⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
Video-T1: Test-Time Scaling for Video Generation
Authors:Fangfu Liu, Hanyang Wang, Yimo Cai, Kaiyan Zhang, Xiaohang Zhan, Yueqi Duan
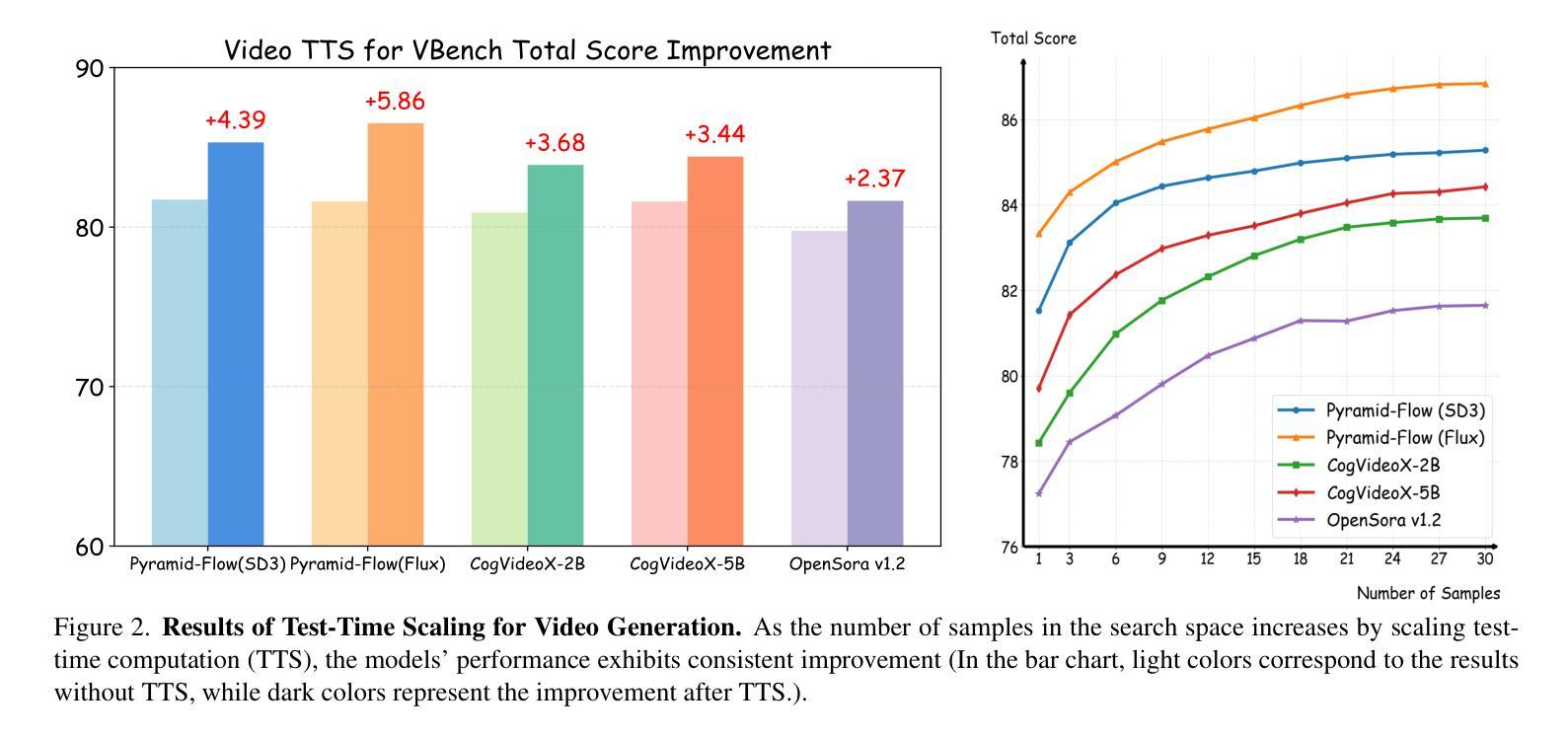
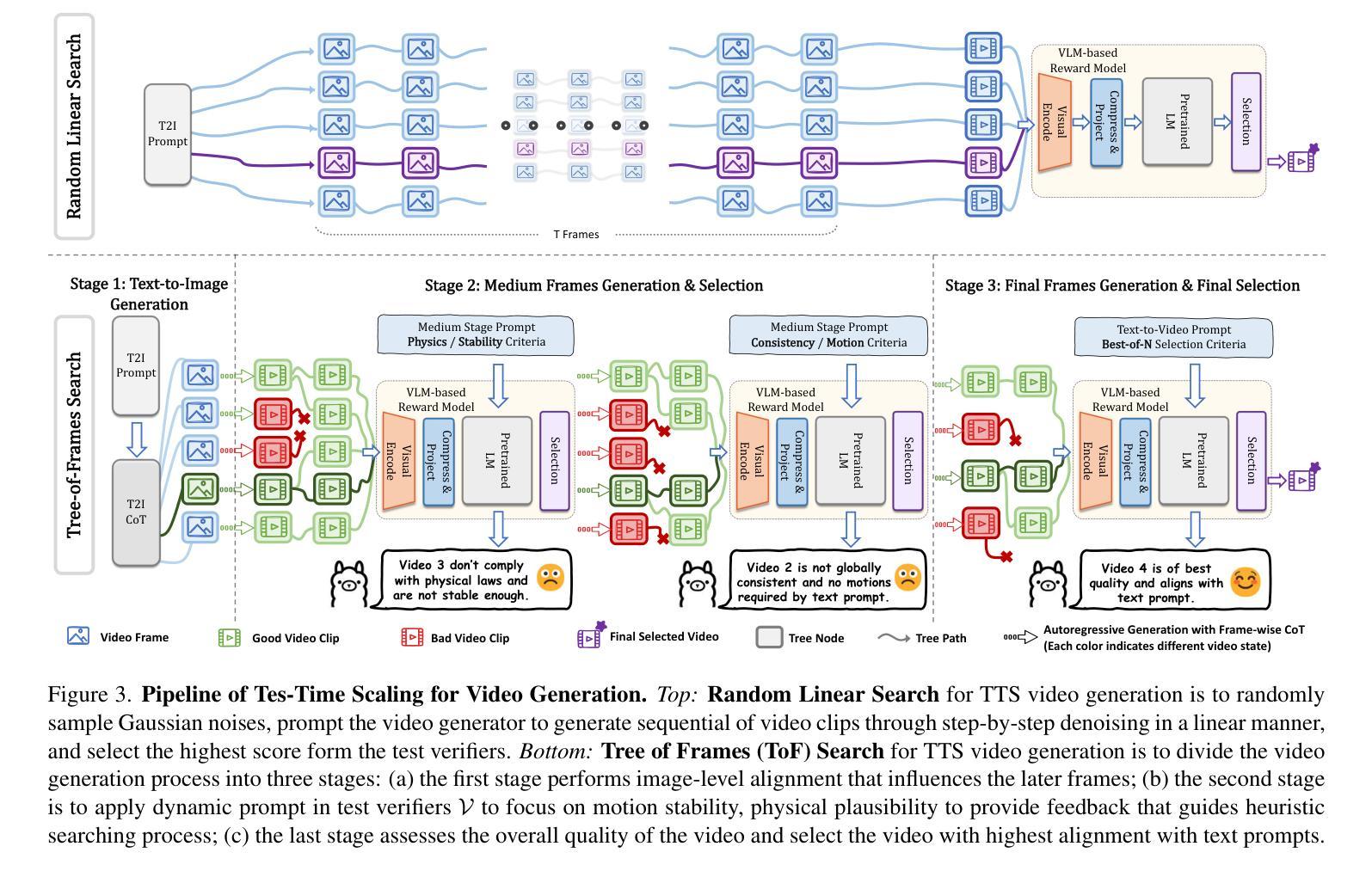
With the scale capability of increasing training data, model size, and computational cost, video generation has achieved impressive results in digital creation, enabling users to express creativity across various domains. Recently, researchers in Large Language Models (LLMs) have expanded the scaling to test-time, which can significantly improve LLM performance by using more inference-time computation. Instead of scaling up video foundation models through expensive training costs, we explore the power of Test-Time Scaling (TTS) in video generation, aiming to answer the question: if a video generation model is allowed to use non-trivial amount of inference-time compute, how much can it improve generation quality given a challenging text prompt. In this work, we reinterpret the test-time scaling of video generation as a searching problem to sample better trajectories from Gaussian noise space to the target video distribution. Specifically, we build the search space with test-time verifiers to provide feedback and heuristic algorithms to guide searching process. Given a text prompt, we first explore an intuitive linear search strategy by increasing noise candidates at inference time. As full-step denoising all frames simultaneously requires heavy test-time computation costs, we further design a more efficient TTS method for video generation called Tree-of-Frames (ToF) that adaptively expands and prunes video branches in an autoregressive manner. Extensive experiments on text-conditioned video generation benchmarks demonstrate that increasing test-time compute consistently leads to significant improvements in the quality of videos. Project page: https://liuff19.github.io/Video-T1
随着训练数据、模型规模和计算成本的规模能力不断提升,视频生成在数字创作中取得了令人印象深刻的结果,使用户能够在各种领域表达创造力。最近,大型语言模型(LLM)的研究人员将规模扩展到了测试阶段,通过增加推理时间计算来显著提高LLM的性能。我们并不通过昂贵的训练成本来扩大视频基础模型的规模,而是探索视频生成中测试时间缩放(TTS)的力量,旨在回答一个问题:如果视频生成模型允许使用非微不足道的推理时间计算量,那么在具有挑战性的文本提示下,它能提高多少生成质量。在这项工作中,我们将视频生成的测试时间缩放重新解释为搜索问题,从高斯噪声空间更好地采样轨迹以到达目标视频分布。具体来说,我们构建了具有测试时间验证器的搜索空间来提供反馈和启发式算法来指导搜索过程。给定一个文本提示,我们首先探索一种直观的线性搜索策略,通过增加推理时间时的噪声候选者来进行。由于同时完全去噪所有帧需要大量的测试时间计算成本,我们进一步为视频生成设计了一种更有效的TTS方法,称为“帧树”(ToF),该方法以自回归的方式自适应地扩展和修剪视频分支。在文本条件视频生成基准测试上的大量实验表明,增加测试时间计算始终导致视频质量显著提高。项目页面:链接。
论文及项目相关链接
PDF Project page: https://liuff19.github.io/Video-T1
Summary
近期研究在视频生成领域应用测试时扩展(TTS)方法,允许模型在推理阶段使用更多计算资源以提高生成质量。本研究将视频生成的测试时扩展重新解释为搜索问题,通过构建搜索空间并利用启发式算法指导搜索过程。通过直观线性搜索策略和高效Tree-of-Frames(ToF)方法,实验证明增加推理阶段计算资源可有效提升视频生成质量。
Key Takeaways
- 视频生成领域通过增加训练数据、模型规模和计算成本,实现了令人印象深刻的数字创作能力。
- 测试时扩展(TTS)在大型语言模型(LLMs)中的应用可以显著提高LLM性能。
- 本研究将视频生成的测试时扩展解释为搜索问题,旨在通过增加推理时间计算来提高生成质量。
- 构建搜索空间,利用测试时验证器提供反馈和启发式算法指导搜索过程。
- 提出一种直观的线性搜索策略,通过增加噪声候选在推理阶段改进视频生成。
- 提出Tree-of-Frames(ToF)方法,以自适应地扩展和修剪视频分支,实现高效视频生成。
点此查看论文截图


From Faces to Voices: Learning Hierarchical Representations for High-quality Video-to-Speech
Authors:Ji-Hoon Kim, Jeongsoo Choi, Jaehun Kim, Chaeyoung Jung, Joon Son Chung
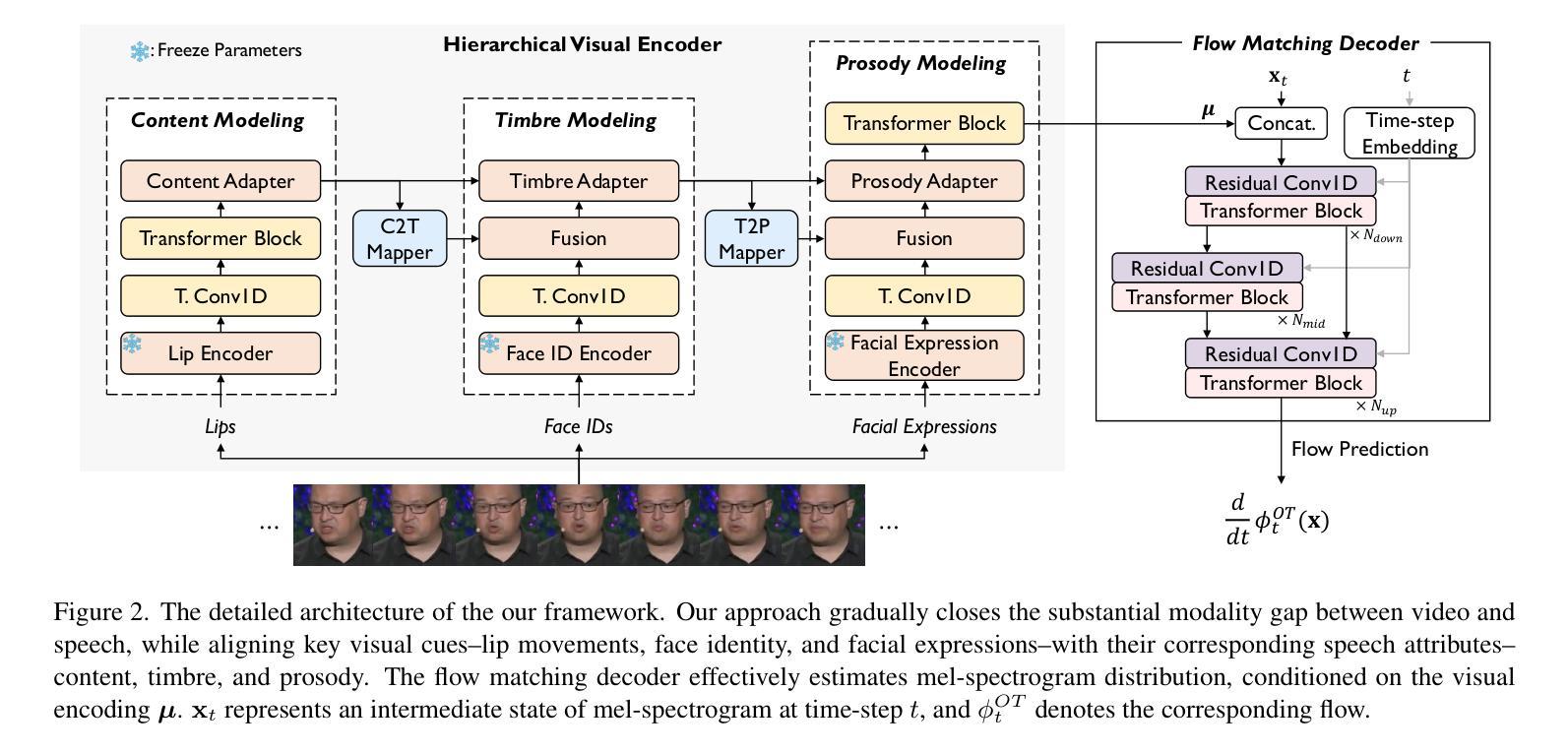
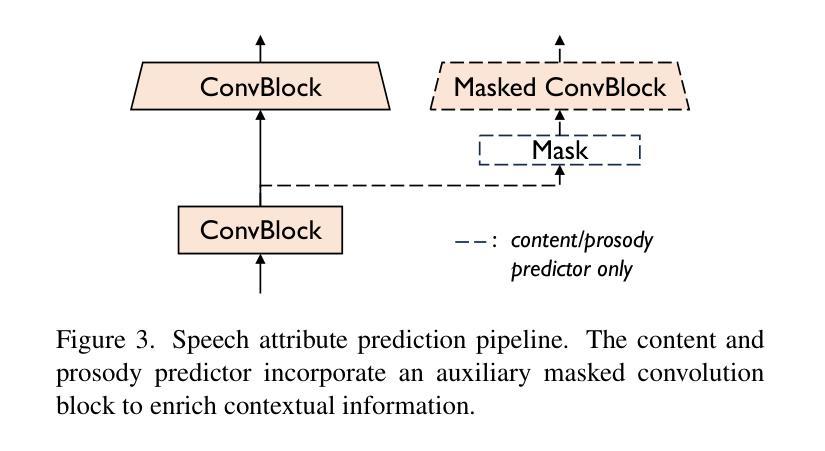
The objective of this study is to generate high-quality speech from silent talking face videos, a task also known as video-to-speech synthesis. A significant challenge in video-to-speech synthesis lies in the substantial modality gap between silent video and multi-faceted speech. In this paper, we propose a novel video-to-speech system that effectively bridges this modality gap, significantly enhancing the quality of synthesized speech. This is achieved by learning of hierarchical representations from video to speech. Specifically, we gradually transform silent video into acoustic feature spaces through three sequential stages – content, timbre, and prosody modeling. In each stage, we align visual factors – lip movements, face identity, and facial expressions – with corresponding acoustic counterparts to ensure the seamless transformation. Additionally, to generate realistic and coherent speech from the visual representations, we employ a flow matching model that estimates direct trajectories from a simple prior distribution to the target speech distribution. Extensive experiments demonstrate that our method achieves exceptional generation quality comparable to real utterances, outperforming existing methods by a significant margin.
本文的研究目标是从无声的对话视频生成高质量语音,这一任务也被称为视频到语音的合成。视频到语音合成面临的一个重大挑战是无声视频和多面语音之间存在的巨大模态差距。在本文中,我们提出了一种新型的视频到语音系统,该系统有效地弥合了这种模态差距,大大提高了合成语音的质量。这是通过学习从视频到语音的分层表示来实现的。具体来说,我们通过三个阶段——内容、音色和语调建模,逐步将无声视频转换为声音特征空间。在每个阶段,我们将视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音因素进行对齐,以确保无缝转换。此外,为了从视觉表示生成真实且连贯的语音,我们采用了一种流动匹配模型,该模型从简单的先验分布估计到目标语音分布的直接轨迹。大量实验表明,我们的方法达到了与真实话语相当的生成质量,显著优于现有方法。
论文及项目相关链接
PDF CVPR 2025, demo page: https://mm.kaist.ac.kr/projects/faces2voices/
Summary
高质量视频转语音合成研究,旨在从无声面部视频生成高质量语音。该研究面临的主要挑战在于视频和语音之间的模态差距。该研究提出了一种新的视频转语音系统,通过从视频到语音学习层次表示来有效弥合这一模态差距,显著提高合成语音的质量。具体通过内容、音质和韵律建模三个阶段逐步将无声视频转换为声音特征空间,并在每个阶段将视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音特征进行对齐,以确保无缝转换。此外,为了从视觉表示生成真实且连贯的语音,该研究采用了一种流量匹配模型,该模型可从简单先验分布估计到目标语音分布的直接轨迹。实验表明,该方法达到了与真实语音相比的出色生成质量,并大幅度超越了现有方法。
Key Takeaways
- 研究旨在实现高质量的视频转语音合成,即从不说话的面部视频生成逼真的语音。
- 研究的挑战在于处理视频和语音之间存在的模态差距。
- 提出了一种新的视频转语音系统,通过层次表示学习来弥合模态差距,进而提高合成语音质量。
- 系统设计包括三个主要阶段:内容建模、音质建模和韵律建模,将无声视频逐步转化为声音特征空间。
- 在每个阶段,研究通过视觉因素(如嘴唇动作、面部身份和面部表情)与声音特征的精确对齐来实现无缝转换。
- 采用流量匹配模型生成真实且连贯的语音,该模型可从简单先验分布估计到目标语音分布的直接轨迹。
点此查看论文截图

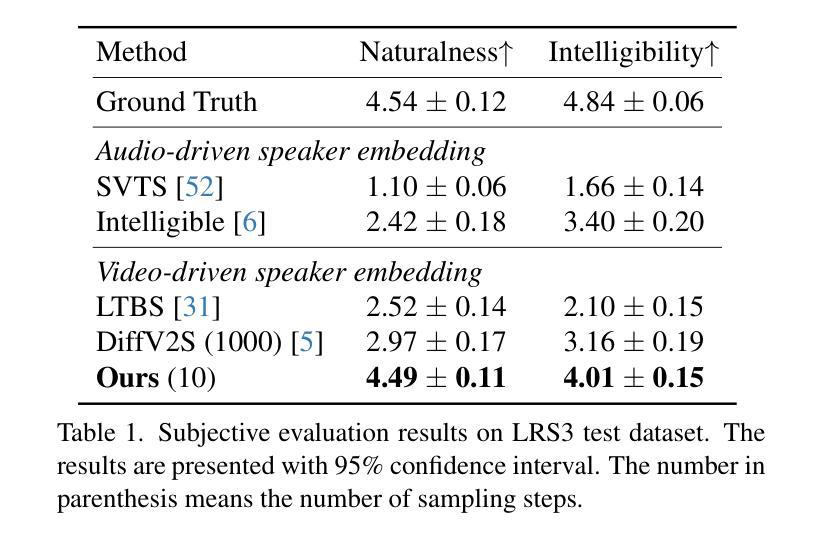
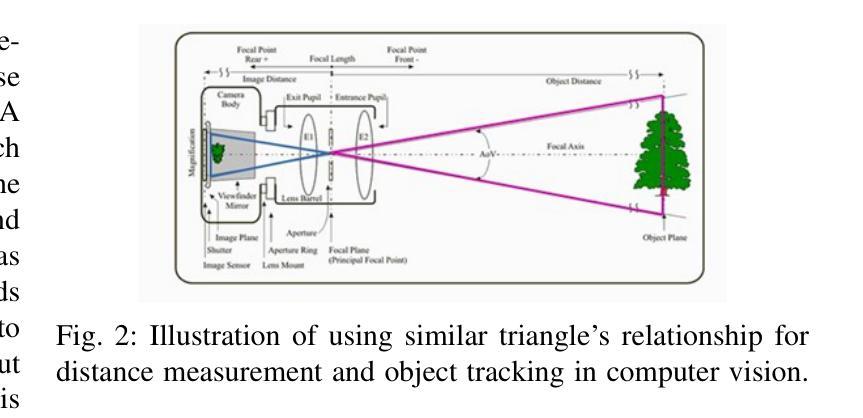
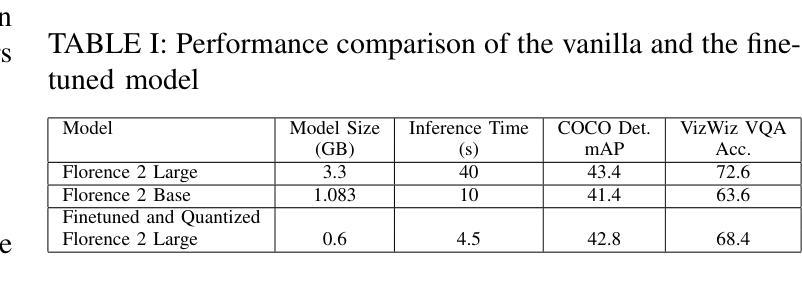
VocalEyes: Enhancing Environmental Perception for the Visually Impaired through Vision-Language Models and Distance-Aware Object Detection
Authors:Kunal Chavan, Keertan Balaji, Spoorti Barigidad, Samba Raju Chiluveru
With an increasing demand for assistive technologies that promote the independence and mobility of visually impaired people, this study suggests an innovative real-time system that gives audio descriptions of a user’s surroundings to improve situational awareness. The system acquires live video input and processes it with a quantized and fine-tuned Florence-2 big model, adjusted to 4-bit accuracy for efficient operation on low-power edge devices such as the NVIDIA Jetson Orin Nano. By transforming the video signal into frames with a 5-frame latency, the model provides rapid and contextually pertinent descriptions of objects, pedestrians, and barriers, together with their estimated distances. The system employs Parler TTS Mini, a lightweight and adaptable Text-to-Speech (TTS) solution, for efficient audio feedback. It accommodates 34 distinct speaker types and enables customization of speech tone, pace, and style to suit user requirements. This study examines the quantization and fine-tuning techniques utilized to modify the Florence-2 model for this application, illustrating how the integration of a compact model architecture with a versatile TTS component improves real-time performance and user experience. The proposed system is assessed based on its accuracy, efficiency, and usefulness, providing a viable option to aid vision-impaired users in navigating their surroundings securely and successfully.
随着促进视力障碍者独立性和移动性的辅助技术需求不断增加,本研究提出了一种创新性的实时系统,该系统为用户提供周围环境的音频描述,以提高情境意识。该系统获取实时视频输入,并使用经过量化和精细调整的Florence-2大型模型进行处理,以4位精度调整,可在低功耗边缘设备上高效运行,例如NVIDIA Jetson Orin Nano。通过将视频信号转换为具有5帧延迟的帧,该模型迅速提供与上下文相关的物体、行人和障碍物的描述,以及它们的估计距离。系统采用轻量级、适应性强的Parler TTS Mini文本到语音(TTS)解决方案,提供高效音频反馈。它容纳了34种不同的扬声器类型,并可根据用户需求定制语音语调、语速和风格。本研究探讨了用于此应用程序的量化和微调技术,说明了紧凑模型架构与通用TTS组件的集成如何提高实时性能和用户体验。所提议的系统基于其准确性、效率和实用性进行评估,为视力受损用户提供了一种可行的选择,以安全且成功地导航周围环境。
论文及项目相关链接
摘要
本研究提出一种创新型实时系统,通过音频描述用户周围环境来提高视觉障碍人士的情境意识。系统获取实时视频输入,使用针对低功率边缘设备优化的Florence-2大模型的量化与微调版本进行处理。通过转换视频信号为帧,提供对物体、行人和障碍物的快速且语境相关的描述,以及它们的大致距离。系统采用轻量级、可定制的文本到语音(TTS)解决方案Parler TTS Mini,可提供高效的音频反馈,并适应34种不同的演讲者类型,用户可根据需求调整语音的语调、速度和风格。本研究探讨了用于此应用程序的Florence-2模型的量化和微调技术,说明了紧凑模型架构与通用TTS组件的融合如何改善实时性能和用户体验。所提出的系统已根据其准确性、效率和实用性进行评估,为视觉障碍用户提供了一种安全且成功的导航周围环境的可行选择。
要点
- 实时系统通过音频描述周围环境提高视觉障碍人士的情境意识。
- 系统使用量化与微调后的Florence-2模型处理视频输入,适用于低功率边缘设备。
- 模型提供快速、与上下文相关的障碍物和物体描述,及其大致距离。
- 采用Parler TTS Mini进行音频反馈,可适应多种语音类型和用户定制需求。
- 研究了模型的量化和微调技术,展示了紧凑模型架构与TTS组件的融合优势。
- 系统评估包括准确性、效率和实用性,为视觉障碍者提供安全导航的选择。
- 该系统有助于视觉障碍人士更好地独立行动和移动。
点此查看论文截图


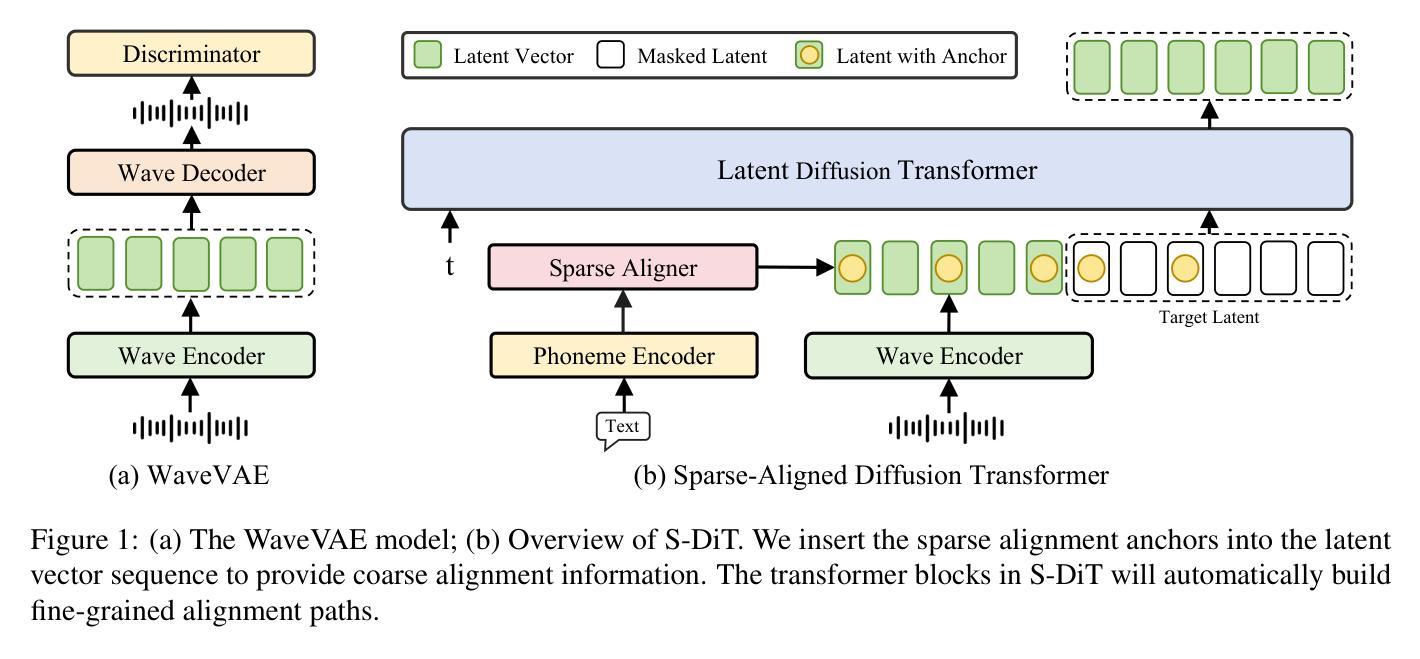
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Authors:Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, Zhou Zhao
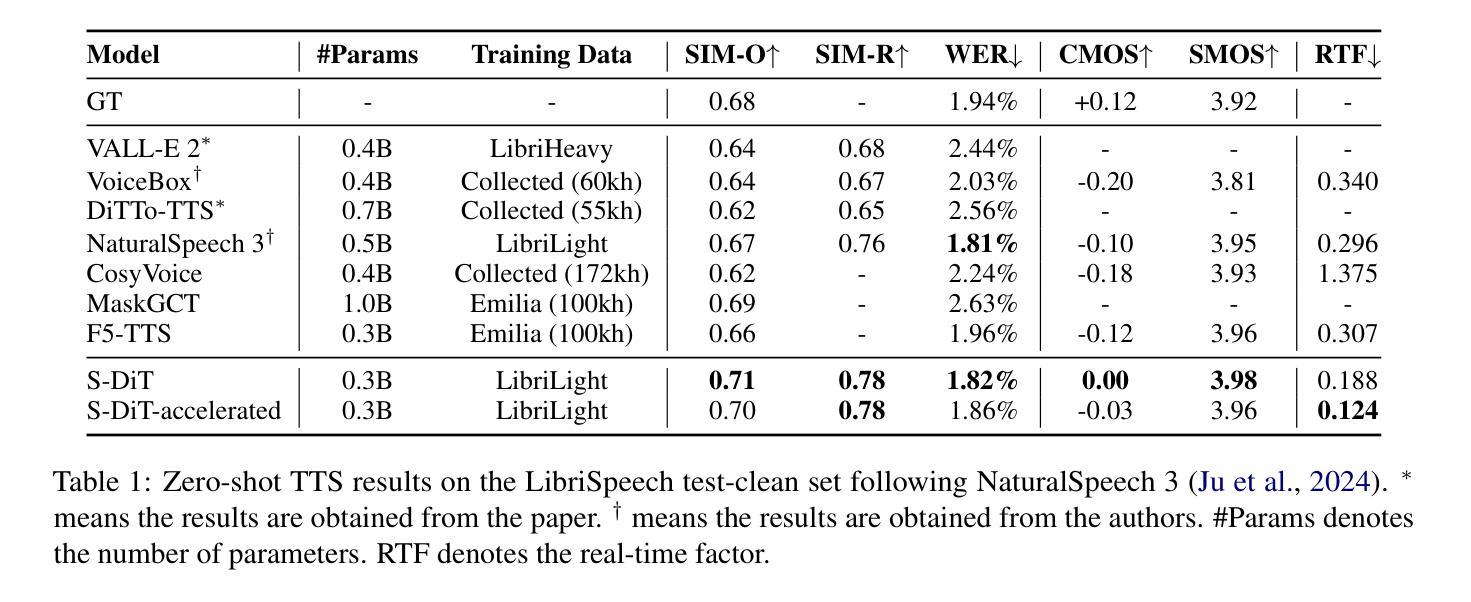
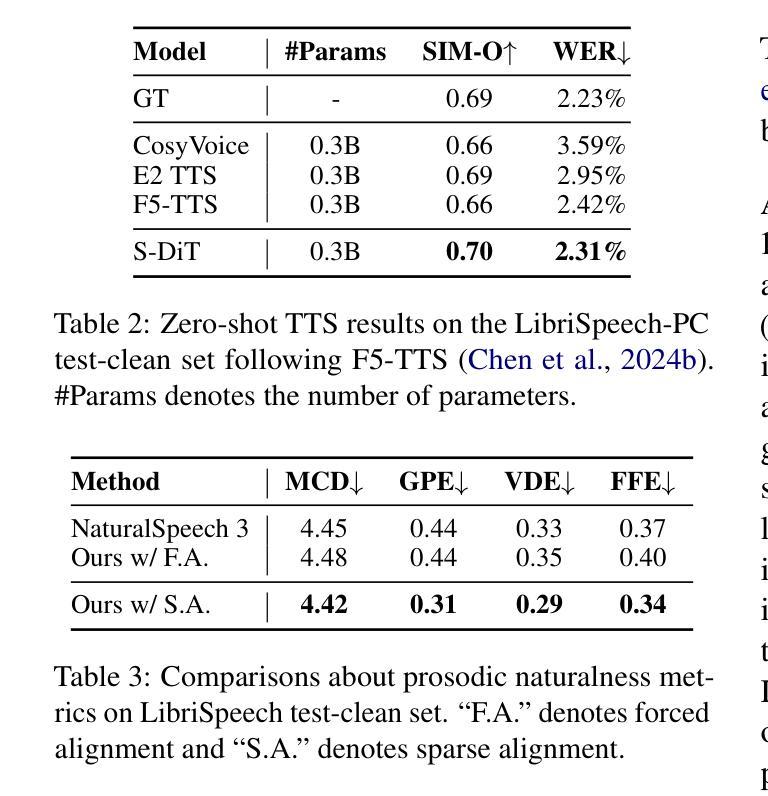
While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
尽管最近的零样本文本到语音(TTS)模型在语音质量和表达力方面有了显著的提升,主流系统仍然面临与语音文本对齐建模相关的问题:1)没有明确的语音文本对齐建模的模型表现出较低的稳健性,特别是在实际应用中的复杂句子;2)基于预定义对齐的模型受到强制对齐的自然性约束的影响。本文介绍了S-DiT,一个具有创新稀疏对齐算法的TTS系统,该算法引导潜在扩散变压器(DiT)。具体来说,我们为S-DiT提供稀疏对齐边界,以减少对齐学习的难度,同时不限制搜索空间,从而实现高自然度。此外,我们采用多条件无分类指导策略进行口音强度调整,并采用分段校正流技术来加速生成过程。实验表明,S-DiT达到了最先进的零样本TTS语音质量,并支持对口音强度进行高度灵活的控制。值得注意的是,我们的系统只需8个采样步骤就能生成高质量的一分钟语音。音频样本可在https://sditdemo.github.io/sditdemo/找到。
论文及项目相关链接
Summary
本文提出了一种新型的文本转语音(TTS)系统S-DiT,它采用稀疏对齐算法指导潜在扩散转换器(DiT)。通过提供稀疏对齐边界,减少了对齐学习的难度且不会限制搜索空间,从而提高语音的自然性。同时采用多条件分类自由指导策略进行口音强度调整,并使用分段整流流技术加速生成过程。实验证明,S-DiT在零样本TTS语音质量方面达到最佳水平,并支持高度灵活的口音强度控制。同时生成高质量一分钟语音仅需要八次采样步骤。相关音频样本已在网站公开。
Key Takeaways
- S-DiT是一种新型的文本转语音(TTS)系统,基于稀疏对齐算法改进语音和文本的对齐问题。
- S-DiT通过提供稀疏对齐边界减少了对齐学习难度,提高了语音的自然性。
- 系统采用多条件分类自由指导策略,实现口音强度的灵活调整。
- 分段整流流技术被用于加速语音生成过程。
- 实验证明S-DiT在零样本TTS语音质量方面表现优异。
- S-DiT系统能够生成高质量一分钟的语音,仅需要八次采样步骤。
点此查看论文截图

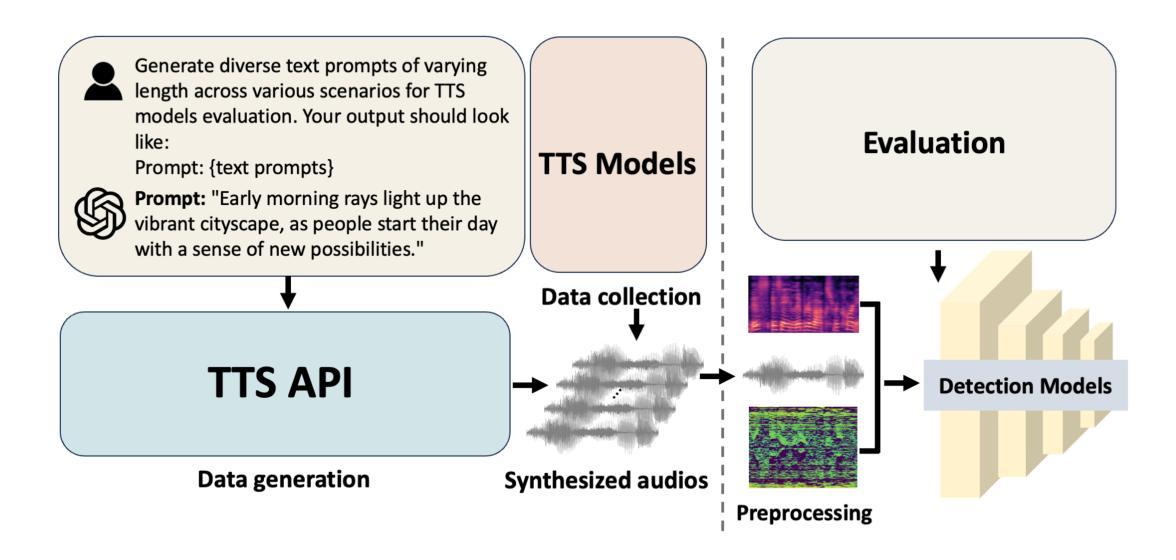
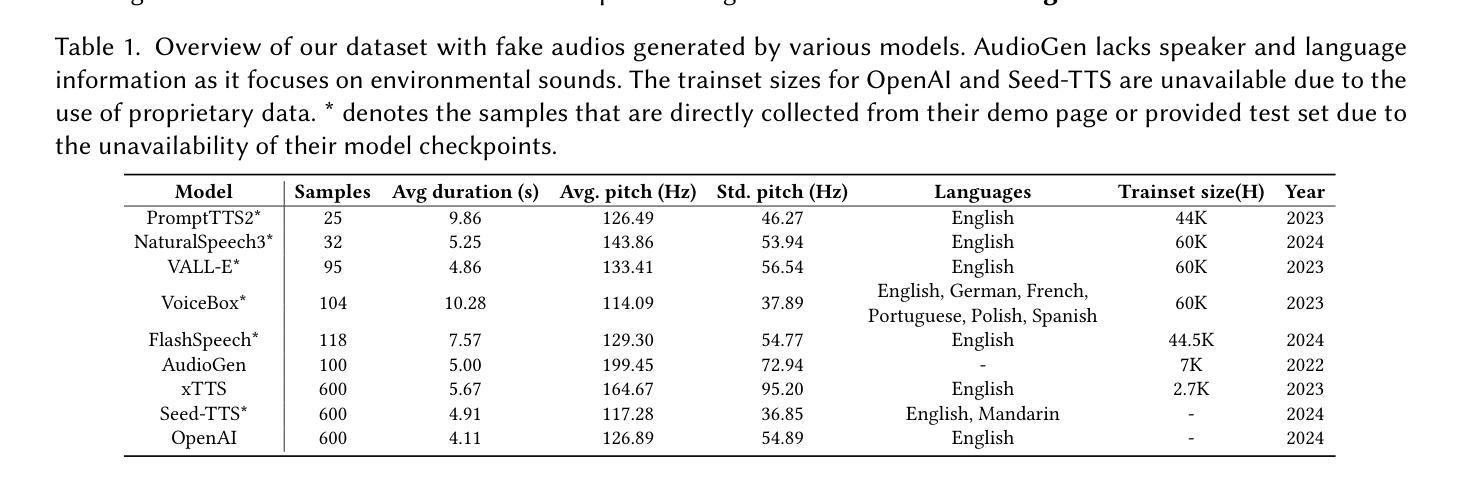
Where are we in audio deepfake detection? A systematic analysis over generative and detection models
Authors:Xiang Li, Pin-Yu Chen, Wenqi Wei
Recent advances in Text-to-Speech (TTS) and Voice-Conversion (VC) using generative Artificial Intelligence (AI) technology have made it possible to generate high-quality and realistic human-like audio. This poses growing challenges in distinguishing AI-synthesized speech from the genuine human voice and could raise concerns about misuse for impersonation, fraud, spreading misinformation, and scams. However, existing detection methods for AI-synthesized audio have not kept pace and often fail to generalize across diverse datasets. In this paper, we introduce SONAR, a synthetic AI-Audio Detection Framework and Benchmark, aiming to provide a comprehensive evaluation for distinguishing cutting-edge AI-synthesized auditory content. SONAR includes a novel evaluation dataset sourced from 9 diverse audio synthesis platforms, including leading TTS providers and state-of-the-art TTS models. It is the first framework to uniformly benchmark AI-audio detection across both traditional and foundation model-based detection systems. Through extensive experiments, (1) we reveal the limitations of existing detection methods and demonstrate that foundation models exhibit stronger generalization capabilities, likely due to their model size and the scale and quality of pretraining data. (2) Speech foundation models demonstrate robust cross-lingual generalization capabilities, maintaining strong performance across diverse languages despite being fine-tuned solely on English speech data. This finding also suggests that the primary challenges in audio deepfake detection are more closely tied to the realism and quality of synthetic audio rather than language-specific characteristics. (3) We explore the effectiveness and efficiency of few-shot fine-tuning in improving generalization, highlighting its potential for tailored applications, such as personalized detection systems for specific entities or individuals.
近期在文本转语音(TTS)和语音转换(VC)方面利用生成式人工智能(AI)技术的进展,使得生成高质量、逼真的类似人类音频成为可能。这带来了日益增长的挑战,即区分AI合成的语音和真正的人类声音,并可能引起关于滥用身份冒充、欺诈、传播误导信息和诈骗的担忧。然而,现有的AI合成音频检测手段并未跟上这一发展速度,往往无法在不同数据集之间进行泛化。在本文中,我们介绍了SONAR,一个合成AI音频检测框架和基准测试,旨在为区分前沿AI合成听觉内容提供全面评估。SONAR包括一个新颖的评价数据集,来源于9个多样化的音频合成平台,包括领先的TTS提供商和先进的TTS模型。它是第一个能够在传统和基于基础模型的检测系统之间统一基准测试AI音频的检测框架。通过广泛的实验,(1)我们揭示了现有检测方法的局限性,并证明基础模型表现出更强的泛化能力,这可能是由于其模型大小以及预训练数据的规模和品质。 (2)语音基础模型展现出强大的跨语言泛化能力,在各种语言中都表现出强劲的性能,尽管它们只针对英语语音数据进行微调。这一发现还表明,音频深度伪造检测的主要挑战更紧密地与合成音频的真实性和质量有关,而与语言特性无关。(3)我们探讨了少量样本微调在提升泛化能力方面的有效性和效率,并突出了其在定制应用方面的潜力,例如针对特定实体或个人的个性化检测系统。
论文及项目相关链接
摘要
近期文本转语音(TTS)和语音转换(VC)领域利用生成式人工智能(AI)技术的进展,已能够生成高质量、逼真的类似人类音频。这给区分AI合成语音和真实人类声音带来了日益增长的挑战,并可能引起关于滥用、欺诈、传播虚假信息和诈骗的担忧。然而,现有的AI合成音频检测方法的进步速度却未能与之匹配,往往无法在跨不同数据集时保持普遍适应性。本文介绍SONAR,一个合成AI音频检测框架与基准测试,旨在提供区分最前沿AI合成听觉内容的全面评估。SONAR包括一个来自9个不同音频合成平台的新型评估数据集,涵盖领先的TTS提供商和最新TTS模型。它是第一个能够在传统和基于基础模型的检测系统之间统一基准测试的AI音频检测框架。通过广泛的实验,(1)我们揭示了现有检测方法的局限性,并证明基础模型展现出更强的泛化能力,这可能是由于其模型大小以及预训练数据的规模和质量的缘故。(2)语音基础模型表现出强大的跨语言泛化能力,即使在仅对英语语音数据进行微调的情况下也能保持对不同语言的强大性能。这一发现还表明,音频深度伪造检测的主要挑战更紧密地联系着合成音频的真实性和质量,而非语言特性。(3)我们探讨了少量样本微调在改进泛化方面的有效性和效率,突显其在定制应用中的潜力,如针对特定实体或个人的个性化检测系统。
要点提炼
- 近期AI技术在TTS和VC领域的进展使得生成高质量、逼真的类似人类音频成为可能,引发关于区分AI合成语音和真实人类声音的挑战。
- 现有AI合成音频检测方法进步缓慢,难以适应跨不同数据集的需求。
- SONAR框架旨在提供全面的AI合成音频检测评估,包括来自多个合成平台的评估数据集。
- 基础模型展现出更强的泛化能力,这与其模型大小及预训练数据的规模和质量有关。
- 语音基础模型具备跨语言泛化能力,能在不同语言间保持性能。
- 音频深度伪造检测的挑战更在于合成音频的真实性和质量,而非语言特性。
点此查看论文截图