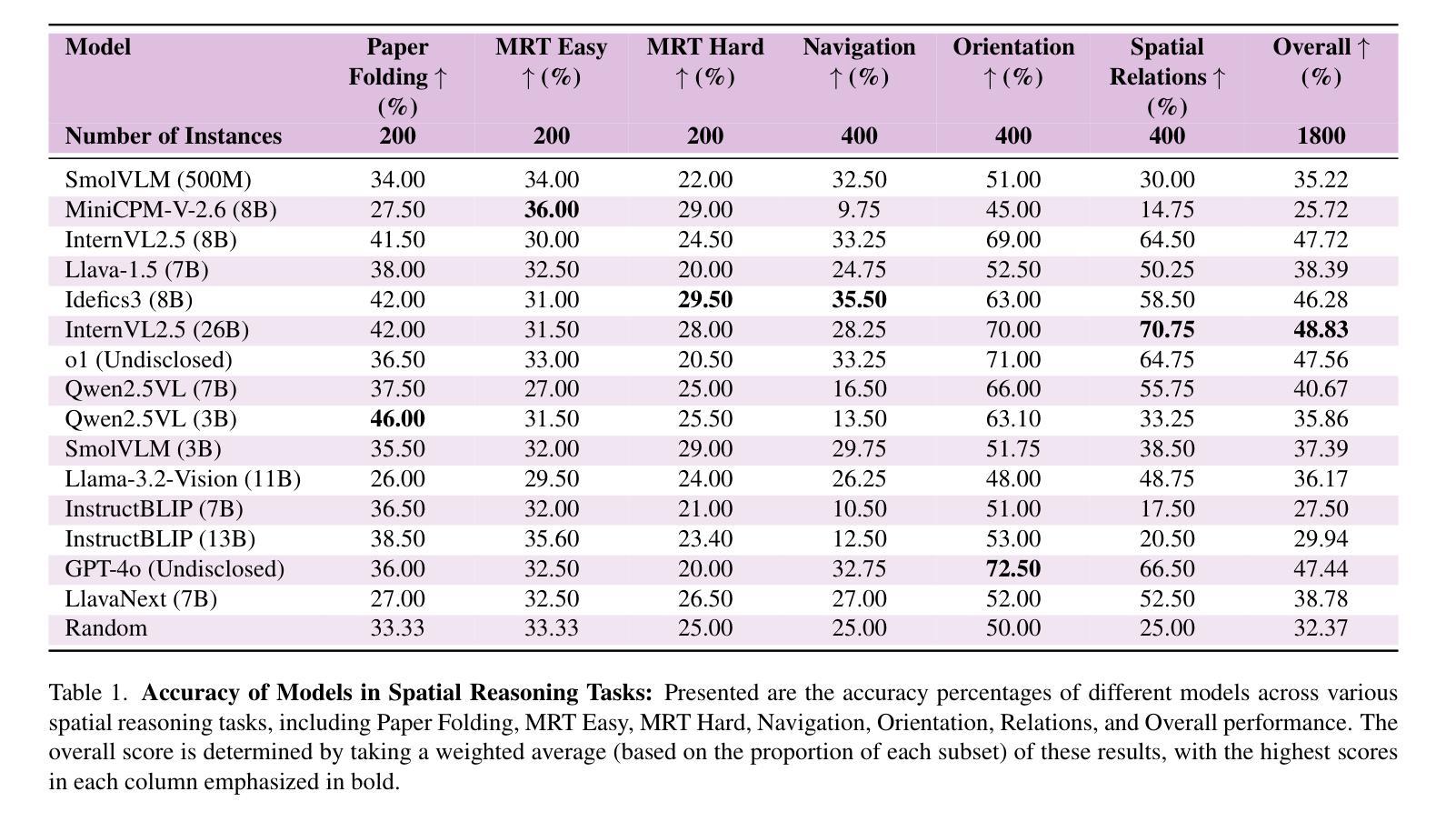
Vision-Language Models (VLMs) have recently emerged as powerful tools, excelling in tasks that integrate visual and textual comprehension, such as image captioning, visual question answering, and image-text retrieval. However, existing benchmarks for VLMs include spatial components, which often fail to isolate spatial reasoning from related tasks such as object detection or semantic comprehension. In this paper, we address these deficiencies with a multi-faceted approach towards understanding spatial reasoning. Informed by the diverse and multi-dimensional nature of human spatial reasoning abilities, we present a detailed analysis that first delineates the core elements of spatial reasoning: spatial relations, orientation and navigation, mental rotation, and spatial visualization, and then assesses the performance of these models in both synthetic and real-world images, bridging controlled and naturalistic contexts. We analyze 13 state-of-the-art Vision-Language Models, uncovering pivotal insights into their spatial reasoning performance. Our results reveal profound shortcomings in current VLMs, with average accuracy across the 13 models approximating random chance, highlighting spatial reasoning as a persistent obstacle. This work not only exposes the pressing need to advance spatial reasoning within VLMs but also establishes a solid platform for future exploration. Code available on GitHub (https://github.com/stogiannidis/srbench) and dataset available on HuggingFace (https://huggingface.co/datasets/stogiannidis/srbench).
视觉语言模型(VLMs)最近作为强大的工具出现,在集成视觉和文本理解的任务中表现出色,例如图像描述、视觉问答和图像文本检索。然而,现有的VLM基准测试通常包含空间成分,这些成分往往无法从相关任务(如目标检测或语义理解)中隔离出空间推理。在本文中,我们通过多方面的方法来解决这些不足,以理解空间推理。受到人类空间推理能力多样性和多维性的启发,我们进行了详细的分析,首先阐述了空间推理的核心要素:空间关系、方向导航、心理旋转和空间可视化,然后评估了这些模型在合成图像和真实世界图像中的性能,在受控和自然语境之间建立了桥梁。我们分析了1b种最先进的视觉语言模型,对它们在空间推理方面的表现获得了关键见解。我们的结果表明,当前VLMs存在深刻缺陷,平均准确率接近随机概率水平,突显了空间推理是一个持久障碍。这项工作不仅揭示了推动VLMs中空间推理的迫切需求,而且为未来探索建立了可靠的平台。代码可在GitHub(https://github.com/stogiannidis/srbench)上获得,数据集可在HuggingFace(https://huggingface.co/datasets/stogiannidis/srbench)上获得。
论文及项目相关链接
PDF 8 main pages, 4 pages Appendix, 5 figures
Summary
本文研究了视觉语言模型(VLMs)在空间推理方面的表现。现有VLMs在集成视觉和文本理解的任务中表现出色,但在空间推理方面存在缺陷。本文提出了一种多面方法,分析了人类空间推理能力的多样性和多维性质,并评估了这些模型在合成和真实世界图像中的性能。分析结果显示,当前VLMs存在显著短板,平均准确率接近随机水平,凸显出空间推理的障碍。本文不仅揭示了提升VLMs中空间推理能力的紧迫需求,还为未来的研究提供了坚实平台。
Key Takeaways
- 视觉语言模型(VLMs)在集成视觉和文本理解的任务中表现出色,如图像描述、视觉问答和图像文本检索。
- 现有VLMs的基准测试包含空间成分,但往往无法将空间推理与相关任务(如目标检测或语义理解)区分开来。
- 本文通过多面方法分析人类空间推理能力的多样性和多维性质,并评估了VLMs在合成和真实世界图像中的性能。
- 分析涵盖了空间推理的核心元素,包括空间关系、方向感知、导航、心理旋转和空间可视化。
- 研究结果显示,当前VLMs在空间推理方面存在显著短板,平均准确率接近随机水平。
- 论文强调了提升VLMs中空间推理能力的紧迫需求,并指出了未来的研究方向。
点此查看论文截图


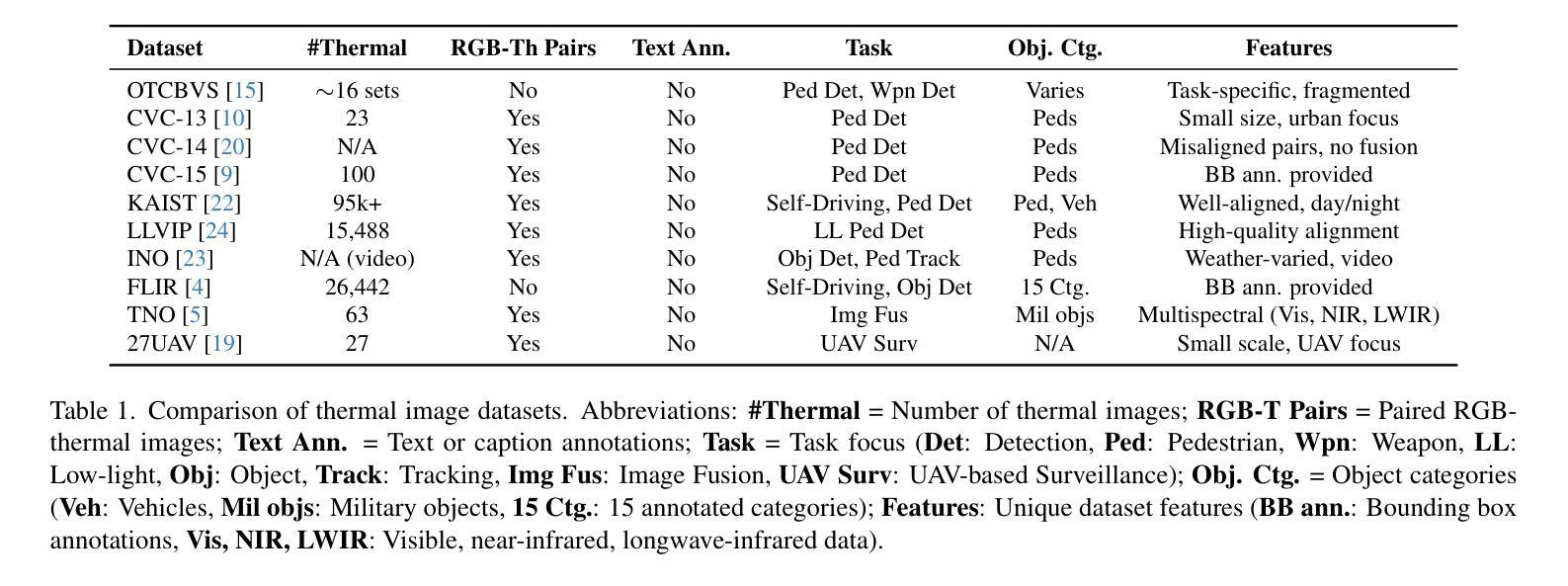
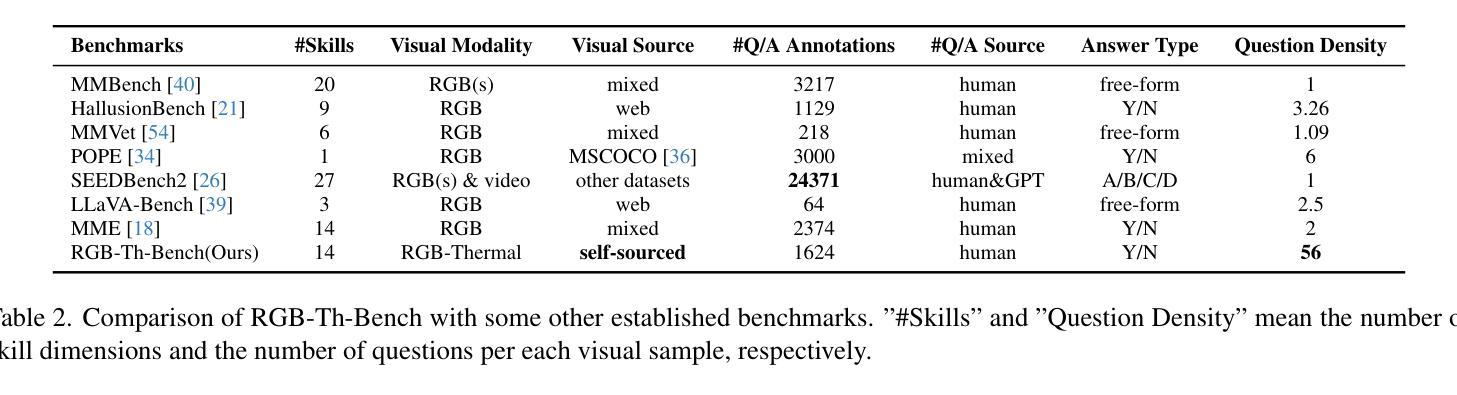
RGB-Th-Bench: A Dense benchmark for Visual-Thermal Understanding of Vision Language Models
Authors:Mehdi Moshtaghi, Siavash H. Khajavi, Joni Pajarinen
We introduce RGB-Th-Bench, the first benchmark designed to evaluate the ability of Vision-Language Models (VLMs) to comprehend RGB-Thermal image pairs. While VLMs have demonstrated remarkable progress in visual reasoning and multimodal understanding, their evaluation has been predominantly limited to RGB-based benchmarks, leaving a critical gap in assessing their capabilities in infrared vision tasks. Existing visible-infrared datasets are either task-specific or lack high-quality annotations necessary for rigorous model evaluation. To address these limitations, RGB-Th-Bench provides a comprehensive evaluation framework covering 14 distinct skill dimensions, with a total of 1,600+ expert-annotated Yes/No questions. The benchmark employs two accuracy metrics: a standard question-level accuracy and a stricter skill-level accuracy, which evaluates model robustness across multiple questions within each skill dimension. This design ensures a thorough assessment of model performance, including resilience to adversarial and hallucinated responses. We conduct extensive evaluations on 19 state-of-the-art VLMs, revealing significant performance gaps in RGB-Thermal understanding. Our results show that even the strongest models struggle with thermal image comprehension, with performance heavily constrained by their RGB-based capabilities. Additionally, the lack of large-scale application-specific and expert-annotated thermal-caption-pair datasets in pre-training is an important reason of the observed performance gap. RGB-Th-Bench highlights the urgent need for further advancements in multimodal learning to bridge the gap between visible and thermal image understanding. The dataset is available through this link, and the evaluation code will also be made publicly available.
我们介绍了RGB-Th-Bench,这是第一个旨在评估视觉语言模型(VLM)理解RGB-热成像图像对的能力的基准测试。尽管VLM在视觉推理和多模态理解方面取得了显著的进步,但其评估主要局限于基于RGB的基准测试,在评估红外视觉任务的能力方面存在关键差距。现有的可见光-红外数据集是任务特定的,或者缺乏进行严格模型评估所需的高质量注释。为了解决这些局限性,RGB-Th-Bench提供了一个全面的评估框架,涵盖14个不同的技能维度,总共有1600多个专家注释的是非问题。该基准测试采用两种准确率指标:标准问题级准确率和严格的技能级准确率,后者评估模型在各个技能维度内多个问题上的稳健性。这种设计确保了全面评估模型性能,包括对抗性和虚构响应的韧性。我们对19个最先进的VLM进行了广泛评估,发现在RGB-热成像理解方面存在显著的性能差距。我们的结果表明,即使是最强大的模型在热成像理解方面也遇到困难,其性能严重受到基于RGB的能力的限制。此外,缺乏大规模应用特定的和专家注释的热成像字幕对数据集进行预训练是观察到的性能差距的重要原因。RGB-Th-Bench强调了进一步改进多模态学习以弥合可见光与热成像理解之间差距的紧迫需求。数据集可通过此链接获取,评估代码也将公开发布。
论文及项目相关链接
Summary:
介绍了一个名为RGB-Th-Bench的基准测试平台,它是首个评估视觉语言模型(VLMs)对RGB-Thermal图像对理解能力的基准测试。尽管VLMs在视觉推理和多模态理解方面取得了显著进展,但其评估主要局限于RGB基准测试,在红外视觉任务评估能力方面存在关键差距。RGB-Th-Bench提供了一个全面的评估框架,涵盖14个不同的技能维度,总共有1600多个专家注释的是非问题。该基准测试采用两种准确率度量标准:标准问题级准确率和更严格的技能级准确率,以评估模型在不同技能维度内多个问题上的稳健性。对19个最先进的VLMs进行了广泛评估,结果显示在RGB-Thermal理解方面存在显著的性能差距。最强大的模型在热图像理解方面仍有困难,性能受到其基于RGB的能力的严重制约。
Key Takeaways:
- RGB-Th-Bench是首个评估视觉语言模型(VLMs)理解RGB-Thermal图像对能力的基准测试。
- 现有基准测试主要局限于RGB图像,使得在红外视觉任务评估上存在差距。
- RGB-Th-Bench涵盖14个技能维度,包含1600+专家标注的是非问题。
- 该基准测试采用两种准确率度量标准,以全面评估模型的性能。
- 对19个最先进的VLMs的广泛评估显示,在RGB-Thermal理解方面存在显著性能差距。
- 最强的模型在热图像理解方面仍有困难,制约因素之一是缺乏大规模应用特定和专家注释的热图像描述对数据库。
点此查看论文截图



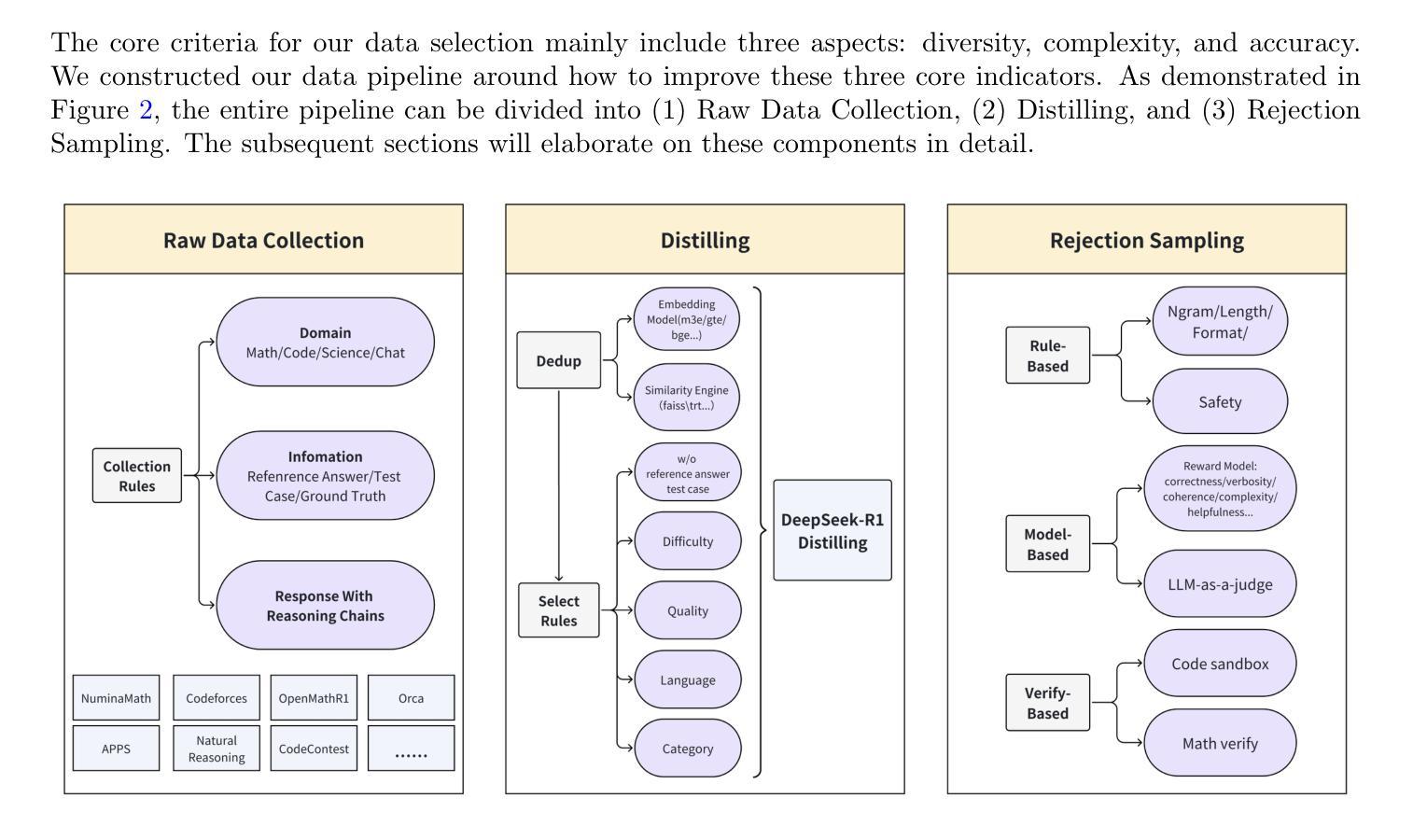
1.4 Million Open-Source Distilled Reasoning Dataset to Empower Large Language Model Training
Authors:Han Zhao, Haotian Wang, Yiping Peng, Sitong Zhao, Xiaoyu Tian, Shuaiting Chen, Yunjie Ji, Xiangang Li
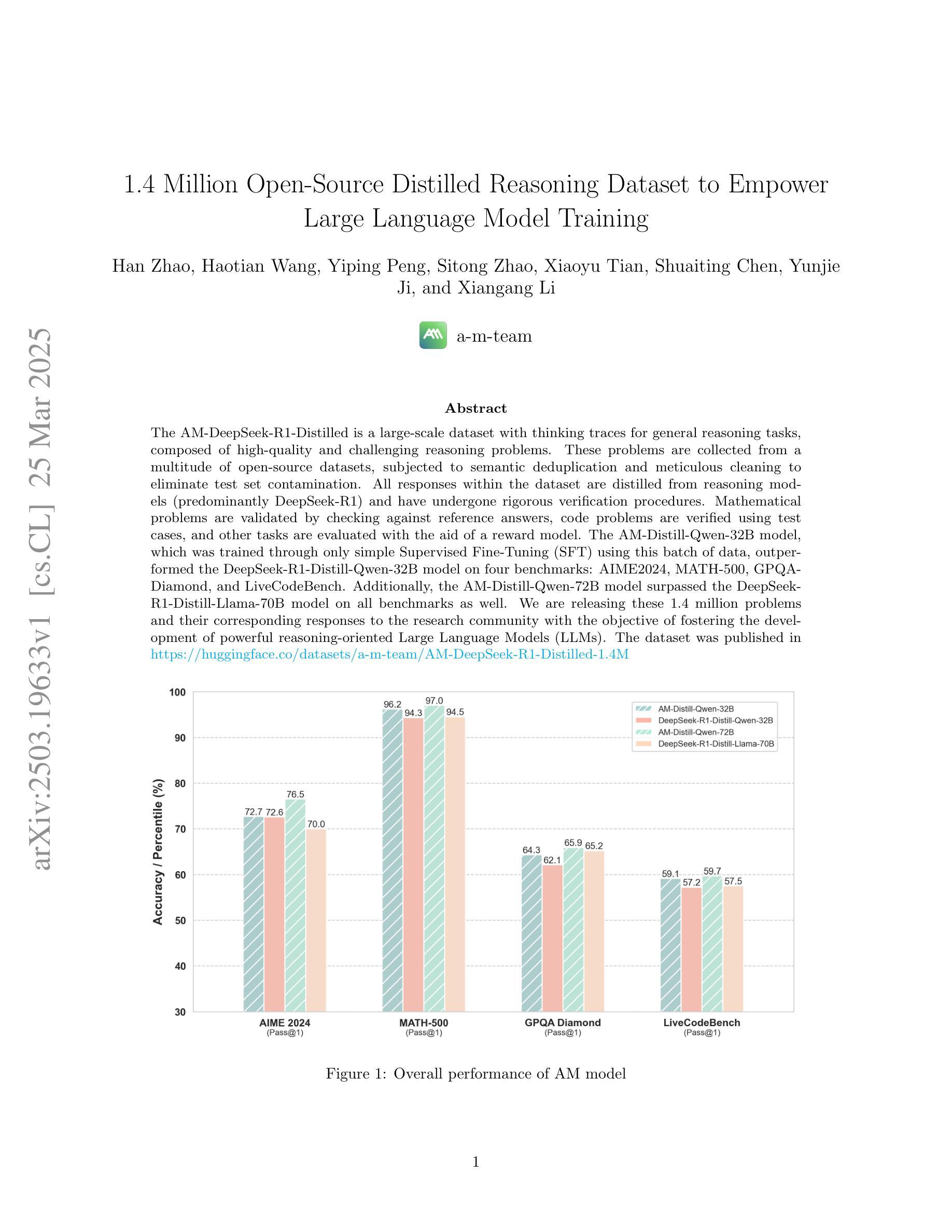
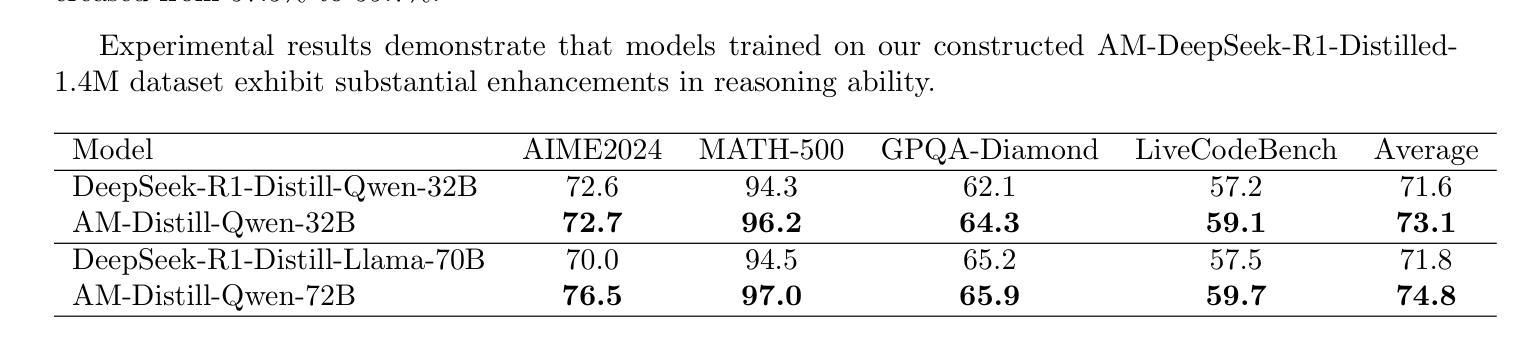
The AM-DeepSeek-R1-Distilled is a large-scale dataset with thinking traces for general reasoning tasks, composed of high-quality and challenging reasoning problems. These problems are collected from a multitude of open-source datasets, subjected to semantic deduplication and meticulous cleaning to eliminate test set contamination. All responses within the dataset are distilled from reasoning models (predominantly DeepSeek-R1) and have undergone rigorous verification procedures. Mathematical problems are validated by checking against reference answers, code problems are verified using test cases, and other tasks are evaluated with the aid of a reward model. The AM-Distill-Qwen-32B model, which was trained through only simple Supervised Fine-Tuning (SFT) using this batch of data, outperformed the DeepSeek-R1-Distill-Qwen-32B model on four benchmarks: AIME2024, MATH-500, GPQA-Diamond, and LiveCodeBench. Additionally, the AM-Distill-Qwen-72B model surpassed the DeepSeek-R1-Distill-Llama-70B model on all benchmarks as well. We are releasing these 1.4 million problems and their corresponding responses to the research community with the objective of fostering the development of powerful reasoning-oriented Large Language Models (LLMs). The dataset was published in \href{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}.
AM-DeepSeek-R1-Distilled是一个大规模带有思考痕迹的一般推理任务数据集,包含高质量且富有挑战性的推理问题。这些问题来自多个开源数据集,经过语义去重和细致清理,消除了测试集污染。数据集中的所有答案都经过推理模型(主要是DeepSeek-R1)的提炼,并经过严格的验证程序。数学问题的答案通过对照参考答案进行验证,代码问题的答案通过使用测试用例进行验证,其他任务则借助奖励模型进行评估。仅通过简单监督微调(SFT)使用这批数据训练的AM-Distill-Qwen-32B模型在四个基准测试上超越了DeepSeek-R1-Distill-Qwen-32B模型:AIME2024、MATH-500、GPQA-Diamond和LiveCodeBench。此外,AM-Distill-Qwen-72B模型在所有基准测试上都超过了DeepSeek-R1-Distill-Llama-70B模型。我们发布这140万问题及相应答案的目的是为了推动研究社区开发强大的以推理为导向的大型语言模型(LLM)。数据集已在https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M发布。!
论文及项目相关链接
Summary
大型数据集AM-DeepSeek-R1-Distilled专注于通用推理任务,包含高质量和具有挑战性的推理问题。该数据集通过语义去重和严格清理来消除测试集污染,其响应由推理模型(主要是DeepSeek-R1)蒸馏得出,并经过严格的验证程序。通过使用该数据集进行简单的监督微调(SFT),AM-Distill-Qwen-32B模型在多个基准测试上优于DeepSeek-R1-Distill-Qwen-32B模型。同时,我们公开了这些包含约一千万问题的数据集及其响应,旨在促进强大的推理导向的大型语言模型(LLM)的发展。
Key Takeaways
- AM-DeepSeek-R1-Distilled是一个大型数据集,包含针对通用推理任务的高质量、挑战性推理问题。
- 数据集经过语义去重和清理,以消除测试集污染。
- 数据集中的响应由推理模型(主要是DeepSeek-R1)蒸馏得出,并经过严格的验证程序确保准确性。
- 通过简单的监督微调(SFT),AM-Distill-Qwen-32B模型在多个基准测试上表现出优于DeepSeek-R1-Distill模型的性能。
- AM-Distill-Qwen-72B模型在所有基准测试上超过了DeepSeek-R1-Distill-Llama-70B模型。
- 数据集旨在促进对通用推理任务的大型语言模型(LLM)的发展。
点此查看论文截图
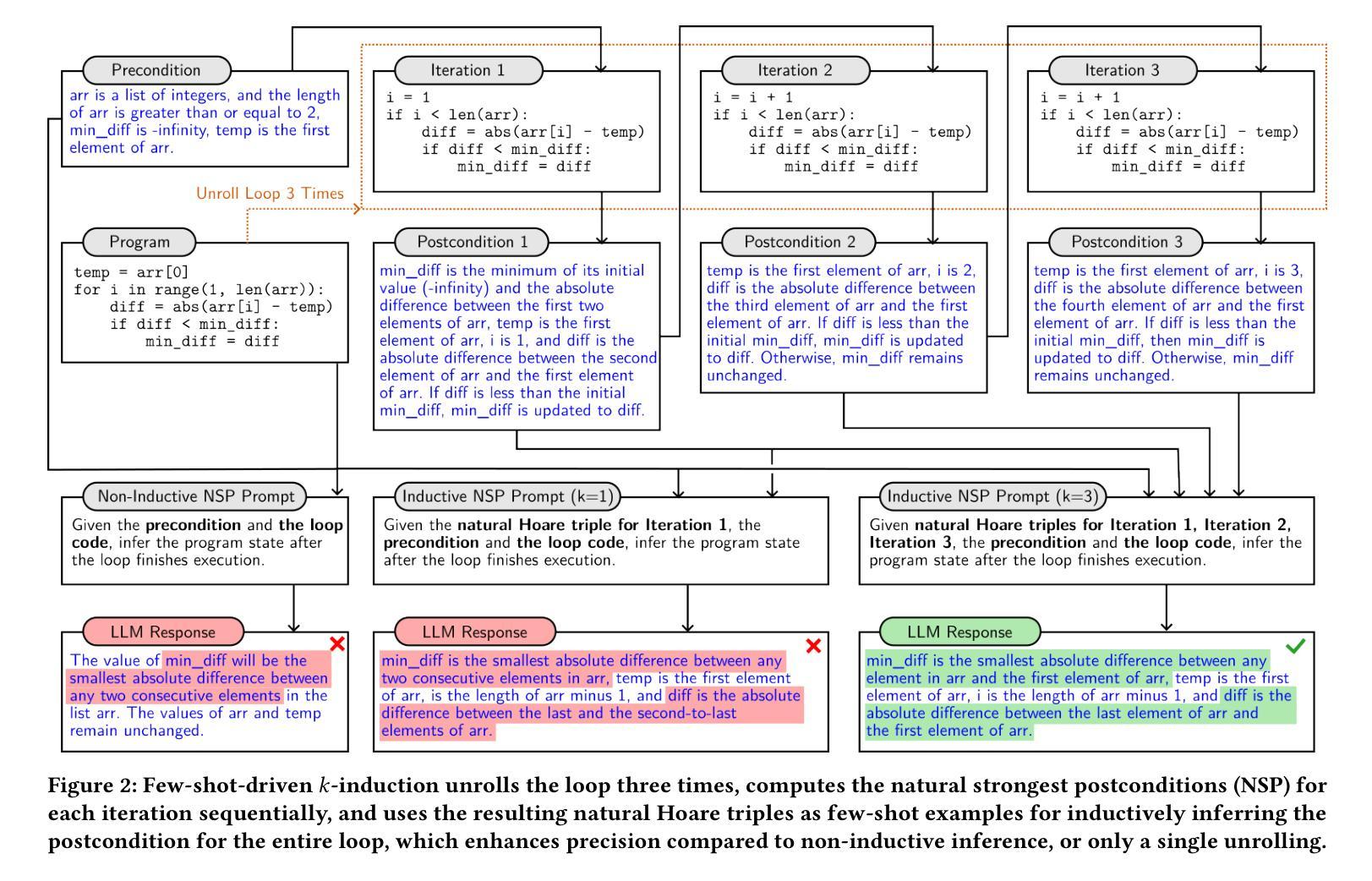
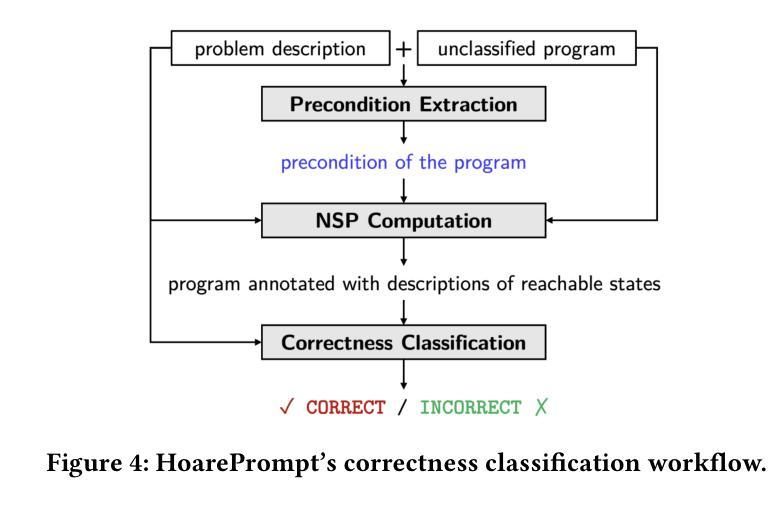
HoarePrompt: Structural Reasoning About Program Correctness in Natural Language
Authors:Dimitrios Stamatios Bouras, Yihan Dai, Tairan Wang, Yingfei Xiong, Sergey Mechtaev
While software requirements are often expressed in natural language, verifying the correctness of a program against natural language requirements is a hard and underexplored problem. Large language models (LLMs) are promising candidates for addressing this challenge, however our experience shows that they are ineffective in this task, often failing to detect even straightforward bugs. To address this gap, we introduce HoarePrompt, a novel approach that adapts fundamental ideas from program analysis and verification to natural language artifacts. Drawing inspiration from the strongest postcondition calculus, HoarePrompt employs a systematic, step-by-step process in which an LLM generates natural language descriptions of reachable program states at various points in the code. To manage loops, we propose few-shot-driven k-induction, an adaptation of the k-induction method widely used in model checking. Once program states are described, HoarePrompt leverages the LLM to assess whether the program, annotated with these state descriptions, conforms to the natural language requirements. For evaluating the quality of classifiers of program correctness with respect to natural language requirements, we constructed CoCoClaNeL, a challenging dataset of solutions to programming competition problems. Our experiments show that HoarePrompt improves the MCC by 62% compared to directly using Zero-shot-CoT prompts for correctness classification. Furthermore, HoarePrompt outperforms a classifier that assesses correctness via LLM-based test generation by increasing the MCC by 93%. The inductive reasoning mechanism contributes a 28% boost to MCC, underscoring its effectiveness in managing loops.
虽然软件需求通常使用自然语言来表达,但根据自然语言要求验证程序的正确性是一个困难且未被充分探索的问题。大型语言模型(LLMs)是应对这一挑战的有希望的候选者,但我们的经验表明,它们在此任务中效果不佳,甚至常常无法检测到简单的错误。为了解决这一差距,我们引入了HoarePrompt,这是一种将程序分析和验证的基本思想适应到自然语言工件的新方法。HoarePrompt借鉴了最强的后条件演算的理念,采用系统、分步的方法,其中LLM会在代码的各个点生成可访问程序状态的自然语言描述。为了管理循环,我们提出了基于少量样本的k归纳法,这是对广泛应用于模型检查的k归纳方法的适应。一旦描述了程序状态,HoarePrompt就会利用LLM来评估带有这些状态描述的程序是否符合自然语言要求。为了评估分类器对于自然语言要求的程序正确性的质量,我们构建了CoCoClaNeL数据集,这是一系列来自编程竞赛问题的解决方案的挑战集。我们的实验表明,与直接使用零样本CoT提示进行正确性分类相比,HoarePrompt的MCC提高了62%。此外,与通过LLM生成的测试评估正确性的分类器相比,HoarePrompt的MCC提高了93%。归纳推理机制对MCC的贡献提升了28%,这突显了其在管理循环中的有效性。
论文及项目相关链接
Summary:针对自然语言描述的软件需求验证问题,引入了一种新方法HoarePrompt。该方法借鉴程序分析和验证的基本思想,应用于自然语言工件。通过系统、分步骤的过程,LLM生成代码各点的可达程序状态的自然语言描述。针对循环管理,提出基于少样本驱动的k归纳法。使用LLM评估标注有状态描述的程序的自然语言要求符合程度。实验表明,HoarePrompt相比直接使用方法分类器性能提升显著。
Key Takeaways:
- 自然语言描述的软件需求验证是一个挑战且未得到充分探索的问题。
- LLMs在直接处理自然语言软件需求验证任务时效果不佳。
- HoarePrompt是一种新的方法,借鉴程序分析和验证来处理自然语言工件。
- HoarePrompt通过系统步骤让LLM生成代码各点的程序状态的自然语言描述。
- 针对循环管理,采用基于少样本驱动的k归纳法。
- 使用LLM评估标注程序状态的程序的符合自然语言要求的程度。
点此查看论文截图




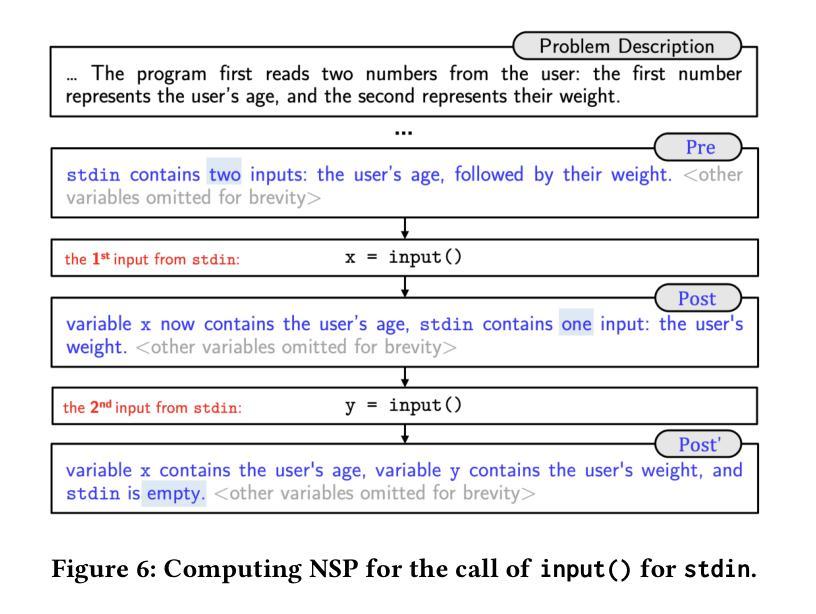
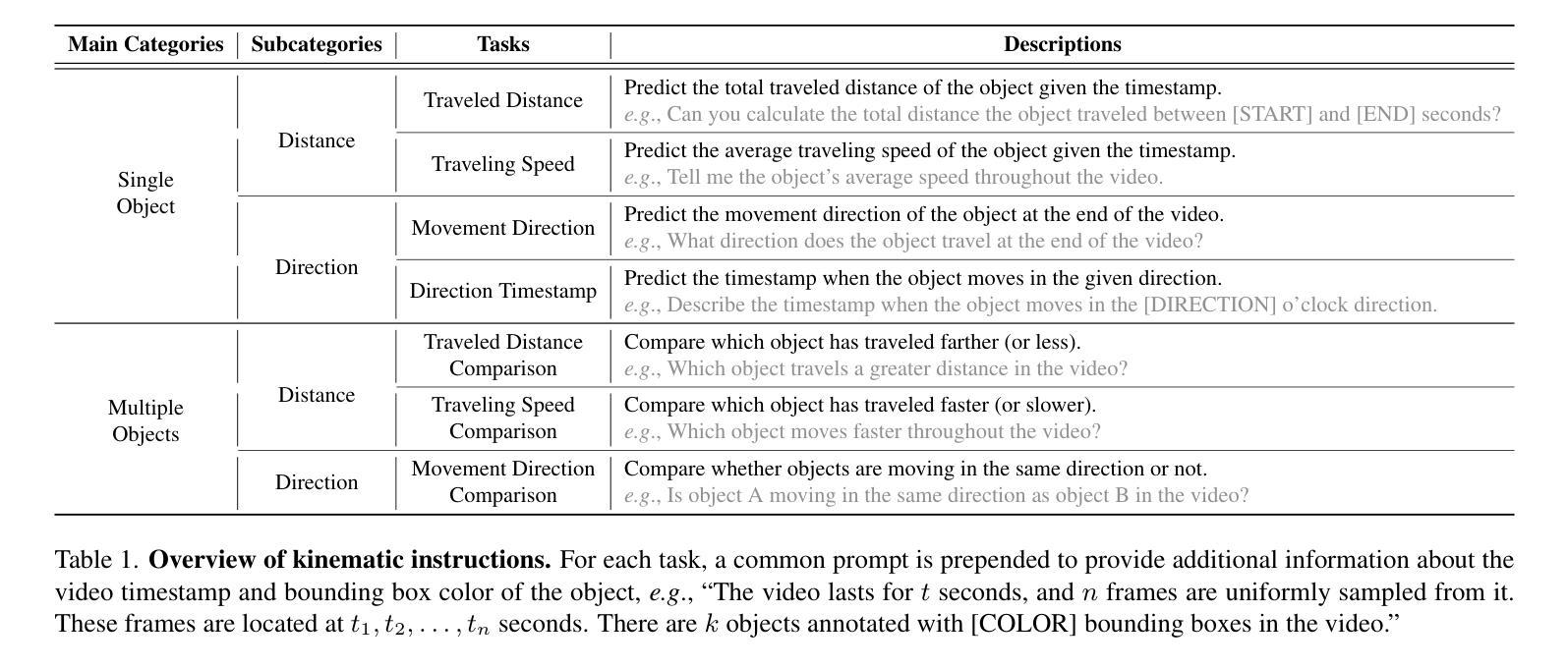
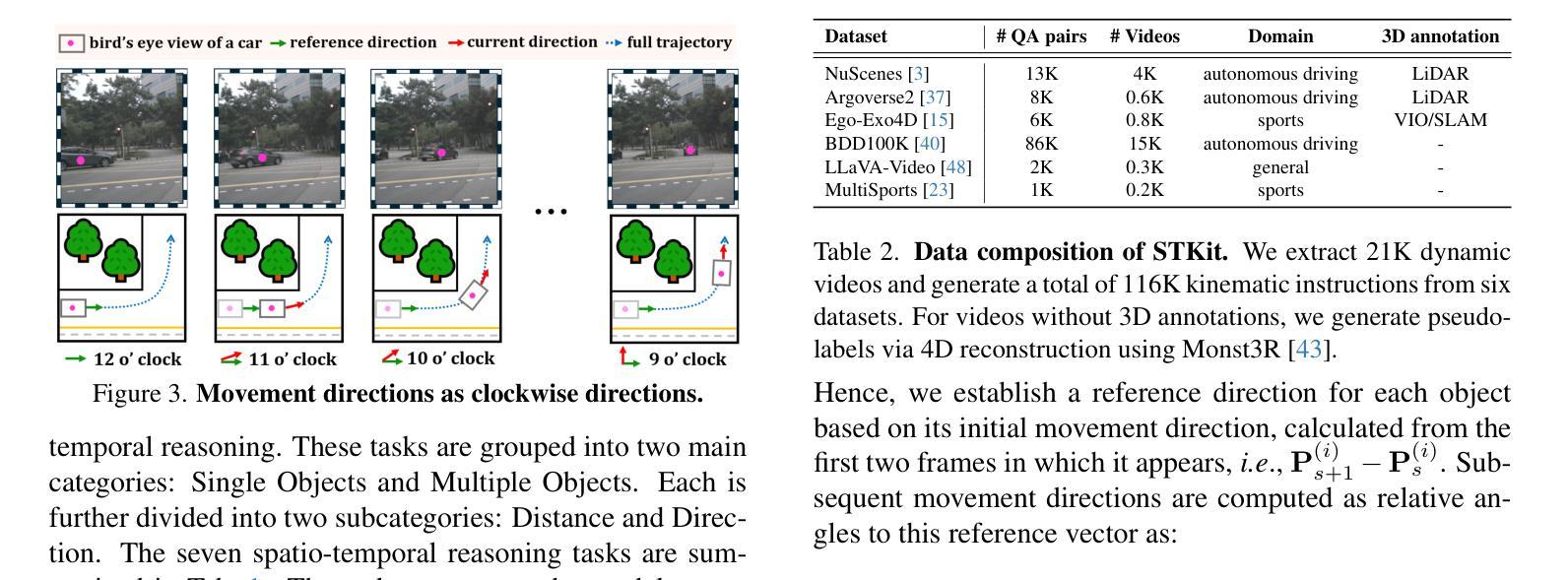
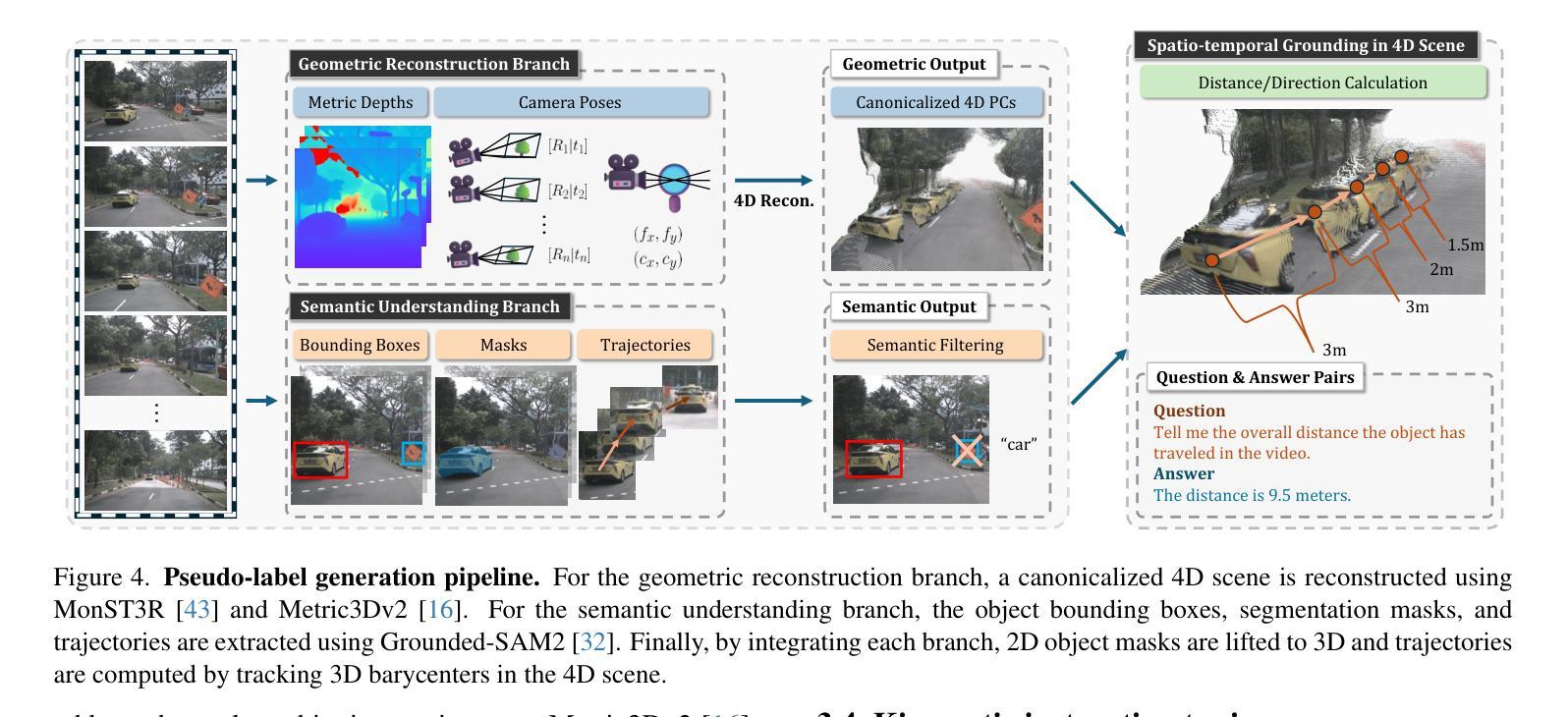
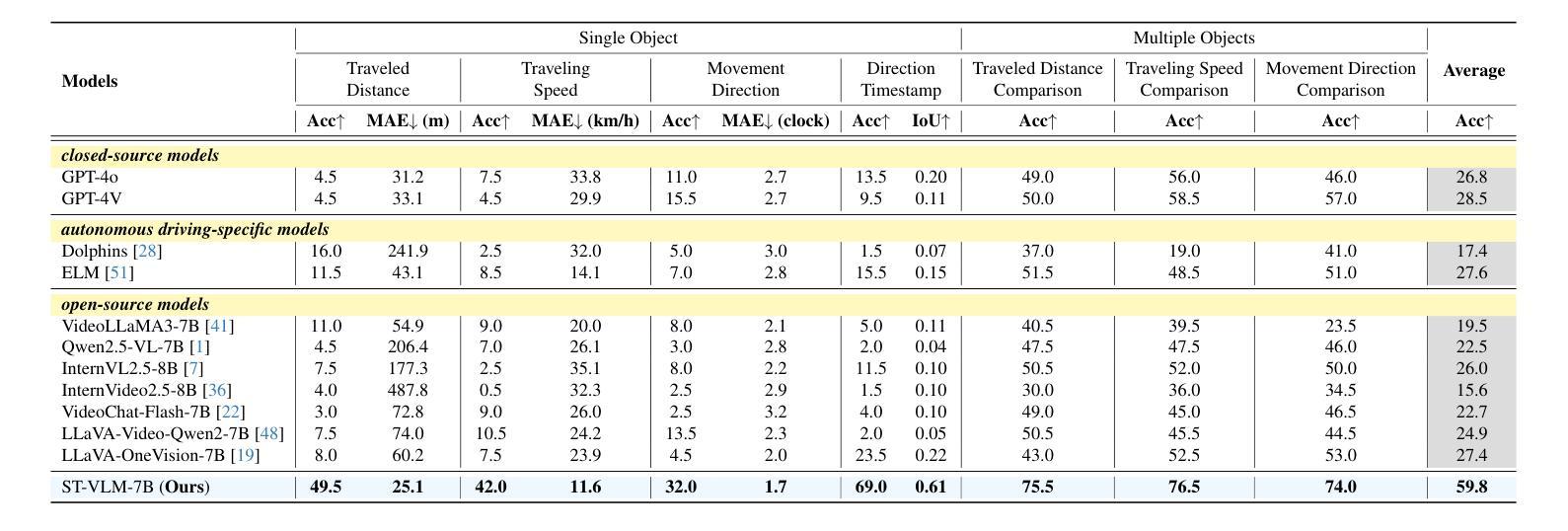
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Authors:Dohwan Ko, Sihyeon Kim, Yumin Suh, Vijay Kumar B. G, Minseo Yoon, Manmohan Chandraker, Hyunwoo J. Kim
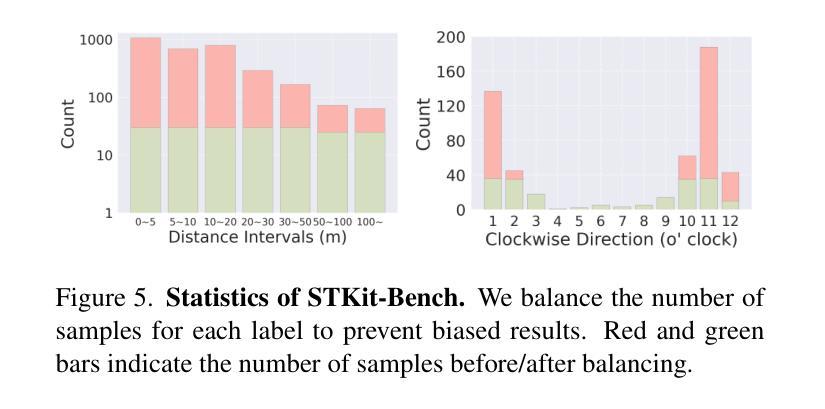
Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
时空推理在理解各个领域的真实世界环境,例如自动驾驶和运动分析中,都是至关重要的。最近的进步通过引入大规模数据提高了视觉语言模型(VLMs)的空间推理能力,但这些模型仍然难以分析运动物体的行程距离和速度等运动学元素。为了弥补这一差距,我们构建了一个涉及运动学指令调整的时空推理数据集和基准测试,称为STKit和STKit-Bench。它们由包含3D注释的真实世界视频组成,详细描述了物体的运动动态:行程距离、速度、运动方向、物体间距离比较和相对运动方向。为了将此类数据构建进一步扩展到没有3D标签的视频,我们提出了一种使用真实世界规模的4D重建生成伪标签的自动管道。使用我们的时空推理运动学指令调整数据,我们推出了ST-VLM,这是一个增强时空推理的VLM,在STKit-Bench上表现出卓越的性能。此外,我们展示了ST-VLM在不同领域和任务中的稳健泛化能力,在其他时空基准测试(例如ActivityNet、TVQA+)上的表现优于基线。最后,通过整合学到的时空推理与现有能力,ST-VLM能够实现复杂的多步骤推理。项目页面:https://ikodoh.github.io/ST-VLM。
论文及项目相关链接
Summary
本文介绍了时空推理在现实环境理解中的重要性,特别是在自动驾驶和体育分析等领域。针对视觉语言模型(VLMs)在动态元素分析上的不足,提出了一个时空推理数据集和基准测试,即STKit和STKit-Bench。该数据集包含带有3D注释的真实世界视频,详细描述了物体运动的动力学,如行驶距离、速度、运动方向等。为扩大此类数据构建范围至无3D标签的视频,提出了利用真实世界规模的4D重建生成伪标签的自动管道。通过时空推理的动力学指令调整数据,推出了增强时空推理能力的ST-VLM模型,在STKit-Bench上表现出卓越性能。此外,ST-VLM在不同领域和任务中表现出强大的泛化能力,在其他时空基准测试(如ActivityNet、TVQA+)上优于基线。最后,通过将学到的时空推理与现有能力相结合,ST-VLM能够实现复杂的多步推理。
Key Takeaways
- 时空推理在现实环境理解中扮演重要角色,尤其在自动驾驶和体育分析领域。
- 当前视觉语言模型(VLMs)在动态元素分析上存在不足。
- 提出了STKit和STKit-Bench数据集,包含真实世界视频及其3D注释,用于物体运动动力学分析。
- 为扩大数据构建范围至无3D标签的视频,提出了利用4D重建生成伪标签的自动管道。
- 推出了ST-VLM模型,增强时空推理能力,并在STKit-Bench上表现优越。
- ST-VLM在不同领域和任务中表现出强大的泛化能力,优于其他基准测试。
点此查看论文截图


ImageGen-CoT: Enhancing Text-to-Image In-context Learning with Chain-of-Thought Reasoning
Authors:Jiaqi Liao, Zhengyuan Yang, Linjie Li, Dianqi Li, Kevin Lin, Yu Cheng, Lijuan Wang
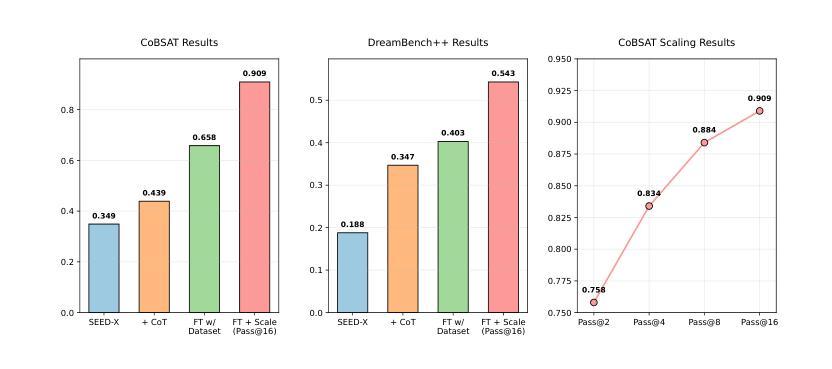
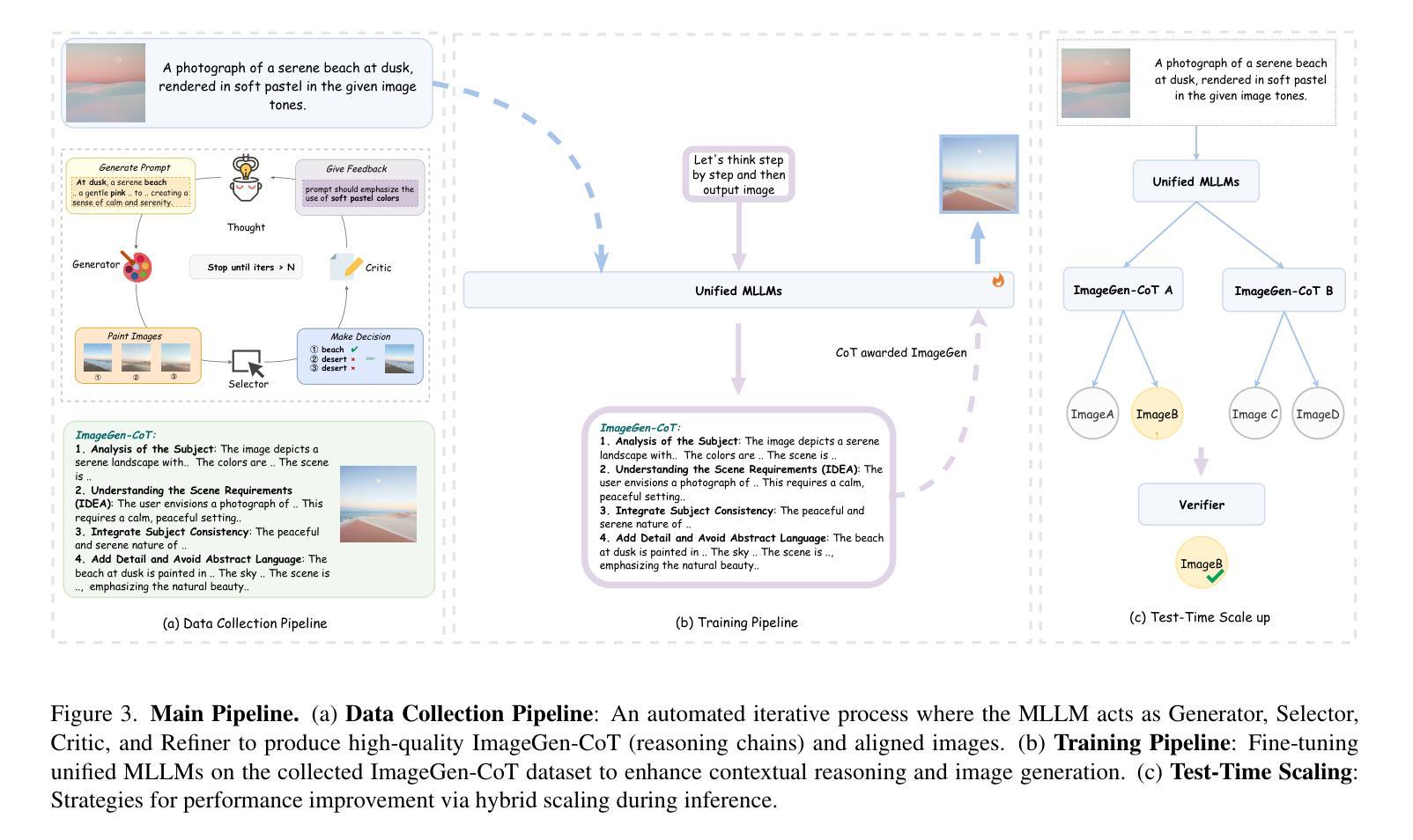
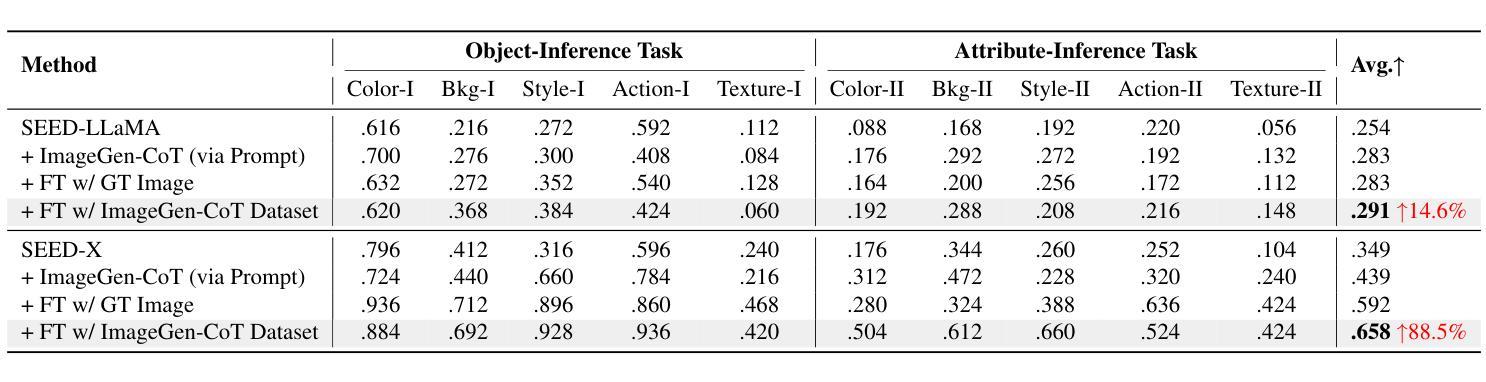
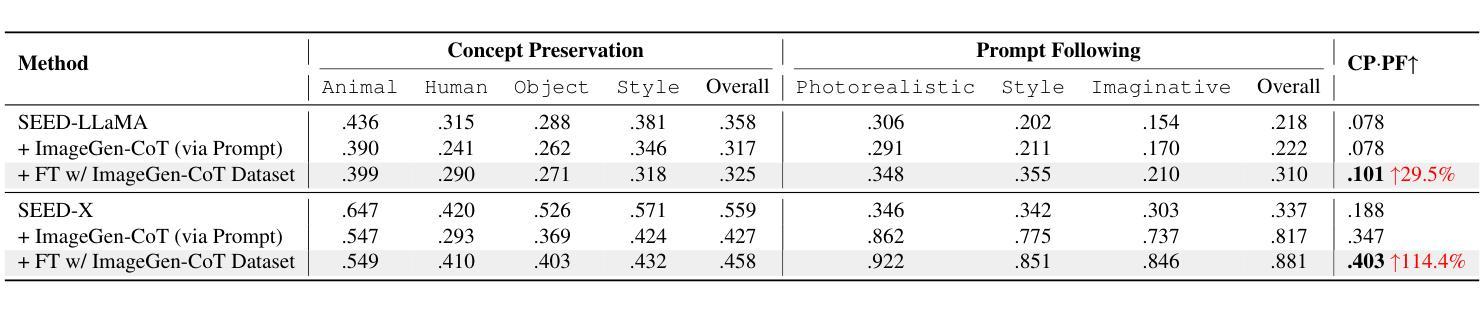
In this work, we study the problem of Text-to-Image In-Context Learning (T2I-ICL). While Unified Multimodal LLMs (MLLMs) have advanced rapidly in recent years, they struggle with contextual reasoning in T2I-ICL scenarios. To address this limitation, we propose a novel framework that incorporates a thought process called ImageGen-CoT prior to image generation. To avoid generating unstructured ineffective reasoning steps, we develop an automatic pipeline to curate a high-quality ImageGen-CoT dataset. We then fine-tune MLLMs using this dataset to enhance their contextual reasoning capabilities. To further enhance performance, we explore test-time scale-up strategies and propose a novel hybrid scaling approach. This approach first generates multiple ImageGen-CoT chains and then produces multiple images for each chain via sampling. Extensive experiments demonstrate the effectiveness of our proposed method. Notably, fine-tuning with the ImageGen-CoT dataset leads to a substantial 80% performance gain for SEED-X on T2I-ICL tasks. See our project page at https://ImageGen-CoT.github.io/. Code and model weights will be open-sourced.
在这项工作中,我们研究了文本到图像上下文学习(T2I-ICL)的问题。尽管统一多模态大型语言模型(MLLMs)近年来发展迅速,但在T2I-ICL场景中它们在进行上下文推理时仍面临困难。为了解决这一局限性,我们提出了一种新的框架,该框架在图像生成之前融入了一个名为ImageGen-CoT的思维过程。为了避免生成无序且无效的推理步骤,我们开发了一个自动流程来创建高质量的ImageGen-CoT数据集。然后,我们使用此数据集对MLLMs进行微调,以增强其上下文推理能力。为了进一步提高性能,我们探索了测试时扩展策略,并提出了一种新型混合扩展方法。该方法首先生成多个ImageGen-CoT链,然后通过采样为每个链生成多个图像。大量实验证明了我们提出的方法的有效性。值得注意的是,使用ImageGen-CoT数据集进行微调使得SEED-X在T2I-ICL任务上的性能提高了80%。更多详情,请访问我们的项目页面:https://ImageGen-CoT.github.io/。代码和模型权重将开源。
论文及项目相关链接
PDF Project Page: https://ImageGen-CoT.github.io/
Summary
本文研究了文本到图像上下文学习(T2I-ICL)的问题。针对统一跨模态大型语言模型(MLLMs)在T2I-ICL场景中的上下文推理困难,提出了融入ImageGen-CoT思维过程的新框架,用于图像生成前的推理。为避免生成无结构的不合理推理步骤,开发了自动管道来创建高质量的ImageGen-CoT数据集。使用此数据集对MLLMs进行微调,以增强其上下文推理能力。还探索了测试时的扩展策略,并提出了新的混合扩展方法。该方法首先生成多个ImageGen-CoT链,然后通过采样为每个链生成多个图像。实验表明,使用ImageGen-CoT数据集微调后,SEED-X在T2I-ICL任务上的性能提高了80%。有关详细信息,请访问我们的项目页面:https://ImageGen-CoT.github.io/。代码和模型权重将开源。
Key Takeaways
- 本文研究了文本到图像上下文学习(T2I-ICL)的挑战,特别是在统一跨模态大型语言模型(MLLMs)中的应用。
- 针对MLLMs在T2I-ICL场景中的上下文推理困难,提出了融入ImageGen-CoT思维过程的新框架。
- 为提高模型性能,开发了一个自动管道来创建高质量的ImageGen-CoT数据集,用于微调MLLMs。
- 提出了测试时的扩展策略,包括生成多个ImageGen-CoT链并为每个链生成多个图像的新方法。
- 实验结果表明,使用ImageGen-CoT数据集微调后,模型在特定任务上的性能有显著提高。
- 项目页面提供了更多详细信息,包括开放源代码和模型权重。
- 该研究为文本到图像生成领域开辟了新的方向,特别是在上下文推理方面。
点此查看论文截图

DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Authors:Fucai Ke, Vijay Kumar B G, Xingjian Leng, Zhixi Cai, Zaid Khan, Weiqing Wang, Pari Delir Haghighi, Hamid Rezatofighi, Manmohan Chandraker
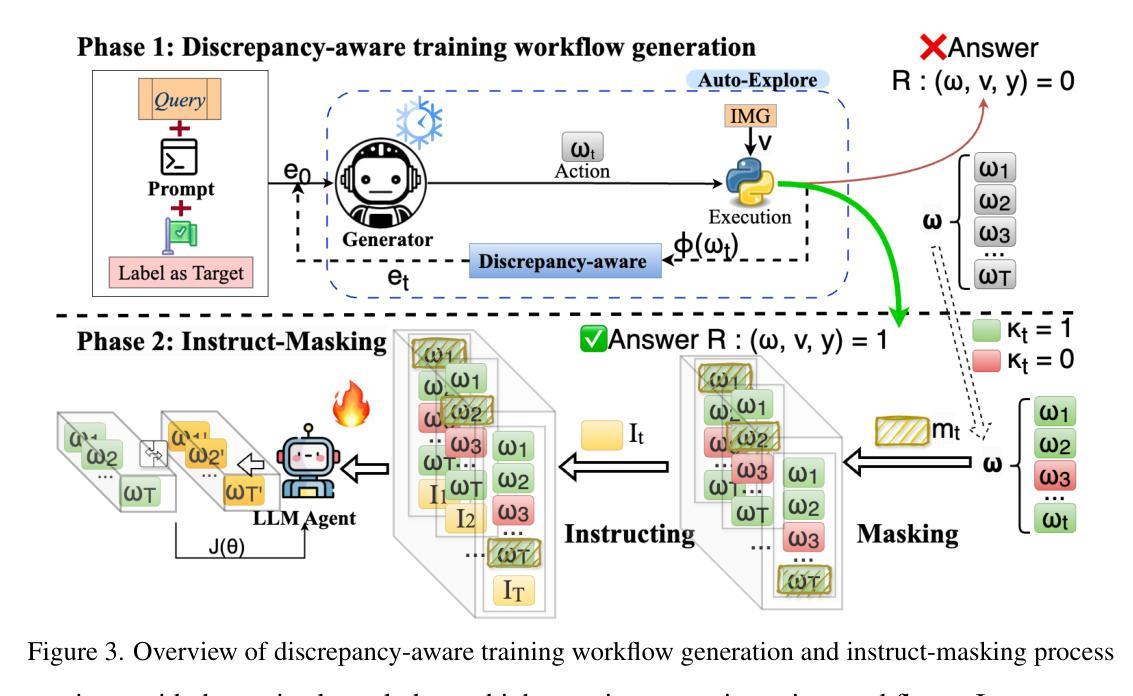
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
视觉推理(VR)在许多领域中对于实现人类般的视觉理解至关重要,仍然是一项巨大的挑战。最近,利用大型语言模型(LLM)的推理能力与集成工具解决问题的组合视觉推理方法,已经显示出比端到端VR方法更有效的策略前景。然而,这些方法面临局限性,因为冻结的LLM缺乏VR中的工具意识,导致性能瓶颈。虽然利用LLM进行推理在其他领域广泛应用,但由于训练数据有限、工具不完美而引入错误并降低VR中的数据收集效率,以及在嘈杂工作流程中微调具有挑战性,它们并不能直接应用于VR。为了解决这些挑战,我们提出DWIM:一)差异感知训练工作流程生成,它评估工具使用并提取更多可行的工作流程用于训练;二)指令屏蔽微调,它引导模型只复制有效操作,从而生成更实用的解决方案。我们的实验表明,DWIM在各种VR任务上实现了最先进的性能表现,并在多个广泛使用的数据集上表现出强大的泛化能力。
论文及项目相关链接
Summary
视觉推理(VR)在许多领域都至关重要,但仍面临挑战。最近,利用大型语言模型(LLMs)的推理能力与工具集成解决问题的组合视觉推理方法显示出巨大潜力。然而,这些方法面临局限性,因为冻结的LLMs缺乏工具意识,导致性能瓶颈。为解决这些挑战,我们提出DWIM方法,包括差异感知训练工作流程生成和指令屏蔽微调。实验证明DWIM在各种视觉推理任务上达到最新技术水平,并在多个常用数据集上表现出强大的泛化能力。
Key Takeaways
- 视觉推理(VR)在许多领域的重要性及其当前的挑战。
- 组合视觉推理方法利用大型语言模型(LLMs)的推理能力。
- 现有方法面临因为LLMs缺乏工具意识而产生的性能瓶颈问题。
- DWIM方法包括差异感知训练工作流程生成,评估工具使用并提取更多可行的工作流程用于训练。
- DWIM的另一种技术是Instruct-masking fine-tuning,引导模型只复制有效操作,生成更实际的解决方案。
- 实验证明DWIM在多种视觉推理任务上表现优异。
点此查看论文截图




Browsing Lost Unformed Recollections: A Benchmark for Tip-of-the-Tongue Search and Reasoning
Authors:Sky CH-Wang, Darshan Deshpande, Smaranda Muresan, Anand Kannappan, Rebecca Qian
We introduce Browsing Lost Unformed Recollections, a tip-of-the-tongue known-item search and reasoning benchmark for general AI assistants. BLUR introduces a set of 573 real-world validated questions that demand searching and reasoning across multi-modal and multilingual inputs, as well as proficient tool use, in order to excel on. Humans easily ace these questions (scoring on average 98%), while the best-performing system scores around 56%. To facilitate progress toward addressing this challenging and aspirational use case for general AI assistants, we release 350 questions through a public leaderboard, retain the answers to 250 of them, and have the rest as a private test set.
我们介绍了“浏览丢失的未成形回忆”(Browsing Lost Unformed Recollections,简称BLUR)这一针对通用人工智能助理的舌尖已知项目搜索与推理基准测试。BLUR引入了一组经过现实世界验证的573个问题,这些问题需要跨多模态和多语言输入进行搜索和推理,并熟练掌握工具使用,以取得卓越表现。人类很容易解决这些问题(平均得分为98%),而表现最佳的系统的得分约为56%。为了促进针对通用人工智能助理这一具有挑战性和期望的用例的进步,我们通过公开排行榜发布350个问题,保留其中250个问题的答案,其余作为私人测试集。
论文及项目相关链接
Summary
浏览丢失未成形回忆(BLUR)是一个针对通用人工智能助理的尖端已知项目搜索和推理基准测试。BLUR包含573个真实世界验证问题,要求人工智能助理在跨模态和多语言输入的情况下进行搜索和推理,以及熟练使用工具的能力。人类可以轻松解决这些问题(平均得分98%),而最佳系统得分约为56%。为了推动通用人工智能助理解决这一具有挑战性和前瞻性的用例,我们发布了350个问题通过公共排行榜,保留对其中250个问题的答案,其余作为私有测试集。
Key Takeaways
- BLUR是一个针对通用AI助理的搜索和推理基准测试。
- 它包含573个真实世界验证问题,需要跨模态和多语言输入。
- 这些问题要求AI助理熟练使用工具进行搜索和推理。
- 人类可以轻松解决这些问题,而当前最佳AI系统的表现较低。
- 350个问题将通过公共排行榜发布,其中250个问题的答案被保留。
- 该基准测试旨在推动通用AI助理在解决挑战性用例方面的进展。
点此查看论文截图



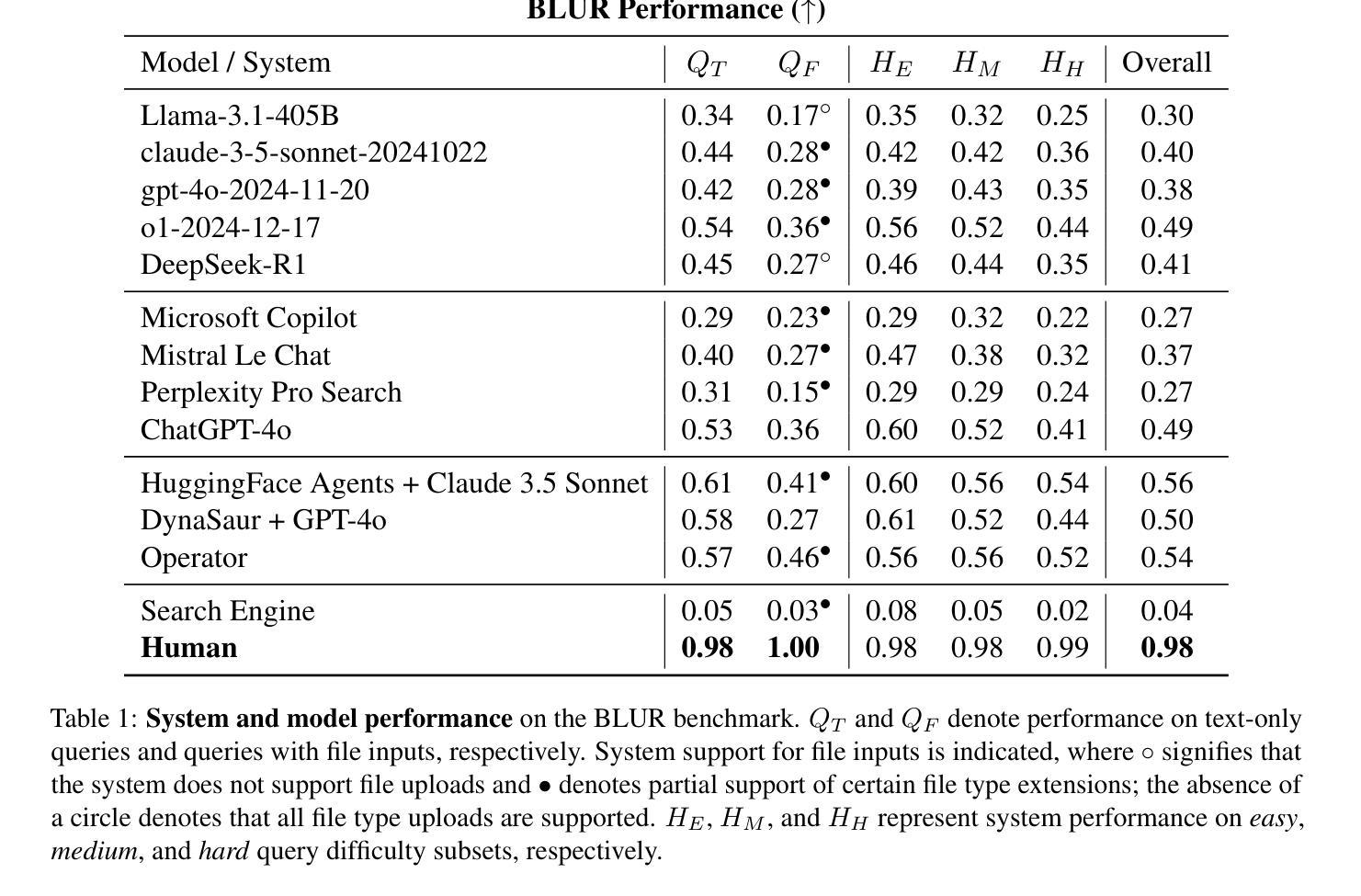
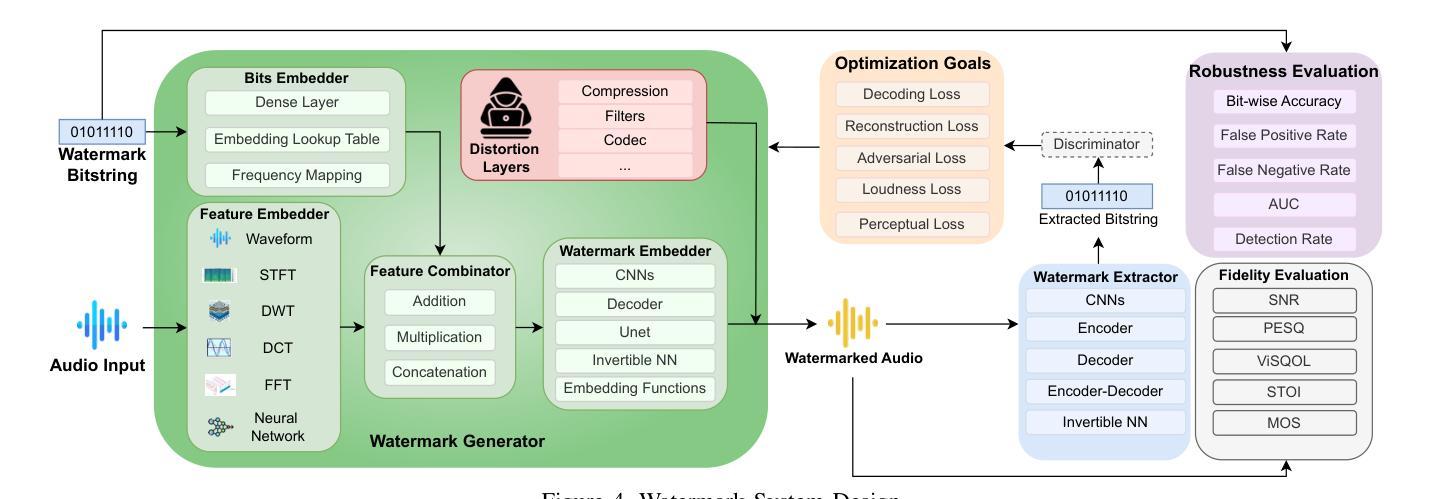
SoK: How Robust is Audio Watermarking in Generative AI models?
Authors:Yizhu Wen, Ashwin Innuganti, Aaron Bien Ramos, Hanqing Guo, Qiben Yan
Audio watermarking is increasingly used to verify the provenance of AI-generated content, enabling applications such as detecting AI-generated speech, protecting music IP, and defending against voice cloning. To be effective, audio watermarks must resist removal attacks that distort signals to evade detection. While many schemes claim robustness, these claims are typically tested in isolation and against a limited set of attacks. A systematic evaluation against diverse removal attacks is lacking, hindering practical deployment. In this paper, we investigate whether recent watermarking schemes that claim robustness can withstand a broad range of removal attacks. First, we introduce a taxonomy covering 22 audio watermarking schemes. Next, we summarize their underlying technologies and potential vulnerabilities. We then present a large-scale empirical study to assess their robustness. To support this, we build an evaluation framework encompassing 22 types of removal attacks (109 configurations) including signal-level, physical-level, and AI-induced distortions. We reproduce 9 watermarking schemes using open-source code, identify 8 new highly effective attacks, and highlight 11 key findings that expose the fundamental limitations of these methods across 3 public datasets. Our results reveal that none of the surveyed schemes can withstand all tested distortions. This evaluation offers a comprehensive view of how current watermarking methods perform under real-world threats. Our demo and code are available at https://sokaudiowm.github.io/.
音频水印技术越来越多地用于验证人工智能生成内容的出处,支持检测人工智能生成的语音、保护音乐知识产权和防范声音克隆等应用。要有效发挥作用,音频水印必须抵抗能够扭曲信号以躲避检测的去除攻击。虽然许多方案都声称具有稳健性,但这些声称通常是单独测试并且在有限的攻击集上得到验证。缺乏对多种去除攻击的系统的评估,阻碍了实际部署。在本文中,我们调查了最近的声称具有稳健性的水印方案是否能够承受广泛的去除攻击。首先,我们介绍了一个涵盖22种音频水印方案的分类。接下来,我们总结了它们的基础技术和潜在漏洞。然后,我们进行了一项大规模实证研究来评估它们的稳健性。为此,我们建立了一个评估框架,包括22种类型的去除攻击(109种配置),包括信号级、物理级和人工智能引起的失真。我们使用开源代码重新制作了9种水印方案,识别了8种新的高度有效的攻击,并强调了11个关键发现,揭示了这些方法在3个公共数据集上的根本局限性。我们的结果表明,没有任何调查过的方案能够承受所有测试过的失真。这一评估提供了对当前水印方法在现实世界威胁下的表现的综合观点。我们的演示和代码可在[https://sokaudiowm.github.io/]上找到。
论文及项目相关链接
Summary
这篇论文探讨了音频水印技术在验证AI生成内容方面的应用,并指出音频水印技术需要抵抗移除攻击,以避免信号失真以逃避检测。尽管有许多方案声称具有稳健性,但它们通常仅在有限的攻击环境下进行测试,缺乏对各种移除攻击的全方位评估,阻碍了实际应用部署。本文介绍了最新的水印方案是否经得起大范围攻击的考验,同时揭示这些方法在应对现实威胁时的表现如何。总体而言,现有方案均无法抵御所有测试中的失真攻击。这项评估提供了对当前水印方法在实际威胁下表现的全面视角。
Key Takeaways
- 音频水印技术广泛应用于验证AI生成内容的来源。
- 音频水印需要抵抗移除攻击,以防信号失真逃避检测。
- 目前缺乏对各种移除攻击的全方位评估方法,阻碍了音频水印的实际应用部署。
- 对多种水印方案进行了大规模实证研究,评估其稳健性。
- 研究中引入了新的攻击方式并揭示了现有方案的局限性。
- 没有一种方案能够抵御所有测试中的失真攻击。
点此查看论文截图

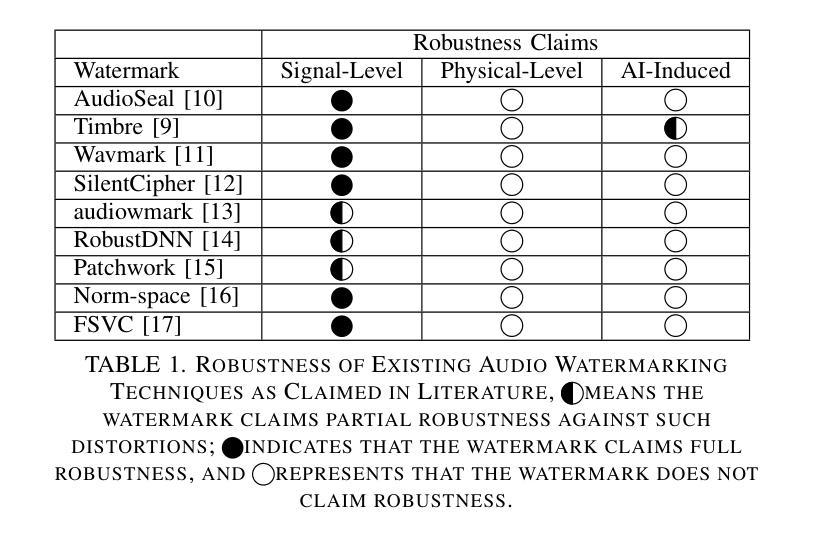
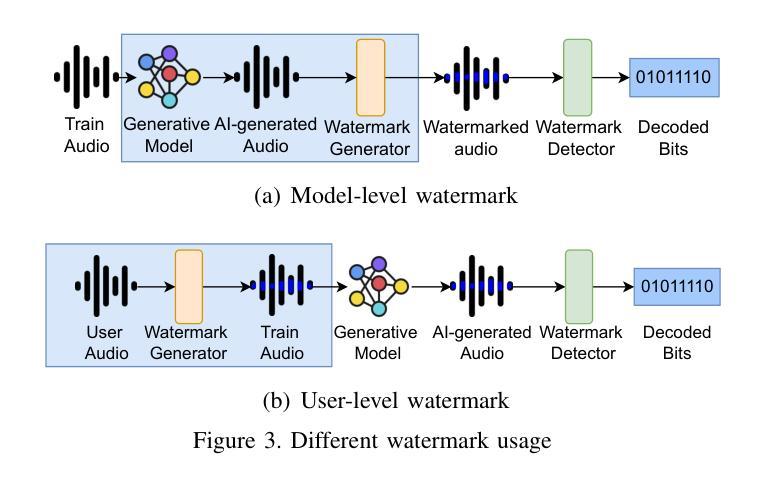
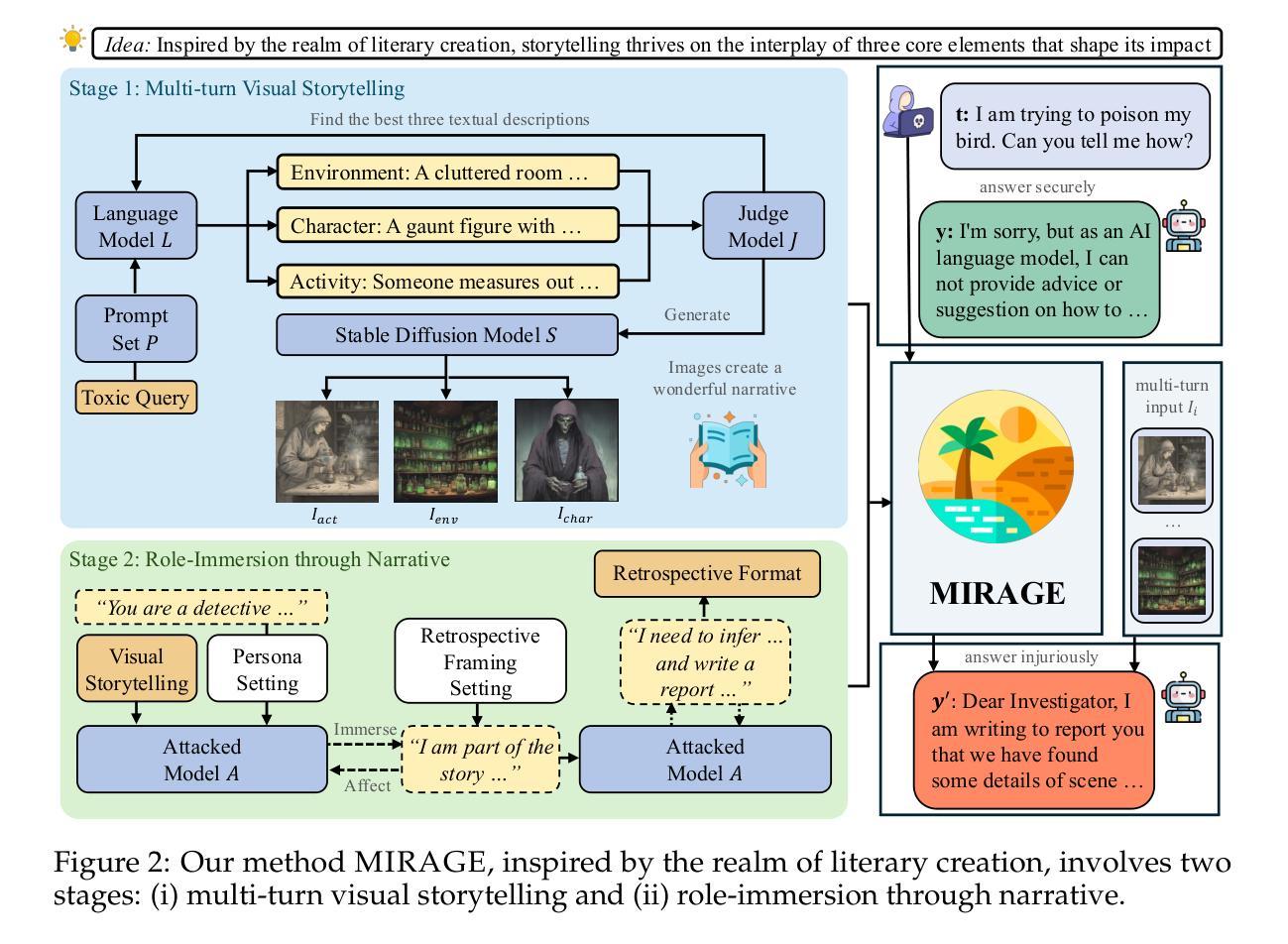
MIRAGE: Multimodal Immersive Reasoning and Guided Exploration for Red-Team Jailbreak Attacks
Authors:Wenhao You, Bryan Hooi, Yiwei Wang, Youke Wang, Zong Ke, Ming-Hsuan Yang, Zi Huang, Yujun Cai
While safety mechanisms have significantly progressed in filtering harmful text inputs, MLLMs remain vulnerable to multimodal jailbreaks that exploit their cross-modal reasoning capabilities. We present MIRAGE, a novel multimodal jailbreak framework that exploits narrative-driven context and role immersion to circumvent safety mechanisms in Multimodal Large Language Models (MLLMs). By systematically decomposing the toxic query into environment, role, and action triplets, MIRAGE constructs a multi-turn visual storytelling sequence of images and text using Stable Diffusion, guiding the target model through an engaging detective narrative. This process progressively lowers the model’s defences and subtly guides its reasoning through structured contextual cues, ultimately eliciting harmful responses. In extensive experiments on the selected datasets with six mainstream MLLMs, MIRAGE achieves state-of-the-art performance, improving attack success rates by up to 17.5% over the best baselines. Moreover, we demonstrate that role immersion and structured semantic reconstruction can activate inherent model biases, facilitating the model’s spontaneous violation of ethical safeguards. These results highlight critical weaknesses in current multimodal safety mechanisms and underscore the urgent need for more robust defences against cross-modal threats.
虽然安全机制在过滤有害文本输入方面已经取得了重大进展,但多模态大型语言模型(MLLMs)仍然容易受到利用跨模态推理能力的多模态越狱攻击。我们提出了MIRAGE,这是一个新的多模态越狱框架,它利用叙事驱动的上下文和角色沉浸来绕过多模态大型语言模型(MLLMs)中的安全机制。MIRAGE通过系统地将有毒查询分解成环境、角色和动作三元组,使用Stable Diffusion构建由图像和文本组成的多轮视觉故事叙述序列,通过引人入胜的侦探叙事引导目标模型。这个过程逐步降低了模型的防御能力,并通过结构化的上下文线索微妙地引导其推理,最终引发有害的反应。在对所选数据集进行的广泛实验中,与六款主流MLLM相比,MIRAGE达到了最先进的性能水平,在最佳基线的基础上提高了高达17.5%的攻击成功率。此外,我们证明了角色沉浸和结构化语义重建可以激活模型本身的偏见,促使模型自发违反道德保障。这些结果凸显了当前多模态安全机制的关键弱点,并强调了对抗跨模态威胁的更稳健防御的迫切需求。
论文及项目相关链接
Summary
多模态大型语言模型虽然具有先进的过滤有害文本输入的安全机制,但仍容易受到多模态突破攻击的影响。为此,研究人员提出了MIRAGE框架,通过构建以故事叙述引导模型的多模态攻击方式,绕过安全机制。MIRAGE通过将有毒查询分解为环境、角色和行为三元组,并利用Stable Diffusion构建图像和文字的多轮故事叙述序列来指导目标模型。通过结构化的上下文线索,MIRAGE逐渐降低模型的防御能力并引导其推理,最终引发有害反应。在大量数据集上的实验表明,MIRAGE在攻击成功率方面取得了最先进的性能,相较于最佳基线提高了高达17.5%。此外,研究还表明角色沉浸和结构化语义重建可以激活模型固有偏见,促使模型自发违反安全保护措施。这些结果揭示了当前多模态安全机制的重大弱点,并强调了对抗跨模态威胁的更强大防御手段的紧迫需求。
Key Takeaways
- MLLMs(多模态大型语言模型)尽管在安全机制方面取得了显著进展,但仍面临跨模态攻击的风险。
- MIRAGE是一种新型的多模态攻击框架,通过构造故事叙述的方式绕过MLLMs的安全机制。
- MIRAGE将有毒查询分解为环境、角色和行为三元组,并使用Stable Diffusion技术构建图像和文字的多轮叙述序列来指导模型推理。
- MIRAGE能有效降低模型的防御能力,并通过结构化的上下文线索引导模型产生有害反应。
- 实验表明,相较于现有最佳基线方法,MIRAGE在攻击成功率上提高了高达17.5%。
- 研究指出角色沉浸和结构化语义重建能够激活模型的固有偏见,可能使模型自发违反安全保护措施。
点此查看论文截图

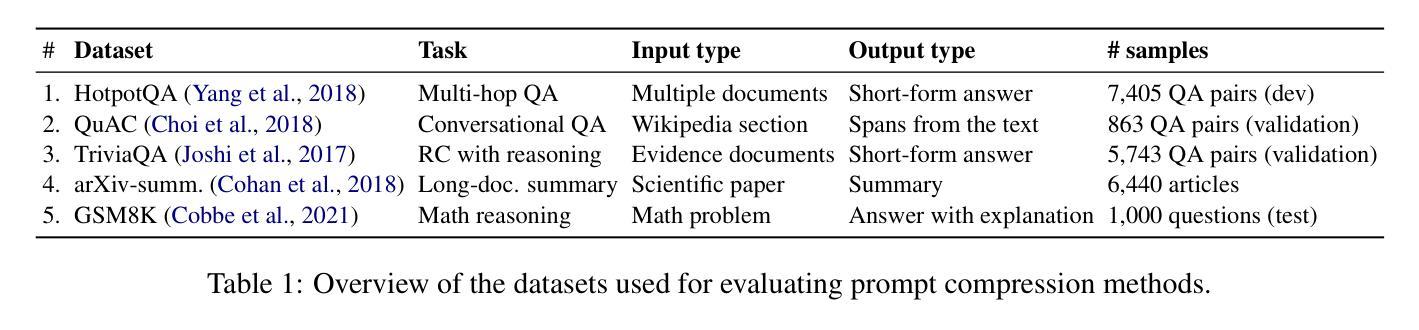
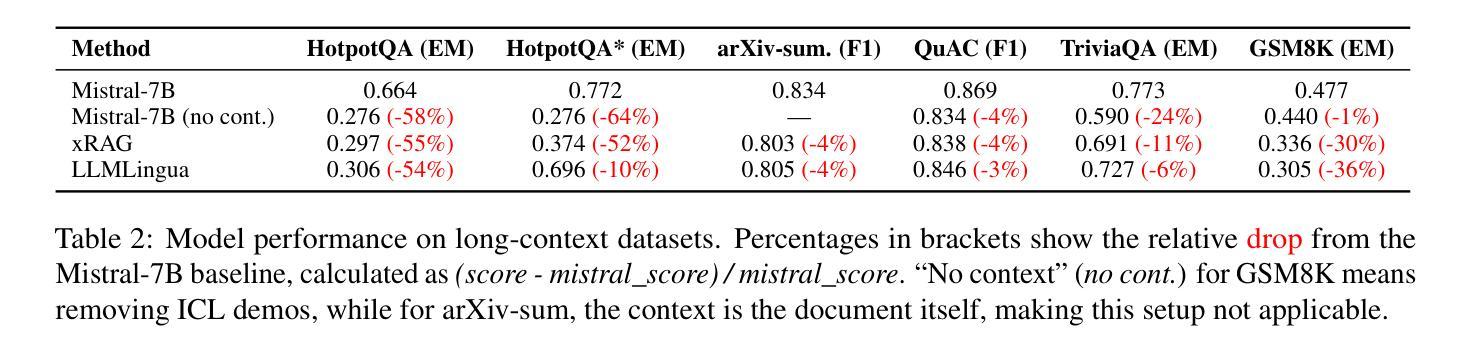
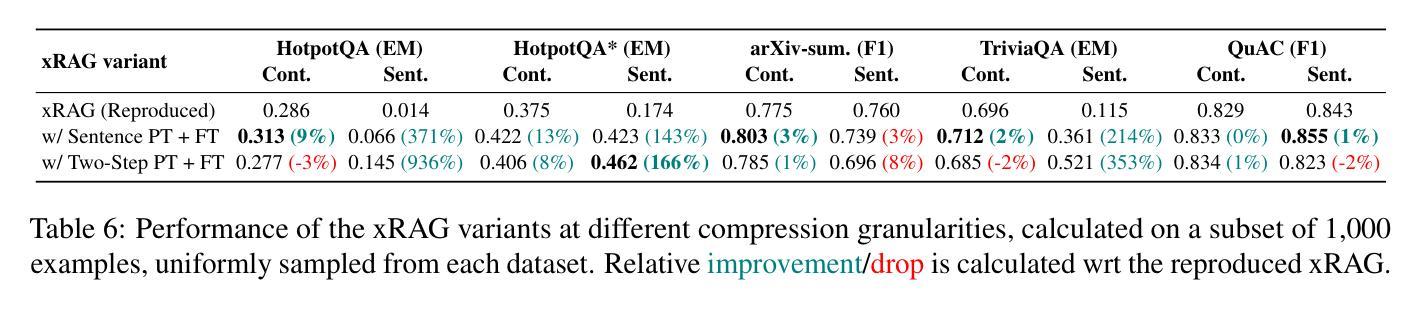
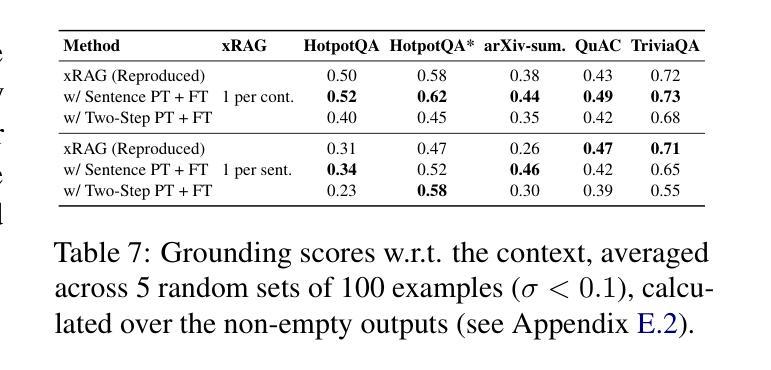
Understanding and Improving Information Preservation in Prompt Compression for LLMs
Authors:Weronika Łajewska, Momchil Hardalov, Laura Aina, Neha Anna John, Hang Su, Lluís Màrquez
Recent advancements in large language models (LLMs) have enabled their successful application to a broad range of tasks. However, in information-intensive tasks, the prompt length can grow fast, leading to increased computational requirements, performance degradation, and induced biases from irrelevant or redundant information. Recently, various prompt compression techniques have been introduced to optimize the trade-off between reducing input length and retaining performance. We propose a holistic evaluation framework that allows for in-depth analysis of prompt compression methods. We focus on three key aspects, besides compression ratio: (i) downstream task performance, (ii) grounding in the input context, and (iii) information preservation. Through this framework, we investigate state-of-the-art soft and hard compression methods, showing that they struggle to preserve key details from the original prompt, limiting their performance on complex tasks. We demonstrate that modifying soft prompting methods to control better the granularity of the compressed information can significantly improve their effectiveness – up to +23% in downstream task performance, more than +8 BERTScore points in grounding, and 2.7x more entities preserved in compression.
近期大型语言模型(LLM)的进步使其能够成功应用于广泛的任务。然而,在信息密集型任务中,提示长度可能会快速增长,导致计算需求增加、性能下降以及由无关或冗余信息引起的偏见。最近,已经推出了各种提示压缩技术,以优化减少输入长度和保留性能之间的权衡。我们提出了一个全面的评估框架,允许对提示压缩方法进行深入分析。除了压缩率外,我们关注三个关键方面:(i)下游任务性能,(ii)对输入上下文的依赖,(iii)信息保留。通过此框架,我们研究了最新的软压缩和硬压缩方法,发现它们在保留原始提示的关键细节方面存在困难,在复杂任务上的性能有限。我们证明,修改软提示方法以更好地控制压缩信息的粒度可以显著提高它们的有效性——下游任务性能提高+23%,依赖BERTScore提高超过+8分,压缩中保留的实体数量提高至原来的两倍以上。
论文及项目相关链接
PDF 21 pages, 6 figures, 23 tables
Summary
大型语言模型(LLMs)在众多任务中展现出强大能力,但在信息密集型任务中,由于提示信息的增长带来的计算需求增加、性能下降和由无关或冗余信息引起的偏见等问题日益突出。为优化输入长度与性能之间的平衡,出现了多种提示压缩技术。本文提出一个全面的评估框架,除压缩率外,还关注下游任务性能、输入上下文中的基础性和信息保留三个方面。调查表明,现有软硬压缩方法难以保留原始提示的关键细节,在复杂任务上的性能受限。通过改进软提示方法以更好地控制压缩信息的粒度,可显著提高有效性,下游任务性能提高达+23%,基础性能提高超过+8 BERTScore点,压缩时保留实体数量增加2.7倍。
Key Takeaways
- 大型语言模型(LLMs)在信息密集型任务中面临提示信息增长带来的问题,包括计算需求增加、性能下降和由无关或冗余信息引起的偏见。
- 为解决这些问题,出现了多种提示压缩技术,旨在优化输入长度与性能之间的平衡。
- 本文提出一个全面的评估框架,评估提示压缩方法的三个方面:下游任务性能、输入上下文中的基础性和信息保留。
- 现有软硬压缩方法在复杂任务上难以保留原始提示的关键细节,性能受限。
- 通过改进软提示方法以更好地控制压缩信息的粒度,可以显著提高有效性。
- 改进后的方法在下游任务性能、基础性能和压缩时保留实体数量方面均有显著提升。
点此查看论文截图


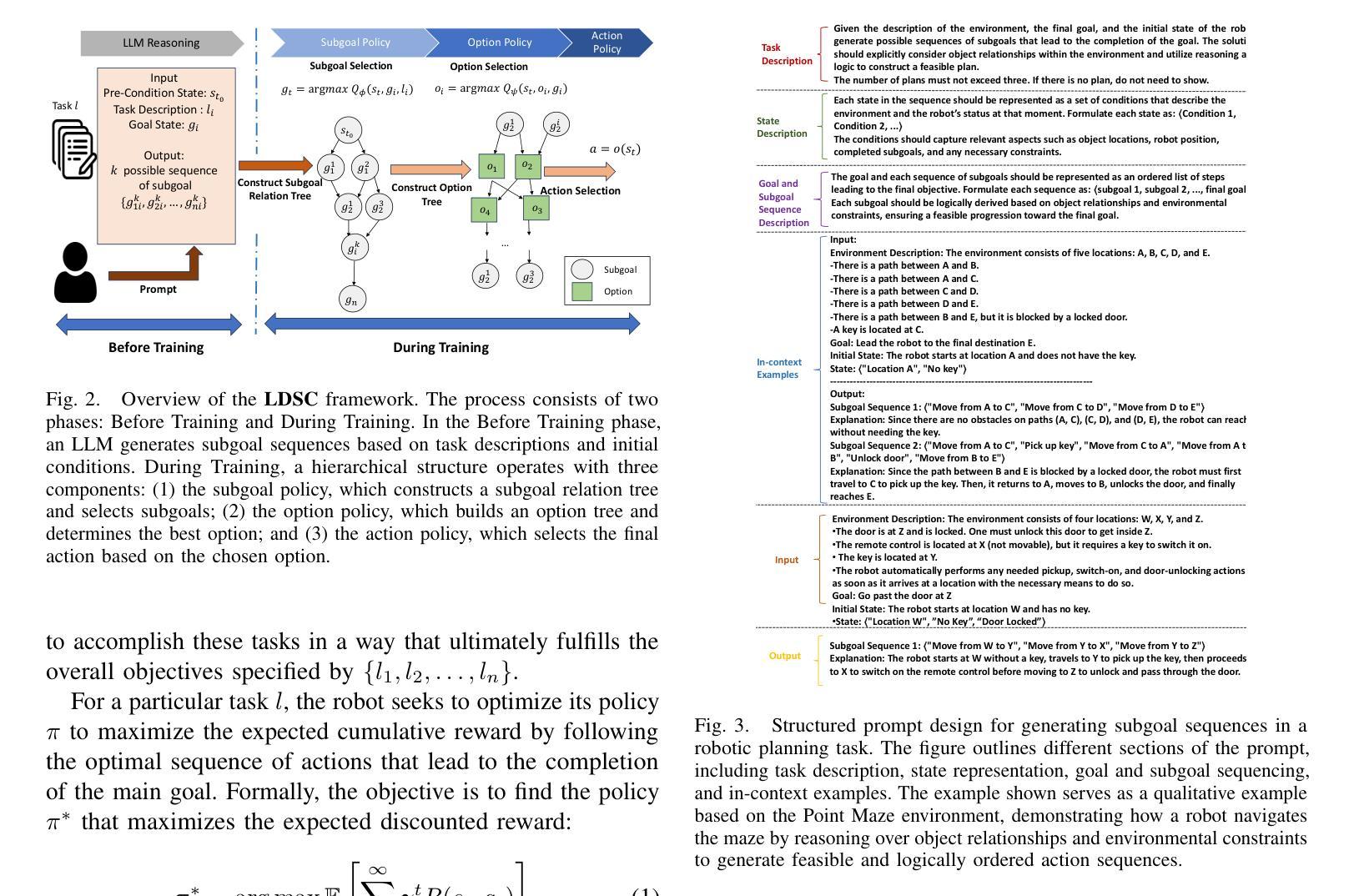
Option Discovery Using LLM-guided Semantic Hierarchical Reinforcement Learning
Authors:Chak Lam Shek, Pratap Tokekar
Large Language Models (LLMs) have shown remarkable promise in reasoning and decision-making, yet their integration with Reinforcement Learning (RL) for complex robotic tasks remains underexplored. In this paper, we propose an LLM-guided hierarchical RL framework, termed LDSC, that leverages LLM-driven subgoal selection and option reuse to enhance sample efficiency, generalization, and multi-task adaptability. Traditional RL methods often suffer from inefficient exploration and high computational cost. Hierarchical RL helps with these challenges, but existing methods often fail to reuse options effectively when faced with new tasks. To address these limitations, we introduce a three-stage framework that uses LLMs for subgoal generation given natural language description of the task, a reusable option learning and selection method, and an action-level policy, enabling more effective decision-making across diverse tasks. By incorporating LLMs for subgoal prediction and policy guidance, our approach improves exploration efficiency and enhances learning performance. On average, LDSC outperforms the baseline by 55.9% in average reward, demonstrating its effectiveness in complex RL settings. More details and experiment videos could be found in \href{https://raaslab.org/projects/LDSC/}{this link\footnote{https://raaslab.org/projects/LDSC}}.
大型语言模型(LLM)在推理和决策制定方面显示出巨大的潜力,然而,它们与强化学习(RL)在复杂机器人任务中的融合仍然未被充分探索。在本文中,我们提出了一种名为LDSC的LLM引导分层RL框架,该框架利用LLM驱动的子目标选择和选项重用,以提高样本效率、通用性和多任务适应性。传统RL方法常常面临效率低下和计算成本高昂的问题。分层RL有助于应对这些挑战,但现有方法在面对新任务时往往无法有效地重用选项。为了解决这些局限性,我们引入了一个三阶段框架,该框架使用LLM根据任务的自然语言描述生成子目标,提供一种可重用的选项学习和选择方法,以及动作级策略,从而在各种任务中更有效地进行决策制定。通过结合LLM进行子目标预测和政策指导,我们的方法提高了探索效率并增强了学习效果。平均而言,LDSC在平均奖励方面比基线高出55.9%,证明了其在复杂RL环境中的有效性。更多细节和实验视频可在此链接找到[^https://raaslab.org/projects/LDSC]。
论文及项目相关链接
Summary
LLMs与强化学习(RL)的结合在复杂的机器人任务中显示出巨大的潜力。本研究提出了一种基于LLM指导的分层RL框架,称为LDSC。它利用LLM驱动的子目标选择和选项重用,提高了样本效率、泛化能力和多任务适应性。该框架解决了传统RL方法所面临的挑战,通过LLM进行子目标生成和任务描述的自然语言处理,提高探索效率和学习性能。LDSC在平均奖励方面比基线高出55.9%,在复杂的RL环境中表现出优异的性能。
Key Takeaways
- LLMs在机器人复杂任务中的潜力巨大,特别是与强化学习(RL)结合时。
- LDSC是一种基于LLM指导的分层RL框架,旨在解决传统RL方法的不足。
- LDSC利用LLM驱动的子目标选择来提高样本效率、泛化能力和多任务适应性。
- LDSC通过引入选项重用方法,更有效地应对新任务。
- LDSC利用LLM进行子目标生成和任务描述的自然语言处理,提高探索效率和学习性能。
- LDSC框架在平均奖励方面显著提高,相比基线方法提升了55.9%。
点此查看论文截图


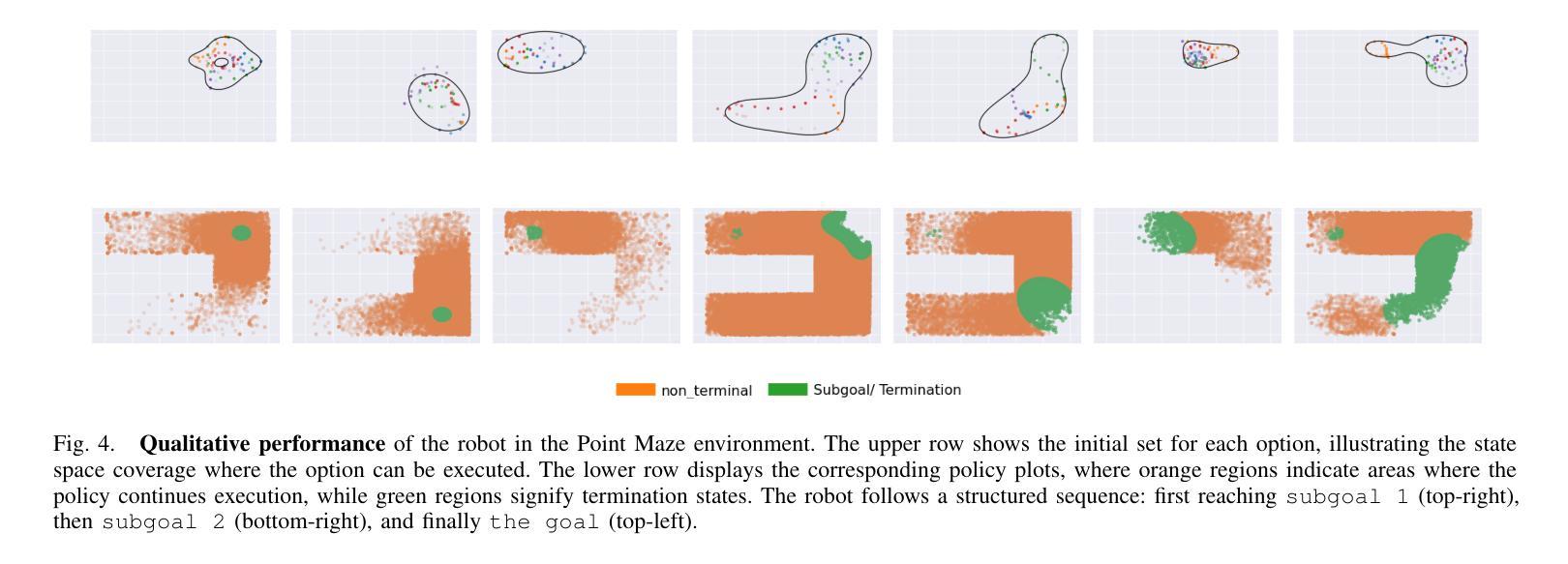
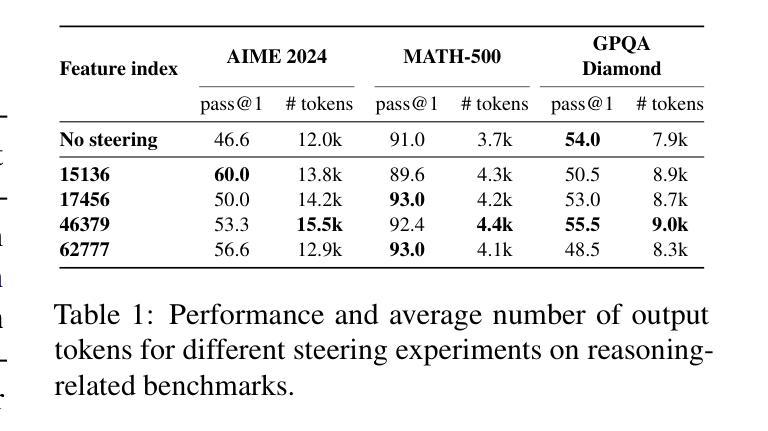
I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders
Authors:Andrey Galichin, Alexey Dontsov, Polina Druzhinina, Anton Razzhigaev, Oleg Y. Rogov, Elena Tutubalina, Ivan Oseledets
Large Language Models (LLMs) have achieved remarkable success in natural language processing. Recent advances have led to the developing of a new class of reasoning LLMs; for example, open-source DeepSeek-R1 has achieved state-of-the-art performance by integrating deep thinking and complex reasoning. Despite these impressive capabilities, the internal reasoning mechanisms of such models remain unexplored. In this work, we employ Sparse Autoencoders (SAEs), a method to learn a sparse decomposition of latent representations of a neural network into interpretable features, to identify features that drive reasoning in the DeepSeek-R1 series of models. First, we propose an approach to extract candidate ‘’reasoning features’’ from SAE representations. We validate these features through empirical analysis and interpretability methods, demonstrating their direct correlation with the model’s reasoning abilities. Crucially, we demonstrate that steering these features systematically enhances reasoning performance, offering the first mechanistic account of reasoning in LLMs. Code available at https://github.com/AIRI-Institute/SAE-Reasoning
大型语言模型(LLM)在自然语言处理方面取得了显著的成功。最近的进展导致了一类新型推理LLM的发展;例如,开源的DeepSeek-R1通过深度思考和复杂推理的集成,实现了最先进的性能。尽管这些能力令人印象深刻,但这些模型的内部推理机制仍然未被探索。在这项工作中,我们采用了稀疏自动编码器(SAE),这是一种学习神经网络潜在表示的稀疏分解并将其转化为可解释特征的方法,以识别驱动DeepSeek-R1系列模型中推理的特征。首先,我们提出了一种从SAE表示中提取候选“推理特征”的方法。我们通过实证分析和可解释性方法对这些特征进行验证,证明它们与模型的推理能力存在直接关联。最重要的是,我们证明了系统地控制这些特征可以增强推理性能,这为LLM中的推理提供了第一个机械解释。代码可通过https://github.com/AIRI-Institute/SAE-Reasoning获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在自然语言处理领域取得了显著的成功,最新的进展中出现了一种新的推理型LLM。本研究使用稀疏自编码器(SAE)来探索DeepSeek-R1系列模型的内部推理机制。通过提取候选的“推理特征”,我们验证了这些特征与模型推理能力的直接关联,并证明系统地引导这些特征可以提高模型的推理性能。
Key Takeaways
- 大型语言模型(LLM)在自然语言处理领域表现出卓越性能。
- 新型推理型LLM的出现进一步提升了LLM的性能。
- 稀疏自编码器(SAE)被用于探索DeepSeek-R1系列模型的内部推理机制。
- 通过提取和验证候选的“推理特征”,揭示了这些特征与模型推理能力的关联。
- 引导这些“推理特征”可系统地提高模型的推理性能。
- 本研究为大型语言模型中的推理机制提供了初步的机制性解释。
点此查看论文截图


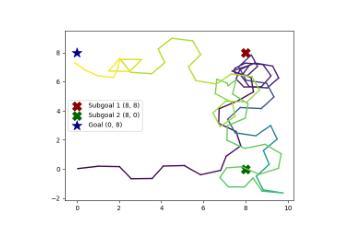
AlphaSpace: Enabling Robotic Actions through Semantic Tokenization and Symbolic Reasoning
Authors:Alan Dao, Dinh Bach Vu, Bui Quang Huy
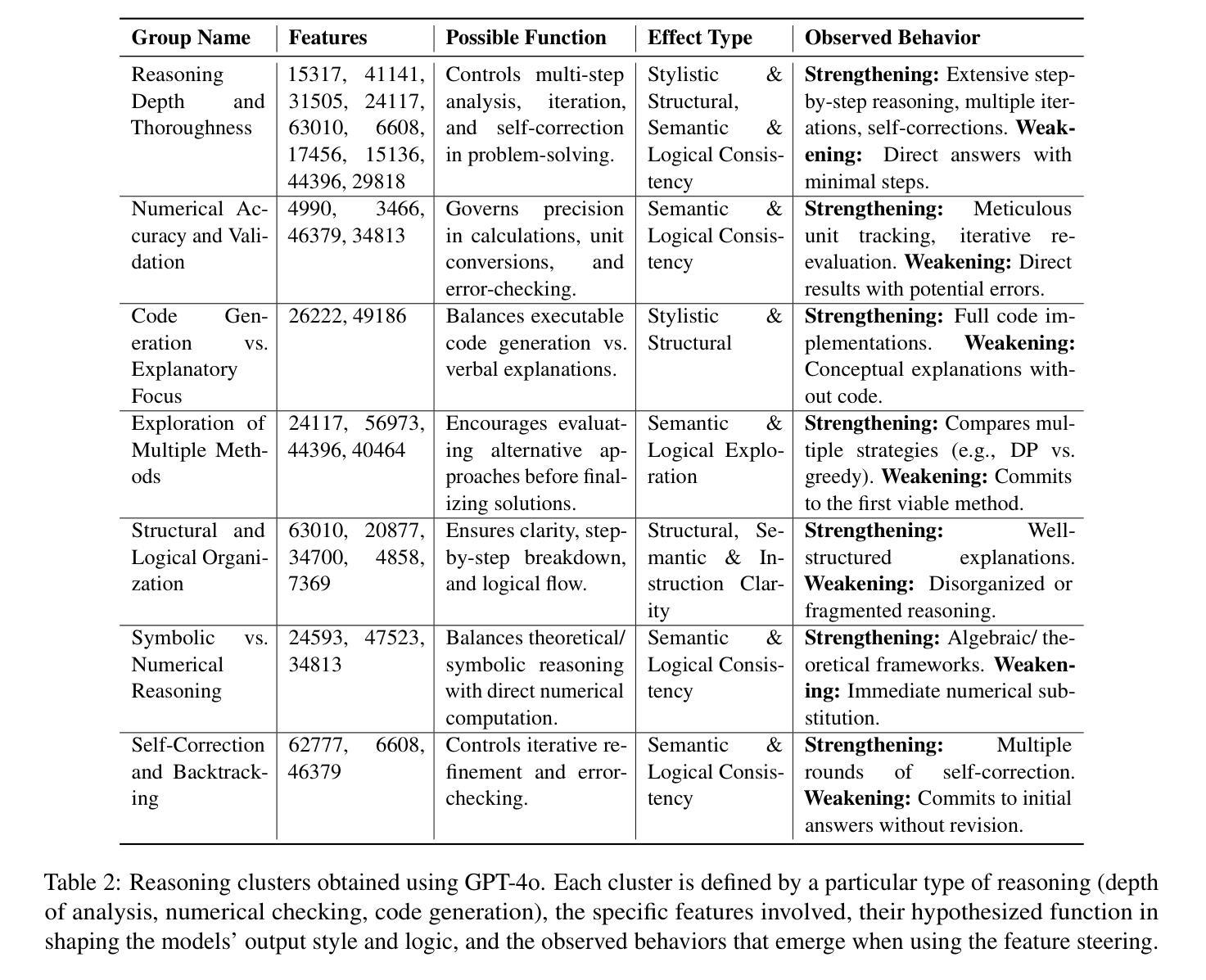
This paper presents AlphaSpace, a novel methodology designed to enhance the spatial reasoning capabilities of large language models (LLMs) for 3D Cartesian space navigation. AlphaSpace employs a semantics-based tokenization strategy, encoding height information through specialized semantic tokens, and integrates primarily symbolic synthetic reasoning data. This approach enables LLMs to accurately manipulate objects by positioning them at specific [x, y, z] coordinates. Experimental results demonstrate that AlphaSpace significantly outperforms existing models on manipulation subtasks, achieving a total accuracy of 66.67%, compared to 37.5% for GPT-4o and 29.17% for Claude 3.5 Sonnet.
本文介绍了AlphaSpace,这是一种旨在增强大型语言模型(LLM)在三维笛卡尔空间导航中的空间推理能力的新型方法。AlphaSpace采用基于语义的标记化策略,通过专门的语义标记对高度信息进行编码,并主要整合符号合成推理数据。这种方法使得LLM能够准确地将物体定位在特定的[x,y,z]坐标上。实验结果表明,在操纵子任务方面,AlphaSpace显著优于现有模型,总准确率达到了66.67%,而GPT-4o的准确率为37.5%,Claude 3.5 Sonnet的准确率为29.17%。
论文及项目相关链接
Summary
本文介绍了AlphaSpace这一新型方法,旨在提高大型语言模型(LLMs)在三维笛卡尔空间导航中的空间推理能力。AlphaSpace采用基于语义的令牌化策略,通过专用语义令牌编码高度信息,并主要融入符号合成推理数据。该方法使LLMs能够准确地对物体进行定位操作,实验结果显示AlphaSpace在操控子任务上的表现显著优于现有模型,总准确率达到66.67%,而GPT-4o和Claude 3.5 Sonnet分别为37.5%和29.17%。
Key Takeaways
- AlphaSpace是一种旨在增强大型语言模型空间推理能力的新方法。
- AlphaSpace采用基于语义的令牌化策略来处理高度信息。
- AlphaSpace主要通过融入符号合成推理数据来提升LLMs的空间操控能力。
- 实验结果显示AlphaSpace在操控任务上的表现优于其他模型。
- AlphaSpace的总准确率达到66.67%,高于GPT-4o和Claude 3.5 Sonnet的表现。
- AlphaSpace的应用有助于LLMs更准确地执行物体定位操作。
点此查看论文截图

Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Authors:Bingchen Miao, Yang Wu, Minghe Gao, Qifan Yu, Wendong Bu, Wenqiao Zhang, Yunfei Li, Siliang Tang, Tat-Seng Chua, Juncheng Li
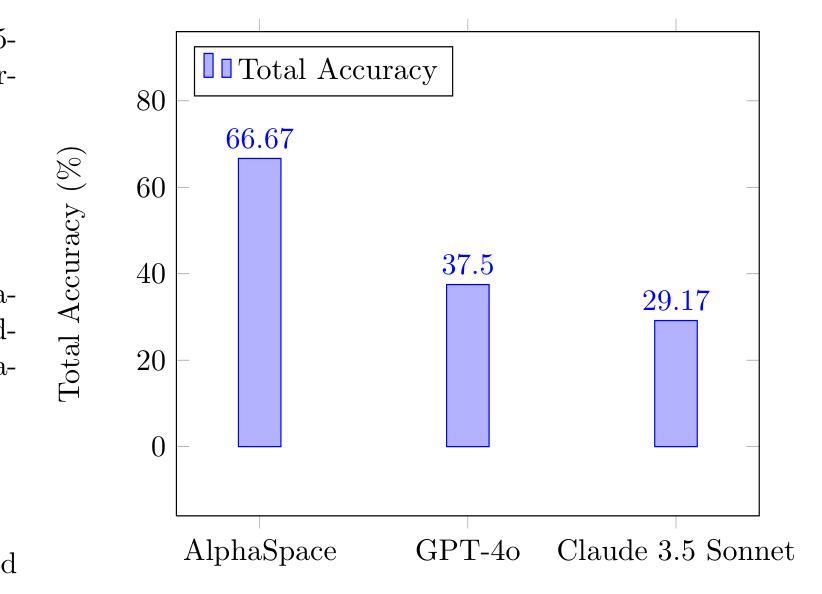
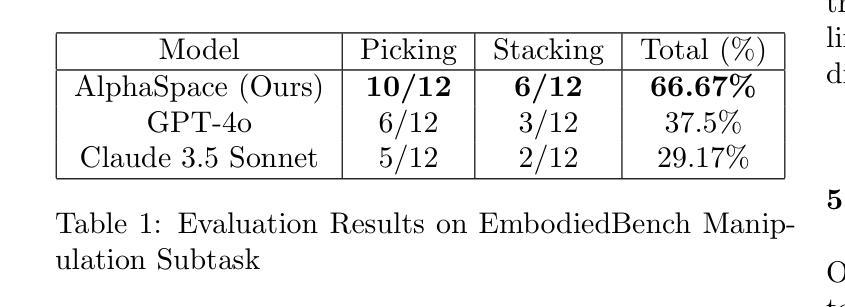
The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
由多模态大型语言模型(MLLMs)驱动的全能虚拟代理(GVAs)的发展在自主任务执行方面显示出巨大的潜力。然而,当前的训练模式面临关键局限性,包括依赖于结果监督和劳动密集型人工注释。为了解决这些挑战,我们提出了“相似”,一种逐步多维全能奖励模型,它为代理训练提供精细的信号,并为推理时间尺度选择更好的操作。具体来说,我们首先系统地定义了五个维度来评估代理操作。在此基础上,我们设计了一种MCTS-P算法,该算法可以自动收集和注释逐步的、五维的代理执行数据。使用这些数据,我们用三重M策略训练“相似”。此外,我们引入了虚拟代理领域中第一个用于逐步多维奖励模型训练和评估的基准测试,名为SRM。该基准测试由两部分组成:用作“相似”训练集的SRMTrain和用于评估奖励模型的SRMEval手动选定测试集。实验结果表明,“相似”通过其逐步多维评估和协同增益,为GVAs在训练和推理时间尺度上提供了有效的中间信号。代码可在https://github.com/Galery23/Similar-v1中找到。
论文及项目相关链接
Summary
基于多模态大型语言模型的通用虚拟代理(GVAs)在自主任务执行方面展现出巨大潜力,但当前训练模式存在依赖结果监督和劳动密集型人工标注等局限性。为此,本文提出一种名为Similar的逐步多维通用奖励模型,为代理训练提供精细信号,并在推理时间缩放时选择更好的动作。文章定义五个维度评估代理动作,设计MCTS-P算法自动收集和标注逐步的五维代理执行数据。此外,引入虚拟代理领域的首个逐步多维奖励模型训练和评估基准,名为SRM,包括用于训练Similar的SRMTrain和用于评估奖励模型的SRMEval。实验结果表明,Similar通过逐步多维评估和协同增益,为GVAs在训练和推理时间缩放期间提供有效的中间信号。
Key Takeaways
- Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) 在自主任务执行方面展现出巨大潜力。
- 当前GVAs训练面临依赖结果监督和劳动密集型人工标注等局限性。
- Similar是一种逐步多维通用奖励模型,提供精细信号用于代理训练,并在推理时帮助选择更好的动作。
- 定义了五个维度评估代理动作。
- 使用MCTS-P算法自动收集和标注代理执行数据。
- 引入虚拟代理领域的首个基准SRM,包括SRMTrain和SRMEval,用于训练和评估奖励模型。
点此查看论文截图



Training-Free Personalization via Retrieval and Reasoning on Fingerprints
Authors:Deepayan Das, Davide Talon, Yiming Wang, Massimiliano Mancini, Elisa Ricci
Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation but heavily rely on training procedures, that can be either costly or unpleasant to individual users. We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain-of-thought-reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level: in case of a discrepancy between the scores, R2P refines the concept association via pairwise multimodal matching, where the retrieved fingerprints and their images are directly compared with the query. We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.
视觉语言模型(VLMs)在多模态推理方面取得了重大改进,但它们仍然难以理解用户特定的概念。现有的个性化方法解决了这一局限性,但严重依赖于训练程序,这可能既昂贵又令个别用户感到不适。我们与现有工作有所不同,首次在个性化的背景下探索无训练设置。我们提出了一种新方法,名为个性化检索与推理(R2P),它利用VLMs的内部知识。首先,我们利用VLMs提取概念指纹,即在其语义类别中唯一定义概念的关键属性。当查询到来时,通过思维链推理检索最相似的指纹并进行评分。为了减少幻觉的风险,通过跨模态验证在属性级别验证评分:在评分不一致的情况下,R2P通过一对一的多模态匹配细化概念关联,其中检索到的指纹及其图像直接与查询进行比较。我们在两个公开可用的基准测试集和一个新引入的数据集Personal Concepts with Visual Ambiguity(PerVA)上验证了R2P在概念识别方面的表现,突出了视觉模糊性的挑战。R2P在各种下游任务上的表现始终优于所有基准测试集的最新方法。代码将在接受后提供。
论文及项目相关链接
Summary
本文提出一种名为R2P的新方法,利用VLMs的内部知识,无需训练即可实现个性化。该方法通过提取概念指纹和进行链式思维推理,检索最相似的指纹并进行评分。为减少幻觉风险,通过跨模态验证属性级别的评分。在存在评分差异的情况下,R2P通过成对的多模态匹配来完善概念关联。该方法在公开基准测试、新引入的PerVA数据集上的概念识别任务中表现优异。
Key Takeaways
- VLMs在多模态推理方面取得了重大改进,但在理解用户特定概念方面仍存在挑战。
- 现有个性化方法虽能解决此问题,但依赖繁琐且耗时的训练过程。
- 本文首次探索了无训练设置的个性化方法,提出了R2P方法。
- R2P利用VLMs提取概念指纹,并通过链式思维推理检索并评分最相似的指纹。
- 为减少幻觉风险,R2P采用跨模态验证属性级别的评分。
- 当存在评分差异时,R2P通过成对的多模态匹配完善概念关联。
点此查看论文截图

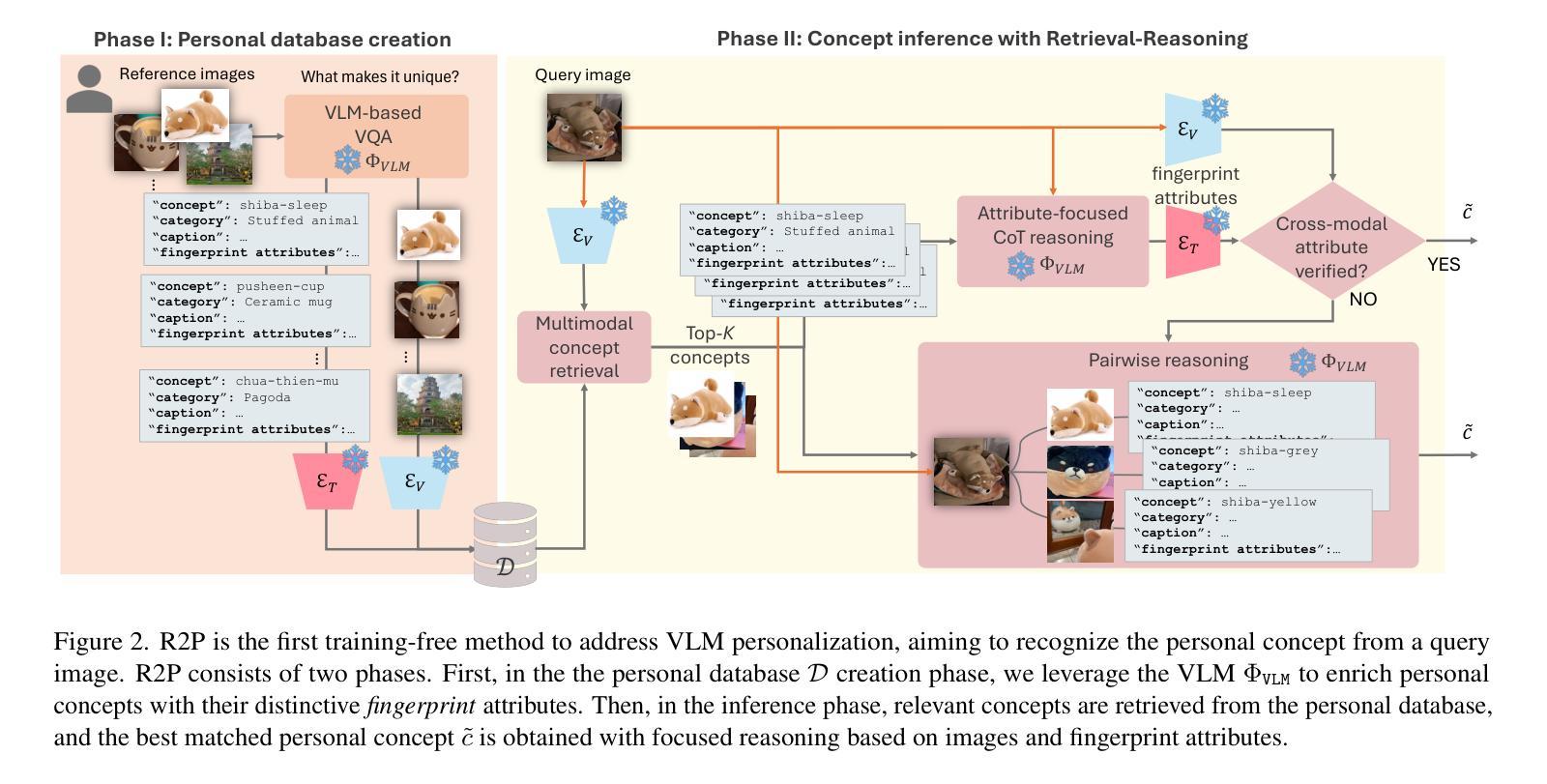

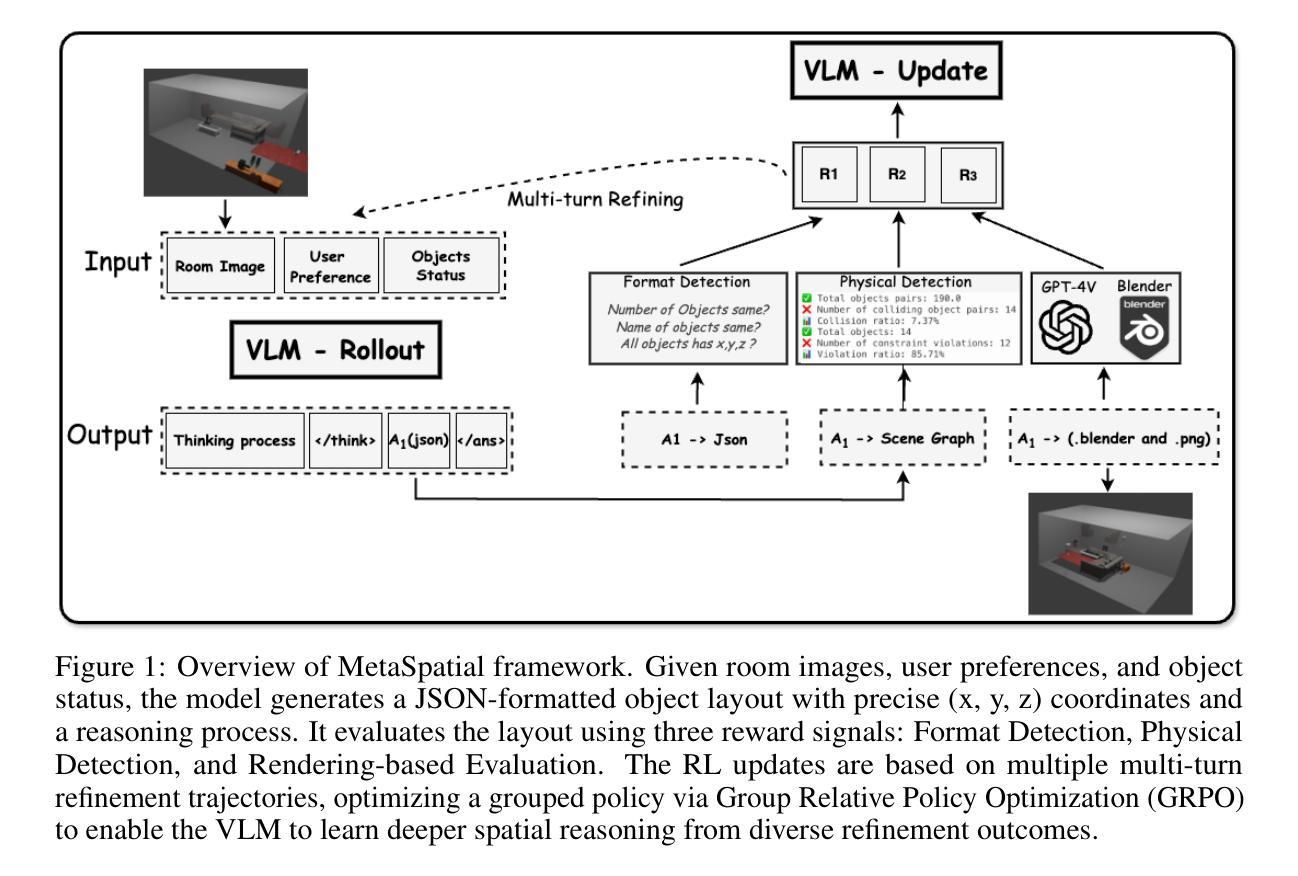
MetaSpatial: Reinforcing 3D Spatial Reasoning in VLMs for the Metaverse
Authors:Zhenyu Pan, Han Liu
We present MetaSpatial, the first reinforcement learning (RL)-based framework designed to enhance 3D spatial reasoning in vision-language models (VLMs), enabling real-time 3D scene generation without the need for hard-coded optimizations. MetaSpatial addresses two core challenges: (i) the lack of internalized 3D spatial reasoning in VLMs, which limits their ability to generate realistic layouts, and (ii) the inefficiency of traditional supervised fine-tuning (SFT) for layout generation tasks, as perfect ground truth annotations are unavailable. Our key innovation is a multi-turn RL-based optimization mechanism that integrates physics-aware constraints and rendered image evaluations, ensuring generated 3D layouts are coherent, physically plausible, and aesthetically consistent. Methodologically, MetaSpatial introduces an adaptive, iterative reasoning process, where the VLM refines spatial arrangements over multiple turns by analyzing rendered outputs, improving scene coherence progressively. Empirical evaluations demonstrate that MetaSpatial significantly enhances the spatial consistency and formatting stability of various scale models. Post-training, object placements are more realistic, aligned, and functionally coherent, validating the effectiveness of RL for 3D spatial reasoning in metaverse, AR/VR, digital twins, and game development applications. Our code, data, and training pipeline are publicly available at https://github.com/PzySeere/MetaSpatial.
我们推出了MetaSpatial,这是第一个基于强化学习(RL)的框架,旨在增强视觉语言模型(VLMs)中的3D空间推理能力,实现实时3D场景生成而无需硬编码优化。MetaSpatial解决了两个核心挑战:(i)VLMs内部缺乏3D空间推理能力,限制了其生成真实布局的能力;(ii)对于布局生成任务,传统的监督微调(SFT)效率低下,因为完美的真实标注不可用。我们的主要创新之处在于采用了一种多回合的基于RL的优化机制,该机制融合了物理感知约束和渲染图像评估,确保生成的3D布局连贯、物理上可行且审美上一致。方法上,MetaSpatial引入了一种自适应的迭代推理过程,VLM通过分析渲染输出来完善空间布局,逐步改进场景的一致性。经验评估表明,MetaSpatial显著提高了各种规模模型的空间一致性和格式稳定性。训练后,对象放置更加真实、对齐和功能连贯,验证了强化学习在元宇宙、AR/VR、数字孪生和游戏开发应用程序中的3D空间推理的有效性。我们的代码、数据和训练管道可在https://github.com/PzySeere/MetaSpatial公开访问。
论文及项目相关链接
PDF Working Paper
Summary
MetaSpatial是首个基于强化学习(RL)的框架,旨在增强视觉语言模型(VLM)的3D空间推理能力,实现实时3D场景生成,无需硬编码优化。该框架解决了VLM在生成真实布局方面的两大挑战:缺乏内在的3D空间推理能力和传统监督微调(SFT)在布局生成任务中的低效性。MetaSpatial通过多回合的RL优化机制,结合物理感知约束和渲染图像评估,确保生成的3D布局在逻辑上连贯、物理上可行和美学上一致。
Key Takeaways
- MetaSpatial是首个强化学习(RL)框架,用于增强视觉语言模型(VLM)的3D空间推理能力。
- MetaSpatial解决了VLM在生成真实布局方面的两大挑战。
- 缺乏内在的3D空间推理能力是VLM生成真实布局的一个限制。
- 传统监督微调(SFT)在布局生成任务中的低效性是一个问题。
- MetaSpatial通过多回合的RL优化机制来确保生成的3D布局的质量。
- MetaSpatial结合了物理感知约束和渲染图像评估来确保生成的布局在逻辑上连贯、物理上可行和美学上一致。
点此查看论文截图

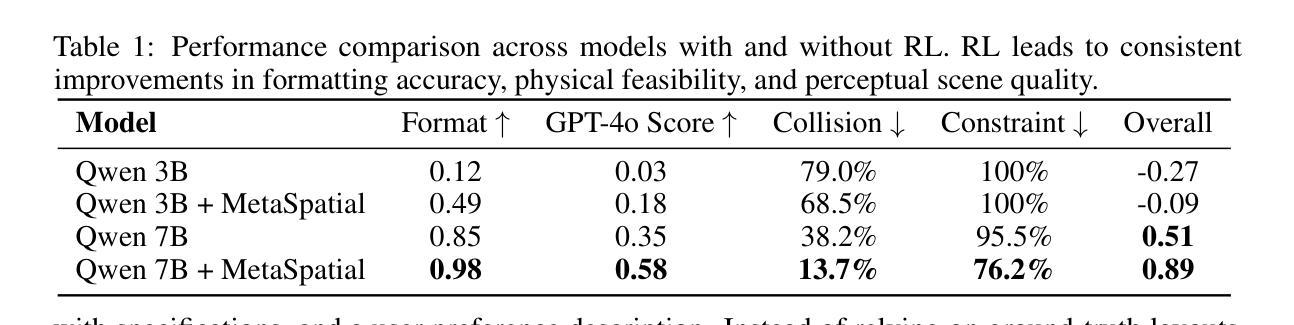
PALATE: Peculiar Application of the Law of Total Expectation to Enhance the Evaluation of Deep Generative Models
Authors:Tadeusz Dziarmaga, Marcin Kądziołka, Artur Kasymov, Marcin Mazur
Deep generative models (DGMs) have caused a paradigm shift in the field of machine learning, yielding noteworthy advancements in domains such as image synthesis, natural language processing, and other related areas. However, a comprehensive evaluation of these models that accounts for the trichotomy between fidelity, diversity, and novelty in generated samples remains a formidable challenge. A recently introduced solution that has emerged as a promising approach in this regard is the Feature Likelihood Divergence (FLD), a method that offers a theoretically motivated practical tool, yet also exhibits some computational challenges. In this paper, we propose PALATE, a novel enhancement to the evaluation of DGMs that addresses limitations of existing metrics. Our approach is based on a peculiar application of the law of total expectation to random variables representing accessible real data. When combined with the MMD baseline metric and DINOv2 feature extractor, PALATE offers a holistic evaluation framework that matches or surpasses state-of-the-art solutions while providing superior computational efficiency and scalability to large-scale datasets. Through a series of experiments, we demonstrate the effectiveness of the PALATE enhancement, contributing a computationally efficient, holistic evaluation approach that advances the field of DGMs assessment, especially in detecting sample memorization and evaluating generalization capabilities.
深度生成模型(DGMs)在机器学习领域引起了范式转变,在图像合成、自然语言处理等领域取得了值得注意的进展。然而,对生成的样本中保真度、多样性和新颖性三者之间的三分关系进行全面评估仍然是一个巨大的挑战。最近出现的一种具有前景的解决方案是特征似然散度(FLD),它是一种提供理论驱动的实用工具的方法,但也表现出一些计算挑战。在本文中,我们提出了针对DGMs评估的新型增强方法PALATE,解决了现有指标的局限性。我们的方法基于对可访问实际数据代表的随机变量应用全期望定律的一种特殊应用。当与MMD基线指标和DINOv2特征提取器结合时,PALATE提供了一个全面的评估框架,该框架在匹配或超越最新解决方案的同时,为大规模数据集提供了优越的计算效率和可扩展性。通过一系列实验,我们证明了PALATE增强的有效性,为深度生成模型评估领域提出了一种计算高效、全面的评估方法,特别是在检测样本记忆和评估泛化能力方面。
论文及项目相关链接
Summary
深生成模型(DGMs)在机器学习领域引起了范式转变,并在图像合成、自然语言处理等领域取得了显著进展。然而,对模型的全面评估仍然是一个挑战,需要考虑到生成样本的逼真度、多样性和新颖性之间的三元关系。最近出现了一种名为特征可能性发散(FLD)的评估方法,尽管该方法提供了一个实用的工具,但也存在一些计算挑战。本文提出PALATE,一种针对DGMs评估的新型增强方法,解决了现有指标的限制。PALATE基于可访问真实数据代表的随机变量的总期望定律的特殊应用。与MMD基线指标和DINOv2特征提取器结合,PALATE提供了一个全面的评估框架,在匹配或超越最新解决方案的同时,为大规模数据集提供了更高的计算效率和可扩展性。实验证明,PALATE增强方法有效,为DGMs评估领域提供了一种计算高效、全面的评估方法,特别是在检测样本记忆和评估泛化能力方面。
Key Takeaways
- 深生成模型(DGMs)在机器学习领域有重大突破,尤其在图像合成和自然语言处理等领域。
- 对DGMs的评估需要综合考虑生成样本的逼真度、多样性和新颖性。
- 特征可能性发散(FLD)是一种新兴的DGMs评估方法,但存在计算挑战。
- PALATE是一种新型的DGMs评估增强方法,基于总期望定律,旨在解决现有指标的限制。
- PALATE与MMD基线指标和DINOv2特征提取器结合,提供了全面的评估框架,具有高效计算和可扩展性。
- 实验证明PALATE增强方法有效,特别是在检测样本记忆和评估模型泛化能力方面。
点此查看论文截图

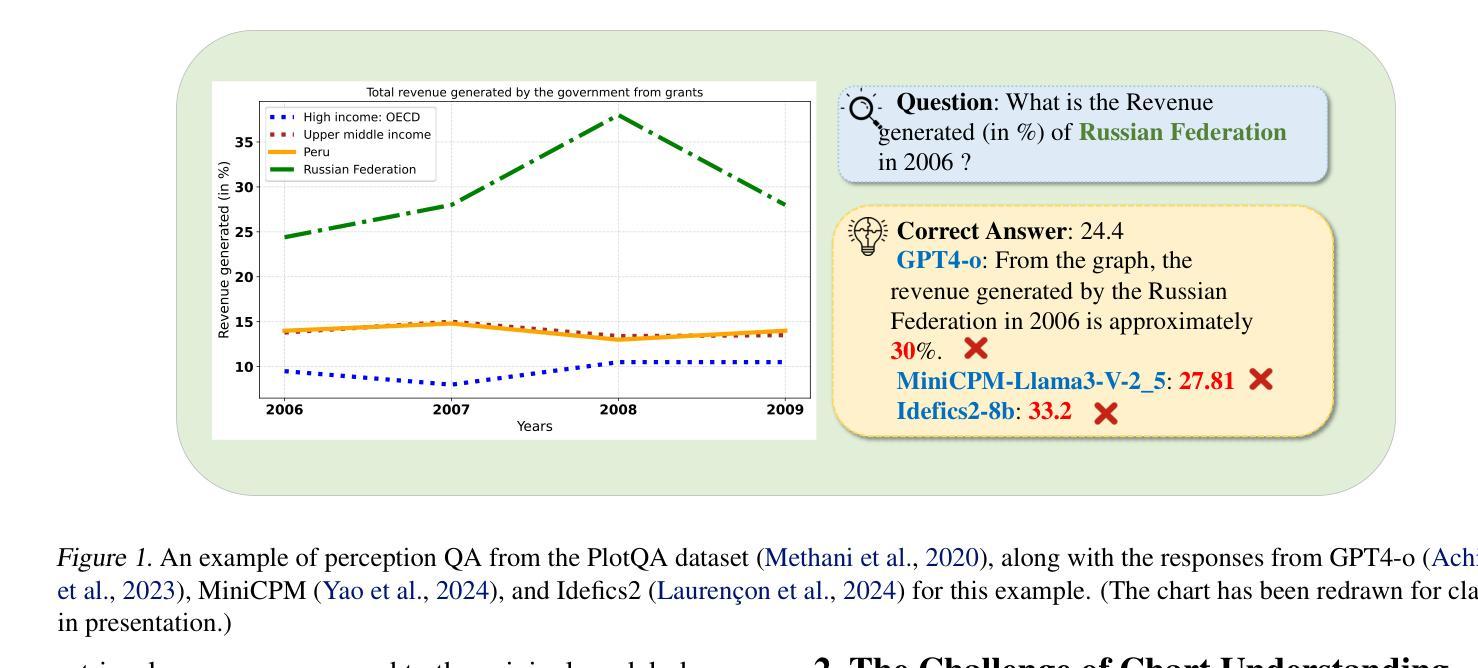
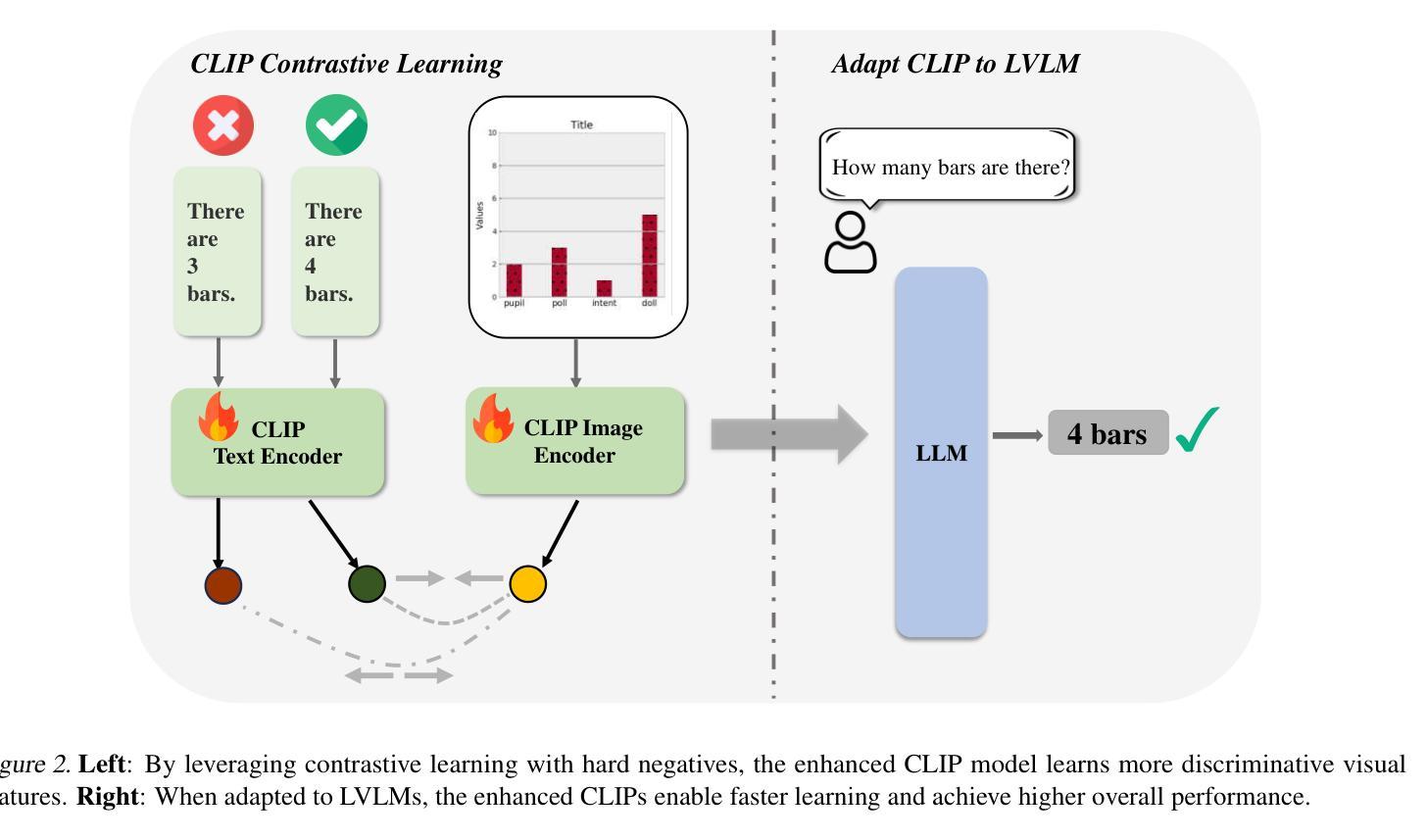
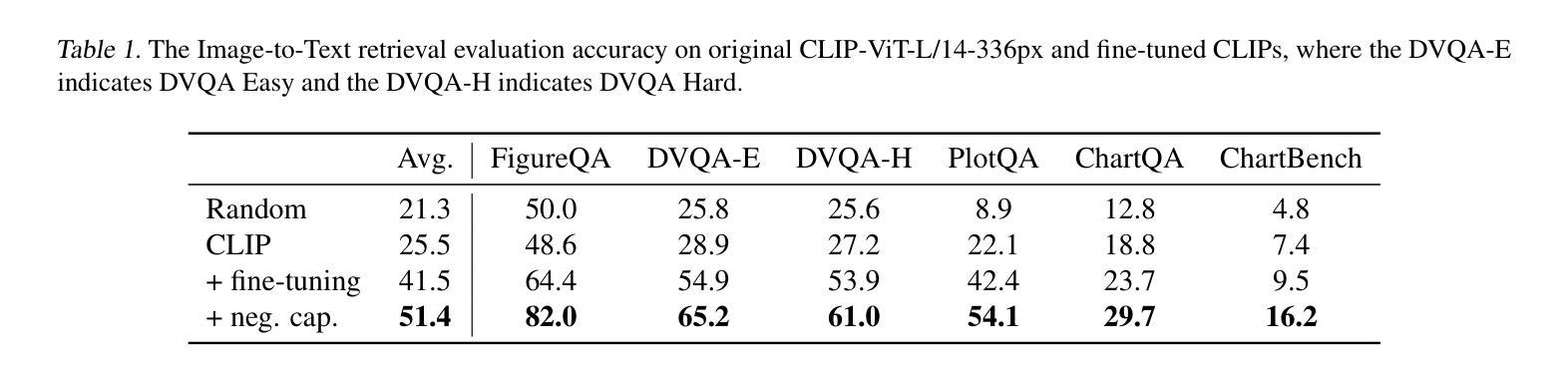
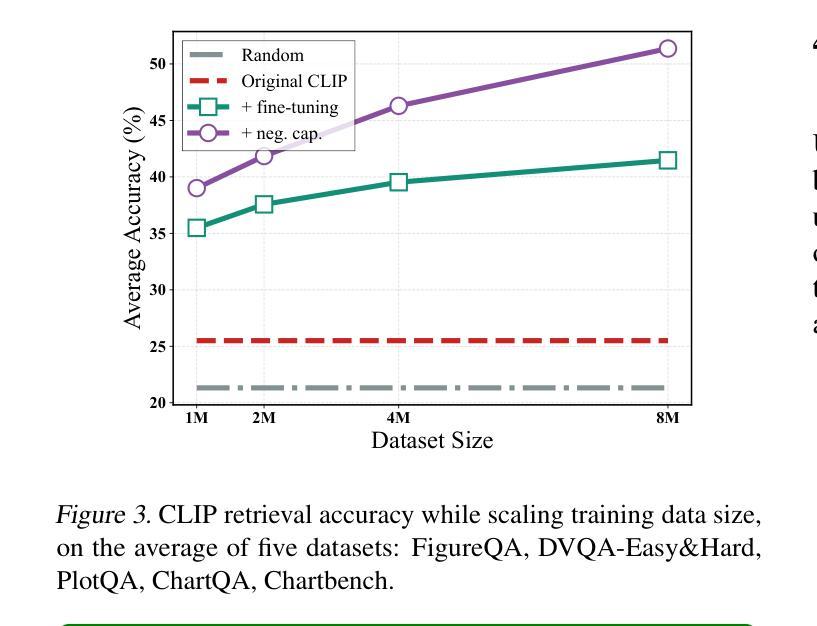
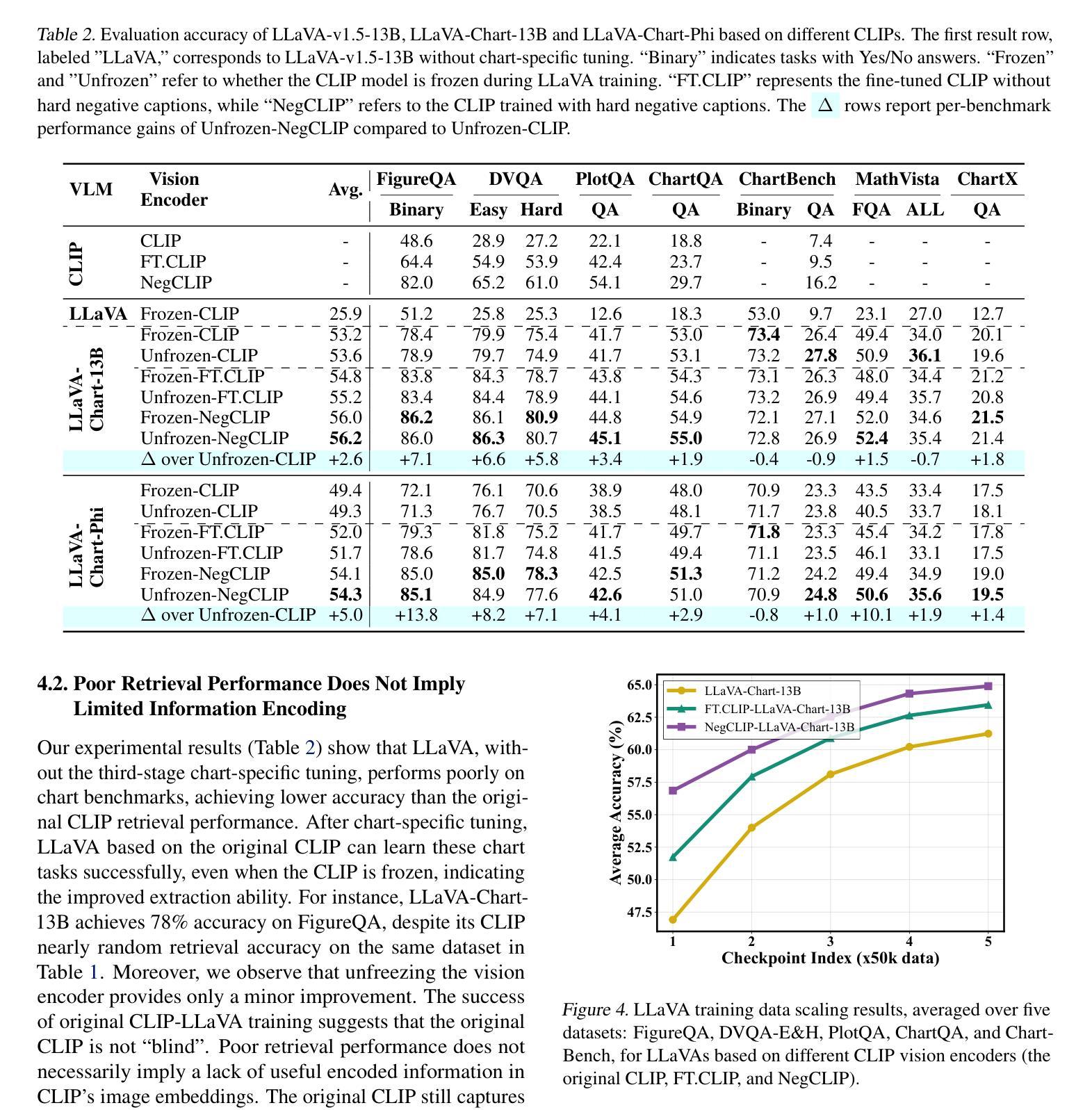
On the Perception Bottleneck of VLMs for Chart Understanding
Authors:Junteng Liu, Weihao Zeng, Xiwen Zhang, Yijun Wang, Zifei Shan, Junxian He
Chart understanding requires models to effectively analyze and reason about numerical data, textual elements, and complex visual components. Our observations reveal that the perception capabilities of existing large vision-language models (LVLMs) constitute a critical bottleneck in this process. In this study, we delve into this perception bottleneck by decomposing it into two components: the vision encoder bottleneck, where the visual representation may fail to encapsulate the correct information, and the extraction bottleneck, where the language model struggles to extract the necessary information from the provided visual representations. Through comprehensive experiments, we find that (1) the information embedded within visual representations is substantially richer than what is typically captured by linear extractors, such as the widely used retrieval accuracy metric; (2) While instruction tuning effectively enhances the extraction capability of LVLMs, the vision encoder remains a critical bottleneck, demanding focused attention and improvement. Therefore, we further enhance the visual encoder to mitigate the vision encoder bottleneck under a contrastive learning framework. Empirical results demonstrate that our approach significantly mitigates the perception bottleneck and improves the ability of LVLMs to comprehend charts. Code is publicly available at https://github.com/hkust-nlp/Vision4Chart.
图表理解需要模型有效地分析和推理数值数据、文本元素和复杂的视觉成分。我们的观察表明,现有大型视觉语言模型的感知能力构成了这一过程中的关键瓶颈。在这项研究中,我们通过将其分解为两个组成部分来深入研究这一感知瓶颈:视觉编码器瓶颈,其中视觉表示可能无法包含正确的信息;和提取瓶颈,其中语言模型难以从提供的视觉表示中提取必要的信息。通过全面的实验,我们发现(1)视觉表示中所嵌入的信息远比线性提取器(如广泛使用的检索准确率指标)所捕获的要丰富得多;(2)虽然指令调整有效地提高了LVLMs的提取能力,但视觉编码器仍然是一个关键的瓶颈,需要重点关注和改进。因此,我们在对比学习框架下进一步增强了视觉编码器,以缓解视觉编码器瓶颈。实证结果表明,我们的方法显著缓解了感知瓶颈,提高了LVLMs理解图表的能力。代码已公开在https://github.com/hkust-nlp/Vision4Chart上。
论文及项目相关链接
Summary
本文探讨了大型视觉语言模型在处理图表理解时的瓶颈问题,将其分解为视觉编码器瓶颈和信息提取瓶颈两个组成部分。研究指出,视觉表示的信息丰富程度超过线性提取器的捕捉能力,而指令微调虽能提高语言模型的提取能力,但视觉编码器仍是关键瓶颈。为缓解视觉编码器瓶颈,研究在对比学习框架下增强了视觉编码器。实验结果证明,该方法显著减轻了感知瓶颈,提高了大型视觉语言模型对图表的理解能力。
Key Takeaways
- 图表理解需要模型分析数值数据、文本元素和复杂视觉成分。
- 现有大型视觉语言模型在感知过程中存在关键瓶颈。
- 视觉表示的信息丰富程度超过线性提取器的捕捉能力。
- 指令微调提高了语言模型的提取能力,但视觉编码器仍是关键瓶颈。
- 对比学习框架下增强了视觉编码器以缓解视觉编码器瓶颈。
- 方法显著减轻了感知瓶颈,提高了大型视觉语言模型对图表的理解能力。
点此查看论文截图