⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-04 更新
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Authors:Andrea Boscolo Camiletto, Jian Wang, Eduardo Alvarado, Rishabh Dabral, Thabo Beeler, Marc Habermann, Christian Theobalt
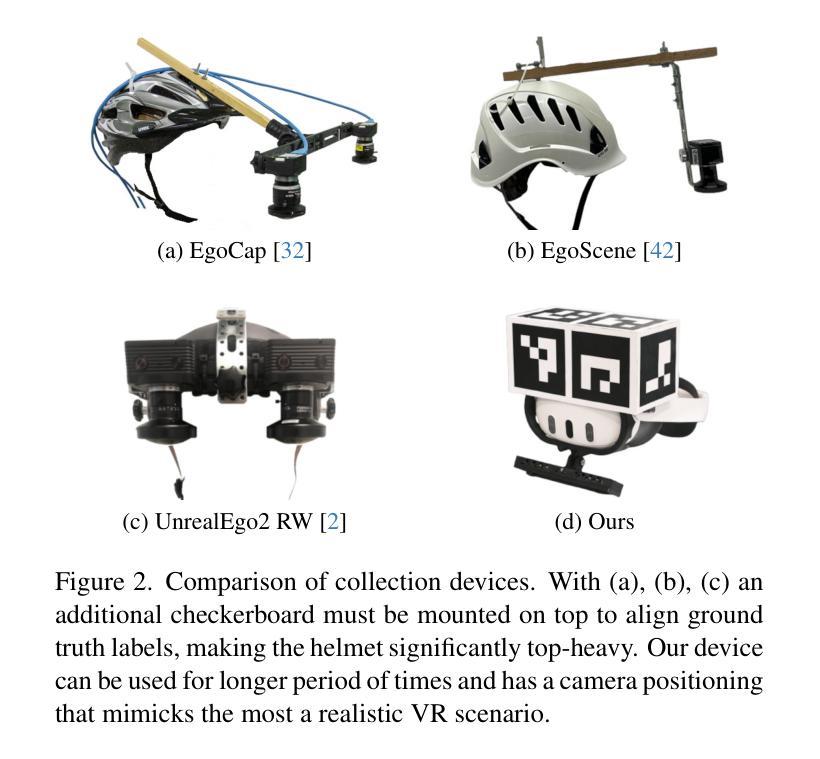
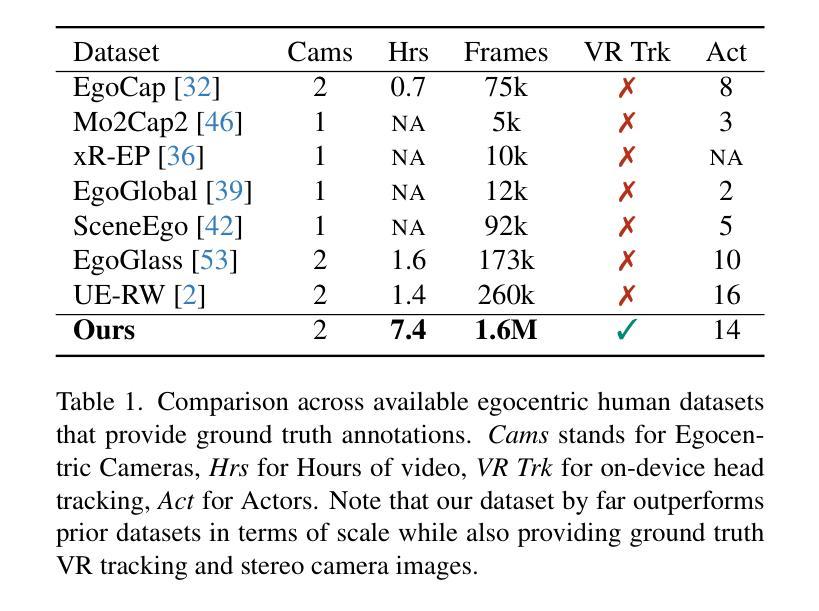
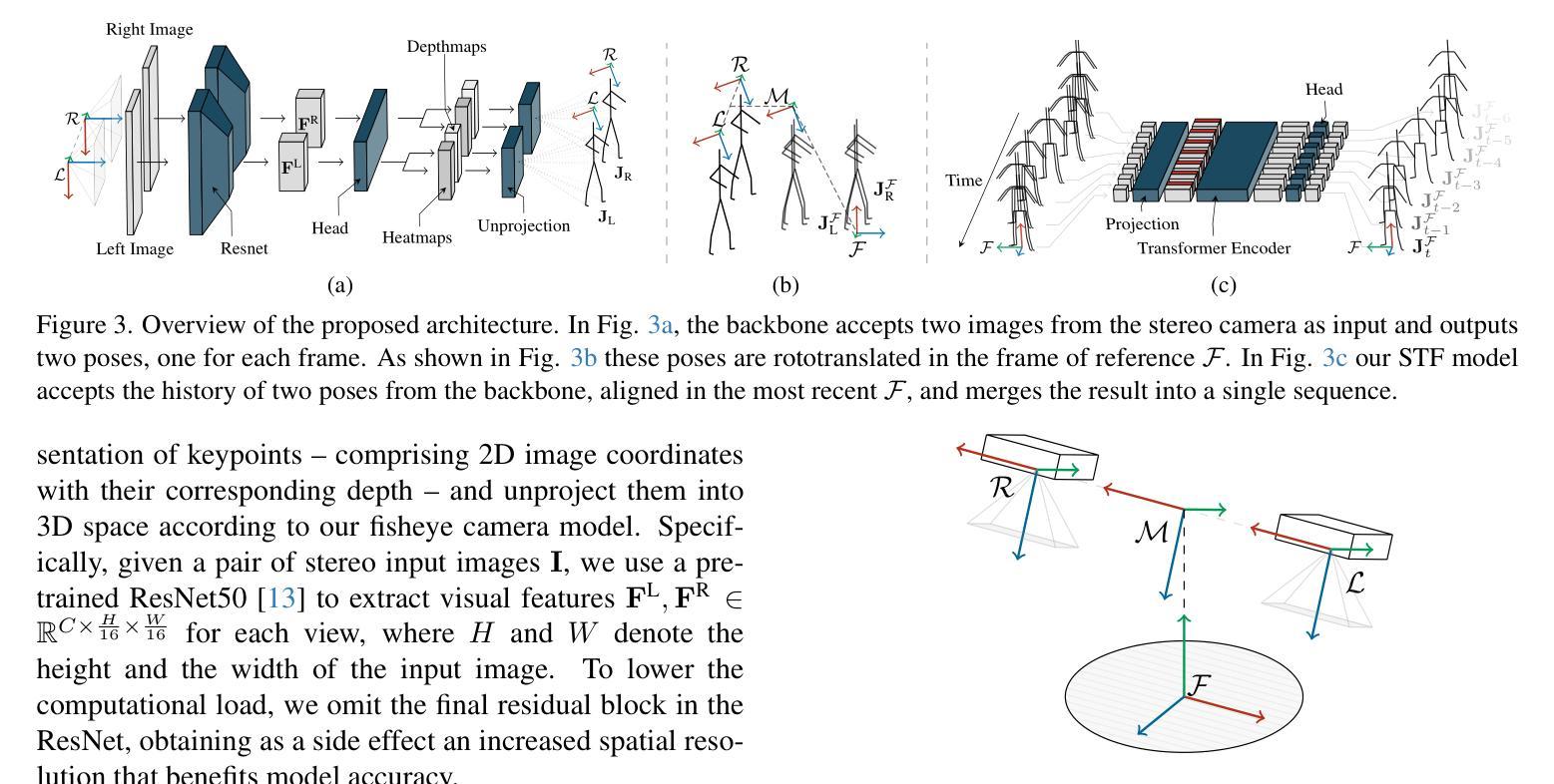
Egocentric motion capture with a head-mounted body-facing stereo camera is crucial for VR and AR applications but presents significant challenges such as heavy occlusions and limited annotated real-world data. Existing methods rely on synthetic pretraining and struggle to generate smooth and accurate predictions in real-world settings, particularly for lower limbs. Our work addresses these limitations by introducing a lightweight VR-based data collection setup with on-board, real-time 6D pose tracking. Using this setup, we collected the most extensive real-world dataset for ego-facing ego-mounted cameras to date in size and motion variability. Effectively integrating this multimodal input – device pose and camera feeds – is challenging due to the differing characteristics of each data source. To address this, we propose FRAME, a simple yet effective architecture that combines device pose and camera feeds for state-of-the-art body pose prediction through geometrically sound multimodal integration and can run at 300 FPS on modern hardware. Lastly, we showcase a novel training strategy to enhance the model’s generalization capabilities. Our approach exploits the problem’s geometric properties, yielding high-quality motion capture free from common artifacts in prior works. Qualitative and quantitative evaluations, along with extensive comparisons, demonstrate the effectiveness of our method. Data, code, and CAD designs will be available at https://vcai.mpi-inf.mpg.de/projects/FRAME/
以头戴式面向身体立体相机进行的以自我为中心的动态捕捉对于VR和AR应用至关重要,但它面临着严重的挑战,如严重的遮挡和有限的标注现实世界数据。现有方法依赖于合成预训练,难以在真实世界环境中生成平滑和准确的预测,特别是对于下肢。我们的工作通过引入基于轻量级VR的数据收集设置来解决这些限制,该设置具备内置实时6D姿态追踪功能。使用该设置,我们收集了迄今为止规模最大、动作变化最多的面向自我的头戴式相机真实世界数据集。有效整合这种多模式输入——设备姿态和相机馈送,由于每个数据源的特性不同,因此具有挑战性。为了解决这一问题,我们提出了FRAME,这是一种简单有效的架构,它通过几何稳健的多模式整合结合设备姿态和相机馈送,以进行最先进的身体姿态预测,并且可以在现代硬件上以300 FPS的速度运行。最后,我们展示了一种新型训练策略,以提高模型的泛化能力。我们的方法利用问题的几何属性,实现了高质量的运动捕捉,避免了先前工作中的常见伪影。定性和定量评估以及广泛的比较都证明了我们的方法的有效性。数据、代码和CAD设计将在https://vcai.mpi-inf.mpg.de/projects/FRAME/上提供。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
头显式VR装置对虚拟和增强现实应用中的自我运动捕捉非常重要,但面临严重遮挡和真实世界数据缺乏的问题。现有方法依赖于合成预训练,在真实场景中难以生成流畅准确的预测结果,尤其是对下肢的预测。为解决这些问题,本文提出了一种基于VR的轻量级数据采集设置方案,具有实时跟踪的六自由度姿态跟踪功能。我们收集了迄今为止规模最大、动作变化最多的面向自我、头戴式相机数据集。为了有效地整合设备姿态和相机输入,我们提出了FRAME架构,它通过几何结构合理的多模态整合,实现了最先进的姿态预测功能,可以在现代硬件上以每秒三百帧的速度运行。我们还展示了提高模型泛化能力的新训练策略。我们的方法利用问题的几何特性,实现了高质量的运动捕捉效果,消除了先前工作中的常见伪影。
Key Takeaways
- 头显式VR装置对于VR和AR应用的运动捕捉至关重要,但存在遮挡和真实数据缺乏的挑战。
- 现有方法依赖合成预训练,在真实场景中预测结果不够流畅和准确,尤其对下肢预测困难。
- 提出了一种基于VR的轻量级数据采集设置方案,结合实时六自由度姿态跟踪功能。
- 收集大规模、动作多样的面向自我、头戴式相机数据集。
- 引入FRAME架构,通过几何结构合理的多模态整合实现先进姿态预测功能。
- 展示提高模型泛化能力的新训练策略。
点此查看论文截图

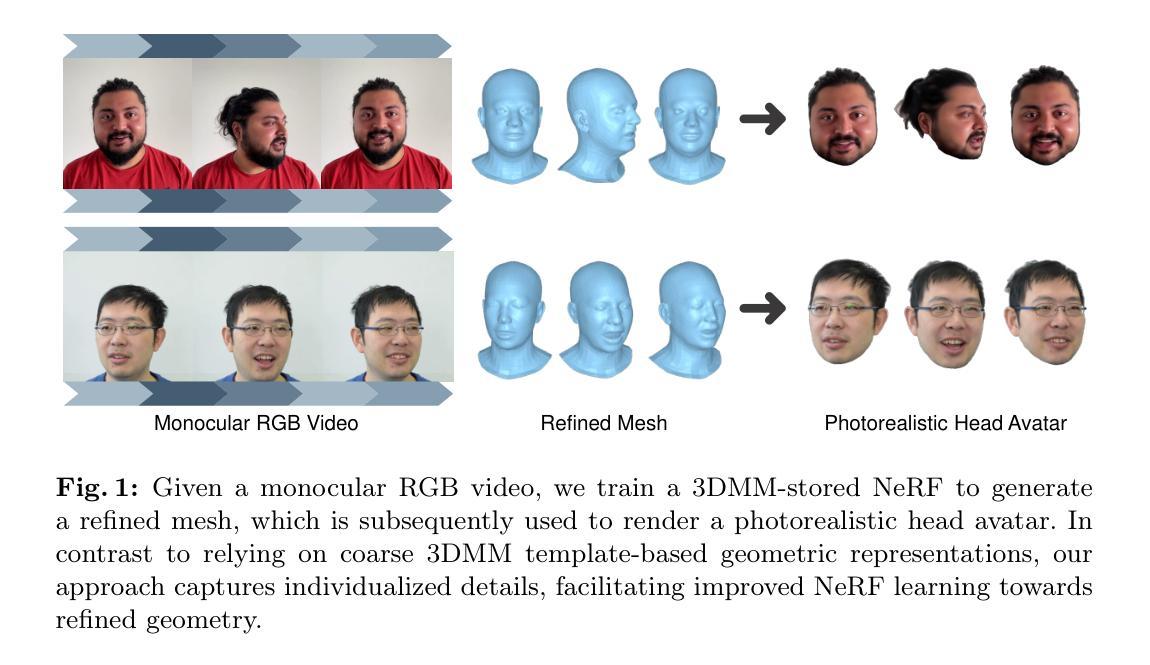
Refined Geometry-guided Head Avatar Reconstruction from Monocular RGB Video
Authors:Pilseo Park, Ze Zhang, Michel Sarkis, Ning Bi, Xiaoming Liu, Yiying Tong
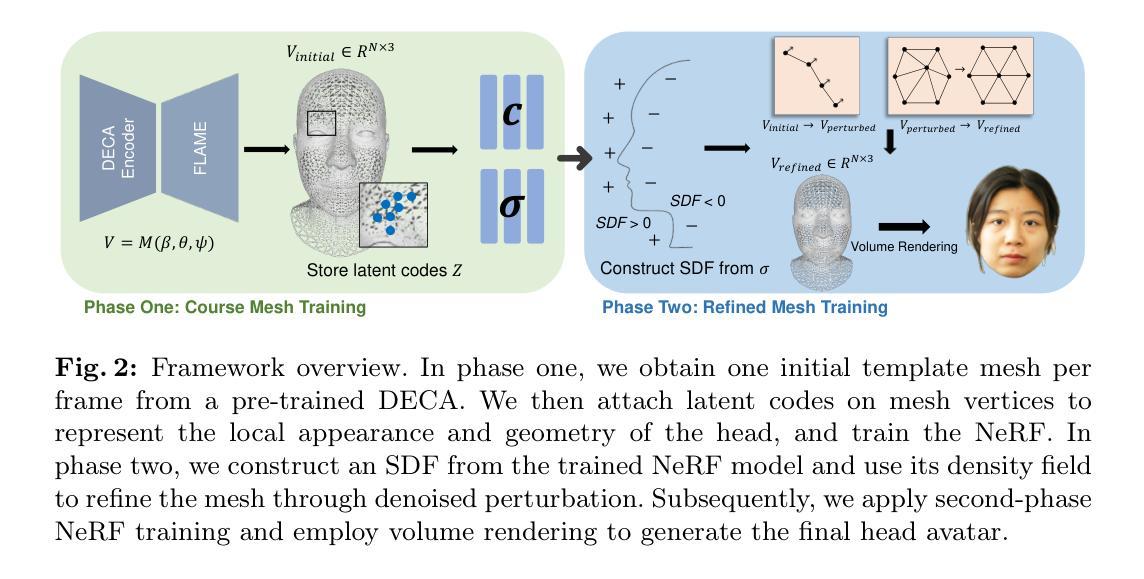
High-fidelity reconstruction of head avatars from monocular videos is highly desirable for virtual human applications, but it remains a challenge in the fields of computer graphics and computer vision. In this paper, we propose a two-phase head avatar reconstruction network that incorporates a refined 3D mesh representation. Our approach, in contrast to existing methods that rely on coarse template-based 3D representations derived from 3DMM, aims to learn a refined mesh representation suitable for a NeRF that captures complex facial nuances. In the first phase, we train 3DMM-stored NeRF with an initial mesh to utilize geometric priors and integrate observations across frames using a consistent set of latent codes. In the second phase, we leverage a novel mesh refinement procedure based on an SDF constructed from the density field of the initial NeRF. To mitigate the typical noise in the NeRF density field without compromising the features of the 3DMM, we employ Laplace smoothing on the displacement field. Subsequently, we apply a second-phase training with these refined meshes, directing the learning process of the network towards capturing intricate facial details. Our experiments demonstrate that our method further enhances the NeRF rendering based on the initial mesh and achieves performance superior to state-of-the-art methods in reconstructing high-fidelity head avatars with such input.
从头部的单目视频中重建高保真头像对于虚拟人类应用来说是非常理想的,但在计算机图形学和计算机视觉领域仍然是一个挑战。在本文中,我们提出了一种两阶段的头部头像重建网络,该网络结合了精细的3D网格表示。我们的方法与现有方法不同,后者依赖于从3DMM派生的粗糙模板基础上的3D表示。我们的方法旨在学习一个适合NeRF的精细网格表示,以捕捉复杂的面部细微差别。在第一阶段,我们使用初始网格对存储NeRF进行训练,以利用几何先验并整合跨帧的观察结果,使用一致的潜在代码集。在第二阶段,我们利用基于初始NeRF密度场构建的SDF的新型网格细化程序。为了减轻NeRF密度场的典型噪声,同时不损害3DMM的特征,我们对位移场应用拉普拉斯平滑处理。随后,我们使用这些精细网格进行第二阶段训练,引导网络学习捕捉复杂的面部细节。我们的实验表明,我们的方法在基于初始网格的NeRF渲染上进行了进一步的增强,并在使用此类输入重建高保真头像方面达到了优于最新技术的方法的性能。
论文及项目相关链接
Summary
高保真重建头显虚拟角色对于虚拟人类应用具有重要意义,在计算机图形学和计算机视觉领域具有挑战性。本文提出了一种采用精细三维网格表示的两阶段头显虚拟角色重建网络。该方法旨在学习适合NeRF的精细网格表示,以捕捉复杂的面部细节,而不依赖于基于粗糙模板的三维模型。首先训练基于初始网格的三维模型NeRF,利用几何先验知识和跨帧观察的一致潜在代码集进行集成。然后在第二阶段,利用基于初始NeRF密度场的符号距离函数(SDF)构建的新颖网格优化程序进行网格优化。通过对位移场应用拉普拉斯平滑,减轻了NeRF密度场的典型噪声,同时不损失三维模型的特征。实验表明,该方法在基于初始网格的NeRF渲染上取得了进一步的提升,并在重建高保真头显虚拟角色方面达到了优于现有技术的方法的性能。
Key Takeaways
- 高保真重建头显虚拟角色在计算机图形学和计算机视觉领域具有挑战性。
- 提出了一种采用精细三维网格表示的两阶段头显虚拟角色重建网络。
- 方法不依赖于基于粗糙模板的三维模型,旨在学习适合NeRF的精细网格表示。
- 第一阶段训练基于初始网格的三维模型NeRF,利用几何先验知识和跨帧观察进行集成。
- 第二阶段利用基于初始NeRF密度场的符号距离函数进行网格优化。
- 通过拉普拉斯平滑处理NeRF密度场的噪声,同时保持三维模型的特征。
点此查看论文截图

Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
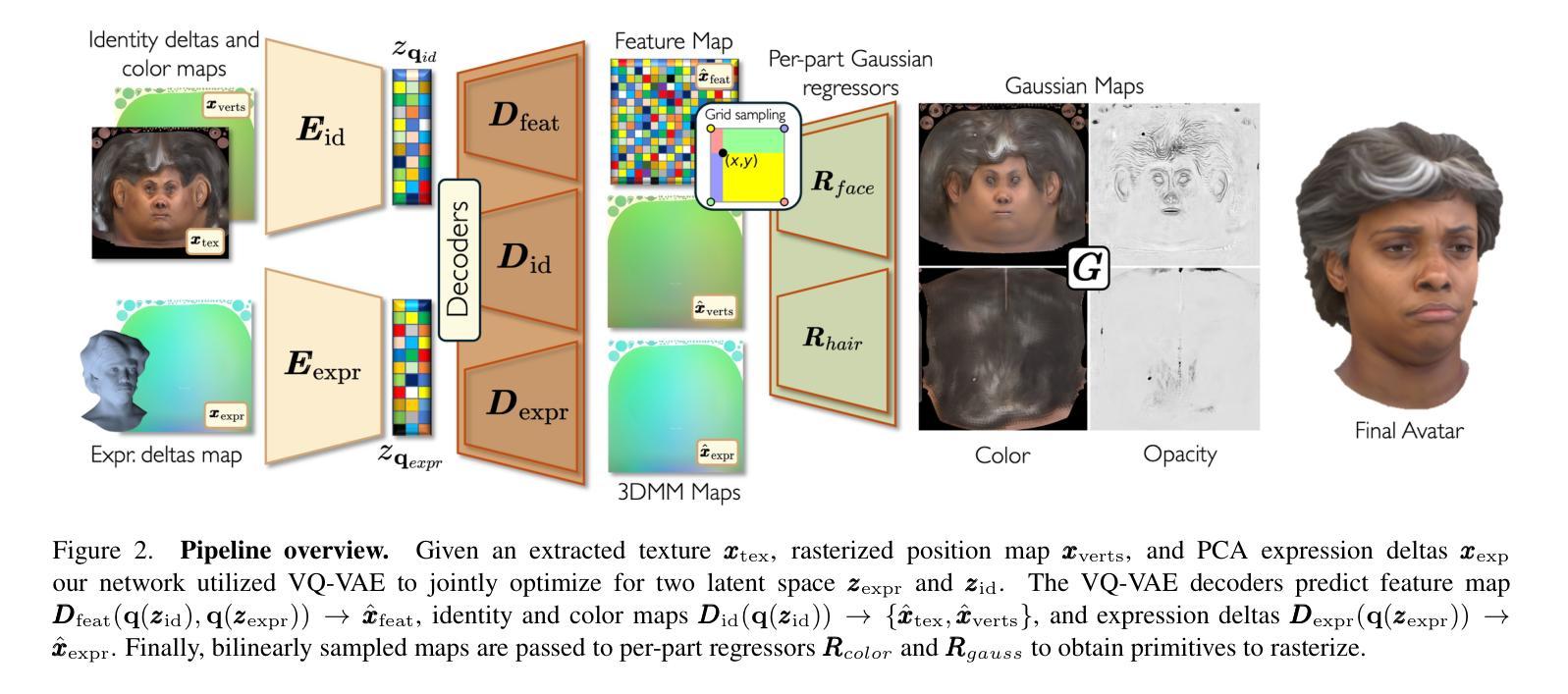
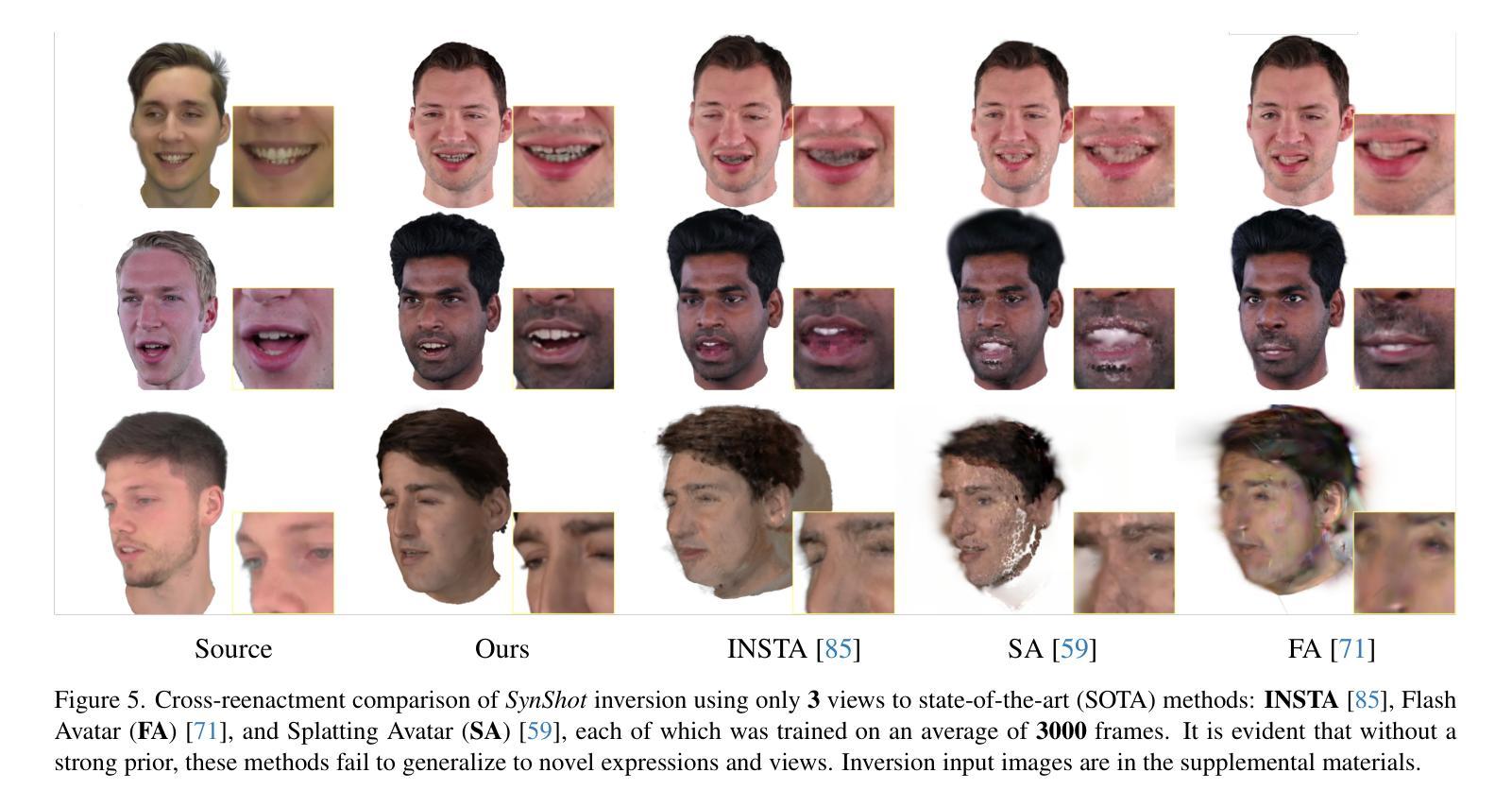
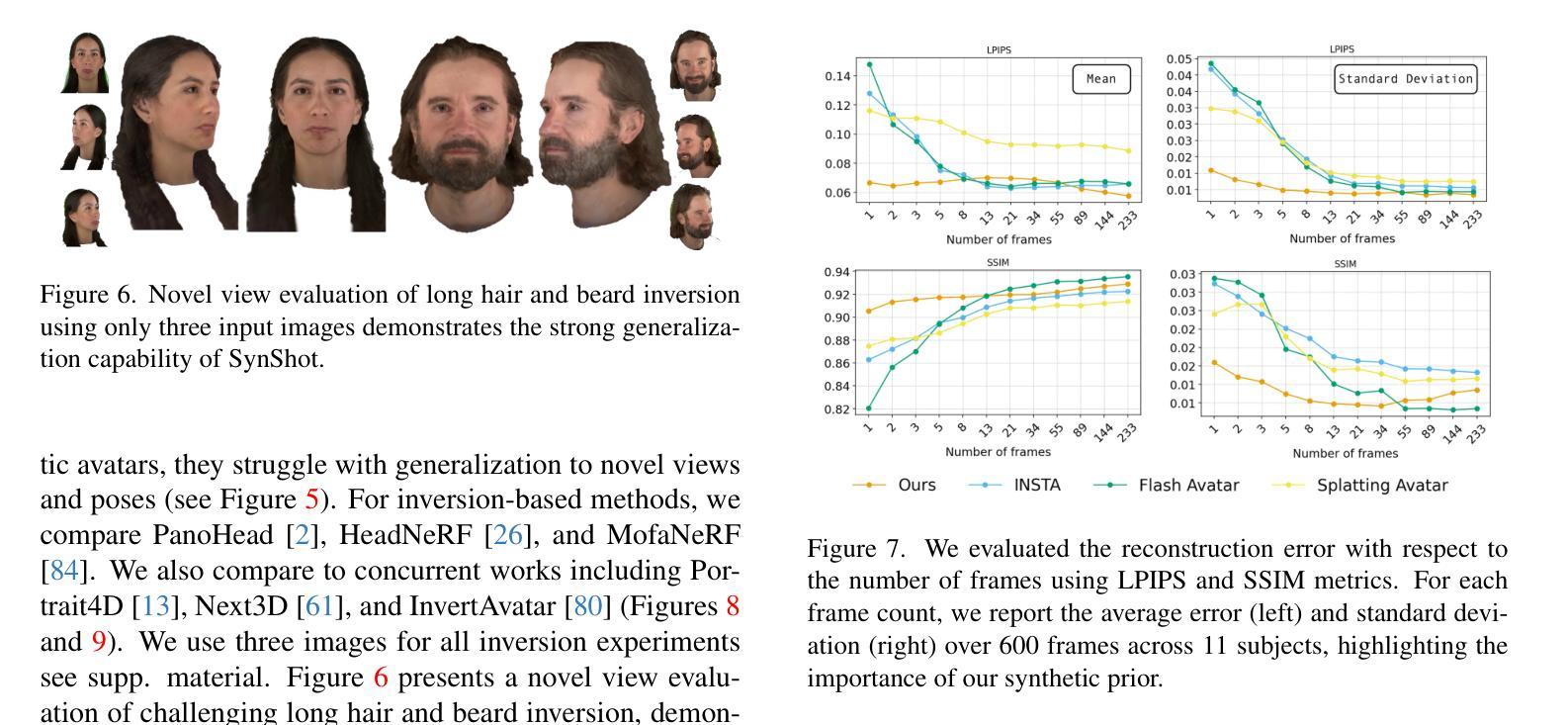
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了一种名为SynShot的新方法,用于基于合成先验的少数驱动头部化身倒置。我们解决了三个主要挑战。首先,训练可控的3D生成网络需要大量的不同序列,而图像和高品质跟踪网格的配对并不总是可用。其次,真实数据的使用受到严格监管(例如,根据《通用数据保护条例》,当参与者的同意被撤回时,需要频繁删除模型和数剧)。不受这些约束的合成数据是一个吸引人的替代方案。第三,最先进的单眼化身模型很难推广到新的视角和表情,缺乏强大的先验知识,并且经常过度适应特定的视角分布。受仅受合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从包含各种身份、表情和视角的大型合成头部数据集中学习先验模型。凭借少数输入图像,SynShot微调了预训练的合成先验,以弥合领域差距,建模一个通用到各种表情和视角的光头化身。我们使用三维高斯拼贴和卷积编码器-解码器来建模头部化身,输出UV纹理空间的高斯参数。为了考虑头部不同部分的建模复杂性(例如皮肤和头发),我们在先验嵌入中嵌入了一种显式控制机制,用于增加每个部分的原始数量。与最新单眼和基于GAN的方法相比,SynShot在新型视角和表情合成方面取得了显著改善。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
在应对缺乏数据以及保护数据隐私等多重挑战下,我们提出了一种名为SynShot的新方法,用于基于合成先验的少数驱动头部化身。通过利用合成数据摆脱现实数据的限制,并结合大型合成头部数据集学习先验模型,我们的方法在少量输入图像的基础上精细调整先验模型,缩小领域差距,创建能够推广到全新表情和视点的逼真头部化身。此外,我们还采用3D高斯涂片和卷积编码器-解码器进行头部化身建模,并在UV纹理空间中输出高斯参数。为了应对头部不同部分的建模复杂性差异(如皮肤和头发),我们在先验嵌入中加入了明确的控制机制,可以按需增加各部分原始数据的数量。相较于当前主流的单目和基于GAN的方法,SynShot在新型视角和表情合成方面表现更为出色。
Key Takeaways
- SynShot是一种基于合成先验的少数驱动头部化身方法。
- 该方法解决了训练可控的3D生成网络中的主要挑战,如数据多样性和真实数据的监管问题。
- 使用合成数据作为替代,摆脱了真实数据的限制。
- 通过大型合成头部数据集学习先验模型。
- 精细调整先验模型以缩小领域差距,创建逼真的头部化身,并能推广到新的表情和视角。
- 采用3D高斯涂片和卷积编码器-解码器进行头部化身建模。
点此查看论文截图