⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-29 更新
GateLens: A Reasoning-Enhanced LLM Agent for Automotive Software Release Analytics
Authors:Arsham Gholamzadeh Khoee, Shuai Wang, Yinan Yu, Robert Feldt, Dhasarathy Parthasarathy
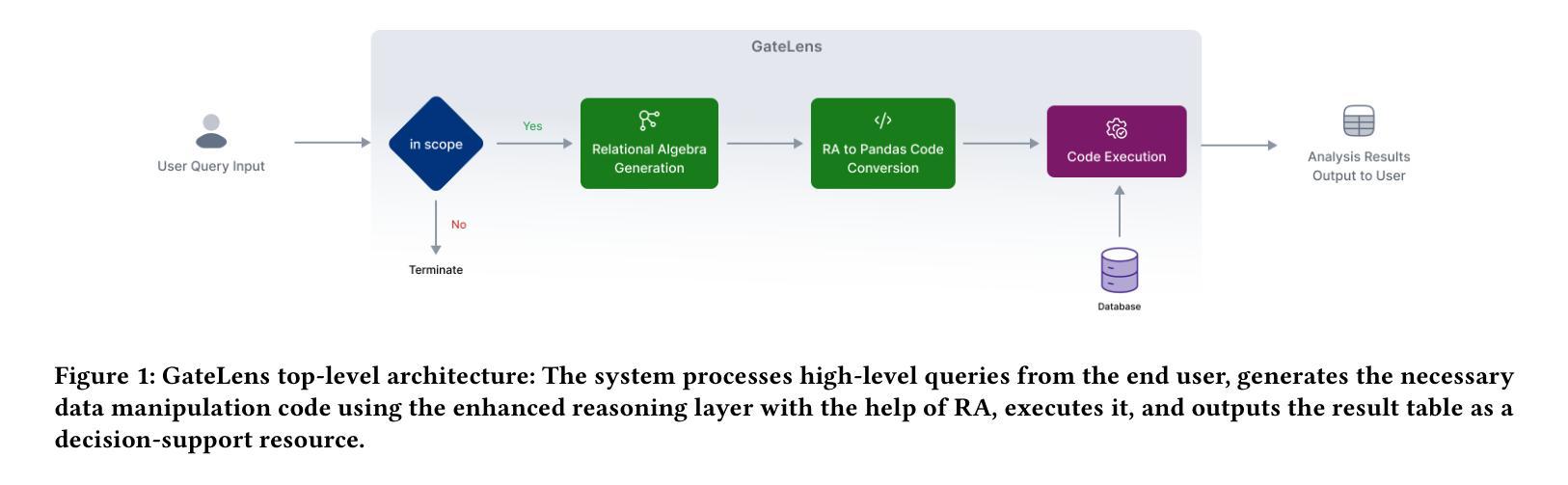
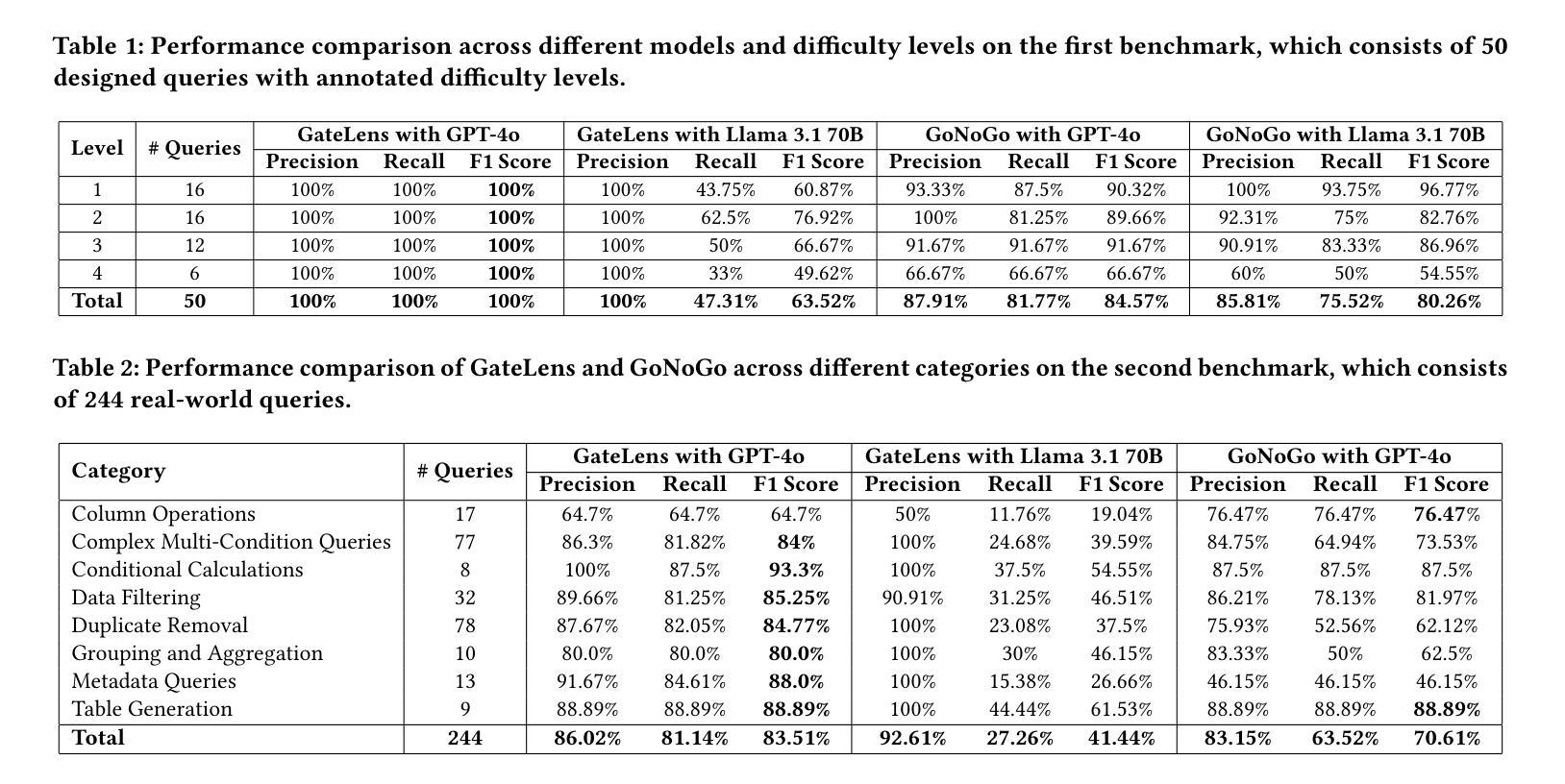
Ensuring the reliability and effectiveness of software release decisions is critical, particularly in safety-critical domains like automotive systems. Precise analysis of release validation data, often presented in tabular form, plays a pivotal role in this process. However, traditional methods that rely on manual analysis of extensive test datasets and validation metrics are prone to delays and high costs. Large Language Models (LLMs) offer a promising alternative but face challenges in analytical reasoning, contextual understanding, handling out-of-scope queries, and processing structured test data consistently; limitations that hinder their direct application in safety-critical scenarios. This paper introduces GateLens, an LLM-based tool for analyzing tabular data in the automotive domain. GateLens translates natural language queries into Relational Algebra (RA) expressions and then generates optimized Python code. It outperforms the baseline system on benchmarking datasets, achieving higher F1 scores and handling complex and ambiguous queries with greater robustness. Ablation studies confirm the critical role of the RA module, with performance dropping sharply when omitted. Industrial evaluations reveal that GateLens reduces analysis time by over 80% while maintaining high accuracy and reliability. As demonstrated by presented results, GateLens achieved high performance without relying on few-shot examples, showcasing strong generalization across various query types from diverse company roles. Insights from deploying GateLens with a partner automotive company offer practical guidance for integrating AI into critical workflows such as release validation. Results show that by automating test result analysis, GateLens enables faster, more informed, and dependable release decisions, and can thus advance software scalability and reliability in automotive systems.
确保软件发布决策的可信度和有效性至关重要,特别是在汽车系统这样的安全关键领域。发布验证数据的精确分析在此过程中扮演着重要角色,这些数据通常呈现为表格形式。然而,传统的方法依赖于对大量测试数据集和验证指标的手动分析,容易出现延迟和成本高昂的问题。大型语言模型(LLMs)提供了有前景的替代方案,但在分析推理、上下文理解、处理超出范围查询以及处理结构化测试数据的连贯性方面面临挑战;这些局限性阻碍了它们在安全关键场景中的直接应用。本文介绍了GateLens,一个基于LLM的汽车领域表格数据分析工具。GateLens将自然语言查询翻译成关系代数(RA)表达式,然后生成优化的Python代码。它在基准数据集上的表现优于基准系统,实现了更高的F1分数,并更稳健地处理复杂和模糊查询。消融研究证实了RA模块的关键作用,在省略该模块时性能急剧下降。工业评估表明,GateLens将分析时间减少了80%以上,同时保持了高准确性和可靠性。所呈现的结果证明,GateLens在不需要依赖少量示例的情况下实现了高性能,展示了在各种查询类型和公司角色中的强大泛化能力。通过与一家汽车合作伙伴公司部署GateLens所获得的见解,为将人工智能集成到关键工作流程(如发布验证)中提供了实际指导。结果表明,通过自动化测试结果分析,GateLens能够做出更快、更明智、更可靠的发布决策,从而推动汽车系统软件的可扩展性和可靠性提升。
论文及项目相关链接
Summary
本文介绍了一款名为GateLens的基于大型语言模型(LLM)的工具,用于分析汽车领域的表格数据。GateLens能将自然语言查询翻译成关系代数(RA)表达式,并生成优化的Python代码,实现对汽车系统测试数据的快速分析。相较于传统方法,GateLens表现出更高的性能,能够在减少80%分析时间的同时维持高准确性和可靠性。通过在实际工业环境中的部署评价,验证了GateLens在提高软件发布决策的速度和可靠性方面的潜力。
Key Takeaways
- 软件发布决策在安全性关键领域如汽车系统中至关重要,需要精确分析发布验证数据。
- 传统手动分析方法存在延迟和成本高昂的问题。
- 大型语言模型(LLM)提供了有前景的替代方案,但面临解析复杂数据的挑战。
- GateLens是一款基于LLM的工具,用于分析汽车领域的表格数据,可将自然语言查询转化为关系代数表达式并生成Python代码。
- GateLens在基准测试数据集上表现出优越性能,包括高F1分数和稳健处理复杂模糊查询的能力。
- 工业评估显示,GateLens减少了超过80%的分析时间并保持高准确性和可靠性。
点此查看论文截图


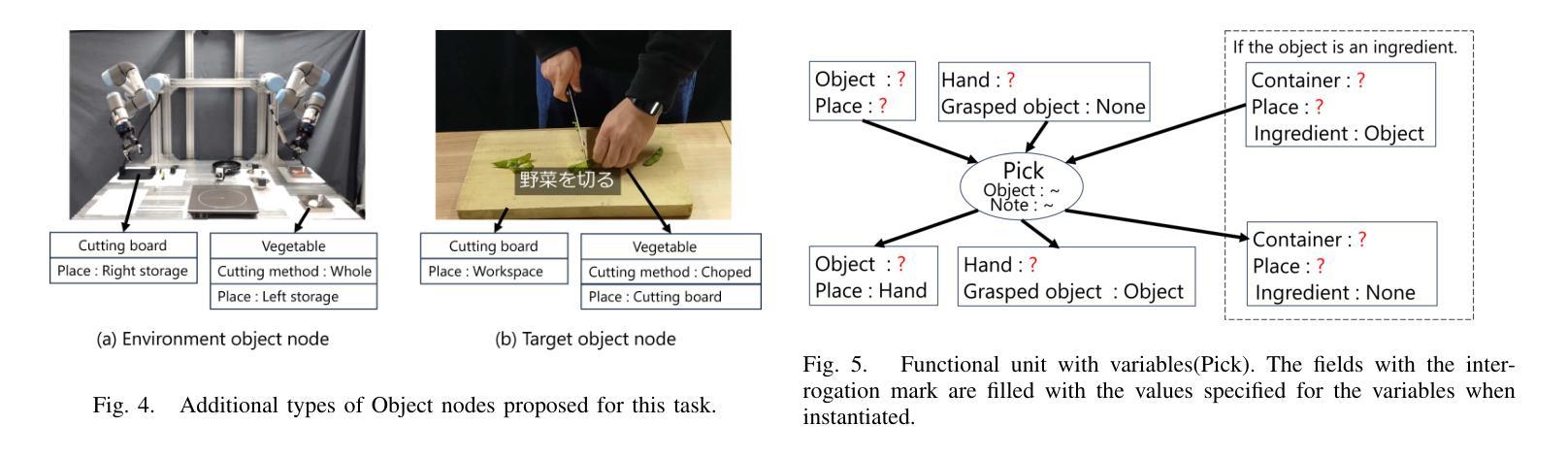
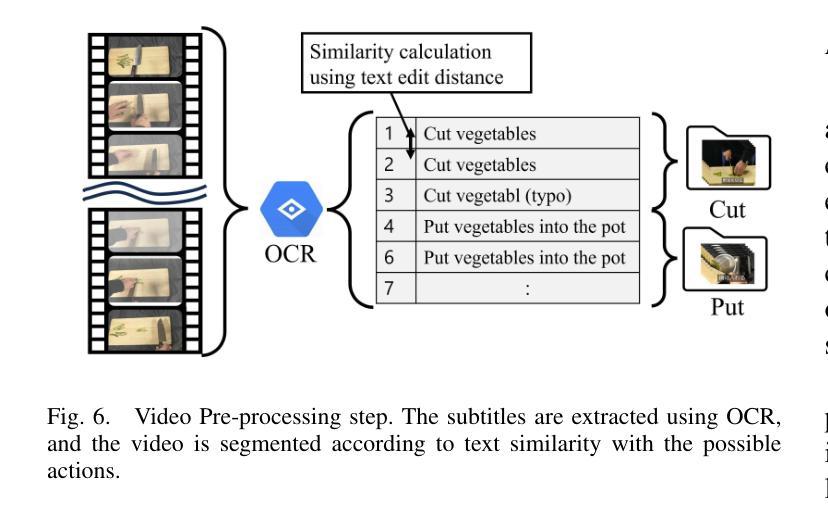
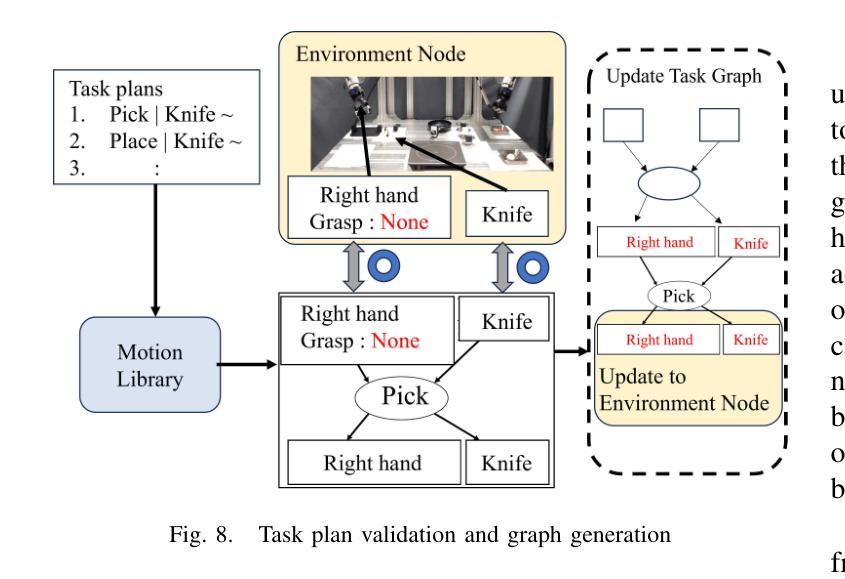
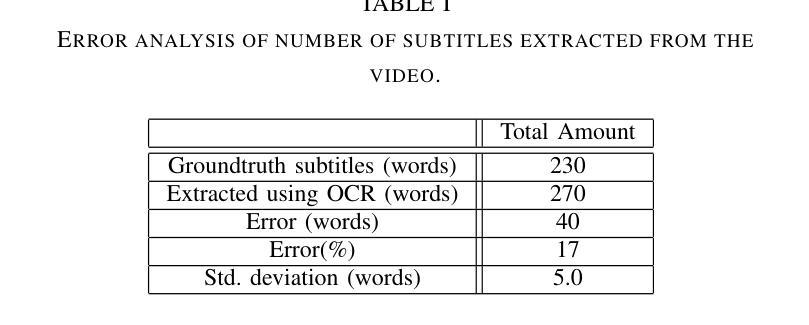
Cooking Task Planning using LLM and Verified by Graph Network
Authors:Ryunosuke Takebayashi, Vitor Hideyo Isume, Takuya Kiyokawa, Weiwei Wan, Kensuke Harada
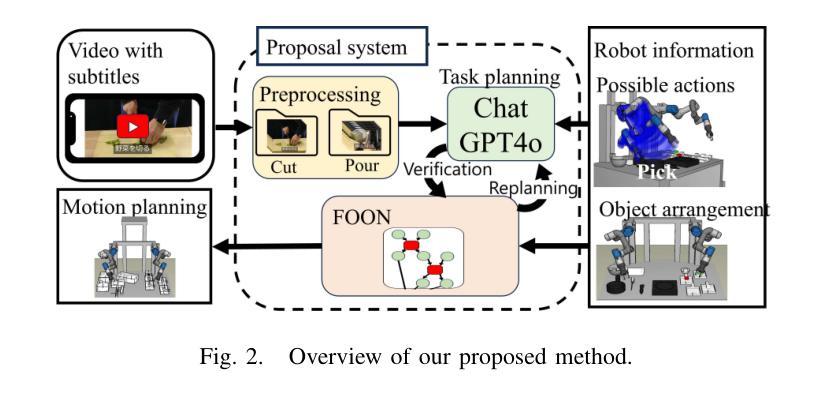
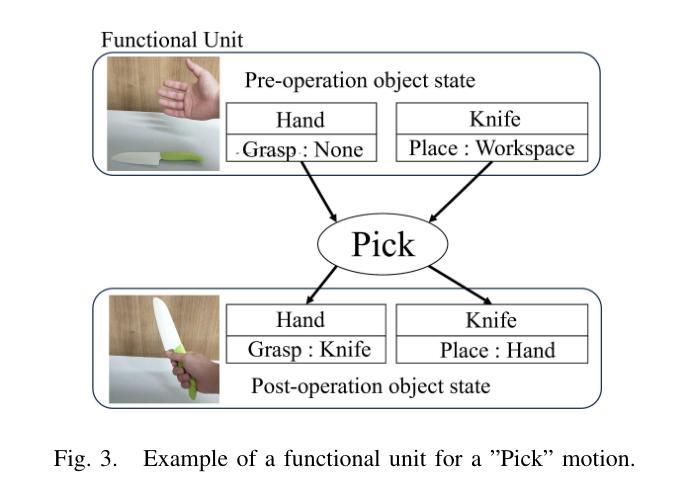
Cooking tasks remain a challenging problem for robotics due to their complexity. Videos of people cooking are a valuable source of information for such task, but introduces a lot of variability in terms of how to translate this data to a robotic environment. This research aims to streamline this process, focusing on the task plan generation step, by using a Large Language Model (LLM)-based Task and Motion Planning (TAMP) framework to autonomously generate cooking task plans from videos with subtitles, and execute them. Conventional LLM-based task planning methods are not well-suited for interpreting the cooking video data due to uncertainty in the videos, and the risk of hallucination in its output. To address both of these problems, we explore using LLMs in combination with Functional Object-Oriented Networks (FOON), to validate the plan and provide feedback in case of failure. This combination can generate task sequences with manipulation motions that are logically correct and executable by a robot. We compare the execution of the generated plans for 5 cooking recipes from our approach against the plans generated by a few-shot LLM-only approach for a dual-arm robot setup. It could successfully execute 4 of the plans generated by our approach, whereas only 1 of the plans generated by solely using the LLM could be executed.
烹饪任务对于机器人来说仍然是一个具有挑战性的问题,因为它们具有复杂性。人们烹饪的视频是此类任务的有价值的信息来源,但如何将这些数据转化为机器人环境却存在大量的变数。本研究旨在简化这一过程,重点研究任务计划生成步骤,利用基于大型语言模型(LLM)的任务与运动规划(TAMP)框架,从带有字幕的视频中自主生成烹饪任务计划并执行。传统的基于LLM的任务规划方法不适合解释烹饪视频数据,因为视频中存在不确定性,且其输出存在幻觉风险。为了解决这两个问题,我们探索将LLM与面向功能的网络(FOON)相结合,以验证计划并在失败时提供反馈。这种结合可以生成逻辑正确且机器人可执行的带有操作运动的任务序列。我们将通过我们的方法与仅使用几次射击LLM的方法生成的计划对比,执行了五种烹饪食谱的计划。我们的方法生成的计划中有四个成功执行,而仅使用LLM生成的计划中只有一个可以执行。
论文及项目相关链接
Summary
本文研究了利用大型语言模型(LLM)和任务与运动规划(TAMP)框架,从带有字幕的烹饪视频自主生成任务计划,并执行的流程。针对烹饪视频数据的不确定性及输出中的幻视风险,结合功能面向对象网络(FOON)进行计划验证和反馈。该组合能为机器人生成逻辑正确且可执行的操控动作序列。在双机械臂机器人设置上,对比了使用我们的方法与仅使用少数LLM生成计划的执行效果,我们的方法成功执行了4个计划,而仅使用LLM的计划仅有1个可以执行。
Key Takeaways
- 烹饪任务对机器人而言仍然具有挑战性,需要复杂的技术解决。
- 烹饪视频是一个有价值的信息来源,但将其转化为机器人环境存在很大的变数。
- 研究旨在通过大型语言模型(LLM)和任务与运动规划(TAMP)框架简化这一过程。
- 结合功能面向对象网络(FOON)可以解决视频数据的不确定性及幻视输出问题。
- 该组合能为机器人生成逻辑正确且可执行的操控动作序列。
- 对比实验显示,我们的方法在执行烹饪任务时表现出更高的成功率。
点此查看论文截图


From User Preferences to Optimization Constraints Using Large Language Models
Authors:Manuela Sanguinetti, Alessandra Perniciano, Luca Zedda, Andrea Loddo, Cecilia Di Ruberto, Maurizio Atzori
This work explores using Large Language Models (LLMs) to translate user preferences into energy optimization constraints for home appliances. We describe a task where natural language user utterances are converted into formal constraints for smart appliances, within the broader context of a renewable energy community (REC) and in the Italian scenario. We evaluate the effectiveness of various LLMs currently available for Italian in translating these preferences resorting to classical zero-shot, one-shot, and few-shot learning settings, using a pilot dataset of Italian user requests paired with corresponding formal constraint representation. Our contributions include establishing a baseline performance for this task, publicly releasing the dataset and code for further research, and providing insights on observed best practices and limitations of LLMs in this particular domain
本文探讨了使用大型语言模型(LLM)将用户偏好翻译为家用电器能源优化约束的任务。在可再生能源社区(REC)的宏观背景下,以及在意大利场景中,我们描述了一种将自然语言用户表达转换为智能电器的正式约束的任务。我们评估了目前可用于意大利语的多种LLM在此类偏好翻译中的有效性,采用经典的零样本、单样本和少量样本学习场景,并使用配有相应正式约束表示的意大利用户请求试点数据集。我们的贡献包括为这项任务设定基准性能,公开发布数据集和代码以供进一步研究,并提供关于在此特定领域中观察到的最佳实践和LLM局限性的见解。
论文及项目相关链接
Summary
本文探讨了利用大型语言模型(LLMs)将用户偏好转化为家庭能源优化约束的研究。研究在一个可再生能源社区(REC)的背景下,将自然语言用户语句转化为智能家电的正式约束。文章以意大利为背景,评估了当前可用的各种意大利语LLMs在采用经典零样本、一样本和少样本学习设置下转换这些偏好的有效性。本文的贡献包括为这项任务建立基准性能,公开发布数据集和代码以供进一步研究,并提供在此特定领域观察到的最佳实践和LLMs局限性的见解。
Key Takeaways
- 研究利用大型语言模型(LLMs)将用户偏好转化为家庭能源优化约束。
- 研究背景设置在可再生能源社区(REC),并专注于意大利场景。
- 评估了多种LLMs在转化用户偏好的有效性,这些偏好通过经典学习设置(零样本、一样本和少样本)实现。
- 建立此任务的基础性能标准。
- 公开数据集和代码以促进进一步研究。
- 提供关于LLMs在此特定领域的最佳实践和观察到的局限性见解。
点此查看论文截图

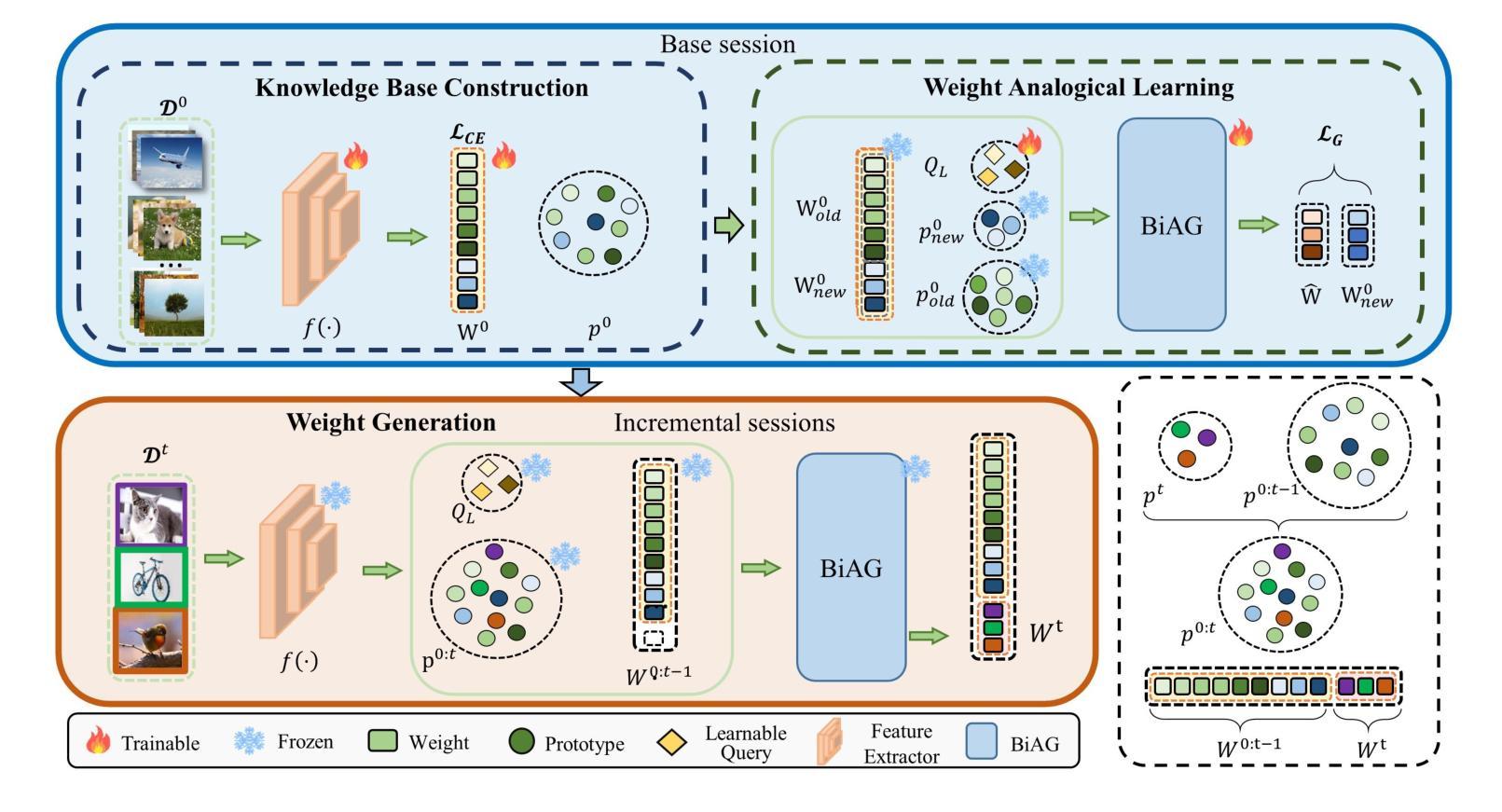
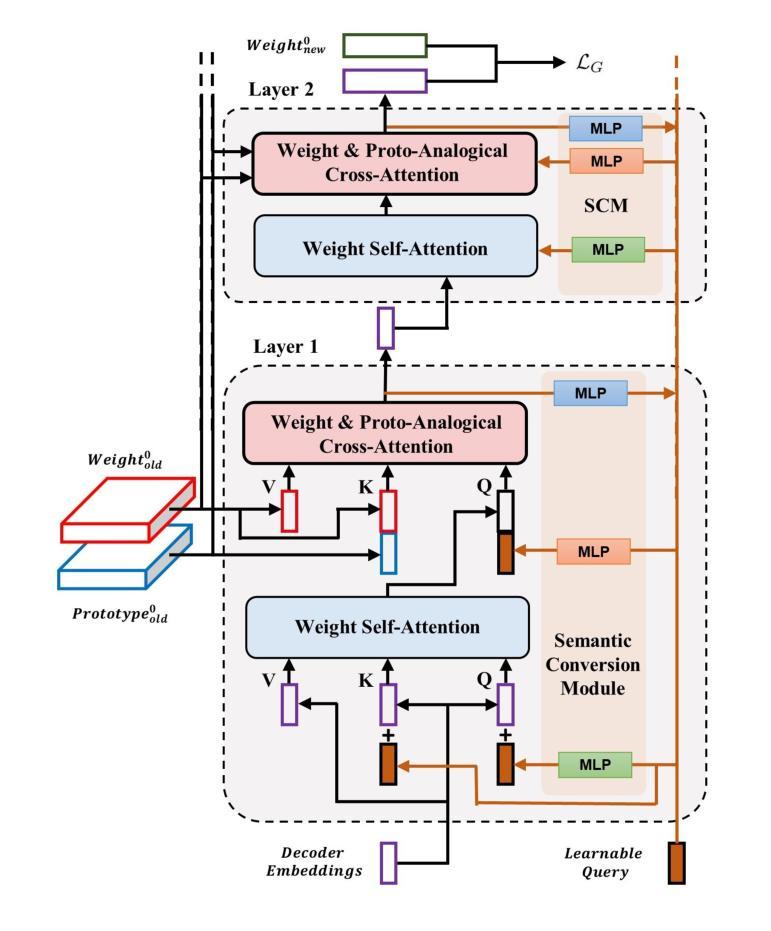
Learn by Reasoning: Analogical Weight Generation for Few-Shot Class-Incremental Learning
Authors:Jizhou Han, Chenhao Ding, Yuhang He, Songlin Dong, Qiang Wang, Xinyuan Gao, Yihong Gong
Few-shot class-incremental Learning (FSCIL) enables models to learn new classes from limited data while retaining performance on previously learned classes. Traditional FSCIL methods often require fine-tuning parameters with limited new class data and suffer from a separation between learning new classes and utilizing old knowledge. Inspired by the analogical learning mechanisms of the human brain, we propose a novel analogical generative method. Our approach includes the Brain-Inspired Analogical Generator (BiAG), which derives new class weights from existing classes without parameter fine-tuning during incremental stages. BiAG consists of three components: Weight Self-Attention Module (WSA), Weight & Prototype Analogical Attention Module (WPAA), and Semantic Conversion Module (SCM). SCM uses Neural Collapse theory for semantic conversion, WSA supplements new class weights, and WPAA computes analogies to generate new class weights. Experiments on miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our method achieves higher final and average accuracy compared to SOTA methods.
少量样本类增量学习(FSCIL)使模型能够在有限数据上学习新类别,同时保持对先前学习类别的性能。传统的FSCIL方法通常需要利用有限的新类别数据进行参数微调,并且存在学习新类别和利用旧知识之间的分离问题。受人类大脑类比学习机制的启发,我们提出了一种新型的类比生成方法。我们的方法包括脑启发类比生成器(BiAG),它能够在增量阶段从现有类别中推导出新的类别权重,而无需进行参数微调。BiAG包含三个组件:权重自注意力模块(WSA)、权重与原型类比注意力模块(WPAA)和语义转换模块(SCM)。SCM使用神经崩溃理论进行语义转换,WSA补充新的类别权重,WPAA计算类比以生成新的类别权重。在miniImageNet、CUB-200和CIFAR-100数据集上的实验表明,我们的方法相较于最新技术方法达到了更高的最终和平均准确率。
论文及项目相关链接
总结
Few-shot类增量学习(FSCIL)使模型能够在有限的数据中学习新类别,同时保持对先前学习类别的性能。传统FSCIL方法通常需要利用有限的新类别数据进行参数微调,并面临学习新类别和利用旧知识之间的分离问题。受人类大脑类比学习机制的启发,我们提出了一种新颖的类比生成方法,包括Brain-Inspired Analogical Generator(BiAG)。BiAG通过现有类别导出新类别权重,在增量阶段无需参数微调。它由三个组件组成:Weight Self-Attention Module(WSA),Weight & Prototype Analogical Attention Module(WPAA)和Semantic Conversion Module(SCM)。SCM利用神经网络崩溃理论进行语义转换,WSA补充新类别权重,WPAA计算类比以生成新类别权重。在miniImageNet、CUB-200和CIFAR-100数据集上的实验表明,我们的方法相较于最新技术方法具有更高的最终和平均准确率。
关键见解
- Few-shot类增量学习(FSCIL)允许模型在有限数据中学习新类别,同时保持对旧知识的性能。
- 传统FSCIL方法需要微调参数,面临学习新类别和利用旧知识之间的分离问题。
- Brain-Inspired Analogical Generator(BiAG)可以从现有类别导出新类别权重,无需在增量阶段进行参数微调。
- BiAG包含三个组件:Weight Self-Attention Module(WSA),Weight & Prototype Analogical Attention Module(WPAA)和Semantic Conversion Module(SCM)。
- WSA模块用于补充新类别权重。
- WPAA模块计算类比以生成新类别权重,有助于模型的灵活性和适应性。
点此查看论文截图

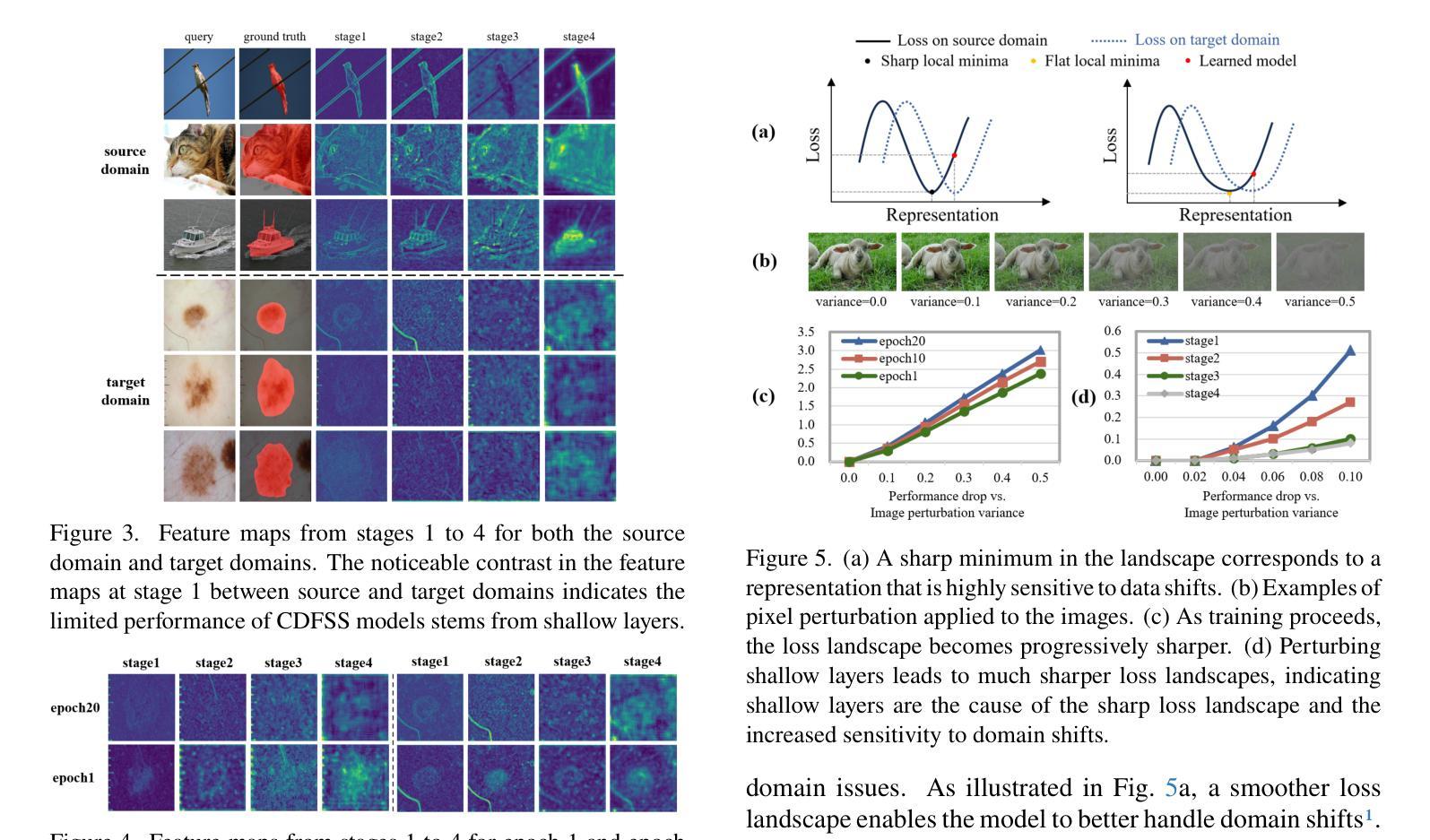
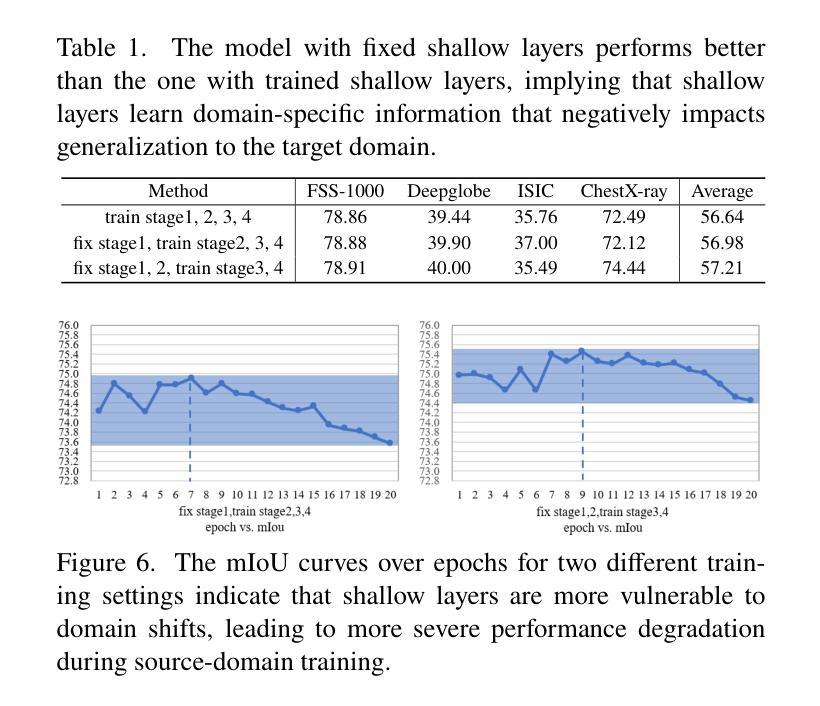
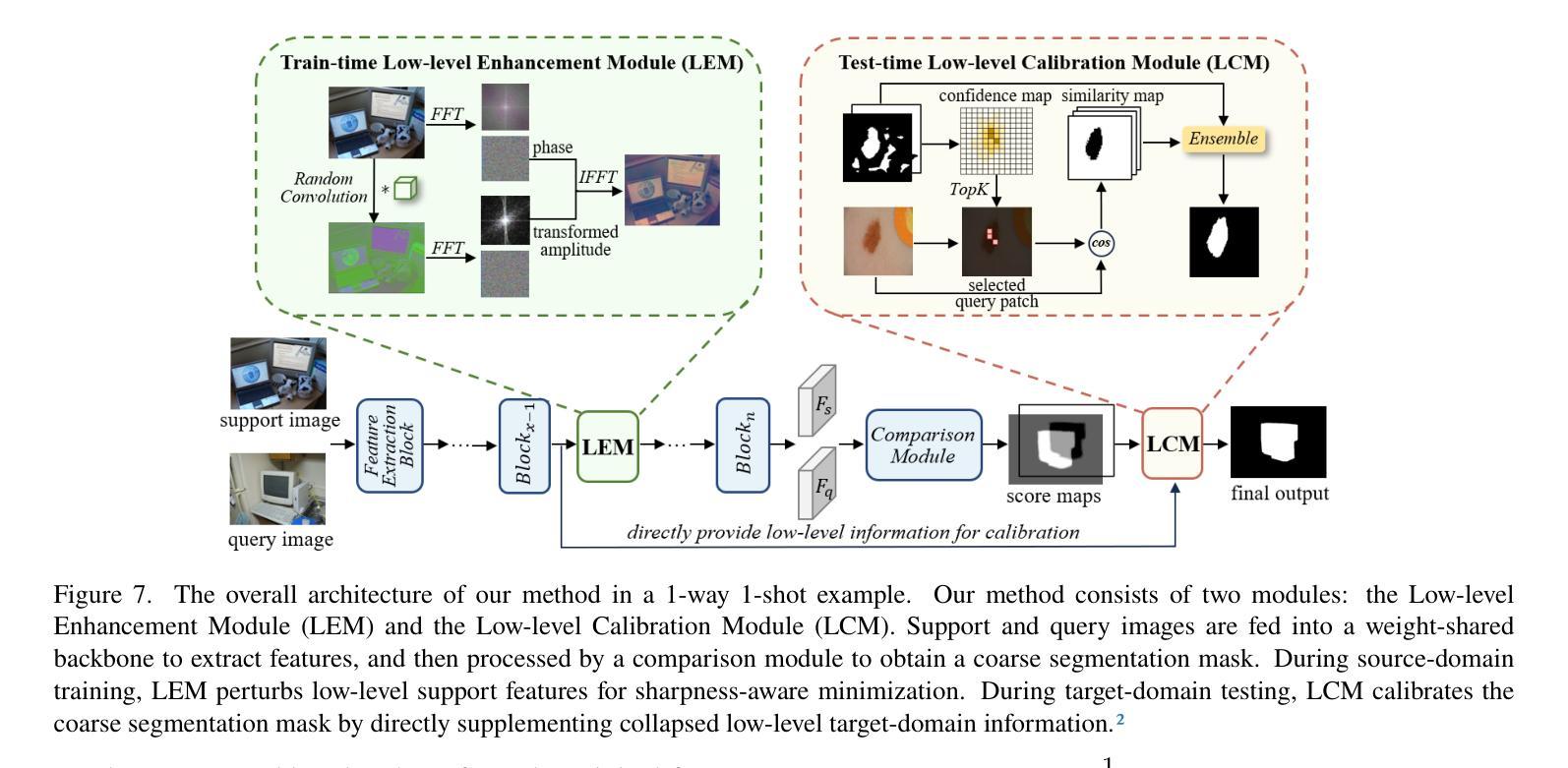
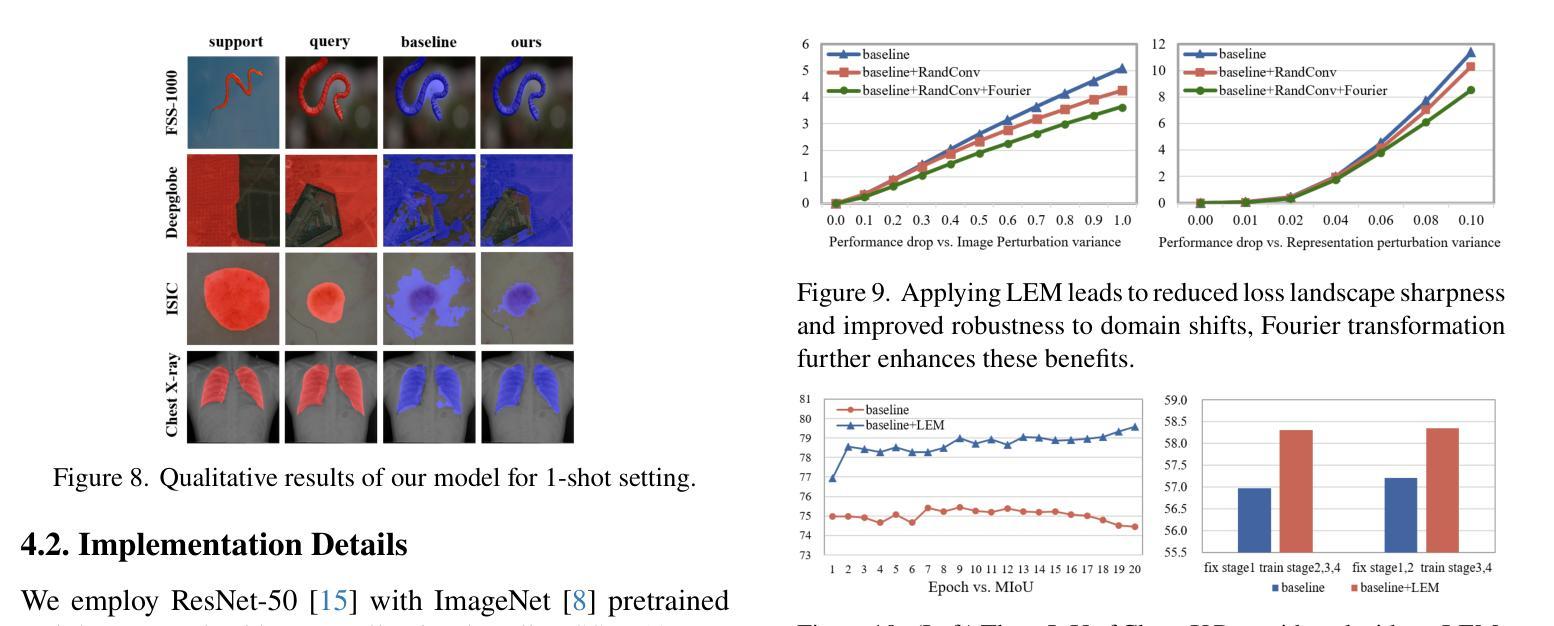
The Devil is in Low-Level Features for Cross-Domain Few-Shot Segmentation
Authors:Yuhan Liu, Yixiong Zou, Yuhua Li, Ruixuan Li
Cross-Domain Few-Shot Segmentation (CDFSS) is proposed to transfer the pixel-level segmentation capabilities learned from large-scale source-domain datasets to downstream target-domain datasets, with only a few annotated images per class. In this paper, we focus on a well-observed but unresolved phenomenon in CDFSS: for target domains, particularly those distant from the source domain, segmentation performance peaks at the very early epochs, and declines sharply as the source-domain training proceeds. We delve into this phenomenon for an interpretation: low-level features are vulnerable to domain shifts, leading to sharper loss landscapes during the source-domain training, which is the devil of CDFSS. Based on this phenomenon and interpretation, we further propose a method that includes two plug-and-play modules: one to flatten the loss landscapes for low-level features during source-domain training as a novel sharpness-aware minimization method, and the other to directly supplement target-domain information to the model during target-domain testing by low-level-based calibration. Extensive experiments on four target datasets validate our rationale and demonstrate that our method surpasses the state-of-the-art method in CDFSS signifcantly by 3.71% and 5.34% average MIoU in 1-shot and 5-shot scenarios, respectively.
跨域小样本分割(CDFSS)旨在将在大规模源域数据集上学习到的像素级分割能力转移到下游目标域数据集上,并且每个类别只有少量标注图像。在本文中,我们重点关注CDFSS中一个常见但尚未解决的问题:对于目标域,尤其是那些远离源域的目标域,分割性能在最初几个训练周期达到峰值,随着源域训练的进行,性能会急剧下降。我们深入研究了这一现象,并对其进行了解释:低级特征容易受到域迁移的影响,导致源域训练过程中的损失景观更加陡峭,这是CDFSS的难题。基于这种现象和解释,我们进一步提出了一种方法,包括两个即插即用的模块:一个在源域训练期间通过一种新的尖锐度感知最小化方法来平滑低级特征的损失景观,另一个通过在目标域测试期间基于低级特征进行校准来直接补充目标域信息到模型中。在四个目标数据集上的大量实验验证了我们的合理性,并证明我们的方法在CDFSS中超越了现有技术,在1-shot和5-shot场景中平均MIoU分别提高了3.71%和5.34%。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary:跨域小样本分割(CDFSS)旨在将从大规模源域数据集学到的像素级分割能力转移到下游目标域数据集,而每个类别只需要少量标注图像。本文针对CDFSS中观察到的现象进行研究,即在目标域,尤其是与源域距离较远的领域,分割性能在初期达到峰值后随着源域训练的进行而急剧下降。基于对这种现象的解读,我们提出了一种方法,包括两个即插即用的模块:一个在源域训练期间对低层次特征损失景观进行平滑处理的新颖锐度感知最小化方法,另一个通过低层次特征校准在目标域测试期间直接向模型补充目标域信息。在四个目标数据集上的实验验证了我们方法的合理性,并且在CDFSS领域中超过了最新方法的平均MIoU指标,在单样本和五样本场景中分别提高了3.71%和5.34%。
Key Takeaways:
- Cross-Domain Few-Shot Segmentation (CDFSS)旨在利用源域数据集的分割能力在目标域进行小样本分割。
- 针对CDFSS中观察到的现象:在目标域上,尤其在远离源域的领域,分割性能在初期达到峰值后会随训练进行急剧下降。
- 该现象的原因是低层次特征容易受到领域偏移的影响,导致在源域训练期间损失景观更加尖锐。
- 为了解决这一问题,提出了两个模块:一个用于在源域训练期间平滑低层次特征的损失景观;另一个用于在目标域测试期间补充目标域信息。
- 实验证明该方法的有效性,相较于现有方法在CDFSS领域有所提升,特别是在单样本和五样本场景下的平均MIoU指标。
- 方法具有普遍适用性,在四个目标数据集上均验证了其合理性。
点此查看论文截图


“Whose Side Are You On?” Estimating Ideology of Political and News Content Using Large Language Models and Few-shot Demonstration Selection
Authors:Muhammad Haroon, Magdalena Wojcieszak, Anshuman Chhabra
The rapid growth of social media platforms has led to concerns about radicalization, filter bubbles, and content bias. Existing approaches to classifying ideology are limited in that they require extensive human effort, the labeling of large datasets, and are not able to adapt to evolving ideological contexts. This paper explores the potential of Large Language Models (LLMs) for classifying the political ideology of online content in the context of the two-party US political spectrum through in-context learning (ICL). Our extensive experiments involving demonstration selection in label-balanced fashion, conducted on three datasets comprising news articles and YouTube videos, reveal that our approach significantly outperforms zero-shot and traditional supervised methods. Additionally, we evaluate the influence of metadata (e.g., content source and descriptions) on ideological classification and discuss its implications. Finally, we show how providing the source for political and non-political content influences the LLM’s classification.
社交媒体平台的快速发展引发了人们对极端化、信息茧房和内容偏向的担忧。现有的意识形态分类方法存在局限性,需要大量的人力投入,对大量数据进行标注,并且无法适应不断变化的意识形态环境。本文通过上下文学习(ICL)探索大型语言模型(LLM)在基于两党美国政治谱系的在线内容政治意识形态分类中的潜力。我们在三个包含新闻文章和YouTube视频的数据集上进行了平衡标签的演示选择实验,结果显示我们的方法显著优于零样本和传统监督方法。此外,我们还评估了元数据(如内容来源和描述)对意识形态分类的影响,并讨论了其意义。最后,我们展示了提供政治和非政治内容的来源如何影响LLM的分类。
论文及项目相关链接
Summary
社交媒体平台的快速发展引发了人们对极端化、信息茧房和内容偏见的担忧。现有分类意识形态的方法需要大量人力、标注大规模数据集,并且无法适应不断变化的意识形态环境。本文探索了大型语言模型(LLM)通过上下文学习(ICL)对美国两党政治光谱背景下在线内容的政治意识形态进行分类的潜力。在三个包含新闻文章和YouTube视频的数据集上进行的广泛实验显示,该方法显著优于零样本和传统监督方法。此外,我们还评估了元数据(如内容来源和描述)对意识形态分类的影响,并讨论了其影响。最后,我们展示了提供政治和非政治内容的来源如何影响LLM的分类效果。
Key Takeaways
- 社交媒体平台的快速发展引发了关于极端化、信息茧房和内容偏见的担忧。
- 现有意识形态分类方法存在局限性,需要改进以适应不断变化的环境。
- 大型语言模型(LLM)在分类政治意识形态方面具有潜力。
- 通过上下文学习(ICL),LLM在分类美国两党政治光谱下的在线内容方面表现出优异性能。
- 在新闻文章和YouTube视频数据上的实验显示,LLM方法优于零样本和传统监督方法。
- 元数据对意识形态分类有影响,这一点在研究中得到了评估。
点此查看论文截图



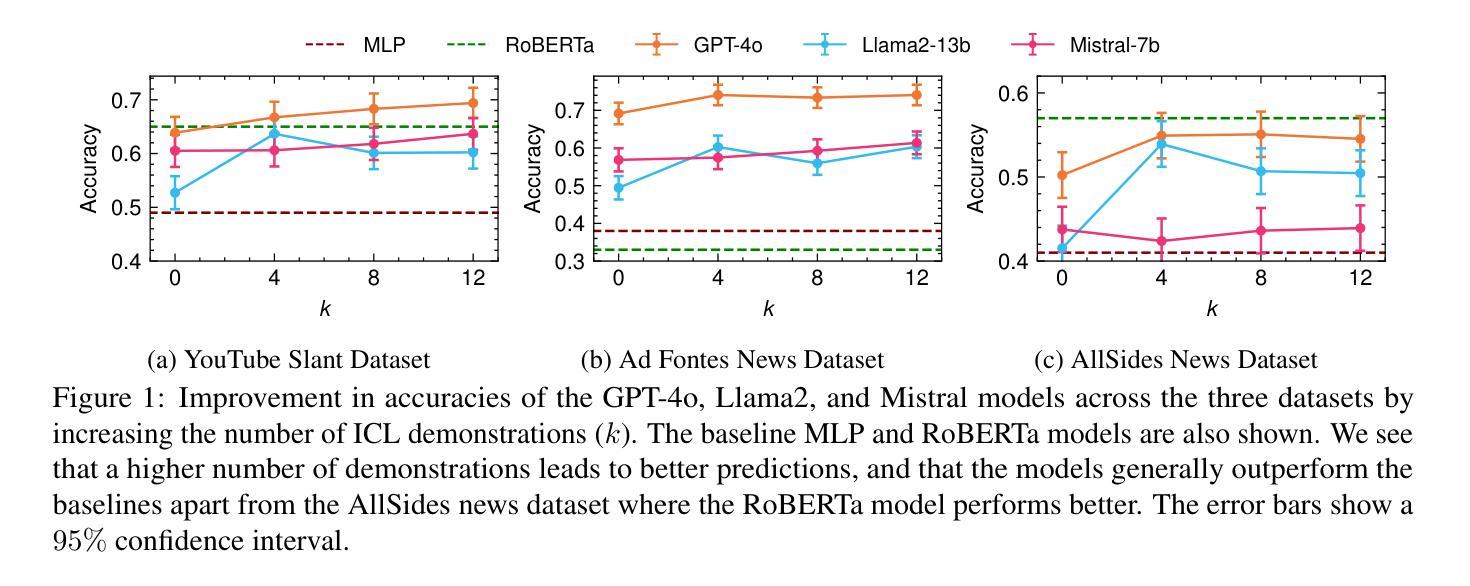
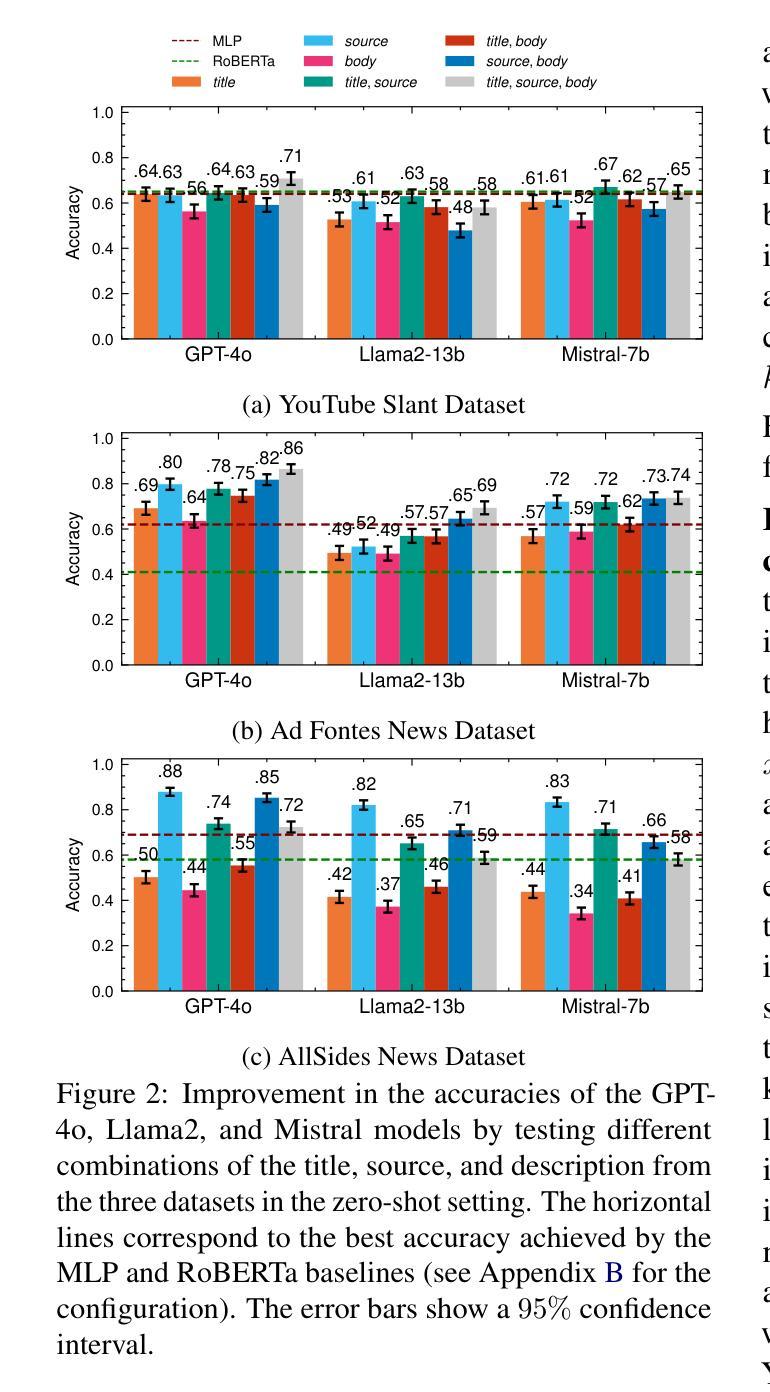
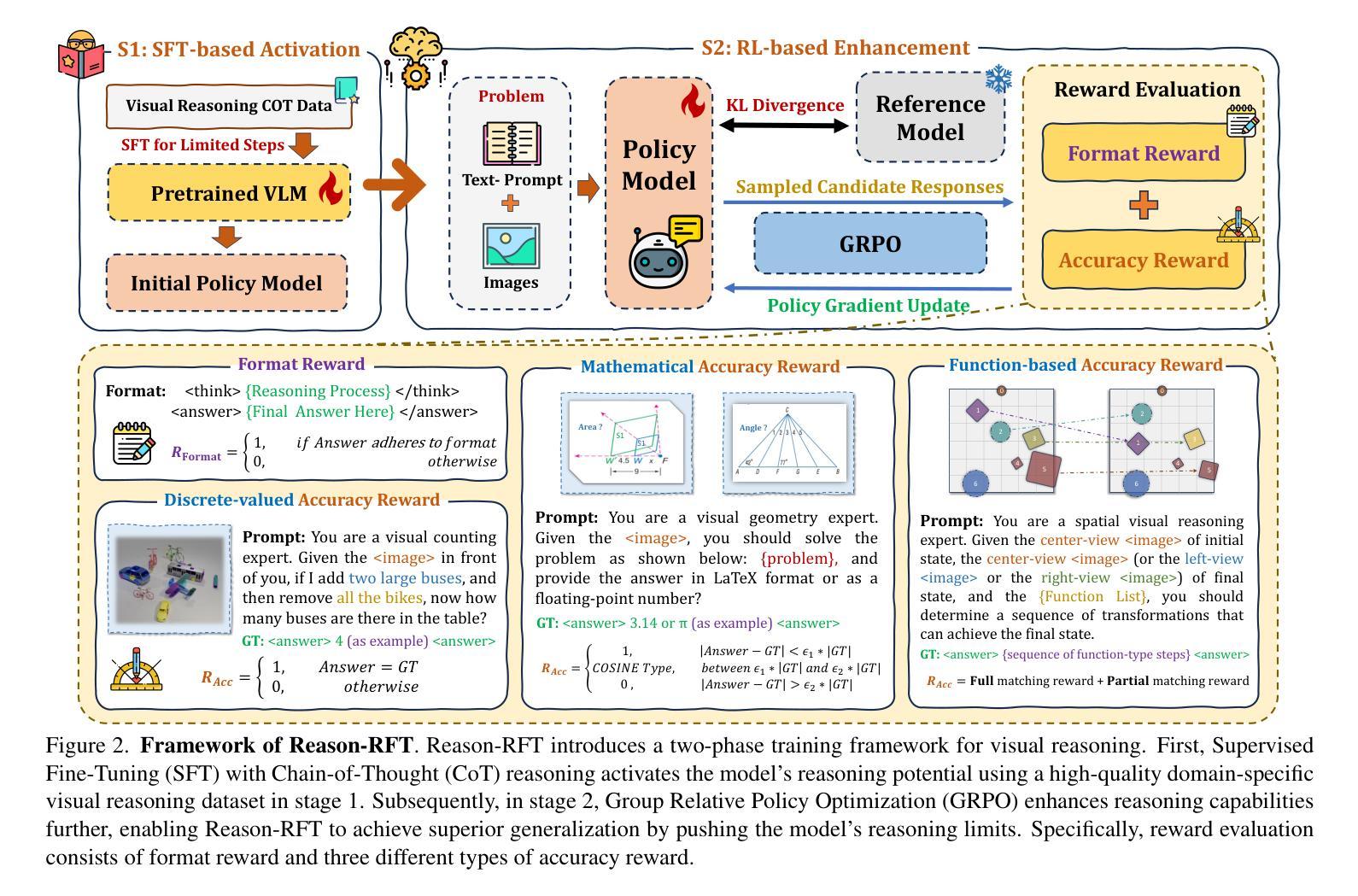
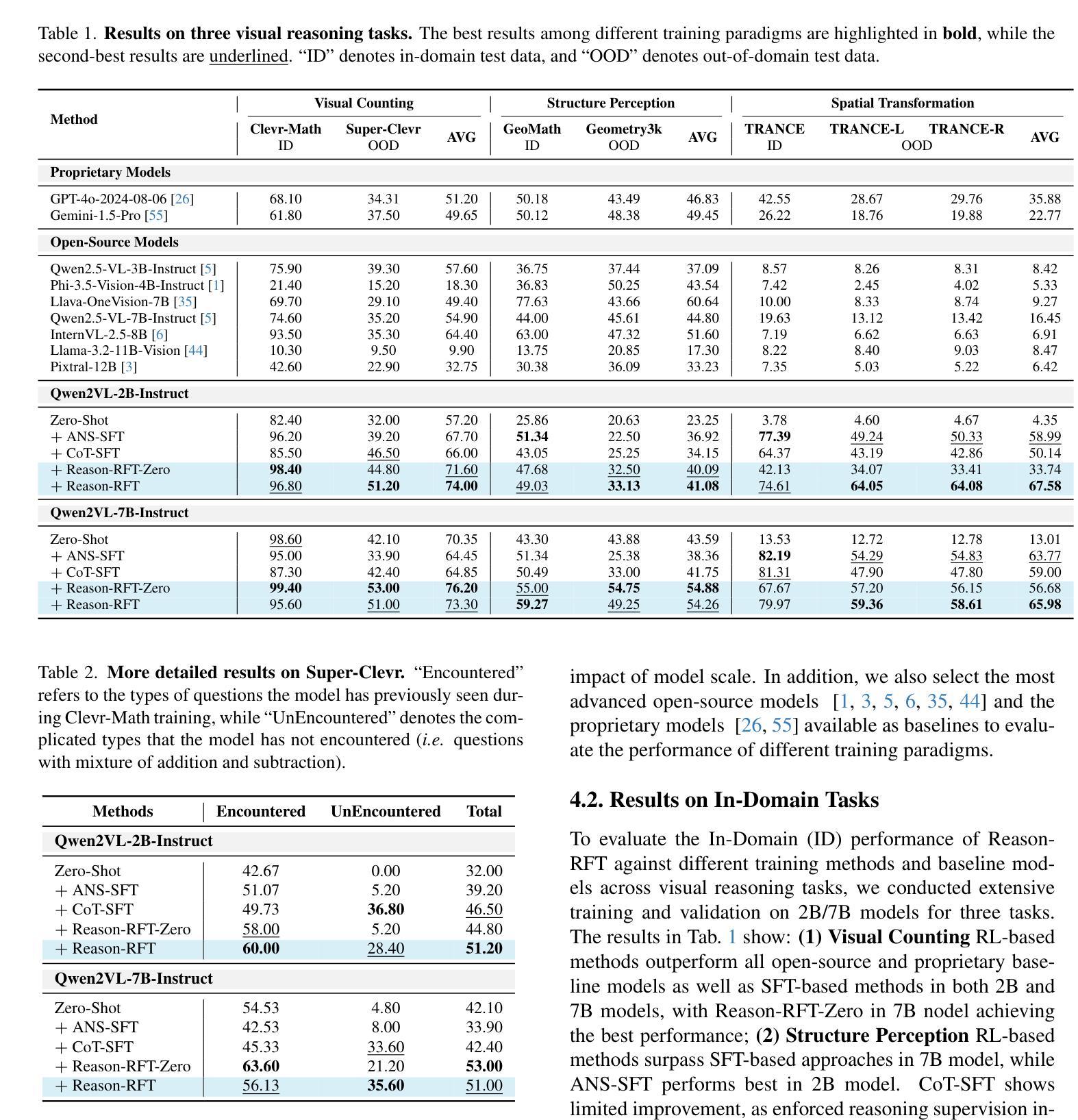
Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning
Authors:Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang
Visual reasoning abilities play a crucial role in understanding complex multimodal data, advancing both domain-specific applications and artificial general intelligence (AGI). Existing methods improve VLM reasoning via Chain-of-Thought (CoT) supervised fine-tuning, using meticulously annotated training data to enhance visual reasoning capabilities. However, this training paradigm may lead to overfitting and cognitive rigidity, restricting the model’s ability to transfer visual reasoning skills across domains and limiting its real-world applicability. To address these limitations, we propose Reason-RFT, a novel reinforcement fine-tuning framework that significantly enhances generalization capabilities in visual reasoning tasks. Reason-RFT introduces a two-phase training framework for visual reasoning: (1) Supervised Fine-Tuning (SFT) with curated Chain-of-Thought (CoT) data activates the reasoning potential of Vision-Language Models (VLMs), followed by (2) Group Relative Policy Optimization (GRPO)-based reinforcement learning that generates multiple reasoning-response pairs, significantly enhancing generalization in visual reasoning tasks. To evaluate Reason-RFT’s visual reasoning capabilities, we reconstructed a comprehensive dataset spanning visual counting, structure perception, and spatial transformation. Experimental results demonstrate Reasoning-RFT’s three key advantages: (1) Performance Enhancement: achieving state-of-the-art results across multiple tasks, outperforming most mainstream open-source and proprietary models; (2) Generalization Superiority: consistently maintaining robust performance across diverse tasks and domains, outperforming alternative training paradigms; (3) Data Efficiency: excelling in few-shot learning scenarios while surpassing full-dataset SFT baselines. Project website: https://tanhuajie.github.io/ReasonRFT
视觉推理能力在理解复杂的多模态数据、推动领域特定应用和人工智能通用智能(AGI)方面发挥着至关重要的作用。现有方法通过基于思维链(Chain-of-Thought,简称CoT)的监督微调(Supervised Fine-Tuning)来提升视觉语言模型(Vision-Language Models,简称VLM)的推理能力,使用精心标注的训练数据以增强视觉推理能力。然而,这种训练模式可能会导致过拟合和认知僵化,限制了模型在不同领域应用视觉推理技能的能力,以及其在现实世界中的适用性。为了解决这些局限性,我们提出了Reason-RFT,这是一种新型强化微调框架,能够显著提高视觉推理任务的泛化能力。Reason-RFT引入了用于视觉推理的两阶段训练框架:首先,使用精选的思维链(CoT)数据进行监督微调(Supervised Fine-Tuning,简称SFT),以激发视觉语言模型(VLMs)的推理潜力;其次,基于群体相对策略优化(Group Relative Policy Optimization,简称GRPO)的强化学习生成多个推理响应对,这显著提高了视觉推理任务的泛化能力。为了评估Reason-RFT的视觉推理能力,我们重新构建了一个综合数据集,涵盖了视觉计数、结构感知和空间转换。实验结果表明,Reasoning-RFT具有三大优势:(1)性能增强:在多任务上实现最佳结果,优于大多数主流开源和专有模型;(2)泛化优势:在各种任务和领域中始终保持良好的性能,优于其他训练模式;(3)数据效率:在少数学习场景中表现优异,超越全数据集的SFT基准。项目网站:https://tanhuajie.github.io/ReasonRFT
论文及项目相关链接
PDF 35 pages, 22 figures
摘要
视觉推理能力对于理解复杂的多模态数据、推动领域特定应用和通用人工智能(AGI)的发展起着至关重要的作用。现有方法通过链式思维(CoT)监督微调(SFT)提升视觉语言模型(VLM)的推理能力,但可能导致过拟合和认知僵化,限制模型跨域转移视觉推理技能的能力及其在实际世界中的应用。为解决这些问题,我们提出了Reason-RFT,一种新型强化微调框架,显著提高了视觉推理任务的泛化能力。Reason-RFT引入了两阶段训练框架:首先使用精选的链式思维(CoT)数据进行监督微调(SFT),激活视觉语言模型(VLM)的推理潜力,接着采用基于群体相对策略优化(GRPO)的强化学习生成多个推理-响应对,从而显著增强视觉推理任务的泛化能力。为评估Reason-RFT的视觉推理能力,我们重建了一个综合数据集,涵盖视觉计数、结构感知和空间变换。实验结果表明Reasoning-RFT具有三大优势:性能提升、泛化优势和数据效率。
关键见解
- 视觉推理能力在理解复杂多模态数据和推动人工智能发展方面至关重要。
- 现有方法通过链式思维(CoT)监督微调提升视觉语言模型(VLM)的推理能力,但存在过拟合和认知僵化问题。
- Reason-RFT框架通过引入两阶段训练法增强模型泛化能力:监督微调(SFT)和基于群体相对策略优化(GRPO)的强化学习。
- Reason-RFT在视觉计数、结构感知和空间变换等多项任务上实现卓越性能,优于主流开源和专有模型。
- Reason-RFT在不同任务和领域上表现出稳健的性能,超越了其他训练范式。
- 在小样学习场景下,Reason-RFT的数据效率表现优异,超越了全数据集的SFT基线。
点此查看论文截图

Cognitive-Mental-LLM: Evaluating Reasoning in Large Language Models for Mental Health Prediction via Online Text
Authors:Avinash Patil, Amardeep Kour Gedhu
Large Language Models (LLMs) have demonstrated potential in predicting mental health outcomes from online text, yet traditional classification methods often lack interpretability and robustness. This study evaluates structured reasoning techniques-Chain-of-Thought (CoT), Self-Consistency (SC-CoT), and Tree-of-Thought (ToT)-to improve classification accuracy across multiple mental health datasets sourced from Reddit. We analyze reasoning-driven prompting strategies, including Zero-shot CoT and Few-shot CoT, using key performance metrics such as Balanced Accuracy, F1 score, and Sensitivity/Specificity. Our findings indicate that reasoning-enhanced techniques improve classification performance over direct prediction, particularly in complex cases. Compared to baselines such as Zero Shot non-CoT Prompting, and fine-tuned pre-trained transformers such as BERT and Mental-RoBerta, and fine-tuned Open Source LLMs such as Mental Alpaca and Mental-Flan-T5, reasoning-driven LLMs yield notable gains on datasets like Dreaddit (+0.52% over M-LLM, +0.82% over BERT) and SDCNL (+4.67% over M-LLM, +2.17% over BERT). However, performance declines in Depression Severity, and CSSRS predictions suggest dataset-specific limitations, likely due to our using a more extensive test set. Among prompting strategies, Few-shot CoT consistently outperforms others, reinforcing the effectiveness of reasoning-driven LLMs. Nonetheless, dataset variability highlights challenges in model reliability and interpretability. This study provides a comprehensive benchmark of reasoning-based LLM techniques for mental health text classification. It offers insights into their potential for scalable clinical applications while identifying key challenges for future improvements.
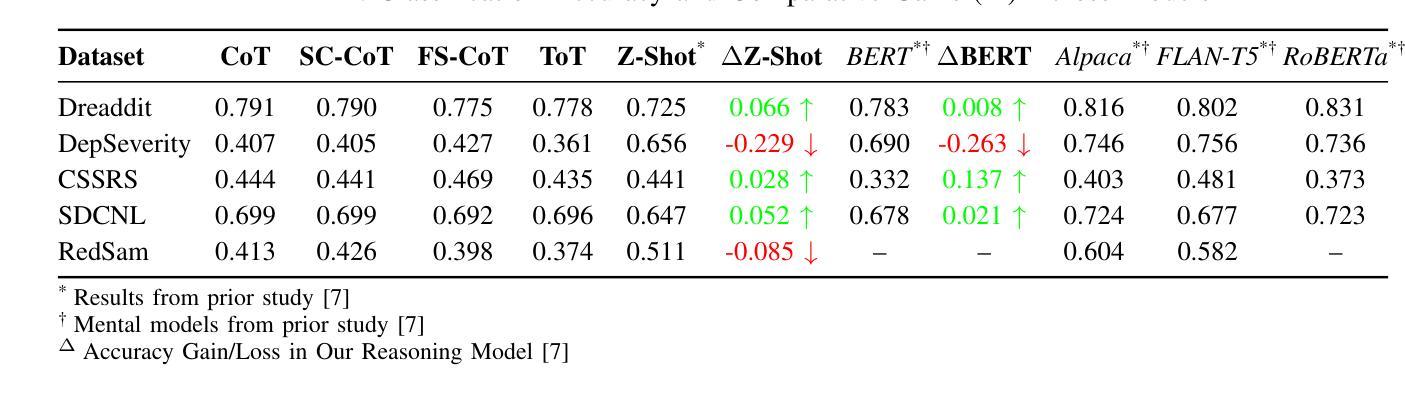
大型语言模型(LLM)已显示出从在线文本预测心理健康结果的潜力,但传统分类方法往往缺乏可解释性和稳健性。本研究评估了基于结构化推理技术——思维链(CoT)、自我一致性(SC-CoT)和思维树(ToT)——以提高在多个来自Reddit的心理健康数据集上的分类准确率。我们分析了以推理为核心的提示策略,包括零样本CoT和少样本CoT,使用平衡精度、F1分数、灵敏度和特异度等关键性能指标。我们的研究结果表明,采用推理增强技术的分类性能优于直接预测,特别是在复杂情况下。与基线方法(如零样本非CoT提示)以及微调过的预训练转换器(如BERT和Mental-RoBerta)以及微调过的开源LLM(如Mental Alpaca和Mental-Flan-T5)相比,基于推理的LLM在数据集(如Dreaddit(+ 0.52%相对于M-LLM,+ 0.8i相对于BERT)和SDCNL(+ 4.67%相对于M-LLM,+ 2.17%相对于BERT))上取得了显著的提升。然而,在抑郁症严重程度和CSSRS预测方面的表现下降表明,特定数据集存在局限性,这可能是由于我们使用了更广泛的测试集。在提示策略中,少样本CoT始终表现最好,这进一步证明了基于推理的LLM的有效性。然而,数据集的变化也突显了模型可靠性和可解释性的挑战。本研究为基于推理的LLM技术在心理健康文本分类方面提供了全面的基准测试。它为可扩展的临床应用潜力提供了见解,并指出了未来改进的关键挑战。
论文及项目相关链接
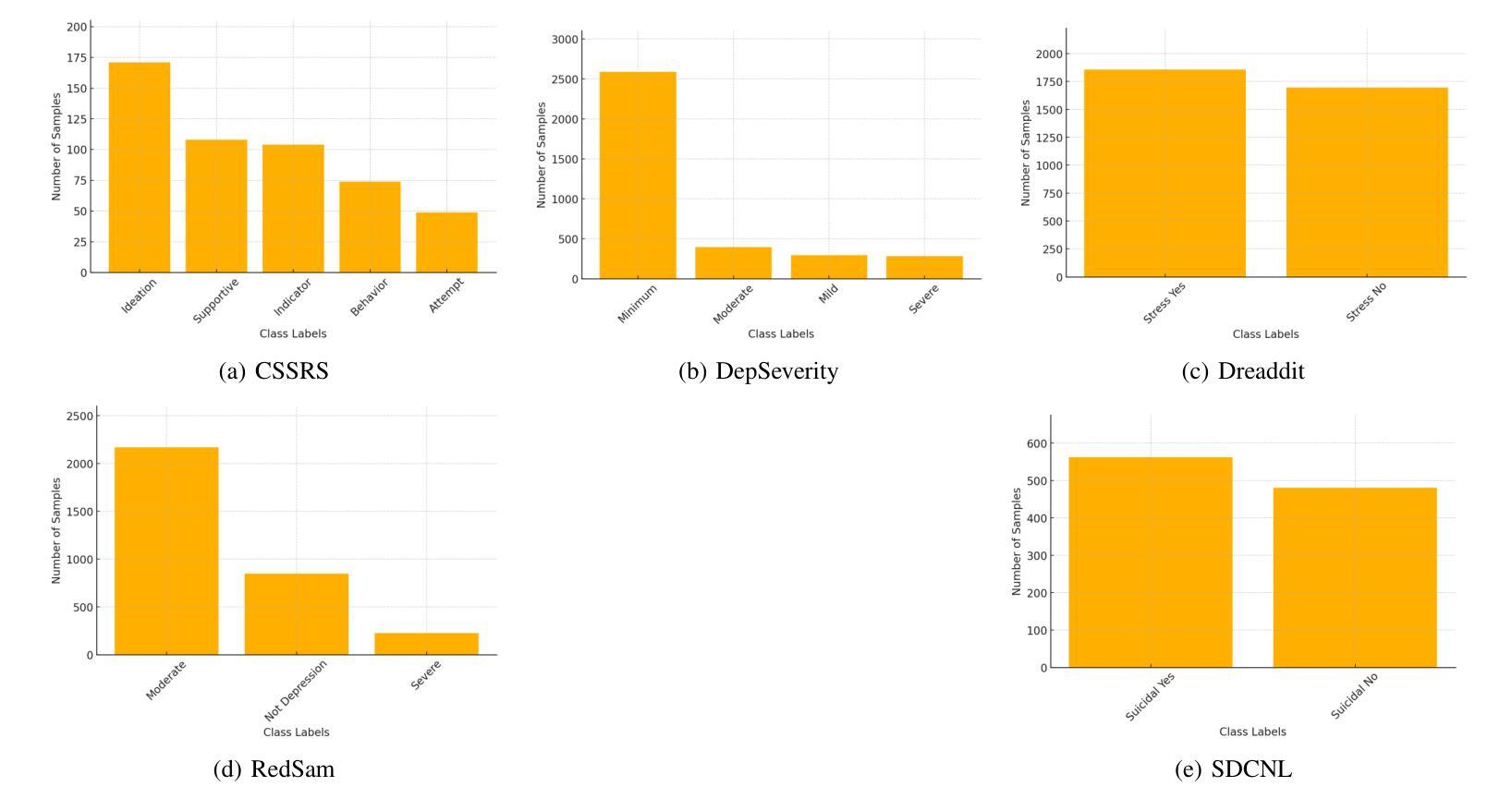
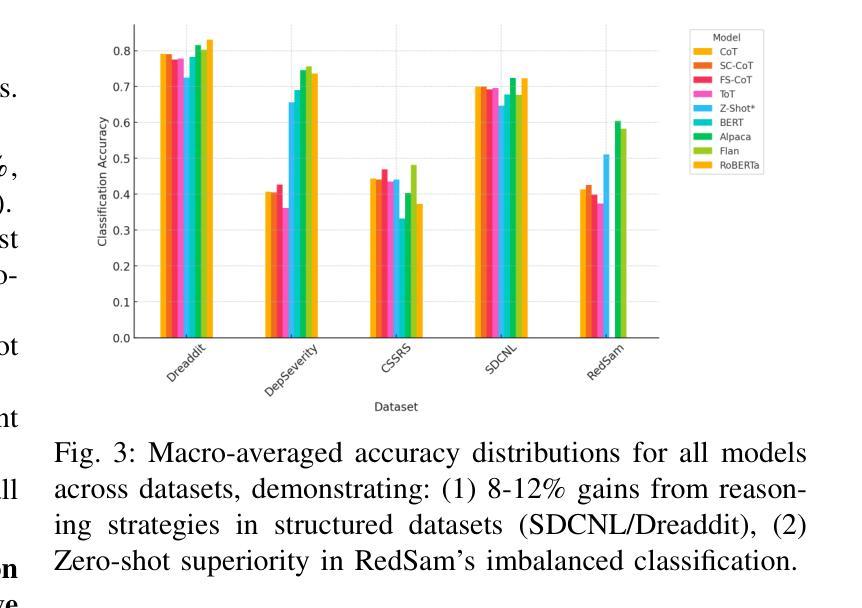
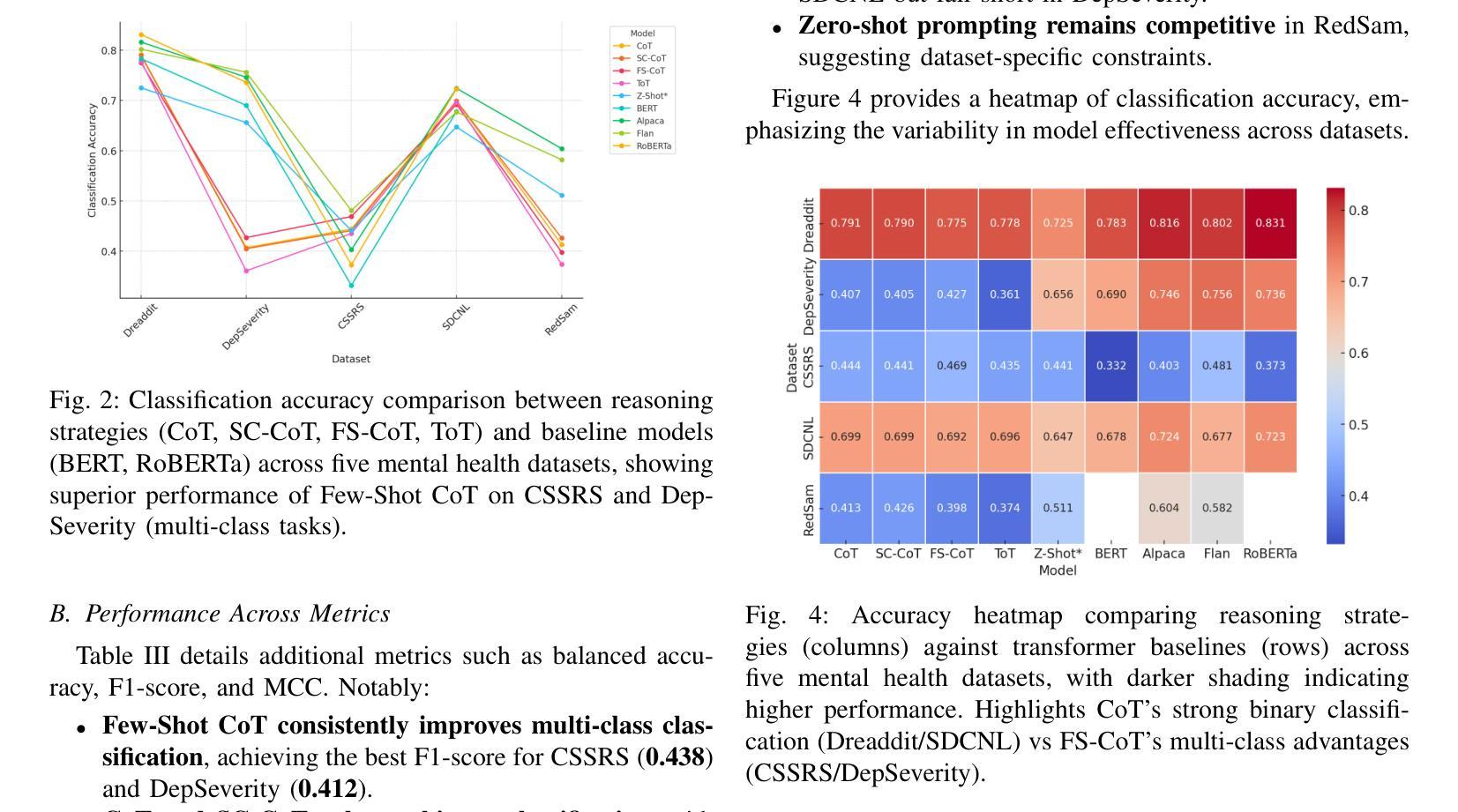
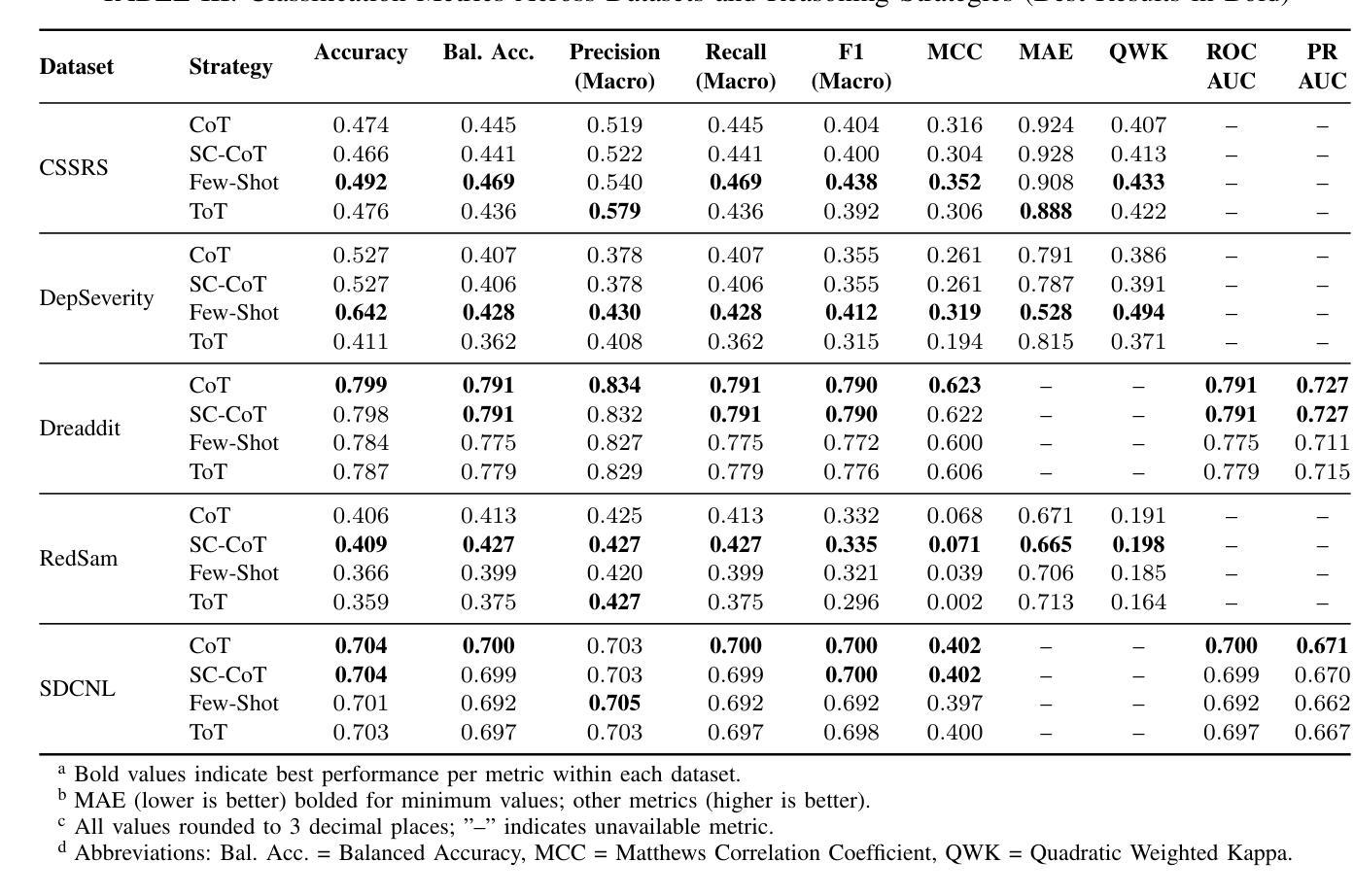
PDF 8 pages, 4 Figures, 3 tables
Summary
本文探讨了大型语言模型(LLMs)在预测网络文本中的心理健康结果方面的潜力。针对传统分类方法缺乏解释性和稳健性的问题,本研究评估了链式思维(CoT)、自我一致性(SC-CoT)和思维树(ToT)等结构化推理技术,以提高在多个来自Reddit的心理健康数据集上的分类准确性。研究分析了基于推理的提示策略,包括零射CoT和少射CoT,并使用平衡精度、F1分数和敏感性/特异性等关键性能指标进行评估。结果表明,与基线方法和精细调整的预训练转换器相比,推理增强技术能提高分类性能,特别是在复杂情况下。然而,在抑郁症严重性和CSSRS预测方面的性能下降表明,数据集特定局限性可能存在。本研究提供了基于推理的LLM技术在心理健康文本分类方面的综合基准测试,为临床应用的潜在可能性提供了见解,并指出了未来改进的关键挑战。
Key Takeaways
- 大型语言模型(LLMs)能够从网络文本中预测心理健康结果。
- 传统分类方法在心理健康文本分类中缺乏解释性和稳健性。
- 结构化推理技术如链式思维(CoT)能提高分类准确性。
- 基于推理的提示策略如少射CoT在复杂情况下表现更好。
- 与基线方法和精细调整的预训练转换器相比,推理增强技术显著提高分类性能。
- 数据集特定局限性存在,性能在特定预测方面可能下降。
点此查看论文截图


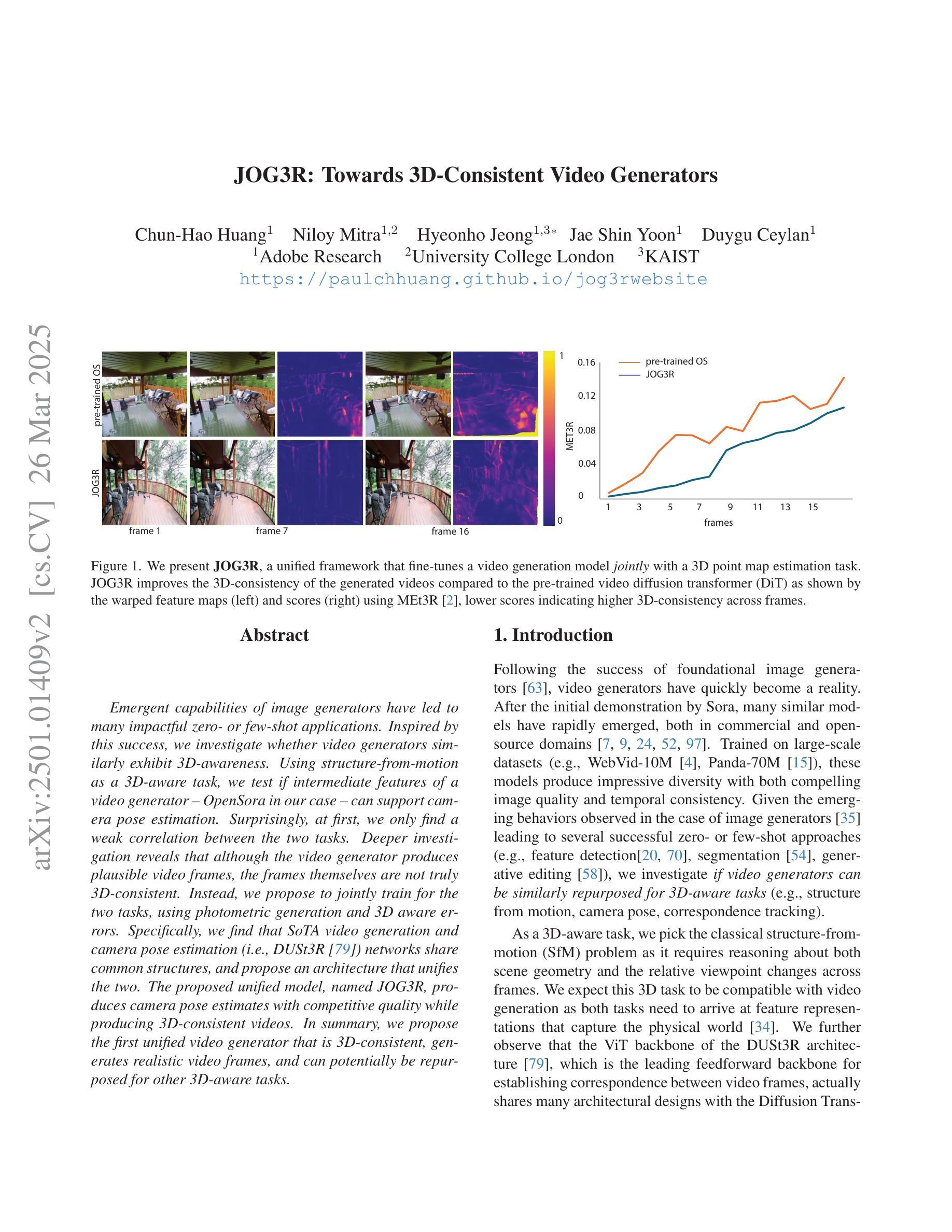
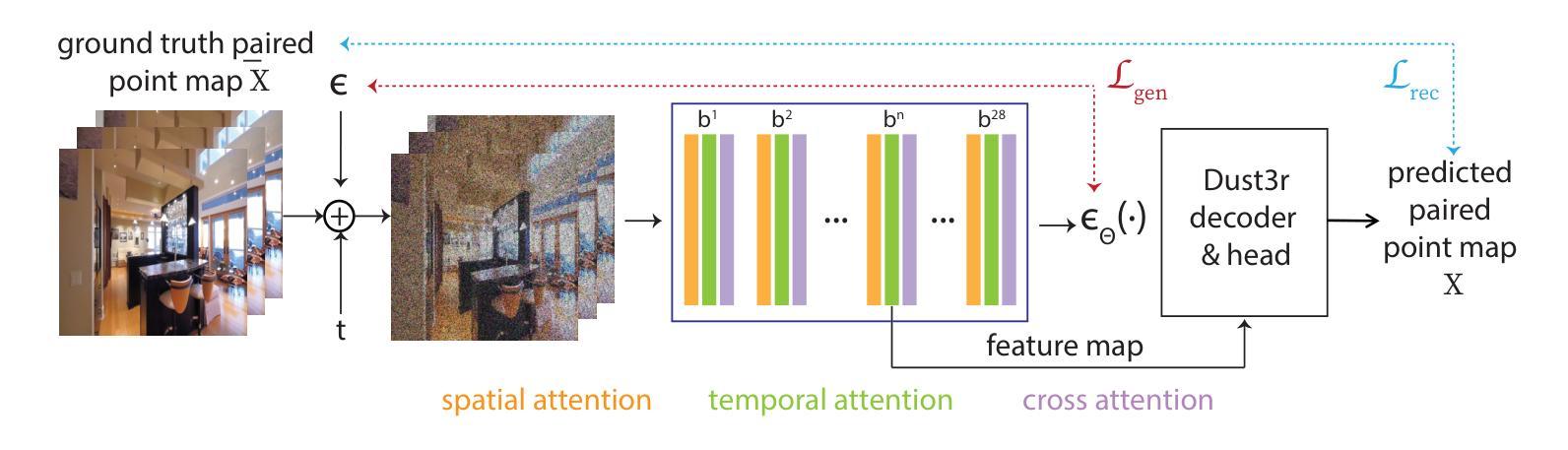
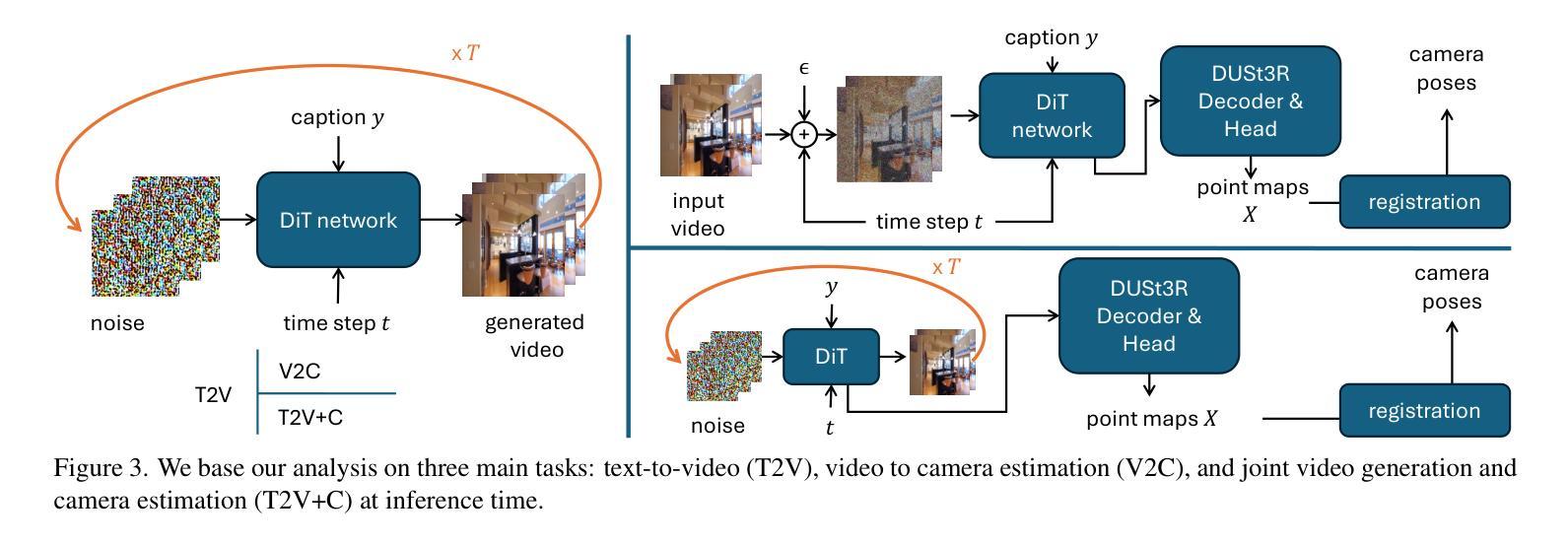
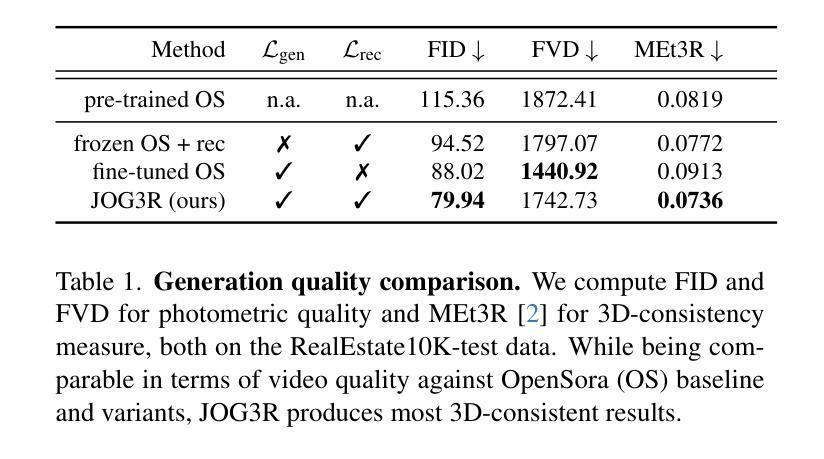
JOG3R: Towards 3D-Consistent Video Generators
Authors:Chun-Hao Paul Huang, Niloy Mitra, Hyeonho Jeong, Jae Shin Yoon, Duygu Ceylan
Emergent capabilities of image generators have led to many impactful zero- or few-shot applications. Inspired by this success, we investigate whether video generators similarly exhibit 3D-awareness. Using structure-from-motion as a 3D-aware task, we test if intermediate features of a video generator - OpenSora in our case - can support camera pose estimation. Surprisingly, at first, we only find a weak correlation between the two tasks. Deeper investigation reveals that although the video generator produces plausible video frames, the frames themselves are not truly 3D-consistent. Instead, we propose to jointly train for the two tasks, using photometric generation and 3D aware errors. Specifically, we find that SoTA video generation and camera pose estimation (i.e.,DUSt3R [79]) networks share common structures, and propose an architecture that unifies the two. The proposed unified model, named \nameMethod, produces camera pose estimates with competitive quality while producing 3D-consistent videos. In summary, we propose the first unified video generator that is 3D-consistent, generates realistic video frames, and can potentially be repurposed for other 3D-aware tasks.
图像生成器的突发能力已经导致了许多具有影响力的零样本或少样本应用。受此成功的启发,我们调查视频生成器是否同样具备3D感知能力。我们使用从运动中获取结构作为3D感知任务,测试视频生成器的中间特征(在我们的情况下为OpenSora)是否能够支持相机姿态估计。令人惊讶的是,起初我们只在两项任务之间发现了微弱的相关性。更深入的研究表明,尽管视频生成器可以生成合理的视频帧,但这些帧本身并不真正具有3D一致性。相反,我们提出联合训练这两个任务,使用光度生成和3D感知错误。具体来说,我们发现最新的视频生成和相机姿态估计(即DUSt3R[79])网络具有共同的结构,并提出了一种统一两者的架构。所提出的统一模型被称为\nameMethod,它产生的相机姿态估计具有竞争性的质量,同时生成具有3D一致性的视频。总之,我们提出了第一个统一的视频生成器,它具有3D一致性,可以生成逼真的视频帧,并且可能用于其他3D感知任务。
论文及项目相关链接
Summary
新一代图像生成器的涌现能力为很多零样本或小样例应用带来了影响。本研究受此启发,探索视频生成器是否同样具备3D感知能力。通过结构从运动作为3D感知任务进行测试,我们发现视频生成器的中间特征并不直接支持相机姿态估计。为此,我们提出联合训练两个任务的方法,使用光度生成和3D感知误差。我们设计了一种统一模型,名为“nameMethod”,该模型能在生成3D一致视频的同时,提供具有竞争力的相机姿态估计质量。总之,我们提出了首个统一的、能生成3D一致视频的视频生成器,可为其他3D感知任务提供潜力。
Key Takeaways
- 视频生成器需探索是否具备3D感知能力。
- 结构从运动作为测试任务揭示视频生成器中间特征并不直接支持相机姿态估计。
- 视频生成器产生的视频帧虽然看似合理,但并不具备真正的3D一致性。
- 提出联合训练相机姿态估计和视频生成任务的方法。
- SoTA视频生成和相机姿态估计网络具有共同结构。
- 提出的统一模型“nameMethod”能生成具有竞争力的相机姿态估计质量,同时产生3D一致的视频。
点此查看论文截图
SF-Speech: Straightened Flow for Zero-Shot Voice Clone
Authors:Xuyuan Li, Zengqiang Shang, Hua Hua, Peiyang Shi, Chen Yang, Li Wang, Pengyuan Zhang
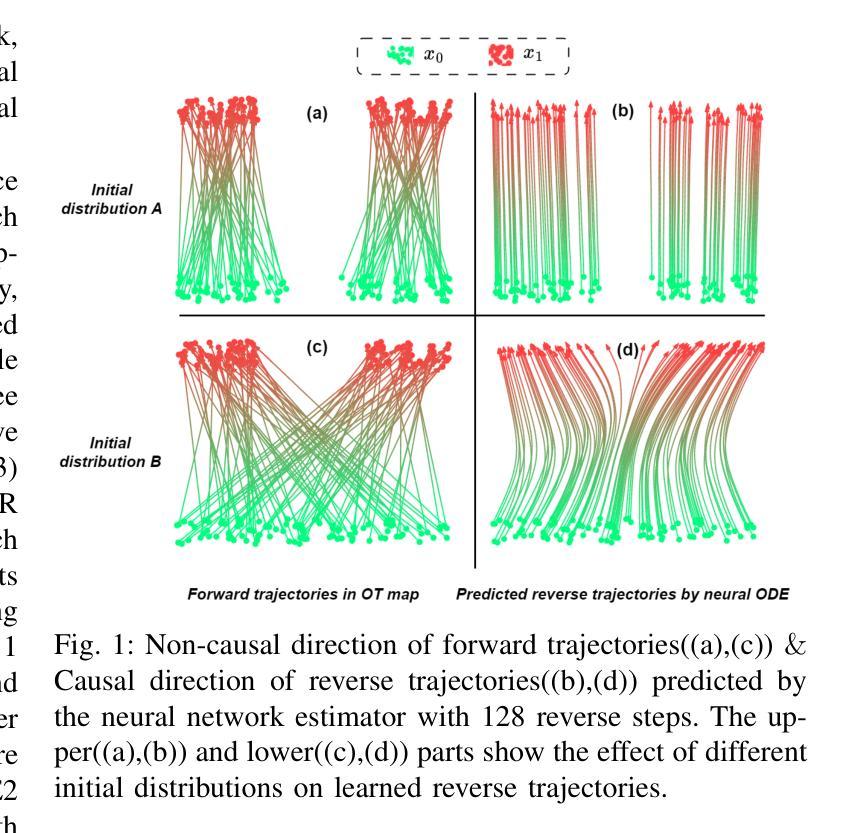
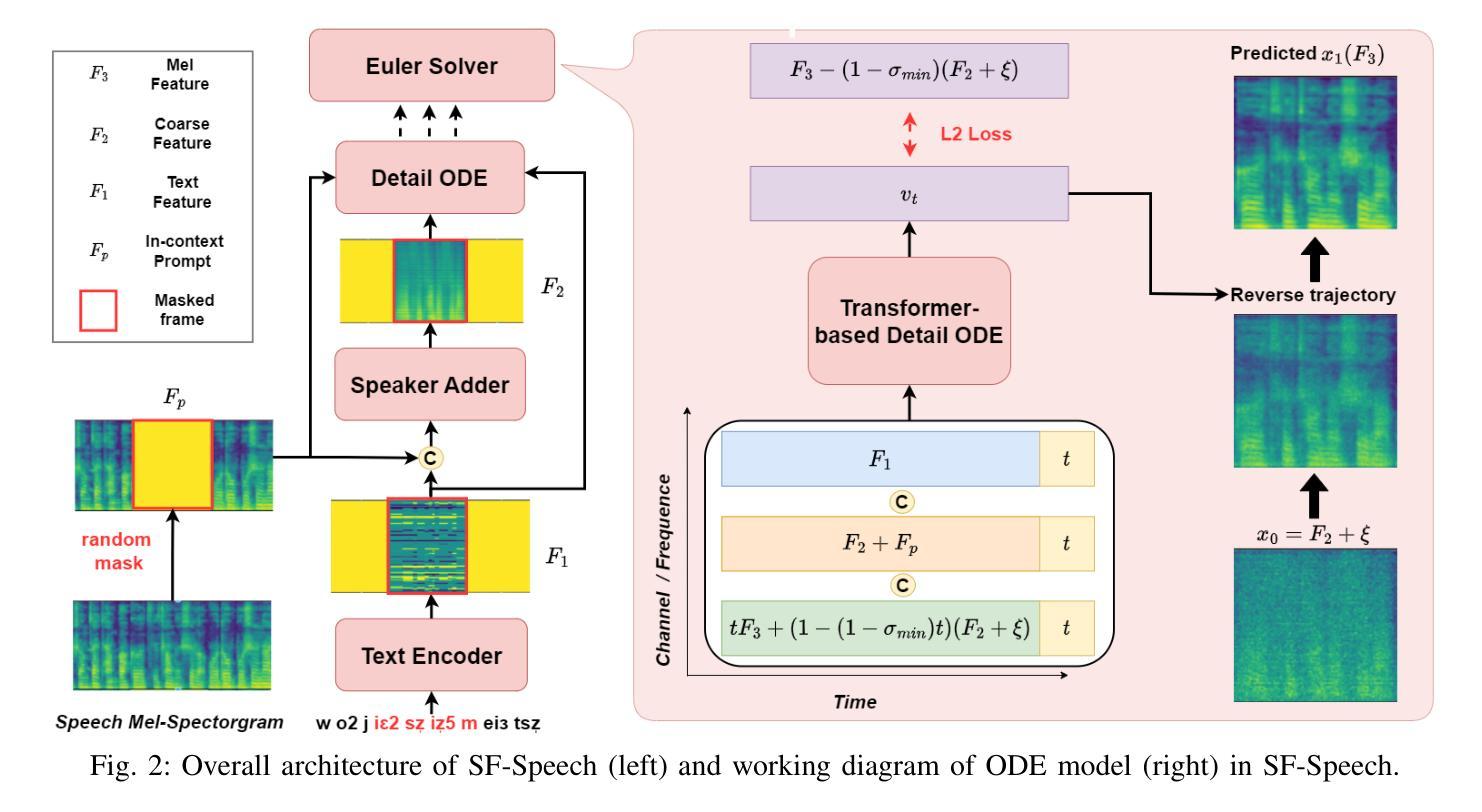
Recently, neural ordinary differential equations (ODE) models trained with flow matching have achieved impressive performance on the zero-shot voice clone task. Nevertheless, postulating standard Gaussian noise as the initial distribution of ODE gives rise to numerous intersections within the fitted targets of flow matching, which presents challenges to model training and enhances the curvature of the learned generated trajectories. These curved trajectories restrict the capacity of ODE models for generating desirable samples with a few steps. This paper proposes SF-Speech, a novel voice clone model based on ODE and in-context learning. Unlike the previous works, SF-Speech adopts a lightweight multi-stage module to generate a more deterministic initial distribution for ODE. Without introducing any additional loss function, we effectively straighten the curved reverse trajectories of the ODE model by jointly training it with the proposed module. Experiment results on datasets of various scales show that SF-Speech outperforms the state-of-the-art zero-shot TTS methods and requires only a quarter of the solver steps, resulting in a generation speed approximately 3.7 times that of Voicebox and E2 TTS. Audio samples are available at the demo page\footnote{[Online] Available: https://lixuyuan102.github.io/Demo/}.
最近,使用流匹配训练的神经常微分方程(ODE)模型在零样本语音克隆任务上取得了令人印象深刻的性能。然而,假设标准高斯噪声作为ODE的初始分布会导致流匹配的拟合目标内部出现许多交集,这给模型训练带来了挑战,并增强了学习生成轨迹的曲率。这些弯曲的轨迹限制了ODE模型在几步内生成理想样本的能力。本文提出了SF-Speech,这是一种基于ODE和上下文学习的新型语音克隆模型。不同于以前的工作,SF-Speech采用轻量级的多阶段模块来为ODE生成更确定的初始分布。我们没有引入任何额外的损失函数,而是通过与所提出模块进行联合训练,有效地校正了ODE模型的弯曲反向轨迹。在各种规模的数据集上的实验结果表明,SF-Speech优于最先进的零样本TTS方法,并且仅需四分之一的求解器步骤,生成速度大约是Voicebox和E2 TTS的3.7倍。音频样本可在演示页面获得\footnote{[在线]可用:https://lixuyuan102.github.io/Demo/}。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Audio, Speech and Language Processing
Summary
本文介绍了基于神经常微分方程(ODE)和上下文学习的语音克隆模型SF-Speech。该模型通过采用轻量级的多阶段模块生成更确定的初始分布,有效拉直ODE模型的反向曲线轨迹,从而提高生成样本的质量和效率。实验结果表明,SF-Speech在零样本TTS方法上表现优异,且求解步骤仅需四分之一,生成速度大约是Voicebox和E2 TTS的3.7倍。
Key Takeaways
- 神经常微分方程(ODE)模型在零样本语音克隆任务上表现出卓越性能。
- 使用标准高斯噪声作为ODE的初始分布会导致目标拟合中出现多个交集,为模型训练带来挑战。
- SF-Speech是一个新颖的语音克隆模型,基于ODE和上下文学习,旨在解决上述问题。
- SF-Speech采用轻量级的多阶段模块来生成更确定的初始分布,有效拉直ODE模型的反向轨迹。
- 实验结果显示,SF-Speech在多种数据集上优于现有零样本TTS方法。
- SF-Speech减少了ODE求解的步骤需求,大幅度提高了生成语音的速度。
点此查看论文截图

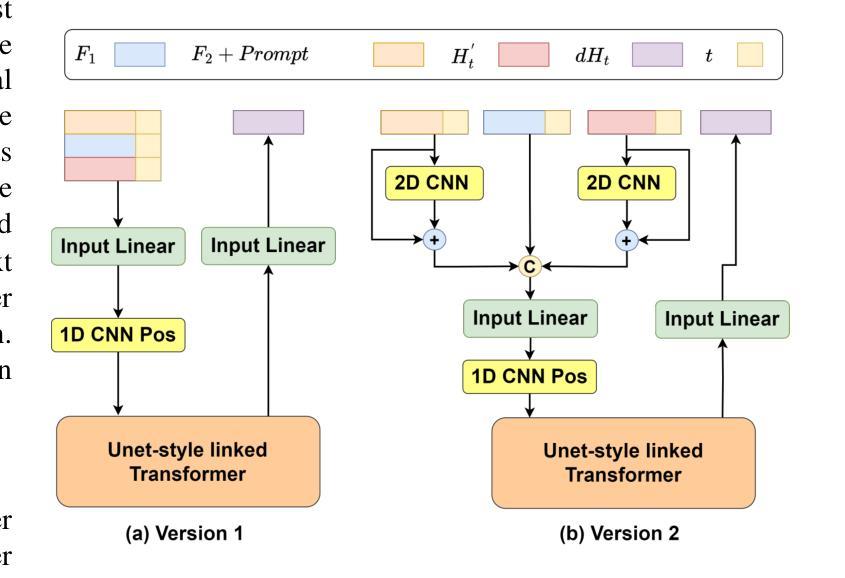
Whistle: Data-Efficient Multilingual and Crosslingual Speech Recognition via Weakly Phonetic Supervision
Authors:Saierdaer Yusuyin, Te Ma, Hao Huang, Wenbo Zhao, Zhijian Ou
There exist three approaches for multilingual and crosslingual automatic speech recognition (MCL-ASR) - supervised pretraining with phonetic or graphemic transcription, and self-supervised pretraining. We find that pretraining with phonetic supervision has been underappreciated so far for MCL-ASR, while conceptually it is more advantageous for information sharing between different languages. This paper explores the approach of pretraining with weakly phonetic supervision towards data-efficient MCL-ASR, which is called Whistle. We relax the requirement of gold-standard human-validated phonetic transcripts, and obtain International Phonetic Alphabet (IPA) based transcription by leveraging the LanguageNet grapheme-to-phoneme (G2P) models. We construct a common experimental setup based on the CommonVoice dataset, called CV-Lang10, with 10 seen languages and 2 unseen languages. A set of experiments are conducted on CV-Lang10 to compare, as fair as possible, the three approaches under the common setup for MCL-ASR. Experiments demonstrate the advantages of phoneme-based models (Whistle) for MCL-ASR, in terms of speech recognition for seen languages, crosslingual performance for unseen languages with different amounts of few-shot data, overcoming catastrophic forgetting, and training efficiency. It is found that when training data is more limited, phoneme supervision can achieve better results compared to subword supervision and self-supervision, thereby providing higher data-efficiency. To support reproducibility and promote future research along this direction, we release the code, models and data for the entire pipeline of Whistle at https://github.com/thu-spmi/CAT/tree/master/egs/cv-lang10.
对于多语言和跨语言自动语音识别(MCL-ASR),存在三种方法:带有语音或字形转录的监督预训练以及自监督预训练。我们发现迄今为止,对于MCL-ASR而言,监督预训练的重要性尚未得到充分认可,尽管在概念上它在不同语言之间的信息共享方面具有更多优势。本文探讨了使用弱语音监督进行预训练的方法,以实现数据高效的多语言自动语音识别,称为“口哨”(Whistle)。我们放宽了对金标准人工验证语音转录的要求,并利用LanguageNet的字形到语音(G2P)模型获取基于国际语音字母表的转录。我们基于CommonVoice数据集构建了一个通用实验设置,称为CV-Lang10,包含10种可见语言和两种未见语言。在CV-Lang10上进行了一系列实验,尽可能公平地比较三种MCL-ASR方法的预训练方法。实验证明了基于音素模型的口哨在多语言自动语音识别方面的优势,包括识别可见语言的语音、在不同数量的少量数据下对未见语言的跨语言性能、克服灾难性遗忘以及训练效率方面。发现当训练数据更加有限时,音素监督可以比词素监督和自我监督实现更好的结果,从而提供了更高的数据效率。为了支持可重复性和促进未来在这一方向的研究,我们发布了整个口哨管道的代码、模型和数据:https://github.com/thu-spmi/CAT/tree/master/egs/cv-lang10。
论文及项目相关链接
PDF Accepted by IEEE-TASLP
Summary
本文探讨了多语言和跨语言自动语音识别(MCL-ASR)的三种预训练策略,包括语音或字形转录的有监督预训练、自监督预训练,以及弱语音监督预训练。研究指出,弱语音监督预训练策略在数据效率方面表现出优势,特别是在有限训练数据的情况下,语音监督相较于子词监督和自监督能取得更好的结果。实验证明,该策略在已知语言的语音识别、不同少量数据的未知语言的跨语言性能、克服灾难性遗忘和提高训练效率等方面具有优势。
Key Takeaways
- 多语言和跨语言自动语音识别(MCL-ASR)存在三种预训练策略:语音或字形转录的有监督预训练、自监督预训练以及弱语音监督预训练。
- 弱语音监督预训练策略在数据效率方面具有优势,特别是当训练数据有限时,语音监督相较于其他方法能取得更好的结果。
- 实验证明,弱语音监督预训练策略在已知语言的语音识别和未知语言的跨语言性能上表现优异。
- 该策略有助于克服灾难性遗忘并提高训练效率。
- 为了支持可重复性和促进未来研究,研究者公开了整个管道的代码、模型和数据。
- 使用LanguageNet的grapheme-to-phoneme(G2P)模型来获得基于国际音标(IPA)的转录,降低了对金标准人类验证语音转录的要求。
点此查看论文截图

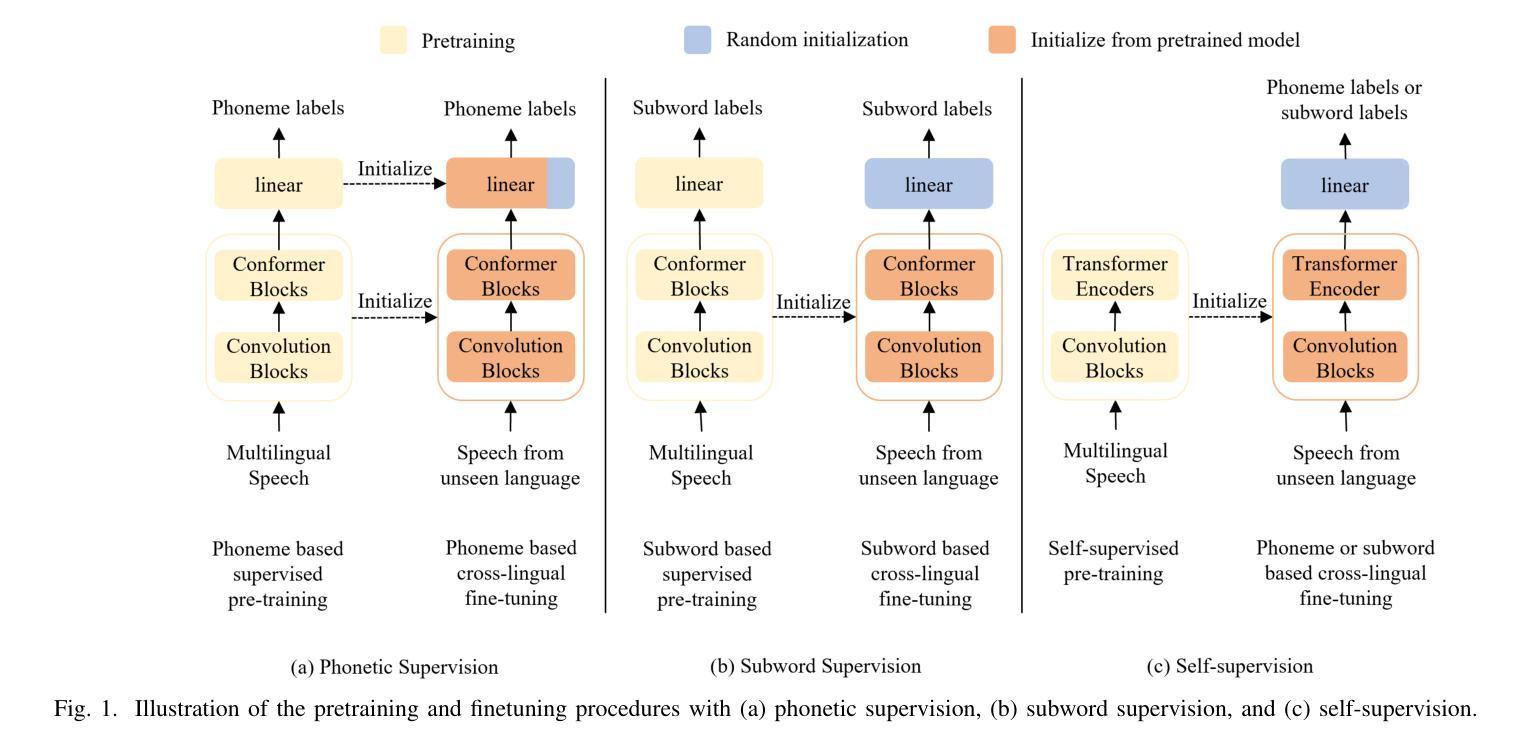
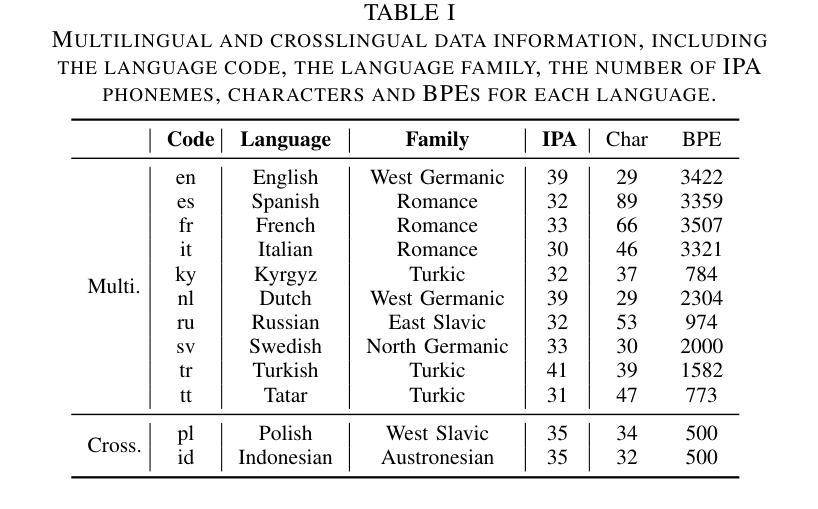
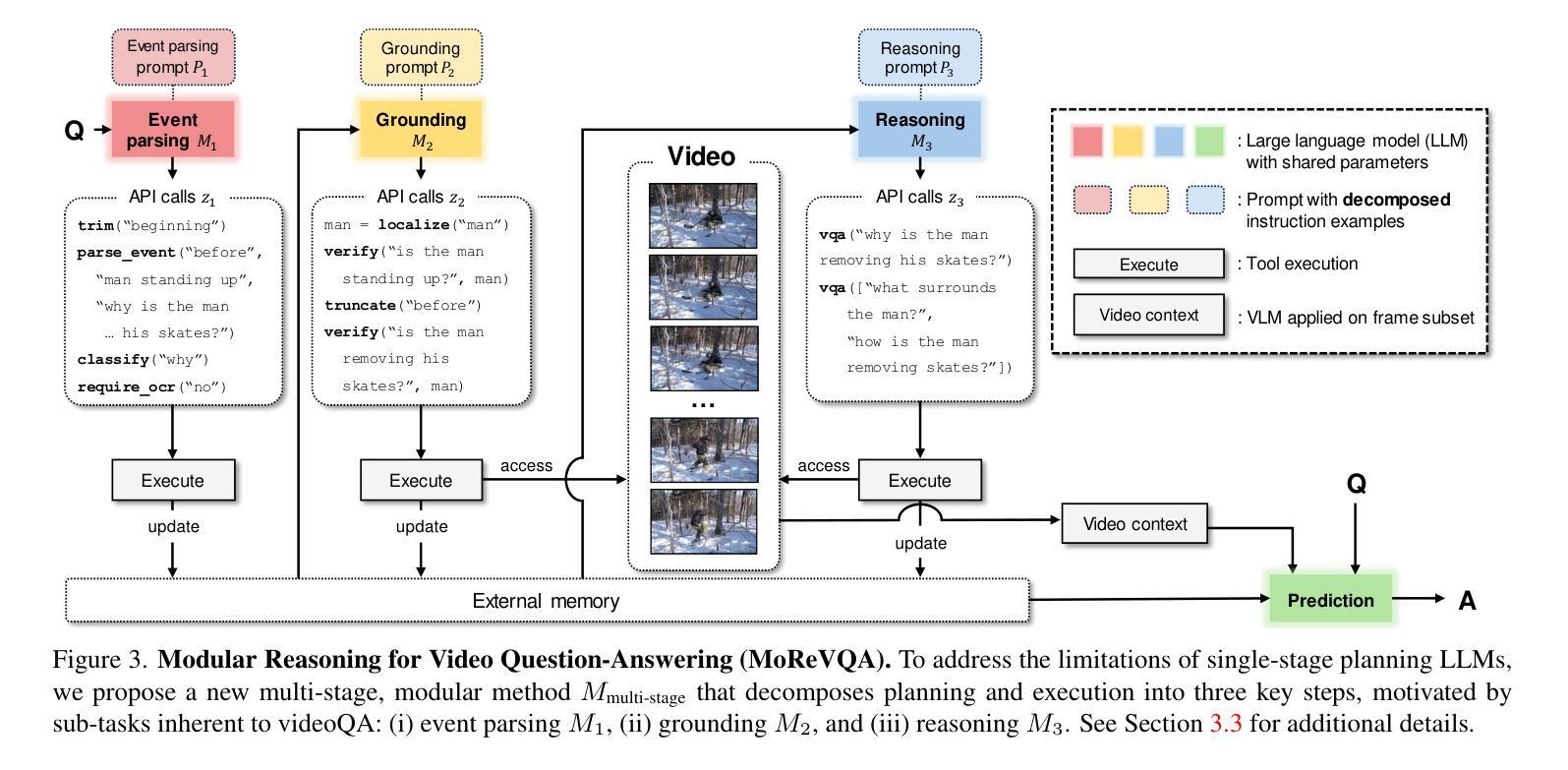
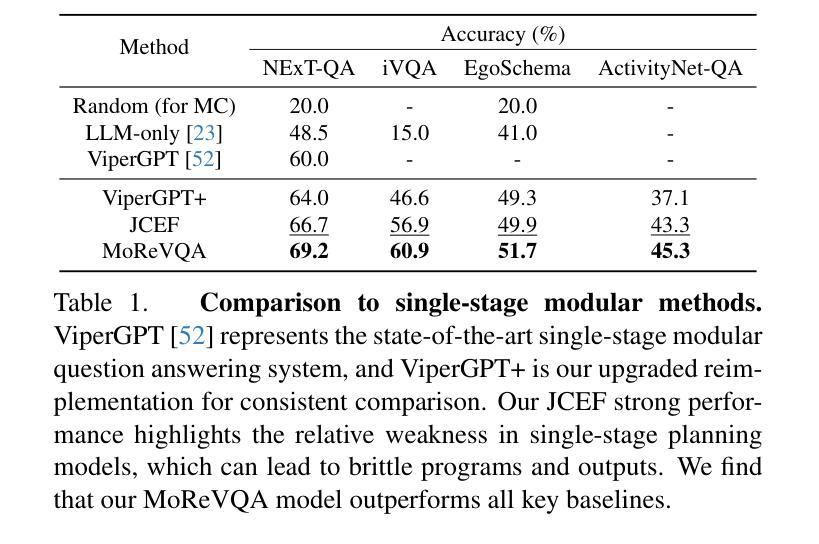
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Authors:Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, Cordelia Schmid
This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
本文通过一个分解的多阶段、模块化推理框架来解决视频问答(VideoQA)的任务。虽然之前的模块化方法在单一规划阶段未基于视觉内容展现出明显优势,但我们通过一个简单有效的基线发现,在挑战性较大的视频问答场景中,这样的系统实际上可能导致行为变得脆弱。因此,不同于传统的单阶段规划方法,我们提出了一种多阶段系统,该系统包括事件解析器、定位阶段和与外部记忆相结合的最终推理阶段。所有阶段均无需训练,利用大型模型的少量提示进行少数镜头提示即可完成,每个阶段都会产生可解释的中间输出。通过分解底层规划和任务复杂性,我们的MoReVQA方法在传统视频问答基准测试(NExT-QA、iVQA、EgoSchema、ActivityNet-QA)上实现了超越先前工作的最新结果,并且可以扩展到相关任务(基于定位的视频问答、段落标注)。
论文及项目相关链接
PDF CVPR 2024; updated NExT-GQA results in Appendix
Summary
该论文提出了一种用于视频问答(VideoQA)的分解式多阶段模块化推理框架。针对传统单阶段规划方法在实践中面对挑战视频问答场景时表现出的脆弱性,论文提出了一种多阶段系统,包括事件解析器、定位阶段和最终推理阶段与外部存储相结合。所有阶段都是无训练的,利用大型模型的少量提示进行执行,每个阶段都能产生可解释的中间输出。通过分解规划和任务复杂性,MoReVQA方法在标准视频问答基准测试(如NExT-QA、iVQA、EgoSchema、ActivityNet-QA)上取得了优于先前工作的最新结果,并扩展到相关任务(如基于定位的视频问答、段落标题生成)。
Key Takeaways
- 该论文提出了一种新的视频问答方法,即分解式多阶段模块化推理框架。
- 针对传统单阶段规划方法在视频问答中的局限性,论文提出了一种多阶段系统。
- 该系统包括事件解析器、定位阶段和最终推理阶段,每个阶段都有其独特的功能。
- 系统结合了外部存储,用于存储和检索与视频内容相关的信息。
- 所有阶段都是无训练的,利用大型模型的少量提示进行执行。
- MoReVQA方法在多个标准视频问答基准测试上取得了最新结果,证明了其有效性。
点此查看论文截图

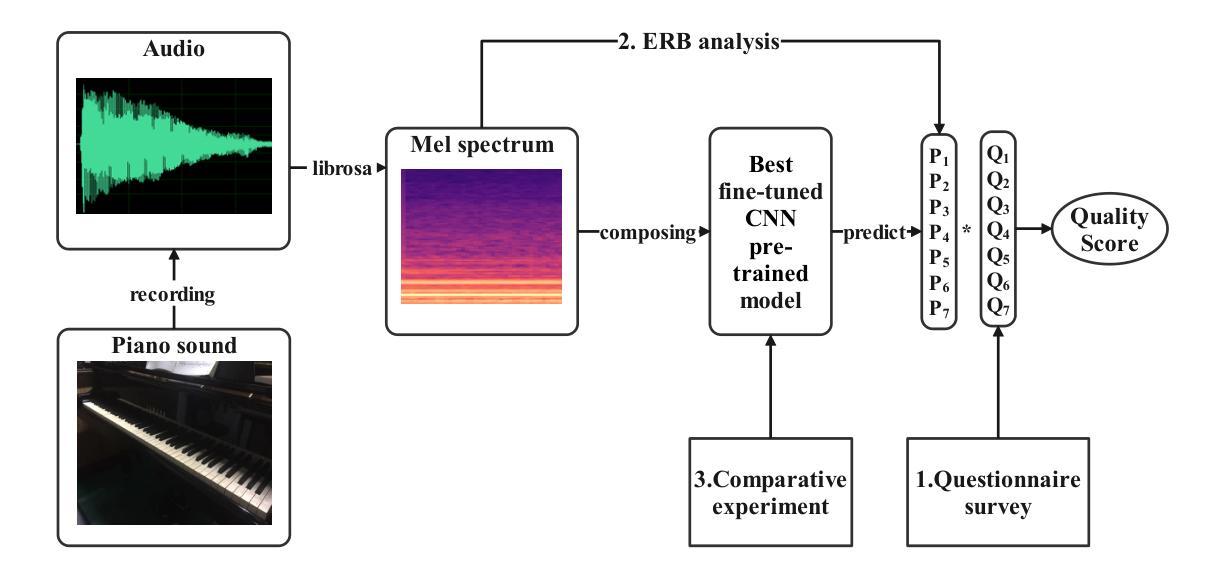
A Holistic Evaluation of Piano Sound Quality
Authors:Monan Zhou, Shangda Wu, Shaohua Ji, Zijin Li, Wei Li
This paper aims to develop a holistic evaluation method for piano sound quality to assist in purchasing decisions. Unlike previous studies that focused on the effect of piano performance techniques on sound quality, this study evaluates the inherent sound quality of different pianos. To derive quality evaluation systems, the study uses subjective questionnaires based on a piano sound quality dataset. The method selects the optimal piano classification models by comparing the fine-tuning results of different pre-training models of Convolutional Neural Networks (CNN). To improve the interpretability of the models, the study applies Equivalent Rectangular Bandwidth (ERB) analysis. The results reveal that musically trained individuals are better able to distinguish between the sound quality differences of different pianos. The best fine-tuned CNN pre-trained backbone achieves a high accuracy of 98.3% as the piano classifier. However, the dataset is limited, and the audio is sliced to increase its quantity, resulting in a lack of diversity and balance, so we use focal loss to reduce the impact of data imbalance. To optimize the method, the dataset will be expanded, or few-shot learning techniques will be employed in future research.
本文旨在开发一种全面的钢琴音质评估方法,以辅助购买决策。不同于以往专注于钢琴演奏技巧对音质影响的研究,本研究旨在评估不同钢琴的固有音质。为了得出质量评估系统,研究基于钢琴音质数据集采用主观问卷调查的方法。该方法通过比较不同预训练模型的微调结果,选择最佳的钢琴分类模型。为了提高模型的解释性,研究采用了等效矩形带宽(ERB)分析。结果表明,受过音乐训练的人更能区分不同钢琴的音质差异。最佳的微调CNN预训练骨干作为钢琴分类器,实现了高达98.3%的准确率。然而,数据集有限,音频被切片以增加其数量,导致缺乏多样性和平衡性,因此我们使用焦点损失来减少数据不平衡的影响。为了优化该方法,未来将扩大数据集或采用小样本学习技术。
论文及项目相关链接
PDF 15 pages, 9 figures
Summary
本文旨在开发一种全面的钢琴音质评估方法,以辅助购买决策。研究不同于以往关注钢琴演奏技巧对音质影响的研究,而是评估不同钢琴的固有音质。研究使用基于钢琴音质数据集的主观问卷来推导质量评估系统,通过比较不同预训练模型的微调结果来选择最佳的钢琴分类模型。为提高模型的可解释性,研究应用了等效矩形带宽(ERB)分析。结果显示,受过音乐训练的人更能区分不同钢琴的音质差异。最佳微调CNN预训练主干作为钢琴分类器,准确率高达98.3%。但数据集有限,音频被切片以增加数量,导致缺乏多样性和平衡性,因此使用焦点损失来减少数据不平衡的影响。未来研究将扩大数据集或采用少量学习技术来优化方法。
Key Takeaways
- 研究旨在开发全面的钢琴音质评估方法,侧重于不同钢琴的固有音质。
- 通过主观问卷和基于数据集的方法推导质量评估系统。
- 使用卷积神经网络(CNN)预训练模型,并通过微调选择最佳钢琴分类模型。
- 应用等效矩形带宽(ERB)分析提高模型的可解释性。
- 调查显示,受过音乐训练的人更能区分不同钢琴的音质差异。
- 最佳钢琴分类模型的准确率高达98.3%。
点此查看论文截图



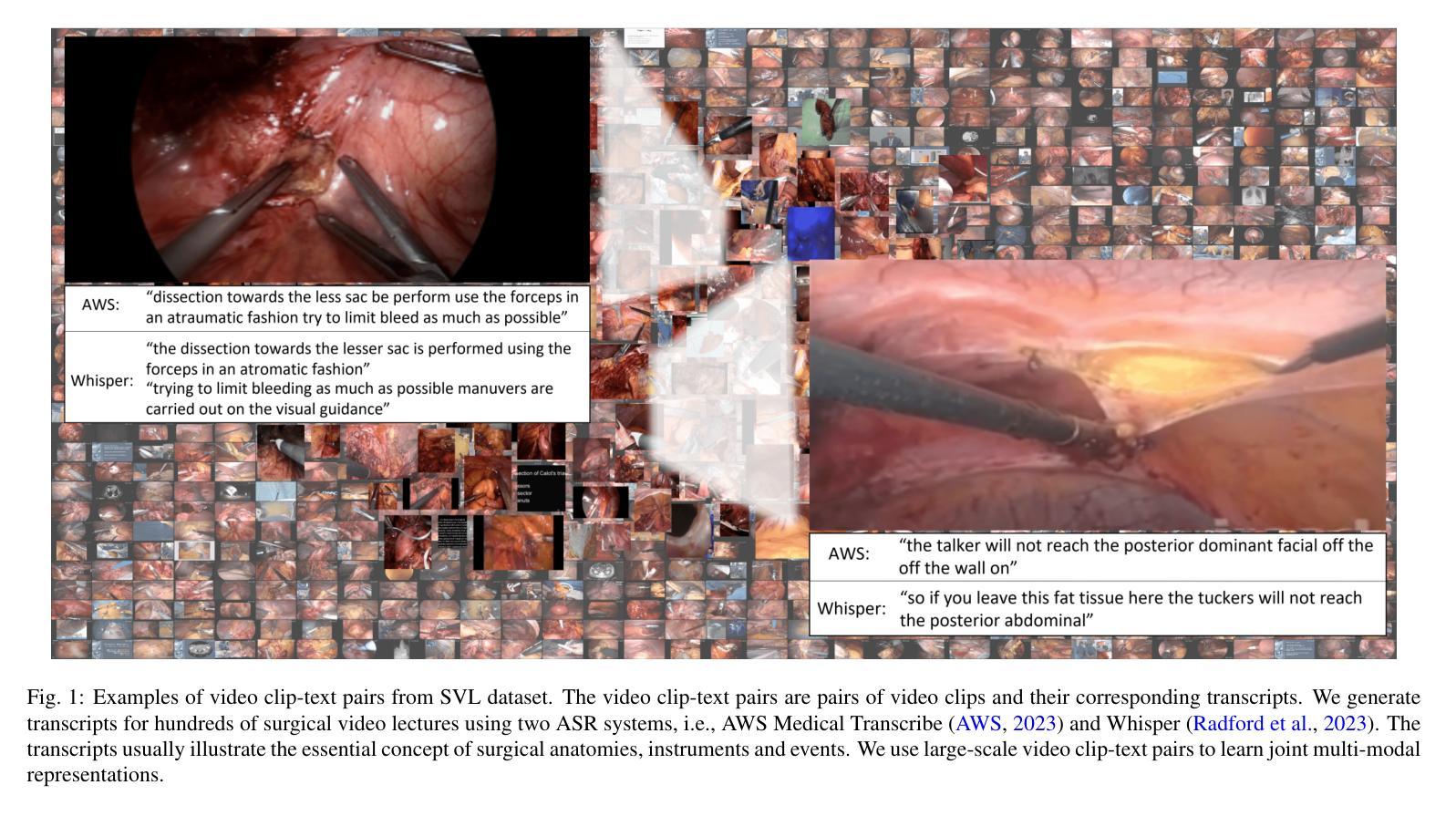
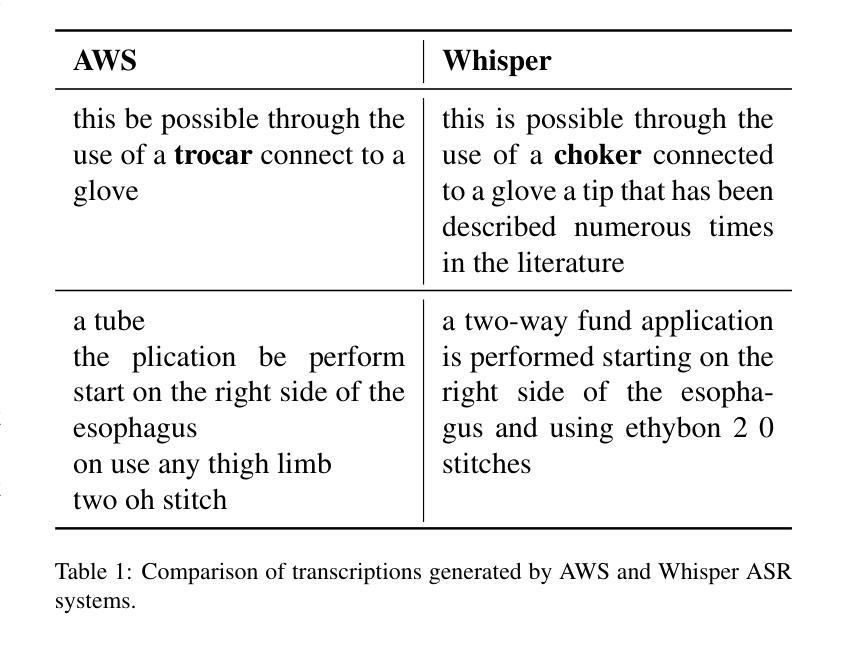
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Authors:Kun Yuan, Vinkle Srivastav, Tong Yu, Joel L. Lavanchy, Jacques Marescaux, Pietro Mascagni, Nassir Navab, Nicolas Padoy
Recent advancements in surgical computer vision applications have been driven by vision-only models, which do not explicitly integrate the rich semantics of language into their design. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective vision and language supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. Extensive experiments across diverse surgical procedures and tasks demonstrate that the multi-modal representations learned by SurgVLP exhibit strong transferability and adaptability in surgical video analysis. Furthermore, our zero-shot evaluations highlight SurgVLP’s potential as a general-purpose foundation model for surgical workflow analysis, reducing the reliance on extensive manual annotations for downstream tasks, and facilitating adaptation methods such as few-shot learning to build a scalable and data-efficient solution for various downstream surgical applications. The training code and weights are public.
近期外科计算机视觉应用的进展主要得益于仅依赖视觉的模型,这些模型在设计时并没有明确融入丰富的语言语义。这些方法依赖于手动标注的手术视频来预测固定的目标类别,从而限制了它们对未见过的手术程序和下游任务的泛化能力。在这项工作中,我们提出通过公开的外科电子学习平台获取的手术视频讲座可以提供有效的视觉和语言监督信号,用于多模态表示学习,而无需依赖手动注释。为了解决手术视频讲座中特有的语言挑战,我们采用了多个互补的自动语音识别系统来生成文本转录。然后我们提出了一种新的方法,即SurgVLP——外科视觉语言预训练,用于多模态表示学习。在多种手术程序和任务上的广泛实验表明,SurgVLP所学习的多模态表示在手术视频分析中具有很强的可迁移性和适应性。此外,我们的零样本评估突显了SurgVLP作为外科工作流程分析的通用基础模型的潜力,减少了下游任务对大量手动注释的依赖,并促进了少样本学习等适应方法,为各种下游外科应用构建可扩展和高效的数据解决方案。训练代码和权重均已公开。
论文及项目相关链接
Summary
本文介绍了最近外科视觉应用方面的进展,这些进展主要得益于仅依赖视觉的模型。然而,这些模型在设计时并未明确融入丰富的语言语义,限制了其在未见过的手术程序和下游任务中的通用性。研究团队提出了利用公开手术电子学习平台上的手术视频讲座进行多模态表示学习的新思路,通过多个互补的自动语音识别系统应对手术视频讲座中的语言挑战。此外,该研究还提出了一种新型方法SurgVLP,用于进行多模态表示学习。实验证明,通过SurgVLP学到的多模态表示具有强大的迁移性和适应性。该模型的零样本评估凸显了其作为手术工作流程分析通用基础模型的潜力,减少了下游任务对大量手动注释的依赖,并促进了如小样本学习等适应方法的开发,为各种下游手术应用构建可扩展和高效的数据解决方案。模型和权重已公开。
Key Takeaways
- 近期外科视觉应用的进展主要依赖仅依赖视觉的模型驱动,但缺乏整合丰富的语言语义。
- 手动注释的手术视频限制了模型的通用性。
- 利用公开手术电子学习平台上的手术视频讲座进行多模态表示学习是一种新思路。
- 通过多个自动语音识别系统应对手术视频讲座中的语言挑战。
- 提出了一种新型方法SurgVLP用于多模态表示学习。
- SurgVLP模型具有较强的迁移性和适应性,已进行广泛实验验证。
点此查看论文截图