⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-03 更新
Is Temporal Prompting All We Need For Limited Labeled Action Recognition?
Authors:Shreyank N Gowda, Boyan Gao, Xiao Gu, Xiaobo Jin
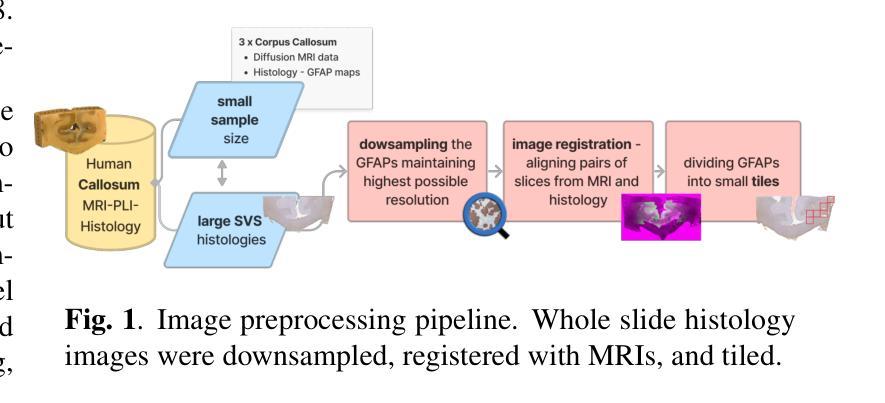
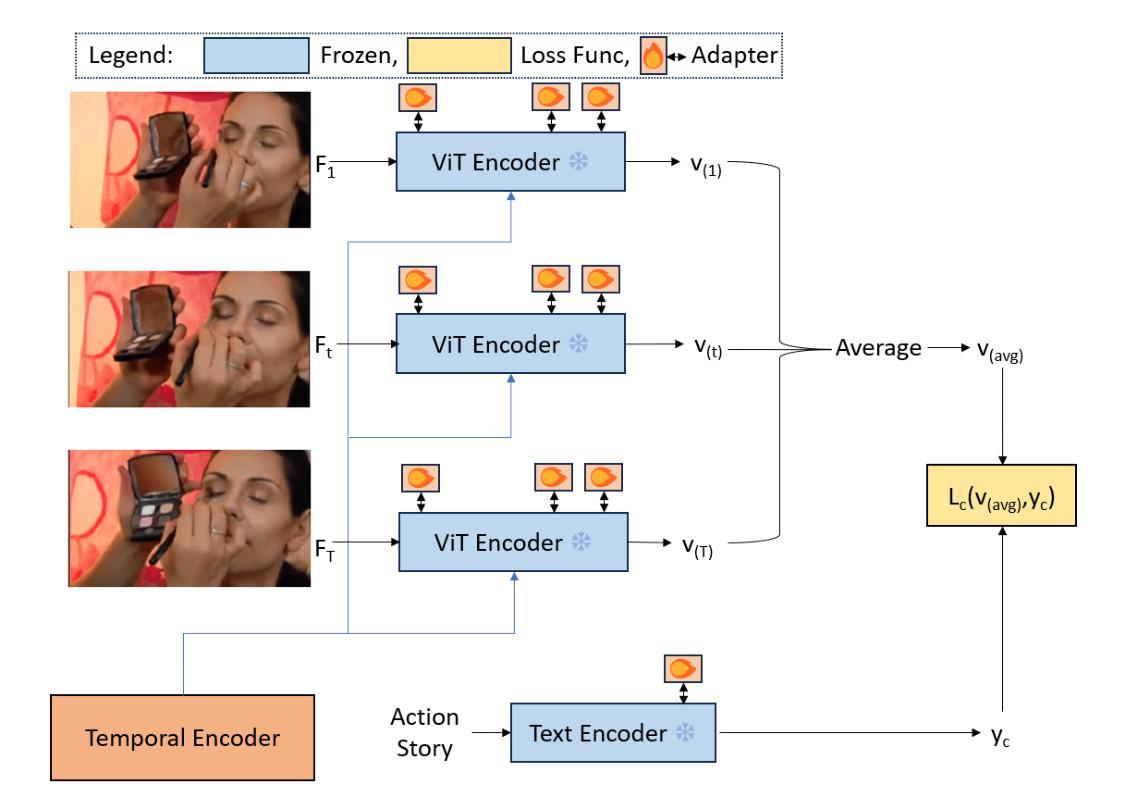
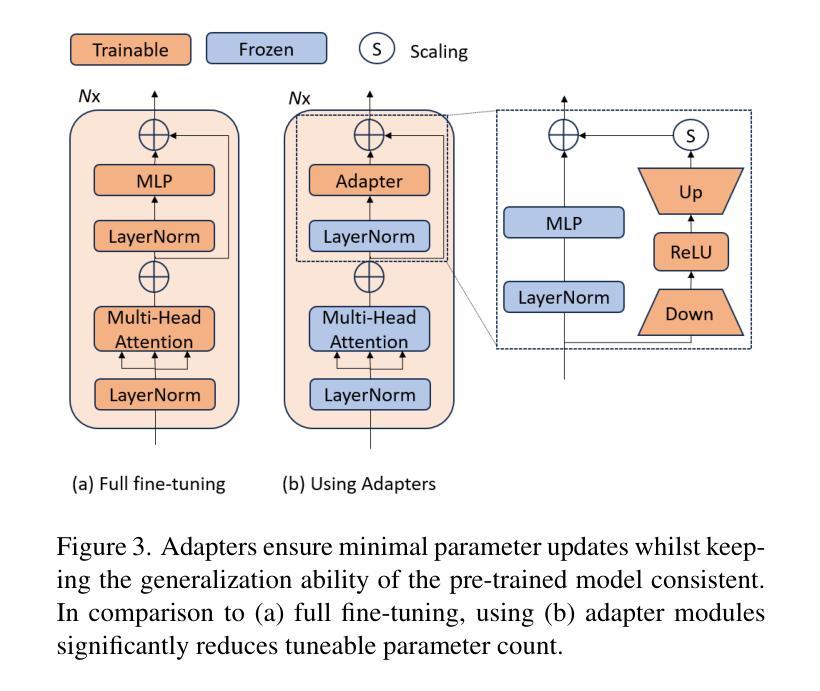
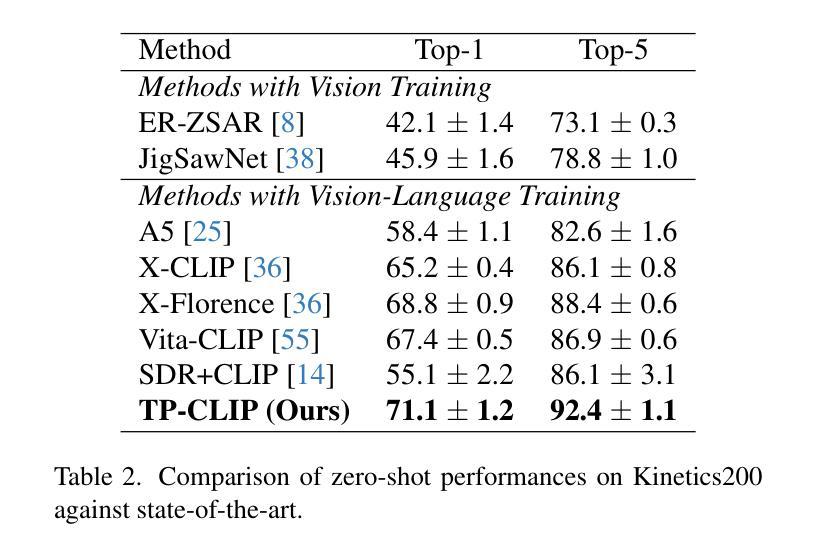
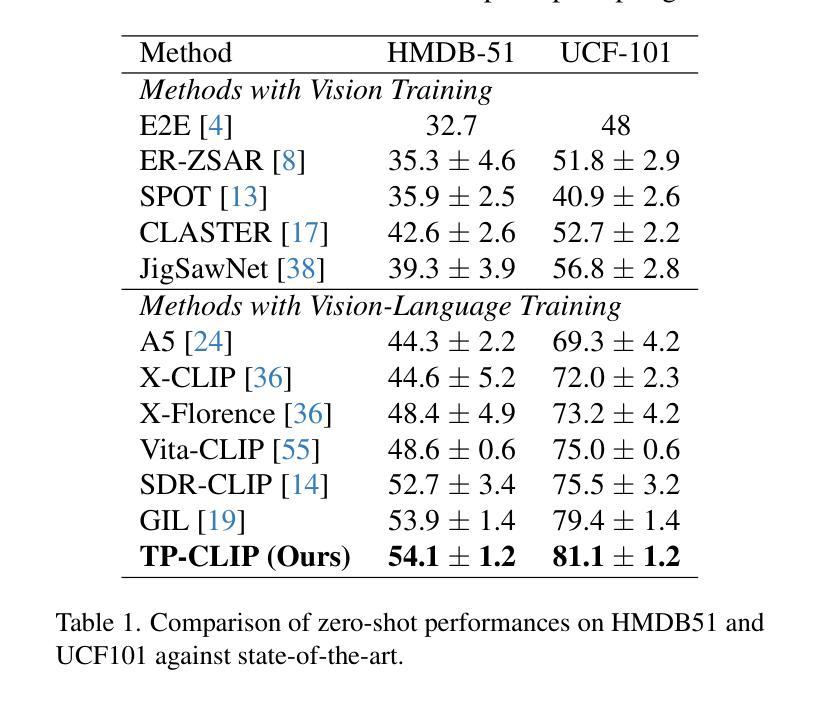
Video understanding has shown remarkable improvements in recent years, largely dependent on the availability of large scaled labeled datasets. Recent advancements in visual-language models, especially based on contrastive pretraining, have shown remarkable generalization in zero-shot tasks, helping to overcome this dependence on labeled datasets. Adaptations of such models for videos, typically involve modifying the architecture of vision-language models to cater to video data. However, this is not trivial, since such adaptations are mostly computationally intensive and struggle with temporal modeling. We present TP-CLIP, an adaptation of CLIP that leverages temporal visual prompting for temporal adaptation without modifying the core CLIP architecture. This preserves its generalization abilities. TP-CLIP efficiently integrates into the CLIP architecture, leveraging its pre-trained capabilities for video data. Extensive experiments across various datasets demonstrate its efficacy in zero-shot and few-shot learning, outperforming existing approaches with fewer parameters and computational efficiency. In particular, we use just 1/3 the GFLOPs and 1/28 the number of tuneable parameters in comparison to recent state-of-the-art and still outperform it by up to 15.8% depending on the task and dataset.
视频理解在最近几年取得了显著的进步,这很大程度上依赖于大规模标注数据集的可用性。基于对比预训练的视觉语言模型的最新进展在零样本任务中表现出了显著的泛化能力,有助于克服对标注数据集的依赖。此类模型对视频的适应通常涉及调整视觉语言模型的架构以适应视频数据。然而,这并不是一件简单的事,因为这种适应通常需要大量的计算并且面临时间建模的挑战。我们提出了TP-CLIP,这是CLIP的一种适应版本,它利用时间视觉提示进行时间适应,而无需修改CLIP架构的核心部分,从而保留了其泛化能力。TP-CLIP有效地集成到CLIP架构中,利用其对视频数据的预训练能力。在不同数据集上的大量实验表明,它在零样本和少样本学习中的有效性,使用较少的参数和计算效率就能超越现有方法。特别是,我们使用的GFLOPs只有最近的先进水平的1/3,可调参数的数量是1/28,根据任务和数据集的不同,仍然能超出其性能高达15.8%。
论文及项目相关链接
PDF Accepted in CVPR-W 2025
Summary
视觉理解和视觉语言模型在近年的研究中取得显著进步,尤其依赖大规模标注数据集。基于对比预训练的模型在零样本任务中展现出强大的泛化能力。本文介绍TP-CLIP模型,它在CLIP模型基础上进行改进,通过利用时空视觉提示实现时空适应,无需修改核心CLIP架构,保留了其泛化能力。TP-CLIP高效集成于CLIP架构中,利用其对视频数据的预训练能力。实验证明其在零样本和少样本学习中的有效性,相较于其他最新技术使用更少的参数和计算资源,表现出更高的性能。特别是在与最新技术相比,使用较少的GFLOPs和参数数量的情况下,依然能在不同任务和数据集上高出最高达15.8%的性能。
Key Takeaways
- 视频理解和视觉语言模型依赖大规模标注数据集取得显著进步。
- 基于对比预训练的模型展现出强大的零样本任务泛化能力。
- TP-CLIP模型改进了CLIP架构,利用时空视觉提示实现时空适应。
- TP-CLIP保留了CLIP的泛化能力且无需修改核心架构。
- TP-CLIP集成了高效的视频数据处理能力,利用预训练能力应对视频数据。
- 实验证明TP-CLIP在零样本和少样本学习中的有效性优于其他技术。
- TP-CLIP在参数和计算资源使用上更为高效,性能表现优异。
点此查看论文截图

CoRAG: Collaborative Retrieval-Augmented Generation
Authors:Aashiq Muhamed, Mona Diab, Virginia Smith
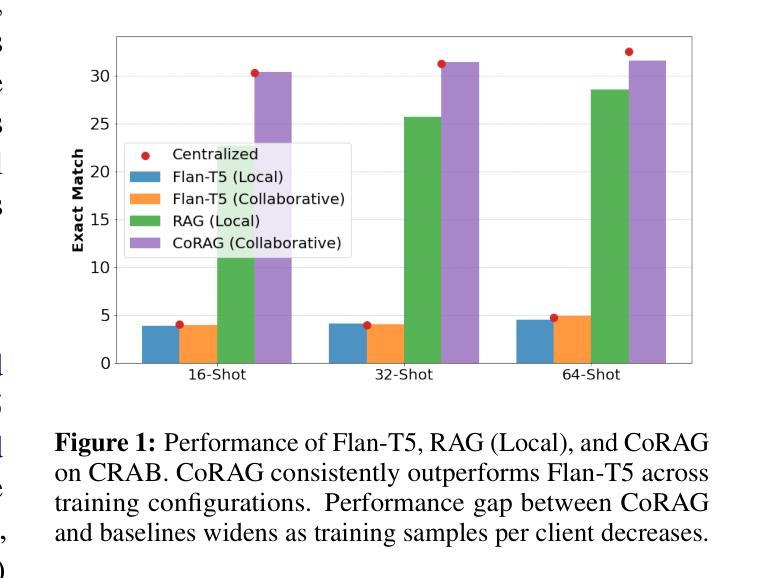
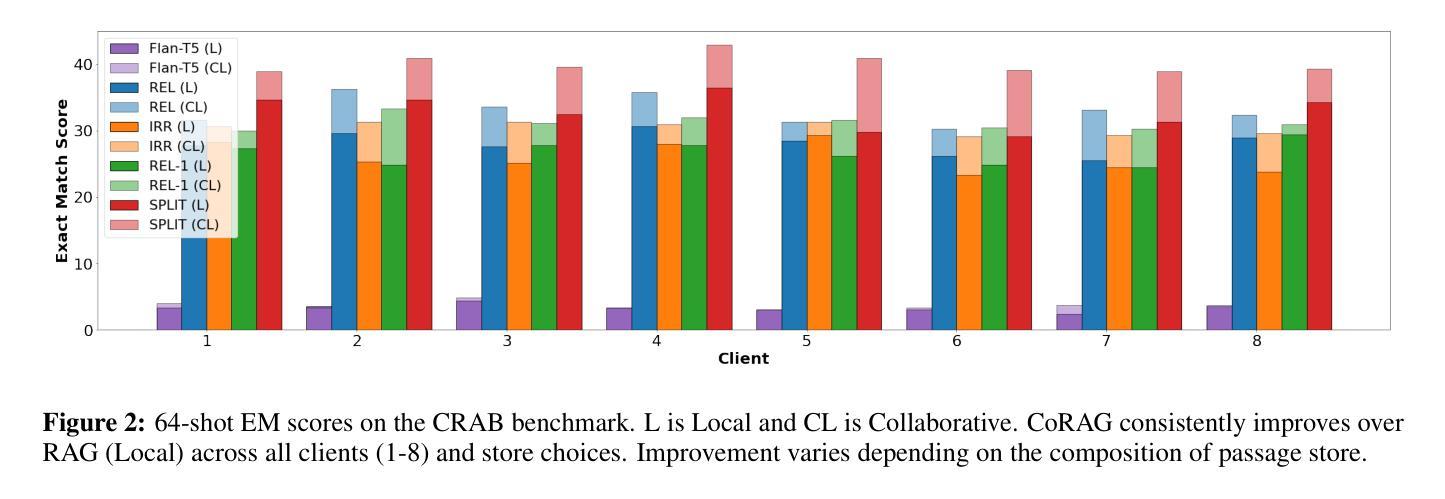
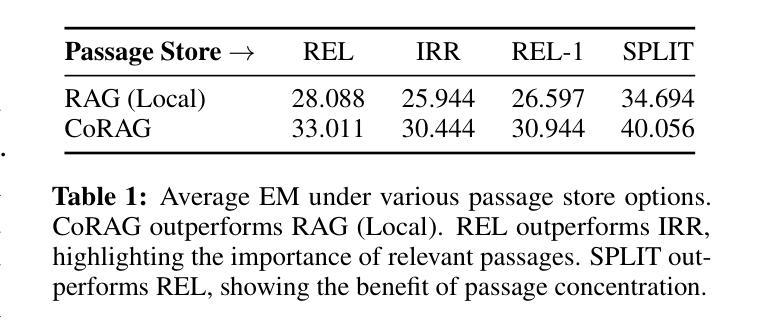
Retrieval-Augmented Generation (RAG) models excel in knowledge-intensive tasks, especially under few-shot learning constraints. We introduce CoRAG, a framework extending RAG to collaborative settings, where clients jointly train a shared model using a collaborative passage store. To evaluate CoRAG, we introduce CRAB, a benchmark for collaborative homogeneous open-domain question answering. Our experiments demonstrate that CoRAG consistently outperforms both parametric collaborative learning methods and locally trained RAG models in low-resource scenarios. Further analysis reveals the critical importance of relevant passages within the shared store, the surprising benefits of incorporating irrelevant passages, and the potential for hard negatives to negatively impact performance. This introduces a novel consideration in collaborative RAG: the trade-off between leveraging a collectively enriched knowledge base and the potential risk of incorporating detrimental passages from other clients. Our findings underscore the viability of CoRAG, while also highlighting key design challenges and promising avenues for future research.
检索增强生成(RAG)模型在知识密集型任务上表现出色,尤其是在小样本学习约束下。我们介绍了CoRAG,这是一个将RAG扩展到协作设置中的框架,客户端使用协作段落存储来共同训练共享模型。为了评估CoRAG,我们推出了CRAB,这是一个用于协作同构开放域问答的基准测试。我们的实验表明,在资源匮乏的场景下,CoRAG始终优于参数化协作学习方法以及本地训练的RAG模型。进一步的分析揭示了共享存储中的相关段落的重要性,以及融入不相关段落的意外好处,以及硬负样本可能对性能产生的负面影响。这为协作RAG引入了一种新的考虑因素:在利用集体丰富的知识库和可能的风险之间权衡,后者来自融入来自其他客户端的不利段落。我们的研究结果强调了CoRAG的可行性,同时突出了关键的设计挑战以及未来研究的希望方向。
论文及项目相关链接
PDF NAACL 2024
Summary
CoRAG框架扩展了RAG模型,使其适应协作环境。在知识密集型任务中,特别是在小样本学习场景下,CoRAG通过共同训练共享模型和协作段落存储来表现出色。通过引入CRAB基准测试来评估CoRAG的效果,显示其在低资源场景中始终优于参数化协作学习方法和本地训练的RAG模型。研究进一步分析了共享存储中的关键段落的重要性,并揭示了不相关段落和硬负样本对性能的影响,为协作RAG提出了权衡考虑:在利用集体丰富的知识库和可能引入有害段落之间取得平衡。研究强调了CoRAG的可行性,并指出了关键的设计挑战和未来的研究方向。
Key Takeaways
- CoRAG框架扩展了RAG模型,使其能在协作环境中运行。
- CoRAG在知识密集型任务中表现出色,尤其是在小样本学习场景中。
- CoRAG通过共同训练共享模型和协作段落存储来提升性能。
- CRAB基准测试用于评估CoRAG的效果。
- CoRAG在低资源场景中优于其他方法。
- 分析了共享存储中的关键段落的重要性。
点此查看论文截图


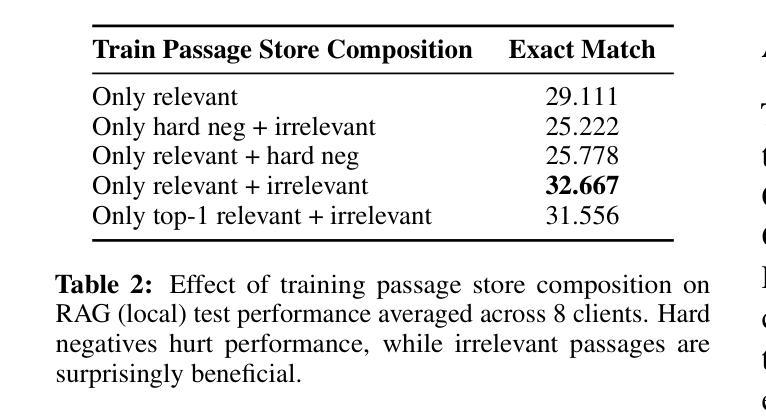
UniFault: A Fault Diagnosis Foundation Model from Bearing Data
Authors:Emadeldeen Eldele, Mohamed Ragab, Xu Qing, Edward, Zhenghua Chen, Min Wu, Xiaoli Li, Jay Lee
Machine fault diagnosis (FD) is a critical task for predictive maintenance, enabling early fault detection and preventing unexpected failures. Despite its importance, existing FD models are operation-specific with limited generalization across diverse datasets. Foundation models (FM) have demonstrated remarkable potential in both visual and language domains, achieving impressive generalization capabilities even with minimal data through few-shot or zero-shot learning. However, translating these advances to FD presents unique hurdles. Unlike the large-scale, cohesive datasets available for images and text, FD datasets are typically smaller and more heterogeneous, with significant variations in sampling frequencies and the number of channels across different systems and applications. This heterogeneity complicates the design of a universal architecture capable of effectively processing such diverse data while maintaining robust feature extraction and learning capabilities. In this paper, we introduce UniFault, a foundation model for fault diagnosis that systematically addresses these issues. Specifically, the model incorporates a comprehensive data harmonization pipeline featuring two key innovations. First, a unification scheme transforms multivariate inputs into standardized univariate sequences while retaining local inter-channel relationships. Second, a novel cross-domain temporal fusion strategy mitigates distribution shifts and enriches sample diversity and count, improving the model generalization across varying conditions. UniFault is pretrained on over 9 billion data points spanning diverse FD datasets, enabling superior few-shot performance. Extensive experiments on real-world FD datasets demonstrate that UniFault achieves SoTA performance, setting a new benchmark for fault diagnosis models and paving the way for more scalable and robust predictive maintenance solutions.
机器故障诊断(FD)是预测性维护中的一项关键任务,能够实现早期故障检测并防止意外故障。尽管其重要性很高,但现有的FD模型都是针对特定操作的,在多种数据集上的泛化能力有限。基础模型(FM)在视觉和语言领域都展现出了引人注目的潜力,即使在通过少量数据的情况下,也能实现令人印象深刻的泛化能力。然而,将这些进展应用于FD却存在独特的障碍。与可用于图像和文本的大规模、连贯数据集不同,FD数据集通常较小且更加多样化,不同系统和应用之间的采样频率和数据通道数量存在重大差异。这种异质性使得设计一个能够处理这种多样化数据的通用架构变得更加复杂,同时还需要保持强大的特征提取和学习能力。在本文中,我们介绍了UniFault,这是一个用于故障诊断的基础模型,系统地解决了这些问题。具体来说,该模型采用全面的数据调和管道,包含两个关键创新点。首先,统一方案将多元输入转换为标准化的单变量序列,同时保留局部通道间关系。其次,一种新的跨域时间融合策略缓解了分布偏移问题并丰富了样本的多样性和数量,提高了模型在不同条件下的泛化能力。UniFault在跨越多种FD数据集超过9亿个数据点上进行预训练,实现了出色的少量样本性能。在真实世界的FD数据集上进行的广泛实验表明,UniFault达到了最新技术性能,为故障诊断模型设定了新的基准,并为更可扩展和稳健的预测性维护解决方案铺平了道路。
论文及项目相关链接
Summary
本文介绍了UniFault这一故障预测模型,该模型解决了现有故障预测模型在多样数据集上泛化能力受限的问题。文章通过引入数据调和管道和跨域时间融合策略,实现了对多元输入的标准化一元序列转换,并丰富了样本多样性和数量,提高了模型在不同条件下的泛化能力。UniFault在真实故障预测数据集上的表现达到了最新水平,为故障预测模型树立了新的标杆,为更可扩展和稳健的预测维护解决方案铺平了道路。
Key Takeaways
以下是基于文本内容的七个关键见解:
- 故障诊断(FD)是预测性维护中的关键任务,有助于早期故障检测并避免意外故障。
- 尽管重要,但现有的FD模型在操作上具有特定性,在多样数据集上的泛化能力受限。
- Foundation模型(FM)在视觉和语言领域展现了巨大的潜力,即使在少量数据下也能实现令人印象深刻的泛化能力。
- 将FM的进展应用于FD面临独特挑战,因为FD数据集通常较小、更异质。
- UniFault是一个针对故障诊断的foundation模型,通过数据调和管道解决这些问题。
- UniFault模型包含两个关键创新:统一方案将多元输入转换为标准化一元序列,同时保留局部通道间关系;跨域时间融合策略缓解分布偏移并丰富样本多样性和数量。
点此查看论文截图

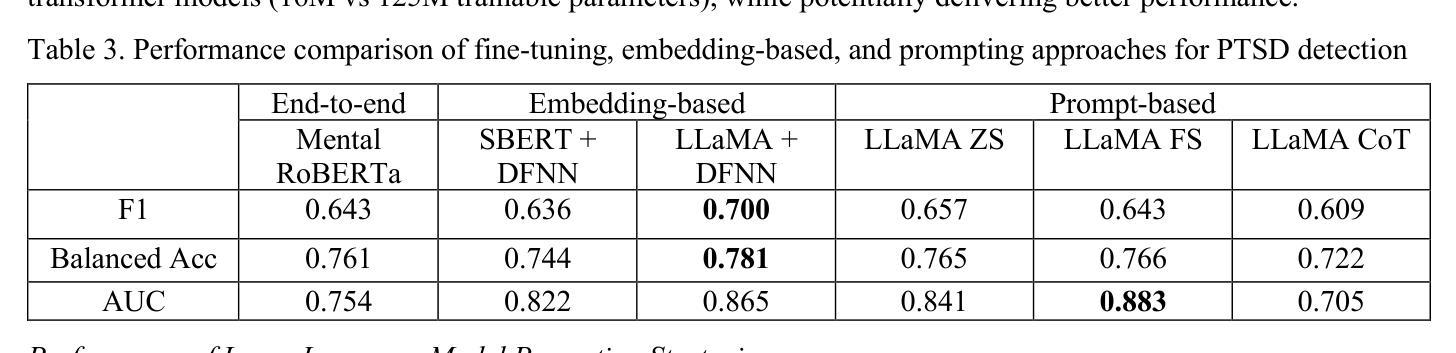
Detecting PTSD in Clinical Interviews: A Comparative Analysis of NLP Methods and Large Language Models
Authors:Feng Chen, Dror Ben-Zeev, Gillian Sparks, Arya Kadakia, Trevor Cohen
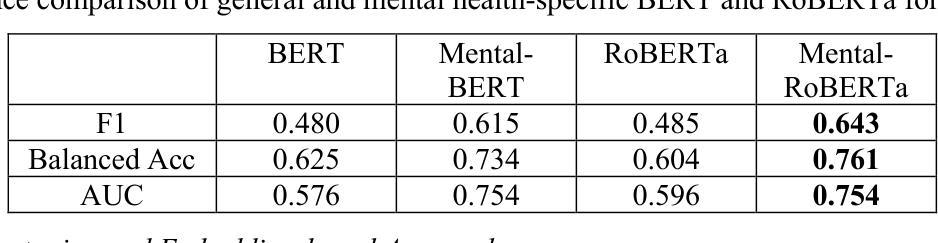
Post-Traumatic Stress Disorder (PTSD) remains underdiagnosed in clinical settings, presenting opportunities for automated detection to identify patients. This study evaluates natural language processing approaches for detecting PTSD from clinical interview transcripts. We compared general and mental health-specific transformer models (BERT/RoBERTa), embedding-based methods (SentenceBERT/LLaMA), and large language model prompting strategies (zero-shot/few-shot/chain-of-thought) using the DAIC-WOZ dataset. Domain-specific models significantly outperformed general models (Mental-RoBERTa F1=0.643 vs. RoBERTa-base 0.485). LLaMA embeddings with neural networks achieved the highest performance (F1=0.700). Zero-shot prompting using DSM-5 criteria yielded competitive results without training data (F1=0.657). Performance varied significantly across symptom severity and comorbidity status, with higher accuracy for severe PTSD cases and patients with comorbid depression. Our findings highlight the potential of domain-adapted embeddings and LLMs for scalable screening while underscoring the need for improved detection of nuanced presentations and offering insights for developing clinically viable AI tools for PTSD assessment.
创伤后应激障碍(PTSD)在临床环境中的诊断率仍然较低,为自动检测识别患者提供了机会。本研究评估了从临床访谈记录中检测PTSD的自然语言处理方法。我们比较了通用和心理健康专用变压器模型(BERT/RoBERTa)、基于嵌入的方法(SentenceBERT/LLaMA),以及大型语言模型的提示策略(零样本/少样本/思维链)使用DAIC-WOZ数据集。特定领域的模型显著优于通用模型(Mental-RoBERTa的F1分数为0.643,而RoBERTa-base的F1分数为0.485)。LLaMA嵌入与神经网络相结合取得了最佳性能(F1分数为0.700)。使用DSM-5标准的零样本提示在没有训练数据的情况下取得了具有竞争力的结果(F1分数为0.657)。性能在症状严重程度和合并症状态之间差异显著,严重PTSD患者和伴有抑郁症患者的准确率更高。我们的研究结果突出了领域适应嵌入和大型语言模型在可扩展筛查中的潜力,同时强调了需要改进微妙表现的检测,并为开发用于PTSD评估的临床可行的AI工具提供了见解。
论文及项目相关链接
PDF 10 pages, 4 tables, 1 figure
Summary
本文研究使用自然语言处理技术对创伤后应激障碍(PTSD)进行自动检测。通过对比多种模型方法,发现特定领域的模型在检测PTSD时表现优于通用模型,LLaMA嵌入神经网络的方法性能最佳。此外,使用DSM-5标准的零样本提示法在无训练数据的情况下也表现出竞争力。性能会因症状严重程度和共病状况而有所不同,对于严重PTSD和共病抑郁症患者的检测准确性更高。研究为开发临床可行的AI工具进行PTSD评估提供了重要见解。
Key Takeaways
- 自然语言处理技术可用于自动检测创伤后应激障碍(PTSD)。
- 特定领域的模型在检测PTSD时表现优于通用模型。
- LLaMA嵌入神经网络的方法在性能上表现最佳。
- 零样本提示法在无训练数据的情况下具有竞争力。
- 性能会因症状严重程度和共病状况而有所不同。
- 严重PTSD和共病抑郁症患者的检测准确性更高。
点此查看论文截图


Aplicação de Large Language Models na Análise e Síntese de Documentos Jurídicos: Uma Revisão de Literatura
Authors:Matheus Belarmino, Rackel Coelho, Roberto Lotudo, Jayr Pereira
Large Language Models (LLMs) have been increasingly used to optimize the analysis and synthesis of legal documents, enabling the automation of tasks such as summarization, classification, and retrieval of legal information. This study aims to conduct a systematic literature review to identify the state of the art in prompt engineering applied to LLMs in the legal context. The results indicate that models such as GPT-4, BERT, Llama 2, and Legal-Pegasus are widely employed in the legal field, and techniques such as Few-shot Learning, Zero-shot Learning, and Chain-of-Thought prompting have proven effective in improving the interpretation of legal texts. However, challenges such as biases in models and hallucinations still hinder their large-scale implementation. It is concluded that, despite the great potential of LLMs for the legal field, there is a need to improve prompt engineering strategies to ensure greater accuracy and reliability in the generated results.
大型语言模型(LLM)在法律文档的分析和合成中得到了越来越多的应用,实现了摘要、分类和检索等法律信息的自动化。本研究旨在进行文献的系统回顾,以确定在法律背景下应用于LLM的提示工程的最先进状态。结果表明,GPT-4、BERT、Llama 2和Legal-Pegasus等模型在法律领域得到了广泛应用,而Few-shot Learning、Zero-shot Learning和Chain-of-Thought提示等技术已被证明在提高法律文本解释方面非常有效。然而,模型中的偏见和幻觉等挑战仍然阻碍其大规模实施。因此,尽管LLM对法律领域具有巨大潜力,但仍需要改进提示工程策略,以确保生成结果具有更高的准确性和可靠性。
论文及项目相关链接
PDF in Portuguese language
Summary
LLMs已广泛应用于法律文档的分析与合成优化,实现了如摘要、分类和检索等任务的自动化。本研究旨在通过系统文献综述,识别在LLMs中应用于法律语境的提示工程现状。研究表明,GPT-4、BERT、Llama 2和Legal-Pegasus等模型在法律领域广泛应用,而少样本学习、零样本学习和链式思维提示等技术能有效提高法律文本的解释能力。然而,模型的偏见和幻觉等挑战仍阻碍其大规模实施。尽管LLMs在法律领域具有巨大潜力,但仍需改进提示工程策略以确保更高的准确性和可靠性。
Key Takeaways
- LLMs已广泛应用于法律文档处理,实现了自动化处理如摘要、分类和检索等任务。
- GPT-4、BERT、Llama 2和Legal-Pegasus等模型在法律领域广泛应用。
- 少样本学习、零样本学习和链式思维提示等技术能显著提高法律文本的解释能力。
- LLMs在处理法律文本时面临模型偏见和幻觉等挑战。
- 需要改进提示工程策略以提高LLMs在处理法律文档时的准确性和可靠性。
- 当前研究主要关注LLMs在法律领域的系统文献综述和提示工程现状。
点此查看论文截图



GLiNER-biomed: A Suite of Efficient Models for Open Biomedical Named Entity Recognition
Authors:Anthony Yazdani, Ihor Stepanov, Douglas Teodoro
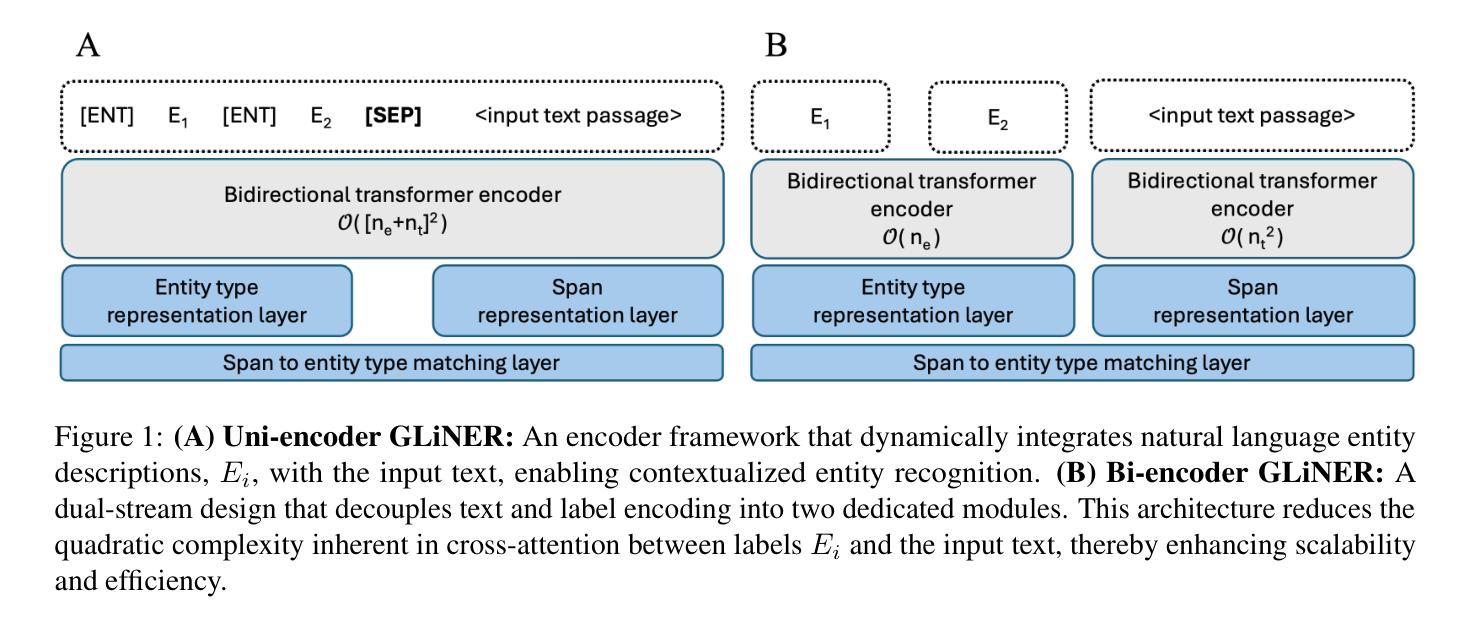
Biomedical named entity recognition (NER) presents unique challenges due to specialized vocabularies, the sheer volume of entities, and the continuous emergence of novel entities. Traditional NER models, constrained by fixed taxonomies and human annotations, struggle to generalize beyond predefined entity types or efficiently adapt to emerging concepts. To address these issues, we introduce GLiNER-biomed, a domain-adapted suite of Generalist and Lightweight Model for NER (GLiNER) models specifically tailored for biomedical NER. In contrast to conventional approaches, GLiNER uses natural language descriptions to infer arbitrary entity types, enabling zero-shot recognition. Our approach first distills the annotation capabilities of large language models (LLMs) into a smaller, more efficient model, enabling the generation of high-coverage synthetic biomedical NER data. We subsequently train two GLiNER architectures, uni- and bi-encoder, at multiple scales to balance computational efficiency and recognition performance. Evaluations on several biomedical datasets demonstrate that GLiNER-biomed outperforms state-of-the-art GLiNER models in both zero- and few-shot scenarios, achieving 5.96% improvement in F1-score over the strongest baseline. Ablation studies highlight the effectiveness of our synthetic data generation strategy and emphasize the complementary benefits of synthetic biomedical pre-training combined with fine-tuning on high-quality general-domain annotations. All datasets, models, and training pipelines are publicly available at https://github.com/ds4dh/GLiNER-biomed.
生物医学命名实体识别(NER)由于专业词汇、实体数量庞大以及新实体不断涌现,面临着独特的挑战。传统NER模型受限于固定的分类体系和人工标注,难以推广到预定义实体类型之外或有效适应新兴概念。为了解决这些问题,我们推出了GLiNER-biomed,这是一个专门为生物医学NER定制的领域适应性强的GLiNER模型套件。与传统的NER方法不同,GLiNER使用自然语言描述来推断任意实体类型,从而实现零样本识别。我们的方法首先提炼了大语言模型的标注能力,并将其转化为更小、更高效的模型,从而生成高覆盖率的合成生物医学NER数据。随后,我们训练了两个GLiNER架构,单编码器和双编码器,以平衡计算效率和识别性能。在多个生物医学数据集上的评估表明,GLiNER-biomed在零样本和少样本场景中均优于最新的GLiNER模型,相较于最强基线模型在F1分数上提高了5.96%。消融研究突显了我们合成数据生成策略的有效性,并强调了合成生物医学预训练与高质量通用域标注微调之间的互补优势。所有数据集、模型和训练管道均可在https://github.com/ds4dh/GLiNER-biomed公开访问。
论文及项目相关链接
Summary
GLiNER-biomed是一个针对生物医学命名实体识别(NER)任务的通用和轻量化模型套件。它通过自然语言描述来推断任意实体类型,实现了零样本识别。该研究首先利用大型语言模型(LLM)的注释能力,训练出更小、更高效的模型,生成高覆盖度的合成生物医学NER数据。随后,研究团队训练了两种GLiNER架构,单编码器和双编码器,以在计算效率和识别性能之间取得平衡。在多个生物医学数据集上的评估结果表明,GLiNER-biomed在零样本和少样本场景中均优于最新的GLiNER模型,F1分数提高了5.96%。
Key Takeaways
- 传统的生物医学命名实体识别模型受限于固定的分类和人工标注,难以应对新实体的快速涌现和大量的数据实体问题。
- 提出了一种新型的解决方案——GLiNER-biomed模型套件,旨在针对生物医学命名实体识别问题做出有效改进。它可以通过自然语言描述推断任意实体类型实现零样本识别。
- GLiNER-biomed模型使用大型语言模型的注释能力生成合成数据,该数据具有高覆盖度,并有助于提高模型的效率与性能。采用了单编码器和双编码器两种架构来实现性能的平衡和优化。模型注重实体识别功能且具有较高的通用性,具有广阔的实用价值和应用前景。模型在两个实验设置中都表现良好。相对最佳基线而言,它在F1得分方面表现出更高的优势,提高了5.96%。同时公开了所有数据集、模型和训练管道供公众使用。这一创新性的解决方案对生物医学文本挖掘和文本分析等领域具有重要意义。它不仅可以改善相关领域的效率和质量,也可以推动自然语言处理技术的进一步发展和应用。这为构建更具智能化、高效化的生物医学信息提取系统提供了新的思路和方向。
点此查看论文截图

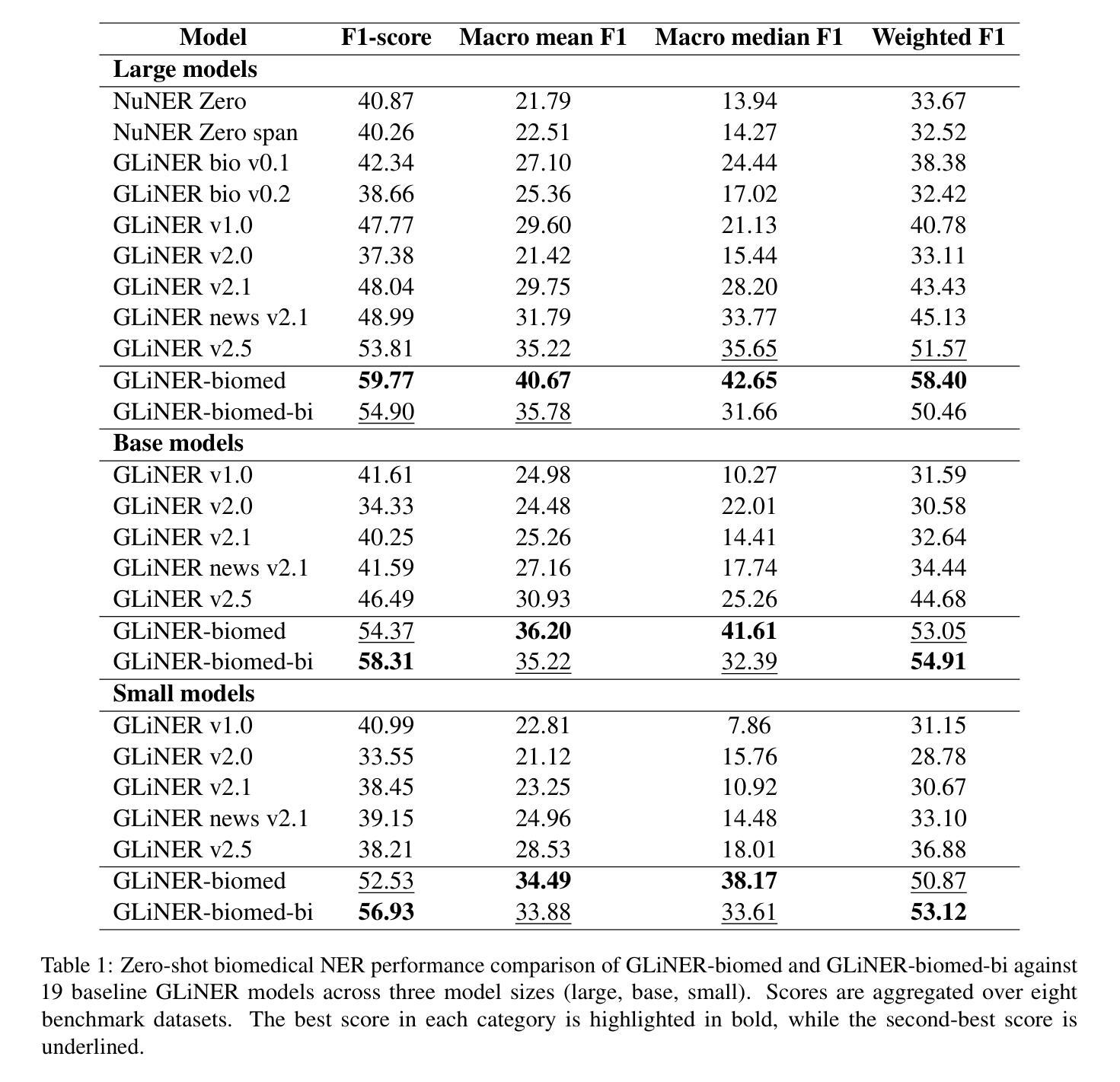
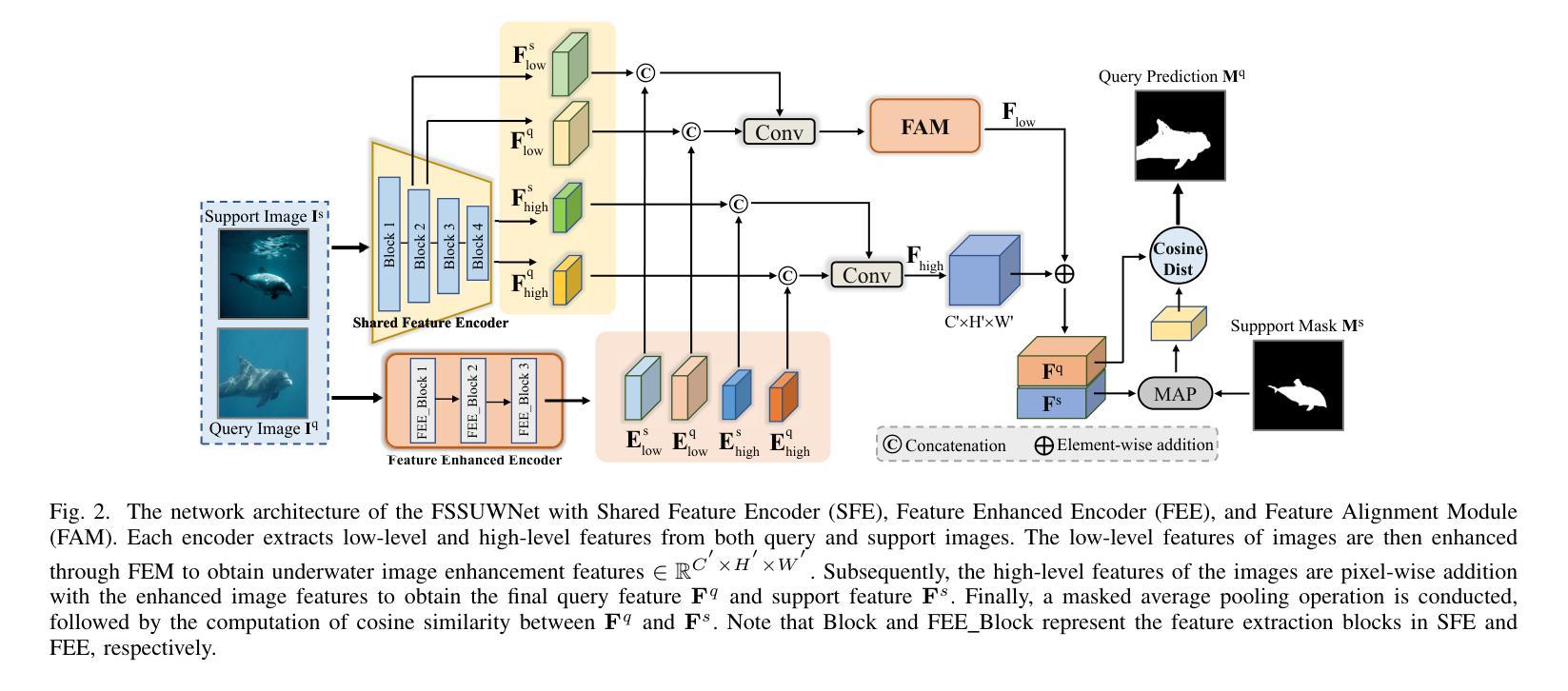
FSSUWNet: Mitigating the Fragility of Pre-trained Models with Feature Enhancement for Few-Shot Semantic Segmentation in Underwater Images
Authors:Zhuohao Li, Zhicheng Huang, Wenchao Liu, Zhuxing Zhang, Jianming Miao
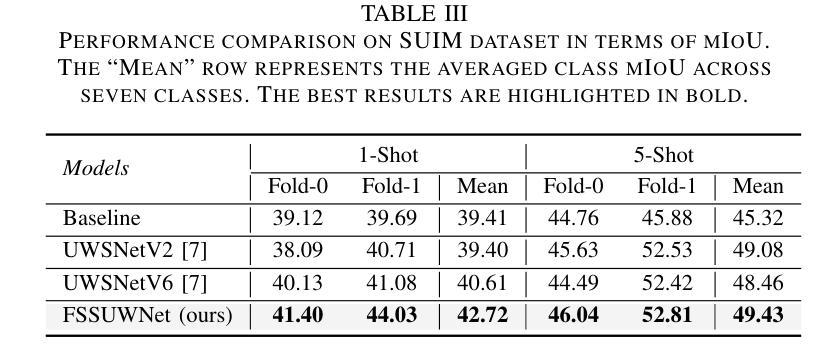
Few-Shot Semantic Segmentation (FSS), which focuses on segmenting new classes in images using only a limited number of annotated examples, has recently progressed in data-scarce domains. However, in this work, we show that the existing FSS methods often struggle to generalize to underwater environments. Specifically, the prior features extracted by pre-trained models used as feature extractors are fragile due to the unique challenges of underwater images. To address this, we propose FSSUWNet, a tailored FSS framework for underwater images with feature enhancement. FSSUWNet exploits the integration of complementary features, emphasizing both low-level and high-level image characteristics. In addition to employing a pre-trained model as the primary encoder, we propose an auxiliary encoder called Feature Enhanced Encoder which extracts complementary features to better adapt to underwater scene characteristics. Furthermore, a simple and effective Feature Alignment Module aims to provide global prior knowledge and align low-level features with high-level features in dimensions. Given the scarcity of underwater images, we introduce a cross-validation dataset version based on the Segmentation of Underwater Imagery dataset. Extensive experiments on public underwater segmentation datasets demonstrate that our approach achieves state-of-the-art performance. For example, our method outperforms the previous best method by 2.8% and 2.6% in terms of the mean Intersection over Union metric for 1-shot and 5-shot scenarios in the datasets, respectively. Our implementation is available at https://github.com/lizhh268/FSSUWNet.
少数样本语义分割(FSS)旨在利用有限的标注样本对图像中的新类别进行分割,最近在数据稀缺领域取得了进展。然而,在这项工作中,我们展示了现有的FSS方法在水下环境中往往难以推广。具体来说,由于水下图像的独特挑战,预训练模型提取的先验特征是脆弱的。为了解决这个问题,我们提出了FSSUWNet,这是一个针对水下图像的FSS框架,具有特征增强功能。FSSUWNet利用互补特征的集成,强调图像的低级和高级特征。除了使用预训练模型作为主要编码器外,我们还提出了一个名为特征增强编码器的辅助编码器,用于提取互补特征,以更好地适应水下场景特征。此外,简单有效的特征对齐模块旨在提供全局先验知识,并在维度上对齐低级特征和高级特征。鉴于水下图像的稀缺性,我们基于水下图像分割数据集引入了一个交叉验证数据集版本。在公共水下分割数据集上的大量实验表明,我们的方法达到了最新性能。例如,在我们的方法中,与之前最佳方法相比,在数据集的一次射击和五次射击场景中,平均交并比指标分别提高了2.8%和2.6%。我们的实现可在https://github.com/lizhh268/FSSUWNet上找到。
论文及项目相关链接
Summary
本文介绍了针对水下图像分割的新方法——FSSUWNet。针对水下环境独特的挑战,该网络框架采用辅助编码器,强化了水下场景特征的提取,并利用特征对齐模块将低级与高级特征相结合。此外,为了提高性能,建立了一个基于水下影像分割数据集版本进行交叉验证的版本。实验结果在公开的水下分割数据集上显示出该方法的卓越性能,相比以前的最优方法平均提高了约百分之二点几的交并比。
Key Takeaways
点此查看论文截图


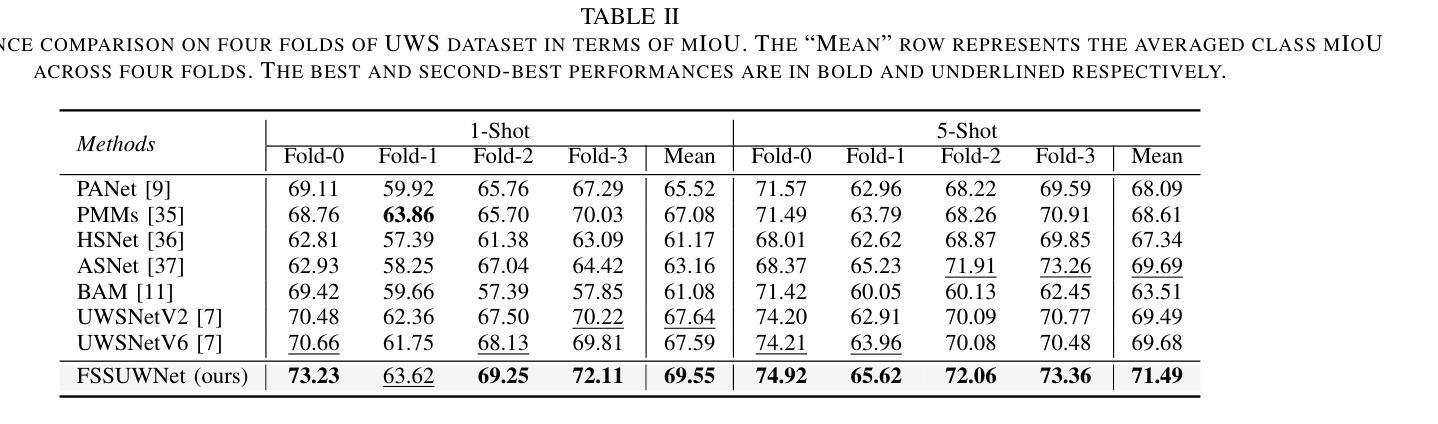
Self-Evolving Visual Concept Library using Vision-Language Critics
Authors:Atharva Sehgal, Patrick Yuan, Ziniu Hu, Yisong Yue, Jennifer J. Sun, Swarat Chaudhuri
We study the problem of building a visual concept library for visual recognition. Building effective visual concept libraries is challenging, as manual definition is labor-intensive, while relying solely on LLMs for concept generation can result in concepts that lack discriminative power or fail to account for the complex interactions between them. Our approach, ESCHER, takes a library learning perspective to iteratively discover and improve visual concepts. ESCHER uses a vision-language model (VLM) as a critic to iteratively refine the concept library, including accounting for interactions between concepts and how they affect downstream classifiers. By leveraging the in-context learning abilities of LLMs and the history of performance using various concepts, ESCHER dynamically improves its concept generation strategy based on the VLM critic’s feedback. Finally, ESCHER does not require any human annotations, and is thus an automated plug-and-play framework. We empirically demonstrate the ability of ESCHER to learn a concept library for zero-shot, few-shot, and fine-tuning visual classification tasks. This work represents, to our knowledge, the first application of concept library learning to real-world visual tasks.
我们研究构建用于视觉识别的视觉概念库的问题。构建有效的视觉概念库具有挑战性,因为手动定义需要大量劳动力,而仅依赖大型语言模型(LLMs)进行概念生成可能会导致缺乏辨别力的概念,或者无法解释概念之间的复杂交互。我们的方法ESCHER采用图书馆学习视角来迭代地发现和改进视觉概念。ESCHER使用视觉语言模型(VLM)作为批判者,迭代地完善概念库,包括解释概念之间的交互以及它们如何影响下游分类器。通过利用LLMs的上下文学习能力以及各种概念的性能历史记录,ESCHER根据VLM批评者的反馈动态改进其概念生成策略。最后,ESCHER不需要任何人工注释,因此是一个自动化的即插即用框架。我们通过实证证明了ESCHER在零样本、少样本和微调视觉分类任务中学习概念库的能力。据我们所知,这项工作代表了概念库学习在现实世界视觉任务中的首次应用。
论文及项目相关链接
PDF CVPR camera ready
Summary
本文研究了建立用于视觉识别的视觉概念库的挑战性问题。针对手动定义工作量大、单纯依赖LLMs进行概念生成可能导致概念鉴别力不足或忽视概念间复杂交互的问题,提出了ESCHER方法。该方法采用图书馆学习视角,迭代发现和改进视觉概念。ESCHER使用视觉语言模型(VLM)作为批评者,迭代优化概念库,包括考虑概念间的交互以及它们对下游分类器的影响。利用LLMs的上下文学习能力及不同概念的性能历史记录,ESCHER根据VLM批评者的反馈动态改进其概念生成策略。最终,ESCHER无需人工注释,是一个自动化的即插即用框架。实证表明,ESCHER在零样本、少样本和微调视觉分类任务中学习概念库的能力。本文据我们所知,是概念库学习在真实视觉任务中的首次应用。
Key Takeaways
- ESCHER方法旨在解决建立视觉概念库的挑战,包括手动定义的劳动密集度和单纯依赖LLMs导致的问题。
- ESCHER采用图书馆学习视角,通过迭代发现和改进视觉概念。
- 使用视觉语言模型(VLM)作为批评者,ESCHER能够迭代优化概念库,包括考虑概念间的交互及其对下游分类器的影响。
- ESCHER利用LLMs的上下文学习能力及不同概念的性能历史反馈来动态改进其概念生成策略。
- ESCHER框架无需人工注释,具备自动化特性。
- 实证表明,ESCHER在多种视觉任务中学习概念库的能力。
点此查看论文截图

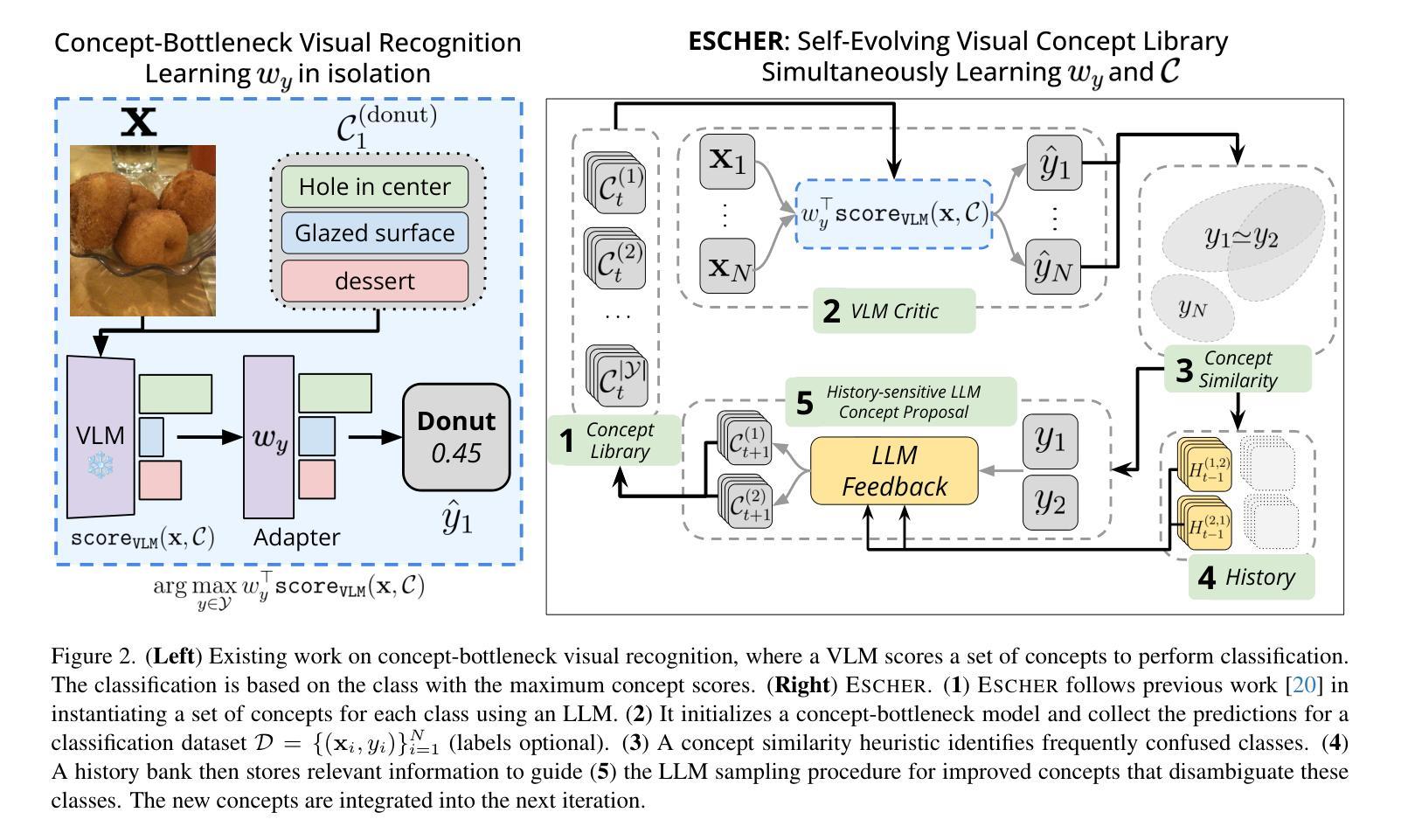

AI-Assisted Colonoscopy: Polyp Detection and Segmentation using Foundation Models
Authors:Uxue Delaquintana-Aramendi, Leire Benito-del-Valle, Aitor Alvarez-Gila, Javier Pascau, Luisa F Sánchez-Peralta, Artzai Picón, J Blas Pagador, Cristina L Saratxaga
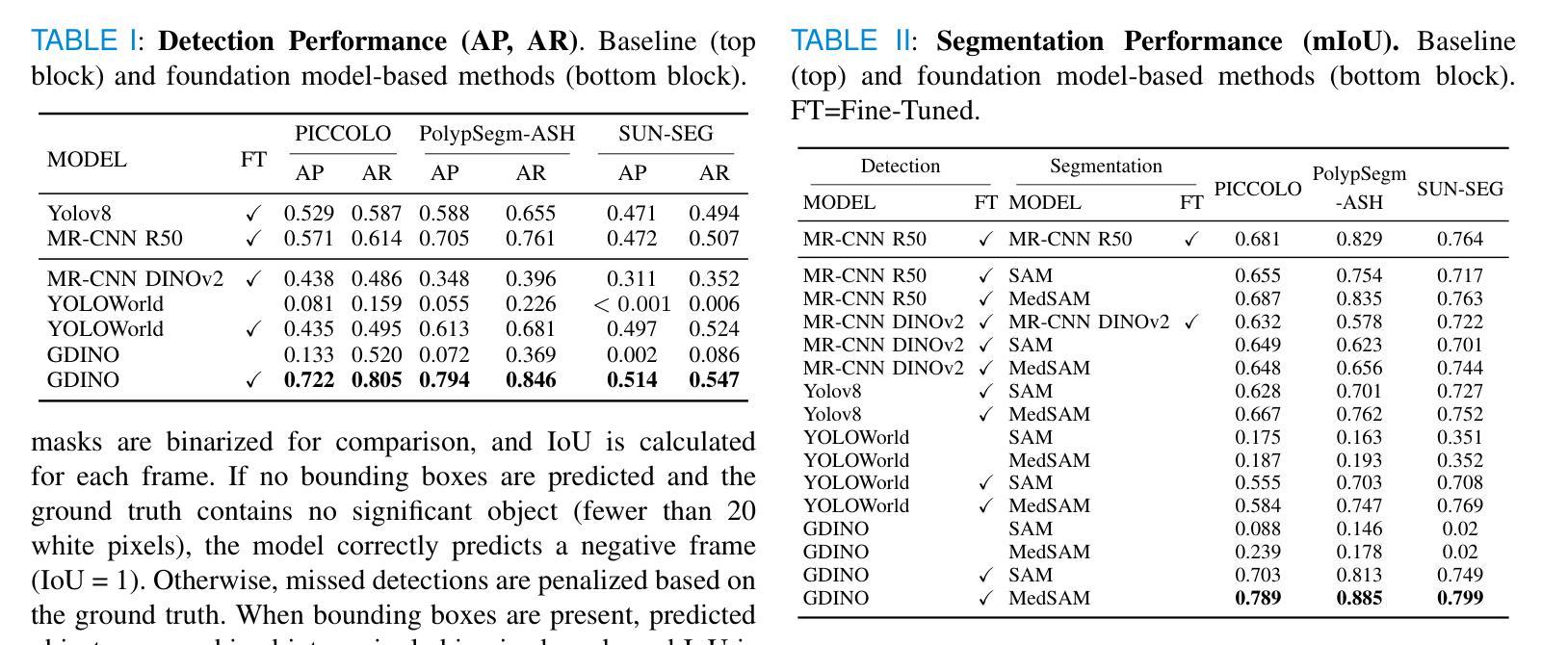
In colonoscopy, 80% of the missed polyps could be detected with the help of Deep Learning models. In the search for algorithms capable of addressing this challenge, foundation models emerge as promising candidates. Their zero-shot or few-shot learning capabilities, facilitate generalization to new data or tasks without extensive fine-tuning. A concept that is particularly advantageous in the medical imaging domain, where large annotated datasets for traditional training are scarce. In this context, a comprehensive evaluation of foundation models for polyp segmentation was conducted, assessing both detection and delimitation. For the study, three different colonoscopy datasets have been employed to compare the performance of five different foundation models, DINOv2, YOLO-World, GroundingDINO, SAM and MedSAM, against two benchmark networks, YOLOv8 and Mask R-CNN. Results show that the success of foundation models in polyp characterization is highly dependent on domain specialization. For optimal performance in medical applications, domain-specific models are essential, and generic models require fine-tuning to achieve effective results. Through this specialization, foundation models demonstrated superior performance compared to state-of-the-art detection and segmentation models, with some models even excelling in zero-shot evaluation; outperforming fine-tuned models on unseen data.
在结肠镜检查中,借助深度学习模型可以检测到80%遗漏的息肉。在寻找能够应对这一挑战的算法时,基础模型表现出巨大的潜力。它们具备零样本或少样本学习能力,能够轻松推广到新的数据或任务,而无需进行大量的微调。这一概念在医学成像领域特别有利,因为该领域缺乏用于传统训练的大型注释数据集。在此背景下,对基础模型进行了全面的息肉分割评估,包括检测和界定两个方面。为了进行研究,采用了三个不同的结肠镜检查数据集,比较了五种不同基础模型(DINOv2、YOLO-World、GroundingDINO、SAM和MedSAM)与两个基准网络(YOLOv8和Mask R-CNN)的性能。结果表明,基础模型在息肉表征方面的成功高度依赖于领域专业化。为了在医疗应用中获得最佳性能,领域特定模型是不可或缺的,而通用模型需要微调才能实现有效结果。通过专业化,基础模型表现出优于最新检测和分割模型的性能,部分模型甚至在零样本评估中表现出色,在未见过的数据上超越了微调模型。
论文及项目相关链接
PDF This work has been submitted to the IEEE TMI for possible publication
Summary
深度学习模型可检测出结肠镜检查中未发现的约八成的息肉。基础模型以其零样本或少样本学习能力,展现出对新数据或任务的快速适应潜力,尤其在缺少大量标注数据的医学影像领域具有显著优势。针对基础模型在息肉分割上的应用进行了全面评估,比较了五种基础模型(DINOv2、YOLO-World、GroundingDINO、SAM和MedSAM)与两个基准网络YOLOv8和Mask R-CNN在三个结肠镜检查数据集上的表现。结果强调了在医疗应用中,基础模型的领域专业化对性能至关重要。对于最佳表现,需要领域特定模型,通用模型需要微调以实现有效结果。基础模型显示出优于最新检测和分割模型的表现,部分模型在零样本评估中表现尤为出色,在未标注数据上超越了微调模型。
Key Takeaways
- 深度学习模型能有效检测结肠镜检查中未发现的多数息肉。
- 基础模型具备零样本和少样本学习能力,能快速适应新数据或任务。
- 在医学影像领域,基础模型因缺少大量标注数据而显得格外重要。
- 基础模型在息肉分割方面的全面评估显示,领域专业化对医疗应用性能至关重要。
- 领域特定模型对于获得最佳表现是必要的,而通用模型需要微调。
- 基础模型在医疗图像分析方面显示出显著优势,优于许多最新的检测和分割模型。
点此查看论文截图

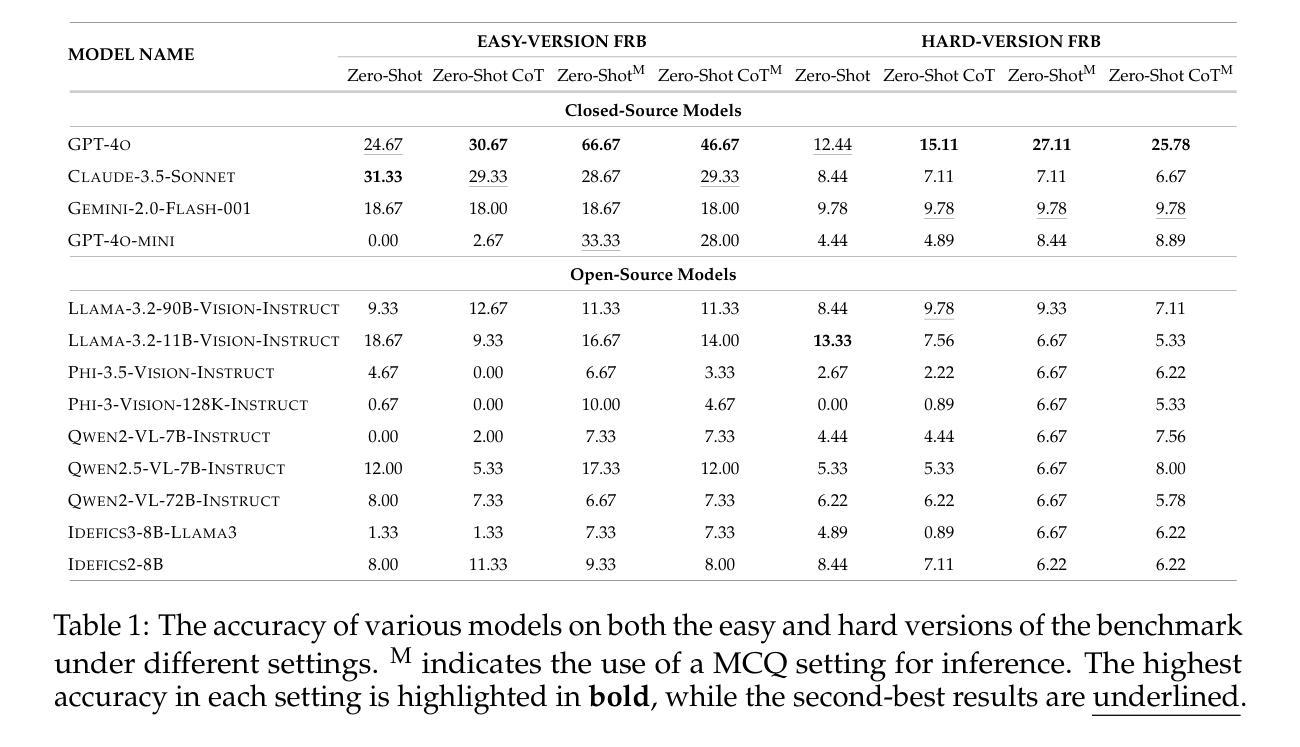
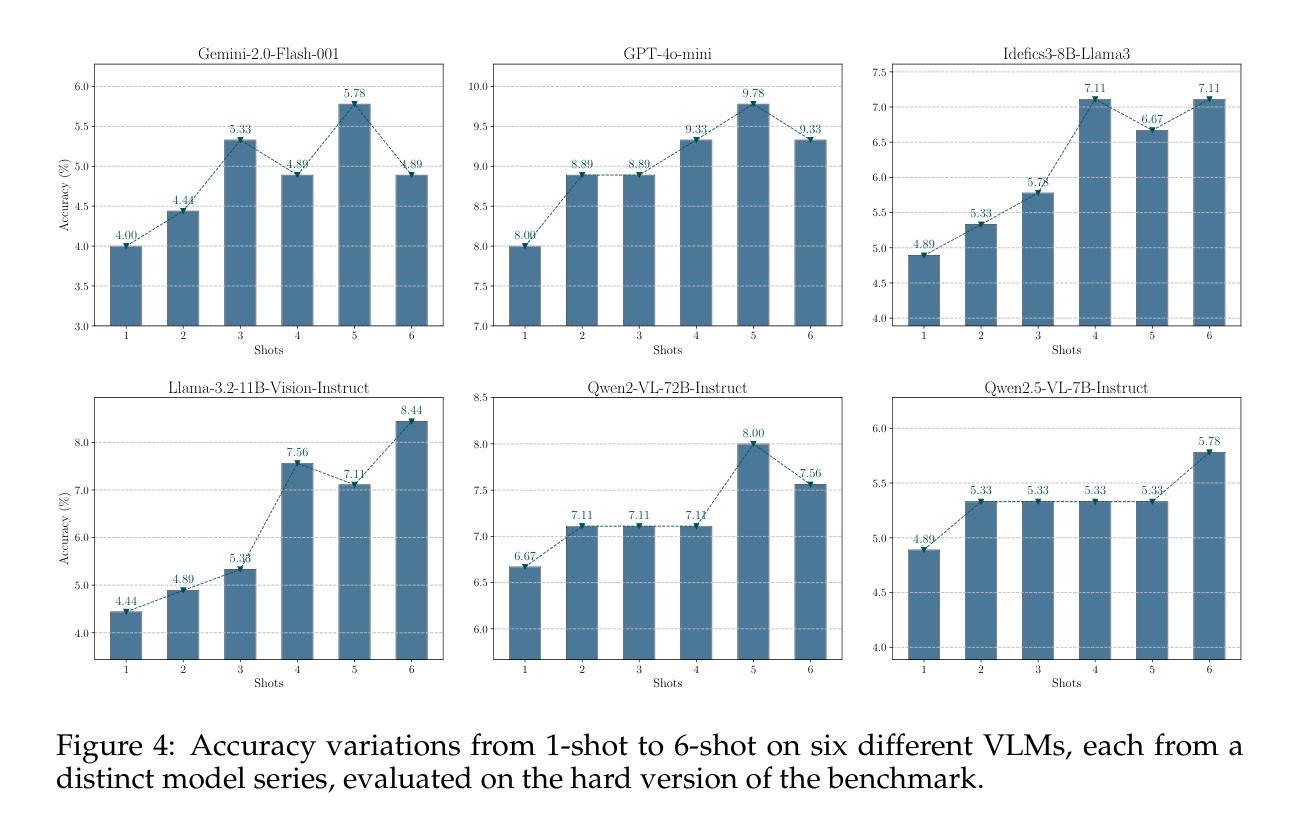
Texture or Semantics? Vision-Language Models Get Lost in Font Recognition
Authors:Zhecheng Li, Guoxian Song, Yujun Cai, Zhen Xiong, Junsong Yuan, Yiwei Wang
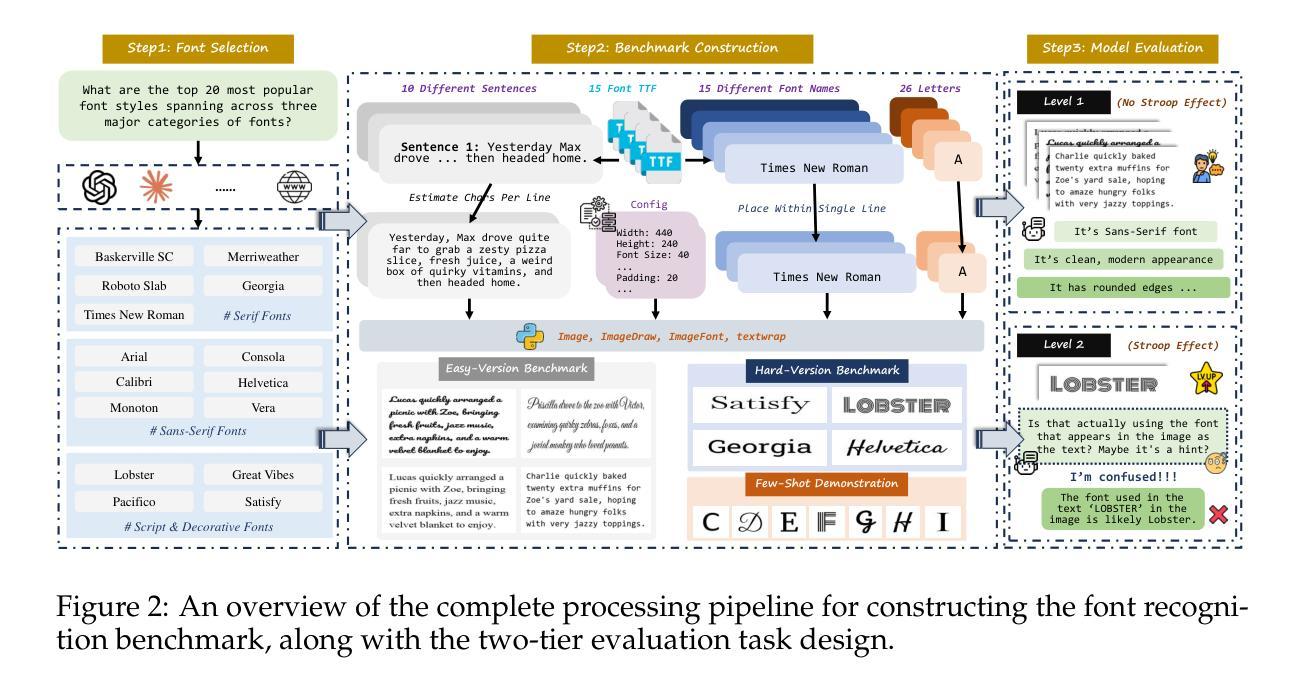
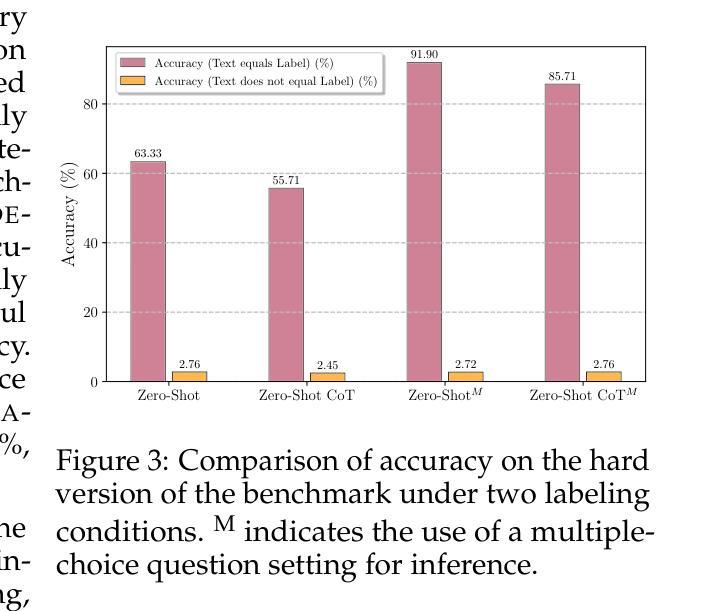
Modern Vision-Language Models (VLMs) exhibit remarkable visual and linguistic capabilities, achieving impressive performance in various tasks such as image recognition and object localization. However, their effectiveness in fine-grained tasks remains an open question. In everyday scenarios, individuals encountering design materials, such as magazines, typography tutorials, research papers, or branding content, may wish to identify aesthetically pleasing fonts used in the text. Given their multimodal capabilities and free accessibility, many VLMs are often considered potential tools for font recognition. This raises a fundamental question: Do VLMs truly possess the capability to recognize fonts? To investigate this, we introduce the Font Recognition Benchmark (FRB), a compact and well-structured dataset comprising 15 commonly used fonts. FRB includes two versions: (i) an easy version, where 10 sentences are rendered in different fonts, and (ii) a hard version, where each text sample consists of the names of the 15 fonts themselves, introducing a stroop effect that challenges model perception. Through extensive evaluation of various VLMs on font recognition tasks, we arrive at the following key findings: (i) Current VLMs exhibit limited font recognition capabilities, with many state-of-the-art models failing to achieve satisfactory performance. (ii) Few-shot learning and Chain-of-Thought (CoT) prompting provide minimal benefits in improving font recognition accuracy across different VLMs. (iii) Attention analysis sheds light on the inherent limitations of VLMs in capturing semantic features.
现代视觉语言模型(VLMs)展现出令人瞩目的视觉和语言能力,在各种任务中取得了令人印象深刻的表现,如图像识别和物体定位。然而,它们在精细任务中的有效性仍然是一个悬而未决的问题。在日常场景中,个人遇到设计材料,如杂志、排版教程、研究论文或品牌内容等,可能会想要识别文本中使用的吸引人的字体。考虑到它们的多模式能力和自由可访问性,许多VLMs通常被认为是字体识别的潜在工具。这就引发了一个根本性的问题:VLMs是否真的具备识别字体的能力?为了调查这一点,我们引入了字体识别基准测试(FRB),这是一个由15种常用字体组成的紧凑且结构良好的数据集。FRB包括两个版本:(i)简单版本,其中10个句子以不同的字体呈现;(ii)困难版本,其中每个文本样本由这15种字体的名称组成,引入了一种斯特鲁普效应,挑战了模型的感知能力。通过对各种VLM在字体识别任务上的广泛评估,我们得出以下关键发现:(i)当前VLM的字体识别能力有限,许多最先进的模型无法取得令人满意的性能。(ii)小样本学习和思维链提示对改善不同VLM的字体识别准确性提供有限的好处。(iii)注意力分析揭示了VLM在捕获语义特征方面的内在局限性。
论文及项目相关链接
Summary
本文介绍了现代视觉语言模型(VLMs)在字体识别方面的表现。虽然这些模型在图像识别和物体定位等任务上表现出色,但在精细任务如字体识别上仍存在局限性。为探究VLMs在字体识别方面的真正能力,引入了字体识别基准测试(FRB),包括两个版本:简单版与困难版。评估发现,当前VLMs的字体识别能力有限,少样本学习与Chain-of-Thought(CoT)提示对提升模型性能效果甚微,注意力分析揭示了VLMs捕捉语义特征的内在局限。
Key Takeaways
- 现代视觉语言模型(VLMs)在字体识别任务上的表现引人关注。
- 引入的字体识别基准测试(FRB)包含简单版和困难版,用于评估VLMs的字体识别能力。
- 当前VLMs在字体识别方面存在局限性,表现并不令人满意。
- 少样本学习与Chain-of-Thought(CoT)提示对提升VLMs在字体识别任务上的性能效果甚微。
- 注意力分析表明,VLMs在捕捉语义特征方面存在内在局限。
- FRB为研究和改进VLMs在字体识别任务上的性能提供了有价值的基准。
点此查看论文截图


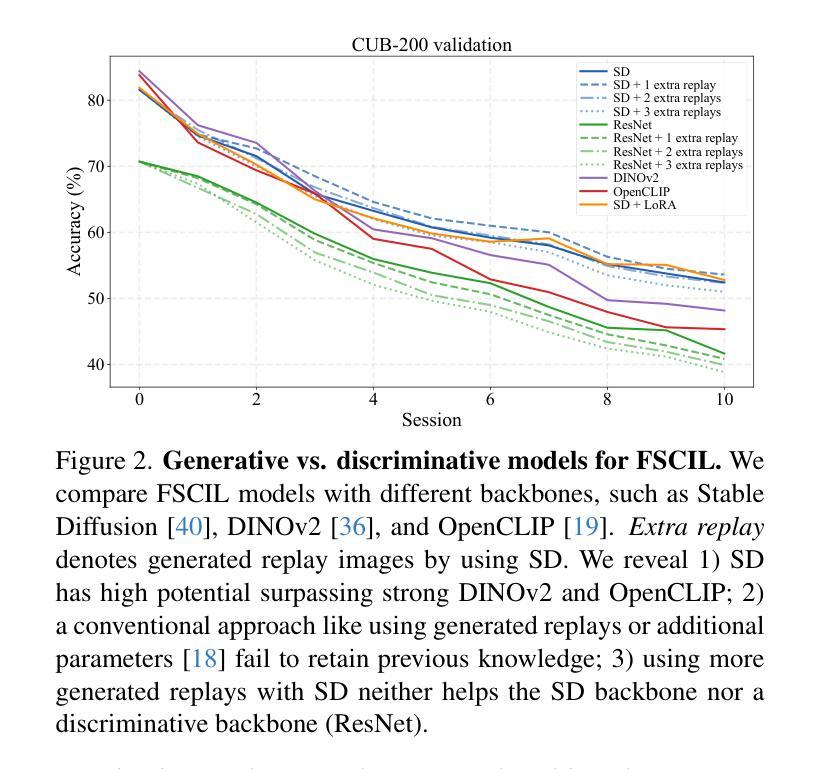
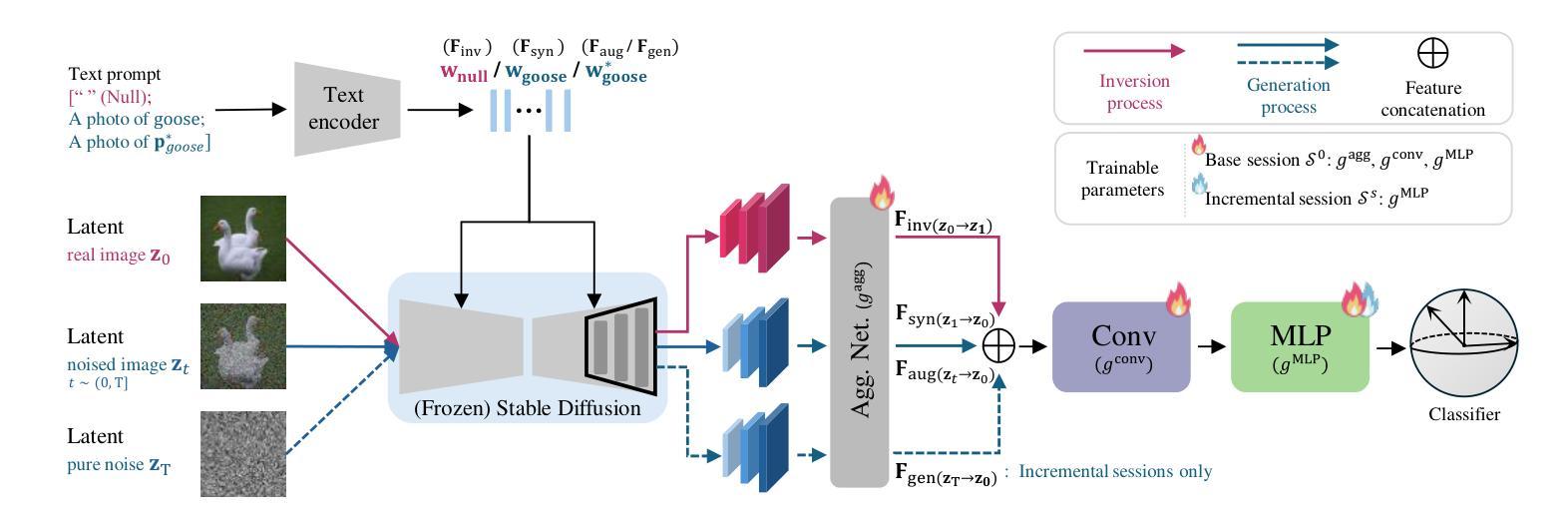
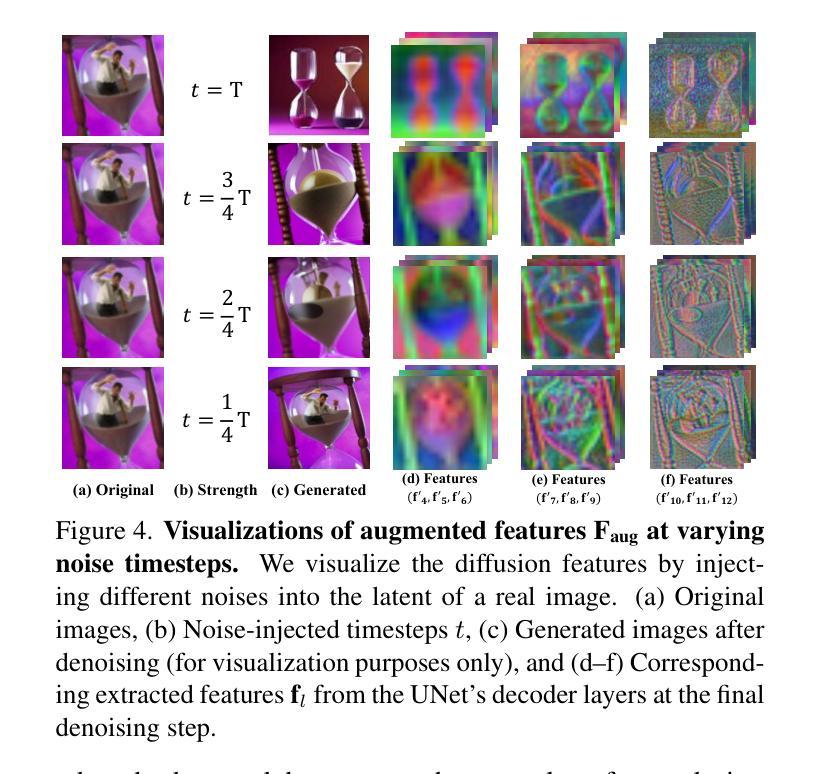
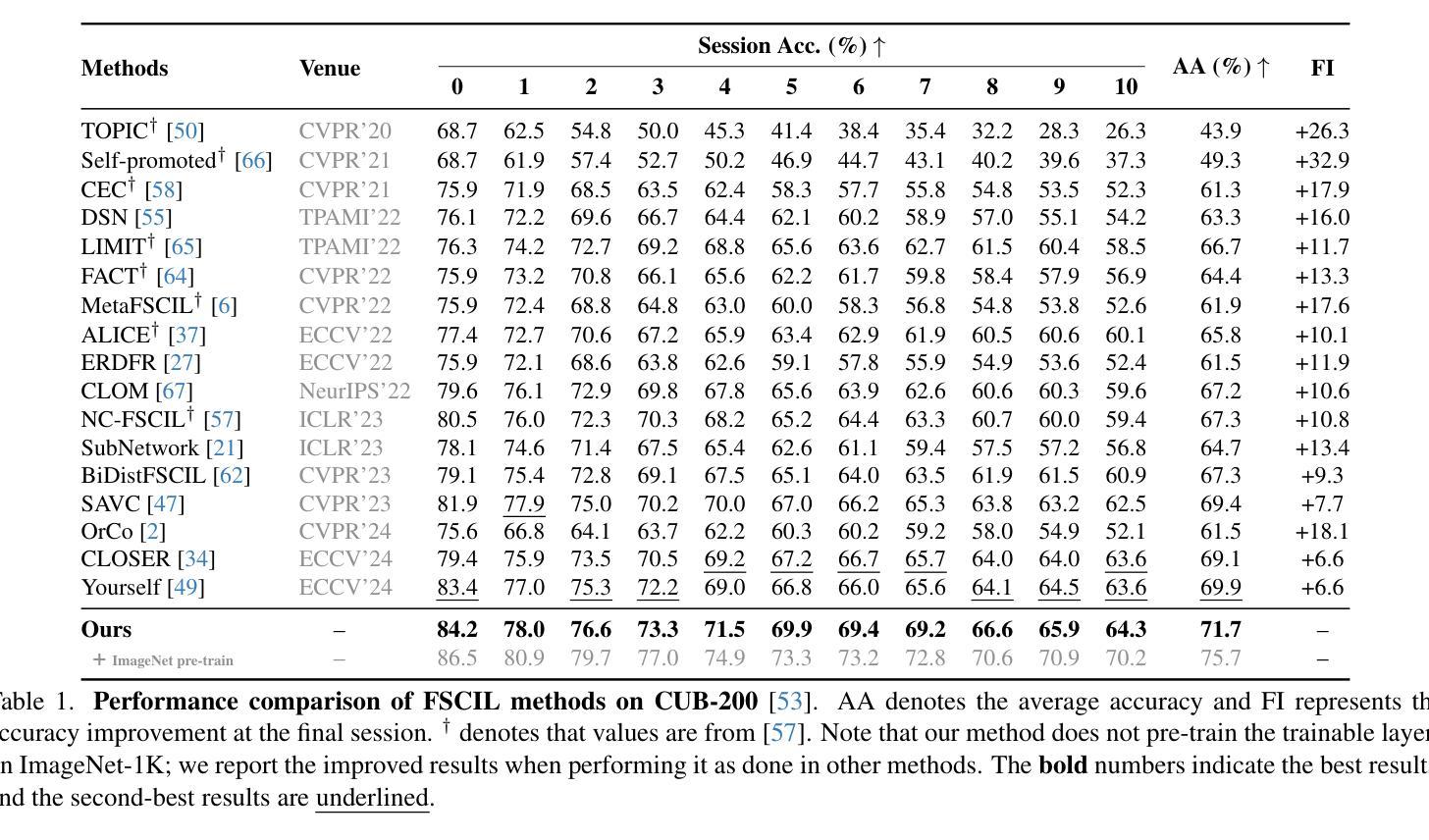
Diffusion Meets Few-shot Class Incremental Learning
Authors:Junsu Kim, Yunhoe Ku, Dongyoon Han, Seungryul Baek
Few-shot class-incremental learning (FSCIL) is challenging due to extremely limited training data; while aiming to reduce catastrophic forgetting and learn new information. We propose Diffusion-FSCIL, a novel approach that employs a text-to-image diffusion model as a frozen backbone. Our conjecture is that FSCIL can be tackled using a large generative model’s capabilities benefiting from 1) generation ability via large-scale pre-training; 2) multi-scale representation; 3) representational flexibility through the text encoder. To maximize the representation capability, we propose to extract multiple complementary diffusion features to play roles as latent replay with slight support from feature distillation for preventing generative biases. Our framework realizes efficiency through 1) using a frozen backbone; 2) minimal trainable components; 3) batch processing of multiple feature extractions. Extensive experiments on CUB-200, miniImageNet, and CIFAR-100 show that Diffusion-FSCIL surpasses state-of-the-art methods, preserving performance on previously learned classes and adapting effectively to new ones.
少数类增量学习(FSCIL)因为训练数据的极度有限而具有挑战性,同时还需要减少灾难性遗忘并学习新信息。我们提出了Diffusion-FSCIL,这是一种采用文本到图像扩散模型作为冻结主干的新型方法。我们的假设是,利用大型生成模型的能力可以解决FSCIL问题,受益于1)通过大规模预训练产生的生成能力;2)多尺度表示;3)通过文本编码器实现的表示灵活性。为了最大化表示能力,我们提出提取多个互补的扩散特征,作为潜在回放的角色,略微支持特征蒸馏,以防止生成偏见。我们的框架通过以下方式实现效率:1)使用冻结的主干;2)最少的可训练组件;3)多个特征提取的批处理。在CUB-200、miniImageNet和CIFAR-100上的大量实验表明,Diffusion-FSCIL超越了最先进的方法,既保留了以前学习的类的性能,又能有效地适应新类。
论文及项目相关链接
PDF pre-print
Summary
基于有限训练数据的挑战,提出一种新颖的解决少量样本类增量学习(FSCIL)的方法——Diffusion-FSCIL。该方法采用文本到图像扩散模型作为冻结主干,借助大型生成模型的多种能力来解决FSCIL问题。通过提取多种互补扩散特征来实现高效表示,并利用轻微的特征蒸馏支持来防止生成偏见。实验证明,Diffusion-FSCIL在CUB-200、miniImageNet和CIFAR-100上超过了现有方法,能够在保持对先前学习类的性能的同时,有效地适应新类。
Key Takeaways
- Diffusion-FSCIL采用文本到图像扩散模型作为冻结主干,以解决少量样本类增量学习(FSCIL)的挑战。
- 大型生成模型的多重能力,包括生成能力、多尺度表示和文本编码器的表征灵活性,被用于解决FSCIL问题。
- 提取多种互补扩散特征以实现强大的表示能力,同时利用轻微的特征蒸馏来防止生成偏见。
- Diffusion-FSCIL框架具有效率优势,体现在使用冻结主干、少量可训练组件以及多特征提取的批量处理上。
- 该方法在CUB-200、miniImageNet和CIFAR-100上的实验表现超过现有方法。
- Diffusion-FSCIL能够在保持对先前学习类的性能的同时,有效地适应新类。
- Diffusion-FSCIL的成功在于结合生成模型的强大能力与增量学习的需求,展示了在有限数据下实现高效学习的可能性。
点此查看论文截图

Ethereum Price Prediction Employing Large Language Models for Short-term and Few-shot Forecasting
Authors:Eftychia Makri, Georgios Palaiokrassas, Sarah Bouraga, Antigoni Polychroniadou, Leandros Tassiulas
Cryptocurrencies have transformed financial markets with their innovative blockchain technology and volatile price movements, presenting both challenges and opportunities for predictive analytics. Ethereum, being one of the leading cryptocurrencies, has experienced significant market fluctuations, making its price prediction an attractive yet complex problem. This paper presents a comprehensive study on the effectiveness of Large Language Models (LLMs) in predicting Ethereum prices for short-term and few-shot forecasting scenarios. The main challenge in training models for time series analysis is the lack of data. We address this by leveraging a novel approach that adapts existing pre-trained LLMs on natural language or images from billions of tokens to the unique characteristics of Ethereum price time series data. Through thorough experimentation and comparison with traditional and contemporary models, our results demonstrate that selectively freezing certain layers of pre-trained LLMs achieves state-of-the-art performance in this domain. This approach consistently surpasses benchmarks across multiple metrics, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and Root Mean Squared Error (RMSE), demonstrating its effectiveness and robustness. Our research not only contributes to the existing body of knowledge on LLMs but also provides practical insights in the cryptocurrency prediction domain. The adaptability of pre-trained LLMs to handle the nature of Ethereum prices suggests a promising direction for future research, potentially including the integration of sentiment analysis to further refine forecasting accuracy.
加密货币凭借其创新的区块链技术和波动的价格走势,为金融市场带来了挑战和机遇,从而实现了金融市场的转型。以太坊作为领先的加密货币之一,市场波动显著,使其价格预测成为一个吸引人但又复杂的问题。本文全面研究了大型语言模型(LLMs)在短期和少量样本预测场景中对以太坊价格预测的效力。时间序列分析模型训练的主要挑战是数据缺乏。我们通过采用一种新方法来解决这个问题,该方法适应于在数十亿个令牌上预先训练的现有LLMs的自然语言或图像,并将其应用于以太坊价格时间序列数据的独特特征。通过与传统和当代模型的实验比较,我们的结果表明,选择性冻结预训练LLMs的某些层可以在该领域实现最新性能。该方法在多个指标上均超越基准测试,包括均方误差(MSE)、平均绝对误差(MAE)和均方根误差(RMSE),证明了其有效性和稳健性。我们的研究不仅为LLMs的现有知识体系做出了贡献,而且还为加密货币预测领域提供了实际见解。预训练LLMs适应以太坊价格特性的能力为未来的研究提供了一个有前景的方向,未来可能包括情感分析的整合,以进一步提高预测精度。
论文及项目相关链接
Summary
本文研究了大型语言模型(LLMs)在预测以太坊价格短期和少量预测场景中的有效性。研究面临的主要挑战是缺乏时间序列分析的数据。通过适应现有的预训练LLMs,将其从自然语言或图像数十亿令牌的特征转换为以太坊价格时间序列数据的独特特征来解决此挑战。实验结果表明,有选择地冻结预训练LLMs的某些层可实现该领域的最新性能。此方法在多个指标上均超过基准测试,包括均方误差(MSE)、平均绝对误差(MAE)和均方根误差(RMSE),证明了其有效性和稳健性。
Key Takeaways
- 区块链技术与以太坊价格的大幅波动对金融市场预测带来了挑战与机遇。
- 利用预训练的大型语言模型对以太坊价格进行短期和少量预测是有效的。
- 训练模型面临的主要挑战是缺乏时间序列分析数据。为此,研究人员利用现有预训练的大型语言模型的自然语言或图像特征来适应以太坊价格数据的独特性。
- 通过选择性冻结预训练模型的某些层以获得最佳性能,实验证明这一方法在多个预测指标上都达到了领域最佳水平。该方法展示了提高预测性能的前沿技术和潜力。
- 研究不仅丰富了大型语言模型的知识体系,也为加密货币预测领域提供了实际见解。这表明预训练的大型语言模型能够适应以太坊价格特性,为未来研究提供了方向。
- 未来研究可整合情感分析来进一步提高预测准确性。以太坊价格的预测可能受到市场情绪的影响,因此整合情感分析可能有助于更准确地捕捉市场动态并改进预测模型。
点此查看论文截图

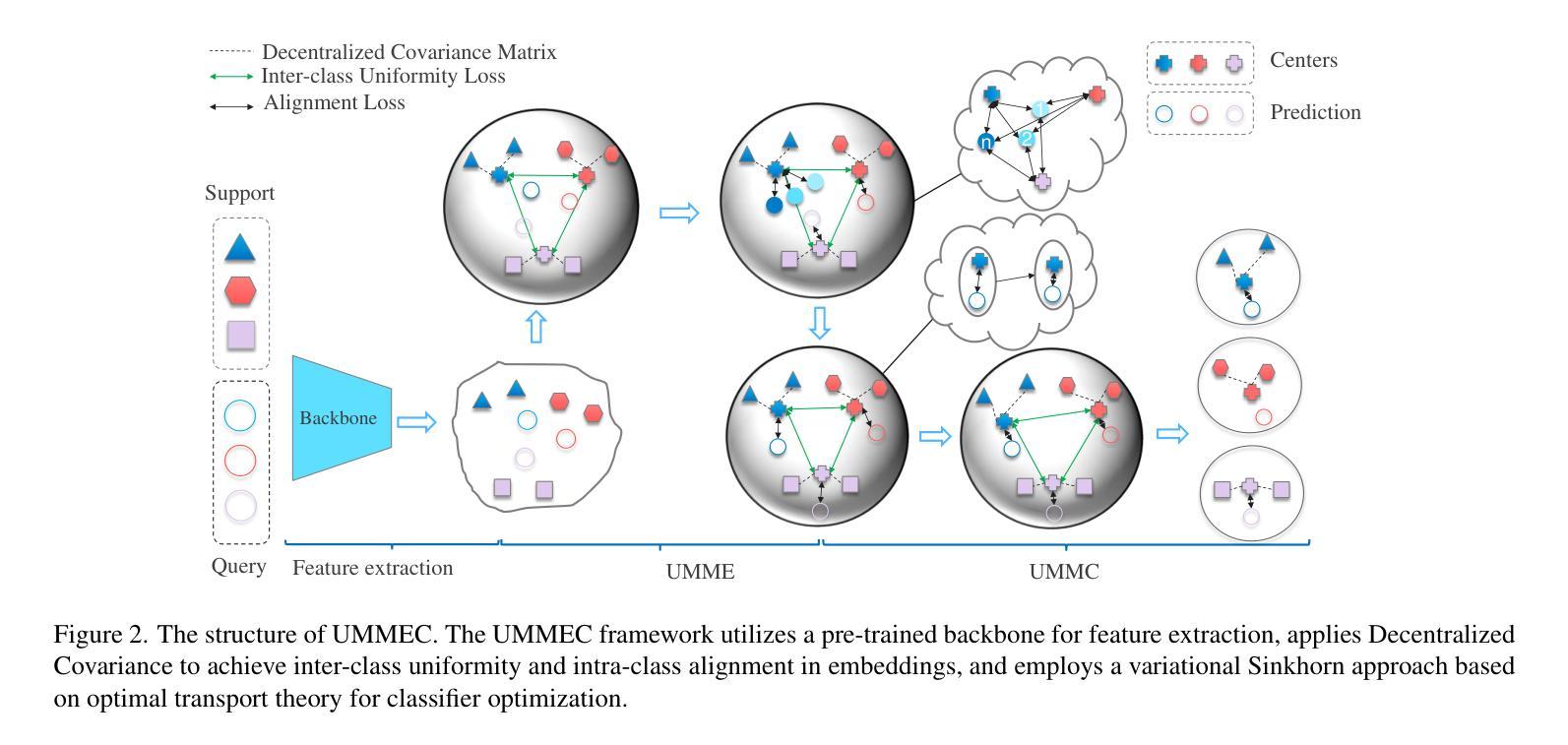
Unbiased Max-Min Embedding Classification for Transductive Few-Shot Learning: Clustering and Classification Are All You Need
Authors:Yang Liu, Feixiang Liu, Jiale Du, Xinbo Gao, Jungong Han
Convolutional neural networks and supervised learning have achieved remarkable success in various fields but are limited by the need for large annotated datasets. Few-shot learning (FSL) addresses this limitation by enabling models to generalize from only a few labeled examples. Transductive few-shot learning (TFSL) enhances FSL by leveraging both labeled and unlabeled data, though it faces challenges like the hubness problem. To overcome these limitations, we propose the Unbiased Max-Min Embedding Classification (UMMEC) Method, which addresses the key challenges in few-shot learning through three innovative contributions. First, we introduce a decentralized covariance matrix to mitigate the hubness problem, ensuring a more uniform distribution of embeddings. Second, our method combines local alignment and global uniformity through adaptive weighting and nonlinear transformation, balancing intra-class clustering with inter-class separation. Third, we employ a Variational Sinkhorn Few-Shot Classifier to optimize the distances between samples and class prototypes, enhancing classification accuracy and robustness. These combined innovations allow the UMMEC method to achieve superior performance with minimal labeled data. Our UMMEC method significantly improves classification performance with minimal labeled data, advancing the state-of-the-art in TFSL.
卷积神经网络和深度学习的监督学习已经在多个领域取得了显著的成功,但它们受限于需要大量标注数据集的问题。小样本学习(FSL)通过让模型仅从少数标注样本中进行推广来克服这一限制。跨传导的小样本学习(TFSL)则利用标注的和未标注的数据来增强FSL,尽管它面临着诸如中心问题(hubness problem)等挑战。为了克服这些局限性,我们提出了无偏最大最小嵌入分类(UMMEC)方法,它通过三个创新点解决了小样本学习的关键挑战。首先,我们引入分散的协方差矩阵来缓解中心问题,确保嵌入的更均匀分布。其次,我们的方法通过自适应权重和非线性变换结合局部对齐和全局均匀性,平衡了类内聚类和类间分离。第三,我们采用变分辛克霍恩小样本分类器来优化样本与类原型之间的距离,提高分类精度和稳健性。这些综合创新使得UMMEC方法在极少量标注数据的情况下实现卓越性能。我们的UMMEC方法能在极少标注数据的情况下显著提高分类性能,推动了跨传导的小样本学习(TFSL)的最新进展。
论文及项目相关链接
Summary
卷积神经网络和监督学习在多个领域取得了显著成功,但受限于需要大量标注数据集。少样本学习(FSL)通过模型从少量标注样本中泛化来解决此问题。传递式少样本学习(TFSL)利用标注和无标签数据,但面临如中心问题。为解决这些限制,我们提出了无偏最大最小嵌入分类(UMMEC)方法,通过三个创新贡献解决少样本学习的关键挑战。首先,引入分散协方差矩阵缓解中心问题,确保更均匀的嵌入分布。其次,结合局部对齐和全局均匀性,通过自适应权重和非线性变换平衡类内聚类和类间分离。最后,采用变分辛克霍恩少样本分类器优化样本与类别原型的距离,提高分类准确性和稳健性。这些方法创新使UMMEC在少量标注数据的情况下实现卓越性能,在TFSL领域取得了最新进展。
Key Takeaways
- 卷积神经网络和监督学习虽取得显著成功,但需大量标注数据集。
- 少样本学习(FSL)通过模型泛化解决此问题,传递式少样本学习(TFSL)进一步利用无标签数据。
- TFSL面临挑战如中心问题,需通过有效策略解决。
- UMMEC方法通过引入分散协方差矩阵缓解中心问题,确保更均匀的嵌入分布。
- UMMEC结合局部对齐和全局均匀性以平衡类内聚类和类间分离。
- 采用变分辛克霍恩少样本分类器优化样本与类别原型间的距离。
点此查看论文截图


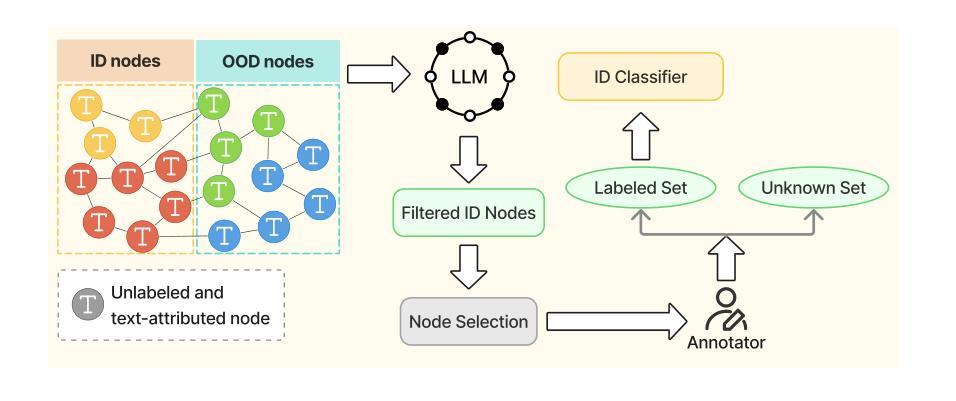
Few-Shot Graph Out-of-Distribution Detection with LLMs
Authors:Haoyan Xu, Zhengtao Yao, Yushun Dong, Ziyi Wang, Ryan A. Rossi, Mengyuan Li, Yue Zhao
Existing methods for graph out-of-distribution (OOD) detection typically depend on training graph neural network (GNN) classifiers using a substantial amount of labeled in-distribution (ID) data. However, acquiring high-quality labeled nodes in text-attributed graphs (TAGs) is challenging and costly due to their complex textual and structural characteristics. Large language models (LLMs), known for their powerful zero-shot capabilities in textual tasks, show promise but struggle to naturally capture the critical structural information inherent to TAGs, limiting their direct effectiveness. To address these challenges, we propose LLM-GOOD, a general framework that effectively combines the strengths of LLMs and GNNs to enhance data efficiency in graph OOD detection. Specifically, we first leverage LLMs’ strong zero-shot capabilities to filter out likely OOD nodes, significantly reducing the human annotation burden. To minimize the usage and cost of the LLM, we employ it only to annotate a small subset of unlabeled nodes. We then train a lightweight GNN filter using these noisy labels, enabling efficient predictions of ID status for all other unlabeled nodes by leveraging both textual and structural information. After obtaining node embeddings from the GNN filter, we can apply informativeness-based methods to select the most valuable nodes for precise human annotation. Finally, we train the target ID classifier using these accurately annotated ID nodes. Extensive experiments on four real-world TAG datasets demonstrate that LLM-GOOD significantly reduces human annotation costs and outperforms state-of-the-art baselines in terms of both ID classification accuracy and OOD detection performance.
现有图外分布(OOD)检测的方法通常依赖于使用大量的已标注内分布(ID)数据来训练图神经网络(GNN)分类器。然而,由于文本属性图(TAGs)的复杂文本和结构特性,获取高质量标注节点具有挑战性和成本高昂。大型语言模型(LLMs)在文本任务中表现出强大的零样本能力,显示出潜力,但难以自然地捕获TAGs所固有的关键结构信息,从而限制了其直接效果。
为了解决这些挑战,我们提出了LLM-GOOD,这是一个有效结合LLMs和GNNs优势的通用框架,以提高图OOD检测中的数据效率。具体而言,我们首先利用LLMs的强大零样本能力来筛选出可能的OOD节点,从而大大减少了人工标注的负担。为了最小化LLM的使用和成本,我们只使用它来标注一小部分未标记的节点。然后,我们使用这些带噪声的标签训练一个轻量级的GNN过滤器,该过滤器能够利用文本和结构信息对所有其他未标记节点进行ID状态的高效预测。从GNN过滤器获得节点嵌入后,我们可以应用基于信息的方法来选择最有价值的节点进行精确的人工标注。最后,我们使用这些准确标注的ID节点训练目标ID分类器。在四个真实世界的TAG数据集上的广泛实验表明,LLM-GOOD显著降低了人工标注成本,并且在ID分类准确性和OOD检测性能方面均优于最新基线。
论文及项目相关链接
Summary
本文提出一种结合大型语言模型(LLMs)和图神经网络(GNNs)的通用框架LLM-GOOD,以提高文本属性图(TAGs)中图异常值检测的数据效率。该框架利用LLMs的强大零样本能力过滤出可能的异常节点,减少人工标注负担。然后训练轻量级GNN滤波器使用这些噪声标签进行预测,利用文本和结构信息提高预测效率。最后,使用精选的准确标注的节点训练目标分类器。该框架在四个真实世界TAG数据集上的实验表明,它显著降低了人工标注成本,并在身份分类准确性和异常检测性能上优于最新基线。
Key Takeaways
- 提出LLM-GOOD框架,结合LLMs和GNNs以提高文本属性图(TAGs)中的图异常值检测数据效率。
- 利用LLMs的强大零样本能力过滤可能的异常节点,降低人工标注负担。
- 使用轻量级GNN滤波器进行预测,利用文本和结构信息提高预测效率。
- 通过信息性方法选择最有价值的节点进行精确人工标注。
- 训练目标分类器使用准确标注的节点。
- 在四个真实世界TAG数据集上的实验表明LLM-GOOD的有效性。
点此查看论文截图

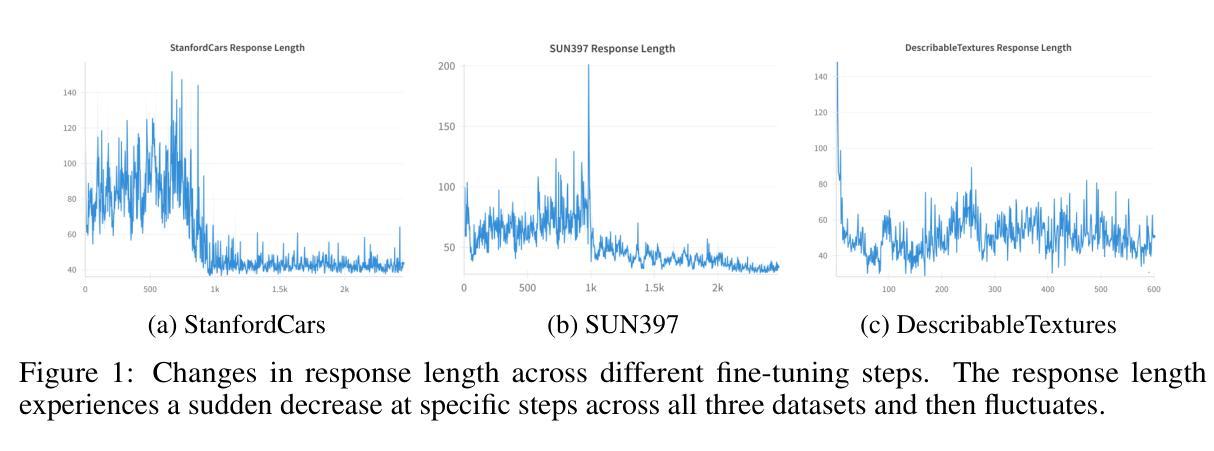
Think or Not Think: A Study of Explicit Thinking inRule-Based Visual Reinforcement Fine-Tuning
Authors:Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Kaipeng Zhang
This paper investigates rule-based reinforcement learning (RL) fine-tuning for visual classification using multi-modal large language models (MLLMs) and the role of the thinking process. We begin by exploring \textit{CLS-RL}, a method that leverages verifiable signals as rewards to encourage MLLMs to ‘think’ before classifying. Our experiments across \textbf{eleven} datasets demonstrate that CLS-RL achieves significant improvements over supervised fine-tuning (SFT) in both base-to-new generalization and few-shot learning scenarios. Notably, we observe a ‘free-lunch’ phenomenon where fine-tuning on one dataset unexpectedly enhances performance on others, suggesting that RL effectively teaches fundamental classification skills. However, we question whether the explicit thinking, a critical aspect of rule-based RL, is always beneficial or indispensable. Challenging the conventional assumption that complex reasoning enhances performance, we introduce \textit{No-Thinking-RL}, a novel approach that minimizes the model’s thinking during fine-tuning by utilizing an equality accuracy reward. Our experiments reveal that No-Thinking-RL achieves superior in-domain performance and generalization capabilities compared to CLS-RL, while requiring significantly less fine-tuning time. This underscores that, contrary to prevailing assumptions, reducing the thinking process can lead to more efficient and effective MLLM fine-tuning for some visual tasks. Furthermore, No-Thinking-RL demonstrates enhanced performance on other visual benchmarks, such as a 6.4% improvement on CVBench. We hope our findings provides insights into the impact of thinking in RL-based fine-tuning.
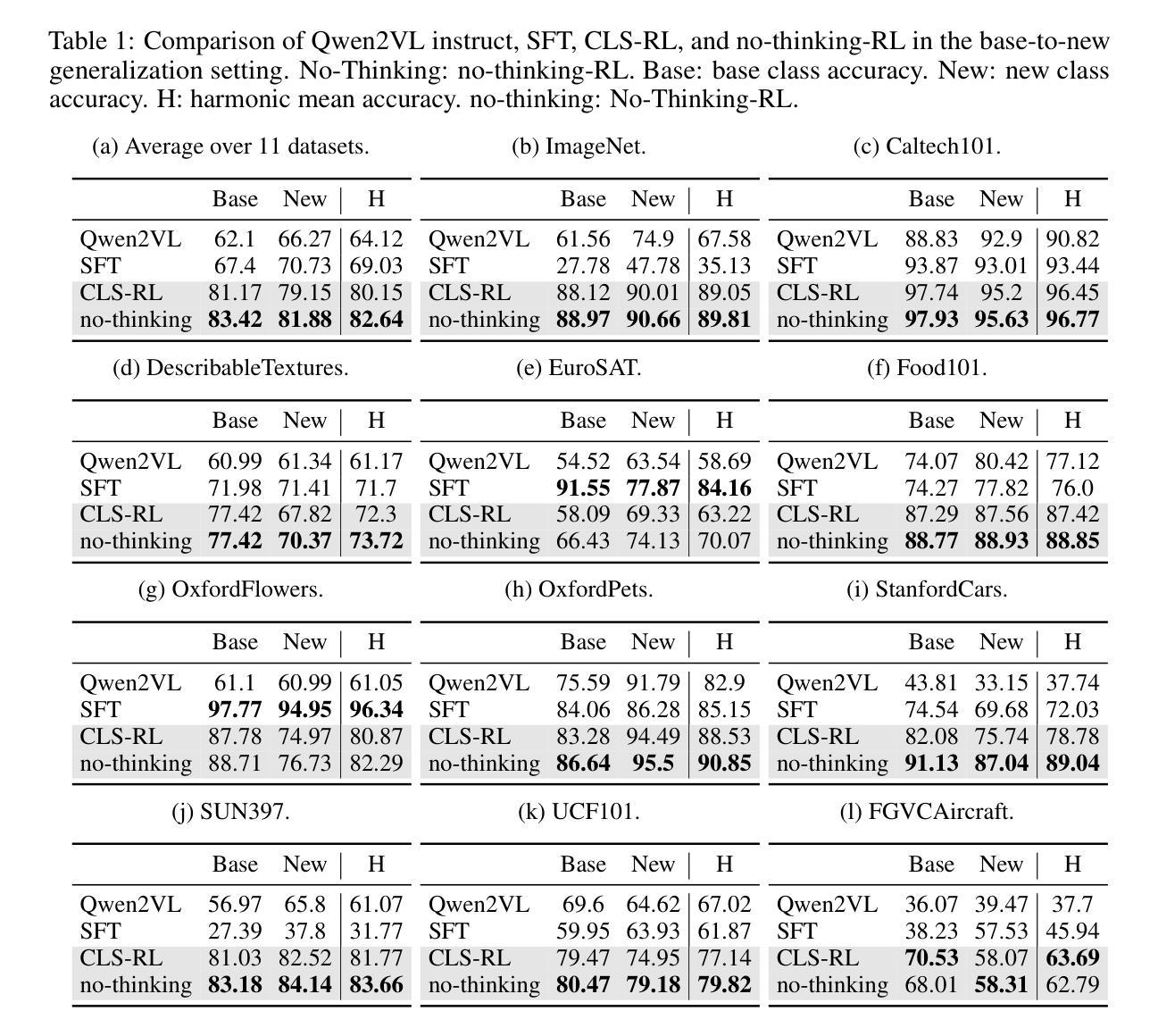
本文探讨了基于规则的强化学习(RL)在多模态大型语言模型(MLLMs)的视觉分类任务中的微调方法,以及思考过程的作用。首先,我们探讨了CLS-RL方法,该方法利用可验证的信号作为奖励来鼓励MLLM在分类之前进行“思考”。我们的实验跨越了十一个数据集,证明了CLS-RL在基础到新的泛化和少样本学习场景中均显著优于监督微调(SFT)。值得注意的是,我们观察到了一种“免费午餐”现象,即在一个数据集上的微调意外地提高了其他数据集的性能,这表明RL有效地传授了基本的分类技能。然而,我们质疑基于规则的RL中的明确思考是否总是有益或不可或缺。我们挑战了复杂推理能提高性能的常规假设,并引入了No-Thinking-RL这一新方法,它通过采用平等准确性奖励来最小化模型在微调过程中的思考。我们的实验表明,与CLS-RL相比,No-Thinking-RL在域内性能和泛化能力方面更胜一筹,同时显著减少了微调时间。这强调了一个事实:与普遍假设相反,减少思考过程可以为某些视觉任务提供更高效、更有效的MLLM微调。此外,No-Thinking-RL在其他视觉基准测试中也表现出卓越的性能,如在CVBench上提高了6.4%。我们希望这些发现能为基于RL的微调中的思考影响提供见解。
论文及项目相关链接
PDF Preprint, work in progress. Add results on CVBench
Summary
本文探讨了基于规则的强化学习(RL)在视觉分类方面的微调,使用了多模态大型语言模型(MLLMs)。通过CLS-RL方法利用可验证信号作为奖励来鼓励MLLM在分类之前进行思考。实验结果表明,CLS-RL在基础到新的泛化能力和少样本学习场景下均优于监督微调(SFT)。还观察到了一个现象:在一个数据集上进行微调会意外地提高在其他数据集上的性能,这表明RL实际上教会了基本的分类技能。此外,本文质疑了显式思考是否总是有益或不可或缺。提出了No-Thinking-RL方法,通过平等准确性奖励来最小化模型的思考过程。实验表明,No-Thinking-RL在域内性能和泛化能力上优于CLS-RL,且微调时间大大减少。这打破了减少思考过程会导致性能下降的常规假设,并为某些视觉任务的MLLM微调提供了更有效的途径。
Key Takeaways
- CLS-RL方法利用可验证信号作为奖励鼓励MLLM在分类前思考,在多个数据集上表现优于监督微调。
- RL在视觉分类任务中能有效教会模型基本分类技能。
- 出现了“免费午餐”现象:在一个数据集上的微调能提高在其他数据集上的性能。
- 质疑了显式思考在RL微调中的必要性。
- No-Thinking-RL方法通过最小化模型思考过程,实现了优异的域内性能和泛化能力。
- No-Thinking-RL相较于CLS-RL显著减少了微调时间。
点此查看论文截图

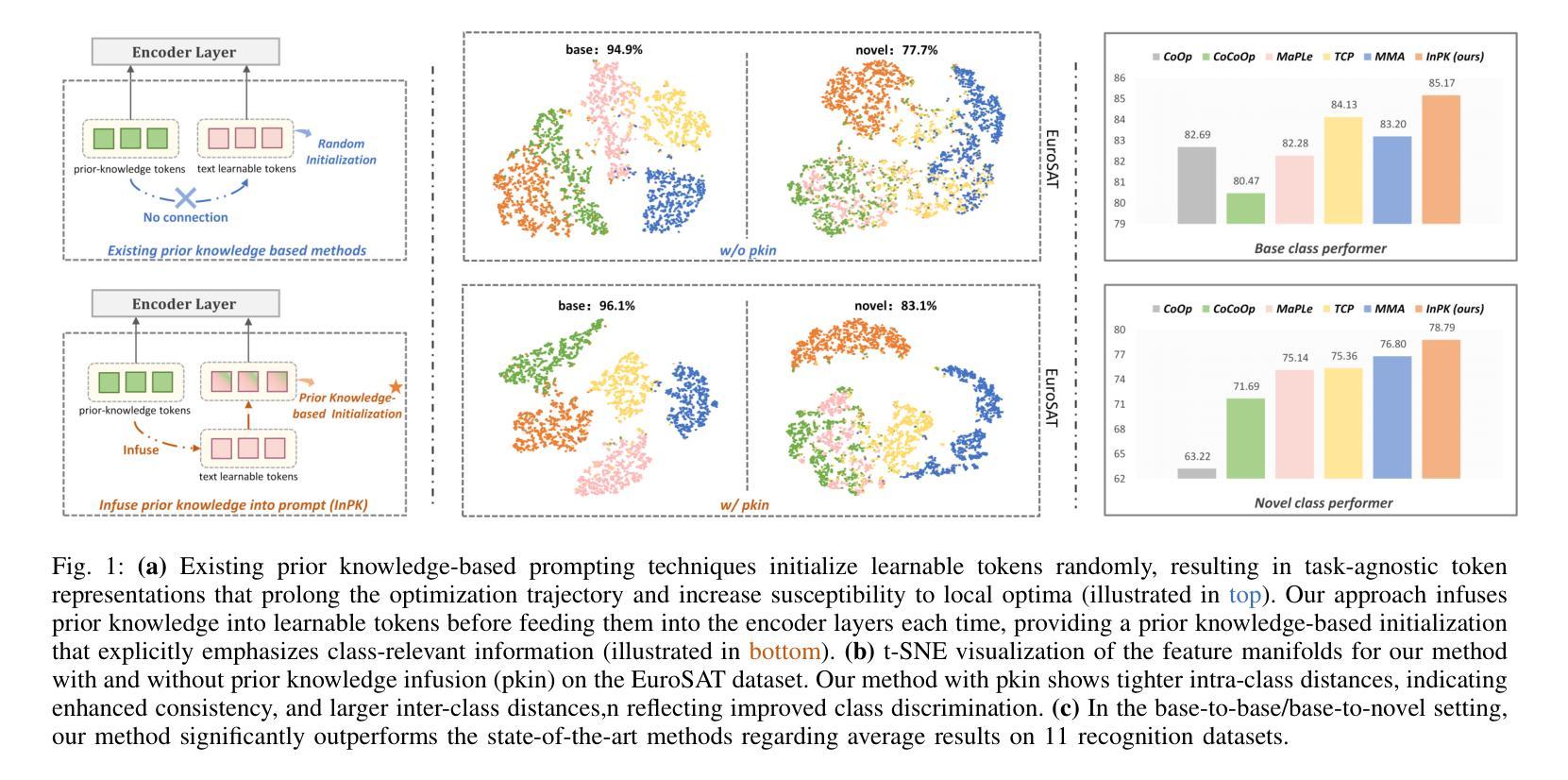
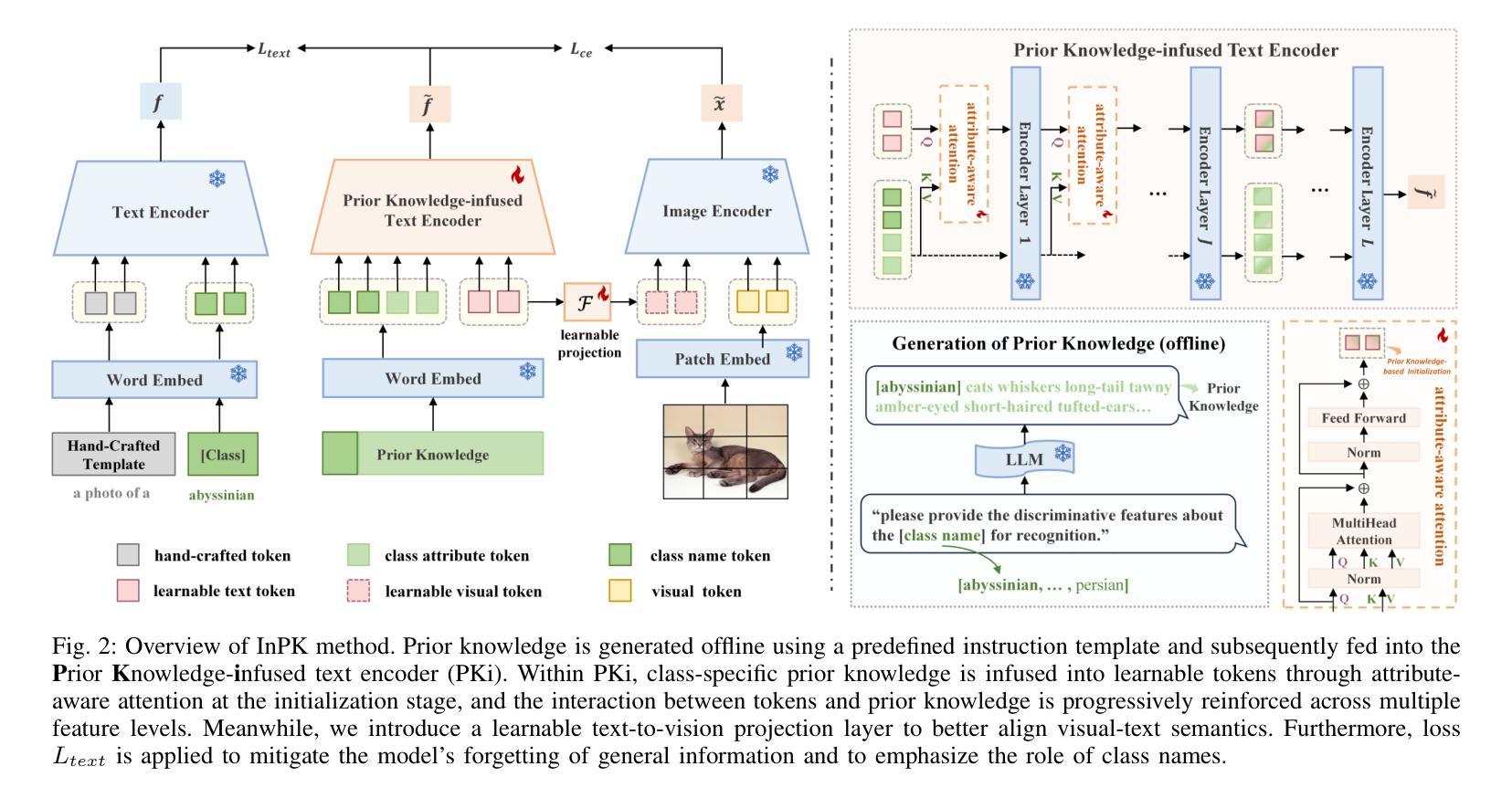
InPK: Infusing Prior Knowledge into Prompt for Vision-Language Models
Authors:Shuchang Zhou, Jiwei Wei, Shiyuan He, Yuyang Zhou, Chaoning Zhang, Jie Zou, Ning Xie, Yang Yang
Prompt tuning has become a popular strategy for adapting Vision-Language Models (VLMs) to zero/few-shot visual recognition tasks. Some prompting techniques introduce prior knowledge due to its richness, but when learnable tokens are randomly initialized and disconnected from prior knowledge, they tend to overfit on seen classes and struggle with domain shifts for unseen ones. To address this issue, we propose the InPK model, which infuses class-specific prior knowledge into the learnable tokens during initialization, thus enabling the model to explicitly focus on class-relevant information. Furthermore, to mitigate the weakening of class information by multi-layer encoders, we continuously reinforce the interaction between learnable tokens and prior knowledge across multiple feature levels. This progressive interaction allows the learnable tokens to better capture the fine-grained differences and universal visual concepts within prior knowledge, enabling the model to extract more discriminative and generalized text features. Even for unseen classes, the learned interaction allows the model to capture their common representations and infer their appropriate positions within the existing semantic structure. Moreover, we introduce a learnable text-to-vision projection layer to accommodate the text adjustments, ensuring better alignment of visual-text semantics. Extensive experiments on 11 recognition datasets show that InPK significantly outperforms state-of-the-art methods in multiple zero/few-shot image classification tasks.
提示调整已成为适应视觉语言模型(VLM)到零/少样本视觉识别任务的流行策略。一些提示技术由于其丰富性而引入了先验知识,但是当可学习令牌随机初始化并与先验知识断开连接时,它们往往会在已见类别上过度拟合,并且在未见类别上因领域偏移而挣扎。为了解决这个问题,我们提出了InPK模型,该模型在初始化期间将特定类别的先验知识注入可学习令牌中,从而使模型能够显式关注与类别相关的信息。此外,为了减轻多层编码器对类别信息的削弱,我们跨多个特征层面持续加强可学习令牌和先验知识之间的交互。这种渐进的交互允许可学习令牌更好地捕捉先验知识中的细微差别和通用视觉概念,使模型能够提取更具辨别力和通用化的文本特征。即使对于未见过的类别,学习到的交互也允许模型捕获它们的通用表示并推断它们在现有语义结构中的适当位置。此外,我们引入了一个可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。在11个识别数据集上的大量实验表明,InPK在多个零/少样本图像分类任务中显著优于最新技术的方法。
论文及项目相关链接
Summary
本文介绍了针对视觉语言模型(VLMs)在零/少样本视觉识别任务中的适应策略——提示调整技术。针对现有提示技术中可学习标记随机初始化并脱离先验知识导致的过度拟合已见类别和面对未见类别时域偏移的问题,提出了InPK模型。该模型在初始化时融入类别特定的先验知识到可学习标记中,使模型能显式关注类别相关信息。同时,为了减轻多层编码器对类别信息的削弱,InPK模型在多特征级别上持续强化可学习标记和先验知识之间的交互。这种渐进的交互使可学习标记能够更好地捕捉先验知识中的细微差别和通用视觉概念,从而提取更具鉴别力和泛化的文本特征。对于未见类别,这种学习交互使模型能够捕捉其共同表示并推断其在现有语义结构中的适当位置。此外,还引入了一个可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。在多个数据集上的实验表明,InPK在多个零/少样本图像分类任务中显著优于现有技术。
Key Takeaways
- 引出问题:现有的提示调整技术在视觉语言模型中随机初始化可学习标记导致过度拟合已见类别并难以适应未见类别的域偏移问题。
- 提出解决方案:InPK模型通过初始化时融入类别特定先验知识到可学习标记中解决上述问题。
- 模型特性:InPK模型在多特征级别上强化可学习标记和先验知识之间的交互,以提取更具鉴别力和泛化的文本特征。
- 适应未见类别:模型能够通过学习交互捕捉未见类别的共同表示并推断其在现有语义结构中的位置。
- 创新点:引入可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。
- 实验验证:在多个数据集上的实验证明InPK模型在零/少样本图像分类任务中显著优于现有技术。
点此查看论文截图

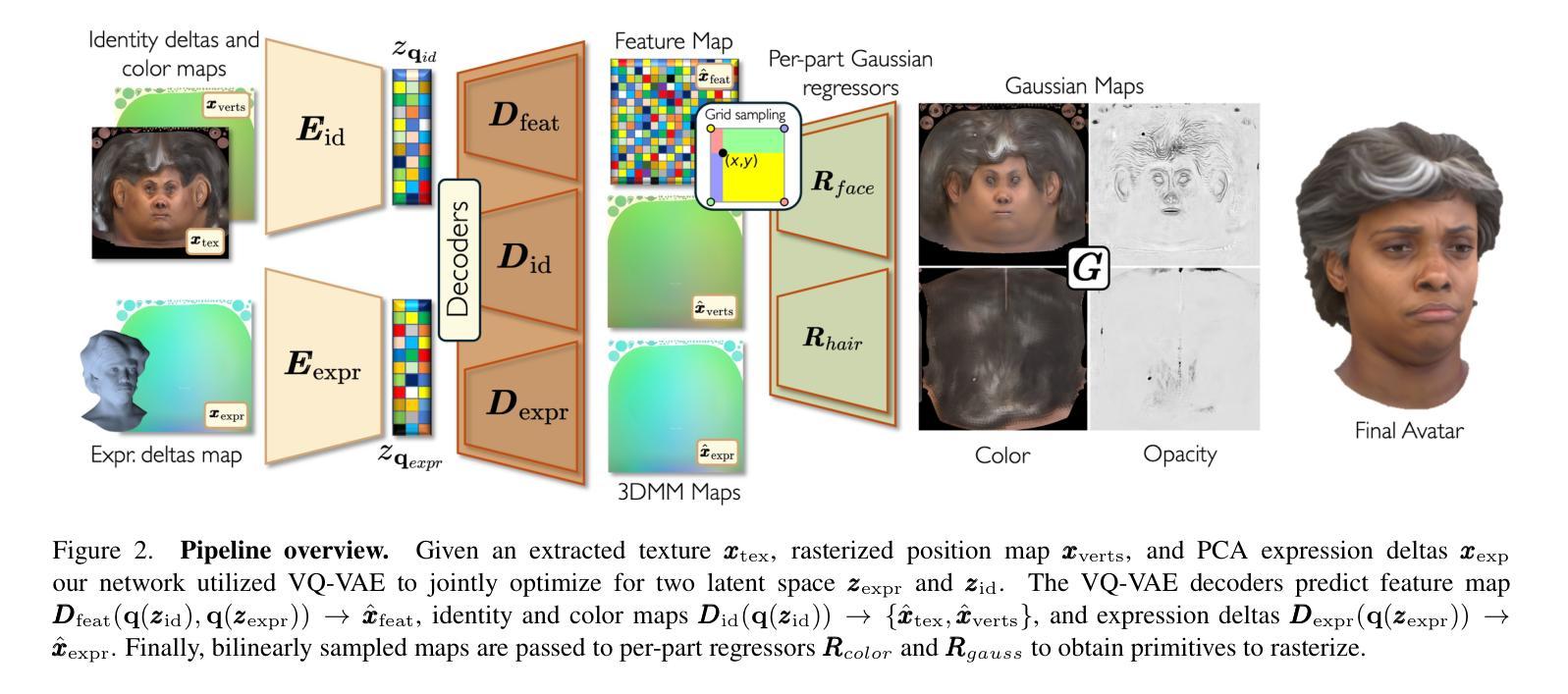
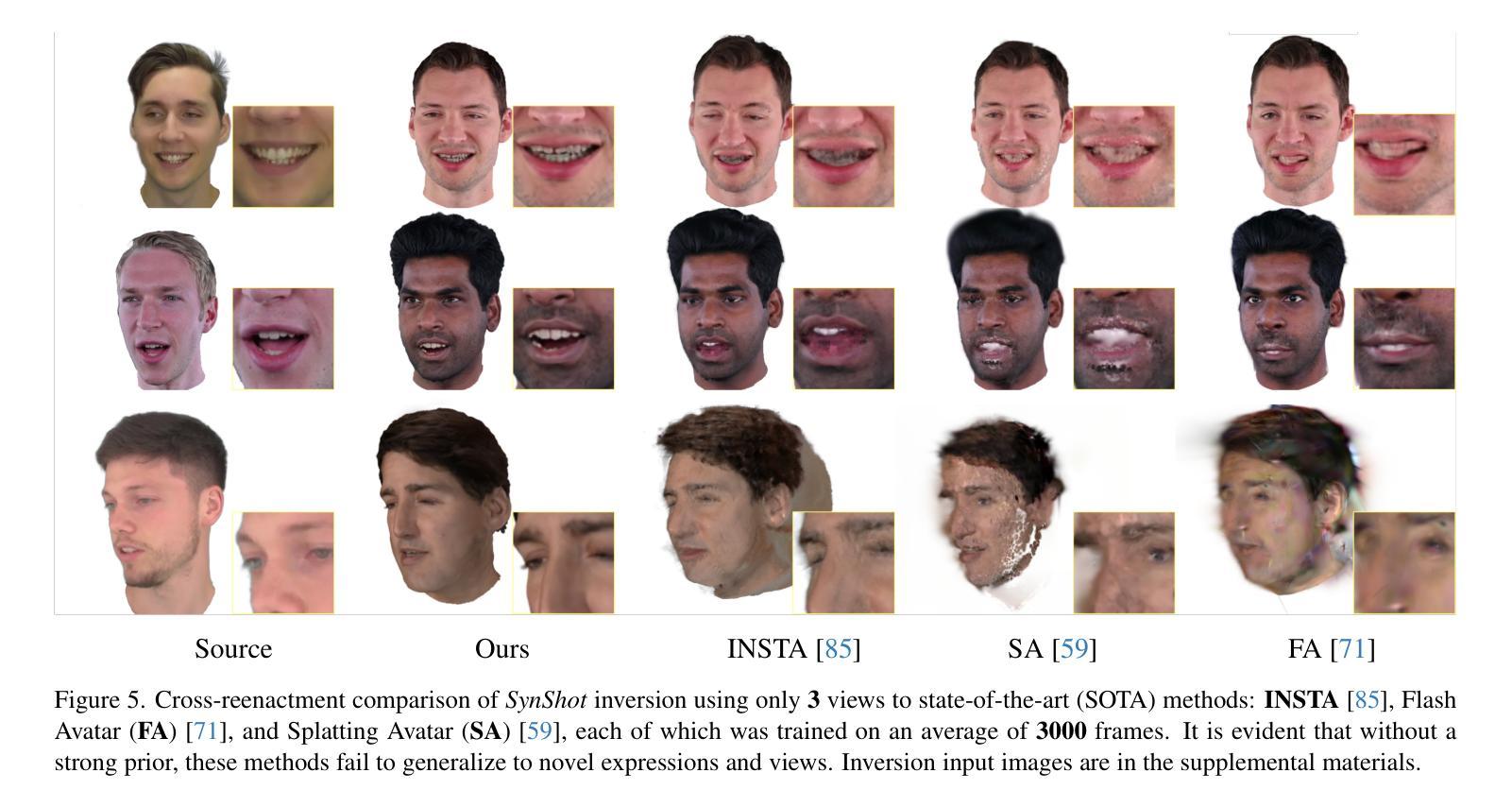
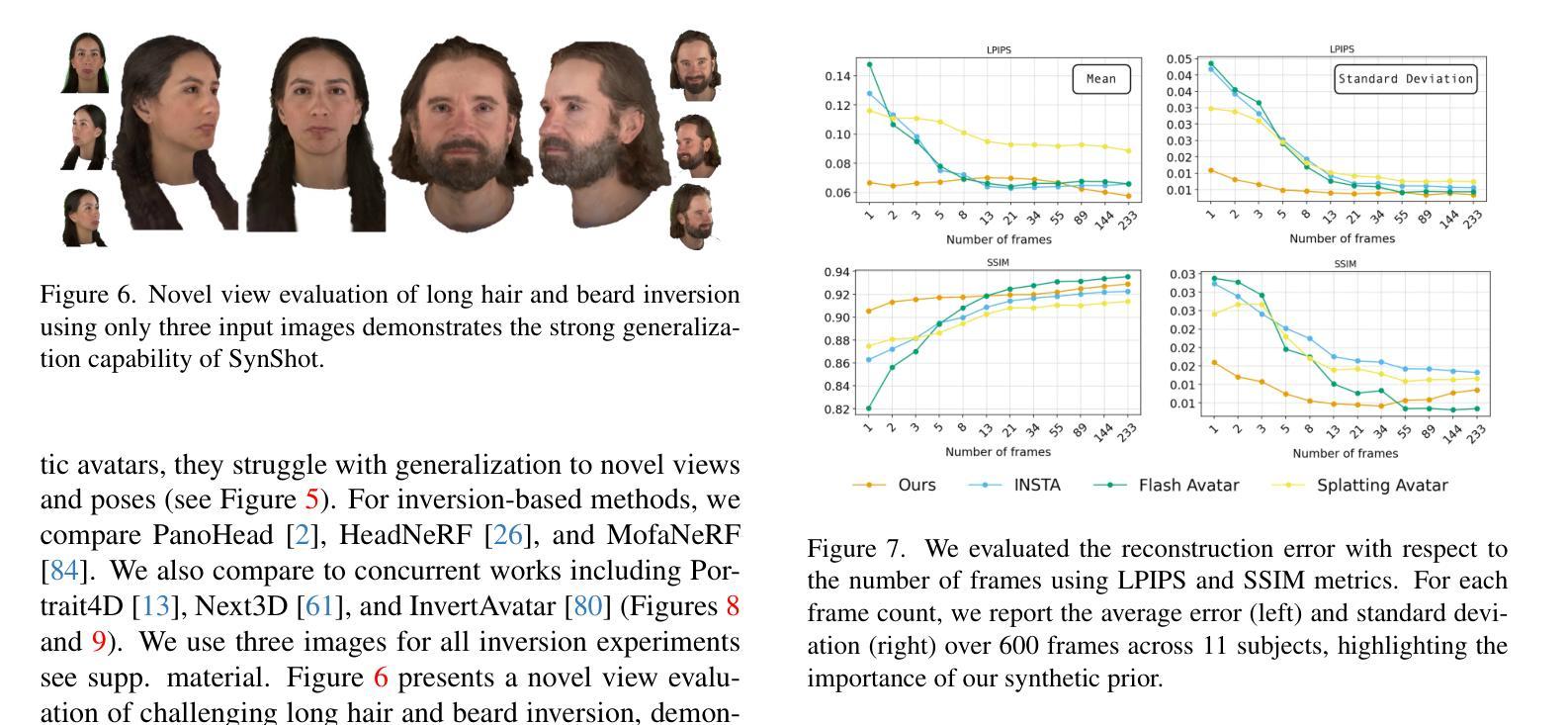
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了SynShot,这是一种基于合成先验的新颖的少样本驱动头部化身反转方法。我们解决了三个主要挑战。首先,训练可控的3D生成网络需要大量的不同序列,而图像和高质量跟踪网格的配对并不总是可用的。其次,真实数据的使用受到严格监管(例如,根据《通用数据保护条例》,当参与者同意撤回时,需要频繁删除模型和数据进行适应)。不受这些约束的合成数据是一个吸引人的选择。第三,最先进的单眼化身模型在应对新视角和表情时面临难以推广的问题,缺乏强大的先验知识并且经常过度适应特定的视角分布。受仅受合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从合成头部的大数据集中学习先验模型,这些合成头部具有不同的身份、表情和视角。凭借少量的输入图像,SynShot微调了预训练的合成先验以弥合领域差距,从而建立一个逼真的头部化身模型,该模型能够推广到新的表情和视角。我们使用三维高斯涂片和卷积编码器解码器建立头部化身模型,该编码器解码器以UV纹理空间输出高斯参数。考虑到头部各部位建模复杂性的差异(例如皮肤和头发),我们将先验与用于增加每个部位原始数量的上采样显式控制相结合。与最先进的单眼和基于GAN的方法相比,SynShot在新型视角和表情合成方面显著提高了性能。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
本文介绍了基于合成先验的SynShot方法,用于基于少数图像进行可驾驶头部角色的反向操作。解决了三个主要问题:训练可控的3D生成网络需要大量多样序列的数据,但真实数据受限且受到严格监管;当前主流的单眼头像模型难以泛化到新的视角和表情;以及通过利用合成数据的先验模型进行填充克服以上挑战,将头部角色进行建模并实现高质量的面部和纹理表现。在只有少数图像的情况下,SynShot方法可对预训练的合成先验进行微调以弥补领域间的差距,同时能适应不同视点表达和姿态动作场景生成虚拟头部模型的新视图与表达合成。这种方法利用UV纹理空间中的卷积编码器解码器来生成模型,并利用合成数据的优势对头部进行建模与局部建模调整来实现特效头部形象的准确再现和更加广泛的现实表现力与自由发挥想象能力的领域应用。相较于其他单眼和基于GAN的方法,SynShot显著提高了新视角和表情合成的质量。
Key Takeaways
- SynShot是一种用于驱动头部角色的新颖方法,它解决了当前面临的数据稀缺问题以及模型的泛化问题。
- 该方法基于合成先验,解决了真实数据获取困难的问题,并避免了真实数据使用中的法规限制。
点此查看论文截图



COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Adaptation
Authors:Arnav M. Das, Gantavya Bhatt, Lilly Kumari, Sahil Verma, Jeff Bilmes
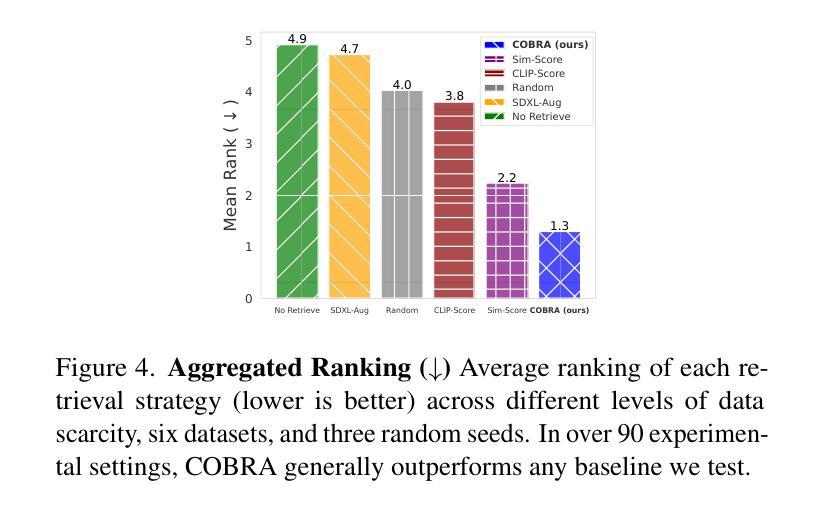
Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot adaptation settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
检索增强是通过从大型辅助池中检索额外数据的一种实践,已成为在低数据情况下提高模型性能的有效技术。之前的方法仅采用基于最近邻的策略进行数据选择,检索与目标任务实例高度相似的辅助样本。然而,这些方法容易选择高度冗余的样本,因为它们没有融入任何多样性的概念。在我们的工作中,我们首先证明,先前用于增强少数镜头适应的检索数据选择策略可以使用称为组合互信息(CMI)度量的一类函数进行概括。然后,我们提出了COBRA(组合检索增强),它采用一种替代的CMI度量,同时考虑多样性和对目标数据集的相似性。在LAION-2B检索样本进行图像分类任务和少量学习任务时,COBRA始终优于之前的检索方法。COBRA在检索过程中增加了可忽略的计算开销,同时为下游模型性能提供了显著的改进。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
本文介绍了数据检索增强技术在低数据环境下的应用,通过从大型辅助池中检索额外数据来提高模型性能。先前的方法仅使用基于最近邻的策略进行数据选择,容易选取冗余样本,未考虑多样性。本文提出了使用组合互信息(CMI)度量的数据选择策略,并设计了COBRA方法,结合多样性和相似性进行目标数据集检索。在图像分类任务和少量学习任务中,COBRA从LAION-2B中检索样本的性能优于以前的方法,同时对检索的计算开销影响较小,大大提高了下游模型的性能。
Key Takeaways
- 检索增强技术通过从大型辅助池中检索额外数据在低数据环境下提高模型性能。
- 以往方法使用基于最近邻的策略进行数据选择,存在选取冗余样本的问题。
- 本文使用组合互信息(CMI)度量来改进数据选择策略。
- COBRA方法结合了多样性和相似性进行目标数据集检索。
- COBRA在图像分类任务和少量学习任务中的性能优于先前的方法。
- COBRA对检索的计算开销影响较小。
点此查看论文截图


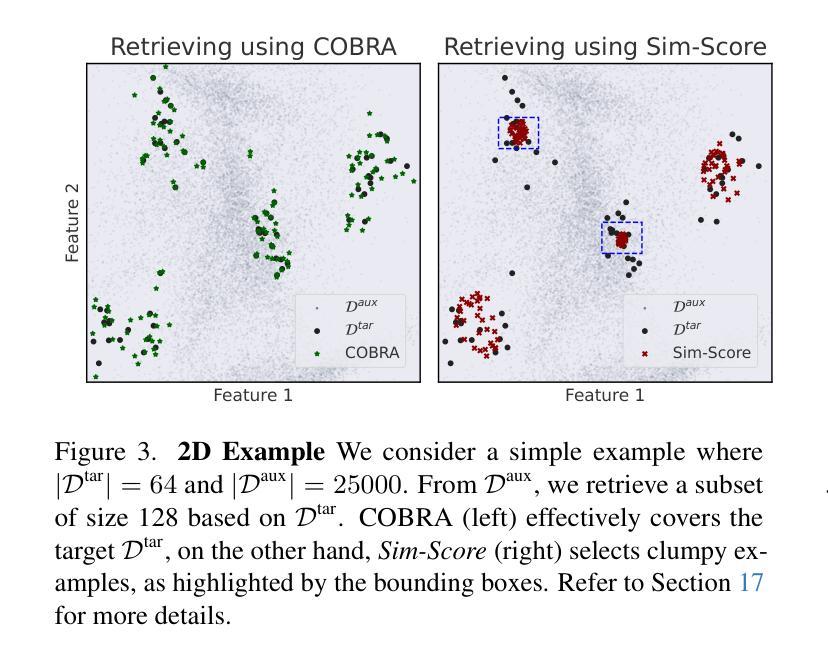

MVREC: A General Few-shot Defect Classification Model Using Multi-View Region-Context
Authors:Shuai Lyu, Rongchen Zhang, Zeqi Ma, Fangjian Liao, Dongmei Mo, Waikeung Wong
Few-shot defect multi-classification (FSDMC) is an emerging trend in quality control within industrial manufacturing. However, current FSDMC research often lacks generalizability due to its focus on specific datasets. Additionally, defect classification heavily relies on contextual information within images, and existing methods fall short of effectively extracting this information. To address these challenges, we propose a general FSDMC framework called MVREC, which offers two primary advantages: (1) MVREC extracts general features for defect instances by incorporating the pre-trained AlphaCLIP model. (2) It utilizes a region-context framework to enhance defect features by leveraging mask region input and multi-view context augmentation. Furthermore, Few-shot Zip-Adapter(-F) classifiers within the model are introduced to cache the visual features of the support set and perform few-shot classification. We also introduce MVTec-FS, a new FSDMC benchmark based on MVTec AD, which includes 1228 defect images with instance-level mask annotations and 46 defect types. Extensive experiments conducted on MVTec-FS and four additional datasets demonstrate its effectiveness in general defect classification and its ability to incorporate contextual information to improve classification performance. Code: https://github.com/ShuaiLYU/MVREC
少样本缺陷多分类(FSDMC)是工业制造中质量控制的新兴趋势。然而,当前的FSDMC研究往往由于缺乏普遍性而专注于特定数据集。此外,缺陷分类严重依赖于图像中的上下文信息,而现有方法不足以有效地提取这些信息。为了解决这些挑战,我们提出了一种通用的FSDMC框架,名为MVREC,它有两个主要优点:(1)MVREC通过融入预训练的AlphaCLIP模型,提取缺陷实例的通用特征。(2)它利用区域上下文框架,通过利用掩膜区域输入和多视图上下文增强来增强缺陷特征。此外,模型中引入了少样本Zip-Adapter(-F)分类器,以缓存支持集的视觉特征并执行少样本分类。我们还基于MVTec AD引入了新的FSDMC基准测试MVTec-FS,其中包括具有实例级掩膜注释的1228个缺陷图像和46种缺陷类型。在MVTec-FS和另外四个数据集上进行的广泛实验证明了其在一般缺陷分类中的有效性以及结合上下文信息提高分类性能的能力。代码:https://github.com/ShuaiLYU/MVREC
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
该摘要针对工业制造中的质量控制领域的新兴趋势——少样本缺陷多分类问题(FSDMC)展开。当前研究因过于依赖特定数据集而缺乏泛化能力。为解决此问题,提出一种名为MVREC的通用FSDMC框架,其利用预训练的AlphaCLIP模型提取缺陷实例的一般特征,并采用区域上下文框架增强缺陷特征,通过利用掩模区域输入和多视图上下文增强实现。此外,引入少样本Zip-Adapter(-F)分类器以缓存支持集的视觉特征并执行少样本分类。同时介绍基于MVTec AD的新FSDMC基准数据集MVTec-FS,包含带有实例级掩模注释的1228个缺陷图像和46种缺陷类型。在MVTec-FS和其他四个数据集上的大量实验证明了其在通用缺陷分类中的有效性以及利用上下文信息提高分类性能的能力。
Key Takeaways
- FSDMC是当前工业制造中质量控制的重要研究领域,但现有方法因数据集局限性导致泛化能力弱。
- MVREC框架利用预训练的AlphaCLIP模型提取缺陷实例的一般特征,增强了模型的泛化能力。
- MVREC采用区域上下文框架,通过掩模区域输入和多视图上下文增强,有效增强缺陷特征。
- 引入少样本Zip-Adapter(-F)分类器以缓存支持集的视觉特征并执行少样本分类任务。
- MVTec-FS是一个基于MVTec AD的新FSDMC基准数据集,包含大量带有实例级掩模注释的缺陷图像和多种缺陷类型。
- 在多个数据集上的实验证明了MVREC框架在通用缺陷分类中的有效性。
点此查看论文截图

PICLe: Pseudo-Annotations for In-Context Learning in Low-Resource Named Entity Detection
Authors:Sepideh Mamooler, Syrielle Montariol, Alexander Mathis, Antoine Bosselut
In-context learning (ICL) enables Large Language Models (LLMs) to perform tasks using few demonstrations, facilitating task adaptation when labeled examples are hard to obtain. However, ICL is sensitive to the choice of demonstrations, and it remains unclear which demonstration attributes enable in-context generalization. In this work, we conduct a perturbation study of in-context demonstrations for low-resource Named Entity Detection (NED). Our surprising finding is that in-context demonstrations with partially correct annotated entity mentions can be as effective for task transfer as fully correct demonstrations. Based off our findings, we propose Pseudo-annotated In-Context Learning (PICLe), a framework for in-context learning with noisy, pseudo-annotated demonstrations. PICLe leverages LLMs to annotate many demonstrations in a zero-shot first pass. We then cluster these synthetic demonstrations, sample specific sets of in-context demonstrations from each cluster, and predict entity mentions using each set independently. Finally, we use self-verification to select the final set of entity mentions. We evaluate PICLe on five biomedical NED datasets and show that, with zero human annotation, PICLe outperforms ICL in low-resource settings where limited gold examples can be used as in-context demonstrations.
上下文学习(ICL)使得大型语言模型(LLM)能够在少量演示的情况下完成任务,在难以获取标注样本时促进任务适应。然而,ICL对演示的选择很敏感,尚不清楚哪些演示属性能够实现上下文泛化。在这项工作中,我们对低资源命名实体检测(NED)的上下文演示进行扰动研究。我们意外地发现,带有部分正确注释的实体提及的上下文演示与完全正确的演示一样有效,都能实现任务迁移。基于我们的发现,我们提出了伪注释上下文学习(PICLe)框架,该框架使用带有噪声的伪注释演示进行上下文学习。PICLe首先利用LLM在零样本首次通过中注释许多演示。然后我们对这些合成演示进行聚类,从每个集群中抽取特定的上下文演示集,并独立使用每个集合预测实体提及。最后,我们使用自我验证选择最终的实体提及集合。我们在五个生物医学NED数据集上评估PICLe,结果表明,在无需人工标注的情况下,PICLe在低资源环境中优于ICL,在那里可以使用有限数量的黄金样本作为上下文演示。
论文及项目相关链接
PDF In Proceedings of NAACL2025
Summary
本论文研究了基于大型语言模型(LLM)的上下文学习(ICL)在命名实体检测(NED)任务中的表现。通过扰动分析发现,部分正确标注的实体提及的上下文演示与完全正确的演示在任务迁移中具有相同的效果。基于此发现,论文提出了伪标注上下文学习(PICLe)框架,该框架利用LLM进行零样本首次标注大量演示内容,并将其聚类。从每个集群中采样特定的上下文演示集,独立预测实体提及,并使用自我验证选择最终的实体提及集。在五个生物医学NED数据集上的评估结果表明,在无需人工标注的情况下,PICLe在低资源设置中的表现优于ICL。
Key Takeaways
- ICL(上下文学习)在命名实体检测任务中,可以利用少量演示完成任务适应,当难以获取标记示例时尤其有用。
- ICL对演示的选择很敏感,尚不清楚哪些演示属性有助于上下文泛化。
- 研究发现,部分正确标注的实体提及的演示与完全正确的演示在任务迁移中具有相似效果。
- 基于这一发现,提出了PICLe(伪标注上下文学习)框架,该框架利用LLM进行零样本首次标注大量演示内容。
- PICLe通过将合成演示内容聚类,从每个集群中采样特定的上下文演示集来预测实体提及。
- 使用自我验证选择最终的实体提及集,提高了准确性。
点此查看论文截图