⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-29 更新
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model
Authors:Abdelrahman Shaker, Muhammad Maaz, Chenhui Gou, Hamid Rezatofighi, Salman Khan, Fahad Shahbaz Khan
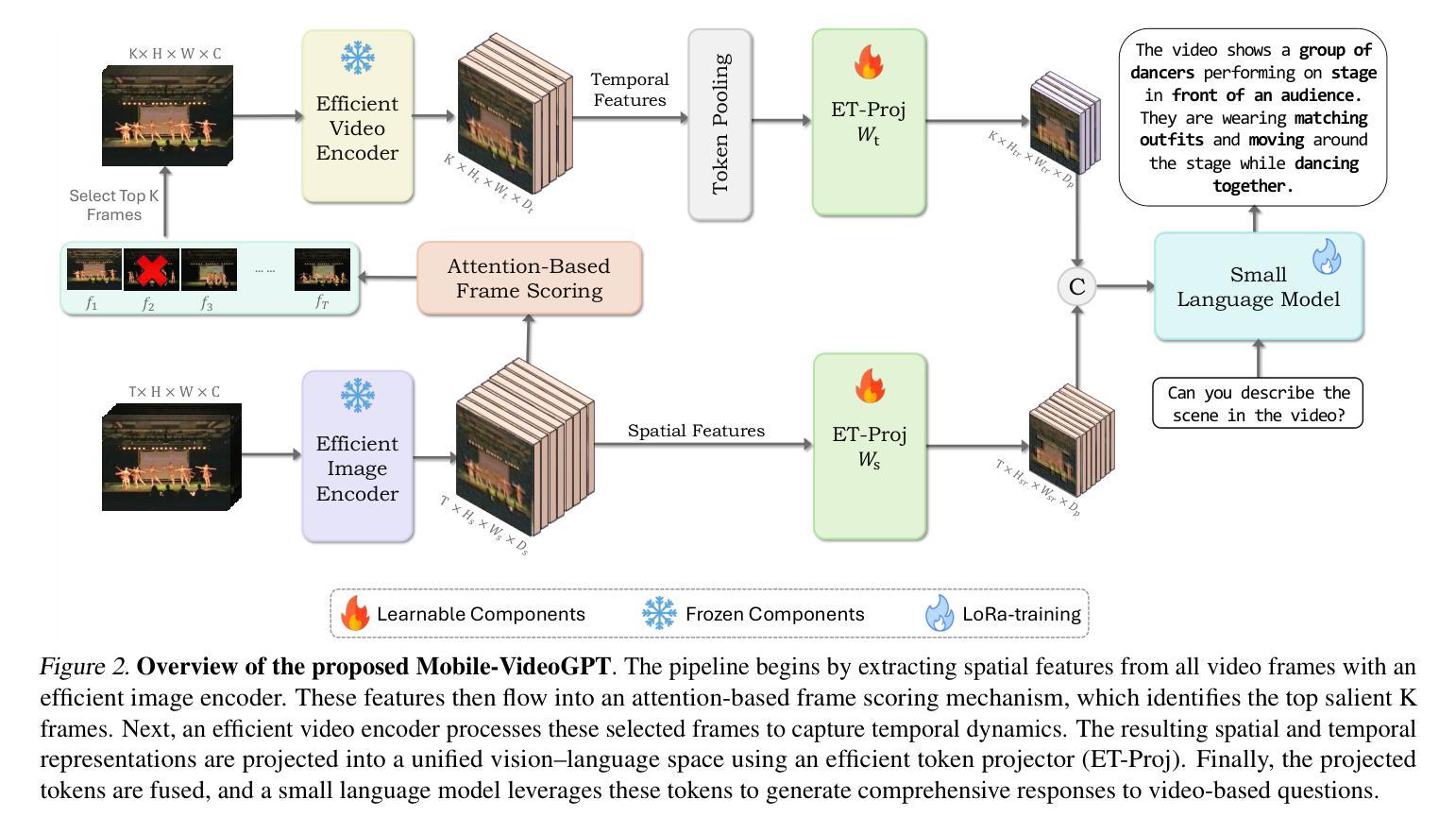
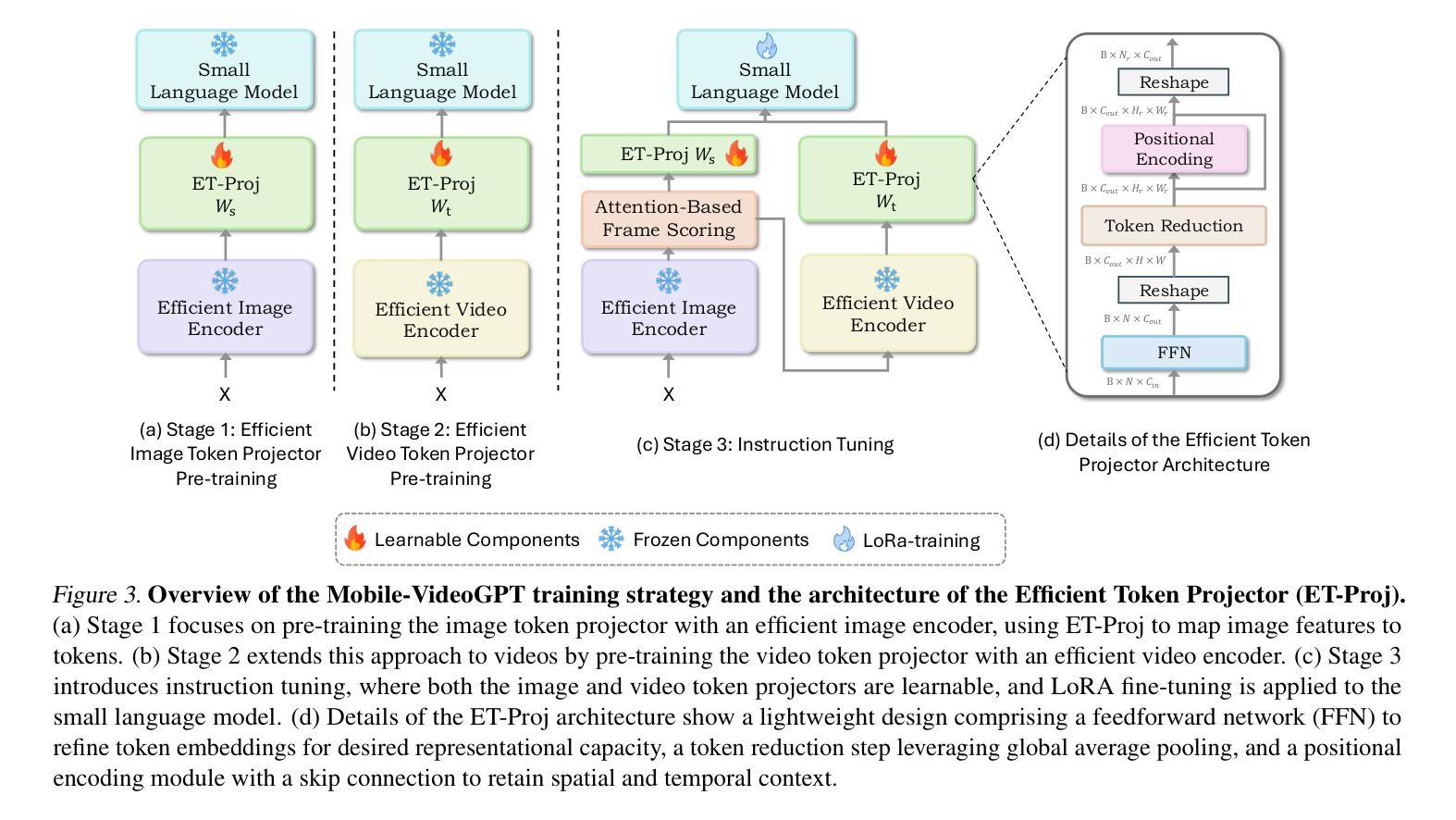
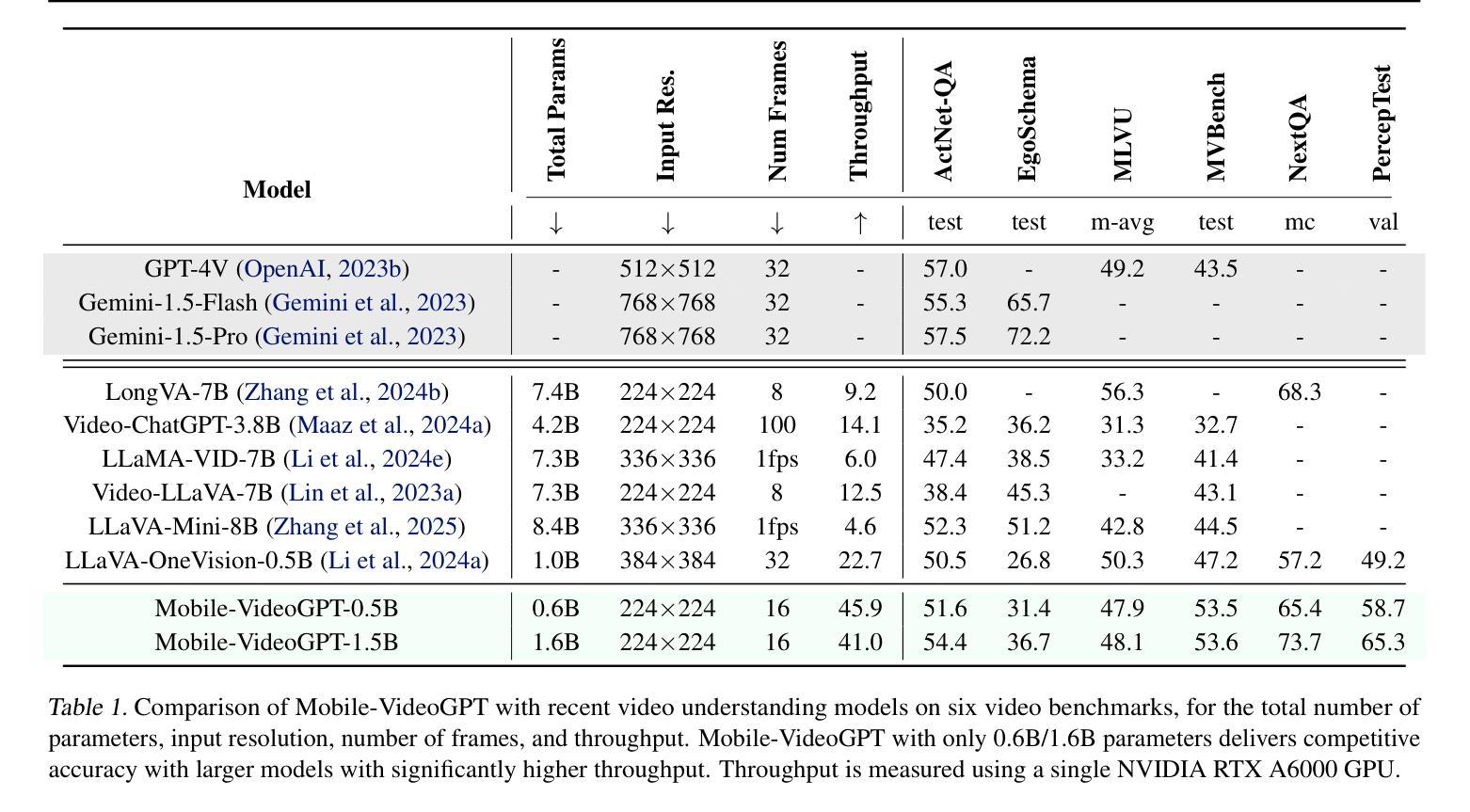
Video understanding models often struggle with high computational requirements, extensive parameter counts, and slow inference speed, making them inefficient for practical use. To tackle these challenges, we propose Mobile-VideoGPT, an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models (LMMs), Mobile-VideoGPT consists of lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time throughput. To further improve efficiency, we present an Attention-Based Frame Scoring mechanism to select the key-frames, along with an efficient token projector that prunes redundant visual tokens and preserves essential contextual cues. We evaluate our model across well-established six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, and PercepTest). Our results show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing state-of-the-art 0.5B-parameter models by 6 points on average with 40% fewer parameters and more than 2x higher throughput. Our code and models are publicly available at: https://github.com/Amshaker/Mobile-VideoGPT.
视频理解模型通常面临高计算要求、大量参数和缓慢推理速度的难题,使得它们在实际应用中效率低下。为了应对这些挑战,我们提出了Mobile-VideoGPT,这是一个高效的多媒体框架,设计用于处理不到十亿个参数。与传统的视频大型多媒体模型(LMM)不同,Mobile-VideoGPT由轻量级的双视觉编码器、高效投影仪和小型语言模型(SLM)组成,可实现实时处理。为了进一步提高效率,我们提出了一种基于注意力的帧评分机制来选择关键帧,以及一个高效的令牌投影仪,可以删除冗余的视觉令牌并保留重要的上下文线索。我们在六个公认的视频理解基准测试(例如MVBench、EgoSchema、NextQA和PercepTest)上评估了我们的模型。结果表明,Mobile-VideoGPT-0.5B每秒可以生成高达46个令牌,同时在性能上超过了现有的最先进的0.5B参数模型,平均高出6个点,同时参数减少了40%,吞吐量提高了两倍以上。我们的代码和模型可在以下网址公开获取:https://github.com/Amshaker/Mobile-VideoGPT。
论文及项目相关链接
PDF Technical Report. Project Page: https://amshaker.github.io/Mobile-VideoGPT
Summary
本文介绍了针对视频理解模型存在的计算要求高、参数多、推理速度慢等问题,提出的Mobile-VideoGPT高效多模态框架。该框架使用轻量级双视觉编码器、高效投影器和小型语言模型,实现实时处理速度。同时,引入基于注意力的帧评分机制和有效的令牌投影器,以提高效率并保留关键上下文线索。在多个视频理解基准测试中,Mobile-VideoGPT-0.5B表现出卓越性能,生成令牌速度高达每秒46个,同时在平均指标上优于现有最先进的0.5B参数模型,且使用参数更少、吞吐量更高。
Key Takeaways
- Mobile-VideoGPT是一个高效的多模态框架,旨在解决视频理解模型的高计算要求和低效率问题。
- 该框架使用轻量级组件,如双视觉编码器、高效投影器和小型语言模型(SLM),以实现实时处理速度。
- 引入基于注意力的帧评分机制,以选择关键帧,提高模型效率。
- 通过有效的令牌投影器,去除冗余视觉令牌,保留关键上下文线索。
- Mobile-VideoGPT-0.5B在多个视频理解基准测试中表现优越,生成令牌速度高。
- 与现有最先进的0.5B参数模型相比,Mobile-VideoGPT平均指标更优,且使用更少的参数和更高的吞吐量。
点此查看论文截图

BOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding
Authors:Shuming Liu, Chen Zhao, Tianqi Xu, Bernard Ghanem
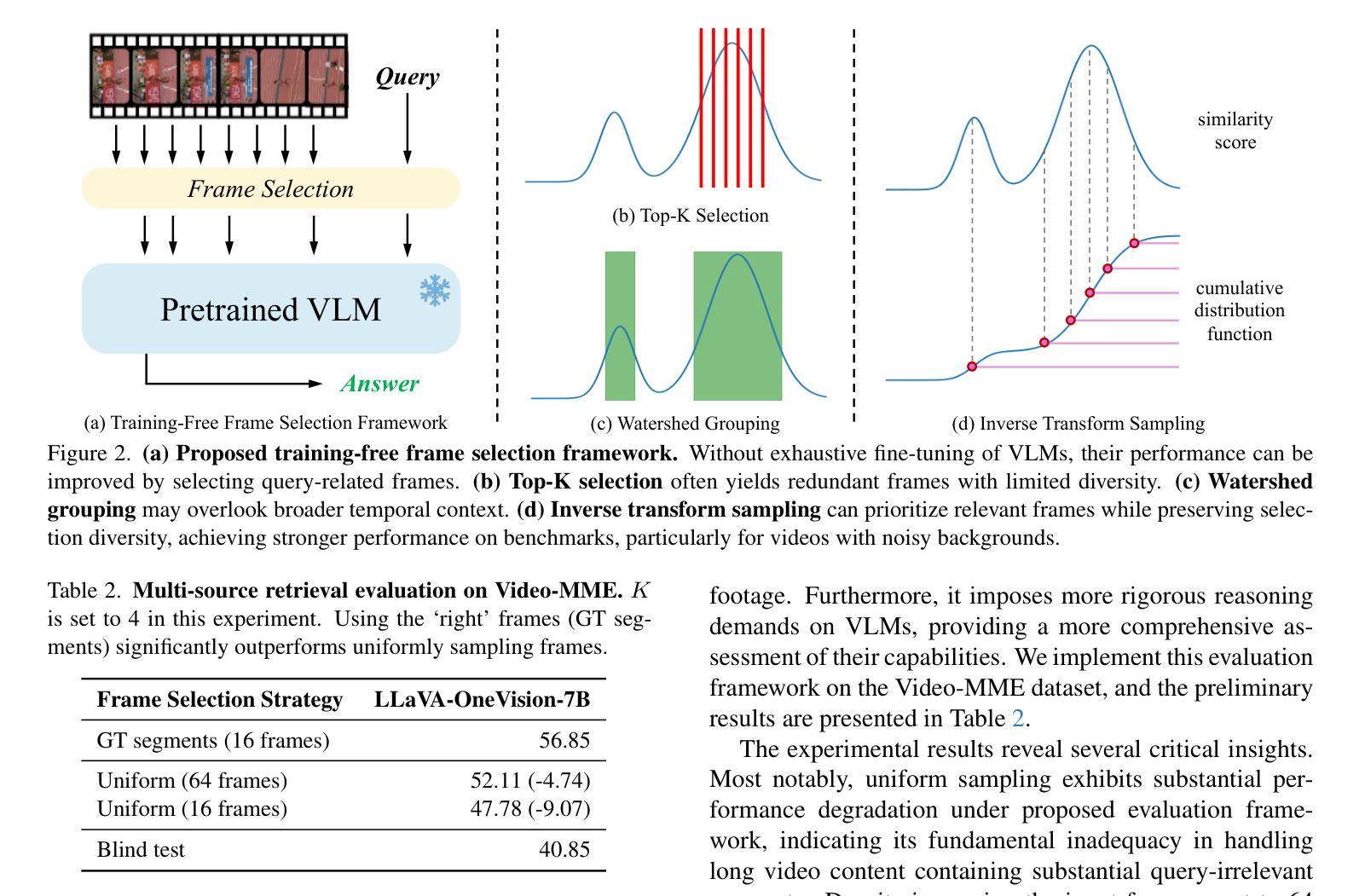
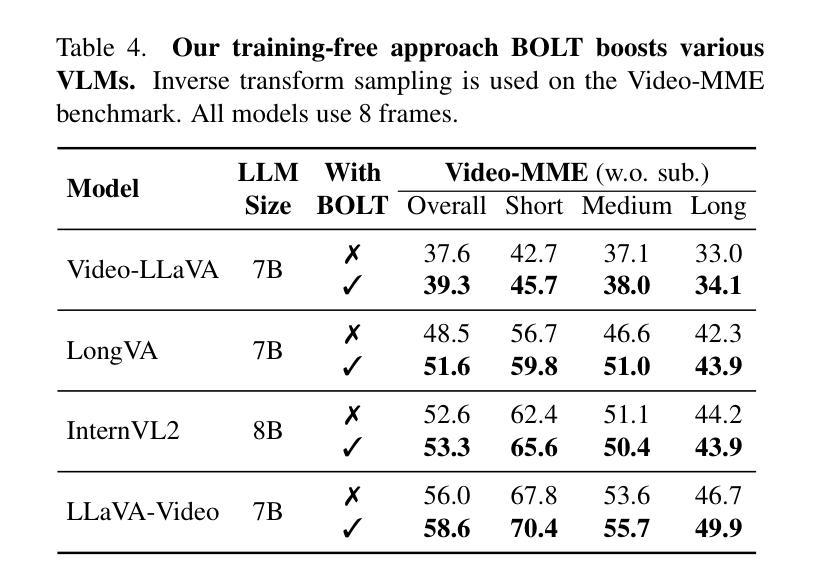
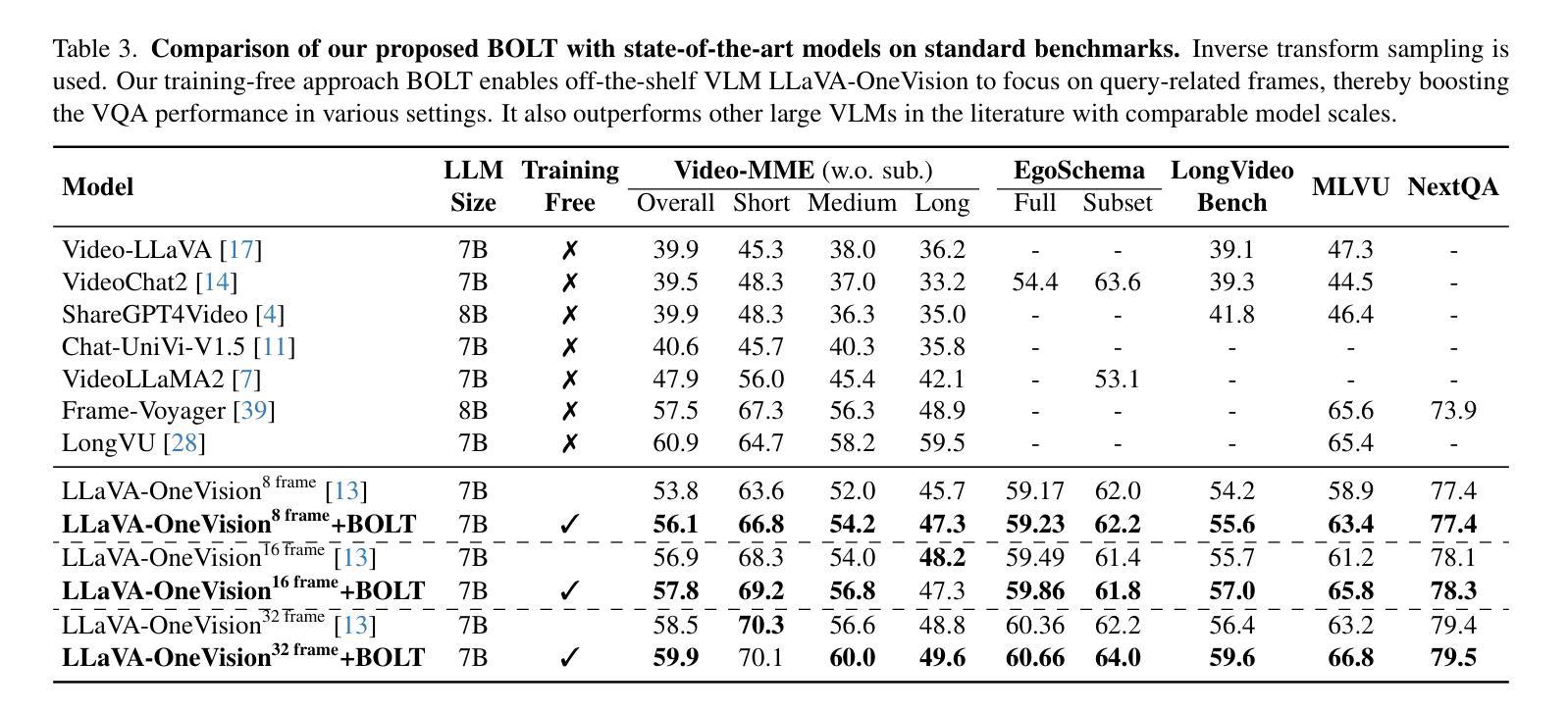
Large video-language models (VLMs) have demonstrated promising progress in various video understanding tasks. However, their effectiveness in long-form video analysis is constrained by limited context windows. Traditional approaches, such as uniform frame sampling, often inevitably allocate resources to irrelevant content, diminishing their effectiveness in real-world scenarios. In this paper, we introduce BOLT, a method to BOost Large VLMs without additional Training through a comprehensive study of frame selection strategies. First, to enable a more realistic evaluation of VLMs in long-form video understanding, we propose a multi-source retrieval evaluation setting. Our findings reveal that uniform sampling performs poorly in noisy contexts, underscoring the importance of selecting the right frames. Second, we explore several frame selection strategies based on query-frame similarity and analyze their effectiveness at inference time. Our results show that inverse transform sampling yields the most significant performance improvement, increasing accuracy on the Video-MME benchmark from 53.8% to 56.1% and MLVU benchmark from 58.9% to 63.4%. Our code is available at https://github.com/sming256/BOLT.
大型视频语言模型(VLMs)在各种视频理解任务中取得了令人瞩目的进展。然而,它们在长视频分析中的有效性受限于有限的上下文窗口。传统方法(如均匀帧采样)通常不可避免地会将资源分配给无关内容,从而降低了它们在现实场景中的有效性。在本文中,我们介绍了BOLT,这是一种通过深入研究帧选择策略,无需额外训练即可提升大型VLM性能的方法。首先,为了更现实地评估VLM在长视频理解中的性能,我们提出了一个跨源检索评估环境。我们的研究结果表明,在嘈杂的上下文中均匀采样表现较差,突显了选择正确帧的重要性。其次,我们基于查询帧相似性探索了多种帧选择策略,并分析了它们在推理阶段的效率。我们的结果表明,逆变换采样带来了最显著的性能提升,在Video-MME基准测试集上的准确率从53.8%提高到56.1%,在MLVU基准测试集上的准确率从58.9%提高到63.4%。我们的代码位于https://github.com/sming256/BOLT。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
大型视频语言模型(VLMs)在视频理解任务中展现出巨大潜力,但在长视频分析中受限于有限的上下文窗口。本文提出BOLT方法,通过深入研究帧选择策略,提升VLMs性能而无需额外训练。首先,提出多源检索评估设置,更现实地评估VLMs在长视频理解中的表现。研究发现,均匀采样在嘈杂环境下表现不佳,强调选择正确帧的重要性。其次,探索基于查询帧相似性的多种帧选择策略,并在推理时间分析它们的效率。结果显示,逆变换采样带来最显著的性能提升,在Video-MME和MLVU基准测试上的准确率分别提升至56.1%和63.4%。
Key Takeaways
- 大型视频语言模型(VLMs)在视频理解任务中表现优异,但在长视频分析中存在上下文窗口限制。
- 提出BOLT方法,通过帧选择策略提升VLMs性能,无需额外训练。
- 引入多源检索评估设置,更现实地评估VLMs在长视频理解中的效果。
- 均匀采样在嘈杂环境下表现不佳,需要选择正确的帧。
- 逆变换采样策略能显著提升性能。
- BOLT方法在Video-MME和MLVU基准测试上实现性能提升。
点此查看论文截图


RoadSocial: A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video Narratives
Authors:Chirag Parikh, Deepti Rawat, Rakshitha R. T., Tathagata Ghosh, Ravi Kiran Sarvadevabhatla
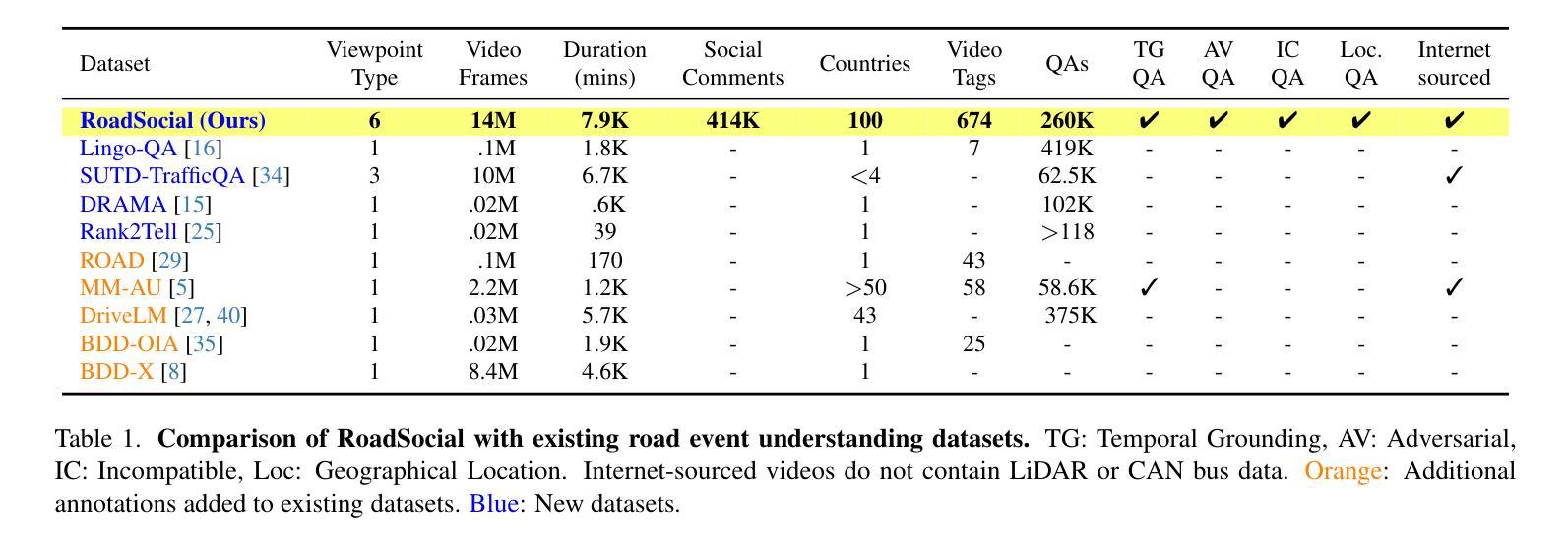
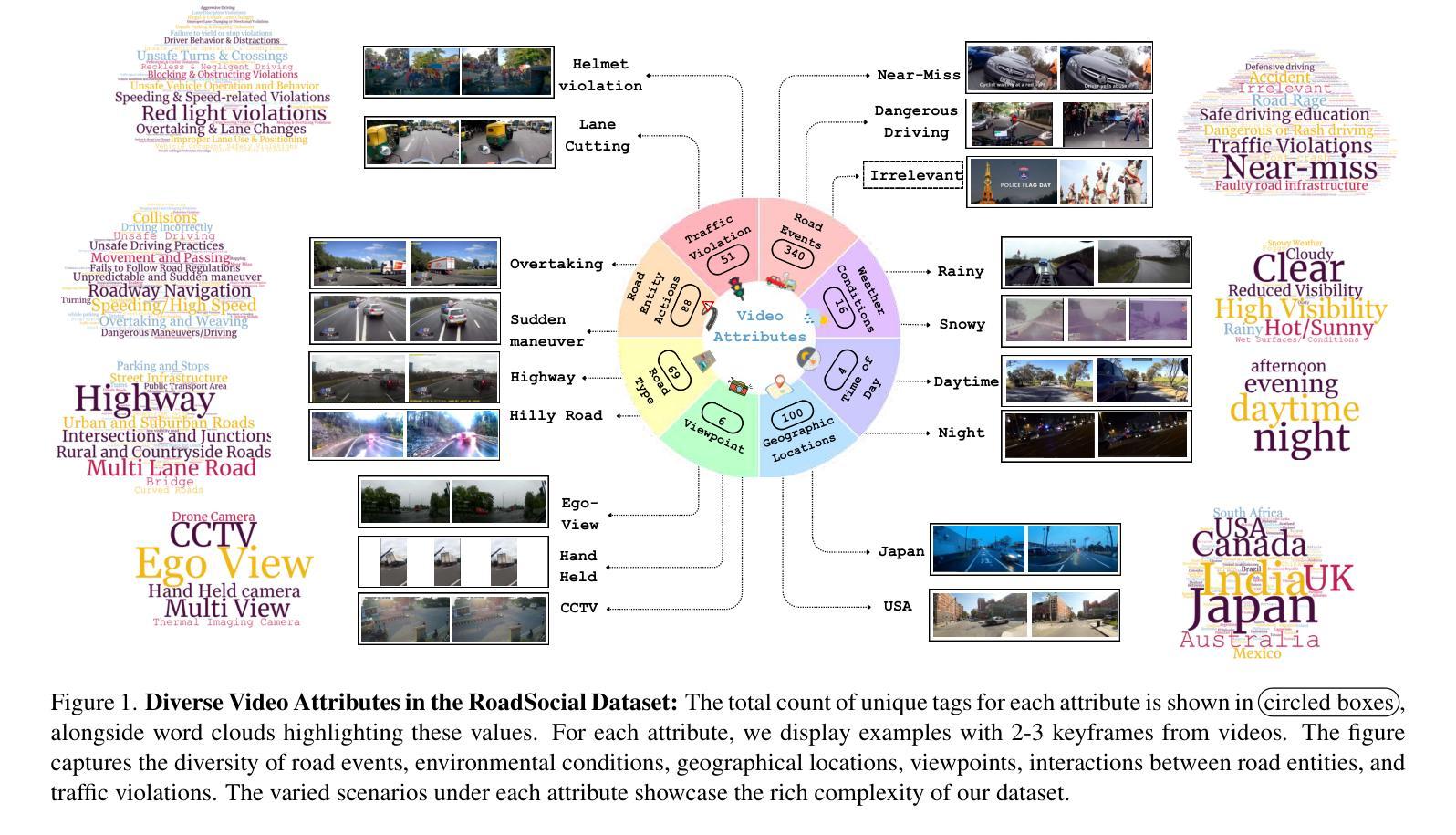
We introduce RoadSocial, a large-scale, diverse VideoQA dataset tailored for generic road event understanding from social media narratives. Unlike existing datasets limited by regional bias, viewpoint bias and expert-driven annotations, RoadSocial captures the global complexity of road events with varied geographies, camera viewpoints (CCTV, handheld, drones) and rich social discourse. Our scalable semi-automatic annotation framework leverages Text LLMs and Video LLMs to generate comprehensive question-answer pairs across 12 challenging QA tasks, pushing the boundaries of road event understanding. RoadSocial is derived from social media videos spanning 14M frames and 414K social comments, resulting in a dataset with 13.2K videos, 674 tags and 260K high-quality QA pairs. We evaluate 18 Video LLMs (open-source and proprietary, driving-specific and general-purpose) on our road event understanding benchmark. We also demonstrate RoadSocial’s utility in improving road event understanding capabilities of general-purpose Video LLMs.
我们介绍了RoadSocial,这是一个针对社交媒体叙事中通用道路事件理解的大规模、多样化的VideoQA数据集。与现有受地区偏见、观点偏见和专家驱动标注限制的数据集不同,RoadSocial通过捕捉全球各地的道路事件,捕捉到了多样化的地理、相机视角(闭路电视、手持相机、无人机等)和丰富的社会话语的复杂性。我们的可扩展的半自动标注框架利用文本LLM和视频LLM生成涵盖12项挑战性问答任务的全面问答对,从而推动道路事件理解的边界。RoadSocial来源于社交媒体视频,包含1400万帧和41.4万条社交评论,形成了一个包含1.32万段视频、674个标签和26万条高质量问答对的数据集。我们在道路事件理解基准测试上评估了18个视频LLM(包括开源和专有、专用驾驶和通用)。我们还展示了RoadSocial在提高通用视频LLM对道路事件理解能力方面的实用性。
论文及项目相关链接
PDF Accepted at CVPR 2025; Project Page: https://roadsocial.github.io/
摘要
RoadSocial是一个大规模、多样化的VideoQA数据集,专为从社交媒体叙事中理解通用道路事件而设计。与其他受地域偏见、视角偏见和专家驱动标注限制的现有数据集不同,RoadSocial捕捉了全球道路事件的复杂性,具有多样的地理、摄像头视角(如CCTV、手持设备、无人机)和丰富的社会话语。我们的可扩展的半自动标注框架利用文本LLM和视频LLM生成涵盖12项具有挑战性的问答任务的全面问答对,突破了对道路事件理解的界限。RoadSocial来源于包含14M帧和41.4万条社会评论的社交媒体视频,形成了一个包含1.32万个视频、674个标签和26万条高质量问答对的数据集。我们在道路事件理解基准测试上评估了18个视频LLM(包括开源和专有、驾驶专用和通用)。我们还展示了RoadSocial在提高通用视频LLM对道路事件的理解能力方面的实用性。
关键见解
- RoadSocial是一个针对社交媒体中道路事件理解的大规模、多样化VideoQA数据集。
- 与现有数据集相比,RoadSocial更具全球性和复杂性,涵盖多样的地理和摄像头视角,以及丰富的社会话语。
- 采用半自动标注框架,利用文本LLM和视频LLM生成全面的问答对。
- RoadSocial包含来自社交媒体视频的13.2K视频、674个标签和26万条高质量问答对。
- 对18个视频LLM进行了道路事件理解基准测试,包括开源和专有、驾驶专用和通用LLM。
- RoadSocial有助于提高通用视频LLM对道路事件的理解能力。
- RoadSocial数据集的创建和应用为道路事件理解研究提供了新的视角和挑战。
点此查看论文截图





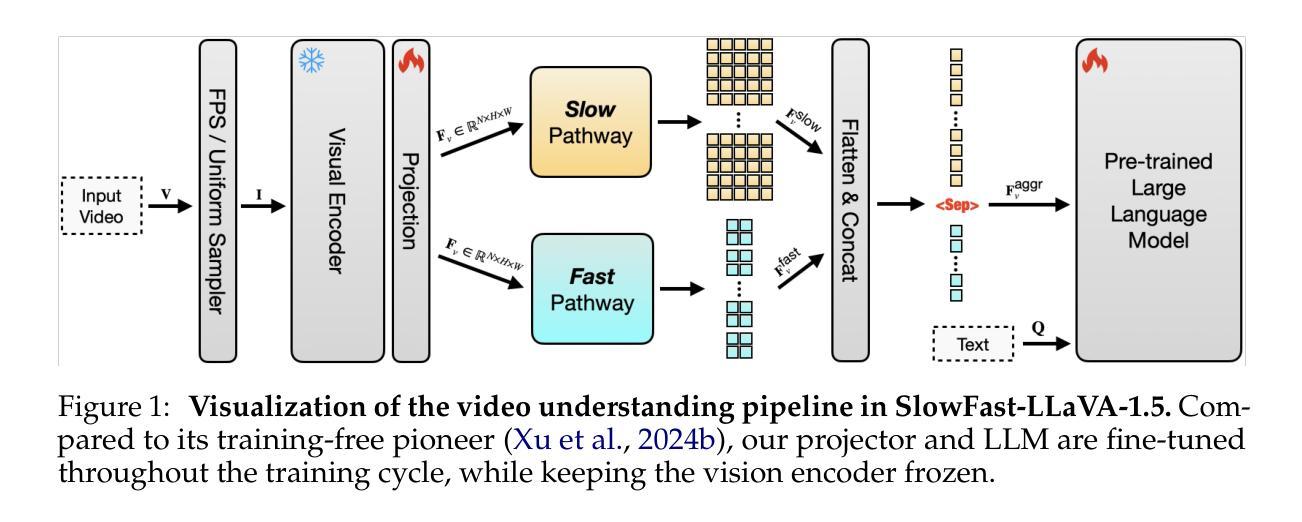
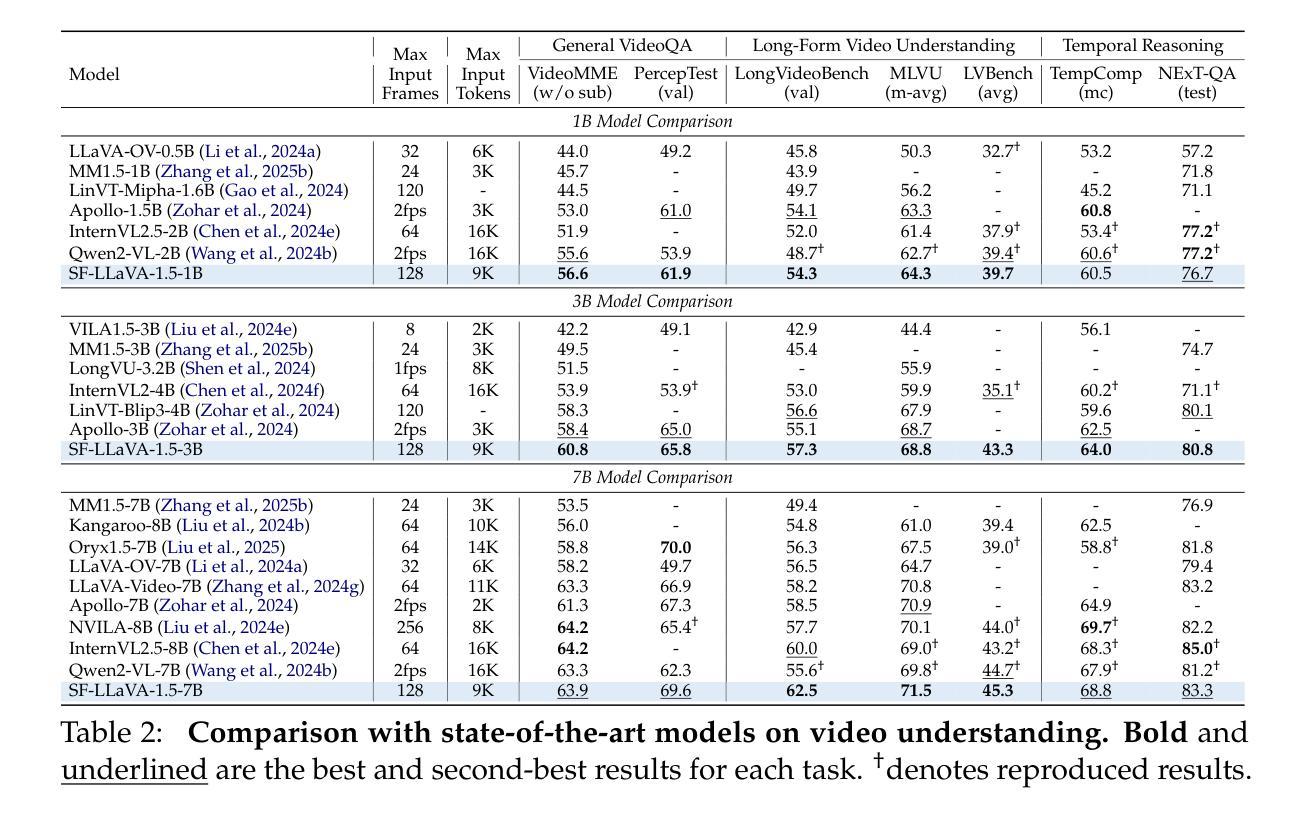
SlowFast-LLaVA-1.5: A Family of Token-Efficient Video Large Language Models for Long-Form Video Understanding
Authors:Mingze Xu, Mingfei Gao, Shiyu Li, Jiasen Lu, Zhe Gan, Zhengfeng Lai, Meng Cao, Kai Kang, Yinfei Yang, Afshin Dehghan
We introduce SlowFast-LLaVA-1.5 (abbreviated as SF-LLaVA-1.5), a family of video large language models (LLMs) offering a token-efficient solution for long-form video understanding. We incorporate the two-stream SlowFast mechanism into a streamlined training pipeline, and perform joint video-image training on a carefully curated data mixture of only publicly available datasets. Our primary focus is on highly efficient model scales (1B and 3B), demonstrating that even relatively small Video LLMs can achieve state-of-the-art performance on video understanding, meeting the demand for mobile-friendly models. Experimental results demonstrate that SF-LLaVA-1.5 achieves superior performance on a wide range of video and image tasks, with robust results at all model sizes (ranging from 1B to 7B). Notably, SF-LLaVA-1.5 achieves state-of-the-art results in long-form video understanding (e.g., LongVideoBench and MLVU) and excels at small scales across various video benchmarks.
我们介绍了SlowFast-LLaVA-1.5(简称SF-LLaVA-1.5),这是一系列视频大型语言模型(LLM),为长视频理解提供了一种高效的令牌解决方案。我们将双流的SlowFast机制纳入简化的训练管道中,并在经过精心筛选的仅公开可用的数据集混合体上进行联合视频图像训练。我们的主要焦点是高效模型规模(1B和3B),证明即使相对较小的视频LLM也可以在视频理解方面实现最先进的性能,满足对移动友好型模型的需求。实验结果表明,SF-LLaVA-1.5在广泛的视频和图像任务上表现卓越,在各种模型规模(从1B到7B)下均表现出稳健的结果。值得注意的是,SF-LLaVA-1.5在长视频理解方面达到了最新水平(例如LongVideoBench和MLVU),并在各种视频基准测试中表现出色,尤其在小规模测试中表现尤为突出。
论文及项目相关链接
PDF Technical report
Summary
SF-LLaVA-1.5是一种高效的视频大型语言模型(LLM),采用两流的SlowFast机制进行训练,并在公开数据集上进行联合视频图像训练。该模型关注高效模型规模,展示即使在较小的视频LLM中也能实现视频理解的卓越性能。实验结果显示,SF-LLaVA-1.5在各种视频和图像任务上表现优异,模型大小从百亿到七十亿不等,且在长视频理解方面达到业界领先。
Key Takeaways
- SF-LLaVA-1.5是一个针对长形式视频理解的高效视频大型语言模型。
- 采用两流的SlowFast机制进行训练以提高模型的效率。
- 模型在公开数据集上进行联合视频图像训练,增强了模型的泛化能力。
- 模型关注高效模型规模,满足移动设备的性能需求。
- 实验结果显示SF-LLaVA-1.5在各种视频和图像任务上表现卓越。
- SF-LLaVA-1.5在长视频理解方面达到了业界领先的性能。
点此查看论文截图


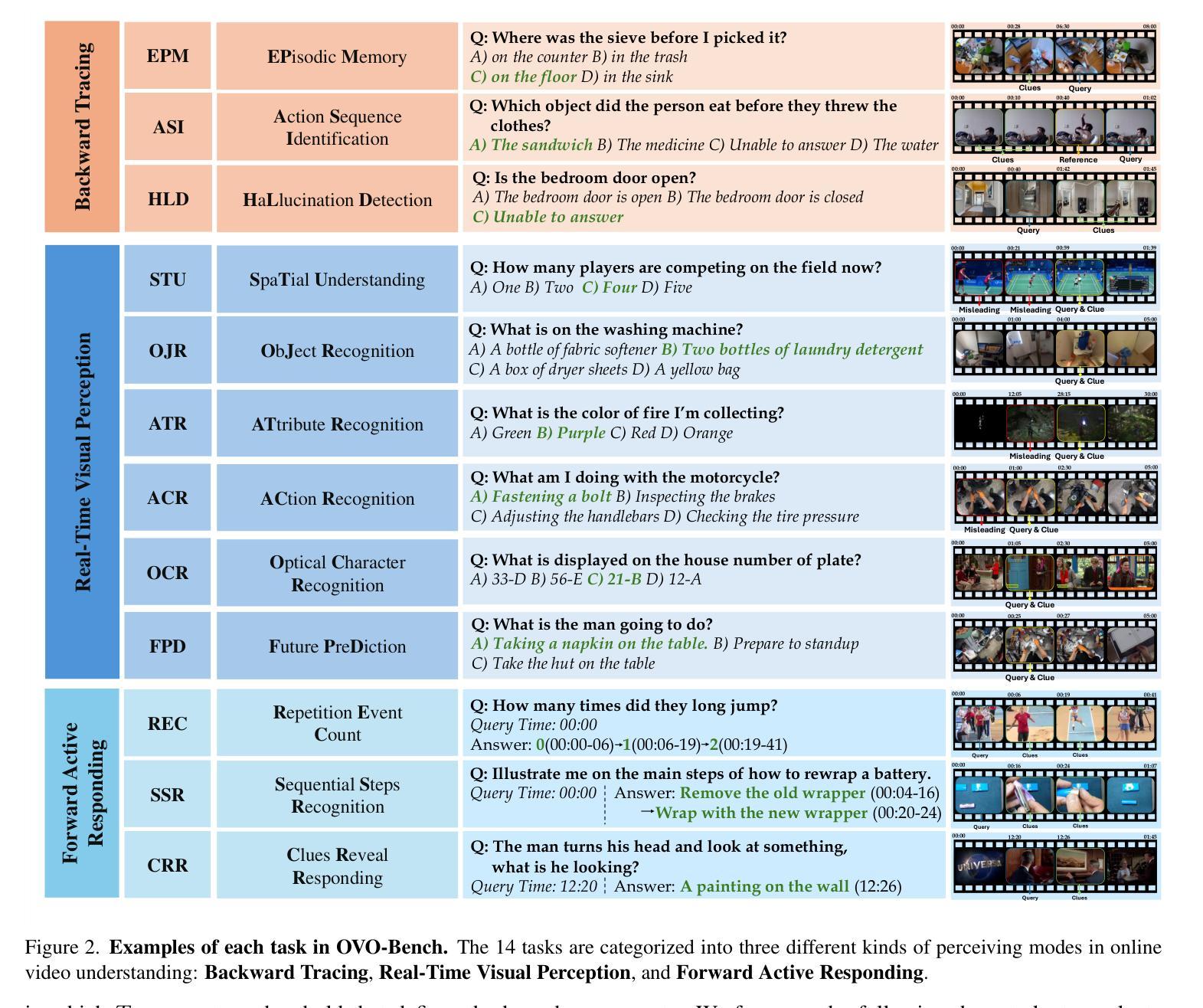
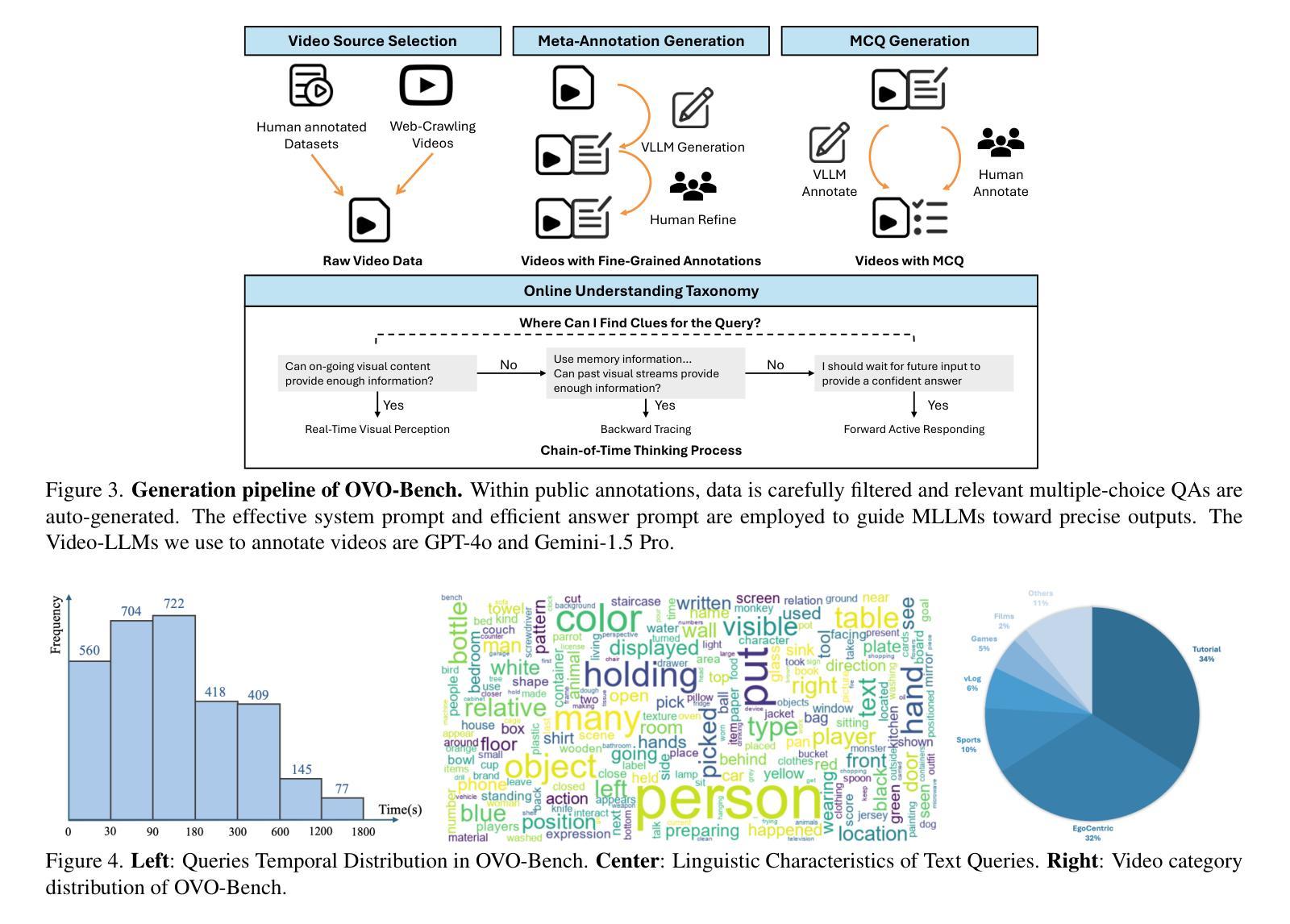
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Authors:Yifei Li, Junbo Niu, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
时间感知能力是区分离线与在线视频LLM的关键区别,它可以根据提出问题的时间戳进行动态推理。与依赖完整视频进行静态事后分析的离线模型不同,在线模型会逐步处理视频流,并根据提出问题的时间戳动态调整其响应。尽管时间感知能力非常重要,但在现有的基准测试中并未得到足够评估。为了填补这一空白,我们推出了OVO-Bench(在线视频基准测试),这是一个新的视频基准测试,它强调时间戳对于高级在线视频能力评估的重要性。OVO-Bench评估视频LLM在三种不同场景下对发生在特定时间戳的事件进行推理和响应的能力:(1)向后追踪:追溯过去的事件以回答问题。(2)实时理解:理解并响应当前时间戳上发生的事件。(3)向前主动响应:延迟响应,直到收集到足够的未来信息来准确回答问题。OVO-Bench包含12项任务,包含644个独特视频和约由人类精心制作的2800个精细元注释以及精确的时间戳。我们将自动化生成管道与人类制作相结合。通过这些高质量的样本,我们进一步开发了一个评估管道,以系统地查询视频LLM沿视频时间线的表现。对九个视频LLM的评估表明,尽管在传统基准测试上取得了进展,但当前模型在在线视频理解方面仍然面临困难,与人类代理人相比存在明显差距。我们希望OVO-Bench能够促进视频LLM的进步,并激发未来在线视频推理的研究灵感。我们的基准测试和代码可在https://github.com/JoeLeelyf/OVO-Bench访问。
论文及项目相关链接
PDF CVPR 2025
摘要
在线视频理解的关键是时间感知能力,即基于问题提出的时间戳进行动态推理的能力。与依赖完整视频进行静态、事后分析的离线模型不同,在线模型能够增量处理视频流并根据问题的时间戳动态调整其响应。尽管时间感知能力非常重要,但在现有的基准测试中并未得到充分评估。为填补这一空白,本文提出了OVO-Bench(在线视频基准测试),这是一个重视时间戳重要性的新型视频基准测试,用于评估视频LLM(大型语言模型)的高级在线视频理解能力的基准测试。OVO-Bench评估视频LLM在三个不同场景下的特定时间戳上推理和回应事件的能力:(1)向后追踪:追溯过去的事件来回答问题;(2)实时理解:理解并响应当前时间戳上发生的事件;(3)向前主动响应:延迟响应,直到未来有足够的信息来准确回答问题。OVO-Bench包含12项任务,由644个独特视频和约经人工精细标注的2800个精确时间戳组成。我们结合自动化生成管道和人工审核,通过这些高质量样本进一步开发了一个评估管道,以系统地查询视频LLM沿视频时间线的表现。对九个视频LLM的评估表明,尽管在传统基准测试上有所进展,但当前模型在线视频理解方面仍存在差距,与人类代理人相比存在较大差距。我们希望OVO-Bench能够促进视频LLM的进步,并激发未来在线视频推理的研究灵感。我们的基准测试和代码可访问于:https://github.com/JoeLeelyf/OVO-Bench。
关键见解
- 在线视频理解的关键是时间感知能力,即根据问题提出的时间戳进行动态推理的能力。
- OVO-Bench是首个重视时间感知的视频基准测试,旨在评估视频LLM的在线视频理解能力。
- OVO-Bench包含多种任务场景,包括向后追踪、实时理解和向前主动响应等。
- 当前视频LLM模型在线视频理解方面仍存在挑战,与人类表现有较大差距。
- OVO-Bench提供了高质量的视频样本和精细标注,有助于促进视频LLM的研究进展。
- 通过OVO-Bench的评估结果,发现现有视频LLM在应对未来信息的需求方面存在不足。
点此查看论文截图

LongViTU: Instruction Tuning for Long-Form Video Understanding
Authors:Rujie Wu, Xiaojian Ma, Hai Ci, Yue Fan, Yuxuan Wang, Haozhe Zhao, Qing Li, Yizhou Wang
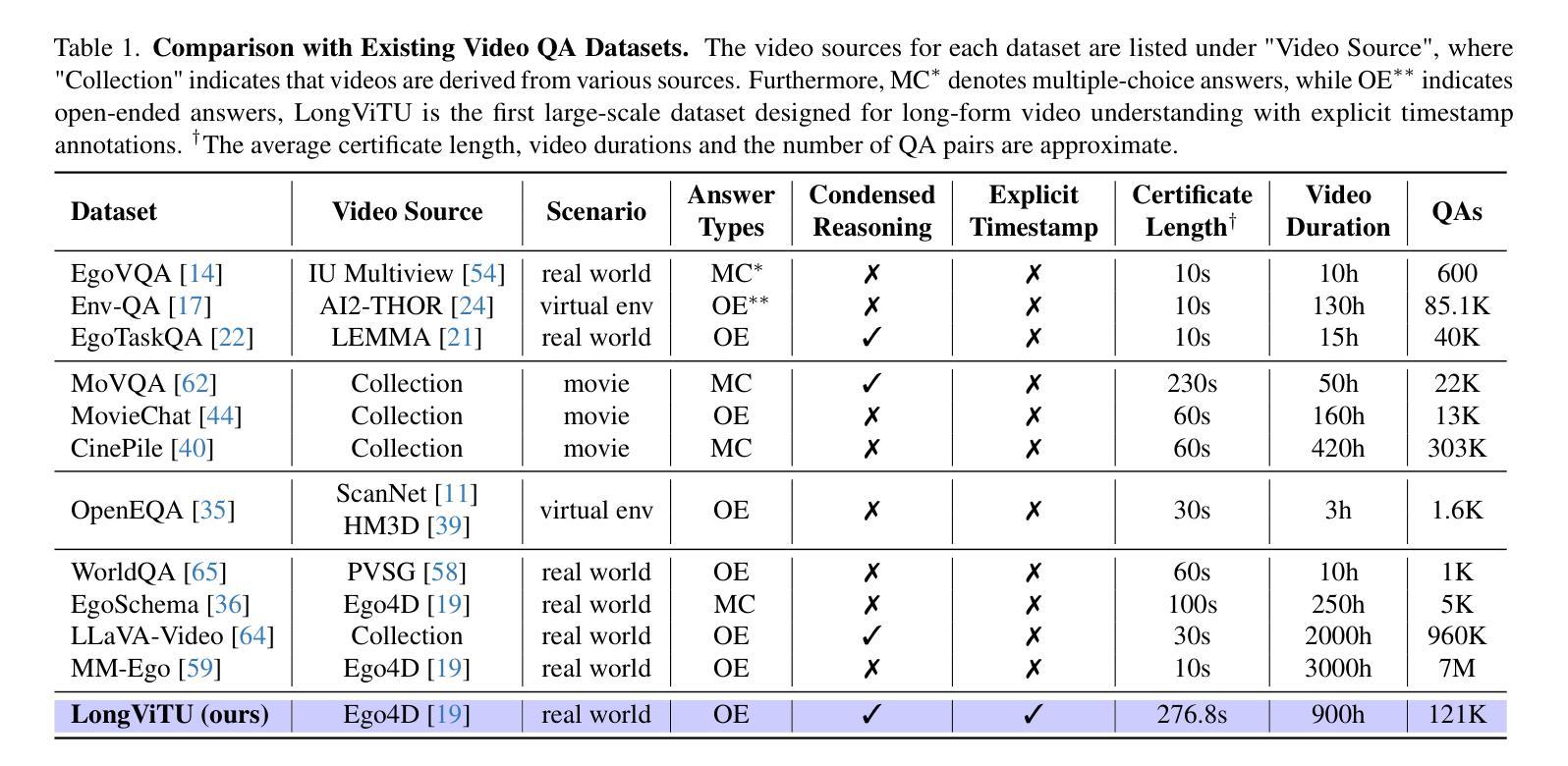
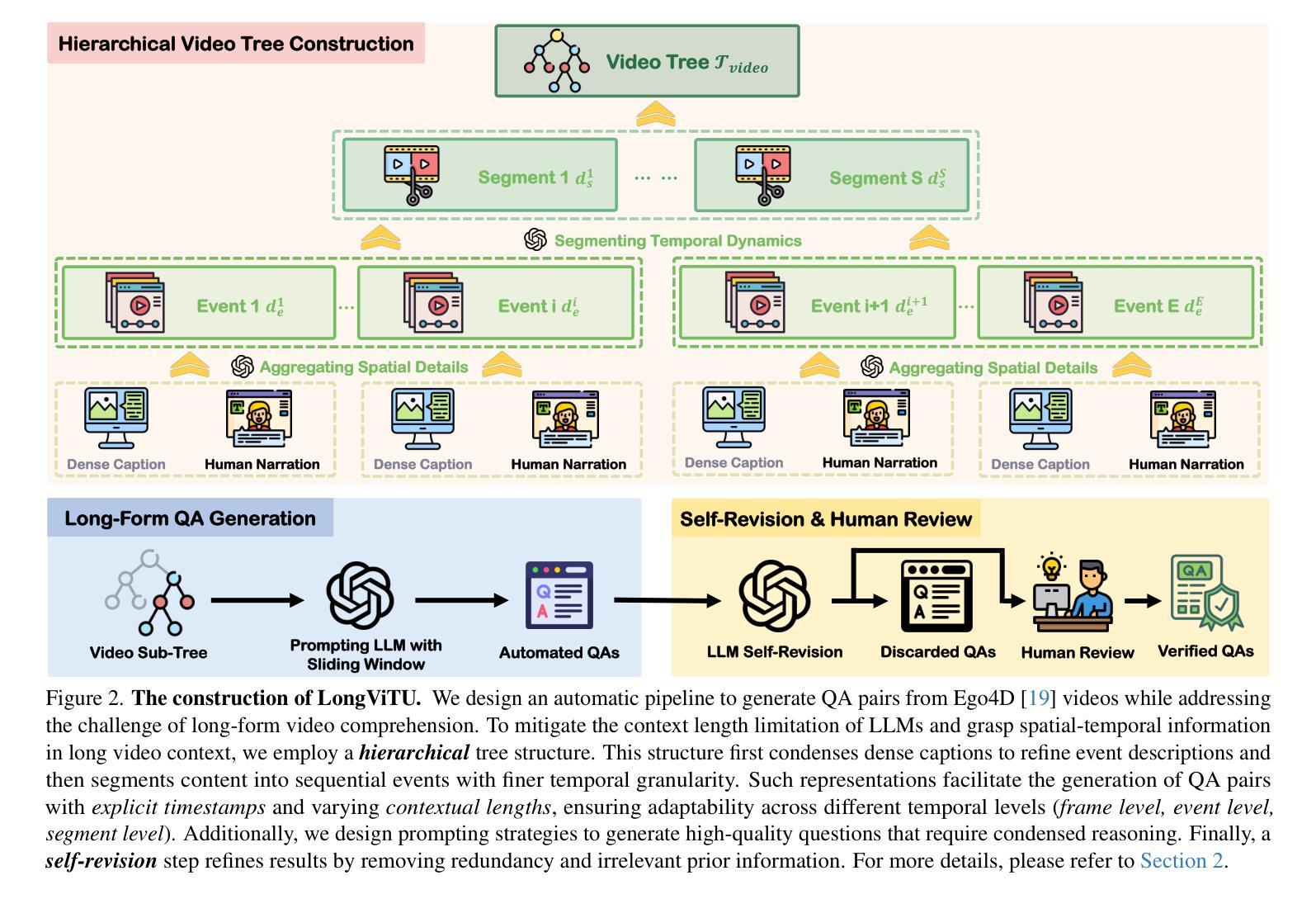
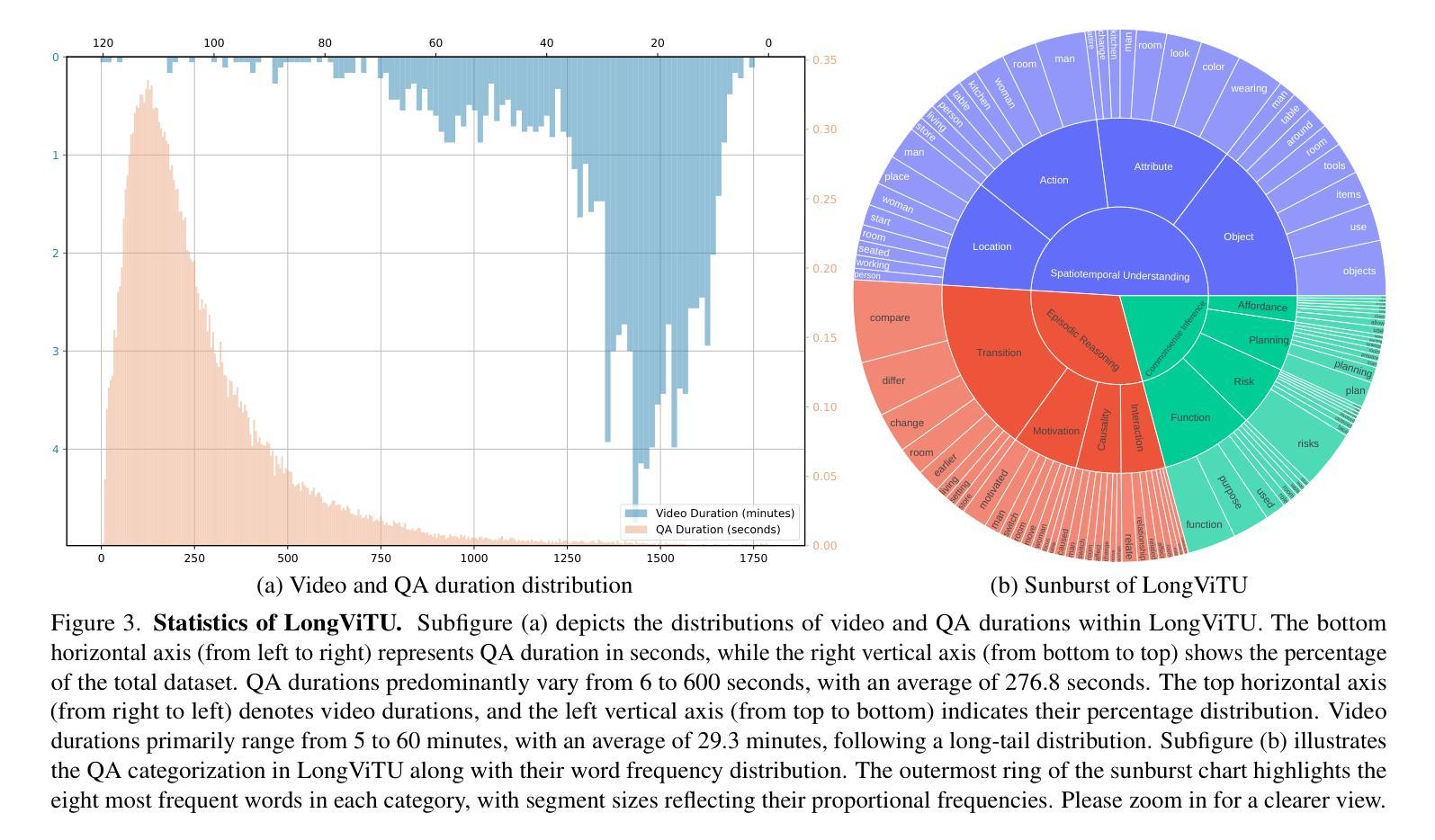
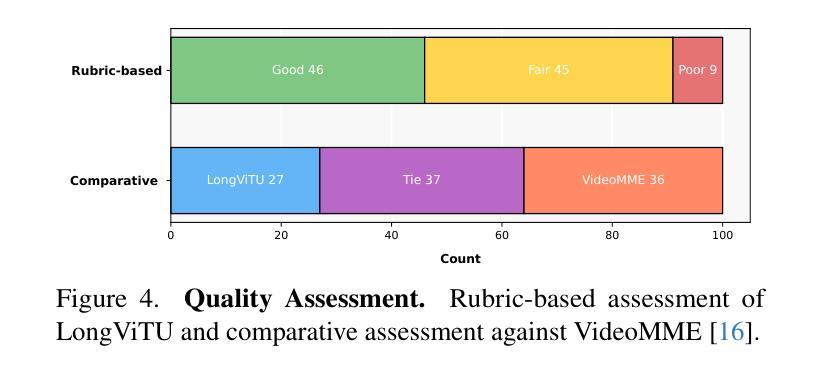
This paper introduces LongViTU, a large-scale (~121k QA pairs, ~900h videos), automatically generated dataset for long-form video understanding. We propose a systematic approach that organizes videos into a hierarchical tree structure for QA generation and incorporates self-revision mechanisms to ensure high-quality QA pairs. Each QA pair in LongViTU features: 1) long-term context (average certificate length of 4.6 minutes); 2) rich knowledge and condensed reasoning (commonsense, causality, planning, etc.)). We also offer explicit timestamp annotations of relevant events for each QA pair. We have conducted extensive human studies on LongViTU, and the results prove the quality of our dataset. To better evaluate the challenges posed by LongViTU’s emphasis on long-term context and condensed reasoning, we manually curate a subset of LongViTU into a benchmark. Evaluations using a state-of-the-art open-source model (LongVU), a proprietary model (Gemini-1.5-Pro), and human annotators yield GPT-4 scores of 49.9, 52.3, and 81.0, respectively, underscoring the substantial difficulty presented by LongViTU questions. Performing supervised fine-tuning (SFT) of LongVU and LLaVA-Video on LongViTU data results in average performance gains of 2.5% and 3.7%, respectively, across a suite of long video understanding benchmarks (EgoSchema, VideoMME-Long, MLVU, LVBench).
本文介绍了LongViTU,这是一个大规模(
12.1万对问答对,900小时视频)的自动生成的用于长格式视频理解的数据集。我们提出了一种系统的方法,将视频组织成层次树结构来进行问答生成,并引入了自我修正机制以确保高质量的问答对。LongViTU中的每个问答对具有以下特点:1)长期上下文(平均证书长度为4.6分钟);2)丰富的知识和精炼的推理(常识、因果、规划等)。我们还为每个问答对提供了相关事件的时间戳注释。我们对LongViTU进行了广泛的人类研究,结果证明了数据集的质量。为了更好地评估LongViTU对长期上下文和精炼推理的重视所带来的挑战,我们从LongViTU中手动筛选出一个基准数据集。使用最先进的开源模型(LongVU)、专有模型(Gemini-1.5-Pro)和人类注释者进行评估,分别得到GPT-4的分数为49.9、52.3和81.0,这凸显了LongViTU问题所构成的重大挑战。对LongVU和LLaVA-Video进行LongViTU数据的监督微调(SFT)后,在多个长视频理解基准测试(EgoSchema、VideoMME-Long、MLVU、LVBench)上的性能平均提高了2.5%和3.7%。
论文及项目相关链接
Summary
本文介绍了LongViTU数据集,这是一个大规模自动生成的用于长视频理解的数据集。该数据集采用系统性方法组织视频为层次树结构进行问答生成,并引入自我修正机制确保高质量的问答对。LongViTU中的每个问答对都具有长期上下文、丰富知识和精炼推理的特点。此外,还为每个问答对提供了相关事件的时间戳注释。通过广泛的人类研究验证了数据集的质量。为了评估LongViTU对长期上下文和精炼推理的重视所带来的挑战,我们从LongViTU中手动筛选出一个基准测试集。使用先进开源模型LongVU、专有模型Gemini-1.5-Pro和人类评估者的评估结果,表明LongViTU问题的实质性难度。通过对LongVU和LLaVA-Video进行LongViTU数据的监督微调(SFT),在一系列长视频理解基准测试(EgoSchema、VideoMME-Long、MLVU、LVBench)上的平均性能分别提高了2.5%和3.7%。
Key Takeaways
- LongViTU是一个大规模自动生成的用于长视频理解的数据集。
- 采用系统性方法组织视频为层次树结构进行问答生成,确保高质量问答对。
- 每个问答对具有长期上下文、丰富知识和精炼推理的特点。
- 数据集提供每个问答对的相关事件时间戳注释。
- 通过广泛的人类研究验证了数据集质量。
- LongViTU问题的实质难度得到了评估,先进模型与人类的性能表现存在差异。
点此查看论文截图

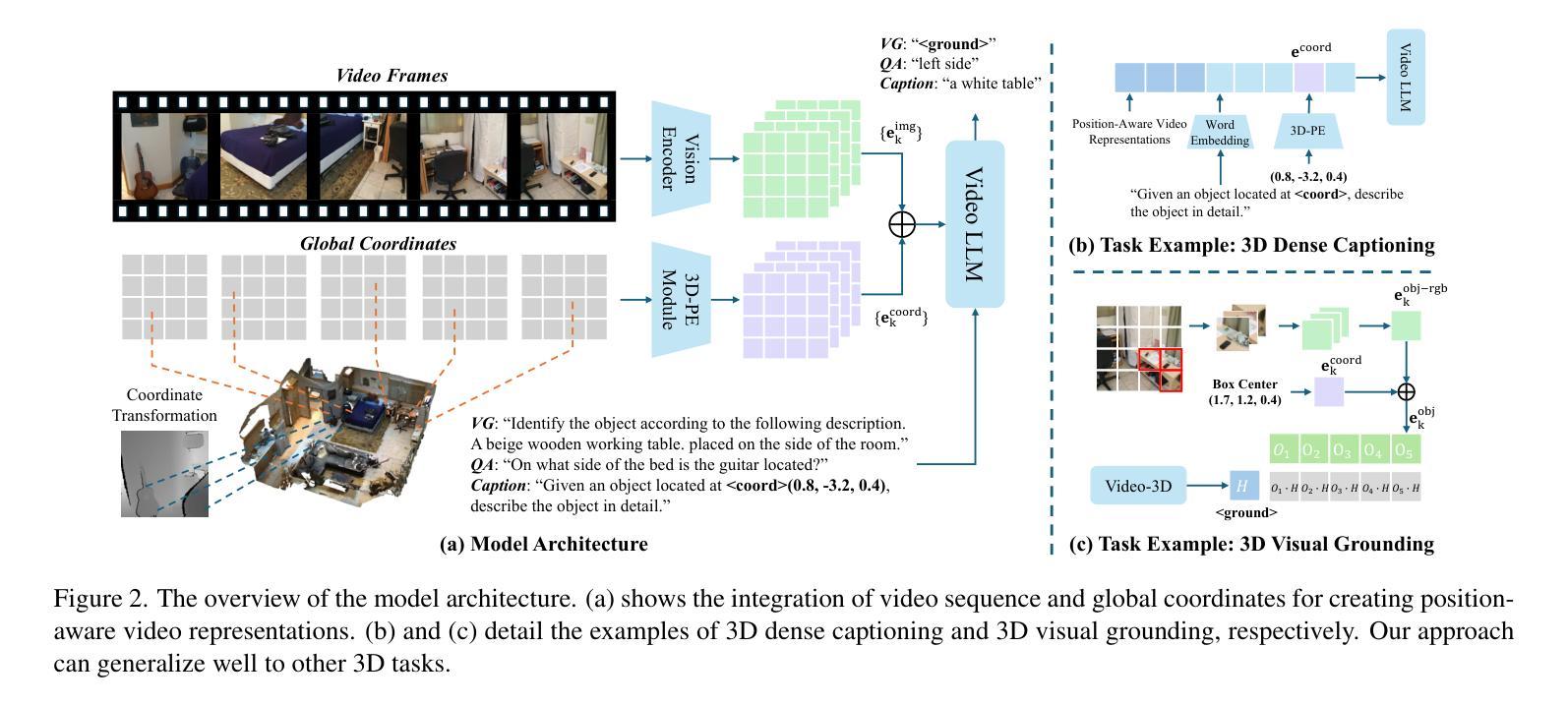
Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding
Authors:Duo Zheng, Shijia Huang, Liwei Wang
The rapid advancement of Multimodal Large Language Models (MLLMs) has significantly impacted various multimodal tasks. However, these models face challenges in tasks that require spatial understanding within 3D environments. Efforts to enhance MLLMs, such as incorporating point cloud features, have been made, yet a considerable gap remains between the models’ learned representations and the inherent complexity of 3D scenes. This discrepancy largely stems from the training of MLLMs on predominantly 2D data, which restricts their effectiveness in comprehending 3D spaces. To address this issue, in this paper, we propose a novel generalist model, i.e., Video-3D LLM, for 3D scene understanding. By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately. In addition, we have implemented a maximum coverage sampling technique to optimize the trade-off between computational cost and performance. Extensive experiments demonstrate that our model achieves state-of-the-art performance on several 3D scene understanding benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D.
随着多模态大型语言模型(MLLMs)的快速发展,它对各种多模态任务产生了重大影响。然而,这些模型在处理需要在三维环境中进行空间理解的任务时面临挑战。为了增强MLLMs的功能,已经做出了努力,如融入点云特征等,但模型学到的表示与三维场景固有复杂性之间仍存在较大差距。这种差异主要源于MLLMs主要在二维数据上进行训练,这限制了它们在理解三维空间方面的有效性。为了解决这个问题,本文提出了一种新型通用模型,即Video-3D LLM,用于三维场景理解。通过将三维场景视为动态视频并将三维位置编码融入这些表示中,我们的Video-3D LLM能够更准确地使视频表示与真实世界空间上下文对齐。此外,我们实现了一种最大覆盖采样技术,以优化计算成本与性能之间的平衡。大量实验表明,我们的模型在多个三维场景理解基准测试中达到了最先进的性能,包括ScanRefer、Multi3DRefer、Scan2Cap、ScanQA和SQA3D。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
多任务模态的大型语言模型(MLLMs)的快速进步对多种模态的任务产生了重大影响,但在需要理解三维环境空间的任务中仍面临挑战。为弥补这一差距,本文提出了一种新的通用模型——Video-3D LLM,用于三维场景理解。通过把三维场景当作动态视频并融入三维位置编码,Video-3D LLM能更准确地匹配视频表现和真实世界空间背景。同时,我们实施了一种最大覆盖采样技术,以优化计算成本和性能之间的平衡。实验证明,我们的模型在多个三维场景理解基准测试中达到了最佳性能。
Key Takeaways
- 多模态大型语言模型(MLLMs)的进步推动了多种模态任务的进展。
- MLLMs在处理需要三维空间理解的任务时存在挑战。
- 当前模型主要基于二维数据的训练,限制了其在三维空间理解中的有效性。
- 为解决上述问题,提出了一种新的通用模型——Video-3D LLM用于三维场景理解。
- Video-3D LLM通过将三维场景视为动态视频并融入三维位置编码,更准确地匹配视频表现和真实世界空间背景。
- Video-3D LLM采用了最大覆盖采样技术来平衡计算成本和性能。
点此查看论文截图