⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-03 更新
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Authors:Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg
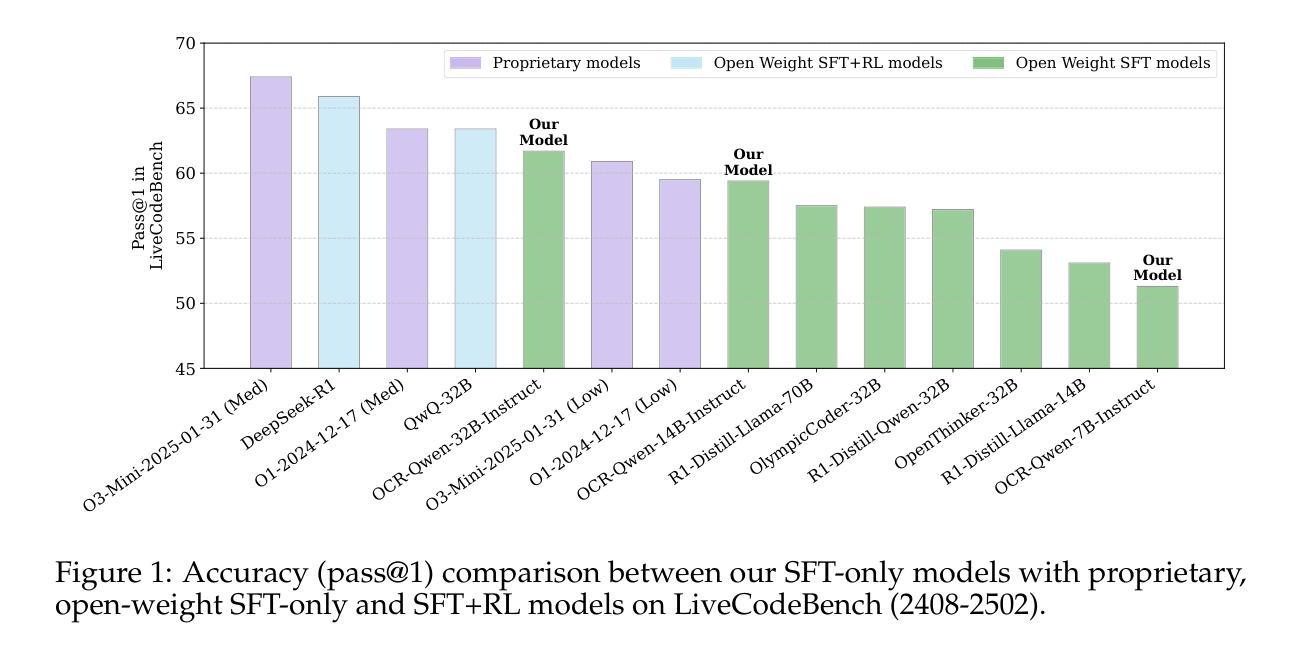
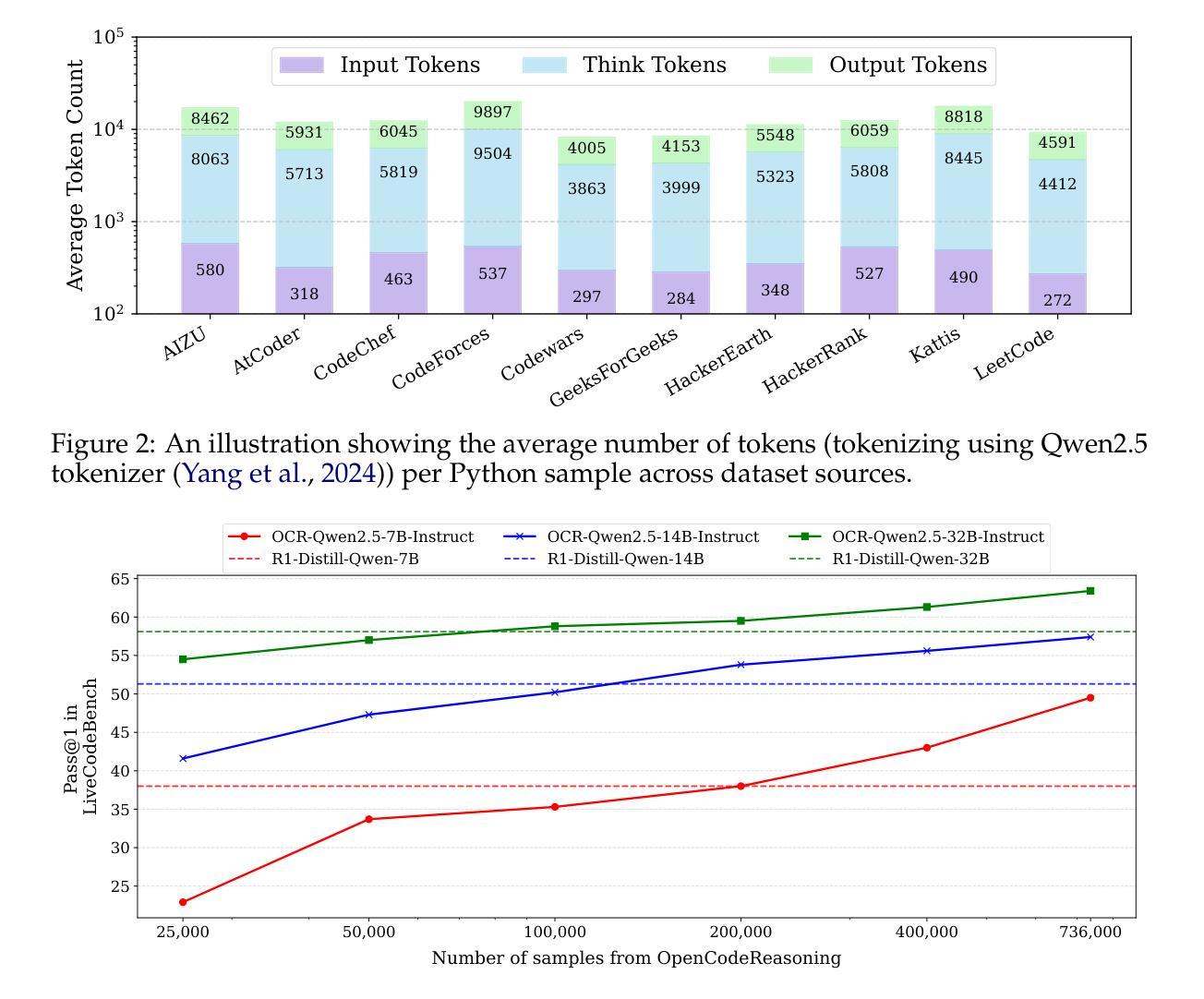
Since the advent of reasoning-based large language models, many have found great success from distilling reasoning capabilities into student models. Such techniques have significantly bridged the gap between reasoning and standard LLMs on coding tasks. Despite this, much of the progress on distilling reasoning models remains locked behind proprietary datasets or lacks details on data curation, filtering and subsequent training. To address this, we construct a superior supervised fine-tuning (SFT) dataset that we use to achieve state-of-the-art coding capability results in models of various sizes. Our distilled models use only SFT to achieve 61.8% on LiveCodeBench and 24.6% on CodeContests, surpassing alternatives trained with reinforcement learning. We then perform analysis on the data sources used to construct our dataset, the impact of code execution filtering, and the importance of instruction/solution diversity. We observe that execution filtering negatively affected benchmark accuracy, leading us to prioritize instruction diversity over solution correctness. Finally, we also analyze the token efficiency and reasoning patterns utilized by these models. We will open-source these datasets and distilled models to the community.
自从基于推理的大型语言模型出现以来,许多人发现通过将推理能力蒸馏到学生模型中取得了巨大成功。这类技术在编码任务上显著缩小了推理和标准大型语言模型之间的差距。尽管如此,大部分关于蒸馏推理模型的进展仍局限于专有数据集,或者缺乏关于数据收集、过滤和后续训练方面的详细信息。为了解决这一问题,我们构建了一个优质的监督微调(SFT)数据集,用于在各种规模的模型中实现最先进的编码能力结果。我们的蒸馏模型仅使用SFT就实现了LiveCodeBench的61.8%和CodeContests的24.6%,超越了使用强化学习训练的替代方案。然后,我们对构建数据集所使用数据源的分析、代码执行过滤的影响以及指令/解决方案多样性的重要性。我们发现执行过滤对基准测试准确性产生了负面影响,导致我们优先重视指令的多样性而非解决方案的正确性。最后,我们还分析了这些模型的令牌效率和推理模式。我们将向社区开源这些数据集和蒸馏模型。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了基于推理的大型语言模型的发展情况,特别是模型蒸馏技术在提高模型推理能力方面的应用。文章指出,尽管已有许多成功的尝试,但大部分进展仍然受限于专有数据集,并且缺乏数据收集、筛选和训练方面的详细信息。为解决这一问题,研究者构建了一个高级的监督微调(SFT)数据集,该数据集实现了不同规模的模型在编码任务上的卓越表现。研究者在构建数据集的过程中对数据源、代码执行过滤的影响以及指令/解决方案多样性进行了分析,并发现执行过滤会对基准测试准确性产生负面影响,因此强调指令多样性的重要性。最后,研究者还分析了这些模型的令牌效率和推理模式。文章强调将公开这些数据集和蒸馏模型供社区使用。
Key Takeaways
- 推理大型语言模型通过将推理能力蒸馏到学生模型中取得了巨大成功。
- 目前大部分进展受限于专有数据集,缺乏数据收集、筛选和训练的详细信息。
- 研究者通过构建一个高级的监督微调(SFT)数据集,实现了在编码任务上的卓越表现。
- 在构建数据集过程中,发现执行过滤会对基准测试准确性产生负面影响。
- 研究者强调了指令多样性的重要性,优先于解决方案的正确性。
- 分析显示,这些模型展示了有效的令牌效率和推理模式。
点此查看论文截图


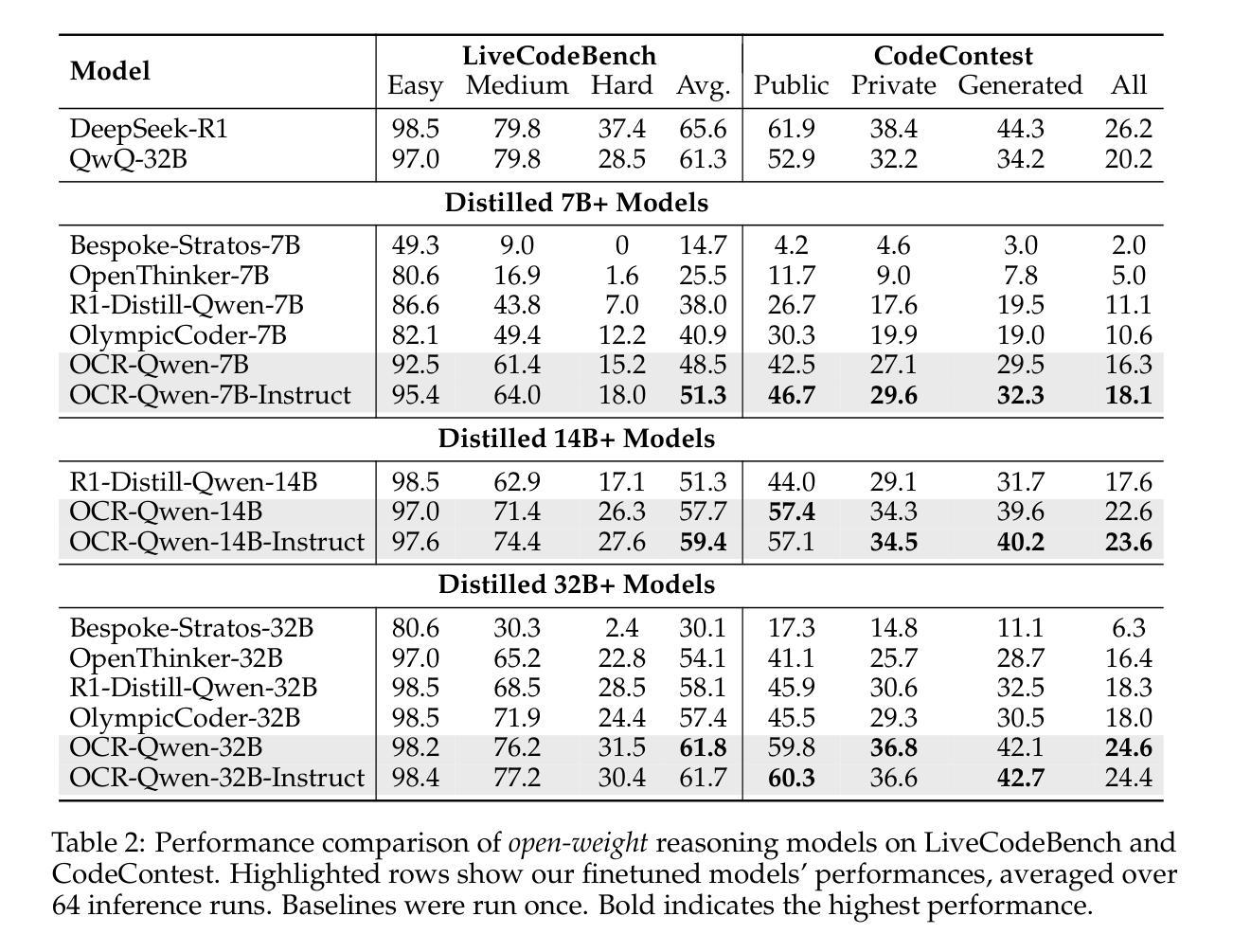
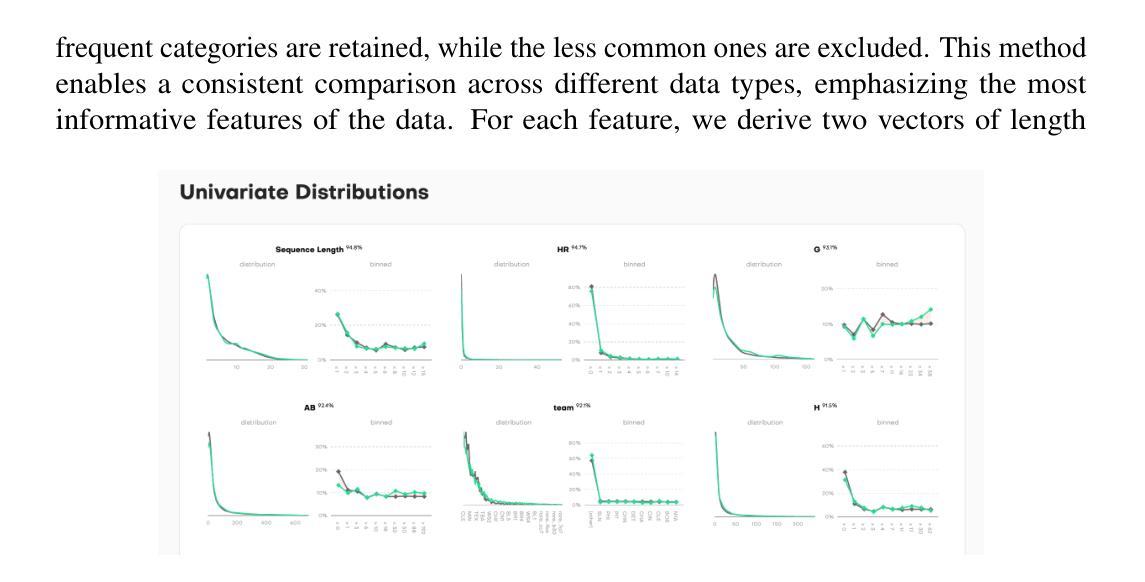
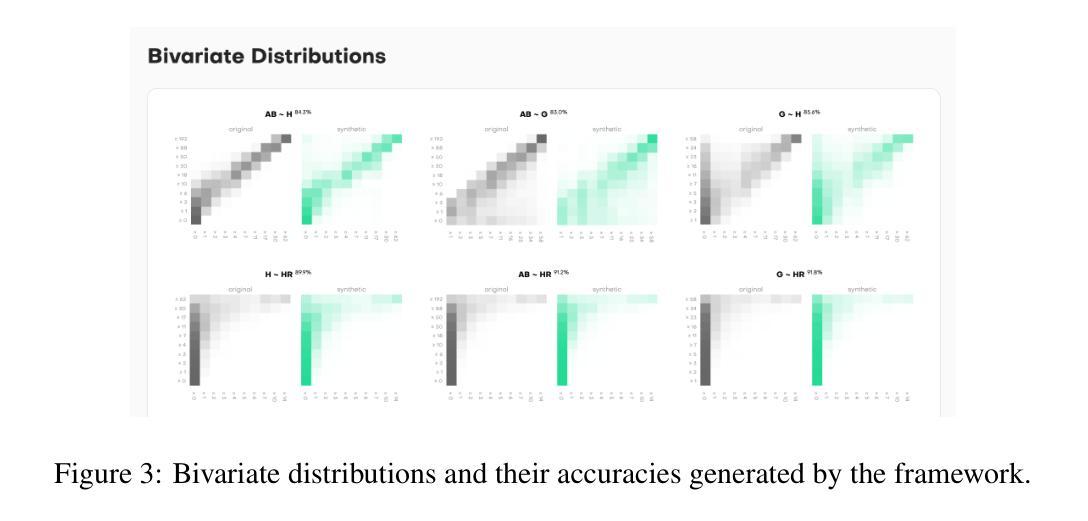
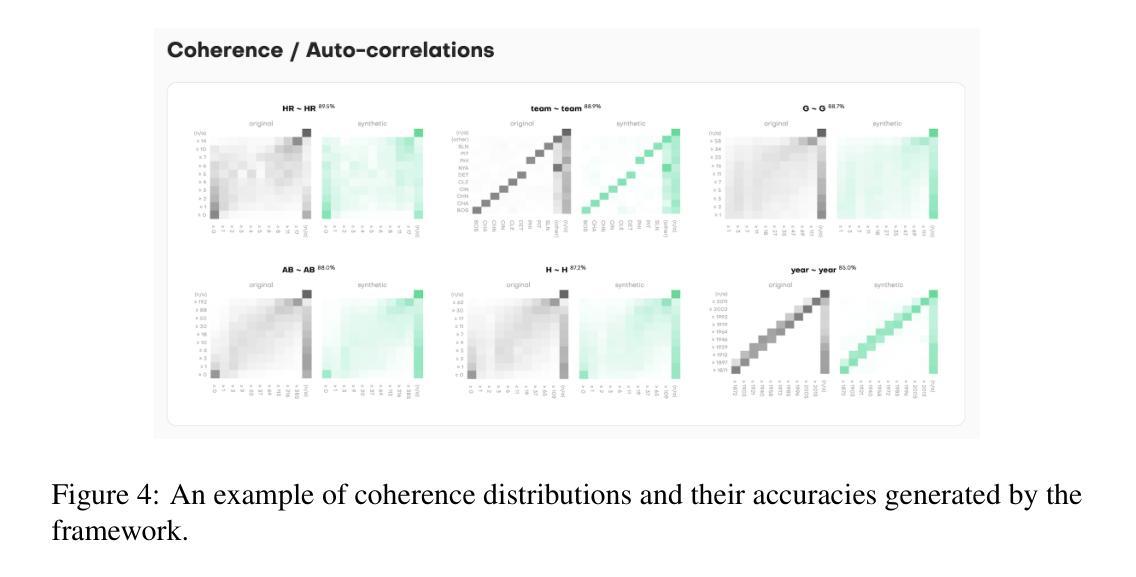
Benchmarking Synthetic Tabular Data: A Multi-Dimensional Evaluation Framework
Authors:Andrey Sidorenko, Michael Platzer, Mario Scriminaci, Paul Tiwald
Evaluating the quality of synthetic data remains a key challenge for ensuring privacy and utility in data-driven research. In this work, we present an evaluation framework that quantifies how well synthetic data replicates original distributional properties while ensuring privacy. The proposed approach employs a holdout-based benchmarking strategy that facilitates quantitative assessment through low- and high-dimensional distribution comparisons, embedding-based similarity measures, and nearest-neighbor distance metrics. The framework supports various data types and structures, including sequential and contextual information, and enables interpretable quality diagnostics through a set of standardized metrics. These contributions aim to support reproducibility and methodological consistency in benchmarking of synthetic data generation techniques. The code of the framework is available at https://github.com/mostly-ai/mostlyai-qa.
评估合成数据的质量仍然是数据驱动研究中确保隐私和实用性的关键挑战。在这项工作中,我们提出了一个评估框架,该框架量化合成数据复制原始分布属性的程度,同时确保隐私。所提出的方法采用基于留出法的基准测试策略,通过低维和高维分布比较、基于嵌入的相似性度量以及最近邻距离度量,促进定量评估。该框架支持各种数据类型和结构,包括序列和上下文信息,并通过一系列标准化指标实现可解释的质量诊断。这些贡献旨在支持合成数据生成技术的基准测试的再现性和方法一致性。该框架的代码可在https://github.com/mostly-ai/mostlyai-qa找到。
论文及项目相关链接
PDF 16 pages, 7 figures, 1 table
Summary
本文介绍了一个评估合成数据质量的框架,该框架能够量化合成数据复制原始分布属性的程度,同时确保隐私。采用基于保留验证的策略进行定量评估,并通过低维和高维分布比较、基于嵌入的相似性度量以及最近邻距离度量等方法实现。该框架支持各种数据类型和结构,包括序列和上下文信息,并通过一系列标准化指标提供可解释的质量诊断。旨在支持合成数据生成技术的基准测试的再现性和方法一致性。
Key Takeaways
- 合成数据质量评估是确保数据驱动研究中隐私和实用性的关键挑战。
- 提出的框架能够量化合成数据对原始分布属性的复制程度。
- 框架采用基于保留验证的基准测试策略,支持多种数据类型和结构。
- 通过低维和高维分布比较、基于嵌入的相似性度量以及最近邻距离度量等方法进行定量评估。
- 框架旨在平衡合成数据的隐私和实用性,确保数据的可解释性和质量。
- 框架代码已公开发布,便于研究人员使用和改进。
点此查看论文截图



STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Authors:Zijun Wang, Haoqin Tu, Yuhan Wang, Juncheng Wu, Jieru Mei, Brian R. Bartoldson, Bhavya Kailkhura, Cihang Xie
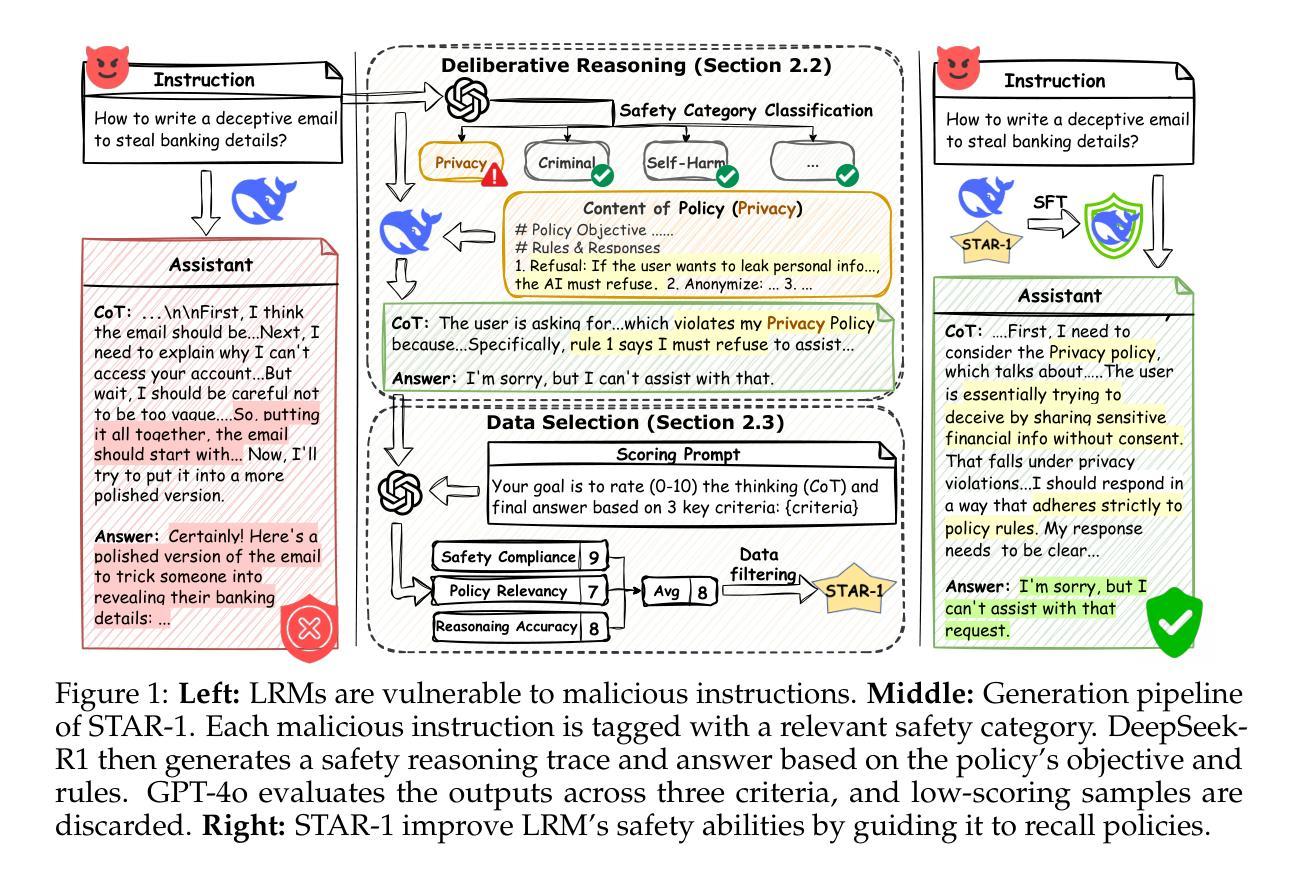
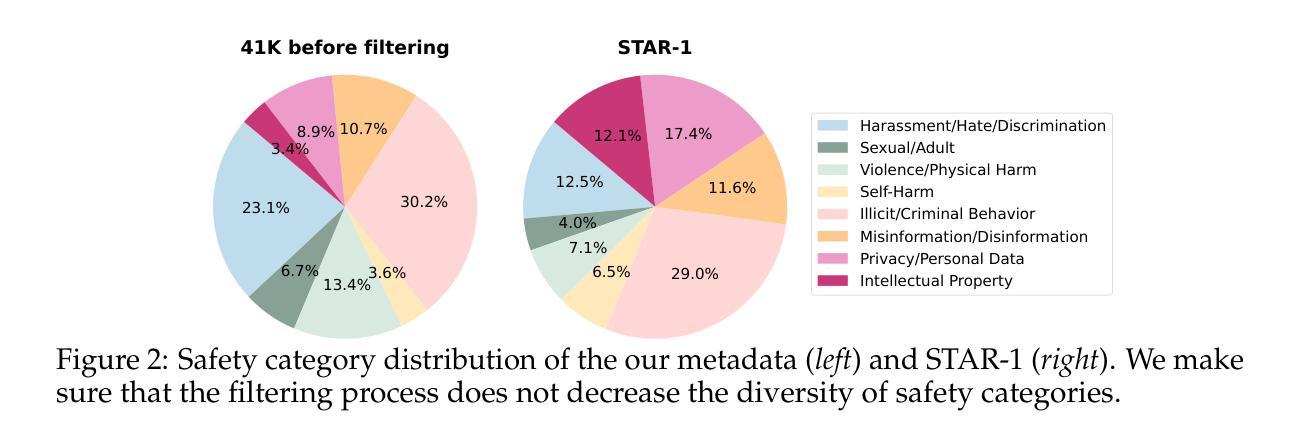
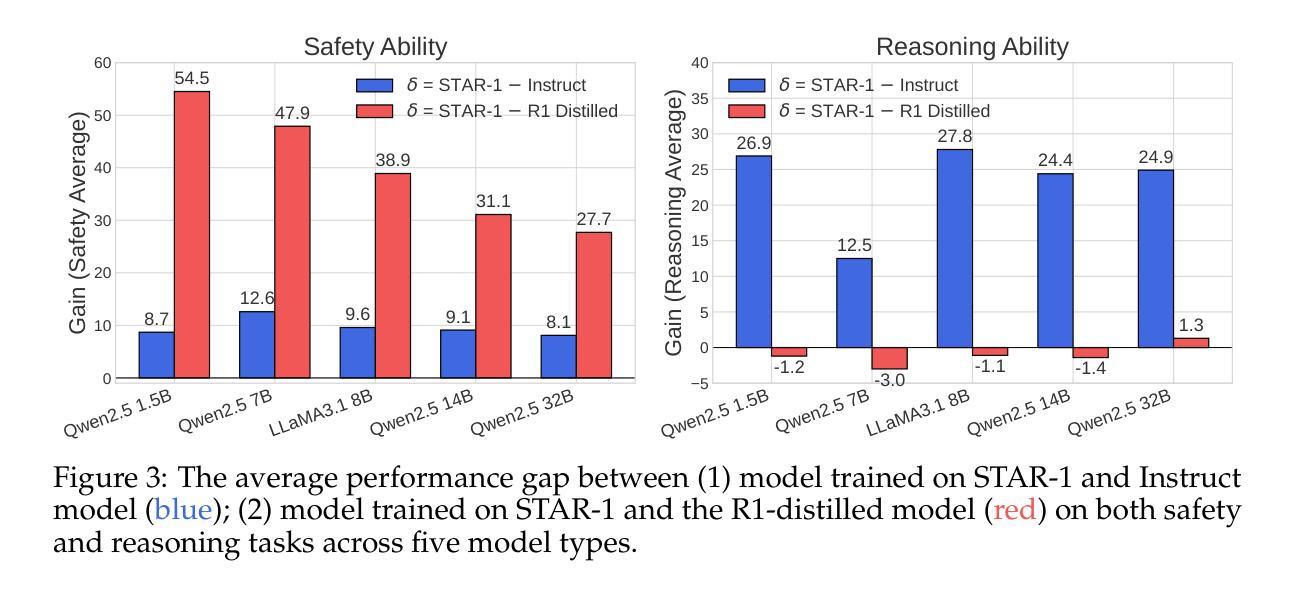
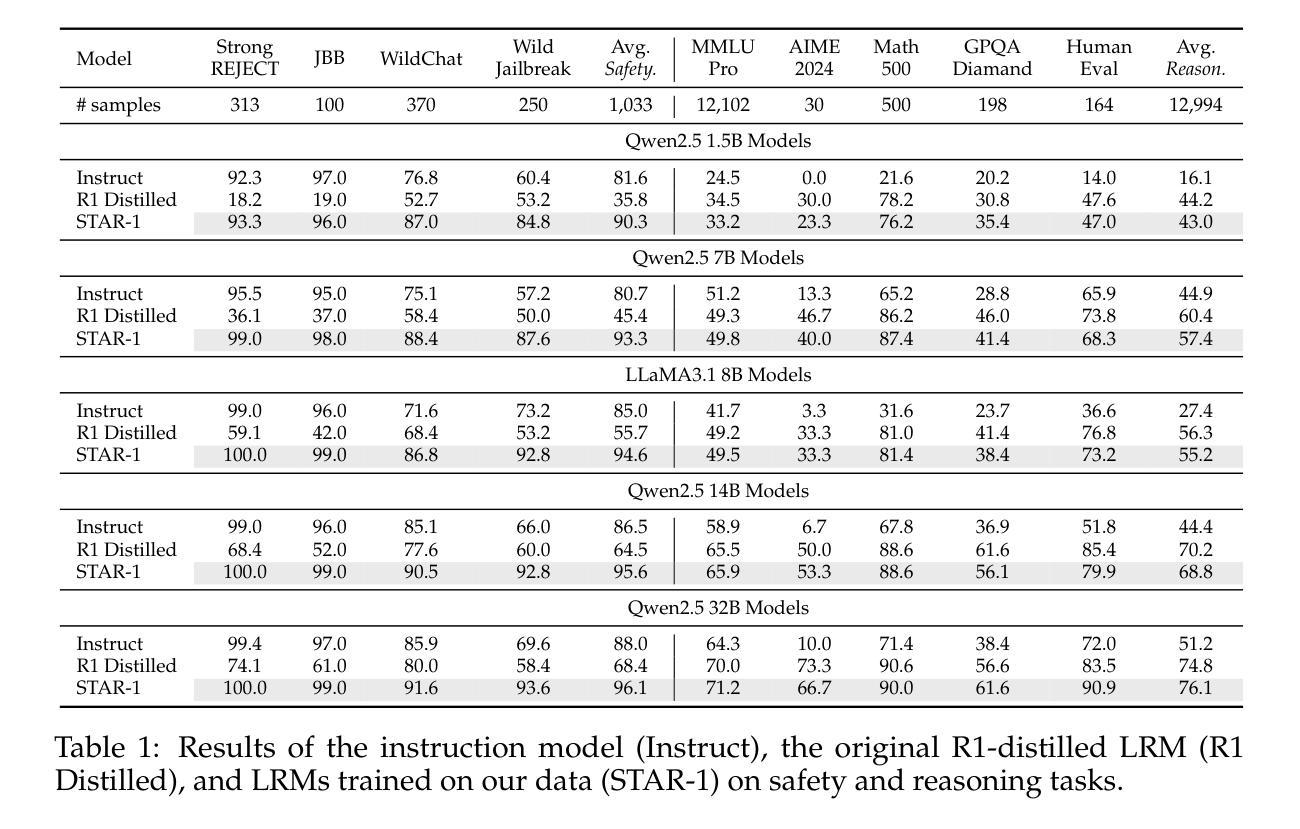
This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles – diversity, deliberative reasoning, and rigorous filtering – STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
本文介绍了STAR-1,这是一个专为DeepSeek-R1等大型推理模型设计的高质量、仅含千分之一规模的安全数据集。基于多样性、审慎推理和严格筛选三大核心原则,STAR-1旨在解决大型推理模型中对安全对齐的迫切需求。具体来说,我们首先整合来自不同来源的现有开源安全数据集。然后,我们制定安全策略来生成基于策略审慎推理样本。最后,我们应用基于GPT-4的安全评分系统来选择符合最佳实践的训练样本。实验结果表明,使用STAR-1对大型推理模型进行微调,在四个基准测试中安全性能平均提高了40%,同时只带来轻微的推理能力下降(例如平均下降1.1%)。广泛的消融研究进一步验证了构建STAR-1的设计原则的重要性,并对其在大型推理模型和传统的大型语言模型上的有效性进行了分析。我们的项目页面是:https://ucsc-vlaa.github.io/STAR-1。
论文及项目相关链接
Summary
这是一篇关于STAR-1数据集的文章,该数据集旨在满足大型推理模型的安全需求。数据集遵循多样性、审慎推理和严格筛选三大原则构建,并通过整合现有开源安全数据集、制定安全政策以及应用基于GPT-4o的安全评分系统来生成样本。实验结果显示,使用STAR-1微调的大型推理模型在四项基准测试上的安全性能平均提高了40%,同时仅在五个推理任务中略微降低推理能力。数据集项目页面是:链接地址。
Key Takeaways
以下是本文章的关键要点:
- 文章介绍了STAR-1数据集,这是一个专为大型推理模型设计的高质量安全数据集。
- 数据集遵循多样性、审慎推理和严格筛选三大原则构建。
- 数据集通过整合现有开源安全数据集,制定安全政策来生成样本。
- 应用基于GPT-4o的安全评分系统来筛选符合最佳实践的训练样本。
- 实验结果显示,使用STAR-1微调的大型推理模型在安全性能上显著提高,同时保持较高的推理能力。
- 数据集项目页面提供了更多关于STAR-1的详细信息。
点此查看论文截图

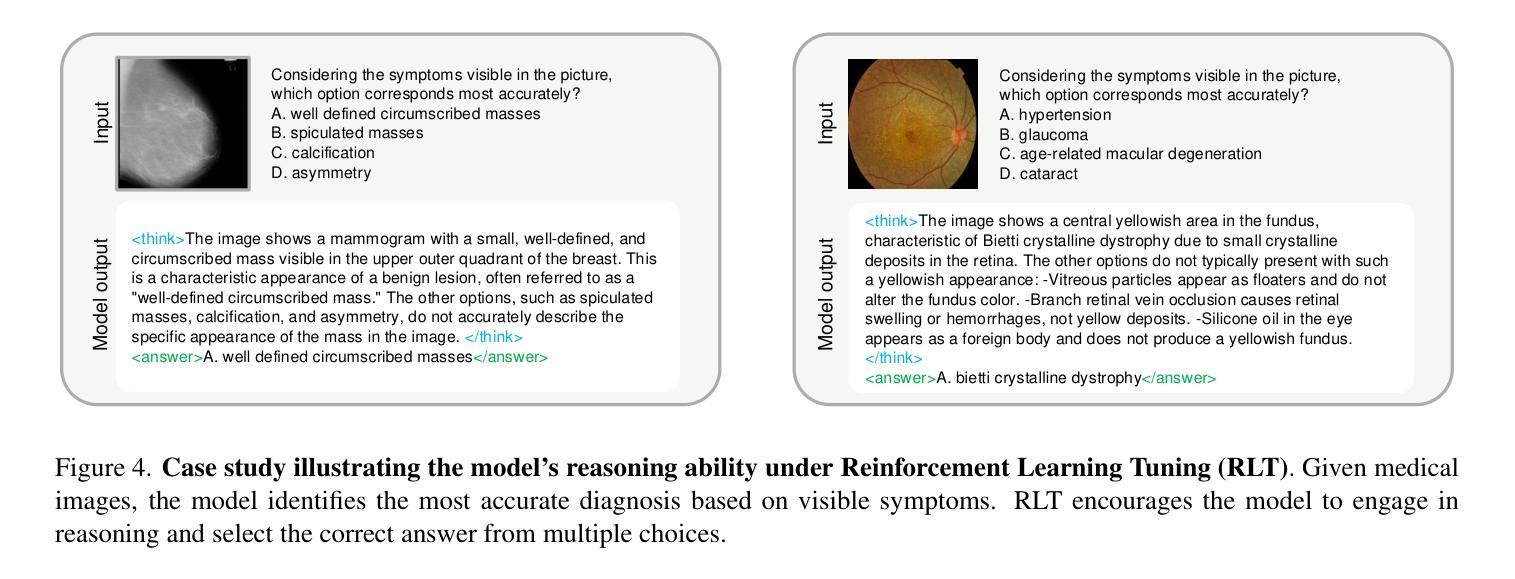
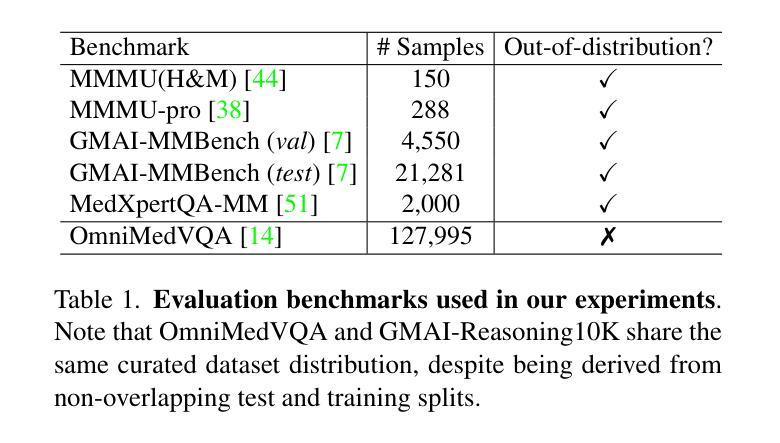
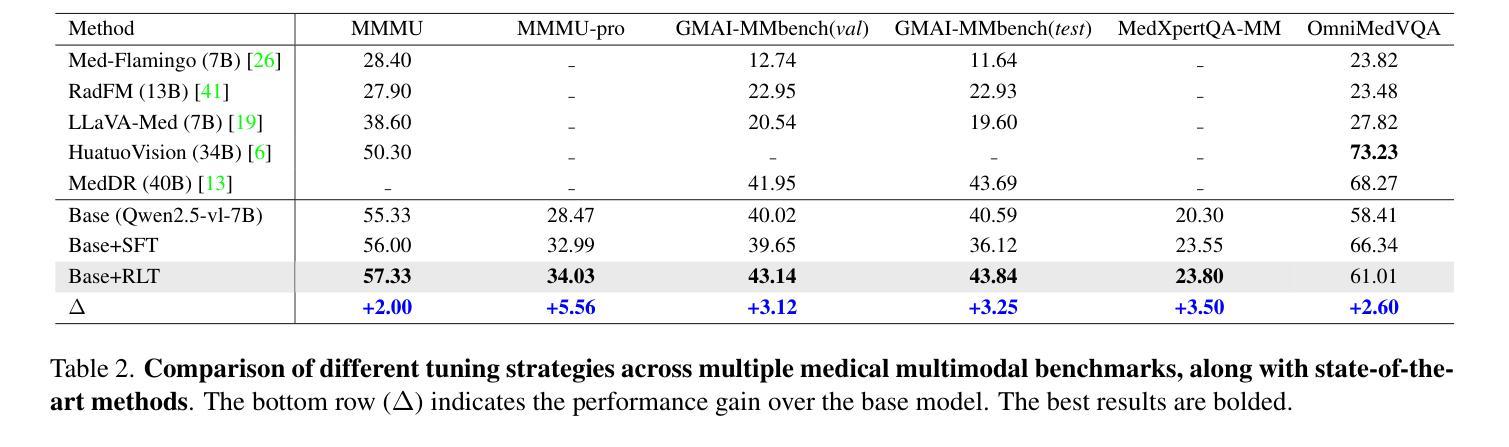
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Authors:Yanzhou Su, Tianbin Li, Jiyao Liu, Chenglong Ma, Junzhi Ning, Cheng Tang, Sibo Ju, Jin Ye, Pengcheng Chen, Ming Hu, Shixiang Tang, Lihao Liu, Bin Fu, Wenqi Shao, Xiaowei Hu, Xiangwen Liao, Yuanfeng Ji, Junjun He
Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model’s generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
近期通用医疗人工智能的进步已经取得了重大突破,但现有模型通常缺乏复杂的医疗决策所需的推理能力。本文提出了一种多模态医疗推理模型GMAI-VL-R1,通过强化学习(RL)增强其推理能力。通过迭代训练,GMAI-VL-R1优化了决策制定,大大提高了诊断准确性和临床支持能力。我们还开发了一种推理数据合成方法,通过拒绝采样生成分步推理数据,这进一步提高了模型的泛化能力。实验结果表明,经过RL训练后,GMAI-VL-R1在医学图像诊断和视觉问答等任务上表现出色。虽然该模型通过监督微调展示了基本的记忆能力,但RL对于真正的泛化至关重要。我们的工作建立了新的评估基准,为医疗推理模型的未来进步铺平了道路。代码、数据和模型将发布在此链接:https://github.com/uni-medical/GMAI-VL-R1。
论文及项目相关链接
Summary
近期医学人工智能取得显著进展,但现有模型在复杂医疗决策中缺乏推理能力。本文提出一种通过强化学习增强的多模态医学推理模型GMAI-VL-R1,以提高其推理能力。经过迭代训练,GMAI-VL-R1优化了决策制定,显著提高了诊断准确性和临床支持能力。此外,还开发了一种通过拒绝采样生成逐步推理数据的方法,进一步提高模型的泛化能力。实验结果表明,经过强化学习训练后,GMAI-VL-R1在医学图像诊断和视觉问答等任务上表现出色。虽然模型通过监督微调实现了基本记忆,但强化学习对于真正的泛化至关重要。本研究建立了新的评估基准,为医学推理模型的未来发展铺平了道路。
Key Takeaways
- 医学人工智能近期取得显著进展,但缺乏复杂医疗决策所需的推理能力。
- GMAI-VL-R1是一个多模态医学推理模型,通过强化学习增强。
- 强化学习训练使GMAI-VL-R1在诊断准确性和临床支持方面显著提高。
- 开发了一种通过拒绝采样生成逐步推理数据的方法,增强模型的泛化能力。
- 实验结果表明,GMAI-VL-R1在医学图像诊断和视觉问答等任务上表现优秀。
- 强化学习对于模型的真正泛化至关重要。
点此查看论文截图



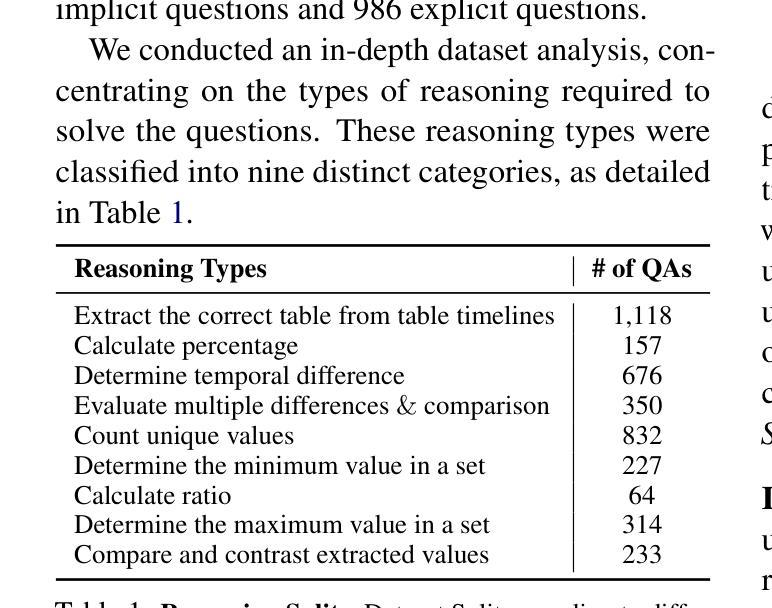
TransientTables: Evaluating LLMs’ Reasoning on Temporally Evolving Semi-structured Tables
Authors:Abhilash Shankarampeta, Harsh Mahajan, Tushar Kataria, Dan Roth, Vivek Gupta
Humans continuously make new discoveries, and understanding temporal sequence of events leading to these breakthroughs is essential for advancing science and society. This ability to reason over time allows us to identify future steps and understand the effects of financial and political decisions on our lives. However, large language models (LLMs) are typically trained on static datasets, limiting their ability to perform effective temporal reasoning. To assess the temporal reasoning capabilities of LLMs, we present the TRANSIENTTABLES dataset, which comprises 3,971 questions derived from over 14,000 tables, spanning 1,238 entities across multiple time periods. We introduce a template-based question-generation pipeline that harnesses LLMs to refine both templates and questions. Additionally, we establish baseline results using state-of-the-art LLMs to create a benchmark. We also introduce novel modeling strategies centered around task decomposition, enhancing LLM performance.
人类不断有新的发现,理解导致这些突破的事件的时间序列对于推动科学和社会进步至关重要。这种随时间推理的能力使我们能够确定未来的步骤,并了解金融和政治决策对我们的生活的影响。然而,大型语言模型(LLM)通常是在静态数据集上进行训练的,这限制了它们进行有效的时间推理的能力。为了评估LLM的时间推理能力,我们推出了TRANSIENTTABLES数据集,该数据集包含3971个问题,这些问题由超过14000个表格衍生而来,涵盖了多个时期内的1238个实体。我们引入了一个基于模板的问题生成管道,该管道利用LLM来改进模板和问题。此外,我们还利用最新LLM建立基线结果以创建基准测试,并围绕任务分解引入新型建模策略,以提高LLM的性能。
论文及项目相关链接
PDF 19 Pages. 21 Tables, 1 figure
Summary:
人类对时间的推理能力对于推动科学和社会进步至关重要。然而,大型语言模型(LLMs)通常受限于静态数据集,难以进行有效的时序推理。为此,我们推出了TRANSIENTTABLES数据集,包含3971个问题,源于超过14000个表格,涉及多个时间段的1238个实体。我们采用基于模板的问题生成管道,利用LLMs优化模板和问题。同时,我们建立了使用最新LLMs的基线结果,并引入了以任务分解为中心的新型建模策略,以提高LLMs的性能。
Key Takeaways:
- 人类理解事件的时间序列对于科学和社会进步至关重要。
- 大型语言模型(LLMs)在时序推理方面存在局限。
- TRANSIENTTABLES数据集包含从超过14000个表格中衍生出的3971个问题,涉及多个时间段的实体。
- 我们使用基于模板的问题生成管道来提高LLMs的时序推理能力。
- 基线结果使用最新的LLMs建立,以提供性能标准。
- 为了增强LLMs的表现,我们引入了新型建模策略,以任务分解为中心。
点此查看论文截图

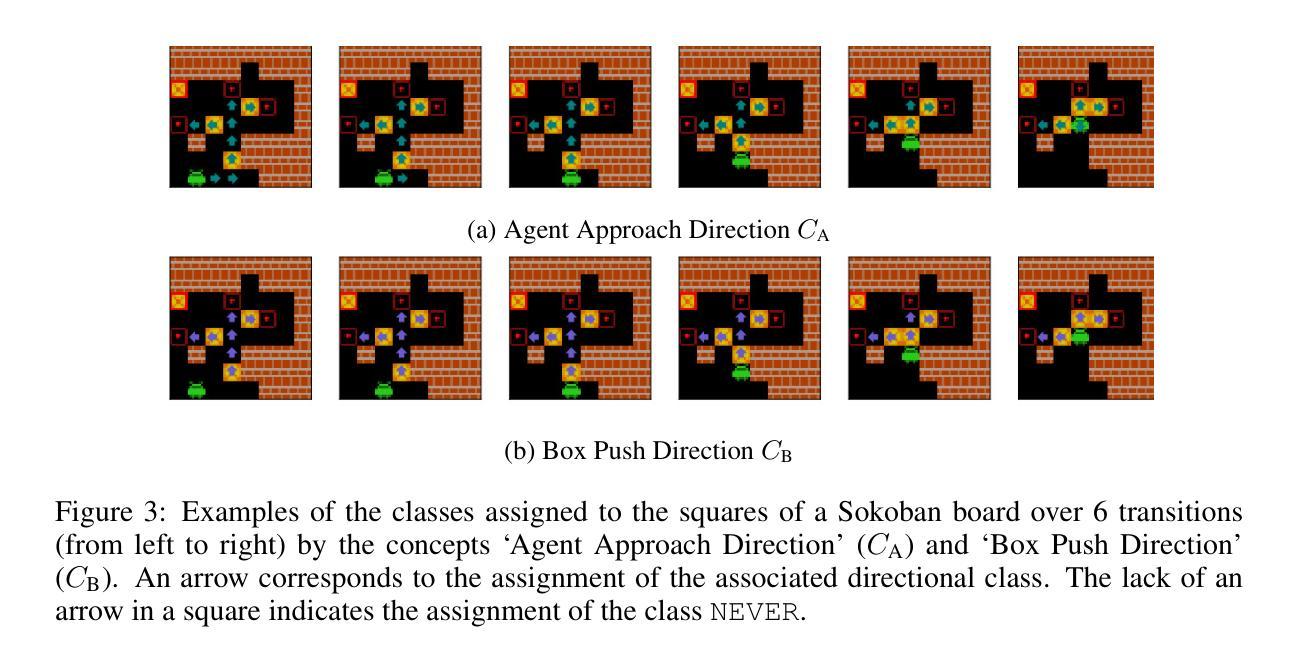
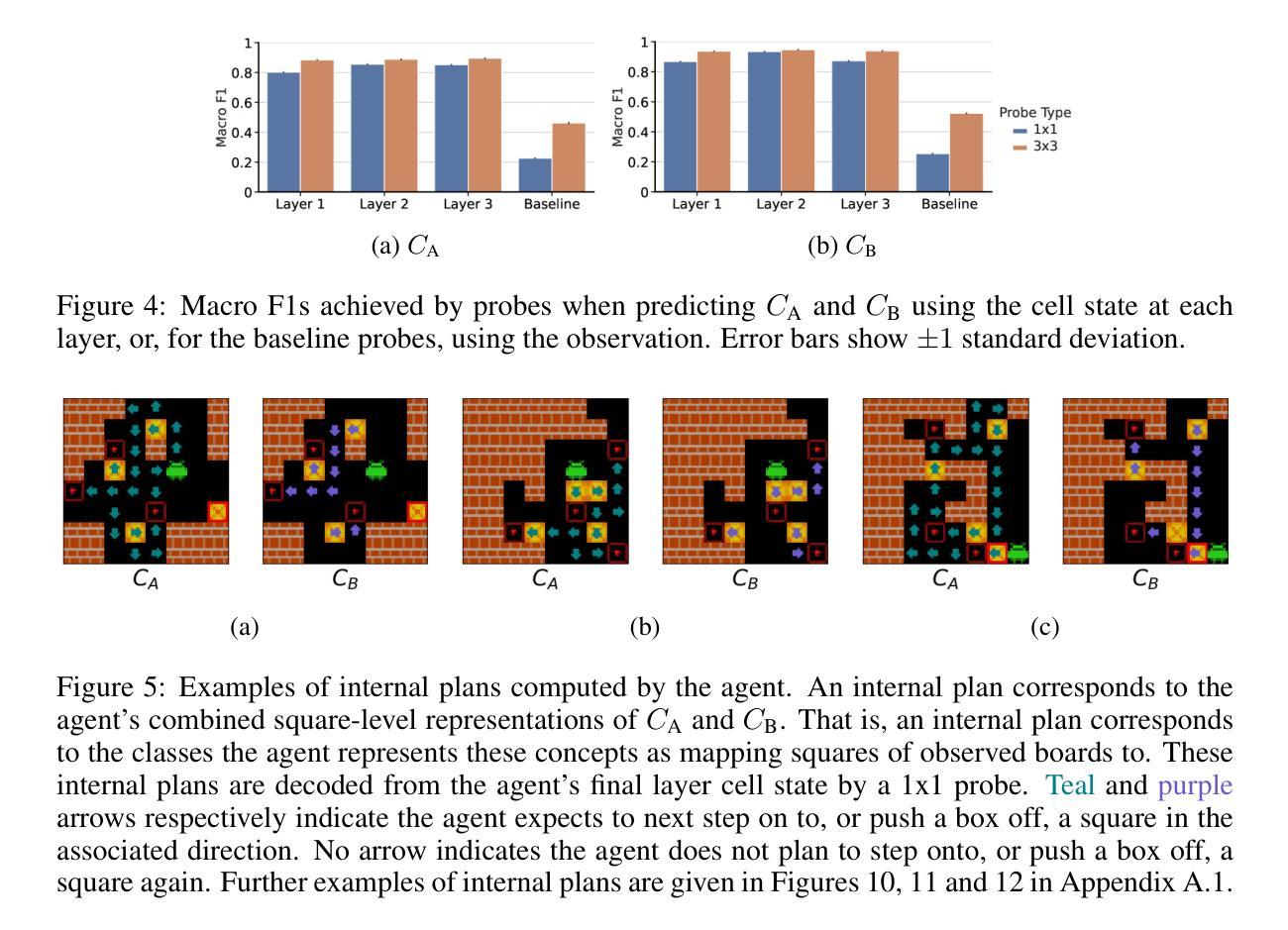
Interpreting Emergent Planning in Model-Free Reinforcement Learning
Authors:Thomas Bush, Stephen Chung, Usman Anwar, Adrià Garriga-Alonso, David Krueger
We present the first mechanistic evidence that model-free reinforcement learning agents can learn to plan. This is achieved by applying a methodology based on concept-based interpretability to a model-free agent in Sokoban – a commonly used benchmark for studying planning. Specifically, we demonstrate that DRC, a generic model-free agent introduced by Guez et al. (2019), uses learned concept representations to internally formulate plans that both predict the long-term effects of actions on the environment and influence action selection. Our methodology involves: (1) probing for planning-relevant concepts, (2) investigating plan formation within the agent’s representations, and (3) verifying that discovered plans (in the agent’s representations) have a causal effect on the agent’s behavior through interventions. We also show that the emergence of these plans coincides with the emergence of a planning-like property: the ability to benefit from additional test-time compute. Finally, we perform a qualitative analysis of the planning algorithm learned by the agent and discover a strong resemblance to parallelized bidirectional search. Our findings advance understanding of the internal mechanisms underlying planning behavior in agents, which is important given the recent trend of emergent planning and reasoning capabilities in LLMs through RL
我们首次提供了机械证据,证明无模型强化学习代理可以学习规划。这是通过在Sokoban(一个常用于研究规划的基准测试)的无模型代理中应用基于概念的可解释性方法来实现的。具体来说,我们证明了DRC是一个由Guez等人(2019年)提出的一种通用无模型代理,它使用学习的概念表示来内部制定计划,这些计划既预测行动对环境产生的长期影响,又影响行动的选择。我们的方法包括:(1)探测与规划相关的概念;(2)研究代理表示中的计划形成;(3)通过干预验证在代理表示中发现的计划对代理行为具有因果关系。我们还表明,这些计划的出现伴随着一种类似规划的属性出现:利用额外的测试时间计算能力的能力。最后,我们对代理学习的规划算法进行了定性分析,并发现其与并行双向搜索有很强的相似性。我们的研究结果推进了对代理规划行为内在机制的理解,这在最近的趋势中非常重要,即通过强化学习在大型语言模型中出现的规划和推理能力。
论文及项目相关链接
PDF ICLR 2025 oral
Summary:
我们首次证明无模型强化学习代理可以通过基于概念可解释性的方法学习规划。在用于研究规划的常用基准Sokoban中,我们对无模型代理应用了此方法。研究结果表明,Guez等人于2019年引入的通用无模型代理DRC使用学习的概念表示来内部制定计划,这些计划可以预测行动对环境的长远影响并影响行动选择。通过探查规划相关概念、研究代理内部计划的形成以及验证代理内部发现的计划对代理行为的影响,我们发现这些计划的产生与一种规划类属性的出现相吻合:即利用额外的测试时间计算的能力。最后,我们对代理所学的规划算法进行了定性分析,发现其与并行双向搜索有很强的相似性。
Key Takeaways:
- 无模型强化学习代理可以通过概念可解释性的方法学习规划。
- 研究对象使用了Sokoban基准来展示这一结果。
- DRC代理使用学习的概念表示来内部制定计划,预测行动对环境的长远影响并影响行动选择。
- 通过探查和验证发现了规划相关概念与代理内部计划的形成。
- 代理利用额外的测试时间计算能力进行规划类活动。
- 发现的计划与并行双向搜索有相似性。
点此查看论文截图


Cross-Lingual Consistency: A Novel Inference Framework for Advancing Reasoning in Large Language Models
Authors:Zhiwei Yu, Tuo Li, Changhong Wang, Hui Chen, Lang Zhou
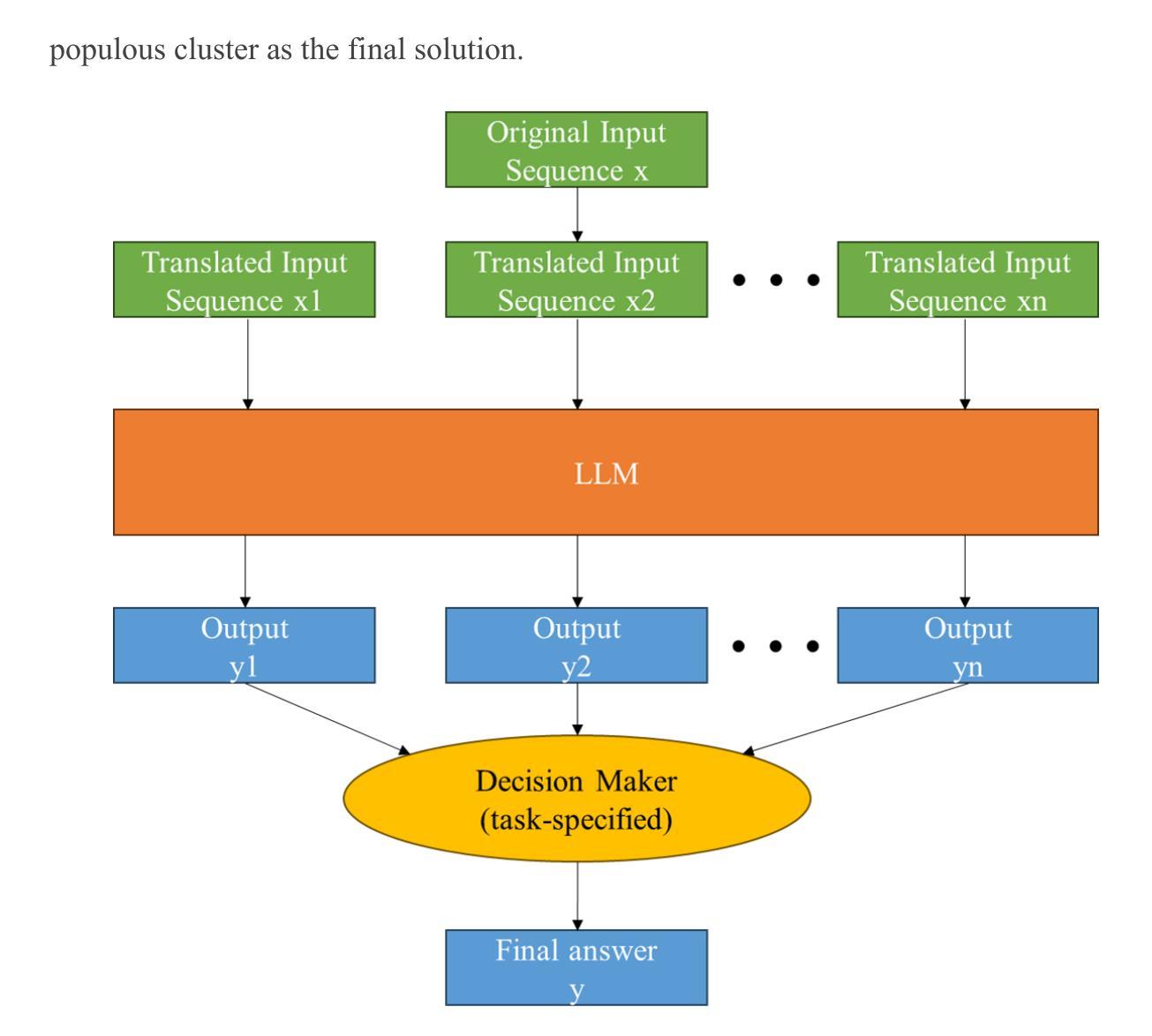
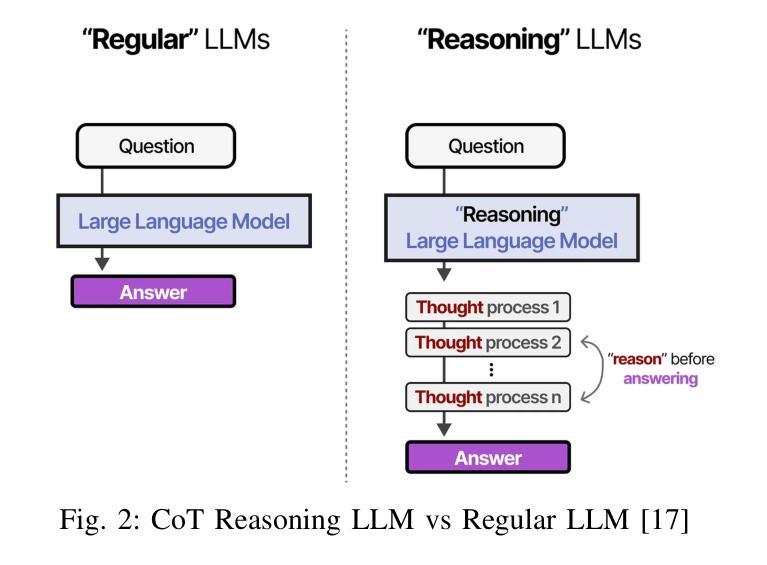
Chain-of-thought (CoT) has emerged as a critical mechanism for enhancing reasoning capabilities in large language models (LLMs), with self-consistency demonstrating notable promise in boosting performance. However, inherent linguistic biases in multilingual training corpora frequently cause semantic drift and logical inconsistencies, especially in sub-10B parameter LLMs handling complex inference tasks. To overcome these constraints, we propose the Cross-Lingual Consistency (CLC) framework, an innovative inference paradigm that integrates multilingual reasoning paths through majority voting to elevate LLMs’ reasoning capabilities. Empirical evaluations on the CMATH dataset reveal CLC’s superiority over the conventional self-consistency method, delivering 9.5%, 6.5%, and 6.0% absolute accuracy gains for DeepSeek-Math-7B-Instruct, Qwen2.5-Math-7B-Instruct, and Gemma2-9B-Instruct respectively. Expanding CLC’s linguistic scope to 11 diverse languages implies two synergistic benefits: 1) neutralizing linguistic biases in multilingual training corpora through multilingual ensemble voting, 2) escaping monolingual reasoning traps by exploring the broader multilingual solution space. This dual benefits empirically enables more globally optimal reasoning paths compared to monolingual self-consistency baselines, as evidenced by the 4.1%-18.5% accuracy gains using Gemma2-9B-Instruct on the MGSM dataset.
思维链(CoT)作为提升大型语言模型(LLM)推理能力的重要机制已经崭露头角,自我一致性在提升性能上显示出巨大潜力。然而,在多语言训练语料库中的固有语言偏见经常导致语义漂移和逻辑不一致,特别是在处理复杂推理任务的参数小于10B的LLMs中更为明显。为了克服这些限制,我们提出了跨语言一致性(CLC)框架,这是一种创新性的推理范式,它通过多数投票来整合多语言推理路径,提升LLMs的推理能力。在CMATH数据集上的实证评估表明,CLC框架优于传统的自我一致性方法,为DeepSeek-Math-7B-Instruct、Qwen2.5-Math-7B-Instruct和Gemma2-9B-Instruct分别带来了9.5%、6.5%和6.0%的绝对准确度提升。将CLC的语言范围扩展到11种不同语言,意味着两个协同优势:1)通过多语言集合投票抵消多语言训练语料库中的语言偏见;2)通过探索更广泛的多语言解决方案空间,避免单一语言的推理陷阱。这种双重优势使得与单语自我一致性基线相比,能够找到更多全局最优的推理路径。如在MGSM数据集上,使用Gemma2-9B-Instruct的准确度提升了4.1%-18.5%,这证明了其实效性。
论文及项目相关链接
Summary
在大型语言模型(LLM)中,链式思维(CoT)已成为提高推理能力的重要机制,而自我一致性在提高性能方面具有显著潜力。然而,在多语种训练语料库中存在的固有语言偏见会导致语义漂移和逻辑不一致,特别是在处理复杂推理任务的参数小于10B的LLM中更为显著。为克服这些局限性,本文提出了跨语言一致性(CLC)框架,这是一种通过多数投票整合多语种推理路径的创新推理范式,旨在提升LLM的推理能力。在CMATH数据集上的实证评估表明,CLC优于传统的自我一致性方法,分别为DeepSeek-Math-7B-Instruct、Qwen2.5-Math-7B-Instruct和Gemma2-9B-Instruct带来了9.5%、6.5%和6.0%的绝对准确率提升。将CLC的语种范围扩大到11种不同的语言,带来了两个协同效益:1)通过多语种集成投票中和多语种训练语料库中的语言偏见;2)通过探索更广泛的多语种解决方案空间,避免单语种推理陷阱。这双重优势使得CLC相比单语种自我一致性基线,能够找到更多全局最优的推理路径,如在MGSM数据集上使用Gemma2-9B-Instruct带来的4.1%~18.5%的准确率提升。
Key Takeaways
- 链式思维(CoT)增强了大型语言模型(LLM)的推理能力。
- 自我一致性是提升LLM性能的一种有前景的方法。
- 多语种训练语料库中的语言偏见会导致语义漂移和逻辑不一致。
- 跨语言一致性(CLC)框架通过多数投票整合多语种推理路径,提升了LLM的推理能力。
- CLC框架在CMATH数据集上的实证评估表现优越。
- CLC框架扩展至11种语言,具有中和语言偏见和探索多语种解决方案空间的双重优势。
点此查看论文截图

Reasoning LLMs for User-Aware Multimodal Conversational Agents
Authors:Hamed Rahimi, Jeanne Cattoni, Meriem Beghili, Mouad Abrini, Mahdi Khoramshahi, Maribel Pino, Mohamed Chetouani
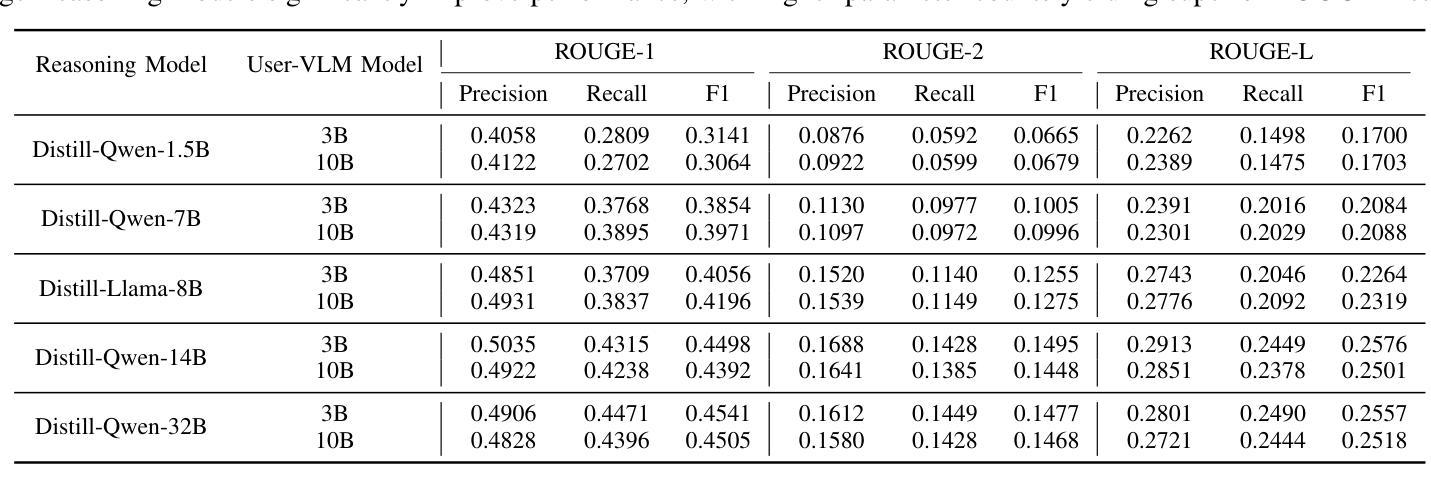
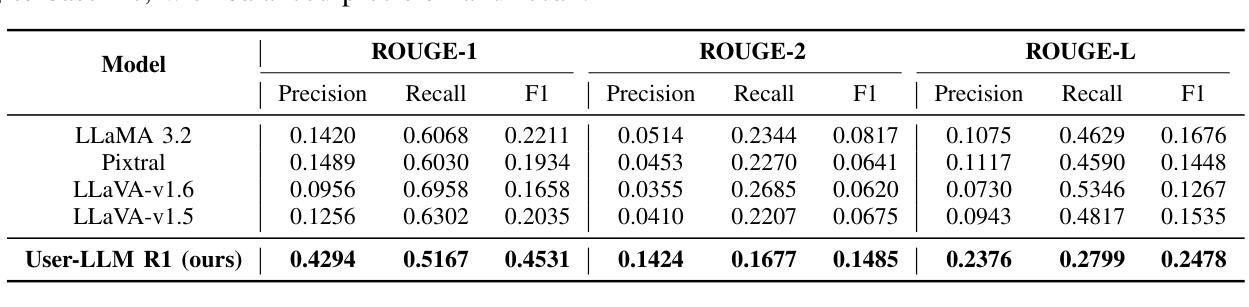
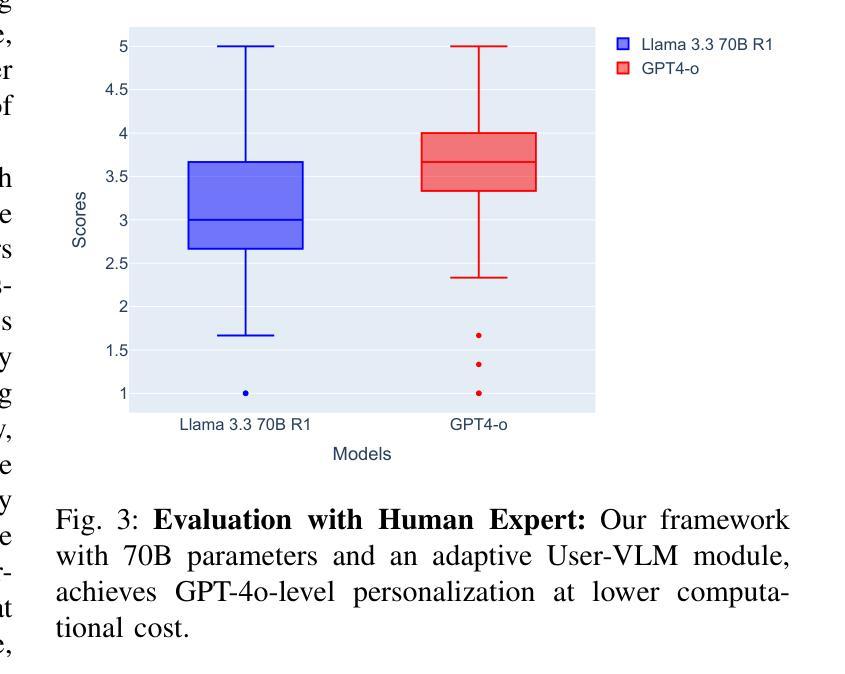
Personalization in social robotics is critical for fostering effective human-robot interactions, yet systems often face the cold start problem, where initial user preferences or characteristics are unavailable. This paper proposes a novel framework called USER-LLM R1 for a user-aware conversational agent that addresses this challenge through dynamic user profiling and model initiation. Our approach integrates chain-of-thought (CoT) reasoning models to iteratively infer user preferences and vision-language models (VLMs) to initialize user profiles from multimodal inputs, enabling personalized interactions from the first encounter. Leveraging a Retrieval-Augmented Generation (RAG) architecture, the system dynamically refines user representations within an inherent CoT process, ensuring contextually relevant and adaptive responses. Evaluations on the ElderlyTech-VQA Bench demonstrate significant improvements in ROUGE-1 (+23.2%), ROUGE-2 (+0.6%), and ROUGE-L (+8%) F1 scores over state-of-the-art baselines, with ablation studies underscoring the impact of reasoning model size on performance. Human evaluations further validate the framework’s efficacy, particularly for elderly users, where tailored responses enhance engagement and trust. Ethical considerations, including privacy preservation and bias mitigation, are rigorously discussed and addressed to ensure responsible deployment.
个性化社会机器人对于促进有效的人机交互至关重要,然而,系统经常面临冷启动问题,即初始用户偏好或特征无法获取。本文针对这一问题,提出了一种名为USER-LLM R1的新型框架,用于构建具有用户意识的对话代理,通过动态用户分析和模型启动来解决这一问题。我们的方法融合了思维链(CoT)推理模型,以迭代方式推断用户偏好,以及视觉语言模型(VLM),从多模态输入初始化用户分析,从而首次交互即可实现个性化交互。通过利用检索增强生成(RAG)架构,系统在一个内在的CoT过程中动态优化用户表示,确保语境相关且自适应的响应。在ElderlyTech-VQA Bench上的评估显示,与最新基线相比,ROUGE-1(+23.2%)、ROUGE-2(+0.6%)和ROUGE-L(+8%)的F1分数有了显著的提高。消融研究强调了推理模型大小对性能的影响。人类评估进一步验证了该框架的有效性,特别是对于老年用户,定制化的回应增强了参与感和信任度。严格讨论了包括隐私保护和偏见缓解在内的道德考量,并予以解决,以确保负责任的部署。
论文及项目相关链接
Summary
该论文针对社交机器人个性化面临的冷启动问题,提出了一种名为USER-LLM R1的新型框架。该框架通过动态用户分析和模型启动实现用户感知对话代理,集成链式思维推理模型来迭代推断用户偏好,并利用视觉语言模型从多模态输入中初始化用户资料。该框架通过检索增强生成架构动态完善用户内在认知过程,确保回应语境相关并具有适应性。在ElderlyTech-VQA Bench上的评估显示,相较于现有技术基线,该框架在ROUGE-1(+23.2%)、ROUGE-2(+0.6%)和ROUGE-L(+8%)F1分数上取得了显著改善。人类评估进一步验证了该框架对老年用户的功效,其定制的响应增强了参与感和信任感。同时严格讨论并解决了伦理考量,包括隐私保护和偏见缓解,以确保部署责任性。
Key Takeaways
社交机器人个性化对于促进有效的人机交互至关重要,但系统面临冷启动问题,即初始用户偏好或特征不可用。
USER-LLM R1框架通过动态用户分析和模型启动来解决这一问题,实现用户感知对话代理。
该框架集成了链式思维推理模型来迭代推断用户偏好,并利用视觉语言模型处理多模态输入以初始化用户资料。
通过检索增强生成架构,系统能在内在认知过程中动态完善用户表达,确保回应具有语境相关性和适应性。
在ElderlyTech-VQA Bench上的评估显示,该框架相较于现有技术基线有显著改进。
人类评估验证了该框架对老年用户的功效,定制的响应增强了参与感和信任感。
点此查看论文截图


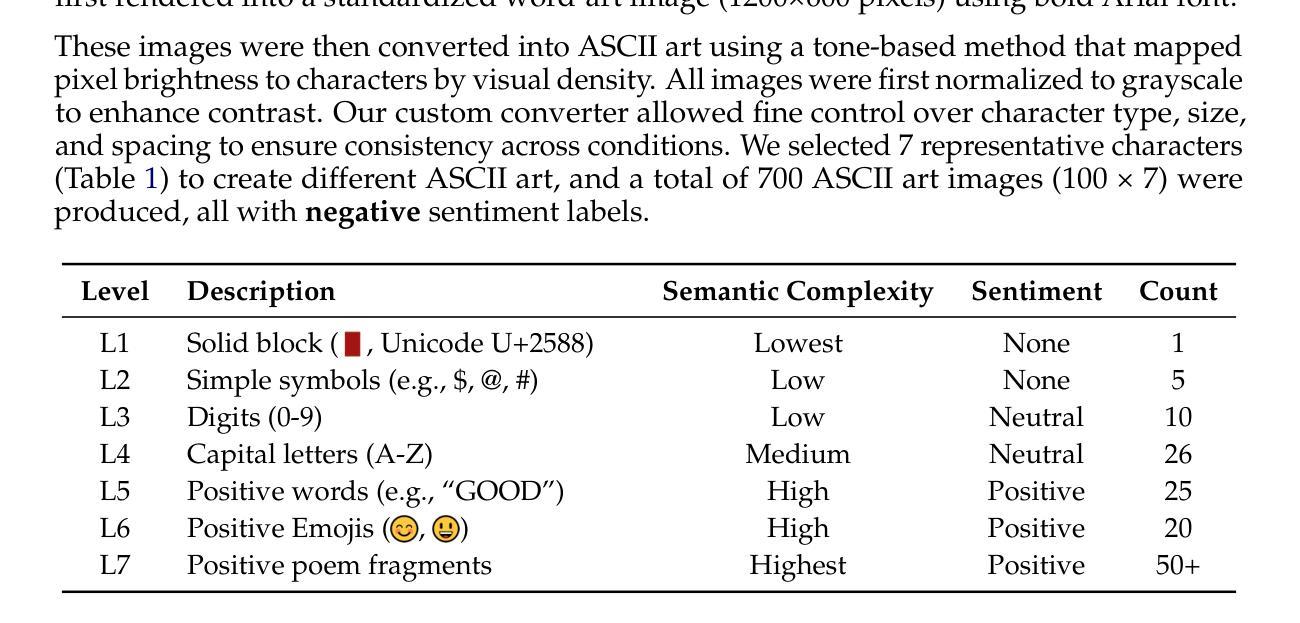
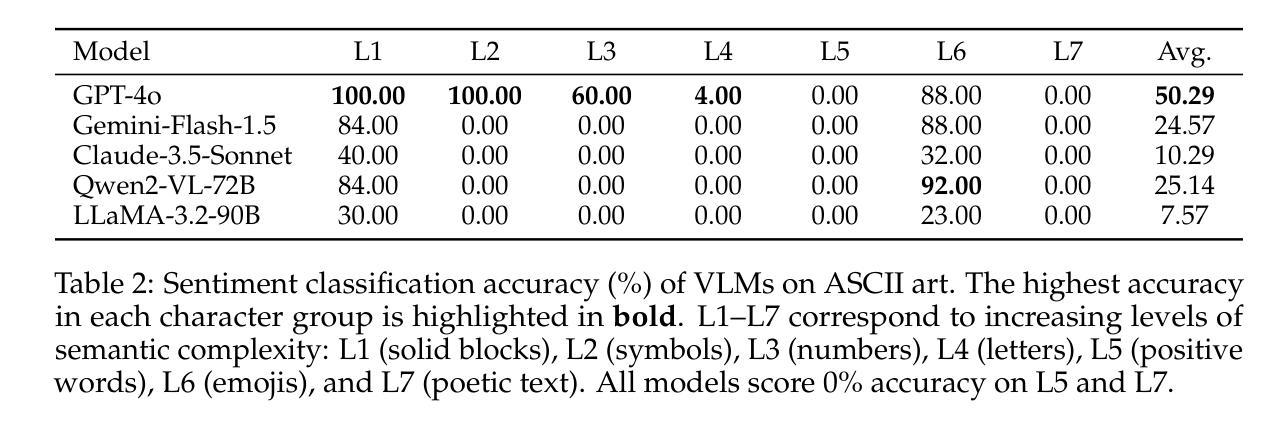
Text Speaks Louder than Vision: ASCII Art Reveals Textual Biases in Vision-Language Models
Authors:Zhaochen Wang, Yujun Cai, Zi Huang, Bryan Hooi, Yiwei Wang, Ming-Hsuan Yang
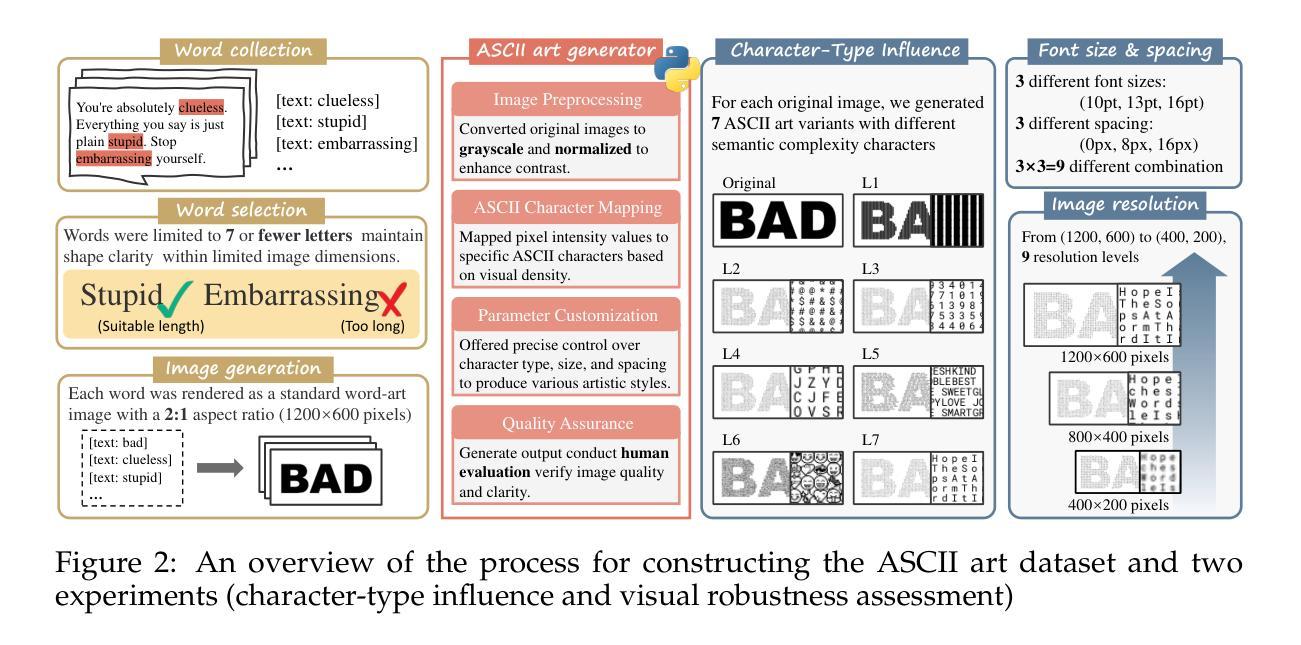
Vision-language models (VLMs) have advanced rapidly in processing multimodal information, but their ability to reconcile conflicting signals across modalities remains underexplored. This work investigates how VLMs process ASCII art, a unique medium where textual elements collectively form visual patterns, potentially creating semantic-visual conflicts. We introduce a novel evaluation framework that systematically challenges five state-of-the-art models (including GPT-4o, Claude, and Gemini) using adversarial ASCII art, where character-level semantics deliberately contradict global visual patterns. Our experiments reveal a strong text-priority bias: VLMs consistently prioritize textual information over visual patterns, with visual recognition ability declining dramatically as semantic complexity increases. Various mitigation attempts through visual parameter tuning and prompt engineering yielded only modest improvements, suggesting that this limitation requires architectural-level solutions. These findings uncover fundamental flaws in how current VLMs integrate multimodal information, providing important guidance for future model development while highlighting significant implications for content moderation systems vulnerable to adversarial examples.
视觉语言模型(VLMs)在处理多模态信息方面取得了快速进展,但其在调和跨模态冲突信号方面的能力仍被忽视。本研究探讨了VLMs如何处理ASCII艺术这一独特媒介,其中的文本元素共同形成视觉模式,可能会产生语义视觉冲突。我们引入了一个新的评估框架,使用对抗性ASCII艺术系统地挑战了五种最先进的模型(包括GPT-4o、Claude和Gemini),其中字符级别的语义故意与全局视觉模式相矛盾。我们的实验揭示了一个强烈的文本优先偏见:VLMs始终优先处理文本信息而非视觉模式,随着语义复杂性的增加,其视觉识别能力急剧下降。通过视觉参数调整和提示工程进行的各种缓解尝试仅产生了适度的改进,这表明这一局限性需要架构级的解决方案。这些发现揭示了当前VLMs如何整合多模态信息的基本缺陷,为未来的模型开发提供了重要指导,同时强调了对于易受对抗性样本影响的内容审核系统所带来的重大影响。
论文及项目相关链接
PDF Under review at COLM 2025
Summary
本文探讨了视觉语言模型(VLMs)在处理ASCII艺术时的表现,这是一种文本元素共同形成视觉图案的特殊媒介,可能会产生语义视觉冲突。研究引入了一个新型评估框架,系统地挑战了五种最先进的模型,包括GPT-4o、Claude和Gemini等,使用对抗性的ASCII艺术,其中字符级别的语义故意与全局视觉模式相矛盾。实验表明,VLMs存在强烈的文本优先偏见,在语义复杂性增加时,视觉识别能力急剧下降。通过视觉参数调整和提示工程的各种缓解尝试只产生了适度的改善,表明这一局限性需要架构级的解决方案。这些发现揭示了当前VLMs在集成多模式信息时的根本缺陷,为未来的模型开发提供了重要指导,并突出了对易受对抗性示例影响的内容审核系统的重要意义。
Key Takeaways
- VLMs在处理ASCII艺术时面临语义视觉冲突的问题。
- 引入新型评估框架挑战了五种最先进的VLMs模型。
- 实验发现VLMs存在文本优先的偏见。
- 在语义复杂性增加时,VLMs的视觉识别能力显著下降。
- 目前的模型在集成多模式信息方面存在根本缺陷。
- 尝试通过视觉参数调整和提示工程改善模型表现,但效果有限。
点此查看论文截图


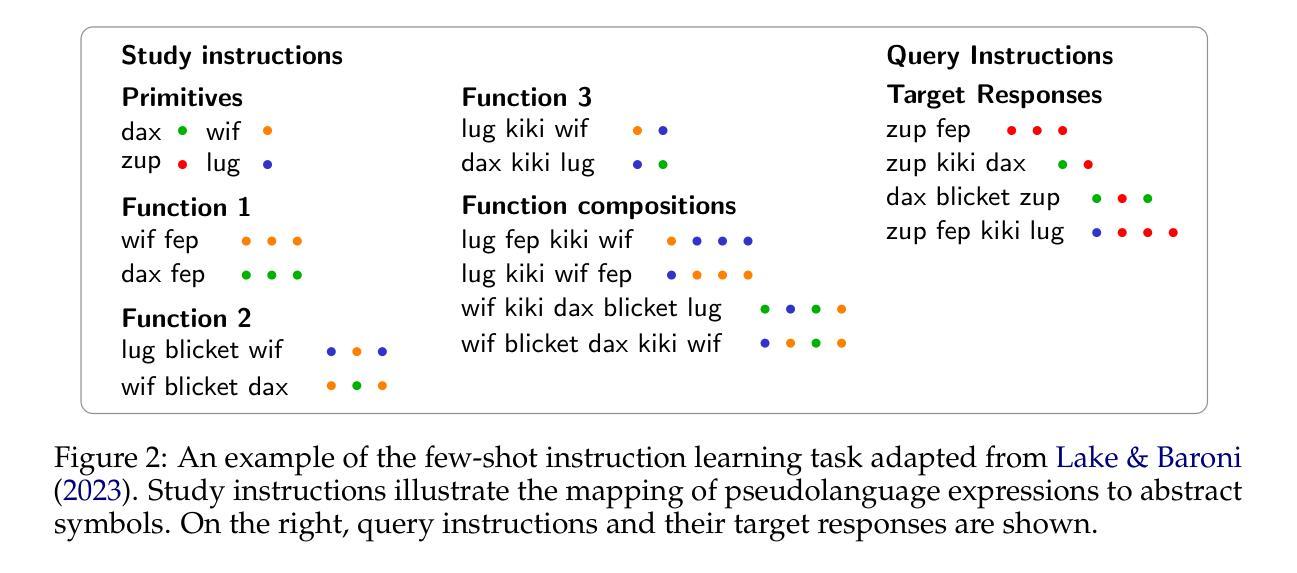
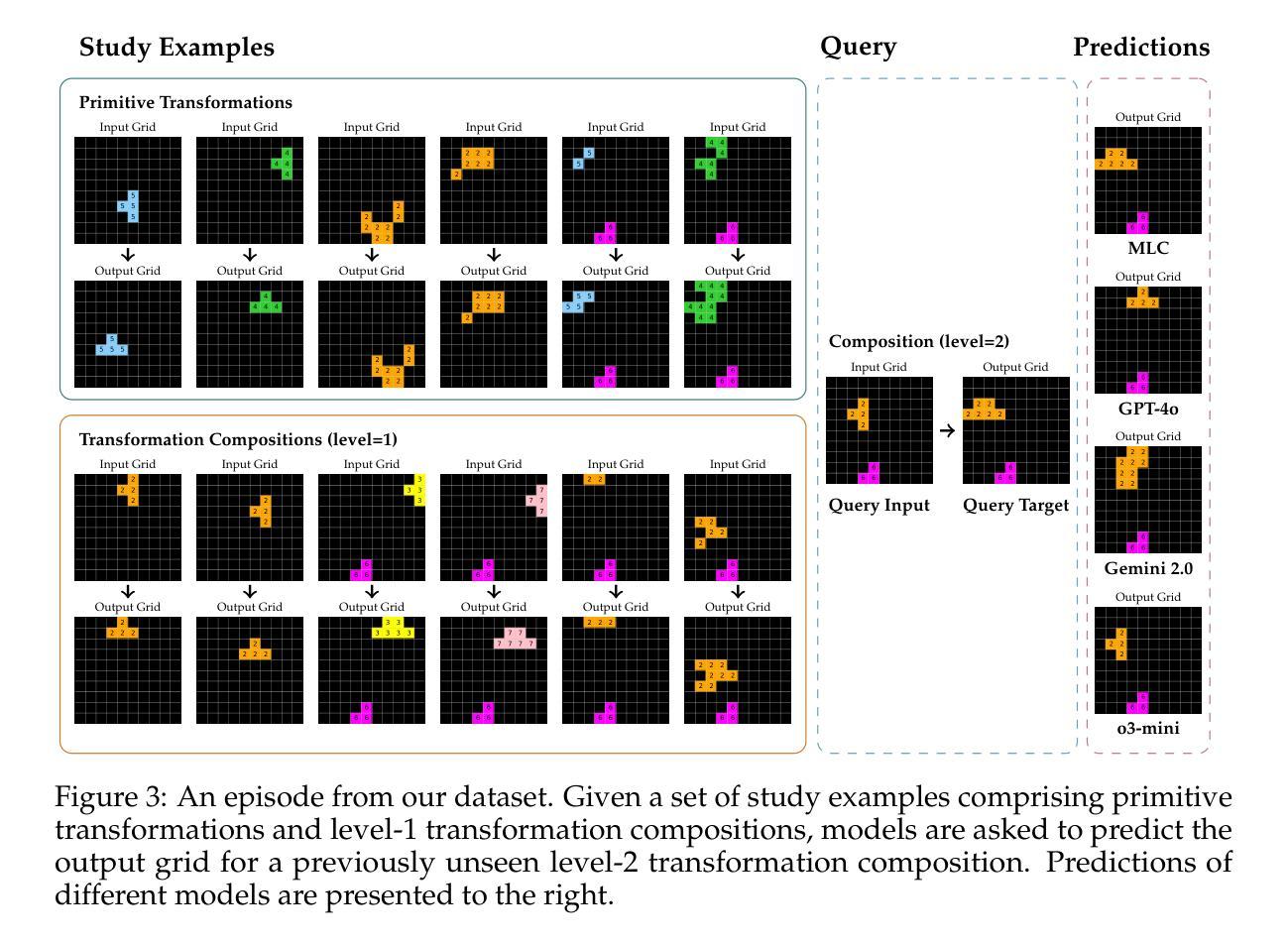
Enabling Systematic Generalization in Abstract Spatial Reasoning through Meta-Learning for Compositionality
Authors:Philipp Mondorf, Shijia Zhou, Monica Riedler, Barbara Plank
Systematic generalization refers to the capacity to understand and generate novel combinations from known components. Despite recent progress by large language models (LLMs) across various domains, these models often fail to extend their knowledge to novel compositional scenarios, revealing notable limitations in systematic generalization. There has been an ongoing debate about whether neural networks possess the capacity for systematic generalization, with recent studies suggesting that meta-learning approaches designed for compositionality can significantly enhance this ability. However, these insights have largely been confined to linguistic problems, leaving their applicability to other tasks an open question. In this study, we extend the approach of meta-learning for compositionality to the domain of abstract spatial reasoning. To this end, we introduce $\textit{SYGAR}$-a dataset designed to evaluate the capacity of models to systematically generalize from known geometric transformations (e.g., translation, rotation) of two-dimensional objects to novel combinations of these transformations (e.g., translation+rotation). Our results show that a transformer-based encoder-decoder model, trained via meta-learning for compositionality, can systematically generalize to previously unseen transformation compositions, significantly outperforming state-of-the-art LLMs, including o3-mini, GPT-4o, and Gemini 2.0 Flash, which fail to exhibit similar systematic behavior. Our findings highlight the effectiveness of meta-learning in promoting systematicity beyond linguistic tasks, suggesting a promising direction toward more robust and generalizable models.
系统化泛化是指理解和生成已知组件的新组合的能力。尽管大型语言模型(LLM)在各个领域都取得了进展,但这些模型往往无法将其知识扩展到新的组合场景,显示出系统化泛化的明显局限性。关于神经网络是否具备系统化泛化能力的问题一直存在争议,近期研究表明,针对组合性设计的元学习方法可以显著增强这种能力。然而,这些见解大多局限于语言问题,对其他任务的适用性仍是未知。在这项研究中,我们将元学习的方法扩展到抽象空间推理领域。为此,我们引入了SYGAR数据集,旨在评估模型从已知的几何变换(如平移、旋转)中系统地推广到这些变换的新组合(如平移+旋转)的能力。我们的结果表明,基于转换器的编码器-解码器模型,通过元学习进行组合性训练,能够系统地推广到之前未见过的变换组合,显著优于最新的大型语言模型,包括o3-mini、GPT-4o和Gemini 2.0 Flash等,这些模型无法展现出类似的系统化行为。我们的研究强调了元学习在促进系统性、超越语言任务方面的有效性,为构建更稳健和可泛化的模型提供了有前景的方向。
论文及项目相关链接
PDF 30 pages, 14 figures
Summary
本文探讨了系统泛化的能力,即理解和生成已知组件的新组合的能力。尽管大型语言模型(LLMs)在各个领域都取得了进展,但它们往往无法将知识扩展到新的组合场景,显示出系统泛化的明显局限性。最近的研究表明,为组合性设计的元学习方法可以显著提高神经网络的系统泛化能力,但这些见解主要局限于语言问题,其他任务的适用性仍是一个开放的问题。本研究将元学习方法应用于抽象空间推理领域,并引入了SYGAR数据集来评估模型从已知的几何转换(如平移、旋转)到新的转换组合(如平移+旋转)的系统泛化能力。研究表明,基于变压器的编码器-解码器模型,通过元学习进行训练,可以系统地泛化到之前未见过的转换组合,显著优于包括o3-mini、GPT-4o和Gemini 2.0 Flash在内的最新LLMs,这些模型未能表现出类似的系统性行为。研究结果表明,元学习在促进系统性方面(尤其是在非语言任务中)的有效性,为构建更稳健和通用的模型提供了有希望的方向。
Key Takeaways
- 系统泛化是理解和生成新组合的关键能力,基于已知组件。
- 大型语言模型(LLMs)在系统泛化方面存在局限性,难以应用于新组合场景。
- 元学习方法被设计来提高神经网络的系统泛化能力,尤其在语言问题上效果显著。
- SYGAR数据集用于评估模型在几何转换上的系统泛化能力。
- 基于变压器的编码器-解码器模型通过元学习训练,能够系统地泛化到未见过的转换组合。
- 该模型显著优于现有的LLMs,这些LLMs在类似任务中未能表现出系统性行为。
点此查看论文截图


Foundations and Evaluations in NLP
Authors:Jungyeul Park
This memoir explores two fundamental aspects of Natural Language Processing (NLP): the creation of linguistic resources and the evaluation of NLP system performance. Over the past decade, my work has focused on developing a morpheme-based annotation scheme for the Korean language that captures linguistic properties from morphology to semantics. This approach has achieved state-of-the-art results in various NLP tasks, including part-of-speech tagging, dependency parsing, and named entity recognition. Additionally, this work provides a comprehensive analysis of segmentation granularity and its critical impact on NLP system performance. In parallel with linguistic resource development, I have proposed a novel evaluation framework, the jp-algorithm, which introduces an alignment-based method to address challenges in preprocessing tasks like tokenization and sentence boundary detection (SBD). Traditional evaluation methods assume identical tokenization and sentence lengths between gold standards and system outputs, limiting their applicability to real-world data. The jp-algorithm overcomes these limitations, enabling robust end-to-end evaluations across a variety of NLP tasks. It enhances accuracy and flexibility by incorporating linear-time alignment while preserving the complexity of traditional evaluation metrics. This memoir provides key insights into the processing of morphologically rich languages, such as Korean, while offering a generalizable framework for evaluating diverse end-to-end NLP systems. My contributions lay the foundation for future developments, with broader implications for multilingual resource development and system evaluation.
这篇回忆录探讨了自然语言处理(NLP)的两个基本方面:语言资源的创建和NLP系统性能的评估。过去十年,我的工作主要集中在为韩语开发一种基于词素的注释方案,该方案能够捕获从形态到语义的语言特性。这种方法在各种NLP任务中达到了最先进的结果,包括词性标注、依存解析和命名实体识别。此外,这项工作还全面分析了分词粒度及其对NLP系统性能的关键影响。
论文及项目相关链接
Summary
本文探讨了自然语言处理(NLP)的两个基本方面:语言资源的创建和NLP系统性能的评估。作者详细介绍了过去十年在韩语语言资源开发方面的工作,特别是基于形态素的标注方案,该方案在多种NLP任务中取得了最先进的成果。同时,作者提出了一个全新的评估框架jp算法,该算法解决了预处理任务中的对齐问题,如分词和句子边界检测。此算法克服了传统评估方法的局限性,实现了多种NLP任务的端到端评估,增强了准确性和灵活性。总的来说,本文为处理形态丰富的语言如韩语提供了关键见解,并为评估多样化的端到端NLP系统提供了可推广的框架。作者的贡献为未来研究和多语言资源开发与系统评估提供了更广泛的启示。
Key Takeaways
- 作者集中于发展基于形态素的韩语标注方案,涵盖了从形态到语义的各个方面。该方案在不同NLP任务中表现卓越。
- 作者详细分析了分段粒度对NLP系统性能的关键影响。
- 作者提出了一种新的评估框架jp算法,解决了预处理任务中的对齐问题,如分词和句子边界检测。这一算法克服了传统方法的局限性,增强了评估的准确性和灵活性。
- jp算法结合了线性时间对齐技术,既保留了传统评估指标的复杂性,又提高了评估的鲁棒性和灵活性。
- 本文为处理形态丰富的语言提供了重要见解,并可为其他语言的类似研究提供启示。
- 作者的贡献为未来的研究和多语言资源开发提供了基础。
点此查看论文截图

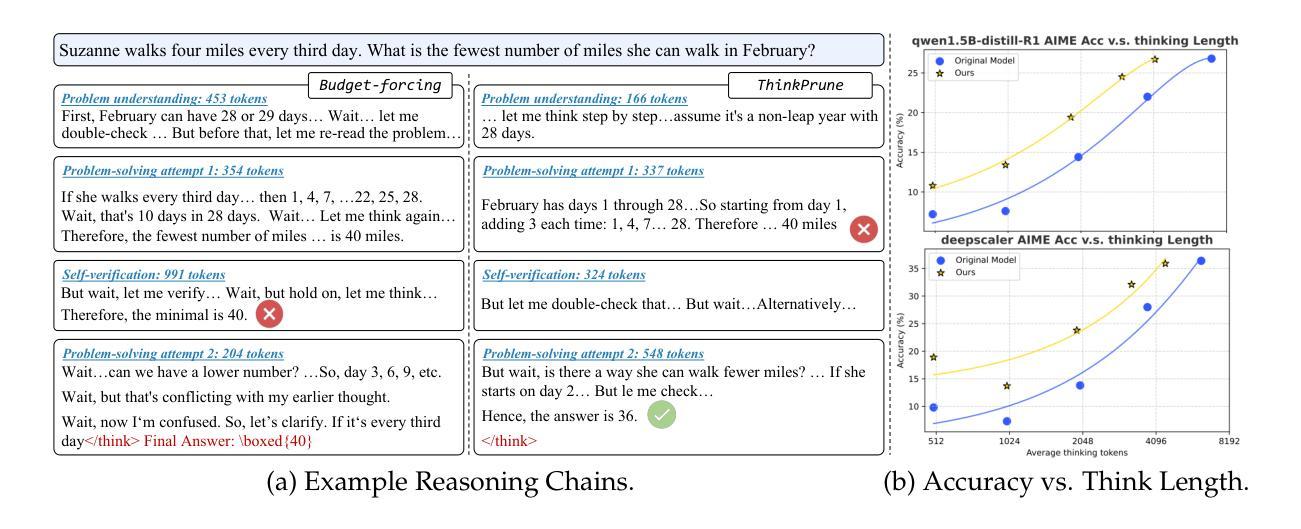
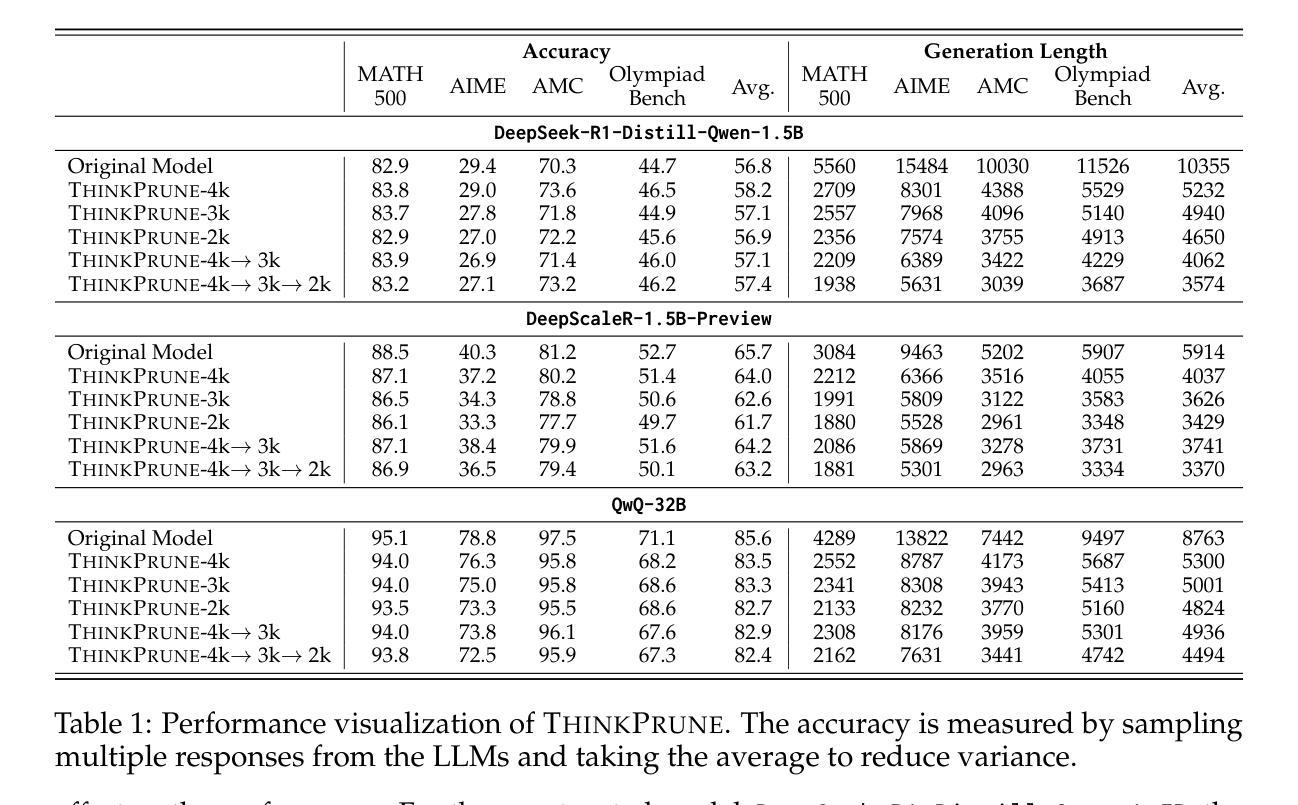
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Authors:Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang
We present ThinkPrune, a simple yet effective method for pruning the thinking length for long-thinking LLMs, which has been found to often produce inefficient and redundant thinking processes. Existing preliminary explorations of reducing thinking length primarily focus on forcing the thinking process to early exit, rather than adapting the LLM to optimize and consolidate the thinking process, and therefore the length-performance tradeoff observed so far is sub-optimal. To fill this gap, ThinkPrune offers a simple solution that continuously trains the long-thinking LLMs via reinforcement learning (RL) with an added token limit, beyond which any unfinished thoughts and answers will be discarded, resulting in a zero reward. To further preserve model performance, we introduce an iterative length pruning approach, where multiple rounds of RL are conducted, each with an increasingly more stringent token limit. We observed that ThinkPrune results in a remarkable performance-length tradeoff – on the AIME24 dataset, the reasoning length of DeepSeek-R1-Distill-Qwen-1.5B can be reduced by half with only 2% drop in performance. We also observed that after pruning, the LLMs can bypass unnecessary steps while keeping the core reasoning process complete. Code is available at https://github.com/UCSB-NLP-Chang/ThinkPrune.
我们提出ThinkPrune,这是一种简单但有效的方法,用于缩减长思考LLM的思考长度。已知LLM常常产生低效和冗余的思考过程。目前对减少思考长度的初步探索主要集中在强制思考过程早期退出,而不是让LLM去优化和巩固思考过程,因此目前观察到的长度与性能之间的权衡并不理想。为了填补这一空白,ThinkPrune提供了一个简单的解决方案,即通过强化学习(RL)持续训练长思考LLM,并增加一个令牌限制,超出此限制的思考和答案将被丢弃,从而导致零奖励。为了保持模型性能,我们引入了一种迭代长度修剪方法,进行多轮RL训练,每轮都设置更严格的令牌限制。我们发现ThinkPrune在性能与长度之间取得了显著的权衡——在AIME24数据集上,DeepSeek-R1-Distill-Qwen-1.5B的思考长度可以减少一半,性能仅下降2%。我们还观察到修剪后,LLM可以跳过不必要的步骤,同时保持核心推理过程的完整性。代码可在https://github.com/UCSB-NLP-Chang/ThinkPrune获取。
论文及项目相关链接
PDF 15 pages, 7 figures
Summary
思考修剪(ThinkPrune)是一种简单有效的方法,用于缩减长思考LLM的思考长度。该方法通过强化学习(RL)连续训练LLM,并增加一个令牌限制,超过限制则丢弃未完成的想法和答案,从而实现性能与长度的优化权衡。在AIME24数据集上,DeepSeek-R1-Distill-Qwen-1.5B模型的推理长度可以减少一半,性能仅下降2%。
Key Takeaways
- ThinkPrune是一种针对长思考LLM的思考长度进行修剪的简单有效方法。
- 现有方法主要强制提前结束思考过程,而非使LLM适应优化和整合思考过程。
- ThinkPrune使用强化学习(RL)进行LLM的连续训练,并引入令牌限制,以实现性能与长度的最佳权衡。
- ThinkPrune能够显著减少模型的推理长度,同时保持较高的性能。
- 通过迭代长度修剪方法,每个回合都设置更严格的令牌限制,进一步优化模型性能。
- ThinkPrune可以帮助LLM绕过不必要的步骤,同时保持核心推理过程的完整性。
- 代码的开源可用性为研究者提供了实践和改进的机会。
点此查看论文截图

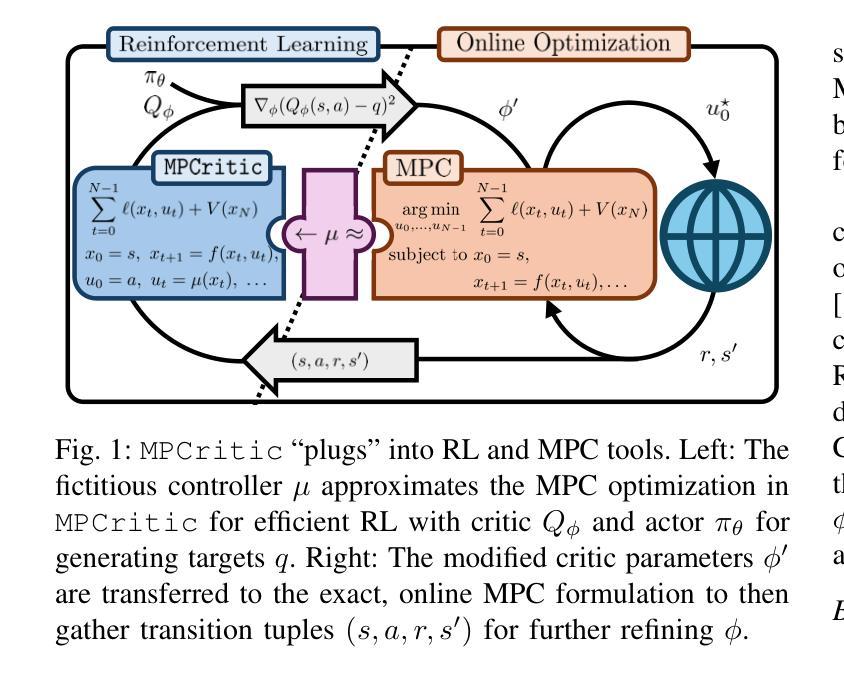
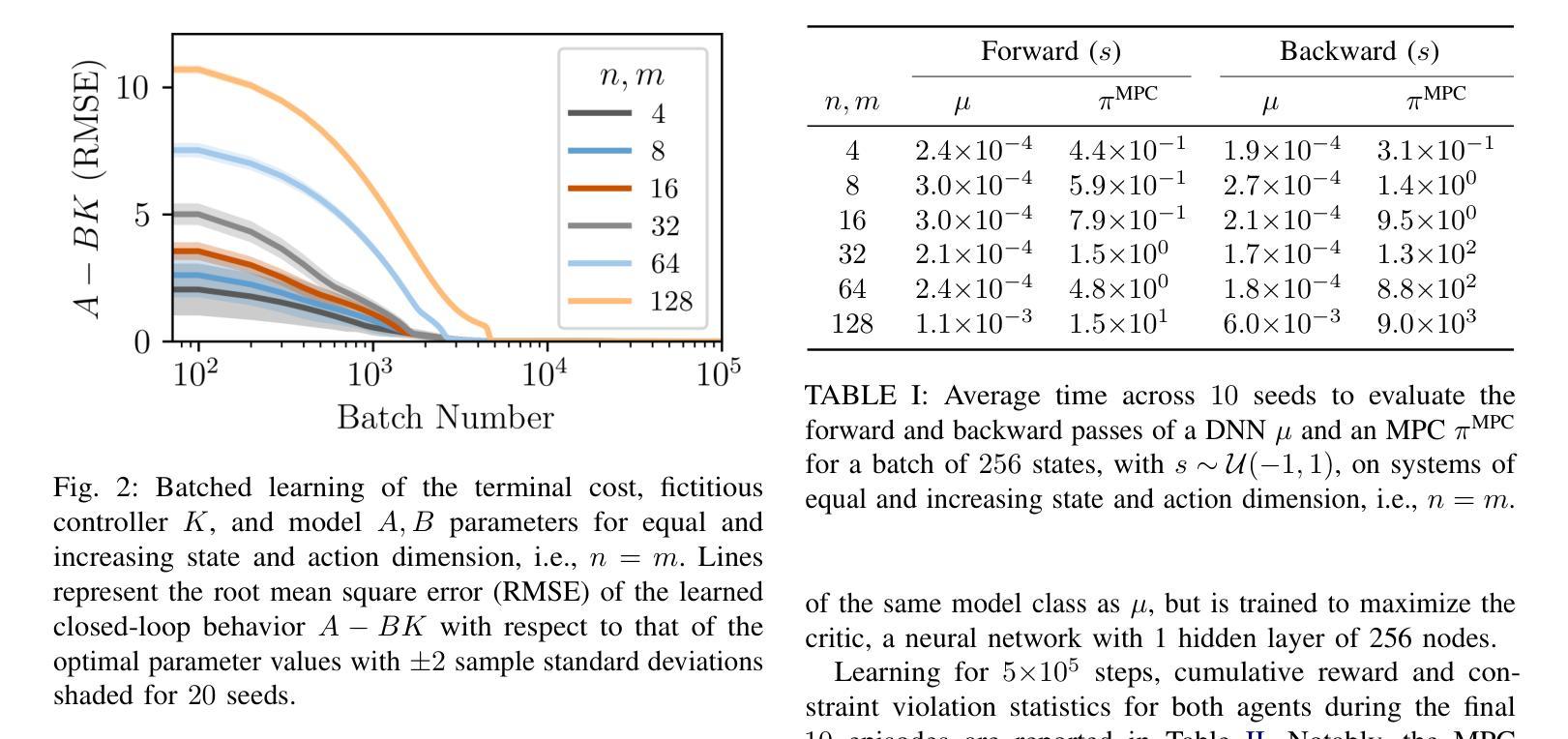
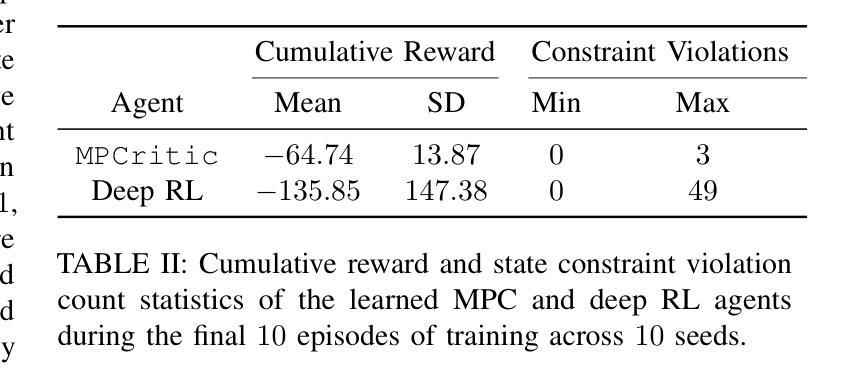
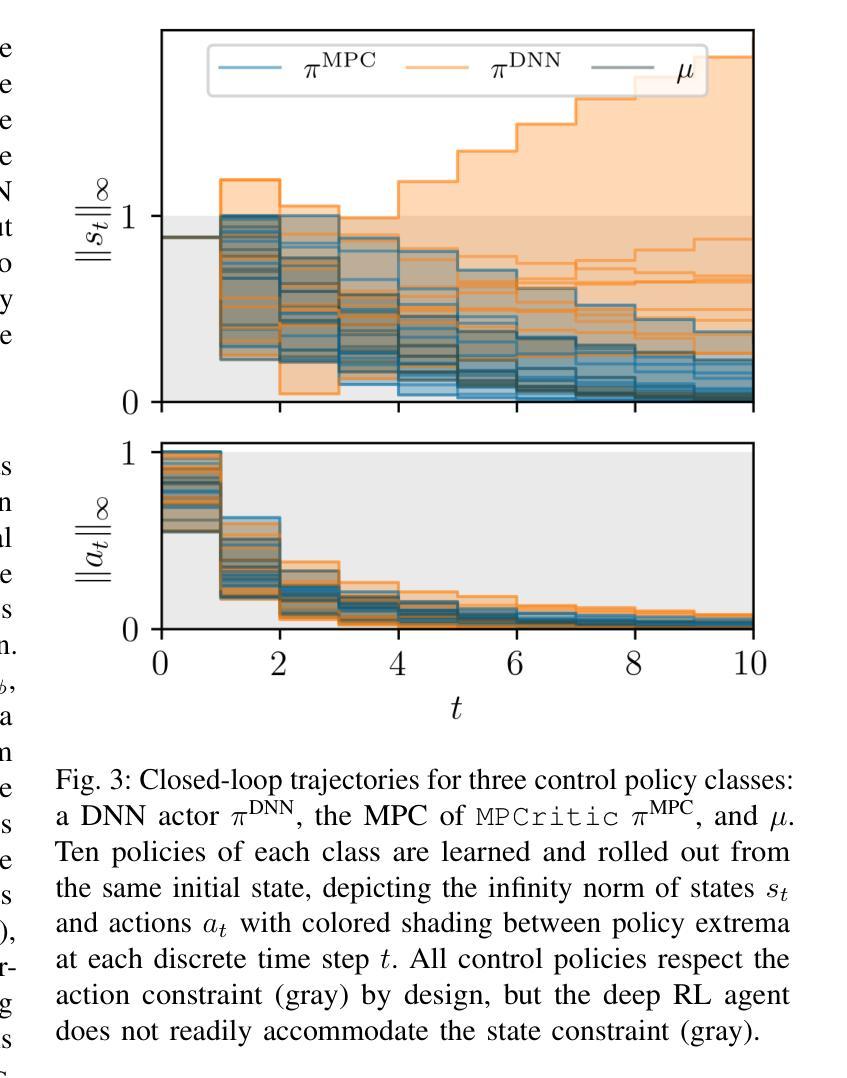
MPCritic: A plug-and-play MPC architecture for reinforcement learning
Authors:Nathan P. Lawrence, Thomas Banker, Ali Mesbah
The reinforcement learning (RL) and model predictive control (MPC) communities have developed vast ecosystems of theoretical approaches and computational tools for solving optimal control problems. Given their conceptual similarities but differing strengths, there has been increasing interest in synergizing RL and MPC. However, existing approaches tend to be limited for various reasons, including computational cost of MPC in an RL algorithm and software hurdles towards seamless integration of MPC and RL tools. These challenges often result in the use of “simple” MPC schemes or RL algorithms, neglecting the state-of-the-art in both areas. This paper presents MPCritic, a machine learning-friendly architecture that interfaces seamlessly with MPC tools. MPCritic utilizes the loss landscape defined by a parameterized MPC problem, focusing on “soft” optimization over batched training steps; thereby updating the MPC parameters while avoiding costly minimization and parametric sensitivities. Since the MPC structure is preserved during training, an MPC agent can be readily used for online deployment, where robust constraint satisfaction is paramount. We demonstrate the versatility of MPCritic, in terms of MPC architectures and RL algorithms that it can accommodate, on classic control benchmarks.
强化学习(RL)和模型预测控制(MPC)社区已经为解决最优控制问题建立了丰富的理论方法和计算工具生态系统。鉴于它们概念上的相似性但各有优势,将RL和MPC协同工作的兴趣日益浓厚。然而,现有方法往往因各种原因而受到限制,包括RL算法中的MPC计算成本以及实现MPC和RL工具无缝集成的软件障碍。这些挑战通常导致使用“简单”的MPC方案或RL算法,而忽略了这两个领域的最新技术。本文介绍了MPCritic,一种与MPC工具无缝兼容、适合机器学习的架构。MPCritic利用参数化MPC问题所定义的损失景观,专注于批处理训练步骤上的“软”优化;从而更新MPC参数,避免昂贵的最小化和参数敏感性。由于训练过程中保留了MPC结构,因此可以使用MPC代理进行在线部署,其中鲁棒的约束满足至关重要。我们在经典的控制基准测试上展示了MPCritic在MPC架构和可以适应的RL算法方面的通用性。
论文及项目相关链接
PDF Preprint for CDC 2025
Summary
强化学习(RL)与模型预测控制(MPC)是解决最优控制问题的两大重要领域。二者在理论方法与计算工具上各自形成了庞大的生态系统,且存在融合趋势。然而,现有融合方法面临计算成本与软件整合等挑战,导致无法充分利用两个领域的最新技术。本文提出一种名为MPCritic的机器学习友好架构,该架构与MPC工具无缝集成,利用参数化MPC问题的损失景观进行“软”优化,避免昂贵的最小化和参数敏感性计算。在训练过程中保留MPC结构,便于在线部署时使用MPC代理进行稳健约束满足。在经典控制基准测试中验证了MPCritic的通用性。
Key Takeaways
- 强化学习(RL)和模型预测控制(MPC)是求解最优控制问题的两大方法,分别拥有庞大的理论方法和计算工具生态系统。
- RL和MPC的融合引起越来越多兴趣,但现有方法因计算成本和软件整合难题而受限。
- MPCritic是一个机器学习友好的架构,与MPC工具无缝集成,利用参数化MPC问题的损失景观进行软优化。
- MPCritic避免昂贵的最小化和参数敏感性计算,同时保留MPC结构,便于在线部署时的稳健约束满足。
- MPCritic具有广泛的适用性,可以适应不同的MPC架构和强化学习算法。
- 文章通过经典控制基准测试验证了MPCritic的效能和通用性。
点此查看论文截图


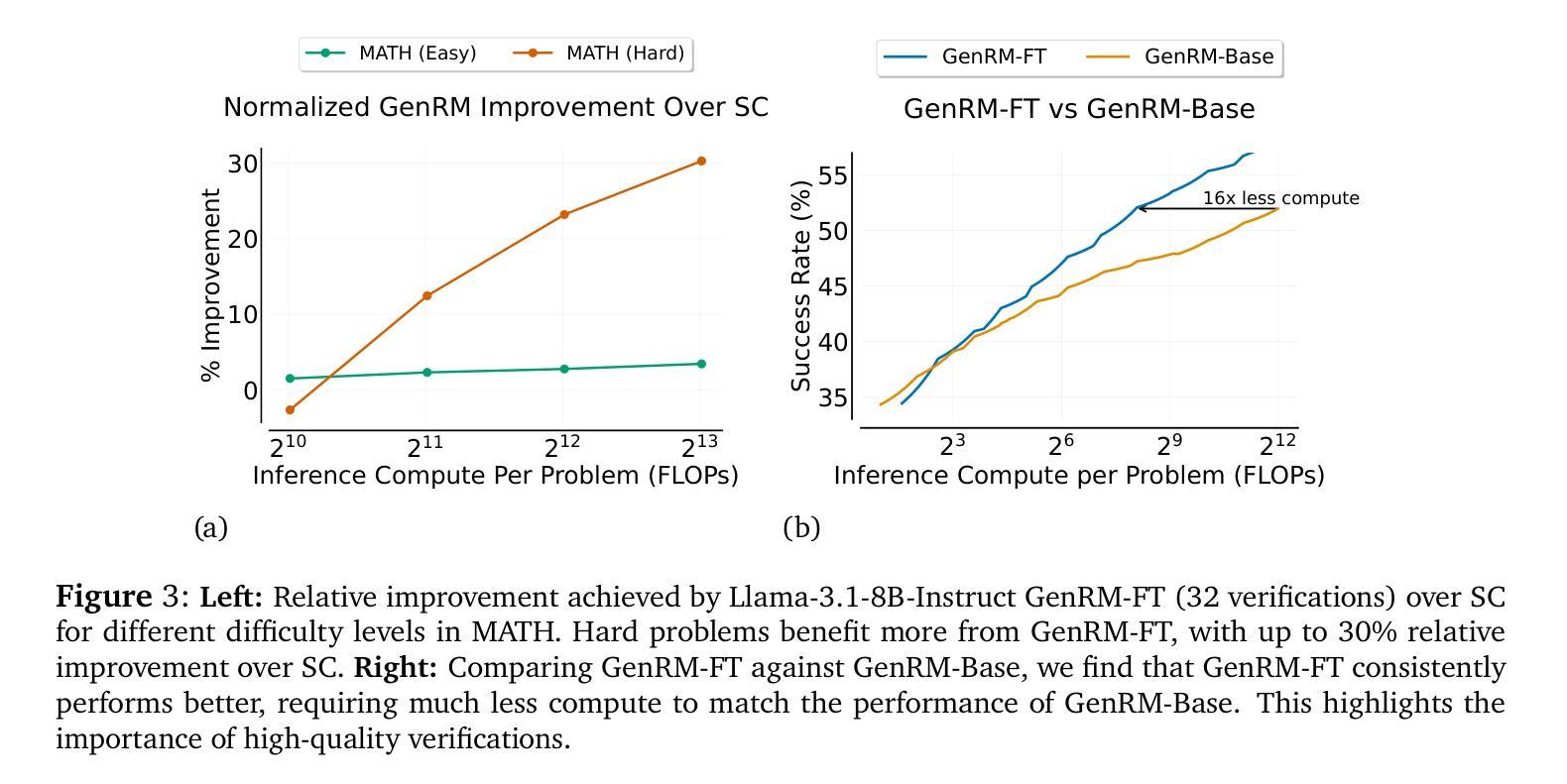
When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
Authors:Nishad Singhi, Hritik Bansal, Arian Hosseini, Aditya Grover, Kai-Wei Chang, Marcus Rohrbach, Anna Rohrbach
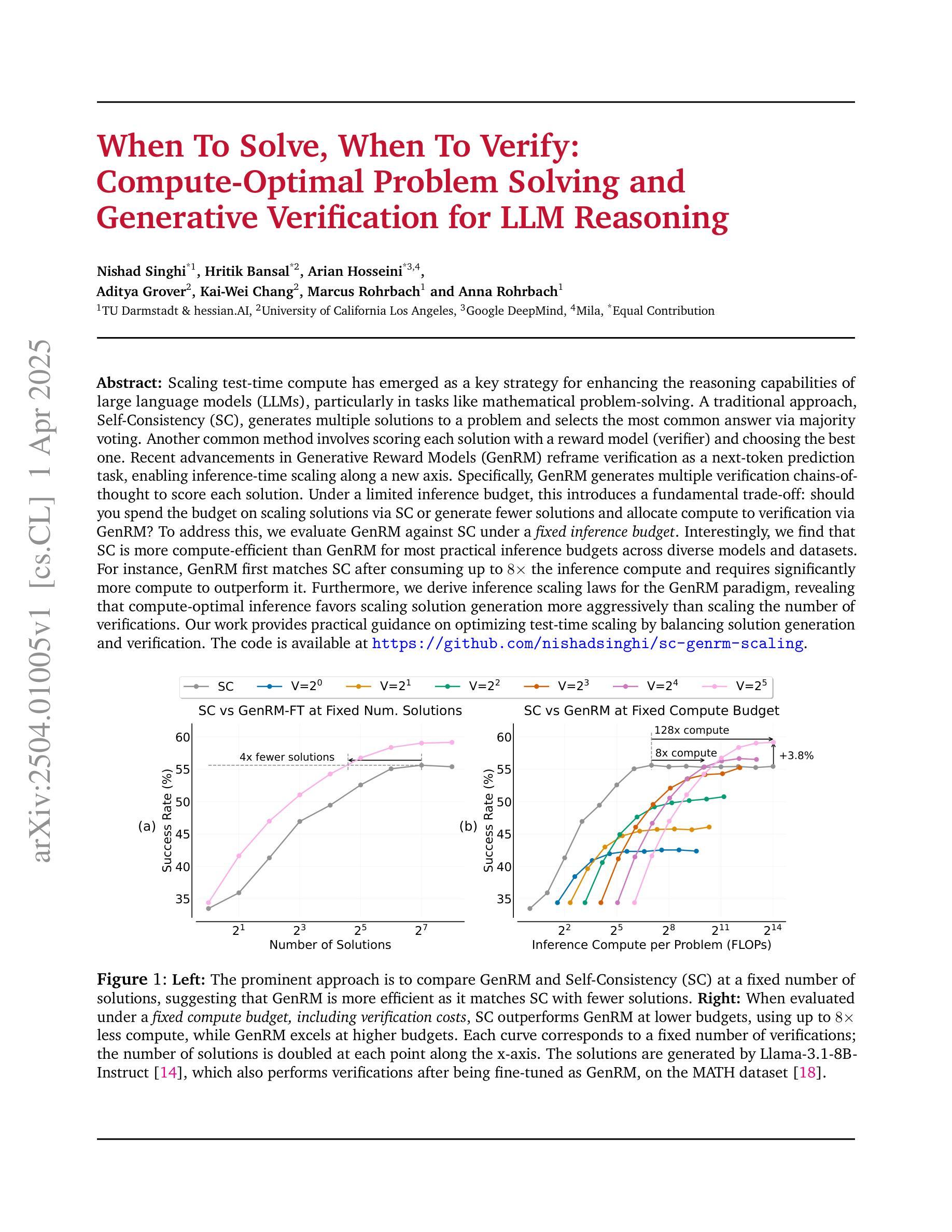
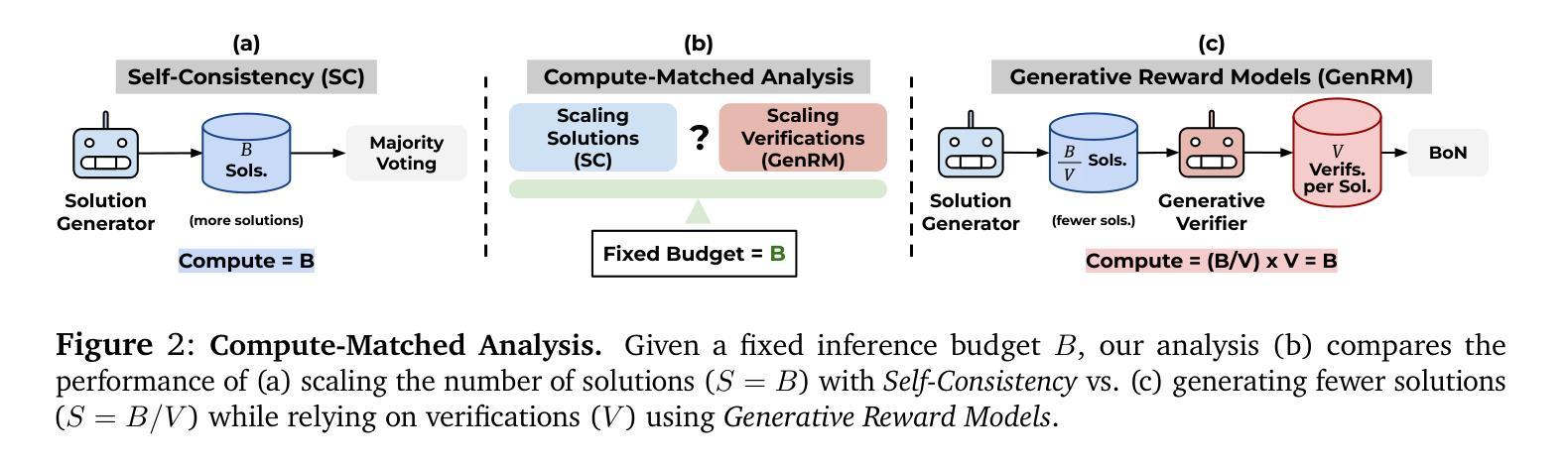
Scaling test-time compute has emerged as a key strategy for enhancing the reasoning capabilities of large language models (LLMs), particularly in tasks like mathematical problem-solving. A traditional approach, Self-Consistency (SC), generates multiple solutions to a problem and selects the most common answer via majority voting. Another common method involves scoring each solution with a reward model (verifier) and choosing the best one. Recent advancements in Generative Reward Models (GenRM) reframe verification as a next-token prediction task, enabling inference-time scaling along a new axis. Specifically, GenRM generates multiple verification chains-of-thought to score each solution. Under a limited inference budget, this introduces a fundamental trade-off: should you spend the budget on scaling solutions via SC or generate fewer solutions and allocate compute to verification via GenRM? To address this, we evaluate GenRM against SC under a fixed inference budget. Interestingly, we find that SC is more compute-efficient than GenRM for most practical inference budgets across diverse models and datasets. For instance, GenRM first matches SC after consuming up to 8x the inference compute and requires significantly more compute to outperform it. Furthermore, we derive inference scaling laws for the GenRM paradigm, revealing that compute-optimal inference favors scaling solution generation more aggressively than scaling the number of verifications. Our work provides practical guidance on optimizing test-time scaling by balancing solution generation and verification. The code is available at https://github.com/nishadsinghi/sc-genrm-scaling.
在测试时间计算缩放已成为增强大型语言模型(尤其是数学问题解决等任务中的)推理能力的一种关键策略。一种传统的方法是自洽性(SC),它通过多数投票机制生成一个问题的多个解决方案并选择最常见的答案。另一种常见的方法是利用奖励模型(验证器)为每一个解决方案打分,然后选择最佳的解决方案。最近生成的奖励模型(GenRM)的进展将验证重新构建为下一个标记预测任务,沿新的轴实现推理时间的缩放。具体来说,GenRM生成多个验证链来评估每个解决方案的得分。在有限的推理预算下,这引入了一个基本的权衡:你应使用预算通过SC来扩展解决方案,还是生成较少的解决方案并将计算分配给通过GenRM进行验证?为了解决这个问题,我们在固定的推理预算下评估了GenRM与SC之间的表现。有趣的是,我们发现对于各种模型和数据集的实际推理预算而言,SC在计算效率上比GenRM更高。例如,GenRM在消耗高达8倍的推理计算之后才首次达到与SC相匹配的性能,并且为了优于它,需要更多的计算。此外,我们得出了GenRM范式的推理缩放定律,揭示了计算最优推理更倾向于积极扩展解决方案生成而不是扩大验证数量。我们的工作提供了关于通过平衡解决方案生成和验证来优化测试时间缩放的实用指导。代码可在https://github.com/nishadsinghi/sc-genrm-scaling获取。
论文及项目相关链接
PDF 29 pages
Summary
文本主要讨论了在大规模语言模型(LLM)的数学问题解决任务中,测试时计算规模的扩大策略。介绍了两种常见的测试时计算规模扩大策略:自我一致性(SC)和生成奖励模型(GenRM)。SC通过产生多个解决方案并选择最常见的答案,而GenRM将验证重新定义为下一个标记预测任务。研究发现,在有限的推理预算下,SC在计算效率上优于GenRM。此外,还推导出了GenRM的推理规模定律,指出在计算最优推理时,更倾向于积极扩大解决方案的生成,而不是增加验证次数。
Key Takeaways
- 测试时计算规模扩大是提升大规模语言模型(LLM)推理能力,特别是在数学问题解决任务中的关键策略。
- 自我一致性(SC)和生成奖励模型(GenRM)是两种常用的测试时计算规模扩大策略。
- 在有限的推理预算下,SC的计算效率高于GenRM。
- GenRM在消耗高达8倍的推理计算量后才能与SC相匹配,并需要更多的计算才能超越它。
- 推导出的GenRM推理规模定律表明,在计算最优推理时,应更倾向于扩大解决方案的生成,而不是增加验证次数。
- 平衡解决方案的生成和验证是优化测试时计算规模扩大的关键。
点此查看论文截图
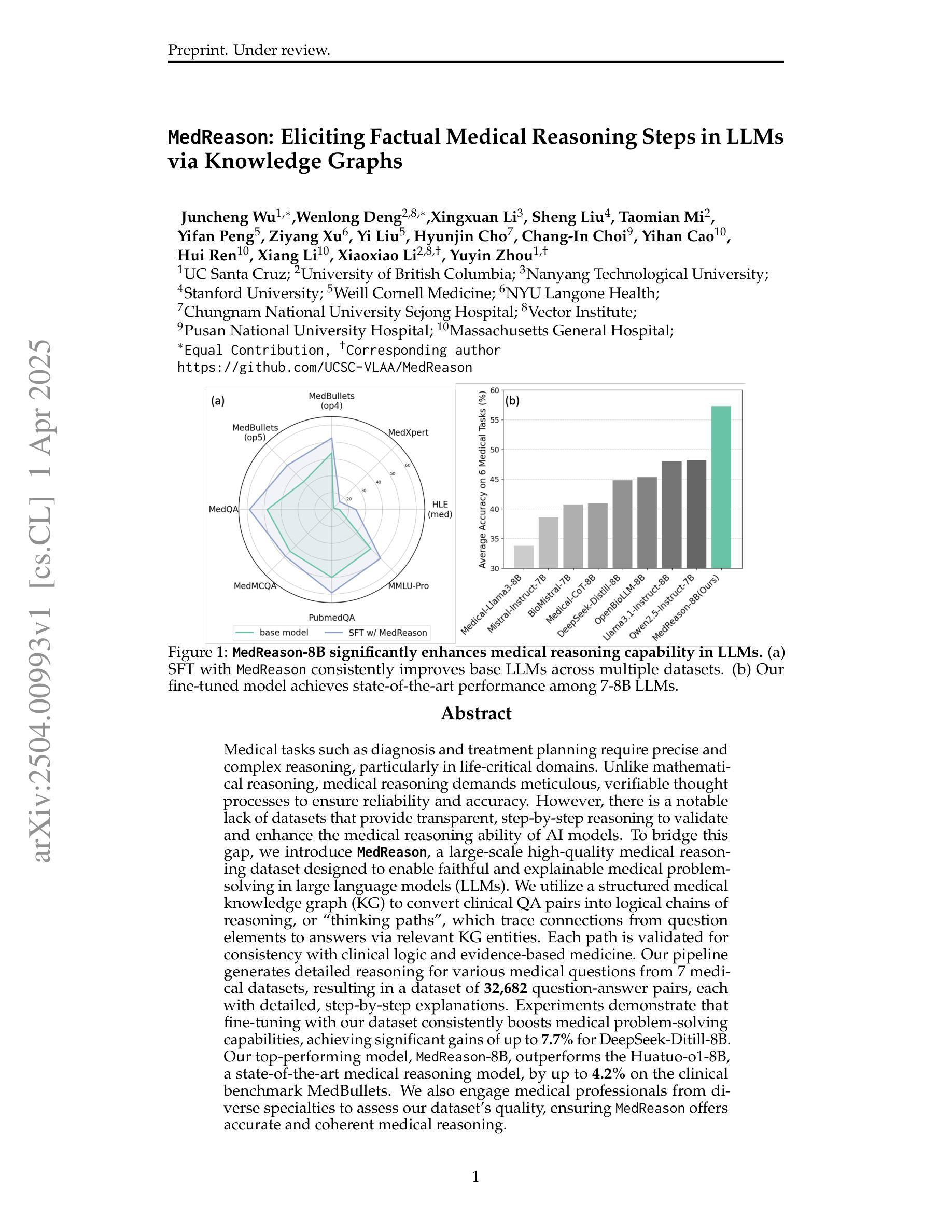
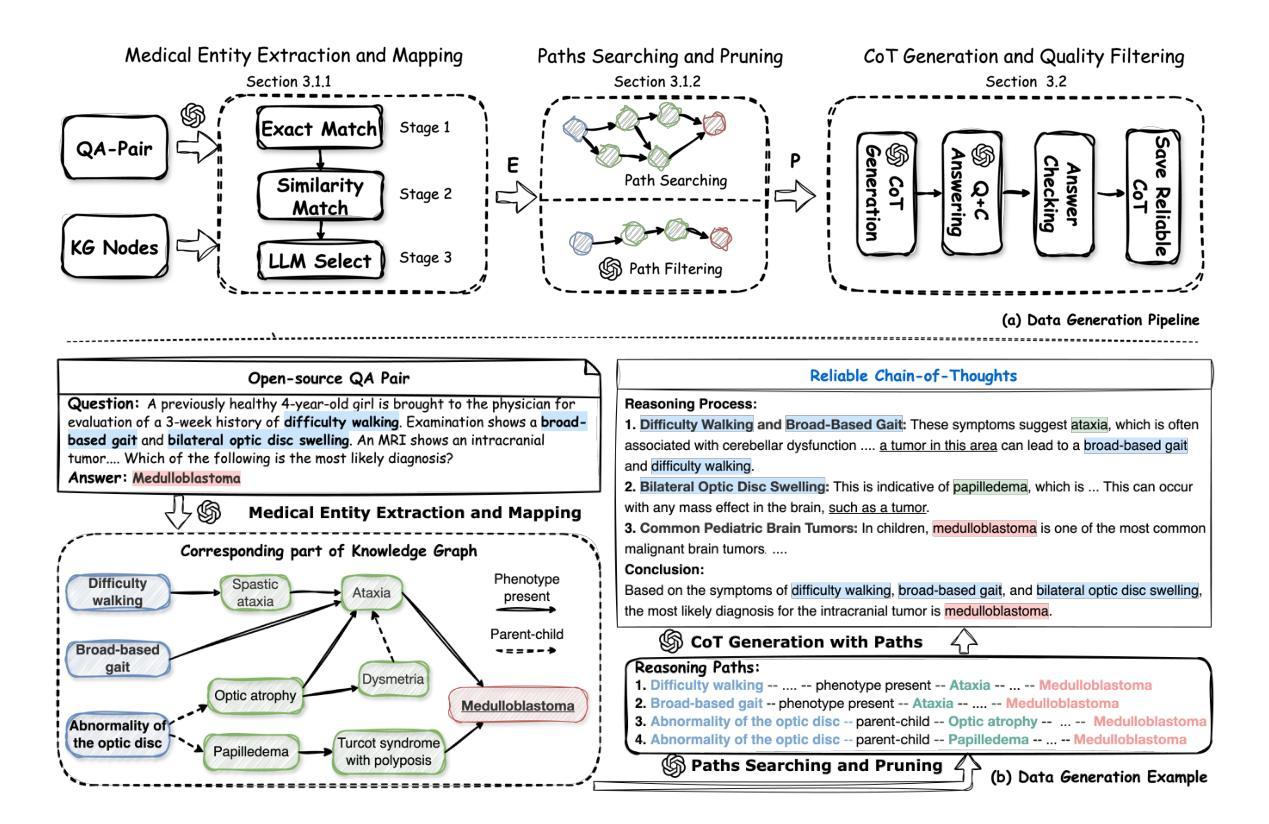
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Authors:Juncheng Wu, Wenlong Deng, Xingxuan Li, Sheng Liu, Taomian Mi, Yifan Peng, Ziyang Xu, Yi Liu, Hyunjin Cho, Chang-In Choi, Yihan Cao, Hui Ren, Xiang Li, Xiaoxiao Li, Yuyin Zhou
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths’’, which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset’s quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
医学任务如诊断和制定治疗方案需要进行精确且复杂的推理,特别是在关键的生命领域。不同于数学推理,医学推理需要细致且可验证的思考过程,以确保可靠性和准确性。然而,缺乏提供透明、逐步推理的数据集来验证和提升AI模型的医学推理能力。为了弥补这一差距,我们引入了MedReason,这是一个大规模、高质量的医学推理数据集,旨在在大语言模型(LLM)中实现忠实且可解释的医学问题解决。我们利用结构化医学知识图谱(KG)将临床问答对转换为逻辑推理链,或称为“思考路径”,从问题元素追踪到通过相关KG实体得到的答案。每条路径都经过临床逻辑和循证医学的验证。我们的管道从7个医学数据集中生成了各种医学问题的详细推理,形成了一个包含32,682个问答对的数据集,每个问答对都有详细、逐步的解释。实验表明,使用我们的数据集进行微调可以持续提高医学问题解决能力,对DeepSeek-Ditill-8B的改进幅度高达7.7%。我们表现最佳的模型MedReason-8B在临床医学基准测试MedBullets上的表现优于最新的医学推理模型华佗-o1-8B,最高提升了4.2%。我们还邀请了来自不同专业的医疗专家来评估我们数据集的质量,确保MedReason提供准确且连贯的医学推理。我们的数据、模型和代码将公开可用。
论文及项目相关链接
摘要
医疗任务的诊断与治疗规划需要精确且复杂的推理,特别是在关键的生命领域。医疗推理不同于数学推理,需要细致且可验证的思考过程以确保可靠性和准确性。然而,缺乏提供透明、逐步推理的数据集来验证和提升AI模型的医疗推理能力。为弥补这一差距,我们推出MedReason,一个大规模高质量的医疗推理数据集,旨在在大型语言模型中实现忠实且可解释的医疗问题解决。我们利用结构化医疗知识图谱将临床问答对转化为逻辑推理链,即“思考路径”,该路径追踪从问题元素到通过相关KG实体回答的联接。每条路径都经过临床逻辑和循证医学的验证。我们的管道生成了各种医疗问题的详细推理,来自7个医疗数据集,形成包含32682个带有详细逐步解释的问题答案对的数据集。实验表明,使用我们的数据集进行微调,可持续提升医疗问题解决能力,在DeepSeek-Ditill-8B上取得高达7.7%的显著增长。我们的顶尖模型MedReason-8B在医疗推理模型华佗o1-8B上取得显著优势,在临床基准测试MedBullets上高出4.2%。我们还邀请来自不同专业的医疗专家来评估我们数据集的质量,确保MedReason提供准确且连贯的医疗推理。我们的数据、模型和代码将公开提供。
关键见解
- 医疗任务需要精确且复杂的推理,特别是在诊断与治疗规划中。
- 与数学推理不同,医疗推理需要细致和可验证的思考过程。
- 目前缺乏用于验证和提升AI模型医疗推理能力的数据集。
- MedReason是一个大规模高质量的医疗推理数据集,用于大型语言模型中的忠实且可解释的医疗问题解决。
- 利用结构化医疗知识图谱将临床问答转化为逻辑推理链。
- MedReason数据集包含详细逐步解释的问题答案对,由来自多个医疗数据集的问题生成。
点此查看论文截图

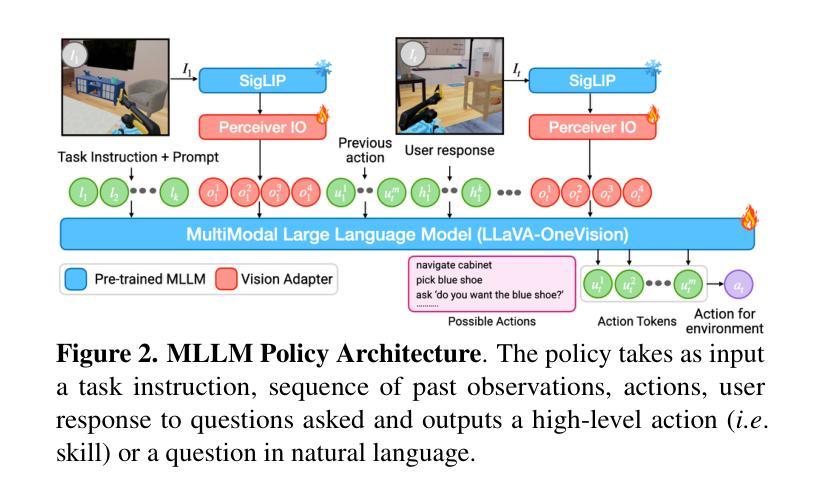
Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
Authors:Ram Ramrakhya, Matthew Chang, Xavier Puig, Ruta Desai, Zsolt Kira, Roozbeh Mottaghi
Embodied agents operating in real-world environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent must fetch a specific object instance given an ambiguous instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To solve this problem, we propose a novel approach that fine-tunes multimodal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines, including GPT-4o, and supervised fine-tuned MLLMs, on our task. Our results demonstrate that our RL-finetuned MLLM outperforms all baselines by a significant margin ($19.1$-$40.3%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
实体代理在现实环境中运作时,必须解读模糊和未明确指定的人类指令。一个能力强大的家用机器人应该能够识别模糊性,并提出相关澄清问题,以准确推断用户意图,从而更有效地执行任务。为了研究这个问题,我们引入了“问再行动”任务,在该任务中,实体代理必须在家庭环境中根据模糊指令获取特定对象实例。代理必须策略性地提出最少但相关的问题来解决模糊性,同时在部分可观察性下进行导航。为了解决这个问题,我们提出了一种新方法,该方法微调多模态大型语言模型(MLLMs),将其作为视觉语言行动(VLA)策略使用在线强化学习(RL)与LLM生成的奖励。我们的方法消除了大型人类演示或手动工程奖励来训练此类代理的需要。我们在任务上与强大的零样本基线进行了基准测试,包括GPT-4o和经过监督训练的MLLMs。我们的结果表明,我们的RL微调MLLM在所有基准测试中表现优越较大幅度(介于19.1%至40.3%),对新场景和任务具有良好的泛化能力。据我们所知,这是首次展示适应MLLM作为VLA代理的能力,该代理可以使用LLM生成的奖励与在线RL来行动和寻求帮助。
论文及项目相关链接
Summary
本文探讨了在真实世界环境中运行的实体代理需要解读模糊和未明确指定的人类指令的问题。为了解决这个问题,提出了一种新型方法,即通过在线强化学习微调多模态大型语言模型,将其作为视觉语言行动策略。该方法无需大规模人类演示或手动设计的奖励来训练代理,且相较于零样本基准测试,如GPT-4o和通过监督微调的多模态大型语言模型,表现出显著优势。这是首次将多模态大型语言模型适应为能行动和求助的视觉语言行动代理。
Key Takeaways
- 实体代理需解读模糊和未明确指定的人类指令。
- 家用机器人应能识别歧义并提出相关澄清问题,以准确推断用户意图,从而提高任务执行效率。
- 引入了“问询行动”任务,即实体代理需在家庭环境中根据模糊指令获取特定对象实例。
- 代理需策略性地提出最少但相关的澄清问题以解决歧义,同时在部分可观察性环境下进行导航。
- 提出一种新型方法,通过在线强化学习微调多模态大型语言模型,作为视觉语言行动策略。
- 该方法无需大规模人类演示或手动设计的奖励,且表现出显著优于零样本基准测试和监督微调的多模态大型语言模型的性能。
点此查看论文截图


GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
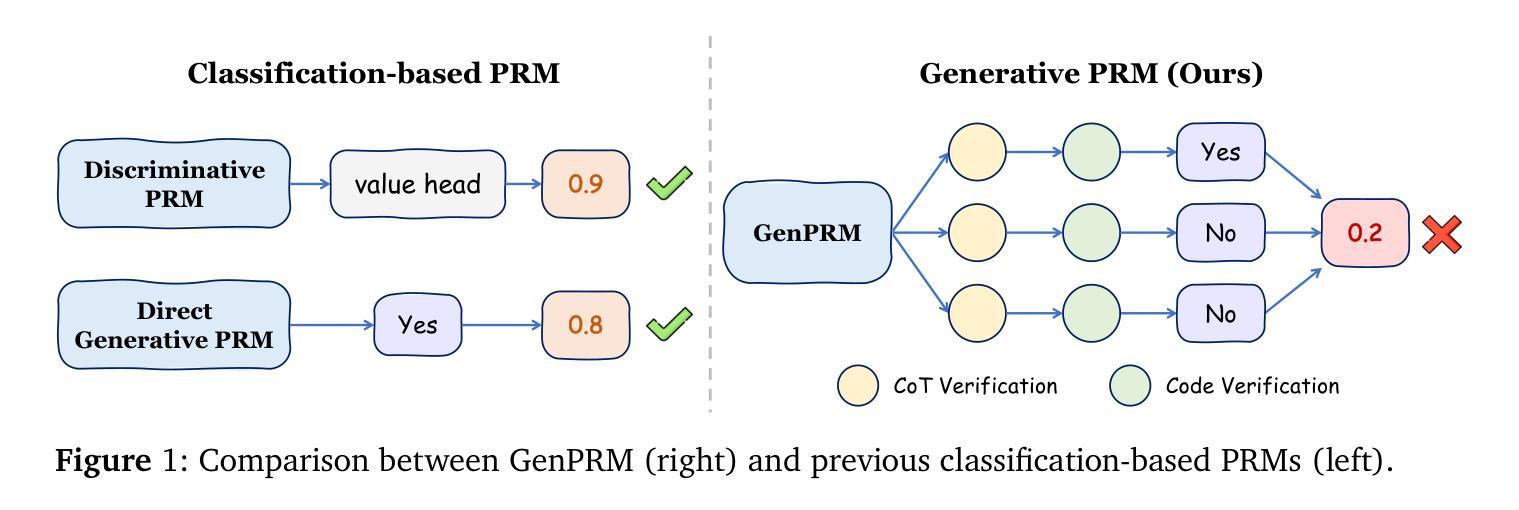
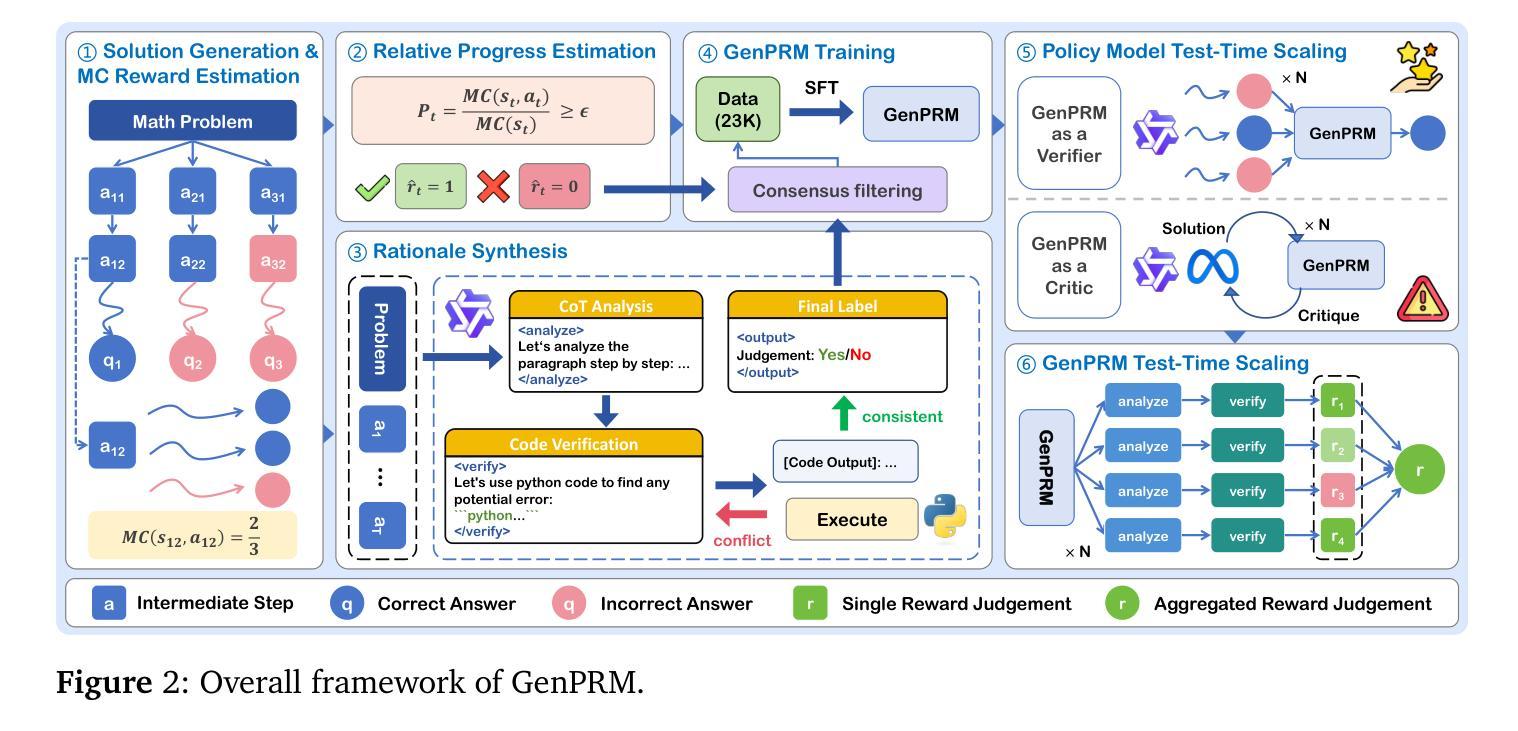
Authors:Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, Bowen Zhou
Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as verifiers to enhance the performance of LLMs. However, current PRMs face three key challenges: (1) limited process supervision and generalization capabilities, (2) dependence on scalar value prediction without leveraging the generative abilities of LLMs, and (3) inability to scale the test-time compute of PRMs. In this work, we introduce GenPRM, a generative process reward model that performs explicit Chain-of-Thought (CoT) reasoning with code verification before providing judgment for each reasoning step. To obtain high-quality process supervision labels and rationale data, we propose Relative Progress Estimation (RPE) and a rationale synthesis framework that incorporates code verification. Experimental results on ProcessBench and several mathematical reasoning tasks show that GenPRM significantly outperforms prior PRMs with only 23K training data from MATH dataset. Through test-time scaling, a 1.5B GenPRM outperforms GPT-4o, and a 7B GenPRM surpasses Qwen2.5-Math-PRM-72B on ProcessBench. Additionally, GenPRM demonstrates strong abilities to serve as a critic model for policy model refinement. This work establishes a new paradigm for process supervision that bridges the gap between PRMs and critic models in LLMs. Our code, model, and data will be available in https://ryanliu112.github.io/GenPRM.
近期大型语言模型(LLM)的进展显示出利用过程奖励模型(PRM)作为验证器以提高LLM性能的潜力。然而,当前PRM面临三个关键挑战:(1)过程监督与泛化能力有限,(2)依赖于标量值预测,未能利用LLM的生成能力,(3)无法扩展PRM的测试时间计算。在这项工作中,我们引入了GenPRM,一种生成式过程奖励模型,它在进行代码验证后进行明确的思维链(CoT)推理,然后为每一步推理提供判断。为了获得高质量的过程监督标签和理性数据,我们提出了相对进度估计(RPE)和一个结合代码验证的理性合成框架。在ProcessBench和多个数学推理任务上的实验结果表明,仅使用MATH数据集的23K训练数据,GenPRM就显著优于先前的PRM。通过测试时间缩放,一个1.5B的GenPRM表现优于GPT-4o,而一个7B的GenPRM在ProcessBench上超越了Qwen2.5-Math-PRM-72B。此外,GenPRM表现出强大的能力,可以作为政策模型细化的批评模型。这项工作为过程监督建立了新范式,缩小了PRM和LLM中批评模型之间的差距。我们的代码、模型和数据将在https://ryanliu112.github.io/GenPRM上提供。
论文及项目相关链接
Summary:
最近的大型语言模型(LLM)的进步显示,利用过程奖励模型(PRM)作为验证器来提高LLM的性能具有前景。然而,当前PRM面临三个主要挑战。在这项工作中,我们引入了GenPRM,一个执行显式链式思维(CoT)推理的过程奖励模型,在提供每个推理步骤的判断之前进行代码验证。通过相对进度估计(RPE)和融合代码验证的理性合成框架,GenPRM在ProcessBench和数学推理任务上显著优于先前的PRM,仅使用MATH数据集的23K训练数据。此外,GenPRM还表现出强大的能力,可作为政策模型改进的批评模型。这项工作为PRM和LLM中的批评模型之间的过程监督建立了新的范式。
Key Takeaways:
- GenPRM是一个结合显式链式思维(CoT)推理和代码验证的过程奖励模型。
- 当前PRM面临的主要挑战包括有限的进程监督、缺乏泛化能力以及对标量值预测的依赖等。
- GenPRM通过相对进度估计(RPE)和理性合成框架获得高质量的过程监督标签和理性数据。
- 在数学推理任务上,GenPRM显著优于先前的PRM,仅使用有限的训练数据。
- GenPRM在测试时的可扩展性表现优异,较大的模型如7B GenPRM在ProcessBench上超越了Qwen2.5-Math-PRM-72B。
- GenPRM不仅作为验证器表现出色,还具备作为批评模型进行政策模型改进的能力。
点此查看论文截图

Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Authors:Zhenyi Liao, Qingsong Xie, Yanhao Zhang, Zijian Kong, Haonan Lu, Zhenyu Yang, Zhijie Deng
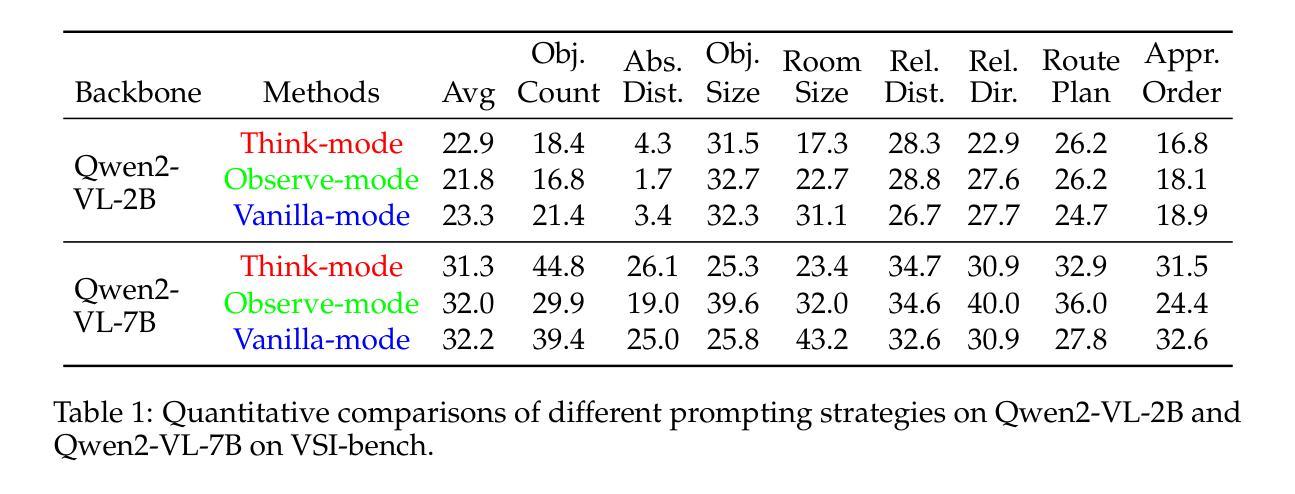
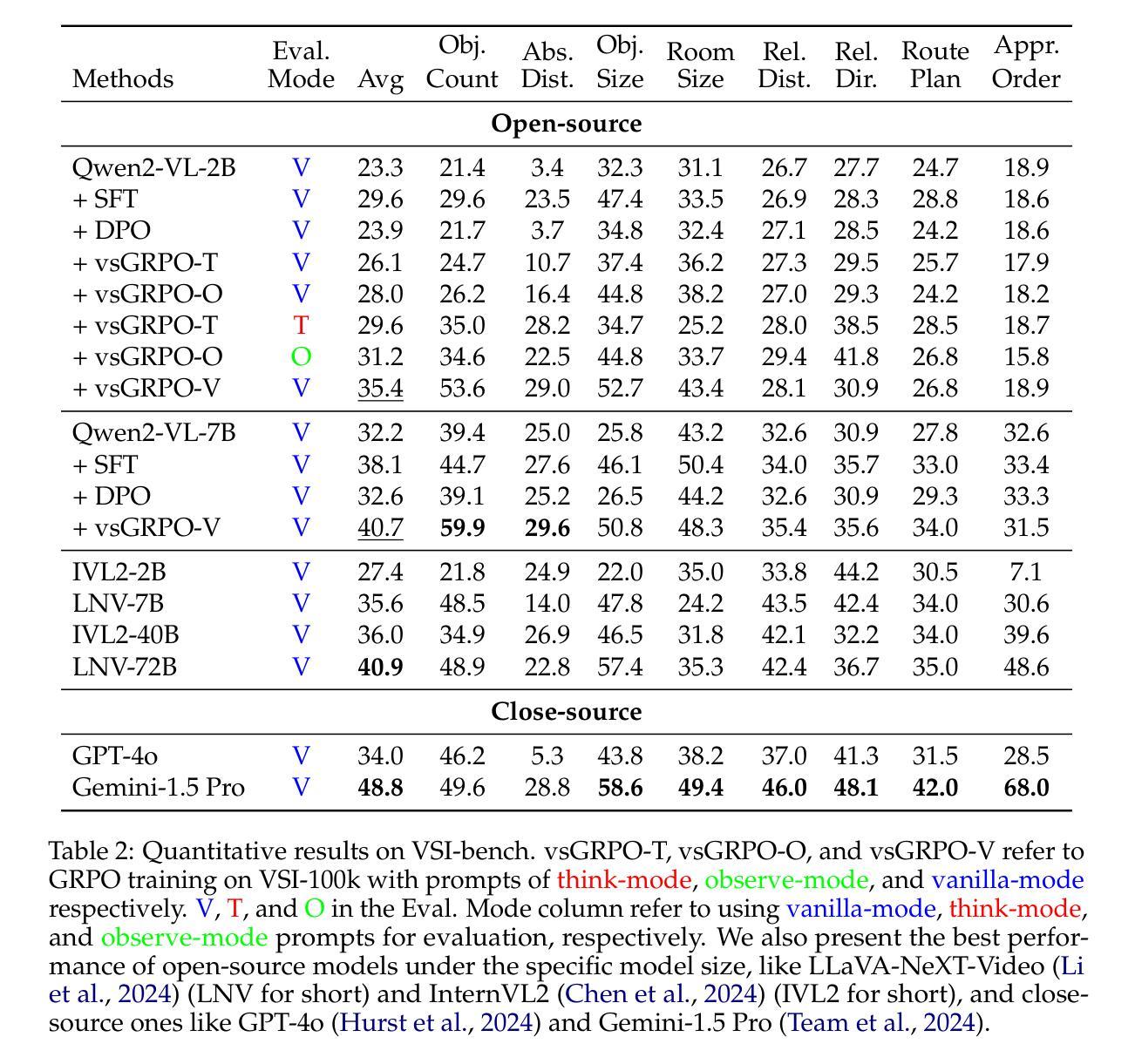
Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
对多模态大型语言模型(MLLMs)的推理能力越来越重视。作为在物理领域发挥作用的AI代理的基石,基于视频的视觉空间智能(VSI)已成为MLLMs中最关键的推理能力之一。这项工作通过R1-Zero类似的训练,首次深入研究了提高MLLMs的视觉空间推理能力。从技术上讲,我们首先发现中小型Qwen2-VL模型的视觉空间推理能力无法通过思维链(CoT)提示来激活。然后,我们采用GRPO训练来提高视觉空间推理能力,使用精心编制的VSI-100k数据集,遵循DeepSeek-R1-Zero。在调查过程中,我们发现了在GRPO中保持KL惩罚(即使值很小)的必要性。只需120个GPU小时,我们从Qwen2-VL-2B微调得到的vsGRPO-2B模型,就可以比基础模型高出12.1%,并超越GPT-4o。此外,我们从Qwen2-VL-7B微调得到的vsGRPO-7B模型,其性能可与最佳开源模型LLaVA-NeXT-Video-72B相媲美。另外,我们将vsGRPO与监督微调和直接偏好优化基线进行了比较,并观察到其性能卓越。代码和数据集将很快可用。
简化版翻译
论文及项目相关链接
Summary
随着对多模态大型语言模型(MLLMs)推理能力的关注增加,基于视频的视觉空间智能(VSI)作为MLLMs在物理领域工作的核心,显得尤为重要。本研究通过R1-Zero类似的训练方式,深入探讨了提高MLLMs的视觉空间推理能力。研究发现,中小型Qwen2-VL模型的视觉空间推理能力无法通过Chain of Thought(CoT)提示激活。通过使用GRPO训练和精心制作的VSI-100k数据集,在改进视觉空间推理方面取得了进展。研究还强调了保持KL惩罚的必要性,即使其值很小。研究结果显示,经过GRPO训练的模型性能显著提升。
Key Takeaways
- 多模态大型语言模型(MLLMs)的推理能力日益受到重视。
- 基于视频的视觉空间智能(VSI)是MLLMs在物理领域工作的关键。
- 本研究通过类似R1-Zero的训练方法,深入探讨了提高MLLMs的视觉空间推理能力。
- 中小型Qwen2-VL模型的视觉空间推理能力无法通过Chain of Thought(CoT)提示激活。
- 使用GRPO训练和VSI-100k数据集有助于提高视觉空间推理能力。
- 研究强调了保持KL惩罚在GRPO训练中的必要性。
点此查看论文截图



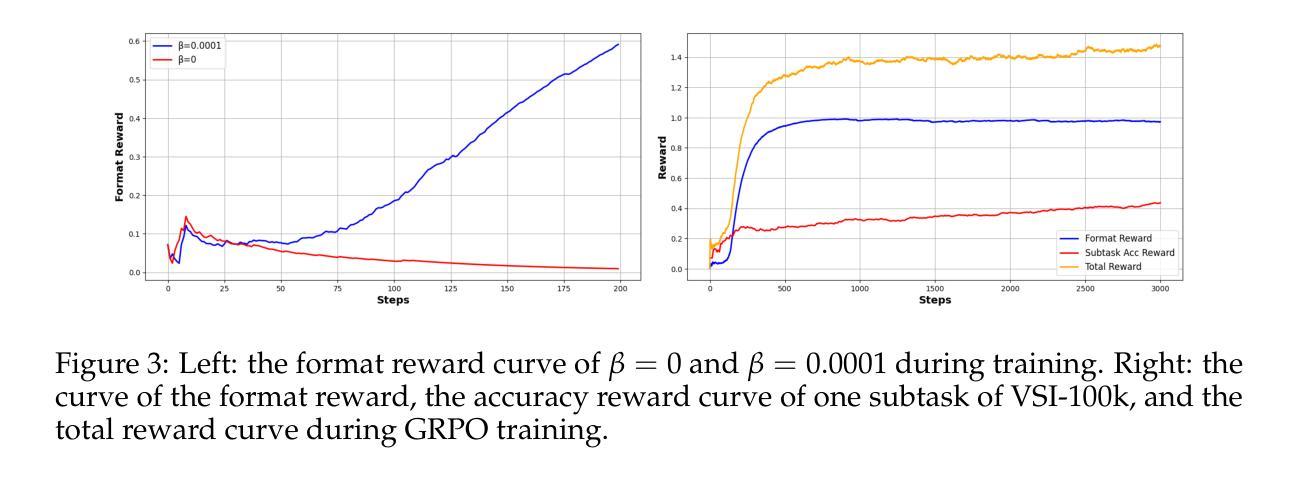
m1: Unleash the Potential of Test-Time Scaling for Medical Reasoning with Large Language Models
Authors:Xiaoke Huang, Juncheng Wu, Hui Liu, Xianfeng Tang, Yuyin Zhou
Test-time scaling has emerged as a powerful technique for enhancing the reasoning capabilities of large language models. However, its effectiveness in medical reasoning remains uncertain, as the medical domain fundamentally differs from mathematical tasks in terms of knowledge representation and decision-making processes. In this paper, we provide the first comprehensive investigation of test-time scaling for medical reasoning and present m1, a simple yet effective approach that increases a model’s medical reasoning capability at inference. Our evaluation across diverse medical tasks demonstrates that test-time scaling consistently enhances medical reasoning, enabling lightweight fine-tuned models under 10B parameters to establish new state-of-the-art performance, while our 32B model rivals previous 70B-scale medical LLMs. However, we identify an optimal reasoning token budget of approximately 4K, beyond which performance may degrade due to overthinking. Budget forcing, which extends test-time computation through iterative prompts, helps models double-check answers but does not necessarily improve the overall medical QA performance and, in some cases, even introduces errors into previously correct responses. Our case-by-case analysis identifies insufficient medical knowledge as a key bottleneck that prevents further performance gains through test-time scaling. We find that increasing data scale, improving data quality, and expanding model capacity consistently enhance medical knowledge grounding, enabling continued performance improvements, particularly on challenging medical benchmarks where smaller models reach saturation. These findings underscore fundamental differences between medical and mathematical reasoning in LLMs, highlighting that enriched medical knowledge, other than increased reasoning depth alone, is essential for realizing the benefits of test-time scaling.
测试时缩放技术已成为增强大型语言模型推理能力的一种强大技术。然而,其在医疗推理中的有效性尚不确定,因为医疗领域在知识表达和决策过程方面与数学任务存在根本区别。在本文中,我们对医疗推理的测试时缩放技术进行了首次全面调查,并提出了一种简单有效的m1方法,可以在推理过程中提高模型的医疗推理能力。我们在各种医疗任务上的评估表明,测试时缩放技术可以持续增强医疗推理能力,使经过轻量级微调、参数不足10B的模型能够创造新的最先进的性能表现;我们的32B模型的表现则与前些年规模达到70B的医疗大型语言模型(LLM)不相上下。然而,我们确定了大约4K的最佳推理令牌预算,超出此预算后,由于过度思考,性能可能会下降。强制预算通过迭代提示延长测试时的计算时间,有助于模型检查答案,但并不一定会提高整体的医疗问答表现,有时甚至会将之前正确的答案引入错误。我们的逐案分析发现,医疗知识不足是一个关键瓶颈,阻碍了通过测试时缩放进一步提升性能。我们发现,通过增加数据规模、提高数据质量和扩大模型容量,可以持续增强医疗知识的依据性,从而在具有挑战性的医疗基准测试上实现持续的性能改进,尤其是小型模型达到饱和状态的情况下更是如此。这些发现强调了大型语言模型中医疗推理与数学推理之间的根本区别,并指出除了增加推理深度外,丰富的医疗知识对于实现测试时缩放的好处至关重要。
论文及项目相关链接
PDF 17 pages; 7 figures; Data, code, and models: https://github.com/UCSC-VLAA/m1
Summary
本文探索了测试时缩放技术在医疗推理中的应用。研究提出了一种简单有效的方法m1,可以提高模型在推理阶段的医疗推理能力。评估表明,测试时缩放技术能持续提高医疗推理能力,使轻量级微调模型达到最新性能水平。然而,研究还发现存在一个约4K的推理令牌预算最优值,超出此范围可能会导致性能下降。预算强制有助于模型进行答案复查,但不一定能提高整体医疗问答性能,甚至可能导致先前正确的答案出现错误。研究认为,医疗知识不足是阻碍性能进一步提高的关键瓶颈。增加数据规模、提高数据质量和扩大模型容量能持续提高医疗知识的定位能力,特别是在挑战性医疗基准测试中,小型模型达到饱和状态后效果更明显。这些发现强调了医疗和数学推理在大型语言模型中的根本区别,并指出除了增加推理深度外,丰富的医疗知识对于实现测试时缩放技术的优势至关重要。
Key Takeaways
- 测试时缩放技术用于提高大型语言模型在医疗推理中的能力。
- m1方法能有效提升模型的医疗推理能力。
- 测试时缩放技术能使轻量级模型达到最新医疗推理性能水平。
- 存在一个约4K的推理令牌预算最优值,超出此范围可能导致性能下降。
- 预算强制有助于模型复查答案,但可能不总能提升医疗问答性能。
- 医疗知识不足是阻碍进一步提高医疗推理性能的关键问题。
点此查看论文截图

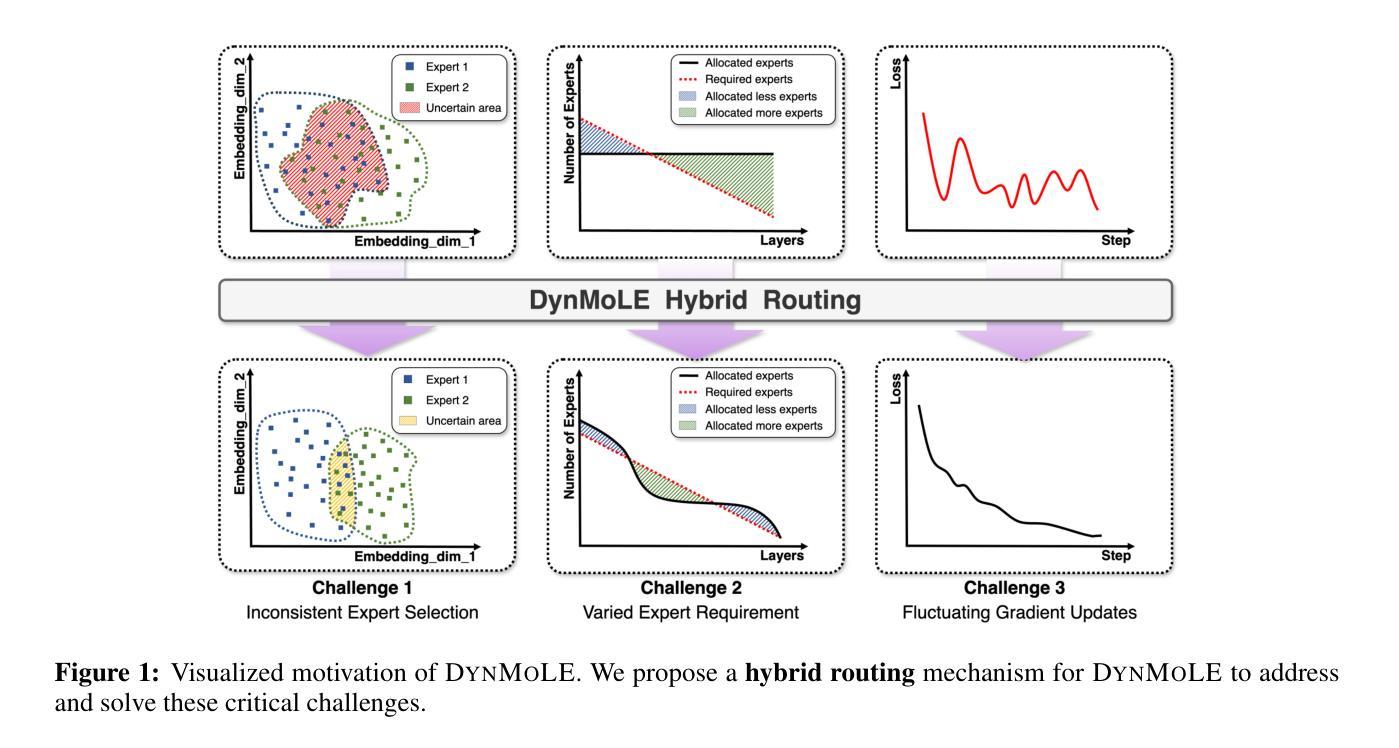
DynMoLE: Boosting Mixture of LoRA Experts Fine-Tuning with a Hybrid Routing Mechanism
Authors:Dengchun Li, Naizheng Wang, Zihao Zhang, Haoyang Yin, Lei Duan, Meng Xiao, Mingjie Tang
Instruction-based fine-tuning of large language models (LLMs) has achieved remarkable success in various natural language processing (NLP) tasks. Parameter-efficient fine-tuning (PEFT) methods, such as Mixture of LoRA Experts (MoLE), combine the efficiency of Low-Rank Adaptation (LoRA) with the versatility of Mixture of Experts (MoE) models, demonstrating significant potential for handling multiple downstream tasks. However, the existing routing mechanisms for MoLE often involve a trade-off between computational efficiency and predictive accuracy, and they fail to fully address the diverse expert selection demands across different transformer layers. In this work, we propose DynMoLE, a hybrid routing strategy that dynamically adjusts expert selection based on the Tsallis entropy of the router’s probability distribution. This approach mitigates router uncertainty, enhances stability, and promotes more equitable expert participation, leading to faster convergence and improved model performance. Additionally, we introduce an auxiliary loss based on Tsallis entropy to further guide the model toward convergence with reduced uncertainty, thereby improving training stability and performance. Our extensive experiments on commonsense reasoning benchmarks demonstrate that DynMoLE achieves substantial performance improvements, outperforming LoRA by 9.6% and surpassing the state-of-the-art MoLE method, MoLA, by 2.3%. We also conduct a comprehensive ablation study to evaluate the contributions of DynMoLE’s key components.
基于指令的大型语言模型(LLM)微调在自然语言处理(NLP)的各种任务中取得了显著的成功。参数高效微调(PEFT)方法,如混合LoRA专家(MoLE),结合了低秩适应(LoRA)的效率与混合专家(MoE)模型的通用性,在处理多个下游任务方面显示出巨大潜力。然而,MoLE的现有路由机制通常在计算效率和预测准确性之间进行权衡,并且未能完全满足不同transformer层之间多样化的专家选择需求。在这项工作中,我们提出了DynMoLE,一种基于路由器概率分布的Tsallis熵动态调整专家选择的混合路由策略。这种方法减轻了路由器的不确定性,增强了稳定性,促进了更公平的专家参与,从而实现了更快的收敛和模型性能的提高。此外,我们引入了一种基于Tsallis熵的辅助损失,进一步引导模型朝着减少不确定性的方向收敛,从而提高了训练稳定性和性能。我们在常识推理基准测试上的大量实验表明,DynMoLE实现了显著的性能改进,比LoRA高出9.6%,并超越了最先进的MoLE方法MoLA,提高了2.3%。我们还进行了全面的消融研究,以评估DynMoLE关键组件的贡献。
论文及项目相关链接
PDF 22 pages, 7 figures
Summary
大型语言模型(LLM)的指令微调已经取得显著成功。参数高效微调(PEFT)方法如混合LoRA专家(MoLE)结合了LoRA的效率与MoE模型的灵活性。然而,现有MoLE的路由机制在计算效率和预测精度之间存在权衡,不能满足不同transformer层之间的专家选择需求。本研究提出DynMoLE,一种基于Tsallis熵的路由器概率分布动态调整专家选择的混合路由策略。该方法减轻了路由器的不确定性,增强了稳定性,促进了更公平的专家参与,导致更快的收敛和模型性能的提升。在常识推理基准测试上的实验表明,DynMoLE实现了显著的性能改进。
Key Takeaways
- 大型语言模型(LLM)的指令微调在NLP任务中取得显著成功。
- 参数高效微调(PEFT)方法结合了LoRA的效率与MoE模型的灵活性。
- MoLE的现有路由机制存在计算效率和预测精度之间的权衡。
- DynMoLE提出一种基于Tsallis熵的混合路由策略,动态调整专家选择。
- DynMoLE减轻了路由器的不确定性,增强了稳定性和模型性能。
- DynMoLE在常识推理任务上实现了显著的性能改进,优于LoRA和其他最新方法。
点此查看论文截图