⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-04 更新
Are you really listening? Boosting Perceptual Awareness in Music-QA Benchmarks
Authors:Yongyi Zang, Sean O’Brien, Taylor Berg-Kirkpatrick, Julian McAuley, Zachary Novack
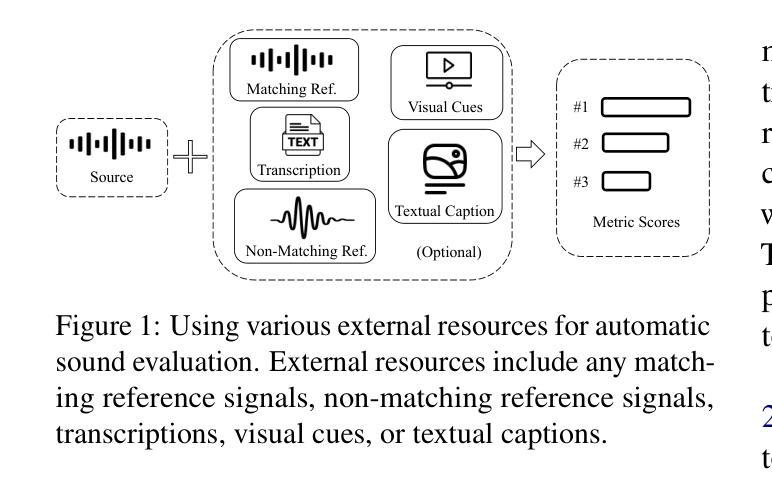
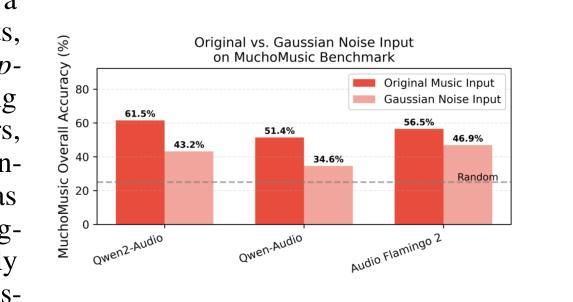
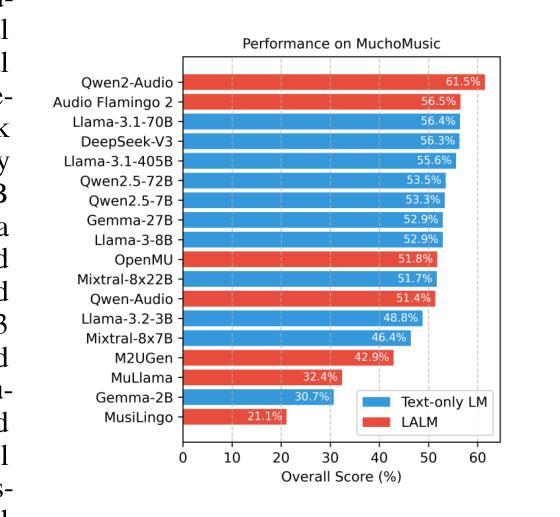
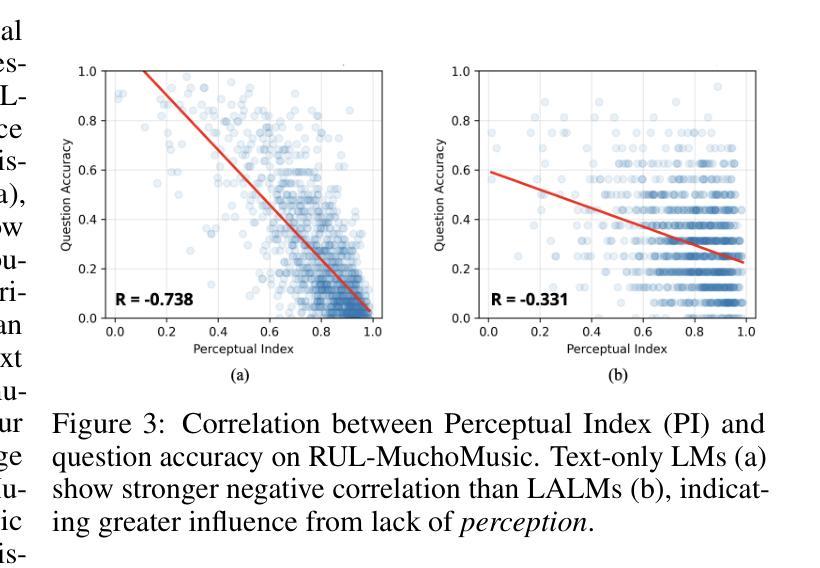
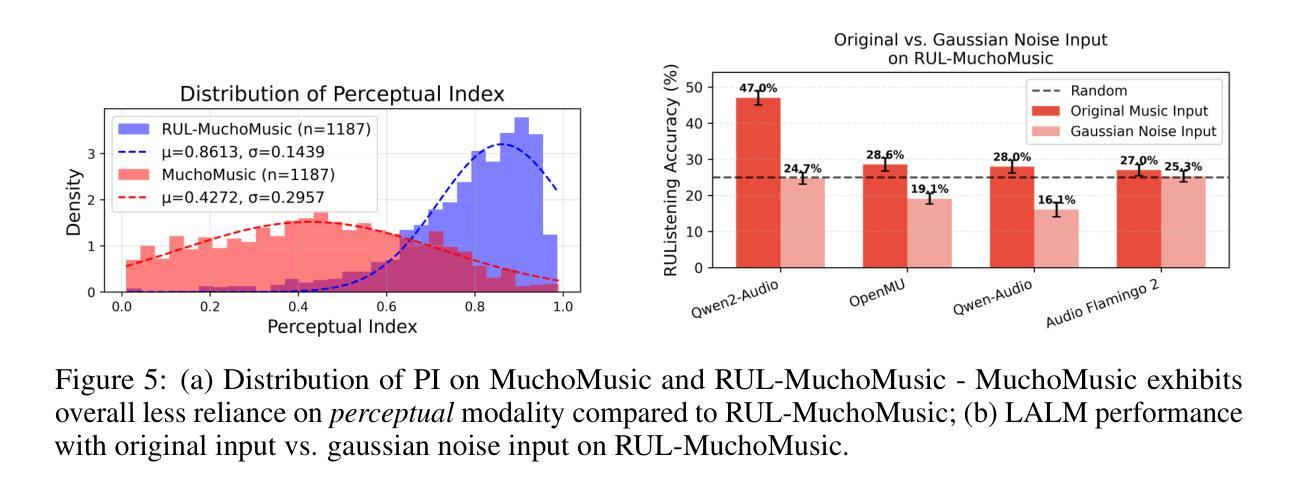
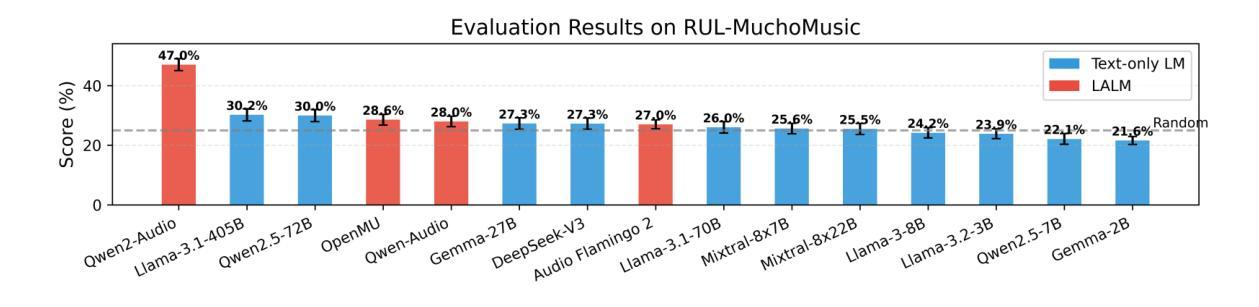
Large Audio Language Models (LALMs), where pretrained text LLMs are finetuned with audio input, have made remarkable progress in music understanding. However, current evaluation methodologies exhibit critical limitations: on the leading Music Question Answering benchmark, MuchoMusic, text-only LLMs without audio perception capabilities achieve surprisingly high accuracy of up to 56.4%, on par or above most LALMs. Furthermore, when presented with random Gaussian noise instead of actual audio, LALMs still perform significantly above chance. These findings suggest existing benchmarks predominantly assess reasoning abilities rather than audio perception. To overcome this challenge, we present RUListening: Robust Understanding through Listening, a framework that enhances perceptual evaluation in Music-QA benchmarks. We introduce the Perceptual Index (PI), a quantitative metric that measures a question’s reliance on audio perception by analyzing log probability distributions from text-only language models. Using this metric, we generate synthetic, challenging distractors to create QA pairs that necessitate genuine audio perception. When applied to MuchoMusic, our filtered dataset successfully forces models to rely on perceptual information-text-only LLMs perform at chance levels, while LALMs similarly deteriorate when audio inputs are replaced with noise. These results validate our framework’s effectiveness in creating benchmarks that more accurately evaluate audio perception capabilities.
大规模音频语言模型(LALMs)通过在音频输入上微调预训练的文本大型语言模型(LLMs),在音乐理解方面取得了显著的进步。然而,当前的评估方法存在明显的局限性:在领先的Music Question Answering基准测试MuchoMusic上,没有音频感知能力的纯文本LLMs出人意料地达到了高达56.4%的高准确率,与大多数LALM的表现持平或更高。此外,当面对随机高斯噪声而非实际音频时,LALM的表现仍然显著高于随机水平。这些发现表明,现有的基准测试主要评估的是推理能力,而不是音频感知能力。为了克服这一挑战,我们提出了RUListening:通过倾听实现稳健理解,这是一个增强音乐问答基准测试中感知评估的框架。我们引入了感知指数(PI)这一量化指标,通过分析纯文本语言模型的日志概率分布来衡量问题对音频感知的依赖程度。使用该指标,我们生成了合成且具有挑战性的干扰项,以创建必须依赖真实音频感知的QA对。在MuchoMusic上的应用显示,我们的过滤数据集成功迫使模型依赖感知信息——纯文本LLMs的表现达到了随机水平,而当将音频输入替换为噪声时,LALM的表现也类似地下降。这些结果验证了我们的框架在创建更能准确评估音频感知能力的基准测试方面的有效性。
论文及项目相关链接
Summary
预训练文本LLM通过音频输入微调后形成的大型音频语言模型(LALMs)在音乐理解方面取得了显著进展。然而,现有的评估方法存在重大缺陷,因为即便是在领先的音乐问答基准测试MuchoMusic上,不具备音频感知能力的文本LLM也能达到令人惊讶的高准确率(高达56.4%),与大多数LALM的表现不相上下。甚至当面对随机高斯噪声而非实际音频时,LALM的表现也显著优于随机水平。这些发现表明,当前基准测试主要评估的是推理能力而非音频感知能力。为此,我们提出RUListening:通过倾听实现稳健理解,一个增强音乐问答基准测试中感知评估的框架。我们引入了感知指数(PI)这一量化指标,通过分析文本模型的日志概率分布来衡量问题对音频感知的依赖程度。利用这一指标,我们生成了具有挑战性的合成干扰项来创建需要真实音频感知的问答对。在MuchoMusic上的应用显示,我们的筛选数据集成功迫使模型依赖感知信息——文本LLM的表现接近随机水平,而LALM在音频输入被噪声替代时表现同样不佳。这些结果验证了我们的框架在创建更准确地评估音频感知能力的基准测试方面的有效性。
Key Takeaways
- LALMs在音乐理解方面取得显著进步。
- 当前评估方法主要评估推理能力而非音频感知能力。
- 文本LLM在基准测试中表现出高准确率,即使不具备音频感知能力。
- 随机噪声对LALM的影响显示其并非真正依赖于音频感知。
- 提出RUListening框架以增强音乐问答基准测试中的感知评估。
- 引入感知指数(PI)来衡量问题对音频感知的依赖程度。
点此查看论文截图

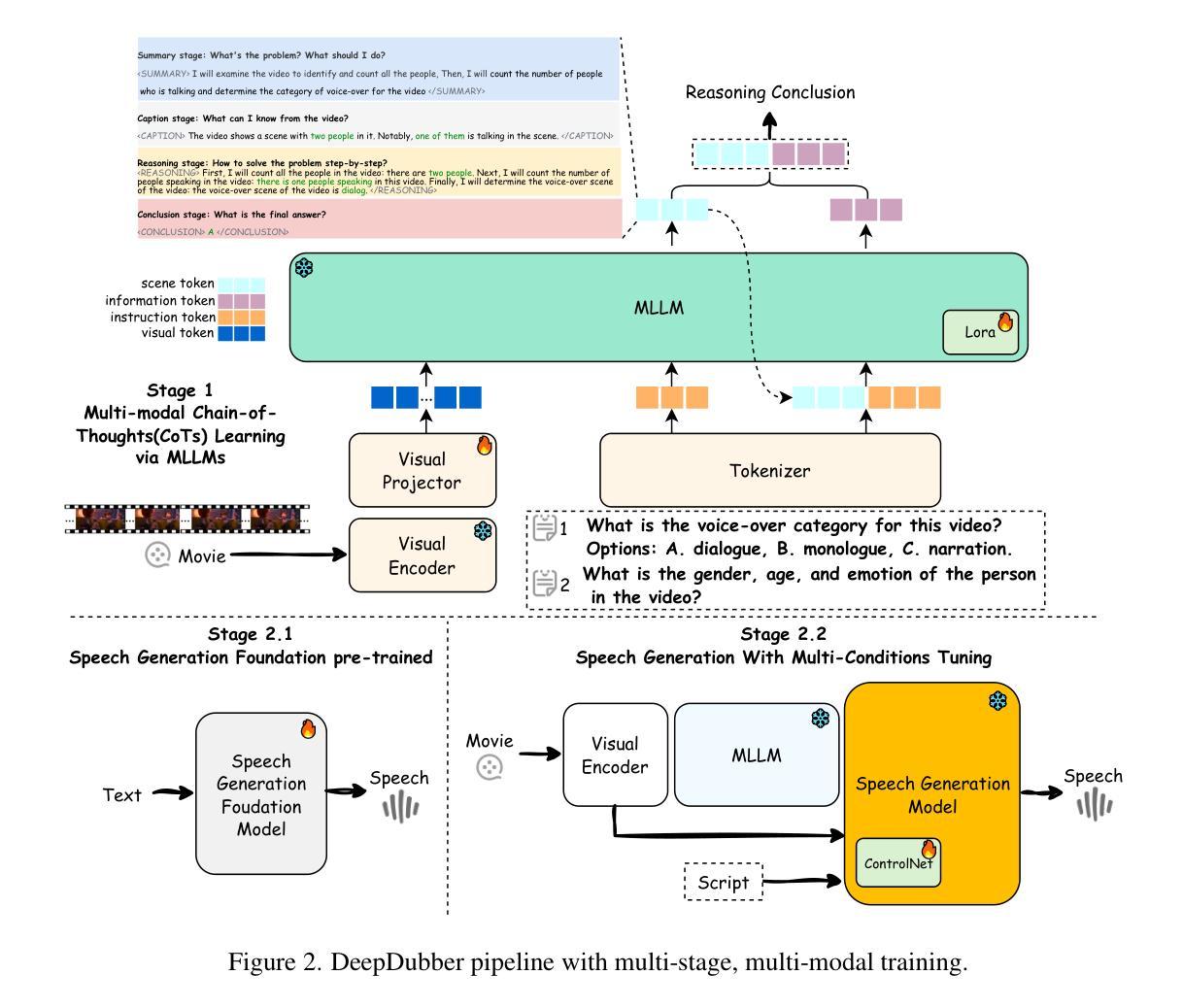
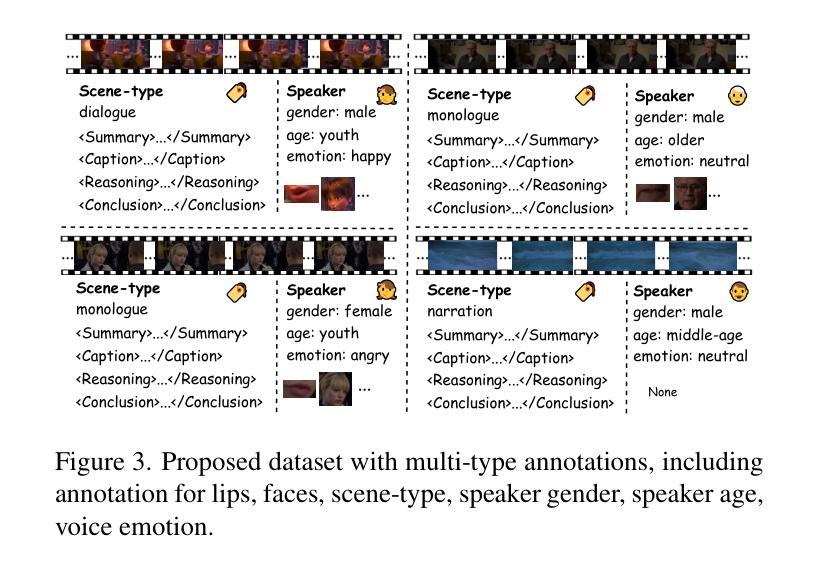
DeepDubber-V1: Towards High Quality and Dialogue, Narration, Monologue Adaptive Movie Dubbing Via Multi-Modal Chain-of-Thoughts Reasoning Guidance
Authors:Junjie Zheng, Zihao Chen, Chaofan Ding, Xinhan Di
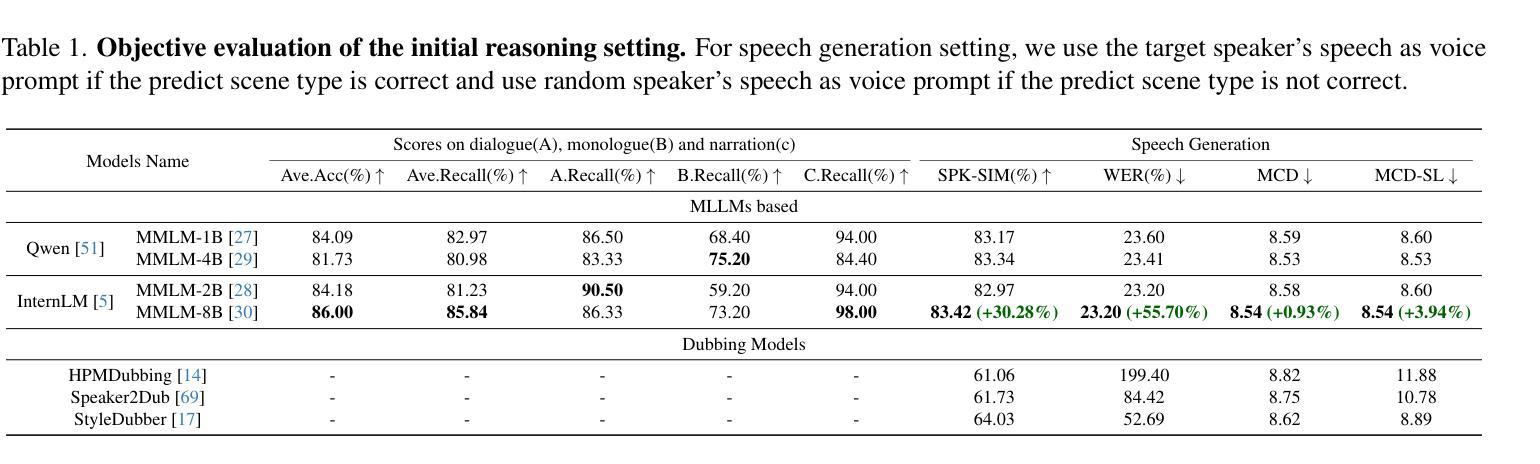
Current movie dubbing technology can generate the desired voice from a given speech prompt, ensuring good synchronization between speech and visuals while accurately conveying the intended emotions. However, in movie dubbing, key aspects such as adapting to different dubbing styles, handling dialogue, narration, and monologue effectively, and understanding subtle details like the age and gender of speakers, have not been well studied. To address this challenge, we propose a framework of multi-modal large language model. First, it utilizes multimodal Chain-of-Thought (CoT) reasoning methods on visual inputs to understand dubbing styles and fine-grained attributes. Second, it generates high-quality dubbing through large speech generation models, guided by multimodal conditions. Additionally, we have developed a movie dubbing dataset with CoT annotations. The evaluation results demonstrate a performance improvement over state-of-the-art methods across multiple datasets. In particular, for the evaluation metrics, the SPK-SIM and EMO-SIM increases from 82.48% to 89.74%, 66.24% to 78.88% for dubbing setting 2.0 on V2C Animation dataset, LSE-D and MCD-SL decreases from 14.79 to 14.63, 5.24 to 4.74 for dubbing setting 2.0 on Grid dataset, SPK-SIM increases from 64.03 to 83.42 and WER decreases from 52.69% to 23.20% for initial reasoning setting on proposed CoT-Movie-Dubbing dataset in the comparison with the state-of-the art models.
当前的电影配音技术可以根据给定的语音提示生成所需的声音,确保语音和视觉之间的良好同步,同时准确传达预期的情绪。然而,在电影配音中,如何适应不同的配音风格、有效处理对话、旁白和独白,以及理解如说话人的年龄和性别等细微细节尚未得到很好的研究。为了应对这一挑战,我们提出了一个多模态大语言模型框架。首先,它利用视觉输入的链式思维(CoT)推理方法,理解配音风格和精细属性。其次,通过大型语音生成模型生成高质量的配音,在多模态条件下进行引导。此外,我们还开发了一个带有CoT注释的电影配音数据集。评估结果表明,与最先进的方法相比,我们在多个数据集上的性能有所提高。特别是,在V2C动画数据集的配音设置2.0上,SPK-SIM和EMO-SIM分别从82.48%提高到89.74%,从66.24%提高到78.88%;在Grid数据集的配音设置2.0上,LSE-D和MCD-SL分别从14.79下降到14.63,从5.24下降到4.74;在与最新模型的比较中,我们在提出的CoT-Movie-Dubbing数据集上的初步推理设置上,SPK-SIM从64.03%提高到83.42%,WER从52.69%降低到23.20%。
论文及项目相关链接
PDF 11 pages, 5 figures
摘要
当前电影配音技术可根据给定的语音提示生成所需的配音,确保语音与视觉的良好同步,同时准确传达情感。然而,在电影配音中,如何适应不同的配音风格、有效处理对话、旁白和独白,以及理解如说话人的年龄和性别等细微之处尚未得到深入研究。为应对这些挑战,我们提出了多模态大型语言模型框架。首先,它利用视觉输入的多模态Chain-of-Thought(CoT)推理方法,理解配音风格和精细属性。其次,通过大型语音生成模型生成高质量的配音,由多模态条件指导。此外,我们还开发了带有CoT注释的电影配音数据集。评估结果表明,与最新方法相比,我们在多个数据集上的表现有所提高。特别是在评估指标上,V2C动画数据集的说话人相似性(SPK-SIM)和情感相似性(EMO-SIM)分别从82.48%提高到89.74%和从66.24%提高到78.88%,Grid数据集的说话人位置估计偏差(LSE-D)和音乐与说话人感知距离(MCD-SL)分别从14.79降至到14.63和从5.24降至到4.74。与我们提出的CoT-Movie-Dubbing数据集上的初步推理设置相比,SPK-SIM从64.03%提高到83.42%,单词错误率(WER)从52.69%降至到到23.20%。
Key Takeaways
- 当前电影配音技术可以同步语音和视觉,但还需要研究如何适应不同的配音风格和处理对话、旁白和独白等。
- 提出了多模态大型语言模型框架来解决这些问题,结合视觉输入的多模态Chain-of-Thought(CoT)推理和大型语音生成模型。
- 开发了带有CoT注释的电影配音数据集以进行评估。
- 与现有方法相比,该框架在多个数据集上的表现有所提升。
- 在V2C动画数据集上,SPK-SIM和EMO-SIM指标有明显提高。
- 在Grid数据集上,LSE-D和MCD-SL指标有所改善。
点此查看论文截图


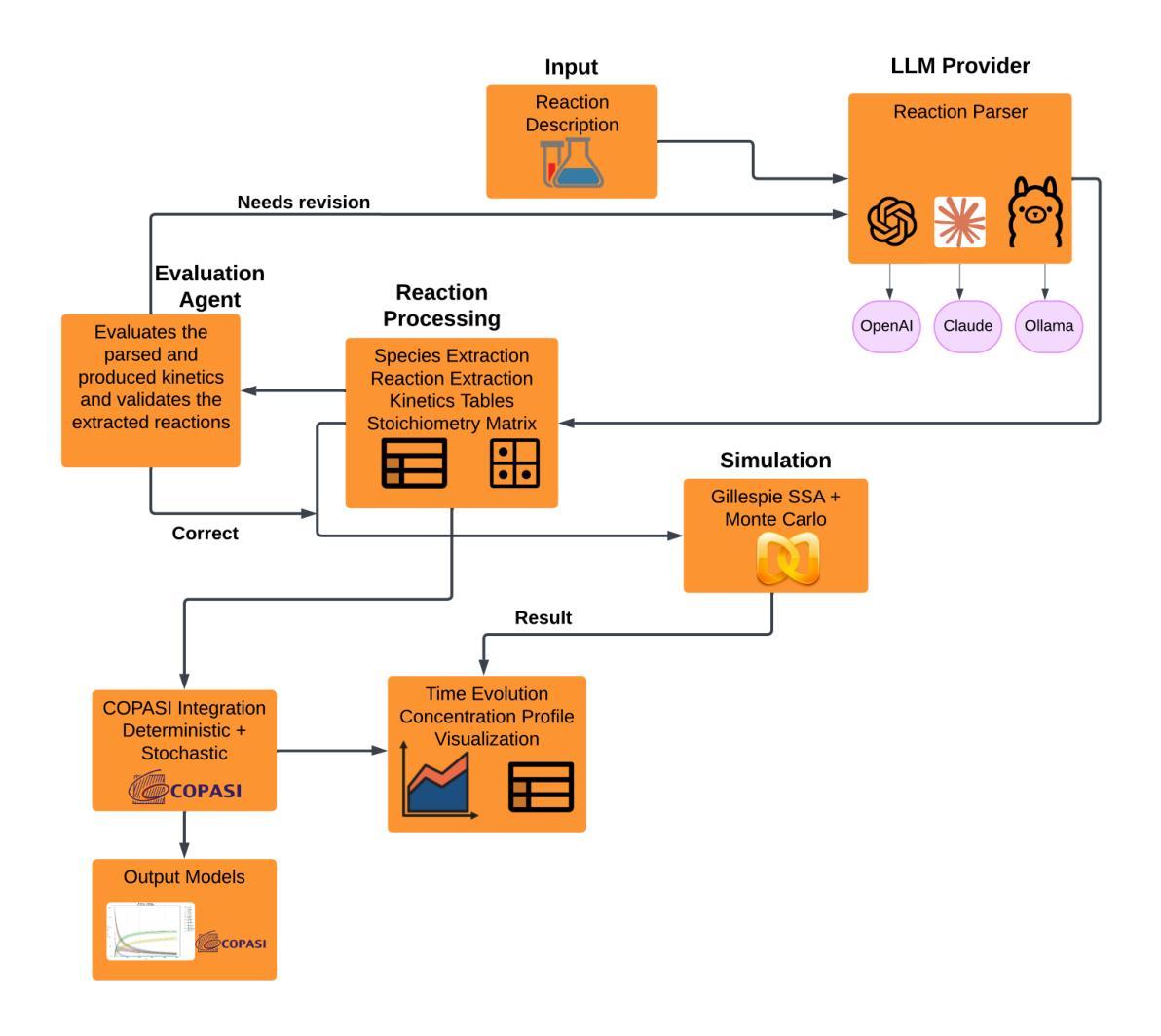
Integrating Large Language Models For Monte Carlo Simulation of Chemical Reaction Networks
Authors:Sadikshya Gyawali, Ashwini Mandal, Manish Dahal, Manish Awale, Sanjay Rijal, Shital Adhikari, Vaghawan Ojha
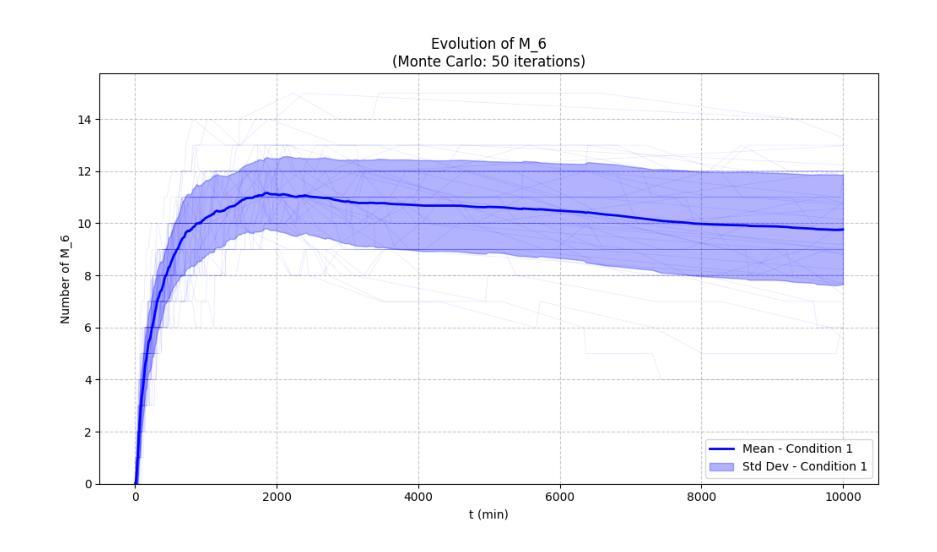
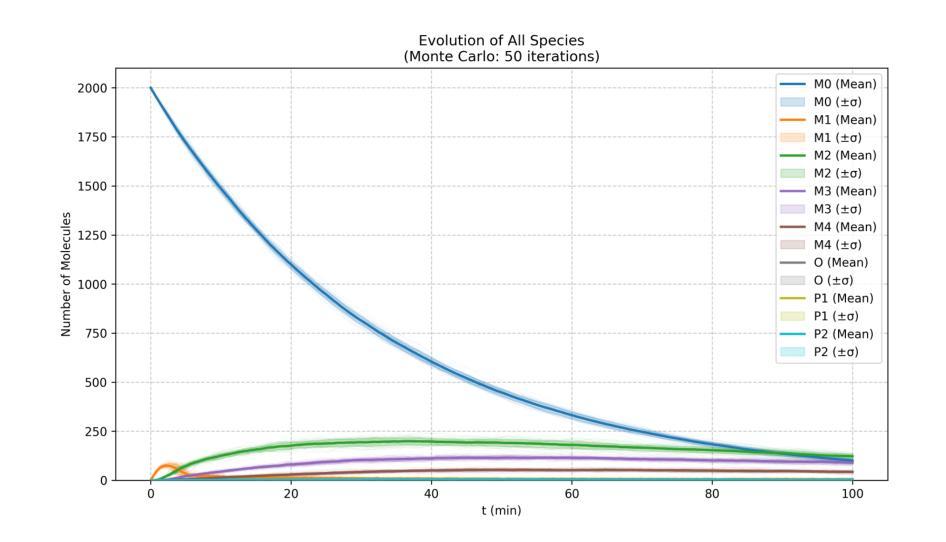
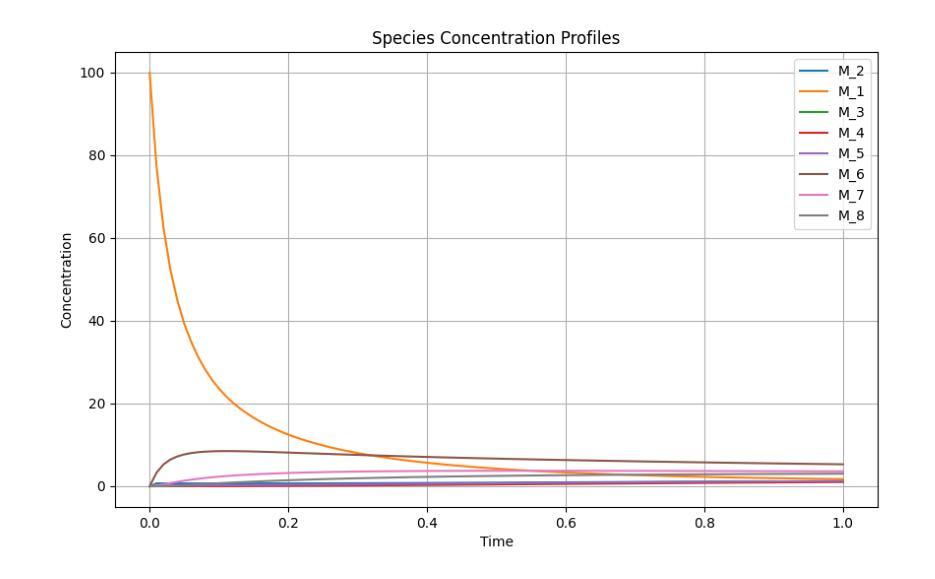
Chemical reaction network is an important method for modeling and exploring complex biological processes, bio-chemical interactions and the behavior of different dynamics in system biology. But, formulating such reaction kinetics takes considerable time. In this paper, we leverage the efficiency of modern large language models to automate the stochastic monte carlo simulation of chemical reaction networks and enable the simulation through the reaction description provided in the form of natural languages. We also integrate this process into widely used simulation tool Copasi to further give the edge and ease to the modelers and researchers. In this work, we show the efficacy and limitations of the modern large language models to parse and create reaction kinetics for modelling complex chemical reaction processes.
化学反应网络是系统生物学中建模和探索复杂生物过程、生物化学交互以及不同动态行为的重要方法。但是,制定这样的反应动力学需要相当长的时间。在本文中,我们利用现代大型语言模型的效率,自动进行化学反应网络的随机蒙特卡洛模拟,并通过自然语言形式提供的反应描述启用模拟。我们还将此过程整合到广泛使用的模拟工具Copasi中,以进一步为建模人员和研究人员提供优势和便利。在这项工作中,我们展示了现代大型语言模型在解析和创建反应动力学以模拟复杂的化学反应过程中的有效性和局限性。
论文及项目相关链接
PDF Accepted on MadeAI 2025 Conference
Summary
化学反应网络是系统生物学中模拟和探索复杂生物过程、生物化学相互作用以及不同动力学行为的重要方法,但构建反应动力学需要消耗大量时间。本文利用现代大型语言模型的效率,实现化学反应网络的随机蒙特卡洛模拟自动化,并通过自然语言形式提供的反应描述进行模拟。我们还将此过程集成到广泛使用的模拟工具Copasi中,为建模人员和研究人员提供优势和便利。本文展示了现代大型语言模型在解析和创建反应动力学以模拟复杂化学反应过程中的效果和局限性。
Key Takeaways
- 化学反应网络是模拟复杂生物过程、生物化学相互作用和系统生物学中不同动力学行为的重要方法。
- 构建化学反应网络的反应动力学需要消耗大量时间。
- 现代大型语言模型可以有效地自动化化学反应网络的随机蒙特卡洛模拟。
- 自然语言的反应描述形式可以用于模拟过程。
- 将此过程集成到Copasi等广泛使用的模拟工具中,为建模人员和研究人员提供了便利。
- 现代大型语言模型在解析和创建反应动力学方面表现出良好的效果。
点此查看论文截图

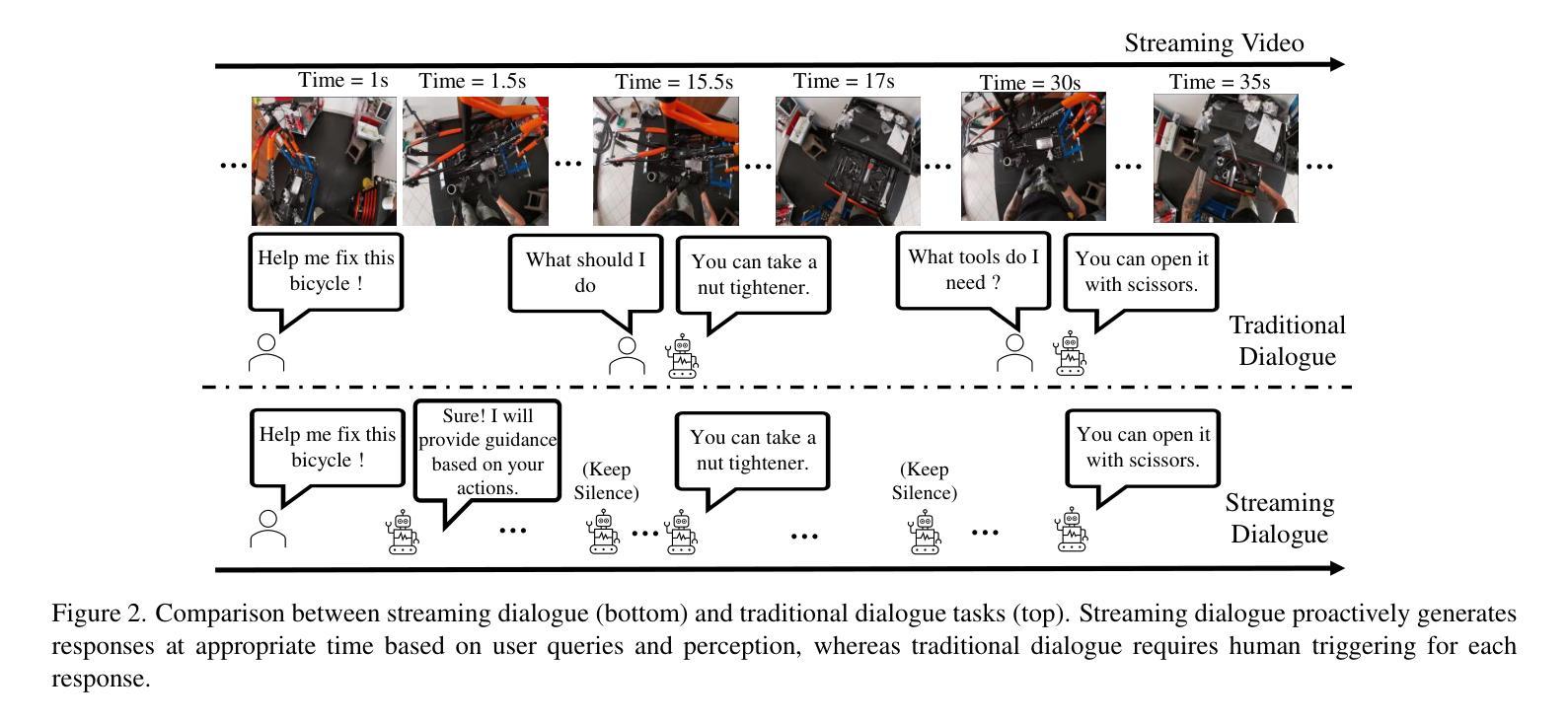
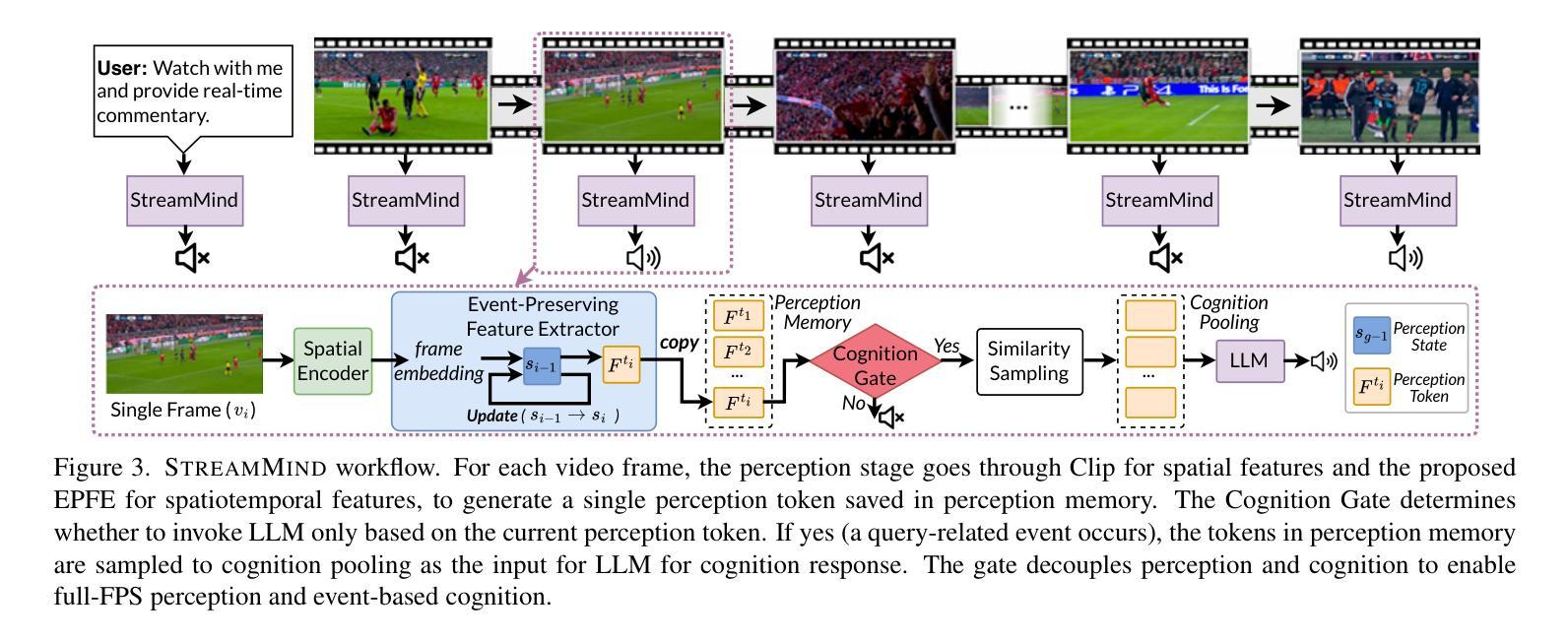
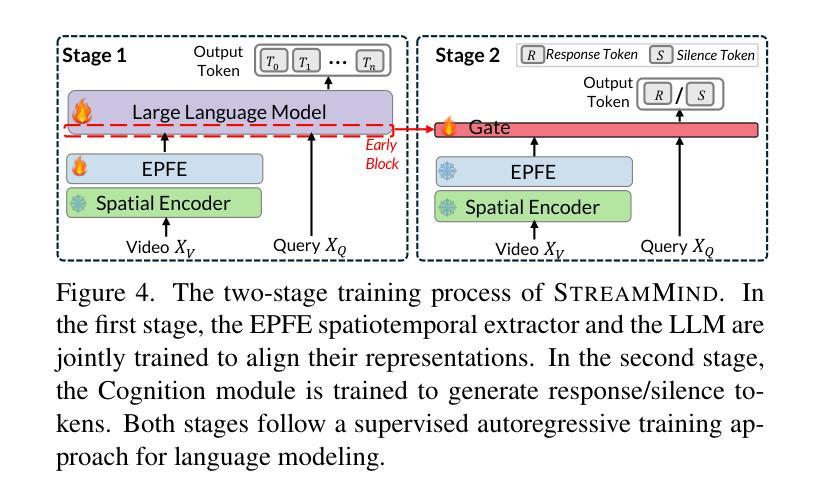
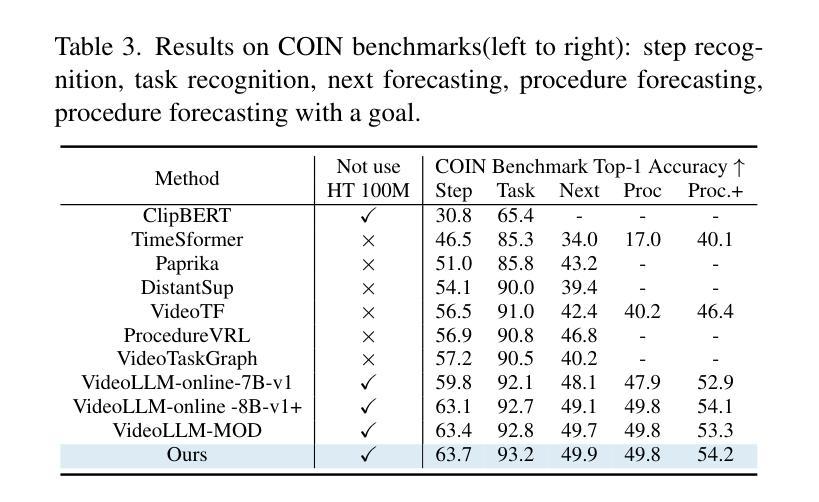
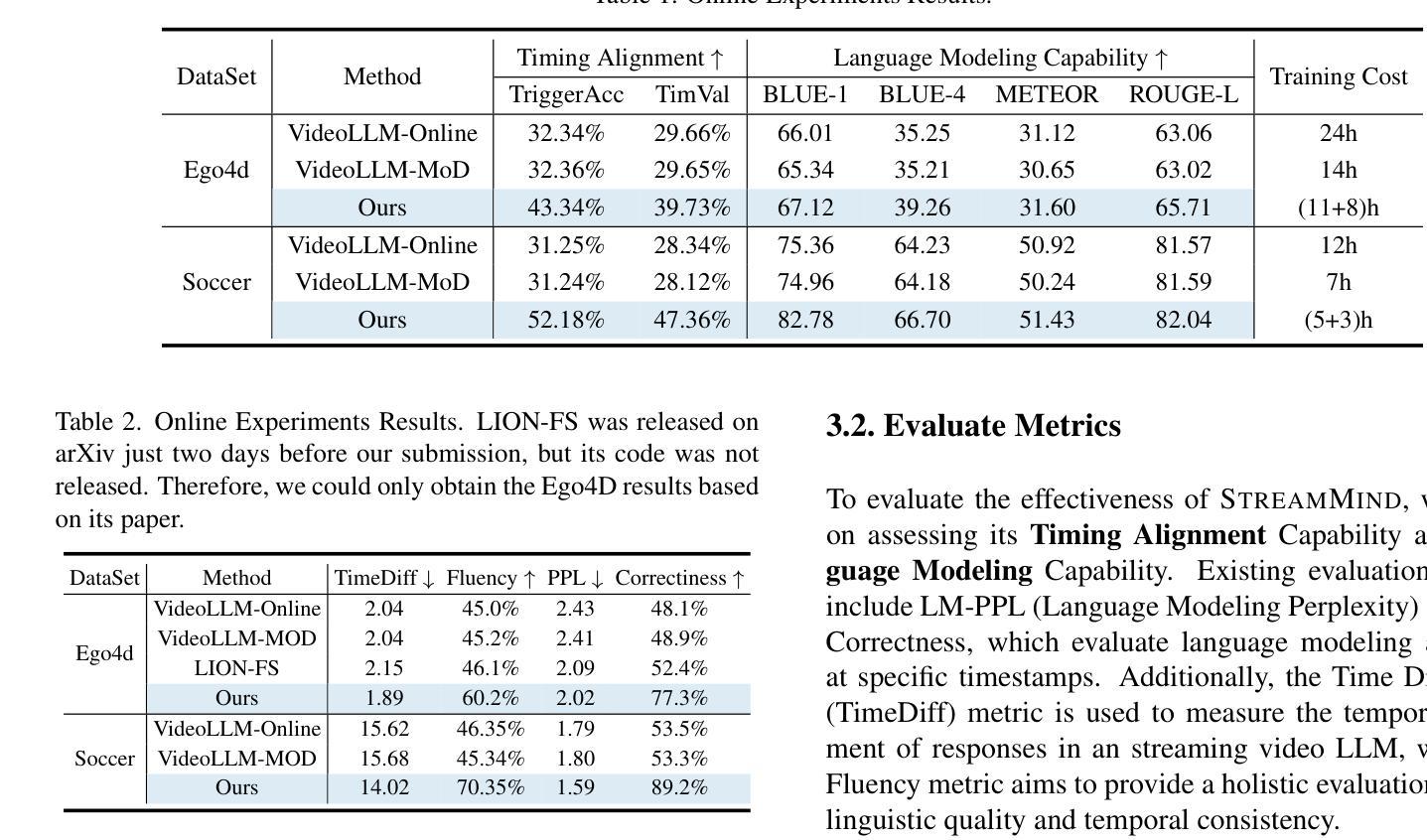
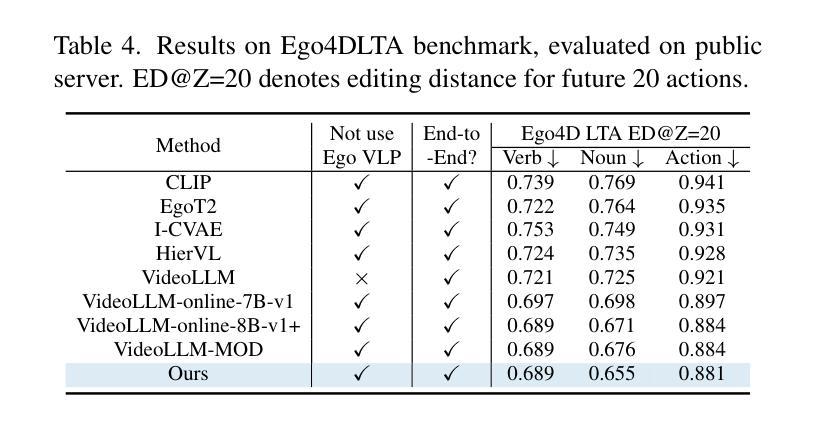
StreamMind: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition
Authors:Xin Ding, Hao Wu, Yifan Yang, Shiqi Jiang, Donglin Bai, Zhibo Chen, Ting Cao
With the rise of real-world human-AI interaction applications, such as AI assistants, the need for Streaming Video Dialogue is critical. To address this need, we introduce StreamMind, a video LLM framework that achieves ultra-FPS streaming video processing (100 fps on a single A100) and enables proactive, always-on responses in real time, without explicit user intervention. To solve the key challenge of the contradiction between linear video streaming speed and quadratic transformer computation cost, we propose a novel perception-cognition interleaving paradigm named ‘’event-gated LLM invocation’’, in contrast to the existing per-time-step LLM invocation. By introducing a Cognition Gate network between the video encoder and the LLM, LLM is only invoked when relevant events occur. To realize the event feature extraction with constant cost, we propose Event-Preserving Feature Extractor (EPFE) based on state-space method, generating a single perception token for spatiotemporal features. These techniques enable the video LLM with full-FPS perception and real-time cognition response. Experiments on Ego4D and SoccerNet streaming tasks, as well as standard offline benchmarks, demonstrate state-of-the-art performance in both model capability and real-time efficiency, paving the way for ultra-high-FPS applications, such as Game AI and interactive media. The code and data is available at https://aka.ms/StreamMind.
随着人工智能助手等现实世界中人机交互应用的兴起,对流式视频对话的需求变得至关重要。为了解决这一需求,我们推出了StreamMind,这是一款视频LLM框架,可实现超FPS流式视频处理(在单个A100上达到100fps),并可在不需要用户明确干预的情况下,实现实时主动响应。为了解决线性视频流速度与二次方转换器计算成本之间的主要矛盾,我们提出了一种名为“事件门控LLM调用”的新型感知认知交替范式,这与现有的按时间步长LLM调用形成对比。通过在视频编码器和LLM之间引入认知网关网络,只有在相关事件发生时才调用LLM。为了以恒定成本实现事件特征提取,我们提出了基于状态空间方法的Event-Preserving Feature Extractor(EPFE),为时空特征生成单个感知令牌。这些技术使视频LLM具备全FPS感知和实时认知响应能力。在Ego4D和SoccerNet流媒体任务以及标准离线基准测试上的实验表明,其在模型能力和实时效率方面都达到了最先进的性能,为超高FPS应用(如游戏AI和交互式媒体)铺平了道路。代码和数据可通过https://aka.ms/StreamMind获取。
论文及项目相关链接
Summary
随着人工智能助手等现实世界中人机交互应用的兴起,流式视频对话的需求变得至关重要。为应对这一需求,我们推出了StreamMind,这是一款视频LLM框架,可实现超帧速率流式视频处理(单A100上达100fps),并能在无需用户明确干预的情况下实时进行前瞻性、全天候响应。为解决线性视频流速度与二次方转换器计算成本之间的主要矛盾,我们提出了一种名为“事件门控LLM调用”的新型感知认知交替范式,与现有的按时间步长调用LLM的方法形成对比。通过视频编码器和LLM之间增加一个认知门网络,只有在相关事件发生时才会调用LLM。我们提出了基于状态空间方法的Event-Preserving Feature Extractor(EPFE),以恒定成本实现事件特征提取,为时空特征生成单个感知令牌。这些技术使视频LLM具备全帧感知和实时认知响应能力。在Ego4D、SoccerNet流任务以及标准离线基准测试上的实验证明了其在模型能力和实时效率方面的卓越性能,为超高帧率应用(如游戏AI和交互式媒体)铺平了道路。
Key Takeaways
- StreamMind框架满足流式视频对话需求,支持实时、前瞻性、全天候响应。
- 通过引入事件门控LLM调用解决线性视频流速度与计算成本矛盾。
- 认知门网络仅在相关事件发生时调用LLM,提高效率。
- Event-Preserving Feature Extractor实现恒定成本的事件特征提取。
- 技术使视频LLM具备全帧感知和实时认知响应能力。
- 在多个基准测试上表现出卓越性能。
- 代码和数据可供公众访问。
点此查看论文截图


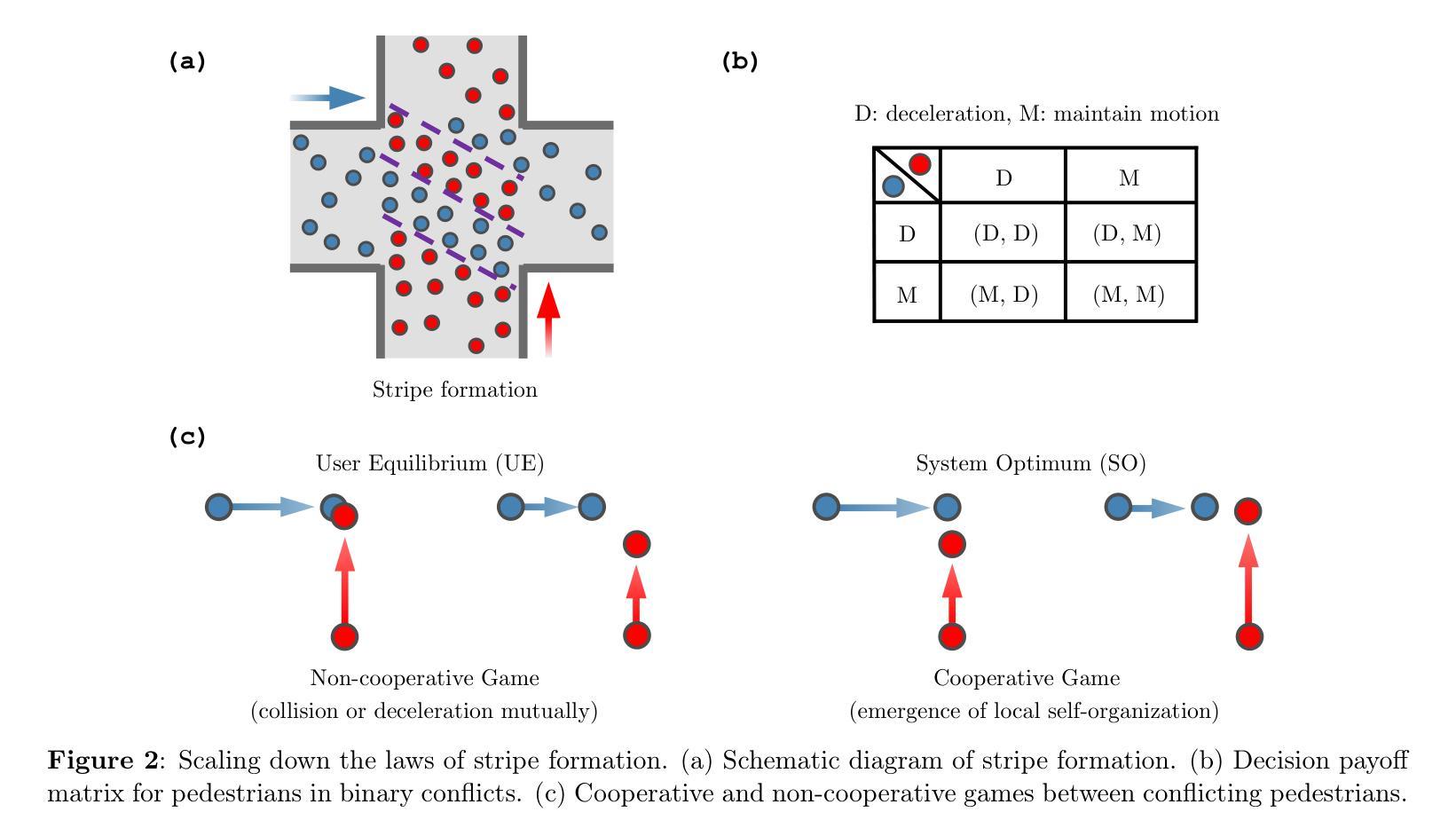
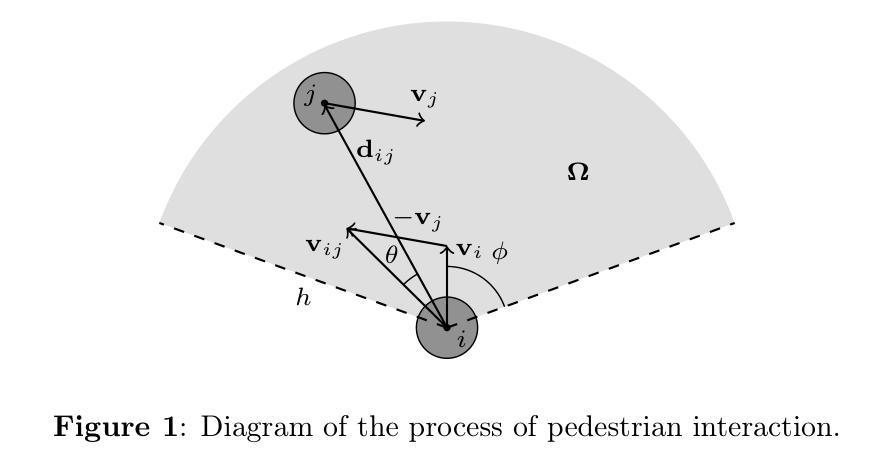
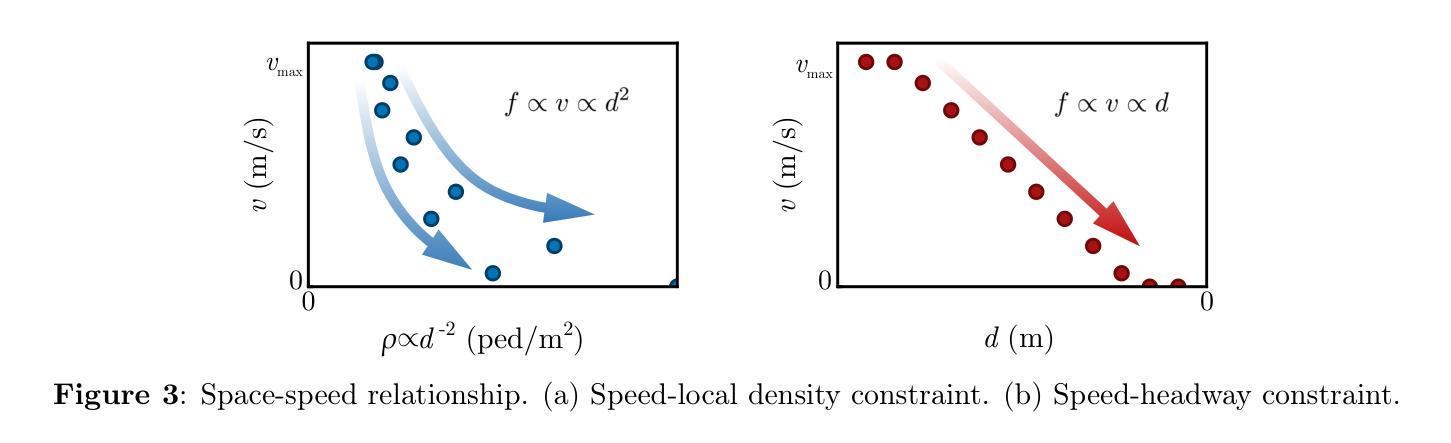
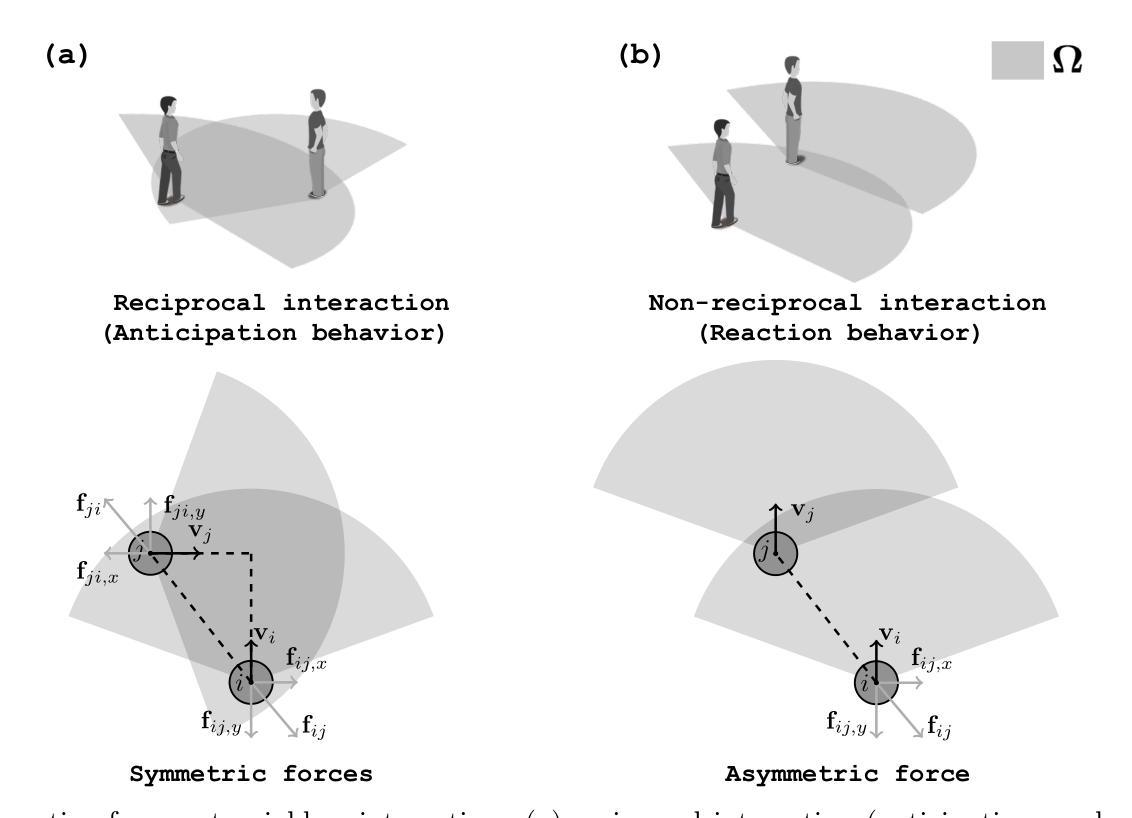
CosForce: A Force-Based General Pedestrian Model with Anticipation and Reaction Mechanisms
Authors:Jinghui Wang, Wei Lv, Shuchao Cao, Chenglin Guo
In this study, we developed a force-based general pedestrian model named CosForce. To the best of our knowledge, this may represent the simplest version of the force-based method. The model employs cosine functions to characterize asymmetric interactions, implicitly incorporating anticipation and reaction mechanisms. By focusing on binary interactions, the CosForce model provides new insights into pedestrian modeling while achieving linear computational complexity. Two specific scenarios in crowd dynamics were analyzed: self-organization (entropy decrease) and crowd collapse (entropy increase). The average normalized speed and order parameter were introduced to quantitatively describe the processes of crowd dynamics. Quantitative evaluations demonstrate that phase separation in crowds is effectively reproduced by the model, including lane formation, stripe formation, and cross-channel formation. Next, in the simulation of mass gathering, within a density-accumulating scenario, processes of critical phase transition in high-density crowds are clearly revealed through time series observations of the order parameter. These findings provide valuable insights into crowd dynamics.
在这项研究中,我们开发了一种基于力的一般行人模型,名为CosForce。据我们所知,这可能是基于力方法的最简单版本。该模型采用余弦函数来表征不对称相互作用,隐含地融入了预期和反应机制。通过关注二元交互,CosForce模型在行人建模方面提供了新的见解,同时实现了线性计算复杂度。分析了人群动力学中的两个特定场景:自组织(熵减少)和人群崩溃(熵增加)。引入平均归一化速度和顺序参数来定量描述人群动力学的过程。定量评估表明,该模型有效地再现了人群中的相分离,包括车道形成、条纹形成和跨通道形成。接下来,在模拟聚集时,在密度累积的场景下,通过秩序参数的时间序列观察,清楚地揭示了高密度人群中的临界相变过程。这些发现对人群动力学提供了有价值的见解。
论文及项目相关链接
PDF 28 pages, 25 figures
Summary
本研究开发了一种基于力量的通用行人模型——CosForce。据我们所知,这可能是基于力量的方法中最简单的版本。该模型采用余弦函数来表征不对称的相互作用,隐含地融入了预期和反应机制。通过关注二元交互,CosForce模型为行人建模提供了新的见解,同时实现了线性的计算复杂度。分析了人群动力学的两个特定场景:自组织(熵减少)和人群崩溃(熵增加)。引入平均归一化速度和秩序参数来定量描述人群动力学过程。定量评估表明,该模型有效地再现了人群中的相位分离,包括车道形成、条纹形成和跨通道形成。在模拟密度累积场景的大规模聚集时,通过秩序参数的时间序列观察,清晰地揭示了高密度人群中的临界相变过程。
Key Takeaways
- 开发了一种名为CosForce的基于力量的通用行人模型,可能是迄今为止最简化的力量模型版本。
- 该模型利用余弦函数描述不对称的相互作用,包含预期和反应机制。
- CosForce模型专注于二元交互,为行人建模提供新视角,具有线性计算复杂度。
- 分析了人群动力学的两个重要场景:自组织和人群崩溃(熵的增加和减少)。
- 通过平均归一化速度和秩序参数定量描述人群动力学过程。
- 评估表明,模型能有效模拟人群中的相位分离现象,如车道、条纹和跨通道的形成。
点此查看论文截图

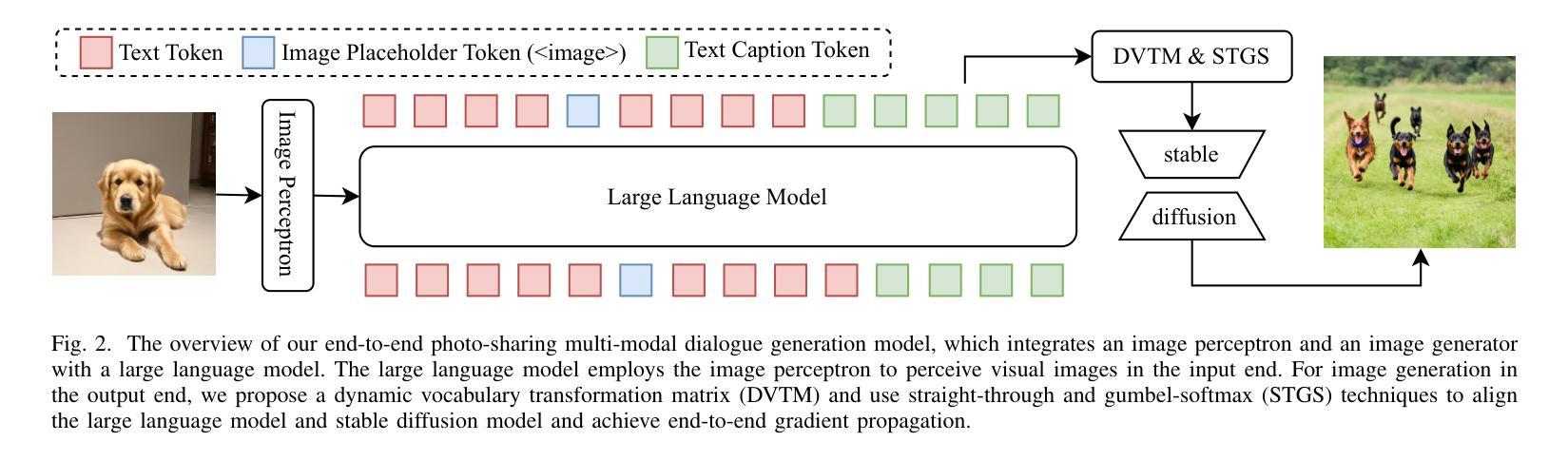
An End-to-End Model for Photo-Sharing Multi-modal Dialogue Generation
Authors:Peiming Guo, Sinuo Liu, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, Min Zhang
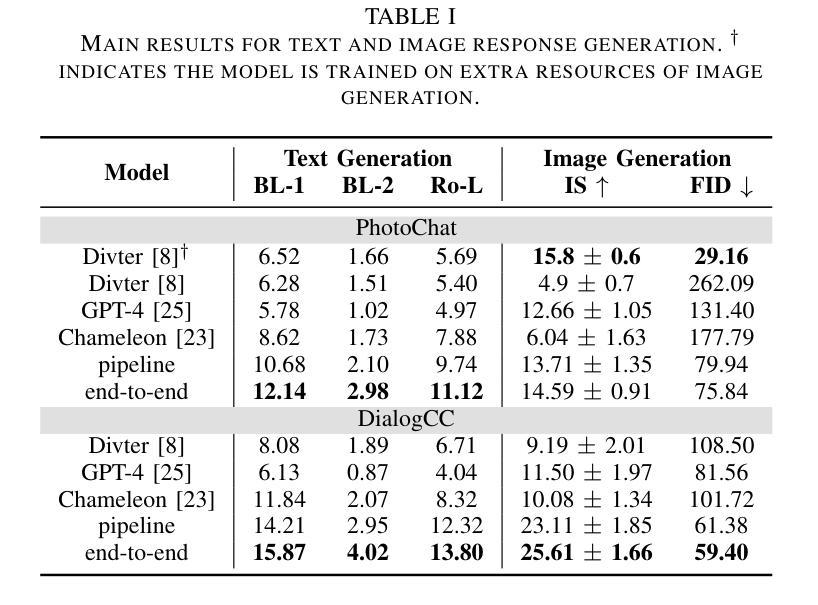
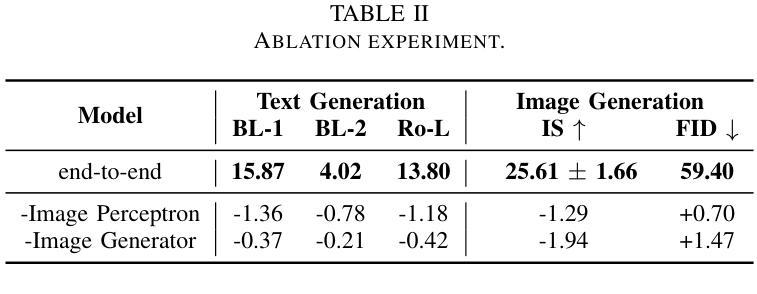
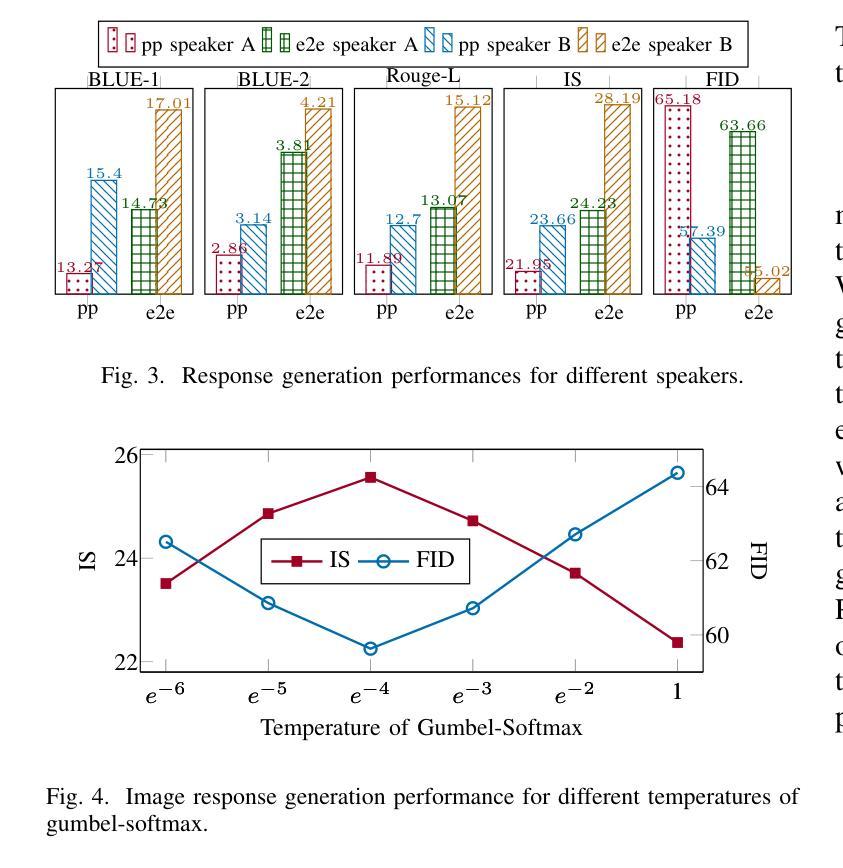
Photo-Sharing Multi-modal dialogue generation requires a dialogue agent not only to generate text responses but also to share photos at the proper moment. Using image text caption as the bridge, a pipeline model integrates an image caption model, a text generation model, and an image generation model to handle this complex multi-modal task. However, representing the images with text captions may loss important visual details and information and cause error propagation in the complex dialogue system. Besides, the pipeline model isolates the three models separately because discrete image text captions hinder end-to-end gradient propagation. We propose the first end-to-end model for photo-sharing multi-modal dialogue generation, which integrates an image perceptron and an image generator with a large language model. The large language model employs the Q-Former to perceive visual images in the input end. For image generation in the output end, we propose a dynamic vocabulary transformation matrix and use straight-through and gumbel-softmax techniques to align the large language model and stable diffusion model and achieve end-to-end gradient propagation. We perform experiments on PhotoChat and DialogCC datasets to evaluate our end-to-end model. Compared with pipeline models, the end-to-end model gains state-of-the-art performances on various metrics of text and image generation. More analysis experiments also verify the effectiveness of the end-to-end model for photo-sharing multi-modal dialogue generation.
图片共享多模态对话生成要求对话代理不仅生成文本响应,还必须在适当的时刻共享照片。以图像文本标题作为桥梁,管道模型通过整合图像标题模型、文本生成模型和图像生成模型来处理这项复杂的多模态任务。然而,用文本标题表示图像可能会丢失重要的视觉细节和信息,并在复杂对话系统中引起误差传播。此外,管道模型将这三个模型分开处理,因为离散的图像文本标题会阻碍端到端的梯度传播。我们提出了第一个针对图片共享多模态对话生成端到端模型,该模型将图像感知器和图像生成器与大型语言模型集成在一起。大型语言模型采用Q-Former感知输入端的视觉图像。在输出端进行图像生成时,我们提出了动态词汇转换矩阵,并使用直通和软轴混合技术将大型语言模型和稳定扩散模型对齐,以实现端到端的梯度传播。我们在PhotoChat和DialogCC数据集上进行了实验,以评估我们的端到端模型。与管道模型相比,端到端模型在文本和图像生成的各项指标上均达到了最先进的性能。更多的分析实验也验证了端到端模型在图片共享多模态对话生成中的有效性。
论文及项目相关链接
PDF Accepted by ICME2025
Summary
多模态对话生成在照片共享场景下要求对话智能体不仅生成文本回应,还需在适当时候分享照片。当前使用图像文本描述作为桥梁的管道模型整合了图像描述模型、文本生成模型和图像生成模型来完成这项复杂的多模态任务。然而,用文本描述来表示图像可能会丢失重要的视觉细节和信息,并在复杂的对话系统中造成误差传播。此外,管道模型将三个模型孤立分开,因为离散的图像文本描述阻碍了端到端的梯度传播。为此,我们提出了首个端到端模型用于照片共享多模态对话生成,该模型整合了图像感知器和图像生成器与大型语言模型。大型语言模型在输入端采用Q-Former感知视觉图像,在输出端则通过动态词汇转换矩阵、直通和Gumbel-softmax技术实现与稳定扩散模型的对接,并达成端到端的梯度传播。我们在PhotoChat和DialogCC数据集上对我们的端到端模型进行了实验评估。相较于管道模型,端到端模型在文本和图像生成的各项指标上取得了最先进的性能表现。进一步的分析实验也验证了该端到端模型在照片共享多模态对话生成中的有效性。
Key Takeaways
- 多模态对话生成在照片共享场景下要求对话智能体具备生成文本回应和分享照片的能力。
- 当前使用的管道模型通过图像文本描述来连接各模型,但存在丢失视觉细节和信息的风险,并可能导致误差传播。
- 提出的端到端模型首次整合了图像感知器、图像生成器和大型语言模型,以提高多模态对话的效率和准确性。
- 大型语言模型采用Q-Former技术感知视觉图像,并实现了与稳定扩散模型的对接。
- 通过动态词汇转换矩阵、直通和Gumbel-softmax技术,实现了端到端的梯度传播,提高了模型的性能。
- 在PhotoChat和DialogCC数据集上的实验表明,端到端模型在文本和图像生成方面表现优异。
点此查看论文截图

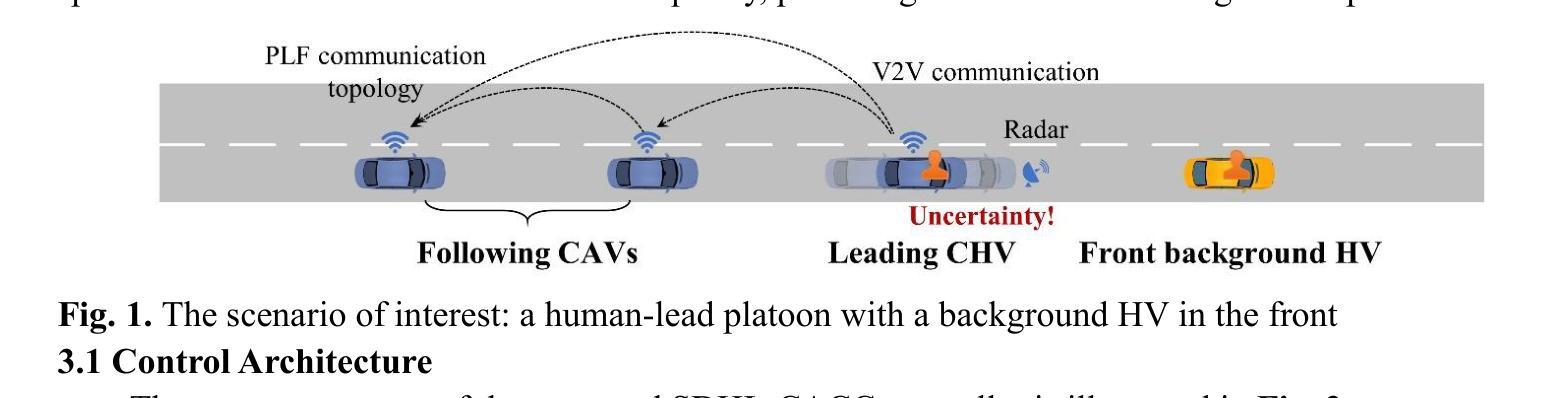
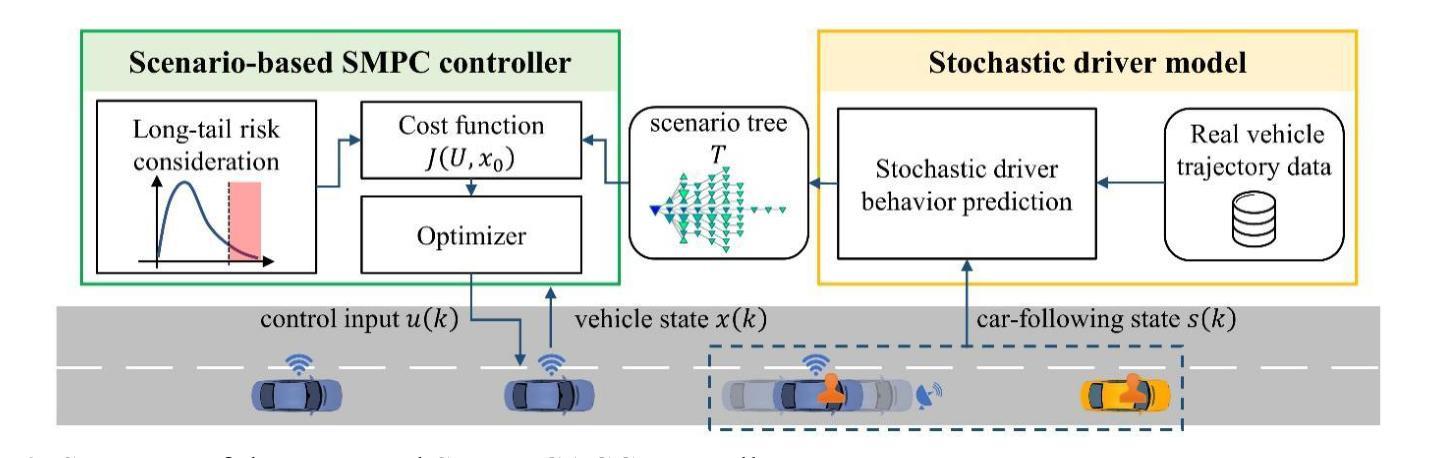
Safety-Aware Human-Lead Vehicle Platooning by Proactively Reacting to Uncertain Human Behaving
Authors:Jia Hu, Shuhan Wang, Yiming Zhang, Haoran Wang, Zhilong Liu, Guangzhi Cao
Human-Lead Cooperative Adaptive Cruise Control (HL-CACC) is regarded as a promising vehicle platooning technology in real-world implementation. By utilizing a Human-driven Vehicle (HV) as the platoon leader, HL-CACC reduces the cost and enhances the reliability of perception and decision-making. However, state-of-the-art HL-CACC technology still has a great limitation on driving safety due to the lack of considering the leading human driver’s uncertain behavior. In this study, a HL-CACC controller is designed based on Stochastic Model Predictive Control (SMPC). It is enabled to predict the driving intention of the leading Connected Human-Driven Vehicle (CHV). The proposed controller has the following features: i) enhanced perceived safety in oscillating traffic; ii) guaranteed safety against hard brakes; iii) computational efficiency for real-time implementation. The proposed controller is evaluated on a PreScan&Simulink simulation platform. Real vehicle trajectory data is collected for the calibration of the simulation. Results reveal that the proposed controller: i) improves perceived safety by 19.17% in oscillating traffic; ii) enhances actual safety by 7.76% against hard brakes; iii) is confirmed with string stability. The computation time is approximately 3.2 milliseconds when running on a laptop equipped with an Intel i5-13500H CPU. This indicates the proposed controller is ready for real-time implementation.
人类主导的协同自适应巡航控制(HL-CACC)被认为是一种有前景的车辆编队技术,在实际应用中具有广阔的前景。通过利用人类驾驶车辆(HV)作为车队领导者,HL-CACC降低了感知和决策的成本,提高了其可靠性。然而,最先进的HL-CACC技术在驾驶安全方面仍有很大局限,因为该技术未能充分考虑领头的人类驾驶员的不确定性行为。本研究设计了一种基于随机模型预测控制(SMPC)的HL-CACC控制器。它能够预测领先的人车互联(CHV)的驾驶意图。该控制器具有以下特点:一、在振荡交通中增强了感知安全性;二、对急刹车情况保证安全;三、具有实时实现的计算效率。该控制器在PreScan&Simulink仿真平台上进行了评估。收集了真实车辆轨迹数据对仿真进行校准。结果表明,该控制器:一、在振荡交通中提高了19.17%的感知安全性;二、在急刹车情况下提高了7.76%的实际安全性;三、具有队列稳定性。在配备Intel i5-13500H CPU的笔记本电脑上运行时,计算时间约为3.2毫秒,这表明该控制器已准备好进行实时实现。
论文及项目相关链接
Summary
基于随机模型预测控制(SMPC)设计的人类引导合作自适应巡航控制(HL-CACC)控制器,能预测领先连接人类驾驶车辆(CHV)的驾驶意图,具有增强感知安全、保障硬制动安全和计算效率高等特点。模拟评估显示,该控制器在提高感知安全和实际安全性方面有明显效果,并具备实时实施条件。
Key Takeaways
- HL-CACC技术利用人类驾驶车辆作为车队领导者,降低成本并增强感知和决策可靠性。
- 当前HL-CACC技术在驾驶安全方面存在局限,未能充分考虑领先人类驾驶员的不确定性行为。
- 基于SMPC设计的HL-CACC控制器能够预测CHV的驾驶意图。
- 控制器在振荡交通中增强了感知安全,并对硬刹车情况提供了安全保障。
- 控制器在模拟评估中表现出良好的性能,包括提高感知安全和实际安全性,以及具备字符串稳定性。
- 控制器计算时间短,具备实时实施条件。
点此查看论文截图