⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-29 更新
Test-Time Visual In-Context Tuning
Authors:Jiahao Xie, Alessio Tonioni, Nathalie Rauschmayr, Federico Tombari, Bernt Schiele
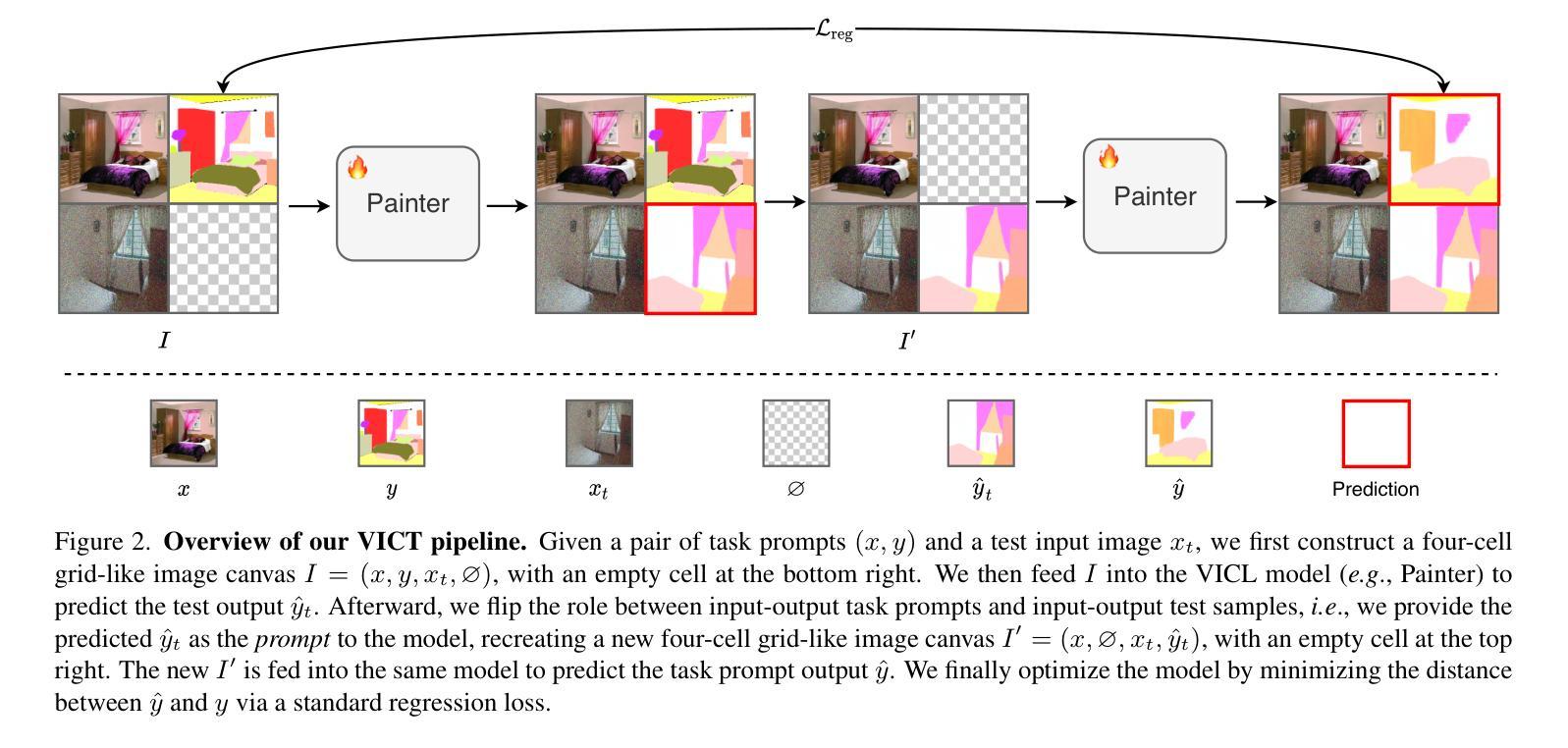
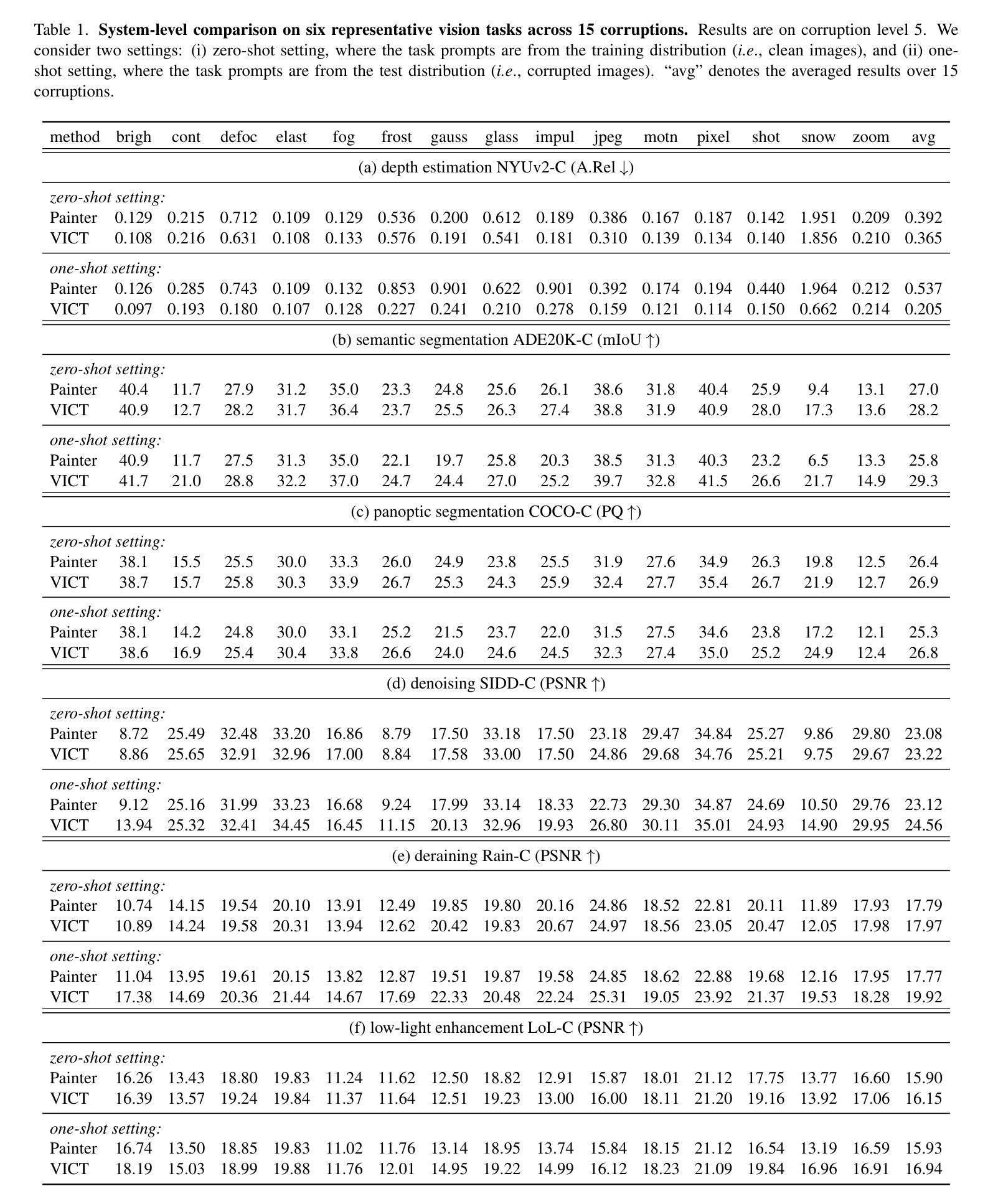
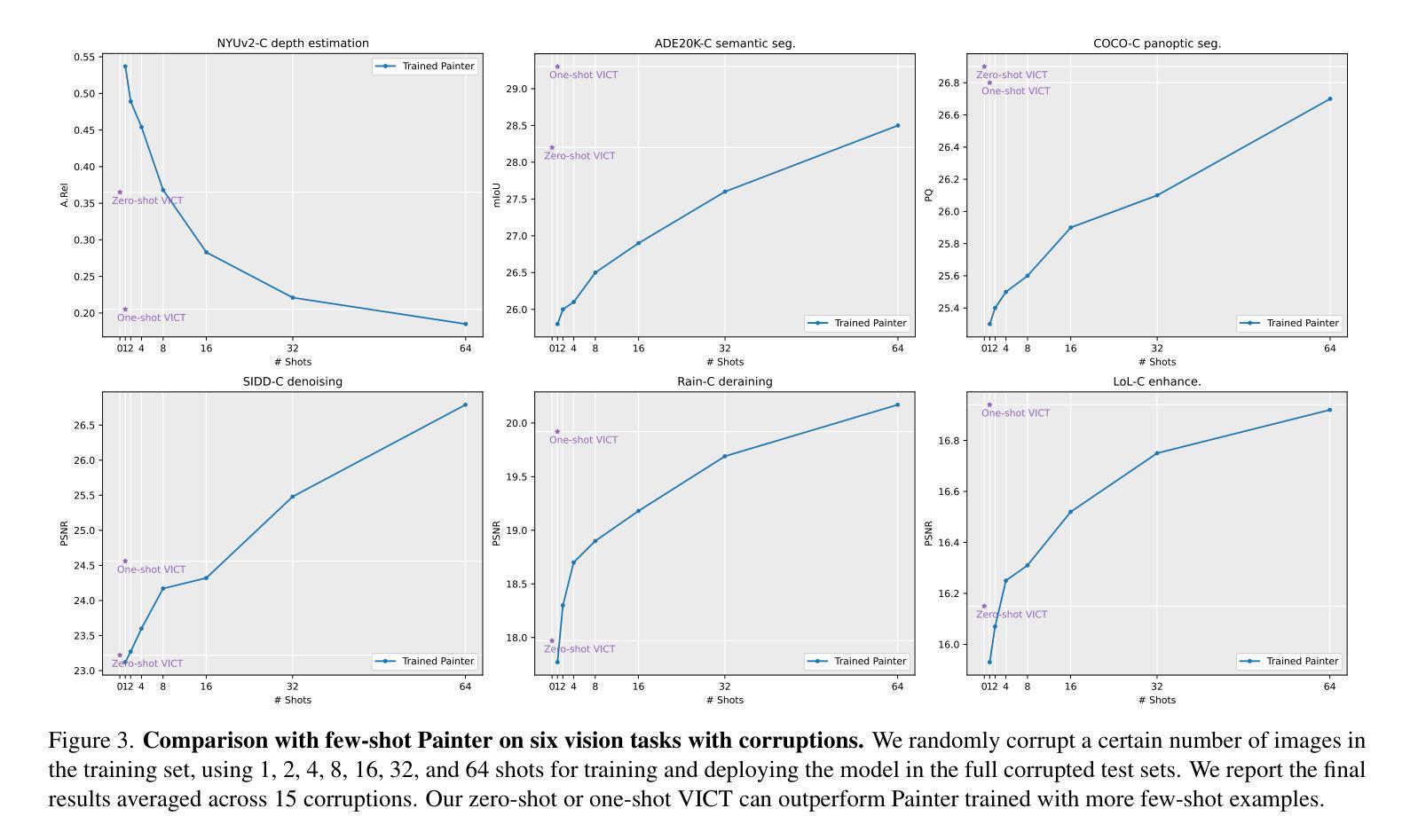
Visual in-context learning (VICL), as a new paradigm in computer vision, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples. While effective, the existing VICL paradigm exhibits poor generalizability under distribution shifts. In this work, we propose test-time Visual In-Context Tuning (VICT), a method that can adapt VICL models on the fly with a single test sample. Specifically, we flip the role between the task prompts and the test sample and use a cycle consistency loss to reconstruct the original task prompt output. Our key insight is that a model should be aware of a new test distribution if it can successfully recover the original task prompts. Extensive experiments on six representative vision tasks ranging from high-level visual understanding to low-level image processing, with 15 common corruptions, demonstrate that our VICT can improve the generalizability of VICL to unseen new domains. In addition, we show the potential of applying VICT for unseen tasks at test time. Code: https://github.com/Jiahao000/VICT.
视觉上下文学习(VICL)作为计算机视觉领域的一种新范式,允许模型仅通过少量提示和示例即可快速适应各种任务。虽然有效,但现有的VICL范式在分布转移下表现出较差的泛化能力。在此工作中,我们提出了测试时的视觉上下文调整(VICT)方法,该方法可以即时适应VICL模型,只需一个测试样本即可。具体来说,我们反转了任务提示和测试样本的角色,并使用循环一致性损失来重建原始任务提示输出。我们的关键见解是,如果模型能够成功恢复原始任务提示,那么它应该意识到新的测试分布。在六个代表性视觉任务(从高级视觉理解到低级图像处理)以及15种常见损坏上的大量实验表明,我们的VICT可以提高VICL在未见领域上的泛化能力。此外,我们展示了在测试阶段将VICT应用于未见任务的潜力。代码:https://github.com/Jiahao000/VICT。
论文及项目相关链接
PDF CVPR 2025. Code: https://github.com/Jiahao000/VICT
摘要
视觉上下文学习(VICL)作为计算机视觉领域的新范式,能够让模型仅通过少量提示和示例快速适应各种任务。然而,现有的VICL范式在分布转移下表现出较差的泛化能力。本文提出测试时视觉上下文调整(VICT)方法,能够在单一测试样本上即时适应VICL模型。我们特别将任务提示和测试样本的角色进行翻转,并利用循环一致性损失来重建原始任务提示输出。我们的关键见解是,如果一个模型能够成功恢复原始任务提示,它应该对新的测试分布有所察觉。在涵盖高级视觉理解和低级图像处理的六个代表性视觉任务上,以及面对常见的15种腐蚀情况下进行的广泛实验表明,我们的VICT能够提高VICL在新未见领域的泛化能力。此外,我们还展示了在测试时对未见任务应用VICT的潜力。
要点
- VICL作为计算机视觉新范式,能快速适应任务,但泛化能力有待提高。
- VICT方法能在单一测试样本上即时适应VICL模型,通过翻转任务提示和测试样本角色并利用循环一致性损失重建原始任务提示输出。
- VICT的关键在于模型应能成功恢复原始任务提示以增强对新的测试分布的察觉。
- VICT在多个视觉任务上的实验证明其提高VICL在新未见领域的泛化能力。
- VICT具有在测试时应用于未见任务的潜力。
- 具体代码实现可通过链接访问。
点此查看论文截图


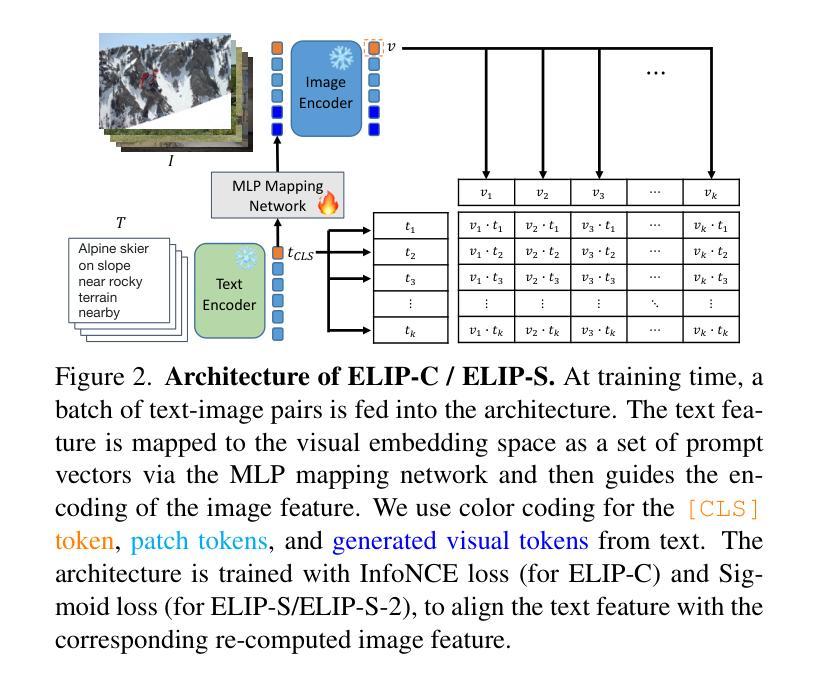
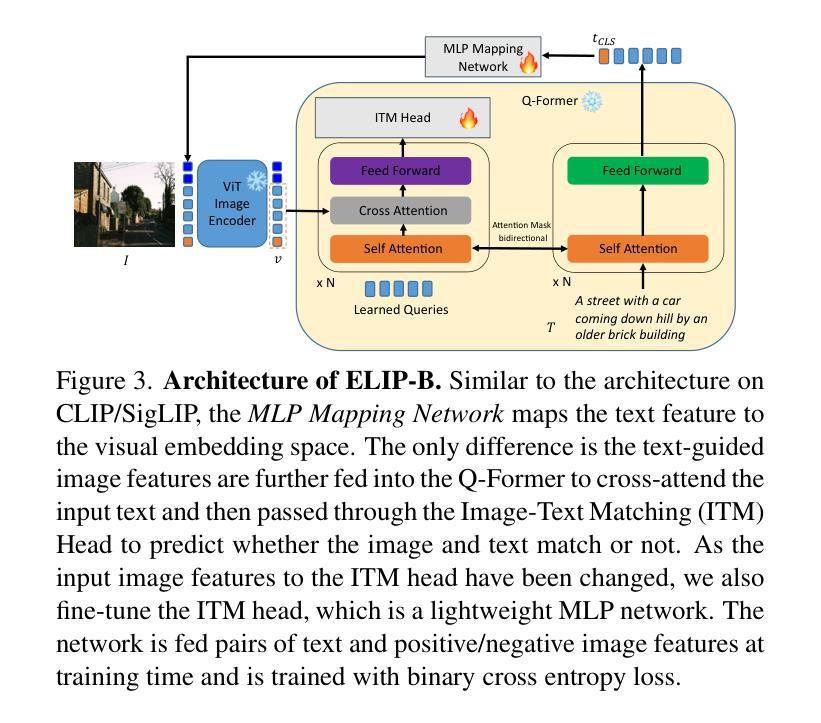
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
Authors:Guanqi Zhan, Yuanpei Liu, Kai Han, Weidi Xie, Andrew Zisserman
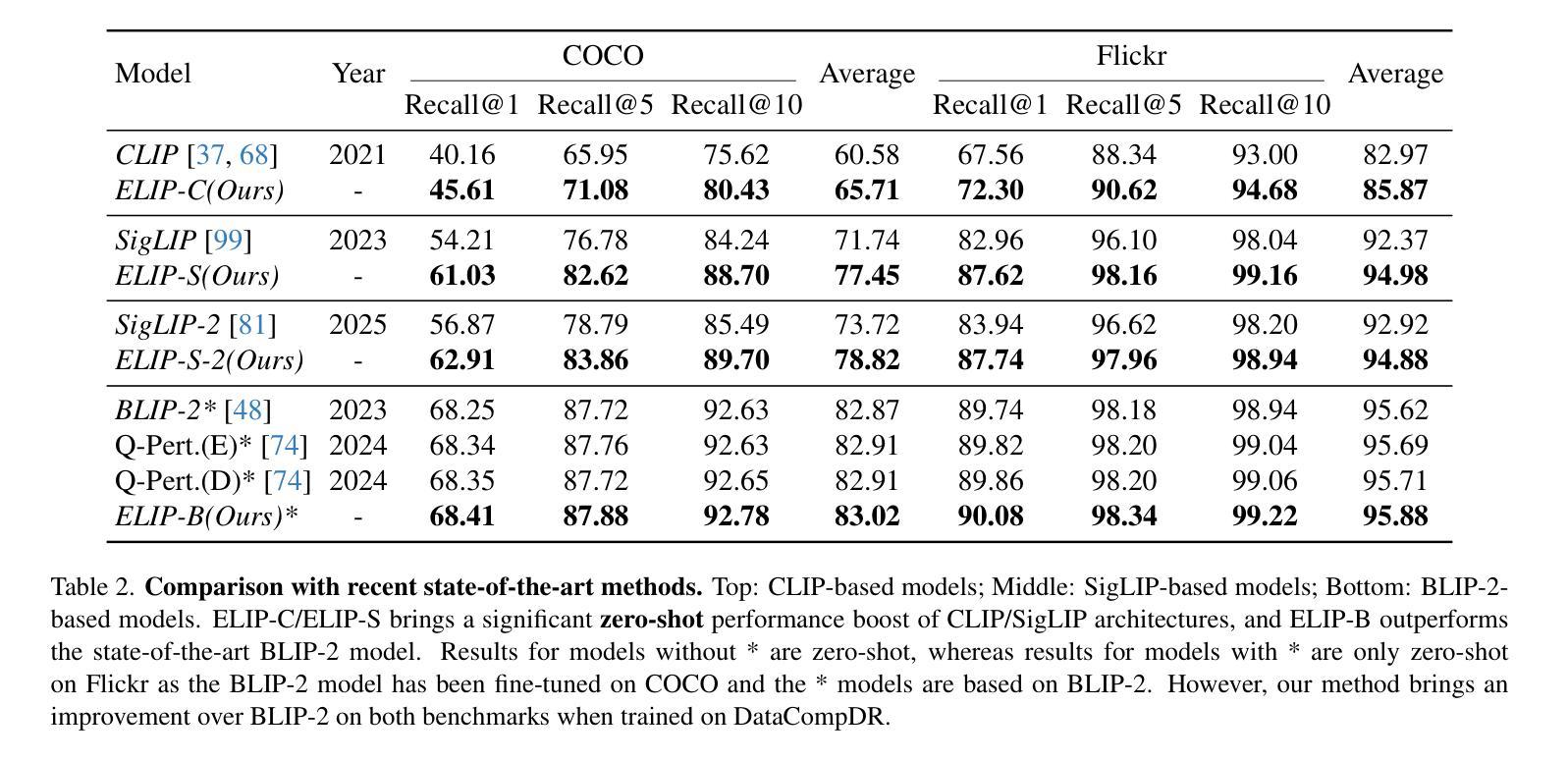
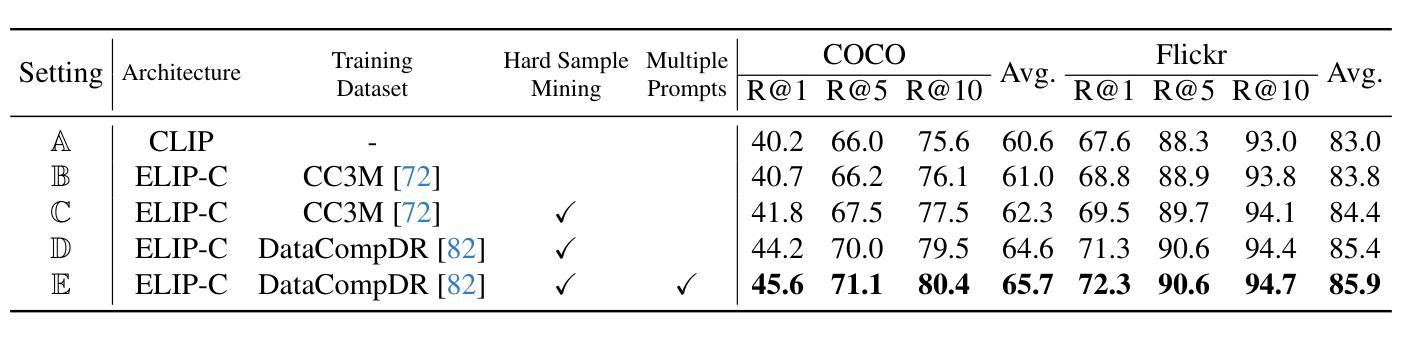
The objective in this paper is to improve the performance of text-to-image retrieval. To this end, we introduce a new framework that can boost the performance of large-scale pre-trained vision-language models, so that they can be used for text-to-image re-ranking. The approach, Enhanced Language-Image Pre-training (ELIP), uses the text query, via a simple MLP mapping network, to predict a set of visual prompts to condition the ViT image encoding. ELIP can easily be applied to the commonly used CLIP, SigLIP and BLIP-2 networks. To train the architecture with limited computing resources, we develop a ‘student friendly’ best practice, involving global hard sample mining, and curation of a large-scale dataset. On the evaluation side, we set up two new out-of-distribution (OOD) benchmarks, Occluded COCO and ImageNet-R, to assess the zero-shot generalisation of the models to different domains. The results demonstrate that ELIP significantly boosts CLIP/SigLIP/SigLIP-2 text-to-image retrieval performance and outperforms BLIP-2 on several benchmarks, as well as providing an easy means to adapt to OOD datasets.
本文的目标是提高文本到图像的检索性能。为此,我们引入了一种新的框架,该框架可以提升大规模预训练视觉语言模型的性能,使其可用于文本到图像的重新排序。这种方法称为增强语言图像预训练(ELIP)。ELIP通过使用文本查询和简单的MLP映射网络来预测一组视觉提示,以调节ViT图像编码。ELIP可以轻松应用于常用的CLIP、SigLIP和BLIP-2网络。为了用有限的计算资源来训练架构,我们制定了一种“学生友好型”的最佳实践方法,包括全局硬样本挖掘和大规模数据集的整理。在评估方面,我们建立了两个新的超出分布(OOD)基准测试,即被遮挡的COCO和ImageNet-R,以评估模型在不同领域的零样本泛化能力。结果表明,ELIP显著提高了CLIP/SigLIP/SigLIP-2的文本到图像检索性能,并在多个基准测试中优于BLIP-2,同时还提供了一种适应OOD数据集的简便方法。
论文及项目相关链接
Summary
文本介绍了通过引入新的框架Enhanced Language-Image Pre-training (ELIP)来提升大规模预训练视觉语言模型在文本到图像检索任务中的性能。ELIP使用文本查询通过简单的MLP映射网络预测一组视觉提示来影响ViT图像编码。本文还介绍了在训练架构方面,利用全球硬样本挖掘和大规模数据集的方法以节省计算资源。此外,通过设立两个新的域外分布(OOD)基准测试来评估模型在不同领域的零样本泛化能力。研究结果表明,ELIP能显著提升CLIP/SigLIP/SigLIP-2在文本到图像检索任务上的性能,并在多个基准测试中优于BLIP-2,同时易于适应OOD数据集。
Key Takeaways
- 引入Enhanced Language-Image Pre-training (ELIP)框架,旨在提高大规模预训练视觉语言模型在文本到图像检索任务中的性能。
- ELIP通过利用文本查询预测视觉提示来影响图像编码,适用于CLIP、SigLIP和BLIP-2等网络。
- 采用全球硬样本挖掘和大规模数据集的方法,以有限的计算资源进行架构训练。
- 设立两个新的域外分布(OOD)基准测试,即Occluded COCO和ImageNet-R,以评估模型在不同领域的零样本泛化能力。
- ELIP显著提升了CLIP/SigLIP/SigLIP-2在文本到图像检索任务上的表现。
- ELIP在多个基准测试中优于BLIP-2。
点此查看论文截图