⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-29 更新
COMI-LINGUA: Expert Annotated Large-Scale Dataset for Multitask NLP in Hindi-English Code-Mixing
Authors:Rajvee Sheth, Himanshu Beniwal, Mayank Singh
The rapid growth of digital communication has driven the widespread use of code-mixing, particularly Hindi-English, in multilingual communities. Existing datasets often focus on romanized text, have limited scope, or rely on synthetic data, which fails to capture realworld language nuances. Human annotations are crucial for assessing the naturalness and acceptability of code-mixed text. To address these challenges, We introduce COMI-LINGUA, the largest manually annotated dataset for code-mixed text, comprising 100,970 instances evaluated by three expert annotators in both Devanagari and Roman scripts. The dataset supports five fundamental NLP tasks: Language Identification, Matrix Language Identification, Part-of-Speech Tagging, Named Entity Recognition, and Translation. We evaluate LLMs on these tasks using COMILINGUA, revealing limitations in current multilingual modeling strategies and emphasizing the need for improved code-mixed text processing capabilities. COMI-LINGUA is publically availabe at: https://huggingface.co/datasets/LingoIITGN/COMI-LINGUA.
数字通信的快速发展推动了跨语言社区中混合代码,特别是印度混合英语的广泛使用。现有的数据集往往侧重于罗马化文本,范围有限,或者依赖于合成数据,无法捕捉现实世界的语言细微差别。人类注释对于评估混合代码的自然性和可接受性至关重要。为了应对这些挑战,我们推出了COMI-LINGUA,这是混合代码最大的手动注释数据集,包含由Devanagari和罗马脚本中的三名专业注释者评估的100970个实例。该数据集支持五项基本NLP任务:语言识别、矩阵语言识别、词性标注、命名实体识别和翻译。我们使用COMI-LINGUA对这些任务进行评估大型语言模型,揭示了当前多语言建模策略的局限性,并强调了提高混合文本处理能力的必要性。COMI-LINGUA公开可用:https://huggingface.co/datasets/LingoIITGN/COMI-LINGUA。
论文及项目相关链接
Summary:随着数字通信的快速发展,多语言社区中混合代码的使用越来越普遍,尤其是印度语和英语的混合。现有的数据集主要关注罗马化文本,存在范围有限或依赖合成数据的问题,无法捕捉真实世界的语言细微差别。为了评估混合文本的自然性和可接受性,我们引入了COMI-LINGUA数据集,这是最大的手动注释的混合文本数据集,包含由三位专家注释者在Devanagari和Roman脚本中评估的10万多个实例。该数据集支持五项基本NLP任务,包括语言识别、矩阵语言识别、词性标注、命名实体识别和翻译。我们在这些任务上评估了大型语言模型,揭示了当前多语言建模策略的局限性,并强调了改进混合文本处理能力的必要性。COMI-LINGUA数据集可在huggingface.co/datasets/LingoIITGN/COMI-LINGUA获取。
Key Takeaways:
- 数字通信的快速发展推动了多语言社区中混合代码(尤其是印度语和英语)的广泛使用。
- 现有数据集存在局限性,主要关注罗马化文本或依赖合成数据,无法捕捉真实语言的细微差别。
- 人类注释对于评估混合文本的自然性和可接受性至关重要。
- 引入了COMI-LINGUA数据集,这是最大的手动注释的混合文本数据集。
- 该数据集包含五项基本NLP任务:语言识别、矩阵语言识别、词性标注、命名实体识别和翻译。
- 在这些任务上评估大型语言模型时,揭示了当前多语言建模策略的局限性。
点此查看论文截图

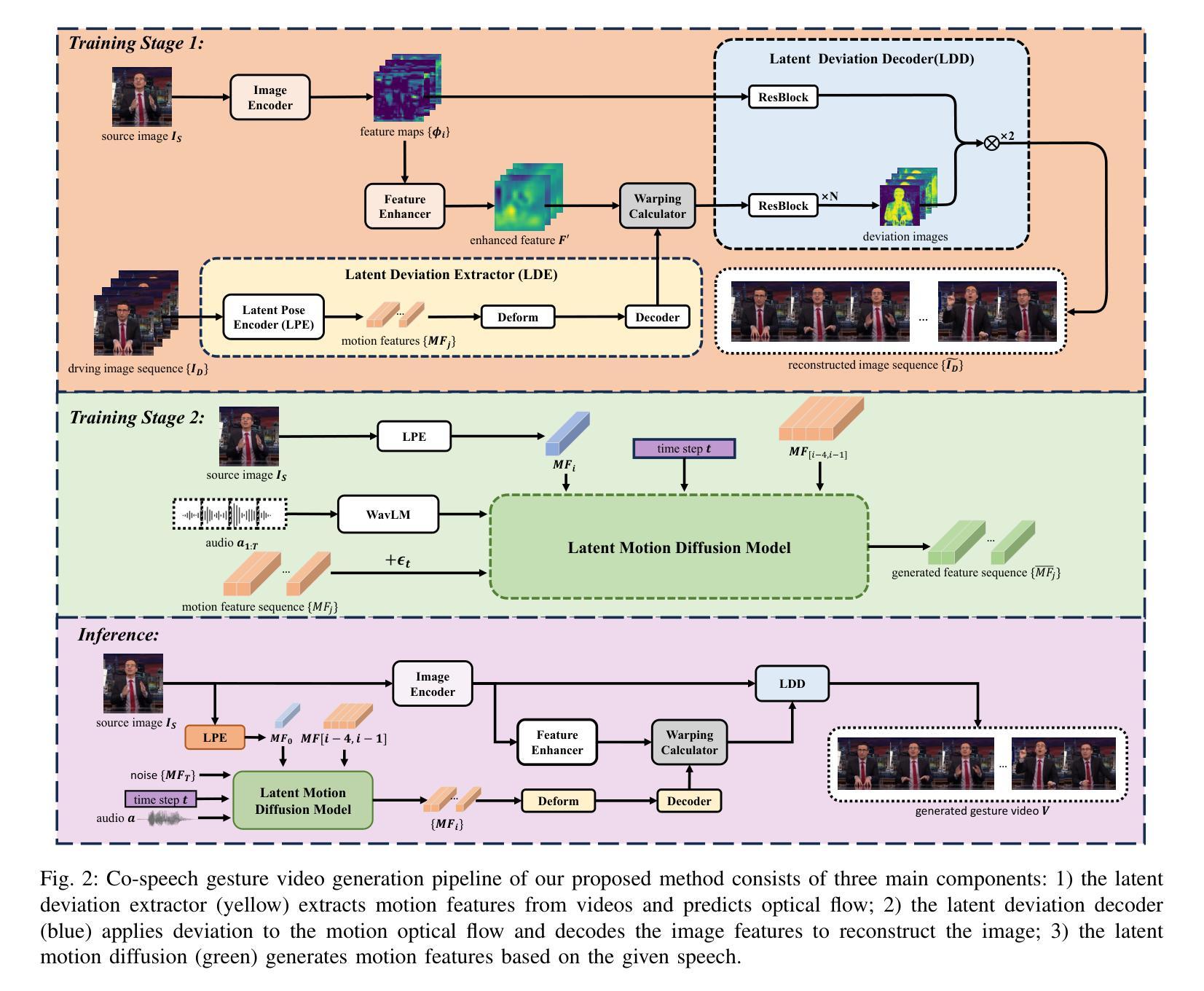
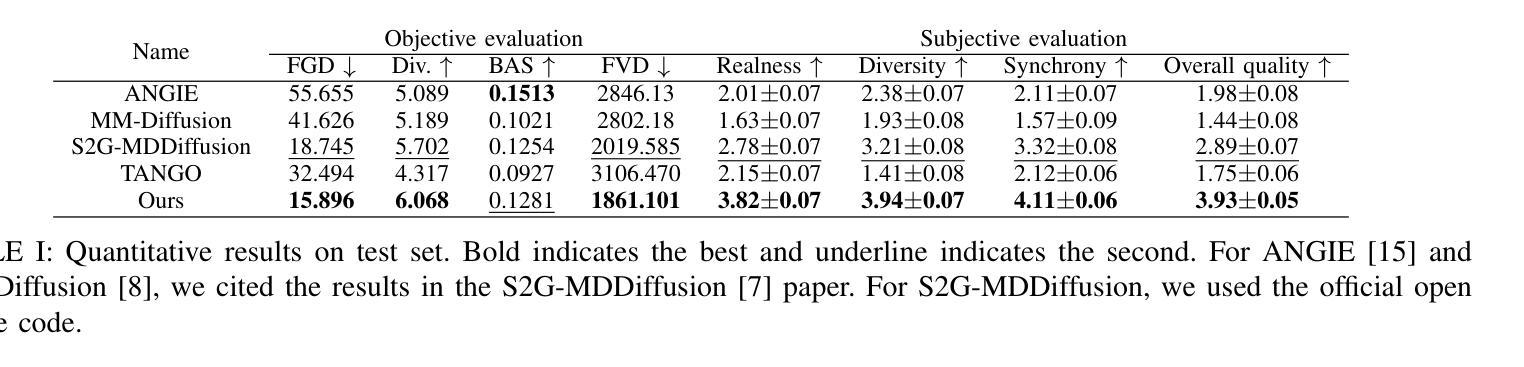
Audio-driven Gesture Generation via Deviation Feature in the Latent Space
Authors:Jiahui Chen, Yang Huan, Runhua Shi, Chanfan Ding, Xiaoqi Mo, Siyu Xiong, Yinong He
Gestures are essential for enhancing co-speech communication, offering visual emphasis and complementing verbal interactions. While prior work has concentrated on point-level motion or fully supervised data-driven methods, we focus on co-speech gestures, advocating for weakly supervised learning and pixel-level motion deviations. We introduce a weakly supervised framework that learns latent representation deviations, tailored for co-speech gesture video generation. Our approach employs a diffusion model to integrate latent motion features, enabling more precise and nuanced gesture representation. By leveraging weakly supervised deviations in latent space, we effectively generate hand gestures and mouth movements, crucial for realistic video production. Experiments show our method significantly improves video quality, surpassing current state-of-the-art techniques.
手势对于增强共语沟通、提供视觉重点和补充言语交流至关重要。虽然早期的研究集中在点状运动或完全基于数据的监督方法上,但我们专注于共语手势,提倡弱监督学习和像素级运动偏差。我们引入了一个弱监督框架来学习潜在表示的偏差,专门用于共语手势视频的生成。我们的方法采用扩散模型来整合潜在的运动特征,使手势表达更加精确和细致。通过利用潜在空间中的弱监督偏差,我们可以有效地生成对真实视频制作至关重要的手势和口型运动。实验表明,我们的方法显著提高了视频质量,超越了当前最先进的技术。
论文及项目相关链接
PDF 6 pages, 5 figures
Summary
本文强调共语手势的重要性,提出一种针对共语手势视频的弱监督学习框架。该框架利用扩散模型整合潜在运动特征,学习潜在表示偏差,以生成更精确和细微的手势表示。实验表明,该方法能有效生成手势和口型动作,显著提高了视频质量。
Key Takeaways
- 共语手势在增强沟通、视觉强调和补充言语交互方面至关重要。
- 现有工作主要集中在点状运动或全监督数据驱动的方法上,而本文专注于共语手势。
- 提倡弱监督学习方法和像素级运动偏差。
- 引入一种弱监督框架,用于学习针对共语手势视频的潜在表示偏差。
- 使用扩散模型整合潜在运动特征,实现更精确和细微的手势表示。
- 利用弱监督下的潜在空间偏差有效生成手势和口型动作。
点此查看论文截图





Magnitude-Phase Dual-Path Speech Enhancement Network based on Self-Supervised Embedding and Perceptual Contrast Stretch Boosting
Authors:Alimjan Mattursun, Liejun Wang, Yinfeng Yu, Chunyang Ma
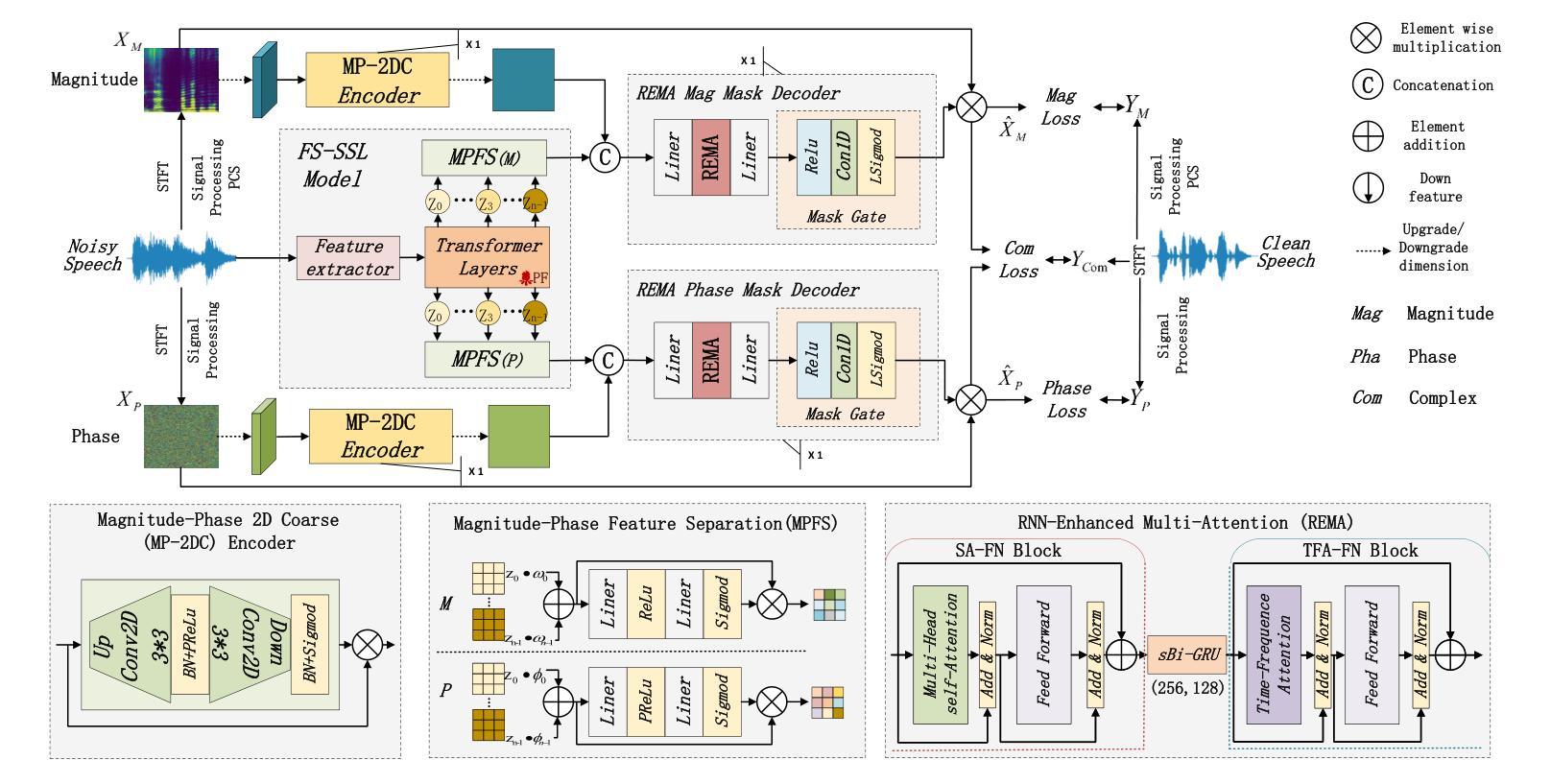
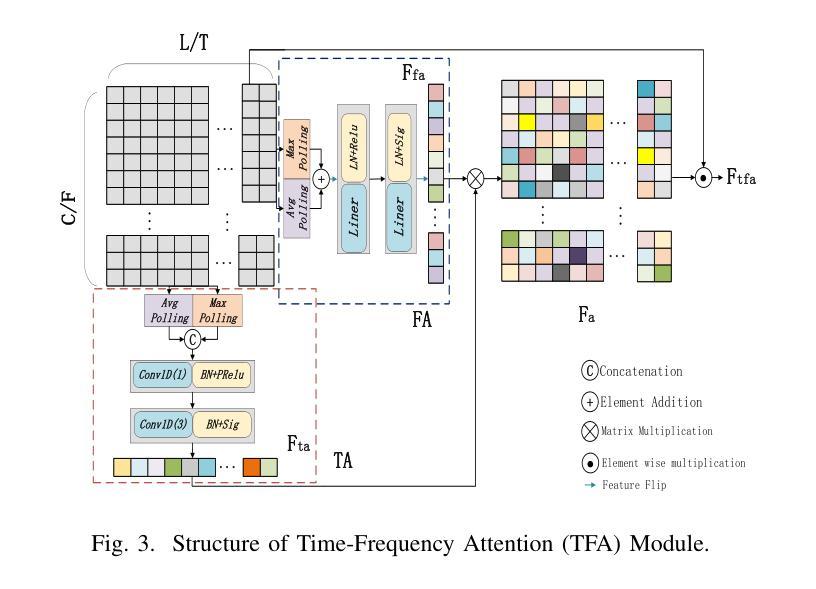
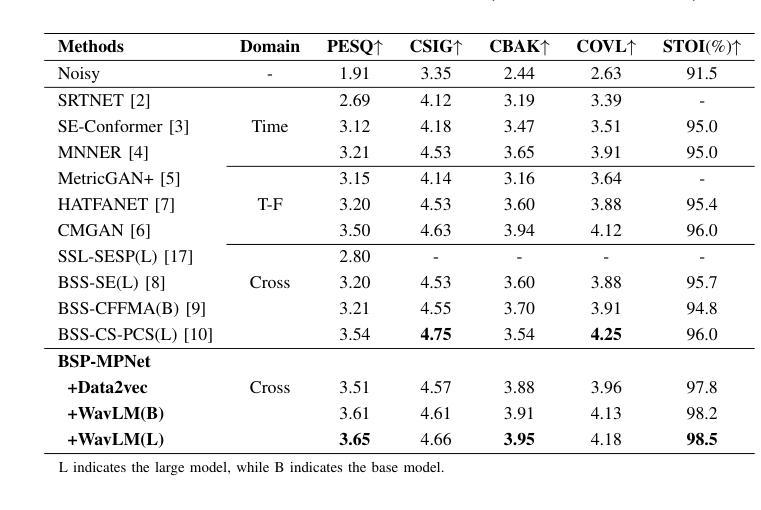
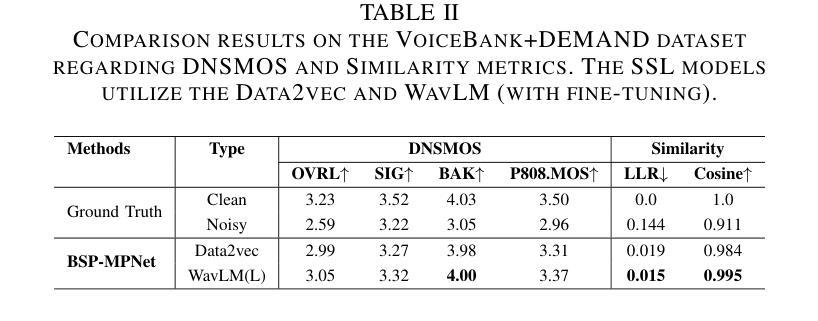
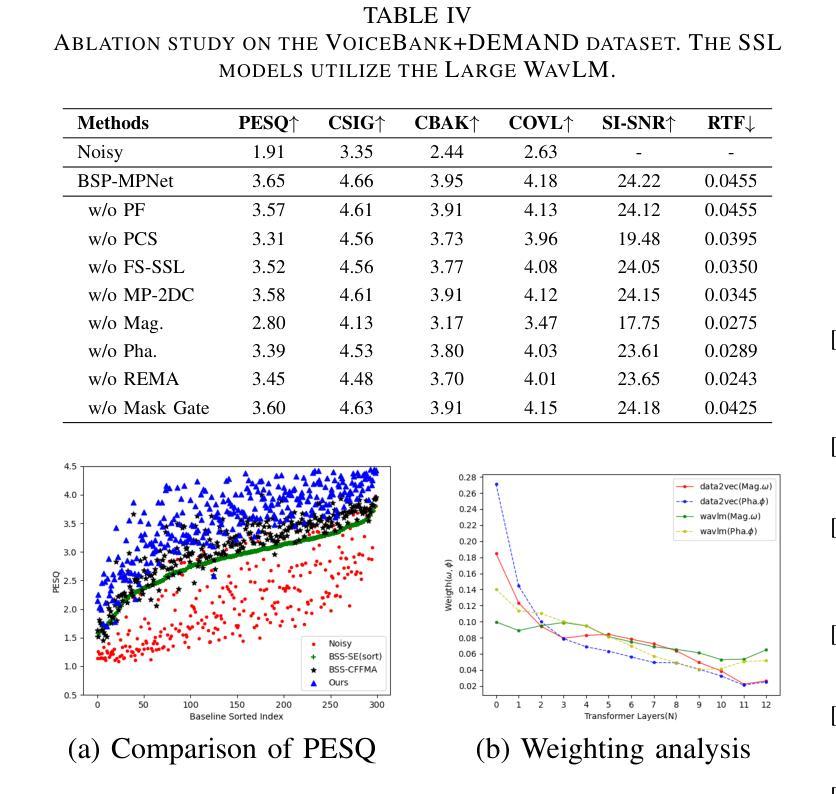
Speech self-supervised learning (SSL) has made great progress in various speech processing tasks, but there is still room for improvement in speech enhancement (SE). This paper presents BSP-MPNet, a dual-path framework that combines self-supervised features with magnitude-phase information for SE. The approach starts by applying the perceptual contrast stretching (PCS) algorithm to enhance the magnitude-phase spectrum. A magnitude-phase 2D coarse (MP-2DC) encoder then extracts coarse features from the enhanced spectrum. Next, a feature-separating self-supervised learning (FS-SSL) model generates self-supervised embeddings for the magnitude and phase components separately. These embeddings are fused to create cross-domain feature representations. Finally, two parallel RNN-enhanced multi-attention (REMA) mask decoders refine the features, apply them to the mask, and reconstruct the speech signal. We evaluate BSP-MPNet on the VoiceBank+DEMAND and WHAMR! datasets. Experimental results show that BSP-MPNet outperforms existing methods under various noise conditions, providing new directions for self-supervised speech enhancement research. The implementation of the BSP-MPNet code is available online\footnote[2]{https://github.com/AlimMat/BSP-MPNet. \label{s1}}
语音自监督学习(SSL)在各项语音处理任务中取得了巨大的进步,但在语音增强(SE)方面仍有改进空间。本文提出了BSP-MPNet,这是一个双路径框架,结合了自监督特征和幅度相位信息用于SE。该方法首先应用感知对比度拉伸(PCS)算法增强幅度相位谱。然后,幅度相位2D粗略(MP-2DC)编码器从增强后的谱中提取粗略特征。接下来,特征分离自监督学习(FS-SSL)模型分别为幅度和相位分量生成自监督嵌入。这些嵌入融合在一起以创建跨域特征表示。最后,两个并行RNN增强多注意力(REMA)掩码解码器对特征进行精炼,应用于掩码,并重建语音信号。我们在VoiceBank+DEMAND和WHAMR!数据集上评估了BSP-MPNet。实验结果表明,在各种噪声条件下,BSP-MPNet优于现有方法,为自监督语音增强研究提供了新的方向。BSP-MPNet的代码实现可在网上找到[^2](https://github.com/AlimMat/BSP-MPNet。\label{s1})。
论文及项目相关链接
PDF Main paper (6 pages). Accepted for publication by ICME 2025
Summary:
本研究提出了一种基于自监督学习的语音增强方法BSP-MPNet,该方法结合双路径框架与幅度相位信息。实验结果表明,该方法在各种噪声条件下表现优于现有方法,为自监督语音增强研究提供了新的方向。其代码实现已在线公开。
Key Takeaways:
- 本研究提出了BSP-MPNet模型,一个结合自监督学习与幅度相位信息的双路径框架用于语音增强。
- 利用感知对比拉伸(PCS)算法增强幅度相位谱。
- 采用幅度相位2D粗编码(MP-2DC)从增强谱中提取特征。
- 特征分离自监督学习(FS-SSL)模型为幅度和相位成分分别生成自监督嵌入。
- 通过融合嵌入创建跨域特征表示。
- 两个并行RNN增强多注意力(REMA)掩码解码器对特征进行精炼,应用于掩码并重建语音信号。
点此查看论文截图

VALLR: Visual ASR Language Model for Lip Reading
Authors:Marshall Thomas, Edward Fish, Richard Bowden
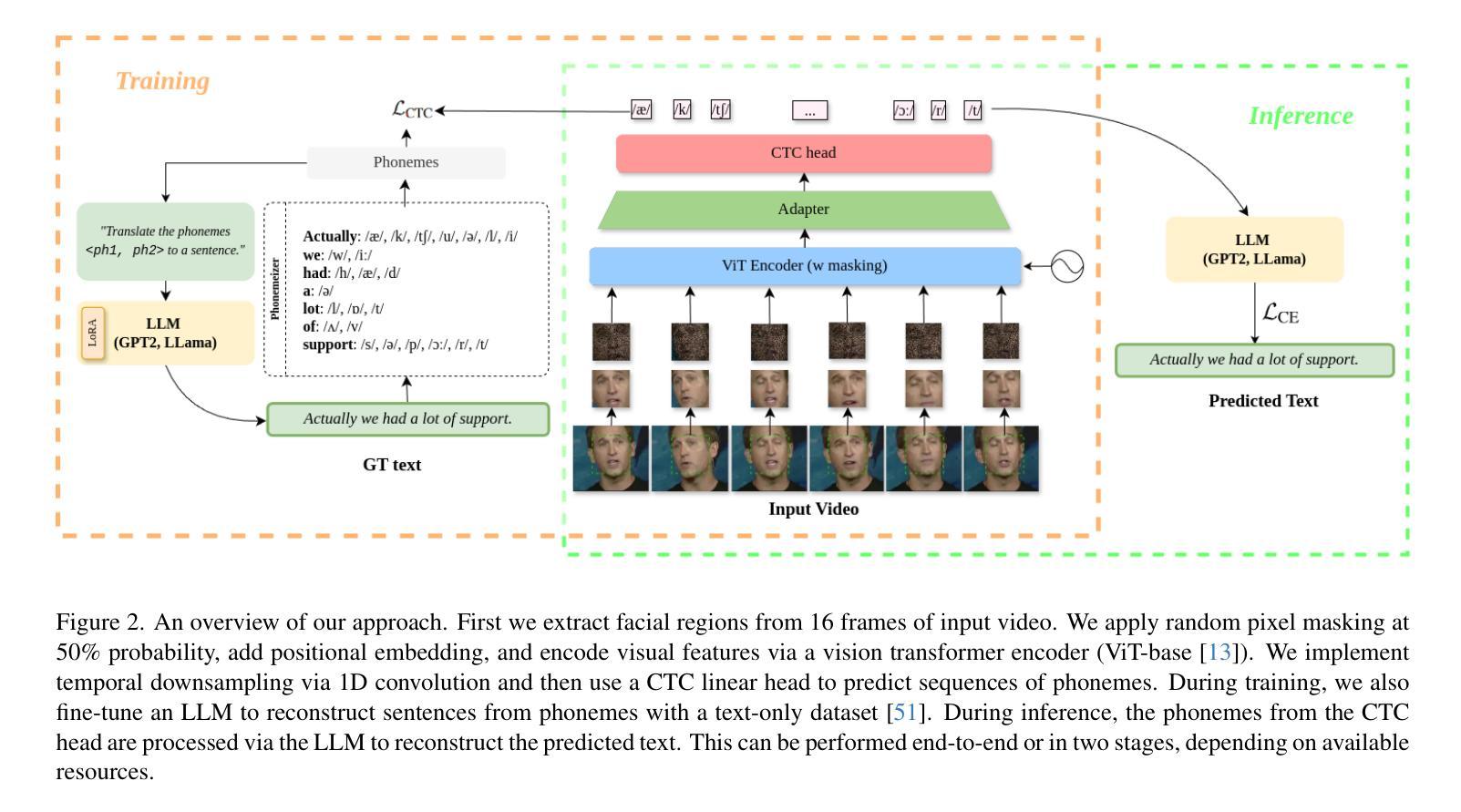
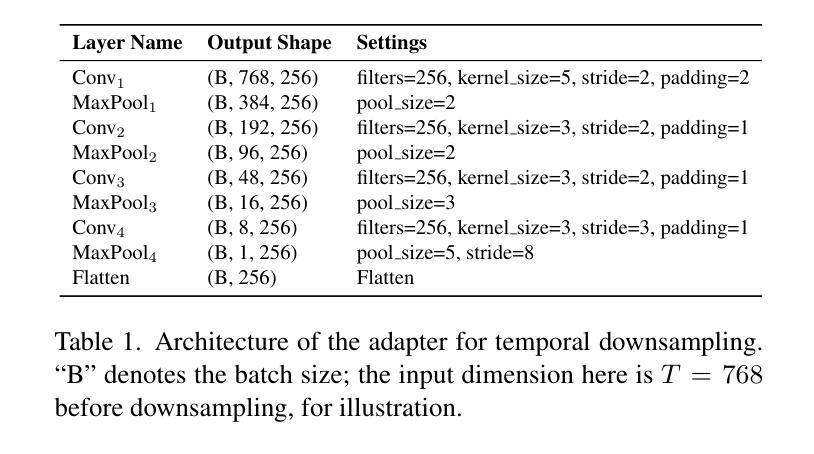
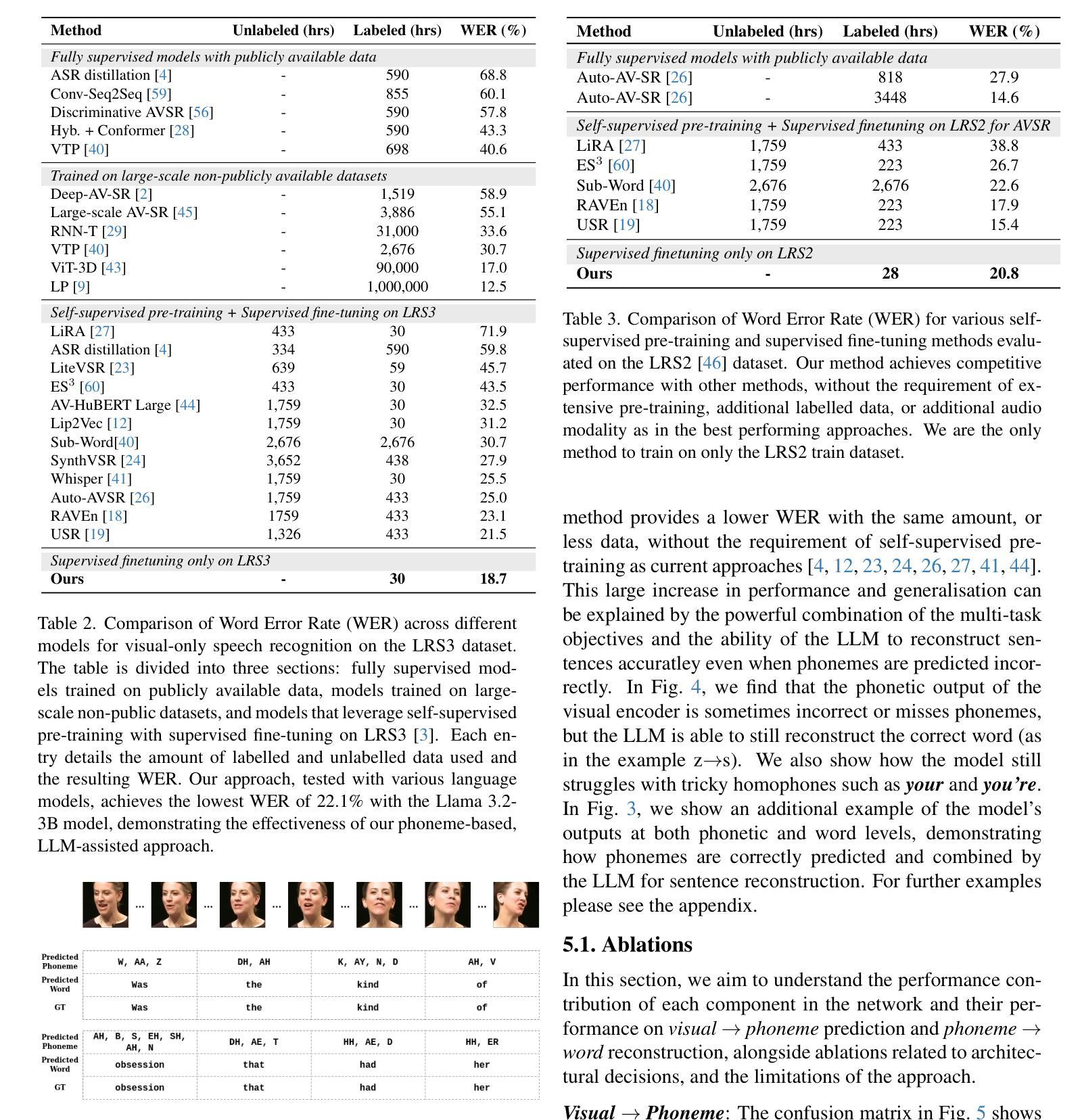
Lip Reading, or Visual Automatic Speech Recognition (V-ASR), is a complex task requiring the interpretation of spoken language exclusively from visual cues, primarily lip movements and facial expressions. This task is especially challenging due to the absence of auditory information and the inherent ambiguity when visually distinguishing phonemes that have overlapping visemes where different phonemes appear identical on the lips. Current methods typically attempt to predict words or characters directly from these visual cues, but this approach frequently encounters high error rates due to coarticulation effects and viseme ambiguity. We propose a novel two-stage, phoneme-centric framework for Visual Automatic Speech Recognition (V-ASR) that addresses these longstanding challenges. First, our model predicts a compact sequence of phonemes from visual inputs using a Video Transformer with a CTC head, thereby reducing the task complexity and achieving robust speaker invariance. This phoneme output then serves as the input to a fine-tuned Large Language Model (LLM), which reconstructs coherent words and sentences by leveraging broader linguistic context. Unlike existing methods that either predict words directly-often faltering on visually similar phonemes-or rely on large-scale multimodal pre-training, our approach explicitly encodes intermediate linguistic structure while remaining highly data efficient. We demonstrate state-of-the-art performance on two challenging datasets, LRS2 and LRS3, where our method achieves significant reductions in Word Error Rate (WER) achieving a SOTA WER of 18.7 on LRS3 despite using 99.4% less labelled data than the next best approach.
唇读或视觉自动语音识别(V-ASR)是一项复杂的任务,它要求仅通过视觉线索(主要是嘴唇动作和面部表情)来解释口语。由于缺少听觉信息以及视觉上区分具有重叠可见语音的不同语音的固有模糊性,这项任务尤其具有挑战性。当前的方法通常尝试直接从这些视觉线索中预测单词或字符,但由于协同发音效应和可见语音的模糊性,这种方法经常遇到较高的错误率。我们提出了一种针对视觉自动语音识别(V-ASR)的两阶段、以语音为核心的新型框架,以解决这些长期存在的挑战。首先,我们的模型使用带有CTC头部的视频转换器从视觉输入中预测紧凑的语音序列,从而降低任务复杂性并实现稳健的说话者不变性。然后,这个语音输出作为微调的大型语言模型(LLM)的输入,该模型通过利用更广泛的语境重建连贯的单词和句子。与现有的直接预测单词的方法或在视觉上相似的语音上经常出错的方法不同,或者依赖于大规模多模式预训练的方法不同,我们的方法明确编码中间的语言结构,同时保持高度数据效率。我们在两个具有挑战性的数据集LRS2和LRS3上展示了最先进的表现,我们的方法在LRS3上实现了显著的单词错误率(WER)降低,尽管我们使用的标记数据比下一个最佳方法少了99.4%,但仍达到了SOTA的WER为18.7。
论文及项目相关链接
Summary
本文介绍了视觉自动语音识别(V-ASR)的新挑战及新方法。针对仅通过视觉线索解读口语的问题,提出了一种新颖的两阶段、以音素为中心的框架。该框架使用视频变压器(Video Transformer)结合CTC头部预测紧凑的音素序列,实现稳健的说话者不变性,并将预测的音素作为精细调整的大型语言模型(LLM)的输入,重建连贯的单词和句子。该方法在LRS2和LRS3两个挑战数据集上实现了卓越的性能,显著降低了词错误率(WER),尤其是在使用较少标注数据的情况下。
Key Takeaways
- Lip Reading或Visual Automatic Speech Recognition (V-ASR) 是通过视觉线索解读口语的复杂任务。
- 当前方法直接通过视觉线索预测单词或字符,但存在高误差率。
- 提出的两阶段、以音素为中心的框架使用Video Transformer和CTC头部预测音素序列,实现稳健的说话者不变性。
- 该框架使用LLM重建连贯的单词和句子,利用更广泛的语境。
- 方法在LRS2和LRS3数据集上实现卓越性能,显著减少词错误率(WER)。
- 即使在使用较少标注数据的情况下,该方法也达到了最先进的性能。
点此查看论文截图

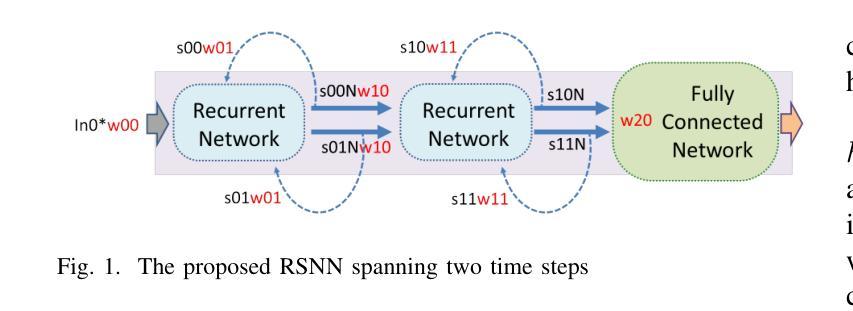
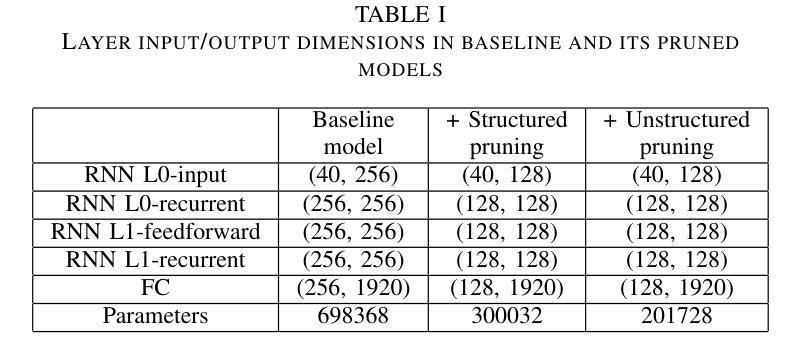
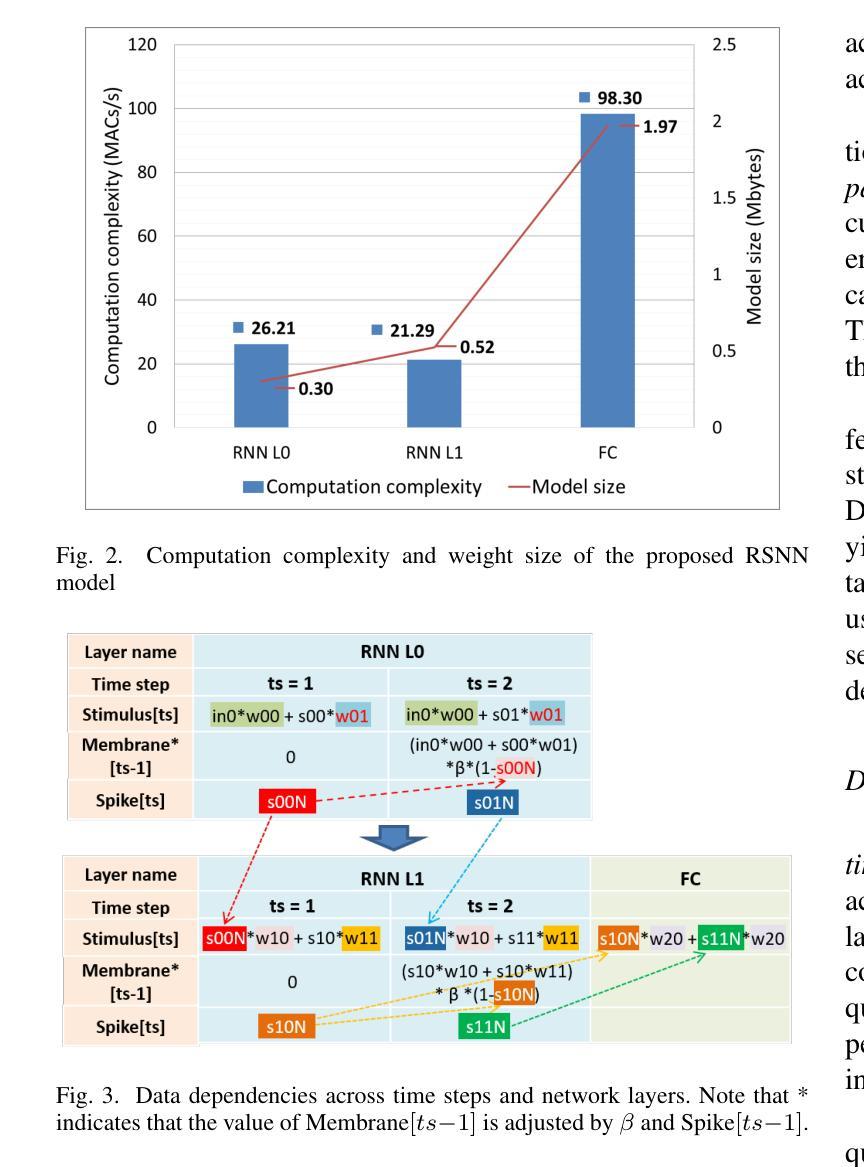
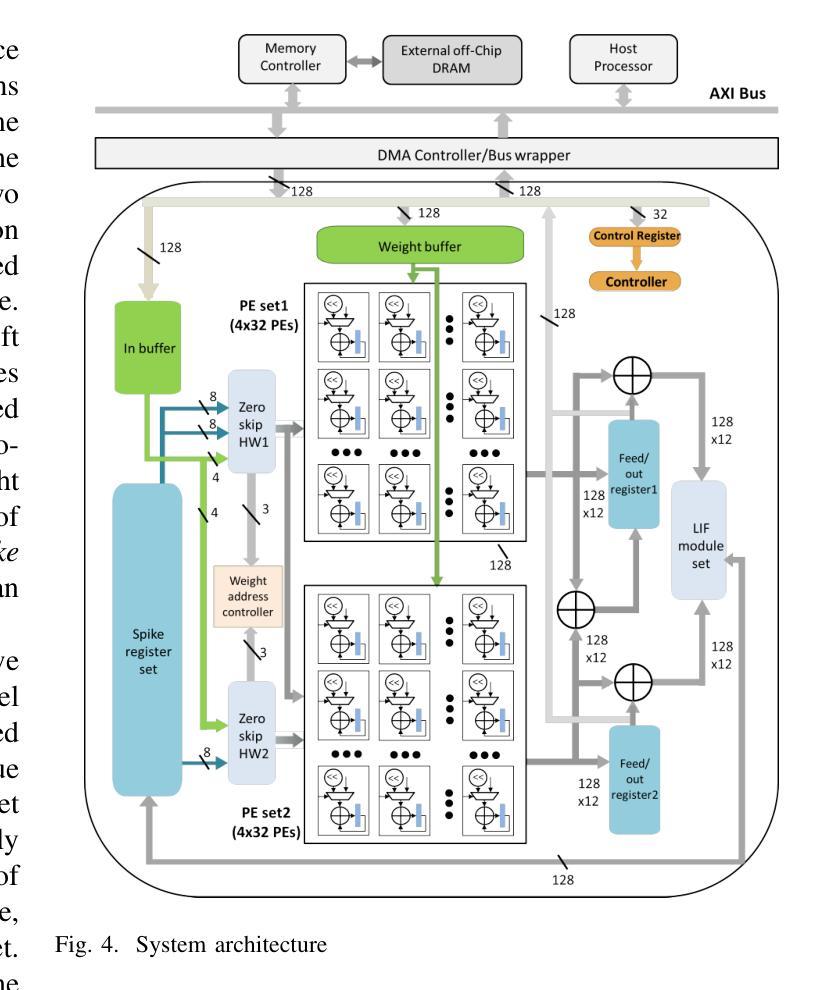
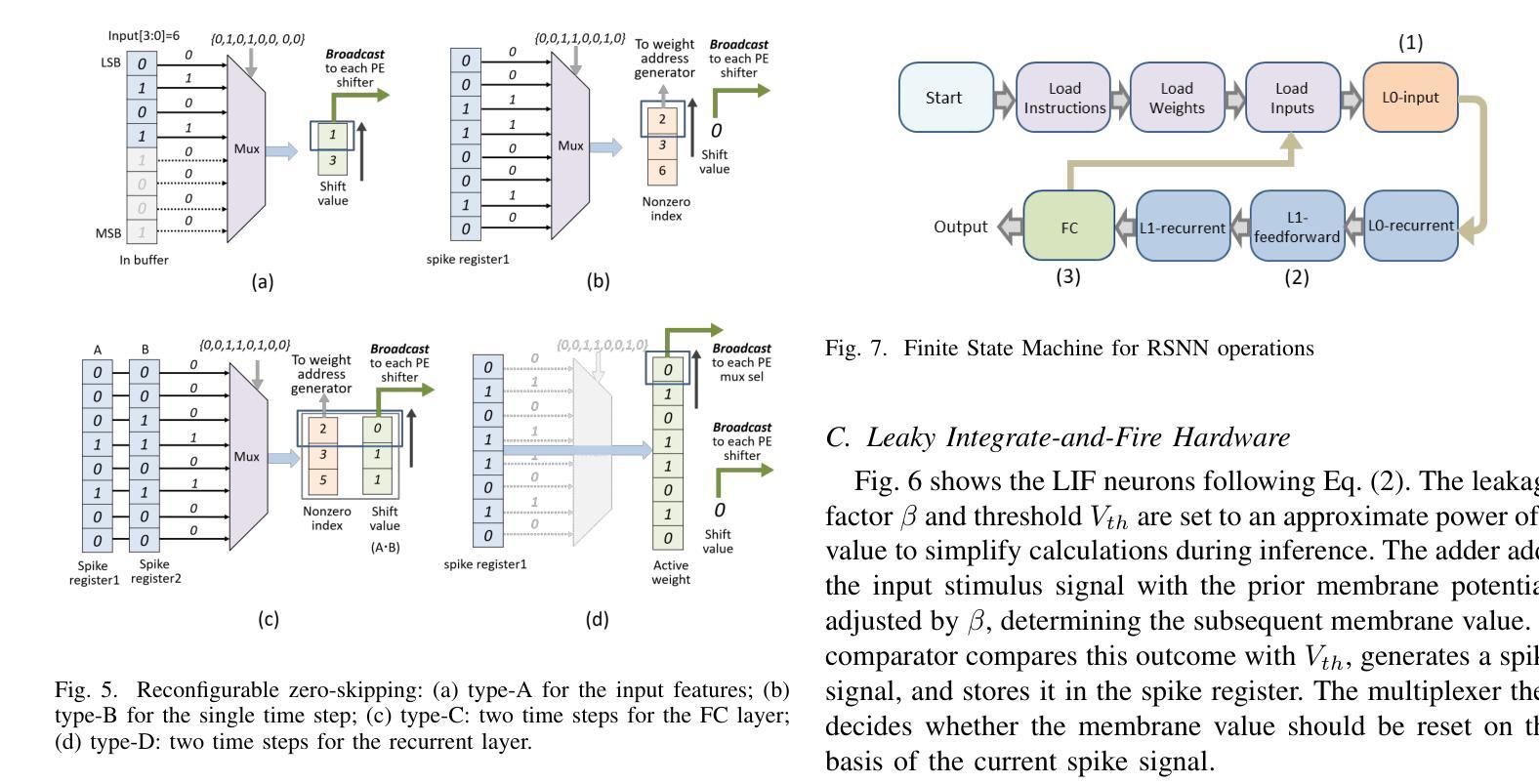
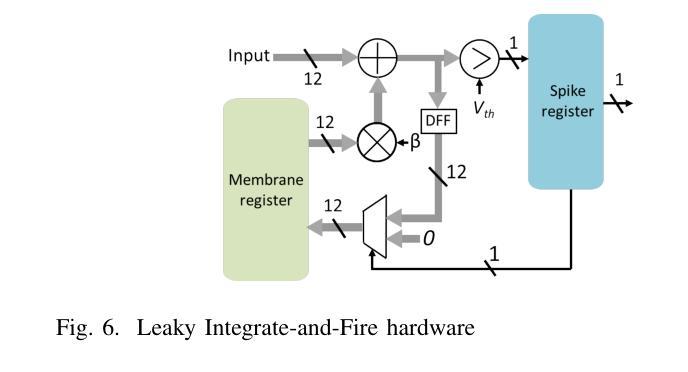
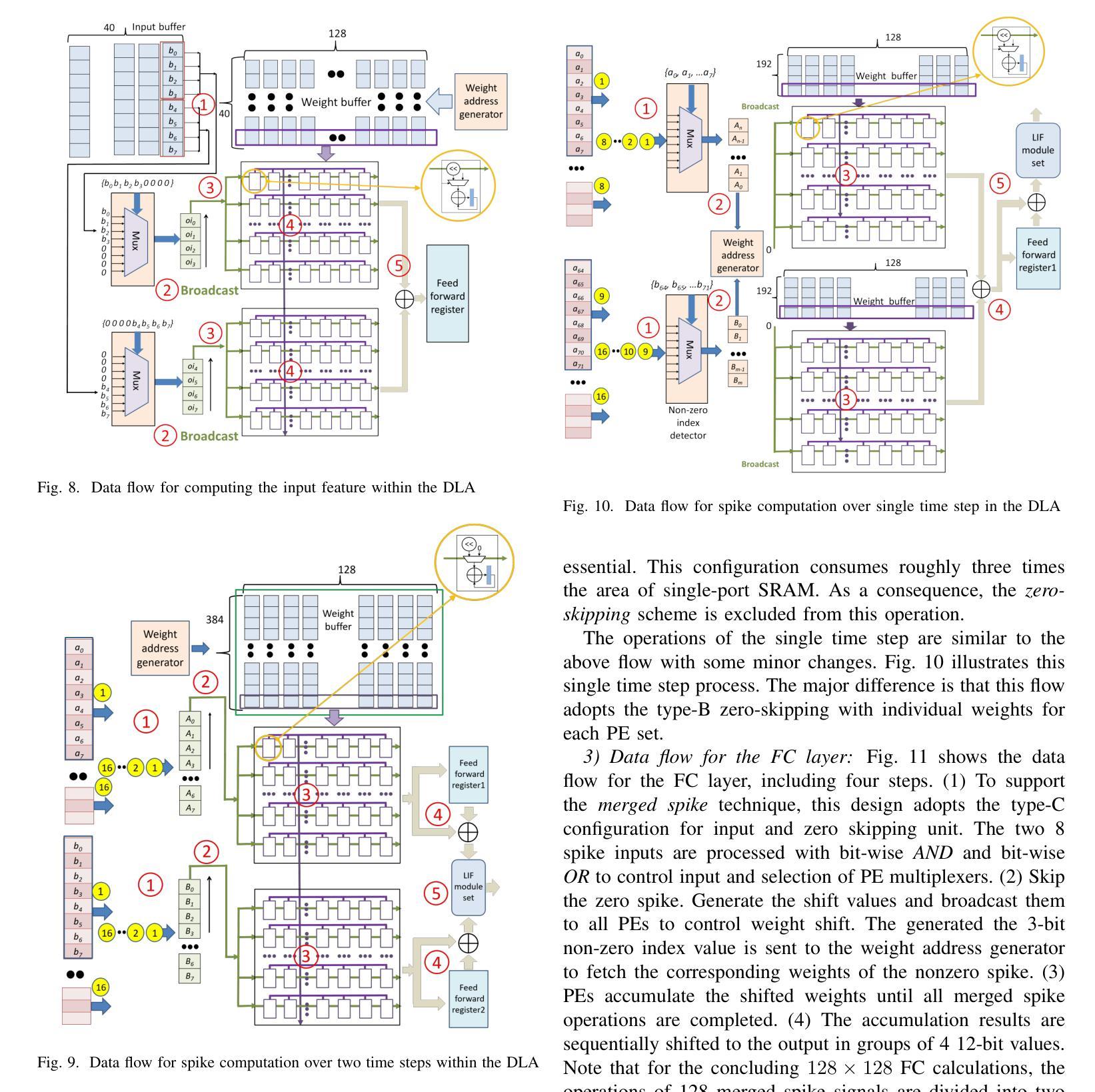
A 71.2-$μ$W Speech Recognition Accelerator with Recurrent Spiking Neural Network
Authors:Chih-Chyau Yang, Tian-Sheuan Chang
This paper introduces a 71.2-$\mu$W speech recognition accelerator designed for edge devices’ real-time applications, emphasizing an ultra low power design. Achieved through algorithm and hardware co-optimizations, we propose a compact recurrent spiking neural network with two recurrent layers, one fully connected layer, and a low time step (1 or 2). The 2.79-MB model undergoes pruning and 4-bit fixed-point quantization, shrinking it by 96.42% to 0.1 MB. On the hardware front, we take advantage of \textit{mixed-level pruning}, \textit{zero-skipping} and \textit{merged spike} techniques, reducing complexity by 90.49% to 13.86 MMAC/S. The \textit{parallel time-step execution} addresses inter-time-step data dependencies and enables weight buffer power savings through weight sharing. Capitalizing on the sparse spike activity, an input broadcasting scheme eliminates zero computations, further saving power. Implemented on the TSMC 28-nm process, the design operates in real time at 100 kHz, consuming 71.2 $\mu$W, surpassing state-of-the-art designs. At 500 MHz, it has 28.41 TOPS/W and 1903.11 GOPS/mm$^2$ in energy and area efficiency, respectively.
本文介绍了一款针对边缘设备实时应用设计的71.2微瓦语音识别加速器,重点强调了超低功耗设计。通过算法和硬件的协同优化,我们提出了一种紧凑的循环脉冲神经网络,包含两层循环层、一层全连接层以及较低的时间步长(1或2)。该模型大小为2.79MB,经过剪枝和4位定点量化处理,缩小了96.42%,达到仅0.1MB的大小。在硬件方面,我们利用多级剪枝、零跳过和合并脉冲等技术,将复杂度降低了90.49%,达到每秒处理13.86百万乘加操作(MMAC/S)。并行时间步执行解决了时间步之间的数据依赖问题,并通过权重共享实现了权重缓冲器的节能。利用稀疏脉冲活动,输入广播方案消除了零计算,进一步节省了功耗。该设计采用台积电(TSMC)的28纳米工艺实现,能以实时速度100kHz运行,功耗仅为71.2微瓦,超越了当前最先进的设计。在500兆赫兹的频率下,其在能效和面积效率方面分别达到了每瓦特处理次数(TOPS/W)为28.41和每平方毫米处理次数(GOPS/mm²)为每秒百万指令操作(OPS)。利用超稀疏脉冲信号干扰探测这一操作以降低噪声,实际应用展示该设计可大幅提高能源效率和计算性能。
论文及项目相关链接
摘要
本文介绍了一款针对边缘设备实时应用设计的71.2μW语音识别加速器,重点实现超低功耗设计。通过算法和硬件协同优化,提出了一种紧凑的循环脉冲神经网络,包含两层循环层、一层全连接层,并采用较低的时间步长(1或2)。模型经过剪枝和4位定点量化,缩小了96.42%至0.1MB。在硬件方面,利用混合级别剪枝、零跳过和合并脉冲等技术,复杂度降低了90.49%至13.86MMAC/S。通过并行时间步执行解决跨时间步数据依赖问题,并通过权重共享实现权重缓冲区功耗节省。利用稀疏脉冲活动,输入广播方案消除了零计算,进一步节省了功耗。在TSMC 28纳米工艺上实现的设计,实时运行频率为100 kHz,功耗为71.2μW,超越了现有设计。在能量和面积效率方面,该设计在500 MHz时达到了28.41 TOPS/W和1903.11 GOPS/mm²。
关键见解
- 提出了针对边缘设备实时应用的超低功耗语音识别加速器设计。
- 通过算法和硬件协同优化,实现了紧凑的循环脉冲神经网络模型。
- 模型经过剪枝和量化,大幅缩小了模型大小。
- 利用混合级别剪枝、零跳过和合并脉冲等技术,降低了硬件复杂度。
- 采用了并行时间步执行技术,解决了数据依赖问题,并降低了功耗。
- 输入广播方案消除了零计算,进一步提升了能效。
点此查看论文截图

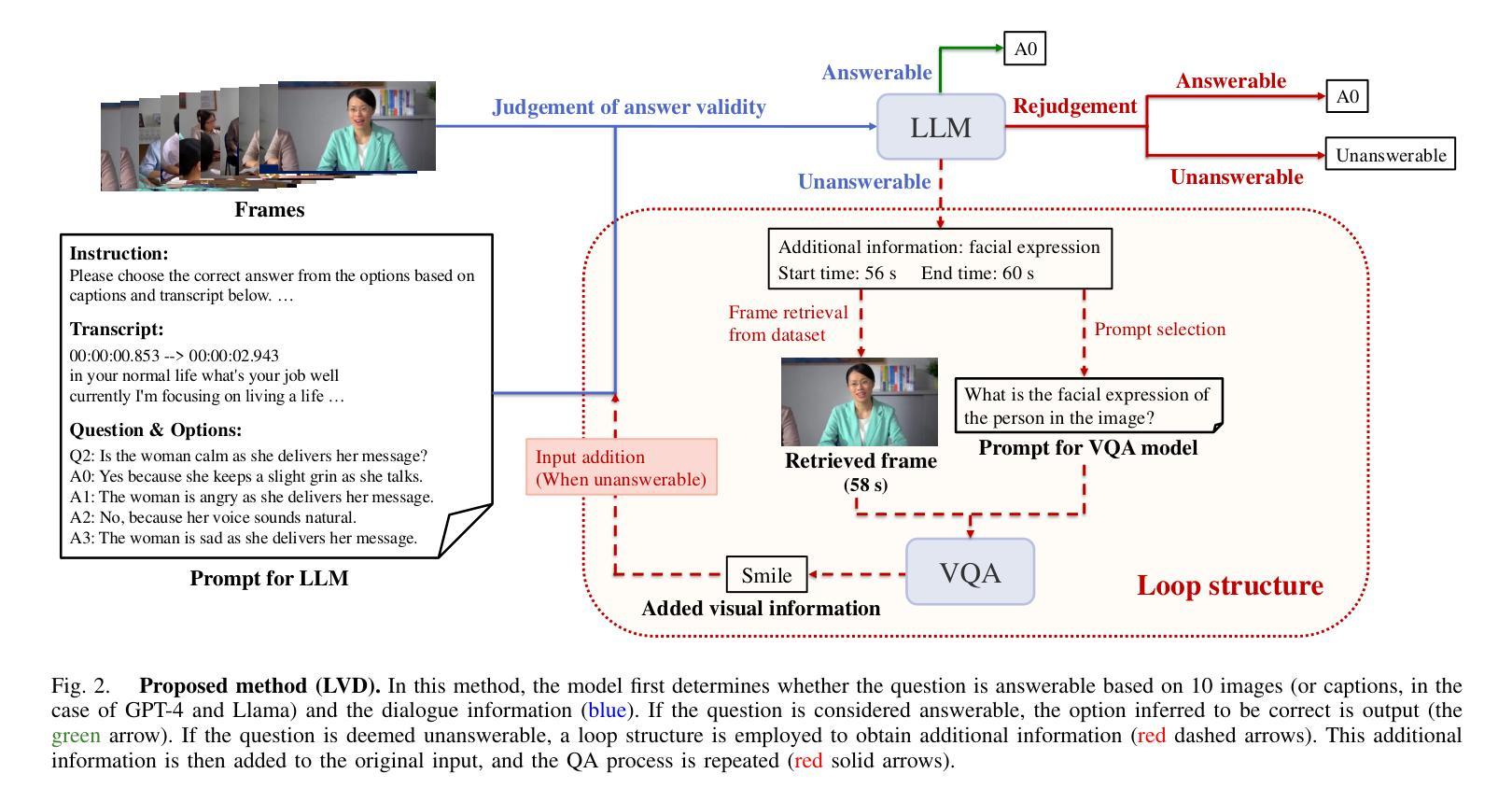
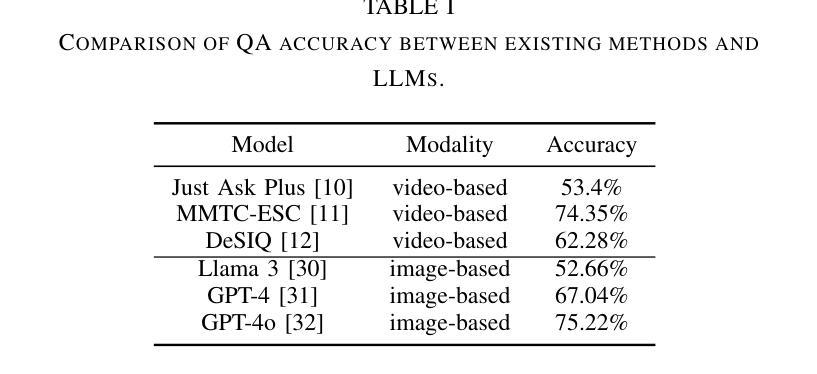
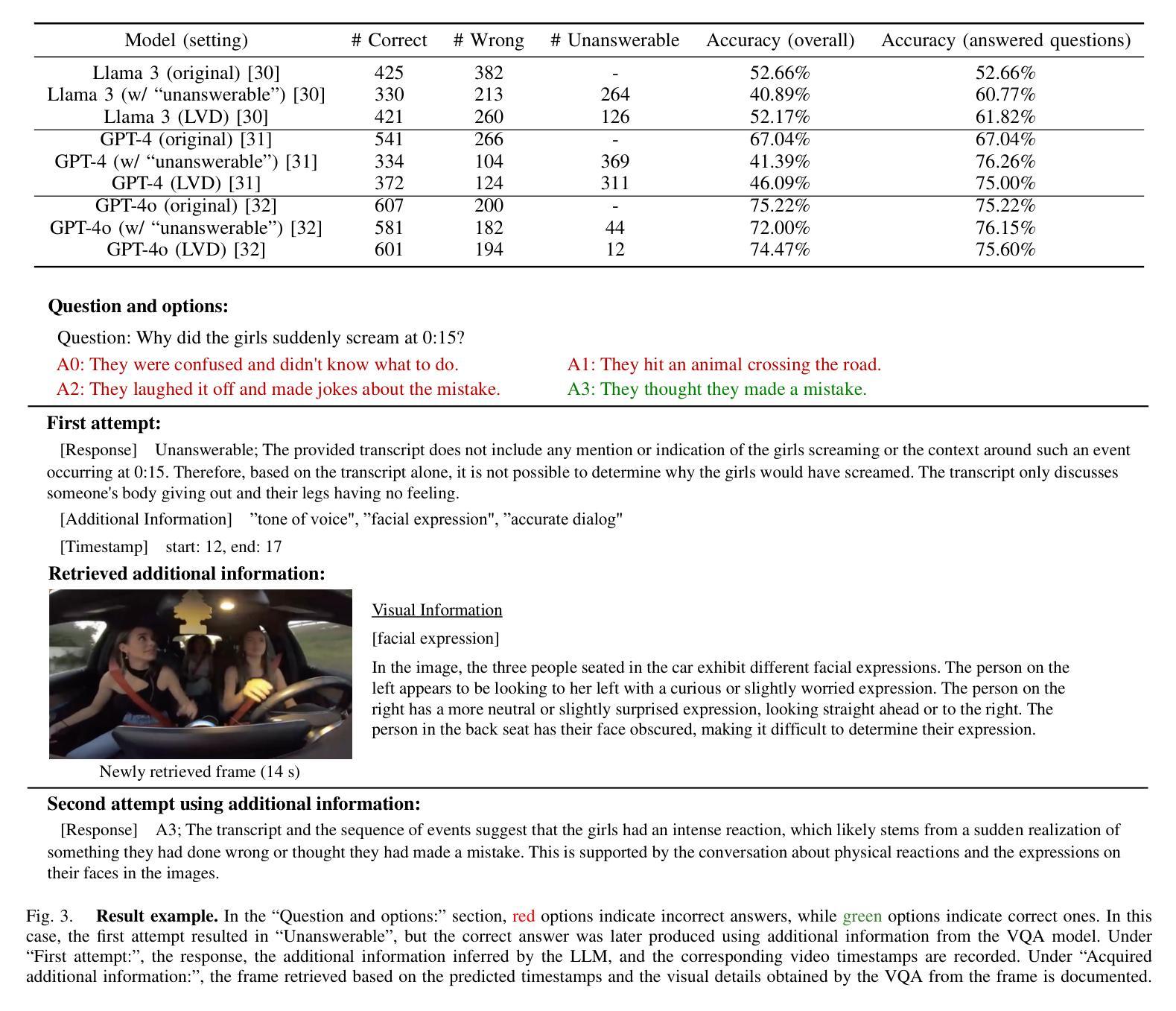
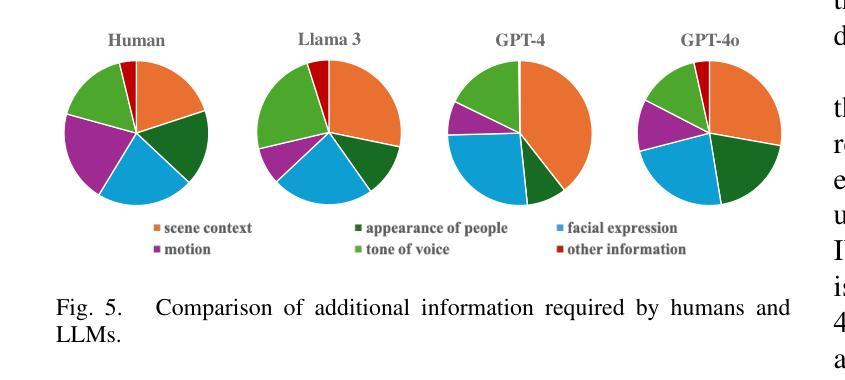
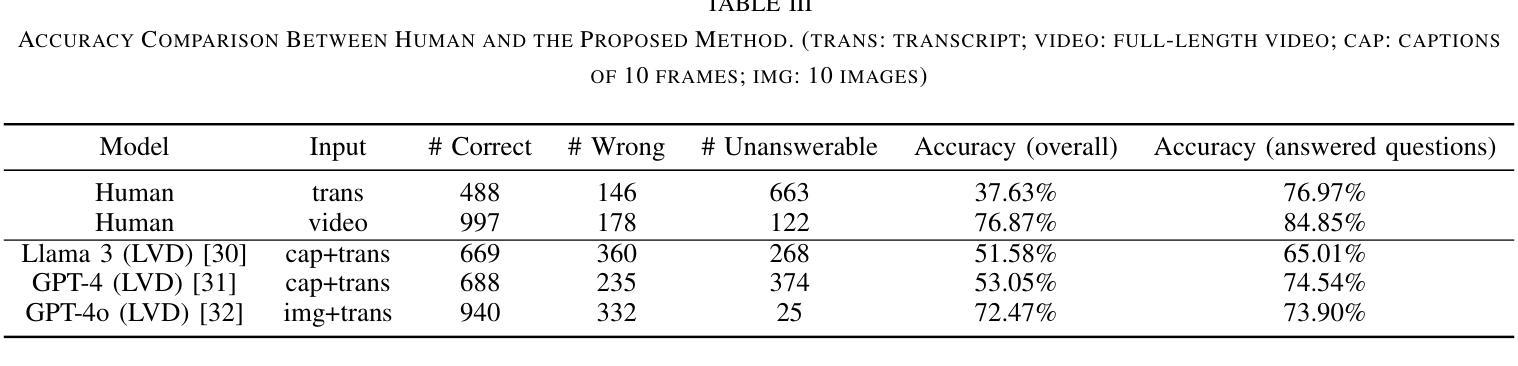
Leveraging LLMs with Iterative Loop Structure for Enhanced Social Intelligence in Video Question Answering
Authors:Erika Mori, Yue Qiu, Hirokatsu Kataoka, Yoshimitsu Aoki
Social intelligence, the ability to interpret emotions, intentions, and behaviors, is essential for effective communication and adaptive responses. As robots and AI systems become more prevalent in caregiving, healthcare, and education, the demand for AI that can interact naturally with humans grows. However, creating AI that seamlessly integrates multiple modalities, such as vision and speech, remains a challenge. Current video-based methods for social intelligence rely on general video recognition or emotion recognition techniques, often overlook the unique elements inherent in human interactions. To address this, we propose the Looped Video Debating (LVD) framework, which integrates Large Language Models (LLMs) with visual information, such as facial expressions and body movements, to enhance the transparency and reliability of question-answering tasks involving human interaction videos. Our results on the Social-IQ 2.0 benchmark show that LVD achieves state-of-the-art performance without fine-tuning. Furthermore, supplementary human annotations on existing datasets provide insights into the model’s accuracy, guiding future improvements in AI-driven social intelligence.
社会智能,即解读情感、意图和行为的能力,对于有效沟通和适应性反应至关重要。随着机器人在护理、医疗和教育领域的使用日益普及,对能够自然与人类互动的AI的需求也在增长。然而,创建无缝集成多种模式(如视觉和语音)的AI仍然是一个挑战。当前基于视频的社会智能方法依赖于通用视频识别或情感识别技术,往往会忽略人类互动中固有的独特元素。为解决这一问题,我们提出了循环视频辩论(LVD)框架,该框架将大型语言模型(LLM)与面部表情和身体动作等视觉信息相结合,提高了涉及人类互动视频的问答任务的透明度和可靠性。我们在Social-IQ 2.0基准测试上的结果表明,LVD在不进行微调的情况下达到了最先进的性能。此外,对现有数据集进行补充人工注释,为模型的准确性提供了见解,指导未来AI驱动的社会智能的改进。
论文及项目相关链接
Summary
社会智能,即解读情感、意图和行为的能力,对于有效沟通和适应反应至关重要。随着机器人和人工智能系统在护理、医疗和教育等领域的普及,对能自然与人类互动的人工智能的需求不断增长。然而,创建能无缝集成多种模式(如视觉和语音)的人工智能仍是一个挑战。为解决此问题,我们提出了循环视频辩论(LVD)框架,它将大型语言模型(LLM)与面部表情和身体动作等视觉信息相结合,提高了涉及人类互动视频的问答任务的透明度和可靠性。我们在Social-IQ 2.0基准测试上的结果表明,LVD在不进行微调的情况下即可实现最佳性能。此外,对现有数据集进行的人类附加注释提供了关于模型准确性的见解,为改进AI驱动的社会智能提供了指导。
Key Takeaways
- 社会智能对于有效沟通和适应反应至关重要。
- 随着AI在多个领域的应用增长,对能自然与人类互动的智能体的需求也在增长。
- 创建能无缝集成多种模式(如视觉和语音)的AI是一个挑战。
- 提出的LVD框架结合了大型语言模型和视觉信息,提高了涉及人类互动视频的AI性能。
- LVD框架在Social-IQ 2.0基准测试上实现了最佳性能。
- 通过人类附加注释对现有数据集进行分析,为改进AI的社会智能提供了指导。
点此查看论文截图


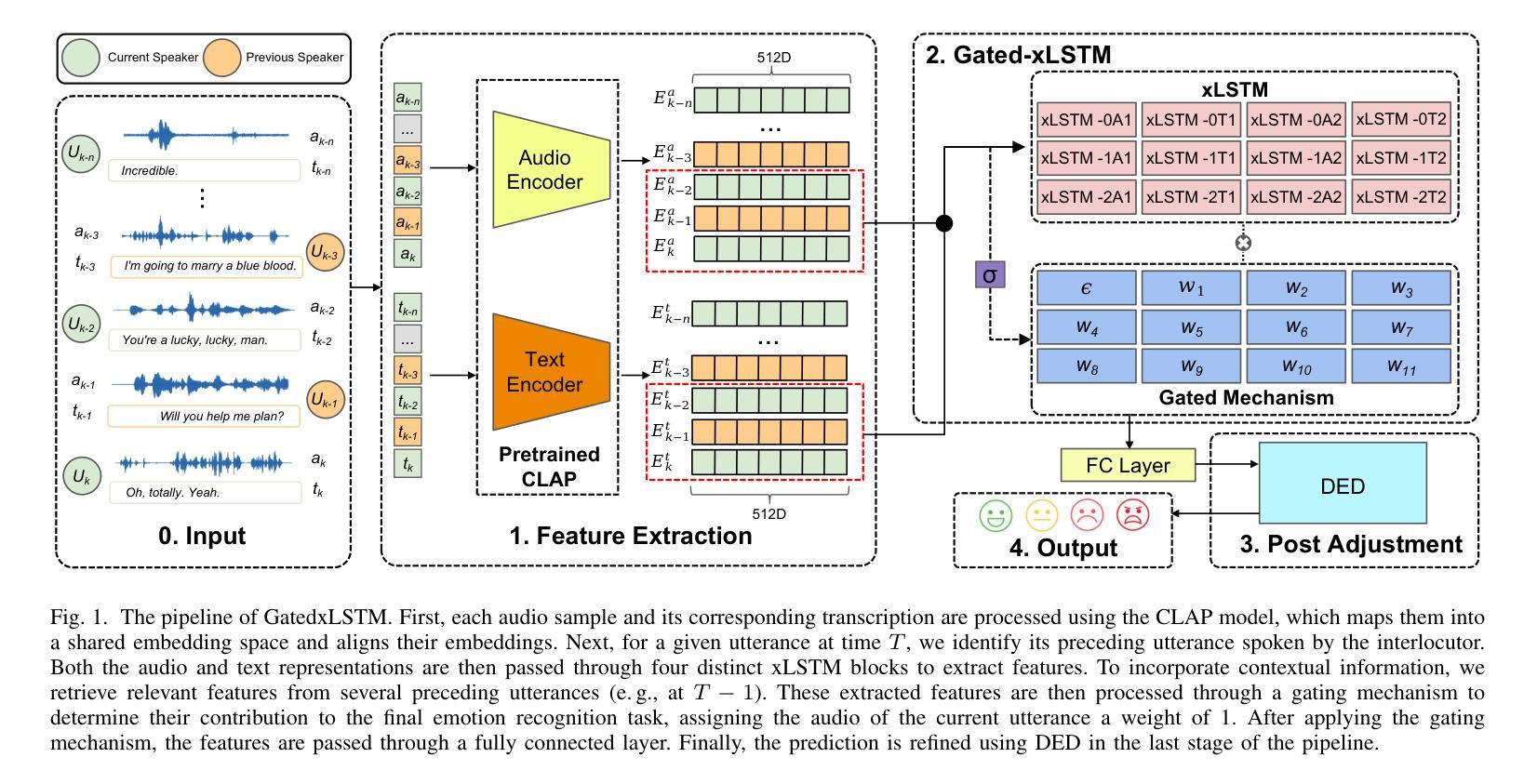
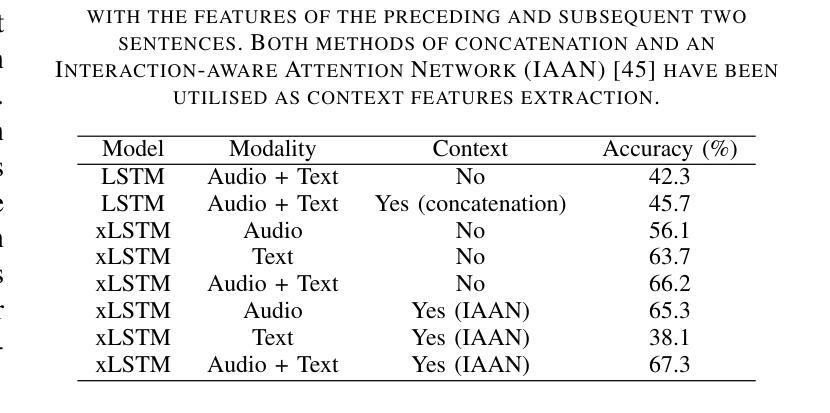
GatedxLSTM: A Multimodal Affective Computing Approach for Emotion Recognition in Conversations
Authors:Yupei Li, Qiyang Sun, Sunil Munthumoduku Krishna Murthy, Emran Alturki, Björn W. Schuller
Affective Computing (AC) is essential for advancing Artificial General Intelligence (AGI), with emotion recognition serving as a key component. However, human emotions are inherently dynamic, influenced not only by an individual’s expressions but also by interactions with others, and single-modality approaches often fail to capture their full dynamics. Multimodal Emotion Recognition (MER) leverages multiple signals but traditionally relies on utterance-level analysis, overlooking the dynamic nature of emotions in conversations. Emotion Recognition in Conversation (ERC) addresses this limitation, yet existing methods struggle to align multimodal features and explain why emotions evolve within dialogues. To bridge this gap, we propose GatedxLSTM, a novel speech-text multimodal ERC model that explicitly considers voice and transcripts of both the speaker and their conversational partner(s) to identify the most influential sentences driving emotional shifts. By integrating Contrastive Language-Audio Pretraining (CLAP) for improved cross-modal alignment and employing a gating mechanism to emphasise emotionally impactful utterances, GatedxLSTM enhances both interpretability and performance. Additionally, the Dialogical Emotion Decoder (DED) refines emotion predictions by modelling contextual dependencies. Experiments on the IEMOCAP dataset demonstrate that GatedxLSTM achieves state-of-the-art (SOTA) performance among open-source methods in four-class emotion classification. These results validate its effectiveness for ERC applications and provide an interpretability analysis from a psychological perspective.
情感计算(AC)对推动人工智能通用智能(AGI)的发展至关重要,情感识别是其中的关键组成部分。然而,人类情感本质上是动态的,不仅受到个人表达的影响,还受到与他人互动的影响,单一模式的方法往往无法捕捉其全部动态。多模态情感识别(MER)利用多种信号,但传统上依赖于话语层面的分析,忽视了情感对话中的动态特征。对话中的情感识别(ERC)解决了这一局限性,但现有方法难以对齐多模态特征并解释情感如何在对话中演变。为了弥补这一差距,我们提出了GatedxLSTM,这是一种新颖的语音文本多模态ERC模型,它明确考虑了说话者和他们的对话伙伴的语音和文本转录,以识别推动情感变化的最有影响力的句子。通过集成对比语言音频预训练(CLAP)以改进跨模态对齐,并采用门控机制来强调情感上有影响力的言论,GatedxLSTM提高了可解释性和性能。此外,对话情感解码器(DED)通过模拟上下文依赖性来完善情感预测。在IEMOCAP数据集上的实验表明,GatedxLSTM在四类情感分类中实现了开源方法中的最新技术表现。这些结果验证了其在ERC应用中的有效性,并从心理角度提供了可解释性分析。
论文及项目相关链接
Summary
本文介绍了情感计算在推进人工智能通用智能方面的重要性,并指出情感识别是其中的关键组成部分。然而,人类情感具有动态性,单模态方法无法捕捉其全面信息。多模态情感识别(MER)采用多种信号,但传统方法侧重于话语层面的分析,忽略了情感对话中的动态变化。为此,提出了基于门控长短期记忆网络(GatedxLSTM)的语音文本多模态情感识别模型,该模型能明确考虑说话者及其对话伙伴的声音和文字,以识别推动情感变化的关键句子。该模型通过对比语言音频预训练(CLAP)提高跨模态对齐能力,并采用门控机制强调情感影响大的话语。此外,对话情感解码器(DED)通过模拟上下文依赖关系,提高了情感预测的准确性。在IEMOCAP数据集上的实验表明,GatedxLSTM在四类别情感分类上实现了最佳性能,验证了其在情感识别对话应用中的有效性,并从心理角度提供了可解释性分析。
Key Takeaways
- 情感计算对推进人工智能通用智能至关重要,其中情感识别是关键组成部分。
- 人类情感具有动态性,单模态方法无法全面捕捉。
- 多模态情感识别(MER)采用多种信号,但传统方法忽略情感对话中的动态变化。
- 提出的GatedxLSTM模型能识别推动情感变化的关键句子,考虑说话者及其对话伙伴的声音和文字。
- GatedxLSTM模型通过对比语言音频预训练(CLAP)提高跨模态对齐能力。
- GatedxLSTM模型采用门控机制强调情感影响大的话语,并通过对话情感解码器(DED)提高情感预测准确性。
点此查看论文截图

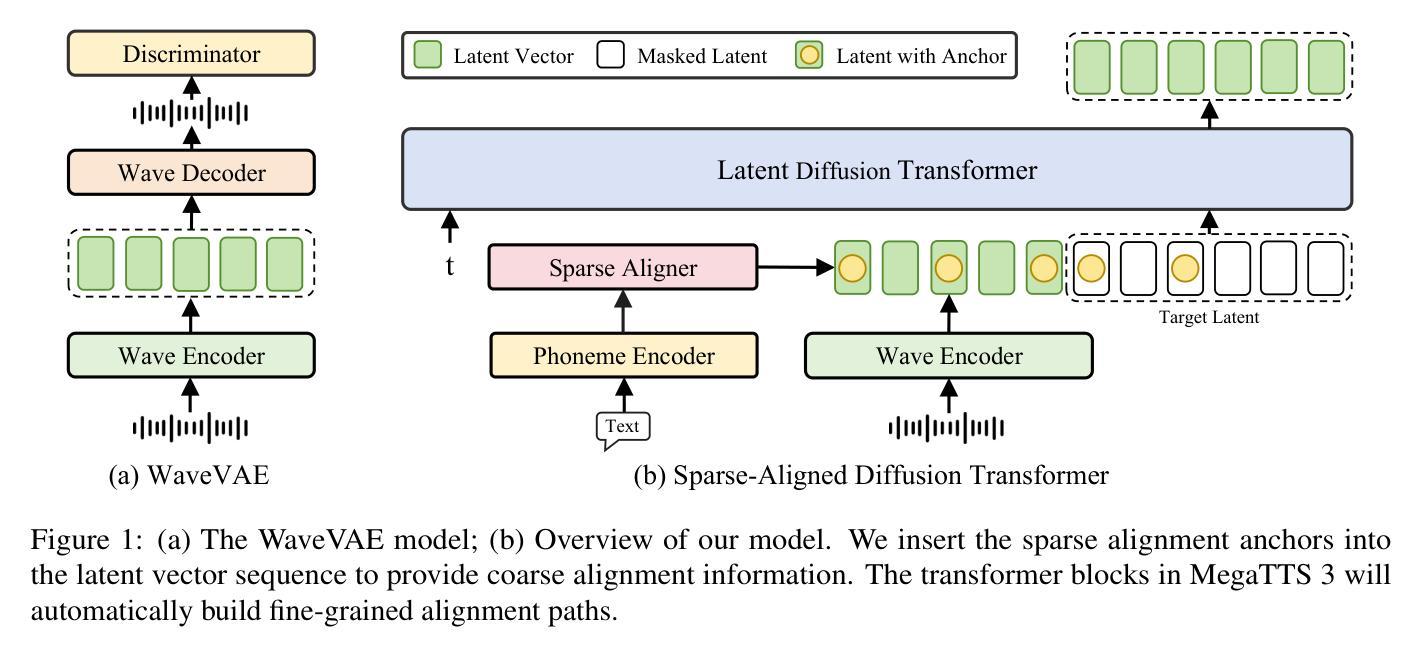
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Authors:Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, Zhou Zhao
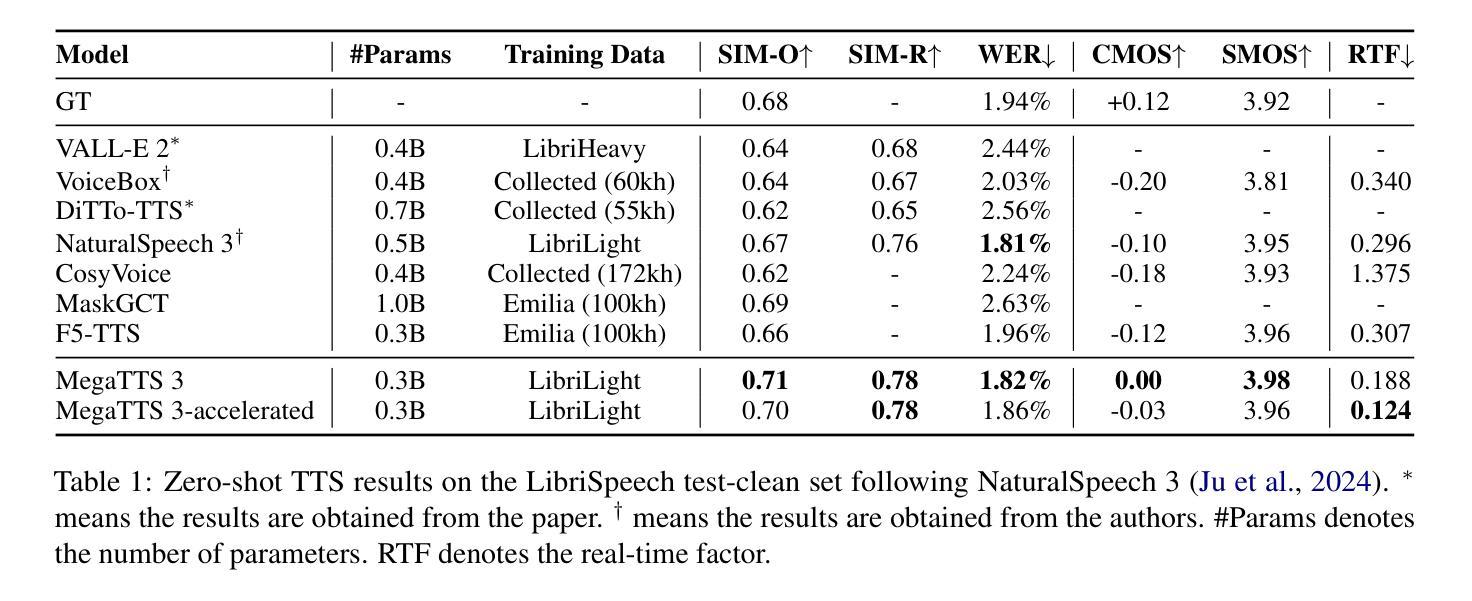
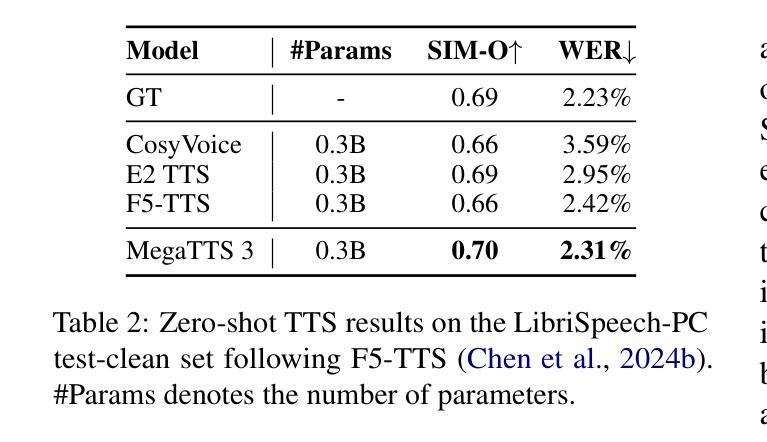
While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{MegaTTS 3}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to MegaTTS 3 to reduce the difficulty of alignment without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that MegaTTS 3 achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
近年来,零样本文本到语音(TTS)模型在语音质量和表现力方面取得了显著改进,但主流系统仍存在与语音文本对齐建模相关的问题:1)没有明确的语音文本对齐建模的模型表现出较低的稳健性,特别是在实际应用的复杂句子中;2)基于预定义对齐的模型受到强制对齐的自然性约束。本文介绍了MegaTTS 3,这是一个具有创新稀疏对齐算法的TTS系统,该算法指导潜在扩散变压器(DiT)。具体来说,我们为MegaTTS 3提供稀疏对齐边界,以减少对齐难度而不限制搜索空间,从而实现高自然度。此外,我们采用多条件无分类指导策略进行口音强度调整,并采用分段校正流技术来加速生成过程。实验表明,MegaTTS 3达到了最先进的零样本TTS语音质量,并对口音强度实现了高度灵活的控制。值得注意的是,我们的系统只需8个采样步骤就能生成高质量的一分钟语音。音频样本可在https://sditdemo.github.io/sditdemo/找到。
论文及项目相关链接
Summary
最新一代的零样本文本转语音(TTS)模型虽然大幅提升了语音质量和表达力,但主流系统仍存在语音与文本对齐建模的问题。本文提出一种名为MegaTTS 3的TTS系统,采用创新的稀疏对齐算法引导潜在扩散转换器(DiT)。通过提供稀疏对齐边界降低对齐难度且不限制搜索空间,提高了自然度。同时采用多条件无分类指导策略调节口音强度并采用分段整流流技术加速生成过程。实验证明MegaTTS 3实现了零样本TTS的最优语音质量,并支持高度灵活的口音强度控制。可生成仅需8步采样的一分钟高质量语音。具体参见[https://sditdemo.github.io/sditdemo/]了解音频样本。
Key Takeaways
- 主流文本转语音(TTS)模型仍存在语音与文本对齐建模的问题。
- MegaTTS 3系统采用创新的稀疏对齐算法,提高了语音自然度。
- MegaTTS 3实现了零样本TTS的最优语音质量。
- 系统支持高度灵活的口音强度控制。
- MegaTTS 3采用分段整流流技术以加速语音生成过程。
- 系统可生成一分钟的高质量语音,仅需要8步采样。
点此查看论文截图

VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Authors:Jiatong Shi, Hye-jin Shim, Jinchuan Tian, Siddhant Arora, Haibin Wu, Darius Petermann, Jia Qi Yip, You Zhang, Yuxun Tang, Wangyou Zhang, Dareen Safar Alharthi, Yichen Huang, Koichi Saito, Jionghao Han, Yiwen Zhao, Chris Donahue, Shinji Watanabe
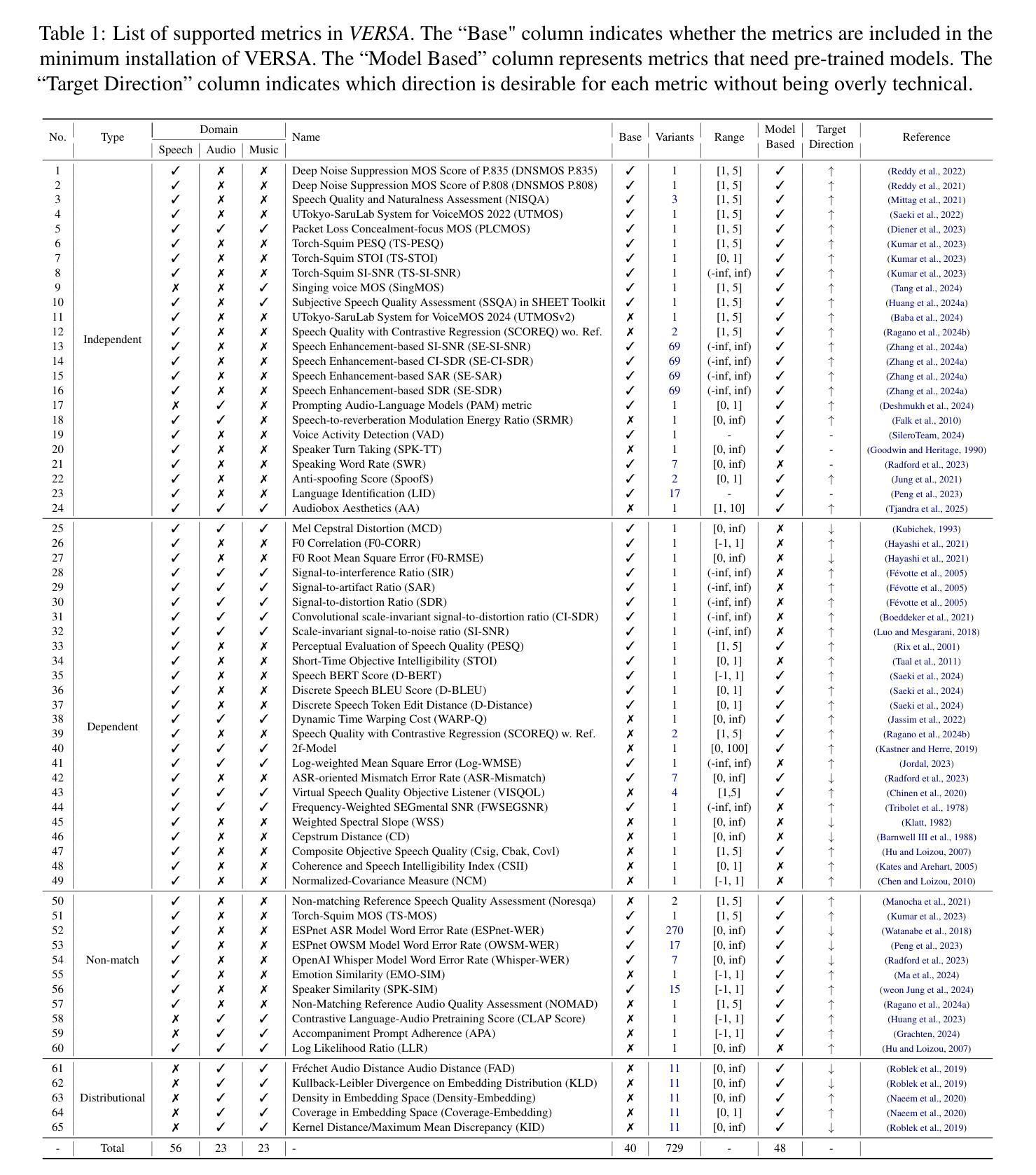
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 65 metrics with 729 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/wavlab-speech/versa.
在这项工作中,我们介绍了VERSA,这是一个为各种语音、音频和音乐信号设计的统一、标准化的评估工具包。该工具包具有Python风格的接口,具有灵活的配置和依赖控制,使其友好且高效。在完全安装后,VERSA提供基于不同配置的65种指标和729种指标变体。这些指标涵盖了利用多种外部资源的评估,包括匹配和非匹配的参考音频、文本转录和文本描述。作为一个轻便而全面的工具包,VERSA支持对各种下游场景的评估。为了证明其能力,这项工作重点介绍了VERSA的示例用例,包括音频编码、语音合成、语音增强、歌唱合成和音乐生成。该工具包可在https://github.com/wavlab-speech/versa中找到。
论文及项目相关链接
Summary
VERSA是一个统一标准化的评估工具包,适用于各种语音、音频和音乐信号的评价。它具备Pythonic接口、灵活的配置和依赖控制,用户友好且高效。VERSA提供65种度量指标,基于不同配置有729种度量指标变化,涵盖利用多种外部资源的评估,如匹配和非匹配参考音频、文本转录和文本字幕。它支持多种下游场景的评价。
Key Takeaways
- VERSA是一个统一标准化的评价工具包,适用于语音、音频和音乐信号的评价。
- VERSA具备Pythonic接口,具备灵活的配置和依赖控制。
- VERSA提供65种度量指标,基于不同配置有729种度量指标变化。
- VERSA的度量指标涵盖利用多种外部资源的评估,如匹配和非匹配参考音频、文本转录和文本字幕。
- VERSA支持多种下游场景的评价,包括音频编码、语音合成、语音增强、歌唱合成和音乐生成等。
- VERSA在GitHub上有公开的代码库。
点此查看论文截图



Towards Controllable Speech Synthesis in the Era of Large Language Models: A Survey
Authors:Tianxin Xie, Yan Rong, Pengfei Zhang, Wenwu Wang, Li Liu
Text-to-speech (TTS), also known as speech synthesis, is a prominent research area that aims to generate natural-sounding human speech from text. Recently, with the increasing industrial demand, TTS technologies have evolved beyond synthesizing human-like speech to enabling controllable speech generation. This includes fine-grained control over various attributes of synthesized speech such as emotion, prosody, timbre, and duration. In addition, advancements in deep learning, such as diffusion and large language models, have significantly enhanced controllable TTS over the past several years. In this work, we conduct a comprehensive survey of controllable TTS, covering approaches ranging from basic control techniques to methods utilizing natural language prompts, aiming to provide a clear understanding of the current state of research. We examine the general controllable TTS pipeline, challenges, model architectures, and control strategies, offering a comprehensive and clear taxonomy of existing methods. Additionally, we provide a detailed summary of datasets and evaluation metrics and shed some light on the applications and future directions of controllable TTS. To the best of our knowledge, this survey paper provides the first comprehensive review of emerging controllable TTS methods, which can serve as a beneficial resource for both academic researchers and industrial practitioners.
文本转语音(TTS),也称为语音合成,是一个突出的研究领域,旨在从文本生成听起来很自然的人类语音。最近,随着工业需求的增加,TTS技术已经超越了合成类似人类的语音,实现了可控的语音生成。这包括对合成语音的各种属性的精细控制,如情绪、语调、音质和持续时间。此外,深度学习中的扩散和大型语言模型等技术的进步,在过去的几年里极大地增强了可控TTS。在这项工作中,我们对可控TTS进行了全面的调查,涵盖了从基本控制技术到利用自然语言提示的方法,旨在提供对当前研究状态的清晰理解。我们研究了通用的可控TTS管道、挑战、模型架构和控制策略,提供了现有方法的全面清晰的分类。此外,我们还对数据集和评估指标进行了详细的总结,并指出了可控TTS的应用和未来发展方向。据我们所知,这篇综述论文提供了对新兴的可控TTS方法的首次全面回顾,可以作为学术研究人员和工业从业者的有益资源。
论文及项目相关链接
PDF A comprehensive survey on controllable TTS, 26 pages, 7 tables, 6 figures, 317 references. Under review
Summary
文本转语音(TTS)又称语音合成,是生成自然流畅的人类语音的重要研究领域。近年来,随着工业需求的增加,TTS技术不仅合成类似人类的声音,还能实现可控的语音生成,包括精细控制合成语音的各种属性,如情感、语调、音质和持续时间。深度学习领域的进步,如扩散模型和大型语言模型,在过去几年中显著增强了可控TTS的性能。本文全面综述了可控TTS,涵盖从基本控制技术到利用自然语言提示的方法,旨在提供对当前研究状态的清晰理解。我们考察了可控TTS的通用流程、挑战、模型架构和控制策略,对现有方法进行了全面清晰的分类。此外,我们还详细总结了数据集和评估指标,并指出了可控TTS的应用和未来发展方向。
Key Takeaways
- TTS(文本转语音)不仅是生成类似人类的声音,还能实现可控的语音生成。
- 可控TTS允许对合成语音的各种属性进行精细控制,如情感、语调、音质和持续时间。
- 深度学习领域的进步,如扩散模型和大型语言模型,显著增强了可控TTS的性能。
- 本文全面概述了可控TTS的研究现状,包括其通用流程、挑战、模型架构和控制策略。
- 文章详细阐述了可控TTS的数据集和评估指标。
- 可控TTS具有广泛的应用场景,并在未来具有巨大的发展潜力。
点此查看论文截图

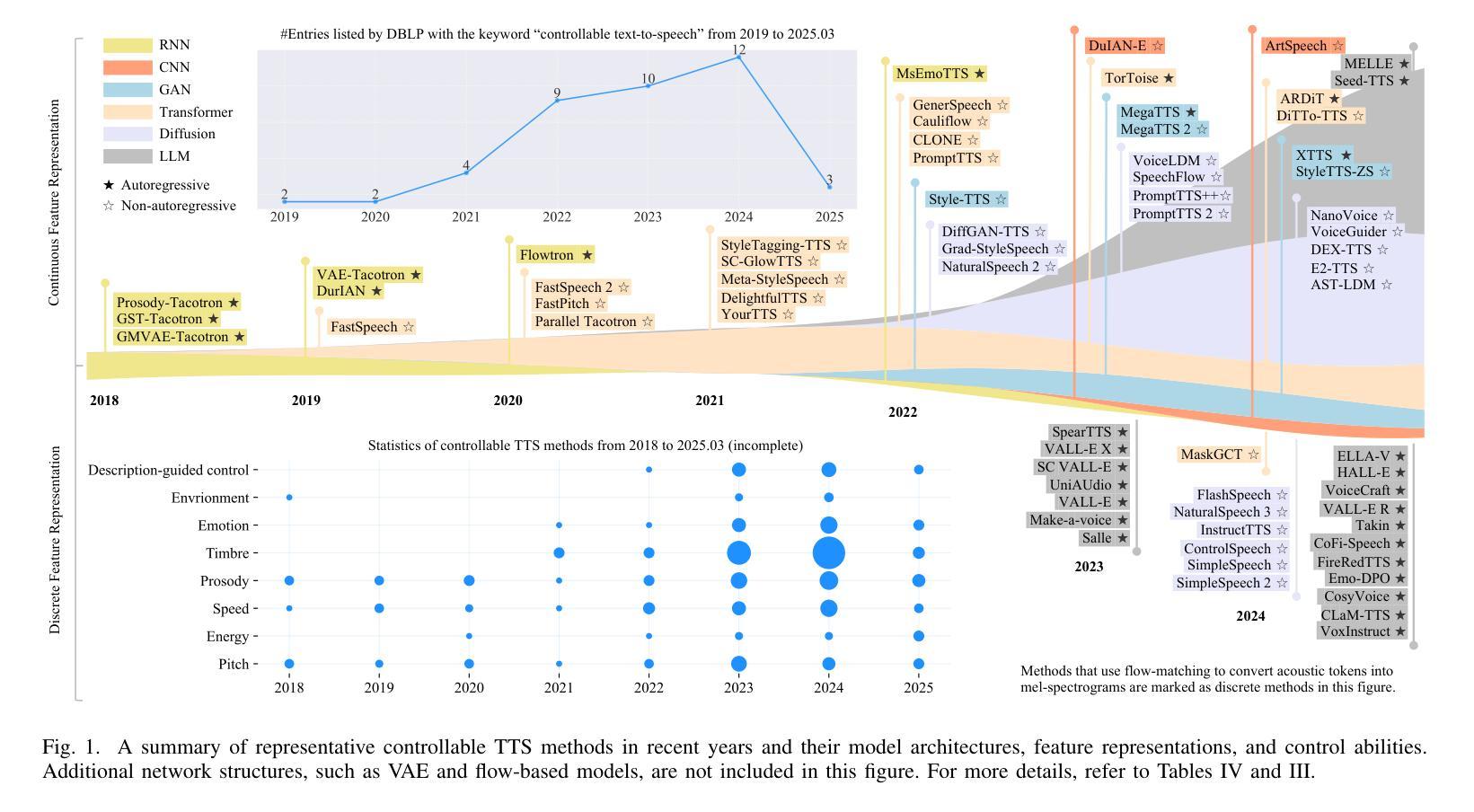

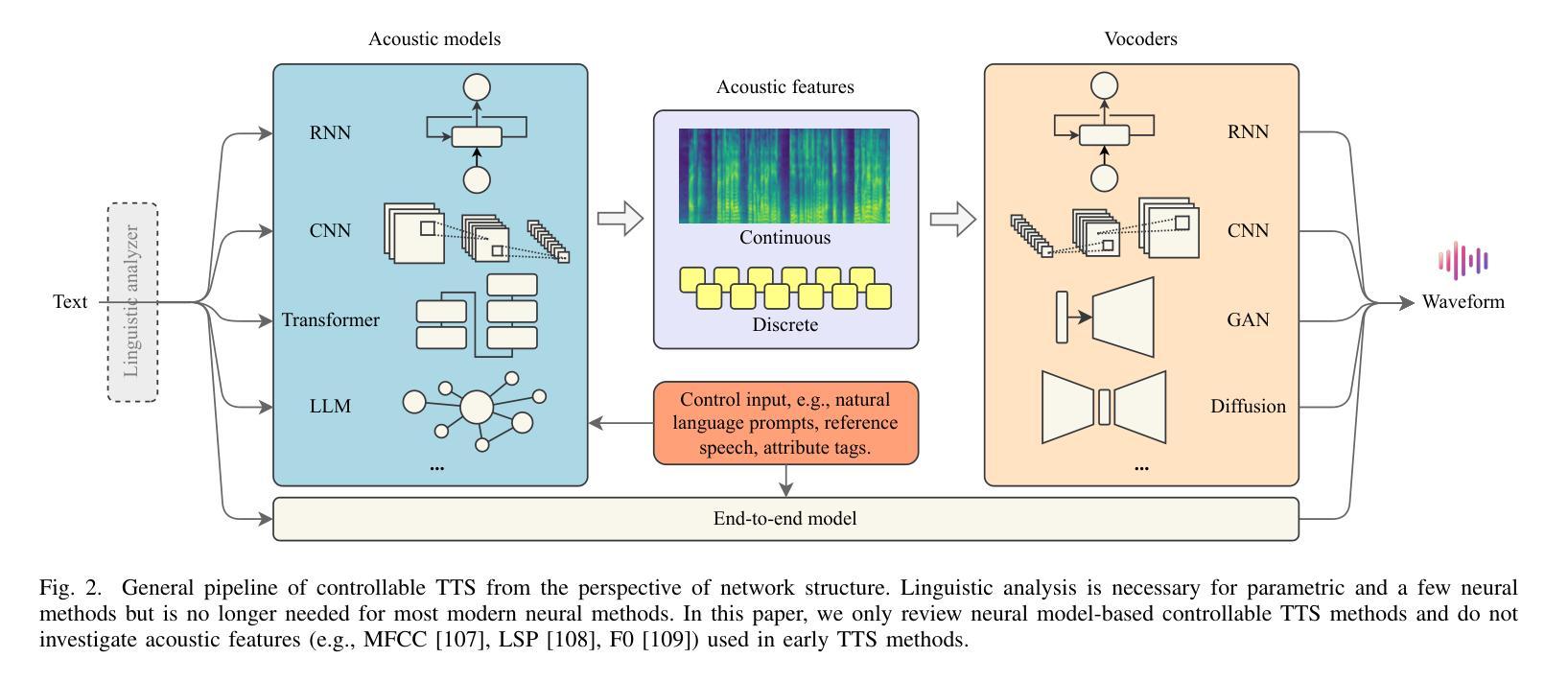
SF-Speech: Straightened Flow for Zero-Shot Voice Clone
Authors:Xuyuan Li, Zengqiang Shang, Hua Hua, Peiyang Shi, Chen Yang, Li Wang, Pengyuan Zhang
Recently, neural ordinary differential equations (ODE) models trained with flow matching have achieved impressive performance on the zero-shot voice clone task. Nevertheless, postulating standard Gaussian noise as the initial distribution of ODE gives rise to numerous intersections within the fitted targets of flow matching, which presents challenges to model training and enhances the curvature of the learned generated trajectories. These curved trajectories restrict the capacity of ODE models for generating desirable samples with a few steps. This paper proposes SF-Speech, a novel voice clone model based on ODE and in-context learning. Unlike the previous works, SF-Speech adopts a lightweight multi-stage module to generate a more deterministic initial distribution for ODE. Without introducing any additional loss function, we effectively straighten the curved reverse trajectories of the ODE model by jointly training it with the proposed module. Experiment results on datasets of various scales show that SF-Speech outperforms the state-of-the-art zero-shot TTS methods and requires only a quarter of the solver steps, resulting in a generation speed approximately 3.7 times that of Voicebox and E2 TTS. Audio samples are available at the demo page\footnote{[Online] Available: https://lixuyuan102.github.io/Demo/}.
最近,使用流匹配训练的神经常微分方程(ODE)模型在零样本语音克隆任务上取得了令人印象深刻的性能。然而,假设标准高斯噪声作为ODE的初始分布会导致流匹配的目标拟合中出现许多交点,这给模型训练带来了挑战,并增强了学习生成轨迹的曲率。这些弯曲的轨迹限制了ODE模型在几步内生成理想样本的能力。本文提出了SF-Speech,这是一种基于ODE和上下文学习的新型语音克隆模型。不同于以前的工作,SF-Speech采用轻量级的多阶段模块来为ODE生成更确定的初始分布。我们没有引入任何额外的损失函数,而是通过与所提出的模块进行联合训练,有效地校正了ODE模型的弯曲反向轨迹。在各种规模数据集上的实验结果表明,SF-Speech优于最新的零样本文本到语音转换方法,并且仅需要四分之一的求解器步骤,生成速度大约是Voicebox和E2 TTS的3.7倍。音频样本可在演示页面获得^[可通过以下网址获得:https://lixuyuan102.github.io/Demo/]^。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Audio, Speech and Language Processing
Summary
神经常微分方程(ODE)模型在零样本语音克隆任务上表现出令人瞩目的性能。然而,将标准高斯噪声设为ODE的初始分布会产生诸多问题,如目标流动的匹配中出现许多交点,这给模型训练带来挑战,并增加了学习轨迹的曲率。本文提出一种基于ODE和上下文学习的全新语音克隆模型SF-Speech。不同于以往的工作,SF-Speech采用轻量级的多阶段模块来生成更确定的ODE初始分布。无需引入任何额外的损失函数,通过与所提模块联合训练,我们有效地校正了ODE模型的弯曲反向轨迹。在多种规模数据集上的实验结果表明,SF-Speech优于目前最先进的零样本TTS方法,且所需的求解器步骤仅为四分之一,生成速度大约是Voicebox和E2 TTS的3.7倍。
Key Takeaways
- 神经常微分方程(ODE)模型在零样本语音克隆任务上表现优异。
- 将标准高斯噪声设为ODE初始分布会产生交点问题,增加模型训练难度和学习轨迹的曲率。
- SF-Speech是一种基于ODE和上下文学习的语音克隆模型,采用轻量级多阶段模块生成更确定的初始分布。
- SF-Speech通过联合训练校正ODE模型的弯曲反向轨迹,无需额外损失函数。
- 实验结果显示SF-Speech优于现有零样本TTS方法,求解器步骤减少至四分之一。
- SF-Speech生成速度较快,大约是Voicebox和E2 TTS的3.7倍。
点此查看论文截图

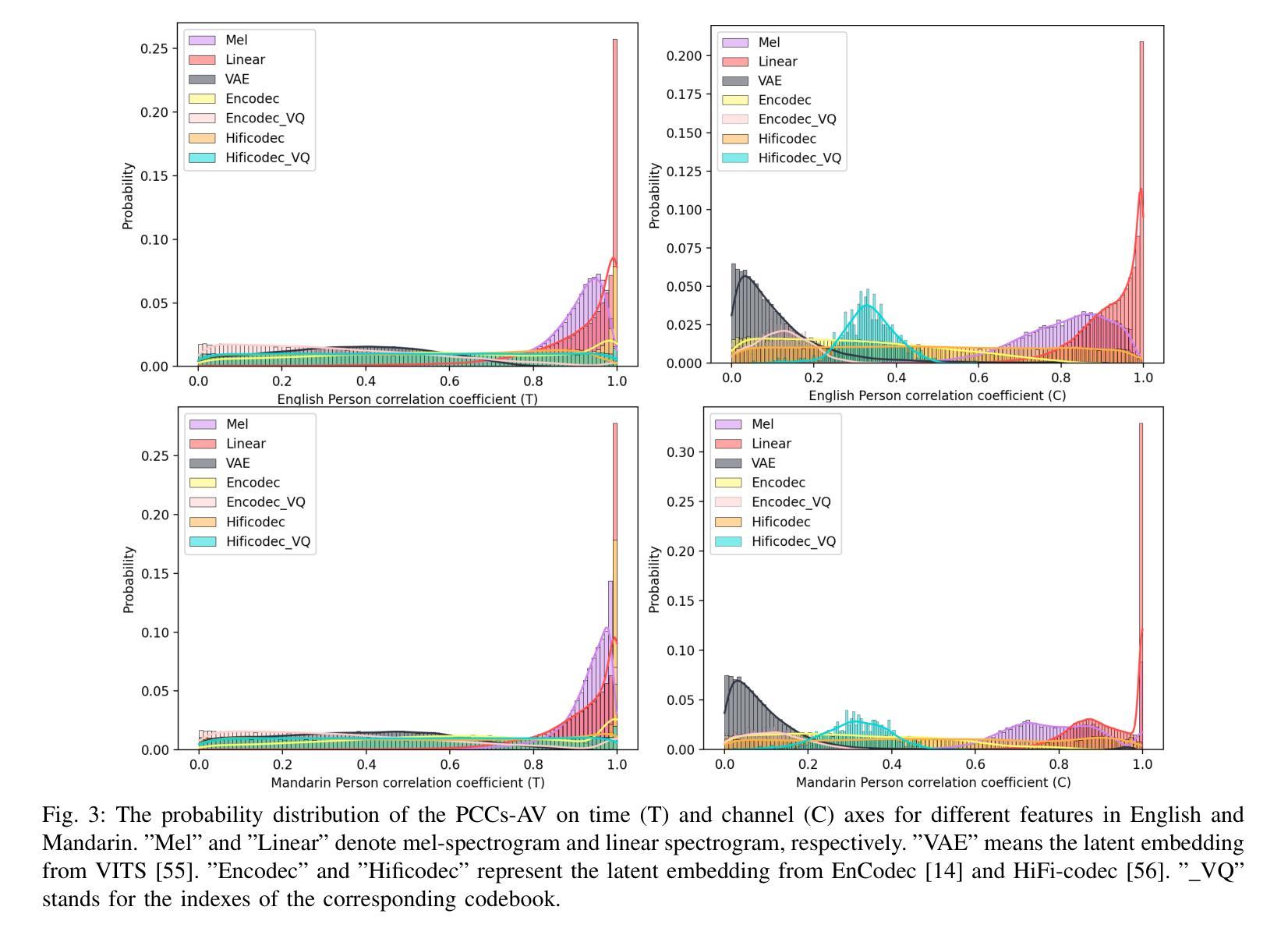
Vibravox: A Dataset of French Speech Captured with Body-conduction Audio Sensors
Authors:Julien Hauret, Malo Olivier, Thomas Joubaud, Christophe Langrenne, Sarah Poirée, Véronique Zimpfer, Éric Bavu
Vibravox is a dataset compliant with the General Data Protection Regulation (GDPR) containing audio recordings using five different body-conduction audio sensors: two in-ear microphones, two bone conduction vibration pickups, and a laryngophone. The dataset also includes audio data from an airborne microphone used as a reference. The Vibravox corpus contains 45 hours per sensor of speech samples and physiological sounds recorded by 188 participants under different acoustic conditions imposed by a high order ambisonics 3D spatializer. Annotations about the recording conditions and linguistic transcriptions are also included in the corpus. We conducted a series of experiments on various speech-related tasks, including speech recognition, speech enhancement, and speaker verification. These experiments were carried out using state-of-the-art models to evaluate and compare their performances on signals captured by the different audio sensors offered by the Vibravox dataset, with the aim of gaining a better grasp of their individual characteristics.
Vibravox是一个符合通用数据保护条例(GDPR)要求的数据集,其中包含使用五种不同的体传音频传感器录制的音频记录:两个入耳式麦克风,两个骨传导振动拾音器和一个喉传声器。该数据集还包括用作参考的空气传播麦克风的音频数据。Vibravox语料库包含由188名参与者在由高级三维环绕声系统施加的不同声学条件下录制的每传感器45小时的语音样本和生理声音。关于录音条件和语言转录的注释也包含在语料库中。我们在各种与语音相关的任务上进行了一系列实验,包括语音识别、语音增强和语音验证。这些实验使用的是最前沿的模型,旨在评估和比较它们在Vibravox数据集提供的不同音频传感器捕获的信号上的性能,以便更好地了解它们各自的特性。
论文及项目相关链接
PDF 23 pages, 42 figures
Summary
Vibravox数据集包含符合GDPR规定的音频记录,使用了五种不同的体传音频传感器,包括两个耳内麦克风、两个骨传导振动拾音器和一个喉头话筒。此外,还包括作为参考的空气传播麦克风录制的音频数据。该数据集包含由188名参与者在由高级三维空间化程序产生不同声学条件下录制的共45小时的语音样本和生理声音记录。此外,还包括有关录音条件和语言转录的注释。研究团队对该数据集进行了一系列实验,涵盖了语音识别、语音增强和语音验证等多种任务。使用先进的模型来评估不同音频传感器性能,旨在更好地了解它们各自的特性。
Key Takeaways
- Vibravox是一个符合GDPR规定的数据集,包含多种体传音频传感器录制的音频记录。
- 数据集包含由不同声学条件下录制的语音样本和生理声音记录。
- 数据集中还包括有关录音条件和语言转录的注释。
- 研究团队进行了包括语音识别、语音增强和语音验证在内的多种任务实验。
- 实验使用了先进的模型来评估不同音频传感器的性能。
- 数据集旨在帮助更好地理解不同音频传感器的特性。
点此查看论文截图




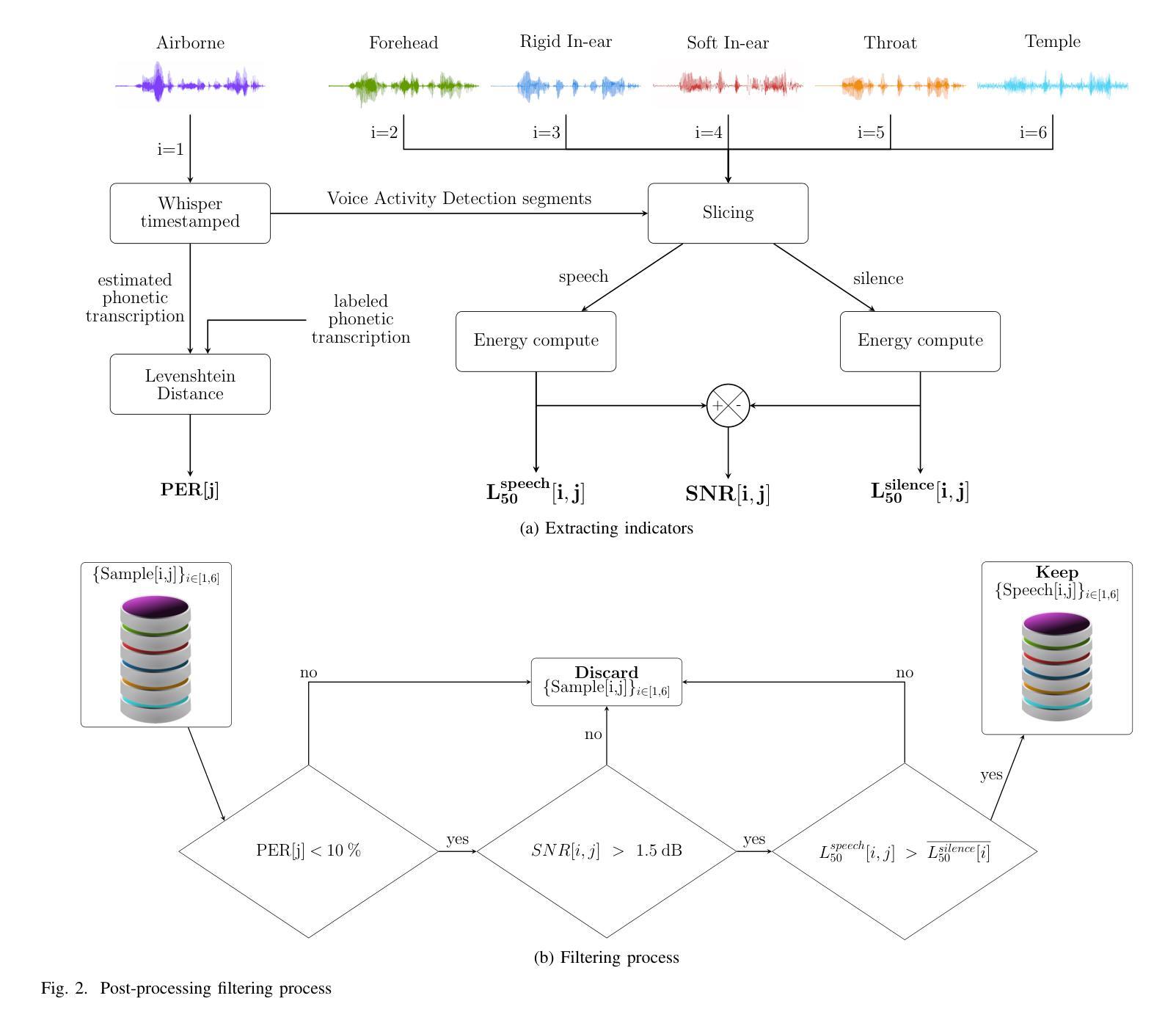
Whistle: Data-Efficient Multilingual and Crosslingual Speech Recognition via Weakly Phonetic Supervision
Authors:Saierdaer Yusuyin, Te Ma, Hao Huang, Wenbo Zhao, Zhijian Ou
There exist three approaches for multilingual and crosslingual automatic speech recognition (MCL-ASR) - supervised pretraining with phonetic or graphemic transcription, and self-supervised pretraining. We find that pretraining with phonetic supervision has been underappreciated so far for MCL-ASR, while conceptually it is more advantageous for information sharing between different languages. This paper explores the approach of pretraining with weakly phonetic supervision towards data-efficient MCL-ASR, which is called Whistle. We relax the requirement of gold-standard human-validated phonetic transcripts, and obtain International Phonetic Alphabet (IPA) based transcription by leveraging the LanguageNet grapheme-to-phoneme (G2P) models. We construct a common experimental setup based on the CommonVoice dataset, called CV-Lang10, with 10 seen languages and 2 unseen languages. A set of experiments are conducted on CV-Lang10 to compare, as fair as possible, the three approaches under the common setup for MCL-ASR. Experiments demonstrate the advantages of phoneme-based models (Whistle) for MCL-ASR, in terms of speech recognition for seen languages, crosslingual performance for unseen languages with different amounts of few-shot data, overcoming catastrophic forgetting, and training efficiency. It is found that when training data is more limited, phoneme supervision can achieve better results compared to subword supervision and self-supervision, thereby providing higher data-efficiency. To support reproducibility and promote future research along this direction, we release the code, models and data for the entire pipeline of Whistle at https://github.com/thu-spmi/CAT/tree/master/egs/cv-lang10.
对于多语言和跨语言自动语音识别(MCL-ASR),存在三种方法:基于语音或字形转录的有监督预训练以及自监督预训练。我们发现迄今为止,对于MCL-ASR而言,有监督的语音预训练一直被低估了,虽然在概念上它对于不同语言间的信息共享更为有利。本文探讨了弱语音监督的预训练方法,以提高数据效率的多语言自动语音识别效率,这被称为“哨子”。我们放宽了金标准人工验证的语音转录要求,并利用LanguageNet的字形到音素(G2P)模型获得基于国际音标(IPA)的转录。我们在CommonVoice数据集的基础上构建了一个通用实验设置,称为CV-Lang10,包含10种已知语言和2种未知语言。在CV-Lang10上进行一系列实验,尽可能公平地比较三种MCL-ASR方法。实验证明了基于音素的模型(哨子)在MCL-ASR方面的优势,包括识别已知语言的语音、对具有不同数量少量数据的未知语言的跨语言性能、克服灾难性遗忘和提高训练效率。发现当训练数据更加有限时,与单词监督和自监督相比,音素监督可以达到更好的效果,从而提高了数据效率。为了支持可复制性和促进未来在这一方向的研究,我们在https://github.com/thu-spmi/CAT/tree/master/egs/cv-lang10发布了哨子整个管道的代码、模型和数据。
论文及项目相关链接
PDF Accepted by IEEE-TASLP
摘要
该论文探索了使用弱语音监督进行多语言和跨语言自动语音识别(MCL-ASR)的方法,即称为“哨声”(Whistle)的技术。它通过使用LanguageNet的字母到语音(G2P)模型来获得基于国际音标(IPA)的转录,从而放宽了对金标准人类验证语音转录的要求。论文构建了一个基于CommonVoice数据集的实验设置CV-Lang10,包含10种已知语言和两种未知语言。一系列实验在CV-Lang10上进行,以尽可能公平的方式比较三种MCL-ASR方法。实验表明,基于音素模型的哨声(Whistle)在MCL-ASR方面具有优势,特别是在已知语言的语音识别、不同少量数据的未知语言的跨语言性能、克服灾难性遗忘和提高训练效率方面。研究还发现,当训练数据有限时,音素监督可以实现比子词监督和自我监督更好的结果,从而提高了数据效率。为了支持可重复性和促进这一方向上的未来研究,我们发布了哨声整个流程的代码、模型和数据。
关键见解
- 论文介绍了三种多语言和跨语言自动语音识别(MCL-ASR)的方法,包括使用语音或字母转录的有监督预训练以及自监督预训练。
- 研究发现,迄今为止对使用语音监督进行MCL-ASR的评估不足,但从概念上讲,它对不同语言之间的信息共享更有利。
- 论文通过引入弱语音监督方法(称为“哨声”)探索了数据高效MCL-ASR的可行性。通过利用LanguageNet的字母到语音(G2P)模型获得国际音标(IPA)为基础的转录,降低了对人类验证语音转录的高标准需求。
- 实验表明,基于音素的模型(哨声)在MCL-ASR方面具有优势,特别是在已知语言的语音识别和未知语言的跨语言性能上。
- 当训练数据有限时,音素监督相较于子词监督和自监督能更好地实现结果,表现出较高的数据效率。
- 论文构建了一个实验设置CV-Lang10来比较三种MCL-ASR方法在各种情况下的表现。该设置基于CommonVoice数据集,包含多种语言和不同数量的少数据集。
点此查看论文截图

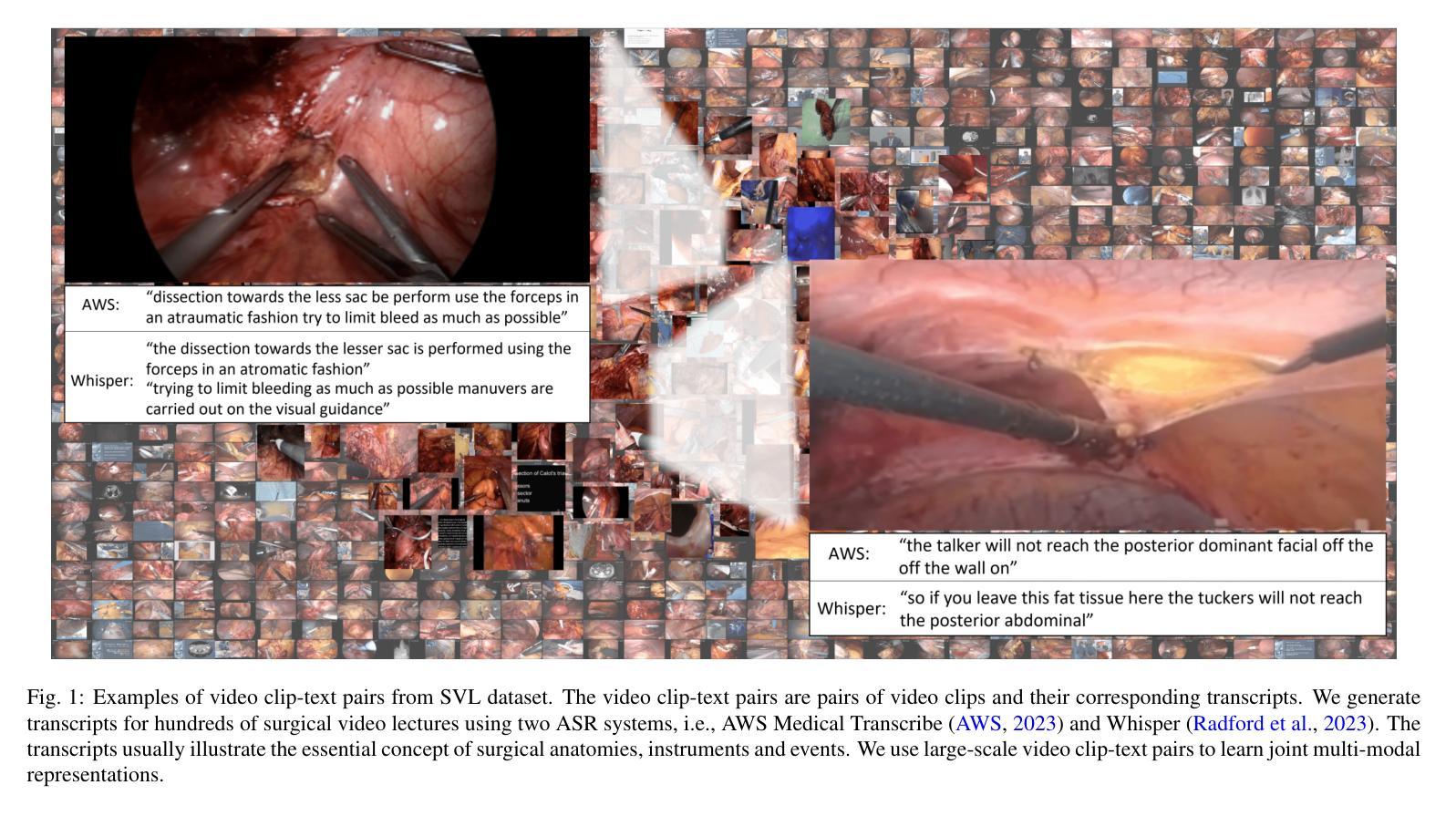
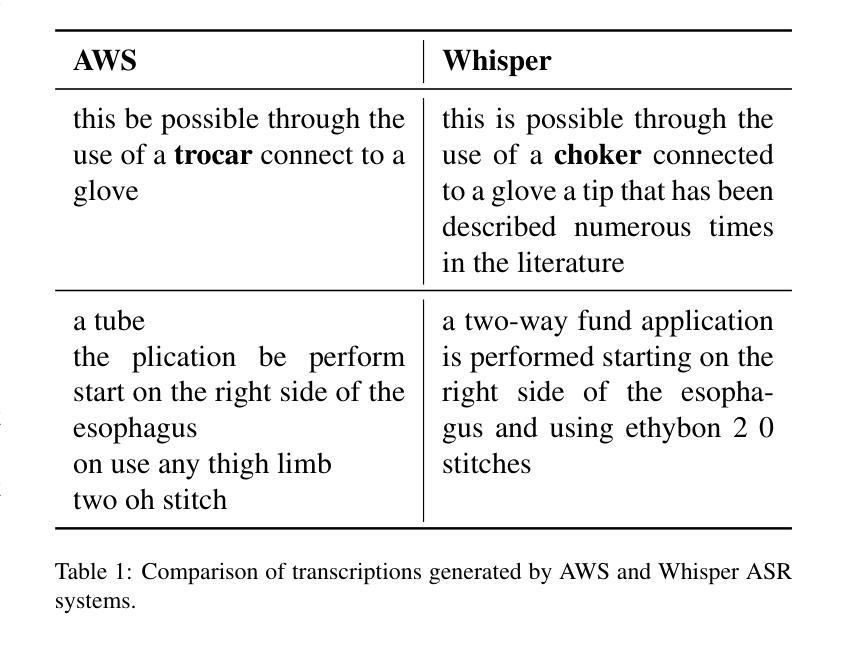
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Authors:Kun Yuan, Vinkle Srivastav, Tong Yu, Joel L. Lavanchy, Jacques Marescaux, Pietro Mascagni, Nassir Navab, Nicolas Padoy
Recent advancements in surgical computer vision applications have been driven by vision-only models, which do not explicitly integrate the rich semantics of language into their design. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective vision and language supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. Extensive experiments across diverse surgical procedures and tasks demonstrate that the multi-modal representations learned by SurgVLP exhibit strong transferability and adaptability in surgical video analysis. Furthermore, our zero-shot evaluations highlight SurgVLP’s potential as a general-purpose foundation model for surgical workflow analysis, reducing the reliance on extensive manual annotations for downstream tasks, and facilitating adaptation methods such as few-shot learning to build a scalable and data-efficient solution for various downstream surgical applications. The training code and weights are public.
近期外科计算机视觉应用的进展主要得益于仅依赖视觉的模型,这些模型在设计时并没有明确融入丰富的语言语义。这些方法依赖于手动标注的手术视频来预测固定的目标类别集,导致其难以推广到未见过的手术程序和下游任务。在此工作中,我们提出通过公开手术电子学习平台获取的手术视频讲座可以提供有效的视觉和语言监督信号,用于多模态表示学习,而无需依赖手动注释。我们采用多个互补的自动语音识别系统来解决手术视频讲座中特有的语言挑战,以生成文本转录。然后,我们提出了一种新的方法,称为SurgVLP(手术视觉语言预训练),用于多模态表示学习。在多种手术程序和任务上的广泛实验表明,SurgVLP所学习的多模态表示在手术视频分析中具有强大的迁移性和适应性。此外,我们的零样本评估凸显了SurgVLP作为手术工作流程分析的通用基础模型的潜力,减少了下游任务对大量手动注释的依赖,并促进了诸如小样本学习等适应方法,为各种下游手术应用构建可扩展和高效的数据解决方案。训练代码和权重均已公开。
论文及项目相关链接
Summary
近期外科计算机视觉应用的进展主要得益于仅依赖视觉的模型。然而,这些模型没有将丰富的语言语义整合到设计中,因此它们在预测未知手术程序和下游任务方面的泛化能力受限。本研究利用公开外科电子学习平台上的手术视频讲座,提出一种无需手动注释的多模态表示学习方法。通过采用多种互补的自动语音识别系统,应对手术视频讲座中特有的语言学挑战,生成文本转录。然后,我们提出了一种新的方法SurgVLP——外科视觉语言预训练,用于多模态表示学习。在多种手术程序和任务上的实验表明,SurgVLP所学习的多模态表示具有强大的可转移性和适应性。此外,我们的零样本评估突显了SurgVLP作为外科手术工作流分析通用基础模型的潜力,减少下游任务对大量手动注释的依赖,并促进如小样本学习等适应方法,为各种下游外科应用构建可扩展和高效的数据解决方案。
Key Takeaways
- 近期外科计算机视觉应用的进展主要得益于仅依赖视觉的模型,但它们在预测未知手术程序和下游任务方面的泛化能力受限。
- 手术视频讲座提供了有效的视觉和语言监督信号,可用于多模态表示学习,无需依赖手动注释。
- 采用多种自动语音识别系统应对手术视频讲座中的语言学挑战。
- 提出了一种新的多模态表示学习方法SurgVLP,具有强大的可转移性和适应性。
- SurgVLP在多种手术程序和任务上的实验证明了其有效性。
- SurgVLP具有潜力成为外科手术工作流分析通用基础模型,并减少下游任务对大量手动注释的依赖。
点此查看论文截图