⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Authors:Jiazhi Guan, Kaisiyuan Wang, Zhiliang Xu, Quanwei Yang, Yasheng Sun, Shengyi He, Borong Liang, Yukang Cao, Yingying Li, Haocheng Feng, Errui Ding, Jingdong Wang, Youjian Zhao, Hang Zhou, Ziwei Liu
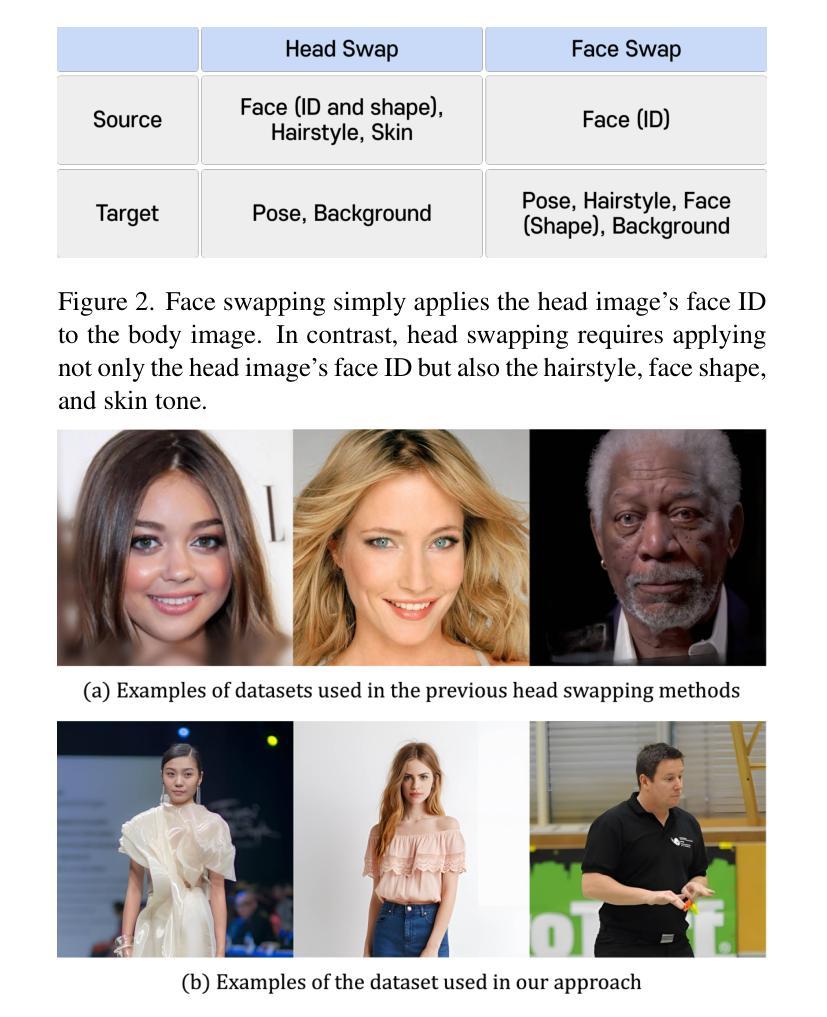
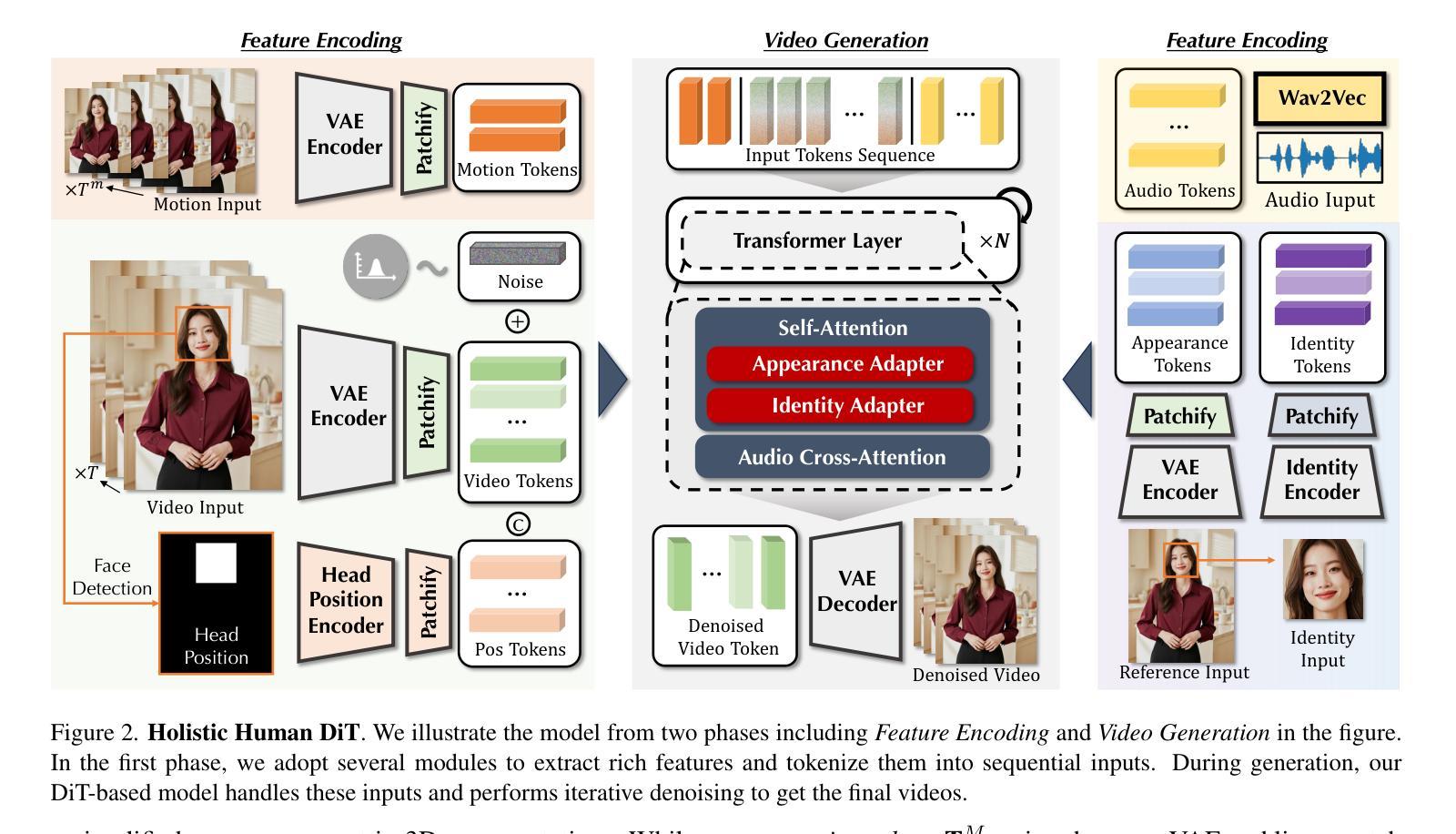
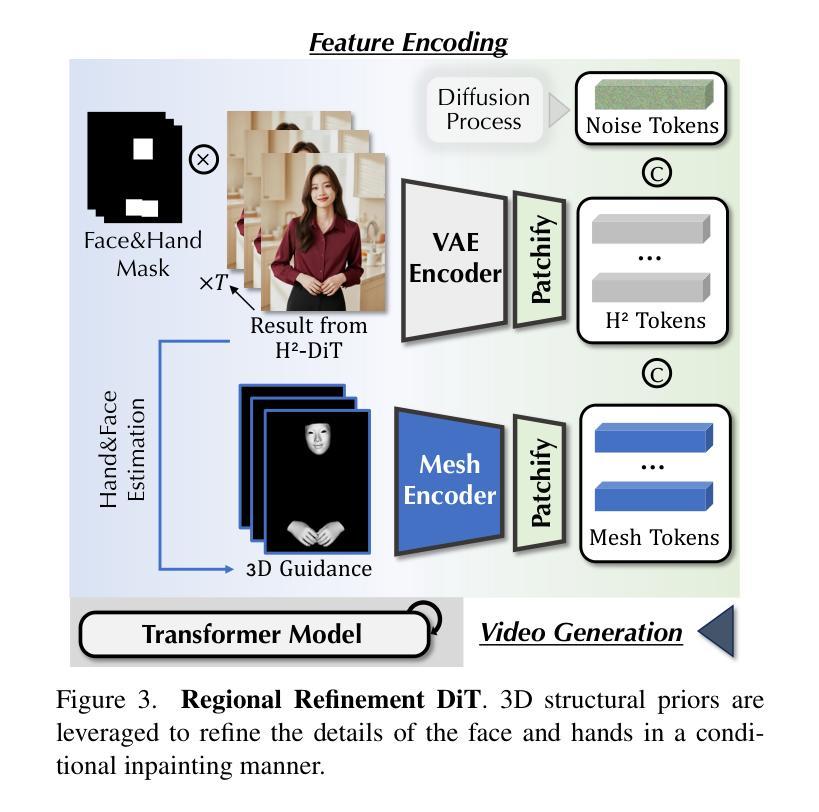
Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
尽管最近音频驱动的视频生成取得了进展,但现有方法主要集中在驱动面部运动上,导致头部和身体的动态非连贯。展望未来,对于根据给定音频生成兼具精确唇同步和精细随讲话手势的完整人类视频,既是可取的也是具有挑战性的。在这项工作中,我们提出了AudCast,这是一个采用级联扩散转换器(DiTs)范式的一般化音频驱动人类视频生成框架,它基于参考图像和给定音频合成完整的人类视频。1)首先,提出了一种音频调节的全身人类DiT架构,可直接驱动任何人体运动,具有生动的手势动态。2)然后,为了提高手和脸的细节(这是众所周知的难以处理的部分),区域细化DiT利用区域3D拟合作为桥梁来重塑信号,产生最终结果。大量实验表明,我们的框架能够生成具有时间连贯性和精细面部及手部细节的忠实音频驱动完整人类视频。资源可在https://guanjz20.github.io/projects/AudCast找到。
论文及项目相关链接
PDF Accepted to IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Project page: https://guanjz20.github.io/projects/AudCast
Summary
文本提出一种名为AudCast的音频驱动人体视频生成框架,采用级联扩散变换器(DiTs)范式,基于参考图像和给定音频合成全身人体视频。该框架能驱动任何人体动作,具有生动的手势动态,并在手和面部细节上进行了优化处理。
Key Takeaways
- AudCast是一个音频驱动的人体视频生成框架,可以合成全身人体视频。
- 框架采用了级联扩散变换器(DiTs)范式。
- 提出了一个音频条件下的全身人体DiT架构,能直接驱动任何人体动作,包括手势动态。
- 为了增强手和面部的细节处理,采用了区域细化DiT,利用区域3D拟合作为桥梁来优化信号。
- 该框架生成的视频具有高保真度,并且具有时间连贯性和精细的面部和手部细节。
- 该框架的资源和实验结果可以在指定的网页上找到。
点此查看论文截图

Boosting the Transferability of Audio Adversarial Examples with Acoustic Representation Optimization
Authors:Weifei Jin, Junjie Su, Hejia Wang, Yulin Ye, Jie Hao
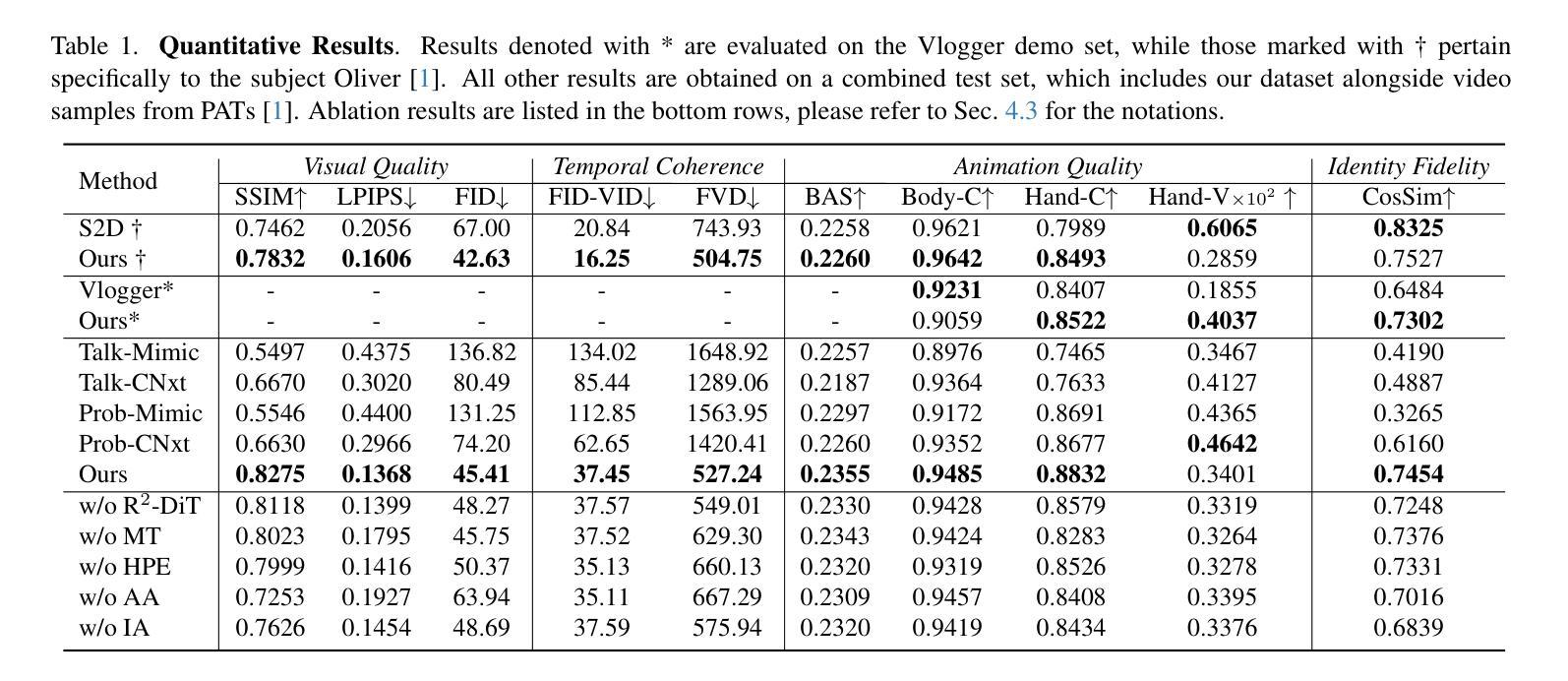
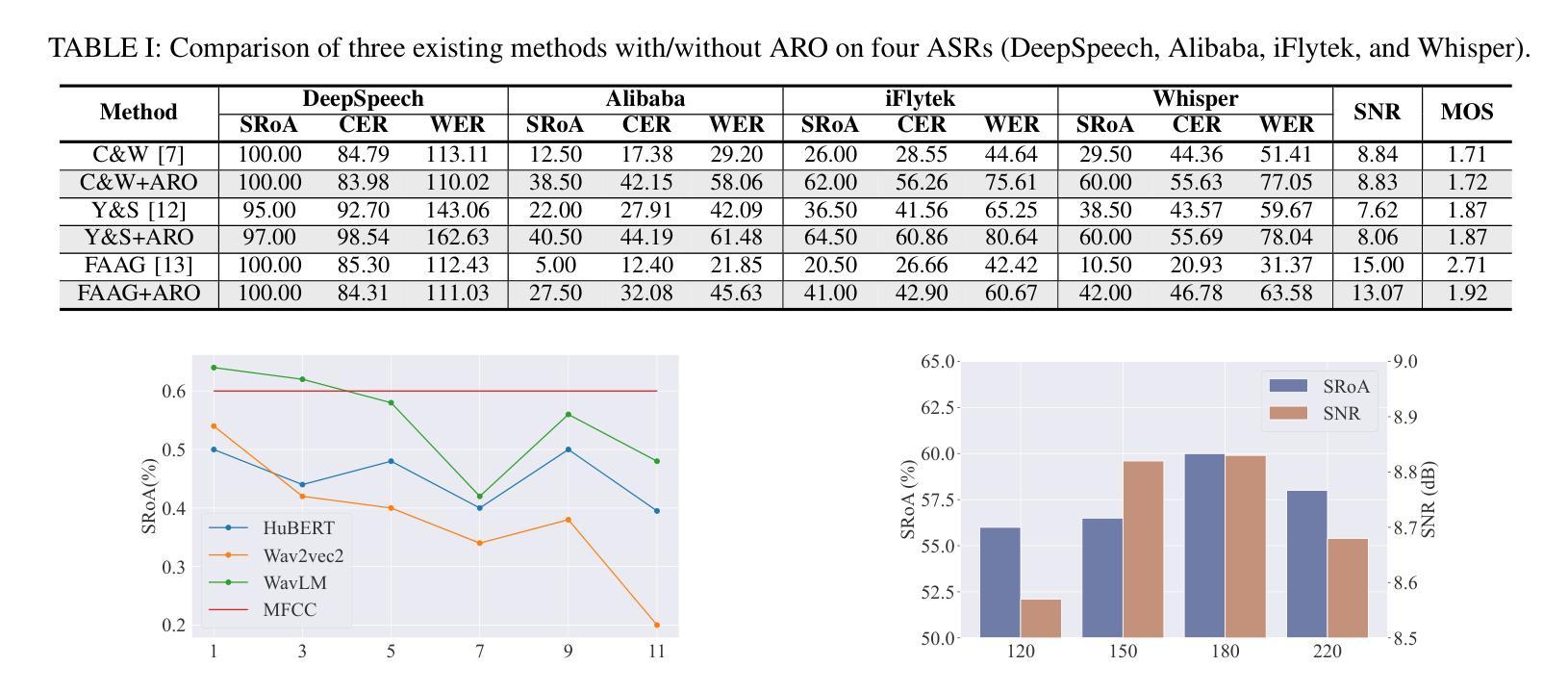
With the widespread application of automatic speech recognition (ASR) systems, their vulnerability to adversarial attacks has been extensively studied. However, most existing adversarial examples are generated on specific individual models, resulting in a lack of transferability. In real-world scenarios, attackers often cannot access detailed information about the target model, making query-based attacks unfeasible. To address this challenge, we propose a technique called Acoustic Representation Optimization that aligns adversarial perturbations with low-level acoustic characteristics derived from speech representation models. Rather than relying on model-specific, higher-layer abstractions, our approach leverages fundamental acoustic representations that remain consistent across diverse ASR architectures. By enforcing an acoustic representation loss to guide perturbations toward these robust, lower-level representations, we enhance the cross-model transferability of adversarial examples without degrading audio quality. Our method is plug-and-play and can be integrated with any existing attack methods. We evaluate our approach on three modern ASR models, and the experimental results demonstrate that our method significantly improves the transferability of adversarial examples generated by previous methods while preserving the audio quality.
随着自动语音识别(ASR)系统的广泛应用,它们易受对抗性攻击的影响已得到了广泛研究。然而,大多数现有的对抗性示例仅在特定单个模型上生成,导致缺乏可转移性。在现实世界中,攻击者往往无法获得关于目标模型的详细信息,这使得基于查询的攻击变得不可行。为了解决这一挑战,我们提出了一种名为声学表示优化的技术,该技术将对战扰动与从语音表示模型中得出的低级声学特征对齐。我们的方法并不依赖于特定模型的较高层次抽象,而是利用基本声学表示,这些表示形式在多种ASR架构中保持一致。通过强制实施声学表示损失来引导扰动朝向这些稳健的较低级别表示,我们能够在不降低音频质量的情况下,增强对抗性示例的跨模型可转移性。我们的方法是即插即用,可以与任何现有的攻击方法相结合。我们在三个现代ASR模型上评估了我们的方法,实验结果表明,我们的方法在保持音频质量的同时,显著提高了之前方法生成的对抗性示例的可转移性。
论文及项目相关链接
PDF Accepted to ICME 2025
Summary
本文研究了自动语音识别(ASR)系统的脆弱性,指出其易受到对抗性攻击的问题。现有的对抗性示例大多针对特定模型生成,缺乏迁移性。为解决这一问题,提出一种名为声学表示优化的技术,该技术将对抗性扰动与基于语音表示模型的低级声学特性相结合。该方法利用跨不同ASR架构保持一致的底层声学表示,通过强制实施声学表示损失来引导扰动朝向这些稳健的底层表示,从而提高对抗性示例的跨模型迁移能力,且不影响音频质量。此方法可与现有的攻击方法相结合,显著提高了先前方法生成的对抗性示例的迁移性。
Key Takeaways
- 自动语音识别(ASR)系统易受对抗性攻击的影响。
- 现有对抗性示例大多针对特定模型生成,缺乏迁移性。
- 提出一种名为声学表示优化的技术,结合对抗性扰动与低级声学特性。
- 利用跨不同ASR架构保持一致的底层声学表示。
- 通过强制实施声学表示损失,提高对抗性示例的跨模型迁移能力。
- 该方法可集成到任何现有的攻击方法中。
点此查看论文截图

MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation
Authors:Yukang Lin, Hokit Fung, Jianjin Xu, Zeping Ren, Adela S. M. Lau, Guosheng Yin, Xiu Li
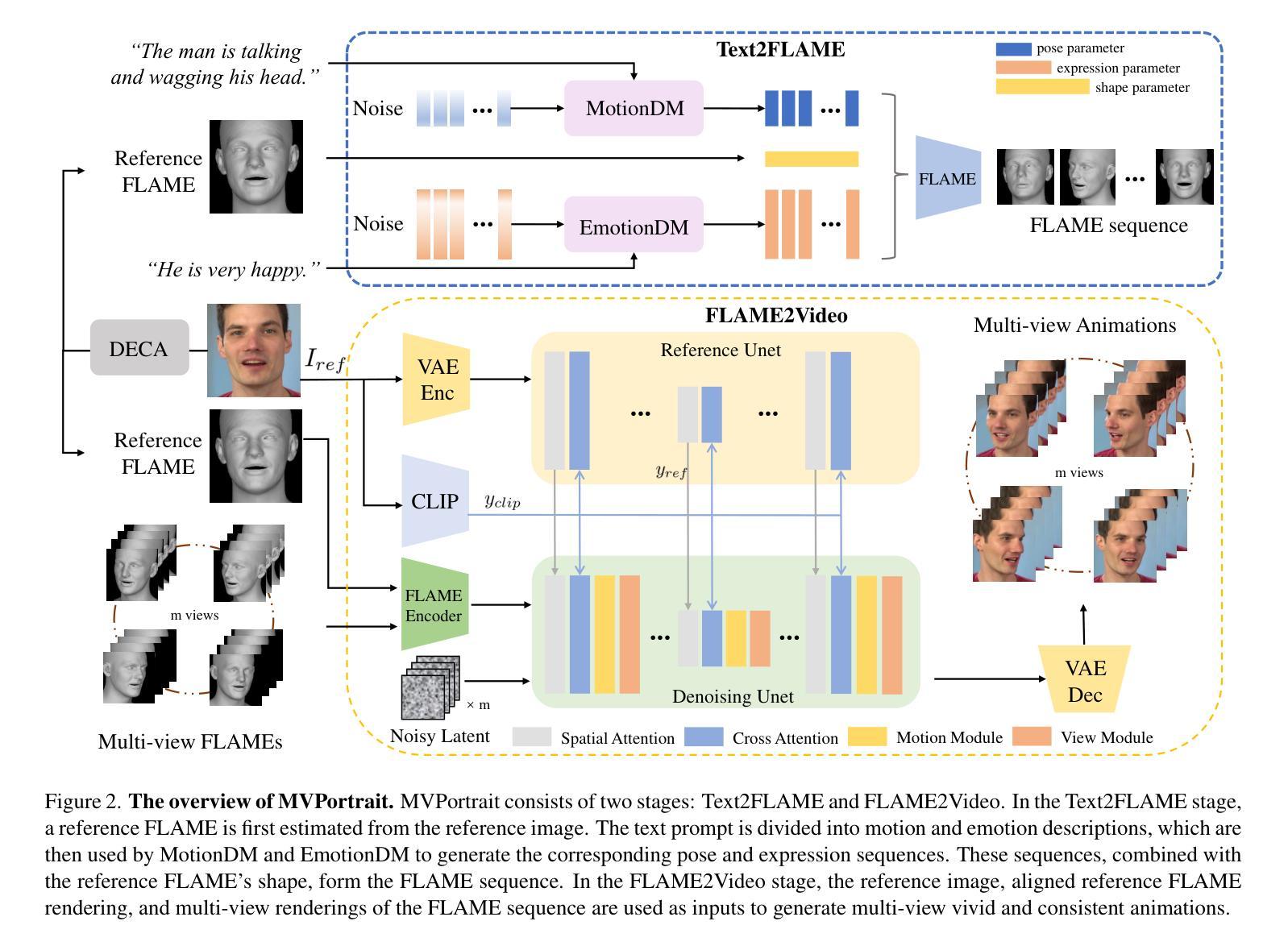
Recent portrait animation methods have made significant strides in generating realistic lip synchronization. However, they often lack explicit control over head movements and facial expressions, and cannot produce videos from multiple viewpoints, resulting in less controllable and expressive animations. Moreover, text-guided portrait animation remains underexplored, despite its user-friendly nature. We present a novel two-stage text-guided framework, MVPortrait (Multi-view Vivid Portrait), to generate expressive multi-view portrait animations that faithfully capture the described motion and emotion. MVPortrait is the first to introduce FLAME as an intermediate representation, effectively embedding facial movements, expressions, and view transformations within its parameter space. In the first stage, we separately train the FLAME motion and emotion diffusion models based on text input. In the second stage, we train a multi-view video generation model conditioned on a reference portrait image and multi-view FLAME rendering sequences from the first stage. Experimental results exhibit that MVPortrait outperforms existing methods in terms of motion and emotion control, as well as view consistency. Furthermore, by leveraging FLAME as a bridge, MVPortrait becomes the first controllable portrait animation framework that is compatible with text, speech, and video as driving signals.
最近的肖像动画方法在生成逼真的唇同步方面取得了重大进展。然而,它们通常缺乏对头部运动和面部表情的明确控制,并且不能从多个视角生成视频,导致动画的可控性和表现力较差。尽管文本引导的肖像动画因其用户友好性而受到欢迎,但它仍然是一个被忽略的领域。我们提出了一种新颖的文本引导两阶段框架——MVPortrait(多视角生动肖像),以生成表现丰富的多视角肖像动画,忠实呈现描述的动作和情感。MVPortrait首次引入FLAME作为中间表示,有效地在其参数空间中嵌入面部动作、表情和视角转换。在第一阶段,我们基于文本输入分别训练FLAME动作和情感扩散模型。在第二阶段,我们训练一个以参考肖像图像和第一阶段的多视角FLAME渲染序列为条件的多视角视频生成模型。实验结果表明,MVPortrait在动作、情感控制和视角一致性方面优于现有方法。此外,通过利用FLAME作为桥梁,MVPortrait成为第一个可控的肖像动画框架,可与文本、语音和视频作为驱动信号。
论文及项目相关链接
PDF CVPR 2025
Summary
最新的人像动画方法在生成逼真的唇同步方面取得了显著进展。然而,它们通常对头部运动和面部表情的控制不明确,无法从多个视角生成视频,导致动画的可控性和表现力较低。本文提出了一种新颖的文本引导的两阶段框架MVPortrait(多视角生动人像),用于生成表达力强的多视角人像动画,忠实捕捉描述的动作和情感。MVPortrait首次引入FLAME作为中间表示,有效地在其参数空间中嵌入面部动作、表情和视角转换。在第一阶段,我们基于文本输入分别训练FLAME运动和情感扩散模型。在第二阶段,我们训练了一个多视角视频生成模型,以参考人像图像和第一阶段的多视角FLAME渲染序列为条件。实验结果表明,MVPortrait在动作和情感控制以及视角一致性方面优于现有方法。此外,借助FLAME作为桥梁,MVPortrait成为首个兼容文本、语音和视频的驱动信号的可控制人像动画框架。
Key Takeaways
- 最新人像动画方法在唇同步方面取得显著进展,但缺乏对头部的运动和面部表情的明确控制。
- MVPortrait是一种新颖的文本引导的两阶段框架,用于生成多视角人像动画,并忠实捕捉动作和情感。
- MVPortrait首次引入FLAME作为中间表示,嵌入面部动作、表情和视角转换。
- MVPortrait通过两个阶段分别训练运动和情感扩散模型,基于文本输入进行训练。
- MVPortrait能够生成多视角视频,从多个角度展示人像动画。
- 实验表明,MVPortrait在动作和情感控制以及视角一致性方面优于现有方法。
点此查看论文截图

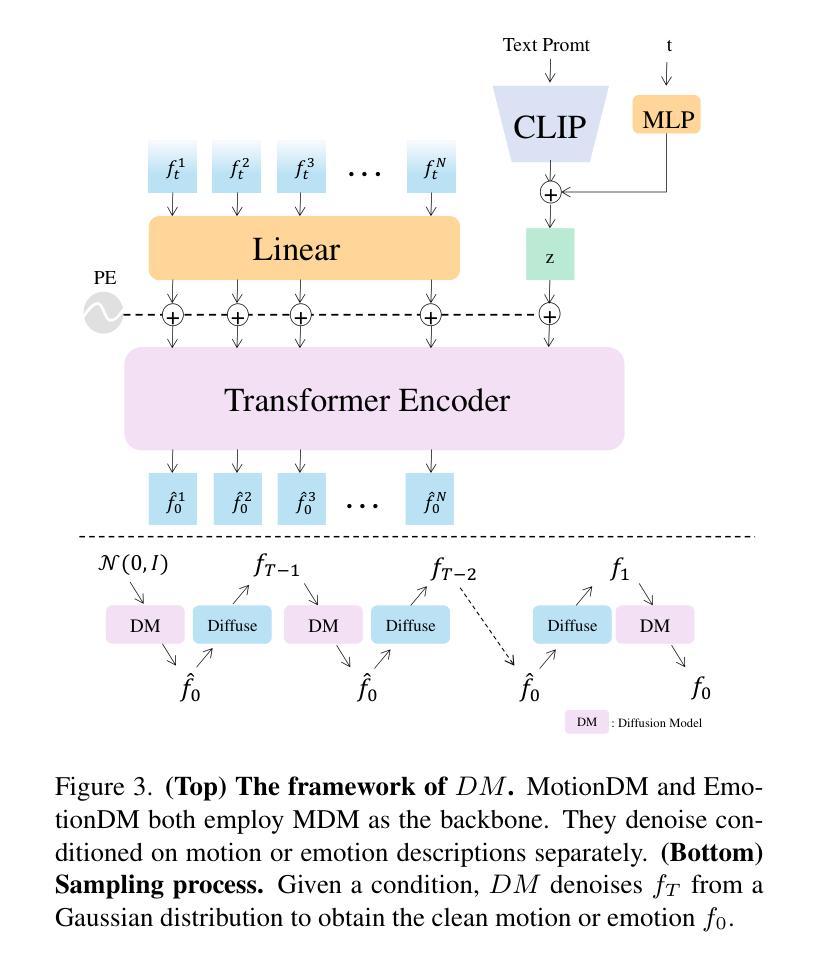
Unifying EEG and Speech for Emotion Recognition: A Two-Step Joint Learning Framework for Handling Missing EEG Data During Inference
Authors:Upasana Tiwari, Rupayan Chakraborty, Sunil Kumar Kopparapu
Computer interfaces are advancing towards using multi-modalities to enable better human-computer interactions. The use of automatic emotion recognition (AER) can make the interactions natural and meaningful thereby enhancing the user experience. Though speech is the most direct and intuitive modality for AER, it is not reliable because it can be intentionally faked by humans. On the other hand, physiological modalities like EEG, are more reliable and impossible to fake. However, use of EEG is infeasible for realistic scenarios usage because of the need for specialized recording setup. In this paper, one of our primary aims is to ride on the reliability of the EEG modality to facilitate robust AER on the speech modality. Our approach uses both the modalities during training to reliably identify emotion at the time of inference, even in the absence of the more reliable EEG modality. We propose, a two-step joint multi-modal learning approach (JMML) that exploits both the intra- and inter- modal characteristics to construct emotion embeddings that enrich the performance of AER. In the first step, using JEC-SSL, intra-modal learning is done independently on the individual modalities. This is followed by an inter-modal learning using the proposed extended variant of deep canonically correlated cross-modal autoencoder (E-DCC-CAE). The approach learns the joint properties of both the modalities by mapping them into a common representation space, such that the modalities are maximally correlated. These emotion embeddings, hold properties of both the modalities there by enhancing the performance of ML classifier used for AER. Experimental results show the efficacy of the proposed approach. To best of our knowledge, this is the first attempt to combine speech and EEG with joint multi-modal learning approach for reliable AER.
随着计算机接口向多模态交互方式发展,为了更好地实现人机交互,自动情绪识别(AER)的使用变得至关重要。虽然语音是AER中最直接和直观的方式,但它并不可靠,因为人类可能会故意伪装自己的情感表达。另一方面,像脑电图(EEG)这样的生理指标更为可靠且无法伪装。然而,在实际场景中应用EEG却不可行,因为需要专业的记录设备。本文的主要目标之一是依靠EEG模态的可靠性来促进语音模态上的稳健AER。我们的方法是在训练过程中同时使用这两种模态,即使在缺乏更可靠的EEG模态的情况下,也能在推理时可靠地识别情感。我们提出了一种分两步进行的联合多模态学习方法(JMML),它利用跨内和跨模态特性来构建情感嵌入,以丰富AER的性能。第一步是使用JEC-SSL进行独立模态内的学习。接下来是利用提出的深度典型相关跨模态自编码器的扩展变体进行跨模态学习。该方法通过将两种模态映射到一个共同的表示空间来学习它们的联合属性,使得这两种模态之间的相关性最大化。这些情感嵌入包含了两种模态的属性,从而提高了用于AER的机器学习分类器的性能。实验结果表明了该方法的有效性。据我们所知,这是首次尝试结合语音和脑电图数据,采用联合多模态学习方法进行可靠的自动情绪识别。
论文及项目相关链接
PDF 10 pages, 5 figures
摘要
本研究探讨利用多模态计算机界面提升人类与计算机的交互体验。研究中通过采用自动情绪识别技术增强交互的自然性和意义性。虽然语音是最直接且直觉性的情绪识别模态,但其可靠性因人为干扰而受限。相反,脑电图等生理模态更为可靠且难以伪造,但在现实场景中应用却不可行。本研究旨在利用脑电图的可靠性,推动基于语音模态的稳健自动情绪识别。采用双模态训练方法,在推断时即使缺乏更可靠的脑电图模态,也能可靠地识别情绪。研究提出一种分两步进行的联合多模态学习方法,利用跨模态特性构建情感嵌入,提高自动情绪识别的性能。首先进行独立模态内学习,然后使用扩展的深度典型相关跨模态自编码器进行跨模态学习。该方法通过映射到共同表征空间,使两种模态的最大相关性得以实现,所生成的情感嵌入融合了两种模态的特性,进而提升用于情绪识别的机器学习分类器性能。实验结果证明了该方法的有效性。据我们所知,这是首次尝试结合语音和脑电图,采用联合多模态学习方法进行可靠的自动情绪识别。
关键见解
- 计算机界面正朝着多模态发展,以改进人机交互体验。
- 自动情绪识别技术可增强交互的自然性和意义性。
- 语音作为情绪识别的主要模态虽直观但可靠性受限,而生理模态如脑电图更可靠但实际应用困难。
- 研究旨在结合语音和脑电图模态,利用后者的可靠性提升前者的情绪识别性能。
- 提出一种分两步的联合多模态学习方法,通过跨模态学习增强自动情绪识别的稳健性。
- 该方法通过映射到共同表征空间融合两种模态的特性,提升机器学习分类器性能。
点此查看论文截图


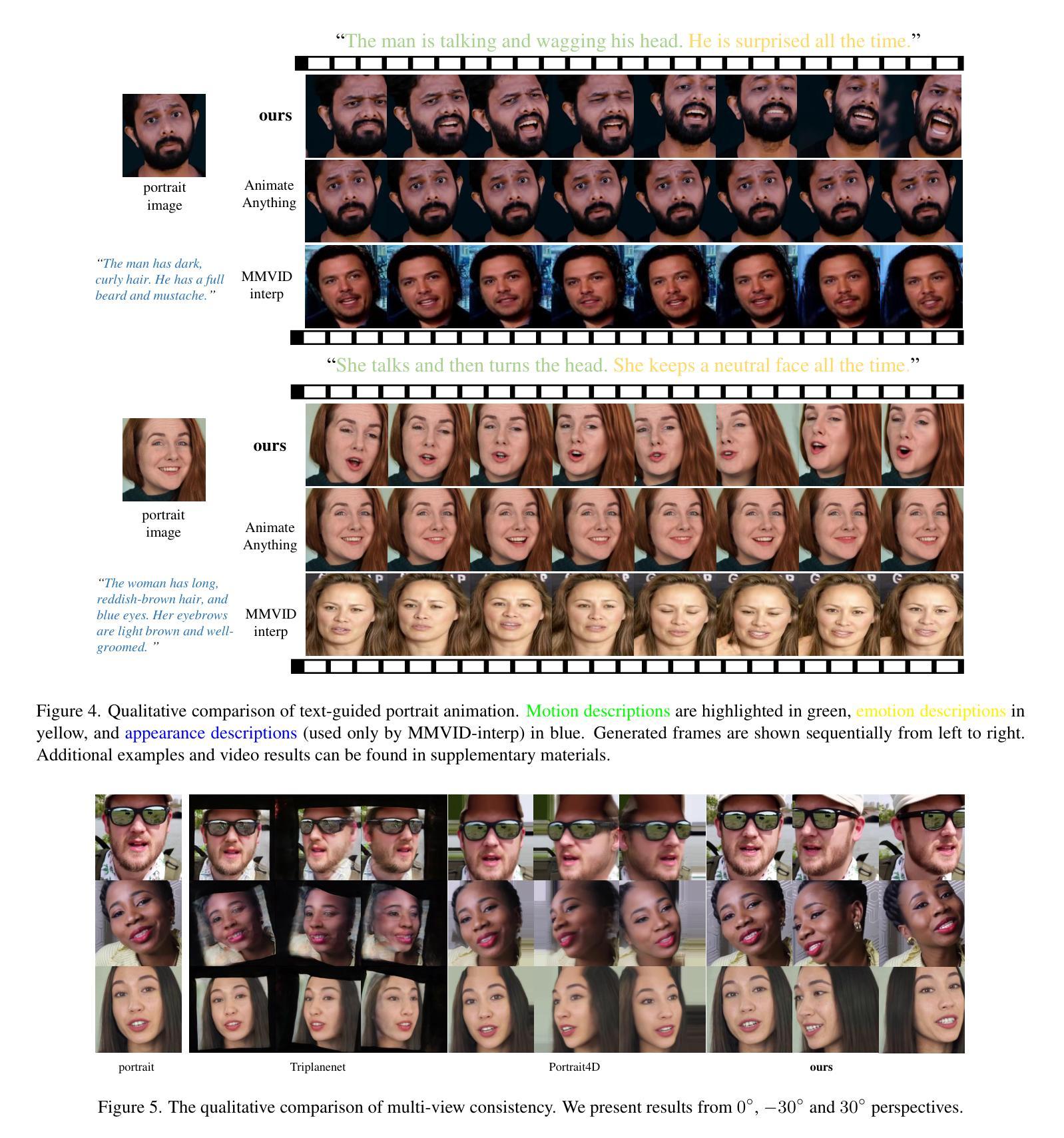
Seeing Speech and Sound: Distinguishing and Locating Audios in Visual Scenes
Authors:Hyeonggon Ryu, Seongyu Kim, Joon Son Chung, Arda Senocak
We present a unified model capable of simultaneously grounding both spoken language and non-speech sounds within a visual scene, addressing key limitations in current audio-visual grounding models. Existing approaches are typically limited to handling either speech or non-speech sounds independently, or at best, together but sequentially without mixing. This limitation prevents them from capturing the complexity of real-world audio sources that are often mixed. Our approach introduces a ‘mix-and-separate’ framework with audio-visual alignment objectives that jointly learn correspondence and disentanglement using mixed audio. Through these objectives, our model learns to produce distinct embeddings for each audio type, enabling effective disentanglement and grounding across mixed audio sources. Additionally, we created a new dataset to evaluate simultaneous grounding of mixed audio sources, demonstrating that our model outperforms prior methods. Our approach also achieves comparable or better performance in standard segmentation and cross-modal retrieval tasks, highlighting the benefits of our mix-and-separate approach.
我们提出了一种统一模型,能够同时在视觉场景中对口语和非语音声音进行定位,解决了当前视听定位模型的关键局限性。现有方法通常仅限于独立处理语音或非语音声音,或者最多一起处理但无法混合。这种局限性使他们无法捕捉经常混合的复杂现实世界音频源的精髓。我们的方法引入了一个“混合与分离”框架,该框架具有视听对齐目标,使用混合音频联合学习对应关系和分离。通过这些目标,我们的模型学会为每种音频类型生成独特的嵌入,从而实现跨混合音频源的有效分离和定位。此外,我们创建了一个新的数据集来评估混合音频源的同时定位性能,证明我们的模型优于以前的方法。我们的方法在标准分割和跨模态检索任务中也实现了相当或更好的性能,突显了我们的“混合与分离”方法的好处。
论文及项目相关链接
PDF CVPR 2025
Summary
本文提出了一种统一模型,能够同时将在视觉场景中的口语和非语音声音进行定位,解决了当前音频视觉定位模型的关键限制。现有方法通常只能独立处理语音或非语音声音,或者最多同时处理但不能混合。这限制了它们捕捉真实世界音频源混合的复杂性。本文通过引入一个带有视听对齐目标的“混合分离”框架,联合学习对应关系和分离任务,使用混合音频。通过这些目标,我们的模型学会为每种音频类型生成独特的嵌入,实现有效的分离和混合音频源的定位。此外,我们创建了一个新的数据集来评估混合音频源的同时定位效果,显示我们的模型优于之前的方法。
Key Takeaways
- 提出了一种统一模型,能够同时处理口语和非语音声音的定位问题。
- 解决了现有音频视觉定位模型在处理混合音频源时的局限性。
- 引入了一个“混合分离”框架和视听对齐目标进行建模。
- 模型能生成独特嵌入以区分不同的音频类型。
- 通过创建新的数据集评估模型性能。
- 模型在混合音频源定位方面优于以前的方法。
点此查看论文截图

Wireless Hearables With Programmable Speech AI Accelerators
Authors:Malek Itani, Tuochao Chen, Arun Raghavan, Gavriel Kohlberg, Shyamnath Gollakota
The conventional wisdom has been that designing ultra-compact, battery-constrained wireless hearables with on-device speech AI models is challenging due to the high computational demands of streaming deep learning models. Speech AI models require continuous, real-time audio processing, imposing strict computational and I/O constraints. We present NeuralAids, a fully on-device speech AI system for wireless hearables, enabling real-time speech enhancement and denoising on compact, battery-constrained devices. Our system bridges the gap between state-of-the-art deep learning for speech enhancement and low-power AI hardware by making three key technical contributions: 1) a wireless hearable platform integrating a speech AI accelerator for efficient on-device streaming inference, 2) an optimized dual-path neural network designed for low-latency, high-quality speech enhancement, and 3) a hardware-software co-design that uses mixed-precision quantization and quantization-aware training to achieve real-time performance under strict power constraints. Our system processes 6 ms audio chunks in real-time, achieving an inference time of 5.54 ms while consuming 71.6 mW. In real-world evaluations, including a user study with 28 participants, our system outperforms prior on-device models in speech quality and noise suppression, paving the way for next-generation intelligent wireless hearables that can enhance hearing entirely on-device.
传统观点认为,设计超紧凑、受电池限制的无线可穿戴听力设备,并搭载设备端的语音人工智能模型是一项挑战,原因在于流式深度学习模型的高计算需求。语音人工智能模型需要连续、实时的音频处理,这就带来了严格的计算和输入/输出约束。我们提出了NeuralAids,这是一种用于无线可穿戴设备的完全设备端语音人工智能系统,能够在紧凑、电池受限的设备上实现实时语音增强和降噪。我们的系统通过三项关键技术贡献,填补了先进语音增强深度学习技术与低功耗人工智能硬件之间的空白:1)一个集成了语音人工智能加速器的无线可穿戴平台,用于高效的设备端流式推理;2)一个针对低延迟、高质量语音增强的优化双路径神经网络;3)一种软硬件协同设计,采用混合精度量化和量化感知训练,在严格的功率约束下实现实时性能。我们的系统实时处理6毫秒的音频块,推理时间为5.54毫秒,功耗为71.6毫瓦。在包括28名参与者的用户研究在内的真实世界评估中,我们的系统在语音质量和噪声抑制方面超越了先前的设备端模型,为下一代能够在设备上完全增强听力的智能无线可穿戴设备铺平了道路。
论文及项目相关链接
Summary
针对电池受限的无线听力设备,提出了一种全新的全设备语音AI系统NeuralAids,实现了实时语音增强和降噪。该系统通过三项关键技术突破实现了高性能:集成了语音AI加速器的无线听力平台、为低延迟高音质语音增强设计的优化双路径神经网络以及实现实时性能的低功耗软硬件协同设计。其在严格的电源限制下取得了实际运行效果和用户评价上的优异表现。
Key Takeaways
- NeuralAids是一种全设备语音AI系统,专为电池受限的无线听力设备设计,可实现实时语音增强和降噪。
- 系统通过集成语音AI加速器实现了高效的设备流推断。
- 采用优化双路径神经网络,旨在实现低延迟和高音质语音增强。
- 软硬件协同设计通过混合精度量化和量化感知训练实现实时性能,满足严格的电源限制。
- 系统能够处理实时音频块,具有快速推断时间(5.54毫秒)和低功耗消耗(71.6毫瓦)。
- 在包括用户研究在内的实际评估中,该系统在语音质量和噪声抑制方面优于先前的设备模型。
点此查看论文截图

Whispering in Amharic: Fine-tuning Whisper for Low-resource Language
Authors:Dawit Ketema Gete, Bedru Yimam Ahamed, Tadesse Destaw Belay, Yohannes Ayana Ejigu, Sukairaj Hafiz Imam, Alemu Belay Tessema, Mohammed Oumer Adem, Tadesse Amare Belay, Robert Geislinger, Umma Aliyu Musa, Martin Semmann, Shamsuddeen Hassan Muhammad, Henning Schreiber, Seid Muhie Yimam
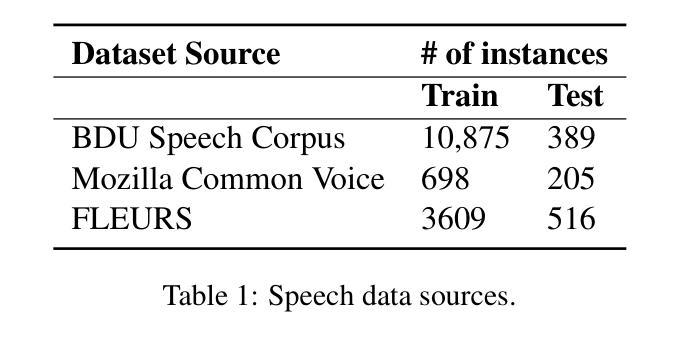
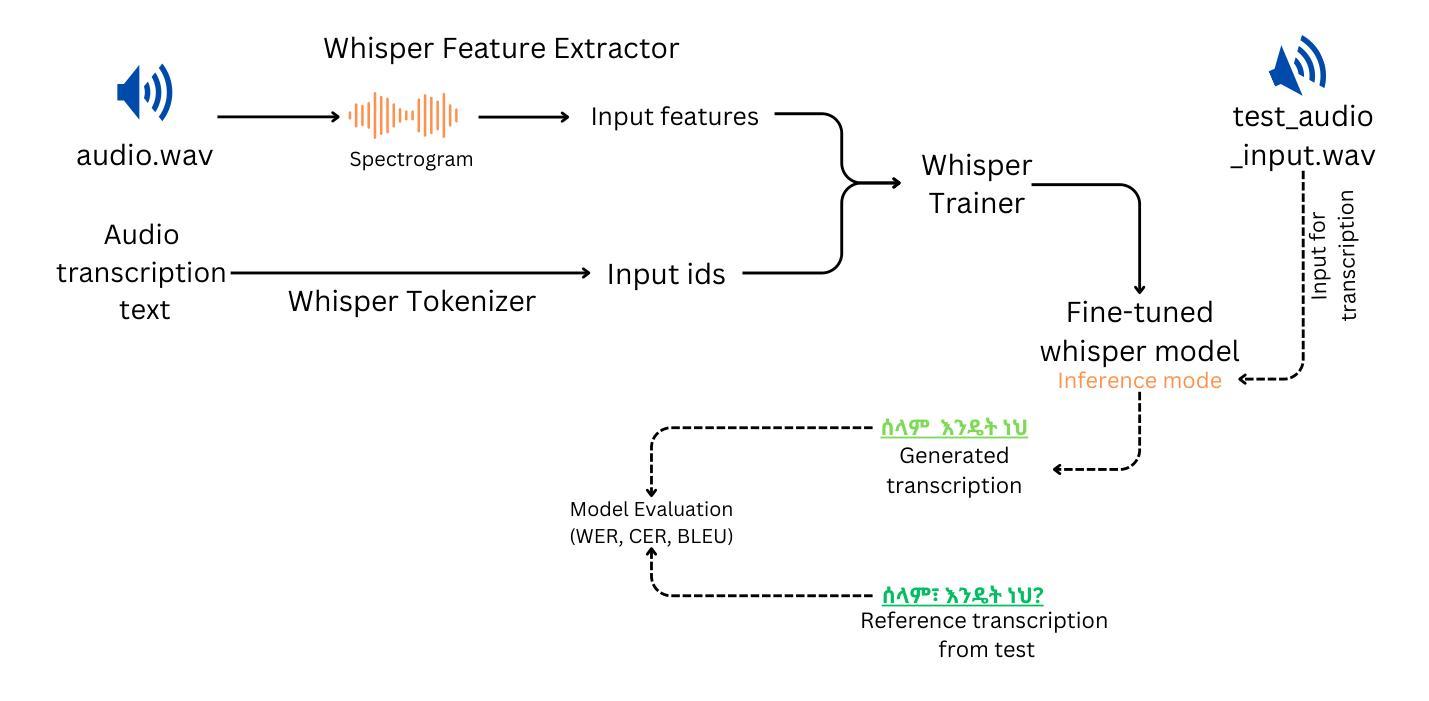
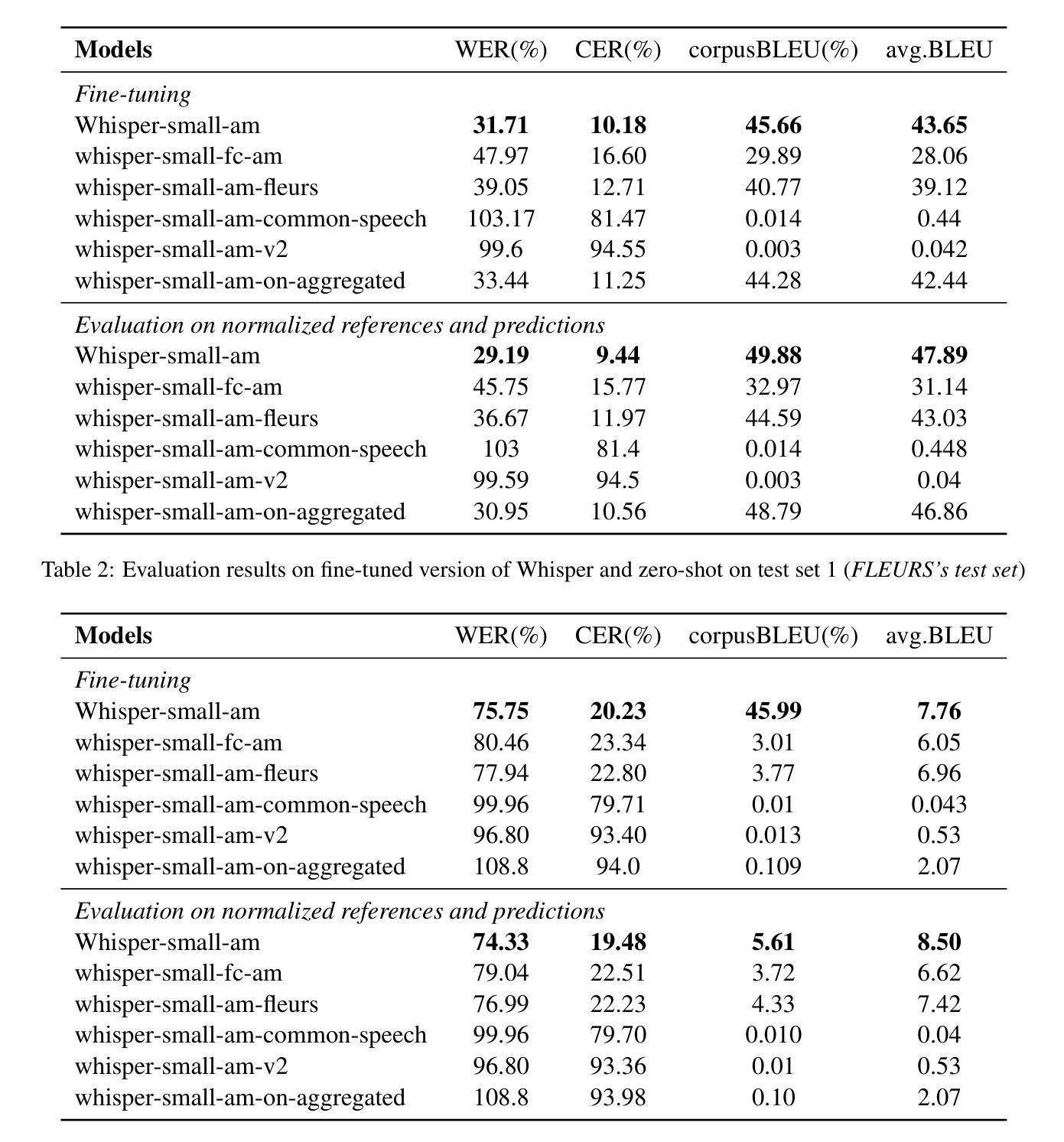
This work explores fine-tuning OpenAI’s Whisper automatic speech recognition (ASR) model for Amharic, a low-resource language, to improve transcription accuracy. While the foundational Whisper model struggles with Amharic due to limited representation in its training data, we fine-tune it using datasets like Mozilla Common Voice, FLEURS, and the BDU-speech dataset. The best-performing model, Whispersmall-am, significantly improves when finetuned on a mix of existing FLEURS data and new, unseen Amharic datasets. Training solely on new data leads to poor performance, but combining it with FLEURS data reinforces the model, enabling better specialization in Amharic. We also demonstrate that normalizing Amharic homophones significantly enhances Word Error Rate (WER) and Bilingual Evaluation Understudy (BLEU) scores. This study underscores the importance of fine-tuning strategies and dataset composition for improving ASR in low-resource languages, providing insights for future Amharic speech recognition research.
这项工作探讨了针对阿姆哈拉语(一种低资源语言)对OpenAI的自动语音识别(ASR)模型进行微调,以提高转录准确性。虽然基础whisper模型由于训练数据中阿姆哈拉语的代表性有限而难以应对阿姆哈拉语,但我们使用Mozilla Common Voice、FLEURS和BDU-speech等数据集对其进行微调。表现最佳的模型Whispersmall-am,在现有的FLEURS数据和新的未见过的阿姆哈拉语数据集混合进行微调时,性能得到了显著提升。仅在新数据上进行训练会导致性能不佳,但将其与FLEURS数据相结合可以加强模型,使阿姆哈拉语专业化更好。我们还证明,对阿姆哈拉语的同音字进行归一化处理可以显著提高单词错误率(WER)和双语评估下研究(BLEU)的分数。本研究强调了微调策略和数据集组成在提高低资源语言的自动语音识别中的重要性,为未来阿姆哈拉语语音识别研究提供了启示。
论文及项目相关链接
总结
本文探讨了针对阿姆哈拉语(一种资源匮乏的语言)对OpenAI的Whisper自动语音识别(ASR)模型进行微调,以提高转录准确性。在基础Whisper模型由于其训练数据中阿姆哈拉语代表性有限而面临挑战时,我们使用Mozilla Common Voice、FLEURS和BDU-speech等数据集对其进行微调。表现最佳的模型Whispersmall-am,在现有FLEURS数据和新的未见过的阿姆哈拉语数据集的混合上微调时表现显著改善。仅在新数据上进行训练会导致性能不佳,但将其与FLEURS数据相结合可以加强模型的训练,使其在阿姆哈拉语中更好地专业化。我们还证明,对阿姆哈拉语的同音字进行归一化处理可以显著提高单词错误率和双语评估下的得分。本研究强调了微调策略和数据集组成对于提高低资源语言的语音识别能力的重要性,为未来阿姆哈拉语语音识别研究提供了见解。
关键见解
- 通过微调OpenAI的Whisper模型,针对阿姆哈拉语这一低资源语言提高了自动语音识别(ASR)的转录准确性。
- 使用多种数据集如Mozilla Common Voice、FLEURS和BDU-speech对模型进行微调。
- 表现最佳的模型Whispersmall-am在混合现有FLEURS数据和新的阿姆哈拉语数据集上微调时表现最佳。
- 仅依赖新数据训练模型会导致性能下降,需要与FLEURS数据结合以达到更好的效果。
- 对阿姆哈拉语的同音字进行归一化处理能显著提高单词错误率和双语评估得分。
- 微调策略和数据集组成对于提高低资源语言的语音识别能力至关重要。
点此查看论文截图

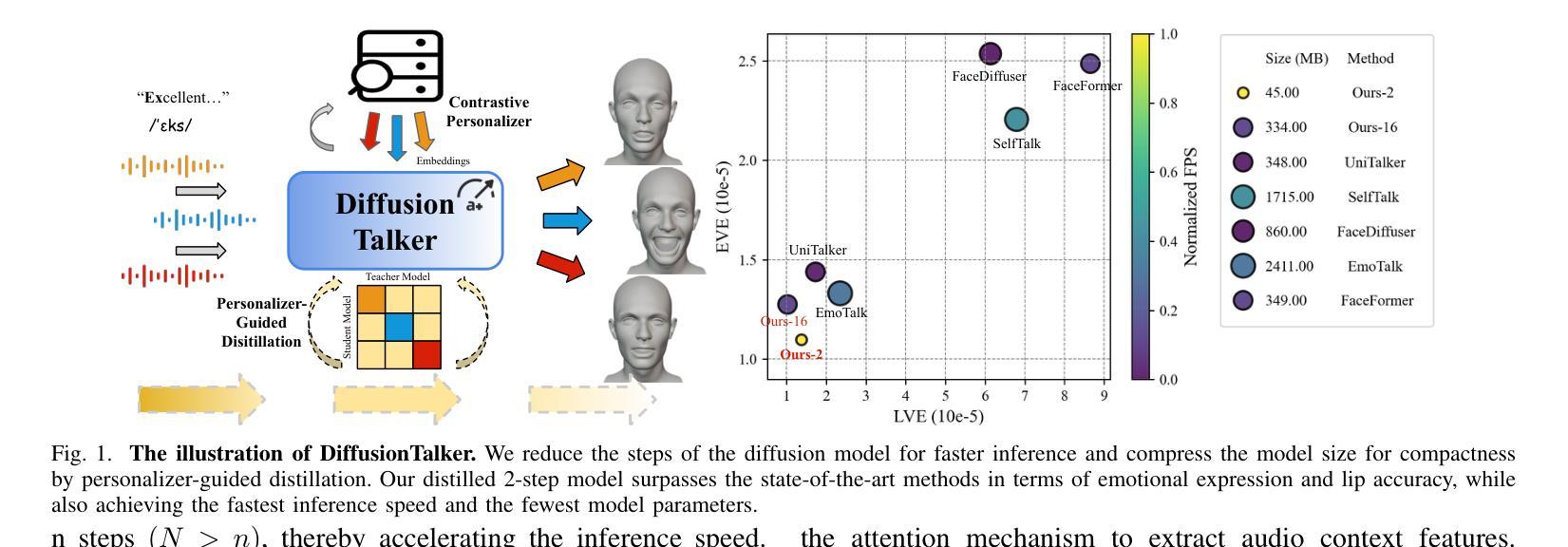
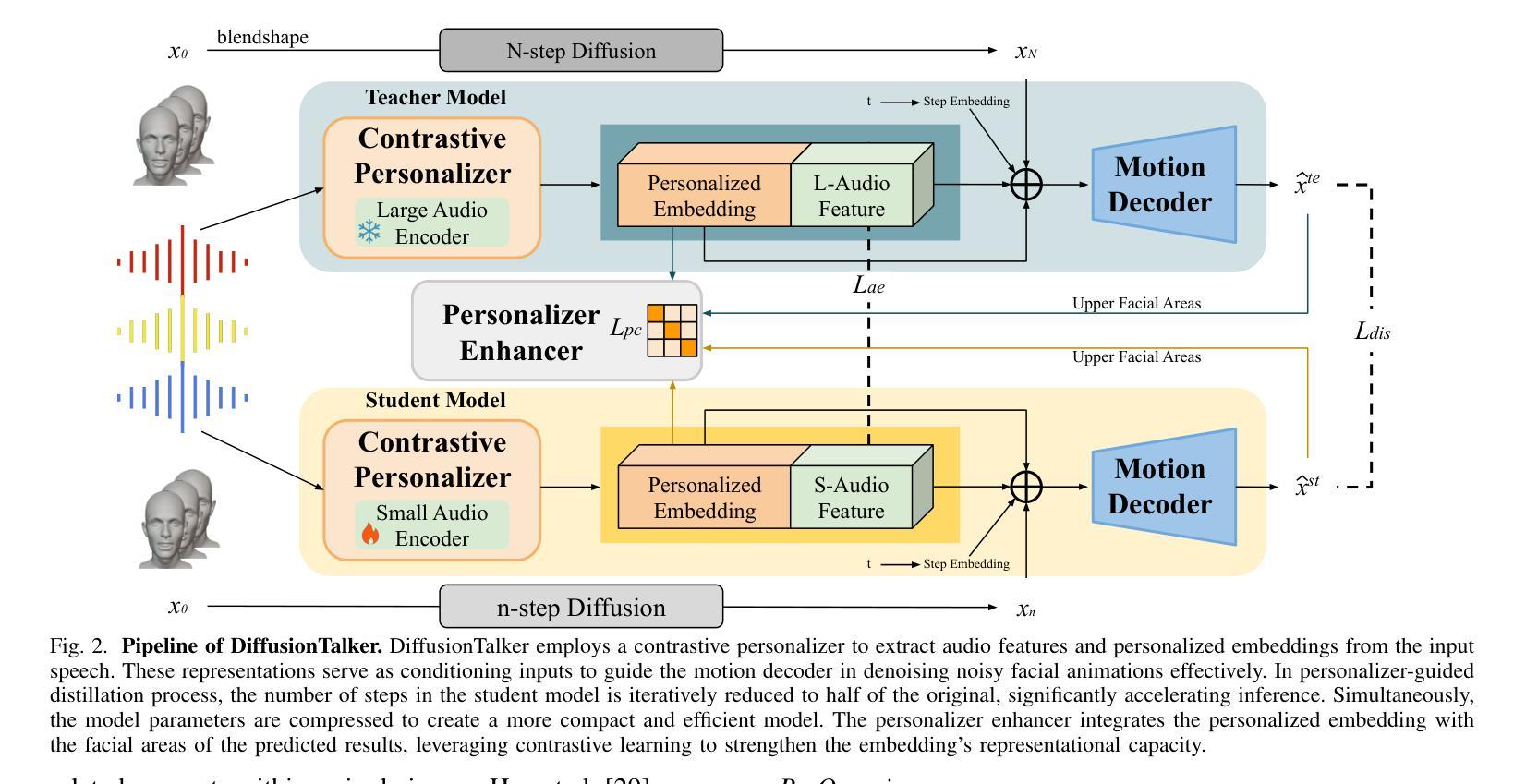
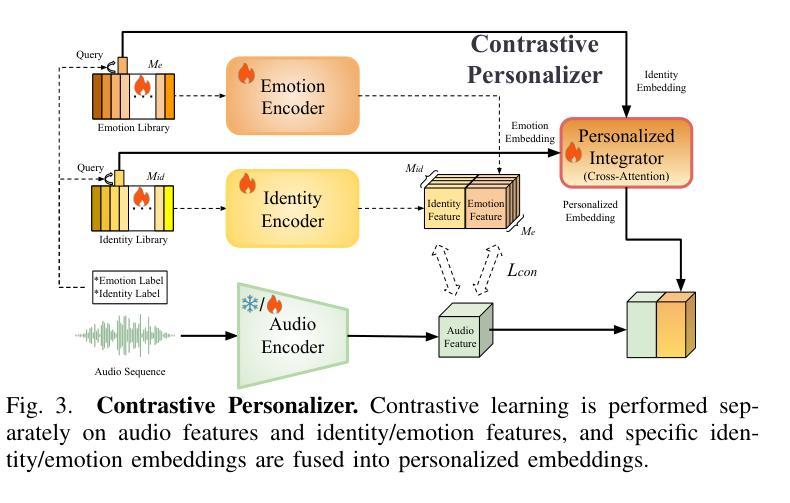
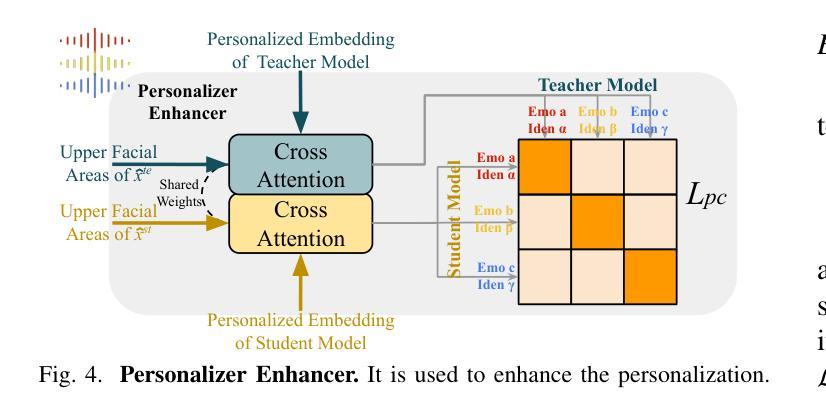
DiffusionTalker: Efficient and Compact Speech-Driven 3D Talking Head via Personalizer-Guided Distillation
Authors:Peng Chen, Xiaobao Wei, Ming Lu, Hui Chen, Feng Tian
Real-time speech-driven 3D facial animation has been attractive in academia and industry. Traditional methods mainly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the nondeterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. Existing diffusion-based methods can improve the diversity of facial animation. However, personalized speaking styles conveying accurate lip language is still lacking, besides, efficiency and compactness still need to be improved. In this work, we propose DiffusionTalker to address the above limitations via personalizer-guided distillation. In terms of personalization, we introduce a contrastive personalizer that learns identity and emotion embeddings to capture speaking styles from audio. We further propose a personalizer enhancer during distillation to enhance the influence of embeddings on facial animation. For efficiency, we use iterative distillation to reduce the steps required for animation generation and achieve more than 8x speedup in inference. To achieve compactness, we distill the large teacher model into a smaller student model, reducing our model’s storage by 86.4% while minimizing performance loss. After distillation, users can derive their identity and emotion embeddings from audio to quickly create personalized animations that reflect specific speaking styles. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released at: https://github.com/ChenVoid/DiffusionTalker.
实时语音驱动的三维面部动画在学术界和工业界都具有吸引力。传统方法主要关注从语音到动画的确定性映射学习。最近的方法开始考虑语音驱动的三维面部动画的非确定性因素,并采用扩散模型来完成此任务。现有的基于扩散的方法可以提高面部动画的多样性。然而,除了缺乏传达准确唇语的个性化说话风格外,还需要提高效率和紧凑性。在这项工作中,我们提出使用DiffusionTalker通过个性化引导蒸馏来解决上述局限性。在个性化方面,我们引入对比个性化器来学习身份和情感嵌入,以从音频中捕获说话风格。我们进一步提出了在蒸馏过程中的个性化增强器,以增强嵌入对面部动画的影响。为提高效率,我们使用迭代蒸馏来减少动画生成所需的步骤,并在推理过程中实现了超过8倍的速度提升。为实现紧凑性,我们将大型教师模型蒸馏到小型学生模型中,将模型的存储减少了86.4%,同时最小化性能损失。经过蒸馏后,用户可以从音频中导出他们的身份和情感嵌入,快速创建反映特定说话风格的个性化动画。进行了大量实验,证明我们的方法优于最新技术。代码发布在:https://github.com/ChenVoid/DiffusionTalker。
论文及项目相关链接
PDF Accepted by ICME2025
摘要
本文提出一种基于扩散模型的实时语音驱动3D面部动画方法,旨在解决现有方法的个性化、效率和紧凑性问题。通过引入对比个性化器和学习身份和情感嵌入,提高动画的个性化程度;采用迭代蒸馏技术,减少动画生成步骤,提高推理效率;同时将大型教师模型蒸馏到小型学生模型,减少模型存储大小。实验证明,该方法优于现有技术。
关键见解
- 引入对比个性化器和学习身份、情感嵌入,提高语音驱动3D面部动画的个性化程度。
- 采用迭代蒸馏技术,提高动画生成效率,实现超过8倍的推理速度提升。
- 通过将大型教师模型蒸馏到小型学生模型,减少模型存储大小,降低性能损失。
- 提出一种新型的基于扩散模型的面部动画方法,能够捕捉更多的语音风格。
- 用户可以通过音频获取身份和情感嵌入,快速创建反映特定语音风格的个性化动画。
- 扩散Talker方法在实验上表现出优于现有技术的性能。
点此查看论文截图

Elevating Robust Multi-Talker ASR by Decoupling Speaker Separation and Speech Recognition
Authors:Yufeng Yang, Hassan Taherian, Vahid Ahmadi Kalkhorani, DeLiang Wang
Despite the tremendous success of automatic speech recognition (ASR) with the introduction of deep learning, its performance is still unsatisfactory in many real-world multi-talker scenarios. Speaker separation excels in separating individual talkers but, as a frontend, it introduces processing artifacts that degrade the ASR backend trained on clean speech. As a result, mainstream robust ASR systems train the backend on noisy speech to avoid processing artifacts. In this work, we propose to decouple the training of the speaker separation frontend and the ASR backend, with the latter trained on clean speech only. Our decoupled system achieves 5.1% word error rates (WER) on the Libri2Mix dev/test sets, significantly outperforming other multi-talker ASR baselines. Its effectiveness is also demonstrated with the state-of-the-art 7.60%/5.74% WERs on 1-ch and 6-ch SMS-WSJ. Furthermore, on recorded LibriCSS, we achieve the speaker-attributed WER of 2.92%. These state-of-the-art results suggest that decoupling speaker separation and recognition is an effective approach to elevate robust multi-talker ASR.
尽管深度学习在自动语音识别(ASR)方面的应用取得了巨大成功,但在现实世界的多说话人场景中,其表现仍然不尽人意。说话人分离技术擅长分离单个说话人,但作为前端技术,它引入了处理伪影,这些伪影会恶化在干净语音上训练的ASR后端性能。因此,主流的鲁棒ASR系统会对后端进行噪声语音训练,以避免处理伪影。在这项工作中,我们提出了将说话人分离前端和ASR后端的训练解耦,后端仅在干净语音上进行训练。我们的解耦系统实现了Libri2Mix开发/测试集上的5.1%词错误率(WER),显著优于其他多说话人ASR基准。其有效性还体现在最先进的1通道和6通道的SMS-WSJ的7.60%/5.74% WER。此外,在录制的LibriCSS上,我们达到了2.92%的说话人属性WER。这些最先进的结果表明,将说话人分离和识别解耦是一种有效的提高鲁棒多说话人ASR的方法。
论文及项目相关链接
摘要
虽然深度学习在自动语音识别(ASR)上取得了巨大成功,但在多说话人现实场景中,其表现仍不尽如人意。尽管说话人分离技术在分离单个说话人方面表现出色,但作为前端技术,它引入了处理伪迹,这些伪迹会破坏对干净语音进行训练的ASR后端的性能。因此,主流的鲁棒ASR系统都对含噪语音进行后端训练,以避免处理伪迹。在这项工作中,我们提出了将说话人分离前端和ASR后端训练解耦的方法,后端仅在干净语音上进行训练。我们的解耦系统在Libri2Mix开发/测试集上实现了5.1%的词错误率(WER),显著优于其他多说话人ASR基线。其在SMS-WSJ的1通道和6通道上的最新性能分别为7.60%/5.74%的WER。此外,在录制的LibriCSS上,我们实现了说话人归因的WER为2.92%。这些最新结果表明,解耦说话人分离和识别是一种有效的提高鲁棒多说话人ASR的方法。
关键见解
- 自动语音识别(ASR)在真实世界的多说话人场景中仍存在性能挑战。
- 说话人分离技术虽然擅长分离单个说话人,但作为前端技术,容易引入处理伪迹。
- 处理伪迹可能会影响对干净语音进行训练的ASR后端的性能。
- 当前主流做法是对含噪语音进行后端训练以避免处理伪迹。
- 本研究提出了将说话人分离前端和ASR后端训练解耦的方法。
- 解耦系统在Libri2Mix开发/测试集上实现了显著的词错误率(WER)性能提升。
点此查看论文截图

Measuring the Robustness of Audio Deepfake Detectors
Authors:Xiang Li, Pin-Yu Chen, Wenqi Wei
Deepfakes have become a universal and rapidly intensifying concern of generative AI across various media types such as images, audio, and videos. Among these, audio deepfakes have been of particular concern due to the ease of high-quality voice synthesis and distribution via platforms such as social media and robocalls. Consequently, detecting audio deepfakes plays a critical role in combating the growing misuse of AI-synthesized speech. However, real-world scenarios often introduce various audio corruptions, such as noise, modification, and compression, that may significantly impact detection performance. This work systematically evaluates the robustness of 10 audio deepfake detection models against 16 common corruptions, categorized into noise perturbation, audio modification, and compression. Using both traditional deep learning models and state-of-the-art foundation models, we make four unique observations. First, our findings show that while most models demonstrate strong robustness to noise, they are notably more vulnerable to modifications and compression, especially when neural codecs are applied. Second, speech foundation models generally outperform traditional models across most scenarios, likely due to their self-supervised learning paradigm and large-scale pre-training. Third, our results show that increasing model size improves robustness, albeit with diminishing returns. Fourth, we demonstrate how targeted data augmentation during training can enhance model resilience to unseen perturbations. A case study on political speech deepfakes highlights the effectiveness of foundation models in achieving high accuracy under real-world conditions. These findings emphasize the importance of developing more robust detection frameworks to ensure reliability in practical deployment settings.
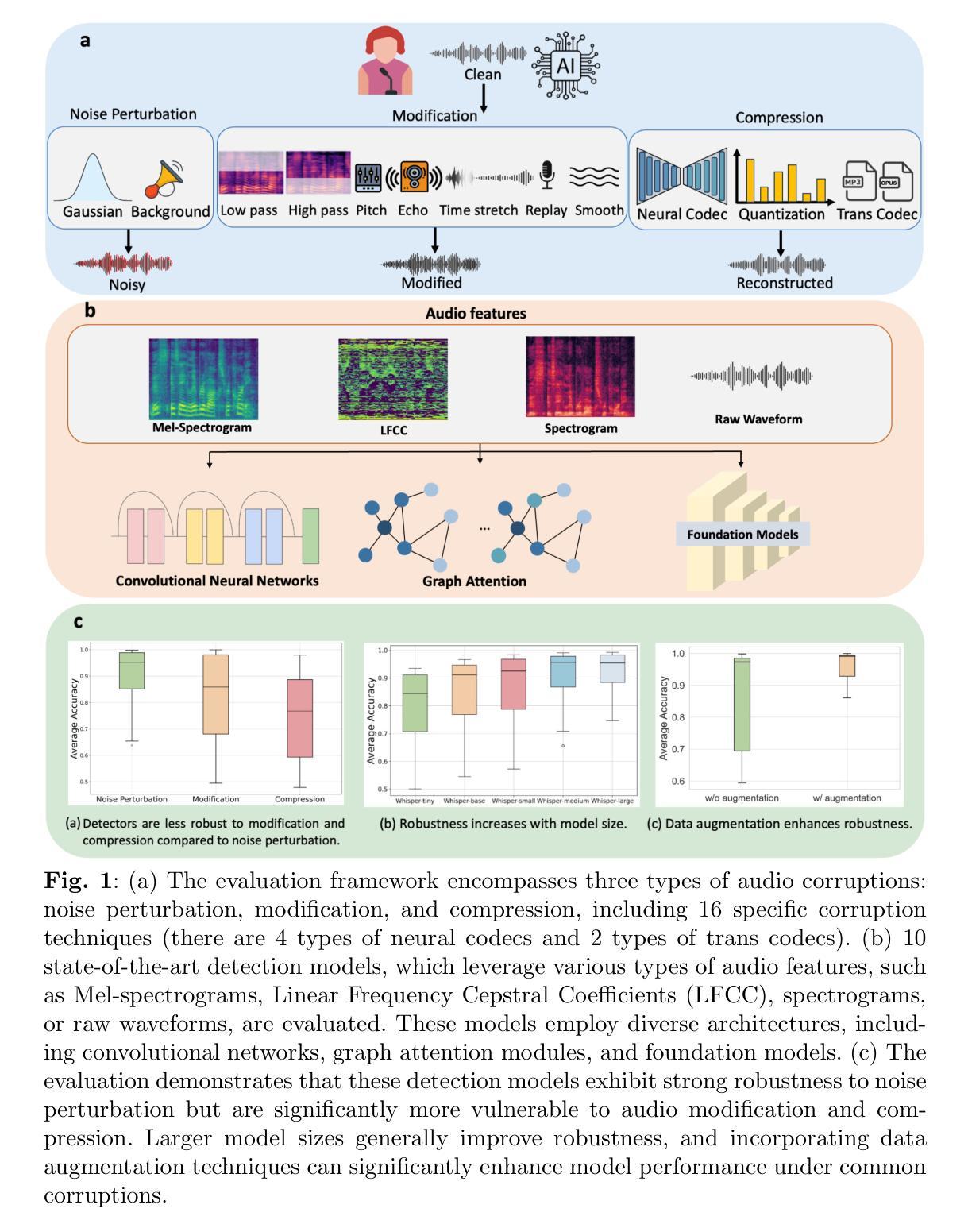
深度伪造已经成为生成式人工智能在全媒体时代所面临的普遍且日益加剧的担忧,涉及的媒体类型包括图像、音频和视频等。其中,音频深度伪造尤为引人关注,因为通过社交媒体和机器人电话等平台,高质量的声音合成和传播变得轻而易举。因此,检测音频深度伪造在打击日益增长的AI合成语音滥用中扮演着至关重要的角色。然而,现实场景中的音频往往存在各种失真,如噪声、修改和压缩等,这些失真可能会对检测性能产生重大影响。这项工作系统地评估了10种音频深度伪造检测模型对16种常见失真的鲁棒性,这些失真被分类为噪声扰动、音频修改和压缩。我们使用了传统的深度学习模型和最新的基础模型,并做出了四个独特的观察。首先,我们的研究发现,虽然大多数模型对噪声具有很强的鲁棒性,但它们对修改和压缩的敏感性显著更高,特别是应用神经网络编码时。其次,语音基础模型在大多数场景中的表现通常优于传统模型,这可能是由于其自我监督的学习模式和大规模预训练所致。第三,我们的结果表明,增加模型大小虽然可以提高其鲁棒性,但收益会递减。第四,我们展示了在训练过程中有针对性的数据增强如何增强模型对未见扰动的抗性。关于政治演讲深度伪造案例研究突出了基础模型在现实世界条件下实现高准确性的有效性。这些发现强调开发更稳健的检测框架的重要性,以确保在实际部署环境中的可靠性。
论文及项目相关链接
摘要
深度伪造已逐渐成为生成式人工智能在图像、音频和视频等多种媒体类型中的普遍且日益加剧的关切点。特别是音频深度伪造引发了人们的特别关注,因为高质量的声音合成非常容易实现,并且可以通过社交媒体和语音机器人电话等平台广泛传播。因此,检测音频深度伪造在打击人工智能合成语音的滥用方面发挥着至关重要的作用。然而,现实世界的场景经常会引入各种音频失真,如噪声、修改和压缩等,这些失真可能会对检测性能产生重大影响。这项工作系统地评估了10种音频深度伪造检测模型对16种常见失真的鲁棒性,这些失真被分类为噪声扰动、音频修改和压缩。通过使用传统的深度学习模型和最新的基础模型,我们得出了四个独特的观察结果。首先,我们的研究发现,虽然大多数模型对噪声具有很强的鲁棒性,但它们对修改和压缩的敏感性更高,特别是应用神经网络编码时。其次,语音基础模型在大多数情况下一般表现优于传统模型,这可能是由于它们的大型预训练和自监督学习模式。第三,我们的结果表明,虽然收益递减,但增加模型大小可以提高其稳健性。第四,我们展示了在训练过程中有针对性的数据增强如何增强模型对未见过的扰动的抵抗力。政治演讲深度伪造案例研究突出了基础模型在实际条件下实现高准确性的有效性。这些发现强调了开发更稳健的检测框架的重要性,以确保在实际部署环境中的可靠性。
关键见解
- 音频深度伪造是生成式人工智能的一个重要关切点,特别是在社交媒体和语音机器人电话等平台的广泛传播下。
- 现实世界的音频失真,如修改和压缩,对音频深度伪造检测模型的性能有重大影响。
- 语音基础模型在音频深度伪造检测方面表现优异,得益于其大型预训练和自监督学习模式。
- 模型大小增加可以提高其稳健性,但收益会递减。
- 针对性的数据增强可以提高模型对未见过的扰动的抵抗力。
- 在政治演讲深度伪造的案例研究中,基础模型在高准确性方面表现出色。
点此查看论文截图

DIDiffGes: Decoupled Semi-Implicit Diffusion Models for Real-time Gesture Generation from Speech
Authors:Yongkang Cheng, Shaoli Huang, Xuelin Chen, Jifeng Ning, Mingming Gong
Diffusion models have demonstrated remarkable synthesis quality and diversity in generating co-speech gestures. However, the computationally intensive sampling steps associated with diffusion models hinder their practicality in real-world applications. Hence, we present DIDiffGes, for a Decoupled Semi-Implicit Diffusion model-based framework, that can synthesize high-quality, expressive gestures from speech using only a few sampling steps. Our approach leverages Generative Adversarial Networks (GANs) to enable large-step sampling for diffusion model. We decouple gesture data into body and hands distributions and further decompose them into marginal and conditional distributions. GANs model the marginal distribution implicitly, while L2 reconstruction loss learns the conditional distributions exciplictly. This strategy enhances GAN training stability and ensures expressiveness of generated full-body gestures. Our framework also learns to denoise root noise conditioned on local body representation, guaranteeing stability and realism. DIDiffGes can generate gestures from speech with just 10 sampling steps, without compromising quality and expressiveness, reducing the number of sampling steps by a factor of 100 compared to existing methods. Our user study reveals that our method outperforms state-of-the-art approaches in human likeness, appropriateness, and style correctness. Project is https://cyk990422.github.io/DIDiffGes.
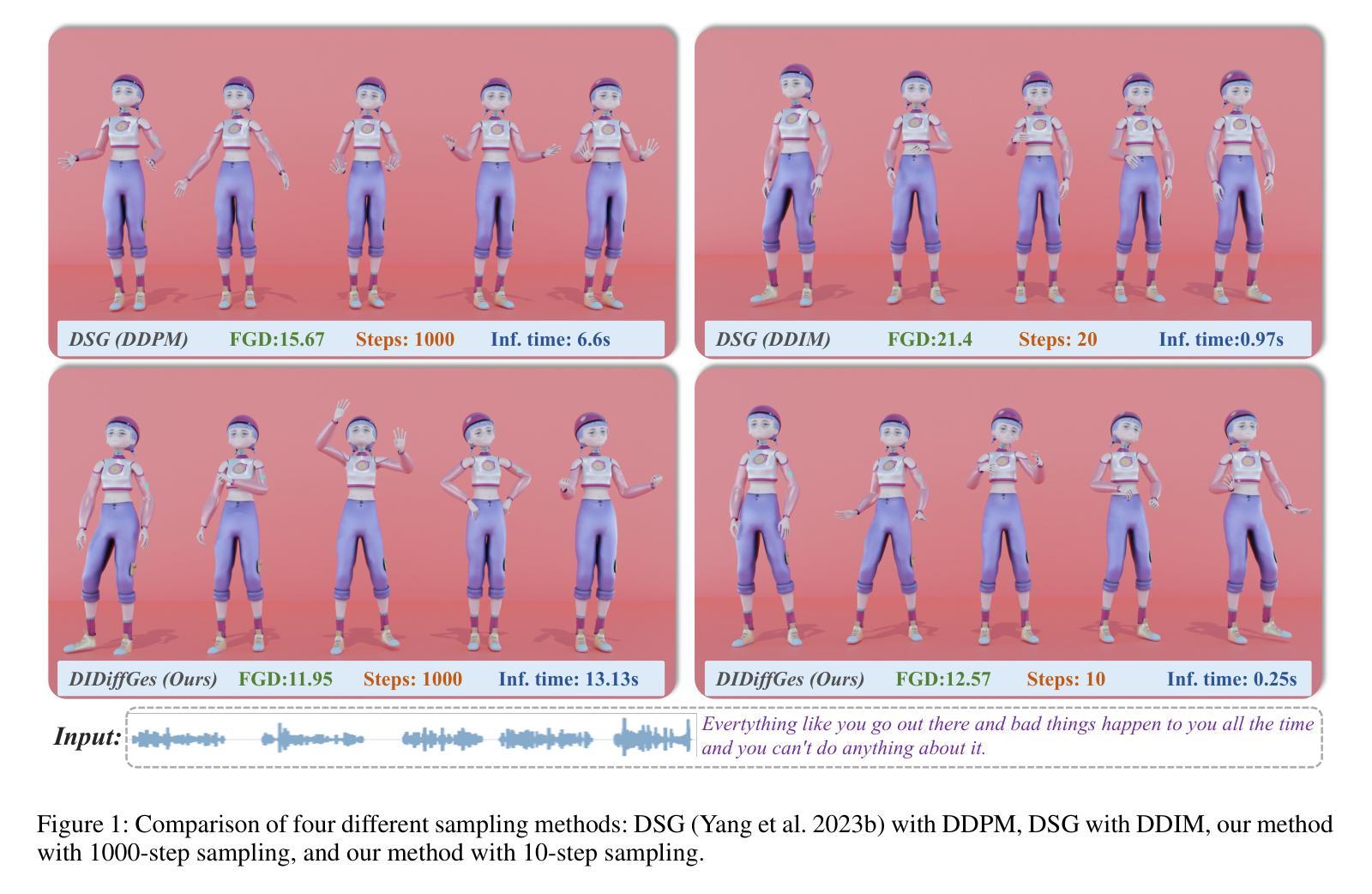
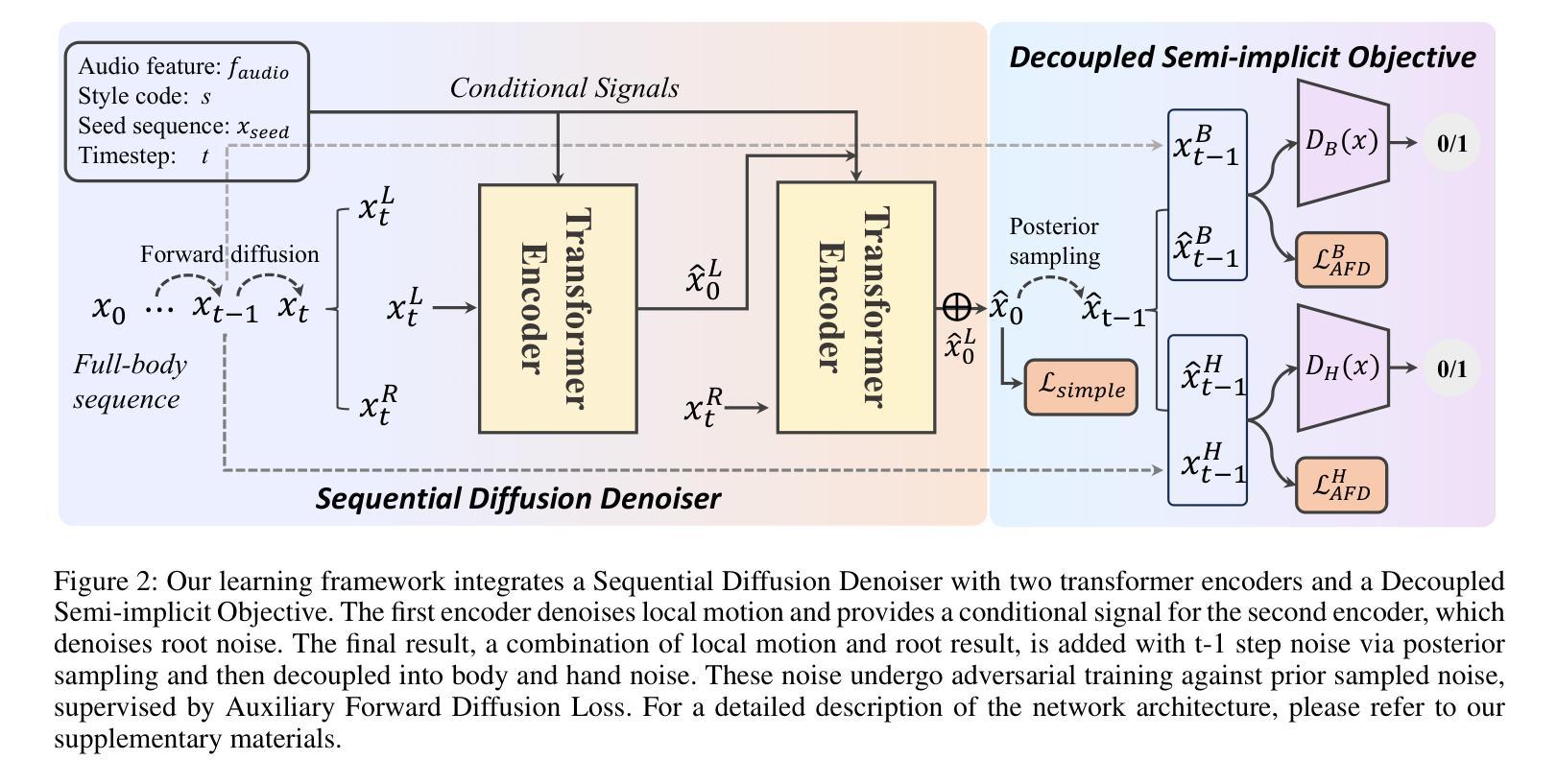
扩散模型在生成伴随语音的手势时表现出了卓越的合成质量和多样性。然而,与扩散模型相关的计算密集型的采样步骤阻碍了其在现实世界应用中的实用性。因此,我们提出了DIDiffGes,这是一个基于解耦半隐式扩散模型的框架,它仅使用少数采样步骤就能从语音中合成高质量、表达丰富的手势。我们的方法利用生成对抗网络(GANs)来实现扩散模型的大步采样。我们将手势数据解耦为身体和手部分布,并进一步将它们分解为边缘分布和条件分布。GANs隐式地建模边缘分布,而L2重建损失显式地学习条件分布。这种策略提高了GAN的训练稳定性,并确保了生成的全身手势的表达性。我们的框架还学习在局部身体表征的条件下消除根噪声,保证稳定性和真实性。DIDiffGes只需10个采样步骤就能从语音中生成手势,且不妥协于质量和表达性,与现有方法相比,采样步骤的数量减少了100倍。我们的用户研究表明,我们的方法在人的相似性、适当性和风格正确性方面优于现有先进技术。项目是https://cyk990422.github.io/DIDiffGes。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了DIDiffGes,一种基于解耦半隐式扩散模型的框架,能够在较少的采样步骤内从语音合成高质量、表达丰富的手势。该研究利用生成对抗网络(GANs)实现大步采样扩散模型,将手势数据解耦为身体和手部分布并进一步分解为边际和条件分布。该方法增强了GAN训练稳定性,确保生成的全身手势的表达性。DIDiffGes能够仅在10个采样步骤内从语音生成手势,且不影响质量和表现力,与现有方法相比减少了100倍采样步骤。用户研究结果表明,该方法在人性化、适当性和风格正确性方面优于现有方法。
Key Takeaways
- DIDiffGes是一个基于解耦半隐式扩散模型的框架,用于从语音生成高质量、表达丰富的手势。
- 研究利用生成对抗网络(GANs)实现大步采样扩散模型。
- DIDiffGes将手势数据解耦为身体和手部分布,并进一步分解为边际和条件分布。
- 通过隐式建模边际分布和显式学习条件分布的策略,增强了GAN训练稳定性并保证了手势的表达性。
- DIDiffGes能够在仅10个采样步骤内生成手势,较现有方法减少了采样步骤数量。
- 用户研究结果显示,DIDiffGes在人性化、适当性和风格正确性方面优于当前主流方法。
点此查看论文截图

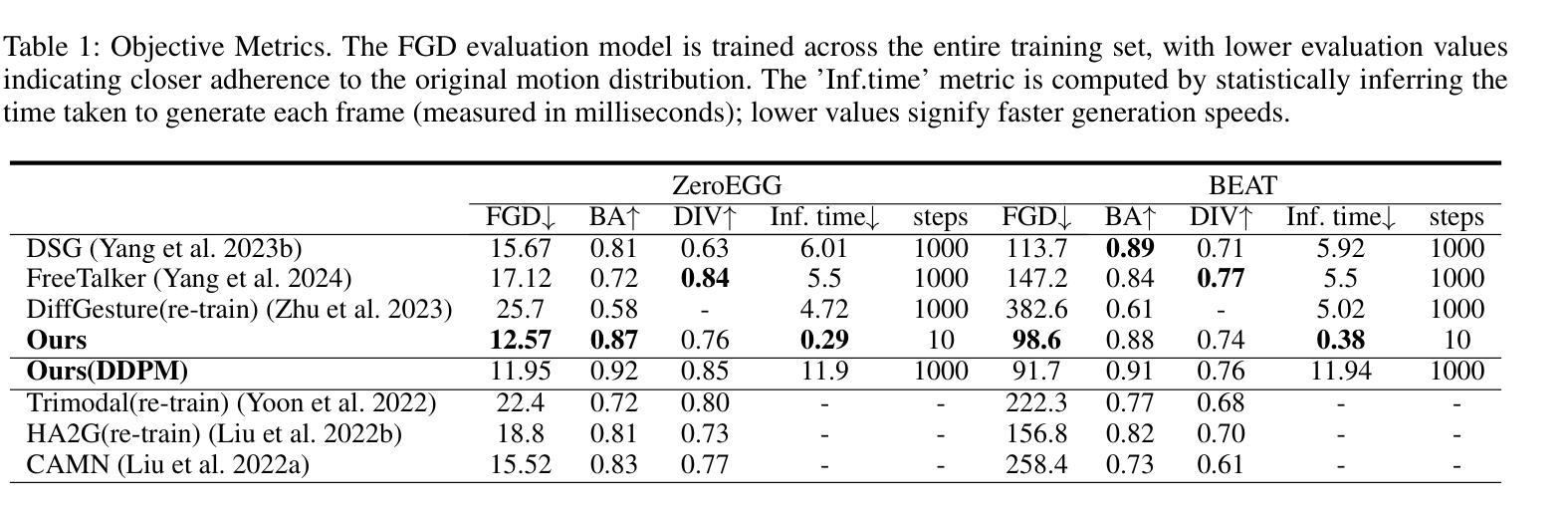
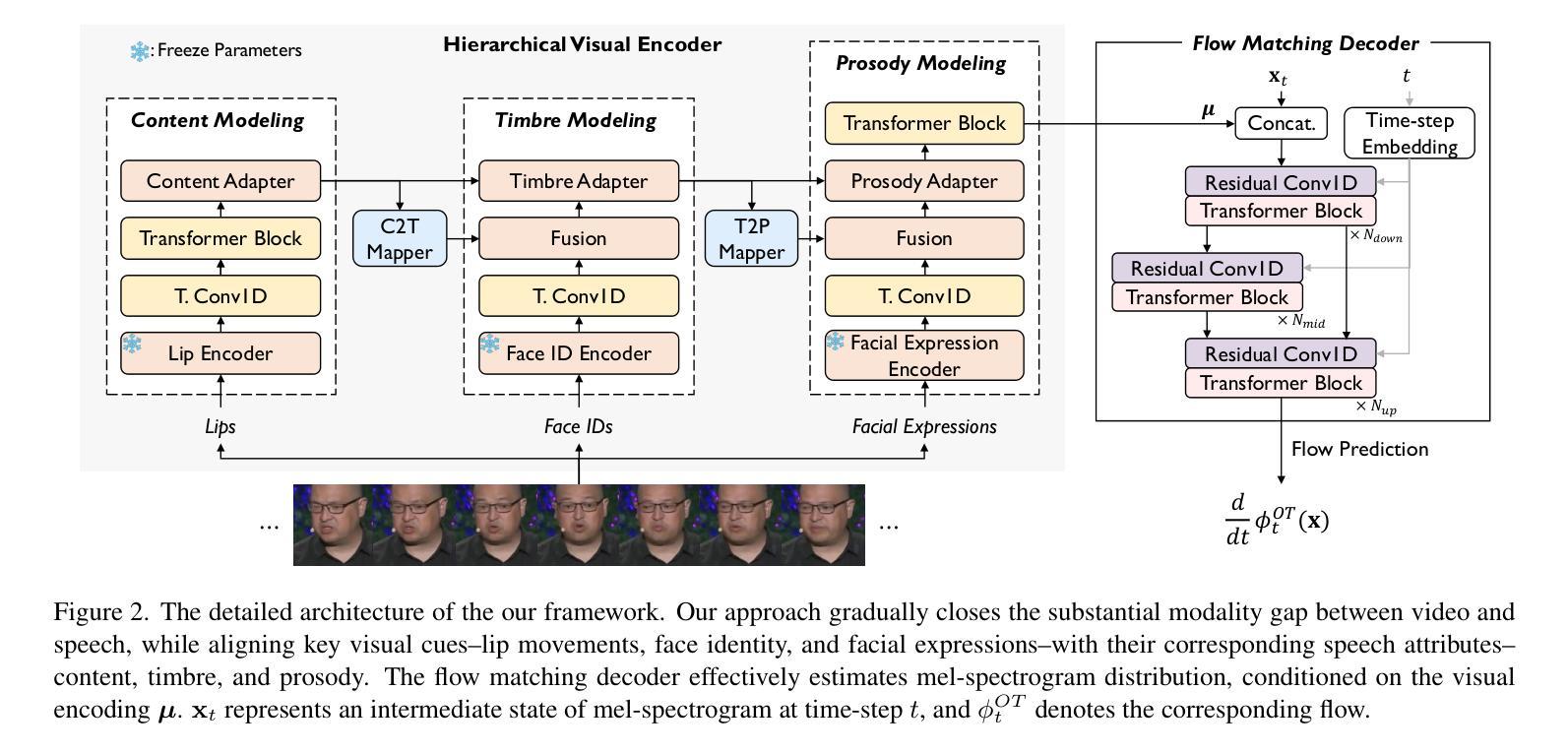
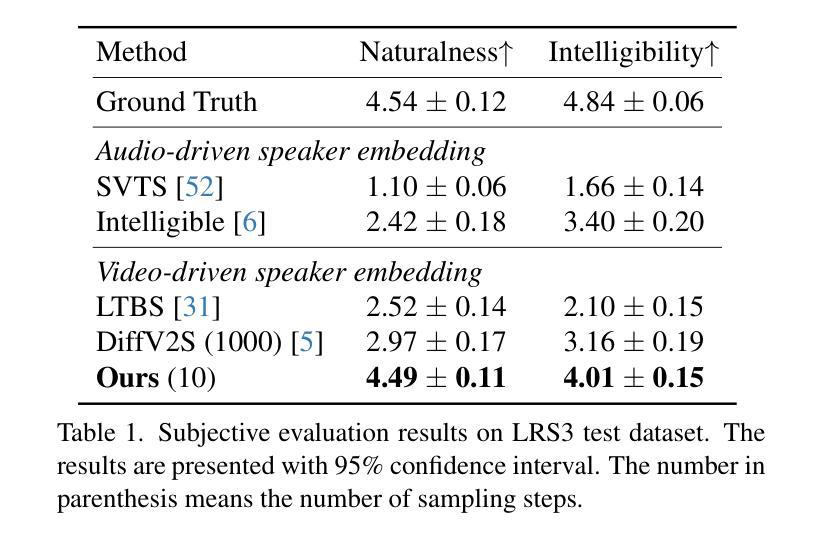
From Faces to Voices: Learning Hierarchical Representations for High-quality Video-to-Speech
Authors:Ji-Hoon Kim, Jeongsoo Choi, Jaehun Kim, Chaeyoung Jung, Joon Son Chung
The objective of this study is to generate high-quality speech from silent talking face videos, a task also known as video-to-speech synthesis. A significant challenge in video-to-speech synthesis lies in the substantial modality gap between silent video and multi-faceted speech. In this paper, we propose a novel video-to-speech system that effectively bridges this modality gap, significantly enhancing the quality of synthesized speech. This is achieved by learning of hierarchical representations from video to speech. Specifically, we gradually transform silent video into acoustic feature spaces through three sequential stages – content, timbre, and prosody modeling. In each stage, we align visual factors – lip movements, face identity, and facial expressions – with corresponding acoustic counterparts to ensure the seamless transformation. Additionally, to generate realistic and coherent speech from the visual representations, we employ a flow matching model that estimates direct trajectories from a simple prior distribution to the target speech distribution. Extensive experiments demonstrate that our method achieves exceptional generation quality comparable to real utterances, outperforming existing methods by a significant margin.
本文的目标是从无声的对话视频生成高质量语音,这一任务也称为视频到语音的合成。视频到语音合成中的一大挑战在于无声视频和多维度的语音之间存在的巨大模态差距。在本文中,我们提出了一种新型的视频到语音系统,该系统有效地弥补了这一模态差距,大大提高了合成语音的质量。这是通过从视频到语音学习层次化表示来实现的。具体来说,我们通过三个连续阶段——内容、音质和语调建模,将无声视频逐渐转化为声音特征空间。在每个阶段,我们将视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音对应因素进行对齐,以确保无缝转换。此外,为了从视觉表示生成现实且连贯的语音,我们采用了一种流匹配模型,该模型从简单的先验分布估计出到目标语音分布的直接轨迹。大量实验表明,我们的方法达到了与真实语音相比的出色生成质量,显著优于现有方法。
论文及项目相关链接
PDF CVPR 2025, demo page: https://mm.kaist.ac.kr/projects/faces2voices/
Summary
本研究旨在从无声的脸部视频生成高质量语音,也被称为视频到语音的合成。该挑战在于无声视频和多元化的语音之间有着显著的模式差距。本文提出了一种新颖的视频到语音系统,通过从视频学习层级表达来有效地弥合这一模式差距,从而极大地提高了合成语音的质量。具体地,我们通过内容、音质和语调建模三个阶段,逐步将无声视频转化为声音特征空间。在每个阶段中,我们都能将视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音因素进行匹配,确保流畅的转化过程。此外,为了从视觉表达生成真实连贯的语音,我们采用流量匹配模型估算从简单先验分布到目标语音分布的轨迹。大量实验表明,我们的方法实现了与真实发音相比的出色生成质量,并大幅度超越了现有方法。
Key Takeaways
- 本研究旨在实现视频到语音的合成技术,即从无声的脸部视频生成高质量语音。
- 视频与语音间存在模式差距,为此提出一种新颖的视频到语音系统来弥合这一差距。
- 通过内容、音质和语调建模三个阶段,将无声视频转化为声音特征空间。
- 在每个阶段中匹配视觉和声音因素,确保流畅的转化过程。
- 采用流量匹配模型生成真实连贯的语音。
- 实验证明,该方法在生成质量上大幅度超越了现有技术。
点此查看论文截图

Modelling Emotions in Face-to-Face Setting: The Interplay of Eye-Tracking, Personality, and Temporal Dynamics
Authors:Meisam Jamshidi Seikavandi, Jostein Fimland, Maria Barrett, Paolo Burelli
Accurate emotion recognition is pivotal for nuanced and engaging human-computer interactions, yet remains difficult to achieve, especially in dynamic, conversation-like settings. In this study, we showcase how integrating eye-tracking data, temporal dynamics, and personality traits can substantially enhance the detection of both perceived and felt emotions. Seventy-three participants viewed short, speech-containing videos from the CREMA-D dataset, while being recorded for eye-tracking signals (pupil size, fixation patterns), Big Five personality assessments, and self-reported emotional states. Our neural network models combined these diverse inputs including stimulus emotion labels for contextual cues and yielded marked performance gains compared to the state-of-the-art. Specifically, perceived valence predictions reached a macro F1-score of 0.76, and models incorporating personality traits and stimulus information demonstrated significant improvements in felt emotion accuracy. These results highlight the benefit of unifying physiological, individual and contextual factors to address the subjectivity and complexity of emotional expression. Beyond validating the role of user-specific data in capturing subtle internal states, our findings inform the design of future affective computing and human-agent systems, paving the way for more adaptive and cross-individual emotional intelligence in real-world interactions.
精确的情绪识别对于微妙且引人入胜的人机交互至关重要,然而仍难以实现,特别是在动态、类似对话的环境中。在这项研究中,我们展示了如何整合眼球追踪数据、时间动态和人格特质,可以极大地提高感知情绪和感受情绪的识别。73名参与者观看了来自CREMA-D数据集的包含语音的短片,同时记录眼球追踪信号(瞳孔大小、注视模式)、五大人格评估和自报的情绪状态。我们的神经网络模型结合了这些多样化的输入,包括刺激情绪标签作为上下文线索,与最新技术相比取得了显著的性能提升。具体来说,感知价值预测的宏观F1分数达到了0.76,结合人格特质和刺激信息的模型在感受情绪准确性方面表现出了显著的改进。这些结果强调了统一生理、个体和上下文因素的好处,以解决情绪表达的主观性和复杂性。除了验证用户特定数据在捕捉微妙内部状态中的作用之外,我们的研究还为未来情感计算和人机代理系统的设计提供了信息,为现实世界中更自适应和跨个体的情绪智能铺平了道路。
论文及项目相关链接
Summary
该研究探讨了将眼动数据、时间动态以及人格特质融合,对感知和内在情绪进行识别的研究进展。研究采用了73名参与者的实验数据,分析瞳孔大小、注视模式等眼动信号以及基于“五大人格模型”的个性评估与自我报告情感状态的结果。利用神经网络模型,结合情绪标签作为上下文线索处理各种数据输入,相比于传统模型展现出了显著的识别提升效果。该研究强化了个性化心理状况的统一整合理念的重要性。其实验证明了针对个性化和情境的框架具有可行性及有效改进内心情感状态的检测。这对于发展更为智能化的人类情感分析技术和促进现实场景中更为人性化的人工智能应用意义重大。因此总结起来该文章的核心内容在于,多模态信息融合,尤其是将人格特质融入情绪识别领域能够有效提高准确性,推动情感计算的进步和人工智能交互体验的发展。该研究成果对人机交互系统未来的设计产生了重要的启示作用。同时对于理解人类情绪表达的复杂性和主观性,有助于为建立适应性更广的个人化智能提供基础支持。未来的情绪识别技术在预测模型中可以借鉴并纳入多种形式的认知融合作为判断依据来提升结果准确率和精细度,将真实环境对互动所造成的影响细化入心理辅助以及沟通界面改善策略之中。此项研究验证了利用生理信息辅助理解情感感知的有效性和可行性。该发现也为设计更人性化的交互系统和情绪响应界面指明了方向。将有利于情绪分析技术和未来跨个体差异情绪理解的推进和未来发展优化现有模型的性能和局限性对于扩大现实应用的情境使用范畴将产生巨大影响以及应用价值方面的长远挖掘和创新延伸都有极其重要意义作用未来具备更深入人性的情商水平人工智能体系化的全面发展进程之优化融合多个维度的信息来共同提升情绪感知的精准度。未来研究可以进一步探索不同文化背景下情感表达方式的差异以及如何利用这些差异提升情绪识别的精度。对整体语言习惯和视觉环境的共同影响和深化多维融合对未来完善语境细化因素也将推进此项研究有广泛应用空间适用于支持多任务推理和未来跨界计算的不断尝试和提高产品成熟能力人工智能已涉足当下瞬息万变的个性化综合信息处理领域在面临更复杂的情感表达挑战时提供了更灵活有效的应对方案在个性化服务领域有着广阔的应用前景。该研究将对提高人机交互的准确性和精细度产生深远影响是推进情感智能发展的重要一步同时提供了将心理情感认知应用于现实互动场景的理论依据和可能路径并推动了情感计算领域的进一步发展提供了有价值的参考和启示为未来的研究和应用提供了重要的思路和方向。对于未来的智能交互系统来说具有极其重要的意义。通过融合多源信息构建更加精准的情绪识别系统来提高用户情感分析的准确性和完整性为解决情感计算和人机交互领域的复杂问题提供了新的思路和方法同时为改善人机交互的流畅性和提升用户体验提供了有力的支持并推动了人工智能领域的发展进步和革新突破具有广阔的应用前景和重要的社会价值。该研究在情绪识别方面取得了显著的进展为未来的研究和应用提供了重要的参考和启示同时也面临着一些挑战如不同文化背景下的情感表达差异以及新技术不断涌现给这一领域带来的新的挑战需要进一步探索和研究为人类的心理健康和心理服务提供更加全面有效的支持为构建更加和谐的人机交互环境提供有力支持。Key Takeaways
- 准确情感识别对于自然且富有内涵的人机交互至关重要,尤其对于动态对话场景而言尤为重要。
- 通过结合眼动数据(如瞳孔大小和注视模式)、时间动态以及人格特质,能够显著提高情感检测的准确性。
- 利用神经网络模型处理多种输入数据(包括刺激情绪标签),可获取显著的性能提升,特别是在感知价值预测方面达到较高的F1得分。
- 当模型融入人格特质和刺激信息时,能够显著改善内在情感的准确度识别。
- 研究结果强调了整合生理、个体及上下文因素的重要性,以应对情感表达中的主观性和复杂性。
- 除了验证用户特定数据在捕捉微妙内在状态中的作用外,该研究还为情感计算和人机交互系统的未来设计提供了宝贵见解。
点此查看论文截图





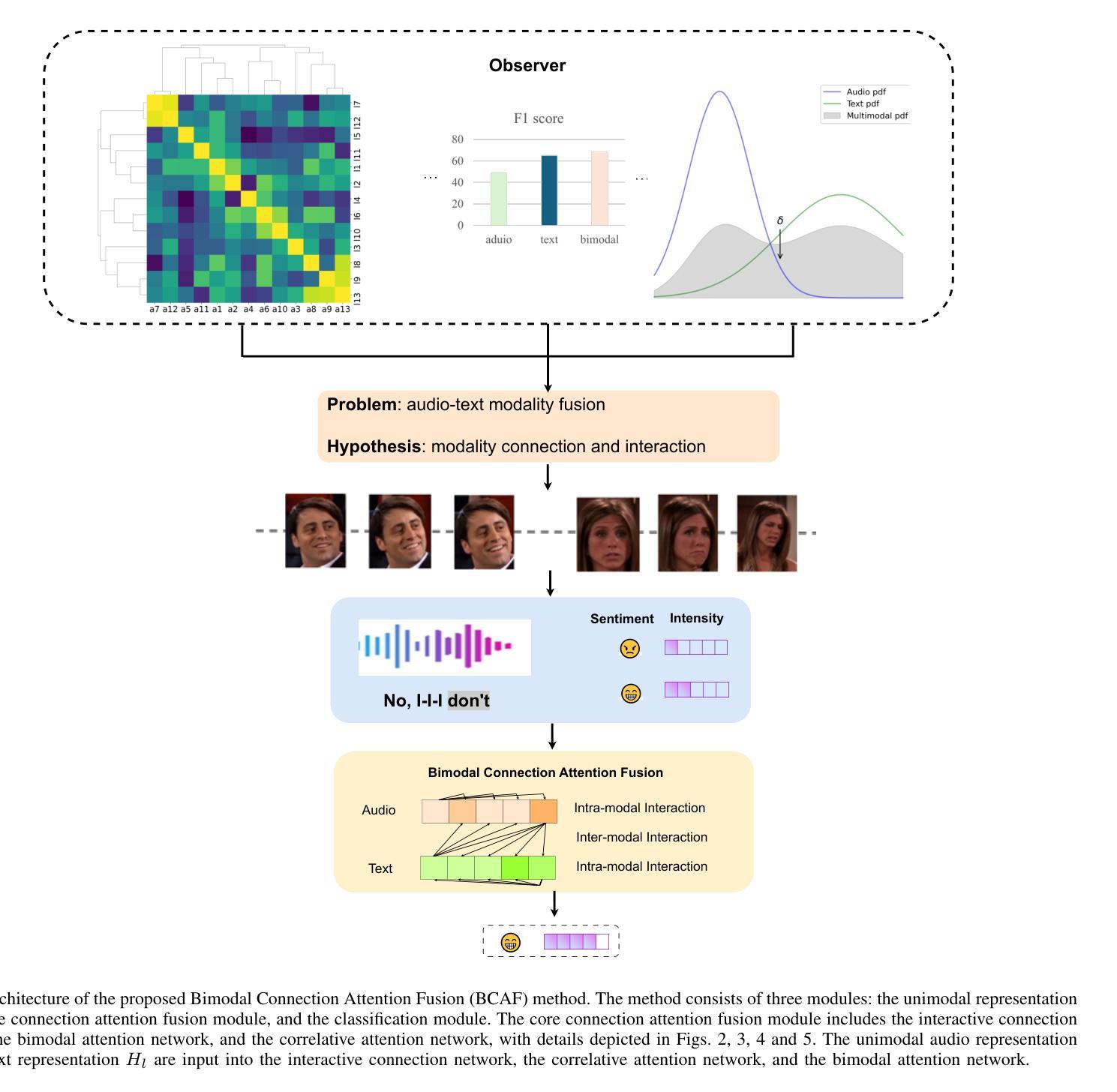
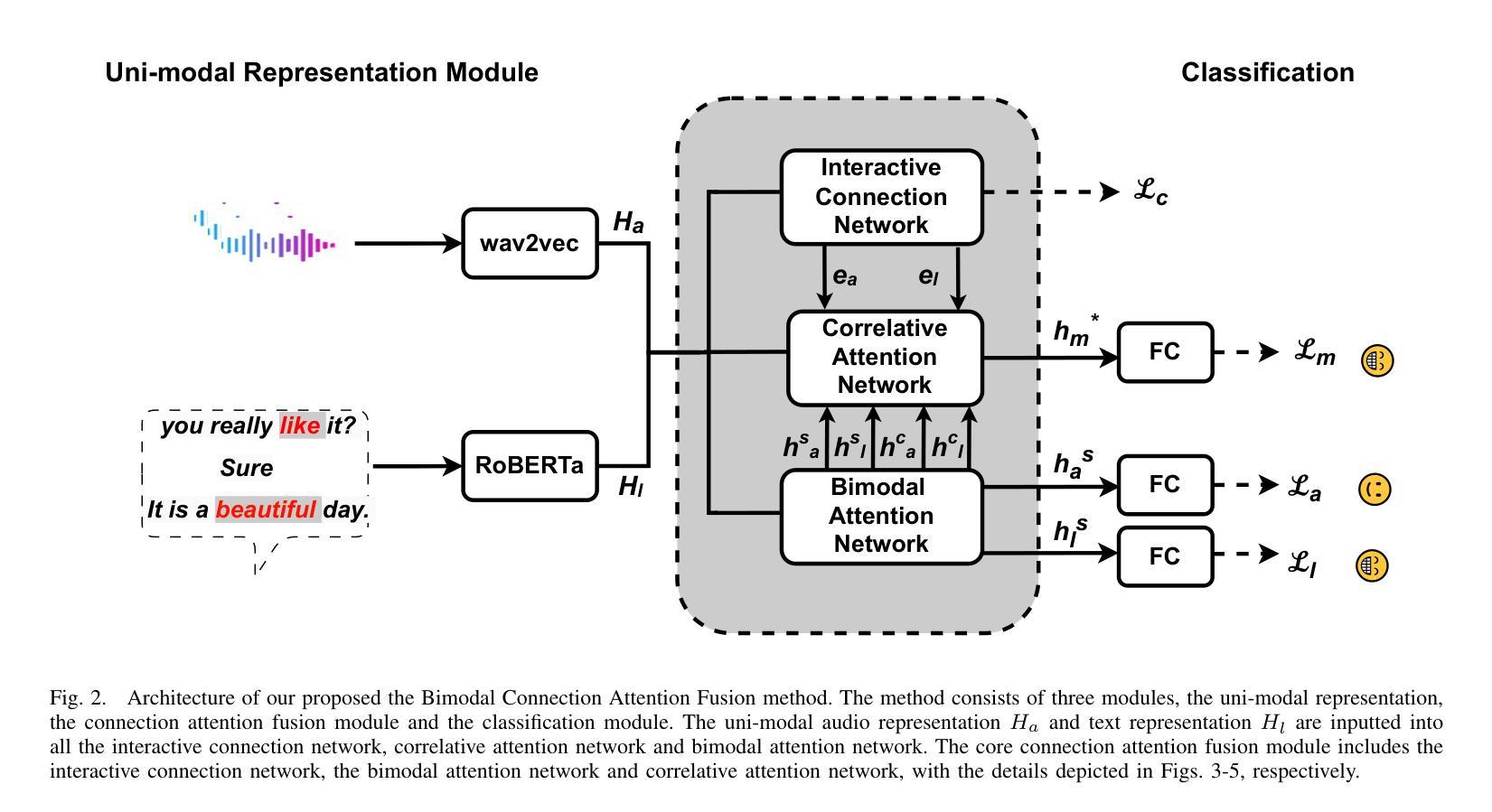
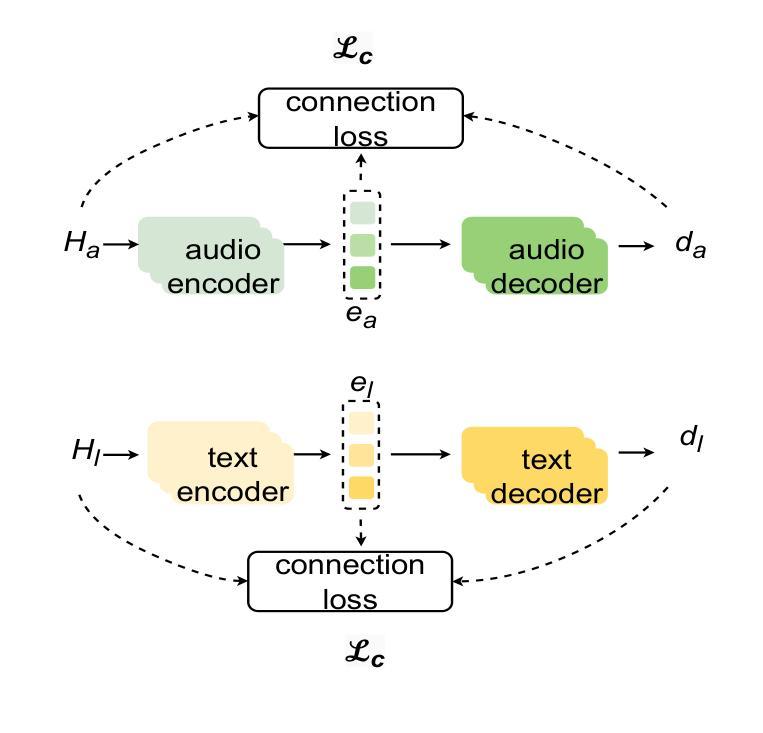
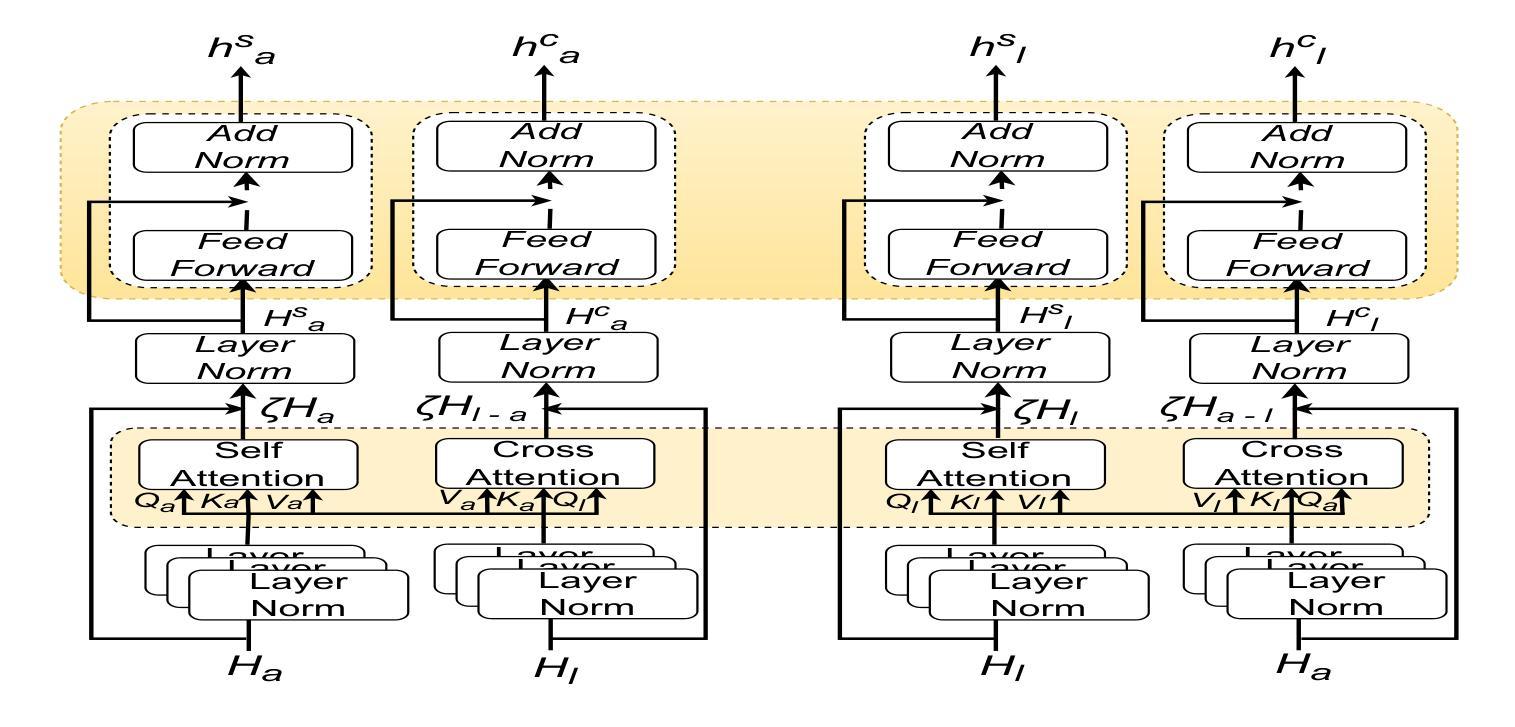
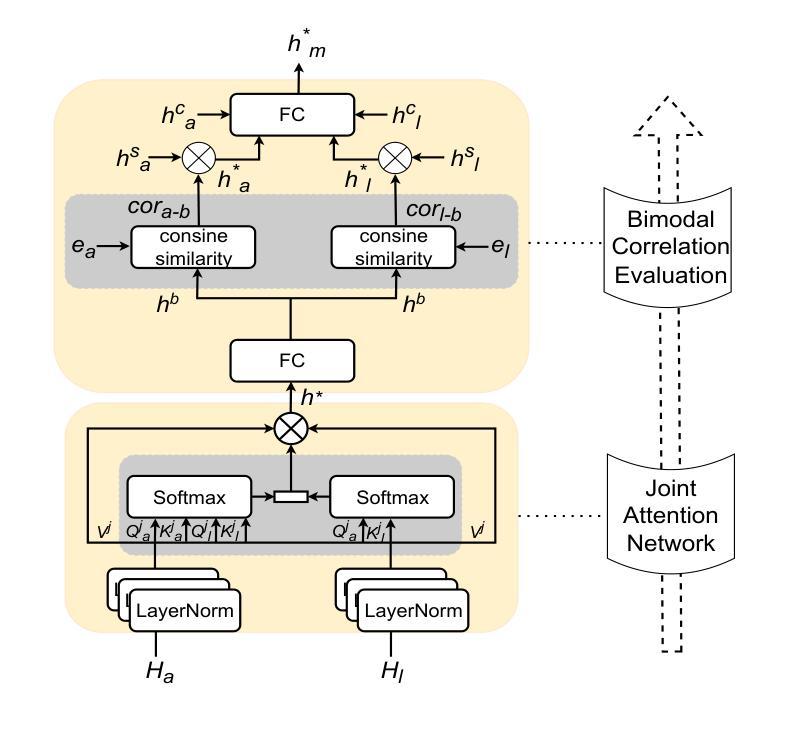
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Authors:Jiachen Luo, Huy Phan, Lin Wang, Joshua D. Reiss
Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
多模态情感识别在提取捕捉微妙情感差异的特征方面存在挑战。理解多模态交互和连接是构建有效的双模态语音情感识别系统的关键。在这项工作中,我们提出了双模态连接注意力融合(BCAF)方法,主要包括三个模块:交互连接网络、双模态注意力网络和相关性注意力网络。交互连接网络采用编码器-解码器架构,对音频和文本之间的模态连接进行建模,同时利用模态特定特征。双模态注意力网络增强了语义补充,并挖掘了模态内部和模态之间的交互。相关性注意力网络降低了跨模态噪声,捕捉了音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有的最先进的基线方法。
论文及项目相关链接
总结
本文提出了多模态情感识别的挑战在于提取捕捉细微情感差异的特征的难度。为了建立有效的双模态语音情感识别系统,理解多模态交互和连接是关键。为此,本文提出了双模态连接注意力融合(BCAF)方法,包括三个主要模块:交互连接网络、双模态注意力网络和相关性注意力网络。交互连接网络利用编码器-解码器架构对音频和文本之间的模态连接进行建模,同时利用模态特定特征。双模态注意力网络增强了语义补充性并探讨了模态内部和模态间的交互作用。相关性注意力网络减少了跨模态噪声并捕捉了音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有的最新基线方法。
关键见解
- 多模态情感识别的核心挑战在于提取捕捉细微情感差异的特征。
- 建立有效的双模态语音情感识别系统需要理解多模态交互和连接。
- BCAF方法包括三个主要模块:交互连接网络、双模态注意力网络和相关性注意力网络。
- 交互连接网络利用编码器-解码器架构建模音频和文本之间的模态连接,同时利用模态特定特征。
- 双模态注意力网络增强了语义补充性,探讨了模态内部和模态间的交互作用。
- 相关性注意力网络减少了跨模态噪声,增强了模型对音频和文本之间相关性的捕捉能力。
点此查看论文截图

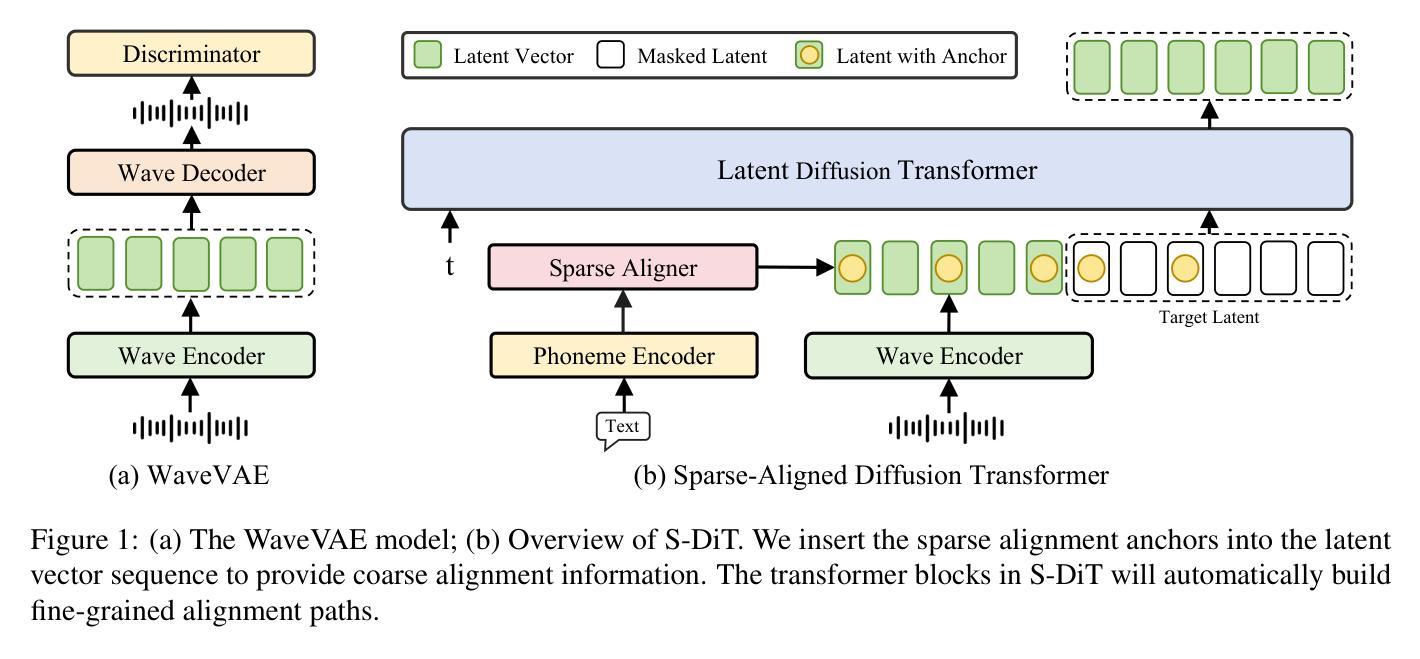
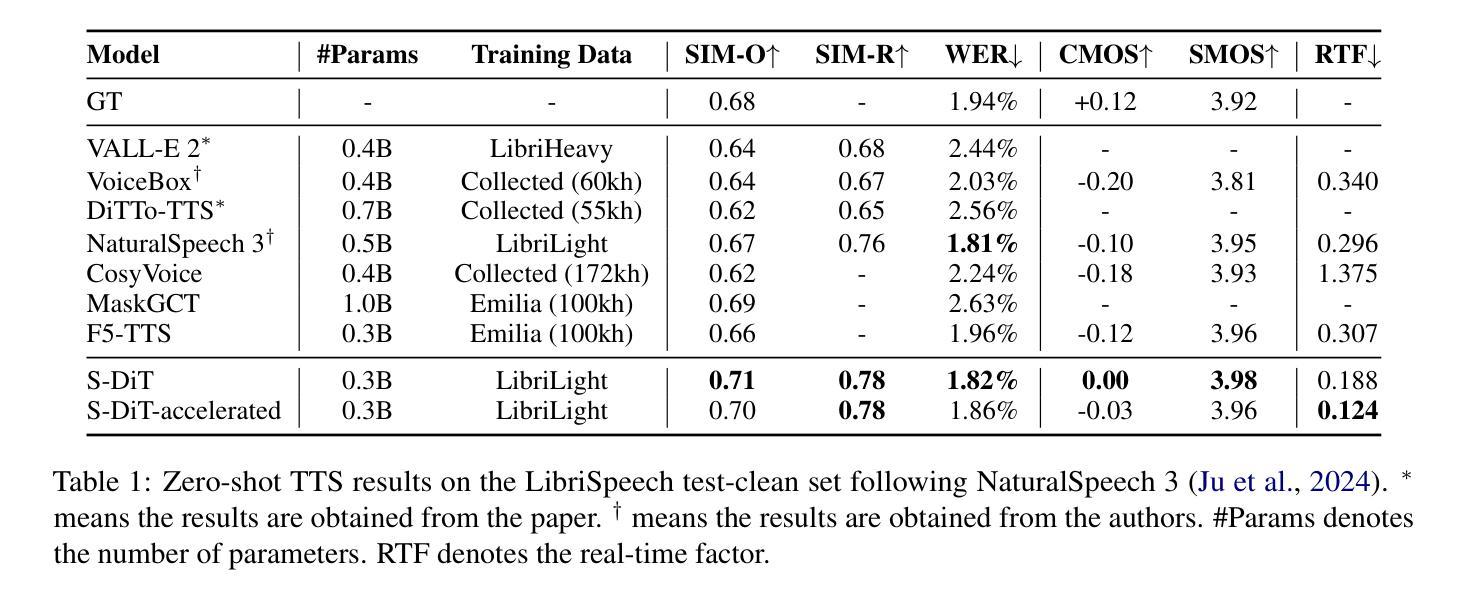
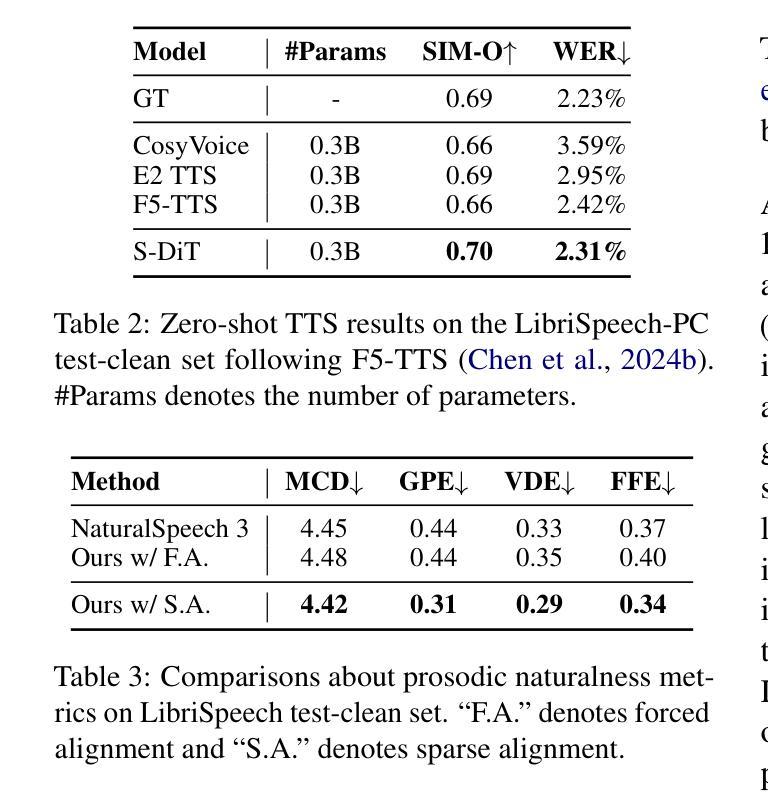
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Authors:Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, Zhou Zhao
While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
尽管最近的零样本文本到语音(TTS)模型已经显著提高了语音质量和表现力,但主流系统仍然面临与语音文本对齐建模相关的问题:1)没有明确的语音文本对齐建模的模型表现出较低的稳健性,特别是在实际应用中的难句;2)基于预定义对齐的模型受到强制对齐的自然性约束。本文介绍了S-DiT,一种具有创新稀疏对齐算法的TTS系统,该系统指导潜在扩散变压器(DiT)。具体来说,我们为S-DiT提供稀疏对齐边界,以减少对齐学习的难度,同时不限制搜索空间,从而实现高自然度。此外,我们采用多条件无分类指导策略进行口音强度调整,并采用分段整流流技术来加速生成过程。实验表明,S-DiT达到了最先进的零样本TTS语音质量,并对口音强度实现了高度灵活的控制。值得注意的是,我们的系统可以在仅8个采样步骤内生成高质量的一分钟语音。音频样本可在https://sditdemo.github.io/sditdemo/找到。
论文及项目相关链接
Summary
本文介绍了一种名为S-DiT的文本转语音(TTS)系统,其采用创新的稀疏对齐算法指导潜在扩散转换器(DiT)。通过提供稀疏对齐边界,S-DiT降低了对齐学习的难度,同时不限制搜索空间,实现了高度自然性。此外,该系统还采用多条件无分类引导策略进行口音强度调整,并采用分段整流流技术加速生成过程。实验表明,S-DiT在零样本TTS语音质量方面达到最新水平,并支持高度灵活的口音强度控制。
Key Takeaways
- S-DiT是一种新型的文本转语音(TTS)系统,采用稀疏对齐算法指导潜在扩散转换器(DiT)。
- 稀疏对齐算法提供稀疏对齐边界,降低对齐学习难度,同时保持搜索空间的高度灵活。
- S-DiT系统实现了高度自然的语音生成。
- 采用多条件无分类引导策略进行口音强度调整。
- 分段整流流技术被用于加速语音生成过程。
- 实验结果表明,S-DiT在零样本TTS语音质量方面达到最新水平。
点此查看论文截图

Multimodal Large Language Models for Image, Text, and Speech Data Augmentation: A Survey
Authors:Ranjan Sapkota, Shaina Raza, Maged Shoman, Achyut Paudel, Manoj Karkee
In the past five years, research has shifted from traditional Machine Learning (ML) and Deep Learning (DL) approaches to leveraging Large Language Models (LLMs) , including multimodality, for data augmentation to enhance generalization, and combat overfitting in training deep convolutional neural networks. However, while existing surveys predominantly focus on ML and DL techniques or limited modalities (text or images), a gap remains in addressing the latest advancements and multi-modal applications of LLM-based methods. This survey fills that gap by exploring recent literature utilizing multimodal LLMs to augment image, text, and audio data, offering a comprehensive understanding of these processes. We outlined various methods employed in the LLM-based image, text and speech augmentation, and discussed the limitations identified in current approaches. Additionally, we identified potential solutions to these limitations from the literature to enhance the efficacy of data augmentation practices using multimodal LLMs. This survey serves as a foundation for future research, aiming to refine and expand the use of multimodal LLMs in enhancing dataset quality and diversity for deep learning applications. (Surveyed Paper GitHub Repo: https://github.com/WSUAgRobotics/data-aug-multi-modal-llm. Keywords: LLM data augmentation, Grok text data augmentation, DeepSeek image data augmentation, Grok speech data augmentation, GPT audio augmentation, voice augmentation, DeepSeek for data augmentation, DeepSeek R1 text data augmentation, DeepSeek R1 image augmentation, Image Augmentation using LLM, Text Augmentation using LLM, LLM data augmentation for deep learning applications)
过去五年,研究已从传统机器学习和深度学习(DL)方法转向利用大型语言模型(LLM),包括多模态数据增强来提升泛化能力,并应对深度卷积神经网络训练中的过拟合问题。然而,尽管现有调查主要集中在ML和DL技术或有限模式(文本或图像)上,但在解决基于LLM的方法的最新进展和多模态应用方面仍存在差距。本调查通过探索利用多模态LLM增强图像、文本和音频数据的最新文献来填补这一空白,全面理解这些过程。我们概述了基于LLM的图像、文本和语音增强所采用的各种方法,并讨论了当前方法中所识别的局限性。此外,我们从文献中确定了解决这些局限性的潜在解决方案,以提高使用多模态LLM的数据增强实践的有效性。本调查为未来研究奠定了基础,旨在完善并扩大多模态LLM在深度学习应用中的使用,以提高数据集的质量和多样性。(已调查论文GitHub仓库:https://github.com/WSUAgRobotics/data-aug-multi-modal-llm。关键词:LLM数据增强、Grok文本数据增强、DeepSeek图像数据增强、Grok语音数据增强、GPT音频增强、语音增强、DeepSeek用于数据增强、DeepSeek R1文本数据增强、DeepSeek R1图像增强、利用LLM进行图像增强、利用LLM进行文本增强、LLM数据增强在深度学习应用)
论文及项目相关链接
PDF 52 pages
摘要
这篇调研论文填补了关于多模态大型语言模型在数据增强领域的空白,详细探讨了利用多模态大型语言模型增强图像、文本和语音数据的最新文献。文章概述了基于大型语言模型的图像、文本和语音增强的各种方法,并讨论了当前方法的局限性以及从文献中识别出的解决这些局限性的潜在解决方案。这为未来研究提供了基础,旨在改进和拓展多模态大型语言模型在提升深度学习应用数据集质量和多样性方面的使用。
关键见解
- 调研论文填补了关于多模态大型语言模型(LLMs)在数据增强领域的空白。
- 论文详细探讨了LLMs在图像、文本和语音数据增强中的最新应用。
- 文章概述了基于LLMs的各种数据增强方法,并指出了它们的局限性。
- 调研论文从文献中识别出了解决LLMs数据增强方法局限性的潜在解决方案。
- 该论文旨在为未来的研究提供基础,特别是在改进和拓展多模态LLMs在提高深度学习数据集质量和多样性方面的应用。
- 论文强调了多模态LLMs在深度学习领域的重要性,特别是在数据增强和对抗过拟合方面的应用。
点此查看论文截图

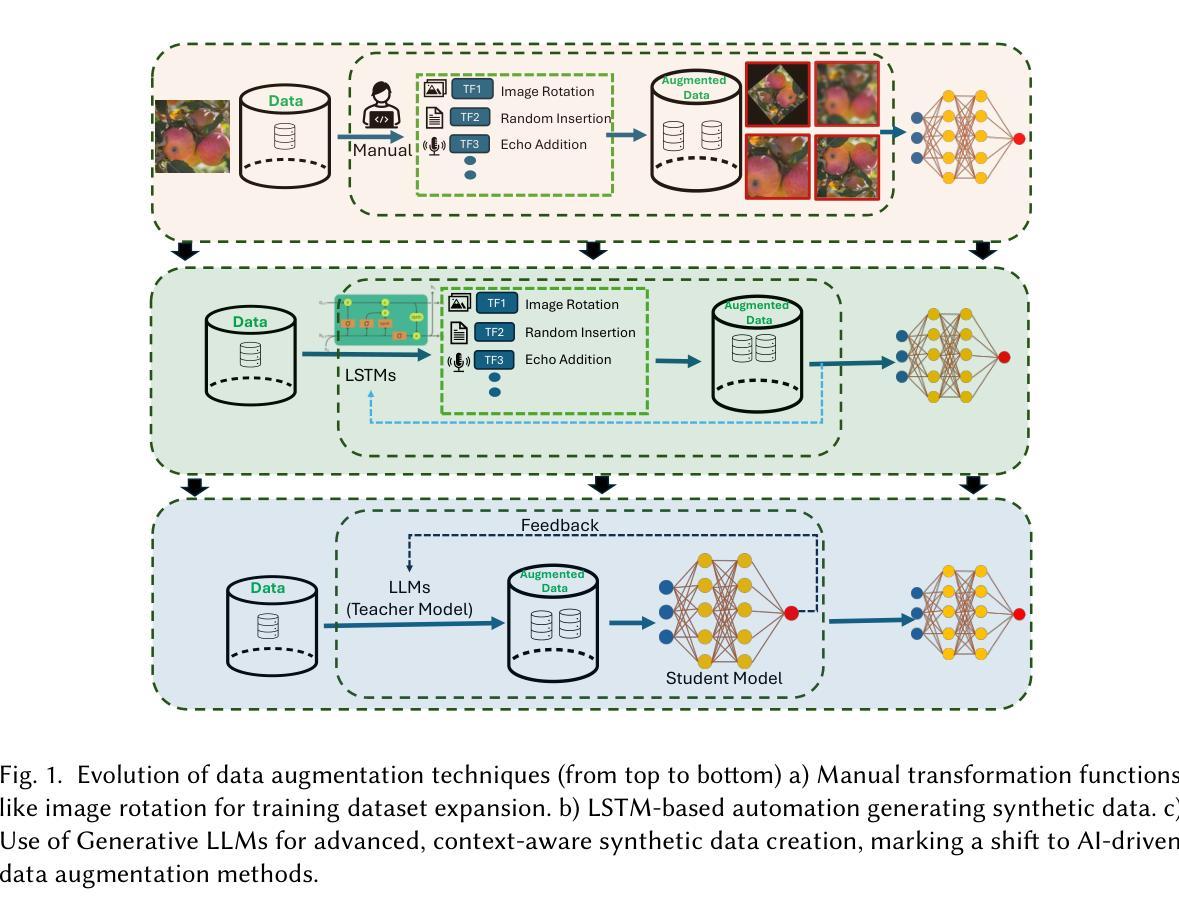
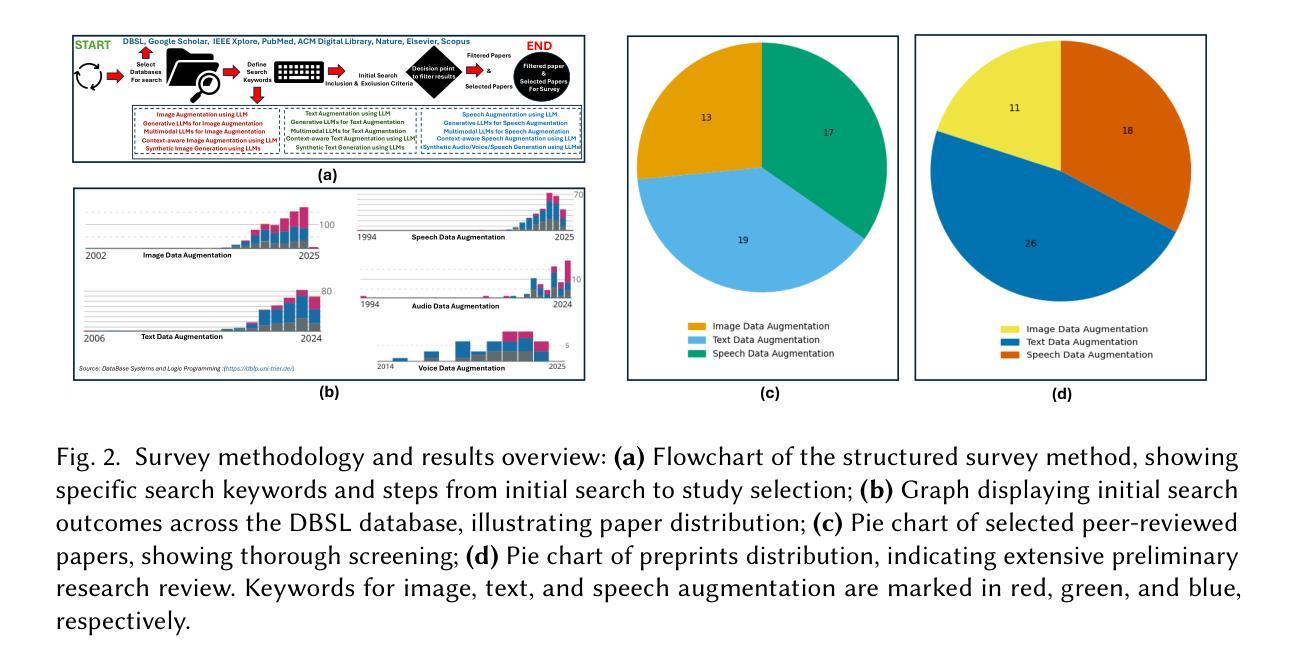
k2SSL: A Faster and Better Framework for Self-Supervised Speech Representation Learning
Authors:Yifan Yang, Jianheng Zhuo, Zengrui Jin, Ziyang Ma, Xiaoyu Yang, Zengwei Yao, Liyong Guo, Wei Kang, Fangjun Kuang, Long Lin, Daniel Povey, Xie Chen
Self-supervised learning (SSL) has achieved great success in speech-related tasks. While Transformer and Conformer architectures have dominated SSL backbones, encoders like Zipformer, which excel in automatic speech recognition (ASR), remain unexplored in SSL. Concurrently, inefficiencies in data processing within existing SSL training frameworks, such as fairseq, pose challenges in managing the growing volumes of training data. To address these issues, we propose k2SSL, an open-source framework that offers faster, more memory-efficient, and better-performing self-supervised speech representation learning, focusing on downstream ASR tasks. The optimized HuBERT and proposed Zipformer-based SSL systems exhibit substantial reductions in both training time and memory usage during SSL training. Experiments on LibriSpeech demonstrate that Zipformer Base significantly outperforms HuBERT and WavLM, achieving up to a 34.8% relative WER reduction compared to HuBERT Base after fine-tuning, along with a 3.5x pre-training speedup in GPU hours. When scaled to 60k hours of LibriLight data, Zipformer Large exhibits remarkable efficiency, matching HuBERT Large’s performance while requiring only 5/8 pre-training steps.
自监督学习(SSL)在语音相关任务中取得了巨大成功。虽然Transformer和Conformer架构在SSL主干中占据主导地位,但像Zipformer这样的编码器在自动语音识别(ASR)方面表现出色,但在SSL中仍未被探索。同时,现有SSL训练框架(如fairseq)在数据处理方面的低效性,为管理不断增长的训练数据带来了挑战。为了解决这些问题,我们提出了k2SSL,这是一个开源框架,提供更快、更省内存、性能更好的自监督语音表示学习,专注于下游ASR任务。优化的HuBERT和提出的基于Zipformer的SSL系统,在SSL训练过程中实现了训练时间和内存使用的显著减少。在LibriSpeech上的实验表明,Zipformer Base在微调后相对于HuBERT和WavLM有显著的优势,实现了高达34.8%的相对WER(词错误率)降低。此外,与HuBERT Base相比,Zipformer Large在扩展到60k小时的LibriLight数据时,展现了卓越的效率,匹配了HuBERT Large的性能,但仅需要5/8的预训练步骤。
论文及项目相关链接
PDF Accepted in ICME 2025
Summary
SSL在语音任务中取得了巨大成功,但现有的框架如fairseq在处理大量训练数据时存在效率问题。为此,我们提出了k2SSL框架,专注于下游ASR任务的自我监督语音表示学习,具有更快、更省内存、性能更好的特点。基于Zipformer的SSL系统优化后,在LibriSpeech上的实验显示,Zipformer Base在微调后相对于HuBERT和WavLM有显著的性能提升,相对字错误率(WER)降低了34.8%。同时,GPU小时预训练速度提高了3.5倍。当扩展到LibriLight的6万小时数据时,Zipformer Large展现了卓越的效率,匹配了HuBERT Large的性能,但预训练步骤仅需要其五分之八。
Key Takeaways
- SSL在语音任务中的成功应用被广泛报道,但仍存在数据处理效率问题。
- k2SSL框架旨在解决这些问题,提供更高效、更快速的自我监督语音表示学习。
- Zipformer作为一种新的编码器架构,在SSL中表现出良好性能,特别是在ASR任务中。
- 在LibriSpeech数据集上进行的实验显示,Zipformer Base相对于其他模型显著提高了性能。
- Zipformer Large在处理大量数据时展现出卓越的效率。
点此查看论文截图

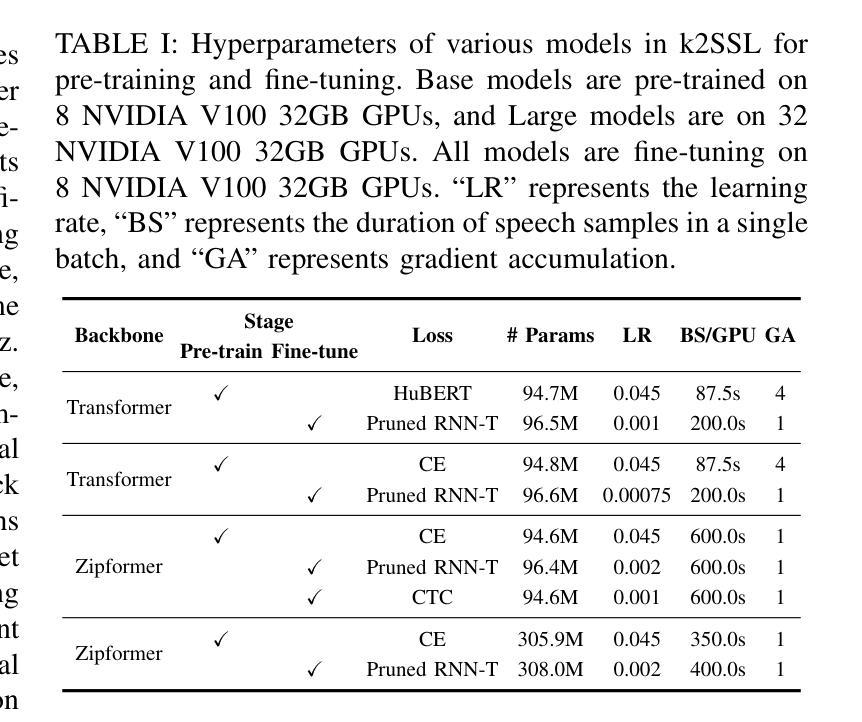
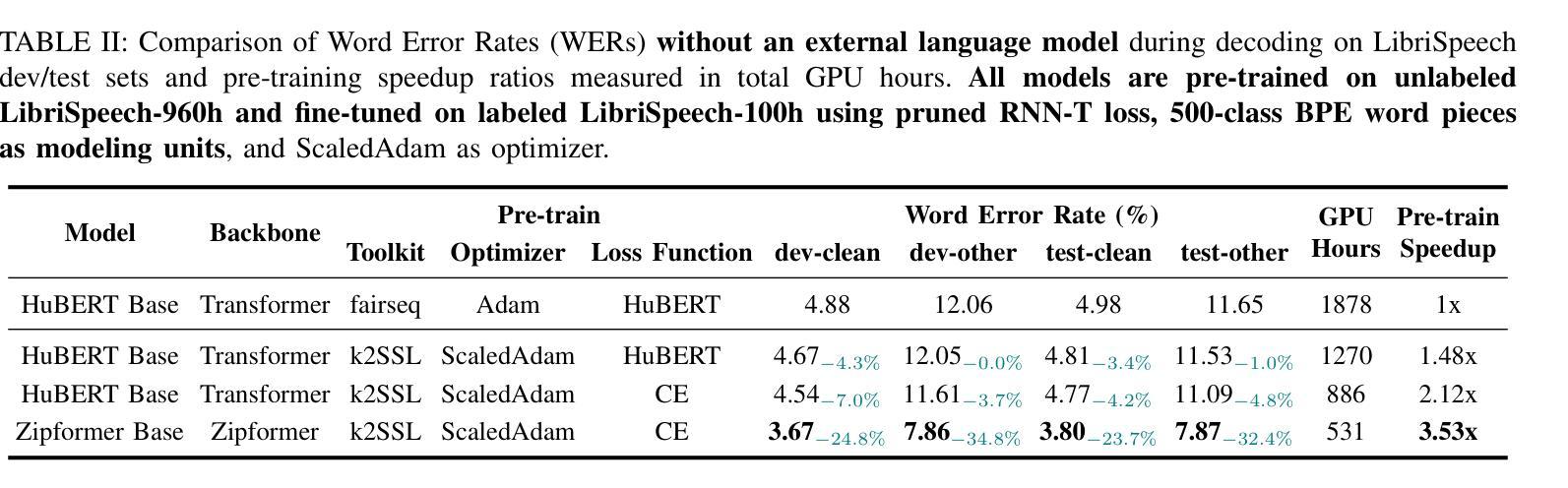
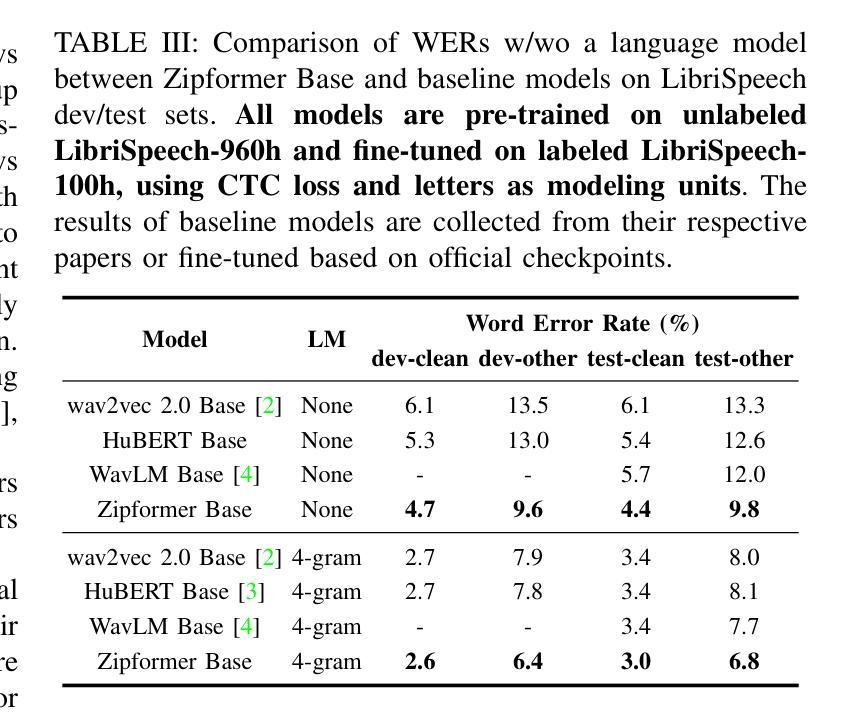
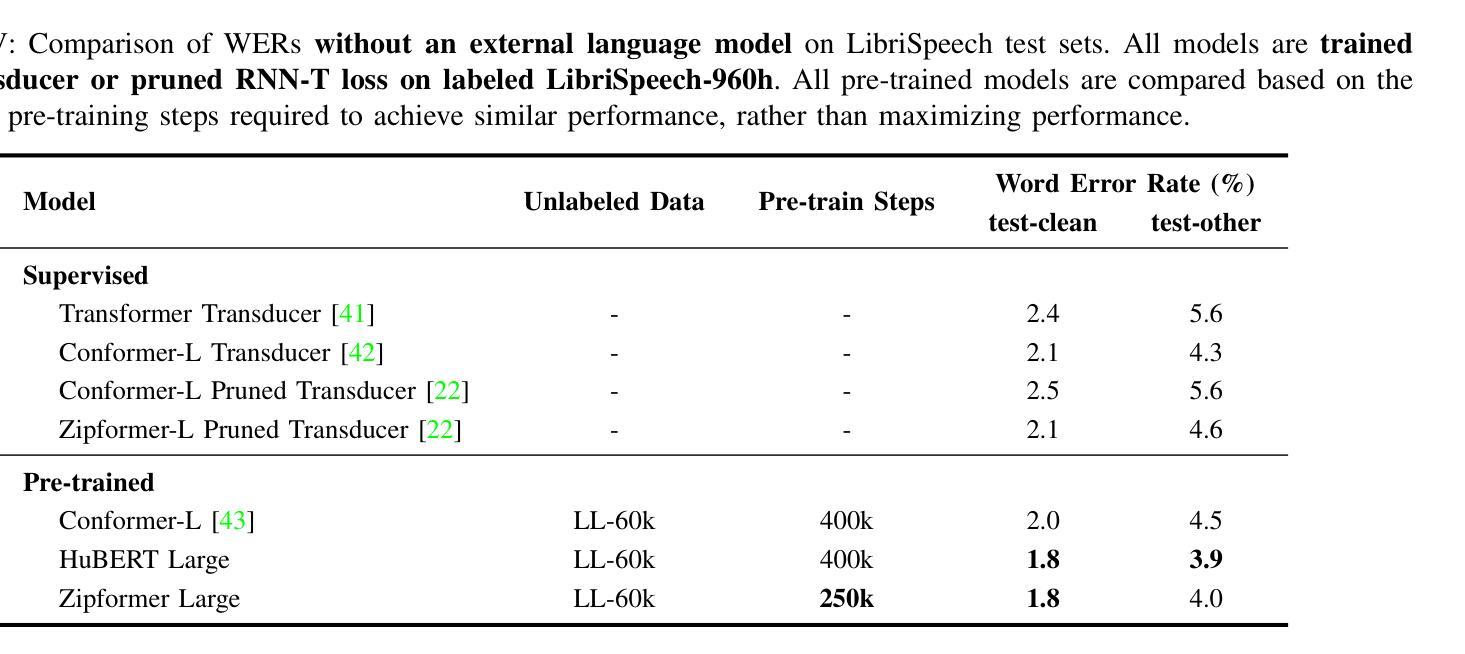
Enhancing Multimodal Sentiment Analysis for Missing Modality through Self-Distillation and Unified Modality Cross-Attention
Authors:Yuzhe Weng, Haotian Wang, Tian Gao, Kewei Li, Shutong Niu, Jun Du
In multimodal sentiment analysis, collecting text data is often more challenging than video or audio due to higher annotation costs and inconsistent automatic speech recognition (ASR) quality. To address this challenge, our study has developed a robust model that effectively integrates multimodal sentiment information, even in the absence of text modality. Specifically, we have developed a Double-Flow Self-Distillation Framework, including Unified Modality Cross-Attention (UMCA) and Modality Imagination Autoencoder (MIA), which excels at processing both scenarios with complete modalities and those with missing text modality. In detail, when the text modality is missing, our framework uses the LLM-based model to simulate the text representation from the audio modality, while the MIA module supplements information from the other two modalities to make the simulated text representation similar to the real text representation. To further align the simulated and real representations, and to enable the model to capture the continuous nature of sample orders in sentiment valence regression tasks, we have also introduced the Rank-N Contrast (RNC) loss function. When testing on the CMU-MOSEI, our model achieved outstanding performance on MAE and significantly outperformed other models when text modality is missing. The code is available at: https://github.com/WarmCongee/SDUMC
在多模态情感分析中,由于标注成本更高和自动语音识别(ASR)质量的不一致性,收集文本数据通常比视频或音频更具挑战性。为了应对这一挑战,我们的研究开发了一个稳健的模型,该模型能够有效地整合多模态情感信息,即使在缺少文本模式的情况下也是如此。具体来说,我们开发了双流自蒸馏框架,包括统一模态交叉注意(UMCA)和模态想象自编码器(MIA),它擅长处理具有完整模态的场景和缺失文本模态的场景。在细节上,当缺少文本模态时,我们的框架使用基于LLM的模型来模拟从音频模态的文本表示,而MIA模块补充了来自其他两个模态的信息,以使模拟的文本表示与真实的文本表示相似。为了进一步对齐模拟和真实表示,并使模型能够捕获情感价回归任务中样本顺序的连续性,我们还引入了Rank-N Contrast(RNC)损失函数。在CMU-MOSEI上进行测试时,我们的模型在MAE上表现卓越,并且在缺少文本模态的情况下显著优于其他模型。代码可访问:https://github.com/WarmCongee/SDUMC
论文及项目相关链接
Summary
本文研究了多模态情感分析中的文本数据收集挑战,提出了一种双流自蒸馏框架,包括统一模态跨注意力和模态想象自编码器,能够在缺失文本模态的情况下有效地整合多模态情感信息。该框架利用大型语言模型从音频模态模拟文本表示,并使用MIA模块补充其他两个模态的信息,以生成逼真的文本表示。此外,引入了Rank-N Contrast损失函数,以进一步对齐模拟和真实表示,并捕获情感价值回归任务中样本顺序的连续性。在CMU-MOSEI数据集上的测试表明,该模型在MAE上表现出卓越的性能,并在缺失文本模态的情况下显著优于其他模型。
Key Takeaways
- 多模态情感分析中,文本数据收集面临高标注成本和自动语音识别质量不一致的挑战。
- 提出的双流自蒸馏框架能够整合多模态情感信息,尤其在缺失文本模态时表现优异。
- 利用大型语言模型从音频模态模拟文本表示,以填补文本缺失的问题。
- 引入MIA模块来补充其他模态的信息,增强模拟文本表示的真实性。
- 采用Rank-N Contrast损失函数,以对齐模拟和真实表示,并捕获情感价值回归任务的样本连续性。
- 在CMU-MOSEI数据集上的测试显示,模型在MAE上表现卓越。
点此查看论文截图

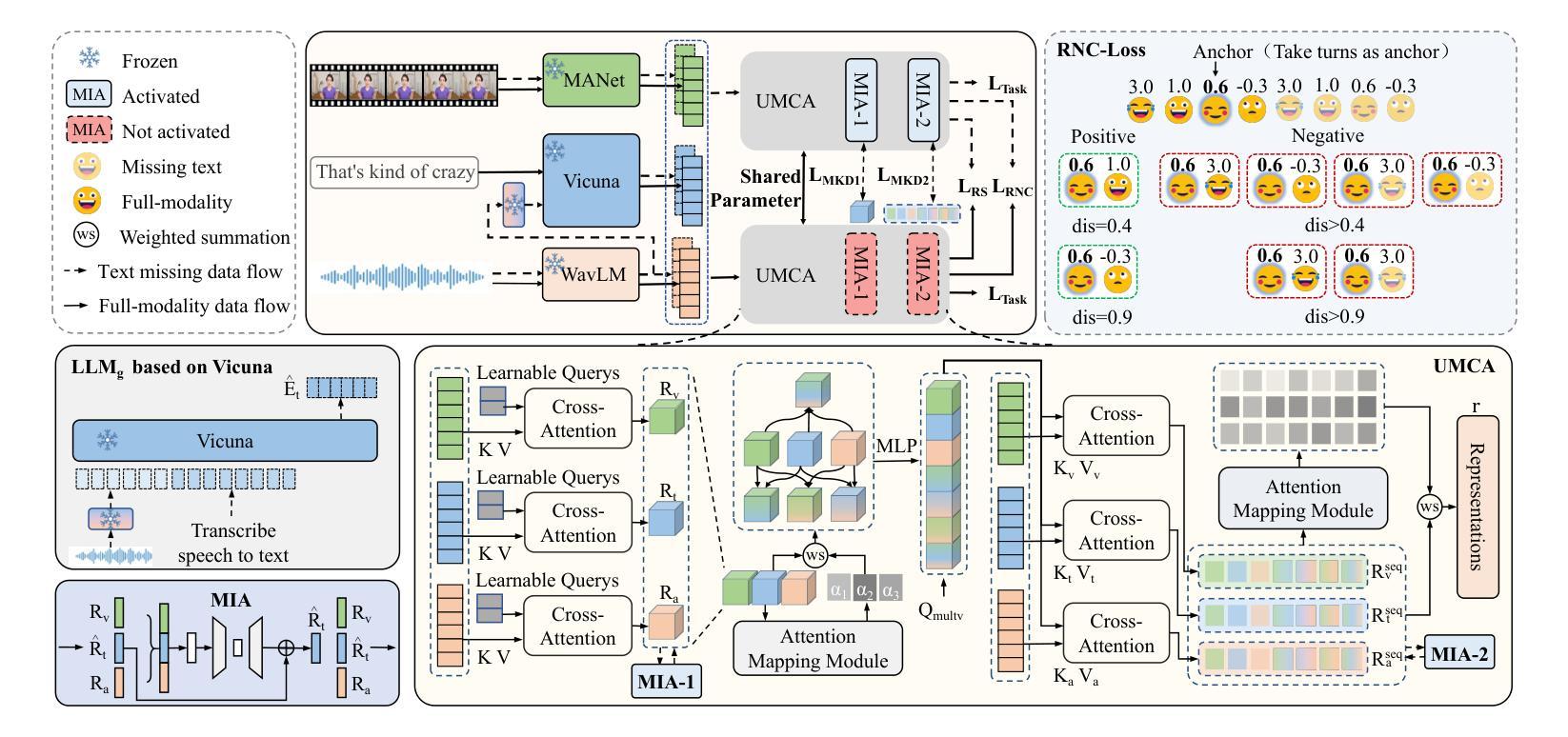

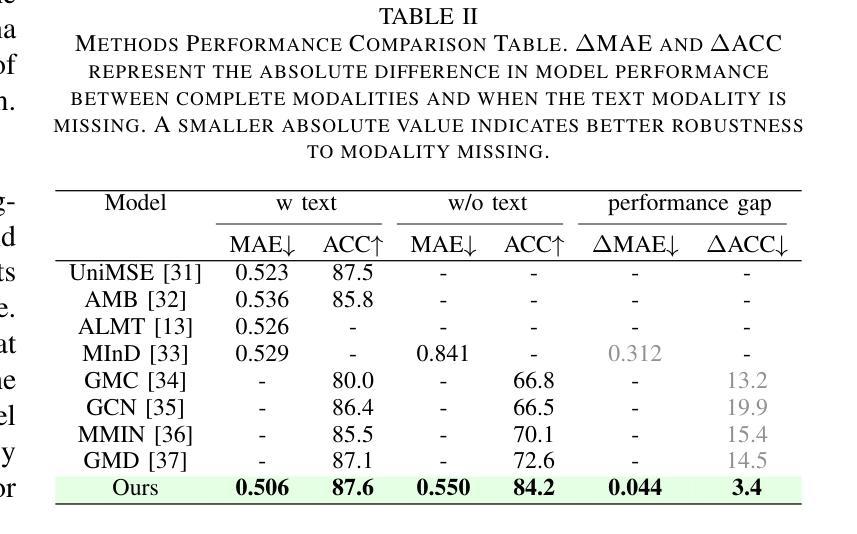
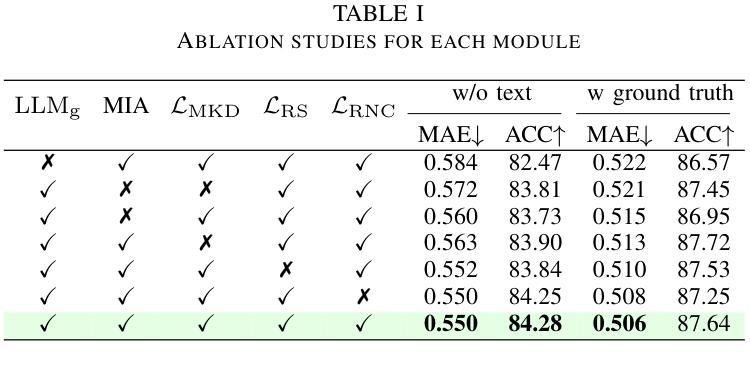
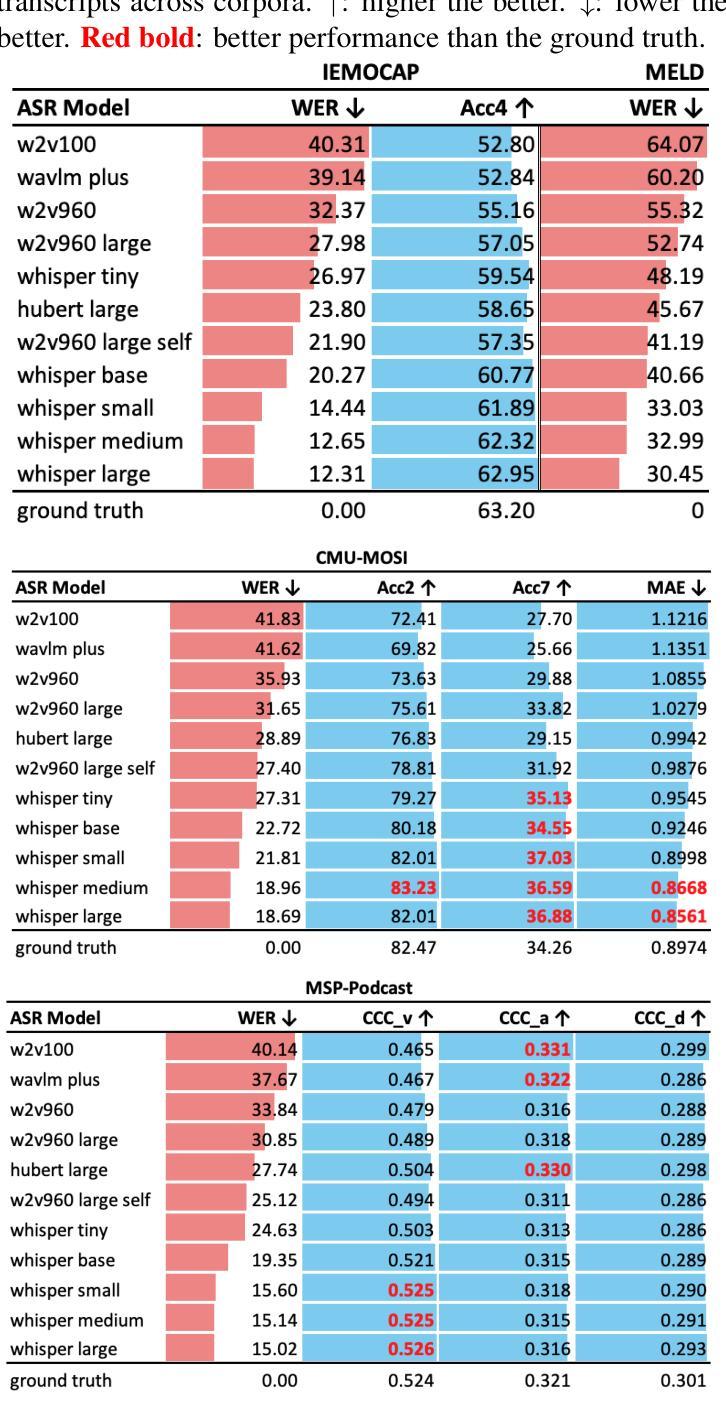
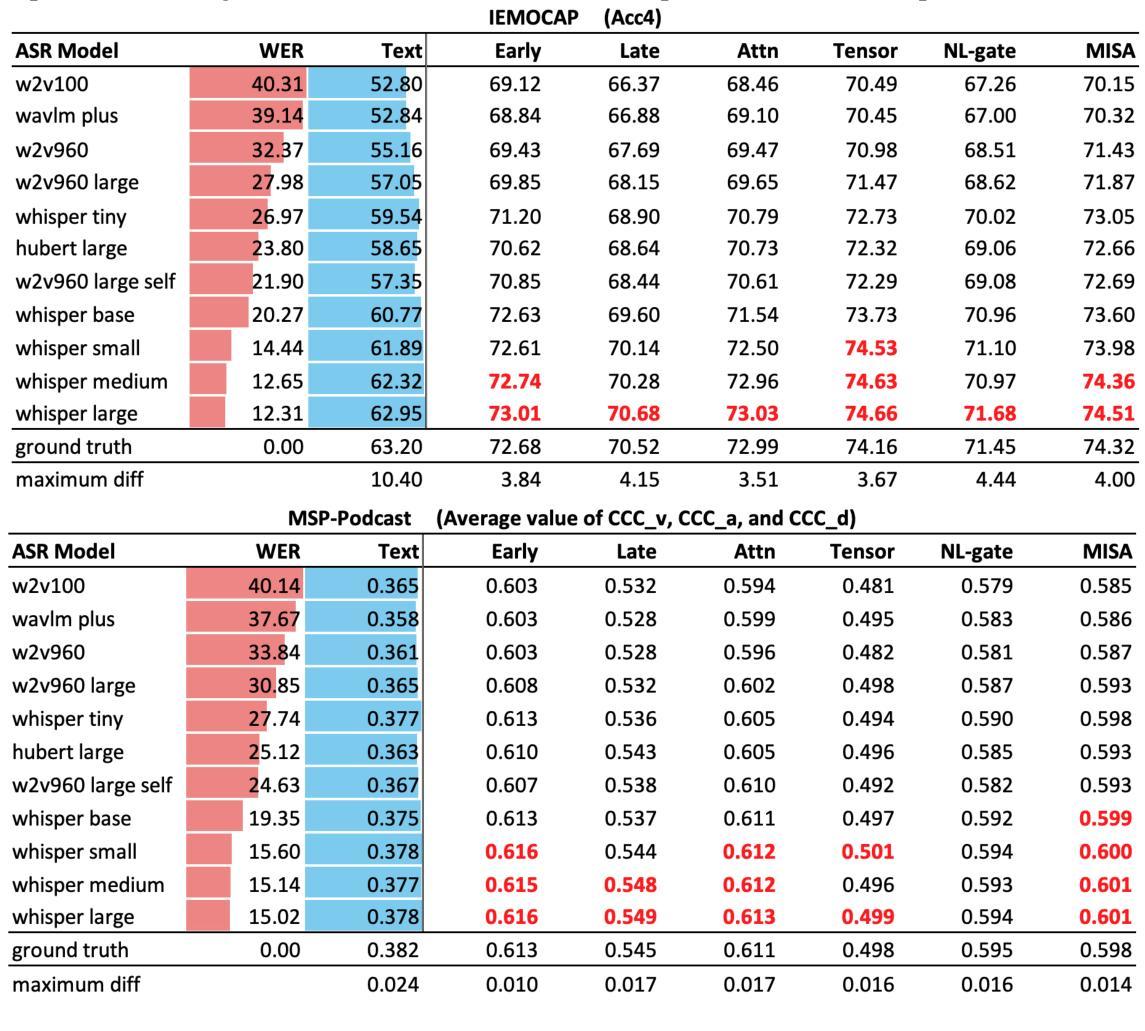
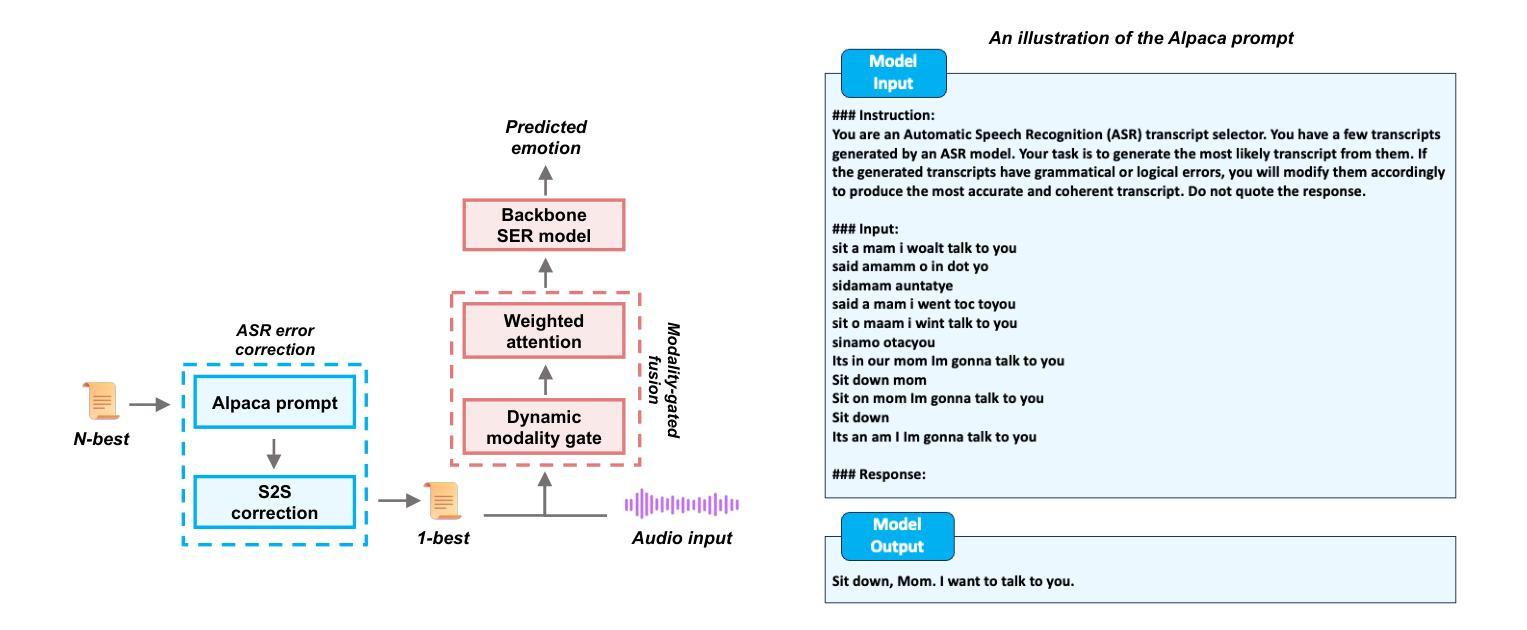
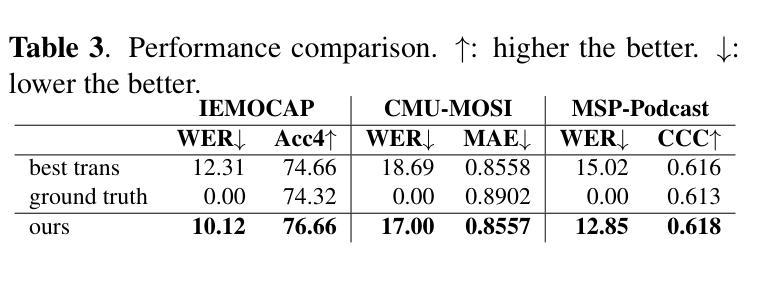
Speech Emotion Recognition with ASR Transcripts: A Comprehensive Study on Word Error Rate and Fusion Techniques
Authors:Yuanchao Li, Peter Bell, Catherine Lai
Text data is commonly utilized as a primary input to enhance Speech Emotion Recognition (SER) performance and reliability. However, the reliance on human-transcribed text in most studies impedes the development of practical SER systems, creating a gap between in-lab research and real-world scenarios where Automatic Speech Recognition (ASR) serves as the text source. Hence, this study benchmarks SER performance using ASR transcripts with varying Word Error Rates (WERs) from eleven models on three well-known corpora: IEMOCAP, CMU-MOSI, and MSP-Podcast. Our evaluation includes both text-only and bimodal SER with six fusion techniques, aiming for a comprehensive analysis that uncovers novel findings and challenges faced by current SER research. Additionally, we propose a unified ASR error-robust framework integrating ASR error correction and modality-gated fusion, achieving lower WER and higher SER results compared to the best-performing ASR transcript. These findings provide insights into SER with ASR assistance, especially for real-world applications.
文本数据通常作为主要的输入,用来提高语音情感识别(SER)的性能和可靠性。然而,大多数研究对人类转录文本的依赖阻碍了实用SER系统的发展,从而在实验室研究和现实世界的场景之间产生了一个差距,在现实世界的场景中,自动语音识别(ASR)作为文本来源。因此,本研究以ASR转录稿的单词错误率(WER)为基准,评估了十一个模型在三个知名语料库(IEMOCAP、CMU-MOSI和MSP-Podcast)上的SER性能。我们的评估包括仅使用文本和双向SER两种方法,使用六种融合技术,旨在进行全面的分析,揭示当前SER研究面临的新发现和挑战。此外,我们提出了一个统一的ASR错误鲁棒框架,融合了ASR错误校正和模态门融合技术,实现了较低的WER和较高的SER结果,超过了表现最佳的ASR转录。这些发现对ASR辅助的SER有深入见解,特别是在现实世界的应用中。
论文及项目相关链接
PDF Accepted to IEEE SLT 2024. Fixed table and figure reference mistakes in the IEEE Xplore version
Summary
本文主要探讨了语音情感识别(SER)中利用文本数据作为主输入的问题。研究中对自动语音识别(ASR)转写的文本在各种情况下的性能进行了评估,并提出了一个统一的ASR误差鲁棒框架,旨在提高SER在真实世界应用中的性能和可靠性。
Key Takeaways
- 文本数据是增强语音情感识别(SER)性能和可靠性的主要输入。
- 大多数研究过于依赖人工转写的文本,阻碍了实际SER系统的发展。
- 研究者对ASR转写的文本在不同情况下的性能进行了评估,选择了三个著名语料库和十一款模型进行了测试。
- 采用多种融合技术的全面评估包括文本模式和双模态SER,旨在发现新的研究问题和挑战。
点此查看论文截图