⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-27 更新
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Authors:Jiazhi Guan, Kaisiyuan Wang, Zhiliang Xu, Quanwei Yang, Yasheng Sun, Shengyi He, Borong Liang, Yukang Cao, Yingying Li, Haocheng Feng, Errui Ding, Jingdong Wang, Youjian Zhao, Hang Zhou, Ziwei Liu
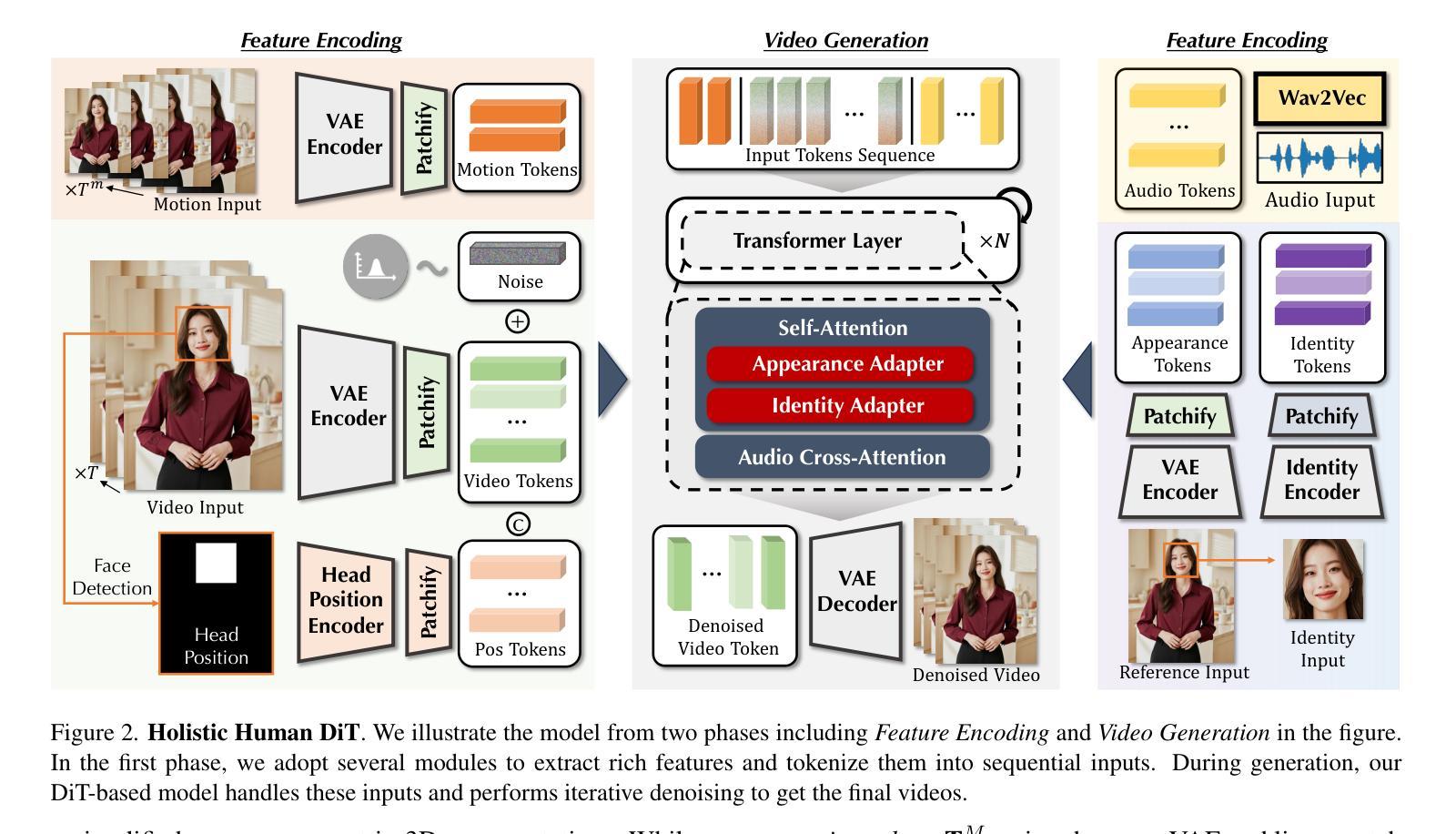
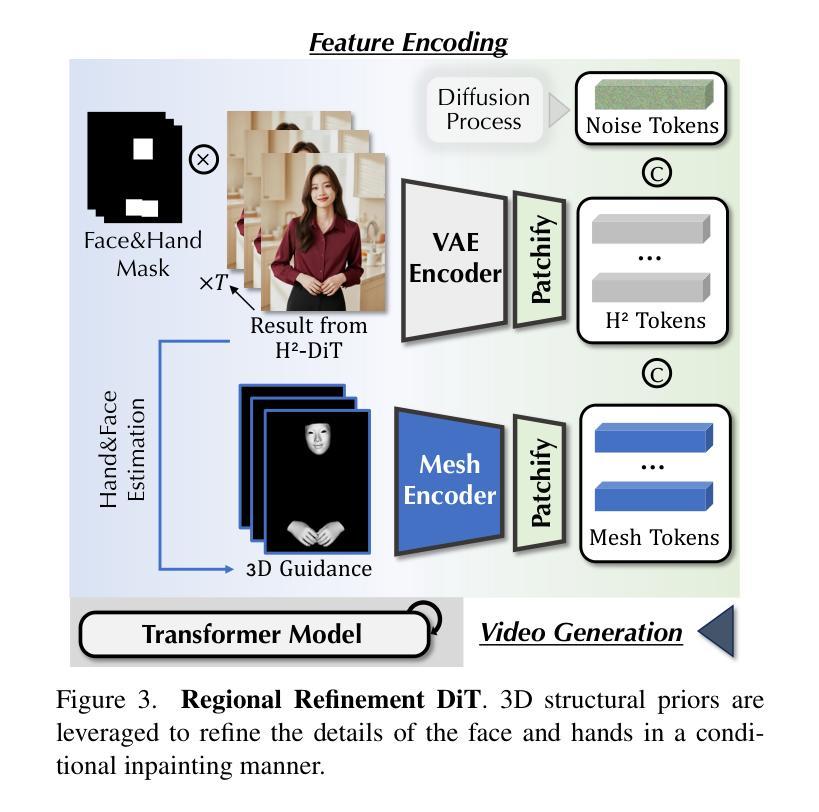
Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
尽管近期音频驱动视频生成技术有所进展,但现有方法大多专注于驱动面部运动,导致头部和身体的动态不一致。未来,对于给定音频,生成兼具精确唇同步和细腻语音手势的全人类视频是令人向往但具有挑战性的。在这项工作中,我们提出了AudCast,一个采用级联扩散变压器(DiTs)模式的通用音频驱动人类视频生成框架,该框架基于参考图像和给定音频合成全人类视频。1)首先,提出了一种音频调节的全人类DiT架构,可直接驱动任何人类身体的运动,具有生动的手势动态。2)然后,为了增强手和脸部的细节(这些细节是众所周知的难以处理的),区域细化DiT利用区域3D拟合作为桥梁来重建信号,产生最终结果。大量实验表明,我们的框架能够生成高保真度的音频驱动全人类视频,具有时间连贯性和精细的面部和手部细节。资源可在https://guanjz20.github.io/projects/AudCast找到。
论文及项目相关链接
PDF Accepted to IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Project page: https://guanjz20.github.io/projects/AudCast
摘要
随着音频驱动的视频生成技术的近期进展,现有方法主要关注面部运动的驱动,导致头部和身体的动态不一致。因此,生成与给定音频相对应的具有准确唇同步和精细语音手势的完整人类视频既具有挑战性又令人向往。在这项工作中,我们提出了AudCast,这是一个采用级联扩散变压器(DiTs)范式的通用音频驱动人类视频生成框架,它基于参考图像和给定音频合成完整的人类视频。首先,我们提出了一种受音频控制的整体人类DiT架构,可以直接驱动任何人的身体运动,呈现生动的手势动态。其次,为了提高手和脸部的细节处理(这是众所周知的难点),区域细化DiT利用区域3D拟合作为桥梁来重塑信号,产生最终结果。大量实验表明,我们的框架能够生成高保真度的音频驱动完整人类视频,具有时间连贯性和精细的面部和手部细节。
要点
- 现有音频驱动的视频生成技术主要关注面部运动,导致头部和身体的动态不一致。
- 提出AudCast框架,采用级联扩散变压器(DiTs)范式,基于参考图像和音频合成完整人类视频。
- 引入受音频控制的整体人类DiT架构,直接驱动任何人的身体运动,包括生动的手势动态。
- 采用区域细化DiT,结合区域3D拟合,提高手和脸部的细节处理。
- AudCast框架生成的高保真音频驱动视频具有时间连贯性和精细的面部及手部细节。
- 框架适用于广泛的音频和视频生成任务,为电影、动画、虚拟现实等领域提供有力支持。
点此查看论文截图

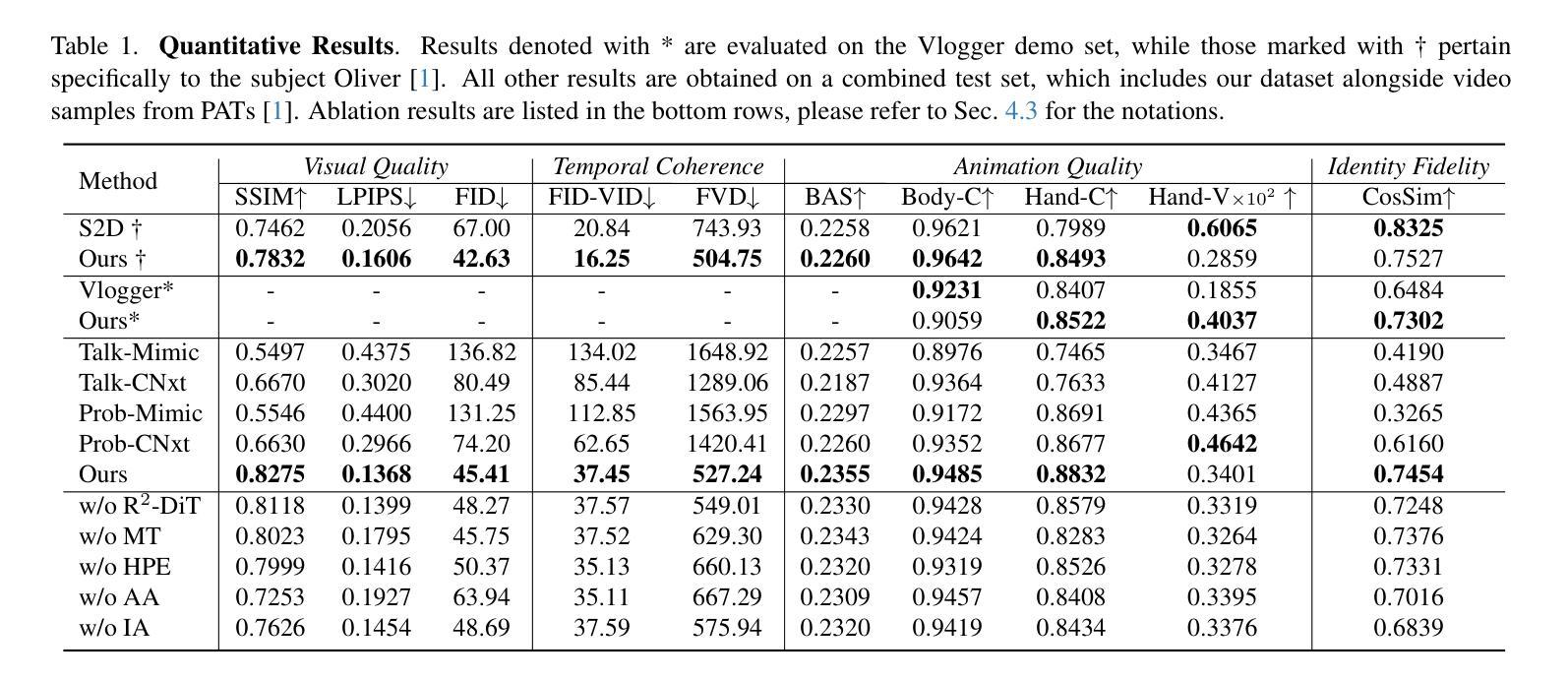
DisentTalk: Cross-lingual Talking Face Generation via Semantic Disentangled Diffusion Model
Authors:Kangwei Liu, Junwu Liu, Yun Cao, Jinlin Guo, Xiaowei Yi
Recent advances in talking face generation have significantly improved facial animation synthesis. However, existing approaches face fundamental limitations: 3DMM-based methods maintain temporal consistency but lack fine-grained regional control, while Stable Diffusion-based methods enable spatial manipulation but suffer from temporal inconsistencies. The integration of these approaches is hindered by incompatible control mechanisms and semantic entanglement of facial representations. This paper presents DisentTalk, introducing a data-driven semantic disentanglement framework that decomposes 3DMM expression parameters into meaningful subspaces for fine-grained facial control. Building upon this disentangled representation, we develop a hierarchical latent diffusion architecture that operates in 3DMM parameter space, integrating region-aware attention mechanisms to ensure both spatial precision and temporal coherence. To address the scarcity of high-quality Chinese training data, we introduce CHDTF, a Chinese high-definition talking face dataset. Extensive experiments show superior performance over existing methods across multiple metrics, including lip synchronization, expression quality, and temporal consistency. Project Page: https://kangweiiliu.github.io/DisentTalk.
近期在说话人脸生成方面的进展极大地推动了面部动画合成的进步。然而,现有方法存在基本局限:基于3DMM的方法保持了时间一致性,但缺乏精细的区域控制,而基于Stable Diffusion的方法实现了空间操作,但存在时间不一致的问题。这些方法的融合受到控制机制不兼容和面部表示语义纠缠的阻碍。本文提出DisentTalk,引入数据驱动语义解耦框架,将3DMM表达式参数分解成有意义的子空间,以实现精细的面部控制。基于这种解耦的表示,我们建立了一个分层潜在扩散架构,该架构在3DMM参数空间中进行操作,并结合区域感知注意力机制,以确保空间精度和时间连贯性。为了解决高质量中文训练数据的稀缺问题,我们引入了CHDTF,这是一个中文高清说话人脸数据集。大量实验表明,与现有方法相比,该方法在多个指标上表现优越,包括嘴唇同步、表情质量和时间一致性。项目页面:https://kangweiiliu.github.io/DisentTalk。
论文及项目相关链接
Summary
本文介绍了DisentTalk框架,该框架结合了3DMM方法和Stable Diffusion方法的优点,解决了面部动画合成中的关键问题。通过数据驱动的语义解耦技术,实现对表情参数的精细控制,并开发了一种层次化的潜在扩散架构,保证了空间精度和时间连贯性。此外,为了解决高质量中文训练数据稀缺的问题,还推出了中文高清对话人脸数据集CHDTF。实验表明,该框架在多个指标上均优于现有方法。
Key Takeaways
- DisentTalk结合了3DMM和Stable Diffusion方法的优点,旨在解决面部动画合成中的挑战。
- 通过数据驱动的语义解耦技术,实现对表情参数的精细控制。
- 开发了一种层次化的潜在扩散架构,该架构在3DMM参数空间内操作,确保了空间精度和时间连贯性。
- 引入了一个新的中文高清对话人脸数据集CHDTF,用于解决高质量中文训练数据的稀缺问题。
- 通过广泛实验验证,DisentTalk在多个评估指标上表现出卓越性能。
- DisentTalk提供了一种有效的解决方案,解决了现有方法如3DMM和Stable Diffusion所面临的时空连贯性问题。
点此查看论文截图

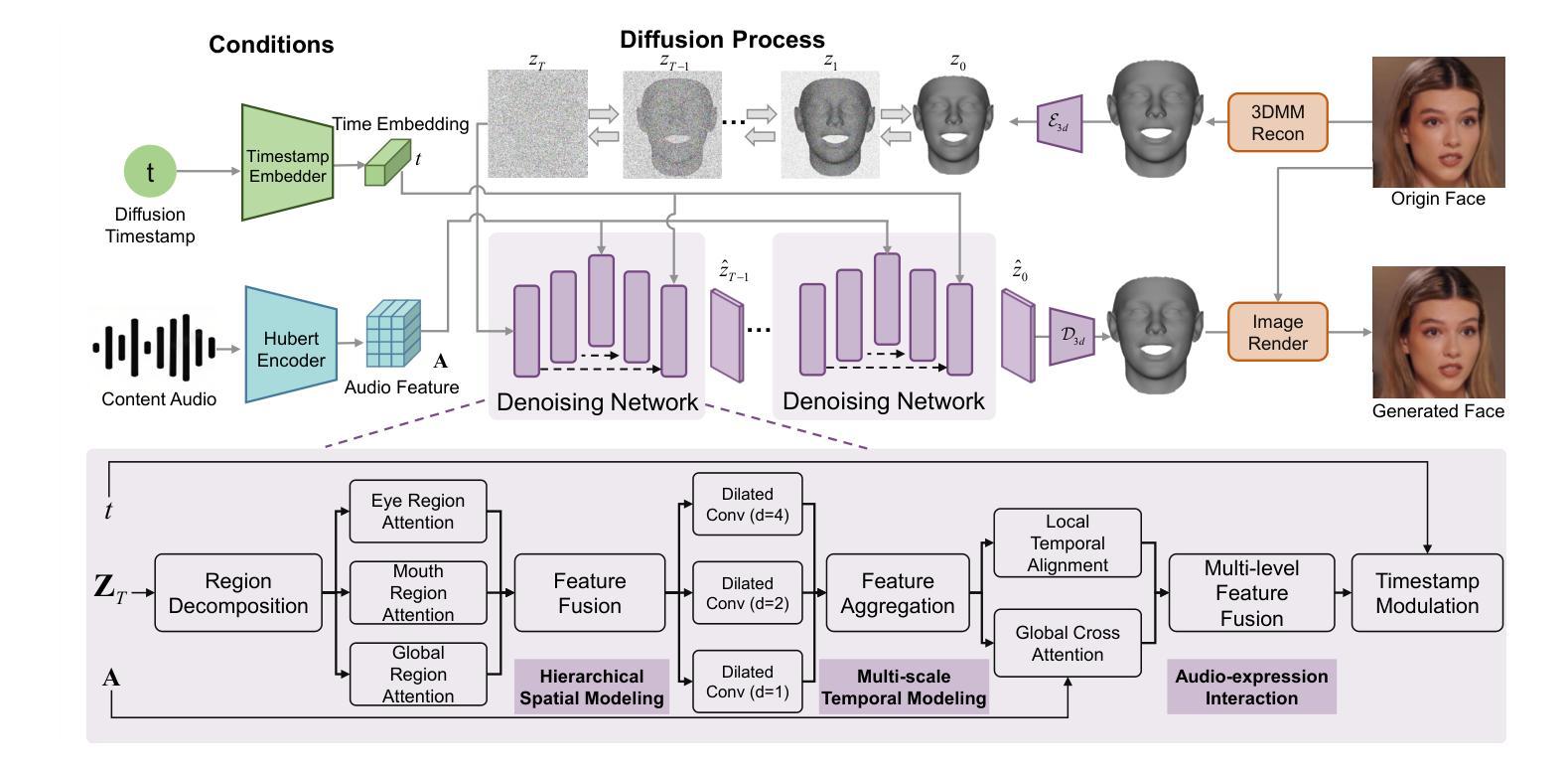

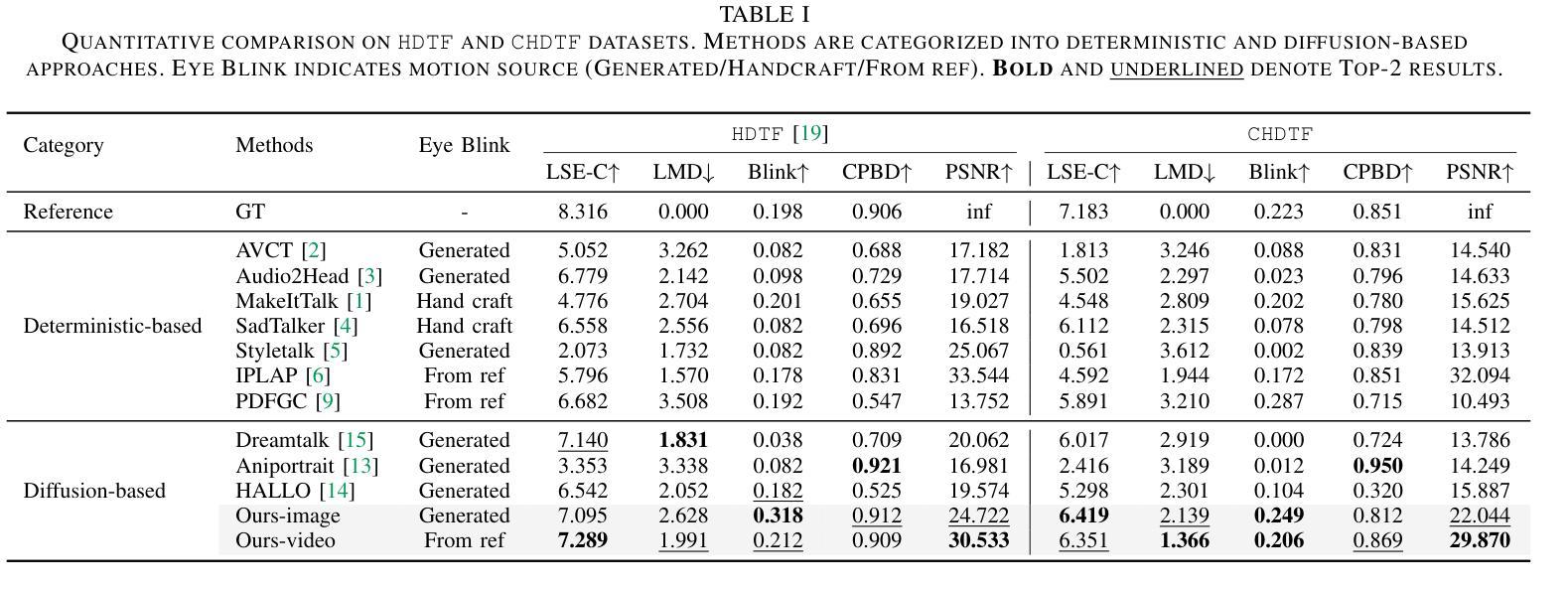
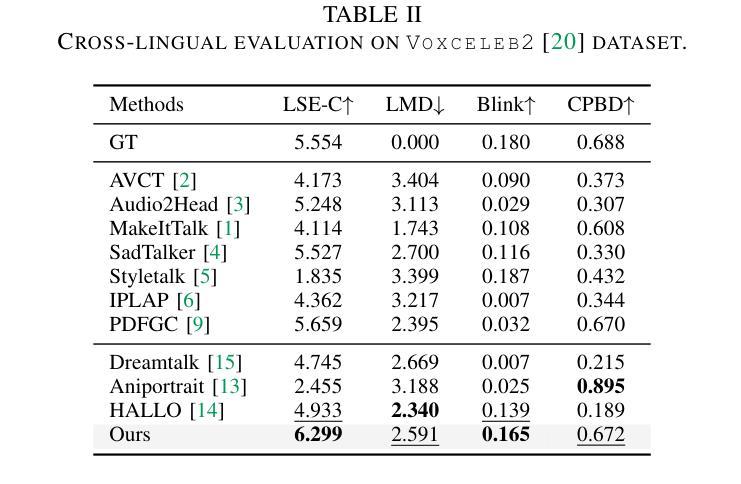
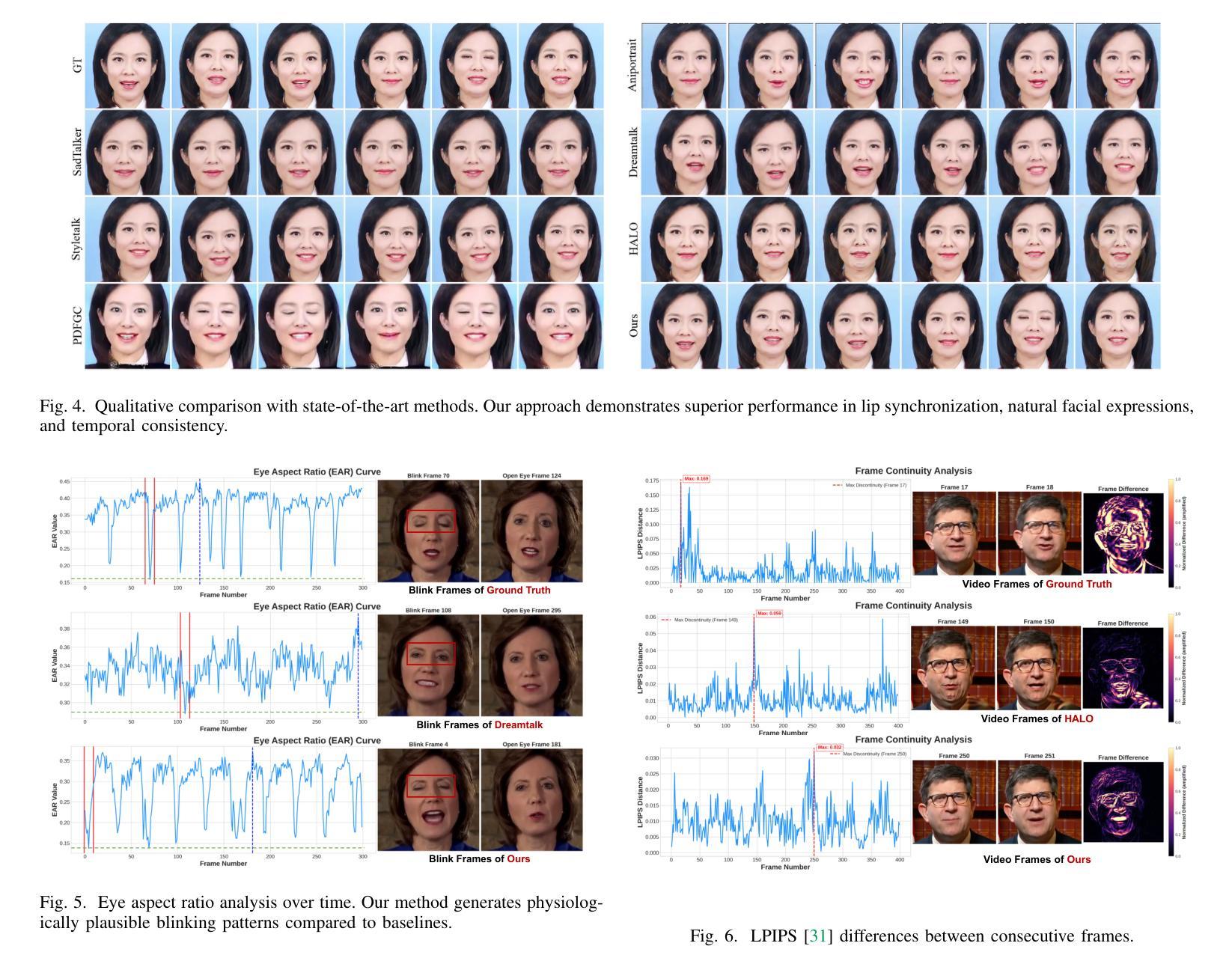
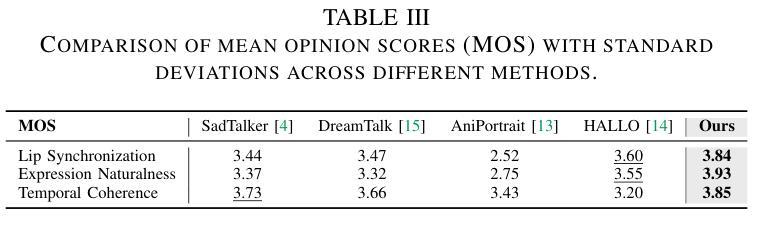
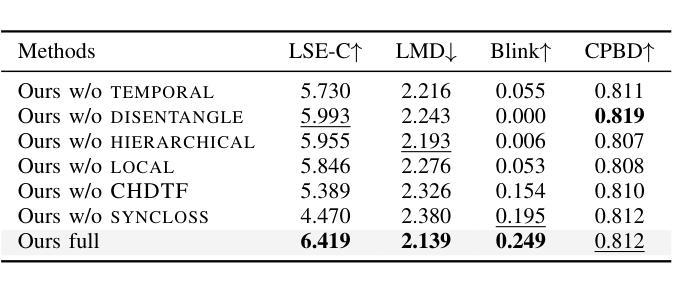
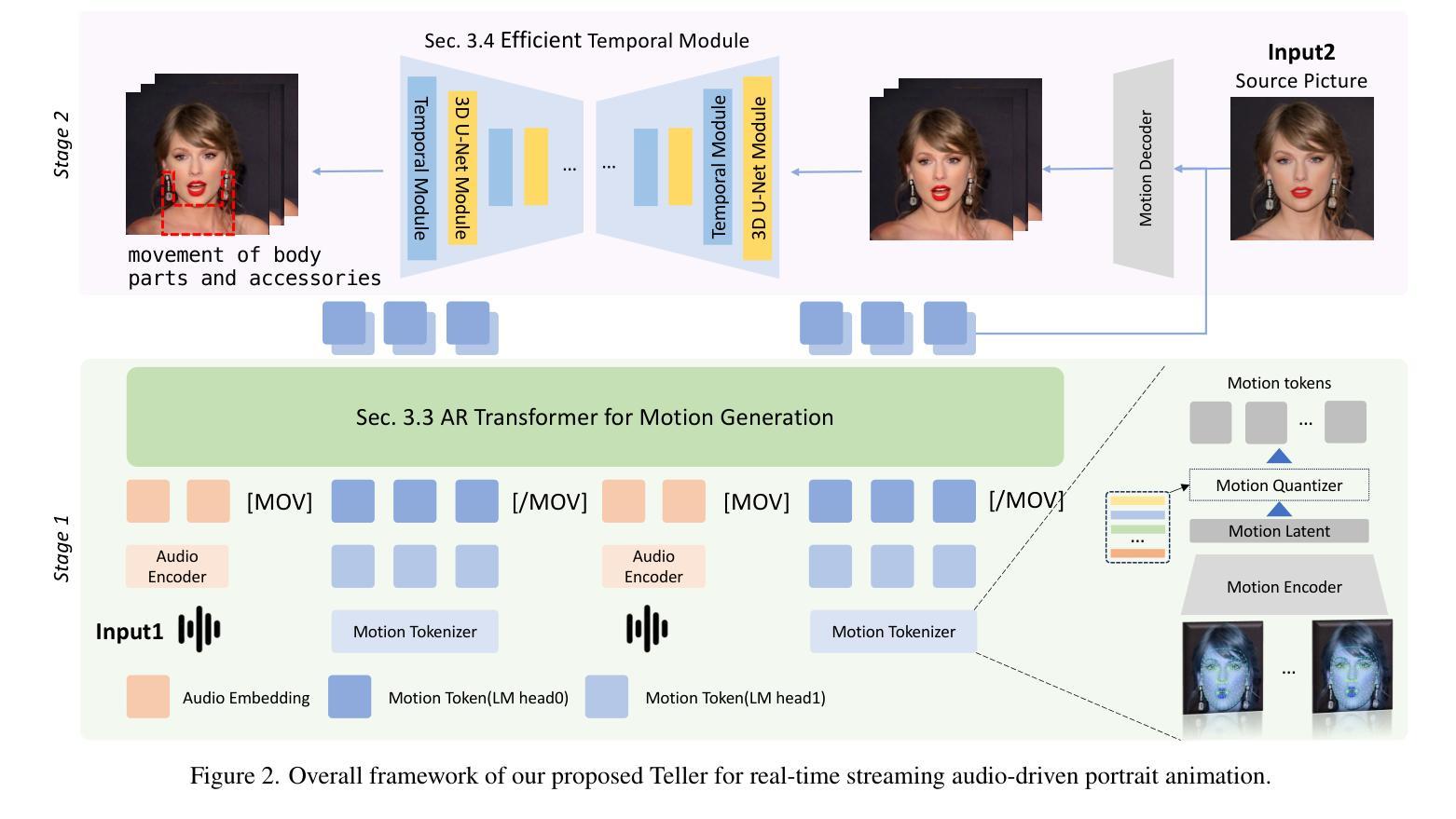
Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation
Authors:Dingcheng Zhen, Shunshun Yin, Shiyang Qin, Hou Yi, Ziwei Zhang, Siyuan Liu, Gan Qi, Ming Tao
In this work, we introduce the first autoregressive framework for real-time, audio-driven portrait animation, a.k.a, talking head. Beyond the challenge of lengthy animation times, a critical challenge in realistic talking head generation lies in preserving the natural movement of diverse body parts. To this end, we propose Teller, the first streaming audio-driven protrait animation framework with autoregressive motion generation. Specifically, Teller first decomposes facial and body detail animation into two components: Facial Motion Latent Generation (FMLG) based on an autoregressive transfromer, and movement authenticity refinement using a Efficient Temporal Module (ETM).Concretely, FMLG employs a Residual VQ model to map the facial motion latent from the implicit keypoint-based model into discrete motion tokens, which are then temporally sliced with audio embeddings. This enables the AR tranformer to learn real-time, stream-based mappings from audio to motion. Furthermore, Teller incorporate ETM to capture finer motion details. This module ensures the physical consistency of body parts and accessories, such as neck muscles and earrings, improving the realism of these movements. Teller is designed to be efficient, surpassing the inference speed of diffusion-based models (Hallo 20.93s vs. Teller 0.92s for one second video generation), and achieves a real-time streaming performance of up to 25 FPS. Extensive experiments demonstrate that our method outperforms recent audio-driven portrait animation models, especially in small movements, as validated by human evaluations with a significant margin in quality and realism.
在本次工作中,我们首次引入了一种实时音频驱动肖像动画(也称为谈话头)的自回归框架。除了动画时间长的挑战外,真实谈话头生成的关键挑战在于保持不同身体部位的自然运动。为此,我们提出了Teller,这是一个带有自回归运动生成功能的流式音频驱动肖像动画框架。具体来说,Teller首先将面部和身体的细节动画分解为两部分:基于自回归转换器的面部运动潜在生成(FMLG)和使用高效时间模块(ETM)进行运动真实性优化。具体来说,FMLG采用残差VQ模型将面部运动潜在从基于隐关键点的模型映射到离散运动令牌,然后与音频嵌入进行时间切片。这使AR转换器能够实时学习音频到运动的映射。此外,Teller结合了ETM来捕捉更精细的运动细节。该模块确保身体部位和配饰(如颈部肌肉和耳环)的物理一致性,提高了这些运动的真实性。Teller设计高效,超越了基于扩散的模型的推理速度(Hallo为生成一秒视频需要20.93秒,而Teller只需0.92秒),并实现了高达25 FPS的实时流处理能力。大量实验表明,我们的方法在音频驱动的肖像动画模型中表现最佳,特别是在细微运动中,如人类评估所示,在质量和真实性方面有很大优势。
论文及项目相关链接
PDF Accept in CVPR 2025 Conference Submission
Summary
本文介绍了一种基于音频驱动的自回归实时肖像动画框架Teller,实现了真实说话的头部生成。它通过分解面部和动作动画为两部分来解决挑战:基于自回归转换器的面部运动潜在生成(FMLG)和运动真实性的精细时间模块(ETM)精炼。Teller使用高效的架构,达到实时的流式处理性能,同时提高运动质量,特别是在小动作方面展现出优势。通过大量实验证明,其在音频驱动的肖像动画模型中表现优秀。
Key Takeaways
- Teller是一个实时音频驱动的肖像动画框架,用于生成真实说话的头部。
- 它通过分解面部和动作动画为两部分来解决挑战,包括面部运动潜在生成和运动真实性的精炼。
- Teller引入了一种新的面部运动潜在生成方法(FMLG),基于自回归转换器,实现音频与运动的实时映射。
- Teller采用精细时间模块(ETM)来捕捉更精细的运动细节,确保身体部位的物理一致性,提高运动真实感。
点此查看论文截图

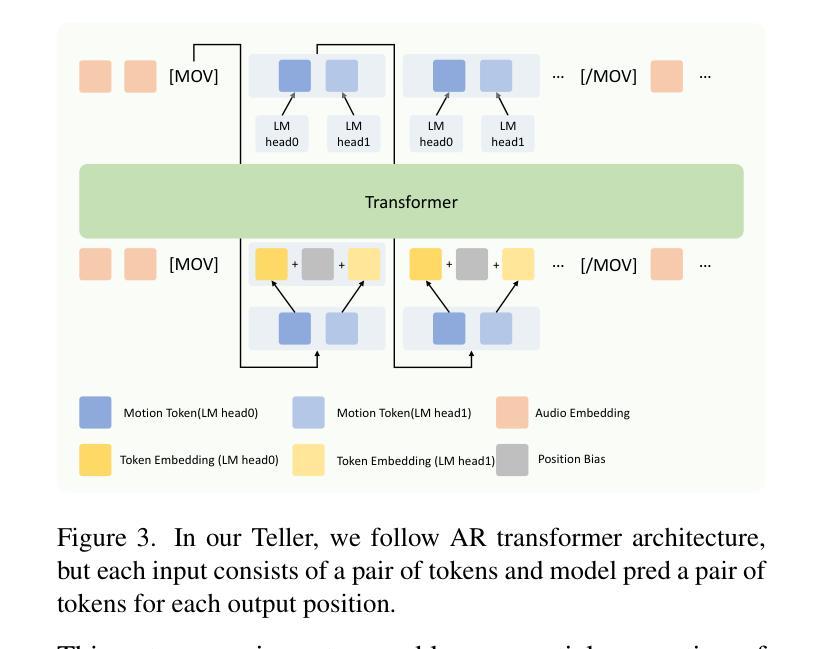


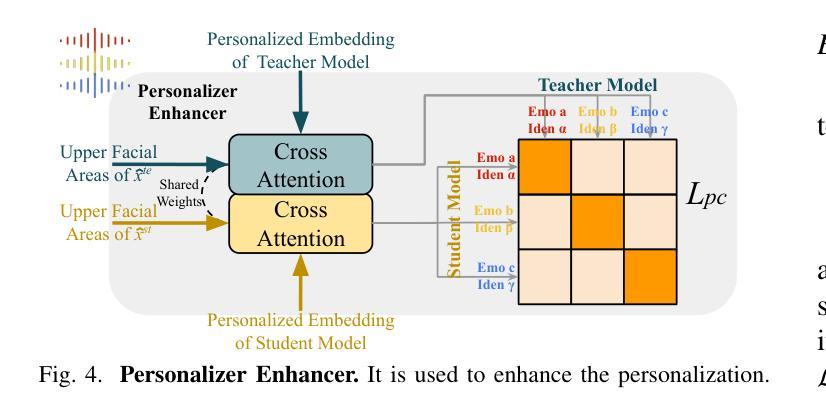
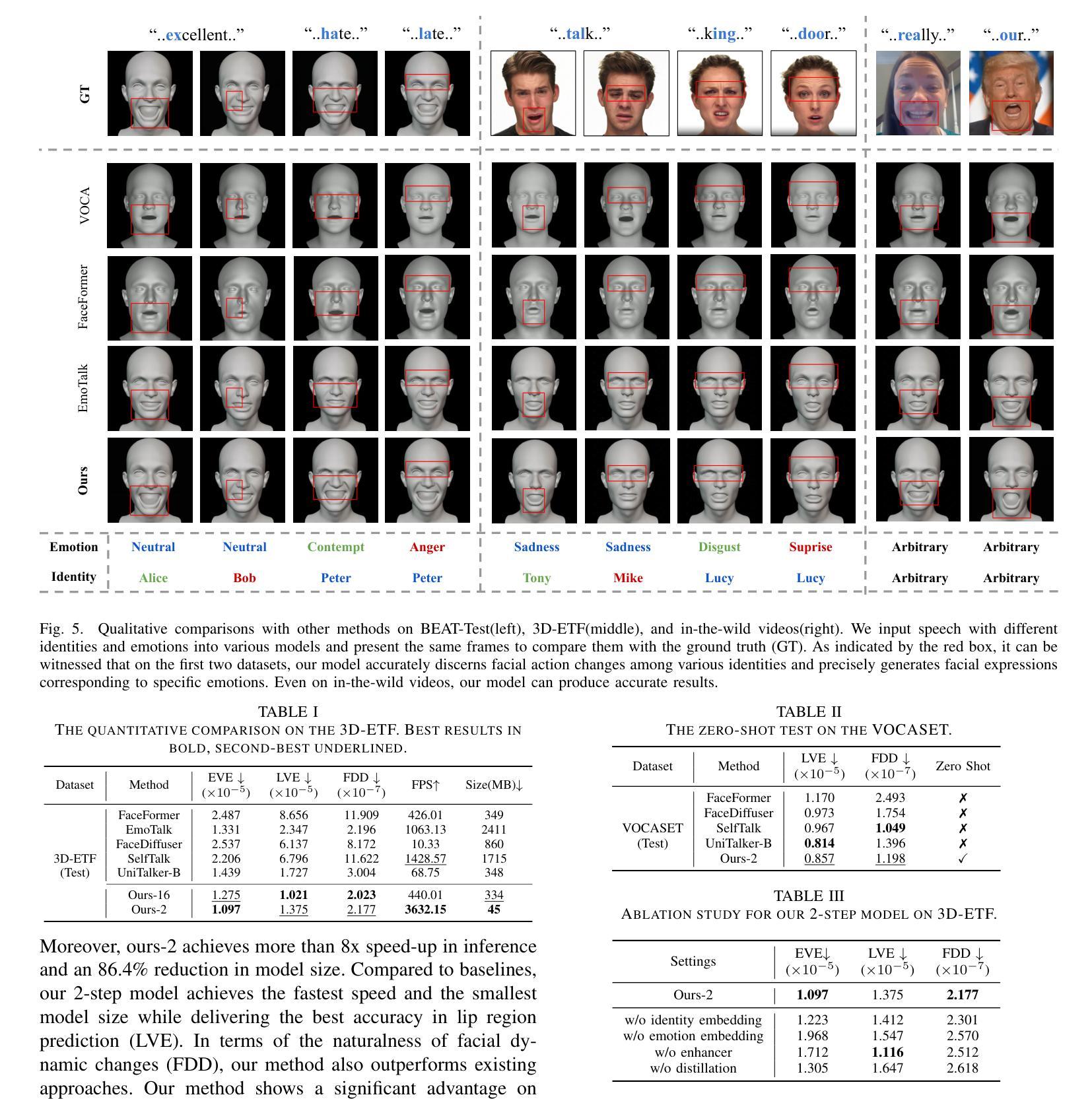
DiffusionTalker: Efficient and Compact Speech-Driven 3D Talking Head via Personalizer-Guided Distillation
Authors:Peng Chen, Xiaobao Wei, Ming Lu, Hui Chen, Feng Tian
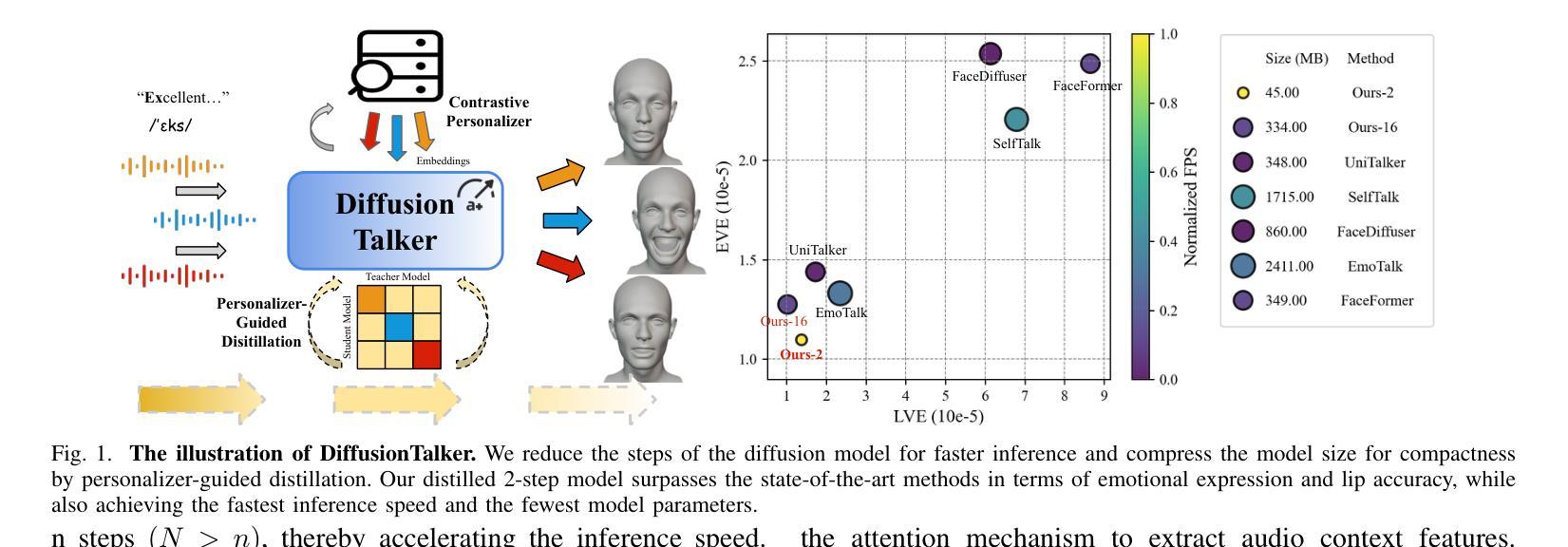
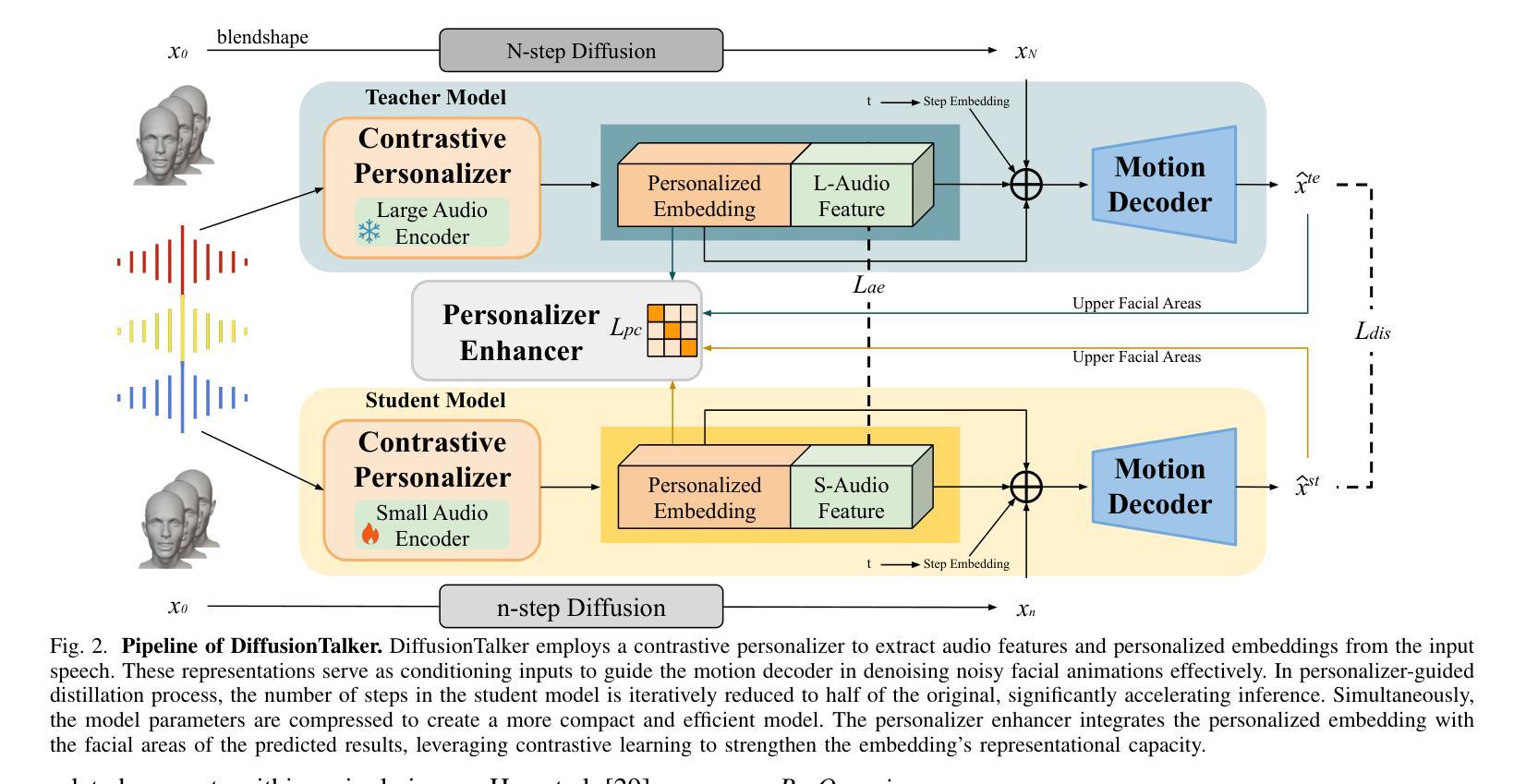
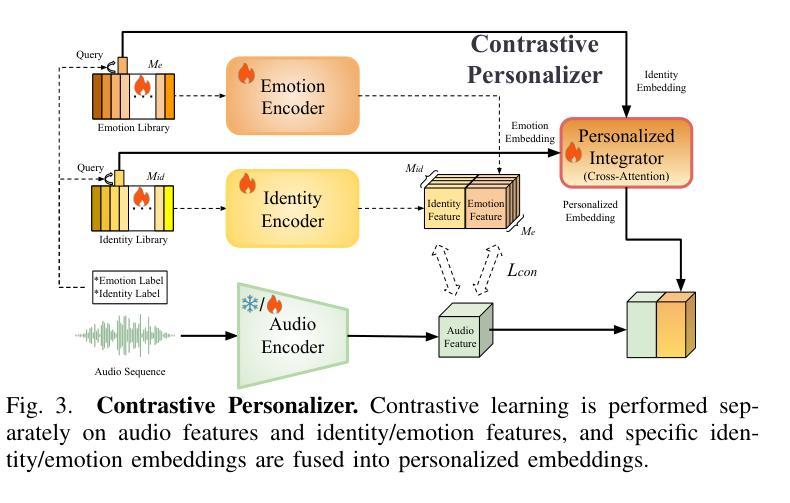
Real-time speech-driven 3D facial animation has been attractive in academia and industry. Traditional methods mainly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the nondeterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. Existing diffusion-based methods can improve the diversity of facial animation. However, personalized speaking styles conveying accurate lip language is still lacking, besides, efficiency and compactness still need to be improved. In this work, we propose DiffusionTalker to address the above limitations via personalizer-guided distillation. In terms of personalization, we introduce a contrastive personalizer that learns identity and emotion embeddings to capture speaking styles from audio. We further propose a personalizer enhancer during distillation to enhance the influence of embeddings on facial animation. For efficiency, we use iterative distillation to reduce the steps required for animation generation and achieve more than 8x speedup in inference. To achieve compactness, we distill the large teacher model into a smaller student model, reducing our model’s storage by 86.4% while minimizing performance loss. After distillation, users can derive their identity and emotion embeddings from audio to quickly create personalized animations that reflect specific speaking styles. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released at: https://github.com/ChenVoid/DiffusionTalker.
实时语音驱动的3D面部动画在学术界和工业界都具有吸引力。传统方法主要关注学习从语音到动画的确定性映射。最近的方法开始考虑语音驱动的3D面部动画的非确定性因素,并采用扩散模型完成任务。现有的基于扩散的方法可以提高面部动画的多样性。然而,除了缺乏传达准确唇语的个性化说话风格外,还需要提高效率和紧凑性。在这项工作中,我们提出DiffusionTalker,通过个性化引导蒸馏解决上述局限性。在个性化方面,我们引入对比个性化器来学习身份和情感嵌入,从音频中捕捉说话风格。我们进一步提出在蒸馏过程中使用个性化增强器,以增强嵌入对面部动画的影响。为了提高效率,我们使用迭代蒸馏减少动画生成所需的步骤,并在推理过程中实现了超过8倍的加速。为了实现紧凑性,我们将大型教师模型蒸馏到小型学生模型中,在尽量减少性能损失的同时,将我们的模型存储减少了8.4%。蒸馏后,用户可以从音频中得出自己的身份和情感嵌入,快速创建反映特定说话风格的个性化动画。进行了大量实验,证明我们的方法优于现有最先进的方法。代码将在https://github.com/ChenVoid/DiffusionTalker发布。
论文及项目相关链接
PDF Accepted by ICME2025
Summary
本文提出一种基于扩散模型的实时语音驱动3D面部动画方法,称为DiffusionTalker。该方法通过个性化引导蒸馏解决现有方法的局限性,包括提高动画的多样性和准确性,同时提高效率和紧凑性。通过引入对比个性化器学习身份和情感嵌入,捕捉音频中的说话风格。在蒸馏过程中提出个性化增强器,增强嵌入对面部动画的影响。使用迭代蒸馏减少动画生成所需的步骤,实现推理时超过8倍的加速。通过将大型教师模型蒸馏到小型学生模型,减少模型存储量达86.4%,同时尽量减少性能损失。用户可以从音频中提取身份和情感嵌入,快速创建反映特定说话风格的个性化动画。
Key Takeaways
- DiffusionTalker是一种基于扩散模型的实时语音驱动3D面部动画方法。
- 通过个性化引导蒸馏提高动画的多样性和准确性。
- 引入对比个性化器学习身份和情感嵌入,以捕捉音频中的说话风格。
- 提出个性化增强器在蒸馏过程中增强嵌入对动画的影响。
- 使用迭代蒸馏加速动画生成,提高推理效率。
- 通过将大型教师模型蒸馏到小型学生模型,实现模型的紧凑性,减少存储需求。
点此查看论文截图

TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
Authors:Jianchuan Chen, Jingchuan Hu, Gaige Wang, Zhonghua Jiang, Tiansong Zhou, Zhiwen Chen, Chengfei Lv
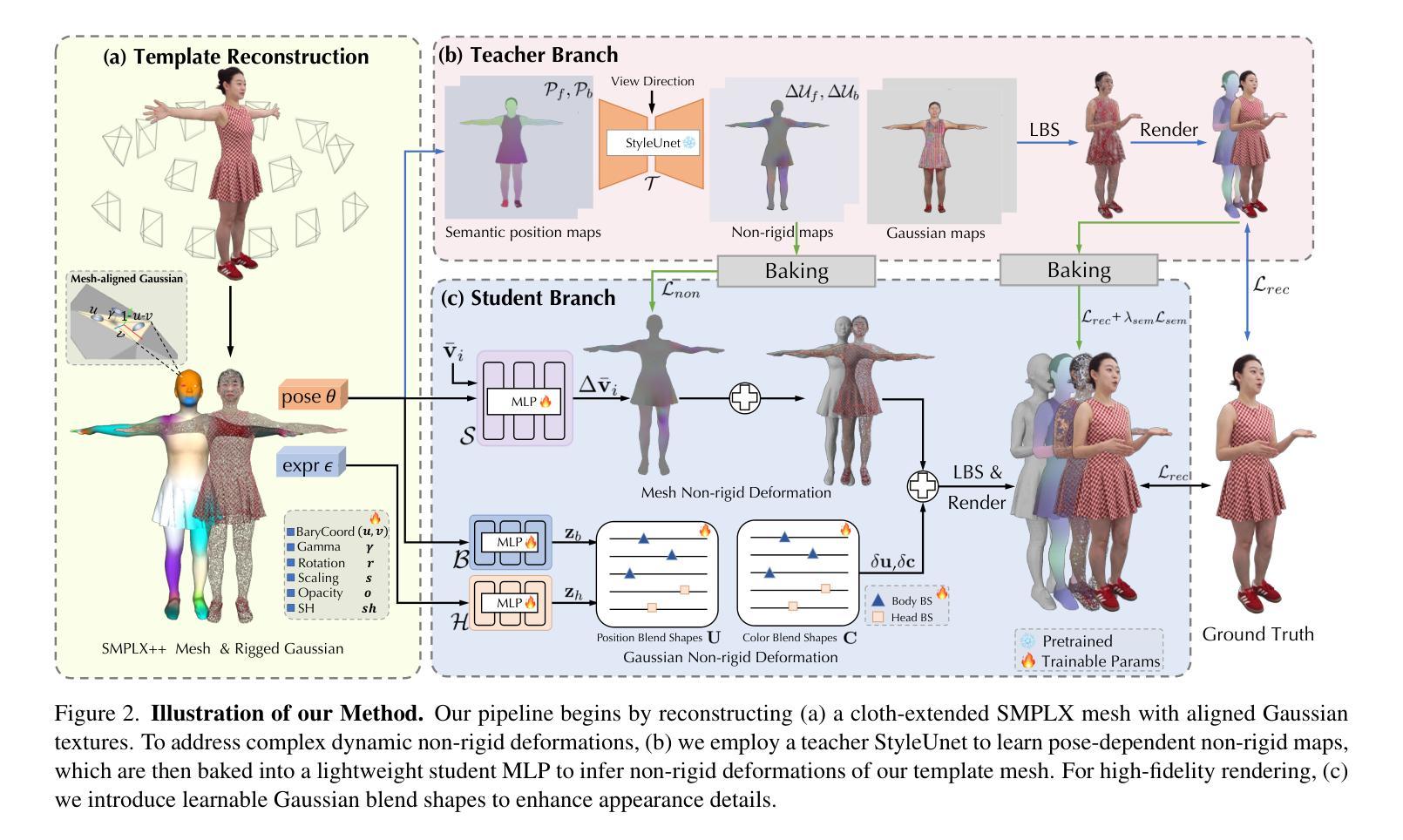
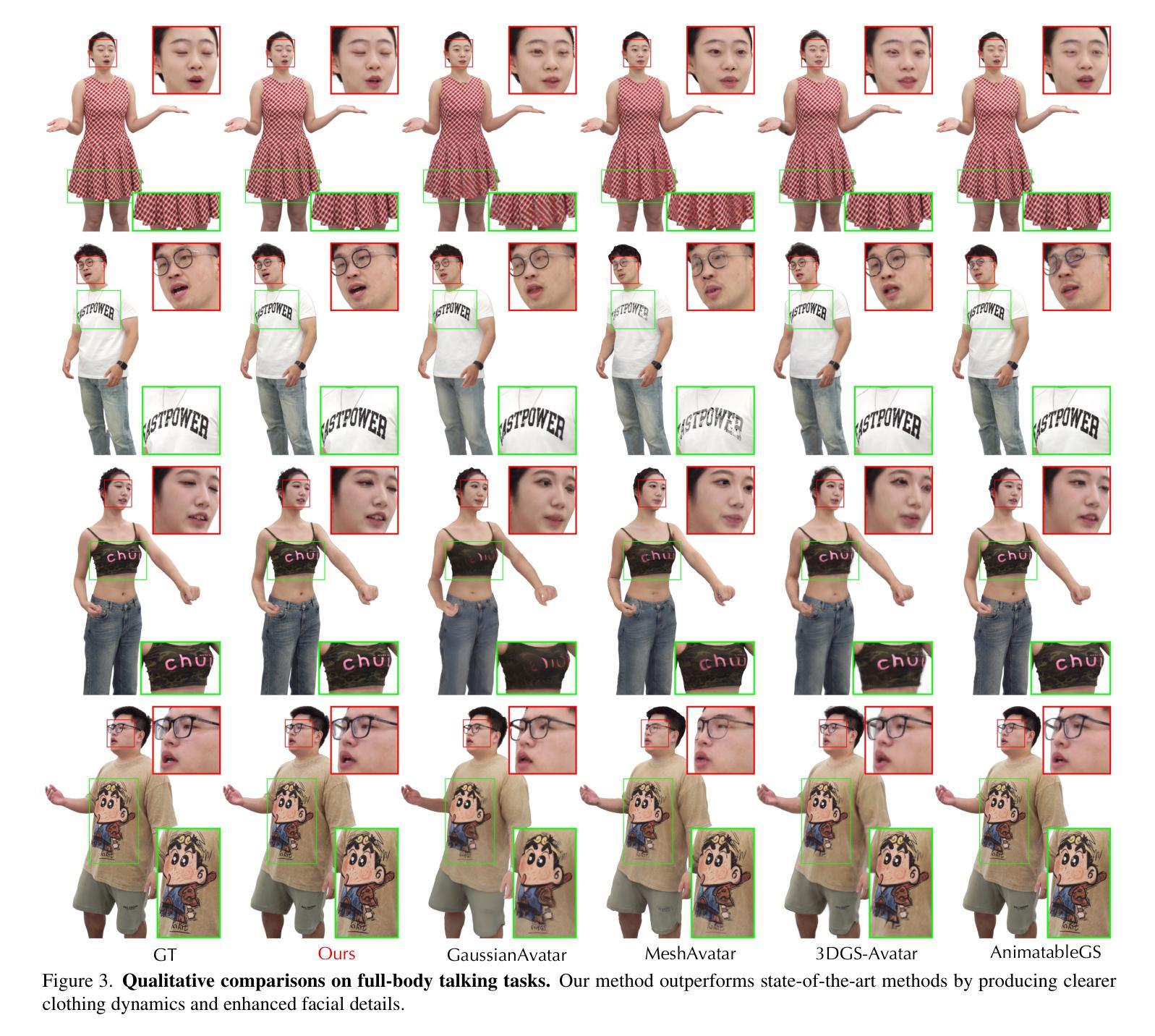
Realistic 3D full-body talking avatars hold great potential in AR, with applications ranging from e-commerce live streaming to holographic communication. Despite advances in 3D Gaussian Splatting (3DGS) for lifelike avatar creation, existing methods struggle with fine-grained control of facial expressions and body movements in full-body talking tasks. Additionally, they often lack sufficient details and cannot run in real-time on mobile devices. We present TaoAvatar, a high-fidelity, lightweight, 3DGS-based full-body talking avatar driven by various signals. Our approach starts by creating a personalized clothed human parametric template that binds Gaussians to represent appearances. We then pre-train a StyleUnet-based network to handle complex pose-dependent non-rigid deformation, which can capture high-frequency appearance details but is too resource-intensive for mobile devices. To overcome this, we “bake” the non-rigid deformations into a lightweight MLP-based network using a distillation technique and develop blend shapes to compensate for details. Extensive experiments show that TaoAvatar achieves state-of-the-art rendering quality while running in real-time across various devices, maintaining 90 FPS on high-definition stereo devices such as the Apple Vision Pro.
在增强现实(AR)领域,逼真的3D全身对话半身像具有巨大的潜力,其应用场景从电子商务直播到全息通信等不一而足。尽管在用于创建逼真半身像的3D高斯贴图(3DGS)方面取得了进展,但现有方法在全身对话任务中的面部表情和躯体动作的精细控制方面仍面临挑战。此外,它们通常缺乏足够的细节,无法在移动设备上实时运行。我们推出了TaoAvatar,这是一个高保真、轻量级的3DGS全身对话半身像,由各种信号驱动。我们的方法首先是通过绑定高斯来创建个性化的穿衣人体参数模板来代表外观。然后,我们预先训练一个基于StyleUnet的网络来处理复杂的姿势相关非刚性变形,该网络能够捕获高频外观细节,但对于移动设备来说资源过于密集。为了克服这一问题,我们使用蒸馏技术将非刚性变形“烘焙”到一个基于MLP的轻量级网络中,并开发混合形状以弥补细节。大量实验表明,TaoAvatar在运行时实现了卓越的质量渲染效果,同时跨越各种设备进行实时渲染,在高分辨率立体声设备上如苹果视觉专业版上保持90帧每秒的运行速度。
论文及项目相关链接
PDF Accepted by CVPR 2025, project page: https://PixelAI-Team.github.io/TaoAvatar
Summary
基于实时信号驱动的高保真轻量化3D全身说话Avatar的研究。该研究使用3D高斯贴图技术创建个性化模板,并引入StyleUnet网络处理复杂姿态相关的非刚性变形。为解决移动设备资源消耗过大的问题,研究采用蒸馏技术将非刚性变形“烘焙”至轻量级MLP网络中,并通过blend shapes补偿细节。TaoAvatar在保持高渲染质量的同时实现实时运行,适用于各种设备,并在高清立体声设备上保持90 FPS的帧率。
Key Takeaways
- 3D全身说话Avatars在AR中有广泛应用潜力,从电商直播到全息通信。
- 现有3D高斯贴图技术在精细面部表达和全身动作控制上遇到困难。
- TaoAvatar利用个性化模板和StyleUnet网络处理复杂姿态的非刚性变形。
- 为解决移动设备资源消耗问题,采用蒸馏技术优化网络。
- 通过blend shapes补偿细节,实现高保真渲染。
- TaoAvatar达成实时运行与高质量渲染的平衡,适用于各种设备。
- TaoAvatar在高清立体声设备上保持90 FPS的帧率。
点此查看论文截图

From Faces to Voices: Learning Hierarchical Representations for High-quality Video-to-Speech
Authors:Ji-Hoon Kim, Jeongsoo Choi, Jaehun Kim, Chaeyoung Jung, Joon Son Chung
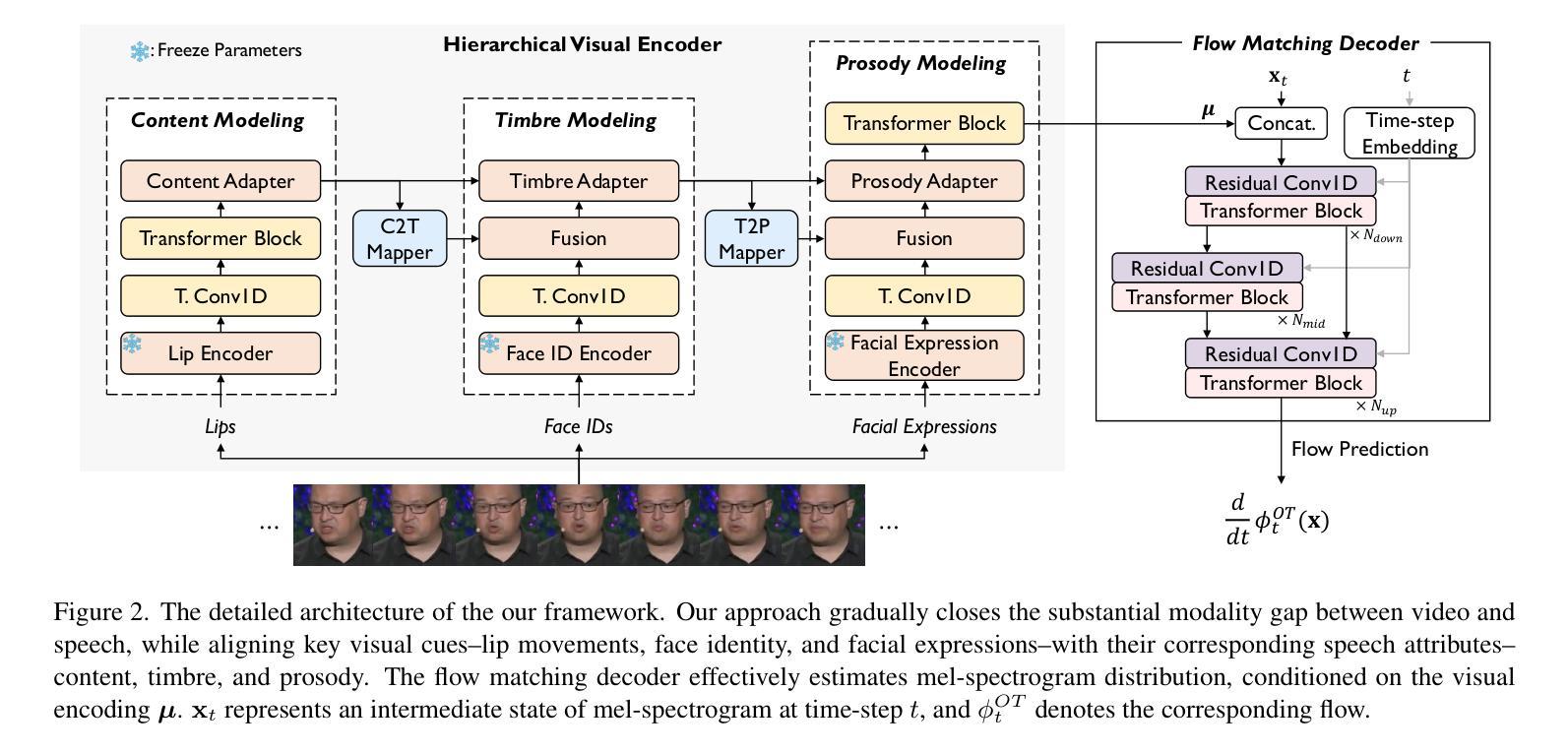
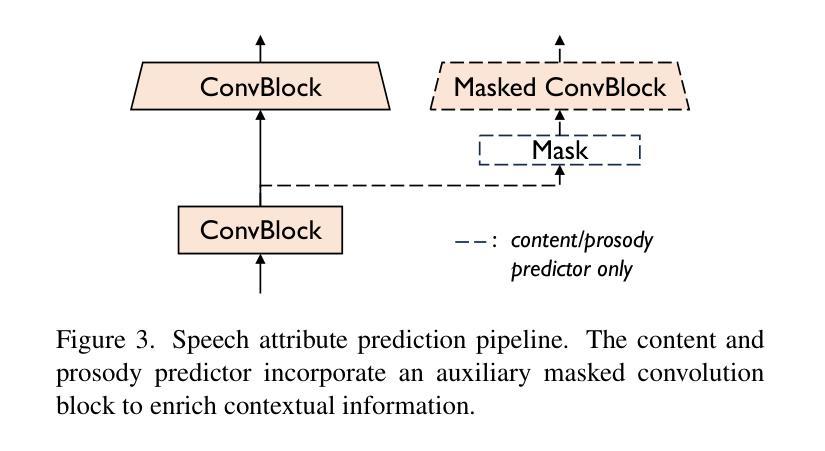
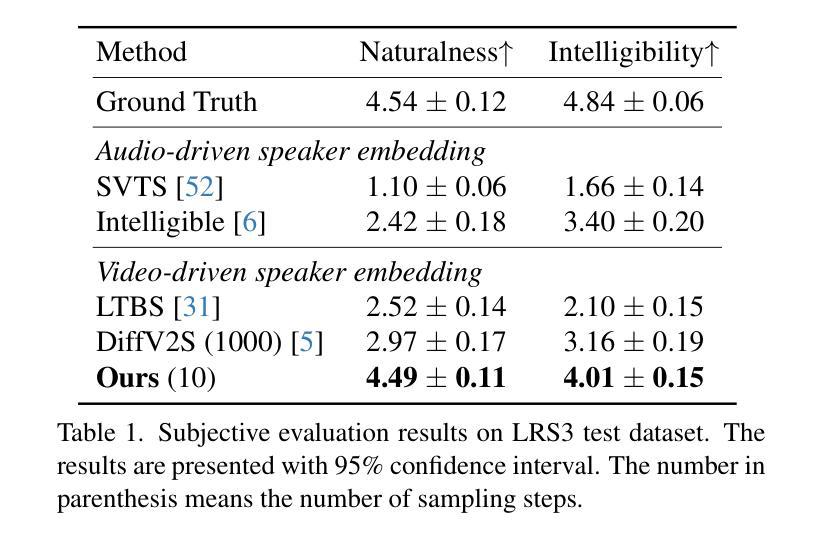
The objective of this study is to generate high-quality speech from silent talking face videos, a task also known as video-to-speech synthesis. A significant challenge in video-to-speech synthesis lies in the substantial modality gap between silent video and multi-faceted speech. In this paper, we propose a novel video-to-speech system that effectively bridges this modality gap, significantly enhancing the quality of synthesized speech. This is achieved by learning of hierarchical representations from video to speech. Specifically, we gradually transform silent video into acoustic feature spaces through three sequential stages – content, timbre, and prosody modeling. In each stage, we align visual factors – lip movements, face identity, and facial expressions – with corresponding acoustic counterparts to ensure the seamless transformation. Additionally, to generate realistic and coherent speech from the visual representations, we employ a flow matching model that estimates direct trajectories from a simple prior distribution to the target speech distribution. Extensive experiments demonstrate that our method achieves exceptional generation quality comparable to real utterances, outperforming existing methods by a significant margin.
本文的研究目标是从无声的对话视频生成高质量语音,这一任务也被称为视频到语音的合成。视频到语音合成中的一个重大挑战在于无声视频和多元语音之间存在的巨大模态差距。在本文中,我们提出了一种新型的视频到语音系统,该系统有效地桥接了这一模态差距,大大提高了合成语音的质量。这是通过学习从视频到语音的分层表示来实现的。具体来说,我们通过三个连续阶段——内容、音调和韵律建模,逐渐将无声视频转换为声音特征空间。在每个阶段,我们将视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音对应因素进行对齐,以确保无缝转换。此外,为了从视觉表示生成真实且连贯的语音,我们采用了一种流量匹配模型,该模型从简单的先验分布估计出目标语音分布的直接轨迹。大量实验表明,我们的方法达到了与真实语音相比的优秀生成质量,大大优于现有方法。
论文及项目相关链接
PDF CVPR 2025, demo page: https://mm.kaist.ac.kr/projects/faces2voices/
Summary
提供一种新的视频转语音系统生成高质量语音。通过视频学习层次表示以缩小视频和复杂语音之间的模态差距。通过内容、音质和语调建模将静音视频转换为声音特征空间。利用流量匹配模型从视觉表示生成逼真、连贯的语音。
Key Takeaways
- 视频转语音合成中的挑战在于静默视频与复杂语音之间的模态差距。
- 提出了一种新的视频转语音系统,通过学习层次表示来有效地缩短模态差距。
- 系统通过将静默视频逐步转换为声音特征空间,包括内容、音质和语调建模三个阶段。
- 在每个阶段,视觉因素(如嘴唇动作、面部身份和面部表情)与相应的声音对应物对齐,以确保无缝转换。
- 利用流量匹配模型从视觉表示生成逼真的语音,表现出优越的性能。
- 实验证明,该方法在生成质量方面表现出卓越的性能,与真实语音相比具有竞争力,并大幅度超越了现有方法。
点此查看论文截图

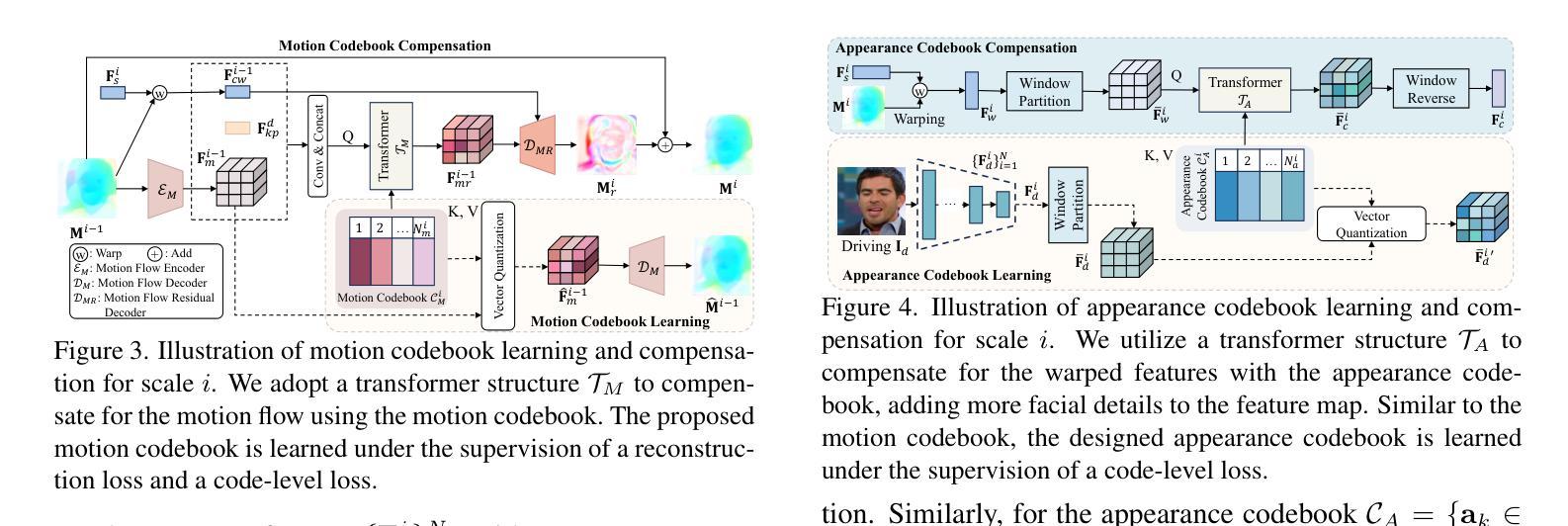
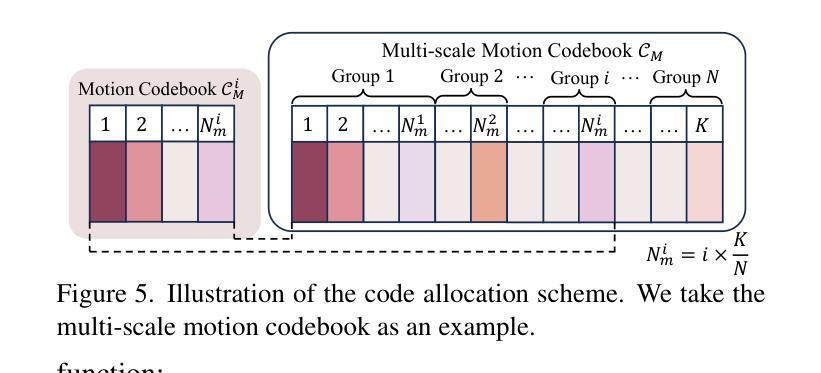
Synergizing Motion and Appearance: Multi-Scale Compensatory Codebooks for Talking Head Video Generation
Authors:Shuling Zhao, Fa-Ting Hong, Xiaoshui Huang, Dan Xu
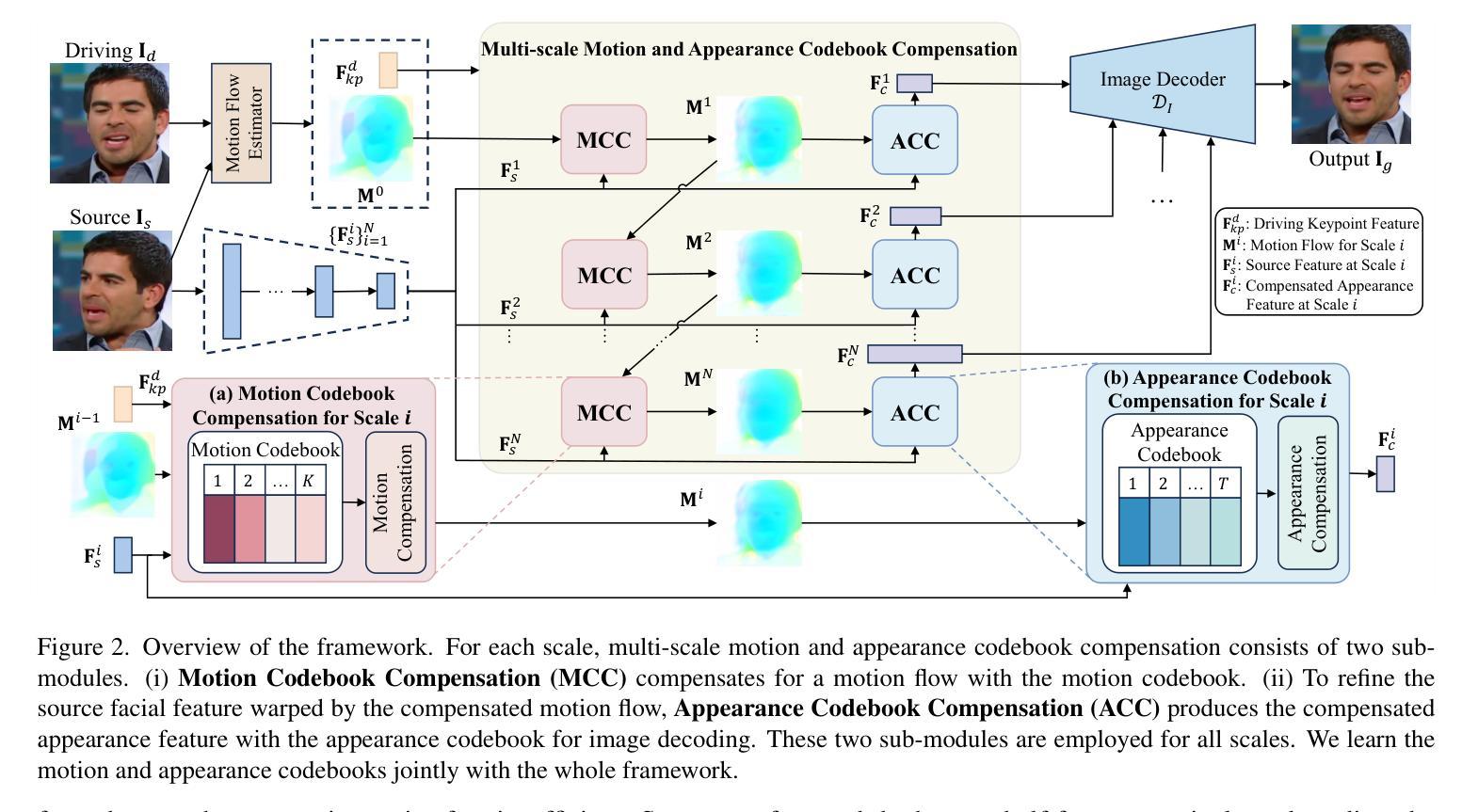
Talking head video generation aims to generate a realistic talking head video that preserves the person’s identity from a source image and the motion from a driving video. Despite the promising progress made in the field, it remains a challenging and critical problem to generate videos with accurate poses and fine-grained facial details simultaneously. Essentially, facial motion is often highly complex to model precisely, and the one-shot source face image cannot provide sufficient appearance guidance during generation due to dynamic pose changes. To tackle the problem, we propose to jointly learn motion and appearance codebooks and perform multi-scale codebook compensation to effectively refine both the facial motion conditions and appearance features for talking face image decoding. Specifically, the designed multi-scale motion and appearance codebooks are learned simultaneously in a unified framework to store representative global facial motion flow and appearance patterns. Then, we present a novel multi-scale motion and appearance compensation module, which utilizes a transformer-based codebook retrieval strategy to query complementary information from the two codebooks for joint motion and appearance compensation. The entire process produces motion flows of greater flexibility and appearance features with fewer distortions across different scales, resulting in a high-quality talking head video generation framework. Extensive experiments on various benchmarks validate the effectiveness of our approach and demonstrate superior generation results from both qualitative and quantitative perspectives when compared to state-of-the-art competitors.
头部说话视频生成旨在从源图像中保留人的身份和驱动视频中的动作,生成逼真的头部说话视频。尽管该领域取得了令人瞩目的进展,但同时生成具有准确姿势和精细面部细节的视频仍然是一个具有挑战性和关键性的问题。本质上,面部动作通常非常复杂,难以精确建模,而且由于在生成过程中动态姿势的改变,单次源面部图像无法提供足够的外观指导。为了解决这个问题,我们提出联合学习运动与外观码本,并执行多尺度码本补偿,以有效地调整面部运动条件和外观特征,用于解码说话面部图像。具体来说,设计的多尺度运动与外观码本是在统一框架中同时学习的,以存储代表性的全局面部运动流和外观模式。然后,我们提出了一种新颖的多尺度运动和外观补偿模块,该模块利用基于变压器的码本检索策略,从两个码本中检索互补信息进行联合运动和外观补偿。整个过程产生了更大灵活性的运动流和在不同尺度上较少变形的外观特征,从而构建了一个高质量的头部说话视频生成框架。在各种基准测试上的大量实验验证了我们的方法的有效性,与最先进的竞争对手相比,从定性和定量两个角度都展示了更优越的生成结果。
论文及项目相关链接
PDF Accepted by CVPR 2025. Project page: https://shaelynz.github.io/synergize-motion-appearance/
Summary
视频生成技术在创建真实感强的说话人视频方面取得了显著进展。然而,生成同时包含准确姿势和精细面部细节的视频仍然是一个挑战。本文提出了一种联合学习运动与外观码本并进行多尺度码本补偿的方法,以提高面部运动条件和特征表现的精细度。实验证明,该方法在说话人头部视频生成方面效果显著。
Key Takeaways
- 说话头视频生成旨在从源图像中保留个人身份并从驱动视频中获取动作。
- 精确建模面部运动并保持动态姿势变化中的身份一致性是一个关键挑战。
- 提出了一种联合学习运动与外观码本的方法,以存储代表性的面部运动流和外观模式。
- 引入了多尺度运动与外观补偿模块,利用基于变压器的码本检索策略,从两个码本中查询互补信息进行联合运动和外观补偿。
- 该方法提高了运动流的灵活性和不同尺度下外观特征的真实性。
- 与现有先进技术相比,从定性和定量两个角度验证了该方法的有效性。
点此查看论文截图

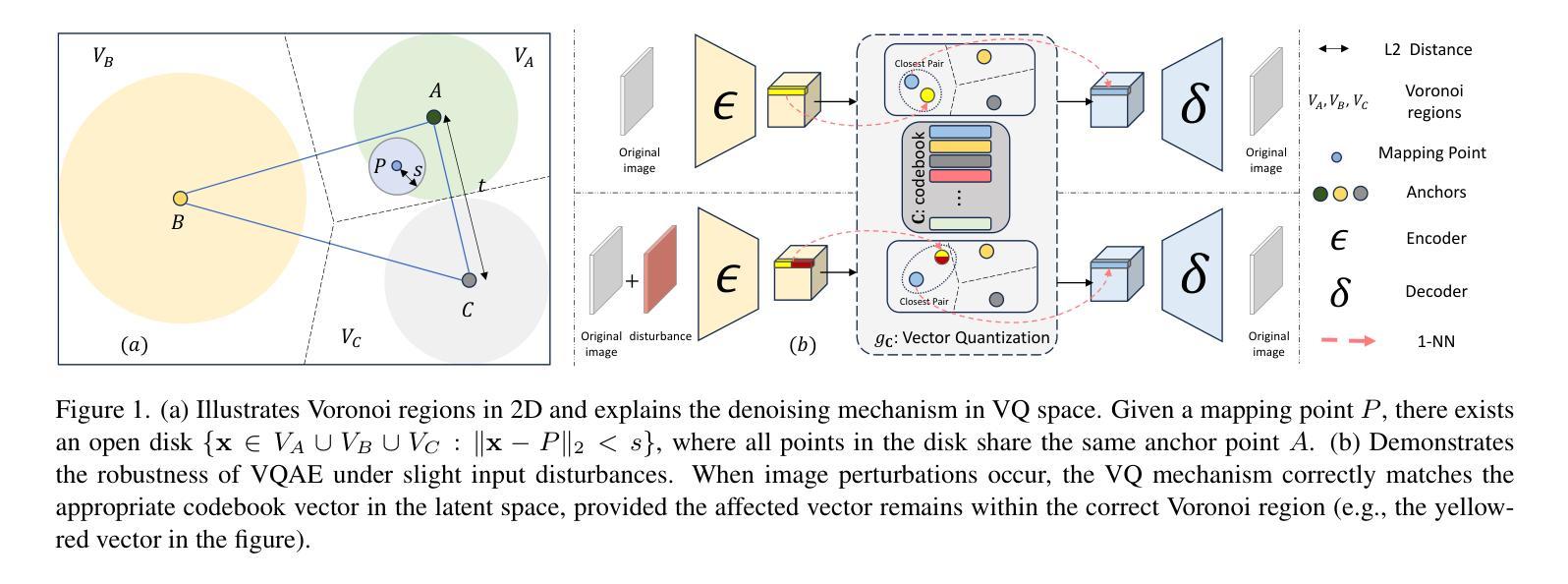
LaDTalk: Latent Denoising for Synthesizing Talking Head Videos with High Frequency Details
Authors:Jian Yang, Xukun Wang, Wentao Wang, Guoming Li, Qihang Fang, Ruihong Yuan, Tianyang Wang, Xiaomei Zhang, Yeying Jin, Zhaoxin Fan
Audio-driven talking head generation is a pivotal area within film-making and Virtual Reality. Although existing methods have made significant strides following the end-to-end paradigm, they still encounter challenges in producing videos with high-frequency details due to their limited expressivity in this domain. This limitation has prompted us to explore an effective post-processing approach to synthesize photo-realistic talking head videos. Specifically, we employ a pretrained Wav2Lip model as our foundation model, leveraging its robust audio-lip alignment capabilities. Drawing on the theory of Lipschitz Continuity, we have theoretically established the noise robustness of Vector Quantised Auto Encoders (VQAEs). Our experiments further demonstrate that the high-frequency texture deficiency of the foundation model can be temporally consistently recovered by the Space-Optimised Vector Quantised Auto Encoder (SOVQAE) we introduced, thereby facilitating the creation of realistic talking head videos. We conduct experiments on both the conventional dataset and the High-Frequency TalKing head (HFTK) dataset that we curated. The results indicate that our method, LaDTalk, achieves new state-of-the-art video quality and out-of-domain lip synchronization performance.
音频驱动的谈话头生成是电影制作和虚拟现实中的一个关键领域。尽管现有方法已经遵循端到端范式取得了重大进展,但由于其在该领域的表达能力有限,它们在生成具有高频细节的视频时仍面临挑战。这一局限性促使我们探索一种有效的后处理方法来合成逼真的谈话头视频。具体来说,我们采用预训练的Wav2Lip模型作为基础模型,利用其稳健的音频-嘴唇对齐功能。借助Lipschitz连续性的理论,我们从理论上建立了向量量化自动编码器(VQAE)的噪声鲁棒性。我们的实验进一步表明,通过我们引入的空间优化向量量化自动编码器(SOVQAE),可以持续恢复基础模型的高频纹理缺陷,从而有助于创建逼真的谈话头视频。我们在自己整理的常规数据集和高频谈话头(HFTK)数据集上进行了实验。结果表明,我们的LaDTalk方法实现了最新的视频质量和域外嘴唇同步性能。
论文及项目相关链接
Summary
本文探讨了音频驱动说话人头部生成在影视制作和虚拟现实领域的重要性。现有方法虽然遵循端到端范式取得了显著进展,但在生成具有高频细节的视频时仍面临挑战。为此,本文探索了一种有效的后处理方法来合成逼真的说话人头视频。基于Lipschitz连续性的理论,从理论上证明了向量量化自编码器(VQAEs)的噪声鲁棒性。实验表明,引入的空间优化向量量化自编码器(SOVQAE)可以弥补基础模型的高频纹理缺陷,从而生成更逼真的说话人头视频。在常规数据集和我们整理的高频说话人头(HFTK)数据集上进行的实验结果表明,LaDTalk方法实现了新的视频质量里程碑和出色的跨域唇同步性能。
Key Takeaways
- 音频驱动说话头生成在影视制作和虚拟现实领域具有重要性。
- 现有方法虽然有所进展,但在生成高频细节丰富的视频时仍面临挑战。
- 提出了一种有效的后处理方法来合成逼真的说话人头视频。
- 利用向量量化自编码器(VQAEs)的噪声鲁棒性理论来增强视频质量。
- 引入空间优化向量量化自编码器(SOVQAE)来弥补基础模型的高频纹理缺陷。
- LaDTalk方法实现了高质量的视频合成和出色的跨域唇同步性能。
点此查看论文截图



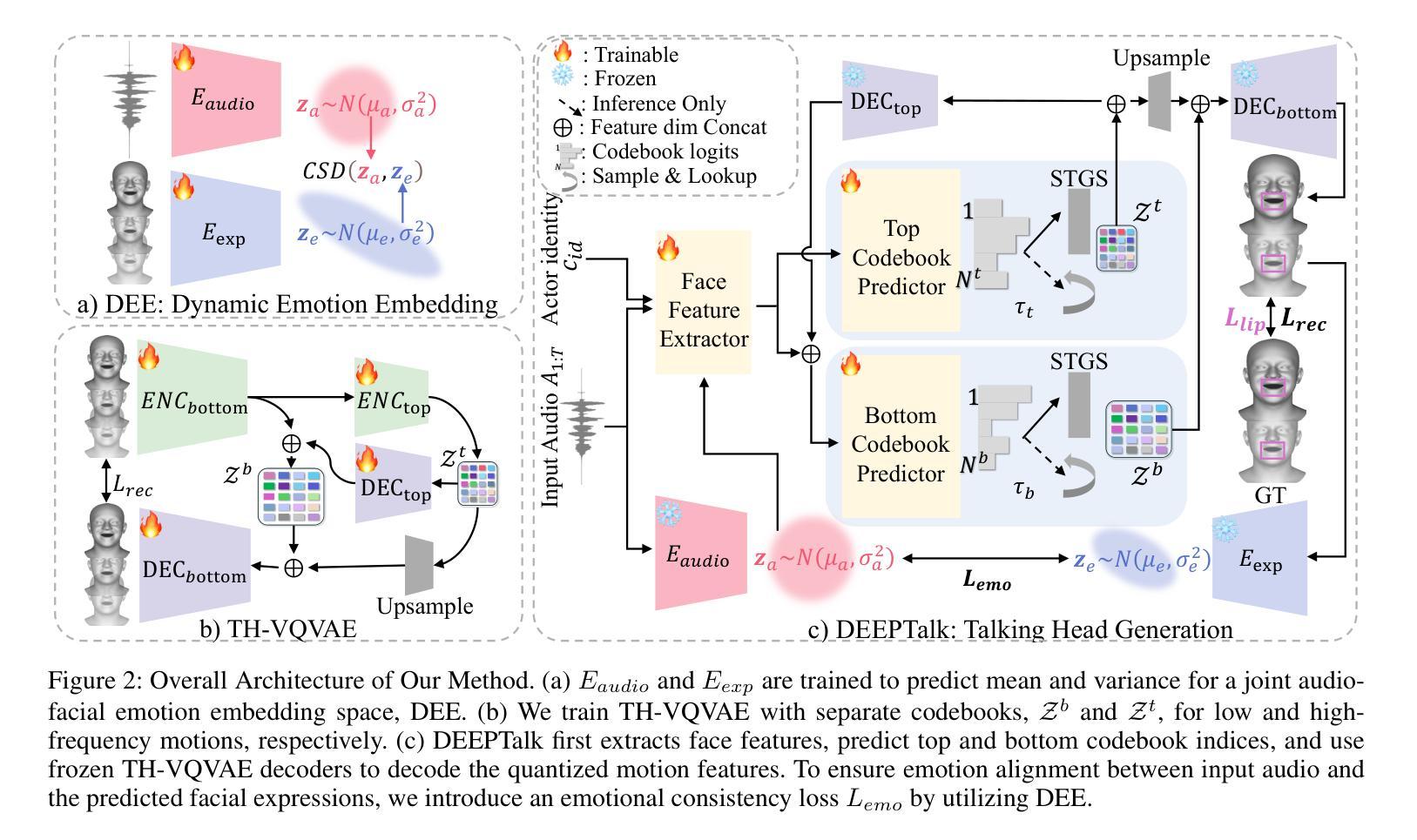
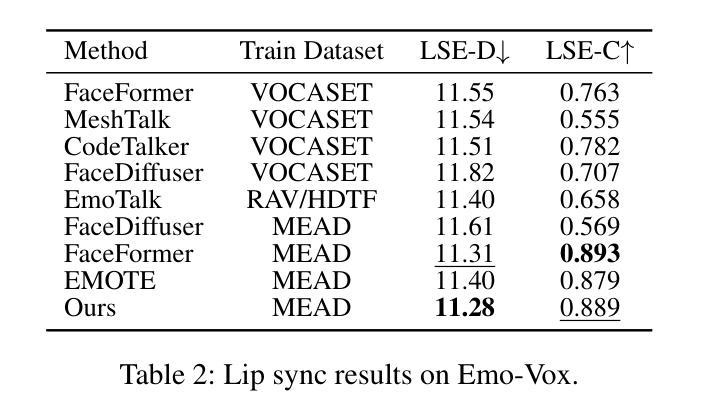
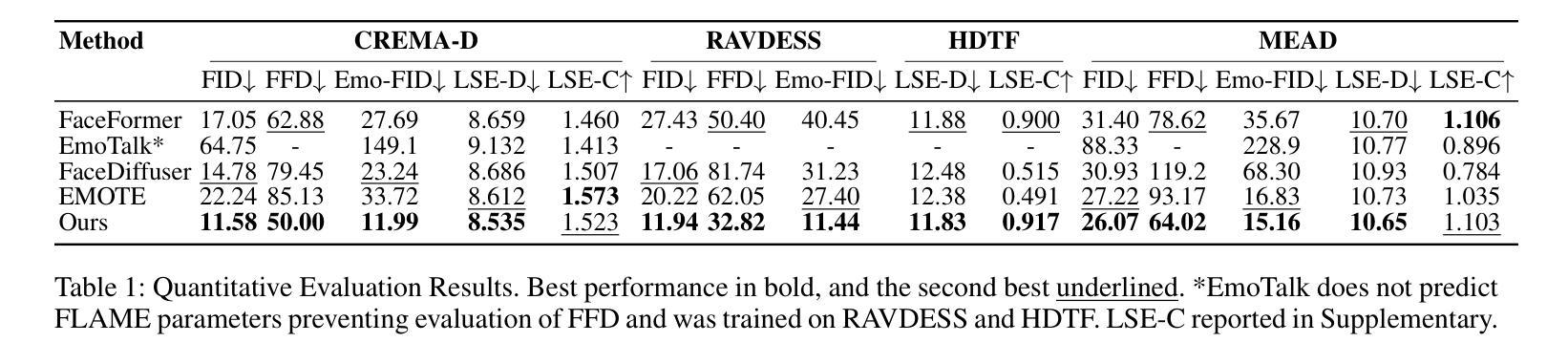
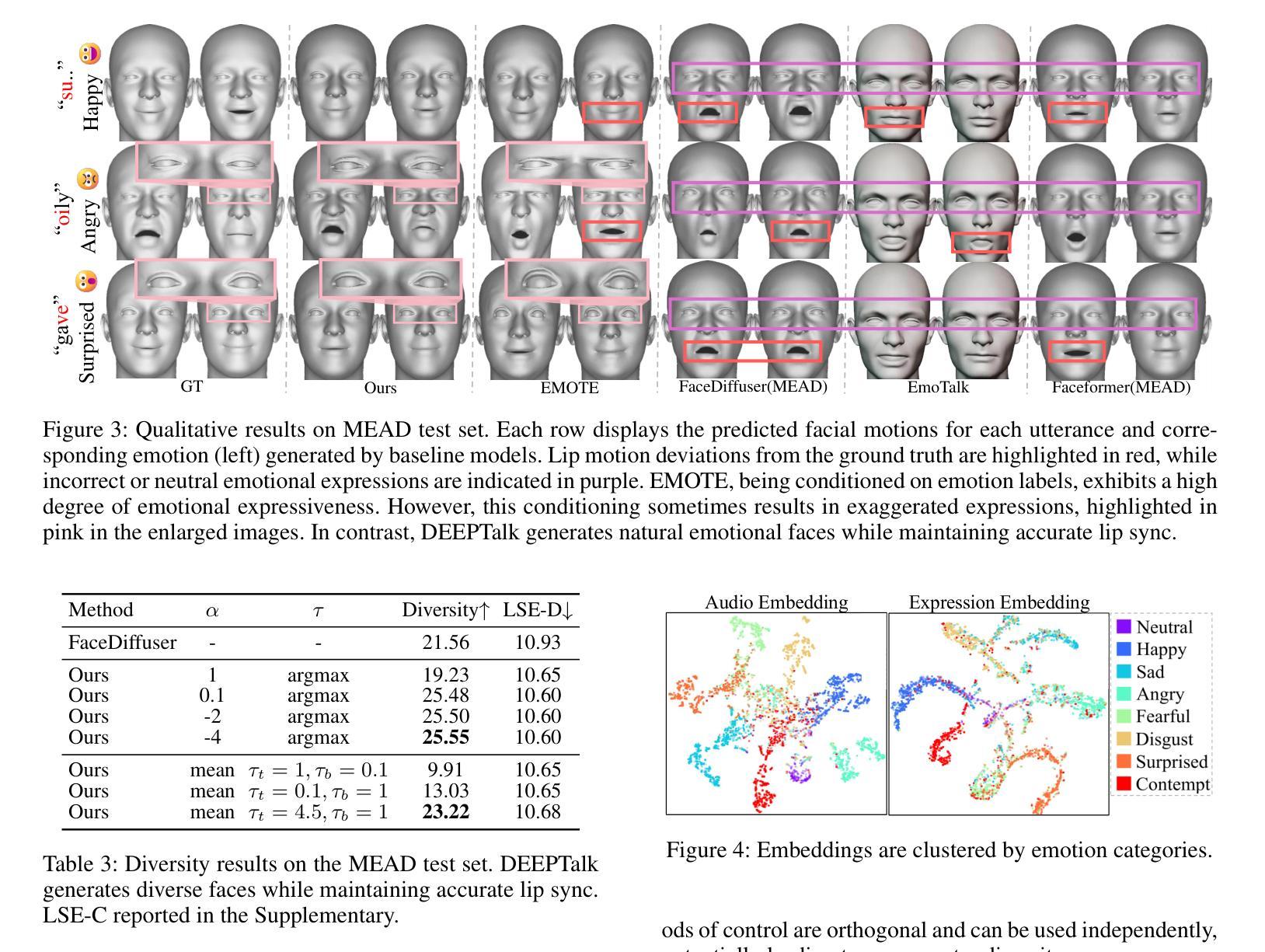
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Authors:Jisoo Kim, Jungbin Cho, Joonho Park, Soonmin Hwang, Da Eun Kim, Geon Kim, Youngjae Yu
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, a talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Our project page is available at https://whwjdqls.github.io/deeptalk\_website/
语音驱动的三维面部动画因其广泛的应用而备受关注。尽管最近实现了现实主义的唇部运动,但当前的方法无法捕捉通过语音传达的微妙情绪细微差别,并产生单调的面部运动。这些局限性导致面部动画生硬且重复,降低了用户参与度并阻碍了其适用性。为了应对这些挑战,我们引入了DEEPTalk,这是一种从语音输入直接生成多样且情感丰富的3D面部表情的新方法。为了实现这一点,我们首先训练DEE(动态情绪嵌入),它使用概率对比学习来构建包含语音和面部运动的联合情绪嵌入空间。此概率框架捕捉了从语音和面部运动中解释情绪的的不确定性,从而能够从多元情绪空间中得出情绪向量。此外,为了生成动态面部运动,我们设计了TH-VQVAE(时序分层VQ-VAE)作为表现力强且稳健的运动先验,克服了VAE和VQ-VAE的局限性。利用这些强大的先验知识,我们开发了DEEPTalk面部说话者生成器,它以非自回归方式预测编码本索引来创建动态面部运动,并结合了新颖的情绪一致性损失。在多个数据集上的广泛实验表明,我们的方法在创建多样且情感丰富的说话面部方面非常有效,同时保持了准确的唇同步。我们的项目页面可在https://whwjdqls.github.io/deeptalk_website/找到。
论文及项目相关链接
PDF First two authors contributed equally. This is a revised version of the original submission, which has been accepted for publication at AAAI 2025
Summary
语音驱动的3D面部动画因广泛的应用领域而受到关注。当前的方法无法实现从语音中捕捉微妙的情绪变化,导致动画表情单调。为解决此问题,我们提出DEEPTalk方法,直接从语音输入生成丰富情感的3D面部表情。通过训练动态情感嵌入(DEE)和使用TH-VQVAE作为动态面部运动生成器,我们的方法能够创建具有多样性和情感表达的说话人脸。
Key Takeaways
- 当前语音驱动的3D面部动画存在无法捕捉情绪细微变化的问题,导致动画表情单调。
- DEEPTalk是一种新颖的方法,能够直接从语音输入生成丰富情感的3D面部表情。
- DEEPTalk通过训练动态情感嵌入(DEE)和使用TH-VQVAE技术来解决传统方法的局限性。
- 动态情感嵌入(DEE)采用概率对比学习,为语音和面部运动创建联合情感嵌入空间。
- TH-VQVAE作为一种表达性强且稳健的运动先验,能够克服传统VAE和VQ-VAE的局限性。
- DEEPTalk利用强大的先验知识非自回归地预测代码本索引,以创建动态面部运动。
- 在多个数据集上的实验表明,DEEPTalk方法能创建多样且情感丰富的说话人脸,同时保持准确的唇同步。
点此查看论文截图